EP0310636B1 - Distance measurement control of a multiple detector system - Google Patents
Distance measurement control of a multiple detector system Download PDFInfo
- Publication number
- EP0310636B1 EP0310636B1 EP88901684A EP88901684A EP0310636B1 EP 0310636 B1 EP0310636 B1 EP 0310636B1 EP 88901684 A EP88901684 A EP 88901684A EP 88901684 A EP88901684 A EP 88901684A EP 0310636 B1 EP0310636 B1 EP 0310636B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- voiced
- value
- calculating
- frames
- unvoiced
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/93—Discriminating between voiced and unvoiced parts of speech signals
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Transmission Systems Not Characterized By The Medium Used For Transmission (AREA)
- Measurement Of Velocity Or Position Using Acoustic Or Ultrasonic Waves (AREA)
- Radar Systems Or Details Thereof (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
- Time-Division Multiplex Systems (AREA)
- Testing Or Calibration Of Command Recording Devices (AREA)
Abstract
Description
- This invention relates to determining whether or not speech has a fundamental frequency present. This is also referred to as a voicing decision. More particularly, the invention is directed to selecting one of a plurality of voiced detectors which are concurrently processing speech samples for making the voicing decision with the selection being based on a distance measurement calculation.
- In low bit rate voice coders, degradation of voice quality is often due to inaccurate voicing decisions. The difficulty in correctly making these voicing decisions lies in the fact that no single speech classifier can reliably distinguish voiced speech from unvoiced speech. The use of multiple voiced detectors and the selection of one of these detectors to make the determination of whether the speech is voiced or unvoiced is disclosed in the paper of J.P. Campbell, et al., "Voiced/Unvoiced Classification of Speech with Applications to the U.S Government LPC-10E Algorithm," IEEE International Conference on Acoustics, Speech, and Signal Processing, 1986, Tokyo, Vol. 9. 11.4, pp. 473-476. This paper discloses the utilization of multiple linear discriminant voiced detectors each utilizing different weights and threshold values to process the same speech classifiers for each frame of speech. The weights and thresholds for each detector are determined by utilizing training data. For each detector, a different level of white noise is added to the training data. During the processing of actual speech, the detector to be utilized to make the voicing decision is determined by examining the signal-to-noise ratio, SNR. The range of possible values that the SNR can have is subdivided into subranges with each subrange being assigned to one of the detectors. For each frame, the SNR is calculated, the subrange is determined, and the detector associated with this subrange is selected to make the voicing decision.
- In "A pattern recognition approach to voiced-unvoiced-silence classification with applications to speech recognition" (IEEE Transactions on Acoustics, Speech and Signal Processing, vol ASSP-24, No. 3, June 1976, pages 201 -212) Atal and Rabiner disclose a system in which various measures (zero crossings, log energy, autocorrelation, first linear prediction coefficient and normalised prediction error) are combined, using predetermined mean values and covariances for the three classes of signal (voiced, unvoiced and silence) to produce three distances, one for each class. The class with the smallest distance is then assigned to the signal.
- A problem with the prior art approach is that it does not perform well with respect to a speech environment in which characteristics of the speech itself have been altered. In addition, the method used by Campbell is only adapted to white noise and cannot adjust for coloured noise. Therefore, there exists a need for a method of selecting between a plurality of voiced detectors that allows detection in a varying speech environment.
- According to the invention there is provided apparatus as claimed in claim 1 and a method as claimed in claim 17. Preferred forms of the invention are set out in the dependent claims.
- The invention may be better understood from the following detailed description which when read with reference to the drawing in which:
- FIG. 1 is a block diagram illustrating the present invention;
- FIG. 2 illustrates, in block diagram form,
statistical voice detector 103 of FIG. 1; - FIGS. 3 and 4 illustrate, in greater detail, the functions performed by statistical voiced
detector 103 of FIG. 2; and - FIG. 5 illustrates, in greater detail, functions performed by
block 340 of FIG. 4. - FIG. 1 illustrates an apparatus for performing the unvoiced/voiced decision operation by selecting between one of two voiced detectors. It would obvious to one skilled in the art to use more than two voiced detectors in FIG. 1. The selection between
detectors distance comparator 104. Each generated distance measurement represents a merit value indicating the correctness of the generating detector's voicing decision.Distance comparator 104 compares the two distance measurement values and controls amultiplexer 105 such that the detector generating the greatest distance measurement value is selected to make the unvoiced/voiced decision. However, for other types of measurements, the lowest merit value would indicate the detector making the most accurate voicing decision. Advantageously, the distance measurement may be the Mahalanobis distance. Advantageously,detector 102 is a discriminant detector, anddetector 103 is a statistical detector. However, it would be obvious to one skilled in the art that the detectors could all be of the same type and that there could be more than two detectors present in the system. - Consider now the overall operation of the apparatus illustrated in FIG. 1.
Classifier generator 101 is responsive to each frame of speech to generate classifiers which advantageously may be the log of the speech energy, the log of the LPC gain, the log area ratio of the first reflection coefficient, and the squared correlation coefficient of two speech segments one frame long which are offset by one pitch period. The calculation of these classifiers involves digitally sampling analog speech, forming frames of the digital samples, and processing those frames and is well known in the art.Generator 101 transmits the classifiers todetectors path 106. -
Detectors path 106 to make unvoiced/voiced decisions and transmit these decisions viapaths paths comparator 104. Advantageously, these distances may be Mahalanobis distances or other generalized distances.Comparator 104 is responsive to the distances received viapaths multiplexer 105 so that the latter multiplexer selects the output of the detector that is generating the largest distance. - FIG. 2 illustrates, in greater detail, statistical voiced
detector 103. For each frame of speech, a set of classifiers also referred to as a vector of classifiers is received viapath 106 fromclassifier generator 101.Silence detector 201 is responsive to these classifiers to determine whether or not speech is present in the present frame. If speech is present,detector 201 transmits a signal viapath 210. If no speech (silence) is present in the frame, then onlysubtractor 207 and U/V determinator 205 are operational for that particular frame. Whether speech is present or not, the unvoiced/voiced decision is made for every frame bydeterminator 205. - In response to the signal from
detector 201,classifier averager 202 maintains an average of the individual classifiers received viapath 106 by averaging in the classifiers for the present frame with the classifiers for previous frames. If speech (non-silence) is present in the frame,silence detector 201 signalsstatistical calculator 203,generator 206, and averager 202 viapath 210. -
Statistical calculator 203 calculates statistical distributions for voiced and unvoiced frames. In particular,calculator 203 is responsive to the signal received viapath 210 to calculate the overall probability that any frame is unvoiced and the probability that any frame is voiced. In addition,statistical calculator 203 calculates the statistical value that each classifier would have if the frame was unvoiced and the statistical value that each classifier would have if the frame was voiced. Further,calculator 203 calculates the covariance matrix of the classifiers. Advantageously, that statistical value may be the mean. The calculations performed bycalculator 203 are not only based on the present frame but on previous frames as well.Statistical calculator 203 performs these calculations not only on the basis of the classifiers received for the present frame viapath 106 and the average of the classifiers receivedpath 211 but also on the basis of the weight for each classifiers and a threshold value defining whether a frame is unvoiced or voiced received viapath 213 fromweights calculator 204. -
Weights calculator 204 is responsive to the probabilities, covariance matrix, and statistical values of the classifiers for the present frame as generated bycalculator 203 and received viapath 212 to recalculate the values used as weight vector a, for each of the classifiers and the threshold value b, for the present frame. Then, these new values of a and b are transmitted back tostatistical calculator 203 viapath 213. - Also,
weights calculator 204 transmits the weights and the statistical values for the classifiers in both the unvoiced and voiced regions viapath 214,determinator 205, andpath 208 togenerator 206. The latter generator is responsive to This information to calculate the distance measure which is subsequently transmitted viapath 109 tocomparator 104 as illustrated in FIG. 1. - U/
V determinator 205 is responsive to the information transmitted viapaths path 110 to multiplexer 105 of FIG. 1. - Consider now in greater detail the operation of each block illustrated in FIG. 2 which is now given in terms of vector and matrix mathematics.
Averager 202,statistical calculator 203, andweights calculator 204 implement an improved EM algorithm similar to that suggested in the article by N. E. Day entitled "Estimating the Components of a Mixture of Normal Distributions ", Biometrika, Vol. 56, no. 3, pp. 463-474, 1969. Utilizing the concept of a decaying average,classifier averager 202 calculates the average for the classifiers for the present and previous frames by calculating following equations 1, 2, and 3:


xn is a vector representing the classifiers for the present frame, and n is the number of frames that have been processed up to 2000. z represents the decaying average coefficient, and Xn represents the average of the classifiers over the present and past frames.Statistical calculator 203 is responsive to receipt of the z, xn and Xn information to calculate the covariance matrix, T, by first calculating the matrix of sums of squares and products, Qn, as follows:
After Qn has been calculated, T is calculated as follows:
The means are subtracted from the classifiers as follows:
Next,calculator 203 determines the probability that the frame represented by the present vector xn is unvoiced by solving equation 7 shown below where, advantageously, the components of vector a are initialized as follows: component corresponding to log of the speech energy equals 0.3918606, component corresponding to log of the LPC gain equals -0.0520902, component corresponding to log area ratio of the first reflection coefficient equals 0.5637082, and component corresponding to squared correlation coefficient equals 1. 361249; and b initially equals -8.36454:
After solving equation 7,calculator 203 determines the probability that the classifiers represent a voiced frame by solving the following:
Next,calculator 203 determines the overall probability that any frame will be unvoiced by solving equation 9 for pn:
- After determining the probability that a frame will be unvoiced,
calculator 203 then determines two vectors, u and v, which give the mean values of each classifier for both unvoiced and voiced type frames. Vectors u and v are the statistical averages for unvoiced and voiced frames, respectively. Vector u, statistical average unvoiced vector, contains the mean values of each classifier if a frame is unvoiced; and vector v, statistical average voiced vector, gives the mean value for each classifier if a frame is voiced. Vector u for the present frame is solved by calculating equation 10, and vector v is determined for the present frame by calculating equation 11 as follows:

Calculator 203 now communicates the u and v vectors, T matrix, and probability p toweights calculator 204 viapath 212. -
Weights calculator 204 is responsive to this information to calculate new values for vector a and scalar b. These new values are then transmitted back tostatistical calculator 203 viapath 213. This allowsdetector 103 to adapt rapidly to changing environments. Advantageously, if the new values for vector a and scalar b are not transmitted back tostatistical calculator 203,detector 103 will continue to adapt to changing environments since vectors u and v are being updated. As will be seen,determinator 205 uses vectors u and v as well as vector a and scalar b to make the voicing decision. If n is greater than advantageously 99, vector a and scalar b are calculated as follows. Vector a is determined by solving the following equation:
Scalar b is determined by solving the following equation:
After calculatingequations 12 and 13,weights calculator 204 transmits vectors a, u, and v to block 205 viapath 214. If the frame contained silence only equation 6 is calculated. -
Determinator 205 is responsive to this transmitted information to decide whether the present frame is voiced or unvoiced. If the element of vector (vn - un) corresponding to power is positive, then, a frame is declared voiced if the following equation is true:
or if the element of vector (vn - un) corresponding to power is negative, then, a frame is declared voiced if the following equation is true:
Equation 14 can also be rewritten as:
Equation 15 can also be rewritten as: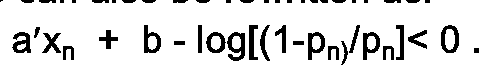
If the previous conditions are not meet,determinator 205 declares the frame unvoiced. Equations 14 and 15 represent decision regions for making the voicing decision. The log term of the rewritten forms of equations 14 and 15 can be eliminated with some change of performance. Advantageously, in the present example, the element corresponding to power is the log of the speech energy. -
Generator 206 is responsive to the information received viapath 214 fromcalculator 204 to calculate the distance measure, A, as follows. First, the discriminant viable, d, is calculated by equation 16 as follows:
Advantageously, it would be obvious to one skilled in the art to use different types of voicing detectors to generate a value similar to d for use in frame following equations. One such detector would be an auto-correlation detector. If the frame is voiced, the equations 17 through 20 are solved as follows:


where m₁ is the mean for voiced frames and k₁ is the variance for voiced frames. - The probability, Pd, that
determinator 205 will declare a frame unvoiced is calculated by the following equation:
Advantageously, Pd is initially set to .5. - If the frame is unvoiced, equations 21 through 24 are solved as follows:



- The probability, Pd, that
determinator 205 will declare a frame unvoiced is calculated by the following equation:
After calculating equation 16 through 22 the distance measure or merit value is calculated as follows:
Equation 25 uses Hotelling's two-sample T² statistic to calculate the distance measure. For equation 25, the larger the merit value the greater the separation. However, other merit values exist where the smaller the merit value the greater the separation. Advantageously, the distance measure can also be the Mahalanobis distance which is given in the following equation:
- Advantageously, a third technique is given in the following equation:

- Advantageously, a fourth technique for calculating the distance measure is illustrated in the following equation:

-
Discriminant detector 102 makes the unvoiced/voiced decision by transmitting information to multiplexer 105 viapath 107 indicating a voiced frame if a′x+b > 0. If this condition is not true, thendetector 102 indicates an unvoiced frame. The values for vector a and scalar b used bydetector 102 are advantageously identical to the initial values of a and b for statisticalvoiced detector 103. -
Detector 102 determines the distance measure in a manner similar togenerator 206 by performing calculations similar to those given in equations 16 through 28. - In flow chart form, FIGS. 3 and 4 illustrate, in greater detail, the operations performed by statistical
voiced detector 103 of FIG.2.Blocks blocks Blocks 304 through 318 implementstatistical calculator 203.Blocks weights calculator 204, and blocks 326 through 338 implementblock 205 of FIG.2.Generator 206 of FIG. 2 is implemented byblock 340.Subtractor 207 is implemented byblock 308 or block 324. -
Block 302 calculates the vector which represents the average of the classifiers for the present frame and all previous frames.Block 300 determines whether speech or silence is present in the present frame; and if silence is present in the present frame, the mean for each classfier is subtracted from each classifier byblock 324 before control is transferred todecision block 326. However, if speech is present in the present frame, then the statistical and weights calculations are performed byblocks 304 through 322. First, the average vector is found inblock 302. Second, the sums of the squares and products matrix is calculated inblock 304. The latter matrix along with the vector X representing the mean of the classifiers for the present and past frames is then utilized to calculate the covariance matrix, T, inblock 306. The mean X is then subtracted from the classifier vector xn inblock 308. -
Block 310 then calculates the probability that the present frame is unvoiced by utilizing the present weight vector a, the present threshold value b, and the classifier vector for the present frame, xn. After calculating the probability that the present frame is unvoiced, the probability that the present frame is voiced is calculated byblock 312. Then, the overall probability, pn, that any frame will be unvoiced is calculated byblock 314. -
Blocks - After execution of
blocks decision block 320. If N is greater than 99, control is transferred to block 322; otherwise, control is transferred to block 326. Upon receiving control, block 322 then calculates a new weight vector a and a new treshold value b. The vector a and value b are used in the next sequential frame by the preceding blocks in FIG. 3. Advantageously, if N is required to be greater than infinity, vector a and scalar b will never be changed, anddetector 103 will adapt solely in response to vectors v and u as illustrated inblocks 326 through 338. -
Blocks 326 through 338 implement u/v determinator 205 of FIG. 2.Block 326 determines whether the power term of vector v of the present frame is greater than or equal to the power term of vector u. If this condition is true, thendecision block 328 is executed. The latter decision block determines whether the test for voiced or unvoiced is met. If the frame is found to be voiced indecision block 328, then the frame is so marked as voiced byblock 330 otherwise the frame is marked as unvoiced byblock 332. If the power term of vector v is less than the power term of vector u for the present frame, blocks 334 through 338 function are executed and function in a similar manner. Finally, block 340 calculates the distance measure. - In flow chart form, FIG. 5 illustrates, in greater detail the operations performed by
block 340 of FIG. 4.Decision block 501 determines whether the frame has been indicated as unvoiced or voiced by examining thecalculations path 507 is selected.Block 510 calculates probability Pd, and block 502 recalculates the mean, m₁, for the voiced frames and block 503 recalculates the variance, k₁, for voiced frames. If the frame was determined to be unvoiced,decision block 501 selectspath 508.Block 509 recalculates probability Pd, and block 504 recalculates mean, m₀, for unvoiced frames, and block 505 recalculates the variance k₀ for unvoiced frames. Finally, block 506 calculates the distance measure by performing the calculations indicated.
Claims (23)
- An apparatus for determining the presence of a voiced sound in frames of speech,having a plurality of independent detecting means (102,103) for detecting said voiced sound in a frame characterised in that
each of the detecting means comprises means (209) for calculating a merit value defining the separation between voiced and unvoiced ones of said frames of speech; and in that said apparatus comprises
means (104,105) for selecting one of said detecting means to indicate the presence of said voiced sound upon the selected one of said detecting means calculating a merit value better than any other one of said detecting means' calculated merit value. - The apparatus of claim 1 wherein said calculating means of each of said detecting means perform a statistical calculation to determine said merit value.
- The apparatus of claim 2 wherein said statistical calculations are distance measurement calculations.
- The apparatus of claim 2 wherein said one of said detecting means comprises means for indicating a frame is voiced upon detecting said voiced sound and indicating a frame is unvoiced upon said voiced sound being absent;
said calculating means for said one of said detecting means further comprises means for determining a discriminant variable for each ones of previous and present frames;
means for determining a mean value for voiced ones of said previous and present frames;
means for determining a variance value of said voiced ones of said previous and present frames;
means for determining a mean value of said unvoiced ones of said previous and present frames;
means for determining a variance value of said unvoiced ones of said previous and present frames; and
means for determining the merit value of said one of said detecting means from the determined voiced mean and variance values and the determined unvoiced mean and variance values. - The apparatus of claim 4 wherein said means for determining the merit value for said one of said detecting means comprises means for summing said variance values;
means for calculating a weighted sum of said variance values;
means for subtracting the mean value of said unvoiced frames from said mean value of said voiced frames;
means for squaring the subtracted value; and
means for dividing said weighted sum by the sum of said squared values, thereby generating said merit value for said one of said detecting means. - The apparatus of claim 5 wherein said means for calculating said weighted sum comprises means for calculating a first probability that said one of said detecting means indicates the presence of said voiced sound in said present frame;
means for calculating a second probability that said one of said detecting means indicates the absence of said voiced sound in said present frame;
means for multiplying said variance of said voiced ones of said previous and present frames by said first probability and said variance of said unvoiced ones of said previous and present frames by said second probability; and
means for forming said weighted sum from the results of said multiplications. - The apparatus of claim 6 wherein said means for dividing comprises means for multiplying the results of the division of said weighted sum by the sum of said squared values by said first and second probabilities to generate said merit value of said one of said detecting means.
- The apparatus of claim 7 wherein said means for indicating said frame is voiced and unvoiced comprises a means responsive to a set of classifiers defining speech attributes of said present frame of speech for calculating a set of statistical parameters;
means responsive to the calculated set of parameters for calculating a set of weights each associated with one of said classifiers; and
means responsive to the calculated set of weights and classifiers and said set of parameters for determining the presence of said voiced sound in said frame of speech. - The apparatus of claim 8 wherein said means for calculating said set of weights comprises means for calculating a threshold value in response to said set of said parameters;
means for communicating said set of weights and said threshold value to said means for calculating said set of statistical parameters to be used for calculating another set of parameters for another one of said frames of speech; and
said means for calculating said set of statistical parameters further responsive to the communicated set of weights and another set of classifiers defining said speech attributes of said other frame for calculating another set of statistical parameters. - An apparatus for determining the presence of a voiced sound in frames of speech, comprising:
first means (102) for generating a first signal indicating the presence of said fundamental frequency in one of said frames of speech;
second means (103) for generating a second signal indicating the presence of said fundamental frequency in said one of said frames of speech; and characterised in that
said first means comprises means for calculating a first generalized distance value representing the degree of separation between voiced and unvoiced frames as determined by said first means;
said second means comprises means (206) for calculating a second generalized distance value representing the degree of separation between voiced and unvoiced frames as determined by said second means; and in that it includes
means (104,105) for selecting said first signal to indicate the presence of said voiced sound upon said first generalized value being better than said second generalized value and for selecting said second signal to indicate the presence of said voiced sound upon said second generalized value being better than said first generalized value. - The apparatus of claim 10 wherein said generalized distance values are the Mahalanobis distance values.
- The apparatus of claim 11 wherein said first means further comprises a means responsive to a set of classifiers defining speech attributes of one frame of speech for calculating a set of statistical parameters;
means responsive to the calculated set of parameters for calculating a set of weights each associated with one of said classifiers; and
means responsive to the calculated set of weights and classifiers and said set of parameters for determining the presence of said voiced sound in said frame of speech. - The apparatus of claim 12 wherein said means for calculating said first generalized distant value comprises means responsive to said calculated set of parameters and said calculated set of weights for determining said first generalized distance value.
- The apparatus of claim 13 wherein said second means is a discriminant voiced detector.
- The apparatus of claim 14 wherein said means for calculating said second generalized distance value comprises means for determining a mean value for voiced ones of said previous and present frames;
means for determining a mean value of said unvoiced ones of said previous and present frames;
means for determining a variance value of said unvoiced ones of said previous and present frames; and
means for determining said second distance measurement value from the determined voiced mean and variance values and the determined unvoiced mean and variance values. - The apparatus of claim 15 wherein said means for determining said second distance measurement value comprises
means for calculating the weighted sum of said variance values;
means for subtracting the mean value of said unvoiced frames from said mean value of said voiced frames;
means for squaring the subtracted value; and
means for dividing said weighted sum of said variance values by the sum of said squared values thereby generating said second distance measurement value. - A method for determining the presence of a voiced sound in frames of speech based on using a first and second voiced detection methods (102,103) for detecting said voiced sound in a frame, characterised by
calculating a first merit value defining the separation between voiced and unvoiced ones of said frames of speech by said first voiced detection method,
calculating a second merit value defining separation between said ones of said voiced and unvoiced frames of speech by said second voiced detection method; and
selecting (104,105) said first voiced detection method to indicate the presence of said voiced sound upon said first merit value being better than said second value and selecting said second voiced detection method to indicate the presence of said voiced sound upon said second merit value being better than said first value. - The method of claim 17 wherein said steps of calculating said first and second values each comprises the step of performing a statistical calculation to determine said first and second values, respectfully.
- The method of claim 18 wherein said statistical calculations are distance measurement calculations.
- The method of claim 18 wherein said method further comprises the steps of indicating a frame is voiced upon detecting said voiced sound and indicating a frame is unvoiced upon said voiced sound being detected as absent by said first voiced detection method
said step of calculating said first value further comprises the steps of determining a discriminant variable for each ones of previous and present frames;
determining a mean value for voiced ones of said previous and present frames;
determining a variance value of said voiced ones of said previous and present frames;
determining a mean value of said unvoiced ones of said previous and present frames;
determining a variance value of said unvoiced ones of said previous and present frames; and
determining said first value from the determined voiced mean and variance values and the determined unvoiced mean and variance values. - The method of claim 20 wherein said step of determining said first value comprises the steps of summing said variance values;
calculating the weighted sum of said variance values;
subtracting the mean value of said unvoiced frames from said mean value of said voiced frames;
squaring the subtracted values; and
dividing said weighted sum of variance values by the sum of said squared variance values thereby generating said statistical value. - The method of claim 21 wherein said step of calculating said weighted sum comprises the steps of calculating a first probability that said said step of determining said first value indicates the presence of said voiced sound in said present frame;
calculating a second probability that said step of determining said first value indicates the absence of said voiced sound in said present frame;
multiplying said variance of said voiced ones of said previous and present frames by said first probability and said variance of said unvoiced ones of said previous and present frames by said second probability; and
forming said weighted sum from the results of said multiplications. - The method of claim 22 wherein said step of dividing comprises the step of multiplying the results of the division of said weighted sum by the sum of said squared values by said first and second probabilities to generate said first value.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| AT88901684T ATE80488T1 (en) | 1987-04-03 | 1988-01-11 | DISTANCE MEASUREMENT CONTROL OF A MULTI-DETECTOR SYSTEM. |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US3429787A | 1987-04-03 | 1987-04-03 | |
| US34297 | 1987-04-03 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP0310636A1 EP0310636A1 (en) | 1989-04-12 |
| EP0310636B1 true EP0310636B1 (en) | 1992-09-09 |
Family
ID=21875527
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP88901684A Expired - Lifetime EP0310636B1 (en) | 1987-04-03 | 1988-01-11 | Distance measurement control of a multiple detector system |
Country Status (8)
| Country | Link |
|---|---|
| EP (1) | EP0310636B1 (en) |
| JP (1) | JPH0795238B2 (en) |
| AT (1) | ATE80488T1 (en) |
| CA (1) | CA1336212C (en) |
| DE (1) | DE3874471T2 (en) |
| HK (1) | HK108993A (en) |
| SG (1) | SG59693G (en) |
| WO (1) | WO1988007740A1 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU696092B2 (en) * | 1995-01-12 | 1998-09-03 | Digital Voice Systems, Inc. | Estimation of excitation parameters |
| JP3670217B2 (en) | 2000-09-06 | 2005-07-13 | 国立大学法人名古屋大学 | Noise encoding device, noise decoding device, noise encoding method, and noise decoding method |
| JP4517045B2 (en) * | 2005-04-01 | 2010-08-04 | 独立行政法人産業技術総合研究所 | Pitch estimation method and apparatus, and pitch estimation program |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60114900A (en) * | 1983-11-25 | 1985-06-21 | 松下電器産業株式会社 | Voice/voiceless discrimination |
| JPS60200300A (en) * | 1984-03-23 | 1985-10-09 | 松下電器産業株式会社 | Voice head/end detector |
| JPS6148898A (en) * | 1984-08-16 | 1986-03-10 | 松下電器産業株式会社 | Voice/voiceless discriminator for voice |
-
1988
- 1988-01-11 DE DE8888901684T patent/DE3874471T2/en not_active Expired - Fee Related
- 1988-01-11 WO PCT/US1988/000123 patent/WO1988007740A1/en active IP Right Grant
- 1988-01-11 JP JP63501560A patent/JPH0795238B2/en not_active Expired - Fee Related
- 1988-01-11 AT AT88901684T patent/ATE80488T1/en active
- 1988-01-11 EP EP88901684A patent/EP0310636B1/en not_active Expired - Lifetime
- 1988-03-29 CA CA000562766A patent/CA1336212C/en not_active Expired - Fee Related
-
1993
- 1993-05-07 SG SG596/93A patent/SG59693G/en unknown
- 1993-10-14 HK HK1089/93A patent/HK108993A/en not_active IP Right Cessation
Non-Patent Citations (2)
| Title |
|---|
| ICASSP 86 Proceedings, IEEE-IECEJ-ASJ International Conference on Acoustics, Speech, and Signal Processing, 7-11 April 1986, Tokyo, Japan, volume 1 of 4, IEEE, (New York, US), D.P. Prezas et al.: "Fast and accurate pitch detection using pattern recognition and adaptive time-domain analysis", pages 109-112 see pages 110, 111: "Final voicing and pitch" * |
| IEEE Transactions on Acoustics, Speech, and Signal Processing, volume ASSP-24, no. 3, June 1976, (New York, US), B.S. Atal et al.: "A pattern recognition approach to voiced-unvoiched-silence classification with applications to speech recognition", pages 201-212 see page 201, right-hand column, lines 14-26 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0310636A1 (en) | 1989-04-12 |
| DE3874471D1 (en) | 1992-10-15 |
| JPH0795238B2 (en) | 1995-10-11 |
| AU1242988A (en) | 1988-11-02 |
| ATE80488T1 (en) | 1992-09-15 |
| HK108993A (en) | 1993-10-22 |
| DE3874471T2 (en) | 1993-02-25 |
| CA1336212C (en) | 1995-07-04 |
| AU602957B2 (en) | 1990-11-01 |
| WO1988007740A1 (en) | 1988-10-06 |
| JPH01502853A (en) | 1989-09-28 |
| SG59693G (en) | 1993-07-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP0335521B1 (en) | Voice activity detection | |
| US6314396B1 (en) | Automatic gain control in a speech recognition system | |
| US6993481B2 (en) | Detection of speech activity using feature model adaptation | |
| JPH0844386A (en) | Detecting method of starting point and end point for word recognition | |
| US4937870A (en) | Speech recognition arrangement | |
| US5046100A (en) | Adaptive multivariate estimating apparatus | |
| US4864307A (en) | Method and device for the automatic recognition of targets from "Doppler" ec | |
| US5007093A (en) | Adaptive threshold voiced detector | |
| US4890328A (en) | Voice synthesis utilizing multi-level filter excitation | |
| US4972490A (en) | Distance measurement control of a multiple detector system | |
| US5806031A (en) | Method and recognizer for recognizing tonal acoustic sound signals | |
| EP0310636B1 (en) | Distance measurement control of a multiple detector system | |
| EP0308433B1 (en) | An adaptive multivariate estimating apparatus | |
| EP0421744B1 (en) | Speech recognition method and apparatus for use therein | |
| EP0309561B1 (en) | An adaptive threshold voiced detector | |
| JP2002258881A (en) | Device and program for detecting voice | |
| AU612737B2 (en) | A phoneme recognition system | |
| JP3373532B2 (en) | Speech analysis method and device | |
| JP3032215B2 (en) | Sound detection device and method | |
| KR100349656B1 (en) | Apparatus and method for speech detection using multiple sub-detection system | |
| JPH067352B2 (en) | Voice recognizer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AT BE DE FR GB IT NL |
|
| 17P | Request for examination filed |
Effective date: 19890328 |
|
| 17Q | First examination report despatched |
Effective date: 19910402 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AT BE DE FR GB IT NL |
|
| REF | Corresponds to: |
Ref document number: 80488 Country of ref document: AT Date of ref document: 19920915 Kind code of ref document: T |
|
| REF | Corresponds to: |
Ref document number: 3874471 Country of ref document: DE Date of ref document: 19921015 |
|
| ET | Fr: translation filed | ||
| ITF | It: translation for a ep patent filed |
Owner name: MODIANO & ASSOCIATI S.R |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: BE Payment date: 20000106 Year of fee payment: 13 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: AT Payment date: 20000330 Year of fee payment: 13 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: AT Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20010111 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20010131 |
|
| BERE | Be: lapsed |
Owner name: AMERICAN TELEPHONE AND TELEGRAPH CY Effective date: 20010131 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20011221 Year of fee payment: 15 |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: IF02 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: NL Payment date: 20020107 Year of fee payment: 15 Ref country code: GB Payment date: 20020107 Year of fee payment: 15 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20020328 Year of fee payment: 15 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20030111 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20030801 Ref country code: DE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20030801 |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee | ||
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20030930 |
|
| NLV4 | Nl: lapsed or anulled due to non-payment of the annual fee |
Effective date: 20030801 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: ST |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20050111 |