EP0179280A2 - Nichtlineare Signalverarbeitung in einem Spracherkennungssystem - Google Patents
Nichtlineare Signalverarbeitung in einem Spracherkennungssystem Download PDFInfo
- Publication number
- EP0179280A2 EP0179280A2 EP85111905A EP85111905A EP0179280A2 EP 0179280 A2 EP0179280 A2 EP 0179280A2 EP 85111905 A EP85111905 A EP 85111905A EP 85111905 A EP85111905 A EP 85111905A EP 0179280 A2 EP0179280 A2 EP 0179280A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- neurotransmitter
- loudness
- frequency band
- neural
- rate
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000012545 processing Methods 0.000 title claims abstract description 9
- 238000010304 firing Methods 0.000 claims abstract description 68
- 230000001537 neural effect Effects 0.000 claims abstract description 41
- 239000002858 neurotransmitter agent Substances 0.000 claims abstract description 40
- 238000000034 method Methods 0.000 claims abstract description 17
- 230000008859 change Effects 0.000 claims description 13
- 238000005259 measurement Methods 0.000 claims description 10
- 230000001419 dependent effect Effects 0.000 claims description 3
- 238000009790 rate-determining step (RDS) Methods 0.000 claims 2
- 230000002269 spontaneous effect Effects 0.000 abstract description 8
- 230000000694 effects Effects 0.000 abstract description 5
- 230000002411 adverse Effects 0.000 abstract 2
- 230000004044 response Effects 0.000 description 16
- 210000000721 basilar membrane Anatomy 0.000 description 11
- 239000013598 vector Substances 0.000 description 9
- 230000006870 function Effects 0.000 description 8
- 238000001914 filtration Methods 0.000 description 5
- 230000014509 gene expression Effects 0.000 description 5
- 230000006872 improvement Effects 0.000 description 5
- 230000001052 transient effect Effects 0.000 description 5
- 238000013459 approach Methods 0.000 description 4
- 210000000860 cochlear nerve Anatomy 0.000 description 4
- 210000005036 nerve Anatomy 0.000 description 4
- 230000007423 decrease Effects 0.000 description 3
- 210000002768 hair cell Anatomy 0.000 description 3
- 210000000067 inner hair cell Anatomy 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000003044 adaptive effect Effects 0.000 description 2
- 210000004556 brain Anatomy 0.000 description 2
- 230000008034 disappearance Effects 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- NJPPVKZQTLUDBO-UHFFFAOYSA-N novaluron Chemical compound C1=C(Cl)C(OC(F)(F)C(OC(F)(F)F)F)=CC=C1NC(=O)NC(=O)C1=C(F)C=CC=C1F NJPPVKZQTLUDBO-UHFFFAOYSA-N 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000036982 action potential Effects 0.000 description 1
- 208000010587 benign idiopathic neonatal seizures Diseases 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 210000000653 nervous system Anatomy 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 231100000656 threshold model Toxicity 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
Definitions
- the elements in the system may be associated in various ways.
- the speaker and acoustic processor may be combined to form an acoustic channel wherein the speaker transforms the text into a speech waveform and wherein the acoustic processor acts as a data transducer and compressor which provides a string of labels to the linguistic decoder.
- the linguistic decoder recovers the original text from the string of labels.
- an acoustic wave input enters an analog-to-digital converter, which samples at a prescribed rate.
- the digital signals are then transformed to frequency spectrum outputs to be processed to produce characteristic labels representing the speech wave input.
- the selection of appropriate features is a key factor in deriving these labels and the present invention relates to improved feature selection means as well as the front end processor and the speech-recognition system in which such feature selection means is included.
- the feature selection element of the present invention responds so as to model the peripheral auditory system, that is, considers the auditory nerve firing rates at selected frequencies as the features which define the acoustic input. While the ear has, in the past, been modelled by others (see “Model for Mechanical to Neural Transduction In the Auditory Receptor” by Hall and Schroeder,
- the present invention incorporates a model based on neural firings in the ear for use as a feature selection element which results in notably enhanced speech recognition relative to prior art systems.
- Schroeder and Hall in the above-noted article, suggest a model for the ear which relates to the transduction of mechanical motion or vibration of the basilar membrane into action potentials or "spikes" in the auditory nerve.
- the Schroeder and Hall model is based on the generation and depletion of electrochemical quanta in a hypothetical hair cell.
- the Schroeder and Hall model involves three features: the fixed rate of generation of quanta of an electrochemical agent, the rate of disappearance of quanta without any neural firing, and the firing probability with no signal.
- the auditory model of the present invention seeks closer conformance with neurophysiological data than conventional threshold models of the ear.
- the present model as implemented employs both a different time scale and a different compressive non-linearity preceding the firing rate computation.
- This new formulation allows macroscopic neural data to be used in setting parameter values, and its output is appropriate for use directly in the front end of a speech recognition system.
- the present model unlike Schroeder and Hall is used in a speech recognition system.
- the implemented model accounts for factors that are not addressed, or are resolved differently, by Schroeder and Hall. For example, with a large dynamic range of speech amplitude inputs, the Schroeder and Hall model provides firing rates that do not appear accurate.
- the model implemented in the present invention overcomes this problem.
- the present invention has as an object improvement in performance of a speech recognition system, by employing in the parameter selection element, an auditory model based on neural firings.
- the present invention employs critical band filtering to reflect the action of the basilar membrane of the ear as a frequency analyzer. That is, like the basilar membrane which experiences increased loudness as two components of an audio input spread to reside in different critical bands, the present invention also preferably provides a response that filters the acoustic wave input according to similar bands.
- the present invention includes an equal loudness adjustment element and a loudness scaling element to achieve normalization.
- the feature selection element achieves the above objects in a speech recognition system and contributes to the realization of large vocabulary recognition in a real-time system that is preferably speaker-trained and preferably of the isolated word variety.
- the present model which achieves the above-noted objects processes the acoustic (speech) wave input by initially digitizing the waveform and then determining waveform magnitude as a function of frequency for successive discrete periods of time.
- the magnitudes are preferably grouped according to critical bands (as with the basilar membrane).
- f a rate of a modelled neurotransmitter
- the rate of change of neurotransmitter for each critical band is viewed as a func- ion of neurotransmitter replenishment -- which is considered to be at a rate Ao -- and neurotransmitter loss.
- the loss in neurotransmitter over time is viewed as having several components: (1) (Sh x n), Sh corresponding to the natural decay or disappearance of neurotransmitter over time independent of acoustic wave input; (2) (So x n) So corresponding to the rate of spontaneous neural firings which occur regardless of acoustic wave input, and (3) DLn corresponding to neural firings as a function of loudness L scaled by a factor D.
- the model is represented by the equations:
- Equations (1) and (2) are defined for each critical frequency band, where t is time.
- the present invention is also concerned with determining the "next state" of the neurotransmitter amount that is to be used in the next determination of firing rate f.
- the next state may be defined by the following equation:
- next state equation (3) and neurotransmitter change equation (1) help define the next value of the firing rate f.
- the firing rate f (for each frequency band) is nonlinear in that it depends multiplicatively on the previous state. This -- as noted above - closely tracks the time adaptive nature of the auditory system.
- the firing rates for the various respective frequency bands together provide the features for speech recognition labelling.
- twenty bands for example, twenty firing rates -- one for each band -- together provide a vector in 20-dimension space that can be entered into the labeller 114 so that vectors corresponding to the acoustic wave input can be matched against stored data and labels generated.
- Equations (4) and (5) constitute a special case output equation and state update equation, respectively, applied to the signal of each critical frequency band during successive frames in time.
- Equation (4) for each frequency band defines a vector dimension for each time frame that is improved over the basic output from equations (1) through (3).
- the performance of a speech recognition system can be improved by adjusting or modifying the values of parameters which affect the feature values.
- testing the system for improvement after each adjustment or modification is a time-consuming process, especially where there are a number of parameters which can be adjusted or modified. It is thus another object of the invention to provide a functional auditory model for use as a feature selection element with as few free parameters as possible.
- the invention thereby permits the model to be adjusted by altering a single parameter to determine how system performance may be changed or improved.
- the single parameter is a ratio defined as:
- R represents the ratio of (a) the steady firing rate when the loudness is at a maximum (e.g. the threshold of feeling) to (b) the steady firing rate when the loudness is at the minimum (e.g. zero).
- R is preferably the only variable of the system which is varied to adjust or modify the parameter.
- a further improvement is proposed wherein the relationship between loudness and intensity is derived from the acoustic input. Specifically, histograms are maintained at each critical frequency band. When a predefined number of filters (at critical frequency bands) have outputs which exceed a given value for a prescribed time, speech is presumed. A threshold-of-feeling and a threshold-of-hearing are then determined for use in loudness normalization based on the histograms during the prescribed time of presumed speech.
- the present invention thus provides an enhanced auditory model and employs it in a speech recognition system.
- the invention relates to a method of processing acoustic wave input in a speech recognition system, the method comprising the steps of: measuring the sound of the acoustic wave input in each of at least one frequency band; determining, in an auditory model, a neural firing rate for and as a function of the measured sound level at each frequency band; representing the acoustic wave input as the neural firing rates determined for the respective frequency bands; determining, for each frequency band, the current amount of neurotransmitter available for neural firing; and determining, for each frequency band, a rate of change of neurotransmitter based on (a) a replenishment constant that represents the rate at which neurotransmitter is produced and (b) the determined neural firing rate for the respective frequency band; the neural firing rate being dependent on the amount of neurotransmitter available for neural firing, the amount of neurotransmitter available for neural firing in the next state being based on the amount of neurotransmitter available
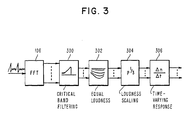
- FIG. 1 a specific embodiment of an acoustic processor 100 is illustrated.
- An acoustic wave input e.g., natural speech
- enters an analog-to-digital converter 102 which samples at a prescribed rate.
- a typical sampling rate is one sample every 50 microseconds.
- a time window generator 104 is provided to shape the edges of the digital signal.
- the output of the window 104 enters a fast fourier transform (FFT) element 106 which provides a frequency spectrum output for each time window.
- FFT fast fourier transform
- the output of the FFT element 106 is then processed to produce labels L,L,---L, .
- prototypes are defined as points (or vectors) in the space based on selected features and acoustic inputs and are then characterized by the same selected features to provide corresponding points (or vectors), in space that can be compared to the prototypes.
- cluster element 110 sets of points are grouped together as respective cluster by cluster element 110.
- a prototype of each cluster -- relating to the centroid or other characteristic of the cluster -- is generated by the prototype element 112.
- the generated prototypes and acoustic input -- both characterized by the same selected features -- enter the labeller 114.
- the labeller 114 performs a matching procedure.
- the conventional audio channel typically provides a plurality of parameters which may be adjusted in value to after performance.
- To examine changes in performance in response to parameter variations requires that the entire acoustic processor 100 be run which typically takes a day.
- the design philosophy of the present invention is to provide an acoustic processor 100 that has a minimal number of adjustable parameters to facilitate performance improvement.
- an auditory model is derived and applied in an acoustic processor of a speech recognition system.
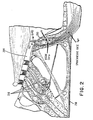
- FIG. 2 shows part of the inner human ear.
- an inner hair cell 200 is shown with end portions 202 extending therefrom into a fluidcon- taining channel 204.
- outer hair cells 206 also shown with end portions extending into the channel 204.
- nerves which convey information to the brain.
- nerve neurons undergo electrochemical changes which result in electrical impulses being conveyed along a nerve to the brain for processing. Effectuation of the electrochemical changes, is stimulated by the mechanical motion of the basilar membrane 210.
- the basilar membrane 210 serves as a frequency analyzer for acoustic waveform inputs and that portions along the basilar membrane 210 respond to respective critical frequency bands. That different portions of the basilar membrane 210 respond to corresponding frequency bands has an impact on the loudness perceived for an acoustic waveform input That is, the loudness of tones is perceived to be greater when two tones are in different critical frequency bands than when two tones of similar power intensity occupy the same frequency band. It has been found that there are on the order of twenty-two critical frequency bands defined by the basilar membrane 210.
- the present invention in its preferred form physically defines the acoustic waveform input into some or all of the critical frequency bands and then examines the signal component for each defined critical frequency band separately. This function is achieved by appropriately filtering the signal from the FFT element 106 (see FIG. 1) to provide a separate signal in the feature selection element 108 for each examined critical frequency band.
- the feature selection element 108 preferably includes twenty-two signals -- each of which represents sound intensity in a given frequency band for one frame in time after another.
- the filtering is preferably performed by a conventional critical band filter 300 of FIG. 3.
- the separate signals are then processed by an equal loudness converter 302 which accounts for perceived loudness variations as a function of frequency.
- the converter 302 can be based on empirical data, converting the signals in the various frequency bands so that each is measured by a similar loudness scale.
- the converter 302 can map from acoustic power to equal loudness based on studies of Fletcher and Munson in 1933, subject to certain modifications. The modified results of these studies are depicted in FIG. 4 .
- a 1 KHz tone at 40dB is comparable in loudness level to a 100Hz tone at 60dB as shown by the X in the figure.
- the converter 302 adjusts loudness preferably in accordance with the contours of FIG. 4 to effect equal loudness regardless of frequency.
- loudness scaling element 304 which compresses loudness in a predefined fashion.
- the loudness scaling element compresses power P by a cube-root factor to p 1/3 by replacing loudness amplitude measure in phons by sones.
- FIG. 5 illustrates a known representation of phons versus sones determined empirically. By employing sones, the present model remains substantially accurate at large speech signal amplitudes.
- One sone, it should be recognized, has been defined as the loudness of a 1 KHz tone at 40dB.
- a novel time varying response element 306 which acts on the equal loudness, loudness scaled signals associated with each critical frequency band.
- a neural firing rate f is determined at each time frame.
- the firing rate f is defined in accordance with the invention as: where n is an amount of neurotransmitter; So is a spontaneous firing constant which relates to neural firings independent of acoustic waveform input L is a measurement of loudness; and D is a displacement constant. So x n corresponds to the spontaneous neural firing rate which occurs whether or not there is an acoustic wave input and DLn corresponds to the firing rate due to the acoustic wave input
- Equation (8) also reflects the fact that the present invention is non-linear in that the next amount of neurotransmitter and the next firing rate are dependent multiplicatively on the current conditions of at least the neurotransmitter amount. That is, the amount of neurotransmitter at a state (t+ ⁇ t) is equal to the amount of neurotransmitter at a state t plus dn/dt, or
- Equations (7), (8), and (9) describe a time varying signal analyzer which, it is suggested, addresses the fact that the auditory system appears to be adaptive over time, causing signals on the auditory nerve to be non-linearly related to acoustic wave input.
- the present invention provides the first model which embodies non-linear signal processing in a speech recognition system, so as to better conform to apparent time variations in the nervous system.
- ⁇ is a measure of the time it takes for an auditory response to drop to 37% of its maximum after an audio wave input is generated.
- So and Sh are defined by equations (12) and (13) as: where f steady scate
- a threshold-of-feeling T f and a threshold-of-hearing T h are initially defined for each filtered frequency band m to be 120dB and OdB respectively. Thereafter, a speech counter, total frames register, and a histogram register are reset.
- a frame from the filter output of a respective frequency band is examined and bins in the appropriate histograms -one per filter -- are incremented.
- the total number of bins in which the amplitude exceeds 55dB are summed for each filter (i.e. frequency band) and the number of filters indicating the presence of speech is determined. If there is not a minimum of filters (e.g. six of twenty) to suggest speech, the next frame is examined. If there are enough filters to indicate speech, a speech counter is incremented. The speech counter is incremented until 10 seconds of speech have occurred whereupon new values for T f and T h are defined for each filter.
- T f and T h values are determined for a given filter as follows.
- T f the dB value of the bin holding the 35th sample from the top of 1000 bins (i.e. the 96.5th percentile of speech) is defined as BIN H .
- T h the dB value of the bin holding the (.01) (TOTAL BINS - SPEECH COUNT) th value from the lowest bin is defined as BIN L . That is, BIN L is the bin in the histogram which is 1 % of the number of samples in the histogram excluding the number of samples classified as speech.
- the sound amplitudes are converted to sones and scaled based on the updated thresholds as described hereinbefore.
- An alternative method of deriving sones and scaling is by taking the filter amplitudes "a" (after the bins have been incremented) and converting to dB according to the expression:
- Each filter amplitude is then scaled to a range between 0 and 1 20 to provide equal loudness according to the expression:
- the loudness in sones L s is then provided as input to the equations (7) and (8) to determine the output firing rate f for each frequency band.
- a twenty-two dimension vector characterizes the acoustic wave inputs over successive time frames.
- twenty frequency bands are examined by employing a mel-scaled filter bank defined by FIG. 8.
- the acoustic processor hereinbefore described is subject to improvement in applications where the firing rate f and neurotransmiter amount n have large DC pedestals. That is, where the dynamic range of the terms of the f and n equations is important, the following equations are derived to reduce the pedestal height
- equation (8) can be solved for a steady-state internal state - n:
- So x n is a constant, while all other terms include either the varying part of n or the input signal represented by (D x L). Future processing will involve only the squared differ ences between output vectors, so that constant terms may be disregarded. Including equation (19) for n, we get
- equations for f, dn/dt, and n(t + 1 ) are replaced by equations (17) and (22) which define special case expressions for firing rate f and next state n (t+ A t) respectively.
- the auditory model of the invention embodies, in preferred form, the following characteristics:
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
- Circuit For Audible Band Transducer (AREA)
- Soundproofing, Sound Blocking, And Sound Damping (AREA)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US66540184A | 1984-10-26 | 1984-10-26 | |
| US665401 | 1984-10-26 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP0179280A2 true EP0179280A2 (de) | 1986-04-30 |
| EP0179280A3 EP0179280A3 (en) | 1987-07-15 |
| EP0179280B1 EP0179280B1 (de) | 1990-04-25 |
Family
ID=24669962
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP19850111905 Expired EP0179280B1 (de) | 1984-10-26 | 1985-09-20 | Nichtlineare Signalverarbeitung in einem Spracherkennungssystem |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP0179280B1 (de) |
| JP (1) | JPS61126600A (de) |
| CA (1) | CA1222320A (de) |
| DE (1) | DE3577364D1 (de) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100571574B1 (ko) * | 2004-07-26 | 2006-04-17 | 한양대학교 산학협력단 | 비선형 분석을 이용한 유사화자 인식방법 및 그 시스템 |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1333300C (en) * | 1987-04-03 | 1994-11-29 | Jont Brandon Allen | Speech analysis arrangement |
| CN109477904B (zh) | 2016-06-22 | 2020-04-21 | 休斯敦大学系统 | 地震或声波频散的非线性信号比较和高分辨率度量 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3211832A (en) * | 1961-08-28 | 1965-10-12 | Rca Corp | Processing apparatus utilizing simulated neurons |
| US4536844A (en) * | 1983-04-26 | 1985-08-20 | Fairchild Camera And Instrument Corporation | Method and apparatus for simulating aural response information |
-
1985
- 1985-05-23 CA CA000482183A patent/CA1222320A/en not_active Expired
- 1985-09-20 EP EP19850111905 patent/EP0179280B1/de not_active Expired
- 1985-09-20 DE DE8585111905T patent/DE3577364D1/de not_active Expired - Lifetime
- 1985-09-26 JP JP21122985A patent/JPS61126600A/ja active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100571574B1 (ko) * | 2004-07-26 | 2006-04-17 | 한양대학교 산학협력단 | 비선형 분석을 이용한 유사화자 인식방법 및 그 시스템 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0179280B1 (de) | 1990-04-25 |
| CA1222320A (en) | 1987-05-26 |
| DE3577364D1 (de) | 1990-05-31 |
| JPS61126600A (ja) | 1986-06-14 |
| EP0179280A3 (en) | 1987-07-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US5054085A (en) | Preprocessing system for speech recognition | |
| Ghitza | Temporal non-place information in the auditory-nerve firing patterns as a front-end for speech recognition in a noisy environment | |
| US4905285A (en) | Analysis arrangement based on a model of human neural responses | |
| Strope et al. | A model of dynamic auditory perception and its application to robust word recognition | |
| US5381512A (en) | Method and apparatus for speech feature recognition based on models of auditory signal processing | |
| US5621854A (en) | Method and apparatus for objective speech quality measurements of telecommunication equipment | |
| KR940009391B1 (ko) | 잡음 억제 시스템 | |
| US5794188A (en) | Speech signal distortion measurement which varies as a function of the distribution of measured distortion over time and frequency | |
| EP0856961B1 (de) | Testen von Nachrichtenübertragungsgerät | |
| CA2225407C (en) | Assessment of signal quality | |
| Zolfaghari et al. | Formant analysis using mixtures of Gaussians | |
| Combrinck et al. | On the mel-scaled cepstrum | |
| EP0248593A1 (de) | Vorverarbeitungssystem zur Spracherkennung | |
| US5768474A (en) | Method and system for noise-robust speech processing with cochlea filters in an auditory model | |
| EP0179280B1 (de) | Nichtlineare Signalverarbeitung in einem Spracherkennungssystem | |
| US5944672A (en) | Digital hearing impairment simulation method and hearing aid evaluation method using the same | |
| Alku et al. | On the linearity of the relationship between the sound pressure level and the negative peak amplitude of the differentiated glottal flow in vowel production | |
| Kasper et al. | Exploiting the potential of auditory preprocessing for robust speech recognition by locally recurrent neural networks | |
| KR0185310B1 (ko) | 디지털 난청 시뮬레이션 방법 | |
| Gajic | Auditory based methods for robust speech feature extraction | |
| van Wieringen et al. | PERCEPTUAL ASYMMETRY BETWEEN INITIAL AND FINAL GLIDES: PSYCHO ACOUSTICS AND COCHLEAR ENCODING | |
| Haque et al. | An auditory motivated asymmetric compression technique for speech recognition | |
| Dologlou et al. | Comparison of a model of the peripheral auditory system and LPC analysis in a speech recognition system | |
| Houshang et al. | Stimulus signal estimation from auditory-neural transduction inverse processing. | |
| Liu et al. | Modeling of three types of auditory nerve and its application in speech recognition |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): CH DE FR GB IT LI NL |
|
| 17P | Request for examination filed |
Effective date: 19860819 |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): CH DE FR GB IT LI NL |
|
| 17Q | First examination report despatched |
Effective date: 19890405 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): CH DE FR GB IT LI NL |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Effective date: 19900425 |
|
| REF | Corresponds to: |
Ref document number: 3577364 Country of ref document: DE Date of ref document: 19900531 |
|
| ET | Fr: translation filed | ||
| ITF | It: translation for a ep patent filed | ||
| NLV1 | Nl: lapsed or annulled due to failure to fulfill the requirements of art. 29p and 29m of the patents act | ||
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LI Effective date: 19900930 Ref country code: CH Effective date: 19900930 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| ITTA | It: last paid annual fee | ||
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 19920904 Year of fee payment: 8 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 19920925 Year of fee payment: 8 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 19930826 Year of fee payment: 9 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 19940531 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Effective date: 19940601 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: ST |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Effective date: 19940920 |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 19940920 |