CN1223991C - 声频信号处理设备及方法 - Google Patents
声频信号处理设备及方法 Download PDFInfo
- Publication number
- CN1223991C CN1223991C CNB028129784A CN02812978A CN1223991C CN 1223991 C CN1223991 C CN 1223991C CN B028129784 A CNB028129784 A CN B028129784A CN 02812978 A CN02812978 A CN 02812978A CN 1223991 C CN1223991 C CN 1223991C
- Authority
- CN
- China
- Prior art keywords
- sequence
- audio signal
- sampling
- window
- processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000012545 processing Methods 0.000 title claims abstract description 53
- 230000005236 sound signal Effects 0.000 title claims abstract description 42
- 238000000034 method Methods 0.000 title claims description 53
- 238000005070 sampling Methods 0.000 claims description 83
- 230000008569 process Effects 0.000 claims description 16
- 230000009467 reduction Effects 0.000 claims description 16
- 230000004048 modification Effects 0.000 claims description 15
- 238000012986 modification Methods 0.000 claims description 15
- 230000008030 elimination Effects 0.000 claims description 8
- 238000003379 elimination reaction Methods 0.000 claims description 8
- 230000003595 spectral effect Effects 0.000 claims description 5
- 230000009466 transformation Effects 0.000 claims description 4
- 230000001360 synchronised effect Effects 0.000 abstract description 8
- 230000011218 segmentation Effects 0.000 abstract description 6
- 238000006243 chemical reaction Methods 0.000 description 10
- 230000006870 function Effects 0.000 description 9
- 238000005516 engineering process Methods 0.000 description 7
- 238000001228 spectrum Methods 0.000 description 7
- 238000004891 communication Methods 0.000 description 6
- 238000000465 moulding Methods 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 238000004590 computer program Methods 0.000 description 4
- 238000005457 optimization Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 3
- 230000014509 gene expression Effects 0.000 description 3
- 230000003044 adaptive effect Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000005055 memory storage Effects 0.000 description 2
- 238000004833 X-ray photoelectron spectroscopy Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000005265 energy consumption Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000003672 processing method Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0212—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using orthogonal transformation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Telephone Function (AREA)
- Stereo-Broadcasting Methods (AREA)
- Input Circuits Of Receivers And Coupling Of Receivers And Audio Equipment (AREA)
- Signal Processing Not Specific To The Method Of Recording And Reproducing (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Noise Elimination (AREA)
- Soundproofing, Sound Blocking, And Sound Damping (AREA)
- Stereophonic System (AREA)
Abstract
声频信号处理方法。本发明涉及声频信号处理方法,它包括:源声频信号的第一处理步骤(205),所述步骤对第一取样序列实施至少一次数学变换,所述第一取样序列是第一分割窗口(505,506,700,701)应用在所述源声频信号上而获得的;及第二声音处理步骤(206),所述步骤应用在第二取样序列上,所述取样序列是第二分割窗口(507,508)应用在所述第一步骤时发出的信号上而获得,所述第二分割窗口不同于所述第一分割窗口;两连续第一窗口及/或两连续第二窗口交迭,所述交迭即表示各分割是同步的。
Description
技术领域
本发明涉及声频信号处理领域。
更准确地说,本发明尤其涉及降低或消除由数字通讯设备例如数字电话及/或免提型移动无线电话处理的声频信号中夹杂的噪声。
背景技术
当声音数字通讯设备应用在噪声环境中(一般乘车时),所述噪声环境会极大干扰声频信号,从而降低通讯的质量。
根据已知技术,利用插入一噪声衰减器或抑制器——所述装置在对声频信号作特殊处理前,作用于麦克风捕捉到的信号——来解决这一问题。
根据第一已知技术,在捕捉声频信号的麦克风和声频信号处理装置之间插入一回声或噪声衰减或降低装置。所述装置提高了有用信号与噪声的比率,或减少回声,以使随后信号可在最佳条件下被处理。但所述现有技术必需一专门的特殊装置,这样既增加了成本,又加大了使用的复杂性。
根据第二已知技术,基于使用快速傅里叶变换(英文FFT即“Fast Fourier Tranform”)的降低噪声功能集成在数字通讯装置中,所述FFT应用于连续的声音取样流。首先,取样流被格式窗分割成256个取样的窗口,窗口的一半交迭在一起(一窗口的第一128个取样对应于前一窗口的后128个取样)。FFT应用于各窗口,FFT的结果再通过噪声或回声降低或消除函数进行处理。
所述函数结果再由逆快速傅里叶变换(即IFFT)进行处理,以复原声音取样流,使其能被声音处理函数处理。
所述现有技术的缺点在于实施相对比较复杂。
发明内容
根据其不同特征,本发明的目的尤其在于弥补现有技术的所述缺陷。
更准确地说,本发明的一目的在于,提供一种声音处理方法及装置,它可降低基于数学变换的处理的复杂性,所述数学变换应用在数据块上,同时使应用于声频帧的声音处理效果达到最佳。
本发明的另一目的在于,使基于数学变换的处理及声频处理的集成处理最佳。
本发明的目的还在于最佳化所述处理时间。
本发明的另一目的在于降低所述处理所必需的计算容量。
为此,本发明提出一种声频信号处理方法,它包括:
——源声频信号的第一处理步骤,所述第一处理步骤对第一取样序列实施至少一次数学变换,所述取样序列是第一分割窗口应用在源声频信号上而获得的;及
——第二声音处理步骤,所述第二处理步骤应用在第二取样序列上,所述取样序列是第二分割窗口应用在第一步骤时发出的信号上而获得的,所述第二分割窗口不同于第一分割窗口;
其特征在于,两连续第一窗口及/或两连续第二窗口交迭,所述交迭即表示分割是同步的。
因此,声频处理步骤可连续实施或在一多任务环境中实施。另外,所述实施由于使用了尺寸可预测、准确且经济的存储器而简化了。
根据一特别特征,所述方法的特征在于,第二分割窗口是连续帧。
因此,根据本发明,所述处理方法的处理时间最佳化了。
根据一特别特征,所述方法的特征在于,第一序列的最后一个取样,经过第一步骤后,也是相应的第二序列的最后一个取样。
因此,第二声频处理步骤最好在没有无效等待中实施,以优化总的声音处理时间。
根据一特别特征,所述方法的特征在于,各第一分割窗口为完全重建窗口,它是通过卷积(convolution)以下窗口获得的:
——第一中间完全重建窗口,——所述窗口具有适合数学变换的频谱特性;及
——第二中间矩形窗口。
因此,第一分割窗口的交迭部分为完全重建型,这可使在相对简单的第一处理过程中,能重新组合信号。
另外,由于第一中间窗口适合数学变换(尤其可衰减相对强的窗口的旁瓣,而主瓣仍是平的),提高了相应处理质量。
此外,第二中间窗口为矩形状,相应取样处理简单而有效。
根据一特别特征,所述方法的特征在于,应用于各第一序列的第一处理步骤还包括:
——应用于第一序列的预定处理子步骤;
——应用于第一序列的已处理取样的逆数学变换子步骤;
——相加来自应用于第一序列的相反数学变换子步骤的声音取样和来自应用于前第一步骤的逆数学变换子步骤的相应的声音取样。
根据一特别特征,所述方法的特征在于,预定处理子步骤包括降低或消除声频信号中的噪声。
根据一特别特征,所述方法的特征在于,预定处理子步骤包括至少一种处理,所述处理属于一组,所述组包括:
——降低或消除声频信号内的回声;
——识别声频信号内的声音。
因此,有利地是,所述方法在一装置(如电话、个人计算机或遥控系统)中,把如降低及/或消除噪声及/或回声及/或声音识别结合在一起,这样既降低了复杂性,又优化了所述处理的功效及/或装置的高集成性(因而降低了成本,减少了能量消耗,这些尤其对使用电池作动力的通信设备来说,相对更高)。
根据一特殊特征,所述方法的特征在于,所述数学变换属于这样一组,所述组包括:
——快速傅里叶变换(FFT)及其变型;
——快速哈达马特变换(FHT)及其变型;及
——离散余弦变换(DCT)及其变型。
因此,有利地是,本发明可使用一种或多种适合第一声频处理的数学变换,所述变换可应用在和第二分割窗口尺寸不同的尺寸的数据块上。
根据一特殊特征,所述方法的特征在于,源声频信号为一声频信号。
因此,本发明还适用于第二声频处理,当它专门针对语音如,语音编码(“声码处理”)及/或语音压缩,以进行存储及/或远距离传输时。
本发明还涉及一声频信号处理装置,它包括:
——源声频信号的第一处理装置,它对第一取样序列实施至少一次数学变换,所述第一取样序列是第一分割窗口应用在源声频信号上而获得的;及
——第二声频处理装置,它应用在第二取样序列上,所述第二取样序列是由第二分割窗口应用在第一步骤时发出的信号上而获得的,所述第二分割窗口不同于第一分割窗口;
其特征在于,两连续第一窗口及/或两连续第二窗口交迭,所述交迭即表示分割是同步的。
另外,本发明还涉及一计算机程序产品,所述程序产品包括程序元件,这些元件记录在由至少一微处理器可读的介质上,其特征在于,程序元件控制一个或多个微处理器,以使其执行:
——源声频信号的第一处理步骤,对第一取样序列实施至少一次数学变换,所述第一取样序列是第一分割窗口应用在声频源信号上而获得的;及
——第二声频处理步骤,它应用在第二取样序列上,所述第二取样序列是第二分割窗口应用在第一步骤时发出的信号上而获得,所述第二分割窗口不同于第一分割窗口;
两连续第一窗口及/或连续第二窗口交迭,所述交迭即表示分段是同步的。
另外,本发明还涉及一计算机程序产品,其特征在于,所述程序包括指令系列,当所述程序在计算机上执行时,所述系列指令可实施声频处理方法。
声频信号处理装置、计算机程序产品的优点与声频信号处理方法的优点相同,这里就不再详述了。
附图说明
本发明的其它特征和优点将在后文参照附图、以非限制性方式描述一最佳实施例中体现出来。附图中:
——图1示出了根据一特别实施例的符合本发明的一无线电话机的总框架图;
——图2示出了图1中的无线电话机对一声频信号实施的连续处理;
——图3示出了根据图2的降低或消除噪声算法;
——图4示出了根据图2的声音处理应用于一帧;
——图5描述了如图3、4的处理所实施的取样流窗口化;
——图6示出了一已知成型窗口;
——图7示出了一成型窗口,所述窗口最佳化,并运用在根据本发明一最佳实施例的图3的窗口化操作中;及
——图8详细描述了图3中所示的一降低噪声型处理。
具体实施方式
本发明的基本原理即以下处理的同步:
——基于FFT的处理,尤其消除或降低噪声处理;及
——语音编码型声音处理。
事实上,FFT(快速傅里叶变换算法)与IFFT处理窗口包括有2的整数次方个取样(一般为128或256)。
相反地,语音编码考虑到了大小不同的窗口(通常,GSM领域内的声音处理考虑160取样窗口)。
例如,若为符合ETSI(“European TelecommunicationStandard Institute”)公布的GSM标准的无线电话,声音信号在以每帧20ms的压缩形式传输给用户前,在8千赫兹频率被采样。
可看出,根据GSM标准,语音编码由一声码器在160取样帧上实施。所述编码是所需速率的函数,下列文件尤其专门描述过它:
——《Full Rate(FR)speech transcoding》(GSM06.10)(《全速率语音代码转换》)
——《Half Rate(HR)speech transcoding》(GSM06.20)(《半速率语音代码转换》)
——《Enhanced Full Rate(EFR)speech transcoding》(GSM06.60)(《增强的全速率语音代码转换》);及
——《Adaptive Multi-Rate(AMR)speech transcoding》(GSM06.90)(《自适应多速率语音代码转换》)
根据目前技术现状,通过考虑一已作声音处理的160取样窗口,噪声及/或回声降低或消除装置处理一256长度的窗口,所述窗口可分段成长度160的三个窗口。其中,现有技术固有的异步性使得这些处理变得复杂,还必需大尺寸存储器、计算容量及/或DSP(用于计算的Processeur de Traitement de Signal,数字信号处理器)时钟。
根据本发明,可系统地使一噪声及/或回声消除或降低窗口的末端与声音处理帧、最好与声音处理帧的末端重合,以使两类处理同步。因此,如果噪声降低或消除窗口的尺寸等于256取样,如果声音处理帧的尺寸等于160取样,则回声降低或消除窗口会包含一完整声音处理帧及前一窗口的96取样(即256减去160)。
因此,可保持噪声降低或消除窗口与声音处理帧之间的同步性,最佳化总处理时间。
根据本发明,成型窗口(适合于有关160点的取样帧及256点的FFT)最好:
——为完全重建型,即两窗口重合的振幅和等于1(在重叠部分上);
——长度256的窗口各侧有96的长度重合。
例如,这种窗口可通过把宽度97的Hanning窗口(记作Hanning(97))与长度160的矩形窗口(记作Rect(160))卷积(convolution)而获得。
因此,一256点FFT可应用在与160取样帧上同步的各256取样窗口。FFT的实施已为本领域技术人员熟知,尤其在PressW.H.、Teukolsky S.A.、Vetterling W.T.及Flannery B.P.撰写的书籍《Numerical Recipes in C,2nd edition》(《C语言数字方法,第二版》)(1992年由剑桥大学出版社出版)中详细讲述过。
在实施逆变换(记作IFFT)前,可把本领域技术人员已知的各种降低噪声算法运用在所述256取样块上。
因此,256取样块连续被处理。IFFT后,当前窗口已处理的前96个取样再添加在前一窗口已处理的后96个取样中。添加后,当前窗口的前160个取样被传输给声码器,以根据本领域人员已知的语音编码方法、必要时符合已实施标准,进行处理。
图1示出了实施本发明的一无线电话。
图1简略示出了根据一最佳实施例的符合本发明的无线电话的总框架图。
无线电话100包括以下各元件,所述各元件之间通过一地址及数据总线103连接起来:
——麦克风107;
——模拟/数字转换器108;
——扬声器109;
——数字/模拟转换器110;
——信号处理器(DSP)104;
——非易失存储器105;
——随机存储器106;
——无线接口111;
——数据帧交换和协议的管理及控制单元112;及
——人/机接口(一般为一键盘和一屏幕)113。
图1所示各元件为本领域技术人员已知。所以此处就不再描述这些共同元件了。
还可看出,整个说明书所使用的词《寄存器》在所有所述存储器中,既指一低容量(几个二进制数据)存储区,也指一高容量存储区(可储存整个程序或所有事务处理数据序列)。
非易失存储器105(即ROM)在寄存器中,出于方便考虑,仍使用和它们保存的数据相同的名,它们保存:
——在《prog》寄存器308中,DSP 104的运行程序;
——值L(一般为256),它表示第一分割窗口尺寸,所述窗口尺寸与寄存器115中FFT所考虑的点数相对应;
——值L’(一般为160),它表示第二窗口尺寸,所述窗口尺寸和寄存器115中声码器处理的帧的尺寸相对应;及
——值α、β、γ、κ与βf,它们表示信号中噪声的降低。
随机存储器106保存数据、变量及中间处理结果,尤其包括:
——寄存器117,其中保存着已接收信号的噪声取样值;
——寄存器118,其中保存着已处理取样值;及
——用于声码器的已处理取样序列。
DSP尤其适合傅里叶变换与语音编码型处理。例如,可使用由《DSP GROUP》(注册商标)公司生产的DSP芯,以《OAK》(注册商标)标识。
图2示出了图1的无线电话对声音信号实施的连续处理。
可看出,进入麦克风107的信号为下列之和203:
——一声音信号,所速声音信号可能受到回声干扰(以发生信号200与发生延迟信号之和标记);及
——一噪声202
麦克风107捕捉到的带噪声的信号被传送给模拟/数字转换器204,此处,步骤204中,它将其变换成数字取样序列。根据GSM标准,可看出,采样一般在8千赫兹的频率上。
步骤205中,处理数字取样序列。
步骤206中,已处理取样帧L’(160)由声码器根据一已知方法(一般在GSM标准中规定)进行编码。
步骤207中,已“声码处理的”帧通过单元112格式化(成型),再由无线模块111根据已知技术(例如根据GSM标准)传输。
图3示出了图2中处理步骤205中实施的噪声消除或降低算法。
启动步骤300中,DSP 104在RAM 106中,初始化第一96取样块为0,它对应于所接收的最后取样及处理205良好运行所必需的变量。
步骤301中,DSP 104在前面接收的取样后,把来自转换器108的160个输入取样序列存储在RAM 106中。
步骤302中,DSP 104把长度256的分段窗口应用于已接收的最后256取样形成的序列。(可看到,所述窗口将在后文参照图7进行描述)
于是,256点的FFT型数学变换,可运用在通过应用分段窗口而获得的序列中。
步骤303中,噪声降低型处理(后文将参照图8进行描述)应用于数学变换产生的序列。
步骤304中,步骤302中变换的逆IFFT型变换应用在已处理序列中。
步骤305中,必要时(即第一次重复后),DSP 104把前面已处理的序列的后96个取样添加在当前序列的已处理的前96个取样中。
步骤306中,当前已处理前160个取样形成的序列或帧传输给声码器。
步骤307中,把和步骤305中被传输160个取样相对应的已接收160个取样从存储器106中抹去。
重复步骤301。
图4示出了图2的步骤206所实施的语音编码。
初始化步骤400中,DSP 104在RAM 106中初始化编码206良好运行所必需的所有变量。
步骤401中,DSP 104把步骤307中已传输的106取样帧存储在RAM 106中。
步骤402中,DSP 104根据一已知技术,把语音编码处理应用在160个取样帧中。
步骤403中,已编码帧被格式化,传输给单元102,以发送给收信方。
步骤404中,160取样帧从存储器RAM 106中抹去。
重复步骤401。
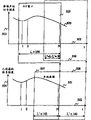
图5描述了如图3、4的处理所实施的取样序列的窗口化。
第一图描画出了作为时间t502的函数的,由转换器108直接接收到的信号强度503的曲线500。
第二图描画出了作为时间t502的函数的,步骤205中已处理的信号强度504的曲线500。
从第一图中可看出,时间被分割成长度L为256的两连续窗口505、506,所述两窗口在长度为96的L”上交迭且在步骤302中获得。
从第二图中还可看出,时间被分割成长度为160的L’的两连续帧507、508,它们没有交迭,且在传输步骤306中获得。
信号分段是这样的:窗口505(或506)与507(或502)完全同步。
因此,根据最佳实施方式,窗口505(或506)与507(或502)在处理前后(根据步骤303、304及305)在同一取样上结束。
采用这种方式,在长度L”上是交迭的。
图6示出了一已知成型窗口。
图中给出作为取样序列601的函数的长度为256且重叠128的Hanning窗口603、604。
可看出,根据所述已知分段,窗口无论如何都不可能与160个取样帧分段同步。
图7示出了根据本发明已优化的已成型窗口700、701(分别对应图5的窗口505、506,但更准确)。
和上述的一样,图中给出作为取样601函数的窗口振幅602。
可看出,窗口700、701为Hanning窗口,所述窗口是通过把长度97的中间Hanning窗口与长度160的矩形窗口卷积而形成。因此,通过160个取样的窗口的连续偏移,可获得完全重建窗口。
图8详细描述了图3中所示的噪声降低型处理步骤303。
所述噪声降低处理尤其在下列文件中描述过:
——《Spectral substration based on minimum statistics》(《基于最小统计的频谱扣减),作者R.Martin,发表在《SignalProcessing VII:Theories and applications,1994,EURASIP》,1182至1185页;
——《Computationally efficient speech enhancement byspectral minima tracking in subbands》(《通过研究分波段里的频谱最小值,提高用于计算的有效声音》),作者G.DOBLINGER,发表在大会《ESCA.EUROPSPEECH’95,4th European Conference onspeech communication and technology》的报告(第1513至1516页);及
——《A combination of noise reduction and improved echocancellation》(《改善的噪声降低及回声消除法》),由Darmstadt技术大学以德语发表在《Fachgebiet Theorie der Signale》上。
经步骤302处理后,包括256频谱分量的帧801——对应一带噪声声音信号——可根据后面所述的处理303进行处理。
用Xk(m)表示第m个带噪声声音信号帧的第k个分量。
步骤802中,DSP 104把直角坐标帧801的分量转换为极坐标的,以把相位与频谱振幅分离开。
在不同处理过程中,只有频谱振幅会改变,而相位保持不变。
在步骤803,首先根据下列关系式估计短期的信号功率Pxk(m):
Pxk(1)=(1-α)|Xk(1)|2(其中,可能加入一校正值,以提高估计的收敛速度);
Pxk(m)=αPxk(m-1)+(1-α)|Xk(m)|2其中m>1
而“遗忘”系数α的值介于0.7至0.9之间,这可确保寻找到合适的短期固定语音的频谱。
这些关系式尤其体现出两大好处:
——其计算简单;及
——不必引入任何测量延时。
根据一实施变型,可使用一经改善的噪声降低算法。但在所述算法中引入了一附加延时,这就要求存储器的尺寸更大,以存储复数值的频谱分量。
再根据以下非线性估计器(某种程度上它在寻找Pxk(m)的临时最小值),估计噪声的频谱功率Pnk(m):
Pnk(1)=Pxk(1)
其中m严格大于1(m>1):
如果Pnk(m-1)<Pxk(m)
则Pnk(m)=γPnk(m-1)+{(1-γ)/(1-β)}(Pxk(m)-βPxk(m-1));
否则,Pnk(m)=Pxk(m)
随后步骤806中,DSP 104根据下列关系式计算实数值的增益因数gk(m):
否则,gk(m)=βf
系数κ为一引入的噪声的高估因数,以使降低噪声算法性能更佳。
βf为一最低频谱值。βf把噪声降低过滤器的衰减限制在一正值,以使信号内的噪声最小。
步骤807中,DSP 104把振幅|Xk(m)|乘以相应的增益因数gk(m),以根据下列关系式获得改善后的信号振幅:
|Yk(m)|=gk(m)·|Xk(m)|,k在1至256之间。
在极坐标转换为直角坐标的步骤808中,DSP 104根据步骤807中确定的振幅|Yk(m)|与步骤802中提取的信号相位,构建噪声已降低的信号809。
于是,信号809根据逆傅里叶变换步骤304被处理。
当然,本发明并不局限于上述实施例中。
尤其地,本领域技术人员可在本发明的应用中实施各种变型,并不只局限在移动电话(尤其是GSM、UMTS、IS95型……)中,还可扩展到任何类型的装置,所述装置包括在对输入声频信号进行数学变换前、后的一声频编码。
另外,本发明不仅适用于处理源声频信号,而且适用于任何类型的声频处理。
根据本发明,所实施的数学变换尤其为可应用在特殊长度的取样块上,所述特殊长度不等于根据声频处理所处理的帧的尺寸,或并不是接收所述帧尺寸的倍数或除数。因此,本发明可适合这种情况:声频帧的尺寸等于160,或更广泛地讲,不是2的几次方,及数学变换适用于长度256、128、512或更广泛地2n(此处,n为一整数)的块的尺寸上,尤其是FFT,FHT(Fast哈达马特Transform)或DCT(离散余弦变换:Discrete Cosine Transform)或这些变换的变型(例如,通过把这些变换中的一种或几种与其它一种或几种变换结合起来)……
另外,本发明适用于任何与数学变换相关的处理,所述处理可在语音编码前、后实施,尤其当识别声音或消除及/或减小回声时。
需注意,本发明并不局限于单纯的设备安装,它还可以为计算机程序的序列指令形式或综合部分硬件、部分软件的任何混合形式。当本发明部分或全部以软件形式安装时,相应的指令序列可存储在一可拆卸或不可拆卸的存储装置(如软盘、CD-ROM或DVD-ROM)中,所述存储装置可由计算机或微处理器部分地或完全地读取。
Claims (20)
1、声频信号处理方法,它包括:
——源声频信号的第一处理步骤(205),所述第一处理步骤对第一取样序列实施至少一次数学变换,所述第一取样序列是对所述源声频信号应用第一分割窗口(505,506,700,701)而获得的;及
——第二声频处理步骤(206),所述第二处理步骤应用在第二取样序列上,所述第二取样序列是将第二分割窗口(507,508)应用在所述第一步骤得到的信号上而获得的,所述第二分割窗口不同于所述第一分割窗口;
其特征在于,相继的两第一窗口及/或相继的两第二窗口交迭,所述交迭使所述分割同步。
2、根据权利要求1所述的方法,其特征在于,所述第二分割窗口是相继的帧。
3、根据权利要求1所述的方法,其特征在于,第一序列的最后一个取样在经过第一步骤后也是相应的第二序列的最后一个取样。
4、根据权利要求2所述的方法,其特征在于,第一序列的最后一个取样在经过第一步骤后也是相应的第二序列的最后一个取样。
5、根据权利要求1至4中任一项所述的方法,其特征在于,每个所述第一分割窗口(700,701)是完全重建窗口,它是通过卷积以下窗口获得的:
——第一完全重建中间窗口,该窗口具有适合数学变换的频谱特性;及
——第二矩形中间窗口。
6、根据权利要求1至4中任一项所述的方法,其特征在于,应用于每个第一序列的所述第一处理步骤还包括:
——应用于所述第一序列的预定处理子步骤(303);
——应用于所述第一序列的已处理取样的逆数学变换子步骤(304);
——相加步骤(305),相加来自应用于所述第一序列的所述逆数学变换子步骤的声音取样和来自应用于前一个第一序列的所述逆数学变换子步骤的相应的声音取样。
7、根据权利要求5所述的方法,其特征在于,应用于每个第一序列的所述第一处理步骤还包括:
—应用于所述第一序列的预定处理子步骤(303);
——应用于所述第一序列的已处理取样的逆数学变换子步骤(304);
——相加步骤(305),相加来自应用于所述第一序列的所述逆数学变换子步骤的声音取样和来自应用于前一个第一序列的所述逆数学变换子步骤的相应的声音取样。
8、根据权利要求6所述的方法,其特征在于,所述预定处理子步骤包括降低或消除所述声频信号内的噪声。
9、根据权利要求7所述的方法,其特征在于,所述预定处理子步骤包括降低或消除所述声频信号内的噪声。
10、根据权利要求6所述的方法,其特征在于,所述预定处理子步骤包括至少一种选自下列处理的处理:
——降低或消除声频信号中的回声;
——对声频信号进行声音识别。
11、根据权利要求7所述的方法,其特征在于,所述预定处理子步骤包括至少一种选自下列处理的处理:
——降低或消除声频信号中的回声;
——对声频信号进行声音识别。
12、根据权利要求8所述的方法,其特征在于,所述预定处理子步骤包括至少一种选自下列处理的处理:
——降低或消除声频信号中的回声;
——对声频信号进行声音识别。
13、根据权利要求9所述的方法,其特征在于,所述预定处理子步骤包括至少一种选自下列处理的处理:
——降低或消除声频信号中的回声;
——对声频信号进行声音识别。
14、根据权利要求1至4中任一项所述的方法,其特征在于,所述一种或多种数学变换选自下列变换:
——快速傅里叶变换(FFT)及其变型;
——快速哈达马特变换(FHT)及其变型;及
——离散余弦变换(DCT)及其变型。
15、根据权利要求12所述的方法,其特征在于,所述一种或多种数学变换选自下列变换:
——快速傅里叶变换(FFT)及其变型;
——快速哈达马特变换(FHT)及其变型;及
——离散余弦变换(DCT)及其变型。
16、根据权利要求13所述的方法,其特征在于,所述一种或多种数学变换选自下列变换:
——快速傅里叶变换(FFT)及其变型;
——快速哈达马特变换(FHT)及其变型;及
——离散余弦变换(DCT)及其变型。
17、根据权利要求1至4中任一项所述的方法,其特征在于,所述源声频信号为一声音信号。
18、根据权利要求15所述的方法,其特征在于,所述源声频信号为一声音信号。
19、根据权利要求16所述的方法,其特征在于,所述源声频信号为一声音信号。
20、声频信号处理装置,它包括:
——源声频信号的第一处理装置,它对第一取样序列实施至少一个数学变换,所述第一取样序列是将第一分割窗口应用在所述源声频信号上而获得的;及
——第二声频处理装置,它应用在第二取样序列上,所述第二取样序列是将第二分割窗口应用在该第一步骤得到的信号上而获得,所述第二分割窗口不同于第一分割窗口;
其特征在于,相继的两第一窗口及/或相继的两第二窗口相互交迭,所述交迭使所述分割同步。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR0106412A FR2824978B1 (fr) | 2001-05-15 | 2001-05-15 | Dispositif et procede de traitement d'un signal audio |
| FR01/06412 | 2001-05-15 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1520589A CN1520589A (zh) | 2004-08-11 |
| CN1223991C true CN1223991C (zh) | 2005-10-19 |
Family
ID=8863317
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB028129784A Expired - Fee Related CN1223991C (zh) | 2001-05-15 | 2002-05-15 | 声频信号处理设备及方法 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US7295968B2 (zh) |
| EP (1) | EP1395981B1 (zh) |
| JP (1) | JP2004527797A (zh) |
| KR (1) | KR20040005965A (zh) |
| CN (1) | CN1223991C (zh) |
| AT (1) | ATE377244T1 (zh) |
| DE (1) | DE60223246D1 (zh) |
| FR (1) | FR2824978B1 (zh) |
| IL (2) | IL158797A0 (zh) |
| WO (1) | WO2002093558A1 (zh) |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8219391B2 (en) * | 2005-02-15 | 2012-07-10 | Raytheon Bbn Technologies Corp. | Speech analyzing system with speech codebook |
| EP2024863B1 (en) | 2006-05-07 | 2018-01-10 | Varcode Ltd. | A system and method for improved quality management in a product logistic chain |
| US7562811B2 (en) | 2007-01-18 | 2009-07-21 | Varcode Ltd. | System and method for improved quality management in a product logistic chain |
| ATE520120T1 (de) * | 2006-06-29 | 2011-08-15 | Nxp Bv | Klangrahmenlängenanpassung |
| JP2010526386A (ja) | 2007-05-06 | 2010-07-29 | バーコード リミティド | バーコード標識を利用する品質管理のシステムと方法 |
| CN101802812B (zh) | 2007-08-01 | 2015-07-01 | 金格软件有限公司 | 使用互联网语料库的自动的上下文相关的语言校正和增强 |
| WO2009063465A2 (en) | 2007-11-14 | 2009-05-22 | Varcode Ltd. | A system and method for quality management utilizing barcode indicators |
| US11704526B2 (en) | 2008-06-10 | 2023-07-18 | Varcode Ltd. | Barcoded indicators for quality management |
| CA2787390A1 (en) | 2010-02-01 | 2011-08-04 | Ginger Software, Inc. | Automatic context sensitive language correction using an internet corpus particularly for small keyboard devices |
| EP2372704A1 (en) | 2010-03-11 | 2011-10-05 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | Signal processor and method for processing a signal |
| US20140025374A1 (en) * | 2012-07-22 | 2014-01-23 | Xia Lou | Speech enhancement to improve speech intelligibility and automatic speech recognition |
| US8807422B2 (en) | 2012-10-22 | 2014-08-19 | Varcode Ltd. | Tamper-proof quality management barcode indicators |
| EP2848300A1 (en) | 2013-09-13 | 2015-03-18 | Borealis AG | Process for olefin production by metathesis and reactor system therefore |
| CN105830152B (zh) * | 2014-01-28 | 2019-09-06 | 三菱电机株式会社 | 集音装置、集音装置的输入信号校正方法以及移动设备信息系统 |
| CN104914307B (zh) * | 2015-04-23 | 2017-09-12 | 深圳市鼎阳科技有限公司 | 一种频谱仪及其多参数并行扫频的频谱测量方法 |
| WO2016185474A1 (en) | 2015-05-18 | 2016-11-24 | Varcode Ltd. | Thermochromic ink indicia for activatable quality labels |
| WO2017006326A1 (en) | 2015-07-07 | 2017-01-12 | Varcode Ltd. | Electronic quality indicator |
| US10594530B2 (en) * | 2018-05-29 | 2020-03-17 | Qualcomm Incorporated | Techniques for successive peak reduction crest factor reduction |
| US20210020191A1 (en) * | 2019-07-18 | 2021-01-21 | DeepConvo Inc. | Methods and systems for voice profiling as a service |
| CN113272895A (zh) * | 2019-12-16 | 2021-08-17 | 谷歌有限责任公司 | 音频编码中的与振幅无关的窗口大小 |
| CN118430527B (zh) * | 2024-07-05 | 2024-09-06 | 青岛珞宾通信有限公司 | 一种基于pda端边缘计算处理的声音识别方法 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1062963C (zh) * | 1990-04-12 | 2001-03-07 | 多尔拜实验特许公司 | 用于产生高质量声音信号的解码器和编码器 |
| JPH07264144A (ja) * | 1994-03-16 | 1995-10-13 | Toshiba Corp | 信号圧縮符号化装置および圧縮信号復号装置 |
| FI100840B (fi) * | 1995-12-12 | 1998-02-27 | Nokia Mobile Phones Ltd | Kohinanvaimennin ja menetelmä taustakohinan vaimentamiseksi kohinaises ta puheesta sekä matkaviestin |
| AU3690197A (en) * | 1996-08-02 | 1998-02-25 | Universite De Sherbrooke | Speech/audio coding with non-linear spectral-amplitude transformation |
| US5903872A (en) * | 1997-10-17 | 1999-05-11 | Dolby Laboratories Licensing Corporation | Frame-based audio coding with additional filterbank to attenuate spectral splatter at frame boundaries |
| US5913191A (en) * | 1997-10-17 | 1999-06-15 | Dolby Laboratories Licensing Corporation | Frame-based audio coding with additional filterbank to suppress aliasing artifacts at frame boundaries |
| US6370500B1 (en) * | 1999-09-30 | 2002-04-09 | Motorola, Inc. | Method and apparatus for non-speech activity reduction of a low bit rate digital voice message |
| US6418405B1 (en) * | 1999-09-30 | 2002-07-09 | Motorola, Inc. | Method and apparatus for dynamic segmentation of a low bit rate digital voice message |
| FI116643B (fi) * | 1999-11-15 | 2006-01-13 | Nokia Corp | Kohinan vaimennus |
-
2001
- 2001-05-15 FR FR0106412A patent/FR2824978B1/fr not_active Expired - Fee Related
-
2002
- 2002-05-15 DE DE60223246T patent/DE60223246D1/de not_active Expired - Lifetime
- 2002-05-15 IL IL15879702A patent/IL158797A0/xx active IP Right Grant
- 2002-05-15 KR KR10-2003-7014895A patent/KR20040005965A/ko not_active Application Discontinuation
- 2002-05-15 CN CNB028129784A patent/CN1223991C/zh not_active Expired - Fee Related
- 2002-05-15 US US10/477,816 patent/US7295968B2/en not_active Expired - Fee Related
- 2002-05-15 EP EP02743323A patent/EP1395981B1/fr not_active Expired - Lifetime
- 2002-05-15 JP JP2002590150A patent/JP2004527797A/ja active Pending
- 2002-05-15 AT AT02743323T patent/ATE377244T1/de not_active IP Right Cessation
- 2002-05-15 WO PCT/FR2002/001640 patent/WO2002093558A1/fr active IP Right Grant
-
2003
- 2003-11-10 IL IL158797A patent/IL158797A/en not_active IP Right Cessation
Also Published As
| Publication number | Publication date |
|---|---|
| KR20040005965A (ko) | 2004-01-16 |
| IL158797A0 (en) | 2004-05-12 |
| DE60223246D1 (de) | 2007-12-13 |
| EP1395981B1 (fr) | 2007-10-31 |
| FR2824978A1 (fr) | 2002-11-22 |
| FR2824978B1 (fr) | 2003-09-19 |
| CN1520589A (zh) | 2004-08-11 |
| US20040236572A1 (en) | 2004-11-25 |
| EP1395981A1 (fr) | 2004-03-10 |
| JP2004527797A (ja) | 2004-09-09 |
| ATE377244T1 (de) | 2007-11-15 |
| WO2002093558A1 (fr) | 2002-11-21 |
| IL158797A (en) | 2009-02-11 |
| US7295968B2 (en) | 2007-11-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1223991C (zh) | 声频信号处理设备及方法 | |
| CN1130691C (zh) | 音频译码装置 | |
| CN1288625C (zh) | 音频编码与解码设备及其方法 | |
| CN1264138C (zh) | 复制语音信号、解码语音、合成语音的方法和装置 | |
| CN1192358C (zh) | 声音信号加工方法和声音信号加工装置 | |
| CN1104710C (zh) | 在语音数字传输系统中产生悦耳噪声的方法与装置 | |
| CN1284139C (zh) | 噪声减少的方法和装置 | |
| CN1192360C (zh) | 噪声抑制装置 | |
| CN1165891C (zh) | 对过采样合成宽带信号进行高频分量恢复的方法与设备 | |
| CN1669074A (zh) | 话音增强装置 | |
| CN1310431C (zh) | 用于编码音频信号的设备和方法 | |
| CN1113335A (zh) | 降低语音信号中噪声的方法和检测噪声域的方法 | |
| CN1689069A (zh) | 声音编码设备和声音编码方法 | |
| CN1281006C (zh) | 信息编码/译码方法和装置和信息传输方法 | |
| CN101057275A (zh) | 矢量变换装置以及矢量变换方法 | |
| CN1496032A (zh) | 噪声抑制装置 | |
| CN1274456A (zh) | 语音编码器 | |
| CN1794758A (zh) | 一种无线电话及在该无线电话中处理音频信号的方法 | |
| CN1240978A (zh) | 音频信号编码装置、解码装置及音频信号编码、解码装置 | |
| CN1109264A (zh) | 包括至少一个编码器的传输系统 | |
| CN101031960A (zh) | 可扩展性编码装置和可扩展性解码装置及其方法 | |
| CN1584982A (zh) | 语音处理装置 | |
| CN1026274C (zh) | 采用长期预测器的语言合成方法及其装置 | |
| CN1741393A (zh) | 一种音频编码中比特分配的方法 | |
| CN1864158A (zh) | 用于处理至少两个输入值的装置和方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20051019 |