Disclosure of Invention
To reduce inefficient computational behavior in singular value decomposition based image compressionThe invention provides an image compression method based on four-column vector block singular value decomposition, which is characterized in that a
base 4 strategy with 4 column pixels as a block replaces the
traditional base 2 strategy with 2 column pixels as a block for an input image to be compressed, an average block is carried out on an input image matrix, 4 column pixels in each block, namely 4 column vectors, can be combined in pairs, 3 combinations can be provided, each combination comprises 2 pairs of column vectors, and the method is characterized in that the unit vector inner product gamma is calculated by
Is determined by gamma/as a decision condition for inefficient convergence behaviour>
The ordering rules determine the final column vector pair combination mode of each block in the loop iteration process. In addition, aiming at the fact that the row dimension m in the image size is overlarge, an s-segment type data structure is adopted, pixel elements of the image are uniformly distributed in s-block SRAM (static random access memory) for storage, so that synchronous access and calculation are carried out among the s-block SRAM, and according to an on-chip distributed SRAM storage architecture formed by the s-segment data structure, a calculation circuit is embedded among all SRAM macro units, and a near-memory calculation hardware circuit architecture is realized.
The aim of the invention is achieved by the following technical scheme:
on the one hand, the image compression method based on four-column vector block singular value decomposition is characterized in that the pixels of an input image are m rows and n columns, the pixels are taken as the input of a singular value decomposition compression circuit in a matrix form, every 4 columns of image elements are a group, the 4 columns of image elements correspond to the 4 columns of column vectors, the input image is divided evenly, if n/4 can not be divided evenly, the tail of the image to be compressed is supplemented with 1 column of all 0 elements in advance, so that the operation is divided evenly and shared
Column vector block->
Representing an upward rounding; each column vector block is composed of a 2 x 2 structure of 4 columns of column vectors, each columnThe column vector in the lower left corner of the vector block is denoted as A
i The column vector in the upper left corner is denoted as A
j The column vector in the lower right corner is denoted as A
p The column vector in the upper right corner is denoted as A
q ;
The intra-block calculation steps for each column vector partition are as follows:
s1: calculation A
i 、A
j 、A
p 、A
q Respective second order norms alpha
i 、α
j 、α
p 、α
q Combining four column vectors two by two, and calculating the inner product gamma between two column vectors in each combination
ij And gamma is equal to
pq ,γ
ip And gamma is equal to
jq ,γ
iq And gamma is equal to
jp And corresponding unit vector inner product
And->
,/>
And->
,/>
And->
;
S2: sorting 6 unit vector inner products in the column vector block, and taking the rest candidate combinations as final combinations if the two unit vector inner products with the minimum absolute value are distributed in 2 candidate combinations; if the two unit vector inner products with the minimum absolute value and the second smallest are distributed in the same candidate combination, the candidate group with the absolute value of the second smallest unit vector inner product is eliminated, and the last remaining candidate combination is selected as a final combination;
s3: if the final combination is A i And A is a j ,A p And A is a q Then there is no need to sourceInput execution exchanges data operations; if final combination A i And A is a q ,A p And A is a j At this time, the ith column is exchanged with the p column vector data source; if final combination A i And A is a p ,A q And A is a j At this time, the p-th column is exchanged with the j-th column vector data source;
s4: executing Givens rotation calculation operation of 2 pairs of column vectors in column vector block according to classical unilateral Jacobi algorithm;
s5: according to the source exchange rule of the column vector input data in the step S3, the output of the updated result of the Givens rotary calculation is written back and covers the original column vector data according to the corresponding rule;
s6: and repeatedly executing S1-S4 until a convergence condition is reached, sorting the obtained singular values in a descending order, selecting the first k singular values, thereby converting the storage of the pixel matrix of the original m rows and n columns into a left singular matrix of the m rows and k columns and a right singular matrix of the k rows and n columns, and compressing the storage of the input image to the original (m+n+1) k/(m n).
On the other hand, a column vector storage circuit based on an image compression method of four column vector block singular value decomposition, for each column vector, a data structure of s segments is customized, s segments correspond to s-block SRAMs, and taking the ith column vector as an example, column vector elements, namely a (1, i), a (2, i), a (3,i), …, a (m, i), are sequentially stored in the s-block SRAMs in a row-first mode.
In yet another aspect, a computer readable storage medium has stored thereon a program which, when executed by a processor, implements an image compression method based on four-column vector block singular value decomposition.
The beneficial effects of the invention are as follows:
(1) The invention replaces the
traditional base 2 strategy by the
base 4 strategy, increases the combination options of column vector pairs under the condition of the same access times, and passes the unit vector inner product gamma ∈
Sequencing and serving as a judging condition of the low-efficiency convergence behavior, reducing the low-efficiency convergence calculation behavior, and furtherAnd the reduction of the total calculated amount of singular value decomposition is realized.
(2) Aiming at 3 possible column vector pair combination modes, a nominal column index method is adopted, only input sources and output results participating in Givens rotation calculation are exchanged, and the simplicity and the easy realization of a round-robin sequence strategy are maintained.
(3) The invention can obviously reduce the low-efficiency convergence calculation amount of singular value decomposition of a large dense matrix, reduce the clock cycle number required by data access and calculation, and improve the time sequence of the whole circuit, thereby obviously improving the convergence speed.
(4) The invention can adjust and extract the ratio of the first k singular values and the corresponding singular vectors according to the compression ratio to realize elastic compression.
Detailed Description
Reference will now be made in detail to exemplary embodiments, examples of which are illustrated in the accompanying drawings. When the following description refers to the accompanying drawings, the same numbers in different drawings refer to the same or similar elements, unless otherwise indicated. The implementations described in the following exemplary examples are not representative of all implementations consistent with the present application. Rather, they are merely examples of apparatus and methods consistent with some aspects of the present application as detailed in the accompanying claims.
The terminology used in the present application is for the purpose of describing particular embodiments only and is not intended to be limiting of the present application. As used in this application and the appended claims, the singular forms "a," "an," and "the" are intended to include the plural forms as well, unless the context clearly indicates otherwise. It should also be understood that the term "and/or" as used herein refers to and encompasses any or all possible combinations of one or more of the associated listed items.
It should be understood that although the terms first, second, third, etc. may be used herein to describe various information, these information should not be limited by these terms. These terms are only used to distinguish one type of information from another. For example, a first message may also be referred to as a second message, and similarly, a second message may also be referred to as a first message, without departing from the scope of the present application. The word "if" as used herein may be interpreted as "at … …" or "at … …" or "responsive to a determination", depending on the context.
As shown in fig. 1, in the image compression method based on four-column vector block singular value decomposition of the present embodiment, the pixels of the input image are m rows×n columns, and are used as the input of the singular value decomposition compression circuit in matrix form, each 4 columns of image elements are a group, the 4 columns of image elements correspond to the 4 columns of column vectors, the input image is divided into average groups, if n/4 cannot be divided, the end of the image to be compressed is supplemented with 1 column of all 0 elements in advance, so that the operation is divided and shared
Column vector block->
Representing an upward rounding; each column vector block is composed of a 2 x 2 structure of 4 column vectors, with the column vector in the lower left corner of each column vector block denoted as a
i The column vector in the upper left corner is denoted as A
j The column vector in the lower right corner is denoted asA
p The column vector in the upper right corner is denoted as A
q ;
The intra-block calculation steps for each column vector partition are as follows:
s1: calculation A
i 、A
j 、A
p 、A
q Respective second order norms alpha
i 、α
j 、α
p 、α
q And combining four column vectors two by two, namely A
i ~A
j And A is a
p ~A
q ,A
i ~A
p And A is a
j ~A
q ,A
i ~A
q And A is a
j ~A
p The method comprises the steps of carrying out a first treatment on the surface of the Calculating the inner product gamma between two column vectors in each combination
ij And gamma is equal to
pq ,γ
ip And gamma is equal to
jq ,γ
iq And gamma is equal to
jp And corresponding unit vector inner product
And (3) with
,/>
And->
,/>
And->
。
S2: sorting 6 unit vector inner products in the column vector block, and taking the rest candidate combinations as final combinations if the two unit vector inner products with the minimum absolute value are distributed in 2 candidate combinations; if the two unit vector inner products with the smallest absolute value are distributed in the same candidate combination, the candidate group with the absolute value being the unit vector inner product with the next smallest absolute value is excluded, and the last remaining candidate combination is selected as the final combination.
As one of the embodiments, assume that
Is the unit vector inner product with the smallest amplitude, < ->
Is the unit vector inner product with the smallest amplitude, at this time, due to +.>
And->
Distributed among 2 candidate combinations, thus, directly selecting the remaining A
i ~A
q And A is a
j ~A
p As a final combination; let->
Is the unit vector inner product with the smallest amplitude,
is the unit vector inner product of the amplitude of the sub-small, < >>
Is the unit vector inner product with the next smallest amplitude, at this time, due to
、/>
Distributed over the same candidate combination, thus excluding the next smallest +.>
The combination is selected to be the rest A
i ~A
j And A is a
p ~A
q As a final combination.
S3: according to the final combination mode of 4 column vectors in S2, determining the column vector data input source in the Givens rotation calculation: if the final combination is A i And A is a j ,A p And A is a q The data exchange operation is not required to be executed for the source input; if final combination A i And A is a q ,A p And A is a j At this time, the ith column is exchanged with the p column vector data source; if final combination A i And A is a p Or A q And A is a j At this time, the p-th column is exchanged with the j-th column for vector data source.
Each time a round of Givens rotation calculation is executed, a column switching rule in a column vector block is as follows:
column vector 1 block: the lower left is exchanged for lower right, the upper left is exchanged for lower left, and the upper right is exchanged for upper left;
first, the
The column vectors are partitioned: the lower left is exchanged for lower right, and the upper right is exchanged for upper left;
first, the
Column vector partitioning: the column vector in the upper right corner is kept stationary, the lower right is swapped to the upper left, and the lower left is swapped to the lower right.
Each time a round of Givens rotation computation is performed, the inter-block column exchange rule of column vector partitioning is: the lower right of the previous column vector block is swapped to the lower left of the current column vector block and the upper left of the current column vector block is swapped to the upper right of the previous column vector block.
S4: executing Givens rotation calculation operation of 2 pairs of column vectors in column vector block according to classical unilateral Jacobi algorithm; the formula for the Givens rotation calculation is as follows:
wherein cos θ and sin θ take the following values:
wherein,,
and->
Column vector inputs representing the ith and jth columns prior to the r-th round of Givens transform, are>
And
column vector outputs representing the ith and jth columns after the r-th round of Givens transform update, if gamma
ij Not less than 0 and alpha
i -α
j Not less than 0, or gamma
ij < 0 and alpha
i -α
j If the value is less than 0, sin theta takes positive sign, otherwise takes negative sign, and cos theta and sin theta form a Givens rotation matrix; another pair of column vectors in the partition->
And->
The same operation is performed.
S5: and (3) according to the source exchange rule of the column vector input data in the step (S3), writing back and covering the original column vector data according to the corresponding rule by the output of the updated result of the Givens rotation calculation.
The write-back rule is:
if the current combination is A i And A is a j ,A p And A is a q Outputting the result without executing exchange processing;
if the current combination is A
p And A is a
j ,A
i And A is a
q Outputting the result
Write back and cover the corresponding SRAM memory of the p-th column vector,/in the SRAM memory>
Writing back and covering the SRAM storage corresponding to the ith column vector;
if the current combination is A
i And A is a
p ,A
q And A is a
j Outputting the result
Write back and cover the corresponding SRAM memory of the jth column vector,/in the column vector>
Writing back and covering the SRAM storage corresponding to the p-th column vector.
In the whole column vector calculation process, as shown in fig. 3, a round-robin scheduling mechanism is used to perform counterclockwise cyclic scheduling on the column vector after Givens rotation calculation, namely, according to a nominal column vector index, column vector 1 is transmitted to column vector 3, column vector 3 is transmitted to column vector 5, column vector 5 is transmitted to column vectors 7 and …, column vector n-3 is transmitted to column vector n-1, column vector n-1 is transmitted to n-2, column vector n-2 is transmitted to n-4 and …, column vector 4 is transmitted to 2, and column vector 2 is transmitted to column vector 1. And repeatedly executing the operation until the absolute convergence or the custom convergence condition is reached.
And S3, inputting a switching rule by a data source and outputting a switching rule by a calculation result in S5, wherein the q-th column vector in the upper right corner is kept fixed, and the rest column vector data are switched. The nominal column vector index is kept unchanged, namely is consistent with the classical unilateral Jacobi algorithm, and real data corresponding to the nominal column vector index is processed according to an S5 exchange rule;
in S4
And->
、/>
And->
The source data is input into the column vector which is processed by the switching rule according to the finally determined combination mode in the step S3, and the second-order norm and the vector inner product are correspondingly calculated based on the processing of the switching rule.
S6: and repeatedly executing S1-S4 until convergence conditions are reached, sorting the obtained singular values in a descending order, selecting the first k singular values, and accordingly converting the storage of the pixel matrix of m rows and n columns of the input image into only k singular values, and the left singular matrix of m rows and k columns and the right singular matrix of k rows and n columns, so that the compression ratio of the image is (m+n+1) k/(m n).
After reaching the preset convergence condition, obtaining a right singular matrix V, wherein each column vector is the right singular vector V
i Calculating square root of second order norm of n columns of vectors of the input matrix to obtain n singular values, dividing each column of vectors by the corresponding singular value to obtain left singular vector U
i I=1, 2, …, n; extracting the first k singular values and the corresponding singular vectors in descending order to perform image reverse construction to obtain
And k is less than or equal to n, so that image compression is realized.
In addition, the singular value decomposition acceleration method of the embodiment of the invention has better effect on large dense matrixes with n more than or equal to 100 and m more than or equal to n.
On the other hand, the embodiment of the invention provides a column vector storage circuit of a singular value decomposition accelerating method based on single-side Jacobian of four column vector blocks, wherein for each column vector, a data structure of s segments is customized, the s segments correspond to s-block SRAMs, and the i-th column vector is taken as an example, and column vector elements, namely A (1, i), A (2, i), A (3,i), … and A (m, i), are sequentially stored in the s-block SRAMs according to a row priority mode.
For on-chip distributed SRAM storage formed by a customized s-segment data structure, a calculation logic circuit comprising a column vector second-order norm, a column vector inner product, a unit vector inner product and Givens transformation is embedded among all SRAM macro units, so that near-memory calculation is realized.
The s-sectional data structure improves the data access and calculation efficiency by s times, and the clock beat is reduced to 1/s; according to the abundant distributed SRAM formed by the s-sectional data structure, computational logic resources are embedded among SRAM macro cells, so that the delay of a data channel is reduced, the time sequence of a circuit is improved, the problem of a storage wall of singular value decomposition of a large dense matrix is effectively relieved, and the effect of near-memory computation is achieved.
Taking the image to be compressed with 224 rows by 224 columns as an example, which is common in the deep learning field, each pixel bit width is 8 bits, the s segmentation method adopts 4 segments, and the specification bit depth of the SRAM is 64 depths by 8 bits, which belongs to the small-scale memory macro unit which is common in the integrated circuit design field. Therefore, 224 data in total of each 1 column of pixels of the image to be compressed is averagely distributed to 4 SRAMs for storage, and each block of SRAMs is enough for storing 224/4=56 pixel data, and provides a certain redundancy, and the 224 row×224 column size of the image to be compressed occupies 896 small SRAMs in total, so as to form a distributed SRAM hardware storage circuit architecture. By embedding the calculation logic circuit between the distributed SRAM macro units, as shown in fig. 1, the column vector can carry out access and operation of singular value decomposition with s=4 times of parallel efficiency, meanwhile, the routing delay of a data channel is reduced, the time sequence quality of the circuit is improved, the problem of a storage wall is relieved, the effect of a near-memory calculation hardware circuit architecture is realized, and the image compression performance is improved. The 4-segment data of the 1 st column element of the image to be compressed is shown in fig. 2 according to the row priority storage sequence.
According to the classical unilateral Jacobi algorithm, 224 columns of image pixels are divided into 112 pairs of column vectors and calculated in parallel, if a traditional base 2 strategy singular value decomposition method is adopted, each sweep needs to execute 223 rounds of 112 pairs of column vector Givens rotation update calculation, and at least 8 times of sweep can meet the convergence condition, namely at least 224× (224-1) ×8= 399616 clock beats are needed. By adopting the image compression method based on the four-column vector block singular value decomposition, the convergence condition can be met only by 6 times of sweep, the clock beat number is close to (224/4+4-1) x (224-1) x 6= 78942, and only about 19.75% of the original clock beat number is needed, so that the calculated amount is obviously reduced, the convergence progress is improved, and the real-time performance of image compression is improved. And for the 224 singular values and the corresponding singular vectors, the first 22 largest singular values and singular vectors are extracted according to the first 10%, compression transmission and reverse image construction are carried out, the compression ratio is close to 5:1, the image main body information is reserved, and the subsequent transmission bandwidth and storage capacity are reduced.
The specific implementation process of this embodiment is as follows:
step 1: the image to be compressed in 224 rows by 224 columns is divided into blocks averagely by adopting a
base 4 strategy, the 1 st block is the 1 st image element in the 1 st to 4 th columns, the 2 nd block is the 5 th to 8 th image elements in the … th columns, and the 56 th block is the 221 st to 224 th image elements, as shown in fig. 3, wherein n=224. Calculating the second order norm alpha inside the 1 st partition
1 、α
2 、α
3 And alpha
4 According to the combination of two by two, there are 3 alternative modes, namely A
1 ~A
2 And A is a
3 ~A
4 ,A
1 ~A
3 And A is a
2 ~A
4 ,A
1 ~A
4 And A is a
2 ~A
3 Thus respectively calculating the corresponding inner products gamma
12 And gamma is equal to
34 ,γ
13 And gamma is equal to
24 ,γ
14 And gamma is equal to
23 And unit vector inner product thereof
And->
,/>
And->
,
And->
A block second order norm, vector inner product and unit vector inner product calculation circuit is shown in fig. 4; the remaining 49 blocks are concurrently synchronized to perform similar calculations.
Step 2: taking the 1 st partition as an example, for
、/>
,/>
、/>
,/>
And
the 6 unit vector inner products are sequenced, the unit vector inner products are important indexes for representing the mutual orthogonality degree among the column vectors, and the 6 unit vector inner products are sequenced to select from 3 optional combinations; still taking the 1 st block as an example, assume +.>
Is the unit vector inner product in which the absolute value is the smallest, < >>
Is the unit vector inner product with the absolute value being the next smallest, at this time, A is selected
1 ~A
4 And A is a
2 ~A
3 As a final combination; however, it is assumed that the two unit vector inner products with the smallest absolute values are simultaneously distributed in one candidate combination, e.g. +.>
And->
If the absolute value is the least and the next least unit vector inner products, then the candidate group of the absolute value next least unit vector inner products needs to be further confirmed, and the assumption is that
Is the unit vector inner product with the absolute value of the next smallest, at this time, A is selected
1 ~A
3 And A is a
2 ~A
4 As a final column vector pair combination; through the optimization selection of the combination of the step of column vectors, the obvious reduction of the low-efficiency convergence calculation behavior can be realized. Correspondingly, the rest 55 blocksAnd similar operations are performed concurrently and synchronously.
Step 3: according to the final combination of 4 column vectors, i.e. 4 column image elements in step 2, the switching of the column vector data input sources in the subsequent Givens rotation calculation is determined, and here, taking the 2 nd block as an example, for the 5 th to 8 th column image elements, as shown in fig. 5, the switching rule of the column vector data input sources is shown. As in (a) of fig. 5, assuming that the final combination is a pair of 5 th and 6 th column image elements and a pair of 7 th and 8 th column image elements, no exchange of data input sources is required. As in (b) of fig. 5, assuming that the final combination is a pair of 5 th and 7 th column image elements, and a pair of 6 th and 8 th column image elements, the nominal column index is unchanged for the 6 th and 7 th column image elements, but the data actually involved in Givens calculation is exchanged at the output of the SRAM read port, i.e., for the 6 th column image element, the nominal column index is 6, but the real data is from the column index 7; for the 7 th column image element, it is nominally column indexed 7, but the real data comes from column index 6. Similarly, as in (c) of fig. 5, assuming that the final combination is a pair of 5 th and 8 th column image elements and a pair of 6 th and 7 th column image elements, the nominal column index is unchanged for the 5 th and 7 th column image elements, but the data actually involved in Givens calculation is exchanged at the output of the SRAM read port, i.e., for the 5 th column image pixel, its nominal column index is 5, but the real data comes from the column index of 7; for the 7 th column image element, it is nominally column indexed 7, but the real data comes from column index 5. During this process, the 8 th column of picture element column index in the upper right corner remains unchanged. Accordingly, the remaining 55 blocks concurrently perform similar operations in synchronization.
Step 4: according to the unilateral Jacobi algorithm, performing Givens transformation calculation operation on 2 pairs of column vectors in each block, and calculating a Givens matrix by a second-order norm and a vector inner product according to the combination mode finally determined in the
step 2
According to the data exchange rule of
step 3, givens rotation is performed on elements from 1 st row to m=224 th row of each column vector respectivelyTurning to a computing update, and s=4, so that the rotating computing update operation is also improved by 4 times of parallel computing efficiency; the Givens rotation calculation detailed circuit is shown in fig. 6.
Step 5: according to the column vector input data source exchange rule in the
step 3, the output of the updated result of the Givens rotation calculation is written back and covers the original column vector data according to the corresponding rule. Taking the 2 nd block as an example, if the combination in the
step 3 is that the 5 th and the 6 th column image elements are in a pair, the 7 th and the 8 th column image elements are in a pair, the nominal column index is consistent with the real data source, and the output result does not need to be exchanged; if the 5 th and 7 th column image pixels are paired in
step 3, the 6 th and 8 th column image pixels are paired, and the 6 th and 7 th column image elements participate in Givens rotation calculation to exchange the input source, the result is written back and covers the original data, namely the nominal data
Calculating the output of the updated result and writing back the SRAM storage input port where the 7 th column of image elements are actually located, and nominally +.>
Calculating an updating result, outputting and writing back to an SRAM storage input port where the 6 th column of image elements are truly positioned; if the 5 th and 8 th column image elements are in a pair and the 6 th and 7 th column image elements are in a pair in the
step 3, the result is written back and covers the original data in the original direction, namely, the nominal->
Calculating the output of the updated result and writing back the SRAM storage input port where the 7 th column of image elements are actually located, and nominally +.>
And outputting and writing the calculated and updated result back to the SRAM storage input port where the 5 th column image pixel is actually positioned. The remaining 55 blocks are concurrently synchronized with similar processing.
Step 6: column vectors of the 224 th column are fixed, and counterclockwise cyclic scheduling is carried out on the column vectors after Givens rotation calculation by a round-robin scheduling mechanism, namely according to a nominal column vector index, the 1 st column image element is transmitted to the 3 rd column image element, the 3 rd column image element is transmitted to the 5 th column image element, the 5 th column image element is transmitted to the 7 th column image element, …, the 197 th column image element is transmitted to the 199 th column image element, the 199 th column image element is transmitted to the 198 th column image element, the 198 th column image element is transmitted to the 196 th column image element, the …, the 4 th column image element is transmitted to the 2 nd column image element, and the 2 nd column image element is transmitted to the 1 st column image element.
Step 7: and (3) repeatedly executing the steps 1-6, wherein the preset convergence judgment condition can be met through 6 times of sweep.
Step 8: according to
step 7, 224 singular values are obtained, S
1 ,S
2 ,S
3 ,…,S
224 And 224 rows by 224 columns of left singular matrix U and right singular matrix V, the 224 columns of column vectors being divided by the respective corresponding singular values to obtain left singular vector U
i I=1, 2,3, …,224, each column of right singular matrix V has a column vector V
i Namely right singular vectors. Fig. 7 is a compression schematic diagram based on four-column vector singular value decomposition, and when the value of k is far smaller than n, the compression ratio can be large, and the magnitude of k can be adjusted to realize elastic compression. As shown in fig. 8, the present invention is used to compare before and after compression, where (a) in fig. 8 is original image, and (b) in fig. 8 is k=22, i.e. the maximum first 10% singular value and the corresponding singular vector are extracted, and the method uses
Reverse construction is carried out, and the compression ratio is close to 5:1; in fig. 8 (c) k=34, i.e. the first 15% of maximum singular values and corresponding singular vectors are extracted, using +.>
Reverse construction was performed with a compression ratio approaching 10:3.
Compared with the classical unilateral Jacobian algorithm for realizing singular value decomposition image compression, the embodiment of the invention can realize singular value decomposition image compression, and the invention has the same access and storageThe column vector pair combining option is increased under the condition of times, by the unit vector inner product gamma-
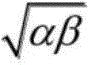
Sequencing and serving as a judging condition of the low-efficiency convergence behavior, reducing the number of the low-efficiency convergence calculation behaviors, further reducing the total calculated amount of singular value decomposition, and further improving the real-time performance of image compression; aiming at a possible 3 column vector pair combination mode, a nominal column index sequence is adopted, only input sources and output results which participate in Givens rotation calculation are exchanged, and the simplicity and the easy realization of a round-robin sequence strategy are maintained; the s-sectional data structure improves the data access and calculation efficiency by s times, and the clock beat is 1/s of the original clock; according to the abundant distributed SRAM formed by the s-sectional data structure, computational logic resources are embedded among SRAM macro cells, so that the delay of a data channel is reduced, the time sequence of a circuit is improved, the problem of a storage wall of singular value decomposition of a large dense matrix is effectively relieved, and the effect of near-memory computation is achieved. Therefore, the invention can realize the reduction of the low-efficiency convergence calculation amount in the matrix singular value decomposition process, the improvement of the parallel access and calculation efficiency and the remarkable acceleration of the convergence speed.
The embodiment of the invention also provides a computer readable storage medium, on which a program is stored, which when executed by a processor, implements the image compression method based on the four-column vector block singular value decomposition in the above embodiment.
Other embodiments of the present application will be apparent to those skilled in the art from consideration of the specification and practice of the disclosure herein. This application is intended to cover any variations, uses, or adaptations of the application following, in general, the principles of the application and including such departures from the present disclosure as come within known or customary practice within the art to which the application pertains. It is intended that the specification and examples be considered as exemplary only, with a true scope and spirit of the application being indicated by the following claims.
It is to be understood that the present application is not limited to the precise arrangements and instrumentalities shown in the drawings, which have been described above, and that various modifications and changes may be effected without departing from the scope thereof. The scope of the application is limited only by the appended claims.








































































































