CN116153367A - 存储器装置及其操作方法 - Google Patents
存储器装置及其操作方法 Download PDFInfo
- Publication number
- CN116153367A CN116153367A CN202210322542.5A CN202210322542A CN116153367A CN 116153367 A CN116153367 A CN 116153367A CN 202210322542 A CN202210322542 A CN 202210322542A CN 116153367 A CN116153367 A CN 116153367A
- Authority
- CN
- China
- Prior art keywords
- encoded
- weight data
- bit
- data
- input data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
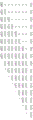
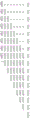

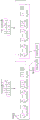
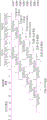



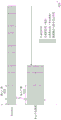

Classifications
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11C—STATIC STORES
- G11C16/00—Erasable programmable read-only memories
- G11C16/02—Erasable programmable read-only memories electrically programmable
- G11C16/06—Auxiliary circuits, e.g. for writing into memory
- G11C16/08—Address circuits; Decoders; Word-line control circuits
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/52—Multiplying; Dividing
- G06F7/523—Multiplying only
- G06F7/527—Multiplying only in serial-parallel fashion, i.e. one operand being entered serially and the other in parallel
- G06F7/5272—Multiplying only in serial-parallel fashion, i.e. one operand being entered serially and the other in parallel with row wise addition of partial products
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/0207—Addressing or allocation; Relocation with multidimensional access, e.g. row/column, matrix
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/0215—Addressing or allocation; Relocation with look ahead addressing means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/0223—User address space allocation, e.g. contiguous or non contiguous base addressing
- G06F12/0284—Multiple user address space allocation, e.g. using different base addresses
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0877—Cache access modes
- G06F12/0882—Page mode
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
- G06F13/1668—Details of memory controller
- G06F13/1673—Details of memory controller using buffers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/544—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices for evaluating functions by calculation
- G06F7/5443—Sum of products
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/60—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers
- G06F7/72—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers using residue arithmetic
- G06F7/729—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers using residue arithmetic using representation by a residue number system
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11C—STATIC STORES
- G11C16/00—Erasable programmable read-only memories
- G11C16/02—Erasable programmable read-only memories electrically programmable
- G11C16/06—Auxiliary circuits, e.g. for writing into memory
- G11C16/10—Programming or data input circuits
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11C—STATIC STORES
- G11C16/00—Erasable programmable read-only memories
- G11C16/02—Erasable programmable read-only memories electrically programmable
- G11C16/06—Auxiliary circuits, e.g. for writing into memory
- G11C16/24—Bit-line control circuits
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/10—Providing a specific technical effect
- G06F2212/1016—Performance improvement
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/10—Providing a specific technical effect
- G06F2212/1041—Resource optimization
- G06F2212/1044—Space efficiency improvement
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/72—Details relating to flash memory management
- G06F2212/7203—Temporary buffering, e.g. using volatile buffer or dedicated buffer blocks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/72—Details relating to flash memory management
- G06F2212/7208—Multiple device management, e.g. distributing data over multiple flash devices
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0495—Quantised networks; Sparse networks; Compressed networks
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Neurology (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Software Systems (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
本公开提供存储器装置与其操作方法。存储器装置的操作方法包括:对一输入数据进行编码,将一编码后输入数据传送至至少一页缓冲器内,以及从该至少一页缓冲器平行读出该编码后输入数据;对一权重数据的一第一部分与一第二部分分别编码为该权重数据的一编码后第一部分与该权重数据的一编码后第二部分,将该权重数据的该编码后第一部分与该权重数据的该编码后第二部分写入至该存储器装置的多个存储器单元内,以及平行读出该权重数据的该编码后第一部分与该权重数据的该编码后第二部分;将该编码后输入数据分别乘上该权重数据的该编码后第一部分与该权重数据的该编码后第二部分,以平行产生多个部分乘积;以及将这些部分乘积累加,以产生一运算结果。
Description
技术领域
本公开有关于一种具有存储器内运算(In-Memory-Computing,IMC)的存储器装置及其操作方法。
背景技术
人工智能(AI)已在许多领域中成为高度有效解决方案。AI的关键操作在于对大量的输入数据(如输入特征图(input feature maps))与权重值进行乘积累加运算(multiply-and-accumulate,MAC)。
然而,以目前的AI架构而言,容易遇到输出入瓶颈(IO bottleneck)与低效率的MAC运算流程。
为达到高准确度,可执行具有多位输入及多位权重值的MAC操作。然而,输出入瓶颈变得更加严重,且效率将更低。
存储器内运算(In-Memory-Computing,IMC)可用于加速MAC运算,因为IMC可减少在中央处理架构下所需要用的复杂算术逻辑单元(Arithmetic logic unit,ALU),且提供存储器内的MAC操作的高并行性(parallelism)。
在进行IMC时,无符号数(unsigned integer)乘法运算与带符号数(signedinteger)乘法运算的说明如下。
例如,想要相乘两个无符号数(皆为8位):a[7:0]与b[7:0]。则可执行8次的单个位乘法来产生8个部分乘积(partial product)p0[7:0]~p7[7:0],各该8个部分乘积相关于被乘数a的各位,该8个部分乘积可表示如下:
p0[7:0]=a[0]×b[7:0]={8{a[0]}}&b[7:0]
p1[7:0]=a[1]×b[7:0]={8{a[1]}}&b[7:0]
p2[7:0]=a[2]×b[7:0]={8{a[2]}}&b[7:0]
p3[7:0]=a[3]×b[7:0]={8{a[3]}}&b[7:0]
p4[7:0]=a[4]×b[7:0]={8{a[4]}}&b[7:0]
p5[7:0]=a[5]×b[7:0]={8{a[5]}}&b[7:0]
p6[7:0]=a[6]×b[7:0]={8{a[6]}}&b[7:0]
p7[7:0]=a[7]×b[7:0]={8{a[7]}}&b[7:0]
其中,{8{a[0]}}代表将a[0]重复8次,其余可依此类推。
为得到乘积,将该8个部分乘积p0[7:0]~p7[7:0]相加,如图1A所示。图1A为两个无符号数(皆为8位)的相乘。
其中,P0=p0[0]+0+0+0+0+0+0+0,而P1=p0[1]+p1[0]+0+0+0+0+0+0,其余可依此类推。
乘积P[15:0]则是将P0~P15而得。乘积P[15:0]代表将两个无符号数(皆为8位)相乘所得到的16位无符号乘积。
而如果b是带符号数,则于加总之前,部分乘积需要做符号展开(sign-extended)至乘积宽度。如果a也是带符号数,则部分乘积P7要从最后总和减去,而不是相加。
图1B为两个符号数(皆为8位)的相乘。在图1B中,符号“~”代表互补,例如,~p1[7]代表p1[7]的互补数。
在进行IMC时,如果能加快“操作速度”及减少容量需要(capacity requirement)的话,对于IMC性能将可有所助益。
发明内容
根据本公开一实例,提出一种存储器装置,包括:多个存储器晶粒,各这些存储器晶粒包括多个存储器平面、多个页缓冲器与一累加电路,各这些存储器平面包括多个存储器单元。其中,对一输入数据进行编码,将一编码后输入数据传送至至少一页缓冲器内,以及,从该至少一页缓冲器平行读出该编码后输入数据;对一权重数据的一第一部分与一第二部分分别编码为该权重数据的一编码后第一部分与该权重数据的一编码后第二部分,并写入至该存储器装置的这些存储器单元内,以及,平行读出该权重数据的该编码后第一部分与该权重数据的该编码后第二部分;将该编码后输入数据分别乘上该权重数据的该编码后第一部分与该权重数据的该编码后第二部分,以平行产生多个部分乘积;以及将这些部分乘积累加,以产生一运算结果。
根据本公开另一实例,提出一种存储器装置的操作方法,包括:对一输入数据进行编码,将一编码后输入数据传送至至少一页缓冲器内,以及,从该至少一页缓冲器平行读出该编码后输入数据;对一权重数据的一第一部分与一第二部分分别编码为该权重数据的一编码后第一部分与该权重数据的一编码后第二部分,并将该权重数据的该编码后第一部分与该权重数据的该编码后第二部分写入至该存储器装置的多个存储器单元内,以及,平行读出该权重数据的该编码后第一部分与该权重数据的该编码后第二部分;将该编码后输入数据分别乘上该权重数据的该编码后第一部分与该权重数据的该编码后第二部分,以平行产生多个部分乘积;以及将这些部分乘积累加,以产生一运算结果。
为了对本公开的上述及其他方面有更佳的了解,下文特举实施例,并配合附图详细说明如下:
附图说明
图1A为两个无符号数的相乘。
图1B为两个符号数的相乘。
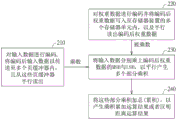
图2为根据本公开一实施例的存储器装置的操作方法流程图。
图3A与图3B为本公开实施例中的错误位容忍数据编码。
图4A为在本公开一实施例中的8位无符号数乘法运算。
图4B为在本公开一实施例中的8位带符号数乘法运算。
图5A为根据本公开一实施例的无符号数乘法运算的操作示意图。
图5B为根据本公开一实施例的带符号数乘法运算的操作示意图。
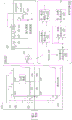
图6为根据本公开一实施例的存储器装置的功能框图。
图7为比较本公开一实施例与现有技术的MAC运算流程时序图。
图8为根据本公开一实施例的存储器装置的操作方法。
附图标记说明
210-240:步骤
600:存储器装置 615:存储器晶粒
620:存储器平面 625:页缓冲器
630:累加电路 631:感应电路
633-641:闩锁单元 643、645:逻辑门
651:部分乘积累加单元 653:单一维度乘积产生单元
655:第一多维度累加单元
657:第二多维度累加单元
659:权重累加控制单元
810-840:步骤
具体实施方式
本说明书的技术用语参照本技术领域的习惯用语,如本说明书对部分用语有加以说明或定义,该部分用语的解释以本说明书的说明或定义为准。本公开的各个实施例分别具有一或多个技术特征。在可能实施的前提下,本技术领域的技术人员可选择性地实施任一实施例中部分或全部的技术特征,或者选择性地将这些实施例中部分或全部的技术特征加以组合。
图2为根据本公开一实施例的存储器装置的操作方法流程图。于步骤210中,对输入数据进行编码并将编码后输入数据(其为矢量)以传送至多个页缓冲器内,且从这些页缓冲器平行读出。至于如何对输入数据进行编码的细节将于底下说明。
在步骤220中,对权重数据进行编码并将编码后权重数据(其为矢量)写入至存储器装置的多个存储器单元内,以及平行读出编码后权重数据。至于如何对权重数据进行编码的细节将于底下说明。其中,在进行编码时,权重数据的最高有效位(most significantbit,MSB)与最低有效位(least significant bit,LSB)被分别编码。
在步骤230中,将输入数据分别乘上编码后权重数据的MSB与LSB,以平行产生多个部分乘积(partial product)。
在步骤240中,将这些部分乘积加总(累积),以产生乘积累加运算(multiply-and-accumulate,MAC)结果或者汉明距离(Hamming distance)运算结果。
本公开一实施例提供可实施多位MAC操作的存储器装置,具有错误位容忍(error-bit-tolerance)数据编码,以容忍错误位及减少面积需求。错误位容忍数据编码乃是使用输入数据复制(duplication)及权重数据平坦化(flattening)技术。此外,本公开实施例的感应技术包括标准的单层单元(single level cell,SLC)读取与逻辑与(AND)功能,进行位乘法以产生部分乘积。在本公开其他可能实施例中,如果在感应过程中,页缓冲器不会将存在闩锁单元内的输入数据移除的话,则SLC读取可由选择位读取所取代,或者被多层单元(Multi-Level Cell,MLC)、三层单元(Triple Level Cell,TLC)、四层单元(Quad-levelcells,QLC)读取操作所取代。此外,本公开一实施例的多位MAC操作运算乃是使用高频宽权重累加器(high bandwidth weighted accumulator)以产生输出结果,该高频宽权重累加器可通过重复使用故障位计数(fail-bit-count,FBC)电路来实施权重化累加(weightedaccumulation)。
本公开另一实施例提高一种可实施汉明距离运算的存储器装置,具有错误位容忍数据编码,以容忍错误位。错误位容忍数据编码乃是使用输入数据复制及权重数据平坦化技术。此外,本公开实施例的感应技术包括标准的单层单元(single level cell,SLC)读取与逻辑异或(EXOR)功能,进行位乘法以产生部分乘积。在本公开其他可能实施例中,如果在感应过程中,页缓冲器不会将存在闩锁单元内的输入数据移除的话,则SLC读取可由选择位读取所取代,或者被MLC、TLC、QLC读取操作所取代。而逻辑异或(EXOR)功能可由逻辑异或非(XNOR)与逻辑非所取代。此外,本公开一实施例的多位汉明距离操作运算乃是使用高频宽未权重累加器(high bandwidth unweighted accumulator)以产生输出结果,该高频宽未权重累加器可通过重复使用故障位计数(fail-bit-count,FBC)电路来实施未权重累加(unweighted accumulation)。
图3A与图3B为本公开实施例中的错误位容忍数据编码。例如但不受限于,输入数据与权重数据为浮点32(floating point 32)数据。在图3A中,将输入数据与权重数据量化成8位二进制整数,其中,输入数据与权重数据皆为8位矢量,且为N维度(N为正整数)。输入数据与权重数据可分别表示为Xi(7:0)与Wi(7:0)。
在图3B中,将这些N维度的各个8位权重矢量分开成MSB矢量与LSB矢量。8位权重矢量的MSB矢量包括4位Wi(7:4),而LSB矢量包括4位Wi(3:0)。
接着,将8位权重矢量的MSB矢量与LSB矢量的各位以一元编码(Unary coding)(也即数值形式(value format))表示。例如,8位权重矢量的MSB矢量的位Wi=0(7)可以表示为8位(复制8次),8位权重矢量的MSB矢量的位Wi=0(6)可以表示为4位(复制4次),8位权重矢量的MSB矢量的位Wi=0(5)可以表示为2位(复制2次),8位权重矢量的MSB矢量的位Wi=0(4)可以表示为1位(复制1次),并且将备用位(spare bit)(0)加入于8位权重矢量的MSB矢量的位Wi=0(4)之后。如此,可将8位权重矢量的4位MSB矢量编码成16位的一元编码(Unarycoding)格式。
同样地,可将8位权重矢量的4位LSB矢量编码成16位的一元编码(Unary coding)格式。
在本公开一实施例中,通过上次的编码方式,可以提高错误位的容忍度。
图4A为在本公开一实施例中的8位无符号数(unsigned integer)乘法运算,而图4B为在本公开一实施例中的8位带符号数(signed integer)乘法运算。
如图4A所示,在进行8位无符号数乘法运算时,在第0周期时,将输入数据的Xi(7)(输入数据已编码成一元编码格式)乘上权重数据的MSB矢量Wi(7:4)(权重数据的MSB矢量已编码成一元编码格式),以得到第一MSB部分乘积。相似地,将输入数据的Xi(7)乘上权重数据的LSB矢量Wi(3:0)(权重数据的LSB矢量已编码成一元编码格式),以得到第一LSB部分乘积。将第一MSB部分乘积位移4位后相加至第一LSB部分乘积,以得到第一部分乘积。
在第1周期时,将输入数据的Xi(6)乘上权重数据的MSB矢量Wi(7:4)(权重数据的MSB矢量已编码成一元编码格式),以得到第二MSB部分乘积。相似地,将输入数据的Xi(6)乘上权重数据的LSB矢量Wi(3:0)(权重数据的LSB矢量已编码成一元编码格式),以得到第二LSB部分乘积。将第二MSB部分乘积位移4位后相加至第二LSB部分乘积以得到第二部分乘积。此外,更将第一部分乘积位移1位相加至第二部分乘积,以得到更新后第二部分乘积。其余周期(第2周期至第7周期)的操作可依此类推,在此不重述。
也即,通过8个周期可以完成8位无符号数乘法运算。
如图4B所示,在进行8位带符号数乘法运算时,在第0周期时,将输入数据的Xi(7)乘上权重数据的MSB矢量Wi(7)(权重数据的MSB矢量已编码成一元编码格式),以及将输入数据的Xi(7)乘上权重数据的MSB矢量Wi(6:4)(权重数据的MSB矢量已编码成一元编码格式)并反相,两者相加,以得到第一MSB部分乘积。将输入数据的Xi(7)乘上权重数据的LSB矢量Wi(3:0)(权重数据的LSB矢量已编码成一元编码格式)并反相以得到第一LSB部分乘积。将第一MSB部分乘积位移4位后相加至第一LSB部分乘积,以得到第一部分乘积。
在第1周期时,将输入数据的Xi(6)乘上权重数据的MSB矢量Wi(7)(权重数据的MSB矢量已编码成一元编码格式)后反相,以及,将输入数据的Xi(6)乘上权重数据的MSB矢量Wi(6:4)(权重数据的MSB矢量已编码成一元编码格式),两者相加,以得到第二MSB部分乘积。相似地,将输入数据的Xi(6)乘上权重数据的LSB矢量Wi(3:0)(权重数据的LSB矢量已编码成一元编码格式),以得到第二LSB部分乘积。将第二MSB部分乘积位移4位后相加至第二LSB部分乘积以得到第二部分乘积。此外,更将第一部分乘积位移1位相加至第二部分乘积,以得到更新后第二部分乘积。其余周期(第2周期至第7周期)的操作可依此类推,在此不重述。
也即,通过8个周期可以完成8位带符号数乘法运算。
上述方式需要8个周期才可以完成8位无符号数乘法运算与8位带符号数乘法运算。
图5A为根据本公开一实施例的无符号数乘法运算的操作示意图。图5B为根据本公开一实施例的带符号数乘法运算的操作示意图。图5A与图5B以输入数据与权重数据都是8位为例做说明,但当知本公开并不受限于此。
在图5A与图5B中,输入数据亦被编码,以及,权重数据的MSB矢量与LSB矢量已编码成一元编码格式。
在图5A与图5B中,将输入数据输入至页缓冲器,而权重数据则是写入至多个存储器单元内。
在图5A中,输入数据从页缓冲器平行读取出,以及,将权重数据从这些存储器单元平行读取出,进行平行乘法,以得到部分乘积。
细言之,输入数据的位Xi(7)乘上权重数据的MSB矢量Wi(7:4),以得到第一MSB部分乘积。输入数据的位Xi(6)乘上权重数据的MSB矢量Wi(7:4),以得到第二MSB部分乘积。其余可依此类推,直到输入数据的位Xi(0)乘上权重数据的MSB矢量Wi(7:4),以得到第八MSB部分乘积。例如,在图5A中,输入数据的位Xi(7)被复制15次,并加上备用位,以成为16位的乘数“0000000000000000”。此16位的乘数“0000000000000000”乘上权重数据的MSB矢量Wi(7:4)“1111111100001100”,以得到第一MSB部分乘积“0000000000000000”。其余可依此类推。所有的MSB部分乘积可以合并成为输入串流(input stream)M。
相似地,将输入数据的Xi(7)乘上权重数据的LSB矢量Wi(3:0),以得到第一LSB部分乘积。将输入数据的Xi(6)乘上权重数据的LSB矢量Wi(3:0),以得到第二LSB部分乘积。其余可依此类推,直到输入数据的位Xi(0)乘上权重数据的LSB矢量Wi(3:0),以得到第八LSB部分乘积。所有的LSB部分乘积可以合并成为输入串流L。
之后,将这些第一至第八MSB部分乘积与这些第一至第八LSB部分乘积合并,并且计数合并值的位1的数量,即可得到无符号数乘法运算的MAC运算结果。
在图5B中,输入数据从页缓冲器平行读取出,以及,将权重数据从这些存储器单元平行读取出,进行平行乘法,以得到部分乘积。
细言之,输入数据的位Xi(7)乘上权重数据的MSB矢量Wi(7:4),以得到第一MSB部分乘积。输入数据的位Xi(6)乘上权重数据的MSB矢量Wi(7:4),以得到第二MSB部分乘积。其余可依此类推,直到输入数据的位Xi(0)乘上权重数据的MSB矢量Wi(7:4),以得到第八MSB部分乘积。
相似地,将输入数据的Xi(7)乘上权重数据的LSB矢量Wi(3:0),以得到第一LSB部分乘积。将输入数据的Xi(6)乘上权重数据的LSB矢量Wi(3:0),以得到第二LSB部分乘积。其余可依此类推,直到输入数据的位Xi(0)乘上权重数据的LSB矢量Wi(3:0),以得到第八LSB部分乘积。
之后,将这些第一至第八MSB部分乘积与这些第一至第八LSB部分乘积合并,并且计数合并值的位1的数量,即可得到带符号数乘法运算的MAC运算结果。
图6为根据本公开一实施例的存储器装置的功能框图。存储器装置600包括多个存储器晶粒(die)615。在图6中以存储器装置600包括4个存储器晶粒615为例做说明,但当知本公开并不受限于此。
存储器晶粒615包括多个存储器平面(memory plane,MP)620、多个页缓冲器625与累加电路630。在图6中以存储器晶粒615包括4个存储器平面620与4个页缓冲器625为例做说明,但当知本公开并不受限于此。存储器平面620包括多个存储器单元(未示出)。权重数据存在这些存储器单元内。
在各存储器晶粒615内,累加电路630由这些存储器平面620所共享,故而,累加电路630依序执行这些存储器平面620的累加运算。此外,各存储器晶粒615可以独立执行本公开实施例的上述多位MAC运算与多位汉明距离运算。
输入数据可以通过多条字线而输入至这些页缓冲器625内。
页缓冲器625包括感应电路631、多个闩锁单元633-641、多个逻辑门643与645。
感应电路631耦接至位线BL,以感应位线BL上的电流。
闩锁单元633-641例如但不受限于,分别为数据闩锁器(data latch,DL)633、闩锁器(L1)635、闩锁器(L2)637、闩锁器(L3)639与共同数据闩锁器(common data latch,CDL)641。闩锁单元633-641例如但不受限于,为单层闩锁器。
数据闩锁器633用以闩锁权重数据,并将权重数据输出至逻辑门643与645。
闩锁器(L1)635与闩锁器(L3)639乃是用于译码。
闩锁器(L2)637用以闩锁输入数据,并将输入数据输出至逻辑门643与645。
共同数据闩锁器641用以闩锁由逻辑门643或645所传来的数据。
逻辑门643与645例如但不受限于,分别为逻辑与门,以及逻辑XOR门。逻辑门643对输入数据与权重数据进行逻辑及运算,并将逻辑运算结果写入至共同数据闩锁器641。逻辑门645对输入数据与权重数据进行逻辑XOR运算,并将逻辑运算结果写入至共同数据闩锁器641。逻辑门643与645分别受控于致能信号AND_EN与XOR_EN。例如,当进行多位MAC运算时,逻辑门643被致能信号AND_EN致能;以及,当进行多位汉明距离运算时,逻辑门645被致能信号XOR_EN致能。
以图5A或图5B来做说明,输入数据的位Xi(7)的1个位输入至闩锁器(L2)637,而已编码成一元编码格式的权重数据的MSB矢量Wi(7:4)的1个位输入至数据闩锁器633。闩锁器(L2)637的输入数据与数据闩锁器633的权重数据则由逻辑门643或645进行逻辑运算后,共同数据闩锁器641用以闩锁由逻辑门643或645所传来的数据。共同数据闩锁器641亦可视为是该位线的数据输出路径。
累加电路630包括:部分乘积累加单元651、单一维度乘积产生单元653、第一多维度累加单元655、第二多维度累加单元657与权重累加控制单元659。
部分乘积累加单元651耦接至页缓冲器625,以接收由页缓冲器625的多个共同数据闩锁器641所传来的多个逻辑运算结果,来产生多个部分乘积。
例如,以图5A或图5B来说,部分乘积累加单元651产生这些第一至第八MSB部分乘积以及这些第一至第八LSB部分乘积。
单一维度乘积产生单元653耦接至部分乘积累加单元651,将部分乘积累加单元651所产生的这些部分乘积累加,以产生单一维度乘积。
例如,以图5A或图5B来说,单一维度乘积产生单元653则将部分乘积累加单元651所产生的这些第一至第八MSB部分乘积以及这些第一至第八LSB部分乘积累加,以产生单一维度乘积。
例如,在第0周期产生第<0>维度乘积后,可在第1周期产生第<1>维度乘积,其余依此类推。
第一多维度累加单元655耦接至单一维度乘积产生单元653,将单一维度乘积产生单元653所产生的多个单一维度乘积累加,以得到多维度乘积累加结果。
例如但不受限于,第一多维度累加单元655将单一维度乘积产生单元653所产生的第<0>至第<7>维度乘积累加,以得到8维度<0:7>乘积累加结果。接着,第一多维度累加单元655将单一维度乘积产生单元653所产生的第<8>至第<15>维度乘积累加,以得到另一个8维度<8:15>乘积累加结果。
第二多维度累加单元657耦接至第一多维度累加单元655,将第一多维度累加单元655所产生的多个多维度乘积累加结果进行累加,以得到输出累加值。例如但不受限于,第二多维度累加单元657将第一多维度累加单元655所产生的64个8维度乘积累加结果进行累加,以得到512维度的输出累加值。
权重累加控制单元659耦接至部分乘积累加单元651、单一维度乘积产生单元653、第一多维度累加单元655。根据进行多位MAC运算操作或多位汉明距离运算操作,权重累加控制单元659被致能或失能。例如但不受限于,当进行多位MAC运算操作时,权重累加控制单元659被致能;以及,当进行多位汉明距离运算操作时,权重累加控制单元659被失能。当权重累加控制单元659被致能时,权重累加控制单元659根据权重累加致能信号WACC_EN而输出控制信号至部分乘积累加单元651、单一维度乘积产生单元653、第一多维度累加单元655。
图6中的单一个页缓冲器620乃是耦接至多条位线BL。例如但不受限于,各页缓冲器620耦接至131072条位线BL,每一个周期内选择128条位线BL上的数据结果给累加电路630进行累加。如此的话,需要1024个周期把131072条位线BL上的数据送完。
此外在上述说明中,部分乘积累加单元651一次接收128位,第一多维度累加单元655产生8维度乘积累加结果,而第二多维度累加单元657产生512维度的输出累加值。但本公开不受限于此。在另一可能实施例中,部分乘积累加单元651一次接收64位(2位为1组),第一多维度累加单元655产生16维度乘积累加结果,而第二多维度累加单元657产生512维度的输出累加值。
图7为比较本公开一实施例与现有技术的MAC运算流程时序图。以图7来看,在输入广播(input broadcasting)时间内,接收输入数据。之后,对于该输入数据与该权重数据进行如上述方式的位乘法与位累加,以产生MAC运算操作结果。
在现有技术中,需要较长的操作时间。相反的,在本公开实施例中,通过平行乘法来产生(1)输入矢量与权重数据的MSB矢量的部分乘积,以及(2)输入矢量与权重数据的LSB矢量的部分乘积。如此可以在1个周期内完成无符号数乘法运算及/或带符号数乘法运算。所以,本公开实施例的操作速度快于现有技术的操作速度。
图8为根据本公开一实施例的存储器装置的操作方法,包括:对一输入数据进行编码,将一编码后输入数据传送至至少一页缓冲器内,以及,从该至少一页缓冲器平行读出该编码后输入数据(810);对一权重数据的一第一部分与一第二部分分别编码为该权重数据的一编码后第一部分与该权重数据的一编码后第二部分,并写入至该存储器装置的多个存储器单元内,以及,平行读出该权重数据的该编码后第一部分与该权重数据的该编码后第二部分(820);将该编码后输入数据分别乘上该权重数据的该编码后第一部分与该权重数据的该编码后第二部分,以平行产生多个部分乘积(830);以及将这些部分乘积累加,以产生一运算结果(840)。
如上述般,在本公开实施例中,通过位错误容忍编码方式可以减少错误位,提高准确度并减少对存储器容量的需求。
此外,本公开一实施例的多位MAC操作运算乃是使用高频宽权重累加器以产生输出结果,该高频宽权重累加器可通过重复使用故障位计数电路来实施权重化累加,故而可以改善累加速度。
本公开一实施例的多位汉明距离操作运算乃是使用高频宽未权重累加器以产生输出结果,该高频宽未权重累加器可通过重复使用故障位计数电路来实施未权重累加,故而可以改善累加速度。
本公开上述实施例可应用于NAND型快闪存储器,或者敏感于错误位的存储器装置,例如但不受限于,NOR型快闪存储器,相变(PCM)型快闪存储器,磁式随机存取存储器(magnetic RAM)或电阻式RAM。
在上述实施例中,累加电路630可以接收由页缓冲器625所传来的128个部分乘积,但在本公开其他实施例中,累加电路630可以接收由页缓冲器625所传来的2、4、8、16…512个部分乘积(为2的幂次方),此亦在本公开精神范围内。
在上述实施例中,累加电路630可以支援加法功能,但在本公开其他实施例中,累加电路630可以支援减法功能,此亦在本公开精神范围内。
在上述实施例中,虽以INT8或UNIT8的MAC运算为例做说明,但在本公开其他实施例中,也可支援INT2、UNIT2、INT4、UNIT4的MAC运算操作,此亦在本公开精神范围内。
虽然上述实施例中,将权重数据分为MSB矢量与LSB矢量(2个矢量),但本公开并不受限于此。在本公开其他可能实施例中,权重数据亦可分为更多个矢量,此亦在本公开精神范围内。
本公开上述实施例可应用于需要MAC运算操作的AI模型设计中,例如但不受限于,完全连接层(fully-connection layer)、卷积层(convolution layer)、多层感知器(multiple layer Perceptron)、支援矢量机器(support vector machine)等AI技术之中。
本公开上述不只可应用于计算用途(computing usage),也可应用于相似性搜寻(similarity search)、分析用途(analysis usage)、聚类分析(clustering analysis)等。
综上所述,虽然本公开已以实施例公开如上,然其并非用以限定本公开。本公开所属技术领域的技术人员,在不脱离本公开的精神和范围内,当可作各种的更动与润饰。因此,本公开的保护范围当视随附的权利要求书范围所界定的为准。
Claims (10)
1.一种存储器装置,包括:
多个存储器晶粒,各这些存储器晶粒包括多个存储器平面、多个页缓冲器与一累加电路,各这些存储器平面包括多个存储器单元,
其中,对一输入数据进行编码,将一编码后输入数据传送至至少一页缓冲器内,以及,从该至少一页缓冲器平行读出该编码后输入数据;
对一权重数据的一第一部分与一第二部分分别编码为该权重数据的一编码后第一部分与该权重数据的一编码后第二部分,并写入至该存储器装置的这些存储器单元内,以及,平行读出该权重数据的该编码后第一部分与该权重数据的该编码后第二部分;
将该编码后输入数据分别乘上该权重数据的该编码后第一部分与该权重数据的该编码后第二部分,以平行产生多个部分乘积;以及
将这些部分乘积累加,以产生一运算结果。
2.根据权利要求1所述的存储器装置,其中,
该权重数据的该第一部分是最高有效位,以及该权重数据的该第二部分是最低有效位。
3.根据权利要求1所述的存储器装置,其中,
在编码时,将该输入数据与该权重数据分别量化成二进制整数矢量;
将该输入数据的各位复制多次并加上一备用位;
将该权重数据分开成该第一部分与该第二部分;以及
将该权重数据的该第一部分与该第二部分的各位以一元编码表示,以得到该权重数据的该编码后第一部分与该权重数据的该编码后第二部分。
4.根据权利要求1所述的存储器装置,其中,
该运算结果包括一乘积累加结果运算结果或者一汉明距离运算结果;以及,
将属同一维度的这些部分乘积累加,以得到单一维度乘积;
将多个单一维度乘积累加,以得到一多维度乘积累加结果;
将多个多维度乘积累加结果累加,以产生该运算结果。
5.根据权利要求4所述的存储器装置,其中,
当进行乘积累加运算时,对该编码后输入数据的各位与该权重数据的该编码后第一部分的各位进行逻辑及运算;以及
当进行汉明距离运算时,对该编码后输入数据的各位与该权重数据的该编码后第一部分的各位进行逻辑异或运算。
6.一种存储器装置的操作方法,包括:
对一输入数据进行编码,将一编码后输入数据传送至至少一页缓冲器内,以及,从该至少一页缓冲器平行读出该编码后输入数据;
对一权重数据的一第一部分与一第二部分分别编码为该权重数据的一编码后第一部分与该权重数据的一编码后第二部分,并将该权重数据的该编码后第一部分与该权重数据的该编码后第二部分写入至该存储器装置的多个存储器单元内,以及,平行读出该权重数据的该编码后第一部分与该权重数据的该编码后第二部分;
将该编码后输入数据分别乘上该权重数据的该编码后第一部分与该权重数据的该编码后第二部分,以平行产生多个部分乘积;以及
将这些部分乘积累加,以产生一运算结果。
7.根据权利要求6所述的存储器装置的操作方法,其中,
该权重数据的该第一部分是最高有效位,以及,该权重数据的该第二部分是最低有效位。
8.根据权利要求6所述的存储器装置的操作方法,其中,
在编码时,将该输入数据与该权重数据分别量化成二进制整数矢量;
将该输入数据的各位复制多次并加上一备用位;
将该权重数据分开成该第一部分与该第二部分;以及
将该权重数据的该第一部分与该第二部分的各位以一元编码表示,以得到该权重数据的该编码后第一部分与该权重数据的该编码后第二部分。
9.根据权利要求6所述的存储器装置的操作方法,其中,
该运算结果包括一乘积累加结果运算结果或者一汉明距离运算结果;以及
将属同一维度的这些部分乘积累加,以得到单一维度乘积;
将多个单一维度乘积累加,以得到一多维度乘积累加结果;
将多个多维度乘积累加结果累加,以产生该运算结果。
10.根据权利要求9所述的存储器装置的操作方法,其中,
当进行乘积累加运算时,对该编码后输入数据的各位与该权重数据的该编码后第一部分的各位进行逻辑及运算;以及
当进行汉明距离运算时,对该编码后输入数据的各位与该权重数据的该编码后第一部分的各位进行逻辑异或运算。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163281734P | 2021-11-22 | 2021-11-22 | |
| US63/281,734 | 2021-11-22 | ||
| US17/701,725 US20230161556A1 (en) | 2021-11-22 | 2022-03-23 | Memory device and operation method thereof |
| US17/701,725 | 2022-03-23 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116153367A true CN116153367A (zh) | 2023-05-23 |
Family
ID=86351261
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210322542.5A Pending CN116153367A (zh) | 2021-11-22 | 2022-03-29 | 存储器装置及其操作方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20230161556A1 (zh) |
| CN (1) | CN116153367A (zh) |
-
2022
- 2022-03-23 US US17/701,725 patent/US20230161556A1/en active Pending
- 2022-03-29 CN CN202210322542.5A patent/CN116153367A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20230161556A1 (en) | 2023-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220399904A1 (en) | Recurrent neural networks and systems for decoding encoded data | |
| CN105049061A (zh) | 基于超前计算的高维基极化码译码器和极化码译码方法 | |
| US11537861B2 (en) | Methods of performing processing-in-memory operations, and related devices and systems | |
| CN117337432A (zh) | 用于使用神经网络对经编码数据进行解码的解码器及系统 | |
| CN108921292B (zh) | 面向深度神经网络加速器应用的近似计算系统 | |
| Liu et al. | Sme: Reram-based sparse-multiplication-engine to squeeze-out bit sparsity of neural network | |
| Sadi et al. | Accelerating deep convolutional neural network base on stochastic computing | |
| Tsai et al. | RePIM: Joint exploitation of activation and weight repetitions for in-ReRAM DNN acceleration | |
| Azamat et al. | Quarry: Quantization-based ADC reduction for ReRAM-based deep neural network accelerators | |
| US20020078110A1 (en) | Parallel counter and a logic circuit for performing multiplication | |
| Ahn et al. | Deeper weight pruning without accuracy loss in deep neural networks: Signed-digit representation-based approach | |
| GB1579100A (en) | Digital arithmetic method and means | |
| Boo et al. | A VLSI architecture for arithmetic coding of multilevel images | |
| TWI796977B (zh) | 記憶體裝置及其操作方法 | |
| CN116153367A (zh) | 存储器装置及其操作方法 | |
| Hao et al. | Stochastic-HD: leveraging stochastic computing on hyper-dimensional computing | |
| Zhao et al. | RACE-IT: A reconfigurable analog CAM-crossbar engine for in-memory transformer acceleration | |
| Zhou et al. | Approximate comparator: Design and analysis | |
| CN114153421A (zh) | 存储器装置及其操作方法 | |
| CN115398392A (zh) | 算术逻辑单元 | |
| Lu et al. | Low Error-Rate Approximate Multiplier Design for DNNs with Hardware-Driven Co-Optimization | |
| Imani | Machine learning in iot systems: From deep learning to hyperdimensional computing | |
| Muscedere | Difficult operations in the multi-dimensional logarithmic number system. | |
| Srikanthan et al. | Area-time efficient sign detection technique for binary signed-digit number system | |
| Xie et al. | Energy-efficient stochastic computing for convolutional neural networks by using kernel-wise parallelism |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |