CN115618024A - 多媒体推荐方法、装置及电子设备 - Google Patents
多媒体推荐方法、装置及电子设备 Download PDFInfo
- Publication number
- CN115618024A CN115618024A CN202211258135.9A CN202211258135A CN115618024A CN 115618024 A CN115618024 A CN 115618024A CN 202211258135 A CN202211258135 A CN 202211258135A CN 115618024 A CN115618024 A CN 115618024A
- Authority
- CN
- China
- Prior art keywords
- multimedia
- data
- similarity
- recommended
- media
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/40—Information retrieval; Database structures therefor; File system structures therefor of multimedia data, e.g. slideshows comprising image and additional audio data
- G06F16/43—Querying
- G06F16/435—Filtering based on additional data, e.g. user or group profiles
- G06F16/437—Administration of user profiles, e.g. generation, initialisation, adaptation, distribution
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Multimedia (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本公开的实施方式提供了一种多媒体推荐方法、装置及电子设备,涉及数据处理技术领域。该方法包括:分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度,以将媒体相似度满足预设条件的候选多媒体作为目标多媒体;根据目标多媒体对应的用户行为数据对待推荐多媒体进行推荐。本公开所采用的多媒体推荐方法,从多个维度对待推荐多媒体和候选多媒体进行相似度的判断,得到准确的媒体相似度,进而得到准确的可推荐用户,提高待推荐多媒体的推荐效果。
Description
技术领域
本公开的实施方式涉及数据处理技术领域,更具体地,本公开的实施方式涉及多媒体推荐方法、多媒体推荐装置及电子设备。
背景技术
本部分旨在为权利要求书中陈述的本公开的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
随着互联网技术的发展,互联网能够为对象提供越来越多的网络服务,例如:用户可以通过互联网浏览多媒体信息,其中,多媒体信息可以为图片、视频、音乐、电子书籍等等。在互联网平台中,用户可以通过搜索功能搜索感兴趣的多媒体信息,同时,为了方便用户获取感兴趣的多媒体信息,互联网平台还可以主动向用户推荐用户可能感兴趣的多媒体信息。
目前多媒体信息的个性化推荐主要依赖用户的交互行为实现,例如,通过分析用户交互行为与多媒体信息之间的关联性,揣摩用户对多媒体信息的喜好,将合适的多媒体信息推送给合适的人群。但是,对于缺乏用户交互行为的多媒体信息,存在多媒体信息推荐精准度不高的问题。
发明内容
为此,本公开提出一种多媒体推荐方法,以通过容器化技术对各集群的数据资源以及算力资源进行分配,并通过控制数据的访问权限保证数据安全,达到在不变更数据归属的前提下,提供安全可控的数据读取、模型训练、模型共享环境。
在本上下文中,本公开的实施方式期望提供一种多媒体推荐方法、多媒体推荐装置、计算机可读存储介质及电子设备。
在本公开实施方式的第一方面中,提供了一种多媒体推荐方法,包括:分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,所述候选多媒体为存在用户行为数据的多媒体,所述用户行为数据是根据用户对所述候选多媒体执行的交互行为得到的;计算所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;根据每个所述模态类型对应的数据相似度,计算所述待推荐多媒体与所述候选多媒体之间的媒体相似度,以将所述媒体相似度满足预设条件的候选多媒体作为目标多媒体;根据所述目标多媒体对应的用户行为数据,得到可推荐用户,以将所述待推荐多媒体推荐给所述可推荐用户。
在本公开实施方式的第二方面中,提供了一种多媒体推荐装置,包括:媒体数据提取模块,用于分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,所述候选多媒体为存在用户行为数据的多媒体,所述用户行为数据是根据用户对所述候选多媒体执行的交互行为得到的;数据相似度计算模块,用于计算所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;目标多媒体确认模块,用于根据每个所述模态类型对应的数据相似度,计算所述待推荐多媒体与所述候选多媒体之间的媒体相似度,以将所述媒体相似度满足预设条件的候选多媒体作为目标多媒体;推荐模块,用于根据所述目标多媒体对应的用户行为数据,得到可推荐用户,以将所述待推荐多媒体推荐给所述可推荐用户。
在本公开实施方式的第三方面中,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述所述的多媒体推荐方法。
在本公开实施方式的第四方面中,提供了一种电子设备,包括:处理器;以及存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时实现如上述所述的多媒体推荐方法。
根据本公开实施方式的技术方案,通过分别计算每个模态类型的模态数据所对应的数据相似度,以对待推荐多媒体与候选多媒体进行全面的对比,且通过直接对每个模态类型的模态数据进行对比的方式,提高计算得到的数据相似度的准确性,然后,再结合这些数据相似度计算待推荐多媒体与候选多媒体之间的媒体相似度,从多个维度对待推荐多媒体和候选多媒体进行相似度的判断,得到准确的媒体相似度,进而得到准确的可推荐用户,提高待推荐多媒体的推荐效果。
附图说明
通过参考附图阅读下文的详细描述,本公开示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本公开的若干实施方式,其中:
图1示意性地示出了根据本公开的示例性实施环境的示意图;
图2示意性地示出了根据本公开的多媒体推荐方法的流程示意图;
图3示意性地示出了根据本公开的获取用户行为数据的示意图;
图4示意性地示出了根据本公开的多媒体推荐方法的流程示意图;
图5示意性地示出了根据本公开的多媒体推荐方法的流程示意图;
图6示意性地示出了根据本公开的进行特征提取的示意图;
图7示意性地示出了根据本公开的获取可推荐用户的示意图;
图8示意性地示出了根据本公开的进行特征提取的示意图;
图9示意性地示出了根据本公开的进行特征提取的示意图;
图10示意性地示出了根据本公开的获取音乐歌词表征的示意图;
图11示意性地示出了根据本公开的模型训练的示意图;
图12示意性地示出了根据本公开的多媒体推荐方法的流程示意图;
图13示意性地示出了根据本公开的多媒体推荐装置的示意框图;
图14示意性地示出了根据本公开的示例实施例的存储介质的示意图;
图15示意性地示出了根据发明的示例实施例的电子设备的方框图。
在附图中,相同或对应的标号表示相同或对应的部分。
具体实施方式
下面将参考若干示例性实施方式来描述本公开的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本公开,而并非以任何方式限制本公开的范围。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
本领域技术人员知道,本公开的实施方式可以实现为一种方法、装置、设备、存储介质或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
本公开所涉及的数据可以为经用户授权或者经过各方充分授权的数据,对数据的采集、传播、使用等,均符合国家相关法律法规要求。
附图中所示的流程图仅是示例性说明,不是必须包括所有的内容和操作/步骤,也不是必须按所描述的顺序执行。例如,有的操作/步骤还可以分解,而有的操作/步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。
根据本公开的实施方式,提出了一种多媒体推荐方法、多媒体推荐装置、计算机可读存储介质及电子设备。
以下对本公开实施例中的部分用语进行解释说明,以便于本领域技术人员理解。
多媒体信息:可以为图片、视频、音乐、电子书、广告等。另外,用户可与多媒体信息进行互动,以音乐为例,可通过网页页面或者预先在终端安装的音乐播放程序向用户展示音乐,用户可以对这些音乐进行相应的操作,如播放、下载、分享、收藏等。
嵌入(Embedding):深度学习的任务就是把高维原始数据(如用户信息、多媒体信息等)映射到低维流形,使得高维的原始数据被映射到低维流形之后变得可分,这个映射就叫嵌入(Embedding)。
例如,Embedding可以用一个低维的向量表示一个物体(如一个词,或是一个商品,或是一个电影等),这个Embedding向量的性质是能使距离相近的向量对应的物体有相近的含义,比如摇滚音乐的Embedding和说唱音乐的Embedding之间的距离就会很接近,但是摇滚音乐的Embedding和古典音乐的Embedding的距离就会远一些。
此外,附图中的任何元素数量均用于示例而非限制,以及任何命名都仅用于区分,而不具有任何限制含义。
下面参考本公开的若干代表性实施方式,详细阐释本公开的原理。
发明概述
目前多媒体信息的个性化推荐主要依赖用户的交互行为实现,例如,通过分析用户交互行为与多媒体信息之间的关联性,揣摩用户对多媒体信息的喜好,将合适的多媒体信息推送给合适的人群。但是,对于缺乏用户交互行为的多媒体信息,存在多媒体信息推荐精准度不高的问题。
基于上述内容,本公开的基本思想在于,分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据,其中,候选多媒体为存在用户行为数据的多媒体,用户行为数据是根据用户对候选多媒体执行的交互行为得到的,然后,计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度,根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度,以分别对比待推荐多媒体和候选多媒体的多个维度之间的相似度,使得到的媒体相似度更加准确,即得到的目标多媒体更加准确,最后,根据目标多媒体对应的用户行为数据,得到可推荐用户,以将待推荐多媒体推荐给可推荐用户,进而可以不用考虑待推荐多媒体是否存在用户交互行为即可对待推荐多媒体进行推荐,提高多媒体信息推荐的准确性。
在介绍了本公开的基本原理之后,下面具体介绍本公开的各种非限制性实施方式。
应用场景总览
首先参考图1,图1示出了可以应用本公开实施例的一种多媒体推荐方法的实施环境示意图。
如图1所示,该实施环境可以包终端101和服务器102,其中,终端101以及服务器102可以通过有线或无线通信方式进行直接或间接地连接,本公开对此不进行限制。
终端101可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能音箱、智能手表等,但并不局限于此。
终端101安装有为用户提供多媒体信息的多媒体平台,该多媒体平台可以包括但不限于:游戏应用下载平台、短视频平台、内容发布平台、音视频播放平台(如音乐播放应用程序、音频电台、视频播放应用程序)以及购物平台等等,终端101可以用于向用户推荐多媒体信息。
可理解的是,该多媒体信息在不同多媒体平台中所指的具体内容不同,例如,在游戏应用下载平台中,该多媒体信息可以是指游戏应用,如单机游戏、网络游戏、手游或小游戏等等;在短视频平台中,多媒体信息可以是指一段视频;在音乐播放平台中,多媒体信息可以是指音乐;在购物平台中,该多媒体信息可以是指购物平台中出售的产品、服务等等;在内容发布平台中,该多媒体信息可以是指一篇文学作品、一则新闻资讯、一篇旅游游记等等。
可理解的是,服务器102可以是指用于为多媒体平台提供后端服务的设备,该服务器102还可以用于存储用户的交互行为,以及多媒体信息的具体内容。其中,服务器102可以是是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(Content Delivery Network,CDN)、以及大数据和人工智能平台等基础云计算服务的云服务器。此外,还可以将多个服务器组成为一个区块链网络,每个服务器为区块链网络中的一个节点。
本公开不对多媒体推荐方法的执行主体进行限定,可选地,服务器102承担主要多媒体推荐工作,终端101承担次要多媒体推荐工作;或者,服务器102承担次要多媒体推荐工作,终端101承担主要多媒体推荐工作;或者,服务器102或终端101分别可以单独承担多媒体推荐工作。
需要说明的是,图1所示的实施环境中终端和服务器的数量仅为举例,例如,终端和服务器的数量可以为多个,本公开并不对终端设备和服务器的数量进行限定。
应该理解的是,图1所示的实施环境仅是本公开的实施例可以在其中得以实现的一个示例。本公开实施例的适用范围不受到该实施环境任何方面的限制。
示例性方法
下面结合图1的实施环境,参考图2来描述根据本公开示例性实施方式的多媒体推荐方法。需要注意的是,上述实施环境仅是为了便于理解本公开的精神和原理而示出,本公开的实施方式在此方面不受任何限制。相反,本公开的实施方式可以应用于适用的任何实施环境。
本公开首先提供了一种多媒体推荐方法,该方法执行主体可以是终端设备,也可以是服务器,本示例实施例中以服务器执行该方法为例进行说明。应理解的是,该方法也可以适用于其它的示例性实施环境,并由其它实施环境中的设备具体执行,本实施例不对该方法所适用的实施环境进行限制。
参照图2所示,在一示例性的实施例中,该多媒体推荐方法可以包括以下步骤S210至步骤S240,详细介绍如下:
步骤S210,分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,候选多媒体为存在用户行为数据的多媒体,用户行为数据是根据用户对候选多媒体执行的交互行为得到的。
需要说明的是,用户关于多媒体信息执行的交互行为针对不同的多媒体信息所指的具体内容不同。
例如,该多媒体信息为音乐,交互行为包括评价、收藏、播放、暂停、退出等等中的至少一种,则用户行为数据包括平均播放时长、播放总次数、是否收藏、评价内容等;该多媒体信息为文章,交互行为包括评价、收藏、阅读、分享、退出等等中的至少一种,则用户行为数据包括平均阅读时长、阅读总次数、是否收藏、是否分享、评价内容等;该多媒体信息为视频,交互行为包括评价、收藏、观看、分享、发送弹幕等等中的至少一种,则用户行为数据包括平均观看时长、观看总次数、弹幕内容、是否收藏、是否分享、评价内容等。
多媒体信息的媒体数据为多媒体信息的基本属性信息,其包括多个模态类型,不同的多媒体信息所包含的模态类型也不同。
例如,该多媒体信息为音乐,该音乐的媒体数据的模态类型可以包括音频参数类型(音乐对应的音频数据)、文本参数类型(音乐对应的标题、音乐对应的歌词、音乐对应的评论等)、图像参数类型(音乐对应的视频短片、音乐对应的主题图像等);该多媒体信息为文章,该文章的媒体数据的模态类型可以包括文本参数类型(文章对应的标题、文章对应的正文、文章对应的摘要等)、图像参数类型(文章对应的插图);该多媒体信息为视频,该视频的媒体数据的模态类型可以包括文本参数类型(视频对应的标题、视频对应的简介、视频对应的评价等)、图像参数类型(视频对应的视频帧数据)、音频参数类型(视频对应的音频数据)。
服务器存储有多媒体信息,待推荐多媒体可以是这些多媒体信息中用户行为数据的数据量小于预设数量阈值的多媒体信息,也可以是发布时间小于预设时间阈值的多媒体信息。进一步地,候选多媒体可以是这些多媒体信息中用户行为数据的数据量大于预设数量阈值的多媒体信息,也可以是发布时间大于预设时间阈值的多媒体信息,本公开对此不进行限制。
确认待推荐多媒体和候选多媒体需要提取的模态类型,分别从待推荐多媒体和候选多媒体中提取这些模态类型对应的媒体数据。
例如,根据待推荐多媒体的类型得到需要提取的模态类型,如待推荐多媒体的类型为音乐,则确认需要提取的模态类型可以包括音频参数类型和文本参数类型;如待推荐多媒体的类型为视频,则确认需要提取的模态类型可以包括音频参数类型、文本参数类型和图像参数类型。然后,基于需要提取的模态类型对待推荐多媒体和候选多媒体提取各个模态类型对应的媒体数据。
可选地,模态类型还可以进一步划分有子模态类型,如待推荐多媒体的类型为音乐时,其包含的文本参数类型中还可以划分为音乐对应的标题、音乐对应的歌词、音乐对应的评论等子模态类型、音乐对应的歌手、音乐对应的语种、音乐对应的曲风等,以进一步增加多媒体相似度分析的维度,提高后续进行相似度分析的准确性。
步骤S220,计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度。
需要说明的是,数据相似度用于表征媒体数据所包含的真实含义之间的相似程度,例如,“番茄”和“西红柿”所对应的真实含义是相同的,则提对应的数据相似度则较高。
根据媒体数据所属的模态类型的不同,计算待推荐多媒体的媒体数据与候选多媒体的媒体数据之间的数据相似度。
例如,待推荐多媒体和候选多媒体为音乐,提取待推荐音乐包含的媒体数据包括音频参数类型和文本参数类型,提取候选音乐包含的媒体数据包括音频参数类型和文本参数类型,计算待推荐音乐的音频参数类型和候选音乐的音频参数类型之间的相似度,得到音频相似度;计算待推荐音乐的文本参数类型和候选音乐的文本参数类型之间的相似度,得到文本相似度。
可选地,模态类型还可以进一步划分有子模态类型,可以分别计算待推荐多媒体和候选多媒体中属于相同子模态类型的媒体数据之间的相似度,得到该模态类型的数据相似度。
例如,音乐的音频参数类型可以划分为副歌、主歌、伴奏,在计算音频相似度时,可以分别对待推荐音乐以及候选音乐包含的副歌、主歌、伴奏,以通过分别计算待推荐音乐的副歌和候选音乐的副歌之间的相似度,得到第一音频相似度;计算待推荐音乐的主歌和候选音乐的主歌之间的相似度,得到第二音频相似度;计算待推荐音乐的伴奏和候选音乐的伴奏之间的相似度,得到第三音频相似度。然后,获取副歌、主歌、伴奏分别对应的权值,以根据得到的权值对第一音频相似度、第二音频相似度和第三音频相似度机进行加权计算,得到音频相似度。
步骤S230,根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度,以将媒体相似度满足预设条件的候选多媒体作为目标多媒体。
需要说明的是,媒体相似度用于表征待推荐多媒体所包含的媒体数据与候选多媒体所包含的媒体数据之间的相似程度。
示例性地,媒体相似度满足预设条件的候选多媒体可以是媒体相似度大于预设媒体相似度阈值的候选多媒体。其中,预设媒体相似度阈值可以是技术人员或用户预先设置的,也可以是当前场景灵活计算的,如根据候选多媒体的数量、待推荐多媒体的推荐优先级、待推荐多媒体的用户行为数据的数量、待推荐多媒体的发布时间等计算预设媒体相似度阈值,以提高目标多媒体筛选的灵活性和准确性。
示例性地,媒体相似度满足预设条件的候选多媒体也可以是根据媒体相似度对候选多媒体进行排序,排序靠前的预设数量的候选多媒体为满足预设条件的候选多媒体。其中,预设数量可以是技术人员或用户预先设置的,也可以是当前场景灵活计算的,如根据候选多媒体的数量、待推荐多媒体的推荐优先级、待推荐多媒体的用户行为数据的数量、待推荐多媒体的发布时间等计算预设数量,以提高目标多媒体筛选的灵活性和准确性。
根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度。例如,可以是将每个模态类型对应的数据相似度之间的平均值作为媒体相似度,也可以是将每个模态类型对应的数据相似度中的中值作为媒体相似度,还可以是对每个模态类型对应的数据相似度进行加权计算得到媒体相似度,本公开对此不进行限制。
然后,根据预设条件对候选多媒体进行筛选,以将媒体相似度满足预设条件的候选多媒体作为目标多媒体。
步骤S240,根据目标多媒体对应的用户行为数据,得到可推荐用户,以将待推荐多媒体推荐给可推荐用户。
需要说明的是,用户行为数据是基于多个用户对目标多媒体执行的交互行为得到的。
例如,如图3所示,在预设时间段内共N个用户分别通过终端对目标多媒体执行了交互操作,分别根据这些交互操作得到各个用户的行为数据。如用户1在预设时间段内对目标多媒体执行的交互操作进行记录,得到行为数据1;对用户2在预设时间段内对目标多媒体执行的交互操作进行记录,得到行为数据2;对用户N在预设时间段内对目标多媒体执行的交互操作进行记录,得到行为数据N,拼接行为数据1、行为数据2...行为数据N,得到目标多媒体对应的用户行为数据。
用户行为数据表明了各个用户针对目标多媒体的喜爱程度。
示例性地,交互行为包括评价、收藏、播放、暂停、退出等等中的至少一种,用户行为数据包括用户针对该多媒体信息的平均播放时长、播放总次数、是否收藏、评价内容等,其中,平均播放时长可以是根据用户对该多媒体信息的播放总次数与播放总时长计算得到的。平均播放时长越长、播放总次数越多、对该多媒体信息进行收藏、评价内容表达的情绪越积极,则表明用户对该多媒体信息的喜爱程度越高;反之,平均播放时长越短、播放总次数越少、对该多媒体信息不进行收藏、评价内容表达的情绪越负面,则表明用户对该多媒体信息的喜爱程度越低。
可以理解的是,用户对目标多媒体的喜爱程度越高,则该用户喜爱与目标多媒体相似的待推荐多媒体的可能性越高。因此,根据目标多媒体对应的用户行为数据,得到目标多媒体执行了交互行为的用户针对该目标多媒体的喜爱程度,进而将喜爱程度满足预设条件的用户作为可推荐用户,并将待推荐多媒体推荐给可推荐用户,实现对待推荐多媒体的精准推荐。
相关技术中,一般是通过对多媒体信息的信息特征进行统一提取得到一个多媒体特征,再通过计算多媒体特征之间的相似度得到多媒体信息之间的相似度,但是由于多媒体信息包含的内容复杂,相关技术中提取得到的多媒体特征可能存在信息的遗漏,且根据多媒体特征进行相似度计算的方式也存在局限,导致相似度计算结果不准确的情况。因此,本公开通过分别计算每个模态类型的模态数据所对应的数据相似度,以对待推荐多媒体与候选多媒体进行全面的对比,且通过直接对每个模态类型的模态数据进行对比的方式,提高计算得到的数据相似度的准确性,然后,再结合这些数据相似度计算待推荐多媒体与候选多媒体之间的媒体相似度,从多个维度对待推荐多媒体和候选多媒体进行相似度的判断,得到准确的媒体相似度,进而得到准确的可推荐用户,提高待推荐多媒体的推荐效果。
在一些实施方式中,如图4所示,多媒体平台可以对应设置有多种推荐方法,可以根据待推荐多媒体含有的用户行为数据的数据量的多少,确认待推荐多媒体对应的推荐方法。例如,步骤S410,获取待推荐多媒体含有的用户行为数据的数据量;步骤S420,判断该数据量是否少于数据量阈值,若待推荐多媒体含有的用户行为数据的数据量少于数据量阈值,则采用本公开实施例的多媒体推荐方法对待推荐多媒体进行推荐,即执行步骤S210至步骤S240;若待推荐多媒体含有的用户行为数据的数据量大于或等于数据量阈值,则执行步骤S430;步骤S430,确认数据量对应的备份多媒体推荐方法,采用该备份多媒体推荐方法对待推荐多媒体进行推荐。
例如,备份多媒体推荐方法可以是:根据用户对每个多媒体执行的交互行为,得到各个用户针对各个多媒体的喜爱程度,根据用户针对各个多媒体的喜爱程度对用户进行划分,如将相同多媒体中喜爱程度大于第一阈值的用户均划分为一组。然后,当同一组中的任意用户对待推荐多媒体的喜爱程度大于第二阈值时,将该待推荐多媒体推荐给与该任意用户属于同一分组中没有接收过该待推荐多媒体的用户。
通过待推荐多媒体含有的用户行为数据的数据量来确认该待推荐多媒体的推荐计算方法,以适用处于不同情况下的多媒体,提高多媒体推荐效果。
在一些实施方式中,模态类型包括文本参数类型、音频参数类型和图像参数类型中的至少两者,相似度计算数据对包括文本相似度计算数据对和音频相似度计算数据对和图像相似度计算数据对中的至少两者。以从至少两个维度对待推荐多媒体和候选多媒体的相似度进行判断,提高相似度判断的准确性。
下面,对于本示例实施方式的多媒体推荐方法的上述步骤进行更加详细的说明。
请参阅图5,图5是本申请的另一示例性实施例示出的多媒体推荐方法的流程图。如图5所示,S220中计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度的过程,可以包括如下所示的步骤S221至步骤S223:
步骤S221,分别从待推荐多媒体和候选多媒体包含的媒体数据中提取出属于相同模态类型的媒体数据作为待计算媒体数据,得到相同模态类型对应的相似度计算数据对。
示例性地,如图6所示,根据多媒体信息的类型确认需要进行分析的模态类型,如多媒体信息为音乐,则需要进行分析的模态类型包括音频参数类型和文本参数类型,从待推荐音乐的媒体数据和候选音乐的媒体数据中分别提取出属于音频参数类型的媒体数据作为待计算媒体数据,得到音频相似度计算数据对,即该音频相似度计算数据对中含有待推荐音乐中属于的音频参数类型的媒体数据以及候选音乐中属于的音频参数类型的媒体数据;并从待推荐音乐的媒体数据和候选音乐的媒体数据中分别提取出属于文本参数类型的媒体数据作为待计算媒体数据,得到文本相似度计算数据对,即该文本相似度计算数据对中含有待推荐音乐中属于的文本参数类型的媒体数据以及候选音乐中属于的文本参数类型的媒体数据。
步骤S222,分别对相似度计算数据对中的待计算媒体数据进行特征提取,得到每个待计算媒体数据对应的媒体特征向量。
可以理解的是,根据待计算媒体数据的模态类型的不同,其进行特征提取所采用的提取算法不同。
例如,模态类型为文本参数类型时,其对应的待计算媒体数据通过提取文字的含义、文字的位置、文字表达的情感等特征得到该待计算媒体数据对应的媒体特征向量;模态类型为图像参数类型时,其对应的待计算媒体数据通过提取图像的颜色、图像的纹理等特征得到该待计算媒体数据对应的媒体特征向量;模态类型为音频参数类型时,其对应的待计算媒体数据通过提取音频的音色、音频的响度、音频的频率等特征得到该待计算媒体数据对应的媒体特征向量,本公开对此不进行限制。
示例性地,多媒体信息为音乐,如图6所示,相似度计算数据对包括音频相似度计算数据对和文本相似度计算数据对,音频相似度计算数据对包括待推荐音乐的音频帧内容1和候选音乐的音频帧内容2,文本相似度计算数据对包括待推荐音乐的字符内容1和候选音乐的字符内容2。对音频相似度计算数据对中属于待推荐音乐的音频帧内容1进行特征提取,得到音频特征向量1,以及对音频相似度计算数据对中属于候选音乐的音频帧内容2进行特征提取,得到音频特征向量2;对文本相似度计算数据对中属于待推荐音乐的字符内容1进行特征提取,得到文本特征向量1,以及对文本相似度计算数据对中属于候选音乐的字符内容2进行特征提取,得到文本特征向量2。
步骤S223,计算相似度计算数据对中待计算媒体数据对应的媒体特征向量之间的距离,得到待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度。
在向量空间中媒体特征向量之间的距离越近,则表明其对应的媒体数据之间越相似,反之,在向量空间中媒体特征向量之间的距离越远,则表明其对应的媒体数据之间越不相似。
其中,可以根据欧氏距离、曼哈顿距离、切比雪夫距离、夹角余弦距离等向量距离计算方法对相似度计算数据对中待计算媒体数据对应的媒体特征向量之间的距离进行计算,本公开对此不进行限制。
示例性地,又如图6所示,计算第一音频特征向量和第二音频特征向量之间的距离,并对得到的距离进行归一化处理,得到待推荐多媒体和候选多媒体的音频相似度;计算第一文本特征向量和第二文本特征向量之间的距离,并对得到的距离进行归一化处理,得到待推荐多媒体和候选多媒体的文本相似度。
通过分别提取相似度计算数据对中的待计算媒体数据的媒体特征向量,以计算待计算媒体数据对应的媒体特征向量之间的距离,进而得到各个模态类型的媒体数据之间的数据相似度,提高计算得到的数据相似度的准确性,便于后续对媒体相似度的计算。
在一些实施方式中,通过将待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据分别输入目标模型中,得到目标模型输出的数据相似度,
例如,如图7所示,多媒体数据库中包括M个候选多媒体,分别提取待推荐多媒体和每个候选多媒体包含的多个模态类型的媒体数据,然后将提取得到的媒体数据输入目标模型中,该目标模型的嵌入层对媒体数据进行特征提取,得到待推荐多媒体的多个媒体特征向量,并得到每个候选多媒体的多个媒体特征向量,进而根据媒体特征向量分别计算待推荐多媒体与每个候选多媒体之间的媒体相似度,根据媒体相似度对候选多媒体进行筛选,得到m个目标多媒体,并根据这些目标多媒体的用户行为数据得到m个可推荐用户的集合。
其中,各个可推荐用户集合之间可能存在相同的用户,可以仅对相同的用户针对待推荐多媒体进行一次媒体推荐即可。也可以根据相同的用户在各个可推荐用户集合中出现的次数得到该用户的推荐优先级,然后根据推荐优先级匹配对应的推荐策略:如推荐优先级越高则对应的推荐策略可以为每间隔预设时间进行一次针对待推荐多媒体的媒体推荐,也可以为通过弹窗、主页、短信提示等方式进行推荐,以提高多媒体推荐效果。
进一步地,可以根据媒体数据的模态类型的不同,其进行特征提取的嵌入层所采用的模型算法也不同。例如,如图8所示,多媒体信息为音乐,其包括音频参数类型的媒体数据和文本参数类型的媒体数据,其中,音频参数类型的媒体数据包括音频帧内容,文本参数类型的媒体数据包括音乐名称和音乐歌词。针对音频帧内容可以选择YAMNet模型算法进行特征提取得到音频向量;针对音乐名称和音乐歌词可以选择Word2Vec模型算法进行特征提取分别得到名称文本向量和歌词文本向量。可以理解的是,也可以采用其他模型算法对音频参数类型、文本参数类型、图像参数类型等进行特征提取,如针对文本参数类型的媒体数据可以选择BERT(Bidirectional Encoder Representations from Transformer)模型算法进行特征提取得到文本向量,本公开对此不进行限制。
在一些实施方式中,如图9所示,媒体数据的不同所采用的特征提取的方式也不同,如多媒体信息为音乐,提取的文本参数类型的媒体数据包括音乐名称、音乐歌词和音频帧,分别对音乐名称、音乐歌词和音频帧进行特征提取,得到音乐名称特征序列、音乐歌词特征序列和音频特征序列。
然后,根据目标模型的多层感知器(Multilayer Perceptron,MLP)模块对音乐名称特征序列进行处理,如将1*1024维的音频特征序列输入MLP模块得到音频向量。进一步地,根据目标模型的平均池化模块对音乐名称特征序列进行平均池化,例如,对3*256维的音乐名称特征序列求平均值,转化为1*256维的向量,得到音乐名称表征。
同时,基于注意力机制对音乐歌词特征序列进行计算,目标模型的Attention模块的具体结构如图10所示,使用一个权重矩阵W以及偏移向量B,对100*256维音乐歌词特征序列X做计算X*W+B,得到一个矩阵key(即图中的K),根据一个单独的可训练的向量作为query(即图中的Q)与key分别内积得到一个中间向量,然后根据softmax函数对中间向量进行计算得到加权权重a,使用加权权重a对最初输入的音乐歌词特征序列做加权求和,转化为1*256维的向量,得到最后的音乐歌词表征,以便于和音乐名称表征进行拼接。
进一步地,拼接音乐歌词表征和音乐名称表征,并输入至MLP模块,得到文本向量,并即将音频特征序列输入至目标模型的MLP,得到音频向量。然后分别计算待推荐音乐的文本向量和候选音乐的文本向量之间的文本相似度,以及待推荐音乐的音频向量和候选音乐的音频向量之间的音频相似度,根据文本相似度和音频相似度计算媒体相似度。
其中,MLP可以使用LeakyReLU作为激活函数,其公式如下:

其中,a为一个预设的超参数,y为MLP的输入。
通过训练完成的目标模型进行数据相似度的计算,以利用机器学习提高计算得到的数据相似度的准确性。
需要说明的是,本公开并不对目标模型的模型结构进行限制,其除了上述实施例示出的结构之外,还可以为卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)等。
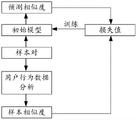
示例性地,目标模型的训练过程包括:提取样本多媒体对应的用户行为数据和样本多媒体包含的多个模态类型的媒体样本数据;根据每个样本多媒体的用户行为数据,计算样本多媒体之间的样本相似度;将每个样本多媒体中属于相同模态类型的媒体样本数据输入待训练的初始模型中,得到初始模型输出的每个样本多媒体中属于相同模态类型的媒体数据之间的预测相似度;根据样本相似度和预测相似度计算损失值,以根据损失值对初始模型进行迭代训练,得到训练完成的目标模型。
例如,多媒体信息为音乐为例进行说明:
服务器中存储有多个样本音乐,每个样本音乐对应有用户行为数据,根据用户行为数据计算每个样本音乐之间的样本相似度。
如将样本音乐划分为基础样本音乐和推荐样本音乐,其中,推荐样本音乐是指根据基础样本音乐向用户推荐的音乐,可以理解的是,一个样本音乐即可以是基础样本音乐,也可以是推荐样本音乐,如包括样本音乐A、样本音乐B、样本音乐C,历史记录中曾根据样本音乐A向用户推荐过样本音乐B,还曾根据样本音乐B向用户推荐过样本音乐C。则样本音乐A作为基础样本音乐时,样本音乐B作为样本音乐A的推荐样本音乐,样本音乐B作为基础样本音乐时,样本音乐B作为样本音乐C的推荐样本音乐。
根据基础样本音乐和推荐样本音乐的用户行为数据,计算基础样本音乐和推荐样本音乐之间的样本相似度。例如,可以计算推荐样本音乐的用户行为数据中基于基础样本音乐的收藏率和完整播放率,收藏率和完整播放率满足预设条件则表明该基础样本音乐和该推荐样本音乐相似,则将基础样本音乐和推荐样本音乐标记为正样本对。其中,收藏率是指推荐样本音乐基于基础样本音乐进行推荐的用户的总数和这些用户中对推荐样本音乐进行收藏操作的数量的占比,完整播放率是指推荐样本音乐基于基础样本音乐进行推荐的用户的总数和这些用户中对推荐样本音乐进行完整播放操作的数量的占比。
负样本对可以是根据随机采样的方式,选取任意两个样本音乐作为负样本对,也可以将不相似的基础样本音乐和推荐样本音乐作为负样本对,本公开对此不进行限制。其中,为了保证模型的训练效果,负样本对的数量大于正样本对的数量,如负样本对的数量为正样本对的数量的10倍。
如图11所示,将样本对(正样本对或负样本对)输入待训练的初始模型中,得到初始模型输出的每个样本多媒体中属于相同模态类型的媒体数据之间的预测相似度,然后根据样本相似度和预测相似度计算损失值,以根据损失值对初始模型进行迭代训练,得到训练完成的目标模型。其中,预测相似度的值处于0至1之间,对于正样本对,训练目标为1,即预测相似度的值尽可能大;负样本对的训练目标为0,即预测相似度的值尽可能小。
计算损失值的损失函数可以为L1范数损失(L1 Loss)、均方误差损失(MSE Loss)、交叉熵损失(Cross Entropy Loss)、KL散度损失(KLDiv Loss)等,本公开对此不进行限制。
例如,损失函数为Focal Loss,其针对正负样本、难易样本添加了加权系数,损失函数公式可以为:
loss=-αt*(1-pt)γ*log(pt)
其中,对于正样本,αt=α,pt=p,对于负样本,αt=1-α,pt=1-p。p为模型预测的预测相似度,α和γ为两个超参数,在本发明中取值分别为0.8和2。Focal Loss相比传统的二分类交叉熵损失函数,多出了αt和(1-pt)γ两个系数。αt主要用于对正负样本加权,本发明中正负样本数量比例是1∶10,其正负比例不均衡,因此需要加权,有利于模型学习。(1-pt)γ项主要用于对难易样本加权,对于一条样本,模型输出的预测相似度与样本相似度相差越大,说明该样本越有学习价值,则该系数会越大,对应的加权系数越大,反之若预测相似度与样本相似度相差越小,则说明这条样本的学习价值较小,对应的加权系数也越小。
基于样本多媒体的用户行为数据,计算样本多媒体之间的样本相似度,以将计算得到的样本相似度作为模型训练的样本标签,在提高了样本标签标记的效率的前提下,还保证了样本标签标记的准确性,提高目标模型的训练效果和效率。
请参阅图12,图12是本申请的另一示例性实施例示出的多媒体推荐方法的流程图。如图12所示,S230中根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度的过程,可以包括如下所示的步骤S231至步骤S232:
步骤S231,获取每个模态类型对应的目标权重。
可以理解的是,模态类型的目标权重越大,则表明该模型类型的媒体数据对于多媒体之间的相似度计算更加重要,反之模态类型的目标权重越小,则表明该模型类型的媒体数据对于多媒体之间的相似度计算不重要。
示例性地,可以根据多媒体信息的类型的不同,获取每个模态类型对应的目标权重。例如,若多媒体信息为音乐,模态类型包括文本参数类型和音频参数类型,获取得到文本参数类型的目标权重可以为0.4,音频参数类型的目标权重可以为0.6;若多媒体信息为视频,模态类型包括文本参数类型、音频参数类型和图像参数类型,获取得到文本参数类型的目标权重可以为0.2,音频参数类型的目标权重可以为0.3,图像参数类型的目标权重可以为0.5。
在一些实施方式中,获取每个模态类型对应的目标权重,包括:根据待推荐多媒体的媒体类型,查询针对每个模态类型预先设置的初始权重;根据每个模态类型的媒体数据包含的数据量,得到每个模态类型的实际重要程度;根据每个模态类型的实际重要程度对每个模态类型预先设置的初始权重进行修改,得到每个模态类型对应的目标权重。
媒体数据包含的数据量越多,则表明该媒体数据的数据内容越多,则该媒体数据的实际重要程度越高;反之媒体数据包含的数据量越少,则表明该媒体数据的数据内容越少,则该媒体数据的实际重要程度越低。
例如,若多媒体信息为音乐,模态类型包括文本参数类型和音频参数类型,文本参数类型的媒体数据包含的数据量为20个字符,音频参数类型的媒体数据包含的数据量为1000个音频帧,计算得到文本参数类型的实际重要程度为0.5,文本参数类型的实际重要程度为1.2。进一步地,获取得到文本参数类型的初始权重可以为0.4,音频参数类型的初始权重可以为0.6,则计算得到文本参数类型的目标权重为0.2,音频参数类型的目标权重可以为0.72。
由于不仅考虑有多媒体信息的类型的不同导致的数据重要程度的不同,还考虑了各模态类型的媒体数据的数据量的不同导致的数据重要程度的不同,因此使得计算得到的目标权重的准确度更高。
可以理解的是,还可以根据其他参数计算模态类型对应的目标权重,如待推荐多媒体的用户行为数据的数据量、待推荐多媒体的发布时间、候选多媒体的数量等,本公开对此不进行限制。
步骤S232,根据目标权重对每个模态类型对应的数据相似度进行加权计算,得到待推荐多媒体与候选多媒体之间的媒体相似度。
根据目标权重对每个模态类型对应的数据相似度进行加权计算,得到待推荐多媒体与候选多媒体之间的媒体相似度,提高计算得到的媒体相似度的准确性,进而提高待推荐多媒体的推荐效果。
在一些实施方式中,步骤S240中根据目标多媒体对应的用户行为数据,得到可推荐用户的过程,可以包括:识别目标多媒体对应的用户行为数据中包含的偏好表示数据,偏好表示数据是用户对目标多媒体执行偏好表示操作后得到的;根据每个用户的偏好表示数据,计算每个用户针对目标多媒体的偏好程度;将偏好程度满足预设条件的用户作为可推荐用户。
需要说明的是,偏好表示操作是指用户对目标多媒体执行的表示喜爱的操作,如对目标多媒体执行的分享、收藏、点赞、带有积极情感的评论、完成播放或阅读的次数等操作。
用户对目标多媒体执行的偏好表示操作越多,则表明该用户对目标多媒体的偏好程度越高;反之用户对目标多媒体执行的偏好表示操作越少,则表明该用户对目标多媒体的偏好程度越低。因此,根据每个用户的偏好表示数据,计算每个用户针对目标多媒体的偏好程度,以将偏好程度满足预设条件的用户作为可推荐用户。
其中,偏好程度满足预设条件的用户可以是偏好程度大于预设程度阈值的用户。偏好程度满足预设条件的用户也可以是根据偏好程度对用户进行排序,排序靠前的预设数量的用户为满足预设条件的用户。预设程度阈值或预设数量可以是技术人员或用户预先设置的,也可以是当前场景灵活计算的,如根据候选多媒体的数量、待推荐多媒体的推荐优先级、待推荐多媒体的用户行为数据的数量、待推荐多媒体的发布时间、用户的数量、用户的历史操作记录等计算预设程度阈值或预设数量,以提高用户筛选的灵活性和准确性。
将筛选通过的用户作为可推荐用户,然后将待推荐多媒体向这些用户进行推荐。
本公开通过目标多媒体对于的用户行为数据中的偏好表示数据,筛选得到可推荐用户,保证了可推荐用户的准确性,提高了待推荐多媒体的推荐效果。
示例性装置
在介绍了本公开示例性实施方式的方法之后,接下来,参考图11对本公开示例性实施例的多媒体推荐装置进行说明。
在图13中,多媒体推荐装置1300可以包括:媒体数据提取模块1310、数据相似度计算模块1320、目标多媒体确认模块1330以及推荐模块1340。
媒体数据提取模块1310,用于分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,候选多媒体为存在用户行为数据的多媒体,用户行为数据是根据用户对候选多媒体执行的交互行为得到的;
数据相似度计算模块1320,用于计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;
目标多媒体确认模块1330,用于根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度,以将媒体相似度满足预设条件的候选多媒体作为目标多媒体;
推荐模块1340,用于根据目标多媒体对应的用户行为数据,得到可推荐用户,以将待推荐多媒体推荐给可推荐用户。
在本公开的一个实施例中,目标多媒体确认模块1330还可以包括目标权重获取单元和媒体相似度计算单元:目标权重获取单元,用于获取每个模态类型对应的目标权重;媒体相似度计算单元,用于根据目标权重对每个模态类型对应的数据相似度进行加权计算,得到待推荐多媒体与候选多媒体之间的媒体相似度。
在本公开的一个实施例中,目标权重获取单元包括初始权重查询单元、重要程度获取单元和权重修改单元:初始权重查询单元,用于根据待推荐多媒体的媒体类型,查询针对每个模态类型预先设置的初始权重;重要程度获取单元,用于根据每个模态类型的媒体数据包含的数据量,得到每个模态类型的实际重要程度;权重修改单元,用于根据每个模态类型的实际重要程度对每个模态类型预先设置的初始权重进行修改,得到每个模态类型对应的目标权重。
在本公开的一个实施例中,数据相似度计算模块1320包括数据对获取单元、特征提取单元确认单元和数据相似度计算单元:数据对获取单元,用于分别从待推荐多媒体和候选多媒体包含的媒体数据中提取出属于相同模态类型的媒体数据作为待计算媒体数据,得到相同模态类型对应的相似度计算数据对;特征提取单元,用于分别对相似度计算数据对中的待计算媒体数据进行特征提取,得到每个待计算媒体数据对应的媒体特征向量;数据相似度计算单元,用于计算相似度计算数据对中待计算媒体数据对应的媒体特征向量之间的距离,得到待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度。
在本公开的一个实施例中,模态类型包括文本参数类型、音频参数类型和图像参数类型中的至少两者,相似度计算数据对包括文本相似度计算数据对和音频相似度计算数据对和图像相似度计算数据对中的至少两者。
在本公开的一个实施例中,推荐模块1340包括偏好表示数据识别单元、偏好程度计算单元和用户筛选单元:偏好表示数据识别单元,用于识别目标多媒体对应的用户行为数据中包含的偏好表示数据,偏好表示数据是用户对目标多媒体执行偏好表示操作后得到的;偏好程度计算单元,用于根据每个用户的偏好表示数据,计算每个用户针对目标多媒体的偏好程度;用户筛选单元,用于将偏好程度满足预设条件的用户作为可推荐用户。
在本公开的一个实施例中,数据相似度计算模块1320包括模型计算单元,用于将待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据分别输入目标模型中,得到目标模型输出的数据相似度。
在本公开的一个实施例中,多媒体推荐装置1300还可以包括:样本行为提取单元,用于提取样本多媒体对应的用户行为数据和样本多媒体包含的多个模态类型的媒体样本数据;样本相似度计算单元,用于根据每个样本多媒体的用户行为数据,计算样本多媒体之间的样本相似度;模型预测单元,用于将每个样本多媒体中属于相同模态类型的媒体样本数据输入待训练的初始模型中,得到初始模型输出的每个样本多媒体中属于相同模态类型的媒体数据之间的预测相似度;模型训练单元,用于根据样本相似度和预测相似度计算损失值,以根据损失值对初始模型进行迭代训练,得到训练完成的目标模型。
由于本公开的示例实施例的多媒体推荐装置的各个功能模块与上述多媒体推荐方法的示例实施例的步骤对应,因此对于本公开装置实施例中未披露的细节,请参照本公开上述的多媒体推荐方法的实施例,此处不再赘述。
应当注意,尽管在上文详细描述中提及了多媒体推荐装置的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本公开的实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。
在本公开实施例的第三方面中,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述第一方面所述的多媒体推荐方法。
示例性介质
在介绍了本公开示例性实施方式的装置之后,接下来,参考图14对本公开示例性实施例的存储介质进行说明。
在一些实施例中,本公开的各个方面还可以实现为一种介质,其上存储有程序代码,当所述程序代码被设备的处理器执行时用于实现本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施例的多媒体推荐方法中的步骤。
例如,所述设备的处理器执行所述程序代码时可以实现如图2中所述的多媒体推荐方法的执行步骤,包括:步骤S210,分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,候选多媒体为存在用户行为数据的多媒体,用户行为数据是根据用户对候选多媒体执行的交互行为得到的;步骤S220,计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;步骤S230,根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度,以将媒体相似度满足预设条件的候选多媒体作为目标多媒体;步骤S240,根据目标多媒体对应的用户行为数据,得到可推荐用户,以将待推荐多媒体推荐给可推荐用户。
参考图14所示,描述了根据本公开的实施例的用于实现上述多媒体推荐方法的程序产品1400,其可以采用便携式紧凑盘只读存储器(CD-ROM)并包括程序代码,并可以在终端设备,例如个人电脑上运行。然而,本公开的程序产品不限于此。
所述程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质。
可以以一种或多种程序设计语言的任意组合来编写用于执行本公开操作的程序代码,所述程序设计语言包括面向对象的程序设计语言-诸如Java、C++等,还包括常规的过程式程序设计语言-诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备。
示例性计算设备
在介绍了本公开示例性实施方式的多媒体推荐方法、多媒体推荐装置以及存储介质之后,接下来,参考图15对本公开示例性实施方式的电子设备进行说明。
所属技术领域的技术人员能够理解,本公开的各个方面可以实现为系统、方法或程序产品。因此,本公开的各个方面可以具体实现为以下形式,即:完全的硬件实施例、完全的软件实施例(包括固件、微代码等),或硬件和软件方面结合的实施例,这里可以统称为电路、模块或系统。
在一些可能的实施例中,根据本公开的电子设备可以至少包括至少一个处理单元、以及至少一个存储单元。其中,所述存储单元存储有程序代码,当所述程序代码被所述处理单元执行时,使得所述处理单元执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施例的多媒体推荐方法中的步骤。例如,所述处理单元可以执行如图2中所示的多媒体推荐方法的执行步骤,包括:步骤S210,分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,候选多媒体为存在用户行为数据的多媒体,用户行为数据是根据用户对候选多媒体执行的交互行为得到的;步骤S220,计算待推荐多媒体和候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;步骤S230,根据每个模态类型对应的数据相似度,计算待推荐多媒体与候选多媒体之间的媒体相似度,以将媒体相似度满足预设条件的候选多媒体作为目标多媒体;步骤S240,根据目标多媒体对应的用户行为数据,得到可推荐用户,以将待推荐多媒体推荐给可推荐用户。
下面参照图15来描述根据本公开的示例实施例的电子设备1500。图15所示的电子设备1500仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
如图15所示,电子设备1500以通用计算设备的形式表现。电子设备1500的组件可以包括但不限于:上述至少一个处理单元1510、上述至少一个存储单元1520、连接不同系统组件(包括存储单元1520和处理单元1510)的总线1530、显示单元1540。
其中,所述存储单元存储有程序代码,所述程序代码可以被所述处理单元1510执行,使得所述处理单元1510执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施例的步骤。
存储单元1520可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(RAM)1521和/或高速缓存存储单元1522,还可以进一步包括只读存储单元(ROM)1523。
存储单元1520还可以包括具有一组(至少一个)程序模块1525的程序/实用工具1524,这样的程序模块1525包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
总线1530可以包括数据总线、地址总线和控制总线。
电子设备1500也可以与一个或多个外部设备1570(例如键盘、指向设备、蓝牙设备等)通信,这种通信可以通过输入/输出(I/O)接口1550进行。并且,电子设备1500还可以通过网络适配器1560与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。如图所示,网络适配器1560通过总线1530与电子设备1500的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备1500使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储系统等。
应当注意,尽管在上文详细描述中提及了多媒体推荐装置的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本公开的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
此外,尽管在附图中以特定顺序描述了本公开方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
虽然已经参考若干具体实施方式描述了本公开的精神和原理,但是应该理解,本公开并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本公开旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
Claims (10)
1.一种多媒体推荐方法,其特征在于,所述方法包括:
分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,所述候选多媒体为存在用户行为数据的多媒体,所述用户行为数据是根据用户对所述候选多媒体执行的交互行为得到的;
计算所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;
根据每个所述模态类型对应的数据相似度,计算所述待推荐多媒体与所述候选多媒体之间的媒体相似度,以将所述媒体相似度满足预设条件的候选多媒体作为目标多媒体;
根据所述目标多媒体对应的用户行为数据,得到可推荐用户,以将所述待推荐多媒体推荐给所述可推荐用户。
2.根据权利要求1所述的方法,其特征在于,所述根据每个所述模态类型对应的数据相似度,计算所述待推荐多媒体与所述候选多媒体之间的媒体相似度,包括:
获取每个所述模态类型对应的目标权重;
根据所述目标权重对每个所述模态类型对应的数据相似度进行加权计算,得到所述待推荐多媒体与所述候选多媒体之间的媒体相似度。
3.根据权利要求2所述的方法,其特征在于,所述获取每个所述模态类型对应的目标权重,包括:
根据所述待推荐多媒体的媒体类型,查询针对每个所述模态类型预先设置的初始权重;
根据每个所述模态类型的媒体数据包含的数据量,得到每个所述模态类型的实际重要程度;
根据每个所述模态类型的实际重要程度对每个所述模态类型预先设置的初始权重进行修改,得到每个所述模态类型对应的目标权重。
4.根据权利要求1所述的方法,其特征在于,所述计算所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度,包括:
分别从所述待推荐多媒体和所述候选多媒体包含的媒体数据中提取出属于相同模态类型的媒体数据作为待计算媒体数据,得到所述相同模态类型对应的相似度计算数据对;
分别对所述相似度计算数据对中的待计算媒体数据进行特征提取,得到每个所述待计算媒体数据对应的媒体特征向量;
计算所述相似度计算数据对中所述待计算媒体数据对应的媒体特征向量之间的距离,得到所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度。
5.根据权利要求4所述的方法,其特征在于,所述模态类型包括文本参数类型、音频参数类型和图像参数类型中的至少两者,所述相似度计算数据对包括文本相似度计算数据对和音频相似度计算数据对和图像相似度计算数据对中的至少两者。
6.根据权利要求1所述的方法,其特征在于,所述根据所述目标多媒体对应的用户行为数据,得到可推荐用户,包括:
识别所述目标多媒体对应的用户行为数据中包含的偏好表示数据,所述偏好表示数据是所述用户对所述目标多媒体执行偏好表示操作后得到的;
根据每个所述用户的所述偏好表示数据,计算每个所述用户针对所述目标多媒体的偏好程度;
将所述偏好程度满足预设条件的用户作为可推荐用户。
7.根据权利要求1至6任一项所述的方法,其特征在于,所述计算所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度,包括:
将所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据分别输入目标模型中,得到所述目标模型输出的数据相似度。
8.根据权利要求7所述的方法,其特征在于,所述目标模型的训练过程包括:
提取样本多媒体对应的用户行为数据和所述样本多媒体包含的多个模态类型的媒体样本数据;
根据每个所述样本多媒体的用户行为数据,计算所述样本多媒体之间的样本相似度;
将每个所述样本多媒体中属于相同模态类型的媒体样本数据输入待训练的初始模型中,得到所述初始模型输出的每个所述样本多媒体中属于相同模态类型的媒体数据之间的预测相似度;
根据所述样本相似度和所述预测相似度计算损失值,以根据所述损失值对所述初始模型进行迭代训练,得到训练完成的目标模型。
9.一种多媒体推荐装置,其特征在于,包括:
媒体数据提取模块,用于分别提取待推荐多媒体和候选多媒体包含的多个模态类型的媒体数据;其中,所述候选多媒体为存在用户行为数据的多媒体,所述用户行为数据是根据用户对所述候选多媒体执行的交互行为得到的;
数据相似度计算模块,用于计算所述待推荐多媒体和所述候选多媒体中属于相同模态类型的媒体数据之间的数据相似度;
目标多媒体确认模块,用于根据每个所述模态类型对应的数据相似度,计算所述待推荐多媒体与所述候选多媒体之间的媒体相似度,以将所述媒体相似度满足预设条件的候选多媒体作为目标多媒体;
推荐模块,用于根据所述目标多媒体对应的用户行为数据,得到可推荐用户,以将所述待推荐多媒体推荐给所述可推荐用户。
10.一种电子设备,其特征在于,包括:
处理器;以及
存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时实现如权利要求1至8中任意一项所述的多媒体推荐方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211258135.9A CN115618024A (zh) | 2022-10-14 | 2022-10-14 | 多媒体推荐方法、装置及电子设备 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211258135.9A CN115618024A (zh) | 2022-10-14 | 2022-10-14 | 多媒体推荐方法、装置及电子设备 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115618024A true CN115618024A (zh) | 2023-01-17 |
Family
ID=84861790
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211258135.9A Pending CN115618024A (zh) | 2022-10-14 | 2022-10-14 | 多媒体推荐方法、装置及电子设备 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115618024A (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116630950A (zh) * | 2023-07-25 | 2023-08-22 | 济南大学 | 一种高精度识别轮辋焊缝的方法 |
| CN117745147A (zh) * | 2024-02-05 | 2024-03-22 | 江苏金寓信息科技有限公司 | 基于数字孪生平台的多媒体筛选系统 |
-
2022
- 2022-10-14 CN CN202211258135.9A patent/CN115618024A/zh active Pending
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116630950A (zh) * | 2023-07-25 | 2023-08-22 | 济南大学 | 一种高精度识别轮辋焊缝的方法 |
| CN117745147A (zh) * | 2024-02-05 | 2024-03-22 | 江苏金寓信息科技有限公司 | 基于数字孪生平台的多媒体筛选系统 |
| CN117745147B (zh) * | 2024-02-05 | 2024-05-10 | 江苏金寓信息科技有限公司 | 基于数字孪生平台的多媒体筛选系统 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111444428B (zh) | 基于人工智能的信息推荐方法、装置、电子设备及存储介质 | |
| CN111708950B (zh) | 内容推荐方法、装置及电子设备 | |
| CN111966914A (zh) | 基于人工智能的内容推荐方法、装置和计算机设备 | |
| CN115618024A (zh) | 多媒体推荐方法、装置及电子设备 | |
| CN111309966B (zh) | 音频匹配方法、装置、设备及存储介质 | |
| Jia et al. | Multi-modal learning for video recommendation based on mobile application usage | |
| CN113515690A (zh) | 内容召回模型的训练方法、内容召回方法、装置及设备 | |
| Wang | A hybrid recommendation for music based on reinforcement learning | |
| CN116977701A (zh) | 视频分类模型训练的方法、视频分类的方法和装置 | |
| CN116955591A (zh) | 用于内容推荐的推荐语生成方法、相关装置和介质 | |
| Yang | [Retracted] Research on Music Content Recognition and Recommendation Technology Based on Deep Learning | |
| CN111753126A (zh) | 用于视频配乐的方法和装置 | |
| CN117391824B (zh) | 基于大语言模型和搜索引擎推荐物品的方法及装置 | |
| CN113868541A (zh) | 推荐对象确定方法、介质、装置和计算设备 | |
| CN114817692A (zh) | 确定推荐对象的方法、装置和设备及计算机存储介质 | |
| CN110569447B (zh) | 一种网络资源的推荐方法、装置及存储介质 | |
| CN112464106A (zh) | 对象推荐方法及装置 | |
| CN116980665A (zh) | 一种视频处理方法、装置、计算机设备、介质及产品 | |
| Kai | Automatic recommendation algorithm for video background music based on deep learning | |
| CN112035740B (zh) | 项目使用时长预测方法、装置、设备及存储介质 | |
| Zhang | Design of the piano score recommendation image analysis system based on the big data and convolutional neural network | |
| CN116628232A (zh) | 标签确定方法、装置、设备、存储介质及产品 | |
| CN113836327A (zh) | 推荐方法、介质、装置和计算设备 | |
| CN113094584A (zh) | 推荐学习资源的确定方法和装置 | |
| CN113392310A (zh) | 一种数据处理方法、装置、设备及介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |