CN1151218A - 用于语音识别的神经网络的训练方法 - Google Patents
用于语音识别的神经网络的训练方法 Download PDFInfo
- Publication number
- CN1151218A CN1151218A CN95193415A CN95193415A CN1151218A CN 1151218 A CN1151218 A CN 1151218A CN 95193415 A CN95193415 A CN 95193415A CN 95193415 A CN95193415 A CN 95193415A CN 1151218 A CN1151218 A CN 1151218A
- Authority
- CN
- China
- Prior art keywords
- mentioned
- data block
- frame
- neural network
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000013528 artificial neural network Methods 0.000 title claims abstract description 85
- 238000000034 method Methods 0.000 title claims description 89
- 238000004458 analytical method Methods 0.000 claims abstract description 21
- 238000006243 chemical reaction Methods 0.000 claims abstract description 14
- 210000002569 neuron Anatomy 0.000 claims description 14
- 230000006870 function Effects 0.000 abstract description 27
- 238000007781 pre-processing Methods 0.000 abstract 1
- 230000003252 repetitive effect Effects 0.000 abstract 1
- 230000008569 process Effects 0.000 description 20
- 230000000875 corresponding effect Effects 0.000 description 13
- 238000005070 sampling Methods 0.000 description 11
- 238000001228 spectrum Methods 0.000 description 9
- 238000010586 diagram Methods 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 8
- 206010038743 Restlessness Diseases 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 230000002596 correlated effect Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000005055 memory storage Effects 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 230000002688 persistence Effects 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 210000004027 cell Anatomy 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000001550 time effect Effects 0.000 description 1
Images


Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/245—Classification techniques relating to the decision surface
- G06F18/2453—Classification techniques relating to the decision surface non-linear, e.g. polynomial classifier
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Nonlinear Science (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Image Analysis (AREA)
Abstract
一用于识别孤立语词的语音识别系统包括一个用来进行模数转换和倒频谱分析的预处理电路和根据多项式扩展计算判定函数的多个神经网络。此系统可利用硬件或软件或两者的结合而实现。讲出的语词的语音波形经过分析转换为一个数据帧序列。该数据帧序列被划分为数据块,然后数据块被广播给多个神经网络。利用数据块神经网络可计算多项式扩展。神经网络的输出用来确定讲出的语词的身份。此神经网络采用的训练算法不要求重复训练并可对每一个给定的样例集产生全局极小。
Description
本发明一般涉及语音识别装置,具体说来涉及用于可以识别与讲话人无关的孤立语词的语音识别系统中的神经网络的训练方法。
多年来科学家一直试图找到一种可以简化人机界面的办法。诸如键盘、鼠标、触摸屏及笔这些输入设备是用来实现人/机界面最为常用的工具。但是人机间更为简单和自然的界面可能是人的语音。一种能够自动识别语音的装置可以提供这样一种界面。
自动语音识别装置的潜在应用包括利用话音命令的数据库查询技术、在制造过程中利用话音输入进行质量控制、使驾驶员在拨号时可集中精神于路面情况的话音拨号式蜂窝电话以及伤残人使用的话音操纵的假肢装置。
令人遗憾的是自动语音识别不是一项可以轻易完成的课题。一个原因是各个人的语音之间的变化很大。比如同一个语词由几个人讲出时其声音会由于口音、语速、姓别或年龄的差异而相差甚远。除了讲话人的变化,协同发音效应、讲话的模式(喊叫/低语)及背景噪声都会给语音识别装置造成巨大的问题。
自60年代未到现在,在自动语音识别方面已引进了各种各样的方法。一些方法立足于相应的试探策略的扩展知识,另一些方法则基于语音数据库和训练方法。后面这一类方法包括动态时间偏差法(DTW)和隐藏马尔可夫模型法(HMM)。对这两种方法,以及时间延迟神经网络(TDNN),将在下面讨论。
动态时间偏差法是一种利用优化原理减小一个未知的发音语词与一个所存储的已知模板语词之间的误差的技术。已报告的数据表明这项DTW技术很有效并能进行良好的识别。然而,DTW技术的计算强度很大。所以要把这种DTW技术应用于现实世界中是不实际的。
隐藏马尔可夫模型法不是直接将一个未知的发音语词与一已知语词的模板进行比较,而是利用各已知语词的随机模型并对各模型产生该未知语词的概率进行比较。当一个未知语词讲出时,HMM技术将检查该语词的序列(或状态)并找出能提供最佳匹配的模型。HMM技术在很多商业应用中运用顺利;但是,此项技术有很多缺点。这些缺点包括不能区分声音类似的语词、对噪声敏感和计算强度大。
最近,神经网络被用来解决一些高度非结构性并且不然就无法解决的问题,如语音识别。时间延迟神经网络是一种采用有限的神经元连系处理语言时间效应的神经网络。就有限的语词识别而言,TDNN的表现略优于HMM方法。但TDNN却受困于某些严重的缺点。
首先,TDNN的训练时间很长,大约为数星期之久。其次,TDNN的训练算法经常收敛为局部极小,非最优解。最优解应是全局极小。
总之,已知的现有自动语音识别方法的缺点(如算法所需计算工作量不实际,对讲话人的改变和背景噪声的容许度有限,训练时间过长等等)严重地限制了语音识别装置在很多有可能应用的领域中的接纳和推广。因此急需一种高度精确、对背景噪声免疫、无需反复训练或复杂计算、可产生全局极小并且对讲话人的差异不敏感的自动语音识别系统。
因此,本发明的一个优点就是可提供一种用于对讲话人的差异及背景噪声不敏感的语音识别系统中的神经网络训练法。
本发明的另一个优点则是可提供一种训练时间不需要重复迭代的语音识别装置的训练法。
本发明的再一个优点是可提供一种对每一给定的训练矢量集可生成全局极小的语音识别装置的训练法。
根据本发明优选实施例中通过对用于语音识别系统中的多个神经网络(每一个神经网络又由多个神经元构成)提供一种训练法取得了上述以及其他优点;该方法产生了多个训练实例,每个训练实例包括有一个输入部分和一个输出部分,该方法由下列步骤构成:(a)接受一个讲出的例词;(b)对该讲出的语词进行模数转换,这种转换会产生一个数字化语词;(c)对该数字语词进行倒频谱分析(cepstral analysis),分析结果产生一个数据帧序列;(d)由该数据帧序列生成多个数据块;(e)从多个数据块中选择一个并使多个训练实例中的一个的输入部分等于所选择的数据块;(f)从多个神经网络中选择一个并确定所选择的神经网络是否可识别所选择的数据块;如果可以,则将该一训练实例的输出部分设置为1,如果不可以,则将该一训练实例的输出部分设置为0;(g)将该一训练实例存储;(h)确定多个数据块中是否有另一个数据块;如果有,返回到步骤(e);如果没有,结束本方法。
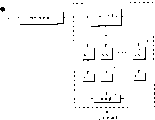
在所附的权利要求书中对本发明已有详细叙述。但是,结合附图并参考下面的详细介绍本发明的其他一些特点将更加清楚并可对之有一个更好的了解,其中
图1是一个语音识别系统的一个上下文框图;
图2是利用本发明的一个语音识别系统的概念图;
图3是图2所示的语音识别系统的操作法的流程图;
图4所示为本发明的分而治之(divide-and-conquer)算法的数据输入和输出。
图5是本发明的分而治之算法的执行法的流程图。
图6是根据本发明的一个优选实施例训练神经网络进行语音识别的方法的流程图。
图1是一个语音识别系统的一个上下文框图。该系统的组成包括一支用于接受语音形式的音频输入并将声音转换为电能的话筒1或等效装置,接受由话筒1送出的电信号并完成各种任务,如波形取样、模数(A/D)转换、倒频谱分析等等的预处理电路3,以及一台执行语音识别程序并相应地产生一个确认所识别的语音的输出的计算机5。
当使用者对话筒1讲话时此系统开始工作。在一优选实施例中,由图1所描述的系统用于孤立语词识别。当对着话筒讲话的人在各语词之间做出一个清晰的停顿时就发生孤立语词识别。
当讲话者讲出一个语词时,话筒1产生一个代表该语词的声音波形的信号。之后此信号被送到预处理电路3由模数转换器(未示出)数字化。对这一数字化信号然后进行倒频谱分析(一种特征抽取方法)处理,这种分析处理也是由预处理电路3完成。计算机5接受倒频谱分析的结果并利用该结果来确定讲出的语词的身份。
下面是对预处理电路3和计算机5的更详细的介绍。为完成其所承担的任务预处理电路3可能包括一组硬件和软件。例如,A/D转换可由一专用集成电路完成,而倒频谱分析可由一套由微处理器执行的软件来完成。
预处理电路3包括适于进行A/D转换的手段。话筒1发出的信号通常是模拟信号。由一A/D转换器(未示出)对话筒1发出的信号每秒钟进行数 千次取样(例如在一优选实施例中为每秒8000~14,000次)。然后将每个取样转换为一个数字字,各字的长度为12至32比特。数字信号一般包括一个或多个这种数字字。本领域的一般技术人员都可以理解A/D转换器的取样率和字长可以变化并且上面所给出的数字并不对本发明所包括的A/D转换器的取样率及字长构成任何限制。
对数字信号进行的倒频谱分析(或称为特征抽取)的结果产生一个表征该讲出的语词的相关特征的一个信号表示。这可以看作是一个可以保持语音重要特征并从数字信号的非相关特征中去掉不需要的干扰的数据简化步骤,结果可使计算机5的决策过程简单。
倒频谱分析过程如下。首先,将构成数字信号数字化取样划分成一个集序列。每个集中包含在一个固定长度时间段中所得到的取样。比如在本发明的一个优选实施例中此时间段为15毫秒。如果一个讲出的语词的长度,比如,是150毫秒,则电路3将会产生一个包括10个数字取样集的序列。
其次,对每一个取样集应用一个P阶(一般P=12~14)线性预测分析以生成P个预测系数。然后将预测系统转换为倒频谱系数,为此使用如下递归公式:
其中c(n)表示倒频谱系数矢量,a(n)表示预测系数,1≤n≤P,P等于倒频谱系数的数目,n表示一个整数指标,k表示整数指标,a(k)表示第k个预测系数,而c(n-k)第(n-k)个倒频谱系数。
倒频谱系数矢量通常由如下形式的正弦窗加权:
α(n)=1+(L/2)sin(πn/L) (2)其中1≤n≤p,而L为一给出加权倒频谱矢量C(n)的整数常数,其中
c(n)=c(n)α(n) (3)
这种加权通常称作倒频谱升降(1iftering)。这一升降过程的效用是使语音取样中频谱的谱峰平滑。另外还发现倒频谱升降可抑制高低倒频谱系数间现存的差异,从而可以大大改善语音识别系统的性能。
于是倒频谱分析的结果就产生一个平滑对数频谱的序列,其中每个频谱对应于讲出的语词那一段时间中的一个离散时间段。
这样一来语音信号中的重要特征就保存在频谱中。对于每一个频谱,预处理电路3都生成一个由频谱中数据点构成的数据帧。对每个频谱生成一个数据帧的,结果是形成一个时间序的数据帧序列、这一序列送往计算机5。
在一优选实施例中,每个数据帧包含12个数据点,其中每个数据点代表倒频谱平滑谱在某个具体频率处的值。数据点是32比特的数字字。本领域的专业人员可以理解本发明并未对每帧数据点的数目或数据点的位长进行限制;每一数据帧中所包含的数据点数可以是12或任何其他合适的数值,而数据点的位长可以是32比特,16比特或任何其他数值。
计算机5的主要功用是确定所讲出的语词的身份。在本发明的一个优选实施例中,计算机5可包含一个用于处理数据帧序列的分段程序、用于计算多项式扩展的多个神经网络以及一个利用神经网络的输出将讲出的语词分类为已知语词的选择器。计算机5的工作的更为详细的情况见后。
图2是利用本发明的一个语音识别系统的概念图。
在一个优选实施例中,语音识别系统可以识别讲出的孤立语词。话筒1接受讲话人的语音输入并将之转换为电信号。这些电信号被送入预处理电路3。
预处理电路3完成上面就图1所描述的功能。电路3完成A/D转换和倒频谱分析,并且电路3可能包括一组硬件和软件以完成其所承担的任务。预处理电路3的输出形式为代表所讲的语词的数据帧序列。每个数据帧包括一个数据点集(32比特字),与讲出该语词的时间的一个离散时间段相对应。电路3的输出传送到计算机5。
计算机5可以是通用数字计算机或专用计算机。计算机5包括适合执行分而治之算法11的硬件和/或软件。计算机5还包括由第1神经网络12、第2神经网络13以及第n神经网络14代表的多个神经网络。各种神经网络12、13和14的输出送入相应的各累加器15、16和17。累加器15~17的输出送入选择器18,选择器18的输出代表所识别的语音语词。
分而治之算法11接受由预处理电路3发出的数据帧序列并由之而生成多个数据块。大体上算法11将数据帧序列划分成数据块集,每个数据块则包括来自输入序列的数据帧的一个子集。分而治之算法11的详细情况在后面的标题为“分而治之算法”一节中给出。在一个优选实施例中,4个数据块中的每一个都包括来自输入序列的5个数据帧。
第1个数据块包含数据帧序列中的第1个数据帧及其后每隔3个的各个数据帧。而第2个数据块包含数据帧序列中的第2数据帧及其后每隔3个的各个数据帧。依此类推,顺次排列的各数据帧都顺次分配给四个数据块的每一个,直到每个数据块包含同样数目的数据帧为止。如果数据帧的数目不足以使各数据块获得相同数目的数据帧,则将序列中最后一个数据帧复制到其余数据块以使各数据块包含同样数目的数据帧。
一个数据块分配装置被用来将数据块从算法11传送到神经网络12、13及14的输入端。每个数据块依次同时传送到神经网络12、13及14。虽然在图2中在语音识别系统中只示出3个神经网络,但一个普通的专业人员都可理解,如果一个具体应用要求多于或少于3个神经网络,可以使用任何数目的神经网络。
一个普通的专业人员也会了解每个神经网络包括多个神经元。
在本发明的一个优选实施例中,各神经网络可能事前已受过训练来识别某一组语音音素。一般讲,一个讲出的语词包括一个或多个语音音素。
神经网络12,13和14的作用如同分类装置,根据数据块确定所讲出的是什么语词。一般而言,一个分类装置决定一个输入模式属于哪一类别。在本发明的一个优选实施例中,每个类别都用一已知语词标记,并且由一个预先确定的讲出的语词集(训练集)取得数据块和用于确定各类别的边界,可使各类别识别性能最佳的边界。
在一个优选实施例中,使用参数决策法来确定所讲出的语词是否属于某一类别。使用这种方法时,每个神经网络计算出一个不同的判别函数Yj(X),其中X={X1,X2,…,Xi}是一个数据块中所包含的数据点集,i是一整数指标,而j是一个与该神经网络相对应的整数指标。在接收到一个数据块时,各该神经网络计算其相应的判别函数。如果由某一神经网络计算出的判别函数大于其他每一网络的判别函数,则此数据块属于与该神经网络相对应的特定类别。
换言之,每一神经网络决定一不同类别;于是每一神经网络识别一个不同的语词。例如,神经网络12可通过训练来识别语词“one”,神经网络13可通过训练来识别语词“two”,依此类推。训练神经网络的方法将在下面标题为“神经网络的训练”一节中介绍。
本发明的神经网络计算的判别函数系根据对多项式扩展的利用以及,在不严格的意义上,利用一个正交函数,如正弦、余弦、指数/对数、傅里叶变换、勒让德多项式、非线性基本函数如维尔特拉函数或一径向基本函数,或其他,或多项式扩展及正交函数的一种组合。
一种优选实施例应用一多项式扩展,其一般形式由下面的等式4代表: 其中的Xi代表协处理器输入并且可以是如Xi=fi(Zj)这样的函数,其中Zj是一任意变量,并且其中的指标i和j可为任意正整数;其中Y代表神经网络协处理器的输出;其中的Wi-1代表第i个神经元的权;其中g1i,…,gni代表第i个神经元的选通函数,为整数,在一优选实施例中为零或大于零;而n为协处理器输入的数目。
等式4的各项代表一神经元输出和与这种神经元相关的权重及选通函数。在神经网络中应用的多项式扩展的项数是基于一些因子的,包括可用神经元数、训练示例数等等。应当了解,多项式扩展的较高阶项通常比较低阶项重要性更小。因此,在一优选实施例中,只要有可能,应根据上面所提到的变化因子选择较低阶的项。还有,因为与各种输入有关的测量单位可能改变,输入在使用之前可能需要归一化。
等式5为等式4的另一表现形式,所示各项达到3阶各项。
+ . . .
(5)其中的变量的意义与等式4中的相同,并且其中的f1(i)是一个在范围n+1到2n中的指标函数;f2(i,j)是一个范围在2n+1到2n+(n)(n-1)/2的指标函数;并且f3(i,j)是一个范围在2n+1(n)(n-1)/2到3n+(n)(n-1)/2。而且f4至f6用类似的方式表示。
本专业的技术人员会看出选通函数嵌入在由等式5表示的各项中。例如,等式5可表示如下:
y=w0+w1 x1+w2 x2+...wi xi+...+wn xn
+wn+1 x1 2+...+w2n xn 2
+w2n+1 x1 x2+w2n+2x1 x3+...
+w3n-1 x1 xn +w3n x2 x3+w3n+1x2 x4+
...w2n+(n)(n-1)/2 xn-1 xn+...
+wN-1 x1g1N x2g2N...xngnN+...
(6)其中的变量的意义与等式4中的相同。
应当注意,虽然选通函数项gin只在等式6的最后示出的项中以显式出现,可以理解,其他各项中的每一项都具有显式示出的giN项(例如对W1X1项g12=1并且gi2=0,i=2,3,…,n)。N为任意正整数并代表网络中的第N个神经元。
在本发明中,一个神经网络将对它所接收到的每一个数据块生成一个输出。因为一个讲出的语词可由一个数据块序列表示,所以每一个神经网络可生成一个输出序列。为了提高语音识别系统的分类性能,每一个输出序列都由一累加器求和。
于是在每个神经网络的输出端都连接一个累加器。如前面就图2所讲过的,累加器15对来自神经网络12的输出起作用,累加器16对来自神经网络13的输出起作用,而累加器17对来自神经网络14的输出起作用。累加器的功能是对来自神经网络的输出序列求和。这可产生与该神经网络相对应的和并且此和就与由一已知语词标记的类别相对应。累加器15将来自神经网络12的顺序输出加到一累积和之上,而且累加器16和17对神经网络13和14分别实现同样的功能。每个累加器将其和作为输出。
选择器18接受来自累加器的和,或顺序接受或同时接受。在前一种情况下,选择器18依次轮流接受来自各累加器的和,比如首先接受来自累加器15的和,其次为来自累加器16的和,依此类推;或者在后一种情况下,选择器18同时接受来自累加器15、16和17的和。在接受和之后,选择器18就确定哪一个和最大并分配相应的已知语词标记,也即识别的语音语词,给语音识别系统的输出。
图3示出图2中的语音识别系统的操作方法。在方框20中使用者通过话筒1接收到一个讲出语词并将之转换为一电信号。
在方框22中对语音信号进行A/D转换。在一优选实施例中,A/D转换由图2中的预处理电路3完成。
之后,在方框24中对由A/D转换所产生的数字化信号进行倒频谱分析。在一个优选实施例中,倒频谱分析也由图2中的预处理电路3完成。倒频谱分析产生一个数据帧序列,这些数据帧包含所讲的语词的相关特征。
在方框26中利用一个分而治之算法(其步骤示于图5)用来从数据帧序列生成多个数据块。分而治之算法是一种将帧序列划分为较小的更便于操作的数据块集的方法。
在方框28中将数据块之一广播给神经网络。从方框28出来后处理过程在方框30中继续进行。
在方框30每个神经网络利用数据块来计算以多项式扩展为根据的判别函数。各个神经网络计算出的判别函数各不相同,生成的判别函数为其输出。由神经网络计算出的判别函数在操作语音识别系统之前通过如图6所示之神经网络训练法来确定。
在方框32对每个神经网络的输出进行相加求和,对每个神经网络都生成一个和。这一步骤生成多个神经网络和,其中每个和对应于一个神经网络。
在决策方框34中,检查是否有另一个数据块要向神经网络广播。如果是,则处理返回到方框28。如果不是,则处理进入方框36。
接着在方框36中选择器确定哪一个神经网络的和最大并将与该和相对应的已知语词标记分配给语音识别系统的输出。
分而治之算法
图4示出本发明的分而治之算法的数据输入和输出。分而治之算法是一种将数据帧序列划分为较小的数据块集的方法。算法的输入是数据帧序列38,在本示例中该序列包含数据帧51-70。数据帧序列38包含代表语音取样相关特征的数据。
在一优选实施例中,每一数据帧包含12个数据点,其中的每个数据点代表一个倒频谱系数值或一个基于倒频谱系数的函数。
数据点是32比特的数字字。每个数据帧对应于讲出语音样例的时间间隔中的一个离散时间段。
本专业的技术人员将会理解本发明对于每帧的数据点数目或数据点位长并未加有任何限制;在每个数据帧中所包含的数据点数可以是12或任何其他值,而数据点的位长可以是32比特、16比特或任何其他值。
此外,数据点可用来表示倒频谱平滑谱包络线的数据以外的数据。例如,在各种应用中,每个数据点可以表示某一频率处的谱线幅值。
分而治之算法11顺序接受语音样例的每一帧并将该帧分配给几个数据块中的一个。每个数据块由输入帧序列的数据帧的子集构成。数据块42、44、46和48是分而治之算法11的输出。虽然图4示出的算法只生成4个数据块,但是分而治之算法11并不限于只生成4个数据块,可以生成多于或少于4个数据块。
图5示出执行本发明的分而治之算法的方法的框图。分而治之算法按照框图步骤将数据序列划分为数据块集。
如方框75中所示,首先计算出本算法要生成的数据块的数目。要生成的数据块的数目用下面的方式计算。首先,接受每个数据块中的帧数及序列中的帧数。块数和帧数均为整数。其次,将帧数除以每块中的帧数。之后,将除得之结果四舍五入得出最接近的整数,而得出应由分而治上算法生成的数据块数目。在退出方框75时处理过程由方框77继续。
在方框77中使帧序列中的首帧等于一称为当前帧的变量。一般人员都可了解当前帧既可以由软件变量代表,也可由硬件,如寄存器或存储装置代表。
接着在方框79,使当前块变量等于第一块。在软件中该当前块可以是代表一个数据块的软件变量。在采用硬件时此当前块可以是一个或多个寄存器或存储装置。在当前块等于第1块之后,当前帧被分配给当前块。然后处理过程转入决策方框81。
之后,如决策方框81所示,检查确定帧序列中是否还有更多的帧要处理。如是,处理过程由方框83继续。如不是,处理过程跳转到方框91。
在方框83中帧序列中的下一帧被接受并使之等于当前帧变量。
在方框85中使当前块变量等于下一块,然后将当前帧变量分配给当前块变量。在退出方框85时,处理过程转入决策方框87。
如决策方框87中所示,如果当前块变量等于末块,则处理过程由方框89继续,否则处理过程返回方框81。
在方框89使下一块等于首块,并且在退出方框89时处理过程返回决策方框81。
由决策方框81进入方框91。在方框91中检查确定当前块变量是否等于末块。如是,处理过程结束。如不是,将当前帧分配给当前块之后的各剩余数据块,直到并包括末块,如前面在介绍图2时所解释的那样。
训练算法
本发明的语音识别系统主要有两种运行模式:(1)训练模式,利用讲出的语词样例来训练神经网络;(2)识别模式,用来辨认所讲的未知语词。参考图2。一般讲,使用者必须对着话筒1将要求系统识别的语词全部讲出以训练神经网络12、13和14。在某些情况下,训练可能局限于几个使用者每个语词进一次。但是,本专业的技术人员会理解训练也可能要求任何数目的不同讲话人将每个语词读出不止一遍。
为了使一个神经网络有用,必须确定每个神经元电路权重。这一点可以通过使用适当的训练算法完成。
在实现本发明的神经网络时,一般将神经元或神经元电路的数目选为等于或少于提供给网络的训练示例的数目。
训练示例的定义为一组给定的输入和产生的输出。在本发明的一个优选实施例中,对图2中的话筒1所讲的每一个语词都至少会生成一个训练示例。
就本发明的一个优选实施例而言,用于神经网络的训练算法示于图6。
图6示出根据本发明的一个优选实施例训练神经网络识别语音的方法的框图。首先,在方框93,作为示例将一个已知语词对着本语音识别系统的话筒讲出。
在方框95,对语音信号进行A/D转换。对由A/D转换输出的数字化信号进行倒频谱分析。倒频谱分析产生包含所讲语词的相关特征的数据帧序列。每个数据帧包括代表对所讲的语词的时间片的倒频谱分析结果的12个32位字。在一个优选实施例中,时间片的持续长度为15毫秒。
本专业的技术人员可以理解本发明对数据帧中的字的位长并无限制;位长可以是32比特、16比特或任何其他值。此外,每个数据帧中的字数和时间片的持续长度可能不同,这取决于本发明应用具体情况。
其次,在方框97中,利用分而治之算法(其步骤示于图5)由数据帧序列产生多个数据块。
在方框99中,从分而治之算法生成的块中选择一个。将训练示例的输入部分设定为等于所选块。
在方框101中,如果神经网络正在接受训练来识别所选定的块,则将块的输出部分设定为1,否则设定为0。在退出方框101时处理过程由103继续。
其次,在方框103中,将训练示例存储于计算机5的存储器中(图1及2)。这样就可以生成和存储多个训练示例。
在决策方框105中检查确定是否有由当前数据帧序列产生的另一个数据块要用来训练此神经网络。如是,处理过程返回方框99。如不是,处理过程前进到决策方框107。
在决策方框107中,确定在训练期间是否有另一个要利用讲出的语词。如是,处理过程返回93,如果不是,处理过程由方框109继续。
在方框109中比较所提供的训练示例数和神经网络中神经元的数目。如果神经元的数目等于训练示例的数目,可以采用矩阵求逆的方法来求出每一个权重的值。如果神经元的数目不等于训练示例的数目,可以采用最小二乘估算法来求出每一个权重的值。适合的最小二乘估算法包括,比如,最小二乘法、扩充最小二乘法、伪逆法、卡尔曼滤波法、极大似然算法、贝斯估算法以及其他。
本说明书中叙述了一种训练用于语音识别的神经网络的方法的概念以及包括一种优选实施方案的数种实施方案。
由于本说明书所描述的语音识别系统的各种实施方案利用了一种分而治之算法来分割语音样例,并且利用了一种合适的方法来训练可对由分而治之算法生成输出进行操作处理的神经网络,所以这些种实施方案对讲话人的差异不敏感,而且不会受到背景噪声的不利影响。
同样令人欣赏的一点是此处所描述的语音识别系统的各种实施方案包括一种不要重复训练和对给定的输入矢量集可产生全局极小的神经网络;因而本发明的各实施方案与已知语音识别系统相比较所需训练时间大为减少而精确度则更高。
另外,对于本专业的技术人员能够清楚了解此处公开的发明可以进行多方面的改变并可提出与前文具体提出和描述的优选实施方案不同的多种实施方案。
可以理解,本发明的概念可以在多方面加以变化。因此,本说明书后附的权利要求各项就力图将符合本发明精神并属本发明的范围的本发明的所有变化方案全部予以涵盖。
Claims (10)
1.一种训练用于语音识别系统中的多个神经网络的方法,上述每个神经网络都包括多个神经元,上述方法可产生多个训练样例,其中上述训练样例中每一个都包括一个输入部分和一个输出部分,上述方法由下面各步骤构成:
(a)接受一个讲出的语词样例;
(b)对上述讲出的语词进行模数转换,上述转换生成一个数字化语词;
(c)对上述数字化语词进行倒频谱分析,上述分析产生一个数据帧序列;
(d)由上述数据帧序列生成多个数据块;
(e)从上述多个数据块中选择一个,并使上述多个训练样例中的一个的上述输入部分等于上述所选择的数据块;
(f)从上述多个神经网络中选择一个,并确定上述选定的神经网络是否用于识别上述选定的数据块;
(i)如是,将上述一个训练样例的上述输出部分设置为1;
(ii)如不是,将上述一个训练样例的上述输出部分设置为0;
(g)存储上述一个训练样例;
(h)确定是否存在上述多个数据块的另外一个;
(i)如是,返回步骤(e);
(ii)如不是,终止上述方法。
2.如权利要求1中所述的方法,其特征在于在步骤(d)上述多个数据块通过下面的(d1)至(d11)的子步骤生成:
(d1)将上述语音样例表示为一个帧序列;
(d2)使一当前帧等于上述帧序列的首帧;
(d3)将上述当前帧分配给上述多个数据块的第一数据块;
(d4)使一当前数据块等于上述第一数据块;
(d5)确定在上述帧序列中是否有下一帧;
(i)如是,进行步骤(d6);
(ii)如不是,进行步骤(d11);
(d6)使上述当前帧等于上述下一帧;
(d7)使上述当前数据块等于上述多个数据块中的下一个数据块;
(d8)将上述当前帧分配给上述当前数据块;
(d9)确定上述当前数据块是否是上述多个数据块中的最后一个;
(i)如是,进行步骤(d10);
(ii)如不是,返回步骤(d8);
(d10)使上述下一个数据块等于上述第一个数据块,并返回步骤(d8);并且
(d11)确定上述当前数据块是否是上述最后数据块;
(i)如不是,将上述当前帧分配给上述多个数据块中其余各块;
3.如权利要求1中所述的方法,其特征在于在步骤(d)上述多个数据块通过下面的(d1)至(d14)的子步骤生成:
(d1)确定表示上述语音样例的上述帧序列中的帧数;
(d2)规定每个数据块中的帧数;并
(d3)计算应生成的数据块数目;
(d4)将上述语音样例表示为一个帧序列;
(d5)使一个当前帧等于上述帧序列的首帧;
(d6)将上述当前帧分配给上述多个数据块的第一数据块;
(d7)使一当前数据块等于上述第一数据块;
(d8)确定在上述帧序列中是否有下一帧;
(i)如是,进行步骤(d9);
(ii)如不是,进行步骤(d11);
(d9)使上述当前帧等于上述下一帧;
(d10)使上述当前数据块等于上述多个数据块中的下一个数据块;
(d11)将上述当前帧分配给上述当前数据块;
(d12)确定上述当前数据块是否是上述多个数据块中最后一个;
(i)如是,进行步骤(d13);
(ii)如不是,返回步骤(d8);
(d13)使上述下一个数据块等于上述第一个数据块,并返回步骤(d8);并
(d14)确定上述当前数据块是否是上述最后数据块;
(i)如不是,将上述当前帧分配给上述多个数据块中其余各块。
4.如权利要求3中所述的方法,其特征在于在步骤(d3)上述数据块的数目由下面的(d31)和(d32)子步骤计算:
(d31)将上述帧数除以上述每数据块的帧数并得出一个结果;并
(d32)将上述结果四舍五入求整。
5.如权利要求1所述的方法,其特征在于上述帧序列中的每一帧都包括多个数据点,其中每个上述数据点代表一个以倒频谱系数为依据的函数值。
6.如权利要求1中所述的方法,其特征在于上述神经网络中的每一个的操作都以一个多项式扩展为依据。
7.如权利要求6中所述的方法,其特征在于上述多项式扩展具有如下形式:
其中Y表示神经网络的输出;
其中Wi-1表示第i个神经元的权值;
其中X1,X2,…,Xn表示上述神经网络的输入;
其中g1i,…,gni表示用于各上述输入的第i个神经元的选通函数;并且
其中n是一正整数。
8.如权利要求7中所述的方法,其特征在于每个Xi都由一个函数Xi=fi(Zj)表示,其中Zj是一任意变量,并且其中指标i和j是任何正整数。
9.如权利要求7中所述的方法,其特征在于上述神经网络中的每一个的动作都是以上述多项式扩展的截断形式为基础。
10.如权利要求1中所陈述的方法,其特征在于每个训练样例都只由上述方法使用一次。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US08/253,893 | 1994-06-03 | ||
| US08/253,893 US5509103A (en) | 1994-06-03 | 1994-06-03 | Method of training neural networks used for speech recognition |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN1151218A true CN1151218A (zh) | 1997-06-04 |
Family
ID=22962136
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN95193415A Pending CN1151218A (zh) | 1994-06-03 | 1995-04-25 | 用于语音识别的神经网络的训练方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US5509103A (zh) |
| CN (1) | CN1151218A (zh) |
| AU (1) | AU2427095A (zh) |
| CA (1) | CA2190631C (zh) |
| DE (1) | DE19581663T1 (zh) |
| GB (1) | GB2303237B (zh) |
| WO (1) | WO1995034035A1 (zh) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100446029C (zh) * | 2007-02-15 | 2008-12-24 | 杨志军 | 智能机器视觉识别系统中的信号处理电路 |
| WO2015180368A1 (zh) * | 2014-05-27 | 2015-12-03 | 江苏大学 | 一种半监督语音特征可变因素分解方法 |
| CN108053025A (zh) * | 2017-12-08 | 2018-05-18 | 合肥工业大学 | 多柱神经网络医学影像分析方法及装置 |
| CN108475214A (zh) * | 2016-03-28 | 2018-08-31 | 谷歌有限责任公司 | 自适应人工神经网络选择技术 |
| CN109313540A (zh) * | 2016-05-13 | 2019-02-05 | 马鲁巴公司 | 口语对话系统的两阶段训练 |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5697369A (en) * | 1988-12-22 | 1997-12-16 | Biofield Corp. | Method and apparatus for disease, injury and bodily condition screening or sensing |
| US5749072A (en) * | 1994-06-03 | 1998-05-05 | Motorola Inc. | Communications device responsive to spoken commands and methods of using same |
| US5621848A (en) * | 1994-06-06 | 1997-04-15 | Motorola, Inc. | Method of partitioning a sequence of data frames |
| US5724486A (en) * | 1995-08-21 | 1998-03-03 | Motorola Inc. | Method for structuring an expert system utilizing one or more polynomial processors |
| US5745874A (en) * | 1996-03-04 | 1998-04-28 | National Semiconductor Corporation | Preprocessor for automatic speech recognition system |
| US6167117A (en) * | 1996-10-07 | 2000-12-26 | Nortel Networks Limited | Voice-dialing system using model of calling behavior |
| US5917891A (en) * | 1996-10-07 | 1999-06-29 | Northern Telecom, Limited | Voice-dialing system using adaptive model of calling behavior |
| US5905789A (en) * | 1996-10-07 | 1999-05-18 | Northern Telecom Limited | Call-forwarding system using adaptive model of user behavior |
| US5912949A (en) * | 1996-11-05 | 1999-06-15 | Northern Telecom Limited | Voice-dialing system using both spoken names and initials in recognition |
| US5864807A (en) * | 1997-02-25 | 1999-01-26 | Motorola, Inc. | Method and apparatus for training a speaker recognition system |
| US5995924A (en) * | 1997-05-05 | 1999-11-30 | U.S. West, Inc. | Computer-based method and apparatus for classifying statement types based on intonation analysis |
| US6192353B1 (en) * | 1998-02-09 | 2001-02-20 | Motorola, Inc. | Multiresolutional classifier with training system and method |
| US6131089A (en) * | 1998-05-04 | 2000-10-10 | Motorola, Inc. | Pattern classifier with training system and methods of operation therefor |
| US7006969B2 (en) * | 2000-11-02 | 2006-02-28 | At&T Corp. | System and method of pattern recognition in very high-dimensional space |
| US7369993B1 (en) | 2000-11-02 | 2008-05-06 | At&T Corp. | System and method of pattern recognition in very high-dimensional space |
| WO2002091358A1 (en) * | 2001-05-08 | 2002-11-14 | Intel Corporation | Method and apparatus for rejection of speech recognition results in accordance with confidence level |
| WO2002091355A1 (en) * | 2001-05-08 | 2002-11-14 | Intel Corporation | High-order entropy error functions for neural classifiers |
| KR100486735B1 (ko) * | 2003-02-28 | 2005-05-03 | 삼성전자주식회사 | 최적구획 분류신경망 구성방법과 최적구획 분류신경망을이용한 자동 레이블링방법 및 장치 |
| FR2881857B1 (fr) * | 2005-02-04 | 2008-05-23 | Bernard Angeniol | Outil informatique de prevision |
| EP2221805B1 (en) * | 2009-02-20 | 2014-06-25 | Nuance Communications, Inc. | Method for automated training of a plurality of artificial neural networks |
| US9240184B1 (en) * | 2012-11-15 | 2016-01-19 | Google Inc. | Frame-level combination of deep neural network and gaussian mixture models |
| US9508347B2 (en) * | 2013-07-10 | 2016-11-29 | Tencent Technology (Shenzhen) Company Limited | Method and device for parallel processing in model training |
| US9786270B2 (en) | 2015-07-09 | 2017-10-10 | Google Inc. | Generating acoustic models |
| US10229672B1 (en) | 2015-12-31 | 2019-03-12 | Google Llc | Training acoustic models using connectionist temporal classification |
| US20180018973A1 (en) | 2016-07-15 | 2018-01-18 | Google Inc. | Speaker verification |
| US10706840B2 (en) | 2017-08-18 | 2020-07-07 | Google Llc | Encoder-decoder models for sequence to sequence mapping |
| US11380315B2 (en) * | 2019-03-09 | 2022-07-05 | Cisco Technology, Inc. | Characterizing accuracy of ensemble models for automatic speech recognition by determining a predetermined number of multiple ASR engines based on their historical performance |
| CN110767231A (zh) * | 2019-09-19 | 2020-02-07 | 平安科技(深圳)有限公司 | 一种基于时延神经网络的声控设备唤醒词识别方法及装置 |
| CN111723873A (zh) * | 2020-06-29 | 2020-09-29 | 南方电网科学研究院有限责任公司 | 一种电力序列数据分类方法和装置 |
| CN114038465B (zh) * | 2021-04-28 | 2022-08-23 | 北京有竹居网络技术有限公司 | 语音处理方法、装置和电子设备 |
| US20240061644A1 (en) * | 2022-08-17 | 2024-02-22 | Jpmorgan Chase Bank, N.A. | Method and system for facilitating workflows via voice communication |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0435282B1 (en) * | 1989-12-28 | 1997-04-23 | Sharp Kabushiki Kaisha | Voice recognition apparatus |
| US5365592A (en) * | 1990-07-19 | 1994-11-15 | Hughes Aircraft Company | Digital voice detection apparatus and method using transform domain processing |
| US5212765A (en) * | 1990-08-03 | 1993-05-18 | E. I. Du Pont De Nemours & Co., Inc. | On-line training neural network system for process control |
| US5408588A (en) * | 1991-06-06 | 1995-04-18 | Ulug; Mehmet E. | Artificial neural network method and architecture |
| FR2689292A1 (fr) * | 1992-03-27 | 1993-10-01 | Lorraine Laminage | Procédé et système de reconnaissance vocale à réseau neuronal. |
| DE69328275T2 (de) * | 1992-06-18 | 2000-09-28 | Seiko Epson Corp., Tokio/Tokyo | Spracherkennungssystem |
-
1994
- 1994-06-03 US US08/253,893 patent/US5509103A/en not_active Expired - Lifetime
-
1995
- 1995-04-25 DE DE19581663T patent/DE19581663T1/de not_active Ceased
- 1995-04-25 CA CA002190631A patent/CA2190631C/en not_active Expired - Fee Related
- 1995-04-25 CN CN95193415A patent/CN1151218A/zh active Pending
- 1995-04-25 AU AU24270/95A patent/AU2427095A/en not_active Abandoned
- 1995-04-25 GB GB9625250A patent/GB2303237B/en not_active Expired - Lifetime
- 1995-04-25 WO PCT/US1995/005002 patent/WO1995034035A1/en active Application Filing
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100446029C (zh) * | 2007-02-15 | 2008-12-24 | 杨志军 | 智能机器视觉识别系统中的信号处理电路 |
| WO2015180368A1 (zh) * | 2014-05-27 | 2015-12-03 | 江苏大学 | 一种半监督语音特征可变因素分解方法 |
| CN108475214A (zh) * | 2016-03-28 | 2018-08-31 | 谷歌有限责任公司 | 自适应人工神经网络选择技术 |
| CN109313540A (zh) * | 2016-05-13 | 2019-02-05 | 马鲁巴公司 | 口语对话系统的两阶段训练 |
| CN108053025A (zh) * | 2017-12-08 | 2018-05-18 | 合肥工业大学 | 多柱神经网络医学影像分析方法及装置 |
| CN108053025B (zh) * | 2017-12-08 | 2020-01-24 | 合肥工业大学 | 多柱神经网络医学影像分析方法及装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| CA2190631C (en) | 2000-02-22 |
| DE19581663T1 (de) | 1997-05-07 |
| CA2190631A1 (en) | 1995-12-14 |
| WO1995034035A1 (en) | 1995-12-14 |
| GB2303237B (en) | 1997-12-17 |
| AU2427095A (en) | 1996-01-04 |
| GB9625250D0 (en) | 1997-01-22 |
| US5509103A (en) | 1996-04-16 |
| GB2303237A (en) | 1997-02-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1151218A (zh) | 用于语音识别的神经网络的训练方法 | |
| CN1112669C (zh) | 采用连续密度隐藏式马尔克夫模型的语音识别方法和系统 | |
| US5638486A (en) | Method and system for continuous speech recognition using voting techniques | |
| US5794196A (en) | Speech recognition system distinguishing dictation from commands by arbitration between continuous speech and isolated word modules | |
| CN1277248C (zh) | 语音识别系统 | |
| US5596679A (en) | Method and system for identifying spoken sounds in continuous speech by comparing classifier outputs | |
| CN1296886C (zh) | 语音识别系统和方法 | |
| US5903863A (en) | Method of partitioning a sequence of data frames | |
| CN111916111B (zh) | 带情感的智能语音外呼方法及装置、服务器、存储介质 | |
| CN1188831C (zh) | 具有多个话音识别引擎的话音识别系统和方法 | |
| US5594834A (en) | Method and system for recognizing a boundary between sounds in continuous speech | |
| EP0617827B1 (en) | Composite expert | |
| US5734793A (en) | System for recognizing spoken sounds from continuous speech and method of using same | |
| CN1150852A (zh) | 采用神经网络的语音识别系统和方法 | |
| CN1215491A (zh) | 语言处理 | |
| CN1013525B (zh) | 认人与不认人实时语音识别的方法和装置 | |
| CN1331467A (zh) | 产生声学模型的方法和装置 | |
| CN111916064A (zh) | 一种端到端的神经网络语音识别模型的训练方法 | |
| CN113920986A (zh) | 会议记录生成方法、装置、设备及存储介质 | |
| CN1198261C (zh) | 基于决策树的语音辨别方法 | |
| Kanisha et al. | Speech recognition with advanced feature extraction methods using adaptive particle swarm optimization | |
| Nijhawan et al. | Real time speaker recognition system for hindi words | |
| CN1295674C (zh) | 模式识别 | |
| CN1163009A (zh) | 用以识别出连续语音中在声音之间的边界的方法和系统 | |
| JPH05323991A (ja) | 音声認識方式 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C01 | Deemed withdrawal of patent application (patent law 1993) | ||
| WD01 | Invention patent application deemed withdrawn after publication |