CN115048969A - 用于评估、理解和改进深度神经网络的视觉分析系统 - Google Patents
用于评估、理解和改进深度神经网络的视觉分析系统 Download PDFInfo
- Publication number
- CN115048969A CN115048969A CN202210184880.7A CN202210184880A CN115048969A CN 115048969 A CN115048969 A CN 115048969A CN 202210184880 A CN202210184880 A CN 202210184880A CN 115048969 A CN115048969 A CN 115048969A
- Authority
- CN
- China
- Prior art keywords
- graphical
- processor
- images
- bins
- outputs
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/10—Interfaces, programming languages or software development kits, e.g. for simulating neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
公开了一种用于评估、理解和改进深度神经网络的视觉分析工作流和系统。所述视觉分析工作流有利地使得能够以最少的人在回路交互来解释和改进例如基于图像的对象检测和分类模型的神经网络模型的性能。数据表示组件提取输入图像数据的语义特征,诸如图像或图像中的对象的颜色、亮度、背景、旋转等。输入图像数据通过神经网络以获得预测结果,诸如对象检测和分类结果。交互式可视化组件将预测结果和语义特征转换成交互式和人类友好的可视化,其中在视觉上取决于输入图像数据的提取的语义特征来布置对预测结果进行编码的图形元素。
Description
技术领域
本文档中公开的设备和方法涉及神经网络,更特别地,涉及用于阐明神经网络性能的视觉分析系统。
背景技术
除非本文另外指示,否则本节中描述的材料不被认为是包含在本节中的现有技术。
可解释人工智能(XAI)对于理解神经网络模型性能至关重要,并且随着复杂深度神经网络模型的发展,已经获得了越来越多的关注。在某些高风险领域,诸如自主驾驶(例如,用于检测交通灯或停车标志的模型)、医疗保健(例如,用于进行医疗诊断预测的模型)、金融服务(例如,用于检测欺诈或评估风险的模型)等,模型可解释性特别重要。
对于XAI,存在两种流行的范式:局部解释和全局解释。局部解释旨在解释神经网络模型对给定数据点的预测,通常是通过扰动一组输入并且观察其对模型预测的影响。相反,全局解释采用本质可解释模型(例如,决策树、规则或线性模型)来近似目标神经网络模型的行为,并且然后这些本质可解释模型被用于理解目标神经网络模型。
然而,这两种方法都面临着使得开发者能够有效地理解和解释神经网络模型的行为的问题,并且需要大量的人工交互和分析工作。特别是,局部解释方法仅示出了在局部数据点处的特征对模型预测的影响,并且缺乏在大尺度上解释模型行为的机制。此外,全局解释必须平衡可解释性和保真度(即,模型解释能够多么真实地近似模型行为)之间的权衡。最后,这两种方法通常都缺乏一种有效的机制来使得能够解释在感兴趣的特定案示例集上的模型行为。因此,需要一种动态且灵活的系统来解释模型行为,而不需要过多的人类交互和分析工作。
发明内容
公开了一种用于对神经网络模型的操作进行可视化的方法。该方法包括利用处理器接收多个图像。该方法进一步包括利用处理器接收多个输出,所述多个输出中的每个输出由神经网络模型响应于多个图像中的对应图像而输出。该方法进一步包括利用处理器接收多个视觉特征集,每个视觉特征集是从多个图像中的对应图像提取的。该方法进一步包括在显示屏上显示包括多个输出的图形描绘的图形用户界面,该图形描绘包括对多个输出进行编码的多个图形元素,所述多个图形元素在视觉上取决于多个视觉特征集来布置。
公开了一种用于对神经网络模型的操作进行可视化的系统。该系统包括显示屏。该系统进一步包括存储器,存储器被配置为存储(i)多个图像,(ii)多个输出,所述多个输出中的每个输出由神经网络模型响应于多个图像中的对应图像而输出,以及(iii)多个视觉特征集,每个视觉特征集从多个图像中的对应图像中提取。该系统进一步包括可操作地连接到显示屏和存储器的处理器。处理器被配置为从存储器读取(i)多个图像,(ii)多个输出,以及(iii)多个视觉特征集。该处理器进一步被配置为生成并操作显示屏来显示包括多个输出的图形描绘的图形用户界面,所述图形描绘包括对多个输出进行编码的多个图形元素,所述多个图形元素在视觉上取决于多个视觉特征集来布置。
公开了一种用于对神经网络模型的操作进行可视化的非暂时性计算机可读介质。该非暂时性计算机可读介质存储程序指令,当由处理器执行时,该程序指令使处理器接收多个图像。该非暂时性计算机可读介质进一步存储程序指令,当由处理器执行时,该程序指令使得处理器接收多个输出,所述多个输出中的每个输出由神经网络模型响应于所述多个图像中的对应图像而输出。该非暂时性计算机可读介质进一步存储程序指令,当由处理器执行时,该程序指令使得处理器接收多个视觉特征集,每个视觉特征集从多个图像中的对应图像中提取。该非暂时性计算机可读介质进一步存储程序指令,当由处理器执行时,该程序指令使得处理器生成并操作显示屏显示包括多个输出的图形描绘的图形用户界面,所述图形描绘包括对多个输出进行编码的多个图形元素,所述多个图形元素在视觉上取决于多个视觉特征集来布置。
附图说明
结合附图,在以下描述中解释了该方法和系统的前述方面和其他特征。
图1示出了用于评估、理解和改进深度神经网络的视觉分析工作流;
图2示出了基于CNN的交通灯检测器的说明性实施例;
图3示出了用于语义特征提取的示例性 变分自动编码器(VAE);
变分自动编码器(VAE);
图4示出了图形用户界面,其包括神经网络模型的性能的多方面高级总结;
图5A示出了包括神经网络模型的性能景观(landscape)可视化的图形用户界面;
图5B示出了包括神经网络模型的性能景观可视化的另一图形用户界面,;
图6A示出了包括神经网络模型的分层平行坐标可视化的图形用户界面;
图6B示出了包括神经网络模型的分层平行坐标可视化的另一图形用户界面;
图7示出了性能景观可视化和分层平行坐标可视化之间的配合;
图8示出了包括图像场景的图形用户界面,该图像场景包括神经网络模型的特定输入图像;
图9示出了视觉分析系统的示例性实施例的框图;
图10示出了用于操作视觉分析系统的方法的流程图。
具体实施方式
为了促进对本公开的原理的理解,现在将参考附图中图示的和以下书面说明书中描述的实施例。应当理解,并非旨在对本公开的范围进行限制。进一步应当理解,本公开包括对所示实施例的任何变更和修改,并且包括如本公开所属领域的技术人员通常会想到的本公开原理的进一步应用。
可视化分析工作流概述
图1示出了用于评估、理解和改进深度神经网络的视觉分析工作流。视觉分析工作流有利地使得能够利用最少的人在回路交互来解释和提高神经网络模型10的性能,例如基于图像的对象检测和分类模型。在视觉分析工作流的描述中,由组件执行某个任务、计算或功能的声明通常是指处理器执行存储在可操作地连接到处理器的非暂时性计算机可读存储介质中的编程指令以操纵数据,或者是指以其他方式执行任务或功能。
总之,视觉分析工作流开始于多个所采集数据20,诸如图像数据。工作流的数据表示组件30提取所采集数据20的语义特征,诸如图像或图像中的对象的颜色、亮度、背景、旋转等。工作流的对抗式学习组件40学习神经网络模型10的预测行为,并且以不可见数据50的形式为神经网络模型10生成有意义的对抗式示例。所采集数据20和不可见数据50通过神经网络10以获得预测结果,诸如对象检测和分类结果。工作流的交互式可视化组件60将预测结果和语义特征转换成交互式和人类友好的可视化。最后,工作流的视觉分析辅助改进组件70涉及与可视化的交互,以导出可执行的见解,并且生成试图提高神经网络模型的准确性和鲁棒性的附加的不可见训练数据。
在本文中关于卷积神经网络(CNN)模型来详细描述视觉分析工作流,该卷积神经网络(CNN)模型被配置为检测图像中的对象并对检测到的对象进行分类。更特别地,本文描述的示例性CNN被配置为检测驾驶场景的图像中的交通灯,并且对交通灯的状态进行分类(例如,红、绿、黄、关闭)。然而,应该强调的是,除了本文描述的说明性交通灯检测器之外,本文描述的视觉分析工作流和系统适用于用于各种图像处理任务的各种深度神经网络模型。
应当领会,这种交通灯检测是自主驾驶中必不可少的组件。它通过定位相关的交通灯来帮助自主汽车感知驾驶环境,并且通过识别交通灯的当前状态来支持自主驾驶汽车做出决策。最先进的交通灯检测器典型地依赖于深度CNN,诸如本文所述的深度CNN,其在许多计算机视觉任务中表现出优异的性能,诸如图像分类、对象检测、语义分割等。这些检测器通常在通用对象检测器上进行训练,并且然后使用领域特定数据(具有交通灯的驾驶场景)进行微调,或者与关于驾驶场景的其他先验知识(诸如场景中的对象分布)相组合。
尽管基于CNN的交通灯检测器的结果很有希望,但一个问题是如何在部署到自主汽车之前彻底评估、理解和改进检测器的性能。关注点是双重的:(1)必须在大量的所采集数据(训练和测试数据)上评估和改进模型的准确性;以及(2)必须在不可见数据(表示潜在缺陷)上评估和改进模型的鲁棒性。然而,评估模型的准确性并且理解模型何时以及为什么会失败是一项重要的任务。模型准确性的常规评估和基准化方法严重依赖于聚合且过度简化的度量,诸如mAP(平均精度均值),并且无法提供可解释的和上下文信息来理解模型性能。更进一步地,虽然一般CNN的可解释性已经受到越来越多的关注,但是仍然需要研究用于揭示如何执行基于CNN的对象检测器的方法。
另一个迫切的需求是能够标识模型的潜在缺陷,然后评估和改进在潜在易损情况上的鲁棒性。最近,对抗式攻击和鲁棒性研究的进展在揭示深度神经网络的缺陷方面具有很大潜力。一般来说,对抗式机器学习利用从模型获得的梯度信息来欺骗具有小的输入扰动的分类器。然而,在应用当前的对抗式攻击方法来理解、评估和改进检测器的鲁棒性方面存在两个重大挑战。首先,大多数对抗式攻击方法不会生成具有有意义改变的示例。相反,这些方法通常旨在通过添加不可感知的噪声来欺骗目标模型,并且因此这些噪声并不对应于开发者容易理解的物理意义或语义,从而为改进物理世界中的模型鲁棒性提供指导。第二,理解对抗式景观和改进模型鲁棒性的机制是合期望的。例如,利用当前的对抗式方法,开发人员不知道学习到的对抗式示例的常见模式是什么,它们为什么存在,或者如何改进它们。
本文描述的视觉分析工作流和系统有利地克服了在现有数据上剖析模型准确性以及还有在不可见情况下评估和改进模型鲁棒性的这些障碍。特别地,视觉分析工作流和系统使得开发者能够评估、理解和改进用于图像处理任务的各种神经网络模型——包括但不限于本文描述的说明性交通灯检测器——的准确性和鲁棒性。视觉分析工作流和系统由语义表示学习和最少的人在回路方法指导。特别地,利用表示学习方法来有效地总结、导航和诊断神经网络模型10在大量数据上的性能。提取输入数据的具有解纠缠的内在(语义)属性(诸如检测到的交通灯的颜色、亮度、背景、旋转等)的低维表示(即潜在空间),并且用作输入数据的基本表示,以用于人类友好的可视化和语义对抗式学习这两者。
说明性对象检测器模型
如上所述,本文关于CNN模型详细描述视觉分析工作流,所述CNN模型被配置为检测图像中的对象并对检测到的对象进行分类。当然,本领域普通技术人员应当领会,CNN模型是一种机器学习模型。如本文所使用的,术语“机器学习模型”指代被配置为实现算法、过程或数学模型(例如,神经网络)的系统或程序指令集和/或数据,所述算法、过程或数学模型基于给定的输入来预测或以其他方式提供期望的输出。应当领会,通常,机器学习模型的许多或大多数参数没有被明确编程,并且在传统意义上,机器学习模型没有被明确设计成遵循特定规则以便为给定输入提供期望的输出。相反,机器学习模型被提供有训练数据的语料库,机器学习模型从该语料库中标识或“学习”数据中的模式和统计关系,所述模式和统计关系被一般化以做出预测或以其他方式提供关于新数据输入的输出。训练过程的结果体现在多个学习到的参数、核权重和/或滤波器值中,所述参数、核权重和/或滤波器值在机器学习模型的各个组件中使用以执行各种操作或功能。
图2示出了基于CNN的交通灯检测器100的说明性实施例。在基于CNN的交通灯检测器100的描述中,层或一些其他组件执行一些过程/功能或被配置为执行一些过程/功能的声明意味着处理器或控制器参考在训练过程中学习到的参数、核权重和/或滤波器值来执行存储在存储器中的对应程序指令,以执行所声明的操作或功能。
应当领会,CNN是一种包含多个卷积层的前馈神经网络。常规的卷积层接收输入,并对输入应用一个或多个卷积滤波器。卷积滤波器也称为核,是权重(也称为参数或滤波器值)的矩阵,卷积滤波器被应用于输入矩阵的各个块,使得权重矩阵在输入矩阵上被卷积以提供输出矩阵。输出矩阵的维度由滤波器的核大小(即权重矩阵的大小)和滤波器的“步幅”决定,步幅表示输入矩阵的块在卷积期间彼此重叠多少或在卷积期间彼此间隔多少。CNN的各种层和滤波器用于检测输入的各种“特征”。
说明性的基于CNN的交通灯检测器100包括单点多盒检测器(SSD),其提供高度准确和快速的检测。基于CNN的交通灯检测器100被配置为接收驾驶场景的图像110作为输入。在所示示例中,图像110具有宽度W、高度H和深度3(对应于图像110的红色、绿色和蓝色输入通道和/或颜色空间)。基于图像110,基于CNN的交通灯检测器100被配置为确定并输出一个或多个边界框b i ,每个边界框b i 定义交通灯的可能位置。在一个实施例中,边界框b i 采取的形式是 ,其中i是特定边界框的索引,
,其中i是特定边界框的索引, ,
, 是到图像110内的中心坐标的偏移,并且
是到图像110内的中心坐标的偏移,并且 分别是边界框b i 的宽度和高度。图像110可以被每个相应的边界框b i 裁剪以产生单独的对象图像o i 。除了边界框b i 之外,基于CNN的交通灯检测器100被配置为针对每个边界框b i 确定和输出每个可能的对象分类或类别(例如,红色、绿色、黄色、关闭和非对象/背景)的概率和/或置信度得分
分别是边界框b i 的宽度和高度。图像110可以被每个相应的边界框b i 裁剪以产生单独的对象图像o i 。除了边界框b i 之外,基于CNN的交通灯检测器100被配置为针对每个边界框b i 确定和输出每个可能的对象分类或类别(例如,红色、绿色、黄色、关闭和非对象/背景)的概率和/或置信度得分 ,其中
,其中 指示可能的对象分类或类别中的特定一个。
指示可能的对象分类或类别中的特定一个。
在说明性实施例中,图像110首先被传递到骨干网络120,诸如ResNet、MobileNet等,其被配置为提取基本特征图(例如,具有512个通道的深度的 特征图)。骨干网络120可以包括多个卷积层,以及各种其他层或过程,诸如池化层(例如,最大池化、平均池化等)、全连接层、丢弃(dropout)层、激活函数(例如,线性整流单元(ReLU))、批归一化或L1/L2归一化。
特征图)。骨干网络120可以包括多个卷积层,以及各种其他层或过程,诸如池化层(例如,最大池化、平均池化等)、全连接层、丢弃(dropout)层、激活函数(例如,线性整流单元(ReLU))、批归一化或L1/L2归一化。
由骨干网络120输出的基本特征图被传递到一个或多个附加网络130,附加网络130将基本特征图的维度减少到一个或多个更小的大小的特征图(例如,具有256个通道的深度的 特征图)。附加网络130可以每个包括多个卷积层、池化层等,其所述层被配置为减少基本特征图的维度。附加网络130可以彼此顺序连接,以产生维度渐进地变小的若干个附加特征图。
特征图)。附加网络130可以每个包括多个卷积层、池化层等,其所述层被配置为减少基本特征图的维度。附加网络130可以彼此顺序连接,以产生维度渐进地变小的若干个附加特征图。
检测组件140为每个特征图(包括基本特征图和每个更小的大小的特征图)的每个单元格(cell)做出具有不同纵横比的k个边界框预测。对于每个预测的边界框,检测组件140利用具有预确定大小(例如 )的卷积预测器来确定p个类得分(即,概率和/或置信度得分),其中p是可能的类的总数。由于检测组件140基于所有的特征图进行预测,所以经常会有基本上对应于相同的预测若干个预测的边界框,但是它们是基于不同大小的特征图进行预测的。为了解决这个问题,非极大值抑制组件150过滤冗余预测和/或组合具有至少阈值相似性或彼此重叠的预测边界框,以得到预测边界框b i 的最终集合。最后,基于CNN的交通灯检测器100被配置为输出预测边界框b i 的最终集合和相关联的类得分c j ,其通过非背景类的最大类得分c j 来进行排序。
)的卷积预测器来确定p个类得分(即,概率和/或置信度得分),其中p是可能的类的总数。由于检测组件140基于所有的特征图进行预测,所以经常会有基本上对应于相同的预测若干个预测的边界框,但是它们是基于不同大小的特征图进行预测的。为了解决这个问题,非极大值抑制组件150过滤冗余预测和/或组合具有至少阈值相似性或彼此重叠的预测边界框,以得到预测边界框b i 的最终集合。最后,基于CNN的交通灯检测器100被配置为输出预测边界框b i 的最终集合和相关联的类得分c j ,其通过非背景类的最大类得分c j 来进行排序。
视觉特征提取
回到图1,如上所述,视觉分析工作流的数据表示组件30提取所采集数据20以及不可见数据50的视觉因子、特征和/或维度(也称为“语义”或“潜在”特征)。给定来自数据20、50的多个对象图像o i ,数据表示组件30从图像中提取视觉因子、特征和/或维度的集合,充当对象图像o i 的语义和/或潜在表示。特定对象图像o i 的语义特征集在本文中被标示为z i ,其中i是特定对象图像o i 的索引。交互式可视化组件60使用这些语义特征z i 来辅助开发者解释和理解神经网络模型10。此外,对抗式学习组件40使用这些语义特征z i 来生成有意义的对抗式示例(即,不可见数据50)。
语义特征z i 可以包括例如:图像的颜色、图像中对象的颜色(例如,交通灯的颜色)、图像的亮度、图像中对象的亮度、图像的背景、图像的旋转、图像中对象的旋转、图像的纹理、图像中对象的纹理、图像的大小、图像中对象的大小、图像的天气状况、图像的一天中时间等。
应当领会,可以使用各种各样的技术从多个对象图像o i 中提取语义特征z i ,这些技术当然可以取决于所提取的特定特征。通常,用于提取的方法将包括(i)基于学习的方法和(ii)用于特定特征的预定义方法。基于学习的方法可以利用无监督方法从数据中有利地提取有意义的视觉因子。例如,如下面所讨论的,变分自动编码器(VAE)可以从训练图像集中学习独立的视觉特征。相反,可以使用各种预定义的方法或算法来提取特定的语义特征。例如,图像的大小或一天中的时间可以直接从图像的元数据中提取,并且图像的天气状况可以使用从外部数据源接收的天气数据来确定。
在一些实施例中,使用解纠缠的表示学习技术来提取多个对象图像的语义特征z i 中的一个或多个。特别地,图3示出了具有损失的定制的正则化的 -VAE 200。给定对象图像
-VAE 200。给定对象图像 (例如,具有
(例如,具有 大小的交通灯),
大小的交通灯), -VAE提取提供对象图像o i 的语义特征表示的潜在向量
-VAE提取提供对象图像o i 的语义特征表示的潜在向量 ,其中D是潜在维度大小。
,其中D是潜在维度大小。 -VAE包括两个组件:编码器210和解码器220。编码器210被配置为将对象图像o i 映射到潜在向量z i 。换句话说,编码器210执行操作
-VAE包括两个组件:编码器210和解码器220。编码器210被配置为将对象图像o i 映射到潜在向量z i 。换句话说,编码器210执行操作 。解码器220被配置为将潜在向量z i 转换成重建的对象图像
。解码器220被配置为将潜在向量z i 转换成重建的对象图像 。换句话说,解码器220执行操作
。换句话说,解码器220执行操作 。
。
在训练期间,参考四个损失项来优化 -VAE 200。首先,基于对象图像o i 和重建的对象图像
-VAE 200。首先,基于对象图像o i 和重建的对象图像 之间的比较来计算重建损失230,例如重建为均方误差:
之间的比较来计算重建损失230,例如重建为均方误差: 。第二,潜在损失240被计算为对象图像o i 和潜在向量z i 之间的相对熵,例如重建为Kullback-leibler散度:
。第二,潜在损失240被计算为对象图像o i 和潜在向量z i 之间的相对熵,例如重建为Kullback-leibler散度: 。重建损失230和潜在损失240被用于通过
。重建损失230和潜在损失240被用于通过 -VAE 200来控制解纠缠(disentanglement)的质量。
-VAE 200来控制解纠缠(disentanglement)的质量。
除了重建损失230和潜在损失240之外,还计算预测损失250和感知损失260,以确保真实图像的重建和生成。CNN分类器270被预先训练以预测交通灯颜色。预先训练的CNN分类器270用于预测重建的对象图像 的颜色
的颜色 。基于实际颜色y i 和预测颜色
。基于实际颜色y i 和预测颜色 之间的比较来计算预测损失250,例如计算为交叉熵损失:
之间的比较来计算预测损失250,例如计算为交叉熵损失: 。预先训练的CNN分类器270进一步用于从CNN分类器270的卷积神经网络(ConvNet)层(来自第l个ConvNet层的
。预先训练的CNN分类器270进一步用于从CNN分类器270的卷积神经网络(ConvNet)层(来自第l个ConvNet层的 )提取对象图像o i 和重建的对象图像
)提取对象图像o i 和重建的对象图像 的特征图。基于从对象图像o i 提取的特征图
的特征图。基于从对象图像o i 提取的特征图 和从重建的对象图像
和从重建的对象图像 提取的特征图
提取的特征图 之间的比较来计算感知损失260,例如,计算为
之间的比较来计算感知损失260,例如,计算为 。
。
用于训练和优化 -VAE 200的最终损失项是上面介绍的重建损失230、潜在损失240、预测损失250和感知损失260的总和:
-VAE 200的最终损失项是上面介绍的重建损失230、潜在损失240、预测损失250和感知损失260的总和:
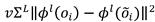 其中
其中 和C是控制解纠缠的参数,
和C是控制解纠缠的参数, 和v是控制重建质量的权重。
和v是控制重建质量的权重。
在数据表示组件30提取语义特征z i 之后,多个对象图像o i 被传递到神经网络模型10,神经网络模型10输出所述多个对象图像o i 的预测结果。特别地,神经网络模型10确定所述多个对象图像o i 的类得分c j 。
模型性能的可视化
回到图1,如上面所提到的,工作流的交互式可视化组件60将类得分c j 、语义特征z i 和其他元数据转换成交互式和人类友好的可视化。特别地,交互式可视化组件60被配置为生成和显示图形用户界面,该图形用户界面包括神经网络模型10的预测结果和提取的语义特征z i 的可视化,其可以由用户经由用户界面来操纵和定制。图形用户界面可以包括各种不同类型的可视化,从高级总结到非常详细的样本级可视化。
在这些可视化和图形用户界面的描述中,可视化或图形用户界面包括一些特征或图形元素的声明通常指代处理器执行存储在可操作地连接到处理器的非暂时性计算机可读存储介质中的编程指令,以在显示设备上显示可视化或图形用户界面,从而包括该特征或图形元素。此外,用户可以选择可视化或图形用户界面的某些方面或以其他方式与之交互的声明通常指代处理器以常规方式经由用户接口(诸如鼠标、键盘或触摸屏)接收来自用户的用户输入。
图4示出了图形用户界面300,其包括神经网络模型10的性能的多方面高级总结。特别地,图形用户界面300包括若干个数字总结310A-F,其在聚合水平上定量地总结神经网络模型10的各种性能度量(例如,“10683个总计对象”、“25592个前10名检测”、“396个假阳性”、“687个假阴性(从未检测到)”,“2046个假阴性(低置信度)”,和“7286个对抗式示例”)。如本文所使用的,“性能度量”指代与神经网络模型10的输入、输出或操作相关的任何定量值。此外,图形用户界面300包括若干个分布总结320A-D,其包括具有多个图形元素(即,水平条)的直方图,这些直方图总结了神经网络模型10在分布水平上的各种性能度量(例如,“大小分布”、“IOU[交并比]分布”、“Conf.[置信度]分布”和“鲁棒性分布”)。应当领会,图形用户界面300中图示的特定性能度量仅仅是示例性的,并且可以总结各种各样的性能度量和其他这样的元数据。
在一些实施例中,分布总结320A-D相互协调以过滤数据并支持多方面的性能分析,以用于其他可视化中的准确性和鲁棒性。特别地,用户可以选择分布总结320A-D之一中的水平条的子集330。响应于该选择,数字总结310A-F以及其他分布总结320A-D将更新以仅表示对应于所选子集330的数据。此外,下面讨论的其他可视化可以类似地更新以仅表示所选数据。
在许多实施例中,可视化包括表示关于数据20、50的多个对象图像o i 中的一个或多个的预测结果和/或语义特征的多个图形元素。所提取的与对象图像o i 相关联的语义特征z i 用于在可视化中以图形方式对图形元素进行布置和排序。此外,可以由用户经由与图形用户界面的交互来定制和调整据其使用语义特征z i 在可视化中以图形方式对图形元素进行布置和排序的方式。
图5A-B示出了图形用户界面400A-B,其包括神经网络模型10的性能景观可视化410。性能景观可视化410包括以二维网格形式布置的多个单元格420。每个单元格420包括表示一个或多个单独的对象图像o i 的图形元素。根据提取的语义特征z i 的可选维度,沿着两个轴布置图形元素。特别地,图形元素被根据第一语义维度(例如,“DIM_PCA0”)沿着水平轴布置,并且根据第二语义维度(例如,“DIM_PCA1”)沿着垂直轴排序。用于水平和垂直轴的语义维度由用户经由与图形用户界面400A-B的用户交互而可选择,并且从语义特征z i 的维度空间中选择。
每个单元格420是一个或多个单独的对象图像o i 的聚合箱(bin)。特别地,多个对象图像o i 中的每一个基于它们对于水平轴和垂直轴的所选语义维度的相应值被分类到相应的单元格420中。在每个箱内,选择代表性的对象图像o i 。例如,代表性对象图像o i 可以是具有在箱内的中值模型得分(例如,置信度得分)或一些其他性能度量或语义特征的中值的对象图像o i 。单元格420的数量和单元格420的相应箱大小取决于为性能景观可视化410的所选缩放级别。缩放级别由用户经由与图形用户界面400A-B的用户交互而可选择。
每个单元格420的图形元素被配置为表示或编码各种类型的信息。如图5A所示,在性能景观可视化410的第一模式中,每个单元格420的图形元素包括相应单元格420的代表性对象图像o i 的缩略图。如图5B所示,在性能景观可视化410的第二模式中,每个单元格420的图形元素包括彩色矩形。在至少一个实施例中,彩色矩形的颜色编码了神经网络模型10相对于被分类到相应单元格420中的一个或多个单独对象图像o i 的模型得分。编码的模型得分可以包括各种性能度量,诸如置信度得分、准确性得分、鲁棒性得分或特定类的类得分。在一个实施例中,性能景观可视化410包括图例430,其解释了单元格420中的不同颜色和神经网络模型10的不同模型得分之间的对应关系。性能景观可视化410的特定模式和由单元格420的图形元素编码的特定信息由用户经由与图形用户界面400A-B的用户交互而可选择。最后,在一个实施例中,性能景观可视化410包括示出了所选语义空间中的数据分布的轮廓密度图,该轮廓密度图叠加在单元格420之上或单元格420之后(在图7中最佳可见)。
在所示实施例中,性能景观可视化410进一步包括沿着水平轴和垂直轴的聚合图像条440、450。聚合图像条440、450每个都包括沿着相应轴的多个图形元素行/列。特别地,在所示实施例中,水平聚合图像条440包括沿着水平轴布置的三个图形元素行,与单元格420网格相邻。类似地,垂直聚合图像条450包括沿着水平轴布置的三个图形元素列,与单元格420网格相邻。对于沿水平轴的每个单元格420列420和沿垂直轴的每个单元格420行,利用与上述相同的方法将多个对象图像o i 归入箱和聚合。
水平聚合图像条440包括第一图形元素行442,该第一图形元素行442是针对相应的单元格420列的代表性对象图像o i 的缩略图形式(例如,对象图像o i 具有箱内的中值模型得分或针对一些其他性能度量或语义特征的中值)。水平聚合图像条440包括彩色矩形形式的第二图形元素行444。在至少一个实施例中,彩色矩形的颜色编码了神经网络模型10相对于每个相应单元格420列中的对象图像o i 的模型得分。如上所述,编码模型得分可以包括各种性能度量,诸如置信度得分、准确性得分、鲁棒性得分或特定类的类得分。此外,在至少一个实施例中,彩色矩形的高度编码了每个相应单元格420列的频次(即,分类到相应单元格420列中的对象图像o i 的总数)。
在一些实施例中,水平聚合图像条440包括彩色箭头形式的第三图形元素行446,其中箭头的颜色和方向编码了分类到单元格420列中的对象图像o i 的神经网络模型10的中间或平均对抗式梯度方向。使用对抗式学习组件40来确定这些对抗式梯度方向。通过该方式,彩色箭头指向数据20、50中最模糊或最具挑战性的对象图像o i ,并且使开发者能够标识神经网络模型10的问题区域。
类似于水平聚合图像条440,垂直聚合图像条450包括:第一图形元素列,该第一图形元素列是相应单元格420行的代表性对象图像o i 的缩略图形式;第二图形元素列,该第而图形元素列是编码相应单元格420行的模型得分和频次的彩色矩形形式;以及第三图形元素列,该第三图形元素列是编码相应单元格420行的对抗式梯度方向的彩色箭头形式。
用户可以经由用户接口与图形用户界面400A-B交互,以缩放和平移性能景观可视化410。此外,用户可以与图形用户界面400A-B交互,以选择用于沿着每个轴排序对象图像o i 的特定语义特征。最后,用户可以与图形用户界面400A-B交互,以选择单元格420和聚合图像条440、450中的各种图形元素编码了什么信息。
图6A-B示出了图形用户界面500A-B,其包括神经网络模型10的分层平行坐标可视化510。分层平行坐标可视化510包括多个聚合图像条520A-E,每个聚合图像条本质上类似于性能景观可视化410的聚合图像条440、450。聚合图像条520A-E中的每一个对应于来自提取的语义特征z i 的特定语义维度(例如,“DIM_PCA0”、“DIM_PCA1”、“DIM_7”、“DIM_4”和“DIM_28”)。在每个聚合图像条520A-E内,以与上面关于性能景观可视化410的单元格420以及聚合图像条440、450的单元格420行和列所讨论的方式类似的方式,将多个对象图像o i 分类并聚合到相应语义维度上的箱中。
聚合图像条520A-E每个包括多个图形元素行。如在图6A中可以看到的,聚合图像条520A-E包括第一图形元素行和第二图形元素行,第一图形元素行是相应箱的代表性对象图像o i 的缩略图形式,第二图形元素行是编码相应箱的模型得分和频次的彩色矩形形式。如图6B所示,聚合图像条520A-E可以进一步包括彩色箭头形式的第三图形元素行,其编码相应箱的对抗式梯度方向。
聚合图像条520A-E以分层方式垂直布置,该分层方式在顶部或者以其他方式在分层平行坐标可视化510内更显著地呈现语义特征z i 的最显著的维度。首先,提取的语义特征z i 利用凝聚方法进行分层聚类,以有效地组织和导航这些维度。特别地,聚类由离差平方和法(ward linkage)形成,离差平方和法最小化聚类内所有语义特征向量z i 之间的欧几里德距离的方差。仅通过应用距离阈值确定的预确定数量的顶部语义特征维度在分层平行坐标可视化510中可见。通过扩展子树可以示出更多的语义特征维度。语义特征z i 的前两个PCA(主成分分析)成分也被包括以捕获所有语义特征维度的主导方差。它们被组织成根节点中的特殊子树。
如在图6B中可以看到的,用户可以选择或悬停在聚合图像条520A-E之一的特定图形元素上。响应于用户选择,分层平行坐标可视化510包括多条曲线530,所述曲线530将跨彼此相关的所有聚合图像条520A-E的图形元素和/或箱互连。换句话说,多条曲线530示出了与所选图形元素的箱相关的其他语义维度的箱。此外,响应于用户选择,分层平行坐标可视化510突出显示所选择的图形元素以及其他语义维度的相关箱的图形元素。
性能景观可视化410和分层平行坐标可视化510可以彼此协同使用,以快速评估、理解和改进神经网络模型10。特别是,利用最少的人工交互,可以获得可执行的见解,以生成试图经由数据扩充来改进模型性能的新的数据。
在一些实施例中,用户可以从分层平行坐标可视化510(即,聚合图像条520A-E之一)中选择任何维度,以沿着性能景观可视化410的水平轴或垂直轴利用。通过该方式,用户可以容易地检查该维度中嵌入了什么视觉语义。此外,用户可以选择或悬停在聚合图像条520A-E之一的特定图形元素和/或箱上,并且作为响应,性能景观可视化410将突出显示其对应于聚合图像条520A-E之一的所选图形元素和/或箱的单元格420。
参考图7,在一些实施例中,用户可以使用套索工具操作或点击并拖动操作来选择性能景观可视化410内的单元格的子集610。响应于该选择,所选子集610在性能景观可视化410内被突出显示。此外,聚合图像条520A-E的对应图形元素和/或箱620在分层平行坐标可视化510内被突出显示,并且多条曲线530被显示以标识跨多个语义维度的相关箱。
在至少一个实施例中,响应于在性能景观可视化410中选择单元格420的子集610,分层平行坐标可视化510被重新组织以分层显示与所选单元格子集610相对应的数据内的语义特征z i 的最显著维度。特别地,分层平行坐标可视化510通过语义特征z i 的重要性对语义特征z i 的维度进行排名,以将选择与其他数据点分开。所选择数据利用第一分类标签标记,并且未选择的数据利用第二分类标签标记。应用机器学习模型来确定语义特征z i 的哪些维度在区分第一类和第二类时最显著。更特别地,被选择和未选择的数据被利用目标变量的不同标签(例如,分类得分)进行标记,并且它们的语义特征z i 被用作估计它们朝向目标变量的互信息(MI)的特征。然后,通过维度的MI值对维度进行排名,并且凝聚地组织为用于分层平行坐标可视化510的树结构。通过该方式,用户可以容易地理解解释关于所选数据的性能的顶部语义维度。
在图7所示的示例中,子集610选自性能景观可视化410的中心区域,其中单元格主要是第一颜色(例如,红色),该第一颜色指示所选单元格子集610的对象图像o i 的低置信度得分。在选择之后,分层平行坐标可视化510被更新,并且传达对应于“暗度”和“模糊度”的语义维度在关于所选单元格子集610的对象图像o i 的糟糕性能中扮演的重要角色。子具有该见解的情况下,开发者可以通过从这两个语义维度获得更多的训练数据并使用附加的训练数据重新训练神经网络模型10来改进神经网络模型10。
最后,图8示出了包括图像场景710的图形用户界面700,图像场景710包括神经网络模型10的特定输入图像。特别地,使用先前描述的可视化中的任何一个,用户可以选择特定的对象图像o i 。响应于这样的选择,显示包括所选对象图像o i 的输入图像710。第一框720(例如绿色)围绕所选对象图像o i 的基准真值边界框绘制,第二框730(例如红色)围绕所选对象图像o i 的预测边界框b i 绘制。最后,为所选对象图像o i 显示性能总结740A-C(例如,“IOU:0.8”,“置信度:0.94”和“鲁棒性:0.96”)。通过观察与特定对象图像o i 相关联的图像场景710,开发者可以更好地理解利用神经网络模型10的性能问题的上下文。
示例性视觉分析系统
图9示出了视觉分析系统800的示例性实施例的框图。视觉分析系统800有利地利用上述视觉分析工作流和交互式可视化,以使得开发者能够评估、理解和改进深度神经网络。特别地,视觉分析系统800通过利用输入数据的提取的语义特征来有利地使得能够以最少的人在回路交互解释和改进神经网络模型的性能,以生成模型的结果和性能的交互式和人类友好的可视化。使用这些可视化,开发人员可以导出可执行的见解,以改进神经网络模型的准确性和鲁棒性。
在图示的示例性实施例中,视觉分析系统800包括至少一个处理器802、至少一个存储器804、通信模块806、显示屏808和用户接口810。然而,应当领会,所示出和描述的视觉分析系统800的组件仅仅是示例性的,并且视觉分析系统800可以包括任何替代配置。特别地,视觉分析系统800可以包括任何计算设备,诸如台式计算机、膝上型电脑、智能电话、平板电脑或其他个人电子设备。因此,视觉分析系统800可以包括常规地被包括在这样的计算设备中的任何硬件组件。
存储器804被配置为存储数据和程序指令,当由至少一个处理器802执行时,所述程序指令使得视觉分析系统800能够执行本文描述的各种操作。如本领域普通技术人员应当认识到的,存储器804可以是能够存储由至少一个处理器802可访问的信息的任何类型的设备,诸如存储卡、ROM、RAM、硬盘驱动器、盘、闪速存储器或充当数据存储设备的各种其他计算机可读介质中的任何一种。另外,本领域普通技术人员应当认识到,“处理器”包括处理数据、信号或其他信息的任何硬件系统、硬件机构或硬件组件。因此,所述至少一个处理器802可以包括中央处理单元、图形处理单元、多个处理单元、用于实现功能的专用电路、可编程逻辑或其他处理系统。此外,应当领会,尽管视觉分析系统800被图示为单个系统,但是视觉分析系统800可以包括协同工作以实现本文所述功能的若干个不同系统。
通信模块806可以包括一个或多个收发器、调制解调器、处理器、存储器、振荡器、天线或常规地被包括在通信模块中的其他硬件,以使得能够实现与各种其他设备的通信。在至少一些实施例中,通信模块806包括被配置为能够与Wi-Fi网络和/或Wi-Fi路由器(未示出)通信的Wi-Fi模块。在进一步的实施例中,通信模块46可以进一步包括蓝牙®模块、以太网适配器和被配置为与无线电话网络通信的通信设备。
显示屏808可以包括各种已知类型显示器中的任何一种,诸如LCD或OLED屏幕,并且被配置为向用户显示各种图形用户界面。在一些实施例中,显示屏808可以包括被配置为接收来自用户的触摸输入的触摸屏。用户接口810可以适当地包括被配置为使得用户能够本地操作视觉分析系统800的各种设备,诸如鼠标、轨迹板或其他定点设备、键盘或其他小键盘、扬声器和麦克风,如本领域普通技术人员应当认识到的。可替代地,在一些实施例中,用户可以从另一计算设备远程操作视觉分析系统800,该另一计算设备经由通信模块806与其通信并且具有类似的用户接口。
存储在存储器804上的程序指令包括视觉分析程序812、神经网络模型指令814和数据表示模型指令816。神经网络模型指令814实现神经网络模型10(例如,基于CNN的交通灯检测器100),并且由处理器802执行以确定预测结果(例如,边界框b i 和相关联的类得分c j )。数据表示模型指令816实现数据表示组件30(例如, -VAE 200和其他学习或预定义模型),并且由处理器802执行以提取语义特征(例如,语义特征z i )。如上所述,处理器802执行视觉分析程序812以生成交互式和人类友好的可视化。
-VAE 200和其他学习或预定义模型),并且由处理器802执行以提取语义特征(例如,语义特征z i )。如上所述,处理器802执行视觉分析程序812以生成交互式和人类友好的可视化。
存储在存储器804上的数据包括输入数据818、模型输出820和语义特征822。例如,输入数据818包括采集的数据20和不可见数据50(例如,多个对象图像o i )。模型输出820包括预测结果(例如,边界框b i 和相关的类得分c j ),以及各种其他元数据,诸如来自神经网络模型10的计算的性能度量或中间数据(例如,CNN特征图)。最后,语义特征822包括从输入数据818提取的语义特征(例如,从多个对象图像o i 提取的语义特征z i )。
用于操作视觉分析系统的方法
图10示出了用于操作视觉分析系统800的方法900的流程图。方法900通过有利地提供神经网络模型10的输出的图形描绘来改进视觉分析系统800的功能,其中表示关于特定对象图像o i 的输出的图形元素在视觉上取决于从那些对象图像o i 提取的相关联的语义特征z i 来布置。通过该方式,语义特征z i 可以用于利用最少的人工交互和分析工作来视觉评估、理解和改进神经网络模型10的性能。
在这些方法的描述中,执行一些任务、计算或功能的说明指代处理器(例如,视觉分析系统800的处理器802)执行存储在非暂时性计算机可读存储介质(例如,视觉分析系统800的存储器804)中的编程指令(例如,视觉分析程序812、神经网络模型指令814和数据表示模型指令816),该非暂时性计算机可读存储介质可操作地连接到处理器以操纵数据或操作视觉分析系统800的一个或多个组件来执行任务或功能。此外,方法的步骤可以以任何可行的时间顺序执行,而不管图中所示的顺序或描述步骤的顺序。
方法900开始于接收多个图像(框910)。特别地,关于本文详细描述的实施例,视觉分析系统800的处理器802被配置为执行视觉分析程序812的程序指令,以接收和/或读取来自存储器804上的输入数据818的多个对象图像o i 。
方法900继续接收或确定多个输出,每个输出由响应于多个图像中的对应图像的神经网络模型输出(框930)。特别地,关于本文详细描述的实施例,处理器802被配置为执行视觉分析程序812的程序指令,以接收和/或读取来自存储器804上的模型输出820的多个输出(例如,边界框b i 和相关联的类得分c j ),以及各种其他元数据,诸如基于来自神经网络模型10的多个输出或中间数据(例如,CNN特征图)计算的性能度量。
在至少一个实施例中,处理器802被配置为执行神经网络模型指令814,以确定关于对象图像o i 中的每一个的上述输出。在一个实施例中,处理器802被配置为将输出(即,模型输出820)存储在存储器804中,以用于由视觉分析程序812稍后使用。然而,在一些实施例中,上述输出可以由一些外部计算设备生成,并且处理器802被配置为操作网络通信模块806来接收来自外部计算设备的输出。
方法900继续接收或确定多个视觉特征集,每个视觉特征集是从多个图像中的对应图像提取的(框950)。特别地,关于本文详细描述的实施例,处理器802被配置为执行视觉分析程序812的程序指令,以接收和/或读取来自存储器804上的语义特征822的多个视觉特征(例如,从多个对象图像o i 提取的语义特征z i )。
在至少一个实施例中,处理器802被配置为执行数据表示模型指令816,以提取关于对象图像o i 中的每一个的上述视觉特征。在一个实施例中,处理器802被配置为将提取的视觉特征(即,语义特征822)存储在存储器804中,以用于由视觉分析程序812稍后使用。然而,在一些实施例中,上述视觉特征可以由一些外部计算设备提取,并且处理器802被配置为操作网络通信模块806以从外部计算设备接收提取的视觉特征。
方法900继续显示包括多个输出的图形描绘的图形用户界面,所述图形描绘包括对多个输出进行编码的图形元素,所述图形元素在视觉上根据多个视觉特征集来布置(框970)。特别地,关于本文详细描述的实施例,处理器802被配置为执行视觉分析程序812的程序指令,以生成多个输出的图形描绘。在一些实施例中,图形描绘可以采取上述可视化的任何组合的形式,包括数字总结310A-F、分布总结320A-D、性能景观可视化410、分层平行坐标可视化510和图像场景710,以及本文没有详细描述的类似可视化。处理器802被配置为操作显示屏808来显示包括所生成的图形描绘和/或可视化的图形用户界面。
在至少一些实施例中,图形描绘和/或可视化具有编码多个输出(例如,相关联的类得分c j 或各种其他元数据,诸如基于类得分c j 计算的性能度量)的多个图形元素。在至少一些实施例中,图形描绘和/或可视化的多个图形元素在视觉上取决于多个视觉特征(例如,从多个对象图像o i 提取的语义特征z i )来布置。
在至少一些实施例中,处理器802被配置为基于多个视觉特征中的至少一个视觉特征(即,基于从多个对象图像o i 提取的语义特征z i 的至少一个特定维度)将多个图像(即,多个对象图像o i )分类到多个箱中。每个箱定义所述至少一个视觉特征的值的范围。在将多个图像分类到多个箱中之后,处理器802被配置为生成图形描绘和/或可视化,使得每个图形元素编码对应于被分类到对应箱中的图像的输出。通过该方式,图形描绘和/或可视化的每个图形元素对应于相应的箱。
在一个实施例中,处理器802生成图形描绘和/或可视化,其中图形元素在视觉上根据由特定视觉特征(即,语义特征z i 的特定维度)的对应箱定义的值范围沿着一个轴布置。例如,在性能景观可视化410(图5A-B)的聚合图像条440、450的情况下,图形元素的行/列在视觉上根据由对应箱定义的值范围沿着水平/垂直轴布置。同样,在分层平行坐标可视化510(图6A-B)的聚合图像条520A-E的每一个中,图形元素行在视觉上根据由对应箱定义的值范围沿着水平轴布置。
在一个实施例中,处理器802生成图形描绘和/或可视化,其中图形元素在视觉上根据由两个特定视觉特征(即,语义特征的两个特定维度z i )的对应箱定义的值范围沿着两个正交轴以网格形式布置。例如,在性能景观可视化410(图5A-B)中,单元格420被布置在二维网格结构内,并且在视觉上根据由对应箱定义的值范围沿着网格结构的水平和垂直轴布置。
在一个实施例中,处理器802生成多个图形描绘和/或可视化。图形描绘和/或可视化中的每一个对应于相应的视觉特征(例如,语义特征z i 的特定维度)。每个图形描绘和/或可视化的图形元素在视觉上根据由相应视觉特征的对应箱定义的值范围沿着至少一个轴布置。在一个示例中,分层平行坐标可视化510(图6A-B)包括多个聚合图像条520A-E,每个对应于特定的视觉特征。处理器802被配置为确定多个图形描绘和/或可视化的相应视觉特征的层级(例如,通过凝聚层级聚类,如上面所讨论的)。处理器802操作显示屏808来显示图形用户界面,该图形用户界面具有根据确定的层级布置的多个图形描绘和/或可视化(例如,如图6A-B所示)。
所生成的图形描绘和/或可视化的图形元素可以采取各种形式。在一些实施例中,处理器802以被分类到对应箱中的多个图像中的代表性图像的缩略图形式生成图形元素中的至少一些。在一些实施例中,处理器802以彩色矩形的形式生成图形元素中的至少一些。彩色矩形具有编码神经网络模型10关于被分类到对应箱中的图像的输出或性能度量的颜色。此外,彩色矩形具有对分类到对应箱中的图像总数进行编码的大小、高度、形状等。
处理器802被配置为操作用户界面810,接收来自用户的用户输入,并取决于接收到的用户输入来调整图形描绘和/或可视化。在一个示例中,处理器802接收定义对特定视觉特征(即,语义特征z i 的特定维度)的选择的用户输入,用于对图形描绘和/或可视化中的图形元素进行分类。处理器802被配置为基于新选择的视觉特征将多个图像重新分类到新的箱中,并相应地更新图形描绘和/或可视化。例如,用户可以选择用于性能景观可视化410的水平轴或垂直轴的视觉特征。
在一个实施例中,处理器802接收选择第一图形描绘内的图形元素的子集。作为响应,处理器802被配置为取决于第一图形描绘内的所选子集图形元素来调整第二图形描绘。在一个实施例中,处理器802被配置为调整第二图形描绘,以便突出显示或以其他方式强调第二图形描绘内的图形元素的子集,对于该子集,由对应箱定义的(一个或多个)视觉特征的值范围与由第一图形描绘内的图形元素的所选子集的对应箱定义的(一个或多个)视觉特征的值范围相关。在一个示例中,响应于选择分层平行坐标可视化510(图6B)的聚合图像条520A的特定图形元素和/或箱,聚合图像条520B-E被调整以突出显示相关的图形元素和/或箱(例如,通过使不相关的图形元素和/或箱变暗并显示多条曲线530)。在另一示例中,响应于在性能景观可视化410(图7)中选择单元格420组,聚合图像条520A-E被调整以突出显示对应于所选单元格420组的图形元素和/或箱(例如,通过使未被选择的图形元素和/或箱变暗并显示多条曲线530)。
在一个实施例中,响应于选择第一图形描绘内的图形元素的子集(例如,图7的性能景观可视化410中的单元格610的子集),处理器重新布置多个附加图形描绘(图7的分层平行坐标可视化510的聚合图像条)。特别地,处理器802仅基于与第一图形描绘内的图形元素子集(例如,图7的单元格610的子集)相对应的所选数据,重新计算与多个附加图形描绘和/或可视化相关联的相应视觉特征的层级(例如,如上所讨论的,通过凝聚层级聚类)。处理器802操作显示屏808来显示具有根据重新计算的层级(例如,如图7所示)布置的多个图形描绘和/或可视化的图形用户界面。
本公开范围内的实施例进一步可以包括用于承载或其上存储有计算机可执行指令(也称为程序指令)或数据结构的非暂时性计算机可读存储介质或机器可读介质。这样的非暂时性计算机可读存储介质或机器可读介质可以是由通用或专用计算机可访问的任何可用介质。作为示例而非限制,这样的非暂时性计算机可读存储介质或机器可读介质可以包括RAM、ROM、EEPROM、CD-ROM或其他光盘存储装置、磁盘存储装置或其他磁存储设备,或者可以用于承载或存储计算机可执行指令或数据结构形式的期望程序代码部件的任何其他介质。上述的组合也应当被包括在非暂时性计算机可读存储介质或机器可读介质的范围内。
计算机可执行指令包括例如使通用计算机、专用计算机或专用处理设备执行特定功能或功能组的指令和数据。计算机可执行指令进一步包括由独立或网络环境中的计算机执行的程序模块。通常,程序模块包括例程、程序、对象、组件和数据结构等,它们执行特定的任务或实现特定的抽象数据类型。计算机可执行指令、相关联的数据结构和程序模块表示用于执行本文公开的方法的步骤的程序代码部件的示例。这样的可执行指令或相关联的数据结构的特定序列表示用于实现这样的步骤中描述的功能的对应动作的示例。
虽然已经在附图和前面的描述中详细说明和描述了本公开,但是这些应当被认为是说明性的,而不是限制性的。应当理解,仅呈现了优选实施例,并且在本公开的精神范围内的所有改变、修改和进一步的应用都期望受到保护。
Claims (20)
1.一种用于对神经网络模型的操作进行可视化的方法,所述方法包括:
利用处理器接收多个图像;
利用所述处理器接收多个输出,所述多个输出中的每个输出由所述神经网络模型响应于所述多个图像中的对应图像而输出;
利用所述处理器接收多个视觉特征集,每个视觉特征集是从所述多个图像中的对应图像提取的;和
在显示屏上显示包括所述多个输出的图形描绘的图形用户界面,所述图形描绘包括对所述多个输出进行编码的多个图形元素,所述多个输出在视觉上根据取决于所述多个视觉特征集来布置。
2.根据权利要求1所述的方法,进一步包括:
经由用户界面接收用户输入;和
利用处理器基于所述用户输入来调整图形描绘,以根据多个视觉特征集以不同的方式布置多个图形元素。
3.根据权利要求1所述的方法,接收多个输出进一步包括:
利用处理器使用神经网络模型基于多个图像中的对应图像来确定多个输出中的每个输出。
4.根据权利要求1所述的方法,其中所述多个输出中的每个输出是以下各项中的至少一个的分类:
(i)特定对象在所述多个图像中的对应图像中的存在,以及(ii)所述特定对象在所述多个图像中的对应图像中的状态。
5.根据权利要求1所述的方法,接收多个视觉特征集进一步包括:
利用处理器基于多个图像中的对应图像来确定多个视觉特征集中的每个视觉特征集。
6.根据权利要求1所述的方法,显示包括图形描绘的图形用户界面进一步包括:
利用处理器,基于对应的视觉特征集中的至少一个视觉特征,将多个图像分类到多个箱中,所述多个箱中的每个箱定义所述至少一个视觉特征的值范围;和
利用所述处理器生成图形描绘,其中多个图形元素中的每个图形元素对所述多个输出中的输出进行编码,所述输出对应于被分类到多个箱中的对应箱中的多个图像中的图像。
7.根据权利要求6所述的方法,生成图形描绘进一步包括:
利用处理器生成所述图形描绘,其中多个图形元素中的每个图形元素取决于由所述多个箱中的对应箱定义的所述至少一个视觉特征的相应值范围沿着所述图形描绘的至少一个轴来布置。
8.根据权利要求6所述的方法,将多个图像分类到多个箱中进一步包括:
利用处理器,基于对应的视觉特征集的第一视觉特征和第二视觉特征,将所述多个图像分类到多个箱中,所述多个箱中的每个箱定义第一视觉特征和第二视觉特征中的每一个的值范围。
9.根据权利要求8所述的方法,生成图形描绘进一步包括:
利用处理器生成所述图形描绘,其中所述多个图形元素中的每个图形元素以具有第一轴和第二轴的网格形式布置,所述多个图形元素取决于由所述多个箱中的对应箱定义的第一特征的相应值范围来沿着第一轴布置,所述多个图形元素取决于由所述多个箱中的对应箱定义的第二特征的相应值范围来沿着第二轴布置。
10.根据权利要求6所述的方法,生成图形描绘进一步包括:
利用处理器生成所述图形描绘,其中所述多个图形元素中的一些图形元素是被分类到所述多个箱中的对应箱中的多个图像的代表性图像的缩略图。
11.根据权利要求6所述的方法,生成图形描绘进一步包括:
利用处理器生成所述图形描绘,其中所述多个图形元素中的一些图形元素编码神经网络模型关于被分类到所述多个箱中的对应箱中的多个图像中的图像的性能度量。
12.根据权利要求11所述的方法,其中以下各项中的至少一个:
所述多个图形元素中的一些图形元素的颜色对性能度量进行编码;和
所述多个图形元素中的一些图形元素的(i)大小和(ii)形状中的至少一个对被分类到多个箱中的对应箱中的图像总数进行编码。
13.根据权利要求6所述的方法,进一步包括:
经由用户界面接收选择对应的视觉特征集合中的至少一个视觉特征的用户输入,基于所述用户输入将多个图像分类到多个箱中。
14.根据权利要求6所述的方法,生成图形描绘进一步包括:
利用处理器生成具有第一多个图形元素的第一图形描绘,所述第一多个图形元素中的每个图形元素对所述多个输出中的输出进行编码,所述输出对应于被分类到所述多个箱中的对应箱中的所述多个图像中的图像,
利用处理器生成具有第二多个图形元素的第二图形描绘,所述第二多个图形元素中的每个图形元素对所述多个输出中的输出进行编码,所述输出对应于被分类到所述多个箱中的对应箱中的所述多个图像中的图像。
15.根据权利要求14所述的方法,进一步包括:
经由用户界面接收选择所述第一多个图形元素的子集的用户输入;和
利用处理器,取决于所述第一多个图形元素的所选子集来调整所述第二图形描绘。
16.根据权利要求15所述的方法,调整第二图形描绘进一步包括:
利用处理器调整所述第二图形描绘,以突出显示所述第二多个图形元素的子集,所述第二多个图形元素的子集对应于定义所述至少一个视觉特征的值范围的所述多个箱中的箱,所述至少一个视觉特征的值范围与由对应于所述第一多个图形元素的所选子集的所述多个箱中的箱定义的所述至少一个视觉特征的值范围相关。
17.根据权利要求6所述的方法,生成图形描绘进一步包括:
利用处理器生成多个图形描绘,所述多个图形描绘中的每个相应图形描绘对应于所述视觉特征集中的相应视觉特征,所述多个图形描绘中的每个相应图形描绘具有相应的多个图形元素, 所述相应的多个图形元素中的每个图形元素对所述多个输出中的输出进行编码,所述输出对应于被分类到所述多个箱中的对应箱中的所述多个图像中的图像,所述相应的多个图形元素的对应箱每个定义了相应视觉特征的值范围;
利用处理器确定对应于多个图形描绘的相应视觉特征的层级;和
在显示屏上显示图形用户界面,所述图形用户界面具有根据确定的层级布置的多个图形描绘。
18.根据权利要求17所述的方法,进一步包括:
利用处理器生成包括另外的多个图形元素的另外图形描绘,所述另外的多个图形元素中的每个图形元素对应于所述多个箱中的对应箱;
经由用户界面接收选择所述另外的多个图形元素的子集的用户输入;和
利用处理器基于所述另外的多个图形元素的所选子集来确定层级。
19.一种用于对神经网络模型的操作进行可视化的系统,所述系统包括:
显示屏;
存储器,所述存储器被配置为存储(i)多个图像,(ii)多个输出,所述多个输出中的每个输出由神经网络模型响应于所述多个图像中的对应图像而输出,以及(iii)多个视觉特征集,每个视觉特征集是从所述多个图像中的对应图像中提取的;和
处理器,所述处理器可操作地连接到显示屏和存储器,所述处理器被配置为:
从所述存储器读取(i)多个图像,(ii)多个输出,和(iii)多个视觉特征集;和
生成并操作所述显示屏来显示包括所述多个输出的图形描绘的图形用户界面,所述图形描绘包括对所述多个输出进行编码的多个图形元素,所述多个图形元素在视觉上取决于所述多个视觉特征集来布置。
20.一种用于对神经网络模型的操作进行可视化的非暂时性计算机可读介质,所述计算机可读介质存储程序指令,当由处理器执行时,所述程序指令使处理器:
接收多个图像;
接收多个输出,所述多个输出中的每个输出由神经网络模型响应于所述多个图像中的对应图像而输出;
接收多个视觉特征集,每个视觉特征集是从所述多个图像中的对应图像中提取的;
生成并操作显示屏以显示包括所述多个输出的图形描绘的图形用户界面,所述图形描绘包括对所述多个输出进行编码的多个图形元素,所述多个图形元素在视觉上取决于所述多个视觉特征集来布置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/186392 | 2021-02-26 | ||
| US17/186,392 US20220277192A1 (en) | 2021-02-26 | 2021-02-26 | Visual Analytics System to Assess, Understand, and Improve Deep Neural Networks |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115048969A true CN115048969A (zh) | 2022-09-13 |
Family
ID=82799484
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210184880.7A Pending CN115048969A (zh) | 2021-02-26 | 2022-02-28 | 用于评估、理解和改进深度神经网络的视觉分析系统 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220277192A1 (zh) |
| CN (1) | CN115048969A (zh) |
| DE (1) | DE102022201780A1 (zh) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11042814B2 (en) * | 2017-03-17 | 2021-06-22 | Visa International Service Association | Mixed-initiative machine learning systems and methods for determining segmentations |
| US11328519B2 (en) * | 2020-07-23 | 2022-05-10 | Waymo Llc | Detecting traffic signaling states with neural networks |
| DE102021119319B4 (de) * | 2021-07-26 | 2023-08-03 | Bayerische Motoren Werke Aktiengesellschaft | Vorrichtung und Verfahren zur Erkennung und/oder Repräsentation einer Signalisierungseinheit |
| US11741123B2 (en) * | 2021-11-09 | 2023-08-29 | International Business Machines Corporation | Visualization and exploration of probabilistic models for multiple instances |
-
2021
- 2021-02-26 US US17/186,392 patent/US20220277192A1/en active Pending
-
2022
- 2022-02-21 DE DE102022201780.3A patent/DE102022201780A1/de active Pending
- 2022-02-28 CN CN202210184880.7A patent/CN115048969A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| DE102022201780A1 (de) | 2022-09-01 |
| US20220277192A1 (en) | 2022-09-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110892414B (zh) | 用于基于分类器的卷积神经网络的视觉分析系统 | |
| Kao et al. | Visual aesthetic quality assessment with a regression model | |
| CN115048969A (zh) | 用于评估、理解和改进深度神经网络的视觉分析系统 | |
| Sedlmair et al. | Data‐driven evaluation of visual quality measures | |
| Höferlin et al. | Inter-active learning of ad-hoc classifiers for video visual analytics | |
| CN106897738B (zh) | 一种基于半监督学习的行人检测方法 | |
| US20220044069A1 (en) | Systems and methods for 3d image distification | |
| US11755190B2 (en) | Synthetic image data generation using auto-detected image parameters | |
| JP2020119154A (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| CN113128329A (zh) | 用于在自主驾驶应用中更新对象检测模型的视觉分析平台 | |
| Sun et al. | Spectral–spatial MLP-like network with reciprocal points learning for open-set hyperspectral image classification | |
| CN118071882A (zh) | 检测对象关系和基于对象关系编辑数字图像 | |
| CN112241758A (zh) | 用于评估显著性图确定器的设备和方法 | |
| CN118096938A (zh) | 从数字图像中移除干扰对象 | |
| Zhang et al. | Visual saliency: from pixel-level to object-level analysis | |
| US11748973B2 (en) | Systems and methods for generating object state distributions usable for image comparison tasks | |
| Li et al. | Global attention network for collaborative saliency detection | |
| Bäuerle et al. | Training de-confusion: an interactive, network-supported visual analysis system for resolving errors in image classification training data | |
| Mara et al. | Dynamic human action recognition and classification using computer vision | |
| Seemanthini et al. | Small human group detection and validation using pyramidal histogram of oriented gradients and gray level run length method | |
| US20230195778A1 (en) | Systems and methods for utilizing object state distributions for image comparison tasks | |
| Bokhari | Computer Vision for determination of fridge contents | |
| Rocks | Towards Explainable AI Using Attribution Methods and Image Segmentation | |
| Abeud et al. | Deep Learning Model for Fashions and Clothes Automated Classification | |
| Littek | Explainable Anomaly Detection in Surveillance Videos: Autoencoder-based Reconstruction and Error Map Visualization |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |