CN114926536A - Semantic-based positioning and mapping method and system and intelligent robot - Google Patents
Semantic-based positioning and mapping method and system and intelligent robot Download PDFInfo
- Publication number
- CN114926536A CN114926536A CN202210845745.2A CN202210845745A CN114926536A CN 114926536 A CN114926536 A CN 114926536A CN 202210845745 A CN202210845745 A CN 202210845745A CN 114926536 A CN114926536 A CN 114926536A
- Authority
- CN
- China
- Prior art keywords
- vector
- feature
- cluster
- semantic
- dynamic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/70—Determining position or orientation of objects or cameras
- G06T7/73—Determining position or orientation of objects or cameras using feature-based methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T17/00—Three dimensional [3D] modelling, e.g. data description of 3D objects
- G06T17/005—Tree description, e.g. octree, quadtree
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T17/00—Three dimensional [3D] modelling, e.g. data description of 3D objects
- G06T17/05—Geographic models
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
- G06T7/246—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments
- G06T7/248—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments involving reference images or patches
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/50—Depth or shape recovery
- G06T7/55—Depth or shape recovery from multiple images
- G06T7/579—Depth or shape recovery from multiple images from motion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/26—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion
- G06V10/267—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion by performing operations on regions, e.g. growing, shrinking or watersheds
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/62—Extraction of image or video features relating to a temporal dimension, e.g. time-based feature extraction; Pattern tracking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/771—Feature selection, e.g. selecting representative features from a multi-dimensional feature space
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/10—Terrestrial scenes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10016—Video; Image sequence
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30248—Vehicle exterior or interior
- G06T2207/30252—Vehicle exterior; Vicinity of vehicle
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Software Systems (AREA)
- Geometry (AREA)
- Computer Graphics (AREA)
- Artificial Intelligence (AREA)
- Databases & Information Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Remote Sensing (AREA)
- Image Analysis (AREA)
Abstract
The invention relates to a semantic-based positioning and mapping method, a semantic-based positioning and mapping system and an intelligent robot. The positioning and mapping method based on the semantics comprises the steps of obtaining a vector characteristic network of a current frame image; pruning the vector feature network, and dividing the vector feature network into a plurality of vector clusters; detecting the motion state of each vector cluster to obtain a fuzzy area of the dynamic target; optimizing a fuzzy area by combining the semantic segmentation result of the current frame image; removing dynamic feature points in the accurate region, and performing pose estimation according to static feature points in the current frame image based on the minimized re-projection error; and based on the current frame image and the pose information of which the dynamic feature points are removed, incrementally updating the octree semantic map. The method can independently detect and remove the dynamic targets in the visual field in a pure physical geometric mode without prior knowledge, improves the positioning accuracy of the robot in a dynamic environment, and can establish a semantic map.
Description
Technical Field
The invention relates to the technical field of visual map construction, in particular to a semantic-based positioning and map construction method and system and an intelligent robot.
Background
Positioning is a fundamental capability of autonomous mobile robots. In known environments, the basic methods currently employed by most positioning systems can be summarized as: the robot senses the environment through a sensor carried by the robot, and then the sensed environment information is matched with an environment map stored in the robot in advance. Through the matching of the real-time sensed environmental information and the map, the robot corrects the positioning error caused by the slippage of the odometer, and therefore the self pose is updated. In an unknown environment, the problem of robot positioning is converted into a problem of Simultaneous positioning and Mapping (SLAM). The SLAM system can synchronously estimate a map of the unknown environment and the pose of the robot in the map only from data received by the sensors on-board the robot.
At present, the SLAM system acquires data according to a camera (monocular, binocular, RGB-D camera, etc.), and can acquire rich visual texture information from the environment, thereby performing self-localization and environmental perception. However, the conventional visual SLAM system is assumed to be in a static environment, that is, an object in the environment is in a static state, and the interference of a moving object often exists in a real environment, so that the estimation accuracy of the pose of the SLAM algorithm is insufficient, and even the positioning fails. Although a visual SLAM system capable of being used for a dynamic scene exists at present, the perception capability of the visual SLAM system on a dynamic target in a visual field is insufficient, and environment semantic information cannot be acquired, so that a robot cannot really understand the environment, and the pose estimation precision cannot be effectively improved.
Disclosure of Invention
The embodiment of the invention provides a semantic-based positioning and mapping method and system and an intelligent robot, and aims to solve the problems that the perception capability of a visual SLAM system to a dynamic target in a visual field is insufficient and the positioning accuracy cannot be guaranteed in the current dynamic environment.
A positioning and mapping method based on semantics comprises the following steps:
acquiring a vector characteristic network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image;
pruning the vector feature network to remove irrelevant features so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used for indicating vector feature sets of the same target;
detecting the motion state of each vector cluster, and acquiring a fuzzy area corresponding to a dynamic target in the current frame image;
optimizing the fuzzy region according to the semantic segmentation result of the current frame image to obtain an accurate region corresponding to the dynamic target;
removing the dynamic characteristic points in the accurate region, and estimating the pose according to the static characteristic points in the current frame image based on a minimized reprojection error mode;
and based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation, updating the octree semantic map in an incremental manner.
A semantic-based localization and mapping system, comprising:
the vector characteristic network acquisition module is used for acquiring a vector characteristic network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image;
the pruning module is used for pruning the vector feature network to remove irrelevant features so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used for indicating vector feature sets of the same target;
the dynamic target detection module is used for detecting the motion state of each vector cluster and determining a dynamic feature cluster;
the fuzzy region acquisition module is used for acquiring a fuzzy region of the dynamic target; wherein the fuzzy area is a minimum bounding polygon corresponding to the dynamic feature cluster;
the optimization module is used for optimizing the fuzzy region by combining the semantic segmentation result of the current frame image to obtain an accurate region of the dynamic target and eliminating dynamic feature points in the accurate region;
the pose estimation module is used for estimating the pose according to the static characteristic points in the current frame image based on the mode of minimizing the reprojection error;
and the map updating module is used for incrementally updating the octree semantic map based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation.
An intelligent robot comprises a sensor, a memory, a processor and a computer program stored in the memory and capable of running on the processor, wherein the processor executes the computer program to realize the semantic-based positioning and mapping method.
In the semantic-based positioning and mapping method and system and the intelligent robot, the relevance between image feature points is established by acquiring the vector feature network corresponding to the current frame image, then the vector feature network is pruned to remove irrelevant features, the vector feature network is divided into a plurality of vector clusters, and the image features of the same target are described through the vector clusters, so that when a dynamic target in the image is detected, the motion state of each vector cluster can be directly detected, namely, the dynamic target in the image can be locked. Then, a fuzzy area corresponding to the dynamic feature cluster is optimized by combining a semantic segmentation result, a more comprehensive accurate area of the dynamic target is obtained, dynamic feature points in the area are eliminated, then the system can utilize a static area in a visual field to estimate the pose, the positioning accuracy of the robot in a dynamic environment is improved, and meanwhile, a semantic map can be constructed based on the current frame image with the dynamic feature points eliminated and the pose information obtained by pose estimation.
Drawings
In order to more clearly illustrate the technical solutions of the embodiments of the present invention, the drawings required to be used in the description of the embodiments of the present invention will be briefly introduced below, and it is obvious that the drawings in the description below are only some embodiments of the present invention, and it is obvious for those skilled in the art that other drawings can be obtained according to the drawings without inventive labor.
FIG. 1 is a flow chart of a semantic-based location and mapping method according to an embodiment of the present invention;
FIG. 2 is a triangulation diagram in accordance with an embodiment of the present invention;
FIG. 3 is a schematic view of a vector feature in an embodiment of the present invention;
FIG. 4 is a detailed flowchart of S102 in FIG. 1;
FIG. 5 is a depth profile in an embodiment of the present invention;
FIG. 6 is a detailed flowchart of step S103 in FIG. 1;
FIG. 7 is a schematic diagram of a projection of a second vector feature according to an embodiment of the present invention;
FIG. 8 is a diagram illustrating a blurred region of a dynamic object according to an embodiment of the present invention;
FIG. 9 is a schematic illustration of a precise area of a dynamic target after rectification in accordance with an embodiment of the invention;
FIG. 10 is a detailed flowchart of S104 in FIG. 1;
FIG. 11 is a diagram of a semantic-based localization and mapping system in accordance with an embodiment of the present invention.
Fig. 12 is a schematic diagram of an intelligent robot in an embodiment of the invention.
Detailed Description
The terms "first," "second," and the like in the description and in the claims of the present application and in the above-described drawings are used for distinguishing between similar elements and not necessarily for describing a particular sequential or chronological order. It is to be understood that the terms so used are interchangeable under appropriate circumstances and are merely descriptive of the various embodiments of the application and how objects of the same nature can be distinguished. Furthermore, the terms "comprises," "comprising," and "having," and any variations thereof, are intended to cover a non-exclusive inclusion, such that a process, method, system, article, or apparatus that comprises a list of elements is not necessarily limited to those elements, but may include other elements not expressly listed or inherent to such process, method, article, or apparatus.
In order to better understand the scheme of the embodiments of the present application, the following first introduces the related terms and concepts that may be involved in the embodiments of the present application. It should be understood that the related conceptual interpretation may be limited by the details of the embodiments of the application, but does not mean that the application is limited to the details, and may be different in the details of different embodiments, which are not limited herein.
Point cloud data, which may be referred to as point cloud (point cloud), refers to a collection of points that represent the spatial distribution of a target and the characteristics of a target surface in the same spatial reference system.
In the embodiment of the application, the point cloud data may be used to represent a pixel value of each point in the point cloud data, a three-dimensional coordinate value of each point in the reference coordinate system, and semantic information.
Semantic segmentation is an important research content in the field of computer vision, and aims to segment an image into regions with different semantic information and label semantic labels (object type information) corresponding to each pixel point (object detection box) in each region. In the embodiment, the semantic segmentation technology is adopted to perform semantic segmentation on the real-time read single-frame image, so that the octree semantic map is updated in an incremental manner based on the semantic information of the single-frame image, and a subsequent robot can identify which map points belong to which specific objects when positioning is performed on the basis of the semantic map, so that interaction with the external environment can be realized, and the positioning accuracy is ensured.
The world coordinate system is a world coordinate system in the field of computer vision, and since a camera can be placed at any position in an environment, a reference coordinate system is selected in the environment to describe the position of the camera and to describe the position of any object in the environment, and the coordinate system is called the world coordinate system.
The camera coordinate system is a coordinate system that is in the 3D coordinate system and is closely related to the viewer.
The image coordinate system is a coordinate system with the center of the image as the origin of coordinates and the X and Y axes parallel to the two sides of the image, and the coordinate values can be expressed by (X, Y).
The pose of the camera, i.e. the position of the camera in space and the orientation of the camera, can be seen as a transformation of the camera from the original position to the current position.
ORB is a characteristic point detection, description and matching algorithm, and the extracted ORB characteristic points are characterized by FAST corner points and binary coded Brief descriptors.
An octree is a recursive, axis-aligned, and spatially-partitioned data structure that recursively partitions a space into eight blocks based on the entire environmental space, the blocks being organized in memory as an octree, with each node of the tree corresponding to a block in the space. In the present embodiment, the point cloud data in the point cloud image is stored by each node in the octree.
The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the drawings in the embodiments of the present invention, and it is obvious that the described embodiments are some, but not all, embodiments of the present invention. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present invention.
In an embodiment, as shown in fig. 1, a semantic-based positioning and mapping method is provided, which includes the following steps:
s101: acquiring a vector characteristic network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image.
The current frame image may refer to a current frame image acquired by an RGB-D camera or a key frame image extracted by a SLAM system, which is not limited herein. The vector feature network comprises a plurality of vector features, and the vector features are used for describing the relevance between every two image feature points in the current frame image. The relevance refers to whether the two image feature points belong to the same object with the same motion state, if a vector feature exists between the two image feature points, the relevance exists between the two image feature points, and if the vector feature does not exist, the relevance does not exist between the two image feature points. The image feature points are ORB feature points in the frame image extracted in advance in the front flow.
Specifically, since the ORB feature points extracted from the frame image are completely independent and there is no relation between feature points, in order to directly and effectively reflect the relevance between the image feature points in the frame image, in this embodiment, the relation between the image feature points is established by acquiring the vector feature network corresponding to the current frame image.
S102: pruning the vector feature network to remove irrelevant features so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used to indicate sets of vector features of the same target.
The pruning processing refers to removing the vector features with insufficient relevance in the vector feature network. The vector clusters may indicate sets of vector features of the same target object or the vector clusters may be used to indicate sets of image feature points of the same target in the frame of image. It can be understood that vector features with insufficient relevance in the vector feature network are removed, that is, vector features which may not belong to the same target in the vector feature network are removed, so that the vector feature network is divided into a plurality of vector clusters based on the matching degree between feature points, each vector cluster represents a vector feature set corresponding to the same target object, and image features of the same target are described in this way.
Specifically, the pruning processing of the vector feature network includes: and performing relevance detection on each vector feature, judging whether the vector feature belongs to an irrelevant feature with insufficient relevance, and if the vector feature belongs to the irrelevant feature, removing the vector feature. The relevance detection is mainly realized through the depth change of the vector characteristics, and specifically comprises the following steps: firstly, judging the length of the vector feature, if the length meets the condition, fitting a depth curve through the depth value of the vector feature, if the gradient value of a target point (which is used for indicating any point in the coordinate range indicated by the vector feature) on the depth curve is larger than a second threshold value, if the gradient value is too large, namely the depth change of the vector feature is large, indicating that the relevance between the image feature points related to the vector feature is insufficient, namely the image feature points are irrelevant features; if the length of the vector feature is too short, the vector feature is considered to contain too few pixel points, a depth curve is not fitted to the pixel points, the depth value difference between two image feature points associated with the vector feature is directly calculated, and if the depth value difference between the two image feature points is larger, the association or similarity between the two points is considered to be lower, so that the vector feature is removed as an irrelevant feature.
In this embodiment, the vector feature network is pruned, that is, the relevance of each vector feature is determined to remove vector features with insufficient relevance in the vector feature set, so that the vector feature set is divided into a plurality of vector clusters, thereby characterizing each target object in the image.
Further, since the background in the frame image does not belong to the observation target, the motion state detection of the vector cluster of the background is not required, and therefore the vector cluster corresponding to the background needs to be removed. In the embodiment, each vector cluster is screened and analyzed to determine whether the vector cluster belongs to the background, and if the vector cluster belongs to the background, the background interference is removed, so that the vector cluster of each observation target is obtained.
The judgment of whether the vector cluster belongs to the background is mainly analyzed through the vector feature number contained in the vector cluster, namely if the vector feature number contained in the vector cluster is smaller than a preset threshold value alpha, the vector cluster is considered to belong to the remote background, and if the vector feature number is not smaller than the preset threshold value alpha, the vector cluster is considered to be an observation target.
S103: and detecting the motion state of each vector cluster and determining the dynamic feature cluster.
The vector clusters represent that the vector features contained in the vector clusters belong to the same target object, so that when a dynamic target in an image is detected, the motion state of each vector cluster can be directly detected, the dynamic target in the visual field can be further detected, the image feature points of the dynamic target related to the vector features can be removed by locking the vector features corresponding to the dynamic target, the interference of the dynamic target in the current frame image can be eliminated, and the positioning accuracy can be further improved.
Specifically, feature matching is performed on a first vector cluster in a current frame and a second vector cluster in a previous frame to detect the motion state of each vector cluster, and if matching fails, the vector clusters are used as dynamic feature clusters to determine a dynamic target, so that image feature points of the dynamic target in the frame image are removed. The feature matching specifically includes performing feature matching on each vector feature in the first vector cluster and a second vector feature in the second vector cluster, and counting the number of successfully matched vector features in the first vector cluster, which is used as a criterion for determining whether the first vector cluster and the second vector cluster are matched, if so, the target is considered to be a non-dynamic target, and if not, the target is considered to be a dynamic target.
It can be understood that, in this embodiment, the vector feature network corresponding to the current frame image is obtained to establish the relevance between the image feature points, then the vector feature network is pruned to remove the irrelevant features, the vector feature network is divided into a plurality of vector clusters, so as to describe the image features of the same target through the vector clusters, so that when detecting a dynamic target in an image, the motion state of each vector cluster can be directly detected, that is, the dynamic target in the image can be locked. In the process of dynamic target detection, the dynamic target in the visual field can be independently detected directly in a pure physical geometric mode without introducing prior knowledge.
S104: acquiring a fuzzy area of a dynamic target; the fuzzy area is a minimum bounding polygon corresponding to the dynamic feature cluster.
S105: and optimizing the fuzzy region according to the semantic segmentation result of the current frame image to obtain an accurate region of the dynamic target, and removing the dynamic feature points in the accurate region.
Specifically, the pixel-level semantic segmentation of the single frame image can be realized by the currently existing semantic segmentation algorithm (for example, a semantic segmentation model realized based on yoolov 3), so as to obtain a semantic segmentation result of the current frame image. The semantic segmentation result is used for representing the specific meaning and contour of each non-dynamic target in the current frame image. It can be understood that which image feature points belong to the dynamic feature points of the dynamic target can be roughly determined in the current frame image through the dynamic feature clusters, but if only the dynamic feature points indicated by the dynamic feature clusters are removed, some dynamic feature points distributed in other areas will still be omitted, so in this embodiment, a more comprehensive area where the dynamic target is located, that is, an accurate area, is obtained based on the dynamic feature clusters.
Specifically, for each dynamic feature cluster, a minimum bounding polygon that can contain all image feature points of the dynamic feature cluster can be found through a covexhull function in OpenCV, and the minimum bounding polygon is filled with multiple deformations to obtain a blurred region of the dynamic object, as shown in fig. 8, where a white region is a blurred region of the dynamic object and a black region is a static object region. Based on the above steps, the fuzzy region of the dynamic target in the visual field may be obtained through a pure physical geometry manner, and then the semantic information of each target is combined to correct the fuzzy region, that is, for each semantic target in the segmentation result, if the overlapping area of the semantic target and the fuzzy region of any dynamic target is greater than the sixth threshold θ (θ is greater than 0.5), the semantic target is considered as a dynamic target, and the semantic segmentation region of the semantic target in the semantic segmentation result is set as the precise region of the dynamic target, and the result is shown in fig. 9.
S106: and estimating the pose according to the static characteristic points in the current frame image based on the mode of minimizing the reprojection error.
S107: and based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation, updating the octree semantic map in an incremental manner.
Specifically, pose estimation can be performed according to static feature points in a current frame image based on a mode of minimizing a reprojection error in the prior art to obtain pose information, and then an octree semantic map is updated incrementally according to the pose based on the current frame image from which the dynamic feature points are removed and the pose information obtained by the pose estimation. The reprojection error refers to a difference value between a pixel point of a three-dimensional space point on a two-dimensional image and a reprojection point, and a value obtained by calculation for various reasons is not completely consistent with an actual condition, namely the error cannot be 0, and at the moment, the sum of the difference values needs to be minimized to obtain an optimal camera pose parameter.
Corresponding semantic information is fused with each body of pixel in the octree semantic map, the semantic information can be obtained by performing semantic segmentation on the current frame image and is used for describing the specific meanings, contours and the like of all targets in the image, and different targets can be distinguished through the semantic information, so that the robot can really understand the environment, and interaction with the environment is realized.
The semantic map is stored through an octree structure, semantic information of the environment is simultaneously blended, so that semantic tags of all nodes are labeled, a three-dimensional semantic map containing rich information can be obtained, and the octree semantic map can be updated in real time in an instant scene based on a current frame image.
Specifically, a conversion matrix Tcw from a world coordinate system to a camera coordinate system is obtained according to pose information of a current frame image, then image feature points (static feature points) of each non-dynamic target in the current frame image are converted into world coordinates according to the conversion matrix Tcw to establish a point cloud map, semantic information is fused into the point cloud map in real time to establish a semantic point cloud map containing rich information, and finally nodes in the semantic map stored in an octree structure are updated based on a local point cloud map of the frame image. The octree semantic map can be updated immediately through the frame images acquired in real time along with the change of the visual field.
In the embodiment, the relevance between image feature points is established by acquiring a vector feature network corresponding to a current frame image, then the vector feature network is pruned to remove irrelevant features, the vector feature network is divided into a plurality of vector clusters, and image features of the same target are described through the vector clusters, so that when a dynamic target in an image is detected, the motion state of each vector cluster can be directly detected, that is, the dynamic target in the image can be locked. Then, a fuzzy region corresponding to the dynamic feature cluster is optimized by combining a semantic segmentation result, a more comprehensive accurate region of the dynamic target is obtained, dynamic feature points in the region are eliminated, then the system can utilize a static region in a visual field to carry out pose estimation, the positioning accuracy of the robot in a dynamic environment is improved, and meanwhile a semantic map can be constructed based on a current frame image with the dynamic feature points eliminated and pose information obtained by pose estimation.
In an embodiment, step S101 specifically includes: triangulation is carried out on the current frame image, and a triangulation network is obtained and serves as a vector feature network; and each edge connecting two image feature points in the triangulation network is used as a vector feature.
In this embodiment, a Delaunay triangulation algorithm is used to triangulate the current frame image, so as to ensure that neither redundant vector features nor any image feature point is present in the vector feature network. The Delaunay triangulation is defined as setting a two-dimensional point set V, wherein E is an edge set consisting of line segments E, and the end points of the line segments E are two points in the point set V; then the Delaunay triangulation diagram of the point set V is T = (V, E), and the resulting subdivision network includes the following properties:
1) the edge e only connects two end points of the edge e, and any other point in the point set V can not be connected any more;
2) all edges E in the edge set E cannot be intersected;
3) all faces in the figure are triangular faces.
Illustratively, DelaunaIf the obtained triangulation network is regarded as an undirected graph and points in the network are regarded as nodes, at least one path exists between any two nodes in the graph, and all edges are ensured to be non-redundant and non-intersecting, as shown in fig. 2. Therefore, in this embodiment, the Delaunay triangulation property is used to triangulate the image feature point set F (as shown in fig. 2 (a)) of the current frame image to obtain an edge set (as shown in (b) of fig. 2). At this time, since the edge set is located in the image coordinate system, the edge set can be set
(as shown in (b) of fig. 2). At this time, since the edge set is located in the image coordinate system, the edge set can be set Any edge in the graph is considered a vector feature.
Any edge in the graph is considered a vector feature.
Exemplarily, set up Is composed of
Is composed of One edge with its end points being characteristic points of the image
One edge with its end points being characteristic points of the image And
And the image feature point comprises FAST key point coordinates and a binary BRIEF descriptor with the length of 256; then will be
the image feature point comprises FAST key point coordinates and a binary BRIEF descriptor with the length of 256; then will be Defined as a vector feature
Defined as a vector feature (as shown in fig. 3), as follows:
(as shown in fig. 3), as follows:





In an embodiment, as shown in fig. 4, in step 102, that is, performing pruning processing on the vector feature network to remove the irrelevant features, the method specifically includes the following steps:
s201: and if the length of the vector feature is larger than the first threshold value, fitting a depth curve according to the depth value of the vector feature. Wherein the depth curve is used to describe the depth variation of the vector feature.
Wherein, the length of the vector feature can be obtained by calculating the modulus of the vector feature, and the calculation formula is as follows: wherein, in the step (A),
wherein, in the step (A), the feature of the vector is represented by,
the feature of the vector is represented by, 、
、 two end points P1 and P2 (i.e. image feature points) representing the vector feature respectively,
two end points P1 and P2 (i.e. image feature points) representing the vector feature respectively, a first threshold value is indicated which is,
a first threshold value is indicated which is, the value range is 5-10.
the value range is 5-10.
If it is Greater than a first threshold
Greater than a first threshold And fitting a corresponding depth curve according to the depth value of the vector feature. The fitting of the depth curve specifically includes, as shown in fig. 5, defining a three-dimensional coordinate system O-x-y-z by using the image coordinate system as x-y plane and the depth value corresponding to the pixel point as z value, and knowing the vector feature from fig. 5
And fitting a corresponding depth curve according to the depth value of the vector feature. The fitting of the depth curve specifically includes, as shown in fig. 5, defining a three-dimensional coordinate system O-x-y-z by using the image coordinate system as x-y plane and the depth value corresponding to the pixel point as z value, and knowing the vector feature from fig. 5 Each pixel point of
Each pixel point of There is a depth value z corresponding to it, so in the coordinate system O-x-y-z, for each pixel point
There is a depth value z corresponding to it, so in the coordinate system O-x-y-z, for each pixel point There is a spatial point corresponding thereto
There is a spatial point corresponding thereto So that in the coordinate system O-x-y-z, there is one and vector feature
So that in the coordinate system O-x-y-z, there is one and vector feature Corresponding depth curve
Corresponding depth curve The target function of the depth curve is calculated by fitting the depth curve based on the depth values of the vector features based on the least square method.
The target function of the depth curve is calculated by fitting the depth curve based on the depth values of the vector features based on the least square method.
First, define The polynomial expression to be solved, namely the objective function, is as follows:
The polynomial expression to be solved, namely the objective function, is as follows:
wherein x and y are vector features And the two-dimensional coordinates of the upper pixel point, and z is the depth value of the pixel point. For the fitting of a depth curve, which is decomposed into the problem of curve fitting in a two-dimensional coordinate system, the depth curve will be fitted twice
And the two-dimensional coordinates of the upper pixel point, and z is the depth value of the pixel point. For the fitting of a depth curve, which is decomposed into the problem of curve fitting in a two-dimensional coordinate system, the depth curve will be fitted twice Projecting the space vector into an x-y plane and a y-z plane to obtain expressions of two space planes in O-x-y-z:
Projecting the space vector into an x-y plane and a y-z plane to obtain expressions of two space planes in O-x-y-z:

wherein, the expression (2) is the feature of the image coordinate system and the vector The maximum times of the expression is 1, so that the expression can be obtained by combining the coordinate based on the pixel point with the least square method.
The maximum times of the expression is 1, so that the expression can be obtained by combining the coordinate based on the pixel point with the least square method.
For expression (3), a least squares curve fit in a two-dimensional plane is required. In particular, for a point in space The projection coordinates in the y-z plane are
The projection coordinates in the y-z plane are Carrying it into the objective function (4) of the formula (3),
Carrying it into the objective function (4) of the formula (3),

in summary, after the least square fitting is completed, the result can be obtained Then combining the two formulas to obtain the intersection line of the two space surfaces in the space
Then combining the two formulas to obtain the intersection line of the two space surfaces in the space Is a vector feature
Is a vector feature So as to reflect the depth change condition of the vector feature.
So as to reflect the depth change condition of the vector feature.
S202: and if the gradient value of the target point on the depth curve is larger than a second threshold value, removing the vector feature as an irrelevant feature. And the target point is in the coordinate range corresponding to the vector characteristic in the three-dimensional coordinate system.
Specifically, if there is a gradient value of the target point (x, y) on the depth curve greater than the second threshold value (
( Greater than 8), i.e.
Greater than 8), i.e. Then, the vector feature is considered to be changed greatly, and the relevance between the image feature points associated with the vector feature is insufficient, that is, the similarity is insufficient, so that the vector feature is removed as an irrelevant feature. The value range of the target point (x, y) refers to the coordinate range indicated by the vector feature in the three-dimensional coordinate system, that is, the coordinate range shown in fig. 5
Then, the vector feature is considered to be changed greatly, and the relevance between the image feature points associated with the vector feature is insufficient, that is, the similarity is insufficient, so that the vector feature is removed as an irrelevant feature. The value range of the target point (x, y) refers to the coordinate range indicated by the vector feature in the three-dimensional coordinate system, that is, the coordinate range shown in fig. 5 Values are taken within the coordinate ranges indicated by two end points P1 and P2 in the three-dimensional coordinate system.
Values are taken within the coordinate ranges indicated by two end points P1 and P2 in the three-dimensional coordinate system.
S203: if the length of the vector feature is not greater than the first threshold, a difference in depth value between two feature points of the vector feature connection is calculated.
S204: and if the depth value difference is larger than a third threshold value, removing the vector feature as an irrelevant feature.
Specifically, if the length of the vector feature is not greater than the first threshold, it is determined that the number of pixels included in the vector feature is too small, so that it is not necessary to fit a depth curve to the vector feature, and the depth value difference between the two end points of the vector feature can be directly calculated, and it is determined whether the depth value difference is greater than the third threshold, and if so, the vector feature is removed as an irrelevant feature.
In an embodiment, step S103 specifically includes: step S301, performing feature matching on the first vector cluster and the second vector cluster, and if the number of successfully matched vector features of the first vector cluster and the second vector cluster is less than a fifth threshold, taking the first vector cluster as a dynamic feature cluster. The first vector cluster is a vector cluster corresponding to the current frame image; the second vector cluster is the vector cluster corresponding to the previous frame of image.
Specifically, in most cases, the motion of the camera in a period of time can be represented by a uniform motion model, so that the matching determination of the vector cluster can be performed based on the uniform motion model in this embodiment. Wherein, the uniform motion model means: is provided with The camera pose of the frame is
The camera pose of the frame is ,
, Representing from the world coordinate system to
Representing from the world coordinate system to A transformation matrix of a frame camera coordinate system is used for representing the camera pose by an algorithm; is provided with
A transformation matrix of a frame camera coordinate system is used for representing the camera pose by an algorithm; is provided with The camera pose of the frame is
The camera pose of the frame is 、
、 The camera pose of the frame is
The camera pose of the frame is ,
, Represents from
Represents from Frame to
Frame to The transformation matrix of the frame is then determined,
The transformation matrix of the frame is then determined, represents from
represents from Frame to
Frame to A transformation matrix of frames, since the camera is in uniform motion
A transformation matrix of frames, since the camera is in uniform motion And
And are equal. In this embodiment, by means of a uniform motion model, a first vector cluster corresponding to a current frame is matched with a second vector cluster corresponding to a previous frame in a reprojection manner, and if the number of vector features successfully matched with the second vector cluster in the first vector cluster is less than a fifth threshold, the vector cluster is considered as a static feature cluster, and if the matching fails, the vector cluster is considered as a dynamic feature cluster.
are equal. In this embodiment, by means of a uniform motion model, a first vector cluster corresponding to a current frame is matched with a second vector cluster corresponding to a previous frame in a reprojection manner, and if the number of vector features successfully matched with the second vector cluster in the first vector cluster is less than a fifth threshold, the vector cluster is considered as a static feature cluster, and if the matching fails, the vector cluster is considered as a dynamic feature cluster.
In one embodiment, as shown in FIG. 6, the vector features are characterized by absolute coordinates and descriptors; in step S301, feature matching is performed on the first vector cluster and the second vector cluster, and if matching fails, the first vector cluster is used as a dynamic feature cluster, which specifically includes the following steps:
s401: traversing each first vector feature in the first vector cluster, and acquiring a second vector feature from the second vector cluster; wherein the second vector feature is a vector feature that matches the descriptor of the first vector feature.
Specifically, for the first vector cluster in the current frame ,
, Is that
Is that Can be clustered from the second vector of the previous frame
Can be clustered from the second vector of the previous frame In obtaining and
In obtaining and second vector feature of descriptor matching
second vector feature of descriptor matching . Wherein descriptor matching can be measured by the Hamming distance between the first vector feature and the second vector feature, i.e. by traversing
. Wherein descriptor matching can be measured by the Hamming distance between the first vector feature and the second vector feature, i.e. by traversing And clustering from the second vector
And clustering from the second vector Obtaining the second vector feature with the minimum Hamming distance
Obtaining the second vector feature with the minimum Hamming distance 。
。
Wherein the Hamming distance is calculated by the following formula Respectively two vector features to be matched
Respectively two vector features to be matched And
And description of the invention, if
description of the invention, if If the Hamming distance is more than 256, the descriptors of the two vector features are not matched, and the minimum value is selected from a plurality of candidate vector features of which the Hamming distance is not more than 256 to be used as the minimum value
If the Hamming distance is more than 256, the descriptors of the two vector features are not matched, and the minimum value is selected from a plurality of candidate vector features of which the Hamming distance is not more than 256 to be used as the minimum value The second vector feature of (1).
The second vector feature of (1).
S402: and matching and verifying the first vector feature and the second vector feature based on the absolute coordinates, wherein if the verification is passed, the first vector feature is successfully matched.
S403: and if the successfully matched first vector feature number is smaller than a fifth threshold value, taking the first vector cluster as a dynamic feature cluster.
Specifically, the pose of the camera in the last frame is set as The pose transformation matrix from the previous frame to the previous frame is
The pose transformation matrix from the previous frame to the previous frame is Then, with the help of the uniform motion model, the approximate pose of the current frame can be obtained
Then, with the help of the uniform motion model, the approximate pose of the current frame can be obtained 。
。
Exemplarily, suppose thatThe second vector feature is identified by two feature points, respectively And
And the corresponding spatial points in the world coordinate system are respectively
the corresponding spatial points in the world coordinate system are respectively And
And thus by the approximate pose of the current frame
thus by the approximate pose of the current frame The spatial points are represented by the following formulas (5) and (6)
The spatial points are represented by the following formulas (5) and (6) And
And projecting the image coordinate system of the current frame to obtain approximate projection coordinates
projecting the image coordinate system of the current frame to obtain approximate projection coordinates And
And as shown in fig. 7.
as shown in fig. 7.

Wherein K is an internal reference matrix of the camera. Understandably, by clustering the vector features to be matched in the second vector The space points under the three-dimensional coordinate system are projected to the image coordinate system of the current frame so as to ensure that the space points are positioned under the image coordinate system of the current frameAnd the first vector feature
The space points under the three-dimensional coordinate system are projected to the image coordinate system of the current frame so as to ensure that the space points are positioned under the image coordinate system of the current frameAnd the first vector feature All are matched under the image coordinate system of the current frame to obtain
All are matched under the image coordinate system of the current frame to obtain And with
And with Then, the obtained product is
Then, the obtained product is Approximate projected coordinates in the current frame
Approximate projected coordinates in the current frame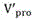 (by passing
(by passing And
And express), so only need to weigh
express), so only need to weigh And
And to determine the vector feature
to determine the vector feature And with
And with Whether it is a true match.
Whether it is a true match.
Further, determining vector features And with
And with Whether or not to determine whether or not to performThe true matching specifically includes 1) first matching the vectors by the following formula
Whether or not to determine whether or not to performThe true matching specifically includes 1) first matching the vectors by the following formula And with
And with The absolute coordinates of the frame are converted into relative coordinates relative to the origin of the image coordinate system of the current frame; 2) calculated by the following equation (9)
The absolute coordinates of the frame are converted into relative coordinates relative to the origin of the image coordinate system of the current frame; 2) calculated by the following equation (9) And
And cosine similarity of
cosine similarity of And determining the cosine similarity
And determining the cosine similarity Whether or not it is greater than a threshold value
Whether or not it is greater than a threshold value (ii) a (3) If it is
(ii) a (3) If it is Greater than a threshold value
Greater than a threshold value (
( Is in the range of 0.5 to 1), the Euclidean distance between the two is calculated by the following formula (10)
Is in the range of 0.5 to 1), the Euclidean distance between the two is calculated by the following formula (10) Whether or not less than a threshold value
Whether or not less than a threshold value (
( The value range of (1) to (5), if the value range of (1) to (5) is smaller than the value range of (5), the verification is passed, and the vector feature is determined
The value range of (1) to (5), if the value range of (1) to (5) is smaller than the value range of (5), the verification is passed, and the vector feature is determined And
And matching is successful; (4) counting the successfully matched first vector feature number in the first vector cluster, and judging whether the counted number is smaller than a fifth threshold value, if so, taking the first vector cluster as a dynamic feature cluster; and if not, the first vector cluster is regarded as the static feature cluster. In this way, the motion state of each vector cluster can be detected by performing the steps (1) to (4) on each first vector cluster, so as to determine whether the first vector cluster is a dynamic feature cluster.
matching is successful; (4) counting the successfully matched first vector feature number in the first vector cluster, and judging whether the counted number is smaller than a fifth threshold value, if so, taking the first vector cluster as a dynamic feature cluster; and if not, the first vector cluster is regarded as the static feature cluster. In this way, the motion state of each vector cluster can be detected by performing the steps (1) to (4) on each first vector cluster, so as to determine whether the first vector cluster is a dynamic feature cluster.

It can be understood that, by performing descriptor matching on each first vector feature in the first vector cluster, a second vector feature similar to the first vector feature can be obtained preliminarily from the second vector cluster, and then, whether the two vector features are really matched is verified, and if the verification is passed and the matching is determined to be successful, finally, whether the target corresponding to the vector cluster moves can be determined by counting the number of the vector features successfully matched between the first vector cluster and the second vector cluster, so that in the embodiment, when a dynamic target is detected, the similarity of the feature level is directly determined, and prior knowledge, such as semantic information of the target and the like, is not needed.
In an embodiment, as shown in fig. 10, in step S107, that is, based on the current frame image from which the dynamic feature points are removed and pose information obtained by pose estimation, the method for incrementally updating the octree semantic map specifically includes the following steps:
s501: and performing three-dimensional reconstruction on the current frame image based on the current frame image and the pose information to obtain a semantic point cloud picture.
The semantic point cloud image is a point cloud set formed by point cloud data of semantic targets (or non-dynamic targets) in a current frame image, each semantic target corresponds to one point cloud data, and the topological position relationship between the targets can be represented through the semantic point cloud image.
In this embodiment, the three-dimensional reconstruction refers to converting three-dimensional coordinates of image feature points corresponding to semantic objects in an object frame image in a camera coordinate system into three-dimensional space point coordinates in a world coordinate according to pose information of a current frame image, so as to generate point cloud data of each non-dynamic object in the image in the three-dimensional space, and simultaneously fusing semantic information corresponding to the non-dynamic object into the point cloud data, so as to obtain point cloud data of each object, where a plurality of point cloud data form a semantic point cloud map.
Specifically, a conversion matrix Tcw from a world coordinate system to a camera coordinate system is obtained according to pose information of a current frame image, then image feature points (static feature points) of each non-dynamic target in the current frame image are converted into corresponding world coordinates, namely point cloud data, according to the conversion matrix Tcw, and corresponding semantic information is simultaneously blended to obtain a semantic point cloud picture.
S502: and performing downsampling on the semantic point cloud picture to obtain a first point cloud picture.
In this embodiment, the semantic point cloud image is downsampled to obtain a first point cloud image, so as to reduce the amount of calculation. The down-sampling manner includes, but is not limited to, uniform down-sampling, farthest point down-sampling, geometric down-sampling, and the like in the prior art, which is not limited herein.
Specifically, the semantic point cloud picture includes point cloud data corresponding to each non-dynamic target, and a first point cloud picture can be obtained by down-sampling each point cloud data, where the first point cloud picture includes the down-sampled point cloud data of each non-dynamic target.
S503: and denoising the first point cloud picture, and removing noise points in the first point cloud picture to obtain a target point cloud picture.
Specifically, due to errors of the camera measurement result and the semantic segmentation, noise points which do not belong to the object exist in the generated semantic point cloud picture and influence the subsequent map updating precision, so in the embodiment, the noise point in the first point cloud picture is removed by performing noise reduction processing on the first point cloud picture, and the target point cloud picture is obtained.
In this embodiment, the noise reduction of the first point cloud image is implemented based on three-dimensional euclidean distance clustering, and the noise reduction process specifically includes:
1) firstly, a certain point in the point cloud data is selected Finding out the nearest n points through the kdTere traversal, and sequentially judging the n points and
Finding out the nearest n points through the kdTere traversal, and sequentially judging the n points and whether the Euclidean distance between is less than the threshold value
whether the Euclidean distance between is less than the threshold value (ii) a If less than the threshold value
(ii) a If less than the threshold value Then the point is recorded into the clustering result
Then the point is recorded into the clustering result Performing the following steps; if not less than the threshold
Performing the following steps; if not less than the threshold If so, removing the point as a noise point;
If so, removing the point as a noise point;
2) re-clustering the results Selecting a point which is not traversed
Selecting a point which is not traversed And (3) repeating the step (1) until the clustering result is obtained
And (3) repeating the step (1) until the clustering result is obtained And adding new points in the process, and finishing clustering.
And adding new points in the process, and finishing clustering.
Specifically, the target point cloud image can be obtained by performing the noise reduction processing of the steps 1) -2) on the point cloud data corresponding to each non-dynamic target in the target point cloud image.
S504: based on the target point cloud picture, updating the octree semantic map in an incremental manner; wherein each voxel node in the octree semantic map contains an occupancy probability that the voxel node is occupied.
The target point cloud image includes point cloud data of each target object, and the point cloud data may include, but is not limited to, three-dimensional coordinates, colors, semantic information, and the like. An octree semantic map is a semantic map in which node information of point cloud data is stored by an octree structure, and may be regarded as being composed of layers of nodes (voxels), and the voxels at least include three-dimensional coordinates, colors, an occupation probability indicating whether the voxels are occupied, semantic information, and the like.
In this embodiment, the octree semantic map is updated incrementally, that is, the node information of the corresponding voxel node in the octree is updated for the original target; for a new object, the system will create a new node in the map to store its point cloud data. It will be appreciated that the presence of noise may cause a change in the occupancy property of a voxel, for example for the same voxel In a
In a Observed to be occupied at frame time, but at
Observed to be occupied at frame time, but at The unoccupied object is observed in the frame, so when the octree semantic map is updated in an incremental mode, the three-dimensional coordinate, the color and the semantic information of each voxel are updated according to the point cloud data in the target point cloud map, and the occupied attribute of each voxel, namely the occupied probability of whether the voxel is occupied by the obstacle or not, is also updated.
The unoccupied object is observed in the frame, so when the octree semantic map is updated in an incremental mode, the three-dimensional coordinate, the color and the semantic information of each voxel are updated according to the point cloud data in the target point cloud map, and the occupied attribute of each voxel, namely the occupied probability of whether the voxel is occupied by the obstacle or not, is also updated.
Specifically, a Bayesian probabilistic model is employed, at each instanceWhen the secondary map is updated in increment, the occupation attribute value (occupation probability) of each voxel node is updated, and the probability model is ,
,
Wherein P (n) represents a prior probability of the occupancy property value of the nth node, a posterior probability representing the occupancy property at the tth frame updated based on the prior probability.
a posterior probability representing the occupancy property at the tth frame updated based on the prior probability.
Using log-of-probability values in voxel nodes To represent the occupation property of the node, so that P (n) is subjected to a logit transformation, i.e.
To represent the occupation property of the node, so that P (n) is subjected to a logit transformation, i.e. Then inverse transformation is performed on the above equation, i.e.
Then inverse transformation is performed on the above equation, i.e. If the observed value of the nth node at the Tth frame is set as
If the observed value of the nth node at the Tth frame is set as Then the logarithm of probability for a node may be:
Then the logarithm of probability for a node may be: 。
。
it should be understood that, the sequence numbers of the steps in the foregoing embodiments do not imply an execution sequence, and the execution sequence of each process should be determined by its function and inherent logic, and should not constitute any limitation to the implementation process of the embodiments of the present invention.
In an embodiment, a positioning and mapping system based on semantics is provided, and the positioning and mapping system based on semantics corresponds to the positioning and mapping method based on semantics in the above embodiment one to one. As shown in fig. 11, the semantic-based positioning and mapping system includes a vector feature network acquisition module 10, a pruning module 20, a dynamic object detection module 30, a fuzzy area acquisition module 40, an optimization module 50, a pose estimation module 60, and a map update module 70. The functional modules are explained in detail as follows:
a vector feature network obtaining module 10, configured to obtain a vector feature network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image;
a pruning module 20, configured to prune the vector feature network to remove irrelevant features, so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used for indicating vector feature sets of the same target;
a dynamic target detection module 30, configured to detect a motion state of each vector cluster, and determine a dynamic feature cluster;
a fuzzy region obtaining module 40, configured to obtain a fuzzy region of the dynamic target; and the fuzzy area is a minimum bounding polygon corresponding to the dynamic feature cluster.
An optimizing module 50, configured to optimize the fuzzy region in combination with the semantic segmentation result of the current frame image, to obtain an accurate region of the dynamic target, and to remove dynamic feature points in the accurate region;
a pose estimation module 60, configured to perform pose estimation according to the static feature points in the current frame image based on a minimized reprojection error manner;
and the map updating module 70 is configured to incrementally update the octree semantic map based on the current frame image from which the dynamic feature points are removed and pose information obtained by pose estimation.
Specifically, the vector feature network obtaining module specifically includes: triangulation is carried out on the current frame image, and a triangulation network is obtained and used as the vector characteristic network; and each edge connecting the two image feature points in the triangulation network is used as the vector feature.
Specifically, the pruning module comprises a depth curve fitting unit, a first processing unit, a depth difference calculating unit and a second processing unit.
A depth curve fitting unit, configured to fit a depth curve according to a depth value of the vector feature if the length of the vector feature is greater than a first threshold; wherein the depth curve is used to describe a depth variation of the vector feature;
the first processing unit is used for removing the vector feature as an irrelevant feature if the gradient value of the target point on the depth curve is larger than a second threshold value; wherein, the target point is in the coordinate range corresponding to the vector feature in the three-dimensional coordinate system;
a depth difference calculation unit, configured to calculate a depth value difference between two feature points associated with the vector feature if the length of the vector feature is not greater than a first threshold;
a second processing unit, configured to remove the vector feature as an irrelevant feature if the depth value difference is greater than a third threshold.
In particular, the dynamic object detection module comprises a feature matching unit.
The feature matching unit is used for performing feature matching on a first vector cluster and a second vector cluster, and if the number of successfully matched vector features of the first vector cluster and the second vector cluster is smaller than a fifth threshold value, the first vector cluster is used as a dynamic feature cluster;
wherein, the first vector cluster is a vector cluster corresponding to the current frame image; and the second vector cluster is a vector cluster corresponding to the previous frame of image.
In particular, the vector features are characterized by absolute coordinates and descriptors; the feature matching unit comprises a description sub-matching sub-unit, a matching verification sub-unit and a dynamic feature cluster determination sub-unit.
The descriptor matching subunit is used for traversing each first vector feature in the first vector cluster and acquiring a second vector feature from the second vector cluster; wherein the second vector feature is a vector feature that matches a descriptor of the first vector feature;
the matching verification subunit is used for performing matching verification on the first vector feature and the second vector feature based on the absolute coordinates, and if the verification is passed, the first vector feature is successfully matched;
and a dynamic feature cluster determining subunit, configured to, if a first vector feature number that is successfully matched in the first vector cluster is smaller than the fifth threshold, take the first vector cluster as a dynamic feature cluster.
Specifically, the optimization module specifically comprises: and if the coincidence area between the semantic segmentation area of any semantic target in the semantic segmentation result and the fuzzy area is larger than a sixth threshold value, taking the semantic segmentation area as the fuzzy area of the dynamic target.
Specifically, the incremental updating module comprises a three-dimensional reconstruction unit, a down-sampling unit, a noise reduction unit and an incremental updating unit.
The three-dimensional reconstruction unit is used for performing three-dimensional reconstruction on the current frame image based on the current frame image and the pose information to obtain a semantic point cloud picture;
the down-sampling unit is used for down-sampling the semantic point cloud picture to obtain a first point cloud picture;
the noise reduction unit is used for carrying out noise reduction processing on the first point cloud picture, removing noise points in the first point cloud picture and obtaining a target point cloud picture;
the increment updating unit is used for updating the octree semantic map in an increment mode based on the target point cloud picture; wherein each voxel node in the octree semantic map contains an occupancy probability that the voxel node is occupied.
For the specific definition of the semantic-based positioning and mapping system, reference may be made to the above definition of the semantic-based positioning and mapping method, which is not described herein again. The various modules in the semantic-based location and mapping system described above may be implemented in whole or in part by software, hardware, and combinations thereof.
In one embodiment, an intelligent robot is provided, comprising a sensor, a memory, a processor, and a computer program stored on the memory and executable on the processor, the processor implementing the following steps when executing the computer program:
acquiring a vector characteristic network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image;
pruning the vector feature network to remove irrelevant features so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used for indicating vector feature sets of the same target;
detecting the motion state of each vector cluster and determining a dynamic feature cluster;
acquiring a fuzzy area of a dynamic target; wherein the fuzzy region is a minimum bounding polygon corresponding to the dynamic feature cluster;
optimizing the fuzzy region by combining the semantic segmentation result of the current frame image to obtain an accurate region of the dynamic target, and eliminating dynamic feature points in the accurate region;
performing pose estimation according to the static feature points in the current frame image based on a minimized reprojection error mode;
and based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation, updating the octree semantic map in an incremental manner.
Alternatively, the processor implements the functions of each module/unit in the embodiment of the semantic-based positioning and mapping system when executing the computer program, for example, the functions of each module/unit shown in fig. 11, and are not described herein again to avoid repetition.
It will be understood by those skilled in the art that all or part of the processes of the methods of the embodiments described above may be implemented by hardware that is instructed by a computer program, and the computer program may be stored in a non-volatile computer-readable storage medium, and when executed, may include the processes of the embodiments of the methods described above. Any reference to memory, storage, database, or other medium used in the embodiments provided herein may include non-volatile and/or volatile memory, among others. Non-volatile memory can include read-only memory (ROM), Programmable ROM (PROM), Electrically Programmable ROM (EPROM), Electrically Erasable Programmable ROM (EEPROM), or flash memory. Volatile memory can include Random Access Memory (RAM) or external cache memory. By way of illustration and not limitation, RAM is available in a variety of forms such as Static RAM (SRAM), Dynamic RAM (DRAM), Synchronous DRAM (SDRAM), Double Data Rate SDRAM (DDRSDRAM), Enhanced SDRAM (ESDRAM), Synchronous Link DRAM (SLDRAM), Rambus Direct RAM (RDRAM), direct bus dynamic RAM (DRDRAM), and memory bus dynamic RAM (RDRAM).
It should be clear to those skilled in the art that, for convenience and simplicity of description, the foregoing division of the functional units and modules is only used for illustration, and in practical applications, the above function distribution may be performed by different functional units and modules as needed, that is, the internal structure of the device is divided into different functional units or modules, so as to perform all or part of the above described functions.
The above examples are only intended to illustrate the technical solution of the present invention, and not to limit it; although the present invention has been described in detail with reference to the foregoing embodiments, it will be understood by those of ordinary skill in the art that: the technical solutions described in the foregoing embodiments may still be modified, or some technical features may be equivalently replaced; such modifications and substitutions do not substantially depart from the spirit and scope of the embodiments of the present invention, and are intended to be included within the scope of the present invention.
Claims (10)
1. A positioning and mapping method based on semantics is characterized by comprising the following steps:
acquiring a vector characteristic network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image;
pruning the vector feature network to remove irrelevant features so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used for indicating vector feature sets of the same target;
detecting the motion state of each vector cluster and determining a dynamic feature cluster;
acquiring a fuzzy area of a dynamic target; wherein the fuzzy region is a minimum bounding polygon corresponding to the dynamic feature cluster;
optimizing the fuzzy region by combining the semantic segmentation result of the current frame image to obtain an accurate region of the dynamic target, and eliminating dynamic feature points in the accurate region;
performing pose estimation according to the static feature points in the current frame image based on a minimized re-projection error mode;
and based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation, updating the octree semantic map in an incremental manner.
2. The semantic-based positioning and mapping method according to claim 1, wherein the obtaining of the vector feature network corresponding to the current frame image comprises:
triangulation is carried out on the current frame image, and a triangulation network is obtained and serves as the vector feature network; and each edge connecting the two image feature points in the triangulation network is used as the vector feature.
3. The semantic-based positioning and mapping method according to claim 1, wherein the pruning of the vector feature network to remove the extraneous features comprises: if the length of the vector feature is larger than a first threshold value, fitting a depth curve according to the depth value of the vector feature; wherein the depth curve is used to describe the depth variation of the vector feature;
if the gradient value of the target point on the depth curve is larger than a second threshold value, removing the vector feature as an irrelevant feature; the target point is in a corresponding coordinate range of the vector feature in a three-dimensional coordinate system;
if the length of the vector feature is not larger than a first threshold value, calculating a depth value difference between two feature points associated with the vector feature;
and if the depth value difference is larger than a third threshold value, removing the vector feature as an irrelevant feature.
4. The semantic-based localization and mapping method of claim 1, wherein said detecting the motion state of each of said vector clusters comprises:
performing feature matching on a first vector cluster and a second vector cluster, and if the number of successfully matched vector features of the first vector cluster and the second vector cluster is less than a fifth threshold value, taking the first vector cluster as a dynamic feature cluster;
the first vector cluster is a vector cluster corresponding to the current frame image; and the second vector cluster is a vector cluster corresponding to the previous frame of image.
5. A semantic-based localization and mapping method according to claim 4, wherein said vector features are characterized by absolute coordinates and descriptors; the performing feature matching on the first vector cluster and the second vector cluster includes:
traversing each first vector feature in the first vector cluster, and acquiring a second vector feature from the second vector cluster; wherein the second vector feature is a vector feature that matches a descriptor of the first vector feature;
based on the absolute coordinates, matching verification is carried out on the first vector features and the second vector features, and if the verification is passed, the first vector features are successfully matched;
and if the successfully matched first vector feature number in the first vector cluster is smaller than the fifth threshold, taking the first vector cluster as a dynamic feature cluster.
6. The semantic-based localization and mapping method according to claim 1, wherein the optimizing the blurred region to obtain the precise region of the dynamic object in combination with the semantic segmentation result of the current frame image comprises:
and if the coincidence area between the semantic segmentation area of any semantic target in the semantic segmentation result and the fuzzy area is larger than a sixth threshold value, taking the semantic segmentation area as the fuzzy area of the dynamic target.
7. The semantic-based positioning and mapping method according to claim 1, wherein the incremental updating of the octree semantic map based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation comprises:
performing three-dimensional reconstruction on the current frame image based on the current frame image and the pose information to obtain a semantic point cloud picture;
performing downsampling on the semantic point cloud picture to obtain a first point cloud picture;
performing noise reduction processing on the first point cloud picture, and removing noise points in the first point cloud picture to obtain a target point cloud picture;
based on the target point cloud picture, incrementally updating the octree semantic map; wherein each voxel node in the octree semantic map contains an occupancy probability that the voxel node is occupied.
8. A semantic-based localization and mapping method according to any of claims 1-7, further comprising, before said detecting the motion state of each of said vector clusters:
detecting and analyzing each vector cluster, and judging whether the vector cluster is a background or not;
if the vector cluster is a background, removing the vector cluster;
the detecting the motion state of each vector cluster comprises: the motion state of each non-background cluster of vectors is detected.
9. A semantic-based positioning and mapping system, comprising: the vector characteristic network acquisition module is used for acquiring a vector characteristic network corresponding to the current frame image; the vector features in the vector feature network are used for describing the relevance between every two image feature points in the current frame image;
the pruning module is used for pruning the vector feature network to remove irrelevant features so as to divide the vector feature network into a plurality of vector clusters; wherein the vector clusters are used for indicating vector feature sets of the same target;
the dynamic target detection module is used for detecting the motion state of each vector cluster and determining a dynamic feature cluster;
the fuzzy region acquisition module is used for acquiring a fuzzy region of the dynamic target; wherein the fuzzy region is a minimum bounding polygon corresponding to the dynamic feature cluster;
the optimization module is used for optimizing the fuzzy region by combining the semantic segmentation result of the current frame image to obtain an accurate region of the dynamic target and eliminating dynamic feature points in the accurate region;
the pose estimation module is used for estimating the pose according to the static characteristic points in the current frame image based on the mode of minimizing the reprojection error;
and the map updating module is used for incrementally updating the octree semantic map based on the current frame image with the dynamic feature points removed and pose information obtained by pose estimation.
10. An intelligent robot comprising sensors, a memory, a processor and a computer program stored in the memory and executable on the processor, the processor implementing a semantic-based localization and mapping method according to any one of claims 1 to 7 or 8 when executing the computer program.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210845745.2A CN114926536B (en) | 2022-07-19 | 2022-07-19 | Semantic-based positioning and mapping method and system and intelligent robot |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210845745.2A CN114926536B (en) | 2022-07-19 | 2022-07-19 | Semantic-based positioning and mapping method and system and intelligent robot |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114926536A true CN114926536A (en) | 2022-08-19 |
| CN114926536B CN114926536B (en) | 2022-10-14 |
Family
ID=82816198
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210845745.2A Active CN114926536B (en) | 2022-07-19 | 2022-07-19 | Semantic-based positioning and mapping method and system and intelligent robot |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114926536B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116612390A (en) * | 2023-07-21 | 2023-08-18 | 山东鑫邦建设集团有限公司 | Information management system for constructional engineering |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180161986A1 (en) * | 2016-12-12 | 2018-06-14 | The Charles Stark Draper Laboratory, Inc. | System and method for semantic simultaneous localization and mapping of static and dynamic objects |
| CN110458863A (en) * | 2019-06-25 | 2019-11-15 | 广东工业大学 | A kind of dynamic SLAM system merged based on RGBD with encoder |
| CN110827395A (en) * | 2019-09-09 | 2020-02-21 | 广东工业大学 | Instant positioning and map construction method suitable for dynamic environment |
| CN111724439A (en) * | 2019-11-29 | 2020-09-29 | 中国科学院上海微系统与信息技术研究所 | Visual positioning method and device in dynamic scene |
| CN113031005A (en) * | 2021-02-22 | 2021-06-25 | 江苏大学 | Crane dynamic obstacle identification method based on laser radar |
| US20210213973A1 (en) * | 2018-08-29 | 2021-07-15 | Movidius Ltd. | Computer vision system |
| CN113516664A (en) * | 2021-09-02 | 2021-10-19 | 长春工业大学 | Visual SLAM method based on semantic segmentation dynamic points |
| CN114119732A (en) * | 2021-12-06 | 2022-03-01 | 福建工程学院 | Joint optimization dynamic SLAM method based on target detection and K-means clustering |
| CN114565675A (en) * | 2022-03-03 | 2022-05-31 | 南京工业大学 | Method for removing dynamic feature points at front end of visual SLAM |
| CN114612525A (en) * | 2022-02-09 | 2022-06-10 | 浙江工业大学 | Robot RGB-D SLAM method based on grid segmentation and double-map coupling |
-
2022
- 2022-07-19 CN CN202210845745.2A patent/CN114926536B/en active Active
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180161986A1 (en) * | 2016-12-12 | 2018-06-14 | The Charles Stark Draper Laboratory, Inc. | System and method for semantic simultaneous localization and mapping of static and dynamic objects |
| US20210213973A1 (en) * | 2018-08-29 | 2021-07-15 | Movidius Ltd. | Computer vision system |
| CN110458863A (en) * | 2019-06-25 | 2019-11-15 | 广东工业大学 | A kind of dynamic SLAM system merged based on RGBD with encoder |
| CN110827395A (en) * | 2019-09-09 | 2020-02-21 | 广东工业大学 | Instant positioning and map construction method suitable for dynamic environment |
| CN111724439A (en) * | 2019-11-29 | 2020-09-29 | 中国科学院上海微系统与信息技术研究所 | Visual positioning method and device in dynamic scene |
| CN113031005A (en) * | 2021-02-22 | 2021-06-25 | 江苏大学 | Crane dynamic obstacle identification method based on laser radar |
| CN113516664A (en) * | 2021-09-02 | 2021-10-19 | 长春工业大学 | Visual SLAM method based on semantic segmentation dynamic points |
| CN114119732A (en) * | 2021-12-06 | 2022-03-01 | 福建工程学院 | Joint optimization dynamic SLAM method based on target detection and K-means clustering |
| CN114612525A (en) * | 2022-02-09 | 2022-06-10 | 浙江工业大学 | Robot RGB-D SLAM method based on grid segmentation and double-map coupling |
| CN114565675A (en) * | 2022-03-03 | 2022-05-31 | 南京工业大学 | Method for removing dynamic feature points at front end of visual SLAM |
Non-Patent Citations (3)
| Title |
|---|
| HAO WANG,LE WANG,BAOFU FANG: "Robust Visual Odeometry Using Semantic Information in Complex Dynamic Scenes", 《COGNITIVE SYSTEMS AND SIGNAL PROCESSING》 * |
| HAO WANG,YINCAN WANG,BAOFU FANG: "RGB-D Visual Odometry Based on Semantic Feature Points in Dynamic Environments", 《ARTIFICIAL INTELLIGENCE》 * |
| 艾青林,王威,刘刚江: "室内动态环境下基于网格分割与双地图耦合的RGB-D SLAM算法", 《机器人》 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116612390A (en) * | 2023-07-21 | 2023-08-18 | 山东鑫邦建设集团有限公司 | Information management system for constructional engineering |
| CN116612390B (en) * | 2023-07-21 | 2023-10-03 | 山东鑫邦建设集团有限公司 | Information management system for constructional engineering |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114926536B (en) | 2022-10-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111563442B (en) | Slam method and system for fusing point cloud and camera image data based on laser radar | |
| Feng et al. | 2d3d-matchnet: Learning to match keypoints across 2d image and 3d point cloud | |
| CN109544677B (en) | Indoor scene main structure reconstruction method and system based on depth image key frame | |
| US8792726B2 (en) | Geometric feature extracting device, geometric feature extracting method, storage medium, three-dimensional measurement apparatus, and object recognition apparatus | |
| CN112132897A (en) | Visual SLAM method based on deep learning semantic segmentation | |
| CN111340922B (en) | Positioning and map construction method and electronic equipment | |
| US20180025496A1 (en) | Systems and methods for improved surface normal estimation | |
| CN112883820B (en) | Road target 3D detection method and system based on laser radar point cloud | |
| CN102236794A (en) | Recognition and pose determination of 3D objects in 3D scenes | |
| CN110992427B (en) | Three-dimensional pose estimation method and positioning grabbing system for deformed object | |
| CN113570629B (en) | Semantic segmentation method and system for removing dynamic objects | |
| CN112651944B (en) | 3C component high-precision six-dimensional pose estimation method and system based on CAD model | |
| CN114494610B (en) | Intelligent understanding system and device for real-time reconstruction of large scene light field | |
| CN115063550B (en) | Semantic point cloud map construction method and system and intelligent robot | |
| CN116662600B (en) | Visual positioning method based on lightweight structured line map | |
| CN114926536B (en) | Semantic-based positioning and mapping method and system and intelligent robot | |
| CN115457130A (en) | Electric vehicle charging port detection and positioning method based on depth key point regression | |
| CN113822996B (en) | Pose estimation method and device for robot, electronic device and storage medium | |
| CN114155406A (en) | Pose estimation method based on region-level feature fusion | |
| CN112446952B (en) | Three-dimensional point cloud normal vector generation method and device, electronic equipment and storage medium | |
| Withers et al. | Modelling scene change for large-scale long term laser localisation | |
| Fehr et al. | Reshaping our model of the world over time | |
| GB2593718A (en) | Image processing system and method | |
| CN113570713B (en) | Semantic map construction method and device for dynamic environment | |
| CN115656991A (en) | Vehicle external parameter calibration method, device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |