CN113822434A - Model selection learning for knowledge distillation - Google Patents
Model selection learning for knowledge distillation Download PDFInfo
- Publication number
- CN113822434A CN113822434A CN202010561319.7A CN202010561319A CN113822434A CN 113822434 A CN113822434 A CN 113822434A CN 202010561319 A CN202010561319 A CN 202010561319A CN 113822434 A CN113822434 A CN 113822434A
- Authority
- CN
- China
- Prior art keywords
- model
- training
- target
- reference models
- prediction
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000013140 knowledge distillation Methods 0.000 title claims abstract description 23
- 238000012549 training Methods 0.000 claims abstract description 160
- 238000009826 distribution Methods 0.000 claims abstract description 94
- 238000000034 method Methods 0.000 claims abstract description 73
- 230000006870 function Effects 0.000 claims description 49
- 238000005070 sampling Methods 0.000 claims description 33
- 238000010200 validation analysis Methods 0.000 claims description 13
- 230000002787 reinforcement Effects 0.000 claims description 7
- 238000012795 verification Methods 0.000 claims description 5
- 239000002131 composite material Substances 0.000 claims description 3
- 238000013459 approach Methods 0.000 description 4
- 230000006835 compression Effects 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000004821 distillation Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000003058 natural language processing Methods 0.000 description 2
- 230000002457 bidirectional effect Effects 0.000 description 1
- 238000013480 data collection Methods 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/004—Artificial life, i.e. computing arrangements simulating life
- G06N3/006—Artificial life, i.e. computing arrangements simulating life based on simulated virtual individual or collective life forms, e.g. social simulations or particle swarm optimisation [PSO]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Feedback Control In General (AREA)
Abstract
The present disclosure provides methods and apparatus for obtaining a target model based on knowledge distillation. A data set and a set of candidate reference models may be obtained. A selected set of reference models selected from the set of candidate reference models may be determined for each training sample in the data set. A set of target probability distributions for the set of selected reference models output for the training samples may be obtained. The target model may be trained using the set of target probability distributions.
Description
Background
With the development of deep learning techniques, various deep pre-training models are continuously developed and have excellent performance in fields such as natural language processing and computer vision. For example, in the field of natural language processing, deep Pre-trained models such as Bidirectional Encoder representation from transducers (BERT) models, Generative Pre-trained transducers (GPT) models, etc. have proven to work well. Such deep pre-training models tend to be complex models that rely on deep networks with a huge number of parameters, e.g., the BERT model may contain 3.4 billion parameters for 24 converter layers, and the GPT model may contain 15 billion parameters for 48 converter layers. Training and using such complex models for inference is time consuming and thus difficult to apply to a practical business scenario. Model compression methods are often employed to obtain a simple model that can be deployed with fewer parameters than a complex model.
Disclosure of Invention
This summary is provided to introduce a selection of concepts that are further described below in the detailed description. This summary is not intended to identify key features or essential features of the claimed subject matter, nor is it intended to be used to limit the scope of the claimed subject matter.
Embodiments of the present disclosure provide methods and apparatus for obtaining a target model based on knowledge-based distillation. A data set and a set of candidate reference models may be obtained. A selected set of reference models selected from the set of candidate reference models may be determined for each training sample in the data set. A set of target probability distributions for the set of selected reference models output for the training samples may be obtained. The target model may be trained using the set of target probability distributions.
It should be noted that one or more of the above aspects include features that are specifically pointed out in the following detailed description and claims. The following description and the annexed drawings set forth in detail certain illustrative features of the one or more aspects. These features are indicative of but a few of the various ways in which the principles of various aspects may be employed and the present disclosure is intended to include all such aspects and their equivalents.
Drawings
The disclosed aspects will hereinafter be described in conjunction with the appended drawings, which are provided to illustrate, but not to limit, the disclosed aspects.
FIG. 1 illustrates an exemplary process for obtaining a target model according to an embodiment of the disclosure.
FIG. 2 illustrates an exemplary process for selecting a reference model in accordance with an embodiment of the disclosure.
FIG. 3 illustrates an exemplary process for training a target model according to an embodiment of the present disclosure
FIG. 4 illustrates a specific example for training a target model according to an embodiment of the present disclosure.
FIG. 5 illustrates an exemplary process for updating policy parameters according to an embodiment of the present disclosure.
FIG. 6 illustrates an exemplary process for initializing policy parameters according to an embodiment of the disclosure.
FIG. 7 is a flow diagram of an exemplary method for obtaining a target model based on knowledge distillation in accordance with an embodiment of the present disclosure.
FIG. 8 illustrates an exemplary apparatus for obtaining a target model based on knowledge distillation in accordance with an embodiment of the disclosure.
FIG. 9 illustrates an exemplary apparatus for obtaining a target model based on knowledge distillation in accordance with an embodiment of the disclosure.
Detailed Description
The present disclosure will now be discussed with reference to several exemplary embodiments. It is to be understood that the discussion of these embodiments is merely intended to enable those skilled in the art to better understand and thereby practice the embodiments of the present disclosure, and does not teach any limitation as to the scope of the present disclosure.
One commonly used model compression method may be based on Knowledge Distillation (Knowledge Distillation). This approach typically migrates knowledge from the complex model to the simple model by the simple model learning the output distribution of the complex model. Knowledge can be thought of as parameters of the complex model and input-to-output mapping of the complex model implementation. The method is based on a teacher-student architecture, wherein a model providing knowledge can be considered a teacher model and a model learning knowledge can be considered a student model. Specifically, in training a student model, training data having not only true annotations, such as artificially provided annotations, but also probability distributions output by a teacher model is provided to the student model. Thus, the student model can optimize its model parameters by learning the probability distribution of the teacher model output in an attempt to achieve the effect of the teacher model. The current knowledge distillation methods can be classified into one-to-one methods, many-to-many methods, and many-to-one methods based on the number of teacher models and student models. In this context, a one-to-one approach refers to one teacher model providing knowledge to one student model, a many-to-many approach refers to multiple teacher models providing knowledge to multiple student models and combining the multiple student models into a set of student models when applied, and a many-to-one approach refers to multiple teacher models providing knowledge to one student model. Recent research and experiments show that the performance of the student model can be improved more effectively by training the student model by a many-to-one method.
Current many-to-one methods typically assign the same weight to each teacher model, or assign different weights to each teacher model, but these weights are fixed throughout the knowledge distillation. However, even if the student model is trained using a set of training data for the same task, the performance of each teacher model for different training samples in the set of training data is different. Taking two training samples for predicting semantic equivalence between two sentences as an example, for the first training sample, the teacher model a may perform better than the teacher model B; whereas for the second training sample, teacher model B may perform better than teacher model a. In addition, the performance of the student model is gradually improved in each stage of knowledge distillation, and the teacher model for training the student model should be changed correspondingly. For example, in the early stages of knowledge distillation, the performance of the student model is weak and its learning from the complex teacher model may not be good, since the complex teacher model captures finer grain patterns in the training data, which may result in the student model overfitting some parts of the training data. With the progress of the training process, the student model has stronger performance, and if the student model is trained by a teacher model with a small performance difference, the student model may not obtain obvious effect. Thus, assigning the same or fixed weights to various teacher models during knowledge distillation may limit the performance gains of student models.
Embodiments of the present disclosure propose to improve the performance of a target model through an improved training process. For example, a target model may be trained using a set of reference models by knowledge distillation. Herein, the target model refers to a structurally simple and deployable model that is desired to be trained, which may also be referred to as a student model, and the reference model refers to a model having a higher complexity than the target model, which may also be referred to as a teacher model, which can be used to assist in training the target model.
In one aspect, embodiments of the present disclosure propose selecting a reference model for training a target model from a set of candidate reference models through Reinforcement Learning (Reinforcement Learning). For example, different weights may be dynamically assigned to the respective reference models for each training sample in the data set used to train the target model. Herein, the weight assigned to a particular reference model may be implemented as a sampling probability corresponding to the reference model, which may be used to determine whether the reference model is selected for training the target model for the training sample.
In another aspect, embodiments of the present disclosure propose determining sampling probabilities of respective reference models for a current training sample by a policy function. The strategy functions for each reference model comprise, for example, strategy parameters, and information about the current training sample and the performance of the reference model for the current training sample, etc. With such a strategy function, it may be helpful to select a reference model that performs well for the current training sample.
In another aspect, embodiments of the present disclosure propose updating policy parameters in a policy function based on the performance of an objective model. For example, a data set used to train a target model may be partitioned into a plurality of data subsets. The policy parameters in the policy function may be updated based on the performance of the trained target model after the target model is trained with a subset of data, thereby affecting the sampling probability of each reference model for the next subset of data. By updating the policy parameters in the policy function based on the performance of the target model, it may be helpful to select a reference model that matches the performance of the current target model.
In another aspect, embodiments of the present disclosure propose initializing policy parameters in the policy function before determining the sampling probabilities of the respective reference models by the policy function. For example, a set of reference models may be selected from a set of candidate reference models by a policy function, and policy parameters in the policy function may be initialized according to an average performance of the selected set of reference models.
In another aspect, embodiments of the present disclosure propose pre-training the target model before training the target model using a set of reference models. For example, a data set may be scored using all reference models in the set of reference models, and the scored data set may be utilized to pre-train the target model.
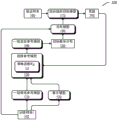
FIG. 1 illustrates an exemplary process 100 for obtaining a target model according to an embodiment of the disclosure. The target model is, for example, the target model 160 in fig. 1, which may be a BERT model with a 3-layer or 6-layer converter.
A data set for training the target model 160 may be obtained first Data collection
Data collection Can be divided into a plurality of data subsets
Can be divided into a plurality of data subsets Where M represents the number of data subsets. Each data subset may include a plurality of training samples. The samples used to train the
Where M represents the number of data subsets. Each data subset may include a plurality of training samples. The samples used to train the target model 160 are referred to herein as training samples. By data subsets For example, it may include m training samples
For example, it may include m training samples For example, training sample i102 (x)i,yi) Wherein x isiIs the ith input, and yiIs directed to xiFor example, a human-provided annotation.
For example, training sample i102 (x)i,yi) Wherein x isiIs the ith input, and yiIs directed to xiFor example, a human-provided annotation.
A set of candidate reference models 110 for training the target model 160 may be obtained. The candidate reference model may be a model with a higher complexity than the target model 160, e.g. a BERT model with a 12-layer converter. The candidate reference model may be obtained by optimizing, e.g. fine-tuning, a pre-trained model with training data for a specific task.
A representation model 120 may also be obtained, which may be capable of efficiently representing xiAny pre-trained model of the content of (1).
The training samples i102 may be provided as input to each reference model in the set of candidate reference models 110 and to the representation model 120 to obtain a set of state information. The set of state information may include at least information about the training sample i102 and the target probability distribution output by each reference model for the training sample i 102. The specific process of obtaining status information will be explained later in conjunction with fig. 2.
Subsequently, at 130, it may be determined, for each candidate reference model in the set of candidate reference models 110, by reinforcement learning, whether to select the candidate reference model for training the target model 160. For example, a policy function π may be utilizedθ132 to determine whether to select the candidate reference model. The selected reference models may be combined into a set of selected reference models 140. The specific process of selecting the reference model will be explained later with reference to fig. 2.
Next, a target probability distribution output by each reference model in the set of selected reference models 140 for the training sample i102 may be obtained to obtain a set of target probability distributions 150. The set of state information used to determine the set of selected reference models 140 may include information about the target probability distribution output by each reference model for the training sample i 102. A set of target probability distributions 150 corresponding to respective reference models in the set of selected reference models 140 may be extracted from the set of state information.
The target model 160 may be trained using the training sample i102 and the set of target probability distributions 150. In one embodiment, the parameters of the target model 160 may be optimized after the above process is performed using a single training sample, thereby obtaining a trained modelA training object model 170. In another embodiment, the subset of data may be utilized, e.g., the subset of data After all the training samples in (b) have been processed, the parameters of the
After all the training samples in (b) have been processed, the parameters of the target model 160 are optimized to obtain the trained target model 170. In this case, the parameters of the target model 160 remain unchanged for all training samples within the same data subset. The specific process of training the target model 160 will be explained later with reference to fig. 3 and 4.
Subsequently, the trained target model 170 performance may be evaluated. The verification samples 180 may be utilized to evaluate the performance of the trained target model 170. The samples used to evaluate the performance of the target model are referred to herein as validation samples, which may be the same as or different from the training samples. The evaluated performance may be converted into a reward 190. The reward 190 may then be used to update the policy function π θ132. The specific process of updating the policy parameters will be explained later in conjunction with fig. 5.
In the case where a trained target model 170 is obtained using a single training sample, updating the policy parameters based on the performance of the trained target model 170 may affect the sampling probability of each reference model for the next training sample. Using subsets of data Where all of the training samples in the set are used to obtain the trained
Where all of the training samples in the set are used to obtain the trained target model 170, updating the policy parameters based on the performance of the trained target model 170 may affect the sampling probability of each reference model for the next data subset. In this case, the policy function π is used for all training samples within the same data subsetθThe policy parameter theta of (a) remains unchanged.
The process 100 generally includes a process of training a target model and a process of updating policy parameters, which may be performed iteratively until the performance of the target model converges. During the process of training the target modelThe parameters of the target model can be optimized and the strategy parameters can be fixed; and during the process of updating the policy parameters, the policy parameters may be optimized while fixing the parameters of the target model. To utilize subsets of data To obtain a trained target model and to update the policy parameters based on the performance of the trained target model. The current parameters of the object model can be set to
To obtain a trained target model and to update the policy parameters based on the performance of the trained target model. The current parameters of the object model can be set to And setting the current policy parameter to θb. The strategy parameter can be fixed to theta firstbAnd using the data subsets
And setting the current policy parameter to θb. The strategy parameter can be fixed to theta firstbAnd using the data subsets After the target model is trained, the parameters of the target model are updated to
After the target model is trained, the parameters of the target model are updated to Next, the parameters of the target model may be fixed to
Next, the parameters of the target model may be fixed to And based on parameters of
And based on parameters of To update the policy parameters to θb+1(ii) a And so on.
To update the policy parameters to θb+1(ii) a And so on.
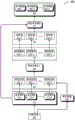
Fig. 2 illustrates an exemplary process 200 for selecting a reference model in accordance with an embodiment of the disclosure. Process 200 may correspond to step 130 in fig. 1. Training sample i 202 (x) may be obtained firsti,yi) Which may correspond to training sample i102 in fig. 1. A set of candidate reference models 210 and a representation model 220 may also be obtained. The set of candidate reference models 210 may include K reference models, such as reference model 210-1, reference models 210-2, … …, reference model 210-K. The set of candidate reference models 210 may correspond to those in FIG. 1And the representation model 220 may correspond to the representation model 120 in fig. 1.
The process 200 may encode states for the training samples i 202 corresponding to the respective reference models as state information and determine whether to select the reference model based on the state information. The state information may include information about the training sample i 202 and the performance of the reference model for the training sample i 202. Using reference model 210-K (1 ≦ K ≦ K) as an example, the state for reference model 210-K may be represented as sjkAnd will be directed to state sjkIs represented as F(s)jk). Status information F(s)jk) May be implemented as a real-valued vector, which for example comprises a concatenation of three features.
The first feature may be a training sample i 202 (x)i,yi) X in (2)iIs shown. X may be obtained, for example, by representation model 220iVector representation of Where d is the hidden size (hidden size).
Where d is the hidden size (hidden size).
The second feature may be the probability distribution output by the reference model 210-k for the training sample i 202. Taking the example where the training sample i 202 is a sample for a classification task, the probability distribution output by the reference model 210-k can be represented as Wherein
Wherein Is x output by the reference model 210-kiProbability of belonging to class C, C being an integer between 1 and C, C being the number of classes, and
Is x output by the reference model 210-kiProbability of belonging to class C, C being an integer between 1 and C, C being the number of classes, and are parameters of the reference model 210-k.
are parameters of the reference model 210-k.
The third feature may be a predicted loss corresponding to the probability distribution. In one embodiment, the prediction may be computed by a cross-entropy functionAnd (4) loss. For example, the probability distribution for the training sample i 202 output with the reference model 210-k may be calculated by the following formula
 Predicting loss
Predicting loss

Wherein, is from the true annotation yiOne-hot vector of (c).
is from the true annotation yiOne-hot vector of (c).
The probability distribution output by the reference model 210-k for the training sample i 202 and the prediction loss corresponding to the probability distribution can be considered as the performance of the reference model 210-k for the training sample i 202.
Vector representation that can be output to representation model 220 Probability distribution of reference model 210-k output
Probability distribution of reference model 210-k output And the probability distribution
And the probability distribution Corresponding prediction loss
Corresponding prediction loss Cascading is performed to obtain state information 230-k F(s) for reference model 210-kjk)。
Cascading is performed to obtain state information 230-k F(s) for reference model 210-kjk)。
A set of state information 230 for each reference model in the set of candidate reference models 210 may be obtained by the process described above, including, for example, state information 230-1, state information 230-2, … …, state information 230-K.

wherein, is state information, σ (-) is with trainable parameters
is state information, σ (-) is with trainable parameters
 Sigmoid function of, and Pθ(ajk|sjk) Is the sampling probability, which is expressed in the state sjkLower selection action value ajkProbability of (a)jkE {0, 1 }. Can utilize Pθ(ajk|sjk) To the action value ajkSampling is performed. When a isjkSampled to a "0" value, indicating that reference model 210-k is not selected; when a isjkSampled to a "1" value, indicates that the reference model 210-k is selected.
Sigmoid function of, and Pθ(ajk|sjk) Is the sampling probability, which is expressed in the state sjkLower selection action value ajkProbability of (a)jkE {0, 1 }. Can utilize Pθ(ajk|sjk) To the action value ajkSampling is performed. When a isjkSampled to a "0" value, indicating that reference model 210-k is not selected; when a isjkSampled to a "1" value, indicates that the reference model 210-k is selected.
A set of sampling probabilities 250, including, for example, sampling probability 250-1, sampling probability 250-2, … …, sampling probability 250-K, and a set of action values 260, including, for example, action value 260-1, action value 260-2, … …, action value 260-K, for each reference model in the set of candidate reference models 210 may be obtained by the above-described process.
After the set of action values 260 is determined, at 270, a set of selected reference models 280 may be determined based on the set of reference models 210 and the set of action values 260, including, for example, reference model 280-1, reference models 280-2, … …, reference model 280-K '(0 ≦ K' ≦ K). Each reference model in the set of selected reference models 280 is, for example, a reference model whose motion value is sampled to "1".
It should be understood that while the foregoing discussion and the following discussion may refer to the selection of at least one reference model to train a target model, it is also possible that none of the reference models is selected. For example, for some training samples, all reference models do not perform well, so the sampling probabilities of all reference models are low, and further, the action values sampled according to the sampling probabilities may all be "0", which results in no reference model being selected.
After the set of selected reference models 280 is determined, a set of target probability distributions output by the set of selected reference models 280 for the training sample i 202 may be obtained. The set of state information 230 determined above includes the target probability distribution output by each reference model in the set of candidate reference models for the training sample i 202. A set of target probability distributions corresponding to each reference model in the set of selected reference models 280 may be extracted from the target probability distributions. The set of target probability distributions may be utilized to train a target model.
FIG. 3 illustrates an exemplary process 300 for training a target model according to an embodiment of the present disclosure. The process 300 may train the target model using the training sample i and a set of target probability distributions output by a selected set of reference models for the training sample i. The training sample i may include a true label.
At 310, the target model may score the training sample i to obtain a predicted probability distribution for the training sample i.
At 320, a sub-prediction penalty corresponding to the target probability distribution can be separately calculated based on the prediction probability distribution and each target probability distribution in the set of target probability distributions to obtain a set of sub-prediction penalties. In one embodiment, the sub-prediction loss may be calculated by a cross-entropy function.
At 330, a first prediction loss corresponding to the training sample i may be calculated based on the number of the set of selected reference models and the set of sub-prediction losses. In one embodiment, the first prediction loss may be calculated by first summing the set of sub-prediction losses to obtain an intermediate prediction loss, and then dividing the intermediate prediction loss by the number of the set of selected reference models.
At 340, a second prediction loss corresponding to the training sample i may be calculated based on the prediction probability distribution and the true label in the training sample i. In one embodiment, the second prediction loss may be calculated by a cross-entropy function.
At 350, a composite prediction loss corresponding to the training sample i may be calculated based on the first prediction loss and the second prediction loss. In one embodiment, the aggregate prediction loss may be calculated by a weighted sum of the first prediction loss and the second prediction loss.
At 360, the objective model may be optimized by minimizing the aggregate prediction loss.
FIG. 4 illustrates a specific example 400 for training a target model according to an embodiment of the present disclosure. In example 400, the training samples used to train the target model may be, for example, training samples 410 (x)i,yi) Wherein x isiIs input, yiIs a real label. A set of target probability distributions that may be output for the training samples 410 using a set of selected reference models 420 To train the
To train the target model 430, wherein The set of selected
The set of selected reference models 420 includes, for example, K 'reference models numbered reference model 420-1, reference models 420-2, … …, reference model 420-K'.
The target model 430 may score the training samples 410 to obtain a predicted probability distribution of the training samples 410 Wherein, Ps(yi=c|xi;Θs) X representing the output of the
Wherein, Ps(yi=c|xi;Θs) X representing the output of the object model 430iProbability of belonging to class C, C being an integer between 1 and C, C being the number of classes, and ΘsAre parameters of the object model 430.
The probability distribution can then be predicted based And a set of target probability distributions
And a set of target probability distributions Each target probability distribution in (2)
Each target probability distribution in (2) To calculate the probability distribution with the target respectively
To calculate the probability distribution with the target respectively Corresponding sub-prediction loss
Corresponding sub-prediction loss To obtain a set of sub-prediction losses
To obtain a set of sub-prediction losses In one embodiment, the sub-prediction loss may be calculated by a cross-entropy function
In one embodiment, the sub-prediction loss may be calculated by a cross-entropy function As shown in the following equation:
As shown in the following equation:

next, a first prediction loss for the training sample i may be calculated based on the number of reference models K' in the set of selected reference models 420 and the set of sub-prediction losses In one embodiment, the method can be usedThe first prediction loss is calculated by first summing the set of sub-prediction losses to obtain an intermediate prediction loss, and then dividing the intermediate prediction loss by the number K' of the set of selected reference models, as shown in the following equation:
In one embodiment, the method can be usedThe first prediction loss is calculated by first summing the set of sub-prediction losses to obtain an intermediate prediction loss, and then dividing the intermediate prediction loss by the number K' of the set of selected reference models, as shown in the following equation:

the predicted probability distribution may then be output based on the target model
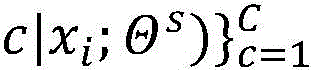 And the true labels y in the training samples iiTo calculate a second prediction loss corresponding to the training sample i
And the true labels y in the training samples iiTo calculate a second prediction loss corresponding to the training sample i In one embodiment, the second prediction loss may be calculated by a cross-entropy function, as shown in the following equation:
In one embodiment, the second prediction loss may be calculated by a cross-entropy function, as shown in the following equation:

after obtaining the first prediction loss corresponding to the training sample i And a second prediction loss
And a second prediction loss Thereafter, a comprehensive prediction loss corresponding to the training sample i may be calculated
Thereafter, a comprehensive prediction loss corresponding to the training sample i may be calculated In one embodiment, the aggregate prediction loss may be calculated by a weighted sum of the first prediction loss and the second prediction loss, as shown in the following equation:
In one embodiment, the aggregate prediction loss may be calculated by a weighted sum of the first prediction loss and the second prediction loss, as shown in the following equation:

where α is a hyper-parameter for balancing the first prediction loss and the second prediction loss.
Can predict loss by synthesis Minimized to optimize the objective model.
Minimized to optimize the objective model.
The process described above in connection with fig. 3 and 4 trains the target model by minimizing the combined prediction loss corresponding to a single training sample. Alternatively, to improve training efficiency, data subsets, e.g., data subsets, may be mapped Performs the above process on all training samples in (1), and obtains a data subset
Performs the above process on all training samples in (1), and obtains a data subset Corresponding comprehensive prediction loss
Corresponding comprehensive prediction loss Can predict loss by integrating
Can predict loss by integrating Minimized to optimize the objective model. In this case, the parameters of the target model remain unchanged for all training samples within the same data subset. And data subsets
Minimized to optimize the objective model. In this case, the parameters of the target model remain unchanged for all training samples within the same data subset. And data subsets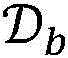 Corresponding comprehensive prediction loss
Corresponding comprehensive prediction loss Can be obtained by the following formula:
Can be obtained by the following formula:

according to embodiments of the present disclosure, after a target model is trained using a training sample or a subset of data, a policy function π may be updated based on the performance of the trained target modelθAnd thus the sampling probability of each reference model for the next training sample or next data subset. Fig. 5 illustrates an exemplary process 500 for updating policy parameters according to an embodiment of the disclosure. The process 500 may utilize the validation samples (x ', y') to evaluate the performance of the trained target model. The validation samples may be compared to training samples (x) used to train the target modeli,yi) The same or different. The evaluated performance may be converted into a reward. Rewards may then be used to update the policy function piθOf (2) is determined.
At 510, the validation samples (x ', y') may be scored through the target model to obtain a predicted probability distribution of the validation samples (x ', y') Wherein Θ issIs the current parameters of the target model.
Wherein Θ issIs the current parameters of the target model.
At 520, a true label y ' and a prediction probability distribution in the validation sample (x ', y ') can be based To calculate a prediction loss corresponding to the validation sample
To calculate a prediction loss corresponding to the validation sample In one embodiment, the second prediction loss may be calculated by a cross-entropy function, as shown in the following equation:
In one embodiment, the second prediction loss may be calculated by a cross-entropy function, as shown in the following equation:

at 530, a loss may be predicted based To calculate a reward v corresponding to the validated samplej. In one embodiment, the reward v may bejCalculated as predicted loss
To calculate a reward v corresponding to the validated samplej. In one embodiment, the reward v may bejCalculated as predicted loss The inverse of (c), as shown in the following equation:
The inverse of (c), as shown in the following equation:

at 540, the reward v may be based onjTo update the policy parameter theta. In one embodiment, the policy parameter θ may be updated by a standard policy gradient method, such as a Monte-Carlo based policy gradient method, as shown in the following equation:

where β is the learning rate and πθ(sjk,ajk) Is a policy function for the kth reference model.
According to an embodiment of the present disclosure, policy parameters in the policy function may be initialized before determining the sampling probability of each reference model by the policy function. For example, at least one reference model from a set of candidate reference models may be selected by a policy function, and policy parameters in the policy function may be initialized according to an average performance of the selected reference models.
Fig. 6 illustrates an exemplary process 600 for initializing policy parameters according to an embodiment of the disclosure. The process 600 may initialize policy parameters using an initialization sample. In the text, the samples used to initialize the policy parameters are referred to as initialization samples, which may be the same as or different from the training samples used to train the target model. The initialization sample may include an input and a real label corresponding to the input.
At 610, a selected set of reference models selected from a set of candidate reference models may be determined by a policy function for the initialization sample. The policy function may have an original policy parameter.
At 620, the initialization samples may be individually scored through the set of selected reference models to obtain a set of probability distributions for the initialization samples.
At 630, a set of prediction losses corresponding to the initialization sample can be computed based on the true labels in the initialization sample and the set of probability distributions. For example, a sub-prediction loss for each probability distribution can be first calculated based on the true label and each probability distribution in the set of probability distributions to obtain a set of sub-prediction losses. In one embodiment, the prediction loss for each probability distribution may be calculated by a cross-entropy function.
At 640, a prediction penalty corresponding to the initialized sample may be calculated based on the number of the set of candidate reference models and the set of sub-prediction penalties. In one embodiment, the predicted loss may be calculated by first summing the set of sub-predicted losses to obtain an intermediate predicted loss, and then dividing the intermediate predicted loss by the number of the set of selected reference models.
At 650, a reward corresponding to the initialization sample may be calculated based on the predicted loss. In one embodiment, the reward may be calculated as the inverse of the predicted loss.
At 660, policy parameters may be initialized based on the reward. In one embodiment, the policy parameters may be initialized by updating the original policy parameters using a standard policy gradient method, as shown in equation (10) above.
According to embodiments of the present disclosure, the target model may be pre-trained prior to training the target model using the set of candidate reference models. In one embodiment, the pre-training data set may be scored using all reference models in the set of candidate reference models, and the target model may be pre-trained using the scored pre-training data set. The set of data used to pre-train the target model is referred to herein as the pre-training set of data. The process for pre-training the target model may be similar to the process for training the target model explained in connection with fig. 3 and 4, except that the set of target probability distributions involved are the probability distributions output for the pre-training samples in the pre-training data set for all reference models in the set of candidate reference models, but not for selected reference models in the set of candidate reference models.
FIG. 7 is a flow diagram of an exemplary method 700 for obtaining a target model based on knowledge distillation in accordance with an embodiment of the present disclosure.
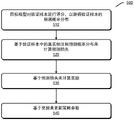
At step 710, a data set and a set of candidate reference models may be obtained.
At step 720, a selected set of reference models selected from the set of candidate reference models may be determined for each training sample in the data set.
At step 730, a set of target probability distributions for the set of selected reference models output for the training sample may be obtained.
At step 740, the target model may be trained using the set of target probability distributions.
In one embodiment, the determining a selected set of reference models may include: determining, for each candidate reference model in the set of candidate reference models, whether to select the candidate reference model by reinforcement learning.
The determining whether to select the candidate reference model may include: determining sampling probabilities of the candidate reference models based on a policy function; sampling motion values of the candidate reference model based on the sampling probabilities; and selecting the candidate reference model based on the sampled action value.
The policy function may have policy parameters. The determining whether to select the candidate reference model may further include: updating the policy parameters based on performance of the target model.
The updating the policy parameters may include: scoring a verification sample through the target model to obtain a predicted probability distribution of the verification sample; calculating a prediction loss corresponding to the validation sample based on the true labels in the validation sample and the prediction probability distribution; calculating a reward corresponding to the validation sample based on the predicted loss; and updating the policy parameters based on the reward.
The data set may include a plurality of data subsets. The strategy parameters of the strategy function may remain unchanged for all training samples within the same data subset.
The determining of the sampling probability may be performed with respect to state information. The state information may include at least: a representation of the training sample, a probability distribution of the candidate reference model output for the training sample, and a prediction penalty corresponding to the probability distribution.
The policy function may have policy parameters. The policy parameters may be initialized by: determining, by the policy function, a selected set of reference models selected from the candidate set of reference models for an initialization sample; scoring the initialization samples through the set of selected reference models, respectively, to obtain a set of probability distributions for the initialization samples; calculating a prediction loss corresponding to the initialization sample based on the true labels in the initialization sample and the set of probability distributions; calculating a reward corresponding to the initialization sample based on the predicted loss; and initializing the policy parameters based on the reward.
In one embodiment, the training samples may include realistic labels. The training the target model may include: scoring the training samples through the target model to obtain a predicted probability distribution of the training samples; calculating a first prediction loss corresponding to the training sample based on the prediction probability distribution and the set of target probability distributions; calculating a second prediction loss corresponding to the training sample based on the prediction probability distribution and the true label; calculating a composite prediction loss corresponding to the training samples based on the first prediction loss and the second prediction loss; and optimizing the objective model by minimizing the synthetic prediction loss.
The calculating the first predicted loss may include: calculating sub-prediction losses corresponding to the target probability distribution based on the prediction probability distribution and each target probability distribution in the set of target probability distributions, respectively, to obtain a set of sub-prediction losses; and calculating the first prediction loss based on the number of reference models in the set of selected reference models and the set of sub-prediction losses.
The data set may include a plurality of data subsets. The parameters of the target model may remain unchanged for all training samples within the same data subset.
In one embodiment, the method 700 may further include: scoring a pre-training data set through the set of candidate reference models; and pre-training the target model using the scored pre-training data set.
In one embodiment, the set of candidate reference models may be models having a higher complexity than the target model.
It should be understood that the method 700 may also include any steps/processes for obtaining a target model based on knowledge-based distillation according to embodiments of the present disclosure described above.
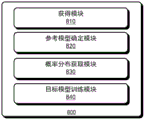
Fig. 8 illustrates an exemplary apparatus 800 for obtaining a target model based on knowledge distillation in accordance with an embodiment of the disclosure. The apparatus 800 may include: an obtaining module 810 for obtaining a data set and a set of candidate reference models; a reference model determination module 820 for determining, for each training sample in the data set, a selected set of reference models selected from the candidate set of reference models; a probability distribution obtaining module 830, configured to obtain a set of target probability distributions output by the set of selected reference models for the training sample; and an object model training module 840 for training the object model using the set of object probability distributions.
In one embodiment, the reference model determination module 820 may be further configured to: determining, for each candidate reference model in the set of candidate reference models, whether to select the candidate reference model by reinforcement learning.
The determining whether to select the candidate reference model may include: determining sampling probabilities of the candidate reference models based on a policy function; sampling motion values of the candidate reference model based on the sampling probabilities; and selecting the candidate reference model based on the sampled action value.
The policy function may have policy parameters. The determining whether to select the candidate reference model may further include: updating the policy parameters based on performance of the target model.
The data set may include a plurality of data subsets. The strategy parameters of the strategy function may remain unchanged for all training samples within the same data subset.
The determining of the sampling probability may be performed with respect to state information. The state information may include at least: a representation of the training sample, a probability distribution of the candidate reference model output for the training sample, and a prediction penalty corresponding to the probability distribution.
It should be understood that the apparatus 800 may also include any other module configured for obtaining a target model based on knowledge distillation according to embodiments of the present disclosure described above.
Fig. 9 illustrates an exemplary apparatus 900 for obtaining a target model based on knowledge distillation in accordance with an embodiment of the disclosure.
The apparatus 900 may include at least one processor 910. The apparatus 900 may also include a memory 920 coupled to the processor 910. The memory 920 may store computer-executable instructions that, when executed, cause the processor 1910 to perform any of the operations of the method for obtaining a target model based on knowledge distillation according to embodiments of the present disclosure described above.
Embodiments of the present disclosure may be embodied in non-transitory computer readable media. The non-transitory computer-readable medium may include instructions that, when executed, cause one or more processors to perform any operations of the method for obtaining a target model based on knowledge distillation according to embodiments of the present disclosure as described above.
It should be appreciated that all of the operations in the methods described above are exemplary only, and the present disclosure is not limited to any of the operations in the methods or the order of the operations, but rather should encompass all other equivalent variations under the same or similar concepts.
It should also be appreciated that all of the modules in the apparatus described above may be implemented in various ways. These modules may be implemented as hardware, software, or a combination thereof. In addition, any of these modules may be further divided functionally into sub-modules or combined together.
The processor has been described in connection with various apparatus and methods. These processors may be implemented using electronic hardware, computer software, or any combination thereof. Whether such processors are implemented as hardware or software depends upon the particular application and the overall design constraints imposed on the system. By way of example, a processor, any portion of a processor, or any combination of processors presented in this disclosure may be implemented with a microprocessor, a microcontroller, a Digital Signal Processor (DSP), a Field Programmable Gate Array (FPGA), a Programmable Logic Device (PLD), a state machine, gated logic units, discrete hardware circuits, and other suitable processing components configured to perform the various functions described in this disclosure. The functionality of a processor, any portion of a processor, or any combination of processors presented in this disclosure may be implemented using software executed by a microprocessor, microcontroller, DSP, or other suitable platform.
Software should be viewed broadly as meaning instructions, instruction sets, code segments, program code, programs, subroutines, software modules, applications, software packages, routines, subroutines, objects, threads of execution, procedures, functions, and the like. The software may reside in a computer readable medium. The computer readable medium may include, for example, memory, which may be, for example, a magnetic storage device (e.g., hard disk, floppy disk, magnetic strip), an optical disk, a smart card, a flash memory device, a Random Access Memory (RAM), a Read Only Memory (ROM), a programmable ROM (prom), an erasable prom (eprom), an electrically erasable prom (eeprom), a register, or a removable disk. Although the memory is shown as being separate from the processor in the aspects presented in this disclosure, the memory may also be located internal to the processor, such as a cache or registers.
The above description is provided to enable any person skilled in the art to practice the various aspects described herein. Various modifications to these aspects will be readily apparent to those skilled in the art, and the generic principles defined herein may be applied to other aspects. Thus, the claims are not intended to be limited to the aspects shown herein. All structural and functional equivalents to the elements of the various aspects described herein that are known or later come to be known to those of ordinary skill in the art are expressly incorporated herein by reference and are intended to be encompassed by the claims.
Claims (20)
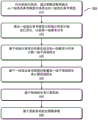
1. A method for obtaining a target model based on knowledge distillation, comprising:
obtaining a data set and a set of candidate reference models;
determining, for each training sample in the data set, a selected set of reference models selected from the candidate set of reference models;
obtaining a set of target probability distributions output by the set of selected reference models for the training sample; and
training the target model using the set of target probability distributions.
2. The method of claim 1, wherein the determining a selected set of reference models comprises:
determining, for each candidate reference model in the set of candidate reference models, whether to select the candidate reference model by reinforcement learning.
3. The method of claim 2, wherein the determining whether to select the candidate reference model comprises:
determining sampling probabilities of the candidate reference models based on a policy function;
sampling motion values of the candidate reference model based on the sampling probabilities; and
selecting the candidate reference model based on the sampled action values.
4. The method of claim 3, wherein the policy function has policy parameters, and the determining whether to select the candidate reference model further comprises:
updating the policy parameters based on performance of the target model.
5. The method of claim 4, wherein the updating the policy parameters comprises:
scoring a verification sample through the target model to obtain a predicted probability distribution of the verification sample;
calculating a prediction loss corresponding to the validation sample based on the true labels in the validation sample and the prediction probability distribution;
calculating a reward corresponding to the validation sample based on the predicted loss; and
updating the policy parameters based on the reward.
6. The method of claim 3, wherein the data set comprises a plurality of data subsets and the policy parameters of the policy function remain unchanged for all training samples within the same data subset.
7. The method of claim 3, wherein the determining sampling probabilities is performed for state information comprising at least: a representation of the training sample, a probability distribution of the candidate reference model output for the training sample, and a prediction penalty corresponding to the probability distribution.
8. The method of claim 3, wherein the policy function has policy parameters, and the policy parameters are initialized by:
determining, by the policy function, a selected set of reference models selected from the candidate set of reference models for an initialization sample;
scoring the initialization samples through the set of selected reference models, respectively, to obtain a set of probability distributions for the initialization samples;
calculating a prediction loss corresponding to the initialization sample based on the true labels in the initialization sample and the set of probability distributions;
calculating a reward corresponding to the initialization sample based on the predicted loss; and
initializing the policy parameters based on the reward.
9. The method of claim 1, wherein the training samples include real labels and the training the target model comprises:
scoring the training samples through the target model to obtain a predicted probability distribution of the training samples;
calculating a first prediction loss corresponding to the training sample based on the prediction probability distribution and the set of target probability distributions;
calculating a second prediction loss corresponding to the training sample based on the prediction probability distribution and the true label;
calculating a composite prediction loss corresponding to the training samples based on the first prediction loss and the second prediction loss; and
optimizing the objective model by minimizing the synthetic prediction loss.
10. The method of claim 9, wherein the calculating a first predicted loss comprises:
calculating sub-prediction losses corresponding to the target probability distribution based on the prediction probability distribution and each target probability distribution in the set of target probability distributions, respectively, to obtain a set of sub-prediction losses; and
calculating the first prediction loss based on the number of reference models in the set of selected reference models and the set of sub-prediction losses.
11. The method of claim 9, wherein the data set comprises a plurality of data subsets and the parameters of the target model remain unchanged for all training samples within the same data subset.
12. The method of claim 1, further comprising:
scoring a pre-training data set through the set of candidate reference models; and
pre-training the target model using the scored pre-training data set.
13. The method of claim 1, wherein the set of candidate reference models are models having a higher complexity than the target model.
14. An apparatus for obtaining a target model based on knowledge distillation, comprising:
an obtaining module for obtaining a data set and a set of candidate reference models;
a reference model determination module for determining, for each training sample in the data set, a selected set of reference models selected from the candidate set of reference models;
a probability distribution obtaining module, configured to obtain a set of target probability distributions output by the selected reference models for the training samples; and
a target model training module to train the target model using the set of target probability distributions.
15. The apparatus of claim 14, wherein the reference model determination module is further configured to:
determining, for each candidate reference model in the set of candidate reference models, whether to select the candidate reference model by reinforcement learning.
16. The apparatus of claim 15, wherein the determination of whether to select the candidate reference model comprises:
determining sampling probabilities of the candidate reference models based on a policy function;
sampling motion values of the candidate reference model based on the sampling probabilities; and
selecting the candidate reference model based on the sampled action values.
17. The apparatus of claim 16, wherein the policy function has policy parameters, and the determining whether to select the candidate reference model further comprises:
updating the policy parameters based on performance of the target model.
18. The apparatus of claim 16, wherein the data set comprises a plurality of data subsets and the policy parameters of the policy function remain unchanged for all training samples within the same data subset.
19. The apparatus of claim 16, wherein the determining sampling probabilities is performed for state information comprising at least: a representation of the training sample, a probability distribution of the candidate reference model output for the training sample, and a prediction penalty corresponding to the probability distribution.
20. An apparatus for obtaining a target model based on knowledge distillation, comprising:
at least one processor; and
a memory storing computer-executable instructions that, when executed, cause the at least one processor to:
a data set and a set of candidate reference models are obtained,
determining, for each training sample in the data set, a selected set of reference models selected from the candidate set of reference models,
obtaining a set of target probability distributions for the training sample output by the set of selected reference models, an
Training the target model using the set of target probability distributions.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010561319.7A CN113822434A (en) | 2020-06-18 | 2020-06-18 | Model selection learning for knowledge distillation |
| PCT/US2021/026288 WO2021257160A1 (en) | 2020-06-18 | 2021-04-08 | Model selection learning for knowledge distillation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010561319.7A CN113822434A (en) | 2020-06-18 | 2020-06-18 | Model selection learning for knowledge distillation |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113822434A true CN113822434A (en) | 2021-12-21 |
Family
ID=75690703
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010561319.7A Pending CN113822434A (en) | 2020-06-18 | 2020-06-18 | Model selection learning for knowledge distillation |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN113822434A (en) |
| WO (1) | WO2021257160A1 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115129975B (en) * | 2022-05-13 | 2024-01-23 | 腾讯科技(深圳)有限公司 | Recommendation model training method, recommendation device, recommendation equipment and storage medium |
| CN115082920B (en) * | 2022-08-16 | 2022-11-04 | 北京百度网讯科技有限公司 | Deep learning model training method, image processing method and device |
| CN117806172B (en) * | 2024-02-28 | 2024-05-24 | 华中科技大学 | Fault diagnosis method based on cloud edge cooperation and self-adaptive knowledge transfer |
-
2020
- 2020-06-18 CN CN202010561319.7A patent/CN113822434A/en active Pending
-
2021
- 2021-04-08 WO PCT/US2021/026288 patent/WO2021257160A1/en active Application Filing
Non-Patent Citations (2)
| Title |
|---|
| LIN WANG,等: "Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks", 《JOURNAL OF LATEX CLASS FILES》, vol. 14, no. 8, 13 April 2020 (2020-04-13), pages 1 - 37 * |
| YAN GAO,等: "Distilling Knowledge from Ensembles of Acoustic Models for Joint CTC-Attention End-to-End Speech Recognition", 《ARXIV》, 19 May 2020 (2020-05-19), pages 1 - 5 * |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021257160A1 (en) | 2021-12-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Joulin et al. | Efficient softmax approximation for GPUs | |
| CN112257449B (en) | Named entity recognition method and device, computer equipment and storage medium | |
| CN113822434A (en) | Model selection learning for knowledge distillation | |
| US11334791B2 (en) | Learning to search deep network architectures | |
| CN113987187B (en) | Public opinion text classification method, system, terminal and medium based on multi-label embedding | |
| CN112905795A (en) | Text intention classification method, device and readable medium | |
| CN109948149A (en) | A kind of file classification method and device | |
| CN110796199A (en) | Image processing method and device and electronic medical equipment | |
| CN112215696A (en) | Personal credit evaluation and interpretation method, device, equipment and storage medium based on time sequence attribution analysis | |
| CN110866113A (en) | Text classification method based on sparse self-attention mechanism fine-tuning Bert model | |
| CN117611932B (en) | Image classification method and system based on double pseudo tag refinement and sample re-weighting | |
| CN117332090B (en) | Sensitive information identification method, device, equipment and storage medium | |
| CN112287656B (en) | Text comparison method, device, equipment and storage medium | |
| CN113656563A (en) | Neural network searching method and related equipment | |
| CN115222950A (en) | Lightweight target detection method for embedded platform | |
| CN112257860A (en) | Model generation based on model compression | |
| CN113988267A (en) | User intention recognition model generation method, user intention recognition method and device | |
| Hu et al. | Saliency-based YOLO for single target detection | |
| Yang et al. | Structured pruning via feature channels similarity and mutual learning for convolutional neural network compression | |
| CN111783688A (en) | Remote sensing image scene classification method based on convolutional neural network | |
| CN111259673A (en) | Feedback sequence multi-task learning-based law decision prediction method and system | |
| CN114692615B (en) | Small sample intention recognition method for small languages | |
| AU2022216431B2 (en) | Generating neural network outputs by enriching latent embeddings using self-attention and cross-attention operations | |
| CN114358579A (en) | Evaluation method, evaluation device, electronic device, and computer-readable storage medium | |
| CN113487453A (en) | Legal judgment prediction method and system based on criminal elements |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |