CN113359744B - 一种基于安全强化学习及视觉传感器的机器人避障系统 - Google Patents
一种基于安全强化学习及视觉传感器的机器人避障系统 Download PDFInfo
- Publication number
- CN113359744B CN113359744B CN202110684879.6A CN202110684879A CN113359744B CN 113359744 B CN113359744 B CN 113359744B CN 202110684879 A CN202110684879 A CN 202110684879A CN 113359744 B CN113359744 B CN 113359744B
- Authority
- CN
- China
- Prior art keywords
- robot
- reinforcement learning
- obstacle avoidance
- module
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000002787 reinforcement Effects 0.000 title claims abstract description 30
- 230000000007 visual effect Effects 0.000 claims abstract description 21
- 238000013527 convolutional neural network Methods 0.000 claims abstract description 18
- 230000001537 neural effect Effects 0.000 claims abstract description 4
- 230000006403 short-term memory Effects 0.000 claims abstract description 4
- 238000000034 method Methods 0.000 claims description 39
- 230000006870 function Effects 0.000 claims description 35
- 238000012549 training Methods 0.000 claims description 29
- 238000003860 storage Methods 0.000 claims description 21
- 238000004088 simulation Methods 0.000 claims description 17
- 230000008569 process Effects 0.000 claims description 16
- 230000004913 activation Effects 0.000 claims description 12
- 238000007781 pre-processing Methods 0.000 claims description 9
- 238000000605 extraction Methods 0.000 claims description 7
- 238000004458 analytical method Methods 0.000 claims description 5
- 238000004364 calculation method Methods 0.000 claims 1
- 238000003062 neural network model Methods 0.000 claims 1
- 238000004519 manufacturing process Methods 0.000 abstract description 4
- 230000007787 long-term memory Effects 0.000 abstract description 2
- 230000009471 action Effects 0.000 description 15
- 238000005516 engineering process Methods 0.000 description 10
- 238000010586 diagram Methods 0.000 description 7
- 238000013500 data storage Methods 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- 238000012545 processing Methods 0.000 description 4
- 241000282414 Homo sapiens Species 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 238000013473 artificial intelligence Methods 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 230000032683 aging Effects 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 238000009776 industrial production Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 235000001968 nicotinic acid Nutrition 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000002922 simulated annealing Methods 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000010408 sweeping Methods 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0231—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means
- G05D1/0238—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means using obstacle or wall sensors
- G05D1/024—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means using obstacle or wall sensors in combination with a laser
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0212—Control of position or course in two dimensions specially adapted to land vehicles with means for defining a desired trajectory
- G05D1/0214—Control of position or course in two dimensions specially adapted to land vehicles with means for defining a desired trajectory in accordance with safety or protection criteria, e.g. avoiding hazardous areas
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0212—Control of position or course in two dimensions specially adapted to land vehicles with means for defining a desired trajectory
- G05D1/0221—Control of position or course in two dimensions specially adapted to land vehicles with means for defining a desired trajectory involving a learning process
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0231—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means
- G05D1/0246—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means using a video camera in combination with image processing means
- G05D1/0251—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means using a video camera in combination with image processing means extracting 3D information from a plurality of images taken from different locations, e.g. stereo vision
-
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0276—Control of position or course in two dimensions specially adapted to land vehicles using signals provided by a source external to the vehicle
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Aviation & Aerospace Engineering (AREA)
- Radar, Positioning & Navigation (AREA)
- Remote Sensing (AREA)
- General Physics & Mathematics (AREA)
- Automation & Control Theory (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Electromagnetism (AREA)
- Multimedia (AREA)
- Optics & Photonics (AREA)
- Manipulator (AREA)
Abstract
本发明公开了一种基于安全强化学习及视觉传感器的机器人避障系统,包括卷积神经模块,所述卷积神经网络模块包括长短期记忆单元;还包括加入LSTM单元、第一卷积层、第二卷积层、第一全连接层、第二全连接层、输出层。本发明采用强化学习算法的增强,使多维,连续,多约束问题能够较好的收敛于信任域内,解决了以往带约束的强化学习算法的诸多问题。可以大幅提高生产安全,普适地应用在不同场合的危险工作上,在解放劳动力的同时,提高了操作安全性、精准性。
Description
技术领域
本发明涉及人工智能领域,主要关于人工智能中安全强化学习算法在机器人避障问题中的应用,特别是涉及一种基于安全强化学习及视觉传感器的机器人避障系统。
背景技术
年来,随着科学技术的不断发展,智能机器人已应用于多个领域,包括工业生产、军事、灾难救援等方面,其中涉及了环境感知、动态决策与规划、自动控制等多种技术。同时,近年来也出现了各种社会问题,如劳动力数量下降、生产成本上升、自动化生产效率较低,产业转型未完成、社会老龄化程度日益严重等问题。机器人在市场中的应用能够有效缓解上述问题,因此,深入研究机器人技术的相关难点并进一步开拓机器人应用市场是十分必要的。并且,机器人技术更是衡量国家科技水平和工业自动化水平的重要指标。
其中,自主避障是智能机器人技术中重要组成部分,是智能机器人的核心技术之一。机器人自主躲避障碍可以极大促进相关智能产品的使用率,减小人力成本,使智能机器人能够更好地代替人类完成部分难度大且危险的工作,例如灾区救援、疫区消毒等。但与此同时,训练避障机器人的过程中,不可避免地会出现相关的安全问题,因此,进一步优化智能机器人避障训练过程中存在的安全隐患能够进一步推进机器人在社会中的应用。
目前,智能机器人要想实现自主避障,需要通过测距传感器以及许多避障算法来实现。典型的测距传感器包括激光传感器、超声波传感器、视觉传感器等,然而这些传感器都存在各自的局限性。在常用的避障算法中,主要有模拟退火法、人工势场法和模糊逻辑方法,这类方法易于实现,但求解时容易陷入局部最优解。A*(A-star)算法、栅格法等方法解决了建模难的问题,但由于其搜索效率较低,使得其难以应用到实际中。遗传算法、人工神经网络算法等智能仿生学方法效率更高,但这类方法在应用中存在易陷入局部最优解及收敛速度较慢。
与此同时,深度学习中的强化学习技术在近年来得到了迅猛的发展,将强化学习技术应用于机器人避障领域已有不少相关研究。主要包括基于值的方法、基于策略的方法以及值与策略相结合的方法。基于值的方法主要适用于离散动作空间,其目标是通过最大化每个状态的值函数来得到最优策略,而值函数则是用来衡量当前状态下机器人选择策略优劣程度,主要有时序差分(TemporalDifference,TD)算法、Q-Learning算法、SARSA(State-Action-Reward-State-Action)算法以及Dyna算法等;基于策略的方法通过直接优化策略得到最优策略,应用于机器人避障中则主要有策略梯度法(Policy Gradient,PG)和模仿学习(ImitationLearning,IL)等;值和策略相结合的方法则主要为Actor-Critic算法。
现有的强化学习技术在机器人避障的研究中,基于DoubleDQN网络和深度强化学习的移动机器人避障方法(专利号:CN201811562344.6),一种基于虚拟场景训练的机器人避障方法(专利号:CN201911183320.4),前者解决了现有的深度强化学习避障方法存在的响应延迟高、所需训练时间长以及避障成功率低的问题,后者以构建虚拟环境的方式,结合基于Sarsa-lamda强化学习模型,实现机械臂轨迹重构以及有效避障,两者均未对动态、连续、高维的控制模型进行分析和建模,同时也未涉及对机器人避障的安全问题进行限制和考量。
总体来说,将强化学习应用于机器人避障的研究取得了一定的成效,但缺少关于安全强化学习(CPO)方面的相关研究,其在安全领域方面的研究仍十分匮乏。在深度RL中的工作任务中,智能体在学习过程中以提高性能的目的自由地探索任何行为。然而,在许多现实领域,给予智能体完全的自由可能是不可接受的。例如,当机器人从A点移动到B点时,我们不仅希望其能够自主避障,选择最短路径,我们还需要其能够在选择最短路径的同时不会对周围环境造成危险。近年来,机器人误伤人类的新闻层出不穷,从这一角度出发,对机器人自主避障过程中实施安全性的约束是具有现实意义的。
发明内容
为了弥补上述现有技术的不足,本发明提出一种基于安全强化学习及视觉传感器的机器人避障系统,对机器人自主避障过程中实施安全性的约束。
本发明的技术问题通过以下的技术方案予以解决:一种基于安全强化学习及视觉传感器的机器人避障系统,包括卷积神经模块,所述卷积神经网络模块包括长短期记忆单元,用于对激光雷达的输入进行编码;包括加入LSTM单元,用于记忆模型学习过程中的信息;还包括第一卷积层,其使用一维卷积核来对LSTM单元编码的结果进行特征提取;还包括第二卷积层,其使用一维卷积核来进行进一步的特征提取;还包括第一全连接层,信息特征输入到所述第一全连接层;还包括第二全连接层,所述第一全连接层的输出连同机器人的目标点的相对坐标和机器人的速度一起输入第二全连接层,最终输出机器人线速度的平均值和角速度的平均值;还包括输出层。
在一些实施例中,还包括如下技术特征:
所述第一卷积层层使用ReLU作为激活函数;所述第一、二全连接层使用的激活函数也是ReLU;所述输出层针对移动机器人的线速度和角速度分别使用sigmoid和tanh作为激活函数。
还包括单目视觉传感器和双目视觉传感器,用于完成对图像信息的收集;所述单目视觉系统只使用一个视觉传感器,所述双目立体视觉系统由两个摄像机组成,利用三角测量原理获得场景的深度信息,并且可以重建周围景物的三维形状和位置;所述双目视觉系统通过匹配准确得到立体视觉系统能够比较准确地恢复视觉场景的三维信息。
包括训练模型,所述训练模型中,对于移动机器人i在t时刻的奖赏函数设计如下:

其中rreached表示移动机器人到达设定目的地基时给予的奖励:

rapproaching表示机器人接近目的地的奖赏:

rcollision表示机器人发生碰撞时的奖赏:

rdeviation表示机器人运动方向与目的地连线夹角过大时的奖赏:

其中 表示当前移动机器人的坐标,gi是该机器人的目标点坐标,ra=30,rb=2。rdeviation中的角度为弧度制,0.785弧度是角度制的45度。
表示当前移动机器人的坐标,gi是该机器人的目标点坐标,ra=30,rb=2。rdeviation中的角度为弧度制,0.785弧度是角度制的45度。 是当前机器人线速度方向与机器人及目标点连线夹角。
是当前机器人线速度方向与机器人及目标点连线夹角。
还包括CPO误差模块,用于对收集到的数据进行误差分析,在安全约束条件内更新卷积神经网络模型和目标模型,利用所述CPO误差模块来确保卷积神经网络模型和目标模型的更新都在安全约束条件内。
还包括云服务器及储存器,实时采集的实时环境图像信息预处理后结果发送到所述云服务器及储存器中。
还包括CPU处理器,用于将预处理后的图像信息发送到CPU处理器中进行运算,其中CPU处理器通过实时与模型训练模块中的目标模型模块进行交互实现对结果的运算。
还包括机器人决策模块,用于将所述CPU处理器运算所得出的结果交由此机器人决策模块进行执行并将执行结果发送到云服务器及储存器中。
还包括仿真平台,用于根据机器人所处的环境进行所述仿真平台上的建模,构成障碍物仿真环境。
本发明采用强化学习算法的增强,使多维,连续,多约束问题能够较好的收敛于信任域内,解决了以往带约束的强化学习算法的诸多问题。可以大幅提高生产安全,普适地应用在不同场合的危险工作上,在解放劳动力的同时,提高了操作安全性、精准性。
附图说明
图1是本发明实施例的模型训练模块框图。
图2是本发明实施例的模型应用模块流程图。
图3是本发明实施例的卷积神经网络模块的网络结构图。
图4是本发明实施例的模型应用模块中的主要流程图。
图5是本发明实施例的模型训练模块中的主要流程图。
具体实施方式
下面对照附图并结合优选的实施方式对本发明作进一步说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
需要说明的是,本实施例中的左、右、上、下、顶、底等方位用语,仅是互为相对概念,或是以产品的正常使用状态为参考的,而不应该认为是具有限制性的。
本发明下述实施例涉及一种基于安全强化学习及视觉传感器的机器人避障系统,该系统主要包括两个模块,分别为模型训练模块和模型应用模块。在模型训练模块中,主要包括数据存储单元、障碍物仿真环境、目标模型、CPO误差模块、卷积神经网络模型;在模型应用模块中,主要包括单目视觉传器、双目视觉传感器、预处理模块、图像存储模块、CPU处理器、机器人决策模块,其中目标模型为模型训练模块中训练好的目标模型,预处理模块为模型训练模块中的卷积神经网络模块;其中,模型应用模块中,利用机器人决策模块和图像存储模块两个单元进行处理后得到的信息将发送到云服务器及储存器进行存储。在模型应用模块中,系统实现的主要流程为:利用单目视觉传感器和双目视觉传感器采集实时环境的图像信息并进行预处理,并将结果存储到图像存储模块中,再发送到云服务器及储存器中;将预处理后的图像信息发送到CPU处理器中进行运算,其中CPU处理器通过实时与模型训练模块中的目标模型模块进行交互实现对结果的运算;将CPU处理器运算所得出的结果交由机器人决策模块执行并将执行结果发送到模型训练模块的数据存储单元以及云服务器及储存器中。在模型训练模块中,系统实现的主要流程为:对障碍物仿真环境收集到的信息利用卷积神经网络模型进行预处理,并将处理后的信息储存到数据存储单元中,再通过CPO误差模块对收集到的数据进行误差分析,在安全约束条件内更新卷积神经网络模型和目标模型。
本发明实施例分层次介绍如下:
1、参见模型训练模块框图(图1),使用了卷积神经模块,在卷积神经网络模块,我们首先使用一个长短期记忆单元(Long Short Term Memory,LSTM)来对激光雷达的输入进行编码,加入LSTM单元来记忆模型学习过程中的信息可以在一定程度上提升深度强化训练的效果。对于移动机器人来说,除了当前时刻的视觉传感器数据外,历史的视觉传感器数据也很有可能提供关于环境中障碍物的有效信息。使用LSTM对视觉传感器进行编码可以将历史帧的信息同当前帧一同编码。之后的第一个卷积层使用了32个大小为5步长为2的一维卷积核来对LSTM单元编码的结果进行特征提取,这一层使用了ReLU作为激活函数。其后的第二个卷积层使用了16个大小为3步长为2的一维卷积核来进行进一步的特征提取。然后,信息特征输入到一个由256个单元的全连接层。本层的输出连同机器人的目标点的相对坐标和机器人的速度一起输入最后一个有128单元的全连接层,最终输出机器人线速度的平均值和角速度的平均值。两个全连接层使用的激活函数也是ReLU,最后的输出层针对移动机器人的线速度和角速度分别使用了sigmoid和tanh作为激活函数。
2、参见模型应用模块框图(图2),结合了单目视觉传感器和双目视觉传感器完成对图像信息的收集。单目视觉系统只使用一个视觉传感器。单目视觉系统在成像过程中由于从三维客观世界投影到N维图像上,在自主移动机器人中已得到广泛应用。而双目立体视觉系统由两个摄像机组成,利用三角测量原理获得场景的深度信息,并且可以重建周围景物的三维形状和位置,类似人眼的体视功能,原理简单。双目视觉系统需要精确地知道两个摄像机之间的空间位置关系,而且场景环境的3D信息需要两个摄像机从不同角度,同时拍摄同一场景的两幅图像,并进行复杂的匹配,才能准确得到立体视觉系统能够比较准确地恢复视觉场景的三维信息。
3、训练模型中的奖励函数的设定,设定奖赏函数的目的是引导机器人进行学习,使之按照研究者预期的目标进行动作的选择。本文的预期是机器人在移动时可以在避免碰撞的情况卜,以尽可能短的时间抵达目的地。对于移动机器人i在t时刻的奖赏函数设计如下:

该奖赏函数由四项组成,其中rreached表示移动机器人到达设定目的地基时给予的奖励:

其中,rapproaching表示机器人接近目的地的奖赏:

rcollision表示机器人发生碰撞时的奖赏:

rdeviation表示机器人运动方向与目的地连线夹角过大时的奖赏:

其中 表示当前移动机器人的坐标,gi是该机器人的目标点坐标,ra=30,rb=2。rdeviation中的角度为弧度制,0.785弧度是角度制的45度。
表示当前移动机器人的坐标,gi是该机器人的目标点坐标,ra=30,rb=2。rdeviation中的角度为弧度制,0.785弧度是角度制的45度。 是当前机器人线速度方向与机器人及目标点连线夹角。
是当前机器人线速度方向与机器人及目标点连线夹角。
4、参见模型训练模块中的主要流程(图4),通过CPO误差模块对收集到的数据进行误差分析,在安全约束条件内更新卷积神经网络模型和目标模型,利用CPO误差模块来确保卷积神经网络模型和目标模型的更新都在安全约束条件内。该过程实现了的多次更新,确保获得稳定、高效的模型。
其中,CPO是基于RL理论的一种进阶策略算法,这一理论限制了政策的奖励和成本之间的差异,收紧了信任区域进行政策搜索的已知界限,并在寻找深度RL的政策搜索理论和实践之间提供了紧密的联系,在保证奖励增加的前提下,满足其他根本约束条件。该方法并不是直接求解目标函数,而是运用了近似替代的方法,根据信息论、概率论等理论,引入代理函数,使用代理函数将更容易从实验集中获得样本估计,并且得到目标和约束的较优的局部近似,该算法将更新的坏情况性能和最坏情况约束违反与依赖于算法超参数的值进行约束。具体算法步骤为:
受信任区域方法的启发提出的CPO,使用信任区域策略,而非对政策分歧的惩罚,以实现更大的步长:


CPO理论中的目标函数和约束条件为:

其中:

dπ=(1-γ)(I-γPπ)-1表示未来折扣后的价值函数
γ折扣因子τ=(s0,a0,s1,…)
S表示一系列的(state)状态
A表示action(动作)
R:S×A×S→R'奖励函数
P:S×A×S→[0,1]转移概率函数
Ci表示转移状态,D表示距离函数
平稳策略π:S→P(A)表示从状态到动作上的概率分布的映射
π(a|s)表示从状态s中选择动作a的概率
g表示目标的梯度,约束的梯度i作为bi,H表示KL的散度
B=[b1,…,bm]
c=[c1,…,cm]T
r=gTH-1B,S=BTH-1B
u=ΔutRt+1Pt
对于目标函数来说,我们只需要推高公式的下界就行了,对于策略的约束来说,只需要保证新策略依然满足约束条件,即:

假设费雪信息矩阵H总是正半定的,这个优化问题是凸的,在可行的时候,可以利用对偶性有效地求解:


其中:
λ,θ在police更新后成为λ*,θ*用D表示
r=gTH-1B
S=BTH-1B
由于近似误差,CPO可能会采取一个错误的步骤,并产生一个不可行的迭代πk。我们通过提出一个更新来纯粹降低约束式(7)来恢复:

具体的算法步骤:


5、参见模型应用模块中的主要流程(图5),实时采集实时环境的图像信息并进行预处理,并将结果发送到云服务器及储存器中。该过程主要结合了单目视觉传感器和双目视觉传感器进行实时环境的信息采集,并利用预处理模块对所收集到的图像进行灰度化、几何变换、图形增强等预处理操作,对预处理后的图像信息利用图像存储模块进行储存,并发送至云服务器及储存器进行进一步的存储。
6、根据模型应用模块中的主要流程,将预处理后的图像信息发送到CPU处理器中进行运算,其中CPU处理器通过实时与模型训练模块中的目标模型模块进行交互实现对结果的运算。该过程实现了机器人在避障过程中的对每一时间节点上的路径规划的运算,利用实时更新的目标模型来进行机器人的避障。
7、根据模型应用模块中的主要流程,将CPU处理器运算所得出的结果交由机器人决策模块进行执行并将执行结果发送到云服务器及储存器中。该过程实现了模型运行结果及环境信息的实时反馈,利用所反馈的信息,可以实现目标模型的不断更新。
8、根据模型训练模块中的主要流程,利用数据存储单元中的信息实现与预先建立好的障碍物仿真环境的交互,从而不断训练。首先根据机器人所处的环境进行仿真平台上的建模,构成障碍物仿真环境;并预先定义好贴合机器人避障要求的states、actions和rewards函数模型。利用数据存储单元中的信息,结合states、actions和rewards函数与仿真平台进行交互,不断优化自身参数,实现的实时更新。在机器人避障中,states可理解为history的函数,即用以决定机器人下一步操作的相关信息,而这些信息则是从history中提取得出,其中,history可理解为在该时刻前,机器人所采取的一系列动作(action)中,每个动作对机器人路径规划所造成的影响;actions可理解为机器人在每一时刻所采取的动作,如向前走、向左(右)转等行为;rewards可理解为机器人从起点移动到终点的时间。其中:
history:Ht=A1,O1,R1,…,At,Ot,Rt
state:St=f(Ht),At=h(St)
Reward:r(x,u)=max(-ε2-|u|,κ)κ为特定常数
实例分析:如:要完成智能扫地机器人回座充电这一过程:在模型训练模块的构建中,我们首先可以在gym上搭建虚拟的障碍物仿真环境,即配置好过程中可能出现的障碍,如客厅中随机摆放的椅子、桌子;设置好初始的卷积神经网络模型,其中,第一个卷积层使用了32个大小为5步长为2的一维卷积核,这一层使用了ReLU作为激活函数。第二个卷积层使用16个大小为3步长为2的一维卷积核来进行进一步的特征提取,使用两个全连接层,分别具有256个单元和128个单元。两个全连接层使用的激活函数也是ReLU,最后的输出层针对移动机器人的线速度和角速度分别使用了sigmoid和tanh作为激活函数;设置好目标模型,即states、actions和rewards函数模型,其中,我们可将action定义为左转、右转、直行,state定义为:前方有障碍物、前方无障碍物,其中的奖励(reward)函数如权利要求3进行设置;将对仿真环境中的信息进行预处理(灰度化、几何变换、图形增强)后输入到数据储存单元中进行储存,再将这些数据作为输入,输入进卷积神经网络模型及目标模型,对两者进行训练,从而得到最优的模型参数,其中,使用CPO误差模块保证这两个模型的训练是在安全约束条件内的,经过足够多次训练后,得到较好的目标模型和卷积神经网络模型。
在模型应用模块中,我们使用LXPS-HS0222-B/C型号的双目视觉传感器和CMV400型号的图像传感器(单目视觉传感器)进行对真实环境中图像信息的采集,并将所采集到的信息进行预处理,之后储存在图像存储模块中,并发送到云服务器与储存器中,若对收集到的信息进行预处理后,得到的环境信息为:机器人前方有障碍物,则利用i5-9400的CPU处理器,将该信息输入进预先训练好的目标模型中进行运算,目标模型将返回一个输出(action),如:右转的指令;CPU将该指令发送至机器人决策模块,该模块将执行该右转指令,从而实现机器人在障碍物面前的右转,完成一次机器人避障。
本发明实施你还具有如下创新点:
1、提出利用安全强化学习的方法解决现阶段应用于多个领域中的可自主避障机器人在训练过程中的可能出现的安全问题。
2、设计出能保障机器人在移动过程中的安全的奖励函数。
3、采用了单目视觉传感器与双目视觉传感器结合的视觉捕捉方式,在保证视觉传感器能提取充分的信息的同时大大提升了算法的运行速度。
4、设计了一种基于卷积神经网络的图像预处理模型。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
Claims (8)
1.一种基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:包括卷积神经模块,所述卷积神经网络模块包括长短期记忆单元,用于对激光雷达的输入进行编码;包括加入LSTM单元,用于记忆模型学习过程中的信息;还包括第一卷积层,其使用一维卷积核来对LSTM单元编码的结果进行特征提取;还包括第二卷积层,其使用一维卷积核来进行进一步的特征提取;还包括第一全连接层,信息特征输入到所述第一全连接层;还包括第二全连接层,所述第一全连接层的输出连同机器人的目标点的相对坐标和机器人的速度一起输入第二全连接层,最终输出机器人线速度的平均值和角速度的平均值;还包括输出层;还包括训练模型,所述训练模型中,对于移动机器人i在t时刻的奖赏函数设计如下:

其中rreached表示移动机器人到达设定目的地基时给予的奖励:

rapproaching表示机器人接近目的地的奖赏:
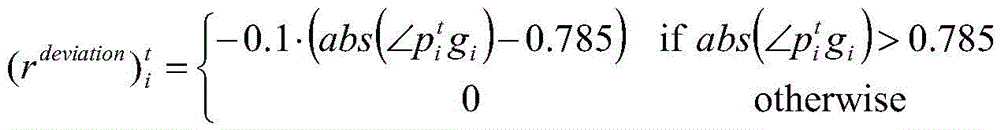
rcollision表示机器人发生碰撞时的奖赏:

rdeviation表示机器人运动方向与目的地连线夹角过大时的奖赏:

其中 表示当前移动机器人的坐标,gi是该机器人的目标点坐标,ra=30,rb=2,rdeviation中的角度为弧度制,0.785弧度是角度制的45度,
表示当前移动机器人的坐标,gi是该机器人的目标点坐标,ra=30,rb=2,rdeviation中的角度为弧度制,0.785弧度是角度制的45度, 是当前机器人线速度方向与机器人及目标点连线夹角。
是当前机器人线速度方向与机器人及目标点连线夹角。
2.如权利要求1所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:所述第一卷积层层使用ReLU作为激活函数;所述第一、二全连接层使用的激活函数也是ReLU;所述输出层针对移动机器人的线速度和角速度分别使用sigmoid和tanh作为激活函数。
3.如权利要求1所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:包括单目视觉传感器和双目视觉传感器,用于完成对图像信息的收集;所述单目视觉系统只使用一个视觉传感器,所述双目立体视觉系统由两个摄像机组成,利用三角测量原理获得场景的深度信息,并且可以重建周围景物的三维形状和位置;所述双目视觉系统通过匹配准确得到立体视觉系统能够比较准确地恢复视觉场景的三维信息。
4.如权利要求1所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:还包括CPO误差模块,用于对收集到的数据进行误差分析,在安全约束条件内更新卷积神经网络模型和目标模型,利用所述CPO误差模块来确保卷积神经网络模型和目标模型的更新都在安全约束条件内。
5.如权利要求1所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:还包括云服务器及储存器,实时采集的实时环境图像信息预处理后结果发送到所述云服务器及储存器中。
6.如权利要求5所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:还包括CPU处理器,用于将预处理后的图像信息发送到CPU处理器中进行运算,其中CPU处理器通过实时与模型训练模块中的目标模型模块进行交互实现对结果的运算。
7.如权利要求6所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:还包括机器人决策模块,用于将所述CPU处理器运算所得出的结果交由此机器人决策模块进行执行并将执行结果发送到云服务器及储存器中。
8.如权利要求6所述的基于安全强化学习及视觉传感器的机器人避障系统,其特征在于:还包括仿真平台,用于根据机器人所处的环境进行所述仿真平台上的建模,构成障碍物仿真环境。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110684879.6A CN113359744B (zh) | 2021-06-21 | 2021-06-21 | 一种基于安全强化学习及视觉传感器的机器人避障系统 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110684879.6A CN113359744B (zh) | 2021-06-21 | 2021-06-21 | 一种基于安全强化学习及视觉传感器的机器人避障系统 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113359744A CN113359744A (zh) | 2021-09-07 |
| CN113359744B true CN113359744B (zh) | 2022-03-01 |
Family
ID=77535291
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110684879.6A Active CN113359744B (zh) | 2021-06-21 | 2021-06-21 | 一种基于安全强化学习及视觉传感器的机器人避障系统 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113359744B (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115016503B (zh) * | 2022-07-12 | 2024-07-19 | 安徽莱陆智能科技有限公司 | 一种消毒机器人场景模拟测试装置 |
| CN115290096B (zh) * | 2022-09-29 | 2022-12-20 | 广东技术师范大学 | 一种基于强化学习差分算法的无人机动态航迹规划方法 |
| CN115890656A (zh) * | 2022-10-25 | 2023-04-04 | 中国电信股份有限公司 | 仓储物流机器人控制方法、系统、电子设备和存储介质 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110472738A (zh) * | 2019-08-16 | 2019-11-19 | 北京理工大学 | 一种基于深度强化学习的无人艇实时避障算法 |
| CN110488821A (zh) * | 2019-08-12 | 2019-11-22 | 北京三快在线科技有限公司 | 一种确定无人车运动策略的方法及装置 |
| CN112130559A (zh) * | 2020-08-21 | 2020-12-25 | 同济大学 | 一种基于uwb与激光雷达的室内行人跟随与避障方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3748455B1 (en) * | 2019-06-07 | 2022-03-16 | Tata Consultancy Services Limited | A method and a system for hierarchical network based diverse trajectory proposal |
-
2021
- 2021-06-21 CN CN202110684879.6A patent/CN113359744B/zh active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110488821A (zh) * | 2019-08-12 | 2019-11-22 | 北京三快在线科技有限公司 | 一种确定无人车运动策略的方法及装置 |
| CN110472738A (zh) * | 2019-08-16 | 2019-11-19 | 北京理工大学 | 一种基于深度强化学习的无人艇实时避障算法 |
| CN112130559A (zh) * | 2020-08-21 | 2020-12-25 | 同济大学 | 一种基于uwb与激光雷达的室内行人跟随与避障方法 |
Non-Patent Citations (7)
| Title |
|---|
| Deep Q Learning Based High Level Driving Policy Determination;Kyushik Min;《2018 IEEE Intelligent Vehicles Symposium》;20180630;全文 * |
| End-to-End Deep Learning for Steering Autonomous Vehicles Considering Temporal Dependencies;Hesham M. Eraqi;《NIPS 2017》;20171231;全文 * |
| 农业车辆双目视觉障碍物感知系统设计与试验;魏建胜;《农业工程学报》;20210531;全文 * |
| 基于卷积神经网络(CNN)的无人车避障方法;耿特;《工业控制计算机》;20191231;全文 * |
| 基于深度强化学习的移动机器人轨迹跟踪和动态避障;吴运雄;《广东工业大学学报》;20190131;第43-46页 * |
| 基于视觉的水下渔网检测及避障方法研究;张硕;《中国优秀硕士论文全文数据库》;20210515;第4.3.3章 * |
| 完善强化学习安全性:UCBerkeley提出约束型策略优化新算法;机器之心;《https://baijiahao.baidu.com/s?id=1572431872229429&wfr=spider&for=pc》;20170709;第1页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113359744A (zh) | 2021-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113359744B (zh) | 一种基于安全强化学习及视觉传感器的机器人避障系统 | |
| Zhu et al. | Deep reinforcement learning based mobile robot navigation: A review | |
| CN109960246B (zh) | 动作控制方法及装置 | |
| CN111487864A (zh) | 一种基于深度强化学习的机器人路径导航方法及系统 | |
| Yudha et al. | Performance comparison of fuzzy logic and neural network design for mobile robot navigation | |
| Taniguchi et al. | Hippocampal formation-inspired probabilistic generative model | |
| Hagras et al. | Outdoor mobile robot learning and adaptation | |
| CN117873116A (zh) | 一种基于深度强化学习的多移动机器人自主避障方法 | |
| Zhang et al. | Intelligent Vector Field Histogram based collision avoidance method for AUV | |
| Zhang et al. | Recent progress, challenges and future prospects of applied deep reinforcement learning: A practical perspective in path planning | |
| Hao et al. | A review of intelligence-based vehicles path planning | |
| Yue et al. | Semantic-driven autonomous visual navigation for unmanned aerial vehicles | |
| Chen et al. | A Study of Unmanned Path Planning Based on a Double-Twin RBM-BP Deep Neural Network. | |
| Lu et al. | Autonomous mobile robot navigation in uncertain dynamic environments based on deep reinforcement learning | |
| Xu et al. | Avoidance of manual labeling in robotic autonomous navigation through multi-sensory semi-supervised learning | |
| Trasnea et al. | GridSim: a vehicle kinematics engine for deep neuroevolutionary control in autonomous driving | |
| CN117968703A (zh) | 基于鸟瞰视角时空对比强化学习的自主导航方法 | |
| Bouraine et al. | NDT-PSO, a new NDT based SLAM approach using particle swarm optimization | |
| Duo et al. | A deep reinforcement learning based mapless navigation algorithm using continuous actions | |
| CN114609925B (zh) | 水下探索策略模型的训练方法及仿生机器鱼水下探索方法 | |
| Weerakoon et al. | Vapor: Legged robot navigation in unstructured outdoor environments using offline reinforcement learning | |
| JP2024025637A (ja) | タスクを実行するための装置および方法 | |
| Afonso et al. | Autonomous navigation of wheelchairs in indoor environments using deep reinforcement learning and computer vision | |
| Gao et al. | Design and development of an intelligent pet-type quadruped robot | |
| Ardilla et al. | Topological Twin for Mobility Support Robots |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20231106 Address after: 014000 Baotou rare earth high tech Industrial Development Zone, Inner Mongolia Autonomous Region Patentee after: INNER MONGOLIA NORTH HAULER JOINT STOCK Co.,Ltd. Address before: 510632 No. 601, Whampoa Avenue, Guangzhou, Guangdong Patentee before: Jinan University |
|
| TR01 | Transfer of patent right |