CN113239288B - 基于加权三部图的协同过滤推荐方法 - Google Patents
基于加权三部图的协同过滤推荐方法 Download PDFInfo
- Publication number
- CN113239288B CN113239288B CN202110538107.1A CN202110538107A CN113239288B CN 113239288 B CN113239288 B CN 113239288B CN 202110538107 A CN202110538107 A CN 202110538107A CN 113239288 B CN113239288 B CN 113239288B
- Authority
- CN
- China
- Prior art keywords
- user
- label
- weighted
- users
- similarity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9536—Search customisation based on social or collaborative filtering
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G06F16/9024—Graphs; Linked lists
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开一种基于加权三部图的协同过滤推荐方法,具体步骤如下:将用户、物品和标签信息视为三类不同的结点,构建物品‑用户‑标签三部图模型;利用用户偏好度算法计算用户偏好度,将用户偏好度作为物品‑用户‑标签加权三部图的权值,构建加权三部图模型;利用热传导方法在加权三部图上进行资源重分配来挖掘更多的相似关系,计算两两用户之间的相似度;在基于用户的协同过滤框架基础上,根据两两用户之间的相似度为未评分物品进行预测评分,降序排列生成每个用户的推荐列表,再根据推荐列表向用户推荐物品。在真实数据集上的实验表明,本发明可以更好地挖掘长尾物品,实现个性化推荐。
Description
技术领域
本发明属于推荐技术领域,尤其是一种基于加权三部图的协同过滤推荐方法。
背景技术
在大数据时代,推荐系统在缓解信息过载问题上成为一种有效的信息过滤工具。目前的推荐算法很多,基于预测评分的推荐算法运用最为广泛,如协同过滤等,主要利用用户对物品的评分、用户的交易记录、用户及物品特征等信息预测出用户对未评分物品的评分值,进而对预测评分值排序选择最大的前L个物品组成top-L列表推荐给用户。因此,这类算法都致力于对未评分物品预测准确性的提高,但是,准确性并不是衡量用户对推荐物品满意度的唯一标准,多样性也是很重要的指标。而且,在实际的推荐系统中,一些流行物品会被很多用户喜欢,基于用户的协同过滤在依靠近邻用户为目标用户进行推荐时,如果目标用户的近邻用户中存在喜欢热门物品的用户,那么这些热门物品有很大的可能会被推荐给目标用户,而那些长尾物品由于不被大多数用户了解,其预测评分值较小,难以出现在用户推荐列表中,事实上这些长尾物品很可能也是满足用户兴趣的,这就导致推荐的物品过度集中在热门物品中,而潜在流行的长尾物品往往被忽略,很大程度上降低了UBCF的推荐多样性和新颖性。
发明内容
本发明是为了解决现有技术所存在的上述技术问题,提供一种基于加权三部图的协同过滤推荐方法。
本发明的技术解决方案是:一种基于加权三部图的协同过滤推荐方法,按照如下步骤进行:
A.将用户、物品和标签信息视为三类不同的结点,构建物品-用户-标签三部图模型;
B.利用用户偏好度算法计算用户偏好度,将用户偏好度作为物品-用户-标签加权三部图的权值,构建加权三部图模型;
C.利用热传导方法在加权三部图上进行资源重分配来挖掘更多的相似关系,计算两两用户之间的相似度;
D.在基于用户的协同过滤框架基础上,根据两两用户之间的相似度为未评分物品进行预测评分,降序排列生成每个用户的推荐列表,再根据推荐列表向用户推荐物品。
所述步骤A具体步骤如下:
A1.获取用户-物品、用户-标签对应的矩阵;
A2.将用户、物品和标签视为抽象的结点,按照用户-物品、用户-标签之间的选择关系将三种结点连接起来,构建物品-用户-标签三部图模型;
所述步骤B具体步骤如下:
B1.将物品-用户-标签三部图IUT视为用户-物品二部图UI和用户-标签二部图UT,利用投影技术将两个二部图中的二元关系映射到两个用户-用户单模网络UI和UT中;如果用户u选择了物品i,则矩阵UI中元素UIui=1,否则UIui=0;如果用户u使用了标签t,则矩阵UT中元素UTut=1,否则UTut=0;所述矩阵UI=UI*UI′表示选择了相同物品的每个用户对之间的关系,矩阵UT=UT*UT′表示使用过相同标签的每个用户对之间的关系,UI′和UT′分别为UI和UT的转置矩阵;
B2.计算用户对物品的偏好度;
计算用户对物品的偏好相似度矩阵UPSI,矩阵中的元素upsi(u,v)为用户u和v对物品的偏好相似度,表示为:

基于用户对物品的偏好相似度,用户对物品的偏好度矩阵UPI表示为:UPI=UI′*UPSI,矩阵UPI中元素upi(i,u)为用户u对物品i的偏好度;
B3.计算用户对标签的偏好度:
计算用户对标签的偏好相似度矩阵UPST,矩阵中的元素upst(u,v)为用户u和v对标签的偏好相似度,表示为:

基于用户对标签的偏好相似度,用户对标签的偏好度矩阵UPT表示为:UPT=UT′*UPST,矩阵UPT中元素upt(t,u)为用户u对标签t的偏好度;
B4.以用户对物品的偏好度值作为物品-用户-标签加权三部图中对应用户-物品连边的权值,以用户对标签的偏好度值作为物品-用户-标签加权三部图中对应用户-标签连边的权值,构建物品-用户-标签加权三部图模型;
所述步骤C具体步骤如下:
C1.将物品-用户-标签加权三部图视为加权的用户-物品和加权的用户-标签两个二部图,分别用矩阵A和A′表示为:

如果用户u选择了物品i,则aui=upi(i,u),否则aui=0;如果用户u使用了标签t,则a′ut=upt(t,u),否则a′ut=0;矩阵A和Α′的转置矩阵为AT=(aiu)n×m和A′T=(a′tu)r×m;
C2.在加权的用户-物品二部图上通过两次热传导的方式进行资源重分配获得物品方面的两两用户间的相似度:
在加权的用户-物品二部图中,假设为目标用户u分配一个单位的初始资源,其他用户资源为0,得到m维初始资源向量 经过热传导扩散后得到所有用户的最终资源向量
经过热传导扩散后得到所有用户的最终资源向量 其中W为热传导过程的状态转移矩阵;
其中W为热传导过程的状态转移矩阵;
第一步用户将资源按照用户-物品之间的边权与每个物品边权之和的比分配给每个物品,扩散后可得物品资源向量 DI是与物品度相关的对角矩阵;
DI是与物品度相关的对角矩阵;
第二步物品按照物品和用户之间的边权与每个用户边权之和的比例将资源传导给用户,得到所有用户的最终资源向量 DU是与用户度相关的对角矩阵;由此可得,状态转移矩阵W=DUADIAT,该矩阵第v行u列的元素Wvu表示用户v从用户u处获得的资源:
DU是与用户度相关的对角矩阵;由此可得,状态转移矩阵W=DUADIAT,该矩阵第v行u列的元素Wvu表示用户v从用户u处获得的资源:





将用户v从用户u处获得的资源Wvu定义为加权user-item二部图中目标用户u和用户v之间的相似度:

其中,upi(i,u)为用户u对物品i的偏好度, 表示user-item加权二部图中用户v的度,
表示user-item加权二部图中用户v的度, 表示user-item加权二部图中物品i的度;Eui表示user-item加权二部图中用户u与物品i之间的连边;
表示user-item加权二部图中物品i的度;Eui表示user-item加权二部图中用户u与物品i之间的连边;
C3.在加权的用户-标签二部图上通过两次热传导的方式进行资源重分配获得标签方面的两两用户间的相似度:
在加权的用户-标签二部图中,假设为目标用户u分配一个单位的初始资源,其他用户资源为0,得到m维初始资源向量 传导扩散后得到所有用户的最终资源向量
传导扩散后得到所有用户的最终资源向量 其中W′为状态转移矩阵;
其中W′为状态转移矩阵;
第一步用户将资源按照用户和标签之间的边权与每个标签边权之和的比分配给每个标签,扩散后可得标签资源向量 DT是与标签度相关的对角矩阵;
DT是与标签度相关的对角矩阵;
第二步标签按照标签和用户之间的边权与每个用户边权之和的比例将资源返回给用户,得到所有用户的最终资源向量 D′U是与用户度相关的对角矩阵,可得状态转移矩阵W′=D′UA′DTA′T,该矩阵第v行u列的元素W′vu表示用户v从用户u处获得的资源:
D′U是与用户度相关的对角矩阵,可得状态转移矩阵W′=D′UA′DTA′T,该矩阵第v行u列的元素W′vu表示用户v从用户u处获得的资源:





将W′vu定义为加权user-tag二部图中目标用户u和用户v之间的相似度:

其中,upt(t,u)为用户u对标签t的偏好度, 表示user-tag二部图中标签t的度;
表示user-tag二部图中标签t的度; 表示user-tag二部图中用户v的度;Eut表示user-tag加权二部图中用户u与标签t之间的边;
表示user-tag二部图中用户v的度;Eut表示user-tag加权二部图中用户u与标签t之间的边;
C4.引入一个可调节的参数λ整合得到的物品方面和标签方面的用户相似度sim(v,u)和sim′(v,u)得到最终的用户相似度为:
similarity(v,u)=λsim(v,u)+(1-λ)sim′(v,u),λ∈[0,1];
所述步骤D具体包括:
D1.给定目标用户u和未选择的物品i,用户u对物品i的预测评分为:

其中,v是已经对物品i评过分的用户,rv,i表示用户v对物品i的评分, 和
和 分别表示用户u和用户v的所有评分的平均评分,Nu(s)表示用户u的s个邻近用户;
分别表示用户u和用户v的所有评分的平均评分,Nu(s)表示用户u的s个邻近用户;
D2.将用户未选择的物品按照预测评分值大小降序排列,将排序靠前的若干个物品推荐给用户。
本发明在传统用户、物品二元关系中引入标签信息构建三部图,通过三部图网络映射到单模网络的方法获得用户偏好度,在用户偏好度加权的物品-用户-标签三部图上,利用热传导方法让资源在加权三部图上传播,求出用户间的相似度;在传统UBCF框架基础上,再进行预测评分并推荐;将三部图中用户更喜欢的物品和标签赋予更高的权值,利用热传导倾向于将资源传播到度小的物品这一特性,与潜在流行的长尾物品建立联系,提高了传统基于用户的协同过滤算法的多样性和覆盖率,同时引入标签丰富了可用的附加信息,还反映了用户兴趣和物品属性,实现个性化推荐。
附图说明
图1为本发明实施例的流程示意图。
图2为本发明实施例构建加权三部图模型的流程图。
图3为本发明实施例加权物品-用户-标签三部图模型图。
图4为本发明实施例计算两两用户相似度的具体流程图。
图5为本发明实施例参数λ对MP值的影响。
图6为本发明实施例参数λ对Coverage值的影响。
图7为本发明实施例参数λ对Novelty值的影响。
图8为本发明实施例与现有四种算法的Novelty值对比图。
具体实施方式
本发明的基于加权三部图的协同过滤推荐方法如图1所示,按照如下步骤进行:
A.将用户、物品和标签信息视为三类不同的结点,构建物品-用户-标签三部图模型,具体如下:
A1.获取用户-物品、用户-标签对应的矩阵;
A2.将用户、物品和标签视为抽象的结点,按照用户-物品、用户-标签之间的选择关系将三种结点连接起来,构建物品-用户-标签三部图模型;
所述物品-用户-标签三部图模型中包含用户、物品和标签三种元素,U={u1,u2,……,um}表示m个用户的集合,I={i1,i2,……,in}表示n个物品的集合,T={t1,t2,……,tr}表示r个标签的集合,三个集合之间的关系用一个三部图IUT=(U,I,T,EUI,EUT)来表示,其中 EUI、EUT分别表示用户与物品及用户与标签之间的连边集合。
EUI、EUT分别表示用户与物品及用户与标签之间的连边集合。
B.利用用户偏好度算法计算用户偏好度,将用户偏好度作为物品-用户-标签加权三部图的权值,构建加权三部图模型;用户偏好度算法主要分为两步,先求出目标用户与其他用户之间的偏好相似度,然后根据用户间的偏好相似度求出用户对不同物品及标签的偏好度,包括用户对物品的偏好度和用户对标签的偏好度;具体如图2所示:
B1.将物品-用户-标签三部图IUT视为用户-物品二部图UI和用户-标签二部图UT,利用投影技术将两个二部图中的二元关系映射到两个用户-用户单模网络UI和UT中;如果用户u选择了物品i,则矩阵UI中元素UIui=1,否则UIui=0;如果用户u使用了标签t,则矩阵UT中元素UTut=1,否则UTut=0;所述矩阵UI=UI*UI′表示选择了相同物品的每个用户对之间的关系,矩阵UT=UT*UT′表示使用过相同标签的每个用户对之间的关系,UI′和UT′分别为UI和UT的转置矩阵;
B2.计算用户对物品的偏好度(如果两个用户选择了某些相同的物品,则他们对物品的偏好是相似的):
计算用户对物品的偏好相似度矩阵UPSI,矩阵中的元素upsi(u,v)为用户u和v对物品的偏好相似度,表示为:

基于用户对物品的偏好相似度,用户对物品的偏好度矩阵UPI表示为:UPI=UI′*UPSI,矩阵UPI中元素upi(i,u)为用户u对物品i的偏好度;
B3.计算用户对标签的偏好度(如果两个用户使用了某些相同的标签,则他们对标签的偏好是相似的):
计算用户对标签的偏好相似度矩阵UPST,矩阵中的元素upst(u,v)为用户u和v对标签的偏好相似度,表示为:

基于用户对标签的偏好相似度,用户对标签的偏好度矩阵UPT表示为:UPT=UT′*UPST,矩阵UPT中元素upt(t,u)为用户u对标签t的偏好度;
B4.以用户对物品的偏好度值作为物品-用户-标签加权三部图中对应用户-物品连边的权值,以用户对标签的偏好度值作为物品-用户-标签加权三部图中对应用户-标签连边的权值,构建物品-用户-标签加权三部图模型,图3所示为物品-用户-标签加权三部图模型;
C.利用热传导方法在加权三部图上进行资源重分配来挖掘更多的相似关系,计算两两用户之间的相似度;考虑计算用户间的相似度,因此将加权物品-用户-标签三部图视为用户-物品、用户-标签两个加权二部图,分别计算物品和标签两方面的用户相似度,最后整合得到用户间的相似度;具体如图4所示:
C1.将物品-用户-标签加权三部图视为加权的用户-物品和加权的用户-标签两个二部图,分别用矩阵A和A′表示为:

如果用户u选择了物品i,则aui=upi(i,u),否则aui=0;如果用户u使用了标签t,则a′ut=upt(t,u),否则a′ut=0;矩阵A和Α′的转置矩阵为AT=(aiu)n×m和A′T=(a′tu)r×m;
C2.在加权的用户-物品二部图上通过两次热传导的方式进行资源重分配获得物品方面的两两用户间的相似度:
在加权的用户-物品二部图中,假设为目标用户u分配一个单位的初始资源,其他用户资源为0,得到m维初始资源向量 经过热传导扩散后得到所有用户的最终资源向量
经过热传导扩散后得到所有用户的最终资源向量 其中W为热传导过程的状态转移矩阵;
其中W为热传导过程的状态转移矩阵;
第一步用户将资源按照用户-物品之间的边权与每个物品边权之和的比分配给每个物品,扩散后可得物品资源向量 DI是与物品度相关的对角矩阵;
DI是与物品度相关的对角矩阵;
第二步物品按照物品和用户之间的边权与每个用户边权之和的比例将资源传导给用户,得到所有用户的最终资源向量 DU是与用户度相关的对角矩阵;由此可得,状态转移矩阵W=DUADIAT,该矩阵第v行u列的元素Wvu表示用户v从用户u处获得的资源:
DU是与用户度相关的对角矩阵;由此可得,状态转移矩阵W=DUADIAT,该矩阵第v行u列的元素Wvu表示用户v从用户u处获得的资源:





将用户v从用户u处获得的资源Wvu定义为加权user-item二部图中目标用户u和用户v之间的相似度:

其中,upi(i,u)为用户u对物品i的偏好度, 表示user-item加权二部图中用户v的度,
表示user-item加权二部图中用户v的度, 表示user-item加权二部图中物品i的度;Eui表示user-item加权二部图中用户u与物品i之间的连边;
表示user-item加权二部图中物品i的度;Eui表示user-item加权二部图中用户u与物品i之间的连边;
C3.在加权的用户-标签二部图上通过两次热传导的方式进行资源重分配获得标签方面的两两用户间的相似度:
在加权的用户-标签二部图中,假设为目标用户u分配一个单位的初始资源,其他用户资源为0,得到m维初始资源向量 传导扩散后得到所有用户的最终资源向量
传导扩散后得到所有用户的最终资源向量 其中W′为状态转移矩阵;
其中W′为状态转移矩阵;
第一步用户将资源按照用户和标签之间的边权与每个标签边权之和的比分配给每个标签,扩散后可得标签资源向量 DT是与标签度相关的对角矩阵;
DT是与标签度相关的对角矩阵;
第二步标签按照标签和用户之间的边权与每个用户边权之和的比例将资源返回给用户,得到所有用户的最终资源向量 D′U是与用户度相关的对角矩阵,可得状态转移矩阵W′=D′UA′DTA′T,该矩阵第v行u列的元素W′vu表示用户v从用户u处获得的资源:
D′U是与用户度相关的对角矩阵,可得状态转移矩阵W′=D′UA′DTA′T,该矩阵第v行u列的元素W′vu表示用户v从用户u处获得的资源:





将W′vu定义为加权user-tag二部图中目标用户u和用户v之间的相似度:

其中,upt(t,u)为用户u对标签t的偏好度, 表示user-tag二部图中标签t的度;
表示user-tag二部图中标签t的度; 表示user-tag二部图中用户v的度;Eut表示user-tag加权二部图中用户u与标签t之间的边;
表示user-tag二部图中用户v的度;Eut表示user-tag加权二部图中用户u与标签t之间的边;
C4.引入一个可调节的参数λ整合得到的物品方面和标签方面的用户相似度sim(v,u)和sim′(v,u)得到最终的用户相似度为:
similarity(v,u)=λsim(v,u)+(1-λ)sim′(v,u),λ∈[0,1];
D.在基于用户的协同过滤框架基础上,根据两两用户之间的相似度为未评分物品进行预测评分,降序排列生成每个用户的推荐列表,再根据推荐列表向用户推荐物品;具体如下:
D1.给定目标用户u和未选择的物品i,用户u对物品i的预测评分为:

其中,v是已经对物品i评过分的用户,rv,i表示用户v对物品i的评分, 和
和 分别表示用户u和用户v的所有评分的平均评分,Nu(s)表示用户u的s个邻近用户;
分别表示用户u和用户v的所有评分的平均评分,Nu(s)表示用户u的s个邻近用户;
D2.重复上面步骤,在得到用户所有未评分物品的预测评分值之后,将目标用户u未选择物品的预测评分进行降序排列,前L个物品作为推荐结果将被推荐给用户u;
本发明实施例有效性的验证实验:
1)准备标准数据集
使用HetRec 2011的hetrec2011-movielens-2k数据集,包括2113位用户、10197部电影和13222个标签,共有855598条用户对电影的评分。评分为1-5分,1表示最不喜欢,5表示最喜欢,评分至少3分表示用户推荐该电影;
2)评价指标
实验采用三种评估指标对比算法性能:平均个性度(Mean Personality,MP)、覆盖率(Coverage)和新颖度(Novelty,N);MP与Coverage用来衡量推荐系统推荐物品的多样性,值越大推荐的多样性就越好;MP与Coverage分别为:


其中,T为推荐的物品数量,#u为用户总数,Ωu(T)和Ωv(T)分别为用户u和v的数量为T的推荐物品集合,U为用户集合,I为物品集合;
为进一步衡量推荐结果,采用Novelty评估推荐系统的新颖性,Novelty值越小,推荐的新颖性越好。给定目标用户u的前T个物品推荐列表表示为Ωu(T),新颖度为:

其中,k(i)为选择过物品i的所有用户数。将所有用户的N值求平均值便得到系统的平均新颖度;
3)参数的设置
合适的调节参数λ值能提高推荐系统的推荐性能;因此,本节就参数λ的不同取值进行对比实验;当λ={0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1}时,计算本发明的MP、Coverage以及Novelty;选取物品推荐列表长度为12,邻近用户数目为20,随着λ的变化,MP、Coverage以及Novelty的变化趋势如图5、6、7所示;
由图5可看出,随着λ值的增大,MP值也随之增大,当λ=0.3时,MP值达到最优,之后不再变化趋向平稳;由图6可看出,Coverage值先随着λ值的增大而增大,在λ为0.4和0.5时达到峰值,然后Coverage值越来越小;由图7可看出,Novelty的值先随着λ值的增大而减小,在λ=0.4时达到最小值,之后变化较小;对实验数据的分析结果表明,当λ=0.4附近时,本发明的的各项指标都达到最优,说明λ的变化能影响推荐系统的性能;因此,在hetrec2011-movielens-2k数据集上将λ的最优值定为0.4;
4)在标准数据集上进行实验
为验证本发明的推荐性能,将本发明基于加权三部图的协同过滤推荐算法(weighted network-based for collaborative filtering,WNBCF)与下述四种算法进行比较:
(1)基于用户的协同过滤算法(User-Based Collaborative Filtering,UBCF):只利用评分信息,通过度量用户间相似度,然后通过用户最近邻进行预测推荐物品;
(2)基于二部图的热传导算法(Heat Spreading Algorithm,HeatS):与ProbS不同的是,它在两次资源扩散中是通过最近邻平均的过程来重新分配资源;
(3)基于二部图的物质扩散算法(Probabilistic Spreading Algorithm,ProbS):在用户-物品二部图中通过两次资源平均分配给最近的邻居工作;
(4)基于增强相似度的协同过滤算法(Enhanced Similarity Measure forCollaborative Filtering,OSimCF):结合基于比率的算法和改进皮尔逊相关系数的方法MSIM来计算用户间的相似度;
选取邻居用户数目为20到50,间隔为5增加,推荐列表长度由2增加到12,间隔为2;分别计算本发明和现有算法的MP、Coverage和Novelty;
表1和表2分别给出在hetrec2011-movielens-2k数据集上五种推荐算法在邻近用户数为20、25、30、35、40、45、50,推荐列表长度为2、4、6、8、10、12时的MP值和Coverage值;相对于其他四种推荐算法,本发明WNBCF具有较高的的MP和Coverage值;
表1 hetrec2011-movielens-2k数据集上五种算法的MP值对比


表2 hetrec2011-movielens-2k数据集上五种算法的Coverage值对比


本发明实施例与现有四种算法的Novelty值对比如图8所示;从图8可以看出:在hetrec2011-movielens-2k数据集上,随着邻近用户数的增加,Novelty的值逐渐升高,当邻近用户数为20时,Novelty的值最低;随着邻近用户数的增加UBCF和ProbS的Novelty值明显高于其他两种算法,推荐质量不佳,而WNBCF具有较低的Novelty,因此WNBCF能够提供更加新颖的推荐;当推荐长度一定时,推荐的多样性和新颖性大多会随着邻近用户数目的增加而降低,因此当邻近用户数目较小时,本发明具有比较理想的推荐效果。
Claims (2)
1.一种基于加权三部图的协同过滤推荐方法,其特征在于按照如下步骤进行:
A.将用户、物品和标签信息视为三类不同的结点,构建物品-用户-标签三部图模型;
B.利用用户偏好度算法计算用户偏好度,将用户偏好度作为物品-用户-标签加权三部图的权值,构建加权三部图模型;
C.利用热传导方法在加权三部图上进行资源重分配来挖掘相似关系,计算两两用户之间的相似度;
D.在基于用户的协同过滤框架基础上,根据两两用户之间的相似度为未评分物品进行预测评分,降序排列生成每个用户的推荐列表,再根据推荐列表向用户推荐物品。
2.根据权利要求1所述的基于加权三部图的协同过滤推荐方法,其特征在于,所述步骤A具体步骤如下:
A1.获取用户-物品、用户-标签对应的矩阵;
A2.将用户、物品和标签视为抽象的结点,按照用户-物品、用户-标签之间的选择关系将三种结点连接起来,构建物品-用户-标签三部图模型;
所述步骤B具体步骤如下:
B1.将物品-用户-标签三部图IUT视为用户-物品二部图UI和用户-标签二部图UT,利用投影技术将两个二部图中的二元关系映射到两个用户-用户单模网络UI和UT中;如果用户u选择了物品i,则矩阵UI中元素UIui=1,否则UIui=0;如果用户u使用了标签t,则矩阵UT中元素UTut=1,否则UTut=0;所述矩阵UI=UI*UI′表示选择了相同物品的每个用户对之间的关系,矩阵UT=UT*UT′表示使用过相同标签的每个用户对之间的关系,UI′和UT′分别为UI和UT的转置矩阵;
B2.计算用户对物品的偏好度;
计算用户对物品的偏好相似度矩阵UPSI,矩阵中的元素upsi(u,v)为用户u和v对物品的偏好相似度,表示为:

基于用户对物品的偏好相似度,用户对物品的偏好度矩阵UPI表示为:UPI=UI′*UPSI,矩阵UPI中元素upi(i,u)为用户u对物品i的偏好度;
B3.计算用户对标签的偏好度:
计算用户对标签的偏好相似度矩阵UPST,矩阵中的元素upst(u,v)为用户u和v对标签的偏好相似度,表示为:

基于用户对标签的偏好相似度,用户对标签的偏好度矩阵UPT表示为:UPT=UT′*UPST,矩阵UPT中元素upt(t,u)为用户u对标签t的偏好度;
B4.以用户对物品的偏好度值作为物品-用户-标签加权三部图中对应用户-物品连边的权值,以用户对标签的偏好度值作为物品-用户-标签加权三部图中对应用户-标签连边的权值,构建物品-用户-标签加权三部图模型;
所述步骤C具体步骤如下:
C1.将物品-用户-标签加权三部图视为加权的用户-物品和加权的用户-标签两个二部图,分别用矩阵A和A′表示为:

如果用户u选择了物品i,则aui=upi(i,u),否则aui=0;如果用户u使用了标签t,则a′ut=upt(t,u),否则a′ut=0;矩阵A和Α′的转置矩阵为AT=(aiu)n×m和A′T=(a′tu)r×m;
C2.在加权的用户-物品二部图上通过两次热传导的方式进行资源重分配获得物品方面的两两用户间的相似度:
在加权的用户-物品二部图中,假设为目标用户u分配一个单位的初始资源,其他用户资源为0,得到m维初始资源向量 经过热传导扩散后得到所有用户的最终资源向量
经过热传导扩散后得到所有用户的最终资源向量 其中W为热传导过程的状态转移矩阵;
其中W为热传导过程的状态转移矩阵;
第一步用户将资源按照用户-物品之间的边权与每个物品边权之和的比分配给每个物品,扩散后可得物品资源向量 DI是与物品度相关的对角矩阵;
DI是与物品度相关的对角矩阵;
第二步物品按照物品和用户之间的边权与每个用户边权之和的比例将资源传导给用户,得到所有用户的最终资源向量 DU是与用户度相关的对角矩阵;由此可得,状态转移矩阵W=DUADIAT,该矩阵第v行u列的元素Wvu表示用户v从用户u处获得的资源:
DU是与用户度相关的对角矩阵;由此可得,状态转移矩阵W=DUADIAT,该矩阵第v行u列的元素Wvu表示用户v从用户u处获得的资源:

将用户v从用户u处获得的资源Wvu定义为加权user-item二部图中目标用户u和用户v之间的相似度:

其中,upi(i,u)为用户u对物品i的偏好度, 表示user-item加权二部图中用户v的度,
表示user-item加权二部图中用户v的度, 表示user-item加权二部图中物品i的度;Eui表示user-item加权二部图中用户u与物品i之间的连边;
表示user-item加权二部图中物品i的度;Eui表示user-item加权二部图中用户u与物品i之间的连边;
C3.在加权的用户-标签二部图上通过两次热传导的方式进行资源重分配获得标签方面的两两用户间的相似度:
在加权的用户-标签二部图中,假设为目标用户u分配一个单位的初始资源,其他用户资源为0,得到m维初始资源向量 传导扩散后得到所有用户的最终资源向量
传导扩散后得到所有用户的最终资源向量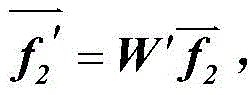 其中W′为状态转移矩阵;
其中W′为状态转移矩阵;
第一步用户将资源按照用户和标签之间的边权与每个标签边权之和的比分配给每个标签,扩散后可得标签资源向量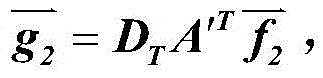 DT是与标签度相关的对角矩阵;
DT是与标签度相关的对角矩阵;
第二步标签按照标签和用户之间的边权与每个用户边权之和的比例将资源返回给用户,得到所有用户的最终资源向量 D′U是与用户度相关的对角矩阵,可得状态转移矩阵W′=D′UA′DTA′T,该矩阵第v行u列的元素W′vu表示用户v从用户u处获得的资源:
D′U是与用户度相关的对角矩阵,可得状态转移矩阵W′=D′UA′DTA′T,该矩阵第v行u列的元素W′vu表示用户v从用户u处获得的资源:

将W′vu定义为加权user-tag二部图中目标用户u和用户v之间的相似度:

其中,upt(t,u)为用户u对标签t的偏好度, 表示user-tag二部图中标签t的度;
表示user-tag二部图中标签t的度; 表示user-tag二部图中用户v的度;Eut表示user-tag加权二部图中用户u与标签t之间的边;
表示user-tag二部图中用户v的度;Eut表示user-tag加权二部图中用户u与标签t之间的边;
C4.引入一个可调节的参数λ整合得到的物品方面和标签方面的用户相似度sim(v,u)和sim′(v,u)得到最终的用户相似度为:
similarity(v,u)=λsim(v,u)+(1-λ)sim′(v,u),λ∈[0,1];
所述步骤D具体包括:
D1.给定目标用户u和未选择的物品i,用户u对物品i的预测评分为:

其中,v是已经对物品i评过分的用户,rv,i表示用户v对物品i的评分, 和
和 分别表示用户u和用户v的所有评分的平均评分,Nu(s)表示用户u的s个邻近用户;
分别表示用户u和用户v的所有评分的平均评分,Nu(s)表示用户u的s个邻近用户;
D2.将用户未选择的物品按照预测评分值大小降序排列,将排序靠前的若干个物品推荐给用户。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2020113185779 | 2020-11-23 | ||
| CN202011318577 | 2020-11-23 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113239288A CN113239288A (zh) | 2021-08-10 |
| CN113239288B true CN113239288B (zh) | 2023-06-20 |
Family
ID=77135069
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110538107.1A Active CN113239288B (zh) | 2020-11-23 | 2021-05-18 | 基于加权三部图的协同过滤推荐方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113239288B (zh) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105956146A (zh) * | 2016-05-12 | 2016-09-21 | 腾讯科技(深圳)有限公司 | 一种物品信息的推荐方法及装置 |
| CN109165847A (zh) * | 2018-08-24 | 2019-01-08 | 广东工业大学 | 一种基于推荐系统的项目推荐方法、装置及设备 |
| CN109308654A (zh) * | 2018-11-20 | 2019-02-05 | 辽宁师范大学 | 基于物品能量扩散和用户偏好的协同过滤推荐方法 |
| CN111400483A (zh) * | 2020-03-17 | 2020-07-10 | 重庆邮电大学 | 基于时间加权的三部图新闻推荐方法 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7461073B2 (en) * | 2006-02-14 | 2008-12-02 | Microsoft Corporation | Co-clustering objects of heterogeneous types |
| US20180253696A1 (en) * | 2017-03-06 | 2018-09-06 | Linkedin Corporation | Generating job recommendations using co-viewership signals |
-
2021
- 2021-05-18 CN CN202110538107.1A patent/CN113239288B/zh active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105956146A (zh) * | 2016-05-12 | 2016-09-21 | 腾讯科技(深圳)有限公司 | 一种物品信息的推荐方法及装置 |
| CN109165847A (zh) * | 2018-08-24 | 2019-01-08 | 广东工业大学 | 一种基于推荐系统的项目推荐方法、装置及设备 |
| CN109308654A (zh) * | 2018-11-20 | 2019-02-05 | 辽宁师范大学 | 基于物品能量扩散和用户偏好的协同过滤推荐方法 |
| CN111400483A (zh) * | 2020-03-17 | 2020-07-10 | 重庆邮电大学 | 基于时间加权的三部图新闻推荐方法 |
Non-Patent Citations (2)
| Title |
|---|
| A Tripartite Graph Recommendation Algorithm Based on Item Information and User Preference;Zhenyu Yao,等;《2019 6th International Conference on Systems and Informatics (ICSAI)》;第1460-1465页 * |
| 基于用户—资源—词汇三部图的社会化推荐算法设计与实现;胡吉明,等;《情报理论与实践》;第第39卷卷(第第3期期);第130-134页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113239288A (zh) | 2021-08-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108205682B (zh) | 一种用于个性化推荐的融合内容和行为的协同过滤方法 | |
| KR100997541B1 (ko) | 신상품 추천문제 해결을 위한 내용기반 필터링과 협업 필터링을 혼합한 사용자 프로파일 기반 이미지 추천 방법 및 장치 | |
| CN104281956B (zh) | 基于时间信息的适应用户兴趣变化的动态推荐方法 | |
| Golbandi et al. | On bootstrapping recommender systems | |
| US20080301582A1 (en) | Taste network widget system | |
| US20080300958A1 (en) | Taste network content targeting | |
| WO2010037286A1 (zh) | 一种基于协同过滤的推荐方法和系统 | |
| CN102063433A (zh) | 相关项推荐方法和装置 | |
| CN105354260B (zh) | 一种融合社会网络和项目特征的移动应用推荐方法 | |
| CN113536105A (zh) | 推荐模型训练方法和装置 | |
| CN109919723B (zh) | 一种基于用户和物品的个性化推荐方法 | |
| KR20170079429A (ko) | 사용자 속성을 고려한 클러스터링 기반의 협업 필터링 방법 및 영화 추천 시스템 | |
| Ho et al. | Who likes it more? Mining worth-recommending items from long tails by modeling relative preference | |
| KR101567684B1 (ko) | 협업필터링 기반의 상품 추천 시스템에서 추천 기법을 선택하는 방법 | |
| CN104182518B (zh) | 一种协同过滤推荐方法及装置 | |
| CN107346333B (zh) | 一种基于链路预测的在线社交网络好友推荐方法与系统 | |
| KR101708254B1 (ko) | 협업적 필터링과 캐릭터 넷을 이용한 스토리 기반의 영화 추전 시스템 및 방법. | |
| CN114169927A (zh) | 基于多臂老虎机算法的产品个性化组合推荐方法 | |
| CN109308654A (zh) | 基于物品能量扩散和用户偏好的协同过滤推荐方法 | |
| CN113239288B (zh) | 基于加权三部图的协同过滤推荐方法 | |
| CN106095974A (zh) | 基于网络结构相似性的推荐系统评分预测与推荐算法 | |
| Guan et al. | Preference of online users and personalized recommendations | |
| CN115271173B (zh) | 一种基于配对法与图卷积神经网络的用户偏好预测方法 | |
| CN106649733B (zh) | 一种基于无线接入点情境分类与感知的在线视频推荐方法 | |
| WO2010009314A2 (en) | System and method of using automated collaborative filtering for decision-making in the presence of data imperfections |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |