CN113055017A - 数据压缩方法及计算设备 - Google Patents
数据压缩方法及计算设备 Download PDFInfo
- Publication number
- CN113055017A CN113055017A CN202010261686.5A CN202010261686A CN113055017A CN 113055017 A CN113055017 A CN 113055017A CN 202010261686 A CN202010261686 A CN 202010261686A CN 113055017 A CN113055017 A CN 113055017A
- Authority
- CN
- China
- Prior art keywords
- data
- compressed
- models
- processor
- data compression
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/17—Details of further file system functions
- G06F16/174—Redundancy elimination performed by the file system
- G06F16/1744—Redundancy elimination performed by the file system using compression, e.g. sparse files
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3068—Precoding preceding compression, e.g. Burrows-Wheeler transformation
- H03M7/3071—Prediction
- H03M7/3073—Time
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/60—General implementation details not specific to a particular type of compression
- H03M7/6064—Selection of Compressor
- H03M7/6082—Selection strategies
- H03M7/6088—Selection strategies according to the data type
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/40—Conversion to or from variable length codes, e.g. Shannon-Fano code, Huffman code, Morse code
- H03M7/4006—Conversion to or from arithmetic code
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Probability & Statistics with Applications (AREA)
- Algebra (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
本申请公开的数据压缩方法及计算设备,涉及数据压缩领域,解决了如何降低利用算术编码进行数据压缩的内存开销和时间开销的问题。所述方法应用于计算设备。所述方法包括:计算设备接收待压缩数据,识别待压缩数据的数据类型;根据数据类型选择一个或多个数据压缩模型,根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
Description
本申请要求于2019年12月28日提交国家知识产权局、申请号为201911385235.6、申请名称为“一种数据压缩方法”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
技术领域
本申请涉及数据压缩领域,尤其涉及数据压缩方法及计算设备。
背景技术
通常,为了降低数据存储成本,处理器可以采用数据压缩算法压缩原始数据,即将原始数据按照特定方法重构,从而降低数据冗余度,缩减原始数据占用的存储容量。常用的数据压缩算法包括字典编码和熵编码。其中,算术编码是熵编码中压缩率最高的熵编码技术。所谓算术编码是对原始数据中每个比特(bit)的概率分别编码为一个0到1区间的小数。根据香农提出的信息论,对信息的预测值越接近真实的概率分布,算术编码的压缩率越高。目前,处理器采用大量的数据压缩模型对原始数据中每个比特的概率进行预测,再根据待压缩数据的概率对待压缩数据进行压缩,得到压缩数据。从而,导致处理器利用算术编码进行数据压缩的内存开销较大,以及编码时间较长。因此,如何降低利用算术编码进行数据压缩的内存开销和时间开销是一个亟待解决的问题。
发明内容
本申请提供的数据压缩方法及计算设备,解决了如何降低利用算术编码进行数据压缩的内存开销和时间开销的问题。
为达到上述目的,本申请采用如下技术方案:
第一方面,本申请提供了一种数据压缩方法,所述方法应用于计算设备,方法包括:接收待压缩数据,识别待压缩数据的数据类型;根据数据类型选择一个或多个数据压缩模型;根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
示例性的,数据类型包括但不限于文本类型、图片类型和视频类型等等。每一种数据类型有其对应的数据压缩模型,例如文本类型对应的数据压缩模型是文本模型、词模型或者嵌套模型;图片模型对应的数据压缩模型是记录模型、图像模型或图像格式jpeg模型;视频类型对应的数据压缩模型是记录模型、声源模型或稀疏模型。可以理解的是每种数据类型对应的数据压缩模型可以是不止一种。
本申请避免了利用所有的数据压缩模型对待压缩数据进行压缩,而是对所述待压缩数据进行数据类型识别,并且根据其数据类型选择适用的数据压缩模型,从而根据选择出的数据压缩模型对所述待压缩数据进行压缩。由于选择出的与数据类型匹配的数据压缩模型的数量小于现有技术中利用算术编码进行数据压缩所使用的数据压缩模型的数量,因此降低了利用算术编码进行数据压缩的内存开销和时间开销。
可选的,第一方面所提供的方法可以由计算设备中的第一处理器执行,第一处理器主要指中央处理器。或者,该方法可以由第一处理器和第二处理器分担。第二处理器亦位于所述计算设备内部,具备计算能力,用于承担数据压缩的功能,被称作协处理器。利用协处理器分担数据压缩的操作,可以进一步地减轻第一处理器的计算负担。具体的,由第一处理器接收待压缩数据,识别所述待压缩数据的数据类型,并且根据所述数据类型选择一个或多个数据压缩模型。由第二处理器根据选择出的所述数据压缩模型对所述待压缩数据压缩。
在一种可能的实现方式中,在利用数据压缩模型对待压缩数据进行压缩之前,方法还包括:对第一样本数据进行训练,生成若干个数据压缩模型;将若干个数据压缩模型或者若干个数据压缩模型的子集存储在计算设备中,从而,以便于利用数据压缩模型对待压缩数据进行压缩。
所述若干个数据压缩模型的子集是指从所述若干个数据压缩模型选择出的一部分具有基础压缩功能的数据压缩模型,这些具有基础压缩功能的数据压缩模型可以通过相互叠加实现其他数据压缩模型的功能。
可选的,计算设备中可以设置人工智能(Artificial Intelligence,AI)芯片,由所述人工智能芯片对所述第一样本数据进行训练,生成若干个数据压缩模型。可选的,计算设备也可以不设置人工智能芯片,由第一处理器或第二处理器对所述第一样本数据进行训练,生成若干个数据压缩模型。如果设置人工智能芯片,由所述人工智能芯片对所述第一样本数据进行训练,生成若干个数据压缩模型,那么可以进一步减轻计算设备内所述第一处理器或第二处理器的计算负担。
具体的,这里包含了至少三种实现方式。(1)将所述若干个数据压缩模型或者若干个数据压缩模型的子集存储在计算设备的存储器中,第一处理器和/或第二处理器均可以从该存储器中获取与所述待压缩数据的数据类型匹配的数据压缩模型;(2)第二处理器具有自己的缓存,所述若干个数据压缩模型或者若干个数据压缩模型的子集存储在第二处理器的缓存中,第二处理器可以从自己的缓存中获取与所述待压缩数据的数据类型匹配的数据压缩模型;(3)由于第二处理器是一个处理芯片,所述若干个数据压缩模型或者若干个数据压缩模型的子集可以烧制在所述处理芯片中。在(2)或(3)的实现中,各个数据压缩模型的标识可以保存在计算设备的存储器以及所述第二处理器的缓存(或烧制在自己的芯片)中,由此,第一处理器在选择出数据类型匹配的数据压缩模型后,可以将该数据压缩模型的标识发送给第二处理器,第二处理器根据该数据压缩模型的标识获取该数据压缩模型。
可选的,方法还包括:对计算设备中存储的数据压缩模型进行升级。这里的升级是指,增加新的数据压缩模型,或者淘汰不使用或者不经常使用的数据压缩模型,或者更新其中一个或几个数据压缩模型。
可选的,方法还包括:对第二样本数据进行训练以生成M个数据类型识别模型。对所述第二样本数据进行训练的操作可以由上面描述的人工智能芯片完成,也可以由第一处理器或第二处理器完成。
在另一种可能的实现方式中,计算设备存储有M个数据类型识别模型,每个数据类型识别模型用于识别P种数据类型出现的概率,识别待压缩数据的数据类型,包括:根据M个数据类型识别模型确定待压缩数据对应的M个概率集合,每个概率集合包含P个初始概率值,P个初始概率值中的每个初始概率值用于指示待压缩数据是一种数据类型的可能性,M为大于或等于1的整数,P为大于或等于1的整数;根据M个概率集合确定待压缩数据的数据类型。
从而,计算设备可以利用数据类型识别模型输出的待压缩数据的多个可能的数据类型的概率,进而根据多个可能的数据类型的概率确定待压缩数据的数据类型,以便于根据待压缩数据的数据类型确定适用的数据压缩模型,利用适用的数据压缩模型对待压缩数据进行数据压缩,由于选择出的与数据类型匹配的数据压缩模型的数量小于现有技术中利用算术编码进行数据压缩所使用的数据压缩模型的数量,因此降低了利用算术编码进行数据压缩的内存开销和时间开销。
另外,由于不同的数据类型识别模型识别不同的数据类型的准确度可能不同。本申请利用多个数据类型识别模型输出该待压缩数据的多个可能的数据类型的不同概率,并依据多个可能的数据类型的不同概率确定待压缩数据的数据类型,从而,提高识别待压缩数据的数据类型的准确率。
可选的,根据M个概率集合确定待压缩数据的数据类型,包括:根据M个概率集合以及M个数据类型识别模型的权重比获得P个中间值;将P个中间值中大于准确度阈值的中间值对应的数据类型确定为待压缩数据的数据类型。
本申请依据数据类型识别模型的权重比和多个可能的数据类型的不同概率确定待压缩数据的数据类型的中间值,并利用准确度阈值和中间值确定待压缩数据的数据类型。从而,提高识别待压缩数据的数据类型的准确率。
第二方面,本申请提供了一种计算设备,计算设备包括一个或多个处理器,其中,所述一个或多个处理器用于接收待压缩数据,识别待压缩数据的数据类型;根据数据类型选择一个或多个数据压缩模型;根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
在一种可能的实现方式中,所述一个或多个处理器包括第一处理器和第二处理器,其中,第一处理器用于接收待压缩数据,识别待压缩数据的数据类型;根据数据类型选择一个或多个数据压缩模型;第二处理器用于根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。从而,由于将数据数据压缩的过程由其他处理器执行,有效地提高了算术编码的压缩性能。
可选的,第一处理器是中央处理器,第二处理器是协处理器。
在另一种可能的实现方式中,计算设备还包括AI芯片,AI芯片用于对第一样本数据进行训练,生成若干个数据压缩模型;第一处理器还用于将若干个数据压缩模型或者若干个数据压缩模型的子集存储在计算设备中。
可选的,第一处理器或第二处理器还用于对计算设备中存储的数据压缩模型进行升级。
在另一种可能的实现方式中,AI芯片还用于对第二样本数据进行训练以生成M个数据类型识别模型。
在另一种可能的实现方式中,每个数据压缩模型具有标识,第一处理器还用于将选择出的数据压缩模型的标识发送给第二处理器;第二处理器还用于根据标识获取对应的数据压缩模型。
在另一种可能的实现方式中,计算设备存储有M个数据类型识别模型,每个数据类型识别模型用于识别P种数据类型出现的概率,第一处理器具体用于根据M个数据类型识别模型确定待压缩数据对应的M个概率集合,每个概率集合包含P个初始概率值,P个初始概率值中的每个初始概率值用于指示待压缩数据是一种数据类型的可能性,M为大于或等于1的整数,P为大于或等于1的整数;根据M个概率集合确定待压缩数据的数据类型。
可选的,第一处理器具体用于根据M个概率集合以及M个数据类型识别模型的权重比获得P个中间值;将P个中间值中大于准确度阈值的中间值对应的数据类型确定为待压缩数据的数据类型。
第三方面,本申请实施例还提供了一种数据压缩装置,有益效果可以参见第一方面的描述此处不再赘述。所述数据压缩装置具有实现上述第一方面的实例中行为的功能。所述功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。所述硬件或软件包括一个或多个与上述功能相对应的模块。在一个可能的设计中,所述数据压缩装置包括:第一处理模块和第二处理模块。所述第一处理模块用于接收待压缩数据,识别待压缩数据的数据类型;根据数据类型选择一个或多个数据压缩模型;所述第二处理模块用于根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。第一处理模块可以实现第一处理器的功能。第二处理模块可以实现第二处理器的功能。这些单元可以执行上述第一方面方法示例中的相应功能,具体参见示例中的详细描述,此处不做赘述。
可选的,所述数据压缩装置还包括存储模块,所述第一处理模块还用于将所述待压缩数据的数据类型与所述一个或多个数据压缩模型之间的对应关系保存在所述存储模块中。所述存储模块可以是计算设备中的缓存或者第二处理器自己的缓存或者其他具有存储功能的组件。
可选的,所述数据压缩装置还包括AI芯片,所述AI芯片用于对第一样本数据进行训练,生成若干个数据压缩模型;所述第一处理模块还用于将所述若干个数据压缩模型或者所述若干个数据压缩模型的子集存储在所述计算设备中。
可选的,所述第一处理模块或所述第二处理模块还用于对所述计算设备中存储的数据压缩模型进行升级。
可选的,每个数据压缩模型具有标识,所述第一处理模块还用于将选择出的所述数据压缩模型的标识发送给所述第二处理模块;所述第二处理模块还用于根据所述标识获取对应的数据压缩模型。
可选的,所述计算设备存储有M个数据类型识别模型,每个数据类型识别模型用于识别P种数据类型出现的概率,所述第一处理模块具体用于根据所述M个数据类型识别模型确定所述待压缩数据对应的M个概率集合,每个概率集合包含P个初始概率值,所述P个初始概率值中的每个初始概率值用于指示所述待压缩数据是一种数据类型的可能性,M为大于或等于1的整数,P为大于或等于1的整数;根据所述M个概率集合确定所述待压缩数据的数据类型。
可选的,所述第一处理模块具体用于根据所述M个概率集合以及所述M个数据类型识别模型的权重比获得P个中间值;将所述P个中间值中大于准确度阈值的中间值对应的数据类型确定为所述待压缩数据的数据类型。
第四方面,提供一种数据压缩方法,该方法应用于计算设备,所述计算设备包括第一处理器和第二处理器。其中,第一处理器用于接收待压缩数据,第二处理器用于对所述待压缩数据进行压缩。
与第一方面提供的数据压缩方法相比,第四方面提供的方法中没有根据待压缩数据的数据类型对数据压缩模型进行筛选,只是设置了第二处理器专门用于处理压缩操作,由此第一处理器可以解放出来处理其他数据业务,从而也减轻了第一处理器的计算负担。
第一处理器和第二处理器与第一方面描述的一致,此处不再赘述。
第五方面,提供一种计算设备,用于执行第四方面提供的数据压缩方法。
第六方面,提供了一种计算机程序产品,所述计算机程序产品包括:计算机程序代码,当所述计算机程序代码并运行时,使得上述各方面中由计算设备执行的方法被执行。
第七方面,本申请提供了一种芯片系统,该芯片系统包括处理器,用于实现上述各方面的方法中计算设备的功能。在一种可能的设计中,所述芯片系统还包括存储器,用于保存程序指令和/或数据。该芯片系统,可以由芯片构成,也可以包括芯片和其他分立器件。
第八方面,本申请提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,当该计算机程序被运行时,实现上述各方面中由计算设备执行的方法。
本申请中,计算设备和数据压缩装置的名字对设备本身不构成限定,在实际实现中,这些设备可以以其他名称出现。只要各个设备的功能和本申请类似,属于本申请权利要求及其等同技术的范围之内。
附图说明
图1为本申请一实施例提供的计算设备的组成示意图;
图2为本申请一实施例提供的数据压缩方法的流程图;
图3为本申请一实施例提供的数据类型识别模型示意图;
图4为本申请一实施例提供的数据压缩方法的流程图;
图5为本申请一实施例提供的数据压缩装置的组成示意图。
具体实施方式
本申请说明书和权利要求书及上述附图中的术语“第一”、“第二”和“第三”等是用于区别不同对象,而不是用于限定特定顺序。
在本申请实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本申请实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
下面将结合附图对本申请实施例的实施方式进行详细描述。
图1为本申请一实施例提供的计算设备的组成示意图,如图1所示,计算设备100可以包括处理器101、存储器102、处理器103和通信总线104。
下面结合图1对计算设备100的各个构成部件进行具体的介绍:
计算设备100可以包括多个处理器,例如图1中所示的处理器101和处理器103。处理器101是计算设备的控制中心。通常情况下,处理器101是一个中央处理器(centralprocessing unit,CPU),包括一个CPU核或多个CPU核,例如图1中所示的CPU0和CPU1。此外,处理器101也可以是特定集成电路(application specific integrated circuit,ASIC),或者是被配置成一个或多个集成电路,例如:一个或多个微处理器(digital signalprocessor,DSP),或,一个或者多个现场可编程门阵列(field programmable gate array,FPGA)。处理器101可以通过运行或执行存储在存储器102内的软件程序,以及调用存储在存储器102内的数据,执行计算设备100的各种功能。
处理器103可以和处理器101具有相同物理形态的处理器,也可以和处理器101具有不同物理形态的处理器。但处理器103是具备计算能力的处理芯片,用于承担数据压缩的功能,以减轻处理器101的计算负担。在本申请实施例中,处理器103用于协助处理器101对待压缩数据进行压缩。例如,处理器103根据处理器101指示的一个或多个数据压缩模型对待压缩数据进行压缩。在实际应用中,处理器103可以是一个加速卡或协处理器或图形处理器(Graphics Processing Unit,GPU)或神经网络处理器(Neural-network ProcessingUnit,NPU)等。在本实施例中,处理器101可以配置一个或多个,处理器103也可以配置一个或多个。然而,需要说明的是,处理器103在本实施例中是一个可选的组件。即使只有一个处理器101,也可以由该处理器101独立完成接收待压缩数据,并识别待压缩数据的数据类型,根据数据类型选择一个或多个数据压缩模型,然后利用所述一个或多个数据压缩模型压缩所述待压缩数据。当计算设备100既包含处理器101也包含处理器103时,可以由处理器101和处理器103共同配合完成上述操作。例如,处理器101主要用于接收待压缩数据,并识别待压缩数据的数据类型,根据数据类型选择一个或多个数据压缩模型,然后,将待压缩数据发送给处理器103,以及指示处理器103根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
处理器101和处理器103均可以通过通信总线104访问存储器102。存储器102中存储有数据压缩模型集合,所述数据压缩模型集合包括多个数据压缩模型。另外,存储器102中还存储待压缩数据的数据类型与一个或多个数据压缩模型之间的对应关系。可理解的,所述对应关系可以是待压缩数据的数据类型与一个或多个数据压缩模型的整体之间的对应关系。或者,所述对应关系可以是待压缩数据的数据类型与所述一个或多个数据压缩模型中的每个数据压缩模型之间的对应关系。处理器101可以从存储器102中调用所述对应关系,根据数据类型和所述对应关系选择一个或多个数据压缩模型。
通常,针对不同的数据类型可以设计不同的数据压缩模型,因此,可以根据不同的数据类型对数据压缩模型分类。存储器102可以存储其他数据类型与一个或多个数据压缩模型之间的对应关系,本申请对数据类型与数据压缩模型的对应关系的个数不予限定。
另外,存储器102还用于存储执行本申请方案的软件程序,并由处理器101来控制执行。
在物理形态上,存储器102可以是只读存储器(read-only memory,ROM)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,RAM)或者可存储信息和指令的其他类型的动态存储设备,也可以是电可擦可编程只读存储器(electrically erasable programmable read-only memory,EEPROM)、只读光盘(compact disc read-only memory,CD-ROM)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器102可以是独立存在,通过通信总线104与处理器101相连接。存储器102也可以和处理器101集成在一起,不予限定。
关于所述数据压缩模型的来源。本实施例至少提供了两种实施方式。一种是从传统技术中所有的数据压缩模型中筛选出常用的数据压缩模型,或者,常用的数据压缩模型叠加生成的其他数据压缩模型作为所述数据压缩模型。所谓由常用的数据压缩模型叠加生成的其他数据压缩模型主要是指通过低阶数据压缩模型叠加生成高阶数据压缩模型。
这些常用的数据压缩模型包括但不限于:嵌套模型(nest model)、上下文模型(context model)、间接模型(indirect model)、文本模型(text model)、稀疏模型(sparsemodel)、可扩展标记语言模型(xml model)、匹配模型(match model)、距离模型(distancemodel)、可执行程序模型(exe model)、词模型(word model)、记录模型(record model)、图像模型(pic model)、部分匹配预测模型(prediction by partial matching model,PPMDmodel)、动态马尔可夫压缩模型(dynamic markov compression model,DMCM)、字节模型(byte model)、线性预测模型(linear predicition model)、自适应预测模型(adaptivepredicition model)、声源模型(wav model)和通用模型(common model)。其中,嵌套模型是根据待预测字节中出现的嵌套符号(比如[])的信息预测后续字节的模型。上下文模型是根据待预测字节之前出现的连续字节上下文来预测后续字节的模型。间接模型是通过待预测字节前1-2个字节的比特的历史信息以及上下文来预测后续字节的模型。文本模型是通过词语、句子和段落等信息来预测后续字节的模型。通常,用于预测文本类数据。稀疏模型是通过查找待预测字节之前不连续的字节作为上下文预测后续字节的模型。比如,待预测字节之前的1个字节和3个字节预测后续字节的模型。可扩展标记语言模型是通过待预测字节包含的标签等特征信息预测后续字节的模型。匹配模型是通过查找待预测字节之前上下文中是否有匹配的信息,并根据匹配信息来预测后续字节的模型。距离模型是利用当前待预测字节和某些特殊字节预测后续字节的模型。比如,特殊字节为空格字符的距离。可执行程序模型模型是利用特定的指令集和操作码预测后续字节的模型。词模型就是根据出现的词语信息预测后续字节的上下文模型。记录模型模型是通过查找文件中的行列信息预测后续字节的上下文。在表格中一行称为一条记录,多用于数据库和表格中。图像模型是利用图片的特征预测后续字节的上下文模型。比如,利用图片的灰度或像素点预测后续字节的上下文模型。部分匹配预测模型是根据待预测字节之前连续出现的多个字节,在待预测字节中进行查找匹配,如果没有找到则减少多个字节中的部分字节,再根据减少后的自己查找匹配,直到找到或者记录为新的字节,以此来预测的模型。动态马尔可夫压缩模型是使用可变长度的比特级上下文历史表预测下一个比特的模型。字节模型是根据比特的历史信息预测后续比特的模型。线性预测模型是根据线性回归分析来预测后续字节的上下文模型。自适应模型是根据其他模型计算出的概率和已知的上下文,来调整计算出的概率的模型。声源模型是通过音频文件中的特征信息预测后续字节的上下文模型。通用模型是对新的数据类型的数据或者未识别的数据类型的数据进行概率预测的模型。该通用模型可以由多个其他模型叠加生成。由于数据压缩模型集合是经过筛选的数据压缩模型,其数量远小于原来使用的数据压缩模型的数量,因此占用的存储空间较低,可以将数据压缩模型集合存储在处理器103上,由处理器103完成压缩数据的操作。从而,减轻了处理器101的计算负担,以及降低了内存开销和时间开销。
在一些实施例中,数据类型与数据压缩模型之间的对应关系可以以表格的形式呈现,即表1呈现了数据类型与数据压缩模型之间的对应关系。处理器101识别到待压缩数据的数据类型后,可以查询表1确定待压缩数据的数据类型对应的一个或多个数据压缩模型。
表1

由表1可知,文本类型对应文本模型、词模型和嵌套模型。若处理器101确定待压缩数据的数据类型是文本类型,处理器101可以查询表1获知文本类型对应文本模型、词模型和嵌套模型,利用文本模型、词模型和嵌套模型对待压缩数据进行压缩。
可执行程序类型对应可执行程序模型和稀疏模型。若处理器101确定待压缩数据的数据类型是可执行程序类型,处理器101可以查询表1获知可执行程序类型对应可执行程序模型和稀疏模型,利用可执行程序模型和稀疏模型对待压缩数据进行压缩。
若处理器101未识别到待压缩数据的数据类型,确定待压缩数据的数据类型为其他(通用)类型,处理器101可以查询表1获知其他(通用)类型对应文本模型、稀疏模型和记录模型,利用文本模型、稀疏模型和记录模型对待压缩数据进行压缩。
需要说明的是,表1只是以表格的形式示意数据类型与数据压缩模型之间的对应关系在存储设备中的存储形式,并不是对数据类型与数据压缩模型之间的对应关系在存储设备中的存储形式的限定,当然,数据类型与数据压缩模型之间的对应关系在存储设备中的存储形式还可以以其他的形式存储,本申请实施例对此不做限定。
具体的,可以通过软件方式将数据压缩模型集合存储在处理器103上。例如,将所述数据压缩模型集合所包含的数据压缩模型存储在与处理器103内置或者相耦合的存储器中。可选的,也可以通过硬件方式在处理器103上实现存储所述数据压缩模型集合。例如,以设计处理器103的电路结构的形式将所述数据压缩模型集合烧制在处理器103上。
随着科学技术的发展,如果产生了新的数据类型,进而对上述数据压缩模型集合进行升级。例如,将新的数据类型对应的数据压缩模型存储在处理器103上。新的数据类型包括基因数据的数据类型和大数据的数据类型,也可以淘汰已有的数据压缩模型中使用频率较低的模型,还可以对已有的某一种或多种数据压缩模型进行修改。
在一些实施例中,可以利用现有的数据压缩模型组合生成新的数据压缩模型,通过软件升级方式对存储在处理器103上的数据压缩模型集合进行更新。例如,高阶数据压缩模型可以通过低阶数据压缩模型实现。从而,无需重新改变硬件电路,极大地降低了处理器103的升级成本。
在另一些实施例中,可以通过设计处理器103的电路结构实现存储不同的数据压缩模型。在对数据压缩模型集合进行升级时,可以改变处理器103的电路结构来对数据压缩模型集合进行升级。由于处理器103存储的是常用的数据压缩模型,因此,即使对数据压缩模型集合进行升级,硬件电路也改动较少,升级成本较低。
再一种实施方式是,在计算设备100设置人工智能(Artificial Intelligent,AI)芯片105,由人工智能芯片105周期性对接收的样本数据进行训练,生成若干个数据压缩模型,通过通信总线104将这些数据压缩模型存储在存储器102,或者传递给处理器103存储。人工智能芯片105的形态可以是一个芯片或者其他物理组件,例如可以是用于构建神经网络模型的训练芯片,也可以是利用神经网络模型进行推理的推理芯片。神经网络模型也可以称为人工神经网络、神经网络(Neural Networks,NNs)或连接模型(Connection Model)。所谓“人工神经网络”是一种应用类似于大脑神经突触联接的结构进行分布式并行信息处理的算法数学模型。该人工神经网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。与前面所列举的实施方式相比,通过人工智能芯片105周期性地对样本数据进行训练,以生成若干个数据压缩模型,可以更好地适应数据压缩模型的变化。
另外,每个数据压缩模型具有一个标识,处理器103中还保存有数据压缩模型与其标识之间的对应关系,因此,处理器103可以根据处理器101发送给它的数据压缩模型的标识获得相应的数据压缩模型,对待压缩数据进行压缩。
通信总线104,可以是工业标准体系结构(industry standard architecture,ISA)总线、外部设备互连(peripheral component,PCI)总线或扩展工业标准体系结构(extended industry standard architecture,EISA)总线等。该总线可以分为地址总线、数据总线、控制总线等。为便于表示,图1中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
图1中示出的设备结构并不构成对计算设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
接下来,结合图2,对本申请一实施例提供的数据压缩方法进行详细说明,该方法应用于图1所示的计算设备100中,在这里以处理器101和处理器103为例进行说明。如图2所示,该方法可以包括以下步骤。
S201、处理器101接收待压缩数据,识别待压缩数据的数据类型。
在识别待压缩数据的数据类型前,可以利用机器学习或人工神经网络(Artificial Neural Networks,ANNs)对大量的样本数据进行训练,得到数据类型识别模型。或者,数据类型识别模型也可以由人工智能芯片105对样本数据进行训练。该数据类型识别模型用于指示待压缩数据与待压缩数据的数据类型的映射关系。进而,处理器101可以利用数据类型识别模型识别待压缩数据的数据类型。
数据类型识别模型包括但不限于:朴素贝叶斯( Bayes,NB)、极限梯度提升决策树(Extreme Gradient Boosting Tree,XGBoost)、多层感知机(MultilayerPerceptron,MLP)和上述这些模型的组合等模型。
Bayes,NB)、极限梯度提升决策树(Extreme Gradient Boosting Tree,XGBoost)、多层感知机(MultilayerPerceptron,MLP)和上述这些模型的组合等模型。
样本数据可以来源于数据块或文件片段。样本数据包括但不限于:文本数据、图片数据、视频数据、基因数据、可执行程序、虚拟硬盘数据和数据库数据等。对应的,样本数据的数据类型包括但不限于:文本类型、图片类型、视频类型、基因类型、可执行程序类型、虚拟硬盘类型和数据库类型等。
可选的,可以从数据库中获取样本数据。或者,样本数据可以是开源数据或测试数据。
在一些实施例中,可以根据已知的数据类型为样本数据设置标识,将样本数据和样本数据的标识输入至人工神经网络进行训练,得到数据类型识别模型。例如,样本数据为文本数据,可以依据文件后缀名来为文本数据设置标识,将文本数据和文本的标识输入至人工神经网络进行训练,得到文本数据与文本类型的映射关系。
示例的,如图3所示,为本申请一实施例提供的数据类型识别模型示意图。将待压缩数据输入至数据类型识别模型,可以识别出文本类型、图片类型、视频类型、基因类型、可执行程序类型、虚拟硬盘类型、数据库类型和其他类型。其他类型可以是指通用类型。
在本申请实施例中,数据类型识别模型可以是由其他设备预先训练得到,再将数据类型识别模型导入到处理器101,以便处理器101利用数据类型识别模型识别待压缩数据的数据类型。
可选的,通过训练上述样本数据优化数据类型识别模型的内部权重后,还可以利用部分样本数据验证数据类型识别模型,检验训练得到的数据类型识别模型是否可靠,并调节迭代次数和学习率等数据类型识别模型的参数。数据类型识别模型的参数包括内部权重、权重比和准确度阈值。由于每一种数据类型识别模型对于不同的数据类型预测能力可能不一样,本申请可以根据不同的准确率为每一种数据类型识别模型的预测概率分配不同的权重。
在识别待压缩数据的数据类型时,处理器101可以先初始化数据类型识别模型的参数。然后,将待压缩数据输入至数据类型识别模型,得到多个数据类型的概率,处理器101可以将多个数据类型的概率中大于准确度阈值的概率对应的数据类型确定为待压缩数据的数据类型。
例如,处理器101将待压缩数据输入至数据类型识别模型,可以得到文本类型的概率、图片类型的概率、视频类型的概率、基因类型的概率、可执行程序类型的概率、虚拟硬盘类型的概率、数据库类型的概率和其他类型的概率。若文本类型的概率大于准确度阈值,处理器101确定待压缩数据的数据类型为文本类型。
可选的,若处理器101未识别出待压缩数据的数据类型,可以确定待压缩数据的数据类型为其他类型。
在一些实施例中,为了提高识别待压缩数据的数据类型的准确率,处理器101可以利用多个数据类型识别模型识别待压缩数据的数据类型。示例的,如图4所示,识别待压缩数据的数据类型可以由以下步骤实现。在这里以M个数据类型识别模型为例,对识别待压缩数据的数据类型进行说明。
S201a、处理器101接收待压缩数据,根据M个数据类型识别模型确定待压缩数据对应的M个概率集合。
可理解的,处理器101将待压缩数据分别输入M个数据类型识别模型,每个数据类型识别模型输出一个概率集合。M个概率集合中的每个概率集合包含P个初始概率值。P个初始概率值中的每个初始概率值用于指示待压缩数据是一种数据类型的可能性。P表示数据类型识别模型可识别的数据类型的个数。其中,M为大于或等于1的整数,P为大于或等于1的整数。
可选的,M个数据类型识别模型中每个数据类型识别模型可识别的数据类型相同。可理解的,对于同一个数据类型,M个数据类型识别模型中每个数据类型识别模型输出该数据类型的一个初始概率值,M个数据类型识别模型可共输出该数据类型的M个初始概率值。
可选的,M个数据类型识别模型共输出M乘以P个初始概率值。对于同一数据类型识别模型确定的P个初始概率值,P个初始概率值可以相同,也可以不同。对于不同数据类型识别模型确定同一个数据类型的初始概率值可以相同也可以不同,不予限定。
示例的,假设M=3,P=6,处理器101将待压缩数据分别输入3个数据类型识别模型,每个数据类型识别模型输出一个概率集合,即得到3个概率集合。3个概率集合中的每个概率集合包含6个初始概率值。3个数据类型识别模型共输出18(3*6)个初始概率值。
S201b、处理器101根据M个概率集合确定待压缩数据的数据类型。
首先,处理器101根据M个概率集合以及M个数据类型识别模型的权重比获得P个中间值。
在一些实施例中,对于P个数据类型中第j个数据类型,处理器101可以根据对应该第j个数据类型的M个初始概率值和M个数据类型识别模型的权重比确定该第j个数据类型的中间值。第j个数据类型的中间值满足公式(1)。

其中,j为整数,j∈[1,P]。Pj表示第j个数据类型的中间值。Wi表示第i个数据类型识别模型的权重比。PMi表示第i个数据类型识别模型输出的第j个数据类型的初始概率值。
可理解的,处理器101确定P个数据类型中每个数据类型的中间值后,得到P个数据类型的中间值。可选的,P个数据类型的中间值可以相同,也可以不同,不予限定。
进一步的,处理器101根据准确度阈值和P个数据类型的中间值确定待压缩数据的数据类型。例如,处理器将P个数据类型的中间值中大于准确度阈值的中间值对应的数据类型确定为待压缩数据的数据类型。
S202、处理器101根据待压缩数据的数据类型选择一个或多个数据压缩模型。
通常,针对不同的数据类型可以设计不同的数据压缩模型,因此,可以针对不同的数据类型预先对数据压缩模型分类。可以预先定义数据类型与数据压缩模型之间的对应关系。在一些实施例中,利用存储器102预先存储数据类型与数据压缩模型之间的对应关系。在处理器101确定数据类型后,可以先从存储器102中调取数据类型与数据压缩模型之间的对应关系,然后根据待压缩数据的数据类型从数据类型与数据压缩模型之间的对应关系中获取一个或多个数据压缩模型。数据类型与数据压缩模型之间的对应关系包含待压缩数据的数据类型与一个或多个数据压缩模型之间的对应关系。
示例的,假设待压缩数据的数据类型为文本类型。处理器101根据文本类型确定文本类型对应的数据压缩模型包括文本模型(TextModel)、词模型(WordModel)和嵌套模型(NestModel)。
S203、处理器101将待压缩数据发送给处理器103,并指示处理器103根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
处理器101可以通过发送指示信息指示处理器103根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
在一些实施例中,数据压缩模型具有标识。指示信息包括待压缩数据和选择出的所述数据压缩模型的标识。处理器103存储有数据压缩模型与其标识之间的对应关系。处理器103可以接收到指示信息后,可以根据数据压缩模型的标识获取数据压缩模型。
在另一些实施例中,处理器101根据待压缩数据的数据类型选择的一个或多个数据压缩模型可以认为是一个数据压缩模型集合。数据压缩模型集合具有标识。指示信息包括待压缩数据和数据压缩模型集合的标识。处理器103存储有数据压缩模型集合与其标识之间的对应关系。处理器103可以接收到指示信息后,可以根据数据压缩模型集合的标识获取数据压缩模型集合,即处理器103获取待压缩数据的数据类型对应的一个或多个数据压缩模型。
S204、处理器103接收待压缩数据,并根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。
可理解的,处理器103中预置有若干个数据压缩模型。处理器103根据数据压缩模型的标识确定了一个或多个数据压缩模型后,从预置的若干个数据压缩模型中获取一个或多个数据压缩模型。
处理器103先根据一个或多个数据压缩模型确定待压缩数据中每个比特的概率,然后根据待压缩数据中每个比特的概率和算术编码算法对待压缩数据编码,得到压缩数据。
在一些实施例中,假设处理器103根据N个数据压缩模型对待压缩数据进行压缩。N为大于或等于1的整数。处理器103可以根据N个数据压缩模型确定待压缩数据对应的N个概率集合,以及根据N个概率集合确定待压缩数据中每个比特的概率。
处理器103将待压缩数据分别输入N个数据压缩模型,每个数据压缩模型输出一个概率集合。N个概率集合中的每个概率集合包含Q个初始概率值。Q个初始概率值中的每个初始概率值用于指示待压缩数据中一个比特的初始概率值。Q表示待压缩数据包括的比特的个数。Q为大于或等于1的整数。
可理解的,对于同一个比特,N个数据压缩模型中每个数据压缩模型输出该比特的一个初始概率值,N个数据压缩模型可共输出该比特的N个初始概率值。
需要说明的是,数据压缩模型预先设置有概率初始值。例如,概率初始值为数据压缩模型预测比特为1的初始概率值。对于待压缩数据的第一位比特,数据压缩模型可以利用概率初始值预测第一位比特的初始概率值。对于待压缩数据的第二位比特,数据压缩模型可以利用第一位比特的初始概率值预测第二位比特的初始概率值。可理解的,对于待压缩数据的第y+1位比特,数据压缩模型可以利用第y位比特的初始概率值预测第y+1位比特的初始概率值。依次类推,得到待压缩数据的每个比特的初始概率值。y为整数,y∈[1,Q]。
可选的,N个数据压缩模型共输出N乘以Q个初始概率值。对于同一数据压缩模型确定的Q个初始概率值,Q个初始概率值可以相同,也可以不同。对于不同数据压缩模型确定同一个比特的初始概率值可以相同也可以不同,不予限定。
示例的,假设N=3,Q=6,处理器103将待压缩数据分别输入3个数据压缩模型,每个数据压缩模型输出一个概率集合,即得到3个概率集合。3个概率集合中的每个概率集合包含6个初始概率值。3个数据压缩模型共输出18(3*6)个初始概率值。
需要说明的是,第y位比特的初始概率值可以是处理器103根据第y-1位比特的初始概率值确定的。或者,可替换描述为,第y位比特的初始概率值可以是处理器103根据第y-1位比特的初始概率值预测得到的。或者,处理器103可以根据第y位比特的初始概率值预测第y+1位比特的初始概率值。
进一步的,处理器103根据N个概率集合以及N个数据压缩模型的权重比获得待压缩数据中每个比特的概率。
在一些实施例中,对于Q个比特中第y位比特,处理器103可以根据对应该第y位比特的N个初始概率值和N个数据压缩模型的权重比确定该第y位比特的概率。第y位比特的概率满足公式(2)。

其中,y为整数,y∈[1,Q]。Py表示第y位比特的概率。Sx表示第x个数据压缩模型的权重比。PNx表示第x个数据压缩模型输出的第y位比特的初始概率值。
可选的,Q个比特的概率可以相同,也可以不同,不予限定。
需要说明的是,在预测待压缩数据包含的比特的概率时,数据压缩模型的参数可以根据已有的预测值不断地进行调整,以此来获得更加准确的比特的概率。例如,可以利用神经网络对数据压缩模型的权重比进行训练,以此来获得更加准确的权重比,进而获得更加准确的比特的概率。
例如,数据压缩模型预先设置有数据压缩模型的初始权重比。例如,初始权重比为数据压缩模型预测比特为1的概率的权重比。数据压缩模型每预测一位比特后,调整数据压缩模型的权重比。对于待压缩数据的第一位比特,数据压缩模型可以根据对应该第一位比特的N个初始概率值和N个数据压缩模型的初始权重比确定该第一位比特的概率。对于待压缩数据的第二位比特,数据压缩模型可以根据对应该第二位比特的N个初始概率值和N个数据压缩模型的调整后的权重比确定该第二位比特的概率。可理解的,数据压缩模型预测第y+1位比特的概率采用的权重比可以是数据压缩模型预测第y位比特的概率后调整的权重比。
相对于传统技术,处理器根据所有的数据压缩模型对待压缩数据进行压缩,导致内存开销和时间开销极高。本申请实施例提供的数据压缩方法,处理器101依据待压缩数据的数据类型筛选一个或多个数据压缩模型,从而减少了数据压缩过程中采用的数据压缩模型的个数,进而减少了预测待压缩数据的概率的时长,降低了利用算术编码进行数据压缩的内存开销和时间开销。进一步地,由于将数据数据压缩的过程卸载到处理器103执行,有效地提高了算术编码的压缩性能。
下面以文本数据为例对本申请实施例提供的数据压缩方法进行举例说明。
在这里,利用样本数据对朴素贝叶斯模型、极限梯度提升决策树模型和多层感知机模型分别进行训练和验证,获得三种模型的内部权重,模型之间的权重比和准确度阈值。假设朴素贝叶斯的权重比为0.4。极限梯度提升决策树的权重比为0.1。多层感知机的权重比为0.5。准确度阈值为0.8。样本数据的数据类型包含文本类型、图片类型、视频类型、基因类型、数据库类型和其他类型。为便于描述,以M1表示朴素贝叶斯模型,M2表示极限梯度提升决策树模型。M3表示多层感知机模型。以W1表示朴素贝叶斯的权重比。以W2表示极限梯度提升决策树的权重比。以W3表示多层感知机的权重比。
在识别文本数据的数据类型时,处理器101将文本数据分别输入至朴素贝叶斯模型、极限梯度提升决策树模型和多层感知机模型,每种模型分别输出六种数据类型的初始概率值,如下所示:
PM1={P文本=0.8,P图片=0.05,P视频=0.02,P基因=0.03,P数据库=0.01,P其他=0.09};
PM2={P文本=0.6,P图片=0.1,P视频=0.02,P基因=0.08,P数据库=0.0,P其他=0.2};
PM3={P文本=0.9,P图片=0.02,P视频=0.01,P基因=0.0,P数据库=0.02,P其他=0.05}。
其中,PM1表示朴素贝叶斯模型输出的概率集合。PM2表示极限梯度提升决策树模型输出的概率集合。PM3表示多层感知机模型输出的概率集合。P文本表示文本类型的初始概率值。P图片表示图片类型的初始概率值。P视频表示视频类型的初始概率值。P基因表示基因类型的初始概率值。P数据库表示数据库类型的初始概率值。P其他表示其他类型的初始概率值。
处理器101根据数据类型识别模型的权重比,计算每种数据类型的中间值。中间值满足公式(3)。
P=W1*PM1+W2*PM2+W3*PM3 (3)
对于文本类型的中间值,P1=0.4*0.8+0.1*0.6+0.5*0.9=0.83。
对于图片类型的中间值,P2=0.4*0.05+0.1*0.1+0.5*0.02=0.04。
对于视频类型的中间值,P3=0.4*0.02+0.1*0.02+0.5*0.01=0.015。
对于基因类型的中间值,P4=0.4*0.03+0.1*0.08+0.5*0.0=0.02。
对于数据库类型的中间值,P5=0.4*0.01+0.1*0.0+0.5*0.02=0.014。
对于其他类型的中间值,P6=0.4*0.09+0.1*0.2+0.5*0.05=0.081。
处理器101根据准确度阈值,确定上述六种中间值中文本类型的中间值大于0.8(P1=0.85),因此输入数据的数据类型为文本类型。
在一些实施例中,可以利用文本类型查询表1,得到文本类型对应的数据压缩模型。文本类型对应的数据压缩模型包括文本模型(text model)、词模型(word model)和嵌套模型(nest model)。
在确定了文本类型后,处理器101将待压缩数据发送给处理器103,并指示处理器103根据文本类型对应的数据压缩模型对待压缩数据进行压缩。假设文本模型预测下一位比特为1的概率初始值均为0.5。词模型预测下一位比特为1的概率初始值均为0.5。嵌套模型预测下一位比特为1的概率初始值均为0.2。文本模型的初始权重比为0.33。词模型的初始权重比为0.33。嵌套模型的初始权重比为0.34。待压缩数据为01001101。可理解的,待压缩数据包括八个比特位,即Q=8。y为整数,y∈[1,8]。当处理器103读取第y位比特时,三个模型预测第y位比特为1的概率更新,将更新后比特的概率显示如下表2所示。
表2

同理,对于各个模型的权重比调整如下表3所示。
表3

处理器103将三个数据压缩模型计算出的比特的初始概率值进行合成,得到待压缩数据的每个比特的概率。每个比特的概率满足公式(4)。
P=S1*PN1+S2*PN2+S3*PN3 (4)
下一个比特为1的概率如下表4所示。
表4

可选的,处理器103可以使用人工神经网络将多个初始概率值进行加权计算得到概率。人工神经网络包括但不限于使用长短期记忆模型(Long Short-Term Memory,LSTM)、门控循环单元(gated recurrent neural,GRU)、全连接模型(full connection,FC)或其他神经网络模型等。从而,利用人工神经网络合成多个初始概率值可以得到更加精确的比特的概率,进而提高待压缩数据的压缩率。
处理器103根据待压缩数据的每个比特的概率和算术编码算法对待压缩数据编码,得到算术编码后区间,如下表5所示。
表5

处理器103根据公式(5)确定压缩数据。
z1≤c*2^(-b)<(c+1)*2^(-c)≤z2 (5)
其中,c为整数,b为最小位数。z1为比特的概率的下限区间,z2为比特的概率的上限区间。假设预测比特为1的概率为P。若读到的比特为1,那么更新下限z1=z1+(1-P)*(z2-z1)。若读到的比特为0,那么更新上限z2=z1+(1-P)*(z2-z1)。
此时,寻找到最小值b为6,得到的c的值为23。最终输出的编码值结果为23的二进制数值,即压缩数据为010111。
在预测上下文匹配信息时,数据压缩模型的参数需要通过已有的概率和更新的上下文的信息进行进行不断调整,以此来输出更加准确的概率预测值。
在一个示例中,处理器103是基于当前连续出现过的比特来预测下一比特的,需要当前比特的信息和次数n。次数n表示之前连续出现的与当前比特相同比特的次数。当n越大,则预测下一个比特和当前比特相同的概率越高。每当出现与之前连续比特不同时,更新当前比特的信息和次数n也更新为1。
假设当前第y位比特为0,且已经连续出现了3个比特为0,即n=3。处理器103在预测第y+1位比特为1的概率为0.3,将概率写入算术编码器后,当读入第y+1位的概率为0时,那么数据压缩模型中所需要的当前比特的信息保持不变,次数n更新为4。而在预测第y+2位比特为1的概率就会变为0.25,因为之前比特0出现的次数增加导致了预测比特为0的概率上升,而预测比特为1的概率则对应下降。如果读入第y+1位的概率为1时,那么当前比特更新为1,n也更新为1。当预测第y+2位比特为1的概率就会上升为0.55。
在一些实施例中,概率更新模块可以基于当前已经读入的比特对概率预测模块所需要的特征信息不断更新,确保概率预测模块预测下一个比特的准确性。
概率混合模型可以将多个概率统计模型计算出的比特的初始概率值进行合成,得到一个最精确的比特的概率。概率混合模块可以使用神经网络将多个初始概率值进行加权计算得到比特的概率。神经网络包括但不限于使用长短期记忆模型、门控循环单元、全连接模型或其他神经网络模型等。
算术编码模块将得到的各比特的概率进行算术编码操作,实现数据压缩。算术编码运算复杂,具有较高的计算开销,并且与概率统计模块结合紧密。为了降低计算开销,算术压缩算法都是按位编码,使用硬件执行该算术编码模块具有非常高的效率。与压缩过程相反,解压阶段使用算术解码器计算出原始数据。由于压缩阶段已将数据压缩模型的参数保存在编码后的数据(如:数据类型对应的数据压缩模型)中,解码阶段只需要使用到数据压缩模型,不需要使用数据类型识别模型,因此解压比压缩过程执行更快。算术编码模块可以由算术编码器实现,算术编码器可以位于处理器103中。
在另一些实施例中,处理器101接收待压缩数据后,由处理器101识别待压缩数据的数据类型,根据数据类型选择一个或多个数据压缩模型。并且由处理器101根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。与上述实施例的区别在于,无需由处理器103根据选择出的一个或多个数据压缩模型对待压缩数据进行压缩。选择一个或多个数据压缩模型和对待压缩数据进行压缩的具体方法可以参考上述实施例的阐述,不予赘述。
在另一些实施例中,可以将若干个数据压缩模型存储到处理器103。处理器103利用若干个数据压缩模型获取待压缩数据的每个比特的概率,根据待压缩数据中每个比特的概率和算术编码算法对待压缩数据编码,得到压缩数据。若干个数据压缩模型包括传统技术中所有的数据压缩模型中常用的数据压缩模型和由常用的数据压缩模型叠加生成的其他数据压缩模型。对待压缩数据进行压缩的具体方法可以参考上述实施例的阐述,不予赘述。
可以理解的是,为了实现上述实施例中功能,计算设备包括了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本申请中所公开的实施例描述的各示例的单元及方法步骤,本申请能够以硬件或硬件和计算机软件相结合的形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用场景和设计约束条件。
图5为本申请的实施例提供的可能的数据压缩装置的结构示意图。这些数据压缩装置可以用于实现上述方法实施例中计算设备的功能,因此也能实现上述方法实施例所具备的有益效果。在本申请的实施例中,该数据压缩装置可以是如图1所示的计算设备100,还可以是应用于计算设备的模块(如芯片)。
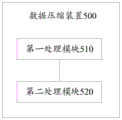
如图5所示,数据压缩装置500包括第一处理模块510和第二处理模块520。数据压缩装置500用于实现上述图2或图4中所示的方法实施例中计算设备的功能。
当数据压缩装置500用于实现图2所示的方法实施例中计算设备的功能时:第一处理模块510用于执行S201至S203;第二处理模块520用于执行S204。
当数据压缩装置500用于实现图4所示的方法实施例中计算设备的功能时:第一处理模块510用于执行S201a、S201b、S202和S203;第二处理模块520用于执行S204。
有关上述第一处理模块510和第二处理模块520更详细的描述可以直接参考图2或图4所示的方法实施例中相关描述直接得到,这里不加赘述。
示例性的,在具体的产品实现上,第一处理模块510可以是图1所示的处理器101,第二处理模块可以是图1所示的处理器103。在其他示例中,第一处理模块510和第二处理模块520可以分别是两个具有计算能力的组件,也可以是同一个组件中的两个计算单元,本实施例并不限定第一处理模块510和第二处理模块520之间的组织形式。
在本申请的各个实施例中,如果没有特殊说明以及逻辑冲突,不同的实施例之间的术语和/或描述具有一致性、且可以相互引用,不同的实施例中的技术特征根据其内在的逻辑关系可以组合形成新的实施例。
本申请中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A,B可以是单数或者复数。在本申请的文字描述中,字符“/”,一般表示前后关联对象是一种“或”的关系;在本申请的公式中,字符“/”,表示前后关联对象是一种“相除”的关系。
可以理解的是,在本申请的实施例中涉及的各种数字编号仅为描述方便进行的区分,并不用来限制本申请的实施例的范围。上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定。
Claims (27)
1.一种数据压缩方法,其特征在于,所述方法应用于计算设备;所述方法包括:
接收待压缩数据,识别所述待压缩数据的数据类型;
根据所述数据类型选择一个或多个数据压缩模型;
根据选择出的所述一个或多个数据压缩模型对所述待压缩数据进行压缩。
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
对第一样本数据进行训练,生成若干个数据压缩模型;
将所述若干个数据压缩模型或者所述若干个数据压缩模型的子集存储在所述计算设备中。
3.根据权利要求2所述的方法,其特征在于,所述方法还包括:
对所述计算设备中存储的数据压缩模型进行升级。
4.根据权利要求1所述的方法,其特征在于,每个数据压缩模型具有标识,所述方法还包括:
根据所述标识获取对应的数据压缩模型。
5.根据权利要求1所述的方法,其特征在于,所述方法还包括:
将所述待压缩数据的数据类型与所述一个或多个数据压缩模型之间的对应关系保存在所述计算设备中。
6.根据权利要求1-5中任一项所述的方法,其特征在于,所述计算设备存储有M个数据类型识别模型,每个数据类型识别模型用于识别P种数据类型出现的概率,所述识别所述待压缩数据的数据类型,包括:
根据所述M个数据类型识别模型确定所述待压缩数据对应的M个概率集合,每个概率集合包含P个初始概率值,所述P个初始概率值中的每个初始概率值用于指示所述待压缩数据是一种数据类型的可能性,M为大于或等于1的整数,P为大于或等于1的整数;
根据所述M个概率集合确定所述待压缩数据的数据类型。
7.根据权利要求6所述的方法,其特征在于,所述根据所述M个概率集合确定所述待压缩数据的数据类型,包括:
根据所述M个概率集合以及所述M个数据类型识别模型的权重比获得P个中间值;
将所述P个中间值中大于准确度阈值的中间值对应的数据类型确定为所述待压缩数据的数据类型。
8.根据权利要求6或7所述的方法,其特征在于,所述方法还包括:
对第二样本数据进行训练以生成所述M个数据类型识别模型。
9.一种计算设备,其特征在于,所述计算设备包括一个或多个处理器,其中,
所述一个或多个处理器用于接收待压缩数据,识别所述待压缩数据的数据类型;
根据所述数据类型选择一个或多个数据压缩模型;
根据选择出的所述一个或多个数据压缩模型对所述待压缩数据进行压缩。
10.根据权利要求9所述的计算设备,其特征在于,所述一个或多个处理器包括第一处理器和第二处理器,其中,
所述第一处理器用于接收所述待压缩数据,识别所述待压缩数据的数据类型;根据所述数据类型选择一个或多个数据压缩模型;
所述第二处理器用于根据选择出的所述一个或多个数据压缩模型对所述待压缩数据进行压缩。
11.根据权利要求10所述的计算设备,其特征在于,所述计算设备还包括存储器,所述第一处理器还用于将所述待压缩数据的数据类型与所述一个或多个数据压缩模型之间的对应关系保存在所述存储器中。
12.根据权利要求10所述的计算设备,其特征在于,所述计算设备还包括人工智能AI芯片,
所述AI芯片用于对第一样本数据进行训练,生成若干个数据压缩模型;
所述第一处理器还用于将所述若干个数据压缩模型或者所述若干个数据压缩模型的子集存储在所述计算设备中。
13.根据权利要求12所述的计算设备,其特征在于,所述第一处理器或所述第二处理器还用于对所述计算设备中存储的数据压缩模型进行升级。
14.根据权利要求10所述的计算设备,其特征在于,每个数据压缩模型具有标识,
所述第一处理器还用于将选择出的所述数据压缩模型的标识发送给所述第二处理器;
所述第二处理器还用于根据所述标识获取对应的数据压缩模型。
15.根据权利要求10-14中任一项所述的计算设备,其特征在于,所述计算设备存储有M个数据类型识别模型,每个数据类型识别模型用于识别P种数据类型出现的概率,
所述第一处理器具体用于根据所述M个数据类型识别模型确定所述待压缩数据对应的M个概率集合,每个概率集合包含P个初始概率值,所述P个初始概率值中的每个初始概率值用于指示所述待压缩数据是一种数据类型的可能性,M为大于或等于1的整数,P为大于或等于1的整数;
根据所述M个概率集合确定所述待压缩数据的数据类型。
16.根据权利要求15所述的计算设备,其特征在于,所述第一处理器具体用于根据所述M个概率集合以及所述M个数据类型识别模型的权重比获得P个中间值;
将所述P个中间值中大于准确度阈值的中间值对应的数据类型确定为所述待压缩数据的数据类型。
17.根据权利要求15或16所述的计算设备,其特征在于,所述计算设备还包括人工智能AI芯片,所述AI芯片还用于对第二样本数据进行训练以生成所述M个数据类型识别模型。
18.根据权利要求10-17中任一项所述的计算设备,其特征在于,所述第一处理器是中央处理器,所述第二处理器是协处理器。
19.一种数据压缩装置,其特征在于,所述装置位于计算设备中,所述装置包括第一处理模块和第二处理模块;
所述第一处理模块用于接收待压缩数据,识别所述待压缩数据的数据类型;根据所述数据类型选择一个或多个数据压缩模型;
所述第二处理模块用于根据选择出的所述一个或多个数据压缩模型对所述待压缩数据进行压缩。
20.根据权利要求19所述的装置,其特征在于,所述数据压缩装置还包括存储模块,所述第一处理模块还用于将所述待压缩数据的数据类型与所述一个或多个数据压缩模型之间的对应关系保存在所述存储模块中。
21.根据权利要求19所述的装置,其特征在于,所述装置还包括人工智能AI芯片,
所述AI芯片用于对第一样本数据进行训练,生成若干个数据压缩模型;
所述第一处理模块还用于将所述若干个数据压缩模型或者所述若干个数据压缩模型的子集存储在所述计算设备中。
22.根据权利要求19所述的装置,其特征在于,所述第一处理模块或所述第二处理模块还用于对所述计算设备中存储的数据压缩模型进行升级。
23.根据权利要求19所述的装置,其特征在于,每个数据压缩模型具有标识,
所述第一处理模块还用于将选择出的所述数据压缩模型的标识发送给所述第二处理模块;
所述第二处理模块还用于根据所述标识获取对应的数据压缩模型。
24.根据权利要求19-23中任一项所述的装置,其特征在于,所述计算设备存储有M个数据类型识别模型,每个数据类型识别模型用于识别P种数据类型出现的概率,
所述第一处理模块具体用于根据所述M个数据类型识别模型确定所述待压缩数据对应的M个概率集合,每个概率集合包含P个初始概率值,所述P个初始概率值中的每个初始概率值用于指示所述待压缩数据是一种数据类型的可能性,M为大于或等于1的整数,P为大于或等于1的整数;
根据所述M个概率集合确定所述待压缩数据的数据类型。
25.根据权利要求24所述的装置,其特征在于,所述第一处理模块具体用于根据所述M个概率集合以及所述M个数据类型识别模型的权重比获得P个中间值;
将所述P个中间值中大于准确度阈值的中间值对应的数据类型确定为所述待压缩数据的数据类型。
26.根据权利要求24或25所述的装置,其特征在于,所述装置还包括人工智能AI芯片,所述AI芯片还用于对第二样本数据进行训练以生成所述M个数据类型识别模型。
27.根据权利要求19-26中任一项所述的装置,其特征在于,所述第一处理模块是中央处理器,所述第二处理模块是协处理器。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2020/136231 WO2021129445A1 (zh) | 2019-12-28 | 2020-12-14 | 数据压缩方法及计算设备 |
| EP20905945.0A EP3944505A4 (en) | 2019-12-28 | 2020-12-14 | Data compression method and computing device |
| JP2021568939A JP7372347B2 (ja) | 2019-12-28 | 2020-12-14 | データ圧縮方法およびコンピューティングデバイス |
| US17/543,635 US20220092031A1 (en) | 2019-12-28 | 2021-12-06 | Data compression method and computing device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911385235 | 2019-12-28 | ||
| CN2019113852356 | 2019-12-28 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113055017A true CN113055017A (zh) | 2021-06-29 |
Family
ID=76507575
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010261686.5A Pending CN113055017A (zh) | 2019-12-28 | 2020-04-04 | 数据压缩方法及计算设备 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20220092031A1 (zh) |
| EP (1) | EP3944505A4 (zh) |
| JP (1) | JP7372347B2 (zh) |
| CN (1) | CN113055017A (zh) |
| WO (1) | WO2021129445A1 (zh) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114095033A (zh) * | 2021-11-16 | 2022-02-25 | 上海交通大学 | 基于上下文的图卷积的目标交互关系语义无损压缩系统及方法 |
| WO2023284851A1 (zh) * | 2021-07-16 | 2023-01-19 | 深圳智慧林网络科技有限公司 | 数据压缩模型训练方法及装置、存储介质 |
| CN115833843A (zh) * | 2023-02-14 | 2023-03-21 | 临沂云斗电子科技有限公司 | 一种车辆运行监控数据存储优化方法及管理平台 |
| WO2023184353A1 (zh) * | 2022-03-31 | 2023-10-05 | 华为技术有限公司 | 一种数据处理方法以及相关设备 |
| CN117278053A (zh) * | 2023-11-17 | 2023-12-22 | 南京智盟电力有限公司 | 一种gltf-json格式数据压缩方法、系统及装置 |
| CN117411875A (zh) * | 2023-12-14 | 2024-01-16 | 国网浙江省电力有限公司 | 一种电力数据传输系统、方法、装置、设备及存储介质 |
| WO2024193243A1 (zh) * | 2023-03-22 | 2024-09-26 | 华为技术有限公司 | 一种数值型数据压缩的方法和计算装置 |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115391298A (zh) * | 2021-05-25 | 2022-11-25 | 戴尔产品有限公司 | 基于内容的动态混合数据压缩 |
| US11775277B2 (en) * | 2021-06-21 | 2023-10-03 | Microsoft Technology Licensing, Llc | Computer-implemented exposomic classifier |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8429111B1 (en) * | 2008-08-04 | 2013-04-23 | Zscaler, Inc. | Encoding and compression of statistical data |
| CN105553937A (zh) * | 2015-12-03 | 2016-05-04 | 华为技术有限公司 | 数据压缩的系统和方法 |
| CN107066401A (zh) * | 2016-12-30 | 2017-08-18 | 广东欧珀移动通信有限公司 | 一种基于移动终端架构的数据传输的方法及移动终端 |
| US20190081637A1 (en) * | 2017-09-08 | 2019-03-14 | Nvidia Corporation | Data inspection for compression/decompression configuration and data type determination |
| CN110196836A (zh) * | 2019-03-29 | 2019-09-03 | 腾讯科技(深圳)有限公司 | 一种数据存储方法及装置 |
| CN110309300A (zh) * | 2018-08-23 | 2019-10-08 | 北京慧经知行信息技术有限公司 | 一种识别理科试题知识点的方法 |
| CN110532466A (zh) * | 2019-08-21 | 2019-12-03 | 广州华多网络科技有限公司 | 直播平台训练数据的处理方法、装置、存储介质及设备 |
| CN110545107A (zh) * | 2019-09-09 | 2019-12-06 | 飞天诚信科技股份有限公司 | 数据处理方法、装置、电子设备及计算机可读存储介质 |
Family Cites Families (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5941938A (en) * | 1996-12-02 | 1999-08-24 | Compaq Computer Corp. | System and method for performing an accumulate operation on one or more operands within a partitioned register |
| US6624761B2 (en) * | 1998-12-11 | 2003-09-23 | Realtime Data, Llc | Content independent data compression method and system |
| US6879988B2 (en) * | 2000-03-09 | 2005-04-12 | Pkware | System and method for manipulating and managing computer archive files |
| US6883087B1 (en) * | 2000-12-15 | 2005-04-19 | Palm, Inc. | Processing of binary data for compression |
| JP3807342B2 (ja) * | 2002-04-25 | 2006-08-09 | 三菱電機株式会社 | デジタル信号符号化装置、デジタル信号復号装置、デジタル信号算術符号化方法、およびデジタル信号算術復号方法 |
| US7136010B2 (en) * | 2002-06-28 | 2006-11-14 | Science Applications International Corporation | Measurement and signature intelligence analysis and reduction technique |
| US7051126B1 (en) * | 2003-08-19 | 2006-05-23 | F5 Networks, Inc. | Hardware accelerated compression |
| US20070233477A1 (en) * | 2006-03-30 | 2007-10-04 | Infima Ltd. | Lossless Data Compression Using Adaptive Context Modeling |
| US7765346B2 (en) * | 2007-12-14 | 2010-07-27 | Bmc Software, Inc. | Dynamic compression of systems management data |
| US8473428B2 (en) * | 2008-12-18 | 2013-06-25 | Cisco Technology, Inc. | Generation and use of specific probability tables for arithmetic coding in data compression systems |
| CN102473175B (zh) * | 2009-07-31 | 2015-02-18 | 惠普开发有限公司 | Xml数据的压缩 |
| US8396841B1 (en) * | 2010-11-30 | 2013-03-12 | Symantec Corporation | Method and system of multi-level and multi-mode cloud-based deduplication |
| US9048862B2 (en) * | 2012-04-11 | 2015-06-02 | Netapp, Inc. | Systems and methods for selecting data compression for storage data in a storage system |
| US11128935B2 (en) * | 2012-06-26 | 2021-09-21 | BTS Software Solutions, LLC | Realtime multimodel lossless data compression system and method |
| GB2503295B (en) * | 2012-08-13 | 2014-08-06 | Gurulogic Microsystems Oy | Encoder and method |
| US9274802B2 (en) * | 2013-01-22 | 2016-03-01 | Altera Corporation | Data compression and decompression using SIMD instructions |
| CA2986555A1 (en) * | 2015-05-21 | 2016-11-24 | Zeropoint Technologies Ab | Methods, devices and systems for hybrid data compression and decompression |
| CN107172886B (zh) * | 2015-12-29 | 2019-07-26 | 华为技术有限公司 | 一种服务器以及服务器压缩数据的方法 |
| US20190026637A1 (en) * | 2016-01-08 | 2019-01-24 | Sunil Mehta | Method and virtual data agent system for providing data insights with artificial intelligence |
| US10375395B2 (en) * | 2016-02-24 | 2019-08-06 | Mediatek Inc. | Video processing apparatus for generating count table in external storage device of hardware entropy engine and associated video processing method |
| US10972569B2 (en) * | 2017-04-24 | 2021-04-06 | International Business Machines Corporation | Apparatus, method, and computer program product for heterogenous compression of data streams |
| CN107204184B (zh) * | 2017-05-10 | 2018-08-03 | 平安科技(深圳)有限公司 | 语音识别方法及系统 |
| US11093342B1 (en) * | 2017-09-29 | 2021-08-17 | EMC IP Holding Company LLC | Efficient deduplication of compressed files |
| US10877959B2 (en) * | 2018-01-17 | 2020-12-29 | Sap Se | Integrated database table access |
| US20200012890A1 (en) * | 2018-07-06 | 2020-01-09 | Capital One Services, Llc | Systems and methods for data stream simulation |
| US10554220B1 (en) * | 2019-01-30 | 2020-02-04 | International Business Machines Corporation | Managing compression and storage of genomic data |
| CN112189205A (zh) * | 2019-02-27 | 2021-01-05 | 华为技术有限公司 | 一种神经网络模型处理方法及装置 |
-
2020
- 2020-04-04 CN CN202010261686.5A patent/CN113055017A/zh active Pending
- 2020-12-14 WO PCT/CN2020/136231 patent/WO2021129445A1/zh unknown
- 2020-12-14 JP JP2021568939A patent/JP7372347B2/ja active Active
- 2020-12-14 EP EP20905945.0A patent/EP3944505A4/en active Pending
-
2021
- 2021-12-06 US US17/543,635 patent/US20220092031A1/en active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8429111B1 (en) * | 2008-08-04 | 2013-04-23 | Zscaler, Inc. | Encoding and compression of statistical data |
| CN105553937A (zh) * | 2015-12-03 | 2016-05-04 | 华为技术有限公司 | 数据压缩的系统和方法 |
| CN107066401A (zh) * | 2016-12-30 | 2017-08-18 | 广东欧珀移动通信有限公司 | 一种基于移动终端架构的数据传输的方法及移动终端 |
| US20190081637A1 (en) * | 2017-09-08 | 2019-03-14 | Nvidia Corporation | Data inspection for compression/decompression configuration and data type determination |
| CN110309300A (zh) * | 2018-08-23 | 2019-10-08 | 北京慧经知行信息技术有限公司 | 一种识别理科试题知识点的方法 |
| CN110196836A (zh) * | 2019-03-29 | 2019-09-03 | 腾讯科技(深圳)有限公司 | 一种数据存储方法及装置 |
| CN110532466A (zh) * | 2019-08-21 | 2019-12-03 | 广州华多网络科技有限公司 | 直播平台训练数据的处理方法、装置、存储介质及设备 |
| CN110545107A (zh) * | 2019-09-09 | 2019-12-06 | 飞天诚信科技股份有限公司 | 数据处理方法、装置、电子设备及计算机可读存储介质 |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023284851A1 (zh) * | 2021-07-16 | 2023-01-19 | 深圳智慧林网络科技有限公司 | 数据压缩模型训练方法及装置、存储介质 |
| CN114095033A (zh) * | 2021-11-16 | 2022-02-25 | 上海交通大学 | 基于上下文的图卷积的目标交互关系语义无损压缩系统及方法 |
| CN114095033B (zh) * | 2021-11-16 | 2024-05-14 | 上海交通大学 | 基于上下文的图卷积的目标交互关系语义无损压缩系统及方法 |
| WO2023184353A1 (zh) * | 2022-03-31 | 2023-10-05 | 华为技术有限公司 | 一种数据处理方法以及相关设备 |
| CN115833843A (zh) * | 2023-02-14 | 2023-03-21 | 临沂云斗电子科技有限公司 | 一种车辆运行监控数据存储优化方法及管理平台 |
| WO2024193243A1 (zh) * | 2023-03-22 | 2024-09-26 | 华为技术有限公司 | 一种数值型数据压缩的方法和计算装置 |
| CN117278053A (zh) * | 2023-11-17 | 2023-12-22 | 南京智盟电力有限公司 | 一种gltf-json格式数据压缩方法、系统及装置 |
| CN117278053B (zh) * | 2023-11-17 | 2024-02-09 | 南京智盟电力有限公司 | 一种gltf-json格式数据压缩方法、系统及装置 |
| CN117411875A (zh) * | 2023-12-14 | 2024-01-16 | 国网浙江省电力有限公司 | 一种电力数据传输系统、方法、装置、设备及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7372347B2 (ja) | 2023-10-31 |
| EP3944505A4 (en) | 2022-06-29 |
| US20220092031A1 (en) | 2022-03-24 |
| JP2022532432A (ja) | 2022-07-14 |
| EP3944505A1 (en) | 2022-01-26 |
| WO2021129445A1 (zh) | 2021-07-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113055017A (zh) | 数据压缩方法及计算设备 | |
| CN111105029B (zh) | 神经网络的生成方法、生成装置和电子设备 | |
| CN112994701B (zh) | 数据压缩方法、装置、电子设备及计算机可读介质 | |
| CN110728350B (zh) | 用于机器学习模型的量化 | |
| US11544542B2 (en) | Computing device and method | |
| US20220222541A1 (en) | Neural Network Representation Formats | |
| US11334791B2 (en) | Learning to search deep network architectures | |
| WO2020204904A1 (en) | Learning compressible features | |
| Yu et al. | Two-level data compression using machine learning in time series database | |
| US20160285473A1 (en) | Scalable High-Bandwidth Architecture for Lossless Compression | |
| CN113327599B (zh) | 语音识别方法、装置、介质及电子设备 | |
| CN110852066B (zh) | 一种基于对抗训练机制的多语言实体关系抽取方法及系统 | |
| CN117933270B (zh) | 大语言模型长文本输出方法、装置、设备及存储介质 | |
| CN114501031B (zh) | 一种压缩编码、解压缩方法以及装置 | |
| CN117633008A (zh) | 语句转换模型的训练方法、装置、设备、存储介质及产品 | |
| CN113807492A (zh) | 类神经网络系统及其操作方法 | |
| CN116362301A (zh) | 一种模型的量化方法以及相关设备 | |
| WO2023070424A1 (zh) | 一种数据库数据的压缩方法及存储设备 | |
| CN111143641A (zh) | 深度学习模型的训练方法、装置及电子设备 | |
| US20210303975A1 (en) | Compression and decompression of weight values | |
| CN117220685A (zh) | 数据压缩方法及装置 | |
| US11769570B2 (en) | Method and systems for genome sequence compression | |
| US20220375240A1 (en) | Method for detecting cells in images using autoencoder, computer device, and storage medium | |
| US20240291503A1 (en) | System and method for multi-type data compression or decompression with a virtual management layer | |
| CN117951100A (zh) | 数据压缩方法、装置及计算机存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |