CN112951237B - 一种基于人工智能的自动语音识别方法及系统 - Google Patents
一种基于人工智能的自动语音识别方法及系统 Download PDFInfo
- Publication number
- CN112951237B CN112951237B CN202110293229.9A CN202110293229A CN112951237B CN 112951237 B CN112951237 B CN 112951237B CN 202110293229 A CN202110293229 A CN 202110293229A CN 112951237 B CN112951237 B CN 112951237B
- Authority
- CN
- China
- Prior art keywords
- professional
- vocabulary
- signal data
- noise
- signal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Processing of the speech or voice signal to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
- G10L25/57—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination for processing of video signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
- G10L2015/0631—Creating reference templates; Clustering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
- G10L2015/0631—Creating reference templates; Clustering
- G10L2015/0633—Creating reference templates; Clustering using lexical or orthographic knowledge sources
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Quality & Reliability (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Machine Translation (AREA)
- Telephonic Communication Services (AREA)
Abstract
本发明公开了一种基于人工智能的自动语音识别方法及系统,该方法包括应用词汇分类模板,将所述识别结果中的词汇于所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比,结合占比判断是否需要专业词汇的语音识别,采用本发明提供的方案可以提高对专业词汇识别的精确度和准确率,特别是增强专业领域中视频会议记录的准确性、精准性,特别是专业性,提高企业在相关专业领域的专业性,更重要的是减少因为对专业词汇的自动识别语音识别时造成的词汇识别的误解,防止因为语音识别造成误解进而造成重大损失。同时,由于以词汇分类模板做基础,提高专业词汇的搜索速率,进而提高了针对专业词汇的自动语音的识别效率。
Description
技术领域
本发明涉及人工智能技术领域,具体涉及一种基于人工智能的自动语音识别方法及系统。
背景技术
自动语音识别技术(Automatic Speech Recognition,简称“ASR”)是一种将人的语音转换为文本的技术。语音识别是一个多学科交叉的领域,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。由于语音信号的多样性和复杂性,语音识别系统只能在一定的限制条件下获得满意的性能,或者说只能应用于某些特定的场合。
自动语音识别技术的目标是让计算机能够“听写”出不同人所说出的连续语音,也就是俗称的“语音听写机”,是实现“声音”到“文字”转换的技术。
但是,现有的自动语音识别技术应用在包含专业词汇的语音识别中存在一定的问题,由于专业词汇的特殊性及应用专业词汇的人员的特定性,具有相应专业领域知识的人员可能辨识某些词汇的含义,因此,通过普通的自动语音识别技术可能存在识别专业词汇不准确的情况,或者针对专业词汇的识别效率低的情况。
因此,亟需一种自动语音识别方法可以解决上述技术问题。
发明内容
本发明提供一种基于人工智能的自动语音识别方法及系统,用以解决现有技术中存在的识别专业词汇不准确,以及专业词汇的识别效率低的问题。
本发明提供一种基于人工智能的自动语音识别方法,该方法包括:
接收待识别的语音信号;
对所述待识别的语音信号进行预处理,获得语音输入信号;
将所述语音输入信号进行时域到频域的转换,提取语音特征参数;
对所述语音特征参数进行随机取样,获得若干个样本特征参数;
将所述样本特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果;
将所述识别结果输入至词汇分类模板,将所述识别结果中的词汇于所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比;
判断所述占比是否超出预设值,若是,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率;
若否,将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本。
可选的,在所述并输出对应的文本之后,包括:
将输出的所述文本输入至拼写纠错模型,获得纠错后文本;
将纠错后的文本作为最终文本输出。
可选的,所述词汇分类模板构建方法包括:
获取大量分属于不同行业的专业词汇;
将所述专业词汇采用卷积神经网络按照专业词汇所属的行业进行分类训练;
获得分类结果,并将所述分类结果存储于分类数据库中,构成词汇分类模板。
可选的,所述专业词汇声学模型构建方法包括:
将词汇分类模板中的分类数据库设置为专业词汇字典;
基于音素或其组合优先从所述专业词汇字典中进行映射;
若所述专业词汇字典中无映射内容,则基于声学模型中的字典进行映射;
根据上述映射结果获取相应音素及其组合的声学得分。
可选的,所述专业词汇语言模型的构建方法包括:
基于词汇分类模板中分类数据库中存储的专业词汇,结合词典获取专业词汇的词序及连接词;所述词序及连接词的概率值排序为前五位;
将所述获取到的词序及连接词结合专业词汇记录在专业词汇语言数据库中;
基于所述声学得分及所述专业词汇语言数据库,确定语言得分。
可选的,所述对所述语音信号进行预处理的方法包括:
A1,获取环境中有规律噪声的频谱;
A2,获取收音装置噪声的频谱;
A3,基于环境噪声的频谱和收音装置噪声的频谱,结合最小方差无畸变响应滤波器增强后的信号采用下述公式确定:

其中,NT(f,t,n)为环境中有规律噪声的频谱;Ni(f,t,n)为收音装置噪声的频谱;Yi(f,t,n)为包含噪声的语音信号;wi(f)为滤波器的加权系数;S(f,t,n)是获得的语音输入信号;xi(f,t,n)为待降噪的信号;
f为当前频率,t为当前时间,n为当前帧,P为收音装置的数量,i=1,2...P,T为有规律噪声出现的次数,t=1,2...T。Ri是训练误差取最小值时对应的初始系数,ε表示训练误差的最小值;
A4,基于所述获得的语音输入信号,采用下述公式对所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值G大于预设的判定阈值,则将该信号数据判定为噪声点,其中G值的计算公式为:

其中,ak信号数据集合M中的第k个信号数据;ai代表信号据集合M中的第i个信号数据,aj代表信号数据集合M中的第j个信号数据,i=1,2,3...N,j=1,2,3...N;Gi代表信号数据集合M中第i个信号数据的噪声判定值,π代表自然常数,exp代表指数函数,a代表信号数据集合M中信号数据的中值;
A5,将数据集合M中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
本发明提供一种基于人工智能的自动语音识别系统,该系统包括:
接收装置,用于接收待识别的语音信号;
预处理装置,用于对所述待识别的语音信号进行预处理,获得语音输入信号;
提取装置,用于将所述语音输入信号进行时域到频域的转换,提取语音特征参数;
抽样装置,用于对所述语音特征参数进行随机取样,获得若干个样本特征参数;
结果获取装置,用于将所述样本特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果;
专业词汇设置装置,用于将所述识别结果输入至词汇分类模板,将所述识别结果中的词汇于所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比;
判断装置,用干判断所述占比是否超出预设值;
第一输出装置,用于当判断装置的判断结果为是时,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率;
第二输出装置,用于当判断装置的判断结果为否时,将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本。
可选的,所述专业词汇设置装置中词汇分类模板包括:
获取子装置,用于获取大量分属于不同行业的专业词汇;
训练子装置,用于将所述专业词汇采用卷积神经网络按照专业词汇所属的行业进行分类训练;
分类结果获取子装置,用于获得分类结果,并将所述分类结果存储于分类数据库中,构成词汇分类模板。
可选的,所述第一输出装置中所述专业词汇声学模型包括:
分类子装置,用于将词汇分类模板中的分类数据库设置为专业词汇字典;
第一映射子装置,用于基于音素或其组合优先从所述专业词汇字典中进行映射;
第二映射子装置,用于当第一映射子装置中所述专业词汇字典中无映射内容时,则基于声学模型中的字典进行映射;
声学得分子装置,用于根据上述映射结果获取相应音素及其组合的声学得分。
可选的,所述预处理装置包括:
第一噪声频谱获取子装置,用于获取环境中有规律噪声的频谱;
第二噪声频谱获取子装置,用于获取收音装置噪声的频谱;
信号确定子装置,用于基于环境噪声的频谱和收音装置噪声的频谱,结合最小方差无畸变响应滤波器增强后的信号采用下述公式确定:

其中,NT(f,t,n)为环境中有规律噪声的频谱;Ni(f,t,n)为收音装置噪声的频谱;Yi(f,t,n)为包含噪声的语音信号;wi(f)为滤波器的加权系数;S(f,t,n)是获得的语音输入信号;xi(f,t,n)为待降噪的信号;
f为当前频率,t为当前时间,n为当前帧,P为收音装置的数量,i=1,2...P,T为有规律噪声出现的次数,t=1,2...T。Ri是训练误差取最小值时对应的初始系数,ε表示训练误差的最小值;
判定值确定子装置,用于基于所述获得的语音输入信号,采用下述公式对所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值G大于预设的判定阈值,则将该信号数据判定为噪声点,其中G值的计算公式为:

其中,ak信号数据集合M中的第k个信号数据;ai代表信号据集合M中的第i个信号数据,aj代表信号数据集合M中的第j个信号数据,i=1,2,3...N,j=1,2,3...N;Gi代表信号数据集合M中第i个信号数据的噪声判定值,π代表自然常数,exp代表指数函数,a代表信号数据集合M中信号数据的中值;
判定子装置,用于将数据集合M中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
本发明提供一种基于人工智能的自动语音识别方法,采用本发明提供的方案可以提高对专业词汇识别的精确度和准确率,特别是增强专业领域中视频会议记录的准确性、精准性,特别是专业性,提高企业在相关专业领域的专业性,更重要的是减少因为对专业词汇的自动识别语音识别造成的专业误解,防止因为语音识别造成误解进而造成重大损失。同时,由于以词汇分类模板做基础,提高专业词汇的搜索速率,进而提高了针对专业词汇的自动语音的识别效率。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种基于人工智能的自动语音识别方法的流程图;
图2为本发明实施例中一种基于人工智能的自动语音识别系统的结构示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:
本发明实施例提供了一种基于人工智能的自动语音识别方法,图1为本发明实施例中一种基于人工智能的自动语音识别方法的流程图,请参照图1,该方法包括以下步骤:
步骤S101,接收待识别的语音信号;
步骤S102,对所述待识别的语音信号进行预处理,获得语音输入信号;
步骤S103,将所述语音输入信号进行时域到频域的转换,提取语音特征参数;
步骤S104,对所述语音特征参数进行随机取样,获得若干个样本特征参数;
步骤S105,将所述样本特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果;
步骤S106,将所述识别结果输入至词汇分类模板,将所述识别结果中的词汇于所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比;
步骤S107,判断所述占比是否超出预设值;若判断结果为是,则执行步骤S108,若判断结果为否,则执行步骤S109。
步骤S108,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率;
步骤S109,将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本。
上述技术方案的工作原理为:本实施例采用的方案是通过对待识别语音信号提取的语音特征参数进行随机取样,并对采样的参数基于声学模型和语言模型获取识别结果,再次对所述识别结果基于词汇分类模板判断是否属于涉及专业词汇的语音识别,若是,则说明待识别的语音信号是与专业方面相关的语音,而对此类的语音的识别需要相对专业的词汇库提供基础支持。因此,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率。而对于判断不属于专业词汇的语音识别时,则进行普通的自动语音识别技术,即将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本。
需要说明的是,将所述语音输入信号进行时域到频域的转换,提取语音特征参数,可采用的方式包括梅尔频率倒谱的方式提取语音特征,通过梅尔频率倒谱获得声谱,然后将声谱通过滤波器进行滤波处理。
另外,所述语音特征的提取还可以采用深度卷积神经网络的原理进行语音特征的提取,获得语音特征参数。
此外,对词汇分类模板进行简单的介绍和说明,所述词汇分类模板中包含有专业词汇数据库,并且不同行业的专业词汇也不同,因此,可以按照行业的不同分别设置不同类别的专业词汇,根据所需专业词汇分类的不同,可以从不同的分类的数据库中进行相关词汇的搜索。
本实施例提供的方案可以应用的范围很广,例如涉及到专业度高的行业会议的会议记录,某些产品的现场展示视频中语音的自动识别等,如果涉及到专业领域的视频或录音等需要自动语音识别的场合都可采用本实施例提供的方案。
上述技术方案的有益效果为:采用本实施例提供的方案可以提高对专业词汇识别的精确度和准确率,特别是增强专业领域中视频会议记录的准确性、精准性,特别是专业性,提高企业在相关专业领域的专业性,更重要的是减少因为对专业词汇的自动识别语音识别造成的专业误解,防止因为语音识别造成误解进而造成重大损失。同时,由于以词汇分类模板做基础,提高专业词汇的搜索速率,进而提高了针对专业词汇的自动语音的识别效率。
实施例2:
在实施例1的基础上,在所述并输出对应的文本之后,包括:
将输出的所述文本输入至拼写纠错模型,获得纠错后文本;
将纠错后的文本作为最终文本输出。
上述技术方案的工作原理及有益效果为:本实施例采用的方案是对输入的文本进行拼写纠错的过程,通过声学模型和语言模型之后,其输出的文本可能会存在拼写的错误等形式的问题,为了保证自动语音识别的精准性和专业性,需要后续对输出的文本的拼写进行纠错,通过设置拼写纠错模型保证输出的最终文本没有形式的拼写错误,提高自动语音识别的精准度。
实施例3:
在实施例1的基础上,所述词汇分类模板构建方法包括:
获取大量分属于不同行业的专业词汇;
将所述专业词汇采用卷积神经网络按照专业词汇所属的行业进行分类训练;
获得分类结果,并将所述分类结果存储于分类数据库中,构成词汇分类模板。
上述技术方案的工作原理为:本实施例采用的方案是对词汇分类模板的构建方法的描述。通过获取大量的不同行业的专业词汇,采用卷积神经网络对上述专业词汇按照以行业为基准进行分类训练,也就是不同的行业包含的专业词汇是不同的,通过词汇分类模板将不同专业词汇进行分类,并将分类结果存储于分类数据库中,便于后续过程中对相应的专业词汇进行查询。
上述技术方案的有益效果为:采用本实施例提供的方案将专业词汇进行汇总并分类,由于以词汇分类模板做基础,提高专业词汇的搜索速率,进而提高了针对专业词汇的自动语音的识别效率。另外,采用本实施例提供的方案可以提高对专业词汇识别的精确度和准确率,特别是增强专业领域中视频会议记录的准确性、精准性,特别是专业性,提高企业在相关专业领域的专业性,更重要的是减少因为对专业词汇的自动识别语音识别造成的专业误解,防止因为语音识别造成误解进而造成重大损失。
实施例4:
在实施例3的基础上,所述专业词汇声学模型构建方法包括:
将词汇分类模板中的分类数据库设置为专业词汇字典;
基于音素或其组合优先从所述专业词汇字典中进行映射;
若所述专业词汇字典中无映射内容,则基于声学模型中的字典进行映射;
根据上述映射结果获取相应音素及其组合的声学得分。
上述技术方案的工作原理为:本实施例采用的方案是对专业词汇声学模型的构建方法的描述。通过将词汇分类模板中的分类数据库设置为专业词汇字典,结合声学模型中的字典共同对待识别语音信号的拆解出的因素或其契合进行映射,其映射顺序为先从所述专业词汇字典中进行映射,当所述专业词汇字典中没有映射内容,则基于声学模型中的字典进行映射,综上所述映射以获得相应音素及其组合的声学得分,进而构成所述专业词汇声学模型。
上述技术方案的有益效果为:采用本实施例提供的方案构建的专业词汇声学模型,优先采用词汇分了模板中的分类数据库作为字典进行搜索,当分类数据库有对应的专业词汇时,直接从该数据库读取映射,当该分类数据库没有相应的词汇时,则采用声学模型中的字典进行词汇映射。因此,采用本实施例的方案一方面提高专业词汇的识别准确性,另一方面,由于以分类数据库中的专业词汇为基础,采用本实施例方案也可以提高专业词汇的识别效率。
实施例5:
在实施例3的基础上,所述专业词汇语言模型的构建方法包括:
基于词汇分类模板中分类数据库中存储的专业词汇,结合词典获取专业词汇的词序及连接词;所述词序及连接词的概率值排序为前五位;
将所述获取到的词序及连接词结合专业词汇记录在专业词汇语言数据库中;
基于所述声学得分及所述专业词汇语言数据库,确定语言得分。
上述技术方案的工作原理及工作原理为:本实施例采用的方案是构建专业词汇语言模型的方法,基于词汇分类模板中分类数据库中存储的专业词汇,结合词典获取专业词汇的词序及连接词,并将专业词汇的词序及连接词按照概率值由高到低进行排序,并提取概率值排序前五位的词序及连接词,将排序后的词序及连接词结合专业词汇记录在专业词汇语言数据库中,最后再结合声学得分及专业词汇语言数据库,确定语言得分,最终通过本实施例构建成所述专业词汇语言模型。
因此,采用本实施例的方案一方面提高专业词汇的识别准确性,另一方面,由于以分类数据库中的专业词汇为基础,采用本实施例方案也可以提高专业词汇的识别效率。
实施例6:
在实施例1的基础上,所述对所述待识别的语音信号进行预处理的方法包括:
A1,获取环境中有规律噪声的频谱;
A2,获取收音装置噪声的频谱;
A3,基于环境噪声的频谱和收音装置噪声的频谱,结合最小方差无畸变响应滤波器增强后的信号采用下述公式确定:

其中,NT(f,t,n)为环境中有规律噪声的频谱;Ni(f,t,n)为收音装置噪声的频谱;Yi(f,t,n)为包含噪声的语音信号;wi(f)为滤波器的加权系数;S(f,t,n)是获得的语音输入信号;xi(f,t,n)为待降噪的信号;
f为当前频率,t为当前时间,n为当前帧,P为收音装置的数量,i=1,2...P,T为有规律噪声出现的次数,t=1,2...T。Ri是训练误差取最小值时对应的初始系数,ε表示训练误差的最小值;
A4,基于所述获得的语音输入信号,采用下述公式对所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值G大于预设的判定阈值,则将该信号数据判定为噪声点,其中G值的计算公式为:

其中,ak信号数据集合M中的第k个信号数据;ai代表信号据集合M中的第i个信号数据,aj代表信号数据集合M中的第j个信号数据,i=1,2,3...N,j=1,2,3...N;Gi代表信号数据集合M中第i个信号数据的噪声判定值,π代表自然常数,exp代表指数函数,a代表信号数据集合M中信号数据的中值;
A5,将数据集合M中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
上述技术方案的工作原理及有益效果为:本实施例采用的方案是对所述待识别的语音信号进行预处理的方法。该方法是对环境中有规律噪声以及收音装置的噪声进行降噪处理的过程。首先有规律噪声例如需要对视频会议做语音识别的会议记录,当视频会议过程中,需要在电脑上敲击键盘,敲击键盘造成的噪声,以及为了提醒会议进度设置的定时计时铃声等,这些均属于有规律的噪声。另外,针对视频会议中麦克风装置本身收声时产生的噪声等也需要进行噪声的消除。由于上述两类噪声出现的频率较高,因此,将上述两类造成作为降噪的主动对象。采用本实施例提供的公式进行降噪处理,可以最大程度的降低上述两类噪声对输入的语音信号的干扰,通过降噪处理,以提高待识别的语音信号的质量,保证自动语音识别的准确性。
另外,通过设置所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值G大于预设的判定阈值,则将该信号数据判定为噪声点,将数据集合M中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。进一步通过噪声判定值的方式减少噪声点,提高所述语音输入信号的质量,进而提供高自动语音识别的准确性。
实施例7:
本实施例提供一种基于人工智能的自动语音识别系统,图2为本发明实施例中一种基于人工智能的自动语音识别系统的结构示意图,请参照图2,该系统包括以下装置:
接收装置201,用于接收待识别的语音信号;
预处理装置202,用于对所述待识别的语音信号进行预处理,获得语音输入信号;
提取装置203,用于将所述语音输入信号进行时域到频域的转换,提取语音特征参数;
抽样装置204,用于对所述语音特征参数进行随机取样,获得若干个样本特征参数;
结果获取装置205,用于将所述样本特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果;
专业词汇设置装置206,用于将所述识别结果输入至词汇分类模板,将所述识别结果中的词汇于所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比;
判断装置207,用于判断所述占比是否超出预设值;
第一输出装置208,用于当判断装置的判断结果为是时,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率;
第二输出装置209,用于当判断装置的判断结果为否时,将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本。
上述技术方案的工作原理为:本实施例采用的方案是通过对待识别语音信号提取的语音特征参数进行随机取样,并对采样的参数基于声学模型和语言模型获取识别结果,再次对所述识别结果基于词汇分类模板判断是否属于涉及专业词汇的语音识别,若是,则说明待识别的语音信号是与专业方面相关的语音,而对此类的语音的识别需要相对专业的词汇库提供基础支持。因此,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率。而对于判断不属于专业词汇的语音识别时,则进行普通的自动语音识别技术,即将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本。
需要说明的是,将所述语音输入信号进行时域到频域的转换,提取语音特征参数,可采用的方式包括梅尔频率倒谱的方式提取语音特征,通过梅尔频率倒谱获得声谱,然后将声谱通过滤波器进行滤波处理。
另外,所述语音特征的提取还可以采用深度卷积神经网络的原理进行语音特征的提取,获得语音特征参数。
此外,对词汇分类模板进行简单的介绍和说明,所述词汇分类模板中包含有专业词汇数据库,并且不同行业的专业词汇也不同,因此,可以按照行业的不同分别设置不同类别的专业词汇,根据所需专业词汇分类的不同,可以从不同的分类的数据库中进行相关词汇的搜索。
本实施例提供的方案可以应用的范围很广,例如涉及到专业度高的行业会议的会议记录,某些产品的现场展示视频中语音的自动识别等,如果涉及到专业领域的视频或录音等需要自动语音识别的场合都可采用本实施例提供的方案。
上述技术方案的有益效果为:采用本实施例提供的方案可以提高对专业词汇识别的精确度和准确率,特别是增强专业领域中视频会议记录的准确性、精准性,特别是专业性,提高企业在相关专业领域的专业性,更重要的是减少因为对专业词汇的自动识别语音识别造成的专业误解,防止因为语音识别造成误解进而造成重大损失。同时,由于以词汇分类模板做基础,提高专业词汇的搜索速率,进而提高了针对专业词汇的自动语音的识别效率。
实施例8:
在实施例7的基础上,所述专业词汇设置装置中词汇分类模板包括:
获取子装置,用于获取大量分属于不同行业的专业词汇;
训练子装置,用于将所述专业词汇采用卷积神经网络按照专业词汇所属的行业进行分类训练;
分类结果获取子装置,用于获得分类结果,并将所述分类结果存储于分类数据库中,构成词汇分类模板。
上述技术方案的工作原理为:本实施例采用的方案是对词汇分类模板的构建方法的描述。通过获取大量的不同行业的专业词汇,采用卷积神经网络对上述专业词汇按照以行业为基准进行分类训练,也就是不同的行业包含的专业词汇是不同的,通过词汇分类模板将不同专业词汇进行分类,并将分类结果存储于分类数据库中,便于后续过程中对相应的专业词汇进行查询。
上述技术方案的有益效果为:采用本实施例提供的方案将专业词汇进行汇总并分类,由于以词汇分类模板做基础,提高专业词汇的搜索速率,进而提高了针对专业词汇的自动语音的识别效率。另外,采用本实施例提供的方案可以提高对专业词汇识别的精确度和准确率,特别是增强专业领域中视频会议记录的准确性、精准性,特别是专业性,提高企业在相关专业领域的专业性,更重要的是减少因为对专业词汇的自动识别语音识别造成的专业误解,防止因为语音识别造成误解进而造成重大损失。
实施例9:
在实施例7的基础上,所述第一输出装置中所述专业词汇声学模型包括:
分类子装置,用于将词汇分类模板中的分类数据库设置为专业词汇字典;
第一映射子装置,用于基于音素或其组合优先从所述专业词汇字典中进行映射;
第二映射子装置,用于当第一映射子装置中所述专业词汇字典中无映射内容时,则基于声学模型中的字典进行映射;
声学得分子装置,用于根据上述映射获结果取相应音素及其组合的声学得分。
上述技术方案的工作原理为:本实施例采用的方案是对专业词汇声学模型的构建方法的描述。通过将词汇分类模板中的分类数据库设置为专业词汇字典,结合声学模型中的字典共同对待识别语音信号的拆解出的因素或其契合进行映射,其映射顺序为先从所述专业词汇字典中进行映射,当所述专业词汇字典中没有映射内容,则基于声学模型中的字典进行映射,综上所述映射以获得相应音素及其组合的声学得分,进而构成所述专业词汇声学模型。
上述技术方案的有益效果为:采用本实施例提供的方案构建的专业词汇声学模型,优先采用词汇分了模板中的分类数据库作为字典进行搜索,当分类数据库有对应的专业词汇时,直接从该数据库读取映射,当该分类数据库没有相应的词汇时,则采用声学模型中的字典进行词汇映射。因此,采用本实施例的方案一方面提高专业词汇的识别准确性,另一方面,由于以分类数据库中的专业词汇为基础,采用本实施例方案也可以提高专业词汇的识别效率。
实施例10:
在实施例1的基础上,所述预处理装置包括:
第一噪声频谱获取子装置,用于获取环境中有规律噪声的频谱;
第二噪声频谱获取子装置,用于获取收音装置噪声的频谱;
信号确定子装置,用于基于环境噪声的频谱和收音装置噪声的频谱,结合最小方差无畸变响应滤波器增强后的信号采用下述公式确定:

其中,NT(f,t,n)为环境中有规律噪声的频谱;Ni(f,t,n)为收音装置噪声的频谱;Yi(f,t,n)为包含噪声的语音信号;wi(f)为滤波器的加权系数;S(f,t,n)是获得的语音输入信号;xi(f,t,n)为待降噪的信号;
f为当前频率,t为当前时间,n为当前帧,P为收音装置的数量,i=1,2...P,T为有规律噪声出现的次数,t=1,2...T。Ri是训练误差取最小值时对应的初始系数,ε表示训练误差的最小值;
判定值确定子装置,用于基于所述获得的语音输入信号,采用下述公式对所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值G大于预设的判定阈值,则将该信号数据判定为噪声点,其中G值的计算公式为:

其中,ak信号数据集合M中的第k个信号数据;ai代表信号据集合M中的第i个信号数据,aj代表信号数据集合M中的第j个信号数据,i=1,2,3...N,j=1,2,3...N;Gi代表信号数据集合M中第i个信号数据的噪声判定值,π代表自然常数,exp代表指数函数,a代表信号数据集合M中信号数据的中值;
判定子装置,用于将数据集合M中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
上述技术方案的工作原理及有益效果为:本实施例采用的方案是对所述待识别的语音信号进行预处理的方法。该方法是对环境中有规律噪声以及收音装置的噪声进行降噪处理的过程。首先有规律噪声例如需要对视频会议做语音识别的会议记录,当视频会议过程中,需要在电脑上敲击键盘,敲击键盘造成的噪声,以及为了提醒会议进度设置的定时计时铃声等,这些均属于有规律的噪声。另外,针对视频会议中麦克风装置本身收声时产生的噪声等也需要进行噪声的消除。由于上述两类噪声出现的频率较高,因此,将上述两类造成作为降噪的主动对象。采用本实施例提供的公式进行降噪处理,可以最大程度的降低上述两类噪声对输入的语音信号的干扰,通过降噪处理,以提高待识别的语音信号的质量,保证自动语音识别的准确性。
另外,通过设置所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值G大于预设的判定阈值,则将该信号数据判定为噪声点,将数据集合M中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。进一步通过噪声判定值的方式减少噪声点,提高所述语音输入信号的质量,进而提供高自动语音识别的准确性。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
Claims (8)
1.一种基于人工智能的自动语音识别方法,其特征在于,包括:
接收待识别的语音信号;
对所述待识别的语音信号进行预处理,获得语音输入信号;
将所述语音输入信号进行时域到频域的转换,提取语音特征参数;
对所述语音特征参数进行随机取样,获得若干个样本特征参数;
将所述样本特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果;
将所述识别结果输入至词汇分类模板,将所述识别结果中的词汇与 所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比;
判断所述占比是否超出预设值,若是,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率;
若否,将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本;
所述对所述待识别的语音信号进行预处理的方法包括:
A1,获取环境中有规律噪声的频谱;
A2,获取收音装置噪声的频谱;
A3,基于环境噪声的频谱和收音装置噪声的频谱,结合最小方差无畸变响应滤波器增强后的信号采用下述公式确定:

其中, 为环境中有规律噪声的频谱;
为环境中有规律噪声的频谱;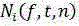 为收音装置噪声的频谱;
为收音装置噪声的频谱; 为滤波器的加权系数;
为滤波器的加权系数; 是获得的语音输入信号;
是获得的语音输入信号;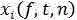 为待降噪的信号;
为待降噪的信号;

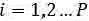



A4,基于所述获得的语音输入信号,采用下述公式对所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值 大于预设的判定阈值,则将该信号数据判定为噪声点,其中
大于预设的判定阈值,则将该信号数据判定为噪声点,其中 值的计算公式为:
值的计算公式为:
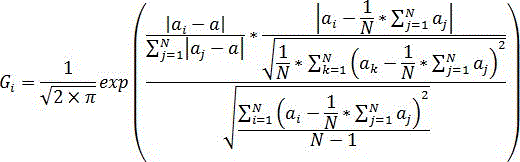
其中, 代表信号数据集合
代表信号数据集合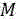 中的第
中的第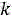 个信号数据;
个信号数据;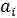 代表信号数据集合
代表信号数据集合 中的第
中的第 个信号数据,
个信号数据, 代表信号数据集合
代表信号数据集合 中的第
中的第 个信号数据,
个信号数据,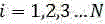 ,
, ;
; 代表信号数据集合
代表信号数据集合 中第
中第 个信号数据的噪声判定值,
个信号数据的噪声判定值, 代表自然常数,
代表自然常数,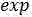 代表指数函数,
代表指数函数, 代表信号数据集合
代表信号数据集合 中信号数据的中值;
中信号数据的中值;
A5,将数据集合 中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
2.根据权利要求1所述的基于人工智能的自动语音识别方法,其特征在于,将输出的所述文本输入至拼写纠错模型,获得纠错后文本;
将纠错后的文本作为最终文本输出。
3.根据权利要求1所述的基于人工智能的自动语音识别方法,其特征在于,所述词汇分类模板构建方法包括:
获取大量分属于不同行业的专业词汇;
将所述专业词汇采用卷积神经网络按照专业词汇所属的行业进行分类训练;
获得分类结果,并将所述分类结果存储于分类数据库中,构成词汇分类模板。
4.根据权利要求3所述的基于人工智能的自动语音识别方法,其特征在于,所述专业词汇声学模型构建方法包括:
将词汇分类模板中的分类数据库设置为专业词汇字典;
基于音素或其组合从所述专业词汇字典中进行映射;
若所述专业词汇字典中无映射内容,则基于声学模型中的字典进行映射;
根据上述映射结果获取相应音素及其组合的声学得分。
5.根据权利要求4所述的基于人工智能的自动语音识别方法,其特征在于,所述专业词汇语言模型的构建方法包括:
基于词汇分类模板中分类数据库中存储的专业词汇,结合词典获取专业词汇的词序及连接词;所述词序及连接词的概率值排序为前五位;
将获取到的词序及连接词结合专业词汇记录在专业词汇语言数据库中;
基于所述声学得分及所述专业词汇语言数据库,确定语言得分。
6.一种基于人工智能的自动语音识别系统,其特征在于,包括:
接收装置,用于接收待识别的语音信号;
预处理装置,用于对所述待识别的语音信号进行预处理,获得语音输入信号;
提取装置,用于将所述语音输入信号进行时域到频域的转换,提取语音特征参数;
抽样装置,用于对所述语音特征参数进行随机取样,获得若干个样本特征参数;
结果获取装置,用于将所述样本特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果;
专业词汇设置装置,用于将所述识别结果输入至词汇分类模板,将所述识别结果中的词汇与 所述词汇分类模板中的专业词汇进行比对,获得识别结果中的词汇中专业词汇的占比;
判断装置,用于判断所述占比是否超出预设值;
第一输出装置,用于当判断装置的判断结果为是时,将所述语音特征参数输入至专业词汇声学模型和专业词汇语言模型,经过输出层的搜索对综合信息进行解码,输出对应的文本;所述专业词汇声学模型和专业词汇语言模型中对专业词汇的权重进行了重新匹配,提高获得专业词汇的概率;
第二输出装置,用于当判断装置的判断结果为否时,将所述语音特征参数输入至声学模型和语言模型,经过解码搜索获取识别结果,并输出对应的文本;
所述预处理装置包括:
第一噪声频谱获取子装置,用于获取环境中有规律噪声的频谱;
第二噪声频谱获取子装置,用于获取收音装置噪声的频谱;
信号确定子装置,用于基于环境噪声的频谱和收音装置噪声的频谱,结合最小方差无畸变响应滤波器增强后的信号采用下述公式确定:

其中, 为环境中有规律噪声的频谱;
为环境中有规律噪声的频谱; 为收音装置噪声的频谱;
为收音装置噪声的频谱; 为滤波器的加权系数;
为滤波器的加权系数; 是获得的语音输入信号;
是获得的语音输入信号; 为待降噪的信号;
为待降噪的信号;




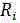
判定值确定子装置,用于基于所述获得的语音输入信号,采用下述公式对所述语音输入信号的噪声判定值,若每个信号数据的噪声判定值 大于预设的判定阈值,则将该信号数据判定为噪声点,其中
大于预设的判定阈值,则将该信号数据判定为噪声点,其中 值的计算公式为:
值的计算公式为:

其中, 代表信号数据集合
代表信号数据集合 中的第
中的第 个信号数据;
个信号数据; 代表信号数据集合
代表信号数据集合 中的第
中的第 个信号数据,
个信号数据, 代表信号数据集合
代表信号数据集合 中的第
中的第 个信号数据,
个信号数据, ,
,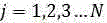 ;
; 代表信号数据集合
代表信号数据集合 中第
中第 个信号数据的噪声判定值,
个信号数据的噪声判定值, 代表自然常数,
代表自然常数, 代表指数函数,
代表指数函数, 代表信号数据集合
代表信号数据集合 中信号数据的中值;
中信号数据的中值;
判定子装置,用于将数据集合 中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
中的每个信号数据都进行一一判定,当为噪声点时,则进行剔除,不为噪声点时,则进行保留,将保留后的信号数据形成最后处理后的信号。
7.根据权利要求6所述的基于人工智能的自动语音识别系统,其特征在于,所述专业词汇设置装置中词汇分类模板包括:
获取子装置,用于获取大量分属于不同行业的专业词汇;
训练子装置,用于将所述专业词汇采用卷积神经网络按照专业词汇所属的行业进行分类训练;
分类结果获取子装置,用于获得分类结果,并将所述分类结果存储于分类数据库中,构成词汇分类模板。
8.根据权利要求6所述的基于人工智能的自动语音识别系统,其特征在于,所述第一输出装置中所述专业词汇声学模型包括:
分类子装置,用于将词汇分类模板中的分类数据库设置为专业词汇字典;
第一映射子装置,用于基于音素或其组合从所述专业词汇字典中进行映射;
第二映射子装置,用于当第一映射子装置中所述专业词汇字典中无映射内容时,则基于声学模型中的字典进行映射;
声学得分子装置,用于根据上述映射结果获取相应音素及其组合的声学得分。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110293229.9A CN112951237B (zh) | 2021-03-18 | 2021-03-18 | 一种基于人工智能的自动语音识别方法及系统 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110293229.9A CN112951237B (zh) | 2021-03-18 | 2021-03-18 | 一种基于人工智能的自动语音识别方法及系统 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112951237A CN112951237A (zh) | 2021-06-11 |
| CN112951237B true CN112951237B (zh) | 2022-03-04 |
Family
ID=76227907
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110293229.9A Active CN112951237B (zh) | 2021-03-18 | 2021-03-18 | 一种基于人工智能的自动语音识别方法及系统 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112951237B (zh) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114778648B (zh) * | 2022-04-24 | 2023-10-31 | 深圳科瑞德健康科技有限公司 | 一种水溶液氧化还原电位值的测试系统及测量方法 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU7978098A (en) * | 1997-07-07 | 1999-02-08 | Motorola, Inc. | Modular speech recognition system and method |
| JP3232289B2 (ja) * | 1999-08-30 | 2001-11-26 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 記号挿入装置およびその方法 |
| CN110111780B (zh) * | 2018-01-31 | 2023-04-25 | 阿里巴巴集团控股有限公司 | 数据处理方法和服务器 |
| CN109599114A (zh) * | 2018-11-07 | 2019-04-09 | 重庆海特科技发展有限公司 | 语音处理方法、存储介质和装置 |
| CN109360554A (zh) * | 2018-12-10 | 2019-02-19 | 广东潮庭集团有限公司 | 一种基于语深度神经网络的语言识别方法 |
| CN110544477A (zh) * | 2019-09-29 | 2019-12-06 | 北京声智科技有限公司 | 一种语音识别方法、装置、设备及介质 |
| CN110610700B (zh) * | 2019-10-16 | 2022-01-14 | 科大讯飞股份有限公司 | 解码网络构建方法、语音识别方法、装置、设备及存储介质 |
| CN112397054B (zh) * | 2020-12-17 | 2023-11-24 | 北京中电飞华通信有限公司 | 一种电力调度语音识别方法 |
-
2021
- 2021-03-18 CN CN202110293229.9A patent/CN112951237B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN112951237A (zh) | 2021-06-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109410914B (zh) | 一种赣方言语音和方言点识别方法 | |
| CN105957531B (zh) | 基于云平台的演讲内容提取方法及装置 | |
| US5621857A (en) | Method and system for identifying and recognizing speech | |
| JP5330450B2 (ja) | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル | |
| CN102074234B (zh) | 语音变异模型建立装置、方法及语音辨识系统和方法 | |
| CN111105785B (zh) | 一种文本韵律边界识别的方法及装置 | |
| CN107564543B (zh) | 一种高情感区分度的语音特征提取方法 | |
| CN108877769B (zh) | 识别方言种类的方法和装置 | |
| CN112397054B (zh) | 一种电力调度语音识别方法 | |
| KR20200119410A (ko) | 전역 및 지역 문맥 기반 한국어 대화문 감정 인식 시스템 및 방법 | |
| CN112735404A (zh) | 一种语音反讽检测方法、系统、终端设备和存储介质 | |
| CN112015874A (zh) | 学生心理健康陪伴对话系统 | |
| CN112687291A (zh) | 一种发音缺陷识别模型训练方法以及发音缺陷识别方法 | |
| CN112951237B (zh) | 一种基于人工智能的自动语音识别方法及系统 | |
| CN107123419A (zh) | Sphinx语速识别中背景降噪的优化方法 | |
| CN113555133A (zh) | 一种医疗问诊数据处理方法和装置 | |
| CN112231440A (zh) | 一种基于人工智能的语音搜索方法 | |
| JP3444108B2 (ja) | 音声認識装置 | |
| CN115376547A (zh) | 发音评测方法、装置、计算机设备和存储介质 | |
| CN112767961B (zh) | 一种基于云端计算的口音矫正方法 | |
| Qasim et al. | Arabic speech recognition using deep learning methods: Literature review | |
| CN115424616A (zh) | 一种音频数据筛选方法、装置、设备及计算机可读介质 | |
| Zhou et al. | Environmental sound classification of western black-crowned gibbon habitat based on spectral subtraction and VGG16 | |
| CN113516987B (zh) | 一种说话人识别方法、装置、存储介质及设备 | |
| Nair et al. | Pair-wise language discrimination using phonotactic information |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |