CN112948552B - 一种事理图谱在线扩展方法及装置 - Google Patents
一种事理图谱在线扩展方法及装置 Download PDFInfo
- Publication number
- CN112948552B CN112948552B CN202110217425.8A CN202110217425A CN112948552B CN 112948552 B CN112948552 B CN 112948552B CN 202110217425 A CN202110217425 A CN 202110217425A CN 112948552 B CN112948552 B CN 112948552B
- Authority
- CN
- China
- Prior art keywords
- event
- text data
- news text
- map
- adaptive
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Artificial Intelligence (AREA)
- Human Computer Interaction (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了一种事理图谱在线扩展方法及装置,该方法包括以下步骤:获取历史新闻文本数据,构建事理图谱;获取最新新闻文本数据,对最新新闻文本数据进行事件关系的匹配及事件抽取;基于自适应泛化模型,利用抽取到的最新新闻文本数据的前件事件和后件事件,对构建的事理图谱进行在线扩展。该方法降低了人工成本,提高了扩展效率,增强了事理图谱的可移植性。
Description
技术领域
本发明涉及事理图谱在线扩展技术领域,特别地涉及一种基于自适应泛化模型的事理图谱在线扩展方法及装置。
背景技术
事理图谱是继知识图谱之后,以(前件事件,关系,后件事件)作为三元组所形成的事理知识库。与知识图谱所不同,事理图谱能够描绘出事件之间的演化规律和模式,可以应用于基于事理的问答,事件预测等。现有的事理图谱的构造方式都是基于大数据直接生成,实则为静态事理图谱。
现有的事理图谱的生成方法为:事件关系抽取,事件的抽取,事件泛化,可视化。在事理图谱的在线扩展方面研究尤其罕见。在事件泛化上,现有的技术主要分为有监督学习和无监督学习两种方式:其中有监督学习为利用提前标注好的事件种子集作为训练集,通过特征提取配合深度学习进行分类任务,完成事件泛化。无监督学习主要是利用基于K-means的改良,利用欧式距离进行聚类。
上述的利用有监督的方式进行事件泛化,其需要大量的训练样本集,目前并无完善统一的训练样本,故需要根据自身需求花费大量人力资源,进行标注,并且深度学习模型的训练时长较长,需要很高的时间成本。
上述的无监督事件泛化的方式虽然降低了人力要求,但是依旧无法在线扩展节点,只能生成特定领域的静态事理图谱,可移植性,可扩展性差,不能够识别未知事件,仅能根据先验知识进行手工扩展。
发明内容
有鉴于此,本发明提出一种基于自适应泛化模型的事理图谱在线扩展方法及装置,降低了人工成本,提高了扩展效率,增强了事理图谱的可移植性。
本发明第一方面提供一种事理图谱在线扩展方法,该方法包括以下步骤:
获取历史新闻文本数据,构建事理图谱;
获取最新新闻文本数据,对最新新闻文本数据进行事件关系的匹配及事件抽取;
基于自适应泛化模型,利用抽取到的最新新闻文本数据的前件事件和后件事件,对构建的事理图谱进行在线扩展。
进一步地,所述事理图谱的构建方法为:
利用事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件;
对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组;
基于事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值。
进一步地,所述对构建的事理图谱进行在线扩展的步骤包括:
将最新新闻文本数据的前件事件和后件事件进行向量化表示,并输入自适应泛化模型;
根据自适应泛化模型中事理图谱的记忆权值,计算得到最新新闻文本数据的前件事件和后件事件的竞争获胜者,并分别计算竞争获胜者与输入事件的相似度,将相似度与设定的阈值进行比较;
若最新新闻文本数据的前件事件和后件事件中至少一个事件的所有获胜者相似度均小于设定的阈值,利用最新新闻文本数据的前件事件和/或后件事件激活自适应泛化模型中新的计算单元,并根据计算单元所指类别中动词和名词出现的频率,人工标注新事件节点标签,生成新的事件边;
若最新新闻文本数据的前件事件和后件事件两者的所有获胜者的相似度均大于设定的阈值,则调整事理图谱的记忆权值。
本发明第二方面提供一种事理图谱在线扩展装置,该装置包括:
事理图谱初步构建模块,用于获取历史新闻文本数据,构建事理图谱;
数据获取模块,用于获取最新新闻文本数据;
事件抽取模块,用于对最新新闻文本数据进行事件关系的匹配及事件抽取;
事理图谱扩展模块,用于基于自适应泛化模型,利用抽取到的最新新闻文本数据的前件事件和后件事件,对构建的事理图谱进行在线扩展。
进一步地,所述事理图谱初步构建模块构建事理图谱的步骤包括:
利用事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件;
对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组;
基于事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值。
进一步地,所述事理图谱扩展模块对构建的事理图谱进行在线扩展的步骤包括:
将最新新闻文本数据的前件事件和后件事件进行向量化表示,并输入自适应泛化模型;
根据自适应泛化模型中记忆权值,计算得到最新新闻文本数据的前件事件和后件事件的竞争获胜者,并分别计算竞争获胜者与输入事件的相似度,将相似度与设定的阈值进行比较;
若最新新闻文本数据的前件事件和后件事件中仅有一个事件的所有获胜者相似度均小于设定的阈值,利用所有获胜者的相似度均小于设定的阈值的事件激活自适应泛化模型中新的计算单元,对新的计算单元按照该类别中动词和名词出现的频率进行人工标注标签,生成新事件节点;
若最新新闻文本数据的前件事件和后件事件两者的所有获胜者的相似度均小于设定的阈值,利用最新新闻文本数据的前件事件和后件事件激活自适应泛化模型中新的计算单元,对最新新闻文本数据的前件事件和后件事件,分别按照该类别中动词和名词出现的频率进行人工标注,生成新的事件边,并增加两者的因果边赋予初始权值;
若最新新闻文本数据的前件事件和后件事件两者的所有获胜者的相似度均大于设定的阈值,则调整事理图谱的记忆权值。
上述的基于自适应泛化模型的事理图谱在线扩展方法,基于自适应泛化模型,利用网络结构的记忆性,进行事件泛化,能够在较少的人为干预下,在线生成新的事件节点,完成事理图谱的在线扩展,能够动态生成事理图谱,增强了事理图谱在不同领域应用的可移植性,可扩展性。
附图说明
为了说明而非限制的目的,现在将根据本发明的优选实施例、特别是参考附图来描述本发明,其中:
图1是实施例一提供的事理图谱在线扩展方法的流程图。
图2(a)、2(b)和2(c)是事件聚类示意图。
图3是自适应泛化模型的结构示意图。
图4是实施例二提供的事理图谱在线扩展装置的结构框图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施例对本发明进行详细描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
实施例一
图1是本发明实施例一提供的一种基于自适应泛化模型的事理图谱在线扩展方法的流程图。
在本实施例中,所述事理图谱在线扩展方法可以应用于计算机装置中,对于需要进行事理图谱在线扩展的计算机装置,可以直接在计算机装置上集成本发明的方法所提供的用于事理图谱在线扩展的功能,或者以软件开发工具包(Software Development Kit,SDK)的形式运行在计算机装置上。
如图1所示,所述事理图谱在线扩展方法具体包括以下步骤,根据不同的需求,该流程图中步骤的顺序可以改变,某些步骤可以省略。
本实施例中,所述计算机装置可以为个人电脑、服务器、智能电视、便携式电子设备如手机、平板电脑等设备。
步骤S101、所述计算机装置获取历史新闻文本数据,对历史新闻文本数据进行事件关系的匹配及事件的抽取,基于事件泛化的聚类方法和自适应泛化模型,进行事件泛化,形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值wij和wji。
上述步骤S1中所述计算机装置获取历史新闻文本数据,对历史新闻文本数据进行事件关系的匹配及事件抽取的步骤包括:
首先,所述计算机装置利用现有语言领域的事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件。
接着,所述计算机装置对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组<Pre,r,Post>,其中Pre和Post分别表示历史新闻文本数据的前件事件与后件事件,r指历史新闻文本数据的前件事件和后件事件之间的因果关系。所述计算机装置定义事件为E={x|x=Vmax∪Nmax},其中Vmax为前/后件中出现次数最多的动词,Nmax为前件事件和后件事件中出现次数最多的词语。
上述的步骤S101中事件泛化的聚类方法为:
所述计算机装置统计历史新闻文本数据的三元组中前件事件和后件事件完全相同的元组数量,并记为count,形成多个Pre——count——Post的图谱形式。如图2(a)所示,统计三元组e1中前件事件和后件事件完全相同的元组数量。
接着,所述计算机装置将历史新闻文本数据的三元组中语义相似的事件聚为一类,并将这些事件所对应的count值相加。如图2(b)所示,对语义相似的事件e2、e4进行聚类形成事件e'。
所述计算机装置根据每个事件的元组数量及元组数量总和,计算每个事件的概率pi,如图2(c)所示。其中,概率pi的计算表达式如下:

式中,n为i节点的出度。
所述自适应泛化模型是对自适应共振网络的改进,应用于事件泛化领域。自适应共振网络是采用自稳机制和竞争学习的一种自组织学习。其结构如图3所示,其中,F1为输入比较层,可以抑制噪声;F2为识别层,可以输出分类;空心箭头表示兴奋激励,实心箭头表示抑制激励。所述自适应泛化模型的具体公式如下:
zi=xi+aui (2)

vi=f(qi)+bf(si) (4)


其中,xi为输入变量,zi为x向量的线性组合,|Z|为z向量的模长,qi为z的归一化向量,si为p的归一化向量,f(x)为滤波函数,ui为v的归一化向量,|V|为v向量的模长。
由于word2vec向量化后含有负向量,故f(x)改进为式(5),a,b>0,式(3)和式(6)可看做zi和vi的归一化处理,其中e为极小的正数,e<<1。


由顶向下


其中,a,b,c,d,e,ρ,θ为自适应泛化模型的超参数,其中a,b为正反馈系数,c为r向量的计算参数,d为调整的步幅值,e为弱归一化参数,ρ为设定的阈值,θ为门限值,I为获胜类别,yj为输出向量,M为最大类别数,ui为v的归一化向量,pi为F1层和F2层交互向量,w为记忆权值,ri为相似度向量,|U|为u向量的模长,|R|为r向量的模长。
当|R|+e≤ρ,则系统进入谐振,按照式(9)和式(10)更新权值;否则F2重置。其中,I为事件类别号,0≤d≤1,cd/(1-d)≤1,上述a,b,c,d,e,ρ,θ均为自适应泛化模型的超参数,其会具体影响泛化效果,可以利用各种参数调节方法,如遗传算法等提前计算得出。
所述计算机装置基于上述的事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存事理图谱的记忆权值wij和wji。
步骤S102、所述计算机装置获取最新的一篇新闻文本数据,对最新的一篇新闻文本数据进行事件关系的匹配及事件的抽取。
上述步骤S102中所述计算机装置对最新的一篇新闻文本数据进行事件关系的匹配及事件抽取的步骤包括:
首先,所述计算机装置根据因果事件规则库中事件关系规则,对最新的一篇新闻文本数据进行事件关系匹配,提取出最新新闻文本数据的前件和后件。
接着,所述计算机装置对提取出的最新新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成最新新闻文本数据的三元组<P′re,r′,P′ost>,其中P′re和P′ost分别表示最新新闻文本数据的前件事件与后件事件,r′指最新新闻文本数据的前件事件和后件事件之间的因果关系。
步骤S103、所述计算机装置基于自适应泛化模型,计算最新新闻文本数据的前件事件和后件事件的相似度,并比较相似度与设定阈值的大小。
所述计算机装置分别将最新新闻文本数据的前件事件P′re和后件事件P′ost利用word2vec向量化表示,传入自适应泛化模型中F1层,依据记忆权值wij计算,逐次得到自适应泛化模型中F2层中的竞争获胜者,逐个计算竞争获胜者与输入事件的相似度,将相似度与设定阈值ρ进行比较。若最新新闻文本数据的前件事件P′re和后件事件P′ost中仅有一个的所有获胜者相似度均小于设定阈值ρ,则转至步骤S4,若最新新闻文本数据的前件事件P′re和后件事件P′ost两者的所有获胜者的相似度均小于设定的阈值ρ,转至步骤S105;否则转至步骤S106。
本实施例基于自适应泛化模型,与传统的K-means及其改进相比较,自适应泛化模型具备记忆性,并且能够对非平稳,有噪声环境进行学习,具备更优的泛化效果。
本实施例使用自适应泛化模型进行事件扩展,可以对新事件进行在线生成,通过比较|R|+e≤ρ判断是否在F2层激活新的神经元,来判断所输入事件是否为新增事件,从而决定对后续的事理图谱扩展节点还是动态调整权值。
步骤S104、所述计算机装置将所有获胜者相似度均小于设定阈值ρ的事件记为e1;另一事件记为e2,其所属类别为E2。e1会激活自适应泛化模型中新的F2层神经元,对新神经元按照该类别中动词和名词出现的频率进行人工标注标签,生成新事件节点E1。事理图谱中增加E1与E2因果边并赋予初始权值,转至步骤S7。
本实施例在事理图谱在新增事件节点的过程,仅在为事件类别打上可视化标签需要人工参与,其余部分完全由算法完成,降低了人工的成本,提高了效率。
步骤S105、所述计算机装置利用最新新闻文本数据的前件事件P′re和后件事件P′ost激活新的F2层神经元,对最新新闻文本数据的前件事件P′re和后件事件P′ost分别按照该类别中动词和名词出现的频率人工标注,生成新的事件边,并增加两者的因果边赋予初始权值,转至步骤S7。
步骤S106、所述计算机装置更新最新新闻文本数据的前件事件P′re和后件事件P′ost所属事件类别之间边的权值,转至步骤S107。
步骤S107、所述计算机装置调整已有自适应泛化模型中事理图谱的记忆权值wij和wji,转至步骤S102,依次循环,实现事理图谱在线扩展。
本实施例提出的事理图谱在线扩展方法,基于自适应泛化模型可以在非平稳的环境下进行无监督的学习的特点,利用自适应泛化模型进行事件泛化,不需要逐个事件分类标注,大大地降低了人工标注成本。
本实施例提出的事理图谱在线扩展方法所采用的自适应泛化模型应用了记忆权值,其中蕴含已泛化事件信息,具有长期记忆性,故每次发现新事件时仅需要为新事件标签,不需要重新训练已有的事件,其应用在事理图谱扩展上提高了工作的效率。
利用本实施例提出的事理图谱在线扩展方法所提出的自适应泛化模型进行事理图谱扩展,可将事理图谱在水平领域进行应用,从而完成更多事件预测等事理图谱下游任务,增强了事理图谱的可移植性。
实施例二
图4是本发明实施例二提供的基于自适应泛化模型的事理图谱在线扩展装置20的结构框图。
在本实施例中,所述事理图谱在线扩展装置20可以应用于计算机装置中,所述事理图谱在线扩展装置20可以包括多个由程序代码段所组成的功能模块。所述事理图谱在线扩展装置20中的各个程序段的程序代码可以存储于计算机装置的存储器中,并由所述计算机装置的至少一个处理器所执行,以实现(详见图1描述)事理图谱在线扩展功能。
本实施例中,所述事理图谱在线扩展装置20根据其所执行的功能,可以被划分为多个功能模块。所述功能模块可以包括:事理图谱初步构建模块201、数据获取模块202、事件抽取模块203以及事理图谱扩展模块204。本发明所称的模块是指一种能够被至少一个处理器所执行并且能够完成固定功能的一系列计算机程序段,其存储在存储器中。在本实施例中,关于各模块的功能将在后续的实施例中详述。
所述事理图谱初步构建模块201,用于获取历史新闻文本数据,对历史新闻文本数据进行事件关系的匹配及事件的抽取,基于事件泛化的聚类方法和自适应泛化模型,进行事件泛化,初步形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值为wij和wji。
所述事理图谱初步构建模块201获取历史新闻文本数据,对历史新闻文本数据进行事件关系的匹配及事件抽取的步骤包括:
首先,利用现有语言领域的事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件。
接着,对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组<Pre,r,Post>,其中Pre和Post分别表示历史新闻文本数据的前件事件与后件事件,r指历史新闻文本数据的前件事件和后件事件之间的因果关系。
所述事理图谱初步构建模块201基于事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存事理图谱的记忆权值为wij和wji。
所述数据获取模块202,用于获取最新的一篇新闻文本数据。
所述事件抽取模块203,用于对最新新闻文本数据进行事件关系的匹配及事件的抽取。
上述事件抽取模块203对最新的一篇新闻文本数据进行事件关系的匹配及事件抽取的步骤包括:
首先,根据因果事件规则库中事件关系规则,对最新的一篇新闻文本数据进行事件关系匹配,提取出最新新闻文本数据的前件和后件。
接着,对提取出的最新新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成最新新闻文本数据的三元组<P′re,r′,P′ost>,其中P′re和P′ost分别表示最新新闻文本数据的前件事件与后件事件,r′指最新新闻文本数据的前件事件和后件事件之间的因果关系。
所述事理图谱扩展模块204,用于基于自适应泛化模型,计算最新新闻文本数据的前件事件和后件事件的相似度,并比较相似度与设定阈值的大小,根据相似度与设定阈值的比较结果,利用自适应泛化模型对初步形成的事理图谱进行在线扩展。
所述事理图谱扩展模块204分别将最新新闻文本数据的前件事件P′re和后件事件P′ost利用word2vec向量化表示,传入自适应泛化模型中F1层,依据参数wij计算,逐次得到自适应泛化模型中F2层中的竞争获胜者,逐个计算竞争获胜者与输入事件的相似度,将相似度与设定阈值ρ进行比较,便于后续事理图谱扩展。
本实施例基于自适应泛化模型,与传统的K-means及其改进相比较,自适应泛化模型具备记忆性,并且能够对非平稳,有噪声环境进行学习,具备更优的泛化效果。
本实施例使用自适应泛化模型进行事件扩展,可以对新事件进行在线生成,通过比较|R|+e≤ρ判断是否在F2层激活新的神经元,来判断所输入事件是否为新增事件,从而决定对后续的事理图谱扩展节点还是动态调整权值。
上述的事理图谱扩展模块205根据相似度与设定阈值的比较结果,利用自适应泛化模型对初步形成的事理图谱进行在线扩展的具体实现过程包括:
若最新新闻文本数据的前件事件P′re和后件事件P′ost中仅有一个的所有获胜者相似度均小于设定阈值ρ,则将所有获胜者相似度均小于设定阈值ρ的事件记为e1;另一事件记为e2,其所属类别为E2。e1会激活自适应泛化模型中新的F2层神经元,对新神经元进行人工标注标签,生成新事件节点E1。事理图谱中增加E1与E2因果边并赋予初始权值,调整已有自适应泛化模型中事理图谱的记忆权值wij和wji。
若最新新闻文本数据的前件事件P′re和后件事件P′ost两者的所有获胜者的相似度均小于ρ,利用最新新闻文本数据的前件事件P′re和后件事件P′ost激活新的F2层神经元,对最新新闻文本数据的前件事件P′re和后件事件P′ost分别人工标注,生成新的事件边,并增加两者的因果边赋予初始权值,调整已有自适应泛化模型中事理图谱的记忆权值wij和wji。
本实施例提出的事理图谱在线扩展装置,基于自适应泛化模型可以在非平稳的环境下进行无监督的学习的特点,利用自适应泛化模型进行事件泛化,不需要逐个事件分类标注,大大地降低了人工标注成本。
本实施例提出的事理图谱在线扩展装置所采用的自适应泛化模型应用了记忆权值,其中蕴含已泛化事件信息,具有长期记忆性,故每次发现新事件时仅需要为新事件标签,不需要重新训练已有的事件,其应用在事理图谱扩展上提高了工作的效率。
利用本实施例提出的事理图谱在线扩展装置所提出的自适应泛化模型进行事理图谱扩展,可将事理图谱在水平领域进行应用,从而完成更多事件预测等事理图谱下游任务,增强了事理图谱的可移植性。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
Claims (7)
1.一种事理图谱在线扩展方法,其特征是,该方法包括以下步骤:
获取历史新闻文本数据,构建事理图谱;
获取最新新闻文本数据,对最新新闻文本数据进行事件关系的匹配及事件抽取;
基于自适应泛化模型,利用抽取到的最新新闻文本数据的前件事件和后件事件,对构建的事理图谱进行在线扩展;
其中,所述事理图谱的构建方法为:
利用事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件;
对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组;
基于事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值;
其中,所述自适应泛化模型为:
zi=xi+aui

vi=f(qi)+bf(si)








其中,a,b为正反馈系数,c为r向量的计算参数,d为调整的步幅值,e为弱归一化参数,ρ为设定的阈值,θ为门限值,I为获胜类别,xi为输入变量,zi为x向量的线性组合,|Z|为z向量的模长,qi为z的归一化向量,si为p的归一化向量,f(x)为滤波函数,|V|为v向量的模长;yj为输出向量,M为最大类别数,ui为v的归一化向量,w为记忆权值,ri为相似度向量,|U|为u向量的模长,pi为F1层和F2层交互向量,F1为输入比较层,F2为识别层,|R|为r向量的模长;当|R|+e≤ρ,则系统进入谐振,按照式 和式
和式 更新权值。
更新权值。
2.根据权利要求1所述的事理图谱在线扩展方法,其特征是,所述事件泛化的聚类方法为:
统计新闻文本数据的三元组中前件事件和后件事件完全相同的元组数量;
将历史新闻文本数据的三元组中语义相似的事件聚为一类,并将这些事件所对应的元组数量值相加,得到元组数量总和;
根据每个事件的元组数量及元组数量总和,计算每个事件的概率。
3.根据权利要求2所述的事理图谱在线扩展方法,其特征是,所述每个事件的概率的计算方法为:

其中,i为事件,n为i事件的出度,counti为事件i的元组数量。
4.根据权利要求1所述的事理图谱在线扩展方法,其特征是,所述对构建的事理图谱进行在线扩展的步骤包括:
将最新新闻文本数据的前件事件和后件事件进行向量化表示,并输入自适应泛化模型;
根据自适应泛化模型中事理图谱的记忆权值,计算得到最新新闻文本数据的前件事件和后件事件的竞争获胜者,并分别计算竞争获胜者与输入事件的相似度,将相似度与设定的阈值进行比较;
若最新新闻文本数据的前件事件和后件事件中至少一个事件的所有获胜者相似度均小于设定的阈值,利用最新新闻文本数据的前件事件和/或后件事件激活自适应泛化模型中新的计算单元,并根据计算单元所指类别中动词和名词出现的频率,人工标注新事件节点标签,生成新的事件边;
若最新新闻文本数据的前件事件和后件事件两者的所有竞争获胜者的相似度均大于设定的阈值,则调整自适应泛化模型中事理图谱的记忆权值。
5.根据权利要求4所述的事理图谱在线扩展方法,其特征是,所述利用最新新闻文本数据的前件事件和/或后件事件激活自适应泛化模型中新的计算单元的步骤包括:
若最新新闻文本数据的前件事件和后件事件中仅有一个事件的所有获胜者相似度均小于设定的阈值,利用所有竞争获胜者的相似度均小于设定的阈值的事件激活自适应泛化模型中新的计算单元,对新的计算单元按照其类别中动词和名词出现的频率进行人工标注标签,生成新事件节点;
若最新新闻文本数据的前件事件和后件事件两者的所有竞争获胜者的相似度均小于设定的阈值,利用最新新闻文本数据的前件事件和后件事件激活自适应泛化模型中新的计算单元,对最新新闻文本数据的前件事件和后件事件,分别按照其类别中动词和名词出现的频率进行人工标注,生成新的事件边,并增加两者的因果边赋予初始权值。
6.一种事理图谱在线扩展装置,其特征是,包括:
事理图谱初步构建模块,用于获取历史新闻文本数据,构建事理图谱;
数据获取模块,用于获取最新新闻文本数据;
事件抽取模块,用于对最新新闻文本数据进行事件关系的匹配及事件抽取;
事理图谱扩展模块,用于基于自适应泛化模型,利用抽取到的最新新闻文本数据的前件事件和后件事件,对构建的事理图谱进行在线扩展;
其中,所述事理图谱的构建方法为:
利用事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件;
对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组;
基于事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值;
其中,所述自适应泛化模型为:
zi=xi+aui

vi=f(qi)+bf(si)




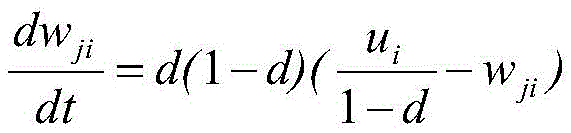



其中,a,b为正反馈系数,c为r向量的计算参数,d为调整的步幅值,e为弱归一化参数,ρ为设定的阈值,θ为门限值,I为获胜类别,xi为输入变量,zi为x向量的线性组合,|Z|为z向量的模长,qi为z的归一化向量,si为p的归一化向量,f(x)为滤波函数,|V|为v向量的模长;yj为输出向量,M为最大类别数,ui为v的归一化向量,w为记忆权值,ri为相似度向量,|U|为u向量的模长,pi为F1层和F2层交互向量,F1为输入比较层,F2为识别层,|R|为r向量的模长;当|R|+e≤ρ,则系统进入谐振,按照式 和式
和式 更新权值;
更新权值;
所述事理图谱初步构建模块构建事理图谱的步骤包括:
利用事件关系规则,构建因果事件规则库,根据因果事件规则库中事件关系规则,对历史新闻文本数据进行事件关系匹配,提取出历史新闻文本数据的前件和后件;
对提取出的历史新闻文本数据的前件和后件进行分词,抽取历史新闻文本数据的前件和后件中的事件,形成历史新闻文本数据的三元组;
基于事件泛化的聚类方法和自适应泛化模型,对历史新闻文本数据的三元组中前件事件和后件事件进行泛化,初步形成事理图谱,并保存自适应泛化模型中事理图谱的记忆权值。
7.根据权利要求6所述的事理图谱在线扩展装置,其特征是,所述事理图谱扩展模块对构建的事理图谱进行在线扩展的步骤包括:
将最新新闻文本数据的前件事件和后件事件进行向量化表示,并输入自适应泛化模型;
根据自适应泛化模型中记忆权值,计算得到最新新闻文本数据的前件事件和后件事件的竞争获胜者,并分别计算竞争获胜者与输入事件的相似度,将相似度与设定的阈值进行比较;
若最新新闻文本数据的前件事件和后件事件中仅有一个事件的所有获胜者相似度均小于设定的阈值,利用所有竞争获胜者的相似度均小于设定的阈值的事件激活自适应泛化模型中新的计算单元,对新的计算单元按照其类别中动词和名词出现的频率进行人工标注标签,生成新事件节点;
若最新新闻文本数据的前件事件和后件事件两者的所有竞争获胜者的相似度均小于设定的阈值,利用最新新闻文本数据的前件事件和后件事件激活自适应泛化模型中新的计算单元,对最新新闻文本数据的前件事件和后件事件,分别按照该类别中动词和名词出现的频率进行人工标注,生成新的事件边,并增加两者的因果边赋予初始权值;
若最新新闻文本数据的前件事件和后件事件两者的所有竞争获胜者的相似度均大于设定的阈值,则调整自适应泛化模型的记忆权值。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110217425.8A CN112948552B (zh) | 2021-02-26 | 2021-02-26 | 一种事理图谱在线扩展方法及装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110217425.8A CN112948552B (zh) | 2021-02-26 | 2021-02-26 | 一种事理图谱在线扩展方法及装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112948552A CN112948552A (zh) | 2021-06-11 |
| CN112948552B true CN112948552B (zh) | 2023-06-02 |
Family
ID=76246485
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110217425.8A Active CN112948552B (zh) | 2021-02-26 | 2021-02-26 | 一种事理图谱在线扩展方法及装置 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112948552B (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114817575B (zh) * | 2022-06-24 | 2022-09-02 | 国网浙江省电力有限公司信息通信分公司 | 基于扩展模型的大规模电力事理图谱处理方法 |
| CN116304100A (zh) * | 2023-03-21 | 2023-06-23 | 日本电气株式会社 | 用于信息呈现的方法和设备 |
| CN116304340A (zh) * | 2023-03-21 | 2023-06-23 | 日本电气株式会社 | 用于信息处理的方法和设备 |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6118850A (en) * | 1997-02-28 | 2000-09-12 | Rutgers, The State University | Analysis methods for energy dispersive X-ray diffraction patterns |
| CN105844298A (zh) * | 2016-03-23 | 2016-08-10 | 中国石油大学(华东) | 一种基于Fuzzy ARTMAP神经网络的高光谱溢油影像分类方法 |
| CN107633044A (zh) * | 2017-09-14 | 2018-01-26 | 国家计算机网络与信息安全管理中心 | 一种基于热点事件的舆情知识图谱构建方法 |
| CN108763333A (zh) * | 2018-05-11 | 2018-11-06 | 北京航空航天大学 | 一种基于社会媒体的事件图谱构建方法 |
| CN109977237A (zh) * | 2019-05-27 | 2019-07-05 | 南京擎盾信息科技有限公司 | 一种面向法律领域的动态法律事件图谱构建方法 |
| CN110134797A (zh) * | 2019-04-29 | 2019-08-16 | 贳巽(北京)国际商业数据技术股份公司 | 一种基于事理图谱和多因子模型研判金融市场变化的方法 |
| CN110968699A (zh) * | 2019-11-01 | 2020-04-07 | 数地科技(北京)有限公司 | 一种基于事理推荐的逻辑图谱构建及预警方法和装置 |
| WO2020244262A1 (zh) * | 2019-06-05 | 2020-12-10 | 厦门邑通软件科技有限公司 | 一种基于事件图谱技术的设备故障智能监控方法 |
| CN112241457A (zh) * | 2020-09-22 | 2021-01-19 | 同济大学 | 一种融合扩展特征的事理知识图谱事件检测方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10841404B2 (en) * | 2016-07-11 | 2020-11-17 | Facebook, Inc. | Events discovery context |
-
2021
- 2021-02-26 CN CN202110217425.8A patent/CN112948552B/zh active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6118850A (en) * | 1997-02-28 | 2000-09-12 | Rutgers, The State University | Analysis methods for energy dispersive X-ray diffraction patterns |
| CN105844298A (zh) * | 2016-03-23 | 2016-08-10 | 中国石油大学(华东) | 一种基于Fuzzy ARTMAP神经网络的高光谱溢油影像分类方法 |
| CN107633044A (zh) * | 2017-09-14 | 2018-01-26 | 国家计算机网络与信息安全管理中心 | 一种基于热点事件的舆情知识图谱构建方法 |
| CN108763333A (zh) * | 2018-05-11 | 2018-11-06 | 北京航空航天大学 | 一种基于社会媒体的事件图谱构建方法 |
| CN110134797A (zh) * | 2019-04-29 | 2019-08-16 | 贳巽(北京)国际商业数据技术股份公司 | 一种基于事理图谱和多因子模型研判金融市场变化的方法 |
| CN109977237A (zh) * | 2019-05-27 | 2019-07-05 | 南京擎盾信息科技有限公司 | 一种面向法律领域的动态法律事件图谱构建方法 |
| WO2020244262A1 (zh) * | 2019-06-05 | 2020-12-10 | 厦门邑通软件科技有限公司 | 一种基于事件图谱技术的设备故障智能监控方法 |
| CN110968699A (zh) * | 2019-11-01 | 2020-04-07 | 数地科技(北京)有限公司 | 一种基于事理推荐的逻辑图谱构建及预警方法和装置 |
| CN112241457A (zh) * | 2020-09-22 | 2021-01-19 | 同济大学 | 一种融合扩展特征的事理知识图谱事件检测方法 |
Non-Patent Citations (7)
| Title |
|---|
| Carpenter G A 等.ART 2-A: An adaptive resonance algorithm for rapid category learning and recognition.Neural networks.1991,第4卷(第4期),493-504. * |
| 单晓红 ; 庞世红 ; 刘晓燕 ; 杨娟 ; .基于事理图谱的网络舆情事件预测方法研究.情报理论与实践.2020,43(第10期),165-170+156. * |
| 单晓红 等.基于事理图谱的网络舆情演化路径分析——以医疗舆情为例.情报理论与实践.2019,第42卷(第09期),99-103+85. * |
| 庄文英 等.突发事件舆情演化与治理研究——基于拓展多意见竞争演化模型.情报杂志.2021,第40卷(第12期),127-134+185. * |
| 张海涛 ; 张连峰 ; 王丹 ; 刘健 ; .基于自组织神经网络的图书馆关联知识聚合研究.情报理论与实践.2015,38(第09期),73-78. * |
| 王兰成 ; 娄国哲 ; .基于知识图谱的网络舆情管理方法与实践研究.情报理论与实践.2019,43(第06期),97-101. * |
| 王军平 等.面向大数据领域的事理认知图谱构建与推断分析.中国科学:信息科学.2020,第50卷(第07期),988-1002. * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112948552A (zh) | 2021-06-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110222160B (zh) | 智能语义文档推荐方法、装置及计算机可读存储介质 | |
| CN110059181B (zh) | 面向大规模分类体系的短文本标签方法、系统、装置 | |
| CN111400432B (zh) | 事件类型信息处理方法、事件类型识别方法及装置 | |
| CN106815369B (zh) | 一种基于Xgboost分类算法的文本分类方法 | |
| CN112948552B (zh) | 一种事理图谱在线扩展方法及装置 | |
| CN109189925A (zh) | 基于点互信息的词向量模型和基于cnn的文本分类方法 | |
| CN109960763A (zh) | 一种基于用户细粒度摄影偏好的摄影社区个性化好友推荐方法 | |
| CN108595632A (zh) | 一种融合摘要与主体特征的混合神经网络文本分类方法 | |
| CN107818164A (zh) | 一种智能问答方法及其系统 | |
| CN110297888B (zh) | 一种基于前缀树与循环神经网络的领域分类方法 | |
| CN111061939B (zh) | 基于深度学习的科研学术新闻关键字匹配推荐方法 | |
| CN108874783A (zh) | 电力信息运维知识模型构建方法 | |
| CN111581368A (zh) | 一种基于卷积神经网络的面向智能专家推荐的用户画像方法 | |
| CN112632984B (zh) | 基于描述文本词频的图模型移动应用分类方法 | |
| CN113672718A (zh) | 基于特征匹配和领域自适应的对话意图识别方法及系统 | |
| CN113822419B (zh) | 一种基于结构信息的自监督图表示学习运行方法 | |
| CN113536810A (zh) | 一种无监督算法实现语料意图发现方法 | |
| CN114781611A (zh) | 自然语言处理方法、语言模型训练方法及其相关设备 | |
| Ma et al. | Dirichlet process mixture of generalized inverted Dirichlet distributions for positive vector data with extended variational inference | |
| CN116304518B (zh) | 用于信息推荐的异质图卷积神经网络模型构建方法及系统 | |
| CN117216012A (zh) | 主题建模方法、装置、电子设备和计算机可读存储介质 | |
| CN111475647A (zh) | 一种文档处理方法、装置及服务器 | |
| CN114969511A (zh) | 基于分片的内容推荐方法、设备及介质 | |
| CN120316537A (zh) | 数字人情感分类方法及装置、计算机程序产品、电子设备 | |
| CN114724167B (zh) | 一种营销文本识别方法及系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |