CN112000787B - 语音交互方法、服务器和语音交互系统 - Google Patents
语音交互方法、服务器和语音交互系统 Download PDFInfo
- Publication number
- CN112000787B CN112000787B CN202010827011.2A CN202010827011A CN112000787B CN 112000787 B CN112000787 B CN 112000787B CN 202010827011 A CN202010827011 A CN 202010827011A CN 112000787 B CN112000787 B CN 112000787B
- Authority
- CN
- China
- Prior art keywords
- voice
- score
- current round
- round
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000003993 interaction Effects 0.000 title claims abstract description 56
- 238000000034 method Methods 0.000 title claims abstract description 44
- 238000012545 processing Methods 0.000 claims abstract description 27
- 239000013598 vector Substances 0.000 claims description 32
- 239000011159 matrix material Substances 0.000 claims description 13
- 238000011176 pooling Methods 0.000 claims description 9
- 238000004364 calculation method Methods 0.000 claims description 8
- 238000012790 confirmation Methods 0.000 claims description 5
- 238000010200 validation analysis Methods 0.000 claims description 2
- 230000008569 process Effects 0.000 abstract description 10
- 238000013507 mapping Methods 0.000 description 11
- 238000005516 engineering process Methods 0.000 description 8
- 238000010586 diagram Methods 0.000 description 6
- 230000006870 function Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 238000013527 convolutional neural network Methods 0.000 description 4
- 241000989913 Gunnera petaloidea Species 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000036651 mood Effects 0.000 description 2
- 230000004075 alteration Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000013145 classification model Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 239000000446 fuel Substances 0.000 description 1
- 238000010295 mobile communication Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation or dialogue systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G06F40/35—Discourse or dialogue representation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1822—Parsing for meaning understanding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Telephonic Communication Services (AREA)
Abstract
本发明公开了一种语音交互方法、服务器和语音交互系统。语音交互方法用于服务器。语音交互方法包括:接收车机系统转发的按时间输入的多轮语音,多轮语音包括当前轮语音和在先轮语音;根据多轮语音,计算出当前轮语音的语境得分和自然语言理解得分;根据当前轮语音和当前轮语音的语境得分和自然语言理解得分,获取当前轮语音的回复及拒识结果;根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互。上述语音交互方法中,能够控制车机系统以合适的处理方式来对用户语音进行处理,减少过拒等问题,提升用户体验。
Description
技术领域
本发明涉及语音技术领域,特别涉及一种语音交互方法、服务器和语音交互系统。
背景技术
目前,随着互联网的发展,汽车的车机系统可与用户进行人机对话以实现用户相应的操作。在免唤醒持续倾听的车机系统中,车机系统稳定可靠执行用户指令,指令话术不被误拒的能力是良好用户体验的基础。具体地,用户对车机发出的正常指令应该被执行,非正常指令应该拒识。
车机系统中的会话一般是连续多轮的,包含上下文语境和信息。因此语义拒识系统的能力应该具备对多轮信息的判断,然后选择合适的处理方式,而不是单纯的拒绝用户话术。
发明内容
本发明的实施方式提供一种语音交互方法、服务器和语音交互系统。
本发明实施方式的语音交互方法用于服务器,所述语音交互方法包括:
接收车机系统转发的按时间输入的多轮语音,所述多轮语音包括当前轮语音和在先轮语音;
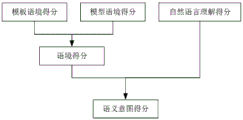
根据所述多轮语音,计算出所述当前轮语音的语境得分和自然语言理解得分;
根据所述当前轮语音和所述当前轮语音的语境得分和自然语言理解得分,获取所述当前轮语音的回复及拒识结果;
根据所述当前轮语音的回复及拒识结果,完成所述车机系统和用户的语音交互。
在某些实施方式中,根据所述多轮语音,计算出所述当前轮语音的语境得分,包括:
根据所述在先轮语音,计算所述当前轮语音的模板语境得分;
根据所述多轮语音,计算所述当前轮语音的模型语境得分;
根据所述当前轮语音的模板语境得分和模型语境得分计算所述语境得分。
在某些实施方式中,所述语境得分由以下公式计算:A=α*B+(1-α)*C,其中,A表示所述语境得分,B表示所述模型语境得分,C表示所述模板语境得分,α表示预设权重。
在某些实施方式中,根据所述在先轮语音,计算所述当前轮语音的模板语境得分,包括:
获取每个所述在先轮语音的领域得分和意图得分;
根据每个所述在先轮语音的领域得分和意图得分计算所述当前轮语音的模板语境得分。
在某些实施方式中,根据所述多轮语音,计算所述当前轮语音的模型语境得分,包括:
根据预设维度,词嵌入处理所述多轮语音,以获取数值矩阵;
根据预设步长的过滤器,卷积处理所述数值矩阵,以提取多个词向量;
最大池化处理所述多个词向量,以获取多个低维度词向量;
全连接并分类所述多个低维度词向量,以计算出所述当前轮语音的模型语境得分。
在某些实施方式中,根据所述多轮语音,计算出所述当前轮语音的自然语言理解得分,包括:
处理所述当前轮语音以获取所述当前轮语音的至少一个领域;
根据所述当前轮语音的至少一个领域确定所述当前轮语音的自然语言理解得分。
在某些实施方式中,根据所述当前轮语音和所述当前轮语音的语境得分和自然语言理解得分,获取所述当前轮语音的回复及拒识结果,包括:
根据所述当前轮语音,获取所述当前轮语音的自然语言理解候选列表;
根据所述当前轮语音的语境得分和自然语言理解得分,计算所述当前轮语音的自然语言理解候选列表的相似度得分;
在所述相似度得分不小于预设值的情况下,根据所述当前轮语音的自然语言理解候选列表,从预设回复索引表确定所述当前轮语音的回复结果;
在所述相似度得分小于所述预设值的情况下,确定所述当前轮语音的拒识结果。
在某些实施方式中,所述语音交互方法包括:
在所述当前轮语音的回复结果包括多个回复结果的情况下,按所述相似度得分大小顺序进行轮播确认。
在某些实施方式中,按所述相似度得分大小顺序进行轮播确认,包括:
先回复所述相似度得分最大所对应的所述回复结果;
在获取到肯定语音的情况下,执行相应指令;
在获取到否定语音的情况下,再回复所述相似度得分次大所对应的所述回复结果。
本发明实施方式的服务器包括:
接收模块,所述接收模块用于接收车机系统转发的按时间输入的多轮语音,所述多轮语音包括当前轮语音和在先轮语音;
计算模块,所述计算模块用于根据所述多轮语音,计算出所述当前轮语音的语境得分和自然语言理解得分;
获取模块,所述获取模块用于根据所述当前轮语音和所述当前轮语音的语境得分和自然语言理解得分,获取所述当前轮语音的回复及拒识结果;
完成模块,所述完成模块用于根据所述当前轮语音的回复及拒识结果,完成所述车机系统和用户的语音交互。
本发明实施方式的语音交互系统包括车辆和上述实施方式的服务器。
上述语音交互方法、服务器和语音交互系统中,通过接收车机系统转发的按时间输入的多轮语音来获取当前轮语音的语境得分和自然语言理解得分,进而获取当前轮语音的回复及拒识结果,并根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互,这样能够控制车机系统以合适的处理方式来对用户语音进行处理,减少过拒等问题,提升用户体验。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1-图6是本发明实施方式的语音交互方法的流程示意图;
图7是本发明实施方式的语音交互方法的卷积神经网络模型的流程示意图;
图8是本发明实施方式的语音交互方法的另一流程示意图;
图9是本发明实施方式的语音交互方法的兼顾正负例自然语言理解模型的分类示意图;
图10是本发明实施方式的语音交互方法的又一流程示意图;
图11是本发明实施方式的语音交互方法的再一流程示意图;
图12是本发明实施方式的服务器的模块示意图;
图13是本发明实施方式的语音交互系统的场景示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
在本发明的实施方式的描述中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个所述特征。在本发明的实施方式的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
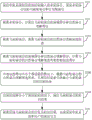
请参阅图1-图3,本发明实施方式的语音交互方法用于服务器,语音交互方法包括:
步骤S12:接收车机系统转发的按时间输入的多轮语音,多轮语音包括当前轮语音和在先轮语音;
步骤S14:根据多轮语音,计算出当前轮语音的语境得分和自然语言理解得分;
步骤S16:根据当前轮语音和当前轮语音的语境得分和自然语言理解得分,获取当前轮语音的回复及拒识结果;
步骤S18:根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互。
上述语音交互方法中,通过接收车机系统转发的按时间输入的多轮语音来获取当前轮语音的语境得分和自然语言理解得分,进而获取当前轮语音的回复及拒识结果,并根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互,这样能够控制车机系统以合适的处理方式来对用户语音进行处理,减少过拒等问题,提升用户体验。
相关技术中的基于单轮指令的语义拒识与放行技术,免唤醒持续倾听的车机系统可根据语义拒识分类模型、命名实体识别模型、模板匹配等自然语言理解模型的处理结果,形成融合模型,对接收到的单条指令进行判断。这种语义拒识与放行技术存在响应用户表达范围有限,不能扩展语音场景,非定义内的语音场景基本都会被拒识的问题,会影响用户体验,例如,当接收到非定义内的语音场景“我想看电影”时,如果直接拒识,会导致用户体验较差;如果放行,由于语音场景未被定义,所以会回复“暂时不会此功能”,同样会导致用户体验较差。同时,这种语义拒识与放行技术存在定义内语音场景支持的语言表达有限,在语言表达泛化的情况下,基本也会被拒识的问题,例如,多人对话过程中,虽然接收到定义内的语音场景“我饿了”,但是由于无法判断用户是与人交流还是与车机系统交流,通常倾向于拒绝回复以减少主副驾闲聊带来的影响,从而导致用户损失了获取餐馆推荐的体验。
此外,相关技术中的上下文语境继承技术,免唤醒持续倾听的车机系统可根据用户在先轮语音中出现过的领域意图,通过领域意图槽位的跳转或继承,来判断当前轮的领域意图。这种上下文语境继承技术根据历史复现领域意图构建相同语音场景,存在跨场景领域意图继承比较生硬,不够平滑,逻辑容易混乱等问题,例如,请结合表1,表1为向上追溯3轮的上下文语境映射表,用户实际闲聊过程中,车机系统接收到当前轮语音(query)“晴天”,由于在先轮语音中出现过“我想听歌”,此时大概率继承第1轮语音的领域意图槽位(domain-intent-slot),然后播放歌曲《晴天》,一定程度上干扰到用户闲聊,导致用户体验较差。
表1


也即是说,在相关技术中,免唤醒持续倾听的车机系统不能够根据上下文语境和信息对当前轮语音做出准确的回复及拒识,存在回复非正常指令、过度拒识正常指令的情况,不能够给用户带来良好的体验。
而本实施方式的语音交互方法,根据上下文语境对当前轮语音进行打分,进而根据分值确定当前轮语音的回复及拒识结果,可有效避免过度拒识正常指令的情况发生,提升用户体验。
具体地,在步骤S12中,接收到的多轮语音保存在上下文语境映射表中,上下文语境映射表至少包括轮次信息、语音(query)信息、领域(domain)信息和意图(intent)信息,即上下文语境映射表包括当前轮语音和在先轮语音对应的轮次信息、领域信息和意图信息。其中,当前轮语音对应有至少一组领域信息和意图信息,每一条在先轮语音只对应一组领域信息和意图信息。在步骤S14中,语境得分可由模板语境得分和模型语境得分计算得到。在步骤S16中,根据当前轮语音的语境得分和自然语言理解得分,可计算出语义意图得分(confidence);根据当前轮语音和语义意图得分,可获取当前轮语音的回复及拒识结果。在步骤S18中,根据当前轮语音的回复及拒识结果,控制车机系统直接回复、拒识或连续追问用户,以完成车机系统和用户的语音交互。
在一个例子中,多轮语音包括:第1轮“听歌吧”;第2轮“心情不错哈哈哈”;第3轮“打开导航”;当前轮“我饿了”。相关技术中,车机系统拒识当前轮语音,因为无法判断用户当前轮是与人交流还是与车机系统交流;而本实施方式的语音交互方法中,车机系统可直接回复“为您找到附近的餐馆”,因为可通过分析上下文语境,确定用户当前轮是与车机系统交流。
在另一个例子中,多轮语音包括:第1轮“打开导航”;第2轮“今天天气怎么样”;第3轮“我没吃饭你饿吗”;当前轮“我饿了”。相关技术中,车机系统拒识当前轮语音,因为无法判断用户当前轮是与人交流还是与车机系统交流;而本实施方式的语音交互方法中,车机系统拒识当前轮语音,因为通过分析上下文语境,确定用户当前轮是与人交流,不需要车机系统回复。
在又一个例子中,多轮语音包括:第1轮“哈哈”;第2轮“今天天气咋样”;第3轮“想听一首歌”;当前轮“晴天怎么样”。相关技术中,车机系统拒识当前轮语音,因为判断当前轮语音为噪音;而本实施方式的语音交互方法中,车机系统回复“请问是否要听周杰伦的晴天呢”,因为通过分析上下文语境,确定用户当前轮是与车机系统交流,且用户可能是想要听歌或者问询天气,因此向连续追问用户进行确认。
请参阅图4,在某些实施方式中,步骤S14包括:
步骤S22:根据在先轮语音,计算当前轮语音的模板语境得分;
步骤S24:根据多轮语音,计算当前轮语音的模型语境得分;
步骤S26:根据当前轮语音的模板语境得分和模型语境得分计算语境得分。
如此,通过融合模板语境得分和模型语境得分,可获得精准的语境得分。具体地,当前轮语音的模板语境得分根据在先轮语音计算得出,当前轮语音的模型语境得分根据在先轮语音和当前轮语音计算得出。按照一定规则,将当前轮语音的模板语境得分和模型语境得分进行融合,可计算出当前轮语音的语境得分。
在某些实施方式中,语境得分由以下公式计算:A=α*B+(1-α)*C,其中,A表示语境得分,B表示模型语境得分,C表示模板语境得分,α表示预设权重。
如此,通过加权融合模板语境得分和模型语境得分,可获得更加精准的语境得分。具体地,预设权重的计算公式为:α=(n-1)/n,其中n∈[2,+∞),n为在先轮语音的总轮数。预设权重与在先轮语音的总轮数相关,在先轮语音的总轮数越多,模型优势越大,能力越强;在先轮语音的总轮数越少,模板优势越大,能力越强。
在一个例子中,向上追溯3轮的上下文语境映射表中,模板语境得分为{“music-music_play”:0.5,“chat-chat_confirm”:0.333,“info-weather_search”:0.167},模型语境得分为{“music-music_play”:0.7,“chat-chat_confirm”:0.2,“info-weather_search”:0.1},由于在先轮语音的总轮数为3,即n=3,求得预设权重α=(3-1)/3≈0.67,根据公式可计算“music-music_play”得分:0.67*0.5+0.33*0.7=0.634,“chat-chat_confirm”得分:0.67*0.333+0.33*0.2=0.24389,“info-weather_search”得分:0.67*0.167+0.33*0.1=0.12211,因此,语境得分为{“music-music_play”:0.634,“chat-chat_confirm”:0.24389,“info-weather_search”:0.12211}。
请参阅图5,在某些实施方式中,步骤S22包括:
步骤S222:获取每个在先轮语音的领域得分和意图得分;
步骤S224:根据每个在先轮语音的领域得分和意图得分计算当前轮语音的模板语境得分。
如此,可获得当前轮语音的模板语境得分。
具体地,在步骤S222中,通过每个在先轮语音的轮次权重D计算得到每个在先轮语音的领域得分和意图得分,并录入上下文语境映射表中,上下文语境映射表包括轮次信息。第i轮语音的轮次权重Di可通过以下公式计算:Di=i/(1+...+n)=2i/[(n+1)*n],其中,i∈[1,n],n为在先轮语音的总轮数。则第i轮语音的领域得分=1*Di,第i轮语音的意图得分=1*Di。
在步骤S224中,将不同在先轮语音中相同领域的领域得分相加,形成具有互异性的领域得分汇总;将不同在先轮语音中相同意图的意图得分相加,形成具有互异性的意图得分汇总。根据在先轮语音中存在的领域-意图映射关系、领域得分汇总和意图得分汇总,可计算出当前轮语音的模板语境得分,其中,模板语境得分包括多个领域-意图得分,每个领域-意图得分为对应领域得分与对应意图得分的算数平均数。
在一个例子中,请结合表2,表2为向上追溯4轮的上下文语境映射表,其中第1-4轮均为在先轮,即在先轮语音的总轮数为4,可依次计算出在先轮语音的轮次权重、领域得分和意图得分,计算结果如表2所示:
表2
| 轮次 | 轮次权重 | query | domain,得分 | intent,得分 |
| 第1轮 | 0.1 | 好天气啊多少度 | info,0.1 | weather_search,0.1 |
| 第2轮 | 0.2 | 我想听歌 | music,0.2 | music_play,0.2 |
| 第3轮 | 0.3 | 对啊 | chat,0.3 | chat_confirm,0.3 |
| 第4轮 | 0.4 | 换一首 | music,0.4 | music_conrol_next,0.4 |
| 当前轮 | -- | 晴天 | -- | -- |
则领域得分汇总为{“info”:0.1,“chat”:0.3,“music”:0.6},意图得分汇总为{“weather_search”:0.1,“chat_confirm”:0.3,“music_play”:0.2,“music_conrol_next”:0.4}。结合表2中存在的领域-意图映射关系,可计算“music-music_control_next”得分:(0.6+0.4)/2=0.5,“music-music_play”得分:(0.6+0.2)/2=0.4,“chat-chat_confirm”得分:(0.3+0.3)/2=0.3,“info-weather_search”得分:(0.1+0.1)/2=0.1,因此,当前轮语音的模板语境得分为{“music-music_control_next”:0.5,“music-music_play”:0.4,“chat-chat_confirm”:0.3,“info-weather_search”:0.1}。
在另一个例子中,请结合表3,表3为向上追溯3轮的上下文语境映射表,其中第1-3轮均为在先轮,即在先轮语音的总轮数为3,可依次计算出在先轮语音的轮次权重、领域得分和意图得分,计算结果如表3所示:
表3
| 轮次 | 轮次权重 | query | domain,得分 | intent,得分 |
| 第1轮 | 0.167 | 好天气啊多少度 | info,0.167 | weather_search,0.167 |
| 第2轮 | 0.333 | 对啊 | chat,0.333 | chat_confirm,0.333 |
| 第3轮 | 0.5 | 我想听歌 | music,0.5 | music_play,0.5 |
| 当前轮 | -- | 晴天 | -- | -- |
则领域得分汇总为{“info”:0.167,“chat”:0.333,“music”:0.5},意图得分汇总为{“weather_search”:0.167,“chat_confirm”:0.333,“music_play”:0.5},结合表3中存在的领域-意图映射关系,可计算“music-music_play”得分:(0.5+0.5)/2=0.5,“chat-chat_confirm”得分:(0.333+0.333)/2=0.333,“info-weather_search”得分:(0.167+0.167)/2=0.167,因此,当前轮语音的模板语境得分为{“music-music_play”:0.5,“chat-chat_confirm”:0.333,“info-weather_search”:0.167}。
请参阅图6和图7,在某些实施方式中,步骤S24包括:
步骤S242:根据预设维度,词嵌入处理多轮语音,以获取数值矩阵;
步骤S244:根据预设步长的过滤器,卷积处理数值矩阵,以提取多个词向量;
步骤S246:最大池化处理多个词向量,以获取多个低维度词向量;
步骤S248:全连接并分类多个低维度词向量,以计算出当前轮语音的模型语境得分。
如此,基于卷积神经网络(Text-CNN)模型,可计算出的模型语境得分。具体地,请结合图7,卷积神经网络模型包括输入层(bert_embeding)、卷积层(convolutional-layer)、池化层(max-pooling-layer)和全连接的softmax层(full-connected-layer)。
步骤S242发生在输入层,预设维度为(128*768),特征表示包括向量矩阵,词嵌入即就是将多轮语音中的每个字进行向量化,即用词向量唯一表示一个字,并将所有词向量组成向量矩阵,其中,词向量的长度也即是向量矩阵的行大小为128,向量矩阵的列大小为768。
步骤S244发生在卷积层,预设步长包括2,3,4,利用步长为2,3,4的过滤器,分别卷积处理向量矩阵,提取多个特征向量。
步骤S246发生在池化层,因为卷积过程中使用了不同步长的过滤器,使得通过卷积层后得到的特征向量的维度会不一致,所以在池化层中,将每个特征向量降低维度池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征,这样,多个不同维度的特征向量转化为相同维度特征向量。
步骤S248发生在全连接的softmax层,所有相同维度特征向量拼接成一个最终特征向量,对最终特征向量进行领域-意图语境分类,并通过soft-max函数输出每一类领域-意图语境的概率,从而获得当前轮语音的模型语境得分。
在一个例子中,多轮语音包括:好天气啊多少度-info-weatherr_search;对呀-chat-chat_confirm;我想听歌-music-music_play;晴天。在经过输入层、卷积层、池化层和全连接的softmax层的处理后,获得当前轮语音的模型语境得分为{“music-music_play”:0.7,“chat-chat_confirm”:0.2,“info-weather_search”:0.1}。
请参阅图8和图9,在某些实施方式中,步骤S14包括:
步骤S32:处理当前轮语音以获取当前轮语音的至少一个领域;
步骤S34:根据当前轮语音的至少一个领域确定当前轮语音的自然语言理解得分。
如此,请结合图9,基于兼顾正负例自然语言理解(NLU)模型,可计算出当前轮语音的自然语言理解得分。具体地,兼顾正负例自然语言理解模型包括清晰(clear)和噪声(noise)。在一个实施方式中,清晰的场景领域至少包括导航(navi)领域、音乐(music)领域、资讯(info)领域、系统(system)领域、全球(global)领域、控制(control)领域、科技(ac)领域、游戏(game)领域和问答(qa)领域,噪声的场景领域至少包括未知(unkonown)领域、闲聊(chat)领域、不清晰(unclear)领域、不支持(unsupport)领域和部分第三方应用领域。步骤S32包括处理当前轮语音以获取当前轮语音在清晰中的至少一个领域,和处理当前轮语音以获取当前轮语音在噪声中的至少一个领域。步骤S34包括根据当前轮语音在清晰中的至少一个领域和当前轮语音在噪声中的至少一个领域,确定清晰得分和噪声得分,其中,清晰得分与噪声得分的和为1,可以理解,清晰得分表示当前轮语音对应的领域属于清晰的概率,噪声得分表示当前轮语音对应的领域属于噪声的概率;清晰得分高则噪声得分低,清晰得分低则噪声得分高。
在一个例子中,当前轮语音为“我们去吃烧烤吧”,在清晰中,当前轮语音可为导航领域,在噪声中,当前轮语音可为闲聊领域,兼顾正负例自然语言理解模型确定当前轮语音属于导航领域的概率为0.15,当前轮语音属于闲聊领域的概率为0.85,即清晰得分为0.15,噪声得分为0.85,因此,当前轮语音的自然语言理解得分为{“clear”:0.15,“noise”:0.85}。
请参阅图10,在某些实施方式中,步骤S16包括:
步骤S162:根据当前轮语音,获取当前轮语音的自然语言理解候选列表;
步骤S164:根据当前轮语音的语境得分和自然语言理解得分,计算当前轮语音的自然语言理解候选列表的相似度得分;
步骤S166:在相似度得分不小于预设值的情况下,根据当前轮语音的自然语言理解候选列表,从预设回复索引表确定当前轮语音的回复结果;
步骤S168:在相似度得分小于预设值的情况下,确定当前轮语音的拒识结果。
如此,能够根据相似度得分与预设值的关系,以合适的处理方式处理当前轮语音,减少过拒等问题,提升用户体验。具体地,在步骤S162中,当前轮语音的自然语言理解候选列表可包括语音信息、领域信息和意图信息,当前轮语音对应有至少一组领域信息和意图信息。
步骤S164包括:步骤一,融合当前轮语音的语境得分和自然语言理解得分,以获得语义意图得分;步骤二,根据语义意图得分,计算当前轮语音的自然语言理解候选列表的相似度得分(score)。
进一步地,在步骤一中,自然语言理解得分中的清晰得分,按照比例均摊至语境得分中属于清晰的多个领域对应的分数,以获得多个属于清晰的对应领域的语义意图得分;语境得分中属于噪声的多个领域对应的分数求和后,与自然语言理解得分中的噪声得分做乘积,以获得一个噪声的语义意图得分。在一个例子中,语境得分为{“music-music_play”:0.5,“chat-chat_confirm”:0.333,“info-weather_search”:0.167},自然语言理解得分为{“clear”:0.15,“noise”:0.85},可计算清晰中“music-music_play”得分:0.15*(0.5/(0.5+0.167))+0.5=0.6125,“info-weather_search”得分:0.15*(0.167/(0.5+0.167))+0.167=0.174,噪声中“noise”得分:0.333*0.85=0.285,因此语义意图得分为{“music-music_play”:0.6125,“noise”:0.285,“info-weather_search”:0.174}。在另一个例子中,语境得分为{“music-music_play”:0.7,“info-weather_search”:0.3},自然语言理解得分为{“clear”:0.15,“noise”:0.85},可计算清晰中“music-music_play”得分:0.15*(0.7/(0.7+0.3))+0.7=0.805,“info-weather_search”得分:0.15*(0.3/(0.7+0.3))+0.3=0.345,噪声中“noise”得分:0*0.85=0,因此语义意图得分为{“music-music_play”:0.805,“info-weather_search”:0.345,“noise”:0,}。在又一个例子中,语境得分为{“chat-chat_a”:0.5,“chat-chat_b”:0.4,chat-chat_c”:0.1},自然语言理解得分为{“clear”:0.15,“noise”:0.85},可计算噪声中“noise”得分:(0.5+0.4+0.1)*0.85=0.85,因此语义意图得分为{“noise”:0.85}。
在步骤二中,当前轮语音的自然语言理解候选列表的相似度得分为:score=编辑距离相似度*confidence,其中编辑距离相似度为基于编辑距离计算出的当前轮语音的domain-intent字符串与语义意图得分中的相似语境的domain-intent字符串的相似度。
进一步地,在一个例子中,预设值为0.3,在相似度得分不小于0.3的情况下,根据当前轮语音的自然语言理解候选列表,从预设回复索引表确定当前轮语音的回复结果(tts);在相似度得分小于0.3的情况下,确定当前轮语音的拒识结果。
在一个例子中,多轮语音包括:第1轮“听歌吧”;第2轮“心情不错哈哈哈”;第3轮“打开导航”;当前轮“我饿了”。请结合表4-表8,其中,表4为语义意图表,表5为当前轮语音的自然语言理解候选列表,表6为当前轮语音的自然语言理解候选列表的相似度表,表7为预设回复索引表,表8为当前轮语音的候选回复表。根据表5可知,当前轮语音的领域-意图字符串为“navi-navi_search_food”,在表4中与其语境相似的领域-意图字符串为“navi-navi_search”,且对应的语义意图得分为0.6,因此,当前轮语音的自然语言理解候选列表的相似度得分=计算编辑距离相似度*0.6=0.5,如表6所示。由于相似度得分不小于0.3,从表7中确定当前轮语音的回复结果为“为您找到附近的餐馆”,并形成表8。
表4
| domain | intent | confidence |
| noise | noise | 0.2 |
| navi | navi_search | 0.6 |
| music | music_play | 0.1 |
| -- | -- | -- |
表5
| query | domain | intent |
| 我饿了 | navi | navi_search_food |
表6
| domain | intent | score |
| navi | navi_search_food | 0.5 |
表7


表8
| domain | intent | tts |
| navi | navi_search | 为您找到附近的餐馆 |
在另一个例子中,多轮语音包括:第1轮“打开导航”;第2轮“今天天气怎么样”;第3轮“我没吃饭你饿吗”;当前轮“我饿了”。请结合表9-表11,其中,表9为语义意图表,表10为当前轮语音的自然语言理解候选列表,表11为当前轮语音的自然语言理解候选列表的相似度表。据表10可知,当前轮语音的领域-意图字符串为“navi-navi_search_food”,在表9中与其语境相似的领域-意图字符串为“navi-navi_search”,且对应的语义意图得分为0.1,因此,当前轮语音的自然语言理解候选列表的相似度得分=计算编辑距离相似度*0.1=0.09,如表11所示。由于相似度得分小于0.3,确定拒识当前轮语音。
表9
| domain | intent | confidence |
| noise | noise | 0.6 |
| info | weather_search | 0.2 |
| navi | navi_search | 0.1 |
| -- | -- | -- |
表10
| query | domain | intent |
| 我饿了 | navi | navi_search_food |
表11
| domain | intent | score |
| navi | navi_search_food | 0.09 |
在又一个例子中,多轮语音包括:第1轮“哈哈”;第2轮“今天天气咋样”;第3轮“想听一首歌”;当前轮“晴天怎么样”。请结合表12-表16,其中,表12为语义意图表,表13为当前轮语音的自然语言理解候选列表,表14为当前轮语音的相似度得分表,表15为预设回复索引表,表16为当前轮语音的候选回复表。根据表13可知,当前轮语音的领域-意图字符串包括“music-music_play”和“info-weather_search”,在表12中与其语境相似的领域-意图字符串对应为“music-music_play”和“info-weather_search”,且对应的语义意图得分为0.4和0.3,计算可得当前轮语音的自然语言理解候选列表的相似度得分对应为0.4和0.3,如表14所示。由于当前轮语音的两种相似度得分均不小于0.3,从表15中可确定当前轮语音的回复结果包括“请问要播放xx的xx吗”和“要查看xx天气吗”,并形成表16。
表12
| domain | intent | confidence |
| noise | noise | 0.2 |
| music | music_play | 0.4 |
| info | weather_search | 0.3 |
| -- | -- | -- |
表13
| query | domain | intent |
| 晴天怎么样 | music | music_play |
| 晴天怎么样 | info | weather_search |
表14
| domain | intent | score |
| music | music_play | 0.4 |
| info | weather_search | 0.3 |
表15
| domain | intent | tts |
| music | music_play | 请问要播放xx的xx吗 |
| music | music_control_next | 请问要播放下一首吗 |
| music | music_control_pre | 请问要播放上一首吗 |
| info | weather_search | 要查看xx天气吗 |
| info | news_search | 要查看xx新闻吗 |
| info | film_search | 要查看xx电影吗 |
| navi | navi_search | 要导航去xx吗 |
| navi | navi_location | 要查询当前位置吗 |
表16
| domain | intent | tts |
| music | music_play | 请问要播放xx的xx吗 |
| info | weather_search | 要查看xx天气吗 |
当输入下一轮语音“导航不好用”时,请结合表17和表18,表17为下一轮语音的自然语言理解候选列表,表18为下一轮语音的自然语言理解候选列表的相似度得分表。计算可得下一轮语音的自然语言理解候选列表的相似度得分分别为0.2和0.2,由于下一轮语音的两种相似度得分均小于0.3,确定拒识下一轮语音。
表17
| query | domain | intent |
| 导航不好用 | navi | navi_search |
表18


请参阅图11,在某些实施方式中,语音交互方法包括:
步骤S167:在当前轮语音的回复结果包括多个回复结果的情况下,按相似度得分大小顺序进行轮播确认。
如此,通过连续追问的方式,能够较可靠地执行用户指令,提升用户体验。具体地,在某些实施方式中,按相似度得分大小顺序进行轮播确认,包括:先回复相似度得分最大所对应的回复结果;在获取到肯定语音的情况下,执行相应指令;在获取到否定语音的情况下,再回复相似度得分次大所对应的回复结果。如此,提供更丰富的回复层级,提升用户体验。
在一个例子中,请结合表14和表16,表14为当前轮语音的相似度得分表,表16为当前轮语音的候选回复表,相似度得分0.4对应的回复结果为“请问要播放xx的xx吗”,相似度得分0.3对应的回复结果为“要查看xx天气吗”,按照相似度的大小顺序,先回复“请问要播放xx的xx吗”,在获取到肯定语音的情况下,执行相应指令;在获取到否定语音的情况下,回复“要查看xx天气吗”,若获取到肯定语音,则执行相应指令,若获取到否定语音,则等待下一轮语音。
请参阅图12,本发明实施方式的服务器100包括接收模块102、计算模块104、获取模块106和完成模块108。接收模块102用于接收车机系统转发的按时间输入的多轮语音,多轮语音包括当前轮语音和在先轮语音。计算模块104用于根据多轮语音,计算出当前轮语音的语境得分和自然语言理解得分。获取模块106用于根据当前轮语音和当前轮语音的语境得分和自然语言理解得分,获取当前轮语音的回复及拒识结果。完成模块108用于根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互。
上述服务器100中,通过接收车机系统转发的按时间输入的多轮语音来获取当前轮语音的语境得分和自然语言理解得分,进而获取当前轮语音的回复及拒识结果,并根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互,这样能够控制车机系统以合适的处理方式来对用户语音进行处理,减少过拒等问题,提升用户体验。
需要说明的是,上述对语音交互方法的实施方式和有益效果的解释说明,也适用于本实施方式的服务器100,为避免冗余,在此不再详细展开。
请参阅图13,本发明实施方式的语音交互系统1000包括车辆200和上述的服务器100。
上述语音交互系统1000中,通过接收车机系统转发的按时间输入的多轮语音来获取当前轮语音的语境得分和自然语言理解得分,进而获取当前轮语音的回复及拒识结果,并根据当前轮语音的回复及拒识结果,完成车机系统和用户的语音交互,这样能够控制车机系统以合适的处理方式来对用户语音进行处理,减少过拒等问题,提升用户体验。
具体地,车辆200可以通过无线通信方式(如WIFI、移动通信网络等)连接服务器100。车辆200包括但不限于纯电动车、混合动力电动车、增程式电动车、燃油车等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
Claims (7)
1.一种语音交互方法,用于服务器,其特征在于,所述语音交互方法包括:
接收车机系统转发的按时间输入的多轮语音,所述多轮语音包括当前轮语音和在先轮语音;
根据所述多轮语音,计算出所述当前轮语音的语境得分和自然语言理解得分;
根据所述当前轮语音和所述当前轮语音的语境得分和自然语言理解得分,获取所述当前轮语音的回复及拒识结果;
根据所述当前轮语音的回复及拒识结果,完成所述车机系统和用户的语音交互;
所述根据所述多轮语音,计算出所述当前轮语音的语境得分,包括:
根据所述在先轮语音,计算所述当前轮语音的模板语境得分;
根据所述多轮语音,计算所述当前轮语音的模型语境得分;
根据所述当前轮语音的模板语境得分和模型语境得分计算所述语境得分;
所述根据所述在先轮语音,计算所述当前轮语音的模板语境得分,包括:
获取每个所述在先轮语音的领域得分和意图得分;
根据每个所述在先轮语音的领域得分和意图得分计算所述当前轮语音的模板语境得分;
所述根据所述多轮语音,计算所述当前轮语音的模型语境得分,包括:
根据预设维度,词嵌入处理所述多轮语音,以获取数值矩阵;
根据预设步长的过滤器,卷积处理所述数值矩阵,以提取多个词向量;
最大池化处理所述多个词向量,以获取多个低维度词向量;
全连接并分类所述多个低维度词向量,以计算出所述当前轮语音的模型语境得分;
所述根据所述多轮语音,计算出所述当前轮语音的自然语言理解得分,包括:
处理所述当前轮语音以获取所述当前轮语音的至少一个领域;
根据所述当前轮语音的至少一个领域确定所述当前轮语音的自然语言理解得分。
2.根据权利要求1所述的语音交互方法,其特征在于,所述语境得分由以下公式计算:A=α*B+(1-α)*C,其中,A表示所述语境得分,B表示所述模型语境得分,C表示所述模板语境得分,α表示预设权重。
3.根据权利要求1所述的语音交互方法,其特征在于,根据所述当前轮语音和所述当前轮语音的语境得分和自然语言理解得分,获取所述当前轮语音的回复及拒识结果,包括:
根据所述当前轮语音,获取所述当前轮语音的自然语言理解候选列表;
根据所述当前轮语音的语境得分和自然语言理解得分,计算所述当前轮语音的自然语言理解候选列表的相似度得分;
在所述相似度得分不小于预设值的情况下,根据所述当前轮语音的自然语言理解候选列表,从预设回复索引表确定所述当前轮语音的回复结果;
在所述相似度得分小于所述预设值的情况下,确定所述当前轮语音的拒识结果。
4.根据权利要求3所述的语音交互方法,其特征在于,所述语音交互方法包括:
在所述当前轮语音的回复结果包括多个回复结果的情况下,按所述相似度得分大小顺序进行轮播确认。
5.根据权利要求4所述的语音交互方法,其特征在于,按所述相似度得分大小顺序进行轮播确认,包括:
先回复所述相似度得分最大所对应的所述回复结果;
在获取到肯定语音的情况下,执行相应指令;
在获取到否定语音的情况下,再回复所述相似度得分次大所对应的所述回复结果。
6.一种服务器,其特征在于,包括:
接收模块,所述接收模块用于接收车机系统转发的按时间输入的多轮语音,所述多轮语音包括当前轮语音和在先轮语音;
计算模块,所述计算模块用于根据所述多轮语音,计算出所述当前轮语音的语境得分和自然语言理解得分;
获取模块,所述获取模块用于根据所述当前轮语音和所述当前轮语音的语境得分和自然语言理解得分,获取所述当前轮语音的回复及拒识结果;
完成模块,所述完成模块用于根据所述当前轮语音的回复及拒识结果,完成所述车机系统和用户的语音交互;
所述计算模块还用于根据所述在先轮语音,计算所述当前轮语音的模板语境得分;根据所述多轮语音,计算所述当前轮语音的模型语境得分;根据所述当前轮语音的模板语境得分和模型语境得分计算所述语境得分;
所述计算模块还用于获取每个所述在先轮语音的领域得分和意图得分;根据每个所述在先轮语音的领域得分和意图得分计算所述当前轮语音的模板语境得分;
所述计算模块还用于根据预设维度,词嵌入处理所述多轮语音,以获取数值矩阵;根据预设步长的过滤器,卷积处理所述数值矩阵,以提取多个词向量;最大池化处理所述多个词向量,以获取多个低维度词向量;全连接并分类所述多个低维度词向量,以计算出所述当前轮语音的模型语境得分;
所述计算模块还用于处理所述当前轮语音以获取所述当前轮语音的至少一个领域;根据所述当前轮语音的至少一个领域确定所述当前轮语音的自然语言理解得分。
7.一种语音交互系统,其特征在于,包括车辆和权利要求6所述的服务器。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010827011.2A CN112000787B (zh) | 2020-08-17 | 2020-08-17 | 语音交互方法、服务器和语音交互系统 |
| EP20904249.8A EP4006899B1 (en) | 2020-08-17 | 2020-12-10 | Speech interaction method, server and speech interaction system |
| PCT/CN2020/135132 WO2022036944A1 (zh) | 2020-08-17 | 2020-12-10 | 语音交互方法、服务器和语音交互系统 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010827011.2A CN112000787B (zh) | 2020-08-17 | 2020-08-17 | 语音交互方法、服务器和语音交互系统 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112000787A CN112000787A (zh) | 2020-11-27 |
| CN112000787B true CN112000787B (zh) | 2021-05-14 |
Family
ID=73472608
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010827011.2A Active CN112000787B (zh) | 2020-08-17 | 2020-08-17 | 语音交互方法、服务器和语音交互系统 |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP4006899B1 (zh) |
| CN (1) | CN112000787B (zh) |
| WO (1) | WO2022036944A1 (zh) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112000787B (zh) * | 2020-08-17 | 2021-05-14 | 上海小鹏汽车科技有限公司 | 语音交互方法、服务器和语音交互系统 |
| CN112632252B (zh) * | 2020-12-25 | 2021-09-17 | 中电金信软件有限公司 | 对话应答方法、装置、计算机设备和存储介质 |
| CN113221580B (zh) * | 2021-07-08 | 2021-10-12 | 广州小鹏汽车科技有限公司 | 语义拒识方法、语义拒识装置、交通工具及介质 |
| CN113470649A (zh) * | 2021-08-18 | 2021-10-01 | 三星电子(中国)研发中心 | 语音交互方法及装置 |
| CN115457945B (zh) * | 2022-11-10 | 2023-03-31 | 广州小鹏汽车科技有限公司 | 语音交互方法、服务器和存储介质 |
| CN116483960B (zh) * | 2023-03-30 | 2024-01-02 | 阿波罗智联(北京)科技有限公司 | 对话识别方法、装置、设备以及存储介质 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101989424A (zh) * | 2009-07-30 | 2011-03-23 | 索尼公司 | 语音处理设备和方法及程序 |
| CN107665708A (zh) * | 2016-07-29 | 2018-02-06 | 科大讯飞股份有限公司 | 智能语音交互方法及系统 |
| CN108446286A (zh) * | 2017-02-16 | 2018-08-24 | 阿里巴巴集团控股有限公司 | 一种自然语言问句答案的生成方法、装置及服务器 |
| CN109063035A (zh) * | 2018-07-16 | 2018-12-21 | 哈尔滨工业大学 | 一种面向出行领域的人机多轮对话方法 |
| CN109739961A (zh) * | 2018-12-24 | 2019-05-10 | 科大讯飞股份有限公司 | 一种人机语言交互方法及装置 |
| CN110765270A (zh) * | 2019-11-04 | 2020-02-07 | 苏州思必驰信息科技有限公司 | 用于口语交互的文本分类模型的训练方法及系统 |
| CN111046132A (zh) * | 2019-10-25 | 2020-04-21 | 众安信息技术服务有限公司 | 一种检索多轮对话的客服问答处理方法及其系统 |
| CN111081220A (zh) * | 2019-12-10 | 2020-04-28 | 广州小鹏汽车科技有限公司 | 车载语音交互方法、全双工对话系统、服务器和存储介质 |
| CN111177338A (zh) * | 2019-12-03 | 2020-05-19 | 北京博瑞彤芸科技股份有限公司 | 一种基于上下文的多轮对话方法 |
| CN111414195A (zh) * | 2019-02-03 | 2020-07-14 | 北京邮电大学 | 通用可配置、兼容多模型、领域可迁移的多轮对话系统 |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9269354B2 (en) * | 2013-03-11 | 2016-02-23 | Nuance Communications, Inc. | Semantic re-ranking of NLU results in conversational dialogue applications |
| US10162813B2 (en) * | 2013-11-21 | 2018-12-25 | Microsoft Technology Licensing, Llc | Dialogue evaluation via multiple hypothesis ranking |
| US9466297B2 (en) * | 2014-12-09 | 2016-10-11 | Microsoft Technology Licensing, Llc | Communication system |
| US9836452B2 (en) * | 2014-12-30 | 2017-12-05 | Microsoft Technology Licensing, Llc | Discriminating ambiguous expressions to enhance user experience |
| US10418032B1 (en) * | 2015-04-10 | 2019-09-17 | Soundhound, Inc. | System and methods for a virtual assistant to manage and use context in a natural language dialog |
| CN106407333B (zh) * | 2016-09-05 | 2020-03-03 | 北京百度网讯科技有限公司 | 基于人工智能的口语查询识别方法及装置 |
| EP3625793B1 (en) * | 2017-05-15 | 2022-03-30 | Apple Inc. | Hierarchical belief states for digital assistants |
| CN107316643B (zh) * | 2017-07-04 | 2021-08-17 | 科大讯飞股份有限公司 | 语音交互方法及装置 |
| US11005786B2 (en) * | 2018-06-28 | 2021-05-11 | Microsoft Technology Licensing, Llc | Knowledge-driven dialog support conversation system |
| CN109271498B (zh) * | 2018-09-14 | 2022-02-22 | 南京七奇智能科技有限公司 | 面向虚拟机器人的自然语言交互方法及系统 |
| CN110096567B (zh) * | 2019-03-14 | 2020-12-25 | 中国科学院自动化研究所 | 基于qa知识库推理的多轮对话回复选择方法、系统 |
| CN109918673B (zh) * | 2019-03-14 | 2021-08-03 | 湖北亿咖通科技有限公司 | 语义仲裁方法、装置、电子设备和计算机可读存储介质 |
| CN110008322B (zh) * | 2019-03-25 | 2023-04-07 | 创新先进技术有限公司 | 多轮对话场景下的话术推荐方法和装置 |
| CN110265013A (zh) * | 2019-06-20 | 2019-09-20 | 平安科技(深圳)有限公司 | 语音的识别方法及装置、计算机设备、存储介质 |
| CN110309287B (zh) * | 2019-07-08 | 2021-07-06 | 北京邮电大学 | 建模对话轮次信息的检索式闲聊对话打分方法 |
| CN111177359A (zh) * | 2020-04-10 | 2020-05-19 | 支付宝(杭州)信息技术有限公司 | 多轮对话方法和装置 |
| CN112000787B (zh) * | 2020-08-17 | 2021-05-14 | 上海小鹏汽车科技有限公司 | 语音交互方法、服务器和语音交互系统 |
-
2020
- 2020-08-17 CN CN202010827011.2A patent/CN112000787B/zh active Active
- 2020-12-10 WO PCT/CN2020/135132 patent/WO2022036944A1/zh unknown
- 2020-12-10 EP EP20904249.8A patent/EP4006899B1/en active Active
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101989424A (zh) * | 2009-07-30 | 2011-03-23 | 索尼公司 | 语音处理设备和方法及程序 |
| CN107665708A (zh) * | 2016-07-29 | 2018-02-06 | 科大讯飞股份有限公司 | 智能语音交互方法及系统 |
| CN108446286A (zh) * | 2017-02-16 | 2018-08-24 | 阿里巴巴集团控股有限公司 | 一种自然语言问句答案的生成方法、装置及服务器 |
| CN109063035A (zh) * | 2018-07-16 | 2018-12-21 | 哈尔滨工业大学 | 一种面向出行领域的人机多轮对话方法 |
| CN109739961A (zh) * | 2018-12-24 | 2019-05-10 | 科大讯飞股份有限公司 | 一种人机语言交互方法及装置 |
| CN111414195A (zh) * | 2019-02-03 | 2020-07-14 | 北京邮电大学 | 通用可配置、兼容多模型、领域可迁移的多轮对话系统 |
| CN111046132A (zh) * | 2019-10-25 | 2020-04-21 | 众安信息技术服务有限公司 | 一种检索多轮对话的客服问答处理方法及其系统 |
| CN110765270A (zh) * | 2019-11-04 | 2020-02-07 | 苏州思必驰信息科技有限公司 | 用于口语交互的文本分类模型的训练方法及系统 |
| CN111177338A (zh) * | 2019-12-03 | 2020-05-19 | 北京博瑞彤芸科技股份有限公司 | 一种基于上下文的多轮对话方法 |
| CN111081220A (zh) * | 2019-12-10 | 2020-04-28 | 广州小鹏汽车科技有限公司 | 车载语音交互方法、全双工对话系统、服务器和存储介质 |
Non-Patent Citations (2)
| Title |
|---|
| "Evaluating Natural Language Understanding Services for Conversational Question Answering Systems";Daniel Braun 等;《Proceedings of the SIGDIAL 2017 Conference》;20170817;174-185 * |
| "智能回复系统研究综述";岳世峰 等;《信息安全学报》;20200131;第5卷(第1期);20-34 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4006899B1 (en) | 2023-09-06 |
| WO2022036944A1 (zh) | 2022-02-24 |
| EP4006899A1 (en) | 2022-06-01 |
| EP4006899C0 (en) | 2023-09-06 |
| CN112000787A (zh) | 2020-11-27 |
| EP4006899A4 (en) | 2022-06-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112000787B (zh) | 语音交互方法、服务器和语音交互系统 | |
| CN109785828B (zh) | 基于用户语音风格的自然语言生成 | |
| CN107943998B (zh) | 一种基于知识图谱的人机对话控制系统及方法 | |
| CN107240398B (zh) | 智能语音交互方法及装置 | |
| US11043205B1 (en) | Scoring of natural language processing hypotheses | |
| CN101535983B (zh) | 协作会话语音用户界面的系统和方法 | |
| US9188456B2 (en) | System and method of fixing mistakes by going back in an electronic device | |
| US11861315B2 (en) | Continuous learning for natural-language understanding models for assistant systems | |
| US20150149177A1 (en) | Sharing Intents to Provide Virtual Assistance in a Multi-Person Dialog | |
| US11081104B1 (en) | Contextual natural language processing | |
| CN113168832A (zh) | 交替响应生成 | |
| CN110415679A (zh) | 语音纠错方法、装置、设备和存储介质 | |
| CN113486170B (zh) | 基于人机交互的自然语言处理方法、装置、设备及介质 | |
| CN111402894A (zh) | 语音识别方法及电子设备 | |
| CN110085217A (zh) | 语音导航方法、装置及终端设备 | |
| CN113239178A (zh) | 意图生成方法、服务器、语音控制系统和可读存储介质 | |
| WO2023078370A1 (zh) | 对话情绪分析方法、装置和计算机可读存储介质 | |
| CN111611358A (zh) | 信息交互方法、装置、电子设备及存储介质 | |
| US20220270617A1 (en) | Electronic device for supporting artificial intelligence agent services to talk to users | |
| CN116226344A (zh) | 对话生成方法、对话生成装置和存储介质 | |
| US20220358917A1 (en) | Multi-device Mediation for Assistant Systems | |
| US11544504B1 (en) | Dialog management system | |
| CN113821620A (zh) | 多轮对话任务处理方法、装置及电子设备 | |
| US11861479B2 (en) | Digital personal assistant with configurable personality | |
| CN110634481B (zh) | 一种输出最优识别结果的语音整合方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |