CN111753290A - Software type detection method and related equipment - Google Patents
Software type detection method and related equipment Download PDFInfo
- Publication number
- CN111753290A CN111753290A CN202010454339.4A CN202010454339A CN111753290A CN 111753290 A CN111753290 A CN 111753290A CN 202010454339 A CN202010454339 A CN 202010454339A CN 111753290 A CN111753290 A CN 111753290A
- Authority
- CN
- China
- Prior art keywords
- software
- detected
- api sequence
- type
- dynamic api
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000001514 detection method Methods 0.000 title claims abstract description 32
- 230000004927 fusion Effects 0.000 claims abstract description 109
- 238000012549 training Methods 0.000 claims abstract description 75
- 238000000034 method Methods 0.000 claims abstract description 52
- 239000013598 vector Substances 0.000 claims description 265
- 244000035744 Hura crepitans Species 0.000 claims description 27
- 241000700605 Viruses Species 0.000 claims description 18
- ZXQYGBMAQZUVMI-GCMPRSNUSA-N gamma-cyhalothrin Chemical compound CC1(C)[C@@H](\C=C(/Cl)C(F)(F)F)[C@H]1C(=O)O[C@H](C#N)C1=CC=CC(OC=2C=CC=CC=2)=C1 ZXQYGBMAQZUVMI-GCMPRSNUSA-N 0.000 claims description 18
- 238000013145 classification model Methods 0.000 claims description 15
- 208000015181 infectious disease Diseases 0.000 claims description 9
- 230000002458 infectious effect Effects 0.000 claims description 9
- 238000004590 computer program Methods 0.000 claims description 6
- 230000010365 information processing Effects 0.000 claims description 5
- 239000010410 layer Substances 0.000 description 36
- 238000013527 convolutional neural network Methods 0.000 description 31
- 238000012360 testing method Methods 0.000 description 15
- 230000008569 process Effects 0.000 description 14
- 230000006399 behavior Effects 0.000 description 10
- 239000002356 single layer Substances 0.000 description 9
- 230000000694 effects Effects 0.000 description 6
- 238000013528 artificial neural network Methods 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 4
- 230000009286 beneficial effect Effects 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 239000012634 fragment Substances 0.000 description 3
- 238000009499 grossing Methods 0.000 description 3
- 238000012795 verification Methods 0.000 description 3
- 230000002155 anti-virotic effect Effects 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000013136 deep learning model Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000007723 transport mechanism Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/50—Monitoring users, programs or devices to maintain the integrity of platforms, e.g. of processors, firmware or operating systems
- G06F21/52—Monitoring users, programs or devices to maintain the integrity of platforms, e.g. of processors, firmware or operating systems during program execution, e.g. stack integrity ; Preventing unwanted data erasure; Buffer overflow
- G06F21/53—Monitoring users, programs or devices to maintain the integrity of platforms, e.g. of processors, firmware or operating systems during program execution, e.g. stack integrity ; Preventing unwanted data erasure; Buffer overflow by executing in a restricted environment, e.g. sandbox or secure virtual machine
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/50—Monitoring users, programs or devices to maintain the integrity of platforms, e.g. of processors, firmware or operating systems
- G06F21/55—Detecting local intrusion or implementing counter-measures
- G06F21/56—Computer malware detection or handling, e.g. anti-virus arrangements
Abstract
The embodiment of the invention discloses a software type detection method and related equipment, wherein one method comprises the following steps: determining the gray-scale map characteristic and the dynamic API sequence characteristic of the software to be detected; splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain fusion characteristics of the software to be detected; and inputting the fusion characteristics of the software to be detected into a pre-trained first software recognition model, and outputting the first type of the software to be detected. Therefore, the software type identification accuracy can be greatly improved by detecting through the fusion characteristics of training and identification software.
Description
Technical Field
The present invention relates to network security technologies, and in particular, to a method and related device for detecting a software type.
Background
In recent years, under the assistance of a large amount of illegal funds, the black gray industry is developed vigorously, and the market value reaches the scale of billions of yuan. On the basis, hackers develop various tools for escaping the anti-virus software according to the existing loopholes of the anti-virus software. If the malicious software cannot be identified correctly, the malicious software can be spread manly, and great harm can be brought to the whole society and the country. Therefore, it is important to detect malware.
In the application of detecting the malicious software, most methods train a single feature of the malicious software by using a deep learning model so as to detect and identify the malicious software. For example, a convolutional neural network is trained on image sample data of malware so as to identify the malware by using the trained convolutional neural network. For another example, the dynamic behavior data of the malware is trained using a machine learning algorithm to identify the malware using a trained model.
Therefore, the detection method of the malicious software in the prior art only detects the malicious software by training and recognizing the single characteristics of the software, so that the accuracy of the malicious software recognition is not high enough.
Disclosure of Invention
In view of this, an embodiment of the present invention provides a method for detecting a software type, including:
determining the gray-scale map characteristic and the dynamic API sequence characteristic of the software to be detected;
splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain fusion characteristics of the software to be detected;
inputting the fusion characteristics of the software to be detected into a first software recognition model which is trained in advance, and outputting a first type of the software to be detected;
the first software identification model is an XGboost two-class model obtained by training an XGboost model through a first software sample, the fusion characteristics of software are used as input, and the first type of the software is used as output; the first software sample is a fusion feature which is marked with a first type and is respectively formed by a plurality of pieces of software.
The embodiment of the invention also provides a software type detection method, which comprises the following steps:
determining the gray-scale map characteristic and the dynamic API sequence characteristic of the software to be detected;
splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain fusion characteristics of the software to be detected;
inputting the fusion characteristics of the software to be detected into a pre-trained third software identification model, and outputting a third type of the software to be detected;
the third software identification model is an XGboost multi-classification model obtained by training an XGboost model through a third software sample, the fusion characteristics of software are used as input, and the third type of the software is used as output; the third software sample is a fusion feature labeled with a third type for each of a plurality of different types of software.
An embodiment of the present invention further provides an electronic device, including: the software type detection device comprises a memory, a processor and a computer program which is stored on the memory and can run on the processor, wherein when the computer program is executed by the processor, the software type detection method is realized by any one of the software types.
The embodiment of the invention also provides a computer-readable storage medium, wherein an information processing program is stored on the computer-readable storage medium, and when the information processing program is executed by a processor, the method for detecting the software type of any one of the above software types is realized.
According to the technical scheme provided by the embodiment of the invention, the detection is carried out through the fusion characteristics of the training and recognition software, so that the accuracy rate of software type recognition can be greatly improved.
Drawings
The accompanying drawings are included to provide an understanding of the present disclosure and are incorporated in and constitute a part of this specification, illustrate embodiments of the disclosure and together with the examples serve to explain the principles of the disclosure and not to limit the disclosure.
Fig. 1 is a schematic flowchart of a software type detection method according to an embodiment of the present invention;
FIG. 2 is a flowchart illustrating a method for detecting a software type according to another embodiment of the present invention;
FIG. 3 is a schematic flow chart illustrating a model training method according to an embodiment of the present invention;
fig. 4 is a schematic structural diagram of a multilayer CNN according to an embodiment of the present invention;
FIG. 5 is a flowchart illustrating a method for detecting a software type according to another embodiment of the present invention;
FIG. 6 is a flowchart illustrating a method for detecting a software type according to another embodiment of the present invention;
FIG. 7 is a flowchart illustrating a method for detecting a software type according to another embodiment of the present invention;
FIG. 8 is a flowchart illustrating an apparatus for detecting software type according to an embodiment of the present invention;
fig. 9 is a flowchart illustrating a software type detection apparatus according to another embodiment of the present invention.
Detailed Description
The present application describes embodiments, but the description is illustrative rather than limiting and it will be apparent to those of ordinary skill in the art that many more embodiments and implementations are possible within the scope of the embodiments described herein. Although many possible combinations of features are shown in the drawings and discussed in the detailed description, many other combinations of the disclosed features are possible. Any feature or element of any embodiment may be used in combination with or instead of any other feature or element in any other embodiment, unless expressly limited otherwise.
The present application includes and contemplates combinations of features and elements known to those of ordinary skill in the art. The embodiments, features and elements disclosed in this application may also be combined with any conventional features or elements to form a unique inventive concept as defined by the claims. Any feature or element of any embodiment may also be combined with features or elements from other inventive aspects to form yet another unique inventive aspect, as defined by the claims. Thus, it should be understood that any of the features shown and/or discussed in this application may be implemented alone or in any suitable combination. Accordingly, the embodiments are not limited except as by the appended claims and their equivalents. Furthermore, various modifications and changes may be made within the scope of the appended claims.
Further, in describing representative embodiments, the specification may have presented the method and/or process as a particular sequence of steps. However, to the extent that the method or process does not rely on the particular order of steps set forth herein, the method or process should not be limited to the particular sequence of steps described. Other orders of steps are possible as will be understood by those of ordinary skill in the art. Therefore, the particular order of the steps set forth in the specification should not be construed as limitations on the claims. Further, the claims directed to the method and/or process should not be limited to the performance of their steps in the order written, and one skilled in the art can readily appreciate that the sequences may be varied and still remain within the spirit and scope of the embodiments of the present application.
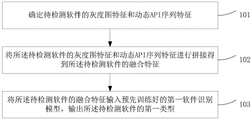
Fig. 1 is a schematic flowchart of a software type detection method according to an embodiment of the present invention, as shown in fig. 1, the method includes:
102, splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain fusion characteristics of the software to be detected;
103, inputting the fusion characteristics of the software to be detected into a first software recognition model which is trained in advance, and outputting a first type of the software to be detected;
the first software identification model is an XGboost two-class model obtained by training an XGboost model through a first software sample, the fusion characteristics of software are used as input, and the first type of the software is used as output; the first software sample is a fusion feature which is marked with a first type and is respectively formed by a plurality of pieces of software.
In an example, the first type is normal software or malware.
In an example, when the first type of the software to be detected is malware, the method further comprises:
inputting the fusion characteristics of the software to be detected into a second software recognition model which is trained in advance, and outputting a second type of the software to be detected;
the second software identification model is an XGboost multi-classification model obtained by training an XGboost model through a second software sample, the fusion characteristics of software are used as input, and the second type of the software is used as output; the second software sample is a fusion feature labeled with a second type for each of a plurality of different types of malware.
In one example, the second type includes all or some of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
In one example, the determining the gray-scale map feature of the software to be detected includes:
disassembling the software to be detected to obtain a binary code file of the software;
converting the binary code file into a gray scale map;
and extracting the characteristic vector of the gray scale image as the gray scale image characteristic of the software to be detected.
In one example, the determining the dynamic API sequence characteristics of the software to be detected includes:
simulating the software to be detected in a dynamic sandbox to obtain a dynamic API sequence after operation;
performing at least one of:
extracting a feature vector of the dynamic API sequence; determining an N-gram feature vector of the dynamic API sequence; determining a distributed word vector for the dynamic API sequence;
the dynamic API sequence features include one or more of:
the feature vector of the dynamic API sequence, the N-gram feature vector of the dynamic API sequence, and the distributed word vector of the dynamic API sequence.
According to the technical scheme provided by the embodiment of the invention, the detection is carried out through the fusion characteristics of the training and recognition software, so that the accuracy rate of software type recognition can be greatly improved.
Fig. 2 is a schematic flow chart of a software type detection method according to another embodiment of the present invention, as shown in fig. 2, the method includes:
the first software identification model is an XGboost two-class model obtained by training an XGboost model through a first software sample, the fusion characteristics of software are used as input, and the first type of the software is used as output.
The first software sample is a fusion feature which is marked with a first type and is respectively formed by a plurality of pieces of software.
Wherein the first type is normal software or malicious software.
The fusion feature of the software is a feature formed by splicing the gray-scale image feature and the dynamic API sequence feature of the software. The gray scale image features of the software refer to feature vectors of a gray scale image corresponding to the software, and the dynamic API sequence features of the software comprise one or more of the following: a feature vector of the dynamic API sequence, an N-gram feature of the dynamic API sequence, and a distributed word vector of the dynamic API sequence.
The training process of the first software identification model comprises fusion learning of two modalities of a gray-scale map feature and a dynamic API sequence feature of the first software sample. Because the two modalities have different physical meanings, it is impossible to directly convert one modality into the other modality for learning (for example, converting text information into an image, and vice versa), for example, the dimension of a text is the length of the text and the number of word vectors, while the dimension of an image is the length of the image and the two modalities cannot be converted together without processing; if the dimension of the text is forcibly scaled to the dimension of the image, a large amount of information is inevitably lost; a specific and feasible scheme must be designed to enable fusion learning of the features of the two modalities. In addition, the neural network has strong learning ability, can automatically extract features, but is easy to cause overfitting phenomenon, has inexplicability and is not beneficial to product iteration, and the XGboost is a lifting tree model and has the characteristics of difficult overfitting, interpretability, high training speed and the like. The interpretability of the XGboost model is extremely important, and the importance of the features can be obtained after training, so that the effect and the stability of the model can be obtained through reverse deduction. For example, the top ten features are obtained, the differences of the ten features among different categories are obtained through statistics, if the differences are large, the distinguishing features are selected, the model effect is good, and vice versa.
Therefore, in the embodiment, by combining the advantages of the two, feature vectors of different levels in different modes are extracted through a CNN (convolutional neural Networks) network, and then the extracted feature vectors and feature vectors of other dimensions are input to the XGBoost for learning training. For example, as shown in fig. 3, in the gray scale pattern mode learning, a feature vector is extracted through a multi-layer CNN network, and an input of a penultimate layer, i.e., a second fully-connected layer, is used as an extracted feature vector, i.e., a gray scale feature; in the dynamic API sequence modal learning, because a dynamic API sequence is text in nature, distributed word vectors are obtained first, a single-layer TextCNN network is used for extracting feature vectors based on the distributed word vectors, the feature vectors extracted by the two modalities, N-gram features of the API sequence and the distributed word vectors are spliced together, and then the spliced fusion features are input into BooXGate for learning. For example, the feature vector extracted by the multi-layer CNN is 512 dimensions, the feature vector extracted by the TextCNN is 128 dimensions, the N-gram feature vector is 90000 dimensions, and the feature of the distributed word vector is 300, so that the spliced feature vector is 90000+300+128+512 + 90940. In the API sequence modal learning, the three features are fused, because the main information of the three features is different, the length of a convolution kernel in the TextCNN can be set to be larger (such as 10-20), so that the features corresponding to long paragraphs with larger influence on text classification are extracted, the N-gram represents the features of short paragraphs with larger influence on text classification due to the limitation of N (generally not more than 3, otherwise, dimension disaster can be caused), and the distributed word vector represents the overall semantics of the text, so that the distributed word vector has certain abstraction and summarization capability compared with other features. Of course, only one or two of the three features of the API sequence may be selected and concatenated with the grayscale map feature vector and then input to the XGBoost.
In an example, the training the XGBoost model through the first software sample to obtain the first software recognition model includes:
performing the following for each software in the first software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
splicing the feature vector of the gray level image and the feature vector of the dynamic API sequence to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost binary model obtained by training as the first software identification model.
In another example, the training the XGBoost model through the first software sample to obtain the first software recognition model includes:
performing the following for each software in the first software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
determining the N-gram characteristics of the dynamic API sequence;
splicing the feature vector of the gray level image, the feature vector of the dynamic API sequence and the N-gram feature to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost binary model obtained by training as the first software identification model.
In another example, the training the XGBoost model through the first software sample to obtain the first software recognition model includes:
performing the following for each software in the first software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
determining the N-gram characteristics of the dynamic API sequence;
determining a distributed word vector for the dynamic API sequence;
splicing the feature vector of the gray level image, the feature vector of the dynamic API sequence, the N-gram feature and the distributed word vector to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost binary model obtained by training as the first software identification model.
In one example, determining a grayscale map of software includes:
disassembling the software to obtain a binary code file of the software;
the binary code file is converted into a gray scale map.
Wherein, since the range of each byte of the software is between hexadecimal 00-FF, it just corresponds to 0-255 decimal gray scale (0 is black, 255 is white), which just covers the whole range of the gray scale value. Therefore, the binary code file of the software is divided according to the bytes, and then the gray value corresponding to each byte is obtained based on the corresponding relation between the hexadecimal code and the image gray value, so that the binary code file can be converted into a gray map.
In one example, determining a dynamic API sequence for software includes:
and simulating the software in a dynamic sandbox to obtain a dynamic API sequence after running.
Where a sandbox (sandbox) is a virtual system program that allows a browser or other program to be run in a sandbox environment, changes made by the run may be subsequently removed. The method creates an independent operation environment similar to a sandbox, and programs running in the environment cannot permanently influence a hard disk. In network security, sandboxing refers to the tools used to test the behavior of untrusted files or applications, etc., in an isolated environment. The dynamic sandbox may include a virtual operating system layer, the file to be detected is firstly run in the virtual operating system layer of the dynamic sandbox, then a call operation is simulated to an Application Programming Interface (API) of the operating system in the running process, the generated dynamic behavior information is extracted and is a dynamic API sequence, and the dynamic API sequence is text information, for example, dynamic behavior information such as reading a file, writing a registry and the like.
In the API sequence modality learning, since the API sequence is text in nature, a single-layer TextCNN network is used to extract the feature vector.
The N-Gram is an algorithm based on a statistical language model, and the basic idea is that the content in the text is subjected to sliding window operation with the size of N according to bytes to form a byte fragment sequence with the length of N. Each byte segment is called as a gram, the occurrence frequency of all the grams is counted, and filtering is performed according to a preset threshold value to form a key gram list, namely the vector feature of the text is the N-gram feature, and each gram in the list is a feature vector dimension.
In one example, determining a distributed word vector for a dynamic API sequence includes: the distributed word vectors of the dynamic API sequence are trained using a word vector algorithm.
Wherein the word vector algorithm comprises one or more of the following: word2vec, Glove, Fasttext. For example, Word vectors are trained by using three methods of Word2vec, Glove and Fasttext, and three Word vectors corresponding to the dynamic API sequence are merged together to serve as a distributed Word vector of the dynamic API sequence.
determining the gray scale image characteristics of the software to be detected comprises the following steps:
disassembling the software to obtain a binary code file of the software;
converting the binary code file into a gray scale map;
and extracting the characteristic vector of the gray scale image as the gray scale image characteristic of the software to be detected.
In an example, the feature vectors of the gray scale map may be extracted through a Convolutional Neural Network (CNN). For example, a feature vector is extracted using the multi-layer CNN network shown in fig. 4, and the input of the second last layer, i.e., the second fully-connected layer, is used as the extracted feature vector, i.e., the grayscale feature.
Determining the dynamic API sequence characteristics of the software to be detected comprises the following steps:
simulating the software in a dynamic sandbox to obtain a dynamic API sequence after running;
performing at least one of:
extracting a feature vector of the dynamic API sequence;
and/or, determining N-gram characteristics of the dynamic API sequence;
and/or determining a distributed word vector for the dynamic API sequence.
Wherein the dynamic API sequence characteristics include one or more of:
the feature vector of the dynamic API sequence, the N-gram feature vector of the dynamic API sequence, and the distributed word vector of the dynamic API sequence.
In an example, a single-layer TextCNN network may be used to extract the feature vectors of the dynamic API sequence.
in one example, when the dynamic API sequence features of the software include: when the feature vector of the dynamic API sequence is used, the splicing of the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristic of the software to be detected and the characteristic vector of the dynamic API sequence of the software to be detected to obtain the fusion characteristic of the software.
For example, if the grayscale map feature, i.e., the feature vector extracted by the multi-layer CNN, is 512-dimensional, and the feature vector of the dynamic API sequence, i.e., the feature vector extracted by the TextCNN, is 128-dimensional, the feature vector after concatenation is 512+128 — 640.
In one example, when the dynamic API sequence features of the software include: when the feature vector of the dynamic API sequence and the N-gram feature vector are used, the step of splicing the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristic of the software to be detected, the characteristic vector of the dynamic API sequence of the software to be detected and the N-gram characteristic vector to obtain the fusion characteristic of the software.
For example, if the grayscale map feature, i.e., the feature vector extracted by the multi-layer CNN, is 512-dimensional, the feature vector extracted by the dynamic API sequence, i.e., the feature vector extracted by the TextCNN, is 128-dimensional, and the N-gram feature vector is 90000-dimensional, the spliced feature vector is 512+128+ 90000-90640.
In one example, when the dynamic API sequence features of the software include: when the feature vector, the N-gram feature vector and the distributed word vector of the dynamic API sequence are used, the step of splicing the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristics of the software to be detected, the characteristic vector of the dynamic API sequence of the software to be detected, the N-gram characteristic vector and the distributed word vector to obtain the fusion characteristics of the software.
For example, the feature vector extracted by the multi-layer CNN is 512 dimensions, the feature vector extracted by the TextCNN is 128 dimensions, the N-gram feature vector is 90000 dimensions, and the feature of the distributed word vector is 300, so that the spliced feature vector is 90000+300+128+512 + 90940.
According to the technical scheme provided by the embodiment of the invention, the first software identification model is trained in advance, and then the type of the software to be detected is detected by utilizing the first software identification model, so that the accuracy rate of software type identification can be greatly improved, and the detection efficiency is improved.
Fig. 5 is a schematic flowchart of a software type detection method according to another embodiment of the present invention, as shown in fig. 5, the method includes:
the specific training process is the same as the previous embodiment, and is not described herein again.
502, training the XGboost model through a second software sample to obtain a second software identification model;
the second software identification model is an XGboost multi-classification model obtained by training an XGboost model through a second software sample, the fusion characteristics of the software are used as input, and the second type of the software is used as output.
And the second software sample is the fusion feature labeled with the second type of each of a plurality of different types of malicious software.
Wherein the second type comprises all or part of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
The second software identification model takes the fusion characteristics of the malicious software as input and takes the malicious software type of the software as output. The fusion feature of the software is a feature formed by splicing the gray-scale image feature and the dynamic API sequence feature of the software. The gray scale image features of the software refer to feature vectors of a gray scale image corresponding to the software, and the dynamic API sequence features of the software comprise one or more of the following: a feature vector of the dynamic API sequence, an N-gram feature of the dynamic API sequence, and a distributed word vector of the dynamic API sequence.
And the training process of the second software identification model comprises fusion learning of two modalities of a gray-scale map and a dynamic API sequence of the second software sample. In addition, the neural network has strong learning ability, can automatically extract features, but is easy to cause overfitting phenomenon, has inexplicability and is not beneficial to product iteration, and the XGboost is a lifting tree model and has the characteristics of difficult overfitting, interpretability, high training speed and the like. Therefore, in the embodiment, by combining the advantages of the two, the feature vectors of different levels in different modalities are extracted through the CNN network, and then the extracted feature vectors and the feature vectors of other dimensions are input to the XGBoost for learning training. For example, as shown in fig. 3, in the gray scale pattern mode learning, a feature vector is extracted through a multi-layer CNN network, and an input of a penultimate layer, i.e., a second fully-connected layer, is used as an extracted feature vector, i.e., a gray scale feature; in the dynamic API sequence modal learning, because a dynamic API sequence is text in nature, distributed word vectors are obtained first, a single-layer TextCNN network is used for extracting feature vectors based on the distributed word vectors, the feature vectors extracted by the two modalities, N-gram features of the API sequence and the distributed word vectors are spliced together, and then the spliced fusion features are input into BooXGate for learning. For example, the feature vector extracted by the multi-layer CNN is 512 dimensions, the feature vector extracted by the TextCNN is 128 dimensions, the N-gram feature vector is 90000 dimensions, and the feature of the distributed word vector is 300, so that the spliced feature vector is 90000+300+128+512 + 90940. In the API sequence modal learning, the three features are fused, because the main information of the three features is different, the length of a convolution kernel in the TextCNN can be set to be larger (such as 10-20), so that the features corresponding to long paragraphs with larger influence on text classification are extracted, the N-gram represents the features of short paragraphs with larger influence on text classification due to the limitation of N (generally not more than 3, otherwise, dimension disaster can be caused), and the distributed word vector represents the overall semantics of the text, so that the distributed word vector has certain abstraction and summarization capability compared with other features. Of course, only one or two of the three features of the API sequence may be selected and concatenated with the grayscale map feature vector and then input to the XGBoost.
In an example, the training the XGBoost model through the second software sample to obtain the second software recognition model includes:
performing the following for each software in the second software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
splicing the feature vector of the gray level image and the feature vector of the dynamic API sequence to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost multi-classification model obtained by training as the second software identification model.
In another example, the training the XGBoost model through the second software sample to obtain the second software recognition model includes:
performing the following for each software in the second software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
determining the N-gram characteristics of the dynamic API sequence;
splicing the feature vector of the gray level image, the feature vector of the dynamic API sequence and the N-gram feature to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost multi-classification model obtained by training as the second software identification model.
In another example, the training the XGBoost model through the second software sample to obtain the second software recognition model includes:
performing the following for each software in the second software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
determining the N-gram characteristics of the dynamic API sequence;
determining a distributed word vector for the dynamic API sequence;
splicing the feature vector of the gray level image, the feature vector of the dynamic API sequence, the N-gram feature and the distributed word vector to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost multi-classification model obtained by training as the second software identification model.
In one example, determining a grayscale map of software includes:
disassembling the software to obtain a binary code file of the software;
the binary code file is converted into a gray scale map.
Wherein, since the range of each byte of the software is between hexadecimal 00-FF, it just corresponds to 0-255 decimal gray scale (0 is black, 255 is white), which just covers the whole range of the gray scale value. Therefore, the binary code file of the software is divided according to the bytes, and then the gray value corresponding to each byte is obtained based on the corresponding relation between the hexadecimal code and the image gray value, so that the binary code file can be converted into a gray map.
In one example, determining a dynamic API sequence for software includes:
and simulating the software in a dynamic sandbox to obtain a dynamic API sequence after running.
Where a sandbox (sandbox) is a virtual system program that allows a browser or other program to be run in a sandbox environment, changes made by the run may be subsequently removed. The method creates an independent operation environment similar to a sandbox, and programs running in the environment cannot permanently influence a hard disk. In network security, sandboxing refers to the tools used to test the behavior of untrusted files or applications, etc., in an isolated environment. The dynamic sandbox may include a virtual operating system layer, the file to be detected is firstly run in the virtual operating system layer of the dynamic sandbox, then a call operation is simulated to an Application Programming Interface (API) of the operating system in the running process, the generated dynamic behavior information is extracted and is a dynamic API sequence, and the dynamic API sequence is text information, for example, dynamic behavior information such as reading a file, writing a registry and the like.
In the API sequence modality learning, since the API sequence is text in nature, a single-layer TextCNN network is used to extract the feature vector.
The N-Gram is an algorithm based on a statistical language model, and the basic idea is that the content in the text is subjected to sliding window operation with the size of N according to bytes to form a byte fragment sequence with the length of N. Each byte segment is called as a gram, the occurrence frequency of all the grams is counted, and filtering is performed according to a preset threshold value to form a key gram list, namely the vector feature of the text is the N-gram feature, and each gram in the list is a feature vector dimension.
In one example, determining a distributed word vector for a dynamic API sequence includes: the distributed word vectors of the dynamic API sequence are trained using a word vector algorithm.
Wherein the word vector algorithm comprises one or more of the following: word2vec, Glove, Fasttext. For example, Word vectors are trained by using three methods of Word2vec, Glove and Fasttext, and three Word vectors corresponding to the dynamic API sequence are merged together to serve as a distributed Word vector of the dynamic API sequence.
determining the gray scale image characteristics of the software to be detected comprises the following steps:
disassembling the software to obtain a binary code file of the software;
converting the binary code file into a gray scale map;
and extracting the characteristic vector of the gray scale image as the gray scale image characteristic of the software to be detected.
In an example, the feature vectors of the gray scale map may be extracted through a Convolutional Neural Network (CNN). For example, a feature vector is extracted using the multi-layer CNN network shown in fig. 3, and the input of the second last layer, i.e., the second fully-connected layer, is used as the extracted feature vector, i.e., the grayscale feature.
Determining the dynamic API sequence characteristics of the software to be detected comprises the following steps:
simulating the software in a dynamic sandbox to obtain a dynamic API sequence after running;
performing at least one of:
extracting a feature vector of the dynamic API sequence;
and/or, determining N-gram characteristics of the dynamic API sequence;
and/or determining a distributed word vector for the dynamic API sequence.
Wherein the dynamic API sequence characteristics include one or more of:
the feature vector of the dynamic API sequence, the N-gram feature vector of the dynamic API sequence, and the distributed word vector of the dynamic API sequence.
In an example, a single-layer TextCNN network may be used to extract the feature vectors of the dynamic API sequence.
in one example, when the dynamic API sequence features of the software include: when the feature vector of the dynamic API sequence is used, the splicing of the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristic of the software to be detected and the characteristic vector of the dynamic API sequence of the software to be detected to obtain the fusion characteristic of the software.
For example, if the grayscale map feature, i.e., the feature vector extracted by the multi-layer CNN, is 512-dimensional, and the feature vector of the dynamic API sequence, i.e., the feature vector extracted by the TextCNN, is 128-dimensional, the feature vector after concatenation is 512+128 — 640.
In one example, when the dynamic API sequence features of the software include: when the feature vector of the dynamic API sequence and the N-gram feature vector are used, the step of splicing the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristic of the software to be detected, the characteristic vector of the dynamic API sequence of the software to be detected and the N-gram characteristic vector to obtain the fusion characteristic of the software.
For example, if the grayscale map feature, i.e., the feature vector extracted by the multi-layer CNN, is 512-dimensional, the feature vector extracted by the dynamic API sequence, i.e., the feature vector extracted by the TextCNN, is 128-dimensional, and the N-gram feature vector is 90000-dimensional, the spliced feature vector is 512+128+ 90000-90640.
In one example, when the dynamic API sequence features of the software include: when the feature vector, the N-gram feature vector and the distributed word vector of the dynamic API sequence are used, the step of splicing the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristics of the software to be detected, the characteristic vector of the dynamic API sequence of the software to be detected, the N-gram characteristic vector and the distributed word vector to obtain the fusion characteristics of the software.
For example, the feature vector extracted by the multi-layer CNN is 512 dimensions, the feature vector extracted by the TextCNN is 128 dimensions, the N-gram feature vector is 90000 dimensions, and the feature of the distributed word vector is 300, so that the spliced feature vector is 90000+300+128+512 + 90940.
Wherein the second type comprises all or part of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
According to the technical scheme provided by the embodiment of the invention, a first software identification model and a second software identification model are trained in advance, and then the first software identification model is utilized to detect the type of software to be detected; when the software to be detected is malicious software, detecting the specific type of the malicious software by using a second software identification model; whether the software is the malicious software or not can be detected, the specific type of the malicious software can be detected, the accuracy of software type identification is greatly improved, and the detection efficiency is improved.
Fig. 6 is a schematic flowchart of a software type detection method according to another embodiment of the present invention, as shown in fig. 6, the method includes:
the third software identification model is an XGboost multi-classification model obtained by training an XGboost model through a third software sample, the fusion characteristics of software are used as input, and the third type of the software is used as output; the third software sample is a fusion feature labeled with a third type for each of a plurality of different types of software.
In one example, the third type includes normal software, and all or some of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
According to the technical scheme provided by the embodiment of the invention, the specific type of the software to be detected is detected by directly utilizing the trained third software identification model, so that the accuracy of software type identification is greatly improved, and the detection efficiency is improved.
Fig. 7 is a schematic flowchart of a software type detection method according to another embodiment of the present invention, as shown in fig. 7, the method includes:
the third software identification model is an XGboost multi-classification model obtained by training an XGboost model through a third software sample, the fusion characteristics of the software are used as input, and the third type of the software is used as output.
Wherein the third software sample is a fusion feature labeled with a third type for each of a plurality of different types of software.
Wherein the third type comprises normal software and all or part of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
Wherein the third software identification model takes the fusion characteristics of the software as input and takes the third type of the software as output. The fusion feature of the software is a feature formed by splicing the gray-scale image feature and the dynamic API sequence feature of the software. The gray scale image features of the software refer to feature vectors of a gray scale image corresponding to the software, and the dynamic API sequence features of the software comprise one or more of the following: a feature vector of the dynamic API sequence, an N-gram feature of the dynamic API sequence, and a distributed word vector of the dynamic API sequence.
And the training process of the third software identification model comprises fusion learning of two modes of a gray-scale map and a dynamic API sequence of the second software sample. In addition, the neural network has strong learning ability, can automatically extract features, but is easy to cause overfitting phenomenon, has inexplicability and is not beneficial to product iteration, and the XGboost is a lifting tree model and has the characteristics of difficult overfitting, interpretability, high training speed and the like. Therefore, in the embodiment, by combining the advantages of the two, the feature vectors of different levels in different modalities are extracted through the CNN network, and then the extracted feature vectors and the feature vectors of other dimensions are input to the XGBoost for learning training. For example, as shown in fig. 3, in the gray scale pattern mode learning, a feature vector is extracted through a multi-layer CNN network, and an input of a penultimate layer, i.e., a second fully-connected layer, is used as an extracted feature vector, i.e., a gray scale feature; in the dynamic API sequence modal learning, because a dynamic API sequence is text in nature, distributed word vectors are obtained first, a single-layer TextCNN network is used for extracting feature vectors based on the distributed word vectors, the feature vectors extracted by the two modalities, N-gram features of the API sequence and the distributed word vectors are spliced together, and then the spliced fusion features are input into BooXGate for learning. For example, the feature vector extracted by the multi-layer CNN is 512 dimensions, the feature vector extracted by the TextCNN is 128 dimensions, the N-gram feature vector is 90000 dimensions, and the feature of the distributed word vector is 300, so that the spliced feature vector is 90000+300+128+512 + 90940. In the API sequence modal learning, the three features are fused, because the main information of the three features is different, the length of a convolution kernel in the TextCNN can be set to be larger (such as 10-20), so that the features corresponding to long paragraphs with larger influence on text classification are extracted, the N-gram represents the features of short paragraphs with larger influence on text classification due to the limitation of N (generally not more than 3, otherwise, dimension disaster can be caused), and the distributed word vector represents the overall semantics of the text, so that the distributed word vector has certain abstraction and summarization capability compared with other features. Of course, only one or two of the three features of the API sequence may be selected and concatenated with the grayscale map feature vector and then input to the XGBoost.
In an example, the training the XGBoost model with the third software sample to obtain a third software recognition model includes:
performing the following for each software in the third software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
splicing the feature vector of the gray level image and the feature vector of the dynamic API sequence to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost multi-classification model obtained by training as the third software identification model.
In another example, the training the XGBoost model with the third software sample to obtain a third software recognition model includes:
performing the following for each software in the third software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
determining the N-gram characteristics of the dynamic API sequence;
splicing the feature vector of the gray level image, the feature vector of the dynamic API sequence and the N-gram feature to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost multi-classification model obtained by training as the third software identification model.
In another example, the training the XGBoost model with the third software sample to obtain a third software recognition model includes:
performing the following for each software in the third software sample:
determining a gray scale map and a dynamic API sequence of the software;
extracting a feature vector of the gray scale image;
extracting a feature vector of the dynamic API sequence;
determining the N-gram characteristics of the dynamic API sequence;
determining a distributed word vector for the dynamic API sequence;
splicing the feature vector of the gray level image, the feature vector of the dynamic API sequence, the N-gram feature and the distributed word vector to obtain the fusion feature of the software;
and training the fusion characteristics of the software by using an XGboost model, and taking the XGboost multi-classification model obtained by training as the third software identification model.
In one example, determining a grayscale map of software includes:
disassembling the software to obtain a binary code file of the software;
the binary code file is converted into a gray scale map.
Wherein, since the range of each byte of the software is between hexadecimal 00-FF, it just corresponds to 0-255 decimal gray scale (0 is black, 255 is white), which just covers the whole range of the gray scale value. Therefore, the binary code file of the software is divided according to the bytes, and then the gray value corresponding to each byte is obtained based on the corresponding relation between the hexadecimal code and the image gray value, so that the binary code file can be converted into a gray map.
In one example, determining a dynamic API sequence for software includes:
and simulating the software in a dynamic sandbox to obtain a dynamic API sequence after running.
Where a sandbox (sandbox) is a virtual system program that allows a browser or other program to be run in a sandbox environment, changes made by the run may be subsequently removed. The method creates an independent operation environment similar to a sandbox, and programs running in the environment cannot permanently influence a hard disk. In network security, sandboxing refers to the tools used to test the behavior of untrusted files or applications, etc., in an isolated environment. The dynamic sandbox may include a virtual operating system layer, the file to be detected is firstly run in the virtual operating system layer of the dynamic sandbox, then a call operation is simulated to an Application Programming Interface (API) of the operating system in the running process, the generated dynamic behavior information is extracted and is a dynamic API sequence, and the dynamic API sequence is text information, for example, dynamic behavior information such as reading a file, writing a registry and the like.
In the API sequence modality learning, since the API sequence is text in nature, a single-layer TextCNN network is used to extract the feature vector.
The N-Gram is an algorithm based on a statistical language model, and the basic idea is that the content in the text is subjected to sliding window operation with the size of N according to bytes to form a byte fragment sequence with the length of N. Each byte segment is called as a gram, the occurrence frequency of all the grams is counted, and filtering is performed according to a preset threshold value to form a key gram list, namely the vector feature of the text is the N-gram feature, and each gram in the list is a feature vector dimension.
In one example, determining a distributed word vector for a dynamic API sequence includes: the distributed word vectors of the dynamic API sequence are trained using a word vector algorithm.
Wherein the word vector algorithm comprises one or more of the following: word2vec, Glove, Fasttext. For example, Word vectors are trained by using three methods of Word2vec, Glove and Fasttext, and three Word vectors corresponding to the dynamic API sequence are merged together to serve as a distributed Word vector of the dynamic API sequence.
determining the gray scale image characteristics of the software to be detected comprises the following steps:
disassembling the software to obtain a binary code file of the software;
converting the binary code file into a gray scale map;
and extracting the characteristic vector of the gray scale image as the gray scale image characteristic of the software to be detected.
In an example, the feature vectors of the gray scale map may be extracted through a Convolutional Neural Network (CNN). For example, a feature vector is extracted using the multi-layer CNN network shown in fig. 3, and the input of the second last layer, i.e., the second fully-connected layer, is used as the extracted feature vector, i.e., the grayscale feature.
Determining the dynamic API sequence characteristics of the software to be detected comprises the following steps:
simulating the software in a dynamic sandbox to obtain a dynamic API sequence after running;
performing at least one of:
extracting a feature vector of the dynamic API sequence;
and/or, determining N-gram characteristics of the dynamic API sequence;
and/or determining a distributed word vector for the dynamic API sequence.
Wherein the dynamic API sequence characteristics include one or more of:
the feature vector of the dynamic API sequence, the N-gram feature vector of the dynamic API sequence, and the distributed word vector of the dynamic API sequence.
In an example, a single-layer TextCNN network may be used to extract the feature vectors of the dynamic API sequence.
in one example, when the dynamic API sequence features of the software include: when the feature vector of the dynamic API sequence is used, the splicing of the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristic of the software to be detected and the characteristic vector of the dynamic API sequence of the software to be detected to obtain the fusion characteristic of the software.
For example, if the grayscale map feature, i.e., the feature vector extracted by the multi-layer CNN, is 512-dimensional, and the feature vector of the dynamic API sequence, i.e., the feature vector extracted by the TextCNN, is 128-dimensional, the feature vector after concatenation is 512+128 — 640.
In one example, when the dynamic API sequence features of the software include: when the feature vector of the dynamic API sequence and the N-gram feature vector are used, the step of splicing the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristic of the software to be detected, the characteristic vector of the dynamic API sequence of the software to be detected and the N-gram characteristic vector to obtain the fusion characteristic of the software.
For example, if the grayscale map feature, i.e., the feature vector extracted by the multi-layer CNN, is 512-dimensional, the feature vector extracted by the dynamic API sequence, i.e., the feature vector extracted by the TextCNN, is 128-dimensional, and the N-gram feature vector is 90000-dimensional, the spliced feature vector is 512+128+ 90000-90640.
In one example, when the dynamic API sequence features of the software include: when the feature vector, the N-gram feature vector and the distributed word vector of the dynamic API sequence are used, the step of splicing the gray-scale image feature and the dynamic API sequence feature of the software to be detected to obtain the fusion feature of the software to be detected comprises the following steps:
and splicing the gray-scale image characteristics of the software to be detected, the characteristic vector of the dynamic API sequence of the software to be detected, the N-gram characteristic vector and the distributed word vector to obtain the fusion characteristics of the software.
For example, the feature vector extracted by the multi-layer CNN is 512 dimensions, the feature vector extracted by the TextCNN is 128 dimensions, the N-gram feature vector is 90000 dimensions, and the feature of the distributed word vector is 300, so that the spliced feature vector is 90000+300+128+512 + 90940.
And 704, inputting the fusion characteristics of the software to be detected into a pre-trained third software identification model, and outputting a third type of the software to be detected.
According to the technical scheme provided by the embodiment of the invention, the specific type of the software to be detected is detected by directly utilizing the trained third software identification model, so that the accuracy of software type identification is greatly improved, and the detection efficiency is improved.
In another embodiment of the present invention, based on the above embodiments, in order to improve the effect of neural network learning and suppress the over-fitting phenomenon, label smoothing and mixup techniques are adopted. The label smoothing is to convert the label, wherein the label before conversion is one-hot to indicate that:

the converted class is shown below, where e is a small number, such as 0.001.

And mixup is the generation of new training data from existing training data. Randomly selecting two data i and j, generating a random number lambda epsilon [0,1], and then the new training data is:
x=λxi+(1-λ)xjy=λyi+(1-λ)yi
therefore, the label smoothing and mixup technology is adopted to process the sample data in advance, the overfitting phenomenon can be inhibited, and the neural network learning effect is improved.
In another embodiment of the present invention, on the basis of the above embodiments, in the process of detecting the software to be detected, two parts, namely online prediction and offline prediction, are included. Online prediction refers to the prediction of each sample on the line in real time using a service. The off-line prediction comprises two modes, one mode is to retrain the model based on batch test data, and the other mode is to directly predict based on the existing model. Retraining the model based on batch test data is proposed because the trained model will not work well on the test set when the distribution of the training set and the test set is very different. It is necessary to first determine whether the training set and the test set have large differences through the model. For example, put training set and test set data together; then defining a secondary classification task, judging whether the sample belongs to a training set or a test set, and using the learning process mentioned above to only modify the learning target of the XGboost into secondary classification, namely outputting the probability of predicting that the sample belongs to the test set; and observing the learning effect of the two classification tasks, and if the AUC (area under the ROC curve) corresponding to the model exceeds a certain threshold (such as 0.8), indicating that the difference between the training set and the test set is large. If the difference between the training set and the test set is large, the training set samples are sorted according to the probability of belonging to the test set in the task, for example, the first 20% of samples are used as the retraining verification set, and the remaining 80% are used as the training set samples. Since the selection of the verification set is crucial to the selection of the parameters, the training set and the verification set are regenerated according to the method for learning, and the effect of the test set can be improved to a certain extent.
An embodiment of the present invention further provides a software type detection apparatus, as shown in fig. 8, the apparatus including:
the determining unit is used for determining the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected;
the splicing unit is used for splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain the fusion characteristics of the software to be detected;
the first detection unit is used for inputting the fusion characteristics of the software to be detected into a first software recognition model which is trained in advance and outputting a first type of the software to be detected;
the first software identification model is an XGboost two-class model obtained by training an XGboost model through a first software sample, the fusion characteristics of software are used as input, and the first type of the software is used as output; the first software sample is a fusion feature which is marked with a first type and is respectively formed by a plurality of pieces of software.
In an example, the first type is normal software or malware.
In one example, the apparatus further comprises:
the second detection unit is used for inputting the fusion characteristics of the software to be detected into a second software recognition model which is trained in advance and outputting the second type of the software to be detected when the first type of the software to be detected is malicious software;
the second software identification model is an XGboost multi-classification model obtained by training an XGboost model through a second software sample, the fusion characteristics of software are used as input, and the second type of the software is used as output; the second software sample is a fusion feature labeled with a second type for each of a plurality of different types of malware.
In one example, the second type includes all or some of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
In an example, the determining unit is configured to disassemble the software to be detected to obtain a binary code file of the software to be detected;
converting the binary code file into a gray scale map;
and extracting the characteristic vector of the gray scale image as the gray scale image characteristic of the software to be detected.
In an example, the determining unit is configured to simulate the to-be-detected software to run in a dynamic sandbox to obtain a running dynamic API sequence;
performing at least one of:
extracting a feature vector of the dynamic API sequence; determining an N-gram feature vector of the dynamic API sequence; determining a distributed word vector for the dynamic API sequence;
the dynamic API sequence features include one or more of:
the feature vector of the dynamic API sequence, the N-gram feature vector of the dynamic API sequence, and the distributed word vector of the dynamic API sequence.
In an example, the apparatus further comprises a display unit;
the display unit is set to display the first type or the second type of the software to be detected.
According to the technical scheme provided by the embodiment of the invention, the detection is carried out through the fusion characteristics of the training and recognition software, so that the accuracy rate of software type recognition can be greatly improved.
Another embodiment of the present invention also provides another software type detecting apparatus, as shown in fig. 9, including:
the determining unit is used for determining the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected;
the splicing unit is used for splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain the fusion characteristics of the software to be detected;
the third detection unit is used for inputting the fusion characteristics of the software to be detected into a third software identification model which is trained in advance and outputting a third type of the software to be detected;
the third software identification model is an XGboost multi-classification model obtained by training an XGboost model through a third software sample, the fusion characteristics of software are used as input, and the third type of the software is used as output; the third software sample is a fusion feature labeled with a third type and respectively formed by a plurality of different types of software
In one example, the third type includes normal software, and all or some of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
In an example, the apparatus further comprises a display unit;
the display unit is configured to display a third type of the software to be detected.
According to the technical scheme provided by the embodiment of the invention, the detection is carried out through the fusion characteristics of the training and recognition software, so that the accuracy rate of software type recognition can be greatly improved.
An embodiment of the present invention further provides an electronic device, including: the software type detection device comprises a memory, a processor and a computer program which is stored on the memory and can run on the processor, wherein when the computer program is executed by the processor, the software type detection method is realized by any one of the software types.
An embodiment of the present invention further provides a computer-readable storage medium, where an information processing program is stored on the computer-readable storage medium, and when the information processing program is executed by a processor, the method for detecting a software type in any one of the above items is implemented.
It will be understood by those of ordinary skill in the art that all or some of the steps of the methods, systems, functional modules/units in the devices disclosed above may be implemented as software, firmware, hardware, and suitable combinations thereof. In a hardware implementation, the division between functional modules/units mentioned in the above description does not necessarily correspond to the division of physical components; for example, one physical component may have multiple functions, or one function or step may be performed by several physical components in cooperation. Some or all of the components may be implemented as software executed by a processor, such as a digital signal processor or microprocessor, or as hardware, or as an integrated circuit, such as an application specific integrated circuit. Such software may be distributed on computer readable media, which may include computer storage media (or non-transitory media) and communication media (or transitory media). The term computer storage media includes volatile and nonvolatile, removable and non-removable media implemented in any method or technology for storage of information such as computer readable instructions, data structures, program modules or other data, as is well known to those of ordinary skill in the art. Computer storage media includes, but is not limited to, RAM, ROM, EEPROM, flash memory or other memory technology, CD-ROM, Digital Versatile Disks (DVD) or other optical disk storage, magnetic cassettes, magnetic tape, magnetic disk storage or other magnetic storage devices, or any other medium which can be used to store the desired information and which can accessed by a computer. In addition, communication media typically embodies computer readable instructions, data structures, program modules or other data in a modulated data signal such as a carrier wave or other transport mechanism and includes any information delivery media as known to those skilled in the art.
Claims (10)
1. A method of detecting a software type, comprising:
determining the gray-scale map characteristic and the dynamic API sequence characteristic of the software to be detected;
splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain fusion characteristics of the software to be detected;
inputting the fusion characteristics of the software to be detected into a first software recognition model which is trained in advance, and outputting a first type of the software to be detected;
the first software identification model is an XGboost two-class model obtained by training an XGboost model through a first software sample, the fusion characteristics of software are used as input, and the first type of the software is used as output; the first software sample is a fusion feature which is marked with a first type and is respectively formed by a plurality of pieces of software.
2. The detection method according to claim 1,
the first type is normal software or malicious software.
3. The method according to claim 2, wherein when the first type of software to be detected is malware, the method further comprises:
inputting the fusion characteristics of the software to be detected into a second software recognition model which is trained in advance, and outputting a second type of the software to be detected;
the second software identification model is an XGboost multi-classification model obtained by training an XGboost model through a second software sample, the fusion characteristics of software are used as input, and the second type of the software is used as output; the second software sample is a fusion feature labeled with a second type for each of a plurality of different types of malware.
4. The detection method according to claim 3,
the second type includes all or part of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
5. The method according to claim 1, wherein the determining the gray-scale map features of the software to be detected comprises:
disassembling the software to be detected to obtain a binary code file of the software;
converting the binary code file into a gray scale map;
and extracting the characteristic vector of the gray scale image as the gray scale image characteristic of the software to be detected.
6. The detection method according to claim 1,
the determining of the dynamic API sequence characteristics of the software to be detected comprises the following steps:
simulating the software to be detected in a dynamic sandbox to obtain a dynamic API sequence after operation;
performing at least one of:
extracting a feature vector of the dynamic API sequence; determining an N-gram feature vector of the dynamic API sequence; determining a distributed word vector for the dynamic API sequence;
the dynamic API sequence features include one or more of:
the feature vector of the dynamic API sequence, the N-gram feature vector of the dynamic API sequence, and the distributed word vector of the dynamic API sequence.
7. A method of detecting a software type, comprising:
determining the gray-scale map characteristic and the dynamic API sequence characteristic of the software to be detected;
splicing the gray-scale image characteristics and the dynamic API sequence characteristics of the software to be detected to obtain fusion characteristics of the software to be detected;
inputting the fusion characteristics of the software to be detected into a pre-trained third software identification model, and outputting a third type of the software to be detected;
the third software identification model is an XGboost multi-classification model obtained by training an XGboost model through a third software sample, the fusion characteristics of software are used as input, and the third type of the software is used as output; the third software sample is a fusion feature labeled with a third type for each of a plurality of different types of software.
8. The detection method according to claim 7,
the third type comprises normal software and all or part of the following types: lemonavirus, pit digging programs, DDos Trojan horse, worm virus, infectious virus, backdoor program, Trojan horse program.
9. An electronic device, comprising: memory, processor and computer program stored on the memory and executable on the processor, which computer program, when executed by the processor, implements a method of detecting a software type according to any one of claims 1 to 8.
10. A computer-readable storage medium, characterized in that an information processing program is stored thereon, which when executed by a processor implements a method of detecting a software type as claimed in any one of claims 1 to 8.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010454339.4A CN111753290A (en) | 2020-05-26 | 2020-05-26 | Software type detection method and related equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010454339.4A CN111753290A (en) | 2020-05-26 | 2020-05-26 | Software type detection method and related equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111753290A true CN111753290A (en) | 2020-10-09 |
Family
ID=72673907
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010454339.4A Pending CN111753290A (en) | 2020-05-26 | 2020-05-26 | Software type detection method and related equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111753290A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113139187A (en) * | 2021-04-22 | 2021-07-20 | 北京启明星辰信息安全技术有限公司 | Method and device for generating and detecting pre-training language model |
| CN113221115A (en) * | 2021-07-09 | 2021-08-06 | 四川大学 | Visual malicious software detection method based on collaborative learning |
| CN113722713A (en) * | 2021-09-10 | 2021-11-30 | 上海观安信息技术股份有限公司 | Malicious code detection method and device, electronic equipment and storage medium |
| CN115828248A (en) * | 2023-02-17 | 2023-03-21 | 杭州未名信科科技有限公司 | Method and device for detecting malicious codes based on interpretable deep learning |
| CN116910752A (en) * | 2023-07-17 | 2023-10-20 | 重庆邮电大学 | Malicious code detection method based on big data |
| CN117113351A (en) * | 2023-10-18 | 2023-11-24 | 广东省科技基础条件平台中心 | Software classification method and device based on multiple multistage pre-training |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105205396A (en) * | 2015-10-15 | 2015-12-30 | 上海交通大学 | Detecting system for Android malicious code based on deep learning and method thereof |
| CN107315954A (en) * | 2016-04-27 | 2017-11-03 | 腾讯科技(深圳)有限公司 | A kind of file type identification method and server |
| CN110210218A (en) * | 2018-04-28 | 2019-09-06 | 腾讯科技(深圳)有限公司 | A kind of method and relevant apparatus of viral diagnosis |
-
2020
- 2020-05-26 CN CN202010454339.4A patent/CN111753290A/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105205396A (en) * | 2015-10-15 | 2015-12-30 | 上海交通大学 | Detecting system for Android malicious code based on deep learning and method thereof |
| CN107315954A (en) * | 2016-04-27 | 2017-11-03 | 腾讯科技(深圳)有限公司 | A kind of file type identification method and server |
| CN110210218A (en) * | 2018-04-28 | 2019-09-06 | 腾讯科技(深圳)有限公司 | A kind of method and relevant apparatus of viral diagnosis |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113139187A (en) * | 2021-04-22 | 2021-07-20 | 北京启明星辰信息安全技术有限公司 | Method and device for generating and detecting pre-training language model |
| CN113139187B (en) * | 2021-04-22 | 2023-12-19 | 北京启明星辰信息安全技术有限公司 | Method and device for generating and detecting pre-training language model |
| CN113221115A (en) * | 2021-07-09 | 2021-08-06 | 四川大学 | Visual malicious software detection method based on collaborative learning |
| CN113221115B (en) * | 2021-07-09 | 2021-09-17 | 四川大学 | Visual malicious software detection method based on collaborative learning |
| CN113722713A (en) * | 2021-09-10 | 2021-11-30 | 上海观安信息技术股份有限公司 | Malicious code detection method and device, electronic equipment and storage medium |
| CN115828248A (en) * | 2023-02-17 | 2023-03-21 | 杭州未名信科科技有限公司 | Method and device for detecting malicious codes based on interpretable deep learning |
| CN116910752A (en) * | 2023-07-17 | 2023-10-20 | 重庆邮电大学 | Malicious code detection method based on big data |
| CN116910752B (en) * | 2023-07-17 | 2024-03-08 | 重庆邮电大学 | Malicious code detection method based on big data |
| CN117113351A (en) * | 2023-10-18 | 2023-11-24 | 广东省科技基础条件平台中心 | Software classification method and device based on multiple multistage pre-training |
| CN117113351B (en) * | 2023-10-18 | 2024-02-20 | 广东省科技基础条件平台中心 | Software classification method and device based on multiple multistage pre-training |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111753290A (en) | Software type detection method and related equipment | |
| CN109302410B (en) | Method and system for detecting abnormal behavior of internal user and computer storage medium | |
| CN106778241B (en) | Malicious file identification method and device | |
| CN111027069B (en) | Malicious software family detection method, storage medium and computing device | |
| CN108021806B (en) | Malicious installation package identification method and device | |
| CN110704840A (en) | Convolutional neural network CNN-based malicious software detection method | |
| RU2708356C1 (en) | System and method for two-stage classification of files | |
| CN112329016A (en) | Visual malicious software detection device and method based on deep neural network | |
| KR101858620B1 (en) | Device and method for analyzing javascript using machine learning | |
| CN113360912A (en) | Malicious software detection method, device, equipment and storage medium | |
| CN109145030B (en) | Abnormal data access detection method and device | |
| CN111062036A (en) | Malicious software identification model construction method, malicious software identification medium and malicious software identification equipment | |
| CN111626367A (en) | Countermeasure sample detection method, apparatus, device and computer readable storage medium | |
| CN111881289A (en) | Training method of classification model, and detection method and device of data risk category | |
| CN112052451A (en) | Webshell detection method and device | |
| CN111866004A (en) | Security assessment method, apparatus, computer system, and medium | |
| CN115100739B (en) | Man-machine behavior detection method, system, terminal device and storage medium | |
| CN112733140A (en) | Detection method and system for model tilt attack | |
| CN110879888A (en) | Virus file detection method, device and equipment | |
| KR20200063067A (en) | Apparatus and method for validating self-propagated unethical text | |
| CN110705622A (en) | Decision-making method and system and electronic equipment | |
| CN111488574B (en) | Malicious software classification method, system, computer equipment and storage medium | |
| CN111191238A (en) | Webshell detection method, terminal device and storage medium | |
| CN112163217B (en) | Malware variant identification method, device, equipment and computer storage medium | |
| CN115828239A (en) | Malicious code detection method based on multi-dimensional data decision fusion |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |