CN111401552B - Federal learning method and system based on batch size adjustment and gradient compression rate adjustment - Google Patents
Federal learning method and system based on batch size adjustment and gradient compression rate adjustment Download PDFInfo
- Publication number
- CN111401552B CN111401552B CN202010166667.4A CN202010166667A CN111401552B CN 111401552 B CN111401552 B CN 111401552B CN 202010166667 A CN202010166667 A CN 202010166667A CN 111401552 B CN111401552 B CN 111401552B
- Authority
- CN
- China
- Prior art keywords
- gradient
- terminal
- batch size
- learning
- time delay
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Mobile Radio Communication Systems (AREA)
Abstract
The invention discloses a federal learning method and a system based on batch size adjustment and gradient compression ratio, which are used for improving model training performance and comprise the following steps: in a federal learning scene, a plurality of terminals share uplink wireless channel resources, and complete the training of a neural network model together with an edge server based on the training data of a local terminal; in the model training process, the terminal calculates the gradient by adopting a batch method in local calculation, and in the uplink transmission process, the gradient needs to be compressed before transmission; and adjusting the batch size and the gradient compression ratio according to the computing power of each terminal and the channel state of each terminal so as to improve the convergence rate of model training while ensuring the training time and not reducing the model accuracy.
Description
Technical Field
The invention relates to the field of artificial intelligence and communication, in particular to a federal learning method and a federal learning system based on batch size adjustment and gradient compression rate adjustment.
Background
In recent years, with the increasing level of hardware and software, artificial Intelligence (AI) technology has come to the peak of development. It digs key information from massive data to realize various applications, such as face recognition, voice recognition, data mining, etc. However, for a scene where data privacy is relatively sensitive, such as patient information of a hospital, customer information of a bank, and the like, data is often difficult to obtain, which is commonly called as information islanding. If the existing artificial intelligence training method is still adopted, effective results are difficult to obtain due to insufficient data.
Federal Learning (FL) proposed by Google is used for solving the information islanding problem, and is mainly oriented to services with sensitive data privacy and safety, upcoming scenes such as automatic driving and Internet of things. The model training is dispersed to a plurality of terminals for carrying out, and the terminals do not need to send original data to an edge server and replace the original data with parameters or gradient information of the model. Based on the traditional training method with descending random gradient, the average gradient method applied to the federal learning scene can still obtain good learning performance. In a 5G wireless communication scene with high reliability and low time delay, automatic driving is realized, and intelligent analysis, decision making and the like of the Internet of things can not be learned from the federal.
In a traditional federal learning scene, because a terminal and a server are connected by a wire, communication overhead and local calculation time delay can be ignored. However, with the development of mobile communication networks and the rapid growth of mobile intelligent devices, in order to rapidly realize the application of the internet of things and automatic driving, artificial intelligent model training can be placed at a mobile intelligent terminal, and traditional wired communication can be changed into wireless communication, so that the joining and exiting of the training terminal become very convenient, namely the combination of federal learning and a wireless communication network is the future development direction.
Applying wireless communications to the federal learned scenario presents a number of problems. First, the local computation latency increases. Although the computing power of the local terminal is continuously increased, and the artificial intelligence model can be deployed, the gap between the local terminal and a desktop or a server is still large, and the computing delay caused by local gradient computation cannot be ignored. On the other hand, due to the shortage of wireless communication bandwidth resources and the instability of a wireless channel, a large amount of model gradient information transmission brings huge communication overhead, and causes a large transmission delay.
In order to solve the problem of higher training time delay caused by local calculation and gradient transmission, a local batch data processing and gradient compression technology is applied in the model training process. In each round of training interaction, the terminal can calculate the gradient of the model according to only part of data to reduce the time delay generated by local calculation, and meanwhile, in the transmission process, the gradient information is compressed to represent the original gradient information by a small data amount, so that the communication transmission time is reduced. However, both batch processing and gradient compression have an effect on the convergence rate of the model.
Therefore, the convergence rate of the model needs to be considered while controlling the model training delay. How to adjust the batch size and the gradient compression ratio in a reasonable mode to ensure the training time delay and improve the convergence rate is an urgent problem to be solved.
Disclosure of Invention
The invention aims to provide a federal learning method and a system based on batch size adjustment and gradient compression ratio adjustment, the federal learning method improves the convergence rate of a model within the specified learning time by adjusting the batch size and the gradient compression ratio, original data does not need to be transmitted during the federal learning, and the privacy and the safety of a user are better protected.
In order to achieve the aim, the invention provides the following technical scheme:
in a first aspect, a federated learning method based on batch size adjustment and gradient compression ratio is provided, where a system for implementing the federated learning includes an edge server and a plurality of terminals in wireless communication with the edge server, where the terminals perform model learning according to local data, and the federated learning method includes:
the edge server adjusts the batch size and the gradient compression rate of the terminal according to the current batch size and the gradient compression rate and by combining the computing capacity of the terminal and the communication capacity between the edge server and the terminal, and transmits the adjusted batch size and the gradient compression rate to the terminal;
the terminal performs model learning according to the received batch size, compresses gradient information obtained by the model learning according to the received extraction compression ratio and outputs the gradient information to the edge server;
after the edge server averages all the received gradient information, the gradient average value is synchronized to the terminal;
and the terminal updates the model according to the received gradient average value.
In the invention, in order to reduce the calculation time of the terminal and the requirements of equipment hardware, the local terminal calculates the gradient in a batch mode, namely, a certain batch size is selected for each calculation to carry out gradient calculation. In order to reduce the transmission information from the terminal to the edge server, save communication overhead, and reduce communication time, the terminal needs to compress the gradient information before uploading the gradient information.
In one possible implementation manner, the adjusting the batch size and the gradient compression rate of the terminal according to the current batch size and the gradient compression rate and by combining the computing power of the terminal and the communication power between the edge server and the terminal includes:
(a) Calculating the current learning time delay according to the current batch size and the gradient compression rate and by combining the calculation capability of the terminal and the communication capability between the edge server and the terminal;
(b) Comparing the current learning time delay with a specified learning time delay, wherein the current learning time delay is larger than the specified learning time delay, the batch size is reduced, and the gradient compression rate is increased; when the current learning time delay is smaller than the specified learning time delay, the batch size is increased and the gradient compression rate is reduced;
(c) And (c) repeating the step (a) and the step (b) until the current learning delay is equal to the specified learning delay, wherein the batch size and the gradient compression ratio corresponding to the current learning delay equal to the specified learning delay are the adjusted batch size and the gradient compression ratio.
The current learning time delay is higher than the specified learning time, namely the current training can not be completed on time, and at the moment, the batch size should be reduced and the compression rate should be increased so as to save the time of local terminal calculation and wireless transmission; the current learning time delay is less than the specified learning time, namely the current training can be completed, but the convergence rate can be further improved, and at the moment, the batch size can be properly increased and the compression rate of the gradient can be reduced, so that the convergence performance can be improved.
Particularly, when the learning time is extremely short, i.e. the training task is very tense, the batch size of each terminal should be as small as possible, and the compression rate should be as large as possible to ensure the learning delay; when the learning time is extremely long, i.e. the task has no strict learning time requirement, the batch size of each terminal should be as large as possible, and the compression rate should be as small as possible to ensure the best convergence performance.
In the step (a), the calculation process of the current learning time delay is as follows:
calculating the time required by the terminal to calculate the gradient according to the current batch size according to the terminal learning capacity and the batch size;
calculating the time for uploading the compressed gradient information to the edge server through a wireless channel according to the communication capacity and the gradient compression rate;
calculating the time required for obtaining average gradient information on average after summarizing all gradient information;
calculating the time required by the edge server to send the average gradient information to each terminal;
calculating the time required by each terminal for updating the model after receiving the average gradient information;
the sum of the five parts of time is the current learning delay.
The current learning time delay can be obtained according to the calculation process of the current learning time delay, the current learning time delay can be changed by adjusting the batch size and the gradient compression ratio, when the batch size is increased or the gradient compression ratio is decreased, the current learning time delay is increased, and when the batch size is decreased or the gradient compression ratio is increased, the current learning time delay is decreased.
In one possible implementation, when compressing the gradient information, the gradient may be quantized with a quantization loss, where the quantization loss is defined as a compression rate, that is, the gradient compression rate includes a compression rate obtained by performing gradient quantization on the gradient information, and is expressed as:

wherein x denotes gradient information, Q (x) denotes a quantization function, c denotes a compression rate, representing the square of the two norms.
representing the square of the two norms.
The convergence rate for the corresponding model training can be expressed as:

wherein alpha is 1 ,β 1 Is a coefficient associated with the model, and alpha 1 >0,β 1 B is the sum of the batch sizes of the terminals, C is the average value of the gradient compression ratios of the terminals, and S is the training step number.
When the gradient compression rate adopts a compression rate obtained by a gradient quantization manner, the gradient compression rate is increased or decreased by increasing or decreasing the number of quantization bits used by the quantization function.
In one possible implementation manner, the gradient compression ratio includes a compression ratio obtained by performing sparsification on gradient information, that is, a maximum m gradients in a gradient matrix are selected for transmission, where a transmission amount of the gradients is defined as a compression ratio, and is expressed as:

where M represents the size of the model.
The convergence rate for the corresponding model training can be expressed as:

wherein alpha is 2 ,β 2 Is a coefficient associated with the model, and alpha 2 >0,β 2 B is the sum of the batch sizes of the terminals, C is the average value of the gradient compression ratios of the terminals, and S is the training step number.
When the gradient compression rate is obtained by adopting a gradient sparsification method, the gradient compression rate is increased or decreased by increasing or decreasing the number of gradients.
In one possible implementation, the gradient average is obtained using the following equation:

wherein, g k (w) tableAnd G (w) represents the gradient calculated by the terminal, w represents a model parameter, K represents the terminal index, and K represents the total number of the terminals.
In one possible implementation, the model is updated from the gradient mean using the following formula:
w t+1 =w t -αG(w t )
where t is the number of iterations, G (w) t ) Represents the mean value of the gradient at the t-th iteration, w t 、w t+1 And respectively representing the model parameters of the terminal at the t th iteration and the t +1 th iteration.
In a second aspect, a federated learning system based on batch sizing and gradient compression ratio adjustment is provided, which includes an edge server connected to a base communication end, a plurality of terminals in wireless communication with the edge server,
the edge server adjusts the batch size and the gradient compression rate of the terminal according to the current batch size and the gradient compression rate and by combining the computing capacity of the terminal and the communication capacity between the edge server and the terminal, and transmits the adjusted batch size and the gradient compression rate to the terminal;
the terminal performs model learning according to the received batch size, compresses gradient information obtained by the model learning according to the received extraction compression rate and outputs the gradient information to the edge server;
after the edge server averages all the received gradient information, the gradient average value is synchronized to the terminal;
and the terminal updates the model according to the received gradient average value.
It can be seen from the above technical solutions that the federate learning method and system based on batch size adjustment and gradient compression ratio provided by the embodiments of the present application have the following advantages: compared with direct data transmission, the transmission gradient can fully protect the privacy and the security of user data; the compression of the gradient can reduce the pressure of communication transmission and reduce time delay; the batch size and the compression rate are dynamically adjusted according to the requirement of learning time, so that the convergence rate of the model can be improved while the training time and the model training accuracy are ensured.
Drawings
In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the drawings used in the description of the embodiments or the prior art will be briefly described below, it is obvious that the drawings in the following description are only some embodiments of the present invention, and for those skilled in the art, other drawings can be obtained according to these drawings without creative efforts.
FIG. 1 is a schematic diagram of a federal learning system based on a wireless communication network in an embodiment of the present application;
FIG. 2 is a diagram illustrating a quantization method in gradient compression according to an embodiment of the present application;
FIG. 3 is a flow chart of batch size and compression ratio adjustments for one embodiment provided in embodiments of the present application;
FIG. 4 is a schematic diagram of an overall training interaction of one embodiment provided in the embodiments of the present application;
FIG. 5 is a schematic diagram of a sparsification method in gradient compression in an embodiment of the present application;
FIG. 6 is a flow chart of batch size and compression ratio adjustments of another embodiment provided in an embodiment of the present application;
FIG. 7 is a schematic diagram of an overall training interaction of another embodiment provided in the embodiments of the present application.
Detailed Description
In order to make the objects, technical solutions and advantages of the present invention more apparent, the present invention will be further described in detail with reference to the accompanying drawings and examples. It should be understood that the detailed description and specific examples, while indicating the scope of the invention, are intended for purposes of illustration only and are not intended to limit the scope of the invention.
The terms "first," "second," "third," "fourth," and the like in the description and in the claims of the present application and in the drawings described above, if any, are used for distinguishing between similar elements and not necessarily for describing a particular sequential or chronological order. It will be appreciated that the data so used may be interchanged under appropriate circumstances such that the embodiments described herein may be practiced otherwise than as specifically illustrated or described herein. Furthermore, the terms "comprises," "comprising," and "having," and any variations thereof, are intended to cover a non-exclusive inclusion, such that a process, method, system, article, or apparatus that comprises a list of steps or elements is not necessarily limited to those steps or elements expressly listed, but may include other steps or elements not expressly listed or inherent to such process, method, article, or apparatus.
Fig. 1 is a federal learning system based on a wireless communication network in an embodiment of the present application, where the federal learning system includes an edge server and a terminal that are connected to a communication terminal such as a base station, and the terminal shares uplink wireless channel resources and completes training of a neural network model together with the edge server based on training data of a local terminal. The federal learning method based on batch size adjustment and gradient compression rate adjustment can be realized by using the federal learning system. Specifically, for the calculation delay caused by local calculation, the batch size can be adjusted according to the calculation capability of the terminal, so as to reduce the calculation delay; on the other hand, for the communication bottleneck problem, the communication overhead can be reduced by reducing the amount of transmitted information, namely, the gradient compression technology. And adjusting the gradient compression ratio according to the state of the wireless channel where the terminal is located, so as to reduce the communication delay. In order to meet the requirement of training time, the batch size and compression ratio adjusting method can improve the convergence rate of model training while ensuring the training time delay.
Example one
The federal learning method based on batch size adjustment and gradient compression ratio provided by this embodiment is suitable for a scenario in which a plurality of mobile terminals and an edge server connected to a communication hotspot (such as a base station) train an artificial intelligence model together, and for other wireless communication technologies, the artificial intelligence model can work in the same working mode, so in this embodiment, the situation of the mobile communication technology is mainly considered.
In this embodiment, each terminal performs local calculation by using a batch method, the gradient compression method is quantization, and particularly, the quantization uses fixed-length quantization, the quantization process is as shown in fig. 2, and gradient information is quantized and encoded by a certain bit and then transmitted to the edge server as gradient information. When the gradient is expressed by adopting high quantization digit, original gradient information can be kept as much as possible, and the transmitted information quantity is increased; when the gradient is quantized with a low number of quantization bits, the quantized gradient information deviates from the original gradient information, but the amount of transmitted information decreases. At this time, the compression ratio of the gradient can be expressed by quantization error, i.e.

Where Q (x) represents a quantization function and x represents a gradient.
When gradient quantization is used, the convergence rate of model training can be expressed as:

wherein alpha is 1 ,β 1 Is a coefficient associated with the model, and alpha 1 >0,β 1 B is the sum of the batch sizes of the terminals, C is the average value of the gradient compression ratios of the terminals, and S is the training step number.
In this embodiment, on the basis of satisfying the training delay, the final goal is to adjust the batch size and the compression rate according to the computing power of each terminal and the state of the wireless channel, so as to improve the convergence rate of the model training.
Specifically, the algorithm for adjusting the batch size and the compression rate is shown in fig. 3, and includes the following parts:
301. calculating the current training time delay, wherein the training time delay comprises five parts:
(1) The time required to locally calculate the gradient in batch size b;
(2) The gradient information is compressed and then uploaded to an edge server through a wireless channel for the elapsed time;
(3) So the time required for averaging the summary after the summary of the gradient information;
(4) The edge server sends the calculated average gradient information to the time required by each terminal;
(5) After each terminal receives the gradient information, updating the model;
302. since the present embodiment aims to increase the convergence rate while ensuring the training time, it is necessary to compare the current training time with the predetermined training time T max By comparison, three cases are divided to make corresponding changes.
303. When the training time is less than the specified training time, the batch size and the number of quantized bits should be increased appropriately to increase the rate of convergence.
304. When the training time is longer than the specified training time, the batch size and the quantization digits should be properly reduced to complete the training in time and meet the time requirement.
305. When the training time is equal to the specified training time, the batch size and compression rate at that time can be used for training.
When the adjustment process is used in the actual training of federal learning, the specific interaction process between the terminal and the base station is as shown in fig. 4, which specifically includes the following contents:
401. initialization, each terminal needs to upload related information, such as computing power, and the state of the wireless channel, to the base station.
402. The base station obtains the batch size b and the gradient compression ratio c by using the adjustment method described in fig. 3 according to the information uploaded by each terminal.
403. Each terminal calculates local gradient information.
404. And obtaining corresponding quantization bits according to the gradient compression rate, namely the quantization error, carrying out quantization coding on the gradient, and transmitting by using a wireless channel.
405. And the base station receives the gradient information, averages the gradient and sends the gradient to each terminal.
406. Each terminal downloads the average gradient information.
407. Each terminal updates the model using the average gradient information.
The best model performance can be obtained by using the method of the invention.
Example two
The adjusting method provided by the embodiment is suitable for a scene in which a plurality of mobile terminals and an edge server connected with a communication hotspot (such as a base station) jointly train an artificial intelligence model, and for other wireless communication technologies, the method can work in the same working mode, so that in the embodiment, the mobile communication condition is mainly considered.
In this embodiment, each terminal performs local calculation by using a batch method, the gradient compression method is a thinning method, and particularly, the thinning method is to select a part of large gradients for transmission, the thinning process is as shown in fig. 5, and after the gradient information is thinned, the selected gradient information and the serial number thereof are transmitted to the edge server. When more gradient information is reserved, the loss of the gradient information can be reduced, and the transmitted information amount is increased; when less gradient information is retained, more gradient information is lost, but the amount of information transmitted is reduced. At this time, the compression rate of the gradient can be expressed as a ratio of the total number of models to the number of transmitted gradients, i.e.

Where M represents the size of the model.
With gradient sparsification, the convergence rate of model training can be expressed as:

wherein alpha is 2 ,β 2 Is a coefficient associated with the model, and alpha 2 >0,β 2 B is the sum of the batch sizes at each end, C is the average of the gradient compression ratios at each end, and S is the number of training steps.
In this embodiment, on the basis of satisfying the training delay, the final goal is to adjust the batch size and the compression rate according to the computing power of each terminal and the state of the wireless channel, so as to improve the convergence rate of the model training.
Specifically, the algorithm for adjusting the batch size and the compression rate as shown in fig. 6 includes the following parts:
601. calculating the current training time delay, wherein the training time delay comprises five parts:
(1) The time required to calculate the gradient locally with the batch size b;
(2) The gradient information is compressed and then uploaded to an edge server through a wireless channel for the elapsed time;
(3) So the time required for averaging summarization after summarization of the gradient information;
(4) The edge server sends the calculated average gradient information to the time required by each terminal;
(5) After each terminal receives the gradient information, the terminal updates the model;
602. since the present embodiment aims to increase the convergence rate while ensuring the training time, it is necessary to compare the current training time with the predetermined training time T max By comparison, three cases are divided to make corresponding changes.
603. When the training time is shorter than the specified training time, the batch size and the number of transmission gradients should be increased appropriately to increase the convergence rate.
604. When the training time is longer than the specified training time, the batch size and the number of transmission gradients are properly reduced, the training is completed in time, and the time requirement is met.
605. When the training time is equal to the specified training time, the batch size and compression rate at this time can be used for training.
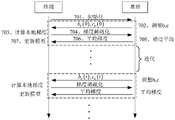
When the adjustment process is used in the actual training of federal learning, the specific interaction process between the terminal and the base station is as shown in fig. 7, which specifically includes the following contents:
701. initialization, each terminal needs to upload related information, such as computing power, and the state of the wireless channel, to the base station.
702. The base station obtains the batch size b and the gradient compression ratio c by using the adjustment method described in fig. 6 according to the information uploaded by each terminal.
703. Each terminal calculates local gradient information.
704. And obtaining the number of gradients to be transmitted according to the gradient compression rate, sequencing and selecting the gradients, selecting the maximum gradient and the position thereof, and transmitting by using a wireless channel.
705. And the base station receives the gradient information, averages the gradient and sends the gradient to each terminal.
706. Each terminal downloads the average gradient information.
707. Each terminal updates the model using the average gradient information.
The best model performance can be obtained by using the method of the invention.
According to the federated learning method, the convergence rate of the model is improved within the specified learning time by adjusting the batch size and the gradient compression rate, and original data does not need to be transmitted during federated learning, so that the privacy and the safety of a user are better protected.
EXAMPLE III
The third embodiment provides a federal learning system based on batch size adjustment and gradient compression ratio adjustment, which comprises an edge server connected to a base communication terminal, a plurality of terminals in wireless communication with the edge server,
the edge server adjusts the batch size and the gradient compression ratio of the terminal according to the current batch size and the gradient compression ratio by combining the computing capacity of the terminal and the communication capacity between the edge server and the terminal, and transmits the adjusted batch size and the adjusted gradient compression ratio to the terminal;
the terminal performs model learning according to the received batch size, compresses gradient information obtained by the model learning according to the received extraction compression ratio and outputs the gradient information to the edge server;
after averaging all the received gradient information, the edge server synchronizes the gradient average value to the terminal;
and the terminal updates the model according to the received gradient average value.
It can be clearly understood by those skilled in the art that, for convenience and brevity of description, the federal learning system and the federal learning method based on batch size adjustment and gradient compression ratio provided in the first and second embodiments implement the same specific processes, and reference may be made to the corresponding processes in the foregoing method embodiments, which are not described herein again.
According to the federal learning system, the convergence rate of the model is improved within the specified learning time by adjusting the batch size and the gradient compression rate, original data does not need to be transmitted during federal learning, and the privacy and the safety of a user are better protected.
The above-mentioned wireless communication mode may be an existing mobile communication network, i.e., an LTE (Long-term Evolution) or 5G network, or a WiFi network.
The processor capacity of the edge server is far higher than the computing capacity of the local terminal, and the edge server has the capacity of independently performing model training. The processor may be a general purpose Central Processing Unit (CPU), a Graphics Processing Unit (GPU), a microprocessor, an Application Specific Integrated Circuit (ASIC), or one or more Integrated circuits for program execution for model training as described above.
The local terminal can be a mobile terminal which can support model training, such as a modern smart phone, a tablet computer, a notebook computer, an automatic driving automobile and the like, is provided with a wireless communication system, and can be accessed to a mainstream wireless communication network such as a mobile communication network and WiFi.
The above-mentioned embodiments are intended to illustrate the technical solutions and advantages of the present invention, and it should be understood that the above-mentioned embodiments are only the most preferred embodiments of the present invention, and are not intended to limit the present invention, and any modifications, additions, equivalents, etc. made within the scope of the principles of the present invention should be included in the scope of the present invention.
Claims (9)
1. A system for realizing the federal learning comprises an edge server and a plurality of terminals in wireless communication with the edge server, wherein the terminals carry out model learning according to local data, and the federal learning method is characterized by comprising the following steps:
the edge server adjusts the batch size and the gradient compression rate of the terminal according to the current batch size and the gradient compression rate and by combining the computing power of the terminal and the communication capacity between the edge server and the terminal, and the method comprises the following steps:
(a) Calculating the current learning time delay according to the current batch size and the gradient compression rate and by combining the calculation capability of the terminal and the communication capability between the edge server and the terminal;
(b) Comparing the current learning time delay with a specified learning time delay, wherein the current learning time delay is larger than the specified learning time delay, and reducing the batch size and increasing the gradient compression rate; when the current learning time delay is smaller than the specified learning time delay, the batch size is increased and the gradient compression rate is reduced;
(c) Repeating the step (a) and the step (b) until the current learning time delay is equal to the specified learning time delay, wherein the batch size and the gradient compression ratio corresponding to the current learning time delay equal to the specified learning time delay are the adjusted batch size and the gradient compression ratio;
the edge server transmits the adjusted batch size and the gradient compression rate to the terminal;
the terminal performs model learning according to the received batch size, compresses gradient information obtained by the model learning according to the received extraction compression rate and outputs the gradient information to the edge server;
after averaging all the received gradient information, the edge server synchronizes the gradient average value to the terminal;
and the terminal updates the model according to the received gradient average value.
2. The federal learning method based on batch sizing and gradient compression ratios as claimed in claim 1, wherein in step (a), the calculation process of the current learning delay is as follows:
calculating the time required by the terminal to calculate the gradient according to the current batch size according to the terminal learning capacity and the batch size;
calculating the time for uploading the compressed gradient information to the edge server through a wireless channel according to the communication capacity and the gradient compression rate;
calculating the time required for obtaining average gradient information on average after summarizing all gradient information;
calculating the time required by the edge server to send the average gradient information to each terminal;
calculating the time required by each terminal for updating the model after receiving the average gradient information;
the sum of the five parts of time is the current learning delay.
3. The federal learning method based on adjusted batch size and gradient compression ratio as claimed in claim 1, wherein the gradient compression ratio comprises a compression ratio obtained by gradient quantization of gradient information, expressed as:

wherein x denotes gradient information, Q (x) denotes a quantization function, c denotes a compression rate, represents the square of the two norms;
represents the square of the two norms;
the convergence rate for the corresponding model training is expressed as:

wherein alpha is 1 ,β 1 Is a coefficient associated with the model, and alpha 1 >0,β 1 More than 0, B is the sum of the batch sizes of the terminals, C is the ladder of the terminalsThe average of the degree compression ratios, S, is the number of training steps.
4. The federal learning method based on batch size adjustment and gradient compression ratio as claimed in claim 1, wherein the gradient compression ratio includes a compression ratio obtained by thinning gradient information, that is, the maximum m gradients in a gradient matrix are selected for transmission, and the transmission amount of the gradients is defined as the compression ratio and expressed as:

wherein M represents the size of the model;
the convergence rate for the corresponding model training is expressed as:

wherein alpha is 2 ,β 2 Is a coefficient associated with the model, and alpha 2 >0,β 2 B is the sum of the batch sizes at each end, C is the average of the gradient compression ratios at each end, and S is the number of training steps.
5. The federal learning method for adjusting batch size and gradient compression ratio as claimed in claim 3, wherein when the gradient compression ratio is obtained by gradient quantization, the gradient compression ratio is increased or decreased by increasing or decreasing the number of quantization bits used by the quantization function.
6. The federal learning method for adjusting batch size and gradient compression ratio as claimed in claim 4, wherein when the gradient compression ratio is obtained by gradient sparsification, the gradient compression ratio is increased or decreased by increasing or decreasing the number of gradients.
7. The federal learning method for adjusting batch size and gradient compressibility of claim 1, wherein the gradient mean is obtained using the following formula:

wherein, g k (w) represents the gradient calculated by the terminal, G (w) represents the average value of the gradient, w represents the model parameter, K represents the terminal index, and K represents the total number of terminals.
8. The federal learning method for adjusting batch size and gradient compressibility of claim 1, wherein the model is updated from the gradient mean using the following formula:
w t+1 =w t -αG(w t )
where t is the number of iterations, G (w) t ) Represents the mean value of the gradient at the t-th iteration, w t 、w t+1 And respectively representing the model parameters of the terminal at the t th iteration and the t +1 th iteration.
9. A federated learning system based on batch size adjustment and gradient compression ratio comprises an edge server connected to a base communication terminal, and a plurality of terminals in wireless communication with the edge server,
the edge server adjusts the batch size and the gradient compression ratio of the terminal according to the current batch size and the gradient compression ratio and by combining the computing power of the terminal and the communication power between the edge server and the terminal, and the method comprises the following steps: (a) Calculating the current learning time delay according to the current batch size and the gradient compression rate and by combining the calculation capability of the terminal and the communication capability between the edge server and the terminal;
(b) Comparing the current learning time delay with a specified learning time delay, wherein the current learning time delay is larger than the specified learning time delay, and reducing the batch size and increasing the gradient compression rate; when the current learning time delay is smaller than the specified learning time delay, the batch size is increased and the gradient compression rate is reduced;
(c) Repeating the step (a) and the step (b) until the current learning time delay is equal to the specified learning time delay, wherein the batch size and the gradient compression ratio corresponding to the current learning time delay equal to the specified learning time delay are the adjusted batch size and the gradient compression ratio;
the edge server transmits the adjusted batch size and the gradient compression rate to the terminal;
the terminal performs model learning according to the received batch size, compresses gradient information obtained by the model learning according to the received extraction compression ratio and outputs the gradient information to the edge server;
after averaging all the received gradient information, the edge server synchronizes the gradient average value to the terminal;
and the terminal updates the model according to the received gradient average value.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010166667.4A CN111401552B (en) | 2020-03-11 | 2020-03-11 | Federal learning method and system based on batch size adjustment and gradient compression rate adjustment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010166667.4A CN111401552B (en) | 2020-03-11 | 2020-03-11 | Federal learning method and system based on batch size adjustment and gradient compression rate adjustment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111401552A CN111401552A (en) | 2020-07-10 |
| CN111401552B true CN111401552B (en) | 2023-04-07 |
Family
ID=71428616
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010166667.4A Active CN111401552B (en) | 2020-03-11 | 2020-03-11 | Federal learning method and system based on batch size adjustment and gradient compression rate adjustment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111401552B (en) |
Families Citing this family (34)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112070207B (en) * | 2020-07-31 | 2024-11-19 | 华为技术有限公司 | A model training method and device |
| CN112001502B (en) * | 2020-08-24 | 2022-06-21 | 平安科技(深圳)有限公司 | Federal learning training method and device for high-delay network environment robustness |
| CN114091679A (en) * | 2020-08-24 | 2022-02-25 | 华为技术有限公司 | Method for updating machine learning model and communication device |
| WO2022051964A1 (en) * | 2020-09-10 | 2022-03-17 | Qualcomm Incorporated | Reporting for information aggregation in federated learning |
| CN111931950B (en) * | 2020-09-28 | 2021-01-26 | 支付宝(杭州)信息技术有限公司 | A method and system for updating model parameters based on federated learning |
| CN112182633B (en) * | 2020-11-06 | 2023-03-10 | 支付宝(杭州)信息技术有限公司 | Privacy-preserving model joint training method and device |
| US20240054351A1 (en) * | 2020-12-11 | 2024-02-15 | Lg Electronics Inc. | Device and method for signal transmission in wireless communication system |
| CN112231742B (en) * | 2020-12-14 | 2021-06-18 | 支付宝(杭州)信息技术有限公司 | Model joint training method and device based on privacy protection |
| CN112560059B (en) * | 2020-12-17 | 2022-04-29 | 浙江工业大学 | Vertical federal model stealing defense method based on neural pathway feature extraction |
| EP4258104A4 (en) * | 2020-12-31 | 2024-02-07 | Huawei Technologies Co., Ltd. | METHOD AND DEVICE FOR TRANSMITTING MODEL DATA |
| US20220245527A1 (en) * | 2021-02-01 | 2022-08-04 | Qualcomm Incorporated | Techniques for adaptive quantization level selection in federated learning |
| CN112800468B (en) * | 2021-02-18 | 2022-04-08 | 支付宝(杭州)信息技术有限公司 | Data processing method, device and equipment based on privacy protection |
| CN113807534B (en) * | 2021-03-08 | 2023-09-01 | 京东科技控股股份有限公司 | Model parameter training method and device of federal learning model and electronic equipment |
| CN113222179B (en) * | 2021-03-18 | 2023-06-20 | 北京邮电大学 | A Federated Learning Model Compression Method Based on Model Sparsification and Weight Quantization |
| CN113298191B (en) * | 2021-04-01 | 2022-09-06 | 山东大学 | User behavior identification method based on personalized semi-supervised online federal learning |
| CN113095510B (en) * | 2021-04-14 | 2024-03-01 | 深圳前海微众银行股份有限公司 | A federated learning method and device based on blockchain |
| CN113098806B (en) * | 2021-04-16 | 2022-03-29 | 华南理工大学 | A Channel Adaptive Gradient Compression Method for Edge-End Collaboration in Federated Learning |
| CN113238867B (en) * | 2021-05-19 | 2024-01-19 | 浙江凡双科技股份有限公司 | A federated learning method based on network offloading |
| JP7546254B2 (en) * | 2021-07-06 | 2024-09-06 | 日本電信電話株式会社 | Processing system, processing method, and processing program |
| CN115700565B (en) * | 2021-07-27 | 2025-12-09 | 中国移动通信有限公司研究院 | Transverse federal learning method and device |
| CN113504999B (en) * | 2021-08-05 | 2023-07-04 | 重庆大学 | Scheduling and resource allocation method for high-performance hierarchical federal edge learning |
| KR20230026137A (en) * | 2021-08-17 | 2023-02-24 | 삼성전자주식회사 | A server for distributed learning and distributed learning method |
| CN113923605B (en) * | 2021-10-25 | 2022-08-09 | 浙江大学 | Distributed edge learning system and method for industrial internet |
| CN116073923A (en) * | 2021-11-01 | 2023-05-05 | 中国移动通信有限公司研究院 | Conversion method, device, communication device and storage medium of model optimization algorithm |
| CN114841370B (en) * | 2022-04-29 | 2022-12-09 | 杭州锘崴信息科技有限公司 | Processing method and device of federal learning model, electronic equipment and storage medium |
| CN115150288B (en) * | 2022-05-17 | 2023-08-04 | 浙江大学 | Distributed communication system and method |
| CN114710415B (en) * | 2022-05-23 | 2022-08-12 | 北京理工大学 | A Redundant Coded Passive Message Reliable Transmission and Processing System |
| WO2024050659A1 (en) * | 2022-09-05 | 2024-03-14 | 华南理工大学 | Federated learning lower-side cooperative channel adaptive gradient compression method |
| CN116050540B (en) * | 2023-02-01 | 2023-09-22 | 北京信息科技大学 | An adaptive federated edge learning method based on joint dual-dimensional user scheduling |
| CN116321255A (en) * | 2023-02-22 | 2023-06-23 | 北京邮电大学 | A high time-effective model compression and user scheduling method in wireless federated learning |
| CN116405491B (en) * | 2023-06-09 | 2023-09-15 | 北京随信云链科技有限公司 | File batch uploading method and system, electronic equipment and computer readable storage medium |
| CN119697040A (en) * | 2023-09-25 | 2025-03-25 | 华为技术有限公司 | A data processing method and a communication device |
| CN117857647B (en) * | 2023-12-18 | 2024-09-13 | 慧之安信息技术股份有限公司 | Federal learning communication method and system based on MQTT oriented to industrial Internet of things |
| CN118245809B (en) * | 2024-05-27 | 2024-08-16 | 合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室) | Batch size adjustment method in distributed data parallel online asynchronous training |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109934802A (en) * | 2019-02-02 | 2019-06-25 | 浙江工业大学 | A Cloth Defect Detection Method Based on Fourier Transform and Image Morphology |
| CN110633805A (en) * | 2019-09-26 | 2019-12-31 | 深圳前海微众银行股份有限公司 | Vertical federated learning system optimization method, device, equipment and readable storage medium |
| CN110782042A (en) * | 2019-10-29 | 2020-02-11 | 深圳前海微众银行股份有限公司 | Horizontal and vertical federation methods, devices, equipment and media |
| CN110874484A (en) * | 2019-10-16 | 2020-03-10 | 众安信息技术服务有限公司 | Data processing method and system based on neural network and federal learning |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6303332B2 (en) * | 2013-08-28 | 2018-04-04 | 富士通株式会社 | Image processing apparatus, image processing method, and image processing program |
| US11475350B2 (en) * | 2018-01-22 | 2022-10-18 | Google Llc | Training user-level differentially private machine-learned models |
-
2020
- 2020-03-11 CN CN202010166667.4A patent/CN111401552B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109934802A (en) * | 2019-02-02 | 2019-06-25 | 浙江工业大学 | A Cloth Defect Detection Method Based on Fourier Transform and Image Morphology |
| CN110633805A (en) * | 2019-09-26 | 2019-12-31 | 深圳前海微众银行股份有限公司 | Vertical federated learning system optimization method, device, equipment and readable storage medium |
| CN110874484A (en) * | 2019-10-16 | 2020-03-10 | 众安信息技术服务有限公司 | Data processing method and system based on neural network and federal learning |
| CN110782042A (en) * | 2019-10-29 | 2020-02-11 | 深圳前海微众银行股份有限公司 | Horizontal and vertical federation methods, devices, equipment and media |
Non-Patent Citations (2)
| Title |
|---|
| Haijian Sun .Adaptive Federated Learning With Gradient Compression in Uplink NOMA.《arXiv》.2020,1-10. * |
| 刘俊旭.机器学习的隐私保护研究综述.《计算机研究与发展》.2020,346-362. * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111401552A (en) | 2020-07-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111401552B (en) | Federal learning method and system based on batch size adjustment and gradient compression rate adjustment | |
| CN109814951B (en) | Joint optimization method for task unloading and resource allocation in mobile edge computing network | |
| CN110418416B (en) | Resource allocation method based on multi-agent reinforcement learning in mobile edge computing system | |
| CN109240818B (en) | A task offloading method based on user experience in edge computing network | |
| CN110740473B (en) | A management method and edge server for mobile edge computing | |
| CN113507712B (en) | Resource allocation and calculation task unloading method based on alternate direction multiplier | |
| WO2018090774A1 (en) | Method and system for bit rate control and version selection for dynamic adaptive video streaming media | |
| CN110392079A (en) | The node calculating task dispatching method and its equipment calculated towards mist | |
| CN111199740B (en) | An offloading method for accelerating automatic speech recognition tasks based on edge computing | |
| CN112104867A (en) | Video processing method, video processing device, intelligent equipment and storage medium | |
| CN116506953A (en) | Multi-channel switching method, system and medium applied to intelligent communication system | |
| CN113986370A (en) | Base station selection and task offloading method, device, device and medium for mobile edge computing system | |
| CN112770398A (en) | Far-end radio frequency end power control method based on convolutional neural network | |
| CN112423320A (en) | Multi-user computing unloading method based on QoS and user behavior prediction | |
| CN114827289B (en) | Communication compression method, system, electronic device and storage medium | |
| CN113613270A (en) | Fog access network calculation unloading method based on data compression | |
| WO2025214068A1 (en) | Quantization parameter determination method and related apparatus | |
| CN113965962A (en) | Cache resource management method and system for Internet of things slices | |
| CN113784372B (en) | A joint optimization method for terminal multi-service model | |
| CN112954739B (en) | Millimeter wave MEC unloading transmission method based on circular game algorithm | |
| CN117479232A (en) | Task offloading methods, systems, storage media, and equipment for mobile edge computing | |
| CN117750406A (en) | Communication resource joint optimization algorithm under electric power 5G mixed scene | |
| CN119031412A (en) | Downlink multiple access method, device, electronic device and storage medium | |
| CN115633369A (en) | A Multi-Edge Device Selection Method Oriented to User Task and Power Joint Allocation | |
| CN116918377A (en) | A transmission parameter adjustment method and communication device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |