CN110414432B - 对象识别模型的训练方法、对象识别方法及相应的装置 - Google Patents
对象识别模型的训练方法、对象识别方法及相应的装置 Download PDFInfo
- Publication number
- CN110414432B CN110414432B CN201910690389.XA CN201910690389A CN110414432B CN 110414432 B CN110414432 B CN 110414432B CN 201910690389 A CN201910690389 A CN 201910690389A CN 110414432 B CN110414432 B CN 110414432B
- Authority
- CN
- China
- Prior art keywords
- model
- loss value
- training
- image
- orientation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Multimedia (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Human Computer Interaction (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
Abstract
本申请实施例提供了一种对象识别模型的训练方法、对象识别方法及相应的装置,该方法包括:获取训练样本集;构建包括对象识别模型,以及分别与对象识别模型的输出连接的第一分类模块和第二分类模块的待训练模型;将各样本图像输入至待训练模型,根据第一分类模型输出的预测身份信息和样本图像的标注的身份信息确定第一训练损失值,根据第二分类模型输出的预测身份及朝向信息,与样本图像的标注的身份信息及朝向信息,确定第二训练损失值;根据由第一训练损失值和第二训练损失值确定的总损失值对待训练模型的模型参数进行调整,直至总损失值满足预设条件,得到训练好的对象识别模型。基于该方法,提高了将对象识别模型用于对象识别时的识别准确性。
Description
技术领域
本申请涉及计算机技术领域,具体而言,本申请涉及一种对象识别模型的训练方法、对象识别方法及相应的装置。
背景技术
行人重识别(ReID,Person Re-Identification)技术是利用计算机视觉技术判断图像或视频序列中是否存在特定行人的技术。具体地,给定目标行人的行人图像,从多个具有不同监控视野的监控设备中获取图像或视频序列,并从其中识别和检索该目标行人,进而实现对目标行人的轨迹跟踪。
现有的图像识别技术,多是采用模型进行行人识别,而模型是基于标注有身份信息的样本图像进行训练得到的。但是,在实际应用中,行人图像具有多种朝向,而目前的图像识别方案中并未考虑图像中行人的朝向信息,因此,图像识别的准确性较低。
发明内容
本申请的目的旨在至少能解决上述的技术缺陷之一,本申请实施例所提供的技术方案如下:
第一方面,本申请实施例提供了一种识别模型的训练方法,包括:
获取训练样本集,训练样本集中包括对象的样本图像,样本图像标注有图像中的对象的身份标签和朝向标签,身份标签用于表征对象的身份信息,朝向标签用于表征对象的朝向信息;
构建待训练模型,待训练模型包括对象识别模型,以及分别与对象识别模型的输出连接的第一分类模块和第二分类模块,其中,第一分类模型用于输出样本图像中对象的预测身份信息,第二分类模型用于输出样本图像中对象的预测身份及朝向信息;
将各样本图像输入至待训练模型中,根据第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值;
基于第一训练损失值和第二训练损失值,确定总损失值;
根据总损失值对待训练模型的模型参数进行调整,直至总损失值满足预设条件,得到训练好的对象识别模型。
在一种可选的实施方式中,该方法还包括:
根据第二分类模型的模型参数,确定训练样本集中同一对象的不同朝向的样本图像之间的差异值;
基于第一训练损失值和第二训练损失值,确定总损失值,包括:
基于第一训练损失值、第二训练损失值和差异值,确定总损失值。
在一种可选的实施方式中,根据第二分类模型的模型参数,确定训练样本集中同一对象的不同朝向的样本图像之间的差异值,包括:
计算第二分类模型的模型参数中,同一对象的不同朝向的样本图像所对应的参数向量之间的距离,将距离作为差异值。
在一种可选的实施方式中,基于第一训练损失值、第二训练损失值和差异值,确定总损失值,包括:
获取第二训练损失值的第一权重,以及差异值的第二权重;
根据第二训练损失值、第一权重、差异值、以及第二权重,确定第三训练损失值;
根据第一训练损失值和第三训练损失值,确定总损失值。
在一种可选的实施方式中,根据第一训练损失值和第三训练损失值,确定总损失值,包括:
获取第一训练损失值的第三权重,以及第三训练损失值的第四权重;
根据第一训练损失值、第三权重、第三训练损失值、以及第四权重,确定总损失值。
在一种可选的实施方式中,对象识别模型为特征提取模型。
在一种可选的实施方式中,样本图像的朝向标签是通过以下方式获取到的:
将样本图像输入至预训练好的朝向分类模型中,基于朝向分类模型的输出得到样本图像的朝向标签。
在一种可选的实施方式中,朝向标签为正向标签、侧向标签或背向标签。
第二方面,本申请适时合理提供了一种对象识别方法,该方法包括:
获取待识别的对象图像;
将待识别的对象图像输入对象识别模型,到对象图像的识别结果,其中,对象识别模型是通过第一方面或第一方面的任一可选实施方式中所提供的对象识别模型的训练方法训练得到的。
在一种可选的实施方式中,对象识别模型为特征提取模型,对象图像的识别结果为对象图像的图像特征,待识别的对象图像包括待检测对象图像和目标对象图像,将待识别的对象图像输入对象识别模型,得到对象图像的识别结果之后,该方法还包括:
确定待检测对象图像的图像特征和目标对象图像的图像特征的相似度;
根据相似度,确定待检测对象图像中的对象是否为目标对象图像中的对象。
第三方面,本申请实施例提供了一种对象识别模型的训练装置,包括:
样本获取模块,用于获取训练样本集,训练样本集中包括对象的样本图像,样本图像标注有图像中的对象的身份标签和朝向标签,身份标签用于表征对象的身份信息,朝向标签用于表征对象的朝向信息;
模型构建模块,用于构建待训练模型,待训练模型包括对象识别模型,以及分别与对象识别模型的输出连接的第一分类模块和第二分类模块,其中,第一分类模型用于输出样本图像中对象的预测身份信息,第二分类模型用于输出样本图像中对象的预测身份及朝向信息;
第一损失确定模块,用于将各样本图像输入至待训练模型中,根据第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值;
第二损失确定模块,用于基于第一训练损失值和第二训练损失值,确定总损失值;
参数调整模块,用于根据总损失值对待训练模型的模型参数进行调整,直至总损失值满足预设条件,得到训练好的对象识别模型。
第四方面,本申请实施例提供了一种对象识别装置,包括:
图像获取模块,用于获取待识别的对象图像;
特征提取模块,用于将待识别的对象图像输入对象识别模型,得到对象图像的识别结果,其中,对象识别模型是通过第一方面提供的对象识别模型的训练方法训练得到的。
第五方面,本申请实施例提供了一种电子设备,包括存储器和处理器;
存储器中存储有计算机程序;
处理器,用于执行计算机程序以实现第一方面实施例、第一方面任一可选实施例、第二方面实施例或第二方面任一可选实施例中所提供的方法。
第六方面,本申请实施例提供了一种计算机可读存储介质,其特征在于,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现第一方面实施例、第一方面任一可选实施例、第二方面实施例或第二方面任一可选实施例中所提供的方法。
本申请实施例所提供的方案的有益效果在于:
本申请实施例所提供的方案,通过将对象识别模型与用于预测样本图像中对象身份信息的第一分类模型,以及用于预测样本图像中对象的身份及朝向信息的第二分类模型组合构成待训练模型后,再基于带有身份标签和朝向标签的样本图像对待训练模型进行训练,直至待训练模型的总损失值满足预设条件,得到训练好的对象识别模型。该方案通过引入第一分类模型所对应的第一训练损失值和第二分类模型所对应的第二训练损失值,实现了基于图像中对象的身份信息和对象的朝向信息对模型的优化训练,由于训练过程中引入了对应于朝向信息设置的训练损失值,使得训练好的对象识别模型对于对象朝向的鲁棒性更强,提高了将其用于对象识别时的识别准确性。
本申请附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
本申请上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为本申请实施例提供的一种对象识别模型的训练方法的流程示意图;
图2为本申请实施例提供的一种样本图像的朝向标签的获取过程的示意图;
图3a为本申请一示例中提供的一种行人识别模型的训练过程的原理示意图;
图3b为图3a中三种不同损失函数的效果示意图;
图4为本申请实施例提供的一种对象识别方法的流程示意图;
图5为本申请实施例提供的一种对象识别模型的训练装置的结构示意图;
图6为本申请实施例提供的一种对象识别装置的结构框图;
图7为本申请实施例提供的一种电子设备的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本申请,而不能解释为对本申请的限制。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本申请的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服等,相信随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。
本申请实施例提供的方案涉及人工智能的计算机视觉技术、机器学习等技术,具体通过如下实施例进行说明,首先对几个名词进行解释和说明:
人工智能(Artificial Intelligence,AI)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
计算机视觉技术(Computer Vision,CV)计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取信息的人工智能系统。计算机视觉技术通常包括图像处理、图像识别、图像语义理解、图像检索、OCR、视频处理、视频语义理解、视频内容/行为识别、三维物体重建、3D技术、虚拟现实、增强现实、同步定位与地图构建等技术,还包括常见的人脸识别、指纹识别等生物特征识别技术。
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
行人图像具有多种角度即朝向,在行人识别和行人检索等多种应用场景中,图像中行人朝向的多样性是制约图像识别准确率的一大问题。但是在现有的图像识别方法中,并未考虑行人图像中行人的朝向这一信息,从而导致行人识别的准确率降低。
针对现有技术中所存在的上述问题,本申请实施例提供了一种对象识别模型的训练方法,如图1所示,该方法可以包括:
步骤S101,获取训练样本集,训练样本集中包括对象的样本图像,样本图像具有身份标签和朝向标签,身份标签用于表征样本图像中对象的身份信息,朝向标签用于表征样本图像中对象的朝向信息。
其中,对象可以是人,也可以是动物等。朝向是指对象的主体在样本图像中的朝向,例如,在对象为行人时,行人的朝向是指行人身体在样本图像中的朝向,具体来说,行人朝向为侧向是指在样本图像中行人身体的朝向为侧向。
具体的,为了提高训练样本集的获取效率,训练样本集中的样本图像可以通过对带有身份标签的对象图像进行朝向标注得到。例如,在对象是行人时,可以从公开数据集如market1501、Duke等中获取带有身份标签的行人图像,再对带有身份标签的行人图像进行朝向标注得到样本图像。当然,样本图像也可以通过对不带标签的对象图像进行身份标注和朝向标注得到。
步骤S102,构建待训练模型,待训练模型包括对象识别模型,以及分别与对象识别模型的输出连接的第一分类模块和第二分类模块,其中,第一分类模型用于输出样本图像中对象的预测身份信息,第二分类模型用于输出样本图像中对象的预测身份及朝向信息。
其中,将对象识别模型与第一分类模块和第二分类模块组合构成待训练模型,且第一分类模块和第二分类模块为并行的两个分支,对象识别模块的输出分别作为第一分类模块和第二分类模块的输入。
本申请实施例中,对于对象识别模型、第一分类模块和第二分类模块的具体网络结构不做限定,可以根据实际应用需求选择及配置。例如,可选的,对象识别模型具体可以是用于提取图像特征的特征提取网络,如骨干网络(Backbone Network)、残差网络(Residual Neural Network)等等,第一分类模块可以为全连接层结构,第二分类模块也可以是全连接层结构。
步骤S103,将各样本图像输入至待训练模型中,根据第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值。
其中,为了提高模型的识别准确性,分别为待训练模型的上述并行的两个分支设置了对应的第一损失函数和第二损失函数,以使得模型能够同时学习到图像中对象的身份特征和朝向特征,从而提高模型识别的准确性。在训练过程中,第一损失函数的值即为第一训练损失值,第二损失函数的值即为第二训练损失值。
可以理解的是,针对第一分类模型,第一损失函数对应于其输出的预测身份信息进行设置,针对第二分类模型,第二损失函数对应于其输出预测身份及朝向信息进行设置。设置第二损失函数的目的是通过预测的样本图像中对象的身份和朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息的差异来优化待训练模型的模型参数。换言之,通过第二损失函数来约束身份及朝向的损失,以使同一对象的相同朝向的图像的识别结果之间的差异尽可能小,提高模型对同一对象同一朝向的识别准确性。
本申请实施例中,对于第一损失函数和第二损失函数具体函数形式不做限定。可选的,第一损失函数或第二损失函数可以为cross entropy(交叉熵)损失、lsr(LabelSmoothing Regularization,标签平滑正则化)损失、triple(三元组)损失、arcface损失或center loss(中心损失)等类型。
具体地,在训练过程中,通过损失函数计算对应的训练损失值,将样本图像的预测身份信息和样本图像的身份标签所对应的身份信息代入第一损失函数,即可得到对应的第一训练损失值,将样本图像的预测身份及朝向信息和样本图像的身份及朝向标签所对应的身份及朝向信息代入第二损失函数,即可得到对应的第二训练损失值。
步骤S104,基于第一训练损失值和第二训练损失值,确定总损失值。
其中,为了联合第一损失函数和第二损失函数对待训练模型进行训练,本申请实施例还基于第一损失函数和第二损失函数为待训练模型设置了总损失函数,在训练过程中,总损失函数的值即为总损失值。
具体地,在训练过程中通过损失函数计算对应训练损失值,将第一训练损失值和第二训练损失值代入总损失函数即可得到总损失值。例如,作为一可选方式,总损失值可以为第一训练损失值和第二训练损失值的和。
步骤S105,根据总损失值对待训练模型的模型参数进行调整,直至总损失值满足预设条件,得到训练好的对象识别模型。
预设条件即模型训练结束的条件,即模型的总损失函数收敛。预设条件可以根据实际需求进行相应的配置。例如,总损失值满足预设条件可以是总损失函数值小于预设值,也可以是总损失值的变化趋近于平稳,即相邻两次或多次训练对应的总损失值的差值小于设定值,也就是总损失值基本不再变化。
可以理解的是,在通过训练样本集对待训练模型的训练过程中,不断根据每次训练的总损失值对待训练模型的模型参数进行调整,其中包括对对象识别模型的模型参数的调整,以及对第一分类模块和第二分类模型的模型参数的调整,当总损失值满足预设条件时,得到训练好的待训练模型的同时也得到训练好的对象识别模型。
具体地,上述训练过程具体可以包括:首先,可以将训练样本集划分为多个批次。可选地,为了更好的保证样本图像的客观性,提升训练效果,每一批次中不同身份的对象的样本图像数量可以相同,同一身份的不同朝向的对象的样本图像的数量可以相同。然后,将每一批次的样本图像分别输入待训练模型中进行训练,直至总损失值满足预设条件,即完成对待训练模型的训练。
每一批次的样本图像对应的具体训练过程可以包括以下步骤:
步骤一,将该批次中的样本图像输入至对象识别模型,再将对象识别模型的输出分别输入第一分类模块和第二分类模块,第一分类模块输出预测身份信息,第二分类模块输出预测身份及朝向信息。
步骤二,将样本图像的预测身份信息和样本图像的身份标签所对应的身份信息代入第一损失函数,得到对应的第一训练损失值,将样本图像的预测身份及朝向信息和样本图像的身份及朝向标签所对应的身份及朝向信息代入第二损失函数,得到对应的第二训练损失值,再将第一训练损失值和第二训练损失值代入总损失函数得到总损失值。
步骤三,根据总损失值对待训练模型的模型参数进行调整,即完成该批次的训练。
在本申请实施例中,每个批次对应的训练过程中,优化算法可以采用随机梯度下降法(SGD,Stochastic gradient descent)。
本申请实施例提供的该种对象识别模型训练方法,通过将对象识别模型与用于预测样本图像中对象身份信息的第一分类模型,以及用于预测样本图像中对象的身份及朝向信息的第二分类模型组合构成待训练模型后,再基于带有身份标签和朝向标签的样本图像对待训练模型进行训练,直至待训练模型的总损失值满足预设条件,得到训练好的对象识别模型。该方案通过引入第一分类模型所对应的第一训练损失值和第二分类模型所对应的第二训练损失值,实现了基于图像中对象的身份信息和对象的朝向信息对模型的优化训练,由于训练过程中引入了对应于朝向信息设置的训练损失值,使得训练好的对象识别模型对于对象朝向的鲁棒性更强,提高了将其用于对象识别时的识别准确性。
在本申请的可选实施例中,该方法还可以包括:
根据第二分类模型的模型参数,确定训练样本集中同一对象的不同朝向的样本图像之间的差异值;
基于第一训练损失值和第二训练损失值,确定总损失值,包括:
基于第一训练损失值、第二训练损失值和差异值,确定总损失值。
其中,为了进一步基于对象的朝向信息对待训练模型的模型参数进行优化,本申请实施例为第二分类模型设置了朝向差异函数,在训练过程中,朝向差异函数的值即为差异值。通过上述朝向差异函数来约束同一对象的不同朝向图像的预测结果之间的差异,从而使得待训练模型(包括对象识别模型)在训练过程中学习到相同身份不同朝向的对象的样本图像之间的相似性,即同一对象的不同朝向的图像的预测结果之间的差异也尽可能小,以使得即使在同一对象的朝向不同时,模型也能够准确的识别出不同朝向的图像中的对象是同一个对象。同时,为了联合第一损失函数、第二损失函数以及朝向差异函数对待训练模型进行训练,进一步为待训练模型基于第一损失函数、第二损失函数以及朝向差异函数设置总损失函数。
具体地,在训练过程中,根据第二分类模型的模型参数,以及朝向差异函数可以得到训练样本集中同一对象的不同朝向的样本图像之间的差异值。进而,根据第一训练损失值、第二训练损失值和差异值,可以确定总损失值。可选的,总损失值可以等于第一训练训练损失值、第二训练损失值和上述差异值之和。
在本申请的可选实施例中,根据第二分类模型的模型参数,确定训练样本集中同一对象的不同朝向的样本图像之间的差异值,包括:
计算第二分类模型的模型参数中,同一对象的不同朝向的样本图像所对应的参数向量之间的距离,将距离作为差异值。
其中,第二分类模型的模型参数包括该模型中所有神经元的网络参数,每个神经元的网络参数即为该神经元对应的所有权重及偏置,将该模型中每个神经元的网络参数作为矩阵的元素即可得到该模型的权重矩阵(即网络参数矩阵),其中,权重矩阵中每一行的所有元素即为一个神经元的网络参数。由于第二分类模型的每个神经元对应一个分类结果,那么可以将该模型的权重矩阵中每一行的元素构成的向量作为对应的分类结果的参数向量。同一对象的不同朝向的样本图像对应的不同的参数向量可以从权重矩阵中获取,通过计算这些参数向量中每对参数向量之间的距离,即可得到同一对象的不同朝向的样本图像的差异值。
作为一示例,假设对象为人,训练样本集中包括C个人的样本图像,这些图像中共有M种不同朝向的图像,即样本图像中对象的身份有C种,朝向的类别为M种,那第二分类模块的神经元的数量则为C*M种,假设对象识别模型的输出为N维列向量(如对象识别模型用于提取图像特征,则该向量即为图像特征的表示向量),那第二分类模块的权重矩阵Q则为行数为C*M、列数为N的矩阵。那么,权重矩阵Q中每一行构成的行向量即为对应的一个神经元的预测结果在目标空间的参数向量。获取每一相同身份不同朝向的预测结果的参数向量,计算每对参数向量之间的差异(如距离),即可得到同一对象的不同朝向的样本图像的差异值。其中,每对参数向量之间的距离可以是欧氏距离,也可以是余弦距离等。
具体的,假设对象识别模型的输出为4维列向量,其中有3种身份的对象,每种对象有3种朝向,即N=4,C=3,M=3,那么第二分类模块的神经元的个数为9,其权重矩阵Q为9*4维,可以表示如下:

假设该权重矩阵Q中第一行对应于第二分类模块中预测结果为第一身份第一朝向的神经元,第二行对应于分类层中预测结果为第一身份第二朝向的神经元,第三行对应于分类层中预测结果为第一身份第三朝向的神经元。那么,第一身份第一朝向的预测结果的参数向量为(a11,a12,a13,a14),第一身份第二朝向的预测结果的参数向量为(a21,a22,a23,a24),第一身份第三朝向的预测结果的参数向量为(a31,a32,a33,a34)。计算(a11,a12,a13,a14),(a21,a22,a23,a24)以及(a31,a32,a33,a34)中每对参数向量之间的距离,即可得到第一身份的三个朝向的样本图像中两两对应的差异值。
在本申请的可选实施例中,上述朝向差异函数的表达式可以为:

其中,k≠l;其中,lossfc表示差异值,C表示训练样本集中的所有样本图像中不同对象的数量,j表示C个对象中的第j个对象,n表示训练样本集中的所有样本图像中对象的不同朝向的数量,Dk和Dl分别表示n个朝向中的第k个朝向和第l个朝向, 表示第j个对象的第k个朝向所对应的参数向量和第l个朝向所对应的参数向量之间的距离。
表示第j个对象的第k个朝向所对应的参数向量和第l个朝向所对应的参数向量之间的距离。
在一示例中,假设朝向包括正向(front)、侧向(side)以及背向(back),则上述朝向差异函数的表达式可以为:

其中,C为对象的数量, 表示第j个身份的对象的正向样本图像的预测结果与侧向样本图像的预测结果两者在目标空间中的参数向量之间的距离,
表示第j个身份的对象的正向样本图像的预测结果与侧向样本图像的预测结果两者在目标空间中的参数向量之间的距离, 表示第j个身份的对象的前向样本图像的预测结果与背向样本图像的预测结果两者在目标空间中的参数向量之间的距离,
表示第j个身份的对象的前向样本图像的预测结果与背向样本图像的预测结果两者在目标空间中的参数向量之间的距离,
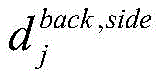
在本申请的可选实施例中,基于第一训练损失值、第二训练损失值和差异值,确定总损失值,包括:
获取第二训练损失值的第一权重,以及差异值的第二权重;
根据第二训练损失值、第一权重、差异值、以及第二权重,确定第三训练损失值;
根据第一训练损失值和第三训练损失值,确定总损失值。
其中,由于第二损失函数和朝向差异函数都是基于朝向信息的函数,在训练过程中都是为了让模型学习朝向特征,故可以将两者组合构成第三损失函数,训练过程中,该损失函数的值为第三训练损失值。第三损失函数的表达式可以为:
lossd=αlossview+βlossfc
其中,lossd表示第三损失函数,lossview表示第二损失函数(该函数的值即为第二训练损失值),lossfc表示朝向差异函数(该值即为上述差异值),α为第一权重,β为第二权重。
在实际应用中,可以根据实际应用场景的需要,来配置第一权重和第二权重,即上述α、β的取值。具体地,可以根据第一损失函数和朝向差异函数各自在训练过程中的重要程度来设置α、β的取值,例如,将α设置为0.3,即第一损失函数的权重为0.3,β设置为0.7,即朝向差异函数的权重为0.7,即认为朝向差异函数更重要。
可以理解的是,在实际应用中,也可以不设置各损失函数的权重,或者只设置其中一个或多个损失函数的权重,例如,上述第三损失函数中,第三损失函数还可以表示为lossd=lossview+γlossfc,即只设置了朝向差异函数的权重γ。
具体的,在训练过程中将第二训练损失值和差异值代入第三损失函数计算得到第三训练损失值,再根据第三训练损失值和第一训练损失值,即可得到总损失值。
在本申请的可选实施例中,根据第一训练损失值和第三训练损失值,确定总损失值,包括:
获取第一训练损失值的第三权重,以及第三训练损失值的第四权重;
根据第一训练损失值、第三权重、第三训练损失值、以及第四权重,确定总损失值。
具体的,总损失函数的表达式可以为:
loss=χlossid+δlossd
其中,loss为总损失函数,lossid为第一损失函数(其值即为第一训练损失值),lossd为第三损失函数(其值即为第三训练损失值),χ第三权重,δ为第四权重。
在实际应用中,可以根据实际应用场景的需要,来配置第三权重和第四权重,即上述χ、δ的取值。具体地,可以根据第一损失函数和第三损失函数各自在训练过程中的重要程度来设置χ、δ的取值,例如,将χ设置为0.4,即第一损失函数的权重为0.4,将δ设置为0.6,即第三损失函数的权重为0.6,即认为第三损失函数更重要。
具体的,在训练过程中将第一训练损失值和第三训练损失值代入上述总损失函数,即可得到总损失值。
在本申请的可选实施例中,对象识别模型为特征提取模型。
具体地,特征提取模型的输入为样本图像,其输出为样本图像的图像特征,基于图像特征可以对样本图像中的对象进行识别。
在本申请的可选实施例中,样本图像的朝向标签是通过以下方式获取到的:
将样本图像输入至预训练好的朝向分类模型中,基于朝向分类模型的输出得到样本图像的朝向标签。
其中,需要对朝向分类模型进行训练得到预训练好的朝向分类模型,具体可以包括:首先对部分对象图像的朝向进行标注,作为训练样本集;然后,基于该训练样本集对朝向分类模型进行训练,得到预训练好的朝向分类模型。
具体的,将对象图像输入至预训练好的朝向分类模型,其中的特征提取层提取对象图像的图像特征,再将图像特征输入朝向分类层输出对应的朝向,该朝向即为该对象图像的朝向标签。
在一示例中,图2示出了一种朝向分类模型的结构示意图,如图中所示,该朝向分类模型包括依次级联的卷积神经网络(还可以是骨干网络或其他特征提取网络等)和全连接层(还可以是其他分类网络,全连接层可以是一层,也可以是多层),卷积神经网络用于提取样本图像的图像特征,全连接层用于基于该图像特征输出朝向信息。当对象为行人时,图2示出了行人图像的朝向标签的获取过程,将行人图像输入预训练好的朝向分类模型,其中的卷积神经网络提取行人图像的图像特征,再将图像特征输入权连接层输出对应的朝向信息,该朝向信息即为行人图像的朝向标签。进一步地,利用朝向标签和身份标签对行人图像进行标注即可得到对应的样本图像。
其中,朝向分类模型也是基于训练样本集训练得到的,作为一可选方式,在实际应用中,对于上述训练样本集中的样本图像(标注朝向标签之前),可以将其中的部分图像采用人工标注的方式,标注图像中对象的朝向信息(如正向、背向、侧向等),可以采用监督学习的方式,基于这些人工标注的样本图像对朝向分类模型进行训练,从而得到训练好的朝向分类模型。之后,可以通过该训练好的朝向分类模型来预测出训练样本集中未标注朝向信息的样本图像,从而得到训练样本集中每个样本图像的朝向信息。
在本申请的可选实施例中,朝向标签为正向标签、侧向标签或背向标签。
具体地,在选定参考基准后,不同样本图像中对象的主体与参考基准之间会有多种角度关系,则可以将主体与参考基准之间角度在特定范围内的对象的朝向定义为正向,将主体与参考基准之间角度在另一特定范围内的对象的朝向定义为侧向,将主体与参考基准之间角度在另一特定范围内的对象的朝向定义为背向,每一样本图像的朝向标签为正向标签、侧向标签或背向标签。可以理解的是,根据上述朝向定义原则,也可以将对象的朝向划分为2个或多于3个。
当然,如果采用人工标注方式或者模型预测的方式来得到样本图像的朝向标签时,则可以基于由人为判定或基于模型预测结果确定出样本图像的朝向标签。
为了更好的说明本申请实施例的该方法,下面结合一个具体示例来对本申请实施例进行进一步说明。
该示例中,假设对象为行人,即对象识别模型为行人识别模型,该模型的对象识别模型具体为骨干网络。如图3a所示,将骨干网络与第一分类模块和第二分类模块组合构成待训练模型,且第一分类模块和第二分类模块为并行的分支一和分支二,其中,第一分类模块为行人身份分类模块,第二分类模块为行人身份及朝向分类模块。图3b示出了图3a中虚线椭圆部分的放大效果示意图。
该示例中,训练样本集中所有样本图像(该示例中为行人图像)中的行人的身份共有3种,即三个不同行人的图像,样本图像中有三种身份标签(即为ID lable)三个行人的身份标识分别记为ID1、ID2和ID3;行人的朝向共有3种,分别是正向(front)、侧向(side)以及背向(back)。待训练模型的总损失函数包括第一损失函数lossid、第二损失函数lossview和朝向差异函数lossfc。
在模型训练时:将行人图像送入骨干网络提取图像特征,之后图像特征分别被送入两个分支(图中所示的分支一和分支二),即送入第一分类模块和第二分类模块,基于第一分类模块和第二分类模块的输出便可以分别计算第一训练损失值、第二训练损失值和差异值,从而得到总损失值。如图3a和图3b中所示,基于第一分类模块的输出得到第一训练损失值,即lossid的值,基于第二分类模块的输出得到第二训练损失值,即lossview的值,基于第二分类模块的权重矩阵得到差异值,即lossfc的值。
其中,分支一的目的是通过学习图像的特征,预测图像中行人的身份,即输出图像中行人身份的预测结果,具体的,图像特征经过第一分类模块之后,即输出ID(即行人身份)预测结果。分支二的目的是通过学习同一行人的图像的特征,来预测图像中行人的身份及朝向,即输出图像中行人的融合了身份及朝向的预测结果。对于第二分支,由于要学习朝向信息,因此,此时样本图像的标签种类有3*3个(对象数目为3个,每个对象均对应有3个朝向的图像)。
下面结合图3b对上述各损失函数的意义进行进一步说明,图3b中的每个小黑点、大黑点或者黑色的菱形均表示一张行人图像的预测结果。
对于第一损失函数,图中301部分的每个圆圈可以表示一个分类结果,每个圆圈对应预测结果为一个行人的预测结果,如301部分的ID1对应的圆圈,则表示预测结果是身份标识为ID1的这个行人的预测结果。第一分类模块对应的损失函数lossid则用于约束模型对身份识别的准确性,使同一行人的预测结果尽可能相同,不同行人的结果尽可能不同,如301部分的箭头所示意的,不同ID的行人图像的预测结果尽可能不同,而同一ID的行人图像尽可能的相似,位于同一个分类结果中。
对于第二损失函数lossview,如图中所示意的,lossview用于使模型的预测结果中同一行人的同一朝向的图像的预测结果尽可能相同,如图中lossview部分以 为例所示意的,lossview约束该ID1行人的不同背向的图像之间的预测结果尽可能相同(图中箭头所示的尽可能靠近)。
为例所示意的,lossview约束该ID1行人的不同背向的图像之间的预测结果尽可能相同(图中箭头所示的尽可能靠近)。
对于朝向差异函数lossfc,如图中所示意的,lossfc计算的是同一行人的不同朝向图像之间的预测损失,如图中以ID1为例, 和
和 分别表示ID1这个行人的正向、侧向和背向的三种预测结果,如图中该部分的箭头所示意的,lossfc用于约束同一行人的不同朝向之间的差异,使同一行人的不同朝向的预测结果之间的差异尽可能小。
分别表示ID1这个行人的正向、侧向和背向的三种预测结果,如图中该部分的箭头所示意的,lossfc用于约束同一行人的不同朝向之间的差异,使同一行人的不同朝向的预测结果之间的差异尽可能小。
本申请实施例所提供的方案,通过联合多损失函数对待训练模型进行训练,使得训练好的对象识别模型对于对象朝向的鲁棒性更强,进而提高了将其用于对象识别时识别结果的准确率。
图4为本申请实施例提供的一种对象识别方法的流程示意图,如图4所示,该方法可以包括:
步骤S401,获取待识别的对象图像。
其中,待识别的对象图像一般为只包含一个对象的图像,其一般通过获取包含该对象的原始图像后,对原始图像进行图像分割和调整后得到。例如,若对象为行人,对象图像则为行人图像,待识别的行人图像一般只包含一个行人,可以从监控设备的视频序列中获取包含该行人的原始图像,再对原始图像进行图像分割和调整后得到该行人图像。
步骤S402,将待识别的对象图像输入对象识别模型,得到对象图像的识别结果。其中,对象识别模型是通过上述实施例中的对象识别模型的训练方法训练得到的。
具体的,上述实施例中的对象识别模型的训练方法是对由对象识别模型、第一分类模块以及第二分类模块组成的待训练模型整体进行训练,在总损失值满足预设条件后,得到训练好的特征提取模块,即得到训练好的对象识别模型。在步骤S402中进行对象识别时,用到的即是训练好的对象识别模型。
本申请实施例提供的一种对象识别方法,利用对象识别模型对对象图像进行识别,该对象识别模型的训练过程通过将对象识别模型与用于预测样本图像中对象身份信息的第一分类模型,以及用于预测样本图像中对象的身份及朝向信息的第二分类模型组合构成待训练模型后,再基于带有身份标签和朝向标签的样本图像对待训练模型进行训练,直至待训练模型的总损失值满足预设条件,得到训练好的对象识别模型。该方案通过引入第一分类模型所对应的第一训练损失值和第二分类模型所对应的第二训练损失值,实现了基于图像中对象的身份信息和对象的朝向信息对模型的优化训练,由于训练过程中引入了对应于朝向信息设置的训练损失值,使得训练好的对象识别模型对于对象朝向的鲁棒性更强,提高了将其用于对象识别时的识别准确性。
在本申请的可选实施例中,对象识别模型为特征提取模型,对象图像的识别结果为对象图像的图像特征,待识别的对象图像包括待检测对象图像和目标对象图像,将待识别的对象图像输入对象识别模型,得到对象图像的识别结果之后,该方法还包括:
确定待检测对象图像的图像特征和目标对象图像的图像特征的相似度;根据相似度,确定待检测对象图像中的对象是否为目标对象图像中的对象。
其中,计算上述两个图像特征之间的距离,根据该距离确定待检测对象图像的图像特征和目标对象图像的图像特征的相似度。可以理解的是,该距离可以是欧式距离或余弦距离。
具体地,若相似度高于预设相似度,则确定待检测对象图像中的对象是目标对象图像中的对象,否则确定待检测对象图像中的对象不是目标对象图像中的对象。
进一步地,可以将该对象识别方法应用于ReID中,ReID是利用计算机视觉技术判断图像或视频序列中是否存在特定行人的技术。具体地,给定特定行人的图像,从多个具有不同监控视野的监控设备中获取图像或视频序列,并从其中检索该特定行人,进而实现对特定行人的轨迹跟踪。其中,该特定行人的图像称为query图像(查询图像),从多个具有不同监控视野的监控设备中获取的图像或视频序列称为gallery图像(参考图像)。将该对象识别方法应用于ReID中,具体可以包括:
首先,根据要跟踪或检索的特定行人信息确定出查询图像(query图像),然后从多个具有不同监控视野的监控设备中获取图像或视频序列,并根据图像或视频序列得到参考图像(gallery图像)。
然后,将query图像和gallery图像分别输入上述对象识别模型中,得到query图像的图像特征和gallery图像的图像特征,并获取query图像的图像特征和每一gallery图像的图像特征之间的相似度。
最后,根据相似度确定gallery图像的图像特征哪些图像中的行人与query图像中的行人是同一行人,即完成行人重识别。
由于上述行人重识别过程采用了本申请实施例提供的对象识别模型,该对象识别模型训练过程中引入了对应于朝向信息设置的损失函数,使得训练好的对象识别模型对于对象朝向的鲁棒性更强,提高了将其用于行人重识别时的识别准确性。
图5为本申请实施例提供的一种对象识别模型的训练装置的结框图,如图5所示,该装置50包括:样本获取模块51、模型构建模块52、第一损失确定模块53、第二损失确定模块54以及参数调整模块55,其中:
样本获取模块51用于获取训练样本集,训练样本集中包括对象的样本图像,样本图像标注有图像中的对象的身份标签和朝向标签,身份标签用于表征对象的身份信息,朝向标签用于表征对象的朝向信息;
模型构建模块52用于构建待训练模型,待训练模型包括对象识别模型,以及分别与对象识别模型的输出连接的第一分类模块和第二分类模块,其中,第一分类模型用于输出样本图像中对象的预测身份信息,第二分类模型用于输出样本图像中对象的预测身份及朝向信息;
第一损失确定模块53用于将各样本图像输入至待训练模型中,根据第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值;
第二损失确定模块54用于基于第一训练损失值和第二训练损失值,确定总损失值;
参数调整模块55用于根据总损失值对待训练模型的模型参数进行调整,直至总损失值满足预设条件,得到训练好的对象识别模型。
本申请实施例提供的装置,通过将对象识别模型与用于预测样本图像中对象身份信息的第一分类模型,以及用于预测样本图像中对象的身份及朝向信息的第二分类模型组合构成待训练模型后,再基于带有身份标签和朝向标签的样本图像对待训练模型进行训练,直至待训练模型的总损失值满足预设条件,得到训练好的对象识别模型。该方案通过引入第一分类模型所对应的第一训练损失值和第二分类模型所对应的第二训练损失值,实现了基于图像中对象的身份信息和对象的朝向信息对模型的优化训练,由于训练过程中引入了对应于朝向信息设置的训练损失值,使得训练好的对象识别模型对于对象朝向的鲁棒性更强,提高了将其用于对象识别时的识别准确性。
可选的,该装置还包括差异值确定模块,用于:
根据第二分类模型的模型参数,确定训练样本集中同一对象的不同朝向的样本图像之间的差异值;
基于第一训练损失值和第二训练损失值,确定总损失值,包括:
基于第一训练损失值、第二训练损失值和差异值,确定总损失值。
可选的,差异值确定模块具体用于:
计算第二分类模型的模型参数中,同一对象的不同朝向的样本图像所对应的参数向量之间的距离,将距离作为差异值。
可选的,第二损失确定模块,具体用于:
获取第二训练损失值的第一权重,以及差异值的第二权重;
根据第二训练损失值、第一权重、差异值、以及第二权重,确定第三训练损失值;
根据第一训练损失值和第三训练损失值,确定总损失值。
可选的,第二损失确定模块,具体用于:
获取第一训练损失值的第三权重,以及第三训练损失值的第四权重;
根据第一训练损失值、第三权重、第三训练损失值、以及第四权重,确定总损失值。
可选的,对象识别模型为特征提取模型。
可选的,样本图像的朝向标签是通过以下方式获取到的:
将样本图像输入至预训练好的朝向分类模型中,基于朝向分类模型的输出得到样本图像的朝向标签。
可选的,朝向标签为正向标签、侧向标签或背向标签
需要说明的是,由于本申请实施例所提供的装置为可以执行本申请实施例中的方法的装置,故而基于本申请实施例中所提供的方法,本领域所属技术人员能够了解本申请实施例的装置的具体实施方式以及其各种变化形式,所以在此对于该装置如何实现本申请实施例中的方法不再详细介绍,该装置所执行的各步骤具体实现可以参见前文中相应的方法部分中的描述。只要本领域所属技术人员实施本申请实施例中的方法所采用的装置,都属于本申请所欲保护的范围。
图6为本申请实施例提供的一种对象识别装置的结构框图,如图6所示,该装置60包括图像获取模块61和特征提取模块62,其中:
图像获取模块61用于获取待识别的对象图像;
特征提取模块62用于将待识别的对象图像输入对象识别模型,得到对象图像的识别结果,其中,对象识别模型是通过本申请实施例中提供的对象识别模块的训练方法训练得到的。
可选的,对象识别模型为特征提取模型,对象图像的识别结果为对象图像的图像特征,待识别的对象图像包括待检测对象图像和目标对象图像,该装置还包括相似度确定模块和对象确定模块,其中:
相似度确定模块,用于确定待检测对象图像的图像特征和目标对象图像的图像特征的相似度;
对象确定模块,用于根据相似度,确定待检测对象图像中的对象是否为目标对象图像中的对象。
基于相同的原理,本申请实施例还提供了一种电子设备,该电子设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行该计算机程序时,实现本申请任一可选实施例中所提供的方法,具体可实现如下几种情况:
情况一:获取训练样本集,训练样本集中包括对象的样本图像,样本图像标注有图像中的对象的身份标签和朝向标签,身份标签用于表征对象的身份信息,朝向标签用于表征对象的朝向信息;构建待训练模型,待训练模型包括对象识别模型,以及分别与对象识别模型的输出连接的第一分类模块和第二分类模块,其中,第一分类模型用于输出样本图像中对象的预测身份信息,第二分类模型用于输出样本图像中对象的预测身份及朝向信息;将各样本图像输入至待训练模型中,根据第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值;基于第一训练损失值和第二训练损失值,确定总损失值;根据总损失值对待训练模型的模型参数进行调整,直至总损失值满足预设条件,得到训练好的对象识别模型。
情况二:获取待识别的对象图像;将待识别的对象图像输入对象识别模型,得到对象图像的识别结果,其中,对象识别模型是通过本申请实施例中提供的对象识别模型的训练方法训练得到的。
本申请实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该程序被处理器执行时实现本申请任一实施例所示的方法。
可以理解的是,介质中存储的可以是对象识别模型的训练方法对应的计算机程序,也可以是对象识别方法对应的计算机程序。
图7中示出了本申请实施例所适用的一种电子设备的结构示意图,如图7所示,图7所示的电子设备700包括:处理器701和存储器703。其中,处理器701和存储器703相连,如通过总线702相连。进一步地,电子设备700还可以包括收发器704,电子设备700可以通过收发器704与其他电子设备进行数据的交互。需要说明的是,实际应用中收发器704不限于一个,该电子设备700的结构并不构成对本申请实施例的限定。
其中,处理器701应用于本申请实施例中,可以用于实现图5所示的第一训练模块与训练模块的功能,也可以用于实现图6所示的第二获取模块与特征提取模块的功能。
处理器701可以是CPU,通用处理器,DSP,ASIC,FPGA或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本申请公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器701也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,DSP和微处理器的组合等。
总线702可包括一通路,在上述组件之间传送信息。总线702可以是PCI总线或EISA总线等。总线702可以分为地址总线、数据总线、控制总线等。为便于表示,图7中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
存储器703可以是ROM或可存储静态信息和指令的其他类型的静态存储设备,RAM或者可存储信息和指令的其他类型的动态存储设备,也可以是EEPROM、CD-ROM或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。
存储器703用于存储执行本申请方案的应用程序代码,并由处理器701来控制执行。处理器701用于执行存储器703中存储的应用程序代码,以实现图5所示实施例提供的对象识别模型的训练装置的动作,或者实现图6所示实施例提供的对象识别装置的动作。
应该理解的是,虽然附图的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,其可以以其他的顺序执行。而且,附图的流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,其执行顺序也不必然是依次进行,而是可以与其他步骤或者其他步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
以上仅是本申请的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。
Claims (13)
1.一种对象识别模型的训练方法,其特征在于,包括:
获取训练样本集,所述训练样本集中包括对象的样本图像,所述样本图像标注有图像中的对象的身份标签和朝向标签,所述身份标签用于表征对象的身份信息,所述朝向标签用于表征对象的朝向信息;
构建待训练模型,所述待训练模型包括所述对象识别模型,以及分别与所述对象识别模型的输出连接的第一分类模块和第二分类模块,其中,所述第一分类模型用于输出所述样本图像中对象的预测身份信息,所述第二分类模型用于输出所述样本图像中对象的预测身份及朝向信息;
将各样本图像输入至所述待训练模型中,根据所述第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据所述第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值;
基于所述第一训练损失值和所述第二训练损失值,确定总损失值;
根据所述总损失值对所述待训练模型的模型参数进行调整,直至所述总损失值满足预设条件,得到训练好的对象识别模型。
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
根据所述第二分类模型的模型参数,确定所述训练样本集中同一对象的不同朝向的样本图像之间的差异值;
所述基于所述第一训练损失值和所述第二训练损失值,确定总损失值,包括:
基于所述第一训练损失值、所述第二训练损失值和所述差异值,确定所述总损失值。
3.根据权利要求2所述的方法,其特征在于,所述根据所述第二分类模型的模型参数,确定所述训练样本集中同一对象的不同朝向的样本图像之间的差异值,包括:
计算所述第二分类模型的模型参数中,同一对象的不同朝向的样本图像所对应的参数向量之间的距离,将所述距离作为所述差异值。
4.根据权利要求2所述的方法,其特征在于,所述基于所述第一训练损失值、所述第二训练损失值和所述差异值,确定所述总损失值,包括:
获取所述第二训练损失值的第一权重,以及所述差异值的第二权重;
根据所述第二训练损失值、所述第一权重、所述差异值、以及所述第二权重,确定第三训练损失值;
根据所述第一训练损失值和所述第三训练损失值,确定总损失值。
5.根据权利要求4所述的方法,其特征在于,所述根据所述第一训练损失值和所述第三训练损失值,确定总损失值,包括:
获取所述第一训练损失值的第三权重,以及所述第三训练损失值的第四权重;
根据所述第一训练损失值、所述第三权重、所述第三训练损失值、以及所述第四权重,确定总损失值。
6.根据权利要求5所述的方法,其特征在于,所述对象识别模型为特征提取模型。
7.根据权利要求1至6中任一项所述方法,其特征在于,所述样本图像的朝向标签是通过以下方式获取到的:
将所述样本图像输入至预训练好的朝向分类模型中,基于所述朝向分类模型的输出得到所述样本图像的朝向标签。
8.根据权利要求1至6中任一项所述方法,其特征在于,所述朝向标签为正向标签、侧向标签或背向标签。
9.一种对象识别方法,其特征在于,包括:
获取待识别的对象图像;
将所述待识别的对象图像输入对象识别模型,得到所述对象图像的识别结果,其中,所述对象识别模型是通过权利要求1至8中任一项所述的方法训练得到的。
10.一种对象识别模型的训练装置,其特征在于,包括:
样本获取模块,用于获取训练样本集,所述训练样本集中包括对象的样本图像,所述样本图像标注有图像中的对象的身份标签和朝向标签,所述身份标签用于表征对象的身份信息,所述朝向标签用于表征对象的朝向信息;
模型构建模块,用于构建待训练模型,所述待训练模型包括所述对象识别模型,以及分别与所述对象识别模型的输出连接的第一分类模块和第二分类模块,其中,所述第一分类模型用于输出所述样本图像中对象的预测身份信息,所述第二分类模型用于输出所述样本图像中对象的预测身份及朝向信息;
第一损失确定模块,用于将各样本图像输入至所述待训练模型中,根据所述第一分类模型输出的预测身份信息和样本图像的身份标签所对应的身份信息确定第一训练损失值,根据所述第二分类模型输出的预测身份及朝向信息,与样本图像的身份标签和朝向标签所对应的身份信息及朝向信息,确定第二训练损失值;
第二损失确定模块,用于基于所述第一训练损失值和所述第二训练损失值,确定总损失值;
参数调整模块,用于根据所述总损失值对所述待训练模型的模型参数进行调整,直至所述总损失值满足预设条件,得到训练好的对象识别模型。
11.一种对象识别装置,其特征在于,包括:
图像获取模块,用于获取待识别的对象图像;
特征提取模块,用于将所述待识别的对象图像输入对象识别模型,得到所述对象图像的识别结果,其中,所述对象识别模型是通过权利要求1至8中任一项所述的方法训练得到的。
12.一种电子设备,其特征在于,包括存储器和处理器;
所述存储器中存储有计算机程序;
所述处理器,用于执行所述计算机程序以实现权利要求1至9中任一项所述的方法。
13.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1至9中任一项所述的方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910690389.XA CN110414432B (zh) | 2019-07-29 | 2019-07-29 | 对象识别模型的训练方法、对象识别方法及相应的装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910690389.XA CN110414432B (zh) | 2019-07-29 | 2019-07-29 | 对象识别模型的训练方法、对象识别方法及相应的装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110414432A CN110414432A (zh) | 2019-11-05 |
| CN110414432B true CN110414432B (zh) | 2023-05-16 |
Family
ID=68363794
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910690389.XA Active CN110414432B (zh) | 2019-07-29 | 2019-07-29 | 对象识别模型的训练方法、对象识别方法及相应的装置 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110414432B (zh) |
Families Citing this family (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111079813B (zh) * | 2019-12-10 | 2023-07-07 | 北京百度网讯科技有限公司 | 基于模型并行的分类模型计算方法和装置 |
| CN111191601B (zh) * | 2019-12-31 | 2023-05-12 | 深圳云天励飞技术有限公司 | 同行用户识别方法、装置、服务器及存储介质 |
| CN113128539B (zh) * | 2019-12-31 | 2024-06-18 | 财团法人工业技术研究院 | 基于适应标注的物件侦测模型的训练方法及系统 |
| CN111275170B (zh) * | 2020-01-19 | 2023-11-24 | 腾讯科技(深圳)有限公司 | 一种模型训练方法和相关装置 |
| CN111401192B (zh) * | 2020-03-10 | 2023-07-18 | 深圳市腾讯计算机系统有限公司 | 基于人工智能的模型训练方法和相关装置 |
| CN111488798B (zh) * | 2020-03-11 | 2023-12-29 | 天津极豪科技有限公司 | 指纹识别方法、装置、电子设备及存储介质 |
| CN111491258B (zh) * | 2020-03-26 | 2022-07-12 | 微民保险代理有限公司 | 一种对象类型的检测方法和装置 |
| CN113515980B (zh) * | 2020-05-20 | 2022-07-05 | 阿里巴巴集团控股有限公司 | 模型训练方法、装置、设备和存储介质 |
| CN111626353A (zh) * | 2020-05-26 | 2020-09-04 | Oppo(重庆)智能科技有限公司 | 一种图像处理方法及终端、存储介质 |
| CN111814846B (zh) * | 2020-06-19 | 2023-08-01 | 浙江大华技术股份有限公司 | 属性识别模型的训练方法、识别方法及相关设备 |
| CN111950591B (zh) * | 2020-07-09 | 2023-09-01 | 中国科学院深圳先进技术研究院 | 模型训练方法、交互关系识别方法、装置及电子设备 |
| CN112819024B (zh) * | 2020-07-10 | 2024-02-13 | 腾讯科技(深圳)有限公司 | 模型处理方法、用户数据处理方法及装置、计算机设备 |
| CN112541096B (zh) * | 2020-07-27 | 2023-01-24 | 中咨数据有限公司 | 一种用于智慧城市的视频监控方法 |
| CN112052789B (zh) * | 2020-09-03 | 2024-05-14 | 腾讯科技(深圳)有限公司 | 人脸识别方法、装置、电子设备及存储介质 |
| CN112258572A (zh) * | 2020-09-30 | 2021-01-22 | 北京达佳互联信息技术有限公司 | 目标检测方法、装置、电子设备及存储介质 |
| CN112206541B (zh) * | 2020-10-27 | 2024-06-14 | 网易(杭州)网络有限公司 | 游戏外挂识别方法、装置、存储介质及计算机设备 |
| CN112288012A (zh) * | 2020-10-30 | 2021-01-29 | 杭州海康威视数字技术股份有限公司 | 图像识别方法、装置及存储介质 |
| CN112579884B (zh) * | 2020-11-27 | 2022-11-04 | 腾讯科技(深圳)有限公司 | 一种用户偏好估计方法及装置 |
| CN114612706B (zh) * | 2020-12-04 | 2024-10-15 | 腾讯科技(深圳)有限公司 | 图像处理方法、装置、电子设备及可读存储介质 |
| CN112464916B (zh) * | 2020-12-31 | 2023-09-19 | 上海齐感电子信息科技有限公司 | 人脸识别方法及其模型训练方法 |
| CN113159095B (zh) * | 2021-01-30 | 2024-04-30 | 华为技术有限公司 | 一种训练模型的方法、图像检索的方法以及装置 |
| CN113378833B (zh) * | 2021-06-25 | 2023-09-01 | 北京百度网讯科技有限公司 | 图像识别模型训练方法、图像识别方法、装置及电子设备 |
| CN113344121B (zh) * | 2021-06-29 | 2023-10-27 | 北京百度网讯科技有限公司 | 训练招牌分类模型和招牌分类的方法 |
| CN113191461B (zh) | 2021-06-29 | 2021-09-17 | 苏州浪潮智能科技有限公司 | 一种图片识别方法、装置、设备及可读存储介质 |
| CN113537380A (zh) * | 2021-07-29 | 2021-10-22 | 北京数美时代科技有限公司 | 一种色情图像识别方法、系统、存储介质和电子设备 |
| CN113887447B (zh) * | 2021-10-08 | 2024-08-27 | 中国科学院半导体研究所 | 一种针对密集群体目标的密度估计、分类预测模型的训练、推理方法及装置 |
| CN113920397A (zh) * | 2021-10-12 | 2022-01-11 | 京东科技信息技术有限公司 | 用于训练图像分类模型和用于图像分类的方法、装置 |
| CN113918700B (zh) * | 2021-10-15 | 2022-07-12 | 浙江百世技术有限公司 | 一种带噪的半监督意图识别模型训练方法 |
| CN114266012B (zh) * | 2021-12-21 | 2022-10-04 | 浙江大学 | 基于WiFi的非接触式博物馆多区域观众计数方法 |
| CN114358205B (zh) * | 2022-01-12 | 2024-10-01 | 平安科技(深圳)有限公司 | 模型训练方法、模型训练装置、终端设备及存储介质 |
| CN114694253A (zh) * | 2022-03-31 | 2022-07-01 | 深圳市爱深盈通信息技术有限公司 | 行为识别模型训练方法、行为识别方法以及相关装置 |
| CN114693995B (zh) * | 2022-04-14 | 2023-07-07 | 北京百度网讯科技有限公司 | 应用于图像处理的模型训练方法、图像处理方法和设备 |
| CN114937231B (zh) * | 2022-07-21 | 2022-09-30 | 成都西物信安智能系统有限公司 | 一种目标识别跟踪的方法 |
| CN116978087A (zh) * | 2022-11-01 | 2023-10-31 | 腾讯科技(深圳)有限公司 | 模型更新方法、装置、设备、存储介质及程序产品 |
| CN115661722B (zh) * | 2022-11-16 | 2023-06-06 | 北京航空航天大学 | 一种结合属性与朝向的行人再识别方法 |
| CN115661586B (zh) * | 2022-12-09 | 2023-04-18 | 云粒智慧科技有限公司 | 模型训练和人流量统计方法、装置及设备 |
| CN117351289A (zh) * | 2023-11-02 | 2024-01-05 | 北京联影智能影像技术研究院 | 图像分类模型的训练方法和图像分类方法 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017215240A1 (zh) * | 2016-06-14 | 2017-12-21 | 广州视源电子科技股份有限公司 | 基于神经网络的人脸特征提取建模、人脸识别方法及装置 |
| CN107862300A (zh) * | 2017-11-29 | 2018-03-30 | 东华大学 | 一种基于卷积神经网络的监控场景下行人属性识别方法 |
| CN108537743A (zh) * | 2018-03-13 | 2018-09-14 | 杭州电子科技大学 | 一种基于生成对抗网络的面部图像增强方法 |
| CN109191453A (zh) * | 2018-09-14 | 2019-01-11 | 北京字节跳动网络技术有限公司 | 用于生成图像类别检测模型的方法和装置 |
| WO2019105285A1 (zh) * | 2017-11-28 | 2019-06-06 | 腾讯科技(深圳)有限公司 | 人脸属性识别方法、电子设备及存储介质 |
| CN109886167A (zh) * | 2019-02-01 | 2019-06-14 | 中国科学院信息工程研究所 | 一种遮挡人脸识别方法及装置 |
-
2019
- 2019-07-29 CN CN201910690389.XA patent/CN110414432B/zh active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017215240A1 (zh) * | 2016-06-14 | 2017-12-21 | 广州视源电子科技股份有限公司 | 基于神经网络的人脸特征提取建模、人脸识别方法及装置 |
| WO2019105285A1 (zh) * | 2017-11-28 | 2019-06-06 | 腾讯科技(深圳)有限公司 | 人脸属性识别方法、电子设备及存储介质 |
| CN107862300A (zh) * | 2017-11-29 | 2018-03-30 | 东华大学 | 一种基于卷积神经网络的监控场景下行人属性识别方法 |
| CN108537743A (zh) * | 2018-03-13 | 2018-09-14 | 杭州电子科技大学 | 一种基于生成对抗网络的面部图像增强方法 |
| CN109191453A (zh) * | 2018-09-14 | 2019-01-11 | 北京字节跳动网络技术有限公司 | 用于生成图像类别检测模型的方法和装置 |
| CN109886167A (zh) * | 2019-02-01 | 2019-06-14 | 中国科学院信息工程研究所 | 一种遮挡人脸识别方法及装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110414432A (zh) | 2019-11-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110414432B (zh) | 对象识别模型的训练方法、对象识别方法及相应的装置 | |
| CN111709409B (zh) | 人脸活体检测方法、装置、设备及介质 | |
| CN111797893B (zh) | 一种神经网络的训练方法、图像分类系统及相关设备 | |
| CN112446398B (zh) | 图像分类方法以及装置 | |
| AlDahoul et al. | Real‐Time Human Detection for Aerial Captured Video Sequences via Deep Models | |
| CN111476806B (zh) | 图像处理方法、装置、计算机设备和存储介质 | |
| CN111709311A (zh) | 一种基于多尺度卷积特征融合的行人重识别方法 | |
| CN113836992B (zh) | 识别标签的方法、训练标签识别模型的方法、装置及设备 | |
| CN113011387B (zh) | 网络训练及人脸活体检测方法、装置、设备及存储介质 | |
| CN112801236B (zh) | 图像识别模型的迁移方法、装置、设备及存储介质 | |
| CN116524593A (zh) | 一种动态手势识别方法、系统、设备及介质 | |
| Fan | Research and realization of video target detection system based on deep learning | |
| Wang et al. | A novel multiface recognition method with short training time and lightweight based on ABASNet and H-softmax | |
| CN116597336A (zh) | 视频处理方法、电子设备、存储介质及计算机程序产品 | |
| Xu et al. | Representative feature alignment for adaptive object detection | |
| Ammous et al. | Improved YOLOv3-tiny for silhouette detection using regularisation techniques. | |
| CN116863260A (zh) | 数据处理方法及装置 | |
| CN114764870A (zh) | 对象定位模型处理、对象定位方法、装置及计算机设备 | |
| CN113762331A (zh) | 关系型自蒸馏方法、装置和系统及存储介质 | |
| CN115620122A (zh) | 神经网络模型的训练方法、图像重识别方法及相关设备 | |
| Hu et al. | Progeo: Generating prompts through image-text contrastive learning for visual geo-localization | |
| CN117011577A (zh) | 图像分类方法、装置、计算机设备和存储介质 | |
| CN117011569A (zh) | 一种图像处理方法和相关装置 | |
| CN115841605A (zh) | 目标检测网络训练与目标检测方法、电子设备、存储介质 | |
| CN117011566A (zh) | 一种目标检测方法、检测模型训练方法、装置及电子设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |