CN109670552B - 一种图像分类方法、装置、设备及可读存储介质 - Google Patents
一种图像分类方法、装置、设备及可读存储介质 Download PDFInfo
- Publication number
- CN109670552B CN109670552B CN201811585699.7A CN201811585699A CN109670552B CN 109670552 B CN109670552 B CN 109670552B CN 201811585699 A CN201811585699 A CN 201811585699A CN 109670552 B CN109670552 B CN 109670552B
- Authority
- CN
- China
- Prior art keywords
- image
- feature
- weight vector
- images
- weight
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
- G06F18/24147—Distances to closest patterns, e.g. nearest neighbour classification
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了一种图像分类方法,该方法在计算众多图像的特征权重矩阵时,仅关注不同图像之间的距离,而不关注图像的类别,因此当众多图像中包括多类别的图像时,该方法仍然适用;并且该方法处理的图像集合中包括有标签图像和无标签图像,因此能够很好地处理有标签图像和无标签图像。所以本发明打破了现有的图像分类方法的局限,提高了图像分类方法的通用性。相应地,本发明公开的一种图像分类装置、设备及可读存储介质,也同样具有上述技术效果。
Description
技术领域
本发明涉及图像处理技术领域,更具体地说,涉及一种图像分类方法、装置、设备及可读存储介质。
背景技术
图像分类技术在社会生产生活中应用广泛。例如:在人们广泛使用的手机和平板中,图像分类技术用于将用户下载和拍摄得到的图像分为风景图像、人物图像或其他,以便于用户查看。为了净化网络空间,网络安全工作人员需要记录并删除网络中传播的影响社会安定的图像;但由于网络中流传的图像多而复杂,就需要图像分类技术将这些复杂而繁多的图像进行分类,筛选出影响社会安定的图像,使我们的网络传播更多正能量信息。
在现有技术中,图像分类技术涉及的算法分为:全监督、无监督和半监督。全监督的算法包括:RELIEF算法和Logistic I-Relief(LIR)算法等,其能够很好地处理有标签图像,但无法很好地处理无标签图像。无监督的算法包括:Laplacian Score等,其能够很好地处理无标签图像,但无法很好地处理有标签图像。半监督的算法能够很好地处理无标签图像和有标签图像,但其仅适用于与二分类问题,无法处理多分类问题,即无法将批量图像分为多个类别。因此现有的图像分类方法具有很大的局限性,通用性较差。其中,有标签图像即为携带有表示图像特征的图像,无标签图像即为未携带有表示图像特征的图像。
因此,如何提高图像分类方法的通用性,是本领域技术人员需要解决的问题。
发明内容
本发明的目的在于提供一种图像分类方法、装置、设备及可读存储介质,以提高图像分类方法的通用性。
为实现上述目的,本发明实施例提供了如下技术方案:
一种图像分类方法,包括:
获取待分类的图像集合,并计算图像集合包含的各个特征对应的权重向量;图像集合中包括有标签图像和无标签图像;
判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
若是,则根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得图像集合的分类结果;
若否,则迭代执行计算图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤;
其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量。
其中,根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,包括:
按照间隔计算公式计算有标签图像在特征权重空间的间隔,间隔计算公式为:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,间隔为图像
在特征权重空间的间隔,间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;












其中, 表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
其中,根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵,包括:
按照特征权重矩阵计算公式计算图像集合的特征权重矩阵,特征权重矩阵计算公式为:

其中,K表示近邻的个数,KNN(xj)表示图像xj的K个近邻集合。
其中,根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量,包括:
按照目标公式计算图像集合包含的各个特征对应的权重向量,目标公式为:

其中,w(t)表示当前特征的第t次迭代计算获得的特征权重向量,L=D-Sij,L表示拉普拉斯矩阵,D表示对角矩阵。
其中,通过KNN算法对特征序列进行分类,获得图像集合的分类结果,包括:
将特征序列中权重向量低于预设的权重阈值的特征删除,得到目标特征序列;
通过KNN算法对目标特征序列进行分类,获得图像集合的分类结果。
其中,通过KNN算法对特征序列进行分类,获得图像集合的分类结果,包括:
根据特征序列生成多个特征子序列,每个特征子序列中的特征按照权重向量的大小降序排序,且每个特征子序列中的特征数量不同;
将每个特征子序列作为图像集合的特征序列,并分别通过KNN算法对每个特征序列进行分类,获得图像集合的多个分类结果;
计算每个分类的精度,并将精度最高的分类结果确定为图像集合的最终分类结果;
将最终分类结果和最终分类结果对应的特征序列进行可视化展示。
一种图像分类方法,包括:
爬取网络中的被浏览图像,得到图像集合,并计算图像集合包含的各个特征对应的权重向量;图像集合中包括有标签图像和无标签图像;
判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
若是,则根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得被浏览图像的分类结果,通过分类结果确定影响社会安定的图像子集,并记录图像子集中的每个图像的来源,生成网络净化报告;
若否,则迭代执行计算图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤;
其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量。
一种图像分类装置,包括:
获取模块,用于获取待分类的图像集合,并计算图像集合包含的各个特征对应的权重向量;图像集合中包括有标签图像和无标签图像;其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量;
判断模块,用于判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
分类模块,用于当每个特征的当前计算得到的权重向量与前次权重向量的差异小于预设的阈值时,根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得图像集合的分类结果;
执行模块,用于当存在当前计算得到的权重向量与前次权重向量的差异不小于预设的阈值的特征时,迭代执行计算图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤。
一种图像分类设备,包括:
存储器,用于存储计算机程序;
处理器,用于执行计算机程序时实现上述任意一项的图像分类方法的步骤。
一种可读存储介质,可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述任意一项的图像分类方法的步骤。
通过以上方案可知,本发明实施例提供的一种图像分类方法,包括:获取待分类的图像集合,并计算图像集合包含的各个特征对应的权重向量;图像集合中包括有标签图像和无标签图像;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;若是,则根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得图像集合的分类结果;若否,则迭代执行计算图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤。
其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量。
可见,所述方法在计算众多图像的特征权重矩阵时,仅关注不同图像之间的距离,而不关注图像的类别,因此当众多图像中包括多类别的图像时,上述方法仍然适用;并且上述方法处理的图像集合中包括有标签图像和无标签图像,因此能够很好地处理有标签图像和无标签图像。因此本发明打破了现有的图像分类方法的局限,提高了图像分类方法的通用性。
相应地,本发明实施例提供的一种图像分类装置、设备及可读存储介质,也同样具有上述技术效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例公开的一种图像分类方法流程图;
图2为本发明实施例公开的另一种图像分类方法流程图;
图3为本发明实施例公开的一种图像分类装置示意图;
图4为本发明实施例公开的一种图像分类设备示意图;
图5为本发明实施例公开的不同分类方法处理同一批图像得到的不同分类结果的精度对比图;
图6为本发明实施例公开的不同分类方法处理同一批图像的去噪能力示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种图像分类方法、装置、设备及可读存储介质,以提高图像分类方法的通用性。
参见图1,本发明实施例提供的一种图像分类方法,包括:
S101、获取待分类的图像集合;图像集合中包括有标签图像和无标签图像;
具体的,获取图像的方式可以为:读取图像数据库的接口或图像数据库通过网络链路主动发送图像。
S102、计算图像集合包含的各个特征对应的权重向量;
S103、判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;若是,则执行S104;若否,则执行S102;
S104、根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得图像集合的分类结果。
其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量。
可见,本实施例提供了一种图像分类方法,所述方法在计算众多图像的特征权重矩阵时,仅关注不同图像之间的距离,而不关注图像的类别,因此当众多图像中包括多类别的图像时,上述方法仍然适用;并且上述方法处理的图像集合中包括有标签图像和无标签图像,因此能够很好地处理有标签图像和无标签图像。因此本发明打破了现有的图像分类方法的局限,提高了图像分类方法的通用性。
本发明实施例公开了另一种图像分类方法,相对于上一实施例,本实施例对技术方案作了进一步的说明和优化。
参见图2,本发明实施例提供的另一种图像分类方法,包括:
S201、爬取网络中的被浏览图像,得到集合,图像集合中包括有标签图像和无标签图像;
具体的,爬取网络中被浏览图像,即采用爬虫方式获取网络传播的图像。爬虫的实现方式为:从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。一般通过队列记录爬取过的URL和未爬取过的URL。
S202、计算图像集合包含的各个特征对应的权重向量;
S203、判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;若是,则执行S204;若否,则执行S202;
S204、根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得被浏览图像的分类结果,并执行S205;
S205、通过分类结果确定影响社会安定的图像子集,并记录图像子集中的每个图像的来源,生成网络净化报告。
具体的,生成的网络净化报告可以按照不同的文件格式进行可视化展示,以便于工作人员查看和记录。
其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量。
可见,本实施例提供了另一种图像分类方法,所述方法在计算众多图像的特征权重矩阵时,仅关注不同图像之间的距离,而不关注图像的类别,因此当众多图像中包括多类别的图像时,上述方法仍然适用;并且上述方法处理的图像集合中包括有标签图像和无标签图像,因此能够很好地处理有标签图像和无标签图像。因此本发明打破了现有的图像分类方法的局限,提高了图像分类方法的通用性。
同时,本实施例中的图像分类方法能够确定网络中传播的一些影响社会安定的图像并记录这些图像的来源,生成网络净化报告,网络安全工作人员可以依照网络净化报告净化网络空间,追踪图像来源,从而为营造良好的网络环境提供了有效的帮助。
基于上述任意实施例,需要说明的是,在获取到图像集合后,需要对图像集合中的图像进行归一化处理,使所有图像数据落入固定的区间内。
基于上述任意实施例,需要说明的是,所述根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,包括:按照间隔计算公式计算所述有标签图像在特征权重空间的间隔,所述间隔计算公式为:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,所述间隔为图像
在特征权重空间的间隔,所述间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;












其中, 表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
需要说明的是,概率计算体现了特征权重空间。 表示所述图像
表示所述图像 是所述图像
是所述图像 异类近邻的概率,
异类近邻的概率, 表示所述图像
表示所述图像 是所述图像
是所述图像 同类近邻的概率。在计算的过程中,先计算这两个图像之间的距离,然后乘以权重,具体过程可参见函数f。
同类近邻的概率。在计算的过程中,先计算这两个图像之间的距离,然后乘以权重,具体过程可参见函数f。
基于上述任意实施例,需要说明的是,所述根据所述图像集合中的不同图像之间的距离计算所述图像集合的特征权重矩阵,包括:按照特征权重矩阵计算公式计算所述图像集合的特征权重矩阵,所述特征权重矩阵计算公式为:

其中,K表示近邻的个数,KNN(xj)表示图像xj的K个近邻集合。
基于上述任意实施例,需要说明的是,所述根据所述有标签图像在特征权重空间的间隔和所述特征权重矩阵计算所述图像集合包含的各个特征对应的权重向量,包括:按照目标公式计算所述图像集合包含的各个特征对应的权重向量,所述目标公式为:

其中,w(t)表示当前特征的第t次迭代计算获得的特征权重向量,L=D-Sij,L表示拉普拉斯矩阵,D表示对角矩阵。
基于上述任意实施例,需要说明的是,所述通过KNN算法对所述特征序列进行分类,获得所述图像集合的分类结果,包括:
将所述特征序列中权重向量低于预设的权重阈值的特征删除,得到目标特征序列;
通过所述KNN算法对所述目标特征序列进行分类,获得所述图像集合的分类结果。
需要说明的是,一个特征对应一个权重向量中的权重,因此图像集合包含几个特征,就会有几个权重;假设图像集合包含5个特征,分别为A、B、C、D、E,其中,A、B、C、C、E分别对应的权重大小依次递减。那么特征序列按照权重的大小降序排列,即为:[A,B,C,D,E],当然特征序列也可以按照权重的大小升序排列。KNN算法对特征序列进行分类,即可以认为,用特征序列代表图像集合,使KNN算法对图像集合进行分类。
为了降低特征序列的维度,即降低计算复杂度,可以删除特征序列中权重向量比较小的特征,即:将所述特征序列中权重向量低于预设的权重阈值的特征删除。其中,由于特征的权重向量比较小,因此其对分类结果的影响也较小,所以删除权重向量比较小的特征一般不会影响分类结果,反而可以降低特征维度和分类的计算复杂度,提高分类效率。
需要说明的是,权重向量是以向量形式表示的权重。“预设的权重阈值”与上述提及的“预设的阈值”不应该混淆。
基于上述任意实施例,需要说明的是,通过KNN算法对特征序列进行分类,获得图像集合的分类结果,包括:
根据特征序列生成多个特征子序列,每个特征子序列中的特征按照权重向量的大小降序排序,且每个特征子序列中的特征数量不同;
将每个特征子序列作为图像集合的特征序列,并分别通过KNN算法对每个特征序列进行分类,获得图像集合的多个分类结果;
计算每个分类的精度,并将精度最高的分类结果确定为图像集合的最终分类结果;
将最终分类结果和最终分类结果对应的特征序列进行可视化展示。
当图像集合包含5个特征,分别为A、B、C、D、E,其中,A、B、C、D、E分别对应的权重的大小依次递减,那么其得到的特征序列[A,B,C,D,E]可以划分为多个特征子序列,分别为:[A]、[A,B]、[A,B,C]、[A,B,C,D]、[A,B,C,D,E]。
其中,每个特征子序列均可以代表图像集合,因此KNN算法对每个特征序列进行分类,可以得到图像集合的多个分类结果,并按照每个分类结果的精度确定精度最高的最终分类结果,同时将最终分类结果和最终分类结果对应的特征子序列进行可视化展示,以便确定能够获得最准确分类结果的特征子序列。
基于上述任意实施例,需要说明的是,判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值,包括:
在迭代过程中,针对每个特征的权重向量,比较当前计算得到的权重向量与前次权重向量的差异。当第一次计算权重向量时,前次权重向量即为初始化权重向量。
具体的,可以按照下述判断条件进行判断,判断条件即为:
||w(t)-w(t-1)||<0.01
其中,W(t)为当前计算得到的权重向量,W(t-1)为前次权重向量,t表示计算次数。一般计算次数可以设置为小于等于50。当不满足迭代截止条件,即前一次的权重向量与当前次的权重向量之间的欧式距离大于0.01,且计算次数不超过50时,t加一,迭代计算权重向量,直至计算得到的权重向量与前次权重向量之间的欧式距离小于0.01,则将当前计算得到的权重向量作为输出,并停止计算。
需要说明的是,上式的判断条件是以向量的形式计算的,即计算前一次的权重向量与当前次的权重向量之间的欧式距离,若距离大于0.01,则继续迭代;也就是说,每次迭代得到的是一个新的特征权重向量。
下面对本发明实施例提供的一种图像分类装置进行介绍,下文描述的一种图像分类装置与上文描述的一种图像分类方法可以相互参照。
参见图3,本发明实施例提供的一种图像分类装置,包括:
获取模块301,用于获取待分类的图像集合,并计算图像集合包含的各个特征对应的权重向量;图像集合中包括有标签图像和无标签图像;其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量;
判断模块302,用于判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
分类模块303,用于当每个特征的当前计算得到的权重向量与前次权重向量的差异小于预设的阈值时,根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得图像集合的分类结果;
执行模块304,用于当存在当前计算得到的权重向量与前次权重向量的差异不小于预设的阈值的特征时,迭代执行计算图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤。
下面对本发明实施例提供的另一种图像分类装置进行介绍,下文描述的另一种图像分类装置与上文描述的另一种图像分类方法可以相互参照。
本发明实施例提供的另一种图像分类装置,包括:
获取模块,用于爬取网络中的被浏览图像,得到图像集合,并计算图像集合包含的各个特征对应的权重向量;图像集合中包括有标签图像和无标签图像;其中,计算图像集合包含的各个特征对应的权重向量,包括:根据有标签图像的各个特征的初始化权重向量计算有标签图像在特征权重空间的间隔,并根据图像集合中的不同图像之间的距离计算图像集合的特征权重矩阵;根据有标签图像在特征权重空间的间隔和特征权重矩阵计算图像集合包含的各个特征对应的权重向量;
判断模块,用于判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
分类模块,用于当每个特征的当前计算得到的权重向量与前次权重向量的差异小于预设的阈值时,根据计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对特征序列进行分类,获得被浏览图像的分类结果,通过分类结果确定影响社会安定的图像子集,并记录图像子集中的每个图像的来源,生成网络净化报告;
执行模块,用于当存在当前计算得到的权重向量与前次权重向量的差异不小于预设的阈值的特征时,迭代执行计算图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤。
基于上述任意装置实施例,需要说明的是,获取模块具体用于:
按照间隔计算公式计算有标签图像在特征权重空间的间隔,间隔计算公式为:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,间隔为图像
在特征权重空间的间隔,间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;




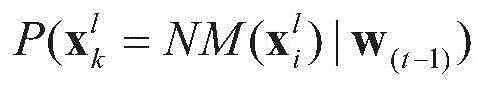







其中, 表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
其中,获取模块具体用于:
按照特征权重矩阵计算公式计算图像集合的特征权重矩阵,特征权重矩阵计算公式为:

其中,K表示近邻的个数,KNN(xj)表示图像xj的K个近邻集合。
其中,获取模块具体用于:
按照目标公式计算图像集合包含的各个特征对应的权重向量,目标公式为:

其中,w(t)表示当前特征的第t次迭代计算获得的特征权重向量,L=D-Sij,L表示拉普拉斯矩阵,D表示对角矩阵。
其中,分类模块包括:
删除单元,用于将特征序列中权重向量低于预设的权重阈值的特征删除,得到目标特征序列;
分类单元,用于通过KNN算法对目标特征序列进行分类,获得图像集合的分类结果。
其中,分类模块包括:
生成单元,用于根据特征序列生成多个特征子序列,每个特征子序列中的特征按照权重向量的大小降序排序,且每个特征子序列中的特征数量不同;
多分类单元,用于将每个特征子序列作为图像集合的特征序列,并分别通过KNN算法对每个特征序列进行分类,获得图像集合的多个分类结果;
计算单元,用于计算每个分类的精度,并将精度最高的分类结果确定为图像集合的最终分类结果;
可视化单元,用于将最终分类结果和最终分类结果对应的特征序列进行可视化展示。
下面对本发明实施例提供的一种图像分类设备进行介绍,下文描述的一种图像分类设备与上文描述的一种图像分类方法及装置可以相互参照。
参见图4,本发明实施例提供的一种图像分类设备,包括:
存储器401,用于存储计算机程序;
处理器402,用于执行所述计算机程序时实现上述任意实施例所述的图像分类方法的步骤。
下面对本发明实施例提供的一种可读存储介质进行介绍,下文描述的一种可读存储介质与上文描述的一种图像分类方法、装置及设备可以相互参照。
一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任意实施例所述的图像分类方法的步骤。
为了更详细地说明本发明的优点,本发明在图像分割数据集(Statlog Data Set)上进行了测试,该图像分割数据集包含2310个图像,共有7个类别,图像类别分别是:砖面、天空、叶子、水泥、窗口、路径和草地。其中,每个图像有19个属性,分别为:
region-centroid-col、region-centroid-row、region-pixel-count、short-line-density-5、short-line-density-2、vedge-mean、vegde-sd、hedge-mean、hedge-sd、intensity-mean、rawred-mean、rawblue-mean、rawgreen-mean、exred-mean、exblue-mean、exgreen-mean、value-mean、saturatoin-mean、hue-mean。
所有属性都是连续性的数据,无缺少的属性值。在进行特征选择之前,给每一维的数据添加100个不相关的噪声特征,添加噪声之后的数据维度为119维,前19维是原始数据特征,后100维是添加的噪声。我们取图像数据集的2/3作为训练样本,1/3作为测试样本。其中,在2/3的训练数据中,5%的样本为有标签样本,其余的为无标签样本。具体过程如下:
输入图像分割数据的训练样本集X=Xl∪Xu,其中 为有标签图像集,
为有标签图像集, I=119,L=90;yi是图像
I=119,L=90;yi是图像 对应的标签,且yi∈{1,2,...,7}。
对应的标签,且yi∈{1,2,...,7}。 为无标签样本集,
为无标签样本集, 是无标签图像,样本数量U=1450。
是无标签图像,样本数量U=1450。
对训练样本进行预处理,首先将图像的特征归一化,每个特征值落入在[0,1]区间。
初始化权重向量W(0),其中:

设置学习速率η=0.03,正则化参数λ1=1和λ2=2;停止准则θ=0.01,即判断条件的阈值;最大迭代次数T,并初始化迭代次数t=1。
计算有标签数据样本 在权重空间的间隔:
在权重空间的间隔:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,间隔为图像
在特征权重空间的间隔,间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;












其中, 表示核函数,f(d)=exp(-dTd/σ2)并使用计算条件概率。
表示核函数,f(d)=exp(-dTd/σ2)并使用计算条件概率。
计算所有数据样本集合X的权重矩阵:

其中,K=3表示近邻的个数,KNN(xj)表示图像xj的K个近邻集合。
计算权重向量W(t):

其中,w(t)表示当前特征的第t次迭代计算获得的特征权重向量,L=D-Sij,L表示拉普拉斯矩阵,D表示对角矩阵。
若||w(t)-w(t-1)||<0.01且t≤50,则流程结束,输出W(t),将W(t)作为当前特征的权重向量;否则t=t+1,重新计算当前特征的权重向量,直至满足||w(t)-w(t-1)||<0.01且t≤50。
将特征按照其权重大小递减排序,生成特征序列F1,F2,...,F19,其中|Fi|=i,1≤i≤19。在每个特征序列Fi中,包含了前i个权重最大的特征。根据生成的特征序列,利用KNN分类器分类测试集中的图像,并计算分类结果的精度。
具体测试过程为:当选择包含最大权值的特征子集F1时,分类器对测试集分类,得出分类结果和对应的分类精度;当选择包含前两个权值较大的特征子集F2时,分类器对测试集分类,得出分类结果和对应的分类精度;直至得出F19的分类结果和分类精度。其每个分类结果的精度可以取10次预测结果的均值。
为了体现本发明的优势,针对同一批数据,分别使用六种不同的分类方法进行分类,分类结果的精度对比图请参见图5。六种分类方法分别为:LIR,,RELIEF-F,Laplacian,LSDF,Semi-fisher和本发明提供的方法,new method即为本发明提供的分类方法。这六种分类方法处理同一批图像的去噪能力对比请参见图6。
可见,本发明能够有效地去除添加的部分噪声,使得噪声特征的权重为0,并挑选出与分类相关的特征。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
Claims (9)
1.一种图像分类方法,其特征在于,包括:
获取待分类的图像集合,并计算所述图像集合包含的各个特征对应的权重向量;所述图像集合中包括有标签图像和无标签图像;
判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
若是,则根据所述计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对所述特征序列进行分类,获得所述图像集合的分类结果;
若否,则迭代执行所述计算所述图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤;
其中,所述计算所述图像集合包含的各个特征对应的权重向量,包括:根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,并根据所述图像集合中的不同图像之间的距离计算所述图像集合的特征权重矩阵;根据所述有标签图像在特征权重空间的间隔和所述特征权重矩阵计算所述图像集合包含的各个特征对应的权重向量;
其中,所述根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,包括:
按照间隔计算公式计算所述有标签图像在特征权重空间的间隔,所述间隔计算公式为:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,所述间隔为图像
在特征权重空间的间隔,所述间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;












其中, 表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
2.根据权利要求1所述的图像分类方法,其特征在于,所述根据所述图像集合中的不同图像之间的距离计算所述图像集合的特征权重矩阵,包括:
按照特征权重矩阵计算公式计算所述图像集合的特征权重矩阵,所述特征权重矩阵计算公式为:

其中,K表示近邻的个数,KNN(xj)表示图像xj的K个近邻集合。
3.根据权利要求2所述的图像分类方法,其特征在于,所述根据所述有标签图像在特征权重空间的间隔和所述特征权重矩阵计算所述图像集合包含的各个特征对应的权重向量,包括:
按照目标公式计算所述图像集合包含的各个特征对应的权重向量,所述目标公式为:

其中,w(t)表示当前特征的第t次迭代计算获得的特征权重向量,w(t-1)表示第t-1次迭代计算获得的特征权重向量;L=D-Sij,L表示拉普拉斯矩阵,D表示对角矩阵。
4.根据权利要求1-3任意一项所述的图像分类方法,其特征在于,所述通过KNN算法对所述特征序列进行分类,获得所述图像集合的分类结果,包括:
将所述特征序列中权重向量低于预设的权重阈值的特征删除,得到目标特征序列;
通过所述KNN算法对所述目标特征序列进行分类,获得所述图像集合的分类结果。
5.根据权利要求1-3任意一项所述的图像分类方法,其特征在于,所述通过KNN算法对所述特征序列进行分类,获得所述图像集合的分类结果,包括:
根据所述特征序列生成多个特征子序列,每个特征子序列中的特征按照权重向量的大小降序排序,且每个特征子序列中的特征数量不同;
将每个特征子序列作为所述图像集合的特征序列,并分别通过所述KNN算法对每个特征序列进行分类,获得所述图像集合的多个分类结果;
计算每个分类的精度,并将精度最高的分类结果确定为所述图像集合的最终分类结果;
将所述最终分类结果和所述最终分类结果对应的特征序列进行可视化展示。
6.一种图像分类方法,其特征在于,包括:
爬取网络中的被浏览图像,得到图像集合,并计算所述图像集合包含的各个特征对应的权重向量;所述图像集合中包括有标签图像和无标签图像;
判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
若是,则根据所述计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对所述特征序列进行分类,获得所述被浏览图像的分类结果,通过所述分类结果确定影响社会安定的图像子集,并记录所述图像子集中的每个图像的来源,生成网络净化报告;
若否,则迭代执行所述计算所述图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤;
其中,所述计算所述图像集合包含的各个特征对应的权重向量,包括:根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,并根据所述图像集合中的不同图像之间的距离计算所述图像集合的特征权重矩阵;根据所述有标签图像在特征权重空间的间隔和所述特征权重矩阵计算所述图像集合包含的各个特征对应的权重向量;
其中,所述根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,包括:
按照间隔计算公式计算所述有标签图像在特征权重空间的间隔,所述间隔计算公式为:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,所述间隔为图像
在特征权重空间的间隔,所述间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;












其中, 表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
7.一种图像分类装置,其特征在于,包括:
获取模块,用于获取待分类的图像集合,并计算所述图像集合包含的各个特征对应的权重向量;所述图像集合中包括有标签图像和无标签图像;其中,所述计算所述图像集合包含的各个特征对应的权重向量,包括:根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,并根据所述图像集合中的不同图像之间的距离计算所述图像集合的特征权重矩阵;根据所述有标签图像在特征权重空间的间隔和所述特征权重矩阵计算所述图像集合包含的各个特征对应的权重向量;
判断模块,用于判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值;
分类模块,用于当每个特征的当前计算得到的权重向量与前次权重向量的差异小于预设的阈值时,根据所述计算得到的每个特征的权重向量的大小生成特征序列,并通过KNN算法对所述特征序列进行分类,获得所述图像集合的分类结果;
执行模块,用于当存在当前计算得到的权重向量与前次权重向量的差异不小于预设的阈值的特征时,迭代执行所述计算所述图像集合包含的各个特征对应的权重向量;判断每个特征的当前计算得到的权重向量与前次权重向量的差异是否小于预设的阈值的步骤;
其中,所述根据所述有标签图像的各个特征的初始化权重向量计算所述有标签图像在特征权重空间的间隔,包括:
按照间隔计算公式计算所述有标签图像在特征权重空间的间隔,所述间隔计算公式为:

其中, 表示图像
表示图像 与图像
与图像 在特征权重空间的间隔,所述间隔为图像
在特征权重空间的间隔,所述间隔为图像 与图像
与图像 的距离与图像
的距离与图像 与图像
与图像 为近邻关系的概率的乘积;
为近邻关系的概率的乘积;












其中, 表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
表示核函数,并使用f(d)=exp(-dTd/σ2)计算条件概率。
8.一种图像分类设备,其特征在于,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现如权利要求1-6任意一项所述的图像分类方法的步骤。
9.一种可读存储介质,其特征在于,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1-6任意一项所述的图像分类方法的步骤。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811585699.7A CN109670552B (zh) | 2018-12-24 | 2018-12-24 | 一种图像分类方法、装置、设备及可读存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811585699.7A CN109670552B (zh) | 2018-12-24 | 2018-12-24 | 一种图像分类方法、装置、设备及可读存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109670552A CN109670552A (zh) | 2019-04-23 |
| CN109670552B true CN109670552B (zh) | 2023-03-10 |
Family
ID=66146833
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811585699.7A Active CN109670552B (zh) | 2018-12-24 | 2018-12-24 | 一种图像分类方法、装置、设备及可读存储介质 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109670552B (zh) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110516092B (zh) * | 2019-09-02 | 2020-12-01 | 中国矿业大学(北京) | 一种基于k近邻和随机游走算法的图像自动标注方法 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104318242A (zh) * | 2014-10-08 | 2015-01-28 | 中国人民解放军空军工程大学 | 一种高效的svm主动半监督学习算法 |
| JP6090286B2 (ja) * | 2014-10-31 | 2017-03-08 | カシオ計算機株式会社 | 機械学習装置、機械学習方法、分類装置、分類方法、プログラム |
| CN108416384B (zh) * | 2018-03-05 | 2021-11-05 | 苏州大学 | 一种图像标签标注方法、系统、设备及可读存储介质 |
| CN108629373B (zh) * | 2018-05-07 | 2022-04-12 | 苏州大学 | 一种图像分类方法、系统、设备及计算机可读存储介质 |
| CN108763873A (zh) * | 2018-05-28 | 2018-11-06 | 苏州大学 | 一种基因分类方法及相关设备 |
-
2018
- 2018-12-24 CN CN201811585699.7A patent/CN109670552B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN109670552A (zh) | 2019-04-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109063163B (zh) | 一种音乐推荐的方法、装置、终端设备和介质 | |
| WO2021143267A1 (zh) | 基于图像检测的细粒度分类模型处理方法、及其相关设备 | |
| CN114780746A (zh) | 基于知识图谱的文档检索方法及其相关设备 | |
| US20180260414A1 (en) | Query expansion learning with recurrent networks | |
| US11301506B2 (en) | Automated digital asset tagging using multiple vocabulary sets | |
| US20170147944A1 (en) | Adapted domain specific class means classifier | |
| CN111966886B (zh) | 对象推荐方法、对象推荐装置、电子设备及存储介质 | |
| JP2020518938A (ja) | ニューラルネットワークを用いたシーケンスデータの分析 | |
| CN109840413B (zh) | 一种钓鱼网站检测方法及装置 | |
| US11941792B2 (en) | Machine learning-based analysis of computing device images included in requests to service computing devices | |
| US20240312252A1 (en) | Action recognition method and apparatus | |
| CN112101360A (zh) | 一种目标检测方法、装置以及计算机可读存储介质 | |
| CN114882321A (zh) | 深度学习模型的训练方法、目标对象检测方法和装置 | |
| JP2017527013A (ja) | サービスとしての適応特徴化 | |
| CN111260243A (zh) | 风险评估方法、装置、设备及计算机可读存储介质 | |
| CN110428139A (zh) | 基于标签传播的信息预测方法及装置 | |
| CN114724174A (zh) | 基于增量学习的行人属性识别模型训练方法及装置 | |
| CN120412984B (zh) | 一种基于大模型的企业智能诊断方法、系统、设备及介质 | |
| US20260065053A1 (en) | Data processing method and related apparatus | |
| CN113761002A (zh) | 信息推送方法、装置、设备和计算机可读存储介质 | |
| Huynh et al. | An efficient model for copy-move image forgery detection | |
| CN109670552B (zh) | 一种图像分类方法、装置、设备及可读存储介质 | |
| CN113259369B (zh) | 一种基于机器学习成员推断攻击的数据集认证方法及系统 | |
| CN113239215B (zh) | 多媒体资源的分类方法、装置、电子设备及存储介质 | |
| CN113408546A (zh) | 基于相互全局上下文注意力机制的单样本目标检测方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |