CN109360226B - Multi-target tracking method based on time series multi-feature fusion - Google Patents
Multi-target tracking method based on time series multi-feature fusion Download PDFInfo
- Publication number
- CN109360226B CN109360226B CN201811210852.8A CN201811210852A CN109360226B CN 109360226 B CN109360226 B CN 109360226B CN 201811210852 A CN201811210852 A CN 201811210852A CN 109360226 B CN109360226 B CN 109360226B
- Authority
- CN
- China
- Prior art keywords
- tracking
- target
- frame
- candidate
- tracking target
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
- G06T7/246—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments
- G06T7/251—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments involving models
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10016—Video; Image sequence
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
The invention provides a multi-target tracking method based on time series multi-feature fusion. The method comprises the steps of obtaining the category and the candidate frame of a tracking target according to a multi-target detection algorithm; calculating a motion prediction center point and screening candidate frames by using a convolution network and a correlation filter; calculating an appearance similarity score; calculating a motion similarity score; calculating an interactive feature similarity score; converting the candidate frame in the tracking frame of the current frame image after screening, and updating the characteristic information of the tracking target; calculating a moving prediction central point of a tracking target which is not matched with the candidate frame and screening the candidate frame; associating unmatched candidate frames with the existing tracking target to construct a new tracking target; calculating the overlapping degree of each tracking target by adopting an intersection ratio; and identifying the tracking target continuously in the lost state in the multi-frame image as the lost target. Compared with the prior art, the invention improves the tracking precision.
Description
Technical Field
The invention relates to the technical field of computer vision and target tracking, in particular to a multi-target tracking method based on time series multi-feature fusion.
Background
The target tracking means that in an image sequence, a target which is interested in a system is detected, the target is accurately positioned, and then the motion information of the target is continuously updated in the moving process of the target, so that the target is continuously tracked. The target tracking can be divided into multi-target tracking and single-target tracking, the single-target tracking only focuses on one interested target, the task is to design a motion model or an appearance model to solve the influence of factors such as scale transformation, target shielding, illumination and the like, and the image position corresponding to the interested target is calibrated frame by frame. Compared with single target tracking, multi-target tracking also needs to solve two additional tasks: discovering and processing newly appearing and disappearing objects in the video sequence; individual target-specific identities are maintained.
Initialization of tracking targets, frequent occlusion, target leaving detection area, similar appearance of multiple targets, and interaction between multiple targets all add difficulty to multi-target tracking. In order to timely judge newly appearing targets and disappearing targets, multi-target tracking algorithms often need multi-target detection as the basis for algorithm implementation.
In recent years, with the development of deep learning, the development of the computer vision field is very rapid. The target detection algorithm is very accurate and has higher processing speed. However, in the field of multi-target tracking, because the difficulty of multi-target tracking is not completely solved, the data association algorithm based on detection still has a great promotion space. The invention has the innovation points that the positions of all targets are predicted by using a related filtering algorithm, the dependence degree of a detection algorithm is reduced, an LSTM (Long Short-Term Memory) network framework based on the positions, appearances, motions and interactive multi-features of objects is provided, the problem of multi-target shielding is solved by extracting a feature model with high discrimination degree, and the precision of multi-target tracking is improved.
At present, a popular mode in the field of multi-target tracking is a data association algorithm depending on a detector, the method well solves the problems of target initialization, extinction, scale transformation and the like, but still cannot well solve the problems of excessive dependence on the performance of the detector, mutual shielding among multiple targets, target areas with similar appearances and the like.
Disclosure of Invention
In order to solve the technical problem, the invention provides a multi-target tracking method based on time series multi-feature data association.
The technical scheme of the invention is a multi-target tracking method based on time series multi-feature data association, which specifically comprises the following steps:
step 1: detecting a tracking target in the frame image according to an SSD multi-target detection algorithm, and counting the category of the tracking target and a candidate frame of the tracking target by comparing the confidence coefficient of the SSD detected tracking target with a confidence coefficient threshold;
step 2: extracting convolution characteristics of a tracking target in a position frame of a current frame by using a convolution network, calculating a response confidence score of each position in the current frame image through a correlation filter of the tracking target, defining a point with the highest score as a mobile prediction central point of the tracking target under the current frame image, and screening candidate frames through the mobile prediction central point;
and step 3: calculating appearance similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frame;
and 4, step 4: calculating the motion similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frame;
and 5: calculating interactive feature similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frames;
step 6: if the tracking target in the tracking state or the lost state is matched with the candidate frame, comparing the total similarity score with a matching score threshold value, when the total similarity score is greater than the matching score threshold value, converting the candidate frame into a tracking frame of the tracking target in the current frame image, and updating the appearance characteristic, the speed characteristic and the interactive characteristic information of the tracking target; if the tracking target in the tracking state or the lost state is not matched with the candidate frame, updating the state information of the tracking target through the step 2;
and 7: associating unmatched candidate frames with existing tracking targets, determining the unmatched candidate frames as new tracking targets, initializing the new tracking targets, establishing the new tracking targets, constructing a position feature model, an appearance feature model, a speed feature model and an interaction feature model of the new tracking targets, updating the states of the position feature model, the appearance feature model, the speed feature model and the interaction feature model into tracking states, and performing data association matching tracking in subsequent frame images;
and 8: retrieving all tracking targets in a tracking state of the current frame again, and calculating the overlapping degree of all tracking targets by adopting an intersection ratio;
and step 9: and recognizing the tracking target continuously in a lost state in the continuous multi-frame images as a disappeared target, storing the data information of the tracking state, and not performing data matching operation on the tracking target.
Preferably, the frame image in step 1 is an m-th image, and the number of categories of the tracking target in step 1 is NmIn step 1, the candidate frame of the tracking target is:
Di,m={xi,m∈[li,m,li,m+lenthi,m],yi,m∈[wi,m,wi,m+widthi,m]|(xi,m,yi,m)},i∈[1,Km]
wherein, KmNumber of candidate frames for tracking target in mth frame image, li,mCoordinates of the start point of the X axis of the frame candidate for the i-th tracking target in the m-th frame image, wi,mLength as the coordinates of the start point of the Y axis of the frame candidate of the ith tracking target in the mth frame imagei,mWidth for the length of the i-th tracked target candidate frame in the m-th frame imagei,mA width of a candidate frame for an ith tracking target in an mth frame image;
preferably, the convolutional network in the step 2 is a VGG16 network pre-trained in an ImageNet classification task, and a first layer of feature vectors of a tracking target position frame are extracted through a VGG16 network;
two-dimensional feature vector through channel c The interpolation model of (2) is to calculate the two-dimensional feature vector of the channel c
The interpolation model of (2) is to calculate the two-dimensional feature vector of the channel c Converting into a feature vector of a one-dimensional continuous space:
Converting into a feature vector of a one-dimensional continuous space:

wherein the content of the first and second substances, is a two-dimensional feature vector of channel c, bcIs defined as a cubic interpolation function of three, NcIs composed of
is a two-dimensional feature vector of channel c, bcIs defined as a cubic interpolation function of three, NcIs composed of L is the length of the eigenvector of the one-dimensional continuous space, and Channel is the number of channels;
L is the length of the eigenvector of the one-dimensional continuous space, and Channel is the number of channels;
the convolution operator is:
wherein, yi,mIs a response value of the tracking target i of the mth image, is the two-dimensional feature vector of Channel c, Channel is the number of channels,
is the two-dimensional feature vector of Channel c, Channel is the number of channels, the feature vectors of the one-dimensional continuum of channels c,
the feature vectors of the one-dimensional continuum of channels c, the correlation filter is used for tracking the channel c of the target i in the mth frame image;
the correlation filter is used for tracking the channel c of the target i in the mth frame image;
training the correlation filter through the training samples is:
given n training sample pairs { (y)i,q,y'i,q)}(q∈[m-n,m-1]) Training is carried out to obtain a correlation filter by optimizing a minimized objective function:

wherein, yi,m-jIs the response value, y ', of the tracking target i of the m-j-th image'i,m-jIs yi,m-jThe ideal gaussian distribution of the total number of the particles, is a heelThe correlation filter of the trace target i in the channel c of the mth frame image, and the weight value alphajThe influence factor of the training sample j is determined by a penalty function w, and the correlation filter of each channel is obtained through training
is a heelThe correlation filter of the trace target i in the channel c of the mth frame image, and the weight value alphajThe influence factor of the training sample j is determined by a penalty function w, and the correlation filter of each channel is obtained through training
Response value y of tracking target i through m-th imagei,m(l) L is belonged to [0, L), find the maximum value yi,m(l) Corresponding to lp,i,m:
lp,i,m=argmax(yi,m(l))l∈[0,L)
Wherein, L is the length of the feature vector of the one-dimensional continuous space;
will lp,i,mPoints converted into two-dimensional feature vectors of channels After being reduced into two-dimensional coordinates, the coordinates are mapped into coordinate points p under the current framei,m=(xp,i,m,yp,i,m) I.e. tracking the target T for the ith frame in the mth frame imageiThe movement prediction center point of (a);
After being reduced into two-dimensional coordinates, the coordinates are mapped into coordinate points p under the current framei,m=(xp,i,m,yp,i,m) I.e. tracking the target T for the ith frame in the mth frame imageiThe movement prediction center point of (a);
if tracking the target TiIn a tracking state, only the candidate frames around the prediction position area are selected for subsequent target data matching:
setting tracking target TiLength of the previous frame is lengthi,m-1Width ofi,m-1I th tracking target T in m th frame imageiHas a movement prediction center point of pi,m=(xp,i,m,yp,i,m) The candidate frame center point of the ith tracking target in the mth frame image is ci,m=(li,m+lenthi,m/2,wi,m+widthi,m/2)i∈[1,Km]And when the distance between the candidate frame central point and the mobile prediction central point meets the condition:
d(pi,m,ci,m)=(xp,i,m-li,m-lenthi,m/2)2+(yp,i,m-wi,m-widthi,m/2)2<min(lenthi,m-1/2,widthi,m-1/2)
performing subsequent target data matching on the candidate frames meeting the conditions;
if tracking the target TiIn the lost state, a candidate frame is selected to be screened near the position of the frame before it disappears:
taking the moving prediction central point t when the moving prediction central point disappears in the previous framei,m=(xt,i,m,yt,i,m) Length of lengthi,m-1Width ofi,m-1When the distance d (t) between the candidate frame center and the vanishing centeri,ci,m) When the following conditions are satisfied:
d(ti,m,ci,m)=(xt,i,m-li,m-lenthi,m/2)2+(yt,i,m-wi,m-widthi,m/2)2<min(lenthi,m-1/2,widthi,m-1/2)
performing subsequent target data matching on the candidate frames meeting the conditions;
if tracking the target TiIn the unsuccessful matching tracking state, its candidate box center point may be updated using the moving predicted center point:
updating tracking target TiThe candidate frame center point of (2) is a movement prediction center point pi,m=(xp,i,m,yp,i,m) The length of the candidate frame, the width of the candidate frame and the m-1 frame image are kept unchanged;
preferably, the candidate frame after screening in step 3 is a candidate frame screened according to the moving prediction center point in step 2;
the appearance similarity score in step 3 is specifically calculated as:
candidate frame D after screening of ith tracking target in mth frame image in step 2i,mRemoving the connecting layer VGG16 network of the last layer of VGG16 to obtain the tracking target T in the mth frame image of N dimensioniAppearance feature vector of
Training in an end-to-end training mode through a training set given by the multi-target tracking public data set to respectively obtain an LSTM network with appearance characteristics and a first full connection layer FC 1;
will track the target TiExtracting M N-dimensional appearance feature vectors by removing the VGG16 network of the last layer of the VGG16 from the data of the previous M frames of images, and then extracting N-dimensional combined historical appearance feature vectors by the LSTM network of the appearance features
Joint connection And
And through the first full connection layer FC1, the tracking target T is obtainediAnd candidate frame Di,m(ii) an appearance similarity score of SA(Ti,Di,m) If the target T isiIf the image data of the previous frame is not generated, replacing the image data with a value of 0;
through the first full connection layer FC1, the tracking target T is obtainediAnd candidate frame Di,m(ii) an appearance similarity score of SA(Ti,Di,m) If the target T isiIf the image data of the previous frame is not generated, replacing the image data with a value of 0;
preferably, the motion similarity score in step 4 is calculated as:
(li,m+lenthi,m/2,wi,m+widthi,m/2)
target T is tracked by previous frame imageiThe center position of the candidate frame of (1) is:
(li,m-1+lenthi,m-1/2,wi,m-1+widthi,m-1/2)
the speed feature vector of the ith tracking target in the mth frame image is as follows:

training in an end-to-end training mode through a training set given by the multi-target tracking public data set to respectively obtain an LSTM network with speed characteristics and a second full connection layer FC 2;
extracting the speed characteristic vector of the ith tracking target in the M frames of images through an LSTM network of speed characteristics to obtain a motion characteristic vector of a joint history sequence
Joint connection And
And passing through the second fully-connected layer FC2, thereby tracking target T in a tracking state or a lost stateiAnd candidate frame Di,mHas a motion similarity score of SV(Ti,Di,m) If the target T isiIf the motion data of the previous frame is not generated, the motion data is replaced by a value of 0;
passing through the second fully-connected layer FC2, thereby tracking target T in a tracking state or a lost stateiAnd candidate frame Di,mHas a motion similarity score of SV(Ti,Di,m) If the target T isiIf the motion data of the previous frame is not generated, the motion data is replaced by a value of 0;
preferably, the interactive feature similarity score in step 5 is calculated as:
to screen the candidate frame Di,mC of center coordinatei,m=(li,m+lenthi,m/2,wi,m+widthi,mAnd/2) establishing a fixed-size box with the length and the width H by taking the center as the center, and connecting the center coordinates c of the box with other candidate boxesi',mThe coincident point is set as 1, the center of the fixed-size box is also set as 1, and the rest positions are set as 0, so that:

wherein the content of the first and second substances,
x∈[li,m+lenthi,m/2-H/2,li,m+lenthi,m/2+H/2]
y∈[wi,m+widthi,m/2-H/2,wi,m+widthi,m/2+H/2]
then will be Conversion to length H2The one-dimensional vector of (1) to obtain an interactive feature vector of the candidate frame of
Conversion to length H2The one-dimensional vector of (1) to obtain an interactive feature vector of the candidate frame of
Training in an end-to-end training mode through a training set given by the multi-target tracking public data set to respectively obtain an LSTM network and a third full connection layer FC3 of interactive features;
with a target TiEstablishing a frame with a fixed length and a fixed width H by taking the central coordinate of a certain frame of image as a center, setting a point which is superposed with the central coordinate of other tracking targets in the frame as 1, setting the center of the frame with the fixed length as 1, and setting the rest positions as 0 to obtain a target TiIn the interactive feature vector of the frame, the target T isiThe interactive feature vector of the previous M frames is extracted to a combined historical interactive feature vector through an LSTM network of interactive features
Association And
And through the third full connection layer FC3, T is obtainediAnd Di,mIs given by the interaction feature similarity score SI(Ti,Di,m) If the target T isiIf the interactive feature vector of the previous frame is not generated, replacing the interactive feature vector with a value of 0;
through the third full connection layer FC3, T is obtainediAnd Di,mIs given by the interaction feature similarity score SI(Ti,Di,m) If the target T isiIf the interactive feature vector of the previous frame is not generated, replacing the interactive feature vector with a value of 0;
preferably, the total similarity score in step 6 is:
Stotal,i=α1SA(Ti,Di,m)+α2SV(Ti,Di,m)+α3SI(Ti,Di,m)
wherein alpha is1Similarity coefficient for appearance feature,α2Is a velocity feature similarity coefficient, alpha3Is an interactive feature similarity coefficient;
the total similarity score is greater than the match score threshold Stotal,iBeta. then candidate frame Di,mConverting the image into a tracking frame of the tracking target in the m frames of images;
step 6, updating the state information of the tracking target through the step 2 to keep the tracking target in a tracking state, converting the tracking target in the tracking state which is not successfully matched by a plurality of continuous frames into a lost state, and not adopting the method in the step 2;
preferably, the overlapping degree between the tracking targets in step 8 is:

wherein A is a tracking target TaArea of the tracking frame, B is the tracking target TbFor the tracking target T with IOU > 0.8aAnd tracking target TbAccording to the total similarity score S obtained in the step 6total,aAnd Stotal,bComparing S with Stotal,aAnd Stotal,bThe lower tracking target is converted into a lost state and keeps Stotal,aAnd Stotal,bThe higher tracking target is in a tracking state;
preferably, the multi-frame image in step 9 is MDAnd (5) frame.
Compared with the prior art, the invention has the following advantages and beneficial effects:
according to the method, an LSTM network frame is constructed according to the characteristic data of each target in the time sequence, so that the system can solve the problem of long-time shielding of the target, and the accuracy of target data matching is better improved by combining the characteristics of historical data;
the method combines the characteristics of the position, the appearance, the movement and the interaction of the tracking target, and adopts the convolution network to extract the appearance deep layer characteristic information and the shallow layer characteristic information of the object, so that the discrimination of the tracking target characteristics is improved; by using the direction and speed information of each frame of motion of the object, the accuracy of target matching is improved on the basis of the continuity characteristic of the motion information of the object; through the interaction characteristic information of the objects under the continuous frames, an interaction model is provided, and the acting force relation between the tracking target and other surrounding targets is analyzed, so that the matching accuracy is improved. The accuracy of target tracking is improved by using a multi-clue joint data matching mode;
and (3) calculating the moving position of the target under the current frame by adopting a rapid correlation filtering self-tracking method for each target, screening out a candidate frame conforming to a position area, and well reducing the calculation amount of a data correlation algorithm. The self-tracking algorithm can automatically track the tracking state target which is missed to be detected in the target detection, and the problem that the performance of the target detector is excessively depended on is solved.
Drawings
FIG. 1: the technical scheme of the invention is a general block diagram;
FIG. 2: a survival state diagram for a single target;
FIG. 3: an appearance characteristic model matching graph;
FIG. 4: matching graph of speed characteristic model;
FIG. 5: interactive feature model matching graphs;
FIG. 6: interactive characteristic LSTM network model matching graph;
FIG. 7: and (5) a system multi-target tracking schematic diagram.
Detailed Description
In order to facilitate the understanding and implementation of the present invention for those of ordinary skill in the art, the present invention is further described in detail with reference to the accompanying drawings and examples, it is to be understood that the embodiments described herein are merely illustrative and explanatory of the present invention and are not restrictive thereof.
Embodiments of the present invention are described below with reference to fig. 1 to 6. The technical scheme of the embodiment is a multi-target tracking method based on time series multi-feature data association, which specifically comprises the following steps:
step 1: detecting a tracking target in the frame image according to an SSD multi-target detection algorithm, and counting the category of the tracking target and a candidate frame of the tracking target by comparing the confidence coefficient of the SSD detected tracking target with a confidence coefficient threshold;
the frame image in the step 1 is the mth image, and the category number of the tracking target in the step 1 is NmIn step 1, the candidate frame of the tracking target is:
Di,m={xi,m∈[li,m,li,m+lenthi,m],yi,m∈[wi,m,wi,m+widthi,m]|(xi,m,yi,m)},i∈[1,Km]
wherein, KmNumber of candidate frames for tracking target in mth frame image, li,mCoordinates of the start point of the X axis of the frame candidate for the i-th tracking target in the m-th frame image, wi,mLength as the coordinates of the start point of the Y axis of the frame candidate of the ith tracking target in the mth frame imagei,mWidth for the length of the i-th tracked target candidate frame in the m-th frame imagei,mA width of a candidate frame for an ith tracking target in an mth frame image;
step 2: extracting convolution characteristics of a tracking target in a position frame of a current frame by using a convolution network, calculating a response confidence score of each position in the current frame image through a correlation filter of the tracking target, defining a point with the highest score as a mobile prediction central point of the tracking target under the current frame image, and screening candidate frames through the mobile prediction central point;
in the step 2, the convolutional network is a VGG16 network pre-trained in an ImageNet classification task, and a first layer of feature vectors of a tracking target position frame are extracted through a VGG16 network;
two-dimensional feature vector through channel c The interpolation model of (2) is to calculate the two-dimensional feature vector of the channel c
The interpolation model of (2) is to calculate the two-dimensional feature vector of the channel c Converting into a feature vector of a one-dimensional continuous space:
Converting into a feature vector of a one-dimensional continuous space:

wherein the content of the first and second substances, is a two-dimensional feature vector of channel c, bcIs defined as a cubic interpolation function of three, NcIs composed of
is a two-dimensional feature vector of channel c, bcIs defined as a cubic interpolation function of three, NcIs composed of L is the length of the eigenvector of the one-dimensional continuous space, and Channel 512 is the number of channels;
L is the length of the eigenvector of the one-dimensional continuous space, and Channel 512 is the number of channels;
the convolution operator is:
wherein, yi,mIs a response value of the tracking target i of the mth image, is the two-dimensional feature vector of Channel c, Channel is the number of channels,
is the two-dimensional feature vector of Channel c, Channel is the number of channels, the feature vectors of the one-dimensional continuum of channels c,
the feature vectors of the one-dimensional continuum of channels c, the correlation filter is used for tracking the channel c of the target i in the mth frame image;
the correlation filter is used for tracking the channel c of the target i in the mth frame image;
training the correlation filter through the training samples is:
given n training sample pairs { (y)i,q,y'i,q)}(q∈[m-n,m-1]) Training is carried out to obtain a correlation filter by optimizing a minimized objective function:

wherein, yi,m-jIs the response value of the tracking target i of the m-j-th image,y'i,m-jis yi,m-jThe ideal gaussian distribution of the total number of the particles, for tracking the correlation filter of the target i in the channel c of the mth frame image, the weight value alphajThe influence factor of the training sample j is determined by a penalty function w, and the correlation filter of each channel is obtained through training
for tracking the correlation filter of the target i in the channel c of the mth frame image, the weight value alphajThe influence factor of the training sample j is determined by a penalty function w, and the correlation filter of each channel is obtained through training The number n of training samples is 30;
The number n of training samples is 30;
response value y of tracking target i through m-th imagei,m(l) L is belonged to [0, L), find the maximum value yi,m(l) Corresponding to lp,i,m:
lp,i,m=argmax(yi,m(l))l∈[0,L)
Wherein, L is the length of the feature vector of the one-dimensional continuous space;
will lp,i,mPoints converted into two-dimensional feature vectors of channels After being reduced into two-dimensional coordinates, the coordinates are mapped into coordinate points p under the current framei,m=(xp,i,m,yp,i,m) I.e. tracking the target T for the ith frame in the mth frame imageiThe movement prediction center point of (a);
After being reduced into two-dimensional coordinates, the coordinates are mapped into coordinate points p under the current framei,m=(xp,i,m,yp,i,m) I.e. tracking the target T for the ith frame in the mth frame imageiThe movement prediction center point of (a);
if tracking the target TiIn a tracking state, only the candidate frames around the prediction position area are selected for subsequent target data matching:
setting tracking target TiLength of the previous frame is lengthi,m-1Width ofi,m-1I th tracking target T in m th frame imageiHas a movement prediction center point of pi,m=(xp,i,m,yp,i,m) The candidate frame center point of the ith tracking target in the mth frame image is ci,m=(li,m+lenthi,m/2,wi,m+widthi,m/2)i∈[1,Km]And when the distance between the candidate frame central point and the mobile prediction central point meets the condition:
d(pi,m,ci,m)=(xp,i,m-li,m-lenthi,m/2)2+(yp,i,m-wi,m-widthi,m/2)2<min(lenthi,m-1/2,widthi,m-1/2)
performing subsequent target data matching on the candidate frames meeting the conditions;
if tracking the target TiIn the lost state, a candidate frame is selected to be screened near the position of the frame before it disappears:
taking the moving prediction central point t when the moving prediction central point disappears in the previous framei,m=(xt,i,m,yt,i,m) Length of lengthi,m-1Width ofi,m-1When the distance d (t) between the candidate frame center and the vanishing centeri,ci,m) When the following conditions are satisfied:
d(ti,m,ci,m)=(xt,i,m-li,m-lenthi,m/2)2+(yt,i,m-wi,m-widthi,m/2)2<min(lenthi,m-1/2,widthi,m-1/2)
performing subsequent target data matching on the candidate frames meeting the conditions;
if tracking the target TiIn the unsuccessful matching tracking state, its candidate box center point may be updated using the moving predicted center point:
updating tracking target TiThe candidate frame center point of (2) is a movement prediction center point pi,m=(xp,i,m,yp,i,m) The length of the candidate frame, the width of the candidate frame and the m-1 frame image are kept unchanged;
and step 3: calculating appearance similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frame;
the candidate frame after screening in the step 3 is the candidate frame screened according to the moving prediction center point in the step 2;
the appearance similarity score in step 3 is specifically calculated as:
candidate frame D of the ith tracking target in the mth frame image in the step 1i,mBy removing VGG16One layer of connection layer VGG16 network obtains the tracking target T in the m frame image with the dimension of N being 1000iAppearance feature vector of
Training in an end-to-end training mode through a training set given by a multi-target tracking public data set MOT17-Challenge to respectively obtain an LSTM network with appearance characteristics and a first full connection layer FC 1;
will track the target TiExtracting M N-dimensional appearance feature vectors by removing the VGG16 network of the last layer of the VGG16 from the data of the previous M frames of images, and then extracting N-dimensional combined historical appearance feature vectors by the LSTM network of the appearance features
Joint connection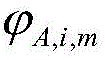 And
And through the first full connection layer FC1, the tracking target T is obtainediAnd candidate frame Di,m(ii) an appearance similarity score of SA(Ti,Di,m) If the target T isiIf the image data of the previous frame is not generated, replacing the image data with a value of 0;
through the first full connection layer FC1, the tracking target T is obtainediAnd candidate frame Di,m(ii) an appearance similarity score of SA(Ti,Di,m) If the target T isiIf the image data of the previous frame is not generated, replacing the image data with a value of 0;
and 4, step 4: calculating the motion similarity scores of the tracking target and the candidate frame in the tracking state or the loss state;
the motion similarity score in step 4 is calculated as:
candidate frame D after screening of ith tracking target in mth frame image in step 2i,mThe central point of (a) is:
(li,m+lenthi,m/2,wi,m+widthi,m/2)
target T is tracked by previous frame imageiThe center position of the candidate frame of (1) is:
(li,m-1+lenthi,m-1/2,wi,m-1+widthi,m-1/2)
the speed feature vector of the ith tracking target in the mth frame image is as follows:

training by a training set given by a multi-target tracking public data set MOT17-Challenge in an end-to-end training mode to respectively obtain an LSTM network and a second full connection layer FC2 of speed characteristics;
extracting the speed characteristic vector of the ith tracking target in the M frames of images through an LSTM network of speed characteristics to obtain a motion characteristic vector of a joint history sequence
Joint connection And
And passing through the second fully-connected layer FC2, thereby tracking target T in a tracking state or a lost stateiAnd candidate frame Di,mHas a motion similarity score of SV(Ti,Di,m) If the target T isiIf the motion data of the previous frame is not generated, the motion data is replaced by a value of 0;
passing through the second fully-connected layer FC2, thereby tracking target T in a tracking state or a lost stateiAnd candidate frame Di,mHas a motion similarity score of SV(Ti,Di,m) If the target T isiIf the motion data of the previous frame is not generated, the motion data is replaced by a value of 0;
and 5: calculating the interactive feature similarity scores of the tracking target and the candidate frames in the tracking state or the loss state;
in step 5, the interactive feature similarity score is calculated as:
to screen the candidate frame Di,mC of center coordinatei,m=(li,m+lenthi,m/2,wi,m+widthi,mAnd/2) establishing a fixed-size box with the length and the width H by taking the center as the center, and connecting the center coordinates c of the box with other candidate boxesi',mThe coincident point is set to be 1, and the center of the square frame with fixed sizeAlso set to 1, the remaining positions are 0, resulting in:

wherein the content of the first and second substances,
x∈[li,m+lenthi,m/2-H/2,li,m+lenthi,m/2+H/2]
y∈[wi,m+widthi,m/2-H/2,wi,m+widthi,m/2+H/2]
then will be Conversion to length H2The one-dimensional vector of (1) to obtain an interactive feature vector of the candidate frame of
Conversion to length H2The one-dimensional vector of (1) to obtain an interactive feature vector of the candidate frame of
Training by a training set given by a multi-target tracking public data set MOT17-Challenge in an end-to-end training mode to respectively obtain an LSTM network with interactive characteristics and a third full connection layer FC 3;
with a target TiEstablishing a fixed-size frame with the length and width H being 300 by taking the central coordinate of a certain frame image as the center, setting the point which is superposed with the central coordinate of other tracking targets in the frame as 1, setting the center of the fixed-size frame as 1, and setting the rest positions as 0 to obtain a target TiIn the interactive feature vector of the frame, the target T isiThe interactive feature vector of the previous M frames is extracted to a combined historical interactive feature vector through an LSTM network of interactive features
Association And
And through the thirdFull connection layer FC3, giving TiAnd Di,mIs given by the interaction feature similarity score SI(Ti,Di,m) If the target T isiIf the interactive feature vector of the previous frame is not generated, replacing the interactive feature vector with a value of 0;
through the thirdFull connection layer FC3, giving TiAnd Di,mIs given by the interaction feature similarity score SI(Ti,Di,m) If the target T isiIf the interactive feature vector of the previous frame is not generated, replacing the interactive feature vector with a value of 0;
step 6: if the tracking target in the tracking state or the lost state is matched with the candidate frame, comparing the total similarity score with a matching score threshold value, when the total similarity score is greater than the matching score threshold value, converting the candidate frame into a tracking frame of the tracking target in the current frame image, and updating the appearance characteristic, the speed characteristic and the interactive characteristic information of the tracking target; if the tracking target in the tracking state or the lost state is not matched with the candidate frame, updating the state information of the tracking target through the step 2;
the total similarity score in step 6 is:
Stotal,i=α1SA(Ti,Di,m)+α2SV(Ti,Di,m)+α3SI(Ti,Di,m)
wherein alpha is1Is an appearance feature similarity coefficient, alpha2Is a velocity feature similarity coefficient, alpha3Is an interactive feature similarity coefficient;
the total similarity score is greater than the match score threshold Stotal,iBeta. then candidate frame Di,mConverting the image into a tracking frame of the tracking target in the m frames of images;
step 6, updating the state information of the tracking target through the step 2 to keep the tracking target in a tracking state, converting the tracking target in the tracking state which is not successfully matched by a plurality of continuous frames into a lost state, and not adopting the method in the step 2;
and 7: associating unmatched candidate frames with existing tracking targets, determining the unmatched candidate frames as new tracking targets, initializing the new tracking targets, establishing the new tracking targets, constructing a position feature model, an appearance feature model, a speed feature model and an interaction feature model of the new tracking targets, updating the states of the position feature model, the appearance feature model, the speed feature model and the interaction feature model into tracking states, and performing data association matching tracking in subsequent frame images;
and 8: retrieving all tracking targets in a tracking state of the current frame again, and calculating the overlapping degree of all tracking targets by adopting an intersection ratio;
in step 8, the overlapping degree between the tracking targets is as follows:

wherein A is a tracking target TaArea of the tracking frame, B is the tracking target TbFor the tracking target T with IOU > 0.8aAnd tracking target TbAccording to the total similarity score S obtained in the step 6total,aAnd Stotal,bComparing S with Stotal,aAnd Stotal,bThe lower tracking target is converted into a lost state and keeps Stotal,aAnd Stotal,bThe higher tracking target is in a tracking state;
and step 9: and recognizing the tracking target continuously in the lost state in the multi-frame image as the disappeared target, storing the data information of the tracking state, and not performing data matching operation on the tracking target.
In step 9, the multi-frame image is MD30 frames of images.
It should be understood that parts of the specification not set forth in detail are well within the prior art.
It should be understood that the above description of the preferred embodiments is given for clarity and not for any purpose of limitation, and that various changes, substitutions and alterations can be made herein without departing from the spirit and scope of the invention as defined by the appended claims.
Claims (9)
1. A multi-target tracking method based on time series multi-feature fusion is characterized by comprising the following steps:
step 1: detecting a tracking target in the frame image according to an SSD multi-target detection algorithm, and counting the category of the tracking target and a candidate frame of the tracking target by comparing the confidence coefficient of the SSD detected tracking target with a confidence coefficient threshold;
step 2: extracting convolution characteristics of a tracking target in a position frame of a current frame by using a convolution network, calculating a response confidence score of each position in the current frame image through a correlation filter of the tracking target, defining a point with the highest score as a mobile prediction central point of the tracking target under the current frame image, and screening candidate frames through the mobile prediction central point;
and step 3: calculating appearance similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frame;
and 4, step 4: calculating the motion similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frame;
and 5: calculating interactive feature similarity scores of the tracking target in the tracking state or the lost state and the screened candidate frames;
step 6: if the tracking target in the tracking state or the lost state is matched with the candidate frame, comparing the total similarity score with a matching score threshold value, when the total similarity score is greater than the matching score threshold value, converting the candidate frame into a tracking frame of the tracking target in the current frame image, and updating the appearance characteristic, the speed characteristic and the interactive characteristic information of the tracking target; if the tracking target in the tracking state or the lost state is not matched with the candidate frame, updating the state information of the tracking target through the step 2;
and 7: associating unmatched candidate frames with existing tracking targets, determining the unmatched candidate frames as new tracking targets, initializing the new tracking targets, establishing the new tracking targets, constructing a position feature model, an appearance feature model, a speed feature model and an interaction feature model of the new tracking targets, updating the states of the position feature model, the appearance feature model, the speed feature model and the interaction feature model into tracking states, and performing data association matching tracking in subsequent frame images;
and 8: retrieving all tracking targets in a tracking state of the current frame again, and calculating the overlapping degree of all tracking targets by adopting an intersection ratio;
and step 9: and recognizing the tracking target continuously in a lost state in the continuous multi-frame images as a disappeared target, storing the data information of the tracking state, and not performing data matching operation on the tracking target.
2. The multi-target tracking method based on time series multi-feature fusion according to claim 1, characterized in that: the frame image in the step 1 is the mth image, and the category number of the tracking target in the step 1 is NmIn step 1, the candidate frame of the tracking target is:
Di,m={xi,m∈[li,m,li,m+lenthi,m],yi,m∈[wi,m,wi,m+widthi,m]|(xi,m,yi,m)},i∈[1,Km]
wherein, KmNumber of candidate frames for tracking target in mth frame image, li,mCoordinates of the start point of the X axis of the frame candidate for the i-th tracking target in the m-th frame image, wi,mLength as the coordinates of the start point of the Y axis of the frame candidate of the ith tracking target in the mth frame imagei,mWidth for the length of the i-th tracked target candidate frame in the m-th frame imagei,mThe width of the candidate frame for the i-th tracking target in the m-th frame image.
3. The multi-target tracking method based on time series multi-feature fusion as claimed in claim 2, characterized in that: in the step 2, the convolutional network is a VGG16 network pre-trained in an ImageNet classification task, and a first layer of feature vectors of a tracking target position frame are extracted through a VGG16 network;
two-dimensional feature vector through channel c The interpolation model of (2) is to calculate the two-dimensional feature vector of the channel c
The interpolation model of (2) is to calculate the two-dimensional feature vector of the channel c Converting into a feature vector of a one-dimensional continuous space:
Converting into a feature vector of a one-dimensional continuous space:

wherein the content of the first and second substances, is a two-dimensional feature vector of channel c, bcIs defined as a cubic interpolation function of three, NcIs composed of
is a two-dimensional feature vector of channel c, bcIs defined as a cubic interpolation function of three, NcIs composed of L is the length of the eigenvector of the one-dimensional continuous space, and Channel is the number of channels;
L is the length of the eigenvector of the one-dimensional continuous space, and Channel is the number of channels;
the convolution operator is:
wherein, yi,mIs a response value of the tracking target i of the mth image, is the two-dimensional feature vector of Channel c, Channel is the number of channels,
is the two-dimensional feature vector of Channel c, Channel is the number of channels, the feature vectors of the one-dimensional continuum of channels c,
the feature vectors of the one-dimensional continuum of channels c, the correlation filter is used for tracking the channel c of the target i in the mth frame image;
the correlation filter is used for tracking the channel c of the target i in the mth frame image;
training the correlation filter through the training samples is:
given n training sample pairs { (y)i,m-j,y′i,m-j)},j∈[1,n]And training to obtain a correlation filter by minimizing the optimization of an objective function:

wherein, yi,m-jIs the response value, y ', of the tracking target i of the m-j-th image'i,m-jIs yi,m-jThe ideal gaussian distribution of the total number of the particles, for tracking the correlation filter of the target i in the channel c of the mth frame image, the weight value alphajThe influence factor of the training sample j is determined by a penalty function w, and the correlation filter of each channel is obtained through training
for tracking the correlation filter of the target i in the channel c of the mth frame image, the weight value alphajThe influence factor of the training sample j is determined by a penalty function w, and the correlation filter of each channel is obtained through training
Response value y of tracking target i through m-th imagei,m(l) L is belonged to [0, L), find the maximum value yi,m(l) Corresponding to lp,i,m:
lp,i,m=argmax(yi,m(l))l∈[0,L)
Wherein, L is the length of the feature vector of the one-dimensional continuous space;
will lp,i,mPoints converted into two-dimensional feature vectors of channels After being reduced into two-dimensional coordinates, the coordinates are mapped into coordinate points p under the current framei,m=(xp,i,m,yp,i,m) I.e. tracking the target T for the ith frame in the mth frame imageiThe movement prediction center point of (a);
After being reduced into two-dimensional coordinates, the coordinates are mapped into coordinate points p under the current framei,m=(xp,i,m,yp,i,m) I.e. tracking the target T for the ith frame in the mth frame imageiThe movement prediction center point of (a);
if tracking the target TiIn a tracking state, only the candidate frames around the prediction position area are selected for subsequent target data matching:
setting tracking target TiLength of the previous frame is lengthi,m-1Width ofi,m-1I th tracking target T in m th frame imageiHas a movement prediction center point of pi,m=(xp,i,m,yp,i,m) The candidate frame center point of the ith tracking target in the mth frame image is ci,m=(li,m+lenthi,m/2,wi,m+widthi,m/2)i∈[1,Km]And when the distance between the candidate frame central point and the mobile prediction central point meets the condition:
d(pi,m,ci,m)=(xp,i,m-li,m-lenthi,m/2)2+(yp,i,m-wi,m-widthi,m/2)2<min(lenthi,m-1/2,widthi,m-1/2)
performing subsequent target data matching on the candidate frames meeting the conditions;
if tracking the target TiIn the lost state, a candidate frame is selected to be screened near the position of the frame before it disappears:
taking the moving prediction central point t when the moving prediction central point disappears in the previous framei,m=(xt,i,m,yt,i,m) Length of lengthi,m-1Width ofi,m-1When the distance d (t) between the candidate frame center and the vanishing centeri,ci,m) When the following conditions are satisfied:
d(ti,m,ci,m)=(xt,i,m-li,m-lenthi,m/2)2+(yt,i,m-wi,m-widthi,m/2)2<min(lenthi,m-1/2,widthi,m-1/2)
performing subsequent target data matching on the candidate frames meeting the conditions;
if tracking the target TiIn the unsuccessful matching tracking state, its candidate box center point may be updated using the moving predicted center point:
updating tracking target TiThe candidate frame center point of (2) is a movement prediction center point pi,m=(xp,i,m,yp,i,m) The length of the candidate frame, the width of the candidate frame and the m-1 frame image remain unchanged.
4. The multi-target tracking method based on time series multi-feature fusion according to claim 1, characterized in that: the candidate frame after screening in the step 3 is the candidate frame screened according to the moving prediction center point in the step 2;
the appearance similarity score in step 3 is specifically calculated as:
marking the candidate frame after calculation and screening in the step 2 as Di,mRemoving the connecting layer VGG16 network of the last layer of VGG16 to obtain the tracking target T in the mth frame image of N dimensioniAppearance feature vector of
Training in an end-to-end training mode through a training set given by the multi-target tracking public data set to respectively obtain an LSTM network with appearance characteristics and a first full connection layer FC 1;
will track the target TiExtracting M N-dimensional appearance feature vectors from the data of the previous M frames of images through the same VGG16 network of the last layer of the connection layer without VGG16, and then extracting N-dimensional combined historical appearance feature vectors through the LSTM network of appearance features
Joint connection And
And through the first full connection layer FC1, the tracking target T is obtainediAnd candidate frame Di,m(ii) an appearance similarity score of SA(Ti,Di,m) If the target T is trackediIf the image data of the previous frame is not generated, the value of 0 is substituted.
through the first full connection layer FC1, the tracking target T is obtainediAnd candidate frame Di,m(ii) an appearance similarity score of SA(Ti,Di,m) If the target T is trackediIf the image data of the previous frame is not generated, the value of 0 is substituted.
5. The multi-target tracking method based on time series multi-feature fusion as claimed in claim 2, characterized in that: the motion similarity score in step 4 is calculated as:
setting a candidate frame D after calculation and screening in the step 2i,mThe central point of (a) is:
(li,m+lenthi,m/2,wi,m+widthi,m/2)
target T is tracked by previous frame imageiThe center position of the candidate frame of (1) is:
(li,m-1+lenthi,m-1/2,wi,m-1+widthi,m-1/2)
the speed feature vector of the ith tracking target in the mth frame image is as follows:

training in an end-to-end training mode through a training set given by the multi-target tracking public data set to respectively obtain an LSTM network with speed characteristics and a second full connection layer FC 2;
extracting the speed characteristic vector of the ith tracking target in the M frames of images through an LSTM network of speed characteristics to obtain a motion characteristic vector of a joint history sequence
Joint connection And
And passing through the second fully-connected layer FC2, thereby tracking target T in a tracking state or a lost stateiAnd candidate frame Di,mHas a motion similarity score of SV(Ti,Di,m) If the target T is trackediIf the motion data of the previous frame is not generated, the motion data is replaced by a value of 0.
passing through the second fully-connected layer FC2, thereby tracking target T in a tracking state or a lost stateiAnd candidate frame Di,mHas a motion similarity score of SV(Ti,Di,m) If the target T is trackediIf the motion data of the previous frame is not generated, the motion data is replaced by a value of 0.
6. The multi-target tracking method based on time series multi-feature fusion as claimed in claim 2, characterized in that: in step 5, the interactive feature similarity score is calculated as:
to screen the candidate frame Di,mC of center coordinatei,m=(li,m+lenthi,m/2,wi,m+widthi,mAnd/2) establishing a fixed-size box with the length and the width H by taking the center as the center, and connecting the center coordinates c of the box with other candidate boxesi',mThe coincident point is set as 1, the center of the fixed-size box is also set as 1, and the rest positions are set as 0, so that:

wherein the content of the first and second substances,
x∈[li,m+lenthi,m/2-H/2,li,m+lenthi,m/2+H/2]
y∈[wi,m+widthi,m/2-H/2,wi,m+widthi,m/2+H/2]
then will be Conversion to length H2The one-dimensional vector of (1) to obtain an interactive feature vector of the candidate frame of
Conversion to length H2The one-dimensional vector of (1) to obtain an interactive feature vector of the candidate frame of
Training in an end-to-end training mode through a training set given by the multi-target tracking public data set to respectively obtain an LSTM network with interactive characteristics and a third full connection layer FC 3;
to track a target TiEstablishing a frame with a fixed length and a fixed width H by taking the central coordinate of a certain frame of image as a center, setting a point which is superposed with the central coordinate of other tracking targets in the frame as 1, setting the center of the frame with the fixed length as 1, and setting the rest positions as 0 to obtain a tracking target TiIn the interactive feature vector of the frame, the target T is trackediThe interactive feature vector of the previous M frames is extracted to a combined historical interactive feature vector through an LSTM network of interactive features
Association And
And through the third full connection layer FC3, T is obtainediAnd Di,mIs given by the interaction feature similarity score SI(Ti,Di,m) If the target T is trackediIf the interactive feature vector of the previous frame is not generated, the value of 0 is substituted.
through the third full connection layer FC3, T is obtainediAnd Di,mIs given by the interaction feature similarity score SI(Ti,Di,m) If the target T is trackediIf the interactive feature vector of the previous frame is not generated, the value of 0 is substituted.
7. The multi-target tracking method based on time series multi-feature fusion according to claim 1, characterized in that: the total similarity score in step 6 is:
Stotal,i=α1SA(Ti,Di,m)+α2SV(Ti,Di,m)+α3SI(Ti,Di,m)
wherein alpha is1Is an appearance feature similarity coefficient, alpha2Is a velocity feature similarity coefficient, alpha3Is the similarity coefficient of the interactive features, and SA(Ti,Di,m)、SV(Ti,Di,m)、SI(Ti,Di,m) Respectively obtaining an appearance similarity score, a motion similarity score and an interaction feature similarity score according to the steps 3-5;
the total similarity score is greater than the match score threshold Stotal,iBeta. then candidate frame Di,mConverting the image into a tracking frame of the tracking target in the m frames of images;
and 6, updating the state information of the tracking target through the step 2 to keep the tracking target in a tracking state, converting the tracking target in the tracking state which is not successfully matched by the continuous multiple frames into a lost state, and not adopting the method in the step 2.
8. The multi-target tracking method based on time series multi-feature fusion according to claim 1, characterized in that: in step 8, the overlapping degree of each tracking target is as follows:

wherein A is a tracking target TaArea of the tracking frame, B is the tracking target TbFor the tracking target T with IOU > 0.8aAnd tracking target TbAccording to the total similarity score S obtained in the step 6total,aAnd Stotal,bComparing S with Stotal,aAnd Stotal,bThe lower tracking target is converted into a lost state and keeps Stotal,aAnd Stotal,bThe higher tracking target is in a tracking state.
9. The multi-target tracking method based on time series multi-feature fusion according to claim 1, characterized in that: in step 9, the multi-frame image is MDAnd (5) frame.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811210852.8A CN109360226B (en) | 2018-10-17 | 2018-10-17 | Multi-target tracking method based on time series multi-feature fusion |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811210852.8A CN109360226B (en) | 2018-10-17 | 2018-10-17 | Multi-target tracking method based on time series multi-feature fusion |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109360226A CN109360226A (en) | 2019-02-19 |
| CN109360226B true CN109360226B (en) | 2021-09-24 |
Family
ID=65349536
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811210852.8A Active CN109360226B (en) | 2018-10-17 | 2018-10-17 | Multi-target tracking method based on time series multi-feature fusion |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109360226B (en) |
Families Citing this family (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109919974B (en) * | 2019-02-21 | 2023-07-14 | 上海理工大学 | Online multi-target tracking method based on R-FCN frame multi-candidate association |
| CN109886243B (en) * | 2019-03-01 | 2021-03-26 | 腾讯医疗健康(深圳)有限公司 | Image processing method, device, storage medium, equipment and system |
| CN110047095B (en) * | 2019-03-06 | 2023-07-21 | 平安科技(深圳)有限公司 | Tracking method and device based on target detection and terminal equipment |
| CN109798888B (en) * | 2019-03-15 | 2021-09-17 | 京东方科技集团股份有限公司 | Posture determination device and method for mobile equipment and visual odometer |
| CN109993772B (en) * | 2019-03-26 | 2022-12-20 | 东北大学 | Example level feature aggregation method based on space-time sampling |
| CN110148153B (en) * | 2019-04-03 | 2021-09-14 | 深圳云天励飞技术有限公司 | Multi-target tracking method and related device |
| CN110032635B (en) * | 2019-04-22 | 2023-01-20 | 齐鲁工业大学 | Problem pair matching method and device based on depth feature fusion neural network |
| CN110163890B (en) * | 2019-04-24 | 2020-11-06 | 北京航空航天大学 | Multi-target tracking method for space-based monitoring |
| CN110288627B (en) * | 2019-05-22 | 2023-03-31 | 江苏大学 | Online multi-target tracking method based on deep learning and data association |
| CN110223316B (en) * | 2019-06-13 | 2021-01-29 | 哈尔滨工业大学 | Rapid target tracking method based on cyclic regression network |
| CN110288051B (en) * | 2019-07-03 | 2022-04-22 | 电子科技大学 | Multi-camera multi-target matching method based on distance |
| CN110414443A (en) * | 2019-07-31 | 2019-11-05 | 苏州市科远软件技术开发有限公司 | A kind of method for tracking target, device and rifle ball link tracking |
| JP7370759B2 (en) * | 2019-08-08 | 2023-10-30 | キヤノン株式会社 | Image processing device, image processing method and program |
| CN110675430B (en) * | 2019-09-24 | 2022-09-27 | 中国科学院大学 | Unmanned aerial vehicle multi-target tracking method based on motion and appearance adaptation fusion |
| CN111027370A (en) * | 2019-10-16 | 2020-04-17 | 合肥湛达智能科技有限公司 | Multi-target tracking and behavior analysis detection method |
| CN110991283A (en) * | 2019-11-21 | 2020-04-10 | 北京格灵深瞳信息技术有限公司 | Re-recognition and training data acquisition method and device, electronic equipment and storage medium |
| CN111179310B (en) * | 2019-12-20 | 2024-06-25 | 腾讯科技(深圳)有限公司 | Video data processing method, device, electronic equipment and computer readable medium |
| CN111179318B (en) * | 2019-12-31 | 2022-07-12 | 浙江大学 | Double-flow method-based complex background motion small target detection method |
| CN111354022B (en) * | 2020-02-20 | 2023-08-22 | 中科星图股份有限公司 | Target Tracking Method and System Based on Kernel Correlation Filtering |
| CN111429483A (en) * | 2020-03-31 | 2020-07-17 | 杭州博雅鸿图视频技术有限公司 | High-speed cross-camera multi-target tracking method, system, device and storage medium |
| CN111523424A (en) * | 2020-04-15 | 2020-08-11 | 上海摩象网络科技有限公司 | Face tracking method and face tracking equipment |
| CN111612822B (en) * | 2020-05-21 | 2024-03-15 | 广州海格通信集团股份有限公司 | Object tracking method, device, computer equipment and storage medium |
| CN111709975B (en) * | 2020-06-22 | 2023-11-03 | 上海高德威智能交通系统有限公司 | Multi-target tracking method, device, electronic equipment and storage medium |
| CN112001252B (en) * | 2020-07-22 | 2024-04-12 | 北京交通大学 | Multi-target tracking method based on different composition network |
| CN112866370A (en) * | 2020-09-24 | 2021-05-28 | 汉桑(南京)科技有限公司 | Pet interaction method, system and device based on pet ball and storage medium |
| CN114822084A (en) * | 2021-01-28 | 2022-07-29 | 阿里巴巴集团控股有限公司 | Traffic control method, target tracking method, system, device, and storage medium |
| CN113192106B (en) * | 2021-04-25 | 2023-05-30 | 深圳职业技术学院 | Livestock tracking method and device |
| CN114219836B (en) * | 2021-12-15 | 2022-06-03 | 北京建筑大学 | Unmanned aerial vehicle video vehicle tracking method based on space-time information assistance |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101783020A (en) * | 2010-03-04 | 2010-07-21 | 湖南大学 | Video multi-target fast tracking method based on joint probability data association |
| CN104200488A (en) * | 2014-08-04 | 2014-12-10 | 合肥工业大学 | Multi-target tracking method based on graph representation and matching |
| CN108573496A (en) * | 2018-03-29 | 2018-09-25 | 淮阴工学院 | Multi-object tracking method based on LSTM networks and depth enhancing study |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080123900A1 (en) * | 2006-06-14 | 2008-05-29 | Honeywell International Inc. | Seamless tracking framework using hierarchical tracklet association |
-
2018
- 2018-10-17 CN CN201811210852.8A patent/CN109360226B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101783020A (en) * | 2010-03-04 | 2010-07-21 | 湖南大学 | Video multi-target fast tracking method based on joint probability data association |
| CN104200488A (en) * | 2014-08-04 | 2014-12-10 | 合肥工业大学 | Multi-target tracking method based on graph representation and matching |
| CN108573496A (en) * | 2018-03-29 | 2018-09-25 | 淮阴工学院 | Multi-object tracking method based on LSTM networks and depth enhancing study |
Non-Patent Citations (2)
| Title |
|---|
| 《Tracking by Detection of Multiple Faces using SSD and CNN Features》;Tai Do Nhu,et al;《ResearchGate》;20180930;第1-10页 * |
| 《监控视频中多类目标检测与多目标跟踪算法研究》;周纪强;《中国优秀硕士学位论文全文数据库 信息科技辑》;20180215(第2期);第I138-1954页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109360226A (en) | 2019-02-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109360226B (en) | Multi-target tracking method based on time series multi-feature fusion | |
| CN109766830B (en) | Ship target identification system and method based on artificial intelligence image processing | |
| Shen et al. | Fast online tracking with detection refinement | |
| CN106709449B (en) | Pedestrian re-identification method and system based on deep learning and reinforcement learning | |
| CN110197502B (en) | Multi-target tracking method and system based on identity re-identification | |
| CN106897666B (en) | Closed loop detection method for indoor scene recognition | |
| WO2023065395A1 (en) | Work vehicle detection and tracking method and system | |
| CN107145862B (en) | Multi-feature matching multi-target tracking method based on Hough forest | |
| Yang et al. | Multi-object tracking with discriminant correlation filter based deep learning tracker | |
| CN109165540B (en) | Pedestrian searching method and device based on prior candidate box selection strategy | |
| CN107633226B (en) | Human body motion tracking feature processing method | |
| CN110288627B (en) | Online multi-target tracking method based on deep learning and data association | |
| CN113674328A (en) | Multi-target vehicle tracking method | |
| CN111476817A (en) | Multi-target pedestrian detection tracking method based on yolov3 | |
| CN111882586B (en) | Multi-actor target tracking method oriented to theater environment | |
| CN111080673B (en) | Anti-occlusion target tracking method | |
| CN110009060B (en) | Robustness long-term tracking method based on correlation filtering and target detection | |
| CN112651995A (en) | On-line multi-target tracking method based on multifunctional aggregation and tracking simulation training | |
| Fang et al. | Online hash tracking with spatio-temporal saliency auxiliary | |
| Tsintotas et al. | DOSeqSLAM: Dynamic on-line sequence based loop closure detection algorithm for SLAM | |
| CN111931571B (en) | Video character target tracking method based on online enhanced detection and electronic equipment | |
| CN111652070A (en) | Face sequence collaborative recognition method based on surveillance video | |
| CN112818905A (en) | Finite pixel vehicle target detection method based on attention and spatio-temporal information | |
| Kshirsagar et al. | Modified yolo module for efficient object tracking in a video | |
| CN113129336A (en) | End-to-end multi-vehicle tracking method, system and computer readable medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |