Disclosure of Invention
The invention provides a semi-supervised optical flow learning method based on a hole convolution stack network, which aims to train mixed data with labels and without labels, design a shielding perception loss function, combine an end point error cost function for supervised learning with a data item and a smooth item for unsupervised learning, construct a semi-supervised learning optical flow model named SA-Net, adopt a stack network structure on a network architecture, introduce hole convolution into a convolution layer to increase the perception field of a convolution kernel, and design a shielding perception layer to estimate a shielding area, wherein the network can carry out end-to-end semi-supervised learning optical flow.
The purpose of the invention is realized as follows:
step one, constructing a 1 st optical flow learning sub-network, and naming the optical flow learning sub-network as SA-Net _1, wherein the SA-Net _1 optical flow learning network adopts a full convolution architecture and is composed of 2 parts of contraction and expansion, the contraction part firstly extracts feature maps from 2 images by adopting 4 layers of standard convolution operation, then the 2 feature maps are input into related layers for feature matching and merging, optical flow features are extracted through 4 layers of cavity convolution layers, the expansion part comprises 4 layers of deconvolution layers, and the optical flow extracted by the contraction part is restored to the resolution of an original image.
And step two, constructing a 2 nd optical flow learning sub-network, which is named as SA-Net _2, wherein the SA-Net _2 optical flow learning network adopts a full convolution architecture and consists of 2 parts of contraction and expansion, an input layer inputs 2 images into the network after stacking, the network extracts optical flows between image pairs through 4 layers of standard convolution layers and 4 layers of cavity convolution layers, a contraction part consists of 4 layers of deconvolution layers, and the optical flows extracted by the contraction part are restored to the resolution of the original images.
And step three, constructing 2 stacking networks, connecting 2 SA-Net _2 sub-networks after the SA-Net _1 sub-network to form a 1 st stacking network, deforming the 2 nd image to the 1 st image at the connection part of each sub-network by adopting a deformation technology, taking the deformed images and the 1 st image as the input of the next sub-network, and calculating the optical flow increment of the 2 images. The 2 nd stacking network and the 1 st stacking network share network architecture and parameters, 2 images at the t moment and the t +1 moment are input into the input end of the 1 st stacking network, forward optical flow between image pairs is extracted, meanwhile, the images at the t moment and the t +1 moment are input into the 2 nd stacking network in a switching order, and reverse optical flow between the image pairs is extracted.
And step four, training 2 stacking networks, wherein only the 1 st stacking network is required to be trained, the 2 nd network shares the updated network weight, when the subnetworks at the corresponding positions of the 2 stacking networks are synchronously trained, each 1 layer of the expansion part respectively outputs forward optical flows and reverse optical flows with different resolutions, the forward optical flows and the reverse optical flows of each layer are simultaneously input into the shielding perception layer, the shielding area is judged through the consistency check function, and the positive and negative consistency check is stopped until the forward optical flows are restored to the original resolution.
And step five, designing a shielding perception loss function, and performing semi-supervised learning on the network. The end point error cost function for supervised learning is combined with the data item and the smooth item for unsupervised learning, so that the labeled data and the unlabeled data can be trained, wherein the data item is designed with a constant assumption based on image structure texture decomposition and Census transformation, the smooth item is designed by isotropic diffusion based on image driving, and the loss function can be used for semi-supervised training network end to end through back propagation.
And step six, in the training stage, firstly inputting a large amount of label-free data at the input end of the network, obtaining total loss by summing the loss weights, then training the network by using a back propagation algorithm to obtain an initial network weight, and then training the network by using a small amount of labeled data to obtain a final network model.
And step seven, testing by using the trained model, inputting the image pair, and outputting the corresponding optical flow.
Compared with the prior art, the invention has the advantages that:
the method provided by the invention introduces cavity convolution in the network convolution layer to increase the receptive field, designs a layer of shielding sensing layer to fuse the shielding area into the network training process to improve the optical flow estimation precision, further provides a shielding sensing loss function to semi-supervise the training network, and also designs a stacked network structure on the network architecture to further improve the network performance.
Detailed Description
The invention is described in more detail below with reference to the accompanying drawings.
Step one, as shown in fig. 2, 1 optical flow learning subnetwork SA-Net _1 is constructed, firstly, feature maps of images at time t and time t +1 are respectively extracted from a contraction part through 4 layers of standard convolution layers, a network is helped to match the feature maps through a related layer, and a corresponding relation between the feature maps is found, wherein a related function of the related layer is defined as follows:
wherein
The characteristic diagrams at time t and time t +1 are shown, respectively, and pi indicates a blob of size K × K centered on pixel x.
The method comprises the steps of respectively taking 2 blobs which are centered at x1 and x2 in 2 images, multiplying the blobs at corresponding positions and then adding the blobs, carrying out correlation operation on the whole image by a correlation layer, simultaneously merging the features of the 2 images, and then extracting features of higher levels by 4 layers of hole convolution layers, wherein a hole convolution schematic diagram can be shown in a figure 5, and the figure 5 shows 1 hole convolution kernel with the size of 3 x 3 and the interval of 1. The convolution kernel size of the standard convolution layer is 3 × 3, the step size is 2, the cavity convolution kernel size is 3 × 3, the step size is 1, the interval value increases exponentially from small to large and is respectively 2, 4, 8 and 16, the ReLU layer is arranged next to each convolution layer and the cavity convolution layer, and other parameter settings and details can be shown in FIG. 2. The expansion part of the network is composed of 4 layers of deconvolution layers, the convolution kernel size is 3 x 3, the step length is 2, each layer of deconvolution layer is connected with a ReLU layer, and the feature diagram is restored to the original image resolution size through a series of deconvolution operations, so that the final optical flow is obtained.
And step two, as shown in FIG. 3, constructing a 2 nd optical flow learning subnetwork SA-Net _2, inputting images at the time t and the time t +1 into a network in a stacking mode, wherein firstly, a contraction part is composed of 4 layers of standard convolutional layers and 4 layers of cavity convolutional layers, the network extracts optical flow information through the standard convolutional layers and the cavity convolutional layers, an expansion part is composed of 4 layers of deconvolution layers, and the optical flow is restored to the resolution of the original image. The convolution kernel size of the standard convolution layer is 3 x 3, the step size is 2, the convolution kernel size of the cavity convolution layer is 3 x 3, the step size is 1, the intervals increase in an exponential mode and are respectively 2, 4, 8 and 12, the convolution kernel size of the deconvolution layer is 5 x 5, the step size is 2, and each convolution layer is connected with the nonlinear ReLU layer. Since the SA-Net _1 and SA-Net _2 sub-networks do not contain a fully connected layer, the input to both networks can be an image of any size.
Step three, training 2 stacked learning networks with the same architecture simultaneously, and learning a forward optical flow and a backward optical flow between two images in a semi-supervised mode, wherein each stacked learning network is formed by stacking 1 SA-Net _1 sub-network and 2 SA-Net _2 sub-networks, in order to evaluate the result of the previous sub-network and update the calculation increment of the whole network more easily, a deformation operation is added between each stacked sub-network, the output optical flow of the previous sub-network is used for performing a deformation operation on the image at the t +1 th moment, and the obtained image can be represented by the following formula:
wherein I
t+1,
Representing the pre-and post-warped images, respectively, u, v representing the optical flow values at pixels x, y, respectively.
Will be deformed
the images at the moment t and their brightness errors are used as the input of the next sub-networkNetwork learning
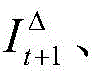
Incremental optical flow between images at time t. The morphing operation is realized by a guided bilinear interpolation algorithm, so that the stacked network can be trained end to end. In the training stage, only the 1 st stacking network needs to be trained, the 2 nd stacking network shares the weight of the stacking network, the training strategy adopted by the stacking network is to train the SA-Net _1 sub-network firstly, provide a good initial value for the next two sub-networks, keep the weight of the SA-Net _1 unchanged, train the next stacking sub-network SA-Net _2, then fix the weight of the previous 2 sub-networks unchanged, train the 3 rd stacking sub-network, and update the weight. The SA-Net increases the depth of the network in a network stacking mode, and increases the iteration times during network training, so that the overall performance of the network is improved.
Step four, as shown in fig. 6, in the non-shielded area, a pixel point returns to the original pixel position after being subjected to forward optical flow mapping and reverse optical flow mapping, and in the shielded area, the pixel point position of the pixel point after being subjected to the forward optical flow mapping and the reverse optical flow mapping has a deviation from the original pixel point position, and the shielded area is a concentrated area where such errors occur, so that the shielded area with a large optical flow estimation error can be obtained by performing positive and negative consistency check on the forward optical flow and the reverse optical flow. The positive and negative consistency check discriminant function is as follows:
wherein
And
representing the forward and reverse optical flows at pixel x, respectively, with epsilon being the threshold of the discriminant function.
Defining an occlusion tagging function OxWhen the discriminant function is greater thanWhen the threshold value is reached, the optical flow solution of the area has larger error, the area is judged to be shielded, and O is usedx1. When the discriminant function is smaller than the threshold value, the optical flow solution of the area is accurate, the area is judged to be a non-shielding area, and O is enabledx0. During training, consistency check is carried out on each 1-layer forward optical flow and reverse optical flow of 2 stacked network expansion parts, and an occlusion area is estimated to be used in a network training process. The sheltered area participates in the network training process, and the optical flow precision is improved.
And fifthly, designing a shielding perception loss function for restraining pixels in the shielding area, wherein the shielding perception loss function is suitable for a semi-supervised learning optical flow network, the loss function is only applied to a training stage, and the semi-supervised learning optical flow network is trained through back propagation. Compared with the supervised learning optical flow model, the semi-supervised learning optical flow model is not limited by difficulty in acquiring the true value of the optical flow, can learn the optical flow with or without supervision, and is more suitable for solving the problem of motion information extraction in the real world.
Loss function ElossThe following were used:
Eloss=αEepe+(1-α)(Edata+γEsmooth), (4)
wherein EepeAs an end point error cost function, EdataConstraining the cost function for the data item, EsmoothAnd motion smoothing constraint, wherein alpha and gamma are weights, alpha is 1 when the input data are labeled data, and alpha is 0 when the input data are unlabeled data.
End point error cost function EepeThe following were used:
where m and n are the width and height, respectively, of the input image, ui,jAnd vi,jRespectively, predicted optical flow values, ui′,jAnd vi′,jIs the corresponding optical flow true value.
Data item cost function EdataThe following were used:
wherein κxIs the optical flow at pixel point x, N is the number of pixel points, T (x) represents the value of texture quantity at pixel point x, C (x) represents the value of Census transformation at pixel point x, and phi is the robust penalty function (x)2+δ2)α,δ=0.001,OxRepresenting an occlusion flag function.
Image texture algorithm decomposes an image into a part I containing geometric informationS(x) And a part I containing image texture informationT(x) Namely, the following formula:
I(x)=IS(x)+IT(x), (7)
wherein the texture part I of the imageT(x) Hardly affected by light intensity changes such as illumination and shadows.
Census transform is a nonlinear transform, has conservation property under the condition of severe and monotonous illumination, represents pixels in a certain rectangular transform window in an image by a string of binary sequences, and is applied to data item constraints after being simply improved, and the concrete realization formula is as follows:
wherein W (p) represents a rectangular transformation window with p as a central pixel point, q is other points in the rectangular transformation window, I (p), I (q) are the gray values of p, q pixel points respectively,
σ is a threshold value of the discriminant.
The motion smoothing cost function is as follows:
wherein
And
the gradient values of the optical flow in the horizontal direction and the vertical direction, respectively.
And step six, inputting a small amount of labeled data and a large amount of unlabeled data at the input end of the network, summing the different loss weights to obtain the total loss, and training the semi-supervised learning network by using a back propagation algorithm.
And step seven, inputting labeled data and unlabeled data in the trained model, testing the semi-supervised learning optical flow network, and outputting corresponding dense optical flow.



































