CN108564117B - 一种基于svm的贫困生辅助认定方法 - Google Patents
一种基于svm的贫困生辅助认定方法 Download PDFInfo
- Publication number
- CN108564117B CN108564117B CN201810290654.0A CN201810290654A CN108564117B CN 108564117 B CN108564117 B CN 108564117B CN 201810290654 A CN201810290654 A CN 201810290654A CN 108564117 B CN108564117 B CN 108564117B
- Authority
- CN
- China
- Prior art keywords
- student
- kernel function
- svm
- mixed kernel
- probability
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims abstract description 28
- 238000012706 support-vector machine Methods 0.000 claims abstract description 33
- 238000012549 training Methods 0.000 claims abstract description 26
- 238000004422 calculation algorithm Methods 0.000 claims abstract description 17
- 230000002068 genetic effect Effects 0.000 claims abstract description 13
- 238000007637 random forest analysis Methods 0.000 claims abstract description 13
- 238000007781 pre-processing Methods 0.000 claims abstract description 8
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 7
- 210000000349 chromosome Anatomy 0.000 claims description 43
- 230000035772 mutation Effects 0.000 claims description 14
- 230000008569 process Effects 0.000 claims description 13
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 10
- 238000003066 decision tree Methods 0.000 claims description 8
- 238000012790 confirmation Methods 0.000 claims description 6
- 230000009977 dual effect Effects 0.000 claims description 6
- 238000009396 hybridization Methods 0.000 claims description 4
- 241000867077 Macropes Species 0.000 claims description 3
- 238000002790 cross-validation Methods 0.000 claims description 3
- 230000013011 mating Effects 0.000 claims description 3
- 238000005457 optimization Methods 0.000 claims description 3
- 238000012545 processing Methods 0.000 claims description 3
- 238000006073 displacement reaction Methods 0.000 claims 1
- 238000011156 evaluation Methods 0.000 abstract description 3
- 230000006870 function Effects 0.000 description 57
- 208000032140 Sleepiness Diseases 0.000 description 3
- 206010041349 Somnolence Diseases 0.000 description 3
- 230000037321 sleepiness Effects 0.000 description 3
- 238000013459 approach Methods 0.000 description 2
- 230000008303 genetic mechanism Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000004880 explosion Methods 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000011160 research Methods 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2411—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on the proximity to a decision surface, e.g. support vector machines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/20—Education
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Tourism & Hospitality (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Biology (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Artificial Intelligence (AREA)
- Educational Administration (AREA)
- Educational Technology (AREA)
- Evolutionary Computation (AREA)
- Health & Medical Sciences (AREA)
- Economics (AREA)
- General Health & Medical Sciences (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明公开了一种基于SVM的贫困生辅助认定方法,包括以下步骤:采集学生数据,并对学生数据进行预处理;对预处理学生数据提取特征,通过随机森林对特征重要性进行排名;在满足Mercer条件下,构造混合核函数,并植入SVM中;使用遗传算法对混合核函数参数进行寻优,得到最优混合核函数参数;将最优混合核函数参数代入SVM,并对学生数据进行训练,得到分类器模型;将需要认定的学生数据输入分类器模型,输出分类结果;本发明采用遗传算法对基于SVM混合核函数参数进行寻优,用适应度作为评价依据,通过随机重组重要基因,让群体中的个体不断进化,获取最优解,减少全局搜索时间,提高了分类器的推广泛化能力,并降低成本。
Description
技术领域
本发明涉及SVM核函数研究领域,特别涉及一种基于SVM的贫困生辅助认定方法。
背景技术
随着高等教育的发展,越来越多贫困生进入大学,资助贫困生也成为高校重要的学生工作。而贫困生资格认定是高校资助工作的前提和基础。
目前主流的认定方式是通过人工甄别申请材料,认定过程中存在认定程序僵化、责任主体缺乏伦理监督等问题,难以保证公平客观公正。在信息爆炸时代,兴起的机器学习方法尚不能提出很好的解决方案,在分类器的训练上、分类器的拟合上都存着各种各样的问题。基于统计学习理论提出的支持向量机SVM遵循结构风险最小化原则,有效地避免了维数灾难,但其算法训练时间复杂度较高,泛化能力不够理想,在贫困生辅助认定的应用中始终乏力。
发明内容
本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于SVM的贫困生辅助认定方法。
本发明的目的通过以下的技术方案实现:
一种基于SVM的贫困生辅助认定方法,包括以下步骤:
S1、采集学生数据,并对学生数据进行预处理;
S2、对预处理学生数据提取特征,通过随机森林对特征重要性进行排名;
S3、在满足Mercer条件下,构造混合核函数,并植入支持向量机SVM中;
S4、使用遗传算法对混合核函数参数进行寻优,得到最优混合核函数参数;
S5、将最优混合核函数参数代入SVM中进行训练,训练之后得到分类器模型;
S6、将学生数据输入分类器模型,输出分类结果。
步骤S1中,所述学生数据包含学生一卡通流水记录、学生基本信息、学生成绩和贫困生名单;所述学生基本信息包含学生ID、学生性别、学生名字;学生基本信息包含学生ID、学生性别、学生名字。
步骤S1中,所述预处理包含去重、缺失值处理和格式化;
所述去重为:将学生数据按学生ID进行排序,通过比较邻近记录是否相似来检测记录是否重复,重复则删除重复记录;
所述缺失值处理为:学生数据中某个记录的某个字段为空,则使用平均值进行填充;
所述格式化为:将消费时间格式化为yyyy-MM-dd;消费金额统一单位为分,超限则四舍五入;通过预处理,是数据更合理。
步骤S2具体过程为:
U1、从学生一卡通流水记录构造特征;从时间维度、地点维度和交易维度统计均值和方差;
U2、将学生一卡通流水记录和学生基本信息、学生成绩、贫困生名单,进行归一化数据特征;
U3、使用随机森林对特征重要性进行排名,根据排名,选择前30个特征。
使用随机森林对特征重要性进行排名,具体为:
Y1、设定N个样本,每个样本有M个特征;
Y2、从N个样本中有放回的随机抽取,抽取N次,作为训练一棵决策树的样本;
Y3、每个节点随机抽取m个特征,m<M,从中选取信息增益最大的特征作为决策树的分裂节点,在决策树成长的过程中,m值保持不变;
Y4、重复步骤Y2、Y3,建立大量的决策树,构成随机森林;
Y5、计算每个特征在随机森林中每棵树上的评分均值,作为特征重要性依据。
步骤S3,具体过程为:
基于对局部核函数和全局核函数,构造混合核函数,并植入支持向量机SVM中:

其中,ρ为混合核函数权系数;
步骤S4中,所述寻优过程具体如下:
V1、设置参数:初始种群数量为60,选择代购为0.8,交叉概率为0.6,变异概率为0.06;
V2、使用遗传算法确认混合核函数最优混合核函数参数,确认惩罚因子和确认混合核函数权系数;
V3、混合核函数参数、混合核函数权系数和惩罚因子采用二进制编码,并把其二进制编码组合得到个体染色体基因串,构造出多个染色体组合一个初始种群;
V4、根据初始种群计算适应度值:


其中,P为查准率,R为查全率,TP为真正例数目,FP为假正例数目,FN为假反例数目;
ρ决定了核函数在混合核函数中的比重;若ρ>0.5,则全局核函数占主导;若ρ<0.5,局部核函数占主导;否则二者重要程度相当。可通过调节ρ来灵活组合局部核函数和全局核函数,同时发挥二者长处。
设遗传算法中的适应度值为f(Xi),即10折交叉验证的macroF1值,则有:



其中,Pi为第i次训练查准率;macroP为宏查准率,是10次训练查准率平均值;Ri为第i次训练查全率;macroR为宏查全率,是10次训练查全率平均值;macroF1为宏F1,是基于宏查准率和宏查全率的调和平均值,即为适应度值;
V5、根据适应度值计算染色体入选种群概率:

其中,p(Xi)为第i个染色体入选种群概率,Xi为第i个染色体;
V6、根据入选种群概率的高低,选择代沟为0.8,即保留概率较高的80%染色体,将保留的染色体进行交叉运算和变异运算:
所述交叉运算为随机选取两条染色体,随机选择一个交配点做单点杂交,将产生的新的两条染色体代替原来的染色体,放回初始种群;交叉运算概率为0.6;
所述变异运算为杂交后的个体进行变异运算,随机选取一条染色体;
V7、通过不断进化,获取最优混合核函数系数、最优确认惩罚因子和最优确认混合核函数权系数。
步骤S5,具体过程为:
根据步骤S4获得的最优混合核函数系数,使用SMO算法通过训练学生数据得到最优的 其中,
其中, 为拉格朗日乘子的最优解,
为拉格朗日乘子的最优解, 为分类超平面的最优解;即:SMO每次选取两个拉格朗日乘子,固定其余参数;求解:
为分类超平面的最优解;即:SMO每次选取两个拉格朗日乘子,固定其余参数;求解:


其中,ai、aj为拉格朗日乘子;yi为第i个学生标识,yj为第j个学生标识;
获得更新后的ai、aj;
求解非线性支持向量机和其对偶问题,重复选取和求解,得到
其中非线性支持向量机为:

其中,ω为分类超平面法向量,ξ为松弛变量,Φ(xi)为将xi映射后的特征向量;
对偶问题:

通过 得到分类器模型:
得到分类器模型:

其中,x为需要认定的学生数据特征值。
步骤S6,具体如下:
将需要认定的学生数据输入到分类器模型中,通过分类器模型,得出f(x),若为正则表示这个学生大概率为贫困生,若为负则表示这个学生大概率不是贫困生,再通过实际考核,认定新的贫困生,添加到贫困生名单中,得到新的贫困生名单。
本发明与现有技术相比,具有如下优点和有益效果:
本发明采用遗传算法对混合核函数参数进行寻优,模拟生物的自然选择和遗传机制,用编码空间代替问题参数空间,用适应度作为评价依据,通过随机重组重要基因,让群体中的个体不断进化,逐步接近最优解,减少全局搜索时间,充分发挥局部核函数和全局核函数的优势,在不增加训练时间复杂度的前提下,提高了分类器的推广泛化能力,降低成本。
附图说明
图1是本发明一种基于SVM的贫困生辅助认定的方法流程框图;
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,一种基于SVM的贫困生辅助认定方法,包括以下步骤:
第一步:采集学生数据,并对学生数据进行预处理;学生数据包含学生一卡通流水记录、学生基本信息、学生成绩和贫困生名单;学生基本信息包含学生ID、学生性别、学生名字;
预处理包含去重、缺失值处理和格式化;
去重为:将学生数据按学生ID进行排序,通过比较邻近记录是否相似来检测记录是否重复,重复则删除重复记录;
缺失值处理为:学生数据中某个记录的摸个字段为空,则使用平均值进行填充;
格式化为:将消费时间格式化为yyyy-MM-dd;消费金额统一单位为分,超限则四舍五入。
第二步:对预处理学生数据提取特征,通过随机森林对特征重要性进行排名;从一卡通流水记录中构造特征,即各时间段、各地点的消费、充值等行为的总额、均值计数等统计量。其中,时间维度可分为一天、周末、早、中、晚等几个时间段,地点维度可分为饭堂、商铺、图书馆、西餐厅,交易维度分为消费和充值,对交易金额的统计量分为均值、方差、计数等。比如学生周末在图书馆的消费总额、早上八点前在饭堂的消费均值、在商铺西餐厅的消费次数和均值等;具体过程为:
从学生一卡通流水记录构造特征;从时间维度、地点维度和交易维度统计均值和方差;
将学生一卡通流水记录和学生基本信息、学生成绩、贫困生名单,进行归一化数据特征;
使用随机森林对特征重要性进行排名,根据排名,选择前30个特征。
第三步:在满足Mercer条件下,构造混合核函数,并植入支持向量机SVM中;基于对局部核函数和全局核函数,构造混合核函数:

其中,ρ为混合核函数权系数, 为高斯核,属于局部核函数;σ为高斯核的带宽,σ>0,[(xi·xj)+c]d为多项式核,属于全局核函数,c为自由参数,c≥0;d为多项式次数,d≥1,xi为第i个样本的特征值向量,xj为第j个特征值向量;将混合核函数植入SVM中。
为高斯核,属于局部核函数;σ为高斯核的带宽,σ>0,[(xi·xj)+c]d为多项式核,属于全局核函数,c为自由参数,c≥0;d为多项式次数,d≥1,xi为第i个样本的特征值向量,xj为第j个特征值向量;将混合核函数植入SVM中。
第四步:使用遗传算法对混合核函数参数进行寻优,得到最优混合核函数参数;寻优过程具体如下:
设置参数:初始种群数量为60,选择代购为0.8,交叉概率为0.6,变异概率为0.06;
使用遗传算法确认混合核函数最优混合核函数参数,确认惩罚因子和确认混合核函数权系数;
混合核函数参数(σ、c、d)、混合核函数权系数ρ和惩罚因子C采用二进制编码,并把其二进制编码组合得到个体染色体基因串,群体空间如下:

假设n1=n2=n3=n4=7,则这五个参数的二进制编码都是七位,每一位取值0或1,则每个参数的取值范围是0~127。比如:
| 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 |
其中一个染色体,表示五个参数都是127。
| 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 |
另外一个染色体,表示五个参数都是0。以此类推,可以构造出多个染色体构成一个初始种群。而后,根据这个初始种群计算适应度值。
用个体染色体基因串,构造出多个染色体组合一个初始种群;
根据初始种群计算适应度值:
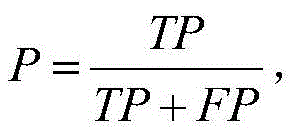

其中,P为查准率,R为查全率,TP为真正例数目,FP为假正例数目,FN为假反例数目;
设遗传算法中的适应度值为f(Xi),即10折交叉验证的macroF1值,则有:



其中,Pi为第i次训练查准率;macroP为宏查准率,是10次训练查准率平均值;Ri为第i次训练查全率;macroR为宏查全率,是10次训练查全率平均值;macroF1为宏F1,是基于宏查准率和宏查全率的调和平均值,即为适应度值;
根据适应度值计算染色体入选种群概率:

其中,p(Xi)为第i个染色体入选种群概率,Xi为第i个染色体,f(Xj)为第j个染色体的适应度值;
根据入选种群概率的高低,选择代沟为0.8,即保留概率较高的80%染色体,将保留的染色体进行交叉运算和变异运算:
交叉运算为随机选取两条染色体,随机选择一个交配点做单点杂交,将产生的新的两条染色体代替原来的染色体,放回初始种群;交叉运算概率为0.6;
| 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 |
| 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 |
单点杂交后:
| 0 | …… | 0 | …… | 0 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 |
| 1 | …… | 1 | …… | 1 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 |
变异运算为杂交后的个体进行变异运算,随机选取一条染色体;
| 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 | …… | 0 |
变异运算后:
| 0 | …… | 0 | …… | 0 | …… | 1 | …… | 1 | …… | 1 | …… | 1 | …… | 1 |
遗传算法模拟生物的自然选择和遗传机制,用编码空间代替问题的参数空间,用适应度函数作为评价依据。通过随机重组重要的基因,让群体中的个体不断进化,逐步接近最优解,并减少全局搜索时间。
通过不断进化,获取最优混合核函数系数、最优确认惩罚因子和最优确认混合核函数权系数,即得到多项式核函数与径向基核函数的调整比重,混合核函数的权系数ρ=0.8253,以及C=5.9801、σ=0.0192、c=0、d=2。
第五步:将最优混合函数系数代入最优分类函数,并对学生数据进行训练,得到分类器模型;具体过程为:
根据步骤S4获得的最优混合核函数系数,使用SMO算法通过训练学生数据得到最优的 其中,
其中, 为拉格朗日乘子的最优解,
为拉格朗日乘子的最优解, 为分类超平面的最优解;即:SMO每次选取两个拉格朗日乘子,固定其余参数;求解:
为分类超平面的最优解;即:SMO每次选取两个拉格朗日乘子,固定其余参数;求解:


其中,ai、aj为拉格朗日乘子;yi为第i个学生标识,yj为第j个学生标识;
获得更新后的ai、aj;
求解非线性支持向量机和其对偶问题,重复选取和求解,得到
其中非线性支持向量机为:

对偶问题:

通过 得到分类器模型:
得到分类器模型:

其中,x为需要认定的学生数据特征值。
第六步:将需要认定的学生数据输入到分类器模型中,通过分类器模型计算,得出f(x),若f(x)为正则表示这个学生大概率为贫困生,若f(x)为负则表示这个学生大概率不是贫困生,再通过实际考核,认定新的贫困生,添加到贫困生名单中,得到新的贫困生名单。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
Claims (7)
1.一种基于SVM的贫困生辅助认定方法,其特征在于,包括以下步骤:
S1、采集学生数据,并对学生数据进行预处理;
S2、对预处理学生数据提取特征,通过随机森林对特征重要性进行排名;
S3、在满足Mercer条件下,构造混合核函数,并植入SVM中;
具体过程为:
基于对局部核函数和全局核函数,构造混合核函数,并植入SVM中:

其中,ρ为混合核函数权系数, 为高斯核,属于局部核函数;σ为高斯核的带宽,σ>0,[(xi·xj)+c]d为多项式核,属于全局核函数,c为自由参数,c≥0;d为多项式次数,d≥1,xi为第i个样本的特征值向量,xj为第j个样本的特征值向量;
为高斯核,属于局部核函数;σ为高斯核的带宽,σ>0,[(xi·xj)+c]d为多项式核,属于全局核函数,c为自由参数,c≥0;d为多项式次数,d≥1,xi为第i个样本的特征值向量,xj为第j个样本的特征值向量;
S4、使用遗传算法对混合核函数参数进行寻优,得到最优混合核函数参数;
S5、将最优混合核函数参数代入SVM中进行训练,训练之后得到分类器模型;具体过程为:
根据步骤S4获得的最优混合核函数系数,使用SMO算法通过训练学生数据得到最优的 其中,
其中,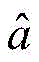 为拉格朗日乘子的最优解,
为拉格朗日乘子的最优解, 为分类超平面的位移最优解;即:SMO每次选取两个拉格朗日乘子,固定其余参数;求解:
为分类超平面的位移最优解;即:SMO每次选取两个拉格朗日乘子,固定其余参数;求解:


其中,ai、aj为拉格朗日乘子;yi为第i个学生标识,yj为第j个学生标识;
获得更新后的ai、aj;
求解非线性支持向量机和其对偶问题,重复选取和求解,得到
其中非线性支持向量机为:

对偶问题:

通过 得到分类器模型:
得到分类器模型:

其中,x为需要认定的学生数据特征值;
S6、将需要认定的学生数据输入分类器模型,输出分类结果。
2.根据权利要求1所述的一种基于SVM的贫困生辅助认定方法,其特征在于,步骤S1中,所述学生数据包含学生一卡通流水记录、学生基本信息、学生成绩和贫困生名单;所述学生基本信息包含学生ID、学生性别、学生名字。
3.根据权利要求1所述的一种基于SVM的贫困生辅助认定方法,其特征在于,步骤S1中,所述预处理包含去重、缺失值处理和格式化;
所述去重为:将学生数据按学生ID进行排序,通过比较邻近记录是否相似来检测记录是否重复,重复则删除重复记录;
所述缺失值处理为:学生数据中某个记录的某个字段为空,则使用平均值进行填充;
所述格式化为:将消费时间格式化为yyyy-MM-dd;消费金额统一单位为分,超限则四舍五入。
4.根据权利要求1所述的一种基于SVM的贫困生辅助认定方法,其特征在于,所述步骤S2具体过程为:
U1、从学生一卡通流水记录构造特征;从时间维度、地点维度和交易维度统计均值和方差;
U2、将学生一卡通流水记录数据特征、学生基本信息数据特征、学生成绩数据特征和贫困生名单数据特征,进行归一化;
U3、使用随机森林对特征重要性进行排名,根据排名,选择前30个特征。
5.根据权利要求4所述的一种基于SVM的贫困生辅助认定方法,其特征在于,所述使用随机森林对特征重要性进行排名具体为:
Y1、设定N个样本,每个样本有M个特征;
Y2、从N个样本中有放回的随机抽取,抽取N次,作为训练一棵决策树的样本;
Y3、每个节点随机抽取m个特征,m<M,从中选取信息增益最大的特征作为决策树的分裂节点,在决策树成长的过程中,m值保持不变;
Y4、重复步骤Y2、Y3,建立大量的决策树,构成随机森林;
Y5、计算每个特征在随机森林中每棵树上的评分均值,作为特征重要性依据。
6.根据权利要求1所述的一种基于SVM的贫困生辅助认定方法,其特征在于,步骤S4中,所述寻优过程具体如下:
V1、设置参数:初始种群数量为60,选择代购为0.8,交叉概率为0.6,变异概率为0.06;
V2、使用遗传算法确认混合核函数最优混合核函数参数,确认惩罚因子和确认混合核函数权系数;
V3、混合核函数参数、混合核函数权系数和惩罚因子采用二进制编码,并把其二进制编码组合得到个体染色体基因串,构造出多个染色体组合一个初始种群;
V4、根据初始种群计算适应度值:


其中,P为查准率,R为查全率,TP为真正例数目,FP为假正例数目,FN为假反例数目;
设遗传算法中的适应度值为f(Xi),即10折交叉验证的macroF1值,则有:



其中,Pi为第i次训练查准率;macroP为宏查准率,是10次训练查准率平均值;Ri为第i次训练查全率;macroR为宏查全率,是10次训练查全率平均值;macroF1为宏F1,是基于宏查准率和宏查全率的调和平均值,即为适应度值;
V5、根据适应度值计算染色体入选种群概率:

其中,p(Xi)为第i个染色体入选种群概率;Xi为第i个染色体;f(Xj)为第j个染色体的适应度值;
V6、根据入选种群概率的高低,选择代沟为0.8,即保留概率较高的80%染色体,将保留的染色体进行交叉运算和变异运算:
所述交叉运算为随机选取两条染色体,随机选择一个交配点做单点杂交,将产生的新的两条染色体代替原来的染色体,放回初始种群;交叉运算概率为0.6;
所述变异运算为杂交后的个体进行变异运算,随机选取一条染色体,该染色体某个二进制位有6%的概率变异,即由0变1或由1变0;
V7、通过不断进化,获取最优混合核函数系数、最优确认惩罚因子和最优确认混合核函数权系数,从而确定混合核函数。
7.根据权利要求1所述的一种基于SVM的贫困生辅助认定方法,其特征在于,所述步骤S6,具体如下:
将需要认定的学生数据输入到分类器模型中,通过分类器模型,得出f(x),若为正则表示这个学生大概率为贫困生,若为负则表示这个学生大概率不是贫困生,再通过实际考核,认定新的贫困生,添加到贫困生名单中,得到新的贫困生名单。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810290654.0A CN108564117B (zh) | 2018-03-30 | 2018-03-30 | 一种基于svm的贫困生辅助认定方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810290654.0A CN108564117B (zh) | 2018-03-30 | 2018-03-30 | 一种基于svm的贫困生辅助认定方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108564117A CN108564117A (zh) | 2018-09-21 |
| CN108564117B true CN108564117B (zh) | 2022-03-29 |
Family
ID=63533802
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810290654.0A Expired - Fee Related CN108564117B (zh) | 2018-03-30 | 2018-03-30 | 一种基于svm的贫困生辅助认定方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108564117B (zh) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109472299A (zh) * | 2018-10-19 | 2019-03-15 | 浙江正元智慧科技股份有限公司 | 一种基于智能卡大数据的贫困大学生识别方法 |
| CN111144430B (zh) * | 2018-11-05 | 2023-08-01 | 中国移动通信集团广东有限公司 | 基于遗传算法的养卡号码识别方法及装置 |
| CN109670998A (zh) * | 2018-12-27 | 2019-04-23 | 三盟科技股份有限公司 | 基于校园大数据环境下的精准资助多级认定方法及系统 |
| CN109871992A (zh) * | 2019-01-30 | 2019-06-11 | 北京工业大学 | 基于r-svm的tft-lcd工业智能预测方法 |
| CN111178699B (zh) * | 2019-12-15 | 2023-05-23 | 贵州电网有限责任公司 | 一种调度操作票智能校核系统构建方法 |
| CN112215385B (zh) * | 2020-03-24 | 2024-03-19 | 北京桃花岛信息技术有限公司 | 一种基于贪婪选择策略的学生困难程度预测方法 |
| CN113780637B (zh) * | 2021-08-27 | 2023-10-17 | 广东工业大学 | 基于辅助优化与拉格朗日优化的支持向量机学习方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102058413A (zh) * | 2010-12-03 | 2011-05-18 | 上海交通大学 | 基于连续小波变换的脑电信号警觉度检测方法 |
| CN104009886A (zh) * | 2014-05-23 | 2014-08-27 | 南京邮电大学 | 基于支持向量机的入侵检测方法 |
| CN106897703A (zh) * | 2017-02-27 | 2017-06-27 | 辽宁工程技术大学 | 基于aga‑pkf‑svm的遥感影像分类方法 |
| US9721181B2 (en) * | 2015-12-07 | 2017-08-01 | The Climate Corporation | Cloud detection on remote sensing imagery |
| CN107357966A (zh) * | 2017-06-21 | 2017-11-17 | 山东科技大学 | 一种回采巷道围岩稳定性预测与评估方法 |
-
2018
- 2018-03-30 CN CN201810290654.0A patent/CN108564117B/zh not_active Expired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102058413A (zh) * | 2010-12-03 | 2011-05-18 | 上海交通大学 | 基于连续小波变换的脑电信号警觉度检测方法 |
| CN104009886A (zh) * | 2014-05-23 | 2014-08-27 | 南京邮电大学 | 基于支持向量机的入侵检测方法 |
| US9721181B2 (en) * | 2015-12-07 | 2017-08-01 | The Climate Corporation | Cloud detection on remote sensing imagery |
| CN106897703A (zh) * | 2017-02-27 | 2017-06-27 | 辽宁工程技术大学 | 基于aga‑pkf‑svm的遥感影像分类方法 |
| CN107357966A (zh) * | 2017-06-21 | 2017-11-17 | 山东科技大学 | 一种回采巷道围岩稳定性预测与评估方法 |
Non-Patent Citations (3)
| Title |
|---|
| 华南理工大学节能监管平台建设;彭新一;《建设科技》;20100131(第2期);第22-23页 * |
| 基于校园一卡通消费数据对高校贫困生分类的应用研究;张玺,呙森林,孙宗良;《数字技术与应用》;20160831(第8期);第100页 * |
| 基于遗传算法和SVM的遥感图像检索;彭晏飞等;《小型微型计算机系统》;20160430;第37卷(第4期);第875-880页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108564117A (zh) | 2018-09-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108564117B (zh) | 一种基于svm的贫困生辅助认定方法 | |
| CN112070125A (zh) | 一种基于孤立森林学习的不平衡数据集的预测方法 | |
| CN113517066B (zh) | 基于候选基因甲基化测序和深度学习的抑郁症评估方法及系统 | |
| CN111899882B (zh) | 一种预测癌症的方法及系统 | |
| CN111641608A (zh) | 异常用户识别方法、装置、电子设备及存储介质 | |
| CN112926640A (zh) | 一种基于两阶段深度特征选择的癌症基因分类方法、设备及存储介质 | |
| CN114093426B (zh) | 基于基因调控网络构建的标志物筛选方法 | |
| CN110471854A (zh) | 一种基于高维数据混合约简的缺陷报告指派方法 | |
| CN109934286A (zh) | 基于文本特征提取和不平衡处理策略的Bug报告严重程度识别方法 | |
| CN109992592B (zh) | 基于校园消费卡流水数据的高校贫困生识别方法 | |
| CN115995262B (zh) | 基于随机森林及lasso回归解析玉米遗传机理的方法 | |
| CN111708865A (zh) | 一种基于改进XGBoost算法的技术预见及专利预警分析方法 | |
| CN117575745A (zh) | 基于ai大数据的课程教学资源个性推荐方法 | |
| CN111128300A (zh) | 基于突变信息的蛋白相互作用影响判断方法 | |
| CN113704464B (zh) | 基于网络新闻的时评类作文素材语料库的构建方法及系统 | |
| CN113421176B (zh) | 一种学生成绩分数中异常数据智能筛选方法 | |
| CN113838519B (zh) | 基于自适应基因交互正则化弹性网络模型的基因选择方法及系统 | |
| CN116153396A (zh) | 一种基于迁移学习的非编码变异预测方法 | |
| Nahid et al. | Home occupancy classification using machine learning techniques along with feature selection | |
| CN114943866A (zh) | 基于进化神经网络结构搜索的图像分类方法 | |
| JP5852902B2 (ja) | 遺伝子間相互作用解析システム、その方法及びプログラム | |
| CN115269572A (zh) | 基于海量科研资料的课题立项决策推荐方法及装置 | |
| CN112348275A (zh) | 一种基于在线增量学习的区域生态环境变化预测方法 | |
| Kimmel et al. | Modeling neutral evolution of Alu elements using a branching process | |
| CN116992098B (zh) | 引文网络数据处理方法及系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20220329 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |