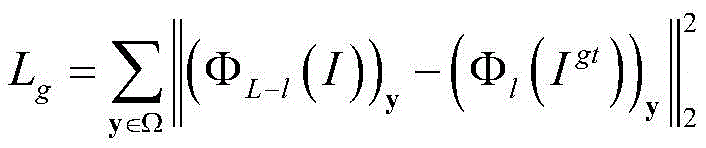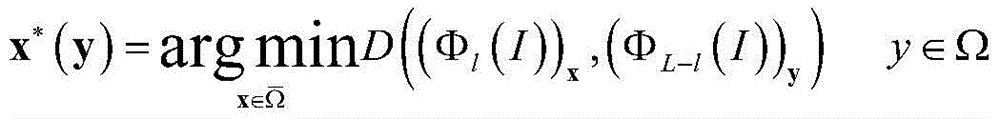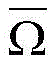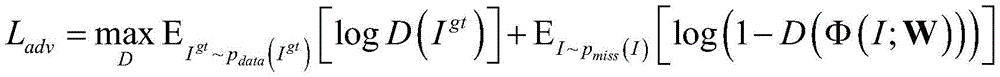Image filling system of convolutional neural network based on feature map nearest neighbor replacement
Technical Field
The invention relates to an image filling system, and belongs to the technical field of image filling.
Background
Image filling is a fundamental problem in the field of computer vision and image processing, and is mainly used for performing restoration reconstruction on damaged images or removing unnecessary objects in the images.
The existing image filling methods mainly include a diffusion-based image filling method, a sample-based image filling method and a depth learning-based image filling method.
The basic idea of the diffusion-based image filling method is as follows: and diffusing the image information at the edge of the region to be filled into the inner part of the region to be filled by taking the pixel points as units. When the area of the area to be filled is small, the structure is simple, and the texture is single, the image filling method can well complete the image filling task. However, when the area of the region to be filled is large, the definition of the filled image obtained by the image filling method is poor.
The basic idea of the sample-based image filling method is as follows: and gradually filling the image blocks from the known area of the image to the area to be filled by taking the image blocks as units. And filling the area to be filled with the image blocks which are most similar to the image blocks at the edge of the area to be filled in the known area of the image each time the image blocks are filled. Compared with the image filling method based on diffusion, the filled image obtained by the image filling method based on the sample has better texture and higher definition. However, since the sample-based image filling method gradually replaces the unknown image blocks in the region to be filled with similar image blocks in the known region of the image, a filled image with uniform overall semantics cannot be obtained by using the image filling method.
The image filling method based on deep learning mainly refers to the application of a deep neural network to the field of image filling. Currently, it is proposed to use an encoder-decoder network to perform image filling on an image with missing intermediate regions. However, this image filling method is only applicable to 128 × 128 RGB images. Although the filled image obtained by the image filling method can meet the requirement of uniform overall semantics, the definition of the filled image is poor. In response to this problem, some researchers have attempted to perform a clear filling of large graphs using multi-scale iterative updating. However, although such image filling methods result in filled images with overall semantic consistency and good sharpness, they are extremely slow. In the Titan X display running environment, it takes tens of seconds to several minutes to fill a 256 × 256 RGB image.
Disclosure of Invention
The invention provides an image filling system of a convolutional neural network based on nearest neighbor replacement of a feature map, which aims to solve the problem that the existing image filling method cannot quickly obtain a filled image with consistent integral semantics and good definition.
The image filling system of the convolutional neural network based on feature map nearest neighbor replacement comprises a generating network and a judging network;
the generation network comprises an encoder and a decoder, wherein the encoder comprises N convolution layers, the decoder comprises N deconvolution layers, and N is more than or equal to 2;
the generation network obtains the filled image by a mode of firstly encoding and then decoding the image to be filled;
for any M deconvolution layers from the first deconvolution layer to the N-1 th deconvolution layer, generating a network based on an output result of each deconvolution layer and an output result of a convolution layer corresponding to the deconvolution layer, obtaining an additional feature map by adopting a feature map nearest neighbor replacement mode, and taking the output result of each deconvolution layer, the output result of the convolution layer corresponding to the deconvolution layer and the obtained additional feature map as input objects of the next deconvolution layer;
1≤M≤N-1;
the judgment network is used for judging whether the filled image is a real image corresponding to the image to be filled, and further restricting the weight learning of the generated network.
Preferably, the encoder includes a convolutional layer E1-convolutional layer E8The decoder includes an deconvolution layer D1Inverse convolution layer D8;
The image to be filled is a convolution layer E1The input object of (1);
for convolution layer E1-convolutional layer E8The output result of the former is used as the input object of the latter after being sequentially subjected to batch normalization and activation of a Leaky ReLU function;
convolution layer E8The output result of (A) is used as an deconvolution layer D after being sequentially subjected to batch normalization and activation of a Leaky ReLU function1The input object of (1);
deconvolution layer D1The output result of (A) is used as a deconvolution layer D after being activated by a ReLU function2The first input object of (1);
for deconvolution layer D2Inverse convolution layer D8The output result of the former is used as a first input object of the latter after being sequentially activated by a ReLU function and normalized in batches;
deconvolution layer D2Inverse convolution layer D8The second input object of (2) is a convolutional layer in turnE7-convolutional layer E1The output result is sequentially subjected to batch normalization and Leaky ReLU function activation;
deconvolution layer D after Tanh function activation8The output of (1) is a filled image;
convolution layer E1The convolution operation is used for performing 64 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E2The convolution operation is used for performing 128 4-by-4 convolution operations with the step size of 2 on the input object;
convolution layer E3The convolution operation is used for carrying out 256 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E4-convolutional layer E8All used for carrying out 512 convolution operations with 4 × 4 and 2 steps on the input object;
deconvolution layer D1Inverse convolution layer D4All used for carrying out 512 deconvolution operations with 4 × 4 and step length of 2 on the input object;
deconvolution layer D5The deconvolution operation is used for carrying out 256 operations with 4 × 4 and the step size of 2 on the input object;
deconvolution layer D6The deconvolution operation is carried out on the input objects with 128 4 × 4 steps of 2;
deconvolution layer D7The deconvolution device is used for carrying out 64 deconvolution operations with 4 × 4 and the step size of 2 on the input object;
deconvolution layer D8The deconvolution operation is performed on the input object by 3 times 4 with the step size of 2;
generating networks based on deconvolution layer D5Output result of (2) and convolutional layer E3And obtaining an additional feature map by adopting a feature map nearest neighbor replacement mode, and taking the additional feature map as a deconvolution layer D6The third input object of (1).
Preferably, the generation network is based on the deconvolution layer D5Output result of (2) and convolutional layer E3The specific process of obtaining the additional feature map by adopting the feature map nearest neighbor replacement mode is as follows:
selecting a feature map to be assigned with feature values of 0The feature map and the deconvolution layer D5Output feature map of (2) and convolutional layer E3The output feature maps of (a) have equal channel numbers and the same space size;
calculating to obtain the deconvolution layer D5Mask region of the output feature map of (1) and convolution layer E3And simultaneously cutting the masked areas and the unmasked areas into a plurality of feature blocks;
the characteristic blocks are cuboids with the size of C h w, wherein C, h and w are deconvolution layers D respectively5The number of channels of the output characteristic diagram, the length of the cuboid and the width of the cuboid;
for each feature block p in the masked area1Selecting a feature block p from the plurality of feature blocks of the non-mask region1Nearest feature block p2;
Selecting a region to be assigned in the feature map to be assigned, wherein the region to be assigned and the feature block p1At the deconvolution layer D5The positions in the output feature map of (a) are consistent;
will the characteristic block p2The characteristic value of (2) is given to the area to be assigned.
Preferably, the feature block p2And feature block p1The cosine of (c) is closest.
Preferably, the calculation method of the masked area and the unmasked area of the output feature map is as follows:
giving a mask image to replace an image to be filled, wherein the mask image and the image to be filled have the same size, the number of channels is 1, and the characteristic value is 0 or 1;
0 represents that the corresponding position of the characteristic point on the image to be filled is a non-filling point;
1 represents that the corresponding position of the characteristic point on the image to be filled is a point to be filled;
calculating a mask region and a non-mask region of a feature map of a mask image through a convolution network, wherein the convolution network comprises a first convolution layer to a third convolution layer;
the mask image is an input object of the first convolution layer;
for the first convolution layer to the third convolution layer, the output result of the former is the input object of the latter;
the first convolution layer to the third convolution layer are all used for carrying out 1 convolution operation with 4 x 4 and step length of 2 on the input object;
the output result of the third convolution layer is a feature map of the mask image, the size of the feature map is 32 × 32, and the channel is 1;
for the feature map of the mask image, when one feature value of the feature map is larger than a set threshold value, judging that the feature point is a mask point, otherwise, judging that the feature point is a non-mask point;
the mask area of the feature map of the mask image is a set of mask points, and the unmasked area of the feature map of the mask image is a set of unmasked points;
the mask area of the output characteristic diagram is equal to the mask area of the characteristic diagram of the mask image, and the unmasked area of the output characteristic diagram is equal to the unmasked area of the characteristic diagram of the mask image.
Preferably, the generated network is trained in a guidance loss constraint mode, wherein the specific guidance loss constraint mode is to perform feature similarity constraint on the real image and the input image in any convolution layer or deconvolution layer in the network generation training process;
the input image is a real image subjected to the masking operation.
Preferably, the specific way of generating the network for training is as follows:
the target image IgtInputting the data into a generation network, calculating a mask region of a characteristic diagram of the l-th layer, and obtaining (phi)l(Igt))yInformation;
inputting the image I to be filled into a generation network, calculating a mask region of a characteristic diagram of the L-L layer, and obtaining (phi)L-l(I))yInformation;
at this point a guidance loss constraint L is definedg:
Where Ω is the mask area, L is the total number of layers to generate the network, y is any coordinate point within the mask area, ΦL-l(I) When the input object is an image to be filled, a characteristic diagram output by the network at the L-L level is generated, (phi)L-l(I))yInformation of y in the masked region of the output feature map for the L-L-th layer, Φl(Igt) When the input object is a target image, generating a characteristic diagram output by the network at the l-th layer (phi)l(Igt))yAnd the information of y in the mask area of the output characteristic diagram of the l-th layer.
Preferably, the discriminating network comprises a convolutional layer E9-convolutional layer E13;
Convolution layer E9The input object of (1) is a filled image;
convolution layer E9The output result of (A) is activated by a Leaky ReLU function and then used as a convolution layer E10The input object of (1);
for convolution layer E10-convolutional layer E13The output result of the former is used as the input object of the latter after being sequentially subjected to batch normalization and activation of a Leaky ReLU function;
convolutional layer E sequentially subjected to batch normalization and Sigmoid function activation13The output result of (1) is the output result of the discrimination network;
convolution layer E9The convolution operation is used for performing 64 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E10The convolution operation is used for performing 128 4-by-4 convolution operations with the step size of 2 on the input object;
convolution layer E11The convolution operation is used for carrying out 256 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E12The convolution operation is used for carrying out 512 convolution operations with 4 x 4 and step size of 1 on the input object;
convolution layer E13For performing 1 convolution operation with 4 × 4 and step size of 1 on the input object.
Preferably, the filled image is an RGB image of 256 × 256, and the convolution layer E is formed13The space of the output result is largeSmall 64 x 64, channel 1.
Preferably, the image population system is trained end-to-end using an Adam optimization algorithm.
The image filling system of the convolutional neural network based on feature map nearest neighbor replacement takes an image to be filled as an input object of the image, and performs feature map nearest neighbor replacement through intermediate output of a network decoding part, so that the filled image with integral semantic consistency and good definition can be obtained through one-time forward propagation. Compared with the existing image filling method, the image filling system can obtain the filled image more quickly because only one forward propagation is needed.
Drawings
The image filling system of the convolutional neural network based on feature map nearest neighbor replacement according to the present invention will be described in more detail below based on embodiments and with reference to the accompanying drawings, in which:
FIG. 1 is a block diagram of a network according to an embodiment;
FIG. 2 is a block diagram of a discrimination network according to an embodiment;
FIG. 3 is an arbitrarily missing image to be filled;
FIG. 4 is a filled image obtained after inputting any missing image to be filled into the generation network;
FIG. 5 is a missing-centered image to be filled;
fig. 6 is a filled image obtained by inputting an image to be filled with a missing center into the generation network.
Detailed Description
The image filling system based on the convolutional neural network with feature map nearest neighbor replacement according to the present invention will be further described with reference to the accompanying drawings.
Example (b): the present embodiment will be described in detail with reference to fig. 1 to 6.
The image filling system of the convolutional neural network based on feature map nearest neighbor replacement described in this embodiment includes a generation network and a discrimination network;
the generation network comprises an encoder and a decoder, wherein the encoder comprises N convolution layers, the decoder comprises N deconvolution layers, and N is more than or equal to 2;
the generation network obtains the filled image by a mode of firstly encoding and then decoding the image to be filled;
for any M deconvolution layers from the first deconvolution layer to the N-1 th deconvolution layer, generating a network based on an output result of each deconvolution layer and an output result of a convolution layer corresponding to the deconvolution layer, obtaining an additional feature map by adopting a feature map nearest neighbor replacement mode, and taking the output result of each deconvolution layer, the output result of the convolution layer corresponding to the deconvolution layer and the obtained additional feature map as input objects of the next deconvolution layer;
1≤M≤N-1;
the judgment network is used for judging whether the filled image is a real image corresponding to the image to be filled, and further restricting the weight learning of the generated network.
The encoder of the present embodiment includes a convolution layer E1-convolutional layer E8The decoder includes an deconvolution layer D1Inverse convolution layer D8;
The image to be filled is a convolution layer E1The input object of (1);
for convolution layer E1-convolutional layer E8The output result of the former is used as the input object of the latter after being sequentially subjected to batch normalization and activation of a Leaky ReLU function;
convolution layer E8The output result of (A) is used as an deconvolution layer D after being sequentially subjected to batch normalization and activation of a Leaky ReLU function1The input object of (1);
deconvolution layer D1The output result of (A) is used as a deconvolution layer D after being activated by a ReLU function2The first input object of (1);
for deconvolution layer D2Inverse convolution layer D8The output result of the former is used as a first input object of the latter after being sequentially activated by a ReLU function and normalized in batches;
deconvolution layer D2Inverse convolution layer D8The second input object of (2) is sequentially a convolutional layer E7-convolutional layer E1The output result is sequentially subjected to batch normalization and Leaky ReLU function activation;
deconvolution layer D after Tanh function activation8The output of (1) is a filled image;
convolution layer E1The convolution operation is used for performing 64 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E2The convolution operation is used for performing 128 4-by-4 convolution operations with the step size of 2 on the input object;
convolution layer E3The convolution operation is used for carrying out 256 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E4-convolutional layer E8All used for carrying out 512 convolution operations with 4 × 4 and 2 steps on the input object;
deconvolution layer D1Inverse convolution layer D4All used for carrying out 512 deconvolution operations with 4 × 4 and step length of 2 on the input object;
deconvolution layer D5The deconvolution operation is used for carrying out 256 operations with 4 × 4 and the step size of 2 on the input object;
deconvolution layer D6The deconvolution operation is carried out on the input objects with 128 4 × 4 steps of 2;
deconvolution layer D7The deconvolution device is used for carrying out 64 deconvolution operations with 4 × 4 and the step size of 2 on the input object;
deconvolution layer D8The deconvolution operation is performed on the input object by 3 times 4 with the step size of 2;
generating networks based on deconvolution layer D5Output result of (2) and convolutional layer E3And obtaining an additional feature map by adopting a feature map nearest neighbor replacement mode, and taking the additional feature map as a deconvolution layer D6The third input object of (1).
The generation network of this embodiment is based on deconvolution layer D5Output result of (2) and convolutional layer E3The specific process of obtaining the additional feature map by adopting the feature map nearest neighbor replacement mode is as follows:
selecting a feature map to be assigned with feature values of 0, and comparing the feature map with a deconvolution layer D5Output feature map of (2) and convolutional layer E3The output feature maps of (a) have equal channel numbers and the same space size;
calculating to obtain the deconvolution layer D5Mask region of the output feature map of (1) and convolution layer E3And simultaneously cutting the masked areas and the unmasked areas into a plurality of feature blocks;
the characteristic blocks are cuboids with the size of C h w, wherein C, h and w are deconvolution layers D respectively5The number of channels of the output characteristic diagram, the length of the cuboid and the width of the cuboid;
for each feature block p in the masked area1Selecting a feature block p from the plurality of feature blocks of the non-mask region1Nearest feature block p2;
Selecting a region to be assigned in the feature map to be assigned, wherein the region to be assigned and the feature block p1At the deconvolution layer D5The positions in the output feature map of (a) are consistent;
will the characteristic block p2The characteristic value of (2) is given to the area to be assigned.
The calculation mode of the mask region and the non-mask region of the output characteristic diagram is as follows:
giving a mask image to replace an image to be filled, wherein the mask image and the image to be filled have the same size, the number of channels is 1, and the characteristic value is 0 or 1;
0 represents that the corresponding position of the characteristic point on the image to be filled is a non-filling point;
1 represents that the corresponding position of the characteristic point on the image to be filled is a point to be filled;
calculating a mask region and a non-mask region of a feature map of a mask image through a convolution network, wherein the convolution network comprises a first convolution layer to a third convolution layer;
the mask image is an input object of the first convolution layer;
for the first convolution layer to the third convolution layer, the output result of the former is the input object of the latter;
the first convolution layer to the third convolution layer are all used for carrying out 1 convolution operation with 4 x 4 and step length of 2 on the input object;
the output result of the third convolution layer is a feature map of the mask image, the size of the feature map is 32 × 32, and the channel is 1;
for the feature map of the mask image, when one feature value of the feature map is larger than a set threshold value, judging that the feature point is a mask point, otherwise, judging that the feature point is a non-mask point;
the mask area of the feature map of the mask image is a set of mask points, and the unmasked area of the feature map of the mask image is a set of unmasked points;
the mask area of the output characteristic diagram is equal to the mask area of the characteristic diagram of the mask image, and the unmasked area of the output characteristic diagram is equal to the unmasked area of the characteristic diagram of the mask image.
The generation network of the embodiment is trained in a guidance loss constraint mode, wherein the specific guidance loss constraint mode is to perform feature similarity constraint on a real image and an input image in any convolutional layer or deconvolution layer in the network generation training process;
the input image is a real image subjected to the masking operation.
The specific way of training the generated network of this embodiment is as follows:
inputting the target image Igt into a generation network, calculating a mask region of a characteristic diagram of the l-th layer, and obtaining (phi)l(Igt))yInformation;
inputting the image I to be filled into a generation network, calculating a mask region of a characteristic diagram of the L-L layer, and obtaining (phi)L-l(I))yInformation;
at this point a guidance loss constraint L is definedg:
Where Ω is the mask area, L is the total number of layers to generate the network, y is any coordinate point within the mask area, ΦL-l(I) When the input object is an image to be filled, generatingCharacteristic diagram of network output at L-L layer (phi)L-l(I))yInformation of y in the masked region of the output feature map for the L-L-th layer, Φl(Igt) When the input object is a target image, generating a characteristic diagram output by the network at the l-th layer (phi)l(Igt))yAnd the information of y in the mask area of the output characteristic diagram of the l-th layer.
In addition, the image I to be filled is recorded as phi (I; W) after passing through the generation network, wherein W is a parameter for generating a network model. Defining reconstruction loss
For each (phi)L-l(I))yOf which is in contact with (phi)l(I))xThe distance of (d) is calculated as follows:
x is any coordinate point in the non-mask region (phi)
l(I))
xIs the information of x in the unmasked region of the output feature map of the l-th layer,
non-masked areas.
Wherein the distance metric is formulated as follows:
find the closest point x
*After (y), using x
*(y) substitution
In the same plane as y in the area
Is an additional feature map to be input into the next deconvolution layer.
Namely, the method comprises the following steps:
the discriminating network of this embodiment includes a convolutional layer E9-convolutional layer E13;
Convolution layer E9The input object of (1) is a filled image;
convolution layer E9The output result of (A) is activated by a Leaky ReLU function and then used as a convolution layer E10The input object of (1);
for convolution layer E10-convolutional layer E13The output result of the former is used as the input object of the latter after being sequentially subjected to batch normalization and activation of a Leaky ReLU function;
convolutional layer E sequentially subjected to batch normalization and Sigmoid function activation13The output result of (1) is the output result of the discrimination network;
convolution layer E9The convolution operation is used for performing 64 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E10The convolution operation is used for performing 128 4-by-4 convolution operations with the step size of 2 on the input object;
convolution layer E11The convolution operation is used for carrying out 256 convolution operations with 4 × 4 and the step size of 2 on the input object;
convolution layer E12The convolution operation is used for carrying out 512 convolution operations with 4 x 4 and step size of 1 on the input object;
convolution layer E13For performing 1 convolution operation with 4 × 4 and step size of 1 on the input object.
256 × 256 RGB image as filled image, convolution layer E13The spatial size of the output result of (1) is 64 × 64, and the channel is 1.
Determining if the network input is phi (I; W) or I generating the output of the networkgtGenerating a network and judging the network to carry out the confrontation training, and generating the confrontation loss L at the momentadv:
In the formula, pdata(Igt) For distribution of real images, pmiss(I) For the distribution of the input image, D (-) means that the image of the discrimination network input into the discrimination network is from pdata(Igt) Log is a logarithmic function, IgtIs the target image and I is the image to be filled.
Thus, when training the generating network, the total loss is L:
wherein λgAnd λadvAre all hyper-parameters.
Fig. 3 is an image to be filled which is arbitrarily missing, and fig. 4 is a filled image obtained after the image to be filled which is arbitrarily missing is input into the generation network. Comparing fig. 3 with fig. 4, it can be seen that: the image filling system of the convolutional neural network based on feature map nearest neighbor replacement is suitable for filling any missing image to be filled, and can obtain a good filling effect.
Fig. 5 is an image to be filled with a missing center, and fig. 6 is a filled image obtained by inputting the image to be filled with a missing center into the generation network. Comparing fig. 5 with fig. 6, it can be seen that: the image filling system of the convolutional neural network based on feature map nearest neighbor replacement is suitable for filling images to be filled with missing centers, and can obtain a good filling effect.
Through simulation experiments, the image filling system based on the convolutional neural network with feature map nearest neighbor replacement described in this embodiment takes about 80ms for a 256 × 256 RGB image. Compared with the existing image filling method which takes tens of seconds to several minutes, the image filling system of the embodiment has a significant improvement in filling speed.
The image filling system of the convolutional neural network based on feature map nearest neighbor replacement described in this embodiment performs end-to-end training by using an Adam optimization algorithm.
Although the invention herein has been described with reference to particular embodiments, it is to be understood that these embodiments are merely illustrative of the principles and applications of the present invention. It is therefore to be understood that numerous modifications may be made to the illustrative embodiments and that other arrangements may be devised without departing from the spirit and scope of the present invention as defined by the appended claims. It should be understood that features described in different dependent claims and herein may be combined in ways different from those described in the original claims. It is also to be understood that features described in connection with individual embodiments may be used in other described embodiments.