CN107484080B - 音频处理装置及用于估计声音信号的信噪比的方法 - Google Patents
音频处理装置及用于估计声音信号的信噪比的方法 Download PDFInfo
- Publication number
- CN107484080B CN107484080B CN201710400529.6A CN201710400529A CN107484080B CN 107484080 B CN107484080 B CN 107484080B CN 201710400529 A CN201710400529 A CN 201710400529A CN 107484080 B CN107484080 B CN 107484080B
- Authority
- CN
- China
- Prior art keywords
- signal
- noise ratio
- estimate
- noise
- priori
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012545 processing Methods 0.000 title claims abstract description 105
- 238000000034 method Methods 0.000 title claims abstract description 53
- 230000005236 sound signal Effects 0.000 title claims abstract description 25
- 238000004422 calculation algorithm Methods 0.000 claims abstract description 65
- 230000009467 reduction Effects 0.000 claims abstract description 44
- 238000009499 grossing Methods 0.000 claims description 79
- 230000006870 function Effects 0.000 claims description 73
- 238000007476 Maximum Likelihood Methods 0.000 claims description 39
- 230000003044 adaptive effect Effects 0.000 claims description 27
- 238000004458 analytical method Methods 0.000 claims description 23
- 238000004590 computer program Methods 0.000 claims description 7
- 238000001914 filtration Methods 0.000 description 32
- 230000003595 spectral effect Effects 0.000 description 22
- 230000000694 effects Effects 0.000 description 18
- 230000001419 dependent effect Effects 0.000 description 15
- 238000013507 mapping Methods 0.000 description 15
- 238000006243 chemical reaction Methods 0.000 description 12
- 238000004891 communication Methods 0.000 description 11
- 238000010586 diagram Methods 0.000 description 11
- 230000008901 benefit Effects 0.000 description 10
- 238000005070 sampling Methods 0.000 description 10
- 210000000613 ear canal Anatomy 0.000 description 9
- 230000001965 increasing effect Effects 0.000 description 9
- 230000008859 change Effects 0.000 description 6
- 239000000203 mixture Substances 0.000 description 6
- 238000013459 approach Methods 0.000 description 5
- 230000006399 behavior Effects 0.000 description 5
- 230000003247 decreasing effect Effects 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 238000001228 spectrum Methods 0.000 description 5
- 210000004027 cell Anatomy 0.000 description 4
- 238000012937 correction Methods 0.000 description 4
- 230000014509 gene expression Effects 0.000 description 4
- 208000016354 hearing loss disease Diseases 0.000 description 4
- 230000003447 ipsilateral effect Effects 0.000 description 4
- 210000003625 skull Anatomy 0.000 description 4
- 230000005540 biological transmission Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 210000000988 bone and bone Anatomy 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 210000003477 cochlea Anatomy 0.000 description 3
- 230000006835 compression Effects 0.000 description 3
- 238000007906 compression Methods 0.000 description 3
- 210000000959 ear middle Anatomy 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000004088 simulation Methods 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 206010011878 Deafness Diseases 0.000 description 2
- LTXREWYXXSTFRX-QGZVFWFLSA-N Linagliptin Chemical compound N=1C=2N(C)C(=O)N(CC=3N=C4C=CC=CC4=C(C)N=3)C(=O)C=2N(CC#CC)C=1N1CCC[C@@H](N)C1 LTXREWYXXSTFRX-QGZVFWFLSA-N 0.000 description 2
- 101150059859 VAD1 gene Proteins 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 210000000860 cochlear nerve Anatomy 0.000 description 2
- 230000003930 cognitive ability Effects 0.000 description 2
- 230000010485 coping Effects 0.000 description 2
- 230000001934 delay Effects 0.000 description 2
- 210000003027 ear inner Anatomy 0.000 description 2
- 230000010370 hearing loss Effects 0.000 description 2
- 231100000888 hearing loss Toxicity 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 230000000644 propagated effect Effects 0.000 description 2
- 208000032041 Hearing impaired Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 229940121991 Serotonin and norepinephrine reuptake inhibitor Drugs 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 210000003926 auditory cortex Anatomy 0.000 description 1
- 239000003990 capacitor Substances 0.000 description 1
- 210000003710 cerebral cortex Anatomy 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 239000004020 conductor Substances 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 210000000883 ear external Anatomy 0.000 description 1
- 210000005069 ears Anatomy 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 210000002768 hair cell Anatomy 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000012886 linear function Methods 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000035484 reaction time Effects 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 238000007493 shaping process Methods 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 210000003454 tympanic membrane Anatomy 0.000 description 1
Images


















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L21/0232—Processing in the frequency domain
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0264—Noise filtering characterised by the type of parameter measurement, e.g. correlation techniques, zero crossing techniques or predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers, loudspeakers or microphones
- H04R3/12—Circuits for transducers, loudspeakers or microphones for distributing signals to two or more loudspeakers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/10—Earpieces; Attachments therefor ; Earphones; Monophonic headphones
- H04R1/1016—Earpieces of the intra-aural type
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/10—Earpieces; Attachments therefor ; Earphones; Monophonic headphones
- H04R1/1083—Reduction of ambient noise
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/50—Customised settings for obtaining desired overall acoustical characteristics
- H04R25/505—Customised settings for obtaining desired overall acoustical characteristics using digital signal processing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61F—FILTERS IMPLANTABLE INTO BLOOD VESSELS; PROSTHESES; DEVICES PROVIDING PATENCY TO, OR PREVENTING COLLAPSING OF, TUBULAR STRUCTURES OF THE BODY, e.g. STENTS; ORTHOPAEDIC, NURSING OR CONTRACEPTIVE DEVICES; FOMENTATION; TREATMENT OR PROTECTION OF EYES OR EARS; BANDAGES, DRESSINGS OR ABSORBENT PADS; FIRST-AID KITS
- A61F11/00—Methods or devices for treatment of the ears or hearing sense; Non-electric hearing aids; Methods or devices for enabling ear patients to achieve auditory perception through physiological senses other than hearing sense; Protective devices for the ears, carried on the body or in the hand
- A61F11/06—Protective devices for the ears
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04B—TRANSMISSION
- H04B1/00—Details of transmission systems, not covered by a single one of groups H04B3/00 - H04B13/00; Details of transmission systems not characterised by the medium used for transmission
- H04B1/38—Transceivers, i.e. devices in which transmitter and receiver form a structural unit and in which at least one part is used for functions of transmitting and receiving
- H04B1/3827—Portable transceivers
- H04B1/3833—Hand-held transceivers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M1/00—Substation equipment, e.g. for use by subscribers
- H04M1/60—Substation equipment, e.g. for use by subscribers including speech amplifiers
- H04M1/6033—Substation equipment, e.g. for use by subscribers including speech amplifiers for providing handsfree use or a loudspeaker mode in telephone sets
- H04M1/6041—Portable telephones adapted for handsfree use
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/50—Customised settings for obtaining desired overall acoustical characteristics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/55—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception using an external connection, either wireless or wired
- H04R25/558—Remote control, e.g. of amplification, frequency
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Acoustics & Sound (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Otolaryngology (AREA)
- General Health & Medical Sciences (AREA)
- Neurosurgery (AREA)
- Circuit For Audible Band Transducer (AREA)
- Obtaining Desirable Characteristics In Audible-Bandwidth Transducers (AREA)
- Noise Elimination (AREA)
- Signal Processing Not Specific To The Method Of Recording And Reproducing (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
- Telephone Function (AREA)
Abstract
本申请公开了音频处理装置及用于估计声音信号的信噪比的方法,其中所述音频处理装置包括:至少一输入单元,用于提供表示由来自目标声源TS的目标语音信号分量S(k,n)和来自不同于目标声源的其它声源的噪声信号分量N(k,n)组成的时变声音信号的电输入信号的时频表示Y(k,n),其中k和n分别为频带和时间帧指数;降噪系统,配置成确定所述电输入信号的后验信噪比估计量γ(k,n)及基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的先验目标信噪比估计量ζ(k,n);及从下面的估计量确定第n个时间帧的先验目标信噪比估计量ζ(k,n):第n‑1时间帧的先验目标信噪比估计量ζ(k,n‑1)及第n时间帧的后验信噪比估计量γ(k,n)。
Description
技术领域
本申请涉及听力装置领域,如助听器。
背景技术
语音增强和噪声减小可通过在时频域应用快速变化的增益获得。应用快速变化的增益的目标在于保持语音为主的时频窗口不被改变,同时噪声为主的时频窗口被抑制。藉此,增强的信号的合成调制增加并将通常变得类似于初始语音信号的调制,导致更高的语音可懂度。
发明内容
本发明涉及音频处理装置如助听器及用于估计表示声音的电输入信号的信噪比的方法。本发明尤其涉及用于通过后验信噪比估计量的非线性平滑(例如实施为具有自适应低通截止频率的低通滤波)获得先验信噪比估计量的方案。
在本说明书中,“后验信噪比”SNRpost意为在给定时间点t观察到的(可得到的)有噪声信号(目标信号S+噪声N,Y(t)=S(t)+N(t))如一个或多个传声器拾取的信号例如有噪声信号的能量与噪声N(t)如噪声的估计量 例如噪声信号的能量之间的比即
例如噪声信号的能量之间的比即 或者
或者 “后验信噪比”SNRpost例如可在时频域中定义为每一频带(指数k)和时间帧(指数n)的值,即SNRpost=SNRpost(k,n),即例如
“后验信噪比”SNRpost例如可在时频域中定义为每一频带(指数k)和时间帧(指数n)的值,即SNRpost=SNRpost(k,n),即例如
 产生“后验信噪比”的例子在图1A和1B中示出,分别针对一个传声器和多传声器设置。
产生“后验信噪比”的例子在图1A和1B中示出,分别针对一个传声器和多传声器设置。
在本说明书中,“先验信噪比”SNRprio意为目标信号振幅S(t)(或目标信号能量S(t)2)与噪声信号振幅N(t)(或噪声信号能量N(t)2)的比,如在给定时间点的这些信号的估计量之间的比,例如 或者SNRprio=SNRprio(k,n),即例如
或者SNRprio=SNRprio(k,n),即例如
音频处理装置如听力装置例如助听器
在本申请的第一方面,提供一种音频处理装置。该音频处理装置如助听器包括:
-至少一输入单元,用于提供表示由来自目标声源TS的目标语音信号分量S(k,n)和噪声信号分量N(k,n)组成的时变声音信号的电输入信号的时频表示Y(k,n),其中k和n分别为频带和时间帧指数;
-降噪系统,配置成
--确定所述电输入信号的第一后验信噪比估计量γ(k,n);及
--基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的第二先验目标信噪比估计量ζ(k,n);及
--从下面的估计量确定第n个时间帧的先验目标信噪比估计量ζ(k,n)
---第n-1时间帧的先验目标信噪比估计量ζ(k,n-1);及
---第n时间帧的后验信噪比估计量γ(k,n)。
在实施例中,递归算法实施具有单位DC增益及自适应时间常数(或低通截止频率)的一阶IIR低通滤波器。
在本申请的第二方面,提供一种音频处理装置。该音频处理装置如助听器包括:
-至少一输入单元,用于提供表示由来自目标声源TS的目标语音信号分量S(k,n)和噪声信号分量N(k,n)组成的时变声音信号的电输入信号的时频表示Y(k,n),其中k和n分别为频带和时间帧指数;
-降噪系统,配置成针对每一频带
--确定所述电输入信号的第一后验信噪比估计量γ(k,n);及
--基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的第二先验目标信噪比估计量ζ(k,n),其中所述递归算法实施具有自适应时间常数或低通截止频率的低通滤波器。
换言之,第二先验目标信噪比估计量ζ(k,n)通过对第一后验信噪比估计量γ(k,n)低通滤波进行确定。
在实施例中,低通滤波器的自适应时间常数或低通截止频率根据第一后验信噪比估计量和/或第二先验信噪比估计量确定。
在实施例中,低通滤波器对于给定频率指数k(也称为频道k)的自适应时间常数或低通截止频率根据唯一对应于该频率指数k的第一后验信噪比估计量和/或第二先验信噪比估计量确定。
在实施例中,低通滤波器对于给定频率指数k(也称为频道k)的自适应时间常数或低通截止频率根据对应于多个频率指数k’的第一后验信噪比估计量和/或第二先验信噪比估计量确定,多个频率指数k’例如至少包括相邻的频率指数k-1,k,k+1,例如根据预定(或自适应)方案。
在实施例中,低通滤波器对于给定频率指数k(也称为频道k)的自适应时间常数或低通截止频率根据来自一个或多个检测器(如起始指示器、风噪或话音检测器等)的输入确定。
在实施例中,低通滤波器为一阶IIR低通滤波器。在实施例中,一阶IIR低通滤波器具有单位DC增益。
在实施例中,低通滤波器在给定时刻n的自适应时间常数或低通截止频率根据在该时刻n的第二先验目标信噪比估计量的第一最大似然估计量和/或在先前时刻n-1的第二先验目标信噪比估计量确定。。
从而可提供改善的降噪。
噪声信号分量N(k,n)例如可源自不同于目标声源TS的一个或多个其它声源NSi(i=1,…,Ns)。在实施例中,噪声信号分量N(k,n)包括来自目标信号的后期混响(例如目标信号分量到达用户比所涉及的目标信号分量的主峰晚50ms以上)。
换言之,ζ(k,n)=F(ζ(k,n-1),γ(k,n))。在确定先验SNR(SNR=信噪比)时使用后验SNR的最近帧能量例如可有利于语音起始段处的SNR估计,其中SNR通常短时间内出现大的增加。
在实施例中,降噪系统配置成在γ(k,n)大于或等于1的假设下确定第n时间帧的先验目标信噪比估计量ζ(k,n)。在实施例中,电输入信号Y(k,n)的后验信噪比估计量γ(k,n)例如定义为电输入信号Y(k,n)的当前值的信号功率谱密度|Y(k,n)|2与电输入信号Y(k,n),的当前噪声功率谱密度的估计量<σ2>之间的比,即γ(k,n)=|Y(k,n)|2/<σ2>。
在实施例中,降噪系统配置成从第n-1时间帧的先验目标信噪比估计量ζ(k,n-1)和从第n时间帧的先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量ζML(k,n)确定第n时间帧的先验目标信噪比估计量ζ(k,n)。
在实施例中,降噪系统配置成将最大似然SNR估计量ζML(k,n)确定为MAX{ζML min(k,n);γ(k,n)-1},其中MAX为最大值算子,及ζML min(k,n)为最大似然SNR估计量ζML(k,n)的最小值。在实施例中,最大似然SNR估计量ζML(k,n)的最小值ζML min(k,n)例如可取决于频带指数。在实施例中,最小值ζML min(k,n)独立。在实施例中,ζML min(k,n)取为等于“1”(即在对数标尺上=0dB)。这例如为在目标信号分量S(k,m)可忽略的情形,即在输入信号Y(k,m)中仅存在噪声分量N(k,m)时。
在实施例中,降噪系统配置成通过后验信噪比估计量γ的非线性平滑或源自其的参数确定先验目标信噪比估计量ζ。源自其的参数例如可以是最大似然SNR估计量ζML。非线性平滑例如可通过具有自适应低通截止频率的低通滤波实施,例如通过具有单位DC增益的一阶IIR低通滤波器及自适应时间常数。
在实施例中,降噪系统配置成提供随SNR而变的平滑,使在低SNR条件下相较高SNR条件进行更多平滑。这可具有减少音乐噪声的优点。术语“低SNR条件”和“高SNR条件”用于指第一和第二条件,其中真实的SNR在第一条件下低于第二条件下的SNR。在实施例中,“低SNR条件”和“高SNR条件”意为分别低于和高于0dB。优选地,控制平滑的时间常数的依赖性根据SNR展现逐渐的变化。在实施例中,平滑涉及的时间常数越高,SNR越低。在“低SNR条件”下,SNR估计量通常相对弱于“高SNR条件”的情形(因此在较低SNR下不太值得信赖,因此进行更多平滑的驱动器)。
在实施例中,降噪系统配置成对低SNR条件相较于 提供负偏差。这可具有在仅有噪声的时间段中降低音乐噪声的可听度的优点。在本说明书中,术语“偏差”用于反映最大似然SNR估计量ζML(k,n)的预期值
提供负偏差。这可具有在仅有噪声的时间段中降低音乐噪声的可听度的优点。在本说明书中,术语“偏差”用于反映最大似然SNR估计量ζML(k,n)的预期值 与先验信噪比ζ(k,n)的预期值E(ζn)之间的差。换言之,对于“低SNR条件”(如对于真实SNR<0dB),
与先验信噪比ζ(k,n)的预期值E(ζn)之间的差。换言之,对于“低SNR条件”(如对于真实SNR<0dB), (例如如图3中反映的)。
(例如如图3中反映的)。
在实施例中,降噪系统配置成提供递归偏差,使能从低到高和从高到低SNR条件的可配置的变化。
第n时间帧的先验信噪比的对数表示可表达为sn=s(k,n)=10log(ζ(k,n)),及对应地第n时间帧的最大似然SNR估计量:sML n=sML(k,n)=10log(ζML(k,n))。
在实施例中,降噪系统配置成根据下面的递归算法从第n-1时间帧的先验目标信噪比估计量ζ(k,n-1)和从第n时间帧的先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量ζML(k,n)确定第n时间帧的先验目标信噪比估计量ζ(k,n):

其中ρ(sn-1)表示第n-1时间帧的偏差函数或参数,及λ(sn-1)表示平滑函数或参数。
在实施例中,ρ(sn-1)被选择为等于下面的值:

ξ满足

其中

为如等式(8)中定义的非线性函数。
在实施例中,平滑函数λ(sn-1)被选择为等于下面函数在0dB交叉的位置处(即当sn ML-sn=ρ(sn-1)时)的斜率 (参见图3中的曲线)。
(参见图3中的曲线)。

在实施例中,音频处理装置包括滤波器组,其包含用于提供电输入信号的时频表示Y(k,n)的分析滤波器组。在实施例中,电输入信号可得到为多个子频带信号Y(k,n),k=1,2,…,K。在实施例中,先验信噪比估计量ζ(k,n)取决于相邻子频带信号的后验信噪比估计量γ(k,n)(如γ(k-1,n)和/或γ(k+1,n))。
在实施例中,音频处理装置配置成使得所述分析滤波器组被过采样。在实施例中,音频处理装置配置成使得所述分析滤波器组为DFT调制的分析滤波器组。
在实施例中,用于确定第n时间帧的先验目标信噪比估计量ζ(k,n)的算法的递归循环包括高阶延迟元件,如循环缓冲器。在实施例中,高阶延迟元件配置成补偿分析滤波器组的过采样。
在实施例中,降噪系统配置成使用于确定第n时间帧的先验目标信噪比估计量ζ(k,n)的算法适于补偿分析滤波器组的过采样。在实施例中,该算法包括平滑参数(λ)和/或偏差参数(ρ)。
在实施例中,两个函数λ和ρ将平滑量和SNR偏差量控制为估计的SNR的递归函数。
在实施例中,平滑参数(λ)和/或偏差参数(ρ)适于补偿采样率,例如参见图5。在实施例中,不同的过采样率通过调整参数α进行补偿,例如参见图8。
在实施例中,音频处理装置包括听力装置如助听器、头戴式耳机、耳麦、耳朵保护装置或其组合。
在实施例中,音频处理装置适于提供随频率而变的增益和/或随电平而变的压缩和/或一个或多个频率范围到一个或多个其它频率范围的移频(具有或没有频率压缩)以补偿用户的听力受损和/或补偿对声环境的挑战。在实施例中,音频处理装置包括用于增强输入信号并提供处理后的输出信号的信号处理单元。
在实施例中,音频处理装置包括输出单元,用于基于处理后的电信号提供由用户感知为声信号的刺激。在实施例中,输出单元包括耳蜗植入物的多个电极或者骨导听力装置的振动器。在实施例中,输出单元包括输出变换器。在实施例中,输出变换器包括用于将刺激作为声信号提供给用户的接收器(扬声器)。在实施例中,输出变换器包括用于将刺激作为颅骨的机械振动提供给用户的振动器(例如在附着到骨头的或骨锚式听力装置中)。
在实施例中,音频处理装置包括用于提供表示声音的电输入信号的输入单元。在实施例中,输入单元包括用于将输入声音转换为电输入信号的输入变换器如传声器。在实施例中,输入单元包括用于接收包括声音的无线信号并提供表示所述声音的电输入信号的无线接收器。
在实施例中,音频处理装置为便携装置,例如包括本机能源如电池例如可再充电电池的装置。
在实施例中,形成双耳助听器系统的一部分的给定助听器的先验SNR估计量基于来自双耳助听器系统的两个助听器的后验SNR估计量。在实施例中,形成双耳助听器系统的一部分的给定助听器的先验SNR估计量基于双耳助听器系统的所述给定助听器的后验SNR估计量及另一助听器的先验SNR估计量。
在实施例中,音频处理装置包括输入变换器(传声器系统和/或直接电输入(如无线接收器))和输出变换器之间的正向(或信号)通路。在实施例中,信号处理单元位于正向通路中。在实施例中,信号处理单元适于根据用户的特定需要提供随频率而变的增益。在实施例中,音频处理装置包括具有用于分析输入信号(如确定电平、调制、信号类型、声反馈估计量等)及可能控制正向通路的处理的功能件的分析(或控制)通路。在实施例中,分析通路和/或信号通路的部分或所有信号处理在频域进行。在实施例中,分析通路和/或信号通路的部分或所有信号处理在时域进行。
在实施例中,分析(或控制)通路在比正向通路少的通道(或子频带)中运行。例如这样做以在音频处理装置如便携式音频处理装置例如助听器中节能,其中功耗是重要的参数。
在实施例中,表示声信号的模拟电信号在模数(AD)转换过程中转换为数字音频信号,其中模拟信号以预定采样频率或采样速率fs进行采样,fs例如在从8kHz到48kHz的范围中(适应应用的特定需要)以在离散的时间点tn(或n)提供数字样本xn(或x[n]),每一音频样本通过预定的Ns比特表示声信号在tn时的值,Ns例如在从1到16比特的范围中。数字样本x具有1/fs的时间长度,如50μs,对于fs=20kHz。在实施例中,多个音频样本按时间帧安排。在实施例中,一时间帧包括64个或128个音频数据样本。根据实际应用可使用其它帧长度。在实施例中,在过采样情形下(例如在临界采样(无帧重叠)对应于3.2ms的帧长度的情形下(例如对于fs=20kHz,及每帧64个样本)),每ms或每2ms移帧。换言之,帧重叠,使得从给定帧到下一帧,样本只有某一部分是新的,例如样本的25%或50%或75%。
在实施例中,音频处理装置包括模数(AD)转换器以按预定的采样速率如20kHz对模拟输入进行数字化。在实施例中,音频处理装置包括数模(DA)转换器以将数字信号转换为模拟输出信号,例如用于经输出变换器呈现给用户。
在实施例中,音频处理装置如传声器单元和/或收发器单元包括TF转换单元,用于提供输入信号的时频表示。在实施例中,时频表示包括所涉及信号在特定时间和频率范围的相应复值或实值的阵列或映射。在实施例中,TF转换单元包括滤波器组,用于对(时变)输入信号进行滤波并提供多个(时变)输出信号,每一输出信号包括截然不同的输入信号频率范围。在实施例中,TF转换单元包括用于将时变输入信号转换为频域中的(时变)信号的傅里叶变换单元。在实施例中,音频处理装置考虑的、从最小频率fmin到最大频率fmax的频率范围包括从20Hz到20kHz的典型人听频范围的一部分,例如从20Hz到12kHz的范围的一部分。在实施例中,音频处理装置的正向通路和/或分析通路的信号拆分为NI个频带,其中NI例如大于5,如大于10,如大于50,如大于100,如大于500,至少部分频带个别地处理。在实施例中,音频处理装置适于在NP个不同频道处理正向和/或分析通路的信号(NP≤NI)。频道可以宽度一致或不一致(如宽度随频率增加)、重叠或不重叠。
在实施例中,音频处理装置包括多个检测器,其配置成提供与音频处理装置的当前物理环境(如当前声环境)有关、和/或与佩戴音频处理装置的用户的当前状态有关、和/或与音频处理装置的当前状态或运行模式有关的状态信号。作为备选或另外,一个或多个检测器可形成与助听器(如无线)通信的外部装置的一部分。外部装置例如可包括另一助听装置、遥控器、音频传输装置、电话(如智能电话)、外部传感器等。
在实施例中,多个检测器中的一个或多个对全带信号起作用(时域)。在实施例中,多个检测器中的一个或多个对频带拆分的信号起作用((时-)频域)。
在实施例中,多个检测器包括电平检测器,用于估计正向通路的信号的当前电平。在实施例中,预定判据包括正向通路的信号的当前电平是高于还是低于给定(L-)阈值。
在特定实施例中,音频处理装置包括话音检测器(VD),用于确定输入信号是否包括话音信号(在特定时间点)。在本说明书中,话音信号包括来自人类的语音信号。其还可包括由人类语音系统产生的其它形式的发声(如唱歌)。在实施例中,话音检测器单元适于将用户当前的声环境分类为话音或无话音环境。这具有下述优点:包括用户环境中的人类发声(如语音)的电传声器信号的时间段可被识别,因而与仅包括其它声源(如人工产生的噪声)的时间段分离。在实施例中,话音检测器适于还将用户自己的话音检测为话音。作为备选,话音检测器适于从话音检测排除用户自己的话音。
在实施例中,音频处理装置包括自我话音检测器,用于检测特定输入声音(如话音)是否源自系统用户的话音。在实施例中,音频处理装置的传声器系统适于能够在用户自己的话音和另一人的话音之间进行区分及可能与非话音声音区分开。
在实施例中,助听装置包括分类单元,配置成基于来自(至少部分)检测器的输入信号及可能其它输入对当前情形进行分类。在本说明书中,“当前情形”由下面的一个或多个定义:
a)物理环境(如包括当前电磁环境,例如出现计划或未计划由助听器接收的电磁信号(包括音频和/或控制信号),或者当前环境不同于声学的其它性质);
b)当前声学情形(输入电平、反馈等);
c)用户的当前模式或状态(运动、温度等);
d)助听装置和/或与助听器通信的另一装置的当前模式或状态(所选程序、自上次用户交互之后消逝的时间等)。
在实施例中,音频处理装置还包括用于所涉及应用的其它适宜功能,如压缩、放大、反馈减少等。
在实施例中,音频处理装置包括听音装置,例如助听器,例如听力仪器,例如适于位于耳朵处或者完全或部分位于用户耳道中的听力仪器,例如头戴式耳机、耳麦、耳朵保护装置或其组合。
用途
此外,本发明提供上面描述的、“具体实施方式”中详细描述的及权利要求中限定的音频处理装置的用途。在实施例中,提供在包括音频分布的系统中的用途。在实施例中,提供在包括一个或多个听力仪器、头戴式耳机、耳麦、有源耳朵保护系统等的系统中的用途,例如免提电话系统、远程会议系统、广播系统、卡拉OK系统、教室放大系统等。
方法
一方面,本申请还提供估计表示由目标语音分量和噪声分量组成的时变声音信号的电输入信号的时频表示Y(k,n)的先验信噪比ζ(k,n)的方法,其中k和n分别为频带和时间帧指数。所述方法包括:
-确定所述电输入信号Y(k,n)的后验信噪比估计量γ(k,n);及
-基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的先验目标信噪比估计量ζ(k,n);及
-从第n-1时间帧的先验目标信噪比估计量ζ(k,n-1)及第n时间帧的后验信噪比估计量γ(k,n)确定第n时间帧的先验目标信噪比估计量ζ(k,n)。
在本申请的另一方面,本申请还提供估计表示由目标语音分量和噪声分量组成的时变声音信号的电输入信号的时频表示Y(k,n)的先验信噪比ζ(k,n)的方法,其中k和n分别为频带和时间帧指数。所述方法包括:
-确定所述电输入信号Y(k,n)的后验信噪比估计量γ(k,n);及
-基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的先验目标信噪比估计量ζ(k,n),其中所述递归算法实施具有自适应时间常数或低通截止频率的低通滤波器。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的或权利要求中限定的装置的部分或所有结构特征可与本发明方法的实施结合,反之亦然。方法的实施具有与对应装置一样的优点。
在实施例中,目标语音分量的量值的估计量 从电输入信号Y(k,n)乘以增益函数G确定,其中增益函数G为后验信噪比估计量γ(k,n)和先验目标信噪比估计量ζ(k,n)的函数。
从电输入信号Y(k,n)乘以增益函数G确定,其中增益函数G为后验信噪比估计量γ(k,n)和先验目标信噪比估计量ζ(k,n)的函数。
在实施例中,该方法包括提供随SNR而变的平滑,使能在低SNR条件下比高SNR条件进行更多平滑。
在实施例中,该方法包括平滑参数(λ)和/或偏差参数(ρ)和/或旁路参数κ。
在实施例中,平滑参数(λ)和/或偏差参数(ρ)取决于后验SNRγ或者取决于电输入信号的谱密度|Y|2及噪声谱密度<σ2>。在实施例中,平滑参数(λ)和/或偏差参数(ρ)和/或参数κ根据用户的听力损失、认知能力或语音可懂度评分进行选择。在实施例中,平滑参数(λ)和/或偏差参数(ρ)和/或参数κ被选择成,所涉及用户的听觉能力、认知能力或语音可懂度能力越差,提供越多平滑。
在实施例中,该方法包括调节平滑参数(λ)以考虑滤波器组过采样。
在实施例中,该方法包括使得平滑和/或偏差参数取决于输入是递增还是递减。
在实施例中,该方法包括使得平滑参数(λ)和/或偏差参数(ρ)和/或参数κ从用户接口进行选择。在实施例中,用户接口实施为智能电话的APP。
在实施例中,该方法包括通过选择的最小值 提供第n时间帧的先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量ζML(k,n)的预平滑。这用于对付
提供第n时间帧的先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量ζML(k,n)的预平滑。这用于对付 的情形。
的情形。
在实施例中,递归算法配置成在计算偏差和平滑参数时使最大似然SNR估计量能绕过先前帧的先验估计量。在实施例中,递归算法配置成使当前最大似然SNR估计量sn ML能绕过先前帧的先验估计量sn-1,如果当前最大似然SNR估计量sn ML减去参数κ后大于先前的先验SNR估计量sn-1(参见图4)。在实施例中,馈给图4中的映射单元MAP的值为sn ML-κ,如图4中所示,但在另一实施例中,sn ML直接馈给映射单元MAP(当满足条件(sn ML-κ>sn-1)时)。在实施例中,递归算法包括位于递归循环中的最大值算子,使在经参数κ计算偏差和平滑参数时最大似然SNR估计量能绕过先前帧的先验估计量。从而(大的)SNR起始段可被立即检测到(因而可降低语音起始段过衰减的风险)。
在实施例中,电输入信号Y(k,n)的后验信噪比估计量γ(k,n)提供为组合的后验信噪比,其产生为第一和第二后验信噪比的混合。其它组合(不同于后验估计量)也可使用(如噪声方差估计量<σ2>)。
在实施例中,两个后验信噪比分别从单一传声器结构和从多传声器结构产生。在实施例中,第一后验信噪比比第二后验信噪比更快地产生。在实施例中,组合的后验信噪比产生为第一和第二后验信噪比的加权混合。在实施例中,组合为同侧助听器的后验信噪比的第一和第二后验信噪比分别源自双耳助听器系统的同侧和对侧助听器。
计算机可读介质
本发明进一步提供保存包括程序代码的计算机程序的有形计算机可读介质,当计算机程序在数据处理系统上运行时,使得数据处理系统执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
作为例子但非限制,前述有形计算机可读介质可包括RAM、ROM、EEPROM、CD-ROM或其他光盘存储器、磁盘存储器或其他磁性存储装置,或者可用于执行或保存指令或数据结构形式的所需程序代码并可由计算机访问的任何其他介质。如在此使用的,盘包括压缩磁盘(CD)、激光盘、光盘、数字多用途盘(DVD)、软盘及蓝光盘,其中这些盘通常磁性地复制数据,同时这些盘可用激光光学地复制数据。上述盘的组合也应包括在计算机可读介质的范围内。除保存在有形介质上之外,计算机程序也可经传输介质如有线或无线链路或网络如因特网进行传输并载入数据处理系统从而在不同于有形介质的位置处运行。
计算机程序
本申请还提供包括指令的计算机程序(产品),当所述程序由计算机运行时,使得计算机执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法(的步骤)。
数据处理系统
一方面,本发明进一步提供数据处理系统,包括处理器和程序代码,程序代码使得处理器执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
听力系统
另一方面,本发明提供包括上面描述的、“具体实施方式”中详细描述的及权利要求中限定的音频处理装置及包括辅助装置的听力系统。
在实施例中,该听力系统适于在音频处理装置和辅助装置之间建立通信链路以使信息(如控制和状态信号,可能音频信号)能在其间进行交换或从一装置转发给另一装置。
在实施例中,音频处理装置是或包括听力装置如助听器。在实施例中,音频处理装置是或包括电话。
在实施例中,辅助装置是或包括音频网关设备,其适于(如从娱乐装置例如TV或音乐播放器,从电话装置例如移动电话,或从计算机例如PC)接收多个音频信号,及适于选择和/或组合所接收音频信号(或信号组合)中的适当信号以传给音频处理装置。在实施例中,辅助装置是或包括遥控器,用于控制音频处理装置或听力装置的功能和运行。在实施例中,遥控器的功能实施在智能电话中,该智能电话可能运行使能经智能电话控制音频处理装置的功能的APP(音频处理装置包括适当的到智能电话的无线接口,例如基于蓝牙或一些其它标准化或专有方案)。
在实施例中,辅助装置为另一音频处理装置,例如听力装置如助听器。在实施例中,听力系统包括适于实施双耳听力系统如双耳听力装置系统的两个听力装置。
APP
另一方面,本发明还提供称为APP的非短暂应用。APP包括可执行指令,其配置成在辅助装置上运行以实施用于上面描述的、“具体实施方式”中详细描述的及权利要求中限定的听力装置或听力系统的用户接口。在实施例中,该APP配置成在移动电话如智能电话或另一使能与所述听力装置或听力系统通信的便携装置上运行。
定义
在本说明书中,“听力装置”指适于改善、增强和/或保护用户的听觉能力的装置如听力仪器或有源耳朵保护装置或其它音频处理装置,其通过从用户环境接收声信号、产生对应的音频信号、可能修改该音频信号、及将可能已修改的音频信号作为可听见的信号提供给用户的至少一只耳朵而实现。“听力装置”还指适于以电子方式接收音频信号、可能修改该音频信号、及将可能已修改的音频信号作为听得见的信号提供给用户的至少一只耳朵的装置如头戴式耳机或耳麦。听得见的信号例如可以下述形式提供:辐射到用户外耳内的声信号、作为机械振动通过用户头部的骨结构和/或通过中耳的部分传到用户内耳的声信号、及直接或间接传到用户耳蜗神经的电信号。
听力装置可构造成以任何已知的方式进行佩戴,如作为佩戴在耳后的单元(具有将辐射的声信号导入耳道内的管或者具有安排成靠近耳道或位于耳道中的扬声器)、作为整个或部分安排在耳廓和/或耳道中的单元、作为连到植入在颅骨内的固定结构的单元、或作为整个或部分植入的单元等。听力装置可包括单一单元或几个彼此电子通信的单元。
更一般地,听力装置包括用于从用户环境接收声信号并提供对应的输入音频信号的输入变换器和/或以电子方式(即有线或无线)接收输入音频信号的接收器、用于处理输入音频信号的(通常可配置的)信号处理电路、及用于根据处理后的音频信号将听得见的信号提供给用户的输出装置。在一些听力装置中,放大器可构成信号处理电路。信号处理电路通常包括一个或多个(集成或单独的)存储元件,用于执行程序和/或用于保存在处理中使用(或可能使用)的参数和/或用于保存适合听力装置功能的信息和/或用于保存例如结合到用户的接口和/或到编程装置的接口使用的信息(如处理后的信息,例如由信号处理电路提供)。在一些听力装置中,输出装置可包括输出变换器,例如用于提供空传声信号的扬声器或用于提供结构或液体传播的声信号的振动器。在一些听力装置中,输出装置可包括一个或多个用于提供电信号的输出电极。
在一些听力装置中,振动器可适于经皮或由皮将结构传播的声信号传给颅骨。在一些听力装置中,振动器可植入在中耳和/或内耳中。在一些听力装置中,振动器可适于将结构传播的声信号提供给中耳骨和/或耳蜗。在一些听力装置中,振动器可适于例如通过卵圆窗将液体传播的声信号提供到耳蜗液体。在一些听力装置中,输出电极可植入在耳蜗中或植入在颅骨内侧上,并可适于将电信号提供给耳蜗的毛细胞、一个或多个听觉神经、听觉皮层和/或大脑皮层的其它部分。
“听力系统”指包括一个或两个听力装置的系统。“双耳听力系统”指包括两个听力装置并适于协同地向用户的两只耳朵提供听得见的信号的系统。听力系统或双耳听力系统还可包括一个或多个“辅助装置”,其与听力装置通信并影响和/或受益于听力装置的功能。辅助装置例如可以是遥控器、音频网关设备、移动电话(如智能电话)、广播系统、汽车音频系统或音乐播放器。听力装置、听力系统或双耳听力系统例如可用于补偿听力受损人员的听觉能力损失、增强或保护正常听力人员的听觉能力和/或将电子音频信号传给人。
本发明的实施例如可用在下述应用中:助听器、头戴式耳机、耳麦、耳朵保护系统、免提电话系统、移动电话等。
附图说明
本发明的各个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在整个说明书中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
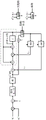
图1A示出了单通道降噪单元,其中单一传声器(M)获得目标声音(x)和噪声(v)的混合y(t)。
图1B示出了多通道降噪单元,其中多个传声器(M1,M2)获得目标声音(x)和噪声(v)的混合y(t)。
图2将以[dB]计的最大似然估计量 的均值示为以[dB]计的真实SNR的函数,示出了偏差,其由最大似然先验SNR估计量
的均值示为以[dB]计的真实SNR的函数,示出了偏差,其由最大似然先验SNR估计量 中的单向校正引入。
中的单向校正引入。
图3通过用于STSA[1]增益函数的等式(5)的数值评估示出了DD*-算法的输入-输出关系(Δoutput=f(Δinput))(α=0.98)。
图4示出了所提出的受控偏差和平滑算法(DBSA,Directed Bias and SmoothingAlgorithm,由单元Po2Pr实施)的示例性实施的图。
图5示出了ρ和λ可怎样从决策引导的方法给出的参数得到。
图6A示出了对于STSA增益函数=0.98,函数 的斜率λ。
的斜率λ。
图6B示出了对于STSA增益函数=0.98,函数 的零交叉ρ。
的零交叉ρ。
图7示出了根据本发明的DBSA算法的响应(交叉)和使用图6A、6B中配备的函数的DD-算法的响应(直线)的比较,其中曲线表示从-30dB到+30dB(步长为5dB)范围的先验SNR值。
图8示出了DBSA算法(图4中所示)为顺应滤波器组过采样进行的修改,其中在递归循环中插入另外的D帧延迟的目的是模拟具有较少过采样的系统的动态性态。
图9A示出了根据本发明的音频处理装置如助听器的实施例。
图9B示出了根据本发明的降噪系统的实施例,例如用在图9A的示例性音频处理装置中(对于M=2)。
图10示出了从两个后验信噪比产生组合的后验信噪比,其中一个从单传声器通道产生,另一个从多传声器结构产生。
图11示出了根据本发明的助听器的实施例,包括位于用户耳后的BTE部分及位于用户耳道中的ITE部分。
图12A示出了所提出的受控偏差和平滑算法(DBSA,例如通过图1A、1B中的Po2Pr单元实施)的第一另外的示例性实施的图。
图12B示出了所提出的受控偏差和平滑算法的第二另外的示例性实施的图。
图12C示出了所提出的受控偏差和平滑算法的第三另外的示例性实施的图。
图13A示出了提供用在图12A、12B、12C中所示的DBSA算法实施例中的起始标志的一般例子。
图13B示出了基于来自相邻频带的输入提供可能用在图12A、12B、12C中所示的DBSA算法实施例中的起始标志的起始检测器(控制器)的示例性实施例。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域技术人员来说,基于下面的详细描述,本发明的其它实施方式将显而易见。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。装置和方法的几个方面通过多个不同的块、功能单元、模块、元件、电路、步骤、处理、算法等(统称为“元素”)进行描述。根据特定应用、设计限制或其他原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
电子硬件可包括微处理器、微控制器、数字信号处理器(DSP)、现场可编程门阵列(FPGA)、可编程逻辑器件(PLD)、选通逻辑、分立硬件电路、及配置成执行本说明书中描述的多个不同功能的其它适当硬件。计算机程序应广义地解释为指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、可执行、执行线程、程序、函数等,无论是称为软件、固件、中间件、微码、硬件描述语言还是其他名称。
假定观察到的信号y(t)为目标语音信号x(t)与噪声v(t)的和(例如由传声器或多个传声器拾取),在分析滤波器组(FBA;FBA1,FBA2)中进行处理以产生对应于频率k(频率指数k在此被丢掉以使记法简单)和时间帧n的子频带信号Ykn(Y(n,k))(例如参见图1A、1B)。例如,Yn可包括从DFT滤波器组获得的复数系数(或由其组成)。谱语音增强方法依赖于估计每一时频窗口中相较于噪声量N的目标信号量X,即信噪比(SNR)。在谱降噪中,SNR通常使用两个不同的项描述:1)后验SNR,定义为

其中 为第n时间帧的噪声谱密度的估计量(噪声谱功率方差);及2)先验SNR,定义为
为第n时间帧的噪声谱密度的估计量(噪声谱功率方差);及2)先验SNR,定义为

其中|Xn|2为目标信号谱密度。后验SNR需要噪声功率谱密度的估计量 而先验SNR需要有权使用语音谱密度Xn|2和噪声功率谱密度
而先验SNR需要有权使用语音谱密度Xn|2和噪声功率谱密度 如果可得到先验SNR,对于每一时间和频率单位,我们可得到目标信号的估计量:
如果可得到先验SNR,对于每一时间和频率单位,我们可得到目标信号的估计量:

这表示Wiener增益方法。然而,可使用其它SNR-增益函数。术语“后验”和“先验”例如在[4]中使用。
图1A示出了单通道降噪单元,其中单一传声器M接收目标声音x和噪声v的混合信号y(t),图1B示出了多通道降噪单元,其中多个传声器M1,M2接收目标声音x和噪声v的混合信号y(t)。
在本发明中,假定,只要适当,应用模数转换单元以从传声器提供数字化电输入信号。同样,假定,只要适当,数模转换单元应用于输出信号(例如应用于将由扬声器转换为声信号的信号)。
混合信号通过相应的分析滤波器组(在图1A和1B中分别记为FBA(分析)和FBA1(分析)、FBA2(分析))变换到频域并获得信号Y(n,k)(在图1A和1B中分别记为Y(n,k)和Y(n,k)1,Y(n,k)2)。在每一情形下,后验SNRγ(图1A和1B中的后验SNR,γn)按混合信号内包含目标信号的功率谱密度|Yn|2(由相应的量值平方计算单元|·|2提供)与噪声功率谱密度的估计量 (在图1A、1B中记为<σ2>并由相应的噪声估计单元NT提供)之间的比得到(参见图1A、1B中的组合单元·/·)。在一个以上传声器的情形下(例如图1B),混合信号内的噪声可通过传声器信号的线性组合Y(n,k)=w(k)1·Y(n,k)1+w(k)2·Y(n,k)2减少,及剩余噪声可通过使用传声器信号的目标在于抵消目标信号的另一线性组合N(n,k)更好地估计,N(n,k)=w(k)3·Y(n,k)1+w(k)4·Y(n,k)2,如图1B中来自波束形成器滤波单元BFU的输出信号指明的。
(在图1A、1B中记为<σ2>并由相应的噪声估计单元NT提供)之间的比得到(参见图1A、1B中的组合单元·/·)。在一个以上传声器的情形下(例如图1B),混合信号内的噪声可通过传声器信号的线性组合Y(n,k)=w(k)1·Y(n,k)1+w(k)2·Y(n,k)2减少,及剩余噪声可通过使用传声器信号的目标在于抵消目标信号的另一线性组合N(n,k)更好地估计,N(n,k)=w(k)3·Y(n,k)1+w(k)4·Y(n,k)2,如图1B中来自波束形成器滤波单元BFU的输出信号指明的。
先验信噪比(先验SNR,图1A、1B中的ζn)通过实施根据本发明的算法的转换单元Po2Pr确定,其在下面进一步描述。先验SNR例如可在非必需的SNR-增益转换单元SNR2G中转换为增益,从而提供合成的当前降噪增益GNR(例如基于Wiener增益函数),其可在组合单元X中应用于信号Y(n,k)(图1A中的输入信号及图1B中的空间滤波的信号)以提供噪声减少的信号YNR(n,k)。
假定噪声功率密度的估计量 (图1A、1B中记为<σ2>)可用,我们可直接得到后验SNR(参见图1A、1B中的组合(在此为相除)单元·/·)。由于我们通常未取得目标功率谱密度An 2,An为未知目标量值的估计量|Xn|,我们不能直接取得先验SNR。为估计先验SNR的估计量,已提出决策引导的(DD)算法[1]:
(图1A、1B中记为<σ2>)可用,我们可直接得到后验SNR(参见图1A、1B中的组合(在此为相除)单元·/·)。由于我们通常未取得目标功率谱密度An 2,An为未知目标量值的估计量|Xn|,我们不能直接取得先验SNR。为估计先验SNR的估计量,已提出决策引导的(DD)算法[1]:

其中 为目标信号量值(在第n时间帧)的估计量,
为目标信号量值(在第n时间帧)的估计量, 为在所涉及频率的噪声谱方差(功率谱密度),及α为加权因子。上面的表达式为先验SNR ξn的两个估计量的线性组合:(因为γ-1=(|Y|2/σ2)-1==(|Y|2-σ2)/σ2)~ζ)递归部分
为在所涉及频率的噪声谱方差(功率谱密度),及α为加权因子。上面的表达式为先验SNR ξn的两个估计量的线性组合:(因为γ-1=(|Y|2/σ2)-1==(|Y|2-σ2)/σ2)~ζ)递归部分

(由于 通常取决于ξn)及2)非递归部分max(0,γn-1)。加权参数α通常在0.94–0.99的区间中选择,但显然α可取决于帧率及可能其它参数。噪声估计量
通常取决于ξn)及2)非递归部分max(0,γn-1)。加权参数α通常在0.94–0.99的区间中选择,但显然α可取决于帧率及可能其它参数。噪声估计量 假定可从谱噪声估计器如噪声跟踪器得到(例如参见[2]EP2701145A1、[3]),例如使用话音活动检测器和电平估计器(在未检测到话音时估计噪声电平;对子频带起作用)。语音量值估计量
假定可从谱噪声估计器如噪声跟踪器得到(例如参见[2]EP2701145A1、[3]),例如使用话音活动检测器和电平估计器(在未检测到话音时估计噪声电平;对子频带起作用)。语音量值估计量 使用语音估计器获得,几个语音估计器可用。通常语音估计器可由对应的增益函数G表示
使用语音估计器获得,几个语音估计器可用。通常语音估计器可由对应的增益函数G表示

增益函数可根据价值函数或将要最小化的目标及语音和噪声处理的统计假定w.r.t.进行选择。众所周知的例子为STSA增益函数[1]、LSA[4]、MOSIE[5]、Wiener及谱减增益函数[5],[7]。在STSA(STSA=最小均方误差短时频谱振幅估计器)、LSA和MOSIE依赖于(估计的)先验SNR ξn和后验SNR的同时,

Wiener及谱减增益函数为一维函数且仅依赖于ξn。如[5]中描述的, 可使用下面的已知为MOSIE估计器的等式进行估计:
可使用下面的已知为MOSIE估计器的等式进行估计:

其中Γ(.)为伽马函数,Φ(a,b;x)为合流超线几何函数,及

组合(2)和(3),我们可写出

LSA估计器(例如参见[4])可被很好地逼近,具有β=0.001和μ=1(例如参见[5])。通过决策引导的方法估计的先验SNR因而为max(0,γn-1)的平滑版,取决于平滑因子α和为获得 而选择的估计器。
而选择的估计器。
如上面提及的,α可取决于帧率。在实施例中,如[1]中原始提出的决策引导的方法设计成每第八毫秒(ms)移帧。在听力仪器中,帧通常以高得多的帧率更新(例如每一毫秒)。滤波器组的该较高的过采样因子使系统能快得多地反应(例如为更好地保持语音起始段)。可能较快的反应时间的优点仅通过根据较高的帧率调节α并不能完全实现。因此,我们提出一种方法,其在利用较高的过采样因子方面更好。
DD算法(1)可重新表示为递归函数

作为第一简化,我们考虑稍微修改的算法,我们将其称为DD*。DD*中的递归改变成仅依赖于当前帧观察数据和先前的先验估计量:

该修改对先验估计量的影响可通过数值模拟(参见后面的部分)进行量化,其中该影响被发现通常很小,尽管听得见。实际上,在增益函数中使用后验SNR的最近的帧能量似乎有利于语音起始段处的SNR估计。
现在,考虑最大似然SNR估计量,其表示具有最高可能性的SNR值。我们在此进行标准的假设,即噪声和语音处理为不相关的高斯处理,及谱系数跨时间和频率独立[1]。则最大似然SNR估计量 由下式给出:
由下式给出:

应注意,最大似然估计量不是中心估计量,因为其均值不同于真实值。在该情形下,中心估计量的例子为

其可取复值。
图2将以[dB]计的最大似然估计量 的均值示为以[dB]计的真实SNR的函数,示出了偏差,其由最大似然先验SNR估计量
的均值示为以[dB]计的真实SNR的函数,示出了偏差,其由最大似然先验SNR估计量 中的单向校正引入。目标信号假定为高斯的信号。对于仅有噪声的输入,估计的SNR等于ξML=e-1≈-4.3dB(假定
中的单向校正引入。目标信号假定为高斯的信号。对于仅有噪声的输入,估计的SNR等于ξML=e-1≈-4.3dB(假定 参见[5]),参见图2中的偏差。DD方法的一个效果是对该偏差提供补偿。
参见[5]),参见图2中的偏差。DD方法的一个效果是对该偏差提供补偿。
输入-输出关系
在下面,提出等式(5)中的DD*算法的函数逼近。为了数学方便,在下面我们假定

并得到前述逼近。该假设简化了非递归部分,因为ξn=max(0,γn-1)简化为ξn=γn-1和γn=ξn+1。已证明该假设的(结果)的影响确实较小。因而,忽略这些情形,其中

等式(5)中的DD*算法可描述为下面的 函数
函数

由于

函数Ψ将先验估计量的相对变化映射为当前先验SNR估计量 和先前先验SNR估计量ξn-1之间的比的函数。因而,我们得到
和先前先验SNR估计量ξn-1之间的比的函数。因而,我们得到

通过将SNR比表示在对数(dB)标尺上,上面的关系表达DD*算法表示的非线性输入-输出关系。
图3通过用于STSA[1]增益函数的等式(5)的数值评估示出了DD*-算法的输入-输出关系(Δoutput=f(Δinput))(α=0.98)。在低先验SNR估计量时(如标记-30dB的曲线),平滑有效果,因为对于中等输入变化,输出小变化。此外,偏差被引入,通过非零横坐标零交叉看到,导致平均估计的先验SNR低于平均最大似然SNR估计量。尽管术语“偏差”通常用于反映预期值E()和“真实”参考值之间的差,该术语在此用于反映预期值 和
和 之间的差。图3给出了使能从知道当前的最大似然估计量
之间的差。图3给出了使能从知道当前的最大似然估计量 和先前的先验SNR估计量ζn-1之间的差(或比)(及先前的先验SNR估计量ζn-1的绝对值)(输入)而确定当前的先验SNR估计量ζn和先前的先验SNR估计量ζn-1(输出)之间的差(或比)的图形关系。
和先前的先验SNR估计量ζn-1之间的差(或比)(及先前的先验SNR估计量ζn-1的绝对值)(输入)而确定当前的先验SNR估计量ζn和先前的先验SNR估计量ζn-1(输出)之间的差(或比)的图形关系。
图3示出了该关系,展现了两个显著的效果:对于低先验SNR值(例如标记为ζn-1=-30dB的曲线),输出变化小于输入变化,有效地实施了最大似然SNR估计量 的低通滤波/平滑。对于高先验SNR值(ζn-1=+30dB),DD*先验SNR估计量ξn与
的低通滤波/平滑。对于高先验SNR值(ζn-1=+30dB),DD*先验SNR估计量ξn与 的变化差不多地变化,导致非常小量的平滑。其次,低先验SNR值的曲线的零交叉移到
的变化差不多地变化,导致非常小量的平滑。其次,低先验SNR值的曲线的零交叉移到 的正dB值,直到约10dB。这意味着对于低SNR区域,先验SNR估计量ξn应安排在比ξML的平均值低约10dB的值。
的正dB值,直到约10dB。这意味着对于低SNR区域,先验SNR估计量ξn应安排在比ξML的平均值低约10dB的值。
图3给出了使能从知道当前的最大似然估计量 和先前的先验SNR估计量ζn-1之间的差(或比)(及先前的先验SNR估计量ζn-1的绝对值)(输入)而确定当前的先验SNR估计量ζn和先前的先验SNR估计量ζn-1(输出)之间的差(或比)的图形关系。
和先前的先验SNR估计量ζn-1之间的差(或比)(及先前的先验SNR估计量ζn-1的绝对值)(输入)而确定当前的先验SNR估计量ζn和先前的先验SNR估计量ζn-1(输出)之间的差(或比)的图形关系。
将在下面讨论的平滑参数λDD和偏差参数ρ的值可从图3中所示的与先验SNRζn-1=-30dB,ζn-1=0dB和ζn-1=+30dB有关的曲线读出。偏差参数ρ被发现为该曲线与水平轴的零交点。平滑参数λDD被发现为斜率,指示为所涉及曲线在零交点处的α(·)。这些值例如被提取并保存在先验SNR的有关值的表中,例如参见图4中的映射单元MAP。
图4示出了实施在转换单元Po2Pr中的、所提出的受控偏差和平滑算法(DBSA)的示例性实施的图。
受控偏差和平滑算法(DBSA)
图4示出了所提出的受控偏差和平滑算法(DBSA,由单元Po2Pr实施)的图,其目标在于提供DD方法的可配置的备选实施,包含DD的三个主要效果:
1、随SNR而变的平滑,使能在低SNR条件下进行更多平滑,减少音乐噪声;
2、相较于低SNR条件的 负偏差,在只有噪声的时间段降低音乐噪声的可听度;
负偏差,在只有噪声的时间段降低音乐噪声的可听度;
3、递归偏差,使能快速从低到高及从高到低SNR条件切换。
DBSA算法在DB域用SNR估计量运行;因而引入

和
sn=10log10(ξn)
所提出的算法实施例的中心部分为具有单位DC增益和自适应时间常数的一阶IIR低通滤波器。两个函数λ(sn)和ρ(sn)控制平滑量和SNR偏差量,作为估计的SNR的递归函数。
在下面,我们将得到控制函数以模拟上面描述的DD系统的输入-输出关系。设sn和 为按dB表示的先验和最大似然SNR,并忽略max运算(暂时设κ→∞),DBSA输入-输出关系由下式定义
为按dB表示的先验和最大似然SNR,并忽略max运算(暂时设κ→∞),DBSA输入-输出关系由下式定义

因而,认为DBSA与DD*方法相仿相当于逼近

为在(10)中完全详述DBSA,偏差函数ρ(sn)和平滑函数λ(sn)必须被详述。由于我们的目标是模拟DD*方法的性态,我们例如可测量零交点位置及下面的函数在该位置的斜率

(评估为 的函数),及选择函数ρ(sn)和λ(sn)具有一样的值。因而,对于偏差函数ρ(sn),我们选择其等于下面的值
的函数),及选择函数ρ(sn)和λ(sn)具有一样的值。因而,对于偏差函数ρ(sn),我们选择其等于下面的值

ξ满足

同样,平滑函数λ(sn-1)可设定为等于图3中的曲线在其0dB相交位置处(即当 时)的斜率(w.r.t.
时)的斜率(w.r.t. )。
)。
图4示出了作为DD方法的备选方案的受控偏差和平滑算法(DBSA)的实施。图4的右上部的虚线框表示具有单位DC增益和可变平滑系数λ(图4中的λn-1)的一阶IIR低通滤波器。该部分连同向一阶IIR低通滤波器提供输入的组合单元+(提供信号 -ρn-1)和映射单元MAP(分别提供平滑和偏差参数λ,ρ)一起实施下面的等式10(参见图4中的“来自等式(10)”的指示)。两个映射函数λ(s)和ρ(s)(参见映射单元MAP)分别控制平滑量λ和偏差ρ,作为估计的先验SNR的递归函数(图4中的sn-1(ζn-1))。图4的左部提供第n时间帧的先验信噪比的最大似然值
-ρn-1)和映射单元MAP(分别提供平滑和偏差参数λ,ρ)一起实施下面的等式10(参见图4中的“来自等式(10)”的指示)。两个映射函数λ(s)和ρ(s)(参见映射单元MAP)分别控制平滑量λ和偏差ρ,作为估计的先验SNR的递归函数(图4中的sn-1(ζn-1))。图4的左部提供第n时间帧的先验信噪比的最大似然值 其实施上面的等式(6)(参见图4中“来自等式(6)”的指示)。先验信噪比的最大似然值
其实施上面的等式(6)(参见图4中“来自等式(6)”的指示)。先验信噪比的最大似然值 由“dB”单元转换到对数域。映射单元MAP例如实施为存储器,包括具有用于先验SNRζ的有关值的(例如用于较大范围的ζ和/或用于较大数量的值,例如每5dB一条曲线或者每dB一条)、从图3提取的平滑和偏差参数λ和ρ的值(或等同数据材料)的查询表。用于(离线)计算相应平滑和偏差参数λ和ρ以存储在映射单元MAP的存储器中的算法的实施在图5中示出。图4的实施例另外包括用于先验SNR的当前最大似然值
由“dB”单元转换到对数域。映射单元MAP例如实施为存储器,包括具有用于先验SNRζ的有关值的(例如用于较大范围的ζ和/或用于较大数量的值,例如每5dB一条曲线或者每dB一条)、从图3提取的平滑和偏差参数λ和ρ的值(或等同数据材料)的查询表。用于(离线)计算相应平滑和偏差参数λ和ρ以存储在映射单元MAP的存储器中的算法的实施在图5中示出。图4的实施例另外包括用于先验SNR的当前最大似然值 的较大值的旁路分支,由单元BPS实施。旁路单元BPS包括组合单元+和最大值运算单元max。组合单元+将参数κ取为输入。κ的值被从当前的最大似然值
的较大值的旁路分支,由单元BPS实施。旁路单元BPS包括组合单元+和最大值运算单元max。组合单元+将参数κ取为输入。κ的值被从当前的最大似然值 减去,所得的值
减去,所得的值 -κ连同先验SNR的先前的值sn-1馈给最大值单元max。从而先验SNR的当前最大似然值
-κ连同先验SNR的先前的值sn-1馈给最大值单元max。从而先验SNR的当前最大似然值 的相对大的值(大于sn-1+κ)被使能对映射单元MAP的输入具有直接影响。在实施例中,参数κ随频率而变(即,例如对于不同的频道k而不同)。
的相对大的值(大于sn-1+κ)被使能对映射单元MAP的输入具有直接影响。在实施例中,参数κ随频率而变(即,例如对于不同的频道k而不同)。
图5示出了偏差参数ρ和平滑参数λ可怎样从决策引导的方法的参数得到(参见等式5)。图5示出了用于产生给图4中的映射单元MAP的相应数据的算法的实施例。该算法从先验SNR的当前最大似然值 及先前的先验SNR值sn-1确定偏差参数ρ和平滑参数λ。与具有ρ和λ的单一映射相反,我们可根据输入是递增还是递减选择具有不同组的ρ和λ。这对应于对于ρ和λ具有不同的增高和释放值。前述多组参数可从对应于不同的增高和释放时间的α的不同值得到(并随后保存在映射单元MAP中)。如后面提及的,优选实施平滑参数的补偿以考虑不同于LSA方法[4]中使用的帧率(或帧长度)(使得映射单元中保存的平滑参数λ的值可直接应用)。这在下面例如结合图8进一步论述。
及先前的先验SNR值sn-1确定偏差参数ρ和平滑参数λ。与具有ρ和λ的单一映射相反,我们可根据输入是递增还是递减选择具有不同组的ρ和λ。这对应于对于ρ和λ具有不同的增高和释放值。前述多组参数可从对应于不同的增高和释放时间的α的不同值得到(并随后保存在映射单元MAP中)。如后面提及的,优选实施平滑参数的补偿以考虑不同于LSA方法[4]中使用的帧率(或帧长度)(使得映射单元中保存的平滑参数λ的值可直接应用)。这在下面例如结合图8进一步论述。
图6A和6B分别示出了对于STSA增益函数[1],函数 的斜率λ和零交叉ρ,在两个情形下均使用α=0.98。图7示出了根据本发明的DBSA算法的响应(交叉)和使用图6A、6B中配备的函数的DD-算法的响应(直线)的比较,其中曲线表示从-30dB到+30dB(步长为5dB)范围的先验SNR值。
的斜率λ和零交叉ρ,在两个情形下均使用α=0.98。图7示出了根据本发明的DBSA算法的响应(交叉)和使用图6A、6B中配备的函数的DD-算法的响应(直线)的比较,其中曲线表示从-30dB到+30dB(步长为5dB)范围的先验SNR值。
图6A-6B示出了数值评估的结果,图7示出了DD*算法和DBSA算法的输入-输出响应之间的比较。该差在大多数情形下非常小,如后面部分的模拟所示。
低观察SNR的情形
现在考虑 的情形。在DBSA中,该情形通过最小值
的情形。在DBSA中,该情形通过最小值 绊住,其限制影响。回想等式(2),
绊住,其限制影响。回想等式(2), 我们注意到,该类可表达为Wiener增益函数的能量的增益函数通常在
我们注意到,该类可表达为Wiener增益函数的能量的增益函数通常在 时具有
时具有 这种性质使DD算法偏差非常大且为负,其可在DBSA中用相对低的
这种性质使DD算法偏差非常大且为负,其可在DBSA中用相对低的 值模拟。
值模拟。
另一方面,对于STSA,LSA和MOSIE增益函数,大于0dB的增益在 时出现,导致极限中的非零
时出现,导致极限中的非零 该效果在一定程度上可通过较大的
该效果在一定程度上可通过较大的 处理。在实践中,DD*方法和DBSA之间的余差可被使得可忽略。
处理。在实践中,DD*方法和DBSA之间的余差可被使得可忽略。
数值问题
应注意,在一些情形下(通常对于低先验SNR值),函数

没有零交叉。这反映了在系统可产生的实际先验SNR值的范围的限制。当增益函数

受一些最小增益值Gmin限制时出现一个特定例子。将该最小值插入到等式(5)内,其可容易地表明

这样,当ξn-1足够低时,函数Ψ将大于1,其再次意味着对函数10log10Ψ没有零交叉。数值实施将需要检测该情形并仍然对ρ(sn)和λ(sn)指明一些合理的查询表值。使用的准确值实际上将不要紧,因为它们极可能将仅在从初始状态收敛期间被采样。
最大值算子及更多
在图4中,最大值算子位于递归循环中,使最大似然SNR估计量能在(经参数κ)计算偏差和平滑参数时绕过先前帧的先验估计量。该元素的原因是帮助检测SNR起始段,因而降低语音起始段过衰减的风险。在DD方法等式(1)中,项(1-α)在当前帧中允许大的起始段以快速减少负偏差,最大值模拟该受参数κ控制的性态。因而我们有能力使用因子κ绕过平滑。通过增大κ,我们可更好地保持语音起始段。另一方面,增大的κ也可提升噪底。然而,增大的噪底将仅在我们应用高衰减量时有影响。因而,所选的κ值取决于选择的最大衰减。
代替最大值算子(图4、5和8中的max),更一般的选择方案可用于识别(突然的)SNR变化(如起始段),例如参见图12A、12B和12C所示实施例中的“选择”单元。前述更一般的方案例如可包括声环境中的事件(变化)的考虑(如噪声源(如风噪)的突然出现或消除,或者其它声源如语音源例如自我话音的突然变化),例如参见图13A,和/或包括所考虑的频带附近的多个频带上的信号变化的考虑(例如评估所有频带并应用逻辑判据以对所涉及的频带提供所得的起始标志),例如参见图13B。
滤波器组过采样
滤波器组参数对DD方法的结果具有大影响。过采样是要考虑的主要参数,因为其对平滑效果和引入先验SNR估计量的偏差量有直接影响。
怎样校正DD方法中的滤波器组过采样在文献中尚未有较彻底的描述。在原始公式[1]中,256点FFT与汉宁窗口一起使用,具有对应于四倍过采样的192样本重叠及8kHz的采样率。总的来说,通常为两倍过采样(50%帧重叠),参见[1]及其中的引用文献。然而,在助听器及其它低等待时间应用中,过采样16或更高的因子不现实。
过采样降低DD方法和DBSA方法的递归效果。在“无限”采样的限制中,递归偏差用渐近线偏差函数代替。
用于过采样补偿的一个可能的方法是对DD/DBSA估计下采样一正比于过采样的因子,保持先验估计量跨多个帧恒定不变。该方法的缺点在于增益猛增被引入,这在结合过采样的滤波器组使用时可降低声音质量。使用过采样,等效的合成滤波器组更短,及可能不足以衰减因增益猛增引入的卷积噪声。
使用DBSA方法,时间性态(即SNR估计量的平滑和对起始段的响应性)由受控递归平滑和受控递归偏差的组合控制。更多计算需求但理论上更精确的处理滤波器组过采样的方法是借助于递归循环中更高阶的延迟元件(循环缓冲器),如图8中所示。
图8示出了DBSA算法(图4中所示)为顺应滤波器组过采样进行的修改,其中在递归循环中插入另外的D帧延迟的目的是模拟具有较少过采样的系统的动态性态。
相较于图4、5和8中例示的DBSA算法的实施例,图12A、12B和12C中所示的实施例的不同之处在于,max算子已被选择算子(“选择”)替代,其例如可由起始标志控制。与仅影响局部频道k的max算子相反,起始标志可取决于根据如预定或自适应(如逻辑)方案(例如参见图1A)适格的多个“控制输入”,和/或还包括其它频道(例如参见图13B)。在实施例中,偏差参数随频率而变(即,例如对不同的频道k而不同)。
图12A示出了所提出的受控偏差和平滑算法(DBSA,例如通过图1A、1B和9B中的Po2Pr单元实施)的第一另外的示例性实施的图。与仅影响局部频道k的max算子,起始标志还可取决于其它频道(例如参见图13B)。起始标志的优点在于(假定起始段同时影响许多频道)在具有高SNR的几个频道中检测到的起始段信息可传播到具有较低SNR的频道。藉此,藉此,起始段信息可在低SNR频道更快地应用。在实施例中,可使用宽带起始检测器及给定频道k的起始标志(或作为用于确定起始标志的判据的输入)。作为备选,如果在K个频道(如所涉及的频道k和每一侧的相邻频道如k-1,k+1,参见图13B)中的偏差校正的最新(最大似然(先验)估计量)SNR值 高于先前的(先验)SNR值sn-1,这为起始段的指示。不同于直接相邻的频道的其它频道和/或其它起始指示可在确定给定频道k的起始标志时考虑。在实施例中,特定频道k中的起始标志根据在至少q个频道中是否已检测到局部起始段进行确定,其中q为1和K之间的数。
高于先前的(先验)SNR值sn-1,这为起始段的指示。不同于直接相邻的频道的其它频道和/或其它起始指示可在确定给定频道k的起始标志时考虑。在实施例中,特定频道k中的起始标志根据在至少q个频道中是否已检测到局部起始段进行确定,其中q为1和K之间的数。
图12B示出了所提出的受控偏差和平滑算法(DBSA,例如通过图1A、1B和9B中的Po2Pr单元实施)的第二另外的示例性实施的图。除了取决于SNR之外,λ和ρ还可取决于SNR是递增还是递减。如果SNR增大,如 所指明的,我们选择一组λ(s)和ρ(s),即λatk(s),ρatk(s);如果SNR递减,如
所指明的,我们选择一组λ(s)和ρ(s),即λatk(s),ρatk(s);如果SNR递减,如 所指明的,我们选择另一组λ(s)和ρ(s),即λrel(s),ρrel(s)。平滑参数λ(s)和ρ(s)的示例性进程分别在图6A和6B中示出。
所指明的,我们选择另一组λ(s)和ρ(s),即λrel(s),ρrel(s)。平滑参数λ(s)和ρ(s)的示例性进程分别在图6A和6B中示出。
此外,在另一优选实施例中,“选择”单元可能不仅取决于检测到的起始段。其还可取决于检测到的自我话音或风噪或所提及的(或其它)检测器的任何组合(例如参见图13A)。
图12C示出了所提出的受控偏差和平滑算法(DBSA,例如通过图1A、1B和9B中的Po2Pr单元实施)的第三另外的示例性实施的图。除取决于SNR之外,λ和ρ还可取决于SNR是递增或递减的另一指示。如果SNR增大,如 所指明的,我们选择一组λ和ρ,即λatk,ρatk;如果SNR减小,如
所指明的,我们选择一组λ和ρ,即λatk,ρatk;如果SNR减小,如 所指明的,我们选择另一组λ和ρ,即λrel,ρrel。
所指明的,我们选择另一组λ和ρ,即λrel,ρrel。
图13A示出了提供用在图12A、12B、12C中所示的DBSA算法实施例中的起始标志的一般例子。音频处理装置如助听器可包括多个(ND个)检测器或指示器IND1,…,INDND,提供音频处理装置周围的声学场景的变化起始段的多个指示信号(信号IX1,…,IXND),其可导致音频处理装置的正向通路考虑的信号的SNR改变。前述指示器例如可包括用于检测时变输入声音s(t)(例如参见图9A)的突然变化如其调制的一般起始检测器、风噪检测器、话音检测器如自我话音检测器等及其组合。来自指示器IND1,…,INDND的输出IX1,…,IXND被馈给控制器,其实施用于对给定频道k提供起始指示信号(信号起始标志)的算法。前述方案的具体实施(或部分实施)在图13B中示出。
图13B示出了基于来自相邻频带的输入提供可能用在图12A、12B、12C中所示的DBSA算法实施例中的起始标志的控制器(“控制”)的示例性实施例。所示方案提供输入指示信号IXp,…,IXq,包括评估SNR随时间的变化的指示,如 在所考虑的频带k周围的多个频带k’上被满足(例如评估k’=k-1,k和k+1的表达)还是仅对其中之一满足或者“三个中的两个”满足等所指明的,或者评估针对所有频带k=1,…,K(或所选范围,例如预期出现语音和/或噪声的频带)的表达并应用逻辑判据提供所涉及频带的起始标志。在实施例中,仅考虑与给定频道k直接相邻的频带,即在提供每一频道的起始标志时包括三个频道。在实施例中,这样的方案与来自结合图13A提及的其它检测器的输入组合。在实施例中,表达式
在所考虑的频带k周围的多个频带k’上被满足(例如评估k’=k-1,k和k+1的表达)还是仅对其中之一满足或者“三个中的两个”满足等所指明的,或者评估针对所有频带k=1,…,K(或所选范围,例如预期出现语音和/或噪声的频带)的表达并应用逻辑判据提供所涉及频带的起始标志。在实施例中,仅考虑与给定频道k直接相邻的频带,即在提供每一频道的起始标志时包括三个频道。在实施例中,这样的方案与来自结合图13A提及的其它检测器的输入组合。在实施例中,表达式 或其它类似表达式针对所涉及频道周围的多个频道进行评估,例如所有频道,及用于提供所得的起始标志的方案应用于输入指示信号IXp,…,IXq。偏差常数可跨频率恒定不变,或者在频道间不同,或者对一些频道不同。
或其它类似表达式针对所涉及频道周围的多个频道进行评估,例如所有频道,及用于提供所得的起始标志的方案应用于输入指示信号IXp,…,IXq。偏差常数可跨频率恒定不变,或者在频道间不同,或者对一些频道不同。
所提出的实施的优点
所提出的实施相较决策引导的方法具有下述优点:
-我们可调节平滑参数以考虑滤波器组过采样,这对在低等待时间的应用如听力仪器中的实施很重要;
-代替使平滑和偏差依赖于所选的增益函数,平滑λ(s)和偏差ρ(s)通过两个映射函数的参数化直接控制。这使能单独地调谐每一映射函数以在降噪和声音质量之间实现合乎需要的平衡。例如,目标能量可通过过度强调偏差而得以更好地保持。同样,这些参数可被设定以解决感兴趣的某一SNR范围。前述的参数组可对各个用户选择为不同,因为一些用户主要受益于低SNR区域的降噪(在波动增益方面)及不需要在较高信噪比时降噪。另一方面,其它用户可能需要在较高信噪比区域时降噪,及在低信噪比时恒定不变的衰减;
-作为所提出的系统的延伸,平滑和偏差参数可依赖于输入是递增还是递减。即,我们可使用两个参数的不同的增高和释放值;
-决策引导的方法变为仅依赖于当前帧观察数据及先前的先验估计量似乎有利于语音起始段处的SNR估计;
-同样,由参数κ控制的最大值算子可用于降低过度衰减语音起始段的风险。所选的值可取决于选择的最大值衰减;



-噪声估计器可依赖于多通道及单通道输入、或者依赖于二者、和/或依赖于双耳输入,例如参见图10。DBSA参数可根据噪声估计器是依赖于单通道输入还是多通道输入进行不同地调节。
图9A示出了根据本发明的音频处理装置APD如助听器的实施例。时变输入声音s(t)假定包括目标信号分量x(t)和噪声信号分量v(t)的混合并由音频处理装置拾取、处理及作为听得见的信号提供给用户。图9A的音频处理装置(在此为助听器)包括多个输入单元IUj,j=1,…,M,每一输入单元按时频表示(k,m)提供表示声音s(t)的电输入信号Si。在图9A的实施例中,每一输入单元IUi包括输入变换器ITi,用于将来自环境的(输入单元IUi处接收的)输入声音si转换为电时域信号s’i,i=1,…,M。输入单元IUi还包括分析滤波器组FBAi,用于将电时域信号s’i转换为多个子频带信号(k=1,…,K),从而按时频表示Si(k,m)提供电输入信号。助听器还包括多输入降噪系统NRS,基于多个电输入信号Si,i=1,…,M提供噪声减少的信号YNR。多输入降噪系统NRS包括多输入波束形成器滤波单元BFU、后滤波器单元PSTF和控制单元CONT。多输入波束形成器滤波单元BFU(及控制单元CONT)接收多个电输入信号Si,i=1,…,M并提供信号Y和N。控制单元CONT包括存储器MEM,其中保存复数权重Wij。复数权重Wij定义波束形成器滤波单元BFU的可能的预定的固定波束形成器(经信号Wij馈给BFU),例如参见图9B。控制单元CONT还包括一个或多个话音活动检测器VAD,用于估计给定输入信号(如输入信号的给定时频单元)是否包括话音(或话音为主)。相应的控制信号V-N1和VN-2分别馈给波束形成器滤波单元BFU和后滤波单元PSTF。控制单元CONT从输入单元IUi接收多个电输入信号Si,i=1,…,M及从波束形成器滤波单元BFU接收信号Y。信号Y包括目标信号分量的估计量,信号N包括噪声信号分量的估计量。(单通道)后滤波单元PSTF接收(空间滤波的)目标信号估计量Y和(空间滤波的)噪声信号估计量N,并基于从噪声信号估计量N提取的噪声的知识提供(进一步)噪声减少的目标信号估计量YNR。助听器还包括信号处理单元SPU,用于(进一步)处理噪声减少的信号并提供处理后的信号ES。信号处理单元SPU可配置成对噪声减少的信号YNR应用随电平和频率而变的整形,例如以补偿用户的听力受损。助听器还包括合成滤波器组FBS,用于将处理后的子频带信号ES转换为时域信号es,其馈给输出单元OT以将刺激es(t)作为可感知为声音的信号提供给用户。在图9A的实施例中,输出单元包括用于将处理后的信号es作为声音呈现给用户的扬声器。助听器的从输入单元到输出单元的正向通路在此在时频域运行(在多个子频带FBk,k=1,…,K进行处理)。在另一实施例中,助听器的从输入单元到输出单元的正向通路可在时域运行。助听器还可包括用户接口和一个或多个检测器,使用户输入和检测器输入能由降噪系统NRS如波束形成器滤波单元BFU接收。可提供波束形成器滤波单元BFU的自适应功能。
图9B示出了根据本发明的降噪系统NRS的实施例的框图,例如用在图9A的示例性音频处理装置如助听器中(对于M=2)。图9A的降噪系统的示例性实施例在图9B中进一步细化。图9B示出了根据本发明的自适应波束形成器滤波单元BFU的实施例。该波束形成器滤波单元包括第一(全向)和第二(目标抵消)波束形成器(在图9B中记为固定的BF O和固定的BFC并通过对应的波束图进行符号表示)。第一和第二固定波束形成器将波束成形信号O和C分别提供为第一和第二电输入信号S1和S2的线性组合,其中表示相应的波束图的第一和第二组复数权重常数Wo1(k)*,Wo2(k)*和Wc1(k)*,Wc2(k)*保存在存储器单元MEM中(参见图9A的控制单元CONT中的存储器单元MEM和信号Wij)。*指复共轭。波束形成器滤波单元BFU还包括自适应波束形成器(自适应BF,ADBF),提供表示自适应确定的波束图的自适应常数βada(k)。通过组合波束形成器滤波单元BFU的固定和自适应波束形成器,目标信号的合成(自适应)估计量Y被提供为Y=O-βadaC。波束形成器滤波单元BFU还包括话音活动检测器VAD1,提供指明输入信号(在此为O或者Si之一)是否(或以何种概率)包括话音内容(如语音)的控制信号V-N1(如基于信号O或者输入信号Si之一),其使自适应波束形成器能在话音活动检测器VAD1指明没有(或低概率地具有)话音/语音的时间段期间更新噪声估计量<σc 2>(在此基于目标抵消波束形成器C)。
来自波束形成器滤波单元的合成(空间滤波或波束成形的)目标信号估计量Y因而可表达为
Y(k)=O(k)–βada(k)·C(k)
Y(k)=(Wo1 *·S1+Wo2 *·S2)–βada(k)·(Wc1 *·S1+Wc2 *·S2)
然而,仅计算应用于每一传声器信号的实际合成权重而不是计算用于获得合成信号的不同波束形成器在计算上有利。
图9B的后滤波单元PSTF的实施例接收输入信号Y(空间滤波的目标信号估计量)和<σc 2>(噪声功率谱估计量)并基于其提供输出信号YBF(噪声减少的目标信号估计量)。后滤波单元PSTF包括降噪校正单元N-COR,用于改善从波束形成器滤波单元接收的噪声功率谱估计量<σc 2>并提供改善的噪声功率谱估计量<σ2>。改善源自话音活动检测器VAD2的使用,其指明空间滤波的目标信号估计量Y中非话音时频单元的存在(参见信号V-N2)。后滤波单元PSTF还包括量值平方(|·|2)和相除(·/·)处理单元,用于分别提供目标信号功率谱估计量|Y|2和后验信噪比γ=|Y|2/<σ2>。后滤波单元PSTF还包括转换单元Po2Pr,用于将后验信噪比估计量γ转换为先验信噪比估计量ζ,从而实施根据本发明的算法。后滤波单元PSTF还包括转换单元SNR2G,配置成将先验信噪比估计量ζ转换为对应的增益GNR,其将被应用于空间滤波的目标信号估计量(在此通过相乘单元X)以提供合成的噪声减少的目标信号估计量YBF。为简单起见,频率和时间指数k和n未在图9B中示出。但假定对应的时间帧可用于处理后的信号,例如|Yn|2,<σn 2>,γn,ζn,GNR,n等。
包括多输入波束形成器滤波单元BFU和单通道后滤波单元PSTF的多输入降噪系统例如可按[2]中所述实施,但具有本发明中提出的修改。
在图9B的实施例中,噪声功率谱<σ2>基于两个传声器波束形成器(目标抵消波束形成器C),但也可基于单通道噪声估计量,如基于调制的分析(如话音活动检测器)。
图10示出了包括电连接到相应的分析滤波器组FBA1和FBA2的传声器M1和M2并提供相应的混合电输入子频带信号Y(n,k)1,Y(n,k)2的(如助听器的)输入级,如结合图1B所述。基于第一和第二传声器信号的电输入信号Y(n,k)1,Y(n,k)2馈给多输入(在此2个)后验信噪比计算单元APSNR-M,用于提供多输入后验SNRγn,m(对于第n时间帧),例如上面结合图1B所述。两个电输入信号Y(n,k)1,Y(n,k)2之一或者第三不同的电输入信号(如波束成形信号或基于第三传声器例如对侧助听器的传声器或者单独传声器的信号)馈给单输入后验信噪比计算单元APSNR-S,用于提供单输入后验SNRγn,s(对于第n时间帧),如上面结合图1A所述。两个后验SNRγn,m和γn,s馈给混合单元MIX,用于从两个后验信噪比产生组合的(合成)后验信噪比γn,res。两个独立的后验估计量的组合通常将提供比每一估计量单独更好的估计量。由于多通道估计量γn,m通常比单通道估计量γn,s更可靠,多通道估计量相较单输入通道噪声估计量将需要较少的平滑。因而,对于多传声器后验SNR估计量γn,m和单传声器后验SNR估计量γn,s的平滑,需要不同组的平滑参数ρ(偏差)、λ(平滑)和κ(偏差)(参见图3、4)。混合两个估计量以提供合成后验SNR估计量γn,res例如可提供为两个估计量γn,m,γn,s的加权和。
在双耳助听器系统的实施例中,来自对侧听力仪器的后验SNR、先验SNR、噪声估计量或增益传给同侧听力仪器并在同侧听力仪器中使用。
除来自同侧听力仪器的后验估计量之外,先验估计量也可依赖于来自对侧听力仪器的后验估计量、先验估计量或噪声估计量(或增益估计量)。再次地,改善的先验SNR估计量可通过结合不同的独立SNR估计量得到。
图11示出了根据本发明的助听器的实施例,包括位于用户耳后的BTE部分和位于用户耳道中的ITE部分。
图11示出了形成为耳内接收器式(RITE)助听器的示例性助听器HD,其包括适于位于耳廓后面的BTE部分(BTE)和适于位于用户耳道中并具有输出变换器(如扬声器/接收器,SPK)的部分(ITE)(例如图9A例示的助听器HD)。BTE部分和ITE部分通过连接元件IC连接(如电连接)。在图11的助听器实施例中,BTE部分包括两个输入变换器MBTE1,MBTE2(在此为传声器),每一输入变换器提供表示来自环境的输入声音信号SBTE的电输入音频信号(在图11的场合,来自声源S)。图11的助听器还包括两个无线接收器WLR1,WLR2,用于提供相应的直接接收的辅助音频和/或信息信号。助听器HD还包括衬底SUB,其上安装多个功能上根据所涉及应用进行划分的电子元件(模拟、数字、无源元件等),但包括彼此连接并经电导体Wx连接到输入和输出单元的可配置的信号处理单元SPU、波束形成器滤波单元BFU和存储器单元MEM。所提及的功能单元(及其它元件)可根据所涉及的应用按电路和元件进行划分(例如为了大小、功耗、模拟-数字处理等),例如集成在一个或多个集成电路中,或者作为一个或多个集成电路和一个或多个分开的电子元件(如电感器、电容器等)的组合。可配置的信号处理单元SPU提供增强的音频信号(参见图9A中的信号ES),其用于呈现给用户。在图11的助听器装置实施例中,ITE部分包括扬声器(接收器)SPK形式的输出单元,用于将电信号(图9A中的es)转换为声信号(提供或贡献于耳膜处的声信号SED)。在实施例中,ITE部分还包括包含输入变换器(如传声器)MITE的输入单元,用于将表示来自环境的输入声音信号SITE的电输入音频信号提供在耳道处或耳道中。在另一实施例中,助听器可仅包括BTE传声器MBTE1,MBTE2。在又一实施例中,助听器可包括位于不同于耳道处的别处的输入单元IT3与位于BTE部分和/或ITE部分中的一个或多个输入单元结合。ITE部分还包括引导元件如圆顶DO,用于引导并将ITE部分定位在用户耳道中。
图11中例示的助听器HD为便携装置,及还包括用于对BTE部分和ITE部分的电子元件供电的电池BAT。
助听器HD包括定向传声器系统(波束形成器滤波单元BFU),适于增强佩戴助听器装置的用户的局部环境中的多个声源中的目标声源。在实施例中,该定向系统适于检测(如自适应检测)传声器信号的特定部分(如目标部分和/或噪声部分)源自哪一方向和/或从用户接口(如遥控器或智能电话)接收关于目前的目标方向的输入。存储器单元MEM包括预定(或自适应确定)的复值、随频率而变的常数,其定义根据本发明的预定或固定(或自适应确定的“固定”)波束图连同定义波束成形信号Y(例如参见图9A、9B)。
图11的助听器可构成或形成根据本发明的助听器和/或双耳助听器系统的一部分。
根据本发明的助听器HD可包括用户接口UI,例如如图11中所示实施在辅助装置AUX如遥控器中,例如实施为智能电话或其它便携(或固定不动的)电子装置中的APP。在图11的实施例中,用户接口UI的屏幕示出了平滑波束形成APP。控制或影响波束形成降噪系统的信噪比的当前平滑的参数,在此为参数ρ(偏差)、λ(平滑)(参见结合图3、4的描述),可经平滑波束形成APP(具有副标题“定向性、配置平滑参数”)进行控制。偏差参数ρ可经滑动块设定为最小值(如0)和最大值如10dB之间的值。当前设定的值(在此为5dB)被图示在跨越可配置的值范围的(灰色阴影)条上的滑动块位置处的屏幕上。同样,平滑参数λ可经滑动块设定为最小值(如0)和最大值如1之间的值。当前设定的值(在此为0.6)被图示在跨越可配置的值范围的(灰色阴影)条上的滑动块位置处的屏幕上。屏幕底部的箭头使能变到APP的前一和后一屏,及两个箭头之间的圆点上的标签带出使能选择装置的其它APP或特征的菜单。与平滑有关的参数ρ和λ可不必然可由用户看见。ρ,λ的设置可从第三参数(如平静-攻击降噪条或经环境检测器设置)得到。
辅助装置和助听器适于使能经例如无线通信链路(参见图11中的虚线箭头WL2)将表示当前选择的平滑参数的数据传给助听器。通信链路WL2例如可基于远场通信,例如蓝牙或蓝牙低功率(或类似技术),通过助听器HD和辅助装置AUX中的适当天线和收发器电路实施,由助听器中的收发器单元WLR2指明。通信链路可配置成提供单向通信(如APP到听力仪器)或者双向通信(如音频和/或控制或信息信号)。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的和/或权利要求中限定的装置的结构特征可与本发明方法的步骤结合。
除非明确指出,在此所用的单数形式“一”、“该”的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非另行指明,在此公开的任何方法的步骤不精确限于相应说明的顺序。
应意识到,本说明书中提及“一实施例”或“实施例”或“方面”或者“可”包括的特征意为结合该实施例描述的特定特征、结构或特性包括在本发明的至少一实施方式中。此外,特定特征、结构或特性可在本发明的一个或多个实施方式中适当组合。提供前面的描述是为了使本领域技术人员能够实施在此描述的各个方面。各种修改对本领域技术人员将显而易见,及在此定义的一般原理可应用于其他方面。
权利要求不限于在此所示的各个方面,而是包含与权利要求语言一致的全部范围,其中除非明确指出,以单数形式提及的元件不意指“一个及只有一个”,而是指“一个或多个”。除非明确指出,术语“一些”指一个或多个。
因而,本发明的范围应依据权利要求进行判断。
参考文献
[1]Ephraim,Y.;Malah,D.,"Speech enhancement using a minimum-meansquare error short-time spectral amplitude estimator",IEEE Transactions onAcoustics,Speech and Signal Processing,vol.32,no.6,pp.1109-1121,Dec 1984
URL:http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1164453&isnu mber=26187
[2]EP2701145A1
[3]Martin,R.,“Noise Power Spectral Density Estimation Based onOptimal Smoothing and Minimum Statistics”,IEEE Transactions on Speech andAudio Processing,vol.9,no.5,pp.504-512,Apr 2001
[4]Ephraim,Y.;Malah,D.,"Speech enhancement using a minimum mean-square error log-spectral amplitude estimator",IEEE Transactions onAcoustics,Speech and Signal Processing,vol.33,no.2,pp.443-445,Apr 1985
URL:http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1164550&isnu mber=26190
[5]Breithaupt,C.;Martin,R.,"Analysis of the Decision-Directed SNREstimator for Speech Enhancement With Respect to Low-SNR and TransientConditions",IEEE Transactions on Audio,Speech,and Language Processing,vol.19,no.2,pp.277-289,Feb.2011 URL:http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5444986&isnumber=5609232
[6]Cappe,O.,"Elimination of the musical noise phenomenon with theEphraim and Malah noise suppressor,"Speech and Audio Processing,IEEETransactions on,vol.2,no.2,pp.345-349,Apr 1994
URL:http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=279283&isnu mber=6926
[7]Loizou,P.(2007).Speech Enhancement:Theory and Practice,CRC Press,Boca Raton:FL
Claims (24)
1.一种音频处理装置,包括:
-至少一输入单元,用于提供表示由来自目标声源TS的目标语音信号分量S(k,n)和来自不同于目标声源的其它声源的噪声信号分量N(k,n)组成的时变声音信号的电输入信号的时频表示Y(k,n),其中k和n分别为频带和时间帧指数;
-降噪系统,配置成
--确定所述电输入信号的后验信噪比估计量γ(k,n);及
--基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的先验目标信噪比估计量ζ(k,n);及
-从下面的估计量确定第n个时间帧的先验目标信噪比估计量ζ(k,n)
--第n-1时间帧的先验目标信噪比估计量ζ(k,n-1);及
--第n时间帧的后验信噪比估计量γ(k,n)。
2.根据权利要求1所述的音频处理装置,其中所述递归算法配置成实施具有自适应时间常数的低通滤波器。
3.根据权利要求1或2所述的音频处理装置,其中低通滤波器的自适应时间常数根据后验信噪比估计量和/或先验信噪比估计量确定。
4.根据权利要求1所述的音频处理装置,其中低通滤波器对于给定频率指数k的自适应时间常数根据唯一对应于该频率指数k的后验信噪比估计量和/或先验信噪比估计量确定。
5.根据权利要求1所述的音频处理装置,其中低通滤波器对于给定频率指数k的自适应时间常数根据预定或自适应方案根据对应于多个频率指数k’的后验信噪比估计量和/或先验信噪比估计量确定。
6.根据权利要求1所述的音频处理装置,其中低通滤波器对于给定频率指数k的自适应时间常数根据来自一个或多个检测器的输入确定。
7.根据权利要求1所述的音频处理装置,其中所述降噪系统配置成在γ(k,n)大于或等于1的假设下确定第n时间帧的先验目标信噪比估计量ζ(k,n)。
8.根据权利要求1所述的音频处理装置,其中所述降噪系统配置成从第n-1时间帧的先验目标信噪比估计量ζ(k,n-1)和从第n时间帧的先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量ζML(k,n)确定第n时间帧的先验目标信噪比估计量ζ(k,n)。
9.根据权利要求8所述的音频处理装置,其中所述降噪系统配置成将最大似然SNR估计量ζML(k,n)确定为MAX{ζML min(k,n);γ(k,n)-1},其中MAX为最大值算子,及ζML min(k,n)为最大似然SNR估计量ζML(k,n)的最小值。
10.根据权利要求1所述的音频处理装置,其中所述降噪系统配置成通过后验信噪比估计量γ的非线性平滑确定先验目标信噪比估计量ζ。
11.根据权利要求10所述的音频处理装置,其中所述降噪系统配置成提供随SNR而变的平滑,使在低SNR条件下相较高SNR条件进行更多平滑。
12.根据权利要求1所述的音频处理装置,其中所述降噪系统配置成对低SNR条件相较于 提供负偏差,其中
提供负偏差,其中 为先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量。
为先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量。
13.根据权利要求12所述的音频处理装置,其中所述降噪系统配置成提供递归偏差,使能从低到高和从高到低SNR条件的可配置的变化。
14.根据权利要求8-13任一所述的音频处理装置,其中所述降噪系统配置成根据下面的递归算法从第n-1时间帧的先验目标信噪比估计量ζ(k,n-1)和从第n时间帧的先验目标信噪比估计量ζ(k,n)的最大似然SNR估计量ζML(k,n)确定第n时间帧的先验目标信噪比估计量ζ(k,n):

其中ρ(sn-1)表示第n-1时间帧的偏差函数或参数,及λ(sn-1)表示平滑函数或参数,及其中sn=s(k,n)=10log(ζ(k,n)),sML n=sML(k,n)=10log(ζML(k,n))。
15.根据权利要求1所述的音频处理装置,包括滤波器组,其包含用于提供电输入信号的时频表示Y(k,n)的分析滤波器组。
16.根据权利要求15所述的音频处理装置,配置成使得所述分析滤波器组被过采样。
17.根据权利要求16所述的音频处理装置,其中用于确定第n时间帧的先验目标信噪比估计量ζ(k,n)的算法的递归循环包括高阶延迟元件。
18.根据权利要求16或17所述的音频处理装置,其中降噪系统配置成使用于确定第n时间帧的先验目标信噪比估计量ζ(k,n)的算法适于补偿分析滤波器组的过采样。
19.根据权利要求1所述的音频处理装置,包括助听器、头戴式耳机、耳麦、耳朵保护装置或其组合。
20.估计表示由目标语音分量和噪声分量组成的时变声音信号的电输入信号的时频表示Y(k,n)的先验信噪比ζ(k,n)的方法,其中k和n分别为频带和时间帧指数,所述方法包括:
-确定所述电输入信号Y(k,n)的后验信噪比估计量γ(k,n);
-基于递归算法从后验信噪比估计量γ(k,n)确定所述电输入信号的先验目标信噪比估计量ζ(k,n);及
-从第n-1时间帧的先验目标信噪比估计量ζ(k,n-1)及第n时间帧的后验信噪比估计量γ(k,n)确定第n时间帧的先验目标信噪比估计量ζ(k,n)。
21.根据权利要求20所述的方法,其中所述递归算法配置成实施具有自适应时间常数的低通滤波器。
22.根据权利要求20或21所述的方法,其中目标语音分量的量值的估计量 从电输入信号Y(k,n)乘以增益函数G确定,其中增益函数G为后验信噪比估计量γ(k,n)和先验目标信噪比估计量ζ(k,n)的函数。
从电输入信号Y(k,n)乘以增益函数G确定,其中增益函数G为后验信噪比估计量γ(k,n)和先验目标信噪比估计量ζ(k,n)的函数。
23.一种数据处理系统,包括处理器和程序代码,所述程序代码用于使得所述处理器执行根据权利要求20-22任一所述的方法。
24.一种计算机存储介质,其上存储有包括指令的计算机程序,当所述计算机程序由计算机执行时,使得所述计算机执行根据权利要求20-22任一所述的方法。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP16171986.9 | 2016-05-30 | ||
| EP16171986.9A EP3252766B1 (en) | 2016-05-30 | 2016-05-30 | An audio processing device and a method for estimating a signal-to-noise-ratio of a sound signal |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107484080A CN107484080A (zh) | 2017-12-15 |
| CN107484080B true CN107484080B (zh) | 2021-07-16 |
Family
ID=56092808
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201710400529.6A Active CN107484080B (zh) | 2016-05-30 | 2017-05-31 | 音频处理装置及用于估计声音信号的信噪比的方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US10269368B2 (zh) |
| EP (2) | EP3252766B1 (zh) |
| JP (1) | JP7250418B2 (zh) |
| KR (1) | KR102424257B1 (zh) |
| CN (1) | CN107484080B (zh) |
| DK (2) | DK3252766T3 (zh) |
Families Citing this family (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10555094B2 (en) * | 2017-03-29 | 2020-02-04 | Gn Hearing A/S | Hearing device with adaptive sub-band beamforming and related method |
| US10438588B2 (en) * | 2017-09-12 | 2019-10-08 | Intel Corporation | Simultaneous multi-user audio signal recognition and processing for far field audio |
| EP4236359A3 (en) | 2017-12-13 | 2023-10-25 | Oticon A/s | A hearing device and a binaural hearing system comprising a binaural noise reduction system |
| CN112041160B (zh) | 2018-01-24 | 2024-06-11 | Ctc环球公司 | 高架电缆的端接装置 |
| US10313786B1 (en) | 2018-03-20 | 2019-06-04 | Cisco Technology, Inc. | Beamforming and gainsharing mixing of small circular array of bidirectional microphones |
| DE102018206689A1 (de) * | 2018-04-30 | 2019-10-31 | Sivantos Pte. Ltd. | Verfahren zur Rauschunterdrückung in einem Audiosignal |
| DK3582513T3 (da) * | 2018-06-12 | 2022-01-31 | Oticon As | Høreanordning omfattende adaptiv lydkildefrekvensreduktion |
| CN110738990B (zh) * | 2018-07-19 | 2022-03-25 | 南京地平线机器人技术有限公司 | 识别语音的方法和装置 |
| US11750985B2 (en) * | 2018-08-17 | 2023-09-05 | Cochlear Limited | Spatial pre-filtering in hearing prostheses |
| CN109256153B (zh) * | 2018-08-29 | 2021-03-02 | 云知声智能科技股份有限公司 | 一种声源定位方法及系统 |
| CN109087657B (zh) * | 2018-10-17 | 2021-09-14 | 成都天奥信息科技有限公司 | 一种应用于超短波电台的语音增强方法 |
| TWI700004B (zh) * | 2018-11-05 | 2020-07-21 | 塞席爾商元鼎音訊股份有限公司 | 減少干擾音影響之方法及聲音播放裝置 |
| CN109643554B (zh) * | 2018-11-28 | 2023-07-21 | 深圳市汇顶科技股份有限公司 | 自适应语音增强方法和电子设备 |
| US11227622B2 (en) * | 2018-12-06 | 2022-01-18 | Beijing Didi Infinity Technology And Development Co., Ltd. | Speech communication system and method for improving speech intelligibility |
| EP3671739A1 (en) * | 2018-12-21 | 2020-06-24 | FRAUNHOFER-GESELLSCHAFT zur Förderung der angewandten Forschung e.V. | Apparatus and method for source separation using an estimation and control of sound quality |
| US20220124444A1 (en) * | 2019-02-08 | 2022-04-21 | Oticon A/S | Hearing device comprising a noise reduction system |
| EP3694229A1 (en) * | 2019-02-08 | 2020-08-12 | Oticon A/s | A hearing device comprising a noise reduction system |
| US11146607B1 (en) * | 2019-05-31 | 2021-10-12 | Dialpad, Inc. | Smart noise cancellation |
| CN110265052B (zh) * | 2019-06-24 | 2022-06-10 | 秒针信息技术有限公司 | 收音设备的信噪比确定方法、装置、存储介质及电子装置 |
| KR102690400B1 (ko) | 2019-07-01 | 2024-08-01 | 현대자동차주식회사 | 차량 및 그 제어 방법 |
| US10839821B1 (en) * | 2019-07-23 | 2020-11-17 | Bose Corporation | Systems and methods for estimating noise |
| CN110517708B (zh) * | 2019-09-02 | 2024-06-07 | 平安科技(深圳)有限公司 | 一种音频处理方法、装置及计算机存储介质 |
| CN111417053B (zh) * | 2020-03-10 | 2023-07-25 | 北京小米松果电子有限公司 | 拾音音量控制方法、装置以及存储介质 |
| WO2021195429A1 (en) * | 2020-03-27 | 2021-09-30 | Dolby Laboratories Licensing Corporation | Automatic leveling of speech content |
| US11532313B2 (en) * | 2020-08-27 | 2022-12-20 | Google Llc | Selectively storing, with multiple user accounts and/or to a shared assistant device: speech recognition biasing, NLU biasing, and/or other data |
| CN112349277B (zh) * | 2020-09-28 | 2023-07-04 | 紫光展锐(重庆)科技有限公司 | 结合ai模型的特征域语音增强方法及相关产品 |
| CN112652323B (zh) * | 2020-12-24 | 2023-01-20 | 北京猿力未来科技有限公司 | 音频信号筛选方法、装置、电子设备及存储介质 |
| EP4270392A4 (en) * | 2020-12-28 | 2024-07-24 | Shenzhen Shokz Co Ltd | AUDIO NOISE REDUCTION METHOD AND SYSTEM |
| CN113038338A (zh) * | 2021-03-22 | 2021-06-25 | 联想(北京)有限公司 | 降噪处理方法和装置 |
| CN113096677B (zh) * | 2021-03-31 | 2024-04-26 | 深圳市睿耳电子有限公司 | 一种智能降噪的方法及相关设备 |
| CN114390401A (zh) * | 2021-12-14 | 2022-04-22 | 广州市迪声音响有限公司 | 用于音响的多通道数字音频信号实时音效处理方法及系统 |
| US20230308817A1 (en) | 2022-03-25 | 2023-09-28 | Oticon A/S | Hearing system comprising a hearing aid and an external processing device |
| DE102023202367A1 (de) * | 2023-03-16 | 2024-09-19 | Sivantos Pte. Ltd. | Verfahren zum Betrieb eines Hörgerätes, Hörgerät und Computerprogrammprodukt |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101916567A (zh) * | 2009-11-23 | 2010-12-15 | 瑞声声学科技(深圳)有限公司 | 应用于双麦克风系统的语音增强方法 |
| CN101976566A (zh) * | 2010-07-09 | 2011-02-16 | 瑞声声学科技(深圳)有限公司 | 语音增强方法及应用该方法的装置 |
| CN102347027A (zh) * | 2011-07-07 | 2012-02-08 | 瑞声声学科技(深圳)有限公司 | 双麦克风语音增强装置及其语音增强方法 |
| CN102402987A (zh) * | 2010-09-07 | 2012-04-04 | 索尼公司 | 噪声抑制装置、噪声抑制方法和程序 |
| CN105280193A (zh) * | 2015-07-20 | 2016-01-27 | 广东顺德中山大学卡内基梅隆大学国际联合研究院 | 基于mmse误差准则的先验信噪比估计方法 |
| CN105575406A (zh) * | 2016-01-07 | 2016-05-11 | 深圳市音加密科技有限公司 | 一种基于似然比测试的噪声鲁棒性的检测方法 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6098038A (en) | 1996-09-27 | 2000-08-01 | Oregon Graduate Institute Of Science & Technology | Method and system for adaptive speech enhancement using frequency specific signal-to-noise ratio estimates |
| US7058572B1 (en) | 2000-01-28 | 2006-06-06 | Nortel Networks Limited | Reducing acoustic noise in wireless and landline based telephony |
| EP1953736A4 (en) | 2005-10-31 | 2009-08-05 | Panasonic Corp | STEREO CODING DEVICE AND METHOD FOR PREDICTING STEREO SIGNAL |
| US8521530B1 (en) | 2008-06-30 | 2013-08-27 | Audience, Inc. | System and method for enhancing a monaural audio signal |
| US8244523B1 (en) * | 2009-04-08 | 2012-08-14 | Rockwell Collins, Inc. | Systems and methods for noise reduction |
| KR101726737B1 (ko) * | 2010-12-14 | 2017-04-13 | 삼성전자주식회사 | 다채널 음원 분리 장치 및 그 방법 |
| WO2013065010A1 (en) * | 2011-11-01 | 2013-05-10 | Cochlear Limited | Sound processing with increased noise suppression |
| JP2013148724A (ja) | 2012-01-19 | 2013-08-01 | Sony Corp | 雑音抑圧装置、雑音抑圧方法およびプログラム |
| US9576590B2 (en) | 2012-02-24 | 2017-02-21 | Nokia Technologies Oy | Noise adaptive post filtering |
| DK3190587T3 (en) * | 2012-08-24 | 2019-01-21 | Oticon As | Noise estimation for noise reduction and echo suppression in personal communication |
| JP6361156B2 (ja) * | 2014-02-10 | 2018-07-25 | 沖電気工業株式会社 | 雑音推定装置、方法及びプログラム |
| WO2015189261A1 (en) | 2014-06-13 | 2015-12-17 | Retune DSP ApS | Multi-band noise reduction system and methodology for digital audio signals |
-
2016
- 2016-05-30 EP EP16171986.9A patent/EP3252766B1/en active Active
- 2016-05-30 DK DK16171986.9T patent/DK3252766T3/da active
-
2017
- 2017-05-30 JP JP2017106326A patent/JP7250418B2/ja active Active
- 2017-05-30 EP EP17173455.1A patent/EP3255634B1/en active Active
- 2017-05-30 DK DK17173455.1T patent/DK3255634T3/da active
- 2017-05-30 KR KR1020170067119A patent/KR102424257B1/ko active IP Right Grant
- 2017-05-30 US US15/608,224 patent/US10269368B2/en active Active
- 2017-05-31 CN CN201710400529.6A patent/CN107484080B/zh active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101916567A (zh) * | 2009-11-23 | 2010-12-15 | 瑞声声学科技(深圳)有限公司 | 应用于双麦克风系统的语音增强方法 |
| CN101976566A (zh) * | 2010-07-09 | 2011-02-16 | 瑞声声学科技(深圳)有限公司 | 语音增强方法及应用该方法的装置 |
| CN102402987A (zh) * | 2010-09-07 | 2012-04-04 | 索尼公司 | 噪声抑制装置、噪声抑制方法和程序 |
| CN102347027A (zh) * | 2011-07-07 | 2012-02-08 | 瑞声声学科技(深圳)有限公司 | 双麦克风语音增强装置及其语音增强方法 |
| CN105280193A (zh) * | 2015-07-20 | 2016-01-27 | 广东顺德中山大学卡内基梅隆大学国际联合研究院 | 基于mmse误差准则的先验信噪比估计方法 |
| CN105575406A (zh) * | 2016-01-07 | 2016-05-11 | 深圳市音加密科技有限公司 | 一种基于似然比测试的噪声鲁棒性的检测方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US10269368B2 (en) | 2019-04-23 |
| US20170345439A1 (en) | 2017-11-30 |
| CN107484080A (zh) | 2017-12-15 |
| JP7250418B2 (ja) | 2023-04-03 |
| DK3255634T3 (da) | 2021-09-06 |
| JP2018014711A (ja) | 2018-01-25 |
| EP3255634A1 (en) | 2017-12-13 |
| US20180233160A9 (en) | 2018-08-16 |
| DK3252766T3 (da) | 2021-09-06 |
| KR102424257B1 (ko) | 2022-07-22 |
| EP3252766A1 (en) | 2017-12-06 |
| EP3252766B1 (en) | 2021-07-07 |
| EP3255634B1 (en) | 2021-07-07 |
| KR20170135757A (ko) | 2017-12-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107484080B (zh) | 音频处理装置及用于估计声音信号的信噪比的方法 | |
| US11109163B2 (en) | Hearing aid comprising a beam former filtering unit comprising a smoothing unit | |
| US10861478B2 (en) | Audio processing device and a method for estimating a signal-to-noise-ratio of a sound signal | |
| CN107360527B (zh) | 包括波束形成器滤波单元的听力装置 | |
| CN110060666B (zh) | 听力装置的运行方法及基于用语音可懂度预测算法优化的算法提供语音增强的听力装置 | |
| US10433076B2 (en) | Audio processing device and a method for estimating a signal-to-noise-ratio of a sound signal | |
| CN110035367B (zh) | 反馈检测器及包括反馈检测器的听力装置 | |
| CN107872762B (zh) | 话音活动检测单元及包括话音活动检测单元的听力装置 | |
| CN109660928B (zh) | 包括用于影响处理算法的语音可懂度估计器的听力装置 | |
| CN107801139B (zh) | 包括反馈检测单元的听力装置 | |
| CN107046668B (zh) | 单耳语音可懂度预测单元、助听器及双耳听力系统 | |
| CN106507258B (zh) | 一种听力装置及其运行方法 | |
| CN107454537B (zh) | 包括滤波器组和起始检测器的听力装置 | |
| US11483663B2 (en) | Audio processing device and a method for estimating a signal-to-noise-ratio of a sound signal | |
| CN111629313B (zh) | 包括环路增益限制器的听力装置 | |
| CN114697846A (zh) | 包括反馈控制系统的助听器 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |