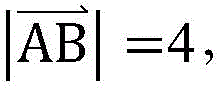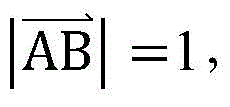一种用户信用模型建立方法及装置
技术领域
本申请涉及互联网技术领域,尤其涉及一种用户信用模型建立方法及装置。
背景技术
当前互联网金融的最大风险是用户信用风险,建立一个良好的信用评估体系对于互联网金融的健康发展具有重大意义。
现行的信用评估系统通常需要基于预先训练好的用户信用模型计算用户的信用分值。用户信用模型的训练离不开大数据的支持,除了直接相关的信贷数据,在信用模型训练中还会引入大量非结构化的信用弱相关数据,
现有的信用评估系统一般针对所有用户使用统一的信用模型,也即在一套评分体系中完成对所有人群的信用评估。然而针对具有不同的群体特性的人群,统一的普适性模型往往无法很好地刻画所有用户的信用情况,使用统一的信用模型计算出来的用户信用分值准确度较低。
发明内容
本申请实施例提供一种用户信用模型建立方法及装置,用以解决现有技术中使用统一的信用模型计算出来的用户信用分值准确度较低的问题。
本申请实施例提供一种用户信用模型建立方法,包括:
从用户数据库中,选取至少一个用户作为一个簇中的核心对象;
针对所述簇中的核心对象,根据该核心对象和所述用户数据库中除所述簇中的核心对象外的其它各个用户分别在多种特征参数下的特征值,确定所述其它各个用户分别与该核心对象之间的相似度,并根据所述其它各个用户分别与该核心对象之间的相似度,确定划分到所述簇中的其它用户;
采用所述簇对应的建模方式,建立针对所述簇中各个用户的用户信用模型。
可选地,所述从用户数据库中,选取至少一个用户作为一个簇中的核心对象,包括:
从用户数据库中,选取在至少一种指定特征参数下的特征值符合预设的取值区间的用户,并将选取的用户作为一个簇中的核心对象。
可选地,根据该核心对象和所述其它各个用户分别在多种特征参数下的特征值,确定所述其它各个用户分别与该核心对象之间的相似度,包括:
根据该核心对象和所述其它各个用户分别在多种特征参数下的特征值,以及其中每种特征参数的权重,确定所述其它各个用户分别与该核心对象之间的相似度;其中,在所述多种特征参数中所述至少一种指定特征参数的权重大于其它特征参数的权重。
可选地,所述从用户数据库中,选取至少一个用户作为一个簇中的核心对象,包括:
从用户数据库中选取至少一个指定用户作为一个簇中的核心对象。
可选地,所述根据所述其它各个用户分别与该核心对象之间的相似度,确定划分到所述簇中的其它用户,包括:
若与所述核心对象之间的相似度大于设定相似度阈值的邻域用户的数量大于设定数量阈值,则将该核心对象的邻域用户划分到候选集中;
从所述候选集中选取一个用户,若与选取的用户之间的相似度大于设定相似度阈值的领域用户的数量大于设定数量阈值,则将所述选取的用户从所述候选集中移入到所述簇中,并将所述选取的用户的邻域用户中未移入所述簇中的邻域用户划分到所述候选集中,否则,将所述选取的用户作为噪声从所述候选集中移入到噪声集中;
返回上述从候选集中选取一个用户的步骤,直到所述候选集为空。
可选地,所述方法还包括:
将所述噪声集中的用户划分到一个簇中,并建立针对该簇中各个用户的用户信用模型。
本申请实施例提供一种用户信用模型建立装置,包括:
选取模块,用于从用户数据库中,选取至少一个用户作为一个簇中的核心对象;
确定模块,用于针对所述簇中的每个核心对象,根据该核心对象和所述用户数据库中除所述簇中的核心对象外的其它各个用户分别在多种特征参数下的特征值,确定所述其它各个用户分别与该核心对象之间的相似度,并根据所述其它各个用户分别与该核心对象之间的相似度,确定划分到所述簇中的其它用户;
模型建立模块,用于采用所述簇对应的建模方式,建立针对所述簇中各个用户的用户信用模型。
本申请实施例将用户进行分簇后,可以针对每个簇的特点分别精准地构建用户信用模型。采用本申请实施例建立的用户信用模型可以更加精确地描述每个簇内用户的信用情况,同时由于一开始分簇时就为每个簇选取了符合特定要求的核心对象,因此被分离出的簇的和在该簇上建立的用户信用模型便具有较好的可解释性。
附图说明
图1为选择簇内的核心对象;
图2为本申请实施例一提供的用户信用模型建立方法流程图;
图3为进行簇的扩展的流程示意图;
图4为基于这些分群进行用户信用模型训练的示意图。
图5为本申请实施例二提供的用户信用模型建立方法流程图;
图6为本申请实施例提供的用户信用模型建立装置结构示意图。
具体实施方式
本申请实施例提出了一种先对用户分簇(或称分群),再针对每个簇分别建立用户信用模型的思想。在对用户分簇时,采用了一种将有监督方式和无监督方式相结合的思想,首先基于有监督的人为干预的方式选取符合要求的一些核心对象,然后在这些核心对象的基础上基于无监督方式进行簇的扩展,将相似度在一定阈值范围内的用户划分为一个簇中。这样,本申请实施例无需限制划分的簇的个数,也无需限制簇内的用户数,可以发现符合需求的任意大小的簇。
另外,在选取符合要求的核心对象时,本申请实施例中给出了两种方式,在具体实施中,可以仅选择其中一种方式使用,也可以将这两种方式结合使用:
在一种方式下,首先建立至少一个符合特定要求的区域,每个区域对应一个簇,该区域内的用户为对应的簇内的核心用户。这里,符合特定要求的区域内的用户为在至少一种指定特征参数下的特征值符合预设的取值区间的用户。另外,在确定两个用户之间的相似度时,会加大这至少一种指定特征参数的权重。如图1所示,在区域1和区域4内的用户为基于这种方式选择的簇内的核心对象,分别以区域1和区域4内的核心对象为基础,进行簇的扩展,最终形成两个簇。
对于有些用户,通过对其进行历史行为数据分析,发现这些用户具有我们所关注的某个用户特点,但是对于该用户特点,却无法很确切地提取影响它的特征参数,比如,这里的用户特点可以是“收入稳定”、“富有爱心”、“责任感强”等,此时可以选用第二种方式:直接指定具有某个用户特点的一些核心用户。如图1所示,在区域2和区域3的用户为直接指定的分别对应不同用户特点的核心对象,分别以区域2和区域3的核心对象为基础,进行簇的扩展,也最终形成两个簇。
下面结合说明书附图对本申请实施例作进一步详细描述。
实施例一
在该实施例下,首先建立一些符合特定要求的区域,每个区域对应一个簇。这里,符合特定要求的区域内的用户为在至少一种指定特征参数下的特征值符合预设的取值区间的用户。另外,在确定两个用户之间的相似度时,加大这至少一种指定特征参数的权重。
如图2所示,以一个簇的形成为例,介绍本申请实施例一提供的用户信用模型建立方法流程图,包括以下步骤:
S201:从用户数据库中,选取在至少一种指定特征参数下的特征值符合预设的取值区间的至少一个用户,并将选取的至少一个用户作为一个簇中的核心对象。
在具体实施中,可以根据实际需要预先设置一些关注的指定特征参数,比如当希望建立一个单身独立女性群体时,可以将性别、婚姻状况、经济状况设置为所述指定特征参数,比如对于性别,用特征值1表示男士,0表示女士,则针对性别所预设的取值区间为一个值0;对于婚姻状况,用1表示未婚,0表示已婚,则针对婚姻状况所预设的取值区间为一个值1;对于经济状况,将年收入0~20万归一化到0~1之间,比如若年收入10万,则特征值为0.5,若年收入在20万以上,则特征值取为1,针对经济状况所预设的取值区间为[0.4,1]。基于此,该步骤就是将性别、婚姻状况和经济状况对应的特征值分别符合0、1、[0.4,1]的用户选取为一个簇中的核心对象。
S202:针对所述簇中的每个核心对象,根据该核心对象和所述用户数据库中除所述簇中的核心对象外的其它各个用户分别在多种特征参数下的特征值,以及其中每种特征参数的权重,确定所述其它各个用户分别与该核心对象之间的相似度,并根据所述其它各个用户分别与该核心对象之间的相似度,确定划分到所述簇中的其它用户;其中,在所述多种特征参数中所述至少一种指定特征参数的权重大于其它特征参数的权重。
该步骤中,针对选取的一个簇中的每个核心对象,分别以该核心对象为基础进行簇的扩展。本申请实施例中,由于指定特征参数相比其它特征参数的重要度更高,因此将指定特征参数在计算相似度时的权重设置的大于其它特征参数的权重。
在具体实施中,可以采用多种算法计算两个用户之间的相似度,比如可以采用欧式距离法、余弦相似性、皮尔森系数等,在实际实施中,可以根据实际需要进行选择。下面以欧式距离为例进行介绍。
比如,在计算两个用户之间的相似度时,针对每个用户,可以将该用户在每个特征参数下的特征值乘以该特征参数的权重,得到该用户对应的多维坐标点的坐标值,通过计算两个用户各自对应的多维坐标点之间的距离,得到这两个用户之间的相似度。这里,所述距离越大,两个用户之间的相似度越小,则具体可以将相似度设置为与距离成反比例的值,比如可以采用距离的倒数作为相似度(当然还可以定义其它的方式)。比如某个用户在性别、婚姻状况、经济状况、支出状况这四个特征参数下的特征值分别为0、1、0.5、0.2,这四个特征参数中性别、婚姻状况、经济状况为指定特征参数,这三个指定特征参数的权重为4,支出状况为非指定特征参数,权重为1,则该用户对应的多维坐标点的坐标即为A(0,4,2,0.2)。假设另一用户对应的多维坐标点的坐标为B(4,4,2,0.2),则这两个用户对应的多维坐标点之间的距离即为
可以将其相似度取值为1/4。
在具体实施中,可以依次选择每个核心对象进行簇的扩展,也可以以多个核心对象为基础,并行进行簇的扩展,若选择第一种依次扩展的方式,则在以下一个核心对象为基础进行簇的扩展时,可以自动忽略已归入簇中的用户。若选择第二种并行扩展的方式,以不同核心对象为基础扩展的用户可能存在重复,不过这对实施结果并无影响,最后合并扩展的用户时,对重复的用户作去重处理即可。
如图3所示,在具体实施中,针对任一核心对象,具体可以根据以下进行簇的扩展:
S2a:确定所述用户数据库中除簇中的核心对象外的其它各个用户分别与该核心对象之间的相似度。
S2b:判断与该核心对象之间的相似度大于设定相似度阈值的邻域用户的数量是否大于设定数量阈值,若是,则进入S2c,否则,选择下一个核心对象,并返回S2b,或结束操作。
S2c:将该核心对象的邻域用户划分到候选集中,进入S2d。
S2d:从所述候选集中选取一个用户,判断与选取的用户之间的相似度大于设定相似度阈值的领域用户的数量是否大于设定数量阈值,若是,则进入S2e,否则进入S2f。
S2e:将所述选取的用户从所述候选集中移入到所述簇中,并将所述选取的用户的邻域用户中未移入所述簇中的邻域用户划分到所述候选集中,返回S2d,直到所述候选集为空。
这里,选取的用户的邻域用户中可能包括已经移入所述簇中的邻域用户、已经划分到候选集中但未移入簇中的邻域用户、以及其它用户,这里将其它用户移入候选集中,已经划分到候选集中但未移入簇中的邻域用户则仍将其部署在候选集中。
S2f:将所述选取的用户作为噪声从所述候选集中移入到噪声集中,返回S2d,直到所述候选集为空。
S203:采用所述簇对应的建模方式,建立针对所述簇中各个用户的用户信用模型。
在具体实施中,针对每个簇的特点,分别选择对应建模方式(其中可以包括特征筛选算法及评价算法等),建立适用于每个簇的特有的用户信用模型。比如,有的簇使用遗传算法进行特征筛选的效果较好,有的簇则可能使用层次聚类算法进行特征筛选效果更好;有的簇可能使用逻辑回归算法作为评价算法较好,有的簇则可能使用随机森林算法作为评价算法更好。
另外,在具体实施中,还可以将噪声集中的所有用户都划分到一个簇中,并针对该簇中各个用户建立一个统一的用户信用模型。
这里,由于本申请实施例希望做到精确分群,所以在实施中可以加大对噪声的过滤程度,对于那些不能够被精确划分到有特定特点的簇的用户,可以将其一律划分到一个单独的簇中,并对这个簇沿用原来的算法来建立信用模型。
本申请实施例将用户进行分群(簇)后,可以针对每个分群的特点分别精准地构建用户信用模型,如图4所示,为基于这些分群进行用户信用模型训练的示意图。本申请实施例能够精确分群,并针对每个分群分别建模,采用本申请实施例建立的用户信用模型可以更加精确地描述每个人群的信用情况,同时由于一开始分群时就为每个分群选取了符合特定要求的核心对象,因此被分离出的群体的和在该群体上建立的用户信用模型便具有较好的可解释性。
实施例二
通过对一些用户进行历史行为数据分析,可能发现这些用户具有我们所关注的某个用户特点,但是对于该用户特点,却无法很确切地提取影响它的特征参数,此时可以选用直接指定核心用户的方式。
如图5所示,为本申请实施例二提供的用户信用模型建立方法流程图,包括以下步骤:
S501:从用户数据库中选取至少一个指定用户作为一个簇中的核心对象。
在具体实施中,根据关注的一些用户特点,通过对一些用户进行历史行为数据分析,直接指定一些用户作为簇中的核心对象,针对不同的用户特点,可以指定不同簇中的核心用户。这里以一个簇为例进行说明。
S502:针对所述簇中的每个核心对象,根据该核心对象和所述用户数据库中除所述簇中的核心对象外的其它各个用户分别在多种特征参数下的特征值,确定所述其它各个用户分别与该核心对象之间的相似度,并根据所述其它各个用户分别与该核心对象之间的相似度,确定划分到所述簇中的其它用户。
这里,针对任一核心对象,具体进行簇的扩展的方式可以参见实施例一的描述,这里不再赘述。
以采用欧式距离法计算相似度为例,在计算两个用户之间的相似度时,针对每个用户,可以将该用户在每个特征参数下的特征值,作为该用户对应的多维坐标点的坐标值,通过计算两个用户各自对应的多维坐标点之间的距离,得到这两个用户之间的相似度。比如某个用户在性别、婚姻状况、经济状况、支出状况这四个特征参数下的特征值分别为0、1、0.5、0.2,则该用户对应的多维坐标点的坐标即为A(0,1,0.5,0.2)。假设另一用户对应的多维坐标点的坐标为B(1,1,0.5,0.2),则这两个用户对应的多维坐标点之间的距离即为
相似度可以取值为距离的倒数。
S503:采用所述簇对应的建模方式,建立针对所述簇中各个用户的用户信用模型。
具体参见实施例一的描述,这里不再赘述。
基于同一发明构思,本申请实施例中还提供了一种与用户信用模型建立方法对应的用户信用模型建立装置,由于该装置解决问题的原理与本申请实施例用户信用模型建立方法相似,因此该装置的实施可以参见方法的实施,重复之处不再赘述。
如图6所示,为本申请实施例提供的用户信用模型建立装置结构示意图,包括:
选取模块61,用于从用户数据库中,选取至少一个用户作为一个簇中的核心对象;
确定模块62,用于针对所述簇中的每个核心对象,根据该核心对象和所述用户数据库中除所述簇中的核心对象外的其它各个用户分别在多种特征参数下的特征值,确定所述其它各个用户分别与该核心对象之间的相似度,并根据所述其它各个用户分别与该核心对象之间的相似度,确定划分到所述簇中的其它用户;
模型建立模块63,用于采用所述簇对应的建模方式,建立针对所述簇中各个用户的用户信用模型。
可选地,选取模块61具体用于:
从用户数据库中,选取在至少一种指定特征参数下的特征值符合预设的取值区间的用户,并将选取的用户作为一个簇中的核心对象。
可选地,确定模块62具体用于:
根据该核心对象和所述其它各个用户分别在多种特征参数下的特征值,以及其中每种特征参数的权重,确定所述其它各个用户分别与该核心对象之间的相似度;其中,在所述多种特征参数中所述至少一种指定特征参数的权重大于其它特征参数的权重。
可选地,选取模块61具体用于:
从用户数据库中选取至少一个指定用户作为一个簇中的核心对象。
可选地,确定模块62具体用于:
若与所述核心对象之间的相似度大于设定相似度阈值的邻域用户的数量大于设定数量阈值,则将该核心对象的邻域用户划分到候选集中;
从所述候选集中选取一个用户,若与选取的用户之间的相似度大于设定相似度阈值的领域用户的数量大于设定数量阈值,则将所述选取的用户从所述候选集中移入到所述簇中,并将所述选取的用户的邻域用户中未移入所述簇中的邻域用户划分到所述候选集中,否则,将所述选取的用户作为噪声从所述候选集中移入到噪声集中;
返回上述从候选集中选取一个用户的步骤,直到所述候选集为空。
可选地,模型建立模块63还用于:
将所述噪声集中的用户划分到一个簇中,并建立针对该簇中各个用户的用户信用模型。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、装置(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。