CN103617150A - 一种基于gpu的大规模电力系统潮流并行计算系统及其方法 - Google Patents
一种基于gpu的大规模电力系统潮流并行计算系统及其方法 Download PDFInfo
- Publication number
- CN103617150A CN103617150A CN201310588919.2A CN201310588919A CN103617150A CN 103617150 A CN103617150 A CN 103617150A CN 201310588919 A CN201310588919 A CN 201310588919A CN 103617150 A CN103617150 A CN 103617150A
- Authority
- CN
- China
- Prior art keywords
- partiald
- matrix
- gpu
- module
- delta
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Abstract
本发明涉及一种基于GPU的大规模电力系统潮流并行计算系统及其方法,所述系统包括符号雅克比矩阵形成与分解模块、初始化模块、潮流方程右端项计算模块、雅克比矩阵赋值模块、LU分解模块和前代回代模块;所述符号雅克比矩阵形成与分解模块位于主机端,主机端将计算数据传送到设备端;所述雅克比矩阵右端项计算模块、雅克比矩阵的赋值模块、LU分解模块和前代回代模块在设备端依次连接。所述方法包括:(1)将计算所需数据全部传送到主机端;(2)生成符号雅克比矩阵并对其进行符号分解;(3)主机端将分解结果传送到设备端;(4)执行潮流方程右端项计算;(5)执行雅克比矩阵赋值;(6)执行LU分解;(7)执行前代回代。
Description
技术领域
本发明属于电网仿真技术领域,具体讲涉及一种基于GPU的大规模电力系统潮流并行计算系统及其方法。
背景技术
潮流计算的任务是根据给定的运行条件确定系统的运行状况。具体地说就是已知电网的接线方式与参数及运行条件,计算电力系统稳态运行各母线电压、各支路电流、功率及网损。对于正在运行的系统,通过潮流计算可以判断电网母线电压、支路电流和功率是否越限,如有越限则调整运行方式。对于正在规划的电力系统,潮流计算可以为选择电网的供电方法和电气设备提供依据。除此之外,潮流计算还可以为继电保护和自动装置整定计算、电力系统故障计算和稳定计算等等提供潮流初值。
潮流计算的计算结果是进行电力系统静态和暂态稳定计算的基础。一些故障分析以及优化计算也需要潮流计算作配合。这些都是潮流计算在电力系统规划设计及运行方式分析安排中的应用,属于离线计算的范畴。随着现代化的调度控制中心的建立,为了对电力系统进行实时安全监控,需要根据实时数据库提供的信息,随时判断系统当前的运行状况并对预想事故进行安全分析。这就需要进行广泛的潮流计算,并且对计算速度提出了更高的要求,从而产生了潮流的在线计算。
潮流计算作为电力系统计算的基础,其方法可以运用到很多其他仿真计算场合,稀疏线性方程组的算法在很多涉及计算的场合也均有应用。潮流计算的计算平台有CPU、GPU、FPGA等等。GPU和CPU在芯片设计上有很大的不同。CPU芯片中将更多的晶体管用于构造复杂的控制单元和缓存,并以此来提高少数执行单元的执行效率。GPU芯片中则没有这些复杂的控制单元,但是却拥有大量的执行单元。根据这样的芯片设计,CPU更适合处理逻辑性强的工作,GPU更适合并行度高,基本不需要逻辑,程序分支少的工作。根据GPU芯片的特点,配合其使用的显存也和内存有比较大的不同。内存芯片一般采用DDR SDRAM,而显存芯片一般采用GDDR SDRAM。尽管GDDR由DDR改进而来,采用的是相似的技术,但是两者在性能上还是有所不同。显存的带宽更高,延迟更高(400到800个时钟周期);内存的带宽较低,延迟也很低。
并行系统中耗费时间最多的数值分解模块在算法上没有分支,在数据结构上全部使用简单的一维数组,所以不需要复杂的逻辑判断;在计算过程中没有额外的指令需求,所以计算量上没有增加。性能上唯一的瓶颈指向了存储器的读取与写入。在我们这个程序数值分解过程中,整体数据量不大,但是数据存取写入次数频繁,这导致了程序性能低下。
发明内容
针对现有技术的不足,本发明提供一种基于GPU的大规模电力系统潮流并行计算方法,具体涉及用于加速牛顿-拉夫逊法潮流计算的基于GPU的潮流计算雅克比矩阵并行生成模块,稀疏矩阵并行分解模块、前代回代算法模块。潮流计算的核心是求解潮流方程,从数学的角度上讲,这是一个非线性的方程组。牛顿-拉夫逊法是求取非线性方程组近似解的常用办法,其核心思想是将非线性方程组的求解转化为一系列的线性方程组的求解。由于电力网络稀疏的特点,潮流方程转化得到的一系列线性方程组系数矩阵均为稀疏矩阵。为了减少矩阵分解的数值计算量,减少矩阵分解过程中的非零元填充,会采用MD(最小度)算法或者MDML(最小度最小层)算法对网络节点进行重新编号。为了解析稀疏矩阵的元素依赖关系,指导节点消去顺序,常常引入消去树结构。矩阵分解通常分为符号分解、数值分解几部分,符号分解确定矩阵分解过程中的非零元填充位置,随后的数值分解确定矩阵分解的数值结果。矩阵分解过程完成后,求解过程称为前代回代过程。其实质为连续求取系数矩阵为下三角矩阵和上三角矩阵的两个线性方程组。
本发明在GPU上并行实现了牛顿-拉夫逊法潮流计算中的循环迭代过程,并通过大规模电网的潮流计算对算法正确性、有效性进行了检验。系统首先将计算所需数据全部传送到显存上,然后雅克比矩阵并行生成模块为每个节点分配一个线程,每个线程负责生成雅克比矩阵中的一行数据。生成的雅克比矩阵将按照消去树分层并行的方式以秩为二的矩阵为最小单位元素进行分解。准备处理消去树某层节点时,矩阵并行LU分解模块将为该层的每一个节点分配一个线程,每个线程均按照up-looking的节点消去方法对该节点进行消去。雅克比矩阵数值分解完成之后,同样按照消去树分层并行的方式执行前代回代过程。其中,
潮流计算:潮流计算是电力系统分析中的一种最基本的计算,他的任务是对给定的运行条件确定系统的运行状态,如各母线上的电压(幅值及相角)、网络中的功率分布及功率损耗等。
并行计算:并行计算是一个广义的概念,根据其实现层次的不同可以分为几种方式:单核指令集并行,多核并行,多处理器并行,集群分布式并行。最微观的是单核指令级并行,让单个处理器的执行单元同时执行多条指令;向上一层是多核并行,即在一个芯片上集成多个处理器核心,实现线程级并行;再往上是多处理器并行,在一块电路板上安装多个处理器,实现线程和进程级并行;最后可以借助网络实现大规模的集群或者分布式并行,每个节点都是一台独立的计算机。
GPU:中文名为“图形处理器”,英文全称是Graphic Processing Unit。传统上,GPU只负责图形渲染,大部分的处理工作交给了中央处理器(CPU)。但是由于图形渲染的高度并行性,使得GPU可以通过增加并行处理单元和存储器控制单元的方式提高处理能力和存储器带宽。GPU设计者将更多的晶体管用作执行单元,而不是像CPU那样用作复杂的控制单元和缓存并以此来提高少量执行单元的执行效率。目前,主流GPU的单精度浮点处理能力已经达到了同时期CPU的10倍左右,而其外部存储器的带宽则是CPU的5倍左右;在架构上,目前主流的GPU采用了统一设备架构单元,并且实现了细粒度的线程间通信,大大拓展了应用范围。
稀疏矩阵:是包含很多非零元的矩阵。
消去树:是一种树状数据结构,可以提供稀疏矩阵分解过程中的许多重要信息,包括矩阵元素在分解过程中的数据依赖关系等等,在多种求解稀疏线性方程组的算法中用于指导稀疏矩阵分解的节点消去顺序。
本发明的目的是采用下述技术方案实现的:
一种基于GPU的大规模电力系统潮流并行计算系统,其改进之处在于,所述系统包括符号雅克比矩阵形成与分解模块、初始化模块、潮流方程右端项计算模块、雅克比矩阵赋值模块、LU分解模块和前代回代模块;
所述符号雅克比矩阵形成与分解模块位于主机端,主机端将计算数据传送到设备端;
所述雅克比矩阵右端项计算模块、雅克比矩阵的赋值模块、LU分解模块和前代回代模块在设备端依次连接。
本发明基于另一目的提供一种基于GPU的大规模电力系统潮流并行计算方法,其改进之处在于,所述方法包括:
(1)将计算所需数据全部传送到主机端;
(2)生成符号雅克比矩阵并对其进行符号分解;
(3)主机端将分解结果传送到设备端;
(4)执行潮流方程右端项计算;
(5)执行雅克比矩阵赋值;
(6)执行LU分解;
(7)执行前代回代。
优选的,所述步骤(2)中矩阵通过CSR格式按行存储。
优选的,所述步骤(2)中矩阵通过纵向链的数据结构表示导纳矩阵中元素的纵向联系。
优选的,所述步骤(4)中潮流方程右端项计算包括
计算雅克比矩阵中间变量为
优选的,所述步骤(5)中雅克比矩阵赋值包括
当i≠j时
当i=j时
优选的,所述步骤(6)包括将生成数据将按照消去树分层并行的方式以秩为二的矩阵为最小单位元素进行分解。
优选的,所述步骤(6)的分解方法采用GPU的一级缓存、内部寄存器储存中间数据,将任务按照block占优的原则进行分配。
优选的,所述步骤(6)中LU分解包括每个线程均按照up-looking的节点消去方法对该节点进行消去。
进一步的,所述步骤(6)包括
(I)对矩阵一行的元素进行消去运算,算式如下:
其中,L矩阵指系数矩阵分解后得到的下三角矩阵,U矩阵指系数矩阵分解后得到的上三角矩阵,d向量指系数矩阵分解后对角元组成的向量;算式均以秩为二的矩阵为最小单元进行计算;
(II)对U矩阵一行进行规格化运算,算式如下:
从矩阵运算的角度来分析,对式(5)中的所有方程式做完消元和规格化运算,其对应的简写形式即为
-LUΔV=ΔW (7)。
优选的,所述步骤(7)包括按照分层后的消去树指导,在GPU上并行执行消去树同一层节点的前代回代过程。
与现有技术比,本发明的有益效果为:
1、本发明采用GPU这种新型的器件实现了牛顿-拉夫逊法潮流计算中的全部循环迭代过程。
2、本发明在GPU上实现了雅克比矩阵的并行生成方法。
3、本发明针对潮流方程线性化得到的线性方程组,提出了适合牛顿-拉夫逊法的基于消去树分层的LU分解并行方法。
4、本发明针对线性方程组求解过程,提出了基于消去树分层的前代回代并行方法。
5、本发明针对GPU一级缓存的硬件特点,提出采用结构数组的数据结构优化缓存命中率,提升数据读取速度。
6、本发明针对GPU寄存器读取速度快的硬件特点,提出采用寄存器预存中间变量的方式,减少全局显存的访问次数,加速数据读取。
7、本发明针对GPU的线程分配机制,提出了任务的合理分配方法,提升了GPU的硬件资源利用率。
附图说明
图1为本发明提供一种基于GPU的大规模电力系统潮流并行计算方法流程图。
图2为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中雅克比矩阵元素分布。
图3为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中雅克比矩阵赋值并行结构流程图。
图4为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中雅克比矩阵赋值并行结构示意图。
图5为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中分层后的消去树示意图。
图6为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中基于消去树分层的矩阵分解并行结构图。
图7为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中前代过程示意图。
图8为本发明提供的一种基于GPU的大规模电力系统潮流并行计算方法中利用空间局部性重新组织数组元素示意图。
图9为本发明提供的一种效率不高的任务分配方式示意图。
图10为本发明提供的一种较好的任务分配方式示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步的详细说明。
对于N个节点的电力网络(地作为参考节点不包含在内),如果网络结构和元件参数已知,则网络方程可表示为
式(1)中,Y为N×N阶节点导纳矩阵; 为N×1维节点电压列向量;
为N×1维节点电压列向量; 为N×1维节点注入电流列矢量。如果不计网络元件非线性,也不考虑移相变压器,则Y为对称矩阵。
为N×1维节点注入电流列矢量。如果不计网络元件非线性,也不考虑移相变压器,则Y为对称矩阵。
电力系统计算中,给定的运行变量是节点注入功率,而不是节点注入电流,这两者之间有如下关系:
式中, 为节点的注入复功率,是N×1维列矢量;
为节点的注入复功率,是N×1维列矢量; 是
是 的共轭;
的共轭; 是由节点电压的共轭组成的N×N阶对角线矩阵。由式(1)和式(2),可得
是由节点电压的共轭组成的N×N阶对角线矩阵。由式(1)和式(2),可得
上式就是潮流方程的复数形式,是N维的非线性复数代数方程组。将其展开,有
式中,i=1,2,…,N。j∈i表示所有和i相连的节点j,包括j=i。
如果节点电压用直角坐标系表示,即令 代入式(4)中有
代入式(4)中有
式中,i=1,2,…,N。j的含义和式(4)相同。一般也可以将式(5)等式右边累加的部分先计算出来,表示为
Pi-jQi=(ei-jfi)(ai+jbi) (6)
式中
故有
式(7)和式(8)是直接坐标系表示的潮流计算方程。从潮流方程中可以看出,变量一共四个,分别是有功功率P、无功功率Q、电压幅值V、电压相角δ,给出其中两个值,才能解出另外三个值。而给出的定解条件即为PQ节点的有功功率和无功功率,以及PV节点的有功功率和电压幅值。
本发明具体流程为:
如图1所示,本发明系统开始工作后,以下模块依次执行:符号雅克比矩阵的生成与分解模块,初始化模块,雅克比矩阵右端项计算模块,雅克比矩阵赋值模块,雅克比矩阵LU分解模块,前代回代模块。其中符号雅克比矩阵的生成与分解模块内部执行过程的逻辑性较强,在主机端完成。符号分解完成之后,主机端将计算数据传送到设备端。上述模块在整个执行过程中,仅仅进行一次。随后,潮流方程右端项计算模块、雅克比矩阵的赋值模块、LU分解模块、前代回代模块将在GPU上顺序执行。四个模块执行完一次之后,就将结果数据传回主机端判断是否满足收敛条件。如果不满足收敛条件,那么重复执行上述四个模块直到达到收敛精度。
其中,由于雅克比矩阵中对角元元素的计算和非对角元元素的计算在计算量方面有比较大的差别,具体为:
1、计算雅克比矩阵中间变量:
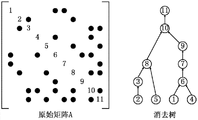
考虑到雅克比矩阵稀疏的特点,导纳矩阵的存储主要采用CSR格式按行存储,另外采用纵向链的数据结构辅助表达导纳矩阵中元素的纵向联系。以wepri36节点算例为例,其导纳矩阵非零元分布如附图2所示。图中黑色方块表示该位置存在非零元,黑色叉号表示消去过程中新增加的非零元。以下讲解雅克比矩阵的生成过程。以图中的第21号节点为例,计算其对应的中间变量ai、bi的过程中j的取值实际为12、15、16、21、30、32。具体过程如下:
首先读取CSR格式中对应导纳矩阵第21行的元素列标。由于导纳矩阵是对称矩阵,采取CSR格式存储时仅存储了其上三角部分的元素列标,存储的第21行元素实际上只有位于对角元右侧的两个。也就是可以完成j=30、32时的累加过程。
然后通过纵向链寻找附图2中第21列的元素行标。遍历该列所有元素即可完成j=12、15、16时的累加过程。
注意在计算过程中只需要读取导纳矩阵的元素值,但是不修改导纳矩阵,所以上述过程的计算互相之间是没有影响的,比如中间变量a1是否计算完成不影响a2的计算。该过程具有良好的并行性,容易实现细粒度的并行。本发明设计的算法中通过给GPU硬件分配大量线程,每个线程完成一个节点的中间变量计算过程,来实现所有节点对应中间变量的计算。
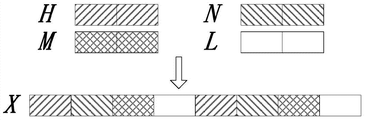
2、雅克比矩阵中间变量的计算完成之后,第二步就是给雅克比矩阵赋值。计算公式如下:
当i≠j时
当i=j时
(11)、(12)两式中的计算同样不对输入数据进行修改。所以和第一步的并行方法一样,只需要对每个节点分配一个线程进行计算即可。上述两步的并行结构如附图3所示:
3、基于消去树分层的LU分解模块,本模块采用的基础算法up-looking方法是按行消元并进行规格化的普适性算法,秩为二表示矩阵分解是以秩为二的矩阵为最小单元进行计算。消去树是表征稀疏矩阵元素依赖关系的数据结构,可以用于指导矩阵分解顺序。潮流方程线性化得到的修正方程式写成分块矩阵的形式为:
或者简写为
ΔW=-JΔV (14)
其中Jij是2×2阶方阵,ΔWi和ΔVi都是二维列向量。
对于PQ节点
对于PV节点
按照up-looking方法,具体的消去过程作法如下:
(I)对矩阵一行的元素进行消去运算,算式如下:
其中,L矩阵指系数矩阵分解后得到的下三角矩阵,U矩阵指系数矩阵分解后得到的上三角矩阵,d向量指系数矩阵分解后对角元组成的向量。算式均以秩为二的矩阵为最小单元进行计算。
(II)对U矩阵一行进行规格化运算,算式如下:
将上述步骤从矩阵运算的角度来分析,对方程组(14)中的所有方程式做完消元和规格化运算之后,其对应的简写形式即为
-LUΔV=ΔW (17)
之后通过前代回代运算,即可得到最后的解向量。
对于系数矩阵为稀疏矩阵的情况,由于大量的非零元存在,消去过程中矩阵元素间的数据依赖关系没有稠密矩阵那样严格。下面不加证明地给出数据依赖规则:
如果i>j,那么第i行的元素受第j行的元素影响的充要条件是lij≠0。
其中,lij指的是对称的系数矩阵A符号分解后得到的矩阵中的元素。为了表达上述数据依赖关系,一种树状结构被引用进来,即消去树。消去树又叫道路树、因子树,可以通过对图的搜索形成。
附图4所示为一个11维的原始系数矩阵及其对应的消去树结构。根据消去树可知,第1、2、4、5行的数据可以直接消去,不依赖其他行;第3行的数据消去前首先要消去第2行,第6行的数据消去前首先要消去第1行、第4行……依此类推,最后才能消去第11行。而且,如果某两个树节点之间没有父子关系,比如附图4中的节点3和节点6,那么这两个节点的消去过程在时间上没有要求。
根据以上分析,本专利方法将消去树按照一定规则进行分层。这个规则是:如果消去树中某个父节点的所有子节点中层号最大的为i,那么该父节点的层号为i+1。分层后的消去树如附图5所示:
由于没有父子关系的节点的消去顺序没有要求,所以可以利用多线程对在同一层的节点同时进行消去操作。其中,每个节点的消去操作均按照up-looking方法的流程执行。如附图5所示的消去树中第0层的4个节点就可以首先同时消去。第0层的节点消去完成后,第1层的两个节点就可以同时消去。依此类推,经过消去树的指导,系数矩阵的消去可以在每一层内实现并行。根据经验,在稀疏矩阵的消去树结构中,树的最底层包含的节点个数占总数的百分之四十左右。处于底部的三层包含的节点个数占总数的百分之七十左右。所以,如附图6所示,层内并行的方法在算法上是具有较高并行度的。
4、基于消去树分层并行的前代回代模块,消去树不仅仅可以指导系数矩阵的数值分解过程,紧随其后的前代回代过程也可以按照其指导进行并行。
附图7所示为矩阵分解的前代过程。由图可见,未知数x1,x2,x3的求解是相互独立的,x4的求解依赖于x1的求解,x5的求解依赖于x1,x4的求解。实际上,按照消去树结构,x1,x2,x3应该位于最底层,或者说第0层。x4位于消去树第1层。x5位于消去树第2层。那么,x1,x2,x3的求解可以同时进行,x4的求解必须在x1之后,x5的求解必须在x1,x4之后。附图7所示的例子只显示了矩阵的部分元素,实际算例中消去树底层有非常多的节点,所以和前文数值分解部分一样,消去树指导的前代回代并行也具有较高的并行度。由于并行的基本思想一致,前代回代过程的并行结构与前文所述的矩阵分解并行结构类似,这里不再赘述。
5、系统运行优化
优化系统首先要对系统进行分析,找到提升性能的瓶颈。通过对本发明系统中各模块函数执行过程计时发现,雅克比矩阵的数值分解在并行版本的系统中依然是制约性能的瓶颈。从理论上来讲并行系统应该较串行系统有很大的改进。但是由于硬件设计的不同,未经优化的并行系统执行效果并不好。
5.1 利用一级缓存的变量储存方法、
现代CPU上的缓存技术已经非常成熟,而且缓存技术的好坏也在一定程度上决定了CPU性能的强弱。一般的分类认为,缓存技术主要利用了程序的局部性原理。局部性原理包含四个部分。其中,时间局部性是指如果一个地址空间上的数据被访问,那么该数据在不久之后很可能被再次访问。空间局部性是指如果一个地址空间上的数据被访问,那么空间上邻近的数据在不久之后很可能被访问。
一般在CPU上运行的程序在数据的读写方面,由于有缓存的加速,所以程序在这方面的优化显得并不那么重要。但是在GPU上运行的程序,由于硬件缓存技术的不成熟,缓存因素对程序性能的影响变得比较突出。之所以说GPU缓存技术不成熟,是因为其缓存仅仅利用了局部性原理中的空间局部性,而没有利用时间局部性,并且对写操作没有加速的效果。
针对其仅仅利用空间局部性的特点,结合程序数据结构特点,本文将存储雅克比矩阵元素的4个工作数组(4个工作数组分别对应雅克比矩阵中的h,j,n,l对应的行)合为1个,h,j,n,l四个元素依次寻址。具体地说,原工作数组有4个,分别命名为x_h,x_j,x_n,x_l。工作数组合并之后留存1个,命名为x。原x_h数组中的元素x_h[i],现在映射到x[4*i]的位置;原x_j数组中的元素x_j[i]映射到x[4*i+1];原x_n数组中的元素x_n[i]映射到x[4*i+2];原x_l数组中的元素x_l[i]映射到x[4*i+3]。除此之外,雅克比矩阵元素值和分解后的元素值也按相同的组织方式存储。
利用GPU L1 cache加速原理,对各个数组重新进行组织的图形演示如附图8所示。如果不进行这种优化,如果我们需要读取4个数组的第1个元素,至少需要对显存进行4次访问,才能够实现目的。通过上述优化,仅仅需要对显存进行一次访问,其他三个元素就会被缓存在L1 cache中,数据读取的时间大大减小。
5.2 利用内部寄存器的变量储存方法
一般运行在CPU上的程序不需要考虑片上寄存器对程序的影响,一方面是因为内存访问速度足够快,缓存技术成熟;另一方面的原因是,为了防止程序运行时寄存器不足严重影响程序性能,C语言程序中的变量一般不会特意声明存储在寄存器上。但是GPU内核函数上的变量会优先存储在寄存器上,如果寄存器数量不足,线程内的变量才会存储在共享内存或者全局显存上。而且,由于GPU上的缓存并没有利用时间局部性,读取过一次的数据在下次读取时需要再次访问全局显存,所以才会有利用寄存器提高程序性能的方法。
该方法的大致思想是将短期内需要重复使用的数据存储在寄存器上,之后的计算过程中均只对寄存器进行读写操作。
比如,程序中需要做大量的秩为2的矩阵乘法。
其中
c0=a0b0+a1b2 (19)
c1=a0b1+a1b3 (20)
c2=a2b0+a3b2 (21)
c3=a2b1+a3b3 (22)
对上述4个算式进行分析可见,如果不利用寄存器缓存数据,a0需要从全局显存中读取2次。如果利用寄存器首先缓存数据a0,那么在上述计算中,a0仅需要从全局显存中读取1次。
5.3 block优先的任务方法
CUDA编程模型没有实现完全的硬件透明,但是在线程方面实现了透明扩展。没有实现硬件透明体现在很多方面,比如在存储器结构上存在较大的层次差别,线程在硬件上以线程束为单位执行等等。透明扩展指的是一个程序在编译一次之后,就能在拥有不同核心数量的硬件上正确运行。为了实现这一点,CUDA将计算任务映射为大量的可以并行执行的线程,并由硬件动态调度和执行这些线程。
内核函数(kernel)以线程网格(grid)的形式组织,每个线程网格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。实质上,kernel在软件上是以block为单位执行的。各个block是并行执行的,block间无法通信,也没有执行顺序。为了方便编程,CUDA中使用了dim3类型的内建变量threadIdx和blockIdx。这样,就可以使用一维、二维或者三维的索引来标识线程,构成一维、二维或三维线程块。
该优化方法的构思即来源于对GPU活动线程数的考虑。尽管GPU上核数众多,在本文的测试平台上,Tesla C2050 GPU内一共包含14组SM(Streaming Multiprocessor),这14组完整的核可以进一步划分为448个流处理器(Streaming processor),但是CUDA软件机制并不能隐式地保证这些核都能被充分利用。实际上,GPU通过在一个SM中发射多个线程块,保存多个block上下文来隐藏显存延迟。限制SM中活动线程块的因素包括:SM中的活动线程块数量不超过8个;所有活动线程块中的warp数之和在计算能力1.3的设备上不超过32;所有活动线程块使用的寄存器和共享存储器之和不超过SM中的资源限制。在Tesla系列的GPU上,每个SM中至少要有6个active warp才能有效地隐藏流水线延迟。此外,如果所有的active warp都来自同一block,当这个block中的线程进行存储器访问或者同步时,执行单元就会闲置。一方面,为了隐藏数据读取的延迟,希望在每个核上分配更多的线程块。另一方面,每个核上的活动线程个数是一定的,能够同时执行的线程数量其实是一定的,线程数大于最大活动线程数时,线程间就不是完全并行执行。
基于上述硬件架构特点,在给GPU上SM分配线程时,优先考虑将各个block平均分配到各个SM上。而每个block中的threads个数不必那么多。比如,在并行处理消去树某层节点时,如果该层节点较少,可以考虑给每个节点分配一个block,而不是分配一个block,在该block内给每个节点分配一个thread。
如附图9所示,CUDA软件在将各个block发射到各个SM上时,并不一定保证任务的均分。如果将图中消去树最底层的4个节点对应的线程分配在2个block中,这两个block将会占用两个SM。但是如果给每个节点分配一个block,那么每个节点都会占用一个SM。如附图10所示:
这样的做法减少了因为最大活动线程数量限制导致程序并行效率低下的可能。在线程数不是特别多又不是特别少的情况下,该优化效果明显。
最后应当说明的是:以上实施例仅用以说明本发明的技术方法而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求范围当中。
Claims (11)
1.一种基于GPU的大规模电力系统潮流并行计算系统,其特征在于,所述系统包括符号雅克比矩阵形成与分解模块、初始化模块、潮流方程右端项计算模块、雅克比矩阵赋值模块、LU分解模块和前代回代模块;
所述符号雅克比矩阵形成与分解模块位于主机端,主机端将计算数据传送到设备端;
所述雅克比矩阵右端项计算模块、雅克比矩阵的赋值模块、LU分解模块和前代回代模块在设备端依次连接。
2.一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述方法包括:
(1)将计算所需数据全部传送到主机端;
(2)生成符号雅克比矩阵并对其进行符号分解;
(3)主机端将分解结果传送到设备端;
(4)执行潮流方程右端项计算;
(5)执行雅克比矩阵赋值;
(6)执行LU分解;
(7)执行前代回代。
3.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(2)中矩阵通过CSR格式按行存储。
4.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(2)中矩阵通过纵向链的数据结构表示导纳矩阵中元素的纵向联系。
5.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(4)中潮流方程右端项计算包括
计算雅克比矩阵中间变量为
6.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(5)中雅克比矩阵赋值包括
当i≠j时
当i=j时
7.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(6)包括将生成数据将按照消去树分层并行的方式以秩为二的矩阵为最小单位元素进行分解。
8.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(6)的分解方法采用GPU的一级缓存、内部寄存器储存中间数据,将任务按照block占优的原则进行分配。
9.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(6)中LU分解包括每个线程均按照up-looking的节点消去方法对该节点进行消去。
10.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(6)包括
(I)对矩阵一行的元素进行消去运算,算式如下:
其中,L矩阵指系数矩阵分解后得到的下三角矩阵,U矩阵指系数矩阵分解后得到的上三角矩阵,d向量指系数矩阵分解后对角元组成的向量;算式均以秩为二的矩阵为最小单元进行计算;
(II)对U矩阵一行进行规格化运算,算式如下:
从矩阵运算的角度来分析,对式(5)中的所有方程式做完消元和规格化运算,其对应的简写形式即为
-LUΔV=ΔW (7)。
11.如权利要求2所述的一种基于GPU的大规模电力系统潮流并行计算方法,其特征在于,所述步骤(7)包括按照分层后的消去树指导,在GPU上并行执行消去树同一层节点的前代回代过程。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201310588919.2A CN103617150B (zh) | 2013-11-19 | 2013-11-19 | 一种基于gpu的大规模电力系统潮流并行计算的系统及其方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201310588919.2A CN103617150B (zh) | 2013-11-19 | 2013-11-19 | 一种基于gpu的大规模电力系统潮流并行计算的系统及其方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN103617150A true CN103617150A (zh) | 2014-03-05 |
| CN103617150B CN103617150B (zh) | 2018-01-19 |
Family
ID=50167853
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201310588919.2A Active CN103617150B (zh) | 2013-11-19 | 2013-11-19 | 一种基于gpu的大规模电力系统潮流并行计算的系统及其方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN103617150B (zh) |
Cited By (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104142810A (zh) * | 2014-07-14 | 2014-11-12 | 中国南方电网有限责任公司电网技术研究中心 | 一种形成节点导纳矩阵的并行方法 |
| CN104484234A (zh) * | 2014-11-21 | 2015-04-01 | 中国电力科学研究院 | 一种基于gpu的多波前潮流计算方法和系统 |
| CN105391057A (zh) * | 2015-11-20 | 2016-03-09 | 国家电网公司 | 一种电力潮流雅克比阵计算的gpu线程设计方法 |
| CN105576648A (zh) * | 2015-11-23 | 2016-05-11 | 中国电力科学研究院 | 一种基于gpu-cpu异构计算平台的静态安全分析双层并行方法 |
| CN106026107A (zh) * | 2016-07-26 | 2016-10-12 | 东南大学 | 一种gpu加速的电力潮流雅可比矩阵的qr分解方法 |
| CN106201985A (zh) * | 2016-07-07 | 2016-12-07 | 三峡大学 | 一种基于pq法的分布式并行潮流计算系统开发方法 |
| CN106294022A (zh) * | 2016-08-12 | 2017-01-04 | 东南大学 | 一种用于静态安全分析的雅可比矩阵冗余存储方法 |
| CN106354479A (zh) * | 2016-08-12 | 2017-01-25 | 东南大学 | 一种大量同构稀疏矩阵的gpu加速qr分解方法 |
| CN107392429A (zh) * | 2017-06-22 | 2017-11-24 | 东南大学 | 一种gpu加速的电力潮流下三角方程组前推方法 |
| CN107423259A (zh) * | 2017-06-22 | 2017-12-01 | 东南大学 | 一种多米诺优化的gpu加速电力上三角方程组回代方法 |
| CN107767372A (zh) * | 2017-10-23 | 2018-03-06 | 苏州茂特斯自动化设备有限公司 | 一种分层并行计算的芯片管脚在线视觉检测系统及其方法 |
| CN108964058A (zh) * | 2018-06-15 | 2018-12-07 | 国家电网有限公司 | 基于图计算的电力系统分层并行分解潮流计算方法和装置 |
| CN109062865A (zh) * | 2018-07-13 | 2018-12-21 | 清华大学 | 基于懒惰分层的电力系统下三角方程组求解方法和系统 |
| CN109062866A (zh) * | 2018-07-13 | 2018-12-21 | 清华大学 | 基于贪婪分层的电力系统上三角方程组求解方法和系统 |
| CN109299531A (zh) * | 2018-09-12 | 2019-02-01 | 清华四川能源互联网研究院 | 电磁暂态仿真方法及装置 |
| CN109885406A (zh) * | 2019-02-27 | 2019-06-14 | 上海燧原智能科技有限公司 | 算子计算优化方法、装置、设备及存储介质 |
| CN110021339A (zh) * | 2017-12-27 | 2019-07-16 | 北京大学 | 基于蛋白质折叠测算蛋白质结构的集群并行计算加速方法 |
| CN112084198A (zh) * | 2020-09-16 | 2020-12-15 | 云南电网有限责任公司 | 一种压缩存储形式的节点导纳矩阵直接列写方法及装置 |
| CN112861461A (zh) * | 2021-03-05 | 2021-05-28 | 北京华大九天科技股份有限公司 | 一种用于电路仿真模型的异常检测方法及装置 |
| CN112949238A (zh) * | 2021-03-19 | 2021-06-11 | 梁文毅 | 一种基于迭代法的电气仿真方法 |
| CN112949232A (zh) * | 2021-03-17 | 2021-06-11 | 梁文毅 | 一种基于分布式建模的电气仿真方法 |
| CN113191105A (zh) * | 2021-03-22 | 2021-07-30 | 梁文毅 | 一种基于分布式并行运算方法的电气仿真方法 |
| CN113255259A (zh) * | 2021-05-21 | 2021-08-13 | 北京华大九天科技股份有限公司 | 一种基于大规模集成电路划分的并行求解方法 |
| US20220317029A1 (en) * | 2021-04-02 | 2022-10-06 | Abb Schweiz Ag | Systems and methods for skewed basis set fitting |
| CN117311948A (zh) * | 2023-11-27 | 2023-12-29 | 湖南迈曦软件有限责任公司 | Cpu与gpu异构并行的自动多重子结构数据处理方法 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1286446A (zh) * | 1999-11-30 | 2001-03-07 | 深圳市中兴通讯股份有限公司 | 一种配电网状态的在线监视方法 |
| CN1641957A (zh) * | 2004-01-06 | 2005-07-20 | 中国电力科学研究院 | 电力系统潮流分网并行计算方法 |
| US20110213606A1 (en) * | 2009-09-01 | 2011-09-01 | Aden Seaman | Apparatus, methods and systems for parallel power flow calculation and power system simulation |
-
2013
- 2013-11-19 CN CN201310588919.2A patent/CN103617150B/zh active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1286446A (zh) * | 1999-11-30 | 2001-03-07 | 深圳市中兴通讯股份有限公司 | 一种配电网状态的在线监视方法 |
| CN1641957A (zh) * | 2004-01-06 | 2005-07-20 | 中国电力科学研究院 | 电力系统潮流分网并行计算方法 |
| US20110213606A1 (en) * | 2009-09-01 | 2011-09-01 | Aden Seaman | Apparatus, methods and systems for parallel power flow calculation and power system simulation |
Non-Patent Citations (3)
| Title |
|---|
| 夏俊峰 等: "基于GPU的电力系统并行潮流计算的实现", 《电力系统保护与控制》, vol. 38, no. 18, 16 September 2010 (2010-09-16) * |
| 李敏: "电力系统潮流无解问题分析和调整方法研究", 《中国优秀硕士学位论文全文数据库 工程科技Ⅱ辑》, no. 03, 15 March 2008 (2008-03-15) * |
| 梁阳豆: "CUDA平台下的电力系统最优潮流并行计算研究", 《中国优秀硕士学位论文全文数据库 工程科技Ⅱ辑》, no. 03, 15 March 2013 (2013-03-15) * |
Cited By (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104142810A (zh) * | 2014-07-14 | 2014-11-12 | 中国南方电网有限责任公司电网技术研究中心 | 一种形成节点导纳矩阵的并行方法 |
| CN104484234A (zh) * | 2014-11-21 | 2015-04-01 | 中国电力科学研究院 | 一种基于gpu的多波前潮流计算方法和系统 |
| CN104484234B (zh) * | 2014-11-21 | 2017-12-05 | 中国电力科学研究院 | 一种基于gpu的多波前潮流计算方法和系统 |
| CN105391057B (zh) * | 2015-11-20 | 2017-11-14 | 国家电网公司 | 一种电力潮流雅克比阵计算的gpu线程设计方法 |
| CN105391057A (zh) * | 2015-11-20 | 2016-03-09 | 国家电网公司 | 一种电力潮流雅克比阵计算的gpu线程设计方法 |
| CN105576648B (zh) * | 2015-11-23 | 2021-09-03 | 中国电力科学研究院 | 一种基于gpu-cpu异构计算平台的静态安全分析双层并行方法 |
| CN105576648A (zh) * | 2015-11-23 | 2016-05-11 | 中国电力科学研究院 | 一种基于gpu-cpu异构计算平台的静态安全分析双层并行方法 |
| CN106201985A (zh) * | 2016-07-07 | 2016-12-07 | 三峡大学 | 一种基于pq法的分布式并行潮流计算系统开发方法 |
| CN106201985B (zh) * | 2016-07-07 | 2019-09-24 | 三峡大学 | 一种基于pq法的分布式并行潮流计算系统开发方法 |
| CN106026107A (zh) * | 2016-07-26 | 2016-10-12 | 东南大学 | 一种gpu加速的电力潮流雅可比矩阵的qr分解方法 |
| CN106026107B (zh) * | 2016-07-26 | 2019-01-29 | 东南大学 | 一种gpu加速的电力潮流雅可比矩阵的qr分解方法 |
| CN106294022A (zh) * | 2016-08-12 | 2017-01-04 | 东南大学 | 一种用于静态安全分析的雅可比矩阵冗余存储方法 |
| CN106354479A (zh) * | 2016-08-12 | 2017-01-25 | 东南大学 | 一种大量同构稀疏矩阵的gpu加速qr分解方法 |
| CN106294022B (zh) * | 2016-08-12 | 2019-03-29 | 东南大学 | 一种用于静态安全分析的雅可比矩阵冗余存储方法 |
| CN106354479B (zh) * | 2016-08-12 | 2019-01-29 | 东南大学 | 一种大量同构稀疏矩阵的gpu加速qr分解方法 |
| CN107392429A (zh) * | 2017-06-22 | 2017-11-24 | 东南大学 | 一种gpu加速的电力潮流下三角方程组前推方法 |
| CN107423259A (zh) * | 2017-06-22 | 2017-12-01 | 东南大学 | 一种多米诺优化的gpu加速电力上三角方程组回代方法 |
| CN107767372A (zh) * | 2017-10-23 | 2018-03-06 | 苏州茂特斯自动化设备有限公司 | 一种分层并行计算的芯片管脚在线视觉检测系统及其方法 |
| CN107767372B (zh) * | 2017-10-23 | 2020-03-20 | 苏州茂特斯自动化设备有限公司 | 一种分层并行计算的芯片管脚在线视觉检测系统及其方法 |
| CN110021339A (zh) * | 2017-12-27 | 2019-07-16 | 北京大学 | 基于蛋白质折叠测算蛋白质结构的集群并行计算加速方法 |
| CN110021339B (zh) * | 2017-12-27 | 2021-04-30 | 北京大学 | 基于蛋白质折叠测算蛋白质结构的集群并行计算加速方法 |
| CN108964058A (zh) * | 2018-06-15 | 2018-12-07 | 国家电网有限公司 | 基于图计算的电力系统分层并行分解潮流计算方法和装置 |
| CN108964058B (zh) * | 2018-06-15 | 2021-03-30 | 国家电网有限公司 | 基于图计算的电力系统分层并行分解潮流计算方法和装置 |
| CN109062866A (zh) * | 2018-07-13 | 2018-12-21 | 清华大学 | 基于贪婪分层的电力系统上三角方程组求解方法和系统 |
| CN109062865A (zh) * | 2018-07-13 | 2018-12-21 | 清华大学 | 基于懒惰分层的电力系统下三角方程组求解方法和系统 |
| CN109062866B (zh) * | 2018-07-13 | 2020-06-09 | 清华大学 | 基于贪婪分层的电力系统上三角方程组求解方法和系统 |
| CN109299531A (zh) * | 2018-09-12 | 2019-02-01 | 清华四川能源互联网研究院 | 电磁暂态仿真方法及装置 |
| CN109885406A (zh) * | 2019-02-27 | 2019-06-14 | 上海燧原智能科技有限公司 | 算子计算优化方法、装置、设备及存储介质 |
| CN112084198B (zh) * | 2020-09-16 | 2022-09-16 | 云南电网有限责任公司 | 一种压缩存储形式的节点导纳矩阵直接列写方法及装置 |
| CN112084198A (zh) * | 2020-09-16 | 2020-12-15 | 云南电网有限责任公司 | 一种压缩存储形式的节点导纳矩阵直接列写方法及装置 |
| CN112861461B (zh) * | 2021-03-05 | 2022-05-17 | 北京华大九天科技股份有限公司 | 一种用于电路仿真模型的异常检测方法及装置 |
| CN112861461A (zh) * | 2021-03-05 | 2021-05-28 | 北京华大九天科技股份有限公司 | 一种用于电路仿真模型的异常检测方法及装置 |
| CN112949232A (zh) * | 2021-03-17 | 2021-06-11 | 梁文毅 | 一种基于分布式建模的电气仿真方法 |
| CN112949238A (zh) * | 2021-03-19 | 2021-06-11 | 梁文毅 | 一种基于迭代法的电气仿真方法 |
| CN113191105A (zh) * | 2021-03-22 | 2021-07-30 | 梁文毅 | 一种基于分布式并行运算方法的电气仿真方法 |
| US20220317029A1 (en) * | 2021-04-02 | 2022-10-06 | Abb Schweiz Ag | Systems and methods for skewed basis set fitting |
| US11639892B2 (en) * | 2021-04-02 | 2023-05-02 | Abb Schweiz Ag | Systems and methods for skewed basis set fitting |
| CN113255259B (zh) * | 2021-05-21 | 2022-05-24 | 北京华大九天科技股份有限公司 | 一种基于大规模集成电路划分的并行求解方法 |
| CN113255259A (zh) * | 2021-05-21 | 2021-08-13 | 北京华大九天科技股份有限公司 | 一种基于大规模集成电路划分的并行求解方法 |
| CN117311948A (zh) * | 2023-11-27 | 2023-12-29 | 湖南迈曦软件有限责任公司 | Cpu与gpu异构并行的自动多重子结构数据处理方法 |
| CN117311948B (zh) * | 2023-11-27 | 2024-03-19 | 湖南迈曦软件有限责任公司 | Cpu与gpu异构并行的自动多重子结构数据处理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN103617150B (zh) | 2018-01-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103617150A (zh) | 一种基于gpu的大规模电力系统潮流并行计算系统及其方法 | |
| CN105022670A (zh) | 一种云计算平台中的异构分布式任务处理系统及其处理方法 | |
| CN103970960A (zh) | 基于gpu并行加速的无网格伽辽金法结构拓扑优化方法 | |
| Peng et al. | GLU3. 0: Fast GPU-based parallel sparse LU factorization for circuit simulation | |
| Kelly | GPU computing for atmospheric modeling | |
| Gan et al. | Accelerating solvers for global atmospheric equations through mixed-precision data flow engine | |
| CN103345580B (zh) | 基于格子Boltzmann方法的并行CFD方法 | |
| CN110516316B (zh) | 一种间断伽辽金法求解欧拉方程的gpu加速方法 | |
| CN104182209A (zh) | 一种基于PETSc的GCRO-DR算法并行处理方法 | |
| CN106026107B (zh) | 一种gpu加速的电力潮流雅可比矩阵的qr分解方法 | |
| CN106776466A (zh) | 一种fpga异构加速计算装置及系统 | |
| CN101937425A (zh) | 基于gpu众核平台的矩阵并行转置方法 | |
| Mostafazadeh Davani et al. | Unsteady Navier-Stokes computations on GPU architectures | |
| CN103246541A (zh) | 自动并行化多级并行代价评估方法 | |
| He et al. | A multiple-GPU based parallel independent coefficient reanalysis method and applications for vehicle design | |
| Xu et al. | Optimizing finite volume method solvers on Nvidia GPUs | |
| Nguyen et al. | GPU parallelization of multigrid RANS solver for three-dimensional aerodynamic simulations on multiblock grids | |
| CN111651208B (zh) | 面向异构众核并行计算机的模态并行计算方法及系统 | |
| Yamagishi et al. | Gpu acceleration of a non-hydrostatic ocean model with a multigrid poisson/helmholtz solver | |
| Xia et al. | OpenACC-based GPU acceleration of a 3-D unstructured discontinuous galerkin method | |
| Diamantopoulos et al. | A system-level transprecision FPGA accelerator for BLSTM using on-chip memory reshaping | |
| Liu et al. | LSRB-CSR: A low overhead storage format for SpMV on the GPU systems | |
| CN109299725A (zh) | 一种基于张量链并行实现高阶主特征值分解的预测系统和装置 | |
| Gan et al. | Million-core-scalable simulation of the elastic migration algorithm on Sunway TaihuLight supercomputer | |
| Oancea et al. | Developing a high performance software library with MPI and CUDA for matrix computations |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |