CN100440250C - 印刷体蒙古文字符识别方法 - Google Patents
印刷体蒙古文字符识别方法 Download PDFInfo
- Publication number
- CN100440250C CN100440250C CNB2007100642959A CN200710064295A CN100440250C CN 100440250 C CN100440250 C CN 100440250C CN B2007100642959 A CNB2007100642959 A CN B2007100642959A CN 200710064295 A CN200710064295 A CN 200710064295A CN 100440250 C CN100440250 C CN 100440250C
- Authority
- CN
- China
- Prior art keywords
- omega
- character
- chi
- class
- sigma
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Abstract
印刷体蒙古文字符识别方法属于字符识别领域,其特征在于,提取蒙古文字符集中字符独特的字符形式信息和字符区域信息进行预分类,确定输入字符所属的字符类别子集,然后抽取能很好反映字符笔划构成信息的方向特征,在此基础上采用两个步骤进行特征优化处理:1.特征整形;2.由LDA(线性鉴别分析)进行特征变换,最后运用MQDF(改进的二次鉴别函数)统计分类器实现分类判决。本发明在多字体多字号印刷体蒙古文字符测试集上的识别正确率达到99.35%。
Description
技术领域
印刷体蒙古文字符识别方法属于字符识别领域。
背景技术
蒙古语属阿尔泰语系蒙古语族,是广泛分布在我国内蒙古、新疆、北京、辽宁、黑龙江、吉林、甘肃、青海等省区的蒙古族使用的主要语言。其书面表现形式——蒙古文(现行)是以回鹘字母为基础的拼音文字,在形体、写法变化等方面均有独特之处。
蒙古文以词为单位纵向书写或印刷,词与词之间由明显的空格加以分隔。每一个词由一个或多个字母组成,在词的内部,各字符沿着基线互相连接(图6)。蒙古文共有35个字母,其中元音7个,辅音28个,这些字母是蒙古文字符的名义形式。每个字母根据其在词中位置的不同表现为词首形式、词中形式和词尾形式等3种不同的字符形式,反映在文本图像上就是字母的顶部和底部与相邻字母的连接关系的不尽相同:1)词首形式:底部与下一个字母顶部直接相连而顶部不与其它字母直接相连;2)词中形式:顶部和底部分别与其上下相邻字母的底部和顶部直接连接;3)词尾形式:顶部与上一个字母底部直接相连而底部不与其它字母直接相连。这样,35个可以演化成多个不同的字符形式,它们构成蒙古文字符的变形显现形式(图5)。
蒙古文是我国重要的少数民族文字,开展蒙古文字符识别技术研究是中文多文种信息处理系统发展的迫切需要。此外,锡伯文、满文等少数民族文字无论在字母体系、字符来源还是语法构成上均与蒙古文极其相似,因而蒙古文字符识别的研究也必定会对这些类似的少数民族文字识别技术的发展产生积极的促进作用。目前,针对蒙古文字符集的字符识别的研究才刚刚起步,各方面都要远远落后于其它广泛使用的文字(如拉丁字母、汉字、日文等)字符识别的研究,现有的方法可以分成两大类:
1.结构方法。对于给定的字符集,抽取数量有限的不可分割的最小子模式(基元),将这些基元按照特定的顺序和规则组合起来可以构成该字符集中的任何字符。这样,利用字符结构与语言之间的相似性,字符识别可以借助形式语言学的文法(包含了句法规则)来描述和剖析字符的结构。由于蒙古文字符集的文本仅由35个基本字母拼写而成,而且字符笔划往往不多,结构不是非常复杂,所以按照拼音文字常用的方法,采用结构分析方法来识别字符,在理论上可期望得到非常高的识别率。现有的研究均侧重于该类方法。但由于结构方法本身的局限性(易受各种噪声影响,鲁棒性不强)和蒙古文字符集的特殊性(大量相似字符的存在),此种方法的实际应用效果极不理想。
2.统计方法。抽取字符的统计特征,每个字符模式用一个特征向量表示,它被看成是特征空间中的一个点。识别的过程就是运用统计分类器在特征空间中将待识别字符模式正确地划分到所属的类别中。该方法具有抗噪性能好,可推广性强的优点。但如何选取简洁有效的特征来表示字符以及如何设计合理的分类器,是直接影响识别性能的关键环节。目前虽有少量基于统计方法的蒙古文字符识别技术见诸文献,但选用的基本上局限于笔画密度、连续区域数目、宽高比等简单直接的字符表示特征,分类判决则采用欧氏距离这样简单的判决准则。因为特征的局部刻画能力严重不足,又未能充分利用特征空间的高阶信息,现有统计方法的识别性能距离实用需求尚有不小差距。
字符笔划数少且笔划构成以弧线为主,笔划结构信息欠丰富且不易提取、字符集中相似字子集多,相似程度极高、字符宽度和高度都不具有一致性、字符上下边界存在不确定性、不同字体间字型差异大,某些字体接近手写草体、常用字号偏小等特点给蒙古文字符集的字符识别研究带来了极大挑战。
本发明提出了一种基于统计模式识别方法的印刷体蒙古文字符识别的完整的方法。根据字符本身的特点(空间区域信息和字符形式信息)进行预分类,提取方向特征,经特征优化处理,由修正二次鉴别函数完成分类判决,实现了高性能印刷体蒙古文字符识别方法,这是目前所有其他文献里都没有使用过的方法。
发明内容
本发明的目的在于实现一个印刷体蒙古文字符识别方法。以单个印刷体字符作为处理对象,首先对字符对象进行预分类处理,确定其所属的字符类别子集,然后提取能很好反映字符特点的方向特征,再经过特征整形和LDA(线性鉴别分析)方法对特征进行优化,最后运用MQDF(改进的二次鉴别函数)统计分类器进行分类判决。由此,可以得到极高的单字识别正确率。根据该方法,实现了一个多字体多字号的印刷体蒙古文字符识别系统。
作为一个印刷体蒙古文字符识别系统还包括单字样本的采集,即系统首先扫描输入多字体多字号的印刷体蒙古文文本,采用自动的方式进行字符切分和字符预分类信息提取,得到单字符的训练样本库和相应的预分类信息集。利用预分类信息集,对字符全集进行初始划分,形成字符类别子集库;利用采集建立的训练样本数据库,进行方向特征的抽取和特征优化,得到训练样本的特征数据库。在训练样本的特征数据库的基础上,通过实验确定分类器的参数。对未知的输入字符样本,先对其进行预分类以确定其所属字符类别子集,然后采用同样的方法抽取特征,再送入分类器与特征库进行分类比较,从而判断输入字符的类别属性。
本发明由以下几部分组成:预分类、特征提取、特征优化、分类器设计。
1.预分类
预分类信息I:空间区域信息ZI(Zone Information)
因蒙古文字符集中的字符的宽度各不相同,受排列方式的制约,在水平方向上占据的空间区域也不一样。文本行的基线(Baseline)将空间区域在水平方向上分为三个区,从左到右依次为:基线左方的左侧区域(Left Zone)、基线所在的基准区域(Base Zone)、基线右方的右侧区域(Right Zone),如图7所示。
根据占据区域的不同,可将实际文本中出现的字符分为2种类型,通过对ZI赋予不同的数值来加以区分。ZI的2种合法取值对应于字符的2种类型,如下表所示:
表1 ZI的取值与对应的字符占据空间区域的关系
| ZI | 字符占据的区域 |
| 0 | 左侧区域+基准区域 |
| 1 | 左侧区域+基准区域+右侧区域 |
预分类信息II:字符形式信息FI(Form Information)
蒙古文字符集中的基本字母在实际文本表现为3种字符形式:首写形式(Initial Form)、中间形式(Medial Form)、尾写形式(Final Form)。严格来说,蒙古文字符只有上述3种字符形式,但一些特殊词尾字符在其上侧因特殊控制符的插入而出现一些空隙,效果上等价于将这些词尾字符独立开来,在某些特定字体中这种情况尤其常见;此外,蒙古文中的数字、符号等也是单独书写和印刷的。有鉴于此,在词首、词中、词尾等3种标准字符形式之外,本发明引入一种单写形式(Isolated Form)来表示那些被单独隔离开来的特殊的词尾字符和数字、符号。通过检测字符图像的上下两侧与其它字符之间的连接关系,任何一个蒙古文字符均能被分入由全体单写字符组成的单写字符子集、由全体词首形式字符组成的词首字符子集、由全体词中形式字符组成的词中字符子集和由全体词尾形式字符组成的词尾字符子集等4个字符子集中的某一个,即,所以出现在实际文本中的每个字符必定为这4种字符形式中的一种。假设χ为实际文本中的一个字符,判断其字符形式的准则为:
若χ在其上侧和下侧均不与其它字符直接相连,则χ为单写形式字符,令FI=0表示;
若χ在其上侧不与其它字符直接相连,而在其下侧与其它字符直接相连,则χ为首写形式字符,令FI=1表示;
若χ在其上侧和下侧均与其它字符直接相连,则χ为中间形式字符,令FI=2表示;
若χ在其上侧与其它字符直接相连,而在其下侧不与其它字符直接相连,则χ为尾写形式字符,令FI=3表示;
在以上准则中,两个字符“直接相连”是指这两个字符在基线位置处连结在一起,中间不存在空隙。
这样,根据字符形式信息,可将实际文本中出现的字符集划分为4个不同的子集。
基于上述分析,一组包含区域信息ZI和字符形式信息FI的预分类信息可将整个待处理字符集Ω={ω1,ω2,…,ωc},c为字符集Ω中字符类别的数量,划分成2×4=8个字符类别子集Ωk,k=1,2,…,8,ck为字符类别子集Ωk中字符类别的数量,c和ck,k=1,2,…,8均为正整数,有

其中 表示空集。而且,划分子集后可使每个ck均远小于c。
表示空集。而且,划分子集后可使每个ck均远小于c。
将预分类信息表示为向量形式IPC=[ZI,FI]T,其分量分别表示区域信息和字符形式信息,记 和
和 分别表示字符集合Ωk的预分类信息向量和单个字符类别ωm的预分类信息向量。由以上分析可知,每个字符子集Ωk均为具有完全相同的预分类信息的字符类别组成的集合,即:
分别表示字符集合Ωk的预分类信息向量和单个字符类别ωm的预分类信息向量。由以上分析可知,每个字符子集Ωk均为具有完全相同的预分类信息的字符类别组成的集合,即:
对于输入未知类别的字符χ,用IPC χ表示其预分类信息向量,将IPC χ与 比较可确定χ所属的字符类别子集
比较可确定χ所属的字符类别子集 其中‖·‖表示欧氏距离。
2.特征提取
2.1象素特征分配
设原始二值字符图像为:
其中W为图像宽度,H为图像高度,图像位于第i行、第j列的象素点的值为B(i,j),i=0,1,…,H-1,j=0,1,…,W-1。采用双线性插值方法对[B(i,j)]H×W进行归一化处理得到高度为M、宽度为N的字符点阵图像:
假定字符图像其笔划所对应的点为黑象素点,用“1”表示、背景所对应的点为白象素点,用“0”表示,即:
其中δstroke和δbackground分别表示图像中由字符笔划对应的点和背景点所组成的点的集合。
本发明采用16种基本方向特征元模板[R(k)(i,j)]5×5,k=1,2,…,16,来进行象素特征的分配,每个基本特征元模板大小均为5×5,如图10所示。将这16个模板分别作用于字符图像[G(i,j)]M×N,得到字符的16个基本特征平面:
其中[P(k)(i,j)]M×N中的各元素P(k)(i,j),i=0,1,…,M-1,j=0,1,…,N-1,是[R(k)(i,j)]5×5与[G(i,j)]M×N进行如下计算得到的:
2.2分块压缩
将每个M×N的基本特征平面[P(k)(i,j)]M×N,k=1,2,…,16均匀划分成高为u0、宽为v0的子区域(图11),每个子区域跟相邻的子区域之间在垂直方向有u1个象素的重合、在水平方向上有v1个象素的重合,故由每个M×N基本特征平面得到M′×N′个子区域,其中 将基本特征平面中每一个大小为u0×v0的子区域映射成大小为M′×N′的平面上一个点,得到压缩特征平面为:
[E(k)(i,j)]M′×N′中各元素的值为:
式中Θ(k)(m,n),0≤m<u0,0≤n<v0为加权系数:
其中
2.3特征向量形成
将压缩特征平面[E(k)(i,j)]M′×N′,k=1,2,…,16中的各元素按照顺序排列成一个维数为d=16×M′×N′的向量X=[x0,x1,…,xd-1]T,就得到了表示输入字符的d维原始特征的向量X。其中
it,jt,kt与t之间的关系为:

3.特征优化
特征维数的增大和训练样本的不足,将给分类器参数估计和识别计算量都带来很大的问题。根据一般的分类器设计经验,对训练样本的数目的要求是能够达到特征维数的10倍以上。为了减少过高的特征维数和训练样本的相对不足给分类器设计和参数估计带来的困难,本发明在将原始方向特征送入分类器进行字符类别判决前,对特征进行优化降维(图13)。
3.1特征整形
由于后续的LDA变换和MQDF分类器均以高斯分布为基础,提取的特征越接近高斯分布,系统识别性能就越好。为改善特征分布,使之更接近高斯分布,对原始特征向量X=[x0,x1,…,xd-1]T进行整形,得到新的特征向量Y=[y0,y1,…,yd-1]T,yt与xt之间的关系为:
其中α∈(0,1)为整形常数。
3.2特征变换
高维的特征向量Y包含很多冗余的信息。这些信息的存在不仅加大了计算的开销,而且会干扰字符识别的结果,本发明采用改进的LDA(线性鉴别分析)对Y进行特征变换,尽可能去除冗余信息,有效提取最具有鉴别能力的特征。
如“预分类”一节中所述,待处理字符集为Ω={ω1,ω2,…,ωc},c为集Ω中字符类别数,通过预分类被划分成40个字符类别子集Ωk,k=1,2,…,8,ck为字符子集Ωk中字符类别的数量。设第m类字符ωm的训练样本数为m=1,2,…,c,对该字符类别的训练样本采用上述方法提取特征并经特征整形后,得到的d维特征向量集合为
3.2.1计算统计量
计算每个字符类ωm特征向量的中心 和类内散度矩阵
和类内散度矩阵
计算各子集中所有字符类的特征向量的中心
计算各子集的类间散度矩阵和平均类内散度矩阵
3.2.2LDA变换
用矩阵计算工具计算矩阵的本征值 k=1,2,…,8和与各本征值相对应的本征向量
k=1,2,…,8和与各本征值相对应的本征向量 k=1,2,…,8,使得下列方程成立:
k=1,2,…,8,使得下列方程成立:

或等价于

由LDA的理论知:若采用使矩阵 k=1,2,…,8的迹 k=1,2,…,8达到最大的d×r(r为LDA变换后截取的特征维数)矩阵 作为特征变换矩阵,则能使变换后的特征类内散度方差与类间散度方差的比值达到最大,从而达到增加子集中各模式类别间的可分性的目的。同时,数学上已经证明,使
作为特征变换矩阵,则能使变换后的特征类内散度方差与类间散度方差的比值达到最大,从而达到增加子集中各模式类别间的可分性的目的。同时,数学上已经证明,使 达到最大的 是由矩阵
是由矩阵 的最大的r个非零本征值对应的本征向量构成的。所以,将
的最大的r个非零本征值对应的本征向量构成的。所以,将 的本征值按照从大到小的顺序排列,使得
的本征值按照从大到小的顺序排列,使得 同时, 的顺序也作相应的调整,使得它们保持与
的顺序也作相应的调整,使得它们保持与 的对应关系,即满足:
的对应关系,即满足:
由 的秩
的秩 即 的非零本征值最多为
的非零本征值最多为 个,所以本专利选取r可选择为区间
个,所以本专利选取r可选择为区间 上的正整数。于是得到
上的正整数。于是得到 k=1,2,…,8,这就是LDA变换矩阵。
k=1,2,…,8,这就是LDA变换矩阵。
将整形后的d维特征Y=[y0,y1,…,yd-1]T经过变换就得到了r维优化特征
Z=[z0,z1,…,zr-1]T,变换的过程为:
这就形成了最终送入分类器作为字符类型判决依据的特征向量。
4.分类器设计
分类器设计是字符识别的核心技术之一,研究者针对不同的问题提出了许多模式分类器。但在多种因素制约下,最小距离分类器以其简单有效而得到极大的应用。贝叶斯分类器是理论上最优的统计分类器,在处理实际问题时,人们希望尽量去逼近它。当在字符的特征为高斯分布且各类特征分布的先验概率相等的条件下,贝叶斯分类器简化为马氏距离分类器。但该条件在实际中通常不易满足,而且马氏距离分类器的性能随着协方差矩阵估计误差的产生而严重劣化。本发明采用MQDF(修正二次鉴别函数)作为分类度量,它是马氏距离的一个变形。MQDF鉴别函数形式为:
其中Z=[z0,z1,…,zd-1]T为送入分类器的未知字符的优化特征向量, 为字符类别ωm的标准特征向量, 和
和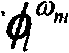 分别为第ωm类样本的优化特征向量的协方差矩阵的第l个本征值和本征向量,K表示所截取的主本征向量的个数,也是模式类的主子空间维数,其最优值由实验确定,h2是对小本征值的实验估计。
分别为第ωm类样本的优化特征向量的协方差矩阵的第l个本征值和本征向量,K表示所截取的主本征向量的个数,也是模式类的主子空间维数,其最优值由实验确定,h2是对小本征值的实验估计。
MQDF产生的是二次判决曲面,因只需估计每个类别协方差阵的前K个主本征向量,避免了小本征值估计误差的负面影响。MQDF鉴别距离可看作是在K维主子空间内的马氏距离和剩余的(r-K)维空间内的欧氏距离的加权和,加权因子为1/h2。
对每一个输入未知字符χ的特征向量进行分类判决时,搜索范围限定于对该输入字符预分类得到的特定子集 若
若 则判定该输入字符属于字符类别ωτ,即
本发明的特征在于,它是一种能够识别印刷体蒙古文字符的识别技术。它依次含有以下步骤:
1.印刷体蒙古文字符识别方法,其特征在于,它在对字符对象进行必要预处理后,首先对输入的单个字符进行预分类,将其划分到恰当的字符类别子集中去,然后提取能很好反映字符结构特点的方向特征,在此基础上,利用特征整形、LDA变换提取最具鉴别性的优化特征,把该特征送入MQDF分类器判定字符所属类别;在由图像采集设备和计算机组成的系统中,它依次含有以下步骤:
训练阶段:
第1步:在计算机中设定以下参数:
字符类别总数c;
归一化后字符高度M、字符宽度N;
基本特征平面分块参数u0、v0、u1、v1,其中
u0为基本特征平面中子区域的高度,
v0为基本特征平面中子区域的宽度,
u1为基本特征平面中子区域与相邻子区域之间在垂直方向上重合的象素个数,
v1为基本特征平面中子区域与相邻子区域之间在水平方向上重合的象素个数;
原始特征向量经特征整形形成更符合高斯分布的新特征向量时采用的整形参数α∈(0,1);特征变换时LDA截取维数r;
第2步:字符样本的采集
第2.1步:用图像采集设备扫描输入多字体多字号的印刷体蒙古文的文本,利用已有算法进行去噪声、二值化等必要的预处理;
第2.2步:对文本图像依次进行行切分、连体字符段切分、单字切分处理以分离单个字符,再对每个字符的图像标定其对应的正确的字符内码,然后把相同字符类别对应的原始字符图像提取出来,保存为用以训练和测试的单字样本集;
第2.3步:定义并标定每个字符类别的空间区域信息、字符形式信息和字符组成部件信息,保存标定结果,形成字符类别预分类信息集;它依次含有以下步骤:
第2.3.1步:形成字符空间区域信息,用ZI表示:
用文本行的基线Baseline将字符所占据的空间区域在水平方向上分为三个区,从左到右依次为:基线左方的左侧区域Left Zone、基线所在的基准区域Base Zone、基线右方的右侧区域Right Zone;
检测输入字符χ在三个空间区域中的分布情况,根据χ占据的区域,给ZI赋值如下:
若χ仅占据左侧区域和基准区域,则ZI=0;
若χ同时占据左侧区域、基准区域和右侧区域,则ZI=1;
第2.3.2步:形成字符形式信息,用FI表示:
蒙古文字符集中的基本字母在实际文本中表现为4种字符形式:首写形式、中间形式、尾写形式、单写形式;输入字符χ必定为这4种字符形式中的一种,依据χ与其左右字符的连接关系判断它的形式信息:
若χ在其上侧和下侧均不与其它字符直接相连,则χ为单写形式字符,令FI=0;
若χ在其上侧不与其它字符直接相连,而在其下侧与其它字符直接相连,则χ为首写形式字符,令FI=1;
若χ在其上侧和下侧均与其它字符直接相连,则χ为中间形式字符,令FI=2;
若χ在其上侧与其它字符直接相连,而在其下侧不与其它字符直接相连,则χ为尾写形式字符,令FI=3;
第2.3.3步:依据同一字符类别的不同单字样本的预分类信息相一致的准则对属于各字符类别的单字样本的预分类信息进行检查纠错后保存起来,形成字符类别预分类信息集;
第3步:字符类别子集的划分
设待处理字符全集为Ω={ω1,ω2,…,ωc};
将第2.3步得到的字符类别预分类信息,用一个向量 表示,m=1,2,…,c;依据 将Ω划分成2×4个字符类别子集Ωk,k=1,2,…,8,Ωk包含的字符类别数为ck,使
将Ω划分成2×4个字符类别子集Ωk,k=1,2,…,8,Ωk包含的字符类别数为ck,使

其中 表示空集;由以上划分得
表示空集;由以上划分得
若用表示Ωk中各字符类别子集的共同的预分类信息向量,则Ωk表示为:
第4步:特征提取
第4.1步:象素特征分配,它依次含有以下步骤:
第4.1.1步:
设原始二值字符图像为:
其中W为原始二值字符图像宽度,
H为原始二值字符图像高度,
B(i,j)为图像位于第i行、第j列的象素点的值,i=0,1,…,H-1,j=0,1,…,W-1;
用双线性插值方法对[B(i,j)]H×W进行归一化处理得到高度为M、宽度为N的归一化字符点阵图像:
第4.1.2步:
设字符图像其笔划所对应的点为黑象素点,用“1”表示、背景所对应的点为白象素点,用“0”表示,即:
其中
δstroke表示图像中由字符笔划对应的点所组成的点的集合,
δbackground表示图像中由背景点所组成的点的集合;
设定16种大小均为5×5的基本方向特征元模板[R(k)(i,j)]5×5,k=1,2,…,16:
将上述16种模板分别作用于字符图像[G(i,j)]M×N,得到字符的16个基本特征平面:
其中[P(k)(i,j)]M×N中的各元素P(k)(i,j),i=0,1,…,M-1,j=0,1,…,N-1,为:
而
而
第4.2步:分块压缩
将每个大小为M×N的基本特征平面[P(k)(i,j)]M×N,k=1,2,…,16,均匀划分成高为u0、宽为v0的子区域,每个子区域跟相邻的子区域之间在垂直方向有u1个象素的重合、在水平方向上有v1个象素的重合;由每个M×N基本特征平面得到M′×N′个子区域,其中
将每个基本特征平面中每一个大小为u0×v0的子区域映射成大小为M′×N′的平面上的一个点,形成压缩特征平面:
其中[E(k)(i,j)]M′×N′中各元素的值为:
而Θ(k)(m,n),0≤m<u0,0≤n<v0为加权系数:
其中
第4.3步:特征向量形成
将压缩特征平面[E(k)(i,j)]M′×N′,k=1,2,…,16,中的各元素按照顺序排列成一个维数为d=16×M′×N′的矢量X=[x0,x1,…,xd-1]T,得到了表示输入字符的d维原始方向特征向量:其中
而it,jt,kt与t之间的关系为:
INT(·)表示向下取整函数;
第5步:特征优化
第5.1步:特征整形
对原始特征向量X=[x0,x1,…,xd-1]T进行整形,得到新的特征向量Y=[y0,y1,…,yd-1]T,yt与xt之间的关系为:
其中α∈(0,1)为整形常数;
第5.2步:特征变换
第5.2.1步:获取字符类别的特征向量集合
如“第3步:字符类别子集的划分”所述,待处理字符集为Ω={ω1,ω2,…,ωc},c为集Ω中字符类别数,通过预分类处理被划分为8个字符类别子集Ωk,k=1,2,…,8,ck为字符类别子集Ωk中字符类别的数量;
设第m类字符ωm的训练样本数为 m=1,2,…,c,对该字符类别的训练样本采用“第4步:特征提取”所述方法提取特征得到的d维原始特征向量集合为
m=1,2,…,c,对该字符类别的训练样本采用“第4步:特征提取”所述方法提取特征得到的d维原始特征向量集合为 则经“第5.1步:特征整形”后,得到的d维特征向量集合为
则经“第5.1步:特征整形”后,得到的d维特征向量集合为
第5.2.2步:统计量计算
计算每个字符类ωm特征向量的中心 和类内散度矩阵
和类内散度矩阵
计算各子集中所有字符类的特征向量的中心
计算各子集的类间散度矩阵 和平均类内散度矩阵
和平均类内散度矩阵
第5.2.3步:LDA变换矩阵生成,它依次含有以下步骤:
第5.2.3.1步:用矩阵计算工具计算矩阵 的本征值
的本征值 k=1,2,…,8和与各本征值相对应的本征向量
k=1,2,…,8和与各本征值相对应的本征向量 k=1,2,…,8,使得下列方程成立:
k=1,2,…,8,使得下列方程成立:

第5.2.3.2步:将 的本征值按从大到小的顺序排列,使
的本征值按从大到小的顺序排列,使 同时, 的顺序也作相应的调整,使得它们保持与
的顺序也作相应的调整,使得它们保持与 的对应关系;
的对应关系;
第5.2.3.2步:取的前r个非零本征值对应的本征向量构成LDA变换矩阵 k=1,2,…,8;r的有效值可根据需要选取为小于或等于矩阵的秩
k=1,2,…,8;r的有效值可根据需要选取为小于或等于矩阵的秩 的正整数
第5.2.4步:变换特征的形成
将整形后的d维特征Y=[y0,y1,…,yd-1]T经过 变换得到r维优化特征Z=[z0,z1,…,zr-1]T,变换的过程为:
变换得到r维优化特征Z=[z0,z1,…,zr-1]T,变换的过程为:
形成最终送入分类器作为字符类型判决依据的字符特征向量Z;将 k=1,2,…,8,存入文件,形成优化参数库;
k=1,2,…,8,存入文件,形成优化参数库;
第6步:设计分类器
对于每个字符子集Ωk,计算包含在Ωk中的各字符类别的优化特征的均值向量 和协方差矩阵
和协方差矩阵
利用矩阵计算工具求取的本征值 和对应得本征向量l=0,1,…,r-1,通过实验确定MQDF分类器的相关参数K、h2;将
和对应得本征向量l=0,1,…,r-1,通过实验确定MQDF分类器的相关参数K、h2;将 K、h2、
K、h2、
 存入文件中;对所有的Ωk,k=1,2,…,8,依次进行如上操作,得到了用于分类判决的字符特征库;
存入文件中;对所有的Ωk,k=1,2,…,8,依次进行如上操作,得到了用于分类判决的字符特征库;
识别阶段:
第1步:预分类,即对输入的未知字符,判定其所属的字符类别子集;它依次包含以下步骤:
第1.1步:获取字符预分类信息
依照“训练阶段第3.2步”所述的方法,分别检测输入未知字符χ的空间区域信息ZI和字符形式信息FI,形成χ的预分类信息向量
第2.2步:确定输入字符所属子集
设χ所属的字符类别子集为 则
则 由下式给出:
由下式给出:
其中‖·‖表示欧氏距离, 为字符子集Ωk的预分类信息;
为字符子集Ωk的预分类信息;
得到后,完成了对χ的预分类;
第2步:特征提取
按照“训练阶段第4步”所述的方法,提取输入未知字符χ的d维原始方向特征向量
第3步:特征优化
第3.1步:特征整形
以“训练部分第一步”所设定的整形参数α对原始方向特征向量 进行整形,得到整形特征 其中:
第3.2步:特征变换
从“训练阶段第第5.2.5步”所生成的优化参数库文件中读取对应于输入字符χ所属字符类别子集 的LDA和K-L混合变换矩阵
的LDA和K-L混合变换矩阵 将d维整形方向特征向量
将d维整形方向特征向量 变换成r维变换特征向量 变换的过程为:
第4步:分类判决,即将未知类别的字符的特征向量与识别库中已有的数据进行比较,以确定输入字符对应的正确的字符代码;它依次含有以下步骤:
第4.1步:从“训练阶段第6步”所生成的字符特征库文件中读取输入字符χ所属字符类别子集 中的所有字符类别的均值向量
中的所有字符类别的均值向量 和相应的分类参数;
第4.2步:分别计算Zx到 中各字符类别的MQDF鉴别距离:
中各字符类别的MQDF鉴别距离:
若 则判定该输入字符χ属于字符类别ωτ,即
实验证明,基于本发明的印刷体蒙古文单字测试集上的识别正确率达到99.35%。
附图说明
图1一个典型的印刷体蒙古文字符识别系统的硬件构成。
图2印刷体蒙古文字符识别系统的单字样本生成。
图3印刷体蒙古文字符识别系统的构成。
图4采用的图像坐标系示意。
图5蒙古文字符集。
(a)蒙古文基本字母及其变形显现形式;(b)蒙古文常用符号、数字。
图6蒙古文字符集的文字构成特点示意。
图7预分类信息示意。
图8预分类流程。
图9方向特征抽取流程。
图1016种基本方向特征元模板。
图11基本特征平面分块示意。
图12方向特征抽取示意。
图13特征优化流程。
图14基于本发明的多字体多字号印刷体蒙古文字符识别系统。
具体实施方式
如图1所示,一个印刷体蒙古文字符识别系统在硬件上由两部分构成:图像采集设备和计算机。图像采集设备一般是扫描仪,用来获取待识别字符的数字图像。计算机用于对数字图像进行处理,并完成判决分类。
图2所示的是单字训练样本和单字测试样本的生成过程。对于一篇印刷体蒙古文样张,首先通过扫描仪将其扫入计算机,使之变为数字图像。对数字图像采取二值化、去除噪声等预处理措施,得到二值化的图像。再对输入图像进行行切分以得到文本行,对文本行进行词切分得到单词,在此基础上对每一个单词进行单字切分,得到单个字符,然后标定每个字符图像所属的字符类别。此后,要进行一次检查,对行文本切分、单词切分、单字切分阶段和字符类别标定阶段产生的错误采用手动方式改正。最后,将相同的字符类别对应的原始字符图像提取出来,并保存,完成单字样本的采集。同时,对每个字符类别的空间区域信息和字符形式信息进行标定,将标定结果保存在文件中,从而完成字符预分类信息的采集。
如图3所示,印刷体蒙古文字符识别算法分为两个部分:训练系统和测试系统。训练系统中,对输入的单字训练样本集中的每一个字符类别的所有样本,依据预分类信息将其划分至恰当的字符子集中,形成子集库。对属于各字符子集的所有字符类别的各单字样本,提取反映其组成信息的方向特征,利用特征整形和特征变换进行优化,然后,采用合适的分类器,训练分类器,得到字符特征库。在测试系统中,对输入的未知类别字符图像,提取预分类信息确定其所属的字符子集,采用和训练系统同样的特征提取和特征优化方法形成表示字符的特征向量,然后送入分类器进行分类,判断输入字符所属的类别。
因而,实用的多字体多字号印刷体蒙古文字符识别系统的实现需要考虑如下几个方面:
A)字符样本的采集
B)训练系统的实现
C)测试系统的实现
下面分别对这三个方面进行详细介绍。
A)字符样本的采集
A.1文本图像的获取
印刷体蒙古文单字样本的获取过程如图2所示。输入的一篇纸质印刷体蒙古文文档,通过扫描仪得到数字图像,完成从纸质文档到计算机存储图像的转换。然后对该图像进行噪声去除、二值化等预处理措施。利用各种滤波方法去除噪声在现有文献中已经有大量记载。二值化方法可采用已有的全局二值化或局部自适应二值化。接着对文档进行版面分析,得到字符区域。
A.2单字样本集的形成
对字符区域分别利用垂直投影直方图进行文本行切分得到单个文本行,再对各文本行采用水平投影直方图分析进行词切分得到单词,进而采用水平象素游程分析方法切分单词,得到单个字符图像。在此阶段的切分错误采用手动的方式进行更正。对得到的单个字符的类别进行标定,一般采用计算机自动标定,对其中的错误进行人工处理(更改、删除等)。最后,把具有相同内码的字符所对应的不同字体、不同字号的原始字符图像保存起来,就得到了印刷体蒙古文单字样本。
A.3预分类信息检测
对单行文本进行垂直象素投影分析,确定行基线Baseline,将以基线为界将该行文本所占的空间区域划分成左侧区域Left zone、基准区域Base zone和右侧区域Right zone,从而在进行单字切分得到单个字符的同时也根据该单字所占的空间区域得到了其空间区域信息ZI。对各连体字符段进行单字切分的同时,检测切割出来的单字上下边界与其它字符之间的连接关系,从而确定其字符形式信息FI。这样就确定了每个字符的预分类信息。具体包含如下步骤(令χ表示输入未知字符):
A.3.1检测空间区域信息ZI
文本行的基线(Baseline)将字符空间区域在水平方向上分为三个区,从左到右依次为:基线左方的左侧区域(Left Zone)、基线所在的基准区域(Base Zone)、基线右方的右侧区域(Right Zone)。检测输入字符在三个空间区域中的分布情况,根据χ占据区域的不同,给ZI赋予不同的取值,对应关系为:
若χ仅占据左侧区域和基准区域,则ZI=0;
若χ同时占据左侧区域、基准区域和右侧区域,则ZI=1;
A.3.2检测字符形式信息FI
蒙古文字符集中的基本字母在实际文本中表现为4种字符形式:首写形式、中间形式、尾写形式、单写形式,χ必定为这4种字符形式中的一种,依据χ与其上下字符的连接关系可判断它的形式信息:
若χ在其上侧和下侧均不与其它字符直接相连,则χ为单写形式字符,此时FI=0;
若χ在其上侧不与其它字符直接相连,而在其下侧与其它字符直接相连,则χ为首写形式字符,此时FI=1;
若χ在其上侧和下侧均与其它字符直接相连,则χ为中间形式字符,此时FI=2;
若χ在其上侧与其它字符直接相连,而在其下侧不与其它字符直接相连,则χ为尾写形式字符,此时FI=3。
A.3.3检查纠错和保存
属于同一字符类别的不同单字样本的预分类信息相同,依据该原则对属于各字符类别的单字样本的预分类信息进行检查,对预分类信息提取过程中产生的错误通过人机交互的方式进行纠正。最后,将每个字符类别的预分类信息保存起来,形成字符类别预分类信息集。
B)训练系统的实现
B.1预分类
根据样本采集环节得到各字符类别的预分类信息向量 m=1,2,…,c,将包含c不同字符类别的待处理字符全集Ω={ω1,ω2,…,ωc}划分成2×4=8个字符类别子集Ωk,k=1,2,…,8,每个Ωk字符包含的字符类别数为ck,使

k=1,2,…,8,其中表示空集。
将各Ωk所含的字符类别的内码和相应的预分类信息保存在文件中,形成子集库。
B.2特征提取
B.2.1象素特征分配
设原始二值字符图像为:
其中W为图像宽度,H为图像高度。采用双线性插值方法对[B(i,j)]H×W进行归一化处理得到高度为M、宽度为N的字符点阵图像:
采用16种5×5基本特征元模板[R(k)(i,j)]5×5,k=1,2,…,16分别作用于字符轮廓图像[Q(i,j)]M×N,得到字符的16个基本特征平面:
其中[P(k)(i,j)]M×N中的各元素P(k)(i,j),i=0,1,…,M-1,j=0,1,…,N-1,是[R(k)(i,j)]5×5与[Q(i,j)]M×N进行如下计算得到的:
B.2.2分块压缩
将每个M×N的基本特征平面[P(k)(i,j)]M×N,k=1,2,…,16均匀划分成高为u0、宽为v0的子区域,每个子区域跟相邻的子区域之间在垂直方向有u1个象素的重合、在水平方向上有v1个象素的重合,故由每个M×N基本特征平面得到M′×N′个子区域,其中 将基本特征平面中每一个大小为u0×v0的子区域映射成一个大小为M′×N′的平面上的一个点,得到压缩特征平面为:
[E(k)(i,j)]M′×N′中各元素的值表示为:
式中Θ(k)(m,n),0≤m<u0,0≤n<v0为加权系数:
其中
B.2.3特征向量形成
将压缩特征平面[E(k)(i,j)]M′×N′,k=1,2,…,16中的各元素按照顺序排列成一个维数为d=16×M′×N′的矢量X=[x0,x1,…,xd-1]T,就得到了表示输入字符的d维原始特征的向量。其中:
it,jt,kt与t之间的关系为:
B.3特征优化
B.3.1特征整形
对原始特征向量X=[x0,x1,…,xd-1]T进行整形,得到新的特征向量Y=[y0,y1,…,yd-1]T,yt与xt之间的关系为:
其中α∈(0,1)为整形常数。
B.3.2特征变换
待处理字符集为Ω={ω1,ω2,…,ωc},c为集Ω中字符类别数,通过预分类已被划分成8个字符子集Ωk,k=1,2,…,8,ck为字符子集Ωk中字符类别的数量。设第m类字符ωm的训练样本数为 m=1,2,…,c,对该字符类别的训练样本采用上述方法提取特征并经特征整形后,得到的d维特征向量集合为
m=1,2,…,c,对该字符类别的训练样本采用上述方法提取特征并经特征整形后,得到的d维特征向量集合为
B.3.2.1计算统计量
计算每个字符类ωm特征向量的中心 和类内散度矩阵
和类内散度矩阵
计算各子集中所有字符类的特征向量的中心
计算各子集的类间散度矩阵 和平均类内散度矩阵
和平均类内散度矩阵
B.3.2.2LDA变换
用矩阵计算工具计算矩阵 的本征值
的本征值 k=1,2,…,8和与各本征值相对应的本征向量
k=1,2,…,8和与各本征值相对应的本征向量 k=1,2,…,8,使得下列方程成立:
k=1,2,…,8,使得下列方程成立:
将 的本征值按照从大到小的顺序排列,使得
的本征值按照从大到小的顺序排列,使得 同时, 的顺序也作相应的调整,使得它们保持与
的顺序也作相应的调整,使得它们保持与 的对应关系。r可根据需要设定为不大于
的对应关系。r可根据需要设定为不大于 的正整数,这样得到的LDA变换矩阵为
B.3.2.3特征变换
整形后的d维特征Y=[y0,y1,…,yd-1]T经过变换得到了r维优化特征Z=[z0,z1,…,zr-1]T,变换的过程为:
将特征整形参数α和各字符类别子集的特征变换矩阵 保存起来,形成特征优化参数库文件。
保存起来,形成特征优化参数库文件。
B.4设计分类器
对于每个字符子集Ωk,计算包含在Ωk中的各字符类别的优化特征的均值向量 和协方差矩阵
和协方差矩阵
利用矩阵计算工具求取 的本征值和本征向量
的本征值和本征向量 l=0,1,…,r-1,通过实验确定MQDF分类器的相关参数K、h2。将
l=0,1,…,r-1,通过实验确定MQDF分类器的相关参数K、h2。将 K、h2、
K、h2、  存入库文件中。对所有的Ωk,k=1,2,…,8,依次进行如上操作,得到了用于分类判决的字符特征库。
存入库文件中。对所有的Ωk,k=1,2,…,8,依次进行如上操作,得到了用于分类判决的字符特征库。
C)测试系统的实现
令χ为输入未知字符。
C.1输入字符的预分类判决
C.1.2检测输入字符的预分类信息
依据“A.3.1~A.3.2”所述的方法分别检测χ的空间区域信息ZI和字符形式信息FI,并将其表示成向量形式
C.1.2确定输入字符所属子集
设χ所属的字符类别子集为 则
则 由下式给出:
由下式给出:
其中‖·‖表示欧氏距离,为字符子集Ωk的预分类信息
C.2特征提取
依据“测试系统”中特征提取的相同办法,提取输入字符χ的原始d维特征向量
C.3特征优化
从优化参数库文件中读取训练得到特征优化参数α和对应于χ所属的字符类别子集 的LDA变换矩阵
的LDA变换矩阵
用α为参数对 进行特征整形,得到 其中:
对 进行特征变换
得到r维特征向量
C.4分类判决
从特征库文件中读取 中所有字符类的均值向量
中所有字符类的均值向量 和相应的分类参数,计算Zχ到 中各字符类别的MQDF鉴别距离
中各字符类别的MQDF鉴别距离
若 则判定该输入字符χ属于字符类别ωτ,即
以下给出一个具体的实现例子。
实施例1:多字体多字号印刷体蒙古文字符识别系统
基于本发明的多字体多字号印刷体蒙古文字符识别系统如图14所示,实验的硬件设备平台为扫描仪(型号:紫光Uniscan 1248US)和普通PC机( 43.00GHz;Memory:1.00GB RAM;XP),实验在收集到l600套印刷体文档上进行,这些样本文档大部分采自当今主要的蒙古文出版系统,也有少量由WindowsTrueType字体直接打印生成。字体包括大部分最常用的、部分次常用的和少量不常用的字体,共计26种。字号从小五号到初号。样本质量不等,正常、断裂、粘连字符的比例约为2∶1∶1。经过扫描输入、文本行切分、单字切分和内码标定过程,将每个语种的1600套文档转换为1600套单字样本(即每个字符类别有1600个单字样本),从中随机抽出1200套组成训练集,其余400套留作测试样本。
43.00GHz;Memory:1.00GB RAM;XP),实验在收集到l600套印刷体文档上进行,这些样本文档大部分采自当今主要的蒙古文出版系统,也有少量由WindowsTrueType字体直接打印生成。字体包括大部分最常用的、部分次常用的和少量不常用的字体,共计26种。字号从小五号到初号。样本质量不等,正常、断裂、粘连字符的比例约为2∶1∶1。经过扫描输入、文本行切分、单字切分和内码标定过程,将每个语种的1600套文档转换为1600套单字样本(即每个字符类别有1600个单字样本),从中随机抽出1200套组成训练集,其余400套留作测试样本。
实验中,采用本发明的方法将输入字符归一化为24×32的点阵,即取M=24,N=32。在特征提取时基本特征平面按图11所示的方式划分,取u0=v0=8,u1=v1=4,故M′=N′=7。依图9所示的流程提取原始方向特征后,采用α=0.75进行特征整形,再采用LDA变换矩阵进行特征变换,各字符子集的LDA变换矩阵的列向量个数r均取96。分类器MQDF中的参数K=24,h2用各字符类的协方差阵的第K个本征值的均值作为估计值。在测试集上的识别正确率达到99.35%,表明本发明所提的方法的有效性。
综上所述,本发明提出的印刷体蒙古文字符识别方法具有以下优点:
1)基于蒙古文字符集的独特特点而提出的预分类方法,缩小了后续分类判决的搜索范围,不仅降低了计算量,而且提高整体识别性能。
2)本发明采用的方向特征符合蒙古文字符集中字符的笔划构成特点,计算方便。
3)本发明采用的特征整形和LDA特征变换方法可以很好改善特征分布,去除冗余信息,提高特征的鉴别能力。
4)本发明提出的方法具有很好的推广性,能够快速方便地移植到其它与蒙古文字符集具有极大相似性的字符集(如锡伯文、满文等)识别中去并可望取得良好的识别性能。
本发明提出的方法在实验中获得了优异的识别性能,具有广泛的应用前景。
Claims (1)
1.印刷体蒙古文字符识别方法,其特征在于,它在对字符对象进行必要预处理后,首先对输入的单个字符进行预分类,将其划分到恰当的字符类别子集中去,然后提取能很好反映字符结构特点的方向特征,在此基础上,利用特征整形、LDA变换提取最具鉴别性的优化特征,把该特征送入MQDF分类器判定字符所属类别;在由图像采集设备和计算机组成的系统中,它依次含有以下步骤:
训练阶段:
第1步:在计算机中设定以下参数:
字符类别总数c;
归一化后字符高度M、字符宽度N;
基本特征平面分块参数u0、v0、u1、v1,其中
u0为基本特征平面中子区域的高度,
v0为基本特征平面中子区域的宽度,
u1为基本特征平面中子区域与相邻子区域之间在垂直方向上重合的象素个数,
v1为基本特征平面中子区域与相邻子区域之间在水平方向上重合的象素个数;
原始特征向量经特征整形形成更符合高斯分布的新特征向量时采用的整形参数α∈(0,1);特征变换时LDA截取维数r;
第2步:字符样本的采集
第2.1步:用图像采集设备扫描输入多字体多字号的印刷体蒙古文的文本,利用已有算法进行去噪声、二值化等必要的预处理;
第2.2步:对文本图像依次进行行切分、连体字符段切分、单字切分处理以分离单个字符,再对每个字符的图像标定其对应的正确的字符内码,然后把相同字符类别对应的原始字符图像提取出来,保存为用以训练和测试的单字样本集;
第2.3步:定义并标定每个字符类别的空间区域信息、字符形式信息和字符组成部件信息,保存标定结果,形成字符类别预分类信息集;它依次含有以下步骤:
第2.3.1步:形成字符空间区域信息,用ZI表示:
用文本行的基线将字符所占据的空间区域在水平方向上分为三个区,从左到右依次为:基线左方的左侧区域、基线所在的基准区域、基线右方的右侧区域;
检测输入字符χ在三个空间区域中的分布情况,根据χ占据的区域,给ZI赋值如下:
若χ仅占据左侧区域和基准区域,则ZI=0;
若χ同时占据左侧区域、基准区域和右侧区域,则ZI=1;
第2.3.2步:形成字符形式信息,用FI表示:
蒙古文字符集中的基本字母在实际文本中表现为4种字符形式:首写形式、中间形式、尾写形式、单写形式;输入字符χ必定为这4种字符形式中的一种,依据χ与其左右字符的连接关系判断它的形式信息:
若χ在其上侧和下侧均不与其它字符直接相连,则χ为单写形式字符,令FI=0;
若χ在其上侧不与其它字符直接相连,而在其下侧与其它字符直接相连,则χ为首写形式字符,令FI=1;
若χ在其上侧和下侧均与其它字符直接相连,则χ为中间形式字符,令FI=2;
若χ在其上侧与其它字符直接相连,而在其下侧不与其它字符直接相连,则χ为尾写形式字符,令FI=3;
第2.3.3步:依据同一字符类别的不同单字样本的预分类信息相一致的准则对属于各字符类别的单字样本的预分类信息进行检查纠错后保存起来,形成字符类别预分类信息集;
第3步:字符类别子集的划分
设待处理字符全集为Ω={ω1,ω2,…,ωc};
将第2.3步得到的字符类别预分类信息,用一个向量 表示,m=1,2,…,c;依据 将Ω划分成2×4个字符类别子集Ωk,k=1,2,…,8,Ωk包含的字符类别数为ck,使
将Ω划分成2×4个字符类别子集Ωk,k=1,2,…,8,Ωk包含的字符类别数为ck,使
m≠n,
其中 表示空集;由以上划分得
表示空集;由以上划分得
若用 表示Ωk中各字符类别子集的共同的预分类信息向量,则Ωk表示为:
表示Ωk中各字符类别子集的共同的预分类信息向量,则Ωk表示为:
第4步:特征提取
第4.1步:象素特征分配,它依次含有以下步骤:
第4.1.1步:
设原始二值字符图像为:
其中W为原始二值字符图像宽度,
H为原始二值字符图像高度,
B(i,j)为图像位于第i行、第j列的象素点的值,i=0,1,…,H-1,j=0,1,…,W-1;
用双线性插值方法对[B(i,j)]H×W进行归一化处理得到高度为M、宽度为N的归一化字符点阵图像:
第4.1.2步:
设字符图像其笔划所对应的点为黑象素点,用“1”表示、背景所对应的点为白象素点,用“0”表示,即:
其中
δstroke表示图像中由字符笔划对应的点所组成的点的集合,
δbackground表示图像中由背景点所组成的点的集合;
设定16种大小均为5×5的基本方向特征元模板[R(k)(i,j)]5×5,k=1,2,…,16:
将上述16种模板分别作用于字符图像[G(i,j)]M×N,得到字符的16个基本特征平面:
其中[P(k)(i,j)]M×N中的各元素P(k)(i,j),i=0,1,…,M-1,j=0,1,…,N-1,为:
而
而
第4.2步:分块压缩
将每个大小为M×N的基本特征平面[P(k)(i,j)]M×N,k=1,2,…,16,均匀划分成高为u0、宽为v0的子区域,每个子区域跟相邻的子区域之间在垂直方向有u1个象素的重合、在水平方向上有v1个象素的重合;由每个M×N基本特征平面得到M′×N′个子区域,其中
将每个基本特征平面中每一个大小为u0×v0的子区域映射成大小为M′×N′的平面上的一个点,形成压缩特征平面:
其中[E(k)(i,j)]M′×N′中各元素的值为:
而Θ(k)(m,n),0≤m<u0,0≤n<v0为加权系数:
其中
第4.3步:特征向量形成
将压缩特征平面[E(k)(i,j)]M′×N′,k=1,2,…,16,中的各元素按照顺序排列成一个维数为d=16×M′×N′的矢量X=[x0,x1,…,xd-1]T得到了表示输入字符的d维原始方向特征向量:其中
而it,jt,kt与t之间的关系为:
INT(·)表示向下取整函数;
第5步:特征优化
第5.1步:特征整形
对原始特征向量X=[x0,x1,…,xd-1]T进行整形,得到新的特征向量Y=[y0,y1,…,yd-1]T,yt与xt之间的关系为:
其中α∈(0,1)为整形常数;
第5.2步:特征变换
第5.2.1步:获取字符类别的特征向量集合
如“第3步:字符类别子集的划分”所述,待处理字符集为Ω={ω1,ω2,…,ωc},c为集Ω中字符类别数,通过预分类处理被划分为8个字符类别子集Ωk,k=1,2,…,8,ck为字符类别子集Ωk中字符类别的数量;
设第m类字符ωm的训练样本数为 ,m=1,2,…,c,对该字符类别的训练样本采用“第4步:特征提取”所述方法提取特征得到的d维原始特征向量集合为
,m=1,2,…,c,对该字符类别的训练样本采用“第4步:特征提取”所述方法提取特征得到的d维原始特征向量集合为 则经“第5.1步:特征整形”后,得到的d维特征向量集合为
第5.2.2步:统计量计算
计算每个字符类ωm特征向量的中心 和类内散度矩阵
和类内散度矩阵
计算各子集中所有字符类的特征向量的中心
计算各子集的类间散度矩阵和平均类内散度矩阵
第5.2.3步:LDA变换矩阵生成,它依次含有以下步骤:
第5.2.3.1步:用矩阵计算工具计算矩阵 的本征值,…,
的本征值,…, k=1,2,…,8和与各本征值相对应的本征向量,k=1,2,…,8,使得下列方程成立:
k=1,2,…,8和与各本征值相对应的本征向量,k=1,2,…,8,使得下列方程成立:

第5.2.3.2步:将的本征值按从大到小的顺序排列,使 同时, 的顺序也作相应的调整,使得它们保持与
的顺序也作相应的调整,使得它们保持与 的对应关系;
第5.2.3.3步:取 的前r个非零本征值对应的本征向量构成LDA变换矩阵k=1,2,…,8;r的有效值可根据需要选取为小于或等于矩阵
的前r个非零本征值对应的本征向量构成LDA变换矩阵k=1,2,…,8;r的有效值可根据需要选取为小于或等于矩阵 的秩
的秩 的正整数
第5.2.4步:变换特征的形成
将整形后的d维特征Y=[y0,y1,…,yd-1]T经过 变换得到r维优化特征Z=[z0,z1,…,zr-1]T,变换的过程为:
变换得到r维优化特征Z=[z0,z1,…,zr-1]T,变换的过程为:
形成最终送入分类器作为字符类型判决依据的字符特征向量Z;将 ,k=1,2,…,8,存入文件,形成优化参数库;
,k=1,2,…,8,存入文件,形成优化参数库;
第6步:设计分类器
对于每个字符子集Ωk,计算包含在Ωk中的各字符类别的优化特征的均值向量 和协方差矩阵
和协方差矩阵
利用矩阵计算工具求取 的本征值
的本征值 和对应的本征向量
和对应的本征向量 ,l=0,1,…,r-1,通过实验确定MQDF分类器的相关参数K、h2;将
,l=0,1,…,r-1,通过实验确定MQDF分类器的相关参数K、h2;将 、K、h2、
、K、h2、 存入文件中;对所有的Ωk,k=1,2,…,8,依次进行如上操作,得到了用于分类判决的字符特征库;识别阶段:
存入文件中;对所有的Ωk,k=1,2,…,8,依次进行如上操作,得到了用于分类判决的字符特征库;识别阶段:
第1步:预分类,即对输入的未知字符,判定其所属的字符类别子集;它依次包含以下步骤:
第1.1步:获取字符预分类信息
依照“训练阶段第2.3步”所述的方法,分别检测输入未知字符χ的空间区域信息ZI和字符形式信息FI,形成χ的预分类信息向量
第1.2步:确定输入字符所属子集
设χ所属的字符类别子集为 ,则
,则 由下式给出:
由下式给出:
其中||·||表示欧氏距离, 为字符子集Ωk的预分类信息;
为字符子集Ωk的预分类信息;
得到 后,完成了对χ的预分类;
后,完成了对χ的预分类;
第2步:特征提取
按照“训练阶段第4步”所述的方法,提取输入未知字符χ的d维原始方向特征向量
第3步:特征优化
第3.1步:特征整形
以“训练部分第1步”所设定的整形参数α对原始方向特征向量 进行整形,得到整形特征 其中:
第3.2步:特征变换
从“训练阶段第5.2.4步”所生成的优化参数库文件中读取对应于输入字符χ所属字符类别子集 的LDA和K-L混合变换矩阵,将d维整形方向特征向量
的LDA和K-L混合变换矩阵,将d维整形方向特征向量 变换成r维变换特征向量 变换的过程为:
第4步:分类判决,即将未知类别的字符的特征向量与识别库中已有的数据进行比较,以确定输入字符对应的正确的字符代码;它依次含有以下步骤:
第4.1步:从“训练阶段第6步”所生成的字符特征库文件中读取输入字符χ所属字符类别子集 中的所有字符类别的均值向量
中的所有字符类别的均值向量 和相应的分类参数;
第4.2步:分别计算Zχ到 中各字符类别的MQDF鉴别距离:
中各字符类别的MQDF鉴别距离:
若 则判定该输入字符χ属于字符类别ωτ,即
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNB2007100642959A CN100440250C (zh) | 2007-03-09 | 2007-03-09 | 印刷体蒙古文字符识别方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNB2007100642959A CN100440250C (zh) | 2007-03-09 | 2007-03-09 | 印刷体蒙古文字符识别方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101017533A CN101017533A (zh) | 2007-08-15 |
| CN100440250C true CN100440250C (zh) | 2008-12-03 |
Family
ID=38726531
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB2007100642959A Expired - Fee Related CN100440250C (zh) | 2007-03-09 | 2007-03-09 | 印刷体蒙古文字符识别方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN100440250C (zh) |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101763505B (zh) * | 2009-12-29 | 2011-12-07 | 重庆大学 | 基于投影对称性的车牌字符特征提取及分类方法 |
| KR101479384B1 (ko) | 2010-01-29 | 2015-01-05 | 노키아 코포레이션 | 물체 인식을 가능하게 하기 위한 방법 및 장치 |
| CN102446275B (zh) * | 2010-09-30 | 2014-04-16 | 汉王科技股份有限公司 | 阿拉伯文字符的识别方法和装置 |
| CN102542269B (zh) * | 2010-12-24 | 2014-12-10 | 北大方正集团有限公司 | 西文单词切分方法和装置 |
| CN102184395B (zh) * | 2011-06-08 | 2012-12-19 | 天津大学 | 基于字符串核的草图识别方法 |
| CN103826028B (zh) * | 2012-11-19 | 2017-08-25 | 腾讯科技(深圳)有限公司 | 一种无损压缩图片的方法和装置 |
| CN103699234B (zh) * | 2013-12-26 | 2016-08-17 | 乌鲁木齐市索贝特数码科技有限公司 | 锡伯文满文拼音输入法及其系统 |
| CN105844205B (zh) * | 2015-01-15 | 2019-05-31 | 新天科技股份有限公司 | 基于图像处理的字符信息识别方法 |
| US9852348B2 (en) * | 2015-04-17 | 2017-12-26 | Google Llc | Document scanner |
| CN104809442B (zh) * | 2015-05-04 | 2017-11-17 | 北京信息科技大学 | 一种东巴象形文字字素智能识别方法 |
| CN105117704B (zh) * | 2015-08-25 | 2018-05-29 | 电子科技大学 | 一种基于多特征的文本图像一致性比较方法 |
| CN106570538B (zh) * | 2015-10-10 | 2019-08-30 | 北大方正集团有限公司 | 字符图片处理方法和装置 |
| CN107025452A (zh) * | 2016-01-29 | 2017-08-08 | 富士通株式会社 | 图像识别方法和图像识别设备 |
| CN106778758A (zh) * | 2016-12-29 | 2017-05-31 | 成都数联铭品科技有限公司 | 用于图像文字识别的字符切分方法 |
| CN108932454A (zh) * | 2017-05-23 | 2018-12-04 | 杭州海康威视系统技术有限公司 | 一种基于图片的字体识别方法、装置及电子设备 |
| CN108596183B (zh) * | 2018-04-24 | 2020-08-04 | 大连民族大学 | 满文部件切分的过分割区域合并方法 |
| CN108564078B (zh) * | 2018-04-24 | 2020-11-13 | 大连民族大学 | 提取满文单词图像中轴线的方法 |
| CN108549896B (zh) * | 2018-04-24 | 2020-08-04 | 大连民族大学 | 满文部件切分中删除多余候选切分行的方法 |
| CN108564089B (zh) * | 2018-04-24 | 2020-10-23 | 大连民族大学 | 满文部件集的构建方法 |
| CN109063670A (zh) * | 2018-08-16 | 2018-12-21 | 大连民族大学 | 基于字头分组的印刷体满文单词识别方法 |
| CN109190630A (zh) * | 2018-08-29 | 2019-01-11 | 摩佰尔(天津)大数据科技有限公司 | 字符识别方法 |
| CN109784151A (zh) * | 2018-12-10 | 2019-05-21 | 重庆邮电大学 | 一种基于卷积神经网络的脱机手写汉字识别方法 |
| CN109753968B (zh) * | 2019-01-11 | 2020-12-15 | 北京字节跳动网络技术有限公司 | 字符识别模型的生成方法、装置、设备及介质 |
| CN110598630A (zh) * | 2019-09-12 | 2019-12-20 | 江苏航天大为科技股份有限公司 | 基于卷积神经网络的城市轨道交通乘客拥挤程度检测方法 |
| CN111241329A (zh) * | 2020-01-06 | 2020-06-05 | 北京邮电大学 | 基于图像检索的古文字考释方法和装置 |
| CN112200188B (zh) * | 2020-10-16 | 2023-09-12 | 北京市商汤科技开发有限公司 | 文字识别方法及装置、存储介质 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5425110A (en) * | 1993-04-19 | 1995-06-13 | Xerox Corporation | Method and apparatus for automatic language determination of Asian language documents |
| CN1567357A (zh) * | 2003-07-08 | 2005-01-19 | 摩托罗拉公司 | 二进制化文字图像的方法 |
| CN1570958A (zh) * | 2004-04-23 | 2005-01-26 | 清华大学 | 多字体多字号印刷体藏文字符识别方法 |
| CN1606028A (zh) * | 2004-11-12 | 2005-04-13 | 清华大学 | 基于阿拉伯字符集的印刷体字符识别方法 |
| CN1741035A (zh) * | 2005-09-23 | 2006-03-01 | 清华大学 | 印刷体阿拉伯字符集文本切分方法 |
| JP2006092027A (ja) * | 2004-09-21 | 2006-04-06 | Fuji Xerox Co Ltd | 文字認識装置、文字認識方法および文字認識プログラム |
-
2007
- 2007-03-09 CN CNB2007100642959A patent/CN100440250C/zh not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5425110A (en) * | 1993-04-19 | 1995-06-13 | Xerox Corporation | Method and apparatus for automatic language determination of Asian language documents |
| CN1567357A (zh) * | 2003-07-08 | 2005-01-19 | 摩托罗拉公司 | 二进制化文字图像的方法 |
| CN1570958A (zh) * | 2004-04-23 | 2005-01-26 | 清华大学 | 多字体多字号印刷体藏文字符识别方法 |
| JP2006092027A (ja) * | 2004-09-21 | 2006-04-06 | Fuji Xerox Co Ltd | 文字認識装置、文字認識方法および文字認識プログラム |
| CN1606028A (zh) * | 2004-11-12 | 2005-04-13 | 清华大学 | 基于阿拉伯字符集的印刷体字符识别方法 |
| CN1741035A (zh) * | 2005-09-23 | 2006-03-01 | 清华大学 | 印刷体阿拉伯字符集文本切分方法 |
Non-Patent Citations (2)
| Title |
|---|
| 印刷体蒙古文字识别中蒙古文字特征的选择. 魏宏喜,高光来.内蒙古大学学报(自然科学版),第37卷第6期. 2006 * |
| 印刷体蒙古文文字识别的研究. 李振宏,高光来,侯宏旭,李伟.内蒙古大学学报(自然科学版),第34卷第4期. 2003 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN101017533A (zh) | 2007-08-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN100440250C (zh) | 印刷体蒙古文字符识别方法 | |
| Sahare et al. | Multilingual character segmentation and recognition schemes for Indian document images | |
| Nagy | Twenty years of document image analysis in PAMI | |
| Pati et al. | Word level multi-script identification | |
| Guo et al. | Separating handwritten material from machine printed text using hidden markov models | |
| US6252988B1 (en) | Method and apparatus for character recognition using stop words | |
| Amara et al. | Classification of Arabic script using multiple sources of information: State of the art and perspectives | |
| Peng et al. | Multi-font printed Mongolian document recognition system | |
| Chamchong et al. | Character segmentation from ancient palm leaf manuscripts in Thailand | |
| Biswas et al. | Writer identification of Bangla handwritings by radon transform projection profile | |
| CN103927539A (zh) | 离线式维吾尔文手写签名识别的一种高效的特征提取方法 | |
| Baechler et al. | Text line extraction using DMLP classifiers for historical manuscripts | |
| Nasrollahi et al. | Printed persian subword recognition using wavelet packet descriptors | |
| CN104834891A (zh) | 一种中文图像型垃圾邮件过滤方法及系统 | |
| Moussa et al. | Fractal-based system for Arabic/Latin, printed/handwritten script identification | |
| Gillies et al. | Arabic text recognition system | |
| Ghosh et al. | R-PHOC: segmentation-free word spotting using CNN | |
| Ferrer et al. | Multiple training-one test methodology for handwritten word-script identification | |
| Van Phan et al. | Collecting handwritten nom character patterns from historical document pages | |
| Khan et al. | A holistic approach to Urdu language word recognition using deep neural networks | |
| Pal | On the developement of an optical character recognition (ocr) system for printed bangla script | |
| Cao et al. | Robust page segmentation based on smearing and error correction unifying top-down and bottom-up approaches | |
| Cecotti et al. | Hybrid OCR combination approach complemented by a specialized ICR applied on ancient documents | |
| Jindal et al. | Structural features for recognizing degraded printed Gurmukhi script | |
| Bharathi et al. | Improvement of Telugu OCR by segmentation of Touching Characters |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20081203 Termination date: 20180309 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |