具体实施方式
图1示意性地显示了一个用于信息管理的系统,其中在所述系统中可以使用本发明。所述系统包括一个纸张形式的基底1、用户单元2和外部单元3。所述纸具有一个位置编码图案4,其中只有一小部分位置编码图案4是以放大状态示意表示的。在这里可以使用用户单元2而以等同于普通的笔的方式而在纸1上进行书写,同时以数字形式来记录书写内容。以数字方式记录的信息可以在用户单元2和/或外部设备3中得到处理,其中可以将所述信息自动(联机)发送到所述装置,也可以由用户用信号通知所述装置发送所述信息。对正确反映了纸上内容并以数字方式记录的信息来说,尽可能正确和完整地解码所述位置,这一点是非常重要的。
下文中将会更详细的描述位置编码图案4,所述位置编码图案4由图形符号构成,这些符号是根据预定规则排列和设计的,这意味着如果正确成像了位置编码图案中的局部区域,其中所述局部区域将会具有预定的最小尺寸,则可以借助于成像局部区域中的符号以及一种预定解码算法来明确判定位置编码图案中的局部区域的位置。所述位置可以作为笛卡尔或另一个坐标系中的一对坐标来获取。
当用户在纸1上借助用户单元2来进行书写的时候,所述用户单元会在用户单元顶端连续记录位置编码图案的局部区域图像。其中每一个图像都解码到一个位置。然后,这种经过解码的位置的序列构成了用户单元2在纸上所做移动的数字表示,由此构成了纸上所写内容的数字表示。
关于位置编码图案的解码可以在用户单元2中进行,也可以在外部单元3中进行,此外还可以在某些其他单元中进行,其中位置编码图案的图像是以一种经过了某种程度的处理的形式发送到所述单元的。
如上所述,局部区域中的信息是借助预定解码算法而被解码的。只要对局部区域恰当成像,那么这种处理可以很好地发挥作用。然而在实际情况中,举例来说,由于不良的照明条件,或者用户将笔保持在一个倾斜位置,从而导致合乎比例地成像所述局部区域,或者所述成像机制致使图像失真,因此用户单元经常不能完全正确地成像局部区域。然后会出现解码算法曲解符号或遗漏符号的情况,这将导致不正确地解码所述位置。如果没有在纸上恰当再现位置编码图案,而是在将其施加到纸上的时候就已经发生了某些程度的失真,那么很有可能会出现差错。如果因为种种原因而不能接受一个位置,例如将其认为是极其不可靠的,那么也可能将所述位置视为是不正确的。
在一定条件下,举例来说,如果位置编码图案包含了能够执行检错的冗余信息,或者相对于先前或随后解码的位置而言,所述解码位置并不合理,则可以发现差错。
图2示意性地显示了如何解决那些关于错误解码的位置的问题。纸200具有一个位置编码图案,其中为了清楚起见,在所述图中并未显示所述图案。第一局部区域A对一个位置P1进行编码,其中所述位置P1已经在未曾检测到任何解码错误的情况下进行了解码并且由此已经作为一个正确解码的位置而被接受。第三局部区域C则对一个已作为正确解码的位置而被接受的位置P3进行编码。在用户单元成像了局部区域A之后并且在其成像局部区域C之前,所述用户单元已经成像了具有位置P2的局部区域B。然而由于图像失真,因此将局部区域B中的信息解码到一个错误位置P2′,所述位置对应于虚线表示的局部区域B′。
在这里执行了一个匹配操作,而不是滤去或排除那些不可用的局部区域B。所述匹配操作不需要立即执行,而是可以在稍后正确解码了一个或多个位置的时候才执行。在这个实例中,所述解码是在正确解码了局部区域C之后才得以执行的。
更为特别的是,从成像局部区域B中确定的信息与如何在局部区域A与C周围的匹配区域M的不同局部区域中组成所述位置编码图案的信息进行匹配和比较。执行所述匹配时所在区域的一个实例是由点划线给出的。在这里可以将所述区域选作一个预定区域,也可以动态选择所述区域。在选择匹配区域的时候,可以对一个或多个已经接受的位置加以考虑,其中可以在位置计算失败之前和/或之后记录所述位置的相应局部区域。特别地,在对位置计算失败的局部区域进行记录之前和/或之后,可以确定用户单元的速度和加速度并且将其用作一个评定所述匹配区域的基准。
所述匹配可以在一个或两个维度上进行。根据位置编码图案的组合,在某些情况下可以分别为各个维度执行位置解码。然后则会出现这样一种情况,那就是第一维度的位置计算成功并为这个维度产生一个已接受的位置,而第二维度的位置计算失败并且在第二维度产生了一个明显错误的位置。于是在大多数情况下都只需要在错误的维度上执行所述匹配。
举例来说,假设关于图2中位置P2的x坐标的计算成功,并且只有关于y坐标的计算是失败的,那么将会得到一个与局部区域B”相对应的位置P2”。在y方向上,由于错误位置远离已接受的位置P1和P3,因此将会检测到所述错误位置。然后,成像局部区域B中的信息只需要与来自不同局部区域的信息进行匹配,其中所述局部区域带有一个在范围M′中发生变化的y坐标。
这样一来,匹配是在两方面的信息之间执行的,其中一方面的信息来自一个成像局部区域并且由此并非始终是100%正确的,而另一方面的信息则是关于不同匹配局部区域中的位置编码图案外部特征的已知信息。在成像局部区域与匹配局部区域之间进行的每次匹配中都会为成像局部区域确定一个对所述匹配局部区域进行成像的概率。在匹配了所述匹配区域中的所有匹配局部区域时,则选择一个与得到最大匹配概率的匹配局部区域相对应的位置。
毫无疑问,较为理想的是匹配尽可能快,由此可以实时以数字方式记录纸上记述的内容并且所述匹配将会需要尽可能少的处理器能力和存储空间。当在用户单元中执行匹配操作时,所述用户单元通常应该只具有有限的处理器能力和有限的存储空间,因此后者尤其是合乎需要的。这样一来,较为理想的是以多种方式来优化所述匹配。
在以上实例中,错误位置P2′和P2″都是纸上的位置。然而,它们也可以是那些不在纸上的位置。
此外还应该指出,为了清楚起见,在图2中相对一个应用实施例而言,其中极大地放大了局部区域相对纸的大小。
图3显示了局部区域300的一个实例,其中所述区域对一个位置进行编码并且包含6*6个符号,这些符号分别是用点310来描述的。为了清楚起见,在这里并未显示符号的不同的值,所有符号都是用相同的点来显示的。每个符号可以采用预定数量的不同值,例如“0”和“1”。所述符号值可以借助不同的参数而被编码,例如点的大小、点的位置或点的形状。很明显,也可以使用那些符号数量不同的局部区域。
局部区域300与已知内容的局部区域的匹配可以在不同级别上进行。举例来说,所述匹配可以在符号级别上进行。在这种情况下,从局部区域300中确定的每个符号值都可以与已知内容的局部区域中的相应符号值比较,并且可以将正确符号值的数目用作局部区域300符合已知内容局部区域的概率指示。作为选择,在对局部区域300中的符号的值进行解码的时候,可以确定每个符号采用“0”和“1”之类的各个可能值的概率。对每个匹配的局部区域而言,可以确定局部区域300中的符号恰好采用匹配局部区域中的值的组合的组合概率。具有最大组合概率的匹配局部区域的位置将被选为局部区域300的解码位置。
作为选择,所述匹配可以在一个“更高”级别上进行。所述符号可以排列在一个群组中,例如排列在列或行矢量中,此外还可以为每个矢量确定一个矢量值。图3显示了用320标记的一个群组的实例。这样一来,在各个局部区域匹配中可以对群组值或矢量值进行比较,而不是对符号值进行比较,对每个局部区域而言,这种处理将会产生更少的比较。与在符号级别上的匹配相似,在这里还有可能确定每个群组/矢量采用每个可能值的概率,并且为经过匹配的每个局部区域确定组合概率。这意味着只需要在各个局部区域匹配中组合更少的概率。对与如何获取不同匹配局部区域中组成位置编码图案相关的信息来说,由于保存或计算群组值而不是符号值就已足够,因此群组级别上的匹配还意味着对其进行简化。
所述匹配还可以结合那些来自成像局部区域并进行了更高程度处理的信息来进行。举例来说,在匹配中可以对来自两个或更多群组的信息进行比较。
在下文中将参考申请人开发的一个具体的位置编码图案来对所述位置编码进行更详细的例示和描述,其中特别要求经由国际专利申请PCT/SE02/01243而对所述图案加以保护,该申请在提交本申请的时候并未公开。在附录A中将会参考图4~9来对位置编码图案及其解码进行详细描述。但在下文中将会给出关于所述图案的一个扼要和简化的描述。
位置编码基于一个数字序列,所述序列在下文中称为差分数字序列。这个差分数字序列具有如下特性,如果采用预定长度的任意局部序列,例如具有五个差分数字的局部序列,那么这个局部序列在差分数字序列中始终具有一个无歧义确定的位置。换句话说,它在差分数字序列中只会出现一次,由此可以将其用于位置确定。更具体的说,差分数字序列是沿着位置编码图案的x轴和y轴“行进”的。
实际位置编码图案由简单的图形符号组成,这些符号可以采用0~3这四个不同的值。参见图6,其中每个符号都包括一个标记,其中举例来说,所述标记可以具有点的形状,并且可以相对于光栅点的标称位置而在四个不同方向中的一个方向上位移一定距离。所述标称位置包括不可视光栅中光栅线之间的一个交叉点。符号值则是由位移方向确定的。每个符号值0~3都可以转换成一个用于对x坐标进行编码的比特和一个用于对y坐标进行编码的比特,也就是转换成比特对0,0;0,1;1,0和1,1。因此,所述编码分别在x和y方向上进行,而图形编码则是结合一个为x和y比特所共有的符号来进行的。
每个位置均由6*6个符号编码,由此可以转换成一个用于所述位置的x坐标的6*6比特矩阵和一个用于所述位置的y坐标的6*6比特矩阵。假设考虑的是x比特矩阵,那么可以将这个矩阵划分成各具有6比特的6个列。一列中的每个比特序列都在一个长为63比特的循环主数字序列中构成一个局部序列,该序列具有如下性质:如果选择了长度为6比特的局部序列,那么这个序列在主数字序列中具有无歧义确定的位置。由此可以将这六个列转换成与主数字序列中的6个位置相对应的6个位置数字或序列值。在这六个位置数字之间,可以成对形成五个差分数字,这五个差分数字构成了差分数字序列的一个局部序列并且由此在同一差分数字序列中具有无歧义确定的位置,进而在x轴上具有无歧义确定的位置。对某个x坐标来说,位置数字的变化取决于y坐标。另一方面,由于位置数字始终是根据主数字序列变化的,因此不管y坐标是什么,所述差分数字都是相同的,其中在整个位置编码图案中,所述主数字序列将会在列中周期性地重复。
相应地,y比特矩阵中的六个行在主数字序列中定义了六个位置数字。这六个位置数字定义了五个差分数字,这些差分数字构成了差分数字序列的一个局部序列并且由此在y轴上具有无歧义确定的位置。
在使用位置编码图案的时候,位置编码图案中不同部分的图像是如上记录的。通常,图像包含的符号明显多于6*6个。事实上,解码通常是以图像中最好的8*8个符号为基础的。其中尤其将附加符号用于检错和/或纠错,在附录A和B中对此进行了更详细的描述。
由于位置编码图案并没有始终在表面上得到完美再现,并且由于用户单元有时会在成像过程中导致位置编码图案失真,因此要相当可靠地确定点的位移将是非常困难的,由此很难确定符号的值。因此在一个实际的实施例中改为确定每个符号采用四个不同的可能数值的概率。由此将成像的局部区域解码到一个矩阵中,所述矩阵具有矩阵中各个矩阵元素的四个概率值,其中每个矩阵元素对应于一个符号。这个矩阵转而可以分成两个矩阵,一个对应于x坐标,另一个对应于y坐标。其中每一个矩阵中都包含了矩阵中每个矩阵元素的两个概率值。其中一个概率值对应于矩阵元素具有值“1”的概率,另一个则对应于矩阵元素具有值“0”的概率。对于位置编码图案中各个图像的处理由此导致产生了两个概率值矩阵Px和Py。参考图10~19,在附录B中更详细地描述了如何确定这些矩阵。其中特别要求在国际专利申请PCT/SE02/01246中保护附录B的内容,在提交当前申请的时候,所述申请并未公开。
下文中参考图20中的流程图来对基于上述Anoto位置编码图案的位置解码进行描述。优选地,所述位置解码借助一个处理器和适当的程序代码来执行,其中所述处理器和程序代码可以存在于图1的用户单元2或外部单元3中,也可以存在于某些其他单元中。
针对程序代码的输入信号包含了以上两个概率值矩阵Px和Py(与图18的矩阵34和35相对应),由此所述矩阵分别涉及的是x坐标和y坐标。根据这些概率矩阵,在步骤1800中,对一个x位置和一个y位置进行计算。在附录A和B中更详细地描述了如何执行这个计算。简要的说,就是为矩阵Px和Py中的每一个矩阵确定各行和各列中的比特序列在主数字序列中具有的最有可能的位置。根据由此确定的位置或位置数字(在附录B中也称为“序列值”),分别为x和y方向确定差分数字。所述差分数字分别为x方向和y方向形成了差分数字序列中的一个局部序列。在差分数字序列中,每个局部序列都具有一个无歧义确定的位置。所述位置可以用附录A中描述的方式来确定。x数字序列的位置确定了x坐标,而y数字序列的位置则确定了y坐标。
所述坐标计算可以产生三种情况。其中一种是这两个坐标的计算取得成功,即1801,另一种则是其中一个坐标的计算取得成功,但是其他坐标的计算失败,也就是1802,还有一种情况是所有坐标的计算都失败,即1803。
如果在所述坐标计算过程中没有检测到差错,则认为所述计算取得成功,并且在步骤1804中将其保存为一个接受的位置。然后如果没有对所述位置进行其他检查,则滤去所有与成像局部区域有关的其他信息。
如果针对某个坐标的计算失败,则保存这个坐标的信息,以便在匹配中加以使用,同时在步骤1805,如果没有对所述位置进行其他检查,则保存那些成功计算的坐标的信息并且滤去相关信息。
如果关于这两个坐标的计算都是失败的,那么毫无疑问,在步骤1806中将会保存这两个坐标的信息。
保存的信息可以是位置计算所基于的全部信息,即一个或多个概率值矩阵Px和/或Py,此外所述信息也可以是或多或少进行过处理的形式的信息。举例来说,可以计算和保存各个列采用每个可能位置数字的概率值。举例来说,作为选择,也可以只保存位置数字最可能的组合,或者将其与相关的概率保存在一起。此外还可以保存上述信息的不同组合或子集。
所述匹配可以立即进行,也可以在稍后对更多位置进行了解码的时候进行。
现在假设针对x的计算取得了成功,但是y坐标的解码则是失败的。x坐标是在具有用于y坐标矩阵中的行定义的所有可能位置数字的概率值的时候得到保存的。
在执行匹配的时候,首先在步骤1807中确定将要匹配的区域。在这种情况下,x坐标是已知的,因此所述匹配只需要沿着y轴进行。沿着y轴的范围可以根据先前与随后接受的y坐标来加以确定。
然后执行的是实际匹配。由于x坐标是已知的,因此对匹配区域中的每个y坐标来说,y坐标对应的位置数字是已知的。在步骤1808,从存储器中读取为这些位置数字保存的概率,并且将组合概率作为与所论述位置数字的概率产物来加以计算。在为匹配区域中的所有y坐标计算了组合概率的时候,在步骤1809中将会选择得到最大组合概率的y坐标。在步骤1810中,将先前保存的x坐标和选定的y坐标作为一个已接受的位置来加以保存,如果不对所述位置进行其他检查,则滤去所有那些为匹配保存的信息。
在一个替换实施例中,只有最有可能用于每一行的位置数字才会得到保存。在这种情况下将会比较用于各个y坐标的相应位置数字的数目。在这里将会选择为最大数量的相应位置数字所获取的y坐标。这个实施例的优点是保存的信息量将会更小。另一方面,就y方向上的位置而言,这将产生一个成像局部区域符合匹配局部区域的更粗略的概率量度。
而在另一个替换实施例中,除了最有可能的位置数字之外,还保存了关于这些位置的概率。然后可以基于相应的位置数字、这些位置的组合概率以及非对应位置数字的组合概率来选择最可能的y坐标。
在步骤1803,举例来说,如果针对这两个坐标的位置计算全都失败,则保存y坐标矩阵Py中每个行的最可能位置数字以及x坐标矩阵Px中每个列的最可能位置数字。
所述匹配每次只为一个坐标执行。假设所述匹配始于x坐标。在步骤1811,首先将匹配区域确定成一个沿着x轴的范围。所述区域的大小可以根据如上所述的相同参数来加以确定。随后在步骤1812中执行实际匹配。
由于y坐标在这个实例中并非已知,因此不同的x坐标对应的位置数字也不是已知的,只有差分数字才是已知的。在这里,一种可能的匹配策略是计算存储位置数字之间的差分并且将这些差分与匹配区域中不同x坐标的差分相匹配。然而由于错误的位置数字会导致两个错误的差分,因此这种策略并不是一种最佳策略。
另一种可能的解决方案是测试位置数字的所有可能组合,其中所述组合为匹配的x坐标产生了差分数字。对每一个匹配差分数字的位置数字组合来说,所述位置数字的概率值将被选择并且相乘。此外还确定了取得最高概率值的x坐标。这种解决方案能够很好的运作,但是需要大量计算,由此花费了很长时间。此外,它还需要存取所有位置数字的概率值。
为了优化匹配,所述匹配可以改为借助一种算法来执行,所述算法根据所匹配的x坐标的差分数字来计算对应于至少一个后续位置数字的位置数字的数目,其中将位置数字视为是从右到左。
假设已经从成像局部区域中确定了8个可以访问的位置P0到P7。这些位置与七个差分数字s0~s6相匹配,其中所述差分数字构成了差分数字的局部序列,所述局部序列对与来自成像局部区域的信息相匹配的x坐标进行编码。所述差分数字则可以通过组合已知的位置编码图案来加以确定。
因此,所述算法是如下运作:
Numbermatch=0
For k=6 down to 0
For i=0 down to 6-k
If Pk+i+1-pk=sum(j=k:k+i)(sj)
Numbermatch=Numbermatch+l;
Interrupt innerm ost loop;
End
End
End
在执行了算法的时候,变量Numbermatch包含了位置数字的数目,依照差分数字局部序列中的差分,这些数字对应于至少一个后续的位置数字。
在执行了所有匹配的时候将会选择Numbermatch最大的x坐标。所述坐标是作为一个成功坐标来保存的。此外,现在很容易确定x坐标的位置数字,以便在以下将要论述的可能进行的后续验证步骤中使用。
现在借助实例来描述以上算法。假设已经成像了一个局部区域,所述局部区域包括为x坐标产生位置数字的后续局部序列P的符号。这些位置数字定义了差分数字的一个局部序列D。进一步假设没有正确成像局部区域并且已经根据来自成像局部区域的信息而在位置计算中得到了错误的局部序列P*。最终假设主数字序列长为63比特,这意味着位置数字之间的差分是63为模来进行计算的,其中所述位置数字表示主数字序列中的位置。
P= 23 12 54 43 7 18 11 35
D= 52 42 52 27 11 56 24
P*=23 55 54 43 7 42 11 35
这样一来,错误解码的是第一个(55,也就是P*中左起第二位置数字)和第五个(42,也就是P*中左起第六个位置数字)位置数字。在这个实例中,上述算法是如下运作的:
Numbermatch=0
P6:
(35-11)mod63=24.P6matched.Numbermatch=1
P5:
(11-42)mod63=32(should be 56)No match
(35-42)mod63=56(should have been 17=
(56+24)mod63.No match.P5not matched.
P4:
(42-7)mod63=35(should have been 11)No match.
(11-7)mod63=4=(11+56)mod63.P4matched.
Numbermatch=2
P3:
(7-43)mod63=27.P3matched.Numbermatch=3
P2:
(43-54)mod63=52.P2matched.Numbermatch=4
P1:
(54-55)mod36=62(should have been 42)No match.
(43-55)mod63=51(should have been 31=(42+52)mod63.
No match.
(7-55)mod63=15(should have been
58=(42+52+27)mod63.No match.
(42-55)mod63=50(should have been
6=(42+52+27+11)mod63.No match.
(11-55)mod63=19(should have been
62=(42+52+27+11+56)mod63.No match.
(35-55)mod63=43(should have been 23)=
(42+52+27+11+56+24)mod63.No match.
P1 not matched.
P0:
(55-23)mod63=32(should have been 52).No match.
(54-23)mod63=31=(52+42)mod63.P0matched.
Numbermatch=5
所述算法由此得出一个事实,那就是根据差分数字局部序列中的差分,有五个位置数字与至少一个后续位置数字相一致。相应位置数字的数目则用作了匹配概率的一个量度。
如果关于两个位置坐标的位置计算全都失败,那么毫无疑问,上述匹配x坐标的实例同样能在所述计算始于y坐标而不是x坐标的时候发挥作用。
在通过匹配确定了第一坐标的时候,可以使用与如上所述只有一个坐标的位置计算失败的情况相同的方法来确定第二坐标,也可以使用与用于两个失败计算中的第一坐标的情况相同的方式来确定第二坐标。
上述算法可以通过同时评估若干种匹配以及更有效处理差分数字之和来进行优化。因此,所述算法如下所示,其中关于每个匹配的ssi都等于sum(s0,......,si)。
对各个匹配来说
For k=0 to 6
For i=0 to 6-k
dp=Pk+i+1-Pk
If dp=ssi
Numbermatchk=Numbermatchk+1
Interrupt innermost loops;
End
End
End
Check whether Numbermatch0 is the greatest so far,in that
case save value of Numbermatch0 and he corresponding x
ccordinate.
For j=0 to 5
Numbermatchi=Numbermatchi+1
End
Numbermatch6=0
d=the next preceding difference number in the difference
number sequence.
For j=6 to 1
ssj=ssj-1+d
End
ss0=d
End
非常有利的是,所述匹配可以用一个验证步骤即步骤1815来终止,该步骤在图20中由虚线表示。实际上,由于匹配算法总是发现一个与先前已接受位置接近的位置,因此将会存在增加差错的风险。这意味着不可能通过查看从已接受位置开始的距离来评定所匹配的位置是否正确。所述验证步骤可以包括借助成像局部区域中可用的全部信息来为获取的位置计算概率。通常在这个步骤中包含了比位置计算中使用的8*8个符号多出很多的符号。举例来说,所述操作可以包括16*16个符号。对其中每个符号来说,在这里已经为符号可以采用的每个值都确定了一个概率值(在附录B中也将其称为值概率)。当借助最好8*8区域确定一个坐标对时,这些8*8符号的值是已知的,因此,分别处于相应的8*8比特的x和y比特矩阵中的列和行的比特也是已知的。由于列和行组成了二进制循环主数字序列的局部序列,因此在知道差分数字序列的情况下确定的是如何在更大的16*16区域中延伸列和行。然后则可以借助16*16区域中的比特的概率值来计算整个16*16区域的概率度量并且将其与一个门限值进行比较,以便确定对于最终要接受的解码位置而言,所述16*16区域的总概率是否足够大。
在图21的框图中概述了整个方法。首先执行一个位置计算1901。如果这个计算成功,则位置继续进行验证1902。如果所述验证成功,则接受所述位置。如果位置计算失败,则执行一个匹配1903。即使对一个位置计算成功的位置来说,如果验证失败,那么也将会执行这个处理。而所述匹配则始终产生一个位置。这个处理进行到验证1902。如果为通过匹配获取的位置所进行的验证取得成功,则接受这个位置,否则位置解码失败,并且不为成像的局部区域记录位置。在位置计算取得成功的特定范例中,如果随后立即进行的验证与匹配之后的验证一样是失败的,但是计算得到位置与所匹配的位置是相等的,那么仍然可以接受所述位置。
为了进行位置解码,可以使用不同类型的设备来读取和解码位置编码图案。这种设备可以具有一个用于产生位置编码图案的数字表示的传感器和一个用于在数字表示中识别位置编码图案并且解码所述图案的信号处理单元。所述信号处理单元可以包括一个带有存储器和适当程序的处理器,也可以包括特定的硬件,此外还可以包括数字和/或模拟电路或者这些设备的适当组合。
所述传感器可以是适合对位置编码图案进行成像的任何类型的传感器,因此所述标记的一个图像是以黑白、灰度或彩色形式获取的。所述传感器可以是固态的单芯片或多芯片设备,它对任何适当波长范围中的电磁辐射都很敏感。例如,所述传感器可以包括一个CCD部件(电荷耦合器件)、CMOS部件(互补金属氧化物半导体)或CID部件(电荷注入器件)。作为选择,所述传感器可以包括一个用于检测所述标记的一个磁性性质的磁传感器阵列。更进一步,在这里可以对所述传感器进行设计,以便形成所述标记的任何一种化学、声学、电容或电感性质的图像。
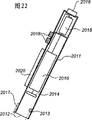
在图22中显示了用于位置解码的设备的一个实例。所述设备可以构成图1中的用户单元。它包括一个与笔具有大致相同的形状的外壳2011。在外壳短的一端具有开口2012。短的一端紧靠表面或者与之保持一个很短距离,其中位置测定是在所述表面上执行的。
所述外壳实质上包括一个光学部分、一个电子线路部分和一个电源。
光学部分包括一个用于照射将要成像的表面的发光二极管2013,并且包括一个用于记录二维图像的感光区域传感器2014,例如CCD或CMOS传感器。可选的,所述设备还可以包括一个光学系统,例如镜子和/或透镜系统。发光二极管可以是一个红外线发射二极管并且传感器可以感知红外线。
设备的电源是从电池2015获得的,所述电池安装在外壳中的分离隔间。此外也可以经由电缆而从外部电源(未显示)获取电源。
电子线路部分包括一个处理器单元2016,所述处理器单元具有经过编程而读取来自传感器的图像并且根据这些图像执行位置计算、匹配和验证的处理器,此外所述电子线路部分还包括一个工作存储器和一个程序存储器。
在这个实施例中,所述设备还包括一个笔尖2017,借助于此,可以在将要执行位置确定的表面上执行基于普通颜料的书写。笔尖2017可以是可扩展和可伸缩的,由此用户可以控制是否对其进行使用。但在某些应用中,所述设备根本不需要具有笔尖。
基于颜料的书写具有一种类型,该类型对红外线而言是透明的,并且所述标记会适当吸收红外线。通过使用发出红外线的发光二极管以及对红外线敏感的传感器,可以在不受到上述与图案在一起的写入干扰的情况下执行图案检测。
所述设备还可以包括按钮2018,并且可以借助于此来激活和控制设备。并且该设备还具有一个收发信机2019,以便进行往返于设备的信息的无线传输,例如使用红外线,无线电波或超声。该设备还可以包括一个用于显示位置或记录信息的显示器2020。
所述设备可以在不同的物理外壳之间分开,其中用于捕获位置编码图案的图像以及将上述信息发送到第二外壳所需的传感器和其它组件位于第一外壳中,而用于执行位置解码所需的信号处理单元和其它组件则位于第二外壳中。
附录A
位置码被用于对一个或多个维度中的位置进行编码。为了简化描述,首先设想所述位置码位于第一维度,在这个实例中,第一维度处于x方向。在这个方向上使用了一个循环主数字序列来进行编码,所述循环主数字序列具有在循环主数字序列中无歧义确定预定长度的各个局部序列位置的特性。在这个实例中,预定长度是6。因此,如果从循环主数字序列中的任何位置提取六个连续的数字,那么这六个数字在主数字序列中只以这个顺序出现一次。如果主数字序列的末端连接到主数字序列的开端,那么这种特性同样适用。由此将主数字序列称为是周期性的。在这个实例中,使用了二进制的主数字序列。如果要无歧义确定具有六个数字的局部序列位置,那么主数字序列由此具有26=64的最大长度,并且在主数字序列中,长度为6的局部序列可以具有位置0-63。然而如下文将要描述的那样,如果选择了长度为63的主数字序列,则可以得到改进的纠错特性。由此在下文中采用主数字序列的长度是63并且由此定义了范围0-62中的唯一位置。实践中,在具有这个长度的主数字序列的情况下,有可能具有一个将各个局部序列转换成主数字序列中的位置的表,反之亦然。
假设主数字序列开端如下所示:
0,0,0,0,0,0,1,0,0,1,1,1,1,1,0,1,0...
然后,例如在主数字序列中,局部序列0,0,0,0,0,0具有无歧义位置0,局部序列1,1,1,1,1,0具有无歧义位置9,局部序列1,1,1,0,1,0具有无歧义位置11。
位置编码基于使用循环主数字序列的不同旋转或循环移位。为了在x方向对位置进行编码,在穿越表面的列中以某些其他方法打印或排列主数字序列,以多种方式对其进行旋转或循环移位,其中所述列处在y方向上,该方向正交于对位置进行编码的方向。可以在同一列中重复打印出主数字序列,如果在y方向编码的位置比对应于主数字序列长度的位置更多,那么这个操作将是必需的。然后则使用主数字序列的相同旋转来进行所有重复。然而也可以在不同的列中使用不同的旋转。
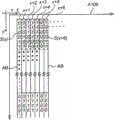
图4示意性显示了一张具有7个列x~x+6的纸A100。在主数字序列的不同旋转中,仅仅打印出了第一数字。整个主数字序列由方框AB做出示意性标记。另外在图4中,在每一列中,具有六个数字的第一局部序列S是用虚线绘制的方框来进行标记的。如上所述,在主数字序列中,每一个局部序列S都具有一个无歧义确定的位置。
每一对相邻的列都定义了一个差分数字(difference number)d。差分数字d是由各个列中第一局部序列的主数字序列位置之间的差分给出的。作为替换,如果在所述列中向下一步的局部序列位置之间选取差分,由于使用相同方式来移动所述位置,因此结果将会是相同的。这样一来,不管在列中以何种“高度”比较主数字序列中的局部序列位置,差分数字d都是相同的。因此,对每一对列来说,差分数字d在y方向上都是常数。
在列x+5中,主数字序列的第一局部序列是0,0,0,0,0,0,它对应的是主数字序列中的位置0。在列x+6中,主数字序列的第一局部序列是1,0,0,0,1,1,它对应了主数字序列中的位置57。因此,这些列中的差分或循环移位是57,所以d(x+5)=57。应该指出的是,所述差分数字是以主数字序列长度为模来确定的。
可以用这种方式编码的差分数字处于范围0~K-1,其中K是主数字序列的长度,在本范例中K=63,借助于此,有可能对范围0~62中的差分数字进行编码。通过选择主数字序列的不同旋转,有可能创建一个差分数字序列,下文中将其称为基本数字序列或基本差分数字序列,所述序列具有这样一种特性,即预定长度的各个局部序列在基本数字序列中都具有无歧义确定的位置。在本实例中,预定长度是5。由于包含5个差分数字的各个局部序列在基本差分数字序列中都具有一个无歧义确定的位置,因此可以将其用于在x方向对位置进行编码。因此,在图4中,局部序列S(x)~S(x+5)对五个差分数字d(x)~d(x+4)进行编码,这些差分数字指定了基本数字序列的一个局部序列。
并且应该指出,在实践中通常不会将局部序列与其确切值一起打印出来,而是将其与一个图形编码一起打印。
主数字序列的二进制数字的列构成了一个矩阵,下文中将其称为x矩阵。
如果主数字序列长度为K,那么基本差分数字序列中的基数等于K,并且其最大长度是K5,在本范例中则是635。然而在实践中,对如此大的基数而言,使用一个表来把局部序列转换成基本差分数字序列中的局部序列,这种处理并不是切实可行的,反之亦然。但是,如果为了能够使用可管理表格而减小基数,则会减少可以编码的位置数目。
这个问题是通过构造更短的差分数字序列的基本差分数字序列来解决的,在下文中将其称为辅助差分数字序列或辅助数字序列,对辅助差分数字序列而言,在对位置码进行编码和解码的时候,通过使用这种辅助差分数字序列,可以在更小的表格中排列局部序列及其位置,以便在基本差分数字序列中确定与特定x坐标相对应的局部序列,反之亦然。
可以如下确定辅助差分数字序列:
首先,只允许差分数字处于这样一个范围,其中不同差分数字的数目可以分解成至少两个因数。在长度为63的基本数字序列的实例中,只允许差分数字处在一个长度为54的范围以内。实际上,数字54可以分解成2*3*3*3。作为选择,也可以选择60个差分数字,也就是5*3*2*2个差分数字,然而为使表格尽可能小,因此选择那些给出尽可能小的因数的数字将是非常有利的。
其次,形成了数目与不同差分数字可以分解的因数数目相同的辅助差分数字序列。因此在这个实例中,辅助差分数字序列的数目等于四。
另外,我们让每个因数在其相应的辅助差分数字序列中形成一个基数。在这个实例中,我们由此得到一个基数为2的辅助差分数字序列以及基数为3的三个辅助差分数字序列。
因此,如果辅助差分数字序列还具有如下特性,即长度为5的局部序列在辅助差分数字序列中具有唯一位置,那么,辅助差分数字序列的最大长度分别是32和243。在具有这种长度的辅助差分数字序列的情况下,实践中可以将局部序列转换成位置,反之亦然。作为替换,如果我们选择使用60个差分数字,那么我们将会得到一个基数为5并且由此最大长度是3125的辅助差分数字序列,这就给出了一个表,所述表占用了大得多的存储器,但仍旧是可以管理的。
最后,对辅助差分数字序列的长度进行选择,以使所述长度成对互质。这意味着对每对辅助差分数字序列而言,一个差分数字序列长度不会与第二差分数字序列长度具有任何相同的因数。另外,这还意味着如果重复每一个差分数字序列,那么,在经过L=l1*l2*......*lm个位置之前,不会从各个辅助差分数字序列中产生相同的局部序列组合。其中l1是辅助差分数字序列1的长度,l2是辅助差分数字序列2的长度,依此类推直到lm,它是最后一个辅助差分数字序列的长度。当然,如果只有两个辅助数字序列,那么L=l1*l2。
图5示意性地描述了这个操作。在顶端显示了基本数字序列PD,所述序列在一个具有差分数字的长序列中行进,在这里,所述差分数字由x表示。在下方示意性显示了辅助数字序列A1~A4。竖线显示了数字序列开始的位置。而基本数字序列的局部序列以及辅助数字序列的相应局部序列则是由虚线表示的。可以看出,局部序列对应于辅助数字序列中的不同位置。
在这个实例中,通过组合辅助差分数字序列的局部序列而显示的基本差分数字序列的局部序列是双射的。然而这并不是必需的。
在这种情况下,在y方向这种第二维度上的位置编码可以根据等同于第一维度中的位置编码的规则来执行。然后在所述表面上,通过不同的循环移位而在行中排列主数字序列,所述行即为图4的x方向。差分数字是在相邻的行之间定义的,这些差分数字形成一个基本差分数字序列,该序列可以由辅助差分数字序列构造。在第二维度中也可以使用另一个主数字序列、另一个基本差分数字序列以及其他辅助差分数字序列。不同数字序列中的基数也可以不同于第一维度中的编码所使用的基数。然而在这个实例中,在x方向和y方向上使用了相同序列。在一种与x方向上的编码相对应的方式中,y方向上的编码产生一个矩阵,在这个矩阵中,行的值包含了主数字序列的二进制数值。
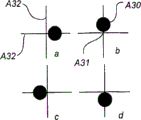
如果重叠x矩阵和y矩阵,对于合成的xy矩阵中的各个点而言,将会具有一个来自x矩阵的二进制数字和一个来自y矩阵的二进制数字。由此可以在各个点获取下面这四个二进制数字组合:0,0;0,1;1,0;和1,1。举例来说,在一个表面上,可以使用图6a~d中显示的方法来对这些不同组合进行图形编码,其中点A30在四个方向中的任何一个方向上从光栅中的标称点A31开始移动,各个标称点对应于光栅中的线条A32之间的交点。WO01/26033中更详细地描述了这种类型的图形编码,然而,实际的基础(underlying)位置编码是以一种不同方式实施的。本实例中使用的编码则如下所示:
|
数值 |
位移 |
二进制数字对 |
|
1 |
右 |
0,1 |
|
2 |
上 |
0,0 |
|
3 |
左 |
1,0 |
|
4 |
下 |
1,1 |
所述光栅矩阵可以是虚拟的,在这种情况下,不会将其与位置码一起明确打印在表面上。
图7示意性地显示了采用了以具有位置码410的纸张400为形式的产品的一部分。应该强调的是,举例来说,图7中的位置码相对于适合例如数字化字迹的版本有了极大增加。另外,光栅420是在图7中标记的。然而,通常并不将所述光栅打印出来。
当然,对这四对二进制数字而言,也可以选择其它类型的图形编码,例如不同大小的四个点,具有不同形状的四个标记或是具有不同旋度的四个标记。
由于位置编码基于主数字序列中不同的局部序列位置之间的差分,并且可以使用不同的局部序列对来得到相同差分,因此可以使用多种方式获取基本差分数字序列。更具体地说,根据选择哪一个局部序列来启动x矩阵中的第一列(x=0)和y矩阵的第一行(y=0),可以得到63个不同“版本”的基本差分数字序列,其中选择局部序列即为选择主数字序列的旋度。由此可以产生K*K(在这个实例中是63*63=3969)个不同“版本”的位置码,这些位置码使用相同的基本差分数字序列来进行x方向和y方向的编码。在下文中,位置码的这些不同版本称为分段。用于x方向的位置码的段编号xs以及用于y方向的位置码的段编号ys可以分别指定成x方向和y方向的附加坐标。
在以上实例中,仅仅使用了在理论上可以使用主数字序列进行编码的差分数字的一个子集,更具体地说,只用到了63个可能差分数字中的54个。理论上可行的差分数字的局部范围可以用多种方式来加以选择。在这个实例中,接近0(以基本数字序列长度为模)的差分数字可能在位置码中产生不必要的规律性。因此在这个实例中,差分数字是在范围(5,58)中选择的。这必须结合基本数字序列中的局部序列与辅助数字序列中的局部序列之间的换算来加以考虑,下文将会对此进行描述。
现在假设位置码排列在一个表面上。读取设备可以具有一个区域传感器,所述传感器检测与至少6*6个点相对应的位置码子集。当读出位置码的时候,可以使用多种方式而使读取设备相对所述位置码而保持旋转。位置码图像本身不会显示位置码与读取设备之间的旋度,因为无论它是否旋转了0、90、180还是270度,位置码大体看来都是一样的。然而,在旋转位置码的时候将会改变各个点的位移方向,这转而导致改变了那些通过点的位移而被编码的二进制数字对。所述变化如何出现则依赖于位移与二进制数字对之间的换算。在下文中,假设所述换算是如上进行的。则其中存在三种不同的情况:
1)在位置码图像旋转了180度的情况下,当试图基于图像来解码所述位置时,向后读取周期性主序列,所述主序列对处于未旋转位置码的x和y位置进行编码。在如上所述将位移与二进制数字对相结合的情况下,由于倒转读取位置码,因此将会反转所解码的二进制数字。
2)在顺时针旋转90度的情况下,在试图解码旋转矩阵中的y位置的时候,将会后向读取一个对无旋转矩阵中x位置进行编码的二进制数字序列,并且将会倒转所述二进制数字。
3)在顺时针旋转270度的情况下,在试图解码旋转矩阵中的x位置的时候,将会后向读取一个对无旋转矩阵中y位置进行编码的二进制数字序列,并且将会倒转所述二进制数字。
这意味着如果在右上方的无旋转矩阵中的局部序列从未在循环主数字序列中出现倒转和反向,则可以检测到90、180和270度的旋转。如果为主数字序列满足这个条件,则意味着将会显著减小其长度,这转而意味着只能对更少的位置进行编码。
为了解决这个问题,取而代之的是,我们为循环主数字序列的更长局部序列满足所述条件。这意味着必须读出比实际位置测定所需序列更长的局部序列。在某些情况下,这种更长局部序列在读出过程中就已经可用。如果对位置坐标进行编码的位置码的最小子集是二次的,与在这个实例中的情况一样,则总是必须读出一部分位置码,这部分位置码很大,并且包括整个最小子集,即使是在相对于位置码而把读取设备旋转了45度的时候。因此,始终会包含至少一个比位置确定所需序列更长的局部序列。这在图8中得到了描述,其中每个正方形50对应于一个点,而涂成灰色的正方形则说明,始终可以读出具有两个额外点的至少一行和一列。
在用于位置确定的主数字序列的局部序列长度为6的当前实例中,可以使用长度为8的局部序列来检测旋转。因此,这些八位的局部序列必须具有不会在主数字序列中出现反向和反转的特性。对一个64位的长主数字序列而言,这一点是无法实现的,这也就是转而将长度改选为63的原因。
在上述两种旋转即90和279度的旋转中,将会读出一个沿正确路线旋转的序列和一个沿错误路线旋转的序列。在使用用于旋转检测的上述方法的情况下,只会在这两个读出方向(x和y)中的第一个方向检测到一个旋转误差。在第二个读出方向上则会看到对正确旋转图像的第一读取方向上的位置进行编码的旋转移位。
在顺时针旋转90度的情况下,当在x方向进行解码的时候,将会看到对正确旋转图像的y坐标进行编码的循环移位。因此,所看到的是y方向的基本差分数字序列的局部序列,但是所述序列沿着错误路线旋转(从右到左而不是从左到右,这是x方向的基本差分数字序列的局部序列的情况)。
在相应的路线上可以看到,当在y方向进行解码的时候,如果旋转了270度,那么x方向的基本差分数字序列的局部序列沿着错误路线旋转。
局部序列沿着错误路线旋转的原因是由于x和y方向的基本差分数字序列的相对定位。从总的位置编码图案边缘开始,x方向的基本差分数字序列是在顺时针方向运转的,而y方向的基本差分数字序列则是在逆时针方向运转的。如果它们在相同方向运转,那么在上述情况中,它们不会沿着错误路线旋转,而是会沿着正确路线旋转。
在相反方向运转基本差分数字序列则具有很多优点。在这些情况中可以看到,基本差分数字序列的局部序列沿着正确路线旋转并且对“正确”坐标进行解码,但却是在错误方向上。这个坐标不但符合从解码所需基本差分数字序列开始的六个循环移位,而且周围的移位证明所解码的坐标是正确的。在基本差分数字序列沿着相反方向运转的情况下,也对来自基本差分数字序列的六个循环移位进行解码,但却是以错误顺序进行的,由此导致产生一个坐标,从统计上讲,这个坐标不会符合错误旋转的基本差分数字序列的周围部分。这个事实导致产生更好的检错概率。
另一个优点则在于,如果基本差分数字序列沿着相反方向行进,那么连续错误即解码到相邻位置的多个连续图像的错误将会更少。更为特殊的是,在一个基本差分数字序列中沿着错误路线旋转的不同相邻组的六个循环移位并不有助于对相邻坐标进行编码。在那些错误坐标范围很大的地方,连续错误要比其他错误更加难以检测。
与用于检测旋转的原理相同的基本原理也可以用于纠错。例如,可以使用如下方式来选择主数字序列,其中不会在比位置确定所需序列更长的某些预定长度的局部序列中出现一个二进制数字的反转。如果确信可以在这种更长的局部序列中检测到除一之外的所有二进制数字,则可以纠正错误位。
位置码的检错和纠错特性可以通过智能选择主数字序列而得到显著改善。更进一步的提高则可以通过选择辅助差分数字序列来实现。
在以上实例中,已经使用以下方法选择了主数字序列和辅助差分数字序列。
主数字序列M:
0,0,0,0,0,0,1,0,0,1,1,1,1,1,0,1,0,0,1,0,0,0,0,1,1,1,0,1,1,1,0,0,1,0,1,0,1,0,0,0,1,0,1,1,0,1,1,0,0,1,1,0,1,0,1,1,1,1,0,0,0,1,1
辅助差分数字序列:
A1=0,0,0,0,0,1,0,0,0,0,2,0,1,0,0,1,0,1,0,0,2,0,0,0,1,1,0,0,0,1,2,0,0,1,0,2,0,0,2,0,2,0,1,1,0,1,0,1,1,0,2,0,1,2,0,1,0,1,2,0,2,1,0,0,1,1,1,0,1,1,1,1,0,2,1,0,1,0,2,1,1,0,0,1,2,1,0,1,1,2,0,0,0,2,1,0,2,0,2,1,1,1,0,0,2,1,2,0,1,1,1,2,0,2,0,0,1,1,2,1,0,0,0,2,2,0,1,0,2,2,0,0,1,2,2,0,2,0,2,2,1,0,1,2,1,2,1,0,2,1,2,1,1,0,2,2,1,2,1,2,0,2,2,0,2,2,2,0,1,1,2,2,1,1,0,1,2,2,2,2,1,2,0,0,2,2,1,1,2,1,2,2,1,0,2,2,2,2,2,0,2,1,2,2,2,1,1,1,2,1,1,2,0,1,2,2,1,2,2,0,1,2,1,1,1,1,2,2,2,0,0,2,1,1,2,2
A2=0,0,0,0,0,1,0,0,0,0,2,0,1,0,0,1,0,1,0,1,1,0,0,0,1,1,1,1,0,0,1,1,0,1,0,0,2,0,0,0,1,2,0,1,0,1,2,1,0,0,0,2,1,1,1,0,1,1,1,0,2,1,0,0,1,2,1,2,1,0,1,0,2,0,1,1,0,2,0,0,1,0,2,1,2,0,0,0,2,2,0,0,1,1,2,0,2,0,0,2,0,2,0,1,2,0,0,2,2,1,1,0,0,2,1,0,1,1,2,1,0,2,0,2,2,1,0,0,2,2,2,1,0,1,2,2,0,0,2,1,2,2,1,1,1,1,1,2,0,0,1,2,2,1,2,0,1,1,1,2,1,1,2,0,1,2,1,1,1,2,2,0,2,2,0,1,1,2,2,2,2,1,2,1,2,2,0,1,2,2,2,0,2,0,2,1,1,2,2,1,0,2,2,0,2,1,0,2,1,1,0,2,2,2,2,0,1,0,2,2,1,2,2,2,1,1,2,1,2,0,2,2,2,
A3=0,0,0,0,0,1,0,0,1,1,0,0,0,1,1,1,1,0,0,1,0,1,0,1,1,0,1,1,1,0,1,
A4=0,0,0,0,0,1,0,2,0,0,0,0,2,0,0,2,0,1,0,0,0,1,1,2,0,0,0,1,2,0,0,2,1,0,0,0,2,1,1,2,0,1,0,1,0,0,1,2,1,0,0,1,0,0,2,2,0,0,0,2,2,1,0,2,0,1,1,0,0,1,1,1,0,1,0,1,1,0,1,2,0,1,1,1,1,0,0,2,0,2,0,1,2,0,2,2,0,1,0,2,1,0,1,2,1,1,0,1,1,1,2,2,0,0,1,0,1,2,2,2,0,0,2,2,2,0,1,2,1,2,0,2,0,0,1,2,2,0,1,1,2,1,0,2,1,1,0,2,0,2,1,2,0,0,1,1,0,2,1,2,1,0,1,0,2,2,0,2,1,0,2,2,1,1,1,2,0,2,1,1,1,0,2,2,2,2,0,2,0,2,2,1,2,1,1,1,1,2,1,2,1,2,2,2,1,0,0,2,1,2,2,1,0,1,1,2,2,1,1,2,1,2,2,2,2,1,2,0,1,2,2,1,2,2,0,2,2,2,1,1。
辅助差分数字序列具有以下特殊的纠错特性:
假设正好只有一个主数字序列的局部序列没有得到正确解码,并且这将导致主数字序列中错误位置的解码。由于各个位置都被用于计算两个相邻的差分数字,因此这些差分数字都会受到不正确解码的影响。如果任何一个差分数字超出了所用差分数字范围(5,58),则会立即检测到所述错误。然而,如果并非如此,那么,在由基本差分数字序列的局部序列所产生的四个辅助差分数字序列的局部序列组合中,在两个相邻位置之间会有至少一个局部序列失真。由于这两个第一辅助差分数字序列A1和A2都具有基数3并且未曾使用的差分数字数目是9=3*3,因此这两个序列中的任何一个序列的失真都具有如下特性,那就是这两个受影响数字的总和始终具有以3为模的相同的值。两个辅助数字序列A1和A2则具有如下特性,即,对长度为7的各个局部序列而言,在辅助数字序列中只会发现单个错误位置解码所产生的14个可能的局部序列失真中的至多一个。另外,第三辅助数字序列A3还具有如下特性,对长度为7的各个局部序列而言,在辅助数字序列中将会发现由单个错误位置解码所产生的13个可能的局部序列失真中的至多一个。而对于28个可能失真中的7个失真而言,第四辅助数字序列A4也具有相同的特性。因此,所检测的主数字序列的局部序列的单个错误解码概率是非常大的。
结合选定的序列,在一个分段的各个维度上,可以对总共410815348个不同位置进行编码。如所述,不同分段的数目可以是632。因此,可以编码的位置总数是632*4108153482=6.7*1020个位置。
如果每个位置都与一个0.3*0.3mm2的表面相对应,那么这相当于能够在六千万平方公里的表面上编码的唯一位置。从理论上讲,可以借助位置码来对这个由所有唯一点构成的表面进行编码,并且可以将这个表面称为虚表面(imaginary surface)。因此,由位置码编码的坐标是虚表面上的点的绝对坐标。一部分位置码可以应用在一个物理基底或表面上。然后,所述位置码对这个基底上的位置进行编码。然而,通常并没有将所述坐标设计成物理基底上的位置的绝对坐标,而是将其设计成虚表面上的点的坐标。
位置解码的实际范例
可以在一个解码设备中对位置码进行解码,所述解码设备可以包括一个用于读出位置码的传感器和一个某种恰当类型的处理器单元。所述处理器单元包括实际处理器、工作存储器和程序存储器,其中保存了具有对所述位置码进行解码的指令的计算机程序。处理器单元可以引入到一个典型的个人计算机之中,也可以引入手持读取设备或其他一些合适的设备之中。作为选择,解码设备可以通过专用硬件来实现,例如ASIC(专用集成电路)、FPGA(现场可编程门阵列)或是可以经过修改而适于这个特定任务的相似单元,并且也可以通过数字和/或模拟电路或是二者的某些恰当组合来实现所述解码器。
以下描述的是解码设备的一个特定实例。
以下描述引用了图9中的流程图。
输入到解码设备的信号包括图像或是测得的位置码子集的某些其他数字表示,所述子集对至少一个点的坐标进行编码,步骤700。在这个实例中,如上所述,位置码是由相对光栅中的光栅点而在预定路线上移动的点来进行图形表示的。
在解码的第一个步骤中,举例来说,解码设备通过使用阈值处理来识别图像中的点并且将光栅适合所述点,步骤705。例如,可以借助于在申请人的专利申请WO01/26033中描述的方式并且使用不同点对之间的距离来确定所述光栅,也可以借助WO01/75783中描述的方式并且使用傅立叶变换来确定所述光栅。对各个光栅点而言,相关点的位移将被确定并且根据所述位移而被给出一个数值0~3。并且至少将会选择一个大小为(n1+1)*(n1+l)的矩阵,其中n1是用于定位的主数字序列的局部序列长度,并且其位置是在主数字序列中无歧义确定的。而在所涉及的实例中则选择了一个8*8的矩阵((n1+2)*(n1+2))。通过在把位移值转换成二进制数字对的表OI中进行查找而将位移值转换成二进制数字对,由此将这个矩阵分成了一个x矩阵(也称作x位置码)和一个y矩阵(也称为y位置码),步骤710。每个二进制数字对中的第一个二进制数字形成了x矩阵,而每个二进制数字对中的第二个二进制数字则形成了y矩阵。
在下一个步骤,对x和y矩阵的四种可能类型的旋转(0、90、180和270度)进行调查并且确定当前旋度,步骤715。在这里使用了先前描述的事实,那就是如果错误旋转矩阵,则会出现主数字序列上丢失的长度为8的局部序列。
同时,可以基于长度为8的局部序列来执行某种程度的纠错。
在确定了正确旋转的时候,后续步骤中仅仅使用了x和y矩阵,这两个矩阵处于正确路线之中并沿着正确路线旋转,其大小为n1*n1,在这个实例中则是两个6*6的矩阵。x矩阵和y矩阵可以并行解码,也可以按照先x后y的顺序或者与此相反的顺序来解码,图9中是通过并行流程对此加以指示的。
在解码x矩阵的第一个步骤720,确定一个基本差分数字序列的局部序列,在图9中将其称为基本局部序列。更具体地说,在x矩阵中,所述矩阵的列中的二进制数字构成了主数字序列的局部序列。主数字序列中的相应位置是通过在表MI中进行查找来确定的,其中表MI将局部序列转换成位置。此后,确定那些由主数字序列的局部序列来进行编码的差分数字。在这个实例中,它们的数目是五。更具体地说,将差分数字确定为相邻局部序列位置之间的差分d,所述差分是通过以主数字序列长度为模来确定的。
这样一来,由此得到的差分数字序列是基本差分数字序列的一个局部序列,所述序列被用于x方向的编码,但是由于其大小,因此并没有将所述序列保存在解码设备中。取而代之的是使用了基本差分数字序列的特性,即各个局部序列都可以转换成来自各个辅助差分数字序列的局部序列的组合。由此在步骤725中将基本局部序列转换成辅助局部序列。更具体地说,如下所示来改写各个差分数字:
d=d1+bi*d2+...+b1*b2 *bn-1*dn,
其中n是辅助差分数字序列的数目,b1是辅助差分数字序列i中的基数。在所涉及的实例中,这将会变成:
d=5+d1+3*d2+9*d3+18*d4
其中可以通过整除或查表来确定d1~d4。
因此,在基本差分数字序列的已解码局部序列中,5个数字中的每一个都会产生四个数字的d1,d2,d3,d4。因此将会得到五个d1的数字,所述数字形成了第一辅助差分数字序列的一个局部序列,此外还获得了五个d2的数字,它们形成了第二辅助差分数字序列的一个局部序列,并且获得了5个d3的数字,它们形成了第三辅助差分数字序列中的一个局部序列,以及五个d4的数字,它们形成了第四辅助差分数字序列的一个局部序列。以下给出了一个实例:
d 23 45 51 9 37
d1 2 0 0 0 1
d2 1 0 2 0 0
d3 0 1 1 1 0
d4 1 2 2 0 2
在辅助差分数字序列中,局部序列的相应位置是通过在四个表格DCIi中进行查找来获取的,步骤730,其中表DCIi把相应的辅助差分数字序列中的局部数字序列转换成相应的辅助差分数字序列中的位置。
对每个局部序列而言,由此得到了一个位置pi。对这些位置而言,事实是:
P=pl(mod l1)
P=p2(mod l2)
.
.
P=pm(mod lm)
其中P是对应于坐标x的基本差分数字序列中的位置,pi是辅助差分数字序列i中的位置,li是辅助差分数字序列i的长度,m是辅助差分数字序列的数目。
举例来说,如在Niven Suckerman,Introduction to the theory ofnumbers,Springer Verlag中详细描述的实例中那样,这个方程组可以使用众所周知的中国余数定理(chinese remainder theorem)求解。由此在步骤735中确定x。
定义L=prod(i=l,m)li以及qi*(L/li)=l(mod li)。
然后可以得到基本差分数字序列中的位置P:
P=(sum(i=l,n)((L/li)*pi*qi))(mod L)
在所涉及的实例中,
L=l1*l2*l3*l4=236*233*31*241=41081534
并且得到了
q1=135
q2=145
q3=17
q4=62。
例如,如果为辅助差分数字序列的局部序列得到了位置p1=97;p2=176;p3=3以及p4=211,那么根据中国余数定理,基本差分数字序列中的相应位置P是170326961。
当确定了P的时候,下一个步骤是确定所述位置属于哪个x分段。首先,这是在首先假设y=0并且通过计算s(x,0)来执行的,也就是说,它是列x的局部数字序列的主数字序列中的位置,xs=0。s(x,0)则是通过与如上所述相同的方式并且结合位置x的位置码判定而使用辅助差分数字序列来计算的。如果从用于x方向定位的六个局部数字序列中的第一局部数字序列的位置中减去s(x,0),则可以得到了y=0的xs。
根据图9的步骤740~755,在一种与关于x方向的上述方式相对应的方式中,y矩阵是在解码x矩阵之前、之后或者与之并行解码的,基本差分数字序列中的一个位置是为y方向确定的。此外,所涉及的y分段ys是以一种与为x分段的上述方式相对应的方式而计算的,但所述计算是在假设x=0的情况下进行的。最后在步骤760,可以通过y加以考虑来确定xs,并且在y=0的条件下将y(与主数字序列的长度相模)从xs中减去以及在x=0的条件下将x从ys(与主数字序列的长度相模)中减去,由此可以对x加以考虑,从而确定ys。
由此可以使用以下表格来对位置码进行解码:
MI:它将主数字序列的局部序列转换成主数字序列中的位置,
DCIi:它将n个辅助差分数字序列中的每一个序列的局部序列转换成n个辅助差分数字序列中的位置,以及
OI:它将位移值转换成二进制数字对。
应该强调的是,图9的流程图是一个如何在例如计算机程序中实现位置解码的粗略的示意性实例。
附录B
以下参考图10中的流程图来对一个如何借助概率计算来解码一个编码图案的实例进行说明。将要解码的编码图案具有在申请人的WO 01/26033中描述的类型。
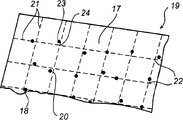
图11a显示了一张有一个表面16的纸15,其中表面16上具有一个处于光可读位置编码形式17的编码图案下方的位置编码图案。所述位置码包括标记18,并且为了清楚起见而被极大地加以放大。图11b显示了图11a中的位置码17的一个进一步放大的部分19。设备被设计为记录位置码的一个局部区域的一个图像(步骤A),标识图像中的多个标记18(步骤B),以及用一个光栅形式的参考系统去适配图像(步骤C),其中光栅具有在光栅点22相交的光栅线21。所述适配以这样一种方式实现:每个标记18与一个光栅点22相关。例如,标记23与光栅点24相关。因此通过光栅适配可以确定每个标记属于哪个光栅点。在本例中,光栅是方格的形式,但也可能是其他形式。此处结合其作为参考的申请人的申请WO 01/75783、WO 01/26034和SE 0104088-0,更详细揭示了光栅对图像中的标记的适配。
在“理想”编码图案中有且仅有一个标记与每个光栅点相关。由于编码图案的图像中的缺陷和不足,因此有可能很难在编码图案的一个图像中确定哪些标记属于该编码图案以及多个标记中的哪一个是与某个特定光栅点相关的那个。由于此原因,在本例中可能在解码数据时将多个标记与同一个光栅点相关联。与一个光栅点光联的标记一起形成属于该光栅点的一个标记元素。
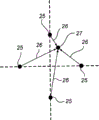
在本例的编码图案中,标记18的值由其相对于其相关的光栅点22的位移定义。更具体地,定义标记值的是一个标记相对于一个光栅点的一个点位置。此点通常是标记的主要点。在本例的编码图案中,每个标记有四个理想位置。这些位置位于四条光栅线21中的每一条上,这四条光栅线从与该标记相关的光栅点22延伸出来。这些位置位于与光栅点相等的距离处。图12a-d中放大显示了一个标记的理想位置25。他们在图12a中的值为“0”,在图12b中的值为“1”,在图12c中的值为“2”,在图12d中的值为“3”。这样每个标记代表四个不同的值“0-3”。
由于多种原因,在记录的图像中标识的标记通常不具有理想位置。因此在许多情况下,可能难以明确地确定一个标记的值。由于此原因,设备被设计为为每个标识的标记计算该标记定义“0-3”中每个值的有关的值概率(步骤D)。每个标记的值概率是标记27到其每个理想位置25的距离26的减函数,参见图13,或者更具体地,通常是从标记27的主要点到每个理想位置的距离的减函数。标记可被假定为在理想位置周围正态分布。这意味着值概率P(di)可由公式P(di)=kexp(-(di)2/v),其中k=常数,di=从标记到理想位置的距离,以及v=常数,在本例中为距离的方差。方差通过经验确定。从而可对每个标记计算四个值概率。有时会出现标记在光栅点中央的情况。在这种情况下,标记的四个值概率将是相等的,因为标记到每个理想位置的距离是一样大的。没有标记与某个光栅点相关的情况,即相关的元素包含零个标记的情况,被看作标记位于光栅点中央的情况,即值概率是相等的。
如果有多个标记与一个光栅点相关,例如三个,即在相关的标记元素中有三个标记,则光栅点或标记元素共有3*4个值概率。由此将设备设计成为每个光栅点或标记元素以及每个值确定一个与光栅点相关的多个标记一起定义此值的值概率(步骤E)。从而这些为光栅点确定的值概率也可被称为光栅点概率。通过计算光栅点的值概率,可在位置确定中考虑记录图像中的所有标记,并可最小化丢失信息的危险。由于上述装置对于每个标记元素,计算该标记元素定义每个值的值概率,因此在以下说明中值“0”-“3”被称为标记元素值。
一个标记元素的值概率可通过被比较的标记元素中的标记的值概率确定,为每个可能的标记元素值选择最高的值概率。作为替换,标记元素的值概率可为标记元素中的标记的每个可能标记元素值的值概率加权和。当然标记元素的值概率也可以通过与上述方法不同的方法确定。
在本例中计算一个标记元素的值概率是通过图14中的数字例子说明的。图14a显示了一个具有两个相关的标记28和29的光栅点22。标记28和29一起组成了属于光栅点22的标记元素。图14b中的表30和31包含各标记的可能值的值概率P1。图14c中的表32包含了得出的标记元素的可能标记元素值的值概率P2。在本例中,标记元素的值概率是相对的。作为替换,它们也可以以一种适当的方式被归一化。如果只有一个标记相关到一个光栅点,即相关的标记元素中只有一个标记,则显然标记和标记元素的值概率是相等的。
当记录一个图像时,设备到表面的距离影响被记录的位置编码的部分的大小,从而也影响能适配到图像中的光栅的大小。为了将图像转化为一个位置,使用预定数目的标记元素,本例中为8*8个标记元素。如果多于8*8个光栅点适配到了图像中,则标识额外的标记元素。因此设备被进一步设计为从所有标识的标记元素中选择提供最多关于表面上的位置的信息的标记元素集合(步骤F)。此标记元素集合是(但并不必须是)连续的。在本例中,标记元素集合中的标记元素对应于一个光栅点矩阵,该光栅点矩阵具有适配到图像的光栅点,但这不是必要条件。换句话说,目的是选择多个标记元素,每个标记元素值具有相关值概率,其能够最大化记录图像的信息量度。为了此目的,对于每个标识的标记元素计算一个熵。然后选择给出最小的熵和的8*8个标记元素,其中最小的熵对应了记录的图像的最大信息量度。如果标记元素的值概率被归一化以使得
则标记元素的熵H根据以下公式计算:
其中P2,i是标记元素值i(i=0,1,2,3)的标记元素值概率,log2是2为底的对数。这样一个标记元素的熵在其值概率相等的时候最大,而在除一个值概率外其他值概率均为零时最小。另一个通过熵计算来选择8*8个标记元素的替换方法是用每个标记元素的最高值概率作为一个信息值。在这种情况下,选择连续的8*8个标记元素,其最大化由这8*8个标记元素的信息值的和组成的信息量度。
正如已提到的,本例中使用的编码图案对表面4上的一个点的两个坐标进行编码。这些坐标可分别被解码。因此,它们可被称为两个维度中的数据。更具体地,编码图案中的每个标记编码一个被用于解码第一坐标的第一比特以及一个被用于解码第二坐标的第二比特。
因此在对记录的图像中的编码图案进行解码时,一个标记元素的每个可能的标记元素值“0”-“3”被转换成一个第一和一个第二解码值,在本例中它们是二进制的。从而设备被设计为对于标记元素集合中的8*8个标记元素中的每一个标记元素将标记元素值“0”-“3”转化为四个不同的比特组合(0,1)(0,0)(1,0)和(1,1)。对于每个标记元素,比特组合具有属于每个标记元素值的值概率,参见图15a的表33中所示的前述数字实施例的后续。在比特组合中,第一比特,即第一解码值,表示第一维度,第二比特,即第二解码值,表示第二维度。相应的标记元素值的值概率P2与第一和第二解码值相关。这样标记元素集合可被用于创建第一维度的具有相关的值概率的第一解码值的第一集合,以及第二维度的具有相关的值概率的第二解码值的第二集合(步骤G)。表33说明了标记元素集合中的一个标记元素。表33’和33”分别包含了具有相关的值概率的第一集合中的相应的第一解码值,以及具有相关的值概率的第二集合中的第二解码值。显然从上述说明中可知,第一和第二解码值中的每一个值为0或1。
设备被设计为对于标记元素集合中的每个标记元素,将第一集合中的每一个不同的可能第一解码值中与一个值概率相关,并将第二集合中的每一个不同的可能第二解码值与一个值概率相关。由于本例中可能的第一和第二解码值为0和1,因此上述操作在第一和第二集合中对标记元素集合中的每个标记元素得到了解码值1的一个值概率和解码值0的一个值概率。以下解码值0的值概率称为0概率,而解码值1的值概率称为1概率。
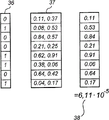
参见表33’,在本例中,通过比较第一集合中的对应于第一解码值为0的值概率来对标记元素集合中的每个标记元素实现上述操作。然后最高的值概率被选为0概率并保存在一个第一矩阵34中。以相同的方法比较第一集合中对应于第一解码值为1的值概率。然后最高的值概率被选为1概率并保存在第一矩阵34中。参见表33”,随后对于第二集合中的值概率、第二解码值和一个第二矩阵35重复上述程序。从而第一和第二集合被用于创建一个具有0和1概率的第一和第二矩阵(步骤H)。在图15b中的数字例子后续说明了该结果。作为替换,通过将第一集合中对应于第一解码值为0的值概率相加,所得的和被存储为0概率,以及通过将第一集合中对应于第一数字为1的值概率相加,所得的和被存为1概率,来创建对于元素集合中的8*8个元素的具有0和1概率的一个第一和一个第二矩阵。然后对于第二集合中的值概率和第二解码值重复此程序。
这样标记元素集合中的8*8个标记元素现在对应于两个矩阵34和35,每个具有8*8个矩阵元素,其中每个矩阵元素包括一个0概率和一个1概率。通过这些第一和第二矩阵,可确定位置的坐标。
在确定记录的图像中所有标记元素的值概率后选择标记元素集合的一个替换方法是,等到已为所有被标识的标记元素确定对应于矩阵34和35的矩阵。在这种情况下,则可根据相应的0和1概率选择每个矩阵中的8*8个矩阵元素。执行此操作的一个方法是选择8*8个矩阵元素,其中0和1概率中的一个为高而另一个为低。在这种情况下,不必选择对应于相同标记元素的矩阵元素用于两个坐标的确定,计算通过两个矩阵的不同的相应标记元素进行。
在本例中位置码在基于一个第一循环主数字序列的第一维度中。这给出了标记元素的标记元素值之间的关系的条件。第一循环主数字序列具有这样的性质:其中每个预定长度的局部序列的位置是明确地确定的。在本例中预定长度是6。如果在第一循环主数字序列中的任意位置取这样6个顺序的数字,则这六个数字只在第一主数字序列中以此顺序出现一次。如果第一主数字序列的末尾连续到第一主数字序列的开始,该性质仍适用。因此,第一主数字序列被称为循环的。在本例中使用一个二进制主数字序列。如果要明确确定一个具有六个数字的局部序列的位置,则第一主数字序列最长可具有26=64的长度,长度为6的局部序列可占有第一主数字序列中的位置0-63。但是如果选择一个长度为63的第一主数字序列,则可提供改进的纠错性质,这可从下面的说明中看到。从而在下面的说明中将假定第一主数字序列的长度为63,并从而定义了0-62范围中的唯一位置。
图16显示了一个可结合位置码使用的第一循环主数字序列的例子。例如,局部序列0,0,0,0,0,0具有第一主数字序列中的明确位置0,局部序列1,1,1,1,1,0具有明确位置9而局部序列1,1,1,0,1,0具有明确位置11。为确定表面上的一个位置,必须在记录的图像中标识6*6个标记元素。但是,如上文所讨论的,位置确定采用的是8*8个标记元素,其原因将从下面的说明中看出。如上文所述,第一维度中的位置码所基于的第一循环主数字序列具有这样的性质:它只包含相互不同的长度为6的局部序列。因此,每个长度为8的局部序列在第一循环主数字序列中的位置是明确确定的。在确定表面上的位置的坐标时利用了此事实。
设备被设计为将第一循环主数字序列中每个长度为8的唯一局部序列与第一矩阵34中的每列匹配(步骤I)。该方法在图17中说明。该图显示了一个长度为8的二进制局部序列36以及第一矩阵34中的一列37(图15b),所述列具有矩阵元素,每个元素包含一个0概率和一个1概率,分别对应于第一解码值为0和为1的概率。对于每个矩阵元素,根据局部序列36中相应的数字选择0和1概率之一。例如,局部序列36中的第一个数字为0,意味着选择0概率作为列37中的第一个矩阵元素。局部序列中的第二个数字为1,意味着选择1概率作为列37中的第二个矩阵元素。对于第一主数字序列中的每个局部序列,对于第一矩阵34中的每一列,设备还被设计为通过将相应选择的矩阵元素的0和1概率相乘计算一个第一序列概率(步骤J)。在图17中,已计算了对应于局部序列36和列37的第一序列概率38。在进行此操作后,将有63个第一序列概率,它们对于第一矩阵34中的每一列具有一个相关的唯一的序列值。这些序列值由相应的局部序列在第一循环主数字序列中的位置定义。设备被设计为对每一列选择最高的第一序列概率以及相应的序列值,并保存它们。
此处第二维度中的位置码是基于一个第二循环主数字序列的,在本例中它与第一循环主数字序列具有相同的性质。
设备被进一步设计为以相应于上述方式的方式,将第二循环主数字序列中每个长度为8的唯一局部序列与第二矩阵35中的每行匹配。正如矩阵34中的列一样,矩阵35中的行具有矩阵元素,每个元素包含一个0概率和一个1概率,分别对应于第二解码值为0和为1的概率。对于每个矩阵元素,根据第二循环主数字序列中的局部序列中相应的数字选择0和1概率之一。对于第二主数字序列中的每个局部序列,对于第二矩阵35中的每一行,设备还被设计为通过将相应选择的矩阵元素的0和1概率相乘计算一个第二序列概率(步骤J)。在进行此操作后,将有63个第二序列概率,它们对于第二矩阵35中的每一列具有一个相关的唯一的序列值。这些序列值由相应的局部序列在第二循环主数字序列中的位置定义。设备被设计为对每一行选择最高的第二序列概率以及相应的序列值,并保存它们。
本例中使用的位置码是基于循环主数字序列的不同旋转或循环移动的使用。例如,为编码x方向的位置,第一主数字序列在表面上按列向不同的方向旋转或循环移动以某种其他的方式印刷或排列,即,在与要编码位置的方向正交的y方向,从上往下。主数字序列可在同一列中重复印刷,如果要在y方向编码多于对应于主数字序列的长度的位置则这一点是必要的。然后在所有重复中使用相同的主数字序列旋转。这意味着在不同的列中可使用不同的旋转。
每对相邻的列定义一个差分数字D。差分数字D由每列中第一局部序列的在主数字序列中的位置之间的差分给出。如果局部序列的位置之间的差分在列中往下一步,则结果将是相同的,因为位置将以相同的方式偏移。从而差分数字D始终是相同的,不论在列中的哪个“高度”比较主数字序列中的局部序列的位置。从而对于每对列,差分数字D在y方向是恒定的。相邻列之间的差分数字形成一个差分数字集合,它可用于获取表面上一个位置在第一维中的坐标。
第二方向的位置码,例如在此情况下为y方向,可基于与第一维度中的位置码相同的原理。然后第二主数字序列被排列为在表面上的行中不同的循环移动,即,在x方向,从左往右。差分数字在相邻行之间定义,且这些差分数字形成一个差分数字集合,它可用于获取表面上的一个位置在第二维度的坐标。
从而位置码由第一方向的一个局部位置编码和第二方向的一个局部位置编码组成。
从上文可见,局部序列不是以其显值写入的,而是以其图形编码写入的。在图形编码中,标记定义了局部位置编码图像的叠加。
由于位置码是基于在表面上以预定方向排列的主数字序列的,因此标记必须在这些方向上被解码,以便正确确定位置。如上文所提到的,正确的解码方向是从上往下和从左往右的。
用于数据解码的设备在记录图像时可以相对于表面和位置编码的不同位置旋转。如图18中的箭头40所示,有四个可能的记录旋转。位置码的记录图像本身不显示位置码和设备之间的相对旋转,因为如果位置码旋转0,90,180或270度其外观实质上是一样的。但是当位置码被旋转时,每个标记相对于其相关的光栅点的位移的方向将会改变。这导致了编码标记的位移的比特组合(第一解码值,第二解码值)改变。通过位置码的“正确”旋转,标记以正确的解码方向在列中从上往下以及在行中从左往右排列。如果位置的正确旋转为0,则以下内容对于错误的旋转成立:
·顺时针90度:具有“正确”旋转的标记的列,即标记从上往下排列的列,将成为标记从右往左排列的行,即为错误的解码方向,而具有“正确”旋转的行,即标记从左往右排列的行,将成为标记从上往下排列的列,即为正确的解码方向。
·180度,具有“正确”旋转的标记的列,将成为标记从下往上排列的列,即为错误的解码方向,而具有“正确”旋转的标记行,将成为标记从右往左排列的行,即为错误的解码方向。
·顺时针270度:具有“正确”旋转的标记的列,将成为标记从左往右排列的行,即为正确的解码方向,而具有“正确”旋转的标记的行,将成为标记从下往上排列的列,即为错误的解码方向。
如果列和行中的标记以错误的解码方向排列,则解码时每个元素的0和1概率将被颠倒。
因此如下文将要说明的,设备被设计为测试记录的图像中的位置码的局部区域的不同旋转。在旋转180度并“倒置”的第一和第二矩阵34和35上(在图15c中分别标示为34’和35’)还执行分别在第一和第二矩阵34和35上执行的操作,即将循环主数字序列中的局部序列分别与矩阵中的列和行进行匹配(步骤I),计算序列概率(步骤J),以及分别选择具有相应的列和行的序列值的最高序列概率。这些旋转的、倒置的矩阵34’和35’对应记录的图像中的位置码的颠倒的局部区域。在显示记录的图像中的一个位置码的一个局部区域的一个例子的图11中解释了其原因。在该图中,为了简便只使用了9个标记,每个与一个光栅点相关以方便说明。位置码45是记录在图像中的那个。位置码45’是同一个颠倒的位置码。矩阵46和47分别对应于向右旋转的位置码45的矩阵34和35,而矩阵48和49分别对应于倒置的位置码45’的矩阵34’和35’。如果倒置的位置码的矩阵48和49旋转180度并倒置,则可获得向右旋转的位置码的矩阵46和47。这里倒置表示每个矩阵元素中的0和1概率改变位置。
经过上述程序后,对于矩阵34和34’中的每一列和对于矩阵35和35’中的每一行有一个具有相应的序列值的序列概率。然后对于矩阵34,34’,35和35’,设备被设计为通过将相应的最高序列概率相乘计算一个旋转概率(步骤K)。根据对应于矩阵34和34’(对应于最高旋转概率)的最高序列概率的序列值,以及对应于矩阵35和35’(对应于最高旋转概率)的最高序列概率的序列值,可计算位置的坐标。
如上文所说明的,不必检查所有四个旋转。这可由一个例子简单地说明。现采用记录的一个图像中的一个位置码的局部区域是图19中显示的那个(45)。再采用位置码的“正确”旋转是相对于记录的编码顺时针旋转90度。根据上述说明,其中正确旋转被采用为旋转0度,这意味着记录的图像中的位置码45相对于“正确”旋转顺时针旋转了270度。因此,位置码45’相对于“正确”旋转顺时针旋转了90度。以上文所述的方式,现在在图19中解码位置码45,45’。如上文所说明的,具有“正确”旋转0度的标记的列排列在位置码45中正确的解码方向。正确的方向引起对应于这些行的序列概率为高,从而引起旋转概率为高。如上所述,具有正确旋转的标记的行是在位置码45中以错误解码方向排列的列。错误的方向与倒置结合引起对应于这些列的值概率为低,从而引起旋转概率为低。对于位置码45’关系将是相反的。如上文所说明的,具有正确旋转0度的标记的列将为位置码45’中以错误的解码方向排列的行。错误的方向与倒置结合引起对应于这些行的序列概率为低,从而引起旋转概率为低。如上所述,具有正确旋转的标记的行是在位置码45’中以正确解码方向排列的列。正确方向引起对应于这些列的序列概率为高,从而引起旋转概率为高。如上文所提到的,当记录位置码的“正确”旋转时,列和行将在图像中的“正确”方向延伸。这意味着对于图15中的例子,矩阵34和35的旋转概率将均高于矩阵34’和35’的旋转概率。这表示已记录了位置码的“正确”旋转。从而可根据对应于矩阵34的最高序列概率的序列值计算一个第一坐标,并根据对应于矩阵35的最高序列概率的序列值计算一个第二坐标。
当记录相对于“正确”旋转旋转180度的位置码时,行和列将在图像中的“错误”的方向延伸。这意味着对于图15中的例子,矩阵34’和35’的旋转概率将均高于矩阵34和35的旋转概率。这表示位置码已经以相对于“正确”旋转180度的旋转记录。从而可根据对应于矩阵34’的最高序列概率的序列值计算一个第一坐标,并根据对应于矩阵35’的最高序列概率的序列值计算一个第二坐标。
相对于“正确”旋转顺时针旋转90或270度的位置码的记录由不属于相同旋转的最高旋转概率表示。如果采用图15b中的矩阵34和35来自相对于正确方向顺时针旋转90度的一个位置码,则矩阵34的旋转概率将高于矩阵34’的旋转概率,而矩阵35的旋转概率将低于矩阵35’的旋转概率。在这种情况下,根据对应于矩阵34的最高序列概率的序列值计算第二坐标,并根据对应于矩阵35’的最高序列概率的序列值计算第一坐标。如果采用图15b中的矩阵34和35来自相对于正确方向顺时针旋转270度的一个位置码,则根据对应于矩阵34’的最高序列概率的序列值计算第二坐标,并根据对应于矩阵35的最高序列概率的序列值计算第一坐标。
允许检测记录的图像中的位置码的旋转的是以下事实:当一个矩阵旋转90,180或270度时,该矩阵的旋转概率会改变。如果位置码的旋转不为0,即如果记录的图像中的位置码的旋转错误,则如上文所述,旋转概率将为低。这取决于以下事实:循环主数字序列中长度为8的唯一局部序列不会倒置或颠倒地出现在主数字序列中。如果对于长度为6的局部序列的主数字序列满足此条件,则意味着主数字序列将显著减少,这意味着能编码的位置更少。因而这是为什么虽然理论上只要求6*6个元素但在位置确定中要使用8*8个标记元素的原因之一。
旋转检测中使用的基本原理可用在纠错中。例如,可选择主数字序列,使得长于位置确定所要求的预定长度的局部序列不会以一比特倒置出现在主数字序列中。这样,如果能确定地检测到这样一个较长的局部序列中除一个比特外的所有比特,则可以纠正错误的比特。这是为什么虽然理论上只要求6*6个元素但在位置确定中要使用8*8个标记元素的另一个原因。
这样,通过适当地选择主数字序列,可相当显著地改进编码图案的检错和纠错属性。
但是,对于64比特长的主数字序列,可能不具备循环主数字序列的长度为8的局部序列不出现倒置或颠倒的这一属性,这是为什么主数字序列的长度选为63的原因。
因此,在解码中使用冗余信息获得纠错属性。在上文说明的例子中,8*8个标记元素被用于解码中,虽然位置信息可根据6*6光栅点提取,即对于确定位置有56比特的冗于信息[(82-62)x2]。在解码中,在使用属于当前图像的值概率的同时,按列和按行将当前图像中的信息与可能出现在位置码中的不同局部序列匹配。关于冗余信息、概率和标记元素值之间的关系已知条件的组合给出对当前图像中的干涉的良好的不敏感性。这样每个标记的值的重要性降低了,因为单个标记的值必须对应于给出最高序列概率的局部序列中的其他值。
如果对于纠错的需求有限,则设备可被替换地设计为,为第一矩阵中的每一列和第二矩阵中的每一行,选择一个对应于每个标记元素的0和1概率的最高者的序列,以及从而选择一个序列值。
当已建立了记录的位置码相对于“正确”旋转的旋转40’时,则可确定位置的第一和第二坐标(步骤L)。如上文所述,此操作是根在图18中对于第一坐标标示为Sx1-Sx8(41)和对于第二坐标标示为Sy1-Sy8(42)的序列值执行。
设备被设计为对序列值Sx1-Sx8和Sy1-Sy8计算相邻序列值之间的差,它产生七个差分数字Dx1-Dx7和Dy1-Dy7的两个集合43和44。然后这些差分数字被用于产生一个第一坐标和一个第二坐标。
但是,如上文所说明的,对于第一坐标的计算,只有序列值Sx1-Sx8中的六个,即差分数字Dx1-Dx7中的五个是必须的。因而根据本例使用了序列值Sx2-Sx7和差分数字Dx2-Dx6。这一点也适用于第二坐标,它由序列值Sy2-Sy7和差分数字Dy2-Dy6计算出。也可分别对每个方向只确定六个序列值,Sx2-Sx7和Sy2-Sy7。
从差分数字到坐标的换化可以多种方式实现,例如以在这里被结合进来作为参考的申请人的申请WO 01/26033中说明的方式实现。
在上文说明的例子中,已经为数据解码在一个记录的图像中标识了8*8个标记元素。但是,有时候会出现不可能标识这么多标记元素的情况。则额外的“空”标记元素被加到标记元素中,它们可在图像中被标识以获得总共8*8个标记元素。如先前所说明的,“空”标记元素的值概率均为相等的。