CN100397332C - 文档分类方法和设备 - Google Patents
文档分类方法和设备 Download PDFInfo
- Publication number
- CN100397332C CN100397332C CNB031068146A CN03106814A CN100397332C CN 100397332 C CN100397332 C CN 100397332C CN B031068146 A CNB031068146 A CN B031068146A CN 03106814 A CN03106814 A CN 03106814A CN 100397332 C CN100397332 C CN 100397332C
- Authority
- CN
- China
- Prior art keywords
- document
- classification
- vector
- similarity
- projection
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
- Y10S707/99934—Query formulation, input preparation, or translation
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
- Y10S707/99935—Query augmenting and refining, e.g. inexact access
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
- Y10S707/99936—Pattern matching access
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99941—Database schema or data structure
- Y10S707/99943—Generating database or data structure, e.g. via user interface
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
Abstract
通过从文档里出现的项中选择分类中所用的项来把文档归类到至少一种文档类别。用为每个文档类别保存的信息来计算输入文档和各个类别之间的相似度。然后修正计算出来的对各个类别的相似度。最的根据对各个类别的修正相似度确定输入文档所属的类别。
Description
技术领域
本发明与包括文档分类的自然语言处理有关。更准确地说,本发明允许人们精确地提取文档集合之间的区别,由此提高处理性能。
背景技术
文档分类是把文档归类到预定组的一种技术,并且在信息流通中变得更重要了,且有上升趋势。关于文档分类,至今已经研究并开发了多种方法,例如向量空间模型、k最近邻居方法(KNN方法)、自然贝叶斯方法、决策树方法、支持向量机方法以及增压方法。M.Nagata和H.Hira已经在“文本分类-识别理论的样本对”中详细描述了文档分类最近的趋势,该文被收集在日本信息处理会议录42卷1号(2001年1月)中。在任何分类方法中,以任意形式描述文档类别上的信息并把它和输入文档进行比较。下面应该称其为“类别模型”。例如,类别模型在向量空间模型中由属于每个类别的文档的平均向量来表示,在KNN方法中由属于每种类别的文档的向量组表示,在增压方法中由一组简单的假定来表示。为了实现精确的分类,类别模型必须精确地描述每个类别。也可以说,在至今提出的高性能分类方法中,类别模型更精确地描述每个类别。
在这点上,虽然很多分类方法针对类别模型的描述精度,但它们没有考虑类别模型重叠。例如,在向量空间模型或KNN方法中,一个特定类别的模型还包括与另一类别匹配的信息。如果在类别模型间发生重叠,它就有可能存在于特定的输入文档和该输入文档并不相属的类别之间并且会导致错误分类。为了消除错误分类的起因,类型模型需要通过找到每种类别的与众不同的信息来描述以减少类别模型的重叠。
发明内容
鉴于上述原因,依照本发明提供一种方法用于提取在每个给定类别中出现但很少在任意其它类别中出现的特征,以及出现在任意其它类别中但很少出现在给定类别中的特征。分类方案包括两个阶段,构造主分类器和子分类器以有效地使用这些特征。在主分类方案中,采用了一种现有的高性能分类方法,同时在子分类方案中使用这些特征。假定主分类方案是以输入文档和各个类别之间的相似度为基础来对输入文档进行分类。
如下所述,使用所有带有指示各个单独文档的类别的标记的练习文档来提取在子分类方案中所用的特征。首先,在主分类方案中,针对每个练习文档为各个类别获取相似度。与一个相干类别之间的相似度超出预设阈值的文档被确定为属于该相干类别。这些文档被分到两个集合中,在第一个集合中文档被正确地归类为它们的正确类别(以下称为“给定类别文档集合”),在第二个集合中文档被归类到给定的类别文档集合中而不管它们还属于其它类别(以下称为“竞争文档集合”)。每个文档由一组句子向量表示。句子向量的每个成分是在相干句子中出现的每个项的频率或者与频率对应的一个量,而其维度是在所有练习文档中出现的项的种类的数量或者所选的项的种类的数量。假定所有文档的所有句子向量都被投影到一个特定的投影轴上。优先采用来自给定类别文档集合的投影值的平方和和来自竞争文档集合的投影值平方和的比值作为指示集合间的差异程度的判别函数。使用使最大化判别函数的投影轴提取用在子分类方案中的特征。
多个这样的投影轴可以表示为普遍的特征值问题的特征向量。更准确地说,当判别函数由(来自给定类别文档集合的投影值的平方和)/(来自竞争文档集合的特征值的平方和)表示时,最大化判别函数的投影轴有一个较大的值作为来自给定类别文档集合的投影值的平方和,并且有一个较小的值作为来自竞争文档集合的投影值的平方和。因此,投影轴反映很少在任意竞争文档中出现但经常出现在给定类别中的信息。因此,这样的投影轴可以称为“正主题差异因子向量”。相反地,当判别函数由(来自竞争文档集合的特征值的平方和)/(来自给定类别文档集合的投影值的平方和)表示时,最大化判别函数的投影轴反映很少出现在给定类别中但经常出现在任意竞争文档中的信息。因此,这样的投影轴被称为“负主题差异因子微量”。
在子分类方案中,把输入文档的句子向量和每个类别的一定数量的正主题差异因子向量之间的点积平方的加权和加到在主分类方案中获得的相干类别的相似度中。从相干类别的相似度中减去输入文档的句子向量和每个类别的一定数量的负主题差异因子向量之间的点积平方的加权和。把这样修正的相似度和每个类别的预定阈值进行比较。
如前所述,在本发明中,由子分类方案修正主分类方案计算出的相似度。如果由子分类方案在一个特定类别中计算输入文档的句子向量和一定数量的正主题差异因子向量之间的点积平方的加权和,正主题差异因子向量就规定该类别中存在的特征。因此,如果输入文档属于该相干类别,上面的加权和通常有大的值,而且相似度也被修正为一个大的值。另一方面,如果输入文档不属于该相干类别,上述加权和通常具有小的值,而且相似度变化也小。此外,如果在该特定类别中计算输入文档的句子向量和一定数量的负主题差异因子向量之间的点积平方的加权和,负主题差异因子向量就规定不应该存在于该类别中的特征。因此,如果输入文档属于该相干类别,上述加权和通常具有小的值而相似度被修正为一个小的值。然而,当输入文档不属于该相干类别时,上述加权和通常具有大的值而相似度被修正为一个小的值。既然用这种方式修正相似度,修正通常会导致对扩大输入文档所属的类别的相似度并减小对输入文档不相属的类别的相似度。因而提高了分类精度。
附图说明
如果结合附图读对示例实施方案的下列详细描述以及权利要求能够明白前面的描述并更好地理解本发明,所有这些都构成了本发明公开的一部分。尽管前面和后面的书面并带有插图的发明公开集中于公开本发明的示例实施方案,但应该清楚地理解只通过图解和示例也是一样的,而且并不是为了把本发明限制在那里。仅由所附权利要求的各项限制本发明的精神和范围。
附图的简短描述表示如下,其中:
图1是显示依照本发明的一种实施方案的文档分类设备的框图;
图2是本发明的一种实施方案的流程图;
图3A-3C是解释文档向量的图示;
图4是依照KNN方法计算输入文档的相似度(图2中的步骤14)的步骤的流程图;
图5是获取正负主题差异因子向量以便修正相似度的步骤的流程图,这些步骤使用给定类别的文档集合以及被错误归类到该给定类别的文档集合或者可能被错误归类到其中的文档集合;
图6A-6C属于类别1的文档的结构的图示;
图7是分类步骤的流程图(图5的步骤22)。
具体实施方式
在开始对主题发明的详细描述之前,先顺序提及下列叙述。在适当时,在区分附图时使用类似的参考数字和字母来指示相同的、对应的或类似的成分。此外,在接下来的详细描述中,给出示例性的大小/模型/数值/范围,尽管本发明并不受限于此。以框图形式显示排列以避免模糊本发明,还由于关于这样的框图排列的实现的细节高度取决于实现本发明的平台,即这样的细节正好在本领域技术人员的范围内。陈述特定的细节,例如电路或流程图,以便描述本发明的示例实施方案,本领域的技术人员应该明白可以在有或没有这些特定细节的变体的情况下实践本发明。最后,应该明白区分硬布线电路和软件指令的组合可以用来实现本发明的实施方案,也就是说,本发明并不局限于硬件和软件的特定实施方案。
图1是依照本发明的一种实施方案的文档分类设备的框图。首先,把要分类的文档输入输入单元110。在数据处理单元120中,对输入的文档进行数据处理,例如项提取和文档段提取。在分类引擎130中,参考包含各个类别的分类信息的单元140,由主分类方案计算相似度,由子分类方案修正相似度。用修正后的相似度确定输入文档所属的类别并把它输出到分类输出单元150。
图2是图1中设备的处理步骤的流程图,从文档输入执行到类别判定。在输入步骤11中向单元110提供文档。在步骤12中,单元120提取并选择项。在步骤13中,单元120提取文档段向量。在步骤14和15中,引擎130分别执行相似度计算和相似度修正。在步骤16中,单元140进行类别判定。步骤11到14对应于主分类方案,而步骤15和16对应于子分类方案。下面用英文文档描述了一个实例。
首先,在文档输入步骤11输入要分类的文档。在项提取和选择步骤12,从文档中提取单词、公式、一系列符号,等。所有单词和系列符号在后面都称为“项”。在书面英文的情况下,已经建立了一种单词分开书写的标记方法,并且因此使得对项的检测更加容易。在项提取和选择步骤12,把项包括在一个项列表中用于分类,并且从输入文档中存在的项之间提取项。用大量标记过的练习文档可以实现对分类中所用的项的选择,而且tf-idf(项频率-反向文档频率)技术、采用X2统计的方法、采用相互信息的方法等等都是提供有利结果的已知方法的实例。文档段向量提取步骤13把文档分成文档片段,并为每个文档段创建一个向量。把文档分割成文档段中最基本的处理是把文档分成句子单元。在书面英语中,句子以句号结束并且后跟一个空格,因此可以很容易地提取句子。其它把文档分割成文档段的方法包括把多个句子收集进文档段中以使文档段的项的数量实际相等的方法,以及从头开始分割文档而不考虑句子以使文档段中所包括的项的数量实际相等的方法,等等。还可以把整个文档作为一个文档段。随后,为每个文档段创建一个向量。向量的分量表示分类中所用的各个项在相干文档段中的频率。换句话说,频率被乘以权重。已经对如何设置权重进行了研究,本领域的技术人员已经知道一些设置权重的有效方法。通过把所有文档段向量加起来而产生的向量称为“文档向量”。下面的描述假定句子向量是文档段向量。当输入由K个句子(图3A)组成的输入文档X时,第k个句子向量由xk(图3B)表示,文档向量由x表示(图3C)。在图3B底部的数字是为了举例说明句子向量的成分。也就是说,这些数字指示对应句子向量xk的各个成分对应的项的频率。
相似度计算步骤14(图2)计算输入文档到各个类别1的相似度。已知有多种找到相似度的方法。在向量空间模型情况下,用练习主体找到各个类别的平均文档向量并把它们保存起来。假设类别1的平均向量为m1,输入文档到类别1的相似度sim(X,1)可以表示为:
sim(X,1)=xTm1/(‖x‖×‖m1‖.....(1)
这里,‖x‖表示x的标准,上标T代表向量转置。
现在参考图4中所示的流程图描述由图1的设备执行的KNN方法。在KNN方法中,假设Yt表示练习文档集合中的第t个文档,并且假设yt表示第t个文档的文档向量,输入文档X到文档Yt的相似度sim(X,Yt)由下面的公式获得:
sim(X,YL)=xTYt/(‖x‖×‖Yt‖.....(2)
在已经获得输入文档X对所有练习文档的相似度之后(步骤142),选择k个对输入文档X的相似度最大的文档(步骤144)。此后,根据每个文档所附的标记为每个类别对k个选中的文档进行分类(步骤146)。随后,计算输入文档到类别1的相似度sim(X,1)(步骤148)。相似度sim(X,1)定义为输入文档X到分类到类别1的文档的相似度之和。也就是说,按照如下公下计算相似度sim(X,1):
这里,Ω1表示在k个文档中属于类别1的练习文档的集合。
在相似度修正步骤15(图2),用已经为每个类别保存的正主题差异因子向量和负主题差异因子向量修正相似度。用在相似度修正中的类别1的正主题差异因子向量由{αi}(i=1,...,Lci)表示,负主题差异因子向量由{βi}(i=1,...,Lp)表示。然后,类别1的修正相似度由simc(X,1)表示,由下列公式给出:

注意a和b是正数的参数,已经和LP、LG一起被预先确定。可以确定参数a、b、LP、LG的值,以便在接连改变各个参数a、b、LP、LG的值的时候发现不用于向量{αi}和{βi}的计算的文档集合的性能,并选择提供最大F度量的数值的组合。F度量定义如下:
精度=(正确分配到各个文档作为分类结果的总类别数)/(分配到各个文档作为分类结果的总类别数)
重复度=(正确分配到各个文档作为分类结果的总类别数)/(每个文档应该所属的类别总数)
F度量=精度×重复度×2/(精度+重复度)
修正后的相似度simc(X,1)由下列公式计算

这种情况下,ai和bi分别是第i个正主题差异因子和第i个负主题差异因子的权重。当给定LP和LG时,可以通过采用线性判别式分析可获得权重ai和bi。更准确地说,为每个未用于向量{αi}和{βi}的计算的文档准备一个LP+LG+1维的向量,而给定(xk Tαi)(i=1,...,LG)、(xk Tβi)(i=1,...,LP)以及sim(X,1)作为分量。随后,在类别1的文档集合和属于另一类别的文档集合之间进行线性判定式分析,并为各自的分量确定最优分离这两个文档集合的权重。“属于另一类别的文档集合”表示属于另一类别的文档,其中到类别1的相似度sim(X,1)超过了特定阈值,在分类步骤22(图5)作为分类结果。通常用线性判别式分析可以发现最优分离两组向量集合的投影轴。计算投影轴以使各个组的平均向量的差额向量被乘以在其中已加上了各个组的协方差矩阵的矩阵的逆矩阵。此后,由sim(X,1)的权重分割(xk Tαi)(i=1,...,LG)和(xk Tβi)(i=1,...,LP)的权重,由此分别确定ai和bi。为所有的LP和LG值的组合执行这样的处理,并可以采用提供最佳分类结果的权重ai和bi的值。
在分类判定步骤16(图2),通过比较各个类别的预定阈值和修正后的相似度确定输入文档所属的类别。如果类别1的修正相似度大于类别1的阈值,就确定输入文档属于类别1。
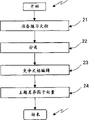
图5是确定用来修在图2的步骤15修正相似度的正主题差异因子向量和负主题差异因子向量的步骤的流程图。在步骤21,准备练习文档。在步骤22,分类发生。在步骤23,完成文档集合编辑。在步骤24,实现主题差异向量分析。
在练习文档准备步骤21,准备用于确定正负主题差异因子向量的练习文档集合,为每个这样的文档获取文档向量和文档段向量。在随后的分类步骤22,选择每个练习文档作为输入文档以便计算它到所有其它练习文档的相似度并由此确定它所属的类别(图2的步骤14和16)。通过执行这样的操作对所有练习文档分类。但在这种情况下不执行图2中步骤15的相似度修正。
下面参考图7的流程图描述图5中的分类步骤22.
步骤221:为所有练习文档执行项提取和文档段提取这样的数据处理。
步骤222:选择一个练习文档作为输入文档。
步骤223:计算输入文档和其它练习文档之间的相似度以根据公式(3)获取到各自的类别的相似度。
步骤224:判断是否已经为所有练习文档获得了到各自的类别的相似度。
步骤225:相似度大于给定类别的阈值的文档被分为包括正确分类文档的文档集合和包括不正确分类文档的竞争文档集合。
现在详细描述图5的流程图。M个文档的集合被正确分类为属于类别1,由D(图6A)表示。假定集合D的第m个文档Dm由KD(m)个句子组成,第k个句子向量由dmk表示(图6B)。竞争文档集合编辑步骤23(图5)创建竞争文档的集合,每个竞争文档都被错误地归类为类别1或者可能被错误地归类到其中,每个类别在分类步骤22上以分类结果为基础。通过选择到类别1的相似度sim(X,1)超过特定阈值来提取类别1的任意竞争文档。该阈值可以根据要选择的竞争文档数任意确定。假定类别1的竞争文档集合T由N个文档组成。假定集合T的第n个文档Tn由KT(n)个句子组成,第k个句子向量由tnk表示(图6C)。主题差因子分析步骤24(图5)使用属于每个类别的文档集合和它的竞争文档集合计算正负主题差异因子向量。用作正主题差异因子向量的投影轴由α表示。假定PD和PT分别表示在文档集合D和T的所有句子向量被投影到坐标轴α的情况下投影值的平方和,获取正主题差异因子向量作为最大化判别函数J(α)=PD(α)/PT(α)的α。最大化J(α)的α反映存在于文档集合D但很少存在于文档集合T中的特征,因为它应该有一个较大的值作为文档集合D的句子向量的投影值的平方和,以及有一个较小的值作为文档集合T的句子向量的投影值的平方和。这种情况下,PD(α)和PT(α)分别表示如下:
因此,判别函数J(α)可以写成:
由方程(10)给出的最大化判别函数J(α)的α可以通过对α微分方程(10)然后设置结果等于0来求得。也就是说,把它当作下列普遍的特征值问题的特征向量:
SDα=λSTα.....(11)
通常可以从公式(11)获得多个特征向量,从它们中间选取的第1到第LG个特征向量在图2的步骤15成为正主题差异因子向量{αi}(i=1,...,Lci)。如果β表示要找的其它投影轴,并且J(β)=PT(β)/PD(β)表示判别函数,那么最大化判别函数J(β)的β就表示应该存在于文档集合T但很少存在于文档集合D中的特征。这种情况下,最大化判别函数J(β)的β被作为下列普遍的特征值问题的特征向量给出,同样对方程(11):
STβ=λSDβ.....(12)
在从方程(12)获得的多个特征向量之间选取的第1到第LP个特征向量在图2的步骤15变成负主题差异因子向量{βi}(i=1,...,LP)。就方程(11)来说,矩阵ST必须是要获取的特征向量的正则矩阵。但实际上在练习文档集合中的句子数小于项的数目时或者特定数量的项对总是一起出现时不可能获取矩阵ST作为正则矩阵。这种情况下,允许通过根据下列方程正则化矩阵ST获得特征向量:
其中σ2表示一个参数,I表示恒等矩阵。在采用方程(13)的情况下,判别函数J(α)与如下方程对应:
J(α)=PD(α)/(PT(α)+σ2.....(14)
在上述实施方案中,没有考虑文档和句子的长度。因此,即使在不考虑文档长度的情况下已经获得了输入文档到每个类别的相似度,也还存在对相似度的修正量级对较长的文档扩大的更多或者相似度的修正量级受长文档影响较大的问题。因此,在图2的步骤15可以替换方程(4)为:

如前所述,K表示输入文档X中的句子的个数。因而,可以减少文档长度的影响。方程(5)同样如此。换句话说,假设Nk表示输入文档中第k个句子中出现的项的个数,可以替代方程(4)为:

因而,可以减少句子长度中偏差的影响。这对方程(5)来说同样正确。
此外,图3B中输入文档的句子向量xk可以很好的规范化如下,以便对方程(4)、(5)、(15)和(16)应用规范化的向量:
通过类似地规范化图6B和6C中的句子向量dmk和tmk来获取正负主题差异因子向量。
如上所述,依照本发明,每种类别的与众不同的信息可以用于分类,并因此显著地提高分类的精度。在一个采用路透社-21578实验中(练习文档的数量是7770,类别的数量是87,测试文档的数量是3019),现有KNN方法(其中没有进行证实对本发明的修正)的数据证明精度为85.93%、重复度为81.57%,F度量为83.69%。相反,根据依照本发明的方程(16)对相似度进行修正可以把精度、重复度和F度量分别增加到90.03%、84.40%和87.14%。
精度 重复度 F度量
现有KNN方法 85.93% 81.57% 83.69%
依照本发明的方法 90.03% 84.40% 87.14%
对精度、重复度和F度量的定义如前所述,在路透社-21578中一个文档可以属于多个类别。
这包括对示例实施方案的描述。虽然至此已经参考多个示例性实施方案对本发明进行了描述,但应该理解本领域的技术人员也可以设计多种符合本发明的原理的精神和范围的其它改进和实施方案。更准确地说,在不偏离本发明的精神的前提下在前述发明公开、附图以及所附权利要求的范围中提供的组合配置的部件和/或配置也可以有合理的变体和改进。除了部件和/或配置的变体和改进外,本领域的技术人员还将明白替代的用途。
Claims (21)
1.一种把给定的输入文档归类到至少一种文档类别的方法,该方法包括以下步骤:
(a)从输入文档中存在的项中选择用于分类的项;
(b)把输入文档分成预定单元的文档段;
(c)产生文档段向量,其分量是与在文档段中出现的选中的项的频率有关的数值,还产生文档向量,其中所有的文档段向量都被加在一起;
(d)用为每个文档类别保存的信息计算输入文档和每个类别之间的相似度;
(e)修正到每个类别的相似度;以及
(f)依照到每个类别的修正相似度确定输入文档所属的类别,
其中到每个类别的相似度是通过把为每个文档类别所保存的至少一个正主题差异因子向量和各自的文档段向量之间的点积平方的加权和加到输入文档到每个类别的相似度进行修正的;并且
通过从对每个类别的相似度减去为每个文档类别保存的至少一个负主题差异因子向量和各自的文档段向量之间的点积平方的加权和来对相似度进行进一步的修正。
2.如权利要求1限定的方法,其中用于修正相似度的每个类别的正负主题差异因子向量是通过以下步骤确定的:
(a)计算给定的练习文档集合中包括的练习文档和单个类别之间的相似度,并对练习文档进行分类;
(b)在对练习文档集合的分类结果的基础上找到一组竞争文档,其中每个文档的相似度都超过为各个类别所选的阈值,不管它还属于另一类别;
(c)找到每个类别的正主题差异因子向量作为最大化一个分数的投影轴,该分数的分子是在属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴上时获得的投影值的平方和,分母是在相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和;以及
(d)找到每个类别的负主题差异因子向量作为最大化一个分数的投影轴,该分数的分母是当属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴时获得的投影值的平方和,分子是当相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和。
3.如权利要求1限定的方法,其中文档段向量和文档向量是通过由它们各自的标准对它们进行分割而实现规范化的。
4.如权利要求1限定的方法,其中每个正或负主题差异因子向量和文档段向量之间的点积平方的加权和是通过由文档段中包括的项的数量对它们进行分割而实现规范化的。
5.如权利要求1限定的方法,其中每个正或负主题差异因子向量和文档段向量之间的点积平方的加权和是通过由输入文档中包含的文档段的数量对它们进行分割而实现规范化的。
6.一种用来把给定的输入文档归类到至少一个预先定义的文档类别的设备,该设备拥有文档输入单元、数据处理单元、分类引擎、分类信息单元和分类输出单元,该设备包括:
(a)选择器,从输入到文档输入单元的输入文档中出现的项中选择用于分类的项;
(b)分割器,把输入文档分割成预定单元的文档段;
(c)向量发生器,产生文档段向量,它的分量是与在文档段中出现的所选的项的频率有关的数值,并产生文档向量,其中文档段向量被加在一起;
(d)第一计算器,用预先为每个文档类别存储的信息计算输入文档和各个类别之间的相似度;
(e)加法器,把预先为每个文档类别存储的至少一个正主题差异因子向量和各自的文档段向量之间的点积平方的加权和加到输入文档到各个类别的相似度上;
(f)减法器,从各个类别的相似度减去预先为每个文档类别存储的至少一个负主题差异因子向量和各自的文档段向量之间的点积平方的加权和;
(g)判断器,根据对各个类别的修正相似度确定并输出输入文档所属的类别。
7.如权利要求6限定的设备,其中用于修正相似度的每种类别的正或负主题差异因子向量是由以下部件确定的:
(a)第二计算器,用于计算给定的练习文档集合中所包括的练习文档与各个类别之间的相似度,并对练习文档归类;
(b)第一探测器,用于在练习文档集合的分类结果的基础上找到一组竞争文档,其中的每个文档具有到各个类别的超过预定的阈值的相似度,而不管它们还属于其它类别;
(c)第二探测器,用于找到各个类别的正主题差异因子向量作为最大化一个分数的投影轴,该分数的分子是在属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴上时获得的投影值的平方和,其分母是在相干类别的竞争文档的文档段向量被投影到投影轴上时获得的投影值的平方和;
(d)第三探测器,用于找到各个类别的负主题差异因子向量作为最大化一个分数的投影轴,该分数的分母是在属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴上时获得的投影值的平方和,其分子是在相干类别的竞争文档的文档段向量被投影到投影轴上时获得的投影值的平方和。
8.一种把给定输入文档归类到至少一种文档类别的文档分类方法,该方法包括以下步骤:
(a)从输入文档里出现的项中选择用于分类的项;
(b)用预先为每种文档类别保存的信息计算输入文档和各个类别之间的相似度;
(c)修正计算出来的相似度;
(d)根据对各个类别的修正相似度确定输入文档所属的类别,
其中计算出来的相似度是通过以下步骤进行修正的:
把预先为每种文档类别保存的至少一个正主题差异因子向量和各自的文档段向量之间的点积平方的加权和加到输入文档对各个类别的相似度;
从对各个类别的相似度减去预先为每个类别保存的至少一个负主题差异因子向量和各自的文档段向量之间的点积平方的加权和。
9.如权利要求8限定的方法,其中用于修正相似度的每种类别的正负主题差异因子向量是由以下步骤决定的:
(a)计算给定的练习文档集合中包括的练习文档和单个类别之间的相似度,并对练习文档进行分类;
(b)在对练习文档集合的分类结果的基础上找到一组竞争文档,其中每个文档具有超过到各个类别的所选的一个阈值的相似度,不管它还属于其它类别;
(c)找到每个类别的正主题差异因子向量作为最大化一个分数的投影轴,该分数的分子是在属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴上时获得的投影值的平方和,分母是在相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和;以及
(d)找到每个类别的负主题差异因子向量作为最大化一个分数的投影轴,该分数的分母是当属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴时获得的投影值的平方和,分子是当相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和。
10.如权利要求8限定的文档分类方法,其中文档段向量和文档向量是通过用它们各自的标准对其进行分割而实现规范化的。
11.如权利要求9限定的方法,其中文档段向量和文档向量是通过用它们各自的标准对其进行分割而实现规范化的。
12.如权利要求8限定的文档分类方法,其中每个正或负主题差异因子向量和文档段向量之间的点积平方的加权和是通过用文档段中所包括的项的个数对其进行分割而实现规范化的。
13.如权利要求8限定的文档分类方法,其中每个正或负主题差异因子向量和文档段向量之间的点积平方的加权和是通过用输入文档中包括的文档段的个数对其进行分割而实现规范化的。
14.一种用来把给定的输入文档归类到至少一个预先定义的文档类别的设备,该设备拥有文档输入单元、数据处理单元、分类引擎、分类信息单元和分类输出单元,该设备包括:
(a)选择器,从输入到文档输入单元中的输入文档中出现的项中选择用于分类的项;
(b)第一计算器,用预先为每种文档类别保存的信息计算输入文档和各个类别之间的相似度;
(c)修正器,用来修正相似度;
(d)判断器,根据对各个类别的修正相似度确定并输出输入文档所属的类别,
其中修正器包括:
加法器,把预先为每种文档类别保存的至少一个正主题差异因子向量和各自的文档段向量之间的点积平方的加权和加到输入文档到各个类别的相似度;
减法器,从输入文档到各个类别的相似度减去预先为每个类别保存的至少一个负主题差异因子向量和各自的文档段向量之间的点积平方的加权和。
15.如权利要求14限定的设备,还包括第二计算器用来计算修正相似度中所用的各个类别的正负主题差异因子向量,该第二计算器包括:
(a)第三计算器,用来计算给定的练习文档集合中包括的练习文档和单个类别之间的相似度,并对练习文档进行分类;
(b)第一探测器,用来在对练习文档集合的分类结果的基础上找到一组竞争文档,其中每个文档具有超过到各个类别预定的一个阈值的相似度,不管它还属于其它类别;
(c)第二探测器,用来找到每个类别的正主题差异因子向量作为最大化一个分数的投影轴,该分数的分子是在属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴上时获得的投影值的平方和,分母是在相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和;以及
(d)第三探测器,找到每个类别的负主题差异因子向量作为最大化一个分数的投影轴,该分数的分母是当属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴时获得的投影值的平方和,分子是当相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和。
16.一种用于把给定文档归类到至少一种文档类别的设备,该设备包括下列步骤的处理装置:
从输入文档中存在的项中选择用于分类的项;
把输入文档分成预定单元中的文档段;
产生文档段向量,其分量是与在文档段中出现的选中的项的频率有关的数值,还产生文档向量,其中所有的文档段向量都被加在一起;
用为每个文档类别保存的信息计算输入文档和每个类别之间的相似度;
修正到每个类别的相似度;以及
依照到每个类别的修正相似度确定输入文档所属的类别,
所述设备还包括通过把为每种文档类别保存的至少一个正主题差异因子向量和各自的文档段向量之间的点积平方的加权和加到输入文档到各个类别的相似度来修正对各个类别的相似度;
还包括通过从输入文档到各个类别的相似度减去为每个文档类别保存的至少一个负主题差异因子向量和各自的文档段向量之间的点积平方的加权和来进一步修正相似度。
17.如权利要求16限定的设备,还包括用以下步骤确定修正相似度中所用的各个类别的正负主题差异因子向量:
计算给定的练习文档集合中包括的练习文档和单个类别之间的相似度,并对练习文档进行分类;
在对练习文档集合的分类结果的基础上找到一组竞争文档,其中每个文档具有超过到各个类别所选的一个阈值的相似度,不管它还属于其它类别;
找到每个类别的正主题差异因子向量作为最大化一个分数的投影轴,该分数的分子是在属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴上时获得的投影值的平方和,分母是在相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和;以及
找到每个类别的负主题差异因子向量作为最大化一个分数的投影轴,该分数的分母是当属于相干类别的所有或选中的文档的文档段向量被投影到该投影轴时获得的投影值的平方和,分子是当相干类别的竞争文档的文档段向量被投影到该投影轴时获得的投影值的平方和。
18.如权利要求16限定的设备,还包括通过用文档段向量和文档向量各自的标准对它们进行分割来实现对它们的规范化。
19.如权利要求17限定的设备,还包括通过用文档段向量和文档向量各自的标准对它们进行分割来实现对它们的规范化。
20.如权利要求16限定的设备,还包括通过用文档段中包括的项的个数对每个正负主题差异因子向量和文档段向量之间的点积平方的加权和进行分割来实现对它们的规范化。
21.如权利要求16限定的设备,还包括通过用输入文档中包括的文档段的个数对每个正负主题差异因子向量和文档段向量之间的点积平方的加权和进行分割来实现对它们的规范化。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP56238/02 | 2002-03-01 | ||
| JP2002056238A JP3726263B2 (ja) | 2002-03-01 | 2002-03-01 | 文書分類方法及び装置 |
| JP56238/2002 | 2002-03-01 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1458580A CN1458580A (zh) | 2003-11-26 |
| CN100397332C true CN100397332C (zh) | 2008-06-25 |
Family
ID=27800082
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB031068146A Expired - Fee Related CN100397332C (zh) | 2002-03-01 | 2003-03-03 | 文档分类方法和设备 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US7185008B2 (zh) |
| EP (1) | EP1365329B1 (zh) |
| JP (1) | JP3726263B2 (zh) |
| CN (1) | CN100397332C (zh) |
| DE (1) | DE60329550D1 (zh) |
Families Citing this family (70)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040083191A1 (en) * | 2002-10-25 | 2004-04-29 | Christopher Ronnewinkel | Intelligent classification system |
| JP2005044330A (ja) * | 2003-07-24 | 2005-02-17 | Univ Of California San Diego | 弱仮説生成装置及び方法、学習装置及び方法、検出装置及び方法、表情学習装置及び方法、表情認識装置及び方法、並びにロボット装置 |
| JP2005158010A (ja) * | 2003-10-31 | 2005-06-16 | Hewlett-Packard Development Co Lp | 分類評価装置・方法及びプログラム |
| US20050228790A1 (en) * | 2004-04-12 | 2005-10-13 | Christopher Ronnewinkel | Coherent categorization scheme |
| US7373358B2 (en) | 2004-04-12 | 2008-05-13 | Sap Aktiengesellschaft | User interface for maintaining categorization schemes |
| US20050229150A1 (en) * | 2004-04-12 | 2005-10-13 | Christopher Ronnewinkel | Design-time creation of run-time modules that use categorization |
| US20050228774A1 (en) * | 2004-04-12 | 2005-10-13 | Christopher Ronnewinkel | Content analysis using categorization |
| JP4634736B2 (ja) * | 2004-04-22 | 2011-02-16 | ヒューレット−パッカード デベロップメント カンパニー エル.ピー. | 専門的記述と非専門的記述間の語彙変換方法・プログラム・システム |
| WO2006008733A2 (en) * | 2004-07-21 | 2006-01-26 | Equivio Ltd. | A method for determining near duplicate data objects |
| US7440944B2 (en) * | 2004-09-24 | 2008-10-21 | Overture Services, Inc. | Method and apparatus for efficient training of support vector machines |
| WO2006039566A2 (en) * | 2004-09-30 | 2006-04-13 | Intelliseek, Inc. | Topical sentiments in electronically stored communications |
| US7814105B2 (en) * | 2004-10-27 | 2010-10-12 | Harris Corporation | Method for domain identification of documents in a document database |
| US7499591B2 (en) * | 2005-03-25 | 2009-03-03 | Hewlett-Packard Development Company, L.P. | Document classifiers and methods for document classification |
| US9158855B2 (en) | 2005-06-16 | 2015-10-13 | Buzzmetrics, Ltd | Extracting structured data from weblogs |
| US7725485B1 (en) * | 2005-08-01 | 2010-05-25 | Google Inc. | Generating query suggestions using contextual information |
| US7512580B2 (en) * | 2005-08-04 | 2009-03-31 | Sap Ag | Confidence indicators for automated suggestions |
| US7747495B2 (en) | 2005-10-24 | 2010-06-29 | Capsilon Corporation | Business method using the automated processing of paper and unstructured electronic documents |
| US8176004B2 (en) | 2005-10-24 | 2012-05-08 | Capsilon Corporation | Systems and methods for intelligent paperless document management |
| US7974984B2 (en) * | 2006-04-19 | 2011-07-05 | Mobile Content Networks, Inc. | Method and system for managing single and multiple taxonomies |
| US20080010388A1 (en) * | 2006-07-07 | 2008-01-10 | Bryce Allen Curtis | Method and apparatus for server wiring model |
| US8196039B2 (en) * | 2006-07-07 | 2012-06-05 | International Business Machines Corporation | Relevant term extraction and classification for Wiki content |
| US8560956B2 (en) | 2006-07-07 | 2013-10-15 | International Business Machines Corporation | Processing model of an application wiki |
| US20080010338A1 (en) * | 2006-07-07 | 2008-01-10 | Bryce Allen Curtis | Method and apparatus for client and server interaction |
| US8775930B2 (en) * | 2006-07-07 | 2014-07-08 | International Business Machines Corporation | Generic frequency weighted visualization component |
| US7954052B2 (en) * | 2006-07-07 | 2011-05-31 | International Business Machines Corporation | Method for processing a web page for display in a wiki environment |
| US20080010345A1 (en) * | 2006-07-07 | 2008-01-10 | Bryce Allen Curtis | Method and apparatus for data hub objects |
| US8219900B2 (en) * | 2006-07-07 | 2012-07-10 | International Business Machines Corporation | Programmatically hiding and displaying Wiki page layout sections |
| US20080010387A1 (en) * | 2006-07-07 | 2008-01-10 | Bryce Allen Curtis | Method for defining a Wiki page layout using a Wiki page |
| US20080010386A1 (en) * | 2006-07-07 | 2008-01-10 | Bryce Allen Curtis | Method and apparatus for client wiring model |
| WO2008029150A1 (en) * | 2006-09-07 | 2008-03-13 | Xploite Plc | Categorisation of data using a model |
| US7917492B2 (en) * | 2007-09-21 | 2011-03-29 | Limelight Networks, Inc. | Method and subsystem for information acquisition and aggregation to facilitate ontology and language-model generation within a content-search-service system |
| US8396878B2 (en) | 2006-09-22 | 2013-03-12 | Limelight Networks, Inc. | Methods and systems for generating automated tags for video files |
| US9015172B2 (en) | 2006-09-22 | 2015-04-21 | Limelight Networks, Inc. | Method and subsystem for searching media content within a content-search service system |
| US8966389B2 (en) * | 2006-09-22 | 2015-02-24 | Limelight Networks, Inc. | Visual interface for identifying positions of interest within a sequentially ordered information encoding |
| US8204891B2 (en) * | 2007-09-21 | 2012-06-19 | Limelight Networks, Inc. | Method and subsystem for searching media content within a content-search-service system |
| US9495358B2 (en) | 2006-10-10 | 2016-11-15 | Abbyy Infopoisk Llc | Cross-language text clustering |
| US9633005B2 (en) | 2006-10-10 | 2017-04-25 | Abbyy Infopoisk Llc | Exhaustive automatic processing of textual information |
| US9235573B2 (en) | 2006-10-10 | 2016-01-12 | Abbyy Infopoisk Llc | Universal difference measure |
| US7783640B2 (en) * | 2006-11-03 | 2010-08-24 | Oracle International Corp. | Document summarization |
| US8027977B2 (en) * | 2007-06-20 | 2011-09-27 | Microsoft Corporation | Recommending content using discriminatively trained document similarity |
| US20090063470A1 (en) | 2007-08-28 | 2009-03-05 | Nogacom Ltd. | Document management using business objects |
| TW200928793A (en) * | 2007-12-26 | 2009-07-01 | Ruei-Jau Chen | Algorithm method capable of enhancing accuracy and computation speed of the computation of corrected sums of products (CSP) of computing hardware |
| US8296301B2 (en) | 2008-01-30 | 2012-10-23 | Commvault Systems, Inc. | Systems and methods for probabilistic data classification |
| JP5467643B2 (ja) * | 2010-04-28 | 2014-04-09 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 文書の類似度を判定する方法、装置及びプログラム。 |
| US20120041955A1 (en) * | 2010-08-10 | 2012-02-16 | Nogacom Ltd. | Enhanced identification of document types |
| US8452774B2 (en) * | 2011-03-10 | 2013-05-28 | GM Global Technology Operations LLC | Methodology to establish term co-relationship using sentence boundary detection |
| US8996350B1 (en) | 2011-11-02 | 2015-03-31 | Dub Software Group, Inc. | System and method for automatic document management |
| US9256862B2 (en) * | 2012-02-10 | 2016-02-09 | International Business Machines Corporation | Multi-tiered approach to E-mail prioritization |
| US9152953B2 (en) * | 2012-02-10 | 2015-10-06 | International Business Machines Corporation | Multi-tiered approach to E-mail prioritization |
| US8831361B2 (en) | 2012-03-09 | 2014-09-09 | Ancora Software Inc. | Method and system for commercial document image classification |
| US9715723B2 (en) | 2012-04-19 | 2017-07-25 | Applied Materials Israel Ltd | Optimization of unknown defect rejection for automatic defect classification |
| US10043264B2 (en) | 2012-04-19 | 2018-08-07 | Applied Materials Israel Ltd. | Integration of automatic and manual defect classification |
| US9607233B2 (en) * | 2012-04-20 | 2017-03-28 | Applied Materials Israel Ltd. | Classifier readiness and maintenance in automatic defect classification |
| US9348899B2 (en) | 2012-10-31 | 2016-05-24 | Open Text Corporation | Auto-classification system and method with dynamic user feedback |
| CN103049263B (zh) * | 2012-12-12 | 2015-06-10 | 华中科技大学 | 一种基于相似性的文件分类方法 |
| US10114368B2 (en) | 2013-07-22 | 2018-10-30 | Applied Materials Israel Ltd. | Closed-loop automatic defect inspection and classification |
| RU2592395C2 (ru) | 2013-12-19 | 2016-07-20 | Общество с ограниченной ответственностью "Аби ИнфоПоиск" | Разрешение семантической неоднозначности при помощи статистического анализа |
| RU2586577C2 (ru) | 2014-01-15 | 2016-06-10 | Общество с ограниченной ответственностью "Аби ИнфоПоиск" | Фильтрация дуг в синтаксическом графе |
| CN105335390A (zh) * | 2014-07-09 | 2016-02-17 | 阿里巴巴集团控股有限公司 | 对象的分类方法、业务的推送方法及服务器 |
| US9626358B2 (en) | 2014-11-26 | 2017-04-18 | Abbyy Infopoisk Llc | Creating ontologies by analyzing natural language texts |
| US20160162576A1 (en) * | 2014-12-05 | 2016-06-09 | Lightning Source Inc. | Automated content classification/filtering |
| US9870420B2 (en) * | 2015-01-19 | 2018-01-16 | Google Llc | Classification and storage of documents |
| CN106708485B (zh) * | 2015-11-13 | 2020-07-14 | 北大方正集团有限公司 | 电子字帖热度管理方法及系统 |
| JP6635966B2 (ja) * | 2017-03-28 | 2020-01-29 | 日本電信電話株式会社 | 可視化装置、可視化方法、及びプログラム |
| JP6974751B2 (ja) * | 2017-03-28 | 2021-12-01 | 日本電信電話株式会社 | 可視化装置、可視化方法、及びプログラム |
| CN110019655A (zh) * | 2017-07-21 | 2019-07-16 | 北京国双科技有限公司 | 先例案件获取方法及装置 |
| US11481389B2 (en) * | 2017-12-18 | 2022-10-25 | Fortia Financial Solutions | Generating an executable code based on a document |
| KR102264232B1 (ko) * | 2018-05-31 | 2021-06-14 | 주식회사 마인즈랩 | 단어, 문장 특징값 및 단어 가중치 간의 상관관계를 학습한 인공 신경망에 의해 생성된 설명이 부가된 문서 분류 방법 |
| CN109684121A (zh) * | 2018-12-20 | 2019-04-26 | 鸿秦(北京)科技有限公司 | 一种文件恢复方法及系统 |
| JP7138981B1 (ja) | 2021-08-11 | 2022-09-20 | Croco株式会社 | 類似度判定装置、類似度判定システム、類似度判定方法、およびプログラム |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1158460A (zh) * | 1996-12-31 | 1997-09-03 | 复旦大学 | 一种跨语种语料自动分类与检索方法 |
| WO1997033250A1 (en) * | 1996-03-06 | 1997-09-12 | Hewlett-Packard Company | Method for optimizing a recognition dictionary to distinguish between patterns that are difficult to distinguish |
| US5671333A (en) * | 1994-04-07 | 1997-09-23 | Lucent Technologies Inc. | Training apparatus and method |
| JPH1153394A (ja) * | 1997-07-29 | 1999-02-26 | Just Syst Corp | 文書処理装置、文書処理プログラムが記憶された記憶媒体、及び文書処理方法 |
| JP2000194723A (ja) * | 1998-12-25 | 2000-07-14 | Just Syst Corp | 類似度表示装置、類似度表示プログラムが記憶された記憶媒体、文書処理装置、文書処理プログラムが記憶された記憶媒体、及び文書処理方法 |
| US6192360B1 (en) * | 1998-06-23 | 2001-02-20 | Microsoft Corporation | Methods and apparatus for classifying text and for building a text classifier |
| CN1363899A (zh) * | 2000-12-28 | 2002-08-14 | 松下电器产业株式会社 | 文本分类参数生成器和使用所生成参数的文本分类器 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2978044B2 (ja) * | 1993-10-18 | 1999-11-15 | シャープ株式会社 | 文書分類装置 |
| GB9625284D0 (en) * | 1996-12-04 | 1997-01-22 | Canon Kk | A data processing method and apparatus for identifying a classification to which data belongs |
| US6003027A (en) * | 1997-11-21 | 1999-12-14 | International Business Machines Corporation | System and method for determining confidence levels for the results of a categorization system |
| US6611825B1 (en) * | 1999-06-09 | 2003-08-26 | The Boeing Company | Method and system for text mining using multidimensional subspaces |
| JP2001331514A (ja) * | 2000-05-19 | 2001-11-30 | Ricoh Co Ltd | 文書分類装置及び文書分類方法 |
-
2002
- 2002-03-01 JP JP2002056238A patent/JP3726263B2/ja not_active Expired - Fee Related
-
2003
- 2003-02-26 DE DE60329550T patent/DE60329550D1/de not_active Expired - Lifetime
- 2003-02-26 EP EP03251175A patent/EP1365329B1/en not_active Expired - Lifetime
- 2003-02-27 US US10/373,689 patent/US7185008B2/en not_active Expired - Fee Related
- 2003-03-03 CN CNB031068146A patent/CN100397332C/zh not_active Expired - Fee Related
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5671333A (en) * | 1994-04-07 | 1997-09-23 | Lucent Technologies Inc. | Training apparatus and method |
| WO1997033250A1 (en) * | 1996-03-06 | 1997-09-12 | Hewlett-Packard Company | Method for optimizing a recognition dictionary to distinguish between patterns that are difficult to distinguish |
| CN1158460A (zh) * | 1996-12-31 | 1997-09-03 | 复旦大学 | 一种跨语种语料自动分类与检索方法 |
| JPH1153394A (ja) * | 1997-07-29 | 1999-02-26 | Just Syst Corp | 文書処理装置、文書処理プログラムが記憶された記憶媒体、及び文書処理方法 |
| US6192360B1 (en) * | 1998-06-23 | 2001-02-20 | Microsoft Corporation | Methods and apparatus for classifying text and for building a text classifier |
| CN1310825A (zh) * | 1998-06-23 | 2001-08-29 | 微软公司 | 用于分类文本以及构造文本分类器的方法和装置 |
| JP2000194723A (ja) * | 1998-12-25 | 2000-07-14 | Just Syst Corp | 類似度表示装置、類似度表示プログラムが記憶された記憶媒体、文書処理装置、文書処理プログラムが記憶された記憶媒体、及び文書処理方法 |
| CN1363899A (zh) * | 2000-12-28 | 2002-08-14 | 松下电器产业株式会社 | 文本分类参数生成器和使用所生成参数的文本分类器 |
Non-Patent Citations (4)
| Title |
|---|
| Data Compression and Local Metrics for NearestNerghbor Classification. Francesco Ricci and Paolo Avesani.IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,Vol.21 No.4. 1999 |
| Data Compression and Local Metrics for NearestNerghbor Classification. Francesco Ricci and Paolo Avesani.IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,Vol.21 No.4. 1999 * |
| Discriminant Adaptive Nearest Neighbor Classification. Trevor Hastie and Robert Tibshirani.IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,Vol.18 No.6. 1996 |
| Discriminant Adaptive Nearest Neighbor Classification. Trevor Hastie and Robert Tibshirani.IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,Vol.18 No.6. 1996 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP3726263B2 (ja) | 2005-12-14 |
| US20030167267A1 (en) | 2003-09-04 |
| US7185008B2 (en) | 2007-02-27 |
| EP1365329A3 (en) | 2006-11-22 |
| CN1458580A (zh) | 2003-11-26 |
| EP1365329B1 (en) | 2009-10-07 |
| EP1365329A2 (en) | 2003-11-26 |
| DE60329550D1 (de) | 2009-11-19 |
| JP2003256441A (ja) | 2003-09-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN100397332C (zh) | 文档分类方法和设备 | |
| US7472131B2 (en) | Method and apparatus for constructing a compact similarity structure and for using the same in analyzing document relevance | |
| US20050097436A1 (en) | Classification evaluation system, method, and program | |
| CN104750844A (zh) | 基于tf-igm的文本特征向量生成方法和装置及文本分类方法和装置 | |
| CN110516074B (zh) | 一种基于深度学习的网站主题分类方法及装置 | |
| CN103699523A (zh) | 产品分类方法和装置 | |
| CN110795564B (zh) | 一种缺少负例的文本分类方法 | |
| CN102024150A (zh) | 图形识别方法及图形识别装置 | |
| CN104750875B (zh) | 一种机器错误数据分类方法及系统 | |
| CN106529580A (zh) | 结合edsvm的软件缺陷数据关联分类方法 | |
| CN110008309A (zh) | 一种短语挖掘方法及装置 | |
| CN109508460B (zh) | 基于主题聚类的无监督作文跑题检测方法及系统 | |
| CN107977454A (zh) | 双语语料清洗的方法、装置及计算机可读存储介质 | |
| CN112347352A (zh) | 一种课程推荐方法、装置及存储介质 | |
| CN114139634A (zh) | 一种基于成对标签权重的多标签特征选择方法 | |
| CN109035025A (zh) | 评价股票评论可靠性的方法和装置 | |
| CN106056146B (zh) | 基于逻辑回归的视觉跟踪方法 | |
| CN105894032A (zh) | 一种针对样本性质提取有效特征的方法 | |
| Liang et al. | Performance evaluation of document structure extraction algorithms | |
| JP2010272004A (ja) | 判別装置及び判別方法、並びにコンピューター・プログラム | |
| Larsson | Classification into readability levels: implementation and evaluation | |
| JP4479745B2 (ja) | 文書の類似度補正方法、プログラムおよびコンピュータ | |
| CN110162629B (zh) | 一种基于多基模型框架的文本分类方法 | |
| CN112132239A (zh) | 一种训练方法、装置、设备和存储介质 | |
| Holden et al. | The effects of initially misclassified data on the effectiveness of discriminant function analysis and finite mixture modeling |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20080625 Termination date: 20110303 |