JP2005199403A - Emotion recognition device and method, emotion recognition method of robot device, learning method of robot device and robot device - Google Patents
Emotion recognition device and method, emotion recognition method of robot device, learning method of robot device and robot device Download PDFInfo
- Publication number
- JP2005199403A JP2005199403A JP2004009690A JP2004009690A JP2005199403A JP 2005199403 A JP2005199403 A JP 2005199403A JP 2004009690 A JP2004009690 A JP 2004009690A JP 2004009690 A JP2004009690 A JP 2004009690A JP 2005199403 A JP2005199403 A JP 2005199403A
- Authority
- JP
- Japan
- Prior art keywords
- emotion
- recognition
- modal
- time
- estimation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images









Abstract
Description
本発明は、情動を認識するための認識対象の情動を、センサ情報から抽出した認識対象の特徴量に基づき認識する情動認識装置及び方法、この情動認識装置を搭載したロボット装置の学習方法、並びに、インタラクション対象の情動を認識するロボット装置及びその情動認識方法に関する。 The present invention relates to an emotion recognition device and method for recognizing emotion to be recognized for recognizing emotion based on the feature quantity of the recognition target extracted from the sensor information, a learning method for a robot apparatus equipped with the emotion recognition device, and The present invention relates to a robot apparatus for recognizing emotion to be interacted with and a method for recognizing the emotion.
従来の感情認識技術やそれを応用したシステムとしては、下記特許文献1乃至特許文献4などがある。例えば特許文献1には、ユーザの音声に含まれる感情に反応してストリーが展開される対話型映画システムの技術が開示されている。また、特許文献2には、音声から感情を認識する認識器と、画像から感情を認識する認識器とを用意し、認識器が認識した感情に応じて重み付けして統合する階層的感情認識装置の技術が開示されている。
Examples of conventional emotion recognition technology and systems to which the technology is applied include
また、特許文献3には、学会などの発表者に対して発表者自身の感情を聴衆の反応に応じて認識し、フィードバックさせる発表支援装置の技術が開示されている。更に、特許文献4には、複数の感情認識器の認識結果を重み付けして統合することで人間の感情を認識し、認識した感情を考慮した行動パターンを提案するための行動パターン処理装置が開示されている。 Further, Patent Document 3 discloses a technology of a presentation support apparatus that recognizes a presenter's own emotion according to a reaction of an audience and gives feedback to a presenter such as an academic society. Furthermore, Patent Document 4 discloses a behavior pattern processing device for recognizing human emotions by weighting and integrating recognition results of a plurality of emotion recognizers and proposing a behavior pattern in consideration of the recognized emotions. Has been.
これら下記特許文献1乃至特許文献4における感情認識技術には下記のような特徴がある。すなわち、
各感情に専用のサブ認識器を設け、出力を論理合成して最終的な出力とする
複数の特徴量に基づく認識結果を重み付けによって組み合わせ、最終的な出力とする
認識結果を統合する重み付けパラメータは実験的に採取した教師データを元に算出している
各認識器で利用するパラメータは認識対象の各個人毎に準備されている。
The emotion recognition techniques in the following
A dedicated sub-recognition device is provided for each emotion, and the output is logically synthesized to obtain the final output. The weighting parameters that combine the recognition results based on multiple feature quantities by weighting and combine the recognition results that are the final output are The parameters used by each recognizer calculated based on experimentally collected teacher data are prepared for each individual to be recognized.
しかしながら、これら特許文献1乃至特許文献4に記載の技術においては、下記のような問題点がある。すなわち、各認識器はその瞬間のセンサ入力情報のベクトルのみに依存してその出力を決定するものである。したがって、感情認識装置が例えば、表情、音声、ジェスチャなどに関するセンサ入力のベクトル情報と、それに対応する感情との写像関係を学習するようなモデルで構成されている場合、そのときのセンサ入力情報、すなわち認識対象の表面的な状態変化のみを絶対的なものとして信頼し、出力を決定するため、少しのセンサ入力の変化で容易に認識結果が変化してしまい、安定することがない。
However, the techniques described in
例えば、機嫌よく話をしている最中に、考え事をして少し顔をしかめただけでその一瞬は嫌悪感を表出していると判断されるようなものである。従来の技術では、上記のような脆弱な認識器から得られた情報をそのまま機器の機能選択やロボット装置の行動選択に利用することが提案されているが、実際のシステムを構築した場合、ちょっとした出力の変化で機能を選択していては、頻繁に機能選択が起こり機器の利用上の支障をきたす。機器の機能選択やロボット装置の行動選択、又はコミュニケーションにおいて重要なのは、認識対象の根底に定常的にある感情の状態である。一瞬の表情の変化や、発話のちょっとした語調の変化から生じる認識結果のブレは何らかの処理によってスムージングされることが必要である。 For example, while talking in good mood, just thinking and making a little frown will determine that you are feeling disgusted for a moment. In the conventional technology, it has been proposed to use the information obtained from the vulnerable recognizer as described above for selecting the function of the device or selecting the action of the robot device as it is. When a function is selected based on a change in output, the function is frequently selected, resulting in trouble in using the device. What is important in device function selection, robot device action selection, or communication is the state of emotion that is constantly at the base of the recognition target. The blurring of the recognition result caused by a momentary change in facial expression or a slight change in speech tone needs to be smoothed by some processing.
本発明は、このような従来の実情に鑑みて提案されたものであり、コンテキストを考慮することで認識対象の情動の状態を安定的に推定する情動推定装置及び方法、そのような情動推定装置を搭載したロボット装置及びその情動認識方法、並びに情動推定装置を搭載したロボット装置及びその学習方法を提供することを目的とする。 The present invention has been proposed in view of such a conventional situation, and an emotion estimation device and method for stably estimating the state of emotion to be recognized by considering the context, and such an emotion estimation device It is an object of the present invention to provide a robot apparatus equipped with a robot apparatus, an emotion recognition method thereof, a robot apparatus equipped with an emotion estimation apparatus, and a learning method thereof.
上述した目的を達成するために、本発明に係る情動認識装置は、時系列のセンサ情報から、情動を認識するための認識対象に関する時系列の特徴量を抽出する特徴量抽出手段と、上記時系列の特徴量に基づき、上記センサ情報のコンテキストを考慮して上記認識対象の情動を推定する情動推定手段とを有することを特徴とする。 In order to achieve the above-described object, an emotion recognition apparatus according to the present invention includes a feature amount extraction unit that extracts time-series feature amounts related to a recognition target for recognizing emotion from time-series sensor information, and the time And an emotion estimation means for estimating the emotion of the recognition target in consideration of the context of the sensor information based on the feature quantity of the sequence.
本発明においては、時系列の特徴量に基づき認識対象の情動を推定する、すなわちセンサ情報のコンテキストを考慮して情動推定を行うため、例えば認識対象の一瞬の情動変化又は瞬間的なセンサ情報から抽出した特徴量に基づく推定結果の誤りなどを反映してしまうことがなく、認識対象の情動推定結果を平滑化したものとして認識することができる。 In the present invention, since the emotion of the recognition target is estimated based on the time-series feature quantity, that is, the emotion estimation is performed in consideration of the context of the sensor information, for example, from the momentary emotion change or the instantaneous sensor information of the recognition target An error in the estimation result based on the extracted feature amount is not reflected, and the emotion estimation result of the recognition target can be recognized as smoothed.
また、上記特徴量抽出手段は、複数のモーダルについて各モーダル毎の上記時系列の特徴量をモーダル別特徴量列として抽出し、上記情動推定手段は、上記モーダル別特徴量列に基づき各モーダル毎に上記情動を認識する複数のモーダル別情動認識手段と、上記各モーダル別情動認識手段の認識結果に基づき上記情動を推定する認識結果統合手段とを有することにより、例えば認識対象の表情、ジェスチャ、音声などのモーダル別に時系列の特徴量を抽出し、モーダル別に情動を認識することができ、認識結果統合手段は、1つのモーダルについて推定された情動を認識結果としたり、複数のモーダルについて推定された情動を統合して認識結果としたりすることができる。 Further, the feature quantity extraction means extracts the time-series feature quantity for each modal for a plurality of modals as a modal feature quantity sequence, and the emotion estimation means performs each modal based on the modal feature quantity sequence. A plurality of modal emotion recognition means for recognizing the emotion and a recognition result integration means for estimating the emotion based on the recognition results of the modal emotion recognition means. Extracts time-series features for each modal such as speech, and can recognize emotions by modal. The recognition result integration means uses the emotion estimated for one modal as the recognition result or estimates for multiple modals. It is possible to integrate emotions into recognition results.
更に、上記情動推定手段は、上記モーダル別情動認識手段により得られた認識結果の予測誤差を算出する予測誤差算出手段を有し、上記認識結果統合手段は、上記各モーダル別情動認識手段により得られた認識結果及びその予測誤差に基づき上記情動を推定することができ、モーダルに応じて異なる情動認識率などを有する場合にこれを上記予測誤差に反映させることで更に情動推定手段の情動推定率(情動認識率)を向上することができる。 Further, the emotion estimation means includes prediction error calculation means for calculating a prediction error of the recognition result obtained by the modal emotion recognition means, and the recognition result integration means is obtained by the modal emotion recognition means. The emotion can be estimated based on the recognition result obtained and its prediction error, and when the emotion recognition rate differs depending on the modal, the emotion estimation rate of the emotion estimation means is further reflected by reflecting this in the prediction error. (Emotion recognition rate) can be improved.
更にまた、上記認識結果統合手段は、上記予測誤差算出手段により得られた予測誤差を信頼度に変換し、各モーダル別情動認識手段により得られた認識結果にその信頼度を重み付けした重み付け認識結果に基づき上記情動を推定することができ、予測誤差をある程度平均化するなどして信頼度とし、重み付け認識結果を求めることで、情動推定手段が推定結果を更に平滑化することができる。 Furthermore, the recognition result integration means converts the prediction error obtained by the prediction error calculation means into reliability, and weighted recognition results obtained by weighting the recognition results obtained by the modal emotion recognition means. The emotion can be estimated based on the above, and the estimation result can be further smoothed by obtaining the weighted recognition result by averaging the prediction error to some extent to obtain the reliability.
また、上記情動推定手段は、時系列のセンサ情報から抽出した認識対象に関する時系列の特徴量を入力データとしたとき、上記時系列のセンサ情報を取得した際の上記認識対象の情動が出力データとなるよう、再帰的学習により予め学習されたものとすることができ、情動推定手段を例えばリカレントネットワークとして学習することができる。 In addition, when the emotion estimation unit uses, as input data, a time-series feature amount related to the recognition target extracted from the time-series sensor information, the emotion of the recognition target when the time-series sensor information is acquired is output data. Thus, it can be learned in advance by recursive learning, and the emotion estimation means can be learned as a recurrent network, for example.
本発明に係るロボット装置は、内部状態及び/又は外部刺激に基づき自律的に行動するロボット装置において、インタラクション対象に関する情報を取得する1以上のセンサと、上記センサから時系列のセンサ情報を受け取り、上記インタラクション対象に関する時系列の特徴量を抽出する特徴量抽出手段と、上記時系列の特徴量に基づき、上記センサ情報のコンテキストを考慮して上記インタラクション対象の情動を推定する情動推定手段とを有することを特徴とする。 The robot apparatus according to the present invention receives one or more sensors for acquiring information related to an interaction target in the robot apparatus acting autonomously based on an internal state and / or an external stimulus, and time-series sensor information from the sensor. Feature amount extraction means for extracting a time-series feature amount related to the interaction target, and emotion estimation means for estimating the emotion of the interaction target in consideration of the context of the sensor information based on the time-series feature amount It is characterized by that.
本発明においては、ロボット装置のインタラクション対象となるユーザなどの情動を、ユーザの特徴量の時系列データに基づき推定する情動推定手段を有するため、ユーザの情動を誤認識や一時的な認識結果によらないものとしてより確実に推定することができる。 In the present invention, since there is an emotion estimation means for estimating the emotion of the user who is the interaction target of the robot apparatus based on the time-series data of the feature quantity of the user, the emotion of the user is misrecognized or temporarily recognized. It can be more reliably estimated that it does not depend.
また、複数の行動から一の行動を選択して実行する行動実行手段と、上記行動実行手段により実行された行動の種類に応じて上記インタラクション対象の情動を予測する情動予測手段と、上記情動推定手段により得られた推定結果と上記情動予測手段により得られた予測結果とに基づき上記インタラクション対象の情動を推定する情動統合手段とを有することができ、更に安定かつ正確に情動を推定することができる。 In addition, an action execution means for selecting and executing one action from a plurality of actions, an emotion prediction means for predicting the emotion of the interaction target according to the type of action executed by the action execution means, and the emotion estimation And an emotion integration means for estimating the emotion of the interaction target based on the estimation result obtained by the means and the prediction result obtained by the emotion prediction means, and can more stably and accurately estimate the emotion. it can.
更に、上記情動予測手段は、一の行動と、該一の行動の実行後に変化すると予想される予想情動変化とが対応づけられた予想情動変化データベースを参照して行動実行後の情動変化を予想し、該予想結果と行動実行前に上記情動推定手段により推定された推定結果とに基づき行動実行後の上記情動を予測することができ、行動実行前後に変化すると考えられるインタラクション対象の情動変化を予測することができる。 Further, the emotion prediction means predicts an emotion change after the execution of the action with reference to an expected emotion change database in which one action is associated with an expected emotion change expected to change after the execution of the one action. The emotion after the execution of the action can be predicted based on the prediction result and the estimation result estimated by the emotion estimation unit before the execution of the action. Can be predicted.
更にまた、上記予想情動変化データベースは、各行動に対してその実行前後の上記インタラクション対象の情動変化に基づき上記予想情動変化が学習されたものとすることができ、例えば一の行動が実行された際の行動実行前後における上記情動推定手段による推定結果や、外部から与えられた行動実行前後における情動変化に基づき、一の行動を実行する毎に更新して上記予想情動データベースを逐次更新することで、行動のコンテキストを考慮した予想情動データベースを構築することができる。 Furthermore, the predicted emotion change database may be such that the expected emotion change is learned based on the emotion change of the interaction target before and after the execution of each action, for example, one action is executed. Update each time an action is executed based on the estimation result by the emotion estimation means before and after the execution of the action and the emotional change before and after the execution of the action given from outside. It is possible to construct a predicted emotion database that takes into account the context of behavior.
また、上記情動統合手段は、行動実行後から時間が経過するに従って上記情動予測手段による予測結果より上記情動推定手段による推定結果を重視するように変化するパラメータにより、上記推定結果及び予測結果に重み付けし、該重み付けした結果に基づき上記情動を推定することができ、情動推定手段における推定結果に対して情動予測手段の予測結果によりトップダウンの補正を行うと共に、行動の実行に関わらず常に得られる情動推定手段の推定結果を、行動実行後の経過時間が長くなるほど重視させるようにすることができる。 In addition, the emotion integration unit weights the estimation result and the prediction result with a parameter that changes so that the estimation result by the emotion estimation unit is more important than the prediction result by the emotion prediction unit as time elapses after execution of the action. Then, the emotion can be estimated based on the weighted result, and the estimation result in the emotion estimation means is top-down corrected by the prediction result of the emotion prediction means, and is always obtained regardless of the execution of the action. The estimation result of the emotion estimation means can be emphasized as the elapsed time after executing the action becomes longer.
本発明に係るロボット装置の学習方法は、与えられた入力データから、インタラクション対象の情動を認識する情動認識装置を搭載したロボット装置の学習方法において、時系列のセンサ情報から抽出したインタラクション対象に関する時系列の特徴量を入力データとし、当該時系列のセンサ情報を取得した際の上記インタラクション対象の情動を出力の目標値として上記情動認識装置の学習をする学習工程を有することを特徴とする。 A learning method for a robot apparatus according to the present invention is a learning method for a robot apparatus equipped with an emotion recognition apparatus for recognizing an emotion of an interaction target from given input data, and relates to an interaction target extracted from time-series sensor information. It has a learning step in which the emotion recognition device learns using the feature quantity of the series as input data and the emotion of the interaction target when the time-series sensor information is acquired as the output target value.
本発明においては、ロボット装置の情動認識装置を、例えばリカレントネットワークなどにより構成することで、時系列の特徴量を入力データとして情動を認識するものとして学習することで、インタラクション対象の情動を、センサ情報のコンテキストを考慮して推定することが可能な情動認識装置を搭載したロボット装置を得ることができる。 In the present invention, the emotion recognition device of the robot apparatus is configured by, for example, a recurrent network, and learning is performed by recognizing the emotion using time-series feature amounts as input data. A robot apparatus equipped with an emotion recognition apparatus that can be estimated in consideration of the context of information can be obtained.
本発明に係る情動認識装置及び方法によれば、時系列のセンサ情報から、インタラクション対象に関する時系列の特徴量を抽出し、これに基づき、上記センサ情報のコンテキストを考慮して上記インタラクション対象の情動を推定するので、例えば瞬間的なセンサ情報に基づいてインタラクション対象の一瞬の表情の変化や、発話の際の一瞬の語調の変化を認識結果に反映させてしまうことを防止し、インタラクション対象の情動推定結果を平滑化してより自然なものとして認識することができる。 According to the emotion recognition apparatus and method of the present invention, a time-series feature amount related to an interaction target is extracted from time-series sensor information, and based on this, the emotion of the interaction target is considered in consideration of the context of the sensor information. For example, it is possible to prevent changes in the facial expression of the interaction target and instantaneous tone changes during the utterance from being reflected in the recognition result based on instantaneous sensor information. The estimation result can be smoothed and recognized as more natural.
更に、本発明に係るロボット装置及びその情動認識方法によれば、時系列のセンサ情報から、インタラクション対象に関する時系列の特徴量を抽出し、これに基づき、上記センサ情報のコンテキストを考慮して上記インタラクション対象の情動を推定する情動認識装置を搭載することで、ロボット装置が、ユーザの一瞬の表情変化や、発話の一瞬の語調の変化に左右されることなく、インタラクション対象となるユーザなどの情動をより正しく認識することができ、ユーザとのインタラクションをより上手に行うことができ、また、時系列のセンサ情報に加え、自身の行動履歴に基づきユーザの情動変化を予測した結果を考慮すれば、センサ情報に基づく認識結果を補正して更に正確にユーザの情動を認識し、より生物らしい振る舞いを行わせることが可能となる。 Furthermore, according to the robot apparatus and the emotion recognition method according to the present invention, the time-series feature amount related to the interaction target is extracted from the time-series sensor information, and based on this, the above-described sensor information context is taken into consideration. Equipped with an emotion recognition device that estimates the emotion of the interaction target, the robot device can affect the emotion of the user or the like that is subject to interaction without being influenced by the momentary facial expression change or the instantaneous tone change of the utterance. If you consider the results of predicting the user's emotional change based on their own action history in addition to time-series sensor information, , Correct the recognition result based on sensor information, recognize the user's emotions more accurately, and behave more biologically Rukoto is possible.
また、本発明に係るロボット装置及びその学習方法によれば、時系列のセンサ情報から抽出したインタラクション対象の時系列の特徴量を入力とし、その際の実際のインタラクション対象の情動を出力目標値として、例えばリカレントネットワークなどの再帰学習により学習を行うことで、センサ情報のコンテキストを考慮してインタラクション対象の情動を認識することが可能な情動認識装置の学習をロボット装置が行うことができる。 Further, according to the robot apparatus and the learning method thereof according to the present invention, the time series feature quantity of the interaction target extracted from the time series sensor information is input, and the actual interaction target emotion at that time is used as the output target value. For example, by performing learning by recursive learning such as a recurrent network, the robot apparatus can learn an emotion recognition apparatus capable of recognizing the emotion of an interaction target in consideration of the context of sensor information.
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。この実施の形態は、本発明を、コンテキストを考慮して、認識対象の情動を認識する情動認識システムを搭載したロボット装置に適用したものである。本実施の形態におけるロボット装置は、外部環境(外部刺激)の時系列データと、行動履歴とから情動の認識対象となるインタラクション対象(以下、ユーザという。)の情動を安定的かつ正しく推定するものである。ここでは、先ず、情動認識システムについて説明し、その後、この情動認識装置を搭載するに好適なロボット装置の一構成例について説明する。 Hereinafter, specific embodiments to which the present invention is applied will be described in detail with reference to the drawings. In this embodiment, the present invention is applied to a robot apparatus equipped with an emotion recognition system that recognizes an emotion to be recognized in consideration of the context. The robot apparatus according to the present embodiment stably and correctly estimates an emotion of an interaction target (hereinafter referred to as a user) as an emotion recognition target from time series data of an external environment (external stimulus) and an action history. It is. Here, the emotion recognition system will be described first, and then a configuration example of a robot apparatus suitable for mounting the emotion recognition device will be described.
A:情動認識システム
上述した如く、従来の情動認識器は、例えばユーザなどのインタラクション対象の瞬間的な音声や画像から得られる特徴量から、インタラクション対象の情動を認識するものであって、コンテキスト情報を無視しているため認識結果が不安定となってしまう。ここでいうコンテキストとは具体的には、インタラクション対象がたった今どのような情動状態であったか、インタラクション対象に対してたった今、ロボット装置自身がどのような行動を行ったのかなどである。
A: Emotion recognition system As described above, the conventional emotion recognizer recognizes the emotion of the interaction target from the feature amount obtained from the instantaneous voice or image of the interaction target of the user, for example, and includes context information. The result of recognition becomes unstable because of ignoring. Specifically, the context here refers to what kind of emotional state the interaction target is just now, what action the robot apparatus itself has just performed on the interaction target, and the like.
そこで、本実施の形態におけるロボット装置は、コンテキストを考慮して情動認識を行うため、それまでの状態を基準とし、次の状態を予測するアルゴリズムの1つとしてリカレントニューラルネットワークなどを利用することによって、入力情報、本実施の形態においては、センサ情報から抽出される特徴量の時間的な変化(コンテキスト)を考慮して情動を推定するものである。 Therefore, the robot apparatus according to the present embodiment performs emotion recognition in consideration of the context, and therefore uses a recurrent neural network or the like as one of algorithms for predicting the next state based on the previous state. In this embodiment, the emotion is estimated in consideration of the temporal change (context) of the feature amount extracted from the sensor information.
さらに、ロボット装置自らが行う行動選択と、当該選択した行動によるインタラクション対象の情動変化の対応関係を予測するモデルを準備し、これによりロボット装置がどのような行動を取るとインタラクション対象にどのような情動変化が起こるかを予測して、センサ情報から推定される情動推定結果にトップダウンの補正をかけることにより、情動推定結果を更に平滑化するものである。 Furthermore, a model that predicts the correspondence between the action selection performed by the robot apparatus itself and the emotional change of the interaction target due to the selected action is prepared. The emotion estimation result is further smoothed by predicting whether an emotional change will occur and applying top-down correction to the emotion estimation result estimated from the sensor information.
すなわち、本実施の形態における情動認識システムは、時系列のセンサ情報からユーザの情動を推定する情動推定装置と、実行した行動の種類に応じてユーザの情動変化を予測するための情動予測装置と、情動推定装置が推定した推定結果(以下、推定情動Esという。)及び情動予測装置が予測した予測結果(以下、予測情動Ebという。)に、行動履歴の時間減衰を考慮した重みを乗算して足し合わせたものを最終的に得られた認識結果(以下、認識情動Eという。)として出力する情動統合部とから構成される。 That is, the emotion recognition system according to the present embodiment includes an emotion estimation device that estimates a user's emotion from time-series sensor information, and an emotion prediction device that predicts a user's emotion change according to the type of action performed. The estimation result estimated by the emotion estimation device (hereinafter referred to as estimated emotion Es) and the prediction result predicted by the emotion prediction device (hereinafter referred to as predicted emotion Eb) are multiplied by a weight that takes into account the time decay of the action history. And an emotion integration unit that outputs a finally obtained recognition result (hereinafter referred to as recognition emotion E).
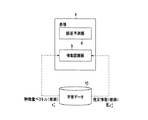
(1)情動推定装置
先ず、センサ情報の時系列データからセンサ情報のコンテキストを考慮した推定情動Esを出力する情動推定装置について説明する。図1は、本実施の形態における情動推定装置を示すブロック図である。図1に示すように、この情動推定装置1は、外部の状況を検出するセンサ部2mと、ジェスチャ、発話、人間の表情などの各モーダル毎にセンサ部2mからのセンサ情報から前処理として特徴量を抽出する特徴量抽出部3nと、同じく各モーダル毎に推定情動Esn及び後述する予測誤差xn^(xn^は、xnハットを示す、以下同様。)を算出するモーダル別情動推定部4nと、予測誤差xn^から推定情動Esnに対する信頼度λnを算出するソフトマックス演算器7nと、推定情動Esnと信頼度λnとを乗算する乗算器8nと、乗算器8nの出力の総和を求め、推定情動Esを出力する加算器9とを有する。
(1) Emotion estimation device First, an emotion estimation device that outputs estimated emotion Es in consideration of the context of sensor information from time-series data of sensor information will be described. FIG. 1 is a block diagram showing an emotion estimation apparatus according to the present embodiment. As shown in FIG. 1, the
センサ部2mは、例えば、周囲の画像を撮像する撮像手段としてのカメラ21、周囲の音声を入力する音声入力手段としてのマイクロホン22などからなり、時系列のセンサ情報(以下、センサ情報列ともいう。)を出力する。
特徴量抽出部3nは、モーダル毎に前処理を行うもので、例えば表情分析部31、ジェスチャ分析部32、発話分析部33などを有し、時系列のセンサ情報から、モーダル毎に、認識対象の時系列の特徴量ベクトルを抽出し、モーダル別特徴量列として出力する。 Amount extracting unit 3 n features, performs a pre-process for each modal, for example the facial expression analyzer 3 1, gesture analysis unit 3 2 has a like speech analysis unit 3 3, from the sensor information of the time series, each modal Then, a time-series feature quantity vector to be recognized is extracted and output as a modal feature quantity sequence.
情動推定部4nは、モーダル毎に用意され、各モーダルに対応した特徴量抽出部3nにて前処理され得られた特徴量ベクトル列が入力され、この特徴量ベクトル列から推定情動Esnを推定して出力するものである。この情動推定部4nは、過去の情動を考慮して現在の情動を予測する情動フォアードモデル(forward model:フォワードモデル又は順モデル)により情動を推定して、モーダル別推定情動Esnとして出力するモーダル別情動認識手段としての情動認識器5nと、この情動認識器5nが出力した推定情動Esnの予測誤差xn^を算出する誤差予測器6nとを有している。誤差予測器6nにおいても、過去の予測誤差xn^を考慮して現在の予測誤差xn^を算出するフォワードモデルにより推定情動Esnの予測誤差xn^を算出するものとすることができる。
The emotion estimation unit 4 n is prepared for each modal, and the feature quantity vector sequence obtained by preprocessing by the feature quantity extraction unit 3 n corresponding to each modal is input, and the estimated emotion Es n is obtained from this feature quantity vector sequence. Is estimated and output. The emotion estimation unit 4 n estimates an emotion by an emotion forward model (forward model or forward model) that predicts the current emotion in consideration of the past emotion, and outputs the estimated emotion as a modal-specific estimate n . It includes an
フォワードモデルは、入出力の写像関係、すなわち本実施の形態においては、時系列の特徴量ベクトルを入力した場合に、推定情動Esnを出力とする写像関係を実現していればよく、数式、パラメータマトリクス、対応表など、どのような表現方法であってもよい。また、本実施の形態においては、センサ入力から情動を予測する方向、すなわちここでは、特徴量ベクトル列を入力とし、推定情動Esnを出力とする方向を順方向(情動フォワードモデル)という。なお、フォワードモデルと入出力データが逆になるモデルをインバースモデル又は逆モデルという。 The forward model only needs to realize the mapping relationship of input / output, that is, in this embodiment, the mapping relationship that outputs the estimated emotion Es n when a time-series feature quantity vector is input. Any expression method such as a parameter matrix or a correspondence table may be used. In the present embodiment, the direction in which emotion is predicted from the sensor input, that is, the direction in which the feature vector sequence is input and the estimated emotion Es n is output is referred to as the forward direction (emotional forward model). A model in which input / output data is reversed from the forward model is referred to as an inverse model or an inverse model.
ソフトマックス演算部7nは、ソフトマックスを求める後述する関数を用いて予測誤差xn^を、各情動推定器5nが算出する推定情動Esnに対する信頼度λnに変換し、乗算器8nは、推定情動Esnに信頼度λnを乗算する。加算器9は、乗算器8nにて信頼度λnで重み付けされた重み付き推定情動λnEsnの総和を求めて推定情動Esとして出力する。これらソフトマックス演算部7n、乗算器8n及び加算器9により、モーダル別情動認識器5nの認識結果を統合するための認識結果統合手段が構成される。
The
ここで、本実施の形態においては、この情動認識器(情動フォワードモデル)及び誤差予測器として、例えばリカレントニューラルネットワークなどを利用して予め学習されたものを使用する。すなわち、情動認識器5nは、時系列の特徴量ベクトルsn *とそれに対応する予め感情が分類された教師データである時系列の感情分類情報Esn *とからなる学習データを使用し、入力として与えられる時系列の特徴量ベクトルから時系列の感情情報を出力する情動認識器5nを学習するものである。すなわち、学習データのうち、時系列の特徴量ベクトルsn *を入力データとし、教師データである時系列の感情情報Esn *を出力データの目標値としてモーダル毎に予め学習する。
Here, in the present embodiment, as the emotion recognizer (emotional forward model) and the error predictor, those previously learned using, for example, a recurrent neural network are used. That is, the
また、誤差予測器6nは、時系列の特徴量ベクトルsn *とそれに対応する予め感情が分類された教師データである時系列の感情分類情報Esn *とからなる学習データを使用して、入力として与えられる情動認識器5nの出力(推定情動Esn)及び/又は特徴量ベクトルsn *から予測誤差を出力する誤差予測器6nを情動認識器5n毎に学習する。ここではまずこれらの学習方法について説明し、次に学習された情動認識器5n及び誤差予測器6nを有する情動推定部4nを使用した情動推定装置における情動推定方法(再現方法)について説明する。
Further, the
(2)モーダル別情動認識器の学習方法
本実施の形態においては、モーダル毎に情動推定部4n、すなわち情動認識器5nを用意する。情動認識器5nは、1つの情動認識器により、例えば「喜び(joy)」、「悲しみ(sadness)」、「怒り(anger)」、「驚き(surprise)」、「嫌悪(disgust)」、及び「恐れ(fear)」などの複数の情動を認識することができ、ある一のモーダルにおいて各感情に対応する特徴量を予め学習しておき、認識の際には、モーダル毎にセンサ入力から特徴量を抽出する前処理を行って、抽出した特徴量に基づきユーザの情動を推定して出力するものである。なお、本実施の形態における情動認識器は、上記6つの基本6感情を認識するものとし、したがってモーダル別情動認識器5nが出力する推定情動Esn及び情動推定装置1が出力する推定情動Esは、6種類の感情を要素とするベクトルとするが、認識する感情の種類はこれに限らない。
(2) Learning method of modal-specific emotion recognizer In the present embodiment, an emotion estimation unit 4 n , that is, an
情動認識器5nが考慮するモーダルとしては、例えば表情、ジェスチャ、発話などがある。学習では、先ず、情動認識器5nの学習を行うための学習データを用意し、次に、モーダル毎に情動認識器5nの学習を行う。
The
情動認識器5nの学習を行うために必要な学習データは、入力データとなる時系列の特徴量ベクトルと、出力データの目標値となる、上記入力データを取得した際のインタラクション対象、本実施の形態においてはユーザの情動である。なお、ユーザの情動は適当に数値化されているものとする。
The learning data necessary for learning the
入力データは、表情分析部31、及びジェスチャ分析部32などからなる特徴量抽出部3nに、画像などの時系列のセンサ情報を供給し、発話分析部33などからなる特徴量抽出部3nに音声などの時系列のセンサ情報を供給し、この時系列のセンサ情報に基づいて、それぞれのモーダルに対応した、時系列のユーザの特徴量(フィーチャー)ベクトルを集める。 The input data, the facial expression analyzer 3 1, and the feature extraction unit 3 n made of the gesture analysis unit 3 2 supplies the sensor information of the time series, such as the image feature extraction made of speech analysis unit 3 3 The time-series sensor information such as voice is supplied to the unit 3 n , and the time-series user feature vector corresponding to each modal is collected based on the time-series sensor information.
例えば、表情分析部31であれば、画像全体の周波数成分や方向成分を抽出するフィルタリング処理を行った結果が特徴量として抽出されたり、例えば額や眉間、頬のしわの密度や方向、目の見開き具合、唇の形など、顔に視覚的に表れている要素の特徴を数値的に現したベクトルデータなどが特徴量として抽出されたりして、特徴量ベクトルの時系列データ(特徴量ベクトル列)が出力される。 For example, if the facial expression analyzer 3 1, as a result of the filtering process for extracting a frequency component and direction component of the entire image or be extracted as a feature quantity, for example the forehead and glabella, cheeks wrinkles density and direction, eye Time-series data of feature vectors (feature vectors), such as vector data that numerically represents the features of elements visually appearing on the face, such as the spread of lips, the shape of lips, etc. Column) is output.
また、ジェスチャ分析部32であれば、手先位置の移動量、移動速度、手先軌道の切り返しの周波数などが特徴量として抽出され特徴量ベクトル列が出力される。 Further, if the gesture analysis unit 3 2, the moving amount of the hand position, moving speed, such as frequency of crosscut of the hand trajectory is output feature vector sequence is extracted as the feature quantity.
また、発話分析部33であれば、認識した発話の平均音圧(パワー)、基本周波数(相似的な波の繰り返しのパターンが現れる周波数)、及びスペクトルなどのデータを特徴量として、抽出された特徴量ベクトル列が出力される。 Further, if the speech analysis unit 3 3, average sound pressure of the recognized utterance (power), the fundamental frequency (repetition frequency pattern appears in homothetic wave), and the feature amount data such as spectra, extracted The feature vector sequence is output.
それぞれのモーダルに対応した情動認識器5nの学習データの収集は、例えば次のように実験的に行うことができる。すなわち、特徴量抽出部3nの前で、決められたシナリオ通りの演技を人間に実際に演じてもらい、その際に観測されたデータ(センサ情報列)から特徴量抽出部3nにより各モーダルに対応した時系列の特徴量ベクトル(フィーチャーベクトル)を抽出し、そのときの人間の感情を示す情報と共に記録することで学習データを収集することができる。また、後述するロボット装置に情動認識システムを搭載する場合には、少なくとも特徴量抽出部3nが搭載されたロボット装置の前で、同様に人間に演技を演じてもらって学習データを収集すればよい。ここで、特徴量ベクトルを抽出した際の人間の感情を示す情報は、上述の基本6感情が数値化されたたベクトル(感情分類情報)であり、認識時において情動認識器5nが出力する推定情動の教師データとなるものである。以下では、この学習データを推定情動(教師)Esn *と記載するものとする。また、学習データのうち、学習に使用する特徴量ベクトルを特徴量ベクトル(教師)sn *と記載する。
Collecting training data of
こうしてこの特徴量抽出部3nにより収集された入力データとなる時系列の特徴量ベクトル(教師)sn *及び、出力の目標値とする、特徴量ベクトル(教師)sn *を取得した際のユーザの推定情動(教師)Esn *からなる学習データを使用して、各情動認識器5nの学習を行う。
Thus the time series feature vector (teacher) s n * and as an input data collected by the feature extraction unit 3 n, a target value of the output, the feature vector (teacher) when acquiring the s n * Learning of each
なお、情動推定部4nの学習は各モーダル毎に個別に行われ、特徴量抽出部3n、情動推定部4n、は各モーダル毎に用意され、情動認識器5n、誤差予測器6nは各情動推定部4n毎に設けられるものであるが、以下の説明においては、特に必要がないときは特徴量抽出部3、情動推定部4、情動認識器5、誤差予測器6ということとする。
The learning of the emotion estimation unit 4 n is performed individually for each modal, and the feature quantity extraction unit 3 n and the emotion estimation unit 4 n are prepared for each modal, and the
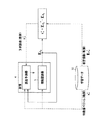
図2は、学習時の情動推定部5を模式的に示す図である。図2に示すように、学習時には、一のモーダル、ここでは「表情」より情動認識する表情用情動認識器5に対して、この「表情」について前処理により得られた学習データが格納されたデータベース10が接続される。情動認識器5は、データベース10から供給される学習データ、すなわち時系列の特徴量ベクトル(教師)sn *とそのときの時系列の推定情動(教師)Esn *とにより、与えられた時系列の特徴量ベクトルから情動を推定するための情動モデルの学習を行う。すなわち、学習データの特徴量ベクトル(教師)sn *を入力としたとき、推定情動(教師)Esn *を出力するよう、モーダル毎に情動認識器(情動フォワードモデル)5を学習させる。
FIG. 2 is a diagram schematically showing the
本実施の形態においては、時系列データから情動を推定する情動認識器(情動フォワードモデル)5を、リカレントニューラルネットワークにより構成する。なお、情動を学習、認識する際に用いるアルゴリズムはリカレントニューラルネットワークに限らず、時系列のデータを出力に反映させることができるものであれば、どのようなアルゴリズムであってもよい。例えば、ある時間幅を有する情報をクラスタリングする手法としては、DP(Dynamic Programming)マッチング(動的計画法)、隠れマルコフモデル(Hidden Markov Model:HMM)などの手法がある。本実施の形態におけるコンテキストとは、その時の状態ベクトルだけではなく、過去を遡り、時間幅を有する状態ベクトルデータ列を指すものであり、このようなデータを入力として出力(推定情動)を得ることができればよい。 In the present embodiment, an emotion recognizer (emotional forward model) 5 that estimates emotion from time-series data is configured by a recurrent neural network. The algorithm used when learning and recognizing emotions is not limited to a recurrent neural network, and any algorithm can be used as long as time series data can be reflected in an output. For example, as a method for clustering information having a certain time width, there are methods such as DP (Dynamic Programming) matching (dynamic programming), Hidden Markov Model (HMM), and the like. The context in the present embodiment refers not only to the state vector at that time, but also to a state vector data string having a time width that goes back in the past, and obtains an output (estimated emotion) using such data as an input. If you can.
図2の情動認識器5には、それぞれのモーダルに対する、前処理によって抽出された字系列の学習データのうち、特徴量ベクトル(教師)sn *がリカレントニューラルネットワークの入力データとして与えられる。そして、入力データを収集した際の推定情動(教師)Esn *が出力データとして与えられ、情動フォワードモデルとしての情動認識器5の学習が行われる。リカレントニューラルネットワークには、図3に示すように、対応するモーダルにおける特徴量ベクトルが入力される入力層11aと、1以上の層からなる中間層12と、対応するモーダルに関する推定情動を出力する出力層13a、13bと、出力層13bの推定情動が入力される入力層11bとを有する。すなわち、入力層11a、11bには、あるタイミングにおける特徴量ベクトル、前のタイミングにて出力層13bから出力された推定情動が入力され、これが中間層12を介して出力層13a、13bから出力され、そのうちの一部が次のタイミングにおいて入力層11bへ戻される。
The
このように、リカレントニューラルネットワークには出力層から入力層(または中間層)にフィードバックする一群のユニット(入力層11b、出力層13b)があり、これらは時系列入力に基づく文脈情報(コンテキスト)を内部表現している。出力層13bから入力層11bへのフィードバックはコンテキストループと呼ばれる。このリカレントニューラルネットワークを利用することで、瞬間的な入出力情報の写像関係ではなく、文脈情報を考慮した現在の情動推定を実現することができる。なお、リカレントニューラルネットワークについての詳細は後述する。 In this way, the recurrent neural network has a group of units (input layer 11b and output layer 13b) that feed back from the output layer to the input layer (or intermediate layer), and these include context information (context) based on time-series input. Expressed internally. The feedback from the output layer 13b to the input layer 11b is called a context loop. By using this recurrent neural network, it is possible to realize current emotion estimation in consideration of context information rather than instantaneous input / output information mapping. Details of the recurrent neural network will be described later.
(3)誤差予測器の学習方法
人間が各モーダルを通じで表現する情動には、必ずしも各感情に相当する表現が平均的に含まれていないことが実験により知られている。例えば上記特許文献2においては、音声又は画像により感情を認識する際、「悲しみ」、及び「恐怖」は、音声のみで認識される度合いが高く、「怒り」、「幸福」、及び「驚き」は、画像のみで認識される度合いが高いことを利用し、音声データ及び画像データからそれぞれ感情認識する感情認識部を設けたとき、例えば音声データから感情認識する感情認識部にて「悲しみ」、又は「恐怖」が認識された場合はその重みを大きくし、画像データから感情認識する感情認識部にて「怒り」、「幸福」、又は「驚き」が認識された場合はその重みを大きくして、これら2つの感情認識部の認識結果を統合するものである。
(3) Learning method of the error predictor It has been experimentally known that emotions that humans express through each modal do not necessarily include expressions corresponding to each emotion on average. For example, in
このように、感情に応じて、認識を得意とするセンサ情報が異なるため、各感情についてモーダル毎の認識結果がどの程度信頼できるかには差が生じる。この差を各認識器の信頼度として予めの学習によって獲得しておき、認識時に各モーダルの認識結果に重み付けして最終的な認識結果とすることで、認識結果の信頼性を高めることができる。 In this way, sensor information that is good at recognition differs depending on the emotion, and therefore a difference occurs in how reliable the recognition result for each modal for each emotion is. The reliability of the recognition result can be increased by acquiring this difference as the reliability of each recognizer by learning in advance and weighting the recognition result of each modal at the time of recognition to obtain the final recognition result. .
上述の図1にて説明したように、本実施の形態の情動推定装置においては、マルチモーダルなセンサ情報から情動を推定するものであり、各モーダルに対応した情動認識器5が要素認識器(情動フォワードモデル)として用いられている。また、それぞれの情動認識器5が出力する情動認識結果を、そのコンテキストでの認識結果の信頼度に応じて重み付けして最終的な出力を決定している。このため、各モーダルに対応したモジュール(情動推定部4)において、情動認識器5と対になって信頼度を算出するための誤差予測器6を有している。ここでいうコンテキストとは、センサ入力状態(時系列のセンサ情報列)、または感情認識状態(時系列の推定情動)などを想定することができる。それぞれの想定に応じて、誤差予測器6への入力データを設定し、例えばセンサ情報のコンテキストを考慮する場合には、入力データとして時系列のセンサ情報から抽出した時系列の特徴量ベクトルを使用したり、感情認識状態のコンテキストを考慮する場合には、入力データとして、情動認識器5の出力を使用するようにすればよい。
As described above with reference to FIG. 1, the emotion estimation apparatus according to the present embodiment estimates emotion from multimodal sensor information, and the
上述した如く、各モーダルに対して個別に学習された要素認識器(情動認識器)の出力をどの程度信頼するかを出力する誤差予測器6の学習においても、センサ入力情報もしくは感情認識状態の履歴情報を元に算出するモデルを適用することができ、センサ情報(またはこれらから抽出された特徴量)、及び/又は感情認識状態を入力として対となる要素認識器の誤差を予測するモデルがリカレントニューラルネットワークによって実現される。ここでは、時系列のセンサ情報から抽出された時系列の特徴量ベクトルと、感情認識器により認識されたモーダル別推定情動とを入力とするモデルについて説明する。
As described above, even in the learning of the
すなわち、誤差予測器6は、図4に示すように、各モーダルについて収集された上述の学習データを再度用い、特徴量ベクトル(教師)sn *及びこの特徴量ベクトル(教師)sn *を入力としたときの情動認識器5の出力データである推定情動Esn *を入力データとし、情動認識器5の出力Esnと特徴量ベクトルsn *に対応する推定情動(教師)Esn *との差分である誤差情報を理想出力xn *とし、この理想出力力xn *を出力の目標値として各モーダルに対応した誤差予測器6の学習を行う。なお、特徴量ベクトル(教師)sn *は複数の特徴量を要素とするベクトルであり、推定情動Esn *、推定情動Esn、理想出力xn *は、上述の6種類の情動を要素とするベクトルである。また、学習に使用する学習データは、情動認識器5の学習に用いた学習データとは異なるものを用意してもよく、このことによりより汎化能力が高い誤差予測器6を得ることができる。
That is, as shown in FIG. 4, the
図5は、リカレントニューラルネットワークを用いた誤差予測器の学習方法を示す。誤差予測器の学習の場合には、対応するモーダルの時系列の特徴量ベクトルsn、対応するモーダルにおける情動予測データである推定情動Esnが入力層21a、21bに入力され、出力層23aから情動予測誤差xn^が出力される。また、出力層23bから出力される予測誤差xn^がコンテキストループによりフィードバックされて入力層11cに供給される。すなわち、時刻t+1における予測誤差xn^は、特徴量ベクトルsn、及び推定情動Esn、並びに時刻tで出力された予測誤差xn^から出力される。
FIG. 5 shows an error predictor learning method using a recurrent neural network. In the case of learning by the error predictor, the corresponding modal time-series feature vector s n and the estimated emotion Es n which is emotion prediction data in the corresponding modal are input to the input layers 21a and 21b, and from the
(4)リカレントニューラルネットワーク
次に、リカレントニューラルネットワークの一例について説明しておく。なお、次に説明する特開平8−6916号公報に記載のリカレント型ニューラルネットワークに限らず、上述したように、時系列データを入力とし、コンテキストを考慮した学習、認識を行うことができるものであればよい。
(4) Recurrent Neural Network Next, an example of a recurrent neural network will be described. Not only the recurrent neural network described in Japanese Patent Laid-Open No. 8-6916 described below, but as described above, learning and recognition can be performed in consideration of the context using time series data as input. I just need it.
ニューラルネットワークとは、人間の脳における神経回路網を簡略化したモデルであり、それは神経細胞ニューロンが、一方向にのみ信号が通過するシナプスを介して結合されているネットワークである。ニューロン間の信号の伝達は、このシナプスを通して行われ、シナプスの抵抗、すなわち、重みを適当に調整することにより、様々な情報処理が可能となる。各ニューロンでは、結合されている他のニューロンからの出力をシナプスの重み付けをして入力し、それらの総和を非線形応答関数の変形を加えて、再度、他のニューロンへ出力する。 A neural network is a simplified model of a neural network in the human brain, which is a network in which neuronal neurons are connected via synapses through which signals pass only in one direction. Signal transmission between neurons is performed through the synapse, and various information processing is possible by appropriately adjusting the resistance of the synapse, that is, the weight. In each neuron, outputs from other connected neurons are input with synaptic weighting, and their sum is added to a non-linear response function and output to another neuron again.
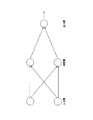
ニューラルネットワークの構造の一つに、図6に示すような多層型ネットワークがある。このタイプのネットワークは層構造を有し、層間の結合のみが許され、層内の結合や自己回帰的な結合は存在しない。この多層型ネットワークは、空間的に広がるパターンの認識や、情報圧縮に適していると考えられている。 One of the neural network structures is a multilayer network as shown in FIG. This type of network has a layered structure, only coupling between layers is allowed, and there is no intra-layer coupling or autoregressive coupling. This multilayer network is considered to be suitable for recognition of spatially spreading patterns and information compression.
一方、図7に示すように、ネットワークの構造にそのような制限を設けず、各ユニット間で任意の結合を許すものが、リカレント型ネットワークとよばれる。厳密に言うと、リカレント型ネットワークには層の概念はないが、ここでは多層型ネットワークとの対応をとるために、便宜的に層という概念を取り入れる。以下では、入力データが入力されるユニット群を入力層、ネットワークの出力を出すユニット群を出力層、その他のユニット群を中間層と呼ぶ。 On the other hand, as shown in FIG. 7, a network that does not have such a restriction and allows arbitrary coupling between units is called a recurrent network. Strictly speaking, there is no concept of layers in the recurrent network, but here the concept of layers is adopted for convenience in order to correspond to the multilayer network. Hereinafter, a unit group to which input data is input is referred to as an input layer, a unit group that outputs network output is referred to as an output layer, and other unit groups are referred to as intermediate layers.
リカレント型ネットワークでは、各ユニットの過去の出力がネットワーク内の他のユニット、または自分自身に戻される結合がある。そのため、時間に依存して各ニューロンの状態が変化するダイナミックスをネットワークの内部に有する。このように、ネットワーク内に時間を有するシステムであるので、リカレント型ネットワークは、時系列パターンの認識や予測に適していると考えられている。なお、多層型ネットワークは、リカレント型ネットワークの特別な場合と見ることができる。 In a recurrent network, there is a connection where the past output of each unit is returned to another unit in the network or to itself. Therefore, the network has dynamics in which the state of each neuron changes depending on time. Thus, since the system has time in the network, the recurrent network is considered to be suitable for time series pattern recognition and prediction. A multi-layer network can be viewed as a special case of a recurrent network.
リカレント型ニューラルネットワークの各ニューロンの従う状態方程式は下記式(1)、式(2)で与えられる。 The equation of state followed by each neuron of the recurrent neural network is given by the following equations (1) and (2).
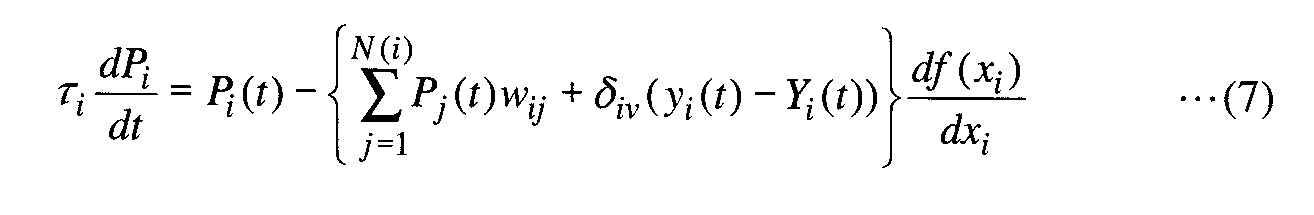
ここで、xi(t)は時刻tにおけるユニットiの内部状態であり、出力値yiは内部状態を非線形変換して決められる。また、τi,Xiはそれぞれユニットiの時定数、外部入力であり、wijはユニットjからユニットiへの結合の重みである。Nは総ユニット数である。 Here, x i (t) is the internal state of unit i at time t, and the output value y i is determined by nonlinearly transforming the internal state. Also, τ i and X i are the time constant and external input of unit i, respectively, and w ij is the weight of coupling from unit j to unit i. N is the total number of units.
時刻t0から時刻tnまでの各時刻におけるネットワークの状態を求める場合は次の手順により求めることができる。まず、初期状態として時刻t0におけるネットワークの内部状態と出力値を適当に設定する。その後、上記式(1)及び式(2)を時間の順方向にt0からtnまで解く。 When obtaining the network status at each time from time t 0 to time t n, it can be obtained by the following procedure. First, as an initial state, the internal state and output value of the network at time t 0 are appropriately set. Thereafter, the above formulas (1) and (2) are solved from t 0 to t n in the forward direction of time.
本実施の形態のように、時系列パターンの認識や予測に、リカレント型ニューラルネットワークを用いる場合、ネットワークが正しい出力を出すように、上述したように、特徴量ベクトル列などの時系列データである入力データと、推定情動などの時系列データである教師データ(出力データ)とが対になった学習データを用意し、それらを用いてネットワークの重み値、時定数、初期状態を予め学習しておく必要がある。これには通常、バックプロパゲーション法と呼ばれる最適化手法を用いて行われる。 As described above, when using a recurrent neural network for time series pattern recognition and prediction as in this embodiment, time series data such as a feature vector sequence is used so that the network outputs a correct output. Prepare learning data in which input data and teacher data (output data) that is time-series data such as estimated emotions are paired, and use them to learn network weight values, time constants, and initial states in advance It is necessary to keep. This is usually done using an optimization technique called backpropagation.
この手法の特徴は、下記式(3)で与えられるようなt0からtnにわたる有限時間区間における誤差を小さくするように、最急降下法に基づき重みを修正することである。 The feature of this method is that the weight is corrected based on the steepest descent method so as to reduce an error in a finite time interval from t 0 to t n as given by the following equation (3).
ここで、Yk(t)は時刻tにおけるユニットkに提示される教師データである。但し、kは出力層に属するユニット群、Nvは出力層に属するユニット数を示す。 Here, Y k (t) is teacher data presented to unit k at time t. Here, k is the unit belonging to the output layer, N v denotes the number of units belonging to the output layer.
重み値、時定数、初期状態の修正量を計算する際に用いられる最急降下方向は下記式(4)、式(5)、式(6)で与えられる。 The steepest descent direction used when calculating the weight value, the time constant, and the correction amount of the initial state is given by the following equations (4), (5), and (6).
ここでPi(t)はそれぞれユニットiの逆伝搬誤差である。逆伝搬誤差は下記式(7)に従って計算される。 Here, P i (t) is the back propagation error of unit i. The back propagation error is calculated according to the following equation (7).
ここで、δikはクロネッカーのデルタ記号である。上記式(7)では、出力層に属するニューロンの逆伝搬誤差は、他のニューロンからの逆伝搬誤差と重みの総和以外に、各時刻毎に出力値の誤差が加算される形になっている。また、df(xi)/dxi、(yi(t)−Yi(t))は、xi(t)、yi(t)が決まらないと計算できない。そこで、xi(t)、yi(t)を時間の順方向に計算した後、時刻tnでは逆伝搬誤差は0であると仮定して、下記式(8)で与えられる境界条件を設定し、逆伝搬誤差をtn→t0の時間の逆方向に計算する。 Where δ ik is the Kronecker delta symbol. In the above equation (7), the back propagation error of the neurons belonging to the output layer is such that the error of the output value is added at each time in addition to the sum of the back propagation errors and weights from other neurons. . Also, df (x i ) / dx i , (y i (t) −Y i (t)) cannot be calculated unless x i (t) and y i (t) are determined. Therefore, after calculating x i (t) and y i (t) in the forward direction of time, assuming that the back-propagation error is 0 at time t n , the boundary condition given by the following equation (8) is Then, the back propagation error is calculated in the reverse direction of the time t n → t 0 .
最急降下方向の計算の手順は以下のように行う。すなわち、まず時刻t0における各ユニットの初期状態を適当に設定した後、上記式(1)及び式(2)に従って各時刻の内部状態と出力値を計算し、その値を保存しておく。次に、時刻tnにおける上記式(8)で与えられる逆伝搬誤差の境界条件を設定する。その後、先程計算した内部状態と出力値を用いて、上記式(7)に従って時間に逆行しながら各時刻の逆伝搬誤差を計算し保存する。最後に、求められた各時刻の出力値と逆伝搬誤差を用いて上記式(4)乃至式(6)で与えられる最急降下方向を計算する。 The calculation procedure for the steepest descent direction is as follows. That is, first, the initial state of each unit at time t 0 is appropriately set, then the internal state and output value at each time are calculated according to the above formulas (1) and (2), and the values are stored. Next, the boundary condition of the back propagation error given by the above equation (8) at time t n is set. Thereafter, using the internal state and the output value calculated earlier, the back propagation error at each time is calculated and stored while reversing the time according to the above equation (7). Finally, the steepest descent direction given by the above formulas (4) to (6) is calculated using the obtained output value and back propagation error at each time.
バックプロパゲーション学習の処理手順の詳細を、図8を用いて示す。
まず、図8における学習データは、例えば、図7のような二つの入力層ニューロンと、一つの出力層ニューロンとを有するネットワークに対する学習データとする。学習データは図9に示すように、入力データと教師データとからなり、それぞれ(入力層ニューロン数×時系列サンプル点数)、(出力層ニューロン数×時系列サンプル点数)だけのデータ数を有する。
The details of the backpropagation learning process procedure will be described with reference to FIG.
First, the learning data in FIG. 8 is, for example, learning data for a network having two input layer neurons and one output layer neuron as shown in FIG. As shown in FIG. 9, the learning data is composed of input data and teacher data, and has the number of data corresponding to (number of input layer neurons × number of time series sample points) and (number of output layer neurons × time series sample points), respectively.
まず、適当な乱数などを用いて重み値、時定数、及び初期状態の初期値を設定する(ステップS1)。そして、逆伝搬誤差が収束するまで次のステップS2からステップS7までの処理を繰り返す。 First, a weight value, a time constant, and an initial value of an initial state are set using an appropriate random number (step S1). Then, the processing from the next step S2 to step S7 is repeated until the back propagation error converges.
まず、適当にネットワークの初期状態、すなわち、ネットワークの内部状態と出力値を設定した後、上記式(1)及び式(2)に従い入力データを用いて時間の順方向に各ユニットの内部状態、出力値を計算してそれを保存する(ステップS2)。 First, after appropriately setting the initial state of the network, that is, the internal state and output value of the network, the internal state of each unit in the forward direction of time using the input data according to the above formulas (1) and (2), An output value is calculated and stored (step S2).
そして、上記式(8)の境界条件を設定し、その後、上記式(7)に従い、教師データを使用して時間の逆方向に各ユニットの逆伝搬誤差Pi(t)を計算し、それを保存する(ステップS3)。 Then, the boundary condition of the above equation (8) is set, and then the back propagation error P i (t) of each unit is calculated in the reverse direction of time using the teacher data according to the above equation (7). Is stored (step S3).
次いで、ステップ2で求めた内部状態及び出力値と、ステップ3で求めた逆伝搬誤差を用いて、上記式(4)乃至式(6)に従い最急降下方向を計算する(ステップS4)。
Next, the steepest descent direction is calculated according to the above formulas (4) to (6) using the internal state and output value obtained in
そして、ステップ24で求めた最急降下方向と、前回の重みの修正量により下記式(9)乃至式(11)に従って今回の重みの修正量を計算する(ステップS5)。 Then, the current weight correction amount is calculated according to the following formulas (9) to (11) based on the steepest descent direction obtained in step 24 and the previous weight correction amount (step S5).
ここでγは学習係数、αはモーメント係数、nは学習回数である。右辺第2項はモーメント項と呼ばれ、学習を加速するために経験的に加える項である。 Here, γ is a learning coefficient, α is a moment coefficient, and n is the number of learnings. The second term on the right side is called a moment term and is an empirically added term to accelerate learning.
次いで、下記式(12)乃至式(14)に従い、各ユニットの重みを修正する(ステップS26)。 Next, the weight of each unit is corrected according to the following formulas (12) to (14) (step S26).
そして、ステップ7にて、誤差が一定の値以下に収束するか否かが判断され、誤差が一定値より大きい場合は、ステップ2からステップ6の処理を繰り返す。以上のようにして、情動認識器5や誤差予測器6の学習を行なうことができ、学習された情動認識器5及び誤差予測器6からなる情動推定部4を用いて情動推定装置1が構成される。
Then, in
(5)各モーダル別の認識結果の統合(再現方法)
次に、情動推定装置1の情動推定方法について説明する。先ず、ロボット装置が有するカメラ21やマイクロホン22などの各種センサ手段が時系列のセンサ情報を取得する。そして、特徴量抽出部3は、この時系列のセンサ情報から、前処理として時系列の特徴量ベクトルを抽出する。すなわち、特徴量抽出部3により、表情、ジェスチャ、発話などのモーダル毎にモーダル別特徴量列として、時系列の特徴量ベクトルを抽出する。
(5) Integration of recognition results by modal (reproduction method)
Next, the emotion estimation method of the
次に、抽出された特徴量を対応する情動推定部4へ供給する。例えば、表情の特徴量であれば、表情用情動推定部41へ、ジェスチャの特徴量であればジェスチャ用情動推定部42へ、発話の特徴量であれば発話用情動推定部43へ、特徴量ベクトル列が供給される。 Next, the extracted feature amount is supplied to the corresponding emotion estimation unit 4. For example, if the feature quantity of the facial expression, the expression for the emotion estimation unit 4 1, if the feature amount of the gesture to a gesture for emotion estimation unit 4 2, to the utterance for emotion estimation unit 4 3 If a feature quantity of speech , A feature vector sequence is supplied.
各情動推定部4は、情動認識器5により時系列の特徴量ベクトルsnから推定情動Esnを出力し、誤差予測器6により予測誤差xn^を算出して出力する。なお、特徴量抽出部3は、情動認識器5や誤差予測器6内に配置に配置してもよい。上述したように、モーダル別推定情動Esnはモーダル毎に設けられた情動認識器5毎に算出された情動推定ベクトルであり、情動の要素として定義した各感情(例えば、基本6感情)のそれぞれの値が含まれる。また、最終的な出力となる推定情動Esも同じく各感情の値が含まれたベクトル情報である。
Each emotion estimation unit 4 outputs the estimated emotional Es n from the feature quantity vector s n in time series by the
誤差予測器6により算出された予測誤差xn^は、対応するモーダルにソフトマックス演算器7に供給される。ソフトマックス演算器7は、誤差予測器6から出力された予測誤差xn^を元に下記式(15)のソフトマックス関数に従って情動認識器5の信頼度λnを算出する。ここでxn^、xl^は各誤差予測器の出力、σは各認識器の誤差をどの程度平均化して責任信号(信頼度)を算出するかを決定するパラメータである。
The prediction error x n ^ calculated by the
それぞれの信頼度λnは、下記式(16)に示すように、対応する各情動認識器5が出力する推定情動Esnに乗算され、これらを加算した総和が、時系列のセンサ入力情報を元に推定された最終的な情動認識結果ベクトルとしての推定情動Esとなる。
As shown in the following equation (16), each reliability λ n is multiplied by the estimated emotion Es n output from the
このように、本実施の形態における情動推定装置1は、各モーダルに対応した情動認識器(要素認識器)5が、瞬間のセンサ情報のみから情動を推定するのではなく、それ以前の過去のセンサ情報も考慮し、時間的な広がりを持ったセンサ情報(時系列のセンサ情報)から特徴量を抽出して情動を推定することで、センサ情報のコンテキストを考慮して情動を認識することができる。すなわち、予め、情動認識器5及び誤差予測器6を再帰的学習方法、例えばリカレントニューラルネットワークなどのアルゴリズムを用いて、それぞれ時系列の特徴量ベクトルから推定情動を出力するフォワードモデル及び時系列の特徴量ベクトル及び/又は推定情動から予測誤差を出力するフォワードモデルを学習しておくことにより、各センサの入力情報から得られる特徴量ベクトルの時系列データを入力とし、コンテキストを考慮して情動を推定する情動推定装置を得ることができる。
As described above, the
また、誤差予測器から得られた予測誤差をソフトマックス関数の処理によって信頼度に変換し、モーダルごとの認識結果に重み付けすることにより、各感情に対してより正確に判定を行うことができると予想されるモーダルの出力を重視した統合結果として推定情動Esを出力することができる。 In addition, by converting the prediction error obtained from the error predictor into reliability by processing of a softmax function and weighting the recognition result for each modal, it is possible to make a more accurate determination for each emotion The estimated emotion Es can be output as an integration result that places importance on the expected modal output.
(6)情動予測装置
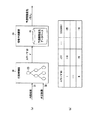
次に、ロボット装置が実行した行動のコンテキストを考慮し、その行動に応じてユーザの情動を予測する情動予測装置について説明する。情動予測装置は、上記のセンサ入力情報の履歴を元に現在のインタラクション対象の情動推定を行うモジュール(情動推定装置)と並列に、ロボット装置自らの行動とそれに対応するインタラクション対象(ユーザ)の情動変化を推定するモジュールである。この情動予測装置は、実行した行動kに応じて、行動実行後のユーザの情動変化を予想し、この予想した情動変化(以下、予想情動変化dEbkという。)と、行動の実行前の上述の情動推定装置における推定結果Es’とを統合し、予測情動Ebを出力する。
(6) Emotion Prediction Device Next, an emotion prediction device that takes into consideration the context of the action performed by the robot apparatus and predicts the user's emotion according to the action will be described. The emotion prediction device, in parallel with the module (emotional estimation device) that estimates the emotion of the current interaction target based on the sensor input information history, the robot device itself and the corresponding interaction target (user) emotion This module estimates changes. This emotion prediction device predicts an emotional change of the user after the execution of the action according to the executed action k, the predicted emotional change (hereinafter referred to as an expected emotional change dEb k ), and the above-mentioned before the execution of the action. Are integrated with the estimation result Es ′ of the emotion estimation apparatus, and a predicted emotion Eb is output.
図10(a)は、ロボット装置における情動予測装置に関わる要部を示す図である。図10(a)に示すように、ロボット装置は、内部状態31及び/又は外部刺激32に基づき自律的に行動を実行するものであって、複数の要素行動(スキーマ)33が木構造に構成されたスキーマツリーを有する行動制御器30を供える。スキーマ33は、内部状態31及び外部刺激32が入力されると、これらから各スキーマが自身に記述された行動の実行優先度を示す行動価値(アクティベーションレベル:Activation level)ALを算出し、この行動価値ALに基づき実行する行動を選択するモジュール(行動記述モジュール)であり、各モジュール毎にステートマシンを用意しており、それ以前の行動(動作)や状況に依存して、センサ入力された外部情報の認識結果を分類し、動作を機体上で発現する。各スキーマ33は、自身に記述された行動に応じて所定の内部状態及び外部刺激が定義されている。
FIG. 10A is a diagram illustrating a main part related to the emotion prediction apparatus in the robot apparatus. As shown in FIG. 10 (a), the robot apparatus autonomously executes actions based on the
ここで外部刺激32とは、ロボット装置の知覚情報等であり、例えばカメラから入力された画像に対して処理された色情報、形情報、顔情報等の対象物情報等が挙げられる。具体的には、例えば、色、形、顔、3D一般物体、及びハンドジェスチャー、その他、動き、音声、接触、距離、場所、時間、及びユーザとのインタラクション回数等が挙げられる。
Here, the
また、内部状態31とは、内部状態管理部(図示せず)にて管理される本能や感情といった情動であり、例えば、疲れ(FATIGUE)、痛み(PAIN)、栄養状態(NOURISHMENT)、乾き(THURST)、愛情(AFFECTION)、好奇心(CURIOSITY)等がある。例えば、内部状態「栄養状態」は、バッテリの残量を基に決定し、内部状態「疲れ」は、消費電力を基に決定することができる。
The
そして、例えば行動出力が「食べる」であるスキーマ33は、外部刺激32として対象物の種類、対象物の大きさ、対象物の距離等を扱い、内部状態31として「NOURISHMENT」(「栄養状態」)、「FATIGUE」(「疲れ」)等を扱う。このように、各スキーマ33毎に、扱う外部刺激32及び/及び内部状態31の種類が定義され、該当する外部刺激32及び/又は内部状態31に対応する行動(要素行動)の行動価値ALが算出される。なお、1つの内部状態、又は外部刺激は、1つの要素行動だけでなく、複数の要素行動に対応付けられていてもよいことはもちろんである。
For example, the
行動価値ALとは、スキーマ33をロボット装置がどれくらいやりたいか(実行優先度)を示すものである。この行動価値ALに基づき、選択されたスキーマ33は自身に記述された行動を出力する。この行動価値ALは、内部状態31及び外部刺激32から算出される。具体的には、例えば、内部状態31から、該当する行動について、どれだけやりたいかを示すモチベーションベクトル(Motivation Vector)が算出され、内部状態31及び外部刺激32から、該当する行動をやれるか否か示すリリーシングベクトル(Releasing Vector)が算出され、これら2つのベクトルから行動価値ALを算出することができる。そして、例えば、アクティベーションレベルが最も高いスキーマを選択したり、アクティベーションレベルが所定の閾値を超えた2以上のスキーマを選択して並列的に行動実行するようにすることができる。但し、並列実行するときは各スキーマ同士でハードウェア・リソースの競合がないことを前提とする。
The action value AL indicates how much the robot device wants to execute the schema 33 (execution priority). Based on this action value AL, the selected
行動制御器30は、選択されたスキーマ33を識別する識別ID(スキーマID)を出力し、このスキーマIDは情動予想装置40に入力される。
The
情動予測装置40は、予想情動変化の値が格納された予想情動変化データベース41を有し、入力されるスキーマIDが示す行動に基づき、当該行動の実行後に変化すると予想される情動変化(予想情動変化)を出力する。予想情動変化は、ロボット装置の行動制御器30における行動制御アルゴリズムと密接な関係を持っており、行動制御アルゴリズムに定義された全てのスキーマ33に対応した予想情動変化の値が定義されている。
The
予想情動変化データベース41は、実際のインタラクションを通じて観測された値を用いて動的に更新することができる。通常は、全てのインタラクション対象の人物について共通の予想情動変化データベースを構築するが、それまでにロボット装置が実際にインタラクションを行い、顔、声、名前などを記憶した人物毎にデータを保持することによって、人物毎に予測モデルとなる予想情動変化データベースを切り替え可能なように、予想情動変化データベースを構築してもよい。また、これらを組み合わせて、よく知っている人物に対しては人物毎に予想情動変化データベースを構築し、初対面の人物など用の共通に使用可能な予想情動データベースを構築しておいてもよい。
The predicted
そして、行動単位(スキーマ)k毎に定義された予想情動変化ベクトル(予測情動変化)をdEbkとし、当該行動実行前の情動を、その行動を実行する前に観測されたセンサ情報から推定された推定情動Es’、すなわち上述の情動推定装置にて算出された行動実行前の推定情動としたとき、これらを組み合わせ、行動履歴の情報を元に推定される下記式(17)に示す予測情動Ebが求められる。予測情動Ebも上記基本6感情を要素とするベクトルである。 The predicted emotion change vector (predicted emotion change) defined for each behavior unit (schema) k is dEb k, and the emotion before execution of the behavior is estimated from the sensor information observed before the behavior is executed. The estimated emotion Es ′, that is, the estimated emotion before the action execution calculated by the above-described emotion estimation device, is combined, and the predicted emotion shown in the following formula (17) estimated based on the behavior history information Eb is determined. The predicted emotion Eb is also a vector having the basic six emotions as elements.
(7)予想情動変化データベースの学習方法
次に、情動予測装置における予想情動変化データベースの構築方法(学習方法)について説明する。予想情動変化データベースは、行動を実行する前と後との情動の差分を表現したデータベースであり、初期状態の情動予測装置40の予想情動変化データベース41は全て0で初期化されており、センサ情報から推定された推定情動Esのみを利用してインタラクション対象の情動が判断される。その後は、実際にロボット装置が行動選択を行ってインタラクションした結果、行動前後におけるインタラクション対象の情動推定結果が得られた場合には、下記式(18)に示すように、行動を実行した後の最終的な情動予測結果Eaと行動を実行した後の行動履歴に基づく推定情動Ebとの差分の値を用いて予想情動変化データベースは更新される。
(7) Learning Method of Expected Emotion Change Database Next, a construction method (learning method) of the expected emotion change database in the emotion prediction device will be described. The predicted emotion change database is a database that expresses the difference between the emotion before and after the action is executed, and the predicted
ここで、dEbkは各行動単位kに対応した予測情動変化ベクトル、Eaはセンサ情報から推定された推定情動Esと、行動履歴の情報を元に推定される予測情動Ebとから得られる後述する最終的な出力としての推定情動E、αは学習係数、時刻T’は前回行動kを行った時間、時刻Tは次回、同一の行動kを行う時間を示し、dEbの値は、行動kに対応した値のみが更新される。また、時刻T’における推定情動Eaを示すEa T’は、例えば行動実行後(時刻T’)に時系列のセンサ情報から抽出したユーザの時系列の特徴量に基づき推定された推定情動Esとして予測情動変化データベースを更新してもよい。また、例えば人為的にデータベースを作成したいときなどにおいては、時刻T’におけるユーザの情動を、教師データとして外部から供給したり、ロボット装置に教えたりすればよい。 Here, dEb k is a predicted emotion change vector corresponding to each behavior unit k, E a is an estimated emotion Es estimated from sensor information, and a predicted emotion Eb estimated based on behavior history information, which will be described later. As a final output, the estimated emotion E, α is a learning coefficient, time T ′ is the time when the previous action k was performed, time T is the time when the same action k is performed next time, and the value of dEb is the action k Only the value corresponding to is updated. Further, E a T ′ indicating the estimated emotion E a at time T ′ is, for example, estimated emotion estimated based on the user's time-series feature amount extracted from time-series sensor information after execution of the action (time T ′). The predicted emotion change database may be updated as Es. In addition, for example, when it is desired to artificially create a database, the user's emotion at time T ′ may be supplied from the outside as teacher data or may be taught to the robot apparatus.
ここで、予想情動変化dEbk Tを更新しようとした場合、目標とする値が推定情動Eaであり、それに対して前回の予測情動変化dEbk T’を考慮して算出された値が今回の予測情動Ebk Tとなるため、上記式(18)の右辺に示すように推定情動Ea T’と予測情動Ebk T’との差分をとり、この値が正ならば予想情動変化dEbk Tをより大きくする必要があり、負ならば予想情動変化dEbk Tをより小さくする必要があることを示す。 Here, when the predicted emotion change dEb k T is to be updated, the target value is the estimated emotion E a , and the value calculated in consideration of the previous predicted emotion change dEb k T ′ is predicted emotion Eb k T, and therefore, taking the difference of the expression 'a prediction affective Eb k T' (18) estimates the emotion E a T as shown in the right-hand side of the expected emotional changes dEb if this value is positive it is necessary to increase the k T, indicating a need to further reduce the expected emotional changes DEB k T if negative.
このように、時刻Tにおける予想情動変化dEbk Tは、時刻T’における予想情動変化dEbk T’に、時刻T’におけるユーザの情動Ea T’と時刻T’における予測情動Ebk T’との差に学習係数αを乗算した値を加算したものとなっており、行動履歴、すなわち行動のコンテキストを考慮したものとなっている。 As described above, the predicted emotion change dEb k T at time T is changed from the expected emotion change dEb k T ′ at time T ′ to the user emotion E a T ′ at time T ′ and the predicted emotion Eb k T ′ at time T ′. And a value obtained by multiplying the difference by the learning coefficient α, and the action history, that is, the action context is taken into consideration.
例えば、図10(b)に示すように、ある時点における予想情動変化データベース41においては、例えばスキーマID(k)=1に記述された行動を実行すると、内部状態「JOY」が上昇し(10)、内部状態「DISGUST」が減少している(−25)。また、スキーマID(k)=6に記述された行動を実行すると、内部状態「JOY」が上昇し(+5)、内部状態「DISGUST」が減少する(−10)ことを示している。
For example, as shown in FIG. 10B, in the predicted
こうしてロボット装置は、行動を実行することで予想情動変化の値を更新し、予想情動変化データベース41を学習することができる。なお、予想情動変化データベース41は、常に更新し続けるものとしてもよいが、所定期間の行動実行結果に応じて更新した後に更新を終了してもよく、予め行動実行後の予想情動変化dEbkが定義された予想情動変化データベースを使用してもよい。
In this way, the robot apparatus can learn the expected
(8)情動認識システムにおける推定情動Eの推定方法
次に、時系列のセンサ入力情報に基づく認識結果と行動履歴に基づく情動予測結果の融合方法について説明する。上述した情動推定装置により、センサ入力情報に基づく認識結果として得られる推定情動Esは、センサ入力の時系列情報に従って逐次出力されるものであるが、情動予測装置により、行動履歴に基づく認識結果として得られる推定情動Ebは、ある要素行動を完了した瞬間に得られる値である。したがって、行動履歴に基づいて予測された予測情動の信頼性は、行動完了後から時間の経過とともに低下する。この効果を反映させた上で、センサ入力に基づいて算出された情動認識結果(推定情動Es)に対するトップダウンの補正を行うアルゴリズムを下記式(19)及び式(20)によって定式化する。これらの式(19)、(20)は、行動完了すぐの段階では、行動履歴に基づく情動予測結果である予測情動Ebを重視し、行動完了から時間が経過するに従ってセンサ情報に基づく情動認識結果である推定情動Esを重視するように変化することを意味している。ここでtはある行動が完了してからの経過時間(異なる行動が完了すると、0にリセットされる)、τ0及びτは時間経過に対する減衰の度合を決定するパラメータである。
(8) Estimation Method of Estimated Emotion E in Emotion Recognition System Next, a method of merging the recognition result based on time-series sensor input information and the emotion prediction result based on the action history will be described. The estimated emotion Es obtained as the recognition result based on the sensor input information by the emotion estimation device described above is sequentially output according to the time-series information of the sensor input, but the emotion prediction device uses the recognition result based on the action history as the recognition result. The obtained estimated emotion Eb is a value obtained at the moment when a certain elemental action is completed. Therefore, the reliability of the predicted emotion predicted based on the action history decreases with the passage of time from the completion of the action. After reflecting this effect, an algorithm for performing top-down correction on the emotion recognition result (estimated emotion Es) calculated based on the sensor input is formulated by the following equations (19) and (20). These formulas (19) and (20) emphasize the predicted emotion Eb, which is the emotion prediction result based on the behavior history, immediately after the completion of the behavior, and the emotion recognition result based on the sensor information as time elapses from the behavior completion. This means that the estimated emotion Es is changed so as to be emphasized. Here, t is an elapsed time after completion of a certain action (reset to 0 when a different action is completed), and τ 0 and τ are parameters for determining the degree of attenuation with respect to the passage of time.
図11は、情動認識システムのうち、情動推定装置1の推定結果である推定情動Esと、情動予測装置40の予測結果である予測情動Ebとを統合する情動統合部52に関する部分を示す図である。図11に示すように、結果統合部52は、情動推定装置1からの推定情動Esと情動予測装置40からの予測情動Ebとが入力され、上記式(19)、(20)に従って推定情動Eを出力する。
FIG. 11 is a diagram illustrating a portion related to the
ここで、情動推定装置1は、上述したように、時系列のセンサ情報列から時系列の特徴量を抽出し、コンテキストを考慮して推定した推定結果を推定情動Esとして出力するセンサ情報分析システムとして作用する。
Here, as described above, the
また情動予測装置40は、行動実行後に、行動履歴、すなわち行動のコンテキストを考慮して学習された予想情動変化データベース41を参照して予想情動変化dEbkを出力する情動変化予測部(行動履歴分析システム)42と、この予想情動変化dEbk及び行動実行前の情動推定装置1’の推定情動Es’から予測情動を算出する予測情動算出部43とを有する。この情動予測装置40は、行動実行後に予測情動Ebを出力するもので、情動推定装置1’から行動実行前の推定情動Es’を受け取り、情動予測部42から実行した行動kに対応づけられた予想情動変化dEbkを受け取り、これらを加算して推定情動Ebを出力する。なお、図11には、推定情動Es’を出力する情動推定装置1’を記載しているが、情動推定装置1から行動開始前の推定情動Es’を入力するようにすればよい。
In addition, the
これらの出力データは、図12のようになる。図12は、ロボット装置が3つの行動B1〜B3を実行した際の推定情動の変化を示すグラフであって、上段から、時系列のセンサ情報に基づき、情動推定装置にて算出された推定情動Es、次段は、この推定情動Esの時間減衰を考慮した値=(1−η)Esを示す。 These output data are as shown in FIG. FIG. 12 is a graph showing changes in the estimated emotion when the robot apparatus executes the three actions B1 to B3. From the upper stage, the estimated emotion calculated by the emotion estimation device based on time-series sensor information. Es, the next stage, shows a value = (1−η) Es in consideration of the time decay of the estimated emotion Es.
また、3段目は、行動履歴に基づき予測された予測情動Ebを示し、その後段は、この予測情動Ebの時間減衰を考慮した値=ηEbを示す。そして、5段目は、(1−η)Es及びηEbを統合して得られる情動認識装置50の認識結果である推定情動Eを示す。
The third row shows the predicted emotion Eb predicted based on the action history, and the subsequent row shows a value = ηEb considering the time decay of the predicted emotion Eb. The fifth row shows the estimated emotion E that is the recognition result of the
本実施の形態においては、複数のモーダルについて、モーダル毎に情動認識器を用意し、入力されるモーダル別の時系列のセンサ情報から抽出した時系列の特徴量ベクトルにより推定情動を算出し、更に、認識結果の予測誤差を求めて信頼度パラメータに変換し、認識結果に重み付けするため、センサ入力情報の時系列(コンテキスト)を考慮した情動を推定することができる。このことにより、センサのノイズによって推定情動が不安定になる、すなわち認識結果が支離滅裂に変化することを抑えて、極めて安定な認識結果とすることができると共に、信頼度λにより認識器の認識結果に重み付けして統合して推定情動Esとすることで極めて正確に情動を推定することができる。 In the present embodiment, for a plurality of modals, an emotion recognizer is prepared for each modal, an estimated emotion is calculated from a time-series feature vector extracted from time-series sensor information input by modal, and Since the prediction error of the recognition result is obtained, converted into the reliability parameter, and the recognition result is weighted, it is possible to estimate the emotion in consideration of the time series (context) of the sensor input information. As a result, it is possible to obtain an extremely stable recognition result by suppressing the estimated emotion from being unstable due to sensor noise, i.e., the recognition result changing to incoherent, and the recognition result of the recognizer by the reliability λ. It is possible to estimate the emotion very accurately by weighting and integrating them into the estimated emotion Es.
更に、センサ入力情報から認識器によって得られた推定情動Esだけではなく、ロボット装置自身の行動のコンテキストから情動変化を予測した予測情動Ebを求め、推定情動Esにトップダウンの補正をかけると共に、センサ情報が入力され次第得ることができる推定情動Esと、行動結果後にのみ出力される予測情動Ebの時間的な誤差を考慮する、すなわち、行動完了すぐの段階では、行動履歴に基づく予測情動Ebの結果を重視し、行動完了から時間が経過するに従ってセンサ情報に基づく情動認識結果(推定情動Es)を重視するようにパラメータηを変化させ、センサ入力に基づく認識結果(推定情動Es)と、行動履歴に基づく情動予測結果(予測情動Eb)とを融合させることで、情動推定システムにて最終的に得られる推定情動を、ユーザの情動変化に対する、生物により近い自然な認識を可能する。 Furthermore, not only the estimated emotion Es obtained by the recognizer from the sensor input information, but also a predicted emotion Eb that predicts the emotion change from the context of the behavior of the robot device itself, and applies a top-down correction to the estimated emotion Es, Considering the temporal error between the estimated emotion Es that can be obtained as soon as the sensor information is input and the predicted emotion Eb that is output only after the behavior result, that is, at the stage immediately after the completion of the behavior, the predicted emotion Eb based on the behavior history. The parameter η is changed so that the emotion recognition result based on the sensor information (estimated emotion Es) is emphasized as time elapses from the completion of the action, the recognition result based on the sensor input (estimated emotion Es), By combining the emotion prediction result (predicted emotion Eb) based on the action history, the estimation finally obtained by the emotion estimation system Emotion, for emotion change of the user, to allow natural recognition closer organism.
また、自らの行動がインタラクション対象のどのような情動変化をもたらすかを推定するための予想情動変化データベース(フォワードモデル)は、情動推定装置1から得られた結果を教師データとして逐次的に、行動−情動予測モデルのリアルタイム学習を行うことができ、その予測精度を向上させることができる。
Moreover, the predicted emotion change database (forward model) for estimating what kind of emotional change of the interaction target is caused by the user's own behavior is sequentially performed using the results obtained from the
このように、センサ情報から得られる推定情動Esだけではなく、それまでの人間とのインタラクション経験から、自らの行動が相手の情動に対してどのような変化をもたらすかの経験、すなわちロボット装置自身の行動のコンテキストを考慮し他者の情動遷移モデルとなる予想情動変化データベースを構築して予測情動Ebを求め、情動推定装置1からの推定情動Esと合わせて判断することで推定情動Eの推定精度を向上することができる。したがって、ロボット装置は、インタラクション対象の情動を示すこの推定情動Eに応じて行動を選択することができ、例えばインタラクション対象を喜ばせたり、楽しませたりといった行動を発現してよりエンターテイメント性を向上することができる。
In this way, not only the estimated emotion Es obtained from the sensor information, but also the experience of how one's own action changes the other's emotion based on the previous experience with human interaction, that is, the robot apparatus itself The estimated emotion E is estimated by constructing a predicted emotion change database that becomes an emotion transition model of the other person in consideration of the context of the other person's behavior, obtaining the predicted emotion Eb, and judging together with the estimated emotion Es from the
B:ロボット装置
次に、上述した情動認識システムを搭載したロボット装置の一具体例について説明する。本実施の形態においては、2足歩行型のロボット装置を例にとって説明するが、2足歩行のロボット装置に限らず、4足又は車輪等により移動可能なロボット装置に適用できることはいうまでもない。
B: Robot Device Next, a specific example of a robot device equipped with the emotion recognition system described above will be described. In the present embodiment, a biped walking robot device will be described as an example, but it is needless to say that the present invention is not limited to a biped walking robot device and can be applied to a robot device that can be moved by four feet or wheels. .
この人間型のロボット装置は、住環境その他の日常生活上の様々な場面における人的活動を支援する実用ロボットであり、内部状態(怒り、悲しみ、喜び、楽しみ等)に応じて行動できるほか、人間が行う基本的な動作を表出できるエンターテインメントロボットである。また、自身の内部状態ではなく、上述の情動認識システムにおいて認識したユーザの情動に応じて行動を発現することも可能である。図13は、本実施の形態におけるロボット装置の概観を示す斜視図である。 This humanoid robot device is a practical robot that supports human activities in various situations in the living environment and other daily life, and can act according to the internal state (anger, sadness, joy, fun, etc.) It is an entertainment robot that can express the basic actions performed by humans. Moreover, it is also possible to express an action according to the emotion of the user recognized by the above emotion recognition system instead of the internal state of the user. FIG. 13 is a perspective view showing an overview of the robot apparatus according to the present embodiment.
図13に示すように、ロボット装置101は、体幹部ユニット102の所定の位置に頭部ユニット103が連結されると共に、左右2つの腕部ユニット104R/Lと、左右2つの脚部ユニット105R/Lが連結されて構成されている(但し、R及びLの各々は、右及び左の各々を示す接尾辞である。以下において同じ。)。
As shown in FIG. 13, the
このロボット装置101が具備する関節自由度構成を図14に模式的に示す。頭部ユニット103を支持する首関節は、首関節ヨー軸111と、首関節ピッチ軸112と、首関節ロール軸113という3自由度を有している。
FIG. 14 schematically shows a joint degree-of-freedom configuration of the
また、上肢を構成する各々の腕部ユニット104R/Lは、肩関節ピッチ軸117と、肩関節ロール軸118と、上腕ヨー軸119と、肘関節ピッチ軸120と、前腕ヨー軸121と、手首関節ピッチ軸122と、手首関節ロール輪123と、手部124とで構成される。手部124は、実際には、複数本の指を含む多関節・多自由度構造体である。ただし、手部124の動作は、ロボット装置101の姿勢制御や歩行制御に対する寄与や影響が少ないので、本明細書では簡単のため、ゼロ自由度と仮定する。したがって、各腕部は7自由度を有するとする。
Each
また、体幹部ユニット102は、体幹ピッチ軸114と、体幹ロール軸115と、体幹ヨー軸116という3自由度を有する。
The
また、下肢を構成する各々の脚部ユニット105R/Lは、股関節ヨー軸125と、股関節ピッチ軸126と、股関節ロール軸127と、膝関節ピッチ軸128と、足首関節ピッチ軸129と、足首関節ロール軸130と、足部131とで構成される。本明細書中では、股関節ピッチ軸126と股関節ロール軸127の交点は、ロボット装置101の股関節位置を定義する。人体の足部131は、実際には多関節・多自由度の足底を含んだ構造体であるが、本明細書においては、簡単のためロボット装置101の足底は、ゼロ自由度とする。したがって、各脚部は、6自由度で構成される。
Each
以上を総括すれば、ロボット装置101全体としては、合計で3+7×2+3+6×2=32自由度を有することになる。ただし、エンターテインメント向けのロボット装置1が必ずしも32自由度に限定されるわけではない。設計・制作上の制約条件や要求仕様等に応じて、自由度すなわち関節数を適宜増減することができることはいうまでもない。
In summary, the
上述したようなロボット装置101がもつ各自由度は、実際にはアクチュエータを用いて実装される。外観上で余分な膨らみを排してヒトの自然体形状に近似させること、2足歩行という不安定構造体に対して姿勢制御を行うこと等の要請から、アクチュエータは小型且つ軽量であることが好ましい。
Each degree of freedom of the
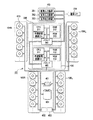
このようなロボット装置は、ロボット装置全体の動作を制御する制御システムを例えば体幹部ユニット102等に備える。図15は、ロボット装置101の制御システム構成を示す模式図である。図15に示すように、制御システムは、ユーザ入力等に動的に反応して情緒判断や感情表現を司る思考制御モジュール300と、アクチュエータ450の駆動等ロボット装置1の全身協調運動を制御する運動制御モジュール400とで構成される。
Such a robot apparatus includes a control system that controls the operation of the entire robot apparatus, for example, in the
思考制御モジュール300は、情緒判断や感情表現に関する演算処理を実行するCPU(Central Processing Unit)311や、RAM(Random Access Memory)312、ROM(Read Only Memory)313及び外部記憶装置(ハード・ディスク・ドライブ等)314等で構成され、モジュール内で自己完結した処理を行うことができる、独立駆動型の情報処理装置である。
The
この思考制御モジュール300は、画像入力装置351から入力される画像データや音声入力装置352から入力される音声データ等、外界からの刺激等に従って、ロボット装置101の現在の感情や意思を決定する。すなわち、上述したように、入力される画像データからユーザの表情を認識し、その情報をロボット装置101の感情や意思に反映させることで、ユーザの表情に応じた行動を発現することができる。ここで、画像入力装置351は、例えばCCD(Charge Coupled Device)カメラを複数備えており、また、音声入力装置352は、例えばマイクロホンを複数備えている。
The
また、思考制御モジュール300は、意思決定に基づいた動作又は行動シーケンス、すなわち四肢の運動を実行するように、運動制御モジュール300に対して指令を発行する。
The
一方の運動制御モジュール400は、ロボット装置101の全身協調運動を制御するCPU411や、RAM412、ROM413及び外部記憶装置(ハード・ディスク・ドライブ等)414等で構成され、モジュール内で自己完結した処理を行うことができる独立駆動型の情報処理装置である。また、外部記憶装置414には、例えば、オフラインで算出された歩行パターンや目標とするZMP軌道、その他の行動計画を蓄積することができる。
One
この運動制御モジュール400には、図14に示したロボット装置101の全身に分散するそれぞれの関節自由度を実現するアクチュエータ450、対象物との距離を測定する距離計測センサ(図示せず)、体幹部ユニット102の姿勢や傾斜を計測する姿勢センサ451、左右の足底の離床又は着床を検出する接地確認センサ452,453、足底131の足底131に設けられる荷重センサ、バッテリ等の電源を管理する電源制御装置454等の各種の装置が、バス・インターフェース(I/F)401経由で接続されている。ここで、姿勢センサ451は、例えば加速度センサとジャイロ・センサの組み合わせによって構成され、接地確認センサ452,453は、近接センサ又はマイクロ・スイッチ等で構成される。
The
思考制御モジュール300と運動制御モジュール400は、共通のプラットフォーム上で構築され、両者間はバス・インターフェース301,401を介して相互接続されている。
The
運動制御モジュール400では、思考制御モジュール300から指示された行動を体現すべく、各アクチュエータ450による全身協調運動を制御する。すなわち、CPU411は、思考制御モジュール300から指示された行動に応じた動作パターンを外部記憶装置414から取り出し、又は、内部的に動作パターンを生成する。そして、CPU411は、指定された動作パターンに従って、足部運動、ZMP軌道、体幹運動、上肢運動、腰部水平位置及び高さ等を設定するとともに、これらの設定内容に従った動作を指示する指令値を各アクチュエータ450に転送する。
The
また、CPU411は、姿勢センサ451の出力信号によりロボット装置101の体幹部ユニット102の姿勢や傾きを検出するとともに、各接地確認センサ452,453の出力信号により各脚部ユニット105R/Lが遊脚又は立脚のいずれの状態であるかを検出することによって、ロボット装置101の全身協調運動を適応的に制御することができる。更に、CPU411は、ZMP位置が常にZMP安定領域の中心に向かうように、ロボット装置101の姿勢や動作を制御する。
In addition, the
また、運動制御モジュール400は、思考制御モジュール300において決定された意思通りの行動がどの程度発現されたか、すなわち処理の状況を、思考制御モジュール300に返すようになっている。このようにしてロボット装置101は、制御プログラムに基づいて自己及び周囲の状況を判断し、自律的に行動することができる。
In addition, the
このようなロボット装置には、動的に変化する作業環境下で一定時間内に応答できるようなヒューマン・インターフェース技術が要求されている。本実施の形態に係るロボット装置101は、情動推定システムを搭載することにより、周囲のユーザ(飼い主又はともだち、若しくは正当なユーザ)の情動を認識すると共に、認識結果に基づいてリアクションを制御することによって、より高いエンターテイメント性を実現することができる。
Such a robot apparatus is required to have a human interface technology that can respond within a predetermined time in a dynamically changing work environment. The
なお、本発明は上述した実施の形態のみに限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能であることは勿論である。また、上述の実施の形態における情動認識システムは、ハードウェアにより実現しても、任意の処理を、演算器にコンピュータプログラムを実行させることにより実現してもよいことは勿論である。この場合、コンピュータプログラムは、記録媒体に記録して提供することも可能であり、また、インターネットその他の伝送媒体を介して伝送することにより提供することも可能である。 It should be noted that the present invention is not limited to the above-described embodiments, and various modifications can be made without departing from the scope of the present invention. In addition, the emotion recognition system in the above-described embodiment may be realized by hardware or may be realized by causing an arithmetic unit to execute a computer program. In this case, the computer program can be provided by being recorded on a recording medium, or can be provided by being transmitted via the Internet or another transmission medium.
1 情動推定装置、2m センサ部、3n 特徴量抽出部、4n モーダル別情動推定部、7n ソフトマックス演算器、8n 乗算器、9 加算器、5n 情動認識器、6n 誤差予測器、10 データベース、31 内部状態、32 外部刺激、30 行動制御器、33 スキーマ、40 情動予測装置、41 予想情動変化データベース、42 予想情動算出部、50 情動推定システム、52 情動統合部
DESCRIPTION OF
Claims (28)
上記時系列の特徴量に基づき、上記センサ情報のコンテキストを考慮して上記認識対象の情動を推定する情動推定手段と
を有することを特徴とする情動推定装置。 A feature quantity extraction means for extracting a time series feature quantity related to a recognition target for recognizing emotion from time series sensor information;
An emotion estimation device comprising: an emotion estimation unit that estimates the emotion of the recognition target in consideration of the context of the sensor information based on the time-series feature amount.
上記情動推定手段は、上記モーダル別特徴量列に基づき各モーダル毎に上記情動を認識する複数のモーダル別情動認識手段と、該各モーダル別情動認識手段の認識結果に基づき上記情動を推定する認識結果統合手段とを有する
ことを特徴とする請求項1記載の情動推定装置。 The feature amount extraction means extracts the time-series feature amount for each modal for a plurality of modals as a modal-specific feature amount sequence,
The emotion estimation means includes a plurality of modal emotion recognition means for recognizing the emotion for each modal based on the modal feature quantity sequence, and a recognition for estimating the emotion based on a recognition result of the modal emotion recognition means. The emotion estimation apparatus according to claim 1, further comprising a result integration unit.
上記認識結果統合手段は、上記各モーダル別情動認識手段により得られた認識結果及びその予測誤差に基づき上記情動を推定する
ことを特徴とする請求項2記載の情動推定装置。 The emotion estimation means includes prediction error calculation means for calculating a prediction error of the recognition result obtained by the modal emotion recognition means,
The emotion estimation apparatus according to claim 2, wherein the recognition result integration unit estimates the emotion based on a recognition result obtained by the modal emotion recognition unit and a prediction error thereof.
ことを特徴とする請求項3記載の情動推定装置。 The prediction error calculation means calculates a prediction error of the recognition result based on the recognition result obtained by the modal feature quantity sequence and / or the modal emotion recognition means. Emotion estimation device.
ことを特徴とする請求項3記載の情動推定装置。 The recognition result integration unit converts the prediction error obtained by the prediction error calculation unit into reliability, and based on the weighted recognition result obtained by weighting the recognition result obtained by each modal emotion recognition unit. The emotion estimation apparatus according to claim 3, wherein the emotion is estimated.
ことを特徴とする請求項1記載の情動推定装置。 When the emotion estimation means uses the time-series feature quantity related to the recognition target extracted from the time-series sensor information as input data, the emotion of the recognition target when the time-series sensor information is acquired is output data. The emotion estimation apparatus according to claim 1, which has been learned in advance by recursive learning.
上記モーダル別情動認識手段は、時系列のセンサ情報から抽出した認識対象に関するモーダル毎の時系列の特徴量を入力データとしたとき、当該時系列のセンサ情報を取得した際の認識対象の情動が出力データとなるよう、再帰的学習により予め学習されたものである
ことを特徴とする請求項3記載の情動推定装置。 When the prediction error calculation means uses, as input data, a time-series feature quantity for each modal related to a recognition target extracted from time-series sensor information and / or a recognition result obtained by the modal-specific emotion recognition means. It is learned in advance by recursive learning so that the difference between the emotion of the recognition target when acquiring the sensor information of the series and the recognition result obtained by the modal-specific emotion recognition means becomes output data,
When the modal emotion recognition means uses the time-series feature quantity for each modal regarding the recognition target extracted from the time-series sensor information as input data, the emotion of the recognition target when the time-series sensor information is acquired is The emotion estimation apparatus according to claim 3, which has been learned in advance by recursive learning so as to be output data.
ことを特徴とする請求項6記載の情動推定装置。 The emotion estimation apparatus according to claim 6, wherein a neural network is used for the recursive learning.
上記時系列の特徴量に基づき、上記センサ情報のコンテキストを考慮して上記認識対象の情動を推定する情動推定工程と
を有することを特徴とする情動推定方法。 A feature quantity extraction step for extracting a time series feature quantity related to a recognition target for recognizing emotion from time series sensor information;
An emotion estimation method comprising: an emotion estimation step of estimating the emotion of the recognition target in consideration of the context of the sensor information based on the time-series feature amount.
上記情動推定工程は、上記モーダル別特徴量列に基づき各モーダル毎に上記情動を認識するモーダル別情動認識工程と、上記モーダル別情動認識工程にて得られたモーダル別認識結果に基づき上記情動を推定する認識結果統合工程とを有する
ことを特徴とする請求項9記載の情動推定方法。 In the feature amount extraction step, the time-series feature amount for each modal is extracted as a feature amount sequence by modal for a plurality of modals,
The emotion estimation step includes the modal emotion recognition step for recognizing the emotion for each modal based on the modal feature quantity sequence, and the modal recognition result obtained in the modal emotion recognition step. An emotion estimation method according to claim 9, further comprising a recognition result integration step for estimation.
上記認識結果統合工程では、上記モーダル別情動認識工程にて得られたモーダル別認識結果及びその予測誤差に基づき上記情動を推定する
ことを特徴とする請求項10記載の情動推定方法。 A prediction error calculation step of calculating a prediction error of the recognition result obtained in the emotion recognition process according to modal,
The emotion estimation method according to claim 10, wherein in the recognition result integration step, the emotion is estimated based on a modal recognition result obtained in the modal emotion recognition step and a prediction error thereof.
ことを特徴とする請求項11記載の情動推定方法。 In the recognition result integration step, the prediction error calculated in the prediction error calculation step is converted into a reliability, and the recognition result obtained in each modal emotion recognition step is weighted to the weighted recognition result. The emotion estimation method according to claim 11, wherein the emotion is estimated based on the emotion.
インタラクション対象に関する情報を取得する1以上のセンサと、
上記センサから時系列のセンサ情報を受け取り、上記インタラクション対象に関する時系列の特徴量を抽出する特徴量抽出手段と、
上記時系列の特徴量に基づき、上記センサ情報のコンテキストを考慮して上記インタラクション対象の情動を推定する情動推定手段とを有する
ことを特徴とするロボット装置。 In a robotic device that behaves autonomously based on internal conditions and / or external stimuli,
One or more sensors that obtain information about the interaction object;
Feature quantity extraction means for receiving time series sensor information from the sensor and extracting time series feature quantities relating to the interaction target;
A robot apparatus comprising: an emotion estimation unit configured to estimate the emotion of the interaction target in consideration of the context of the sensor information based on the time-series feature amount.
上記情動推定手段は、上記モーダル別特徴量列に基づき各モーダル毎に上記情動を認識する複数のモーダル別情動認識手段と、該各モーダル別情動認識手段により得られた認識結果に基づき上記情動を推定する認識結果統合手段とを有する
ことを特徴とする請求項13記載のロボット装置。 The feature amount extraction means extracts the time-series feature amount for each modal as a feature amount sequence by modal for a plurality of modals,
The emotion estimation means includes a plurality of modal emotion recognition means for recognizing the emotion for each modal based on the modal feature quantity sequence, and the emotion based on the recognition result obtained by the modal emotion recognition means. The robot apparatus according to claim 13, further comprising a recognition result integrating unit for estimating.
上記認識結果統合手段は、上記各モーダル別情動認識手段により得られた認識結果及びその予測誤差に基づき上記情動を推定する
ことを特徴とする請求項14記載のロボット装置。 The emotion estimation means includes prediction error calculation means for calculating a prediction error of the recognition result obtained by the modal emotion recognition means,
The robot apparatus according to claim 14, wherein the recognition result integrating unit estimates the emotion based on a recognition result obtained by the modal emotion recognition unit and a prediction error thereof.
上記行動実行手段により実行された行動の種類に応じて上記インタラクション対象の情動を予測する情動予測手段と、
上記情動推定手段により得られた推定結果と上記情動予測手段により得られた予測結果とに基づき上記インタラクション対象の情動を推定する情動統合手段と
を有することを特徴とする請求項13記載のロボット装置。 Action execution means for selecting and executing one action from a plurality of actions;
An emotion prediction means for predicting the emotion of the interaction target according to the type of action executed by the action execution means;
14. The robot apparatus according to claim 13, further comprising emotion integration means for estimating the emotion of the interaction target based on the estimation result obtained by the emotion estimation means and the prediction result obtained by the emotion prediction means. .
ことを特徴とする請求項16記載のロボット装置。 The emotion prediction means predicts an emotional change after execution of an action by referring to an expected emotional change database in which one action and an expected emotional change expected to change after the execution of the one action are associated with each other, The robot apparatus according to claim 16, wherein the emotion after the execution of the behavior is predicted based on the prediction result and the estimation result estimated by the emotion estimation means before the execution of the behavior.
ことを特徴とする請求項17記載のロボット装置。 The robot apparatus according to claim 17, wherein the predicted emotion change database is obtained by learning the expected emotion change based on an emotion change of the interaction target before and after the execution of each action.
ことを特徴とする請求項17記載のロボット装置。 Database learning that updates the predicted emotion change in the predicted emotion change database based on the difference in emotion of the interaction target before and after the execution of the behavior estimated by the emotion estimation unit every time the behavior is executed by the behavior execution unit The robot apparatus according to claim 17, further comprising: means.
ことを特徴とする請求項16記載のロボット装置。 The emotion integration unit weights the estimation result and the prediction result by a parameter that changes so that the estimation result by the emotion estimation unit is more important than the prediction result by the emotion prediction unit as time elapses after execution of the action, The robot apparatus according to claim 16, wherein the emotion is estimated based on the weighted result.
時系列のセンサ情報から、インタラクション対象に関する時系列の特徴量を抽出する特徴量抽出工程と、
上記時系列の特徴量に基づき、上記センサ情報のコンテキストを考慮して上記インタラクション対象の情動を推定する情動推定工程と
ことを特徴とするロボット装置の情動認識方法。 In an emotion recognition method for a robot apparatus that acts autonomously based on an internal state and / or an external stimulus,
A feature amount extraction step of extracting a time series feature amount related to an interaction target from time series sensor information;
An emotion estimation method for a robot apparatus, comprising: an emotion estimation step for estimating an emotion of the interaction target in consideration of the context of the sensor information based on the time-series feature amount.
上記情動推定工程は、上記モーダル別特徴量列に基づき各モーダル毎に上記情動を認識するモーダル別情動認識工程と、上記モーダル別情動認識工程にて得られたモーダル別認識結果に基づき上記情動を推定する認識結果統合工程とを有する
ことを特徴とする請求項21記載のロボット装置の情動認識方法。 In the feature quantity extraction step, the time series feature quantity for each modal is extracted as a modal-specific feature quantity sequence for a plurality of modals,
The emotion estimation step includes the modal emotion recognition step for recognizing the emotion for each modal based on the modal feature quantity sequence, and the modal recognition result obtained in the modal emotion recognition step. The method of recognizing an emotion of a robot apparatus according to claim 21, further comprising a recognition result integrating step of estimating.
上記認識結果統合工程では、上記各モーダル別情動認識工程にて得られた認識結果及びその予測誤差に基づき上記情動を推定する
ことを特徴とする請求項22記載のロボット装置の情動認識方法。 A prediction error calculation step of calculating a prediction error of the recognition result obtained in the emotion recognition process according to modal,
The emotion recognition method for a robot apparatus according to claim 22, wherein, in the recognition result integration step, the emotion is estimated based on the recognition result obtained in the modal emotion recognition step and a prediction error thereof.
上記情動推定工程にて得られた推定結果と上記情動予測工程にて得られた予測結果とに基づき上記インタラクション対象の情動を推定する情動統合工程と
を有することを特徴とする請求項21記載のロボット装置の情動認識方法。 An emotion prediction step of predicting the emotion of the interaction target according to the type of the executed action when the one action is executed by the action executing means for selecting and executing one action from a plurality of actions;
The emotion integration step of estimating the emotion of the interaction target based on the estimation result obtained in the emotion estimation step and the prediction result obtained in the emotion prediction step. An emotion recognition method for a robotic device.
ことを特徴とする請求項24記載のロボット装置の情動認識方法。 In the emotion prediction step, an emotion change after the execution of an action is predicted by referring to an expected emotion change database in which one action and an expected emotion that is expected to change after the execution of the one action are associated with each other. The emotion recognition method for a robot apparatus according to claim 24, wherein the emotion after the execution of the action is predicted based on the result and the estimation result obtained in the emotion estimation step before the execution of the action.
ことを特徴とする請求項24記載のロボット装置の情動認識方法。 In the emotion integration step, the estimation is performed according to a parameter that changes so as to emphasize the estimation result estimated in the emotion estimation step from the prediction result obtained in the emotion prediction step as time elapses after execution of the action. 25. The emotion recognition method for a robot apparatus according to claim 24, wherein a result and a prediction result are weighted, and the emotion is estimated based on the weighted result.
時系列のセンサ情報から抽出したインタラクション対象に関する時系列の特徴量を入力データとし、当該時系列のセンサ情報を取得した際の上記インタラクション対象の情動を出力の目標値として上記情動認識装置の学習をする学習工程を有する
ことを特徴とするロボット装置の学習方法。 In the learning method of the robot apparatus equipped with the emotion recognition device that recognizes the emotion of the interaction target from the given input data,
Learning the emotion recognition device using the time-series feature quantity related to the interaction target extracted from the time-series sensor information as input data and the emotion of the interaction target when the time-series sensor information is acquired as the output target value. A learning method for a robot apparatus, characterized by comprising a learning step.
与えられた入力データから、インタラクション対象の情動を認識する情動認識装置と、
インタラクション対象に関する情報を取得する1以上のセンサと、
上記センサから時系列のセンサ情報を受け取り、上記インタラクション対象に関する時系列の特徴量を抽出する特徴量抽出手段と、
上記時系列のセンサ情報から抽出したインタラクション対象に関する時系列の特徴量を入力データとし、当該時系列のセンサ情報を取得した際の上記インタラクション対象の情動を出力の目標値として上記情動認識装置の学習をする学習手段とを有し、
上記情動認識装置は、上記特徴量抽出手段により抽出された上記時系列の特徴量を上記入力データとして上記情動を認識する
ことを特徴とするロボット装置。
In a robotic device that behaves autonomously based on internal conditions and / or external stimuli,
An emotion recognition device for recognizing the emotion of an interaction target from given input data;
One or more sensors that obtain information about the interaction object;
Feature quantity extraction means for receiving time series sensor information from the sensor and extracting a time series feature quantity relating to the interaction target;
Learning of the emotion recognition apparatus using, as input data, a time-series feature amount related to an interaction target extracted from the time-series sensor information, and using the emotion of the interaction target when the time-series sensor information is acquired as an output target value Learning means to
The emotion recognition apparatus recognizes the emotion using the time-series feature quantity extracted by the feature quantity extraction unit as the input data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004009690A JP2005199403A (en) | 2004-01-16 | 2004-01-16 | Emotion recognition device and method, emotion recognition method of robot device, learning method of robot device and robot device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004009690A JP2005199403A (en) | 2004-01-16 | 2004-01-16 | Emotion recognition device and method, emotion recognition method of robot device, learning method of robot device and robot device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2005199403A true JP2005199403A (en) | 2005-07-28 |
Family
ID=34822652
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004009690A Withdrawn JP2005199403A (en) | 2004-01-16 | 2004-01-16 | Emotion recognition device and method, emotion recognition method of robot device, learning method of robot device and robot device |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2005199403A (en) |
Cited By (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009245236A (en) * | 2008-03-31 | 2009-10-22 | Institute Of Physical & Chemical Research | Information processor, information processing method and program |
| JP2009288934A (en) * | 2008-05-28 | 2009-12-10 | Sony Corp | Data processing apparatus, data processing method, and computer program |
| JP2011090408A (en) * | 2009-10-20 | 2011-05-06 | Canon Inc | Information processor, and action estimation method and program of the same |
| JP2011232822A (en) * | 2010-04-23 | 2011-11-17 | Canon Inc | Information processing device, information processing method and program |
| US8583282B2 (en) * | 2005-09-30 | 2013-11-12 | Irobot Corporation | Companion robot for personal interaction |
| US8780221B2 (en) | 2008-04-09 | 2014-07-15 | Canon Kabushiki Kaisha | Facial expression recognition apparatus, image sensing apparatus, facial expression recognition method, and computer-readable storage medium |
| JP2015114987A (en) * | 2013-12-13 | 2015-06-22 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | Processing device, processing method, and program |
| JP2015171737A (en) * | 2014-03-11 | 2015-10-01 | 本田技研工業株式会社 | Robot and robot control method |
| KR20160066526A (en) * | 2014-12-02 | 2016-06-10 | 삼성전자주식회사 | Device and method for obtaining state data indicating state of user |
| US20160180722A1 (en) * | 2014-12-22 | 2016-06-23 | Intel Corporation | Systems and methods for self-learning, content-aware affect recognition |
| JP2017087344A (en) * | 2015-11-10 | 2017-05-25 | 株式会社国際電気通信基礎技術研究所 | Android robot control system, device, program and method |
| WO2017175447A1 (en) * | 2016-04-05 | 2017-10-12 | ソニー株式会社 | Information processing apparatus, information processing method, and program |
| JP2018072876A (en) * | 2016-10-24 | 2018-05-10 | 富士ゼロックス株式会社 | Emotion estimation system and emotion estimation model generation system |
| CN108229640A (en) * | 2016-12-22 | 2018-06-29 | 深圳光启合众科技有限公司 | The method, apparatus and robot of emotion expression service |
| US10013892B2 (en) | 2013-10-07 | 2018-07-03 | Intel Corporation | Adaptive learning environment driven by real-time identification of engagement level |
| JP2018152004A (en) * | 2017-03-15 | 2018-09-27 | 富士ゼロックス株式会社 | Information processor and program |
| CN109002887A (en) * | 2018-08-10 | 2018-12-14 | 华北理工大学 | The heuristic curiosity cognitive development system of biology and its operation method |
| JP2019508072A (en) * | 2016-12-02 | 2019-03-28 | アヴェント インコーポレイテッド | System and method for navigation of targets to anatomical objects in medical imaging based procedures |
| JP2020075385A (en) * | 2018-11-06 | 2020-05-21 | 株式会社東芝 | Product state estimation device |
| CN111190484A (en) * | 2019-12-25 | 2020-05-22 | 中国人民解放军军事科学院国防科技创新研究院 | Multi-mode interaction system and method |
| KR20200103421A (en) * | 2019-02-25 | 2020-09-02 | 군산대학교산학협력단 | Building method and building apparatus of memory model |
| JP2021030433A (en) * | 2020-07-21 | 2021-03-01 | 株式会社DailyColor | Robot control device |
| JPWO2021095211A1 (en) * | 2019-11-14 | 2021-05-20 | ||
| JP6972434B1 (en) * | 2020-07-30 | 2021-11-24 | 三菱電機株式会社 | Behavior identification device, behavior identification method and behavior identification program |
| US11272888B1 (en) | 2021-06-22 | 2022-03-15 | Nft Ip Holdings Llc | Devices and systems that measure, quantify, compare, package, and capture human content in databases |
| WO2022054292A1 (en) * | 2020-09-14 | 2022-03-17 | 三菱電機株式会社 | Robot control device |
| CN114926837A (en) * | 2022-05-26 | 2022-08-19 | 东南大学 | Emotion recognition method based on human-object space-time interaction behavior |
| US11511414B2 (en) | 2019-08-28 | 2022-11-29 | Daily Color Inc. | Robot control device |
| CN115496113A (en) * | 2022-11-17 | 2022-12-20 | 深圳市中大信通科技有限公司 | Emotional behavior analysis method based on intelligent algorithm |
| US11551708B2 (en) * | 2017-11-21 | 2023-01-10 | Nippon Telegraph And Telephone Corporation | Label generation device, model learning device, emotion recognition apparatus, methods therefor, program, and recording medium |
| WO2023166979A1 (en) * | 2022-03-01 | 2023-09-07 | ソニーグループ株式会社 | Information processing device, information processing method, and program |
| JP7400965B2 (en) | 2020-05-28 | 2023-12-19 | 日本電信電話株式会社 | Mood prediction method, mood prediction device and program |
| CN117523664A (en) * | 2023-11-13 | 2024-02-06 | 书行科技(北京)有限公司 | Training method of human motion prediction model, related method and related product |
-
2004
- 2004-01-16 JP JP2004009690A patent/JP2005199403A/en not_active Withdrawn
Cited By (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8583282B2 (en) * | 2005-09-30 | 2013-11-12 | Irobot Corporation | Companion robot for personal interaction |
| US10661433B2 (en) | 2005-09-30 | 2020-05-26 | Irobot Corporation | Companion robot for personal interaction |
| US9878445B2 (en) | 2005-09-30 | 2018-01-30 | Irobot Corporation | Displaying images from a robot |
| JP2009245236A (en) * | 2008-03-31 | 2009-10-22 | Institute Of Physical & Chemical Research | Information processor, information processing method and program |
| US8780221B2 (en) | 2008-04-09 | 2014-07-15 | Canon Kabushiki Kaisha | Facial expression recognition apparatus, image sensing apparatus, facial expression recognition method, and computer-readable storage medium |
| US9147107B2 (en) | 2008-04-09 | 2015-09-29 | Canon Kabushiki Kaisha | Facial expression recognition apparatus, image sensing apparatus, facial expression recognition method, and computer-readable storage medium |
| US9258482B2 (en) | 2008-04-09 | 2016-02-09 | Canon Kabushiki Kaisha | Facial expression recognition apparatus, image sensing apparatus, facial expression recognition method, and computer-readable storage medium |
| JP2009288934A (en) * | 2008-05-28 | 2009-12-10 | Sony Corp | Data processing apparatus, data processing method, and computer program |
| JP2011090408A (en) * | 2009-10-20 | 2011-05-06 | Canon Inc | Information processor, and action estimation method and program of the same |
| JP2011232822A (en) * | 2010-04-23 | 2011-11-17 | Canon Inc | Information processing device, information processing method and program |
| US10013892B2 (en) | 2013-10-07 | 2018-07-03 | Intel Corporation | Adaptive learning environment driven by real-time identification of engagement level |
| US11610500B2 (en) | 2013-10-07 | 2023-03-21 | Tahoe Research, Ltd. | Adaptive learning environment driven by real-time identification of engagement level |
| JP2015114987A (en) * | 2013-12-13 | 2015-06-22 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | Processing device, processing method, and program |
| JP2015171737A (en) * | 2014-03-11 | 2015-10-01 | 本田技研工業株式会社 | Robot and robot control method |
| JP2016110631A (en) * | 2014-12-02 | 2016-06-20 | 三星電子株式会社Samsung Electronics Co.,Ltd. | State estimation device, state estimation method and program |
| US10878325B2 (en) | 2014-12-02 | 2020-12-29 | Samsung Electronics Co., Ltd. | Method and device for acquiring state data indicating state of user |
| KR102572698B1 (en) * | 2014-12-02 | 2023-08-31 | 삼성전자주식회사 | Device and method for obtaining state data indicating state of user |
| KR20160066526A (en) * | 2014-12-02 | 2016-06-10 | 삼성전자주식회사 | Device and method for obtaining state data indicating state of user |
| US20160180722A1 (en) * | 2014-12-22 | 2016-06-23 | Intel Corporation | Systems and methods for self-learning, content-aware affect recognition |
| JP2017087344A (en) * | 2015-11-10 | 2017-05-25 | 株式会社国際電気通信基礎技術研究所 | Android robot control system, device, program and method |
| WO2017175447A1 (en) * | 2016-04-05 | 2017-10-12 | ソニー株式会社 | Information processing apparatus, information processing method, and program |
| JP2018072876A (en) * | 2016-10-24 | 2018-05-10 | 富士ゼロックス株式会社 | Emotion estimation system and emotion estimation model generation system |
| JP2019508072A (en) * | 2016-12-02 | 2019-03-28 | アヴェント インコーポレイテッド | System and method for navigation of targets to anatomical objects in medical imaging based procedures |
| US10657671B2 (en) | 2016-12-02 | 2020-05-19 | Avent, Inc. | System and method for navigation to a target anatomical object in medical imaging-based procedures |
| CN108229640A (en) * | 2016-12-22 | 2018-06-29 | 深圳光启合众科技有限公司 | The method, apparatus and robot of emotion expression service |
| CN108229640B (en) * | 2016-12-22 | 2021-08-20 | 山西翼天下智能科技有限公司 | Emotion expression method and device and robot |
| JP2018152004A (en) * | 2017-03-15 | 2018-09-27 | 富士ゼロックス株式会社 | Information processor and program |
| US11551708B2 (en) * | 2017-11-21 | 2023-01-10 | Nippon Telegraph And Telephone Corporation | Label generation device, model learning device, emotion recognition apparatus, methods therefor, program, and recording medium |
| CN109002887A (en) * | 2018-08-10 | 2018-12-14 | 华北理工大学 | The heuristic curiosity cognitive development system of biology and its operation method |
| JP2020075385A (en) * | 2018-11-06 | 2020-05-21 | 株式会社東芝 | Product state estimation device |
| JP7021052B2 (en) | 2018-11-06 | 2022-02-16 | 株式会社東芝 | Product condition estimator |
| KR20200103421A (en) * | 2019-02-25 | 2020-09-02 | 군산대학교산학협력단 | Building method and building apparatus of memory model |
| KR102158989B1 (en) | 2019-02-25 | 2020-09-23 | 군산대학교 산학협력단 | Building method and building apparatus of memory model |
| US11511414B2 (en) | 2019-08-28 | 2022-11-29 | Daily Color Inc. | Robot control device |
| JPWO2021095211A1 (en) * | 2019-11-14 | 2021-05-20 | ||
| JP7205646B2 (en) | 2019-11-14 | 2023-01-17 | 富士通株式会社 | Output method, output program, and output device |
| CN111190484A (en) * | 2019-12-25 | 2020-05-22 | 中国人民解放军军事科学院国防科技创新研究院 | Multi-mode interaction system and method |
| CN111190484B (en) * | 2019-12-25 | 2023-07-21 | 中国人民解放军军事科学院国防科技创新研究院 | Multi-mode interaction system and method |
| JP7400965B2 (en) | 2020-05-28 | 2023-12-19 | 日本電信電話株式会社 | Mood prediction method, mood prediction device and program |
| JP2021030433A (en) * | 2020-07-21 | 2021-03-01 | 株式会社DailyColor | Robot control device |
| WO2022024294A1 (en) * | 2020-07-30 | 2022-02-03 | 三菱電機株式会社 | Action identification device, action identification method, and action identification program |
| JP6972434B1 (en) * | 2020-07-30 | 2021-11-24 | 三菱電機株式会社 | Behavior identification device, behavior identification method and behavior identification program |
| JPWO2022054292A1 (en) * | 2020-09-14 | 2022-03-17 | ||
| JP7301238B2 (en) | 2020-09-14 | 2023-06-30 | 三菱電機株式会社 | robot controller |
| WO2022054292A1 (en) * | 2020-09-14 | 2022-03-17 | 三菱電機株式会社 | Robot control device |
| US11382570B1 (en) | 2021-06-22 | 2022-07-12 | Nft Ip Holdings Llc | Encrypted securitized databases for devices and systems that measure, quantify, compare, package, and capture data |
| US11272888B1 (en) | 2021-06-22 | 2022-03-15 | Nft Ip Holdings Llc | Devices and systems that measure, quantify, compare, package, and capture human content in databases |
| WO2023166979A1 (en) * | 2022-03-01 | 2023-09-07 | ソニーグループ株式会社 | Information processing device, information processing method, and program |
| CN114926837A (en) * | 2022-05-26 | 2022-08-19 | 东南大学 | Emotion recognition method based on human-object space-time interaction behavior |
| CN114926837B (en) * | 2022-05-26 | 2023-08-04 | 东南大学 | Emotion recognition method based on human-object space-time interaction behavior |
| CN115496113A (en) * | 2022-11-17 | 2022-12-20 | 深圳市中大信通科技有限公司 | Emotional behavior analysis method based on intelligent algorithm |
| CN117523664A (en) * | 2023-11-13 | 2024-02-06 | 书行科技(北京)有限公司 | Training method of human motion prediction model, related method and related product |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2005199403A (en) | Emotion recognition device and method, emotion recognition method of robot device, learning method of robot device and robot device | |
| US8145492B2 (en) | Robot behavior control system and method, and robot apparatus | |
| Oztop et al. | Mirror neurons and imitation: A computationally guided review | |
| KR100864339B1 (en) | Robot device and behavior control method for robot device | |
| US7133744B2 (en) | Information processing apparatus and method, program storage medium, and program | |
| Zhang et al. | Intelligent affect regression for bodily expressions using hybrid particle swarm optimization and adaptive ensembles | |
| US8484146B2 (en) | Interaction device implementing a bayesian's estimation | |
| Rázuri et al. | Automatic emotion recognition through facial expression analysis in merged images based on an artificial neural network | |
| JPWO2002099545A1 (en) | Control method of man-machine interface unit, robot apparatus and action control method thereof | |
| KR20020008848A (en) | Robot device, robot device action control method, external force detecting device and external force detecting method | |
| JP2007280053A (en) | Data processor, data processing method and program | |
| EP4144425A1 (en) | Behavior control device, behavior control method, and program | |
| JP4179230B2 (en) | Robot apparatus and operation control method thereof | |
| JP2005238422A (en) | Robot device, its state transition model construction method and behavior control method | |
| JP2022546644A (en) | Systems and methods for automatic anomaly detection in mixed human-robot manufacturing processes | |
| Schillaci et al. | Internal simulations for behaviour selection and recognition | |
| Van Der Smagt et al. | Neurorobotics: From vision to action | |
| Weng | On developmental mental architectures | |
| JP2004302644A (en) | Face identification device, face identification method, recording medium and robot device | |
| JP4296736B2 (en) | Robot device | |
| Grüneberg et al. | An approach to subjective computing: A robot that learns from interaction with humans | |
| Xu et al. | Turn-Taking Prediction for Human–Robot Collaborative Assembly Considering Human Uncertainty | |
| Zhong et al. | From continuous affective space to continuous expression space: Non-verbal behaviour recognition and generation | |
| JP2009140454A (en) | Data processor, data processing method, and program | |
| KR20200125026A (en) | A method to infer emotion with convolutional neural network and recurrent neural network using physiological data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A300 | Application deemed to be withdrawn because no request for examination was validly filed |
Free format text: JAPANESE INTERMEDIATE CODE: A300 Effective date: 20070403 |