WO2023139769A1 - Grammar adjustment device and computer-readable storage medium - Google Patents
Grammar adjustment device and computer-readable storage medium Download PDFInfo
- Publication number
- WO2023139769A1 WO2023139769A1 PCT/JP2022/002282 JP2022002282W WO2023139769A1 WO 2023139769 A1 WO2023139769 A1 WO 2023139769A1 JP 2022002282 W JP2022002282 W JP 2022002282W WO 2023139769 A1 WO2023139769 A1 WO 2023139769A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- grammar
- extracted
- speech recognition
- unit
- grammars
- Prior art date
Links
- 238000003860 storage Methods 0.000 title claims description 26
- 238000011156 evaluation Methods 0.000 claims abstract description 50
- 238000000605 extraction Methods 0.000 claims description 18
- 238000004364 calculation method Methods 0.000 claims description 9
- 239000000284 extract Substances 0.000 claims description 8
- 238000000034 method Methods 0.000 description 15
- 230000007704 transition Effects 0.000 description 7
- 238000013500 data storage Methods 0.000 description 6
- 238000001228 spectrum Methods 0.000 description 3
- 238000010586 diagram Methods 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 238000003491 array Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 238000003754 machining Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 239000013598 vector Substances 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
Definitions
- the present invention relates to a speech recognition grammar adjustment device and a computer-readable storage medium.
- the operation part of the device has many buttons and operation screens, but the operation is complicated and it takes time to master.
- a voice input interface allows users to perform desired operations simply by uttering voice commands. Therefore, attempts have been made to improve operability using a voice input interface.
- the voice commands used to operate the device can be assumed depending on the type of device that uses the voice command, the site where the device is installed, and the operation details of the device. Therefore, expected voice commands can be created in grammar (syntax and words). For example, see Patent Document 1.
- Evaluation data is used to evaluate whether the accuracy of the created grammar is high.
- the creator of the speech recognition system checks the accuracy of speech recognition when using the created grammar, and edits the grammar. Speech recognition grammars are often created manually.
- a grammar adjustment device that is an aspect of the present disclosure includes a grammar storage unit that stores a grammar of a voice command for operating an industrial device, a grammar extraction unit that extracts a part of the grammar, a target registration unit that receives registration of a target for the speech recognition evaluation value of the extracted grammar, a speech recognition unit that performs speech recognition of evaluation speech data using the extracted grammar, and an evaluation value calculation unit that calculates the speech recognition evaluation value of the extracted grammar based on the results of speech recognition using the extracted grammar and correct data of the evaluation speech data.
- a grammar selection unit that selects a grammar that satisfies a target from among the one or more extracted grammars extracted by the grammar extraction unit.
- a storage medium which is one aspect of the present disclosure, stores a grammar of a voice command for operating an industrial device, extracts a part of the grammar by being executed by one or more processors, receives a target registration of a speech recognition evaluation value of the extracted grammar, performs speech recognition of evaluation speech data using the extracted grammar, calculates a speech recognition evaluation value of the extracted grammar based on the result of speech recognition using the extracted grammar and correct data of the evaluation speech data, and calculates the speech recognition evaluation value of the extracted grammar among one or more extracted grammars. , stores processor readable instructions for selecting a grammar that satisfies a goal.
- grammar creation for speech recognition can be supported.
- FIG. 1 is a block diagram showing the configuration of a grammar adjustment device
- FIG. FIG. 10 is a diagram showing examples of syntax definitions and word definitions
- It is a figure which shows the combination example of the speaker of the data for evaluation, and a recording place.
- It is a figure which shows the example of the calculation result of an evaluation value.
- It is a figure which shows the example of a goal registration screen.
- It is a figure which shows the example of the accuracy rate of a different grammar.
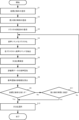
- 4 is a flowchart for explaining processing of the grammar adjustment device; It is a hardware configuration of a grammar adjustment device.
- the grammar adjustment device 100 will be described below.
- the grammar adjustment device 100 is implemented in an information processing device having an arithmetic unit and a storage unit. Examples of such information processing devices include PCs (personal computers) and mobile terminals, but are not limited to these.
- Fig. 1 shows the basic configuration of the grammar adjustment device 100.
- the grammar adjustment device 100 comprises an evaluation data storage unit 11 , a target registration unit 12 , a basic grammar storage unit 13 , a grammar extraction unit 14 , a speech recognition unit 15 , an extracted grammar storage unit 16 , an evaluation value calculation unit 17 and a grammar selection unit 18 .
- the basic grammar storage unit 13 stores grammars of voice commands that serve as bases.
- a voice command is a command for operating equipment in the industrial field by voice.
- the grammar of voice commands consists of syntax and words.
- the basic grammar storage unit 13 includes a syntax storage unit 19 that stores syntax and a word storage unit 20 that stores words. Words include words that make up voice commands and phoneme representations of words. Syntax defines the arrangement of words that make up a voice command.
- the base grammar is exhaustively created to cover as many voice commands as possible that are expected to be used in the field. For example, the syntax of a voice command for setting the "override" of a numerical controller to "30" is assumed to be “override 30", “set override to 30", “set override to 30", and so on.
- a grammar author constructs as many grammars as possible.
- the basic grammar is determined by the type of device that recognizes voice commands, specifications, work content, and so on.
- a plurality of phoneme arrays may be assigned to one word.
- the word “override” can be represented by multiple phonemes such as "o:ba:raido", “oubaaraido” and "oubaraido”.
- the base grammar is constructed to cover as many phonemes of such words as possible.
- FIG. 2 shows an example syntax definition and an example word definition.
- An example syntax definition defines the words that make up a voice command and the order of the words.
- “S” is the start symbol of the voice command
- "NS_B” and “NS_E” are silent sections at the beginning and end of the sentence.
- the second and third lines define "tags" that go into "COMMAND”.
- the second line defines that the syntax element "COMMAND” includes tags "ROBOT” and "INTERFACE”
- the third line defines that the syntax element "COMMAND” includes tags "NAIGAI” and "INTERFACE”.
- the first and second lines of the word definition define the Japanese notation and phoneme notation of the tag "ROBOT".
- the Japanese notation of the tag "ROBOT” is "robot” and the phoneme notation is "roboqto”.
- the 3rd to 5th lines of the word definition define the Japanese notation and the phoneme notation of the Japanese included in the tag "NAIGAI”.
- the tag "NAIGAI” contains two Japanese words, "external” and "internal.”
- the "outside” phoneme is "gaibu” and the "inside” phoneme is "naibu”.
- the 6th to 8th lines of the word definition define the Japanese notation and the phoneme notation of the Japanese included in the tag "INTERFACE".
- the tag "INTERFACE” contains one Japanese word "interface”.
- the “interface” has two types of phoneme notation “iNtafe:su” and “iNta:feisu”. "%NS_B” defines a silence section [s] at the beginning of a sentence, and “%NS_E” defines a silence section [/s] at the end of a sentence.
- the grammar extraction unit 14 extracts a part of the grammar from the exhaustive grammar stored in the basic grammar storage unit 13 .
- cluster division of the k-means method is used.
- a method other than the k-means method may be used for grammar extraction.
- the clustering of the k-means method uses the acoustic distance of the grammar. Acoustic distance can be obtained from an acoustic spectrum, from a phoneme string, or the like. According to the method of calculating the acoustic distance from the acoustic spectrum, the acoustic spectrum of the voice command is vectorized and the cosine distance or Euclidean distance between the vectors is calculated.
- Cosine distance, Levenshtein distance, Jarrowinkler distance, and Hamming distance are used in the method of calculating acoustic distance from a phoneme string. Cosine distance, Euclidean distance, Leberstein distance, Jarrowinkler distance and Hamming distance are well known.
- the acoustic distance of the phonemes of words included in the voice command e.g., "iNtafe:su", “iNtafeisu”, etc.
- a part can be extracted from a cluster of words with close acoustic distances.
- the k-means method uses random numbers to set the centers of K clusters, (a) assigning the nearest center to each voice command (or word), and (b) calculating the center for each cluster. Repeat (a) and (b) until the centers of all clusters do not change to divide the voice commands into clusters.
- the grammar extraction unit 14 extracts grammars (syntax and words) of voice commands included in the same cluster, and outputs them to the voice recognition unit as grammars for evaluation.
- the k-means method is an example of a method for extracting grammars with close distances, and methods other than the k-means method may be used.
- the results of the k-means method are affected by the random number of initial values and the number of clusters K.
- FIG. The random number and the number of clusters K may be set manually by the user, or may be automatically set by the grammar extraction unit 14 .
- the evaluation data storage unit 11 associates and stores voice data including voice commands recorded by a plurality of speakers at a plurality of recording locations with correct data, which is a correct text for the voice data. For example, voice data of utterances of "external interface" by a plurality of speakers at a plurality of recording locations and correct data (text) of "external interface” are stored in association with each other.
- the speech data in the evaluation data storage unit 11 are recorded at different recording locations by speakers with different attributes (gender, age). Since the evaluation data was recorded at the site using the voice command, the noise at the site using the voice command is included.
- FIG. 3 is a table showing the relationship between the speaker of the evaluation data and the recording location.
- the evaluation data in FIG. 3 includes voices recorded by speaker A (male, 60 years old) at factories A and B, voices recorded by speaker B (female, 30 years old) at factories C and D, and the like.
- the voice recognition unit 15 receives a voice command from the evaluation data storage unit 11 and performs voice recognition of the input voice command.
- the speech recognition unit 15 is generally composed of an acoustic model, a language model, and a decoder.
- the acoustic model receives speech data and outputs phonemes (senones) that form the speech data based on the feature amount of the speech data.
- the language model outputs the probability of occurrence of word strings.
- the language model selects hypothetical word strings based on phonemes and outputs linguistically plausible candidates.
- the decoder outputs a word string with a high probability as a recognition result based on the outputs of the acoustic model and language model that are statistically created.
- the extracted grammar storage unit 16 includes a syntax storage unit 21 and a word storage unit 22, and stores the grammars extracted by the grammar extraction unit 14.
- the speech recognition section 15 performs speech recognition using the grammar stored in the extraction grammar storage section 16 .
- the evaluation value calculation unit 17 compares the correct text from the evaluation data storage unit with the recognition result of the speech recognition unit 15, and calculates the accuracy rate of speech recognition.
- FIG. 4 is an example of the accuracy rate as an evaluation value.
- Types of voice commands include, for example, approval commands, numerical commands, and transition commands.
- An approval command is a command indicating approval. Assume that the approval commands include “yes”, “no”, “yes”, “no”, “execute”, “abort”, and the like.
- Numerical commands are commands for designating numerical values such as "0.5", "1", "2", and "100".
- a “transition command” is a command for designating a display screen such as a "home screen” or a "speed setting screen”.
- a "machine operation command” such as "set a workpiece” may be considered.
- the target registration unit 12 accepts registration of target values for speech recognition.
- the target registration unit 12 receives target values such as a target accuracy rate for all voice commands, a target accuracy rate for each type of voice command, and a target search time.
- FIG. 5 is an example of a target registration screen.
- the target accuracy rate for each type of voice command is set as "approval command: 95% or more”, “numerical command: 90% or more”, “transition command: 80% or more”, and maximum execution time "within 30 minutes”.
- the grammar selection unit 18 compares the speech recognition result with the target accuracy rate, and if there is a grammar determined to satisfy the target accuracy rate as a result of the speech recognition, it selects that grammar as an appropriate grammar. The processing of the grammar selection unit 18 is repeated until the target time for grammar adjustment elapses or the target accuracy rate is cleared. When the target time for grammar adjustment has passed, an appropriate grammar is selected from the grammars for which speech recognition has been performed so far.
- the grammar selection unit 18 may present the accuracy rate of each grammar to the creator of the grammar, and the creator of the grammar may select the grammar.
- the accuracy rate of voice commands is calculated for each type of approval command, transition command, and numerical command.
- the approval command is used for confirming the operation, so a high accuracy rate is required.
- Numerical commands that specify numerical values also require a high accuracy rate.
- a transition command that instructs a screen transition may have a lower accuracy rate than an approval command or a numerical command.
- a target accuracy rate can be set for each voice command or for each type of voice command. Automatically select the grammar that achieves the target accuracy rate. For example, FIG. 6 shows the accuracy rate of grammar A and grammar B. In FIG.
- grammar A Since the accuracy rate of "approval command”, “numerical value command”, and “transition command” of grammar A satisfies the target accuracy rate registered by the target registration unit 12, grammar A is selected as an appropriate grammar. Further conditions may be set when a plurality of grammars satisfy the target accuracy rate.
- the grammar adjustment device 100 registers a target accuracy rate of a voice command (step S1, receives registration of the maximum execution time for grammar adjustment (step S2), and receives registration of a cluster division criterion (step S3).
- step S1 receives registration of the maximum execution time for grammar adjustment
- step S3 receives registration of a cluster division criterion.
- the grammar adjustment device 100 clusters the voice commands (or words included in the voice commands) stored in the basic grammar storage unit 13 (step S4), extracts one or more representative voice commands (or words included in the voice commands) from each cluster (step S5), and reconstructs the grammar using the extracted voice commands (or words included in the voice commands) (step S6).
- the grammar adjustment device 100 performs speech recognition on the evaluation data using the grammar reconstructed in step S5 (step S7).
- Grammar adjustment device 100 calculates an evaluation value for speech recognition (step S8).
- Grammar adjustment device 100 compares the evaluation result with the target accuracy rate, and if the evaluation result satisfies the target accuracy rate (step S9; Yes), selects the grammar (step S10).
- step S9 if the evaluation result does not satisfy the target accuracy rate (step S9; No), it is determined whether or not the maximum execution time has been reached.
- the grammar adjustment device 100 presents the grammars that have undergone speech recognition so far to the user and accepts the selection of the grammar (step S10).
- step S9 if the target time for grammar adjustment has not been reached (step S11; No), the process proceeds to step S4, and the processes from step S4 to step S9 are repeated.
- the adjustment of the grammar is finished when the condition of the target accuracy rate is satisfied, but the adjustment may be continued until the maximum execution time is reached without finishing the adjustment.
- the grammar adjustment device 100 of the present disclosure is a device that supports the creation of voice command grammar, extracts a part of the comprehensively created grammar, reconstructs the grammar, and selects a grammar with a high accuracy rate.
- the grammar accuracy rate is calculated for each type of voice command, so it is possible to adjust the grammar so that the accuracy is suitable for the situation where voice recognition is used.
- Grammar evaluation data is recorded at the site where voice commands are used, so it is possible to construct a grammar suitable for recognizing voice data containing noise peculiar to the site or time period.
- recognition candidates are selected from the words and syntax registered in the grammar even if noise is included, so the accuracy rate is improved.
- the grammar adjustment device 100 of the present disclosure automatically adjusts grammar, it can optimize the grammar based on objective criteria without depending on the subjectivity or know-how of the grammar creator. In addition, since the grammar is automatically adjusted, even an inexperienced technician can adjust the grammar.
- the hardware configuration of the grammar adjustment device 100 will be described with reference to FIG.
- the CPU 111 included in the grammar adjustment device 100 is a processor that controls the grammar adjustment device 100 as a whole.
- the CPU 111 reads the system program processed in the ROM 112 via the bus and controls the entire grammar adjustment apparatus 100 according to the system program.
- the RAM 113 temporarily stores calculation data, display data, various data input by the user via the input unit 71, and the like.
- the display unit 70 is a monitor or the like attached to the grammar adjustment device 100 .
- the display unit 70 displays an operation screen, a setting screen, and the like of the grammar adjustment device 100 .
- the input unit 71 is integrated with the display unit 70 or is a keyboard, touch panel, operation button, etc. separate from the display unit 70 .
- the user operates the input unit 71 to perform input to the screen displayed on the display unit 70 .
- the display unit 70 and the input unit 71 may be mobile terminals.
- the non-volatile memory 114 is, for example, a memory that is backed up by a battery (not shown) so that the stored state is retained even when the power of the grammar adjustment apparatus 100 is turned off.
- the non-volatile memory 114 stores machining programs, system programs, available options, billing tables, and the like.
- the nonvolatile memory 114 stores a program read from an external device via an interface (not shown), a program input via the input unit 71, and various data obtained from each part of the grammar adjustment apparatus 100, a machine tool, etc. (for example, setting parameters obtained from the machine tool, etc.). Programs and various data stored in the non-volatile memory 114 may be developed in the RAM 113 at the time of execution/use.
- Various system programs are pre-written in the ROM 112 .
- grammar adjustment device 11 evaluation data storage unit 12 target registration unit 13 basic grammar storage unit 14 grammar extraction unit 15 speech recognition unit 16 extracted grammar storage unit 17 evaluation value calculation unit 18 grammar selection unit 19 syntax storage unit 20 word storage unit 21 syntax storage unit 22 word storage unit 70 display unit 71 input unit 111 CPU 112 ROMs 113 RAM 114 non-volatile memory
Landscapes
- Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Machine Translation (AREA)
Abstract
The present invention stores the grammar of voice commands that operate industrial machinery, uses one or more processors to extract a portion of the grammar, receives registration of a target for an evaluation value for voice recognition of the extracted grammar, uses the extracted grammar to perform voice recognition on voice data for evaluation, calculates an evaluation value for voice recognition of the extracted grammar on the basis of the results of the voice recognition that uses the extracted grammar and of correct answer data for the voice data for evaluation, and selects grammar that satisfies the target from the extracted grammar.
Description
本発明は、音声認識の文法調整装置、及びコンピュータが読み取り可能な記憶媒体に関する。
The present invention relates to a speech recognition grammar adjustment device and a computer-readable storage medium.
現在、製造業などの産業分野では、ロボット、搬送機、工作機械、機械設備などの様々な機器が作動している。このような機器には、操作部を備えたものも多く、PLC(Programmable Logic Controller)、NC(Numerical Controller)、制御盤など、各機器を制御するための機器自体も操作部を備えるものが多い。
Currently, in industrial fields such as the manufacturing industry, various devices such as robots, conveyors, machine tools, and mechanical equipment are in operation. Many of such devices are provided with an operation section, and many devices themselves for controlling each device, such as PLCs (Programmable Logic Controllers), NCs (Numerical Controllers), and control panels, also have an operation section.
機器の操作部は、ボタンや操作画面が多いが、操作が複雑で習熟に時間のかかることがある。音声入力インターフェースは、音声コマンドを発話するだけで目的の操作が実行できる。そのため、音声入力インターフェースを用いた操作性の向上が試みられている。
The operation part of the device has many buttons and operation screens, but the operation is complicated and it takes time to master. A voice input interface allows users to perform desired operations simply by uttering voice commands. Therefore, attempts have been made to improve operability using a voice input interface.
機器の操作に使用する音声コマンドは、音声コマンドを使用する機器の種類、機器を設置する現場、機器の操作内容などにより想定することができる。そのため、想定される音声コマンドを文法(構文及び単語)で作成することができる。例えば、特許文献1参照。
The voice commands used to operate the device can be assumed depending on the type of device that uses the voice command, the site where the device is installed, and the operation details of the device. Therefore, expected voice commands can be created in grammar (syntax and words). For example, see Patent Document 1.
作成した文法の精度が高いか否かは、評価データを用いて評価する。音声認識システムの作成者は、作成した文法を使用した場合の音声認識の精度を確認し、文法を編集する。音声認識の文法は、手動で作成することが多い。
Evaluation data is used to evaluate whether the accuracy of the created grammar is high. The creator of the speech recognition system checks the accuracy of speech recognition when using the created grammar, and edits the grammar. Speech recognition grammars are often created manually.
産業分野では、音声認識の文法作成を支援する技術が望まれている。
In the industrial field, there is a demand for technology that supports grammar creation for speech recognition.
本開示の一態様である文法調整装置は、産業用機器を操作する音声コマンドの文法を記憶する文法記憶部と、文法の一部を抽出する文法抽出部と、抽出した文法の音声認識の評価値の目標の登録を受け付ける目標登録部と、抽出した文法を用いて、評価用音声データの音声認識を行う音声認識部と、抽出した文法を用いた音声認識の結果と評価用音声データの正解データとを基に、抽出した文法の音声認識の評価値を算出する評価値算出部と、文法抽出部が抽出した1つ又は複数の抽出した文法のなかで、目標を満たす文法を選択する文法選択部と、を備える。
本開示の一態様である記憶媒体は、産業用機器を操作する音声コマンドの文法を記憶し、1つ又は複数のプロセッサが実行することにより、文法の一部を抽出し、抽出した文法の音声認識の評価値の目標の登録を受け付け、抽出した文法を用いて、評価用音声データの音声認識を行い、抽出した文法を用いた音声認識の結果と評価用音声データの正解データとを基に、抽出した文法の音声認識の評価値を算出し、1つ又は複数の抽出した文法のなかで、目標を満たす文法を選択する、プロセッサが読み取り可能な命令を記憶する。 A grammar adjustment device that is an aspect of the present disclosure includes a grammar storage unit that stores a grammar of a voice command for operating an industrial device, a grammar extraction unit that extracts a part of the grammar, a target registration unit that receives registration of a target for the speech recognition evaluation value of the extracted grammar, a speech recognition unit that performs speech recognition of evaluation speech data using the extracted grammar, and an evaluation value calculation unit that calculates the speech recognition evaluation value of the extracted grammar based on the results of speech recognition using the extracted grammar and correct data of the evaluation speech data. a grammar selection unit that selects a grammar that satisfies a target from among the one or more extracted grammars extracted by the grammar extraction unit.
A storage medium, which is one aspect of the present disclosure, stores a grammar of a voice command for operating an industrial device, extracts a part of the grammar by being executed by one or more processors, receives a target registration of a speech recognition evaluation value of the extracted grammar, performs speech recognition of evaluation speech data using the extracted grammar, calculates a speech recognition evaluation value of the extracted grammar based on the result of speech recognition using the extracted grammar and correct data of the evaluation speech data, and calculates the speech recognition evaluation value of the extracted grammar among one or more extracted grammars. , stores processor readable instructions for selecting a grammar that satisfies a goal.
本開示の一態様である記憶媒体は、産業用機器を操作する音声コマンドの文法を記憶し、1つ又は複数のプロセッサが実行することにより、文法の一部を抽出し、抽出した文法の音声認識の評価値の目標の登録を受け付け、抽出した文法を用いて、評価用音声データの音声認識を行い、抽出した文法を用いた音声認識の結果と評価用音声データの正解データとを基に、抽出した文法の音声認識の評価値を算出し、1つ又は複数の抽出した文法のなかで、目標を満たす文法を選択する、プロセッサが読み取り可能な命令を記憶する。 A grammar adjustment device that is an aspect of the present disclosure includes a grammar storage unit that stores a grammar of a voice command for operating an industrial device, a grammar extraction unit that extracts a part of the grammar, a target registration unit that receives registration of a target for the speech recognition evaluation value of the extracted grammar, a speech recognition unit that performs speech recognition of evaluation speech data using the extracted grammar, and an evaluation value calculation unit that calculates the speech recognition evaluation value of the extracted grammar based on the results of speech recognition using the extracted grammar and correct data of the evaluation speech data. a grammar selection unit that selects a grammar that satisfies a target from among the one or more extracted grammars extracted by the grammar extraction unit.
A storage medium, which is one aspect of the present disclosure, stores a grammar of a voice command for operating an industrial device, extracts a part of the grammar by being executed by one or more processors, receives a target registration of a speech recognition evaluation value of the extracted grammar, performs speech recognition of evaluation speech data using the extracted grammar, calculates a speech recognition evaluation value of the extracted grammar based on the result of speech recognition using the extracted grammar and correct data of the evaluation speech data, and calculates the speech recognition evaluation value of the extracted grammar among one or more extracted grammars. , stores processor readable instructions for selecting a grammar that satisfies a goal.
本発明の一態様により、音声認識の文法作成を支援することができる。
According to one aspect of the present invention, grammar creation for speech recognition can be supported.
以下、文法調整装置100について説明する。
文法調整装置100は、演算部及び記憶部を備えた情報処理装置に実装される。このような情報処理装置として、例えば、PC(パーソナルコンピュータ)、携帯端末などがあるが、これに限定しない。 Thegrammar adjustment device 100 will be described below.
Thegrammar adjustment device 100 is implemented in an information processing device having an arithmetic unit and a storage unit. Examples of such information processing devices include PCs (personal computers) and mobile terminals, but are not limited to these.
文法調整装置100は、演算部及び記憶部を備えた情報処理装置に実装される。このような情報処理装置として、例えば、PC(パーソナルコンピュータ)、携帯端末などがあるが、これに限定しない。 The
The
図1に、文法調整装置100の基本構成を示す。文法調整装置100は、評価用データ記憶部11、目標登録部12、基盤文法記憶部13、文法抽出部14、音声認識部15、抽出文法記憶部16、評価値算出部17、文法選択部18から構成される。
Fig. 1 shows the basic configuration of the grammar adjustment device 100. The grammar adjustment device 100 comprises an evaluation data storage unit 11 , a target registration unit 12 , a basic grammar storage unit 13 , a grammar extraction unit 14 , a speech recognition unit 15 , an extracted grammar storage unit 16 , an evaluation value calculation unit 17 and a grammar selection unit 18 .
基盤文法記憶部13は、ベースとなる音声コマンドの文法を記憶する。音声コマンドは、産業分野の機器を音声で操作するコマンドである。音声コマンドの文法は、構文と単語から構成される。基盤文法記憶部13は、構文を記憶する構文記憶部19、単語を記憶する単語記憶部20を備える。
単語には、音声コマンドを構成する単語と、単語の音素表現が含まれる。構文は、音声コマンドを構成する単語の配置を定義する。
ベースとなる文法は、現場での使用が想定されるできるだけ多くの音声コマンドをカバーするよう、網羅的に作成される。例えば、数値制御装置の“オーバーライド”を“30”に設定する音声コマンドの構文には、「オーバーライド30」、「オーバーライドを30に設定」、「オーバーライドを30にして」…などが想定される。文法の作成者は、できるだけ多くの文法を構築する。ベースとなる文法は、音声コマンドを認識する機器の種類、仕様、作業内容などによって決まる。
1つの単語に対し、複数の音素配列を割り当てる場合もある。例えば、“オーバーライド”という単語は、“o:ba:raido”、“oubaaraido”“oubaraido”などの複数の音素で表現できる。ベースとなる文法では、このような単語の音素もできるだけ多くカバーするように作成される。 The basicgrammar storage unit 13 stores grammars of voice commands that serve as bases. A voice command is a command for operating equipment in the industrial field by voice. The grammar of voice commands consists of syntax and words. The basic grammar storage unit 13 includes a syntax storage unit 19 that stores syntax and a word storage unit 20 that stores words.
Words include words that make up voice commands and phoneme representations of words. Syntax defines the arrangement of words that make up a voice command.
The base grammar is exhaustively created to cover as many voice commands as possible that are expected to be used in the field. For example, the syntax of a voice command for setting the "override" of a numerical controller to "30" is assumed to be "override 30", "set override to 30", "set override to 30", and so on. A grammar author constructs as many grammars as possible. The basic grammar is determined by the type of device that recognizes voice commands, specifications, work content, and so on.
A plurality of phoneme arrays may be assigned to one word. For example, the word "override" can be represented by multiple phonemes such as "o:ba:raido", "oubaaraido" and "oubaraido". The base grammar is constructed to cover as many phonemes of such words as possible.
単語には、音声コマンドを構成する単語と、単語の音素表現が含まれる。構文は、音声コマンドを構成する単語の配置を定義する。
ベースとなる文法は、現場での使用が想定されるできるだけ多くの音声コマンドをカバーするよう、網羅的に作成される。例えば、数値制御装置の“オーバーライド”を“30”に設定する音声コマンドの構文には、「オーバーライド30」、「オーバーライドを30に設定」、「オーバーライドを30にして」…などが想定される。文法の作成者は、できるだけ多くの文法を構築する。ベースとなる文法は、音声コマンドを認識する機器の種類、仕様、作業内容などによって決まる。
1つの単語に対し、複数の音素配列を割り当てる場合もある。例えば、“オーバーライド”という単語は、“o:ba:raido”、“oubaaraido”“oubaraido”などの複数の音素で表現できる。ベースとなる文法では、このような単語の音素もできるだけ多くカバーするように作成される。 The basic
Words include words that make up voice commands and phoneme representations of words. Syntax defines the arrangement of words that make up a voice command.
The base grammar is exhaustively created to cover as many voice commands as possible that are expected to be used in the field. For example, the syntax of a voice command for setting the "override" of a numerical controller to "30" is assumed to be "override 30", "set override to 30", "set override to 30", and so on. A grammar author constructs as many grammars as possible. The basic grammar is determined by the type of device that recognizes voice commands, specifications, work content, and so on.
A plurality of phoneme arrays may be assigned to one word. For example, the word "override" can be represented by multiple phonemes such as "o:ba:raido", "oubaaraido" and "oubaraido". The base grammar is constructed to cover as many phonemes of such words as possible.
文法は、構文と単語から構成される。図2に、構文定義の例、及び、単語定義の例を示す。構文定義の例では、音声コマンドを構成する単語、及び単語の順序を定義する。図2の構文定義の1行目「S:NS_B COMMAND NS_E」において、“S”は音声コマンドの開始記号、“NS_B”と“NS_E”は文頭及び文末の無音区間である。無音区間の間に構文の要素「COMMAND」が存在する。
2行目及び3行目は、「COMMAND」に入る「タグ」を定義している。2行目は構文の要素「COMMAND」にタグ「ROBOT」「INTERFACE」が入ることを定義しており、3行目は構文の要素「COMMAND」にタグ「NAIGAI」「INTERFACE」が入ることを定義している。 Grammar consists of sentences and words. FIG. 2 shows an example syntax definition and an example word definition. An example syntax definition defines the words that make up a voice command and the order of the words. In the first line "S: NS_B COMMAND NS_E" of the syntax definition in FIG. 2, "S" is the start symbol of the voice command, and "NS_B" and "NS_E" are silent sections at the beginning and end of the sentence. There is a syntactic element "COMMAND" between silent intervals.
The second and third lines define "tags" that go into "COMMAND". The second line defines that the syntax element "COMMAND" includes tags "ROBOT" and "INTERFACE", and the third line defines that the syntax element "COMMAND" includes tags "NAIGAI" and "INTERFACE".
2行目及び3行目は、「COMMAND」に入る「タグ」を定義している。2行目は構文の要素「COMMAND」にタグ「ROBOT」「INTERFACE」が入ることを定義しており、3行目は構文の要素「COMMAND」にタグ「NAIGAI」「INTERFACE」が入ることを定義している。 Grammar consists of sentences and words. FIG. 2 shows an example syntax definition and an example word definition. An example syntax definition defines the words that make up a voice command and the order of the words. In the first line "S: NS_B COMMAND NS_E" of the syntax definition in FIG. 2, "S" is the start symbol of the voice command, and "NS_B" and "NS_E" are silent sections at the beginning and end of the sentence. There is a syntactic element "COMMAND" between silent intervals.
The second and third lines define "tags" that go into "COMMAND". The second line defines that the syntax element "COMMAND" includes tags "ROBOT" and "INTERFACE", and the third line defines that the syntax element "COMMAND" includes tags "NAIGAI" and "INTERFACE".
単語定義の1、2行目は、タグ「ROBOT」の日本語表記と、音素表記を定義している。タグ「ROBOT」の日本語表記は「ロボット」であり、音素表記は「roboqto」である。単語定義の3~5行目は、タグ「NAIGAI」に入る日本語の日本語表記と、音素表記を定義している。タグ「NAIGAI」には、「外部」と「内部」の2つの日本語が入る。「外部」の音素表記は「gaibu」であり、「内部」の音素表記は「naibu」である。単語定義の6~8行目は、タグ「INTERFACE」に入る日本語の日本語表記と、音素表記を定義している。タグ「INTERFACE」には、「インターフェース」という1つの日本語が入る。「インターフェース」には2種類の音素表記「iNtafe:su」と「iNta:feisu」がある。「%NS_B」は文頭の無音区間[s]を定義しており、「%NS_E」は文末の無音区間[/s]を定義している。
The first and second lines of the word definition define the Japanese notation and phoneme notation of the tag "ROBOT". The Japanese notation of the tag "ROBOT" is "robot" and the phoneme notation is "roboqto". The 3rd to 5th lines of the word definition define the Japanese notation and the phoneme notation of the Japanese included in the tag "NAIGAI". The tag "NAIGAI" contains two Japanese words, "external" and "internal." The "outside" phoneme is "gaibu" and the "inside" phoneme is "naibu". The 6th to 8th lines of the word definition define the Japanese notation and the phoneme notation of the Japanese included in the tag "INTERFACE". The tag "INTERFACE" contains one Japanese word "interface". The “interface” has two types of phoneme notation “iNtafe:su” and “iNta:feisu”. "%NS_B" defines a silence section [s] at the beginning of a sentence, and "%NS_E" defines a silence section [/s] at the end of a sentence.
文法抽出部14は、基盤文法記憶部13に記憶する網羅的な文法から一部の文法を抽出する。文法の抽出方法の一例としてk-means法のクラスタ分割を用いる。文法の抽出には、k-means法以外の方法を用いてもよい。k-means法のクラスタ分割では、文法の音響的距離を用いる。音響的距離は、音響的スペクトルから求める方法、音素文字列から求める方法などがある。音響的スペクトルから音響的距離を算出する方法では、音声コマンドの音響的スペクトルをベクトル化し、ベクトル間のコサイン距離やユークリッド距離を算出する。音素文字列から音響的距離を算出する方法では、コサイン距離、レーベンシュタイン距離、ジャロウィンクラー距離、ハミング距離を用いる。コサイン距離、ユークリッド距離、レーベルシュテイン距離、ジャロウィンクラー距離、ハミング距離は、公知である。
なお、音声コマンド全体の距離を求めるだけでなく、音声コマンドに含まれる単語の音素(例えば、「iNtafe:su」、「iNtafeisu」など)の音響的距離を算出し、音響的距離の近い単語のクラスタから一部を抽出することができる。 Thegrammar extraction unit 14 extracts a part of the grammar from the exhaustive grammar stored in the basic grammar storage unit 13 . As an example of the grammar extraction method, cluster division of the k-means method is used. A method other than the k-means method may be used for grammar extraction. The clustering of the k-means method uses the acoustic distance of the grammar. Acoustic distance can be obtained from an acoustic spectrum, from a phoneme string, or the like. According to the method of calculating the acoustic distance from the acoustic spectrum, the acoustic spectrum of the voice command is vectorized and the cosine distance or Euclidean distance between the vectors is calculated. Cosine distance, Levenshtein distance, Jarrowinkler distance, and Hamming distance are used in the method of calculating acoustic distance from a phoneme string. Cosine distance, Euclidean distance, Leberstein distance, Jarrowinkler distance and Hamming distance are well known.
In addition to calculating the distance of the entire voice command, the acoustic distance of the phonemes of words included in the voice command (e.g., "iNtafe:su", "iNtafeisu", etc.) can be calculated, and a part can be extracted from a cluster of words with close acoustic distances.
なお、音声コマンド全体の距離を求めるだけでなく、音声コマンドに含まれる単語の音素(例えば、「iNtafe:su」、「iNtafeisu」など)の音響的距離を算出し、音響的距離の近い単語のクラスタから一部を抽出することができる。 The
In addition to calculating the distance of the entire voice command, the acoustic distance of the phonemes of words included in the voice command (e.g., "iNtafe:su", "iNtafeisu", etc.) can be calculated, and a part can be extracted from a cluster of words with close acoustic distances.
本開示で一例として上げるk-means法では、乱数を用いてK個のクラスタの中心を設定し、(a)各々の音声コマンド(又は単語)に最も近い中心を割り当て、(b)クラスタごとに中心を計算する。全てのクラスタの中心が変化しなくなるまで(a)(b)を繰り返し、音声コマンドをクラスタに分割する。
文法抽出部14は、同じクラスタに含まれる音声コマンドの文法(構文及び単語)を抽出し、評価用の文法として音声認識部に出力する。
なお、k-means法は、距離の近い文法を抽出する方法の一例であって、k-means法以外の方法を用いてもよい。また、k-means法の結果は、初期値の乱数、クラスタ数Kの影響を受ける。乱数及びクラスタ数Kは、ユーザが手動で設定してもよいし、文法抽出部14が自動で設定してもよい。 The k-means method, exemplified in this disclosure, uses random numbers to set the centers of K clusters, (a) assigning the nearest center to each voice command (or word), and (b) calculating the center for each cluster. Repeat (a) and (b) until the centers of all clusters do not change to divide the voice commands into clusters.
Thegrammar extraction unit 14 extracts grammars (syntax and words) of voice commands included in the same cluster, and outputs them to the voice recognition unit as grammars for evaluation.
Note that the k-means method is an example of a method for extracting grammars with close distances, and methods other than the k-means method may be used. Also, the results of the k-means method are affected by the random number of initial values and the number of clusters K. FIG. The random number and the number of clusters K may be set manually by the user, or may be automatically set by thegrammar extraction unit 14 .
文法抽出部14は、同じクラスタに含まれる音声コマンドの文法(構文及び単語)を抽出し、評価用の文法として音声認識部に出力する。
なお、k-means法は、距離の近い文法を抽出する方法の一例であって、k-means法以外の方法を用いてもよい。また、k-means法の結果は、初期値の乱数、クラスタ数Kの影響を受ける。乱数及びクラスタ数Kは、ユーザが手動で設定してもよいし、文法抽出部14が自動で設定してもよい。 The k-means method, exemplified in this disclosure, uses random numbers to set the centers of K clusters, (a) assigning the nearest center to each voice command (or word), and (b) calculating the center for each cluster. Repeat (a) and (b) until the centers of all clusters do not change to divide the voice commands into clusters.
The
Note that the k-means method is an example of a method for extracting grammars with close distances, and methods other than the k-means method may be used. Also, the results of the k-means method are affected by the random number of initial values and the number of clusters K. FIG. The random number and the number of clusters K may be set manually by the user, or may be automatically set by the
評価用データ記憶部11は、複数の話者が複数の収録場所で録音した音声コマンドを含む音声データと、音声データに対する正解テキストである正解データとを関連付けて記憶する。例えば、複数の話者が複数の収録場所で「外部インターフェース」と発話した音声データと、「外部インターフェース」という正解データ(テキスト)とを関連付けて記憶する。
評価用データ記憶部11の音声データは、属性(性別、年齢)の異なる話者により、異なる収録場所で収録される。評価用データは、音声コマンドを使用する現場で収録するため、音声コマンドを使用する現場の雑音が含まれる。図3は、評価用データの話者と収録場所の関係を示す表である。図3の評価用データには、話者A(男、60才)が工場A及び工場Bで収録した音声、話者B(女、30才)が工場C、工場Dで収録した音声などが含まれる。 The evaluationdata storage unit 11 associates and stores voice data including voice commands recorded by a plurality of speakers at a plurality of recording locations with correct data, which is a correct text for the voice data. For example, voice data of utterances of "external interface" by a plurality of speakers at a plurality of recording locations and correct data (text) of "external interface" are stored in association with each other.
The speech data in the evaluationdata storage unit 11 are recorded at different recording locations by speakers with different attributes (gender, age). Since the evaluation data was recorded at the site using the voice command, the noise at the site using the voice command is included. FIG. 3 is a table showing the relationship between the speaker of the evaluation data and the recording location. The evaluation data in FIG. 3 includes voices recorded by speaker A (male, 60 years old) at factories A and B, voices recorded by speaker B (female, 30 years old) at factories C and D, and the like.
評価用データ記憶部11の音声データは、属性(性別、年齢)の異なる話者により、異なる収録場所で収録される。評価用データは、音声コマンドを使用する現場で収録するため、音声コマンドを使用する現場の雑音が含まれる。図3は、評価用データの話者と収録場所の関係を示す表である。図3の評価用データには、話者A(男、60才)が工場A及び工場Bで収録した音声、話者B(女、30才)が工場C、工場Dで収録した音声などが含まれる。 The evaluation
The speech data in the evaluation
音声認識部15は、評価用データ記憶部11から音声コマンドを入力し、入力した音声コマンドの音声認識を行う。音声認識部15は、一般的に、音響モデル、言語モデル、デコーダから構成される。音響モデルは、音声データを入力し、音声データの特徴量に基づき、音声データを構成する音素(セノン)を出力する。言語モデルは、単語列の出現確率を出力する。言語モデルは、音素に基づいて仮説の単語列を選択し、言語的にもっともらしい候補を出力する。デコーダは、統計的に作成した音響モデル及び言語モデルの出力に基づき、確率の高い単語列を認識結果として出力する。
The voice recognition unit 15 receives a voice command from the evaluation data storage unit 11 and performs voice recognition of the input voice command. The speech recognition unit 15 is generally composed of an acoustic model, a language model, and a decoder. The acoustic model receives speech data and outputs phonemes (senones) that form the speech data based on the feature amount of the speech data. The language model outputs the probability of occurrence of word strings. The language model selects hypothetical word strings based on phonemes and outputs linguistically plausible candidates. The decoder outputs a word string with a high probability as a recognition result based on the outputs of the acoustic model and language model that are statistically created.
抽出文法記憶部16は、構文記憶部21と単語記憶部22とを備え、文法抽出部14で抽出した文法を記憶する。音声認識部15は、抽出文法記憶部16に記憶する文法を用いて音声認識を行う。
The extracted grammar storage unit 16 includes a syntax storage unit 21 and a word storage unit 22, and stores the grammars extracted by the grammar extraction unit 14. The speech recognition section 15 performs speech recognition using the grammar stored in the extraction grammar storage section 16 .
評価値算出部17は、評価用データ記憶部から正解のテキストと、音声認識部15の認識結果と比較し、音声認識の正解率を算出する。図4は、評価値としての正解率の例である。本開示では、音声コマンド全体の評価だけでなく、音声コマンドの種類ごとの正解率を算出する。音声コマンドの種類には、例えば、承認コマンド、数値コマンド、遷移コマンドなどがある。承認コマンドとは、承認を示すコマンドである。承認コマンドには、「はい」「いいえ」「イエス」「ノー」「実行します」「中止します」などがあるものとする。数値コマンドは、「0.5」「1」「2」「100」などの数値を指定するコマンドである。「遷移コマンド」は、「ホーム画面」「速度設定画面」などの表示画面を指定するコマンドである。その他、「ワークをセットして」の様に機器の動きを指示する「機械操作コマンド」も考えられる。
The evaluation value calculation unit 17 compares the correct text from the evaluation data storage unit with the recognition result of the speech recognition unit 15, and calculates the accuracy rate of speech recognition. FIG. 4 is an example of the accuracy rate as an evaluation value. In the present disclosure, the accuracy rate is calculated for each type of voice command as well as the evaluation of the voice command as a whole. Types of voice commands include, for example, approval commands, numerical commands, and transition commands. An approval command is a command indicating approval. Assume that the approval commands include "yes", "no", "yes", "no", "execute", "abort", and the like. Numerical commands are commands for designating numerical values such as "0.5", "1", "2", and "100". A "transition command" is a command for designating a display screen such as a "home screen" or a "speed setting screen". In addition, a "machine operation command" such as "set a workpiece" may be considered.
目標登録部12は、音声認識の目標値の登録を受け付ける。目標登録部12では、音声コマンド全体の目標正解率、音声コマンドの種類ごとの目標正解率、探索の目標時間などの目標値を受け付ける。
図5は、目標登録画面の一例である。図5では、音声コマンドの種類ごとの目標正解率として、「承認コマンド:95%以上」、「数値コマンド:90%以上」、「遷移コマンド:80%以上」、最大実行時間「30分以内」と設定されている。 Thetarget registration unit 12 accepts registration of target values for speech recognition. The target registration unit 12 receives target values such as a target accuracy rate for all voice commands, a target accuracy rate for each type of voice command, and a target search time.
FIG. 5 is an example of a target registration screen. In FIG. 5, the target accuracy rate for each type of voice command is set as "approval command: 95% or more", "numerical command: 90% or more", "transition command: 80% or more", and maximum execution time "within 30 minutes".
図5は、目標登録画面の一例である。図5では、音声コマンドの種類ごとの目標正解率として、「承認コマンド:95%以上」、「数値コマンド:90%以上」、「遷移コマンド:80%以上」、最大実行時間「30分以内」と設定されている。 The
FIG. 5 is an example of a target registration screen. In FIG. 5, the target accuracy rate for each type of voice command is set as "approval command: 95% or more", "numerical command: 90% or more", "transition command: 80% or more", and maximum execution time "within 30 minutes".
文法選択部18は、音声認識の結果と目標正解率とを比較し、音声認識の結果、目標正解率を満たすと判定した文法があれば、その文法を適当な文法として選択する。文法選択部18の処理は、文法調整の目標時間が経過するか、目標正解率をクリアするまで繰り返す。文法調整の目標時間が経過した場合には、これまで音声認識を実行した文法から適切な文法を選択する。文法選択部18は、各文法の正解率を文法の作成者に提示し、文法の作成者が文法を選択してもよい。
The grammar selection unit 18 compares the speech recognition result with the target accuracy rate, and if there is a grammar determined to satisfy the target accuracy rate as a result of the speech recognition, it selects that grammar as an appropriate grammar. The processing of the grammar selection unit 18 is repeated until the target time for grammar adjustment elapses or the target accuracy rate is cleared. When the target time for grammar adjustment has passed, an appropriate grammar is selected from the grammars for which speech recognition has been performed so far. The grammar selection unit 18 may present the accuracy rate of each grammar to the creator of the grammar, and the creator of the grammar may select the grammar.
文法の選択方法の一例を説明する。本開示では、音声コマンドの正解率を承認コマンド、遷移コマンド、数値コマンドという種類毎に算出した。これらの音声コマンドのうち承認コマンドは、操作の確認に用いられるため高い正解率が求められる。数値を指定する数値コマンドも高い正解率が要求される。画面遷移を指示する遷移コマンドは、承認コマンドや数値コマンドと比較して、低い正解率でもよい。本開示の文法調整装置では、音声コマンドごと、又は、音声コマンドの種類ごとに目標の正解率を設定することができる。目標の正解率を達成する文法を自動で選択する。
例えば、図6は、文法Aと文法Bの正解率である。文法Aの「承認コマンド」「数値コマンド」「遷移コマンド」の正解率は、目標登録部12で登録した目標正解率を満たすので、文法Aを適切な文法として選択する。なお、複数の文法が目標の正解率を満たす場合には、さらなる条件を設定してもよい。 An example of a grammar selection method will be described. In the present disclosure, the accuracy rate of voice commands is calculated for each type of approval command, transition command, and numerical command. Among these voice commands, the approval command is used for confirming the operation, so a high accuracy rate is required. Numerical commands that specify numerical values also require a high accuracy rate. A transition command that instructs a screen transition may have a lower accuracy rate than an approval command or a numerical command. With the grammar adjustment device of the present disclosure, a target accuracy rate can be set for each voice command or for each type of voice command. Automatically select the grammar that achieves the target accuracy rate.
For example, FIG. 6 shows the accuracy rate of grammar A and grammar B. In FIG. Since the accuracy rate of "approval command", "numerical value command", and "transition command" of grammar A satisfies the target accuracy rate registered by thetarget registration unit 12, grammar A is selected as an appropriate grammar. Further conditions may be set when a plurality of grammars satisfy the target accuracy rate.
例えば、図6は、文法Aと文法Bの正解率である。文法Aの「承認コマンド」「数値コマンド」「遷移コマンド」の正解率は、目標登録部12で登録した目標正解率を満たすので、文法Aを適切な文法として選択する。なお、複数の文法が目標の正解率を満たす場合には、さらなる条件を設定してもよい。 An example of a grammar selection method will be described. In the present disclosure, the accuracy rate of voice commands is calculated for each type of approval command, transition command, and numerical command. Among these voice commands, the approval command is used for confirming the operation, so a high accuracy rate is required. Numerical commands that specify numerical values also require a high accuracy rate. A transition command that instructs a screen transition may have a lower accuracy rate than an approval command or a numerical command. With the grammar adjustment device of the present disclosure, a target accuracy rate can be set for each voice command or for each type of voice command. Automatically select the grammar that achieves the target accuracy rate.
For example, FIG. 6 shows the accuracy rate of grammar A and grammar B. In FIG. Since the accuracy rate of "approval command", "numerical value command", and "transition command" of grammar A satisfies the target accuracy rate registered by the
図7を参照して、本開示の文法調整装置100の処理を説明する。
文法調整装置100は、準備ステップとして、音声コマンドの目標正解率の登録(ステップS1、文法調整の最大実行時間の登録を受け付け(ステップS2)、クラスタ分割基準の登録を受け付ける(ステップS3)。k-means法を用いる場合、クラスタ分割基準として、初期値の乱数、クラスタの数Kの登録を受け付ける。 The processing of thegrammar adjustment device 100 of the present disclosure will be described with reference to FIG.
As a preparation step, thegrammar adjustment device 100 registers a target accuracy rate of a voice command (step S1, receives registration of the maximum execution time for grammar adjustment (step S2), and receives registration of a cluster division criterion (step S3). When using the k-means method, registration of an initial random number and the number of clusters K is received as a cluster division criterion.
文法調整装置100は、準備ステップとして、音声コマンドの目標正解率の登録(ステップS1、文法調整の最大実行時間の登録を受け付け(ステップS2)、クラスタ分割基準の登録を受け付ける(ステップS3)。k-means法を用いる場合、クラスタ分割基準として、初期値の乱数、クラスタの数Kの登録を受け付ける。 The processing of the
As a preparation step, the
文法調整装置100は、基盤文法記憶部13に記憶した音声コマンド(又は音声コマンドに含まれる単語)をクラスタ化し(ステップS4)、各クラスタから代表となる音声コマンド(又は音声コマンドに含まれる単語)を1つ又は複数抽出し(ステップS5)、抽出した音声コマンド(又は音声コマンドに含まれる単語)を用いて文法を再構築する(ステップS6)。
文法調整装置100は、ステップS5で再構築した文法を用いて評価用データの音声認識を行う(ステップS7)。文法調整装置100は、音声認識の評価値を算出する(ステップS8)。文法調整装置100は、評価結果と目標正解率とを比較し、評価結果が目標正解率の条件を満たす場合(ステップS9;Yes)、当該文法を選択する(ステップS10)。 Thegrammar adjustment device 100 clusters the voice commands (or words included in the voice commands) stored in the basic grammar storage unit 13 (step S4), extracts one or more representative voice commands (or words included in the voice commands) from each cluster (step S5), and reconstructs the grammar using the extracted voice commands (or words included in the voice commands) (step S6).
Thegrammar adjustment device 100 performs speech recognition on the evaluation data using the grammar reconstructed in step S5 (step S7). Grammar adjustment device 100 calculates an evaluation value for speech recognition (step S8). Grammar adjustment device 100 compares the evaluation result with the target accuracy rate, and if the evaluation result satisfies the target accuracy rate (step S9; Yes), selects the grammar (step S10).
文法調整装置100は、ステップS5で再構築した文法を用いて評価用データの音声認識を行う(ステップS7)。文法調整装置100は、音声認識の評価値を算出する(ステップS8)。文法調整装置100は、評価結果と目標正解率とを比較し、評価結果が目標正解率の条件を満たす場合(ステップS9;Yes)、当該文法を選択する(ステップS10)。 The
The
ステップS9において、評価結果が目標正解率の条件を満たさない場合(ステップS9;No)、最大実行時間に到達したか否かを判断する。文法調整の目標時間に到達した場合(ステップS11;Yes)、文法調整装置100は、これまでに音声認識を行った文法をユーザに提示し、文法の選択を受け付ける(ステップS10)。
In step S9, if the evaluation result does not satisfy the target accuracy rate (step S9; No), it is determined whether or not the maximum execution time has been reached. When the target time for grammar adjustment is reached (step S11; Yes), the grammar adjustment device 100 presents the grammars that have undergone speech recognition so far to the user and accepts the selection of the grammar (step S10).
ステップS9において、文法調整の目標時間に到達していない場合(ステップS11;No)、ステップS4に処理を移行し、ステップS4からステップS9の処理を繰り返す。
なお、このフローチャートでは、目標正解率の条件を満たすと文法の調整を終了したが、調整を終了せずに、最大実行時間に達するまで調整を継続してもよい。 In step S9, if the target time for grammar adjustment has not been reached (step S11; No), the process proceeds to step S4, and the processes from step S4 to step S9 are repeated.
In this flowchart, the adjustment of the grammar is finished when the condition of the target accuracy rate is satisfied, but the adjustment may be continued until the maximum execution time is reached without finishing the adjustment.
なお、このフローチャートでは、目標正解率の条件を満たすと文法の調整を終了したが、調整を終了せずに、最大実行時間に達するまで調整を継続してもよい。 In step S9, if the target time for grammar adjustment has not been reached (step S11; No), the process proceeds to step S4, and the processes from step S4 to step S9 are repeated.
In this flowchart, the adjustment of the grammar is finished when the condition of the target accuracy rate is satisfied, but the adjustment may be continued until the maximum execution time is reached without finishing the adjustment.
以上説明したように、本開示の文法調整装置100は、音声コマンドの文法作成を支援する装置であって、網羅的に作成した文法の一部を抽出し、文法を再構築し、正解率の高い文法を選択する。
As described above, the grammar adjustment device 100 of the present disclosure is a device that supports the creation of voice command grammar, extracts a part of the comprehensively created grammar, reconstructs the grammar, and selects a grammar with a high accuracy rate.
文法の正解率は、音声コマンドの種類ごとに算出するため、音声認識を使用する現場の状況に適した精度となるように文法を調整することができる。
The grammar accuracy rate is calculated for each type of voice command, so it is possible to adjust the grammar so that the accuracy is suitable for the situation where voice recognition is used.
文法の評価用データは、音声コマンドを使用する現場で収録するため、現場または時間帯特有の雑音を含む音声データの認識に適した文法を構築することができる。また、本開示の文法調整装置では、現場固有の専門用語や表現を文法として登録しているため、雑音を含んでいたとしても文法に登録された単語及び構文から認識候補を選択するので正解率が向上する。
Grammar evaluation data is recorded at the site where voice commands are used, so it is possible to construct a grammar suitable for recognizing voice data containing noise peculiar to the site or time period. In addition, in the grammar adjustment device of the present disclosure, since field-specific technical terms and expressions are registered as grammar, recognition candidates are selected from the words and syntax registered in the grammar even if noise is included, so the accuracy rate is improved.
本開示の文法調整装置100は、自動で文法を調整するため、文法作成者の主観又はノウハウに拠らず、客観的な基準で文法を最適化することができる。また、自動文法を調整するため、経験の少ない技術者も文法の調整をすることができる。
Since the grammar adjustment device 100 of the present disclosure automatically adjusts grammar, it can optimize the grammar based on objective criteria without depending on the subjectivity or know-how of the grammar creator. In addition, since the grammar is automatically adjusted, even an inexperienced technician can adjust the grammar.
[ハードウェア構成]
図8を参照して、文法調整装置100のハードウェア構成を説明する。文法調整装置100が備えるCPU111は、文法調整装置100を全体的に制御するプロセッサである。CPU111は、バスを介してROM112に加工されたシステムプログラムを読み出し、該システムプログラムに従って文法調整装置100の全体を制御する。RAM113には、一時的な計算データや表示データ、入力部71を介してユーザが入力した各種データ等が一時的に格納される。 [Hardware configuration]
The hardware configuration of thegrammar adjustment device 100 will be described with reference to FIG. The CPU 111 included in the grammar adjustment device 100 is a processor that controls the grammar adjustment device 100 as a whole. The CPU 111 reads the system program processed in the ROM 112 via the bus and controls the entire grammar adjustment apparatus 100 according to the system program. The RAM 113 temporarily stores calculation data, display data, various data input by the user via the input unit 71, and the like.
図8を参照して、文法調整装置100のハードウェア構成を説明する。文法調整装置100が備えるCPU111は、文法調整装置100を全体的に制御するプロセッサである。CPU111は、バスを介してROM112に加工されたシステムプログラムを読み出し、該システムプログラムに従って文法調整装置100の全体を制御する。RAM113には、一時的な計算データや表示データ、入力部71を介してユーザが入力した各種データ等が一時的に格納される。 [Hardware configuration]
The hardware configuration of the
表示部70は、文法調整装置100に付属のモニタなどである。表示部70は、文法調整装置100の操作画面や設定画面などを表示する。
The display unit 70 is a monitor or the like attached to the grammar adjustment device 100 . The display unit 70 displays an operation screen, a setting screen, and the like of the grammar adjustment device 100 .
入力部71は、表示部70と一体、又は、表示部70とは別のキーボード、タッチパネル、操作ボタンなどである。ユーザは入力部71を操作して、表示部70に表示された画面への入力などを行う。なお、表示部70及び入力部71は、携帯端末でもよい。
The input unit 71 is integrated with the display unit 70 or is a keyboard, touch panel, operation button, etc. separate from the display unit 70 . The user operates the input unit 71 to perform input to the screen displayed on the display unit 70 . Note that the display unit 70 and the input unit 71 may be mobile terminals.
不揮発性メモリ114は、例えば、図示しないバッテリでバックアップされるなどして、文法調整装置100の電源がオフされても記憶状態が保持されるメモリである。不揮発性メモリ114は、加工プログラム、システムプログラム、使用可能なオプション、課金表などを記憶する。不揮発性メモリ114には、図示しないインターフェースを介して外部機器から読み込まれたプログラムや入力部71を介して入力されたプログラム、文法調整装置100の各部や工作機械等から取得された各種データ(例えば、工作機械から取得した設定パラメータ等)が記憶される。不揮発性メモリ114に記憶されたプログラムや各種データは、実行時/利用時にはRAM113に展開されてもよい。また、ROM112には、各種のシステムプログラムがあらかじめ書き込まれている。
The non-volatile memory 114 is, for example, a memory that is backed up by a battery (not shown) so that the stored state is retained even when the power of the grammar adjustment apparatus 100 is turned off. The non-volatile memory 114 stores machining programs, system programs, available options, billing tables, and the like. The nonvolatile memory 114 stores a program read from an external device via an interface (not shown), a program input via the input unit 71, and various data obtained from each part of the grammar adjustment apparatus 100, a machine tool, etc. (for example, setting parameters obtained from the machine tool, etc.). Programs and various data stored in the non-volatile memory 114 may be developed in the RAM 113 at the time of execution/use. Various system programs are pre-written in the ROM 112 .
100 文法調整装置
11 評価用データ記憶部
12 目標登録部
13 基盤文法記憶部
14 文法抽出部
15 音声認識部
16 抽出文法記憶部
17 評価値算出部
18 文法選択部
19 構文記憶部
20 単語記憶部
21 構文記憶部
22 単語記憶部
70 表示部
71 入力部
111 CPU
112 ROM
113 RAM
114 不揮発性メモリ REFERENCE SIGNSLIST 100 grammar adjustment device 11 evaluation data storage unit 12 target registration unit 13 basic grammar storage unit 14 grammar extraction unit 15 speech recognition unit 16 extracted grammar storage unit 17 evaluation value calculation unit 18 grammar selection unit 19 syntax storage unit 20 word storage unit 21 syntax storage unit 22 word storage unit 70 display unit 71 input unit 111 CPU
112 ROMs
113 RAM
114 non-volatile memory
11 評価用データ記憶部
12 目標登録部
13 基盤文法記憶部
14 文法抽出部
15 音声認識部
16 抽出文法記憶部
17 評価値算出部
18 文法選択部
19 構文記憶部
20 単語記憶部
21 構文記憶部
22 単語記憶部
70 表示部
71 入力部
111 CPU
112 ROM
113 RAM
114 不揮発性メモリ REFERENCE SIGNS
112 ROMs
113 RAM
114 non-volatile memory
Claims (7)
- 産業用機器を操作する音声コマンドの文法を記憶する文法記憶部と、
前記文法の一部を抽出する文法抽出部と、
前記抽出した文法の音声認識の評価値の目標の登録を受け付ける目標登録部と、
前記抽出した文法を用いて、評価用音声データの音声認識を行う音声認識部と、
前記抽出した文法を用いた音声認識の結果と前記評価用音声データの正解データとを基に、前記抽出した文法の音声認識の評価値を算出する評価値算出部と、
前記文法抽出部が抽出した1つ又は複数の前記抽出した文法のなかで、前記目標を満たす文法を選択する文法選択部と、
を備える文法調整装置。 a grammar storage unit that stores grammars of voice commands for operating industrial equipment;
a grammar extraction unit that extracts a part of the grammar;
a target registration unit that accepts registration of targets for speech recognition evaluation values of the extracted grammar;
a speech recognition unit that performs speech recognition of evaluation speech data using the extracted grammar;
an evaluation value calculation unit that calculates an evaluation value of speech recognition of the extracted grammar based on the results of speech recognition using the extracted grammar and correct data of the evaluation speech data;
a grammar selection unit that selects a grammar that satisfies the target from among the one or more extracted grammars extracted by the grammar extraction unit;
A grammar adjuster comprising: - 前記評価値は、前記音声認識の正解率である、請求項1記載の文法調整装置。 The grammar adjustment device according to claim 1, wherein the evaluation value is the accuracy rate of the speech recognition.
- 文法調整の実行時間を受け付け、前記実行時間に到達するまで、前記文法抽出部による文法の抽出、前記音声認識部による前記抽出した文法を用いた音声認識、前記評価値算出部による前記抽出した文法を用いた音声認識の評価値の算出、を繰り返す、請求項1記載の文法調整装置。 The grammar adjustment device according to claim 1, wherein an execution time for grammar adjustment is received, and until the execution time is reached, grammar extraction by the grammar extraction unit, speech recognition using the extracted grammar by the speech recognition unit, and evaluation value calculation of speech recognition using the extracted grammar by the evaluation value calculation unit are repeated.
- 前記文法抽出部は、前記文法記憶部に記憶した文法をクラスタ化し、前記クラスタ化した文法の代表を抽出する、請求項1記載の文法調整装置。 The grammar adjustment device according to claim 1, wherein the grammar extraction unit clusters the grammars stored in the grammar storage unit and extracts a representative of the clustered grammars.
- 前記文法抽出部は、前記文法で定義された音声コマンドの音響的距離を用いて前記文法をクラスタ化する、請求項4記載の文法調整装置。 The grammar adjustment device according to claim 4, wherein said grammar extraction unit clusters said grammars using acoustic distances of speech commands defined in said grammars.
- 前記文法抽出部は、前記文法で定義された音声コマンドに含まれる単語の音響的距離を用いて前記文法をクラスタ化する、請求項4記載の文法調整装置。 The grammar adjustment device according to claim 4, wherein said grammar extraction unit clusters said grammars using acoustic distances of words included in voice commands defined in said grammars.
- 産業用機器を操作する音声コマンドの文法を記憶し、
1つ又は複数のプロセッサが実行することにより、
前記文法の一部を抽出し、
前記抽出した文法の音声認識の評価値の目標の登録を受け付け、
前記抽出した文法を用いて、評価用音声データの音声認識を行い、
前記抽出した文法を用いた音声認識の結果と前記評価用音声データの正解データとを基に、前記抽出した文法の音声認識の評価値を算出し、
1つ又は複数の前記抽出した文法のなかで、前記目標を満たす文法を選択する、
前記プロセッサが読み取り可能な命令を記憶する記憶媒体。 Memorize the grammar of voice commands to operate industrial equipment,
by one or more processors executing:
extracting a portion of said grammar;
Receiving registration of targets for speech recognition evaluation values of the extracted grammar;
using the extracted grammar to perform speech recognition of the evaluation speech data,
calculating an evaluation value of speech recognition of the extracted grammar based on the results of speech recognition using the extracted grammar and correct data of the evaluation speech data;
selecting, among one or more of the extracted grammars, a grammar that meets the goal;
A storage medium storing instructions readable by the processor.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/002282 WO2023139769A1 (en) | 2022-01-21 | 2022-01-21 | Grammar adjustment device and computer-readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/002282 WO2023139769A1 (en) | 2022-01-21 | 2022-01-21 | Grammar adjustment device and computer-readable storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023139769A1 true WO2023139769A1 (en) | 2023-07-27 |
Family
ID=87348531
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/002282 WO2023139769A1 (en) | 2022-01-21 | 2022-01-21 | Grammar adjustment device and computer-readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2023139769A1 (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS602998A (en) * | 1983-06-20 | 1985-01-09 | 富士通株式会社 | Method of composing voice dictionary for voice recognition system |
| JPH0250197A (en) * | 1988-05-06 | 1990-02-20 | Ricoh Co Ltd | Dictionary pattern producing device |
| JP2009217006A (en) * | 2008-03-11 | 2009-09-24 | Nippon Hoso Kyokai <Nhk> | Dictionary correction device, system and computer program |
| JP2009229529A (en) * | 2008-03-19 | 2009-10-08 | Toshiba Corp | Speech recognition device and speech recognition method |
| JP2014191246A (en) * | 2013-03-28 | 2014-10-06 | Nec Corp | Recognition processing control device, recognition processing control method, and recognition processing control program |
-
2022
- 2022-01-21 WO PCT/JP2022/002282 patent/WO2023139769A1/en active Application Filing
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS602998A (en) * | 1983-06-20 | 1985-01-09 | 富士通株式会社 | Method of composing voice dictionary for voice recognition system |
| JPH0250197A (en) * | 1988-05-06 | 1990-02-20 | Ricoh Co Ltd | Dictionary pattern producing device |
| JP2009217006A (en) * | 2008-03-11 | 2009-09-24 | Nippon Hoso Kyokai <Nhk> | Dictionary correction device, system and computer program |
| JP2009229529A (en) * | 2008-03-19 | 2009-10-08 | Toshiba Corp | Speech recognition device and speech recognition method |
| JP2014191246A (en) * | 2013-03-28 | 2014-10-06 | Nec Corp | Recognition processing control device, recognition processing control method, and recognition processing control program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2309489B1 (en) | Methods and systems for considering information about an expected response when performing speech recognition | |
| US10068566B2 (en) | Method and system for considering information about an expected response when performing speech recognition | |
| JP4657736B2 (en) | System and method for automatic speech recognition learning using user correction | |
| US9275637B1 (en) | Wake word evaluation | |
| US20020123894A1 (en) | Processing speech recognition errors in an embedded speech recognition system | |
| US8731928B2 (en) | Speaker adaptation of vocabulary for speech recognition | |
| JP3980791B2 (en) | Man-machine system with speech recognition device | |
| US6952665B1 (en) | Translating apparatus and method, and recording medium used therewith | |
| US6934682B2 (en) | Processing speech recognition errors in an embedded speech recognition system | |
| EP2645364B1 (en) | Spoken dialog system using prominence | |
| JP2012238017A (en) | Speech recognition method with substitution command | |
| US7966177B2 (en) | Method and device for recognising a phonetic sound sequence or character sequence | |
| JP4186992B2 (en) | Response generating apparatus, method, and program | |
| WO2006097975A1 (en) | Voice recognition program | |
| US6963834B2 (en) | Method of speech recognition using empirically determined word candidates | |
| JPH0581920B2 (en) | ||
| JP2019101065A (en) | Voice interactive device, voice interactive method and program | |
| WO2023139769A1 (en) | Grammar adjustment device and computer-readable storage medium | |
| JP2005234332A (en) | Electronic equipment controller | |
| US20060136195A1 (en) | Text grouping for disambiguation in a speech application | |
| JP5544575B2 (en) | Spoken language evaluation apparatus, method, and program | |
| Raux | Automated lexical adaptation and speaker clustering based on pronunciation habits for non-native speech recognition | |
| WO2023139770A1 (en) | Grammar generation support device and computer-readable storage medium | |
| Kuzdeuov et al. | Speech Command Recognition: Text-to-Speech and Speech Corpus Scraping Are All You Need | |
| Avuclu et al. | A Voice Recognition Based Game Design for More Accurate Pronunciation of English |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22921926 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023575014 Country of ref document: JP |