WO2014058254A1 - Composition for estimating risk of onset of systemic lupus erythematosus, comprising primer for detecting dna copy number variation in 1q25.1(rabgap1l) location, 6p21.32 (c4) location and 10.q21.3 location - Google Patents
Composition for estimating risk of onset of systemic lupus erythematosus, comprising primer for detecting dna copy number variation in 1q25.1(rabgap1l) location, 6p21.32 (c4) location and 10.q21.3 location Download PDFInfo
- Publication number
- WO2014058254A1 WO2014058254A1 PCT/KR2013/009074 KR2013009074W WO2014058254A1 WO 2014058254 A1 WO2014058254 A1 WO 2014058254A1 KR 2013009074 W KR2013009074 W KR 2013009074W WO 2014058254 A1 WO2014058254 A1 WO 2014058254A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- primer
- copy number
- deletion
- composition
- pcr
- Prior art date
Links
Images






Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
Definitions
- the present invention relates to a composition for predicting the risk of developing systemic lupus erythematosus, and more specifically, to a systemic erythema when a DNA copy number mutation occurs at 1q25.1 (RABGAP1L) region, 6p21.32 (C4) region, and 10q21.3 region. It relates to a composition characterized in that it is seen as a high risk group for the development of reflective lupus.
- SLE Systemic lupus erythematosus
- SLE is a chronic disease that causes symptoms to improve and worsen over time. SLE patients are particularly prone to blood clotting and blood clots, which can cause coronary artery disease even at a young age, which increases the likelihood of developing angina or myocardial infarction. There is also a risk of stillbirth if you are pregnant. It is also vulnerable to respiratory infections such as influenza and pneumococci. Therefore, it is important to anticipate the risk of SLE in advance to delay or prevent the onset of disease, to reduce symptoms through proper treatment when the disease occurs, and to prevent damage to major organs such as the kidney, lung, and heart. Complications of SLE can be prevented by immunization against influenza and pneumococci and by controlling factors associated with atherosclerosis such as hypertension, blood sugar, and lipid metabolism disorders.
- the present inventors studied new markers capable of early diagnosis of the risk of developing SLE. As a result, deletion variants at the 1q25.1 and 10q21.3 loci of the chromosome were found. If present, the risk of developing SLE is significantly increased, thereby completing the present invention.
- the present invention has been made in the above background, composition for predicting the risk of developing systemic lupus erythematosus comprising primers for detecting DNA copy number mutations at positions 1q25.1, 6p21.32 (C4) and 10q21.3. It is intended to provide a kit.
- the present invention is a composition for predicting the development of Systemic Lupus Erythematosus, wherein the composition is DNA copy number variation of C4 position, 1q25.1 position and / or 10q21.3 position on the chromosome of the sample.
- a composition comprising a primer for detection.
- DNA copy number variations can be deletion-type (0 or 1 copy) and can be gain-type (> 2 copy), but is not limited thereto.
- RABGAPase activating protein 1-like (RABGAP1L) gene located at 1q25.1 encodes a GPTase-activating protein.
- the protein has a phosphotyrosine binding domain and is thought to be a tyrosine-kinase that acts in signaling, but it is not known whether it is involved in specific biological actions or etiology.
- CNV of C4 showed a significant correlation in the present invention.
- the present invention was completed for Korean women, but such copy number variation is highly likely to occur regardless of ethnicity.
- Yang et al.'S paper reported that Westerners reported a lower risk of developing SLE when the number of copies of C4 was small, and a higher risk of developing SLE when they were large, and the same result was observed for Han Chinese.
- the chromosome of the sample can be obtained from the cells of the sample derived from oral epithelium, hair, etc., the source of the cell is not limited thereto.
- the primer for detecting DNA copy number variation at position 1q25.1 is a primer pair for genomic quantitative PCR including DNA sequences of SEQ ID NOs: 1 and 2. It is done.
- the primer for detecting DNA copy number variation at position 10q21.3 is a primer pair for genomic quantitative PCR including DNA sequences of SEQ ID NOs: 3 and 4. It is done.
- the primer for detecting DNA copy number variation at position 1q25.1 includes deletion-typing comprising a DNA sequence selected from the group consisting of SEQ ID NOs: 5-8 Characterized in that it is a primer for PCR.
- the primer for detecting DNA copy number variation at the 10q21.3 position is a primer for deletion-typing PCR including a DNA sequence selected from the group consisting of SEQ ID NOs: 9 to 12.
- the present invention is a kit for predicting the risk of developing Systemic Lupus Erythematosus, wherein the kit is a DNA copy number variation (DNA copy number) at the C4 position, 1q25.1 position and / or 10q21.3 position on the chromosome of the sample. Variation) It provides a kit, characterized in that it comprises a primer (primer) for detection.
- the term 'kit' of the present invention refers to a set that can be commercialized into a configuration including a biomarker and all other materials necessary for various pretreatment and materials for analysis.
- the kit is characterized in that it comprises a primer comprising a DNA sequence selected from the group consisting of SEQ ID NO: 1 to 12.
- the present invention is a.
- A) PCR was performed by adding a primer for detecting DNA copy number variation to the sample DNA sample at the 6p21.32 (C4), 1q25.1 and / or 10q21.3 positions on the chromosome of the sample. Performing; And
- Primer for detecting DNA copy number variation at position 1q25.1 and / or 10q21.3 is a primer for genomic quantitative PCR comprising a DNA sequence selected from the group consisting of SEQ ID NOs: 1-4. It features.
- DNA copy number variation detection, sizing and border primers of the 1q25.1 position and / or 10q21.3 position of step A) is selected from the group consisting of SEQ ID NOs: 5-12 It is characterized in that the primer for deletion-typing PCR containing a DNA sequence.
- compositions of the present invention make it possible to predict the risk of onset by having a replication number variation at the C4, 1q25.1 and 10q21.3 positions having a synergistic effect on the development of systemic lupus erythematosus and is common in most hospital laboratories.
- the use of PCR is a clinically friendly way to reduce errors in analysis that can occur due to new equipment purchases or technical limitations.
- the present invention has the advantage that can be performed in a non-invasive way to the test subject.
- the present invention is expected to be important for early prediction of the possibility of developing systemic lupus erythematosus and for preventing or slowing the progression of the condition.
- FIG. 1 is a diagram illustrating an analysis process ranging from genome-wide CNV discovery to independent replication.
- FIG. 2 is a schematic diagram showing that a region containing a very small number of CNVs is not viewed as a CNVR.
- Fig. 3 shows the allele intensity and qPCR confirmation results of RABGAP1L CNV at 1q25.1 .
- FIG. 5 is a schematic diagram showing a strategy for determining deletion typing PCR and deletion-CNVR boundaries.
- White boxes indicate deleted areas.
- Red arrows in the deleted sites indicate a set to distinguish between HOM and HET.
- the upper diagram shows the strategy diagram of two CNVRs, the middle diagram shows the results of electrophoresis of the deletion-typing PCR product according to each strategy, and the lower diagram shows the deletion breakpoint (pointed by arrow) through DNA sequencing. to be.
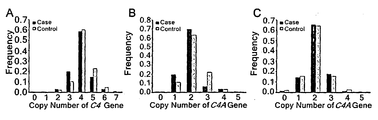
- Figure 6 shows the distribution number distribution for the entire C4, C4A and C4B genes identified by qPCR. Black bars represent patient groups and gray bars represent controls.
- Genotype analysis of the entire genome SNP was performed using Illumina's Human 610s Quad-Bead Chip platform (including 620,901 SNP markers). The average number of probes per known CNV is 37.7. Approximately 750 ng of genomic DNA per sample was used for genotyping. The sample we used showed an average SNP call rate of 99.89 ⁇ 0.16%. To minimize plate or batch effects, all procedures were performed in the same environment for the same period.
- the PennCNV algorithm uses HMM, so there was no threshold on the minimum number of consecutive CNVs (CVVs), but all of the SNPs found in this process were more than three consecutive SNPs (3-1988). A different number of SNPs were found, with the average number of probes per CNV being 13.42, with a median of 7.
- the boundary of each CNV is determined by the length from the linear position of the first SNP probe to the last probe (hg18). General characteristics of CNV are shown in Table 1 below.
- the size of the CNVR may be larger than the actual size (see FIG. 2). To minimize this possibility, areas containing only a small number of CNVs (less than 10% of the total CNVs) were not viewed as CNVRs.
- a total of 18,266 CNVs were identified in 573 samples.
- the median CNV number for an individual was 30 (range of 1-285) and the median size of CNV was 21.0 kb (range 14 bp-18 Mbp).
- Copy number-loss CNV was 1.4 times more frequent than copy number-gain CNV.
- 2,544 CNVRs were identified from 18,266 CNVs. Of those, 144 CNVR were present in over 5% of the individuals.
- Table 2 below shows 144 CNVRs found in 5% or more individuals.
- the OR of CNVRs was calculated based on the 2n individuals. In replication by deletion typing PCR, OR was calculated based on ⁇ 2n. Principal componet analysis (PCA) was performed to correct the effect of population distribution by age group. For regression analysis, the top two principal components derived from PCA analysis, PC1 and PC2, were used as covariates, and SNP-array batch information was also used as a covariate for regression analysis. FDR was calculated as the p-value of 144 CNVR.
- PCA Principal componet analysis
- Genomic qPCR was performed using a Viia 7 system (Life Technologies, Carlsbad, Calif.).
- C4 gene (C4A and C4B)
- the copy number was determined by performing genomic qPCR using two Taqman assays (Hs07226349_cn and Hs07226350_cn (Life Technologies)) designed specifically for C4 A and C4 B.
- a total of 10 ⁇ l of reaction mixture was used, including 10 ng of genomic DNA, TaqMan universal PCR master mix II (Life Technologies), C4A or C4B TaqMan probe, and RNaseP TaqMan probe.
- PCR conditions were carried out with 40 cycles of 1 cycle at 95 °C for 10 minutes, 15 seconds at 95 °C for 1 minute at 60 °C.
- PCR efficiency for the entire primer was determined by standard curve over serial 1: 5 dilution.
- the Ct value is determined by the number of PCR cycles required for the reference gene to reach the threshold of the standard curve.
- the copy number variation for each target was defined as 2 ⁇ CT .
- ⁇ Ct is the difference in threshold cycles for the values obtained from the reference gene (RNase P) and calibrator DNA (individual / calibrator) in the sample to be identified.
- the ratio data is then divided by the nearest integer.
- the frequency distribution of these three CNVRs is shown in the table below (Table 5). The left column is the frequency distribution of CNVR GWAS discovery results, the middle column is the qPCR verification result, and the right column is the deletion typing PCR verification.
- 3 is a genoplot image of the rs4480415 marker (173066744 position, hg18) obtained by Illumina GenomeStudio software.
- the signal strengths at these positions form six distinct clusters of 2X (A / A, A / B / B / B), 1X (A /-, B /-), and 0X (-/-), respectively.
- the figure in the center shows the signal strength ratio around the 1q25.1 region.
- 3 is a diagram confirming the estimated number of copies of the 1q25.1 region by genomic qPCR.
- the X axis represents the state of copy number by PennCNV
- the Y axis represents the estimated DNA copy number by qPCR.
- the frequency distribution of 6p21.32, a CNVR across C4, is shown in Table 6 below.
- the upper table of Table 6 shows CNV GWAS discovery results and the following table shows qPCR verification experiment results.
- Example 5 the inventors performed deletion-typing PCR in order to confirm the exact size and boundary of CNV of the two regions (1q25.1 and 10q21.3) showing significant association with SLE. Amplicons of deleted alleles were sequenced using PCR-direct sequencing. In the case of the C4 region, the deletion-typing PCR design was not possible.
- PCR was performed under the following conditions. 20 ⁇ l of a reaction mixture containing 20 ng of genomic DNA, 0.4 unit of FX DNA polymerase (TOYOBO, Osaka, Japan), 2% DNSO, and 6 pmol of primer was prepared. PCR was performed for 1 cycle at 94 ° C for 2 minutes, at 98 ° C for 10 seconds and at 69 ° C for 1 minute / Kb. After the PCR reaction, 10 ⁇ l of the PCR product was electrophoresed on 0.5% agarose gel. The deleted alleles were sequenced by PCR-direct sequencing method.
- the experiment strategy of FIG. 5 shows that if PCR is performed including a region of expected deletion, a PCR amplification product of the expected size appears in the absence of a deletion, whereas a PCR amplification product of which the length is reduced by that size appears. It is a principle.
- the amplicon size of the total allele of the 1q25.1 region designed by the inventors was 9.4 Kb, and the predicted size of the deletion region at 1q25.1 based on the start-end position of the SNP. was 3.8 Kb. Therefore, the magnitude of the amplification of the deletion allele was calculated to be 5.6 Kb. However, since the actual amplification size of the deleted allele was 4.2 Kb or less, the actual deletion size at 1q25.1 was calculated to be 5.2 Kb or less, not 3.8 Kb.
- a person who shows only 9.4Kb bands can be interpreted as 2n (diploid), a person who shows only 4.2Kb bands can be interpreted as homozygous deletion (HOM), and a person who shows both 9.4Kb and 4.2Kb bands as heterozygous deletion (HET). do.
- the predicted size of the deletion region based on the start-end position of the SNP in the 10q21.3 region was 2.4 Kb and the amplification size of the designed allele was 11.6 Kb. Therefore, a 9.2 Kb-sized deletion typing PCR amplification product is expected, but the size of the amplification product of the deletion allele was 3.3 Kb or less, so the amplification size of the actual deletion allele in the 10q21.3 region was 8.3 Kb or less, not 2.4 Kb. Was calculated.
- a person who shows only 11.6Kb band can be interpreted as 2n (diploid), a person who shows only 3.3 Kb band can be interpreted as homozygous deletion (HOM), and a person who shows 11.6 Kb and 3.3 Kb band at the same time can be interpreted as heterozygous deletion (HET).
- HOM homozygous deletion
- HET heterozygous deletion
- the region 1q25.1 includes Band 1, 9.4 Kb; Band 2, 4.2 Kb; Band 3, 2.3 Kb.
- the 10q21.3 region includes Band 1, 11.6 Kb; Band 2, 3.3 Kb; Band 3, 3.2 Kb.
- P1 and P2 mean primer sets 1 and 2, respectively.
- 5 bottom is an example of a DNA sequence showing deletion breakpoints (parts indicated by arrows) of 1q25.1 and 10q21.3.
- heterozygous samples must have two sizes of amplification (full size and size of deletion), full size amplification is preferred for small size PCR in both CNVRs. for small-sized PCR). Therefore, to distinguish homozygous and heterozygous deletions based on deletion mapping data, we sought to redesign the primers in the deleted sequences to test for the presence of short amplifications that represent the entire allele ( 5, Table 7). If the sample had a heterozygous deletion, the total allele would produce an amplified product of the expected size (2.3 Kb for 1q25.1, 3.2 Kb for 10q21.3), but not for the deletion allele. If the sample had a homozygous deletion, it was expected that no PCR amplification would be produced.
- homozygous deletions are 4.2 Kb band positive, 9.4 Kb band negative, 2.3 Kb band negative
- heterozygous deletions are 4.2 Kb band positive, 2.3 Kb band positive, and the 9.4 Kb band is positive but may not appear. If there is more than one copy number variation, it is 9.4 Kb band positive, 2.3 Kb band positive, 3.2 Kb band negative, 4.2 Kb band negative.
- homozygous deletion will be 3.3 Kb band positive, 3.2 Kb band negative, 11.6 Kb band negative
- heterozygous deletion will be 3.3 Kb band positive, 3.2 Kb band positive, and 11.6 Kb may be positive but may not appear. If there is more than one copy number variation, it will be 11.6 Kb band positive, 3.2 Kb band positive, 3.3 Kb band negative (FIG. 4).
- the present inventors wanted to know the effects of the deletion type CNVR occurring at the same time in three important positions in predicting the risk of developing SLE.
- compositions of the present invention make it possible to predict the risk of onset by having a replication number variation at the C4, 1q25.1 and 10q21.3 positions having a synergistic effect on the development of systemic lupus erythematosus and is common in most hospital laboratories.
- the PCR that is performed as a new device or to reduce the error of analysis that may occur due to technical limitations, there is an advantage that can be performed in a non-invasive way to the subject.
- the present invention can be used to predict the possibility of developing systemic lupus erythematosus early to prevent the worsening of the condition or to delay the onset.
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Analytical Chemistry (AREA)
- Zoology (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Pathology (AREA)
- Immunology (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
The present invention relates to a composition for estimating the risk of onset of systemic lupus erythematosus, and more particularly, to a composition which determines an examinee as having a high risk of onset of systemic lupus erythematosus when a DNA copy number variation has occurred in the C4 region, 1q25.1 region and 10q21.3 region. The composition of the present invention may estimate the risk of onset of systemic lupus erythematosus using the fact that the copy number variation in C4 location, 1q25.1 location and 10q21.3 location has a synergistic effect in the occurrence of systemic lupus erythematosus. The composition of the present invention enables a clinically friendly method that may reduce an error of an analysis which might be caused by a newly purchased device or by technological limitations, by using PCR which is generally performed in most laboratories of hospital. Furthermore, the composition of the present invention has the advantages of being performed on an examinee using a non-invasive method. Thus, the composition of the present invention may estimate the risk of onset of systemic lupus erythematosus at an early stage, and thus can be used in preventing an aggravated state or in delaying the occurrence of the disease.
Description
본 발명은 전신성 홍반성 루푸스 발병 위험도 예측용 조성물에 관한 것으로, 보다 구체적으로는 1q25.1 (RABGAP1L) 영역, 6p21.32 (C4)영역 및 10q21.3 위치에 DNA 복제 수 변이가 발생한 경우 전신성 홍반성 루푸스 발병 고위험군으로 보는 것을 특징으로 하는 조성물에 관한 것이다. The present invention relates to a composition for predicting the risk of developing systemic lupus erythematosus, and more specifically, to a systemic erythema when a DNA copy number mutation occurs at 1q25.1 (RABGAP1L) region, 6p21.32 (C4) region, and 10q21.3 region. It relates to a composition characterized in that it is seen as a high risk group for the development of reflective lupus.
전신성 홍반성 루푸스(SLE)는 여러 장기에 동시에 영향을 주는 만성 자가면역 질환으로서, 주로 가임기의 젊은 여성에게 발병한다. SLE에서, 비정상적인 면역 반응으로 인해 병적인 자가 항체가 생산되고 면역 복합체가 다양한 장기에 축적되어 염증 및 장기 손상을 초래하게 된다. SLE 발병 기전은 아직 확실히 규명되지 않았으나, 일란성 쌍둥이에서 이란성 쌍둥이보다 동시 발병 위험이 높다는 점 및 가족력과 밀접한 관계가 있다는 점 등으로 미루어 볼 때 유전적 요소가 중요한 것으로 밝혀져 있다.Systemic lupus erythematosus (SLE) is a chronic autoimmune disease that affects several organs simultaneously, mainly in young women of childbearing age. In SLE, abnormal immune responses produce pathological autoantibodies and immune complexes accumulate in various organs resulting in inflammation and organ damage. The mechanism of SLE has not yet been fully established, but genetic factors are important because identical twins have a higher risk of developing them than fraternal twins and are closely related to family history.
SLE는 만성 질환으로 증상의 호전과 악화를 반복하게 된다. SLE 환자는 특히 혈액이 잘 응고되어 혈전이 생기는 경향이 있어, 젊은 나이에도 관상동맥질환을 일으킬 수 있고, 이로 인해 협심증이나 심근경색이 발생할 가능성이 높아진다. 임신 중인 경우 태아 사산의 위험도 있다. 또한 인플루엔자와 폐렴구균 등 호흡기 감염 원인균에 취약하다. 따라서 SLE의 발병위험을 미리 예측하여 발병을 늦추거나 예방하고, 발병된 경우 적절한 치료를 통해 증상을 경감시키고, 신장, 폐, 심장 등 주요 장기의 손상을 방지하는 것이 중요하다. SLE의 합병증은 인플루엔자와 폐렴구균에 대한 예방접종을 시행하고, 고혈압, 혈당, 지질대사장애 등 동맥경화와 연관된 인자들을 조절함으로써 예방할 수 있다. SLE is a chronic disease that causes symptoms to improve and worsen over time. SLE patients are particularly prone to blood clotting and blood clots, which can cause coronary artery disease even at a young age, which increases the likelihood of developing angina or myocardial infarction. There is also a risk of stillbirth if you are pregnant. It is also vulnerable to respiratory infections such as influenza and pneumococci. Therefore, it is important to anticipate the risk of SLE in advance to delay or prevent the onset of disease, to reduce symptoms through proper treatment when the disease occurs, and to prevent damage to major organs such as the kidney, lung, and heart. Complications of SLE can be prevented by immunization against influenza and pneumococci and by controlling factors associated with atherosclerosis such as hypertension, blood sugar, and lipid metabolism disorders.
최근 genome-wise association studies(GWAS)를 통해 HLA, IRF5, STAT4, TNFAIP3, PTPN22, BLK, BANK1, TNFSF4, ITGAM, KIAA1542, PXK 등의 후보 유전자에서 밝혀진 다수의 SNP가 다양한 민족에서 SLE 발병 위험과 관계가 있는 것으로 보고되었다. SNP 뿐 아니라, DNA 복제 수 변이(DNA copy number variations, CNVs)도 유전적 혼란을 초래하고 유전자 재배열 현상을 일으켜 단백질 발현에 영향을 주어 SLE 발병에 관여하는 것으로 밝혀졌다. 일 예로, C4와 FCGR3B에서의 CNV는 백인에서 SLE 발병 위험을 높인다는 것이 밝혀져 있다. 그러나 다른 민족에서 이와 관련된 연구가 거의 없는 실정이다. Recent genome-wise association studies (GWAS) have identified a number of SNPs identified in candidate genes such as HLA, IRF5, STAT4, TNFAIP3, PTPN22, BLK, BANK1, TNFSF4, ITGAM, KIAA1542, and PXK in relation to the risk of SLE in various ethnic groups. Has been reported. In addition to SNPs, DNA copy number variations (CNVs) have been shown to cause genetic disruption and gene rearrangement that affect protein expression and contribute to SLE development. For example, CNV in C4 and FCGR3B has been shown to increase the risk of SLE in Caucasians. However, there is little research on this in other peoples.
이러한 배경에 기초하여, 본 발명자들은 SLE 발병 위험성을 조기에 진단할 수 있는 신규한 마커에 대하여 연구한 결과, 염색체의 1q25.1 및 10q21.3 좌위(locus)에서의 결실 돌연변이(deletion variant)가 있는 경우 SLE 발병 위험이 현저히 높아짐을 발견하여 본 발명을 완성하게 되었다.Based on this background, the present inventors studied new markers capable of early diagnosis of the risk of developing SLE. As a result, deletion variants at the 1q25.1 and 10q21.3 loci of the chromosome were found. If present, the risk of developing SLE is significantly increased, thereby completing the present invention.
본 발명은 상기와 같은 배경에서 안출된 것으로, 1q25.1 위치, 6p21.32 (C4) 위치 및 10q21.3 위치의 DNA 복제 수 변이 검출용 프라이머를 포함하는 전신성 홍반성 루푸스 발병 위험도 예측용 조성물 및 키트를 제공함을 목적으로 한다.The present invention has been made in the above background, composition for predicting the risk of developing systemic lupus erythematosus comprising primers for detecting DNA copy number mutations at positions 1q25.1, 6p21.32 (C4) and 10q21.3. It is intended to provide a kit.
그러나 본 발명이 이루고자 하는 기술적 과제는 이상에서 언급한 과제에 제한되지 않으며, 언급되지 않은 또 다른 과제들은 아래의 기재로부터 당업자에게 명확하게 이해될 수 있을 것이다.However, the technical problem to be achieved by the present invention is not limited to the above-mentioned problem, another task that is not mentioned will be clearly understood by those skilled in the art from the following description.
본 발명은 전신성 홍반성 루푸스(Systemic Lupus Erythematosus) 발병 예측용 조성물로서, 상기 조성물은 검체의 염색체상의 C4 위치, 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)를 포함하는 것을 특징으로 하는, 조성물을 제공한다.The present invention is a composition for predicting the development of Systemic Lupus Erythematosus, wherein the composition is DNA copy number variation of C4 position, 1q25.1 position and / or 10q21.3 position on the chromosome of the sample. Provided is a composition comprising a primer for detection.
DNA 복제 수 변이의 범위는 결실 타입(deletion-type)일 수 있고 (0 또는 1 copy) 획득 타입 (gain-type)이 될 수 있으나 (>2 copy), 이에 제한되지 않는다.The range of DNA copy number variations can be deletion-type (0 or 1 copy) and can be gain-type (> 2 copy), but is not limited thereto.
1q25.1에 위치한 RABGAP1L(RAB GTPase activating protein 1-like) 유전자는 GPTase-activating protein을 코딩한다. 이 단백질은 phosphotyrosine 결합 도메인을 갖고 있어 신호전달 과정에서 작용하는 tyrosine-kinase일 것으로 생각되고 있으나, 세부적인 생물학적 작용이나 병인론에 관여하는지 여부는 밝혀져 있지 않다. The RABGAPase activating protein 1-like (RABGAP1L) gene located at 1q25.1 encodes a GPTase-activating protein. The protein has a phosphotyrosine binding domain and is thought to be a tyrosine-kinase that acts in signaling, but it is not known whether it is involved in specific biological actions or etiology.
본 발명자들은 연구 과정에서 RABGAP1L 유전자의 intron 20에 위치한 5.2 Kb 크기의 결실 타입 CNVR을 발견하였으며, 이 CNVR이 선택적 재조합(alternative splicing) 또는 번역 후 변형(posttranslational modification)을 통하여 이 유전자의 발현에 영향을 줄 수 있다는 사실을 발견하였다. 10q21.3 위치에서는 8.3 Kb 크기의 결실 타입 CNVR을 규명하였다. 10q21.3 영역은 코딩하는 유전자가 없으나, 다수의 GWAS 연구에서 비번역 부위도 다양한 표현형에 관련이 있다는 것이 밝혀진 바 있다. 또한 CD34+ 세포의 핵산분해효소 접근 가능 부위(nuclease accessible site, NAS)가 10q21.3 위치와 관련이 있다는 보고가 있다. NAS는 전사인자 결합 부위로 작용하며, 조혈모세포 분화에 관련이 있는 것으로 알려져 있다. 따라서 CD34+ 세포의 골수 분화와 SLE 발병 위험에 이 위치의 결실이 관여하는 것일 수 있다.We found a 5.2 Kb deletion type CNVR located in intron 20 of the RABGAP1L gene in the course of the study, and this CNVR influenced the expression of this gene through selective splicing or posttranslational modification. I found that I could give. In the 10q21.3 position, a 8.3 Kb-sized deletion type CNVR was identified. The 10q21.3 region does not have a gene encoding it, but many GWAS studies have shown that untranslated sites are also involved in various phenotypes. It has also been reported that the nuclease accessible site (NAS) of CD34 + cells is related to the 10q21.3 position. NAS acts as a transcription factor binding site and is known to be involved in hematopoietic stem cell differentiation. Thus, deletion of this position may be involved in the bone marrow differentiation of CD34 + cells and the risk of developing SLE.
GWAS discovery 단계에서 SLE와 관련이 있는 것으로 기존에 제시된 CNV 들 가운데, C4의 CNV 가 본 발명에서도 유의한 상관관계를 보였다.Among CNVs previously suggested to be related to SLE in the GWAS discovery step, CNV of C4 showed a significant correlation in the present invention.
한편 본 발명은 한국인 여성을 대상으로 하여 완성한 것이나, 이러한 복제 수 변이는 민족에 관계없이 발생할 가능성이 높다. 예를 들어서, Yang et al.의 논문에서 서양인에서 C4의 복제수가 작으면 SLE 발병 위험이 높고, 크면 SLE 발병 위험이 낮다고 보고하고 있고, 한족 중국인의 경우에도 동일한 결과가 나타난다고 보고된 바 있다. 그런데 이러한 결과는 본 발명에 대한 실험에서도 밝혀졌다. 구체적으로는 C4의 복제수가 높으면 발병 위험이 낮았다(OR=0.40, 95% CI=0.16-1.03, P=0.057). 따라서 검체는 한국인 여성에 한정되지 않고 어떤 민족도 가능하다.On the other hand, the present invention was completed for Korean women, but such copy number variation is highly likely to occur regardless of ethnicity. For example, Yang et al.'S paper reported that Westerners reported a lower risk of developing SLE when the number of copies of C4 was small, and a higher risk of developing SLE when they were large, and the same result was observed for Han Chinese. However, these results were also found in the experiments of the present invention. Specifically, the higher the number of C4 copies, the lower the risk of development (OR = 0.40, 95% CI = 0.16-1.03, P = 0.057). Therefore, the specimen is not limited to Korean women but can be of any ethnicity.
또한 검체의 염색체는 구강 상피, 머리카락 등에서 유래된 검체의 세포로부터 얻을 수 있으며, 세포의 출처는 이에 제한되지 않는다.In addition, the chromosome of the sample can be obtained from the cells of the sample derived from oral epithelium, hair, etc., the source of the cell is not limited thereto.
본 발명의 일 구현예로서, 상기 1q25.1 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 1 및 2의 DNA 서열을 포함하는 genomic quantitative PCR 용 프라이머 쌍인 것을 특징으로 한다.In one embodiment, the primer for detecting DNA copy number variation at position 1q25.1 is a primer pair for genomic quantitative PCR including DNA sequences of SEQ ID NOs: 1 and 2. It is done.
본 발명의 다른 구현예로서, 상기 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 3 및 4의 DNA 서열을 포함하는 genomic quantitative PCR 용 프라이머 쌍인 것을 특징으로 한다.In another embodiment, the primer for detecting DNA copy number variation at position 10q21.3 is a primer pair for genomic quantitative PCR including DNA sequences of SEQ ID NOs: 3 and 4. It is done.
본 발명의 또 다른 구현예로서, 상기 1q25.1 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 5 내지 8로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 deletion-typing PCR 용 프라이머임을 특징으로 한다.In another embodiment, the primer for detecting DNA copy number variation at position 1q25.1 includes deletion-typing comprising a DNA sequence selected from the group consisting of SEQ ID NOs: 5-8 Characterized in that it is a primer for PCR.
본 발명의 또 다른 구현예로서, 상기 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 9 내지 12로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 deletion-typing PCR 용 프라이머임을 특징으로 한다.As another embodiment of the present invention, The primer for detecting DNA copy number variation at the 10q21.3 position is a primer for deletion-typing PCR including a DNA sequence selected from the group consisting of SEQ ID NOs: 9 to 12.
또한 본 발명은 전신성 홍반성 루푸스(Systemic Lupus Erythematosus) 발병 위험도 예측용 키트로서, 상기 키트는 검체의 염색체상의 C4 위치, 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)를 포함하는 것을 특징으로 하는, 키트를 제공한다. 본 발명의 용어 '키트'는 바이오마커를 포함하고 그 외 각종 전처리에 필요한 물질 및 분석에 필요한 물질 등을 모두 포함하는 구성으로 상용화할 수 있는 세트를 의미한다.In another aspect, the present invention is a kit for predicting the risk of developing Systemic Lupus Erythematosus, wherein the kit is a DNA copy number variation (DNA copy number) at the C4 position, 1q25.1 position and / or 10q21.3 position on the chromosome of the sample. Variation) It provides a kit, characterized in that it comprises a primer (primer) for detection. The term 'kit' of the present invention refers to a set that can be commercialized into a configuration including a biomarker and all other materials necessary for various pretreatment and materials for analysis.
본 발명의 일 구현예로서, 상기 키트는 서열번호 1 내지 12로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 프라이머를 포함하는 것을 특징으로 한다.In one embodiment, the kit is characterized in that it comprises a primer comprising a DNA sequence selected from the group consisting of SEQ ID NO: 1 to 12.
본 발명은 The present invention
A) 검체의 염색체상의 6p21.32 (C4) 위치, 1q25.1 위치 및/또는 10q21.3 위치에 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)를 검체 DNA 시료에 첨가하여 PCR을 수행하는 단계; 및A) PCR was performed by adding a primer for detecting DNA copy number variation to the sample DNA sample at the 6p21.32 (C4), 1q25.1 and / or 10q21.3 positions on the chromosome of the sample. Performing; And
B) 상기 수행된 PCR 결과로부터 검체가 C4 위치, 1q25.1 위치 및/또는 10q21.3 위치에 DNA 복제 수 변이(DNA copy number variation)를 가지고 있는지 여부를 측정하는 단계를 포함하는, 전신성 홍반성 루푸스 발병 위험도를 예측하기 위한 정보를 제공하는 방법을 제공한다.B) determining whether the sample has a DNA copy number variation at the C4, 1q25.1 and / or 10q21.3 positions from the PCR results performed above. It provides a method of providing information for predicting the risk of developing lupus.
본 발명의 일 구현예로서, In one embodiment of the present invention,
상기 A)단계의 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 1 내지 4로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 genomic quantitative PCR 용 프라이머임을 특징으로 한다.Of step A) Primer for detecting DNA copy number variation at position 1q25.1 and / or 10q21.3 is a primer for genomic quantitative PCR comprising a DNA sequence selected from the group consisting of SEQ ID NOs: 1-4. It features.
본 발명의 다른 구현예로서, As another embodiment of the present invention,
상기 A)단계의 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출, 크기측정 및 경계측정용 프라이머(primer)는 서열번호 5 내지 12로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 deletion-typing PCR 용 프라이머임을 특징으로 한다.DNA copy number variation detection, sizing and border primers of the 1q25.1 position and / or 10q21.3 position of step A) is selected from the group consisting of SEQ ID NOs: 5-12 It is characterized in that the primer for deletion-typing PCR containing a DNA sequence.
본 발명의 다른 구현예로서, As another embodiment of the present invention,
상기 방법은 1q25.1 (RABGAP1L), 6p21.32 (C4) 및 10q21.3 세 위치 모두에서 결실이 있는 개체의 경우 (OR=5.52), 세 위치 중 두 위치에서 결실이 있는 경우 (OR=1.78), 세 위치 중 한 위치에서 결실이 있는 경우 (OR=1.43) 및 세 위치 모두에서 결실이 없는 경우 (OR=1) 순서로 전신성 홍반성 루푸스 발병 위험이 높은 것으로 진단하는 것을 특징으로 한다. 결실의 수에 따른 OR은 농도 의존적 증가 양상을 보였다(r2=0.965).The method works for individuals with deletions in all three positions 1q25.1 (RABGAP1L), 6p21.32 (C4) and 10q21.3 (OR = 5.52), and in two of three positions (OR = 1.78). ), The risk of developing systemic lupus erythematosus is diagnosed in the order of deletion in one of the three positions (OR = 1.43) and in the absence of deletion in all three positions (OR = 1). The OR according to the number of deletions showed a concentration-dependent increase (r 2 = 0.965).
본 발명의 조성물은 C4 위치, 1q25.1 위치 및 10q21.3 위치의 복제 수 변이가 전신성 홍반성 루푸스 발병에 시너지 효과를 가짐을 이용하여 발병 위험을 예측 가능하게 하며, 대부분의 병원 검사실에서 보편적으로 행해지고 있는 PCR을 이용함으로써 기기를 새로 구입하거나 기술적 한계로 인해 발생할 수 있는 분석의 오차를 줄일 수 있는 임상친화적 방식이다. 또한 본 발명은 검사 대상자에 비침습적인 방법으로 수행할 수 있는 장점이 있다. 궁극적으로 본 발명은 전신성 홍반성 루푸스 발병 가능성을 조기에 예측하여 상태 악화를 예방하거나 발병을 늦추는 데 중요하게 응용될 수 있을 것으로 기대된다.The compositions of the present invention make it possible to predict the risk of onset by having a replication number variation at the C4, 1q25.1 and 10q21.3 positions having a synergistic effect on the development of systemic lupus erythematosus and is common in most hospital laboratories. The use of PCR is a clinically friendly way to reduce errors in analysis that can occur due to new equipment purchases or technical limitations. In addition, the present invention has the advantage that can be performed in a non-invasive way to the test subject. Ultimately, the present invention is expected to be important for early prediction of the possibility of developing systemic lupus erythematosus and for preventing or slowing the progression of the condition.
도 1은 genome-wide CNV discovery에서 독립적 복제에 이르는 분석 과정을 나타낸 도이다.1 is a diagram illustrating an analysis process ranging from genome-wide CNV discovery to independent replication.
도 2는 극히 적은 수의 CNV가 포함되어 있는 영역은 CNVR로 보지 않음을 표현한 모식도이다.FIG. 2 is a schematic diagram showing that a region containing a very small number of CNVs is not viewed as a CNVR.
도 3은 1q25.1에서의 RABGAP1L CNV의 대립유전자 강도와 qPCR 확인 결과를 나타낸 도이다.Fig. 3 shows the allele intensity and qPCR confirmation results of RABGAP1L CNV at 1q25.1 .
도 4는 1q25.2(RABGAP1L)과 10q21.3의 SLE에 대한 OR을 복제 수별로 나타낸 것으로 이 도에서의 복제 수는 qPCR로 검출된 복제 수를 의미한다. 독립적 복제실험 결과 1q25.1 및 10q21.3 CNV 영역의 결실이 루푸스 리스크와 연관 있는 반면 복제수가 상대적으로 많은 경우는 루푸스 위험이 낮아지는 결과를 나타낸 도이다. 4 shows ORs for SLEs of 1q25.2 (RABGAP1L) and 10q21.3 by the number of copies. In this figure, the number of copies refers to the number of copies detected by qPCR. Independent replication experiments show that the deletions in the 1q25.1 and 10q21.3 CNV regions are associated with lupus risk, whereas those with a relatively high number of copies show a lower lupus risk.
도 5는 결실 타이핑 PCR과 결실-CNVR 경계를 결정한 전략을 나타낸 모식도이다. 하얀 박스는 결실된 영역을 나타낸다. 결실이 있을 것으로 예상되는 부분의 주위 부분(flanking region)의 파란 화살표는 결실을 탐색하기 위한 프라이머 세트를 나타낸다. 결실된 부위 내에 빨간 화살표는 HOM과 HET을 구별하기 위한 세트를 나타낸다. 상단 도는 두 CNVR에 대한 전략모식도이고, 중간 도는 각각의 전략에 따라 실시한 deletion-typing PCR 산물의 전기영동 결과를 나타내며, 하단 도는 DNA 염기서열 분석을 통해 결실 중지점(화살표가 가리키는 부분)을 보여주는 모식도이다. 5 is a schematic diagram showing a strategy for determining deletion typing PCR and deletion-CNVR boundaries. White boxes indicate deleted areas. The blue arrow in the flanking region of the region where the deletion is expected to indicate a primer set to search for the deletion. Red arrows in the deleted sites indicate a set to distinguish between HOM and HET. The upper diagram shows the strategy diagram of two CNVRs, the middle diagram shows the results of electrophoresis of the deletion-typing PCR product according to each strategy, and the lower diagram shows the deletion breakpoint (pointed by arrow) through DNA sequencing. to be.
도 6은 qPCR로 규명된 전체 C4, C4A 및 C4B 유전자에 대한 복제 수 분포를 나타낸 것이다. 검은색 막대는 환자군, 회색 막대는 대조군을 나타낸다.Figure 6 shows the distribution number distribution for the entire C4, C4A and C4B genes identified by qPCR. Black bars represent patient groups and gray bars represent controls.
도 7은 SLE 감수성에 대한 OR의 농도 의존적 경향을 나타낸다. 본 발명자들은 결실의 정도가 클수록 SLE 발병 위험도가 기준보다 높아질 것으로 예상하였다.7 shows the concentration dependent trend of OR for SLE sensitivity. The inventors expected that the greater the degree of deletion, the higher the risk of developing SLE than the criteria.
본 발명자들은 400명의 한국인 SLE 환자와 200명의 건강한 한국인의 genome-wide CNV 프로파일을 SNP array를 이용해 분석함으로써 SLE와 관련된 CNV를 규명하고자 하였다. 이를 위하여, 1단계로 genome-wide CNV 분석을 통해 18,266개의 CNV를 찾았고 이를 바탕으로 2544개의 CNVR을 정의하였으며 이 중 빈도가 5%이상인 144개의 CNVR을 대상으로 연관성 통계분석을 실시하였다. 144개의 common CNVR중에서, 1q25.1, 8q23.3, 10q21.3이 가장 SLE와 관련이 높은 것으로 GWAS 분석 결과 밝혀졌다 (각각 OR=2.28, P=4.4 x 10-3; OR=0.37, P=5.2 x 10-4, OR=1.62, P=0.039).The present inventors attempted to identify CNV related to SLE by analyzing genome-wide CNV profiles of 400 Korean SLE patients and 200 healthy Koreans using SNP arrays. To this end, in the first stage, 18,266 CNVs were found through genome-wide CNV analysis. Based on this, 2544 CNVRs were defined, and correlation analysis was performed on 144 CNVRs with a frequency of 5% or more. Of the 144 common CNVRs, GWAS analysis revealed that 1q25.1, 8q23.3, and 10q21.3 were most relevant to SLE (OR = 2.28, P = 4.4 x 10 -3 ; OR = 0.37, P =, respectively). 5.2 × 10 −4 , OR = 1.62, P = 0.039).
이 3개의 후보 CNVR 구역에 특이적인 프라이머를 디자인하고 1단계의 실험군-대조군 세트보다 더 큰 규모의 독립적 실험군-대조군 세트에 대해 target-specific qPCR을 실시하여 1단계의 결과를 복제한 결과, 1q25.1의 CNV 및 10q21.3의 결실이 성공적으로 복제되었다(각각 OR=1.30, P=0.038; OR=1.90, P=3.6 x 10-5).Designing primers specific for these three candidate CNVR regions and performing target-specific qPCR on a larger set of independent experimental-control groups than the one-step experimental-control set replicated the results of step 1, 1q25. CNV of 1 and deletion of 10q21.3 were replicated successfully (OR = 1.30, P = 0.038; OR = 1.90, P = 3.6 × 10 −5, respectively ).
3개의 후보 CNVR 구역 외에 C4 유전자 구역의 CNVR도 GWAS 발굴 단계에서 SLE와 관련성이 높은 것으로 파악되었기에 qPCR 방식으로 C4에 대한 독립적 검증을 실시한 결과 SLE 발병 위험도가 유의하게 높았다(OR=1.88, P=0.01). 따라서 C4 CNVR도 SLE 발병위험도 예측 모델에 포함시켰다. 그 결과 세 부위 모두에서 결실이 있는 경우 세곳 모두에서 결실이 없는 경우보다 SLE 발병 위험이 현저히 높았다(OR=5.52, P=3.9 x 10-4).In addition to the three candidate CNVR regions, CNVRs in the C4 gene region were found to be highly related to SLE during the GWAS discovery stage. Therefore, the independent verification of C4 using qPCR method showed that the risk of SLE was significantly higher (OR = 1.88, P = 0.01). ). Therefore, C4 CNVR was also included in the SLE risk prediction model. As a result, in all three sites, the risk of developing SLE was significantly higher than in all three sites (OR = 5.52, P = 3.9 x 10 -4 ).
이들의 관계는 결실 타이핑 PCR로 다시 확인하였다. Genomic qPCR방식으로 성공적으로 복제가 확인된 두 해당 CNVR 구역에 대해 직접적으로 결실의 존재 여부, 크기, 경계를 확인할 수 있는 특이적인 프라이머를 디자인하고 이를 이용한 deletion-typing PCR을 수행하여, 결실된 영역의 정확한 크기(1q25.1의 경우 5.2Kb, 10q24.3의 경우 8.3Kb)와 결실 중지점(deletion breakpoint)를 규명하였다. Deletion-typing PCR을 이용한 복제실험에서도 qPCR에서와 마찬가지로 1q25.1 및 10q21.3의 결실과 SLE 위험도간의 연관성이 성공적으로 복제되었다(각각 OR=1.38, P=0.009, OR=1.40, P=0.011).Their relationship was again confirmed by deletion typing PCR. We designed specific primers that can directly identify the presence, size, and boundaries of deletions for two relevant CNVR regions that were successfully cloned by genomic qPCR method, and performed deletion-typing PCR. The exact size (5.2Kb for 1q25.1 and 8.3Kb for 10q24.3) and deletion breakpoints were identified. As with qPCR, the association between deletion of 1q25.1 and 10q21.3 and SLE risk was successfully replicated in replication experiments using deletion-typing PCR (OR = 1.38, P = 0.009, OR = 1.40, P = 0.011, respectively). .
이하, 본 발명의 이해를 돕기 위하여 바람직한 실시예를 제시한다. 그러나 하기의 실시예는 본 발명을 보다 쉽게 이해하기 위하여 제공되는 것일 뿐, 하기 실시예에 의해 본 발명의 내용이 한정되는 것은 아니다.Hereinafter, preferred examples are provided to aid in understanding the present invention. However, the following examples are merely provided to more easily understand the present invention, and the contents of the present invention are not limited by the following examples.
[실시예]EXAMPLE
실시예 1. 연구 대상 및 통계적 분석 방법 Example 1 Study Subject and Statistical Analysis Method
1-1. 연구 대상1-1. Study subject
모든 연구 대상은 한국인 민족으로 구성되었다. All study subjects consisted of Korean ethnic groups.
CNV-GWAS 분석을 위해, 400명의 SLE 환자(전원 여성, 평균 연령 31± 10.0세)를 한양대 병원(대한민국, 서울 소재)의 류머티즘성 질환 부서의 BAE 루푸스 집단으로부터 모집하였다. 이 환자들은 1997 American College of Rheumatology classification criteria에 의해 SLE로 진단된 환자들에 해당한다. 대조군으로, 동일 병원에서 SLE 환자가 아닌 200명의 사람들을 모집하였다(전원 여성, 평균 연령 33± 9.2세). For CNV-GWAS analysis, 400 SLE patients (all women, average age 31 ± 10.0 years) were recruited from the BAE lupus population of the rheumatoid disease department of Hanyang University Hospital (South Korea, Seoul). These patients are those who were diagnosed as SLE by the 1997 American College of Rheumatology classification criteria. As a control group, 200 people who were not SLE patients were recruited from the same hospital (all women, mean age 33 ± 9.2 years).
독립적 복제를 위해서는, 환자 564명과 511명의 대조군(총 1075명)을 동일 병원에서 모집하였다. For independent replication, 564 patients and 511 controls (1075 total) were recruited from the same hospital.
이 연구는 institutional review board(CUMC11U199)의 승인 하에 수행되었다.This study was conducted with the approval of the institutional review board (CUMC11U199).
1-2. 통계적 분석1-2. Statistical analysis
통계적 분석은 Stata software(version 10.0; Stata Corporation, College station, TX)와 SPSS for Windows(version 11.5; SPSS, Chicago, IL)을 이용하여 수행하였다. P value가 0.05 이상인 경우 유의성이 있는 것으로 보았다.Statistical analysis was performed using Stata software (version 10.0; Stata Corporation, College station, TX) and SPSS for Windows (version 11.5; SPSS, Chicago, IL). P value of 0.05 or more was considered significant.
실시예 2. 전체 genome SNP 유전자형(genotype) 분석Example 2 Total Genome SNP Genotype Analysis
Illumina사의 Human 610s Quad-Bead Chip platform(620,901 SNP 마커 포함)을 이용해 전체 genome SNP에 대한 유전자형(genotype) 분석을 수행하였다. 공지된 CNV 당 프로브의 평균 숫자는 37.7이다. 샘플당 약 750ng의 genomic DNA가 유전자형 분석에 사용되었다. 본 발명자들이 사용한 샘플은 99.89± 0.16%의 평균 SNP call rate를 보였다. plate or batch effect를 최소화하기 위해서, 동일한 기간 동안 동일 환경에서 모든 과정을 수행하였다.Genotype analysis of the entire genome SNP was performed using Illumina's Human 610s Quad-Bead Chip platform (including 620,901 SNP markers). The average number of probes per known CNV is 37.7. Approximately 750 ng of genomic DNA per sample was used for genotyping. The sample we used showed an average SNP call rate of 99.89 ± 0.16%. To minimize plate or batch effects, all procedures were performed in the same environment for the same period.
실시예 3. 품질 검증 및 복제 수 변이(CNV) 규명Example 3. Quality Verification and Replication Number Variation (CNV) Identification
Illumina 사의 GenomeStudio software를 이용하여 신호 강도(signal intensity)(log R ratio:LRR)와 대립 유전자 강도(allele intensity)(B 대립유전자 빈도)를 포함하는 실험 데이터를 얻었다. Experimental data including signal intensity (log R ratio (LRR)) and allele intensity (B allele frequency) were obtained using Illumina GenomeStudio software.
3-1. 품질 검증3-1. Quality verification
먼저 이 데이터의 품질을 검증하는 과정을 거쳤다. 성공적인 SNP 추출 비율(SNP call rate)이 90% 미만이거나, LRR 표준 편차가 0.24를 초과하는 경우, B 접합자 빈도 부동(drift)이 0.01을 초과하는 경우, wave factor가 0.05 미만인 경우에 해당 개체들은 실험 결과에서 제외하였다. First, the quality of this data was verified. Subjects were tested if the successful SNP call rate was less than 90%, if the LRR standard deviation was greater than 0.24, if the B conjugate frequency drift was greater than 0.01, and if the wave factor was less than 0.05. Excluded from the results.
3-2. CNV 추출3-2. CNV Extraction
본 발명자들은 신호 강도(signal intensity)(log R ratio:LRR)와 대립 유전자 강도(allele intensity)(B 대립유전자 빈도) 자료를 기초로, PennCNV 알고리즘을 기본 세팅 상태로 사용하여 CNV를 추출했다. We extracted CNV using the PennCNV algorithm as the default setting, based on the signal intensity (log R ratio (LRR)) and allele intensity (B allele frequency) data.
PennCNV 알고리즘은 HMM을 사용하므로 연속적으로 존재하는 CNV(consecutive CNV)의 최소 숫자에 한계값(threshold)이 있지는 않았으나, 이 과정에서 밝혀진 모든 SNP는 3개 이상의 연속적으로 존재하는 SNP(3-1988개에 다다르는 숫자의 SNP가 발견되었다. CNV당 평균 프로브의 개수는 13.42였고, 중앙값은 7이었다)를 포함하고 있었다. 각 CNV의 경계는 첫 SNP 프로브의 선형 위치에서 마지막 프로브(hg18)에 이르는 길이로 결정된다. CNV의 일반적인 특징에 대해서는 하기 표 1에 나타내었다.The PennCNV algorithm uses HMM, so there was no threshold on the minimum number of consecutive CNVs (CVVs), but all of the SNPs found in this process were more than three consecutive SNPs (3-1988). A different number of SNPs were found, with the average number of probes per CNV being 13.42, with a median of 7. The boundary of each CNV is determined by the length from the linear position of the first SNP probe to the last probe (hg18). General characteristics of CNV are shown in Table 1 below.
표 1
Table 1
| Parameters | Case (n=382) | Control(n=191) | Total(n=573) | Mann-WhitneyP-value |
| Total number of CNVs | 12,287 | 5,979 | 18,266 | |
| Avg. CNVs per sample (Median) | 30.8 (30) | 30.2 (30) | 30.6 (30) | 0.906 |
| Gain | 13.4 (11) | 12.0 (11) | 12.9 (11) | 0.153 |
| Loss | 17.9 (17) | 18.3 (18) | 18.0 (18) | 0.096 |
| Avg. of Size (kb) (Median) | 49.2 (20.4) | 54.1 (21.1) | 52.5 (21.0) | 0.012 |
| Gain | 70.1 (30.1) | 71.4 (29.3) | 70.5 (29.8) | 0.107 |
| Loss | 42.4 (13.2) | 34.8 (13.2) | 39.8 (13.2) | 0.548 |
| Ratio (Loss/Gain) | 1.4 | 1.5 | 1.4 |
| Parameters | Case (n = 382) | Control (n = 191) | Total (n = 573) | Mann-WhitneyP-value |
| Total number of CNVs | 12,287 | 5,979 | 18,266 | |
| Avg. CNVs per sample (Median) | 30.8 (30) | 30.2 (30) | 30.6 (30) | 0.906 |
| Gain | 13.4 (11) | 12.0 (11) | 12.9 (11) | 0.153 |
| Los | 17.9 (17) | 18.3 (18) | 18.0 (18) | 0.096 |
| Avg. of Size (kb) (Median) | 49.2 (20.4) | 54.1 (21.1) | 52.5 (21.0) | 0.012 |
| Gain | 70.1 (30.1) | 71.4 (29.3) | 70.5 (29.8) | 0.107 |
| Los | 42.4 (13.2) | 34.8 (13.2) | 39.8 (13.2) | 0.548 |
| Ratio (Loss / Gain) | 1.4 | 1.5 | 1.4 |
각 CNV의 경계(boundaries)는 첫 번째 SNP probe로부터 마지막 SNP 프로브(hg18)까지의 직선 거리로 결정했다.The boundaries of each CNV were determined by the straight line distance from the first SNP probe to the last SNP probe (hg18).
1사분위수(first quartile) -1.5 *IQR < N < 3사분위수(third quartile)+1.5 *IQR 의 공식에 따라 계산하여, 지나치게 적거나 많은 CNV를 포함하는 샘플은 실험 결과에서 제외시켰다. 여기서 N은 각 샘플에서 검출된 CNV의 숫자를 의미하며, IQR은 600명의 연구 대상에서 검출된 CNV 추출 세트로부터 계산된 사분위수 범위(inter-quartile range)를 의미한다. 마지막으로, 총 573개의 샘플(382명의 환자 및 191명의 대조군)을 분석에 포함시켰다. First quartile -1.5 * IQR <N < third quartile +1.5 * Calculated according to the formula, samples containing too little or too many CNV were excluded from the experimental results. Where N is the number of CNVs detected in each sample and IQR is the inter-quartile range calculated from the CNV extraction set detected in 600 subjects. Finally, a total of 573 samples (382 patients and 191 controls) were included in the analysis.
실시예 4. CNV 영역(region) 규명 및 통계적 분석Example 4 CNV Region Identification and Statistical Analysis
본 발명자들은 각 프로브에 대한 CNV 데이터를 만들고 정상(2X), 결실(동형접합 결실=0X; 반접합 결실=1X), 획득(≥3X)으로 구성된 복제 수 상태(status)에 기초해 CNV를 구별했다. 573명의 개체로부터 CNV를 확인하고, Redon et al.에 기재된 방법대로 CNVRuler software를 사용하여 CNV간에 겹치는 부분을 합쳐서 CNV의 일반적인 영역(CNV region, CNVR)을 규명하였다. 이 방법은 직접적으로 CNVR을 규명할 수 있다는 장점이 있으나, CNVR에 포함된 CNV 중 크기가 특별히 큰 CNV가 있는 경우에 CNVR의 크기가 실제보다 크게 산출될 수 있다는 단점이 있다. 또한 모든 CNV 추출이 포함된 경우라도, CNVR의 빈도가 싱글턴(singleton)이나 극히 드문 CNV가 포함되어 있다면 CNVR의 크기가 실제보다 크게 산출될 수 있다(도 2 참조). 이러한 가능성을 최소화하기 위해서, 극히 적은 수의 CNV(전체 CNV의 10%미만)가 포함되어 있는 영역은 CNVR로 보지 않았다. We generate CNV data for each probe and distinguish CNVs based on the number of replicates consisting of normal (2X), deletion (homozygous deletion = 0X; semijunction deletion = 1X), acquisition (≥3X). did. CNV was identified from 573 individuals and the CNV region (CNVR) was identified by combining the overlapping parts between CNVs using CNVRuler software as described in Redon et al. This method has the advantage of directly identifying the CNVR, but has the disadvantage that the size of the CNVR can be calculated larger than the actual one when there is a particularly large CNV among the CNVs included in the CNVR. In addition, even if all CNV extractions are included, if the frequency of the CNVR includes a singleton or a very rare CNV, the size of the CNVR may be larger than the actual size (see FIG. 2). To minimize this possibility, areas containing only a small number of CNVs (less than 10% of the total CNVs) were not viewed as CNVRs.
총 18,266 CNV를 573개의 샘플에서 규명하였다. 개인의 CNV 수의 중간값은 30(1~285의 범위)이었고, CNV의 중간 크기는 21.0kb(14bp~18Mbp의 범위)였다. copy number-loss CNV는 copy number-gain CNV보다 1.4배 더 빈도가 높게 나타났다.A total of 18,266 CNVs were identified in 573 samples. The median CNV number for an individual was 30 (range of 1-285) and the median size of CNV was 21.0 kb (range 14 bp-18 Mbp). Copy number-loss CNV was 1.4 times more frequent than copy number-gain CNV.
18,266개의 CNV로부터 2,544개의 CNVR을 규명하였다. 그 중 144 CNVR이 5% 이상의 개체들에서 나타났다.2,544 CNVRs were identified from 18,266 CNVs. Of those, 144 CNVR were present in over 5% of the individuals.
하기 표 2에는 5% 이상의 개체에서 발견된 144 개의 CNVR을 나타내었다.Table 2 below shows 144 CNVRs found in 5% or more individuals.
표 2
TABLE 2
| CNVR | Chr | Start(bp) | End(bp) | Length (Kb) | G/L | RefSeq gene annotation |
| cnve1 | 1 | 1,610,720 | 1,626,497 | 15.7 | G/L | MMP23A, CDK11B, CDK11A |
| cnve2 | 1 | 12,777,429 | 12,841,261 | 63.8 | G/L | PRAMEF11, LOC649330, HNRNPCL1, PRAMEF2 |
| cnve3 | 1 | 17,085,956 | 17,140,083 | 54.1 | G/L | CROCC |
| cnve4 | 1 | 76,124,315 | 76,124,567 | 0.25 | G/L | MSH4 |
| cnve5 | 1 | 147,292,384 | 147,637,598 | 345.2 | G/L | LOC388692, FCGR1C |
| cnve6 | 1 | 173064490 | 173068262 | 3.7 | G/L | RABGAP1L |
| cnve7 | 1 | 246,837,884 | 246,852,068 | 14.,1 | G/L | - |
| cnve8 | 2 | 24,456,463 | 24,459,556 | 3.1 | L | - |
| cnve9 | 2 | 36,263,684 | 36,264,490 | 0.8 | G/L | - |
| cnve10 | 2 | 41,092,148 | 41,101,972 | 9.8 | G/L | - |
| cnve11 | 2 | 52,613,957 | 52,637,176 | 23.2 | G/L | - |
| cnve12 | 2 | 89731562 | 89885025 | 153.4 | G/L | - |
| cnve13 | 2 | 132,485,521 | 132,588,945 | 103.4 | G/L | - |
| cnve14 | 3 | 1,652,400 | 1,666,090 | 13.7 | L | - |
| cnve15 | 3 | 37,954,886 | 37,961,253 | 6.4 | L | CTDSPL |
| cnve16 | 3 | 53,003,023 | 53,013,826 | 10.8 | L | SFMBT1 |
| cnve17 | 3 | 65,166,887 | 65,187,636 | 20.8 | L | - |
| cnve18 | 3 | 90,421,209 | 90,576,572 | 155.4 | G/L | - |
| cnve19 | 3 | 150,446,085 | 150,450,025 | 3.9 | L | - |
| cnve20 | 3 | 163,699,360 | 163,712,278 | 12.9 | G/L | - |
| cnve21 | 3 | 164,004,033 | 164,101,579 | 97.5 | G/L | - |
| cnve22 | 3 | 191,220,845 | 191,221,750 | 0.9 | G/L | LEPREL1 |
| cnve23 | 4 | 8,980,214 | 9,097,760 | 117.5 | G/L | DEFB131, LOC650293 |
| cnve24 | 4 | 10,006,425 | 10,009,254 | 2.8 | L | - |
| cnve25 | 4 | 20,982,707 | 20,984,915 | 2.2 | L | KCNIP4 |
| cnve26 | 4 | 34,469,747 | 34,499,424 | 29.7 | L | - |
| cnve27 | 4 | 58,417,022 | 58,418,605 | 1.6 | G/L | - |
| cnve28 | 4 | 63,352,170 | 63,367,714 | 15.5 | G/L | - |
| cnve29 | 4 | 64,380,191 | 64,392,223 | 12 | G/L | - |
| cnve30 | 4 | 69,064,675 | 69,163,188 | 98.5 | G/L | UGT2B17 |
| cnve31 | 4 | 70,164,518 | 70,257,471 | 92.9 | G/L | UGT2B28 |
| cnve32 | 4 | 115,398,433 | 115,401,739 | 3.3 | G/L | - |
| cnve33 | 4 | 116,387,607 | 116,393,377 | 5.8 | L | - |
| cnve34 | 4 | 122,504,713 | 122,508,095 | 3.4 | L | QRFPR |
| cnve35 | 4 | 138,312,400 | 138,316,899 | 4.5 | L | - |
| cnve36 | 4 | 162,083,343 | 162,146,977 | 63.6 | G/L | - |
| cnve37 | 5 | 783,022 | 873,185 | 90.2 | G/L | ZDHHC11 |
| cnve38 | 5 | 27,462,485 | 27,462,654 | 0.17 | G/L | - |
| cnve39 | 5 | 32,142,841 | 32,202,977 | 60.1 | G | PDZD2, GOLPH3 |
| cnve40 | 5 | 70,210,770 | 70,415,222 | 204.4 | G/L | GTF2H2, GTF2H2B, GTF2H2D, GTF2H2C, SERF1B, SERF1A, SMN1, SMN2, NAIP, OCLN , LOC647859 |
| cnve41 | 5 | 151,495,149 | 151,499,003 | 3.9 | L | - |
| cnve42 | 5 | 180,327,250 | 180,363,775 | 36.5 | G/L | BTNL3 |
| cnve43 | 6 | 219,847 | 306,547 | 86.7 | G/L | DUSP22 |
| cnve44 | 6 | 29,965,065 | 30,003,207 | 38.1 | G/L | HCG2P7, HCG4P6, HLA-H |
| cnve45 | 6 | 31388080 | 31406722 | 18.6 | G/L | - |
| cnve46 | 6 | 31,445,794 | 31,449,319 | 3.5 | G/L | - |
| cnve47 | 6 | 31,465,370 | 31,561,597 | 96.2 | G/L | MICA, HCP5, HCG26, MICA |
| cnve48 | 6 | 31,979,464 | 31,986,474 | 7 | L | C2 |
| cnve49 | 6 | 32058245 | 32110823 | 52.6 | G/L | STK19, STK19, TNXA, C4A, C4B |
| cnve50 | 6 | 32,563,460 | 32,600,286 | 36.8 | G/L | HLA-DRB5 |
| cnve51 | 6 | 32,608,853 | 32,629,229 | 20.4 | G/L | HLA-DRB6 |
| cnve52 | 6 | 32,630,503 | 32,666,924 | 36.4 | G/L | HLA-DRB1, HLA-DRB6 |
| cnve53 | 6 | 32,672,677 | 32,672,762 | 0.086 | G/L | - |
| cnve54 | 6 | 32,746,293 | 32,756,221 | 9.9 | G/L | - |
| cnve55 | 6 | 57,482,074 | 57,503,129 | 21.1 | G | PRIM2 |
| cnve56 | 6 | 62,241,860 | 62,281,216 | 39.4 | G/L | - |
| cnve57 | 6 | 77,074,879 | 77,081,385 | 6.5 | L | - |
| cnve58 | 6 | 79,029,649 | 79,090,197 | 60.5 | L | - |
| cnve59 | 6 | 81,341,226 | 81,346,109 | 4.9 | G/L | - |
| cnve60 | 6 | 162,655,871 | 162,659,755 | 3.9 | G/L | PARK2 |
| cnve61 | 6 | 169,248,365 | 169,262,485 | 14.1 | L | - |
| cnve62 | 6 | 170,222,030 | 170,223,555 | 1.5 | G/L | - |
| cnve63 | 7 | 136,005 | 164,003 | 27.9 | G/L | - |
| cnve64 | 7 | 61,256,909 | 61,311,414 | 54.5 | G/L | - |
| cnve65 | 7 | 101,931,221 | 102,109,692 | 178.5 | G/L | POLR2J3, SPDYE2, SPDYE2L, POLR2J2, UPK3BL, RASA4 |
| cnve66 | 7 | 141,419,097 | 141,441,259 | 22.2 | G/L | MGAM |
| cnve67 | 8 | 3,773,951 | 3,777,675 | 3.7 | G/L | CSMD1 |
| cnve68 | 8 | 5,583,199 | 5,592,495 | 9.3 | G/L | - |
| cnve69 | 8 | 7,242,915 | 7,459,302 | 216.4 | G/L | DEFB families, |
| cnve70 | 8 | 7,683,445 | 7,830,417 | 146.9 | G/L | DEFB families |
| cnve71 | 8 | 12,570,457 | 12,603,846 | 33.4 | G/L | - |
| cnve72 | 8 | 15,447,307 | 15,455,979 | 8.7 | L | TUSC3 |
| cnve73 | 8 | 25,129,632 | 25,130,278 | 0.64 | G/L | DOCK5 |
| cnve74 | 8 | 39,356,825 | 39,497,557 | 140.7 | G/L | ADAM3A , ADAM5P |
| cnve75 | 8 | 115704806 | 115711712 | 6.9 | G/L | - |
| cnve76 | 9 | 4,516,796 | 4,519,671 | 2.9 | L | SLC1A1 |
| cnve77 | 9 | 11,398,647 | 11,398,865 | 0.22 | G/L | - |
| cnve78 | 9 | 11,786,468 | 12,110,085 | 323.6 | L | - |
| cnve79 | 9 | 43,515,795 | 43,730,292 | 214.5 | G/L | FAM75A6 |
| cnve80 | 9 | 44,708,655 | 44,779,627 | 70.9 | G/L | - |
| cnve81 | 9 | 45,757,243 | 45,837,067 | 79.8 | G/L | - |
| cnve82 | 9 | 66,345,398 | 66,759,835 | 414.4 | G/L | LOC100133920 |
| cnve83 | 9 | 140,149,899 | 140,225,046 | 75.1 | G | TUBBP5 |
| cnve84 | 10 | 38,740,240 | 38,953,282 | 213 | G/L | LOC399744 |
| cnve85 | 10 | 41679826 | 41702521 | 22.7 | G/L | - |
| cnve86 | 10 | 58,575,075 | 58,606,559 | 31.5 | L | - |
| cnve87 | 10 | 66980652 | 66983043 | 2.4 | G/L | - |
| cnve88 | 10 | 81,478,475 | 81,492,542 | 14.1 | G/L | - |
| cnve89 | 11 | 4,217,831 | 4,333,781 | 115.9 | G/L | - |
| cnve90 | 11 | 5,856,461 | 5,891,679 | 35.2 | G | OR52E4 |
| cnve91 | 11 | 48,689,789 | 48,868,236 | 178.4 | G/L | - |
| cnve92 | 11 | 48,886,497 | 48,918,267 | 31.8 | G/L | - |
| cnve93 | 11 | 50,470,172 | 50,687,058 | 216.9 | G/L | - |
| cnve94 | 11 | 54,649,547 | 54,738,983 | 89.4 | G/L | - |
| cnve95 | 11 | 55,124,465 | 55,209,499 | 85 | G/L | OR4S2, OR4P4, OR4C11, OR4C6 |
| cnve96 | 11 | 99,152,896 | 99,160,002 | 7.1 | L | CNTN5 |
| cnve97 | 12 | 9,526,879 | 9,607,393 | 80.5 | G/L | - |
| cnve98 | 12 | 11,398,341 | 11,438,799 | 40.5 | G/L | PRB1, PRB2 |
| cnve99 | 12 | 31,202,075 | 31,237,140 | 35.1 | G/L | - |
| cnve100 | 12 | 33,192,424 | 33,197,122 | 4.7 | L | - |
| cnve101 | 12 | 36,270,798 | 36,667,312 | 396.5 | G/L | - |
| cnve102 | 13 | 18,209,780 | 18,299,097 | 89.3 | G/L | - |
| cnve103 | 13 | 49,238,624 | 49,271,799 | 33.2 | G/L | KPNA3 |
| cnve104 | 13 | 56,648,172 | 56,722,157 | 73.9 | G/L | - |
| cnve105 | 14 | 18,312,221 | 18,373,017 | 60.8 | G/L | - |
| cnve106 | 14 | 19,255,839 | 19,493,705 | 237.9 | G/L | OR4Q3, OR4M1, OR4N2, OR4K2, OR4K1, OR4K5 |
| cnve107 | 14 | 40,679,974 | 40,738,084 | 58.1 | L | - |
| cnve108 | 14 | 43,574,960 | 43,600,472 | 25.5 | L | - |
| cnve109 | 14 | 105,099,614 | 105,259,090 | 159.5 | G/L | - |
| cnve110 | 15 | 18,822,301 | 18,883,654 | 61.3 | G/L | HERC2P3 |
| cnve111 | 15 | 19,095,051 | 19,545,168 | 450.1 | G/L | NF1P1, BCL8, LOC646214, POTEB, CXADRP2 |
| cnve112 | 15 | 19,768,826 | 20,093,116 | 324.3 | G/L | LOC727924, REREP3, OR4N3P, OR4N4, OR4M2 |
| cnve113 | 15 | 22,134,751 | 22,284,089 | 149.3 | G/L | - |
| cnve114 | 15 | 30,272,117 | 30,302,218 | 30.1 | G/L | - |
| cnve115 | 15 | 32,459,510 | 32,595,161 | 135.7 | G/L | MIR1233-1, MIR1233-2, GOLGA8A |
| cnve116 | 15 | 54,579,805 | 54,582,930 | 3.1 | L | - |
| cnve117 | 16 | 16,519,474 | 16,713,816 | 194.3 | G/L | - |
| cnve118 | 16 | 22,538,900 | 22,617,264 | 78.4 | G/L | - |
| cnve119 | 16 | 27,147,411 | 27,147,520 | 0.11 | G/L | NSMCE1 |
| cnve120 | 16 | 32,404,517 | 32,511,911 | 107.4 | G/L | - |
| cnve121 | 16 | 33,778,130 | 33,820,307 | 42.2 | G/L | - |
| cnve122 | 16 | 54,390,068 | 54,420,550 | 30.5 | G/L | CES1 |
| cnve123 | 16 | 68,715,069 | 68,753,813 | 38.7 | G | PDPR |
| cnve124 | 17 | 14,984,724 | 14,998,961 | 14.2 | G/L | - |
| cnve125 | 17 | 31,462,326 | 31,567,477 | 105.2 | G/L | CCL3L1, CCL4L1, CCL4L2, CCL3L3, TBC1D3B |
| cnve126 | 17 | 41,780,482 | 41,922,658 | 142.2 | G/L | NSFP1, ARL17B |
| cnve127 | 18 | 14,170,547 | 14,271,864 | 101.3 | G/L | - |
| cnve128 | 18 | 64,897,188 | 64,906,488 | 9.3 | G/L | - |
| cnve129 | 19 | 20,404,485 | 20,507,068 | 102.6 | L | - |
| cnve130 | 19 | 32,470,668 | 32,730,547 | 259.9 | G/L | - |
| cnve131 | 19 | 33,903,241 | 33,903,289 | 0.05 | G/L | - |
| cnve132 | 19 | 46,041,879 | 46,064,315 | 22.4 | G/L | CYP2A6 |
| cnve133 | 19 | 47,997,996 | 48,235,556 | 237.6 | G/L | PSG6, PSG1, LOC100289650, PSG10, PSG7, PSG11 |
| cnve134 | 19 | 58,023,726 | 58,050,701 | 26.9 | G/L | ZNF468 |
| cnve135 | 20 | 26,235,048 | 28,107,200 | 1,872 | G/L | - |
| cnve136 | 21 | 9,730,102 | 9,870,617 | 140.5 | G/L | - |
| cnve137 | 22 | 22,619,365 | 22,728,586 | 109.2 | G/L | GSTTP1, DDTL, GSTT2B, DDT, GSTT2, LOC391322, GSTT1, GSTTP2 |
| cnve138 | 22 | 49,129,839 | 49,130,879 | 1 | G/L | PPP6R2 |
| cnve139 | X | 16,305,623 | 16,306,395 | 0.8 | G/L | - |
| cnve140 | X | 58406597 | 58580762 | 174.2 | G/L | - |
| cnve141 | X | 61660428 | 61815821 | 155.4 | G/L | - |
| cnve142 | X | 93,289,757 | 93,290,555 | 0.8 | G/L | - |
| cnve143 | X | 110,851,010 | 110,851,339 | 0.33 | G/L | ALG13 |
| cnve144 | X | 145712954 | 145717285 | 4.3 | G/L | - |
| CNVR | Chr | Start (bp) | End (bp) | Length (Kb) | G / L | RefSeq gene annotation |
| cnve1 | One | 1,610,720 | 1,626,497 | 15.7 | G / L | MMP23A, CDK11B, CDK11A |
| cnve2 | One | 12,777,429 | 12,841,261 | 63.8 | G / L | PRAMEF11, LOC649330, HNRNPCL1, PRAMEF2 |
| cnve3 | One | 17,085,956 | 17,140,083 | 54.1 | G / L | CROCC |
| cnve4 | One | 76,124,315 | 76,124,567 | 0.25 | G / L | MSH4 |
| cnve5 | One | 147,292,384 | 147,637,598 | 345.2 | G / L | LOC388692, FCGR1C |
| cnve6 | One | 173064490 | 173068262 | 3.7 | G / L | RABGAP1L |
| cnve7 | One | 246,837,884 | 246,852,068 | 14., 1 | G / L | - |
| cnve8 | 2 | 24,456,463 | 24,459,556 | 3.1 | L | - |
| cnve9 | 2 | 36,263,684 | 36,264,490 | 0.8 | G / L | - |
| cnve10 | 2 | 41,092,148 | 41,101,972 | 9.8 | G / L | - |
| cnve11 | 2 | 52,613,957 | 52,637,176 | 23.2 | G / L | - |
| cnve12 | 2 | 89731562 | 89885025 | 153.4 | G / L | - |
| cnve13 | 2 | 132,485,521 | 132,588,945 | 103.4 | G / L | - |
| cnve14 | 3 | 1,652,400 | 1,666,090 | 13.7 | L | - |
| cnve15 | 3 | 37,954,886 | 37,961,253 | 6.4 | L | CTDSPL |
| cnve16 | 3 | 53,003,023 | 53,013,826 | 10.8 | L | SFMBT1 |
| cnve17 | 3 | 65,166,887 | 65,187,636 | 20.8 | L | - |
| cnve18 | 3 | 90,421,209 | 90,576,572 | 155.4 | G / L | - |
| cnve19 | 3 | 150,446,085 | 150,450,025 | 3.9 | L | - |
| cnve20 | 3 | 163,699,360 | 163,712,278 | 12.9 | G / L | - |
| cnve21 | 3 | 164,004,033 | 164,101,579 | 97.5 | G / L | - |
| cnve22 | 3 | 191,220,845 | 191,221,750 | 0.9 | G / L | LEPREL1 |
| cnve23 | 4 | 8,980,214 | 9,097,760 | 117.5 | G / L | DEFB131, LOC650293 |
| cnve24 | 4 | 10,006,425 | 10,009,254 | 2.8 | L | - |
| cnve25 | 4 | 20,982,707 | 20,984,915 | 2.2 | L | KCNIP4 |
| cnve26 | 4 | 34,469,747 | 34,499,424 | 29.7 | L | - |
| cnve27 | 4 | 58,417,022 | 58,418,605 | 1.6 | G / L | - |
| cnve28 | 4 | 63,352,170 | 63,367,714 | 15.5 | G / L | - |
| cnve29 | 4 | 64,380,191 | 64,392,223 | 12 | G / L | - |
| cnve30 | 4 | 69,064,675 | 69,163,188 | 98.5 | G / L | UGT2B17 |
| cnve31 | 4 | 70,164,518 | 70,257,471 | 92.9 | G / L | UGT2B28 |
| cnve32 | 4 | 115,398,433 | 115,401,739 | 3.3 | G / L | - |
| cnve33 | 4 | 116,387,607 | 116,393,377 | 5.8 | L | - |
| cnve34 | 4 | 122,504,713 | 122,508,095 | 3.4 | L | QRFPR |
| cnve35 | 4 | 138,312,400 | 138,316,899 | 4.5 | L | - |
| cnve36 | 4 | 162,083,343 | 162,146,977 | 63.6 | G / L | - |
| cnve37 | 5 | 783,022 | 873,185 | 90.2 | G / L | ZDHHC11 |
| cnve38 | 5 | 27,462,485 | 27,462,654 | 0.17 | G / L | - |
| cnve39 | 5 | 32,142,841 | 32,202,977 | 60.1 | G | PDZD2, GOLPH3 |
| cnve40 | 5 | 70,210,770 | 70,415,222 | 204.4 | G / L | GTF2H2, GTF2H2B, GTF2H2D, GTF2H2C, SERF1B, SERF1A, SMN1, SMN2, NAIP, OCLN, LOC647859 |
| cnve41 | 5 | 151,495,149 | 151,499,003 | 3.9 | L | - |
| cnve42 | 5 | 180,327,250 | 180,363,775 | 36.5 | G / L | BTNL3 |
| cnve43 | 6 | 219,847 | 306,547 | 86.7 | G / L | DUSP22 |
| cnve44 | 6 | 29,965,065 | 30,003,207 | 38.1 | G / L | HCG2P7, HCG4P6, HLA-H |
| cnve45 | 6 | 31388080 | 31406722 | 18.6 | G / L | - |
| cnve46 | 6 | 31,445,794 | 31,449,319 | 3.5 | G / L | - |
| cnve47 | 6 | 31,465,370 | 31,561,597 | 96.2 | G / L | MICA, HCP5, HCG26, MICA |
| cnve48 | 6 | 31,979,464 | 31,986,474 | 7 | L | C2 |
| cnve49 | 6 | 32058245 | 32110823 | 52.6 | G / L | STK19, STK19, TNXA, C4A, C4B |
| cnve50 | 6 | 32,563,460 | 32,600,286 | 36.8 | G / L | HLA-DRB5 |
| cnve51 | 6 | 32,608,853 | 32,629,229 | 20.4 | G / L | HLA-DRB6 |
| cnve52 | 6 | 32,630,503 | 32,666,924 | 36.4 | G / L | HLA-DRB1, HLA-DRB6 |
| cnve53 | 6 | 32,672,677 | 32,672,762 | 0.086 | G / L | - |
| cnve54 | 6 | 32,746,293 | 32,756,221 | 9.9 | G / L | - |
| cnve55 | 6 | 57,482,074 | 57,503,129 | 21.1 | G | PRIM2 |
| cnve56 | 6 | 62,241,860 | 62,281,216 | 39.4 | G / L | - |
| cnve57 | 6 | 77,074,879 | 77,081,385 | 6.5 | L | - |
| cnve58 | 6 | 79,029,649 | 79,090,197 | 60.5 | L | - |
| cnve59 | 6 | 81,341,226 | 81,346,109 | 4.9 | G / L | - |
| cnve60 | 6 | 162,655,871 | 162,659,755 | 3.9 | G / L | PARK2 |
| cnve61 | 6 | 169,248,365 | 169,262,485 | 14.1 | L | - |
| cnve62 | 6 | 170,222,030 | 170,223,555 | 1.5 | G / L | - |
| cnve63 | 7 | 136,005 | 164,003 | 27.9 | G / L | - |
| cnve64 | 7 | 61,256,909 | 61,311,414 | 54.5 | G / L | - |
| cnve65 | 7 | 101,931,221 | 102,109,692 | 178.5 | G / L | POLR2J3, SPDYE2, SPDYE2L, POLR2J2, UPK3BL, RASA4 |
| cnve66 | 7 | 141,419,097 | 141,441,259 | 22.2 | G / L | MGAM |
| cnve67 | 8 | 3,773,951 | 3,777,675 | 3.7 | G / L | CSMD1 |
| cnve68 | 8 | 5,583,199 | 5,592,495 | 9.3 | G / L | - |
| cnve69 | 8 | 7,242,915 | 7,459,302 | 216.4 | G / L | DEFB families, |
| cnve70 | 8 | 7,683,445 | 7,830,417 | 146.9 | G / L | DEFB families |
| cnve71 | 8 | 12,570,457 | 12,603,846 | 33.4 | G / L | - |
| cnve72 | 8 | 15,447,307 | 15,455,979 | 8.7 | L | TUSC3 |
| cnve73 | 8 | 25,129,632 | 25,130,278 | 0.64 | G / L | DOCK5 |
| cnve74 | 8 | 39,356,825 | 39,497,557 | 140.7 | G / L | ADAM3A, ADAM5P |
| cnve75 | 8 | 115704806 | 115711712 | 6.9 | G / L | - |
| cnve76 | 9 | 4,516,796 | 4,519,671 | 2.9 | L | SLC1A1 |
| cnve77 | 9 | 11,398,647 | 11,398,865 | 0.22 | G / L | - |
| cnve78 | 9 | 11,786,468 | 12,110,085 | 323.6 | L | - |
| cnve79 | 9 | 43,515,795 | 43,730,292 | 214.5 | G / L | FAM75A6 |
| cnve80 | 9 | 44,708,655 | 44,779,627 | 70.9 | G / L | - |
| cnve81 | 9 | 45,757,243 | 45,837,067 | 79.8 | G / L | - |
| cnve82 | 9 | 66,345,398 | 66,759,835 | 414.4 | G / L | LOC100133920 |
| cnve83 | 9 | 140,149,899 | 140,225,046 | 75.1 | G | TUBBP5 |
| cnve84 | 10 | 38,740,240 | 38,953,282 | 213 | G / L | LOC399744 |
| cnve85 | 10 | 41679826 | 41702521 | 22.7 | G / L | - |
| cnve86 | 10 | 58,575,075 | 58,606,559 | 31.5 | L | - |
| cnve87 | 10 | 66980652 | 66983043 | 2.4 | G / L | - |
| cnve88 | 10 | 81,478,475 | 81,492,542 | 14.1 | G / L | - |
| cnve89 | 11 | 4,217,831 | 4,333,781 | 115.9 | G / L | - |
| cnve90 | 11 | 5,856,461 | 5,891,679 | 35.2 | G | OR52E4 |
| cnve91 | 11 | 48,689,789 | 48,868,236 | 178.4 | G / L | - |
| cnve92 | 11 | 48,886,497 | 48,918,267 | 31.8 | G / L | - |
| cnve93 | 11 | 50,470,172 | 50,687,058 | 216.9 | G / L | - |
| cnve94 | 11 | 54,649,547 | 54,738,983 | 89.4 | G / L | - |
| cnve95 | 11 | 55,124,465 | 55,209,499 | 85 | G / L | OR4S2, OR4P4, OR4C11, OR4C6 |
| cnve96 | 11 | 99,152,896 | 99,160,002 | 7.1 | L | CNTN5 |
| cnve97 | 12 | 9,526,879 | 9,607,393 | 80.5 | G / L | - |
| cnve98 | 12 | 11,398,341 | 11,438,799 | 40.5 | G / L | PRB1, PRB2 |
| cnve99 | 12 | 31,202,075 | 31,237,140 | 35.1 | G / L | - |
| cnve100 | 12 | 33,192,424 | 33,197,122 | 4.7 | L | - |
| cnve101 | 12 | 36,270,798 | 36,667,312 | 396.5 | G / L | - |
| cnve102 | 13 | 18,209,780 | 18,299,097 | 89.3 | G / L | - |
| cnve103 | 13 | 49,238,624 | 49,271,799 | 33.2 | G / L | KPNA3 |
| cnve104 | 13 | 56,648,172 | 56,722,157 | 73.9 | G / L | - |
| cnve105 | 14 | 18,312,221 | 18,373,017 | 60.8 | G / L | - |
| cnve106 | 14 | 19,255,839 | 19,493,705 | 237.9 | G / L | OR4Q3, OR4M1, OR4N2, OR4K2, OR4K1, OR4K5 |
| cnve107 | 14 | 40,679,974 | 40,738,084 | 58.1 | L | - |
| cnve108 | 14 | 43,574,960 | 43,600,472 | 25.5 | L | - |
| cnve109 | 14 | 105,099,614 | 105,259,090 | 159.5 | G / L | - |
| cnve110 | 15 | 18,822,301 | 18,883,654 | 61.3 | G / L | HERC2P3 |
| cnve111 | 15 | 19,095,051 | 19,545,168 | 450.1 | G / L | NF1P1, BCL8, LOC646214, POTEB, CXADRP2 |
| cnve112 | 15 | 19,768,826 | 20,093,116 | 324.3 | G / L | LOC727924, REREP3, OR4N3P, OR4N4, OR4M2 |
| cnve113 | 15 | 22,134,751 | 22,284,089 | 149.3 | G / L | - |
| cnve114 | 15 | 30,272,117 | 30,302,218 | 30.1 | G / L | - |
| cnve115 | 15 | 32,459,510 | 32,595,161 | 135.7 | G / L | MIR1233-1, MIR1233-2, GOLGA8A |
| cnve116 | 15 | 54,579,805 | 54,582,930 | 3.1 | L | - |
| cnve117 | 16 | 16,519,474 | 16,713,816 | 194.3 | G / L | - |
| cnve118 | 16 | 22,538,900 | 22,617,264 | 78.4 | G / L | - |
| cnve119 | 16 | 27,147,411 | 27,147,520 | 0.11 | G / L | NSMCE1 |
| cnve120 | 16 | 32,404,517 | 32,511,911 | 107.4 | G / L | - |
| cnve121 | 16 | 33,778,130 | 33,820,307 | 42.2 | G / L | - |
| cnve122 | 16 | 54,390,068 | 54,420,550 | 30.5 | G / L | CES1 |
| cnve123 | 16 | 68,715,069 | 68,753,813 | 38.7 | G | PDPR |
| cnve124 | 17 | 14,984,724 | 14,998,961 | 14.2 | G / L | - |
| cnve125 | 17 | 31,462,326 | 31,567,477 | 105.2 | G / L | CCL3L1, CCL4L1, CCL4L2, CCL3L3, TBC1D3B |
| cnve126 | 17 | 41,780,482 | 41,922,658 | 142.2 | G / L | NSFP1, ARL17B |
| cnve127 | 18 | 14,170,547 | 14,271,864 | 101.3 | G / L | - |
| cnve128 | 18 | 64,897,188 | 64,906,488 | 9.3 | G / L | - |
| cnve129 | 19 | 20,404,485 | 20,507,068 | 102.6 | L | - |
| cnve130 | 19 | 32,470,668 | 32,730,547 | 259.9 | G / L | - |
| cnve131 | 19 | 33,903,241 | 33,903,289 | 0.05 | G / L | - |
| cnve132 | 19 | 46,041,879 | 46,064,315 | 22.4 | G / L | CYP2A6 |
| cnve133 | 19 | 47,997,996 | 48,235,556 | 237.6 | G / L | PSG6, PSG1, LOC100289650, PSG10, PSG7, PSG11 |
| cnve134 | 19 | 58,023,726 | 58,050,701 | 26.9 | G / L | ZNF468 |
| cnve135 | 20 | 26,235,048 | 28,107,200 | 1,872 | G / L | - |
| cnve136 | 21 | 9,730,102 | 9,870,617 | 140.5 | G / L | - |
| cnve137 | 22 | 22,619,365 | 22,728,586 | 109.2 | G / L | GSTTP1, DDTL, GSTT2B, DDT, GSTT2, LOC391322, GSTT1, GSTTP2 |
| cnve138 | 22 | 49,129,839 | 49,130,879 | One | G / L | PPP6R2 |
| cnve139 | X | 16,305,623 | 16,306,395 | 0.8 | G / L | - |
| cnve140 | X | 58406597 | 58580762 | 174.2 | G / L | - |
| cnve141 | X | 61660428 | 61815821 | 155.4 | G / L | - |
| cnve142 | X | 93,289,757 | 93,290,555 | 0.8 | G / L | - |
| cnve143 | X | 110,851,010 | 110,851,339 | 0.33 | G / L | ALG13 |
| cnve144 | X | 145712954 | 145717285 | 4.3 | G / L | - |
이 144개의 CNVR을 이용하여, 로지스틱 회귀 분석을 수행하였다. 이를 통해 연령대 및 실험군별 차이에 따라 실험 결과가 다르게 나타나는 것을 방지하였다. T 다중 비교의 문제를 해결하기 위해 false discovery rate(FDR) 방법을 사용하였다. P<0.05, FDR<0.1인 CNVR은 유의성 있는 것으로 보았다. 그 결과 SLE 발병 위험과 가장 관련성이 높은 1q25.1, 8q23.3, 10q21에서의 3개의 CNVR을 발견하였다. 이에 대해서는 하기 표 3에 나타내었다. Using these 144 CNVRs, logistic regression analysis was performed. This prevented the experimental results from appearing differently according to age groups and experimental groups. To solve the problem of T multiple comparison, a false discovery rate (FDR) method was used. CNVRs with P <0.05 and FDR <0.1 were considered significant. As a result, we found three CNVRs at 1q25.1, 8q23.3, and 10q21 that were most relevant to the risk of SLE. This is shown in Table 3 below.
표 3
TABLE 3
| CNVRLocation | Start* (bp) | End* (bp) | Length (kb) | Type | Genes | GWAS Discovery1 (382 cases vs 191controls) | Replication2 (564 cases vs 511controls) | Replication3 (564 cases vs 495controls) | ||||||
| P | FDR | OR (95% CI) | P | FDR | OR (95% CI) | P | FDR | OR (95% CI) | ||||||
| 1q25.1 | 173,06.490 | 173,068.26 | 3.8 | Loss | RABGAP1L | 4.40E-03 | 0.024 | 2.28 (1.29-4.01) | 0.038 | 0.057 | 1.30 (1.02-1.67) | 0.009 | 0.011 | 1.38 (1.08-1.77) |
| 8q23.3 | 115,704.81 | 115,711.71 | 6.9 | Loss | - | 5.20E-04 | 0.044 | 0.37 (0.21-0.65) | 0.23 | 0.23 | 0.85 (0.65-1.11) | ND | ND | ND |
| 10q21.3 | 66,980.65 | 66,983.04 | 2.4 | Loss | - | 0.039 | 0.066 | 1.62 (1.02-2.56) | 3.60E-05 | 1.10E-04 | 1.90 (1.40-2.58) | 0.011 | 0.011 | 1.40 (1.08-1.81) |
| CNVRLocation | Start * (bp) | End * (bp) | Length (kb) | Type | Genes | GWAS Discovery 1 (382 cases vs 191controls) | Replication 2 (564 cases vs 511controls) | Replication 3 (564 cases vs 495controls) | ||||||
| P | FDR | OR (95% CI) | P | FDR | OR (95% CI) | P | FDR | OR (95% CI) | ||||||
| 1q25.1 | 173,06.490 | 173,068.26 | 3.8 | Los | RABGAP1L | 4.40E-03 | 0.024 | 2.28 (1.29-4.01) | 0.038 | 0.057 | 1.30 (1.02-1.67) | 0.009 | 0.011 | 1.38 (1.08-1.77) |
| 8q23.3 | 115,704.81 | 115,711.71 | 6.9 | Los | - | 5.20E-04 | 0.044 | 0.37 (0.21-0.65) | 0.23 | 0.23 | 0.85 (0.65-1.11) | ND | ND | ND |
| 10q21.3 | 66,980.65 | 66,983.04 | 2.4 | Los | - | 0.039 | 0.066 | 1.62 (1.02-2.56) | 3.60E-05 | 1.10E-04 | 1.90 (1.40-2.58) | 0.011 | 0.011 | 1.40 (1.08-1.81) |
*hg18;* hg18;
1Principal component analysis was performed to adjust population stratification. 1 Principal component analysis was performed to adjust population stratification.
2Replication by qPCR; 2 Replication by qPCR;
3Replication by deletion-typing PCR; 3 Replication by deletion-typing PCR;
† Adjusted for age; ND, not determined † Adjusted for age; ND, not determined
CNVR의 OR은 2n인 개체를 기준으로 하여 계산되었다. 결실 타이핑 PCR에 의한 복제에서, OR은 ≥2n을 기준으로 하여 계산되었다. 연령대별 인구 분포의 효과를 보정하기 위해 principal componet analysis (PCA)를 수행하였다. 회귀 분석을 위해서는, PCA분석에서 도출된 상위 2개의 principal component 즉 PC1과 PC2를 covariate으로 사용하였으며 SNP-array batch 정보도 역시 회귀분석을 위한 covariate으로 사용되었다. FDR은 144 CNVR의 p-value로서 계산되었다.The OR of CNVRs was calculated based on the 2n individuals. In replication by deletion typing PCR, OR was calculated based on ≧ 2n. Principal componet analysis (PCA) was performed to correct the effect of population distribution by age group. For regression analysis, the top two principal components derived from PCA analysis, PC1 and PC2, were used as covariates, and SNP-array batch information was also used as a covariate for regression analysis. FDR was calculated as the p-value of 144 CNVR.
상기한 3종의 CNVR외에 SLE와 관계가 있는 것으로 규명된 바 있는 CNVR 위치 중에서, C4(6p21.32)의 복제 수 결실이 SLE 환자군에서 더 높은 빈도로 나타났고, 획득 타입 CNVR은 오히려 SLE 발병을 막는 효과를 갖는 것으로 나타났다. 그러나 이 결과는 통계적 유의성을 갖는 정도에 이르지는 못했다 (OR=2.35, 95% CI=0.64-8.57, P=0.197 for loss; OR=0.40, 95% CI=0.16-1.03, P=0.057 for gain).Among the CNVR sites that have been identified as being related to SLE in addition to the three CNVRs described above, C4 (6p21.32) replication number deletion was more frequent in the SLE patient group, and acquisition type CNVRs were more likely to develop SLE. It has been shown to have a blocking effect. However, these results did not reach statistical significance (OR = 2.35, 95% CI = 0.64-8.57, P = 0.197 for loss; OR = 0.40, 95% CI = 0.16-1.03, P = 0.057 for gain) .
실시예 5. genomic qPCR을 이용한 SLE와 관련이 있는 CNVR의 검증(validation)Example 5 Validation of CNVRs Associated with SLE Using genomic qPCR
본 발명자들은 genomic quantitative PCR(qPCR)을 위해 특이적인 증폭용 프라이머 세트를 디자인하였다. 이 프라이머 세트를 이용해 GWAS discovery 단계에서 SLE와 관련성이 높은 것으로 밝혀진 CNVR을 복제하여 확인하고자 하였다. We designed a specific primer set for amplification for genomic quantitative PCR (qPCR). This primer set was used to identify and replicate the CNVR found to be highly related to SLE during GWAS discovery.
본 연구에서 사용한 모든 프라이머들이 복제 수 정량에 적합한 것으로 실험상 확인되었다. 이에 대한 정보는 하기 표 4에 표시하였다.All primers used in this study were experimentally confirmed to be suitable for quantifying the number of copies. Information on this is shown in Table 4 below.
표 4
Table 4
| Chr | Start | End | AmpliconSize (bp) | Forward | Reverse | Efficiency (%) | R2 |
| 1 | 173064505 | 173064592 | 88 | AGGTCAAACATCACCTGCTCTGGA(서열번호 1) | TAACGCCAACAGTGGTGCTCTAGT(서열번호 2) | 104.7 | 0.99 |
| 8 | 115705632 | 115705728 | 97 | ACAAGACCATGTGGCCCTATGTGA | CAGCATCTTCTTGCCTAACAGCCT | 90.3 | 0.993 |
| 10 | 66981511 | 66981683 | 173 | ACCCAGCCTCAGGTATTCCTTTGT(서열번호 3) | AGGATTCTGGTGGTGTGGCTAGAA(서열번호 4) | 91.7 | 0.998 |
| Chr | Start | End | AmpliconSize (bp) | Forward | Reverse | Efficiency (%) | R 2 |
| One | 173064505 | 173064592 | 88 | AGGTCAAACATCACCTGCTCTGGA (SEQ ID NO: 1) | TAACGCCAACAGTGGTGCTCTAGT (SEQ ID NO: 2) | 104.7 | 0.99 |
| 8 | 115705632 | 115705728 | 97 | ACAAGACCATGTGGCCCTATGTGA | CAGCATCTTCTTGCCTAACAGCCT | 90.3 | 0.993 |
| 10 | 66981511 | 66981683 | 173 | ACCCAGCCTCAGGTATTCCTTTGT (SEQ ID NO: 3) | AGGATTCTGGTGGTGTGGCTAGAA (SEQ ID NO: 4) | 91.7 | 0.998 |
Viia 7 system(Life Technologies, Carlsbad, CA)을 이용하여 genomic qPCR을 수행하였다.Genomic qPCR was performed using a Viia 7 system (Life Technologies, Carlsbad, Calif.).
1q25.1 및 10q21.3의 qPCR에 있어서는, genomic DNA를 20ng 포함하고 있는 반응 혼합물 20μl, SYBR Premix Ex Taq TM II(TaKaRaBio사), 1xROX, 및 프라이머 10 pmol을 사용하였다. 95℃에서 30초 동안 1 cycle을 수행한 후, 95℃에서 5초, 55℃에서 10초, 72℃에서 30초로 하여 45 cycle을 수행하였다.For qPCRs of 1q25.1 and 10q21.3, 20 μl of a reaction mixture containing 20 ng of genomic DNA, SYBR Premix Ex Taq ™ II (TaKaRaBio), 1 × ROX, and 10 pmol of primer were used. After performing 1 cycle for 30 seconds at 95 ℃, 45 cycle was performed by 5 seconds at 95 ℃, 10 seconds at 55 ℃, 30 seconds at 72 ℃.
C4 유전자의 경우(C4A 및 C4B), 복제 수는 C4A 및 C4B에 특이적으로 디자인된 2종의 Taqman assay(Hs07226349_cn 및 Hs07226350_cn(Life Technologies))를 이용하여 genomic qPCR을 수행하여 결정하였다. 10ng의 genomic DNA, TaqMan universal PCR master mix Ⅱ(Life Technologies), C4A 또는 C4B TaqMan probe, 및 RNaseP TaqMan probe를 포함하는 총 10μl의 반응 혼합물을 사용하였다. PCR 조건은 95℃에서 10분간 1 cycle, 95℃에서 15초간 반응시킨 후 60℃에서 1분간 반응시키기를 40 cycle로 하여 수행하였다. For the C4 gene (C4A and C4B), the copy number was determined by performing genomic qPCR using two Taqman assays (Hs07226349_cn and Hs07226350_cn (Life Technologies)) designed specifically for C4 A and C4 B. A total of 10 μl of reaction mixture was used, including 10 ng of genomic DNA, TaqMan universal PCR master mix II (Life Technologies), C4A or C4B TaqMan probe, and RNaseP TaqMan probe. PCR conditions were carried out with 40 cycles of 1 cycle at 95 ℃ for 10 minutes, 15 seconds at 95 ℃ for 1 minute at 60 ℃.
전체 프라이머에 대한 PCR 효율(PCR efficiency, Ct value)은 standard curve over serial 1:5 dilution으로 결정하였다. Ct value는 reference gene이 standard curve의 역치에 도달하기 위해 요구되는 PCR cycle의 횟수로 결정된다. 각 타겟에 대한 복제 수 변이는 2-△△CT로 정의되었다. 여기서 △Ct는 확인하고자 하는 샘플에서 reference gene(RNase P)와 calibrator DNA(개인/calibrator)로부터 얻은 수치에 대한 역치 사이클의 차이를 말한다. 그 후 비율 데이터는 가장 가까운 정수로 나눈다. 요약하자면, 본 발명자들은 511개의 정상인 대조군 샘플을 이배체(diploid)로 나누고, 모든 측정된 1q25.1과 10q21.3 qPCR 비율 수치를 2개의 복제물에 맞춰 조정하였다. 조정된 비율 수치는 가장 가까운 정수로 반올림하였다. 이 3개의 CNVR의 빈도 분포는 아래 표 (표 5) 에 나타내었다. 좌측 컬럼은 CNVR GWAS 발굴 결과의 빈도분포이고, 중간 컬럼은 qPCR 검증 결과이며, 우측 컬럼은 결실 타이핑 PCR 검증결과이다.PCR efficiency (Cr value) for the entire primer was determined by standard curve over serial 1: 5 dilution. The Ct value is determined by the number of PCR cycles required for the reference gene to reach the threshold of the standard curve. The copy number variation for each target was defined as 2 −ΔΔCT . Where ΔCt is the difference in threshold cycles for the values obtained from the reference gene (RNase P) and calibrator DNA (individual / calibrator) in the sample to be identified. The ratio data is then divided by the nearest integer. In summary, we divided 511 normal control samples into diploids and adjusted all measured 1q25.1 and 10q21.3 qPCR ratio values to two replicates. Adjusted ratio values were rounded to the nearest integer. The frequency distribution of these three CNVRs is shown in the table below (Table 5). The left column is the frequency distribution of CNVR GWAS discovery results, the middle column is the qPCR verification result, and the right column is the deletion typing PCR verification.
표 5 
Table 5
SNP-array intensity signal로부터 array에서 나타났던 CNV의 92.8%가 genomic qPCR에서도 검출된다는 사실을 확인하였다. 1q25.1에서의 RABGAP1L CNV의 대립유전자 강도와 qPCR 확인 결과는 도 3에 나타내었다. From the SNP-array intensity signal, 92.8% of the CNV in the array was also detected in genomic qPCR. The allele intensity and qPCR identification results of RABGAP1L CNV at 1q25.1 are shown in FIG. 3.
도 3의 좌측 도는 Illumina사의 GenomeStudio software로 얻은 rs4480415 마커(173066744 위치, hg18)의 genoplot image이다. 이 위치에서의 신호 강도가 각각 2X(A/A, A/B/ B/B), 1X(A/-, B/-), 0X(-/-)의 6가지 뚜렷한 집단(cluster)을 이루는데, 이에 따라 복제 수 상태를 알 수 있다. 중앙의 도는 1q25.1 영역 주변의 신호 강도 비율을 나타낸 도이다. 도 3의 우측 도는 1q25.1 영역의 추정 복제 수를 genomic qPCR로 확인한 도이다. X축은 PennCNV에 의한 복제 수 상태를 나타내고, Y축은 qPCR에 의한 추정 DNA 복제 수이다. 3 is a genoplot image of the rs4480415 marker (173066744 position, hg18) obtained by Illumina GenomeStudio software. The signal strengths at these positions form six distinct clusters of 2X (A / A, A / B / B / B), 1X (A /-, B /-), and 0X (-/-), respectively. As a result, the number of replicas can be known. The figure in the center shows the signal strength ratio around the 1q25.1 region. 3 is a diagram confirming the estimated number of copies of the 1q25.1 region by genomic qPCR. The X axis represents the state of copy number by PennCNV, and the Y axis represents the estimated DNA copy number by qPCR.
Genomic qPCR을 이용한 독립적 코호트 검증 결과 1q25.1에서 RABGAP1L을 가로지르는 CNVR과 10q21.3 CNVR의 연관성이 독립적 검증 코호트군에서 성공적으로 복제되었다 (표 3). 그러나 8q23.3 위치의 CNVR은 복제되지 않았다. 본 발명자들은 2n을 가진 개체를 SLE 발병 위험도 예측의 기준으로 삼았는데(OR=1.30, 95% CI 1.02-1.67, P=0.038), OR은 복제 수가 증가할수록 감소하는 추세를 보였다(r2=0.939)(도 4 좌측). 10q21.3 위치의 결실 타입 CNVR이 있는 개체들도 복제시 2n인 개체들보다 SLE 발병 위험이 높았으나(OR=1.90, 95% CI 1.40-2.58, P=3.6 x 10-5), 복제 수와 관련해서는 OR에서 어떤 일관된 경향이 나타나지 않았다(r2=0.528)(도 4 우측). Independent Cohort Validation Using Genomic qPCR The association of 10VR2 CNVR with CNVR across RABGAP1L at 1q25.1 was successfully replicated in the independent validation cohort (Table 3). However, the CNVR at position 8q23.3 did not replicate. We used 2n subjects as the basis for predicting the risk of developing SLE (OR = 1.30, 95% CI 1.02-1.67, P = 0.038), but OR decreased with increasing number of copies (r 2 = 0.939). (Figure 4 left). Individuals with a deletion type CNVR at the 10q21.3 position also had a higher risk of developing SLE than those with 2n at replication (OR = 1.90, 95% CI 1.40-2.58, P = 3.6 x 10 -5 ). There was no consistent trend in OR in the context (r 2 = 0.528) (Figure 4 right).
GWAS discovery 단계에서 C4 유전자에서의 CNVR도 SLE 발병 위험도와 관련이 있는 것으로 밝혀졌으므로, 이 CNVR도 독립적으로 복제하였다(308 명의 환자군 및 307명의 대조군). C4의 복제수를 측정하기 위해서는, 이 유전자에 대한 이배체 copy수를 가지고 있는 것으로 알려진 HeLa 세포의 DNA를 이배체 대조군으로 설정하고 이에 맞춰 조정하였다. 2n을 가진 개체를 기준으로 설정했을 때, C4A의 복제 수 결실이 있는 개체는 SLE 발병 위험도가 현저히 높게 나타났고(OR=1.83, 95% CI 0.19-0.49, P=3.6 x 10-6), C4A의 복제 수 획득이 있는 개체는 SLE 발병 위험도가 현저히 낮게 나타났다(OR=0.30, 95% CI 1.15-3.06, P=1.87 x 10-6). 그러나 C4B의 CNVR은 SLE 발병 위험도와 별 관련이 없는 것으로 나타났다. 전체 C4(C4A+C4B)의 복제 수 결실이 있는 개체 역시 4n이 있는 개체보다 SLE 발병 위험도가 현저히 높았다(OR=1.88, 95% CI 1.15-3.06, P=0.01).Since CNVR in the C4 gene was also found to be associated with the risk of SLE during GWAS discovery, this CNVR was also replicated independently (308 patient groups and 307 control groups). To determine the number of copies of C4, DNA of HeLa cells known to have diploid copies of this gene was set as a diploid control and adjusted accordingly. Based on individuals with 2n, individuals with a C4A replication deletion showed a significantly higher risk of developing SLE (OR = 1.83, 95% CI 0.19-0.49, P = 3.6 x 10 -6 ), and C4A Individuals with a copy number of had a significantly lower risk of developing SLE (OR = 0.30, 95% CI 1.15-3.06, P = 1.87 x 10-6 ). However, C4B's CNVR was not associated with the risk of SLE. Individuals with total C4 (C4A + C4B) deletions also had a significantly higher risk of developing SLE than individuals with 4n (OR = 1.88, 95% CI 1.15-3.06, P = 0.01).
C4를 가로지르는 CNVR인 6p21.32의 빈도 분포는 하기 표 6에 나타내었다. 표6의 위쪽표는 CNV GWAS 발굴 결과이고 아래표는 qPCR 검증실험 결과이다.The frequency distribution of 6p21.32, a CNVR across C4, is shown in Table 6 below. The upper table of Table 6 shows CNV GWAS discovery results and the following table shows qPCR verification experiment results.
표 6 
Table 6
실시예 6. deletion-typing PCR을 이용한 CNV의 크기와 경계 확인Example 6 Confirmation of CNV Size and Boundary by Deletion-typing PCR
6-1. CNV의 크기 및 경계 확인6-1. Check size and boundary of CNV
실시예 5의 결과, SLE와 유의한 연관을 보인 두 영역(1q25.1 및 10q21.3)의 CNV의 정확한 크기와 경계를 확인하기 위해, 본 발명자들은 deletion-typing PCR을 수행하였다. 결실된 대립유전자들의 증폭물(amplicon)은 PCR-direct sequencing을 이용해 시퀀싱하였다. C4 구역의 경우 deletion-typing PCR 설계가 불가능하여 실시하지 않았다.As a result of Example 5, the inventors performed deletion-typing PCR in order to confirm the exact size and boundary of CNV of the two regions (1q25.1 and 10q21.3) showing significant association with SLE. Amplicons of deleted alleles were sequenced using PCR-direct sequencing. In the case of the C4 region, the deletion-typing PCR design was not possible.
1q251.과 10q21.3의 정확한 크기와 경계를 파악하기 위해, 본 발명자들은 결실 타이핑 PCR 전략을 세웠다. 예상되는 결실 부위 주변의 flanking sequence와 결실 영역 내에서 프라이머 세트를 디자인하였다. 이에 대한 구체적인 정보는 표 7에 나타내었다. PCR은 하기의 조건으로 수행되었다. genomic DNA를 20ng, FX DNA polymerase(TOYOBO, Osaka, Japan)을 0.4 unit, 2% DNSO, 프라이머 6pmol을 포함하는 반응 혼합물을 20μl 준비하였다. PCR은 94℃에서 2분간 1 cycle, 98℃에서 10초간, 69℃에서 1분/Kb 동안 32 cycle을 수행하였다. PCR 반응 후에, 10μl의 PCR 산물을 0.5% 아가로스 젤에서 전기영동하였다. 결실된 allele는 PCR-direct sequencing 방법으로 시퀀싱하였다.To determine the exact size and boundaries of 1q251. And 10q21.3, we devised a deletion typing PCR strategy. Primer sets were designed in the flanking sequence around the expected deletion site and in the deletion region. Specific information about this is shown in Table 7. PCR was performed under the following conditions. 20 μl of a reaction mixture containing 20 ng of genomic DNA, 0.4 unit of FX DNA polymerase (TOYOBO, Osaka, Japan), 2% DNSO, and 6 pmol of primer was prepared. PCR was performed for 1 cycle at 94 ° C for 2 minutes, at 98 ° C for 10 seconds and at 69 ° C for 1 minute / Kb. After the PCR reaction, 10 μl of the PCR product was electrophoresed on 0.5% agarose gel. The deleted alleles were sequenced by PCR-direct sequencing method.
표 7
TABLE 7
| Target Region | Forward Primer (5´―3´) | Reverse Primer (5’―3’) |
| 1q25.1_Long | AAGCGTCACGTTCTCATTGTGGCA(서열번호 5) | TCCCACCCATTCAAGCACTAAGGT(서열번호 6) |
| 1q25.1_Short | AAGCGTCACGTTCTCATTGTGGCA(서열번호 7) | AGCTGCCAAGCAAGATTCACGTTC(서열번호 8) |
| 10q21.3_Long | GATGGTGGCAGCAAAGTCAACACA(서열번호 9) | CATTCTGCCAAACATGAAGGGCCA(서열번호 10) |
| 10q23.1_Short | GATGGTGGCAGCAAAGTCAACACA(서열번호 11) | TGACCAGGATACTGCAGATGGCAA(서열번호 12) |
| Target Region | Forward Primer (5´―3´) | Reverse Primer (5'-3 ') |
| 1q25.1_Long | AAGCGTCACGTTCTCATTGTGGCA (SEQ ID NO: 5) | TCCCACCCATTCAAGCACTAAGGT (SEQ ID NO: 6) |
| 1q25.1_Short | AAGCGTCACGTTCTCATTGTGGCA (SEQ ID NO: 7) | AGCTGCCAAGCAAGATTCACGTTC (SEQ ID NO: 8) |
| 10q21.3_Long | GATGGTGGCAGCAAAGTCAACACA (SEQ ID NO: 9) | CATTCTGCCAAACATGAAGGGCCA (SEQ ID NO: 10) |
| 10q23.1_Short | GATGGTGGCAGCAAAGTCAACACA (SEQ ID NO: 11) | TGACCAGGATACTGCAGATGGCAA (SEQ ID NO: 12) |
도 5의 실험 전략을 요약하면, 결실 예상구역을 포함하는 PCR을 시행하면 결실이 없는 경우 예상한 크기의 PCR 증폭물이 나타나는 반면, 결실이 존재하면 그 크기만큼 길이가 감소한 PCR 증폭산물이 나타나게 된다는 원리이다. In summary, the experiment strategy of FIG. 5 shows that if PCR is performed including a region of expected deletion, a PCR amplification product of the expected size appears in the absence of a deletion, whereas a PCR amplification product of which the length is reduced by that size appears. It is a principle.
본 발명자들이 디자인한 1q25.1 영역의 전체 대립유전자의 증폭 크기(amplicon size)는 9.4Kb였고, SNP의 시작-종결 위치(start-end position)에 기초한 1q25.1에서의 결실 영역의 예측된 크기는 3.8 Kb였다. 그러므로, 결실 대립유전자의 증폭 크기는 5.6 Kb로 계산되었다. 그러나 결실된 대립유전자의 실제 증폭 크기는 4.2 Kb 이하였으므로, 1q25.1 위치에서의 실제 결실 크기도 3.8 Kb가 아니라 5.2 Kb 이하일 것으로 계산되었다. 따라서 9.4Kb 밴드만을 나타내는 사람은 2n (diploid)로 해석할 수 있고 4.2Kb 밴드만을 나타내는 사람은 homozygous deletion (HOM)으로 해석되며 9.4Kb와 4.2Kb 밴드를 동시에 나타내는 사람은 heterozygous deletion (HET)로 해석된다. The amplicon size of the total allele of the 1q25.1 region designed by the inventors was 9.4 Kb, and the predicted size of the deletion region at 1q25.1 based on the start-end position of the SNP. Was 3.8 Kb. Therefore, the magnitude of the amplification of the deletion allele was calculated to be 5.6 Kb. However, since the actual amplification size of the deleted allele was 4.2 Kb or less, the actual deletion size at 1q25.1 was calculated to be 5.2 Kb or less, not 3.8 Kb. Therefore, a person who shows only 9.4Kb bands can be interpreted as 2n (diploid), a person who shows only 4.2Kb bands can be interpreted as homozygous deletion (HOM), and a person who shows both 9.4Kb and 4.2Kb bands as heterozygous deletion (HET). do.
이와 마찬가지로, 10q21.3 영역에서 SNP의 시작-종결 위치(start-end position)에 기초한 결실 영역의 예측된 크기는 2.4 Kb였으며 디자인한 전체 대립유전자의 증폭 크기는 11.6 Kb였다. 따라서 9.2 Kb 크기의 결실 타이핑 PCR 증폭산물을 이 예상되나 실제 결실 대립유전자의 증폭산물의 크기는 3.3 Kb 이하였으므로, 10q21.3 영역에서의 실제 결실 대립유전자의 증폭 크기는 2.4 Kb가 아니라 8.3 Kb 이하일 것으로 계산되었다. 따라서 11.6Kb 밴드만을 나타내는 사람은 2n (diploid)로 해석할 수 있고 3.3 Kb 밴드만을 나타내는 사람은 homozygous deletion (HOM)으로 해석되며 11.6 Kb와 3.3 Kb 밴드를 동시에 나타내는 사람은 heterozygous deletion (HET)로 해석된다. Likewise, the predicted size of the deletion region based on the start-end position of the SNP in the 10q21.3 region was 2.4 Kb and the amplification size of the designed allele was 11.6 Kb. Therefore, a 9.2 Kb-sized deletion typing PCR amplification product is expected, but the size of the amplification product of the deletion allele was 3.3 Kb or less, so the amplification size of the actual deletion allele in the 10q21.3 region was 8.3 Kb or less, not 2.4 Kb. Was calculated. Therefore, a person who shows only 11.6Kb band can be interpreted as 2n (diploid), a person who shows only 3.3 Kb band can be interpreted as homozygous deletion (HOM), and a person who shows 11.6 Kb and 3.3 Kb band at the same time can be interpreted as heterozygous deletion (HET). do.
본 발명자들은 결실된 유전자의 증폭물을 시퀀싱하고 결실 서열의 정확한 크기와 중지점을 확인하였다. We sequenced the amplifications of the deleted genes and identified the exact size and breakpoint of the deletion sequence.
도 5 중단은 deletion-typing PCR 산물의 전기영동 결과를 나타낸다. 5 disruption shows the results of electrophoresis of deletion-typing PCR products.
도 5 중단 좌측 도에서, 1q25.1 영역은 Band 1, 9.4 Kb; Band 2, 4.2Kb; Band 3, 2.3 Kb로 나타났다. 도 5 중단 우측 도에서, 10q21.3 영역은 Band 1, 11.6Kb; Band 2, 3.3Kb; Band 3, 3.2 Kb로 나타났다. P1과 P2는 각각 프라이머 세트 1, 2를 의미한다. In the left side of FIG. 5, the region 1q25.1 includes Band 1, 9.4 Kb; Band 2, 4.2 Kb; Band 3, 2.3 Kb. In the right side of FIG. 5, the 10q21.3 region includes Band 1, 11.6 Kb; Band 2, 3.3 Kb; Band 3, 3.2 Kb. P1 and P2 mean primer sets 1 and 2, respectively.
도 5 하단은 1q25.1과 10q21.3의 결실 중지점(화살표가 가리키는 부분)을 보여주는 DNA 서열의 예시이다.5 bottom is an example of a DNA sequence showing deletion breakpoints (parts indicated by arrows) of 1q25.1 and 10q21.3.
6-2. 동형접합 결실 및 이형접합 결실의 비교6-2. Comparison of homozygous and heterozygous deletions
이형접합적으로 결실이 일어난 샘플에서는 두 종류 크기의 증폭물(전체 크기 및 결실이 일어난 크기)이 있어야 함에도 불구하고, 전체 크기의 증폭물은 두 CNVR 모두에서 작은 크기의 PCR에 대한 선호 현상(preference for small-sized PCR)으로 인해 나타나지 않을 수 있다. 따라서 결실 매핑(mapping) 데이터에 기초하여 동형접합 결실과 이형접합 결실을 구별하기 위해서, 본 발명자들은 결실된 서열 내에서 프라이머를 재 디자인하여 전체 대립유전자를 의미하는 짧은 증폭물의 존재를 검정하고자 하였다(도 5, 표 7). 샘플이 이형접합 결실을 갖는 경우, 전체 대립유전자는 예측된 크기(1q25.1에 대해서는 2.3 Kb, 10q21.3에 대해서는 3.2 Kb)의 증폭물을 생산할 것이고, 결실 대립유전자에서는 그렇지 않을 것으로 예상하였다. 샘플이 동형접합 결실을 갖고 있는 경우, PCR 증폭물이 생산되지 않을 것으로 예상하였다. Although heterozygous samples must have two sizes of amplification (full size and size of deletion), full size amplification is preferred for small size PCR in both CNVRs. for small-sized PCR). Therefore, to distinguish homozygous and heterozygous deletions based on deletion mapping data, we sought to redesign the primers in the deleted sequences to test for the presence of short amplifications that represent the entire allele ( 5, Table 7). If the sample had a heterozygous deletion, the total allele would produce an amplified product of the expected size (2.3 Kb for 1q25.1, 3.2 Kb for 10q21.3), but not for the deletion allele. If the sample had a homozygous deletion, it was expected that no PCR amplification would be produced.
결과적으로, 본 발명자들은 결실 타입을 다음과 같이 해석하였다. 1q25.1에 대해서 homozygous 결실은 4.2 Kb 밴드 양성, 9.4 Kb 밴드 음성, 2.3 Kb 밴드 음성이고, heterozygous 결실에 대해서는 4.2 Kb 밴드 양성, 2.3 Kb 밴드 양성이고, 9.4 Kb 밴드는 양성이지만 나타나지 않을 수 있다. 2개 이상의 복제 수 변이가 있는 경우, 9.4 Kb 밴드 양성, 2.3 Kb 밴드 양성, 3.2 Kb 밴드 음성, 4.2 Kb 밴드 음성이다. 10q21.3에 대해서는, homozygous deletion은 3.3 Kb 밴드 양성, 3.2 Kb 밴드 음성, 11.6 Kb 밴드 음성일 것이고, heterozygous deletion은 3.3 Kb 밴드 양성, 3.2 Kb 밴드 양성일 것이고, 11.6 Kb는 양성이겠지만 나타나지 않을 수 있다. 2개 이상의 복제 수 변이가 있는 경우에는, 11.6 Kb 밴드 양성, 3.2 Kb 밴드 양성, 3.3 Kb 밴드 음성일 것이다(도 4).As a result, we interpreted the deletion type as follows. For 1q25.1 homozygous deletions are 4.2 Kb band positive, 9.4 Kb band negative, 2.3 Kb band negative, for heterozygous deletions are 4.2 Kb band positive, 2.3 Kb band positive, and the 9.4 Kb band is positive but may not appear. If there is more than one copy number variation, it is 9.4 Kb band positive, 2.3 Kb band positive, 3.2 Kb band negative, 4.2 Kb band negative. For 10q21.3, homozygous deletion will be 3.3 Kb band positive, 3.2 Kb band negative, 11.6 Kb band negative, heterozygous deletion will be 3.3 Kb band positive, 3.2 Kb band positive, and 11.6 Kb may be positive but may not appear. If there is more than one copy number variation, it will be 11.6 Kb band positive, 3.2 Kb band positive, 3.3 Kb band negative (FIG. 4).
이 전략을 통해, HOM, HET, ≥2n을 정확하게 구별할 수 있었다(도 4B 및 4C). 결실된 allele의 복제물을 시퀀싱하여, 결실 부위의 정확한 크기 및 결실 중지점을 알아낼 수 있었다.This strategy was able to accurately distinguish between HOM, HET, ≧ 2n (FIGS. 4B and 4C). Replicates of deleted alleles were sequenced to determine the exact size of the deletion site and the deletion breakpoint.
본 발명자들은 설계한 결실 타이핑 PCR 전략을 독립적 검증 코호트 (564 cases and 495 controls)에 적용하여 결실 타이핑 PCR을 수행하였고, qPCR에 의해 규명된 결실의 95% 이하가 결실 타이핑 PCR 결과와 일치한다는 사실을 밝혔다. Deletion-typing PCR 결과에 기초해, 1q25.1에서 CNVR이 있는 사람은(HOM 및 HET) ≥2n에 비해 SLE 발병 확률이 크게 높게 나타났고(OR=1.38, 95% CI 1.08-1.77, P=0.0009), 10q21.3에서 결실이 있는 경우도 마찬가지였다(OR=1.40, 95% CI 1.08-1.81, P=0.011)(표 3). 1q24.1 또는 10q21.3 HOM은 ≥2n에 비해 상당히 높은 SLE 발병 위험을 보였다(각각 OR=1.82, 95% CI 1.03-3.20, P=0.039; OR=1.46, 95% CI 1.01-2.10, P=0.044). GWAS discovery 및 결실 타이핑 PCR의 메타 분석 결과, CNVR의 상관 관계가 더욱 유의성 있는 자료임을 알 수 있었다(1q24.1의 경우 OR=1.51, 95% CI 1.20-1.89, P=4 x 10-4; 10q21.3의 경우, OR=1.46, 95% CI 1.01-2.10, P=8 x 10-4).We performed deletion typing PCR by applying the designed deletion typing PCR strategy to an independent validation cohort (564 cases and 495 controls) and found that less than 95% of the deletions identified by qPCR are consistent with the deletion typing PCR results. Said. Based on the deletion-typing PCR results, people with CNVR at 1q25.1 (HOM and HET) had a greater chance of developing SLE compared to ≥2n (OR = 1.38, 95% CI 1.08-1.77, P = 0.0009). ), The same was true for the deletion at 10q21.3 (OR = 1.40, 95% CI 1.08-1.81, P = 0.011) (Table 3). 1q24.1 or 10q21.3 HOMs showed a significantly higher risk of developing SLE compared to ≥2n (OR = 1.82, 95% CI 1.03-3.20, P = 0.039; OR = 1.46, 95% CI 1.01-2.10, P = 0.044). The meta-analysis of GWAS discovery and deletion typing PCR showed that CNVR correlation was more significant (OR = 1.51 for 1q24.1, 95% CI 1.20-1.89, P = 4 x 10 -4 ; 10q21). For .3, OR = 1.46, 95% CI 1.01-2.10, P = 8 × 10 −4 ).
또한 본 발명자들은 SLE 발병 위험도 예측에 있어서 3개의 중요 위치에서 동시에 결실 타입 CNVR이 발생한 경우의 효과에 대해 알고자 하였다. RABGAP1L 및 10q21.3의 결실 타입 PCR 결과와 C4에서의 qPCR 결과를 종합해 보았을 때, 세 위치 모두에서 결실이 있는 개체의 경우(본 연구의 환자군의 8.1% 및 대조군의 2.3%) 세 위치 모두에서 ≥2n인 개체(본 연구의 환자군의 10.7% 및 대조군의 16.6%)에 비해 SLE 발병 위험도가 5.5배 높게 나타났다(OR=5.52, 95% CI 2.14-14.21, P=3.9 x 10-4). 1에서 3의 결실의 수에 따른 OR은 농도 의존적 증가 양상을 보였다(r2=0.965).(도 7, 표 8)In addition, the present inventors wanted to know the effects of the deletion type CNVR occurring at the same time in three important positions in predicting the risk of developing SLE. Combining the results of deletion type PCR of RABGAP1L and 10q21.3 with qPCR results at C4, individuals with deletions in all three positions (8.1% of the patient group and 2.3% of the control group) in all three positions The risk of developing SLE was 5.5 times higher compared to individuals> 2n (10.7% of patients in this study and 16.6% of controls) (OR = 5.52, 95% CI 2.14-14.21, P = 3.9 x 10 -4 ). According to the number of deletions 1 to 3, OR showed a concentration-dependent increase (r 2 = 0.965) (FIG. 7, Table 8).
표 8
Table 8
| Type | Case (308) | Control (307) |
| Losses in all 3 loci | 25 (8.1%) | 7 (2.3%) |
| Losses in 2 loci | 122 (39.6%) | 106 (34.5%) |
| Loss in 1 locus | 126 (40.9%) | 136 (44.3%) |
| ≥2n in all 3 loci | 33 (10.7%) | 51 (16.6%) |
| ND | 2 (0.6%) | 7 (2.3%) |
| Type | Case (308) | Control (307) |
| Losses in all 3 loci | 25 (8.1%) | 7 (2.3%) |
| Losses in 2 loci | 122 (39.6%) | 106 (34.5%) |
| Los in 1 locus | 126 (40.9%) | 136 (44.3%) |
| ≥2n in all 3 loci | 33 (10.7%) | 51 (16.6%) |
| ND | 2 (0.6%) | 7 (2.3%) |
전술한 본 발명의 설명은 예시를 위한 것이며, 본 발명이 속하는 기술분야의 통상의 지식을 가진 자는 본 발명의 기술적 사상이나 필수적인 특징을 변경하지 않고서 다른 구체적인 형태로 쉽게 변형이 가능하다는 것을 이해할 수 있을 것이다. 그러므로 이상에서 기술한 실시예들은 모든 면에서 예시적인 것이며 한정적이 아닌 것으로 이해되어야 한다.The foregoing description of the present invention is intended for illustration, and it will be understood by those skilled in the art that the present invention may be easily modified in other specific forms without changing the technical spirit or essential features of the present invention. will be. Therefore, the embodiments described above are to be understood in all respects as illustrative and not restrictive.
본 발명의 조성물은, C4 위치, 1q25.1 위치 및 10q21.3 위치의 복제 수 변이가 전신성 홍반성 루푸스 발병에 시너지 효과를 가짐을 이용하여 발병 위험을 예측 가능하게 하며, 대부분의 병원 검사실에서 보편적으로 행해지고 있는 PCR을 이용함으로써 기기를 새로 구입하거나 기술적 한계로 인해 발생할 수 있는 분석의 오차를 줄일 수 있고, 검사 대상자에 비침습적인 방법으로 수행할 수 있는 장점이 있다. 즉 본 발명은 전신성 홍반성 루푸스 발병 가능성을 조기에 예측하여 상태 악화를 예방하거나 발병을 늦추는 데 중요하게 이용될 수 있다.The compositions of the present invention make it possible to predict the risk of onset by having a replication number variation at the C4, 1q25.1 and 10q21.3 positions having a synergistic effect on the development of systemic lupus erythematosus and is common in most hospital laboratories. By using the PCR that is performed as a new device or to reduce the error of analysis that may occur due to technical limitations, there is an advantage that can be performed in a non-invasive way to the subject. In other words, the present invention can be used to predict the possibility of developing systemic lupus erythematosus early to prevent the worsening of the condition or to delay the onset.
Claims (10)
- 전신성 홍반성 루푸스(Systemic Lupus Erythematosus) 발병 위험도 예측용 조성물로서, 상기 조성물은 검체의 염색체상의 C4, 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)를 포함하는 것을 특징으로 하는, 조성물. A composition for predicting the risk of developing Systemic Lupus Erythematosus, the composition comprising a primer for detecting DNA copy number variation at the C4, 1q25.1 and / or 10q21.3 positions on a chromosome of a sample (primer), characterized in that the composition.
- 제 1항에 있어서, The method of claim 1,상기 1q25.1 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 1 및 2의 DNA 서열을 포함하는 게놈 정량적 PCR(genomic quantitative PCR) 용 프라이머 쌍인 것을 특징으로 하는, 조성물.The primer for detecting DNA copy number variation at the 1q25.1 position is a pair of primers for genomic quantitative PCR (DNA) including DNA sequences of SEQ ID NOs: 1 and 2, Composition.
- 제 1항에 있어서, The method of claim 1,상기 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 3 및 4의 DNA 서열을 포함하는 게놈 정량적 PCR(genomic quantitative PCR) 용 프라이머 쌍인 것을 특징으로 하는, 조성물. The primer for detecting DNA copy number variation at position 10q21.3 is a pair of primers for genomic quantitative PCR (DNA) including DNA sequences of SEQ ID NOs: 3 and 4, Composition.
- 제 1항에 있어서, The method of claim 1,상기 1q25.1 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 5 내지 8로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 결실 타이핑 PCR(deletion-typing PCR) 용 프라이머임을 특징으로 하는, 조성물.The primer for detecting DNA copy number variation at position 1q25.1 is a primer for deletion-typing PCR including a DNA sequence selected from the group consisting of SEQ ID NOs: 5 to 8. Characterized in that the composition.
- 제 1항에 있어서, The method of claim 1,상기 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 9 내지 12로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 결실 타이핑 PCR(deletion-typing PCR) 용 프라이머임을 특징으로 하는, 조성물.The primer for detecting DNA copy number variation at the 10q21.3 position is a primer for deletion-typing PCR including a DNA sequence selected from the group consisting of SEQ ID NOs: 9 to 12. Characterized in that the composition.
- 전신성 홍반성 루푸스(Systemic Lupus Erythematosus) 발병 위험도 예측용 키트로서, 상기 키트는 검체의 염색체상의 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)를 포함하는 것을 특징으로 하는, 키트.A kit for predicting the risk of developing Systemic Lupus Erythematosus, wherein the kit is a primer for detecting DNA copy number variation at 1q25.1 and / or 10q21.3 on a chromosome of a sample. A kit comprising:).
- 제 6항에 있어서,The method of claim 6,상기 프라이머는 서열번호 1 내지 12로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 프라이머인 것을 특징으로 하는, 키트.The primer is a kit, characterized in that the primer comprising a DNA sequence selected from the group consisting of SEQ ID NO: 1 to 12.
- A) 검체의 염색체상의 C4위치, 1q25.1 위치 및/또는 10q21.3 위치에 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)를 검체 DNA 시료에 첨가하여 PCR을 수행하는 단계; 및A) performing PCR by adding a primer for detecting DNA copy number variation to the sample DNA sample at the C4, 1q25.1 and / or 10q21.3 positions on the chromosome of the sample; AndB) 상기 수행된 PCR 결과로부터 검체가 C4위치, 1q25.1 위치 및/또는 10q21.3 위치에 DNA 복제 수 변이(DNA copy number variation)를 가지고 있는지 여부를 측정하는 단계를 포함하는, 전신성 홍반성 루푸스 발병 위험도를 예측하기 위한 정보를 제공하는 방법.B) determining whether the sample has a DNA copy number variation at the C4, 1q25.1 and / or 10q21.3 positions from the PCR results performed above. How to provide information to predict the risk of developing lupus.
- 제 8항에 있어서, The method of claim 8,상기 A)단계의 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 1 내지 4로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 게놈 정량적 PCR(genomic quantitative PCR) 용 프라이머임을 특징으로 하는, 방법.Of step A) Primers for detecting DNA copy number variation at positions 1q25.1 and / or 10q21.3 are genomic quantitative PCRs comprising DNA sequences selected from the group consisting of SEQ ID NOs: 1-4. Characterized in that the primer for PCR).
- 제 8항에 있어서, The method of claim 8,상기 A)단계의 1q25.1 위치 및/또는 10q21.3 위치의 DNA 복제 수 변이(DNA copy number variation) 검출용 프라이머(primer)는 서열번호 5 내지 12로 이루어진 군으로부터 선택된 DNA 서열을 포함하는 결실 타이핑 PCR(deletion-typing PCR) 용 프라이머임을 특징으로 하는, 방법.Of step A) A primer for detecting DNA copy number variation at the 1q25.1 position and / or the 10q21.3 position comprises a deletion typing PCR comprising a DNA sequence selected from the group consisting of SEQ ID NOs: 5-12. a primer for typing PCR).
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201380053236.5A CN104704121A (en) | 2012-10-10 | 2013-10-10 | Composition for estimating risk of onset of systemic lupus erythematosus, comprising primer for detecting dna copy number variation in 1q25.1(RABGAP1L) location, 6P21.32 (c4) location and 10.q21.3 location |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2012-0112495 | 2012-10-10 | ||
| KR20120112495 | 2012-10-10 | ||
| KR20120144720A KR101491214B1 (en) | 2012-10-10 | 2012-12-12 | Composition for Systemic Lupus Erythematosus risk prediction comprising primers detecting copy number variants of 1q25.1 (RABGAP1L), 6p21.32 (C4) and 10q21.3 loci. |
| KR10-2012-0144720 | 2012-12-12 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014058254A1 true WO2014058254A1 (en) | 2014-04-17 |
Family
ID=50477649
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2013/009074 WO2014058254A1 (en) | 2012-10-10 | 2013-10-10 | Composition for estimating risk of onset of systemic lupus erythematosus, comprising primer for detecting dna copy number variation in 1q25.1(rabgap1l) location, 6p21.32 (c4) location and 10.q21.3 location |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2014058254A1 (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20110081161A (en) * | 2008-09-26 | 2011-07-13 | 제넨테크, 인크. | Methods for treating, diagnosing, and monitoring lupus |
| KR20120100969A (en) * | 2009-10-07 | 2012-09-12 | 제넨테크, 인크. | Methods for treating, diagnosing, and monitoring lupus |
-
2013
- 2013-10-10 WO PCT/KR2013/009074 patent/WO2014058254A1/en active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20110081161A (en) * | 2008-09-26 | 2011-07-13 | 제넨테크, 인크. | Methods for treating, diagnosing, and monitoring lupus |
| KR20120100969A (en) * | 2009-10-07 | 2012-09-12 | 제넨테크, 인크. | Methods for treating, diagnosing, and monitoring lupus |
Non-Patent Citations (1)
| Title |
|---|
| Y.L. WU ET AL.: "Phenotypes, genotypes and disease susceptibility associated with gene copy number variations : complement C4 CNVs in European American healthy subjects and those with systemic lupus erythematosus", CYTOGENET GONOME RES., vol. 123, 2008, pages 131 - 141 * |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Souren et al. | DNA methylation signatures of monozygotic twins clinically discordant for multiple sclerosis | |
| Guo et al. | Genotype and cardiovascular phenotype correlations with TBX1 in 1,022 velo‐cardio‐facial/digeorge/22q11. 2 deletion syndrome patients | |
| Castellani et al. | Consensus on the use and interpretation of cystic fibrosis mutation analysis in clinical practice | |
| Deng et al. | Clinical and molecular study of a pediatric patient with sodium taurocholate cotransporting polypeptide deficiency | |
| WO2019199105A1 (en) | Method for assessing risk for alzheimer's disease | |
| Manry et al. | Deciphering the genetic control of gene expression following Mycobacterium leprae antigen stimulation | |
| WO2020027569A1 (en) | Composition for diagnosing alzheimer's disease by using alteration of cpg methylation in promoter of ide gene in skin cells, and use thereof | |
| Handley et al. | ITPase deficiency causes a Martsolf-like syndrome with a lethal infantile dilated cardiomyopathy | |
| Lu et al. | Different cystic fibrosis transmembrane conductance regulator mutations in Chinese men with congenital bilateral absence of vas deferens and other acquired obstructive azoospermia | |
| Yang et al. | Comprehensive genetic diagnosis of patients with Duchenne/Becker muscular dystrophy (DMD/BMD) and pathogenicity analysis of splice site variants in the DMD gene | |
| Tsai et al. | Identification of a CCG-Enriched expanded allele in patients with myotonic dystrophy type 1 using amplification-free long-read sequencing | |
| WO2019078684A9 (en) | Marker tmem43 for sensorineural hearing loss diagnosis, and use thereof | |
| CN110564837A (en) | Genetic metabolic disease gene chip and application thereof | |
| WO2020209590A1 (en) | Composition for diagnosis or prognosis prediction of glioma, and method for providing information related thereto | |
| WO2020060170A1 (en) | Marker composition for diagnosis of atopic dermatitis and method, using same, for prediction or diagnosis of atopic dermatitis | |
| WO2015111852A1 (en) | Composition for predicting risk of thiopurine-induced leukopenia, containing single nucleotide polymorphism marker within nudt15 gene | |
| WO2019132581A1 (en) | Composition for diagnosing cancer such as breast cancer and ovarian cancer, and use thereof | |
| WO2014058254A1 (en) | Composition for estimating risk of onset of systemic lupus erythematosus, comprising primer for detecting dna copy number variation in 1q25.1(rabgap1l) location, 6p21.32 (c4) location and 10.q21.3 location | |
| Botezatu et al. | Comparative molecular approaches in Prader–Willi syndrome diagnosis | |
| JP2020058274A (en) | Prediction of side reaction of regorafenib on the basis of cyp2d6 gene | |
| WO2021107713A1 (en) | Method for diagnosing amyotrophic lateral sclerosis on basis of lats1 gene mutation marker | |
| WO2021172863A1 (en) | Molecular diagnostic test for alzheimer's disease | |
| WO2021172864A1 (en) | Alzheimer's disease diagnosis and prediction using epigenetic methylation modification of gene | |
| Zhao et al. | Whole-Exome Sequencing identified a novel compound heterozygous genotype in ASL in a chinese han patient with argininosuccinate lyase deficiency | |
| WO2020204313A1 (en) | Snp marker for diagnosing cerebral aneurysm, including monobasic polymorphism of gba gene |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13845382 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 13845382 Country of ref document: EP Kind code of ref document: A1 |