WO2010084629A1 - Recommendation system, recommendation method, recommendation program, and information storage medium - Google Patents
Recommendation system, recommendation method, recommendation program, and information storage medium Download PDFInfo
- Publication number
- WO2010084629A1 WO2010084629A1 PCT/JP2009/056686 JP2009056686W WO2010084629A1 WO 2010084629 A1 WO2010084629 A1 WO 2010084629A1 JP 2009056686 W JP2009056686 W JP 2009056686W WO 2010084629 A1 WO2010084629 A1 WO 2010084629A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- user
- users
- recommendation
- preference data
- similarity
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
Definitions
- the present invention relates to a recommendation system, a recommendation method, a recommendation program, and an information storage medium.
- recommendation algorithms are often used in various online services such as information search and online sales.
- collaborative filtering the similarity of preference data is first calculated among users, and another user whose preference data is highly similar to a certain recommendation target user is selected. Then, information to be recommended to the recommendation target user is determined based on the preference of the user thus selected.
- the present invention has been made in view of the above problems, and an object of the present invention is to provide a recommendation system, a recommendation method, a recommendation program, and an information storage medium capable of continuously providing information that brings interest to a recommendation target user. It is to do.
- a recommendation system comprises: preference data storage means for storing preference data of a plurality of users; similarity calculation means for calculating the similarity of preference data among users; A first user who selects one or more of the plurality of users based on the similarity between the preference data of the recommendation target user among the users and the preference data of all or part of the plurality of users Among the plurality of users based on the similarity between the selection means, the preference data of the user selected by the first user selection means, and the preference data of all or part of the plurality of users
- the recommendation target user is selected based on second user selection means for selecting one or more and preference data of some or all of the users selected by the second user selection means. Characterized in that it comprises a recommendation information determining means for determining information to be recommended, to.
- the plurality of the plurality of users can be selected based on the similarity between the preference data of the recommendation target user and the preference data of all or part of the plurality of users. Similarity between a first user selection step of selecting one or more of the users, preference data of the user selected in the first user selection step, and preference data of all or part of the plurality of users. The second user selection step of selecting one or more of the plurality of users based on the degree, and the preference data of some or all of the users selected in the second user selection step And a recommendation information determination step of determining information to be recommended to the recommendation target user.
- the first user selection means selects a user whose similarity degree of preference data with the recommendation target user is equal to or more than a first predetermined value
- the recommendation system The recommendation information determining means further includes third user selection means for selecting a recommended user and a user whose preference degree is less than the first predetermined value and greater than or equal to a second predetermined value smaller than the first predetermined value.
- the information to be recommended to the recommendation target user is determined based on preference data of a user who is a user selected by the second user selection means and is also a user selected by the third user selection means.
- the preference data includes, for each of the plurality of information elements, a numerical value indicating a degree of preference of the user, and the recommendation information determination means determines the second information element for each of the information elements.
- the recommendation information determination means determines the second information element for each of the information elements.
- FIG. 1 is an overall configuration diagram of a recommendation system according to an embodiment of the present invention. It is a figure which shows the method of recommendation typically. It is a functional block diagram of a server. It is a figure which shows the memory content of a preference data storage part. It is a flowchart which shows operation
- FIG. 1 is an overall configuration diagram of a recommendation system according to an embodiment of the present invention.
- the recommendation system 10 includes a server 16 and a plurality of user devices 12 all connected to a communication network 14 such as the Internet.
- the server 16 is configured around a known server computer, and includes functions such as an electronic commerce server and an information service server such as e-learning and news.
- the user device 12 is a known computer such as a personal computer used by each user, a home server, a home television, a portable telephone, etc.
- the user device 12 accesses the server 16 via the communication network 14 and provides the server 16 Receive data related to various services and display it.
- data can be input using a pointing device or a keyboard, and the input data can be transmitted to the server 16 via the communication network 14. ing.
- the server 16 also generates recommendation data for each user device 12.
- the user device 12 receives and displays the recommendation data thus generated.
- the recommendation data is a list of products to be purchased, books to be read by the user, music to be viewed, and educational programs to be taken.
- the server 16 selects a user (second user group) having a high degree of similarity with each user belonging to the first user group. Assuming that a user whose similarity with any user belonging to the first user group is 0.8 or more is a user who should belong to the second user group, the users c and d become the second user group in FIG. It will belong. Furthermore, the server 16 selects users (third user group) having a medium similarity to the user a. For example, assuming that a user having a similarity of 0.6 or more and less than 0.8 is a user who should belong to the third user group, the users c and e belong to the third user group in FIG. Thereafter, the server 16 determines a product set of the second user group and the third user group.
- the server 16 generates recommendation data based on preference data of users belonging to the product set of the second user group and the third user group.
- recommendation data for the user a is generated based on the preference data of the user c.
- the preference data is vector data including a numerical value (evaluation numerical value) indicating the degree to which the user prefers the information item for each information item, and null (*) is evaluated for information items not evaluated by the user. Evaluation values have been input to the information items that have been completed (see FIG. 4).
- the information item is information to be evaluated by the user and to be recommended to the user, and is, for example, information of a product or information of a service such as an educational program.
- the server 16 identifies the information item to which null is input among the preference data of the user a (recommendation target user), and extracts the evaluation numerical value for the information item thus identified from the preference vector of the user belonging to the product set Do. Then, based on those evaluation numerical values and the degree of similarity between the user a and each user who belongs to the product set, a predicted value to the extent that the user a prefers the information item is calculated. In the server 16, a predetermined number of information items are listed in order from a value with a large predicted value obtained in this way to make recommendation data, or an information item whose prediction value is a predetermined value or more is made into a list to make recommendation data. Then, the recommendation data thus obtained is transmitted to the user device 12.
- the recommended item determination unit 31 includes a product set calculation unit 31a, an unevaluated item extraction unit 31b, an evaluated user selection unit 31c, an estimated evaluation value calculation unit 31d, and a recommendation data generation unit 31e. These functions are realized by executing a program in the server 16.
- the program may be stored in an information storage medium such as a CD-ROM and installed from there on the server 16 or may be downloaded from another computer via the communication network 14.
- the preference data storage unit 22 stores preference data of each user of the recommendation system 10.
- FIG. 4 shows the contents stored in the preference data storage unit 22.
- the preference data storage unit 22 evaluates the user ID of each user and the evaluation numerical value for each ID of the information item (similarity Data) are stored in association with each other.
- null NUL
- evaluation numerical values are set for information items that have already been evaluated.
- the similarity calculation unit 23 calculates the similarity of preference data among users based on the preference data stored in the preference data storage unit 22. Specifically, a set Y ij of item IDs to which evaluation numerical values are input among the preference data of the user i and the user j is calculated.
- the following equation (1) shows an example of the set Y ij .
- the similarity calculation unit 23 calculates, as the similarity ⁇ ij of the user i and the user j, a correlation value of vectors having elements of evaluation values of the user i and the user j with respect to item IDs included in the set Y ij. .
- the similarity ⁇ ij is calculated, for example, according to the following equation (2).
- the similarity calculation unit 23 executes the above calculation for all combinations of users, and stores the result in the similarity data storage unit 24.
- the first user selection unit 25 selects one or more of the users of the recommendation system 10 based on the similarity between the preference data of the recommendation target user among the users of the recommendation system 10 and the preference data of the other users. Is selected as the first user group. Specifically, assuming that the recommendation target user is the user a, the user j (the user b in FIG. 2) whose similarity ⁇ aj stored in the similarity data storage unit 24 is equal to or greater than a first predetermined value (for example, 0.8) To configure the first user group. The IDs of the users making up the first user group are stored in the first user storage unit 26.
- the second user selection unit 27 for the user j identified by the user ID stored in the first user storage unit 26, the user i whose similarity ⁇ ij is equal to or more than the first predetermined value (user in FIG.
- the second user group is configured by c and d).
- the IDs of the users making up the second user group are stored in the second user storage unit 28.
- the third user selection unit 29 determines that the similarity rho aj stored in the similarity data storage unit 24 is less than the first predetermined value, not less than a second predetermined value (e.g., 0.6)
- a third group of users is configured by users j (users c and e in FIG. 2).
- the IDs of the users constituting the third user group are stored in the third user storage unit 30.
- the recommended item determination unit 31 identifies users (user c in FIG. 2) belonging to both the second user group and the third user group, and generates recommendation data based on the identified user preference data. Specifically, the product set calculation unit 31 a extracts the user ID stored in both the second user storage unit 28 and the third user storage unit 30. Further, the unevaluated item extraction unit 31 b reads the preference data of the user a who is the evaluation target user from the preference data storage unit 22, and extracts the item IDs of all the information items for which the user a has not yet evaluated.
- the evaluation prediction value calculation unit 31 d calculates the prediction value S ak according to the following equation (4).
- S'x is an average value of evaluation numerical values included in the preference data of the user x.
- the recommendation data generation unit 31e generates recommendation data based on the prediction value S ak of the evaluation of the item k that has not been evaluated by the user a, which is calculated by the evaluation prediction value calculation unit 31d. For example, a list of information items whose predicted value S ak is equal to or more than a predetermined value may be set as recommendation data, or a list of a predetermined number of information items may be set as recommendation data in the descending order of predicted values S ak .
- the recommendation data transmission unit 32 transmits the recommendation data generated in this manner to the user device 12 used by the user a. The user device 12 receives this recommendation data and displays it on the display.
- the input data is transmitted from the user device 12 to the server 16.
- the user may directly input an evaluation value for each information item, and the input value may be transmitted to the server 16.
- the server 16 It may be sent to
- the user input reception unit 20 receives such data, and the preference data update unit 21 updates preference data of each user based on the received data.
- FIG. 5 is a flow chart showing the operation of the server 16.
- the process shown in the figure indicates a process in which the server 16 generates recommendation data and transmits it to the user device 12.
- the similarity calculation unit 23 generates a set Y ij of items for which the user i and the user j have both evaluated (S101).
- the similarity ⁇ ij is calculated according to the above-mentioned equation (2) for the combination of the user i and the user j (S102).
- the similarity calculation unit 23 repeatedly executes the above process for all combinations of users.
- the first user selection unit 25 After that, the first user selection unit 25 generates a set A of users whose similarity to the user a who is a recommendation target user is equal to or more than a first predetermined value, that is, a first user group (S103). Furthermore, the second user selection unit 27 generates a set B of users whose similarity with the users belonging to the first user group is equal to or greater than a first predetermined value, that is, a second user group (S104). Further, the third user selection unit 29 generates a set C of users whose similarity with the user a who is the recommendation target user is less than the first predetermined value and not less than the second predetermined value, that is, a third user group (S105) .
- recommendation data is generated based on preference data of a user indirectly similar to the evaluation target user
- various recommendation data can be generated based on preference data of more users. It will be.
- recommendation data is generated based on preference data of a user (user c in FIG. 2) having a high degree of similarity indirectly even if the degree of similarity with the user to be evaluated is medium. For this reason, it is possible to continuously provide information that makes the recommendation target user interested.
- the present invention is not limited to the above embodiment, and various modifications can be made.
- the predicted value of the similarity between users and the evaluation is not limited to the above equation, and various calculation equations may be used.
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Information which interests a user to be recommended is provided continuously. A recommendation system comprises a taste data storage part (22) wherein taste data relating to a plurality of users is stored; a similarity calculation part (23) which calculates the similarity of the taste data among the users; a first user selection part (25) which selects one or more of the plurality of users on the basis of the similarity between taste data relating to the user to be recommended out of the plurality of users and taste data relating to all or a part of the plurality of users; a second user selection part (27) which selects one or more of the plurality of users on the basis of the similarity between taste data relating to the users selected by the first user selection part (25) and the taste data relating to all or a part of the plurality of users; and a recommended item determination part (31) which determines information to recommend the user to be recommended on the basis of the taste data relating to a part or all of the users selected by the second user selection part (27).
Description
本発明は推薦システム、推薦方法、推薦プログラム及び情報記憶媒体に関する。
The present invention relates to a recommendation system, a recommendation method, a recommendation program, and an information storage medium.
近年、情報検索やオンライン販売などの各種オンラインサービスにおいて、推薦アルゴリズムが利用されることが多くなっている。協調フィルタリングと呼ばれる推薦アルゴリズムでは、最初にユーザ間で嗜好データの類似度を計算し、ある推薦対象ユーザと嗜好データの類似度が高い別のユーザを選出する。そして、こうして選出されるユーザの嗜好を元にして推薦対象ユーザに推薦する情報を判断する。
In recent years, recommendation algorithms are often used in various online services such as information search and online sales. In the recommendation algorithm called collaborative filtering, the similarity of preference data is first calculated among users, and another user whose preference data is highly similar to a certain recommendation target user is selected. Then, information to be recommended to the recommendation target user is determined based on the preference of the user thus selected.
しかしながら上記従来手法によると、推薦アルゴリズムが長期間にわたり使用され、様々な情報が推薦されるにつれて、既に推薦対象ユーザに推薦された情報が再度推薦されるようになり、推薦対象ユーザの新たな興味・関心を掘り起こすことができないという問題がある。嗜好データの類似度がそれほど高くないユーザの嗜好を元にして、さらに多くの情報を推薦することも考えられるが、そうすると推薦される情報の中にノイズも多くなり、却ってユーザの利便性を損なう。
However, according to the above-described conventional method, as the recommendation algorithm is used for a long time and various information is recommended, the information already recommended to the recommendation target user is again recommended, and the new interest of the recommendation target user・ There is a problem that it can not dig up interest. Although it is possible to recommend more information based on the preference of the user whose preference degree of the preference data is not so high, there is also a lot of noise in the recommended information, which in turn impairs the convenience of the user .
本発明は上記課題に鑑みてなされたものであって、その目的は、推薦対象ユーザに対して興味を湧かせる情報を継続的に提供できる推薦システム、推薦方法、推薦プログラム及び情報記憶媒体を提供することにある。
The present invention has been made in view of the above problems, and an object of the present invention is to provide a recommendation system, a recommendation method, a recommendation program, and an information storage medium capable of continuously providing information that brings interest to a recommendation target user. It is to do.
上記課題を解決するために、本発明に係る推薦システムは、複数のユーザの嗜好データを記憶する嗜好データ記憶手段と、ユーザ間の嗜好データの類似度を計算する類似度計算手段と、前記複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出手段と、前記第1ユーザ選出手段により選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出手段と、前記第2ユーザ選出手段により選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定手段と、を含むことを特徴とする。
In order to solve the above problems, a recommendation system according to the present invention comprises: preference data storage means for storing preference data of a plurality of users; similarity calculation means for calculating the similarity of preference data among users; A first user who selects one or more of the plurality of users based on the similarity between the preference data of the recommendation target user among the users and the preference data of all or part of the plurality of users Among the plurality of users based on the similarity between the selection means, the preference data of the user selected by the first user selection means, and the preference data of all or part of the plurality of users The recommendation target user is selected based on second user selection means for selecting one or more and preference data of some or all of the users selected by the second user selection means. Characterized in that it comprises a recommendation information determining means for determining information to be recommended, to.
また、本発明に係る推薦方法は、複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出ステップと、前記第1ユーザ選出ステップにおいて選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出ステップと、前記第2ユーザ選出ステップにおいて選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定ステップと、を含むことを特徴とする。
Further, according to the recommendation method of the present invention, the plurality of the plurality of users can be selected based on the similarity between the preference data of the recommendation target user and the preference data of all or part of the plurality of users. Similarity between a first user selection step of selecting one or more of the users, preference data of the user selected in the first user selection step, and preference data of all or part of the plurality of users The second user selection step of selecting one or more of the plurality of users based on the degree, and the preference data of some or all of the users selected in the second user selection step And a recommendation information determination step of determining information to be recommended to the recommendation target user.
さらに、本発明に係る推薦プログラムは、複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出ステップと、前記第1ユーザ選出ステップにおいて選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出ステップと、前記第2ユーザ選出ステップにおいて選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定ステップと、をコンピュータに実行させるためのプログラムである。このプログラムはコンピュータ可読情報記憶媒体に格納されてよい。
Furthermore, the recommendation program according to the present invention is characterized in that, based on the similarity between the preference data of the recommendation target user among the plurality of users and the preference data of all or part of the plurality of users, Similarity between a first user selection step of selecting one or more of the users, preference data of the user selected in the first user selection step, and preference data of all or part of the plurality of users The second user selection step of selecting one or more of the plurality of users based on the degree, and the preference data of some or all of the users selected in the second user selection step It is a program for making a computer perform recommendation information determination step which determines the information recommended to a recommendation object user. This program may be stored on a computer readable information storage medium.
また、本発明の一態様では、前記第1ユーザ選出手段(ステップ)は、前記推薦対象ユーザと、嗜好データの類似度が第1所定値以上であるユーザを選出し、前記推薦システムは、前記推薦ユーザと、嗜好データの類似度が前記第1所定値未満且つ前記第1所定値よりも小さな第2所定値以上であるユーザを選出する第3ユーザ選出手段をさらに含み、前記推薦情報決定手段は、前記第2ユーザ選出手段により選出されるユーザであり、且つ前記第3ユーザ選出手段により選出されるユーザでもあるユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する。
Further, in one aspect of the present invention, the first user selection means (step) selects a user whose similarity degree of preference data with the recommendation target user is equal to or more than a first predetermined value, and the recommendation system The recommendation information determining means further includes third user selection means for selecting a recommended user and a user whose preference degree is less than the first predetermined value and greater than or equal to a second predetermined value smaller than the first predetermined value. The information to be recommended to the recommendation target user is determined based on preference data of a user who is a user selected by the second user selection means and is also a user selected by the third user selection means.
また、本発明の他の態様では、前記嗜好データは、複数の情報要素のそれぞれについて、ユーザの嗜好の程度を示す数値を含み、前記推薦情報決定手段は、前記各情報要素について、前記第2ユーザ選出手段により選出されるユーザのうち一部又は全部のユーザの嗜好データと前記推薦対象ユーザの嗜好データとの類似度、及び各ユーザの嗜好データに含まれる数値に基づいて、当該情報要素について、前記推薦対象ユーザの嗜好の程度を示す数値を予測する予測手段を含む。
Further, in another aspect of the present invention, the preference data includes, for each of the plurality of information elements, a numerical value indicating a degree of preference of the user, and the recommendation information determination means determines the second information element for each of the information elements. About the information element based on the similarity between preference data of some or all of the users among the users selected by the user selection means and the preference data of the recommendation target user, and the numerical value included in the preference data of each user And a prediction unit that predicts a numerical value indicating the degree of preference of the recommendation target user.
以下、本発明の実施形態について図面に基づき詳細に説明する。
Hereinafter, embodiments of the present invention will be described in detail based on the drawings.
図1は、本発明の実施形態に係る推薦システムの全体構成図である。同図に示すように、推薦システム10は、インターネットなどの通信ネットワーク14にいずれも接続されたサーバ16及び複数のユーザ装置12から構成されている。サーバ16は、公知のサーバコンピュータを中心に構成されており、電子商取引サーバ、e-ラーニングやニュースなどの情報サービスサーバなどの機能を含んでいる。ユーザ装置12は、各ユーザが使用するパーソナルコンピュータ、ホームサーバ、家庭用テレビ受像機、携帯電話機などの公知のコンピュータであり、通信ネットワーク14を介してサーバ16にアクセスして、サーバ16が提供している各種サービスに関わるデータを受信し、それを表示する。また、例えば商品の購入手続きや情報の配信手続きなどの各種手続きのために、ポインティングデバイスやキーボードによりデータを入力し、この入力されたデータを通信ネットワーク14を介してサーバ16に送信できるようになっている。また、サーバ16はユーザ装置12毎に推薦データを生成する。ユーザ装置12はこうして生成される推薦データを受信し、表示する。推薦データは、購入すべき商品、ユーザが読むべき書籍、視聴すべき音楽、受講すべき教育プログラムなどのリストである。
FIG. 1 is an overall configuration diagram of a recommendation system according to an embodiment of the present invention. As shown in the figure, the recommendation system 10 includes a server 16 and a plurality of user devices 12 all connected to a communication network 14 such as the Internet. The server 16 is configured around a known server computer, and includes functions such as an electronic commerce server and an information service server such as e-learning and news. The user device 12 is a known computer such as a personal computer used by each user, a home server, a home television, a portable telephone, etc. The user device 12 accesses the server 16 via the communication network 14 and provides the server 16 Receive data related to various services and display it. Also, for various procedures such as the purchase procedure of goods and the delivery procedure of information, data can be input using a pointing device or a keyboard, and the input data can be transmitted to the server 16 via the communication network 14. ing. The server 16 also generates recommendation data for each user device 12. The user device 12 receives and displays the recommendation data thus generated. The recommendation data is a list of products to be purchased, books to be read by the user, music to be viewed, and educational programs to be taken.
図2は、サーバ16における推薦データの生成方法を模式的に示している。同図において、a~eは推薦システム10のユーザ、すなわち各ユーザ装置12のユーザを示している。ユーザa(推薦対象ユーザ)に対して推薦データを生成する場合、まず推薦システム10のユーザの中から、ユーザaとの類似度が高いユーザ(第1ユーザ群)を選出する。なお、本実施形態では、サーバ16では各ユーザの嗜好データを管理しており、この嗜好データ間の類似度(相関値)をユーザ間の類似度としている。例えばユーザaとの類似度が0.8以上のユーザが第1ユーザ群に属するべきユーザであるとすれば、図2においてはユーザbが第1ユーザ群に属することになり、ユーザc~eは第1ユーザ群には属しない。
FIG. 2 schematically shows a method of generating recommendation data in the server 16. In the figure, a to e indicate users of the recommendation system 10, that is, users of the respective user devices 12. When generating recommendation data for the user a (recommendation target user), first, among the users of the recommendation system 10, users (first user group) having a high degree of similarity with the user a are selected. In the present embodiment, the server 16 manages preference data of each user, and the similarity (correlation value) between the preference data is regarded as the similarity between users. For example, assuming that a user whose similarity to user a is 0.8 or more should belong to the first user group, in FIG. 2, user b belongs to the first user group, and users c to e Does not belong to the first user group.
次に、サーバ16は、第1ユーザ群に属する各ユーザとの類似度が高いユーザ(第2ユーザ群)を選出する。第1ユーザ群に属するいずれかのユーザとの類似度が0.8以上のユーザが第2ユーザ群に属するべきユーザであるとすれば、図2においてはユーザc及びdが第2ユーザ群に属することになる。さらに、サーバ16は、ユーザaとの類似度が中くらいのユーザ(第3ユーザ群)を選出する。例えばユーザとの類似度が0.6以上0.8未満のユーザが第3ユーザ群に属するべきユーザであるとすると、図2においてはユーザc及びeが第3ユーザ群に属することになる。その後、サーバ16は、第2ユーザ群と第3ユーザ群との積集合を判断する。すなわち、推薦システム10のユーザのうち、第2ユーザ群に属し、且つ第3ユーザ群にも属するユーザを調べる。図2においては、ユーザcがこれに該当する。サーバ16では、第2ユーザ群と第3ユーザ群との積集合に属するユーザの嗜好データに基づいて推薦データを生成する。図2の例では、ユーザcの嗜好データに基づいてユーザaに対する推薦データが生成される。嗜好データは、情報アイテムごとにユーザが該情報アイテムを嗜好する程度を示す数値(評価数値)を含むベクトルデータであり、ユーザによる評価が済んでいない情報アイテムにはヌル(※)が、評価が済んでいる情報アイテムには評価数値が入力されている(図4参照)。情報アイテムは、ユーザによる評価の対象となり、且つユーザに対する推薦の対象となる情報であり、例えば商品の情報や教育プログラムなどのサービスの情報である。
Next, the server 16 selects a user (second user group) having a high degree of similarity with each user belonging to the first user group. Assuming that a user whose similarity with any user belonging to the first user group is 0.8 or more is a user who should belong to the second user group, the users c and d become the second user group in FIG. It will belong. Furthermore, the server 16 selects users (third user group) having a medium similarity to the user a. For example, assuming that a user having a similarity of 0.6 or more and less than 0.8 is a user who should belong to the third user group, the users c and e belong to the third user group in FIG. Thereafter, the server 16 determines a product set of the second user group and the third user group. That is, among the users of the recommendation system 10, users belonging to the second user group and to the third user group are checked. In FIG. 2, the user c corresponds to this. The server 16 generates recommendation data based on preference data of users belonging to the product set of the second user group and the third user group. In the example of FIG. 2, recommendation data for the user a is generated based on the preference data of the user c. The preference data is vector data including a numerical value (evaluation numerical value) indicating the degree to which the user prefers the information item for each information item, and null (*) is evaluated for information items not evaluated by the user. Evaluation values have been input to the information items that have been completed (see FIG. 4). The information item is information to be evaluated by the user and to be recommended to the user, and is, for example, information of a product or information of a service such as an educational program.
サーバ16では、ユーザa(推薦対象ユーザ)の嗜好データのうちヌルが入力されている情報アイテムを特定し、こうして特定された情報アイテムに対する評価数値を、上記積集合に属するユーザの嗜好ベクトルから抽出する。そして、それらの評価数値と、ユーザaと上記積集合に属する各ユーザとの類似度と、に基づいて、当該情報アイテムに対してユーザaが嗜好する程度の予測値を算出する。サーバ16では、こうして得られる予測値が大きい値から順に所定数の情報アイテムをリスト化して推薦データとしたり、或いは予測値が所定値以上である情報アイテムをリスト化して推薦データとしたりする。そして、こうして得られる推薦データをユーザ装置12に送信する。
The server 16 identifies the information item to which null is input among the preference data of the user a (recommendation target user), and extracts the evaluation numerical value for the information item thus identified from the preference vector of the user belonging to the product set Do. Then, based on those evaluation numerical values and the degree of similarity between the user a and each user who belongs to the product set, a predicted value to the extent that the user a prefers the information item is calculated. In the server 16, a predetermined number of information items are listed in order from a value with a large predicted value obtained in this way to make recommendation data, or an information item whose prediction value is a predetermined value or more is made into a list to make recommendation data. Then, the recommendation data thus obtained is transmitted to the user device 12.
ここでサーバ16の構成及び動作についてさらに詳細に説明する。図3は、サーバ16の機能ブロック図である。同図に示すように、サーバ16の機能には、ユーザ入力受信部20、嗜好データ更新部21、嗜好データ記憶部22、類似度算出部23、類似度データ記憶部24、第1ユーザ選出部25、第1ユーザ記憶部26、第2ユーザ選出部27、第2ユーザ記憶部28、第3ユーザ選出部29、第3ユーザ記憶部30、推薦アイテム決定部31、推薦データ送信部32が含まれている。推薦アイテム決定部31は、積集合算出部31a、未評価アイテム抽出部31b、評価済みユーザ選出部31c、評価予測値算出部31d、推薦データ生成部31eを含んでいる。これらの機能は、サーバ16においてプログラムが実行されることにより実現されるものである。プログラムはCD-ROMなどの情報記憶媒体に格納され、そこからサーバ16にインストールされてもよいし、通信ネットワーク14を介して他のコンピュータからダウンロードされもよい。
Here, the configuration and operation of the server 16 will be described in more detail. FIG. 3 is a functional block diagram of the server 16. As shown in the figure, the functions of the server 16 include a user input reception unit 20, a preference data update unit 21, a preference data storage unit 22, a similarity calculation unit 23, a similarity data storage unit 24, and a first user selection unit A first user storage unit 26, a second user selection unit 27, a second user storage unit 28, a third user selection unit 29, a third user storage unit 30, a recommended item determination unit 31, and a recommendation data transmission unit 32 are included. It is done. The recommended item determination unit 31 includes a product set calculation unit 31a, an unevaluated item extraction unit 31b, an evaluated user selection unit 31c, an estimated evaluation value calculation unit 31d, and a recommendation data generation unit 31e. These functions are realized by executing a program in the server 16. The program may be stored in an information storage medium such as a CD-ROM and installed from there on the server 16 or may be downloaded from another computer via the communication network 14.
まず嗜好データ記憶部22は、推薦システム10の各ユーザの嗜好データを記憶するものである。図4は、嗜好データ記憶部22の記憶内容を示しており、同図に示されるように、嗜好データ記憶部22は、各ユーザのユーザIDと、情報アイテムのID毎の評価数値(類似度データ)と、を関連づけて記憶している。上述のようにユーザIDにより特定されるユーザが未だ評価をしていない情報アイテムについてはヌル(NUL)が設定されており、既に評価をしている情報アイテムについては評価数値が設定されている。類似度算出部23では、嗜好データ記憶部22に記憶された嗜好データに基づき、ユーザ間の嗜好データの類似度を算出する。具体的には、ユーザi及びユーザjの嗜好データのうち評価数値が入力されているアイテムIDの集合Yijを算出する。次式(1)は集合Yijの一例を示している。
First, the preference data storage unit 22 stores preference data of each user of the recommendation system 10. FIG. 4 shows the contents stored in the preference data storage unit 22. As shown in the figure, the preference data storage unit 22 evaluates the user ID of each user and the evaluation numerical value for each ID of the information item (similarity Data) are stored in association with each other. As described above, null (NUL) is set for information items that the user specified by the user ID has not yet evaluated, and evaluation numerical values are set for information items that have already been evaluated. The similarity calculation unit 23 calculates the similarity of preference data among users based on the preference data stored in the preference data storage unit 22. Specifically, a set Y ij of item IDs to which evaluation numerical values are input among the preference data of the user i and the user j is calculated. The following equation (1) shows an example of the set Y ij .

次に、類似度算出部23では、集合Yijに含まれるアイテムIDに対するユーザi及びユーザjの評価数値を要素とするベクトルの相関値を、ユーザiとユーザjの類似度ρijとして算出する。類似度ρijは、例えば次式(2)に従って算出される。類似度算出部23では、以上の計算をすべてのユーザの組合せに対して実行し、その結果を類似度データ記憶部24に記憶させる。
Next, the similarity calculation unit 23 calculates, as the similarity ρ ij of the user i and the user j, a correlation value of vectors having elements of evaluation values of the user i and the user j with respect to item IDs included in the set Y ij. . The similarity ρ ij is calculated, for example, according to the following equation (2). The similarity calculation unit 23 executes the above calculation for all combinations of users, and stores the result in the similarity data storage unit 24.

第1ユーザ選出部25では、推薦システム10のユーザのうち推薦対象ユーザの嗜好データと、他のユーザの嗜好データと、の類似度に基づいて、推薦システム10のユーザの中から1以上のユーザを第1ユーザ群として選出する。具体的には、推薦対象ユーザをユーザaとすると、類似度データ記憶部24に記憶された類似度ρajが第1所定値(例えば0.8)以上であるユーザj(図2のユーザb)により第1ユーザ群を構成する。第1ユーザ群を構成するユーザのIDは第1ユーザ記憶部26に記憶される。
The first user selection unit 25 selects one or more of the users of the recommendation system 10 based on the similarity between the preference data of the recommendation target user among the users of the recommendation system 10 and the preference data of the other users. Is selected as the first user group. Specifically, assuming that the recommendation target user is the user a, the user j (the user b in FIG. 2) whose similarity ρ aj stored in the similarity data storage unit 24 is equal to or greater than a first predetermined value (for example, 0.8) To configure the first user group. The IDs of the users making up the first user group are stored in the first user storage unit 26.
第2ユーザ選出部27では、第1ユーザ記憶部26に記憶されるユーザIDにより識別されるユーザjに対して、類似度ρijが上記第1所定値以上であるユーザi(図2のユーザc及びd)により第2ユーザ群を構成する。第2ユーザ群を構成するユーザのIDは第2ユーザ記憶部28に記憶される。
In the second user selection unit 27, for the user j identified by the user ID stored in the first user storage unit 26, the user i whose similarity ρ ij is equal to or more than the first predetermined value (user in FIG. The second user group is configured by c and d). The IDs of the users making up the second user group are stored in the second user storage unit 28.
第3ユーザ選出部29は、推薦対象ユーザをユーザaとすると、類似度データ記憶部24に記憶された類似度ρajが上記第1所定値未満、第2所定値(例えば0.6)以上であるユーザj(図2のユーザc及びe)により第3ユーザ群を構成する。第3ユーザ群を構成するユーザのIDは第3ユーザ記憶部30に記憶される。
Assuming that the recommendation target user is the user a, the third user selection unit 29 determines that the similarity rho aj stored in the similarity data storage unit 24 is less than the first predetermined value, not less than a second predetermined value (e.g., 0.6) A third group of users is configured by users j (users c and e in FIG. 2). The IDs of the users constituting the third user group are stored in the third user storage unit 30.
推薦アイテム決定部31は、第2ユーザ群と第3ユーザ群の両方に属するユーザ(図2のユーザc)を特定し、特定されるユーザの嗜好データに基づいて推薦データを生成する。具体的には、積集合算出部31aは、第2ユーザ記憶部28と第3ユーザ記憶部30の両方に記憶されるユーザIDを抽出する。また、未評価アイテム抽出部31bは、評価対象ユーザであるユーザaの嗜好データを嗜好データ記憶部22から読み出し、ユーザaが未だ評価をしていない全ての情報アイテムのアイテムIDを抽出する。評価済みユーザ選出部31cは、積集合算出部31aにより抽出されるユーザIDに関連する嗜好データを嗜好データ記憶部22から読み出し、未評価アイテム抽出部31bにより抽出される各アイテムIDについて評価数値(つまりヌルでない値)が嗜好データに設定されているユーザIDを選出する。こうして、ユーザaによる評価が済んでいない情報アイテムについて、既に評価をしているユーザの集合Ekを決定する。この集合は、積集合算出部31aで算出される集合の部分集合となる。次式(3)は集合Ekの一例を示している。
The recommended item determination unit 31 identifies users (user c in FIG. 2) belonging to both the second user group and the third user group, and generates recommendation data based on the identified user preference data. Specifically, the product set calculation unit 31 a extracts the user ID stored in both the second user storage unit 28 and the third user storage unit 30. Further, the unevaluated item extraction unit 31 b reads the preference data of the user a who is the evaluation target user from the preference data storage unit 22, and extracts the item IDs of all the information items for which the user a has not yet evaluated. The evaluated user selection unit 31c reads out preference data related to the user ID extracted by the product set calculation unit 31a from the preference data storage unit 22, and evaluates each item ID extracted by the unevaluated item extraction unit 31b That is, the user ID in which the non-null value is set in the preference data is selected. Thus, for information items that have not been evaluated by user a, a set Ek of users who have already evaluated is determined. This set is a subset of the set calculated by the product set calculation unit 31a. The following equation (3) shows an example of the set E k .
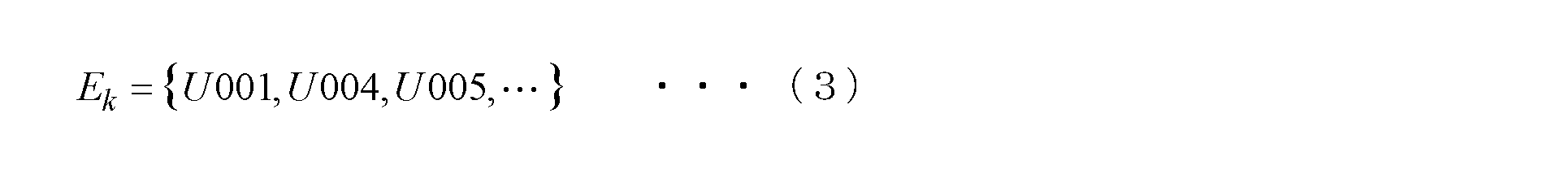
評価予測値算出部31dは、集合Ekに属するユーザiによるアイテムID=kのアイテムに対する評価数値Sikと、各ユーザiとユーザaとの類似度ρaiとに基づいて、ユーザaによるアイテムID=kのアイテムに対する評価の予測値Sakを算出する。具体的には、評価予測値算出部31dは次式(4)に従って予測値Sakを算出する。ここで、S’xはユーザxの嗜好データに含まれる評価数値の平均値である。
The evaluation prediction value calculation unit 31 d is an item by the user a based on the evaluation value S ik for the item with item ID = k by the user i belonging to the set E k and the similarity ai between each user i and the user a The predicted value S ak of the evaluation for the item with ID = k is calculated. Specifically, the evaluation prediction value calculation unit 31 d calculates the prediction value S ak according to the following equation (4). Here, S'x is an average value of evaluation numerical values included in the preference data of the user x.

推薦データ生成部31eは、評価予測値算出部31dにより算出されるユーザaにより評価が未だされていないアイテムkについての評価の予測値Sakに基づいて、推薦データを生成する。例えば、予測値Sakが所定値以上である情報アイテムのリストを推薦データとしたり、予測値Sakが大きいものから順に所定数の情報アイテムのリストを推薦データとしてよい。推薦データ送信部32は、こうして生成される推薦データをユーザaが使用するユーザ装置12に送信する。ユーザ装置12では、この推薦データを受信して表示器により表示する。
The recommendation data generation unit 31e generates recommendation data based on the prediction value S ak of the evaluation of the item k that has not been evaluated by the user a, which is calculated by the evaluation prediction value calculation unit 31d. For example, a list of information items whose predicted value S ak is equal to or more than a predetermined value may be set as recommendation data, or a list of a predetermined number of information items may be set as recommendation data in the descending order of predicted values S ak . The recommendation data transmission unit 32 transmits the recommendation data generated in this manner to the user device 12 used by the user a. The user device 12 receives this recommendation data and displays it on the display.
各情報アイテムについてユーザが評価の入力を行うと、その入力データはユーザ装置12からサーバ16に送信される。例えば、各情報アイテムに対してユーザが直接評価数値を入力し、入力された数値をサーバ16に送信するようにしてもよい。或いは、各情報アイテムに係る商品を購入したり、各情報アイテムに係る教育プログラムを受講したり、といったように情報アイテムに関係して肯定的な手続きが実行された場合に、その情報をサーバ16に送信してもよい。ユーザ入力受信部20では、こうしたデータを受信し、嗜好データ更新部21では、受信されるデータに基づいて各ユーザの嗜好データを更新する。
When the user inputs an evaluation for each information item, the input data is transmitted from the user device 12 to the server 16. For example, the user may directly input an evaluation value for each information item, and the input value may be transmitted to the server 16. Alternatively, if a positive procedure is performed in relation to the information item, such as purchasing a product related to each information item, taking an education program related to each information item, or the like, the server 16 It may be sent to The user input reception unit 20 receives such data, and the preference data update unit 21 updates preference data of each user based on the received data.
図5は、サーバ16の動作を示すフロー図である。同図に示す処理はサーバ16が推薦データを生成し、ユーザ装置12に送信する処理を示している。サーバ16では、まず類似度算出部23がユーザiとユーザjとが共に評価を済ませているアイテムの集合Yijを生成する(S101)。そして、ユーザiとユーザjとの組合せについて類似度ρijを上記式(2)に従って算出する(S102)。類似度算出部23は、以上の処理を全てのユーザの組合せについて繰り返して実行する。
FIG. 5 is a flow chart showing the operation of the server 16. The process shown in the figure indicates a process in which the server 16 generates recommendation data and transmits it to the user device 12. In the server 16, first, the similarity calculation unit 23 generates a set Y ij of items for which the user i and the user j have both evaluated (S101). Then, the similarity ρ ij is calculated according to the above-mentioned equation (2) for the combination of the user i and the user j (S102). The similarity calculation unit 23 repeatedly executes the above process for all combinations of users.
その後、第1ユーザ選出部25が、推薦対象ユーザであるユーザaとの類似度が第1所定値以上であるユーザの集合A、すなわち第1ユーザ群を生成する(S103)。さらに、第2ユーザ選出部27が、第1ユーザ群に属するユーザとの類似度が第1所定値以上であるユーザの集合B、すなわち第2ユーザ群を生成する(S104)。また、第3ユーザ選出部29が、推薦対象ユーザであるユーザaとの類似度が第1所定値未満第2所定値以上であるユーザの集合C、すなわち第3ユーザ群を生成する(S105)。
After that, the first user selection unit 25 generates a set A of users whose similarity to the user a who is a recommendation target user is equal to or more than a first predetermined value, that is, a first user group (S103). Furthermore, the second user selection unit 27 generates a set B of users whose similarity with the users belonging to the first user group is equal to or greater than a first predetermined value, that is, a second user group (S104). Further, the third user selection unit 29 generates a set C of users whose similarity with the user a who is the recommendation target user is less than the first predetermined value and not less than the second predetermined value, that is, a third user group (S105) .
その後、積集合算出部31aが集合Bと集合Cとの積集合Dを算出する(S106)。そして、未評価アイテム抽出部31bが評価対象ユーザであるユーザaが未評価であるアイテムのアイテムID(=k)を特定し、評価済みユーザ選出部31cが集合Dの部分集合Ekを生成する(S107)。そして、評価予測値算出部31dがユーザaのアイテムID=kに対する評価数値の予測値Sakを上記式(4)に従って算出する(S108)。評価評価済みユーザ選出部31c及び評価予測値算出部31dは、S107及びS108の処理をユーザaの全ての未評価アイテムについて繰り返す。その後、推薦データ生成部31eが評価予測値算出部31dで算出される各未評価アイテムの評価予測値に基づいて推薦データを生成し(S109)、それを推薦データ送信部32がユーザaのユーザ装置12に送信する(S110)。
Thereafter, the product set calculation unit 31a calculates a product set D of the set B and the set C (S106). Then, the unevaluated item extraction unit 31 b identifies the item ID (= k) of the item for which the user a who is the evaluation target is unevaluated, and the evaluated user selection unit 31 c generates the subset E k of the set D. (S107). Then, the evaluation prediction value calculation unit 31 d calculates the prediction value S ak of the evaluation numerical value for the item ID = k of the user a according to the above equation (4) (S 108). The evaluated and evaluated user selection unit 31c and the estimated evaluation value calculation unit 31d repeat the processing of S107 and S108 for all unevaluated items of the user a. Thereafter, the recommendation data generation unit 31e generates recommendation data based on the evaluation prediction value of each unrated item calculated by the evaluation prediction value calculation unit 31d (S109), and the recommendation data transmission unit 32 is the user of the user a It transmits to the apparatus 12 (S110).
以上説明した実施形態によると、評価対象ユーザと間接的に類似するユーザの嗜好データを元にして推薦データを生成するので、より多くのユーザの嗜好データを元にして多様な推薦データを生成できるようになる。また、評価対象ユーザとの類似度が中程度であっても、間接的には類似度が高いユーザ(図2のユーザc)の嗜好データを元にして推薦データを生成している。このため、推薦対象ユーザに対して興味を湧かせる情報を継続的に提供できるようになる。
According to the embodiment described above, since the recommendation data is generated based on preference data of a user indirectly similar to the evaluation target user, various recommendation data can be generated based on preference data of more users. It will be. In addition, recommendation data is generated based on preference data of a user (user c in FIG. 2) having a high degree of similarity indirectly even if the degree of similarity with the user to be evaluated is medium. For this reason, it is possible to continuously provide information that makes the recommendation target user interested.
なお、本発明は上記実施形態に限定されるものではなく、種々の変形実施が可能である。例えば、ユーザ間の類似度や評価の予測値は上記式に限定されず、様々な算出式が用いられてよい。
The present invention is not limited to the above embodiment, and various modifications can be made. For example, the predicted value of the similarity between users and the evaluation is not limited to the above equation, and various calculation equations may be used.
Claims (6)
- 複数のユーザの嗜好データを記憶する嗜好データ記憶手段と、
ユーザ間の嗜好データの類似度を計算する類似度計算手段と、
前記複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出手段と、
前記第1ユーザ選出手段により選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出手段と、
前記第2ユーザ選出手段により選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定手段と、
を含むことを特徴とする推薦システム。 Preference data storage means for storing preference data of a plurality of users;
Similarity calculation means for calculating the similarity of preference data between users;
One or more of the plurality of users are selected based on the similarity between preference data of a recommendation target user among the plurality of users and preference data of all or part of the plurality of users. 1 user selection means,
One or more of the plurality of users are selected based on the similarity between the preference data of the user selected by the first user selection means and the preference data of all or part of the plurality of users Second user selection means to
Recommendation information determination means for determining information to be recommended to the recommendation target user based on preference data of some or all of the users selected by the second user selection means;
Recommendation system characterized by including. - 請求の範囲第1項に記載の推薦システムにおいて、
前記第1ユーザ選出手段は、前記推薦対象ユーザと、嗜好データの類似度が第1所定値以上であるユーザを1以上選出し、
前記推薦システムは、前記推薦ユーザと、嗜好データの類似度が前記第1所定値未満且つ前記第1所定値よりも小さな第2所定値以上であるユーザを選出する第3ユーザ選出手段をさらに含み、
前記推薦情報決定手段は、前記第2ユーザ選出手段により選出されるユーザであり、且つ前記第3ユーザ選出手段により選出されるユーザでもあるユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する、
ことを特徴とする推薦システム。 In the recommendation system according to claim 1,
The first user selection unit selects one or more users whose similarity degree of preference data is equal to or greater than a first predetermined value with the recommendation target user,
The recommendation system further includes third user selection means for selecting a user whose similarity degree of preference data is less than the first predetermined value and greater than or equal to a second predetermined value smaller than the first predetermined value. ,
The recommendation information determination unit is recommended to the recommendation target user based on preference data of a user who is a user selected by the second user selection unit and is also a user selected by the third user selection unit. Determine the information,
Recommendation system characterized by. - 請求の範囲第1項又は第2項に記載の推薦システムにおいて、
前記嗜好データは、複数の情報要素のそれぞれについて、ユーザの嗜好の程度を示す数値を含み、
前記推薦情報決定手段は、前記各情報要素について、前記第2ユーザ選出手段により選出されるユーザのうち一部又は全部のユーザの嗜好データと前記推薦対象ユーザの嗜好データとの類似度、及び各ユーザの嗜好データに含まれる数値に基づいて、当該情報要素について、前記推薦対象ユーザの嗜好の程度を示す数値を予測する予測手段を含む、
ことを特徴とする推薦システム。 In the recommendation system according to claim 1 or 2,
The preference data includes, for each of a plurality of information elements, a numerical value indicating the degree of preference of the user,
The recommendation information determination means, for each of the information elements, the degree of similarity between preference data of some or all of the users selected by the second user selection means and the preference data of the recommendation target user, and A prediction unit that predicts a numerical value indicating the degree of preference of the recommendation target user for the information element based on a numerical value included in the preference data of the user;
Recommendation system characterized by. - 複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出ステップと、
前記第1ユーザ選出ステップにおいて選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出ステップと、
前記第2ユーザ選出ステップにおいて選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定ステップと、
を含むことを特徴とする推薦方法。 First, one or more of the plurality of users are selected based on the similarity between the preference data of the recommendation target user among the plurality of users and the preference data of all or part of the plurality of users. User selection step,
One or more of the plurality of users are selected based on the similarity between the preference data of the user selected in the first user selection step and the preference data of all or part of the plurality of users A second user selection step
A recommendation information determination step of determining information to be recommended to the recommendation target user based on preference data of some or all of the users selected in the second user selection step;
Recommendation method characterized by including. - 複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出ステップと、
前記第1ユーザ選出ステップにおいて選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出ステップと、
前記第2ユーザ選出ステップにおいて選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定ステップと、
をコンピュータに実行させるための推薦プログラム。 First, one or more of the plurality of users are selected based on the similarity between the preference data of the recommendation target user among the plurality of users and the preference data of all or part of the plurality of users. User selection step,
One or more of the plurality of users are selected based on the similarity between the preference data of the user selected in the first user selection step and the preference data of all or part of the plurality of users A second user selection step
A recommendation information determination step of determining information to be recommended to the recommendation target user based on preference data of some or all of the users selected in the second user selection step;
Recommendation program for making a computer run. - 複数のユーザのうち推薦対象ユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第1ユーザ選出ステップと、
前記第1ユーザ選出ステップにおいて選出されるユーザの嗜好データと、前記複数のユーザのうち全部又は一部のユーザの嗜好データと、の類似度に基づいて、前記複数のユーザのうち1以上を選出する第2ユーザ選出ステップと、
前記第2ユーザ選出ステップにおいて選出されるユーザのうち一部又は全部のユーザの嗜好データに基づいて、前記推薦対象ユーザに推薦する情報を決定する推薦情報決定ステップと、
をコンピュータに実行させるための推薦プログラムを記憶した情報記憶媒体。
First, one or more of the plurality of users are selected based on the similarity between the preference data of the recommendation target user among the plurality of users and the preference data of all or part of the plurality of users. User selection step,
One or more of the plurality of users are selected based on the similarity between the preference data of the user selected in the first user selection step and the preference data of all or part of the plurality of users A second user selection step
A recommendation information determination step of determining information to be recommended to the recommendation target user based on preference data of some or all of the users selected in the second user selection step;
An information storage medium storing a recommendation program for causing a computer to execute.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010547377A JP5451644B2 (en) | 2009-01-21 | 2009-03-31 | RECOMMENDATION SYSTEM, RECOMMENDATION METHOD, RECOMMENDATION PROGRAM, AND INFORMATION STORAGE MEDIUM |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009011428 | 2009-01-21 | ||
| JP2009-011428 | 2009-01-21 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2010084629A1 true WO2010084629A1 (en) | 2010-07-29 |
Family
ID=42355701
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2009/056686 WO2010084629A1 (en) | 2009-01-21 | 2009-03-31 | Recommendation system, recommendation method, recommendation program, and information storage medium |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP5451644B2 (en) |
| WO (1) | WO2010084629A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102467542A (en) * | 2010-11-11 | 2012-05-23 | 腾讯科技(深圳)有限公司 | Method and device for acquiring user similarity as well as user recommendation method and system |
| JP2013025325A (en) * | 2011-07-14 | 2013-02-04 | Kddi Corp | Recommendation device, recommendation system, recommendation method, and program |
| CN108352028A (en) * | 2015-11-09 | 2018-07-31 | 株式会社电通 | CRM Customer Relationship Management device and method |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000339336A (en) * | 1999-05-28 | 2000-12-08 | Matsushita Electric Ind Co Ltd | Device for providing data and device for generating user model for providing data |
| JP2006302097A (en) * | 2005-04-22 | 2006-11-02 | Matsushita Electric Ind Co Ltd | Cooperative filter device |
-
2009
- 2009-03-31 JP JP2010547377A patent/JP5451644B2/en not_active Expired - Fee Related
- 2009-03-31 WO PCT/JP2009/056686 patent/WO2010084629A1/en active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000339336A (en) * | 1999-05-28 | 2000-12-08 | Matsushita Electric Ind Co Ltd | Device for providing data and device for generating user model for providing data |
| JP2006302097A (en) * | 2005-04-22 | 2006-11-02 | Matsushita Electric Ind Co Ltd | Cooperative filter device |
Non-Patent Citations (1)
| Title |
|---|
| MASAYUKI IHARA ET AL.: "User no Senzaiteki Konomi Suiteiho", THE TRANSACTIONS OF THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS, vol. J82-A, no. 5, 25 May 1999 (1999-05-25), pages 717 - 725 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102467542A (en) * | 2010-11-11 | 2012-05-23 | 腾讯科技(深圳)有限公司 | Method and device for acquiring user similarity as well as user recommendation method and system |
| JP2013025325A (en) * | 2011-07-14 | 2013-02-04 | Kddi Corp | Recommendation device, recommendation system, recommendation method, and program |
| CN108352028A (en) * | 2015-11-09 | 2018-07-31 | 株式会社电通 | CRM Customer Relationship Management device and method |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2010084629A1 (en) | 2012-07-12 |
| JP5451644B2 (en) | 2014-03-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Liu et al. | Use of social network information to enhance collaborative filtering performance | |
| EP2304619B1 (en) | Correlated information recommendation | |
| Capuano et al. | Fuzzy group decision making for influence-aware recommendations | |
| US10904360B1 (en) | Method and apparatus for real-time personalization | |
| JP4898938B2 (en) | Information providing system and information providing method | |
| JP5805548B2 (en) | Information processing apparatus and information processing method | |
| JP6457358B2 (en) | Item recommendation system, item recommendation method and program | |
| JP5371676B2 (en) | RECOMMENDED CONTENT EXTRACTION DEVICE, RECOMMENDED CONTENT EXTRACTION METHOD, AND RECOMMENDED CONTENT EXTRACTION PROGRAM | |
| JP2012003359A (en) | Item recommendation system, item recommendation method, and program | |
| JPWO2010095169A1 (en) | Information recommendation method, system thereof, and server | |
| JP2009265747A (en) | Marketing support system, marketing support method, marketing support program, and computer readable medium | |
| JP2013218638A (en) | Content distribution system and recommendation method | |
| KR101870980B1 (en) | System for recommend the customized application, method thereof and recordable medium storing the method | |
| CN112364203A (en) | Television video recommendation method, device, server and storage medium | |
| JP6087467B2 (en) | Product recommendation service method based on relative comparison, recommendation service device and program therefor | |
| KR102008091B1 (en) | Method for Recommending Product by Using Image | |
| JP6903629B2 (en) | Evaluation system, evaluation method and program | |
| CN109636530B (en) | Product determination method, product determination device, electronic equipment and computer-readable storage medium | |
| WO2010084629A1 (en) | Recommendation system, recommendation method, recommendation program, and information storage medium | |
| JP5056803B2 (en) | Information providing server and information providing method | |
| KR20200044197A (en) | Machine learning based clothing fit recommending apparatus | |
| Coba et al. | Decision Making Based on Bimodal Rating Summary Statistics-An Eye-Tracking Study of Hotels | |
| JP2013029896A (en) | Item recommendation apparatus, method and program | |
| US20160132954A1 (en) | Recommender System Employing Subjective Properties | |
| JP5056801B2 (en) | Information providing server and information providing method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09838819 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010547377 Country of ref document: JP |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 09838819 Country of ref document: EP Kind code of ref document: A1 |