NOVEL PROTEINS AND NUCLEIC ACIDS ENCODING SAME
FIELD OF THE INVENTION
The present invention relates to novel polypeptides that are targets of small molecule drugs and that have properties related to stimulation of biochemical or physiological responses in a cell, a tissue, an organ or an organism. More particularly, the novel polypeptides are gene products of novel genes, or are specified biologically active fragments or derivatives thereof. Methods of use encompass diagnostic and prognostic assay procedures as well as methods of treating diverse pathological conditions.
U.S.S.N. 60/406125, filed August 26, 2002; U.S.S.N. 60/338543, filed November 16, 2001; U.S.S.N. 60/339286, filed December 11, 2001; U.S.S.N. 60/336576, filed December 4, 2001; U.S.S.N. 60/333912, filed November 28, 2001; each of which is incorporated herein by reference in its entirety.
FIELD OF THE INVENTION
The present invention relates to novel polypeptides that are targets of small molecule drugs and that have properties related to stimulation of biochemical or physiological responses in a cell, a tissue, an organ or an organism. More particularly, the novel polypeptides are gene products of novel genes, or are specified biologically active fragments or derivatives thereof. Methods of use encompass diagnostic and prognostic assay procedures as well as methods of treating diverse pathological conditions.
BACKGROUND
Eukaryotic cells are characterized by biochemical and physiological processes which under normal conditions are exquisitely balanced to achieve the preservation and propagation of the cells. When such cells are components of multicellular organisms such as vertebrates, or more particularly organisms such as mammals, the regulation of the biochemical and physiological processes involves intricate signaling pathways. Frequently, such signaling pathways involve extracellular signaling proteins, cellular receptors that bind the signaling proteins and signal transducing components located within the cells. Signaling proteins may be classified as endocrine effectors, paracrine effectors or autocrine effectors. Endocrine effectors are signaling molecules secreted by a given organ into the circulatory system, which are then transported to a distant target organ or tissue. The target cells include the receptors for the endocrine effector, and when the endocrine effector binds, a signaling cascade is induced. Paracrine effectors involve secreting cells and receptor cells in close proximity to each other, for example two different classes of cells in the same tissue or organ. One class of cells secretes the paracrine effector, which then reaches the second class of cells, for example by diffusion through the extracellular fluid. The second class of cells contains the receptors for the paracrine effector; binding of the effector results in induction of the signaling cascade that elicits the corresponding biochemical or physiological effect. Autocrine effectors are highly analogous to paracrine effectors, except that the same cell type that secretes the autocrine effector also contains the receptor. Thus the autocrine effector binds to receptors on the same cell, or on identical neighboring cells. The binding process then elicits the characteristic biochemical or physiological effect.
Signaling processes may elicit a variety of effects on cells and tissues including by way of nonlimiting example induction of cell or tissue proliferation, suppression of growth or proliferation, induction of differentiation or maturation of a cell or tissue, and suppression of differentiation or maturation of a cell or tissue.
Many pathological conditions involve dysregulation of expression of important effector proteins. In certain classes of pathologies the dysregulation is manifested as diminished or suppressed level of synthesis and secretion of protein effectors. In other classes of pathologies the dysregulation is manifested as increased or up-regulated level of synthesis and secretion of protein effectors. In a clinical setting a subject may be suspected of suffering from a condition brought on by altered or mis-regulated levels of a protein
effector of interest. Therefore there is a need to assay for the level of the protein effector of interest in a biological sample from such a subject, and to compare the level with that characteristic of a nonpathological condition. There also is a need to provide the protein effector as a product of manufacture. Administration of the effector to a subject in need thereof is useful in treatment of the pathological condition. Accordingly, there is a need for a method of treatment of a pathological condition brought on by a diminished or suppressed levels of the protein effector of interest. In addition, there is a need for a method of treatment of a pathological condition brought on by a increased or up-regulated levels of the protein effector of interest. Small molecule targets have been implicated in various disease states or pathologies. These targets may be proteins, and particularly enzymatic proteins, which are acted upon by small molecule drugs for the purpose of altering target function and achieving a desired result. Cellular, animal and clinical studies can be performed to elucidate the genetic contribution to the etiology and pathogenesis of conditions in which small molecule targets are implicated in a variety of physiologic, pharmacologic or native states. These studies utilize the core technologies at CuraGen Corporation to look at differential gene expression, protein-protein interactions, large-scale sequencing of expressed genes and the association of genetic variations such as, but not limited to, single nucleotide polymorphisms (SNPs) or splice variants in and between biological samples from experimental and control groups. The goal of such studies is to identify potential avenues for therapeutic intervention in order to prevent, treat the consequences or cure the conditions.
In order to treat diseases, pathologies and other abnormal states or conditions in which a mammalian organism has been diagnosed as being, or as being at risk for becoming, other than in a normal state or condition, it is important to identify new therapeutic agents. Such a procedure includes at least the steps of identifying a target component within an affected tissue or organ, and identifying a candidate therapeutic agent that modulates the functional attributes of the target. The target component may be any biological macromolecule implicated in the disease or pathology. Commonly the target is a polypeptide or protein with specific functional attributes. Other classes of macromolecule may be a nucleic acid, a polysaccharide, a lipid such as a complex lipid or a glycolipid; in addition a target may be a sub-cellular structure or extra-cellular structure that is comprised of more than one of these classes of macromolecule. Once such a target has been
identified, it may be employed in a screening assay in order to identify favorable candidate therapeutic agents from among a large population of substances or compounds.
In many cases the objective of such screening assays is to identify small molecule candidates; this is commonly approached by the use of combinatorial methodologies to develop the population of substances to be tested. The implementation of high throughput screening methodologies is advantageous when working with large, combinatorial libraries of compounds.
SUMMARY OF THE INVENTION The invention includes nucleic acid sequences and the novel polypeptides they encode. The novel nucleic acids and polypeptides are referred to herein as NOVX, or NOV1, NON2, ΝOV3, etc., nucleic acids and polypeptides. These nucleic acids and polypeptides, as well as derivatives, homologs, analogs and fragments thereof, will hereinafter be collectively designated as "NOVX" nucleic acid, which represents the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l, wherein n is an integer between 1 and 226, or polypeptide sequences, which represents the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226.
In one aspect, the invention provides an isolated polypeptide comprising a mature form of a NOVX amino acid. One example is a variant of a mature form of a NOVX amino acid sequence, wherein any amino acid in the mature form is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence of the mature form are so changed. The amino acid can be, for example, a NOVX amino acid sequence or a variant of a NOVX amino acid sequence, wherein any amino acid specified in the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence are so changed. The invention also includes fragments of any of these. In another aspect, the invention also includes an isolated nucleic acid that encodes a NOVX polypeptide, or a fragment, homolog, analog or derivative thereof.
Also included in the invention is a NOVX polypeptide that is a naturally occurring allelic variant of a NOVX sequence. In one embodiment, the allelic variant includes an amino acid sequence that is the translation of a nucleic acid sequence differing by a single nucleotide from a NOVX nucleic acid sequence. In another embodiment, the NOVX polypeptide is a variant polypeptide described therein, wherein any amino acid specified in the chosen sequence is changed to provide a conservative substitution. In one embodiment,
the invention discloses a method for determining the presence or amount of the NOVX polypeptide in a sample. The method involves the steps of: providing a sample; introducing the sample to an antibody that binds immunospecifically to the polypeptide; and determining the presence or amount of antibody bound to the NOVX polypeptide, thereby determining the presence or amount of the NOVX polypeptide in the sample. In another embodiment, the invention provides a method for determining the presence of or predisposition to a disease associated with altered levels of a NOVX polypeptide in a mammalian subject. This method involves the steps of: measuring the level of expression of the polypeptide in a sample from the first mammalian subject; and comparing the amount of the polypeptide in the sample of the first step to the amount of the polypeptide present in a control sample from a second mammalian subject known not to have, or not to be predisposed to, the disease, wherein an alteration in the expression level of the polypeptide in the first subject as compared to the control sample indicates the presence of or predisposition to the disease. In a further embodiment, the invention includes a method of identifying an agent that binds to a NOVX polypeptide. This method involves the steps of: introducing the polypeptide to the agent; and determining whether the agent binds to the polypeptide. In various embodiments, the agent is a cellular receptor or a downstream effector.
In another aspect, the invention provides a method for identifying a potential therapeutic agent for use in treatment of a pathology, wherein the pathology is related to aberrant expression or aberrant physiological interactions of a NOVX polypeptide. The method involves the steps of: providing a cell expressing the NOVX polypeptide and having a property or function ascribable to the polypeptide; contacting the cell with a composition comprising a candidate substance; and determining whether the substance alters the property or function ascribable to the polypeptide; whereby, if an alteration observed in the presence of the substance is not observed when the cell is contacted with a composition devoid of the substance, the substance is identified as a potential therapeutic agent. In another aspect, the invention describes a method for screening for a modulator of activity or of latency or predisposition to a pathology associated with the NOVX polypeptide. This method involves the following steps: administering a test compound to a test animal at increased risk for a pathology associated with the NOVX polypeptide, wherein the test animal recornbinantly expresses the NOVX polypeptide. This method involves the steps of measuring the activity of the NOVX polypeptide in the test animal
after administering the compound of step; and comparing the activity of the protein in the test animal with the activity of the NOVX polypeptide in a control animal not administered the polypeptide, wherein a change in the activity of the NOVX polypeptide in the test animal relative to the control animal indicates the test compound is a modulator of latency of, or predisposition to, a pathology associated with the NOVX polypeptide. In one embodiment, the test animal is a recombinant test animal that expresses a test protein transgene or expresses the transgene under the control of a promoter at an increased level relative to a wild-type test animal, and wherein the promoter is not the native gene promoter of the transgene. In another aspect, the invention includes a method for modulating the activity of the NOVX polypeptide, the method comprising introducing a cell sample expressing the NOVX polypeptide with a compound that binds to the polypeptide in an amount sufficient to modulate the activity of the polypeptide.
The invention also includes an isolated nucleic acid that encodes a NOVX polypeptide, or a fragment, homolog, analog or derivative thereof. In a preferred embodiment, the nucleic acid molecule comprises the nucleotide sequence of a naturally occurring allelic nucleic acid variant. In another embodiment, the nucleic acid encodes a variant polypeptide, wherein the variant polypeptide has the polypeptide sequence of a naturally occurring polypeptide variant. In another embodiment, the nucleic acid molecule differs by a single nucleotide from a NOVX nucleic acid sequence. In one embodiment, the NOVX nucleic acid molecule hybridizes under stringent conditions to the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l, wherein n is an integer between 1 and 226, or a complement of the nucleotide sequence. In another aspect, the invention provides a vector or a cell expressing a NOVX nucleotide sequence.
In one embodiment, the invention discloses a method for modulating the activity of a NOVX polypeptide. The method includes the steps of: introducing a cell sample expressing the NOVX polypeptide with a compound that binds to the polypeptide in an amount sufficient to modulate the activity of the polypeptide. In another embodiment, the invention includes an isolated NOVX nucleic acid molecule comprising a nucleic acid sequence encoding a polypeptide comprising a NOVX amino acid sequence or a variant of a mature form of the NOVX amino acid sequence, wherein any amino acid in the mature form of the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence of the mature form are so changed. In another embodiment, the invention includes an amino acid sequence that is a variant of the
NOVX amino acid sequence, in which any amino acid specified in the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence are so changed.
In one embodiment, the invention discloses a NOVX nucleic acid fragment encoding at least a portion of a NOVX polypeptide or any variant of the polypeptide, wherein any amino acid of the chosen sequence is changed to a different amino acid, provided that no more than 10% of the amino acid residues in the sequence are so changed. In another embodiment, the invention includes the complement of any of the NOVX nucleic acid molecules or a naturally occurring allelic nucleic acid variant. In another embodiment, the invention discloses a NOVX nucleic acid molecule that encodes a variant polypeptide, wherein the variant polypeptide has the polypeptide sequence of a naturally occurring polypeptide variant. In another embodiment, the invention discloses a NOVX nucleic acid, wherein the nucleic acid molecule differs by a single nucleotide from a NOVX nucleic acid sequence. In another aspect, the invention includes a NOVX nucleic acid, wherein one or more nucleotides in the NOVX nucleotide sequence is changed to a different nucleotide provided that no more than 15% of the nucleotides are so changed. In one embodiment, the invention discloses a nucleic acid fragment of the NOVX nucleotide sequence and a nucleic acid fragment wherein one or more nucleotides in the NOVX nucleotide sequence is changed from that selected from the group consisting of the chosen sequence to a different nucleotide provided that no more than 15% of the nucleotides are so changed. In another embodiment, the invention includes a nucleic acid molecule wherein the nucleic acid molecule hybridizes under stringent conditions to a NOVX nucleotide sequence or a complement of the NOVX nucleotide sequence. In one embodiment, the invention includes a nucleic acid molecule, wherein the sequence is changed such that no more than 15% of the nucleotides in the coding sequence differ from the NOVX nucleotide sequence or a fragment thereof.
In a further aspect, the invention includes a method for determining the presence or amount of the NOVX nucleic acid in a sample. The method involves the steps of: providing the sample; introducing the sample to a probe that binds to the nucleic acid molecule; and determimng the presence or amount of the probe bound to the NOVX nucleic acid molecule, thereby determining the presence or amount of the NOVX nucleic
acid molecule in the sample. In one embodiment, the presence or amount of the nucleic acid molecule is used as a marker for cell or tissue type.
In another aspect, the invention discloses a method for determining the presence of or predisposition to a disease associated with altered levels of the NONX nucleic acid molecule of in a first mammalian subject. The method involves the steps of: measuring the amount of ΝOVX nucleic acid in a sample from the first mammalian subject; and comparing the amount of the nucleic acid in the sample of step (a) to the amount of ΝOVX nucleic acid present in a control sample from a second mammalian subject known not to have or not be predisposed to, the disease; wherein an alteration in the level of the nucleic acid in the first subject as compared to the control sample indicates the presence of or predisposition to the disease.
Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. Although methods and materials similar or equivalent to those described herein can be used in the practice or testing of the present invention, suitable methods and materials are described below. All publications, patent applications, patents, and other references mentioned herein are incorporated by reference in their entirety. In the case of conflict, the present specification, including definitions, will control. In addition, the materials, methods, and examples are illustrative only and not intended to be limiting.
Other features and advantages of the invention will be apparent from the following detailed description and claims.
DETAILED DESCRIPTION OF THE INVENTION The present invention provides novel nucleotides and polypeptides encoded thereby. Included in the invention are the novel nucleic acid sequences, their encoded polypeptides, antibodies, and other related compounds. The sequences are collectively referred to herein as "NOVX nucleic acids" or "NOVX polynucleotides" and the corresponding encoded polypeptides are referred to as "NOVX polypeptides" or "NOVX proteins." Unless indicated otherwise, "NOVX" is meant to refer to any of the novel sequences disclosed herein. Table A provides a summary of the NOVX nucleic acids and their encoded polypeptides.
TABLE A. Sequences and Corresponding SEQ ID Numbers
Table A indicates the homology of NOVX polypeptides to known protein families. Thus, the nucleic acids and polypeptides, antibodies and related compounds according to the invention corresponding to a NOVX as identified in column 1 of Table A will be useful in therapeutic and diagnostic applications implicated in, for example, pathologies and disorders associated with the known protein families identified in column 5 of Table A.
Pathologies, diseases, disorders and condition and the like that are associated with NOVX sequences include, but are not limited to: e.g., cardiomyopathy, atherosclerosis, hypertension, congenital heart defects, aortic stenosis, atrial septal defect (ASD), atrioventricular (A-V) canal defect, ductus arteriosus, pulmonary stenosis, subaortic stenosis, ventricular septal defect (VSD), valve diseases, tuberous sclerosis, scleroderma, obesity, metabolic disturbances associated with obesity, transplantation, adrenoleukodystrophy, congenital adrenal hyperplasia, prostate cancer, diabetes, metabolic disorders, neoplasm; adenocarcinoma, lymphoma, uterus cancer, fertility, hemophilia, hypercoagulation, idiopathic thrombocytopenic purpura, immunodeficiencies, graft versus host disease, AIDS, bronchial asthma, Crohn's disease; multiple sclerosis, treatment of Albright Hereditary Ostoeodystrophy, infectious disease, anorexia, cancer-associated
cachexia, cancer, neurodegenerative disorders, Alzheimer's Disease, Parkinson's Disorder, immune disorders, hematopoietic disorders, and the various dyslipidemias,] the metabolic syndrome X and wasting disorders associated with chronic diseases and various cancers, as well as conditions such as transplantation and fertility. NOVX nucleic acids and their encoded polypeptides are useful in a variety of applications and contexts. The various NOVX nucleic acids and polypeptides according to the invention are useful as novel members of the protein families according to the presence of domains and sequence relatedness to previously described proteins. Additionally, NOVX nucleic acids and polypeptides can also be used to identify proteins that are members of the family to which the NOVX polypeptides belong.
Consistent with other known members of the family of proteins, identified in column 5 of Table A, the NOVX polypeptides of the present invention show homology to, and contain domains that are characteristic of, other members of such protein families. Details of the sequence relatedness and domain analysis for each NOVX are presented in Example A.
The NOVX nucleic acids and polypeptides can also be used to screen for molecules, which inhibit or enhance NOVX activity or function. Specifically, the nucleic acids and polypeptides according to the invention may be used as targets for the identification of small molecules that modulate or inhibit diseases associated with the protein families listed in Table A.
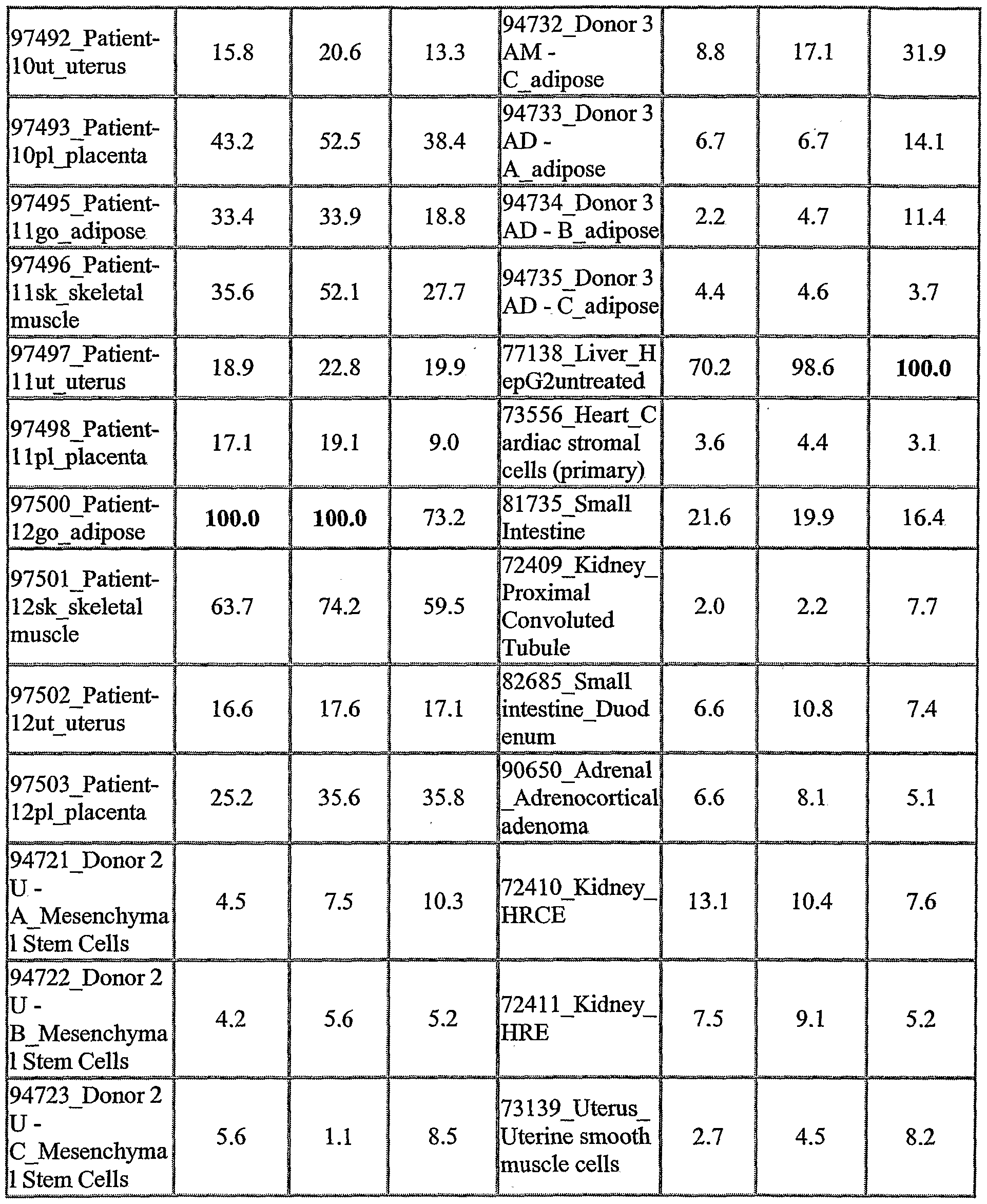
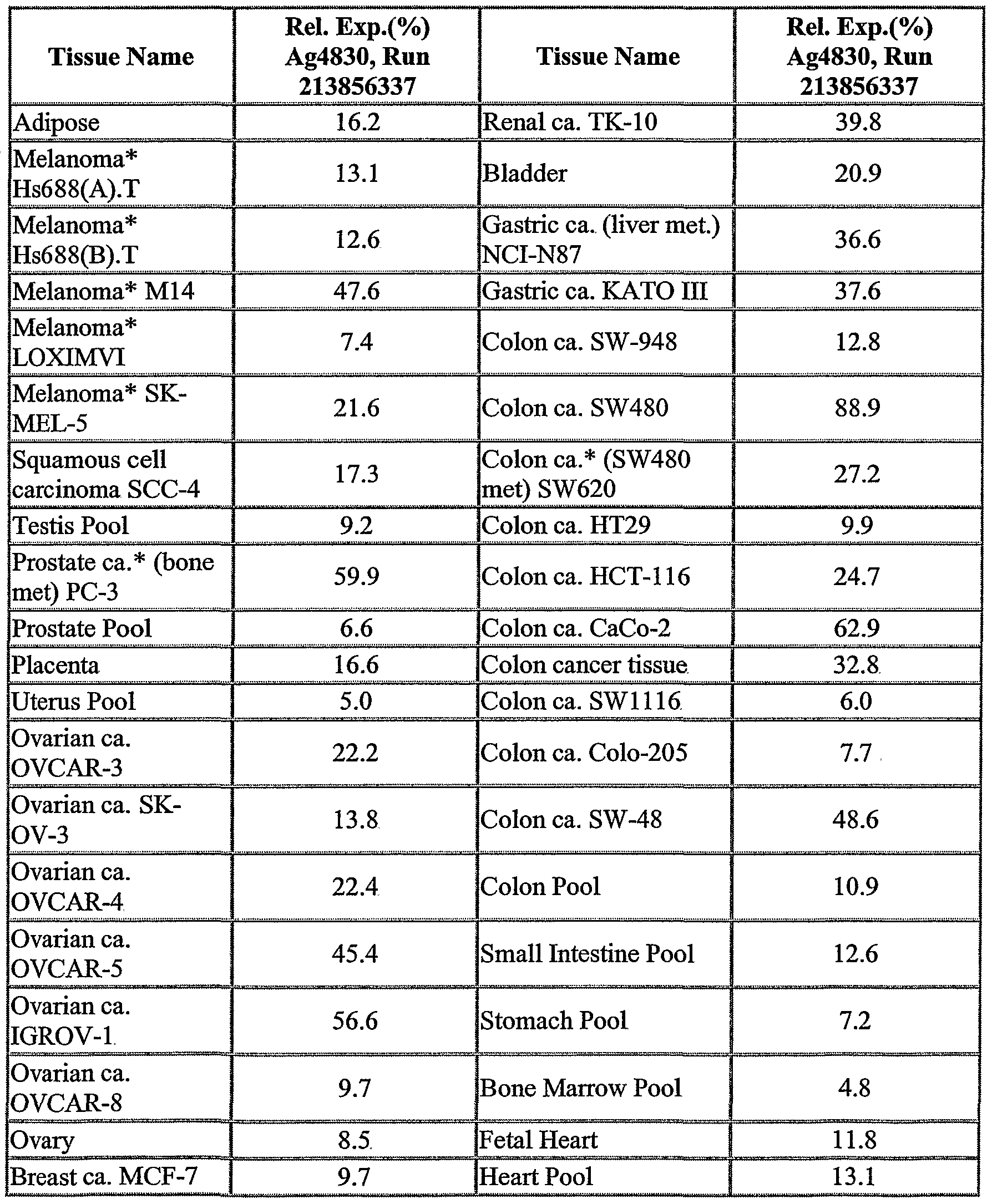
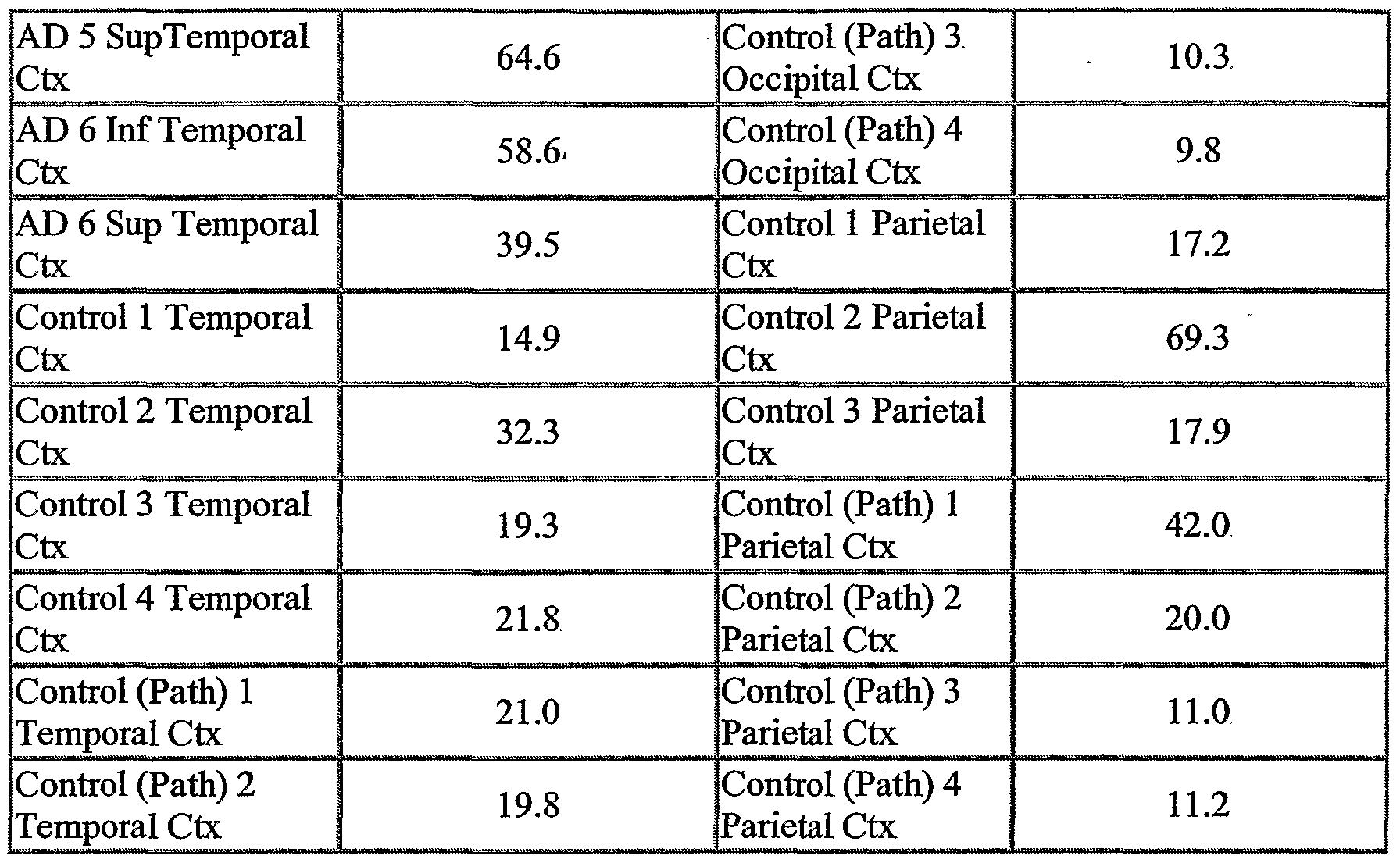
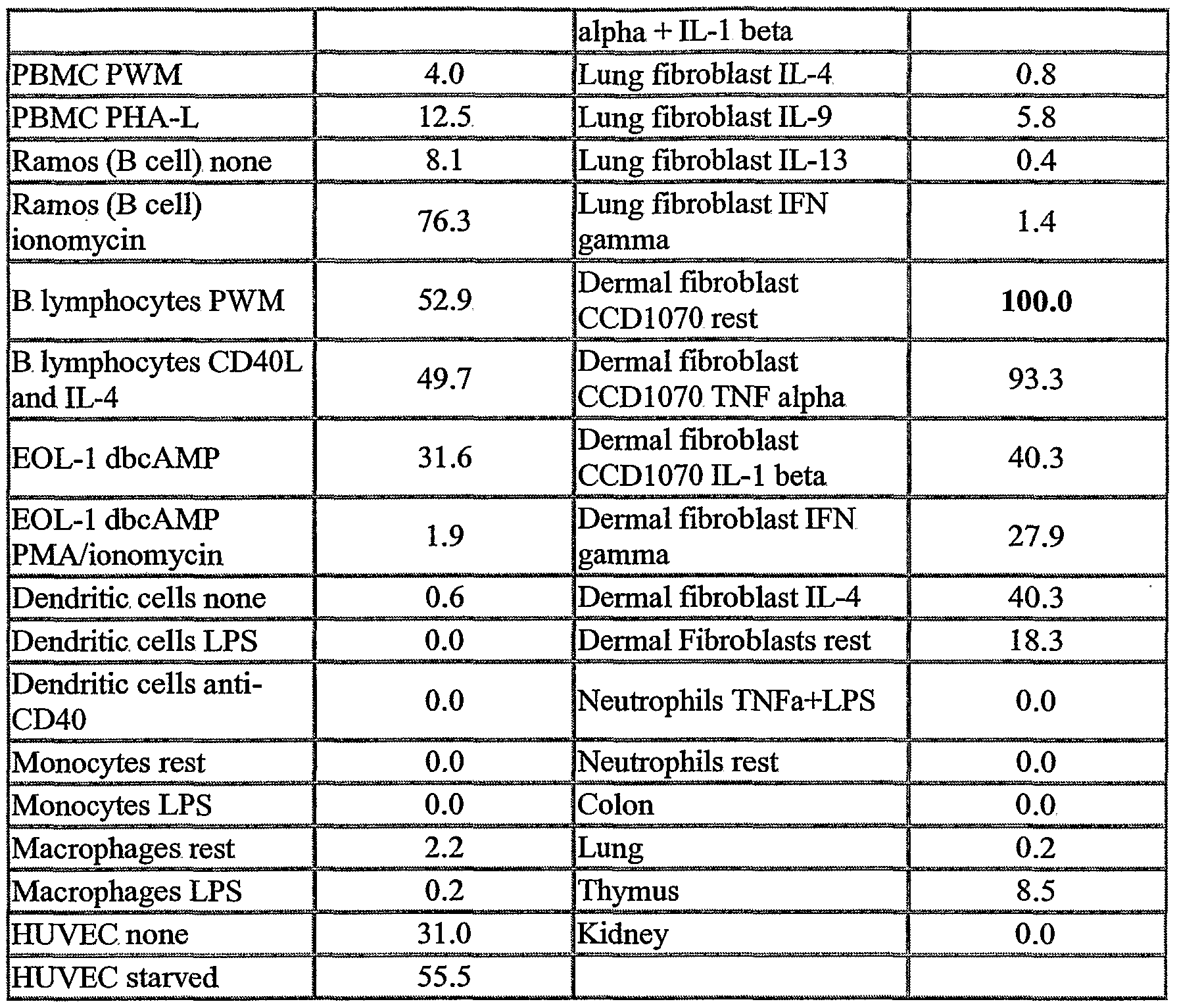
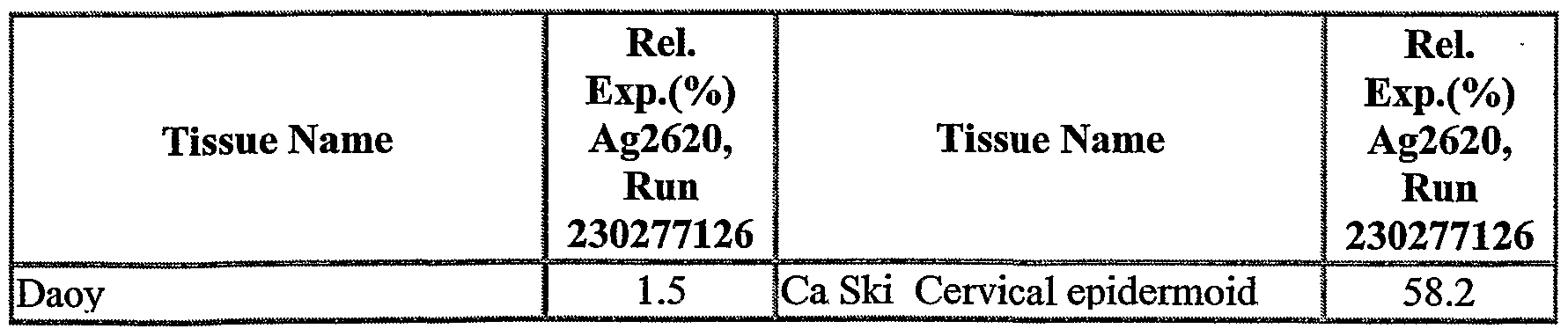
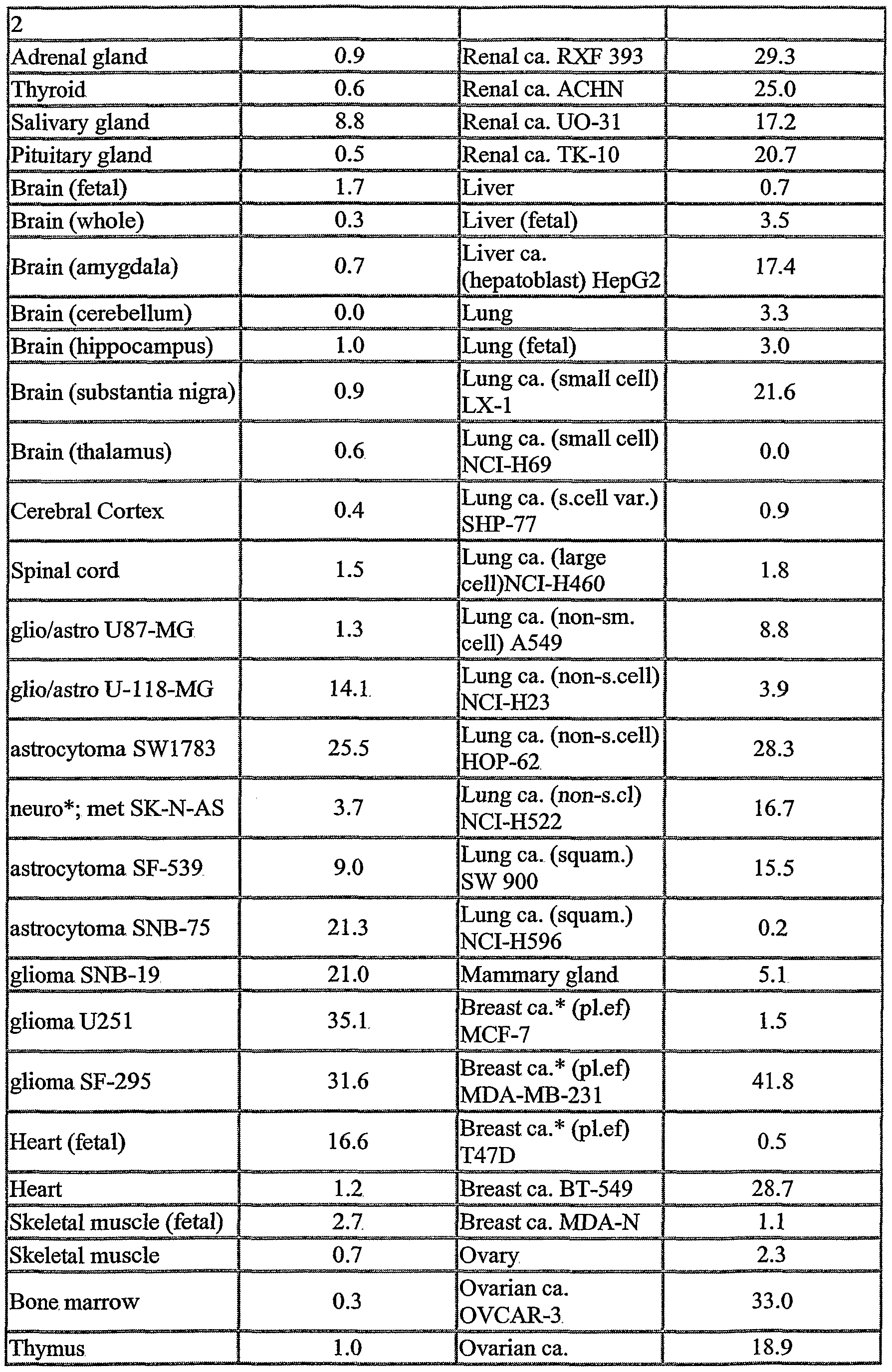
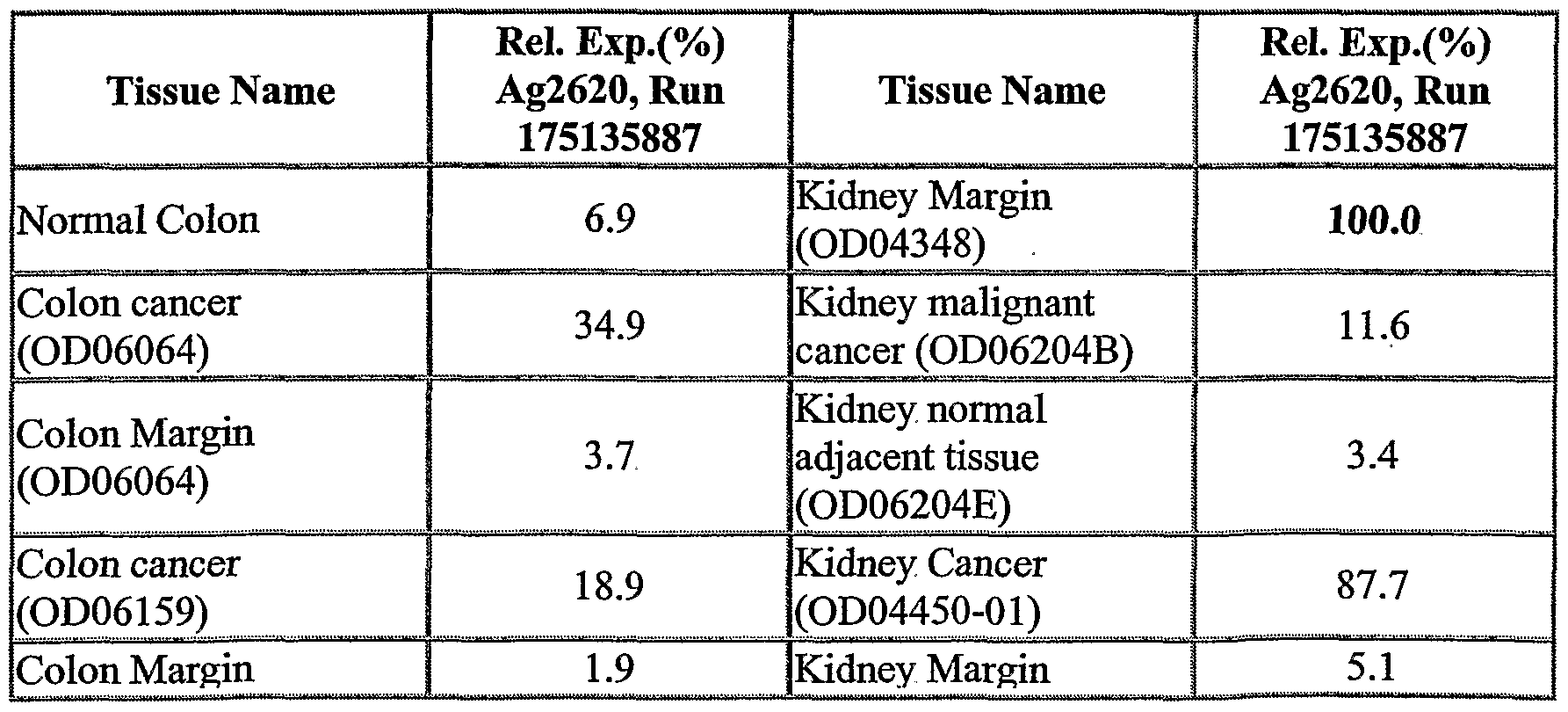
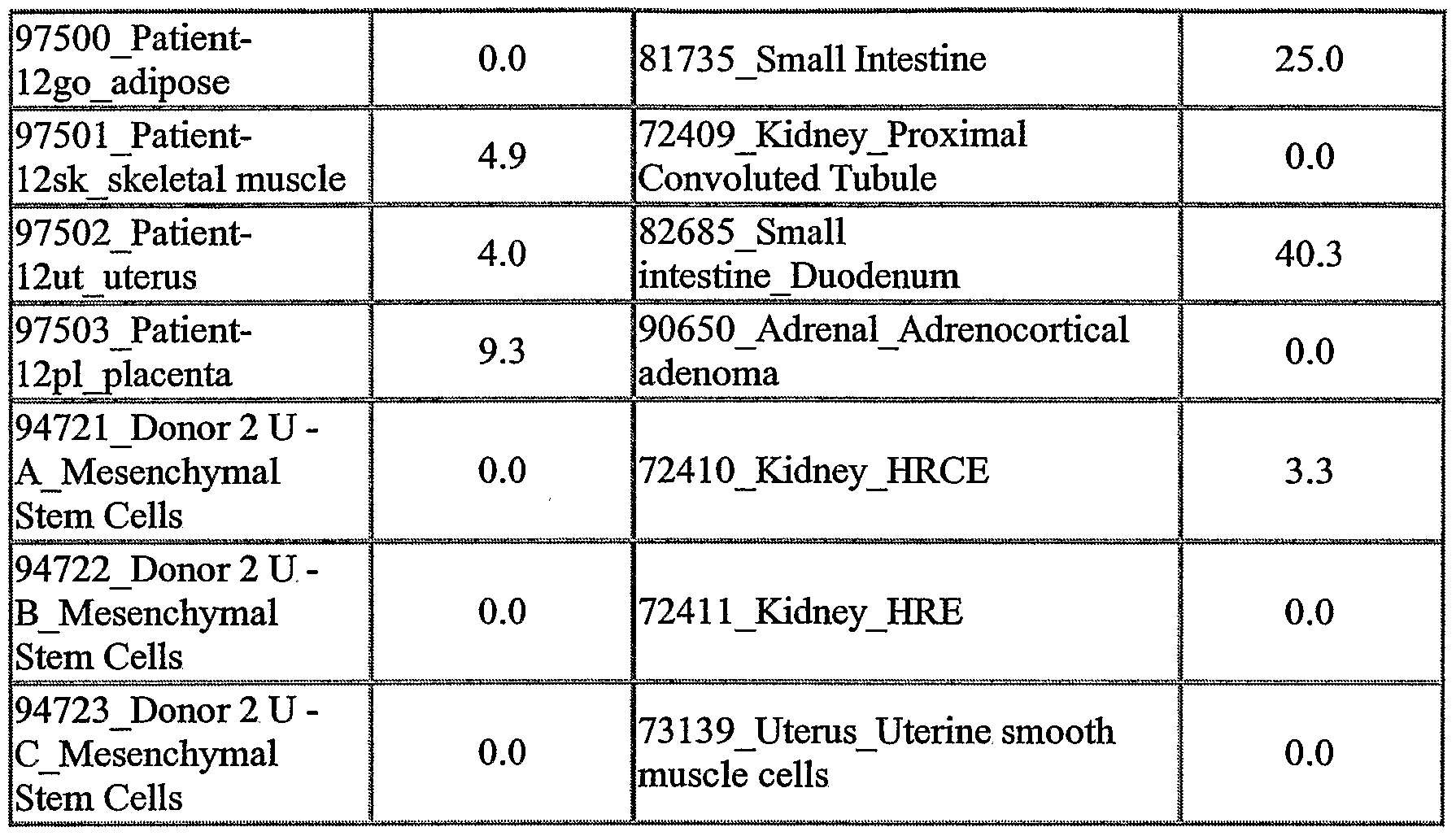
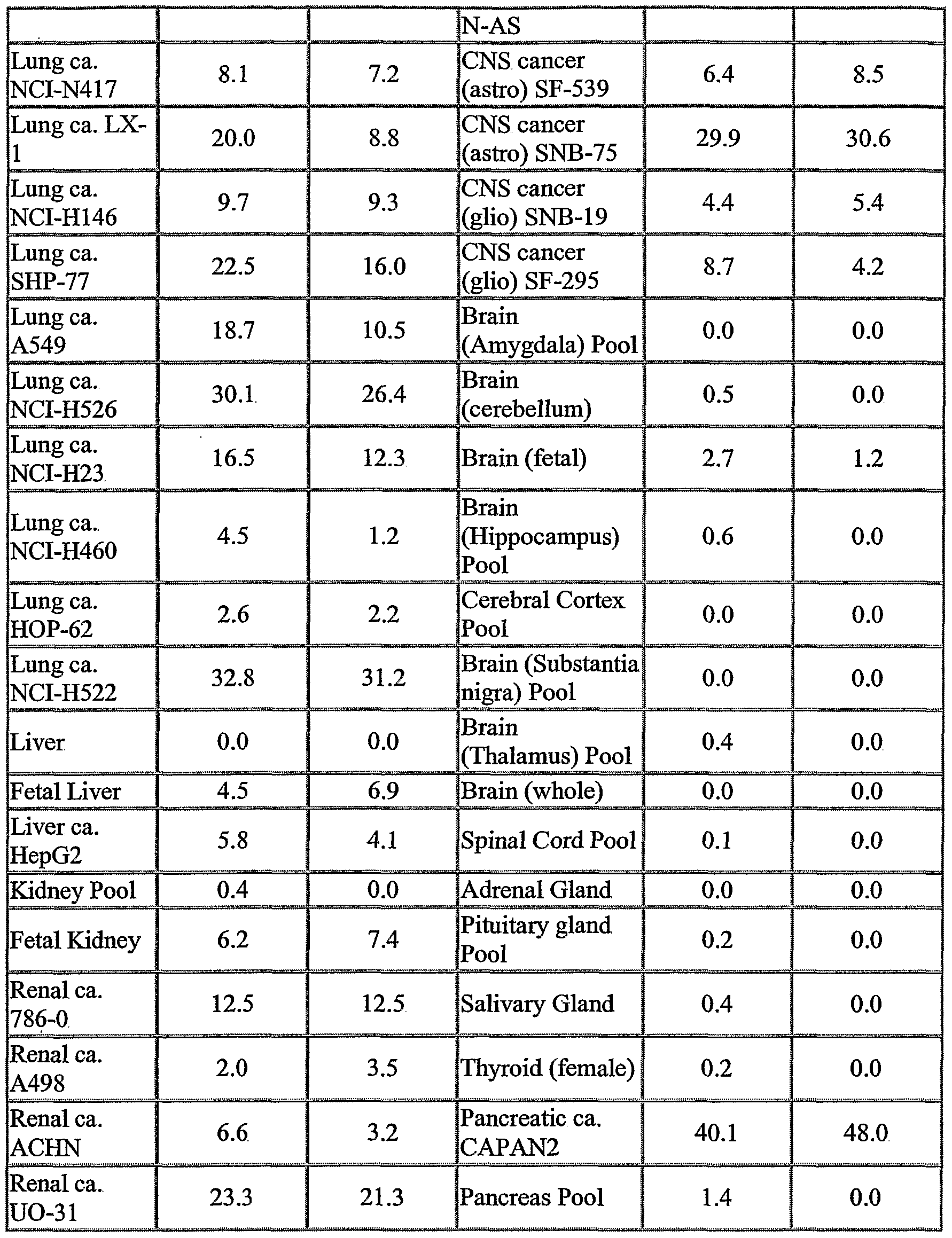
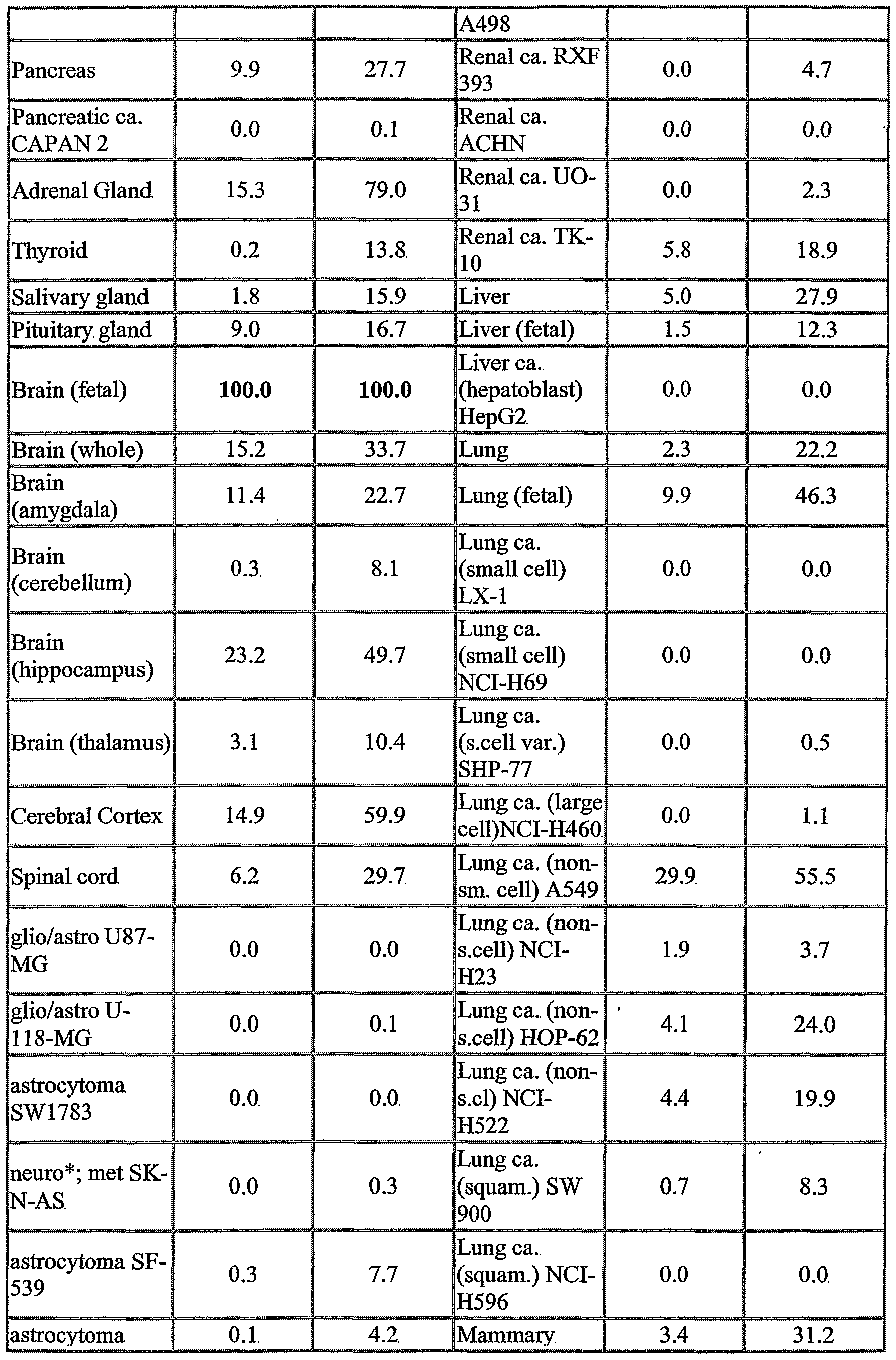
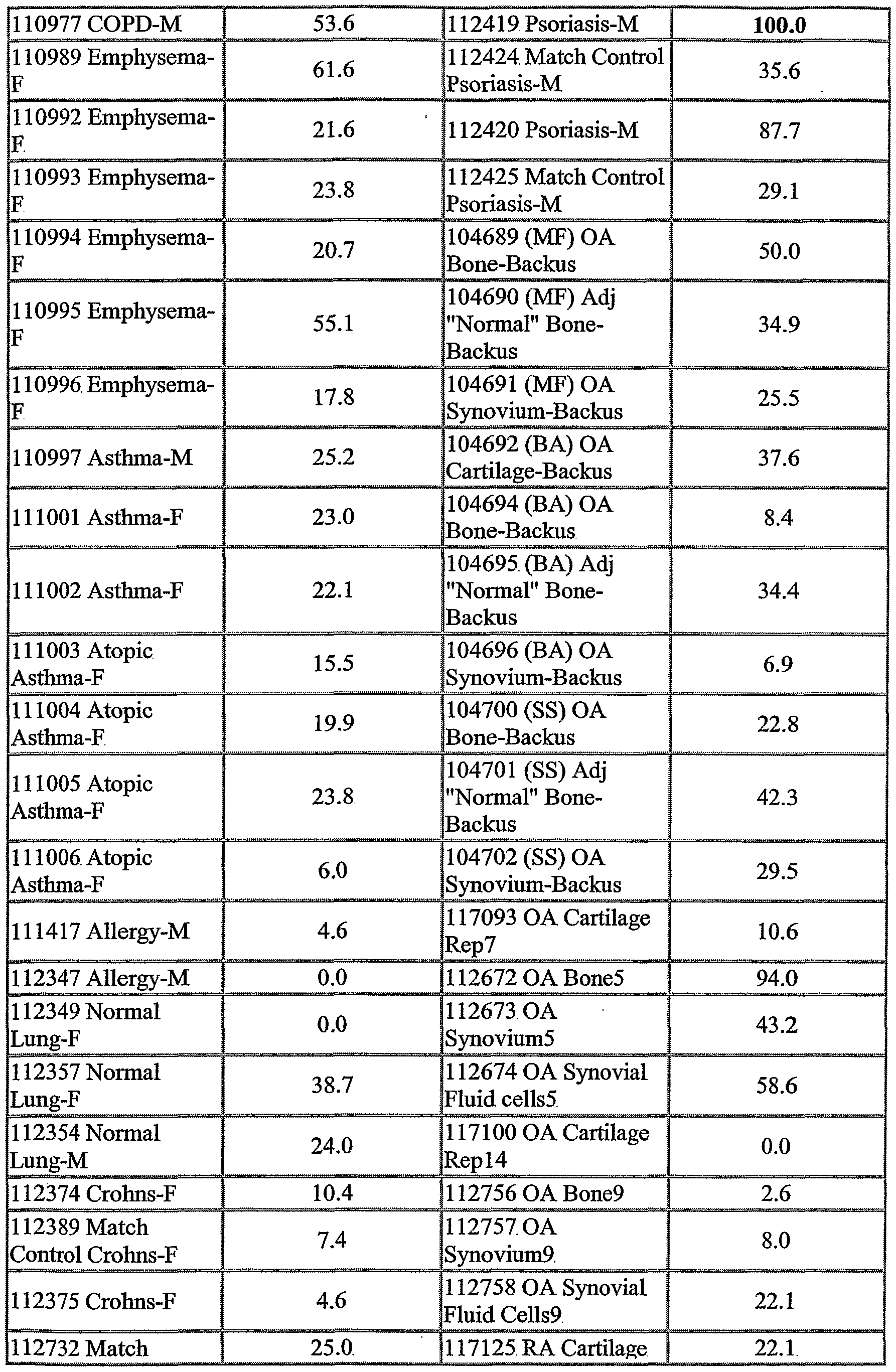
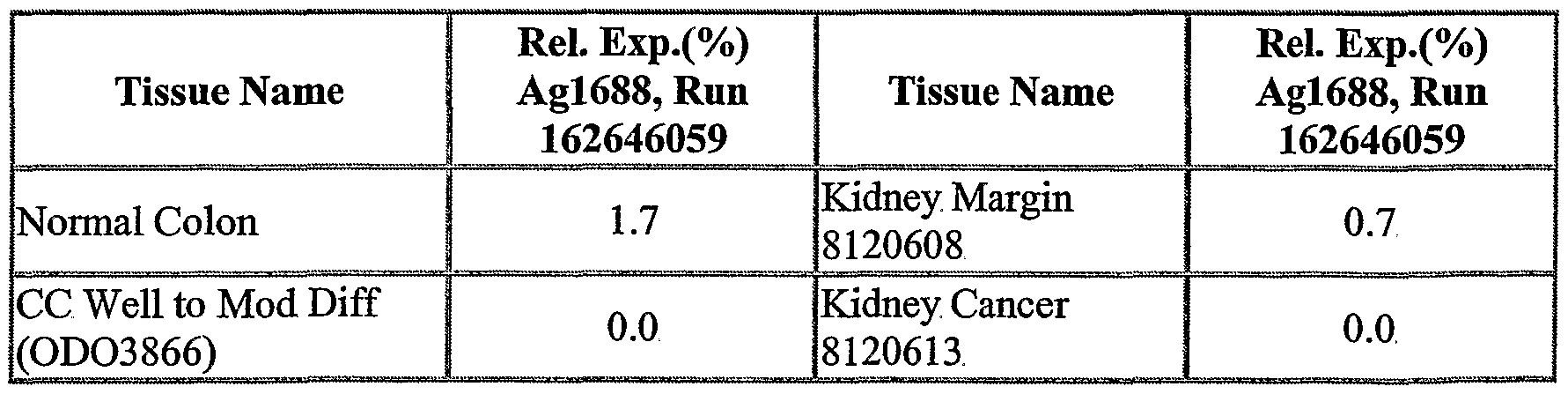
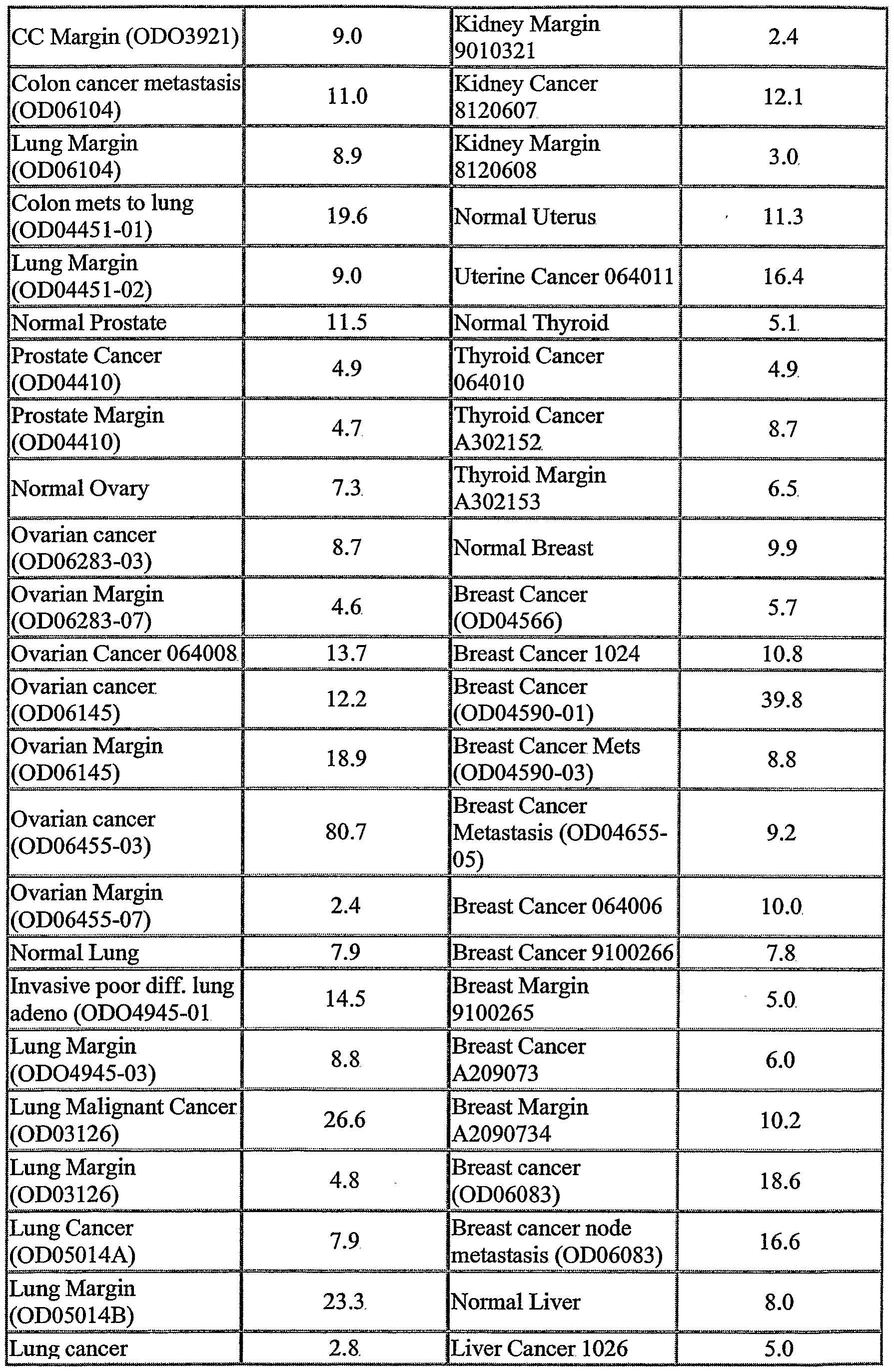
The NOVX nucleic acids and polypeptides are also useful for detecting specific cell types. Details of the expression analysis for each NOVX are presented in Example C. Accordingly, the NOVX nucleic acids, polypeptides, antibodies and related compounds according to the invention will have diagnostic and therapeutic applications in the detection of a variety of diseases with differential expression in normal vs. diseased tissues, e.g. detection of a variety of cancers.
Additional utilities for NOVX nucleic acids and polypeptides according to the invention are disclosed herein.
NOVX clones
NOVX nucleic acids and their encoded polypeptides are useful in a variety of applications and contexts. The various NOVX nucleic acids and polypeptides according to the invention are useful as novel members of the protein families according to the presence
of domains and sequence relatedness to previously described proteins. Additionally, NOVX nucleic acids and polypeptides can also be used to identify proteins that are members of the family to which the NOVX polypeptides belong.
The NOVX genes and their corresponding encoded proteins are useful for preventing, treating or ameliorating medical conditions, e.g., by protein or gene therapy. Pathological conditions can be diagnosed by determining the amount of the new protein in a sample or by determining the presence of mutations in the new genes. Specific uses are described for each of the NOVX genes, based on the tissues in which they are most highly expressed. Uses include developing products for the diagnosis or treatment of a variety of diseases and disorders.
The NOVX nucleic acids and proteins of the invention are useful in potential diagnostic and therapeutic applications and as a research tool. These include serving as a specific or selective nucleic acid or protein diagnostic and/or prognostic marker, wherein the presence or amount of the nucleic acid or the protein are to be assessed, as well as potential therapeutic applications such as the following: (i) a protein therapeutic, (ii) a small molecule drug target, (iii) an antibody target (therapeutic, diagnostic, drug targeting/cytotoxic antibody), (iv) a nucleic acid useful in gene therapy (gene delivery/gene ablation), and (v) a composition promoting tissue regeneration in vitro and in vivo (vi) a biological defense weapon. In one specific embodiment, the invention includes an isolated polypeptide comprising an amino acid sequence selected from the group consisting of: (a) a mature form of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226; (b) a variant of a mature form of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226, wherein any amino acid in the mature form is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence of the mature form are so changed; (c) an amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226; (d) a variant of the amino acid sequence selected from the group consisting of SEQ ID NO:2n, wherein n is an integer between 1 and 226 wherein any amino acid specified in the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence are so changed; and (e) a fragment of any of (a) through (d).
In another specific embodiment, the invention includes an isolated nucleic acid molecule comprising a nucleic acid sequence encoding a polypeptide comprising an amino acid sequence selected from the group consisting of: (a) a mature form of the amino acid sequence given SEQ ID NO: 2n, wherein n is an integer between 1 and 226; (b) a variant of a mature form of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226 wherein any amino acid in the mature form of the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence of the mature form are so changed; (c) the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226; (d) a variant of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226, in which any amino acid specified in the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence are so changed; (e) a nucleic acid fragment encoding at least a portion of a polypeptide comprising the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 226 or any variant of said polypeptide wherein any amino acid of the chosen sequence is changed to a different amino acid, provided that no more than 10% of the amino acid residues in the sequence are so changed; and (f) the complement of any of said nucleic acid molecules. In yet another specific embodiment, the invention includes an isolated nucleic acid molecule, wherein said nucleic acid molecule comprises a nucleotide sequence selected from the group consisting of: (a) the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l, wherein n is an integer between 1. and 226; (b) a nucleotide sequence wherein one or more nucleotides in the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l, wherein n is an integer between 1 and 226 is changed from that selected from the group consisting of the chosen sequence to a different nucleotide provided that no more than 15% of the nucleotides are so changed; (c) a nucleic acid fragment of the sequence selected from the group consisting of SEQ LD NO: 2n-l, wherein n is an integer between 1 and 226; and (d) a nucleic acid fragment wherein one or more nucleotides in the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l, wherein n is an integer between 1 and 226 is changed from that selected from the group consisting of the chosen sequence to a different nucleotide provided that no more than 15% of the nucleotides are so changed.
NOVX Nucleic Acids and Polypeptides
One aspect of the invention pertains to isolated nucleic acid molecules that encode NOVX polypeptides or biologically active portions thereof. Also included in the invention are nucleic acid fragments sufficient for use as hybridization probes to identify NOVX-encoding nucleic acids (e.g., NOVX mRNAs) and fragments for use as PCR primers for the amplification and/or mutation of NOVX nucleic acid molecules. As used herein, the term "nucleic acid molecule" is intended to include DNA molecules (e.g., cDNA or genomic DNA), RNA molecules (e.g., mRNA), analogs of the DNA or RNA generated using nucleotide analogs, and derivatives, fragments and homologs thereof. The nucleic acid molecule may be single-stranded or double-stranded, but preferably is comprised double-stranded DNA.
A NOVX nucleic acid can encode a mature NOVX polypeptide. As used herein, a "mature" form of a polypeptide or protein disclosed in the present invention is the product of a naturally occurring polypeptide or precursor form or proprotein. The naturally occurring polypeptide, precursor or proprotein includes, by way of nonlimiting example, the full-length gene product encoded by the corresponding gene. Alternatively, it may be defined as the polypeptide, precursor or proprotein encoded by an ORF described herein. The product "mature" form arises, by way of nonlimiting example, as a result of one or more naturally occurring processing steps that may take place within the cell (e.g., host cell) in which the gene product arises. Examples of such processing steps leading to a "mature" form of a polypeptide or protein include the cleavage of the N-terminal methionine residue encoded by the initiation codon of an ORF, or the proteolytic cleavage of a signal peptide or leader sequence. Thus a mature form arising from a precursor polypeptide or protein that has residues 1 to N, where residue 1 is the N-terminal methionine, would have residues 2 through N remaining after removal of the N-terminal methionine. Alternatively, a mature form arising from a precursor polypeptide or protein having residues 1 to N, in which an N-terminal signal sequence from residue 1 to residue M is cleaved, would have the residues from residue M+l to residue N remaining. Further as used herein, a "mature" form of a polypeptide or protein may arise from a step of post-translational modification other than a proteolytic cleavage event. Such additional processes include, by way of non-limiting example, glycosylation, myristylation or phosphorylation. In general, a mature polypeptide or protein may result from the operation of only one of these processes, or a combination of any of them.
The term "probe", as utilized herein, refers to nucleic acid sequences of variable length, preferably between at least about 10 nucleotides (nt), about 100 nt, or as many as approximately, e.g., 6,000 nt, depending upon the specific use. Probes are used in the detection of identical, similar, or complementary nucleic acid sequences. Longer length probes are generally obtained from a natural or recombinant source, are highly specific, and much slower to hybridize than shorter-length oligomer probe's. Probes may be single- stranded or double-stranded and designed to have specificity in PCR, membrane-based hybridization technologies, or ELISA-like technologies.
The term "isolated" nucleic acid molecule, as used herein, is a nucleic acid that is separated from other nucleic acid molecules which are present in the natural source of the nucleic acid. Preferably, an "isolated" nucleic acid is free of sequences which naturally flank the nucleic acid (t.e., sequences located at the 5'- and 3'-termini of the nucleic acid) in the genomic DNA of the organism from which the nucleic acid is derived. For example, in various embodiments, the isolated NOVX nucleic acid molecules can contain less than about 5 kb, 4 kb, 3 kb, 2 kb, 1 kb, 0.5 kb or 0.1 kb of nucleotide sequences which naturally flank the nucleic acid molecule in genomic DNA of the cell/tissue from which the nucleic acid is derived (e.g., brain, heart, liver, spleen, etc.). Moreover, an "isolated" nucleic acid molecule, such as a cDNA molecule, can be substantially free of other cellular material, or culture medium, or of chemical precursors or other chemicals. A nucleic acid molecule of the invention, e.g., a nucleic acid molecule having the nucleotide sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, or a complement of this nucleotide sequence, can be isolated using standard molecular biology techniques and the sequence information provided herein. Using all or a portion of the nucleic acid sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, as a hybridization probe, NOVX molecules can be isolated using standard hybridization and cloning techniques (e.g., as described in Sambrook, et al., (eds.), MOLECULAR CLONING: A LABORATORY MANUAL 2nd Ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989; and Ausubel, et al, (eds.), CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, New York, NY, 1993.) A nucleic acid of the invention can be amplified using cDNA, mRNA or alternatively, genomic DNA, as a template with appropriate oligonucleotide primers according to standard PCR amplification techniques. The nucleic acid so amplified can be cloned into an appropriate vector and characterized by DNA sequence analysis.
Furthermore, oligonucleotides corresponding to NOVX nucleotide sequences can be prepared by standard synthetic techniques, e.g., using an automated DNA synthesizer.
As used herein, the term "oligonucleotide" refers to a series of linked nucleotide residues. A short oligonucleotide sequence may be based on, or designed from, a genomic or cDNA sequence and is used to amplify, confirm, or reveal the presence of an identical, similar or complementary DNA or RNA in a particular cell or tissue. Oligonucleotides comprise a nucleic acid sequence having about 10 nt, 50 nt, or 100 nt in length, preferably about 15 nt to 30 nt in length. In one embodiment of the invention, an oligonucleotide comprising a nucleic acid molecule less than 100 nt in length would further comprise at least 6 contiguous nucleotides of SEQ ID NO:2n-l , wherein n is an integer between 1 and 226, or a complement thereof. Oligonucleotides may be chemically synthesized and may also be used as probes.
In another embodiment, an isolated nucleic acid molecule of the invention comprises a nucleic acid molecule that is a complement of the nucleotide sequence shown in SEQ ID NO:2n- 1 , wherein n is an integer between 1 and 226, or a portion of this nucleotide sequence (e.g., a fragment that can be used as a probe or primer or a fragment encoding a biologically-active portion of a NOVX polypeptide). A nucleic acid molecule that is complementary to the nucleotide sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, is one that is sufficiently complementary to the nucleotide sequence of SEQ ID NO:2«- 1 , wherem n is an integer between 1 and 226, that it can hydrogen bond with few or no mismatches to the nucleotide sequence shown in SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, thereby forming a stable duplex.
As used herein, the term "complementary" refers to Watson-Crick or Hoogsteen base pairing between nucleotides units of a nucleic acid molecule, and the term "binding" means the physical or chemical interaction between two polypeptides or compounds or associated polypeptides or compounds or combinations thereof. Binding includes ionic, non-ionic, van der Waals, hydrophobic interactions, and the like. A physical interaction can be either direct or indirect. Indirect interactions may be through or due to the effects of another polypeptide or compound. Direct binding refers to interactions that do not take place through, or due to, the effect of another polypeptide or compound, but instead are without other substantial chemical intermediates.
A "fragment' ' provided herein is defined as a sequence of at least 6 (contiguous) nucleic acids or at least 4 (contiguous) amino acids, a length sufficient to allow for specific
hybridization in the case of nucleic acids or for specific recognition of an epitope in the case of amino acids, and is at most some portion less than a full length sequence. Fragments may be derived from any contiguous portion of a nucleic acid or amino acid sequence of choice. A full-length NOVX clone is identified as containing an ATG translation start codon and an in-frame stop codon. Any disclosed NOVX nucleotide sequence lacking an ATG start codon therefore encodes a truncated C-terminal fragment of the respective NOVX polypeptide, and requires that the corresponding full-length cDNA extend in the 5' direction of the disclosed sequence. Any disclosed NOVX nucleotide sequence lacking an in-frame stop codon similarly encodes a truncated N-terminal fragment of the respective NOVX polypeptide, and requires that the corresponding full-length cDNA extend in the 3' direction of the disclosed sequence.
A "derivative" is a nucleic acid sequence or amino acid sequence formed from the native compounds either directly, by modification or partial substitution. An "analog" is a nucleic acid sequence or amino acid sequence that has a structure similar to, but not identical to, the native compound, e.g. they differs from it in respect to certain components or side chains. Analogs may be synthetic or derived from a different evolutionary origin and may have a similar or opposite metabolic activity compared to wild type. A "homolog" is a nucleic acid sequence or amino acid sequence of a particular gene that is derived from different species.
Derivatives and analogs may be full length or other than full length. Derivatives or analogs of the nucleic acids or proteins of the invention include, but are not limited to, molecules comprising regions that are substantially homologous to the nucleic acids or proteins of the invention, in various embodiments, by at least about 70%, 80%, or 95% identity (with a preferred identity of 80-95%) over a nucleic acid or amino acid sequence of identical size or when compared to an aligned sequence in which the alignment is done by a computer homology program known in the art, or whose encoding nucleic acid is capable of hybridizing to the complement of a sequence encoding the proteins under stringent, moderately stringent, or low stringent conditions. See e.g. Ausubel, et ah, CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, New York, NY, 1993, and below.
A "homologous nucleic acid sequence" or "homologous amino acid sequence," or variations thereof, refer to sequences characterized by a homology at the nucleotide level or
amino acid level as discussed above. Homologous nucleotide sequences include those sequences coding for isoforms of NOVX polypeptides. Isoforms can be expressed in different tissues of the same organism as a result of, for example, alternative splicing of RNA. Alternatively, isoforms can be encoded by different genes. In the invention, homologous nucleotide sequences include nucleotide sequences encoding for a NOVX polypeptide of species other than humans, including, but not limited to: vertebrates, and thus can include, e.g., frog, mouse, rat, rabbit, dog, cat cow, horse, and other organisms. Homologous nucleotide sequences also include, but are not limited to, naturally occurring allelic variations and mutations of the nucleotide sequences set forth herein. A homologous nucleotide sequence does not, however, include the exact nucleotide sequence encoding human NOVX protein. Homologous nucleic acid sequences include those nucleic acid sequences that encode conservative amino acid substitutions (see below) in SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, as well as a polypeptide possessing NOVX biological activity. Various biological activities of the NOVX proteins are described below.
A NOVX polypeptide is encoded by the open reading frame ("ORF") of a NOVX nucleic acid. An ORF corresponds to a nucleotide sequence that could potentially be translated into a polypeptide. A stretch of nucleic acids comprising an ORF is uninterrupted by a stop codon. An ORF that represents the coding sequence for a full protein begins with an ATG "start" codon and terminates with one of the three "stop" codons, namely, TAA, TAG, or TGA. For the purposes of this invention, an ORF may be any part of a coding sequence, with or without a start codon, a stop codon, or both. For an ORF to be considered as a good candidate for coding for a bonaflde cellular protein, a minimum size requirement is often set, e.g., a stretch of DNA that would encode a protein of 50 amino acids or more.
The nucleotide sequences determined from the cloning of the human NOVX genes allows for the generation of probes and primers designed for use in identifying and/or cloning NOVX homologues in other cell types, e.g. from other tissues, as well as NOVX homologues from other vertebrates. The probe/primer typically comprises substantially purified oligonucleotide. The oligonucleotide typically comprises a region of nucleotide sequence that hybridizes under stringent conditions to at least about 12, 25, 50, 100, 150, 200, 250, 300, 350 or 400 consecutive sense strand nucleotide sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226; or an anti-sense strand nucleotide
sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226; or of a naturally occurring mutant of SEQ ID NO:2n-l, wherem n is an integer between 1 and 226.
Probes based on the human NOVX nucleotide sequences can be used to detect transcripts or genomic sequences encoding the same or homologous proteins. In various embodiments, the probe has a detectable label attached, e.g. the label can be a radioisotope, a fluorescent compound, an enzyme, or an enzyme co-factor. Such probes can be used as a part of a diagnostic test kit for identifying cells or tissues which mis-express a NOVX protein, such as by measuring a level of a NOVX-encoding nucleic acid in a sample of cells from a subject e.g., detecting NOVX mRNA levels or determining whether a genomic NOVX gene has been mutated or deleted.
"A polypeptide having a biologically-active portion of a NOVX polypeptide" refers to polypeptides exhibiting activity similar, but not necessarily identical to, an activity of a polypeptide of the invention, including mature forms, as measured in a particular biological assay, with or without dose dependency. A nucleic acid fragment encoding a "biologically-active portion of NOVX" can be prepared by isolating a portion of SEQ ID NO:2n-l, wherein n is an integer between 1 and 226, that encodes a polypeptide having a NOVX biological activity (the biological activities of the NOVX proteins are described below), expressing the encoded portion of NOVX protein (e.g., by recombinant expression in vitro) and assessing the activity of the encoded portion of NOVX.
NOVX Nucleic Acid and Polypeptide Variants
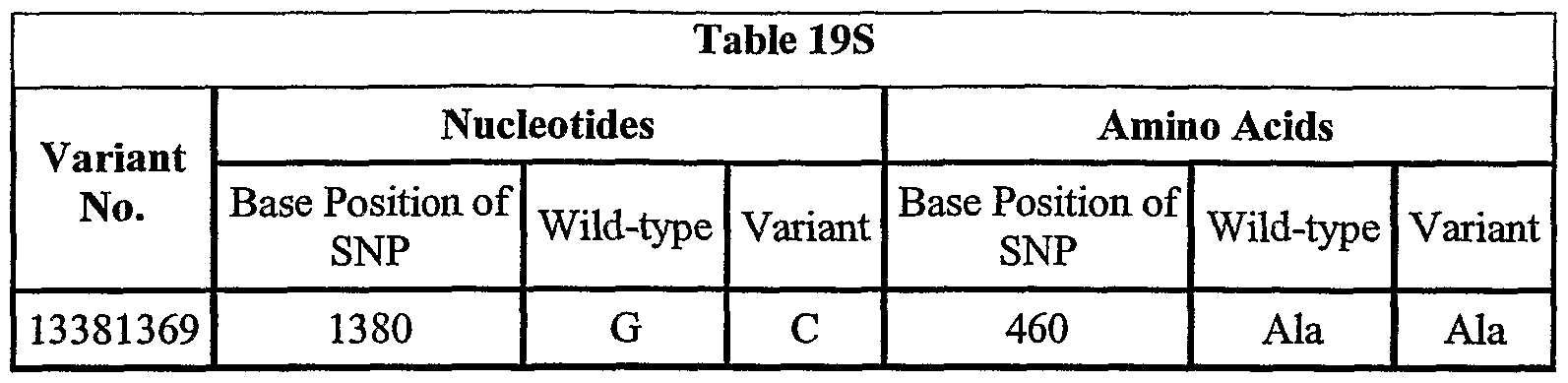
The invention further encompasses nucleic acid molecules that differ from the nucleotide sequences of SEQ ID NO:2«-l, wherein » is an integer between 1 and 226, due to degeneracy of the genetic code and thus encode the same NOVX proteins as that encoded by the nucleotide sequences of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226. In another embodiment, an isolated nucleic acid molecule of the invention has a nucleotide sequence encoding a protein having an amino acid sequence of SEQ ID NO:2n, wherein n is an integer between 1 and 226.
In addition to the human NOVX nucleotide sequences of SEQ ED NO:2»-l, wherein n is an integer between 1 and 226, it will be appreciated by those skilled in the art that DNA sequence polymorphisms that lead to changes in the amino acid sequences of the NOVX polypeptides may exist within a population (e.g., the human population). Such genetic polymorphism in the NOVX genes may exist among individuals within a
population due to natural allelic variation. As used herein, the terms "gene" and "recombinant gene" refer to nucleic acid molecules comprising an open reading frame (ORF) encoding a NOVX protein, preferably a vertebrate NOVX protein. Such natural allelic variations can typically result in 1-5% variance in the nucleotide sequence of the NOVX genes. Any and all such nucleotide variations and resulting amino acid polymorphisms in the NOVX polypeptides, which are the result of natural allelic variation and that do not alter the functional activity of the NOVX polypeptides, are intended to be within the scope of the invention.
Moreover, nucleic acid molecules encoding NOVX proteins from other species, and thus that have a nucleotide sequence that differs from a human SEQ ID NO:2«- 1 , wherein n is an integer between 1 and 226, are intended to be within the scope of the invention. Nucleic acid molecules corresponding to natural allelic variants and homologues of the NOVX cDNAs of the invention can be isolated based on their homology to the human NOVX nucleic acids disclosed herein using the human cDNAs, or a portion thereof, as a hybridization probe according to standard hybridization techniques under stringent hybridization conditions.
Accordingly, in another embodiment, an isolated nucleic acid molecule of the invention is at least 6 nucleotides in length and hybridizes under stringent conditions to the nucleic acid molecule comprising the nucleotide sequence of SEQ IDNO:2«-l, wherein n is an integer between 1 and 226. In another embodiment, the nucleic acid is at least 10, 25, 50, 100, 250, 500, 750, 1000, 1500, or 2000 or more nucleotides in length. In yet another embodiment, an isolated nucleic acid molecule of the invention hybridizes to the coding region. As used herein, the term "hybridizes under stringent conditions" is intended to describe conditions for hybridization and washing under which nucleotide sequences at least about 65% homologous to each other typically remain hybridized to each other.
Homologs (t.e., nucleic acids encoding NOVX proteins derived from species other than human) or other related sequences (e.g., paralogs) can be obtained by low, moderate or high stringency hybridization with all or a portion of the particular human sequence as a probe using methods well known in the art for nucleic acid hybridization and cloning. As used herein, the phrase "stringent hybridization conditions" refers to conditions under which a probe, primer or oligonucleotide will hybridize to its target sequence, but to no other sequences. Stringent conditions are sequence-dependent and will be different in different circumstances. Longer sequences hybridize specifically at higher temperatures
than shorter sequences. Generally, stringent conditions are selected to be about 5 °C lower than the thermal melting point (Tm) for the specific sequence at a defined ionic strength and pH. The Tm is the temperature (under defined ionic strength, pH and nucleic acid concentration) at which 50% of the probes complementary to the target sequence hybridize to the target sequence at equilibrium. Since the target sequences are generally present at excess, at Tm, 50% of the probes are occupied at equilibrium. Typically, stringent conditions will be those in which the salt concentration is less than about 1.0 M sodium ion, typically about 0.01 to 1.0 M sodium ion (or other salts) at pH 7.0 to 8.3 and the temperature is at least about 30 °C for short probes, primers or oligonucleotides (e.g., 10 nt to 50 nt) and at least about 60 °C for longer probes, primers and oligonucleotides.
Stringent conditions may also be achieved with the addition of destabilizing agents, such as formamide.
Stringent conditions are known to those skilled in the art and can be found in Ausubel, et al., (eds.), CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, N.Y. (1989), 6.3.1-6.3.6. Preferably, the conditions are such that sequences at least about 65%, 70%, 75%, 85%, 90%, 95%, 98%, or 99% homologous to each other typically remain hybridized to each other. A non-limiting example of stringent hybridization conditions are hybridization in a high salt buffer comprising 6X SSC, 50 mM Tris-HCl (pH 7.5), 1 mM EDTA, 0.02% PVP, 0.02% Ficoll, 0.02% BSA, and 500 mg/ml denatured salmon sperm DNA at 65°C, followed by one or more washes in 0.2X SSC, 0.01 % BSA at 50°C. An isolated nucleic acid molecule of the invention that hybridizes under stringent conditions to a sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, corresponds to a naturally-occurring nucleic acid molecule. As used herein, a "naturally-occurring" nucleic acid molecule refers to an RNA or DNA molecule having a nucleotide sequence that occurs in nature (e.g. , encodes a natural protein).
In a second embodiment, a nucleic acid sequence that is hybridizable to the nucleic acid molecule comprising the nucleotide sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, or fragments, analogs or derivatives thereof, under conditions of moderate stringency is provided. A non-limiting example of moderate stringency hybridization conditions are hybridization in 6X SSC, 5X Reinhardt's solution, 0.5% SDS and 100 mg/ml denatured salmon sperm DNA at 55 °C, followed by one or more washes in IX SSC, 0.1% SDS at 37 °C. Other conditions of moderate stringency that may be used are well-known within the art. See, e.g., Ausubel, et al. (eds.), 1993, CURRENT PROTOCOLS
IN MOLECULAR BIOLOGY, John Wiley & Sons, NY, and Krieger, 1990; GENE TRANSFER AND EXPRESSION, A LABORATORY MANUAL, Stockton Press, NY.
In a third embodiment, a nucleic acid that is hybridizable to the nucleic acid molecule comprising the nucleotide sequences of SEQ ID NO:2«-l, wherein n is an integer 5 between 1 and 226, or fragments, analogs or derivatives thereof, under conditions of low stringency, is provided. A non-limiting example of low stringency hybridization conditions are hybridization in 35% formamide, 5X SSC, 50 mM Tris-HCl (pH 7.5), 5 mM EDTA, 0.02% PVP, 0.02% Ficoll, 0.2% BSA, 100 mg/ml denatured salmon sperm DNA, 10% (wt/vol) dextran sulfate at 40°C, followed by one or more washes in 2X SSC, 25 mM
10 Tris-HCl (pH 7.4), 5 mM EDTA, and 0.1 % SDS at 50°C. Other conditions of low stringency that may be used are well known in the art (e.g., as employed for cross-species hybridizations). See, e.g., Ausubel, et al. (eds.), 1993, CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, NY, and Kriegler, 1990, GENE TRANSFER AND EXPRESSION, A LABORATORY MANUAL, Stockton Press, NY; Shilo and Weinberg, 1981.
15 Proc Natl Acad Sci USA 78: 6789-6792.
Conservative Mutations
In addition to naturally-occurring allelic variants of NOVX sequences that may exist in the population, the skilled artisan will further appreciate that changes can be
20 introduced by mutation into the nucleotide sequences of SEQ ID NO:2«-l , wherein n is an integer between 1. and 226, thereby leading to changes in the amino acid sequences of the encoded NOVX protein, without altering the functional ability of that NOVX protein. For example, nucleotide substitutions leading to amino acid substitutions at "non-essential" amino acid residues can be made in the sequence of SEQ LD NO:2n, wherein n is an integer
25 between 1 and 226. A "non-essential" amino acid residue is a residue that can be altered from the wild-type sequences of the NOVX proteins without altering their biological activity, whereas an "essential" amino acid residue is required for such biological activity. For example, amino acid residues that are conserved among the NOVX proteins of the invention are predicted to be particularly non-amenable to alteration. Amino acids for
30. which conservative substitutions can be made are well-known within the art.
Another aspect of the invention pertains to nucleic acid molecules encoding NOVX proteins that contain changes in amino acid residues that are not essential for activity. Such NOVX proteins differ in amino acid sequence from SEQ ID NO:2n-l, wherein n is an
integer between 1 and 226, yet retain biological activity. In one embodiment, the isolated nucleic acid molecule comprises a nucleotide sequence encoding a protein, wherein the protein comprises an amino acid sequence at least about 40% homologous to the amino acid sequences of SEQ ID NO:2n, wherein n is an integer between 1 and 226. Preferably, the protein encoded by the nucleic acid molecule is at least about 60% homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 226; more preferably at least about 70% homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 226; still more preferably at least about 80% homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 226; even more preferably at least about 90% homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 226; and most preferably at least about 95% homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 226.
An isolated nucleic acid molecule encoding a NOVX protein homologous to the protein of SEQ ID NO:2n, wherein n is an integer between 1 and 226, can be created by introducing one or more nucleotide substitutions, additions or deletions into the nucleotide sequence of SEQ ID NO:2«-l , wherein n is an integer between 1 and 226, such that one or more amino acid substitutions, additions or deletions are introduced into the encoded protein.
Mutations can be introduced any one of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, by standard techniques, such as site-directed mutagenesis and PCR-mediated mutagenesis. Preferably, conservative amino acid substitutions are made at one or more predicted, non-essential amino acid residues. A "conservative amino acid substitution" is one in which the amino acid residue is replaced with an amino acid residue having a similar side chain. Families of amino acid residues having similar side chains have been defined within the art. These families include amino acids with basic side chains (e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine). Thus, a predicted non-essential amino acid residue in the NOVX protein is replaced with another amino acid residue from the same side chain family. Alternatively, in another embodiment, mutations can be introduced randomly along all or part of a NOVX coding sequence, such as by saturation mutagenesis, and the resultant mutants can be screened for
NOVX biological activity to identify mutants that retain activity. Following mutagenesis of a nucleic acid of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, the encoded protein can be expressed by any recombinant technology known in the art and the activity of the protein can be determined. The relatedness of amino acid families may also be determined based on side chain interactions. Substituted amino acids may be fully conserved "strong" residues or fully conserved "weak" residues. The "strong" group of conserved amino acid residues may be any one of the following groups: STA, NEQK, NHQK, NDEQ, QHRK, MILV, MILF, HY, FYW, wherein the single letter amino acid codes are grouped by those amino acids that may be substituted for each other. Likewise, the "weak" group of conserved residues may be any one of the following: CSA, ATV, SAG, STNK, STPA, SGND, SNDEQK, NDEQHK, NEQHRK, HFY, wherein the letters within each group represent the single letter amino acid code.
In one embodiment, a mutant NOVX protein can be assayed for (i) the ability to form proteimprotein interactions with other NOVX proteins, other cell-surface proteins, or biologically-active portions thereof, (ii) complex formation between a mutant NOVX protein and a NOVX ligand; or (iii) the ability of a mutant NOVX protein to bind to an intracellular target protein or biologically-active portion thereof; (e.g. avidin proteins).
In yet another embodiment, a mutant NOVX protein can be assayed for the ability to regulate a specific biological function (e.g., regulation of insulin release).
Interfering RNA
In one aspect of the invention, NOVX gene expression can be attenuated by RNA interference. One approach well-known in the art is short interfering RNA (siRNA) mediated gene silencing where expression products of a NOVX gene are targeted by specific double stranded NOVX derived siRNA nucleotide sequences that are complementary to at least a 19-25 nt long segment of the NOVX gene transcript, including the 5' untranslated (UT) region, the ORF, or the 3' UT region. See, e.g., PCT applications WO00/44895, WO99/32619, WO01/75164, WO01/92513, WO 01/29058, WO01/89304, WO02/16620, and WO02/29858, each incorporated by reference herein in their entirety. Targeted genes can be a NOVX gene, or an upstream or downstream modulator of the NOVX gene. Nonlimiting examples of upstream or downstream modulators of a NOVX gene include, e.g., a transcription factor that binds the NOVX gene promoter, a kinase or
phosphatase that interacts with a NOVX polypeptide, and polypeptides involved in a NOVX regulatory pathway.
According to the methods of the present invention, NOVX gene expression is silenced using short interfering RNA. A NOVX polynucleotide according to the invention includes a siRNA polynucleotide. Such a NOVX siRNA can be obtained using a NOVX polynucleotide sequence, for example, by processing the NOVX ribopolynucleotide sequence in a cell-free system, such as but not limited to a Drosophila extract, or by transcription of recombinant double stranded NOVX RNA or by chemical synthesis of nucleotide sequences homologous to a NOVX sequence. See, e.g., Tuschl, Zamore, Lehmann, Bartel and Shaφ (1999), Genes & Dev. 13: 3191-3197, incoφorated herein by reference in its entirety. When synthesized, a typical 0.2 micromolar-scale RNA synthesis provides about 1 milligram of siRNA, which is sufficient for 1000 transfection experiments using a 24-well tissue culture plate format.
The most efficient silencing is generally observed with siRNA duplexes composed of a 21-nt sense strand and a 21-nt antisense strand, paired in a manner to have a 2-nt
3' overhang. The sequence of the 2-nt 3' overhang makes an additional small contribution to the specificity of siRNA target recognition. The contribution to specificity is localized to the unpaired nucleotide adjacent to the first paired bases. In one embodiment, the nucleotides in the 3' overhang are ribonucleotides. In an alternative embodiment, the nucleotides in the 3' overhang are deoxyribonucleotides. Using 2'-deoxyribonucleotides in the 3' overhangs is as efficient as using ribonucleotides, but deoxyribonucleotides are often cheaper to synthesize and are most likely more nuclease resistant.
A contemplated recombinant expression vector of the invention comprises a NOVX DNA molecule cloned into an expression vector comprising operatively-linked regulatory sequences flanking the NOVX sequence in a manner that allows for expression (by transcription of the DNA molecule) of both strands. An RNA molecule that is antisense to NOVX mRNA is transcribed by a first promoter (e.g., a promoter sequence 3' of the cloned DNA) and an RNA molecule that is the sense strand for the NOVX mRNA is transcribed by a second promoter (e.g., a promoter sequence 5' of the cloned DNA). The sense and antisense strands may hybridize in vivo to generate siRNA constructs for silencing of the NOVX gene. Alternatively, two constructs can be utilized to create the sense and anti- sense strands of a siRNA construct. Finally, cloned DNA can encode a construct having secondary structure, wherein a single transcript has both the sense and complementary
antisense sequences from the target gene or genes. In an example of this embodiment, a haiφin RNAi product is homologous to all or a portion of the target gene. In another example, a haiφin RNAi product is a siRNA. The regulatory sequences flanking the NOVX sequence may be identical or may be different, such that their expression may be modulated independently, or in a temporal or spatial manner.
In a specific embodiment, siRNAs are transcribed intracellularly by cloning the NOVX gene templates into a vector containing, e.g., a RNA pol III transcription unit from the smaller nuclear RNA (snRNA) U6 or the human RNase P RNA HI . One example of a vector system is the GeneSuppressor™ RNA Interference kit (commercially available from Imgenex). The U6 and HI promoters are members of the type III class of Pol III promoters. The +1 nucleotide of the U6-like promoters is always guanosine, whereas the +1 for HI promoters is adenosine. The termination signal for these promoters is defined by five consecutive thymidines. The transcript is typically cleaved after the second uridine. Cleavage at this position generates a 3' UU overhang in the expressed siRNA, which is similar to the 3' overhangs of synthetic siRNAs. Any sequence less than 400 nucleotides in length can be. transcribed by these promoter, therefore they are ideally suited for the expression of around 21 -nucleotide siRNAs in, e.g., an approximately 50-nucleotide'RNA stem-loop transcript.
A siRNA vector appears to have an advantage over synthetic siRNAs where long term knock-down of expression is desired. Cells transfected with a siRNA expression vector would experience steady, long-term mRNA inhibition. In contrast, cells transfected with exogenous synthetic siRNAs typically recover from mRNA suppression within seven days or ten rounds of cell division. The long-term gene silencing ability of siRNA expression vectors may provide for applications in gene therapy. In general, siRNAs are chopped from longer dsRNA by an ATP-dependent ribonuclease called DICER. DICER is a member of the RNase LTI family of double- stranded RNA-specific endonucleases. The siRNAs assemble with cellular proteins into an endonuclease complex. In vitro studies in Drosophila suggest that the siRNAs/protein complex (siRNP) is then transferred to a second enzyme complex, called an RNA-induced silencing complex (RISC), which contains an endoribonuclease that is distinct from DICER. RISC uses the sequence encoded by the antisense siRNA strand to find and destroy mRNAs of complementary sequence. The siRNA thus acts as a guide, restricting the ribonuclease to cleave only mRNAs complementary to one of the two siRNA strands.
A NOVX mRNA region to be targeted by siRNA is generally selected from a desired NOVX sequence beginning 50 to 100 nt downstream of the start codon. Alternatively, 5' or 3' UTRs and regions nearby the start codon can be used but are generally avoided, as these may be richer in regulatory protein binding sites. UTR-binding proteins and/or translation initiation complexes may interfere with binding of the siRNP or RISC endonuclease complex. An initial BLAST homology search for the selected siRNA sequence is done against an available nucleotide sequence library to ensure that only one gene is targeted. Specificity of target recognition by siRNA duplexes indicate that a single point mutation located in the paired region of an siRNA duplex is sufficient to abolish target mRNA degradation. See, Elbashir et al. 2001 EMBO J. 20(23):6877-88. Hence, consideration should be taken to accommodate SNPs, polymoφhisms, allelic variants or species-specific variations when targeting a desired gene.
In one embodiment, a complete NOVX siRNA experiment includes the proper negative control. A negative control siRNA generally has the same nucleotide composition as the NOVX siRNA but lack significant sequence homology to the genome. Typically, one would scramble the nucleotide sequence of the NOVX siRNA and do a homology search to make sure it lacks homology to any other gene.
Two independent NOVX siRNA duplexes can be used to knock-down a target NOVX gene. This helps to control for specificity of the silencing effect. In addition, expression of two independent genes can be simultaneously knocked down by using equal concentrations of different NOVX siRNA duplexes, e.g., a NOVX siRNA and an siRNA for a regulator of a NOVX gene or polypeptide. Availability of siRNA-associating proteins is believed to be more limiting than target mRNA accessibility.
A targeted NOVX region is typically a sequence of two adenines (AA) and two thymidines (TT) divided by a spacer region of nineteen (N19) residues (e.g., AA(N19)TT). A desirable spacer region has a G/C-content of approximately 30% to 70%, and more preferably of about 50%. If the sequence AA(N19)TT is not present in the target sequence, an alternative target region would be AA(N21). The sequence of the NOVX sense siRNA corresponds to (N19)TT or N21, respectively. In the latter case, conversion of the 3' end of the sense siRNA to TT can be performed if such a sequence does not naturally occur in the NOVX polynucleotide. The rationale for this sequence conversion is to generate a symmetric duplex with respect to the sequence composition of the sense and antisense 3' overhangs. Symmetric 3' overhangs may help to ensure that the siRNPs are formed with
approximately equal ratios of sense and antisense target RNA-cleaving siRNPs. See, e.g., Elbashir, Lendeckel and Tuschl (2001). Genes & Dev. 15: 188-200, incoφorated by reference herein in its entirely. The modification of the overhang of the sense sequence of the siRNA duplex is not expected to affect targeted mRNA recognition, as the antisense siRNA strand guides target recognition.
Alternatively, if the NOVX target mRNA does not contain a suitable AA(N21) sequence, one may search for the sequence NA(N21). Further, the sequence of the sense strand and antisense strand may still be synthesized as 5' (NI 9)TT, as it is believed that the sequence of the 3'-most nucleotide of the antisense siRNA does not contribute to specificity. Unlike antisense or ribozyme technology, the secondary structure of the target mRNA does not appear to have a strong effect on silencing. See, Harborth, et al. (2001) J. Cell Science 114: 4557-4565, incoφorated by reference in its entirety.
Transfection of NOVX siRNA duplexes can be achieved using standard nucleic acid transfection methods, for example, OLIGOFECTAMINE Reagent (commercially available from Invitrogen). An assay for NOVX gene silencing is generally performed approximately 2 days after transfection. No NOVX gene silencing has been observed in the absence of transfection reagent, allowing for a comparative analysis of the wild-type and silenced NOVX phenotypes. In a specific embodiment, for one well of a 24-well plate, approximately 0.84 μg of the siRNA duplex is generally sufficient. Cells are typically seeded the previous day, and are transfected at about 50% confluence. The choice of cell culture media and conditions are routine to those of skill in the art, and will vary with the choice of cell type. The efficiency of transfection may depend on the cell type, but also on the passage number and the confluency of the cells. The time and the manner of formation of siRNA-liposome complexes (e.g. inversion versus vortexing) are also critical. Low transfection efficiencies are the most frequent cause of unsuccessful NOVX silencing. The efficiency of transfection needs to be carefully examined for each new cell line to be used. Preferred cell are derived from a mammal, more preferably from a rodent such as a rat or mouse, and most preferably from a human. Where used for therapeutic treatment, the cells are preferentially autologous, although non-autologous cell sources are also contemplated as within the scope of the present invention.
For a control experiment, transfection of 0.84 μg single-stranded sense NOVX siRNA will have no effect on NOVX silencing, and 0.84 μg antisense siRNA has a weak silencing effect when compared to 0.84 μg of duplex siRNAs. Control experiments again
allow for a comparative analysis of the wild-type and silenced NOVX phenotypes. To control for transfection efficiency, targeting of common proteins is typically performed, for example targeting of lamin A C or transfection of a CMV-driven EGFP-expression plasmid (e.g. commercially available from Clontech). In the above example, a determination of the fraction of lamin A/C knockdown in cells is determined the next day by such techniques as immunofluorescence, Western blot, Northern blot or other similar assays for protein expression or gene expression. Lamin A/C monoclonal antibodies may be obtained from Santa Cruz Biotechnology.
Depending on the abundance and the half life (or turnover) of the targeted NOVX polynucleotide in a cell, a knock-down phenotype may become apparent after 1 to 3 days, or even later. In cases where no NOVX knock-down phenotype is observed, depletion of the NOVX polynucleotide may be observed by immunofluorescence or Western blotting. If the NOVX polynucleotide is still abundant after 3 days, cells need to be split and transferred to a fresh 24-well plate for re-transfection. If no knock-down of the targeted protein is observed, it may be desirable to analyze whether the target mRNA (NOVX or a NOVX upstream or downstream gene) was effectively destroyed by the transfected siRNA duplex. Two days after transfection, total RNA is prepared, reverse transcribed using a target-specific primer, and PCR-amplified with a primer pair covering at least one exon- exon junction in order to control for amplification of pre-mRNAs. RT/PCR of a non- targeted mRNA is also needed as control. Effective depletion of the mRNA yet undetectable reduction of target protein may indicate that a large reservoir of stable NOVX protein may exist in the cell. Multiple transfection in sufficiently long intervals may be necessary until the target protein is finally depleted to a point where a phenotype may become apparent. If multiple transfection steps are required, cells are split 2 to 3 days after transfection. The cells may be transfected immediately after splitting.
An inventive therapeutic method of the invention contemplates administering a NOVX siRNA construct as therapy to compensate for increased or aberrant NOVX expression or activity. The NOVX ribopolynucleotide is obtained and processed into siRNA fragments, or a NOVX siRNA is synthesized, as described above. The NOVX siRNA is administered to cells or tissues using known nucleic acid transfection techniques, as described above. A NOVX siRNA specific for a NOVX gene will decrease or knockdown NOVX transcription products, which will lead to reduced NOVX polypeptide production, resulting in reduced NOVX polypeptide activity in the cells or tissues.
The present invention also encompasses a method of treating a disease or condition associated with the presence of a NOVX protein in an individual comprising administering to the individual an RNAi construct that targets the mRNA of the protein (the mRNA that encodes the protein) for degradation. A specific RNAi construct includes a siRNA or a double stranded gene transcript that is processed into siRNAs. Upon treatment, the target protein is not produced or is not produced to the extent it would be in the absence of the freatment.
Where the NOVX gene function is not correlated with a known phenotype, a control sample of cells or tissues from healthy individuals provides a reference standard for determining NOVX expression levels. Expression levels are detected using the assays described, e.g., RT-PCR, Northern blotting, Western blotting, ELISA, and the like. A subject sample of cells or tissues is taken from a mammal, preferably a human subject, suffering from a disease state. The NOVX ribopolynucleotide is used to produce siRNA constructs, that are specific for the NOVX gene product. These cells or tissues are treated by administering NOVX siRNA' s to the cells or tissues by methods described for the fransfection of nucleic acids into a cell or tissue, and a change in NOVX polypeptide or polynucleotide expression is observed in the subject sample relative to the control sample, using the assays described. This NOVX gene knockdown approach provides a rapid method for determination of a NOVX minus (NOVX") phenotype in the treated subject sample. The NOVX" phenotype observed in the treated subject sample thus serves as a marker for monitoring the course of a disease state during treatment.
In specific embodiments, a NOVX siRNA is used in therapy. Methods for the generation and use of a NOVX siRNA are known to those skilled in the art. Example techniques are provided below.
Production of RNAs
Sense RNA (ssRNA) and antisense RNA (asRNA) of NOVX are produced using known methods such as transcription in RNA expression vectors. In the initial experiments, the sense and antisense RNA are about 500 bases in length each. The- produced ssRNA and asRNA (0.5 μM) in 10 mM Tris-HCl (pH 7.5) with 20 mM NaCl were heated to 95° C for 1 min then cooled and annealed at room temperature for 12 to 16 h. The RNAs are precipitated and resuspended in lysis buffer (below). To monitor annealing, RNAs are electrophoresed in a 2% agarose gel in TBE buffer and stained with
ethidium bromide. See, e.g., Sambrook et al., Molecular Cloning. Cold Spring Harbor Laboratory Press, Plainview, NN. (1989).
Lysate Preparation Untreated rabbit reticulocyte lysate (Ambion) are assembled according to the manufacturer's directions. dsRΝA is incubated in the lysate at 30° C for 10 min prior to the addition of mRΝAs. Then ΝOVX mRΝAs are added and the incubation continued for an additional 60 min. The molar ratio of double stranded RΝA and mRΝA is about 200: 1. The ΝOVX mRΝA is radiolabeled (using known techniques) and its stability is monitored by gel electrophoresis.
In a parallel experiment made with the same conditions, the double stranded RΝA is internally radiolabeled with a 32P-ATP. Reactions are stopped by the addition of 2 X proteinase K buffer and deproteinized as described previously (Tuschl et al., Genes Dev., 13:3191-3197 (1999)). Products are analyzed by electrophoresis in 15% or 18% polyaciylamide sequencing gels using appropriate RΝA standards. By monitoring the gels for radioactivity, the natural production of 10 to 25 nt RΝAs from the double stranded RΝA can be determined.
The band of double stranded RΝA, about 21-23 bps, is eluded. The efficacy of these 21-23 mers for suppressing ΝOVX transcription is assayed in vitro using the same rabbit reticulocyte assay described above using 50 nanomolar of double stranded 21-23 mer for each assay. The sequence of these 21-23 mers is then determined using standard nucleic acid sequencing techniques.
RΝA Preparation 21 nt RΝAs, based on the sequence determined above, are chemically synthesized using Expedite RΝA phosphoramidites and thymidine phosphoramidite (Proligo, Germany). Synthetic oligonucleotides are deprotected and gel-purified (Elbashir, Lendeckel, & Tuschl, Genes & Dev. 15, 188-200 (2001)), followed by Sep-Pak C18 cartridge (Waters, Milford, Mass., USA) purification (Tuschl, et al., Biochemistry, 32:11658-11668 (1993)).
These RΝAs (20 μM) single strands are incubated in annealing buffer (100 mM potassium acetate, 30 mM HEPES-KOH at pH 7.4, 2 mM magnesium acetate) for 1 min at 90° C followed by 1 h at 37° C.
Cell Culture
A cell culture known in the art to regularly express NOVX is propagated using standard conditions. 24 hours before transfection, at approx. 80% confluency, the cells are frypsinized and diluted 1:5 with fresh medium without antibiotics (1-3 X 105 cells/ml) and transferred to.24-well plates (500 ml/well). Transfection is performed using a commercially available lipofection kit and NOVX expression is monitored using standard techniques with positive and negative control. A positive control is cells that naturally express NOVX while a negative control is cells that do not express NOVX. Base-paired 21 and 22 nt siRNAs with overhanging 3' ends mediate efficient sequence-specific mRNA degradation in lysates and in cell culture. Different concentrations of siRNAs are used. An efficient concentration for suppression in vitro in mammalian culture is between 25 nM to 100 nM final concentration. This indicates that siRNAs are effective at concenfrations that are several orders of magnitude below the concentrations applied in conventional antisense or ribozyme gene targeting experiments. The above method provides a way both for the deduction of NOVX siRNA sequence and the use of such siRNA for in vitro suppression. In vivo suppression may be performed using the same siRNA using well known in vivo transfection or gene therapy transfection techniques.
Antisense Nucleic Acids
Another aspect of the invention pertains to isolated antisense nucleic acid molecules that are hybridizable to or complementary to the nucleic acid molecule comprising the nucleotide sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, or fragments, analogs or derivatives thereof. An "antisense" nucleic acid comprises a nucleotide sequence that is complementary to a "sense" nucleic acid encoding a protein (e.g., complementary to the coding strand of a double-stranded cDNA molecule or complementary to an mRNA sequence). In specific aspects, antisense nucleic acid molecules are provided that comprise a sequence complementary to at least about 10, 25, 50, 100, 250 or 500 nucleotides or an entire NOVX coding strand, or to only a portion thereof. Nucleic acid molecules encoding fragments, homologs, derivatives and analogs of a NOVX protein of SEQ ID NO:2«, wherein n is an integer between 1 and 226, or antisense nucleic acids complementary to a NOVX nucleic acid sequence of SEQ ID NO:2n-l, wherein n is an integer between 1 and 226, are additionally provided.
In one embodiment, an antisense nucleic acid molecule is antisense to a "coding region" of the coding strand of a nucleotide sequence encoding a NOVX protein. The term "coding region" refers to the region of the nucleotide sequence comprising codons which are translated into amino acid residues. In another embodiment, the antisense nucleic acid molecule is antisense to a "noncoding region" of the coding sfrand of a nucleotide sequence encoding the NOVX protein. The term "noncoding region" refers to 5' and 3' sequences which flank the coding region that are not translated into amino acids (i.e., also referred to as 5' and 3' untranslated regions).
Given the coding strand sequences encoding the NOVX protein disclosed herein, antisense nucleic acids of the invention can be designed according to the rules of Watson and Crick or Hoogsteen base pairing. The antisense nucleic acid molecule can be complementary to the entire coding region of NOVX mRNA, but more preferably is an oligonucleotide that is antisense to only a portion of the coding or noncoding region of NOVX mRNA. For example, the antisense oligonucleotide can be complementary to the region surrounding the translation start site of NOVX mRNA. An antisense oligonucleotide can be, for example, about 5, 10, 15, 20, 25, 30, 35, 40, 45 or 50 nucleotides in length. An antisense nucleic acid of the invention can be constructed using chemical synthesis or enzymatic ligation reactions using procedures known in the art. For example, an antisense nucleic acid (e.g., an antisense oligonucleotide) can be chemically synthesized using naturally-occurring nucleotides or variously modified nucleotides designed to increase the biological stabilit of the molecules or to increase the. physical stability of the duplex formed between the antisense and sense nucleic acids (e.g., phosphorothioate derivatives and acridine substituted nucleotides can be used).
Examples of modified nucleotides that can be Used to generate the antisense nucleic acid include: 5-fluorouracil, 5-bromouracil, 5-chlorouracil, 5-iodouracil, hypoxanthine, xanthine, 4-acetylcytosine, 5-carboxymethylaminomethyl-2-tWouridine, 5-(carboxyhydroxylmethyl) uracil, 5-carboxymethylaminomethyluracil, dihydrouracil, beta-D-galactosylqueosine, inosine, N6-isopentenyladenine, 1-methylguanine, 1-methylinosine, 2,2-dimethylguanine, 2-methyladenine, 2-methylguanine, 5-methoxyuracil, 3-methylcytosine, 5-methylcytosine, N6-adenine, 7-methylguanine, 5-methylaminomefhyluracil, 5-methoxyaminomethyl-2-thiouracil, 2-thiouracil, 4-thiouracil, beta-D-mannosylqueosine, 5'-methoxycarboxymethyluracil, 2-methylthio-N6-isopentenyladenine, uracil-5-oxyacetic acid (v), wybutoxosine,
pseudouracil, queosine, 2-thiocytosine, 5-methyl-2-thiouracil, 5-methyluracil, uracil-5-oxyacetic acid methylester, uracil-5-oxyacetic acid (v), 5-methyl-2-thiouracil, 3-(3-amino-3-N-2-carboxypropyl) uracil, (acp3)w, and 2,6-diaminopurine. Alternatively, the antisense nucleic acid can be produced biologically using an expression vector into which a nucleic acid has been subcloned in an antisense orientation (i.e., RNA transcribed from the inserted nucleic acid will be of an antisense orientation to a target nucleic acid of interest, described further in the following subsection).
The antisense nucleic acid molecules of the invention are typically administered to a subject or generated in situ such that they hybridize with or bind to cellular mRNA and/or genomic DNA encoding a NOVX protein to thereby inhibit expression of the protein (e.g. , by inhibiting transcription and/or translation). The hybridization can be by conventional nucleotide complementarity to form a stable duplex, or, for example, in the case of an antisense nucleic acid molecule that binds to DNA duplexes, through specific interactions in the major groove of the double helix. An example of a route of administration of antisense nucleic acid molecules of the invention includes direct injection at a tissue site. Alternatively, antisense nucleic acid molecules can be modified to target selected cells and then administered systemically. For example, for systemic administration, antisense molecules can be modified such that they specifically bind to receptors or antigens expressed on a selected cell surface (e.g., by linking the antisense nucleic acid molecules to peptides or antibodies that bind to cell surface receptors or antigens). The antisense nucleic acid molecules can also be delivered to cells using the vectors described herein. To achieve sufficient nucleic acid molecules, vector constructs in which the antisense nucleic acid molecule is placed under the control of a strong pol II or pol III promoter are preferred.
In yet another embodiment, the antisense nucleic acid molecule of the invention is an α-anomeric nucleic acid molecule. An α-anomeric nucleic acid molecule forms specific double-stranded hybrids with complementary RNA in which, contrary to the usual β-units, the strands run parallel to each other. See, e.g., Gaultier, et al., 1987. Nucl. Acids Res. 15: 6625-6641. The antisense nucleic acid molecule can also comprise a 2'-o-methylribonucleotide (See, e.g., Inoue, etal. 1987. Nucl. Acids Res. 15: 6131-6148) or a chimeric RNA-DNA analogue (See, e.g., Inoue, et al., 1987. FEBSLett. 215: 327-330.
Ribozymes and PNA Moieties
Nucleic acid modifications include, by way of non-limiting example, modified bases, and nucleic acids whose sugar phosphate backbones are modified or derivatized. These modifications are carried out at least in part to enhance the chemical stability of the modified nucleic acid, such that they may be used, for example, as antisense binding nucleic acids in therapeutic applications in a subject.
In one embodiment, an antisense nucleic acid of the invention is a ribozyme. Ribozymes are catalytic RNA molecules with ribonuclease activity that are capable of cleaving a single-stranded nucleic acid, such as an mRNA, to which they have a complementary region. Thus, ribozymes (e.g., hammerhead ribozymes as described in Haselhoff and Gerlach 1988. Nature 334: 585-591) can be used to catalytically cleave NOVX mRNA transcripts to thereby inhibit translation of NOVX mRNA. A ribozyme having specificity for a NOVX-encoding nucleic acid can be designed based upon the nucleotide sequence of aNOVX cDNA disclosed herein (i.e., SEQ ID NO:2»-l, wherein n is an integer between 1 and 226). For example, a derivative of a Tetrahymena L-19 IVS RNA can be constructed in which the nucleotide sequence of the active site is complementary to the nucleotide sequence to be cleaved in a NOVX-encoding mRNA. See, e.g., U.S. Patent 4,987,071 to Cech, et al. and U.S. Patent 5,116,742 to Cech, et al. NOVX mRNA can also be used to select a catalytic RNA having a specific ribonuclease activity from a pool of RNA molecules. See, e.g., Bartel et al, (1993) Science 261:1411-1418.
Alternatively, NOVX gene expression can be inhibited by targeting nucleotide sequences complementary to the regulatory region of the NOVX nucleic acid (e.g., the NOVX promoter and/or enhancers) to form triple helical structures that prevent transcription of the NOVX gene in target cells. See, e.g., Helene, 1991. Anticancer Drug Des. 6: 569-84; Helene, et al. 1992. Ann. N. Y. Acad. Sci. 660: 27-36; Maher, 1992. Bioassays 14: 807-15.
In various embodiments, the NOVX nucleic acids can be modified at the base moiety, sugar moiety or phosphate backbone to improve, e.g., the stability, hybridization, or solubility of the molecule. For example, the deoxyribose phosphate backbone of the nucleic acids can be modified to generate peptide nucleic acids. See, e.g., Hyrup, et al, 1996. BioorgMed Chem 4: 5-23. As used herein, the terms "peptide nucleic acids" or "PNAs" refer to nucleic acid mimics (e.g., DNA mimics) in which the deoxyribose phosphate backbone is replaced by a pseudopeptide backbone and only the four natural
nucleotide bases are retained. The neutral backbone of PNAs has been shown to allow for specific hybridization to DNA and RNA under conditions of low ionic strength. The synthesis of PNA oligomer can be performed using standard solid phase peptide synthesis protocols as described in Hyrup, et al., 1996. supra; Perry-O'Keefe, et al., 1996. Proc. Natl. Acad. Sci. USA 93: 14670-14675.
PNAs of NOVX can be used in therapeutic and diagnostic applications. For example, PNAs can be used as antisense or antigene agents for sequence-specific modulation of gene expression by, e.g., inducing transcription or translation arrest or inhibiting replication. PNAs of NOVX can also be used, for example, in the analysis of single base pair mutations in a gene (e.g., PNA directed PCR clamping; as artificial restriction enzymes when used in combination with other enzymes, e.g., Si nucleases (See, Hyrup, et al., 1996.supra); or as probes or primers for DNA sequence and hybridization (See, Hyrup, et al., 1996, supra; Perry-O'Keefe, etal., 1996. supra).
In another embodiment, PNAs of NOVX can be modified, e.g., to enhance their stability or cellular uptake, by attaching lipophilic or other helper groups to PNA, by the formation of PNA-DNA chimeras, or by the use of liposomes or other techniques of drug delivery known in the art. For example, PNA-DNA chimeras of NOVX can be generated that may combine the advantageous properties of PNA and DNA. Such chimeras allow DNA recognition enzymes (e.g., RNase H and DNA polymerases) to interact with the DNA portion while the PNA portion would provide high binding affinity and specificity.
PNA-DNA chimeras can be linked using linkers of appropriate lengths selected in terms of base stacking, number of bonds between the nucleotide bases, and orientation (see, Hyrup, et al., 1996. supra). The synthesis of PNA-DNA chimeras can be performed as described in Hyrup, et al., 1996. supra and Finn, et al., 1996. Nucl Acids Res 24: 3357-3363. For example, a DNA chain can be synthesized on a solid support using standard phosphoramidite coupling chemistry, and modified nucleoside analogs, e.g., 5l-(4-methoxytrityl)amino-5'-deoxy-thymidine phosphoramidite, can be used between the PNA and the 5' end of DNA. See, e.g., Mag, et al., 1989. Nucl Acid Res 17: 5973-5988. PNA monomers are then coupled in a stepwise manner to produce a chimeric molecule with a 5* PNA segment and a 3' DNA segment. See, e.g., Finn, et al., 1996. supra.
Alternatively, chimeric molecules can be synthesized with a 5' DNA segment and a 3' PNA segment. See, e.g., Petersen, et al., 1975. Bioorg. Med. Chem. Lett. 5: 1119-11124.
In other embodiments, the oligonucleotide may include other appended groups such as peptides (e.g., for targeting host cell receptors in vivo), or agents facilitating transport across the cell membrane (see, e.g., Letsinger, et al., 1989. Proc. Natl. Acad. Sci. U.S.A. 86: 6553-6556; Lemaifre, etal, 1987. Proc. Natl. Acad. Sci. 84: 648-652; PCT Publication No. WO88/09810) or the blood-brain barrier (see, e.g., PCT Publication No. WO 89/10134). In addition, oligonucleotides can be modified with hybridization triggered cleavage agents (see, e.g., Krol, et al, 1988. BioTechniques 6:958-976) or intercalating agents (see, e.g., Txm, 1988. Pharm. Res. 5: 539-549). To this end, the oligonucleotide may be conjugated to another molecule, e.g., a peptide, a hybridization triggered cross-linking agent, a transport agent, a hybridization-triggered cleavage agent, and the like.
NOVX Polypeptides
A polypeptide according to the invention includes a polypeptide including the amino acid sequence of NOVX polypeptides whose sequences are provided in any one of SEQ ID NO:2n, wherein n is an integer between 1 and 226. The invention also includes a mutant or variant protein any of whose residues may be changed from the corresponding residues shown in any one of SEQ ID NO:2», wherein n is an integer between 1 and 226, while still encoding a protein that maintains its NOVX activities and physiological functions, or a functional fragment thereof. In general, a NOVX variant that preserves NOVX-like function includes any variant in which residues at a particular position in the sequence have been substituted by other amino acids, and further include the possibility of inserting an additional residue or residues between two residues of the parent protein as well as the possibility of deleting one or more residues from the parent sequence. Any amino acid substitution, insertion, or deletion is encompassed by the invention. In favorable circumstances, the substitution is a conservative substitution as defined above.
One aspect of the invention pertains to isolated NOVX proteins, and biologically-active portions thereof, or derivatives, fragments, analogs or homologs thereof. Also provided are polypeptide fragments suitable for use as immunogens to raise anti-NOVX antibodies. In one embodiment, native NOVX proteins can be isolated from cells or tissue sources by an appropriate purification scheme using standard protein purification techniques. In another embodiment, NOVX proteins are produced by
recombinant DNA techniques. Alternative to recombinant expression, a NOVX protein or polypeptide can be synthesized chemically using standard peptide synthesis techniques. An "isolated" or "purified" polypeptide or protein or biologically-active portion thereof is substantially free of cellular material or other contaminating proteins from the cell or tissue source from which the NOVX protein is derived, or substantially free from chemical precursors or other chemicals when chemically synthesized. The language "substantially free of cellular material" includes preparations of NOVX proteins in which the protein is separated from cellular components of the cells from which it is isolated or recombinantly-produced. In one embodiment, the language "substantially free of cellular material" includes preparations of NOVX proteins having less than about 30% (by dry weight) of non-NOVX proteins (also referred to herein as a "contaminating protein"), more preferably less than about 20% of non-NOVX proteins, still more preferably less than about 10% of non-NOVX proteins, and most preferably less than about 5% of non-NOVX proteins. When the NOVX protein or biologically-active portion thereof is recombinantly-produced, it is also preferably substantially free of culture medium, /. e. , culture medium represents less than about 20%, more preferably less than about 10%, and most preferably less than about 5% of the volume of the NOVX protein preparation. The language "substantially free of chemical precursors or other chemicals" includes preparations of NOVX proteins in which the protein is separated from chemical precursors or other chemicals that are involved in the synthesis of the protein. In one embodiment, the language "substantially free of chemical precursors or other chemicals" includes preparations of NOVX proteins having less than about 30% (by dry weight) of chemical precursors or non-NOVX chemicals, more preferably less than about 20% chemical precursors or non-NOVX chemicals, still more preferably less than about 10% chemical precursors or non-NOVX chemicals, and most preferably less than about 5% chemical precursors or non-NOVX chemicals.
Biologically-active portions of NOVX proteins include peptides comprising amino acid sequences sufficiently homologous to or derived from the amino acid sequences of the NOVX proteins (e.g., the amino acid sequence of SEQ ID NO:2n, wherein n is an integer between 1 and 226) that include fewer amino acids than the full-length NOVX proteins, and exhibit at least one activity of a NOVX protein. Typically, biologically-active portions comprise a domain or motif with at least one activity of the NOVX protein. A
biologically-active portion of a NOVX protein can be a polypeptide which is, for example, 10, 25, 50, 100 or more amino acid residues in length.
Moreover, other biologically-active portions, in which other regions of the protein are deleted, can be prepared by recombinant techniques and evaluated for one or more of the functional activities of a native NOVX protein.
In an embodiment, the NOVX protein has an amino acid sequence of SEQ ID NO:2n, wherein n is an integer between 1 and 226. In other embodiments, the NOVX protein is substantially homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 226, and retains the functional activity of the protein of SEQ ID NO:2n, wherein n is an integer between 1 and 226, yet differs in amino acid sequence due to natural allelic variation or mutagenesis, as described in detail, below. Accordingly, in another embodiment, the NOVX protein is a protein that comprises an amino acid sequence at least about 45% homologous to the amino acid sequence of SEQ ID NO:2«, wherein n is an integer between 1 and 226, and retains the functional activity of the NOVX proteins of SEQ ID NO:2«, wherein n is an integer between 1 and 226.
Determining Homology Between Two or More Sequences
To determine the percent homology of two amino acid sequences or of two nucleic acids, the sequences are aligned for optimal comparison puφoses (e.g., gaps can be introduced in the sequence of a first amino acid or nucleic acid sequence for optimal alignment with a second amino or nucleic acid sequence). The amino acid residues or nucleotides at corresponding amino acid positions or nucleotide positions are then compared. When a position in the first sequence is occupied by the same amino acid residue or nucleotide as the corresponding position in the second sequence, then the molecules are homologous at that position (i.e., as used herein amino acid or nucleic acid "homology" is equivalent to amino acid or nucleic acid "identity").
The nucleic acid sequence homology may be determined as the degree of identity between two sequences. The homology may be determined using computer programs known in the art, such as GAP software provided in the GCG program package. See, Needleman and Wunsch, 1970. JMol Biol 48: 443-453. Using GCG GAP software with the following settings for nucleic acid sequence comparison: GAP creation penalty of 5.0 and GAP extension penalty of 0.3, the coding region of the analogous nucleic acid sequences referred to above exhibits a degree of identity preferably of at least 70%, 75%,
80%, 85%, 90%>, 95%, 98%, or 99%, with the CDS (encoding) part of the DNA sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226.
The term "sequence identity" refers to the degree to which two polynucleotide or polypeptide sequences are identical on a residue-by-residue basis over a particular region of comparison. The term "percentage of sequence identity" is calculated by comparing two optimally aligned sequences over that region of comparison, determining the number of positions at which the identical nucleic acid base (e.g., A, T, C, G, U, or I, in the case of nucleic acids) occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the region of comparison (i.e., the window size), and multiplying the result by 100 to yield the percentage of sequence identity. The term "substantial identity" as used herein denotes a characteristic of a polynucleotide sequence, wherein the polynucleotide comprises a sequence that has at least 80 percent sequence identity, preferably at least 85 percent identity and often 90 to 95 percent sequence identity, more usually at least 99 percent sequence identity as compared to a reference sequence over a comparison region.
Chimeric and Fusion Proteins
The invention also provides NOVX chimeric or fusion proteins. As used herein, a NOVX "chimeric protein" or "fusion protein" comprises a NOVX polypeptide operatively-linked to a non-NOVX polypeptide. An "NOVX polypeptide" refers to a polypeptide having an amino acid sequence corresponding to a NOVX protein of SEQ ID NO:2«, wherein n is an integer between 1 and 226, whereas a "non-NOVX polypeptide" refers to a polypeptide having an amino acid sequenee corresponding to a protein that is not substantially homologous to the NOVX protein, e.g., a protein that is different from the NOVX protein and that is derived from the same or a different organism. Within a NOVX fusion protein the NOVX polypeptide can correspond to all or a portion of a NOVX protein. In one embodiment, a NOVX fusion protein comprises at least one biologically-active portion of a NOVX protein. In another embodiment, a NOVX fusion protein comprises at least two biologically-active portions of a NOVX protein. In yet another embodiment, a NOVX fusion protein comprises at least three biologically-active portions of a NOVX protein. Within the fusion protein, the term "operatively-linked" is intended to indicate that the NOVX polypeptide and the non-NOVX polypeptide are fused
in-frame with one another. The non-NOVX polypeptide can be fused to the N-terminus or C-terminus of the NOVX polypeptide.
In one embodiment, the fusion protein is a GST-NO VX fusion protein in which the NOVX sequences are fused to the C-terminus of the GST (glutathione S-fransferase) sequences. Such fusion proteins can facilitate the purification of recombinant NOVX polypeptides.
In another embodiment, the fusion protein is a NOVX protein containing a heterologous signal sequence at its N-terminus. In certain host cells (e.g., mammalian host cells), expression and/or secretion of NOVX can be increased through use of a heterologous signal sequence.
In yet another embodiment, the fusion protein is a NOVX-immunoglobulin fusion protein in which the NOVX sequences are fused to sequences derived from a member of the immunoglobulin protein family. The NOVX-immunoglobulin fusion proteins of the invention can be incoφorated into pharmaceutical compositions and administered to a subject to inhibit an interaction between a NOVX ligand and a NOVX protein on the surface of a cell, to thereby suppress NOVX-mediated signal transduction in vivo. The NOVX-immunoglobulin fusion proteins can be used to affect the bioavailability of a NOVX cognate ligand. Inhibition of the NOVX ligand/NOVX interaction may be useful therapeutically for both the treatment of proliferative and differentiative disorders, as well as modulating (e.g. promoting or inhibiting) cell survival. Moreover, the
NOVX-immunoglobulin fusion proteins of the invention can be used as immunogens to produce anti-NOVX antibodies in a subject, to purify NOVX ligands, and in screening assays to identify molecules that inhibit the interaction of NOVX with a NOVX ligand.
A NOVX chimeric or fusion protein of the invention can be produced by standard recombinant DNA techniques. For example, DNA fragments coding for the different polypeptide sequences are ligated together in-frame in accordance with conventional techniques, e.g., by employing blunt-ended or stagger-ended termim for ligation, resfriction enzyme digestion to provide for appropriate termini, filling-in of cohesive ends as appropriate, alkaline phosphatase treatment to avoid undesirable joining, and enzymatic ligation. In another embodiment, the fusion gene can be synthesized by conventional techniques including automated DNA synthesizers. Alternatively, PCR amplification of gene fragments can be carried out using anchor primers that give rise to complementary overhangs between two consecutive gene fragments that can subsequently be annealed and
reamplified to generate a chimeric gene sequence (see, e.g., Ausubel, et al. (eds.) CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, 1992). Moreover, many expression vectors are commercially available that already encode a fusion moiety (e.g., a GST polypeptide). A NOVX-encoding nucleic acid can be cloned into such an expression vector such that the fusion moiety is linked in-frame to the NOVX protein.
NOVX Agonists and Antagonists
The invention also pertains to variants of the NOVX proteins that function as either NOVX agonists (t.e., mimetics) or as NOVX antagonists. Variants of the NOVX protein can be generated by mutagenesis (e.g., discrete point mutation or truncation of the NOVX protein). An agonist of the NOVX protein can retain substantially the same, or a subset of, the biological activities of the naturally occurring form of the NOVX protein. An antagonist of the NOVX protein can inhibit one or more of the activities of the naturally occurring form of the NOVX protein by, for example, competitively binding to a downstream or upsfream member of a cellular signaling cascade which includes the NOVX protein. Thus, specific biological effects can be elicited by treatment with a variant of limited function. In one embodiment, treatment of a subject with a variant having a subset of the biological activities of the naturally occurring form of the protein has fewer side effects in a subject relative to treatment with the naturally occurring form of the NOVX proteins.
Variants of the NOVX proteins that function as either NOVX agonists (i.e., mimetics) or as NOVX antagonists can be identified by screening combinatorial libraries of mutants (e.g., truncation mutants) of the NOVX proteins for NOVX protein agonist or antagonist activity. In one embodiment, a variegated library of NOVX variants is generated by combinatorial mutagenesis at the nucleic acid level and is encoded by a variegated gene library. A variegated library of NOVX variants can be produced by, for example, enzymatically ligating a mixture of synthetic oligonucleotides into gene sequences such that a degenerate set of potential NOVX sequences is expressible as individual polypeptides, or alternatively, as a set of larger fusion proteins (e.g., for phage display) containing the set of NOVX sequences therein. There are a variety of methods which can be used to produce libraries of potential NOVX variants from a degenerate oligonucleotide sequence. Chemical synthesis of a degenerate gene sequence can be performed in an automatic DNA synthesizer, and the synthetic gene then ligated into an
appropriate expression vector. Use of a degenerate set of genes allows for the provision, in one mixture, of all of the sequences encoding the desired set of potential NOVX sequences. Methods for synthesizing degenerate oligonucleotides are well-known within the art. See, e.g., Narang, 1983. Tetrahedron 39: 3; Itakura, et al, 1984. Annu. Rev. Biochem. 53: 323; Itakura, et al, 1984. Science 198: 1056; Ike, et al, 1983. Nucl. Acids Res. 11: 477.
Polypeptide Libraries
In addition, libraries of fragments of the NOVX protein coding sequences can be used to generate a variegated population of NOVX fragments for screening and subsequent selection of variants of a NOVX protein. In one embodiment, a library of coding sequence fragments can be generated by treating a double sfranded PCR fragment of a NOVX coding sequence with a nuclease under conditions wherein nicking occurs only about once per molecule, denaturing the double stranded DNA, renaturing the DNA to form double-stranded DNA that can include sense/antisense pairs from different nicked products, removing single stranded portions from reformed duplexes by treatment with Si nuclease, and ligating the resulting fragment library into an expression vector. By this method, expression libraries can be derived which encodes N-terminal and internal fragments of various sizes of the NOVX proteins.
Various techniques are known in the art for screening gene products of combinatorial libraries made by point mutations or truncation, and for screening cDNA libraries for gene products having a selected property. Such techniques are adaptable for rapid screening of the gene libraries generated by the combinatorial mutagenesis of NOVX proteins. The most widely used techniques, which are amenable to high throughput analysis, for screening large gene libraries typically include cloning the gene library into replicable expression vectors, fransforming appropriate cells with the resulting library of vectors, and expressing the combinatorial genes under conditions in which detection of a desired activity facilitates isolation of the vector encoding the gene whose product was detected. Recursive ensemble mutagenesis (REM), a new technique that enhances the frequency of functional mutants in the libraries, can be used in combination with the screening assays to identify NOVX variants. See, e.g., Arkin and Yourvan, 1992. Proc. Natl. Acad. Sci. USA 89: 7811-7815; Delgrave, etal, 1993. Protein Engineering 6:327-331.
Anti-NOVX Antibodies
Included in the invention are antibodies to NOVX proteins, or fragments of NOVX proteins. The term "antibody" as used herein refers to immunoglobulin molecules and immunologically active portions of immunoglobulin (Ig) molecules, i.e., molecules that contain an antigen binding site that specifically binds (immunoreacts with) an antigen. Such antibodies include, but are not limited to, polyclonal, monoclonal, chimeric, single chain, Fab, Fab- and F(ab,)2 fragments, and an Fab expression library. In general, antibody molecules obtained from humans relates to any of the classes IgG, IgM, IgA, IgE and IgD, which differ from one another by the nature of the heavy chain present in the molecule. Certain classes have subclasses as well, such as IgGi, IgG2, and others. Furthermore, in humans, the light chain may be a kappa chain or a lambda chain. Reference herein to antibodies includes a reference to all such classes, subclasses and types of human antibody species.
An isolated protein of the invention intended to serve as an antigen, or a portion or fragment thereof, can be used as an immunogen to generate antibodies that immunospecifically bind the antigen, using standard techniques for polyclonal and monoclonal antibody preparation. The full-length protein can be used or, alternatively, the invention provides antigenic peptide fragments of the antigen for use as immunogens. An antigenic peptide fragment comprises at least 6 amino acid residues of the amino acid sequence of the full length protein, such as an amino acid sequence of SEQ ID NO:2», wherein n is an integer between 1 and 226, and encompasses an epitope thereof such that an antibody raised against the peptide forms a specific immune complex with the full length protein or with any fragment that contains the epitope. Preferably, the antigenic peptide comprises at least 10 amino acid residues, or at least 15 amino acid residues, or at least 20 amino acid residues, or at least 30 amino acid residues. Preferred epitopes encompassed by the antigenic peptide are regions of the protein that are located on its surface; commonly these are hydrophilic regions.
In certain embodiments of the invention, at least one epitope encompassed by the antigenic peptide is a region of NOVX that is located on the surface of the protein, e.g., a hydrophilic region. A hydrophobicity analysis of the human NOVX protein sequence will indicate which regions of a NOVX polypeptide are particularly hydrophilic and, therefore, are likely to encode surface residues useful for targeting antibody production. As a means for targeting antibody production, hydropathy plots showing regions of hydrophilicity. and
hydrophobicity may be generated by any method well known in the art, including, for example, the Kyte Doolittle or the Hopp Woods methods, either with or without Fourier transformation. See, e.g., Hopp and Woods, 1981, Proc. Nat. Acad. Sci. USA 78: 3824-3828; Kyte and Doolittle 1982, J. Mol. Biol. 157: 105-142, each incoφorated herein by reference in their entirety. Antibodies that are specific for one or more domains within an antigenic protein, or derivatives, fragments, analogs or homologs thereof, are also provided herein.
The term "epitope" includes any protein determinant capable of specific binding to an immunoglobulin or T-cell receptor. Epitopic determinants usually consist of chemically active surface groupings of molecules such as amino acids or sugar side chains and usually have specific three dimensional structural characteristics, as well as specific charge characteristics. A ΝOVX polypeptide or a fragment thereof comprises at least one antigenic epitope. An anti-ΝOVX antibody of the present invention is said to specifically bind to antigen ΝONX when the equilibrium binding constant (KD) is <1 μM, preferably < 100 nM, more preferably < 10 nM, and most preferably < 100 pM to about 1 pM, as measured by assays such as radioligand binding assays or similar assays known to. those skilled in the art.
A protein of the invention, or a derivative, fragment, analog, homolog or ortholog thereof, may be utilized as an immunogen in the generation of antibodies that immunospecifically bind these protein components.
Various procedures known within the art may be used for the production of polyclonal or monoclonal antibodies directed against a protein of the invention, or against derivatives, fragments, analogs homologs or orthologs thereof (see, for example, Antibodies: A Laboratory Manual, Harlow E, and Lane D, 1988, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, ΝY, incoφorated herein by reference). Some of these antibodies are discussed below.
Polyclonal Antibodies
For the production of polyclonal antibodies, various suitable host animals (e.g., rabbit, goat, mouse or other mammal) may be immunized by one or more injections with the native protein, a synthetic variant thereof, or a derivative of the foregoing. An appropriate immunogenic preparation can contain, for example, the naturally occurring immunogenic protein, a chemically synthesized polypeptide representing the immunogenic
protein, or a recombinantly expressed immunogenic protein. Furthermore, the protein may be conjugated to a second protein known to be immunogenic in the mammal being immunized. Examples of such immunogenic proteins include but are not limited to keyhole limpet hemocyanin, serum albumin, bovine thyroglobulin, and soybean trypsin inhibitor. The preparation can further include an adjuvant. Various adjuvants used to increase the immunological response include, but are not limited to, Freund's (complete and incomplete), mineral gels (e.g., aluminum hydroxide), surface active substances (e.g., lysolecithin, pluronic polyols, polyanions, peptides, oil emulsions, dinifrophenol, etc.), adjuvants usable in humans such as Bacille Calmette-Guerin and Corynebacterium parvum, or similar immunostimulatory agents. Additional examples of adjuvants which can be employed include MPL-TDM adjuvant (monophosphoryl Lipid A, synthetic trehalose dicorynomycolate).
The polyclonal antibody molecules directed against the immunogenic protein can be isolated from the mammal (e.g., from the blood) and further purified by well known techniques, such as affinity chromatography using protein A or protein G, which provide primarily the IgG fraction of immune serum. Subsequently, or alternatively, the specific antigen which is the target of the immunoglobulin sought, or an epitope thereof, may be immobilized on a column to purify the immune specific antibody by immunoaffinity chromatography. Purification of immunoglobulins is discussed, for example, by D. Wilkinson (The Scientist, published by The Scientist, Inc., Philadelphia PA, Vol. 14, No. 8 (April 17, 2000), pp. 25-28).
Monoclonal Antibodies
The term "monoclonal antibody" (MAb) or "monoclonal antibody composition", as used herein, refers to a population of antibody molecules that contain only one molecular species of antibody molecule consisting of a unique light chain gene product and a unique heavy chain gene product. In particular, the complementarity determining regions (CDRs) of the monoclonal antibody are identical in all the molecules of the population. MAbs thus contain an antigen binding site capable of immunoreacting with a particular epitope of the antigen characterized by a unique binding affinity for it.
Monoclonal antibodies can be prepared using hybridoma methods, such as those described by Kohler and Milstein, Nature, 256:495 (1975). In a hybridoma method, a mouse, hamster, or other appropriate host animal, is typically immunized with an
immunizing agent to elicit lymphocytes that produce or are capable of producing antibodies that will specifically bind to the immunizing agent. Alternatively, the lymphocytes can be immunized in vitro.
The immunizing agent will typically include the protein antigen, a fragment thereof or a fusion protein thereof. Generally, either peripheral blood lymphocytes are used if cells of human origin are desired, or spleen cells or lymph node cells are used if non-human mammalian sources are desired. The lymphocytes are then fused with an immortalized cell line using a suitable fusing agent, such as polyethylene glycol, to form a hybridoma cell (Goding, Monoclonal Antibodies: Principles and Practice, Academic Press, (1986) pp. 59- 103) . Immortalized cell lines are usually transformed mammalian cells, particularly myeloma cells of rodent, bovine and human origin. Usually, rat or mouse myeloma cell lines are employed. The hybridoma cells can be cultured in a suitable culture medium that preferably contains one or more substances that inhibit the growth or survival of the unfused, immortalized cells. For example, if the parental cells lack the enzyme hypoxanthine guanine phosphoribosyl fransferase (HGPRT or HPRT), the culture medium for the hybridomas typically will include hypoxanthine, aminopterin, and thymidine ("HAT medium"), which substances prevent the growth of HGPRT-deficient cells.
Preferred immortalized cell lines are those that fuse efficiently, support stable high level expression of antibody by the selected antibody-producing cells, and are sensitive to a medium such as HAT medium. More preferred immortalized cell lines are murine myeloma lines, which can be obtained, for instance, from the Salk Institute Cell Distribution Center, San Diego, California and the American Type Culture Collection, Manassas, Virginia. Human myeloma and mouse-human heteromyeloma cell lines also have been described for the production of human monoclonal antibodies (Kozbor, J. Immunol., 133:3001 (1984); Brodeur et al., Monoclonal Antibody Production Techniques and Applications, Marcel Dekker, Inc., New York, (1987) pp. 51-63).
The culture medium in which the hybridoma cells are cultured can then be assayed for the presence of monoclonal antibodies directed against the antigen. Preferably, the binding specificity of monoclonal antibodies produced by the hybridoma cells is determined by immunoprecipitation or by an in vitro binding assay, such as radioimmunoassay (RIA) or enzyme-linked immunoabsorbent assay (ELISA). Such techniques and assays are known in the art. The binding affinity of the monoclonal antibody can, for example, be determined by the Scatchard analysis of Munson and Pollard,
Anal. Biochem., 107:220 (1980). It is an objective, especially important in therapeutic applications of monoclonal antibodies, to identify antibodies having a high degree of specificity and a high binding affinity for the target antigen.
After the desired hybridoma cells are identified, the clones can be subcloned by limiting dilution procedures and grown by standard methods (Goding, 1986). Suitable culture media for this puφose include, for example, Dulbecco's Modified Eagle's Medium and RPMI- 1640 medium. Alternatively, the hybridoma cells can be grown in vivo as ascites in a mammal.
The monoclonal antibodies secreted by the subclones can be isolated or purified from the culture medium or ascites fluid by conventional immunoglobulin purification procedures such as, for example, protein A-Sepharose, hydroxylapatite chromatography, gel electrophoresis, dialysis, or affinity chromatography.
The monoclonal antibodies can also be made by recombinant DNA methods, such as those described in U.S. Patent No. 4,816,567. DNA encoding the monoclonal antibodies of the invention can be readily isolated and sequenced using conventional procedures (e.g. , by. using oligonucleotide probes that are capable of binding specifically to genes encoding the heavy and light chains of murine antibodies). The hybridoma cells of the invention serve as a preferred source of such DNA. Once isolated, the DNA can be placed into expression vectors, which are then transfected into host cells such as simian COS cells, Chinese hamster ovary (CHO) cells, or myeloma cells that do not otherwise produce immunoglobulin protein, to obtain the synthesis of monoclonal antibodies in the recombinant host cells. The DNA also can be modified, for example, by substituting the coding sequence for human heavy and light chain constant domains in place of the homologous murine sequences (U.S. Patent No. 4,816,567; Morrison, Nature 368, 812-13 (1994)) or by covalently joining to the immunoglobulin coding sequence all or part of the coding sequence for a non-immunoglobulin polypeptide. Such a non-immunoglobulin polypeptide can be substituted for the constant domains of an antibody of the invention, or can be substituted for the variable domains of one antigen-combining site of an antibody of the invention to create a chimeric bivalent antibody.
Humanized Antibodies
The antibodies directed against the protein antigens of the invention can further comprise humanized antibodies or human antibodies. These antibodies are suitable for
administration to humans without engendering an immune response by the human against the administered immunoglobulin. Humanized forms of antibodies are chimeric immunoglobulins, immunoglobulin chains or fragments thereof (such as Fv, Fab, Fab', F(ab')2 or other antigen-binding subsequences of antibodies) that are principally comprised 5 of the sequence of a human immunoglobulin, and contain minimal sequence derived from a non-human immunoglobulin. Humanization can be performed following the method of Winter and co-workers (Jones et al., Nature, 321:522-525 (1986); Riechmann et al., Nature, 332:323-327 (1988); Verhoeyen et al., Science, 239:1534-1536 (1988)), by substituting rodent CDRs or CDR sequences for the corresponding sequences of a human antibody.
10 (See also U.S. Patent No. 5,225,539.) In some instances, Fv framework residues of the human immunoglobulin are replaced by corresponding non-human residues. Humanized antibodies can also comprise residues which are found neither in the recipient antibody nor in the imported CDR or framework sequences. In general, the humanized antibody will comprise substantially all of at least one, and typically two, variable domains, in which all
15 or substantially all of the CDR regions correspond to those of a non-human immunoglobulin and all or substantially all of the framework regions are those of a human immunoglobulin consensus sequence. The humanized antibody optimally also will comprise at least a portion of an immunoglobulin constant region (Fc), typically that of a human immunoglobulin (Jones et al., 1986; Riechmann et al., 1988; and Presta, Curr. Op.
20 Struct. Biol., 2:593-596 (1992)).
Human Antibodies
Fully human antibodies essentially relate to antibody molecules in which the entire sequence of both the light chain and the heavy chain, including the CDRs, arise from
25 human genes. Such antibodies are termed "human antibodies", or "fully human antibodies" herein. Human monoclonal antibodies can be prepared by the trioma technique; the human B-cell hybridoma technique (see Kozbor, et al., 1983 Immunol Today 4: 72) and the EBV hybridoma technique to produce human monoclonal antibodies (see Cole, et al., 1985 In: MONOCLONAL ANTIBODIES AND CANCER THERAPY, Alan R. Liss, Inc., pp. 77-96). Human
30. monoclonal antibodies may be utilized in the practice of the present invention and may be produced by using human hybridomas (see Cote, et al., 1983. Proc Natl Acad Sci USA 80: 2026-2030) or by transforming human B-cells with Epstein Barr Virus in vitro (see Cole, et
al., 1985 In: MONOCLONAL ANTIBODIES AND CANCER THERAPY, Alan R. Liss, Inc., pp. 77-96).
In addition, human antibodies can also be produced using additional techniques, including phage display libraries (Hoogenboom and Winter, J. Mol. Biol., 227:381 (1991); Marks et al., J. Mol. Biol., 222:581 (1991)). Similarly, human antibodies can be made by introducing human immunoglobulin loci into transgenic animals, e.g., mice in which the endogenous immunoglobulin genes have been partially or completely inactivated. Upon challenge, human antibody production is observed, which closely resembles that seen in humans in all respects, including gene rearrangement, assembly, and antibody repertoire. This approach is described, for example, in U.S. Patent Nos. 5,545,807; 5,545,806; 5,569,825; 5,625,126; 5,633,425; 5,661,016, and in Marks et al. (Bio/Technology 10, 779-783 (1992)); Lonberg et al. (Nature 368 856-859 (1994)); Morrison ( Nature 368, 812-13 (1994)); Fishwild et al,( Nature Biotechnology 14, 845-51 (1996)); Neuberger (Nature Biotechnology 14, 826 (1996)); and Lonberg and Huszar (Intern. Rev. Immunol. 13 65-93 (1995)).
Human antibodies may additionally be produced using transgenic nonhuman animals which are modified so as to produce fully human antibodies rather than the animal's endogenous antibodies in response to challenge by an antigen. (See PCT publication WO94/02602). The endogenous genes encoding the heavy and light immunoglobulin chains in the nonhuman host have been incapacitated, and active loci encoding human heavy and light chain immunoglobulins are inserted into the host's genome. The human genes are incoφorated, for example, using yeast artificial chromosomes containing the requisite human DNA segments. An animal which provides all the desired modifications is then obtained as progeny by crossbreeding intermediate transgenic animals containing fewer than the full complement of the modifications. The preferred embodiment of such a nonhuman animal is a mouse, and is termed the Xenomouse™ as disclosed in PCT publications WO 96/33735 and WO 96/34096. This animal produces B cells which secrete fully human immunoglobulins. The antibodies can be obtained directly from the animal after immunization with an immunogen of interest, as, for example, a preparation of a polyclonal antibody, or alternatively from immortalized B cells derived from the animal, such as hybridomas producing monoclonal antibodies. Additionally, the genes encoding the immunoglobulins with human variable regions can be
recovered and expressed to obtain the antibodies directly, or can be further modified to obtain analogs of antibodies such as, for example, single chain Fv molecules.
An example of a method of producing a nonhuman host, exemplified as a mouse, lacking expression of an endogenous immunoglobulin heavy chain is disclosed in U.S. Patent No. 5,939,598. It can be obtained by a method including deleting the J segment genes from at least one endogenous heavy chain locus in an embryonic stem cell to prevent rearrangement of the locus and to prevent formation of a transcript of a rearranged immunoglobulin heavy chain locus, the deletion being effected by a targeting vector containing a gene encoding a selectable marker; and producing from the embryonic stem cell a transgenic mouse whose somatic and germ cells contain the gene encoding the selectable marker.
A method for producing an antibody of interest, such as a human antibody, is disclosed in U.S. Patent No. 5,916,771. It includes introducing an expression vector that contains a nucleotide sequence encoding a heavy chain into one mammalian host cell in culture, introducing an expression vector containing a nucleotide sequence encoding a light chain into another mammalian host cell, and fusing the two cells to form a hybrid cell. The hybrid cell expresses an antibody containing the heavy chain and the light chain.
In a further improvement on this procedure, a method for identifying a clinically relevant epitope on an immunogen, and a correlative method for selecting an antibody that binds immunospecifically to the relevant epitope with high affinity, are disclosed in PCT publication WO 99/53049.
Fab Fragments and Single Chain Antibodies
According to the invention, techniques can be adapted for the production of single-chain antibodies specific to an antigenic protein of the invention (see e.g., U.S. Patent No. 4,946,778). In addition, methods can be adapted for the construction of Fab expression libraries (see e.g., Huse, et al, 1989 Science 246: 1275-1281) to allow rapid and effective identification of monoclonal Fab fragments with the desired specificity for a protein or derivatives, fragments, analogs or homologs thereof. Antibody fragments that contain the idiotypes to a protein antigen may be produced by techniques known in the art including, but not limited to: (i) an F(aϋ)2 fragment produced by pepsin digestion of an antibody molecule; (ii) an Fab fragment generated by reducing the disulfide bridges of an
F ab,)2 fragment; (iii) an Fab fragment generated by the treatment of the antibody molecule with papain and a reducing agent and (iv) Fv fragments.
Bispecific Antibodies
5 Bispecific antibodies are monoclonal, preferably human or humanized, antibodies that have binding specificities for at least two different antigens. In the present case, one of the binding specificities is for an antigenic protein of the invention. The second binding target is any other antigen, and advantageously is a cell-surface protein or receptor or receptor subunit.
10. Methods for making bispecific antibodies are known in the art. Traditionally, the recombinant production of bispecific antibodies is based on the co-expression of two immunoglobulin heavy-chain/light-chain pairs, where the two heavy chains have different specificities (Milstein and Cuello, Nature, 305:537-539 (1983)). Because of the random assortment of immunoglobulin heavy and light chains, these hybridomas (quadromas)
15 produce a potential mixture often different antibody molecules, of which only one has the correct bispecific structure. The purification of the correct molecule is usually accomplished by affinity chromatography steps. Similar procedures are disclosed in WO 93/08829, published 13 May 1993, and in Traunecker et al., EMBO J., 10:3655-3659 (1991). 0 Antibody variable domains with the desired binding specificities (antibody-antigen combining sites) can be fused to immunoglobulin constant domain sequences. The fusion preferably is with an immunoglobulin heavy-chain constant domain, comprising at least part of the hinge, CH2, and CH3 regions. It is preferred to have the first heavy-chain constant region (CHI) containing the site necessary for light-chain binding present in at 5 least one of the fusions. DNAs encoding the immunoglobulin heavy-chain fusions and, if desired, the immunoglobulin light chain, are inserted into separate expression vectors, and are co-transfected into a suitable host organism. For further details of generating bispecific antibodies see, for example, Suresh et al., Methods in Enzymology, 121:210 (1986).
According to another approach described in WO 96/27011, the interface between a 0 pair of antibody molecules can be engineered to maximize the percentage of heterodimers which are recovered from recombinant cell culture. The preferred interface comprises at least a part of the CH3 region of an antibody constant domain. In this method, one or more small amino acid side chains from the interface of the first antibody molecule are replaced
with larger side chains (e.g. tyrosine or tryptophan). Compensatory "cavities" of identical or similar size to the large side chain(s) are created on the interface of the second antibody molecule by replacing large amino acid side chains with smaller ones (e.g. alanine or threonine). This provides a mechanism for increasing the yield of the heterodimer over other unwanted end-products such as homodimers.
Bispecific antibodies can be prepared as full length antibodies or antibody fragments (e.g. F(ab')2 bispecific antibodies). Techniques for generating bispecific antibodies from antibody fragments have been described in the literature. For example, bispecific antibodies can be prepared using chemical linkage. Brennan et al., Science 229: 81 (1985) describe a procedure wherein intact antibodies are proteolytically cleaved to generate F(ab')2 fragments. These fragments are reduced in the presence of the dithiol complexing agent sodium arsenite to stabilize vicinal dithiols and prevent intermolecular disulfide formation. The Fab' fragments generated are then converted to thionitrobenzoate (TNB) derivatives. One of the Fab'-TNB derivatives is then reconverted to the Fab'-thiol by reduction with mercaptoethylamine and is mixed with an equimolar amount of the other Fab'-TNB derivative to form the bispecific antibody. The bispecific antibodies produced can be used as agents for the selective immobilization of enzymes.
Additionally, Fab' fragments can be directly recovered from E. coli and chemically coupled to form bispecific antibodies. Shalaby et al., J. Exp. Med. 175:217-225 (1992) describe the production of a fully humanized bispecific antibody F(ab')2 molecule. Each Fab' fragment was separately secreted from E. coli and subjected to directed chemical coupling in vitro to form the bispecific antibody. The bispecific antibody thus formed was able to bind to cells overexpressing the ErbB2 receptor and normal human T cells, as well as trigger the lytic activity of human cytotoxic lymphocytes against human breast tumor targets.
Various techniques for making and isolating bispecific antibody fragments directly from recombinant cell culture have also been described. For example, bispecific antibodies have been produced using leucine zippers. Kostelny et al., J. Immunol. 148(5):1547-1553 (1992). The leucine zipper peptides from the Fos and Jun proteins were linked to the Fab' portions of two different antibodies by gene fusion. The antibody homodimers were reduced at the hinge region to form monomers and then re-oxidized to form the antibody heterodimers. This method can also be utilized for the production of antibody homodimers. The "diabody" technology described by Hollinger et al., Proc. Natl. Acad. Sci. USA
90:6444-6448 (1993) has provided an alternative mechanism for making bispecific antibody fragments. The fragments comprise a heavy-chain variable domain (VH) connected to a light-chain variable domain (VL) by a linker which is too short to allow pairing between the two domains on the same chain. Accordingly, the VH and VL domains of one fragment are forced to pair with the complementary VL and VH domains of another fragment, thereby forming two antigen-binding sites. Another strategy for making bispecific antibody fragments by the use of single-chain Fv (sFv) dimers has also been reported. See, Gruber etal., J. Immunol. 152:5368 (1994).
Antibodies with more than two valencies are contemplated. For example, trispecific antibodies can be prepared. Tutt et al., J. Immunol. 147:60 (1991).
Exemplary bispecific antibodies can bind to two different epitopes, at least one of which originates in the protein antigen of the invention. Alternatively, an anti-antigenic arm of an immunoglobulin molecule can be combined with an arm which binds to a triggering molecule on a leukocyte such as a T-cell receptor molecule (e.g. CD2, CD3, CD28, or B7), or Fc receptors for IgG (FcγR), such as FcγRI (CD64), FcγRII (CD32) and FcγRIII (CD 16) so as to focus cellular defense mechanisms to the cell expressing the particular antigen. Bispecific antibodies can also be used to direct cytotoxic agents to cells which express a particular antigen. These antibodies possess an antigen-binding arm and an arm which binds a cytotoxic agent or a radionuclide chelator, such as EOTUBE, DPTA, DOTA, or TETA. Another bispecific antibody of interest binds the protein antigen described herein and further binds tissue factor (TF).
Heteroconjugate Antibodies
Heteroconjugate antibodies are also within the scope of the present invention. Heteroconjugate antibodies are composed of two covalently joined antibodies. Such antibodies have, for example, been proposed to target immune system cells to unwanted cells (U.S. Patent No. 4,676,980), and for treatment of HIV infection (WO 91/00360; WO 92/200373; EP 03089). It is contemplated that the antibodies can be prepared in vitro using known methods in synthetic protein chemistry, including those involving crosslinking agents. For example, immunotoxms can be constructed using a disulfide exchange reaction or by forming a thioether bond. Examples of suitable reagents for this puφose include iminothiolate and methyl-4-mercaptobutyrimidate and those disclosed, for example, in U.S. Patent No. 4,676,980.
Effector Function Engineering
It can be desirable to modify the antibody of the invention with respect to effector function, so as to enhance, e.g., the effectiveness of the antibody in treating cancer. For example, cysteine residue(s) can be introduced into the Fc region, thereby allowing interchain disulfide bond formation in this region. The homodimeric antibody thus generated can have improved intemalization capability and/or increased complement-mediated cell killing and antibody-dependent cellular cytotoxicity (ADCC). See Caron et al., J. Exp Med., 176: 1191-1195 (1992) and Shopes, J. Immunol., 148: 2918-2922 (1992). Homodimeric antibodies with enhanced anti-tumor activity can also be prepared using heterobifunctional cross-linkers as described in Wolff et al. Cancer
Research, 53: 2560-2565 (1993). Alternatively, an antibody can be engineered that has dual Fc regions and can thereby have enhanced complement lysis and ADCC capabilities. See Stevenson et al., Anti-Cancer Drug Design, 3: 219-230 (1989).
Immunoconjugates
The invention also pertains to immunoconjugates comprising an antibody conjugated to. a cytotoxic agent such as a chemotherapeutic agent, toxin (e.g., an enzymatically active toxin of bacterial, fungal, plant, or animal origin, or fragments thereof), or a radioactive isotope (i.e., a radioconjugate). Chemotherapeutic agents useful in the generation of such immunoconjugates have been described above. Enzymatically active toxins and fragments thereof that can be used include diphtheria A chain, nonbinding active fragments of diphtheria toxin, exotoxin A chain (from Pseudomonas aeruginosa), ricin A chain, abrin A chain, modeccin A chain, alpha-sarcin, Aleurites fordii proteins, dianthin proteins, Phytolaca americana proteins (PAPI, PAPLI, and PAP-S), momordica charantia inhibitor, curcin, crotin, sapaonaria officinalis inhibitor, gelonin, mitogellin, restrictocin, phenomycin, enomycin, and the tricothecenes. A variety of radionuclides are available for the production of radioconjugated antibodies. Examples include 212Bi, 1311, 131In, 90Y, and 186Re.
Conjugates of the antibody and cytotoxic agent are made using a variety of bifunctional protein-coupling agents such as N-succinimidyl-3-(2-pyridyldithiol) propionate (SPDP), iminothiolane (IT), bifunctional derivatives of imidoesters (such as dimethyl adipimidate HCL), active esters (such as disuccinimidyl suberate), aldehydes (such as glutareldehyde), bis-azido compounds (such as bis (p-azidobenzoyl)
hexanediamine), bis-diazonium derivatives (such as bis-(p-diazoniumbenzoyl)-ethylenediamine), diisocyanates (such as tolyene 2,6-diisocyanate), and bis-active fluorine compounds (such as l,5-difluoro-2,4-dinitrobenzene). For example, a ricin immunotoxin can be prepared as described in Vitetta et al., Science.238: 1098 (1987). Carbon- 14-labeled l-isothiocyanatobenzyl-3-methyldiethylene triaminepentaacetic acid (MX-DTPA) is an exemplary chelating agent for conjugation of radionucleotide to the antibody. See WO94/11026.
In another embodiment, the antibody can be conjugated to a "receptor" (such streptavidin) for utilization in tumor pretargeting wherein the antibody-receptor conjugate is administered to the patient, followed by removal of unbound conjugate from the circulation using a clearing agent and then administration of a "ligand" (e.g., avidin) that is in turn conjugated to a cytotoxic agent.
Immunoliposomes
The antibodies disclosed herein can also be formulated as immunoliposomes. Liposomes containing the antibody are prepared by methods known in the art, such as described in Epstein et al., Proc. Natl. Acad. Sci. USA, 82: 3688 (1985); Hwang et al., Proc. Natl Acad. Sci. USA, 77: 4030 (1980); and U.S. Pat. Nos. 4,485,045 and 4,544,545. Liposomes with enhanced circulation time are disclosed in U.S. Patent No. 5,013,556. Particularly useful liposomes can be generated by the reverse-phase evaporation method with a lipid composition comprising phosphatidylcholine, cholesterol, and PEG-derivatized phosphatidylethanolamine (PEG-PE). Liposomes are extruded through filters of defined pore size to yield liposomes with the desired diameter. Fab' fragments of the antibody of the present invention can be conjugated to the liposomes as described in Martin et al .,_J. Biol. Chem., 257: 286-288 (1982) via a disulfide-interchange reaction. A chemotherapeutic agent (such as Doxorubicin) is optionally contained within the liposome. See Gabizon et al, J. National Cancer Inst, 81(19): 1484 (1989).
Diagnostic Applications of Antibodies Directed Against the Proteins of the Invention
In one embodiment, methods for the screening of antibodies that possess the desired specificity include, but are not limited to, enzyme linked immunosorbent assay (ELISA) and other immunologically mediated techniques known within the art. In a specific
embodiment, selection of antibodies that are specific to a particular domain of an NOVX protein is facilitated by generation of hybridomas that bind to the fragment of an NOVX protein possessing such a domain. Thus, antibodies that are specific for a desired domain within an NOVX protein, or derivatives, fragments, analogs or homologs thereof, are also provided herein.
Antibodies directed against a NOVX protein of the invention may be used in methods known within the art relating to the localization and/or quantitation of a NOVX protein (e.g., for use in measuring levels of the NOVX protein within appropriate physiological samples, for use in diagnostic methods, for use in imaging the protein, and the like). In a given embodiment, antibodies specific to a NOVX protein, or derivative, fragment, analog or homolog thereof, that contain the antibody derived antigen binding domain, are utilized as pharmacologically active compounds (referred to hereinafter as "Therapeutics").
An antibody specific for a NOVX protein of the invention (e.g., a monoclonal antibody or a polyclonal antibody) can be used to isolate a NOVX polypeptide by standard techniques, such as immunoaffinity, chromatography or immunoprecipitation. An antibody to a NOVX polypeptide can facilitate the purification of a natural NOVX antigen from cells, or of a recombinantly produced NOVX antigen expressed in host cells. Moreover, such an anti-NOVX antibody can be used to detect the antigenic NOVX protein (e.g., in a cellular lysate or cell supernatant) in order to evaluate the abundance and pattern of expression of the antigenic NOVX protein. Antibodies directed against a NOVX protein can be used diagnostically to monitor protein levels in tissue as part of a clinical testing procedure, e.g., to, for example, determine the efficacy of a given treatment regimen. Detection can be facilitated by coupling (i.e., physically linking) the antibody to a detectable substance. Examples of detectable substances include various enzymes, prosthetic groups, fluorescent materials, luminescent materials, bioluminescent materials, and radioactive materials. Examples of suitable enzymes include horseradish peroxidase, alkaline phosphatase, β-galactosidase, or acetylcholinesterase; examples of suitable prosthetic group complexes include streptavidin/biotin and avidin/biotin; examples of suitable fluorescent materials include umbelliferone, fluorescein, fluorescein isothiocyanate, rhodamine, dichlorotriazinylamine fluorescein, dansyl chloride or phycoerythrin; an example of a luminescent material includes luminol; examples of
bioluminescent materials include luciferase, luciferin, and aequorin, and examples of suitable radioactive material include I251, 131I, 35S or 3H.
Antibody Therapeutics Antibodies of the invention, including polyclonal, monoclonal, humanized and fully human antibodies, may used as therapeutic agents. Such agents will generally be employed to treat or prevent a disease or pathology in a subject. An antibody preparation, preferably one having high specificity and high affinity for its target antigen, is administered to the subject and will generally have an effect due to its binding with the target. Such an effect may be one of two kinds, depending on the specific nature of the interaction between the given antibody molecule and the target antigen in question. In the first instance, administration of the antibody may abrogate or inhibit the binding of the target with an endogenous ligand to which it naturally binds. In this case, the antibody binds to the target and masks a binding site of the naturally occurring ligand, wherein the ligand serves as an effector molecule. Thus the receptor mediates a signal transduction pathway for which ligand is responsible.
Alternatively, the effect may be one in which the antibody elicits a physiological result by virtue of binding to an effector binding site on the target molecule. In this case the target, a receptor having an endogenous ligand which may be absent or defective in the disease or pathology, binds the antibody as a surrogate effector ligand, initiating a receptor-based signal transduction event by the receptor.
A therapeutically effective amount of an antibody of the invention relates generally to the amount needed to achieve a therapeutic objective. As noted above, this may be a binding interaction between the antibody and its target antigen that, in certain cases, interferes with the functioning of the target, and in other cases, promotes a physiological response. The amount required to be administered will furthermore depend on the binding affinity of the antibody for its specific antigen, and will also depend on the rate at which an administered antibody is depleted from the free volume other subject to which it is administered. Common ranges for therapeutically effective dosing of an antibody or antibody fragment of the invention may be, by way of nonlimiting example, from about 0.1 mg/kg body weight to about 50 mg/kg body weight. Common dosing frequencies may range, for example, from twice daily to once a week.
Pharmaceutical Compositions of Antibodies
Antibodies specifically binding a protein of the invention, as well as other molecules identified by the screening assays disclosed herein, can be administered for the treatment of various disorders in the form of pharmaceutical compositions. Principles and considerations involved in preparing such compositions, as well as guidance in the choice of components are provided, for example, in Remington : The Science And Practice Of Pharmacy 19th ed. (Alfonso R. Gennaro, et al., editors) Mack Pub. Co., Easton, Pa. : 1995; Drug Absoφtion Enhancement : Concepts, Possibilities, Limitations, And Trends, Harwood Academic Publishers, Langhorne, Pa., 1994; and Peptide And Protein Drug Delivery (Advances In Parenteral Sciences, Vol.4), 1991, M. Dekker, New York.
If the antigenic protein is intracellular and whole antibodies are used as inhibitors, internalizing antibodies are preferred. However, liposomes can also be used to deliver the antibody, or an antibody fragment, into cells. Where antibody fragments are used, the smallest inhibitory fragment that specifically binds to the binding domain of the target protein is preferred. For example, based upon the variable-region sequences of an antibody, peptide molecules can be designed that retain the ability to bind the target protein sequence. Such peptides can be synthesized chemically and/or produced by recombinant DNA technology. See, e.g., Marasco et al., Proc. Natl. Acad. Sci. USA, 90: 7889-7893 (1993). The formulation herein can also contain more than one active compound as necessary for the particular indication being treated, preferably those with complementary activities that do not adversely affect each other. Alternatively, or in addition, the composition can comprise an agent that enhances its function, such as, for example, a cytotoxic agent, cytokine, chemotherapeutic agent, or growth-inhibitory agent. Such molecules are suitably present in combination in amounts that are effective for the puφose intended.
The active ingredients can also be entrapped in microcapsules prepared, for example, by coacervation techniques or by interfacial polymerization, for example, hydroxymethylcellulose or gelatin-microcapsules and poly-(methylmethacrylate) microcapsules, respectively, in colloidal drug delivery systems (for example, liposomes, albumin microspheres, microemulsions, nano-particles, and nanocapsules) or in macroemulsions.
The formulations to be used for in vivo administration must be sterile. This is readily accomplished by filtration through sterile filtration membranes.
Sustained-release preparations can be prepared. Suitable examples of sustained-release preparations include semipermeable matrices of solid hydrophobic polymers containing the antibody, which matrices are in the form of shaped articles, e.g., films, or microcapsules. Examples of sustained-release matrices include polyesters, hydrogels (for example, poly(2-hydroxyethyl-methacrylate), or poly(vinylalcohol)), polylactides (U.S. Pat. No. 3,773,919), copolymers of L-glutamic acid andγ ethyl-L-glutamate, non-degradable ethylene-vinyl acetate, degradable lactic acid-glycolic acid copolymers such as the LUPRON DEPOT ™ (injectable microspheres composed of lactic acid-glycolic acid copolymer and leuprolide acetate), and poly-D-(-)-3-hydroxybutyric acid. While polymers such as ethylene-vinyl acetate, and lactic acid-glycolic acid enable release of molecules for over 100 days, certain hydrogels release proteins for shorter time periods.
ELISA Assay An agent for detecting an analyte protein is an antibody capable of binding to an analyte protein, preferably an antibody with a detectable label. Antibodies can be polyclonal, or more preferably, monoclonal. An intact antibody, or a fragment thereof (e.g., Fab or F(a )2) can be used. The term "labeled", with regard to the probe or antibody, is intended to encompass direct labeling of the probe or antibody by coupling (i.e., physically linking) a detectable substance to the probe or antibody, as well as indirect labeling of the probe or antibody by reactivity with another reagent that is directly labeled. Examples of indirect labeling include detection of a primary antibody using a fluorescently-labeled secondary antibody and end-labeling of a DNA probe with biotin such that it can be detected with fluorescently-labeled streptavidin. The term "biological sample" is intended to include tissues, cells and biological fluids isolated from a subject, as well as tissues, cells and fluids present within a subject. Included within the usage of the term "biological sample", therefore, is blood and a fraction or component of blood including blood serum, blood plasma, or lymph. That is, the detection method of the invention can be used to detect an analyte mRNA, protein, or genomic DNA in a biological sample in vitro as well as in vivo. For example, in vitro, techniques for detection of an analyte mRNA include Northern hybridizations and in situ hybridizations. In vitro techniques for detection of an analyte protein include enzyme linked immunosorbent assays (ELISAs), Western blots, immunoprecipitations, and immunofluorescence. In vitro techniques for detection of an
analyte genomic DNA include Southern hybridizations. Procedures for conducting immunoassays are described, for example in "ELISA: Theory and Practice: Methods in Molecular Biology", Vol. 42, J. R. Crowther (Ed.) Human Press, Totowa, NJ, 1995; "Immunoassay", E. Diamandis and T. Christopoulus, Academic Press, Inc., San Diego, CA, 1996; and "Practice and Thory of Enzyme Immunoassays", P. Tijssen, Elsevier Science Publishers, Amsterdam, 1985. Furthermore, in vivo techniques for detection of an analyte protein include introducing into a subject a labeled anti-an analyte protein antibody. For example, the antibody can be labeled with a radioactive marker whose presence and location in a subject can be detected by standard imaging techniques.
NOVX Recombinant Expression Vectors and Host Cells
Another aspect of the invention pertains to vectors, preferably expression vectors, containing a nucleic acid encoding a NOVX protein, or derivatives, fragments, analogs or homologs thereof. As used herein, the term "vector" refers to a nucleic acid molecule capable of transporting another nucleic acid to which it has been linked. One type of vector is a "plasmid", which refers to a circular double stranded DNA loop into which additional DNA segments can be ligated. Another type of vector is a viral vector, wherein additional DNA segments can be ligated into the viral genome. Certain vectors are capable of autonomous replication in a host cell into which they are introduced (e.g., bacterial vectors having a bacterial origin of replication and episomal mammalian vectors). Other vectors (e.g. , non-episomal mammalian vectors) are integrated into the genome of a host cell upon introduction into the host cell, and thereby are replicated along with the host genome. Moreover, certain vectors are capable of directing the expression of genes to which they are operatively-linked. Such vectors are referred to herein as "expression vectors". In general, expression vectors of utility in recombinant DNA techniques are often in the form of plasmids. In the present specification, "plasmid" and "vector" can be used interchangeably as the plasmid is the most commonly used form of vector. However, the invention is intended to include such other forms of expression vectors, such as viral vectors (e.g., replication defective retroviruses, adenoviruses and adeno-associated viruses), which serve equivalent functions.
The recombinant expression vectors of the invention comprise a nucleic acid of the invention in a form suitable for expression of the nucleic acid in a host cell, which means that the recombinant expression vectors include one or more regulatory sequences, selected
on the basis of the host cells to be used for expression, that is operatively-linked to the nucleic acid sequence to be expressed. Within a recombinant expression vector, "operably-lmked" is intended to mean that the nucleotide sequence of interest is linked to the regulatory sequence(s) in a manner that allows for expression of the nucleotide sequence (e.g. , in an in vitro transcription/translation system or in a host cell when the vector is introduced into the host cell).
The term "regulatory sequence" is intended to includes promoters, enhancers and other expression control elements (e.g. , polyadenylation signals). Such regulatory sequences are described, for example, in Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Regulatory sequences include those that direct constitutive expression of a nucleotide sequence in many types of host cell and those that direct expression of the nucleotide sequence only in certain host cells (e.g., tissue-specific regulatory sequences). It will be appreciated by those skilled in the art that the design of the expression vector can depend on such factors as the choice of the host cell to be transformed, the level of expression of protein desired, etc. The expression vectors of the invention can be introduced into host cells to thereby produce proteins or peptides, including fusion proteins or peptides, encoded by nucleic acids as described herein (e.g., NOVX proteins, mutant forms of NOVX proteins, fusion proteins, etc.). The recombinant expression vectors of the invention can be designed for expression of NOVX proteins in prokaryotic or eukaryotic cells. For example, NOVX proteins can be expressed in bacterial cells such as Escherichia coli, insect cells (using baculovirus expression vectors) yeast cells or mammalian cells. Suitable host cells are discussed further in Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Alternatively, the recombinant expression vector can be transcribed and translated in vitro, for example using T7 promoter regulatory sequences and T7 polymerase.
Expression of proteins in prokaryotes is most often carried out in Escherichia coli with vectors containing constitutive or inducible promoters directing the expression of either fusion or non-fusion proteins. Fusion vectors add a number of amino acids to a protein encoded therein, usually to the amino terminus of the recombinant protein. Such fusion vectors typically serve three puφoses: (i) to increase expression of recombinant protein; (ii) to increase the solubility of the recombinant protein; and (iii) to aid in the
purification of the recombinant protein by acting as a ligand in affinity purification. Often, in fusion expression vectors, a proteolytic cleavage site is introduced at the junction of the fusion moiety and the recombinant protein to enable separation of the recombinant protein from the fusion moiety subsequent to purification of the fusion protein. Such enzymes, and their cognate recognition sequences, include Factor Xa, thrombin and enterokinase. Typical fusion expression vectors include pGEX (Pharmacia Biotech Inc; Smith and Johnson, 1988. Gene 61: 31-40), pMAL (New England Biolabs, Beverly, Mass.) and pRIT5 (Pharmacia, Piscataway, N. J.) that fuse glutathione S-transferase (GST), maltose E binding protein, or protein A, respectively, to the target recombinant protein. Examples of suitable inducible non-fusion E. coli expression vectors include pTrc
(Amrann et al, (1988) Gene 69:301-315) and pET 1 Id (Studier et al, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990) 60-89).
One strategy to maximize recombinant protein expression in E. coli is to express the protein in a host bacteria with an impaired capacity to proteolytically cleave the recombinant protein. See, e.g., Gottesman, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990) 119-128. Another strategy is to alter the nucleic acid sequence of the nucleic acid to be inserted into an expression vector so that the individual codons for each amino acid are those preferentially utilized in E. coli (see, e.g., Wada, et al, 1992. Nucl. Acids Res. 20: 2111-2118). Such alteration of nucleic acid sequences of the invention can be carried out by standard DNA synthesis techniques. In another embodiment, the NOVX expression vector is a yeast expression vector. Examples of vectors for expression in yeast Saccharomyces cerivisae include pYepSecl (Baldari, et al, 1987. EMBOJ. 6: 229-234), pMFa (Kurjan and Herskowitz, 1982. Cell 30: 933-943), pJRY88 (Schultz et al, 1987. Gene 54: 113-123), pYES2 (Invitrogen Coφoration, San Diego, Calif.), and picZ (InVitrogen Coφ, San Diego, Calif.).
Alternatively, NOVX can be expressed in insect cells using baculovirus expression vectors. Baculovirus vectors available for expression of proteins in cultured insect cells (e.g., SF9 cells) include the pAc series (Smith, et al, 1983. Mol. Cell. Biol. 3: 2156-2165) and the pVL series (Lucklow and Summers, 1989. Virology 170: 31-39).
In yet another embodiment, a nucleic acid of the invention is expressed in mammalian cells using a mammalian expression vector. Examples of mammalian expression vectors include pCDM8 (Seed, 1987. Nature 329: 840) andpMT2PC (Kaufman,
etal, 1987. EMBOJ. 6: 187-195). When used in mammalian cells, the expression vector's control functions are often provided by viral regulatory elements. For example, commonly used promoters are derived from polyoma, adenovirus 2, cytomegalovirus, and simian virus 40. For other suitable expression systems for both prokaryotic and eukaryotic cells see, e.g. , Chapters 16 and 17 of Sambrook, et al, MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989.
In another embodiment, the recombinant mammalian expression vector is capable of directing expression of the nucleic acid preferentially in a particular cell type (e.g. , tissue-specific regulatory, elements are used to express the nucleic acid). Tissue-specific regulatory elements are known in the art. Non-limiting examples of suitable tissue-specific promoters include the albumin promoter (liver-specific; Pinkert, et al, 1987. Genes Dev. 1 : 268-277), lymphoid-specific promoters (Calame and Eaton, 1988. Adv. Immunol. 43: 235-275), in particular promoters of T cell receptors (Winoto and Baltimore, 1989. EMBO J. 8: 729-733) and immunoglobulins (Banerji, et al, 1983. Cell 33: 729-740; Queen and Baltimore, 1983. Cell 33: 741-748), neuron-specific promoters (e.g., the neurofilament promoter; Byrne and Ruddle, 1989. Proc. Natl. Acad. Sci. USA 86: 5473-5477), pancreas-specific promoters (Edlund, et al, 1985. Science 230: 912-916), and mammary gland-specific promoters (e.g., milk whey promoter; U.S. Pat. No. 4,873,316 and European Application Publication No. 264,166). Developmentally-regulated promoters are also encompassed, e.g., the murine hox promoters (Kessel and Gruss, 1990. Science 249: <> 374-379) and the α-fetoprotein promoter (Campes and Tilghman, 1989. Genes Dev. 3: 537-546).
The invention further provides a recombinant expression vector comprising a DNA molecule of the invention cloned into the expression vector in an antisense orientation.
That is, the DNA molecule is operatively-linked to a regulatory sequence in a manner that allows for expression (by transcription of the DNA molecule) of an RNA molecule that is antisense to NOVX mRNA. Regulatory sequences operatively linked to a nucleic acid cloned in the antisense orientation can be chosen that direct the continuous expression of the antisense RNA molecule in a variety of cell types, for instance viral promoters and/or enhancers, or regulatory sequences can be chosen that direct constitutive, tissue specific or cell type specific expression of antisense RNA! The antisense expression vector can be in the form of a recombinant plasmid, phagemid or attenuated virus in which antisense nucleic
acids are produced under the control of a high efficiency regulatory region, the activity of which can be determined by the cell type into which the vector is introduced. For a discussion of the regulation of gene expression using antisense genes see, e.g., Weintraub, et al, "Antisense RNA as a molecular tool for genetic analysis," Reviews-Trends in Genetics, Vol. 1(1) 1986.
Another aspect of the invention pertains to host cells into which a recombinant expression vector of the invention has been introduced. The terms "host cell" and "recombinant host cell" are used interchangeably herein. It is understood that such terms refer not only to the particular subject cell but also to the progeny or potential progeny of such a cell. Because certain modifications may occur in succeeding generations due to either mutation or environmental influences, such progeny may not, in fact, be identical to the parent cell, but are still included within the scope of the term as used herein.
A host cell can be any prokaryotic or eukaryotic cell. For example, NOVX protein can be expressed in bacterial cells such as E. coli, insect cells, yeast or mammalian cells (such as Chinese hamster ovary cells (CHO) or COS cells). Other suitable host cells are known to those skilled in the art.
Vector DNA can be introduced into prokaryotic or eukaryotic cells via conventional transformation or transfection techniques. As used herein, the terms "transformation" and "fransfection" are intended to refer to a variety of art-recognized techniques for introducing foreign nucleic acid (e.g. , DNA) into a host cell, including calcium phosphate or calcium chloride co-precipitation, DEAE-dextran-mediated transfection, lipofection, or electroporation. Suitable methods for transforming or transfecting host cells can be found in Sambrook, et al. (MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989), and other laboratory manuals.
For stable transfection of mammalian cells, it is known that, depending upon the expression vector and transfection technique used, only a small fraction of cells may integrate the foreign DNA into their genome. In order to identify and select these integrants, a gene that encodes a selectable marker (e.g., resistance to antibiotics) is generally infroduced into the host cells along with the gene of interest. Various selectable markers include those that confer resistance to drugs, such as G418, hygromycin and methotrexate. Nucleic acid encoding a selectable marker can be introduced into a host cell on the same vector as that encoding NOVX or can be introduced on a separate vector.
Cells stably transfected with the introduced nucleic acid can be identified by drug selection (e.g., cells that have incoφorated the selectable marker gene will survive, while the other cells die).
A host cell of the invention, such as a prokaryotic or eukaryotic host cell in culture, can be used to produce (t.e., express) NOVX protein. Accordingly, the invention further provides methods for producing NOVX protein using the host cells of the invention. In one embodiment, the method comprises culturing the host cell of invention (into which a recombinant expression vector encoding NOVX protein has been introduced) in a suitable medium such that NOVX protein is produced. In another embodiment, the method further comprises isolating NOVX protein from the medium or the host cell.
Transgenic NOVX Animals
The host cells of the invention can also be used to produce non-human transgenic animals. For example, in one embodiment, a host cell of the invention is a fertilized oocyte or an embryonic stem cell into which NOVX protein-coding sequences have been infroduced. Such host cells can then be used to create non-human transgenic animals in which exogenous NOVX sequences have been introduced into their genome or homologous recombinant animals in which endogenous NOVX sequences have been altered. Such animals are useful for studying the function and/or activity of NOVX protein and for identifying and/or evaluating modulators of NOVX protein activity. As used herein, a "transgenic animal" is a non-human animal, preferably a mammal, more preferably a rodent such as a rat or mouse, in which one or more of the cells of the animal includes a transgene. Other examples of transgenic animals include non-human primates, sheep, dogs, cows, goats, chickens, amphibians, etc. A transgene is exogenous DNA that is integrated into the genome of a cell from which a transgenic animal develops and that remains in the genome of the mature animal, thereby directing the expression of an encoded gene product in one or more cell types or tissues of the transgenic animal. As used herein, a "homologous recombinant animal" is a non-human animal, preferably a mammal, more preferably a mouse, in which an endogenous NOVX gene has been altered by homologous recombination between the endogenous gene and an exogenous DNA molecule infroduced into a cell of the animal, e.g., an embryonic cell of the animal, prior to development of the animal.
A transgenic animal of the invention can be created by introducing NOVX-encoding nucleic acid into the male pronuclei of a fertilized oocyte (e.g., by microinjection, retroviral infection) and allowing the oocyte to develop in a pseudopregnant female foster animal. The human NOVX cDNA sequences, i.e., any one of SEQ ID NO:2ra-l, wherein n is an integer between 1 and 226, can be introduced as a transgene into the genome of a non-human animal. Alternatively, a non-human homologue of the human NOVX gene, such as a mouse NOVX gene, can be isolated based on hybridization to the human NOVX cDNA (described further supra) and used as a fransgene. Intronic sequences and polyadenylation signals can also be included in the transgene to increase the efficiency of expression of the transgene. A tissue-specific regulatory sequence(s) can be operably-linked to the NOVX transgene to direct expression of NOVX protein to particular cells. Methods for generating transgenic animals via embryo manipulation and microinjection, particularly animals such as mice, have become conventional in the art and are described, for example, in U.S. Patent Nos. 4,736,866; 4,870,009; and 4,873,191; and Hogan, 1986. In: MANIPULATING THE MOUSE EMBRYO, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. Similar methods are used for production of other transgenic animals. A transgenic founder animal can be identified based upon the presence of the NOVX transgene in its genome and/or expression of NOVX mRNA in tissues or cells of the animals. A transgenic founder animal can then be used to breed additional animals carrying the transgene. Moreover, transgenic animals carrying a transgene-encoding NOVX protein can further be bred to other transgenic animals carrying other transgenes.
To create a homologous recombinant animal, a vector is prepared which contains at least a portion of a NOVX gene into which a deletion, addition or substitution has been infroduced to thereby alter, e.g., functionally disrupt, the NOVX gene. The NOVX gene can be a human gene (e.g., the cDNA of any one of SEQ ID NO:2»-l, wherein n is an integer between 1 and 226), but more preferably, is a non-human homologue of a human NOVX gene. For example, a mouse homologue of human NOVX gene of SEQ ID NO:2R-1, wherein n is an integer between 1 and 226, can be used to construct a homologous recombination vector suitable for altering an endogenous NOVX gene in the mouse genome. In one embodiment, the vector is designed such that, upon homologous recombination, the endogenous NOVX gene is functionally disrupted (i.e., no longer encodes a functional protein; also referred to as a "knock out" vector).
Alternatively, the vector can be designed such that, upon homologous recombination, the endogenous NOVX gene is mutated or otherwise altered but still encodes functional protein (e.g., the upstream regulatory region can be altered to thereby alter the expression of the endogenous NOVX protein). In the homologous recombination vector, the altered portion of the NOVX gene is flanked at its 5'- and 3'-termini by additional nucleic acid of the NOVX gene to allow for homologous recombination to occur between the exogenous NOVX gene carried by the vector and an endogenous NOVX gene in an embryonic stem cell. The additional flanking NOVX nucleic acid is of sufficient length for successful homologous recombination with the endogenous gene. Typically, several kilobases of flanking DNA (both at the 5'- and 3'-termini) are included in the vector. See, e.g., Thomas, et al, 1987. Cell 51:.503 for a description of homologous recombination vectors. The vector is ten introduced into an embryonic stem cell line (e.g., by electroporation) and cells in which the introduced NOVX gene has homologously-recombined with the endogenous NOVX gene are selected. See, e.g., Li, et al, 1992. Cell 69: 915.
The selected cells are then injected into a blastocyst of an animal (e.g., a mouse) to form aggregation chimeras. See, e.g, Bradley, 1987. In: TERATOCARCINOMAS AND EMBRYONIC STEM CELLS: A PRACTICAL APPROACH, Robertson, ed. IRL, Oxford, pp. 113-152. A chimeric embryo can then be implanted into a suitable pseudopregnant female foster animal and the embryo brought to term. Progeny harboring the homologously-recombined DNA in their germ cells can be used to breed animals in which all cells of the animal contain the homologously-recombined DNA by germline transmission of the fransgene. Methods for constructing homologous recombination vectors and homologous recombinant animals are described further in Bradley, 1991. Curr. Opin. Biotechnol. 2: 823-829; PCT International Publication Nos.: WO 90/11354; WO 91/01140; WO 92/0968; and WO 93/04169.
In another embodiment, transgenic non-humans animals can be produced that contain selected systems that allow for regulated expression of the transgene. One example of such a system is the cre/loxP recombinase system of bacteriophage PI . For a description of the cre/loxP recombinase system, See, e.g., Lakso, et al, 1992. Proc. Natl. Acad. Sci. USA 89: 6232-6236. Another example of a recombinase system is the FLP recombinase system of Saccharomyces cerevisiάe. See, O'Gorman, et al, 1991. Science 251:1351-1355. If a cre/loxP recombinase system is used to regulate expression of the transgene, animals
containing transgenes encoding both the Cre recombinase and a selected protein are required. Such animals can be provided through the construction of "double" transgenic animals, e.g., by mating two transgenic animals, one containing a transgene encoding a selected protein and the other containing a transgene encoding a recombinase. Clones of the non-human transgenic animals described herein can also be produced according to the methods described in Wilmut, etal, 1991. Nature 385: 810-813. In brief, a cell (e.g., a somatic cell) from the transgenic animal can be isolated and induced to exit the. growth cycle and enter Go phase. The quiescent cell can then be fused, e.g, through the use of electrical pulses, to an enucleated oocyte from an animal of the same species from which the quiescent cell is isolated. The reconstructed oocyte is then cultured such that it develops to morula or blastocyte and then transferred to pseudopregnant female foster animal. The offspring borne of this female foster animal will be a clone of the animal from which the cell (e.g., the somatic cell) is isolated.
Pharmaceutical Compositions
The NOVX nucleic acid molecules, NOVX proteins, and anti-NOVX antibodies (also referred to herein as "active compounds") of the invention, and derivatives, fragments, analogs and homologs thereof, can be incoφorated into pharmaceutical compositions suitable for administration. Such compositions typically comprise the nucleic acid molecule, protein, or antibody and a pharmaceutically acceptable carrier. As used herein, "pharmaceutically acceptable carrier" is intended to include any and all solvents, dispersion media, coatings, antibacterial and antifungal agents, isotonic and absoφtion delaying agents, and the like, compatible with pharmaceutical administration. Suitable carriers are described in the most recent edition of Remington's Pharmaceutical Sciences, a standard reference text in the field, which is incoφorated herein by reference. Preferred examples of such carriers or diluents include, but are not limited to, water, saline, finger's solutions, dextrose solution, and 5% human serum albumin. Liposomes and non-aqueous vehicles such as fixed oils may also be used. The use of such media and agents for pharmaceutically active substances is well known in the art. Except insofar as any conventional media or agent is incompatible with the active compound, use thereof in the compositions is contemplated. Supplementary active compounds can also be incoφorated into the compositions.
A pharmaceutical composition of the invention is formulated to be compatible with its intended route of administration. Examples of routes of administration include parenteral, e.g., intravenous, intradermal, subcutaneous, oral (e.g., inhalation), transdermal (i.e., topical), transmucosal, and rectal administration. Solutions or suspensions used for parenteral, infradermal, or subcutaneous application can include the following components: a sterile diluent such as water for injection, saline solution, fixed oils, polyethylene glycols, glycerine, propylene glycol or other synthetic solvents; antibacterial agents such as benzyl alcohol or methyl parabens; antioxidants such as ascorbic acid or sodium bisulfite; chelating agents such as ethylenediaminetetraacetic acid (EDTA); buffers such as acetates, citrates or phosphates, and agents for the adjustment of tonicity such as sodium chloride or dextrose. The pH can be adjusted with acids or bases, such as hydrochloric acid or sodium hydroxide. The parenteral preparation can be enclosed in ampoules, disposable syringes or multiple dose vials made of glass or plastic.
Pharmaceutical compositions suitable for injectable use include sterile aqueous solutions (where water soluble) or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersion. For intravenous administration, suitable carriers include physiological saline, bacteriostatic water, Cremophor EL (BASF, Parsippany, N. J.) or phosphate buffered saline (PBS). In all cases, the composition must be sterile and should be fluid to the extent that easy syringeability exists. It must be stable under the conditions of manufacture and storage and must be preserved against the contaminating action of microorganisms such as bacteria and fungi. The carrier can be a solvent or dispersion medium containing, for example, water, ethanol, polyol (for example, glycerol, propylene glycol, and liquid polyethylene glycol, and the like), and suitable mixtures thereof. The proper fluidity can be maintained, for example, by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants. Prevention of the action of microorganisms can be achieved by various antibacterial and antifungal agents, for example, parabens, chlorobutanol, phenol, ascorbic acid, thimerosal, and the like. In many cases, it will be preferable to include isotonic agents, for example, sugars, polyalcohols such as manitol, sorbitol, sodium chloride in the composition. Prolonged absoφtion of the injectable compositions can be brought about by including in the composition an agent which delays absoφtion, for example, aluminum monostearate and gelatin.
Sterile injectable solutions can be prepared by incoφorating the active compound (e.g., a NOVX protein or anti-NOVX antibody) in the required amount in an appropriate solvent with one or a combination of ingredients enumerated above, as required, followed by filtered sterilization. Generally, dispersions are prepared by incoφorating the active compound into a sterile vehicle that contains a basic dispersion medium and the required other ingredients from those enumerated above. In the case of sterile powders for the preparation of sterile injectable solutions, methods of preparation are vacuum drying and freeze-drying that yields a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof. Oral compositions generally include an inert diluent or an edible carrier. They can be enclosed in gelatin capsules or compressed into tablets. For the puφose of oral therapeutic administration, the active compound can be incoφorated with excipients and used in the form of tablets, troches, or capsules. Oral compositions can also be prepared using a fluid carrier for use as a mouthwash, wherein the compound in the fluid carrier is applied orally and swished and expectorated or swallowed. Pharmaceutically compatible binding agents, and/or adjuvant materials can be included as part of the composition. The tablets, pills, capsules, troches and the like can contain any of the following ingredients, or compounds of a similar nature: a binder such as microcrystalline cellulose, gum fragacanth or gelatin; an excipient such as starch or lactose, a disintegrating agent such as alginic acid, Primogel, or corn starch; a lubricant such as magnesium stearate or Sterotes; a glidant such as colloidal silicon dioxide; a sweetening agent such as sucrose or saccharin; or a flavoring agent such as peppermint, methyl salicylate, or orange flavoring.
For administration by inhalation, the compounds are delivered in the form of an aerosol spray from pressured container or dispenser which contains a suitable propellant, e.g., a gas such as carbon dioxide, or a nebulizer.
Systemic administration can also be by transmucosal or transdermal means. For transmucosal or transdermal administration, penetrants appropriate to the barrier to be permeated are used in the formulation. Such penetrants are generally known in the art, and include, for example, for transmucosal administration, detergents, bile salts, and fusidic acid derivatives. Transmucosal administration can be accomplished through the use of nasal sprays or suppositories. For transdermal administration, the active compounds are formulated into ointments, salves, gels, or creams as generally known in the art.
The compounds can also be prepared in the form of suppositories (e.g., with conventional suppository bases such as cocoa butter and other glycerides) or retention enemas for rectal delivery.
In one embodiment, the active compounds are prepared with carriers that will protect the compound against rapid elimination from the body, such as a controlled release formulation, including implants and microencapsulated delivery systems. Biodegradable, biocompatible polymers can be used, such as ethylene vinyl acetate, polyanhydrides, polyglycolic acid, collagen, polyorthoesters, and polylactic acid. Methods for preparation of such formulations will be apparent to those skilled in the art. The materials can also be obtained commercially from Alza Coφoration and Nova Pharmaceuticals, Inc. Liposomal suspensions (including liposomes targeted to infected cells with monoclonal antibodies to viral antigens) can also be used as pharmaceutically acceptable carriers. These can be prepared according to methods known to those skilled in the art, for example, as described in U.S. Patent No. 4,522,811. It is especially advantageous to formulate oral or parenteral compositions in dosage unit form for ease of administration and uniformity of dosage. Dosage unit form as used herein refers to physically discrete units suited as unitary dosages for the subject to be treated; each unit containing a predetermined quantity of active compound calculated to produce the desired therapeutic effect in association with the required pharmaceutical carrier. The specification for the dosage unit forms of the invention are dictated by and directly dependent on the unique characteristics of the active compound and the particular therapeutic effect to be achieved, and the limitations inherent in the art of compounding such an active compound for the treatment of individuals.
The nucleic acid molecules of the invention can be inserted into vectors and used as gene therapy, vectors. Gene therapy vectors can be delivered to a subject by, for example, intravenous injection, local administration (see, e.g., U.S. Patent No. 5,328,470) or by stereotactic injection (see, e.g., Chen, etal, 1994. Proc. Natl. Acad. Sci. USA 91: 3054-3057). The pharmaceutical preparation of the gene therapy vector can include the gene therapy vector in an acceptable diluent, or can comprise a slow release matrix in which the gene delivery vehicle is imbedded. Alternatively, where the complete gene delivery vector can be produced intact from recombinant cells, e.g., retroviral vectors, the pharmaceutical preparation can include one or more cells that produce the gene delivery system.
The pharmaceutical compositions can be included in a container, pack, or dispenser together with instructions for administration.
Screening and Detection Methods The isolated nucleic acid molecules of the invention can be used to express NOVX protein (e.g., via a recombinant expression vector in a host cell in gene therapy applications), to detect NOVX mRNA (e.g., in a biological sample) or a genetic lesion in a NOVX gene, and to modulate NOVX activity, as described further, below. In addition, the NOVX proteins can be used to screen drugs or compounds that modulate the NOVX protein activity or expression as well as to treat disorders characterized by insufficient or excessive production of NOVX protein or production of NOVX protein forms that have decreased or aberrant activity compared to NOVX wild-type protein (e.g.; diabetes (regulates insulin release); obesity (binds and transport lipids); metabolic disturbances associated with obesity, the metabolic syndrome X as well as anorexia and wasting disorders associated with chronic diseases and various cancers, and infectious disease(possesses anti-microbial activity) and the various dyslipidemias. In addition, the anti-NOVX antibodies of the invention can be used to detect and isolate NOVX proteins and modulate NOVX activity. In yet a further aspect, the invention can be used in methods to influence appetite, absoφtion of nutrients and the disposition of metabolic substrates in both a positive and negative fashion.
The invention further pertains to novel agents identified by the screening assays described herein and uses thereof for treatments as described, supra.
Screening Assays The invention provides a method (also referred to herein as a "screening assay") for identifying modulators, i.e., candidate or test compounds or agents (e.g., peptides, peptidomimetics, small molecules or other drugs) that bind to NOVX proteins or have a stimulatory or inhibitory effect on, e.g., NOVX protein expression or NOVX protein activity. The invention also includes compounds identified in the screening assays described herein.
In one embodiment, the invention provides assays for screening candidate or test compounds which bind to or modulate the activity of the membrane-bound form of a NOVX protein or polypeptide or biologically-active portion thereof. The test compounds
of the invention can be obtained using any of the numerous approaches in combinatorial library methods known in the art, including: biological libraries; spatially addressable parallel solid phase or solution phase libraries; synthetic library methods requiring deconvolution; the "one-bead one-compound" library method; and synthetic library methods using affinity chromatography selection. The biological library approach is limited to peptide libraries, while the other four approaches are applicable to peptide, non-peptide oligomer or small molecule libraries of compounds. See, e.g., Lam, 1997. Anticancer Drug Design 12: 145.
A "small molecule" as used herein, is meant to refer to a composition that has a molecular weight of less than about 5 kD and most preferably less than about 4 kD. Small molecules can be, e.g., nucleic acids, peptides, polypeptides, peptidomimetics, carbohydrates, lipids or other organic or inorganic molecules. Libraries of chemical and/or biological mixtures, such as fungal, bacterial, or algal extracts, are known in the art and can be screened with any of the assays of the invention. Examples of methods for the synthesis of molecular libraries can be found in the art, for example in: DeWitt, et al, 1993. Proc. Nat Acad. Sci. US.A. 90: 6909; Erb, et al, 1994. Proc. Natl. Acad. Sci. U.S.A. 91: 11422; Zuckermann, et al, 1994. J. Med. Chem. 37: 2678; Cho, et al, 1993. Science 261 : 1303; Carrell, et al, 1994. Angew. Chem. Int. Ed. Engl. 33: 2059; Carell, et al, 1994. Angew. Chem. bit. Ed. Engl. 33: 2061; and Gallop, et al, 1994. J. Med. Chem. 37: 1233.
Libraries of compounds may be presented in solution (e.g., Houghten, 1992. Biotechniques 13: 412-421), or on beads (Lam, 1991. Nature 354: 82-84), on chips (Fodor, 1993. Nature 364: 555-556), bacteria (Ladner, U.S. Patent No. 5,223,409), spores (Ladner, U.S. Patent 5,233,409), plasmids (Cull, et al, 1992. Proc. Natl. Acad. Sci. USA 89: 1865-1869) or on phage (Scott and Smith, 1990. Science 249: 386-390; Devlin, 1990. Science 249: 404-406; Cwirla, et al, 1990. Proc. Natl. Acad. Sci. U.S.A. 87: 6378-6382; Felici, 1991. J. Mol. Biol. 222: 301-310; Ladner, U.S. Patent No. 5,233,409.).
In one embodiment, an assay is a cell-based assay in which a cell which expresses a membrane-bound form of NOVX protein, or a biologically-active portion thereof, on the cell surface is contacted with a test compound and the ability of the test compound to bind to a NOVX protein determined. The cell, for example, can of mammalian origin or a yeast cell. Determining the ability of the test compound to bind to the NOVX protein can be accomplished, for example, by coupling the test compound with a radioisotope or
enzymatic label such that binding of the test compound to the NOVX protein or biologically-active portion thereof can be determined by detecting the labeled compound in a complex. For example, test compounds can be labeled with 1251, 35S, 14C, or 3H, either directly or indirectly, and the radioisotope detected by direct counting of radioemission or by scintillation counting. Alternatively, test compounds can be enzymatically-labeled with, for example, horseradish peroxidase, alkaline phosphatase, or luciferase, and the enzymatic label detected by determination of conversion of an appropriate substrate to product. In one embodiment, the assay comprises contacting a cell which expresses a membrane-bound form of NOVX protein, or a biologically-active portion thereof, on the cell surface with a known compound which binds NOVX to form an assay mixture, contacting the assay mixture with a test compound, and determining the ability of the test compound to interact with a NOVX protein, wherein determimng the ability of the test compound to interact with a NOVX protein comprises determining the ability of the test compound to preferentially bind to NOVX protein or a biologically-active portion thereof as compared to the known compound.
In another embodiment, an assay is a cell-based assay comprising contacting a cell expressing a membrane-bound form of NOVX protein, or a biologically-active portion thereof, on the cell surface with a test compound and determining the ability of the test compound to modulate (e.g., stimulate or inhibit) the activity of the NOVX protein or biologically-active portion thereof. Determining the ability of the test compound to modulate the activity of NOVX or a biologically-active portion thereof can be accomplished, for example, by determining the ability of the NOVX protein to bind to or interact with a NOVX target molecule. As used herein, a "target molecule" is a molecule with which a NOVX protein binds or interacts in nature, for example, a molecule on the surface of a cell which expresses a NOVX interacting protein, a molecule on the surface of a second cell, a molecule in the extracellular milieu, a molecule associated with the internal surface of a cell membrane or a cytoplasmic molecule. A NOVX target molecule can be a non-NOVX molecule or a NOVX protein or polypeptide of the invention. In one embodiment, a NOVX target molecule is a component of a signal fransduction pathway that facilitates fransduction of an extracellular signal (e.g. a signal generated by binding of a compound to a membrane-bound NOVX molecule) through the cell membrane and into the cell. The target, for example, can be a second intercellular protein that has catalytic
activity or a protein that facilitates the association of downstream signaling molecules with NOVX.
Determimng the ability of the NOVX protein to bind to or interact with a NOVX target molecule can be accomplished by one of the methods described above for determining direct binding. In one embodiment, determining the ability of the NOVX protein to bind to or interact with a NOVX target molecule can be accomplished by determining the activity of the target molecule. For example, the activity of the target molecule can be determined by detecting induction of a cellular second messenger of the target (i.e. intracellular Ca2+, diacylglycerol, IP3, etc.), detecting catalytic/enzymatic activity of the target an appropriate substrate, detecting the induction of a reporter gene (comprising a NOVX-responsive regulatory element operatively linked to a nucleic acid encoding a detectable marker, e.g., luciferase), or detecting a cellular response, for example, cell survival, cellular differentiation, or cell proliferation.
In yet another embodiment, an assay of the invention is a cell-free assay comprising contacting a NOVX protein or biologically-active portion thereof with a test compound and determining the ability of the test compound to bind to the NOVX protein or biologically-active portion thereof. Binding of the test compound to the NOVX protein can be determined either directly or indirectly as described above. In one such embodiment, the assay comprises contacting the NOVX protein or biologically-active portion thereof with a known compound which binds NOVX to form an assay mixture, contacting the assay mixture with a test compound, and determimng the ability of the test compound to interact with a NOVX protein, wherein determining the ability of the test compound to interact with a NOVX protein comprises determining the ability of the test compound to preferentially bind to NOVX or biologically-active portion thereof as compared to the known compound.
In still another embodiment, an assay is a cell-free assay comprising contacting NOVX protein or biologically-active portion thereof with a test compound and determining the ability of the test compound to modulate (e.g. stimulate or inhibit) the activity of the NOVX protein or biologically-active portion thereof. Determining the ability of the test compound to modulate the activity of NOVX can be accomplished, for example, by determining the ability of the NOVX protein to bind to a NOVX target molecule by one of the methods described above for determining direct binding. In an alternative embodiment, determimng the ability of the test compound to modulate the activity of NOVX protein can
be accomplished by determining the ability of the NOVX protein further modulate a NOVX target molecule. For example, the catalytic/enzymatic activity of the target molecule on an appropriate substrate can be determined as described, supra.
In yet another embodiment, the cell-free assay comprises contacting the NOVX protein or biologically-active portion thereof with a known compound which binds NOVX protein to form an assay mixture, contacting the assay mixture with a test compound, and determining the ability of the test compound to interact with a NOVX protein, wherein determining the ability of the test compound to interact with a NOVX protein comprises determining the ability of the NOVX protein to preferentially bind to or modulate the activity of a NOVX target molecule.
The cell-free assays of the invention are amenable to use of both the soluble form or the membrane-bound form of NOVX protein. In the case of cell-free assays comprising the membrane-bound form of NOVX protein, it may be desirable to utilize a solubilizing agent such that the membrane-bound form of NOVX protein is maintained in solution. Examples of such solubilizing agents include non-ionic detergents such as n-octylglucoside, n-dodecylglucoside, n-dodecylmaltoside, octanoyl-N-methylglucamide, decanoyl-N-methylglucamide, Triton® X-100, Triton® X-l 14, Thesit®, Isotridecypoly(ethylene glycol ether)n, N-dodecyl— N,N-dimethyl-3-ammonio-l -propane sulfonate, 3-(3-cholamidopropyl) dimethylamminiol-1 -propane sulfonate (CHAPS), or 3-(3-cholamidopropyl)dimethylamminiol-2-hydroxy-l-propane sulfonate (CHAPSO).
In more than one embodiment of the above assay methods of the invention, it may be desirable to immobilize either NOVX protein or its target molecule to facilitate separation of complexed from uncomplexed forms of one or both of the proteins, as well as to accommodate automation of the assay. Binding of a test compound to NOVX protein, or interaction of NOVX protein with a target molecule in the presence and absence of a candidate compound, can be accomplished in any vessel suitable for containing the reactants. Examples of such vessels include microtiter plates, test tubes, and micro-centrifuge tubes. In one embodiment, a fusion protein can be provided that adds a domain that allows one or both of the proteins to be bound to a matrix. For example, GST-NO VX fusion proteins or GST-target fusion proteins can be adsorbed onto glutathione sepharose beads (Sigma Chemical, St. Louis, MO) or glutathione derivatized microtiter plates, that are then combined with the test compound or the test compound and either the non-adsorbed target protein or NOVX protein, and the mixture is incubated under
conditions conducive to complex formation (e.g., at physiological conditions for salt and pH). Following incubation, the beads or microtiter plate wells are washed to remove any unbound components, the matrix immobilized in the case of beads, complex determined either directly or indirectly, for example, as described, supra. Alternatively, the complexes can be dissociated from the matrix, and the level of NOVX protein binding or activity determined using standard techniques.
Other techniques for immobilizing proteins on matrices can also be used in the screening assays of the invention. For example, either the NOVX protein or its target molecule can be immobilized utilizing conjugation of biotin and streptavidin. Biotinylated NOVX protein or target molecules can be prepared from biotin-NHS
(N-hydroxy-succinimide) using techniques well-known within the art (e.g., biotinylation kit, Pierce Chemicals, Rockford, 111.), and immobilized in the wells of streptavidin-coated 96 well plates (Pierce Chemical). Alternatively, antibodies reactive with NOVX protein or target molecules, but which do not interfere with binding of the NOVX protein to its target molecule, can be derivatized to the wells of the plate, and unbound target or NOVX protein trapped in the wells by antibody conjugation. Methods for detecting such complexes, in addition to those described above for the GST-immobilized complexes, include immunodetection of complexes using antibodies reactive with the NOVX protein or target molecule, as well as enzyme-linked assays that rely on detecting an enzymatic activity associated with the NOVX protein or target molecule.
In another embodiment, modulators of NOVX protein expression are identified in a method wherein a cell is contacted with a candidate compound and the expression of NOVX mRNA or protein in the cell is determined. The level of expression of NOVX mRNA or protein in the presence of the candidate compound is compared to the level of expression of NOVX mRNA or protein in the absence of the candidate compound. The candidate compound can then be identified as a modulator of NOVX mRNA or protein expression based upon this comparison. For example, when expression of NOVX mRNA or protein is greater (i.e., statistically significantly greater) in the presence of the candidate compound than in its absence, the candidate compound is identified as a stimulator of NOVX mRNA or protein expression. Alternatively, when expression of NOVX mRNA or protein is less (statistically significantly less) in the presence of the candidate compound than in its absence, the candidate compound is identified as an inliibitor of NOVX mRNA
or protein expression. The level of NOVX mRNA or protein expression in the cells can be determined by methods described herein for detecting NOVX mRNA or protein.
In yet another aspect of the invention, the NOVX proteins can be used as "bait proteins" in a two-hybrid assay or three hybrid assay (see, e.g., U.S. Patent No. 5,283,317; Zervos, et al, 1993. Cell 72: 223-232; Madura, et al, 1993. J. Biol. Chem. 268:
12046-12054; Bartel, etal, 1993. Biotechniques 14: 920-924; Iwabuchi, et al, 1993. Oncogene 8: 1693-1696; and Brent WO 94/10300), to identify other proteins that bind to or interact with NOVX ("NOVX-binding proteins" or "NOVX-bp") and modulate NOVX activity. Such NOVX-binding proteins are also involved in the propagation of signals by the NOVX proteins as, for example, upstream or downstream elements of the NOVX pathway.
The two-hybrid system is based on the modular nature of most franscription factors, which consist of separable DNA-binding and activation domains. Briefly, the assay utilizes two different DNA constructs. In one construct, the gene that codes for NOVX is fused to a gene encoding the DNA binding domain of a known franscription factor (e.g. , GAL-4). In the other construct, a DNA sequence, from a library of DNA sequences, that encodes an unidentified protein ("prey" or "sample") is fused to a gene that codes for the activation domain of the known franscription factor. If the "bait" and the "prey" proteins are able to interact, in vivo, forming a NOVX-dependent complex, the DNA-binding and activation domains of the transcription factor are brought into close proximity. This proximity allows franscription of a reporter gene (e.g., LacZ) that is operably linked to a transcriptional regulatory site responsive to the franscription factor. Expression of the reporter gene can be detected and cell colonies containing the functional franscription factor can be isolated and used to obtain the cloned gene that encodes the protein which interacts with NOVX. The invention further pertains to novel agents identified by the aforementioned screening assays and uses thereof for treatments as described herein.
Detection Assays
Portions or fragments of the cDNA sequences identified herein (and the corresponding complete gene sequences) can be used in numerous ways as polynucleotide reagents. By way of example, and not of limitation, these sequences can be used to: (i) map their respective genes on a chromosome; and, thus, locate gene regions associated with genetic disease; (ii) identify an individual from a minute biological sample (tissue typing);
and (iii) aid in forensic identification of a biological sample. Some of these applications are described in the subsections, below.
Chromosome Mapping Once the sequence (or a portion of the sequence) of a gene has been isolated, this sequence can be used to map the location of the gene on a chromosome. This process is called chromosome mapping. Accordingly, portions or fragments of the NOVX sequences of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, or fragments or derivatives thereof, can be used to map the location of the NOVX genes, respectively, on a chromosome. The mapping of the NOVX sequences to chromosomes is an important first step in correlating these sequences with genes associated with disease.
Briefly, NOVX genes can be mapped to chromosomes by preparing PCR primers (preferably 15-25 bp in length) from the NOVX sequences. Computer analysis of the NOVX, sequences can be used to rapidly select primers that do not span more than one exon in the genomic DNA, thus complicating the amplification process. These primers can then be used for PCR screening of somatic cell hybrids containing individual human chromosomes. Only those hybrids containing the human gene corresponding to the NOVX sequences will yield an amplified fragment.
Somatic cell hybrids are prepared by fusing somatic cells from different mammals (e.g., human and mouse cells). As hybrids of human and mouse cells grow and divide, they gradually lose human chromosomes in random order, but retain the mouse chromosomes. By using media in which mouse cells cannot grow, because they lack a particular enzyme, but in which human cells can, the one human chromosome that contains the gene encoding the needed enzyme will be retained. By using various media, panels of hybrid cell lines can be established. Each cell line in a panel contains either a single human chromosome or a small number of human chromosomes, and a full set of mouse chromosomes, allowing easy mapping of individual genes to specific human chromosomes. See, e.g., D'Eustachio, et al, 1983. Science 220: 919-924. Somatic cell hybrids containing only fragments of human chromosomes can also be produced by using human chromosomes with translocations and deletions.
PCR mapping of somatic cell hybrids is a rapid procedure for assigning a particular sequence to a particular chromosome. Three or more sequences can be assigned per day using a single thermal cycler. Using the NOVX sequences to design oligonucleotide
primers, sub-localization can be achieved with panels of fragments from specific chromosomes.
Fluorescence in situ hybridization (FISH) of a DNA sequence to a metaphase chromosomal spread can further be used to provide a precise chromosomal location in one step. Chromosome spreads can be made using cells whose division has been blocked in metaphase by a chemical like colcemid that disrupts the mitotic spindle. The chromosomes can be treated briefly with trypsin, and then stained with Giemsa. A pattern of light and dark bands develops on each chromosome, so that the chromosomes can be identified individually. The FISH technique can be used with a DNA sequence as short as 500 or 600 bases. However, clones larger than 1,000 bases have a higher likelihood of binding to a unique chromosomal location with sufficient signal intensity for simple detection. Preferably 1,000 bases, and more preferably 2,000 bases, will suffice to get good results at a reasonable amount of time. For a review of this technique, see, Verma, et al, HUMAN CHROMOSOMES: A MANUAL OF BASIC TECHNIQUES (Pergamon Press, New York 1988). Reagents for chromosome mapping can be used individually to mark a single chromosome or a single site on that chromosome, or panels of reagents can be used for marking multiple sites and/or multiple chromosomes. Reagents corresponding to noncoding regions of the genes actually are preferred for mapping puφoses. Coding sequences are more likely to be conserved within gene families, thus increasing the chance of cross hybridizations during chromosomal mapping.
Once a sequence has been mapped to a precise chromosomal location, the physical position of the sequence on the chromosome can be correlated with genetic map data. Such data are found, e.g., in McKusick, MENDELIAN INHERITANCE IN MAN, available on-line through Johns Hopkins University Welch Medical Library). The relationship between genes and disease, mapped to the same chromosomal region, can then be identified through linkage analysis (co-inheritance of physically adjacent genes), described in, e.g., Egeland, et al, 1987. Nature, 325: 783-787.
Moreover, differences in the DNA sequences between individuals affected and unaffected with a disease associated with the NOVX gene, can be determined. If a mutation is observed in some or all of the affected individuals but not in any unaffected individuals, then the mutation is likely to be the causative agent of the particular disease. Comparison of affected and unaffected individuals generally involves first looking for structural alterations in the chromosomes, such as deletions or translocations that are
visible from chromosome spreads or detectable using PCR based on that DNA sequence. Ultimately, complete sequencing of genes from several individuals can be performed to confirm the presence of a mutation and to distinguish mutations from polymoφhisms.
Tissue Typing
The NOVX sequences of the invention can also be used to identify individuals from minute biological samples. In this technique, an individual's genomic DNA is digested with one or more restriction enzymes, and probed on a Southern blot to yield unique bands for identification. The sequences of the invention are useful as additional DNA markers for RFLP ("restriction fragment length polymoφhisms," described in U.S. Patent No. 5,272,057).
Furthermore, the sequences of the invention can be used to provide an alternative technique that determines the actual base-by-base DNA sequence of selected portions of an individual's genome. Thus, the NOVX sequences described herein can be used to prepare two PCR primers from the 5'- and 3'-termini of the sequences. These primers can then be used to amplify an individual's DNA and subsequently sequence it.
Panels of corresponding DNA sequences from individuals, prepared in this manner, can provide unique individual identifications, as each individual will have a unique set of such DNA sequences due to allelic differences. The sequences of the invention can be used to obtain such identification sequences from individuals and from tissue. The NOVX sequences of the invention uniquely represent portions of the human genome. Allelic variation occurs to some degree in the coding regions of these sequences, and to a greater degree in the noncoding regions. It is estimated that allelic variation between individual humans occurs with a frequency of about once per each 500 bases. Much of the allelic variation is due to single nucleotide polymoφhisms (SNPs), which include restriction fragment length polymoφhisms (RFLPs).
Each of the sequences described herein can, to some degree, be used as a standard against which DNA from an individual can be compared for identification puφoses. Because greater numbers of polymoφhisms occur in the noncoding regions, fewer sequences are necessary to differentiate individuals. The noncoding sequences can comfortably provide positive individual identification with a panel of perhaps 10 to 1,000 primers that each yield a noncoding amplified sequence of 100 bases. If coding sequences, such as those of SEQ ID NO:2n-l, wherein n is an integer between 1 and 226, are used, a
more appropriate number of primers for positive individual identification would be 500-2,000.
Predictive Medicine The invention also pertains to the field of predictive medicine in which diagnostic assays, prognostic assays, pharmacogenomics, and monitoring clinical trials are used for prognostic (predictive) puφoses to thereby, treat an individual prophylactically. Accordingly, one aspect of the invention relates to diagnostic assays for determining NOVX protein and/or nucleic acid expression as well as NOVX activity, in the context of a biological sample (e.g., blood, serum, cells, tissue) to thereby determine whether an individual is afflicted with a disease or disorder, or is at risk of developing a disorder, associated with aberrant NOVX expression or activity. The disorders include metabolic disorders, diabetes, obesity, infectious disease, anorexia, cancer-associated cachexia, cancer, neurodegenerative disorders, Alzheimer's Disease, Parkinson's Disorder, immune disorders, and hematopoietic disorders, and the various dyslipidemias, metabolic disturbances associated with obesity, the metabolic syndrome X and wasting disorders associated with chronic diseases and various cancers. The invention also provides for prognostic (or predictive) assays for determining whether an individual is at risk of developing a disorder associated with NOVX protein, nucleic acid expression or activity. For example, mutations in a NOVX gene can be assayed in a biological sample. Such assays can be used for prognostic or predictive puφose to thereby prophylactically treat an individual prior to the onset of a disorder characterized by or associated with NOVX protein, nucleic acid expression, or biological activity.
Another aspect of the invention provides methods for determining NOVX protein, nucleic acid expression or activity in an individual to thereby select appropriate therapeutic or prophylactic agents for that individual (referred to herein as "pharmacogenomics"). Pharmacogenomics allows for the selection of agents (e.g., drugs) for therapeutic or prophylactic treatment of an individual based on the genotype of the individual (e.g., the genotype of the individual examined to determine the ability of the individual to respond to a particular agent.)
Yet another aspect of the invention pertains to monitoring the influence of agents (e.g., drugs, compounds) on the expression or activity of NOVX in clinical trials.
These and other agents are described in further detail in the following sections.
Diagnostic Assays
An exemplary method for detecting the presence or absence of NOVX in a biological sample involves obtaining a biological sample from a test subject and contacting the biological sample with a compound or an agent capable of detecting NOVX protein or nucleic acid (e.g., mRNA, genomic DNA) that encodes NOVX protein such that the presence of NOVX is detected in the biological sample. An agent for detecting NOVX mRNA or genomic DNA is a labeled nucleic acid probe capable of hybridizing to NOVX mRNA or genomic DNA. The nucleic acid probe can be, for example, a full-length NOVX nucleic acid, such as the nucleic acid of SEQ ID NO:2«-l, wherein n is an integer between 1 and 226, or a portion thereof, such as an oligonucleotide of at least 15, 30, 50, 100, 250 or 500 nucleotides in length and sufficient to specifically hybridize under stringent conditions to NOVX mRNA or genomic DNA. Other suitable probes for use in the diagnostic assays of the invention are described herein.
An agent for detecting NOVX protein is an antibody capable of binding to NOVX protein, preferably an antibody with a detectable label. Antibodies can be polyclonal, or more preferably, monoclonal. An intact antibody, or a fragment thereof (e.g., Fab or F(ab')2) can be used. The term "labeled", with regard to the probe or antibody, is intended to encompass direct labeling of the probe or antibody by coupling (i. e. , physically linking) a detectable substance to the probe or antibody, as well as indirect labeling of the probe or antibody by reactivity with another reagent that is directly labeled. Examples of indirect labeling include detection of a primary antibody using a fluorescently-labeled secondary antibody and end-labeling of a DNA probe with biotin such that it can be detected with fluorescently-labeled streptavidin. The term "biological sample" is intended to include tissues, cells and biological fluids isolated from a subject, as well as tissues, cells and fluids present within a subject. That is, the detection method of the invention can be used to detect NOVX mRNA, protein, or genomic DNA in a biological sample in vitro as well as in vivo. For example, in vitro techniques for detection of NOVX mRNA include Northern hybridizations and in situ hybridizations. In vitro techniques for detection of NOVX protein include enzyme linked immunosorbent assays (ELISAs), Western blots, immunoprecipitations, and immunofluorescence. In vitro techniques for detection of NOVX genomic DNA include Southern hybridizations. Furthermore, in vivo techniques for detection of NOVX protein include introducing into a subject a labeled anti-NOVX
antibody. For example, the antibody can be labeled with a radioactive marker whose presence and location in a subject can be detected by standard imaging techniques.
In one embodiment, the biological sample contains protein molecules from the test subject. Alternatively, the biological sample can contain mRNA molecules from the test subject or genomic DNA molecules from the test subject. A preferred biological sample is a peripheral blood leukocyte sample isolated by conventional means from a subject.
In another embodiment, the methods further involve obtaining a control biological sample from a control subject, contacting the control sample with a compound or agent capable of detecting NOVX protein, mRNA, or genomic DNA, such that the presence of NOVX protein, mRNA or genomic DNA is detected in the biological sample, and comparing the presence of NOVX protein, mRNA or genomic DNA in the control sample with the presence of NOVX protein, mRNA or genomic DNA in the test sample.
The invention also encompasses kits for detecting the presence of NOVX in a biological sample. For example, the kit can comprise: a labeled compound or agent capable of detecting NOVX protein or mRNA in a biological sample; means for determining the amount of NOVX in the sample; and means for comparing the amount of NOVX in the sample with a standard. The compound or agent can be packaged in a suitable container. The kit can further comprise instructions for using the kit to detect NOVX protein or nucleic acid.
Prognostic Assays
The diagnostic methods described herein can furthermore be utilized to identify subjects having or at risk of developing a disease or disorder associated with aberrant NOVX expression or activity. For example, the assays described herein, such as the preceding diagnostic assays or the following assays, can be utilized to identify a subject having or at risk of developing a disorder associated with NOVX protein, nucleic acid expression or activity. Alternatively, the prognostic assays can be utilized to identify a subject having or at risk for developing a disease or disorder. Thus, the invention provides a method for identifying a disease or disorder associated with aberrant NOVX expression or activity in which a test sample is obtained from a subject and NOVX protein or nucleic acid (e.g., mRNA, genomic DNA) is detected, wherein the presence of NOVX protein or nucleic acid is diagnostic for a subject having or at risk of developing a disease or disorder associated with aberrant NOVX expression or activity. As used herein, a "test sample"
refers to a biological sample obtained from a subject of interest. For example, a test sample can be a biological fluid (e.g., serum), cell sample, or tissue.
Furthermore, the prognostic assays described herein can be used to determine whether a subject can be administered an agent (e.g., an agonist, antagonist, peptidomimetic, protein, peptide, nucleic acid, small molecule, or other drug candidate) to treat a disease or disorder associated with aberrant NOVX expression or activity. For example, such methods can be used to determine whether a subject can be effectively treated with an agent for a disorder. Thus, the invention provides methods for determining whether a subject can be effectively treated with an agent for a disorder associated with aberrant NOVX expression or activity in which a test sample is obtained and NOVX protein or nucleic acid is detected (e.g., wherein the presence of NOVX protein or nucleic acid is diagnostic for a subject that can be administered the agent to treat a disorder associated with aberrant NOVX expression or activity).
The methods of the invention can also be used to detect genetic lesions in a NOVX gene, thereby determining if a subject with the lesioned gene is at risk for a disorder characterized by aberrant cell proliferation and/or differentiation. In various embodiments, the methods include detecting, in a sample of cells from the subject, the presence or absence of a genetic lesion characterized by at least one of an alteration affecting the integrity of a gene encoding a NOVX-protein, or the misexpression of the NOVX gene. For example, such genetic lesions can be detected by ascertaining the existence of at least one of: (t) a deletion of one or more nucleotides from a NOVX gene; (ii) an addition of one or more nucleotides to a NOVX gene; (iii) a substitution of one or more nucleotides of a NOVX gene, (iv) a chromosomal rearrangement of a NOVX gene; (v) an alteration in the level of a messenger RNA transcript of a NOVX gene, (vi) aberrant modification of a NOVX gene, such as of the methylation pattern of the genomic DNA, (VH) the presence of a non-wild-type splicing pattern of a messenger RNA transcript of a NOVX gene, (viii) a non-wild-type level of a NOVX protein, (ix) allelic loss of a NOVX gene, and (x) inappropriate post-translational modification of a NOVX protein. As described herein, there are a large number of assay techniques known in the art which can be used for detecting lesions in a NOVX gene. A preferred biological sample is a peripheral blood leukocyte sample isolated by conventional means from a subject. However, any biological sample containing nucleated cells may be used, including, for example, buccal mucosal cells.
In certain embodiments, detection of the lesion involves the use of a probe/primer in a polymerase chain reaction (PCR) (see, e.g., U.S. Patent Nos. 4,683,195 and 4,683,202), such as anchor PCR or RACE PCR, or, alternatively, in a ligation chain reaction (LCR) (see, e.g., Landegran, et al, 1988. Science 241: 1077-1080; and Nakazawa, et al, 1994. Proc. Natl. Acad. Sci. USA 91: 360-364), the latter of which can be particularly useful for detecting point mutations in the NOVX-gene (see, Abravaya, et al, 1995. Nucl. Acids Res. 23: 675-682). This method can include the steps of collecting a sample of cells from a patient, isolating nucleic acid (e.g., genomic, mRNA or both) from the cells of the sample, contacting the nucleic acid sample with one or more primers that specifically hybridize to a NOVX gene under conditions such that hybridization and amplification of the NOVX gene (if present) occurs, and detecting the presence or absence of an amplification product, or detecting the size of the amplification product and comparing the length to a control sample. It is anticipated that PCR and/or LCR may be desirable to use as a preliminary amplification step in conjunction with any of the techniques used for detecting mutations described herein.
Alternative amplification methods include: self sustained sequence replication (see, Guatelli, et al, 1990. Proc. Natl. Acad. Sci. USA 87: 1874-1878), transcriptional amplification system (see, Kwoh, et al, 1989. Proc. Natl. Acad. Sci. USA 86: 1173-1177); Qβ Replicase (see, Lizardi, et al, 1988. BioTechnology 6: 1197), or any other nucleic acid amplification method, followed by the detection of the amplified molecules using techniques well known to those of skill in the art. These detection schemes are especially useful for the detection of nucleic acid molecules if such molecules are present in very low numbers.
In an alternative embodiment, mutations in a NOVX gene from a sample cell can be identified by alterations in restriction enzyme cleavage patterns. For example, sample and control DNA is isolated, amplified (optionally), digested with one or more restriction endonucleases, and fragment length sizes are determined by gel electrophoresis and compared. Differences in fragment length sizes between sample and control DNA indicates mutations in the sample DNA. Moreover, the use of sequence specific ribozymes (see, e.g., U.S. PatentNo. 5,493,531) can be used to score for the presence of specific mutations by development or loss of a ribozyme cleavage site.
In other embodiments, genetic mutations in NOVX can be identified by hybridizing a sample and control nucleic acids, e.g., DNA or RNA, to high-density arrays containing
hundreds or thousands of oligonucleotides probes. See, e.g., Cronin, et al, 1996. Human Mutation 7: 244-255; Kozal, et al, 1996. Nat. Med. 2: 753-759. For example, genetic mutations in NOVX can be identified in two dimensional arrays containing light-generated DNA probes as described in Cronin, et al, supra. Briefly, a first hybridization array of probes can be used to scan through long stretches of DNA in a sample and control to identify base changes between the sequences by making linear arrays of sequential overlapping probes. This step allows the identification of point mutations. This is followed by a second hybridization array that allows the characterization of specific mutations by using smaller, specialized probe arrays complementary to all variants or mutations detected. Each mutation array is composed of parallel probe sets, one complementary to the wild-type gene and the other complementary to the mutant gene.
In yet another embodiment, any of a variety of sequencing reactions known in the art can be used to directly sequence the NOVX gene and detect mutations by comparing the sequence of the sample NOVX with the corresponding wild-type (control) sequence. Examples of sequencing reactions include those based on techniques developed by Maxim and Gilbert, 1977. Proc. Natl. Acad. Sci. USA 74: 560 or Sanger, 1977. Proc. Natl. Acad. Sci. USA 74: 5463. It is also contemplated that any of a variety of automated sequencing procedures can be utilized when performing the diagnostic assays (see, e.g., Naeve, et al, 1995. Biotechniques 19: 448), including sequencing by mass specfrometry (see, e.g., PCT International Publication No. WO 94/16101; Cohen, et al, 1996. Adv. Chromatography 36: 127-162; and Griffin, etal, 1993. Appl. Biochem. Biotechnol. 38: 147-159).
Other methods for detecting mutations in the NOVX gene include methods in which protection from cleavage agents is used to detect mismatched bases in RNA/RNA or RNA/DNA heteroduplexes. See, e.g., Myers, etal, 1985. Science 230: 1242. In general, the art technique of "mismatch cleavage" starts by providing heteroduplexes of formed by hybridizing (labeled) RNA or DNA containing the wild-type NOVX sequence with potentially mutant RNA or DNA obtained from a tissue sample. The double-stranded duplexes are treated with an agent that cleaves single-stranded regions of the duplex such as which will exist due to basepair mismatches between the control and sample strands. For instance, RNA/DNA duplexes can be treated with RNase and DNA/DNA hybrids treated with SΪ nuclease to enzymatically digesting the mismatched regions. In other embodiments, either DNA/DNA or RNA/DNA duplexes can be treated with hydroxylamine or osmium tetroxide and with piperidine in order to digest mismatched
regions. After digestion of the mismatched regions, the resulting material is then separated by size on denaturing polyaciylamide gels to determine the site of mutation. See, e.g., Cotton, et al, 1988. Proc. Natl. Acad. Sci. USA 85: 4397; Saleeba, et al, 1992. Methods Enzymol 217: 286-295. In an embodiment, the control DNA or RNA can be labeled for detection.
In still another embodiment, the mismatch cleavage reaction employs one or more proteins that recognize mismatched base pairs in double-stranded DNA (so called "DNA mismatch repair" enzymes) in defined systems for detecting and mapping point mutations in NOVX cDNAs obtained from samples of cells. For example, the mutY enzyme of E. coli cleaves A at G/A mismatches and the thymidine DNA glycosylase from HeLa cells cleaves T at G/T mismatches. See, e.g., Hsu, et al, 1994. Carcinogenesis 15: 1657-1662. According to an exemplary embodiment, a probe based on a NOVX sequence, e.g., a wild-type NOVX sequence, is hybridized to a cDNA or other DNA product from a test cell(s). The duplex is treated with a DNA mismatch repair enzyme, and the cleavage products, if any, can be detected from elecfrophoresis protocols or the like. See, e.g., U.S. Patent No. 5,459,039.
In other embodiments, alterations in electrophoretic mobility will be used to identify mutations in NOVX genes. For example, single strand conformation polymoφhism (SSCP) may be used to detect differences in electrophoretic mobility between mutant and wild type nucleic acids. See, e.g., Orita, et al, 1989. Proc. Natl. Acad. Sci. USA: 86: 2766; Cotton, 1993. Mutat. Res. 285: 125-144; Hayashi, 1992. Ge«et. Anal. Tech. Appl 9: 73-79. Single-stranded DNA fragments of sample and control NOVX nucleic acids will be denatured and allowed to renature. The secondary structure of single-stranded nucleic acids varies according to sequence, the resulting alteration in electrophoretic mobility enables the detection of even a single base change. The DNA fragments may be. labeled or detected with labeled probes. The sensitivity of the assay may be enhanced by using RNA (rather than DNA), in which the secondary structure is more sensitive to a change in sequence. In one embodiment, the subject method utilizes heteroduplex analysis to separate double stranded heteroduplex molecules on the basis of changes in electrophoretic mobility. See, e.g., Keen, et al, 1991. Trends Genet. 1: 5. In yet another embodiment, the movement of mutant or wild-type fragments in polyaciylamide gels containing a gradient of denaturant is assayed using denaturing gradient gel electrophoresis (DGGE). See, e.g., Myers, et al, 1985. Nature 313: 495.
When DGGE is used as the method of analysis, DNA will be modified to insure that it does not completely denature, for example by adding a GC clamp of approximately 40 bp of high-melting GC-rich DNA by PCR. In a further embodiment, a temperature gradient is used in place of a denaturing gradient to identify differences in the mobility of control and sample DNA. See, e.g., Rosenbaum and Reissner, 1987 '. Biophys. Chem. 265: 12753. Examples of other techniques for detecting point mutations include, but are not limited to, selective oligonucleotide hybridization, selective amplification, or selective primer extension. For example, oligonucleotide primers may be prepared in which the known mutation is placed centrally and then hybridized to target DNA under conditions that permit hybridization only if a perfect match is found. See, e.g., Saiki, et al, 1986. Nature 324: 163; Saiki, et al, 1989. Proc. Natl. Acad. Sci. USA 86: 6230. Such allele specific oligonucleotides are hybridized to PCR amplified target DNA or a number of different mutations when the oligonucleotides are attached to the hybridizing membrane and hybridized with labeled target DNA. Alternatively, allele specific amplification technology that depends on selective
PCR amplification may be used in conjunction with the instant invention. Oligonucleotides used as primers for specific amplification may carry the mutation of interest in the center of the molecule (so that amplification depends on differential hybridization; .see, e.g., Gibbs, et al, 1989. Nucl. Acids Res. 17: 2437-2448) or at the extreme 3'-terminus of one primer where, under appropriate conditions, mismatch can prevent, or reduce polymerase extension (see, e.g., Prossner, 1993. Tibtech. 11: 238). In addition it may be desirable to introduce a novel resfriction site in the region of the mutation to create cleavage-based detection. See, e.g., Gasparini, et al, 1992. Mol. Cell Probes 6: 1. It is anticipated that in certain embodiments amplification may also be performed using Taq ligase for amplification. See, eg, Barany, 1991. Proc. Natl. Acad. Sci. USA 88: 189. In such cases, ligation will occur only if there is a perfect match at the 3 '-terminus of the 5' sequence, making it possible to detect the presence of a known mutation at a specific site by looking for the presence or absence of amplification.
The methods described herein may be performed, for example, by utilizing pre-packaged diagnostic kits comprising at least one probe nucleic acid or antibody reagent described herein, which may be conveniently used, e.g., in clinical settings to diagnose patients exhibiting symptoms or family history of a disease or illness involving a NOVX gene.
Furthermore, any cell type or tissue, preferably peripheral blood leukocytes, in which NOVX is expressed may be utilized in the prognostic assays described herein. However, any biological sample containing nucleated cells may be used, including, for example, buccal mucosal cells.
Pharmacogenomics
Agents, or modulators that have a stimulatory or inhibitory effect on NOVX activity (e.g. , NOVX gene expression), as identified by a screening assay described herein can be administered to individuals to treat (prophylactically or therapeutically) disorders. The disorders include but are not limited to, e.g., those diseases, disorders and conditions listed above, and more particularly include those diseases, disorders, or conditions associated with homologs of a NOVX protein, such as those summarized in Table A.
In conjunction with such freatment, the pharmacogenomics (i.e., the study of the relationship between an individual's genotype and that individual's response to a foreign compound or drug) of the individual may be considered. Differences in metabolism of therapeutics can lead to severe toxicity or therapeutic failure by altering the relation between dose and blood concentration of the pharmacologically active drug. Thus, the pharmacogenomics of the individual permits the selection of effective agents (e.g., drugs) for prophylactic or therapeutic treatments based on a consideration of the individual's genotype. Such pharmacogenomics can further be used to determine appropriate dosages and therapeutic regimens. Accordingly, the activity of NOVX protein, expression of NOVX nucleic acid, or mutation content of NOVX genes in an individual can be determined to thereby select appropriate agent(s) for therapeutic or prophylactic treatment of the individual. Pharmacogenomics deals with clinically significant hereditary variations in the response to drugs due to altered drug disposition and abnormal action in affected persons. See e.g., Eichelbaum, 1996. Clin. Exp. Pharmacol. Physiol, 23: 983-985; Linder, 1997. Clin. Chem., 43: 254-266. In general, two types of pharmacogenetic conditions can be differentiated. Genetic conditions transmitted as a single factor altering the way drugs act on the body (altered drug action) or genetic conditions transmitted as single factors altering the way the body acts on drugs (altered drug metabolism). These pharmacogenetic conditions can occur either as rare defects or as polymoφhisms. For example, glucose-6-phosphate dehydrogenase (G6PD) deficiency is a common inherited
enzymopathy in which the main clinical complication is hemolysis after ingestion of oxidant drugs (anti-malarials, sulfonamides, analgesics, nitrofurans) and consumption of fava beans.
As an illustrative embodiment, the activity of drug metabolizing enzymes is a major determinant of both the intensity and duration of drug action. The discovery of genetic polymoφhisms of drug metabolizing enzymes (e.g., N-acetyltransferase 2 (NAT 2) and cytochrome pregnancy zone protein precursor enzymes CYP2D6 and CYP2C19) has provided an explanation as to why some patients do not obtain the expected drug effects or show exaggerated drug response and serious toxicity after taking the standard and safe dose of a drug. These polymoφhisms are expressed in two phenotypes in the population, the extensive metabolizer (EM) and poor metabolizer (PM). The prevalence of PM is different among different populations. For example, the gene coding for CYP2D6 is highly polymoφhic and several mutations have been identified in PM, which all lead to the absence of functional CYP2D6. Poor metabolizers of CYP2D6 and CYP2C19 quite frequently experience exaggerated drug response and side effects when they receive standard doses. If a metabolite is the active therapeutic moiety, PM show no therapeutic response, as demonstrated for the analgesic effect of codeine mediated by its CYP2D6-formed metabolite moφhine. At the other extreme are the so called ultra-rapid metabolizers who do not respond to standard doses. Recently, the molecular basis of ultra-rapid metabolism has been identified to be due to CYP2D6 gene amplification.
Thus, the activity of NOVX protein, expression of NOVX nucleic acid, or mutation content of NOVX genes in an individual can be determined to thereby select appropriate agent(s) for therapeutic or prophylactic treatment of the individual. In addition, pharmacogenetic studies can be used to apply genotyping of polymoφhic alleles encoding drug-metabolizing enzymes to the identification of an individual's drug responsiveness phenotype. This knowledge, when applied to dosing or drug selection, can avoid adverse reactions or therapeutic failure and thus enhance therapeutic or prophylactic efficiency when treating a subject with a NOVX modulator, such as a modulator identified by one of the exemplary screening assays described herein.
Monitoring of Effects During Clinical Trials
Monitoring the influence of agents (e.g., drugs, compounds) on the expression or activity of NOVX (eg., the ability to modulate aberrant cell proliferation and/or
differentiation) can be applied not only in basic drug screening, but also in clinical trials. For example, the effectiveness of an agent determined by a screening assay as described herein to increase NOVX gene expression, protein levels, or upregulate NOVX activity, can be monitored in clinical trails of subjects exhibiting decreased NOVX gene expression, protein levels, or downregulated NOVX activity. Alternatively, the effectiveness of an agent determined by a screening assay to decrease NOVX gene expression, protein levels, or downregulate NOVX activity, can be monitored in clinical frails of subjects exhibiting increased NOVX gene expression, protein levels, or upregulated NOVX activity. In such clinical trials, the expression or activity of NOVX and, preferably, other genes that have been implicated in, for example, a cellular proliferation or immune disorder can be used as a "read out" or markers of the immune responsiveness of a particular cell.
By way of example, and not of limitation, genes, including NOVX, that are modulated in cells by treatment with an agent (e.g., compound, drug or small molecule) that modulates NOVX activity (e.g., identified in a screening assay as described herein) can be identified. Thus, to study the effect of agents on cellular proliferation disorders, for example, in a clinical trial, cells can be isolated and RNA prepared and analyzed for the levels of expression of NOVX and other genes implicated in the disorder. The levels of gene expression (i.e., a gene expression pattern) can be quantified by Northern blot analysis or RT-PCR, as described herein, or alternatively by measuring the amount of protein produced, by one of the methods as described herein, or by measuring the levels of activity of NOVX or other genes. In this manner, the gene expression pattern can serve as a marker, indicative of the physiological response of the cells to the agent. Accordingly, this response state may be determined before, and at various points during, treatment of the individual with the agent. In one embodiment, the invention provides a method for monitoring the effectiveness of treatment of a subject with an agent (e.g., an agonist, antagonist, protein, peptide, peptidomimetic, nucleic acid, small molecule, or other drug candidate identified by the screening assays described herein) comprising the steps of (i) obtaining a pre-administration sample from a subject prior to administration of the agent; (ii) detecting the level of expression of a NOVX protein, mRNA, or genomic DNA in the preadministration sample; (iii) obtaining one or more post-administration samples from the subject; (iv) detecting the level of expression or activity of the NOVX protein, mRNA, or genomic DNA in the post-administration samples; (v) comparing the level of expression or
activity of the NOVX protein, mRNA, or genomic DNA in the pre-administration sample with the NOVX protein, mRNA, or genomic DNA in the post administration sample or samples; and (vi) altering the administration of the agent to the subject accordingly. For example, increased administration of the agent may be desirable to increase the expression or activity of NOVX to higher levels than detected, i.e., to increase the effectiveness of the agent. Alternatively, decreased administration of the agent may be desirable to decrease expression or activity of NOVX to lower levels than detected, i.e., to decrease the effectiveness of the agent.
Methods of Treatment
The invention provides for both prophylactic and therapeutic methods of treating a subject at risk of (or susceptible to) a disorder or having a disorder associated with aberrant NOVX expression or activity. The disorders include but are not limited to, e.g., those diseases, disorders and conditions listed above, and more particularly include those diseases, disorders, or conditions associated with homologs of a NOVX protein, such as those summarized in Table A.
These methods of treatment will be discussed more fully, below.
Diseases and Disorders Diseases and disorders that are characterized by increased (relative to a subject not suffering from the disease or disorder) levels or biological activity may be treated with Therapeutics that antagonize (i.e., reduce or inhibit) activity. Therapeutics that antagonize activity may be administered in a therapeutic or prophylactic manner. Therapeutics that may be utilized include, but are not limited to: (i) an aforementioned peptide, or analogs, derivatives, fragments or homologs thereof; (ii) antibodies to an aforementioned peptide; (iii) nucleic acids encoding an aforementioned peptide; (iv) administration of antisense nucleic acid and nucleic acids that are "dysfunctional" (i.e., due to a heterologous insertion within the coding sequences of coding sequences to an aforementioned peptide) that are utilized to "knockout" endogenous function of an aforementioned peptide by homologous recombination (see, e.g., Capecchi, 1989. Science 244: 1288-1292); or (v) modulators ( i.e, inhibitors, agonists and antagonists, including additional peptide mimetic of the invention or antibodies specific to a peptide of the invention) that alter the interaction between an aforementioned peptide and its binding partner.
Diseases and disorders that are characterized by decreased (relative to a subject not suffering from the disease or disorder) levels or biological activity may be treated with Therapeutics that increase (i.e., are agonists to) activity. Therapeutics that upregulate activity may be administered in a therapeutic or prophylactic manner. Therapeutics that may be utilized include, but are not limited to, an aforementioned peptide, or analogs, derivatives, fragments or homologs thereof; or an agonist that increases bioavailability.
Increased or decreased levels can be readily detected by quantifying peptide and/or RNA, by obtaining a patient tissue sample (eg., from biopsy tissue) and assaying it in vitro for RNA or peptide levels, structure and/or activity of the expressed peptides (or mRNAs of an aforementioned peptide). Methods that are well-known within the art include, but are not limited to, immunoassays (e.g., by Western blot analysis, immunoprecipitation followed by sodium dodecyl sulfate (SDS) polyaciylamide gel electrophoresis, immunocytochemistiy, etc.) and/or hybridization assays to detect expression of mRNAs (e.g., Northern assays, dot blots, in situ, hybridization, and the like).
Prophylactic Methods
In one aspect, the invention provides a method for preventing, in a subject, a disease or condition associated with an aberrant NOVX expression or activity, by administering to the subject an agent that modulates NOVX expression or at least one NOVX activity. Subjects at risk for a disease that is caused or contributed to by aberrant NOVX expression or activity can be identified by, for example, any or a combination of diagnostic or prognostic assays as described herein. Administration of a prophylactic agent can occur prior to the manifestation of symptoms characteristic of the NOVX aberrancy, such that a disease or disorder is prevented or, alternatively, delayed in its progression. Depending upon the type of NOVX aberrancy, for example, a NOVX agonist or NOVX antagonist agent can be used for treating the subject. The appropriate agent can be determined based on screening assays described herein. The prophylactic methods of the invention are further discussed in the following subsections.
Therapeutic Methods
Another aspect of the invention pertains to methods of modulating NOVX expression or activity for therapeutic puφoses. The modulatory method of the invention involves contacting a cell with an agent that modulates one or more of the activities of
NOVX protein activity associated with the cell. An agent that modulates NOVX protein activity can be an agent as described herein, such as a nucleic acid or a protein, a naturally-occurring cognate ligand of a NOVX protein, a peptide, a NOVX peptidomimetic, or other small molecule. In one embodiment, the agent stimulates one or more NOVX protein activity. Examples of such stimulatory agents include active NOVX protein and a nucleic acid molecule encoding NOVX that has been introduced into the cell. In another embodiment, the agent inhibits one or more NOVX protein activity. Examples of such inhibitory agents include antisense NOVX nucleic acid molecules and anti-NOVX antibodies. These modulatory methods can be performed in vitro (e.g., by culturing the cell with the agent) or, alternatively, in vivo (e.g., by administering the agent to a subject). As such, the invention provides methods of treating an individual afflicted with a disease or disorder characterized by aberrant expression or activity of a NOVX protein or nucleic acid molecule. In one embodiment, the method involves administering an agent (e.g., an agent identified by a screening assay described herein), or combination of agents that modulates (e.g., up-regulates or down-regulates) NOVX expression or activity. In another embodiment, the method involves administering a NOVX protein or nucleic acid molecule as therapy to compensate for reduced or aberrant NOVX expression or activity.
Stimulation of NOVX activity is desirable in situations in which NOVX is abnormally downregulated and or in which increased NOVX activity is likely to have a beneficial effect. One example of such a situation is where a subject has a disorder characterized by aberrant cell proliferation and/or differentiation (e.g., cancer or immune associated disorders). Another example of such a situation is where the subject has a gestational disease (e.g., preclampsia).
Determination of the Biological Effect of the Therapeutic
In various embodiments of the invention, suitable in vitro or in vivo assays are performed to determine the effect of a specific Therapeutic and whether its administration is indicated for treatment of the affected tissue.
In various specific embodiments, in vitro assays may be performed with representative cells of the type(s) involved in the patient's disorder, to determine if a given Therapeutic exerts the desired effect upon the cell type(s). Compounds for use in therapy may be tested in suitable animal model systems including, but not limited to rats, mice, chicken, cows, monkeys, rabbits, and the like, prior to testing in human subjects. Similarly,
for in vivo testing, any of the animal model system known in the art may be used prior to administration to human subjects.
Prophylactic and Therapeutic Uses of the Compositions of the Invention The NOVX nucleic acids and proteins of the invention are useful in potential prophylactic and therapeutic applications implicated in a variety of disorders. The disorders include but are not limited to, eg., those diseases, disorders and conditions listed above, and more particularly include those diseases, disorders, or conditions associated with homologs of a NOVX protein, such as those summarized in Table A. As an example, a cDNA encoding the NOVX protein of the invention may be useful in gene therapy, and the protein may be useful when administered to a subject in need thereof. By way of non-limiting example, the compositions of the invention will have efficacy for freatment of patients suffering from diseases, disorders, conditions and the like, including but not limited to those listed herein. Both the novel nucleic acid encoding the NOVX protein, and the NOVX protein of the invention, or fragments thereof, may also be useful in diagnostic applications, wherein the presence or amount of the nucleic acid or the protein are to be assessed. A further use could be as an anti-bacterial molecule (i.e., some peptides have been found to possess anti-bacterial properties). These materials are further useful in the generation of antibodies, which immunospecifically-bind to the novel substances of the invention for use in therapeutic or diagnostic methods.
The invention will be further described in the following examples, which do not limit the scope of the invention described in the claims.
EXAMPLES
Example A. Polynucleotide and Polypeptide Sequences, and Homology Data
The NOVl clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 1 A.
Table 1A. NOVl Sequence Analysis
SEQ ID NO: 1
NOVla, GGATCCCAGTGGCCCGGCGTGCTCGGCTCCCACAGGCCTGCAGCCAGCATCGCACCGA CG101683-01 iACCTTCGGGGGGCCGCGGCTGGAGCGCTCGGCCGGCGTGGGAGCGCAAGGCCGCAGAT: jGCAATCTTCTTACCGCGAAGAAGCCAGGGGAATAGGTAGCCACATCTTGTTTGCAGAT DNA Sequence AAGAAAGGAAGCTAACGCAGTATCTGCAAAGCCAGGAGTCTGACTCAGTACTTTTCTC
ACTCATGCATACAAGCAGCTAAAAATGACACAGCTTATTTACCATGCCCCTGACACTG
CACTGAGCACTTTATGAGCTTGAACTCTGTTAATCTCACGACCACCTCATGAGACTCT;
CCAGAAAGAGCAACAGTAATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGAi
TTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCT TTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGAC AGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCAT GGTTGTCATCAGTCAGATATGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATAT ATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTA AACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGA TCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTT TGGAAAGGTATACTTGGCTCAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTG ATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATTCAGGCTTGCTTCCGGCACG GAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTAT GGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGA GAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACT CAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAAA AGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCT AAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCC ATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGG CACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATA ATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGA GAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGA CCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTACGAGT CTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTC CTGAGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTCAA GAGGCAACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTGTT CGGGGACCACCAACGCTTGAATATGGCTGAAGGATGCCATGTTTGCCTCTAAATTAAG ACAGCATTGATCTCCTGGAGGCTGGTTCTGCTGCCTCTACACAGGGGCCCGTTACAGT GAATGGTGCCATTTTCGAAGGAGCAGTGTGACCTCCTGTGACCCATGAATGTGCCTCC AAGCGGCCCTGTGTGTTTGACATGTGAAGCTATTTGATATGCACCAGGTCTCAAGGTT CTCATTTCTCAGGTGACGTGATTCTAAGGCAGGAATTTGAGAGTTCACAGAAGGATCG TGTCTGCTGACTGTTTCATTCACTGTGCACTTTGCTCAAAATTTTAAAAATACCAATC ACAAGGATAATAGAGTAGCCTAAAATTACTATTCTTGGTTCTTATTTAAGTATGGAAT ATTCATTTTACTCAGAATAGCCTGTTTTGTGTATATTGGTGTATATTATATAACTCTT TGAGCCTTTATTGGTAAATTCTGGTATACATTGAATTCATTATAATTTGGGTGACTAG AACAACTTGAAGATTGTAGCAATAAGCTGGACTAGTGTCCTAAAAATGGCTAACTGAT GAATTAGAAGCCATCTGACAGACGGCCACTAGTGACAGTTTCTTTTGTGTTCCTATGG AAACATTTTATACTGTACATGCTATGCTGAAGACATTCAAAACGTGATGTTTTGAATG TGGATAAAACTGTGTAAACCACATAATTTTGTACATCCAAGGATGAGGTGTGACCTTT AAGAAAAATGAAAACTTTTGTAAATTATTGATGATTTTGTAATTCTTATGACTAAATT TTCTTTTAAGCATTTGTATATTAAAATAGCATACTGTGTATGTTTTATATCAAATGCC TTCATGAATCTTTCATACATATATATATTTGTAACATGTAAAGTATGTGAGTAGTCTT ATGTAAAGTATGTTTTTACATTATGCAAATAAAACCCAATACTTTTGTCCAATGTGGT TGGTCAAATCAACTGAATAAATTCAGTATTTTGCCTT

GGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTTTGGAAA; GGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTGATCCCA: GTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACGAGAACA! TCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTATGGAAGC AGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGAGAATTT GAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACTCAAAGA AAGTGATCCATCATGATATTAAACCTAGCAACATTGTTXTCATGTCCACAAAAGCTGT TTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCTAAGGAC CTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCCATTCAA CCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGGCACCCC ACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATAATCCAC AAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGAGAGAGC TGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGACCTACT AAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAGTCTGGAC TCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTCCTGAGA ACATTGCTCATCATCACCACCATCACTGAGCGGCCGCAAG
ORF Start: at 1 ORF Stop: TGA at 1303
SEQ ID NO: 6 434 aa MW at49384.9kD
NOVlc, TGST EYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSLMTMCQDSN 253174293 QNDERSKSLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKHFYGQRPQESGILLNM Protein Sequence VITPQNGRYQIDSDVLLIP KLTYR IGSDFIPRGAFGKVYLAQDI TKKRMACKLIP VDQFKPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGGSVLEKLESCGPMREF EII VTKHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDFGIiSVQMTEDVYFPKD LRGTEIY SPEVILCRGHSTKADIYSLGATLIHMQTGTPP VKRYPRSAYPSYLYIIH KQAPPLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEALNPPREDQPRCQSLD SALLERKRLLSRKELELPENIAHHHHHH
SEQ ID NO: 7 1407 bp
NOVld, ACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGATTGATTTATTAATTA
248490584 DNA AACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCTTTATGCAAGTGAAGA Sequence GCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGACAGTAATCAAAACGAT GAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCATGGTTGTCATCAGTCA GATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATATATCCAACACTGCAAA GCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTAAACATGGTCATCACT CCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGATCCCCTGGAAGCTGA CTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTTTGGAAAGGTATACTT GGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTGATCCCAGTAGATCAA TTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACGAGAACATCGCAGAGC TGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTATGGAAGCAGGCGAGGG AGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGAGAATTTGAAATTATT TGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACTCAAAGAAAGTGATCC ATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAAAAGCTGTTTTGGTGGA TTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCTAAGGACCTCCGAGGA ACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCCATTCAACCAAAGCAG ACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGGCACCCCACCCTGGGT GAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATAATCCACAAGCAAGCA CCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGAGAGAGCTGATAGAAG CTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGACCTACTAAAACATGA GGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAGTCTGGACTCTGCCCTC TTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTCCTGAGAACATTGCTG ATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTCAAGAGGCAACGCTCTCT CTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTGTTCGGGGACCACCAACG CTTGAATATGGCTGA
ORF Start: at 1 ORF Stop: TGA at 1405
SEQ ID NO: 8 468 aa MW at 53025.0kD
NOVld, T EYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSLMTMCQDSNQND; 248490584 ERS SLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKHFYGQRPQESGILL MVI PQNGRYQIDSDVLLIP XrTYRNIGSDFIPRGAFGICVYLAQDIKTi KRMACKLIPVDQ:
Protein Sequence FKPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGGSVLEKLESCGPMREFEII VTKHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDFGLSVQMTEDVYFPKDLRG TEIYMSPEVILCRGHSTKADIYSLGAT IHMQTGTPPWVKRYPRSAYPSYLYIIHKQA PPLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEALNPPREDQPRCQSLDSAL LERKRLLSRKELELPENIADSSCTGSTEESEMLKRQRSLYIDLGALAGYFNLVRGPPT LEYG
SEQ ID NO: 9 1448 bp
NOVle, ACGGGATCCACCATGGGACATCATCACCACCATCACGAGTACATGAGCACTGGAAGTG
258054391 DNA ACAATAAAGAAGAGATTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGA Sequence CATTATGGAAAATCTTTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATG ACCATGTGTCAAGACAGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTG GCCAAGAGGTACCATGGTTGTCATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGC TTTTGCAAACCATATATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAA TCTGGAATTTTATTAAACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATT CCGATGTTCTCCTGATCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTAT TCCTCGGGGCGCCTTTGGAAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGA ATGGCGTGTAAACTGATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGG CTTGCTTCCGGCACGAGAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAAC TGTCCATCTCTTTATGGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGC TGTGGACCAATGAGAGAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGAC TTGATTTTCTACACTCAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGT TTTCATGTCCACAAAAGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAA GATGTCTATTTTCCTAAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCA TCCTGTGCAGGGGCCATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCAT CCACATGCAGACGGGCACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCC TCCTACCTGTACATAATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACT GCAGTCCAGGGATGAGAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCG CCCAAGAGCCGCAGACCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAG CCACGCTGTCAGAGTCTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGA AGGAGCTGGAACTTCCTGAGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGA ATCTGAGATGCTCAAGAGGCAACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGC TACTTCAATCTTGTTCGGGGACCACCAACGCTTGAATATGGCTGAGCGGCCGCAAG
ORF Start: at 1 ORF Stop: TGA at 1435
SEQ ID NO: 10 1 78 aa M at 54150.2kD
NOVle, TGST GHHHHHHEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSLM 258054391 TMCQDSNQ DERSKSLLLSGQEVP LSSVRYGTVEDLLAFANHISNTAKHFYGQRPQE SGILLNMVITPQNGRYQIDSDVLLIP KLTYRNIGSDFIPRGAFGKVYLAQDIKTKKR Protein Sequence ACKLIPVDQFKPSDVEIQACFRHENIAELYGAVL GETVHLFMEAGEGGSVLEKLES CGPMREFEII VTKHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDFGLSVQMTE DVYFPKDLRGTEIYMSPEVILCRGHSTKADIYSLGATLIHMQTGTPP VKRYPRSAYP SYLYIIHKQAPPLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEALNPPREDQ PRCQSLDSALLERKRLLSRKELELPENIADSSCTGSTEESEMLKRQRSLYIDLGALAG YFNLVRGPPTLEYG
SEQ ID NO: 11 1278 bp
NOVlf, ACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGATTGATTTATTAATTA
248494549 DNA AACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCTTTATGCAAGTGAAGA GCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGACAGTAATCAAAACGAT Sequence GAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCATGGTTGTCATCAGTCA GATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATATATCCAACACTGCAAA GCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTAAACATGGTCATCACT CCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGATCCCCTGGAAGCTGA CTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTTTGGAAAGGTATACTT GGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTGATCCCAGTAGATCAA TTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACGAGAACATCGCAGAGC TGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTATGGAAGCAGGCGAGGG AGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGAGAATTTGAAATTATT TGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACTCAAAGAAAGTGATCC

260480803 DNA AAGAGATTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGA Sequence AAATCTTTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGT CAAGACAGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGG TACCATGGTTGTCATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAA CCATATATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATT TTATTAAACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTC TCCTGATCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGG CGCCTTTGGAAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGT AAACTGATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCC GGCACGAGAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCT CTTTATGGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCA ATGAGAGAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTC TACACTCAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTC CACAAAAGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTAT TTTCCTAAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCA GGGGCCATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCA GACGGGCACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTG TACATAATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAG GGATGAGAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGC CGCAGACCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGT CAGAGTCTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGG AACTTCCTGAGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGAT GCTCAAGAGGCAACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAAT CTTGTTCGGGGACCACCAACGCTTGAATATGGCTGA
ORF Start: at 1 ORF Stop: TGA at 1426
SEQ ID NO: 16 475 aa MW at53904.9kD
NOVlh, T GHHHHHHEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSLMT C 260480803 QDSNQNDERSKSLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKHFYGQRPQESGI Protein Sequence ^WITPQNGR QIDSDVLL PWKlJTYRN GSDFIPRGAFGK ΛfLAQDIK KKRM C KLIPVDQFKPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGGSVLEKLESCGP MREFEIIWVTKHVIiKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDFGLSVQMTEDVY FPKDLRGTEIYMSPEVILCRGHSTKADIYSLGATLIHMQTGTPPWVKRYPRSAYPSYL YIIHKQAPPLEDIADDCSPGMRELIEASLERNPNHRPRAADLIiKHEAIiNPPREDQPRC QSLDSAL.LERKR LSRKEL.ELPENIADSSCTGSTEESEMLKRQRSLYIDLGALAGYFN LVRGPPTLEYG
SEQ ID NO: 17 1434 bp
NOVli, CGCGGATCCACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGATTGATT
209983329 DNA TATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCTTTATGC AAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGACAGTAAT Sequence CAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCATGGTTGT CATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATATATCCAA CACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTAAACATG GTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGATCCCCT GGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTTTGGAAA GGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTGATCCCA GTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACGAGAACA TCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTATGGAAGC AGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGAGAATTT GAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACTCAAAGA AAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAAAAGCTGX TTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCTAAGGAC CTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCCATTCAA CCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGGCACCCC ACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATAATCCAC AAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGAGAGAGC TGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGACCTACT AAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAGTCTGGAC TCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTCCTGAGA
ACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTCAAGAGGCA ACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTGTTCGGGGA CCACCAACGCTTGAATATGGCTGAGCGGCCGCTTTTTTCCTT
ORF Start: at 1 [ORF Stop: TGA at 1414
SEQ ID NO: 18 471 aa M at 53325.3kD
NOVli, RGSTMEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSL TMCQDSN 209983329 QNDERSKSLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKHFYGQRPQESGILLNM VITPQNGRYQIDSDVLLIPWKLTYRNIGSDFIPRGAFGKVYLAQDIKTKKRMACKLIP Protein Sequence VDQFKPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGGSVLEKLESCGPMREF EIIWVTKHVI.KGLDFLHSKKVIHHDIKPSNIVF STKAVLVDFGLSVQMTEDVYFPKD LRGTEIYMSPEVILCRGHSTKADIYSLGATLIHMQTGTPPWVKRYPRSAYPSYLYIIH KQAPPLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEALNPPREDQPRCQSLD SALLERKRLLSRKELELPENIADSSCTGSTEESEMLKRQRSLYIDLGALAGYFNLVRG PPTLEYG
SEQ ID NO: 19 1772 bp
NOVlj, TGTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGG
212779055 DNA TCTATATAAGCAGAGCTCTCTGGCTAACTAGAGAACCCACTGCTTACTGGCTTATCGA
AATTAATACGACTCACTATAGGGAGACCCAAGCTGGCTAGCGTTTAAACTTAAGCTTG Sequence GTACCGAGCTCGGATCCACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGA GATTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAAT CTTTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAG ACAGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACC ATGGTTGTCATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCAT ATATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTAT TAAACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCT GATCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCC TTTGGAAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAAC TGATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCA CGAGAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTT ATGGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGA GAGAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACA CTCAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACA AAAGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTC CTAAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGG CCATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACG GGCACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACA TAATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGAT GAGAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCA GACCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGA GTCTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACT TCCTGAGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTC AAGAGGCAACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTG TTCGGGGACCACCAACGCTTGAATATGGCTGAGCGGCCGCTCGAGTCTAGAGGGCCCG
TTTAAACCCGCTGATCAGCCTCGACTGTGCCTTCTAGTTGCCAGCCATCTGTTGTTTG
CCCCTCCCCCGTGCCTTCCTTGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAA AAAATGAGGAAATTGCATCGCATTGTCTGAG
ORF Start: at 138 ORF Stop: TGA at 1596
SEQ ID NO: 20 486 aa MW at 54926.2kD
NOVlj, GDPSWLAFKLKLGTELGSTMEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEP 212779055 AVYEPSLMTMCQDSNQNDΞRSKSLLLSGQEVPWLSSVRYGTVEDLIiAFANHISNTAKH FYGQRPQESGILLNMVITPQNGRYQIDSDVLLIPWKLTYRNIGSDFIPRGAFGKVYLA Protein Sequence QDIKTKKRMACKLIPVDQFKPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGG SVLEKLESCGP REFEIIWV KHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDF GLSVQMTEDVYFPKDLRGTEIY SPEVILCRGHSTKADIYSLGATLIHMQTGTPPWVK RYPRSAYPSYLYIIHKQAPPLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEA LNPPREDQPRCQSLDSALLERKRLLSRKELELPENIADSSCTGSTEESEMLKRQRSLY IDLGALAGYFNLVRGPPTLEYG
SEQ ID NO: 21 1770 bp
NOVlk, TTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGT
212779063 DNA CTATATAAGCAGAGCTCTCTGGCTAACTAGAGAACCCACTGCTTACTGGCTTATCGAA!
ATTAATACGACTCACTATAGGGAGACCCAAGCTGGCTAGCGTTTAAACTTAAGCTTGG Sequence TACCGAGCTCGGATCCACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAG ATTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATC TTTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGA CAGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCA TGGTTGTCATCAGTCAGATATGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATA TATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATT AAACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTG ATCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCT TTGGAAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACT GATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCAC GAGAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTA TGGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAG AGAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACAC TCAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAA AAGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCC TAAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGC CATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGG GCACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACAT AATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATG AGAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAG ACCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAG TCTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTT CCTGAGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTCA AGAGGCAACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTGT TCGGGGACCACCAACGCTTGAATATGGCTGAGCGGCCGCTCGAGTCTAGAGGGCCCGT
TTAAACCCGCTGATCAGCCTCGACTGTGCCTTCTAGTTGCCAGCCATCTGTTGTTTGC
CCCTCCCCCGTGCCTTCCTTGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAAT;
AAAATGAGGAAATTGCATCGCATTGTCTGA
ORF Start: at 137 ORF Stop: TGA at 1595 SEQ ID NO: 22 486 aa MW at 54926.2kD
NOVlk, GDPSWLAFKLKLGTELGSTMEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLiYASEEP 212779063 AVYEPSL TMCQDSNQNDERSKSLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKH FYGQRPQESGILLNMVITPQNGRYQIDSDVLLIPWKLTYRNIGSDFIPRGAFGKVYLA Protein Sequence QDIKTKKRMACKLIPVDQFKPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGG SVLEKLESCGPMREFEIIWVTKHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDF GLSVQ TEDVYFPKDLRGTEIY SPEVILCRGHSTKADIYSLGATLIHMQTGTPPWVK RYPRSAYPSYLYIIHKQAPPLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEA LNPPREDQPRCQSLDSALLERKRLLSRKELELPENIADSSCTGSTEESEMLKRQRSLY IDLGALAGYFNLVRGPPTLEYG
SEQ ID NO: 23 1772 bp
NOV11, TGTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGG CG101683-02 TCTATATAAGCAGAGCTCTCTGGCTAACTAGAGAACCCACTGCTTACTGGCTTATCGA
AATTAATACGACTCACTATAGGGAGACCCAAGCTGGCTAGCGTTTAAACTTAAGCTTG DNA Sequence GTACCGAGCTCGGATCCACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGA
GATTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAAT CTTTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAG ACAGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACC ATGGTTGTCATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCAT ATATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTAT TAAACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCT GATCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCC TTTGGAAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAAC TGATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCA CGAGAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTT
ATGGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAj GAGAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACA CTCAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACA AAAGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTC CTAAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGG CCATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACG GGCACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACA TAATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGAT GAGAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCA GACCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGA GTCTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACT TCCTGAGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTC AAGAGGCAACGCTCTCTCTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTG TTCGGGGACCACCAACGCTTGAATATGGCTGAGCGGCCGCTCGAGTCTAGAGGGCCCG
TTTAAACCCGCTGATCAGCCTCGACTGTGCCTTCTAGTTGCCAGCCATCTGTTGTTTG
CCCCTCCCCCGTGCCTTCCTTGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAA:
TAAAATGAGGAAATTGCATCGCATTGTCTGAG
ORF Start: ATG at 195 ORF Stop: TGA at 1596
SEQ ID NO: 24 467 aa MW at 52923.9kD
NOV11, MEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSLMTMCQDSNQNDE CG101683-02 RSKSLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKHFYGQRPQESGILLNMVITP QNGRYQIDSDVLLIPWKLTYRNIGSDFIPRGAFGKVYLAQDIKTKKRMACKLIPVDQF Protein Sequence KPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGGSVLEKLESCGPMREFEIIW VTKHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDFGLSVQMTEDVYFPKDLRGT EIYMSPEVILCRGHSTKADIYSLGATLIHMQTGTPPWVKRYPRSAYPSYLYIIHKQAP PLEDIADDCSPGMRELIEASLERNPNHRPRAADLLKHEALNPPREDQPRCQSLDSALIi ERKRLLSRKELELPENIADSSCTGSTEESEMLKRQRSLYIDLGALAGYFNLVRGPPTL EYG
SEQ ID NO: 25 1425 bp
NOVlm, ACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGATTGATTTATTAATTA CG101683-03 AACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCTTTATGCAAGTGAAGA GCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGACAGTAATCAAAACGAT DNA Sequence GAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCATGGTTGTCATCAGTCA GATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATATATCCAACACTGCAAA GCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTAAACATGGTCATCACT CCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGATCCCCTGGAAGCTGA CTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTTTGGAAAGGTATACTT GGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTGATCCCAGTAGATCAA TTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACGAGAACATCGCAGAGC TGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTATGGAAGCAGGCGAGGG AGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGAGAATTTGAAATTATT TGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACTCAAAGAAAGTGATCC ATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAAAAGCTGTTTTGGTGGA TTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCTAAGGACCTCCGAGGA ACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCCATTCAACCAAAGCAG ACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGGCACCCCACCCTGGGT GAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATAATCCACAAGCAAGCA CCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGAGAGAGCTGATAGAAG CTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGACCTACTAAAACATGA GGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAGTCTGGACTCTGCCCTC TTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTCCTGAGAACATTGCTG ATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTCAAGAGGCAACGCTCTCT CTACATCGACCTCGGCGCTCTGGCTGGCTACTTCAATCTTGTTCGGGGACCACCAACG CTTGAATATGGCCATCATCACCACCATCACTGA
ORF Start: at'l ORF Stop: TGA at 1423
SEQ LD NO: 26 474 aa MW at 53847.9kD jNOVlm, TMEYMSTGSDNKEEIDLLIKHLNVSDVIDIMENLYASEEPAVYEPSIiMTMCQDSNQNDI
SEQ ID NO: 33 1293 bp
NOVlq, GGGCCCCTGGGATCCACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGA CG101683-07 TTGATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCT DNA Sequence TTATGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGAC AGTAATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCAT GGTTGTCATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATAT ATCCAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTA AACATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGA TCCCCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTT TGGAAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTG ATCCCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACG AGAACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTAT GGAAGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGA GAATTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACT CAAAGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAAA AGCTGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCT AAGGACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCC ATTCAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGG CACCCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATA ATCCACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGA GAGAGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGA CCTACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAGT CTGGACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTC CTGAGAACATTGCTTGA
ORF Start: ATG at 19 ORF Stop: TGA at 1291
SEQ ID NO: 34 424 aa MW at 48215.7kD
NOVlq, MEYMSTGSDNKEEIDLLIKHLNVSDVIDI ENLYASEEPAVYEPSLMTMCQDSNQNDE CG101683-07 RSKSLLLSGQEVPWLSSVRYGTVEDLLAFANHISNTAKHFYGQRPQESGILLNMVITP QNGRYQIDSDVLLIPWK_,TYRNIGSDFIPRGAFGKVY_AQDIKTKKRMACKLIPVDQF Protein Sequence KPSDVEIQACFRHENIAELYGAVLWGETVHLFMEAGEGGSVLEKLESCGPMREFEIIW VTKHVLKGLDFLHSKKVIHHDIKPSNIVFMSTKAVLVDFGLSVQ TEDVYFPKDLRGT EIYMSPEVILCRGHSTKADIYSLGATLIHMQTGTPPWVKRYPRSAYPSYLYIIHKQAP PLEDIADDCSPGMRELIEASLΞRNPNHRPRAADLLKHEALNPPREDQPRCQSLDSALL ERKRLLSRKELELPENIA
SEQ ID NO: 35 1428 bp
NOVlr, CACCGCGGCCGCACCATGGAGTACATGAGCACTGGAAGTGACAATAAAGAAGAGATTG CG101683-08 ATTTATTAATTAAACATTTAAATGTGTCTGATGTAATAGACATTATGGAAAATCTTTA TGCAAGTGAAGAGCCAGCAGTTTATGAACCCAGTCTAATGACCATGTGTCAAGACAGT DNA Sequence AATCAAAACGATGAGCGTTCTAAGTCTCTGCTGCTTAGTGGCCAAGAGGTACCATGGT TGTCATCAGTCAGATACGGAACTGTGGAGGATTTGCTTGCTTTTGCAAACCATATATC CAACACTGCAAAGCATTTTTATGGACAACGACCACAGGAATCTGGAATTTTATTAAAC ATGGTCATCACTCCCCAAAATGGACGTTACCAAATAGATTCCGATGTTCTCCTGATCC CCTGGAAGCTGACTTACAGGAATATTGGTTCTGATTTTATTCCTCGGGGCGCCTTTGG AAAGGTATACTTGGCACAAGATATAAAGACGAAGAAAAGAATGGCGTGTAAACTGATC CCAGTAGATCAATTTAAGCCATCTGATGTGGAAATCCAGGCTTGCTTCCGGCACGAGA ACATCGCAGAGCTGTATGGCGCAGTCCTGTGGGGTGAAACTGTCCATCTCTTTATGGA AGCAGGCGAGGGAGGGTCTGTTCTGGAGAAACTGGAGAGCTGTGGACCAATGAGAGAA TTTGAAATTATTTGGGTGACAAAGCATGTTCTCAAGGGACTTGATTTTCTACACTCAA AGAAAGTGATCCATCATGATATTAAACCTAGCAACATTGTTTTCATGTCCACAAAAGC TGTTTTGGTGGATTTTGGCCTAAGTGTTCAAATGACCGAAGATGTCTATTTTCCTAAG GACCTCCGAGGAACAGAGATTTACATGAGCCCAGAGGTCATCCTGTGCAGGGGCCATT CAACCAAAGCAGACATCTACAGCCTGGGGGCCACGCTCATCCACATGCAGACGGGCAC CCCACCCTGGGTGAAGCGCTACCCTCGCTCAGCCTATCCCTCCTACCTGTACATAATC CACAAGCAAGCACCTCCACTGGAAGACATTGCAGATGACTGCAGTCCAGGGATGAGAG AGCTGATAGAAGCTTCCCTGGAGAGAAACCCCAATCACCGCCCAAGAGCCGCAGACCT ACTAAAACATGAGGCCCTGAACCCGCCCAGAGAGGATCAGCCACGCTGTCAGAGTCTG GACTCTGCCCTCTTGGAGCGCAAGAGGCTGCTGAGTAGGAAGGAGCTGGAACTTCCTG AGAACATTGCTGATTCTTCGTGCACAGGAAGCACCGAGGAATCTGAGATGCTCAAGAG

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table IB.
Further analysis of the NOVla protein yielded the following properties shown in Table IC.
Table IC. Protein Sequence Properties NOVla
PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in analysis: mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVla protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table ID.
In a BLAST search of public sequence datbases, the NOVla protein was found to have homology to the proteins shown in the BLASTP data in Table IE.
PFam analysis predicts that the NOVl protein contains the domains shown in the Table IF.
Table IF. Domain Analysis of NOVla
Identities/
Pfam Domain NOVla Match Region Similarities Expect Value for the Matched Region
Example 2.
The NOV2 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 2 A.
Table 2A. NOV2 Sequence Analysis
SEQ ID NO: 37 917 bp
NOV2a, GATGAAGAGAGGGGAGCTCTTTGACTACCTCACTGAGAAGGTCACCTTGAGTGAGAAG CG101996-01 GAAACCAGAAAGATCATGCGAGCTCTGCTGGAGGTGATCTGCACCTTGCACAAACTCA
ACATCGTGCACCGGGACCTGAAGCCCGAGAACATTCTCTTGGATGACAACATGAACAT DNA Sequence CAAGCTCACAGACTTTGGCTTTTCCTGCCAGCTGGAGCCGGGAGAGAGGCTGCGAGGG
TCTGCGGGACCCCCAGTTACCTGGCCCCTGAGATTATCGAGTGCTCCATGAATGAGGA
CCACCCGGGCTACGGGAAAGAGGTGGACATGTGGAGCACTGGCGTCATCATGTACACG
CTGCTGGCCGCTCCCCGCCCTTCTGGCACCGGAAGCAGATGCTGATGCTGAGGATGAT
CATGAGCGGCAACTACCAGTTTGGCTCGCCCGAGTGGGATGATTACTCGGACACCGTG AAGGACCTGGTCTCCCGATTCCTGGTGGTGCAACCCCAGAACCGCTACACAGCGGAAG AGGCCTTGGCACACCCCTTCTTCCAGCAGTACTTGGTGGAGGAAGTGCGGCACTTCAG CCCCCGGGGGAAGTTCAAGGTGATCGCTCTGACCGTGCTGGCTTCAGTGCGGATCTAC TACCAGTACCGCCGGGTGAAGCCTGTGACCCGGGAGATCGTCATCCGAGACCCCTATG CCCTCCGGCCTCTGCGCCGGCTCATCGACGCCTACGCTTTCCGAATCTATGGCCACTG GGTGAAGAAGGGGCAGCAGCAGAACCGGGCAGCCCTTTTCGAGAACACACCCAAGGCC GTGCTCCTCTCCCTGGCCGAGGAGGACTACTGAGGGGCTGGCCAGTCAGGGAGGGCTA
GGGGGCAGGTGGGGAGGGGAAGCCATGGAAATACAAGTCAAAGGGGT
ORF Start: ATG at 387 ORF Stop: TGA at 843
SEQ ID NO: 38 152 aa MW at l8023.7kD
NOV2a, MLMLRMIMSGNYQFGSPEWDDYSDTVKDLVSRFLWQPQNRYTAEEALAHPFFQQYLV CG101996-01 EEVRHFSPRGKFKVIALTVLASVRIYYQYRRVKPVTREIVIRDPYALRPLRRLIDAYA FRIYGHWVKKGQQQNRAALFENTPKAVLLSLAEEDY Protein Sequence
SEQ ID NO: 39 1299 bp
NOV2b, ATGACCCGGGACGAGGCACTGCCGGACTCTCATTCTGCACAGGACTTCTATGAGAATT CG101996-04 ATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGGTCAGGCGATGCATCCA CAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGTCACCGGTGGAGGCAGC DNA Sequence TTCAGCCCGGAGGAGGTGCGGGAGCTGCGAGAAGCCACGCTGAAGGAGGTGGACATCC TGCGCAAGGTCTCAGGGCACCCCAACATCATACAGCTGAAGGACACTTATGAGACCAA CACTTTCTTCTTCTTGGTGTTTGACCTGATGAAGAGAGGGGAGCTCTTTGACTACCTC ACTGAGAAGGTCACCTTGAGTGAGAAGGAAACCAGAAAGATCATGCGAGCTCTGCTGG AGGTGATCTGCACCTTGCACAAACTCAACATCGTGCACCGGGACCTGAAGCCCGAGAA CATTCTCTTGGATGACAACATGAACATCAAGCTCACAGACTTTGGCTTTTCCTGCCAG CTGGAGCCGGGAGAGAGGCTGCGAGTAGAGACAGGGTTTCACCATGTTGGTCAGGCTG GTCTCGAACTCCTGACCTTACGATCCGCCCGCCTCGGCCTCCCAAAGTGCTGTGATTA CAGGCGTGAGCCACCATGCCCAGCAGGGCTAGGCATTTCTTCAGAGGTCTGCGGGACC CCCAGTTACCTGGCCCCTGAGATTATCGAGTGCTCCATGAATGAGGACCACCCGGGCT ACGGGAAAGAGGTGGACATGTGGAGCACTGGCGTCATCATGTACACGCTGCTGGCCGG CTCCCCGCCCTTCTGGCACCGGAAGCAGATGCTGATGCTGAGGATGATCATGAGCGGC AACTACCAGTTTGGCTCGCCCGAGTGGGATGATTACTCGGACACCGTGAAGGACCTGG TCTCCCGATTCCTGGTGGTGCAACCCCAGAACCGCTATACAGCGGAAGAGGCCTTGGC ACACCCCTTCTTCCAGCAGTACTTGGTAGAGGAAGTGCGGCACTTCAGCCCCCGGGGG AAGTTCAAGGTGATCGCTCTGACCGTGCTGGCTTCAGTGCGGATCTACTACCAGTACC GCCGGGTGAAGCCTGTGACCCGGGAGATCGTCATCCGAGACCCCTATGCCCTCCGGCC TCTGCGCCGGCTCATCGACGCCTACGCTTTCCGAATCTATGGCCACTGGGTGAAGAAG GGGCAGCAGCAGAACCGGGCAGCCCTTTTCGAGAACACACCCAAGGCCGTGCTCCTCT


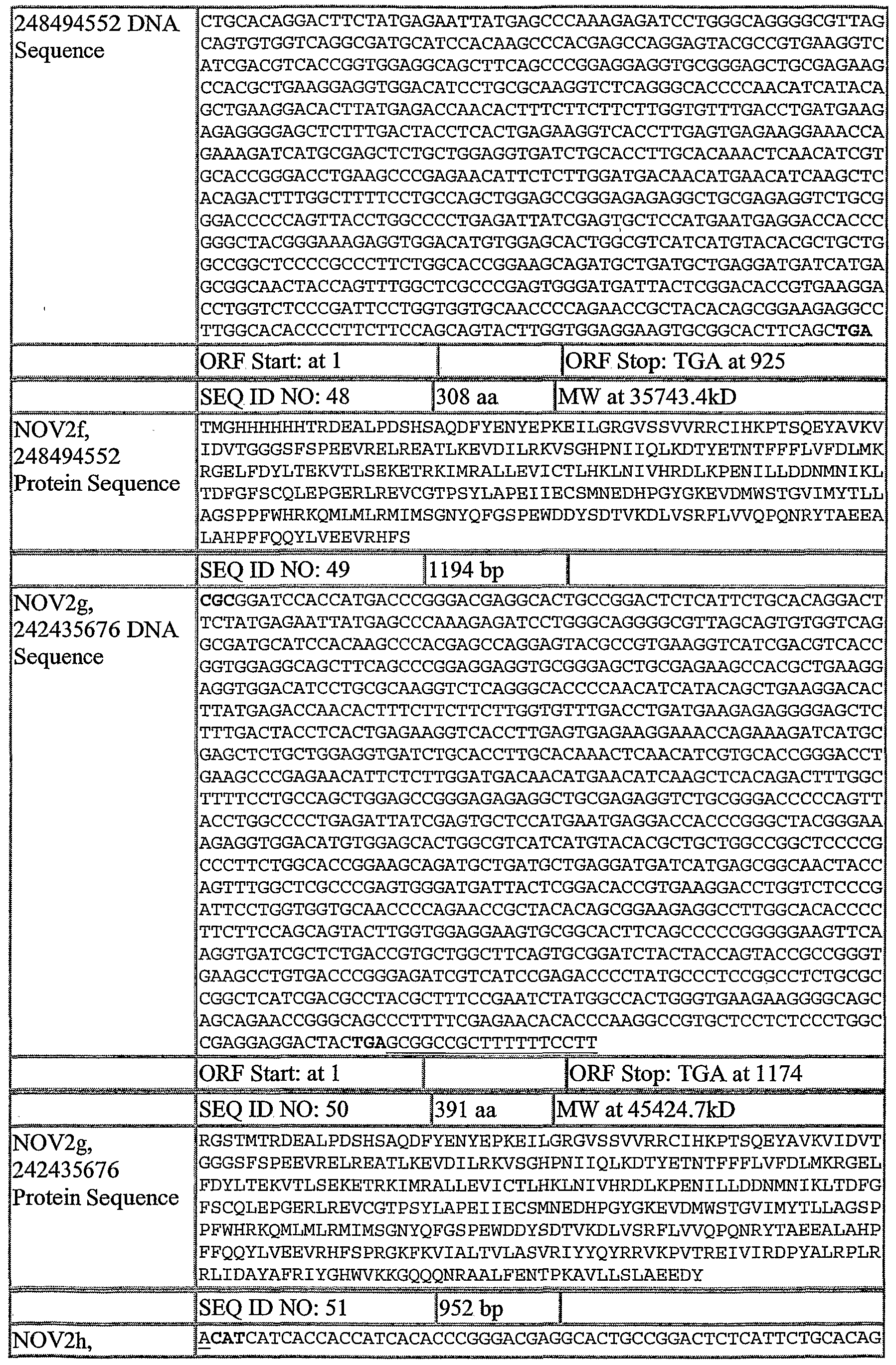
254868664 DNA GACTTCTATGAGAATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGG Sequence TCAGGCGATGCATCCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGT CACCGGTGGAGGCAGCTTCAGCCCGGAGGAGGTGCGGGAGCTGCGAGAAGCCACGCTG AAGGAGGTGGACATCCTGCGCAAGGTCTCAGGGCACCCCAACATCATACAGCTGAAGG ACACTTATGAGACCAACACTTTCTTCTTCTTGGTGTTTGACCTGATGAAGAGAGGGGAi GCTCTTTGACTACCTCACTGAGAAGGTCACCTTGAGTGAGAAGGAAACCAGAAAGATC ATGCGAGCTCTGCTGGAGGTGATCTGCACCTTGCACAAACTCAACATCGTGCACCGGG ACCTGAAGCCCGAGAACATTCTCTTGGATGACAACATGAACATCAAGCTCACAGACTT TGGCTTTTCCTGCCAGCTGGAGCCGGGAGAGAGGCTGCGAGAGGTCTGCGGGACCCCC AGTTACCTGGCCCCTGAGATTATCGAGTGCTCCATGAATGAGGACCACCCGGGCTACG GGAAAGAGGTGGACATGTGGAGCACTGGCGTCATCATGTACACGCTGCTGGCCGGCTC CCCGCCCTTCTGGCACCGGAAGCAGATGCTGATGCTGAGGATGATCATGAGCGGCAAC TACCAGTTTGGCTCGCCCGAGTGGGATGATTACTCGGACACCGTGAAGGACCTGGTCT CCCGATTCCTGGTGGTGCAACCCCAGAACCGCTACACAGCGGAAGAGGCCTTGGCACA CCCCTTCTTCCAGCAGTACTTGGTGGAGGAAGTGCGGCACTTCAGCTGAGCGGCCGCA CTCGAGCACCACCACCACCACCAC
ORF Start: at 2 ORF Stop: TGA at 917
SEQ ID NO: 52 305 aa MW at 35454.0kD
NOV2h, HHHHHHTRDEALPDSHSAQDFYENYEPKEILGRGVSSVVRRCIHKPTSQEYAVKVIDV 254868664 TGGGSFSPEEVRELREATLKEVDILRKVSGHPNIIQLKDTYETNTFFFLVFDLMKRGE FDYLTEKVTLSEKETRKIMRALLEVICTLHKLNIVHRDLKPENILLDDNMNIKLTDF Protein Sequence GFSCQLEPGERLREVCGTPSY APEIIECS NEDHPGYGKEVDMWSTGVIMYTL AGS PPFWHRKQM LRMIMSGNYQFGSPEWDDYSDTVKD VSRF WQPQNRYTAEEA AH PFFQQYLVEEVRHFS
SEQ ID NO: 53 939 bp
NOV2i, CATATGACCCGGGACGAGGCACTGCCGGACTCTCATTCTGCACAGGACTTCTATGAGA
249122191 DNA ATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGGTCAGGCGATGCAT Sequence CCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGTCACCGGTGGAGGC AGCTTCAGCCCGGAGGAGGTGCGGGAGCTGCGAGAAGCCACGCTGAAGGAGGTGGACA TCCTGCGCAAGGTCTCAGGGCACCCCAACATCATACAGCTGAAGGACACTTATGAGAC CAACACTTTCTTCTTCTTGGTGTTTGACCTGATGAAGAGAGGGGAGCTCTTTGACTAC CTCACTGAGAAGGTCACCTTGAGTGAGAAGGAAACCAGAAAGATCATGCGAGCTCTGC TGGAGGTGATCTGCACCTTGCACAAACTCAACATCGTGCACCGGGACCTGAAGCCCGA GAACATTCTCTTGGATGACAACATGAACATCAAGCTCACAGACTTTGGCTTTTCCTGC CAGCTGGAGCCGGGAGAGAGGCTGCGAGAGGTCTGCGGGACCCCCAGTTACCTGGCCC CTGAGATTATCGAGTGCTCCATGAATGAGGACCACCCGGGCTACGGGAAAGAGGTGGA CATGTGGAGCACTGGCGTCATCATGTACACGCTGCTGGCCGGCTCCCCGCCCTTCTGG CACCGGAAGCAGATGCTGATGCTGAGGATGATCATGAGCGGCAACTACCAGTTTGGCT CGCCCGAGTGGGATGATTACTCGGACACCGTGAAGGACCTGGTCTCCCGATTCCTGGT GGTGCAACCCCAGAACCGCTACACAGCGGAAGAGGCCTTGGCACACCCCTTCTTCCAG CAGTACTTGGTGGAGGAAGTGCGGCACTTCAGCTGAGCGGCCGCACTCGAGCACCACC ACCACCACCAC
ORF Start: at 1 ORF Stop: TGA at 904
SEQ ID NO: 54 301 aa MW at 34899.5kD
NOV2i, HMTRDEALPDSHSAQDFYENYEPKEILGRGVSSWRRCIHKPTSQEYAVKVIDVTGGG 249122191 SFSPEEVRELREATLKEVDILRKVSGHPNIIQLKDTYETNTFFFLVFDL KRGELFDY LTEK^TLSEKETRKI_^A EVICTLHK NIVHRD KPE I IDDNMNIK TDFGFSC Protein Sequence QLEPGERLREVCGTPSYLAPEIIECSMNEDHPGYGKEVDMWSTGVI YT LAGSPPFW HRKQ L LRMIMSGNYQFGSPEWDDYSDTVKDLVSRFLVVQPQNRYTAEEALAHPFFQ QYLVEEVRHFS
SEQ ID NO: 55 951 bp
NOV2J, ACCCGGGACGAGGCACTGCCGGACTCTCATTCTGCACAGGACTTCTATGAGAATTATG
249122234 DNA AGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGGTCAGGCGATGCATCCACAA GCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGTCACCGGTGGAGGCAGCTTC Sequence AGCCCGGAGGAGGTGCGGGAGCTGCGAGAAGCCACGCTGAAGGAGGTGGACATCCTGC GCAAGGTCTCAGGGCACCCCAACATCATACAGCTGAAGGACACTTATGAGACCAACAC
TTTCTTCTTCTTGGTGTTTGACCTGATGAAGAGAGGGGAGCTCTTTGACTACCTCACT GAGAAGGTCACCTTGAGTGAGAAGGAAACCAGAAAGATCATGCGAGCTCTGCTGGAGG TGATCTGCACCTTGCACAAACTCAACATCGTGCACCGGGACCTGAAGCCCGAGAACAT TCTCTTGGATGACAACATGAACATCAAGCTCACAGACTTTGGCTTTTCCTGCCAGCTG GAGCCGGGAGAGAGGCTGCGAGAGGTCTGCGGGACCCCCAGTTACCTGGCCCCTGAGA TTATCGAGTGCTCCATGAATGAGGACCACCCGGGCTACGGGAAAGAGGTGGACATGTG GAGCACTGGCGTCATCATGTACACGCTGCTGGCCGGCTCCCCGCCCTTCTGGCACCGG AAGCAGATGCTGATGCTGAGGATGATCATGAGCGGCAACTACCAGTTTGGCTCGCCCG AGTGGGATGATTACTCGGACACCGTGAAGGACCTGGTCTCCCGATTCCTGGTGGTGCA ACCCCAGAACCGCTACACAGCGGAAGAGGCCTTGGCACACCCCTTCTTCCAGCAGTAC TTGGTGGAGGAAGTGCGGCACTTCAGCCATCATCACCACCATCACTGAGCGGCCGCAC TCGAGCACCACCACCACCACCAC
ORF Start: at 1 ORF Stop: TGA at 916
SEQ ID NO: 56 305 aa MW at 35454.0kD
NOV2J, TRDEALPDSHSAQDFYENYEPKEILGRGVSSVVRRCIHKPTSQEYAVKVIDVTGGGSF 249122234 SPEEVRELREATLKEVDILRKVSGHPNIIQLKDTYETNTFFFLVFDLMKRGELFDYLT EKVTLSEKETRKI Pj^LEVICT HKLNIVHRD KPENIL DDNMNIKLTDFGFSCQ Protein Sequence EPGER REVCGTPSYLAPEIIECSMNEDHPGYGKEVDMWSTGVIMYT AGSPPFWHR KQMLMLRMI SGNYQFGSPEWDDYSDTVKDLVSRF WQPQNRYTAEEAAHPFFQQY LVEEVRHFSHHHHHH
SEQ ID NO: 57 1252 bp
NOV2k, CTTTGGGATTCTTGTCAAGCTCCTTCAAGAGCCTGCAAGCACTTAACCAGCCACCCAG CG101996-03 AGTTCCCTCACTGAAGATCTGAGCATGACCCGGGACGAGGCACTGCCGGACTCTCATT
CTGCACAGGACTTCTATGAGAATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAG DNA Sequence CAGTGTGGTCAGGCGATGCATCCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTC ATCGACGTCACCGGTGGAGGCAGCTTCAGCCCGGAGGAGGTGCGGGAGCTGCGAGAAG CCACGCTGAAGGAGGTGGACATCCTGCGCAAGGTCTCAGGGCACCCCAACATCATACA GCTGAAGGACACTTATGAGACCAACACTTTCTTCTTCTTGGTGTTTGACCTGATGAAG AGAGGGGAGCTCTTTGACTACCTCACTGAGAAGGTCACCTTGAGTGAGAAGGAAACCA GAAAGATCATGCGAGCTCTGCTGGAGGTGATCTGCACCTTGCACAAACTCAACATCGT GCACCGGGACCTGAAGCCCGAGAACATTCTCTTGGATGACAACATGAACATCAAGCTC ACAGACTTTGGCTTTTCCTGCCAGCTGGAGCCGGGAGAGAGGCTGCGAGAGGTCTGCG GGACCCCCAGTTACCTGGCCCCTGAGATTATCGAGTGCTCCATGAATGAGGACCACCC GGGCTACGGGAAAGAGGTGGACATGTGGAGCACTGGCGTCATCATGTACACGCTGCTG GCCGGCTCCCCGCCCTTCTGGCACCGGAAGCAGATGCTGATGCTGAGGATGATCATGA GCGGCAACTACCAGTTTGGCTCGCCCGAGTGGGATGATTACTCGGACACCGTGAAGGA CCTGGTCTCCCGATTCCTGGTGGTGCAACCCCAGAACCGCTACACAGCGGAAGAGGCC TTGGCACACCCCTTCTTCCAGCAGTACTTGGTGGAGGAAGTGCGGCACTTCAGCCCCC GGGGGAAGTTCAAGGTGATCGCTCTGACCGTGCTGGCTTCAGTGCGGATCTACTACCA GTACCGCCGGGTGAAGCCTGTGACCCGGGAGATCGTCATCCGAGACCCCTATGCCCTC CGGCCTCTGCGCCGGCTCATCGACGCCTACGCTTTCCGAATCTATGGCCACTGGGTGA AGAAGGGGCAGCAGCAGAACCGGGCAGCCCTTTTCGAGAACACACCCAAGGCCGTGCT CCTCTCCCTGGCCGAGGAGGACTACTGAGGGGCT
ORF Start: ATG at 83 JORF Stop: TGA at 1244
SEQ ID NO: 58 387 aa MW at 45023.3kD
NOV2k, TRDEA PDSHSAQDFYENYEPKEI GRGVSSWRRCIHKPTSQEYAVKVIDVTGGGS CG101996-03 FSPEEVRE REATLKEVDILRKVSGHPNIIQ KDTYETNTFFF VFD KRGELFDYL TEKVT SEKETRKIMRA LEVICTLHKLNIVHRDLKPENILLDDNMNIK TDFGFSCQ Protein Sequence LEPGERLRE¥CGTPSY_APEIIECSMNEDHPGYGKEVDMWSTGVIMYTLLAGSPPFWH RKQMLMLR IMSGNYQFGSPEWDDYSDTVKDLVSRFLWQPQNRYTAEEALAHPFFQQ Y VEEVRHFSPRGKFKVIALTVASVRIYYQYRRVKPVTREIVIRDPYALRP RRLID AYAFRIYGHWVKKGQQQNRAALFENTPKAVLLSLAEEDY
SEQ ID NO: 59 1194 bp
NOV21, CGCGGATCCACCATGACCCGGGACGAGGCACTGCCGGACTCTCATTCTGCACAGGACT CG101996-05 TCTATGAGAATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGGTCAG GCGATGCATCCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGTCACC
lAYAFRIYGHWVKKGQQQNRAALFENTPKAVLLSLAEEDY
SEQ ID NO: 63 927 bp
NOV2n, ACCATGGGACATCATCACCACCATCACACCCGGGACGAGGCACTGCCGGACTCTCATT CG101996-07 CTGCACAGGACTTCTATGAGAATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAG DNA Sequence CAGTGTGGTCAGGCGATGCATCCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTC ATCGACGTCACCGGTGGAGGCAGCTTCAGCCCGGAGGAGGTGCGGGAGCTGCGAGAAG CCACGCTGAAGGAGGTGGACATCCTGCGCAAGGTCTCAGGGCACCCCAACATCATACA GCTGAAGGACACTTATGAGACCAACACTTTCTTCTTCTTGGTGTTTGACCTGATGAAG AGAGGGGAGCTCTTTGACTACCTCACTGAGAAGGTCACCTTGAGTGAGAAGGAAACCA GAAAGATCATGCGAGCTCTGCTGGAGGTGATCTGCACCTTGCACAAACTCAACATCGT GCACCGGGACCTGAAGCCCGAGAACATTCTCTTGGATGACAACATGAACATCAAGCTC ACAGACTTTGGCTTTTCCTGCCAGCTGGAGCCGGGAGAGAGGCTGCGAGAGGTCTGCG GGACCCCCAGTTACCTGGCCCCTGAGATTATCGAGTGCTCCATGAATGAGGACCACCC GGGCTACGGGAAAGAGGTGGACATGTGGAGCACTGGCGTCATCATGTACACGCTGCTG GCCGGCTCCCCGCCCTTCTGGCACCGGAAGCAGATGCTGATGCTGAGGATGATCATGA GCGGCAACTACCAGTTTGGCTCGCCCGAGTGGGATGATTACTCGGACACCGTGAAGGA CCTGGTCTCCCGATTCCTGGTGGTGCAACCCCAGAACCGCTACACAGCGGAAGAGGCC TTGGCACACCCCTTCTTCCAGCAGTACTTGGTGGAGGAAGTGCGGCACTTCAGCTGA
ORF Start: at 1 ORF Stop: TGA at 925
SEQ ID NO: 64 308 aa MW at 35743.4kD
NOV2n, TMGHHHHHHTRDEALPDSHSAQDFYENYEPKEILGRGVSSWRRCIHKPTSQEYAVKV CG101996-07 IDVTGGGSFSPEEVRELREAT-KEVDILRKVSGHPNIIQ KDTYETNTFFFLVFDLMK RGELFDYLTEKVTLSEKETRKIMRA LEVICT HKLNIVHRDLKPENIL DDNMNIKL Protein Sequence TDFGFSCQLEPGERLREVCGTPSY APEIIECSMNEDHPGYGKEVD WSTGVI YT L AGSPPFWHRKQMLMLRMIMSGNYQFGSPEWDDYSDTVKDLVSRFLWQPQNRYTAEEA AHPFFQQYLVEEVRHFS
SEQ ID NO: 65 924 bp
NOV2o, ACCATGACCCGGGACGAGGCACTGCCGGACTCTCATTCTGCACAGGACTTCTATGAGA CG101996-08 ATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGGTCAGGCGATGCAT DNA Sequence CCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGTCACCGGTGGAGGC AGCTTCAGCCCGGAGGAGGTGCGGGAGCTGCGAGAAGCCACGCTGAAGGAGGTGGACA TCCTGCGCAAGGTCTCAGGGCACCCCAACATCATACAGCTGAAGGACACTTATGAGAC CAACACTTTCTTCTTCTTGGTGTTTGACCTGATGAAGAGAGGGGAGCTCTTTGACTAC CTCACTGAGAAGGTCACCTTGAGTGAGAAGGAAACCAGAAAGATCATGCGAGCTCTGC TGGAGGTGATCTGCACCTTGCACAAACTCAACATCGTGCACCGGGACCTGAAGCCCGA GAACATTCTCTTGGATGACAACATGAACATCAAGCTCACAGACTTTGGCTTTTCCTGC CAGCTGGAGCCGGGAGAGAGGCTGCGAGAGGTCTGCGGGACCCCCAGTTACCTGGCCC CTGAGATTATCGAGTGCTCCATGAATGAGGACCACCCGGGCTACGGGAAAGAGGTGGA CATGTGGAGCACTGGCGTCATCATGTACACGCTGCTGGCCGGCTCCCCGCCCTTCTGG CACCGGAAGCAGATGCTGATGCTGAGGATGATCATGAGCGGCAACTACCAGTTTGGCT CGCCCGAGTGGGATGATTACTCGGACACCGTGAAGGACCTGGTCTCCCGATTCCTGGT GGTGCAACCCCAGAACCGCTACACAGCGGAAGAGGCCTTGGCACACCCCTTCTTCCAG CAGTACTTGGTGGAGGAAGTGCGGCACTTCAGCCATCATCACCACCATCACTGA
ORF Start: at 1 ORF Stop: TGA at 922
SEQ ID NO: 66 307 aa MW at 35686.3kD
NOV2o, TMTRDEA PDSHSAQDFYENYEPKEILGRGVSSWRRCIHKPTSQEYAVKVIDVTGGG CG101996-08 SFSPEEVRELREATLKEVDILRKVSGHPNIIQLKDTYETNTFFFLVFD MKRGELFDY TEKVTLSEKETRKI RA LEVI CTLHKLNI VHRDLKPENI L DDNMNI KLTDFGFSC Protein Sequence QLEPGER REVCGTPSY APEIIECS NEDHPGYGKEVDMWSTGVIMYTLLAGSPPFW IffiKQMLMLRMIMSGNYQFGSPEWDDYSDTVKDLVSRFLVVQPQNRYTAEEAIiAHPFFQ QYLVEEVRHFSHHHHHH
SEQ ID NO: 67 939 bp
NOV2p, CATATGACCCGGGACGAGGCACTGCCGGACTCTCATTCTGCACAGGACTTCTATGAGA CG101996-09 ATTATGAGCCCAAAGAGATCCTGGGCAGGGGCGTTAGCAGTGTGGTCAGGCGATGCAT CCACAAGCCCACGAGCCAGGAGTACGCCGTGAAGGTCATCGACGTCACCGGTGGAGGC DNA Sequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 2B.
Further analysis of the NOV2a protein yielded the following properties shown in Table 2C.
Table 2C. Protein Sequence Properties NOV2a
PSort j 0.5098 probability located in microbody (peroxisome); 0.4500 probability analysis: J located in cytoplasm; 0.3051 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV2a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 2D.
In a BLAST search of public sequence datbases, the NOV2a protein was found to have homology to the proteins shown in the BLASTP data in Table 2E.
PFam analysis predicts that the NOV2a protein contains the domains shown in the Table 2F.
Example 3.
The NOV3 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 3 A.
Table 3 A. NOV3 Sequence Analysis
SEQ ID NO: 69 2727 bp
NOV3a, AGAAGAGCGGAGCTGTGAGCAGTACTGCGGCCTCCTCTCCTCTCCTAACCTCGCTCTC CG102822-01 GCGGCCTAGCTTTACCCGCCCGCCTGCTCGGCGACCAGAACACCTTCCACCATGACCA
CCTCAGCAAGTTCCCACTTAAATAAAGGCATCAAGCAGGTGTACATGTCCCTGCCTCA DNA Sequence GGGTGAGAAAGTCCAGGCCATGTATATCTGGATCGATGGTACTGGAGAAGGACTGCGC TGCAAGACCCGGACCCTGGACAGTGAGCCCAAGTGTGTGGAAGAGTTGCCTGAGTGGA ATTTCGATGGCTCTAGTACTTTACAGTCTGAGGGTTCCAACAGTGACATGTATCTCGT GCCTGCTGCCATGTTTCGGGACCCCTTCCGTAAGGACCCTAACAAGCTGGTGTTATGT GAAGTTTTCAAGTACAATCGAAGGCCTGCAGAGACCAATTTGAGGCACACCTGTAAAC GGATAATGGACATGGTGAGCAACCAGCACCCCTGGTTTGGCATGGAGCAGGAGTATAC CCTCATGGGGACAGATGGGCACCCCTTTGGTTGGCCTTCCAACGGCTTCCCAGGGCCC CAGGGTCCATATTACTGTGGTGTGGGAGCAGACAGAGCCTATGGCAGGGACATCGTGG AGGCCCATTACCGGGCCTGCTTGTATGCTGGAGTCAAGATTGCGGGGACTAATGCCGA GGTCATGCCTGCCCAGTGGGAATTTCAGATTGGACCTTGTGAAGGAATCAGCATGGGA GATCATCTCTGGGTGGCCCGTTTCATCTTGCATCGTGTGTGTGAAGACTTTGGAGTGA TAGCAACCTTTGATCCTAAGCCCATTCCTGGGAACTGGAATGGTGCAGGCTGCCATAC CAACTTCAGCACCAAGGCCATGCGGGAGGAGAATGGTCTGAAGTACATCGAGGAGGCC ATTGAGAAACTAAGCAAGCGGCACCAGTACCACATCCGTGCCTATGATCCCAAGGGAG GCCTGGACAATGCCCGACGTCTAACTGGATTCCATGAAACCTCCAACATCAACGACTT TTCTGCTGGTGTAGCCAATCGTAGCGCCAGACTACGCATTCCCCGGACTGTTGGCCAG GAGAAGAAGGGTTACTTTGAAGATCGTCGCCCCTCTGCCAACTGCGAGCCCTTTTCGG TGACAGAAGCCCTCATCCGCACGTGTCTTCTCAATGAAACCGGCGATGAGCCCTTCCA GTACAAAAATTAAGTGGACTAGACCTCCAGCTGTTGAGCCCCTCCTAGTTCTTCATCC CTGACTCCAACTCTTCCCCCTCTCCCAGTTGTCCCGATTGTAACTCAAAGGGTGGAAT
ATCAAGGTCGTTTTTTTCATTCCATGTGCCCAGTTAATCTTGCTTTCTTTTGTTTGGC
TGGGATAGAGGGGTCAAGTTATTAATTTCTTCACACCTACCCTCCTTTTTTTCCCTAT
CACTGAAGC-TTTTAGTGCATTAG-GGGGAGGAGGG-GGGGAGACATAACCACTGCTT CCATTTAATGGGGTGCACCTGTCCAATAGGCGTACGTATCCGGACAGAGCACGTTTGC AGAGGGGTCTCTCTCCAGGTAGCTGAAAGGGAAGACCTGACGTACTCTGGTTAGGTTA GGACTTGCCCTCGTGGTGGAAACTTTTCTTAAAAAGTTATAACCAACTTTTCTATTAA AAGTGGGAATTAGGAGAGAAGGTAGGGGTTGGGAATCAGAGAGAATGGCTTTGGTCTC TTGCTTGTGGGACTAGCCTGGCTTGGGACTAAATGCCCTGCTCTGAACACAAGCTTAG TATAAACTGATGGATATCCCTACCTTGAAAGAAGAAAAGGTTCTTACTGCTTGGTCCT
TGATTTATCACACAAAGCAGAATAGTATTTTTATATTTAAATGTAAAGACAAAAAACT
ATATGTATGGTTTTGTGGATTATGTGTGTTTTGGCTAAAGGAAAAAACCATCCAGGTC
ACGGGGCACCAAATTTGAGACAAATAGTCGGATTAGAAATAAAGCATCTCATTTTGAG TAGAGAGCAAGGAAGTGGTTCTTAGATGGTGATCTGGGATTAGGCCCTCAAGACCCCT TTTGGGTTTCTGCCCTGCCCACCC-CTGGAGAAGGTGGCACTGA-TAGTTAACAGACC AACACCGTTACTAGCAGTCACTGATCTCCGTGGCTTTGGTTTAAAAGACACACTTGTC CACATAGGTTTAGAGATAAGAGTTGGCTGGTCAACTTGAGCATGTTACTGACAGAGGG GGTATTGGGGTTATTTTCTGGTAGGAATAGCATGTCACTAAAGCAGGCCTTTGATATT AAATTTTTTAAAAAGCAAAATTATAGAAGTTTAGATTTTAATCAAATTTGTAGGGTTT

GTTATGTGAAGTTTTCAAGTACAATCGAAGGCCTGCAGAGACCAATTTGAGGCACACC TGTAAACGGATAATGGACATGGTGAGCAACCAGCACCCCTGGTTTGGCATGGAGCAGG AGTATACCCTCATGGGGACAGATGGGCACCCCTTTGGTTGGCCTTCCAACGGCTTCCC AGGGCCCCAGGGTCCATATTACTGTGGTGTGGGAGCAGACAGAGCCTATGGCAGGGAC ATCGTGGAGGCCCATTACCGGGCCTGCTTGTATGCTGGAGTCAAGATTGCGGGGACTA ATGCCGAGGTCATGCCTGCCCAGTGGGAATTTCAGATTGGACCTTGTGAAGGAATCAG CATGGGAGATCATCTCTGGGTGGCCCGTTTCATCTTGCATCGTGTGTGTGAAGACTTT GGAGTGATAGCAACCTTTGATCCTAAGCCCATTCCTGGGAACTGGAATGGTGCAGGCT GCCATACCAACTTCAGCACCAAGGCCATGCGGGAGGAGAATGGTCTGAAGTACATCGA GGAGGCCATTGAGAAACTAAGCAAGCGGCACCAGTACCACATCCGTGCCTATGATCCC AAGGGAGGCCTGGACAATGCCCGACGTCTAACTGGATTCCATGAAACCTCCAACATCA ACGACTTTTCTGCTGGTGTAGCCAATCGTAGCGCCAGCATACGCATTCCCCGGACTGT TGGCCAGGAGAAGAAGGGTTACTTTGAAGATCGTCGCCCCTCTGCCAACTGCGACCCC TTTTCGGTGACAGAAGCCCTCATCCGCACGTGTCTTCTCAATGAAACCGGCGATGAGC CCTTCCAGTACAAAAATTAAGTGGACTAGACCTCCAGCTGTTGAGCCCCTCCTAGTTC
TTCATCCCACTCCAACTCTTCCCCCTCTCCCAGTTGTCCCGATTGTAACTCAAAGGGT
GGAATATCAAGGTCGTTTTTTTCATTCCATGTGCCCAGTTAATCTTGCTTTCTTTGTT
CTATCACTGAAGCTTTTTAGTGCATTAGTGGGGAGGAGGGTGGGGAGACATAACCACT;
GCTTCCATTTAATGGGGTGCACCTGTCCAATAGGCGTAGCTATCCGGACAGAGCACGTi
TTGCAGAAGGGGGTCTCTTCTTCCAGGTAGCTGAAAGGGGAAGACCTGACGTACTCTGJ
GTTAGGTTAGGACTTGCCCTCGTGGTGGAAACTTTTCTTAAAAAGTTATAACCAACTT!
TTCTATTAAAAGTGGGAATTAGGAGAGAAGGTAGGGGTTGGGAATCAGAGAGAATGGC
TTTGGTCTCTTGCTTGTGGGACTAGCCTGGCTTGGGACTAAATGCCCTGCTCTGAACA!
CGAAGCTTAGTATAAACTGATGGATATCCCTACCTTGAAAGAAGAAAAGGTTCTTACT
IGCTTGGTCCTTGATTTATCACACAAAGCAGAATAGTATTTTTATATTTAAATGTAAAG! lACAAAAAACTATATGTATGGTTTTGTGGATTATGTGTGTTTTGCTAAAGGAAAAAACC
ATCCAGGTCACGGGGCACCAAATTTGAGACAAATAGTCGGATTAGAAATAAAGCATCT
CATTTTGAGTAGAGAGCAAGGGAAGTGGTTCTTAGATGGTGATCTGGGATTAGGCCCT
CAAGACCTTTTGGGTTTCTGCCCTGCCCACCCTCTGGAGAAGGTGGGCACTGGATTAG; iTTAACAGACAACACGTTACTAGCAGTCACTTGATCTCCGTGGCTTTGGTTTAAAAGAC!
ACACTTGTCCACATAGGTTTAGAGATAAGAGTTGGCTGGTCAACTTGAGCATGTTACT
GACAGAGGGGGTATTGGGGTTATTTTCTGGTAGGAATAGCATGTCACTAAAGCAGGCC
TTTTGATATTAAATTTTTTAAAAAGCAAAATTATAGAAGTTTAGATTTTAATCAAATT
TGATGGGTTTCTAGGTAATTTTTACAGAATTGCTTGTTTGCTTCAACTGTCTCCTACCi
TCTGCCTCTTGGAGGAGATGGGACAGGGCTGGAGTCAAAACACTTGTAATTTTGTATC iTTGATGTCTTTGTTAAGACTGCTGAAGAATTATTTTTTTTCTTTTATAATAAGGAATA!
AACCCCACCTTTATTCCTTCATTTCATCTACCATTTTCTGGTTCTTGTGTTGGCTGTG!
GCAGGCCAGCTGTGGTTTTCTTTTGCCATGACAACTTCTAATTGCCATGTACAGTATG!
TTCAAAGTCAAATAACTCCTCATTGTAAACAAACTGTGTAACTGCCCAAAGCAGCACT
TATAAATCAGCCTAACATAAG
ORF Start: ATG at 1
SEQ ID NO: 74 373 aa MW at42064.0kD
NOV3c, MTTSASSH NKGIKQVYMSLPQGEKVQAMYIWIDGTGEGLRCKTRTLDSEPKCVEELP CG102822-02 EWNFDGSSTLQSEGSNSDMY VPAAMFRDPFRKDPNKLVLCEVFKYNRRPAETN RHT CKRIMD VSNQHP FGMEQEYTLMGTDGHPFG PSNGFPGPQGPYYCGVGADRAYGRD Protein Sequence IVEAHYRACLYAGVKIAGTNAEVMPAQ EFQIGPCEGISMGDH WVARFILHRVCEDF GVIATFDPKPIPGN NGAGCHTNFSTKAMREENGLKYIEEAIEK SKRHQYHIRAYDP KGGLDNARRLTGFHETSNINDFSAGVANRSASIRIPRTVGQEKKGYFEDRRPSANCDP FSVTEALIRTCLLNETGDEPFQYKN
SEQ ID NO: 75 2775 bp
NOV3d, GGCACGAGGGAAGAGCGGAGCGTGTGAGCAGTACTGCGGCCTCCTCTCCTCTCCTAAC CG102822-04 CTCGCTCTCGCGGCCTACCTTTACCCGCCCGCCTGCTCGGCGACCAGAACACCTTCCA
CCATGACCACCTCAGCAAG-TCCCACTTAAATAAAGGCATCAAGCAGGTGTACA-G-C DNA Sequence CCTGCCTCAGGGTGAGAAAGTCCAGGCCATGTATATCTGGATCGATGGTACTGGAGAA GGACTGCGCTGCAAGACCCGGACCCTGGACAGTGAGCCCAAGTGTGTGGAAGAGTTGC CTGAGTGGAATTTCGATGGCTCCAGTACTTTACAGTCTGAGGGTTCCAACAGTGACAT GTATCTCGTGCCTGCTGCCATGTTTCGGGACCCCTTCCGTAAGGACCCTAACAAGCTG
GTGTTATGTGAAGTTTTCAAGTACAATCGAAGGCCTGCAGAGACCAATTTGAGGCACA CCTGTAAACGGATAATGGACATGGTGAGCAACCAGCACCCCTGGTTTGGCATGGAGCA GGAGTATACCCTCATGGGGACAGATGGGCACCCCTTTGGTTGGCCTTCCAACGGCTTC CCAGGGCCCCAGGGTCCATATTACTGTGGTGTGGGAGCAGACAGAGCCTATGGCAGGG ACATCGTGGAGGCCCATTACCGGGCCTGCTTGTATGCTGGAGTCAAGATTGCGGGGAC TAATGCCGAGGTCATGCCTGCCCAGTGGGAATTTCAGATTGGACCTTGTGAAGGAATC AGCATGGGAGATCATCTCTGGGTGGCCCGTTTCATCTTGCATCGTGTGTGTGAAGACT TTGGAGTGATAGCAACCTTTGATCCTAAGCCCATTCCTGGGAACTGGAATGGTGCAGG CTGCCATACCAACTTCAGCACCAAGGCCATGCGGGAGGAGAATGGTCTGAAGTACATC GAGGAGGCCATTGAGAAACTAAGCAAGCGGCACCAGTACCACATCCGTGCCTATGATC CCAAGGGAGGCCTGGACAATGCCCGACGTCTAACTGGATTCCATGAAACCTCCAACAT CAACGACTTTTCTGCTGGTGTAGCCAATCGTAGCGCCAGCATACGCATTCCCCGGACT GTTGGCCAGGAGAAGAAGGGTTACTTTGAAGATCGTCGCCCCTCTGCCAACTGCGACC CCTTTTCGGTGACAGAAGCCCTCATCCGCACGTGTCTTCTCAATGAAACCGGCGATGA GCCCTTCCAGTACAAAAATTAAGTGGACTAGACCTCCAGCTGTTGAGCCCCTCCTAGT
TCTTCATCCCACTCCAACTCTTCCCCCTCTCCCAGTTGTCCCGATTGTAACTCAAAGG
ΏTGGAATATCAAGGTCGTTTTTTTCATTCCATGTGCCCAGTTAATCTTGCTTTCTTTG;
TTTGGCTGGGATAGAGGGGTCAAGTTATTAATTTCTTCACACCTACCCTCCTTTTTTT
CCCTATCACTGAAGCTTTTTAGTGCATTAGTGGGGAGGAGGGTGGGGAGACATAACCA!
CTGCTTCCATTTAATGGGGTGCACCTGTCCAATAGGCGTAGCTATCCGGACAGAGCAC
GTTTGCAGAAGGGGGACTCTTCTTCCAGGTAGCTGAAAGGGGAAGACCTGACGTACTC
TGGTTAGGTTAGGACTTGCCCTCGTGGTGGAAACTTTTCTTAAAAAGTTATAACCAAC iTTTTCTATTAAAAGTGGGAATTAGGAGAGAAGGTAGGGGTTGGGAATCAGAGAGAATG! iGCTTTGGTCTCTTGCTTGTGGGACTAGCCTGGCTTGGGACTAAATGCCCTGCTCTGAA!
CACGAAGCTTAGTATAAACTGATGGATATCCCTACCTTGAAAGAAGAAAAGGTTCTTA!
CTGCTTGGTCCTTGATTTATCACACAAAGCAGAATAGTATTTTTATATTTAAATGTAA!
AGACAAAAAACTATATGTATGGTTTTGTGGATTATGTGTGTTTTGCTAAAGGAAAAAA!
CCATCCAGGTCACGGGGCACCAAATTTGAGACAAATAGTCGGATTAGAAATAAAGCAT
CTCATTTTGAGTAGAGAGCAAGGGAAGTGGTTCTTAGATGGTGATCTGGGATTAGGCC
CTCAAGACCCTTTTGGGTTTCTGCCCTGCCCACCCTCTGGAGAAGGTGGGCACTGGAT
TAGTTAACAGACGACACGTTACTAGCAGTCACTTGATCTCCGTGGCTTTGGTTTAAAA!
IGACACACTTGTCCACATAGGTTTAGAGATAAGAGTTGGCTGGTCAACTTGAGCATGTT
ACTGACAGAGGGGGTATTGGGGTTATTTTCTGGTAGGAATAGCATGTCACTAAAGCAGI
GCCTTTTGATATTAAATTTTTTAAAAAGCAAAATTATAGAAGTTTAGATTTTAATCAAI
ATTTGTAGGGTTTCTAGGTAATTTTTACAGAATTGCTTGTTTGCTTCAACTGTCTCCT:
ACCTCTGCTCTTGGAGGAGATGGGGACAGGGCTGGAGTCAAAACACTTGTAATTTTGT:
ATCTTGATGTCTTTGTTAAGACTGCTGAAGAATTATTTTTTTCTTTTATAATAAGGAA:
TAAACCCCACCTTTATTCCTTCATTTCATCTACCATTTTCTGGTTCTTGTGTTGGCTG! GGCAGGCCAGCTGTGGTTTTCTTTTGCCATGACAACTTCTAATTGCCATGTACAGTA!
TGTTCAAAGTCAAATAACTCCTCATTGTAAACAAACTGTGTAACTGCCCAAAGCAGCAI
CTTATAAATCAGCCTAACATAAGAAAAAAAAAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 119 ORF Stop: TAA at 1238
SEQ ID NO: 76 373 aa MW at42064.0kD
NOV3d, MTTSASSHLNKGIKQVYMS PQGEKVQAMYIWIDGTGEG RCKTRTLDSEPKCVEELP CG102822-04 EIWFDGSST QSEGSNSDMYLVPAAMFRDPFRKDPNKLV CEVFKYNRRPAETN RHT CKRIMD VSNQHP FG EQEYTLMGTDGHPFGWPSNGFPGPQGPYYCGVGADRAYGRD Protein Sequence IVEAHYRACLYAGVKIAGTNAEVMPAQ EFQIGPCEGISMGDHLWVARFI HRVCEDF GVIATFDPKPIPGNWNGAGCH NFSTKAMREENG KYIEEAIEK SKRHQYHIRAYDP KGG DNARRLTGFHETSNINDFSAGVANRSASIRIPRTVGQEKKGYFEDRRPSANCDP FSVTEALIRTCL NETGDEPFQYKN
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 3B.
Table 3B. Comparison of NOV3a against NO 3b through NO 3d.
Protein Sequence NOVla Residues/ Identifies/
Further analysis of the NOV3a protein yielded the following properties shown in Table 3C.
Table 3C. Protein Sequence Properties NOV3a
PSort 0.5025 probability located in mitochondrial matrix space; 0.4633 probability analysis: located in microbody (peroxisome); 0.2227 probability located in mitochondrial inner membrane; 0.2227 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV3a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 3D.
In a BLAST search of public sequence datbases, the NOV3a protein was found to have homology to the proteins shown in the BLASTP data in Table 3E.
PFam analysis predicts that the NOV3a protein contains the domains shown in the Table 3F.
The NOV4 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 4A.
Table 4A. NOV4 Sequence Analysis
SEQ ID NO: 77 1888 bp
NOV4a, AGCAGCCGGATGCCCGGGCCCACTGGGCGGGCCAGTGGCCGCTTGCGGGATGAGCAGA CG103241-01 CTGCTGGGGGGGACGCTGGAGCGCGTCTGCAAGGCTGTGCTCCTTCTCTGCCTGCTGC DNA Sequence ACTTCCTCGTGGCCGTCATCCTCTACTTTGACGTCTACGCCCAGCACCTGGCCTTCTT CAGCCGCTTCAGTGCCCGAGGCCCTGCCCATGCCCTCCACCCAGCTGCTAGCAGCAGC AGCAGCAGCAGCAACTGCTCCCGGCCCAACGCCACCGCCTCTAGCTCCGGGCTCCCTG AGGTCCCCAGTGCCCTGCCCGGTCCCACGGCTCCCACGCTGCCACCCTGTCCTGACAC CTCCCCGCCTGGTCTTGTGGGCAGACTGCTGATCGAGTTCACCTCACCCATGCCCCTG GAGCGGGTGCAGAGGGAGAACCCAGGCGTGCTCATGGGCGGCCGATACACATCGCCCG ACTGCACCCCAGCCCAGACGGTGGCGGTCATCATCCCCTTTAGACACCGGGAACACCA CCTGCGCTACTGGCTCCACTATCTACACCCCATCTTGAGGCGGCAGCGGCTGCGCTAC TGCGTCTATGTCATCAACCAGCATGGTGAGGACACCTTCAACCGGGCCAAGCTGCTTA ACGTGGGCTTCCTAGAGGCGCTGAAGGAGGATGCCGCCTATGACTGCTTCATCTTCAG CGATGTGGACCTGGTCCCCATGGATGACCGCAACCTATACCGCTGCGGCGACCAACCC CGCCACTTTGCCATTGCCATGGACAAGTTTGGCTTCCGGCTTCCCTATGCTGGCTACT TTGGAGGTGTGTCAGGCCTGAGTAAGGCTCAGTTTCTGAGAATCAATGGCTTCCCCAA TGAGTACTGGGGCTGGGGTGGCGAGGATGATGACATCTTCAACCGGATCTCCCTGACT GGGATGAAGATCTCACGCCCAGACATCCGAATTGGCCGCTACCGCATGATCAAGCACG ACCGCGACAACGATAACGAACCTAACCCTCAGAGGTTTACCAAGATTCAAAACACGAA GCTGACCATGAAGCGGGACGGCATTGGGTCAGTGCGGTACCAGGTCTTGGAGGTGTCT CGGCAACCACTCTTCACCAATATCACAGTGGACATTGGGCGGCCTCCGTCGTGGCCCC CTCGGGGCTGACACTAATGGACAGAGGCTCTCGGTGCCGAAGATTGCCTGCCAGAGGA
CTGACCACAGCCTGGCTGGCAGCTGCTCTGTGGAGGACCTCCAGGACTGAGACTGGGC
TCTGTTTTCCAAGGGTCTTCACTAGGCCCCCTAGCTATACCTGGAAGTTTCAGAACCC
ACTTTGGGGGCCTCTCCGTGGGCAGGCTCTTCAAGTGTGGCCCTCTTTGGAGTCAACC
CTCCTTCCCGACCCCCTCCCCCTAGCCCAGCCCCAGTCACTGTCAGGGTCGGCCAGCC
CCTGCACTGCCTCGCAGAGTGGCCTGGGCTAGGTCACTCCACCTCTCTGTGCCTCAGT
TTCCCCCCCTTGAGTCCCCTTAGGGCCTGGAAGGGTGGGAGGTATGTCTAGGGGGCAA
GTGTCTCTTCCAGGGGGAATTCTCAGCTCTTGGGAACCCCCTTGCTCCCAGGGGAGGG
GAAACCTTTTTCATTCAACATTGTAGGGGGCAAGCTTTGGTGCGCCCCCTGCTGAGGA
GCGAGCCCAGGAGGGGACCAGAGGGGATGCTGTGTCGCTGCCTGGGATCTTGGGGTTG
GCCTTTGCATGGGAGGCAGGTGGGGCTTGGATCAGTAAGTCTGGTTCCCGCCTCCCTG
TCTGAGAGAGGAGGCAGGANCCCAGGGCCGGCTTGTGTTTGTACATTGCACAGAAACT
TGTGTGGGTGCTTTAGTAAAAAACGTGAATGG
ORF Start: ATG at 50 ORF Stop: TGA at 1169
SEQ ID NO: 78 373 aa MW at 42072.7kD
NOV4a, MSRLLGGT ERVCKAVLL C LHFLVAVILYFDVYAQHLAFFSRFSARGPAHALHPAA CG103241-01 SSSSSSSNCSRPNATASSSG PEVPSALPGPTAPTLPPCPDTSPPGLVGRLLIEFTSP MPLΞRVQRENPGVL GGRYTSPDCTPAQTVAVIIPFRHREHHLRYWLHYLHPILRRQR Protein Sequence LRYCVYVINQHGEDTFNRAK LNVGFLEA KEDAAYDCFIFSDVD VPMDDRNLYRCG DQPRHFAIAMDKFGFRLPYAGYFGGVSGLSKAQFLRINGFPNEY G GGEDDDIFNRI SLTGMKISRPDIRIGRYRMIKHDRDNDNEPNPQRFTKIQNTKLTMKRDGIGSVRYQV EVSRQP FTNITVDIGRPPS PPRG
SEQ ID NO: 79 1783 bp
NOV4b, AGCAGCCGGATGCCCGGGCCCACTGGGCGGGCCAGTGGCCGCTTGCGGGATGAGCAGA CG103241-02 CTGCTGGGGGGGACGCTGGAGCGCGTCTGCAAGGCTGTGCTCCTTCTCTGCCTGCTGC ACTTCCTCGTGGCCGTCATCCTCTACTTTGACGTCTACGCCCAGCACCTGGCCTTCTT DNA Sequence CAGCCGCTTCAGTGCCCGAGGCCCTGCCCATGCCCTCCACCCAGCTGCTAGCAGCAGC AGCAGCAGCAGCAACTGCTCCCGGCCCAACGCCACCGCCTCTAGCTCCGGGCTCCCTG AGGTCCCCAGTGCCCTGCCCGGTCCCACGGCTCCCACGCTGCCACCCTGTCCTGACAC CTCCCCGCCTGGTCTTGTGGGCAGACTGCTGATCGAGTTCACCTCACCCATGCCCCTG GAGCGGGTGCAGAGGGAGAACCCAGGCGTGCTCATGGGCGGCCGATACACATCGCCCG ACTGCACCCCAGCCCAGACGGTGGCGGTCATCATCCCCTTTAGACACCGGGAACACCA CCTGCGCTACTGGCTCCACTATCTACACCCCATCTTGAGGCGGCAGCGGCTGCGCTAC TGCGTCTATGTCATCAACCAGCATGGTGAGGACACCTTCAACCGGGCCAAGCTGCTTA ACGTGGGCTTCCTAGAGGCGCTGAAGGAGGATGCCGCCTATGACTGCTTCATCTTCGG CGATGTGGACCTGGTCCCCATGGATGACCGCAACCTATACCGCTGCGGCGACCAACCC CGCCACTTTGCCATTGCCATGGACAAGTTTGGCTTCCGGCTTCCCTATGCTGGCTACT
TTGGAGGTGTGTCAGGCCTGAGTAAGGCTCAGTTTCTGAGAATCAATGGCTTCCCCAA TGAGTACTGGGGCTGGGGTGGCGAGGATGATGACATCTTCAACCGGTTTACCAAGATT CAAAACACGAAGCTGACCATGAAGCGGGACGACATTGGGTCAGTGCGGTACCAGGTCT TGGAGGTGTCTCGGCAACCACTCTTCACCAATATCACAGTGGACATTGGGCGGCCTCC GTCGTGGCCCCCTCGGGGCTGACACTAATGGACAGAGGCTCTCGGTGCCGAAGATTGC
CTGCCAGAGGACTGACCACAGCCTGGCTGGCAGCTGCTCTGTGGAGGACCTCCAGGAC
TGAGACTGGGCTCTGTTTTCCAAGGGTCTTCACTAGGCCCCCTAGCTATACCTGGAAGl
TTTCAGAACCCACTTTGGGGGCCTCTCCGTGGGCAGGCTCTTCAAGTGTGGCCCTCTT iTGGAGTCAACCCTCCTTCCCGACCCCCTCCCCCTAGCCCAGCCCCAGTCACTGTCAGGl
GTCGGCCAGCCCCTGCACTGCCTCGCAGAGTGGCCTGGGCTAGGTCACTCCACCTCTCi
TGTGCCTCAGTTTCCCCCCCTTGAGTCCCCTTAGGGCCTGGAAGGGTGGGAGGTATGT:
CTAGGGGGCAAGTGTCTCTTCCAGGGGGAATTCTCAGCTCTTGGGAACCCCCTTGCTC
CCAGGGGAGGGGAAACCTTTTTCATTCAACATTGTAGGGGGCAAGCTTTGGTGCGCCC:
CCTGCTGAGGAGCGAGCCCAGGAGGGGACCAGAGGGGATGCTGTGTCGCTGCCTGGGA
TCTTGGGGTTGGCCTTTGCATGGGAGGCAGGTGGGGCTTGGATCAGTAAGTCTGGTTC
CCGCCTCCCTGTCTGAGAGAGGAGGCAGGAACCCAGGGCCGGCTTGTGTTTGTACATT
GCACAGAAACTTG G GGGTGCTTTAGTAAAAAACGTGAATGG
ORF Start: ATG at 50 ORF Stop: TGA at 1064
SEQ ID NO: 80 338 aa MW at 37925.0kD
NOV4b, MSR GGT ERVCKAV LLCLLHFLVAVILYFDVYAQHLAFFSRFSARGPAHALHPAA CG103241-02 SSSSSSSNCSRPNATASSSGLPEVPSALPGPTAPTLPPCPDTSPPGLVGR IEFTSP MP ERVQRENPGVLMGGRYTSPDCTPAQTVAVIIPFRHREHH RYW HY HPI RRQR Protein Sequence RYCVΥVINQHGEDTFNRAK LNVGFLEALKEDAAYDCFIFGDVDVPMDDRNLYRCG DQPRHFAIAMDKFGFRLPYAGYFGGVSGLSKAQF RINGFPNEYWG GGEDDDIFNRF TKIQNTKLTMKRDDIGSVRYQVEVSRQP FTNITVDIGRPPSWPPRG
SEQ ID NO: 81 1119 bp
NOV4c, ATGAGCAGACTGCTGGGGGGGACGCTGGAGCGCGTCTGCAAGGCTGTGCTCCTTCTCT CG103241-03 GCCTGCTGCACTTCCTCGTGGCCGTCATCCTCTACTTTGACGTCTACGCCCAGCACCT GGCCTTCTTCAGCCGCTTCAGTGCCCGAGGCCCTGCCCATGCCCTCCACCCAGCTGCT DNA Sequence AGCAGCAGCAGCAGCAGCAGCAACTGCTCCCGGCCCAACGCCACCGCCTCTAGCTCCG GGCTCCCTGAGGTCCCCAGTGCCCTGCCCGGTCCCACGGCTCCCACGCTGCCACCCTG TCCTGACTCGCCACCTGGTCTTGTGGGCAGACTGCTGATCGAGTTCACCTCACCCATG CCCCTGGAGCGGGTGCACAGGGAGAACCCAGGCGTGCTCATGGGCGGCCGATACACAC CGCCCGACTGCACCCCAGCCCAGACGGTGGCGGTCATCATCCCCTTTAGACACCGGGA ACACCACCTGCGCTACTGGCTCCACTATCTACACCCCATCTTGAGGCGGCAGCGGCTG CGCTACGGCGTCTATGTCATCAACCAGCATGGTGAGGACACCTTCAACCGGGCCAAGC TGCTTAACGTGGGCTTCCTAGAGGCGCTGAAGGAGGATGCCGCCTATGACTGCTTCAT CTTCAGCGATGTGGACCTGGTCCCCATGGATGACCGCAACCTATACCGCTGCGGCGAC CAACCCCGCCACTTTGCCATTGCCATGGACAAGTTTGGCTTCCGGCTTCCCTATGCTG GCTACTTTGGAGGTGTGTCAGGCCTGAGTAAGGCTCAGTTTCTGAGAATCAATGGCTT CCCCAATGAGTACTGGGGCTGGGGTGGCGAGGATGATGACATCTTCAACCGGATCTCC CTGACTGGGATGAAGATCTCACGCCCAGACATCCGAATTGGCCGCTACCGCATGATCA AGCACGACCGCGACAAGCATAACGAACCTAACCCTCAGAGGTTTACCAAGATTCAAAA CACGAAGCTGACCATGAAGCGGGACGGCATTGGGTCAGTGCGGTACCAGGTCTTGGAG GTGTCTCGGCAACCACTCTTCACCAATATCACAGTGGACATTGGGCGGCCTCCGTCGT GGCCCCCTCGGGGCTGA
ORF Start: ATG at 1 ORF Stop: TGA at 1117 SEQ ID NO: 82 372 aa MW at41980.7kD
NOV4c, MSR LGGT ERVCKAVL LCL HF VAVILYFDVYAQHLAFFSRFSARGPAHALHPAA CG103241-03 SSSSSSSNCSRPNATASSSG PEVPSALPGPTAPTLPPCPDSPPGVGRLLIEFTSPM P ERVHRENPGVMGGRYTPPDCTPAQTVAVIIPFRHREHH RYW HYLHPILRRQRL Protein Sequence RYGVYVINQHGEDTFNRAKLLNVGFLEAKEDAAYDCFIFSDVDLVPMDDRNLYRCGD QPRHFAIAMDKFGFRLPYAGYFGGVSG SKAQFLRINGFPNEY G GGEDDDIFNRIS TGMKISRPDIRIGRYRMIKHDRDKHNEPNPQRFTKIQNTK TMKRDGIGSVRYQVIiE VSRQPLFTNITVDIGRPPSWPPRG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 4B.
Further analysis of the NOV4a protein yielded the following properties shown in Table 4C.
Table 4C. Protein Sequence Properties NOV4a
PSort 0.8650 probability located in lysosome (lumen); 0.8200 probability located in analysis: outside; 0.2030 probability located in microbody (peroxisome); 0.1000 probability located in endoplasmic reticulum (membrane)
SignalP Cleavage site between residues 37 and 38 analysis:
A search of the NOV4a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 4D.
In a BLAST search of public sequence datbases, the NOV4a protein was found to have homology to the proteins shown in the BLASTP data in Table 4E.
PFam analysis predicts that the NOV4a protein contains the domains shown in the Table
4F.
Example 5.
The NOV5 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 5 A.
Table 5A. NO 5 Sequence Analysis
SEQ ID NO: 83 14215 bp
NOV5a, CGA-GGCATCGGTCAAGGTGGCCGTGAGGGTCCGGCCCATGAATCGCAGGGAAAAGGA CG106249-01 CTTGGAGGCCAAGTTCATTATTCAGATGGAGAAAAGCAAAACGACAATCACAAACTTA DNA Sequence AAGATACCAGAAGGAGGCACTGGGGACTCAGGAAGAGAACGGACCAAGACCTTCACCT ATGACTTTTCTTTTTATTCTGCTGATACAAAAACTACAGACTACGTTTCACAAGAAAT GGTTTTCAAAACCCTCCGCACAGATGTCCTGAATTCTGCATTTGAAGTTTATAATGCT TGTGTCTTTGCATATGGGCAAACTGGATCTGGAAAGTCCTACGCTATGATGGGAAATT CTGGAGATTCTGGCTTAATACCTCGGATCTGTGAAGGACTCTCCATTCGGATTAATGA AACCACCAGATCGGATGAAGCTTCTTTCCGAACTGAAGTCAGCTCCTTAAAAATTTAT AACGAACGTGTGAGAGATCTACTTCGGCGGAAGTCATCTAAAACCTTCAATTTGAGAG TCCGTGAGCATCCCAAAGAAGGCCCTTATGTTGAGGATTTATCCAAACATTTAGTACA GAATTATGGTGACGTAGAAGAACTTATGGATGCGGGCAATATCAACCGGACCACCGCA GCGACTGGGATGAACGACGTCAGTAGCAGGTCTCATGCCATCTTCACCATCAAGTTCA CTCAGGCTAAATTTGATTCTGAAATGCCATGTGAAACCGTCAGTAAGATCCACTTGGT TGATCTTGCCGGAAGTGAGCGTGCAGATGCCACCGGAGCCACCGGGGTTAGGCTAAAG GAAGGGGGAAATATTAACAAGTCCCTTGTGACTCTGGGGAACGTCATTTCTGCCTTAG CTGATTTATCTCAGGATGCTGCAAATACTCTTGCAAAGAAGAAGCAAGTTTTCGTGCC TTACAGGGATTCTGTGTTGACTTGGTTGTTAAAAGATAGCCTTGGAGGAAACTCTAAA ACTATCATGATTGCCACCATTTCACCTGCTGATGTCAATTATGGAGAAACCCTAAGTA CTCTTCGCTATGCAAATAGAGCCAAAAACATCATCAACAAGCCTACCATTAATGAGGA TGCCAACGTCAAACTTATCCGTGAGCTGCGAGCTGAAATAGCCAGACTGAAAACGCTG CTTGCTCAAGGGAATCAGATTGCCCTCTTAGACTCCCCCACAGCTTTAAGTATGGAGG AAAAACTTCAGCAGAATGAAGCAAGAGTTCAAGAATTGACCAAGGAATGGACAAATAA GTGGAATGAAACCCAAAATATTTTGAAAGAACAAACTCTAGCCCTCAGGAAAGAAGGG ATTGGAGTTGTTTTGGATTCTGAACTGCCTCATTTGATTGGCATCGATGATGACCTTT TGAGTACTGGAATCATCTTATATCATTTAAAGGAAGGTCAGACATACGTTGGTAGAGA CGATGCTTCCACGGAGCAAGATATTGTTCTTCATGGCCTTGACTTGGAGAGTGAGCAT TGCATCTTTGAAAATATCGGGGGGACAGTGACTCTGATACCCCTGAGTGGGTCCCAGT GCTCTGTGAATGGTGTTCAGATCGTGGAGGCCACACATCTAAATCAAGGTGCTGTGAT TCTCTTGGGAAGAACCAATATGTTTCGCTTTAACCATCCAAAGGAAGCCGCCAAGCTC AGGGAGAAGAGGAAGAGTGGCCTTCTGTCCTCCTTCAGCTTGTCCATGACCGACCTCT CGAAGTCCCGTGAGAACCTGTCTGCAGTCATGTTGTATAACCCCGGACTTGAGTTTGA GAGGCAACAGCGTGAAGAACTTGAAAAATTAGAAAGTAAAAGGAAACTCATTGAGGAA ATGGAGGAAAAGCAGAAATCGGACAAGGCTGAACTGGAGCGGATGCAGCAGGAGGTGG AGACCCAGCGCAAGGAGACAGAAATCGTGCAGCTCCAGATTCGCAAGCAGGAGGAGAG CCTCAAACGCCGCAGCTTCCACATCGAGAACAAGCTAAAGGATTTACTTGCGGAGAAG GAAAAATTTGAAGAGGAGAGGCTGAGGGAACAGCAGGAAATCGAGCTGCAGAAGAAGA GACAAGAAGAAGAGACCTTTCTCCGCGTCCAAGAAGAACTCCAACGACTCAAAGAACT CAACAACAACGAGAAGGCTGAGAAGTTTCAGATATTTCAAGAACTGGACCAGCTCCAA AAGGAAAAAGATGAACAGTATGCCAAGCTTGAACTGGAAAAAAAGAGACTAGAGGAGC AGGAGAAGGAGCAGGTCATGCTCGTGGCCCATCTGGAAGAGCAGCTCCGAGAGAAGCA GGAGATGATCCAGCTCCTGCGGCGTGGGGAGGTACAGTGGGTGGAAGAGGAGAAGAGG GACCTGGAAGGCATTCGGGAATCCCTCCTGCGGGTGAAGGAGGCTCGTGCCGGAGGGG ATGAAGATGGCGAGGAGTTAGAAAAGGCTCAACTGCGTTTCTTCGAATTCAAGAGAAG

NOV5b, CGGCACGAGGGGGATGAGCGATGGCATCGGTCAAGGTGGCCGTGAGGGTCCGGCCCAT: CG106249-02 GAATCGCAGGGAAAAGGACTTGGAGGCCAAGTTCATTATTCAGATGGAGAAAAGCAAA DNA Sequence ACGACAATCACAAACTTAAAGATACCAGAAGGAGGCACTGGGGACTCAGGAAGAGAAC
GGACCAAGACCTTCACCTATGACTTTTCTTTTTATTCTGCTGATACAAAAAGCCCAGA
TTACGTTTCACAAGAAATGGTTTTCAAAACCCTCGGCACAGATGTCGTGAAGTCTGCA
TTTGAAGGTTATAATGCTTGTGTCTTTGCATATGGGCAAACTGGATCTGGAAAGTCAT
ACACTATGATGGGAAATTCTGGAGATTCTGGCTTAATACCTCGGATCTGTGAAGGACT
CTTCAGTCGGATAAATGAAACCACCAGATGGGATGAAGCTTCTTTTCGAACTGAAGTC
AGCTACTTAGAAATTTATAACGAACGTGTGAGAGATCTACTTCGGCGGAAGTCATCTA
AAACCTTCAATTTGAGAGTCCGTGAGCATCCCAAAGAAGGCCCTTATGTTGAGGATTT
ATCCAAACATTTAGTACAGAATTATGGTGACGTAGAAGAACTTATGGATGCGGGCAAT
ATCAACCGGACCACCGCAGCGACTGGGATGAACGACGTCAGTAGCAGGTCTCATGCCA
TCTTCACCATCAAGTTCACTCAGGCTAAATTTGATTCTGAAATGCCATGTGAAACCGT
CAGTAAGATCCACTTGGTTGATCTTGCCGGAAGTGAGCGTGCAGATGCCACCGGAGCC
ACCGGGGTTAGGCTAAAGGAAGGGGGAAATATTAACAAGTCCCTTGTGACTCTGGGGA
ACGTCATTTCTGCCTTAGCTGATTTATCTCAGGATGCTGCAAATACTCTTGCAAAGAA
GAAGCAAGTTTTCGTGCCTTACAGGGATTCTGTGTTGACTTGGTTGTTAAAAGATAGC
CTTGGAGGAAACTCTAAAACTATCATGATTGCCACCATTTCACCTGCTGATGTCAATT
ATGGAGAAACCCTAAGTACTCTTCGCTATGCAAATAGAGCCAAAAACATCATCAACAA
GCCTACCATTAATGAGGATGCCAACGTCAAACTTATCCGTGAGCTGCGAGCTGAAATA
GCCAGACTGAAAACGCTGCTTGCTCAAGGGAATCAGATTGCCCTCTTAGACTCCCCCA
CAGCTTTAAGTATGGAGGAAAAACTTCAGCAGAATGAAGCAAGAGTTCAAGAATTGAC
CAAGGAATGGACAAATAAGTGGAATGAAACCCAAAATATTTTGAAAGAACAAACTCTA
GCCCTCAGGAAAGAAGGGATTGGAGTTGTTTTGGATTCTGAACTGCCTCATTTGATTG
GCATCGATGATGACCTTTTGAGTACTGGAATCATCTTATATCATTTAAAGGAAGGTCA
GACATACGTTGGTAGAGACGATGCTTCCACGGAGCAAGATATTGTTCTTCATGGCCTT
GACTTGGAGAGTGAGCATTGCATCTTTGAAAATATCGGGGGGACAGTGACTCTGATAC
CCCTGAGTGGGTCCCAGTGCTCTGTGAATGGTGTTCAGATCGTGGAGGCCACACATCT
AAATCAAGGTGCTGTGATTCTCTTGGGAAGAACCAATATGTTTCGCTTTAACCATCCA
AAGGAAGCCGCCAAGCTCAGGGAGAAGAGGAAGAGTGGCCTTCTGTCCTCCTTCAGCT
TGTCCATGACCGACCTCTCGAAGTCCCGTGAGAACCTGTCTGCAGTCATGTTGTATAA
CCCCGGACTTGAATTTGAGAGGCAACAGCGTGAAGAACTTGAAAAATTAGAAAGTAAA
AGGAAACTCATAGAAGAAATGGAGGAAAAGCAGAAATCAGACAAGGCTGAACTGGAGC
GGATGCAGCAGGAGGTGGAGACCCAGCGCAAGGAGACAGAAATCGTGCAGCTCCAGAT
TCGCAAGCAGGAGGAGAGCCTCAAACGCCGCAGCTTCCACATCGAGAACAAGCTAAAG
GATTTACTTGCGGAGAAGGAAAAATTTGAAGAGGAGAGGCTGAGGGAACAGCAGGAAA
TCGAGCTGCAGAAGAAGAGACAAGAAGAAGAGACCTTTCTCCGCGTCCAAGAAGAACT
CCAACGACTCAAAGAACTCAACAACAACGAGAAGGCTGAGAAGTTTCAGATATTTCAA
GAACTGGACCAGCTCCAAAAGGAAAAAGATGAACAGTATGCCAAGCTTGAACTGGAAA
AAAAGAGACTAGAGGAGCAGGAGAAGGAGCAGGTCATGCTCGTGGCCCATCTGGAAGA
GCAGCTCCGAGAGAAGCAGGAGATGATCCAGCTCCTGCGGCGTGGGGAGGTACAGTGG
GTGGAAGAGGAGAAGAGGGACCTGGAAGGCATTCGGGAATCCCTCCTGCGGGTGAAGG
AGGCTCGTGCCGGAGGGGATGAAGATGGCGAGGAGTTAGAAAAGGCTCAACTGCGTTT
CTTCGAATTCAAGAGAAGGCAGCTTGTCAAGCTAGTGAACTTGGAGAAGGACCTGGTT
CAGCAGAAAGACATCCTGAAAAAAGAAGTCCAAGAAGAACAGGAGATCCTAGAGTGTT
TAAAATGTGAACAXGACAAAGAATCTAGATTGTTGGAAAAACATGATGAGAGTGTCAC
AGATGTCACGGAAGTGCCTCAAGATTTCGAGAAAATAAAGCCAGTGGAGTACAGGCTG
CAATATAAAGAACGCCAGCTACAGTACCTCCTGCAGAATCACTTGCCAACTCTGTTGG
AAGAAAAGCAGAGAGCATTTGAAATTCTTGACAGAGGCCCTCTCAGCTTAGACAACAC
TCTTTATCAAGTAGAAAAGGAAATGGAAGAAAAAGAAGAACAGCTTGCACAGTACCAG
GCCAATGCAAACCAGCTGCAAAAGCTCCAAGCCACCTTTGAATTCACTGCCAACATTG
CACGTCAGGAGGAAAAAGTGAGGAAAAAGGAAAAGGAGATTTTGGAGTCCAGAGAGAA
GCAGCAGAGAGAGGCGCTGGAGCGGGCCCTGGCCAGGCTGGAGAGGAGACATTCTGCG
CTGCAGAGGCACTCCACCCTGGGCACGGAGATTGAAGAGCAGAGGCAGAAACTTGCCA
GTCTGAACAGTGGCAGCAGAGAGCAGTCAGGGCTCCAGGCTAGCCTGGAGGCTGAGCA
GGAAGCCCTGGAGAAGGACCAGGAGAGGTTAGAATATGAAATCCAGCAGCTGAAACAG
AAGATTTATGAGGTCGATGGTGTTCAAAAAGATCATCATGGGACCCTGGAAGGGAAGG
TGGCTTCTTCCAGCTTGCCAGTCAGTGCTGAAAAATCACACCTGGTTCCCCTCATGGA
TGCCAGGATCAATGCTTACATTGAAGAAGAAGTCCAAAGACGCCTTCAGGATTTGCAT
CGTGTGATTAGTGAAGGCTGCAGTACATCTGCAGACACGATGAAGGATAATGAGAAAC
TTCACAATGGCACCATTCAACGTAAACTAAAATATGAGCTGTGTCGTGACCTCCTGTG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 5B.
Further analysis of the NOV5a protein yielded the following properties shown in Table 5C.
Table 5C. Protein Sequence Properties NOV5a
PSort 0.6086 probability located in mitochondrial matrix space; 0.3127 probability analysis: located in mitochondrial inner membrane; 0.3127 probability located in mitochondrial intermembrane space; 0.3127 probability located in mitochondrial outer membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV5a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 5D.
In a BLAST search of public sequence datbases, the NOV5a protein was found to have homology to the proteins shown in the BLASTP data in Table 5E.
Table 5E. Public BLASTP Results for NOV5a
Protein NOV5a Identities/ Expect
Accession Protein Organism Length Residues/ Similarities for Value
Number Match the Matched
PFam analysis predicts that the NO V5a protein contains the domains shown in the Table 5F.
Example 6.
The NOV6 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 6A.
ACCGGCCTGGCATCTACACCCGTGTCACCTACTACTTGGACTGGATCCACCACTATGT CCCCAAAAAGCCGTGA
ORF Start: ATG at 1 ORF Stop: TGA at 826
SEQ ID NO: 92 275 aa MW at 30514.9kD
NOV6c, MLNLLLLALPVASRAYAAPAPGQALQRVGIVGGQEAPRSK PWQVSLRVHGPY MHF CGI 06824-02 CGGSLIHPQWVLTAAHCVGPDVKDLAALRVQLREQHIiYYQDQL PVSRIIVHPQFYTA QIGADIAL E EEPVNVSSHVHTVTLPPASETFPPGMPC VTGWGDVDNDERLPPPFP Protein Sequence LKQVKVPIMENHICDAKYHLGAYTGDDVRIVRDDM CAGNTRRDSCQGDSGGP VCKV NGTWLQAGWSWGEGCAQPNRPGIYTRVTYYLD IHHYVPKKP
SEQ ID NO: 93 1145 bp
NOV6d, GGCCAGGATGCTGAATCTGCTGCTGCTGGCGCTGCCCGTCCTGGCGAGCCGCGCCTAC CG106824-03 GCGGCCCCTGCCCCAGGCCAGGCCCTGCAGCGAGTGGGCATCGTTGGGGGTCAGGAGG CCCCCAGGAGCAAGTGGCCCTGGCAGGTGAGCCTGAGAGTCCACGGCCCATACTGGAT DNA Sequence GCACTTCTGCGGGGGCTCCCTCATCCACCCCCAGTGGGTGCTGACCGCAGCGCACTGC GTGGGACCGGACGTCAAGGATCTGGCCGCCCTCAGGGTGCAACTGCGGGAGCAGCACC TCTACTACCAGGACCAGCTGCTGCCGGTCAGCAGGATCATCGTGCACCCACAGTTCTA CACCGCCCAGATCGGAGCGGACATCGCCCTGCTGGAGCTGGAGGAGCCGGTGAAGGTC TCCAGCCACGTCCACACGGTCACCCTGCCCCCTGCCTCAGAGACCTTCCCCCCGGGGA TGCCGTGCTGGGTCACTGGCTGGGGCGATGTGGACAATGATGAGCGCCTCCCACCGCC ATTTCCTCTGAAGCAGGTGAAGGTCCCCATAATGGAAAACCACATTTGTGACGCAAAA TACCACCTTGGCGCCTACACGGGAGACGACGTCCGCATCGTCCGTGACGACATGCTGT GTGCCGGGAACACCCGGAGGGACTCATGCCAGGGCGACTCCGGAGGGCCCCTGGTGTG CAAGGTGAATGGCACCTGGCTGCAGGCGGGCGTGGTCAGCTGGGGCGAGGGCTGTGCC CAGCCCAACCGGCCTGGCATCTACACCCGTGTCACCTACTACTTGGACTGGATCCACC ACTATGTCCCCAAAAAGCCGTGAGTCAGGCCTGGGTTGGCCACCTGGGTCACTGGAGG
ACCAACCCCTGCTGTCCAAAACACCACTGCTTCCTACCCAGGTGGCGACTGCCCCCCA
CACCTTCCCTGCCCCGTCCTGAGTGCCCCTTCCTGTCCTAAGCCCCCTGCTCTCTTCT
GAGCCCCTTCCCCTGTCCTGAGGACCCTTCCCCATCCTGAGCCCCCTTCCCTGTCCTA
AGCCTGACGCCTGCACCGGGCCCTCCGGCCCTCCCCTGCCCAGGCAGCTGGTGGTGGG
CGCTAATCCTCCTGAGTGCTGGACCTCATTAAAGTGCATGGAA
ORF Start: ATG at 8 ORF Stop: TGA at 833
SEQ ID NO: 94 275 aa MW at 30528.9kD
NOV6d, MLNLL ALPV ASRAYAAPAPGQALQRVGIVGGQEAPRSKWP QVSLRVHGPY MHF CG106824-03 CGGSLIHPQ VLTAAHCVGPDVKDLAALRVQLREQH YYQDQLLPVSRIIVHPQFYTA QIGADIALLE EEPVKVSSHVHTVTLPPASETFPPGMPC VTGWGDVDNDERLPPPFP Protein Sequence LKQVKVPIMENHICDAKYHLGAYTGDDVRIVRDDMLCAGNTRRDSCQGDSGGP VCKV NGTWLQAGWSWGEGCAQPNRPGIYTRVTYY D IHHYVPKKP
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 6B.
Further analysis of the NOV6a protein yielded the following properties shown in Table 6C.
Table 6C. Protein Sequence Properties NOV6a
PSort 0.8650 probability located in lysosome (lumen); 0.6950 probability located in analysis: outside; 0.1333 probability located in microbody (peroxisome); 0.1000 probability located in endoplasmic reticulum (membrane)
SignalP Cleavage site between residues 21 and 22 analysis:
A search of the NOV6a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 6D.
In a BLAST search of public sequence datbases, the NOV6a protein was found to have homology to the proteins shown in the BLASTP data in Table 6E.
Table 6E. Public BLASTP Results for NOV6a
Protein 6a Identities/ Expect Accession Protein/Organism/Length NOV Residues/ Similarities fnr Value
PFam analysis predicts that the NOV6a protein contains the domains shown in the Table 6F.
Table 6F. Domain Analysis of NOV6a
Identities/
Pfam Domain NO 6a Match Region Similarities Expect Value for the Matched Region trypsin 39..271 111/264 (42%) 6.4e-89 191/264 (72%)
Example 7.
The NOV7 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 7A.
Table 7A. NOV7 Sequence Analysis
SEQ ID NO: 95 842 bp
NOV7a, GTGGCCGTCCGAGAGCCGAGAGGTGAGGGTGCCCCCGCCTCACCTGCAGAGGGGCCGT CGI 14327-01 TCCGGGCTCGAACCCGGCACCTTCCGGAAAATGGCGGCTGCCAGGCCCAGCCTGGGCC
GAGTCCTCCCAGGATCCTCTGTCCTGTTCCTGTGTGACATGCAGGAGAAGTTCCGCCA DNA Sequence CAACATCGCCTACTTCCCACAGATCGTCTCAGTGGCTGCCCGCATGCTCAAGAACACG ACCCTGGACCTCCTAGACCGGGGGCTGCAGGTCCATGTGGTGGTGGACGCCTGCTCCT CACGCAGCCAGGTGGACCGGCTGGTGGCTCTGGCCCGCATGAGACAGAGTGGTGCCTT CCTCTCCACCAGCGAAGGGCTCATTCTGCAGCTTGTGGGCGATGCCGTCCACCCCCAG TTCAAGGAGATCCAGAAACTCATCAAGGAGCCCGCCCCAGACAGCGGACTGCTGGGCC TCTTCCAAGGCCAGAACTCCCTCCTCCACTGAACTCCAACCCTGCCTTGAGGGAAGAC CACCCTCCTGTCACCCGGACCTCAGTGGAAGCCCGTTCCCCCCATCCCTGGATCCCAA GAGTGGTGCGATCCACCAGGAGTGCCGCCCCCTTGTGGGGGGGGGCAGGGTGCTGCCT TCCCATTGGACAGCTGCTCCCGGAAATGCAAATGAGACTCCTGGAAACTGGGTGGGAA
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 7B.
Further analysis of the NOV7a protein yielded the following properties shown in Table 7C.
Table 7C. Protein Sequence Properties NOV7a
PSort 0.5108 probability located in mitochondrial matrix space; 0.4500 probability analysis: located in cvtonlasm: 0.2553 nrobabilitv located in Ivsosome flu en _ 0.2357
probability located in mitochondrial inner membrane
SignalP Cleavage site between residues 24 and 25 analysis:
A search of the NOV7a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 7D.
In a BLAST search of public sequence datbases, the NOV7a protein was found to have homology to the proteins shown in the BLASTP data in Table 7E.
PFam analysis predicts that the NOV7a protein contains the domains shown in the Table
7F.
Example 8.
The NOV8 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 8 A.
Table 8A. NO 8 Sequence Analysis
SEQ ID NO: 99
NOV8a, TGCGCCAGGATGGAGTTCGTGAAATGCCTTGGCCACCCCGAAGAGTTCTACAACCTGG CGI 19418-01 TGCGCTTCCGGATCGGGGGCAAGCGGAAGGTGATGCCCAAGATGGACCAGGACTCGCT DNA Sequence CAGCAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCA GCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGG TTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGT CCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAG AGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTA GAAATCTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCAT TGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCTGAACAGGAGTGGGACAAGTAC TGCCACTATGTTGCTGGGCTGGTCGGAATTGGCCTTTCCCGTCTTTTCTCAGCCTCAG AGTTTGAAGACCCCTTAGTTGGTGAAGATACAGAACGTGCCAACTCTATGGGCCTGTT TCTGCAGAAAACAAACATCATCCGTGACTATCTGGAAGACCAGCAAGGAGGAAGAGAG TTCTGGCCTCAAGAGGTTTGGAGCAGGTATGTTAAGAAGTTAGGGGATTTTGCTAAGC CGGAGAATATTGACTTGGCCGTGCAGTGCCTGAATGAACTTATAACCAATGCACTGCA CCACATCCCAGATGTCATCACCTACCTTTCGAGACTCAGAAACCAGAGTGTGTTTAAC TTCTGCGCTATTCCACAGGTGATGGCCATTGCCACTTTGGCTGCCTGTTATAATAACC AGCAGGTGTTCAAAGGGGCAGTGAAGATTCGGAAAGGGCAAGCAGTGACCCTGATGAT GGATGCCACCAATATGCCAGCTGTCAAAGCCATCATATATCAGTATATGGAAGAGATT TATCATAGAATCCCCGACTCAGACCCATCTTCTAGCAAAACAAGGCAGATCATCTCCA CCATCCGGACGCAGAATCTTCCCAACTGTCAGCTGATTTCCCGAAGCCACTACTCCCC CATCTACCTGTCGTTTGTCATGCTTTTGGCTGCCCTGAGCTGGCAGTACCTGACCACT CTCTCCCAGGTAACAGAAGACTATGTTCAGACTGGAGAACACTGATCCCAAATTTGTC

Further analysis of the NO V8a protein yielded the following properties shown in Table 8B.
Table 8B. Protein Sequence Properties NOV8a
PSort 0.4500 probability located in cytoplasm; 0.3719 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV8a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 8C.
In a BLAST search of public sequence datbases, the NOV8a protein was found to have homology to the proteins shown in the BLASTP data in Table 8D.
PFam analysis predicts that the NOV8a protein contains the domains shown in the Table 8E.
The NOV9 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 9A.
Table 9A. NOV9 Sequence Analysis
SEQ ID NO: 101 2106 bp
NOV9a, ATGGGGCTTCCTGAGGAGCGGGTCCGGAGCGGCAGCGGGAGCCGGGGCCAGGAGGAAG CG120359-01 CTGGAGCCGGAGGCCGGGCGCGGAGTTGGTCTCCGCCGCCCGAGGTCAGCCGCTCCGC GCACGTCCCCTCGCTGCAGCGCTACCGCGAGCTGCACCGGCGCTCCGTGGAGGAGCCG DNA Sequence CGGGAATTCTGGGGAGACATTGCCAAGGAATTTTACTGGAAGACTCCATGCCCTGGCC CATTCCTTCGGTACAACTTTGATGTGACTAAAGGGAAAATCTTCATTGAGTGGATGAA AGGAGCAACTACCAACATCTGCTACAATGTACTGGATCGAAATGTCCATGAGAAAAAG CTTGGAGATAAAGTTGCTTTTTACTGGGAGGGCAATGAGCCAGGGGAGACCACTCAGA TCACATACCATCAGCTTCTGGTCCAAGTGTGTCAGTTCAGCAATGTTCTCCGAAAACA GGGCATTCAGAAGGGGGACCGAGTGGCCATCTACATGCCTATGATCCCAGAGCTTGTG GTGGCCATGCTGGCATGTGCCCGCATTGGGGCTTTGCACTCCATTGTGTTTGCAGGCT TCTCTTCAGAGTCTCTATGTGAACGGATCTTGGATTCCAGCTGCAGTCTTCTCATCAC TACAGATGCCTTCTACAGGGGGGAAAAGCTTGTGAACCTGAAGGAGCTGGCTGACGAG GCCCTGCAGAAGTGTCAGGAGAAGGGTTTCCCAGTAAGATGCTGCATTGTGGTCAAGC ACCTGGGGCGGGCAGAGCTCGGCATGGGTGACTCCACCAGCCAGTCCCCCCCAATTAA GAGGTCATGCCCAGATGTGCAGATCTCATGGAACCAAGGGATTGACTTGTGGTGGCAT GAGCTCATGCAAGAGGCAGGGGATGAGTGTGAGCCCGAGTGGTGTGATGCCGAGGACC CACTCTTCATCCTGTACACCAGTGGCTCCACAGGCAAACCCAAGGGTGTGGTTCACAC AGTTGGGGGCTACATGCTCTATGTAGCCACAACCTTCAAGTATGTGTTTGACTTCCAT GCAGAGGATGTGTTCTGGTGCACGGCAGACATTGGTTGGATCACTGGTCATTCCTACG TCACCTATGGGCCACTGGCCAATGGTGCCACCAGTGTTTTGTTTGAGGGGATTCCCAC ATATCCGGACGTGAACCGCCTGTGGAGCATTGTGGACAAATACAAGGTGACCAAGTTC TACACAGCACCCACAGCCATCCGTCTGCTCATGAAGTTTGGAGATGAGCCTGTCACCA AGCATAGCCGGGCATCCTTGCAGGTGTTAGGCACAGTGGGTGAACCCATCAACCCTGA GGCCTGGCTATGGTACCACCGGGTGGTAGGTGCCCAGCGCTGCCCCATCGTGGACACC TTCTGGCAAACAGAGACAGGTGGCCACATGTTGACTCCCCTTCCTGGTGCCACACCCA TGAAACCCGGTTCTGCTACTTTCCCATTCTTTGGTGTAGCTCCTGCAATCCTGAATGA GTCCGGGGAAGAGTTGGAAGGTGAAGCTGAAGGTTATCTGGTGTTCAAGCAGCCCTGG CCAGGGATCATGCGCACAGTCTATGGGAACCACGAACGCTTTGAGACAACCTACTTTA AGAAGTTTCCTGGATACTATGTTACAGGAGATGGCTGCCAGCGGGACCAGGATGGCTA TTACTGGATCACTGGCAGGATTGATGACATGCTCAATGTATCTGGACACCTGCTGAGT ACAGCAGAGGTGGAGTCAGCACTTGTGGAACATGAGGCTGTTGCAGAGGCAGCTGTGG TGGGCCACCCTCATCCTGTGAAGGGTGAATGCCTCTACTGCTTTGTCACCTTGTGTGA TGGCCACACCTTCAGCCCCAAGCTCACCGAGGAGCTCAAGAAGCAGATTAGAGAAAAG ATTGGCCCCATTGCCACACCAGACTACATCCAGAATGCACCTGGCTTGCCTAAAACCC GCTCAGGGAAAATCATGAGGCGAGTGCTTCGGAAGATTGCTCAGAATGACCATGACCT CGGGGACATGTCTACTGTGGCTGACCCATCTGTCATCAGTCACCTCTTCAGCCACCGC TGCCTGACCATCCAGTGA
ORF Start: ATG at 1 ORF Stop: TGA at 2104
SEQ ID NO: 102 701 aa MW at 78578.9kD
NOV9a, MG PEERVRSGSGSRGQEEAGAGGRARS SPPPEVSRSAHVPSLQRYRE HRRSVEEP CG120359-01 REFWGDIAKEFY KTPCPGPFLRYNFDVTKGKIFIE KGAT NICYNV DRNVHEKK GDKVAFY EGNEPGETTQITYHQ LVQVCQFSNV RKQGIQKGDRVAIY PMIPELV Protein Sequence VA LACARIGALHSIVFAGFSSESLCERILDSSCS LITTDAFYRGEKVNLKELADE A QKCQEKGFPVRCCIWKH GRAELG GDSTSQSPPIKRSCPDVQISWNQGID H ELMQEAGDECEPE CDAEDPLFILYTSGSTGKPKGWHTVGGYMLYVATTFKYVFDFH AEDVF CTADIG ITGHSYVTYGPLANGATSV FΞGIPTYPDVNRL SIVDKYKVTKF YTAPTAIRLLMKFGDEPVTKHSRASLQV GTVGEPINPEAWL YHRWGAQRCPIVDT FWQTETGGHMLTPLPGATPMKPGSATFPFFGVAPAILNESGEELEGEAEGYLVFKQPW PGI RTVYGlvTHERFETTYFIOCFPGYYVTGDGCQRDQDGYYWITGRIDDMLNVSGHL S TAEVESALVEHEAVAEAAWGHPHPVKGECLYCFVTLCDGHTFSPKLTEE KKQIREK
IGPIATPDYIQNAPGLPKTRSGKIMRRVLRKIAQNDHD GDMSTVADPSVISHLFSHR CLTIQ
SEQ ID NO: 103 2125 bp
NOV9b, CACCGGATCCACCATGGGGCTTCCTGAGGAGCGGGTCCGGAGCGGCAGCGGGAGCCGG 277685717 DNA GGCCAGGAGGAAGCTGGAGCCGGAGGCCGGGCGCGGAGTTGGTCTCCGCCGCCCGAGG TCAGCCGCTCCGCGCACGTCCCCTCGCTGCAGCGCTACCGCGAGCTGCACCGGCGCTC Sequence CGTGGAGGAGCCGCGGGAATTCTGGGGAGACATTGCCAAGGAATTTTACTGGAAGACT CCATGCCCTGGCCCATTCCTTCGGTACAACTTTGATGTGACTAAAGGGAAAATCTTTA TTGAGTGGATGAAAGGAGCAACTACCAACATCTGCTACAATGTACTGGATCGAAATGT CCATGAGAAAAAGCTTGGAGATAAAGTTGCTTTTTACTGGGAGGGCAATGAGCCAGGG GAGACCACTCAGATCACATACCATCAGCTTCTGGTCCAAGTGTGTCAGTTCAGCAATG TTCTCCGAAAACAGGGCATTCAGAAGGGGGACCGAGTGGCCATCTACATGCCTATGAT CCCAGAGCTTGTGGTGGCCATGCTGGCATGTGCCCGCATTGGGGCTTTGCACTCCATT GTGTTTGCAGGCTTCTCTTCAGAGTCTCTATGTGAACGGATCTTGGATTCCAGCTGCA GTCTTCTCATCACTACAGATGCCTTCTACAGGGGGGAAAAGCTTGTGAACCTGAAGGA GCTGGCTGACGAGGCCCTGCAGAAGTGTCAGGAGAAGGGTTTCCCAGTAAGATGCTGC ATTGTGGTCAAGCACCTGGGGCGGGCAGAGCTCGGCATGGGTGACTCCACCAGCCAGT CCCCCCCAATTAAGAGGTCATGCCCAGATGTGCAGATCTCATGGAACCAAGGGATTGA CTTGTGGTGGCATGAGCTCATGCAAGAGGCAGGGGATGAGTGTGAGCCCGAGTGGTGT GATGCCGAGGACCCACTCTTCATCCTGTACACCAGTGGCTCCACAGGCAAACCCAAGG GTGTGGTTCACACAGTTGGGGGCTACATGCTCTATGTAGCCACAACCTTCAAGTATGT GTTTGACTTCCATGCAGAGGATGTGTTCTGGTGCACGGCAGACATTGGTTGGATCACT GGTCATTCCTACGTCACCTATGGGCCACTGGCCAATGGTGCCACCAGTGTTTTGTTTG AGGGGATTCCCACATATCCGGACGTGAACCGCCTGTGGAGCATTGTGGACAAATACAA GGTGACCAAGTTCTACACAGCACCCACAGCCATCCGTCTGCTCATGAAGTTTGGAGAT GAGCCTGTCACCAAGCATAGCCGGGCATCCTTGCAGGTGTTAGGCACAGTGGGTGAAC CCATCAACCCTGAGGCCTGGCTATGGTACCACCGGGTGGTAGGTGCCCAGCGCTGCCC CATCGTGGACACCTTCTGGCAAACAGAGACAGGTGGCCACATGTTGACTCCCCTTCCT GGTGCCACACCCATGAAACCCGGTTCTGCTACTTTCCCATTCTTTGGTGTAGCTCCTG CAATCCTGAATGAGTCCGGGGAAGAGTTGGAAGGTGAAGCTGAAGGTTATCTGGTGTT CAAGCAGCCCTGGCCAGGGATCATGCGCACAGTCTATGGGAACCACGAACGCTTTGAG ACAACCTACTTTAAGAAGTTTCCTGGATACTATGTTACAGGAGATGGCTGCCAGCGGG ACCAGGATGGCTATTACTGGATCACTGGCAGGATTGATGACATGCTCAATGTATCTGG ACACCTGCTGAGTACAGCAGAGGTGGAGTCAGCACTTGTGGAACATGAGGCTGTTGCA GAGGCAGCTGTGGTGGGCCACCCTCATCCTGTGAAGGGTGAATGCCTCTACTGCTTTG TCACCTTGTGTGATGGCCACACCTTCAGCCCCAAGCTCACCGAGGAGCTCAAGAAGCA GATTAGAGAAAAGATTGGCCCCATTGCCACACCAGACTACATCCAGAATGCACCTGGC TTGCCTAAAACCCGCTCAGGGAAAATCATGAGGCGAGTGCTTCGGAAGATTGCTCAGA ATGACCATGACCTCGGGGACATGTCTACTGTGGCTGACCCATCTGTCATCAGTCACCT CTTCAGCCACCGCTGCCTGACCATCCAGCTCGAGGGC
ORF Start: at 2 ORF Stop: end of (sequence
SEQ ID NO: 104 |708 aa IMW at 79224.6kD
NOV9b, TGSTMGLPEERVRSGSGSRGQEEAGAGGRARS SPPPEVSRSAHVPSLQRYRELHRRS 277685717 VEEPREFWGDIAKEFY KTPCPGPFLRYNFDVTKGKIFIE MKGATTNICYNVLDRNV HEKKLGDK^AFY EGNEPGETTQITYHQLLVQVCQFSNV RKQGIQKGDRVAIY P I Protein Sequence PE WAMLACARIGALHSIVFAGFSSESLCERI DSSCS ITTDAFYRGEKVNLKE LADEALQKCQEKGFPVRCCIVVKHLGRAE G GDSTSQSPPIKRSCPDVQIS NQGID L HEL QEAGDECEPE CDAEDP FILYTSGSTGKPKGVVHTVGGYMLYVATTFKYV FDF__3DVFWCTADIGWITGHSYVTYGPLANGATSV FEGIPTYPDVNRLWSIVDKYK V_KFYTAPTAIRLLMKFGDEPVTKHSRASLQVLGTVGEPINPEA LWYHRVVGAQRCP IVDTFWQTETGGHMLTPLPGATPMKPGSATFPFFGVAPAILNESGEE EGEAEGY VF KQP PGIMR VYGNHERFETTYFKKFPGYYVTGDGCQRDQDGYY ITGRIDDMLNVSG HL STAEVESAVEHEAVAEAAWGHPHPVKGECLYCFVTLCDGHTFSPKLTEELKKQ IREKIGPIATPDYIQNAPGLPKTRSGKIMRRVLRKIAQNDHDLGD STVADPSVISH FSHRCLTIQLEG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 9B.
Further analysis of the NOV9a protein yielded the following properties shown in Table 9C.
Table 9C. Protein Sequence Properties NOV9a
PSort 0.9000 probability located in Golgi body; 0.7900 probability located in plasma analysis: membrane; 0.7166 probability located in microbody (peroxisome); 0.2000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV9a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 9D.
In a BLAST search of public sequence datbases, the NOV9a protein was found to have homology to the proteins shown in the BLASTP data in Table 9E.
CoA ligase) (Acyl-activating enzyme) (Acetyl-CoA synthetase) (ACS) (AceCS) - Homo sapiens (Human), 701 aa.
BAC03849 CDNA FLJ34962 fis, clone 1..701 699/714 (97%) 0.0 NTONG2003897, highly similar to 1..714 700/714 (97%) Homo sapiens acetyl-CoA synthetase mRNA - Homo sapiens (Human), 714 aa.
BAC04235 CDNA fis, clone TRACH2001275, 1..701 653/701 (93%) 0.0 highly similar to Mus musculus 1..701 676/701 (96%) acetyl-CoA synthetase mRNA - Mus musculus (Mouse), 701 aa.
Q9QXG4 Acetyl-coenzyme A synthetase, 1..701 651/701 (92%) 0.0 cytoplasmic (EC 6.2.1.1) (Acetate- 1..701 673/701 (95%) Co A ligase) (Acyl-activating enzyme) (Acetyl-CoA synthetase) (ACS) (AceCS) - Mus musculus (Mouse), 701 aa.
Q96FY7 Unknown (protein for MGC: 19474) 260..701 442/442 (100%) 0.0 - Homo sapiens (Human), 442 aa. 1..442 442/442 (100%)
PFam analysis predicts that the NOV9a protein contains the domains shown in the Table 9F.
Example 10.
The NOV10 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 10A.
Table 10A. NOV10 Sequence Analysis
SEQ ID NO: 109 1958 bp
NOVlOa, GCAGGCCAGCCCCATGGGGAAGCGCAGACGCCGGNGCCTGGGCGCTCTGAGATTGTC CG124907-01 CTGCTGTTCCAAGGGCACACGCAGAGGGATTTGGAATTCCTGGAGAGTTGCCTTTGTG!
AGAAGCTGGAAATATTTCTTTCAATTCCATCTCTTAGTTTTCCATAGGAACATCAAGAj DNA Sequence AATCATGAACAACTTTGGTAATGAAGAGTTTGACTGCCACTTCCTCGATGAAGGTTTT
ACTGCCAAGGACATTCTGGACCAGAAAATTAATGAAGTTTCTTCTTCTGATGATAAGG ATGCCTTCTATGTGGCAGACCTGGGAGACATTCTAAAGAAACATCTGAGGTGGTTAAA AGCTCTCCCTCGTGTCACCCCCTTTTATGCAGTCAAATGTAATGATAGCAAAGCCATC
AVNIIAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFNCI YDHAHVKPLLQKRP^ KPDEKYYSSSI GPTCDGLDRIVERCDLPEMHVGDWM FENMGAYTVAAASTFNGFQR! PTIYYVMSGPA QLMQQFQNPDFPPEVEEQDASTLPVSCA ESG KRHRAACASASINi
V
SEQ ID NO: 115 1410 bp
NOVlOd, ACCATGGGCCACCATCACCACCATCACAACAACTTTGGTAATGAAGAGTTTGACTGCC 258252457 DNA ACTTCCTCGATGAAGGTTTTACTGCCAAGGACATTCTGGACCAGAAAATTAATGAAGT TTCTTCTTCTGATGATAAGGATGCCTTCTATGTGGCAGACCTGGGAGACATTCTAAAG Sequence AAACATCTGAGGTGGTTAAAAGCTCTCCCTCGTGTCACCCCCTTTTATGCAGTCAAAT GTAATGATAGCAAAGCCATCGTGAAGACCCTTGCTGCTACCGGGACAGGATTTGACTG TGCTAGCAAGACTGAAATACAGTTGGTGCAGAGTCTGGGGGTGCCTCCAGAGAGGATT ATCTATGCAAATCCTTGTAAACAAGTATCTCAAATTAAGTATGCTGCTAATAATGGAG TCCAGATGATGACTTTTGATAGTGAAGTTGAGTTGATGAAAGTTGCCAGAGCACATCC CAAAGCAAAGTTGGTTTTGCGGATTGCCACTGATGATTCCAAAGCAGTCTGTCGTCTC AGTGTGAAATTCGGTGCCACGCTCAGAACCAGCAGGCTCCTTTTGGAACGGGCGAAAG AGCTAAATATCGATGTTGTTGGTGTCAGCTTCCATGTAGGAAGCGGCTGTACCGATCC TGAGACCTTCGTGCAGGCAATCTCTGATGCCCGCTGTGTTTTTGACATGGGGGCTGAG GTTGGTTTCAGCATGTATCTGCTTGATATTGGCGGTGGCTTTCCTGGATCTGAGGATG TGAAACTTAAATTTGAAGAGATCACCGGCGTAATCAACCCAGCGTTGGACAAATACTT TCCGTCAGACTCTGGAGTGAGAATCATAGCTGAGCCCGGCAGATACTATGTTGCATCA GCTTTCACGCTTGCAGTTAATATCATTGCCAAGAAAATTGTATTAAAGGAACAGACGG GCTCTGATGACGAAGATGAGTCGAGTGAGCAGACCTTTATGTATTATGTGAATGATGG CGTCTATGGATCATTTAATTGCATACTCTATGACCACGCACATGTAAAGCCCCTTCTG CAAAAGAGACCTAAACCAGATGAGAAGTATTATTCATCCAGCATATGGGGACCAACAT GTGATGGCCTCGATCGGATTGTTGAGCGCTGTGACCTGCCTGAAATGCATGTGGGTGA TTGGATGCTCTTTGAAAACATGGGCGCTTACACTGTTGCTGCTGCCTCTACGTTCAAT GGCTTCCAGAGGCCGACGATCTACTATGTGATGTCAGGGCCTGCGTGGCAACTCATGC AGCAATTCCAGAACCCTGACTTCCCACCCGAAGTAGAGGAACAGGATGCCAGCACCCT GCCTGTGTCTTGTGCCTGGGAGAGTGGGATGAAACGCCACAGAGCAGCCTGTGCTTCG GCTAGTATTAATGTGTAG
ORF Start: at 1 ORF Stop: TAG at 1408
SEQ ID NO: 116 469 aa MW at 52128.6kD
NOVlOd, TMGHHHHHHNNFGNEEFDCHFLDEGFTAKDILDQKINEVSSSDDKDAFYVAD GDILK 258252457 KHLR LKALPRVTPFYAVKCNDSKAIVKTLAATGTGFDCASKTEIQLVQS GVPPERI IYANPCKQVSQIKYAANNGVQI^TFDSEVEL KVAP IPKAKLVLRIATDDSKAVCRL Protein Sequence SVKFGAT RTSRLLLERAKELNIDWGVSFHVGSGCTDPETFVQAISDARCVFDMGAE VGFSMYLLDIGGGFPGSEDVK KFEEITGVINPALDKYFPSDSGVRIIAEPGRYYVAS AFTLAVNIIAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLL QKRPKPDEKYYSSSI GPTCDGLDRIVERCD PEMHVGDWMLFENMGAYTVAAASTFN GFQRPTIYYVMSGPA QL QQFQNPDFPPEVEEQDASTLPVSCA ESG KRHRAACAS ASINV
NOVlOe, ACCATGAACAACTTTGGTAATGAAGAGTTTGACTGCCACTTCCTCGATGAAGGTTTTA 258280014 DNA CTGCCAAGGACATTCTGGACCAGAAAATTAATGAAGTTTCTTCTTCTGATGATAAGGA TGCCTTCTATGTGGCAGACCTGGGAGACATTCTAAAGAAACATCTGAGGTGGTTAAAA Sequence GCTCTCCCTCGTGTCACCCCCTTTTATGCAGTCAAATGTAATGATAGCAAAGCCATCG TGAAGACCCTTGCTGCTACCGGGACAGGATTTGACTGTGCTAGCAAGACTGAAATACA GTTGGTGCAGAGTCTGGGGGTGCCTCCAGAGAGGATTATCTATGCAAATCCTTGTAAA CAAGTATCTCAAATTAAGTATGCTGCTAATAATGGAGTCCAGATGATGACTTTTGATA GTGAAGTTGAGTTGATGAAAGTTGCCAGAGCACATCCCAAAGCAAAGTTGGTTTTGCG GATTGCCACTGATGATTCCAAAGCAGTCTGTCGTCTCAGTGTGAAATTCGGTGCCACG CTCAGAACCAGCAGGCTCCTTTTGGAACGGGCGAAAGAGCTAAATATCGATGTTGTTG GTGTCAGCTTCCATGTAGGAAGCGGCTGTACCGATCCTGAGACCTTCGTGCAGGCAAT CTCTGATGCCCGCTGTGTTTTTGACATGGGGGCTGAGGTTGGTTTCAGCATGTATCTG CTTGATATTGGCGGTGGCTTTCCTGGATCTGAGGATGTGAAACTTAAATTTGAAGAGA TCACCGGCGTAATCAACCCAGCGTTGGACAAATACTTTCCGTCAGACTCTGGAGTGAG AATCATAGCTGAGCCCGGCAGATACTATGTTGCATCAGCTTTCACGCTTGCAGTTAAT
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 10B.
Further analysis of the NOVlOa protein yielded the following properties shown in Table IOC.
Table IOC. Protein Sequence Properties NOVlOa
PSort 0.6000 probability located in nucleus; 0.3922 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVlOa protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 10D.
In a BLAST search of public sequence datbases, the NOVlOa protein was found to have homology to the proteins shown in the BLASTP data in Table 10E.
PFam analysis predicts that the NOVlOa protein contains the domains shown in the Table 10F.
Example 11.
The NOVl 1 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 11 A.
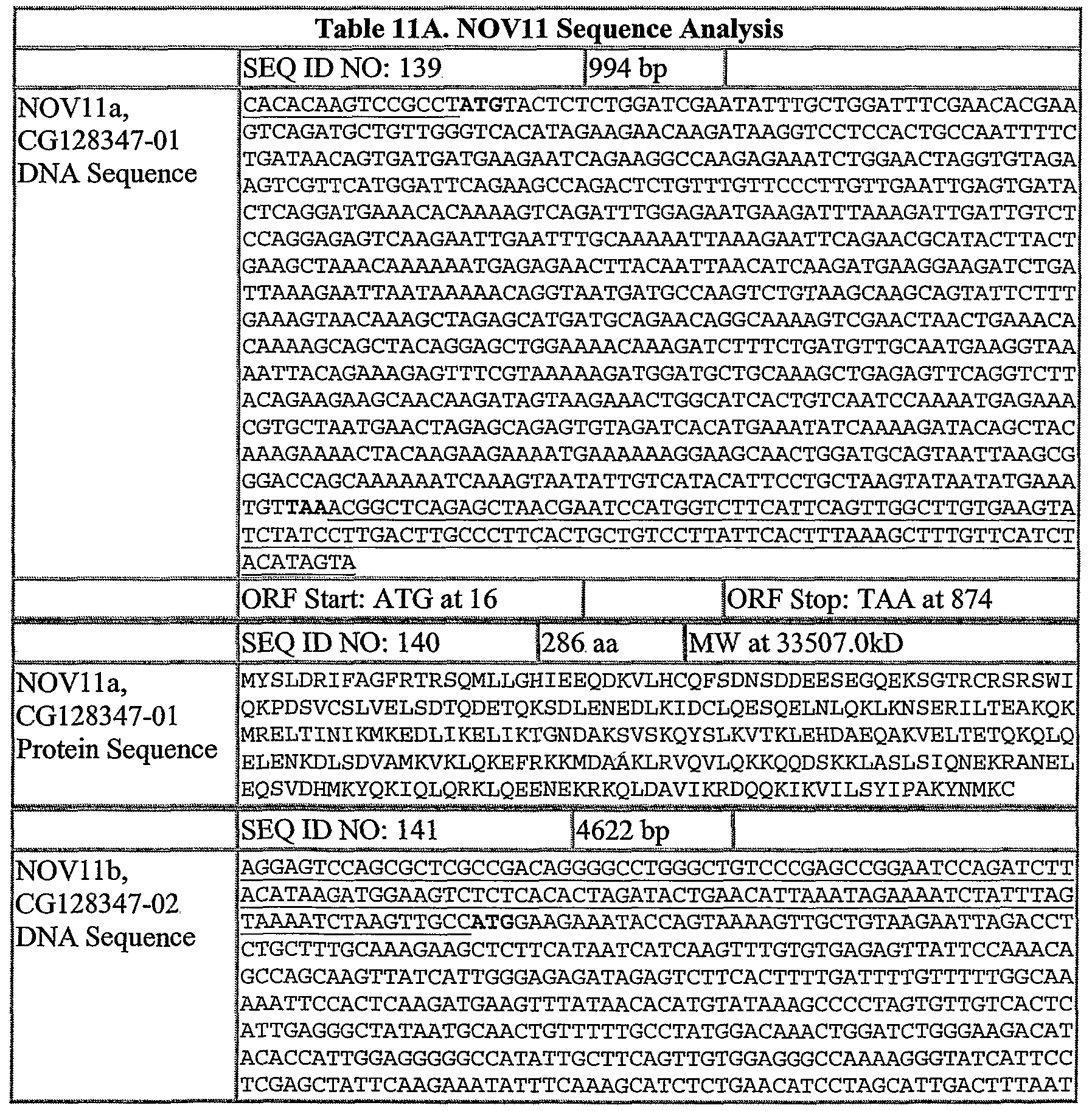
GTAAAAGTATCTTATATAGAAGTGTACAAGGAAGACCTAAGAGATCTTCTAGAATTGG AGACATCCATGAAGGATCTTCACATCCGAGAAGATGAAAAAGGAAACACAGTGATTGT TGGGGCCAAGGAATGCCATGTGGAGAGTGCAGGTGAAGTGATGAGTCTTTTGGAGATG GGGAATGCAGCCAGACATACAGGTACCACTCAAATGAATGAGCACTCCAGCAGATCAC ATGCAATTTTTACAATCAGCATTTGTCAAGTTCATAAAAATATGGAGGCAGCTGAAGA TGGATCATGGTATTCCCCTCGGCATATTGTCTCAAAGTTCCACTTTGTGGATTTGGCA GGATCAGAAAGAGTAACCAAAACGGGGAATACTGGTGAACGGTTCAAAGAATCCATTC AAATCAATAGTGGATTGCTGGCTTTAGGAAATGTAATAAGCGCTCTTGGGGACCCACG CAGGAAGAGTTCACATATTCCATATAGGGATGCTAAAATTACCCGGCTTCTGAAAGAT TCTCTGGGAGGCAGTGCTAAGACTGTCATGATCACATGTGTCAGCCCCTCCTCCTCGA ATTTTGATGAGTCCTTAAATTCTCTCAAATATGCCAACAGAGCACGGAACATTAGAAA CAAACCCACTGTAAACTTCAGCCCCGAGTCAGACCGTATAGATGAAATGGAATTTGAG ATTAAATTGCTTCGAGAAGCTTTGCAAAGCCAGCAGGCTGGTGTCAGCCAAACTACCC AGATCAATCGAGAAGGGAGTCCTGATACAAATAGGATTCATTCTCTTGAGGAGCAAGT AGCTCAGCTTCAAGGAGAATGTCTGGGTTACCAGTGTTGTGTAGAAGAAGCCTTTACC TTCCTGGTTGACCTAAAAGATACTGTCAGACTAAACGAAAAGCAGCAACACAAACTGC AGGAGTGGTTTAACATGATCCAAGAGGTCAGGAAGGCTGTCCTCACCTCATTTCGAGG AATCGGAGGCACTGCAAGTCTGGAAGAAGGACCACAGCATGTTACAGTTCTCCAGCTG AAGAGAGAGCTTAAGAAATGCCAGTGTGTGCTTGCTGCTGATGAAGTAGTATTTAATC AGAAGGAACTGGAGGTGAAGGAACTGAAGAATCAAGTGCAGATGATGGTACAGGAAAA CAAAGGGCATGCTGTATCTTTGAAAGAAGCGCAAAAAGTGAATAGACTGCAGAATGAA AAAATAATAGAACAACAACTTCTTGTGGATCAACTGAGTGAAGAACTAACAAAACTTA ACCTGTCAGTGACTTCTTCAGCTAAAGAAAATTGTGGAGATGGGCCAGATGCCAGGAT CCCTGAAAGGAGACCATATACTGTACCATTTGATACTCATTTGGGGCATTATATTTAT ATCCCATCAAGACAAGATTCCAGGAAGGTCCACACAAGTCCGCCTATGTACTCTCTGG ATCGAATATTTGCTGGATTTCGAACACGAAGTCAGATGCTGTTGGGTCACATAGAAGA ACAAGATAAGGTCCTCCACTGCCAATTTTCTGATAACAGTGATGATGAAGAATCAGAA GGCCAAGAGAAATCTGGAACTAGATGTAGAAGTCGTTCATGGATTCAGAAGCCAGACT CTGTTTGTTCCCTTGTTGAATTGAGTGATACTCAGGATGAAACACAAAAGTCAGATTT GGAGAATGAAGATTTAAAGATTGATTGTCTCCAGGAGAGTCAAGAATTGAATTTGCAA AAATTAAAGAATTCAGAACGCATACTTACTGAAGCTAAACAAAAAATGAGAGAACTTA CAATTAACATCAAGATGAAGGAAGATCTGATTAAAGAATTAATAAAAACAGGTAATGA TGCCAAGTCTGTAAGCAAGCAGTATTCTTTGAAAGTAACAAAGCTAGAGCATGATGCA GAACAGGCAAAAGTCGAACTGATTGAAACACAAAAGCAGCTACAGGAGCTGGAAAACA AAGATCTTTCTGATGTTGCAATGAAGGTAAAATTACAGAAAGAGTTTCGTAAAAAGAT GGATGCTGCAAAGCTGAGAGTTCAGGTCTTGCAGAAGAAGCAACAAGATAGTAAGAAA CTGGCATCACTGTCAATCCAAAATGAGAAACGTGCTAATGAGCTAGAGCAGAGTGTAG ATCACATGAAATATCAAAAGATACAGCTACAAAGAAAACTACGAGAAGAAAATGAAAA AAGGAAGCAACTGGATGCAGTAATTAAGCGGGACCAGCAAAAAATCAAAGTAATACAA TTAAAAACAGGACAGGAAGAAGGTCTAAAACCGAAAGCTGAGGACCTTGATGCATGTA ACTTGAAAAGGAGAAAAGGTTCGTTTGGAAGTATAGACCATCTCCAGAAATTGGATGA GCAAAAGAAATGGTTAGATGAAGAAGTAGAGAAAGTTCTGAACCAACGCCAAGAATTA GAGGAGCTGGAAGCAGACTTAAAGAAACGGGAGGCCATAGTTTCTAAGAAGGAGGCTC TGTTACAGGAGAAGAGTCACCTGGAAAATAAGAAATTGAGATCTAGTCAGGCCTTAAA CACAGATAGTTTGAAAATATCAACTCGCCTGAACTTACTGGAACAAGAGTTGTCTGAA AAGAATGTGCAGCTCCAGACCAGTACAGCTGAGGAGAAAACAAAGATTTCAGAACAAG TTGAAGTCCTCCAGAAAGAAAAGGATCAGCTCCAGAAACGCAGACACGATGTGGATGA AAAACTTAAAAATGGTAGAGTGTTATCACCTGAAGAAGAACATGTTCTTTTCCAACTT GAAGAAGGGATAGAAGCTTTGGAAGCTGCAATTGAATACAGGAATGAAAGTATCCAGA ATCGCCAGAAGTCACTTAGAGCATCATTCCATAACCTCTCTCGTGGTGAAGCAAATGT CTTGGAAAAGCTAGCTTGCCTGAGTCCTGTTGAGATTAGAACTATTCTTTTCAGATAT TTCAATAAGGTGGTGAATTTGCGAGAAGCTGAACGGAAACAACAGTTATATAATGAAG AAATGAAAATGAAAGTTCTGGAACGGGATAATATGGTTCGTGAATTAGAATCTGCACT GGACCATCTAAAATTGCAGTGTGACCGGAGACTGACCCTCCAGCAAAAGGAACACGAA CAAAAGATGCAGTTGCTATTACATCATTTCAAAGAACAAGATGGAGAAGGCATTATGG AAACTTTCAAAACATATGAAGATAAAATCCAGCAGTTGGAAAAAGATCTTTATTTCTA TAAGAAAACCAGCCGGGATCATAAGAAGAAACTTAAGGAACTGGTAGGGGAAGCAATT CGGCGGCAACTAGCATCATCAGAGTATCAAGAGGCTGGAGATGGAGTCCTGAAGCCAG AAGGAGGAGGCATGCTTTCAGAAGAATTAAAATGGGCATCCAGACCTGAAAGTATGAA ATTAAGTGGAAGAGAAAGAGAAATGGACAGTTCAGCAAGCAGCTTAAGAACACAGCCA AATCCTCAAAAGCTCTGGGAAGATATCCCAGAATTACCTCCAATTCATAGTTCTTTAG

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 11B.
Further analysis of the NOVl la protein yielded the following properties shown in Table llC.
Table llC. Protein Sequence Properties NOVlla
PSort 0.5517 nrobabilitv located in mitnchondrial matrix srtace: 0.3000 nrobabilitv
analysis: located in microbody (peroxisome); 0.2717 probability located in mitochondrial inner membrane; 0.2717 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl la protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 1 ID.
In a BLAST search of public sequence datbases, the NOVl la protein was found to have homology to the proteins shown in the BLASTP data in Table 1 IE.
PFam analysis predicts that the NOVl la protein contains the domains shown in the Table 11F.
Table HF. Domain Analysis of NOVlla
Identities/
Pfam Domain NOVlla Match Region Similarities Expect Value for the Matched Region
No Significant Matches Found
Example 12.
The NOVl 2 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 12A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 12B.
Further analysis of the NOVl 2a protein yielded the following properties shown in Table 12C.
Table 12C. Protein Sequence Properties NOV12a
PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in analysis: mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl 2a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 12D.
hi a BLAST search of public sequence datbases, the NOV12a protein was found to have homology to the proteins shown in the BLASTP data in Table 12E.
PFam analysis predicts that the NOVl 2a protein contains the domains shown in the Table 12F.
Table 12F. Domain Analysis of NOV12a
Identities/
Pfam Domain NO 12a Match Region Similarities Expect Value for the Matched Region
Example 13.
The NOVl 3 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 13A.
Table 13A. NO 13 Sequence Analysis
SEQ ID NO: 167 1894 bp }"
NOV13a, CGCCGCTCGCCGCAGACTTACTTCCCCGGCTCAGCAGGGAAAGGTTCCTAGAAGGTGA CG140122-01 GCGCGGACGGTATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAG DNA Sequence TCGCGGCCTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCT GGCCTGGCTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTG AGGCTTCCAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTT TGAGCTGGGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCA GAAGCCAACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCA GCCTCTATTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCC CAAGGACGTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAG GAGTTCTTCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGT TCACCCGAGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTAC CAAGCGCCTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGC AGCTCACACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCC CCGGCGCTCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGA GGGCATCCCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGAC CAGGCCTCAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGAGGGCGACCACA ATCACGACACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGGGGCAGGTGGGA TGAGGATGAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACCGTGAGCTGATCCCGGCG GACCATGTGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTACACCAGTTTCT TCCGGCCAGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCAC CACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGC CTACAGTTTGTGTGGGAGGACGAAGCGGAGAGCCACACCCTCACCTACCCACCTGAGC TCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCA TGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGTGTGATGAC GAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAACCCCAACA TTCCAAAACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTACTTCCGTGG CTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTGGCCAAG CCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCCGGTG AGGCCACCCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCG TGAGGCTGCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGACCTGAGGG CTGTCCTCGCTGCTGAGAAGAGCCACTAACTCGTGACCTCCAGCCTGCCCCTTGCTGC
CGTGTGCTCCTGCCTTCCTGATCCTCTGTAGAAAGGATTTTTATCTTCTGTAGAGCTA
GCCGCCCTGACTGCCTTCAGACCTGGCCCTGTAGCTTT
ORF Start: ATG at 70 ORF Stop: TGA at 1735
SEQ ID NO: 168 555 aa MWat 61871.7kD
NOV13a, MQSCESSGDSADDP SRG RRRGQPRVVVIGAGLAGLAAAKA LEQGFTDVTVLEASS CG140122-01 HIGGRVQSVKLGHATFELGATWIHGSHGNPIYHIiAEANGLLEETTDGERSVGRIS YS KNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTRE Protein Sequence EVRNRIRNDPDDPEATKRLK1__IIQQYLKVESCESSSHS DEVSLSAFGE TEIPGAH HIIPSGFMRWELLAEGIPAHVIQ GKPVRCIHWDQASARPRGPEIEPRGEGDHNHDT GEGGQGGEEPRGGRWDEDEQ SWVECEDRELIPADHVIVTVSLGVLKRQYTSFFRPG LPTEKVAAIHR GIGTTDKIF EFEEPF GPECNSLQFVWEDEAESHTLTYPPEL YR KICGFDVLYPPERYGHVLSG ICGEEAVMEKCDDEAVAEICTE RQFTGNPNIPKP RRI RSA GSNPYFRGSYSYTQVGSSGADVEKAKP PYTESSKTAPMQVLFSGEATH RKYYSTTHGALLSGQREAARLIEMYRDLFQQGT
SEQ ID NO: 172 533 aa MW at 59379.2kD
NOV13c, TMQSCESSGDSADDPLSRGLRRRGQPRVWIGAGLAGLAAAKAL EQGFTDVTVLEAS 246864086 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY Protein Sequence SKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR EEVRNRIRNDPDDPEATKRLKLAMIQQYLKVESCESSSHSMDEVSLSAFGEWTEIPGA HHIIPSGFMRWE IiAEGIPAHVIQLGKPVRCIHWDQASARPRGPEIEPRGVLKRQYT SFFRPGLPTEKVAAIHRLGIGTTDKIFLEFEEPF GPECNSLQFV EDEAESHT TYP PELWYRKICGFDVLYPPERYGHVLSGWICGEEALVMEKCDDEAVAEICTEMLRQFTGN PNIPKPRRI RSA GSNPYFRGSYSYTQVGSSGADVEKAKPLPYTESSKTAHGSSTK QQPGHLFSSKCPEQP DANRGAVKPMQVLFSGEATHRKYYSTTHGALLSGQREAARLI E YRDLFQQGT
SEQ ID NO: 173 j 1693 bp
NOVl 3d, CACCATGGGACATCATCACCACCATCACCAAAGTTGTGAATCCAGTGGTGACAGTGCG 258280083 DNA GATGACCCTCTCAGTCGCGGCCTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCG GCGCCGGCTTGGCTGGCCTGGCTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGA Sequence TGTCACTGTGCTTGAGGCTTCCAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTT GGACACGCCACCTTTGAGCTGGGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTA TCTATCATCTAGCAGAAGCCAACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAG CGTGGGCCGCATCAGCCTCTATTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCAC GGCCGCAGGATCCCCAAGGACGTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCT ATAACTTGACCCAGGAGTTCTTCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAA TAGCGTGGGGGTGTTCACCCGAGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGAC GACCCAGAGGCTACCAAGCGCCTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGG AGAGCTGTGAGAGCAGCTCACACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGA GTGGACCGAGATCCCCGGCGCTCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTG GAGCTGCTGGCGGAGGGCATCCCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCT GCATTCACTGGGACCAGGCCTCAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGG TGAGGGCGACCACAATCACGACACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGG GGGGGCAGGTGGGATGAGGATGAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTG AGCTGATCCCGGCGGACCATGTGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCA GTACACCAGTTTCTTCCGGCCAGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGC CTGGGCATTGGCACCACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCC CTGAGTGCAACAGCCTACAGTTTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCAC CTACCCACCTGAGCTCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCT GAGCGCTACGGCCATGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGG AGAAGTGTGATGACGAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCAC AGGGAACCCCAACATTCCAAAACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAAC CCTTACTTCCGCGGCTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGG AGAAGCTGGCCAAGCCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGT GCTGTTTTCCGGTGAGGCCACCCACCGCAAGTACTATTCCACCACCCACGGTGCTCTG CTGTCCGGCCAGCGTGAGGCTGCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGC AGGGGACCTGA
ORF Start: at 2 ORF Stop: TGA at 1691
SEQIDNO: 174 563 aa MW at 62799.6kD
NOV13d, T GHHHHHHQSCESSGDSADDPLSRGLRRRGQPRVVVIGAGLAGLAAAKALLEQGFTD 258280083 VTVLEASSHIGGRVQSVKLGHATFE GATWIHGSHGNPIYHLAEANGL EETTDGERS VGRISLYSKNGVACYLTNHGRRIPKDWEEFSD YNEVYNLTQEFFRHDKPVNAESQN Protein Sequence SVGVFTREEVRNRIRlsTDPDDPEATKRLKLAMIQQYLKVESCESSSHSMDEVSLSAFGE WTEIPGAHHIIPSGF RWELLAEGIPAHVIQLGKPVRCIH DQASARPRGPEIEPRG EGDHNHDTGEGGQGGEEPRGGR DEDEQ SVWECEDCELIPADHVIVTVSLGVLKRQ YTSFFRPGLPTEKVAAIHRLGIGTTDKIFLEFEEPFWGPECNSLQFV EDEAESHTLT YPPELWYRKICGFDVLYPPERYGHVLSG ICGEEALVMEKCDDEAVAEICTEMLRQFT GNPNIPKPRRILRSA GSNPYFRGSYSYTQVGSSGADVEK AKPLPYTESSKTAPMQV LFSGEATHRKYYSTTHGALLSGQREAARLIE YRDLFQQGT
SEQ ID NO: 175 1672 bp
NOV13e, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG
258280066 DNA CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC Sequence CAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTG GGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCA ACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTA TTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGAC GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGAGGGCGACCACAATCACGA CACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGGGGCAGGTGGGATGAGGAT GAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTGAGCTGATCCCGGCGGACCATG TGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTACACCAGTTTCTTCCGGCC AGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCACCACCGAC AAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGCCTACAGT TTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCACCTACCCACCTGAGCTCTGGTA CCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCATGTGCTG AGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGTGTGATGACGAGGCAG TGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAACCCCAACATTCCAAA ACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTACTTCCGCGGCTCCTAT TCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTGGCCAAGCCCCTGC CGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCAC CCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCT GCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGACCTGA
ORF Start: at 2 ORF Stop: TGA at 1670
SEQ ID NO: 176 556 aa MW at 61919.7kD
NOV13e, T QSCESSGDSADDP SRGLRRRGQPRWVIGAG AGLAAAKALLEQGFTDVTV EAS 258280066 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY SKNGVACY TNHGRRIPKDWEEFSDIiYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR Protein Sequence EEVRNRIRNDPDDPEATKRLKLAMIQQYLKVESCESSSHS DEVSLSAFGEWTEIPGA HHIIPSGFMRWE IiAEGIPAHVIQ GKPVRCIH DQASARPRGPEIEPRGEGDHNHD TGEGGQGGEEPRGGR DEDEQ SVVVECEDCE IPADHVIVTVSLGVLKRQYTSFFRP GLPTEKVAAIHR GIGTTDKIF EFEEPFWGPECNS QFV EDEAESHTLTYPPE WY RKICGFDVLYPPERYGHVLSGWICGEEALVMEKCDDEAVAEICTEMLRQFTGNPNIPK PRRI RSA GSNPYFRGSYSYTQVGSSGADVEK AKPLPYTESSKTAP QV FSGEAT HRKYYSTTHGAL SGQREAAR IE YRDLFQQGT
NOV13f, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC 258329988 DNA CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC Sequence CAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTG GGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCA ACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTA TTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGAC GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGAGGGCGACCACAATCACGA CACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGGGGCAGGTGGGATGAGGAT GAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTGAGCTGATCCCGGCGGACCATG TGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTACACCAGTTTCTTCCGGCC
AGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCACCACCGAC AAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGCCTACAGT TTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCACCTACCCACCTGAGCTCTGGTA CCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCATGTGCTG AGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGTGTGATGACGAGGCAG TGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAACCCCAACATTCCAAA ACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTACTTCCGCGGCTCCTAT TCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTGGCCAAGCCCCTGC CGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCAC CCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCT GCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGACCCATCATCACCACC ATCACTGA
ORF Start: at 2 ORF Stop: TGA at 1688
SEQ ID NO: 178 562 aa MW at 62742.6kD
NOV13f, T QSCESSGDSADDP SRGLRRRGQPRVVVIGAGLAGLAAAKALLEQGFTDVTVLEAS 258329988 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY SKNGVACYLTNHGRRIPKDWEEFSD YNEVYNLTQEFFRHDKPVNAESQNSVGVFTR Protein Sequence EEVRNRIRNDPDDPEATKRLKLA IQQY KVESCESSSHSMDEVSLSAFGE TEIPGA HHIIPSGF RVVE_I__!GIPAHVIQLGKPWCIHWDQASARPRGPEIEPRGEGDHNHD TGEGGQGGEEPRGGR DEDEQ SVWECEDCELIPADHVIVTVS GVLKRQYTSFFRP GLPTEKVAAIHRLGIGTTDKIFLEFEEPFWGPECNS QFV EDEAESHTLTYPPΞLWY RKICGFDVLYPPERYGHV SGWICGEEALVMEKCDDEAVAEICTEMLRQFTGNPNIPK PRRI RSA GSNPYFRGSYSYTQVGSSGADVEK AKPLPYTESSKTAPMQVLFSGEAT HRKYYSTTHGALLSGQREAARLIE YRDLFQQGTHHHHHH
SEQ ID NO: 179 1700 bp
NOV13g, AAGGAAAAAAGCGGCCGCCACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGAT 254047897 DNA GACCCTCTCAGTCGCGGCCTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCG Sequence CCGGCTTGGCTGGCCTGGCTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGT CACTGTGCTTGAGGCTTCCAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGA CACGCCACCTTTGAGCTGGGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCT ATCATCTAGCAGAAGCCAACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGT GGGCCGCATCAGCCTCTATTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGC CGCAGGATCCCCAAGGACGTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATA ACTTGACCCAGGAGTTCTTCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAG CGTGGGGGTGTTCACCCGAGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGAC CCAGAGGCTACCAAGCGCCTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGA GCTGTGAGAGCAGCTCACACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTG GACCGAGATCCCCGGCGCTCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAG CTGCTGGCGGAGGGCATCCCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCA TTCACTGGGACCAGGCCTCAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGA GGGCGACCACAATCACGACACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGG GGCAGGTGGGATGAGGATGAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTGAGC TGATCCCGGCGGACCATGTGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTA CACCAGTTTCTTCCGGCCAGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTG GGCATTGGCACCACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTG AGTGCAACAGCCTACAGTTTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCACCTA CCCACCTGAGCTCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAG CGCTACGGCCATGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGA AGTGTGATGACGAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGG GAACCCCAACATTCCAAAACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCT TACTTCCGCGGCTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGA AGCTGGCCAAGCCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCT GTTTTCCGGTGAGGCCACCCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTG TCCGGCCAGCGTGAGGCTGCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGG GGACCTGATCTAGACTAG
ORF Start: at 2 ORF Stop: TGA at 1688
SEQ ID NO: 180 562 aa MW at 62545.5kD
NOV13g, RKKAAAT QSCESSGDSADDPLSRGLRRRGQPRVVVIGAGIjAG AAAKAIiLEQGFTDV 254047897 TV EASSHIGGRVQSVKLGHATFE GAT IHGSHGNPIYHLAEANGLLEETTDGERSV Protein Sequence GRISLYSKNGVACY-TNHGRRIPKDWEEFSDLYNEVYN TQEFFRHDKPVNAESQNS VGVFTREEVRNRIRNDPDDPEATKRLKLAMIQQYLKVESCESSSHSMDEVSLSAFGEW TEIPGAHHIIPSGFMRWEL AEGIPAHVIQLGKPVRCIH DQASARPRGPEIEPRGE GDHNHDTGEGGQGGEEPRGGR DEDEQWSVWECEDCELIPADHVIVTVSLGV KRQY TSFFRPG PTEKVAAIHR GIGTTDKIFLEFEEPFWGPECNSLQFVWEDEAESHTLTY PPELWYRKICGFDVLYPPERYGHV SGWICGEEALVMEKCDDEAVAEICTEM RQFTG NPNIPKPRRILRSAWGSNPYFRGSYSYTQVGSSGADVEKLAKP PYTESSKTAPMQVL FSGEATHRKYYSTTHGALSGQREAARLIEMYRD FQQGT
SEQ ID NO: 181 1690 bp
NOV13h, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC 258329988 DNA CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC Sequence CAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTG GGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCA ACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTA TTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGAC GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGAGGGCGACCACAATCACGA CACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGGGGCAGGTGGGATGAGGAT GAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTGAGCTGATCCCGGCGGACCATG TGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTACACCAGTTTCTTCCGGCC AGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCACCACCGAC AAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGCCTACAGT TTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCACCTACCCACCTGAGCTCTGGTA CCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCATGTGCTG AGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGTGTGATGACGAGGCAG TGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAACCCCAACATTCCAAA ACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTACTTCCGCGGCTCCTAT TCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTGGCCAAGCCCCTGC CGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCAC CCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCT GCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGACCCATCATCACCACC ATCACTGA
ORF Start: at 2 ORF Stop: TGA at 1688
SEQ ID NO: 182 562 aa MW at 62742.6kD
NOV13h, TMQSCESSGDSADDPLSRG RRRGQPRVWIGAGLAG AAAKA LEQGFTDVTVLEAS 258329988 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGL EETTDGERSVGRISLY SKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR Protein Sequence EEVRNRIRNDPDDPEATKR.LK AMIQQYLKVESCESSSHSMDEVS SAFGE TEIPGA HHIIPSGF RWELLAEGIPAHVIQLGKPVRCIH DQASARPRGPEIEPRGEGDHNHD TGEGGQGGEEPRGGR DEDEQ SVVVECEDCELIPADHVIVTVSLGVLKRQYTSFFRP GLPTEKVAAIHRLGIGTTDKIF EFEEPF GPECNS QFV EDEAESHTLTYPPELWY RKICGFDVLYPPERYGHVLSGWICGEEALVMEKCDDEAVAEICTEMLRQFTGNPNIPK PRRILRSAWGSNPYFRGSYSYTQVGSSGADVEKLAKPLPYTESSKTAP QVLFSGEAT HRKYYSTTHGALLSGQREAARLIEMYRDLFQQGTHHHHHH
NOV13i, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC 258280066 DNA CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG
CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC Sequence mx rτ
*r< TX x rr r^r*7x r
* r
,rp π
i τxr
^7x ^ π
^ Α ^ x\n^^ r^7x 7.rχ
1τx
l ^rr τxr'
i
CTGGGCATTGGCACCACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCC CTGAGTGCAACAGCCTACAGTTTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCAC CTACCCACCTGAGCTCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCT! GAGCGCTACGGCCATGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGG AGAAGTGTGATGACGAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCAC AGGGAACCCCAACATTCCAAAACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAAC CCTTACTTCCGCGGCTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGG AGAAGCTGGCCAAGCCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGT GCTGTTTTCCGGTGAGGCCACCCACCGCAAGTACTATTCCACCACCCACGGTGCTCTG CTGTCCGGCCAGCGTGAGGCTGCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGC AGGGGACCTGA
ORF Start: at 2 ORF Stop: TGA at 1691
SEQ ID NO: 186 563 aa MW at 62799.6kD
NOV13J, TMGHHHHHHQSCESSGDSADDPLSRGLRRRGQPRVWIGAGLAGLAAAKALLEQGFTD 258280083 VTVLEASSHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERS VGRISLYSKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQN Protein Sequence SVGVFTREEVRNRIRNDPDDPEATKRLKLAMIQQYLKVESCESSSHSMDEVSLSAFGE WTEIPGAHHIIPSGFMRWELLAEGIPAHVIQLGKPVRCIHWDQASARPRGPEIEPRG EGDHNHDTGEGGQGGEEPRGGRWDEDEQWSVWECEDCELIPADHVIVTVSLGVLKRQ YTSFFRPGLPTEKVAAIHRLGIGTTDKIFLEFEEPFWGPECNSLQFVWEDEAESHTLT YPPELWYRKICGFDVLYPPERYGHVLSGWICGEEALVMEKCDDEAVAEICTEMLRQFT GNPNIPKPRRILRSAWGSNPYFRGSYSYTQVGSSGADVEKLAKPLPYTESSKTAPMQV LFSGEATHRKYYSTTHGALLSGQREAARLIEMYRDLFQQGT
SEQ ID NO: 187 1993 bp
NOVl 3k, GGCACGAGGGTCCCGGCGGCGGCTGGAGGAGGAAGCCAGGCGGCTGGCGGAGGAGGAG CG140122-02 AGACGGAGGAGGCCGAGACCGGAGCGCCGCTCGCCGCAGACTTACTTCCCCGGCTCAG
CAGGGAAAGGTTCCTAGAAGGTGAGCGCGGACGGTATGCAAAGTTGTGAATCCAGTGG DNA Sequence TGACAGTGCGGATGACCCTCTCAGTCGCGGCCTACGGAGAAGGGGACAGCCTCGTGTG GTGGTGATCGGCGCCGGCTTGGCTGGCCTGGCTGCAGCCAAAGCACTTCTTGAGCAGG GTTTCACGGATGTCACTGTGCTTGAGGCTTCCAGCCACATCGGAGGCCGTGTGCAGAG TGTGAAACTTGGACACGCCACCTTTGAGCTGGGAGCCACCTGGATCCATGGCTCCCAT GGGAACCCTATCTATCATCTAGCAGAAGCCAACGGCCTCCTGGAAGAGACAACCGATG GGGAACGCAGCGTGGGCCGCATCAGCCTCTATTCCAAGAATGGCGTGGCCTGCTACCT TACCAACCACGGCCGCAGGATCCCCAAGGACGTGGTTGAGGAATTCAGCGATTTATAC AACGAGGTCTATAACTTGACCCAGGAGTTCTTCCGGCACGATAAACCAGTCAATGCTG AAAGTCAAAATAGCGTGGGGGTGTTCACCCGAGAGGAGGTGCGTAACCGCATCAGGAA TGACCCTGACGACCCAGAGGCTACCAAGCGCCTGAAGCTCGCCATGATCCAGCAGTAC CTGAAGGTGGAGAGCTGTGAGAGCAGCTCACACAGCATGGACGAGGTGTCCCTGAGCG CCTTCGGGGAGTGGACCGAGATCCCCGGCGCTCACCACATCATCCCCTCGGGCTTCAT GCGGGTTGTGGAGCTGCTGGCGGAGGGCATCCCTGCCCACGTCATCCAGCTAGGGAAA CCTGTCCGCTGCATTCACTGGGACCAGGCCTCAGCCCGCCCCAGAGGCCCTGAGATTG AGCCCCGGGGTGTGCTAAAGAGGCAGTACACCAGTTTCTTCCGGCCAGGCCTGCCCAC AGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCACCACCGACAAGATCTTTCTG GAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGCCTACAGTTTGTGTGGGAGG ACGAAGCGGAGAGCCACACCCTCACCTACCCACCTGAGCTCTGGTACCGCAAGATCTG CGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCATGTGCTGAGCGGCTGGATC TGCGGGGAGGAGGCCCTCGTCATGGAGAAGTGTGATGACGAGGCAGTGGCCGAGATCT GCACGGAGATGCTGCGTCAGTTCACAGGGAACCCCAACATTCCAAAACCTCGGCGAAT CTTGCGCTCGGCCTGGGGCAGCAACCCTTACTTCCGCGGCTCCTATTCATACACGCAG GTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTGGCCAAGCCCCTGCCGTACACGGAGA GCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCACCCACCGCAAGTA CTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCTGCCCGCCTCATT GAGATGTACCGAGACCTCTTCCAGCAGGGGACCTGAGGGCTGTCCTCGCTGCTGAGAA GAGCCACTAACTCGTGACCTCCAGCCTGCCCCTTGCTGCCGTGTGCTCCTGCCTTCCT GATCCTCTGTAGAAAGGATTTTTATCTTCTGTAGAGCTAGCCGCCCTGACTGCCTTCA GACCTGGCCCTGTAGCTTTTCTTTTTCTCCAGGCTGGGCCGTGAGCAGGTGGGCCGTT GAGTTACCTCTGTGCTGGATCCCGTGCCCCCACTTGCCTACCCTCTGTCCTGCCTTGT TATTGTAAGTGCCTTCAATACTTTGCATTTTGGGATAATAAAAAAGGCTCCCTCCCCT
GCAAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 152 ORF Stop: TGA at 1658
SEQ ID NO: 188 502 aa MW at 56090.6kD
NOVl 3k, MQSCESSGDSADDPLSRGLRRRGQPRV IGAGI_G]____CALLEQGFTDVTVLEASS CG140122-02 HIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLYS KNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTRE Protein Sequence EVRNRIRNDPDDPEATKR.LKLAMIQQYLKVESCESSSHSMDEVSLSAFGEWTEIPGAH HIIPSGFMRWELLAEGIPAHVIQLGKPVRCIHWDQASARPRGPEIEPRGVLKRQYTS FFRPGLPTEKVAAIHRLGIGTTDKIFLEFEEPFWGPECNSLQFVWEDEAESHTLTYPP ELWYRKICGFDVLYPPERYGHVLSGWICGEEALVMEKCDDEAVAEICTE LRQFTGNP NIPKPRRILRSAWGSNPYFRGSYSYTQVGSSGADVEKLAKPLPYTESSKTAPMQVLFS GEATHRKYYSTTHGALLSGQREAARLIEMYRDLFQQGT
SEQ ID NO: 189 jl012 bp
NOV131, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC CG140122-03 CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC DNA Sequence CAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTG GGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCA ACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTA TTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGAC GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCTGCCGTACACAGAGAGCTCAAAGAC AGCGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCACCCACCGCAAGTACTATTCCACC ACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCTGCCCGCCTCATTGAGATGTACC GAGACCTCTTCCAGCAGGGGACCTGA
ORF Start: at 2 ORF Stop: TGA at 1010 SEQ ID NO: 190 336 aa MW at 37093.2kD
NOV131, T QSCESSGDSADDPLSRGLRRRGQPRVWIGAGLAGI_sAAKALLEQGFTDVTVLEAS CG140122-03 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY SKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR Protein Sequence EEVRNRIRNDPDDPEATKRLKLAMIQQYLKVESCESSSHS DEVSLSAFGEWTEIPGA HHIIPSGFMRWELLAEGIPAHVIQLGKPVRCIHWDQASARPRGPEIEPLPYTESSKT APMQVLFSGEATHRKYYSTTHGALLSGQREAARLIEMYRDLFQQGT
SEQ ID NO: 191 1603 bp
NOV13m, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC CG140122-04 CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC DNA Sequence CAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTG GGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCA ACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTA TTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGAC GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGTGCTAAAGAGGCAGTACAC CAGTTTCTTCCGGCCAGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGC
ATTGGCACCACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGT GCAACAGCCTACAGTTTGTGTGGGAGGACGAAGCGGAGAGCCACACCCTCACCTACCC ACCTGAGCTCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGC TACGGCCATGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGT GTGATGACGAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAA CCCCAACATTCCAAAACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTAC TTCCGCGGCTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGC TGGCCAAGCCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCATGGAAGCTCCACAAA GCAGCAGCCTGGTCACCTTTTCTCTTCCAAGTGCCCAGAACAGCCCCTGGATGCTAAC AGGGGCGCCGTAAAGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCACCCACCGCAAGT ACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCTGCCCGCCTCAT TGAGATGTACCGAGACCTCTTCCAGCAGGGGACCTGA
ORF Start: at 2 JORF Stop: TGA at 1601^
SEQ ID NO: 192 533 aa MW at 59379.2kD
NOV13m, TMQSCESSGDSADDPLSRGLRRRGQPRVVVIGAGLAGLAAAKALLEQGFTDVTVLEAS CG140122-04 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY SKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR Protein Sequence EEVRNRIRNDPDDPEATKRLKIAMIQQYLKVESCESSSHS DEVSLSAFGEWTEIPGA HHIIPSGFMRVλ^ELLAEGIPAHVIQLGKPVRCIHWDQASARPRGPEIEPRGVLKRQYT SFFRPGLPTEKVAAIHRLGIGTTDKIFLEFEEPFWGPECNSLQFVWEDEAESHTLTYP PELWYRKICGFDVLYPPERYGHVLSGWICGEEALV EKCDDEAVAEICTEMLRQFTGN PNIPKPRRILRSAWGSNPYFRGSYSYTQVGSSGADVEKLAKPLPYTESSKTAHGSSTK QQPGHLFSSKCPEQPLDANRGAVKPMQVLFSGEATHRKYYSTTHGALLSGQREAARLI EMYRDLFQQGT
SEQ ID NO: 193 1513 bp
NOV13n, CACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCGGC CG140122-05 CTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTGG DNA Sequence CTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTC CAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTG GGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCA ACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTA TTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGAC GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGTGCTAAAGAGGCAGTACAC CAGTTTCTTCCGGCCAGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGC ATTGGCACCACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGT GCAACAGCCTACAGTTTGTGTGGGAGGACGAAGCGGAGAGCCACACCCTCACCTACCC ACCTGAGCTCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGC TACGGCCATGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGT GTGATGACGAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAA CCCCAACATTCCAAAACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTAC TTCCGCGGCTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGC TGGCCAAGCCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTT TTCCGGTGAGGCCACCCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCC GGCCAGCGTGAGGCTGCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGA CCTGA
ORF Start: at 2 ORF Stop: TGA at 1511
SEQ ID NO: 194 503 aa MW at 56191.7kD
NOV13n, TMQSCESSGDSADDPLSRGLRRRGQPRWVIGAGLAGLAAAKALLEQGFTDVTVLEAS CG140122-05 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY; SKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR;

GTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCT; TCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCG: AGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGC CTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCAC ACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGC TCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATC CCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCT CAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGAGGGCGACCACAATCACGA CACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGGGGCAGGTGGGATGAGGAT GAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTGAGCTGATCCCGGCGGACCATG TGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTACACCAGTTTCTTCCGGCC AGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCACCACCGAC AAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGCCTACAGT TTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCACCTACCCACCTGAGCTCTGGTA CCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCATGTGCTG AGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAGAAGTGTGATGACGAGGCAG TGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGGAACCCCAACATTCCAAA ACCTCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTACTTCCGCGGCTCCTAT TCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTGGCCAAGCCCCTGC CGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCCGGTGAGGCCAC CCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAGCGTGAGGCT GCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGACCCATCATCACCACC ATCACTGA
ORF Start: at 2 ORF Stop: TGA at 1688
SEQ ID NO: 198 562 aa MW at 62742.6kD
NON13p, TMQSCESSGDSADDPLSRGLRRRGQPRVVVIGAGLAGLAAAKALLEQGFTDVTVLEAS CG140122-07 SHIGGRVQSVKLGHATFELGATWIHGSHGNPIYHLAEANGLLEETTDGERSVGRISLY SKNGVACYLTNHGRRIPKDWEEFSDLYNEVYNLTQEFFRHDKPVNAESQNSVGVFTR Protein Sequence EEVRNRIRNDPDDPEATKRLKLAMIQQYLKVESCESSSHSMDEVSLSAFGEWTEIPGA HHII SGFMRWELLAEGIPAHVIQLGKPVRCIHWDQASARPRGPEIEPRGEGDHNHD TGEGGQGGEEPRGGRWDEDEQWSVWECEDCELIPADHVIVTVSLGVLKRQYTSFFRP GLPTEKVAAIHRLGIGTTDKIFLEFEEPFWGPECNSLQFVWEDEAESHTLTYPPELWY RKICGFDVLYPPERYGHVLSGWICGEEALVMEKCDDEAVAEICTE LRQFTGNPNIPK PRRILRSAWGSNPYFRGSYSYTQVGSSGADVEKLAKPLPYTESSKTAPMQVLFSGEAT HRKYYSTTHGALLSGQREAARLIEMYRDLFQQGTHHHHHH
ΝON13q, TCCACCATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGCG CG140122-08 GCCTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCT GGCTGCAGCCAAAGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCT DΝA Sequence TCCAGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGC TGGGAGCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGC CAACGGCCTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTC TATTCCAAGAATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGG ACGTGGTTGAGGAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTT CTTCCGGCACGATAAACCAGTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACC CGAGAGGAGGTGCGTAACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGC GCCTGAAGCTCGCCATGATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTC ACACAGCATGGACGAGGTGTCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGC GCTCACCACATCATCCCCTCGGGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCA TCCCTGCCCACGTCATCCAGCTAGGGAAACCTGTCCGCTGCATTCACTGGGACCAGGC CTCAGCCCGCCCCAGAGGCCCTGAGATTGAGCCCCGGGGTGAGGGCGACCACAATCAC GACACTGGGGAGGGTGGCCAGGGTGGAGAGGAGCCCCGGGGGGGCAGGTGGGATGAGG ATGAGCAGTGGTCGGTGGTGGTGGAGTGCGAGGACTGTGAGCTGATCCCGGCGGACCA TGTGATTGTGACCGTGTCGCTAGGTGTGCTAAAGAGGCAGTACACCAGTTTCTTCCGG CCAGGCCTGCCCACAGAGAAGGTGGCTGCCATCCACCGCCTGGGCATTGGCACCACCG ACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGGGGCCCTGAGTGCAACAGCCTACA GTTTGTGTGGGAGGACGAAGCAGAGAGCCACACCCTCACCTACCCACCTGAGCTCTGG TACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCTGAGCGCTACGGCCATGTGC

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 13B.
Further analysis of the NOV13a protein yielded the following properties shown in Table 13C.
Table 13C. Protein Sequence Properties NOV13a
PSort 0.7900 probability located in plasma membrane; 0.4802 probability located in analysis: microbody (peroxisome); 0.3000 probability located in Golgi body; 0.2000 probability located in endoplasmic reticulum (membrane)
SignalP Cleavage site between residues 41 and 42 analysis:
A search of the NOV13a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 13D.
In a BLAST search of public sequence datbases, the NOVl 3a protein was found to have homology to the proteins shown in the BLASTP data in Table 13E.
PFam analysis predicts that the NOVl 3a protein contains the domains shown in the Table 13F.
Table 13F. Domain Analysis of NO 13a
Identities/
Pfam Domain NOV13a Match Region Similarities Expect Value for the Matched Region
Example 14.
The NOV14 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 14A.
Table 14A. NOV14 Sequence Analysis
SEQ ID NO: 201 2058 bp
NOV14a, ATGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACCTGCTGACAC CG140316-01 GGAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACAGCAATTGAA CATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTTCTTAGAGTA DNA Sequence GTAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCTTAATGGATC TCCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACATTGAGAAATT CATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATATAGTTTGGTG TTTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATATTGCTTCAG TTCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGATGGAGAGCG TATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTGGGTAAATTG GCTCTATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTGTCATTCTGG ATGTGGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGGACTACGGCA GAGAAGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATGGAGGCAGTT TCTTCCAAGTATGGCATGAATTGCCTTATTCAGTTTGAAGATTTTGCCAATGTGAATG CATTTCGTCTCCTGAACAAGTATCGAAACCAGTATTGCACATTCAATGATGATATTCA AGGAACAGCATCTGTTGCAGTTGCAGGTCTCCTTGCAGCTCTTCGAATAACCAAGAAC AAACTGTCTGATCAAACAATACTATTCCAAGGAGCTGGAGAGGCTGCCCTAGGGATTG CACACCTGATTGTGATGGCCTTGGAAAAAGAAGGTTTACCAAAAGAGAAAGCCATCAA AAAGATATGGCTGGTTGATTCAAAAGGATTAATAGTTAAGGGACGTGCTTCCTTAACA CAAGAGAAAGAGAAGTTTGCCCATGAACATGAAGAAATGAAGAACCTAGAAGCCATTG TTCAAGAAATAAAACCAACTGCCCTCATAGGAGTTGCTGCAATTGGTGGTGCATTCTC AGAACAAATTCTCAAAGATATGGCTGCCTTCAATGAACGGCCTATTATTTTTGCTTTG AGTAATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGCTACAAAATAACCAAGG GACGTGCAATTTTTGCCAGTGGCAGTCCTTTTGATCCAGTCACTCTTCCAAATGGACA GACCCTATATCCTGGCCAAGGCAACAATTCCTACGTGTTCCCTGGAGTTGCTCTTGGT GTTGTGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACTACTGCTGAGG TTATAGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTATCCTCCTTT GAATACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGATTGTGAAAGATGCATAC CAAGAAAAGACAGCCACAGTTTATCCTGAACCGCAAAACAAAGAAGCATTTGTCCGCT CCCAGATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTCTTGGCCTGA AGAGGTGCAGAAAATACAGACCAAAGTTGACCAGTAGGATAATAGCAAACATTTCTAA
CTCTATTAATGAGGTCTTTAAACCTTTCATAATTTTTAAAGGTTGGAATCTTTTATAA
TGATTCATAAGACACTTAGATTAAGATTTTACTTTAACAGTCTAAAAATTGATAGAAG
AATATCGATATAAATTGGGATAAACATCACATGAGACAATTTTGCTTCACTTTGCCTT
CTGGTTATTTATGGTTTCTGTCTGAATTATTCTGCCTACGTTCTCTTTAAAAGCTGTT
GTACGTACTACGGAGAAACTCATCATTTTTATACAGGACACTAATGGGAAGACCAAAA]
TTACTAATAAATTGAAATAACCAACATT
ORF Start: ATG at 1 ORF Stop: TAG at 1717
SEQ ID NO: 202 572 aa MW at 64148.9kD
NOV14a, EPEAPRRRHTHQRGYLLTRNPHLNKDLAFTLEERQQLNIHGLLPPSFNSQEIQVLRV CG140316-01 VKNFEHLNSDFDRYLLLMDLQDR EKLFYRVLTSDIEKFMPIVYTPTVGLACQQYSLV FRKPRGLFITIHDRGHIASVLNA PEDVIKAIWTDGERILGLGDLGCNG GIPVGKL Protein Sequence ALYTACGGM PQECLPVILDVGTElsIEELLKDPLYIGLRQRRVRGSEYDDFLDEFMEAV
SSKYGMNCLIQFEDFA VNAFRLLNKYRNQYCTFNDDIQGTASVAVAGLLAALRITKN KLSDQTILFQGAGEAALGIAHLIVMALEKEGLPKEKAIKKI LVDSKGLIVKGRASLT QEKΞKFAHEHEEMKNLEAIVQEIKPTALIGVAAIGGAFSEQILKDMAAFNERPIIFAL SNPTSKAECΞAEQCYKITKGRAIFASGSPFDPVTLPNGQTLYPGQGN SYVFPGVALG WACGLRQITDNIFLTTAEVIAQQVSDKHLEEGRLYPPLNTIRDVSLKIAEKIVKDAY QEKTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYS PEEVQKIQTKVDQ
SEQ ID NO: 203 2058 bp
NOV14b, ATGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACCTGCTGACAC CG140316-01 GGAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACAGCAATTGAA CATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTTCTTAGAGTA DNA Sequence GTAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCTTAATGGATC TCCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACATTGAGAAATT CATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATATAGTTTGGTG TTTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATATTGCTTCAG TTCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGATGGAGAGCG TATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTGGGTAAATTG GCTCTATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTGTCATTCTGG ATGTGGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGGACTACGGCA GAGAAGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATGGAGGCAGTT TCTTCCAAGTATGGCATGAATTGCCTTATTCAGTTTGAAGATTTTGCCAATGTGAATG CATTTCGTCTCCTGAACAAGTATCGAAACCAGTATTGCACATTCAATGATGATATTCA AGGAACAGCATCTGTTGCAGTTGCAGGTCTCCTTGCAGCTCTTCGAATAACCAAGAAC AAACTGTCTGATCAAACAATACTATTCCAAGGAGCTGGAGAGGCTGCCCTAGGGATTG CACACCTGATTGTGATGGCCTTGGAAAAAGAAGGTTTACCAAAAGAGAAAGCCATCAA AAAGATATGGCTGGTTGATTCAAAAGGATTAATAGTTAAGGGACGTGCTTCCTTAACA CAAGAGAAAGAGAAGTTTGCCCATGAACATGAAGAAATGAAGAACCTAGAAGCCATTG TTCAAGAAATAAAACCAACTGCCCTCATAGGAGTTGCTGCAATTGGTGGTGCATTCTC AGAACAAATTCTCAAAGATATGGCTGCCTTCAATGAACGGCCTATTATTTTTGCTTTG AGTAATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGCTACAAAATAACCAAGG GACGTGCAATTTTTGCCAGTGGCAGTCCTTTTGATCCAGTCACTCTTCCAAATGGACA GACCCTATATCCTGGCCAAGGCAACAATTCCTACGTGTTCCCTGGAGTTGCTCTTGGT GTTGTGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACTACTGCTGAGG TTATAGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTATCCTCCTTT GAATACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGATTGTGAAAGATGCATAC CAAGAAAAGACAGCCACAGTTTATCCTGAACCGCAAAACAAAGAAGCATTTGTCCGCT CCCAGATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTCTTGGCCTGA AGAGGTGCAGAAAATACAGACCAAAGTTGACCAGTAGGATAATAGCAAACATTTCTAA
CTCTATTAATGAGGTCTTTAAACCTTTCATAATTTTTAAAGGTTGGAATCTTTTATAA
TGATTCATAAGACACTTAGATTAAGATTTTACTTTAACAGTCTAAAAATTGATAGAAG
AATATCGATATAAATTGGGATAAACATCACATGAGACAATTTTGCTTCACTTTGCCTT
CTGGTTATTTATGGTTTCTGTCTGAATTATTCTGCCTACGTTCTCTTTAAAAGCTGTT
GTACGTACTACGGAGAAACTCATCATTTTTATACAGGACACTAATGGGAAGACCAAAA
TTACTAATAAATTGAAATAACCAACATT
ORF Start: ATG at 1 ORF Stop: TAG at 1717
SEQ ID NO: 204 572 aa MW at 64148.9kD
NOV14b, MEPEAPRRRHTHQRGYLLTR PHLNKDLAFTLEERQQLNIHGLLPPSFNSQEIQVLRV CG140316-01 VKNFEHLNSDFDRYLLLMDLQDRNEKLFYRVLTSDIEKFMPIVYTPTVGLACQQYSLV FRKPRGLFITIHDRGHIASVLNA PEDVIKAIWTDGERILGLGDLGCNGMGIPVGKL Protein Sequence ALYTACGGMNPQECLPVILDVGTENEELLKDPLYIGLRQRRVRGSEYDDFLDEFMEAV SSKYGMNCLIQFEDFANVNAFRLLNKYRNQYCTFNDDIQGTASVAVAGLLAALRITKN KLSDQTILFQGAGEAALGIAHLIVMALEKEGLPKEKAIKKIWLVDSKGLIVKGRASLT QEKEKFAHEHEEMKNLEAIVQEIKPTALIGVAAIGGAFSEQILKDMAAFNERPIIFAL SNPTSKAECSAEQCYKITKGRAIFASGSPFDPVTLPNGQTLYPGQG SYVFPGVALG VVACGLRQITDNIFLTTAEVIAQQVSDKHLEEGRLYPPLNTIRDVSLKIAEKIVKDAY QEKTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYS PEEVQKIQTKVDQ
SEQ ID NO: 205 1750 bp iNOV14c, ICGCGGATCCATGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACC!
254047949 DNA TGCTGACACGGAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACA Sequence GCAATTGAACATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTT CTTAGAGTAGTAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCT TAATGGATCTCCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACAT TGAGAAATTCATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATAT AGTTTGGTGTTTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATA TTGCTTCAGTTCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGA TGGAGAGCGTATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTG GGTAAATTGGCTCTATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTG TCATTCTGGATGTGGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGG ACTACGGCAGAGAAGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATG GAGGCAGTTTCTTCCAAGTATGGCATGAATTGCCTTATTCAGTTTGAAGATTTTGCCA ATGTGAATGCATTTCGTCTCCTGAACAAGTATCGAAACCAGTATTGCACATTCAATGA TGATATTCAAGGAACAGCATCTGTTGCAGTTGCAGGTCTCCTTGCAGCTCTTCGAATA ACCAAGAACAAACTGTCTGATCAAACAATACTATTCCAAGGAGCTGGGGAGGCTGCCC TAGGGATTGCACACCTGATTGTGATGGCCTTGGAAAAAGAAGGTTTACCAAAAGAGAA AGCCATCAAAAAGATATGGCTGGTTGATTCAAAAGGATTAATAGTTAAGGGACGTGCT TCCTTAACACAAGAGAAAGAGAAGTTTGCCCATGAACATGAAGAAATGAAGAACCTAG AAGCCATTGTTCAAGAAATAAAACCAACTGCCCTCATAGGAGTTGCTGCAATTGGTGG TGCATTCTCAGAACAAATTCTCAAAGATATGGCTGCCTTCAATGAACGGCCTATTATT TTTGCTTTGAGTAATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGCTACAAAA TAACCAAGGGACGTGCAATTTTTGCCAGTGGCAGTCCTTTTGATCCAGTCACTCTTCC AAATGGACAGACCCTATATCCTGGCCAAGGCAACAATTCCTATGTGTTCCCTGGAGTT GCTCTTGGTGTTGTGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACTA CTGCTGAGGTTATAGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTA TCCTCCTTTGAATACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGATTGTGAAA GATGCATACCAAGAAAAGACAGCCACAGTTTATCCTGAACCGCAAAACAAAGAAGCAT TTGTCCGCTCCCAGATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTC TTGGCCTGAAGAGGTGCAGAAAATACAGACCAAAGTTGACCAGTAGGGTGGCGGCCGC TTTTTTCCTT
ORF Størt: at l ORF Stop: TAG at 1726 SEQ ID NO: 206 575 aa MW at 64449.2kD
NOV14c, RGSMEPEAPRRRHTHQRGYLLTRNPHLNKDLAFTLEERQQLNIHGLLPPSFNSQEIQV 254047949 LRWKNFEHLNSDFDRYLLLMDLQDRNEKLFYRVLTSDIEKFMPIVYTPTVGLACQQY SLVFRKPRGLFITIHDRGHIASVL AWPEDVIKAIWTDGERILGLGDLGCNGMGIPV Protein Sequence GKLALYTACGG NPQECLPVILDVGTENEELLKDPLYIGLRQRRVRGSEYDDFLDEF EAVSSKYGMNCLIQFEDFANVNAFRLLNKYRNQYCTFNDDIQGTASVAVAGLLAALRI TKNKLSDQTILFQGAGFJ_.LGIAHLIVMALEKEGLPKEKAIKKIWLVDSKGLIVKGRA SLTQEKEKFAHEHEEMKNLEAIVQEIKPTALIGVAAIGGAFSEQILKDMAAFNERPII FALSNPTSKAECSAEQCYKITKGRAIFASGSPFDPVTLPNGQTLYPGQGNNSYVFPGV ALGWACGLRQITDNIFLTTAEVIAQQVSDKHLEEGRLYPPLNTIRDVSLKIAEKIVK DAYQEKTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYS PEEVQKIQTKVDQ
SEQ ID NO: 207 1752 bp
NOV14d, AGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACCTGCTGACACGGAA 258280122 DNA CCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACAGCAATTGAACATT CATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTTCTTAGAGTAGTAA Sequence AAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCTTAATGGATCTCCA AGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACATTGAGAAATTCATG CCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATATAGTTTGGTGTTTC GGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATATTGCTTCAGTTCT CAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGATGGAGAGCGTATT CTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTGGGTAAATTGGCTC TATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTGTCATTCTGGATGT GGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGGACTACGGCAGAGA AGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATGGAGGCAGTTTCTT CCAAGTATGGCATGAATTGCCTTATTCAGTTTGAAGATTTTGCCAATGTGAATGCATT TCGTCTCCTGAACAAGTATCGAAACCAGTATTGCACATTCAATGATGATATTCAAGGA ACAGCATCTGTTGCAGTTGCAGGTCTCCTTGCAGCTCTTCGAATAACCAAGAACAAAC
TGTCTGATCAAACAATACTATTCCAAGGAGCTGGGGAGGCTGCCCTAGGGATTGCACA CCTGATTGTGATGGCCTTGGAAAAAGAAGGTTTACCAAAAGAGAAAGCCATCAAAAAG ATATGGCTGGTTGATTCAAAAGGATTAATAGTTAAGGGACGTGCTTCCTTAACACAAG AGAAAGAGAAGTTTGCCCATGAACATGAAGAAATGAAGAACCTAGAAGCCATTGTTCA AGAAATAAAACCAACTGCCCTCATAGGAGTTGCTGCAATTGGTGGTGCATTCTCAGAA CAAATTCTCAAAGATATGGCTGCCTTCAATGAACGGCCTATTATTTTTGCTTTGAGTA ATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGCTACAAAATAACCAAGGGACG TGCAATTTTTGCCAGTGGCAGTCCTTTTGATCCAGTCACTCTTCCAAATGGACAGACC CTATATCCTGGCCAAGGCAACAATTCCTATGTGTTCCCTGGAGTTGCTCTTGGTGTTG TGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACTACTGCTGAGGTTAT AGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTATCCTCCTTTGAAT ACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGATTGTGAAAGATGCATACCAAG AAAAGACAGCCACAGTTTATCCTGAACCGCAAAACAAAGAAGCATTTGTCCGCTCCCA GATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTCTTGGCCTGAAGAG GTGCAGAAAATACAGACCAAAGTTGACCAGTAGGGTGGCGGCCGCACTCGAGCACCAC CACCACCACCAC
ORF Start: at 3 ORF Stop: TAG at 1713
SEQ ID NO: 208 570 aa MW at 63888.6kD
NOV14d, PEAPRRRHTHQRGYLLTRNPHLNKDLAFTLEERQQLNIHGLLPPSFNSQEIQVLRWK 258280122 NFEHLNSDFDRYLLL DLQDRNEKLFYRVLTSDIEKF PIVYTPTVGLACQQYSLVFR Protein Sequence KPRGLFITIHDRGHIASVLNAWPEDVIKAIVVTDGERILGLGDLGCNGMGIPVGKLAL YTACGGMNPQECLPVILDVGTENEELLKDPLYIGLRQRRVRGSEYDDFLDEF EAVSS KYGM CLIQFEDFAlsTVNAFRLLNKYRNQYCTFNDDIQGTASVAVAGLLAALRITKNKL SDQTILFQGAGEAALGIAHLIVMALEKEGLPKEKAIKKIWLVDSKGLIVKGRASLTQE KEKFAHEHEEMKNLEAIVQEIKPTALIGVAAIGGAFSEQILKD AAFNERPIIFALSN PTSKAECSAEQCYKITKGRAIFASGSPFDPVTLPNGQTLYPGQGN S VFPGVALGW ACGLRQITDNIFLTTAEVIAQQVSDKHLEEGRLYPPLNTIRDVSLKIAEKIVKDAYQE KTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYS PEEVQKIQTKVDQ
SEQ ID NO: 209 1743 bp
NOV14e, ACCATGGGCCACCATCACCACCATCACGAGCCCGAAGCCCCCCGTCGCCGCCACACCC 258330149 DNA ATCAGCGCGGCTACCTGCTGACACGGAACCCTCACCTCAACAAGGACTTGGCCTTTAC Sequence CCTGGAAGAGAGACAGCAATTGAACATTCATGGATTGTTGCCACCTTCCTTCAACAGT CAGGAGATCCAGGTTCTTAGAGTAGTAAAAAATTTCGAGCATCTGAACTCTGACTTTG ACAGGTATCTTCTCTTAATGGATCTCCAAGATAGAAATGAAAAACTCTTTTATAGAGT GCTGACATCTGACATTGAGAAATTCATGCCTATTGTTTATACTCCCACTGTGGGTCTG GCTTGCCAACAATATAGTTTGGTGTTTCGGAAGCCAAGAGGTCTCTTTATTACTATCC ACGATCGAGGGCATATTGCTTCAGTTCTCAATGCATGGCCAGAAGATGTCATCAAGGC CATTGTGGTGACTGATGGAGAGCGTATTCTTGGCTTGGGAGACCTTGGCTGTAATGGA ATGGGCATCCCTGTGGGTAAATTGGCTCTATATACAGCTTGCGGAGGGATGAATCCTC AAGAATGTCTGCCTGTCATTCTGGATGTGGGAACCGAAAATGAGGAGTTACTTAAAGA TCCACTCTACATTGGACTACGGCAGAGAAGAGTAAGAGGTTCTGAATATGATGATTTT TTGGACGAATTCATGGAGGCAGTTTCTTCCAAGTATGGCATGAATTGCCTTATTCAGT TTGAAGATTTTGCCAATGTGAATGCATTTCGTCTCCTGAACAAGTATCGAAACCAGTA TTGCACATTCAATGATGATATTCAAGGAACAGCATCTGTTGCAGTTGCAGGTCTCCTT GCAGCTCTTCGAATAACCAAGAACAAACTGTCTGATCAAACAATACTATTCCAAGGAG CTGGGGAGGCTGCCCTAGGGATTGCACACCTGATTGTGATGGCCTTGGAAAAAGAAGG TTTACCAAAAGAGAAAGCCATCAAAAAGATATGGCTGGTTGATTCAAAAGGATTAATA GTTAAGGGACGTGCTTCCTTAACACAAGAGAAAGAGAAGTTTGCCCATGAACATGAAG AAATGAAGAACCTAGAAGCCATTGTTCAAGAAATAAAACCAACTGCCCTCATAGGAGT TGCTGCAATTGGTGGTGCATTCTCAGAACAAATTCTCAAAGATATGGCTGCCTTCAAT GAACGGCCTATTATTTTTGCTTTGAGTAATCCAACTAGCAAAGCAGAATGTTCTGCAG AGCAGTGCTACAAAATAACCAAGGGACGTGCAATTTTTGCCAGTGGCAGTCCTTTTGA TCCAGTCACTCTTCCAAATGGACAGACCCTATATCCTGGCCAAGGCAACAATTCCTAT GTGTTCCCTGGAGTTGCTCTTGGTGTTGTGGCGTGTGGATTGAGGCAGATCACAGATA ATATTTTCCTCACTACTGCTGAGGTTATAGCTCAGCAAGTGTCAGATAAACACTTGGA AGAGGGTCGGCTTTATCCTCCTTTGAATACCATTAGAGATGTTTCTCTGAAAATTGCA GAAAAGATTGTGAAAGATGCATACCAAGAAAAGACAGCCACAGTTTATCCTGAACCGC AAAACAAAGAAGCATTTGTCCGCTCCCAGATGTATAGTACTGATTATGACCAGATTCT

iVKDAYQEKTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYS PEEVQKIQTKVDQ
SEQ ID NO: 213 1722 bp
NOV14g, ACCATGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACCTGCTGA 258330562 DNA CACGGAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACAGCAATT GAACATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTTCTTAGA Sequence GTAGTAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCTTAATGG ATCTCCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACATTGAGAA ATTCATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATATAGTTTG GTGTTTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATATTGCTT CAGTTCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGATGGAGA GCGTATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTGGGTAAA TTGGCTCTATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTGTCATTC TGGATGTGGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGGACTACG GCAGAGAAGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATGGAGGCA GTTTCTTCCAAGTATGGCATGAATTGCCTTATTCAGTTTGAAGATTTTGCCAATGTGA ATGCATTTCGTCTCCTGAACAAGTATCGAAACCAGTATTGCACATTCAATGATGATAT TCAAGGAACAGCATCTGTTGCAGTTGCAGGTCTCCTTGCAGCTCTTCGAATAACCAAG AACAAACTGTCTGATCAAACAATACTATTCCAAGGAGCTGGAGAGGCTGCCCTAGGGA TTGCACACCTGATTGTGATGGCCTTGGAAAAAGAAGGTTTACCAAAAGAGAAAGCCAT CAAAAAGATATGGCTGGTTGATTCAAAAGGATTAATAGTTAAGGGACGTGCTTCCTTA ACACAAGAGAAAGAGAAGTTTGCCCATGAACATGAAGAAATGAAGAACCTAGAAGCCA TTGTTCAAGAAATAAAACCAACTGCCCTCATAGGAGTTGCTGCAATTGGTGGTGCATT CTCAGAACAAATTCTCAAAGATATGGCTGCCTTCAATGAACGGCCTATTATTTTTGCT TTGAGTAATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGCTACAAAATAACCA AGGGACGTGCAATTTTTGCCAGTGGCAGTCCTTTTGATCCAGTCACTCTTCCAAATGG ACAGACCCTATATCCTGGCCAAGGCAACAATTCCTATGTGTTCCCTGGAGTTGCTCTT GGTGTTGTGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACTACTGCTG AGGTTATAGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTATCCTCC TTTGAATACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGATTGTGAAAGATGCA TACCAAGAAAAGACAGCCACAGTTTATCCTGAACCGCAAAACAAAGAAGCATTTGTCC GCTCCCAGATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTCTTGGCC TGAAGAGGTGCAGAAAATACAGACCAAAGTTGACCAGTAG
ORF Start: at 1 ORF Stop: TAG at 1720
SEQ ID NO: 214 573 aa MW at 64250.0kD
NOV14g, TMEPEAPRRRHTHQRGYLLTRNPHLNKDLAFTLEERQQLNIHGLLPPSFNSQEIQVLR 258330562 WKNFEHLNSDFDRYLLLMDLQDRNEKLFYRVLTSDIEKFMPIVYTPTVGLACQQYSL VFRKPRGLFITIHDRGHIASVLNA PEDVIKAIWTDGERILGLGDLGCNG GIPVGK Protein Sequence LALYTACGGMNPQECLPVILDVGTENEELLKDPLYIGLRQRRVRGSEYDDFLDEF EA VSSKYG NCLIQFEDFANV AFRLLNKYRNQYCTFNDDIQGTASVAVAGLLAALRITK NKLSDQTILFQGAGEAALGIAHLIλ/ ALEKEGLPKEKAIKKI LVDSKGLIVKGRASL TQEKEKFAHEHEE KNLEAIVQEIKPTALIGVAAIGGAFSEQILKD AAFNERPIIFA LSNPTSKAECSAEQCYKITKGRAIFASGSPFDPVTLPNGQTLYPGQGN SYVFPGVAL GWACGLRQITDNIFLTTAEVIAQQVSDKHLEEGRLYPPLNTIRDVSLKIAEKIVKDA YQEKTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYSWPEEVQKIQTKVDQ
SEQ ED NO: 215 1719 bp
NOV14h, TGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACCTGCTGACACG 258330639 DNA GAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACAGCAATTGAAC ATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTTCTTAGAGTAG Sequence TAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCTTAATGGATCT CCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACATTGAGAAATTC ATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATATAGTTTGGTGT TTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATATTGCTTCAGT TCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGATGGAGAGCGT ATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTGGGTAAATTGG CTCTATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTGTCATTCTGGA TGTGGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGGACTACGGCAG AGAAGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATGGAGGCAGTTT
SNPTSKAECSAEQCYKITKGRAIFASGSPFDPVTLPDGRTLFPGQGNNSYVFPGVALG WACGLRHIDDKVFLTTAEVISQQVSDKHLQEGRLYPPLNTIRDVSLKIAVKIVQDAY KE MATVYPEPQNKEEFVSSQMYSTNYDQILPDCYP PAEVQKIQTKVNQ
SEQ ID NO: 221 1750 bp
NOV14k, CGCGGATCCATGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACC CG140316-03 TGCTGACACGGAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGAGAGACA GCAATTGAACATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTT DNA Sequence CTTAGAGTAGTAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCT TAATGGATCTCCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACAT TGAGAAATTCATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATAT AGTTTGGTGTTTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAGGGCATA TTGCTTCAGTTCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGTGACTGA TGGAGAGCGTATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATCCCTGTG GGTAAATTGGCTCTATATACAGCTTGCGGAGGGATGAATCCTCAAGAATGTCTGCCTG TCATTCTGGATGTGGGAACCGAAAATGAGGAGTTACTTAAAGATCCACTCTACATTGG ACTACGGCAGAGAAGAGTAAGAGGTTCTGAATATGATGATTTTTTGGACGAATTCATG GAGGCAGTTTCTTCCAAGTATGGCATGAATTGCCTTATTCAGTTTGAAGATTTTGCCA ATGTGAATGCATTTCGTCTCCTGAACAAGTATCGAAACCAGTATTGCACATTCAATGA TGATATTCAAGGAACAGCATCTGTTGCAGTTGCAGGTCTCCTTGCAGCTCTTCGAATA ACCAAGAACAAACTGTCTGATCAAACAATACTATTCCAAGGAGCTGGGGAGGCTGCCC TAGGGATTGCACACCTGATTGTGATGGCCTTGGAAAAAGAAGGTTTACCAAAAGAGAA AGCCATCAAAAAGATATGGCTGGTTGATTCAAAAGGATTAATAGTTAAGGGACGTGCT TCCTTAACACAAGAGAAAGAGAAGTTTGCCCATGAACATGAAGAAATGAAGAACCTAG AAGCCATTGTTCAAGAAATAAAACCAACTGCCCTCATAGGAGTTGCTGCAATTGGTGG TGCATTCTCAGAACAAATTCTCAAAGATATGGCTGCCTTCAATGAACGGCCTATTATT TTTGCTTTGAGTAATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGCTACAAAA TAACCAAGGGACGTGCAATTTTTGCCAGTGGCAGTCCTTTTGATCCAGTCACTCTTCC AAATGGACAGACCCTATATCCTGGCCAAGGCAACAATTCCTATGTGTTCCCTGGAGTT GCTCTTGGTGTTGTGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACTA CTGCTGAGGTTATAGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTA TCCTCCTTTGAATACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGATTGTGAAA GATGCATACCAAGAAAAGACAGCCACAGTTTATCCTGAACCGCAAAACAAAGAAGCAT TTGTCCGCTCCCAGATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTC TTGGCCTGAAGAGGTGCAGAAAATACAGACCAAAGTTGACCAGTAGGGTGGCGGCCGC TTTTTTCCTT
ORF Start: ATG at 10 ORF Stop: TAG at 1726
SEQ ID NO: 222 p72 aa JMW at 64148.9kE>
NOV14k, MEPEAPRRRHTHQRGYLLTRNPHLNKDLAFTLEERQQLNIHGLLPPSFNSQEIQVLRV CG140316-03 VKNFEHLNSDFDRYLLLMDLQDR EKLFYRVLTSDIEKFMPIVYTPTVGLACQQYSLV FRKPRGLFITIHDRGHIASVLNAWPEDVIKAIWTDGERILGLGDLGCNG GIPVGKL Protein Sequence ALYTACGGMNPQECLPVILDVGTENEELLKDPLYIGLRQRRVRGSEYDDFLDEFMEAV SSKYGMNCLIQFEDFANVNAFRLLNKYRNQYCTFNDDIQGTASVAVAGLLAALRITKN KLSDQTILFQGAGEAALGIAHLIVMALEKEGLPKEKAIKKIWLVDSKGLIVKGRASLT QEKEKFAHEHEEMKNLEAIVQEIKPTALIGVAAIGGAFSEQILKDMAAFNERPIIFAL SNPTSKAECSAEQCYKITKGRAIFASGSPFDPVTLPNGQTLYPGQGNNSYVFPGVALG WACGLRQITDNIFLTTAEVIAQQVSDKHLEEGRLYPPLNTIRDVSLKIAEKIVKDAY QEKTATVYPEPQNKEAFVRSQMYSTDYDQILPDCYSWPEEVQKIQTKVDQ
SEQ ID NO: 223 1767 bp
NOV141, CACCATCACCACCATCACGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCG CG140316-04 GCTACCTGCTGACACGGAACCCTCACCTCAACAAGGACTTGGCCTTTACCCTGGAAGA GAGACAGCAATTGAACATTCATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATC DNA Sequence CAGGTTCTTAGAGTAGTAAAAAATTTCGAGCATCTGAACTCTGACTTTGACAGGTATC TTCTCTTAATGGATCTCCAAGATAGAAATGAAAAACTCTTTTATAGAGTGCTGACATC TGACATTGAGAAATTCATGCCTATTGTTTATACTCCCACTGTGGGTCTGGCTTGCCAA CAATATAGTTTGGTGTTTCGGAAGCCAAGAGGTCTCTTTATTACTATCCACGATCGAG GGCATATTGCTTCAGTTCTCAATGCATGGCCAGAAGATGTCATCAAGGCCATTGTGGT GACTGATGGAGAGCGTATTCTTGGCTTGGGAGACCTTGGCTGTAATGGAATGGGCATC
Sequence comparison of the above protein sequences yields the following sequence r reellaattiinornisshhipss s shhoowwnn i inn T Taabbllee 1144BR.
Further analysis of the NOVl 4a protein yielded the following properties shown in Table 14C.
Table 14C. Protein Sequence Properties NOV14a
PSort 0.7000 probability located in nucleus; 0.3000 probability located in analysis: microbody (peroxisome); 0.1771 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV14a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 14D.
In a BLAST search of public sequence datbases, the NOV14a protein was found to have homology to the proteins shown in the BLASTP data in Table 14E.
PFam analysis predicts that the NOV14a protein contains the domains shown in the Table 14F.
Table 14F. Domain Analysis of NOV14a
Pfam Domain Identities/
NOV14a Match Region Similarities Expect Value
Example 15.
The NOVl 5 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 15 A.
Table 15A. NOV15 Sequence Analysis
SEQ DO NO: 225 4427 bp
NOVl 5a, GGCACGAGGCCGGGACAAAAGCCGGATCCCGGGAAGCTACCGGCTGCTGGGGTGCTCC CG142427-01 GGATTTTGCGGGGTTCGTCGGGCCTGTGGAAGAAGCGCCGCGCACGGACTTCGGCAGAj DNA Sequence GGTAGAGCAGGTCTCTCTGCAGCCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCA!
AAGAACTCCTTTACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTA TGCTCGGGTCACTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTG CTCAGCCAGAACTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTG GTCTCGTTGGGGTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCT GGGACAGGAAGCCACAGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAG CCCTTCGTCCCCCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAG AAGGGGACTACGTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGC CAAGGCCCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAA AAACACCTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCT CCGGCCTCTTCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCT TGTAGTGACCAAAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACT GCCGACTACATCTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGC GGGAGGCATATCCAGAGGAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAG CCTGAAGCTGACCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGT GGCGCCTCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGG CAAACTATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAA GACTATCCTCTCCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATT GGAGGCAGCATCGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAG CAATTCGAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAG AGGTGGCCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACT GGGATCCCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGG CCCTGGGCCACCGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTT CCTCCTCAACGCCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTT TCTGAGTCCAGGGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCAC AAGATTCAGTCCCAAGTCCAAGATCCCTGCAAGGAAAGAGCACCACCCTCTTCAGCCG CCACACCAAGGCCATTGTGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTGGAC TTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTGGCTGCCATGGTCTACCCTTTCA CTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACAAAGAGATCCTGATCCCTGTCTT CAAGAACATGGCTGATGCCATGAGGAAGCATCCGGAGGTAGATGTGCTCATCAACTTT GCCTCTCTCCGCTCTGCCTATGACAGCACCATGGAGACCATGAACTATGCCCAGATCC GGACCATCGCCATCATAGCTGAAGGCATCCCTGAGGCCCTCACGAGAAAGCTGATCAA GAAGGCGGACCAGAAGGGAGTGACCATCATCGGACCTGCCACTGTTGGAGGCATCAAG CCTGGGTGCTTTAAGATTGGCAACACAGGTGGGATGCTGGACAACATCCTGGCCTCCA AACTGTACCGCCCAGGCAGCGTGGCCTATGTCTCACGTTCCGGAGGCATGTCCAACGA GCTCAACAATATCATCTCTCGGACCACGGATGGCGTCTATGAGGGCGTGGCCATTGGT GGGGACAGGTACCCGGGCTCCACATTCATGGATCATGTGTTACGCTATCAGGACACTC CAGGAGTCAAAATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGGAATATAAGAT TTGCCGGGGCATCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATCGGG ACGTGTGCCACCATGTTCTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTGCCA

CG142427-01 GGATTTTGCGGGGTTCGTCGGGCCTGTGGAAGAAGCGCCGCGCACGGACTTCGGCAGA DNA Sequence GGTAGAGCAGGTCTCTCTGCAGCCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCA
AAGAACTCCTTTACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTA TGCTCGGGTCACTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTG CTCAGCCAGAACTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTG GTCTCGTTGGGGTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCT GGGACAGGAAGCCACAGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAG CCCTTCGTCCCCCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAG AAGGGGACTACGTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGC CAAGGCCCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAA AAACACCTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCT CCGGCCTCTTCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCT TGTAGTGACCAAAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACT GCCGACTACATCTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGC GGGAGGCATATCCAGAGGAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAG CCTGAAGCTGACCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGT GGCGCCTCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGG CAAACTATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAA GACTATCCTCTCCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATT GGAGGCAGCATCGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAG CAATTCGAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAG AGGTGGCCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACT GGGATCCCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGG CCCTGGGCCACCGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTT CCTCCTCAACGCCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTT TCTGAGTCCAGGGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCAC AAGATTCAGTCCCAAGTCCAAGATCCCTGCAAGGAAAGAGCACCACCCTCTTCAGCCG CCACACCAAGGCCATTGTGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTGGAC TTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTGGCTGCCATGGTCTACCCTTTCA CTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACAAAGAGATCCTGATCCCTGTCTT CAAGAACATGGCTGATGCCATGAGGAAGCATCCGGAGGTAGATGTGCTCATCAACTTT GCCTCTCTCCGCTCTGCCTATGACAGCACCATGGAGACCATGAACTATGCCCAGATCC GGACCATCGCCATCATAGCTGAAGGCATCCCTGAGGCCCTCACGAGAAAGCTGATCAA GAAGGCGGACCAGAAGGGAGTGACCATCATCGGACCTGCCACTGTTGGAGGCATCAAG CCTGGGTGCTTTAAGATTGGCAACACAGGTGGGATGCTGGACAACATCCTGGCCTCCA AACTGTACCGCCCAGGCAGCGTGGCCTATGTCTCACGTTCCGGAGGCATGTCCAACGA GCTCAACAATATCATCTCTCGGACCACGGATGGCGTCTATGAGGGCGTGGCCATTGGT GGGGACAGGTACCCGGGCTCCACATTCATGGATCATGTGTTACGCTATCAGGACACTC CAGGAGTCAAAATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGGAATATAAGAT TTGCCGGGGCATCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATCGGG ACGTGTGCCACCATGTTCTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTGCCA ACCAGGCTTCTGAAACTGCAGTAGCCAAGAACCAGGCTTTGAAGGAAGCAGGAGTGTT TGTGCCCCGGAGCTTTGATGAGCTTGGAGAGATCATCCAGTCTGTATACGAAGATCTC GTGGCCAATGGAGTCATTGTACCTGCCCAGGAGGTGCCGCCCCCAACCGTGCCCATGG ACTACTCCTGGGCCAGGGAGCTTGGTTTGATCCGCAAACCTGCCTCGTTCATGACCAG CATCTGCGATGAGCGAGGACAGGAGCTCATCTACGCGGGCATGCCCATCACTGAGGTC TTCAAGGAAGAGATGGGCATTGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGAAAAGGT TGCCTAAGTACTCTTGCCAGTTCATTGAGATGTGTCTGATGGTGACAGCTGATCACGG GCCAGCCGTCTCTGGAGCCCACAACACCATCATTTGTGCGCGAGCTGGGAAAGACCTG GTCTCCAGCCTCACCTCGGGGCTGCTCACCATCGGGGATCGGTTTGGGGGTGCCTTGG ATGCAGCAGCCAAGATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTT TGTGAACAAGATGAAGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAG TCGATAAACAACCCAGACATGCGAGTGCAGATCCTCAAAGATTACGTCAGGCAGCACT TCCCTGCCACTCCTCTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAA GAAGCCAAATCTTATCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATG CTTAGAAACTGTGGGTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTGGAG CCCTCAATGGCATCTTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGA TCAGAAGAGGCTGAAGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTT CTTCCGGAACACATGAGCATGTAACAGAGCCAGGAACCCTACTGCAGTAAACTGAAGA CAAGATCTCTTCCCCCAAGAAAAAGTGTACAGACAGCTGGCAGTGGAGCCTGCTTTAT TTAGCAGGGGCCTGGAATGTAAACAGCCACTGGGGTACAGGCACCGAAGACCAACATC

CCATGTCTTTGGCACAGAGACCCACACTGCAAACTTCCTCCTCAACGCCAGCGGGAGC ACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAGTCCAGGGCCGATGAGG TGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGGAAAGAGCACCACCCTCTT CAGCCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATG CTGGACTTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTGGCTGCCATGGTCTACC CTTTCACTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACAAAGAGATCCTGATCCC TGTCTTCAAGAACATGGCTGATGCCATGAGGAAGCATCCGGAGGTAGATGTGCTCATC AACTTTGCCTCTCTCCGCTCTGCCTATGACAGCACCATGGAGACCACGAACTATGCCC AGATCCGGACCATCGCCATCATAGCTGAAGGCATTCCTGAGGCCCTCACGAGAAAGCT GATCAAGAAGGCGGACCAGAAGGGAGTGACCATCATCGGACCTGCCACTGTTGGAGGC ATCAAGCCTGGGTGCTTTAAGATTGGCAACACAGGTGGGATGCTGGACAACATCCTGG CCTCCAAACTGTACCGCCCAGGCAGCGTGGCCTATGCCTCACGTTCCGGAGGCATGTC CAACGAGCTCAACAATATCATCTCTCGGACCACGGATGGCGTCTATGAGGGCGTGGCC ATTGGTGGGGACAGGTACCCGGGCTCCACATTCATGGATCATGTGTTACGCTATCAGG ACACTCCAGGAGTCAAAATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGGAATA TAAGATTTGCCGGGGCATCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGC ATCGGGACGTGTGCCACCATGTTCTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTT GTGCCAACCAGGCTTCTGAAACTGCAGTAGCCAAGAACCAGGCTTTGAAGGAAGCAGG AGTGTTTGTGCCCCGGAGCTTTGATGAGCTTGGAGAGATCATCCAGTCTGTATACGAA GATCTCGTGGCCAATGGAGTCATTGTACCTGCCCAGGAGGTGCCGCCCCCAACCGTGC CCATGGACTACTCCTGGGCCAGGGAGCTTGGTTTGATCCGCAAACCTGCCTCGTTCAT GACCAGCATCTGCGATGAGCGAGGACAGGAGCTCATCTACGCGGGCATGCCCATCACT GAGGTCTTCAAGGAAGAGATGGGCATTGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGA AAAGGTTGCCTAAGTACTCTTGCCAGTTCATTGAGATGTGTCTGATGGTGACAGCTGA TCACGGGCCAGCCGTCTCTGGAGCCCACAACACCATCATTTGTGCGCGAGCTGGGAAA GACCTGGTCTCCAGCCTCACCTCGGGGCTGCTCACCATCGGGGATCGGTTTGGGGGTG CCTTGGATGCAGCAGCCAAGATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCAT GGAGTTTGTGAACAAGATGAAGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGA GTGAAGTCGATAAACAACCCAGACATGCGAGTGCAGATCCTCAAAGATTACGTCAGGC AGCACTTCCCTGCCACTCCTCTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCAC CTCGAAGAAGCCAAATCTTATCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTA GACATGCTTAGAAACTGTGGGTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACA TTGGAGCCCTCAATGGCATCTTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTA TCTTGATCAGAAGAGGCTGAAGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCA TATGTTCTTCCGGAACACATGAGCATGTAAGCGGCCGCTTTTTTCCTT
ORF Start: at 2 ORF Stop: TAA at 3218 SEQ ID NO: 230 072 aa MW at ll7722.3kD
NOVl 5c, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTD ARLLQDHP LLSQN CG142427-04 LWKPDQLIKRRGKLGLVGVNLTLDGVKSWLKPRLGQEATVGKATGFLKNFLIEPFVP Protein Sequence HSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKAQKLLVGVDEKLNPEDIKKHLL VHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLVVTKDGVYVLDLAAKVDATADYI CKVKWGDIEFPPPFGREAYPEEAYIAGLDAKSGASLKLTLLNPKGRI TMVAGGGASV VYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTILSLMTREKHPDGKILIIGGSI ANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPNYQEGLRVMGEVGKTTGIPI HVFGTETHTANFLLNASGSTSTPAPSRTASFSESRADEVAPAKKAKPAMPQGKSTTLF SRHTKAIVWGMQTRAVQGMLDFDYVCSRDEPSVAAMVYPFTGDHKQKFY GHKEILIP VFKNMADAMRIΗPEVDVLINFASLRSAYDSTMETTNYAQIRTIAIIAEGIPEALTRKL IKKADQKGVTIIGPATVGGIKPGCFKIGNTGGMLDNILASKLYRPGSVAYASRSGGMS NELNNIISRTTDGVYEGVAIGGDRYPGSTF DHVLRYQDTPGVK IWLGEIGGTEEY KICRGIKEGRLTKPIVCWCIGTCATMFSSEVQFGHAGACANQASETAVAKNQALKEAG VFVPRSFDELGEIIQSVYEDLVANGVIVPAQEVPPPTVPMDYSWARELGLIRKPASFM TSICDERGQELIYAGMPITEVFKEE GIGGVLGLL FQKRLPKYSCQFIE CLMVTAD HGPAVSGAHNTIICARAGKDLVSSLTSGLLTIGDRFGGALDAAAKMFSKAFDSGIIPM EFVNK KKEGK_,IMGIGHRVKSIlvmPDMRVQILKDYVRQHFPATPLLDYALEVEKITT SKKPNLILNVDGLIGVAFVDMLRNCGSFTREEADEYIDIGALNGIFVLGRSMGFIGHY LDQKRLKQGLYRHP DDISYVLPEHMSM
SEQ ID NO: 231 3307 bp
NOV15d, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT

NON15d, QΝSTMSAKAISEQTGKELLYKFICTTSAIQΝRFKYARVTPDTD ARLLQDHP LLSQΝ CG142427-02 LVVKPDQLIKRRGKLGLVGVΝLTLDGVKS LKPRLGQEATVGKATGFLKΝFLIEPFVP HSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKAQKLLVGVDEKLΝPEDIKKHLL Protein Sequence VHAPEDKKEILASFISGLFΝFYEDLYFTYLEIΝPLVVTKDGVYVLDLAAKVDATADYI CKVK GDIEFPPPFGREAYPEEAYIADLDAKSGASLKLTLLΝPKGRIWTMVAGGGASV VYSDTICDLGGVΝELAΝYGEYSGAPSEQQTYDYAKTILSL TREKHPDGKILIIGGSI AΝFTΝVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPΝYQEGLRV GEVGKTTGIPI HVFGTETHMTAIVG ALGHRPIPΝQPPTAAHTAΝFLLΝASGSTSTPAPSRTASFSESR ADEVAPAKKAKPA PQGKSTTLFSRHTKAIV GMQTRAVQGMLDFDYVCSRDEPSVAA IWYPFTGDHKQKFY GHKEILIPVFKΝMADARKHPEVDVLIΝFASLRSAYDSTMETM ΝYAQIRTIAIIAEGIPEALTRKLIKKADQKGVTIIGPATVGGIKPGCFKIGΝTGGMLD NILASKLYRPGSVAYVSRSGGMSNELNNIISRTTDGVYEGVAIGGDRYPGSTFMDHVL RYQDTPGVKMIWLGEIGGTEEYKICRGIKEGRLTKPIVCWCIGTCATMFSSEVQFGH AGACANQASETAVAKNQALKEAGVFVPRSFDELGEIIQSVYEDLVANGVIVPAQEVPP PTVPMDYSWARELGLIRKPASFMTSICDERGQELIYAGMPITEVFKEEMGIGGVLGLL WFQKRLPKYSCQFIEMCLMVTADHGPAVSGAHNTIICARAGKDLVSSLTSGLLTIGDR FGGALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINNPDMRVQILKD YVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCGSFTREEADE YIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHPWDDISYVLPEHMSM
SEQ ID NO: 233 2290 bp
NON15e, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT CG142427-03 TACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCA DΝA Sequence CTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAA CTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGG GTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAG CCACAGTGAGTGGGCATGGGGTCAAGATGAACGTGTGTGGTAACAGAAGCAAATATGG TCACCTTCAGGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTC GTCCCCCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGG ACTACGTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGC CCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACAC CTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCC TCTTCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGT GACCAAAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGAC TACATCTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGG CATATCCAGAGGAAGCCTACATTGCAGACCTCGACGCCAAAAGTGGGGCAAGCCTGAA GCTGACCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCC TCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACT ATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAAGACTAT CCTCTCCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGC AGCATCGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTC GAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGG CCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATC CCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGG GCCACCGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCT CAACGCCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAG TCCAGGGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGGAA AGAGCACCACCCTCTTCAGCCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCG GGCCGTGCAAGGCATGCTGGACTTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTG GCTGCCATGGTCTACCCTTTCACTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACA AAGAGATCCTGATCCCTGTCTTCAAGAACATGGCTGATGCCATGAGGAAGCACCCGGA GGTAGATGTGCTCATCAACTTTGCTTCTCTCCGCTCTGCCTTGGATGCAGCAGCCAAG ATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTTTGTGAACAAGATGA AGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATAAACAACCC AGACATGCGAGTGCGGATCCTCAAAGATTACGTCAGGCAGCACTTCCCTGCCACTCCT CTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATCTTA TCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTGTGG GTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTGGAGCCCTCAATGGCATC TTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGATCAGAAGAGGCTGA AGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGAACACAT GAGCATGTAAGCGGCCGCTTTTTTCCTT
ORF Start: at 2 JORF Stop: TAA at 2270
SEQ ID NO: 234 756 aa MW at 83890.7kD
NOV15e, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTD ARLLQDHP LLSQN CG142427-03 LWKPDQLIKRRGKLGLVGVNLTLDGVKS LKPRLGQEATVSGHGVKMNVCGNRSKYG Protein Sequence HLQVGKATGFLKNFLIEPFVPHSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKA QKLLVGVDEKLNPEDIKKHLLVHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLW TKDGVYVLDLAAKVDATADYICKVKGDIEFPPPFGREAYPEEAYIADLDAKSGASLK LTLLNPKGRI TMVAGGGASWYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTI LSLMTREKHPDGKILIIGGSIANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGG PNYQEGLRVMGEVGKTTGIPIHVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLL NASGSTSTPAPSRTASFSESRADEVAPAKKAKPAMPQGKSTTLFSRHTKAIV GMQTR AVQGMLDFDYVCSRDEPSVAAMVYPFTGDHKQKFYWGHKEILIPVFKNMADAMRKHPE VDVLINFASLRSALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINNP DMRVRILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCG SFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHP DDISYVLPEHM SM
NOV15f, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT 256388552 DNA TACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCA CTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAA Sequence CTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGG GTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAG CCACAGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTCGTCCC CCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGGACTAC GTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGCCCAGA AGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACACCTGTT GGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCCTCTTC AATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGTGACCA AAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGACTACAT CTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGGCATAT CCAGAGGAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAGCCTGAAGCTGA CCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCCTCTGT CGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACTATGGG GAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGATTATGCCAAGACTATCCTCT CCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGCAGCAT CGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTCGAGAT TACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGGCCCCA ACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATCCCCAT CCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGGGCCAC CGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCTCAACG CCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAGTCCAG GGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGATTCAGTC CCAAGTCCAAGATCCCTGCAAGGAAAGAGCACCACCCTCTTCAGCCGCCACACCAAGG CCATTGTGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTGGACTTTGACTATGT CTGCTCCCGAGACGAGCCCTCAGTGGCTGCCATGGTCTACCCTTTCACTGGGGACCAC AAGCAGAAGTTTTACTGGGGGCACAAAGAGATCCTGATCCCTGTCTTCAAGAACATGG CTGATGCCATGAGGAAGCACCCGGAGGTAGATGTGCTCATCAACTTTGCCTCTCTCCG CTCTGCCTATGACAGCACCATGGAGACCATGAACTATGCCCAGATCCGGACCATCGCC ATCATAGCTGAAGGCATCCCTGAGGCCCTCACGAGAAAGCTGATCAAGAAGGCGGACC AGAAGGGAGTGACCATCATCGGACCTGCCACTGTTGGAGGCATCAAGCCTGGGTGCTT TAAGATTGGCAACACAGGTGGGATGCTGGACAACATCCTGGCCTCCAAACTGTACCGC CCAGGCAGCGTGGCCTATGTCTCACGTTCCGGAGGCATGTCCAACGAGCTCAACAATA TCATCTCTCGGACCACGGATGGCGTCTATGAGGGCGTGGCCATTGGTGGGGACAGGTA CCCGGGCTCCACATTCATGGATCATGTGTTACGCTATCAGGACACTCCAGGAGTCAAA ATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGGAATATAAGATTTGCCGGGGCA TCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATCGGGACGTGTGCCAC CATGTTCTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTGCCAACCAGGCTTCT IGAAACTGCAGTAGCCAAGAACCAGGCTTTGAAGGAAGCAGGAGTGTTTGTGCCCCGGA IGCTTTGATGAGCTTGGAGAGATCATCCAGTCTGTATACGAAGATCTCGTGGCCAATGG
AGTCATTGTACCTGCCCAGGAGGTGCCGCCCCCAACCGTGCCCATGGACTACTCCTGG GCCAGGGAGCTTGGTTTGATCCGCAAACCTGCCTCGTTCATGACCAGCATCTGCGATG AGCGAGGACAGGAGCTCATCTACGCGGGCATGCCCATCACTGAGGTCTTCAAGGAAGA GATGGGCATTGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGAAAAGGTTGCCTAAGTAC TCTTGCCAGTTCATTGAGATGTGTCTGATGGTGACAGCTGATCACGGGCCAGCCGTCT CTGGAGCCCACAACACCATCATTTGTGCGCGAGCTGGGAAAGACCTGGTCTCCAGCCT CACCTCGGGGCTGCTCACCATCGGGGATCGGTTTGGGGGTGCCTTGGATGCAGCAGCC AAGATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTTTGTGAACAAGA TGAAGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATAAACAA CCCAGACATGCGAGTGCAGATCCTCAAAGATTACGTCAGGCAGCACTTCCCTGCCACT CCTCTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATC TTATCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTG TGGGTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTGGAGCCCTCAATGGC ATCTTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGATCAGAAGAGGC TGAAGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGAACA CATGAGCATGT
ORF Start: at 2 ORF Stop: end of sequence
SEQ ID NO: 236 1106 aa MW at 121268.4 D
NOV15f, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTDWARLLQDHPWLLSQN 256388552 LWKPDQLIKRRGKLGLVGVNLTLDGVKS LKPRLGQEATVGKATGFLKNFLIEPFVP HSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKAQi—LVGVDEKLNPEDIKKHLL Protein Sequence VHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLVVTKDGVYVLDLAAKVDATADYI CKVK GDIEFPPPFGREAYPEEAYIADLDAKSGASLKLTLLNPKGRIWTMVAGGGASy VYSDTICDLGGV ELANYGEYSGAPSEQQTYDYAKTILSLMTREKHPDGKILIIGGSI ANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPNYQEGLRVMGEVGKTTGIPI HVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLLNASGSTSTPAPSRTASFSESR ADEVAPAKKAKPAMPQDSVPSPRSLQGKSTTLFSRHTKAIVWGMQTRAVQGMLDFDYV CSRDEPΞVAAMVYPFTGDHKQKFY GHKEILIPVFKNMADAMRKHPEVDVLINFASLR SAYDSTMETMNYAQIRTIAIIAEGIPEALTRKLIKKADQKGVTIIGPATVGGIKPGCF KIGNTGGMLDNILASKLYRPGSVAYVSRSGGMSNELNNIISRTTDGVYEGVAIGGDRY PGSTFMDHVLRYQDTPGVKMIWLGEIGGTEEYKICRGIKEGRLTKPIVC CIGTCAT MFSSEVQFGHAGACANQASETAVAKNQALKEAGVFVPRSFDELGEIIQSVYEDLVANG VIVPAQEVPPPTVPMDYS ARELGLIRKPASFMTSICDERGQELIYAGMPITEVFKEE MGIGGVLGLLWFQKRLPKYSCQFIEMCLMVTADHGPAVSGAHNTIICARAGKDLVSSL TSGLLTIGDRFGGALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINN PDMRVQILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNC GSFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHPWDDISYVLPEH MSMX
SEQ ID NO: 237
NOV15g, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT 256420210 DNA TACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCA CTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAA Sequence CTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGG GTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAG CCACAGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTCGTCCC CCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGGACTAC GTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGCCCAGA AGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACACCTGTT GGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCCTCTTC AATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGTGACCA AAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGACTACAT CTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGGCATAT CCAGAGGAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAGCCTGAAGCTGA CCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCCTCTGT CGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACTATGGG GAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAAGACTATCCTCT CCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGCAGCAT

YVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCGSFTREEADE jYIDIGALNGI FVLGRSMGFIGHYLDQKRLKQGLYRHP DDI SYVLPEHMSM
SEQ ID NO: 239 2290 bp
NOV15h, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT 256202925 DNA TACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCA CTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAA Sequence CTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGG GTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAG CCACAGTGAGTGGGCATGGGGTCAAGATGAACGTGTGTGGTAACAGAAGCAAATATGG TCACCTTCAGGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTC GTCCCCCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGG ACTACGTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGC CCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACAC CTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCC TCTTCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGT GACCAAAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGAC TACATCTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGG CATATCCAGAGGAAGCCTACATTGCAGACCTCGACGCCAAAAGTGGGGCAAGCCTGAA GCTGACCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCC TCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACT ATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAAGACTAT CCTCTCCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGC AGCATCGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTC GAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGG CCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATC CCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGG GCCACCGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCT CAACGCCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAG TCCAGGGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGGAA AGAGCACCACCCTCTTCAGCCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCG GGCCGTGCAAGGCATGCTGGACTTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTG GCTGCCATGGTCTACCCTTTCACTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACA AAGAGATCCTGATCCCTGTCTTCAAGAACATGGCTGATGCCATGAGGAAGCACCCGGA GGTAGATGTGCTCATCAACTTTGCTTCTCTCCGCTCTGCCTTGGATGCAGCAGCCAAG ATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTTTGTGAACAAGATGA AGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATAAACAACCC AGACATGCGAGTGCGGATCCTCAAAGATTACGTCAGGCAGCACTTCCCTGCCACTCCT CTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATCTTA TCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTGTGG GTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTGGAGCCCTCAATGGCATC TTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGATCAGAAGAGGCTGA AGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGAACACAT GAGCATGTAAGCGGCCGCTTTTTTCCTT
ORF Start: at 2 ORF Stop: TAA at 2270
SEQ ID NO: 240 756 aa MW at 83890.7kD
NOV15h, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTDWARLLQDHPWLLSQN 256202925 LVVKPDQLIKRRGKLGLVGVNLTLDGVKS LKPRLGQEATVSGHGVKMNVCGNRSKYG HLQVGKATGFLKNFLIEPFVPHSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKA Protein Sequence QKLLVGVDEKLNPEDIKKHLLVHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLVV TKDGVYVLDIiAAKVDATADYICKVKWGDIEFPPPFGREAYPEEAYIADLDAKSGASLK LTLLNPKGRIWTMVAGGGASWYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTI LSLMTREKHPDGKILIIGGSIANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGG PNYQEGLRVMGEVGKTTGIPIHVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLL NASGSTSTPAPSRTASFSESRADEVAPAKKAKPAMPQGKSTTLFSRHTKAI GMQTR AVQGMLDFDYVCSRDEPSVAAMVYPFTGDHKQKFYWGHKEILIPVFK2JMADAMRKHPE VDVLINFASLRSALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINNP DMRVRILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCG SFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHP DDISYVLPEHM
SM
SEQ ID NO: 241 3310 bp
NOV15i, CACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTTTACAAGTTC 259856081 DNA ATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCACTCCTGACA Sequence CAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAACTTGGTAGT
CAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGGGTCAACCTC
ACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAGCCACAGTTG
GCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTCGTCCCCCACAGTCA
GGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGGACTACGTCCTGTTC
CACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGCCCAGAAGCTGCTTG
TTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACACCTGTTGGTCCACGC
CCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCCTCTTCAATTTCTAC
GAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGTGACCAAAGATGGAG
TCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGACTACATCTGCAAAGT
GAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGGCATATCCAGAGGAA
GCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAGCCTGAAGCTGACCTTGCTGA
ACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCCTCTGTCGTGTACAG
CGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACTATGGGGAGTACTCA
GGCGCCCCCAGCGAGCAGCAGACCTATGATTATGCCAAGACTATCCTCTCCCTCATGA
CCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGCAGCATCGCAAACTT
CACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTCGAGATTACCAGGGC
CCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGGCCCCAACTATCAGG
AGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATCCCCATCCATGTCTT
TGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGGGCCACCGGCCCATC
CCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCTCAACGCCAGCGGGA
GCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAGTCCAGGGCCGATGA
GGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGATTCAGTCCCAAGTCCA
AGATCCCTGCAAGGAAAGAGCACCACCCTCTTCAGCCGCCACACCAAGGCCATTGTGT
GGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTGGACTTTGACTATGTCTGCTCCCG
AGACGAGCCCTCAGTGGCTGCCATGGTCTACCCTTTCACTGGGGACCACAAGCAGAAG
TTTTACTGGGGGCACAAAGAGATCCTGATCCCTGTCTTCAAGAACATGGCTGATGCCA
TGAGGAAGCACCCGGAGGTAGATGTGCTCATCAACTTTGCCTCTCTCCGCTCTGCCTA
TGACAGCACCATGGAGACCATGAACTATGCCCAGATCCGGACCATCGCCATCATAGCT
GAAGGCATCCCTGAGGCCCTCACGAGAAAGCTGATCAAGAAGGCGGACCAGAAGGGAG
TGACCATCATCGGACCTGCCACTGTTGGAGGCATCAAGCCTGGGTGCTTTAAGATTGG
CAACACAGGTGGGATGCTGGACAACATCCTGGCCTCCAAACTGTACCGCCCAGGCAGC
GTGGCCTATGTCTCACGTTCCGGAGGCATGTCCAACGAGCTCAACAATATCATCTCTC
GGACCACGGATGGCGTCTATGAGGGCGTGGCCATTGGTGGGGACAGGTACCCGGGCTC
CACATTCATGGATCATGTGTTACGCTATCAGGACACTCCAGGAGTCAAAATGATTGTG
GTTCTTGGAGAGATTGGGGGCACTGAGGAATATAAGATTTGCCGGGGCATCAAGGAGG
GCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATCGGGACGTGTGCCACCATGTTCTC
CTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTGCCAACCAGGCTTCTGAAACTGCA
GTAGCCAAGAACCAGGCTTTGAAGGAAGCAGGAGTGTTTGTGCCCCGGAGCTTTGATG
AGCTTGGAGAGATCATCCAGTCTGTATACGAAGATCTCGTGGCCAATGGAGTCATTGT
ACCTGCCCAGGAGGTGCCGCCCCCAACCGTGCCCATGGACTACTCCTGGGCCAGGGAG
CTTGGTTTGATCCGCAAACCTGCCTCGTTCATGACCAGCATCTGCGATGAGCGAGGAC
AGGAGCTCATCTACGCGGGCATGCCCATCACTGAGGTCTTCAAGGAAGAGATGGGCAT
TGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGAAAAGGTTGCCTAAGTACTCTTGCCAG
TTCATTGAGATGTGTCTGATGGTGACAGCTGATCACGGGCCAGCCGTCTCTGGAGCCC
ACAACACCATCATTTGTGCGCGAGCTGGGAAAGACCTGGTCTCCAGCCTCACCTCGGG
GCTGCTCACCATCGGGGATCGGTTTGGGGGTGCCTTGGATGCAGCAGCCAAGATGTTC
AGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTTTGTGAACAAGATGAAGAAGG
AAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATAAACAACCCAGACAT
GCGAGTGCAGATCCTCAAAGATTACGTCAGGCAGCACTTCCCTGCCACTCCTCTGCTC
GATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATCTTATCCTGA
ATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTGTGGGTCCTT
TACTCGGGAGGAAGCTGATGAATATATTGACATTGGAGCCCTCAATGGCATCTTTGTG
CTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGATCAGAAGAGGCTGAAGCAGG
GGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGAACACATGAGCAT
GTAA

ATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGGAATATAAGATTTGCCGGGGCA TCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATCGGGACGTGTGCCAC CATGTTCTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTGCCAACCAGGCTTCT GAAACTGCAGTAGCCAAGAACCAGGCTTTGAAGGAAGCAGGAGTGTTTGTGCCCCGGA GCTTTGATGAGCTTGGAGAGATCATCCAGTCTGTATACGAAGATCTCGTGGCCAATGG AGTCATTGTACCTGCCCAGGAGGTGCCGCCCCCAACCGTGCCCATGGACTACTCCTGG GCCAGGGAGCTTGGTTTGATCCGCAAACCTGCCTCGTTCATGACCAGCATCTGCGATG AGCGAGGACAGGAGCTCATCTACGCGGGCATGCCCATCACTGAGGTCTTCAAGGAAGA GATGGGCATTGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGAAAAGGTTGCCTAAGTAC TCTTGCCAGTTCATTGAGATGTGTCTGATGGTGACAGCTGATCACGGGCCAGCCGTCT CTGGAGCCCACAACACCATCATTTGTGCGCGAGCTGGGAAAGACCTGGTCTCCAGCCT CACCTCGGGGCTGCTCACCATCGGGGATCGGTTTGGGGGTGCCTTGGATGCAGCAGCC AAGATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTTTGTGAACAAGA TGAAGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATAAACAA CCCAGACATGCGAGTGCAGATCCTCAAAGATTACGTCAGGCAGCACTTCCCTGCCACT CCTCTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATC TTATCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTG TGGGTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTGGAGCCCTCAATGGC ATCTTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGATCAGAAGAGGC TGAAGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGAACA CATGAGCATGT
ORF Start: at 2 ORF Stop: end of sequence
SEQ ID NO: 244 1106 aa |MW aU21268.4kD
NOV15J, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTD ARLLQDHP LLSQN 256388552 LWKPDQLIKRRGKLGLVGVNLTLDGVKS LKPRLGQEATVGKATGFLKNFLIEPFVP HSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKAQKLLVGVDEKLNPEDIKKHLL Protein Sequence VHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLVVTKDGVYVLDLAAKVDATADYI CKVK GDIEFPPPFGREAYPEEAYIADLDAKSGASLKLTLLNPKGRI TMVAGGGASV VYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTILSLMTREKHPDGKILIIGGSI ANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPNYQEGLRVMGEVGKTTGIPI HVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLLNASGSTSTPAPSRTASFSESR ADEVAPAKKAKPAMPQDSVPSPRSLQGKSTTLFSRHTKAIV GMQTRAVQGMLDFDYV CSRDEPSVAAMVYPFTGDHKQKFYWGHKEILIPVFKNMADAMRKHPEVDVLINFASLR SAYDSTMETMNYAQIRTIAIIAEGIPEALTRKLIKKADQKGVTIIGPATVGGIKPGCF KIGNTGGMLDNILASKLYRPGSVAYVSRSGGMSNELNNIISRTTDGVYEGVAIGGDRY PGSTFMDHVLRYQDTPGVKMIWLGEIGGTEEYKICRGIKEGRLTKPIVCWCIGTCAT MFSSEVQFGHAGACANQASETAVAKNQALKEAGVFVPRSFDELGEIIQSVYEDLVANG VIVPAQEVPPPTVPMDYS ARELGLIRKPASFMTSICDERGQELIYAGMPITEVFKEE MGIGGVLGLLWFQKRLPKYSCQFIEMCLMVTADHGPAVSGAHNTIICARAGKDLVSSL TSGLLTIGDRFGGALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINN PDMRVQILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNC GSFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHP DDISYVLPEH MSMX
NOV15k, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT 256420210 DNA TACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCA CTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAA Sequence CTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGG GTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAG CCACAGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTCGTCCC CCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGGACTAC GTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGCCCAGA AGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACACCTGTT GGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCCTCTTC AATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGTGACCA AAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGACTACAT CTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGGCATAT
CCAGAGGAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAGCCTGAAGCTGA CCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCCTCTGT CGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACTATGGG GAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAAGACTATCCTCT CCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGCAGCAT CGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTCGAGAT TACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGGCCCCA ACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATCCCCAT CCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGGGCCAC CGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCTCAACG CCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAGTCCAG GGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGGAAAGAGC ACCACCCTCTTCAGCCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCGGGCCG TGCAAGGCATGCTGGACTTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTGGCTGC CATGGTCTACCCTTTCACTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACAAAGAG ATCCTGATCCCTGTCTTCAAGAACATGGCTGATGCCATGAGGAAGCACCCGGAGGTAG ATGTGCTCATCAACTTTGCCTCTCTCCGCTCTGCCTATGACAGCACCATGGAGACCAT GAACTATGCCCAGATCCGGACCATCGCCATCATAGCTGAAGGCATCCCTGAGGCCCTC ACGAGAAAGCTGATCAAGAAGGCGGACCAGAAGGGAGTGACCATCATCGGACCTGCCA CTGTTGGAGGCATCAAGCCTGGGTGCTTTAAGATTGGCAACACAGGTGGGATGCTGGA CAACATCCTGGCCTCCAAACTGTACCGCCCAGGCAGCGTGGCCTATGTCTCACGTTCC GGAGGCATGTCCAACGAGCTCAACAATATCATCTCTCGGACCACGGATGGCGTCTATG AGGGCGTGGCCATTGGTGGGGACAGGTACCCGGGCTCCACATTCATGGATCATGTGTT ACGCTATCAGGACACTCCAGGAGTCAAAATGATTGTGGTTCTTGGAGAGATTGGGGGC ACTGAGGAATATAAGATTTGCCGGGGCATCAAGGAGGGCCGCCTCACTAAGCCCATCG TCTGCTGGTGCATCGGGACGTGTGCCACCATGTTCTCCTCTGAGGTCCAGTTTGGCCA TGCTGGAGCTTGTGCCAACCAGGCTTCTGAAACTGCAGTAGCCAAGAACCAGGCTTTG AAGGAAGCAGGAGTGTTTGTGCCCCGGAGCTTTGATGAGCTTGGAGAGATCATCCAGT CTGTATACGAAGATCTCGTGGCCAATGGAGTCATTGTACCTGCCCAGGAGGTGCCGCC CCCAACCGTGCCCATGGACTACTCCTGGGCCAGGGAGCTTGGTTTGATCCGCAAACCT GCCTCGTTCATGACCAGCATCTGCGATGAGCGAGGACAGGAGCTCATCTACGCGGGCA TGCCCATCACTGAGGTCTTCAAGGAAGAGATGGGCATTGGCGGGGTCCTCGGCCTCCT CTGGTTCCAGAAAAGGTTGCCTAAGTACTCTTGCCAGTTCATTGAGATGTGTCTGATG GTGACAGCTGATCACGGGCCAGCCGTCTCTGGAGCCCACAACACCATCATTTGTGCGC GAGCTGGGAAAGACCTGGTCTCCAGCCTCACCTCGGGGCTGCTCACCATCGGGGATCG GTTTGGGGGTGCCTTGGATGCAGCAGCCAAGATGTTCAGTAAAGCCTTTGACAGTGGC ATTATCCCCATGGAGTTTGTGAACAAGATGAAGAAGGAAGGGAAGCTGATCATGGGCA TTGGTCACCGAGTGAAGTCGATAAACAACCCAGACATGCGAGTGCAGATCCTCAAAGA TTACGTCAGGCAGCACTTCCCTGCCACTCCTCTGCTCGATTATGCACTGGAAGTAGAG AAGATTACCACCTCGAAGAAGCCAAATCTTATCCTGAATGTAGATGGTCTCATCGGAG TCGCATTTGTAGACATGCTTAGAAACTGTGGGTCCTTTACTCGGGAGGAAGCTGATGA ATATATTGACATTGGAGCCCTCAATGGCATCTTTGTGCTGGGAAGGAGTATGGGGTTC ATTGGACACTATCTTGATCAGAAGAGGCTGAAGCAGGGGCTGTATCGTCATCCGTGGG ATGATATTTCATATGTTCTTCCGGAACACATGAGCATGTAAGCGGCCGCTTTTTTCCT T
ORF Start: at 2 ORF Stop: TAA at 3287
SEQ ID NO: 246 1095 aa MW at l20201.2kD
NOV15k, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTD ARLLQDHP LLSQN 256420210 LWKPDQLIKRRGKLGLVGVNLTLDGVKSWLKPRLGQEATVGKATGFLKNFLIEPFVP HSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKAQKLLVGVDEKLNPEDIKKHLL Protein Sequence VHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLVVTKDGVYVLDLAAKVDATADYI CKVK GDIEFPPPFGREAYPEEAYIADLDAKSGASLKLTLLNPKGRI TMVAGGGASV VYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTILSLMTREKHPDGKILIIGGSI ANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPNYQEGLRVMGEVGKTTGIPI HVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLLNASGSTSTPAPSRTASFSESR ADEVAPAKKAKPAMPQGKSTTLFSRHTKAIV GMQTRAVQGMLDFDYVCSRDEPSVAA MVYPFTGDHKQKFY GHKEILIPVFKNMADAMRKHPEVDVLINFASLRSAYDSTMETM l_AQIRTIAIIAEGIPEALTRKLIKKADQKGVTIIGPATVGGIKPGCFKIGNTGGMLD NILASKLYRPGSVAYVSRSGGMSNELNNIISRTTDGVYEGVAIGGDRYPGSTFMDHVL
RYQDTPGVKMIWLGEIGGTEEYKICRGIKEGRLTKPIVCWCIGTCATMFSSEVQFGH AGACANQASETAVAKNQALKEAGVFVPRSFDELGEIIQSVYEDLVANGVIVPAQEVPP PTVPMDYSWARELGLIRKPASFMTSICDERGQELIYAGMPITEVFKEEMGIGGVLGLL FQKRLPKYSCQFIEMCLMVTADHGPAVSGAHNTIICARAGKDLVSSLTSGLLTIGDR FGGALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINNPDMRVQILKD YVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCGSFTREEADE YIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHP DDISYVLPEHMSM
SEQ ID NO: 247 2290 bp
NOVl 51, CCAGAATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTT 256202925 DNA TACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCA CTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAA Sequence CTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGG GTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAG CCACAGTGAGTGGGCATGGGGTCAAGATGAACGTGTGTGGTAACAGAAGCAAATATGG TCACCTTCAGGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTC GTCCCCCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGG ACTACGTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGC CCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACAC CTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCC TCTTCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGT GACCAAAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGAC TACATCTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGG CATATCCAGAGGAAGCCTACATTGCAGACCTCGACGCCAAAAGTGGGGCAAGCCTGAA GCTGACCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCC TCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACT ATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAAGACTAT CCTCTCCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGC AGCATCGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTC GAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGG CCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATC CCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGG GCCACCGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCT CAACGCCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAG TCCAGGGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGGAA AGAGCACCACCCTCTTCAGCCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCG GGCCGTGCAAGGCATGCTGGACTTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTG GCTGCCATGGTCTACCCTTTCACTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACA AAGAGATCCTGATCCCTGTCTTCAAGAACATGGCTGATGCCATGAGGAAGCACCCGGA GGTAGATGTGCTCATCAACTTTGCTTCTCTCCGCTCTGCCTTGGATGCAGCAGCCAAG ATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGAGTTTGTGAACAAGATGA AGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATAAACAACCC AGACATGCGAGTGCGGATCCTCAAAGATTACGTCAGGCAGCACTTCCCTGCCACTCCT CTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATCTTA TCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTGTGG GTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTGGAGCCCTCAATGGCATC TTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCTTGATCAGAAGAGGCTGA AGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGAACACAT GAGCATGTAAGCGGCCGCTTTTTTCCTT
ORF Start: at 2 |ORF Stop: TAA at 2270
SEQ ID NO: 248 756 aa MW at 83890.7kD
NOVl 51, QNSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTD ARLLQDHP LLSQN 256202925 LVVKPDQLIKRRGKLGLVGVNLTLDGVKSWLKPRLGQEATVSGHGVKMNVCGNRSKYG HLQVGKATGFLKNFLIEPFVPHSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKA Protein Sequence QKLLVGVDEKLNPEDIKKHLLVHAPEDKKEILASF SGLFNFYEDLYFTYLEINPLW TKDGVYVLDLAAKVDATADYICKVK GDIEFPPPFGREAYPEEAYIADLDAKSGASLK LTLLNPKGRIWTMVAGGGASVVYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTI LSLMTREKHPDGKILIIGGSIANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGG PNYQEGLRVMGEVGKTTGIPIHVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLL
NASGSTSTPAPSRTASFSESRADEVAPAKKAKPAMPQGKSTTLFSRHTKAIVWGMQ.TR AVQGMLDFDYVCSRDE PS VAAMVYPFTGDHKQKFYWGHKE ILI PVFKNMADAMRKHPE ΛΩVLINFASLRSALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINNP DMRVRILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCG SFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHPWDDISYVLPEHM
SM
SEQ ID NO: 249 3368 bp
NOVl 5m, CCCGGTCCGAAGCGCGCGGATTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGG 296463359 DNA GCAAAGAACTCCTTTACAAGTTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAA GTATGCTCGGGTCACTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGG Sequence CTGCTCAGCCAGAACTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAAC TTGGTCTCGTTGGGGTCAACCTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACG GCTGGGACAGGAAGCCACAGTTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATC GAGCCCTTCGTCCCCCACAGTCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCC GAGAAGGGGACTACGTCCTGTTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGA CGCCAAGGCCCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATC AAAAAACACCTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTA TCTCCGGCCTCTTCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCC CCTTGTAGTGACCAAAGATGGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCC ACTGCCGACTACATCTGCAAAGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCG GGCGGGAGGCATATCCAGAGGAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGC AAGCCTGAAGCTGACCTTGCTGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGG GGTGGCGCCTCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGC TGGCAAACTATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGATTATGC CAAGACTATCCTCTCCCTCATGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATC ATTGGAGGCAGCATCGCAAACTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGA GAGCAATTCGAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCG AAGAGGTGGCCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACC ACTGGGATCCCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCA TGGCCCTGGGCCACCGGCCCATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAA CTTCCTCCTCAACGCCAGCGGGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCT TTTTCTGAGTCCAGGGCCGATGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGC CACAAGATTCAGTCCCAAGTCCAAGATCCCTGCAAGGAAAGAGCACCACCCTCTTCAG CCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTG GACTTTGACTATGTCTGCTCCCGAGACGAGCCCTCAGTGGCTGCCATGGTCTACCCTT TCACTGGGGACCACAAGCAGAAGTTTTACTGGGGGCACAAAGAGATCCTGATCCCTGT CTTCAAGAACATGGCTGATGCCATGAGGAAGCACCCGGAGGTAGATGTGCTCATCAAC TTTGCCTCTCTCCGCTCTGCCTATGACAGCACCATGGAGACCATGAACTATGCCCAGA TCCGGACCATCGCCATCATAGCTGAAGGCATCCCTGAGGCCCTCACGAGAAAGCTGAT CAAGAAGGCGGACCAGAAGGGAGTGACCATCATCGGACCTGCCACTGTTGGAGGCATC AAGCCTGGGTGCTTTAAGATTGGCAACACAGGTGGGATGCTGGACAACATCCTGGCCT CCAAACTGTACCGCCCAGGCAGCGTGGCCTATGTCTCACGTTCCGGAGGCATGTCCAA CGAGCTCAACAATATCATCTCTCGGACCACGGATGGCGTCTATGAGGGCGTGGCCATT GGTGGGGACAGGTACCCGGGCTCCACATTCATGGATCATGTGTTACGCTATCAGGACA CTCCAGGAGTCAAAATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGGAATATAA GATTTGCCGGGGCATCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATC GGGACGTGTGCCACCATGTTCTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTG CCAACCAGGCTTCTGAAACTGCAGTAGCCAAGAACCAGGCTTTGAAGGAAGCAGGAGT GTTTGTGCCCCGGAGCTTTGATGAGCTTGGAGAGATCATCCAGTCTGTATACGAAGAT CTCGTGGCCAATGGAGTCATTGTACCTGCCCAGGAGGTGCCGCCCCCAACCGTGCCCA TGGACTACTCCTGGGCCAGGGAGCTTGGTTTGATCCGCAAACCTGCCTCGTTCATGAC CAGCATCTGCGATGAGCGAGGACAGGAGCTCATCTACGCGGGCATGCCCATCACTGAG GTCTTCAAGGAAGAGATGGGCATTGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGAAAA GGTTGCCTAAGTACTCTTGCCAGTTCATTGAGATGTGTCTGATGGTGACAGCTGATCA CGGGCCAGCCGTCTCTGGAGCCCACAACACCATCATTTGTGCGCGAGCTGGGAAAGAC CTGGTCTCCAGCCTCACCTCGGGGCTGCTCACCATCGGGGATCGGTTTGGGGGTGCCT TGGATGCAGCAGCCAAGATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCATGGA GTTTGTGAACAAGATGAAGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTG AAGTCGATAAACAACCCAGACATGCGAGTGCAGATCCTCAAAGATTACGTCAGGCAGC ACTTCCCTGCCACTCCTCTGCTCGATTATGCACTGGAAGTAGAGAAGATTACCACCTC
GAAGAAGCCAAATCTTATCCTGAATGTAGATGGTCTCATCGGAGTCGCATTTGTAGAC ATGCTTAGAAACTGTGGGTCCTTTACTCGGGAGGAAGCTGATGAATATATTGACATTG GAGCCCTCAATGGCATCTTTGTGCTGGGAAGGAGTATGGGGTTCATTGGACACTATCT TGATCAGAAGAGGCTGAAGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATAT GTTCTTCCGGAACACATGAGCATGCATCATCACCACCATCACTAAGCGGCCGCTTTCG AATC
ORF Start: at 1 ORF Stop: TAA at 3349
SEQ ID NO: 250 1116 aa MW at 122570.8kD
NOVl 5m, PGPKRADSTMSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTDWARLLQDHPW 296463359 LLSQNLWKPDQLIKRRGKLGLVGVNLTLDGVKSWLKPRLGQEATVGKATGFLKNFLI EPFVPHSQAEEFYVCIYATREGDYVLFHHEGGVDVGDVDAKAQKLLVGVDEKLNPEDI Protein Sequence KKHLLVHAPEDKKEILASFISGLFNFYEDLYFTYLEINPLVVTKDGVYVLDLAAKVDA TADYICKVKWGDIEFPPPFGREAYPEEAYIADLDAKSGASLKLTLLNPKGRIWTMVAG GGASWYSDTICDLGGVNELANYGEYSGAPSEQQTYDYAKTILSLMTREKHPDGKILI IGGSIANFTNVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPNYQEGLRVMGEVGKT TGIPIHVFGTETHMTAIVGMALGHRPIPNQPPTAAHTANFLLNASGSTSTPAPSRTAS FSESRADEVAPAKKAKPAMPQDSVPSPRSLQGKSTTLFSRHTKAIVWGMQTRAVQGML DFDYVCSRDEPSVAAMVYPFTGDHKQKFYWGHKEILIPVFKNMADAMRKHPEVDVLIN FASLRSAYDSTMETMNYAQIRTIAIIAEGIPEALTRKLIKKADQKGVTIIGPATVGGI KPGCFKIGNTGGMLDNILASKLYRPGSVAYVSRSGGMSNELNNIISRTTDGVYEGVAI GGDRYPGSTFMDHVLRYQDTPGVKMIWLGEIGGTEEYKICRGIKEGRLTKPIVC CI GTCATMFSSEVQFGHAGACANQASETAVAKNQALKEAGVFVPRSFDELGEIIQSVYED LVANGVIVPAQEVPPPTVPMDYSWARELGLIRKPASFMTSICDERGQELIYAGMPITE VFKEEMGIGGVLGLLWFQKRLPKYSCQFIEMCLMVTADHGPAVSGAHNTIICARAGKD LVSSLTSGLLTIGDRFGGALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRV KSINNPDMRVQILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVD MLRNCGSFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHPWDDISY
VLPEHMSMHHHHHH
SEQ ID NO: 251 3313 bp
NOV15n, TTCCACCATGTCGGCCAAGGCAATTTCAGAGCAGACGGGCAAAGAACTCCTTTACAAG 263470992 DNA TTCATCTGTACCACCTCAGCCATCCAGAATCGGTTCAAGTATGCTCGGGTCACTCCTG ACACAGACTGGGCCCGCTTGCTGCAGGACCACCCCTGGCTGCTCAGCCAGAACTTGGT Sequence AGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGTCTCGTTGGGGTCAAC CTCACTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAGCCACAG TTGGCAAGGCCACAGGCTTCCTCAAGAACTTTCTGATCGAGCCCTTCGTCCCCCACAG TCAGGCTGAGGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGGACTACGTCCTG TTCCACCACGAGGGGGGTGTGGACGTGGGTGATGTGGACGCCAAGGCCCAGAAGCTGC TTGTTGGCGTGGATGAGAAACTGAATCCTGAGGACATCAAAAAACACCTGTTGGTCCA CGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGGCCTCTTCAATTTC TACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGTGACCAAAGATG GAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGACTACATCTGCAA AGTGAAGTGGGGTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGGCATATCCAGAG GAAGCCTACATTGCAGACCTCGATGCCAAAAGTGGGGCAAGCCTGAAGCTGACCTTGC TGAACCCCAAAGGGAGGATCTGGACCATGGTGGCCGGGGGTGGCGCCTCTGTCGTGTA CAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACTATGGGGAGTAC TCAGGCGCCCCCAGCGAGCAGCAGACCTATGATTATGCCAAGACTATCCTCTCCCTCA TGACCCGAGAGAAGCACCCAGATGGCAAGATCCTCATCATTGGAGGCAGCATCGCAAA CTTCACCAACGTGGCTGCCACGTTCAAGGGCATCGTGAGAGCAATTCGAGATTACCAG GGCCCCCTGAAGGAGCACGAAGTCACAATCTTTGTCCGAAGAGGTGGCCCCAACTATC AGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGACCACTGGGATCCCCATCCATGT CTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGGGCCACCGGCCC ATCCCCAACCAGCCACCCACAGCGGCCCACACTGCAAACTTCCTCCTCAACGCCAGCG GGAGCACATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAGTCCAGGGCCGA TGAGGTGGCGCCTGCAAAGAAGGCCAAGCCTGCCATGCCACAAGATTCAGTCCCAAGT CCAAGATCCCTGCAAGGAAAGAGCACCACCCTCTTCAGCCGCCACACCAAGGCCATTG TGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTGGACTTTGACTATGTCTGCTC CCGAGACGAGCCCTCAGTGGCTGCCATGGTCTACCCTTTCACTGGGGACCACAAGCAG AAGTTTTACTGGGGGCACAAAGAGATCCTGATCCCTGTCTTCAAGAACATGGCTGATG


WGDIEFPPPFGREAYPEEAYIADLDAKSGASLKLTLLNPKGRIWTMVAGGGASWYSD TICDLGGVNELANYGEYSGAPSEQQTYDYAKTILSLMTREKHPDGKILIIGGSIANFT NVAATFKGIVRAIRDYQGPLKEHEVTIFVRRGGPNYQEGLRVMGEVGKTTGIPIHVFG TETHMTAIVGMALGHRPIPNQPPTAAHTANFLLNASGSTSTPAPSRTASFSESRADEV APAKKAKPAMPQDSVPSPRSLQGKSTTLFSRHTKAIVWGMQTRAVQGMLDFDYVCSRD EPSVAAMVYPFTGDHKQKFYWGHKEILIPVFKNMADAMRKHPEVDVLINFASLRSAYD STMETMNYAQIRTIAIIAEGIPEALTRKLIKKADQKGVTIIGPATVGGIKPGCFKIGN TGGMLDNILASKLYRPGSVAYVSRSGGMSNELNNIISRTTDGVYEGVAIGGDRYPGST FMDHVLRYQDTPGVKMIVVLGEIGGTEEYKICRGIKEGRLTKPIVC CIGTCATMFSS EVQFGHAGACANQASETAVAKNQALKEAGVFVPRSFDELGEIIQSVYEDLVANGVIVP AQEVPPPTVPMDYSWARELGLIRKPASFMTSICDERGQELIYAGMPITEVFKEEMGIG GVLGLLWFQKRLPKYSCQFIEMCLMVTADHGPAVSGAHNTIICARAGKDLVSSLTSGL LTIGDRFGGALDAAAKMFSKAFDSGIIPMEFVNKMKKEGKLIMGIGHRVKSINNPDMR VQILKDYVRQHFPATPLLDYALEVEKITTSKKPNLILNVDGLIGVAFVDMLRNCGSFT REEADEYIDIGALNGIFVLGRSMGFIGHYLDQKRLKQGLYRHP DDISYVLPEHMSM
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 15B.
Further analysis of the NOVl 5a protein yielded the following properties shown in Table 15C.
Table 15C. Protein Sequence Properties NOV15a
PSort 0.8500 probability located in endoplasmic reticulum (membrane); 0.4450 analysis: probability located in microbody (peroxisome); 0.4400 probability located in plasma membrane; 0.1000 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl 5a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 15D.
In a BLAST search of public sequence datbases, the NOVl 5a protein was found to have homology to the proteins shown in the BLASTP data in Table 15E.
PFam analysis predicts that the NOVl 5a protein contains the domains shown in the Table 15F.
Example 16.
The NOVl 6 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 16A.
AGCTGGGCATGACAAATAGGTTGCCCAAGTGAGGACGGACCCCTTACCGATCTGTGCT
CTCCTAGCCCAAGAGACCCCTGGAGGGGCTGGAGTTTATCCAGCGCCTCGTCGTATGT
TTGGCTGAGCACCTGTGGCCCTGGGTGCAGGTTAACTTCTTGTTATCAGGAGCCCACT
ATGCAGAGGCCAAAGGTCGGCAGCCAGCGAGGCTATGAATTGGACCTTTTTGGTATCT:
GTGTGACTGCTCTGTGCCCATCCTTAGCCAACTTGCTGGCGTGACAAGTGCCCACAAGi
TAACACACCAGGTACCCAGAGCAGGGTGGACAGGAGAGACCTGAATCACAGCAGTGAGi
ORF Start: ATG at 90 ORF Stop: TGA at 1074
SEQ ID NO: 258 328 aa MW at 34702. lkD
NOVl 6b, MMSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGHFCKR AKQGCA CG142631-01 HFVCSSAGNAGMAAAYAARQLGVPATIWPGTTPALTIERLK EGATCKWGELLDEA FELAKAI AK-VlNPG VYIPPFDDPLI EGHASIVKELKETL EKPGAIALSVGGGGLLC Protein Sequence GWQGLQECGWGDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKTVGSQA LKLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPAWGAALAAVYSHVIQKLQLEGN LRTPLPSLWIVCGGSNISLAQLRALKEQLGMTNRLPK
SEQ ID NO: 259 1008 bp
NOVl 6c, ACCATGATGTCTGGAGAACCCCTGCACGTGAAGACCCCCATCCGTGACAGCATGGCCC 248494617 DNA TGTCCAAAATGGCCGGCACCAGCGTCTACCTCAAGATGGACAGTGCCCAGCCCTCCGG Sequence CTCCTTCAAGATCCGGGGCATTGGGCACTTCTGCAAGAGGTGGGCCAAGCAAGGCTGT GCACATTTTGTCTGCTCCTCGGCGGGCAACGCAGGCATGGCGGCTGCATATGCGGCCA GGCAACTCGGCGTCCCCGCCACCATCGTGGTGCCCAGCACCACACCTGCTCTCACCAT TGAGCGCCTCAAGAATGAAGGTGCCACAGTCAAGGTGGTGGGTGAGTTATTGGATGAA GCCTTCGAGCTGGCCAAGGCCCTAGCGAAGAACAACCCGGGTTGGGTCTACATTCCCC CCTTTGATGACCCCCTCATCTGGGAAGGCCACGCTTCCATCGTGAAAGAGCTGAAGGA GACACTGTGGGAAAAGCCGGGGGCCATCGCGCTGTCAGTGGGCGGCGGGGGCCTGCTG TGTGGAGTGGTCCAGGGGCTGCAGGAGGTGGGCTGGGGGGACGTGCCTGTCATCGCCA TGGAGACTTTTGGTGCCCACAGCTTCCACGCTGCCACCACCGCAGGCAAACTTGTCTC CCTGCCCAAGATCACCAGTGTTGCCAAGGCCCTGGGCGTGAAGACTGTGGGGGCTCAG GCCCTGAAGCTGTTTCAGGAACACCCCATTTTCTCTGAAGTTATCTCGGACCAGGAGG CTGTGGCCGCCATTGAGAAGTTCGTGGATGATGAGAAGATCCTGGTGGAGCCCGCCTG CGGGGCAGCCCTGGCCGCTGTCTATAGCCACGTGATCCAGAAGCTCCAACTGGAGGGG AATCTCCGAACCCCGCTGCCATCCCTCGTGGTCATCGTCTGCGGGGGCAGCAACATCA GCCTGGCCCAGCTGCGGGCGCTCAAGGAACAGCTGGGCATGACAAATAGGTTGCCCAA GCATCATCACCACCATCACTGA
ORF Start: at 1 ORF Stop: TGA at 1006
SEQ ID NO: 260 335 aa MW at 35549.0kD
NOVl 6c, TMMSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGHFCKRWAKQGC 248494617 AHFVCSSAGNAGMAAAYAARQLGVPATIWPSTTPALTIERLKNEGATVKWGELLDE AFELAKALAKN PG VYIPPFDDPLIWEGHASIVKELKETLWEKPGAIALSVGGGGLL Protein Sequence CGWQGLQEVGWGDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKTVGAQ ALKLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPACGAALAAVYSHVIQKLQLEG NLRTPLPSLWIVCGGSNISLAQLRALKEQLGMTNRLPKHHHHHH
SEQ ID NO: 261 988 bp
NOV16d, CATGATGTCTGGAGAACCCCTGCACGTGAAGACCCCCATCCGTGACAGCATGGCCCTG 228832711 DNA TCCAAAATGGCCGGCACCAGCGTCTACCTCAAGATGGACAGTGCCCAGCCCTCCGGCT CCTTCAAGATCCGGGGCATTGGGCACTTCTGCAAGAGGTGGGCCAAGCAAGGCTGTGC Sequence ACATTTTGTCTGCTCCTCGGCGGGCAACGCAGGCATGGCGGCTGCATATGCGGCCAGG CAACTCGGCGTCCCCGCCACCATCGTGGTGCCCAGCACCACACCTGCTCTCACCATTG AGCGCCTCAAGAATGAAGGTGCCACAGTCAAGGTGGTGGGTGAGTTATTGGATGAAGC CTTCGAGCTGGCCAAGGCCCTAGCGAAGAACAACCCGGGTTGGGTCTACATTCCCCCC TTTGATGACCCCCTCATCTGGGAAGGCCACGCTTCCATCGTGAAAGAGCTGAAGGAGA CACTGTGGGAAAAGCCGGGGGCCATCGCGCTGTCAGTGGGCGGCGGGGGCCTGCTGTG TGGAGTGGTCCAGGGGCTGCAGGAGGTGGGCTGGGGGGACGTGCCTGTCATCGCCATG GAGACTTTTGGTGCCCACAGCTTCCACGCTGCCACCACCGCAGGCAAACTTGTCTCCC TGCCCAAGATCACCAGTGTTGCCAAGGCCCTGGGCGTGAAGACTGTGGGGGCTCAGGC CCTGAAGCTGTTTCAGGAACACCCCATTTTCTCTGAAGTTATCTCGGACCAGGAGGCT
CGAACCCCGCTGCCATCCCTCGTGGTCATCGTCTGCGGGGGCAGCAACATCAGCCTGG: CCCAGC-GCGGGCGCTCAAGGAACAGCTGGGCATGACAAATAGG-TGCCCAAGTGAGC GGCCGCACTCGAGCACCACCACCACCACCAC
ORF Start: ATG at 1 ORF Stop: TGA at 982
SEQ ID NO: 266 327 aa MW at 34493.8kD
NOVlδf, MSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGHFCKRWAKQGCAH 249117058 FVCSSAGNAGMAAAYAARQLGVPATIWPSTTPALTIERLKNEGATVKWGELLDEAF Protein Sequence ELAKAIΛKNNPG VYIPPFDDPLI EGHASIVKELKETLWEKPGAIALSVGGGGLLCG WQGLQEVGWGDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKTVGAQAL KLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPACGAALAAVYSHVIQKLQLEGNL RTPLPSLWIVCGGSNISLAQLRALKEQLGMTNRLPK
SEQ ID NO: 267 1031 bp
NOV16g, CACCCGTCTCACATGGGACATCATCACCACCATCACATGTCTGGAGAACCCCTGCACG 252790334 DNA TGAAGACCCCCATCCGTGACAGCATGGCCCTGTCCAAAATGGCCGGCACCAGCGTCTA CCTCAAGATGGACAGTGCCCAGCCCTCCGGCTCCTTCAAGATCCGGGGCATTGGGCAC Sequence TTCTGCAAGAGGTGGGCCAAGCAAGGCTGTGCACATTTTGTCTGCTCCTCGGCGGGCA ACGCAGGCATGGCGGCTGCATATGCGGCCAGGCAACTCGGCGTCCCCGCCACCATCGT GGTGCCCAGCACCACACCTGCTCTCACCATTGAGCGCCTCAAGAATGAAGGTGCCACA GTCAAGGTGGTGGGTGAGTTATTGGATGAAGCCTTCGAGCTGGCCAAAGCCCTAGCGA AGAACAACCCGGGTTGGGTCTACATTCCCCCCTTTGATGACCCCCTCATCTGGGAAGG CCACGCTTCCATCGTGAAAGAGCTGAAGGAGACACTGTGGGAAAAGCCGGGGGCCATC GCGCTGTCAGTGGGCGGCGGGGGCCTGCTGTGTGGAGTGGTCCAGGGGCTGCAGGAGG TGGGCTGGGGGGACGTGCCTGTCATCGCCATGGAGACTTTTGGTGCCCACAGCTTCCA CGCTGCCACCACCGCAGGCAAACTTGTCTCCCTGCCCAAGATCACCAGTGTTGCCAAG GCCCTGGGCGTGAAGACTGTGGGGGCTCAGGCCCTGAAGCTGTTTCAGGAACACCCCA TTTTCTCTGAAGTTATCTCGGACCAGGAGGCTGTGGCCGCCATTGAGAAGTTCGTGGA TGATGAGAAGATCCTGGTGGAGCCCGCCTGCGGGGCAGCCCTGGCCGCTGTCTATAGC CACGTGATCCAGAAGCTCCAACTGGAGGGGAATCTCCGAACCCCGCTGCCATCCCTCG TGGTCATCGTCTGCGGGGGCAGCAACATCAGCCTGGCCCAGCTGCGGGCGCTCAAGGA ACAGCTGGGCATGACAAATAGGTTGCCCAAGTGAGCGGCCGCAAG
ORF Start: at 1 ORF Stop: TGA at 1018
SEQ ID NO: 268 339 aa MW at 35963.4kD
NOV16g, HPSHMGHHHHHHMSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGH 252790334 FCKRWAKQGCAHFVCSSAGNAGMAAAYAARQLGVPATIWPSTTPALTIERLKNEGAT VKVVGELLDEAFELAKALAK1WPGWVYIPPFDDPLI EGHASIVKELKETLWEKPGAI Protein Sequence ALSVGGGGLLCGWQGLQEVG GDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAK ALGVKTVGAQALKLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPACGAALAAVYS HVIQKLQLEGNLRTPLPSLWIVCGGSNISLAQLRALKEQLGMTNRLPK
SEQ ID. NO: 269 1036 bp
NOV16h, ACATCATCACCACCATCACATGTCTGGAGAACCCCTGCACGTGAAGACCCCCATCCGT 254869149 DNA GACAGCATGGCCCTGTCCAAAATGGCCGGCACCAGCGTCTACCTCAAGATGGACAGTG CeCAGCCCTCCGGCTCCTTCAAGATCCGGGGCATTGGGCACTTCTGCAAGAGGTGGGC Sequence CAAGCAAGGCTGTGCACATTTTGTCTGCTCCTCGGCGGGCAACGCAGGCATGGCGGCT GCATATGCGGCCAGGCAACTCGGCGTCCCCGCCACCATCGTGGTGCCCAGCACCACAC CTGCTCTCACCATTGAGCGCCTCAAGAATGAAGGTGCCACAGTCAAGGTGGTGGGTGA GTTATTGGATGAAGCCTTCGAGCTGGCCAAGGCCCTAGCGAAGAACAACCCGGGTTGG GTCTACATTCCCCCCTTTGATGACCCCCTCATCTGGGAAGGCCACGCTTCCATCGTGA AAGAGCTGAAGGAGACACTGTGGGAAAAGCCGGGGGCCATCGCGCTGTCAGTGGGCGG CGGGGGCCTGCTGTGTGGAGTGGTCCAGGGGCTGCAGGAGGTGGGCTGGGGGGACGTG CCTGTCATCGCCATGGAGACTTTTGGTGCCCACAGCTTCCACGCTGCCACCACCGCAG GCAAACTTGTCTCCCTGCCCAAGATCACCAGTGTTGCCAAGGCCCTGGGCGTGAAGAC TGTGGGGGCTCAGGCCCTGAAGCTGTTTCAGGAACACCCCATTTTCTCTGAAGTTATC TCGGACCAGGAGGCTGTGGCCGCCATTGAGAAGTTCGTGGATGATGAGAAGATCCTGG TGGAGCCCGCCTGCGGGGCAGCCCTGGCCGCTGTCTATAGCCACGTGATCCAGAAGCT CCAACTGGAGGGGAATCTCCGAACCCCGCTGCCATCCCTCGTGGTCATCGTCTGCGGG GGCAGCAACATCAGCCTGGCCCAGCTGCGGGCGCTCAAGGAACAGCTGGGCATGACAA
jATAGGTTGCCCAAGTGAGCGGCCGCACTCGAGCACCACCACCACCACCAC
ORF Start: at 2 JORF Stop: TGA at 1001
SEQ ID NO: 270 333 aa MW at 35316.7kD
NOV16h, HHHHHHMSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGHFCKRWA 254869149 KQGCAHFVCSSAGNAGMAAAYAARQLGVPATIWPSTTPALTIERLKNEGATVKWGE Protein Sequence LLDEAFELAKALAKNNPGWVYIPPFDDPLI EGHASIVKELKETLWEKPGAIALSVGG GGLLCGWQGLQEVG GDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKT VGAQALKLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPACGAALAAVYSHVIQKL QLEGNLRTPLPSLWIVCGGSNISLAQLRALKEQLGMTNRLPK
SEQ ID NO: 271 988 bp
NOV16i, CATGATGTCTGGAGAACCCCTGCACGTGAAGACCCCCATCCGTGACAGCATGGCCCTG CG 142631-02 TCCAAAATGGCCGGCACCAGCGTCTACCTCAAGATGGACAGTGCCCAGCCCTCCGGCT DNA Sequence CCTTCAAGATCCGGGGCATTGGGCACTTCTGCAAGAGGTGGGCCAAGCAAGGCTGTGC ACATTTTGTCTGCTCCTCGGCGGGCAACGCAGGCATGGCGGCTGCATATGCGGCCAGG CAACTCGGCGTCCCCGCCACCATCGTGGTGCCCAGCACCACACCTGCTCTCACCATTG AGCGCCTCAAGAATGAAGGTGCCACAGTCAAGGTGGTGGGTGAGTTATTGGATGAAGC CTTCGAGCTGGCCAAGGCCCTAGCGAAGAACAACCCGGGTTGGGTCTACATTCCCCCC TTTGATGACCCCCTCATCTGGGAAGGCCACGCTTCCATCGTGAAAGAGCTGAAGGAGA CACTGTGGGAAAAGCCGGGGGCCATCGCGCTGTCAGTGGGCGGCGGGGGCCTGCTGTG TGGAGTGGTCCAGGGGCTGCAGGAGGTGGGCTGGGGGGACGTGCCTGTCATCGCCATG GAGACTTTTGGTGCCCACAGCTTCCACGCTGCCACCACCGCAGGCAAACTTGTCTCCC TGCCCAAGATCACCAGTGTTGCCAAGGCCCTGGGCGTGAAGACTGTGGGGGCTCAGGC CCTGAAGCTGTTTCAGGAACACCCCATTTTCTCTGAAGTTATCTCGGACCAGGAGGCT GTGGCCGCCATTGAGAAGTTCGTGGATGATGAGAAGATCCTGGTGGAGCCCGCCTGCG GGGCAGCCCTGGCCGCTGTCTATAGCCACGTGATCCAGAAGCTCCAACTGGAGGGGAA TCTCCGAACCCCGCTGCCATCCCTCGTGGTCATCGTCTGCGGGGGCAGCAACATCAGC CTGGCCCAGCTGCGGGCGCTCAAGGAACAGCTGGGCATGACAAATAGGTTGCCCAAGT GA
ORF Start: ATG at 2 JORF Stop: TGA at 986
SEQ ID NO: 272 328 aa MW at 34625.0kD
NOV16i, MMSGEPLHVKTPIRDSMALSKMAGTSVYLKMDSAQPSGSFKIRGIGHFCKR AKQGCA CG142631-02 HFVCSSAGNAGMAAAYAARQLGVPATIWPSTTPALTIERLKNEGATVKWGELLDEA Protein Sequence FELAKALAKNNPGWVYIPPFDDPLI EGHASIVKELKETL EKPGAIALSVGGGGLLC GWQGLQEVGWGDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKTVGAQA LKLFQEHPIFSEVISDQEAVAAIEKFVDDEKILVEPACGAALAAVYSHVIQKLQLEGN LRTPLPSLWIVCGGSNISLAQLRALKEQLGMTNRLPK
SEQ ID NO: 273
NOV16J, ACCATGGGACATCATCACCACCATCACATGTCTGGAGAACCCCTGCACGTGAAGACCC CG142631-03 CCATCCGTGACAGCATGGCCCTGTCCAAAATGGCCGGCACCAGCGTCTACCTCAAGAT GGACAGTGCCCAGCCCTCCGGCTCCTTCAAGATCCGGGGCATTGGGCACTTCTGCAAG DNA Sequence AGGTGGGCCAAGCAAGGCTGTGCACATTTTGTCTGCTCCTCGGCGGGCAACGCAGGCA TGGCGGCTGCATATGCGGCCAGGCAACTCGGCGTCCCCGCCACCATCGTGGTGCCCAG CACCACACCTGCTCTCACCATTGAGCGCCTCAAGAATGAAGGTGCCACAGTCAAGGTG GTGGGTGAGTTATTGGATGAAGCCTTCGAGCTGGCCAAGGCCCTAGCGAAGAACAACC CGGGTTGGGTCTACATTCCCCCCTTTGATGACCCCCTCATCTGGGAAGGCCACGCTTC CATCGTGAAAGAGCTGAAGGAGACACTGTGGGAAAAGCCGGGGGCCATCGCGCTGTCA GTGGGCGGCGGGGGCCTGCTGTGTGGAGTGGTCCAGGGGCTGCAGGAGGTGGGCTGGG GGGACGTGCCTGTCATCGCCATGGAGACTTTTGGTGCCCACAGCTTCCACGCTGCCAC CACCGCAGGCAAACTTGTCTCCCTGCCCAAGATCACCAGTGTTGCCAAGGCCCTGGGC GTGAAGACTGTGGGGGCTCAGGCCCTGAAGCTGTTTCAGGAACACCCCATTTTCTCTG AAGTTATCTCGGACCAGGAGGCTGTGGCCGCCATTGAGAAGTTCGTGGATGATGAGAA GATCCTGGTGGAGCCCGCCTGCGGGGCAGCCCTGGCCGCTGTCTATAGCCACGTGATC CAGAAGCTCCAACTGGAGGGGAATCTCCGAACCCCGCTGCCATCCCTCGTGGTCATCG TCTGCGGGGGCAGCAACATCAGCCTGGCCCAGCTGCGGGCGCTCAAGGAACAGCTGGG CATGACAAATAGGTTGCCCAAGTGA
ORF Start: at 1 ORF Stop: TGA at 1009
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 16B.
Further analysis of the NOVl 6a protein yielded the following properties shown in Table 16C.
Table 16C. Protein Sequence Properties NOVl 6a
PSort 0.8500 probability located in endoplasmic reticulum (membrane); 0.4400 analysis: probability located in plasma membrane; 0.1000 probability located in mitochondrial inner membrane; 0.1000 probability located in Golgi body
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl 6a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 16D.
In a BLAST search of public sequence datbases, the NOV16a protein was found to have homology to the proteins shown in the BLASTP data in Table 16E.
PFam analysis predicts that the NOVl 6a protein contains the domains shown in the Table 16F.
The NOVl 7 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 17A.
Further analysis of the NOVl 7a protein yielded the following properties shown in Table 17B.
Table 17B. Protein Sequence Properties NOV17a
PSort 0.6736 probability located in nucleus; 0.5701 probability located in analysis: mitochondrial matrix space; 0.3952 probability located in microbody (peroxisome); 0.2847 probability located in mitochondrial inner membrane
SignalP Cleavage site between residues 49 and 50 analysis:
A search of the NOVl 7a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous r pvrrnottfieiinnss a shnoownn i inn T TaaWblfe> 1177fC~<.
Table 17C. Geneseq Results for NOV17a
NOV17a Identities/
Geneseq Protein Organism Length [Patent Expect Identifier Residues/ Similarities for #, Date] Match I the Matched Value
In a BLAST search of public sequence datbases, the NOVl 7a protein was found to have homology to the proteins shown in the BLASTP data in Table 17D.
PFam analysis predicts that the NOVl 7a protein contains the domains shown in the Table 17E.
Example 18.
The NOVl 8 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 18A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 18B.
Further analysis of the NOVl 8a protein yielded the following properties shown in Table 18C.
Table 18C. Protein Sequence Properties NOV18a
PSort 0.6784 probability located in mitochondrial matrix space; 0.3893 probability analysis: located in microbody (peroxisome); 0.3672 probability located in mitochondrial inner membrane; 0.3672 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl 8a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 18D.
In a BLAST search of public sequence datbases, the NOVl 8a protein was found to have homology to the proteins shown in the BLASTP data in Table 18E.
PFam analysis predicts that the NOVl 8a protein contains the domains shown in the Table 18F.
Example 19.
The NOVl 9 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 19 A.
Further analysis of the NOVl 9a protein yielded the following properties shown in Table 19B.
Table 19B. Protein Sequence Properties NOV19a
PSort 0.8357 probability located in mitochondrial inner membrane; 0.8200 analysis: probability located in plasma membrane; 0.3000 probability located in microbody (peroxisome); 0.2000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl 9a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 19C.
In a BLAST search of public sequence datbases, the NOV19a protein was found to have homology to the proteins shown in the BLASTP data in Table 19D.
PFam analysis predicts that the NOVl 9a protein contains the domains shown in the Table 19E.
Example 20.
The NOV20 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 20A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 20B .
Table 20B. Comparison of NOV20a against NOV20b and NO 20c.
NOV20a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
Further analysis of the NOV20a protein yielded the following properties shown in Table 20C.
Table 20C. Protein Sequence Properties NOV20a
PSort 0.8541 probability located in lysosome (lumen); 0.7189 probability located in analysis: outside; 0.2757 probability located in microbody (peroxisome); 0.1000 probability located in endoplasmic reticulum (membrane)
SignalP Cleavage site between residues 28 and 29 analysis:
A search of the NOV20a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 20D.
In a BLAST search of public sequence datbases, the NOV20a protein was found to have homology to the proteins shown in the BLASTP data in Table 20E.
PFam analysis predicts that the NOV20a protein contains the domains shown in the Table 20F.
Example 21.
The NOV21 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 21 A.
ORF Start: ATG at 1 ORF Stop: TAA at 1288 SEQ ID NO: 292 429 aa MW at 46990.2kD
NOV21a, MGRYSGKTCRLLFMLVLTVAFFVAELVSGYLGNSIALLSDSFNMLSDLISLCVGLSAG CG152547-01 YIARRPTRGFSATYGYARAEWGALSNAVFLTALCFTIFVEAVLRLARPERIDDPELV Protein Sequence LIVGVLGLLVNWGLLIFHHQSLISSNQGHKHCGRPQGPLPRKTRNTQNEPEDMMKKE K SEAI_IIRGVLLHVMGDALGSVVVVITAIIFYVLPLKSEDPCN QCYIDPSLTVLMV I IILSSAFPLI KETAAILLQMVPKGVNMEELMSKLSAVPGI SSVHEVHI ELVSGKI I ATLHIKYPKDRGYQDASTKIREIFHHAGIHNVTIQFENVDLKEPLEQKDLLLLCNSPC ISKGCAKQLCCPPGALPLAHVNGCAEHNGGPSLDTYGSDGLSRRDAREVAIEVSLDSC LSDHGQCLNKTQEDQCYVNRTHF
Further analysis of the NOV21a protein yielded the following properties shown in Table 21B.
Table 21B. Protein Sequence Properties NOV21a
PSort 0.6400 probability located in plasma membrane; 0.4600 probability located in analysis: Golgibody; 0.3700 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 30 and 31 analysis:
A search of the NO V21 a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 21C.
In a BLAST search of public sequence datbases, the NOV21a protein was found to have homology to the proteins shown in the BLASTP data in Table 21D.
PFam analysis predicts that the NOV21a protein contains the domains shown in the Table 21E.
Example 22.
The NOV22 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 22A.
Table 22A. NOV22 Sequence Analysis
Further analysis of the NOV22a protein yielded the following properties shown in Table 22B.
Table 22B. Protein Sequence Properties NOV22a
PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in analysis: mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV22a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 22C.
Table 22C. Geneseq Results for NOV22a
NOV22a Identities/
Geneseq Protein Organism/Length [Patent Residues/ Similarities for I Expect Identifier #, Date] Match the Matched | Value
Residues Region
ABP41274 Human ovarian antigen HOSED43, 147..329 182/183 (99%) e-100 SEO ID NΩ:2406 - Homo saniens. 81..263 183/183 (99%)
In a BLAST search of public sequence datbases, the NOV22a protein was found to have homology to the proteins shown in the BLASTP data in Table 22D.
PFam analysis predicts that the NOV22a protein contains the domains shown in the Table 22E.
Example 23.
The NOV23 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 23 A.
Table 23A. NOV23 Sequence Analysis
NOV23a, AGAGGCTCAAGAGGGGCAGCCCCCGCATAGAGGAGATGCGAGCTCTGCGCTCTGCCAG! CGI 52959-01 GGCCCCGAGCCCGTCAGAGGCCGCCCCGCGCCGCCCGGAAGCCACCGCGGCCCCCCTC jACTCCTAGAGGAAGGGAGCACCGCGAGGCTCACGGCAGGGCCCTGGCGCCGGGCAGGG: DNA Sequence CGAGCCTCGGAAGCCGCCTGGAGGACGTGCTGTGGCTGCAGGAGGTCTCCAACCTGTC
AGAGTGGCTGAGTCCCAGCCCTGGGCCCTGAGCCGGGTCCCCTTCCGCAAGCGCCCAC
CGATCCGGAGGCTGCGGGCAGCCGTTATCCCGTGGTTTAATAAAGCTGCCGCGCGCTC
ACCAAGTCCTCTTCCGCGTCTGCTTCCGCGTCGGGCCCGGGCGGGGCGGGGCGGGGCG
TGGAGCCGCGCCGCGGCCTGACGTCACCCACACCTCCCTGGGACTGCGTCACTGGTGC
GCGCCGCGGGTCAGGGCGCAATGGCGGCGCTGGGCGGGGATGGGCTGCGACTGCTGTC
GGTGTCGCGGCCGGAGCGGCCGCCCGAGTCGGCGGCGCTGGGCGGCCTGGGCCCCGGG CTGTGCTGCTGGGTGTCAGTGTTCTCCTGCCTCAGCCTCGCCTGCTCCTACATGGGCA GCCTCTACGTCTGGAAGAGCGAACTGCCCAGGGACCATCCCGCGGTCATCAAGCGACG CTTCACCAGCGTCCTGGTGGTGTCCAGTCTCTCACCCCTGTGCGTGCTGCTCTGGAGG GAACTCACAGGCATCCAGGCACATCCCTGCTCACCCTGATGGGCTTCAGGCTGGAGGG CATTTTCCCAGCGGCGCTGCTGCCCCTGTTGCTGACCATGATTCTTTTCCTGGGCCCA CTGATGCAGCTCTCTATGGATTGCCCTTGTGACCTGGCAGATGGGCTGAAGGTTGTCC TGGCCCCCCGCTCCTGGGCCCGCTGCCTCACAGACATGCGTTGGCTGCGGAACCAAGT GATCGCCCCGCTGACAGAGGAGCTGGTGTTCCGGGCCTGTATGCTGCCCATGTTAGCA CCGTGCATGGGCCTGGGCCCTGCTGTGTTCACCTGCCCGCTCTTTTTTGGAGTTGCCC ATTTTCACCATATTATTGAGCAGCTGCGTTTCCGCCAGAGCAGCGTGGGGAACATCTT CTTGTCTGCTGCGTTCCAGTTCCCCTACACAGCTGTCTTCGGTGCCTACACTGCTTTC CTCTTCATCCGCACAGGACACCTGATTGGGCCGGTTCTCTGCCATTCCTTCTGCAATT ACATGGGTTTCCCAGCTGTTTGCGCGGCCTTGGAGCACCCACAGAGGCGGCCCCTGCT GGCAGGCTATGCCCTGGGTGTGGGACTCTTCCTGCTTCTGCTCCAGCCCCTCACGGAC CCCAAGCTCTACGGCAGCCTTCCCCTTTGTGTGCTTTTGGAGCGGGCAGGGGACTCAG AGGCTCCCCTGTGCTCCTGACCTATGCTCCTGGATACGCTATGAACTCTCACCGGCTC CCCAGCCCTCCCCACCAAGGGGTACTGCAGGGGAAGGGCTGGCTGGGGTCCCCGAGAT CTCAGGAATTTTTGTAGGGGATTGAAGCCAGAGCTAGTTGCGTCCCAGGGACCAAGAG AAAGAAGCAGATATCCAAAGGGTGCAGCCCCTTTTGAAAGGGGTGTTTACGAGCAGCT GTGAGTGAGGGGACAAGGGGCAGGTCCCAGGAGCCACACACTCCCTTCCTCACTTTGG ACTGCTGCTTCTCTTAGCTCCTCTGCCTCTGAAAAGCTGCTCGGGGTTTTTTATTTAT AAAACCTCTCCCCACCCCCCACCCCCCAACTTCCTGGGTTTTCTCATTGTCTTTTTGC ATCAGTACTTTGTATTGGGATATTAAAGAGATTTAACTTGGGTAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAA

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 23B.
Table 23B. Comparison of NOV23a against NOV23b.
Protein Sequence NOV23a Residues/ Identities/ Match Residues Similarities for the Matched Region
NOV23b 1..96 95/96 (98%) 1..96 96/96 (99%)
Further analysis of the NOV23a protein yielded the following properties shown in Table 23C.
Table 23C. Protein Sequence Properties NOV23a
PSort 0.7000 probability located in plasma membrane; 0.2000 probability located in analysis: endoplasmic reticulum (membrane); 0.1000 probability located in mitochondrial inner membrane; 0.0000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 49 and 50 analysis:
A search of the NOV23a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 23D.
In a BLAST search of public sequence datbases, the NOV23a protein was found to have homology to the proteins shown in the BLASTP data in Table 23E.
Table 23E. Public BLASTP Results for NOV23a
Protein NOV23a ein/Organism/Length Identities/ Expect Accession Prot Residues/ Similarities Value
PFam analysis predicts that the NOV23a protein contains the domains shown in the Table
23F.
Table 23F. Domain Analysis of NO 23a
Identities/
Pfam Domain NOV23a Match Region Similarities Expect Value for the Matched Region
No Significant Matches Found
Example 24.
The NOV24 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 24A.
Table 24A. NOV24 Sequence Analysis
SEQ ID NO: 299 1701 bp
NOV24a, ATGGCTGGACCAGGCAAAGAGGGTGTGGTGTGGTGGGAAGAAAAATCGATGGGACAAC CG153033-01 TGAGGGAAGAAGATAACATTGAGCTGAATGAAGAAGGAAGGCCGGTGCAGACGTCCAG DNA Sequence GCCAAGCCCCCCACTCTGCGACTGCCACTGCTGCGGCCTCCCCAAGCGTTACATCATT GCTATCATGAGTGGGCTGGGATTCTGCATTTCCTTTGGGATCCGGTGCAATCTTGGAG
Further analysis of the NOV24a protein yielded the following properties shown in Table 24B.
Table 24B. Protein Sequence Properties NOV24a
PSort 0.6000 probability located in plasma membrane; 0.4000 probability located in analysis: Golgi body; 0.3000 probability located in endoplasmic reticulum (membrane); 0.3000 probability located in microbody (peroxisome)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV24a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 24C.
In a BLAST search of public sequence datbases, the NOV24a protein was found to have homology to the proteins shown in the BLASTP data in Table 24D.
PFam analysis predicts that the NOV24a protein contains the domains shown in the Table 24E.
Table 24E. Domain Analysis of NO 24a
Identities/
Pfa Domain NOV24a Match Region | Similarities Expect Value for the Matched Region sugar r 64..488 72/506 (14%) 0.04 262/506 (52%)
Example 25.
The NOV25 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 25A.
Table 25A. NOV25 Sequence Analysis
SEQ ID NO: 301 3374 bp
NOV25a, GCAATCATGAAGGACAGCGGGGACTCCAAGGACCAGCAACTCATGGTGGCGCTTCGGG (?G153818-01 TCCGGCCCATCAGCGTGGCAGAGCTGGAGGAAGGAGCTACCCTCATCGCCCATAAAGT DNA Sequence GGATGAGCAGCATTTACCTGCTGCCACCCCCCTCTGCTCCCGGGGTGCTGTAGAGCCA GGCTCAAAGCTGCAAAGGGCCACTGGAGCAGTTCCCTCACAGCCCTCTCAGCTGCGAG TGGAGATCCCCAAGCCCAGCGTGCTGACCTCATCCCTCACCCAGCTGCCTGTGGCTCT TTGCTCTGTCCCAGGCTCTGCCCTGGAGGGGGCCCGGGGTTCCCAGGTGACCGTGGGC CTCCCTCTGGGGACCTTGCAGATGGTGGTTCTCATGGACCCAATGGAGGATCCCGACG ACATCCTGCGGGCGCATCGCTCCCGGGAGAAGTCCTACCTGTTCGACGTGGCCTTTGA CTTCACCGCCACCCAGGAGATGGTGTATCAGGCCACCACCAAGAGCCTCATCGAGGGC GTCATCTCAGGCTACAATGCCACTGTCTTTGCCTATGGCCCACAGGTAAGGGGAATGC CAGACTTGTGCGAGACAGCAATGATCTGCTGTGGGAAAACCTACACCATGCTGGGCAC AGACCAGGAGCCTGGCATCTATGTTCAGACCCTCAACGACCTCTTCCGTGCCATCGAG GAGACCAGCAATGACATGGAGTATGAGGTCTCCATGTCCTACCTGGAGATCTACAATG AGATGATCCGGGACCTGCTGAACCCCTCCCTGGGCTACCTGGAGCTGCGGGAGGACTC TAAGGGGGTGATCCAGGTGGCCGGCATCACCGAAGTCTCCACCATCAATGCCAAGGAG ATCATGCAGCTGCTGATGAAGGGGAACCGGCAGAGGACCCAGGAGCCCACGGCCGCCA ACCAGACGTCCTCCCGCTCCCACGCGGTACTGCAGGTGACCGTGCGCCAGCGCAGCCG GGTCAAGAACATCTTGCAGGAGGCGCAGGGCCGCCTGTTCATGATCGACCTGGCTGGC TCAGAGCGCGCCTCGCAGACACAGAATCGTGGGCAGCGTATGAAGGAGGGGGCCCACA TCAACCGCTCACTGCTGGCACTGGGCAACTGCATCAACGCCCTGAGCGACAAGGGTAG CAACAAGTACATCAACTATCGCGACAGCAAGCTCACCCGGCTCCTGAAGGACTCTCTG GGAGGAAACAGCCGCACAGTGATGATCGCTCACATCAGTCCTGCGAGCAGTGCCTTCG AGGAGTCCCGGAACACCCTGACCTACGCCGGCCGGGCCAAGAACATTAAGACTAGGGT GAAGCAGAACCTCCTGAACGTCTCCTACCACATCGCCCAGTACACCAGCATCATCGCT GACCTGCGGGGCGAGATCCAGCGACTCAAGCGCAAGATTGATGAGCAGACTGGGCGGG GCCAGGCCCGGGGCCGGCAGGATCGGGGTGACATCCGCCACATCCAAGCTGAGGTCCA GCTGCACAGCGGGCAGGGTGAGAAGGCTGGCATGGGACAGCTTCGGGAGCAGCTCGCC AGCGCCTTCCAGGAGCAGATGGATGTGCGGAGGCGCCTGCTGGAGCTGGAGAACCGCG

Further analysis of the NOV25a protein yielded the following properties shown in Table 25B.
Table 25B. Protein Sequence Properties NOV25a
PSort 0.9800 probability located in nucleus; 0.3000 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV25a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 25C.
In a BLAST search of public sequence datbases, the NOV25a protein was found to have homology to the proteins shown in the BLASTP data in Table 25D.
Table 25D. Public BLASTP Results for NOV25a
Protein NOV25a Identities/
Residues/ Similarities for
Accession Protein/Organism/Length Expect
Number Match the Matched Value
PFam analysis predicts that the NOV25a protein contains the domains shown in the Table 25E.
Example 26.
The NOV26 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 26A.

GATGGGCTGCACCCCCTGCCCCAAGTGGAGTTCGAGTTCTGGGACACTCGGCTGCTGA ACCTCAAGTGCATCCATGAACAGCTAAACAGACCCAAAGTGAACAAGATTGTTGAGAT CCTAGAGAAAGCCAAAAGCTGCTACTGGCCAGCCCTGCAAAACGTTTACACCAACGTC ACTGAAGGGCTGAAGGAAGCCAACGACATCGTGCTCTATTTGAAGCCCCTACGGATCC TGCTGGAGGAGATGGAACAAGCCGACTTCACGATGCTCCCCACCTTCATTGCCAAGGT GCTGGACACCATCTGCTTCATCTGGGCCACCTCTGAGTACTATAACACACCTGCCAGG ATCATCGTCATCCTGCAGGAGTTCTGCAACCAAATCATCGAGATGACACGAACCTTCC TGAGCCCGGAAGAGGTGCTGAAGGGCCTGCAAGGTGAAATCGAGGAAGTCCTGAGTGG CATCTCCCTGGCTGTAAATGTGCTGAAGGAGCTCTACCAGACGTACGACTTCTGCTGC GTGAACATGAAGCTTTTCTTTAAGGACAAAGAGCCCGTGCCTTGGGAATTCCCTTCTT CTCTTGCCTTTTCCAGGATAAATTCCTTCTTCCAGCGCATCCAGACCATTGAGGAACT CTATAAAACAGCAATTGAGTTTCTGAAGCTGGAGAAAATCGAGCTTGGGGGCGTGCGT GGGAACCTCCTCGGGAGCCTGGTGACCCGTATCTATGATGAGGTCTTTGAGCTGGTGA AGGTTTTTGCCGACTGCAAATATGATCCCTTGGACCCTGGAGACTCGAATTTTGACCG TGATTATGCTGATTTTGAGATCAAAATCCAAGACCTGGATAGGAGGCTGGCCACGATC TTTTGCCAAGGATTTGATGACTGCAGCTGTATCAAGTCCTCCGCAAAGCTCCTGTACA TGTGTGGGGGCCTCATGGAGCGGCCCCTGATTCTTGCCGAGGTGGCGCCCAGGTATTC AGTCATGCTGGAGCTGTTTGACGCTGAGCTAGACAATGCTAAGATCTTGTACGATGCC CAGATGGCGGCCTCCGAGGAGGGGAACATCCCCCTGATCCACAAAAACATGCCTCCCG TGGCCGGGCAGCTCAAATGGAGCCTGGAGCTGCAGGAGAGGCTAGAGGTGTCCATGAA ACACCTGAAGCACGTCGAACACCCGGTCATGTCTGGAGCAGAGGCCAAGCTGACCTAT CAGAAGTATGACGAGATGATGGAGCTGCTGAGGTGCCACCGCGAGAAGATCTACCAGC AGTGGGTGGCGGGCGTGGACCAGGACTGCCACTTTAACCTGGGGCAGCCGCTGATTCT GCGGGACGCCGCTAGCAACCTCATCCACGTCAACTTCAGCAAAGCGTTGGTGGCAGTT CTGAGAGAAGTCAAGTATTTGAATTTCCAGCAACAGAAAGAGATTCCAGACAGTGCGG AGAGTCTGTTCTCAGAGAACGAAACTTTCCGGAAGTTTGTGGGCAACCTGGAGCTCAT CGTTGGCTGGTATAATGAGATAAAGACTATAGTGAAGGCAGTAGAATTTCTACTAATA AAGTCAGAACTGGAAGCAATTGATGTCAAGTTATTGAGCGCTGAAACGACATTATTCT GGAATGGCGAAGGTGTGTTTCAGTACATTCAAGAGGTGCGAGAAATTCTGCACAACTT GCAGAACAGGATGCAAAAGGCAAAACAAAATATAGAAGGAATTTCCCAGGCTATGAAG GACTGGTCGGCCAACCCGCTGTTTGAAAGAAAGGACAATAAGAAAGAGGCCCTGTTAG ACTTGGATGGAAGAATTGCCAACCTCAACAAGCGCTACGCAGCAGTCAGGGATGCTGG AGTGAAGATCCAAGCCATGGAAAACGCAGAACTATTCAGGGCAGACACACTGAGCCTG CCCTGGAAGGATTATGTCATCTACATTGACGACATGGTCTTAGATGAATTTGACCAGT TCATTCGCAAATCTCTGAGTTTCCTAATGGACAACATGGTTATAGATGAGAGTATCGC TCCCCTGTTTGAGATCCGCATGGAGCTGGACGAGGATGGGCTGACCTTCAACCCGACC CTGGAGGTGGGCTCAGATCGCGGCTTCCTGGCACTGATCGAGGGCCTGGTCAACGACA TCTACAACGTAGCCAGGCTCATCCCTCGGCTGGCCAAGGACAGGATGAACTACAAGAT GGACCTGGAAGATAACACAGACCTCATAGAGATGAGGGAGGAGGTGTCCAGCCTGGTC ATCAATGCCATGAAGGAGGCCGAGGAGTACCAGGATTCCTTTGAGAGGTACTCCTACC TCTGGACGGACAACCTGCAGGAGTTTATGAAGAATTTCCTGATATATGGGTGTGCAGT CACTGCGGAGGACTTGGACACCTGGACAGATGACACCATCCCCAAGACACCGCCCACC CTGGCTCAGTTCCAGGAGCAGATCGACTCCTACGAGAAGCTGTATGAGGAGGTGTCCA AGTGCGAGAACACCAAGGTGTTCCACGGCTGGCTGCAGTGCGACTGCCGCCCCTTCAA GCAGGCCCTGCTCAGCACAATCCGGCGCTGGGGCTTCATGTTCAAGCGGCACCTGAGC AACCACGTCACCAACAGCCTGGCTGACCTGGAAGCCTTCATGAAAGTCGCCAGAATGG GCTTGACCAAGCCCCTCAAGGAGGGGGACTATGATGGGCTTGTGGAGGTGATGGGGCA CCTGATGAAAGTCAAGGAGAGGCAAGCAGCCACCGACAACATGTTTGAGCCCCTGAAG CAAACCATCGAGCTGCTCAAGACCTACGGGGAGGAGATGCCAGAGGAGATCCACTTGA AGCTGCAGGAGCTGCCGGAGCACTGGGCAAATACCAAGAAACTGGCCATTCAGGTGAA GCTGACCGTGGCACCACTCCAGGCCAACGAGGTCAGCATCCTGCGGCGGAAATGCCAG CAATTCGAGCTCAAGCAACATGAGTTCAGGGAGAGGTTCAGGCGCGAGGCCCCGTTCT CCTTCAGCGACCCCAACCCCTACAAGTCCCTGAATAAGCAACAAAAGAGCATCTCCGC CATGGAAGGCATCATGGAGGCGCTGTCCAAGTCCGGGGGCCTGTTCGAGGTCCCCGTC CCAGACTACAAGCAGCTCAAGGCCTGCCACCGGGAGGTCCGCCTACTGAAGGAGCTCT GGGACATGGTTGTTGTGGTAAATACCAGCATCGAGGACTGGAAGACCACCAAGTGGAA AGATATCAACGTTGAGCAGATGGACATAGATTGTAAGAAGTTTGCCAAGGACATGAGG TCTTTGGACAAGGAGATGAAAACCTGGGATGCCTTCGTGGGGCTCGACAACACCGTGA AAAACGTGATCACGTCCCTGCGTGCCGTGAGCGAGCTGCAGAACCCTGCCATTCGGGA ACGCCACTGGCAGCAGCTCATGCAGGCCACCCAGGTGAAATTTAAAATGTCAGAAGAG ACGACCCTGGCAGATTTACTGCAGCTGAACCTCCACAGTTACGAGGATGAGGTCCGCA
ACATCGTGGACAAGGCCGTGAAGGAGTCGGGCATGGAAAAGGTGCTGAAAGCCCTGGA CAGTACCTGGAGCATGATGGAATTCCAGCACGAGCCGCACCCGCGGACAGGCACCATG ATGCTCAAGTCCAGCGAGGTGCTGGTGGAGACGCTGGAGGACAACCAGGTGCAGCTGC AGAACCTGATGATGTCCAAGTACCTGGCCCACTTCCTGAAGGAGGTGACAAGCTGGCA GCAGAAGCTGTCCACGGCGGACTCCGTCATCTCCATCTGGTTTGAGGTCCAGCGAACC TGGAGCCACCTGGAGAGCATCTTCATCGGCTCCGAAGACATCCGCACCCAGCTCCCGG GGGACTCCCAGCGCTTTGACGACATCAACCAGGAATTCAAGGCCTTGATGGAAGATGC AGTGAAAACACCCAACGTGGTGGAAGCCACCAGCAAACCCGGCCTCTACAATAAACTG GAGGCCCTGAAGAAGAGCTTGGCCATCTGTGAAAAGGCTTTGGCAGAGTATTTAGAGA CGAAAAGACTGGCTTTCCCCCGGTTCTATTTTGTCTCCTCGGCTGACCTCCTGGACAT TCTCTCCAATGGCAATGACCCCGTGGAGGTGAGCCGCCACCTGTCCAAACTCTTCGAT AGCCTGTGTAAACTGAAGTTCCGGCTCGATGCCAGTGACAAACCTCTCAAGGTGGGCC TGGGAATGTACAGCAAGGAGGACGAGTACATGGTTTTTGATCAGGAATGCGACCTCTC GGGGCAGGTGGAAGTGTGGCTGAATCGAGTGCTGGACCGAATGTGCTCTACCCTCCGG CACGAAATCCCAGAGGCCGTGGTGACCTACGAAGAGAAGCCGAGGGAGCAGTGGATCC TGGACTACCCAGCCCAGGTGGCCCTGACTTGCACCCAGATCTGGTGGACGACCGAGGT GGGCCTGGCATTTGCCAGGCTGGAGGAAGGCTATGAAAACGCTATCAGAGATTATAAC AAAAAGCAGATTAGCCAGCTGAACGTACTCATCACGCTGCTCATGGGGAACCTCAACG CTGGCGACAGGATGAAGATCATGACCATCTGCACCATCGATGTGCACGCACGGGACGT GGTGGCCAAAATGATCGTGGCCAAGGTGGAGAGTTCTCAGGCCTTCACCTGGCAGGCC CAGCTCCGGCATCGCTGGGACGAAGAGAAGCGACACTGCTTTGCCAACATCTGCGATG CCCAAATCCAGTATTCCTATGAGTATCTGGGCAACACGCCGCGGCTGGTCATCACCCC ACTCACTGACAGGTGCTATATCACCCTGACCCAGTCCCTCCATCTCATCATGGGTGGA GCCCCTGCCGGCCCCGCTGGGACCGGCAAGACTGAGACGACCAAGGACCTGGGCAGAG CCCTGGGCACCATGGTCTACGTCTTCAACTGCTCCGAGCAGATGGACTACAAGTCCTG TGGAAATATCTACAAGGGCCTGGCCCAGACGGGAGCCTGGGGCTGCTTTGACGAGTTT AATCGCATCTCAGTGGAAGTCTTGTCTGTGATTGCCGTGCAGGTAAAATGTGTCCAGG ATGCAATTCGGGCCAAGAAAAAAGCATTCAATTTCCTGGGAGAGATCATAGGCCTCAT TCCCACCGTCGGTATCTTCATCACCATGAACCCTGGGTACGCCGGACGCGCGGAGCTG CCTGAGAACCTAAAAGCCTTATTCAGGCCCTGTGCCATGGTCGTCCCCGACTTCGAAC TGATATGTGAGATCATGCTCATGGCCGAGGGCTTTCTGGAAGCCCGCCTTCTGGCCAG GAAGTTCATCACCCTGTACACCTTGTGCAAGGAGCTGCTCTCGAAGCAGGATCATTAC GACTGGGGCCTGAGAGCCATCAAGTCTGTGCTGGTGGTGGCCGGCTCCCTGAAGAGGG GCGACCCCAGCCGGGCAGAGGACCAGGTGCTCATGCGGGCGCTGAGAGACTTCAACAT CCCCAAGATTGTGACAGACGACCTGCCCGTATTCATGGGACTGATCGGGGACCTCTTC CCGGCTCTGGACGTGCCTCGGAAACGGGACCTGAATTTTGAAAAGATCATCAAGCAGA GCATCGTGGAGCTCAAGCTGCAGGCGGAGGACAGCTTCGTGCTGAAGGTGGTGCAGCT GGAGGAGCTGCTGCAGGTCCGCCACTCCGTGTTCATCGTCGGGAATGCGGGCAGCGGC AAATCTCAGGTCCTCAAATCCCTCAACAAGACCTATCAGAACCTGAAGAGGAAGCCGG TCGCCGTGGACCTGGACCCCAAGGCCGTCACCTGCGACGAGCTCTTTGGCATCATCAA CCCAGTGACCAGGGAATGGAAAGATGGCCTGTTCTCCACCATCATGCGAGACCTGGCC AACATCACCCATGACGGCCCCAAGTGGATCATCCTTGACGGAGACATAGACCCCATGT GGATCGAGTCTCTCAACACAGTCATGGATGACAACAAGGTCCTCACCCTGGCCAGCAA CGAGCGGATCCCCCTGAACCGCACCATGAGGCTGGTGTTCGAAATCAGCCACCTGAGG ACGGCCACCCCAGCCACCGTTTCCAGAGCCGGCATCCTCTACATCAACCCAGCCGACC TGGGATGGAACCCGGTGGTGAGCAGCTGGATCGAGAGGCGCAAGGTGCAGTCGGAGAA GGCCAACCTGATGATCCTCTTTGACAAGTACCTGCCCACGTGCCTGGACAAGTTGCGC TTTGGGTTCAAGAAGATCACGCCAGTGCCGGAGATCACGGTGATCCAAACGATTCTGT ACCTGCTGGAGTGCCTGCTCACGGAGAAGACCGTGCCCCCCGACTCCCCCAGGGAGCT GTACGAGCTGTACTTCGTGTTCACCTGCTTCTGGGCCTTCGGTGGCGCCATGTTCCAG GACCAGCTTGTGGATTATCGAGTGGAGTTCAGTAAATGGTGGATCAACGAATTCAAGA CTATCAAGTTCCCCTCGCAGGGAACGATTTTTGACTACTACATTGATCCTGACACAAA AAAGTTCCTGCCCTGGACAGATAAAGTGCCCTCCTTTGAGCTGGATCCCGATGTCCCA CTGCAGGCCTCTTTGGTCCACACCACGGAAACCATCCGCATCCGCTACTTCATGGACC TGCTCATGGAGAAGTCCTGGCCGGTGATGCTGGTGGGGAACGCGGGGACGGGCAAGTC GGTGCTGATGGGGGACAAGCTGGAAAGCCTGAACACGGACAACTACCTGGTGCAGGCT GTGCCCTTCAACTTCTACACGACCTCAGCCATGCTGCAGGGGGTGCTGGAGAAGCCGC TGGAGAAGAAATCGGGGAGGAACTACGGGCCGCCAGGCACTAAGAAGCTCGTCTACTT CATCGACGACATGAACATGCCCGAGGTGGACAAGTATGGGACGGTGGCCCCGCACACC CTCATCCGGCAGCACATGGACCACCGGCACTGGTATGACAGACATAAGCTGACGTTAA AAGATATCCATAATTGTCAGTACGTGGCCTGCATGAACCCCACTTCCGGATCCTTCAC
CATCGACTCCAGGCTTCAGCGCCATTTCTGCGTGTTTGCTGTGAGCTTCCCCGGCCAG
GAGGCCCTCACCACCATCTACAACACAATCCTGACGCAGCACCTGGCCTTCCGCTCGG
TCTCCATGGCTATCCAGAGGATAAGCAGCCAGCTGGTGGCCGCGGCCCTGGCTTTGCA
TCAGAAAATCACGGCAACATTTCTTCCCACGGCCATTAAGTTTCATTATGTCTTCAAC
CTCAGGGACCTCTCCAATATTTTCCAGGGACTCTTATTTTCCACAGCAGAAGTTCTGA
AAACCCCACTGGACCTCGTCCGCCTTTGGCTACATGAGACTGAACGAGTGTATGGTGA
CAAAATGGTTGACGAAAAAGACCAGGAAACATTGCATAGAGTCACCATGGCCTCCACC
AAGAAGTTCTTTGATGATCTTGGTGATGAACTCTTATTTGCCAAGCCAAATATCTTCT
GCCACTTTGCTCAAGGGATTGGCGATCCCAAATATGTTCCTGTAACCGACATGGCTCC
TCTGAACAAGCTCCTCGTGGACGTCCTGGACAGCTACAATGAAGTTAATGCAGTCATG
AATTTGGTGCTGTTTGAGGACGCCGTGGCTCACATCTGCAGGATTAATCGCATCCTGG
AGTCTCCCCGGGGGAATGCCCTGCTGGTGGGGGTGGGCGGCAGTGGCAAACAGAGCCT
CTCCCGCCTGGCAGCGTACATCAGCGGGCTTGACGTGTTTCAGATCACCCTCAAGAAG
GGCTACGGGATCCCCGACCTCAAGATTGACCTCGCTGCTCAGTACATAAAGGCTGCCG
TGAAGAACGTTCCCTCGGTGTTCCTGATGACAGACTCCCAGGTGGCCGAGGAGCAGTT
TCTGGTGCTGATCAATGACCTGCTGGCCTCAGGAGAGATCCCTGGGCTGTTTATGGAG
GACGAGGTGGAGAACATCATCTCCTCCATGCGACCCCAAGTCAAGTCCCTTGGCATGA
ATGACACTCGGGAAACATGTTGGAAGTTCTTCATCGAAAAAGTGCGCAGACAGCTCAA
GGTGATCCTGTGTTTCTCCCCTGTGGGCTCCGTGCTGCGGGTACGAGCCAGAAAGTTC
CCAGCTGTGGTCAACTGCACGGCCATCGACTGGTTCCACGAGTGGCCGGAAGATGCGC
TGGTGTCCGTCAGCGCCCGCTTCCTGGAGGAGACTGAGGGGATTCCGTGGGAAGTCAA
GGCCTCCATCAGCTTCTTCATGTCCTACGTGCACACCACCGTCAACGAGATGTCCAGG
GTATACCTGGCTACTGAGAGGCGCTACAACTACACCACACCCAAAACCTTTCTGGAGC
AGATCAAACTGTACCAGAACCTGCTGGCCAAGAAGAGAACGGAACTTGTTGCCAAAAT
CGAGAGGCTGGAGAACGGCCTGATGAAGCTGCAGAGCACGGCTTCCCAGGTGGATGAT
TTGAAAGCCAAGTTGGCGATTCAGGAGGCTGAGCTCAAGCAGAAGAATGAGAGCGCAG
ACCAACTGATCCAGGTGGTCGGCATCGAGGCCGAGAAGGTCAGCAAAGAGAAGGCCAT
TGCTGACCAGGAAGAAGTCAAGGTCGAGGTCATCAATAAGAACGTCACTGAGAAGCAA
AAGGCCTGTGAAACAGACCTGGCCAAAGCAGAACCGGCCCTGCTGGCAGCCCAGGAGG
CTCTGGACACTCTGAATAAGAACAACCTGACAGAGCTGAAGTCCTTTGGGTCCCCGCC
GGATGCTGTGGTCAACGTCACCGCCGCCGTCATGATTCTGACCGCACCTGGGGGCAAG
ATCCCCAAGGACAAGAGCTGGAAGGCGGCCAAGATCATGATGGGCAAGGTGGACACCT
TCCTAGACTCCCTGAAGAAGTTCGACAAGGAGCACATCCCTGAGGCCTGCCTGAAGGC
CTTCAAGCCCTACCAAGGCAACCCGACGTTCGACCCCGAGTTCATCCGCTCCAAGTCC
ACGGCCGCCGCCGGCCTGTGCTCCTGGTGCATCAACATCGTCCGCTTCTACGAGGTCT
ACTGCGACGTGGCGCCCAAGAGGCAGGCACTGGAGGAGGCTAATGCAGAGCTGGCAGA
GGCACAAGAGAAGCTGTCCCGGATCAAAAACAAGATTGCCGAACTTAACGCCAACCTG
AGCAACCTAACCTCAGCGTTTGAAAAAGCAACAGCTGAGAAAATCAAGTGTCAGCAAG
AGGCCGATGCCACGAACAGGGTGATCTTACTGGCGAACAGGCTGGTCGGGGGATTAGC
ATCGGAAAACATCCGCTGGGCTGAGTCTGTGGAGAACTTCAGGAGCCAGGGGGTCACG
CTGTGTGGGGACGTCCTGCTCATCTCTGCCTTCGTGTCCTACGTGGGCTACTTCACCA
AGAAATACCGGAATGAGCTGATGGAGAAATTCTGGATCCCTTACATACATAACTTAAA
GGTCCCCATCCCGATCACGAATGGCCTGGATCCCTTGAGCCTGCTGACAGATGACGCG
GACGTGGCCACCTGGAACAACCAGGGCCTCCCCAGCGACCGCATGTCCACCGAGAATG
CCACCATCCTGGGCAACACCGAGCGGTGGCCGCTGATCGTGGACGCCCAGCTCCAAGG
AATCAAGTGGATCAAAAACAAATACAGGAGTGAACTGAAAGCCATCCGCCTGGGACAG
AAGAGCTACCTGGATGTCATCGAGCAGGCCATCTCGGAAGGGGACACCTTGCTCATTG
AGAACATCGGCGAAACCGTGGACCCCGTGCTGGACCCTCTACTGGGCAGGAACACGAT
TAAAAAGGGAAAGTACATTAAGATCGGTGACAAGGAGGTGGAGTACCACCCCAAGTTC
CGCCTGATCCTACACACCAAGTACTTCAACCCACACTACAAGCCAGAGATGCAGGCTC
AGTGCACCCTCATCAACTTCCTGGTCACCAGGGATGGACTCGAGGACCAACTCTTGGC
CGCTGTGGTGGCCAAAGAGCGCCCAGATCTGGAACAGCTGAAGGCAAACCTCACCAAG
TCTCAAAACGAATTTAAGATTGTTCTGAAAGAGCTGGAAGATTCGCTCCTGGCCCGTC
TGTCGGCTGCGTCGGGGAACTTTCTGGGAGACACGGCCTTGGTGGAGAATCTGGAGAC
CACCAAGCACACAGCCAGCGAGATCGAGGAGAAGGTGGTGGAGGCAAAAATCACAGAA
GTTAAAATCAACGAAGCGAGAGAGAACTACCGCCCGGCTGCGGAGAGGGCATCTCTGC
TCTACTTCATACTGAACGATCTCAACAAAATCAACCCCGTCTACCAGTTCTCCCTCAA
GGCCTTCAACGTGGTGTTTGAGAAAGCCATCCAGAGGACCACCCCTGCCAACGAGGTG
AAGCAGCGGGTGATCAACCTGACGGACGAGATCACCTACTCCGTCTACATGTACACGG
CCCGGGGACTCTTCGAGAGGGACAAACTCATTTTCCTGGCACAAGTTACGTTTCAGGT
CCTGTCCATGAAGAAGGAGCTGAACCCAGTGGAGCTGGATTTCCTCCTGCGGTTCCCT
TTTAAGGCCGGAGTGGTCTCACCAGTGGACTTCCTCCAGCATCAAGGCTGGGGCGGGAj TCAAGGCCCTCTCGGAGATGGATGAGTTCAAAAATCTGGACAGTGACATCGAAGGATC TGCCAAGCGCTGGAAAAAGCTGGTGGAGTCGGAAGCCCCCGAGAAGGAGATCTTCCCC AAGGAGTGGAAGAACAAGACGGCCCTGCAGAAGCTGTGCATGGTGCGCTGCCTGCGGC CAGATCGCATGACCTACGCTATCAAGAACTTCGTGGAGGAAAAGATGGGCAGCAAGTT CGTGGAAGGCCGGAGTGTTGAGTTTTCTAAGTCCTACGAGGAGAGCAGCCCCTCCACG TCAATCTTCTTCATCCTCTCCCCGGGGGTTGACCCCTTGAAAGACGTGGAAGCCCTGG GAAAAAAACTAGGGTTTACCATAGACAATGGAAAACTCCATAATGTGTCCCTGGGGCA GGGACAAGAGGTGGTGGCTGAGAACGCCCTGGACGTGGCTGCAGAGAAAGGACACTGG GTCATTCTGCAGAATATCCACCTGGTGGCCCGGTGGCTGGGAACACTGGACAAGAAGC TGGAGTGCTACAGCACGGGCAGCCATGAGGACTACCGGGTGTTCATCAGCGCGGAGCC TGCCCCCAGCCCCGAGACCCACATCATCCCCCAGGGCATTCTGGAGAACGCCATCAAG ATCACCAACGAGCCCCCCACGGGCATGCACGCCAACTTGCACAAGGCCCTGGACCTGT TCACCCAGGACACCCTGGAGATGTGCACCAAGGAGATGGAGTTCAAGTGCATGCTCTT CGCCCTGTGCTACTTCCACGCTGTGGTGGCAGAGAGGCGCAAGTTCGGCGCCCAGGGC TGGAACCGGTCGTACCCCTTCAACAACGGGGACCTCACCATCTCCATCAACGTGCTCT ACAACTACCTGGAGGCCAACCCCAAGGTGCCCTGGGACGATCTCCGCTACCTTTTTGG TGAAATCATGTATGGCGGCCACATCACAGATGACTGGGACCGTCGGCTGTGCAGGACC TACCTGGCTGAATACATCCGGACGGAGATGCTGGAGGGAGACGTCCTGCTGGCCCCCG GCTTTCAGATCCCCCCCAACCTGGACTACAAGGGTTACCACGAATACATCGATGAGAA CCTGCCCCCTGAGAGTCCCTATCTGTATGGCCTGCACCCCAACGCAGAGATTGGCTTT CTGACGGTCACCTCAGAGAAGCTGTTCCGCACTGTCCTGGAAATGCAGCCAAAAGAGA CGGACTCGGGGGCAGGCACGGGAGTGTCCCGCGAGGAGAAGGTGAAGGCCGTGCTGGA CGACATCCTGGAGAAGATTCCGGAGACTTTCAACATGGCTGAGATCATGGCAAAGGCA GCGGAAAAGACCCCCTACGTGGTAGTCGCCTTTCAAGAATGTGAAAGAATGAACATCC TGACCAACGAAATGCGCCGTTCGCTCAAGGAGCTGAACCTGGGGCTGAAGGGAGAACT GACCATCACGACCGACGTGGAAGATCTGTCCACGGCTCTCTTCTATGACACCGTGCCT GATACGTGGGTGGCCCGGGCCTACCCCTCCATGATGGGCCTGGCGGCCTGGTACGCAG ACCTGCTGCTCCGCATCAGGGAACTCGAGGCCTGGACGACAGACTTTGCCCTGCCCAC CACCGTGTGGCTGGCCGGCTTCTTCAACCCCCAGTCGTTCCTCACGGCCATCATGCAG TCCATGGCCAGGAAGAACGAGTGGCCCCTGGACAAGATGTGTCTGTCTGTCGAGGTGA CCAAGAAAAACCGAGAGGACATGACCGCTCCTCCGCGAGAGGGCTCCTACGTGTACGG ACTCTTCATGGAAGGGGCTCGCTGGGACACCCAGACTGGAGTCATCGCTGAAGCGCGG CTGAAAGAGCTGACCCCGGCCATGCCTGTCATCTTCATCAAGGCCATTCCTGTGGACC GCATGGAGACCAAGAACATCTATGAGTGTCCCGTGTACAAAACACGCATCCGCGGCCC CACCTATGTCTGGACCTTTAACTTGAAGACCAAAGAGAAGGCAGCGAAGTGGATCCTG GCAGCCGTGGCGCTGCTCCTACAGGTTTAGCTCGCTCCTGCCTCACAGCCCACACTCC
CTGGGGCTGGACCACAACTCAGCCCTTCACCTGTGCACCTGTGACTTATTCTTTACAG
GAACTGGTGGTGGTTTTTCGTTCTCTTAAATAATCAGGTGCTTTGTAACCAAGCACAT
CGGAACCAGAGGGTGGAGGTTGGTGTGGAAGAGGTGGGGCAGATTAAAGCCAGTGGAG
CCACTCAGCTGTGCCCATCCATTCTGTGCCTGATGGCCACTGTGAGGCCTGGTTCAGG
CTTTGGGGAAAGGCCCCAATTCCCAGCAGCCAGAGGCAAGCATTCC
ORF Start: at 61 ORF Stop: TAG at 13426
SEQ ID NO: 304 4455 aa MW at 508571.2kD
NOV26a, DVRLEYLEEVASIVLKFKPDKWSKLIGAEENVALFTEFFEKPDVQVLVLTLNAAGMII CGI 54435-01 PCLGFPQSLKSKGVYFIKTKSENINKDNYRARLLYGDISPTPVDQLIAWEEVLSSLL NQSENMAG PQVVSΞDIVKQVHRLKNEMFVMSGKIKGKTLLPIPEHLGSLDGTLESME Protein Sequence RIPSSLDNLLLHAIETTIID SHQIRDVLSKDSAQALLDGLHPLPQVEFEFWDTRLL LKCIHEQIJsTRPKV IVEILEKAKSCY PALQ VYTlvrVTEGLKEANDIVLYLKPLRIL LEEMEQADFTMLPTFIAKVLDTICFI ATSEYY TPARIIVILQEFCNQIIEMTRTFL SPEEVLKGLQGEIEEVLSGISLAVNVLKELYQTYDFCCVNMXiFFKDKEPVP EFPSS LAFSRINSFFQRIQTIEELYKTAIEFLKLEKIELGGVRGNLLGSLVTRIYDEVFELVK VFADCKYDPLDPGDSNFDRDYADFEIKIQDLDRRLATIFCQGFDDCSCIKSSAKLLYM CGGLMERPLILAEVAPRYSVMLELFDAELDNAKILYDAQMAASEEGNIPLIHKNMPPV AGQLK SLELQERLEVSMKHLIHVEHPVMSGAEAKLTYQKYDEMMELLRCHREKIYQQ WVAGVDQDCHFNLGQPLILRDAASNLIHVNFSKALVAVLREVKYL FQQQKEIPDSAE SLFSENETFRKFVGNLELIVG YNEIKTIVKAVEFLLIKSELEAIDVKLLSAETTLF NGEGVFQYIQEVREILHNLQNRMQKAKQNIEGISQAMKD SA PLFERKDNKKEALLD LDGRIANLNKRYAAVRDAGVKIQAMENAELFRADTLSLP KDYVIYIDDMVLDEFDQF
IRKSLSFLMDNMVIDESIAPLFEIRMELDEDGLTFNPTLEVGSDRGFLALIEGLλ/NDI YNVARLIPRLAKDRMNYKMDLEDNTDLIEMREEVSSLVINAMKEAEEYQDSFERYSYL WTDNLQEFMKNFLIYGCAVTAEDLDT TDDTIPKTPPTLAQFQEQIDSYEKLYEEVSK CENTKVFHG LQCDCRPFKQALLSTIRR GFMFKRHLSNHVTNSLADLEAFM VARMG LTKPLKEGDYDGLVEVMGHLMKVKERQAATDNMFEPLKQTIELLKTYGEEMPEEIHLK LQELPEHWANTKKLAIQVKLTVAPLQANEVSILRRKCQQFELKQHEFRERFRREAPFS FSDPNPYKSLNKQQKSISAMEGIMEALSKSGGLFEVPVPDYKQLIACHREVRLLKEL DMVVVVNTSIEDWKTTK KDIlsrv/EQMDIDCKKFAKDMRSLDKEMKT DAFVGLDNTVK NVITSLRAVSELQNPAIRERHWQQLMQATQVKFKMSEETTLADLLQLNLHSYEDEVRN IVDKAVKESGMEKVLKALDST SMMEFQHEPHPRTGTMMLKSSEVLVETLEDNQVQLQ NLMMSKYLAHFLKEVTS QQKLSTADSVISIWFEVQRTWSHLESIFIGSEDIRTQLPG DSQRFDDINQEFKALMEDAVKTPNVVEATSKPGLYNKLEALKKSLAICEKALAEYLET KRLAFPRFYFVSSADLLDILSNGNDPVEVSRHLSKLFDSLCKLKFRLDASDKPLKVGL GMYSKEDEYMVFDQECDLSGQVEV L RVLDRMCSTLRHEIPEAWTYEEKPREQWIL DYPAQVALTCTQI TTEVGLAFARLEEGYENAIRDYNKKQISQLNVLITLLMGNLNA GDRMKIMTICTIDVHARDWAKMIVAKVESSQAFT QAQLRHRWDEEKRHCFANICDA QIQYSYEYLGNTPRLVITPLTDRCYITLTQSLHLIMGGAPAGPAGTGKTETTKDLGRA LGTMVYVFNCSEQMDYKSCGNIYKGLAQTGA GCFDEFNRISVEVLSVIAVQVKCVQD AIRAKKKAFNFLGEIIGLIPTVGIFITMNPGYAGRAELPENLKALFRPCAMWPDFEL ICEIMLMAEGFLEARLLARKFITLYTLCKELLSKQDHYDWGLRAIKSVLWAGSL RG DPSRAEDQVLMRALRDFNIPKIVTDDLPVFMGLIGDLFPALDVPRKRDLNFE IIKQS IVELKLQAEDSFVLKWQLEELLQVRHSVFIVGNAGSGKSQVLKSLNKTYQNLKRKPV AVDLDPKAVTCDELFGIINPVTRE KDGLFSTIMRDLANITHDGPKWIILDGDIDPM IESLNTVMDDNKVLTLASNERIPLNRTMRLVFEISHLRTATPATVSRAGILYINPADL GW P SS IERRKVQSEKANLMILFDKYLPTCLDKLRFGFKKITPVPEITVIQTILY LLECLLTEKTVPPDSPRELYELYFVFTCF AFGGAMFQDQLVDYRVEFSK INEFKT IKFPSQGTIFDYYIDPDTKKFLPWTDKVPSFELDPDVPLQASLVHTTETIRIRYFMDL LMEKSWPVMLVGNAGTGKSVLMGDKLESLNTDNYLVQAVPFNFYTTSAMLQGVLEKPL EKKSGRNYGPPGTKKLVYFIDDMNMPEVDKYGTVAPHTLIRQHMDHRH YDRHKLTLK DIHNCQYVACMNPTSGSFTIDSRLQRHFCVFAVSFPGQEALTTIYNTILTQHLAFRSV SMAIQRISSQLVAAALALHQKITATFLPTAIKFHYVFNLRDLSNIFQGLLFSTAEVLK TPLDLVRL LHETERVYGDKMVDEKDQETLHRVTMASTKKFFDDLGDELLFAKPNIFC HFAQGIGDPKYVPVTDMAPIJsJKLLVDVLDSY EVNAVM LVLFEDAVAHICRINRILE SPRGNALLVGVGGSGKQSLSRLAAYISGLDVFQITLKKGYGIPDLKIDLAAQYIKAAV KNVPSVFLMTDSQVAEEQFLVLINDLLASGEIPGLFMEDEVENIISSMRPQVKSLGMN DTRETCWKFFIEKVRRQLKVILCFSPVGSVLRVRARKFPAW CTAID FHEWPEDAL VSVSARFLEETEGIP EVKASISFFMSYVHTTVNEMSRVYLATERRYNYTTPKTFLEQ IKLYQNLIαAKKRTELVAKIERLENGLMKLQSTASQVDDLKAKLAIQEAELKQKNESAD QLIQVVGIEAEIWSKEKAIADQEEVKVEVINKlsTVTEKQIs^CETDLAKAEPALLAAQEA LDTLNKNNLTELKSFGSPPDAWNVTAAVMILTAPGGKIPKDKS KAAKIMMGKVDTF LDSLKKFDKEHIPEACLKAFKPYQGNPTFDPEFIRSKSTAAAGLCS CINIVRFYEVY CDVAPKRQALEEANAELAEAQEKLSRIKNKIAELANLSNLTSAFEKATAEKIKCQQE ADATNRVILLANRLVGGLASENIRWAESVENFRSQGVTLCGDVLLISAFVSYVGYFTK KYRNELMEKF IPYIHNLKVPIPITNGLDPLSLLTDDADVAT NNQGLPSDRMSTENA TILGNTER PLIVDAQLQGIK IKNKYRSELKAIRLGQKSYLDVIEQAISEGDTLLIE NIGETVDPVLDPLLGRNTIKKGKYIKIGDKEVEYHPKFRLILHTKYFNPHYKPEMQAQ CTLINFLVTRDGLEDQLLAAWAKERPDLEQLKANLTKSQNEFKIVLKELEDSLLARL SAASGNFLGDTALVENLETTKHTASEIEEK EAKITEVKINEARENYRPAAERASLL YFILNDLNKINPVYQFSLKAFNWFEKAIQRTTPANEVKQRVINLTDEITYSVYMYTA RGLFERDKLIFLAQVTFQVLSMKKELNPVELDFLLRFPFKAGWSPVDFLQHQG GGI KALSEMDEFKNLDSDIEGSAKR KKLVESEAPEKEIFPKE K KTALQKLCMVRCLRP DRMTYAIKNFVEEKMGSKFVEGRSVEFSKSYEESSPSTSIFFILSPGVDPLKDVEALG KKLGFTIDNGKLHNVSLGQGQEVVAENALDVAAEKGHWVILQNIHLVAR LGTLDKKL ECYSTGSHEDYRVFISAEPAPSPETHIIPQGILENAIKITNEPPTGMHANLHKALDLF TQDTLEMCTKEMEFKCMLFALCYFHAWAERRKFGAQG NRSYPFNNGDLTISINVLY NYLEANPKVP DDLRYLFGEIMYGGHITDD DRRLCRTYLAEYIRTEMLEGDVLLAPG FQIPPNLDYKGYHEYIDENLPPESPYLYGLHPNAEIGFLTVTSEKLFRTVLEMQPKET DSGAGTGVSREEKVKAVLDDILEKIPETFNMAEIMAKAAEKTPYVVVAFQECERMNIL TNEMRRSLKELNLGLKGELTITTDVEDLSTALFYDTVPDTWVARAYPSMMGLAA YAD LLLRIRELEA TTDFALPTTV LAGFFNPQSFLTAIMQSMARKNE PLDKMCLSVEVT KKNREDMTAPPREGSYVYGLFMEGAR DTOTGVIAEARLKELTPAMPVIFIKAIPVDR
METIOJIYECPVYKTRIRGPTYV TFNLKTKEKAAKWILAAVALLLQV
Further analysis of the NOV26a protein yielded the following properties shown in Table 26B.
Table 26B. Protein Sequence Properties NOV26a
PSort 0.6000 probability located in plasma membrane; 0.4000 probability located in analysis: Golgibody; 0.3000 probability located in endoplasmic reticulum (membrane); 0.3000 probability located in microbody (peroxisome)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV26a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 26C.
In a BLAST search of public sequence datbases, the NOV26a protein was found to have homology to the proteins shown in the BLASTP data in Table 26D.
PFam analysis predicts that the NOV26a protein contains the domains shown in the Table 26E.
The NOV27 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 27A.

CG154465-01 CGACGAAAGGTGTCACCACAGTGATGGCAGTGGAGGACAGCACGCTGCAAGTAGTGGT DNA Sequence ACGGGTGCGGCCCCCCACCCCTCGGGAGCTGGACAGTCAGCGGCGGCCAGTGGTTCAG GTGGTGGACGAGCGGGTGCTGGTGTTTAACCCTGAGGAGCCCGATGGAGGGTTCCCTG GCCTGAAATGGGGTGGCACCCATGATGGCCCCAAGAAGAAGGGCAAAGACCTGACGTT TGTCTTTGACCGGGTCTTTGGCGAGGCGGCCACCCAACAGGACGTGTTCCAGCACACC ACGCACAGCGTCCTGGACAGCTTCCTCCAGGGCTACAACTGCTCAGTGTTTGCCTACG GGGCCACCGGGGCTGGGAAGACACACACCATGCTGGGAAGGGAGGGGGACCCCGGCAT CATGTACCTGACCACCGTGGAACTGTACAGGCGCCTGGAGGCCCGCCAGCAGGAGAAG CACTTCGAGGTGCTCATCAGCTACCAGGAGGTCTATAATGAACAGATCCATGACCTCC TGGAGCCCAAGGGGCCCCTTGCCATCCGCGAGGACCCCGACAAGGGGGTGGTGGTGCA AGGACTTTCTTTCCACCAGCCAGCCTCAGCCGAGCAGCTGCTGGAGATACTGACCAGG GGGAACCGTAACCGCACGCAGCACCCCACTGATGCCAACGCGACTTCCTCCCGCTCCC ATGCCATCTTCCAGATCTTTGTGAAGCAGCAGGACCGGGTTCCAGGACTGACCCAGGC TGTCCAGGTGGCCAAGATGAGCCTGATTGACCTGGCTGGCTCAGAGCGGGCATCCAGC ACCCATGCGAAGGGGGAGCGGCTGCGGGAGGGGGCCAACATCAACCGCTCTCTGCTGG CGCTCATCAACGTCCTCAATGCCTTGGCCGATGCAAAGGTAGGCCGCAAGACCCATGT GCCCTACCGGGACAGCAAACTGACCCGCCTGCTCAAAGACTCCCTCGGGGGCAACTGC CGCACAGTGATGATCGCTGCCATCAGCCCCTCCAGCCTGACCTACGAGGACACGTACA ACACCCTCAAATATGCCGACCGGGCCAAGGAGATCAGGCTCTCGCTGAAGAGCAATGT GACCAGCCTGGACTGTCACATCAGCCAGTATGCTACCATCTGCCAACAGCTCCAGGCT GAGGTAGCCGCTCTGAGGAAGAAGCTCCAAGTGTATGAGGGGGGAGGCCAGCCCCCAC CACAGGACCTCCCAGGATCTCCCAAGTCGGGACCACCACCAGAACACCTTCCCAGCTC CCCCTTGCCACCCCACCCTCCCAGCCAGCCCTGCACCCCAGAGCTCCCTGCAGGGCCT AGAGCCCTTCAAGAGGAGAGTCTGGGGATGGAGGCCCAGGTGGAGAGGGCCATGGAAG GGAACTCTTCAGACCAGGAGCAGTCCCCAGAGGATGAGGATGAAGGCCCAGCTGAGGA GGTTCCAACCCAGATGCCAGAGCAGAACCCCACACATGCACTGCCAGAGTCCCCTCGC CTGACCCTGCAGCCCAAGCCAGTCGTGGGCCACTTCTCAGCACGGGAACTGGATGGGG ACCGTTCTAAGCAGTTGGCCCTAAAGGTGCTGTGCGTTGCCCAGCGGCAGTACTCCCT GCTCCAAGCAGCCAACCTCCTGACGCCCGACATGATCACAGAGTTTGAGACCCTACAG CAGCTGGTGCAAGAGGAAAAAATTGAGCCTGGGGCAGAGGCCTTGAGGACTTCAGGCC TGGCCAGGGGGGCACCTCTGGCTCAGGAGCTGTGTTCAGAGTCAATCCCTGTGCCGTC TCCTCTCTGCCCAGAGCCTCCAGGATACACTGGCCCTGTGACCCGGACTATGGCGAGG CGACTGAGTGGCCCCCTGCACACCCTGGGAATCCCGCCTGGACCCAACTGCACCCCAG CCCAGGGGTCCCGATGGCCCATGGAGAAGAAGAGGAGGAGACCAAGCGCCTTGGAGGC AGACAGTCCCATGGCCCCAAAGCGGGGCACCAAGCGCCAGCGCCAGTCCTTCCTGCCC TGCCTAAGGAGAGGGTCTCTGCCTGACACCCAACCTTCACAGGGGCCCAGCACCCCCA AAGGAGAAAGGGCCTCCTCCCCCTGCCATTCCCCTCGCGTTTGCCCAGCCACAGTCAT CAAAAGCCGGGTGCCCCTGGGCCCTTCCGCCATGCAGAACTGCTCCACCCCGCTGGCT CTGCCCACTCGAGACCTCAATGCCACCTTTGATCTCTCTGAGGAGCCTCCCTCAAAGC CCAGTTTCCATGAATGCATTGGCTGGGACAAAATACCCCAGGAGCTGAGCAGGCTGGA CCAGCCCTTCATCCCCAGGGCACCTGTGCCCCTGTTCACCATGAAGGGCCCCAAGCCA ACATCTTCCCTCCCTGGGACCTCTGCCTGCAAGAAGAAGCGCGTTGCGAGTTCCTCAG TCTCCCATGGCCGCAGCCGCATCGCCCGCCTCCCCAGCAGCACTTTGAAGAGGCCAGC TGGGCCCCTTGTACTCCCAGGTGACTGGCACTAGGGACAGGGATAGCCTGGGCCATGG
AGGCCGATGAAGACAAGAAGGAGGAGGGGACGGGGAGCTGAGACCCAGAAGAAAGGAG
GGCCTAG
ORF Start: ATG at 82 ORF Stop: TAG at 2584
SEQ ID NO: 306 834 aa JMW at 91153 _D
NOV27a, MAVEDSTLQWVRVRPPTPRELDSQRRPWQWDERVLVFNPEEPDGGFPGLKWGGTH CG154465-01 DGPKKKGKDLTFVFDRVFGEAATQQDVFQHTTHSVLDSFLQGYNCSVFAYGATGAGKT HTMLGREGDPGIMYLTTVELYRRLEARQQEKHFEVLISYQEVY EQIHDLLEPKGPLA Protein Sequence IREDPDKGVWQGLSFHQPASAEQLLEILTRGNRNRTQHPTDANATSSRSHAIFQIFV KQQDRVPGLTQAVQVAKMSLIDLAGSERASSTHAKGERLREGANINRSLLALINVLNA LADAKVGR THVPYRDSKLTRLLKDSLGGNCRTVMIAAISPSSLTYEDTYNTLKYADR AKEIRLSLKSNVTSLDCHISQYATICQQLQAEVAALRKKLQVYEGGGQPPPQDLPGSP KSGPPPEHLPSSPLPPHPPSQPCTPELPAGPRALQEESLGMEAQVERAMEGNSSDQEQ SPEDEDEGPAEEVPTQMPEQNPTHALPESPRLTLQPKPWGHFSARELDGDRSKQLAL KVLCVAQRQYSLLQAANLLTPDMITEFETLQQLVQEEKIEPGAEALRTSGLARGAPLA QELCSESIPVPSPLCPEPPGYTGPVTRTMARRLSGPLHTLGIPPGPNCTPAQGSR PM
EKKRRRPSALEADSPMAPKRGTKRQRQSFLPCLRRGSLPDTQPSQGPSTPKGERASSP CHSPRVCPATVIKSRVPLGPSAMQNCSTPLALPTRDLNATFDLSEEPPSKPSFHECIG! DKIPQELSRLDQPFIPRAPVPLFTMKGPKPTSSLPGTSACKKKRVASSSVSHGRSRI ARLPSSTLKRPAGPLVLPGD H
Further analysis of the NOV27a protein yielded the following properties shown in Table 27B.
Table 27B. Protein Sequence Properties NOV27a
PSort 0.7000 probability located in nucleus; 0.4267 probability located in analysis: mitochondrial matrix space; 0.3000 probability located in microbody (peroxisome); 0.1042 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV27a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 27C.
In a BLAST search of public sequence datbases, the NOV27a protein was found to have homology to the proteins shown in the BLASTP data in Table 27D.
PFam analysis predicts that the NOV27a protein contains the domains shown in the Table
27E.
Example 28.
The NOV28 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 28 A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 28B.
Further analysis of the NOV28a protein yielded the following properties shown in Table 28C.
Table 28C. Protein Sequence Properties NOV28a
PSort 0.7600 probability located in nucleus; 0.1000 probability located in analysis: mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.1000 probability located in plasma membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV28a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 28D.
Table 28D. Geneseq Results for NOV28a
Geneseq Protein Organism Length [Patent NOV28a Identities/ Expect Identifier #, Date] Residues/ Similarities for Value
In a BLAST search of public sequence datbases, the NOV28a protein was found to have homology to the proteins shown in the BLASTP data in Table 28E.
PFam analysis predicts that the NOV28a protein contains the domains shown in the Table
28F.
Example 29.
The NOV29 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 29 A.
Table 29A. NOV29 Sequence Analysis
NOV29a, CTCCGGACTGGTTTCTTCTTCCTTCCCCCTTCCCCCAACTTCCCTCCACCCCTTCCA CG154509-01 TCATGGCGAACGGGACTGCGGACGTTCGGAAGCTCTTCATCTTCACTACTACCCAGAA TTACTTCGGGTTGATGTCTGAACTCTGGGATCAGCCACTGTTGTGCAACTGTCTTGAA DNA Sequence ATCAACAACTTCTTGGATGACGGCAACCAGATGCTCCTCAGGGTGCAGCGATCCGACG CAGGAATCTCCTTTTCCAACACGATTGAGTTTGGTGACACAAAAGATAAAGTGCTGGT GTTTTTCAAGCTGCGACCTGAAGTAATTACTGATGAGAATCTACATGATAACATTCTT GTTTCATCTATGTTAGAGTCACCTATTAGTTCTCTTTACCAAGCAGTACGGCAAGTAT TCGCACCAATGTTGTTAAAGGATCAGGAATGGAGCAGAAACTTTGATCCCAAACTTCA GAATCTTTTGAGTGAACTAGAAGCTGGGTTGGGTATAGTTCTACGAAGATCAGACACT AACTTAACAAAATTGAAATTTAAGGAAGATGACACACGAGGTATCCTTACACCAAGCG ATGAGTTCCAGTTTTGGATAGAACAAGCTCACCGTGGAAATAAACAGATTAGTAAAGA AAGAGCCAATTATTTTAAAGAATTATTTGAAACAATTGCAAGAGAGTTTTATAACTTG GACAGTCTATCCTTACTAGAAGTTGTTGACTTGGTGGAGACTACTCAGGATGTTGTAG ATGATGTGTGGAGACAAACAGAACATGATCATTATCCTGAGTCACGAATGTTGCATCT CTTAGACATCATAGGTGGTTCATTTGGAAGGTTTGTTCAGAAAAAGTTGGGAACTTTG AACCTGTGGGAAGATCCTTATTATCTTGTGAAAGAAAGTCTGAAAGCTGGTATTTCAA TTTGTGAACAGTGGGTGATAGTCTGTAATCATCTAACAGGTCAGGTGTGGCAGCGCTA TGTTCCTCATCCATGGAAAAATGAAAAATATTTTCCAGAAACACTTGACAAACTTGGC AAACGCCTTGAAGAGGTCTTGGCTATTAGAACAATTCATGAGAAGTTTCTCTATTTTC TACCTGCCAGTGAAGAGAAAATCATATGCCTCACTCGAGTATTTGAACCTTTTACTGG CCTGAATCCTGTGCAATATAATCCATATACTGAGCCCTTGTGGAAAGCTGCGGTGTCT CAATATGAAAAGATTATTGCACCTGCGGAACAAAAAATAGCAGGAAAATTGAAAAATT ATATTTCAGAAATTCAAGACAGTCCACAGCAGCTTCTTCAAGCATTCCTGAAATATAA AGAGTTGGTAAAGCGTCCAACTATAAGCAAAGAATTGATGTTAGAAAGAGAAACTTTA CTGGCAAGACTTGTGGACTCAATTAAAGATTTTCGATTAGACTTTGAGAATCGGTGCC GAGGAATTCCTGGTGATGCATCTGGACCACTTTCTGGCAAAAATCTTTCAGAAGTTGT CAACAGTATAGTTTGGGTTCGCCAGTTGGAATTGAAGGTAGATGATACTATCAAGACT GCAGAGGCTCTTTTATCTGACTTGCCAGGATTTCGATGTTTCCATCAAAGTGCCAAAG ATCTCTTAGACCAGCTTAAACTATATGAACAGGAACAATTTGATGATTGGTCCAGGGA TATTCAATCAGGTTTATCTGATTCCAGATCTGGTTTGTGTATTGAGGCTAGTAGTCGA ATTATGGAATTGGATTCTAATGATGGATTACTAAAAGTGCATTATTCAGATCGTTTGG TGATTCTTCTGAGAGAAGTTCGTCAGCTCTCTGCACTTGGCTTTGTTATTCCTGCCAA AATACAGCAAGTTGCAAACATTGCACAGAAATTCTGCAAGCAAGCAATTATTCTTAAA CAAGTGGCACATTTTTATAATTCTATTGATCAACAAATGATTCAAAGTCAGAGGCCAA
TGATGTTACAATCTGCCTTAGCATTTGAACAGATAATTAAGAATTCAAAAGCAGGAAG TGGAGGGAAATCACAGATAACTTGGGATAATCCTAAAGAATTAGAAGGCTATATCCAA AAACTCCAAAATGCTGCTGAACGGCTTGCCACTGAAAATAGAAAACTGAGAAAATGGC ACACTACATTTTGTGAAAAGGTGGTTGTTCTTATGAATATTGATCTGCTTCGGCAGCA ACAGCGCTGGAAAGATGGATTACAAGAATTGAGAACTGGCTTAGCAACTGTAGAAGCA CAGGGATTCCAAGCAAGTGACATGCATGCATGGAAACAACACTGGAATCATCAACTGT ACAAAGCTCTGGAGCATCAGTACCAGATGGGCTTAGAAGCACTTAATGAGAATTTGCC AGAAATAAATATAGACTTAACTTACAAACAGGGACGATTACAATTCAGGCCCCCTTTT GAAGAAATCCGGGCTAAATATTATAGAGAAATGAAGAGATTCATCGGCATTCCAAATC AGTTTAAGGGAGTGGGTGAGGCCAGGAGCATTAATTCTATTTTTTCTATTATGATTGA TAGAAATGCAAGTGGATTTTTGACGATTTTCAGCAAAGCTGAACATCTGTTTAGAAGA TTGTCAGCTGTTTTACACCAACATAAGGAATGGATTGTAATTGGGCAAGTTGATATGG AAGCTCTGGTGGAAAAGCATCTTTTTACTGTACATGATTGGGAGAAAAATTTTAAAGC ATTAAAAATAAAGGGGAAAGAAGTAGAACGACTTCCAAGTGCTGTCAAGGTAGATTGT TTAAATATTAATTGCAACCCTGTGAAGACTGTGATTGATGATCTCATCCAGAAGTTAT TTGATCTGCTTGTTCTTTCTTTGAAGAAGTCCATACAGGCTCATTTACATGAAATTGA TACATTTGTTACTGAGGCTATGGAAGTCTTAACAATTATGCCCCAGTCTGTGGAAGAA ATTGGTGATGCAAATCTACAATATAGTAAGTTACAAGAACGGAAGCCAGAGATTTTGC CCTTATTTCAAGAAGCTGAAGACAAAAACAGACTTTTACGAACTGTGGCTGGTGGAGG TTTAGAAACAATTAGTAATTTGAAAGCCAAGTGGGATAAATTTGAGTTAATGATGGAA AGTCACCAACTTATGATTAAAGACCAGATTGAAGTGATGAAAGGAAATGTGAAATCAC GTCTTCAGATCTATTATCAAGAACTGGAAAAATTTAAAGCTCGTTGGGACCAACTAAA GCCTGGTGATGATGTTATTGAAACTGGCCAACATAATACTCTTGATAAAAGTGCAAAG TTAATAAAAGAGAAAAAAATTGAGTTTGATGATCTTGAAGTCACAAGAAAAAAGCTGG TTGATGATTGCCATCATTTTAGACTGGAAGAGCCTAATTTCTCCCTGGCAAGTAGTAT CTCTAAAGATATCGAGAGCTGTGCCCAAATTTGGGCCTTTTATGAAGAGTTTCAACAA GGATTTCAGGAAATGGCCAATGAAGACTGGATCACTTTTCGGACTAAGACATACCTGT TTGAGGAATTTTTGATGAACTGGCATGACAGATTAAGGAAGGTTGAAGAACATTCAGT GATGACAGTGAAATTACAATCAGAGGTTGACAAATATAAAATCGTAATTCCTATCTTG AAATATGTGAGAGGGGAGCATCTTTCTCCAGATCACTGGCTTGACCTTTTTCGTCTCC TTGGACTTCCTAGGGGGACTAGTCTAGAGAAACTACTGTTTGGTGATTTGCTCAGAGT AGCTGATACAATTGTAGCCAAAGCTGCCGACCTTAAAGATTTAAATAGTCGGGCACAA GGTGAAGTTACAATCAGAGAAGCTTTACGTGAACTTGATCTTTGGGGAGTTGGAGCAG TGTTTACATTAATTGATTATGAAGACAGCCAAAGTCGAACTATGAAGCTGATTAAAGA CTGGAAAGATATAGTAAATCAGGTTGGAGATAATAGATGCCTTCTCCAATCCTTAAAG GATTCTCCTTATTATAAAGGATTTGAAGATAAAGTATCAATTTGGGAAAGAAAACTTG CAGAGTTAGATGAATACCTGCAGAATTTAAATCATATTCAGAGAAAGTGGGTGTATTT GGAACCCATTTTCGGCCGTGGAGCATTGCCAAAAGAACAGACACGCTTCAACAGAGTT GATGAAGATTTTAGATCAATAATGACTGATATCAAGAAAGACAATAGAGTCACAACAT TAACTACTCATGCTGGAATAAGAAATTCTCTACTAACAATACTTGATCAGCTTCAAAG ATGTCAGAGATCATTAAATGAATTTTTGGAGGAAAAACGCTCAGCATTCCCAAGATTT TATTTTATTGGTGATGATGACTTATTAGAAATATTGGGCCAGTCTACCAACCCATCAG TGATTCAGTCTCACCTGAAGAAGCTTTTTGCTGGTATTAACAGTGTTTGCTTTGATGA GAAATCAAAACATATAACTGCAATGAAATCTTTAGAGGGAGAAGTTGTACCTTTTAAA AATAAAGTTCCTCTATCAAATAATGTAGAGACATGGTTGAATGATTTGGCCTTAGAAA TGAAGAAAACTTTGGAACAGTTGTTGAAGGAATGTGTTACTACTGGGCGAAGTTCTCA AGGTGCAGTTGACCCATCTCTGTTCCCTTCACAGATTTTATGCTTGGCGGAGCAGATT AAATTCACTGAAGATGTAGAAAATGCTATTAAAGATCATAGTCTTCATCAGATTGAAA CACAACTGGTGAATAAGTTAGAGCAATATACTAACATTGATACAAGTTCTGAGGATCC AGGGAATACTGAATCGGGCATCCTGGAGCTTAAACTTAAAGCCCTAATTCTTGACATT ATCCATAATATTGATGTGGTAAAGCAGTTAAACCAAATTCAGGTTCATACAACTGAAG ACTGGGCTTGGAAAAAACAACTTAGATTCTATATGAAAAGTGATCATACATGTTGTGT TCAAATGGTGGATTCTGAATTTCAGTATACTTATGAATATCAGGGTAATGCTTCCAAA CTGGTTTATACTCCACTGACAGACAAGTGCTACTTAACTCTCACTCAAGCCATGAAGA TGGGACTTGGAGGAAATCCTTATGGACCAGCTGGAACTGGGAAAACGGAATCAGTAAA GGCTTTAGGTGGACTTCTTGGAAGACAAGTTTTAGTCTTTAATTGTGATGAGGGCATC GATGTGAAGTCAATGGGACGAATATTTGTTGGTTTGGTGAAGTGTGGGGCCTGGGGTT GTTTTGATGAATTTAATAGGCTGGAAGAATCTGTACTGTCAGCAGTTTCTATGCAAAT CCAGACAATTCAAGATGCTTTGAAGAATCATAGAACTGTATGTGAACTGCTTGGCAAG GAGGTAGAAGTAAATTCTAATTCTGGAATTTTTATCACTATGAATCCTGCTGGAAAAG GTTATGGAGGAAGACAAAAACTGCCTGATAATCTTAAACAGCTTTTCAGGCCCGTAGC
TATGTCTCATCCAGACAATGAGCTTATTGCAGAAGTTATTCTCTATTCGGAAGGCTTT!
AAΆGACGCTAAAGTATTGAGCAGAAAATTGGTAGCTATTTTCAATCTATCTAGGGAAC
TTTTGACACCTCAGCAACATTATGATTGGGGTTTGAGAGCTTTGAAGACAGTTCTGAG
AGGAAGTGGAAATCTCCTTAGACAGCTAAACAAAAGTGGCACTACACAGAATGCTAAT
GAAAGTCATATTGTGGTACAAGCACTGAGGCTTAATACAATGTCAAAGTTTACGTTTA
CTGATTGCACCCGGTTTGATGCACTGATAAAAGATGTCTTTCCGGGAATTGAATTGAA
AGAAGTGGAATATGATGAACTAAGTGCTGCATTAAAGCAGGTCTTTGAAGAGGCCAAT
TATGAAATTATACCCAAT(^GATΑ_VAAAGGCTTTAGAATTGTATGAACAGTTATGCC
AGAGGATGGGAGTTGTTATTGTTGGTCCAAGTGGTGCTGGAAAATCAACGCTTTGGAG
AATGTTAAGGGCTGCGCTTTGTAAAACTGGCAAAGTAGTGAAACAATATACTATGAAT
CCCAAAGCTATGCCTCGATATCAATTATTAGGCCATATTGACATGGACACAAGAGAAT
GGTCTGATGGTGTTTTGACAAATAGTGCTCGTCAAGTGGTTCGGGAACCTCAAGATGT
CAGCTCATGGATAATCTGTGATGGTGATATTGACCCTGAATGGATAGAATCTCTGAAT
TCTGTTCTGGATGATAATCGACTGCTGACTATGCCCAGTGGAGAAAGGATTCAGTTTG
GCCCAAATGTTAACTTTGTATTTGAAACTCATGATTTAAGTTGTGCATCACCAGCCAC
AATATCTAGAATGGGAATGATCTTTCTTAGTGATGAAGAGACAGATCTTAATTCTCTG
ATAAAATCTTGGTTGAGGAATCAGCCTGCTGAATATAGAAATAATCTTGAAAATTGGA
TTGGAGATTATTTTGAAAAGGCTTTACAATGGGTTCTAAAGCAGAATGACTATGTGGT
AGAAACAAGTTTGGTTGGGACTGTGATGAATGGTTTGTCACATCTACATGGTTGCAGA
GATCATGACGAATTCATTATTAATCTCATAAGGGGACTTGGTGGAAATCTGAATATGA
AGTCACGTTTGGAATTTACCAAAGAGGTTTTTCATTGGGCACGAGAATCTCCTCCAGA
CTTTCACAAACCTATGGATACCTACTATGACTCTACTAGGGGTCGATTAGCAACATAT
GTGCTTAAGAAGCCAGAAGACTTGACTGCTGATGATTTCAGTAACGGCTTAACTCTTC
CAGTCATTCAGACTCCTGACATGCAACGAGGTCTAGATTATTTCAAACCATGGTTAAG
TTCTGATACTAAACAGCCCTTTATTCTGGTAGGACCAGAAGGATGTGGCAAAGGGATG
CTGCTCAGGTACGCATTTTCACAACTCCGGTCCACTCAAATTGCTACAGTTCACTGTA
GTGCACAAACCACTTCTCGACATCTCCTGCAGAAACTGAGCCAGACTTGCATGGTAAT
CAGTACTAATACTGGTCGTGTATACAGACCAAAAGACTGTGAAAGACTTGTTCTGTAC
TTAAAAGATATCAACCTACCTAAACTTGATAAATGGGGGACCAGTACTTTGGTAGCAT
TCCTACAACAGGTATTGACGTATCAAGGATTTTATGATGAAAATTTGGAATGGGTTGG
TCTAGAAAATATTCAAATTGTGGCTTCTATGTCAGCTGGAGGAAGACTGGGAAGACAT
AAACTTACTACCAGATTTACTTCCATCGTTCGTCTTTGTTCTATAGATTACCCAGAAA
GAGAGCAGTTACAAACGATTTATGGAGCATATTTGGAACCAGTTCTACATAAAAATCT
GAAGAATCATTCTATTTGGGGTTCTTCATCAAAAATTTATCTTTTAGCAGGATCTATG
GTACAAGTGTATGAACAGGTAGATATGCATCAGGTGCGAGCCAAATTTACAGTTGATG
ATTATAGTCACTATTTCTTTACTCCTTGCATTCTTACCCAATGGGTTCTTGGCTTATT
TAGATATGATTTAGAAGGAGGATCCTCAAACCATCCACTAGATTATGTGTTAGAAATT
GTAGCATATGAGGCACGGCGCTTATTTCGTGACAAAATTGTTGGTGCAAAGGAACTTC
ATTTATTTGACATCATTTTAACATCAGTGTTTCAAGGAGATTGGGGCTCAGACATATT
AGACAATATGTCAGATAGTTTCTACGTTACATGGGGAGCTCGGCATAATTCAGGAGCA
AGGGCAGCCCCAGGACAACCATTACCTCCACATGGAAAACCACTTGGAAAACTAAACT
CTACTGATCTCAAGGATGTTATTAAAAAGGGTCTTATTCATTATGGACGAGATAACCA
GAATTTAGACATTTTACTTTTCCACGAAGTCTTGGAGTATATGTCTAGGATAGATAGA
GTGCTGAGTTTCCCTGGAGGTTCACTTCTATTAGCAGGACGCAGTGGTGTAGGTCGTC
GGACCATCACTTCTTTAGTCAGTCACATGCATGGAGCGGTCCTGTTTTCTCCAAAGAT
TTCCAGAGGATATGAACTGAAGCAGTTCAAAAATGATCTCAAACATGTGCTGCAACTT
GCAGGAATTGAAGCACAACAGGTAGTTTTACTTCTTGAGGATTACCAGTTTGTACATC
CTACATTTTTGGAGATGATCAATAGCCTTTTGTCTTCAGGTGAAGTTCCTGGACTCTA
TACTCTTGAAGAATTAGAGCCCTTGCTGTTACCACTTAAGGATCAAGCTTCACAAGAT
GGTTTTTTTGGACCAGTCTTCAATTACTTCACATATAGAATTCAGCAAAACTTGCATA
TTGTCTTGATAATGGATTCTGCAAATTCAAACTTCATGATAAACTGTGAGAGTAATCC
AGCTTTGCATAAGAAATGCCAGGTGTTGTGGATGGAGGGTTGGTCCAATAGCAGTATG
AAGAAAATACCTGAAATGTTATTCAGTGAAACAGGTGGTGGAGAAAAATACAATGATA
AAAAACGAAAAGAAGAAAAGAAAAAAAATTCAGTTGATCCTGATTTTCTAAAATCATT
TTTATTAATCCATGAATCTTGTAAAGCATATGGTGCTACACCAAGCCGATACATGACC
TTTTTACATGTGTATTCTGCCATTAGTAGTAGCAAGAAAAAGGAATTATTAAAAAGAC
AAAGTCATTTGCAGGCTGGTGTATCTAAACTAAATGAAGCTAAAGCTCTTGTGGATGA
ACTGAACAGAAAAGCTGGAGAACAAAGTGTGTTACTTAAAACGAAGCAAGATGAAGCA
GATGCTGCCCTTCAAATGATCACAGTGTCAATGCAGGATGCTAGTGAGCAAAAAACAG
AACTTGAAAGACTGAAGCACAGAATAGCAGAAGAAGTTGTTAAAATTGAAGAAAGAAA
AAATAAAATTGATGATGAATTAAAAGAAGTACAACCTTTAGTCAATGAAGCTAAACTA
GCAGTTGGAAACATTAAGCCCGAATCACTTTCAGAAATTCGCTCACTACGCATGCCAC CTGATGTAATTAGAGATATTCTTGAAGGAGTTTTAAGGTTGATGGGTATCTTTGATAC ATCTTGGGTGAGCATGAAAAGTTTCCTTGCAAAAAGAGGTGTAAGAGAAGACATAGCA ACCTTTGATGCCCGAAATATTTCAAAGGAAATAAGAGAGAGTGTTGAAGAACTTCTTT TTAAAAATAAAGGCTCTTTTGATCCAAAGAATGCTAAGCGTGCCAGTACTGCAGCTGC ACCTTTGGCTGCCTGGGTGAAAGCCAATATTCAGTATTCCCATGTCTTGGAACGAATT CATCCTTTGGAAACTGAACAGGCAGGATTAGAATCGAATCTGAAGAAAACTGAAGACA GAAAAAGGAAACTAGAGGAGCTTCTTAATTCTGTTGGTCAAAAGGTATCAGAACTCAA AGAAAAATTTCAGAGCAGGACTTCAGAAGCTGCCAAACTTGAGGCTGAAGTAAGCAAG GCACAAGAAACAATCAAAGCTGCAGAAGTCTTAATTAATCAGCTTGACAGAGAACATA AGAGATGGAATGCACAGGTTGTAGAGATAACAGAGGAATTAGCTACTCTTCCTAAAAG AGCTCAACTTGCTGCTGCATTTATTACATATCTTTCTGCTGCTCCTGAATCTCTGAGA AAAACCTGTTTGGAAGAATGGACCAAGTCAGCTGGTCTTGAGAAATTTGATCTGAGGA GATTTCTTTGTACTGAAAGTGAGCAGTTAATTTGGAAAAGTGAAGGCCTACCATCAGA TGACCTTTCCATAGAAAATGCTCTTGTAATATTACAGAGTCGAGTGTGCCCATTTCTT ATAGATCCTTCTTCCCAAGCTACAGAGTGGTTAAAAACACATTTGAAAGACTCACGTT TAGAAGTTATCAATCAGCAGGATAGTAACTTTATCACAGCTCTTGAATTAGCAGTACG TTTTGGGAAAACCCTTATTATACAAGAGATGGATGGTGTAGAACCTGTTCTTTATCCA TTATTGAGACGAGATCTGGTTGCTCAAGGACCACGTTATGTGGTACAAATAGGTGACA AAATTATTGACTACAATGAAGAATTCCGCCTCTTTTTGTCAACAAGAAACCCAAATCC TTTTATTCCACCGGATGCAGCTTCCATTGTTACTGAGGTTAACTTTACTACAACAAGA AGTGGATTACGAGGGCAGCTTTTAGCTTTAACCATTCAGCATGAGAAACCTGATTTAG AAGAACAGAAAACAAAACTATTACAACAGGAAGAAGATAAGAAAATACAGCTAGCCAA GCTCGAAGAATCTCTTCTAGAGACACTTGCCACATCTCAAGGCAATATTTTGGAAAAT AAGGATTTGATTGAGTCTTTGAATCAGACAAAAGCAAGCAGTGCACTTATTCAAGAGT CACTTAAAGAATCTTACAAACTCCAAATTTCCCTTGATCAAGAACGGGATGCCTATCT CCCCCTGGCTGAGAGTGCCAGCAAGATGTACTTCATTATTTCTGATTTGTCCAAAATT AATAACATGTACCGTTTTAGTTTGGCTGCTTTTCTCCGACTTTTCCAACGAGCTCTAC AAAACAAACAGGATTCTGAAAATACAGAACAGAGAATCCAGTCACTTATCAGCTCATT ACAACATATGGTATATGAATATATATGTCGTTGTCTATTTAAGGCTGATCAGTTGATG TTCGCTTTGCATTTTGTTCGAGGCATGCATCCTGAACTTTTTCAAGAAAATGAATGGG ATACGTTTACAGGTGTGGTTGTTGGAGACATGTTACGGAAAGCTGACTCTCAACAAAA AATACGTGATCAGCTTCCGTCTTGGATAGATCAGGAACGAAGCTGGGCCGTGGCAACA TTAAAGATTGCTCTCCCCAGTCTTTATCAGACCCTCTGCTTTGAAGATGCAGCTCTGT GGCGTACTTATTATAATAATTCAATGTGTGAGCAAGAGTTTCCATCTATCCTTGCAAA GAAAGTTTCCTTATTTCAGCAGATTCTTGTAGTACAGGCGCTAAGACCGGACAGATTG CAAAGTGCCATGGCTCTTTTTGCATGTAAAACTCTGGGACTGAAAGAGGTGTCCCCAC TGCCTCTAAATCTCAAACGTTTATACAAAGAGACACTGGAAATTGAACCCATCTTGAT AATTATTTCTCCGGGTGCTGATCCTTCTCAGGAACTTCAAGAACTAGCTAATGCTGAA AGAAGCGGAGAGTGTTATCACCAGGTTGCCATGGGTCAAGGTCAAGCTGATTTAGCAA TTCAAATGCTAAAAGAATGTGCCCGCAATGGAGACTGGCTCTGTTTGAAGAACTTACA TCTTGTGGTATCTTGGCTGCCAGTTCTGGAAAAGGAATTGAATACTCTTCAACCTAAA GATACCTTTCGTCTTTGGCTCACTGCAGAAGTTCATCCCAACTTTACTCCTATTTTAC TACAGTCAAGTCTGAAGATAACATATGAGTCACCTCCAGGTTTAGAGAAGAATTTAAT GCGTACTTATGAGTCTTGGACTCCTGAGCAAATTAGCAAAAAAGATAATACACATCGA GCTCATGCTCTCTTCAGTCTTGCATGGTTTCATGCTGCATGTCAAGAAAGAAGAAACT ATATTCCTCAGGGTTGGACAAAGTTTTATGAATTTTCTTTATCAGATCTTCGGGCTGG GTACAACATTATTGACAGACTTTTTGATGGTGCCAAAGATGTACAATGGGAATTTGTA CATGGTTTACTTGAAAATGCTATTTATGGAGGACGTATAGACAACTATTTTGACCTTA GAGTTCTTCAGTCATACCTGAAGCAGTTTTTTAATTCTTCAGTTATTGATGTATTCAA CCAAAGGAACAAGAAAAGCATTTTTCCATATTCCGTATCTCTACCACAATCCTGCAGC ATTTTGGACTATCGTGCTGTCATTGAGAAAATTCCAGAGGACGACAAACCTAGTTTCT TTGGTCTGCCTGCCAATATCGCTCGCTCATCTCAGCGCATGATCAGTTCTCAGGTTAT TTCACAGTTGAGGATTTTGGGCAGATCCATAACAGCTGGTTCCAAATTTGATAGAGAA ATCTGGTCTAATGAACTTTCTCCTGTCCTCAATCTCTGGAAGAAACTAAACCAGAATT CAAACCTAATACATCAGAAAGTGCCTCCTCCTAACGATCGACAAGGATCTCCAATACT GTCATTCATCATTCTTGAACAATTTAATGCTATTCGTTTAGTACAAAGTGTCCACCAG TCTCTTGCTGCTCTCAGCAAAGTCATCAGAGGAACTACTTTACTGAGTTCAGAAGTAC AAAAATTGGCAAGTGCTTTATTAAACCAAAAGTGTCCTCTCGCATGGCAGAGCAAGTG GGAAGGCCCAGAAGATCCCTTACAATACCTGAGAGGTCTTGTTGCCCGTGCCCTTGCA ATACAGAACTGGGTAGATAAAGCTGAAAAACAGGCTCTTCTCTCTGAAACACTTGACC
TATCAGAACTTTTCCATCCAGACACATTTCTTAATGCTCTTCGCCAGGAAACTGCAAG GGCAGTGGGTCGTTCTGTGGATAGCCTTAAATTTGTAGCCTCATGGAAAGGTCGACTG CAAGAAGCAAAGCTACAAATTAAGATCAGTGGCTTGTTACTAGAAGGATGTAGTTTTG ATGGAAATCAACTTTCTGAAAATCAGCTTGATTCTCCCAGCGTGTCATCAGTGCTCCC TTGTTTTATGGGCTGGATTCCACAGGATGCATGTGGTCCATATTCTCCGGATGAGTGC ATCTCTTTGCCTGTTTACACAAGTGCTGAAAGGGATCGTGTGGTTACCAATATTGATG TTCCATGTGGGGGCAACCAAGACCAGTGGATTCAGTGTGGAGCAGCTCTATTCCTAAA AAATCAGTAGAATCTAATGACAACAAAAGCCATCTTCACAAAAGGGAACATTGATTCT
TTAAGCTTTAAATCAAACATGTGGTCAGTCTACATTTGAAATGTTAGTTCAAAATATT
AACATATAGTTATGTTGTTGATGTCACTGAAATTTTAATGTGTAAAAGCAGCACTGTGI
CATCTTTTAAAGTAATAAATTAATGGAGTTATTGTTAAAACAGAGTATTCTTTTGACA!
ACATTAAATATTTCTGTGAGAAAGTTCACTTTTCCAGTGGCTCAAAAATTTGTTTTAG
GTCAGAGATTTTAAGTGGTATATTAACCAATAATAAATATTTTGGCTGTC
ORF Start: ATG at 61 ORF Stop: TAG at 13000
SEQ ID NO: 312 4313 aa MW at493435.2kD
NOV29a, MA GTADVRKLFIFTTTQNYFGLMSEL DQPLLCNCLEIN FLDDGNQMLLRVQRSDA CGI 54509-01 GISFSNTIEFGDTKDKVLVFFKLRPEVITDENLHDNILVSSMLESPISSLYQAVRQVF APMLLKDQEWSRNFDPKLQNLLSELEAGLGIVLRRSDTNLTKLKFKEDDTRGILTPSD Protein Sequence EFQFWIEQAHRGNKQISKERA YFKELFETIAREFY LDSLSLLEWDLVETTQDWD DVWRQTEHDHYPESRMLHLLDIIGGSFGRFVQKKLGTLNLWEDPYYLVKESLKAGISI CEQ VIVCNHLTGQV QRYVPHPWKNEKYFPETLDKLGKRLEEVLAIRTIHEKFLYFL PASEEKIICLTRVFEPFTGLNPVQYNPYTEPLWKAAVSQYEKIIAPAEQKIAGKLKNY ISEIQDSPQQLLQAFLKYKELVKRPTISKELMLERΞTLLARLVDSIKDFRLDFENRCR GIPGDASGPLSGKNLSEVV SIV VRQLELKVDDTI TAEALLSDLPGFRCFHQSAKD LLDQLKLYEQEQFDD SRDIQSGLSDSRSGLCIEASSRIMELDSNDGLLKVHYSDRLV ILLREVRQLSALGFVIPA IQQVANIAQKFCKQAIILKQVAHFYNSIDQQMIQSQRPM MLQSALAFEQIIK SKAGSGGKSQITWDNPKELEGYIQKLQNAAERLATENRKLRKWH TTFCEKVVVLMNIDLLRQQQR KDGLQELRTGLATVEAQGFQASDMHAWKQHWNHQLY KALEHQYQMGLEALNENLPEINIDLTYKQGRLQFRPPFEEIRAKYYREMKRFIGIPNQ FKGVGEARSINSIFSIMIDRNASGFLTIFSKAEHLFRRLSAVLHQHKEWIVIGQVDME ALVEKHLFTVHD EKNFKALKIKGKEVERLPSAVKVDCLNINCNPVKTVIDDLIQKLF DLLVLSLKKSIQAHLHEIDTFVTEAMEVLTIMPQSVEEIGDA LQYSKLQERKPEILP LFQEAEDK-VJRLLRTVAGGGLETISNLKAK5_KFELMMESHQLMIKDQIEVMKGNVKSR LQIYYQELEKFKAR DQLKPGDDVIETGQHNTLDKSAKLIKEPCKIEFDDLEVTRKKLV DDCHHFRLEEPNFSLASSISKDIESCAQIWAFYEEFQQGFQEMA ED ITFRTKTYLF EEFLMN HDRLRKVEEHSVMTVKLQSEVDKYKIVIPILKYVRGEHLSPDHWLDLFRLL GLPRGTSLEKLLFGDLLRVADTIVAKAADLKDLNSRAQGEVTIREALRELDLWGVGAV FTLIDYEDSQSRTMKLIKD KDIVNQVGDNRCLLQSLKDSPYYKGFEDKVSI ERPLA ELDEYLQNLNHIQRKVYLEPIFGRGALPKEQTRFNRVDEDFRSIMTDIKKDNRVTTL TTHAGIRNSLLTILDQLQRCQRSLNEFLEEKRSAFPRFYFIGDDDLLEILGQSTNPSV IQSHLKKLFAGINSVCFDEKSKHITAMKSLEGEVVPFKNKVPLSNNVET LNDLALEM KKTLEQLLKECVTTGRSSQGAVDPSLFPSQILCLAEQIKFTEDVENAIKDHSLHQIET QLV KLEQYTNIDTSSEDPGNTESGILELKLKALILDIIHNIDWKQLNQIQVHTTED AWKKQLRFYMKSDHTCCVQMVDSEFQYTYEYQGNASKLVYTPLTDKCYLTLTQAMKM GLGGNPYGPAGTGKTESVKALGGLLGRQVLVFNCDEGIDVKSMGRIFVGLVKCGAWGC FDEFNRLEESVLSAVSMQIQTIQDALKNHRTVCELLGKEVEVNSNSGIFITMNPAGKG YGGRQKLPDNLKQLFRPVAMSHPDNELIAEVILYSEGFKDAKVLSRKLVAIFNLSREL LTPQQHYD GLRALKTVLRGSGNLLRQLNKSGTTQNANESHIWQALRLNTMSKFTFT DCTRFDALIKDVFPGIELKEVEYDELSAALKQVFEEANYEIIPNQIKKALELYEQLCQ RMGVVIVGPSGAGKSTL RMLRAALCKTGKVVKQYTMNPKAMPRYQLLGHIDMDTREW SDGVLT SARQWREPQDVSS IICDGDIDPE IESLNSVLDDNRLLTMPSGERIQFG P VNFVFETHDLSCASPATISRMGMIFLSDEETDLNSLIKS LRNQPAEYRNNLEN I GDYFEKALQ VLKQNDYWETSLVGTVMNGLSHLHGCRDHDEFIINLIRGLGGNLNMK SRLEFTKEVFHARESPPDFHKPMDTYYDSTRGRLATYVLKKPEDLTADDFSNGLTLP VIQTPDMQRGLDYFKP LSSDTKQPFILVGPEGCGKGMLLRYAFSQLRSTQIATVHCS AQTTSRHLLQKLSQTCMVISTNTGRVYRPKDCERLVLYLKDINLPKLDKWGTSTLVAF LQQVLTYQGFYDENLEWVGLENIQIVASMSAGGRLGRHKLTTRFTSIVRLCSIDYPER EQLQTIYGAYLEPVLHINLKNHSIWGSSSKIYLLAGSMVQVYEQVDMHQVRAKFTVDD YSHYFFTPCILTQ VLGLFRYDLEGGSSNHPLDYVLEIVAYEARRLFRDKIVGAKELH
LFDIILTSVFQGD GSDILDNMSDSFYVT GARHNSGARAAPGQPLPPHGKPLGKLNS TDLKDVIKKGLIHYGRDNQNLDILLFHEVLEYMSRIDRVLSFPGGSLLLAGRSGVGRR TITSLVSHMHGAVLFSPKISRGYELKQFKNDLKHVLQLAGIEAQQWLLLEDYQFVHP TFLEMINSLLSSGEVPGLYTLEELEPLLLPLKDQASQDGFFGPVFNYFTYRIQQNLHI VLIMDSA SNFMINCESNPALHKKCQVLWMEG SNSSMKKIPEMLFSETGGGEKYNDK KRKEEKKK-VISVDPDFLKSFLLIHESCKAYGATPSRYMTFLHVYSAISSSKKKELLKRQ SHLQAGVSKLNEAKALVDELNRKAGEQSVLLKTKQDEADAALQMITVSMQDASEQKTE LERLKHRIAEEWKIEERKNKIDDELKEVQPLVNEAKLAVGNIKPESLSEIRSLRMPP DVIRDILEGVLRLMGIFDTSWVSMKSFLAKRGVREDIATFDARNISKEIRESVEELLF KNKGSFDPKNAKRASTAAAPLAA VKANIQYSHVLERIHPLETEQAGLESNLKKTEDR lOiKLEELLNSVGQKVSELKEKFQSRTSEAAKLEAEVSKAQETIKAAEVLINQLDREHK RVrøAQVVEITEEIiATLPKRAQLAAAFITYLSAAPESLRKTCLEE TKSAGLEKFDLRR FLCTESEQLI KSEGLPSDDLSIENALVILQSRVCPFLIDPSSQATE LKTHLKDSRL EVINQQDSNFITALELAVRFGKTLIIQEMDGVEPVLYPLLRRDLVAQGPRYWQIGDK IIDYNEEFRLFLSTRNPNPFIPPDAASIVTEVNFTTTRSGLRGQLLALTIQHEKPDLE EQKTKLLQQEEDKKIQLAKLEESLLETLATSQGNILENKDLIESLNQTKASSALIQES LKESYILQISLDQERDAYLPLAESASKMYFIISDLSKI NMYRFSLAAFLRLFQRALQ NKQDSENTEQRIQSLISSLQHMVYEYICRCLFKADQLMFALHFVRGMHPELFQENE D TFTGWVGDMLRKADSQQKIRDQLPS IDQERS AVATLKIALPSLYQTLCFEDAAL RTYYNNSMCEQEFPSILAKKVSLFQQILWQALRPDRLQSAMALFACKTLGLKEVSPL PLNLKRLYKETLEIEPILIIISPGADPSQELQELANAERSGECYHQVAMGQGQADLAI QMLKE(^RNGD LCLKNLHLVVSWLPVLEKEL TLQPKDTFRL LTAEVHPNFTPILL QSSLKITYESPPGLEKNLMRTYES TPEQISKKDNTHRAHALFSLAWFHAACQERRNY IPQGWTKFYEFSLSDLRAGYNIIDRLFDGAKDVQWEFVHGLLENAIYGGRIDNYFDLR VLQSYLKQFFNSSVIDVFNQRNKKSIFPYSVSLPQSCSILDYRAVIEKIPEDDKPSFF GLPANIARSSQRMISSQVISQLRILGRSITAGSKFDREI SNELSPVLNL KKLNQNS NLIHQKVPPPNDRQGSPILSFIILEQFNAIRLVQSVHQSLAALSKVIRGTTLLSSEVQ KLASALLNQKCPLAWQSK EGPEDPLQYLRGLVARAIJAIQN VDKAEKQALLSETLDL SELFHPDTFLNALRQETARAVGRSVDSLKFVASWKGRLQEAKLQIKISGLLLEGCSFD GNQLSENQLDSPSVSSVLPCFMG IPQDACGPYSPDECISLPVYTSAERDRWTNIDV PCGGNQDQ IQCGAALFLKNQ
Further analysis of the NOV29a protein yielded the following properties shown in Table 29B.
Table 29B. Protein Sequence Properties NOV29a
PSort 0.6000 probability located in nucleus; 0.3600 probability located in analysis: mitochondrial matrix space; 0.3249 probability located in microbody (peroxisome); 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV29a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 29C.
In a BLAST search of public sequence datbases, the NOV29a protein was found to have homology to the proteins shown in the BLASTP data in Table 29D.
PFam analysis predicts that the NOV29a protein contains the domains shown in the Table 29E.
Example 30.
The NOV30 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 30A.

GCCGAGGGACAGGAGGATGAGGGGGCGCAGCAGCTGCTGACCCTGCAGAACCAGGTGG CGCGGCTGGAGGAGGAGAACCGAGACTTTCTGGCTGCGCTGGAGGACGCCATGGAGCA GTACAAACTGCAGAGCGACCGGCTGCGTGAGCAGCAGGAGGAGATGGTGGAACTGCGG CTGCGGTTAGAGCTGGTGCGGCCAGGCTGGGGGGGCCCGCGGCTCCTGAATGGCCTGC CTCCCGGGTCCTTTGTGCCTCGACCTCATACAGCCCCCCTGGGGGGTGCCCACGCCCA TGTGCTGGGCATGGTGCCGCCTGCCTGCCTCCCTGGAGATGAAGTTGGCTCTGAGCAG AGGGGAGAGGTGACAAATGGCAGGGAGGCTGGAGCTGAGTTGCTGACTGAGGTGAACA GGCTGGGAAGTGGCTCTTCAGCTGCTTCAGAGGAGGAAGAGGAGGAGGAGGAGCCGCC CAGGCGGACCTTACACCTGCGCAGTTGGGGCAGCAACCTTGACAGGCTGCCTGTTGCA GCAGTTGGTGGGAGCAAGGCCCGAGTTCAGGCCCGCCAGGTCCCCCCTGCCACAGCCT CAGAGTGGCGGCTGGCCCAGGCCCAGCAGAAGATCCGGGAGCTGGCTATCAACATCCG CATGAAGGAGGAGCTTATTGGCGAGCTGGTCCGCACAGGAAAGGCAGCTCAGGCCCTG AACCGCCAGCACAGCCAGCGTATCCGGGAGCTGGAGCAGGAGGCAGAGCAGGTGCGGG CCGAGCTGAGTGAAGGCCAGAGGCAGCTGCGGGAGCTCGAGGGCAAGGAGCTCCAGGA TGCTGGCGAGCGGTCTCGGCTCCAGGAGTTCCGCAGGAGGGTCGCTGCGGCCCAGAGC CAGGTGCAGGTGCTGAAGGAGAAGAAGCAGGCTACGGAGCGGCTGGTGTCACTGTCGG CCCAGAGTGAGAAGCGACTGCAGGAGCTCGAGCGGAACGTGCAGCTCATGCGGCAGCA GCAGGGACAGCTGCAGAGGCGGCTTCGCGAGGAGACGGAGCAGAAGCGGCGCCTGGAG GCAGAAATGAGCAAGCGGCAGCACCGCGTCAAGGAGCTGGAGCTGAAGCATGAGCAAC AGCAGAAGATCCTGAAGATTAAGACGGAAGAGATCGCGGCATTCCAGAGGAAGAGGCG CAGTGGCAGCAACGGCTCTGTGGTCAGCCTGGAACAGCAGCAGGTGGGGCCAGGCTGT GTCCGCACCCAGGGCTCCCCTGGGGGCTGGCTGGTGGGTGCACCTTTCTCCCCAGTGA ACCTCGAGTGGCGGCTGACACAGCCAGAGAAGATTGAGGAGCAGAAGAAGTGGCTGGA CCAGGAGATGGAGAAGGTGCTACAGCAGCGGCGGGCGCTGGAGGAGCTGGGGGAGGAG CTCCACAAGCGGGAGGCCATCCTGGCCAAGAAGGAGGCCCTGATGCAGGAGAAGACGG GGCTGGAGAGCAAGCGCCTGAGATCCAGCCAGGCCCTCAACGAGGACATCGTGCGAGT GTCCAGCCGGCTGGAGCACCTGGAGAAGGAGCTGTCCGAGAAGAGCGGGCAGCTGCGG CAGGGCAGCGCCCAGAGCCAGCAGCAGATCCGCGGGGAGATCGACAGCCTGCGCCAGG AGAAGGACTCGCTGCTCAAGCAGCGCCTGGAGATCGACGGCAAGCTGAGGCAGGGGAG TCTGCTGTCCCCCGAGGAGGAGCGGACGCTGTTCCAGTTGGATGAGGCCATCGAGGCC CTGGATGCTGCCATTGAGTATAAGAATGAGGCCATCACATGCCGCCAGCGGGTGCTTC GGGCCTCAGCCTCGTTGCTGTCCCAGTGCGAGATGAACCTCATGGCCAAGCTCAGCTA CCTCTCATCCTCAGAGACCAGAGCCCTCCTCTGCAAGTATTTTGACAAGGTGGTGACG CTCCGAGAGGAGCAGCACCAGCAGCAGATTGCCTTCTCGGAACTGGAGATGCAGCTGG AGGAGCAGCAGAGGCTGGTGTACTGGCTGGAGGTGGCCCTGGAGCGGCAGCGCCTGGA GATGGACCGCCAGCTGACCCTGCAGCAGAAGGAGCACGAGCAGAACATGCAGCTGCTC CTGCAGCAGAGTCGAGACCACCTCGGTGAAGGGTTAGCAGACAGCAGGAGGCAGTATG AGGCCCGGATTCAAGCTCTGGAGAAGGAACTGGGCCGTTACATGTGGATAAACCAGGA ACTGAAACAGAAGCTCGGCGGTGTGAACGCTGTAGGCCACAGCAGGGGTGGGGAGAAG AGGAGCCTGTGCTCGGAGGGCAGACAGGCTCCTGGAAATGAAGATGAGCTCCACCTGG CACCCGAGCTTCTCTGGCTGTCCCCCCTCACTGAGGGGGCCCCCCGCACCCGGGAGGA GACGCGGGACTTGGTCCACGCTCCGTTACCCTTGACCTGGAAACGCTCGAGCCTGTGT GGGGACTCTTCAACAACACCAATATCAGGACCAGGATCAGAGGACCTCGAGGAACCAC ATGCACAAGGATTATTCCATACCACTTGTAATTAACACTTATTAAGGAGACAGGCAGC
TTCTCACTTAACAAGATCACAAAGATCACAGGGTCTGATAACACCAGTGCTGCTATTC
TGAAATGTGGTACCTTTGTTCTTCTTGAAGTTGTCAAGTTTATCCTCTAGACCATCCAj
CAGCTGACACAGAATGGCTTCTAGGCAACCCCCGCTTTAGTGATCTCTTTGAAGGGGA! lAAGCAATTCCTGGTTGAAAAGATTTCTTCGAACTTTGGTCACTTCTAAAAGCATCAAA
ORF Start: ATG at 63 JORF jtopTτAA at 4035
SEQ ID NO: 314 1324 aa MW at 1480663kD
NOV30a, MGLEAQRLPGAEEAPVRVALRVRPLLPKELLHGHQSCLQVEPGLGRVTLGRDRHFGFH CG155595-01 WLAEDAGQEAVYQACVQPLLEAFFEGFNATVFAYGQTGSGKTYTMGEASVASLLEDE Protein Sequence QGIVPRAMAEAFKLIDENDLLDCLVHVSYLEVYKEEFRDLLEVGTASRDIQLREDERG NWLCGVKEVDVEGLDEVLSLLEMGNAARHTGATHLNHLSSRSHTVFTVTLEQRGRAP SRLPRPAPGQLLVSKFHFVDLAGSERVLKTGSTGERLKESIQINSSLLALGNVISALG DPQRRGSHIPYRDSKITRILKDSLGGNAKTVMIACVSPSSSDFDETLNTLNYASRAQN IRNRATVNWRPEAERPPEETASGARGPPRHRSETRIIHRGRRAPGPATASAAAAMRLG AECARYRACTDAAYSLLRELQAEPGLPGAAARKVRD LCAVEGERSALSSASGPDSGI ESASVEDQAAQGAGGRKVAEGQEDEGAQQLLTLQNQVARLEEENRDFLAALEDAMEQY
KLQSDRLREQQEEMVELRLRLELVRPG GGPRLLNGLPPGSFVPRPHTAPLGGAHAHV LGMVPPACLPGDEVGSEQRGEVTNGREAGAELLTEV RLGSGSSAASEEEEEEEEPPR RTLHLRS GSNLDRLPVAAVGGSKARVQARQVPPATASE RLAQAQQKIRELAINIRM KEELIGELVRTGKAAQALNRQHSQRIRELEQEAEQVRAELSEGQRQLRELEGKELQDA GERSRLQEFRRRVAAAQSQVQVLKEKKQATERLVSLSAQSEKRLQELER VQLMRQQQ GQLQRRLREETEQKRRLEAEMSKRQHRVKELELKHEQQQKILKIKTEEIAAFQRKRRS GSNGSWSLEQQQVGPGCVRTQGSPGGWLVGAPFSPVNLE RLTQPEKIEEQKK LDQ EMEKVLQQRRALEELGEELHKREAILAKKEALMQEKTGLESKRLRSSQALNEDIVRVS SRLEHLEKELSEKSGQLRQGSAQSQQQIRGEIDSLRQEKDSLLKQRLEIDGKLRQGSL LSPEEERTLFQLDEAIEALDAAIEYKNEAITCRQRVLRASASLLSQCEM LMAKLSYL SSSETRALLCKYFDKWTLREEQHQQQIAFSELEMQLEEQQRLVYWLEVALERQRLEM DRQLTLQQKEHEQNMQLLLQQSRDHLGEGLADSRRQYEARIQALEKELGRYMWINQEL KQKLGGVAVGHSRGGEKRSLCSEGRQAPGNEDELHLAPELL LSPLTEGAPRTREET RDLVHAPLPLT KRSSLCGDSSTTPISGPGSEDLEEPHAQGLFHTTCN
Further analysis of the NOV30a protein yielded the following properties shown in Table 30B.
Table 30B. Protein Sequence Properties NOV30a
PSort 0.8800 probability located in nucleus; 0.3000 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV30a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 30C.
In a BLAST search of public sequence datbases, the NOV30a protein was found to have homology to the proteins shown in the BLASTP data in Table 30D.
PFam analysis predicts that the NOV30a protein contains the domains shown in the Table 30E.
The NOV31 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 31 A.
Table 31A. NOV31 Sequence Analysis
SEQ ID NO: 315 5460 bp
NOV31a, ATGTCGGGAGCCTCAGTGAAGGTGGCTGTCCGGGTAAGGCCCTTCAATTCTCGAGAGA CGI 55962-01 CCAGCAAGGAATCCAAATGCATCATTCAGATGCAAGGCAACTCGACCAGTATTATTAA
CCCAAAGAATCCAAAGGAAGCTCCAAAGTCCTTCAGCTTCGACTATTCCTACTGGTCT DNA Sequence CATACCTCACCCGAAGATCCCTGTTTTGCATCTCAAAACCGTGTGTACAATGACATTG
GCAAGGAAATGCTCTTACACGCCTTTGAGGGATATAATGTCTGTATTTTTGCCTATGG
GCAGACTGGTGCTGGAAAATCTTATACAATGATGGGTAAACAAGAAGAAAGCCAGGCT
GGCATCATTCCACAGTTATGTGAAGAACTTTTTGAGAAAATCAATGACAACTGTAATG
AAGAAATGTCTTACTCTGTAGAGGTGAGTTACATGGAAATTTACTGTGAAAGAGTACG
AGATTTGCTGAATCCAAAAAACAAGGGTAATTTGCGTGTGCGTGAACACCCACTTCTT
GGACCCTATGTGGAGGATCTGTCCAAGTTGGCAGTTACTTCCTACACAGACATTGCTG
ACCTCATGGATGCTGGGAACAAAGCCAGGACAGTGGCAGCTACAAACATGAATGAAAC
AAGTAGCCGTTCCCACGCTGTGTTTACGATTGTTTTCACCCAGAAGAAACACGATAAT
GAGACCAACCTTTCCACTGAGAAGGTAGTCAGTAAAATCAGCTTGGTGGATCTAGCAG
GAAGTGAACGAGCTGATTCAACTGGTGCCAAAGGGACTCGATTAAAGGAAGGAGCAAA
TATTAATAAGTCTCTTACAACTTTGGGCAAAGTCATTTCAGCCTTGGCCGAGGTGAGT
AAAAAGAAGAAGAAAACAGATTTTATTCCCTACAGGGATTCTGTACTTACTTGGCTCC
TTCGAGAAAATTTAGGTGGCAATTCTCGGACTGCAATGGTTGCTGCTCTGAGCCCCGC
GGATATCAACTACGATGAGACTTTGAGCACTCTGAGGTACGCAGATCGTGCAAAACAA
ATTAAATGCAATGCTGTTATCAATGAGGACCCCAATGCCAAACTGGTTCGTGAATTAA
AGGAGGAGGTGACACGGCTGAAGGACCTTCTTCGTGCTCAGGGCCTGGGAGATATTAT
TGATGTTGATCCATTGATCGATGATTACTCTGGAAGTGGAAGCAAACTGAAAGATTTT
CAGAACAATAAGCATAGATACTTGCTAGCCTCTGAGAATCAACGCCCTGGCCATTTTT
CCACAGCATCCATGGGGTCCCTCACTTCATCCCCATCTTCCTGCTCACTCAGTAGTCA
GGTGGGCTTGACGTCTGTGACCAGTATTCAAGAGAGGATCATGTCTACACCTGGAGGA
GAGGAAGCTATTGAACGTTTAAAGGAATCAGAGAAGATCATTGCTGAGTTGAATGAAA
CTTGGGAAGAGAAGCTTCGTAAAACAGAGGCCATCAGAATGGAGAGGGAGGCTTTGTT
GGCTGAGATGGGAGTTGCCATTCGGGAAGATGGAGGAACCCTAGGGGTTTTCTCACCT
AAAAAGACCCCACATCTTGTTAACCTCAATGAAGACCCACTAATGTCTGAGTGCCTAC
TTTATTACATCAAAGATGGAATTACAAGGGTTGGCCAAGCAGATGCTGAGCGGCGCCA
GGACATAGTGCTGAGCGGGGCTCACATTAAAGAAGAGCATTGTATCTTCCGGAGTGAG
AGAAGCAACAGCGGGGAAGTTATCGTGACCTTAGAGCCCTGTGAGCGCTCAGAAACCT
ACGTAAATGGCAAGAGGGTGTCCCAGCCTGTTCAGCTGCGCTCAGGTAACCGTATCAT
CATGGGTAAAAACCATGTTTTCCGCTTTAACCACCCGGAACAAGCACGAGCTGAGCGA
GAGAAGACTCCTTCTGCTGAGACCCCCTCTGAGCCTGTGGACTGGACATTTGCCCAGA
GGGAGCTTCTGGAAAAACAAGGAATTGATATGAAACAAGAGATGGAGAAAAGGCTACA
GGAAATGGAGATCTTATACAAAAAGGAGAAGGAAGAAGCAGATCTTCTTTTGGAGCAG
CAGAGACTGGACTATGAGAGTAAATTGCAGGCCTTGCAGAAGCAGGTTGAAACCCGAT
CTCTGGCTGCAGAAACAACTGAAGAGGAGGAAGAAGAGGAAGAAGTTCCTTGGACACA
GCATGAATTTGAGTTGGCCCAATGGGCCTTCCGGAAATGGAAGTCTCATCAGTTTACT
TCATTACGGGACTTACTCTGGGGCAATGCCGTGTACCTAAAGGAGGCCAATGCCATCA
GTGTGGAACTGAAAAAGAAGGTACAGTTTCAGTTTGTTCTGCTGACTGACACACTGTA
CTCCCCTTTGCCTCCTGAATTACTTCCCACTGAGATGGAAAAAACTCATGAGGACAGG
CCTTTCCCTCGCACAGTGGTAGCAGTAGAAGTCCAGGATTTGAAGAATGGAGCAACAC
ACTATTGGTCTTTGGAGAAACTCAAGCAGAGGCTGGATTTGATGCGAGAGATGTATGA
TAGGGCAGGGGAGATGGCCTCCAGTGCCCAAGACGAAAGCGAAACCACTGTGACTGGC
AGCGATCCCTTCTATGATCGGTTCCACTGGTTCAAACTTGTGGGGAGCTCCCCCATTT
TCCACGGCTGTGTGAACGAGCGCCTTGCCGACCGCACACCCTCCCCCACTTTTTCCAC
GGCCGATTCCGACATCACTGAGCTGGCTGACGAGCAGCAAGATGAGATGGAGGATTTT
:GATGATGAGGCATTCGTGGATGACGCCGGCTCTGACGCAGGGACGGAGGAGGGATCAG
ATCTCTTCAGTGACGGGCATGACCCGTTTTACGACCGATCCCCTTGGTTCATTTTAGT
GGGAAGGGCATTTGTTTACCTGAGCAATCTGCTGTATCCCGTGCCCCTGATCCACAGG

SLRDLL GNAVYLKEANAISVELKKKVQFQFVLLTDTLYSPLPPELLPTEMEKTHEDR PFPRTWAVEVQDLKNGATHY SLEKLKQRLDLMREMYDRAGEMASSAQDESETTVTG SDPFYDRFH FKLVGSSPIFHGCVNERLADRTPSPTFSTADSDITELADEQQDEMEDF DDEAFVDDAGSDAGTEEGSDLFSDGHDPFYDRSP FILVGRAFVYLSNLLYPVPLIHR VAIVSEKGEVRGFLRVAVQAIADEEAPDYGSGIRQSGTAKISFDNEYFNQSDFSSVAM TRSGLSLEELRIVEGQGQSSEVITPPEEISRINDLLDLKSSTLLDGKMVMEGFSEΞIG NHLKLGSAFTFRVTVLQASGILPEYADIFCQFSFLHRHDEAFSTEPLKNNGRGSPLAF YHVQNIAVEITESFVDYIKTKPIVFEVFGHYQQHPLHLQGQELNSPPQPCRRFFPPPM PLSKPVPATKLNTMSKTSLGQSMSKYDLLV FEISELEPTGEYIPAWDHTAGLPCQG TFLLHQGIQRRITVTIIHEKGSELH KDVRELWGGRIRNKPEVDEAAVDAILSLNII SAKYLKSSHNSSRTFYRFEAVWDSSLHNSLLLNRVTPYGEKIYMTLSAYLELDHCIQP AVITKDVCMVFYSRDAKISPPRSLRSLFGSGYSKSPDSNRV GIYELSLCKMSDTGSP GKMQRRRRKILDTSVAYVRGEENLAGWRPRGDSLILEHQWELEKLEKTRHFLLLRERL GDSIPKSLSDSLSPSLSSGTLSTSTSISSQISTTTFESAITPSESSGYDSGDIESLVD REKELATKCLQLLTHTFNREFSQVHGSVSDCKVSDISPIGRDPSESSFSSATLTPSST CPSLVDSRSNSLDQKTPEA SRASSPCPEFEQFQIVPAVETPYLARAGKNEFLNLVPD IEEIRSWSKXGYLHFKEPLYSN AKHFVWRRPYVFIY SDKDPVERGIINLSTAQV EYSEDQQAMVKTPNTFAVCTKHRGVLLQALNDKDMNDWLYAFNPLLAGTIRRSKLSRR CPSQSKY
Further analysis of the NO V31 a protein yielded the following properties shown in Table 31B.
Table 31B. Protein Sequence Properties NOV31a
PSort 0.5985 probability located in mitochondrial matrix space; 0.4900 probability analysis: located in nucleus; 0.3052 probability located in mitochondrial inner membrane; 0.3052 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NO V31 a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 31 C.
In a BLAST search of public sequence datbases, the NOV31a protein was found to have homology to the proteins shown in the BLASTP data in Table 3 ID.
PFam analysis predicts that the NOV3 la protein contains the domains shown in the Table 3 IE.
Table 31E. Domain Analysis of NOV31a
Identities/
Pfam Domain NOV31a Match Region Similarities Expect Value for the Matched Region
Example 32.
The NOV32 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 32A.
Table 32A. NOV32 Sequence Analysis
SEQ ID NO: 317 3120 bp
NOV32a, GGAGGCCCGAGCGGCGCCCACCTGAGCCCCCGCGCTGGCGCCATGGCGGAGCAGGAGA CG157477-01 GCCTGGAATTCGGCAAGGCAGACTTCGTGCTGATGGACACCGTCTCCATGCCCGAGTT DNA Sequence CATGGCCAACCTCAGGCTCAGATTTGAAAAAGGGCGCATCTATACGTTCATTGGAGAA GTCGTCGTTTCTGTGAACCCTTACAAGTTGTTGAACATCTATGGAAGAGACACAATTG AGCAGTATAAAGGCCGTGAGCTGTATGAGAGACCGCCTCACCTTTTTGCTATTGCGGA TGCTGCTTACAAGGCTATGAAGAGGCGATCAAAAGACACTTGTATTGTGATATCAGGG GAAAGTGGAGCTGGTAAAACGGAAGCCAGTAAGTACATTATGCAGTATATTGCGGCCA TCACCAACCCCAGTCAGAGAGCAGAGGTTGAAAGAGTGAAGAATATGTTGCTTAAGTC CAACTGTGTTTTGGAAGCTTTTGGAAATGCCAAAACCAACCGTAATGACAACTCAAGC AGGTTTGGAAAATACATGGATATCAACTTTGACTTCAAGGGTGACCCTATTGGTGGGC ATATCAATAACTACTTACTAGAAAAGTCTCGAGTGATTGTGCAACAGCCAGGAGAAAG AAGCTTTCATTCTTTCTATCAGCTACTCCAAGGAGGTTCAGAACAAATGCTACGCTCT CTACATCTCCAGAAATCCCTTTCATCCTACAACTATATTCATGTGGGAGCTCAATTAA AGTCTTCTATCAATGATGCTGCCGAATTCAGAGTTGTTGCTGATGCCATGAAAGTCAT TGGCTTCAAACCTGAGGAGATCCAAACAGTGTATAAGATTTTGGCTGCTATTCTGCAC TTGGGAAATTTAAAATTTGTAGTAGATGGTGACACGCCTCTTATTGAGAATGGCAAAG TAGTATCTATCATAGCAGAATTGCTCTCTACTAAGACAGATATGGTTGAGAAAGCCCT TCTTTACCGGACTGTGGCCACAGGCCGTGACATCATTGACAAGCAGCACACAGAACAA GAGGCCAGCTACGGCAGAGACGCCTTTGCCAAGGCAATATATGAGCGCCTTTTTTGTT GGATCGTTACTCGCATCAATGATATTATTGAGGTCAAGAACTATGACACCACAATCCA TGGGAAGAACACTGTTATTGGTGTCTTGGATATCTATGGCTTTGAAATCTTTGACAAC AACAGTTTTGAACAATTCTGTATCAATTACTGCAATGAGAAACTGCAGCAGCTATTTA TTCAGCTGGTTCTGAAGCAAGAACAAGAGGAATACCAGCGGGAAGGGATCCCCTGGAA ACATATTGACTACTTCAACAATCAGATCATTGTTGACCTCGTGGAGCAACAGCACAAA GGGATCATTGCAATCCTTGATGATGCTTGCATGAATGTCGGCAAAGTCACCGATGAAA TGTTTCTTGAAGCACTTAACAGTAAATTGGGCAAACACGCCCATTTTTCCAGCCGAAA GCTCTGTGCCTCAGACAAAATTCTGGAGTTTGATCGAGATTTTCGAATTCGACATTAT GCAGGCGATGTAGTCTATTCTGTCATTGGTTTTATTGACAAAAATAAAGATACTTTAT TTCAAGATTTCAAGCGCCTTATGTATAACAGTTCAAATCCTGTGCTCAAGAATATGTG GCCTGAAGGCAAACTGAGCATTACAGAGGTGACCAAGCGACCTCTGACTGCTGCTACC TTGTTTAAGAATTCTATGATTGCTCTAGTAGACAACCTTGCATCAAAGGAACCATATT ACGTTCGTTGCATCAAACCCAATGACAAGAAATCTCCACAGATATTTGATGATGAACG CTGCCGGCACCAAGTAGAATATCTTGGACTACTGGAAAATGTGAGAGTGCGTCGGGCA GGATTTGCCTTCCGCCAGACATACGAGAAGTTTCTTCACAGGTATAAGATGATCTCTG AATTCACCTGGCCCAACCATGACCTTCCTTCAGACAAAGAGGCTGTCAAGAAACTAAT TGAACGGTGTGGTTTTCAGGATGATGTAGCTTATGGGAAGACCAAAATTTTCATTCGA ACACCCCGAACATTGTTTACCTTGGAAGAACTCCGTGCCCAGATGCTCATAAGGATTG TCCTCTTTCTACAAAAGGTGTGGCGGGGCACCCTGGCCCGCATGCGGTACAAAAGAAC CAAGGCAGCTCTGACAATAATCAGGTACTACCGGCGCTACAAAGTGAAGTCGTACATC CACGAGGTGGCCAGACGCTTCCATGGCGTCAAGACCATGCGAGACTACGGGAAGCACG TGAAGTGGCCAAGCCCTCCTAAAGTTCTTCGCCGTTTTGAGGAGGCCCTGCAGACGAT

Further analysis of the NOV32a protein yielded the following properties shown in Table 32B.
Table 32B. Protein Sequence Properties NO 32a
PSort 0.7600 probability located in nucleus; 0.3760 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV32a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 32C.
Table 32C. Geneseq Results for NOV32a
Geneseq Protein/Organism/Length NOV32a Identities/ Expect Identifier [Patent #, Date] Resi ues Similarities for Value
In a BLAST search of public sequence datbases, the NOV32a protein was found to have homology to the proteins shown in the BLASTP data in Table 32D.
PFam analysis predicts that the NOV32a protein contains the domains shown in the Table 32E.
Example 33.
The NOV33 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 33 A.
Table 33A. NO 33 Sequence Analysis SEQ ID NO: 319 |3921 bp
NOV33a, CAGAAGTTGCGCGCAGGCCGGCGGGCGGGAGCGGACACCGAGGCCGGCGTGCAGGCGT CG157486-01 GCGGGTGTGCGGGAGCCGGGCTCGGGGGGATCGGACCGAGAGCGAGAAGCGCGGCATG DNA Sequence GAGCTCCAGGCAGCCCGCGCCTGCTTCGCCCTGCTGTGGGGCTGTGCGCTGGCCGCGG CCGCGGCGGCGCAGGGCAAGGAAGTGGTACTGCTGGACTTTGCTGCAGCTGGAGGGGA GCTCGGCTGGCTCACACACCCGTATGGCAAAGGGTGGGACCTGATGCAGAACATCATG AATGACATGCCGATCTACATGTACTCCGTGTGCAACGTGATGTCTGGCGACCAGGACA ACTGGCTCCGCACCAACTGGGTGTACCGAGGAGAGGCTGAGCGTATCTTCATTGAGCT CAAGTTTACTGTACGTGACTGCAACAGCTTCCCTGGTGGCGCCAGCTCCTGCAAGGAG ACTTTCAACCTCTACTATGCCGAGTCGGACCTGGACTACGGCACCAACTTCCAGAAGC GCCTGTTCACCAAGATTGACACCATTGCGCCCGATGAGATCACCGTCAGCAGCGACTT CGAGGCACGCCACGTGAAGCTGAACGTGGAGGAGCGCTCCGTGGGGCCGCTCACCCGC AAAGGCTTCTACCTGGCCTTCCAGGATATCGGTGCCTGTGTGGCGCTGCTCTCCGTCC GTGTCTACTACAAGAAGTGCCCCGAGCTGCTGCAGGGCCTGGCCCACTTCCCTGAGAC CATCGCCGGCTCTGATGCACCTTCCCTGGCCACTGTGGCCGGCACCTGTGTGGACCAT GCCGTGGTGCCACCGGGGGGTGAAGAGCCCCGTATGCACTGTGCAGTGGATGGCGAGT GGCTGGTGCCCATTGGGCAGTGCCTGTGCCAGGCAGGCTACGAGAAGGTGGAGGATGC CTGCCAGGCCTGCTCGCCTGGATTTTTTAAGTTTGAGGCATCTGAGAGCCCCTGCTTG GAGTGCCCTGAGCACACGCTGCCATCCCCTGAGGGTGCCACCTCCTGCGAGTGTGAGG AAGGCTTCTTCCGGGCACCTCAGGACCCAGCGTCGATGCCTTGCACACGACCCCCCTC CGCCCCACACTACCTCACAGCCGTGGGCATGGGTGCCAAGGTGGAGCTGCGCTGGACG CCCCCTCAGGACAGCGGGGGCCGCGAGGACATTGTCTACAGCGTCACCTGCGAACAGT GCTGGCCCGAGTCTGGGGAATGCGGGCCGTGTGAGGCCAGTGTGCGCTACTCGGAGCC TCCTCACGGACTGACCCGCACCAGTGTGACAGTGAGCGACCTGGAGCCCCACATGAAC TACACCTTCACCGTGGAGGCCCGCAATGGCGTCTCAGGCCTGGTAACCAGCCGCAGCT TCCGTACTGCCAGTGTCAGCATCAACCAGACAGAGCCCCCCAAGGTGAGGCTGGAGGG CCGCAGCACCACCTCGCTTAGCGTCTCCTGGAGCATCCCCCCGCCGCAGCAGAGCCGA GTGTGGAAGTACGAGGTCACTTACCGCAAGAAGGGAGACTCCAACAGCTACAATGTGC GCCGCACCGAGGGTTTCTCCGTGACCCTGGACGACCTGGCCCCAGACACCACCTACCT GGTCCAGGTGCAGGCACTGACGCAGGAGGGCCAGGGGGCCGGCAGCAAGGTGCACGAA TTCCAGACGCTGTCCCCGGAGGGATCTGGCAACTTGGCGGTGATTGGCGGCGTGGCTG TCGGTGTGGTCCTGCTTCTGGTGCTGGCAGGAGTTGGCTTCTTTATCCACCGCAGGAG GAAGAACCAGCGTGCCCGCCAGTCCCCGGAGGACGTTTACTTCTCCAAGTCAGAACAA CTGAAGCCCCTGAAGACATACGTGGACCCCCACACATATGAGGACCCCAACCAGGCTG TGTTGAAGTTCACTACCGAGATCCATCCATCCTGTGTCACTCGGCAGAAGGTGATCGG
AGCAGGAGAGTTTGGGGAGGTGTACAAGGGCATGCTGAAGACATCCTCGGGGAAGAAG GAGGTGCCGGTGGCCATCAAGACGCTGAAAGCCGGCTACACAGAGAAGCAGCGAGTGG ACTTCCTCGGCGAGGCCGGCATCATGGGCCAGTTCAGCCACCACAACATCATCCGCCT AGAGGGCGTCATCTCCAAATACAAGCCCATGATGATCATCACTGAGTACATGGAGAAT GGGGCCCTGGACAAGTTCCTTCGGGAGAAGGATGGCGAGTTCAGCGTGCTGCAGCTGG TGGGCATGCTGCGGGGCATCGCAGCTGGCATGAAGTACCTGGCCAACATGAACTATGT GCACCGTGACCTGGCTGCCCGCAACATCCTCGTCAACAGCAACCTGGTCTGCAAGGTG TCTGACTTTGGCCTGTCCCGCGTGCTGGAGGACGACCCCGAGGCCACCTACACCACCA GTGGCGGCAAGATCCCCATCCGCTGGACCGCCCCGGAGGCCATTTCCTACCGGAAGTT CACCTCTGCCAGCGACGTGTGGAGCTTTGGCATTGTCATGTGGGAGGTGATGACCTAT GGCGAGCGGCCCTACTGGGAGTTGTCCAACCACGAGGTGATGAAAGCCATCAATGATG GCTTCCGGCTCCCCACACCCATGGACTGCCCCTCCGCCATCTACCAGCTCATGATGCA GTGCTGGCAGCAGGAGCGTGCCCGCCGCCCCAAGTTCGCTGACATCGTCAGCATCCTG GACAAGCTCATTCGTGCCCCTGACTCCCTCAAGACCCTGGCTGACTTTGACCCCCGCG TGTCTATCCGGCTCCCCAGCACGAGCGGCTCGGAGGGGGTGCCCTTCCGCACGGTGTC CGAGTGGCTGGAGTCCATCAAGATGCAGCAGTATACGGAGCACTTCATGGCGGCCGGC TACACTGCCATCGAGAAGGTGGTGCAGATGACCAACGACGACATCAAGAGGATTGGGG TGCGGCTGCCCGGCCACCAGAAGCGCATCGCCTACAGCCTGCTGGGACTCAAGGACCA GGTGAACACTGTGGGGATCCCCATCTGAGCCTCGACAGGGCCTGGAGCCCCATCGGCC
AAGAATACTTGAAGAAACAGAGTGGCCTCCCTGCTGTGCCATGCTGGGCCACTGGGGA
CTTTATTTATTTCTAGTTCTTTCCTCCCCCTGCAACTTCCGCTGAGGGGTCTCGGATG
LACACCCTGGCCTGAACTGAGGAGATGACCAGGGATGCTGGGCTGGGCCCTCTTTCCCT
IGCGAGACGCACACAGCTGAGCACTTAGCAGGCACCGCCACGTCCCAGCATCCCTGGAG
CAGGAGCCCCGCCACAGCCTTCGGACAGACATATGGGATATTCCCAAGCCGACCTTCC
CTCCGCCTTCTCCCACATGAGGCCATCTCAGGAGATGGAGGGCTTGGCCCAGCGCCAA!
GTAAACAGGGTACCTCAAGCCCCATTTCCTCACACTAAGAGGGCAGACTGTGAACTTG!
ACTGGGTGAGACCCAAAGCGGTCCCTGTCCCTCTAGTGCCTTCTTTAGACCCTCGGGC
CCCATCCTCATCCCTGACTGGCCAAACCCTTGCTTTCCTGGGCCTTTGCAAGATGCTT jGGTTGTGTTGAGGTTTTTAAATATATATTTTGTACTTTGTGGAGAGAATGTGTGTGTGj iTGGCAGGGGGCCCCGCCAGGGCTGGGGACAGAGGGTGTCAAACATTCGTGAGCTGGGG
ACTCAGGGACCGGTGCTGCAGGAGTGTCCTGCCCATGCCCCAGTCGGCCCCATCTCTC
ATCCTTTTGGATAAGTTTCTATTCTGTCAGTGTTAAAGATTTTGTTTTGTTGGACATT
TTTTTCGAATCTTAATTTATTATTTTTTTTATATTTATTGTTAGAAAATGACTTATTT!
CTGCTCTGGAATAAAGTTGCAGATGATTCAAACCG
ORF Start: ATG at 114 ORF Stop: TGA at 3042
SEQ ID NO: 320 976 aa MW at l08265.3kD
NOV33a, MELQAARACFALLWGCALAAAAAAQGKEWLLDFAAAGGELGWLTHPYGKGWDLMQNI CGI 57486-01 MNDMPIYMYSVCNVMSGDQDNWLRTNWVYRGEAERIFIELKFTVRDCNSFPGGASSCK ETFNLYYAESDLDYGTNFQKRLFTKIDTIAPDEITVSSDFEARHVKLNVEERSVGPLT Protein Sequence RKGFYLAFQDIGACVALLSVRVYYK CPELLQGLAHFPETIAGSDAPSLATVAGTCVD HAWPPGGEEPRMHCAVDGE LVPIGQCLCQAGYEKVEDACQACSPGFFKFEASESPC LECPEHTLPSPEGATSCECEEGFFRAPQDPASMPCTRPPSAPHYLTAVGMGAKVELR TPPQDSGGREDIVYSVTCEQC PESGECGPCEASVRYSEPPHGLTRTSVTVSDLΞPHM NYTFTVEARNGVSGLVTSRSFRTASVSINQTEPPKVRLEGRSTTSLSVS SIPPPQQS RVWKYEVTYRKKGDSNSYNVRRTEGFSVTLDDLAPDTTYLVQVQALTQEGQGAGSKVH EFQTLSPEGSGNLAVIGGVAVGWLLLVLAGVGFFIHRRRKNQRARQSPEDVYFSKSE QLKPLKTYVDPHTYEDPNQAVLKFTTEIHPSCVTRQKVIGAGEFGEVYKGMLKTSSGK KEVPVAIKTLKAGYTEKQRVDFLGEAGIMGQFSHHNIIRLEGVISKYKPMM ITEYME NGALDKFLREKDGEFSVLQLVGMLRGIAAGMKYLAISMNYVHRDLAARNILVNSNLVCK VSDFGLSRVLEDDPEATYTTSGG IPIR TAPEAISYRKFTSASDV SFGIVMWEVMT YGERPY ELSNHEVMKAINDGFRLPTPMDCPSAIYQLMMQC QQERARRPKFADIVSI LDKLIRAPDSLKTLADFDPRVSIRLPSTSGSEGVPFRTVSE LESIKMQQYTEHFMAA GYTAIEKWQMTNDDIKRIGVRLPGHQKRIAYSLLGLKDQVNTVGIPI
Further analysis of the NOV33a protein yielded the following properties shown in Table 33B.
Table 33B. Protein Sequence Properties NO 33a
PSort 0.4600 probability located in plasma membrane; 0.1000 probability located in analysis: endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen); 0.1000 probability located in outside
SignalP Cleavage site between residues 24 and 25 analysis:
A search of the NOV33a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 33C.
In a BLAST search of public sequence datbases, the NOV33a protein was found to have homology to the proteins shown in the BLASTP data in Table 33D.
Table 33D. Public BLASTP Results for NOV33a
Protein NOV33a Identities/
Accession Protein/Organism/Length Residues/ Similarities for Expect
Number Match the Matched Value
PFam analysis predicts that the NOV33a protein contains the domains shown in the Table 33E.
Example 34.
The NOV34 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 34A.
Table 34A. NOV34 Sequence Analysis
SEQ ID NO: 321 14399 bp
NOV34a, ATGGCGAACGTGCAGGTCGCCGTGCGGGTCCGGCCGCTCAGCAAGAGGGAGACCAAAG CGI 57505-01 AAGGGGGAAGAATTATTGTGGAAGTTGATGGCAAAGTGGCAAAAATCAGGAATTTAAA DNA Sequence GGTAGACAATCGACCAGATGGCTTTGGGGACTCCCGGGAGAAGGTTATGGCATTTGGC TTTGATTACTGCTACTGGTCAGTCAACCCAGAGGATCCCCAGTATGCATCTCAAGATG TGGTATTCCAGGATTTAGGGATGGAAGTACTGTCTGGAGTTGCCAAAGGCTATAACAT ATGCCTTTTTGCTTATGGACAGACAGGCTCTGGGAAGACATATACCATGCTGGGGACC CCAGCCTCTGTTGGGTTGACACCACGGATATGTGAGGGTCTCTTCGTCAGGGAGAAAG ACTGTGCCTCACTGCCTTCCTCCTGTAGGATAAAAGTAAGTTTTCTAGAAATCTATAA TGAACGGGTGCGGGATCTGTTGAAGCAATCTGGTCAAAAAAAGTCCTATACCCTGCGG GTCAGGGAGCATCCAGAGATGGGGCCCTATGTACAAGGTTTATCTCAACATGTAGTTA CCAATTATAAGCAAGTAATCCAACTCTTGGAGGAGGGAATTGCAAACAGGATCACAGC AGCCACCCATGTTCATGAGGCCAGCAGCAGATCCCACGCCATTTTCACGATCCACTAC ACGCAGGCAATCCTGGAGAACAACCTCCCTTCTGAAATGGCTAGCAAGATCAACCTTG TGGACCTAGCAGGCAGCGAAAGAGCAGATCCCAGTTACTGTAAGGACCGCATTGCTGA AGGAGCCAATATCAACAAGTCCCTTGTGACTCTAGGAATTGTCATCTCCACCTTAGCC CAGAACTCCCAAGTTTTCAGCAGCTGCCAGAGCCTCAACAGCTCAGTCAGCAATGGTG GTGACAGTGGGATCCTTAGCTCTCCTTCTGGGACCAGCAGTGGAGGGGCACCCTCCCG AAGGCAGTCTTATATCCCATACCGAGACTCTGTGTTGACCTGGCTGCTGAAGGACAGC CTTGGAGGCAACTCTAAAACCATCATGGTTGCCAGTGTGTCTCCTGCACACACTAGCT ACAGTGAGACCATGAGCACACTGAGATATGCATCCAGTGCCAAAAACATTATCAACAA GCCACGAGTAAATGAGGATGCAAACTTAAAACTGATTAGAGAACTCAGAGAAGAGATT GAAAGACTGAAAGCCCTGCTGCTGAGCTTTGAACTGAGAAACTTCAGTTCATTGAGTG ATGAAAACCTGAAGGAGCTGGTTCTCCAAAATGAATTGAAGATAGACCAGCTGACTAA AGACTGGACCCAGAAGTGGAATGATTGGCAGGCCCTCATGGAGCATTACAGTGTGGAC ATCAACAGGAGGAGGGCTGGGGTGGTCATCGACTCCAGCCTGCCACACTTGATGGCCT TGGAGGATGATGTGCTCAGCACAGGTGTTGTGCTCTATCATCTCAAGGAAGGGACAAC AAAAATAGGAAGGATTGACTCAGACCAGGAACAGGACATTGTCCTGCAGGGTCAGTGG ATTGAGAGAGACCACTGCACTATCACCAGTGCCTGTGGTGTAGTTGTTCTACGACCTG CCCGTGGGGCCCGCTGTACAGTCAATGGCCGGGAGGTCACTGCCTCCTGCCGTCTGAC TCAAGGAGCTGTCATAACCCTGGGGAAGGCACAGAAGTTCCGATTCAACCACCCAGCA GAGGCTGCTGTCCTGCGGCAGCGAAGGCAGGTTGGAGAGGCTGCTGCTGGTCGTGGCT CGTTGGAGTGGCTGGATTTGGATGGAGATCTCGCTGCCTCCCGGCTGGGTCTCTCCCC TTTGCTTTGGAAGGAAAGGAGAGCGCTTGAAGAGCAATGTGACGAGGACCATCAGACA CCGAGGGATGGAGAGACATCCCACAGGGCCCAGATTCAGCAGCAGCAGAGCTACGTAG AGGATTTGAGGCATCAAATCCTAGCAGAAGAGATTCGAGCTGCGAAGGAACTGGAATT TGACCAAGCTTGGATTAGCCAGCAGATTAAAGAAAACCAGCAGTGTCTGCTCAGAGAA GAGACCTGGCTGGCCAGCTTGCAACAGCAGCAGCAAGAAGACCAGGTAGCAGAGAAAG AACTTGAGGCATCTGTGGCACTTGATGCTTGGCTTCAGACAGATCCTGAGATTCAGCC ATCCCCATTTGTCCAAAGTCAGAAAAGGGTGGTGCACCTGCAGCTCCTGCGGAGACAC ACTCTTCGGGCAGCAGAGCGGAATGTCCGGCGGAAAAAGGTCTCATTCCAGCTAGAGA GAATCATCAAAAAGCAGAGGCTGCTGGAGGCCCAGAAGAGACTGGAGAAGCTCACGAC ATTGTGCTGGCTCCAGGATGACAGCACCCAGGAGCCCCCATACCAGGTCCTCAGCCCT GATGCCACAGTCCCACGGCCTCCATGTAGAAGCAAATTGACGAGTTGCAGTTCTTTGA GCCCCCAAAGACTCTGCAGCAAGCACATGCCCCAGCTACACAGCATTTTCCTAAGTTG GGATCCCTCTACCACATTGCCACCTAGGCCTGACCCTACACACCAAACATCAGAGAAA ACATCATCAGAAGAGCATTTGCCACAGGCTGCTTCCTACCCTGCAAGGACAGGGTGCC TCCGCAAGAACGGCCTGCATTCCTCAGGTCATGGGCAGCCCTGCACAGCCAGAGCAGC CTTGGCCAGGAAGGGAGCCTCAGCTCCAGACGCTTGCCTCACCATGAGTCCCAACTCT GTTGGCATCCAGGAAATGGAGATGGGGGTTAAGCAGCCCCATCAGATGGTGAGCCAGG GCTTAGCATCTCTGAGGAAATCAGCTAACAAACTAAAGCCAAGGCATGAGCCAAAGAT CTTCACCTCTACTACCCAGACCAGAGGGGCGAAGGGACTAGCAGACCCTAGCCACACA CAAGCTGGGTGGCGAAAAGAAGGGAACCTTGGGACCCACAAGGCTGCTAAGGGAGCCA GTTGCAATTCCTTGTATCCTCATGGACCCAGGCAGACTGCTGGGCACGGAAAGGCAGT CAAGACTTTTTGGACAGAATACAAAC(^CCTTCTCa^GCAGGGCATO____-GGCAT CAGAGGGTTCTGGCAACTAGGGTCAGAAATATTACCAAAAAGTCCTCTCACTTGCCTC TTGGCAGTCCTTTGAAGAGACAACAAAATACAAGGGACCCAGACACCATGGTCCCACT CACAGATTTCAGCCCAGTAATGGATCATTCAAGAGAAAAAGACAATGATTTATCTGAC ACAGATAGCAACTACTCATTGGATTCTCTCTCATGTGTCTATGCCAAAGCCCTGATAG
AGCCACTGAAGCCAGAGGAGAGGAAATGGGATTTCCCAGAGCCAGAGAACTCTGAAAG
TGATGACAGCCAACTATCTGAGGACTCACTGGCTGAGAAGAGGTACCAAAGCCCCAAA
AACAGGCTAGGGGGCAATCGTCCCACCAACAACCGTGGCCAACCCAGGACCAGAACTA
GAGCTTCTGTGAGGGGCTTCACTGCAGCCTCAGACAGTGACCTACTTGCTCAAACTCA
TAGGAGCTTCTCCTTGGATAGCCTGATTGATGCAGAGGAAGAACTGGGGGAAGATCAG
CAAGAAGAACCTTTCCCTGGTTCAGCTGACGAGATACCCACAGAGACTTTTTGGCACC
TGGAGGACTCTAGTCTGCCTGTAATGGACCAAGAGGCAATATGCAGGCTTGGTCCCAT
CAACTACAGAACAGCAGCTAGGCTGGATGCCGTCCTGCCAATGAGCAGTTCGTTTTAC
CTTGATCCTCAGTTCCAACCCCATTGTGAGCTCCAACCCCATTGTGAGCTCCAACCCC
ATTGTGAGCTCCAGCCCCATTGTGAGCAGGCTGAATCACAGGTAGAGCCAAGCTACTC
TGAACAAGCCGACTCTCTCCAAGGCATGCAGCTTTCAAGAGAGAGCCCACTGATGTCC
ATGGATTCCTGGTTTTCCTGTGACTCTAAGATCAACCCCAGCAGCCCCCCAGGAATAG
TGGGTTCTTTATGTCCAAGTCCTGATATGCAGGAATTTCACTCCTGTAAGGGGGAGAG
GCCTGGATACTGGCCAAATACTGAGGAACTAAAGCCATCAGATGCAGAAACGGTTCTG
CCATATAGCTCCAAACTGCACCAAGGCAGTACTGAGCTCCTCTGCAGTGCAAGAGATG
AGCACACAGCCTCTGCTGCTGATACGTCTAGGCTGTCTCTCTGGGGAATTCAAAGGCT
TATTCAACCAGGAGCTGATGGCACCTTTCAGGGCAGATGTATCCCTGACATGACCCAG
CAGGGCAGCTCTGAAGCATCCCACAATTCTAGCGTATCAAACGTGCTGGCTGCCTCTG
CCACCACCTTGACTCATGTAGGCAGCACCCATGAAAGGGATTGGTCTGCCCTTCAGCA
GAAGTACCTCCTTGAACTCTCTTGTCCTGTTTTGGAGGCCATAGGAGCACCCAAGCCA
GCTTACCCCTACCTTGAGGAAGACTCTGGTTCCCTGGCCCAAGCTTCTAGCAAAGGAG
GAGATACTCTATTGCCAGTTGGCCCTAGGGTATCTAGCAATCTGAATCTCAACAACTT
TCCAGTCCATCTGTCCAGAATCAGGCGTTTGAGGGCAGAGAAAGAACAGGACAGTTTA
AATGCCAAATTAGAAGGTGTTTCAGATTTCTTTAGCACTAGTGAGAAAGAGGCGAGTT
ATGACGAAACTTATTCGGCAGACTTAGAATCATTGTCTGCTTCTCGATCTACAAATGC
ACAGGTCTTTGCAACAGAGAACGCGATACCAGATTCCATGACAGAAGCATGTGAAGTC
AAGCAGAACAACTTGGAAGAATGCCTTCAGAGTTGCAGGAAACCTGGACTGATGACTT
CCTCTGATGAGGATTTTTTCCAGAAGAACGCTTGTCACAGTAATGTCACTACAGCCAC
CAAAGCAGACCATTGGTCCCAAGGCTGGGCTCCTCTCAGGAAAAATAGTGCAGTCCAG
CCAGGGCAATTAAGTCCCGACAGCCACTACCCACTAGAGGAAGAGAAGACAGATTGCC
AGGAGAGCTCTAAGGAAGCAGTTAGAAGACACATAAATGTTTCCTTTGCCCTTCCTTC
AGGTCCAGAGCTATACCTTCACTCTGCTCCCTGGAATCCATTGTCATCTTCCCTGCAG
CCCCCACTCTTGGAAACATTCTATGTGACCAAAAGCAGGGATGCCCTGACAGAAACTG
CCTTAGAGATTCCAGCTTGCAGAGAAGTAAGGGTACCCTCCCCACCCCCCAGGGAAGC
CTGGGGCTTTGGTCACAACCACCAAGCTCTCCAAGGTGCTTATTTGAAGAATAATTTG
CCAGTGCTGTTACAAAACCAGAATTCTAAGATTGCCTCATCTCAGCAGGTCACAGCTG
AGATACCAGTTGATCTGAATACCAGGGAAGTCATCAGAGAATCAGGTAAATGCCCTGG
AAATATTACAGAAGAAAGCCATGATTCAGTTTATTCTTCTGTTACTCAGAACAGACAT
TTTCTCCCCTCTACCAGCACAAAAGTATGTGAATTTGAAAACCAAGTTGTAATTTTAA
ATAAAAAACACAGTTTTCCAGCACTTGAGGGAGGAGAGGTCACTGCTCAGTCCTGTTG
CGGTGCTTCCTCAGACAGCACTGAGTCTGGGAAGTCTCTCCTCTTTCGTGAATCTGAG
GCACGAGAGGAAGAAGAGCTGGATCAGAATACGGTTCTGAGGCAGACCATCAATGTAA
GCCTTGAGAAAGACATGCCAGGGGAAAGTGCTGTTTCTTTGAAATCCAGATCAGTAGA
TCGTAGAGTAAGCAGCCCAGTGATGGTGGCCCAGGGTGGTGGCCCAACCCCTAAGTGG
GAAGGGAAAAATGAAACTGGGCTTCTTGAAAAAGGTCTTCGTCCCAAAGATAGCTCAG
AAGAGTTTAAGCTTCCAGGTACAAAGCCTGCATATGAAAGGTTCCAGTTAGTTGCATG
CCCTCAGGAAAGAAACCCCAGTGAATGCAAGTCACAAGAAATGTTAAATCCCAACAGA
GAACCTTCTGGAAAGAAACAGAATAAAAGAGTTAATAATACTGATGAAATGGCTAGGC
TAATTAGGAGTGTAATGCAGCTGGAAAATGGCATCTTAGAAATTGAATCTAAGCAGAA
TAAGCAGGTTCATGCTTCCCACACACCAGGAACCGATAAGGAGTTGGTGTTCCAGGAC
CAGAAGGAGCAGGAGAAGACTGACCATGCCTTTAGGCCAGACAGCTCTGGAAACCCTT
TGCCCTCTAAGGATCAGCCATCTTCTCCAAGACAGACAGATGATACTGTCTTTAGGGA
TAGTGAAGCTGGAGCGATGGAGGTTAACAGCATTGGGAACCATCCCCAGGTCCAGAAA
ATCACCCCAAACCCCTTCAGGTCAAGGGAAGGTGTACGAGAGAGTGAACCTGTGAGAG
AGCACACCCACCCAGCTGGATCGGACAGACCTGCCAGGGATATTTGTGATTCTTTAGG
GAAACACACAACTTGCAGAGAGTTCACCAACACTTCTCTTCACCCACAGAGAATGAAA
GCATTGGCTAGAGCTCTGCCATTGCAACCCAGGCTAGAGAGGTCTTCTAAGAATAATG
GCCAGTTTGTAAAAGCATCAGCAAGTCTCAAAGGGCAGCCTTGGGGCTTAGGAAGTCT
TGAGGAATTGGAGACTGTGAAAGGTTTTCAGGAAAGCCAAGTAGCTGAACACGTAAGT
AGTTCCAACCAAGAAGAGCCAAAAGCTCAAGGTAAAGTTGAAGAAATGCCTATGCAAA
GGGGAGGCAGCCTTCAGGAAGAAAATAAAGTGACTCAGAAATTTCCTAGTCTCAGCCA
GCTTTGTAGGGACACGTTTTTCAGGCAGGAAACTGTCAGCCCATTACTAAGCCGGACA
GAATTCTGTACAGCTCCTCTTCACCAAGACCTGAGTAATACCTTGCCCTTGAATTCTC
CAAGGTGGCCAAGAAGGTGTCTTCATGTACCTGTTGCTCTAGGCATCTCTTCACTTGA
CTGTGTGCTGGATCTCACAATGTTGAAAATTCATAACAGTCCCTTGGTAACTGGAGTA
GAGCATCAGGACCAGAGTACGGAGACCAGAAGCCACAGCCCCGAAGGAAATGTTAGAG
GGCGTTCCTCTGAGGCACACACTGCCTGGTGTGGGTCTGTGCGATCCATGGCCATGGG
ATCTCATAGTCAATCTGGTGTACCAGAGAGCATTCCTCTGGGGACAGAGGACAGGATC
TCAGCAAGCACCAGCCCCCAAGACCATGGAAAGGACCTCAGAATCACCTTGCTGGGTT
TCAGTACCAGTGAAGATTTTGCTTCTGAAGCCGAGGTGGCTGTACAAAAAGAAATAAG
AGTCAGTTCACTGAACAAGGTCTCTAGCCAGCCTGAAAAGAGGGTCAGCTTCTCCTTG
GAAGAGGATAGTGACCAAGCCAGCAAGCCAAGGCAGAAGGCAGAGAAGGAGACTGAGG
ACGTCGGACTGACCAGCGGTGTTTCCTTAGCACCTGTTTCCCTGCCGAGGGTGCCCAG
TCCAGAGCCTAGGCTGTTGGAGCCCTCTGACCATGCATCCATGTGCCTGGCCATCTTG
GAGGAGATCAGACAGGCAAAGGCCCAGAGAAAGCAGCTTCATGACTTTGTGGCCAGGG
GCACAGTCCTTTCTTACTGTGAAACTTTACTAGAACCCGAATGTTCTTCAAGGGTTGC
TGGCAGGCCTCAGTGTAAACAAATAGACCAGTCATCATCAGACCAGACCAGGAATGAG
GGTGAAGCACCGGGATTTCATGTGGCATCTCTATCTGCTGAAGCAGGGCAGATAGATC
TGTTACCTGATGAGAGGAAAGTCCAGGCCACATCTCTGTCTGCAGACAGCTTTGAATC
TCTGCCCAATACGGAAACTGACAGAGAGCCATGGGATCCTGTGCAGGCTTTCTCCCAT
GCTGCTCCTGCTCAAGACAGGAAACGTCGTACTGGAGAACTGAGGCAGTTCGCGGGAG
CAAGTGAACCATTTATATGTCACTCTAGTTCTTCTGAAATCATAGAGAAAAAGAAAGA
TGCAACCAGAACACCTTCCTCAGCTGATCCTTTGGCCCCAGACAGTCCTCGTTCTTCA
GCACCTGTGGAGGAGGTCAGGAGGGTAGTATCAAAGAAGGTAGTGGCTGCCTTACCTT
CTCAGGCCCCTTATGATGATCCTAGAGTGACTCTGCATGAGCTAAGTCAGTCAGTTCC
GCAGGAGACTGCAGAGGGCATACCCCCTGGCAGTCAGGACAGCAGCCCAGAGCATCAG
GAACCCAGAACTCTAGACACCACATATGGAGAA-TTTCAGATAATTTGTTAGTGACTG
CACAGGGAGAAAAAACAGCCCATTTTGAAAGTCAGTCTGTGACCTGTGATGTTCAGAA
TTCTACAAGTGCCTCAGGGCCTAAGCAAGACCATGTCCAATGCCCTGAGGCTTCTACT
GGCTTTGAAGAAGGTAGGGCAAGTCCCAAACAAGATACCATTCTGCCTGGAGCTCTGA
CAAGGGTTGCACTGGAAGCTCCCACACAGCAGTGTGTGCAGTGTAAGGAGAGTGTTGG
GTCTGGGTTGACAGAAGTCTGCAGGGCTGGCAGCAAACATTCCAGGCCAATTCCACTG
CCAGATCAAAGACCAAGCGCAAATCCTGGGGGAATTGGGGAGGAAGCCCCATGTAGAC
ACCCAAGGGAAGCTTTAGATGGCCCTGTCTTCTCAAGGAACCCTGAAGGCAGCAGGAC
TCTCAGCCCGTCTAGAGGGAAAGAGAGCAGAACTCTTCCTTGCCGACAGCCATGCAGT
TCTCAACCTGTTGCTACTCATGCTTATTCCTCCCATTCCTCTACTTTACTGTGTTTTA
GAGATGGTGACCTAGGGAAGGAGCCTTTCAAGGCTGCCCCACATACTATCCACCCACC
CTGTGTAGTACCTTCCAGGGCCTATGAAATGGATGAGACAGGAGAGATCTCTAGGGGA
CCTGATGTGCACTTGACACATGGCCTTGAGCCCAAAGATGTTAACAGGGAATTTAGGC
TAACAGAGAGCAGCACTTGTGAGCCTTCTACTGTGGCTGCTGTCCTATCTCGAGCTCA
AGGCTGCAGATCCCCTTCTGCTCCTGACGTGAGGACAGGTTCCTTCAGCCACTCAGCT
ACTGATGGAAGCGTGGGGTTAATAGGGGTTCCTGAGAAAAAGGTTGCTGAGAAGCAAG
CAAGCACAGAACTTGAGGCTGCCTCTTTCCCTGCAGGCATGTACTCTGAGCCCCTGAG
GCAGTTTAGGGACAGCTCTGTAGGTGACCAGAATGCACAGGTGTGTCAAACCAATCCA
GAACCACCTGCAACAACTCAGGGACCACACACCCTGGATTTAAGTGAAGGGTCTGCTG
AGAGCAAGTTGGTGGTAGAGCCACAGCATGAATGTTTAGAAAATACCACTAGATGTTT
TTTGGAAAAGCCACAATTTTCCACTGAGTTGAGGGATCACAATCGCTTGGATTCCCAA
GCCAAGTTTGTAGCAAGGTTAAAACATACCTGCAGCCCCCAGGAAGACAGTCCCTGGC
AGGAAGAAGAGCAGCACAGAGACCAGGCTTCAGGTGGTGGAGAAGGCTTCGCCCAGGG
TGTGAATCCCCTTCCTGATGAAGATGGCTTAGATGGCTGTCAGATTTTAGATGCTGGG
AGAGAGGAGGTGGCTGTGGCCAAGCCTCCTGTGTCCAAGATTTTATCACAGGGCTTCA
AAGACCCAGCCACTGTGTCCTTGAGGCAAAATGAAACACCGCAGCCTGCTGCTCAGAG
GAGTGGCCACCTCTACACTGGCAGAGAGCAGCCAGCACCCAACCACAGGGGCTCACTT
CCTGTGACTACAATCTTCTCTGGCCCCAAACACTCCAGGTCCTCCCCCACACCACAGT
TCTCAGTTGTCGGCTCTTCTCGTTCTCTTCAGGAGCTGAACTTGAGTGTGGAGCCTCC
TTCCCCTACAGACGAAGATACACAGGGGCCTAACAGATTGTGGAACCCACATCTCAGG
GGCTATTCCTCAGGAAAGTCAGTGGCAAGAACATCTCTGCAGGCTGAGGACAGCGATC
AGAAAGCCTCATCTCGCTTGGATGATGGGACTACCGATCACAGGCACCTGAAGCCTGC
CACCCCTCCTTATCCAATGCCTTCCACTCTCTCACACATGCCAACCCCTGATTTCACG
ACCAGCTGGATGTCTGGTACTTTGGAACAAGCCCAACAGGGAAAGCGAGAGAAACTGG
GTGTCCAGGTTAGGCCAGAAAATTGGTGCTCTCAGATGGACAAAGGAATGCTGCACTT
TGGCTCCAGTGACATCAGTCCCTATGCGCTGCCGTGGCGTCCGGAGGAGCCTGCACGT
ATCAGCTGGAAGCAGTATATGTCTGGCAGTGCAGTCGATGTTTCCTGCAGCCAGAAGC CCCAGGGGCTGACACTATCAAATGTGGCCCGGTGCTCCAGCATGGACAATGGCCTAGA AGACCAGAACTCCCCTTTCCACTCCCACCTCAGCACTTACGCCAATATTTGTGATCTG TCAACCACACACAGCAGCACTGAGAATGCCCAGGGTTCAAATGAGGCCTGGGAAGTAT TCCGAGGGAGTTCTTCAATTGCCTTAGGAGACCCCCACATCCCGACGAGCCCTGAAGG AGTAGCCCCCACTTCGGGTCATGACAGAAGGCCTCAGTTCAGGGGCCCTTCTGGTGAA GCAGACTGTCTGAGGAGTAAGCCCCCCTTGGCCAAAGGAAGTGCTGCAGGTCCAGTGG ATGAGATTATGCTGCTGTATCCATCAGAGGCAGGCTGCCCTGTGGGACAGACCAGGAC GAACACATTCGAACAGGGCACACAGACCCTCGGCAGCAGGCGCCACTGGAGCAGCACT GACATCTCCTTTGCTCAGCCTGAAGCCAGTGCAGTATCAGCCTTTGATCTGGCCTCAT GGACCAGCATGCACAATCTGTCTCTCCACCTCTCACAGCTCCTGCACAGTACCTCAGA GCTGCTTGGGAGTCTCTCCCAGCCAGATGTGGCCAGAAGGGAGCAGAACACCAAGAGG GACATCCCAGATAAAGCCCCACAGGCCCTGATGATGGATGGCTCTACTCAGACCACTG TGGATGAGGGCAGCCAGACTGACCTCACCTTACCCACCCTGTGCCTCCAGACTTCAGA GGCTGAACCTCAGGGAGCCAATGTGATCCTTGAAGGGCTAGGCTCAGATACCTCGACT GTGTCTCAAGAAGAGGGAGATGTGCCAGGGGTACCTCAGAAGAGAGAGGCAGAGGAAA CAGCACAGAAAATGGCTCAGCTCCTCTATCTTCAGGAAGAAAGCACTCCCTACAAGCC CCAGAGCCCTTCAATACCCTCATCCCACTTGAGGTTTCAGAAAGCCCCCGTTGGGCAG CATCTTCCTTCTGTGAGCCCCTCAGTTTCTGATGCTTTCCTGCCTCCCAGCTCCCAGC CAGAGGAGTCATATTGCTTAGTTGTCAGCAGTCCCAGTCCCAGCTCCCCTCATTCCCC AGGGCTCTTTCCCAGTACTTCCGAGTATCCTGGGGACTCCAGGGTCCAGAAGAAGCTG GGCCCCACAAGTGCTTTGTTCGTGGACAGGGCCTCCTCCCCAATCCTCACTCTTAGTG CCAGCACCCAAGAGCCGGGTCTTTCCCCAGGCTCTTTGACCCTCTCAGCCCCTTCAAC TCACCCTGTTGAAGGCCACCAGAAGCTTGACTCCAGCCCAGACCCTGTTGATGCCCCA AGGACTCCAATGGATAATTATTCCCAAACCACTGACGAGTTAGGTGGCTCCCAGAGAG GTAGAAGTTCCTTACAAAGGAGTAATGGGAGATCCTTCCTTGAGTTGCACTCCCCACA CAGCCCACAGCAGAGTCCAAAACTCCAATTTAGTTTCTTAGGGCAGCACCCTCAGCAG CTTCAGCCCAGGACAACTATCGGGGTCCAAAGCAGACTGCTGCCACCACCACTGAGGC ACAGGAGCCAAAGGCTGGGCAACAGCTTTGTGCCTGAGAAGGTGGCTTCCCCGGAGCA TTGCCCACTGAGCGGTAGGGAGCCAAGTCAGTGGCAGAGCAGGACAGAAAATGGAGGT GAGAGTTCAGCATCTCCAGGGGAACCACAACGCACTCTGGACCGACCTTCTTCATGGG GAGGCCTCCAGCACCTCAGCCCCTGCCCTGTCTCTGAGTTGACTGATACTGCAGGGCT CCGAGGTTCTGCCTTGGGCCTCCCTCAGGCCTGCCAACCTGAGGAGTTACTGTGCTTC AGTTGCCAGATGTGCATGGCCCCTGAGCACCAGCACCACAGTCTGAGGGACCTCCCGG TGCATAACAAATTTAGTAACTGGTGTGGGGTTCAGAAGGGCTCACCTGGGGGGTTGGA CATGACTGAGGAGGAGCTGGGGGCCAGCGGTGATCTCAGCTCTGAAAAGCAGGAACAG AGTCCCCCACAACCTCCTAATGACCACAGCCAGGATTCTGAGTGGTCCAAGAGGGAGC AGATCCCCCTGCAAGTTGGGGCCCAGAACCTCTCACTCAGCGTGGAACTCACAGAAGC GAAACTGCACCATGGCTTTGGGGAGGCCGATGCCCTGCTCCAGGTGCTGCAGAGTGGG ACAGGGGAGGCGCTTGCTGCTGATGAACCTGTGACATCCACCTGGAAGGAGCTCTATG CACGGCAAAAAAAGGCCATTGAGACCCTCAGGAGAGAGCGGGCTGAGCGACTTGGGAA CTTCTGCCGGACGCGAAGCCTTAGCCCTCAGAAACAACTGAGCCTCCTGCCCAACAAA GATCTCTTCATCTGGGATCTTGACTTGCCCAGCAGACGCCGAGAATACCTGCAGCAAC TGAGGAAGGATGTTGTGGAGACCACCAGGAGCCCAGAGTCAGTGTCAAGGTCAGCTCA CACACCCTCTGACATAGAGTTGATGCTGCAAGACTACCAGCAGGCCCATGAGGAGGCC AAGGTGGAGATTGCCCGGGCCCGAGACCAACTGCGGGAGCGGACTGAACAAGAGAAGC TGAGAATCCACCAGAAGATCATTTCCCAGCTATTGAAGGAAGAGGATAAACTACATAC CTTGGCCAATTCCAGCTCCCTGTGCACCAGCTCTAATGGAAGCCTCTCGTCTGGCATG ACCTCTGGCTATAATAGCAGCCCAGCCTTGTCAGGCCAGCTCCAGTTCCCAGAGAATA TGGGGCATACAAACTTGCCTGATTCCAGGGATGTATGGATAGGGGATGAGCGAGGAGG CCATTCTGCAGTGAGGAAGAACTCTGCCTACAGCCACAGAGCCTCCCTGGGCAGTTGC TGCTGTTCACCATCCAGTCTGTCCAGCTTGGGGACCTGCTTTTCCTCCTCCTACCAGG ATTTGGCCAAGCATGTCGTGGACACTTCTATGGCTGATGTAATGGCTGCTTGTTCGGA TAATTTGCACAACCTCTTCAGCTGCCAGGCAACTGCTGGCTGGAACTATCAGGGTGAG GAGCAGGCGGTGCAGCTTTACTACAAGGTGTTTTCTCCCACTCGGCATGGCTTCCTGG GGGCAGGTGTGGTGTCCCAGCCGCTGTCTCGTGTGTGGGCGGCTGTCAGTGACCCCAC TGTGTGGCCCCTGTATTACAAGCCCATCCAGACAGCAAGGCTGCATCAGCGAGTGACC AACAGCATCAGCCTGGTGTACTTGGTGTGCAACACCACCCTGTGCGCACTGAAGCAGC CACGGGATTTCTGTTGTGTCTGCGTGGAAGCCAAAGAGGGTCACCTGTCTGTCATGGC AGCCCAGTCTGTGTATGATACATCCATGCCAAGACCCAGCAGAAAAATGGTTCACGGG GAGATCCTGCCCAGTGCCTGGATCTTGCAGCCCATCACTGTGGAAGGGAAGGAAGTCA
CCAGAGTCATCTACTTGGCCCAGGTGGAACTTGGTGCTCCAGGCTTCCCACCTCAGCT CCTGAGCTCTTTCATCAAACGGCAGCCACTGGTTATAGCCAGACTGGCTTCCTTCCTT GTGCAGGAAAAGCTGATGCTACCTGCTGTGGCCGATTGGGGCAGACAGCACTGGCCCA GGGATGCTAGCAAAGCCCAGTCAGTACTTGGTCACAGCTGGCACCAGTGCAGAGCAAA CGGCCTGAGCTCCTGGCCCAGACTATCCAGAGTGAATGCAGCTCTGCTCACCTTTTGG ATTTCTCACCTTTCTTTCCTGTTTCTGGGACTCTGCGGCAGACAGGACACTTAAGGAC
CAGGACTGGGCACAGCCAGCAGAGCCGGGGACTGCAGTGCTTTGGCAAGGTGCTTCCG
CAGGCTGGTAGGGAA
ORF Start: ATG at 1
SEQ ID NO: 322 4773 aa MW at 524614.9kD
NOV34a, MANVQVAVRVRPLSKRETKEGGRIIVEVDGKVAKIRlvTLKVDNRPDGFGDSREK^7MAFG CG157505-01 FDYCYWSV PEDPQYASQDWFQDLGMEVLSGVAKGYNICLFAYGQTGSGKTYTMLGT PASVGLTPRICEGLFVRERDCASLPSSCRIKVSFLEIYNERVRDLLKQSGQKKSYTLR Protein Sequence VREHPEMGPYVQGLSQHWTNYKQVIQLLEEGIANRITAATHVHEASSRSHAIFTIHY TQAILENNLPSEMASKINLVDLAGSERADPSYCKDRIAEGANINKSLVTLGIVISTLA QNSQVFSSCQSLNSSVSNGGDSGILSSPSGTSSGGAPSRRQSYIPYRDSVLT LLKDS LGGNSKTIMVASVSPAHTSYSETMSTLRYASSAKNIINKPRVNEDA L LIRELREEI ERLIs^LLLSFELRNFSSLSDENLKELVLQNELKIDQLTKD TQKNDWQALMEHYSVD INRRRAGWIDSSLPHLMALEDDVLSTGWLYHLKEGTTKIGRIDSDQEQDIVLQGQW IERDHCTITSACGVWLRPARGARCTVNGREVTASCRLTQGAVITLGKAQKFRFNHPA EAAVLRQRRQVGEAAAGRGSLE LDLDGDLAASRLGLSPLL KERRALEEQCDEDHQT PRDGETSHRAQIQQQQSYVEDLRHQILAEEIRAAKELEFDQA ISQQIKENQQCLLRE ETWLASLQQQQQEDQVAEKELEASVALDA LQTDPEIQPSPFVQSQKRWHLQLLRRH TLRAAERNVRRKKVSFQLERIIKKQRLLEAQKRLEKLTTLC LQDDSTQEPPYQVLSP DATVPRPPCRSKLTSCSSLSPQRLCSKHMPQLHSIFLSWDPSTTLPPRPDPTHQTSEK TSSEEHLPQAASYPARTGCLRKNGLHSSGHGQPCTARAALARKGASAPDACLTMSPNS VGIQEMEMGVKQPHQMVSQGLASLRKSANKLKPRHEPKIFTSTTQTRGAKGLADPSHT QAGWRKEGNLGTHKAAKGASCNSLYPHGPRQTAGHGIAVKTFWTEYKPPSPSRASKRH QRVLATRVRNITKKSSHLPLGSPLKRQQNTRDPDTMVPLTDFSPVMDHSREKDNDLSD TDSNYSLDSLSCVYAKALIEPLKPEERK DFPEPENSESDDSQLSEDSLAEKRYQSPK NRLGGNRPTNNRGQPRTRTRASVRGFTAASDSDLLAQTHRSFSLDSLIDAEEELGEDQ QEEPFPGSADEIPTETF HLEDSSLPVMDQEAICRLGPINYRTAARLDAVLPMSSSFY LDPQFQPHCELQPHCELQPHCELQPHCEQAESQVEPSYSEQADSLQGMQLSRESPLMS MDS FSCDSKINPSSPPGIVGSLCPSPDMQEFHSC GERPGY PNTEΞLKPSDAETVL PYSSKLHQGSTELLCSARDEHTASAADTSRLSLWGIQRLIQPGADGTFQGRCIPDMTQ QGSSEASHNSSVS VLAASATTLTHVGSTHERDWSALQQKYLLELSCPVLEAIGAPKP AYPYLEEDSGSLAQASSKGGDTLLPVGPRVSSNLNLNNFPVHLSRIRRLRAEKEQDSL NAKLEGVSDFFSTSEKEASYDETYSADLESLSASRSTNAQVFATENAIPDSMTEACEV KQ NLEECLQSCRKPGLMTSSDEDFFQKNACHSNVTTATKADH SQG APLR NSAVQ PGQLSPDSHYPLEEEKTDCQESSKEAVRRHINVSFALPSGPELYLHSAP NPLSSSLQ PPLLETFYVTKSRDALTETALEIPACRE VPSPPPREAWGFGHNHQALQGAYLKNNL PVLLQNQNSKIASSQQVTAEIPVDLNTREVIRESGKCPGNITEESHDSVYSSVTQNRH FLPSTSTKVCEFENQWILNKKHSFPALEGGEVTAQSCCGASSDSTESGKSLLFRESE AREEEELDQNTVLRQTINVSLEKDMPGESAVSLKSRSVDRRVSSPVMVAQGGGPTPKW EGKNETGLLEKGLRPKDSSEEFKLPGTKPAYERFQLVACPQER PSECKSQEMLNPNR EPSGKKQNKRVNNTDEMARLIRSVMQLENGILEIESKQNKQVHASHTPGTDKELVFQD QKEQEKTDHAFRPDSSGNPLPSKDQPSSPRQTDDTVFRDSEAGAMEVNSIGNHPQVQK ITPNPFRSREGVRESEPVREHTHPAGSDRPARDICDSLGKHTTCREFTNTSLHPQRMK ALARALPLQPRLERSSKNNGQFVKASASLKGQPWGLGSLEELETVKGFQESQVAEHVS SSNQEEPKAQGKVEEMPMQRGGSLQEENKVTQKFPSLSQLCRDTFFRQETVSPLLSRT EFCTAPLHQDLSNTLPLNSPR PRRCLHVPVALGISSLDCVLDLTMLKIHNSPLVTGV EHQDQSTETRSHSPEGNVRGRSSEAHTA CGSVRSMAMGSHSQSGVPESIPLGTEDRI SASTSPQDHGKDLRITLLGFSTSEDFASEAEVAVQKEIRVSSL VSSQPEKRVSFSL EEDSDQASKPRQKAEKETEDVGLTSGVSLAPVSLPRVPSPEPRLLEPSDHASMCLAIL EEIRQAKAQRKQLHDFVARGTVLSYCETLLEPECSSRVAGRPQCKQIDQSSSDQTRNE GEAPGFHVASLSAEAGQIDLLPDERKVQATSLSADSFESLPNTETDREP DPVQAFSH AAPAQDRKRRTGELRQFAGASEPFICHSSSSEIIEKKKDATRTPSSADPLAPDSPRSS APVEEVRRWSKKWAALPSQAPYDDPRVTLHELSQSVPQETAEGIPPGSQDSSPEHQ EPRTLDTTYGEVSDNLLVTAQGEKTAHFESQSVTCDVQNSTSASGPKQDHVQCPEAST
GFEEGRASPKQDTILPGALTRVALEAPTQQCVQCKESVGSGLTEVCRAGSKHSRPIPL PDQRPSANPGGIGEEAPCRHPREALDGPVFSRNPEGSRTLSPSRGKESRTLPCRQPCS SQPVATHAYSSHSSTLLCFRDGDLGKEPFKAAPHTIHPPCWPSRAYEMDETGEISRG PDVHLTHGLEPKDVNREFRLTESSTCEPSTVAAVLSRAQGCRSPSAPDVRTGSFSHSA TDGSVGLIGVPEKKVAEKQASTELEAASFPAGMYSEPLRQFRDSSVGDQNAQVCQTNP EPPATTQGPHTLDLSEGSAESKLWEPQHECLENTTRCFLEKPQFSTELRDHNRLDSQ AKFVARLKHTCSPQEDSP QEEEQHRDQASGGGEGFAQGVNPLPDEDGLDGCQILDAG REEVAVAKPPVSKILSQGFKDPATVSLRQNETPQPAAQRSGHLYTGREQPAPNHRGSL PVTTIFSGPKHSRSSPTPQFSWGSSRSLQELNLSVEPPSPTDEDTQGPNRL NPHLR GYSSGKSVARTSLQAEDSDQKASSRLDDGTTDHRHLKPATPPYPMPSTLSHMPTPDFT TSWMSGTLEQAQQGKREKLGVQVRPENWCSQMDKGMLHFGSSDISPYALP RPEEPAR ISWKQYMSGSAVDVSCSQKPQGLTLSNVARCSSMDNGLEDQNSPFHSHLSTYANICDL STTHSSTENAQGSNEAWEVFRGSSSIALGDPHIPTSPEGVAPTSGHDRRPQFRGPSGE ADCLRSKPPLAKGSAAGPVDEIMLLYPSEAGCPVGQTRTNTFEQGTQTLGSRRH SST DISFAQPEASAVSAFDLAS TSMHNLSLHLSQLLHSTSELLGSLSQPDVARREQNTKR DIPDKAPQALMMDGSTQTTVDEGSQTDLTLPTLCLQTSEAEPQGANVILEGLGSDTST VSQEEGDVPGVPQKREAEETAQKMAQLLYLQEESTPYKPQSPSIPSSHLRFQKAPVGQ HLPSVSPSVSDAFLPPSSQPEESYCLWSSPSPSSPHSPGLFPSTSEYPGDSRVQKKL GPTSALFVDRASSPILTLSASTQEPGLSPGSLTLSAPSTHPVEGHQKLDSSPDPVDAP RTPMDNYSQTTDELGGSQRGRSSLQRSNGRSFLELHSPHSPQQSPKLQFSFLGQHPQQ LQPRTTIGVQSRLLPPPLRHRSQRLGNSFVPEKVASPEHCPLSGREPSQ QSRTENGG ESSASPGEPQRTLDRPSSWGGLQHLSPCPVSELTDTAGLRGSALGLPQACQPEELLCF SCQMCMAPEHQHHSLRDLPVHNKFSN CGVQKGSPGGLDMTEEELGASGDLSSEKQEQ SPPQPPNDHSQDSE SKREQIPLQVGAQNLSLSVELTEAKLHHGFGEADALLQVLQSG TGEALAADEPVTST KELYARQKKAIETLRRERAERLGNFCRTRSLSPQKQLSLLPNK DLFI DLDLPSRRREYLQQLRKDWETTRSPESVSRSAHTPSDIELMLQDYQQAHEEA KVΞIARARDQLRERTEQEKLRIHQKIISQLLKEEDKLHTLANSSSLCTSSNGSLSSGM TSGYNSSPALSGQLQFPENMGHTNLPDSRDV IGDERGGHSAVRKNSAYSHRASLGSC CCSPSSLSSLGTCFSSSYQDLAKHVVDTSMADVMAACSDNLHNLFSCQATAG YQGE EQAVQLYYKVFSPTRHGFLGAGWSQPLSRVWAAVSDPTV PLYYKPIQTARLHQRVT NSISLVYLVCNTTLCALKQPRDFCCVCVEAKEGHLSVMAAQSVYDTSMPRPSRKMVHG EILPSA ILQPITVEGKEVTRVIYLAQVELGAPGFPPQLLSSFIKRQPLVIARLASFL VQEKLMLPAVAD GRQH PRDASKAQSVLGHS HQCRANGLSS PRLSRVNAALLTF ISHLSFLFLGLCGRQDT
Further analysis of the NOV34a protein yielded the following properties shown in Table 34B.
Table 34B. Protein Sequence Properties NOV34a
PSort J 0.9000 probability located in nucleus; 0.6640 probability located in plasma analysis: j membrane; 0.3694 probability located in mitochondrial inner membrane; 0.3000 probability located in microbody (peroxisome)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV34a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 34C.
Table 34C. Geneseq Results for NOV34a
NOV34a Identities/
Geneseq Protein/Organism Length [Patent Expect
Similarities for Identifier #, Date] Residues/
In a BLAST search of public sequence datbases, the NOV34a protein was found to have homology to the proteins shown in the BLASTP data in Table 34D.
PFam analysis predicts that the NOV34a protein contains the domains shown in the Table
34E.
Example 35.
The NOV35 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 35 A.
CATGATGGGAAGGTGGTGACTATATTTTCTGCTTCTAATTATTATGAAGAAGGCAGCA ATCGAGGAGCTTACATCAAACTATGTTCTGGTACAACTCCTCGATTTTTCCAGTACCA AGTAACTAAAGCAACGTGCTTTCAGCCTCTTCGCCAAAGAGTGGATACTATGGAAAAC AGCGCCATCAAGATATTAAGAGAGAGAGTGATTTCACGAAAAAGTGACCTTACTCGTG CTTTCCAACTTCAAGACCACAGAAAATCAGGAAAACTTTCTGTGAGCCAGTGGGCTTT TTGCATGGAGAACATTTTGGGGCTGAACTTACCATGGAGATCCCTCAGTTCGAATCTG GTAAACATAGACCAAAATGGAAACGTTGAATACATGTCCAGCTTCCAGAATATCCGCA TTGAAAAACCTGTACAAGAGGCTCATTCTACTCTAGTTGAAACTCTGTACAGATACAG ATCTGACCTGGAAATCATATTTAATGCCATTGACACTGATCACTCAGGCCTGATCTCC GTGGAAGAATTTCGTGCCATGTGGAAACTTTTTAGTTCTCACTACAATGTTCACATTG ATGATTCCCAAGTCAATAAGCTTGCCAACATAATGGACTTGAACAAAGATGGAAGCAT TGACTTTAATGAGTTTTTAAAGGCTTTCTATGTAGTGCATAGATATGAAGACTTGATG AAACCTGATGTCACCAACCTTGGCTAAACACAAATGAGAGCTTCCCTCAGGCTCCCTG
AAACAGCTAGGCCCAAATCACAAGTACAGTCCTTTCCAACACCCCTGAAATTCATAGT
CAGTAGCAG
ORF Start: ATG at 100 ORF Stop: TAA at 1939
SEQ ID NO: 324 613 aa MW at 71315.2kD
NOV35a, MGCSSSSTKTRRSDTSLRAALIIQN YRGYKARLKARQHYALTIFQSIEYADEQGQMQ CG157629-01 LSTFFSFMLENYTHIHKEELELRNQSLESEQDMRDRWDYVDSIDVPDSYNGPRLQFPL TCTDIDLLLEAFKEQQILHAHYVLEVLFETKKVLKQMPNFTHIQTSPSKEVTICGDLH Protein Sequence GKLDDLFLIFYK_JGLPSERNPYVFNGDFVDRGiαjSIEILMILCVSFLVYPNDLHLNRG NHEDFMMNLRYGFTKEILHKYKLHGKR-ILQILEEFYAV^PTETNRDHGTDSKHNKVGV TFNAHGRIKTNGSPTEHLTEHE EQIIDIL SDPRGKNGCFPNTCRGGGCYFGPDVTS KILNKYQLKMLIRSHECKPEGYEICHDGKWTIFSASNYYEEGSNRGAYIKLCSGTTP RFFQYQVTKATCFQPLRQRVDTMENSAIKILRERVISRKSDLTRAFQLQDHRKSGKLS VSQ AFCMENILGLNLPWRSLSSNLVNIDQNGNVEYMSSFQNIRIEKPVQEAHSTLVE TLYRYRSDLEIIFNAIDTDHSGLISVEEFRAMWKLFSSHYWHIDDSQVNK_ANIMDL NKDGSIDFNEFLKAFYWHRYEDLMKPDVTNLG
SEQ ID NO: 325 2039 bp
NOV35b, CTAAGAGTGGTTCCTCGCAGCTTAAAGGGAGGCACTTTTCACACTCTGTCTTAAAATC CG157629-01 AGAAGTTGAATTCATGAACACATATGATTTAGATAGAAGTCATGGGATGCAGCAGTTC
TTCAACGAAAACCAGGAGATCTGACACATCACTGAGAGCTGCGTTGATCATCCAGAAC DNA Sequence TGGTACCGAGGTTACAAAGCTCGACTGAAGGCCAGACAACACTATGCCCTCACCATCT TCCAGTCCATCGAATATGCTGATGAACAAGGCCAAATGCAGTTATCCACCTTCTTTTC CTTCATGTTGGAAAACTACACACATATACATAAGGAAGAGCTAGAATTAAGAAATCAG TCTCTTGAAAGCGAACAGGACATGAGGGATAGATGGGATTATGTGGACTCGATAGATG TCCCAGACTCCTATAATGGTCCTCGGCTACAATTTCCTCTCACTTGTACGGATATTGA TTTACTTCTTGAGGCCTTCAAGGAACAACAGATACTTCATGCCCATTATGTCTTAGAG GTGCTATTTGAAACCAAGAAAGTCCTGAAGCAAATGCCGAATTTCACTCACATACAAA CTTCTCCCTCCAAAGAGGTAACAATCTGTGGTGATTTGCATGGGAAACTGGATGATCT TTTTTTGATCTTCTACAAGAATGGTCTCCCCTCAGAGAGGAACCCGTATGTTTTTAAT GGTGACTTTGTAGATCGAGGAAAGAATTCCATAGAGATCCTAATGATCCTGTGTGTGA GTTTTCTTGTCTACCCCAATGACCTGCACTTGAACAGAGGGAACCACGAAGATTTTAT GATGAATCTGAGGTATGGCTTCACGAAAGAAATTTTGCATAAATATAAGCTACATGGA AAAAGAATCTTACAAATCTTGGAAGAATTCTATGCCTGGCTCCCAACGGAAACAAACA GAGACCATGGCACTGACTCGAAGCACAATAAAGTAGGTGTGACTTTTAATGCACATGG AAGAATCAAAACAAATGGATCTCCTACTGAACACTTAACAGAGCATGAATGGGAACAG ATTATTGATATTCTGTGGAGTGATCCCAGAGGCAAAAATGGCTGTTTTCCAAATACGT GCCGAGGAGGGGGCTGCTATTTTGGACCAGATGTTACTTCCAAGATTCTTAATAAATA CCAGTTGAAGATGCTCATCAGGTCTCATGAATGTAAGCCCGAAGGGTATGAAATCTGT CATGATGGGAAGGTGGTGACTATATTTTCTGCTTCTAATTATTATGAAGAAGGCAGCA ATCGAGGAGCTTACATCAAACTATGTTCTGGTACAACTCCTCGATTTTTCCAGTACCA AGTAACTAAAGCAACGTGCTTTCAGCCTCTTCGCCAAAGAGTGGATACTATGGAAAAC AGCGCCATCAAGATATTAAGAGAGAGAGTGATTTCACGAAAAAGTGACCTTACTCGTG CTTTCCAACTTCAAGACCACAGAAAATCAGGAAAACTTTCTGTGAGCCAGTGGGCTTT TTGCATGGAGAACATTTTGGGGCTGAACTTACCATGGAGATCCCTCAGTTCGAATCTG GTAAACATAGACCAAAATGGAAACGTTGAATACATGTCCAGCTTCCAGAATATCCGCA TTGAAAAACCTGTACAAGAGGCTCATTCTACTCTAGTTGAAACTCTGTACAGATACAG
ATCTGACCTGGAAATCATATTTAATGCCATTGACACTGATCACTCAGGCCTGATCTCC GTGGAAGAATTTCGTGCCATGTGGAAACTTTTTAGTTCTCACTACAATGTTCACATTG ATGATTCCCAAGTCAATAAGCTTGCCAACATAATGGACTTGAACAAAGATGGAAGCAT TGACTTTAATGAGTTTTTAAAGGCTTTCTATGTAGTGCATAGATATGAAGACTTGATG AAACCTGATGTCACCAACCTTGGCTAAACACAAATGAGAGCTTCCCTCAGGCTCCCTG
AAACAGCTAGGCCCAAATCACAAGTACAGTCCTTTCCAACACCCCTGAAATTCATAGT
CAGTAGCAG
ORF Start: ATG at 100 ORF Stop: TAA at 1939 SEQ ID NO: 326 613 aa MW at 71315.2kD
NOV35b, MGCSSSSTKTRRSDTSLRAALIIQNWYRGYKARLKARQHYALTIFQSIEYADEQGQMQ CG157629-01 LSTFFSFMLENYTHIHKEELELRNQSLESEQDMRDR DYVDSIDVPDSYNGPRLQFPL TCTDIDLLLEAFKEQQILHAHYVLEVLFETKKVLKQMPNFTHIQTSPSKEVTICGDLH Protein Sequence GKLDDLFLIFYKNGLPSERNPYVFNGDFVDRGKNSIEILMILCVSFLVYPNDLHLNRG NHEDFMMNLRYGFTKEILHKYKLHGKRILQILEEFYA LPTETNRDHGTDSKHNKVGV TFNAHGRIKTNGSPTEHLTEHE EQIIDIL SDPRGKNGCFPNTCRGGGCYFGPDVTS KILNKYQLKMLIRSHECKPEGYEICHDGKVVTIFSASNYYEEGSNRGAYIKLCSGTTP RFFQYQVTKATCFQPLRQRVDTMENSAIKILRERVISRKSDLTRAFQLQDHRKSGKLS VSQ AFCMENILGLNLP RSLSSNLVNIDQNGNVEYMSSFQNIRIEKPVQEAHSTLVE TLYRYRSDLEIIFNAIDTDHSGLISVEEFRAMWKLFSSHYNVHIDDSQV KLANIMDL NKDGSIDFNEFLKAFYWHRYEDLMKPDVT LG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 35B.
Table 35B. Comparison of NOV35a against NOV35b.
Protein Sequence NOV35a Residues/ Identities/ Match Residues Similarities for the Matched Region
NOV35b 1..613 613/613 (100%) 1..613 613/613 (100%)
Further analysis of the NOV35a protein yielded the following properties shown in Table 35C.
Table 35C. Protein Sequence Properties NOV35a
PSort 0.8171 probability located in mitochondrial matrix space; 0.4962 probability analysis: located in mitochondrial inner membrane; 0.4962 probability located in mitochondrial intermembrane space; 0.4962 probability located in mitochondrial outer membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV35a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 35D.
Table 35D. Geneseq Results for NOV35a
Genesen Prntein/Or«τanism/T.enαth fPatent I NOV. 5a Identities/ F,-nect
In a BLAST search of public sequence datbases, the NOV35a protein was found to have homology to the proteins shown in the BLASTP data in Table 35E.
PFam analysis predicts that the NOV35a protein contains the domains shown in the Table 35F.
Example 36.
The NOV36 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 36A.
Table 36A. NOV36 Sequence Analysis
SEQ ID NO: 327 4037 bp
NOV36a, TTCACCAAAATGGCATCCTGGTTATATGAATGTCTTTGTGAAGCTGAACTTGCACAGT CG157704-01 ATTATTCTCATTTCACTGCCCTTGGCCTTCAGAAAATAGATGAATTAGCCAAGATTAC AATGAAGGACTACTCCAAATTAGGAGTCCATGACATGAACGACCGCAAACGTCTCTTC DNA Sequence CAACTTATCAAAATTATTAAGATTATGCAAGAAGAAGATAAAGCAGTCAGTATCCCAG AGCGTCATCTTCAGACAAGCAGCCTGCGCATCAAATCTCAGGAATTAAGATCTGGCCC TCGCAGACAGCTGAATTTTGATTCTCCTGCTGACAATAAAGACAGAAATGCCAGCAAT GATGGGTTTGAAATGTGCAGTTTATCAGATTTCTCTGCAAATGAACAGAAGTCCACTT ACCTAAAAGTGCTAGAACACATGCTACCAGATGATTCCCAGTACCATACAAAAACAGG AATTCTGAATGCCACAGCTGGTGATTCCTATGTGCAAACAGAAATCAGCACTTCACTC TTTTCACCAAATTACCTTTCTGCAATACTGGGGGATTGTGATATTCCCATTATTCAAA GAATCTCTCATGTTTCAGGGTATAACTATGGAATCCCTCATTCTTGTATCAGACAGAA CACTTCAGAGAAACAGAATCCTTGGACTGAGATGGAGAAAATCAGAGTTTGTGTTCGA AAACGCCCCCTGGGCATGAGGGAGGTACGTCGTGGAGAAATTAATATTATTACTGTAG AAGACAAAGAAACTCTACTTGTGCATGAGAAGAAAGAAGCAGTTGACCTCACTCAATA TATTCTGCAGCATGTTTTTTATTTTGATGAAGTCTTTGGTGAGGCGTGCACCAATCAG
GATGTATACATGAAGACTACTCACCCACTTATTCAGCATATTTTCAATGGAGGCAATG
CCACTTGCTTTGCTTATGGACAGACAGGTGCTGGAAAGACCTACACCATGATAGGAAC
TCATGAGAACCCAGGATTGTATGCTCTAGCTGCCAAAGATATCTTCAGGCAACTAGAA
GTGTCCCAGCCAAGAAAGCACCTCTTTGTGTGGATCAGCTTCTATGAAATTTACTGTG
GACAGCTTTATGACCTCCTAAATAGAAGAAAAAGGCTCTTTGCAAGAGAAGATAGCAA
GCACATGGTGCAGATAGTGGGACTGCAAGAGCTTCAGGTGGACAGTGTGGAGCTCCTC
TTACAGGTGATCTTAAAGGGCAGCAAGGAGCGCAGCACTGGGGCCACTGGAGTTAATG
CAGACTCCTCCCGCTCCCATGCCGTCATCCAAATTCAGATCAAAGATTCAGCCAAGAG
GACATTTGGCAGGATCTCTTTTATTGACTTGGCTGGCAGTGAAAGAGCAGCAGATGCA
AGGGACTCAGATAGACAGACAAAGATGGAAGGTGCAGAAATAAATCAGAGTCTACTGG
CTCTGAAGGAATGTATCCGAGCACTGGATCAGGAACACACCCATACTCCCTTCAGGCA
AAGCAAACTAACTCAGGTCCTGAAGGACTCTTTCATCGGCAATGCCAAAACCTGCATG
ATCGCCAACATCTCACCAAGCCACGTGGCCACTGAACACACTCTCAACACCTTGCGCT
ATGCTGACCGGGTCAAAGAACTAAAGAAAGGCATTAAGTGTTGCACTTCAGTTACCAG
TCGAAATCGGACATCTGGAAACTCCTCTCCAAAACGAATTCAGAGCTCCCCTGGGGCT
TTGTCAGAGGACAAATGTTCTCCCAAAAAAGTCAAGCTGGGATTTCAGCAGTCACTCA
CAGTGGCAGCCCCTGGTTCCACGAGAGGGAAGGTCCATCCTCTGACCAGCCACCCACC
CAACATTCCTTTTACTTCTGCACCTAAGGTCTCTGGTAAAAGGGGTGGCTCCAGAGGG
AGTCCTTCACAAGAGTGGGTCATTCATGCTAGCCCTGTGAAAGGAACTGTGCGCTCTG
GACATGTGGCCAAAAAAAAGCCAGAAGAGTCAGCACCATTGTGCTCTGAGAAAAATCG
AATGGGCAACAAAACTGTCCTTGGGTGGGAAAGCAGGGCCTCAGGCCCAGGAGAAGGC
CTAGTGCGTGGTAAGCTGTCCACCAAGTGCAAGAAAGTGCAGACAGTGCAGCCAGTAC
AGAAGCAGCTTGTGTCTCGAGTTGAGCTCTCCTTTGGCAACGCCCACCACAGGGCTGA
GTACAGTCAAGACAGCCAGAGGGGCACGCCTGCTAGGCCTGCCTCTGAAGCTTGGACA
AACATCCCGCCACATCAGAAGGAGAGGGAGGAACATCTGCGTTTCTATCACCAGCAGT
TCCAACAGCCACCTCTCCTCCAACAGAAGTTAAAATACCAACCACTGAAAAGGTCTTT
ACGCCAGTACAGGCCCCCAGAGGGTCAGCTCACGAATGAGACTCCGCCTCTGTTCCAC
TCTTACTCTGAAAACCATGATGGAGCCCAAGTAGAGGAACTTGATGACAGTGATTTCA
GTGAAGATTCTTTTTCACACATCTCTAGTCAGAGGGCCACAAAGCAAAGGAACACCCT
GGAGAATAGCGAAGACTCATTCTTCCTGCACCAGACGTGGGGACAGGGTCCTGAGAAG
CAGGTGGCAGAAAGACAGCAGAGTCTGTTTTCTAGCCCCAGGACAGGTGACAAGAAAG
ATCTAACTAAAAGCTGGGTGGACTCCAGGGACCCCATAAACCACAGAAGAGCAGCACT
CGATCACAGCTGCAGCCCAAGTAAGGGGCCCGTGGACTGGAGCAGAGAGAACTCTACT
TCCTCAGGGCCTTCTCCCAGAGACAGCCTGGCAGAGAAGCCATACTGTTCACAGGTAG
ATTTCATATATAGACAGGAAAGAGGTGGAGGCTCTTCCTTTGATCTCAGAAAGGATGC
CTCCCAAAGTGAGGTTTCTGGGGAGAATGAGGGCAACTTGCCATCCCCAGAGGAAGAT
GGTTTCACTATCTCATTGTCCCACGTTGCAGTTCCTGGATCCCCAGACCAAAGAGACA
CAGTCACCACACCTCTGAGAGAAGTCAGTGCAGACGGCCCAATCCAGGTGACCAGCAC
TGTGAAAAACGGTCATGCTGTCCCAGGAGAGGATCCTAGGGGGCAGTTAGGCACGCAT
GCTGAATATGCTTCTGGACTCATGTCTCCCCTCACCATGTCCCTCCTGGAGAACCCAG
ACAACGAAGGGTCTCCTCCCTCGGAGCAGCTGGTCCAGGATGGGGCTACGCACAGTCT
AGTGGCAGAGAGCACAGGGGGCCCAGTTGTGAGCCACACAGTGCCATCTGGTGATCAA
GAGGCAGCCTTGCCAGTGTCTTCAGCAACTAGGCACCTGTGGCTGTCCTCATCTCCCC
CTGATAATAAGCCTGGTGGTGATCTTCCAGCTCTGTCCCCATCACCCATCCGTCAGCA
CCCAGCTGACAAGCTGCCCAGCAGGGAGGCAGACCTAGGAGAGGCCTGCCAGAGCAGA
GAGACTGTACTTTTCTCCCACGAACACATGGGTAGTGAGCAGTATGATGCTGATGCAG
AGGAGACGGGGCTGGATGGCTCCTGGGGTTTCCCAGGAAAGCCCTTCACCACCATACA
TATGGGGGTACCCCATTCTGGACCTACACTCACCCCACGAACAGGAAGTAGTGATGTG
GCTGACCAGCTCTGGGCCCAGGAGAGAAAACATCCTACAAGGCTTGGTTGGCAGGAGT
TTGGTTTGTCCACAGACCCCATCAAGTTGCCCTGCAACAGTGAAAATGTCACATGGCT
CAAACCCAGGCCGATCTCAAGGCAGGTGGTCATCCGAGCACACCAGGAACAGCTGGAT
GAAATGGCTGAGCTCGGCTTCAAGGAGGAGACGCTGATGAGCCAGCTGGCTTCTAATG
ATTTTGAAGATTTTGTGACCCAGCTGGATGAAATCATGGTTCTGAAATCCAAGTGTAT
CCAGAGTCTGAGGAGCCAGCTGCAGCTCTATCTCACCTGCCACGGGCCCACCGCAGCC
CCTGAGGGAACAGTGCCGTCTTAGAGCCAGACCCT
ORF Start: ATG at 10 ORF Stop: TAG at 4024
SEQ ID NO: 328 1338 aa MW at 148781. lkD
NOV36a, MAS LYECLCEAELAQYYSHFTALGLQKIDELAKITMKDYSKLGVHDMNDRKRLFQLI CG157704-01 KIIKIMQEEDKAVSIPERHLQTSSLRIKSQELRSGPRRQLNFDSPADNKDRNASNDGF
Protein Sequence EMCSLSDFSANEQKSTYLKVLEHMLPDDSQYHTKTGILNATAGDSYVQTEISTSLFSP NYLSAILGDCDIPIIQRISHVSGYNYGIPHSCIRQNTSEKQNPWTEMEKIRVCVRKRP LGMREVRRGEINIITVEDKETLLVHEKKEAVDLTQYILQHVFYFDEVFGEACTNQDVY MKTTHPLIQHIFNGGNATCFAYGQTGAGKTYTMIGTHENPGLYALAAKDIFRQLEVSQ PRKHLFVWISFYEIYCGQLYDLLNRRKRLFAREDSKHMVQIVGLQELQVDSVELLLQV ILKGSKERSTGATGVNADSSRSHAVIQIQIKDSAKRTFGRISFIDLAGSERAADARDS DRQTKMEGAEINQSLLALKECIRALDQEHTHTPFRQSKLTQVLKDSFIGNAKTCMIAN ISPSHVATEHTLNTLRYADRVKELKKGIKCCTSVTSRNRTSGNSSPKRIQSSPGALSE DKCSPKKVKLGFQQSLTVAAPGSTRGKVHPLTSHPPNIPFTSAPKVSGKRGGSRGSPS QEWIHASPVKGTVRSGHVAKKKPEESAPLCSEKNRMGNKTVLGWESRASGPGEGLVR G LSTKCKKVQTVQPVQKQLVSRVELSFGNAHHRAEYSQDSQRGTPARPASEA TNIP PHQKEREEHLRFYHQQFQQPPLLQQKLKYQPLKRSLRQYRPPEGQLTNETPPLFHSYS ENHDGAQVEELDDSDFSEDSFSHISSQRATKQRNTLENSEDSFFLHQTWGQGPEKQVA ERQQSLFSSPRTGDKKDLTKS VDSRDPINHRRAALDHSCSPSKGPVD SRENSTSSG PSPRDSLAEKPYCSQVDFIYRQERGGGSSFDLRKDASQSEVSGENEGNLPSPEEDGFT ISLSHVAVPGSPDQRDTVTTPLREVSADGPIQVTSTVKNGHAVPGEDPRGQLGTHAEY ASGLMSPLTMSLLENPDNEGSPPSEQLVQDGATHSLVAESTGGPWSHTVPSGDQEAA LPVSSATRHL LSSSPPDNKPGGDLPALSPSPIRQHPADKLPSREADLGEACQSRETV LFSHEHMGSEQYDADAEETGLDGS GFPGKPFTTIHMGVPHSGPTLTPRTGSSDVADQ L AQERKHPTRLG QEFGLSTDPIKLPCNSE VTWLKPRPISRQWIRAHQEQLDEMA ELGFKEETLMSQLASNDFEDFVTQLDEIMVLKSKCIQSLRSQLQLYLTCHGPTAAPEG TVPS
Further analysis of the NOV36a protein yielded the following properties shown in Table 36B.
Table 36B. Protein Sequence Properties NOV36a
PSort 0.8200 probability located in nucleus; 0.3000 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV36a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 36C.
In a BLAST search of public sequence datbases, the NOV36a protein was found to have homology to the proteins shown in the BLASTP data in Table 36D.
PFam analysis predicts that the NOV36a protein contains the domains shown in the Table 36E.
Table 36E. Domain Analysis of NOV36a
Example 37.
The NOV37 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 37A.
Table 37A. NO 37 Sequence Analysis
SEQ ID NO: 329 2770 bp
NOV37a, TTATGGGACCATGATGTTGAGAGTTAGTGTGAAGTGGACCATTGAAAAAGCCAGCCAA CG158218-01 AGTAGCATCTTCATCCGTTTCCAGGCCATGCCCTTTCATTATAACCAGAAGGCCCCAT DNA Sequence GTTCTGAGTGCCATGATCTGATGTGTAGGAATGTCAATTCCACCCCGCAGATCATTGC
AACTTTAGTGGACATACCTATACATGCCAAAAGCATCCTGCCTCCAGGGTCTGCACCT
CTCTCTGCCCAACGGCTTTCTCTGAATGTCAGGGCACACAGGATTTATTCCATAGATG
AAGATGAAAAATTAATACCTAGCTTGGAAATCATCTTACCACGTGATTTGGCAGATGG
GTTTGTGAATAATAAGCGAGAAAGCTACAAATTTAAATTTCAAAGAATTTTTGATCAG
GATGCAAACCAAGAGACCGTTTTTGAAAACATTGCCAAACCAGTTGCTGGGAGGTATC
TCACCCCTGGTGGTAAGGATGTCCTGGCAGGTTACAATGGTACCATCTTTGCATATGG
GCAAACAGGCAGCGGGAAGACATTCACTATCACAGGGGGTGCAGAGCGTTACAGTGAC
AGAGGCATTATCCCAAGGACACTGTCATACATTTTTGAACAGTTACAAAAGGACAGCA
GCAAAATATATACAACACACATTTCCTATTTGGAAATCTACAATGAATGTGGTTATGA TCTTTTGGATCCAAGACATGAAGCCTCCAGTTTGGAAGATTTGCCGAAAGTGACAATA
CTGGAGGATCCTGATCAGAACATTCACCTGAAAAACTTGACTCTCCATCAGGCAACCA CAGAGGAAGAAGCTCTGAATTTGCTTTTTTTAGGAGACACCAACCGAATGATTGCAGA GACTCCTATGAACCAAGCTTCAACCCGTTCCCACTGCATTTTCACCATTCATTTGTCA AGCAAGGAACCAGGATCTGCAACTGTACGACATGCCAAACTCCATCTGGTTGACCTGG CTGGTTCAGAGCGAGTTGCAAAGACTGGAGTAGGGGGCCATCTTCTAACAGAGGCCAA GTATATCAACTTGTCACTACATTACTTAGAACAGGTTATCATTGCCCTTTCAGAAAAG CACCGTTCGCACATTCCTTATAGAAACTCCATGATGACCAGTGTCCTAAGAGACAGTT TGGGAGGGAACTGCATGACAACTATGATTGCAACACTCTCCTTGGAGAAAAGGAATCT TGATGAGTCTATATCAACCTGCAGATTTGCACAGCGAGTGGCACTCATAAAGAATGAA GCTGTTCTTAATGAAGAAATTAACCCCAGATTAGTGATTAAACGCCTACAAAAGGAAA TCCAGGAACTGAAGGATGAACTGGCCATGGTCACTGGGGAGCAGAGGACAGAGGCACT CACAGAAGCAGAGCTCCTTCAGCTGGAAAAACTAATAACATCCTTTTTGGAAGACCAG GATTCAGACAGTAGATTAGAGGTTGGCGCGGATATGCGTAAAGTTCATCACTGTTTTC ATCATTTAAAGAAACTATTGAATGACAAGAAGATCCTTGAAAACAATACAGTCTCCTC TGAAAGCAAAGACCAAGATTGTCAAGAACCATTAAAAGAAGAAGAATATAGAAAGCTA CGAGATATTCTGAAACAGAGAGATAACGAAATCAATATCCTGGTCAACATGTTAAAAA AAGAAAAGAAGAAAGCTCAGGAGGCTCTCCACTTGGCTGGCATGGATAGACGTGAATT CAGACAGTCCCAGAGCCCACCCTTCCGCCTAGGAAACCCAGAAGAAGGTCAAAGAATG CGACTATCCTCAGCTCCCTCACAGGCCCAGGACTTCAGCATTTTGGGGAAAAGATCCA GTTTGCTCCACAAGAAAATAGGAATGAGAGAGGAAATGTCATTAGGATGCCAGGAGGC TTTTGAAATCTTCAAGAGGGACCACGCTGACAGCGTTACCATCGATGACAACAAACAG ATTCTGAAACAGAGATTTTCTGAAGCCAAGGCCCTGGGAGAAAGTATAAATGAAGCAA GAAGTAAAATTGGTCACCTGAAGGAAGAAATCACCCAGCGGCATATACAGCAAGTAGC CCTAGGAATCTCGGAAAACATGGCCGTGCCTCTGATGCCAGACCAGCAGGAGGAGAAG CTGCGATCACAACTGGAGGAAGAAAAGAGAAGGTATAAAACAATGTTCACTCGCCTGA AAGCCCTGAAGGTGGAGATCGAGCACTTGCAGCTGCTCATGGACAAAGCCAAGGTGAA

Further analysis of the NOV37a protein yielded the following properties shown in Table 37B.
Table 37B. Protein Sequence Properties NOV37a
PSort 0.6863 probability located in mitochondrial matrix space; 0.3737 probability analysis: located in mitochondrial inner membrane; 0.3737 probability located in mitochondrial intermembrane space; 0.3737 probability located in mitochondrial outer membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV37a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 37C.
In a BLAST search of public sequence datbases, the NOV37a protein was found to have homology to the proteins shown in the BLASTP data in Table 37D.
PFam analysis predicts that the NOV37a protein contains the domains shown in the Table
Example 38.
The NOV38 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 38 A.
TGTTTCCCCCAGAAGGTGTCAGCATCTGGAATCCTATCCTACTCTGGCAGCCCATCCC GGTGCACACAGTTCCTCTTTCTGAAGATCAGGATTTTATAGCTACCTTGGGAAAACTT TCAGGATTACATGGCCAGGACCTTTTTGGAATTTGGAGTAAAGTCTACGACCCTTTAT ATTGTGAGAGTGTTCACAATTTCACTTTACCCTCCTGGGCCACTGAGGACACCATGAC TAAGTTGAGAGAATTGTCAGAATTGTCCCTCCTGTCCCTCTATGGAATTCACAAGCAG AAAGAGAAATCTAGGCTCCAAGGGGGTGTCCTGGTCAATGAAATCCTCAATCACATGA AGAGAGCAACTCAGATACCAAGCTACAAAAAACTTATCATGTATTCTGCGCATGACAC TACTGTGAGTGGTCTACAGATGGCGCTAGATGTTTACAACGGACTCCTTCCTCCCTAT GCTTCTTGCCACTTGACGGAATTGTACTTTGAGAAGGGGGAGTACTTTGTGGAGATGT ACTACCGGAATGAGACGCAGCACGAGCCGTATCCCCTCATGCTACCTGGCTGCAGCCC CAGCTGTCCTCTGGAGAGGTTTGCTGAGCTGGTTGGCCCTGTGATCCCTCAAGACTGG TCCACGGAGTGTATGACCACAAACAGCCATCAAGGTACTGAGGACAGTACAGATTAGT GTGCACAGAGATCTCTGTAGAAAGAGTAGCTGCCCTTTCTCAGGGCAGATGATGCTTT
GAGAACATACTTTGGCCATTACCC
ORF Start: ATG at 40 ORF Stop: TAG at 1099 SEQ ID NO: 334 353 aa MW at40442.9kD
NOV38b, MRAAPLLLARAASLSLGFLFLLFF LDRSVLAKELKFVTLVFRHGDRSPIDTFPTDPI CGI 58513-02 KESS PQGFGQLTQLGMEQHYELGEYIRKRYRKFLNESYKHEQVYIRSTDVDRTLMSA Protein Sequence MTNLAALFPPEGVSIW PILL QPIPVHTVPLSEDQDFIATLGKLSGLHGQDLFGI S KVYDPLYCESVHNFTLPSWATEDTMTKLRELSELSLLSLYGIHKQKEKSRLQGGVLVN EILNHMKRATQIPSYKKLIMYSAHDTTVSGLQMALDVYNGLLPPYASCHLTELYFEKG EYFVEMYYRNETQHEPYPLMLPGCSPSCPLERFAELVGPVIPQD STECMTTNSHQGT EDSTD
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 38B.
Further analysis of the NOV38a protein yielded the following properties shown in Table 38C.
Table 38C. Protein Sequence Properties NOV38a
PSort 0.4600 probability located in plasma membrane; 0.2083 probability located in analysis: microbody (peroxisome); 0.1000 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 33 and 34 analysis:
A search of the NOV38a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 38D.
In a BLAST search of public sequence datbases, the NOV38a protein was found to have homology to the proteins shown in the BLASTP data in Table 38E.
PFam analysis predicts that the NOV38a protein contains the domains shown in the Table 38F.
Example 39.
The NOV39 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 39 A.
Table 39A. NO 39 Sequence Analysis
SEQ ID NO: 335
NOV39a, GGAGCCATGGCCCTGAGCGAGCTGGCGCTGGTCCGCTGGCTGCAGGAGAGCCGCCGCT CG158583-01 CGCGGAAGCTCATCCTGTTCATCGTGTTCCTGGCGCTGCTGCTGGACAACATGCTGCT CACTGTCGTGGTAGAGAGAGGGTTTCTCCATGTTGGCCAGCCTGGTCTCGAACTCCTG DNA Sequence ACCTCAGGTGATCCACCTGCCTCAGCTTCCCAAAGTCCTGGAATTACAGTCCCCATCA TCCCAAGTTATCTGTACAGCATTAAGCATGAGAAGAATGCTACAGAAATCCAGACGGC CAGGCCAGTGCACACTGCCTCCATCTCAGACAGCTTCCAGAGCATCTTCTCCTATTAT GATAACTCGACTATGGTCACCGGGAATGCTACCAGAGACCTGACACTTCATCAGACCG CCACACAGCACATGGTGACCAACGCGTCCGCTGTTCCTTCCGACTGTCCCAGTGAAGA CAAAGACCTCCTGAATGAAAACGTGCAAGTTGGTCTGTTGTTTGCCTCGAAAGCCACC GTCCAGCTCATCACCAACCCTTTCATAGGACTACTGACCAACAGAATTGGCTATCCAA TTCCCATATTTGCGGGATTCTGCATCATGTTTGTCTCAACAATTATGTTTGCCTTCTC CAGCAGCTATGCCTTCCTGCTGATTGCCAGGTCGCTGCAGGGCATCGGCTCGTCCTGC TCCTCTGTGGCTGGGATGGGCATGCTTGCCAGTGTCTACACAGATGATGAAGAGAGAG GCAACGTCATGGGAATCGCCTTGGGAGGCCTGGCCATGGGGGTCTTAGTGGGCCCCCC CTTCGGGAGTGTGCTCTATGAGTTTGTGGGGAAGACGGCTCCGTTCCTGGTGCTGGCC GCCCTGGTACTCTTGGATGGAGCTATTCAGCTCTTTGTGCTCCAGCCGTCCCGGGTGC AGCCAGAGAGTCAGAAGGGGACACCCCTAACCACGCTGCTGAAGGACCCGTACATCCT CATTGCTGCAGGCTCCATCTGCTTTGCAAACATGGGCATCGCCATGCTGGAGCCAGCC CTGCCCATCTGGATGATGGAGACCATGTGTTCCCGAAAGTGGCAGCTGGGCGTTGCCT TCTTGCCAGCTAGTATCTCTTATCTCATTGGAACCAATATTTTTGGGATACTTGCACA CAAAATGGGGAGGTGGCTTTGTGCTCTTCTGGGAATGATAATTGTTGGAGTCAGCATT TTATGTATTCCATTTGCAAAAAACATTTATGGACTCATAGCTCCGAACTTTGGAGTTG GTTTTGCAATTGGAATGGTGGATTCGTCAATGATGCCTATCATGGGCTACCTCGTAGA CCTGCGGCACGTGTCCGTCTATGGGAGTGTGTACGCCATTGCGGATGTGGCATTTTGT ATGGGGTATGCTATAGGTCCTTCTGCTGGTGGTGCTATTGCAAAGGCAATTGGATTTC CATGGCTCATGACAATTATTGGGATAATTGATATTCTTTTTGCCCCTCTCTGCTTTTT TCTTCGAAGTCCACCTGCCAAAGAAGAAAAAATGGCTATTCTCATGGATCACAACTGC CCTATTAAAACAAAAATGTACACTCAGAATAATATCCAGTCATATCCGATAGGTGAAG ATGAAGAATCTGAAAGTGACTGAGATGAGATCCTCAAAAATCATCAAAGTGTTTAATT
GTATAAAACAGTGTTTCCAGTGACACAACTCATCCAGAACTGTCTTAGTCATACCATC
CATCCCTGGTGAAAGAGTAAAACCAAAGGTTATTATTTCCTTTCCATGGTTATGGTCG
ATTGCCAACAGCCTTATAAAGAAAAAGAAGCTTTTCTAGGGGTTTGTATAAATAGTGT iTGAAACTTTATTTTATGTATTTAATTTTATTAAATATCATACAATATATTTTGATGA
ATAGGTATTGTGTAAATCTATAAATATTTGAATCCAAACCAAATATAATTTCC
ORF Start: ATG at 7 lORF Stop: TGA at 1645
SEQ ID NO: 336 546 aa MW at 58912.5kD
NOV39a, MALSELALVR LQESRRSRKLILFIVFLALLLDNMLLTVWERGFLHVGQPGLELLTS CG158583-01 GDPPASASQSPGITVPIIPSYLYSIKHEKNATEIQTARPVHTASISDSFQSIFSYYDN STMVTGNATRDLTLHQTATQHMVT ASAVPSDCPSEDKDLLNENVQVGLLFASKATVQ Protein Sequence LITNPFIGLLTNRIGYPIPIFAGFCIMFVSTIMFAFSSSYAFLLIARSLQGIGSSCSS VAGMGMLASVYTDDEERGNVMGIALGGLAMGVLVGPPFGSVLYEFVGKTAPFLVLAAL VLLDGAIQLFVLQPSRVQPESQKGTPLTTLLKDPYILIAAGSICFANMGIAMLEPALP IWMMETMCSRKWQLGVAFLPASISYLIGTNIFGILAHKMGR LCALLGMIIVGVSILC IPFAKNIYGLIAPNFGVGFAIGMVDSSMMPIMGYLVDLRHVSVYGSVYAIADVAFCMG YAIGPSAGGAI KAIGFP LMTIIGIIDILFAPLCFFLRSPPAKEEKMAILMDHNCPI KTKMYTQ NIQSYPIGEDEESESD
SEQ ID NO: 337 1952 bp
NOV39b, GCAGGCATCGCAAGCGACCCCGAGCGGAGCCCCGGAGCCATGGCCCTGAGCGAGCTGG CG158583-02 CGCTGGTCCGCTGGCTGCAGGAGAGCCGCCGCTCGCGGAAGCTCATCCTGTTCATCGT GTTCCTGGCGCTGCTGCTGGACAACATGCTGCTCACTGTCGTGGGTTCAAGCGATCCT DNA Sequence CCTTTCTCAGCCTCCAAAGGAGCTGGGATTACAGTCCCCATCATCCCAAGTTATCTGT ACAGCATTAAGCATGAGAAGAATGCTACAGAAATCCAGACGGCCAGGCCAGTGCACAC TGCCTCCATCTCAGACAGCTTCCAGAGCATCTTCTCCTATTATGATAACTCGACTATG GTCACCGGGAATGCTACCAGAGACCTGACACTTCATCAGACCGCCACACAGCACATGG TGACCAACGCGTCCGCTGTTCCTTCCGACTGTCCCAGTGAAGACAAAGACCTCCTGAA TGAAAACGTGCAAGTTGGTCTGTTGTTTGCCTCGAAAGCCACCGTCCAGCTCATCACC AACCCTTTCATAGGACTACTGACCAACAGAATTGGCTATCCAATTCCCATATTTGCGG GATTCTGCATACATGTTGTCTCAACAATTATGTTTGCCTTCTCCAGCAGCTATGCCTT CCTGCTGATTGCCAGGTCGCTGCAGGGCATCGGCTCGTCCTGCTCCTCTGTGGCTGGG ATGGGCATGCTTGCCAGTGTCTACACAGATGATGAAGAGAGAGGCAACGTCATGGGAA TCGCCTTGGGAGGCCTGGCCATGGGGGTCTTAGTGGGCCCCCCCTTCGGGAGTGTGCT CTATGAGTTTGTGGGGAAGACGGCTCCGTTCCTGGTGCTGGCCGCCCTGGTACTCTTG GATGGAGCTATTCAGCTCTTTGTGCTCCAGCCGTCCCGGGTGCAGCCAGAGAGTCAGA AGGGGACACCCCTAACCACGCTGCTGAAGGACCCGTACATCCTCATTGCTGCAGGCTC CATCTGCTTTGCAAACATGGGCATCGCCATGCTGGAGCCAGCCCTGCCCATCTGGATG ATGGAGACCATGTGTTCCCGAAAGTGGCAGCTGGGCGTTGCCTTCTTGCCAGCTAGTA TCTCTTATCTCATTGGAACCAATATTTTTGGGATACTTGCACACAAAATGGGGAGGTG GCTTTGTGCTCTTCTGGGAATGATAATTGTTGGAGTCAGCATTTTATGTATTCCATTT GCAAAAAACATTTATGGACTCATAGCTCCGAACTTTGGAGTTGGTTTTGCAATTGGAA TGGTGGATTCGTCAATGATGCCTATCATGGGCTACCTCGTAGACCTGCGGCACGTGTC CGTCTATGGGAGTGTGTACGCCATTGCGGATGTGGCATTTTGTATGGGGTATGCTATA GGTCCTTCTGCTGGTGGTGCTATTGCAAAGGCAATTGGATTTCCATGGCTCATGACAA TTATTGGGATAATTGATATTCTTTTTGCCCCTCTCTGCTTTTTTCTTCGAAGTCCACC TGCCAAAGAAGAAAAAATGGCTATTCTCATGGATCACAACTGCCCTATTAAAACAAAA ATGTACACTCAGAATAATATCCAGTCATATCCGATAGGTGAAGATGAAGAATCTGAAA GTGACTGAGATGAGATCCTCAAAAATCATCAAAGTGTTTAATTGTATAAAACAGTGTT
TCCAGTGACACAACTCATCCAGAACTGTCTTAGTCATACCATCCATCCCTGGTGAAAG
AGTAAAACCAAAGGTTATTATTTCCTTTCCATGGTTATGGTCGATTGCCAACAGCCTT
ATAAAGAAAAAGAAGCTTTTCTAGGGGTTTGTATAAATAGTGTTGAAACTTTATTTTA
TGTATTTAATTTTATTAAATATCATACAATATATTTTGATGAAATAGGTATTGTGTAA
ATCTATAAATATTTGAATCCAAACCAAATATAATTTCC
ORF Start: ATG at 40 ORF Stop: TGA at 1630
SEQ ID NO: 338 530 aa MW at 57130.4kD
NOV39b, MALSELALVRWLQESRRSRKLILFIVFLALLLD MLLTWGSSDPPFSASKGAGITVP CGI 58583-02 IIPSYLYSIKHEKNATEIQTARPVHTASISDSFQSIFSYYDNSTMVTGNATRDLTLHQ Protein Sequence TATQHMVTNASAVPSDCPSEDΪDLLNENVQVGLLFASKATVQLITNPFIGLLTNRIGY PIPIFAGFCIHWSTIMFAFSSSYAFLLIARSLQGIGSSCSSVAGMGMLASVYTDDEE RGNVMGIALGGI^^GVLVGPPFGSVLYEFVGKTAPFLVLAALVLLDGAIQLFVLQPSR VQPESQKGTPLTTLLKDPYILIAAGSICFANMGIAMLEPALPIWMMETMCSRK QLGV AFLPASISYLIGTNIFGILAHKMGRWLCALLGMIIVGVSILCIPFAKNIYGLIAPNFG VGFAIGMVDSSMMPIMGYLVDLRHVSVYGSVYAIADVAFCMGYAIGPSAGGAIAKAIG FP LMTIIGIIDILFAPLCFFLRSPPAKEEKMAILMDHNCPIKTKMYTQ NIQSYPIG EDEESESD
SEQ ID NO: 339 1647bp
CGI 58583-03 EIQTARPVHTASISDSFQSIFSYYDNSTMVTGNATRDLTLHQTATQHMVTNASAVPSD Protein Sequence CPSEDKDLLNENVQVGLLFASKATVQLITNPFIGLLTNRIGYPIPIFAGFCIMFVSTI MFAFSSSYAFLLIARSLQGIGSSCSSVAGMGMLASVYTDDEERGNVMGIALGGLAMGV LVGPPFGSVLYEFVGKTAPFLVLAALVLLDGAIQLFVLQPSRVQPESQKGTPLTTLLK DPYILIAAGSICFANMGIAMLEPALPIWMMETMCSRKWQLGVAFLPASISYLIGTNIF GILAHKMGRWLCALLGMIIVGVSTLCIPFAKNIYGLIAPNFGVGFAIGMVDSSMMPIM GYLVDLRHVSVYGSVYAIADVAFCMGYAIGPSAGGAIAKAIGFPWLMTIIGIIDILFA PLCFFLRSPPAKEEKMAILMDHNCPIKTKMYTQNSIQSYPIGEDEESESD
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 39B.
Further analysis of the NOV39a protein yielded the following properties shown in Table 39C.
Table 39C. Protein Sequence Properties NOV39a
PSort 0.6400 probability located in plasma membrane; 0.4600 probability located in analysis: Golgi body; 0.3700 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 38 and 39 analysis:
A search of the NOV39a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 39D.
In a BLAST search of public sequence datbases, the NOV39a protein was found to have homology to the proteins shown in the BLASTP data in Table 39E.
PFam analysis predicts that the NOV39a protein contains the domains shown in the Table 39F.
Table 39F. Domain Analysis of NOV39a
Identities/
Pfam Domain NOV39a Match Region Similarities Expect Value for the Matched Region sugar r 98..516 66/523 (13%) 0.019 268/523 (51%)
Example 40.
The NOV40 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 40A.
Table 40A. NOV40 Sequence Analysis
SEQ ID NO: 345 1096 bp
NOV40a, GCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCGGC CG158964-01 TGGCACACGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGΛGGGCC
CCGGGCGCCATTGCTGGCGGTGGGAGCGCCGCCCGGTCTCAGCCCGCCCTCGGCTGCTi DNA Sequence CTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGC
TCGAGAATCAAGGGCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGC
AGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCTGCCGTACGTGGCCCTCGATGTG
CTCTGCGTGTTGCTGGATTATTCTTGGAGAAACCCTGTCTGTTTACTGTAACCTTTTG CACTCAAATTCCTTTATCAGGAATAACTACATAGCCACTATTTACAAAGCCATTGGAA CCTTTTTATTTGGTGCAGCTGCTAGTCAGTCCCTGACTGACATTGCCAAGTATTCAAT AGGCAGACTGCGGCCTCACTTCTTGGATGTTTGTGATCCAGATTGGTCAAAAATCAAC TGCAGCGATGGTTACATTGAATACTACATATGTCGAGGGAATGCAGAAAGAGTTAAGG AAGGCAGGTTGTCCTTCTATTCAGGCCACTCTTCGTTTTCCATGTACTGCATGCTGTT TGTGGCACTTTATCTTCAAGCCAGGATGAAGGGAGACTGGGCAAGACTCTTACGCCCC ACACTGCAATTTGGTCTTGTTGCCGTATCCATTTATGTGGGCCTTTCTCGAGTTTCTG ATTATAAACACCACTGGAGCGATGTGTTGACTGGACTCATTCAGGGAGCTCTGGTTGC AATATTAGTTGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACTTCTTTTAAAGAA AGAAAAGAGGAGGACTCTCATACAACTCTGCATGAAACACCAACAACTGGGAATCACT ATCCGAGCAATCACCAGCCTTGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGGCCTGTT
TTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGG
ORF Start: ATG at 344 ORF Stop: TGA at 1007
SEQ ID NO: 346 |_21 aa |MW at 25083.4kD
NOV40a, MCSACCWIILGETLSVYCNLLHSNSFIRNNYIATIYKAIGTFLFGAAASQSLTDIAKY CG158964-01 SIGRLRPHFLDVCDPD SKINCSDGYIEYYICRGNAERVKEGRLSFYSGHSSFSMYCM Protein Sequence LFVALYLQARMKGDARLLRPTLQFGLVAVSIYVGLSRVSDYKHH SDVLTGLIQGAL VAILVAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP
NOV40b, CGGCCGCGTCGACGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACA CG158964-02 GAGCTGCCGCGGCTGGCACACGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTG
TGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCCGCCCGGTCTCAGCCC DNA Sequence GCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAG CCCCGGCCCGGGCTCGAGAATCAAGGGCCTCGGCCGCCGTCCCGCAGCTCAGTCCATC
GCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCTGCCGTACGT
GGCCCTCGATGTGCTCTGCGTGTTGCTGGATTATTCTTGGAGAAACCCTGTCTGTTTA
CTGTAACCTTTTGCACTCAAATTCCTTTATCAGGAATAACTACATAGCCACTATTTAC AAAGCCATTGGAACCTTTTTATTTGGTGCAGCTGCTAGTCAGTCCCTGACTGACATTG CCAAGTATTCAATAGGCAGACTGCGGCCTCACTTCTTGGATGTTTGTGATCCAGATTG GTCAAAAATCAACTGCAGCGATGGTTACATTGAATACTACATATGTCGAGGGAATGCA GAAAGAGTTAAGGAAGGCAGGTTGTCCTTCTATTCAGGCCACTCTTCGTTTTCCATGT ACTGCATGCTGTTTGTGGCACTTTATCTTCAAGCCAGGATGAAGGGAGACTGGGCAAG ACTCTTACGCCCCACACTGCAATTTGGTCTTGTTGCCGTATCCATTTATGTGGGCCTT TCTCGAGTTTCTGATTATAAACACCACTGGAGCGATGTGTTGACTGGACTCATTCAGG GAGCTCTGGTTGCAATATTAGTTGCTGTATATGTATCGGATTTCTTCAAAGAAAGAAC TTCTTTTAAAGAAAGAAAAGAGGAGGACTCTCATACAACTCTGCATGAAACACCAACA ACTGGGAATCACTATCCGAGCAATCACCAGCCTTGAAAGGCAGCAGGGTGCCCAGGTG
AAGCTGGCCTGTTTTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTC
TTCCTGGTGTACAAGCCTTTAAAGACTTCTGCTGCTGCTATGCCTCTTGGATGCACAG
TTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCTAATAGCTCTAAACTCATTA
AAAAAACTCCAAGCCTTCCACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAA
AAATGTAATGCTTATGTATAAACATGTATGTAATATGCTTTCTATGAATGATGTTTGA
TTTAAATATAATACATATTAAAATGTATGGGAGAACCAAAAAAAAAAAAAAAAA
ORF Start: ATG at 357 ORF Stop: TGA at 1020
SEQ ID NO: 348 221 aa MW at 25083.4kD
NOV40b, MCSACC IILGETLSVYCNLLHSNSFIRNNYIATIYKAIGTFLFGAAASQSLTDIAKY CG158964-02 SIGRLRPHFLDVCDPDWSKINCSDGYIEYYICRGNAERVKEGRLSFYSGHSSFSMYCM LFVALYLQARMKGD ARLLRPTLQFGLVAVSIYVGLSRVSDYKHHSDVLTGLIQGAL Protein Sequence VAILVAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 40B.
Table 40B. Comparison of NO 40a against NOV40b.
Identities/
Protein Sequence NOV40a Residues/ Match Residues SimUarities for the Matched Region
NOV40b 1..221 221/221 (100%) 1..221 221/221 (100%)
Further analysis of the NOV40a protein yielded the following properties shown in Table 40C.
Table 40C. Protein Sequence Properties NOV40a
PSort 0.6400 probability located in endoplasmic reticulum (membrane); 0.4960 analysis: probability located in plasma membrane; 0.3776 probability located in microbody (peroxisome); 0.1900 probability located in Golgi body
SignalP Cleavage site between residues 49 and 50 analysis:
A search of the NOV40a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 40D.
In a BLAST search of public sequence datbases, the NOV40a protein was found to have homology to the proteins shown in the BLASTP data in Table 40E.
PFam analysis predicts that the NOV40a protein contains the domains shown in the Table 40F.
Table 40F. Domain Analysis of NOV40a
Identities/
Pfam Domain NOV40a Match Region Similarities Expect Value for the Matched Region
PAP2 37..188 62/174 (36%) 1.5e-50 133/174 (76%)
Example 41.
The NOV41 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 41 A.
Further analysis of the NOV41a protein yielded the following properties shown in Table 41B.
Table 41B. Protein Sequence Properties NOV41a
PSort 0.5819 probability located in microbody (peroxisome); 0.1000 probability analysis: located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV41a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 41C.
In a BLAST search of public sequence datbases, the NOV41a protein was found to have homology to the proteins shown in the BLASTP data in Table 4 ID.
PFam analysis predicts that the NOV41a protein contains the domains shown in the Table 41E.
The NOV42 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 42A.

DNA Sequence CGTCTTCCCCGCCAAGGCGTCCGCGCCGGGCGCGGGGCCGGCCGCGGCCGAGAAGCGC CTGGGCACCCCGCCGGGGGGCGGCGGGGCCGGCGCGAAGGAGCACGGCAACTCCGTGT GCTTCAAGGTGGACGGCGGTGGCGGCGGTGGCGGCGGCGGCGGCGGCGGCGAGGAGCC GGCGGGGGGCTTCGAAGACGCCGAGGGGCCCCGGCGGCAGTACGGCTTCATGCAGAGG CAGTTCACCTCCATGCTGCAGCCCGGGGTCAACAAATTCTCCCTCCGCATGTTTGGGA GCCAGAAGGCGGTGGAAAAGGAGCAGGAAAGGGTTAAAACTGCAGGCTTCTGGATTAT CCACCCTTACAGTGATTTCAGGTTTTACTGGGATTTAATAATGCTTATAATGATGGTT GGAAATCTAGTCATCATACCAGTTGGAATCACATTCTTTACAGAGCAAACAACAACAC CATGGATTATTTTCAATGTGGCATCAGATACAGTTTTCCTATTGGACCTGATCATGAA TTTTAGGACTGGGACTGTCAATGAAGACAGTTCTGAAATCATCCTGGACCCCAAAGTG ATCAAGATGAATTATTTAAAAAGCTGGTTTGTGGTTGACTTCATCTCATCCATCCCAG TGGATTATATCTTTCTTATTGTAGAAAAAGGAATGGATTCTGAAGTTTACAAGACAGC CAGGGCACTTCGCATTGTGAGGTTTACAAAAATTCTCAGTCTCTTGCGTTTATTACGA CTTTCAAGGTTAATTAGATACATACATCAATGGGAAGAGATATTCCACATGACATATG ATCTCGCCAGTGCAGTGGTGAGAATTTTTAATCTCATCGGCATGATGCTGCTCCTGTG CCACTGGGATGGTTGTCTTCAGTTCTTAGTACCACTACTGCAGGACTTCCCACCAGAT TGCTGGGTGTCTTTAAATGAAATGGTTAATGATTCTTGGGGAAAGCAGTATTCATACG CACTCTTCAAAGCTATGAGTCACATGCTGTGCATTGGGTATGGAGCCCAAGCCCCAGT CAGCATGTCTGACCTCTGGATTACCATGCTGAGCATGATCGTCGGGGCCACCTGCTAT GCCATGTTTGTCGGCCATGCCACCGCTTTAATCCAGTCTCTGGATTCTTCGAGGCGGC AGTATCAAGAGAAGTATAAGCAAGTGGAACAATACATGTCATTCCATAAGTTACCAGC TGATATGCGTCAGAAGATACATGATTACTATGAACACAGATACCAAGGCAAAATCTTT GATGAGGAAAATATTCTCAATGAACTCAATGATCCTCTGAGAGAGGAGATAGTCAACT TCAACTGTCGGAAACTGGTGGCTACAATGCCTTTATTTGCTAATGCGGATCCTAATTT TGTGACTGCCATGCTGAGCAAGTTGAGATTTGAGGTGTTTCAACCTGGAGATTATATC ATACGAGAAGGAGCCGTGGGTAAAAAAATGTATTTCATTCAACACGGTGTTGCTGGTG TCATTACAAAATCCAGTAAAGAAATGAAGCTGACAGATGGCTCTTACTTTGGGGAGAT TTGCCTGCTGACCAAAGGACGTCGTACTGCCAGTGTTCGAGCTGATACATATTGTCGT CTTTACTCACTTTCCGTGGACAATTTCAACGAGGTCCTGGAGGAATATCCAATGATGA GGAGAGCCTTTGAGACAGTTGCCATTGACCGACTAGATCGAATAGGAAAGAAAAATTC AATTCTTCTGCAAAAGTTCCAGAAGGATCTGAACACTGGTGTTTTCAACAATCAGGAG AACGAAATCCTCAAGCAGATTGTGAAACATGACAGGGAGATGGTGCAGGCAATCGCTC CCATCAATTATCCTCAAATGACAACCCTGAATTCCACATCGTCTACTACGACCCCGAC CTCCCGCATGAGGACACAATCTCCACCGGTGTACACAGCGACCAGCCTGTCTCACAGC AACCTGCACTCCCCCAGTCCCAGCACACAGACCCCCCAGCCATCAGCCATCCTGTCAC CCTGCTCCTACACCACCGCGGTCTGCAGCCCTCCTGTACAGAGCCCTCTGGCCGCTCG AACTTTCCACTATGCCTCCCCCACCGCCTCCCAGCTGTCACTCATGCAACAGCAGCCG CAGCAGCAGGTACAGCAGTCCCAGCCGCCGCAGACTCAGCCACAGCAGCCGTCCCCGC AGCCACAGACACCTGGCAGCTCCACGCCGAAAAATGAAGTGCACAAGAGCACGCAGGC GCTTCACAACACCAACCTGACCCGGGAAGTCAGGCCACTCTCCGCCTCGCAGCCCTCG CTGCCCCATGAGGTGTCCACTCTGATTTCCAGACCTCATCCCACTGTGGGCGAGTCCC TGGCCTCCATCCCTCAACCCGTGACGGCGGTCCCCGGAACGGGCCTTCAGGCAGGGGG CAGGAGCACTGTCCCGCAGCGCGTCACCCTCTTCCGACAGATGTCGTCGGGAGCCATC CCCCCGAACCGAGGAGTCCCTCCAGCACCCCCTCCACCAGCAGCTGCTCTTCCAAGAG AATCTTCCTCAGTCTTAAACACAGACCCAGACGCAGAAAAGCCACGATTTGCTTCAAA TTTATGATCCCTGCTGATTGTCAAAGCAGAAAGAAATACTCTCATAAACTGAGACTAT
ACTCAGATCTTATTTTATTCTATCTCCTGATAGATCCCTCTAGCCTACTATGAAGAGA
TATTTTAGACAGCTGTGGCCTACACGTGAAATGTAAAAATATATATACATATACTATA jAAATATATATCTAAATTCCCAAGAGAGGGTCAAAAGACCTGTTTAGCATTCAGTGTTA;
TATGTCTTCCTTTCTTTAAATCATTAAAGGAT
ORF Start: ATG at 61 ORF Stop: TGA at 2731
SEQ ID NO: 352 890 aa MW at 98791.0kD
NOV42a, MEGGGKPNSSSNSRDDGNSVFPAKASAPGAGPAAAEKRLGTPPGGGGAGAKEHGNSVC CG159130-01 FKVDGGGGGGGGGGGGEEPAGGFEDAEGPRRQYGF QRQFTSMLQPGVNKFSLRMFGS QKAVEKEQERVKTAGF IIHPYSDFRFYDLIMLIMMVGNLVIIPVGITFFTEQTTTP Protein Sequence IIF VASDT FLLDLI^_TFRTG NEDSSEIILDPKVIKM YLKSWFVVDFISSIPV DYIFLIVEKGMDSEVYKTARALRIVRFTKILSLLRLLRLSRLIRYIHQ EEIFH TYD lASAVVRIFNLIGM LLLCH DGCLQFLVPLLQDFPPDC VSLNEMVNDS GKQYSYA LFKAMSHMLCIGYGAQAPVS SDL IT LS IVGATCYAMFVGHATALIQSLDSSRRQ
YQEKYKQVEQY SFHKLPADMRQKIHDYYEHRYQGKIFDEENILNELNDPLREEIVNF NCRKLVAT PLFANADPNFVTAMLSKLRFEVFQPGDYIIREGAVGKK YFIQHGVAGV ITKSSKEMKLTDGSYFGEICLLTKGRRTASVRADTYCRLYSLSVDNFNEVLEEYP R RAFETVAIDRLDRIGKKNSILLQKFQKDLNTGVFNNQENEILKQIVKHDREMVQAIAP INYPQMTTLNSTSSTTTPTSRMRTQSPPVYTATSLSHSNLHSPSPSTQTPQPSAILSP CSYTTAVCSPPVQSPLAARTFHYASPTASQLSLMQQQPQQQVQQSQPPQTQPQQPSPQ PQTPGSSTPKNEVHKSTQALHNTNLTREVRPLSASQPSLPHEVSTLISRPHPTVGESL ASIPQPVTAVPGTGLQAGGRSTVPQRVTLFRQMSSGAIPPNRGVPPAPPPPAAALPRE SSSVLNTDPDAEKPRFASNL
Further analysis of the NOV42a protein yielded the following properties shown in Table 42B.
Table 42B. Protein Sequence Properties NOV42a
PSort 0.6000 probability located in plasma membrane; 0.4000 probability located in analysis: Golgi body; 0.3000 probability located in endoplasmic reticulum (membrane); 0.3000 probability located in microbody (peroxisome)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NO V42a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 42C.
In a BLAST search of public sequence datbases, the NOV42a protein was found to have homology to the proteins shown in the BLASTP data in Table 42D.
PFam analysis predicts that the NOV42a protein contains the domains shown in the Table 42E.
Example 43.
The NOV43 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 43 A.
Table 43A. NOV43 Sequence Analysis
SEQ ID NO: 353 1136 bp
NOV43a, AACACCATGAGGGCCCTGGTGCTTCTGCTGTCCCTGTTCCTGCTGGGTGGCCAGGCCC CG159178-01 AGCATGTGTCTGACTGGACCTACTCAGTGCAGATCGGCCTGCCCTCCACCATGCGCAT GACAGTGGCTGACGGCACTGTATACGTAGCCCAGCAGATGCACTTTCACTGGGGAGGT DNA Sequence GCGTCCTCGGAGATCAGCGGCTCTGAGCACACCGTGGACGGGATCAGACATGTGATCG AGATTCACATTGTTCACTACAATTCTAAATACAAGAGCTATGATATAGCCCAAGATGC GCCGGATGGTTTGGCTGTACTGGCAGCCTTCGTTGAGGTGAAGAATTACCCTGAAAAC ACTTATTACAGCAACTTCATTTCTCATCTGGCCAACATCAAGTACCCAGGACAAAGAA CAACCCTGACTGGCCTTGACGTTCAGGACATGCTGCCCAGGAACCTCCAGCACTACTA CACCTACCATGGCTCACTCACCACGCCTCCCTGCACTGAGAACGTCCACTGGTTTGTG CTGGCAGATTTTGTCAAGCTCTCCAGGACACAGGTTTGGAAGCTGGAGAATTCCTTAC TGGATCACCGCAATAAGACCATCCACAACGATTACCGCAGGACCCAGCCCCTGAAACA CAGAGTGGTGGAATCCAACTTCCCGAATCAGGAATACACTCTAGGCTCTGAATTCCAG TTTTACCTACATAAGATTGAGGAAATTCTTGACTACTTAAGAAGAGCATTGAACTGAG GAAAGCTAAGAGGAAGATTCAATAATATTAACTAGCTTGAAGCCTGACCTAGCCAGAA
GTGCCTGTCCGCTGCAGCCGCACCCTACCTTGTCTAAGAAACCATGTGTGTCTGGAAC
ACGCTGCTCCCCTGGGCAGCTGTTGGGATTCTGATTAAAGAGGGGAAACGATCATCCT
GGACAGGAAGTGAGATGGCTTCAGTTCATGAGACGGGATCTGAGTTAGACATCACCAG:
TGGAAATTGATTGGAATAGAAACTTAAAGGAAATGGAACCCTAACTATTCTCCCATCA!
AATCATATATGTTGACCTGTCTGAATTATAAACCAGCCTGACCTTTCCTTTAGCATTAi
GATGTAATAAAATAACTTTGGAAATTTGTCATTT
ORF Start: ATG at 7 ORF Stop: TGA at 751
SEQ ID NO: 354 248 aa MW at 28657.2kD
NOV43a, MRALVLLLSLFLLGGQAQHVSDWTYSVQIGLPSTMRMTVADGTVYVAQQMHFH GGAS CG159178-01 SEISGSEHTVDGIRHVIEIHIVHYNSKYKSYDIAQDAPDGLAVLAAFVEVKNYPENTY YSNFISHLANIKYPGQRTTLTGLDVQDMLPRNLQHYYTYHGSLTTPPCTENVH FVLA Protein Sequence DFVKLSRTQV KLENSLLDHRNKTIHNDYRRTQPLKHRVVESNFPNQEYTLGSEFQFY LHKIEEILDYLRRALN
NOV43b, AACACCATGAGGGCCCTGGTGCTTCTGCTGTCCCTGTTCCTGCTGGGTGGCCAGGCCC CG159178-02 AGCATGTGTCTGACTGGACCTACTCAGAAGGGGCACTGGACGAAGCGCACTGGCCACA GCACTACCCCGCCTGTGGGGGCCAGAGACAGTCGCCTATCAACCTACAGAGGACGAAG DNA Sequence GTGCGGTACAACCCCTCCTTGAAGGGGCTCAATATGACAGGCTATGAGACCCAGGCAG GGGAGTTCCCCATGGTCAACAATGGCCACACAGTGCAGATCGGCCTGCCCTCCACCAT GCGCATGACAGTGGCTGACGGCACTGTATACATAGCCCAGCAGATGCACTTTCACTGG GGAGGTGCGTCCTCGGAGATCAGCGGCTCTGAGCACACCGTGGACGGGATCAGACATG TGATCGAGATTCACATTGTTCACTACAATTCTAAATACAAGAGCTATGATATAGCCCA AGATGCGCCGGATGGTTTGGCTGTACTGGCAGCCTTCGTTGAGGTGAAGAATTACCCT GAAAACACTTATTACAGCAACTTCATTTCTCATCTGGCCAACATCAAGTACCCAGGAC AAAGAACAACCCTGACTGGCCTTGACGTTCAGGACATGCTGCCCAGGAACCTCCAGCA CTACTACACCTACCATGGCTCACTCACCACGCCTCCCTGCACTGAGAACGTCCACTGG TTTGTGCTGGCAGATTTTGTCAAGCTCTCCAGGACACAGGTTTGGAAGCTGGAGAATT CCTTACTGGATCACCGCAATAAGACCATCCACAACGATTACCGCAGGACCCAGCCCCT GAACCACAGAGTGGTGGAATCCAACTTCCCGAATCAGGAATACACTCTAGGCTCTGAA TTCCAGTTTTACCTACATAAGATTGAGGAAATTCTTGACTACTTAAGAAGAGCATTGA ACTGAGGAAAGCTAAGAGGAAGATTCAATATTAACTAGCTTGAAGCCTGACCTAGCCA
AGGGCGATTCCACACACTGC
ORF Start: ATG at 7 ORF Stop: TGA at 931
SEQ ID NO: 356 308 aa MW at 35336.5kD
NOV43b, MRALVLLLSLFLLGGQAQHVSD TYSEGALDEAH PQHYPACGGQRQSPINLQRTKVR CG159178-02 YNPSLKGLNMTGYETQAGEFPMVNNGHTVQIGLPSTMR TVADGTVYIAQQMHFHWGG
Protein Sequence ASSEISGSEHTVDGIRHVIEIHIVHYNSKYKSYDIAQDAPDGLAVLAAFVEVKNYPEN TYYSNFISHLANIKYPGQRTTLTGLDVQDMLPRNLQHYYTYHGSLTTPPCTENVH FV LADFVKLSRTQV KLENSLLDHRNKTIHNDYRRTQPLNHRVVESNFPNQEYTLGSEFQ FYLHKIEEILDYLRRALN
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 43B.
Table 43B. Comparison of NOV43a against NOV43b.
NOV43a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV43b 25..248 220/224 (98%) 85..308 223/224 (99%)
Further analysis of the NOV43a protein yielded the following properties shown in Table 43C.
Table 43C. Protein Sequence Properties NOV43a
PSort 0.4132 probability located in outside; 0.2473 probability located in microbody analysis: (peroxisome); 0.1000 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 18 and 19 analysis:
A search of the NOV43a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 43D.
In a BLAST search of public sequence datbases, the NOV43a protein was found to have homology to the proteins shown in the BLASTP data in Table 43E.
PFam analysis predicts that the NOV43a protein contains the domains shown in the Table 43F.
Example 44.
The NOV44 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 44A.
Table 44A. NOV44 Sequence Analysis
SEQ ID NO: 357 1704 bp
NOV44a, GGTTTCATGGCAGCCTCAAAGAAGGCAGTTTTGGGGCCATTGGTGGGGGCGGTGGACC CG160131-01 AGGGCACCAGTTCGACGCGCTTTTTGGTTTTCAATTCAAAAACAGCTGAACTACTTAG TCATCATCAAGTAGAAATAAAACAAGAGTTCCCAAGAGAAGGATGGGTGGAACAGGAC DNA Sequence CCTAAGGAAATTCTACATTCTGTCTATGAGTGTATAGAGAAAACATGTGAGAAACTTG GACAGCTCAATATTGATATTTCCAACATAAAAGCTATTGGTGTCAGCAACCAGAGGGA AACCACTGTAGTCTGGGACAAGATAACTGGAGAGCCTCTCTACAATGCTGTGGCTGCT CCAGTTTCTCCTGGCCCTTCAGTTCCAGTTGCCGTTGTTCCCTCTGGCTCTTCAGTTC CAGCTCCTGGTACTTCCTCAGTGTGGCTTGATCTAAGAACCCAGTCTACCGTTGAGAG TCTTAGTAAAAGAATTCCAGGAAATAATAACTTTGTCAAGTCCAAGACAGGCCTTCCA CTTAGCACTTACTTCAGTGCAGTGAAACTTCGTTGGCTCCTTGACAATGTGAGAAAAG TTCAAAAGGCCGTTGAAGAAAAACGAGCTCTTTTTGGGACTATTGATTCATGGCTTAT TTGGAGTTTGACAGGAGGAGTCAATGGAGGTGTCCACTGTACAGATGTAACAAATGCA AGTAGGACTATGCTTTTCAACATTCATTCTTTGGAATGGGATAAACAACTCTGCGAAT TTTTTGGAATTCCAATGGAAATTCTTCCAAATGTCCGGAGTTCTTCTGAGATCTATGG CCTAATGAAAGCTGGGGCCTTGGAAGGTGTGCCAATATCTGGGTGTTTAGGGGACCAG TCTGCTGCATTGGTGGGACAAATGTGCTTCCAGATTGGACAAGCCAAAAATACGTATG GAACAGGATGTTTCTTACTATGTAATACAGGCCATAAGTGTGTATTTTCTGATCATGG CCTTCTCACCACAGTGGCTTACAAACTTGGCAGAGACAAACCAGTATATTATGCTTTG GAAGGTTCTGTAGCTATAGCTGGTGCTGTTATTCGCTGGCTAAGAGACAATCTTGGAA TTATAAAGACCTCAGAAGAAATTGAAAAACTTGCTAAAGAAGTAGGTACTTCTTATGG CTGCTACTTCGTCCCAGCATTTTCGGGGTTATATGCACCTTATTGGGAGCCCAGCGCA AGAGGGATAATCTGTGGACTCACTCAGTTCACCAATAAATGCCATATTGCTTTTGCTG CATTAGAAGCTGTTTGTTTCCAAACTCGAGAGATTTTGGATGCCATGAATCGAGACTG TGGAATTCCACTCAGTCATTTGCAGGTAGATGGAGGAATGACCAGCAACAAAATTCTT ATGCAGCTACAAGCAGACATTCTGTATATACCAGTAGTGAAGCCCTCAATGCCCGAAA CCACTGCACTGGGTGCGGCTATGGCGGCAGGGGCTGCAGAAGGAGTCGGCGTATGGAG TCTCGAACCCGAGGATTTGTCTGCCGTCACGATGGAGCGGTTTGAACCTCAGATTAAT GCGGAGGAAAGTGAAATTCGTTATTCTACATGGAAGAAAGCTGTGATGAAGTCAATGG GTTGGGTTACAACTCAATCTCCAGAAAGTGGTATTCCATAAAACCTACCAACTCATGG ATTCCCAAGATGTGAGCTTTTT
ORF Start: ATG at 7 ORF Stop: TAA at 1663
SEQ ID NO: 358 552 aa MW at 59929.2kD
NOV44a, MAASKKAVLGPLVGAVDQGTSSTRFLVFNSKTAELLSHHQVEIKQEFPREG VEQDPK CG160131-01 EILHSVYECIEKTCEKLGQLNIDISNIKAIGVSNQRETTW DKITGEPLYNAVAAPV SPGPSVPVAWPSGSSVPAPGTSSVWLDLRTQSTVESLSKRIPGNNNFVKSKTGLPLS Protein Sequence TYFSAVKLR LLDNVRKVQKAVEEKRALFGTIDS LI SLTGGVNGGVHCTDVTNASR TMLFNIHSLEWDKQLCEFFGIP EILPNVRSSSEIYGLMKAGALEGVPISGCLGDQSA ALVGQMCFQIGQAKNTYGTGCFLLCNTGHKCVFSDHGLLTTVAYKLGRDKPVYYALEG SVAIAGAVIR LRDNLGIIKTSEEIEKLAKEVGTSYGCYFVPAFSGLYAPYWEPSARG IICGLTQFTNKCHIAFAALEAVCFQTREILDAMNRDCGIPLSHLQVDGGMTSNKILMQ LQADILYIPWKPSMPETTALGAAMAAGAAEGVGV SLEPEDLSAVTMERFEPQINAE ESEIRYSTWKKAVMKS GWVTTQSPESGIP
SEQ ID NO: 359
NOV44b, CACCGGATCCATGGCAGCCTCAAAGAAGGCAGTTTTGGGGCCATTGGTGGGGGCGGTG CG160131-04 GACCAGGGCACCAGTTCGACGCGCTTTTTGGTTTTCAATTCAAAAACAGCTGAACTAC TTAGTCATCATCAAGTAGAAATAAAACAAGAGTTCCCAAGAGAAGGATGGGTGGAACA DNA Sequence GGACCCTAAGGAAATTCTACATTCTGTCTATGAGTGTATAGAGAAAACATGTGAGAAA CTTGGACAGCTCAATATTGATATTTCCAACATAAAAGCTATTGGTGTCAGCAACCAGA GGGAAACCACTGTAGTCTGGGACAAGATAACTGGAGAGCCTCTCTACAATGCTGTGGT GTGGCTTGATCTAAGAACCCAGTCTACCGTTGAGAGTCTTAGTAAAAGAATTCCAGGA AATAATAACTTTGTCAAGTCCAAGACAGGCCTTCCACTTAGCACTTACTTCAGTGCAG TGAAACTTCGTTGGCTCCTTGACAATGTGAGAAAAGTTCAAAAGGCCGTTGAAGAAAA
ACGAGCTCTTTTTGGGACTATTGATTCATGGCTTATTTGGAGTTTGACAGGAGGAGTC AATGGAGGTGTCCACTGTACAGATGTAACAAATGCAAGTAGGACTATGCTTTTCAACA TTCATTCTTTGGAATGGGATAAACAACTCTGCGAATTTTTTGGAATTCCAATGGAAAT TCTTCCAAATGTCCGGAGTTCTTCTGAGATCTATGGCCTAATGAAAATCTCTCATAGC GTGAAAGCTGGGGCCTTGGAAGGTGTGCCAATATCTGGGTGTTTAGGGGACCAGTCTG CTGCATTGGTGGGACAAATGTGCTTCCAGATTGGACAAGCCAAAAATACGTATGGAAC AGGATGTTTCTTACTATGTAATACAGGCCATAAGTGTGTATTTTCTGATCATGGCCTT CTCACCACAGTGGCTTACAAACTTGGCAGAGACAAACCAGTATATTATGCTTTGGAAG GTTCTGTAGCTATAGCTGGTGCTGTTATTCGCTGGCTAAGAGACAATCTTGGAATTAT AAAGACCTCAGAAGAAATTGAAAAACTTGCTAAAGAAGTAGGTACTTCTTATGGCTGC TACTTCGTCCCAGCATTTTCGGGGTTATATGCACCTTATTGGGAGCCCAGCGCAAGAG GGATAATCTGTGGACTCACTCAGTTCACCAATAAATGCCATATTGCTTTTGCTGCATT AGAAGCTGTTTGTTTCCAAACTCGAGAGATTTTGGATGCCATGAATCGAGACTGTGGA ATTCCACTCAGTCATTTGCAGGTAGATGGAGGAATGACCAGCAACAAAATTCTTATGC AGCTACAAGCAGACATTCTGTATATACCAGTAGTGAAGCCCTCAATGCCCGAAACCAC TGCACTGGGTGCGGCTATGGCGGCAGGGGCTGCAGAAGGAGTCGGCGTATGGAGTCTC GAACCCGAGGATTTGTCTGCCGTCACGATGGAGCGGTTTGAACCTCAGATTAATGCGG AGGAAAGTGAAATTCGTTATTCTACATGGAAGAAAGCTGTGATGAAGTCAATGGGTTG GGTTACAACTCAATCTCCAGAAAGTGGTATTCCAGTCGACGGC
ORF Start: at 2 ORF Stop: end of sequence
SEQ ID NO: 360 1536 aa MW t58656.8kD
NOV44b, TGSMAASKKAVLGPLVGAVDQGTSSTRFLVFNSKTAELLSHHQVEIKQEFPREGWVEQ CG160131-04 DPKEILHSVYECIEKTCEKLGQLNIDISNIKAIGVSNQRETTVV DKITGEPLYNAVV LDLRTQSTVESLSKRIPGNNNFVKSKTGLPLSTYFSAVKLR LLDNVRKVQKAVEEK Protein Sequence RALFGTIDS LIWSLTGGVNGGVHCTDVTNASRT LFNIHSLEWDKQLCEFFGIPMEI LPNVRSSSEIYGL KISHSVKAGALEGVPISGCLGDQSAALVGQMCFQIGQAKNTYGT GCFLLCNTGHKCVFSDHGLLTTVAYKLGRDKPVYYALEGSVAIAGAVIRWLRDNLGII KTSEEIEKLAKEVGTSYGCYFVPAFSGLYAPYWEPSARGIICGLTQFTNKCHIAFAAL EAVCFQTREILDAMNRDCGIPLSHLQVDGGMTSNKILMQLQADILYIPWKPS PETT ALGAA AAGAAEGVGV SLEPEDLSAVTMERFEPQINAEESEIRYST KKAVMKSMG VTTQSPESGIPVDG
SEQ ID NO: 361 1581 bp
NOV44c, GGTTTCATGGCAGCCTCAAAGAAGGCAGTTTTGGGGCCATTGGTGGGGGCGGTGGACC CG160131-02 AGGGCACCAGTTCGACGCGCTTTTTGGTTTTCAATTCAAAAACAGCTGAACTACTTAG TCATCATCAAGTAGAAATAAAACAAGAGTTCCCAAGAGAAGGATGGGTGGAACAGGAC DNA Sequence CCTAAGGAAATTCTACATTCTGTCTATGAGTGTATAGAGAAAACATGTGAGAAACTTG GACAGCTCAATATTGATATTTCCAACATAAAAGCTATTGGTGTCAGCAACCAGAGGGA AACCACTGTAGTCTGGGACAAGATAACTGGAGAGCCTCTCTACAATGCTGTGGTGTGG CTTGATCTAAGAACCCAGTCTACCGTTGAGAGTCTTAGTAAAAGAATTCCAGGAAATA ATAACTTTGTCAAGTCCAAGACAGGCCTTCCACTTAGCACTTACTTCAGTGCAGTGAA ACTTCGTTGGCTCCTTGACAATGTGAGAAAAGTTCAAAAGGCCGTTGAAGAAAAACGA GCTCTTTTTGGGACTATTGATTCATGGCTTATTTGGAGTTTGACAGGAGGAGTCAATG GAGGTGTCCACTGTACAGATGTAACAAATGCAAGTAGGACTATGCTTTTCAACATTCA TTCTTTGGAATGGGATAAACAACTCTGCGAATTTTTTGGAATTCCAATGGAAATTCTT CCAAATGTCCGGAGTTCTTCTGAGATCTATGGCCTAATGAAAGCTGGGGCCTTGGAAG GTGTGCCAATATCTGGGTGTTTAGGGGACCAGTCTGCTGCATTGGTGGGACAAATGTG CTTCCAGATTGGACAAGCCAAAAATACGTATGGAACAGGATGTTTCTTACTATGTAAT ACAGGCCATAAGTGTGTATTTTCTGATCATGGCCTTCTCACCACAGTGGCTTACAAAC TTGGCAGAGACAAACCAGTATATTATGCTTTGGAAGGTTCTGTAGCTATAGCTGGTGC TGTTATTCGCTGGCTAAGAGACAATCTTGGAATTATAAAGACCTCAGAAGAAATTGAA AAACTTGCTAAAGAAGTAGGTACTTCTTATGGCTGCTACTTCGTCCCAGCATTTTCGG GGTTATATGCACCTTATTGGGAGCCCAGCGCAAGAGGGATAATCTGTGGACTCACTCA GTTCACCAATAAATGCCATATTGCTTTTGCTGCATTAGAAGCTGTTTGTTTCCAAACT CGAGAGATTTTGGATGCCATGAATCGAGACTGTGGAATTCCACTCAGTCATTTGCAGG TAGATGGAGGAATGACCAGCAACAAAATTCTTATGCAGCTACAAGCAGACATTCTGTA TATACCAGTAGTGAAGCCCTCAATGCCCGAAACCACTGCACTGGGTGCGGCTATGGCG GCAGGGGCTGCAGAAGGAGTCGGCGTATGGAGTCTCGAACCCGAGGATTTGTCTGCCG

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 44B.
Further analysis of the NOV44a protein yielded the following properties shown in Table 44C.
Table 44C. Protein Sequence Properties NOV44a
PSort 0.4500 probability located in cytoplasm; 0.3731 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV44a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 44D.
In a BLAST search of public sequence datbases, the NOV44a protein was found to have homology to the proteins shown in the BLASTP data in Table 44E.
PFam analysis predicts that the NOV44a protein contains the domains shown in the Table
44F.
Example 45.
The NOV45 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 45 A.
Table 45A. NOV45 Sequence Analysis
SEQ ID NO: 365
NOV45a, GGCCGGACAGTCCGCCGAGGTGCTCGGTGGAGTCATGGCAGTGCCCTTTGTGGAAGAC CGI 66282-01 TGGGACTTGGTGCAAACCCTGGGAGAAGGTGCCTATGGAGAAGTTCAACTTGCTGTGA ATAGAGTAACTGAAGAAGCAGTCGCAGTGAAGATTGTAGATATGAAGCGTGCCGTAGA DNA Sequence CTGTCCAGAAAATATTAAGAAAGAGATCTGTATCAATAAAATGCTAAATCATGAAAAT GTAGTAAAATTCTATGGTCACAGGAGAGAAGGCAATATCCAATATTTATTTCTGGAGT ACTGTAGTGGAGGAGAGCTTTTTGACAGAATAGAGCCAGACATAGGCATGCCTGAACC AGATGCTCAGAGATTCTTCCATCAACTCATGGCAGGGGTGGTTTATCTGCATGGTATT GGAATAACTCACAGGGATATTAAACCAGAAAATCTTCTGTTGGATGAAAGGGATAACC TCAAAATCTCAGACTTTGGCTTGGCAACAGTATTTCGGTATAATAATCGTGAGCGTTT GTTGAACAAGATGTGTGGTACTTTACCATATGTTGCTCCAGAACTTCTGAAGAGAAGA GAATTTCATGCAGAACCAGTTGATGTTTGGTCCTGTGGAATAGTACTTACTGCAATGC TCGCTGGAGAATTGCCATGGGACCAACCCAGTGACAGCTGTCAGGAGTATTCTGACTG GAAAGAAAAAAAAACATACCTCAACCCTTGGAAAAAAATCGATTCTGCTCCTCTAGCT CTGCTGCATAAAATCTTAGTTGAGAATCCATCAGCAAGAATTACCATTCCAGACATCA AAAAAGATAGATGGTACAACAAACCCCTCAAGAAAGGGGCAAAAAGGCCCCGAGTCAC TTCAGGTGGTGTGTCAGAGTCTCCCAGTGGATTTTCTAAGCACATTCAATCCAATTTG GACTTCTCTCCAGTAAACAGTGCTTCTAGTGAAGAAAATGTGAAGTACTCCAGTTCTC AGCCAGAACCCCGCACAGGTCTTTCCTTATGGGATACCAGCCCCTCATACATTGATAA ATTGGTACAAGGGATCAGCTTTTCCCAGCCCACATGTCCTGATCATATGCTTTTGAAT AGTCAGTTACTTGGCACCCCAGGATCCTCACAGAACCCCTGGCAGCGGTTGGTCAAAA GAATGACACGATTTTTTACCAAATTGGATGCAGACAAATCTTATCAATGCCTGAAAGA GACTTGTGAGAAGTTGGGCTATCAATGGAAGAAAAGTTGTATGAATCAGGGTGATGGA TTGGAGTTCAAGAGACACTTCCTGAAGATTAAAGGGAAGCTGATTGATATTGTGAGCA GCCAGAAGGTTTGGCTTCCTGCCACATGATCGGACCATCGGCTCTGGGGAATCCTGGT
GAATATAGTGCTGCTATGTTGACATTATTCTTCCTAGAGAAGATTATCCTGTCCTGCA
AACTGCAAATAGTAGTTCCTGAAGTGTTCACTTCCCTGTTTATCCAAACATCTTCCAA
TTTATTTTGTTTGTTCGGCATACAAATAATACCTATATCTTAATTGTAAGCAAAACTT
TGGGGAAAGGATGAATAGAATTCATTTGATTATTTCTTCATGTGTGTTTAGTATCTGA!
ATTTGAAACTCATCTGGTGGAAACCAAGTTTCAGGGGACATGAGTTTTCCAGCTTTTA iTACACACGTATCTCATTTTTATCAAAACATTTTGTTT
ORF Start: ATG at 35 lORF Stop: TGA at 1361
SEQ ID NO: 366 J442 aa |M at 50400.3kD
NOV45a, AVPFVEDWDLVQTLGEGAYGEVQLAVlvmVTEEAVAVKIVDMKRAVDCPENIKKEICI CG166282-01 NKMLNHENVVKFYGHRREGNIQYLFLEYCSGGELFDRIEPDIGMPEPDAQRFFHQLMA GVVYHGIGITHRDIKPENL LDERDNLKISDFGLATVFRYNRERLL K CGT PYV Protein Sequence APELLKRI_FHAEPVDVWSCGIV TAM_^GELPVroQPSDSCQEYSDWKEKKTYLNP K KIDSAPLAIiLHKI VENPSARITIPDIKKDR YNKPLKKGAKRPRVTSGGVSESPSGF SKHIQSN DFSPVNSASSEENVKYSSSQPEPRTG SL DTSPSYIDKLVQGISFSQPT CPDHML NSQL GTPGSSQNPWQRLVKRMTRFFTKLDADKSYQC KETCEKLGYQWKK SCMNQGDG EFKRHF KIKGK IDIVSSQKV LPAT
Further analysis of the NOV45a protein yielded the following properties shown in Table 45B.
Table 45B. Protein Sequence Properties NOV45a
PSort 0.3000 probability located in nucleus; 0.1000 probability located in analysis: mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.0423 probability located in microbody (peroxisome)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV45a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 45C.
In a BLAST search of public sequence datbases, the NOV45a protein was found to have homology to the proteins shown in the BLASTP data in Table 45D.
PFam analysis predicts that the NOV45a protein contains the domains shown in the Table 45E.
Table 45E. Domain Analysis of NOV45a
Identities/
Pfam Domain NO 45a Match Region Similarities Expect Value for the Matched Region pkinase 9..265 93/294 (32%) 1.2e-75 201/294 (68%)
Example 46.
The NOV46 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 46A.

TCTTGGAGTGGCTCCCCAAATACCGAGTCAAGGAATGGCTGCTTAGTGACGTCATTTC GGGAGTTAGTACTGGGCTAGTGGCCACGCTGCAAGGACCTTTTCCAGTGGTGAGTTTA ATGGTGGGATCTGTTGTTCTGAGCATGGCCCCCGACGAACACTTTCTCGTATCCAGCA GCAATGGAACTGTATTAAATACTACTATGATAGACACTGCAGCTAGAGATACAGCCAG AGTCCTGATTGCCAGTGCCCTGACTCTGCTGGTTGGAATTATACAGTTGATATTTGGT GGCTTGCAGATTGGATTCATAGTGAGGCACTTGGCAGATCCTTTGGTTGGTGGCTTCA CAACAGCTGCTGCCTTCCAAGTGCTGGTCTCACAGCTAAAGATTGTCCTCAATGTTTC AACCAAAAACTACAATGGAGTTCTCTCTATTATCTATACGCTGGTTGAGATTTTTCAA AATATTGGTGATACCAATCTTGCTGATTTCACTGCTGGATTGCTCACCATTGTCGTCT GTATGGCAGTTAAGGAATTAAATGATCGGTTTAGACACAAAATCCCAGTCCCTATTCC TATAGAAGTAATTGTGACGATAATTGCTACTGCCATTTCATATGGAGCCAACCTGGAA AAAAATTACAATGCTGGCATTGTTAAATCCATCCCAAGGGGGTTTTTGCCTCCTGAAC TTCCACCTGTGAGCTTGTTCTCGGAGATGCTGGCTGCATCATTTTCCATCGCTGTGGT GGCTTATGCTATTGCAGTGTCAGTAGGAAAAGTATATGCCACCAAGTATGATTACACC ATCGATGGGAACCAGGAATTCATTGCCTTTGGGATCAGCAACATCTTCTCAGGATTCT TCTCTTGTTTTGTGGCCACCACTGCTCTTTCCCGCACGGCCGTCCAGGAGAGCACTGG AGGAAAGACACAGGTTGCTGGCATCATCTCTGCTGCGATTGTGATGATCGCCATTCTT GCCCTGGGGAAGCTTCTGGAACCCTTGCAGAAGTCGGTCTTGGCAGCTGTTGTAATTG CCAACCTGAAAGGGATGTTTATGCAGCTGTGTGACATTCCTCGTCTGTGGAGACAGAA TAAGATTGATGCTGTTATCTGGGTGTTTACGTGTATAGTGTCCATCATTCTGGGGCTG GATCTCGGTTTACTAGCTGGCCTTATATTTGGACTGTTGACTGTGGTCCTGAGAGTTC AGTTTCCTTCTTGGAATGGCCTTGGAAGCATCCCTAGCACAGATATCTACAAAAGTAC CAAGAATTACAAAAACATTGAAGAACCTCAAGGAGTGAAGATTCTTAGATTTTCCAGT CCTATTTTCTATGGCAATGTCGATGGTTTTAAAAAATGTATCAAGTCCACAGTTGGAT TTGATGCCATTAGAGTATATAATAAGAGGCTGAAAGCGCTGAGGAAAATACAGAAACT AATAAAAAGTGGACAATTAAGAGCAACGAAGAATGGCATCATAAGTGATGCTGTTTCA ACAAATAATGCTTTTGAGCCCGATGAGGATATTGAAGATCTGGAGGAACTTGATATCC CAACCAAGGAAATAGAGATTCAAGTGGATTGGAACTCTGAGCTTCCAGTCAAAGTGAA CGTTCCCAAAGTGCCAATCCATAGCCTTGTGCTTGACTGTGGAGCTATATCTTTCCTG GACGTTGTTGGAGTGAGATCACTGCGGGTGATTGTCAAAGAATTCCAAAGAATTGATG TGAATGTGTATTTTGCATCACTTCAAGATTATGTGATAGAAAAGCTGGAGCAATGCGG GTTCTTTGACGACAACATTAGAAAGGACACATTCTTTTTGACGGTCCATGATGCTATA CTCTATCTACAGAACCAAGTGAAATCTCAAGAGGGTCAAGGTTCCATTTTAGAAACGA TCACTCTCATTCAGGATTGTAAAGATACCCTTGAATTAGTAGAAACAGAGCTGACGGA AGAAGAACTTGATGTCCAGGATGAGGCTATGCGTACACTTGCATCCTGACTGCAGCCA AG
ORF Start: ATG at 22 fORF Stop: TGA at 2251
SEQ ID NO: 368 743 aa MW at 81685.2kD
NOV46a, MAAPGGRSEPPQLPEYSCSY VSRPVYSE AFQQQHERRLQERKTLRESLAKCCSCSR CGI 70739-01 KRAFGVLKTLVPILE LPKYRVKEWLLSDVISGVSTGLVAT QGPFPVVSLMVGSVVL Protein Sequence S APDEHFVSSSNGTVLNTT IDTAARDTARVLIASALTLLVGIIQ IFGGLQIGFI VRH ADP VGGFTTAAAFQVLVSQLKIVL VSTKNYNGVLSIIYTLVEIFQNIGDTNL ADFTAGL TIWCMAVKELNDRFRHKIPVPIPIEVIVTIIATAISYGANLEKNYNAGI VKSIPRGFLPPELPPVSLFSEMLAASFSIAWAYAIAVSVGKVYATKYDYTIDGNQEF IAFGISNIFSGFFSCFVATTA SRTAVQESTGGKTQVAGIISAAIV IAILALGK E P QKSVLAAWIAN KGMFMQLCDIPRL RQNKIDAVIWVFTCIVSIILGLDLG LAG LIFGLLTWLRVQFPSWNGLGSIPSTDIYKSTKNYKNIEEPQGVKI RFSSPIFYG V DGFKKCIKSTVGFDAIRVY KRLKALRKIQKLIKSGQLRATKNGIISDAVST NAFEP DEDIEDLEELDIPTKEIEIQVυWNSELPVKVNVPKVPIHSLVLDCGAISFLDVVGVRS LRVIVKEFQRIDVNVYFASLQDYVIEKLEQCGFFDDNIRKDTFFLTVHDAILYLQNQV KSQEGQGSILETITLIQDCKDTLELVETELTEEELDVQDEA RTLAS
Further analysis of the NOV46a protein yielded the following properties shown in Table 46B.
Table 46B. Protein Sequence Properties NO 46a
PSort 0.8000 probability located in plasma membrane; 0.4000 probability located in analysis: Golgi body; 0.3000 probability located in endoplasmic reticulum (membrane); 0.0300 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV46a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 46C.
In a BLAST search of public sequence datbases, the NOV46a protein was found to have homology to the proteins shown in the BLASTP data in Table 46D.
PFam analysis predicts that the NOV46a protein contains the domains shown in the Table 46E.
Example 47.
The NOV47 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 47A.
CG171632-01 SPAIPVGVDVQVES DSISEVDMDFTMTLY RHYWKDERLSFPST LS TFDGRLVK Protein Sequence KIWVPD FFVHSKRSFIHDTTTDNVMLRVQPDGKVLYSLRVTVTAMCN DFSRFPLDT QTCSLEIESYAYTEDD MLYWKKGNDSLKTDERIS SQF IQEFHTTTKLAFYSSTGW YNRLYINFTLRRHIFFF PQTYFPATLVVM S VSF IDRRAVPARVP GITTVIJTMS
TIITGVNASMPRVSYIKAVDIYLWVSFVFVF SV EYAAVNYLTTVQERKEQKLREKL PCTSGLPPPNTAM DGNYSDGEVND DNYMPENGEKPDRMMVQLT ASERSSPQRKSQ RSSYVS RIDTHAIDKYSRIIFPAAYILFNIIIY SIFS
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 47B.
Table 47B. Comparison of NOV47a against NOV47b.
NOV47a Residues/ Identities/
Protein Sequence Match Residues SimUarities for the Matched Region
NOV47b 1..444 444/444 (100%) 1..444 444/444 (100%)
Further analysis of the NOV47a protein yielded the following properties shown in Table
47C.
Table 47C. Protein Sequence Properties NO 47a
PSort 0.4600 probability located in plasma membrane; 0.1692 probability located in analysis: microbody (peroxisome); 0.1000 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 16 and 17 analysis:
A search of the NOV47a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 47D.
In a BLAST search of public sequence datbases, the NOV47a protein was found to have homology to the proteins shown in the BLASTP data in Table 47E.
PFam analysis predicts that the NOV47a protein contains the domains shown in the Table
47F.
Table 47F. Domain Analysis of NOV47a
Pfam Domain NO 47a Match Region Identities/ Expect Value
Example 48.
The NOV48 clone was analyzed, andthe nucleotide and encodedpolypeptide sequences are shown inTable 48A.
Table 48A. NOV48 Sequence Analysis
SEQ ID NO: 373 1118bp
NOV48a, GCCCTTAGATCAAGATGCGCTGTAACTGAGAAGCCCCCAAGGCGGAGGCTGAGAATCA CG173066-01 GAGACATTTCAGCAGACATCTACAAATCCGAAAGACAΆAACATGGTTCAAGCATCCGG
GCACAGGCGGTCCACCCGTGGCTCCAAAATGGTCTCCTGGTCCGTGATAGCAAAGATC DNA Sequence CAGGAAATACTGCAGAGGAAGATGGTGCGAGAGTTCCTGGCCGAGTTCATGAGCACAT ATGTCATGATGGTATTCGGCCTTGGTTCCGTGGCCCATATGGTTCTAAATAAAAAATA TGGGAGCTACCTTGGTGTCAACTTGGGTTTTGGCTTCGGAGTCACCATGGGAGTGCAC GTGGCAGGCCGCATCTCTGGAGCCCACATGAACGCAGCTGTGACCTTTGCTAACTGTG CGCTGGGCCGCGTGCCCTGGAGGAAGTTTCCGGTCTATGTGCTGGGGCAGTTCCTGGG CTCCTTCCTGGCGGCTGCCACCATCTACAGTCTCTTCTACACGGCCATTCTCCACTTT TCGGGTGGACAGCTGATGGTGACCGGTCCCGTCGCTACAGCTGGCATTTTTGCCACCT ACCTTCCTGATCACATGACATTGTGGCGGGGCTTCCTGAATGAGGCGTGGCTGACCGG GATGCTCCAGCTGTGCCTCTTCGCCATCACGGACCAGGAGAACAACCCAGCACTGCCA GGAACAGAGGCGCTGGTGATAGGCATCCTCGTGGTCATCATCGGGGTGTCCCTTGGCA TGAACACAGGATATGCCATCAACCCGTCCCGGGACCTGCCCCCCCGCATCTTCACCTT CATTGCTGGTTGGGGCAAACAGGTCTTCAGGTGGCATCATCTACCTGGTCTTCATTGG CTCCACCATCCCACGGGAGCCCCTGAAATTGGAGGATTCTGTGGCGTATGAAGACCAC
GGGATAACCGTATTGCCCAAGATGGGATCTCATGAACCCACGATCTCTCCCCTCACCC
CCGTCTCTGTGAGCCCTGCCAACAGATCTTCAGTCCACCCTGCCCCACCCTTACATGA
ATCCATAGCCCTAGAGCACTTCTAAGCAGAGATTATTTGTGATCCCATCCATTCCCCA lATAAAGCAAGGCTTGT
ORF Start: ATG at 100 ORF Stop: TGA at 919
SEQ ID NO: 374 273 aa MW at29820.8kD
NOV48a, MVQASGHRRSTRGSKMVS SVIAKIQEILQRKMVREFLAEFMSTYVM VFGLGSVAHM CG173066-01 VLNK_KYGSYLGVN GFGFGVT GVHVAGRISGAHMNAAVTFANCALGRVP RKFPVYV LGQFLGSFLAAATIYS FYTAILHFSGGQLMVTGPVATAGIFATY PDHMTL RGF N Protein Sequence EAWLTGMLQLC FAITDQE NPALPGTEALVIGILWIIGVSLGMNTGYAINPSRD P PRIFTFIAGWGKQVFRWHH PGLHWLHHPTGAPEIGGFCGV Further analysis of the NOV48a protein yielded the following properties shown in Table 48B.
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV48a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 48C.
In a BLAST search of public sequence datbases, the NOV48a protein was found to have homology to the proteins shown in the BLASTP data in Table 48D.
PFam analysis predicts that the NOV48a protein contains the domains shown in the Table 48E.
Example 49.
The NOV49 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 49A.
Table 49 A. NOV49 Sequence Analysis
SEQ ID NO: 375 1461 bp
NOV49a, GAATTGAAGTGAATGGAACAGAAGCCAAGCAAGGTGGAGTGTGGGTCAGACCCAGAGG CG173085-01 AGAACAGTGCCAGGTCACCAGATGGAAACCGAAAAAGAAAGAACGGCCAATGTTCCCT GAAAACCAGCATGTCAGGGTATATCCCTAGTTACCTGGACAAAGACGAGCAGTGTGTC DNA Sequence GTGTGTGGGGACAAGGCAACTGGTTATCACTACCGCTGTATCACTTGTGAGGGCTGCA AGGGCTTCTTTCGCCGCACAATCCAGAAGAACCTCCATCCCACCTATTCCTGCAAATA TGACAGCTGCTGTGTCATTGACAAGATCACCCGCAATCAGTGCCAGCTGTGCCGCTTC AAGAAGTGCATCGCCGTGGGCATGGCCATGGACTTGGTTCTAGATGACTCGAAGCGGG TGGCCAAGCGTAAGCTGATTGAGCAGAACCGGGAGCGGCGGCGGAAGGAGGAGATGAT CCGATCACTGCAGCAGCGACCAGAGCCCACTCCTGAAGAGTGGGATCTGATCCACATT GCCACAGAGGCCCATCGCAGCACCAATGCCCAGGGCAGCCATTGGAAACAGAGGCGGA AATTCCTGCCCGATGACATTGGCCAGTCACCCATTGTCTCCATGCCGGACGGAGACAA GGTGGACCTGGAAGCCTTCAGCGAGTTTACCAAGATCATCACCCCGGCCATCACCCGT GTGGTGGACTTTGCCAAAAAACTGCCCATGTTCTCCGAGCTGCCTTGCGAAGACCAGA TCATCCTCCTGAAGGGGTGCTGCATGGAGATCATGTCCCTGCGGGCGGCTGTCCGCTA CGACCCTGAGAGCGACACCCTGACGCTGAGTGGGGAGATGGCTGTCAAGCGGGAGCAG CTCAAGAATGGCGGCCTGGGCGTAGTCTCCGACGCCATCTTTGAACTGGGCAAGTCAC TCTCTGCCTTTAACCTGGATGACACGGAAGTGGCTCTGCTGCAGGCTGTGCTGCTAAT GTCAACAGACCGCTCGGGCCTGCTGTGTGTGGACAAGATCGAGAAGAGTCAGGAGGCG TACCTGCTGGCGTTCGAGCACGACGTCAACCACCGCAAACACAACATTCCGCACTTCT GGCCCAAGCTGCTGATGAAGGGTCCGCAGGTCCGGCAGCTTGAGCAGCAGCTTGGTGA AGCGGGAAGTCTCCAAGGGCCGGTTCTTCAGCACCAGAGCCCGAAGAGCCCGCAGCAG CGTCTCCTGGAGCTGCTCCACCGAAGCGGAATTCTCCATGCCCGAGCGGTCTGTGGGG AAGACGACAGCAGTGAGGCGGACTCCCCGAGCTCCTCTGAGGAGGAACCGGAGGTCTG
CGGGGACCTGGCAGGCAATGCAGCCTCTCCCTGAAGCCCCCCAGAAGGCCGATGGGGA!
AGGAGAAGGAGTGCCATACCTTCTCCCAGGCCTCTGCCCCAAGAGCAGGAGGTGCCTG! lAAAGCTGGGAG
ORF Start: ATG at 13 jORF Stop: TGA at 1366
SEQ ID NO: 376 451 aa MW at 50612. lkD
NOV49a, MEQKPSKVECGSDPEENSARSPDGNRKRKNGQCS KTSMSGYIPSYLDKDEQCWCGD CGI 73085-01 KATGYHYRCITCEGCKGFFRRTIQKNLHPTYSCKYDSCCVIDKITRNQCQLCRFKKCI AVG A DLVLDDSKRVAKRKLIEQNRERRRKEE IRSLQQRPEPTPEE D IHIATEA Protein Sequence HRSTNAQGSH KQRRKFLPDDIGQSPIVSMPDGDKVD EAFSEFTKIITPAITRWDF AKKLPMFSELPCEDQIILLKGCCMEI S RAAVRYDPESDT TLSGE AVKREQ KNG GLGWSDAIFELGKSLSAFN DDTEVA LQAVLLMSTDRSG LCVDKIEKSQEAYLLA FEHDVNHRKHNIPHF PK KGPQVRQLEQQLGEAGSLQGPVLQHQSPKSPQQRLLE LHRSGILHARAVCGEDDSSEADSPSSSEEEPEVCGDLAGNAASP
SEQ ID NO: 377 1375 bp
NOV49b, CACCGGATCCACCATGGAACAGAAGCCAAGCAAGGTGGAGTGTGGGTCAGACCCAGAG 311531811 DNA GAGAACAGTGCCAGGTCACCAGATGGAAAGCGAAAAAGAAAGAACGGCCAATGTTCCC TGAAAACCAGCATGTCAGGGTATATCCCTAGTTACCTGGACAAAGACGAGCAGTGTGT
Sequence CGTGTGTGGGGACAAGGCAACTGGTTATCACTACCGCTGTATCACTTGTGAGGGCTGC AAGGGCTTCTTTCGCCGCACAATCCAGAAGAACCTCCATCCCACCTATTCCTGCAAAT ATGACAGCTGCTGTGTCATTGACAAGATCACCCGCAATCAGTGCCAGCTGTGCCGCTT CAAGAAGTGCATCGCCGTGGGCATGGCCATGGACTTGGTTCTAGATGACTCGAAGCGG GTGGCCAAGCGTAAGCTGATTGAGCAGAACCGGGAGCGGCGGCGGAAGGAGGAGATGA TCCGATCACTGCAGCAGCGACCAGAGCCCACTCCTGAAGAGTGGGATCTGATCCACAT TGCCACAGAGGCCCATCGCAGCACCAATGCCCAGGGCAGCCATTGGAAACAGAGGCGG AAATTCCTGCCCGATGACATTGGCCAGTCACCCATTGTCTCCATGCCGGACGGAGACA AGGTGGACCTGGAAGCCTTCAGCGAGTTTACCAAGATCATCACCCCGGCCATCACCCG TGTGGTGGACTTTGCCAAAAAACTGCCCATGTTCTCCGAGCTGCCTTGCGAAGACCAG ATCATCCTCCTGAAGGGGTGCTGCATGGAGATCATGTCCCTGCGGGCGGCTGTCCGCT ACGACCCTGAGAGCGACACCCTGACGCTGAGTGGGGAGATGGCTGTCAAGCGGGAGCA GCTCAAGAATGGCGGCCTGGGCGTAGTCTCCGACGCCATCTTTGAACTGGGCAAGTCA CTCTCTGCCTTTAACCTGGATGACACGGAAGTGGCTCTGCTGCAGGCTGTGCTGCTAA TGTCAACAGACCGCTCGGGCCTGCTGTGTGTGGACAAGATCGAGAAGAGTCAGGAGGC GTACCTGCTGGCGTTCGAGCACTACGTCAACCACCGCAAACACAACATTCCGCACTTC TGGCCCAAGCTGCTGATGAAGGGTCCGCAGGTCCGGCAGCTTGAGCAGCAGCTTGGTG AAGCGGGAAGTCTCCAAGGGCCGGTTCTTCAGCACCAGAGCCCGAAGAGCCCGCAGCA GCGTCTCCTGGAGCTGCTCCACCGAAGCGGAATTCTCCATGCCCGAGCGGTCTTTGGG GAAGACGACAGCAGTGAGGCGGACTCCCCGAGCTCCTCTGAGGAGGAACCGGAGGTCT GCGAGGACCTGGCAGGCAATGCAGCCTCTCCCGTCGACGGC
ORF Start: at 2 ORF Stop: end of sequence
SEQ ID NO: 378 458 aa MW at 51408.0kD
NOV49b, TGSTMEQKPSKVECGSDPEENSARSPDGKRKRKNGQCSLKTSMSGYIPSY DKDEQCV 311531811 VCGDKATGYHYRCITCEGCKGFFRRTIQKNLHPTYSCKYDSCCVIDKITRNQCQLCRF KKCIAVGMA DLV DDSKRVAKRK IEQNRERRRKEEMIRSLQQRPEPTPEE DLIHI Protein Sequence ATEAHRSTNAQGSH KQRRKFLPDDIGQSPIVSMPDGDKVDLEAFSEFTKIITPAITR WDFAKKLPMFSELPCEDQIILLKGCCMEI S RAAVRYDPESDT TLSGE AVKREQ KNGG GWSDAIFELGKS SAFN DDTEVAL QAVLLMSTDRSG LCVDKIEKSQEA YLLAFEHYVNHRKHNIPHF PK MKGPQVRQLEQQLGEAGS QGPVLQHQSPKSPQQ RLLE LHRSGILHARAVFGEDDSSEADSPSSSEEEPEVCED AGNAASPVDG
Sequence comparison of the above protein sequences yields the following sequence 5. relationships shown in Table 49B .
Table 49B. Comparison of NOV49a against NOV49b.
Further analysis of the NOV49a protein yielded the following properties shown in Table 49C.
Table 49C. Protein Sequence Properties NOV49a
PSort 0.9700 probability located in nucleus; 0.1000 probability located in analysis: mitochondrial matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV49a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 49D.
In a BLAST search of public sequence datbases, the NOV49a protein was found to have homology to the proteins shown in the BLASTP data in Table 49E.
PFam analysis predicts that the NOV49a protein contains the domains shown in the Table 49F.
Example 50.
The NOV50 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 50A.

CG173095-01 TGTAACCACCTCACAGATTCCAGCTTCGGAACAAGAGACCCTGGTTAGACCAAAGCCA DNA Sequence TTGCTTTTGAAGTTATTAAAGTCTGTTGGTGCACAAAAAGACACTTATACTATGAAAG AGAGATGGAGTTTCACTATGTTGCCCAGGCTGGTCTGGAACTCCTGGGCTCAAGGGAT CTGCTTACCTCGGCCTCCTAAAGTGCTAGATTTACAGGTTCTTTTTTATCTTGGCCAG TATATTATGACTAAACGATTATATGATGAGAAGCAACAACATATTGTATATTGTTCAA ATGATCTTCTAGGAGATTTGTTTGGCGTGCCAAGCTTCTCTGTGAAAGAGCACAGGAA AATATATACCATGATCTACAGGAACTTGGTAGTAGTCAATCAGCAGGAATCATCGGAC TCAGGTACATCTGTGAGTGAGAACAGGTGTCACCTTGAAGGTGGGAGTGATCAAAAGG ACCTTGTACAAGAGCTTCAGGAAGAGAAACCTTCATCTTCACATTTGGTTTCTAGACC ATCTACCTCATCTAGAAAGAGAGCAATTAGTGAGACAGAAGAAAATTCAGATGAATTA TCTGGTGAACGACAAAGAAAACGCCACAAATCTGATAGTATTTCCCTTTCCTTTGATG AAAGCCTGGCTCTGTGTGTAATAAGGGAGATATGTTGTGAAAGAAGCAGTAGCAGTGA ATCTACAGGGACGCCATCGAATCCGGATCTTGATGCTGGTGTAAGTGAACATTCAGGT GATTGGTTGGATCAGGATTCAGTTTCAGATCAGTTTAGTGTAGAATTTGAAGTTGAAT CTCTCGACTCAGAAGATTATAGCCTTAGTGAAGAAGGACAAGAACTCTCAGATGAAGA TGATGAGGTATATCAAGTTACTGTGTATCAGGCAGGGGAGAGTGATACAGATTCATTT GAAGAAGATCCTGAAATTTCCTTAGCTGACTATTGGAAATGCACTTCATGCAATGAAA TGAATCCCCCCCTTCCATCACATTGCAACAGATGTTGGGCCCTTCGTGAGAATTGGCT TCCTGAAGATAAAGGGAAAGATAAAGGGGAAATCTCTGAGAAAGCCAAACTGGAAAAC TCAACACAAGCTGAAGAGGGCTTTGATGTTCCTGATTGTAAAAAAACTATAGTGAATG ATTCCAGAGAGTCATGTGTTGAGGAAAATGATGATAAAATTACACAAGCTTCACAATC ACAAGAAAGTGAAGACTATTCTCAGCCATCAACTTCTAGTAGCATTATTTATAGCAGC CAAGAAGATGTGAAAGAGTTTGAAAGGGAAGAAACCCAAGACAAAGAAGAGAGTGTGG AATCTAGTTTGCCCCTTAATGCCATTGAACCTTGTGTGATTTGTCAAGGTCGACCTAA AAATGGTTGCATTGTCCATGGCAAAACAGGACATCTTATGGCCTGCTTTACATGTGCA AAGAAGCTAAAGAAAAGGAATAAGCCCTGCCCAGTATGTAGACAACCAATTCAAATGA TTGTGCTAACTTATTTCCCCTAGTTGACCTGTCTATAAGAGAATTATATATTTCTAAC
TATATAACCCTAGGAATTTAGACAACCTGAAATTTATTCACATATATCAAAGTGAGAA
AATGCCTCAATTCACATAGATTTCTTCTCTTTAGTATAATTGACCTACTTTGGTAGTG
GAATAGTGAATACTTACTATAATTTGACTTGAATATGTAGCTCATCCTTTACACCAAC
TCCTAATTTTAAATAATTTCTACTCTGTCTTAAATGAGAAGTACTTGGTTTTTTTTTT:
CTTAAATATGTATATGACATTTAAATGTAACTTATTATTTTTTTTGAGACCGAGTCTT!
GCTCTGTTACCCAGGCTGGAGTGCAGTGGGTGATCTTGGCTCACTGCAAGCTCTGCCC
TCCCCGGGTTCGCACCATTCTCCTGCCTCAGCCTCCCAATTAGCTTGGCCTACAGTCA
TCTGCCACCACACCTGGCTAATTTTTTGTACTTTTAGTAGAGACAGGGTTTCACCGTG;
TTAGCCAGGATGGTCTCGATCTCCTGACCTCGTGATCCGCCCACCTCGGCCTCCCAAAI
GTGCTGGGATTACAGGCATGAGCCACCG
ORF Start: ATG at 21 ORF Stop: TAG at 1587 SEQ ID NO: 380 522 aa MW at 58895.6kD
NOV50a, MCNTNMSVPTDGAVTTSQIPASEQET VRPKP LKL KSVGAQKDTYT KER SFT CG173095-01 PRLVNS AQGICLPRPPKVLD QVLFY GQYIMTKR YDEKQQHIVYCSNDL GDL FGVPSFSVKEHRKIYT IYRNLVWNQQESSDSGTSVSENRCHLEGGSDQKDLVQELQ Protein Sequence EEKPSSSHLVSRPSTSSRKRAISETEENSDELSGERQRKRHKSDSISLSFDESIiALCV IREICCERSSSSESTGTPSNPDLDAGVSEHSGD LDQDSVSDQFSVEFEVESLDSEDY SLSEEGQELSDEDDEVYQVTVYQAGESDTDSFEEDPEIS ADYWKCTSCNE NPPLPS HCNRC ALREN LPEDKGKDKGEISEKAKLENSTQAEEGFDVPDCKKTIVNDSRESCV EENDDKITQASQSQESEDYSQPSTSSSIIYSSQEDVKEFEREETQDKEESVESSLPLN AIEPCVICQGRPKNGCIVHGKTGHL ACFTCAKiαjKKRNKPCPVCRQPIQMIVLTYFP
NOV50b, GCCCTTTATCGCCGGAATTCATGTGCAATACCAACATGTCTGTACCTACTGATGGTGC CG173095-02 TGTAACCACCTCACAGATTCCAGCTTCGGAACAAGAGACCCTGGTTAGACCAAAGCCA TTGCTTTTGAAGTTATTAAAGTCTGTTGGTGCACAAAAAGACACTTATACTATGAAAG DNA Sequence AGAGATGGAGTTTCACTATGTTGCCCAGGCTGGTCTGGAACTCCTGGGCTCAAGGGAT CTGCTTACCTCGGCCTCCTAAAGTGCTAGATTTACAGGTTCTTTTTTATCTTGGCCAG TATATTATGACTAAACGATTATATGATGAGAAGCAACAACATATTGTATATTGTTCAA ATGATCTTCTAGGAGATTTGTTTGGCGTGCCAAGCTTCTCTGTGAAAGAGCACAGGAA AATATATACCATGATCTACAGGAACTTGGTAGTAGTCAATCAGCAGGAATCATCGGAC TCAGGTACATCTGTGAGTGAGAACAGGTGTCACCTTGAAGGTGGGAGTGATCAAAAGG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 50B.
Table 50B. Comparison of NOV50a against NOV50b.
NO 50a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV50b 1..521 518/521 (99%) 1..521 519/521 (99%)
Further analysis of the NOV50a protein yielded the following properties shown in Table 50C.
Table 50C. Protein Sequence Properties NO 50a
PSort 0.6000 probability located in nucleus; 0.3000 probability located in analysis: microbody (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV50a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 50D.
In a BLAST search of public sequence datbases, the NOV50a protein was found to have homology to the proteins shown in the BLASTP data in Table 50E.
PFam analysis predicts that the NOV50a protein contains the domains shown in the Table 50F.
Example 51.
The NOV51 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 51 A.
Table 51A. NOV51 Sequence Analysis
SEQ ID NO: 383 2066 bp
NOV51a, TATTTCAGAAAGCTTCAAGAACAAGCTGGAGAAGGGAAGAGTTATTCCTCCATATTCAl CG173173-01 CCTGCTTCAACTACTATTCTTATTGGGAATGGACAATGGAATGTTCTCTGGTTTTATC
ATGATCAAAAACCTCCTTCTCTTTTGTATTTCCATGAACTTATCCAGTCACTTTGGCT DNA Sequence TTTCACAGGTGCCAACCAGTTCAGTGAAAGATGAGACCAATGACAACATCACGATATT TACCAGGATCTTGGATGGGCTCTTGGATGGCTACGACAACAGACTTCGGCCCGGGCTG GGAGAGCGCATCACTCAGGTGAGGACCGACATCTACGTCACCAGCTTCGGCCCGGTGT CCGACACGGAAATGGAGTACACCATAGACGTGTTTTTCCGACAAGGCTGGAAAGATGA AAGGCTTCGGTTTAAGGGGCCCATGCAGCGCCTCCCTCTCAACACGTTCTTCCACAAC GGGAAGAAGTCCATCGCTCACAACATGACCACGCCCAACAAGCTGCTGCGGCTGGAGG ACGACGGCACCCTGCTCTACACCATGCGCTTGACCATCTCTGCAGAGTGCCCCATGCA GCTTGAGGACTTCCCGATGGATGCGCACGCTTGCCCTCTGAAATTTGGCAGCTATGCG TACCCTAATTCTGAAGTCGTTTACGTCTGGACCAACGGCTCCACCAAGTCGGTGGTGG TGGCGGAAGATGGCTCCAGACTGAACCAGTACCACCTGATGGGGCAGACGGTGGGCAC TGAGAACATCAGCACCAGCACAGGCGAATACACAATCATGACAGCTCACTTCCACCTG AAAAGGAAGATTGGCTACTTTGTCATCCAGACCTACCTTCCCTGCATAATGACCGTGA
TCTTATCACAGGTGTCCTTTTGGCTGAACCGGGAATCAGTCCCAGCCAGGACAGTTTT TGGGGTCACCACGGTGCTGACCATGACGACCCTCAGCATCAGCGCCAGGAACTCTCTG CCCAAAGTGGCCTACGCCACCGCCATGGACTGGTTCATAGCTGTGTGCTATGCCTTCG TCTTCTCGGCGCTGATAGAGTTTGCCACGGTCAATTACTTTACCAAGAGAGGCTGGGC CTGGGATGGCAAAAAAGCCTTGGAAGCAGCCAAGATCAAGAAAAAGCGTGAAGTCATA CTAAATAAGTCAACAAACGCTTTTACAACTGGGAAGATGTCTCACCCCCCAAACATTC CGAAGGAACAGACCCCAGCAGGGACGTCGAATACAACCTCAGTCTCAGTAAAACCCTC TGAAGAGAAGACTTCTGAAAGCAAAAAGACTTACAACAGTATCAGCAAAATTGACAAA ATGTCCCGAATCGTATTCCCAGTCTTGTTCGGCACTTTCAACTTAGTTTACTGGGCAA CGTATTTGAATAGGGAGCCGGTGATAAAAGGAGCCGCCTCTCCAAAATAACCGGCCAC iACTCCCAAACTCCAAGACAGCCATACTTCCAGCGAAATGGTACCAAGGAGAGGTTTTG
CTCACAGGGACTCTCCATATGTGAGCACTATCTTTCAGGAAATTTTTGCATGTTTAAT
AATATGTACAAATAATATTGCCTTGATGTTTCTATATGTAACTTCAGATGTTTCCAAG!
ATGTCCCATTGATAATTCGAGCAAACAACTTTCTGGAAAAACAGGATACGATGACTGA!
CACTCAGATGCCCAGTATCATACGTTGATAGTTTACAAACAAGATACGTATATTTTTAl
ACTGCTTCAAGTGTTACCTAACAATGTTTTTTATACTTCAAATGTCATTTCATACAAA
TTTTCCCAGTGAATAAATATTTTAGGAAACTCTCCATGATTATTAGAAGACCAACTAT
ATTGCGAGAAACAGAGATCATAAAGAGCACGTTTTCCATTATGAGGAAACTTGGACAT
TTATGTACAAAATGAATTGCCTTTGATAATTCTTACTGTTCTGAAATTAGGAAAGTAC
TTGCATGATCTTACACGAAGAAATAGAATAGGCAAACTTTTATGTAGGCAGATTAATA
ACAGAAATACATCATATGTTAGATACACAAAATATT
ORF Start: ATG at 87 ORF Stop: TAA at 1440
SEQ ID NO: 384 451 aa MW at 50844.0kD
!NOV51a, MDNGMFSGFIMIKN LLFCISMNLSSHFGFSQVPTSSVKDETNDNITIFTRILDG LD CG173173-01 GYDNR RPGLGERITQVRTDIYVTSFGPVSDTEMEYTIDVFFRQGWKDERLRFKGPMQ RLPLNTFFHNGKKSIAHN TTPNKLLR EDDGTLLYTMR TISAECP QLEDFPMDAH Protein Sequence ACPLKFGSYAYPNSEWYVWTNGSTKSVWAEDGSRLNQYHLMGQTVGTENISTSTGE YTIMTAHFH KKKIGYFVIQTY PCIMTVI SQVSF ]_sJRESVPARTVFGVTTV_TMT TLSISAR S PKVAYATAMD FIAVCYAFVFSALIEFATVNYFTKRG ATOGKKA EA AKIKKKREVI NKSTNAFTTGKMSHPPNIPKEQTPAGTSNTTSVSVKPSEEKTSESKK TYNSISKIDKMSRIVFPVLFGTFNLVYWATYLNREPVIKGAASPK
Further analysis of the NOV51a protein yielded the following properties shown in Table 51B.
Table 51B. Protein Sequence Properties NOVSla
PSort 0.7073 probability located in microbody (peroxisome); 0.7000 probability analysis: located in plasma membrane; 0.4477 probability located in mitochondrial inner membrane; 0.2000 probability located in endoplasmic reticulum (membrane)
SignalP Cleavage site between residues 32 and 33 analysis:
A search of the NOV51a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 51C.
Table 51C. Geneseq Results for NOV51a
Geneseq Protein/Organism Length [Patent NOV51a Identities/
Expect
Residues/ Identifier #, Date] SimUarities for
In a BLAST search of public sequence datbases, the NOV51a protein was found to have homology to the proteins shown in the BLASTP data in Table 5 ID.
PFam analysis predicts that the NOV51a protein contains the domains shown in the Table 51E.
Example 52.
The NOV52 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 52A.
Table 52A. NOV52 Sequence Analysis
SEQ ID NO: 385 2266 bp
NOV52a, CTCGGGCCTGGGGCTCTGCCTGAACAACCGGCCCCCCAGACAGGACTTTGTGTACCCG CG51213-01 ACAGTGGCACCGGGCCAAGCCTACGATGCAGATGAGCAATGCCGCTTTCAGCATGGAGj DNA Sequence TCAAATCGCGTCAGTTGGTGCTACAAACGGGTCTGTGTCCCCTTTGGGTCGCGCCCAG jAGGGTGTGGACGGAGCCTGGGGGCCGTGGACTCCATGGGGCGACTGCAGCCGGACCTG
TGGCGGCGGCGTGTCCTCTTCTAGCCGTCACTGCGACAGCCCCAGGCCAACCATCGGG!
GGCAAGTACTGTCTGGGTGAGAGAAGGCGGCACCGCTCCTGCAACACGGATGACTGTC
CCCCTGGCTCCCAGGACTTCAGAGAAGTGCAGTGTTCTGAATTTGACAGCATCCCTTT
CCGTGGGAAATTCTACAAGTGGAAAACGTACCGGGGAAGGTGAGTGTGGGACTCCAAA
GGCTGTGGGGCCGTGAAGGGCAGCCGTGGGAGTGTCCAGCAGCAGGTGGATGAATGCA
GCATCCCGGGGTCTGCCATGAGCCCTGTCCCCACCCGGGGAGACAGAGTACCTGGGAT
ACGGTACCATGGGGGTTCAACGTGACGCTGGGAGCCCCCACTCCCTCTGCCCAAGCTG
CCCTTCCTCTTGGGTCTGGGGTCTGTCCCTCTTGGCCTCACTCCCCCAGGGAGCAAGC AAAGAGTTCCGGGGTGGCCTGGCCCGTGGTGTGACGGGGCCGTGCCCCCCAGGGGGCG TGAAGGCCTGCTCGCTCACGTGCCTAGCGGAAGGCTTCAACTTCTACACGGAGAGGGC GGCAGCCGTGGTGGACGGGACACCCTGCCGTCCAGACACGGTGGACATTTGCGTCAGT GGCGAATGCAAGCACGTGGGCTGCGACCGAGTCCTGGGCTCCGACCTGCGGGAGGACA AGTGCCGAGTGTGTGGCGGTGACGGCAGTGCCTGCGAGACCATCGAGGGCGTCTTCAG CCCAGCCTCACCTGGGGCCGGGTACGAGGATGTCGTCTGGATTCCCAAAGGCTCCGTC CACATCTTCATCCAGGATCTGAACCTCTCTCTCAGTCACTTGGCCCTGAAGGGAGACC AGGAGTCCCTGCTGCTGGAGGGGCTGCCTGGGACCCCCCAGCCCCACCGTCTGCCTCT AGCTGGGACCACCTTTCAACTGCGACAGGGGCCAGACCAGGTCCAGAGCCTCGAAGCC CTGGGACCGATTAATGCATCTCTCATCGTCATGGTGCTGGCCCGGACCGAGCTGCCTG CCCTCCGCTACCGCTTCAATGCCCCCATCGCCCGTGACTCGCTGCCCCCCTACTCCTG GCACTATGCGCCCTGGACCAAGTGCTCGGCCCAGTGTGCAGGCGGTAGCCAGGTGCAG GCGGTGGAGTGCCGCAACCAGCTGGACAGCTCCGCGGTCGCCCCCCACTACTGCAGTG CCCACAGCAAGCTGCCCAAAAGGCAGCGCGCCTGCAACACGGAGCCTTGCCCTCCAGA CTGGGTTGTAGGGAACTGGTCGCTCTGCAGCCGCAGCTGCGATGCAGGCGTGCGCAGC CGCTCGGTCGTGTGCCAGCGCCGCGTCTCTGCCGCGGAGGAGAAGGCGCTGGACGACA GCGCATGCCCGCAGCCGCGCCCACCTGTACTGGAGGCCTGCCACGGCCCCACTTGCCC
TCCGGAGTGGGCGGCCCTCGACTGGTCTGAGTGCACCCCCAGCTGCGGGCCGGGCCTC: CGCCACCGCGTGGTCCTTTGCAAGAGCGCAGACCACCGCGCCACGCTGCCCCCGGCGC ACTGCTCACCCGCCGCCAAGCCACCGGCCACCATGCGCTGCAACTTGCGCCGCTGCCC CCCGGCCCGCTGGGTGGCTGGCGAGTGGGGTGAGTGCTCTGCACAGTGCGGCGTCGGG CAGCGGCAGCGCTCGGTGCGCTGCACCAGCCACACGGGCCAGGCGTCGCACGAGTGCA CGGAGGCCCTGCGGCCGCCCACCACGCAGCAGTGTGAGGCCAAGTGCGACAGCCCAAC CCCCGGGGACGGCCCTGAAGAGTGCAAGGATGTGAACAAGGTCGCCTACTGCCCCCTG GTGCTCAAATTTCAGTTCTGCAGCCGAGCCTACTTCCGCCAGATGTGCTGCAAAACCT GCCAGGGCCACTAGGGGGCGCGCGGCACCCGGAGCCACAGCTGGCGGGGTCTCCGCCG
CCAGCCCTGCAGCTGGGCCGGCCAGAGGGGGCCCCGGGGGGGCGGGAACTGGGAGGGA lAGGG
ORF Start: ATG at 589 |ORF Stop: TAG at 2158
SEQ ID NO: 386 523 aa MW at 56126.2kD
NOV52a, MGVQRDAGSPHSLCPSCPSS VWGLSLLAS PQGASKEFRGGLARGVTGPCPPGGVKA CG51213-01 CSLTC AEGFNFYTERAAAWDGTPCRPDTVDICVSGECKHVGCDRV GSDLREDKCR Protein Sequence VCGGDGSACETIEGVFSPASPGAGYEDWWIPKGSVHIFIQDLNLSLSHLA KGDQES LLEGLPGTPQPHRLPLAGTTFQLRQGPDQVQSLEALGPINASLIV V ARTELPALR YRFNAPIARDSLPPYS HYAP TKCSAQCAGGSQVQAVECRNQLDSSAVAPHYCSAHS K PKRQRACNTEPCPPDWWGNWSLCSRSCDAGVRSRSWCQRRVSAAEEKALDDSAC PQPRPPVLEACHGPTCPPE AALDWSECTPSCGPG RHRW CKSADHRATLPPAHCS PAAKPPATMRCN RRCPPAR VAGEWGECSAQCGVGQRQRSVRCTSHTGQASHECTEA LRPPTTQQCEAKCDSPTPGDGPEECKDVNKVAYCP V KFQFCSRAYFRQMCCKTCQG H
SEQ ID NO: 387 |l866 bp
NOV52b, TCCATAAATGGAGCTTATTGGGAGAGTATAAGTCACAGGCCATGCCCCGCAAGGGGAT CG51213-07 JGCACGAAGACCCACCGCGAGCCAGGAAGGGAGCACCGGGCTCTCTGCTCTGGGACCGG CAGTGAGCCGGACATCTGGGTCCTCCCAAGCCGGGCGGGCTGCCCCAGGGAGGAAGGG DNA Sequence AGGGGGGCGAGCCTGAGCGGGCACCTCGGCCCGCAGGAGGTCTGCAGCGAGCTGTGGT GTCTGAGCAAGAGCAACCGGTGCATCACCAACAGCATCCCGGCCGCCGAGGGCACGCT GTGCCAGACGCACACCATCGACAAGGGGTGGTGCTACAAACGGGTCTGTGTCCCCTTT GGGTCGCGCCCAGAGGGTGTGGACGGAGCCTGGGGGCCGTGGACTCCATGGGGCGACT GCAGCCGGACCTGTGGCGGCGGCGTGTCCTCTTCTAGCCGTCACTGCGACAGCCCCAG GCCAACCATCGGGGGCAAGTACTGTCTGGGTGAGAGAAGGCGGCACCGCTCCTGCAAC ACGGATGACTGTCCCCCTGGCTCCCAGGACTTCAGAGAAGTGCAGTGTTCTGAATTTG ACAGCATCCCTTTCCGTGGGAAATTCTACAAGTGGAAAACGTACCGGGGAGGGGGCGT GAAGGCCTGCTCGCTCACGTGCCTAGCGGAAGGCTTCAACTTCTACACGGAGAGGGCG GCAGCCGTGGTGGACGGGACACCCTGCCGTCCAGACACGGTGGACATTTGCGTCAGTG GCGAATGCAAGCACGTGGGCTGCGACCGAGTCCTGGGCTCCGACCTGCGGGAGGACAA GTGCCGAGTGTGTGGCGGTGACGGCAGTGCCTGCGAGACCATCGAGGGCGTCTTCAGC CCAGCCTCACCTGGGGCCGGGTACGAGGATGTCGTCTGGATTCCCAAAGGCTCCGTCC ACATCTTCATCCAGGATCTGAACCTCTCTCTCAGTCACTTGGCCCTGAAGGGAGACCA GGAGTCCCTGCTGCTGGAGGGGCTGCCCGGGACCCCCCAGCCCCACCGTCTGCCTCTA GCTGGGACCACCTTTCAACTGCGACAGGGGCCAGACCAGGTCCAGAGCCTCGAAGCCC TGGGACCGATTAATGCATCTCTCATCGTCATGGTGCTGGCCCGGACCGAGCTGCCTGC CCTCCGCTACCGCTTCAATGCCCCCATCGCCCGTGACTCGCTGCCCCCCTACTCCTGG CACTATGCGCCCTGGACCAAGTGCTCGGCCCAGTGTGCAGGCGGTAGCCAGGTGCAGG CGGTGGAGTGCCGCAACCAGCTGGACAGCTCCGCGGTCGCCCCCCACTACTGCAGTGC CCACAGCAAGCTGCCCAAAAGGCAGCGCGCCTGCAACACGGAGCCTTGCCCTCCAGAC TGGGTTGTAGGGAACTGGTCGCTCTGCAGCCGCAGCTGCGATGCAGGCGTGCGCAGCC GCTCGGTCGTGTGCCAGCGCCGCGTCTCTGCCGCGGAGGAGAAGGCGCTGGACGACAG CGCATGCCCGCAGCCGCGCCCACCTGTACTGGAGGCCTGCCACGGCCCCACTTGCCCT CCGGAGTGGGCGGCCCTCGACTGGTCTGAGTGCACCCCCAGCTGCGGGCCGGGCCTCC GCCACCGCGTGGTCCTTTGCAAGAGCGCAGACCACCGCGCCACGCTGCCCCCGGCGCA CTGCTCACCCGCCGCCAAGCCACCGGCCACCATGCGCTGCAACTTGCGCCGCTGCCCC CCGGCCCGCTGGGTGGCTGGCGAGTGGGGTGAGTGCTCTGCACAGTGCGGCGTCGGGC AGCGGCAGCGCTCGGTGCGCTGCACCAGCCACACGGGCCAGGCGTCGCACGAGTGCAC GGAGGCCCTG
ORF Start: at 1 ORF Stop: end of
GTGGAGTGCCGCAACCAGCTGGACAGCTCCGCGGTCGCCCCCCACTACTGCAGTGCCC ACAGCAAGCTGCCCAAAAGGCAGCGCGCCTGCAACACGGAGCCTTGCCCTCCAGACTG: GGTTGTAGGGAACTGGTCGCTCTGCAGCCGCAGCTGCGATGCAGGCGTGCGCAGCCGC TCGGTCGTGTGCCAGCGCCGCGTCTCTGCCGCGGAGGAGAAGGCGCTGGACGACAGCG; CATGCCCGCAGCCGCGCCCACCTGTACTGGAGGCCTGCCACGGCCCCACTTGCCCTCC: GGAGTGGGCGGCCCTCGACTGGTCTGAGTGCACCCCCAGCTGCGGGCCGGGCCTCCGC CACCGCGTGGTCCTTTGCAAGAGCGCAGACCACCGCGCCACGCTGCCCCCGGCGCACT GCTCACCCGCCGCCAAGCCACCGGCCACCATGCGCTGCAACTTGCGCCGCTGCCCCCC GGCCCGCTGGGTGGCTGGCGAGTGGGGTGAGTGCTCTGCACAGTGCGGCGTCGGGCAG CGGCAGCGCTCGGTGCGCTGCACCAGCCACACGGGCCAGGCGTCGCACGAGTGCACGG AGGCCCTGC
ORF Start: at 1297 ORF Stop: at 3199
SEQ ID NO: 390 634 aa MW at 68853.1kD
NOV52c, YCLKRYMACIKCSINGAYWΞSISHRPCPARGCTKTHREPGREHRA CSGTGSEPDI V CG51213-02 LPSRAGCPREEGRGASLSGHLGPQEVCSELWCLSKSNRCITNSIPAAEGTLCQTHTID KG CYKRVCVPFGSRPEGVDGA GP TP GDCSRTCGGGVSSSSRHCDSPRPTIGGKY Protein Sequence CLGERRRHRSCNTDDCPPGSQDFREVQCSEFDSIPFRGKFYKWKTYRGGGVKACSLTC LAEGFNFYTERAAAWDGTPCRPDTVDICVSGECKHVGCDRVLGSD REDKCRVCGGD GSACETIEGVFSPASPGAGYEDWWIPKGSVHIFIQDLNLS SHLALKGDQES LLEG LPGTPQPHRLP AGTTFQLRQGPDQVQS EA GPINAS IVMV ARTELPALRYRFNA PIARDSLPPYSWHYAP TKCSAQCAGGSQVQAVECRNQLDSSAVAPHYCSAHSK PKR QRACNTEPCPPDWWGN SLCSRSCDAGVRSRSWCQRRVSAAEEKA DDSACPQPRP PV EACHGPTCPPE AA D SECTPSCGPGLRHRWLCKSADHRATLPPAHCSPAAKP PATMRCN RRCPPAR VAGE GECSAQCGVGQRQRSVRCTSHTGQASHECTEAL
SEQ ID NO.- 391 3700 bp
NOV52d, CTGACATTCCACCCTTGACACCCCCCAACATCCTAACTTAGCTGGTAACTGCAGCACC CG51213-03 CTCTAAGGAATTCCTAAAGAATTCTGAAGCTACTCCTCAACATCTGCTGTGACCCAGG DNA Sequence TATCCTAACAATGATCATGGTGTCTGACATTTACTGAGCTCTCACTATGGGCTAAGCA
ITGTGCTGTGTGTCACCATCTAAACTCCTGACAATCCTGCTAGCCCCCACGTTACAGAG:
GAAGGGACTGAGCCATAGCATAGGGAGGATGACTTGTCCAAGGCCACAGTTTGAGACC
ATGACAGAGCTGGGATTTAAATCCAGGTCTCTCATGACTCTCTAAATTTTACAAAGGG
GCAGGGGAGGGGAGGAGCTGTCAAAATATCAAGCTTGGGCTGGCACTGGCTATATGTT
GAATTGAGCCTTCCTTTTAGTTTTTGAAGGAACATCTTTCAGGCCATCTTGGCAAAGG!
GGGATTTATTTACTAAATGTGAACTGGTTAATATATGTAAAGGGTTCAGCCTGGTGCC
TGGTCCAGAGATAGTGGTGGTCATTGTTACCCCATAATGGCATTGGTGCAAGTCCTTT
CTTATCTATCCTGTCACGTGCCTCATAGCCATTTATATAGGCAAGACAGGCATTAGGC!
TGCCCATCTTGTAGATGAGTAAACTGAGGCCCAGAGAGGGGAAATATATTGCAAGTTGi
GTAGCAGAATTGAGGTCTCTGCACAACTCAAATATGCCACAGTGCCTCCTTGTGGAGA!
GGAGGACAAAAGCAGAGCTGAAATCATTATCTTGAAGAGGTGTCAGAAGTGGGATTGC!
GACAGGACTGATGTGATATTTTTAGATATGGCCAAGAGGACACAGTCTGAGTTTTTAG
CTGAGAAATGTCCTCTATAAGGCAGAAGGCAGAGATTCTAGAGGACCTTTGAGGGAGA
ATGTATTTGAGAACAACTCTTCCAGCTTCTTACATATGTACAGGTATCTCTCAGGGGC:
TGACCTAGGAAGGGTCCTTTCCTGTGGCCATTGATCGATCCAGTCCCACATCTGGAAA!
GCTTACAAGAATTGGGTTCAAAGCGGGGATTACACTTGATAATTACAGAAGGACCACC
TACTTCTTAGAGGAAAGACGCTGGGAGGTTGCTTAGGATGTGGGCCAAGAGGGTCAGAS
GAGGACCACCTACTTTTTAGAGGAAAGACGCTGGGAGGTTGCTTAGGATGTGGGCCAAl
GAGGGTCAGAGATTTTGCTTCACCTGAACTCACTGGGGCTTCTCCAGGGATATTAACC:
TGGACTTTAAGAGTCAGAGTGAGTCCCTGGGACTAGTTCAGCCCATCCAGGATTCAGAl
CGGGAAGAAGGTGGGGCTGATTTTTCACCTGGAGAAAGAGAGGCATGTCCCACACAGA
CCTAACTCGGCATTGTCCCCTCCCAAACTCCCACCCCTCCACATAGCTTAAAAGTGTTi
GGGGGCTTCTCCAGTTTAGATGGGGGAACAAAGAGAACCAACAGCTGGAAAAAACTAGI lAGATGAGGCCGTTGGCCTAGTCATCATCCAGGCCGATTTCTCAGAACCACCACTTTCT
CTTCGGCTACTTTGCCCATCCCATAAAAGAACCCCAAATCCTTCCTGTTCATTCCTCA] iGCAGTTCCCACGTTTCCTTCCAGAAACTCAGAAGGCACCAGGAACTGAATTGCAAAGTi
TCGTTAGAGCACAGACTCTGAATTAAAGAGCTGGGTTAAACTCCAGGCTATTCCCTTA
GTAGCTGTGTGACCTTACCTGTCTGAAGCTTGGTTTTCTCCCAGTAAGATGGGGTAGT
ACTGCCTAAAGAGGTATATGGCATGTATAAAGTGCTCCATAAATGGAGCTTATTGGGA GAGTATAAGTCACAGGCCATGCCCCGCAAGGGGATGCACGAAGACCCACCGCGAGCCA
GGAAGGGAGCACGGGGCTCTCTGCTCTGGGACCGGCAGTGAGCCGGACATCTGGGTCC TCCCAAGCCGGGCGGGCTGCCCCAGGGAGGAAGGGAGGGGGGCGAGCCTGAGCGGGCA CCTCGGCCCGCAGGAGGTCTGCAGCGAGCTGTGGTGTCTGAGCAAGAGCAACCGGTGC ATCACCAACAGCATCCCGGCCGCCGAGGGCACGCTGTGCCAGACGCACACCATCGACA AGGGGTGGTGCTACAAACGGGTCTGTGTCCCCTTTGGGTCGCGCCCAGAGGGTGTGGA CGGAGCCTGGGGGCCGTGGACTCCATGGGGCGACTGCAGCCGGACCTGTGGCGGCGGC GTGTCCTCTTCTAGCCGTCACTGCGACAGCCCCAGGCCAACCATCGGGGGCAAGTACT GTCTGGGTGAGAGAAGGCGGCACCGCTCCTGCAACACGGATGACTGTCCCCCTGGCTC CCAGGACTTCAGAGAAGTGCAGTGTTCTGAATTTGACAGCATCCCTTTCCGTGGGAAA TTCTACAAGTGGAAAACGTACCGGGGAGGGGGCGTGAAGGCCTGCTCGCTCACGTGCC TAGCGGAAGGCTTCAACTTCTACACGGAGAGGGCGGCAGCCGTGGTGGACGGGACACC CTGCCGTCCAGACACGGTGGACATTTGCGTCAGTGGCGAATGCAAGCACGTGGGCTGC GACCGAGTCCTGGGCTCCGACCTGCGGGAGGACAAGTGCCGAGTGTGTGGCGGTGACG GCAGTGCCTGCGAGACCATCGAGGGCGTCTTCAGCCCAGCCTCACCTGGGGCCGGGTA CGAGGATGTCGTCTGGATTCCCAAAGGCTCCGTCCACATCTTCATCCAGGATCTGAAC CTCTCTCTCAGTCACTTGGCCCTGAAGGGAGACCAGGAGTCCCTGCTGCTGGAGGGGC TGCCCGGGACCCCCCAGCCCCACCGTCTGCCTCTAGCTGGGACCACCTTTCAACTGCG ACAGGGGCCAGACCAGGTCCAGAGCCTCGAAGCCCTGGGACCGATTAATGCATCTCTC ATCGTCATGGTGCTGGCCCGGACCGAGCTGCCTGCCCTCCGCTACCGCTTCAATGCCC CCATCGCCCGTGACTCGCTGCCCCCCTACTCCTGGCACTATGCGCCCTGGACCAAGTG CTCGGCCCAGTGTGCAGGCGGTAGCCAGGTGCAGGCGGTGGAGTGCCGCAACCAGCTG GACAGCTCCGCGGTCGCCCCCCACTACTGCAGTGCCCACAGCAAGCTGCCCAAAAGGC AGCGCGCCTGCAACACGGAGCCTTGCCCTCCAGACTGGGTTGTAGGGAACTGGTCGCT CTGCAGCCGCAGCTGCGATGCAGGCGTGCGCAGCCGCTCGGTCGTGTGCCAGCGCCGC GTCTCTGCCGCGGAGGAGAAGGCGCTGGACGACAGCGCATGCCCGCAGCCGCGCCCAC CTGTACTGGAGGCCTGCCACGGCCCCACTTGCCCTCCGGAGTGGGCGGCCCTCGACTG GTCTGAGTGCACCCCCAGCTGCGGGCCGGGCCTCCGCCACCGCGTGGTCCTTTGCAAG AGCGCAGACCACCGCGCCACGCTGCCCCCGGCGCACTGCTCACCCGCCGCCAAGCCAC CGGCCACCATGCGCTGCAACTTGCGCCGCTGCCCCCCGGCCCGCTGGGTGGCTGGCGA GTGGGGTGAGTGCTCTGCACAGTGCGGCGTCGGGCAGCGGCAGCGCTCGGTGCGCTGC ACCAGCCACACGGGCCAGGCGTCGCACGAGTGCACGGAGGCCCTGC
ORF Start: at 1798 ORF Stop: at 3700
SEQ ID NO: 392 "[634 aa MW at 68754.0kD
NOV52d, YC KRYMACIKCSINGAY ESISHRPCPARGCTKTHREPGREHGALCSGTGSEPDI V CG51213-03 PSRAGCPREEGRGASLSGHLGPQEVCSELWCLSKSNRCITNSIPAAEGTLCQTHTID Protein Sequence KG CYKRVCVPFGSRPEGVDGA GP TPWGDCSRTCGGGVSSSSRHCDSPRPTIGGKY CLGERRRHRSCNTDDCPPGSQDFREVQCSEFDSIPFRGKFYK KTYRGGGVKACSLTC AEGFNFYTERAAAWDGTPCRPDTVDICVSGECKHVGCDRV GSD REDKCRVCGGD GSACETIEGVFSPASPGAGYEDW IPKGSVHIFIQD N SLSH ALKGDQESL LEG LPGTPQPHRLPLAGTTFQLRQGPDQVQS EA GPINASLIVVLARTELPALRYRFNA PIARDSLPPYSWHYAP TKCSAQCAGGSQVQAVECRNQ DSSAVAPHYCSAHSK PKR QRACNTEPCPPDWWGN SIiCSRSCDAGVRSRSWCQRRVSAAEEKALDDSACPQPRP PV EACHGPTCPPE AALD SECTPSCGPGLRHRW CKSADHRATLPPAHCSPAAKP PATMRCNLRRCPPARWVAGE GECSAQCGVGQRQRSVRCTSHTGQASHECTEAL
SEQ ID NO: 393 2804 bp
NOV52e, TGGCCAGCCAGGCCTGAAGCGATCGGTCAGCCGAGAGCGCTACGTGGAGACCCTGGTG CG51213-04 GTGGCTGACAAGATGATGGTGGCCTATCACGGGCGCCGGGATGTGGAGCAGTATGTCC
TGGCCATCATGAACATTCAGGTTGCCAAACTTTTCCAGGACTCGAGTCTGGGAAGCAC DNA Sequence CGTTAACATCCTCGTAACTCGCCTCATCCTGCTCACGGAGGACCAGCCCACTCTGGAG ATCACCCACCATGCCGGGAAGTCCCTGGACAGCTTCTGTAAGTGGCAGAAATCCATCG TGAACCACAGCGGCCATGGCAATGCCATTCCAGAGAACGGTGTGGCTAACCATGACAC AGCAGTGCTCATCACACGCTATGACATCTGCATCTACAAGAACAAACCCTGCGGCACA CTAGGCCTGGCCCCGGTGGGCGGAATGTGTGAGCGCGAGAGAAGCTGCAGCGTCAATG AGGACATTGGCCTGGCCACAGCGTTCACCATTGCCCACGAGATCGGGCACACATTCGG CATGAACCATGACGGCGTGGGAAACAGCTGTGGGGCCCGTGGTCAGGACCCAGCCAAG CTCATGGCTGCCCACATTACCATGAAGACCAACCCATTCGTGTGGTCATCCTGCAGCC GTGACTACATCACCAGCTTTCTAGACTCGGGCCTGGGGCTCTGCCTGAACAACCGGCC CCCCAGACAGGACTTTGTGTACCCGACAGTGGCACCGGGCCAAGCCTACGATGCAGAT
TGGAGTACTGGACACGGGAGGGCCTGGCCTGGCAGAGGGCGGCCCGGCCCCACTGCCT
CTACGCTGGTCACCTGCAGGGCCAGGCCAGCAGCTCCCATGTGGCCATCAGCACCTGT
GGAGGCCTGCACGGCCTGATCGTGGCAGACGAGGAAGAGTACCTGATTGAGCCCCTGC
ACGGTGGGCCCAAGGGTTCTCGGAGCCCGGAGGAAAGTGGACCACATGTGGTGTACAA
GCGTTCCTCTCTGCGTCACCCCCACCTGGACACAGCCTGTGGAGTGAGAGATGAGAAA
CCGTGGAAAGGGCGGCCATGGTGGCTGCGGACCTTGAAGCCACCGCCTGCCAGACCCC
TGGGGAATGAAACAGAGCGTGGCCAGCCAGGCCTGAAGCGATCGGTCAGCCGAGAGCG
CTACGTGGAGACCCTGGTGGTGGCTGACAAGATGATGGTGGCCTATCACGGGCGCCGG
GATGTGGAGCAGTATGTCCTGGCCATCATGAACATTGTTGCCAAACTTTTCCAGGACT
CGAGTCTGGGAAGCACCGTTAACATCCTCGTAACTCGCCTCATCCTGCTCACGGAGGA
CCAGCCCACTCTGGAGATCACCCACCATGCCGGGAAGTCCCTAGACAGCTTCTGTAAG
TGGCAGAAATCCATCGTGAACCACAGCGGCCATGGCAATGCCATTCCAGAGAACGGTG
TGGCTAACCATGACACAGCAGTGCTCATCACACGCTATGACATCTGCATCTACAAGAA
CAAACCCTGCGGCACACTAGGCCTGGCCCCGGTGGGCGGAATGTGTGAGCGCGAGAGA
AGCTGCAGCGTCAATGAGGACATTGGCCTGCCACAAGCGTTCACCATTGCCCACGAGA
TCGGGCACACATTCGGCATGAACCATGACGGCGTGGGAAACAGCTGTGGGGCCCGTGG
TCAGGACCCAGCCAAGCTCATGGCTGCCCACATTACCATGAAGACCAACCCATTCGTG
TGGTCATCCTGCAACCGTGACTACATCACCAGCTTTCTAGACTCGGGCCTGGGGCTCT
GCCTGAACAACCGGCCCCCCAGACAGGACTTTGTGTACCCGACAGTGGCACCGGGCCA
AGCCTACGATGCAGATGAGCAATGCCGCTTTCAGCATGGAGTCAAATCGCGTCAGTGT
AAATACGGGGAGGTCTGCAGCGAGCTGTGGTGTCTGAGCAAGAGCAACCGGTGCATCA
CCAACAGCATCCCGGCCGCCGAGGGCACGCTGTGCCAGACGCACACCATCGACAAGGG
GTGGTGCTACAAACGGGTCTGTGTCCCCTTTGGGTCGCGCCCAGAGGGTGTGGACGGA
GCCTGGGGGCCGTGGACTCCATGGGGCGACTGCAGCCGGACCTGTGGCGGCGGCGTGT
CCTCTTCTAGTCGTCACTGCGACAGCCCCAGGCCAACCATCGGGGGCAAGTACTGTCT
GGGTGAGAGAAGGCGGCACCGCTCCTGCAACACGGATGACTGTCCCCCTGGCTCCCAG
GACTTCAGAGAAGTGCAGTGTTCTGAATTTGACAGCATCCCTTTCCGTGGGAAATTCT
ACAAGTGGAAAACGTACCGGGGAGGGGGCGTGAAGGCCTGCTCGCTCACGAGCCTAGC
GGAAGGCTTCAACTTCTACACGGAGAGGGCGGCAGCCGTGGTGGACGGGACACCCTGC
CGTCCAGACACGGTGGACATTTGCGTCAGTGGCGAATGCAAGCACGTGGGCTGCGACC
GAGTCCTGGGCTCCGACCTGCGGGAGGACAAGTGCCGAGTGTGTGGCGGTGACGGCAG
TGCCTGCGAGACCATCGAGGGCGTCTTCAGCCCAGCCTCACCTGGGGCCGGGTACGAG
GATGTCGTCTGGATTCCCAAAGGCTCCGTCCACATCTTCATCCAGGATCTGAACCTCT
CTCTCAGTCACTTGGCCCTGAAGGGAGACCAGGAGTCCCTGCTGCTGGAGGGGCTGCC
TGGGACCCCCCAGCCCCACCGTCTGCCTCTAGCTGGGACCACCTTTCAACTGCGACAG
GGGCCAGACCAGGTCCAGAGCCTCGAAGCCCTGGGACCGATTAATGCATCTCTCATCG
TCATGGTGCTGGCCCGGACCGAGCTGCCTGCCCTCCGCTACCGCTTCAATGCCCCCAT
CGCCCGTGACTCGCTGCCCCCCTACTCCTGGCACTATGCGCCCTGGACCAAGTGCTCG
GCCCAGTGTGCAGGCGGTAGCCAGGTGCAGGCGGTGGAGTGCCGCAACCAGCTGGACA
GCTCCGCGGTCGCCCCCCACTACTGCAGTGCCCACAGCAAGCTGCCCAAAAGGCAGCG
CGCCTGCAACACGGAGCCTTGCCCTCCAGACTGGGTTGTAGGGAACTGGTCGCTCTGC
AGCCGCAGCTGCGATGCAGGCGTGCGCAGTCGCTCGGTCGTGTGCCAGCGCCGCGTCT
CTGCCGCGGAGGAGAAGGCGCTGGACGACAGCGCATGCCCGCAGCCGCGCCCACCTGT
ACTGGAGGCCTGCCACGGCCCCACTTGCCCTCCGGAGTGGGCGGCCCTCGACTGGTCT
GAGTGCACCCCCAGCTGCGGGCCGGGCCTCCGCCACCGCGTGGTCCTTTGCAAGAGCG
CAGACCACCGCGCCACGCTGCCCCCGGCGCACTGCTCACCCGCCGCCAAGCCACCGGC
CACCATGCGCTGCAACTTGCGCCGCTGCCCCCCGGCCCGCTGGGTGGCTGGCGAGTGG
GGTGAGTGCTCTGCACAGTGCGGCGTCGGGCAGCGGCAGCGCTCGGTGCGCTGCACCA
GCCACACGGGCCAGGCGTCGCACGAGTGCACGGAGGCCCTGCGGCCGCCCACCACGCA
GCAGTGTGAGGCCAAGTGCGACAGCCCAACCCCCGGGGACGGCCCTGAAGAGTGCAAG
GATGTGAACAAGGTCGCCTACTGCCCCCTGGTGCTCAAATTTCAGTTCTGCAGCCGAG
CCTACTTCCGCCAGATGTGCTGCAAAACCTGCCAGGGCCACTAGGGGGCGCGCGGCAC
CCGGAGCCACAGCTGGCGGGGTCTCCGCCGCCAGCCCTGCAGCGGGCCGGCCAAAGGGi
GGCCCCGGGGGGGCGGGAACTGGGAGGGAAGGGTGAGACGGAGCCGGAAGTTATTTAT
TGGGAACCCCTGCAGGGCCCTGGCTGGGGGGATGGA
ORF Start: at 1 ORF Stop: TAG at 3232
SEQ ID NO: 396 1077 aa MW at ll8071.4kD
NOV52f, RSQDEFLSS ESYEIAFPTRVDHNGALLAFSPPPPRRQRRGTGATAESRLFYKVASPS CG51213-05 THFLLN TRSSRLLAGHVSVEYWTREGLA QRAARPHCLYAGHLQGQASSSHVAISTC
Protein Sequence GGLHGLIVADEEEYL.IEP HGGPKGSRSPEESGPHWYKRSS RHPHLDTACGVRDEK PWKGRP W RTLKPPPARPLGNETERGQPG KRSVSRERYVET VVADKMMVAYHGRR DVEQYVLAIMNIVAK FQDSS GSTVNI VTR I LTEDQPTLEITHHAGKSLDSFCK WQKSIVNHSGHGNAIPENGVANHDTAVLI RYDICIYKNKPCGTLGLAPVGGMCERER SCSVNEDIGLPQAFTIAHEIGHTFGM HDGVGNSCGARGQDPAKLMAAHIT KTNPFV SSCNRDYITSFLDSGLG C NNRPPRQDFVYPTVAPGQAYDADEQCRFQHGVKSRQC KYGEVCSEL CLSKSNRCITNSIPAAEGTLCQTHTIDKGWCYKRVCVPFGSRPEGVDG AWGPWTPWGDCSRTCGGGVSSSSRHCDSPRPTIGGKYCLGERRRHRSCNTDDCPPGSQ DFREVQCSEFDSIPFRGKFYKWKTYRGGGVKACSLTSLAEGFNFYTERAAAWDGTPC RPDTVDICVSGECKHVGCDRV GSD REDKCRVCGGDGSACETIEGVFSPASPGAGYE DW IPKGSVHIFIQDLN SLSHLALKGDQESLLLEGLPGTPQPHRLP AGTTFQLRQ GPDQVQS EALGPINAS IVKV ARTELPALRYRFNAPIARDS PPYS HYAP TKCS AQCAGGSQVQAVECRNQ DSSAVAPHYCSAHSK PKRQRACNTEPCPPD WGN SLC SRSCDAGVRSRSWCQRRVSAAEEKA DDSACPQPRPPVLEACHGPTCPPE AA DWS ECTPSCGPGLRHRW CKSADHRATLPPAHCSPAAKPPAT RCN RRCPPAR VAGE GECSAQCGVGQRQRSVRCTSHTGQASHECTEARPPTTQQCEAKCDSPTPGDGPEECK DVNKVAYCP VLKFQFCSRAYFRQMCCKTCQGH
SEQ ID NO: 397 978 bp
NOV52g, TCCATAAATGGAGCTTATTGGGAGAGTATAAGTCACAGGCCATGCCCCGCAAGGGGAT CG51213-06 GCACGAAGACCCACCGCGAGCCAGGAAGGGAGCACCGGGCTCTCTGCTCTGGGACCGG CAGTGAGCCGGACATCTGGGTCCTCCCAAGCCGGGCGGGCTGCCCCAGGGAGGAAGGG DNA Sequence AGGGGGGCGAGCCTGAGCGGGCACCTCGGCCCGCAGGAGGTCTGCAGCGAGCTGTGGT GTCTGAGCAAGAGCAACCGGTGCATCACCAACAGCATCCCGGCCGCCGAGGGCACGCT GTGCCAGACGCACACCATCGACAAGGGGTGGTGCTACAAACGGGTCTGTGTCCCCTTT GGGTCGCGCCCAGAGGGTGTGGACGGAGCCTGGGGGCCGTGGACTCCATGGGGCGACT GCAGCCGGACCTGTGGCGGCGGCGTGTCCTCTTCTAGCCGTCACTGCGACAGCCCCAG GCCAACCATCGGGGGCAAGTACTGTCTGGGTGAGAGAAGGCGGCACCGCTCCTGCAAC ACGGATGACTGTCCCCCTGGCTCCCAGGACTTCAGAGAAGTGCAGTGTTCTGAATTTG ACAGCATCCCTTTCCGTGGGAAATTCTACAAGTGGAAAACGTACCGGGGAGGGGGCGT GAAGGCCTGCTCGCTCACGTGCCTAGCGGAAGGCTTCAACTTCTACACGGAGAGGGCG GCAGCCGTGGTGGACGGGACACCCTGCCGTCCAGACACGGTGGACATTTGCGTCAGTG GCGAATGCAAGCACGTGGGCTGCGACCGAGTCCTGGGCTCCGACCTGCGGGAGGACAA GTGCCGAGTGTGTGGCGGTGACGGCAGTGCCTGCGAGACCATCGAGGGCGTCTTCAGC CCAGCCTCACCTGGGGCCGGGTACGAGGATGTCGTCTGGATTCCCAAAGGCTCCGTCC ACATCTTCATCCAGGATCTGAACCTCTCTCTCAGTCACTTGGCCCTGAAG
ORF Start: at 1 ORF Stop: end of sequence
SEQ ID NO: 398 |326 aa JMW at 35330.2kD
NOV52g, SINGAYWESISHRPCPARGCTKTHREPGREHRALCSGTGSEPDIWV PSRAGCPREEG CG51213-06 RGAS SGHLGPQEVCSELWCLSKSNRCITNSIPAAEGTLCQTHTIDKGWCYKRVCVPF GSRPEGVDGA GP TPWGDCSRTCGGGVSSSSRHCDSPRPTIGGKYCLGERRRHRSCN Protein Sequence TDDCPPGSQDFREVQCSEFDSIPFRGKFYK KTYRGGGVKACS TCLAEGFNFYTERA AAWDGTPCRPDTVDICVSGECKHVGCDRV GSD REDKCRVCGGDGSACETIEGVFS PASPGAGYEDW IPKGSVHIFIQDLNLSLSHLALK
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 52B.
Table 52B. Comparison of NO 52a against NOV52b through NOV52g.
NOV52a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV52b 54..465 412/412 (100%) 211..622 412/412 (100%)
Further analysis of the NOV52a protein yielded the following properties shown in Table 52C.
Table 52C. Protein Sequence Properties NOV52a
PSort 0.6400 probability located in plasma membrane; 0.5231 probability located in analysis: outside; 0.1900 probability located in lysosome (lumen); 0.1000 probability located in endoplasmic reticulum (membrane)
SignalP Cleavage site between residues 37 and 38 analysis:
A search of the NOV52a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 52D.
In a BLAST search of public sequence datbases, the NOV52a protein was found to have homology to the proteins shown in the BLASTP data in Table 52E.
PFam analysis predicts that the NOV52a protein contains the domains shown in the Table 52F.
Table 52F. Domain Analysis of NOV52a
Example 53.
The NOV53 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 53A.
Table 53A. NOV53 Sequence Analysis
SEQ ID NO: 399 2245 bp
NOV53a, AGAACAGCTTGAAGACCGTTCATTTTTAAGTGACAAGAGACTCACCTCCAAGAAGCAA; CG56155-01 TTGTGTTTTCAGAATGATTTTATTCAAGCAAGCAACTTATTTCATTTCCTTGTTTGCT DNA Sequence ACAGTTTCCTGTGGATGTCTGACTCAACTCTATGAAAACGCCTTCTTCAGAGGTGGGG ATGTAGCTTCCATGTACACCCCAAATGCCCAATACTGCCAGATGAGGTGCACATTCCA CCCAAGGTGTTTGCTATTCAGTTTTCTTCCAGCAAGTTCAATCAATGACATGGAGAAA AGGTTTGGTTGCTTCTTGAAAGATAGTGTTACAGGAACCCTGCCAAAAGTACATCGAA CAGGTGCAGTTTCTGGACATTCCTTGAAGCAATGTGGTCATCAAATAAGTGCTTGCCA TCGAGACATTTATAAAGGAGTTGATATGAGAGGAGTCAATTTTAATGTGTCTAAGGTT AGCAGTGTTGAAGAATGCCAAAAAAGGTGCACCAATAACATTCGCTGCCAGTTTTTTT CATATGCCACGCAAACATTTCACAAGGCAGAGTACCGGAACAATTGCCTATTAAAGTA CAGTCCCGGAGGAACACCTACCGCTATAAAGGTGCTGAGTAACGTGGAATCTGGATTC TCACTGAAGCCCTGTGCCCTTTCAGAAATTGGTTGCCACATGAACATCTTCCAGCATC TTGCGTTCTCAGATGTGGATGTTGCCAGGGTTCTCACTCCAGATGCTTTTGTGTGTCG GACCATCTGCACCTATCACCCCAACTGCCTCTTCTTTACATTCTATACAAATGTATGG AAAATCGAGTCACAAAGAAATGTTTGTCTTCTTAAAACATCTGAAAGTGGCACACCAA GTTCCTCTACTCCTCAAGAAAACACCATATCTGGATATAGCCTTTTAACCTGCAAAAG AACTTTACCTGAACCCTGCCATTCTAAAATTTACCCGGGAGTTGACTTTGGAGGAGAA GAATTGAATGTGACTTTTGTTAAAGGAGTGAATGTTTGCCAAGAGACTTGCACAAAGA TGATTCGCTGTCAGTTTTTCACTTATTCTTTACTCCCAGAAGACTGTAAGGAAGAGAA GTGTAAGTGTTTCTTAAGATTATCTATGGATGGTTCTCCAACTAGGATTGCGTATGGG ACACAAGGGAGCTCTGGTTACTCTTTGAGATTGTGTAACACTGGGGACAACTCTGTCT GCACAACAAAAACAAGCACACGCATTGTTGGAGGAACAAACTCTTCTTGGGGAGAGTG GCCCTGGCAGGTGAGCCTGCAGGTGAAGCTGACAGCTCAGAGGCACCTGTGTGGAGGG TCACTCATAGGACACCAGTGGGTCCTCACTGCTGCCCACTGCTTTGATGGGCTTCCCC TGCAGGATGTTTGGCGCATCTATAGTGGCATTTTAAATCTGTCAGACATTACAAAAGA TACACCTTTCTCACAAATAAAAGAGATTATTATTCACCAAAACTATAAAGTCTCAGAA GGGAATCATGATATCGCCTTGATAAAACTCCAGGCTCCTTTGAATTACACTGAATTCC AAAAACCAATATGCCTACCTTCCAAAGGTGACACAAGCACAATTTATACCAACTGTTG GGTAACCGGATGGGGCTTCTCGAAGGAGAAAGGTGAAATCCAAAATATTCTACAAAAG GTAAATATTCCTTTGGTAACAAATGAAGAATGCCAGAAAAGATATCAAGATTATAAAA TAACCCAACGGATGGTCTGTGCTGGCTATAAAGAAGGGGGAAAAGATGCTTGTAAGGG AGATTCAGGTGGTCCCTTAGTTTGCAAACACAACGGAATGTGGCGTTTGGTGGGCATC ACAAGCTGGGGTGAAGGCTGTGCCCGCAGGGAGCAACCTGGTGTCTACACCAAAGTCG
CTGAGTACATGGACTGGATTTTAGAGAAAACACAGAGCAGTGATGGAAAAGCTCAGAT GCAGTCACCAGCATGAGAAGCAGTCCAGAGTCTAGGCAATTTTTACAACCTGAGTTCA
AGTCAAATTCTGAGCCTGGGGGGTCCTCATCTGCAAAGCATGGAGAGTGGCATCTTCT
TTGCATCCTAAGGACGAAAGACACAGTGCACTCAGAGCTGCTGAGGACAATGTCTGCT
GAAGCCCGCTTTCAGCACGCCGTAACCAGGGGCTGACAATGCGAGGTCGCAACTGAGAi
TCTCCATGACTGTGTGTTGTGAAATAAAATGGTGAAAGATC
ORF Start: ATG at 72 ORF Stop: TGA at 1986
SEQ ID NO: 400 638 aa MW at 71369.0kD
NOV53a, MILFKQATYF SLFATVSCGCLTQLYENAFFRGGDVASMYTPNAQYCQMRCTFHPRCL CG56155-01 LFSFLPASSINDMEKRFGCFLKDSVTGTLPKVHRTGAVSGHSLKQCGHQISACHRDIY KGVDMRGVNFIWSKVSSVEECQK-RCTNNIRCQFFSYATQTFHKAEYRNNCLLKYSPGG Protein Sequence TPTAIKVLS VESGFSLKPCALSEIGCHMNIFQHLAFSDVDVARVLTPDAFVCRTICT YHPNCLFFTFYTNVWKIESQRNVCLLKTSESGTPSSSTPQENTISGYSLLTCKRTLPE PCHSKIYPGVDFGGEELNVTFVKGVNVCQETCTKMIRCQFFTYSLLPEDCKEEKCKCF LRLS DGSPTRIAYGTQGSSGYSLRLCNTGDNSVCTTKTSTRIVGGTNSS GE P QV SLQVKLTAQRHLCGGSLIGHQ VLTAAHCFDGLPLQDV RIYSGILNLSDITKDTPFS QIKEIIIHQNYKVSEGNHDIALIKLQAPLNYTEFQKPICLPSKGDTSTIYTNCWVTGW GFSKEKGEIQNILQKVNIPLVTNEECQKRYQDYKITQRMVCAGYKEGGKDACKGDSGG PLVCKHNGM RLVGITSWGEGCARREQPGVYTKVAEYMD ILEKTQSSDGKAQMQSPA
SEQ ID NO: 401 2038 bp
NOV53b, GTTTTCAGAATGATTTTATTCAAGCAAGCAACTTATTTCATTTCCTTGTTTGCTACAG CG56155-02 TTTCCTGTGGATGTCTGACTCAACTCTATGAAAACGCCTTCTTCAGAGGTGGGGATGT AGCTTCCATGTACACCCCAAATGCCCAATACTGCCAGATGAGGTGCACATTCCACCCA DNA Sequence AGGTGTTTGCTATTCAGTTTTCTTCCAGCAAGTTCAATCAATGACATGGAGAAAAGGT TTGGTTGCTTCTTGAAAGATAGTGTTACAGGAACCCTGCCAAAAGTACATCGAACAGG TGCAGTTTCTGGACATTCCTTGAAGCAATGTGGTCATCAAATAAGTGCTTGCCATCGA GACATTTATAAAGGAGTTGATATGAGAGGAGTCAATTTTAATGTGTCTAAGGTTAGCA GTGTTGAAGAATGCCAAAAAAGGTGCACCAATAACATTCGCTGCCAGTTTTTTTCATA TGCCACGCAAACATTTCACAAGGCAGAGTACCGGAACAATTGCCTATTAAAGTACAGT CCCGGAGGAACACCTACCGCTATAAAGGTGCTGAGTAACGTGGAATCTGGATTCTCAC TGAAGCCCTGTGCCCTTTCAGAAATTGGTTGCCACATGAACATCTTCCAGCATCTTGC GTTCTCAGATGTGGATGTTGCCAGGTTTCTCACTCCAGATGCTTTTGTGTGTCGGACC ATCTGCACCTATCACCCCAACTGCCTCTTCTTTACATTCTATACAAATGTATGGAAAA TCGAGTCACAAAGAAATGTTTGTCTTCTTAAAACATCTGAAAGTGGCACACCAAGTTC CTCTACTCCTCAAGAAAACACCATATCTGGATATAGCCTTTTAACCTGCAAAAGAACT TTACCTGAACCCTGCCATTCTAAAATTTACCCGGGAGTTGACTTTGGAGGAGAAGAAT TGAATGTGACTTTTGTTAAAGGAGTGAATGTTTGCCAAGAGACTTGCACAAAGATGAT TCGCTGTCAGTTTTTCACTTATTCTTTACTCCCAGAAGACTGTAAGGAAGAGAAGTGT AAGTGTTTCTTAAGATTATCTATGGATGGTTCTCCAACTAGGATTGCGTATGGGACAC AAGGGAGCTCTGGTTACTCTTTGAGATTGTGTAACACTGGGGACAACGCTGTCTGCAC AACAAAAACAAGCACACGCATTGTTGGAGGAACAAACTCTTCTTGGGGAGAGTGGCCC TGGCAGGTGAGCCTGCAGGTGAAGCTGACAGCTCAGAGGCACCTGTGTGGAGGGTCAC TCATAGGACACCAGTGGGTCCTCACTGCTGCCCACTGCTTTGATGGGCTTCCCCTGCA GGATGTTTGGCGCATCTATAGTGGCATTTTAAATCTGTCAGACATTACAAAAGATACA CCTTTCTCACAAATAAAAGAGATTATTATTCACCAAAACTATAAAGTCTCAGAAGGGA ATCATGATATCGCCTTGATAAAACTCCAGGCTCCTTTGAATTACACTGAATTCCAAAA ACCAATATGCCTACCTTCCAAAGGTGACACAAGCACAATTTATACCAACTGTTGGGTA ACCGGATGGGGCTTCTCGAAGGAGAAAGGTGAAATCCAAAATATTCTACAAAAGGTAA ATATTCCTTTGGTAACAAATGAAGAATGCCAGAAAAGATATCAAGATTATAAAATAAC CCAACGGATGGTCTGTGCTGGCTATAAAGAAGGGGGAAAAGATGCTTGTAAGGGAGAT TCAGGTGGTCCCTTAGTTTGCAAACACAACGGAATGTGGCGTTTGGTGGGCATCACCA GCTGGGGTGAAGGCTGTGCCCGCAGGGAGCAACCTGGTGTCTACACCAAAGTCGCTGA GTACATGGACTGGATTTTAGAGAAAACACAGAGCAGTGATGGAAAAGCTCAGATGCAG TCACCAGCATGAGAAGCAGTCCAGAGTCTAGGCAATTTTTACAACCTGAGTTCAAGTC
AAATTCTGAGCCTGGGGGGTCCTCATCTGCAAAGCATGAAGAGTGGCATCTTCTTTGC
ATCCTAAG
ORF Start: ATG at 10 ORF Stop: TGA at 1924
SEQ ID NO: 402 638 aa MW at 71401.1kD
NOV53b, MILFKQATYFISLFATVSCGCLTQLYENAFFRGGDVASMYTPNAQYCQMRCTFHPRCL CG56155-02 LFSFLPASSINDMEKRFGCFLKDSVTGTLPKVHRTGAVSGHSLKQCGHQISACHRDIY Protein Sequence KGVDMRGVNF-WSKVSSVEECQKRCT IRCQFFSYATQTFHKAEYRNNCLLKYSPGG TPTAIKVLSNVESGFSLKPCALSEIGCHMNIFQHLAFSDVDVARFLTPDAFVCRTICT YHPNCLFFTFYTNV KIESQRNVCLLKTSESGTPSSSTPQENTISGYSLLTCKRTLPE PCHSKIYPGVDFGGEELNVTFVKGVNVCQETCTKMIRCQFFTYSLLPEDCKEEKCKCF LRLSMDGSPTRIAYGTQGSSGYSLRLCNTGDNAVCTTKTSTRIVGGTNSS GEWP QV SLQVKLTAQRHLCGGSLIGHQ VLTAAHCFDGLPLQDV RIYSGIL LSDITKDTPFS QIKEIIIHQNYKVSEGNHDIALIKLQAPLNYTEFQKPICLPSKGDTSTIYTNCWVTG GFSKEKGEIQNILQKVNIPLVTNEECQKRYQDYKITQRMVCAGYKEGGKDACKGDSGG PLVCKH GM RLVGITS GEGCARREQPGVYTKVAEYMDWILEKTQSSDGKAQMQSPA
SEQ ID NO: 403 1869 bp
NOV53c, GGATCCGGATGTCTGACTCAACTCTATGAAAACGCCTTCTTCAGAGGTGGGGATGTAGj CG56155-03 CTTCCATGTACACCCCAAATGCCCAATACTGCCAGATGAGGTGCACATTCCACCCAAG DNA Sequence GTGTTTGCTATTCAGTTTTCTTCCAGCAAGTTCAATCAATGACATGGAGAAAAGGTTT GGTTGCTTCTTGAAAGATAGTGTTACAGGAACCCTGCCAAAAGTACATCGAACAGGTG CAGTTTCTGGACATTCCTTGAAGCAATGTGGTCATCAAATAAGTGCTTGCCATCGAGA CATTTATAAAGGAGTTGATATGAGAGGAGTCAATTTTAATGTGTCTAAGGTTAGCAGT GTTGAAGAATGCCAAAAAAGGTGCACCAGTAACATTCGCTGCCAGTTTTTTTCATATG CCACGCAAACATTTCACAAGGCAGAGTACCGGAACAATTGCCTATTAAAGTACAGTCC CGGAGGAACACCTACCGCTATAAAGGTGCTGAGTAACGTGGAATCTGGATTCTCACTG AAGCCCTGTGCCCTTTCAGAAATTGGTTGCCACATGAACATCTTCCAGCATCTTGCGT TCTCAGATGTGGATGTTGCCAGGTTTCTCACTCCAGATGCTTTTGTGTGTCGGACCAT CTGCACCTATCACCCCAACTGCCTCTTCTTTACATTCTATACAAATGTATGGAAAATC GAGTCACAAAGAAATGTTTGTCTTCTTAAAACATCTGAAAGTGGCACACCAAGTTCCT CTACTCCTCAAGAAAACACCATATCTGGATATAGCCTTTTAACCTGCAAAAGAACTTT ACCTGAACCCTGCCATTCTAAAATTTACCCGGGAGTTGACTTTGGAGGAGAAGAATTG AATGTGACTTTTGTTAAAGGAGTGAATGTTTGCCAAGAGACTTGCACAAAGATGATTC GCTGTCAGTTTTTCACTTATTCTTTACTCCCAGAAGACTGTAAGGAAGAGAAGTGTAA GTGTTTCTTAAGATTATCTATGGATGGTTCTCCAACTAGGATTGCGTATGGGACACAA GGGAGCTCTGGTTACTCTTTGAGATTGTGTAACACTGGGGACAACGCTGTCTGCACAA CAAAAACAAGCACACGCATTGTTGGAGGAACAAACTCTTCTTGGGGAGAGTGGCCCTG GCAGGTGAGCCTGCAGGTGAAGCTGACAGCTCAGAGGCACCTGTGTGGAGGGTCACTC ATAGGACACCAGTGGGTCCTCACTGCTGCCCACTGCTTTGATGGGCTTCCCCTGCAGG ATGTTTGGCGCATCTATAGTGGCATTTTAAATCTGTCAGACATTACAAAAGATACACC TTTCTCACAAATAAAAGAGATTATTATTCACCAAAACTATAAAGTCTCAGAAGGGAAT CATGATATCGCCTTGATAAAACTCCAGGCTCCTTTGAATTACACTGAATTCCAAAAAC CAATATGCCTACCTTCCAAAGGTGACACAAGCACAATTTATACCAACTGTTGGGTAAC CGGATGGGGCTTCTCGAAGGAGAAAGGTGAAATCCAAAATATTCTACAAAAGGTAAAT ATTCCTTTGGTAACAAATGAAGAATGCCAGAAAAGATATCAAGATTATAAAATAACCC AACGGATGGTCTGTGCTGGCTATAAAGAAGGGGGAAAAGATGCTTGTAAGGGAGATTC AGGTGGTCCCTTAGTTTGCAAACACAATGGAATGTGGCGTTTGGTGGGCATCACCAGC TGGGGTGAAGGCTGTGCCCGCAGGGAGCAACCTGGTGTCTACACCAAAGTCGCTGAGT ACATGGACTGGATTTTAGAGAAAACACAGAGCAGTGATGGAAAAGCTCAGATGCAGTC ACCAGCACTCGAG
ORF Start: at 7 ORF Stop: at 1864
SEQ ID NO: 404 [619 aa MW at 69208.4kD
NOV53c, GCLTQLYENAFFRGGDVASMYTPNAQYCQMRCTFHPRCLLFSFLPASSINDMEKRFGC CG56155-03 FLKDSVTGTLPKVHRTGAVSGHSLKQCGHQISACHRDIYKGVDMRGVNFNVSKVSSVE Protein Sequence ECQK_CTSNIRCQFFSYATQTFHKAEYRNNCLLKYSPGGTPTAIKVLSNVESGFSLKP CALSEIGCHM IFQHLAFSDVDVARFLTPDAFVCRTICTYHPNCLFFTFYTV KIES QRNVCLLKTSESGTPSSSTPQENTISGYSLLTCKRTLPEPCHSKIYPGVDFGGEELNV TFVKGVNVCQETCTKMIRCQFFTYSLLPEDCKEEKCKCFLRLSMDGSPTRIAYGTQGS SGYSLRLCNTGDNAVCTTKTSTRIVGGTNSS GE PWQVSLQVKLTAQRHLCGGSLIG HQWVLTAAHCFDGLPLQDV RIYSGILNLSDITKDTPFSQIKEIIIHQNYKVSEGNHD IALIKLQAPL YTEFQKPICLPSKGDTSTIYTNCWVTGWGFSKEKGEIQNILQKVNIP LVTNEECQKRYQDYKITQRMVCAGYKEGGKDACKGDSGGPLVCKHNGMWRLVGITS G
EGCARREQPGVYTKVAEYMDWILEKTQSSDGKAQMQSPA
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 53B.
Further analysis of the NOV53a protein yielded the following properties shown in Table 53C.
Table 53C. Protein Sequence Properties NOV53a
PSort 0.3700 probability located in outside; 0.1900 probability located in lysosome analysis: (lumen); 0.1000 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 20 and 21 analysis:
A search of the NOV53a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 53D.
In a BLAST search of public sequence datbases, the NOV53a protein was found to have homology to the proteins shown in the BLASTP data in Table 53E.
PFam analysis predicts that the NO V53a protein contains the domains shown in the Table 53F.
Example 54.
The NOV54 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 54A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 54B.
Table 54B. Comparison of NOV54a against NOV54b and NOV54c.
Further analysis of the NOV54a protein yielded the following properties shown in Table
54C.
Table 54C. Protein Sequence Properties NO 54a
PSort 0.6850 probability located in endoplasmic reticulum (membrane); 0.6400 analysis: probability located in plasma membrane; 0.4600 probability located in Golgi body; 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 24 and 25 analysis:
A search of the NOV54a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 54D.
In a BLAST search of public sequence datbases, the NOV54a protein was found to have homology to the proteins shown in the BLASTP data in Table 54E.
PFam analysis predicts that the NOV54a protein contains the domains shown in the Table
54F.
The NOV55 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 55A.
Table 55A. NOV55 Sequence Analysis
SEQ ID NO: 411 1192 bp
NOV55a, CGGCGACTGACCGTGGTCGTGGGCGGACGGCGGCTTGCAGCGTGGAGGAGCTGGGGTC CG59595-01 IGCTGTGGGTCGCGAAGCAGAGCCCGGGACGTGCGCGCTTGGTGCACGATCCTGAAGGG
GAGCTCCGAGGGGCCCGGGTCGCCAGGGCTGCTGCGGCCATTCCCGGAGCCCGGCGCG! DNA Sequence GGGCCCGCGAGATACTGGTTTAGGCCGTCCCAGGGCTCCGGGCGCACCCGGTGGCCGG
TGCTGCAGCGGAGGGAGCGCGGCGGCGCGGGGGCTCGGAGACAGCGTTTCTCCCGGAA
GTCTTCCTCGGGCAGCAGGTGGGAAGTGGGAGCCGGAGCGGCAGCTGGCAGCGTTCTC
TCCGCAGGTCGGCACCATGCGCCCTGCAGCCCTGCGCGGGGCCCTGCTGGGCTGCCTC
TGCCTGGCGTTGCTTTGCCTGGGCGGTGCGGACAAGCGCCTGCGTGACAACCATGAGT GGAAAAAACTAATTATGGTTCAGCACTGGCCTGAGACAGTATGCGAGAAAATTCAAAA CGACTGTAGAGACCCTCCGGATTACTGGACAATACATGGACTATGGCCCGATAAAAGT GAAGGATGTAATAGATCGTGGCCCTTCAATTTAGAAGAGATTAAGGATCTTTTGCCAG AAATGAGGGCATACTGGCCTGACGTAATTCACTCGTTTCCCAATCGCAGCCGCTTCTG GAAGCATGAGTGGGAAAAGCATGGGACCTGCGCCGCCCAGGTGGATGCGCTCAACTCC CAGAAGAAGTACTTTGGCAGAAGCCTGGAACTCTACAGGGAGCTGGACCTCAACAGTG TGCTTCTAAAATTGGGGATAAAACCATCCATCAATTACTACCAAGTTGCAGATTTTAA AGATGCCCTTGCCAGAGTATATGGAGTGATACCCAAAATCCAGTGCCTTCCACCAAGC CAGGATGAGGAAGTACAGACAATTGGTCAGATAGAACTGTGCCTCACTAAGCAAGACC AGCAGCTGCAAAACTGCACCGAGCCGGGGGAGCAGCCGTCCCCCAAGCAGGAAGTCTG GCTGGCAAATGGGGCCGCCGAGAGCCGGGGTCTGAGAGTCTGTGAAGATGGCCCAGTC TTCTATCCCCCACCTAAAAAGACCAAGCATTGATGCCCAAGTTTTGGAAATATTCTGT TTTAAAAAGCAAGAGAAATTCACAAACTGCAG
ORF Start: ATG at 365 ORF Stop: TGA at 1133
SEQ ID NO: 412 256 aa MW at 29480.5kD
NOV55a, MRPAALRGALLGCLCLALLCLGGADKRLRDNHE KKLIMVQH PETVCEKIQNDCRDP CG59595-01 PDY TIHGLWPDKSEGCNRS PFNLEEIKDLLPEMRAY PDVIHSFPNRSRF KHE E KHGTCAAQVDALNSQKKYFGRSLELYRELDLNSVLLKLGIKPSINYYQVADFKDALAR Protein Sequence VYGVIPKIQCLPPSQDEEVQTIGQIELCLTKQDQQLQNCTEPGEQPSPKQEV LANGA AESRGLRVCEDGPVFYPPPKKTKH
SEQ ED NO: 413 708 bp
NOV55b, GGATCCGACAAGCGCCTGCGTGACAACCATGAGTGGAAAAAACTAATTATGGTTCAGC 169728691 DNA ACTGGCCTGAGACAGTATGCGAGAAAATTCAAAACGACTGTAGAGACCCTCCGGATTA CTGGACAATACATGGACTATGGCCCGATAAAAGTGAAGGATGTAATAGATCGTGGCCC Sequence TTCAATTTAGAAGAGATTAAGGATCTTTTGCCAGAAATGAGGGCATACTGGCCTGACG TAATTCACTCGTTTCCCAATCGCAGCCGCTTCTGGAAGCATGAGTGGGAAAAGCATGG GACCTGCGCCGCCCAGGTGGATGCGCTCAACTCCCAGAAGAAGTACTTTGGCAGAAGC CTGGAACTCTACAGGGAGCTGGACCTCAACAGTGTGCTTCTAAAATTGGGGATAAAAC CATCCATCAATTACTACCAAGTTGCAGATTTTAAAGATGCCCTTGCCAGAGTATATGG AGTGATACCCAAAATCCAGTGCCTTCCACCAAGCCAGGATGAGGAAGTACAGACAATT GGTCAGATAGAACTGTGCCTCACTAAGCAAGACCAGCAGCTGCAAAACTGCACCGAGC CGGGGGAGCAGCCGTCCCCCAAGCAGGAAGTCTGGCTGGCAAATGGGGCCGCCGAGAG CCGGGGTCTGAGAGTCTGTGAAGATGGCCCAGTCTTCTATCCCCCACCTAAAAAGACC AAGCATCTCGAG
ORF Start: at 1 ORF Stop: end of sequence
SEQ ID NO: 414 236 aa MW at27528.0kD
NOV55b, GSDKRLRDNHE KKLIMVQH PETVCEKIQNDCRDPPDY TIHGL PDKSEGCNRS P 169728691 FNLEEIKDLLPEMRAY PDVIHSFPNRSRF KHE EKHGTCAAQVDALNSQKKYFGRS LELYRELDLNSVLLKLGIKPSINYYQVADFKDALARVYGVIPKIQCLPPSQDEEVQTI Protein Sequence GQIELCLTKQDQQLQNCTEPGEQPSPKQEVWLANGAAESRGLRVCEDGPVFYPPPKKT KHLE
SEQ ID NO: 415 709 bp
NOV55c, GGATCCGACAAGCGCCTGCGTGACAACCATGAGTGGAAAAGACTAATTATGGTTCAGC
1 (M7Wft7 TYN.TΛ ACTGGCCTGAGACAGTATGCGAGAAAATTCAAAACGACTGTAGAGACCCTCCGGATTA
169728707 DNA CTGGACAATACATGGACTATGGCCCGATAAAAGTGAAGGATGTAATAGATCGTGGCCC Sequence TTCAATTTAGAAGAGATTAAGGGTCTTTTGCCAGAAATGAGGGCATACTGGCCTGACG TAATTCACTCGTTTCCCAATCGCAGCCGCTTCTGGAAGCATGAGTGGGAAAAGCATGG GACCGGCGCCGCCCAGGTGGATGCGCTCAACTCCCAGAAGAAGTACTTTGGCAGAAGC CTGGAACTCTACAGGGGGCTGGACCTCAACAGTGTGCTTCTAAAATTGGGGATAAAAC CATCCATCAATTACTACCAAGTTGCAGATTTTAAAGATGCCCTTGCCAGAGTATATGG AGTGATACCCAAAATCCAGTGCCTTCCACCAAGCCAGGATGAGGAAGTACAGACAATT GGTCAGATAGAACTGTGCCTCACTAAGCAAGACCAGCAGCTGCAAAACTGCACCGAGC CGGGGGAGCAGCCGTCCCCCAAGCAGGAAGTCTGGCTGGCAAATGGGGCCGCCGAGAG CCGGGGTCTGAGAGTCTGTGAAGATGGCCCAGTCTTCTATCCCCCACCTAAAAAGACC AAGCATCTCGAGA
ORF Start: at 1 ORF Stop: end of sequence
SEQ ID NO: 416 237 aa MW at 27379.8kD
NOV55c, GSDKRLRDNHE KRLI VQHWPETVCEKIQNDCRDPPDY TIHGL PDKSEGCNRSWP 169728707 FNLEEIKGLLPE RAYWPDVIHSFPNRSRFWKHE EKHGTGAAQVDALNSQKKYFGRS Protein Sequence LELYRGLDLNSVLLKLGIKPSINYYQVADFKDALARVYGVIPKIQCLPPSQDEEVQTI GQIELCLTKQDQQLQNCTEPGEQPSPKQEV LANGAAESRGLRVCEDGPVFYPPPKKT KHLEX
SEQ ID NO: 417 708 bp
NOV55d, GGATCCGACAAGCGCCTGCGTGACAACCATGAGTGGAAAAAACTAATTATGGTTCAGC 169728746 DNA ACTGGCCTGAGACAGTATGCGAGAAAATTCAAGACGACTGTAGAGACCCTCCGGATTA CTGGACAATACATGGACTATGGCCCGATAAAAGTGAAGGATGTAATAGATCGTGGCCC Sequence TTCAATTTAGAAGAGATTAAGGATCTTTTGCCAGAAATGAGGGCATACTGGCCTGACG TAATTCACTCGTTTCCCAATCGCAGCCGCTTCTGGAAGCATGAGTGGGAAAAGCATGG GACCTGCGCCGCCCAGGTGGATGCGCTCAACTCCCAGAAGAAGTACTTTGGCAGAAGC CTGGAACTCTACAGGGAGCTGGACCTCAACAGTGTGCTTCTAAAATTGGGGATAAAAC CATCCATCAATTACTACCAAGTTGCGGATTTTAAAGATGCCCTTGCCAGAGTATATGG AGTGATACCCAAAATCCAGTGCCTTCCACCAAGCCGGGATGAGGAAGTACAGACAATT GGTCAGATAGAACTGTGCCTCACTAAGCAAGACCAGCAGCTGCAAAACTGCACCGAGC CGGGGGAGCAGCCGTCCCCCAAGCAGGAAGTCTGGCTGGCAAATGGGGCCGCCGAGAG CCGGGGTCTGAGAGTCTGTGAAGATGGCCCAGTCTTCTATCCCCCACCTAAAAAGACC AAGCATCTCGAG
ORF Start: at 1 ORF Stop: end of {sequence
236 aa MW at 27557.0kD
NOV55d, GSDKRLRDNHE KKLIMVQHWPETVCEKIQDDCRDPPDY TIHGL PDKSEGCNRSWP 169728746 FNLEEIKDLLPEMRAY PDVIHSFPNRSRF KHE EKHGTCAAQVDALNSQKKYFGRS Protein Sequence LELYRELDLNSVLLKLGIKPSINYYQVADFKDALARVYGVIPKIQCLPPSRDEEVQTI GQIELCLTKQDQQLQNCTEPGEQPSPKQEV LANGAAESRGLRVCEDGPVFYPPPKKT KHLE
NOV55e, GGATCCGACAAGCGCCTGCGTGACAACCATGAGTGGAAAAAACTAATTATGGTTCAGC CG59595-02 ACTGGCCTGAGACAGTATGCGAGAAAATTCAAAACGACTGTAGAGACCCTCCGGATTA CTGGACAATACATGGACTATGGCCCGATAAAAGTGAAGGATGTAATAGATCGTGGCCC DNA Sequence TTCAATTTAGAAGAGATTAAGGATCTTTTGCCAGAAATGAGGGCATACTGGCCTGACG TAATTCACTCGTTTCCCAATCGCAGCCGCTTCTGGAAGCATGAGTGGGAAAAGCATGG GACCTGCGCCGCCCAGGTGGATGCGCTCAACTCCCAGAAGAAGTACTTTGGCAGAAGC CTGGAACTCTACAGGGAGCTGGACCTCAACAGTGTGCTTCTAAAATTGGGGATAAAAC CATCCATCAATTACTACCAAGTTGCAGATTTTAAAGATGCCCTTGCCAGAGTATATGG AGTGATACCCAAAATCCAGTGCCTTCCACCAAGCCAGGATGAGGAAGTACAGACAATT GGTCAGATAGAACTGTGCCTCACTAAGCAAGACCAGCAGCTGCAAAACTGCACCGAGC CGGGGGAGCAGCCGTCCCCCAAGCAGGAAGTCTGGCTGGCAAATGGGGCCGCCGAGAG CCGGGGTCTGAGAGTCTGTGAAGATGGCCCAGTCTTCTATCCCCCACCTAAAAAGACC AAGCATCTCGAG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 55B.
Further analysis of the NOV55a protein yielded the following properties shown in Table 55C.
Table 55C. Protein Sequence Properties NO 55a
PSort 0.8200 probability located in outside; 0.1900 probability located in lysosome analysis: (lumen); 0.1000 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in endoplasmic reticulum (lumen)
SignalP Cleavage site between residues 25 and 26 analysis:
A search of the NOV55a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 55D.
In a BLAST search of public sequence datbases, the NOV55a protein was found to have homology to the proteins shown in the BLASTP data in Table 55E.
PFam analysis predicts that the NOV55a protein contains the domains shown in the Table 55F.
Example 56.
The NOV56 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 56A.

TATGGTTGTGTCCGAGTGGATTTTGCACAGCCATTTTCCTTAAAGGAATATTTAGAAA GCCAAAGTCAGAAACCGGTGTCTGCTCTACTTTCCCTGGAGCAAGCGTTGTTACCAGC TATACTTCCTTCAAGACCCAGTGATGCTGCTGATGAAGGTAGAGACACGTCCATTAAT GAGTCCAGAAATGCAACAGATGAATCCCTACGAAGGAGGTTGATTGCAAATCTGGCTG AGCATATTCTATTCACTGCTAGCAAGTCCTGTGCCATTATGTCCACACACATTGTGGC TTGCCTGCTCCTCTACAGACACAGGCAGGGAATTGATCTCTCCACATTGGTCGAAGAC TTCTTTGTGATGAAAGAGGAAGTCCTGGCTCGTGATTTTGACCTGGGGTTCTCAGGAA ATTCAGAAGATGTAGTAATGCATGCCATACAGCTGCTGGGAAATTGTGTCACAATCAC CCACACTAGCAGGAACGATGAGTTTTTTATCACCCCCAGCACAACTGTCCCATCAGTC TTCGAACTCAACTTCTACAGCAATGGGGTACTTCATGTCTTTATCATGGAGGCCATCA TAGCTTGCAGCCTTTATGCAGTTCTGAACAAGAGGGGACTGGGGGGTCCCACTAGCAC CCCACCTAACCTGATCAGCCAGGAGCAGCTGGTGCGGAAGGCGGCCAGCCTGTGCTAC CTTCTCTCCAATGAAGGCACCATCTCACTGCCTTGCCAGACATTTTACCAAGTCTGCC ATGAAACAGTAGGAAAGTTTATCCAGTATGGCATTCTTACAGTGGCAGAGCACGATGA CCAGGAAGATATCAGTCCTAGTCTTGCTGAGCAGCAGTGGGACAAGAAGCTTCCTGAA CCTTTGTCTTGGAGAAGTGATGAAGAAGATGAAGACAGTGACTTTGGGGAGGAACAGC GAGATTGCTACCTGAAGGTGAGCCAATCCAAGGAGCACCAGCAGTTTATCACCTTCTT ACAGAGACTCCTTGGGCCTTTGCTGGAGGCCTACAGCTCTGCTGCCATCTTTGTTCAC AACTTCAGTGGTCCTGTTCCAGAACCTGAGTATCTGCAAAAGTTGCACAAATACCTAA TAACCAGAACAGAAAGAAATGTTGCAGTATATGCTGAGAGTGCCACATATTGTCTTGT GAAGAATGCTGTGAAAATGTTTAAGGATATTGGGGTTTTCAAGGAGACCAAACAAAAG AGAGTGTCTGTTTTAGAACTGAGCAGCACTTTTCTACCTCAATGCAACCGACAAAAAC TTCTAGAATATATTCTGAGTTTTGTGGTGCTGTAGGTAACGTGTGGCACTGCTGGCAA
ATGAAGGTCATGAGATGAGTTCCTTGTAGGTACCAGCTTCTGGCTCAAGAGTTGAAGG
TGCCGTCGCAGGGTCA
ORF Start: ATG at 101 ORF Stop: TAG at 2585
SEQ ID NO: 428 828 aa MW at 93835.7kD
NOV56a, MDESALTLGTIDVSYLPHSSEYSVGRCKHTSEE VECGFRPTIFRSATLK KESLMSR CG92142-01 KRPFVGRCCYSCTPQSWDKFFNPSIPSLGLRNVIYINETHTRHRGLARRLSYVLFIQ ERDVHKGMFATI^n^E VLNSSRVQEAIAEVAAELNPDGSAQQQSKAVNKVKKKAKRIL Protein Sequence QEMVATVSPAMIRLTG VLLKLFNSFF NIQIHKGQLE VKAATETNLPLLFLPVHRS HIDYLLLTFILFCHNIKAPYIASGNNLNIPIFSTLIHKLGGFFIRRRLDETPDGRKDV LYRALLHGHIVELLRQQQFLEIFLEGTRSRSGKTSCARAGLLSWVDTLSTNVIPDIL IIPVGISYDRIIEGHYNGEQLGKPKKNESL SVARGVIRMLRKNYGCVRVDFAQPFSL KEYLESQSQKPVSALLSLEQALLPAILPSRPSDAADEGRDTSINESRNATDESLRRRL IANLAEHILFTASKSCAI STHIVACLLLYRHRQGIDLSTLVEDFFVMKEEVLARDFD LGFSGNSEDWMHAIQLLGNCVTITHTSR DEFFITPSTTVPSVFELNFYSNGVLHVF IMEAIIACSLYAVLNKRGLGGPTSTPPNLISQEQLVRKAASLCYLLSNEGTISLPCQT FYQVCHETVGKFIQYGILTVAEHDDQEDISPSLAEQQ DKKLPEPLS RSDEEDEDSD FGEEQRDCYLKVSQSKEHQQFITFLQRLLGPLLEAYSSAAIFVHNFSGPVPEPEYLQK LHKYLITRTERNVAVYAESATYCLVKNAVKMFKDIGVFKETKQKRVSVLELSSTFLPQ CNRQKLLEYILSFWL
SEQ ID NO: 429 2527 bp
NOV56b, GCACATGATTTGGGAATTACACTTTGTGACATGGATGAATCTGCACTGACCCTTGGTA CG92142-02 CAATAGATGTTTCTTATCTGCCACATTCATCAGAATACAGTGTTGGTCGATGTAAGCA CACAAGTGAGGAATGGGGTGAGTGTGGCTTTAGACCCACCGTCTTCAGATCTGCAACT DNA Sequence TTAAAATGGAAAGAAAGCCTAATGAGTCGGAAAAGGCCATTTGTTGGAAGATGTTGTT ACTCCTGCACTCCCCAGAGCTGGGACAAATTTTTCAACCCCAGTATCCCGTCTTTGGG TTTGCGGAATGTTATTTATATCAATGAAACTCACACAAGACACCGCGGATGGCTTGCA AGACGCCTTTCTTACGTTCTTTTTATTCAAGAGCGAGATGTGCATAAGGGCATGTTTG CCACCAATGTGACTGGAAATGTGCTGAACAGCAGTAGAGTACAAGAGGCAATTGCAGA AGTGGCTGCTGAATTAAACCCTGATGGTTCTGCCCAGCAGCAATCAAAAGCCGTTAAC AAAGTGAAAAAGAAAGCTAAAAGGATTCTTCAAGAAATGGTTGCCACTGTCTCACCGG CAATGATCAGACTGACTGGGTGGGTGCTGCTAAAACTGTTCAACAGCTTCTTTTGGAA CATTCAAATTCACAAAGGTCAACTTGAGATGGTTAAAGCTGCAACTGAGACGAATTTG CCGCTTCTGTTTCTACCAGTTCATAGATCCCATATTGACTATCTGCTGCTCACTTTCA TTCTCTTCTGCCATAACATCAAAGCACCATACATTGCTTCAGGCAATAATCTCAACAT CCCAATCTTCAGTACCTTGATCCATAAGCTTGGGGGCTTCTTCATACGACGAAGGCTC
GATGAAACACCAGATGGACGGAAAGATGTTCTCTATAGAGCTTTGCTCCATGGGCATA TAGTTGAATTACTTCGACAGCAGCAATTCTTGGAGATCTTCCTGGAAGGCACACGTTC TAGGAGTGGAAAAACCTCTTGTGCTCGGGCAGGACTTTTGTCAGTTGTGGTAGATACT CTGTCTACCAATGTCATCCCAGACATCTTGATAATACCTGTTGGAATCTCCTATGATC GCATTATCGAAGGTCACTACAATGGTGAACAACTGGGCAAACCTAAGAAGAATGAGAG CCTGTGGAGTGTAGCAAGAGGTGTTATTAGAATGTTACGAAAAAACTATGGTTGTGTC CGAGTGGATTTTGCACAGCCATTTTCCTTAAAGGAATATTTAGAAAGCCAAAGTCAGA AACCGGTGTCTGCTCTACTTTCCCTGGAGCAAGCGTTGTTACCAGCTATACTTCCTTC AAGACCCAGTGATGCTGCTGATGAAGGTAGAGACACGTCCATTAATGAGTCCAGAAAT GCAACAGATGAATCCCTACGAAGGAGGTTGATTGCAAATCTGGCTGAGCATATTCTAT TCACTGCTAGCAAGTCCTGTGCCATTATGTCCACACACATTGTGGCTTGCCTGCTCCT CTACAGACACAGGCAGGGAATTGATCTCTCCACATTGGTCGAAGACTTCTTTGTGATG AAAGAGGAAGTCCTGGCTCGTGATTTTGACCTGGGGTTCTCAGGAAATTCAGAAGATG TAGTAATGCATGCCATACAGCTGCTGGGAAATTGTGTCACAATCACCCACACTAGCAG GAATGATGAGTTTTTTATCACCCCCAGCACAACTGTCCCATCAGTCTTCGAACTCAAC TTCTACAGCAATGGGGTACTTCATGTCTTTATCATGGAGGCCATCATAGCTTGCAGCC TTTATGCAGTTCTGAACAAGAGGGGACTGGGGGGTCCCACTAGCACCCCACCTAACCT GATCAGCCAGGAGCAGCTGGTGCGGAAGGCGGCCAGCCTGTGCTACCTTCTCTCCAAT GAAGGCACCATCTCACTGCCTTGCCAGACATTTTACCAAGTCTGCCATGAAACAGTAG GAAAGTTTATCCAGTATGGCATTCTTACAGTGGCAGAGCACGATGACCAGGAAGATAT CAGTCCTAGTCTTGCTGAGCAGCAGTGGGACAAGAAGCTTCCTGAACCTTTGTCTTGG AGAAGTGATGAAGAAGATGAAGACAGTGACTTTGGGGAGGAACAGCGAGATTGCTACC TGAAGGTGAGCCAATCCAAGGAGCACCAGCAGTTTATCACCTTCTTACAGAGACTCCT TGGGCCTTTGCTGGAGGCCTACAGCTCTGCTGCCATCTTTGTTCACAACTTCAGTGGT CCTGTTCCAGAACCTGAGTATCTGCAAAAGTTGCACAAATACCTAATAACCAGAACAG AAAGAAATGTTGCAGTATATGCTGAGAGTGCCACATATTGTCTTGTGAAGAATGCTGT GAAAATGTTTAAGGATATTGGGGTTTTCAAGGAGACCAAACAAAAGAGAGTGTCTGTT TTAGAACTGAGCAGCACTTTTCTACCTCAATGCAACCGACAAAGACTTCTAGAATATA TTCTGAGTTTTGTGGTGCTGTAAGTAACGTGTG
ORF Start: ATG at 31 JORF Stop: TAA at 2515
SEQ ID NO: 430 828 aa MW at 93735.6kD
NOV56b, MDESALTLGTIDVSYLPHSSEYSVGRCKHTSEE GECGFRPTVFRSATLK KESLMSR CG92142-02 KRPFVGRCCYSCTPQS DKFFNPSIPSLGLRNVIYINETHTRHRG LARRLSYVLFIQ Protein Sequence ERDVHKGMFATlvrVTGNVLNSSRVQEAIAEVAAELNPDGSAQQQSKAVNKVKKKAKRIL QE VATVSPAMIRLTG VLLKLFNSFFWNIQIHKGQLEMVKAATETNLPLLFLPVHRS HIDYLLLTFILFCHNIKAPYIASGNNL IPIFSTLIHKLGGFFIRRRLDETPDGRKDV LYRALLHGHIVELLRQQQFLEIFLEGTRSRSGKTSCARAGLLSVWDTLST VIPDIL IIPVGISYDRIIEGHYNGEQLGKPKKNESL SVARGVIRMLRKNYGCVRVDFAQPFSL KEYLESQSQKPVSALLSLEQALLPAILPSRPSDAADEGRDTSINESRNATDESLRRRL IANLAEHILFTASKSCAIMSTHIVACLLLYRHRQGIDLSTLVEDFFVMKEEVLARDFD LGFSGNSEDW HAIQLLGNCVTITHTSRNDEFFITPSTTVPSVFELNFYSNGVLHVF IMEAIIACSLYAVLNKRGLGGPTSTPPNLISQEQLVRKAASLCYLLSNEGTISLPCQT FYQVCHETVGKFIQYGILTVAEHDDQEDISPSLAEQQWDKKLPEPLS RSDEEDEDSD FGEEQRDCYLKVSQSKEHQQFITFLQRLLGPLLEAYSSAAIFVHNFSGPVPEPEYLQK LHKYLITRTERNVAVYAESATYCLVKNAVKMFKDIGVFKETKQKRVSVLELSSTFLPQ CNRQRLLEYILSFWL
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 56B.
Further analysis of the NOV56a protein yielded the following properties shown in Table 56C.
Table 56C. Protein Sequence Properties NOV56a
PSort 0.8500 probability located in endoplasmic reticulum (membrane); 0.4400 analysis: probability located in plasma membrane; 0.3000 probability located in nucleus; 0.1000 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV56a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 56D.
In a BLAST search of public sequence datbases, the NOV56a protein was found to have homology to the proteins shown in the BLASTP data in Table 56E.
Table 56E. Public BLASTP Results for NOV56a
Protein 6a Identities/ Expect
Accession Protein/Organism/Length NOV5 Residues/ . Similarities for Value
PFam analysis predicts that the NOV56a protein contains the domains shown in the Table 56F.
Example 57.
The NOV57 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 57A.
Table 57 A. NOV57 Sequence Analysis
SEQ ED NO: 431 1538 bp
NOV57a, CACCGAGCCTCACGGGAGCTGATGGCTGCAAAGAAGACCCACACCTCACAAATTGAAG CG95765-01 TGATCCCTTGCAAAATCTGTGGGGACAAGTCGTCTGGGATCCACTACGGGGTTATCAC
CTGTGAGGGGTGCAAGGGCTTCTTCCGGCCTACTCCTGCACCCGTCAGCAGAACTGCC DNA Sequence CCATCGACCGCACCAGCCGAAACCGATGCCAGCACTGCCGCCTGCAGAAATGCCTGGC
GCTGGGGATGTCCCGAGATGCTGTCAAGTTCGGCCGCATGTCCAAGAAGCAGAGGGAC
AGCCTGCATGCAGAAGTGCAGAAACAGCTGCAGCAGCGGCAACAGCAGCAACAGGAAC CAGTGGTCAAGACCCCTCCAGCAGGGGCCCAAGGAGCAGATACCCTCACCTACACCTT
GGGGCTCCCAGACGGGCAGCTGCCCCTGGGCTCCTCGCCTGACCTGCCTGAGGCTTCT! GCCTGTCCCCCTGGCCTCCTGAAAGCCTCAGGCTCTGGGCCCTCATATTCCAACAACT TGGCCAAGGCAGGGCTCAATGGGGCCTCATGCCACCTTGAATACAGCCCTGAGCGGGG^ CAAGGCTGAGGGCAGAGAGAGCTTCTATAGCACAGGCAGCCAGCTGACCCCTGACCGA TGTGGACTTCGTTTTGAGGAACACAGGCATCCTGGGCTTGGGGAACTGGGACAGGGCC CAGACAGCTACGGCAGCCCCAGTTTCCGCAGCACACCGGAGGCACCCTATGCCTCCCT GACAGAGATAGAGCACCTGGTGCAGAGCGTCTGCAAGTCCTACAGGGAGACATGCCAG CTGCGGCTGGAGGACCTGCTGCGGCAGCGCTCCAACATCTTCTCCCGGGAGGAAGTGA CTGGCTACCAGAGGAAGTCCATGTGGGAGATGTGGGAACGGTGTGCCCACCACCTCAC CGAGGCCATTCAGTACGTGGTGGAGTTCGCCAAGAGGCTCTCAGGCTTTATGGAGCTC TGCCAGAATGACCAGATTGTGCTTCTCAAAGCAGGAGCAATGGAAGTGGTGCTGGTTA GGATGTGCCGGGCCTACAATGCCAACAACCACACAGTCTTTTTTGAAGGCAAATACGG TGGTGTGGAGCTGTTTCGAGCCTTGGGCTGCAGCGAGCTCATCAGCTCCATATTTGAC TTTTCCCACTTCCTCAGCGCCCTGTGTTTTTCCGAGGATGAGATTGCCCTCTACACGG CCCTTGTTCTCATCAATGCCAACCGTCCTGGGCTCCAAGAGAAGAGGAGAGTGGAACA TCTGCAATACAATTTGGAACTGGCTTTCCATCATCATCTCTGCAAGACTCATCGACAA AGCATCCTGGCAAAGCTGCCACCCAAAGGAAAACTCCGGAGCCTGTGTAGCCAGCATG TGGAAAGGCTGCAGATCTTCCAGCACCTCCACCCCATCGTGGTCCAAGCCGCTTTCCC TCCACTCTACAAGGAGCTCTTCAGCACTGAAACCGAGTCACCTGTGGGGCTGTCCAAG TGACCTGGAAGAGGGACTCCTTGCCTCTCC
ORF Start: ATG at 240 JORF Stop: TGA at 1509
SEQ ID NO: 432 423 aa MWat47418.4kD
NOV57a, MSRDAVKFGRMSKKQRDSLHAΞVQKQLQQRQQQQQEPWKTPPAGAQGADTLTYTLGL CG95765-01 PDGQLPLGSSPDLPEASACPPGLLKASGSGPSYSNNLAKAGLNGASCHLEYSPERGKA EGRESFYSTGSQLTPDRCGLRFEEHRHPGLGELGQGPDSYGSPSFRSTPEAPYASLTE Protein Sequence IEHLVQSVCKSYRETCQLRLEDLLRQRSNIFSREEVTGYQRKSM E ERCAHHLTEA IQYVVEFAKRLSGFMELCQNDQIVLLKAGA EVVLVRMCRAY ANNHTVFFEGKYGGV ELFRALGCSELISSIFDFSHFLSALCFSEDEIALYTALVLINANRPGLQEKRRVEHLQ YNLELAFHHHLCKTHRQSILAKLPPKGKLRSLCSQHVERLQIFQHLHPIWQAAFPPL YKELFSTETESPVGLSK
SEQ ID NO: 433 1819 bp
NOV57b, CCCCTGGGCCCTGCTCCCTGCCCTCCTGGGCAGCCAGGGCAGCCAGGACGGCACCAAG CG95765-02 GGAGCTGCCCCATGGACAGGGCCCCACAGAGACAGCACCGAGCCTCACGGGAGCTGCT!
GGCTGCAAAGAAGACCCACACCTCACAAATTGAAGTGATCCCTTGCAAAATCTGTGGG DNA Sequence GACAAGTCGTCTGGGATCCACTACGGGGTTATCACCTGTGAGGGGTGCAAGGGCTTCT TCCGCCGGAGCCAGCGCTGTAACGCGGCCTACTCCTGCACCCGTCAGCAGAACTGCCC CATCGACCGCACCAGCCGAAACCGATGCCAGCACTGCCGCCTGCAGAAATGCCTGGCG CTGGGGATGTCCCGAGATGCTGTCAAGTTCGGCCGCATGTCCAAGAAGCAGAGGGACA GCCTGCATGCAGAAGTGCAGAAACAGCTGCAGCAGCGGCAACAGCAGCAACAGGAACC AGTGGTCAAGACCCCTCCAGCAGGGGCCCAAGGAGCAGATACCCTCACCTACACCTTG GGGCTCCCAGACGGGCAGCTGCCCCTGGGCTCCTCGCCTGACCTGCCTGAGGCTTCTG CCTGTCCCCCTGGCCTCCTGAAAGCCTCAGGCTCTGGGCCCTCATATTCCAACAACTT GGCCAAGGCAGGGCTCAATGGGGCCTCATGCCACCTTGAATACAGCCCTGAGCGGGGC AAGGCTGAGGGCAGAGAGAGCTTCTATAGCACAGGCAGCCAGCTGACCCCTGACCGAT GTGGACTTCGTTTTGAGGAACACAGGCATCCTGGGCTTGGGGAACTGGGACAGGGCCC AGACAGCTACGGCAGCCCCAGTTTCCGCAGCACACCGGAGGCACCCTATGCCTCCCTG ACAGAGATAGAGCACCTGGTGCAGAGCGTCTGCAAGTCCTACAGGGAGACATGCCAGC TGCGGCTGGAGGACCTGCTGCGGCAGCGCTCCAACATCTTCTCCCGGGAGGAAGTGAC TGGCTACCAGAGGAAGTCCATGTGGGAGATGTGGGAACGGTGTGCCCACCACCTCACC GAGGCCATTCAGTACGTGGTGGAGTTCGCCAAGAGGCTCTCAGGCTTTATGGAGCTCT GCCAGAATGACCAGATTGTGCTTCTCAAAGCAGGAGCAATGGAAGTGGTGCTGGTTAG GATGTGCCGGGCCTACAATGCTGACAACCGCACGGTCTTTTTTGAAGGCAAATACGGT GGCATGGAGCTGTTCCGAGCCTTGGGCTGCAGCGAGCTCATCAGCTCCATCTTTGACT TCTCCCACTCCCTAAGTGCCTTGCACTTTTCCGAGGATGAGATTGCCCTCTACACAGC CCTTGTTCTCATCAATGCCCATCGGCCAGGGCTCCAAGAGAAAAGGAAAGTAGAACAG CTGCAGTACAATCTGGAGCTGGCCTTTCATCATCATCTCTGCAAGACTCATCGCCAAA GCATCCTGGCAAAGCTGCCACCCAAGGGGAAGCTTCGGAGCCTGTGTAGCCAGCATGT GGAAAGGCTGCAGATCTTCCAGCACCTCCACCCCATCGTGGTCCAAGCCGCTTTCCCT

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 57B.
Table 57B. Comparison of NO 57a against NOV57b.
Protein Sequence NOV57a Residues/ Identities/ Match Residues SimUarities for the Matched Region
NOV57b 1..420 412/420 (98%) 96..515 416/420 (98%)
Further analysis of the NOV57a protein yielded the following properties shown in Table 57C.
Table 57C. Protein Sequence Properties NOV57a
PSort 0.3600 probability located in mitochondrial matrix space; 0.3000 probability analysis: located in microbody (peroxisome); 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV57a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 57D.
Table 57D. Geneseq Results for NOV57a
Geneseq Protein/Organism/Length [Patent Identifier #, Date]
In a BLAST search of public sequence datbases, the NOV57a protein was found to have homology to the proteins shown in the BLASTP data in Table 57E.
PFam analysis predicts that the NOV57a protein contains the domains shown in the Table
57F.
Table 57F. Domain Analysis of NOV57a
Identities/
Pfa Domain NO 57a Match Region Similarities Expect Value for the Matched Region hormone rec 230..411 56/210 (27%) l.le-34 138/210 (66%)
Example 58.
The NOV58 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 58A.
Table 58A. NOV58 Sequence Analysis
SEQ ID NO: 435 1712 bp
NOV58a, AAGGTCAATGATAGCATCTGCCTAGAGTCAAACCTCCGTGCTTCTCAGACAGTGCCTT CG97178-01 TTCACCATGAGTGGGTGCCCATTTTTAGGAAACAACTTTGGATATACTTTTAAAAAAC DNA Sequence TCCCCGTAGAAGGCAGCGAAGAAGACAAATCACAAACTGGTGTGAATAGAGCCAGCAA AGGAGGTCTTATCTATGGGAACTACCTGCATTTGGAAAAAGTTTTGAATGCACAAGAA CTGCAAAGTGAAACAAAAGGAAATAAAATCCATGATGAACATCTTTTTATCATAACTC ATCAAGCTTATGAACTCTGGTTTAAGCAAATCCTCTGGGAGTTGGATTCTGTTCGAGA GATCTTTCAGAATGGCCATGTCAGAGATGAAAGGAACATGCTTAAGGTTGTTTCTCGG ATGCACCGAGTGTCAGTGATCCTGAAACTGCTGGTGCAGCAGTTTTCCATTCTGGAGA CGATGACAGCCTTGGACTTCAATGACTTCAGAGAGTACTTATCTCCAGCATCAGGCTT CCAGAGTTTGCAATTCCGACTATTAGAAAACAAGATAGGTGTTCTTCAGAACATGAGA GTCCCTTATAACAGAAGACATTATCGTGATAACTTCAAAGGAGAAGAAAATGAACTGC TACTTAAATCTGAGCAGGAAAAGACACTTCTGGAATTAGTGGAGGCATGGCTGGAAAG AACTCCAGGTTTAGAGCCACATGGATTTAACTTCTGGGGAAAGCTTGAAAAAAATATC ACCAGAGGCCTGGAAGAGGAATTCATAAGGATTCAGGCTAAAGAAGAGTCTGAAGAAA AAGAGGAACAGGTGGCTGAATTTCAGAAGCAAAAAGAGGTGCTACTGTCCTTATTTGA TGAGAAACGTCATGAACATCTCCTTAGTAAAGGTGAAAGACGGCTGTCATACAGAGCA CTTCAGGGAGCATTGATGATATATTTTTACAGGGAAGAGCCTAGGTTCCAGGTGCCTT TTCAGTTGCTGACTTCTCTTATGGACATAGATTCACTGATGACCAAATGGAGATATAA CCATGTGTGCATGGTGCACAGAATGCTGGGCAGCAAAGCTGGCACCGGTGGTTCCTCA GGCTATCACTACCTGCGATCAACTGTGAGTGATAGGTACAAGGTATTTGTAGATTTAT TTAATCTTTCAACATACCTGATTCCCCGACACTGGATACCGAAGATGAACCCAACCAT TCACAAATTTCTATATACAGCAGAATACTGTGATAGCTCCTACTTCAGCAGTGATGAA TCAGATTAAAATCGTCTGCAAAATCTATGAAGAATACTGGTTTCACAGCCTATTTTTT
;ATTTTCTATGGATTTTCATAAATACAGTTTGAATATATGTATGCATATATTGTTCAGC!
ACCACGATGCTCTGATTTAATTCTAGAAACAATTTGATTACCTCTTGTTTGTGACAAGI
ACTAAGCATTAAGATGAGAAAGAATACATTTAAATAGTAACATTGTACATAGGGTGTTi
TTCCTATTAAAAATCAGTTTCCCCTGAGACTTAATGTAA.CCACTTAATGTAATCACTA!
TCTCATTGTTTCATCTTTATAAACTTGTAAACTTCATCTATTTCAAATATTTTATGCA:
GTACATTATATΓATΓCTGTACAAAGGCTTTCAAACAAAATTTTTAAAATAATAAAGTA
TTAATCTTTCAAAAAAAAAAAAAAAAAAAA
ORF Start: ATGat65 ORF Stop: TAAat 1283
SEQ ID NO: 436 406 aa lMW at47871.1kD
NOV58a, MSGCPFLG NFGYTFKKLPVEGSEEDKSQTGVNRASKGGLIYGNYLHLEKVLNAQELQ CG97178-01 SETKGNKIHDEHLFIITHQAYEL FKQIL ELDSVREIFQNGHVRDERNMLKVVSRMH RVSVILKLLVQQFSILETMTALDFNDFREYLSPASGFQSLQFRLLENKIGVLQ MRVP Protein Sequence YNRRHYRDNFKGEENELLLKSEQEKTLLELVEAWLERTPGLEPHGFNFWGKLEKNITR GLΞEEFIRIQAKEESEEKEEQVAEFQKQKEVLLSLFDEKRHEHLLSKGERRLSYRALQ GALMIYFYREΞPRFQVPFQLLTSLMDIDSL TK RYNHVCMVHRMLGSKAGTGGSSGY HYLRSTVSDRYKVFVDLFNLSTYLIPRHWIPKMNPTIHKFLYTAEYCDSSYFSSDESD
SEQ ID NO: 437 1298 bp
NOV58b, GTGCTTCTCAGACAGTGCCTTTTCACCATGAGTGGGTGCCCATTTTTAGGAAACAACT CG97178-02 TTGGATATACTTTTAAAAAACTCCCCGTAGAAGGCAGCGAAGAAGACAAATCACAAAC TGGTGTGAATAGAGCCAGCAAAGGAGGTCTTATCTATGGGAACTACCTGCATTTGGAA DNA Sequence AAAGTTTTGAATGCACAAGAACTGCAAAGTGAAACAAAAGGAAATAAAATCCATGATG AACATCTTTTTATCATAACTCATCAAGCTTATGAACTCTGGTTTAAGCAAATCCTCTG GGAGTTGGATTCTGTTCGAGAGATCTTTCAGAATGGCCATGTCAGAGATGAAAGGAAC ATGCTTAAGGTTGTTTCTCGGATGCACCGAGTGTCAGTGATCCTGAAACTGCTGGTGC AGCAGTTTTCCATTCTGGAGACGATGACAGCCTTGGACTTCAATGACTTCAGAGAGTA CTTATCTCCAGCATCAGGCTTCCAGAGTTTGCAATTCCGACTATTAGAAAACAAGATA GGTGTTCTTCAGAACATGAGAGTCCCTTATAACAGAAGACATTATCGTGATAACTTCA AAGGAGAAGAAAATGAACTGCTACTTAAATCTGAGCAGGAAAAGACACTTCTGGAATT AGTGGAGGCATGGCTGGAAAGAACTCCAGGTTTAGAGTCACATGGATTTAACTTCTGG GGAAAGCTTGAAAAAAATATCACCAGAGGCCTGGAAGAGGAATTCATAAGGATTCAGG CTAAAGAAGAGTCTGAAGAAAAAGAGGAACAGGTGGCTGAATTTCAGAAGCAAAAAGA GGTGCTACTGTCCTTATTTGATGAGAAACGTCATGAACATCTCCTTAGTAAAGGTGAA AGACGGCTGTCATACAGAGCACTTCAGGGAGCATTGATGATATATTTTTACAGGGAAG AGCCTAGGTTCCAGGTGCCTTTTCAGTTGCTGACTTCTCTTATGGACATAGATTCACT GATGACCAAATGGAGATATAACCATGTGTGCATGGTGCACAGAATGCTGGGCAGCAAA GCTGGCACCGGTGGTTCCTCAGGCTATCACTACCTGCGATCAACTGTGAGTGATAGGT ACAAGGTATTTGTAGATTTATTTAATCTTTCAACATACCTGATTCCCCGACACTGGAT ACCGAAGATGAACCCAACCATTCACAAATTTCTATATACAGCAGAATACTGTGATAGC TCCTACTTCAGCAGTGATGAATCAGATTAAAATCGTCTGCAAAATCTATGAAGAATAC TGGTTTCACAGCCTATTTAAGG
ORF Start: ATG at 28 j ORF Stop: TAA at 1246
SEQ ID NO: 438 406 aa MW at 47861. lkD
NOV58b, MSGCPFLGΪSrøFGYTFKKLPVEGSEEDKSQTGVNRASKGGLIYGNYLHLEKVLNAQELQ CG97178-02 SETKGNKIHDEHLFIITHQAYEL FKQILWELDSVREIFQNGHVRDERNMLKVVSRMH RVSVILKLLVQQFSILETMTALDFNDFREYLSPASGFQSLQFRLLENKIGVLQN RVP Protein Sequence YNRRHYRDNFKGEENELLLKSEQEKTLLELVEA LERTPGLESHGFNF GKLEKNITR GLEEEFIRIQAKEESEEKEEQVAEFQKQKEVLLSLFDEKRHEHLLSKGERRLSYRALQ GALMIYFYREEPRFQVPFQLLTSUiDIDS]_^TKWRYNHVCMVHRMLGSKAGTGGSSGY HYLRSWSDRYKΛTFVDLFNLSTYLIPRHWIPKMNPTIHKFLYTAEYCDSSYFSSDESD
SEQ ID NO: 439 1240 bp
NOV58c, GCCGGATCCACCATGAGTGGGTGCCCATTTTTAGGAAACAACTTTGGATATACTTTTA 275481043 DNA AAAAACTCCCCGTAGAAGGCAGCGAAGAAGACAAATCACAAACTGGTGTGAATAGAGC CAGCAAAGGAGGTCTTATCTATGGGAACTACCTGCATTTGGAAAAAGTTTTGAATGCA Sequence CAAGAACTGCAAAGTGAAACAAAAGGAAATAAAATCCATGATGAACATCTTTTTATCA TAACTCATCAAGCTTATGAACTCTGGTTTAAGCAAATCCTCTGGGAGTTGGATTCTGT TCGAGAGATCTTTCAGAATGGCCATGTCAGAGATGAAAGGAACATGCTTAAGGTTGTT TCTCGGATGCACCGAGTGTCAGTGATCCTGAAACTGCTGGTGCAGCAGTTTTCCATTC TGGAGACGATGACAGCCTTGGACTTCAATGACTTCAGAGAGTACTTATCTCCAGCATC AGGCTTCCAGAGTTTGCAATTCCGACTATTAGAAAACAAGATAGGTGTTCTTCAGAAC ATGAGAGTCCCTTATAACAGAAGACATTATCGTGATAACTTCAAAGGAGAAGAAAATG AACTGCTACTTAAATCTGAGCAGGAAAAGACACTTCTGGAATTAGTGGAGGCATGGCT GGAAAGAACTCCAGGTTTAGAGTCACATGGATTTAACTTCTGGGGAAAGCTTGAAAAA AATATCACCAGAGGCCTGGAAGAGGAATTCATAAGGATTCAGGCTAAAGAAGAGTCTG AAGAAAAAGAGGAACAGGTGGCTGAATTTCAGAAGCAAAAAGAGGTGCTACTGTCCTT ATTTGATGAGAAACGTCATGAACATCTCCTTAGTAAAGGTGAAAGACGGCTGTCATAC
AGAGCACTTCAGGGAGCATTGATGATATATTTTTACAGGGAAGAGCCTAGGTTCCAGG TGCCTTTTCAGTTGCTGACTTCTCTTATGGACATAGATTCACTGATGACCAAATGGAG ATATAACCATGTGTGCATGGTGCACAGAATGCTGGGCAGCAAAGCTGGCACCGGTGGT TCCTCAGGCTATCACTACCTGCGATCAACTGTGAGTGATAGGTACAAGGTATTTGTAG ATTTATTTAATCTTTCAACATACCTGATTCCCCGACACTGGATACTGAAGATGAACCC AACCATTCACAAATTTCTATATACAGCAGAATACTGTGATAGCTCCTACTTCAGCAGT GATGAATCAGATGTCGACGGTG
ORF Start: at 1 ORF Stop: end of Isequence
NOV58c, AGSTMSGCPFLG-røFGYTFKKLPVEGSEEDKSQTGVNRASKGGLIYG YLHLEKVLNA 275481043 QELQSETKGNKIHDEHLFIITHQAYEL FKQILWELDSVREIFQNGHVRDER LKW SRMHRVSVILKLLVQQFSILETMTALDFNDFREYLSPASGFQSLQFRLLENKIGVLQN Protein Sequence MRVPYNRRHYRDNFKGEENELLLKSEQEKTLLELVEAWLERTPGLESHGFNF GKLEK NITRGLEEEFIRIQAKEESEEKEEQVAEFQKQKEVLLSLFDEKRHEHLLSKGERRLSY RALQGALMIYFYREEPRFQVPFQLLTSLMDIDSL TKWRYNHVCMVHRMLGSKAGTGG SSGYHYLRSTVSDRYKVFVDLFNLSTYLIPRHWILK NPTIHKFLYTAEYCDSSYFSS DESDVDGX
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 58B.
Further analysis of the NOV58a protein yielded the following properties shown in Table 58C.
Table 58C. Protein Sequence Properties NOV58a
PSort 0.5095 probability located in microbody (peroxisome); 0.4500 probability analysis: located in cytoplasm; 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV58a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 58D.
Table 58D. Geneseq Results for NOV58a
Gen seπ Prntein/Orαanism/ enffth fPatent NOVSSa Identities/ F.πiecr
In a BLAST search of public sequence datbases, the NOV58a protein was found to have homology to the proteins shown in the BLASTP data in Table 58E.
PFam analysis predicts that the NOV58a protein contains the domains shown in the Table 58F.
Table 58F. Domain Analysis of NOV58a
Identities/
Pfam Domain NOV58a Match Region SimUarities Expect Value for the Matched Region
No Significant Matches Found
Example 59.
The NOV59 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 59A.
Table 59A. NOV59 Sequence Analysis
SEQ ID NO: 441 1060 bp
NOV59a, CGCGGGCCGACTGGTGTTTATCCGTCACTCGCCGAGGTTCCTTGGGTCATGGTGCCAGJ CG98102-01 CCTGACTGAGAAGAGGACGCTCCCGGGAGACGAATGAGGAACCACCTCCTCCTACTGT
TCAAGTACAGGGGCCTGGTCCGCAAAGGGAAGAAAAGCAAAAGACGAAAATGGCTAAA DNA Sequence TTCGTGATCCGCCCAGCCACTGCCGCCGACTGCAGTGACATACTGCGGCTGATCAAGG AGCTGGCTAAATATGAATACATGGAAGAACAAGTAATCTTAACTGAAAAAGATCTGCT AGAAGATGGTTTTGGAGAGCACCCCTTTTACCACTGCCTGGTTGCAGAAGTGCCGAAA GAGCACTGGACTCCGGAAGGACACAGCATTGTTGGTTTTGCCATGTACTATTTTACCT ATGACCCGTGGATTGGCAAGTTATTGTATCTTGAGGACTTCTTCGTGATGAGTGATTA TAGAGGCTTTGGCATAGGATCAGAAATTCTGAAGAATCTAAGCCAGGTTGCAATGAGG TGTCGCTGCAGCAGCATGCACTTCTTGGTAGCAGAATGGAATGAACCATCCATCAACT TCTATAAAAGAAGAGGTGCTTCTGATCTGTCCAGTGAAGAGGGTTGGAGACTGTTCAA GATCGACAAGGAGTACTTGCTAAAAATGGCAACAGAGGAGTGAGGAGTGCTGCTGTAG
ATGACAACCTCCATTCTATTTTAGAATAAATTCCCAACTTCTCTTGCTTTCTATGCTG
TTTGTAGTGAAATAATAGAATGAGCACCCATTCCAAAGCTTTATTACCAGTGGCGTTG
TTGCATGTTTGAAATGAGGTCTGTTTAAAGTGGCAATCTCAGATGCAGTTTGGAGAGT
CAGATCTTTCTCCTTGAATATCTTTCGATAAACAACAAGGTGGTGTGATCTTAATATA!
TTTGAAAAAAACTTCATTCTCGTGAGTCATTTAAATGTGTACAATGTACACACTGGTA
CTTAGAGTTTCTGTTTGATTCTTTTTTAATAAACTACTCTTTGATTTAAAAAAAAAAA
AAAAAAAAAAAAAAAA
ORF Start: ATG at 166 ORF Stop: TGA at 679
SEQ ID NO: 442 |l71 aa JMW at 20023.8kD
NOV59a, MAKFVIRPATAADCSDILRLIKELAKYEYMEEQVILTEKDLLEDGFGEHPFYHCLVAE
CG98102-01 VPKEH TPEGHSIVGFAMYYFTYDPWIGKLLYLEDFFVMSDYRGFGIGSEILKNLSQV Protein Sequence AMRCRCSSMHFLVAE NEPSINFYKRRGASDLSSEEG RLFKIDKEYLLKMATEE
SEQ ID NO: 443 1052 bp
NOV59b, CGGCCGCGTCGACCGCGGGCTGACTGGTGTTTATCCGTCACTCGCCGAGGTTCCTTGGi CG98102-03 GTCATGGTGCCAGCCTGACTGAGAAGAGGACGCTCCCGGGAGACGAATGAGGAACCAC
CTCCTCCTACTGTTCAAGTACAGGGGCCTGGTCCGCAAAGGGAAGAAAAGCAAAAGAC DNA Sequence GAAAATGGCTAAATTCGTGATCCGCCCAGCCACTGCCGCCGACTGCAGTGACATACTG
CGGCTGATCAAGGAGCTGGCTAAATATGAATACATGGAAGAACAAGTAATCTTAACTG AAAAAGATCTGCTAGAAGATGGTTTTGGAGAGCACCCCTTTTACCACTGCCTGGTTGC AGAAGTGCCGAAAGAGCACTGGACTCCGGAAGGACACAGCATTGTTGGTTTTGCCATG TACTATTTTACCTATGACCCGTGGATTGGCAAGTTATTGTATCTTGAGGACTTTTTCG TGATGAGTGATTATAGAGGCTTTGGCATAGGATCAGAAATTCTGAAGAATCTAAGCCA GGTTGCAATGAGGTGTCGCTGCAGCAGCATGCACTTCTTGGTAGCAGAATGGAATGAA CCATCCATCAACTTCTATAAAAGAAGAGGTGCTTCTGATCTGTCCAGTGAAGAGGGTT GGAGACTGTTCAAGATCGACAAGGAGTACTTGCTAAAAATGGCAACAGAGGAGTGAGG AGTGCTGCTGTAGATGACAACCTCCATTCTATTTTAGAATAAATTCCCAACTTCTCTT
GCTTTCTATGCTGTTTGTAGTGAAATAATAGAATGAGCACCCATTCCAAAGCTTTATT jACCAGTGGCGTTGTTGCATGTTTGAAATGAGGTCTGTTTAAAGTGGCAATCTCAGATG
CAGTTTGGAGAGTCAGATCTTTCTCCTTGAATATCTTTCGATAAACAACAAGGTGGTG
TGATCTTAATATATTTGAAAAAAACTTCATTCTCGTGAGTCATTTAAATGTGTACAAT
GTACACACTGGTACTTAGAGTTTCTGTTTGATTCTTTTTTAATAAACTACTCTTTGAT
TTAAAAAA_
ORF Start: ATG at 179 ORF Stop: TGA at 692
SEQ ID NO: 444 MW at 20023.8kD
NOV59b, MAKFVIRPATAADCSDILRLIKELAKYEYMEEQVILTEKDLLEDGFGEHPFYHCLVAE CG98102-03 VPKEH TPEGHSIVGFAMYYFTYDP IGKLLYLEDFFVMSDYRGFGIGSEILKNLSQV ARCRCSSMHFLVAEWNEPSINFYKRRGASDLSSEEG RLFKIDKEYLLKMATEE Protein Sequence
SEQ ID NO: 445 665 bp
NOV59c, ACCTCCTCCTACTGTTCAAGTACAGGGGCCTGGTCCGCAAAGGGAAGAAAAGCAAAAG! CG98102-02 ACGAAAATGGCTAAATTCGTGATCCGCCCAGCCACTGCCGCCGACTGCAGTGACATAC
TGCGGCTGATCAAGGAGCTGGCTAAATATGAATACATGGAAGAACAAGTAATCTTAAC DNA Sequence TGAAAAAGATCTGCTAGAAGATGGTTTTGGAGAGCACCCCTTTTACCACTGCCTGGTT GCAGAAGTGCCGAAAGAGCACTGGACTCCGGAAGGACACAGCATTGTTGGTTTTGCCA TGTACTATTTTACCTATGACCCGTGGATTGGCAAGTTATTGTATCTTGAGGACTTCTT CGTGATGAGTGATTATAGAGGCTTTGGCATAGGATCAGAAATTCTGAAGAATCTAAGC CAGGTTGCAATGAGGTGTCGCTGCAGCAGCATGCACTTCTTGGTAGCAGAATGGAATG AACCATCCATCAACTTCTATAAAAGAAGAGGTGCTTCTGATCTGTCCAGTGAAGAGGG TTGGAGACTGTTCAAGATCGACAAGGAGTACTTGCTAAAAATGGCAACAGAGGAGTGA GGAGTGCTGCTGTAGATGACAACCTCCATTCTATTTTAGAATAAATTCCCAACTTCTC
TTGCTTTCTATGCTGTTTGTAGTGAAA
ORF Start: ATG at 65 ORF Stop: TGA at 578 SEQ ID NO: 446 171 aa MW at 20023.8kD
NOV59c, AKFVIRPATAADCSDILRLIKELAKYEY EEQVILTEKDLLEDGFGEHPFYHCLVAE CG98102-02 VPKEHWTPEGHSIVGFAMYYFTYDPWIGKLLYLEDFFVMSDYRGFGIGSEILKNLSQV AMRCRCSSMHFLVAEWNEPSINFYKRRGASDLSSEEG RLFKIDKEYLLKMATEE Protein Sequence
SEQ ID NO: 447 596 bp
NOV59d, ACCTCCTCCTACTGTTCAAGTACAGGGGCCTGGTCCGCAAAGGGAAGAAAAGCAAAAG CG98102-04 ACGAAAATGGCTAAATATGAATACATGGAAGAACAAGTAATCTTAACTGAAAAAGATC DNA Sequence TGCTAGAAGATGGTTTTGGAGAGCACCCCTTTTACCACTGCCTGGTTGCAGAAGTGCC GAAAGAGCACTGGACTCCGGAAGGACACAGCATTGTTGGTTTTGCCATGTACTATTTT ACCTATGACCCGTGGATTGGCAAGTTATTGTATCTTGAGGACTTCTTCGTGATGAGTG ATTATAGAGGCTTTGGCATAGGATCAGAAATTCTGAAGAATCTAAGCCAGGTTGCAAT GAGGTGTCGCTGCAGCAGCATGCACTTCTTGGTAGCAGAATGGAATGAACCATCCATC
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 59B.
Further analysis of the NOV59a protein yielded the following properties shown in Table 59C.
Table 59C. Protein Sequence Properties NOV59a
PSort 0.6400 probability located in microbody (peroxisome); 0.6153 probability analysis: located in mitochondrial matrix space; 0.3177 probability located in mitochondrial inner membrane; 0.3177 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV59a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 59D.
Table 59D. Geneseq Results for NO 59a
Geneseq Protein/Organism/Length [Patent NOV59a Identities/ Expect Identifier #, Date] Residues/ Similarities for Value
In a BLAST search of public sequence datbases, the NOV59a protein was found to have homology to the proteins shown in the BLASTP data in Table 59E.
PFam analysis predicts that the NOV59a protein contains the domains shown in the Table 59F.
Table 59F. Domain Analysis of NO 59a
Identities/
Pfam Domain NO 59a Match Region J Similarities Expect Value for the Matched Region
Acetyltransf 63..146 23/85 (27%) 1.6e-16 59/85 (69%)
Example B: Sequencing Methodology and Identification of NOVX Clones
1. GeneCalling™ Technology: This is a proprietary method of performing differential gene expression profiling between two or more samples developed at CuraGen and described by Shimkets, et al., "Gene expression analysis by transcript profiling coupled to a gene database query" Nature Biotechnology 17:198-803 (1999). cDNA was derived from various human samples representing multiple tissue types, normal and diseased states, physiological states, and developmental states from different donors. Samples were obtained as whole tissue, primary cells or tissue cultured primary cells or cell lines. Cells and cell lines may have been treated with biological or chemical agents that regulate gene expression, for example, growth factors, chemokines or steroids. The cDNA thus derived was then digested with up to as many as 120 pairs of restriction enzymes and pairs of linker-adaptors specific for each pair of restriction enzymes were ligated to the appropriate end. The restriction digestion generates a mixture of unique cDNA gene fragments. Limited PCR amplification is performed with primers homologous to the linker adapter sequence where one primer is biotinylated and the other is fluorescently labeled. The doubly labeled material is isolated and the fluorescently labeled single strand is resolved by capillary gel electrophoresis. A computer algorithm compares the electropherograms from an experimental and control group for each of the restriction digestions. This and additional sequence-derived information is used to predict the identity of each differentially expressed gene fragment using a variety of genetic databases. The identity of the gene fragment is confirmed by additional, gene-specific competitive PCR or by isolation and sequencing of the gene fragment.
2. SeqCaUing™ Technology: cDNA was derived from various human samples representing multiple tissue types, normal and diseased states, physiological states, and developmental states from different donors. Samples were obtained as whole tissue, primary cells or tissue cultured primary cells or. cell lines. Cells and cell lines may have been treated with biological or chemical agents that regulate gene expression, for example, growth factors, chemokines or steroids. The cDNA thus derived was then sequenced using CuraGen's proprietary SeqCalling technology. Sequence traces were evaluated manually and edited for corrections if appropriate. cDNA sequences from all samples were assembled together, sometimes including public human sequences, using bioinformatic programs to produce a consensus sequence for each assembly. Each assembly is included in CuraGen Corporation's database. Sequences were included as components for assembly
when the extent of identity with another component was at least 95% over 50 bp. Each assembly represents a gene or portion thereof and includes information on variants, such as splice forms single nucleotide polymorphisms (SNPs), insertions, deletions and other sequence variations. 3. PathCalling™ Technology: The NOVX nucleic acid sequences are derived by laboratory screening of cDNA library by the two-hybrid approach. cDNA fragments covering either the full length of the DNA sequence, or part of the sequence, or both, are sequenced. In silico prediction was based on sequences available in CuraGen Corporation's proprietary sequence databases or in the public human sequence databases, and provided either the full length DNA sequence, or some portion thereof.
The laboratory screening was performed using the methods summarized below: cDNA libraries were derived from various human samples representing multiple tissue types, normal and diseased states, physiological states, and developmental states from different donors. Samples were obtained as whole tissue, primary cells or tissue cultured primary cells or cell lines. Cells and cell lines may have been treated with biological or chemical agents that regulate gene expression, for example, growth factors, chemokines or steroids. The cDNA thus derived was then directionally cloned into the appropriate two-hybrid vector (Gal4-activation domain (Gal4-AD) fusion). Such cDNA libraries as well as commercially available cDNA libraries from Clontech (Palo Alto, CA) were then transferred from E.coli into a CuraGen Coφoration proprietary yeast strain (disclosed in U. S. Patents 6,057,101 and 6,083,693, incoφorated herein by reference in their entireties).
Gal4-binding domain (Gal4-BD) fusions of a CuraGen Coφortion proprietary library of human sequences was used to screen multiple Gal4-AD fusion cDNA libraries resulting in the selection of yeast hybrid diploids in each of which the Gal4-AD fusion contains an individual cDNA. Each sample was amplified using the polymerase chain reaction (PCR) using non-specific primers at the cDNA insert boundaries. Such PCR product was sequenced; sequence traces were evaluated manually and edited for corrections if appropriate. cDNA sequences from all samples were assembled together, sometimes including public human sequences, using bioinformatic programs to produce a consensus sequence for each assembly. Each assembly is included in CuraGen Coφoration's database. Sequences were included as components for assembly when the extent of identity with another component was at least 95% over 50 bp. Each assembly
represents a gene or portion thereof and includes information on variants, such as splice forms single nucleotide polymoφhisms (SNPs), insertions, deletions and other sequence variations.
Physical clone: the cDNA fragment derived by the screening procedure, covering the entire open reading frame is, as a recombinant DNA, cloned into pACT2 plasmid (Clontech) used to make the cDNA library. The recombinant plasmid is inserted into the host and selected by the yeast hybrid diploid generated during the screening procedure by the mating of both CuraGen Coφoration proprietary yeast strains N106' and YULH (U. S. Patents 6,057,101 and 6,083,693). 4. RACE: Techniques based on the polymerase chain reaction such as rapid amplification of cDNA ends (RACE), were used to isolate or complete the predicted sequence of the cDNA of the invention. Usually multiple clones were sequenced from one or more human samples to derive the sequences for fragments. Various human tissue samples from different donors were used for the RACE reaction. The sequences derived from these procedures were included in the SeqCalling Assembly process described in preceding paragraphs.
5. Exon Linking: The NOVX target sequences identified in the present invention were subjected to the exon linking process to confirm the sequence. PCR primers were designed by starting at the most upstream sequence available, for the forward primer, and at the most downstream sequence available for the reverse primer. In each case, the sequence was examined, walking inward from the respective termini toward the coding sequence, until a suitable sequence that is either unique or highly selective was encountered, or, in the case of the reverse primer, until the stop codon was reached. Such primers were designed based on in silico predictions for the full length cDNA, part (one or more exons) of the DNA or protein sequence of the target sequence, or by translated homology of the predicted exons to closely related human sequences from other species. These primers were then employed in PCR amplification based on the following pool of human cDNAs: adrenal gland, bone marrow, brain - amygdala, brain - cerebellum, brain - hippocampus, brain - substantia nigra, brain - thalamus, brain -whole, fetal brain, fetal kidney, fetal liver, fetal lung, heart, kidney, lymphoma - Raji, mammary gland, pancreas, pituitary gland, placenta, prostate, salivary gland, skeletal muscle, small intestine, spinal cord, spleen, stomach, testis, thyroid, trachea, uterus. Usually the resulting amplicons were gel purified, cloned and sequenced to high redundancy. The PCR product derived from
exon linking was cloned into the pCR2.1 vector from Invitrogen. The resulting bacterial clone has an insert covering the entire open reading frame cloned into the pCR2.1 vector. The resulting sequences from all clones were assembled with themselves, with other fragments in CuraGen Coφoration's database and with public ESTs. Fragments and ESTs were included as components for an assembly when the extent of their identity with another component of the assembly was at least 95% over 50 bp. In addition, sequence traces were evaluated manually and edited for corrections if appropriate. These procedures provide the sequence reported herein.
6. Physical Clone: Exons were predicted by homology and the intron/exon boundaries were determined using standard genetic rules. Exons were further selected and refined by means of similarity determination using multiple BLAST (for example, tBlastN, BlastX, and BlastN) searches, and, in some instances, GeneScan and Grail. Expressed sequences from both public and proprietary databases were also added when available to further define and complete the gene sequence. The DNA sequence was then manually corrected for apparent inconsistencies thereby obtaining the sequences encoding the full-length protein.
The PCR product derived by exon linking, covering the entire open reading frame, was cloned into the pCR2.1 vector from Invitrogen to provide clones used for expression and screening puφoses.
Example C: Quantitative expression analysis of clones in various cells and tissues
The quantitative expression of various clones was assessed using microtiter plates containing RNA samples from a variety of normal and pathology-derived cells, cell lines and tissues using real time quantitative PCR (RTQ PCR). RTQ PCR was performed on an Applied Biosystems ABI PRISM® 7700 or an ABI PRISM® 7900 HT Sequence Detection System. Various collections of samples are assembled on the plates, and referred to as Panel 1 (containing normal tissues and cancer cell lines), Panel 2 (containing samples derived from tissues from normal and cancer sources), Panel 3 (containing cancer cell lines), Panel 4 (containing cells and cell lines from normal tissues and cells related to inflammatory conditions), Panel 5D/5I (containing human tissues and cell lines with an emphasis on metabolic diseases), AI_comprehensive_panel (containing normal tissue and samples from automimune/autoinflammatory diseases), Panel CNSD.01 (containing
samples from normal and diseased brains) and CNS_neurodegeneration_panel (containing samples from normal and Alzheimer's diseased brains).
RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electropherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide (2:l to 2.5:1 28s: 18s) and the absence of low molecular weight RNAs that would be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse transcriptase using probe and primer sets designed to amplify across the span of a single exon.
First, the RNA samples were normalized to reference nucleic acids such as constitutively expressed genes (for example, 3-actin and GAPDH). Normalized RNA (5 ul) was converted to cDNA and analyzed by RTQ-PCR using One Step RT-PCR Master Mix Reagents (Applied Biosystems; Catalog No. 4309169) and gene-specific primers according to the manufacturer's instructions.
In other cases, non-normalized RNA samples were converted to single strand cDNA (sscDNA) using Superscript II (Invitrogen Coφoration; Catalog No. 18064-147) and random hexamers according to the manufacturer's instructions. Reactions containing up to 10 μg of total RNA were performed in a volume of 20 μl and incubated for 60 minutes at 42 °C. This reaction can be scaled up to 50 μg of total RNA in a final volume of 100 μl. sscDNA samples are then normalized to reference nucleic acids as described previously, using IX TaqMan® Universal Master mix (Applied Biosystems; catalog No. 4324020), following the manufacturer's instructions.
Probes and primers were designed for each assay according to Applied Biosystems Primer Express Software package (version I for Apple Computer's Macintosh Power PC) or a similar algorithm using the target sequence as input. Default settings were used for reaction conditions and the following parameters were set before selecting primers: primer concentration = 250 nM, primer melting temperature (Tm) range = 58 °-60 °C, primer optimal Tm = 59 °C, maximum primer difference = 2 °C, probe does not have 5'G, probe Tm must be 10 °C greater than primer Tm, amplicon size 75bp to lOObp. The probes and primers selected (see below) were synthesized by Synthegen (Houston, TX, USA). Probes were double purified by HPLC to remove uncoupled dye and evaluated by mass spectroscopy to verify coupling of reporter and quencher dyes to the 5' and 3' ends of the probe, respectively. Their final concentrations were: forward and reverse primers, 900nM each, and probe, 200nM.
PCR conditions: When working with RNA samples, normalized RNA from each tissue and each cell line was spotted in each well of either a 96 well or a 384-well PCR plate (Applied Biosystems). PCR cocktails included either a single gene specific probe and primers set, or two multiplexed probe and primers sets (a set specific for the target clone and another gene-specific set multiplexed with the target probe). PCR reactions were set up using TaqMan® One-Step RT-PCR Master Mix (Applied Biosystems, Catalog No. 4313803) following manufacturer's instructions. Reverse transcription was performed at 48°C for 30 minutes followed by amplification/PCR cycles as follows: 95°C 10 min, then 40 cycles of 95 °C for 15 seconds, 60 °C for 1 minute. Results were recorded as CT values (cycle at which a given sample crosses a threshold level of fluorescence) using a log scale, with the difference in RNA concentration between a given sample and the sample with the lowest CT value being represented as 2 to the power of delta CT. The percent relative expression is then obtained by taking the reciprocal of this RNA difference and multiplying by 100. When working with sscDNA samples, normalized sscDNA was used as described previously for RNA samples. PCR reactions containing one or two sets of probe and primers were set up as described previously, using IX TaqMan® Universal Master mix (Applied Biosystems; catalog No.4324020), following the manufacturer's instructions. PCR amplification was performed as follows: 95 °C 10 min, then 40 cycles of 95 °C for 15 seconds, 60 °C for 1 minute. Results were analyzed and processed as described previously.
Panels 1, 1.1, 1.2, and 1.3D
The plates for Panels 1, 1.1, 1.2 and 1.3D include 2 control wells (genomic DNA control and chemistry control) and 94 wells containing cDNA from various samples. The samples in these panels are broken into 2 classes: samples derived from cultured cell lines and samples derived from primary normal tissues. The cell lines are derived from cancers of the following types: lung cancer, breast cancer, melanoma, colon cancer, prostate cancer, CNS cancer, squamous cell carcinoma, ovarian cancer, liver cancer, renal cancer, gastric cancer and pancreatic cancer. Cell lines used in these panels are widely available through the American Type Culture Collection (ATCC), a repository for cultured cell lines, and were cultured using the conditions recommended by the ATCC. The normal tissues found on these panels are comprised of samples derived from all major organ systems from single adult individuals or fetuses. These samples are derived from the following organs: adult
skeletal muscle, fetal skeletal muscle, adult heart, fetal heart, adult kidney, fetal kidney, adult liver, fetal liver, adult lung, fetal lung, various regions of the brain, the spleen, bone marrow, lymph node, pancreas, salivary gland, pituitary gland, adrenal gland, spinal cord, thymus, stomach, small intestine, colon, bladder, trachea, breast, ovary, uterus, placenta, prostate, testis and adipose.
In the results for Panels 1, 1.1, 1.2 and 1.3D, the following abbreviations are used: ca. = carcinoma, * = established from metastasis, met = metastasis, s cell var = small cell variant, non-s = non-sm = non-small, squam = squamous, pi. eff = pi effusion = pleural effusion, glio = glioma, astro = astrocytoma, and neuro = neuroblastoma.
Ge_eral_screening_panel_vl.4, vl.5, vl.6 and 1.7
The plates for Panels 1.4, 1.5, 1.6 and 1.7 include 2 control wells (genomic DNA control and chemistry control) and 94 wells containing cDNA from various samples. The samples in Panels 1.4, 1.5, 1.6 and 1.7 are broken into 2 classes: samples derived from cultured cell lines and samples derived from primary normal tissues. The cell lines are derived from cancers of the following types: lung cancer, breast cancer, melanoma, colon cancer, prostate cancer, CNS cancer, squamous cell carcinoma, ovarian cancer, liver cancer, renal cancer, gastric cancer and pancreatic cancer. Cell lines used in Panels 1.4, 1.5, and 1.6 are widely available through the American Type Culture Collection (ATCC), a repository for cultured cell lines, and were cultured using the conditions recommended by the ATCC. The normal tissues found on Panels 1.4, 1.5, 1.6, 1.7 are comprised of pools of samples derived from all major organ systems from 2 to 5 different adult individuals or fetuses. These samples are derived from the following organs: adult skeletal muscle, fetal skeletal muscle, adult heart, fetal heart, adult kidney, fetal kidney, adult liver, fetal liver, adult lung, fetal lung, various regions of the brain, the spleen, bone marrow, lymph node, pancreas, salivary gland, pituitary gland, adrenal gland, spinal cord, thymus, stomach, small intestine, colon,
bladder, trachea, breast, ovary, uterus, placenta, prostate, testis and adipose. Abbreviations are as described for Panels 1, 1.1, 1.2, and 1.3D.
Panels 2D, 2.2, 2.3 and 2.4 The plates for Panels 2D, 2.2, 2.3 and 2.4 generally include two control wells and
94 test samples composed of RNA or cDNA isolated from human tissue procured by surgeons working in close cooperation with the National Cancer Institute's Cooperative Human Tissue Network (CHTN) or the National Disease Research Initiative (NDRI) or from Ardais or Clinomics. The tissues are derived from human malignancies and in cases where indicated many malignant tissues have "matched margins" obtained from noncancerous tissue just adjacent to the tumor. These are termed normal adjacent tissues and are denoted "NAT" in the results below. The tumor tissue and the "matched margins" are evaluated by two independent pathologists (the surgical pathologists and again by a pathologist at NDRI/ CHTN/Ardais/Clinomics). Unmatched RNA samples from tissues without malignancy (normal tissues) were also obtained from Ardais or Clinomics. This analysis provides a gross histopathological assessment of tumor differentiation grade. Moreover, most samples include the original surgical pathology report that provides information regarding the clinical stage of the patient. These matched margins are taken from the tissue surrounding (t.e. immediately proximal) to the zone of surgery (designated "NAT", for normal adjacent tissue, in Table RR). In addition, RNA and cDNA samples were obtained from various human tissues derived from autopsies performed on elderly people or sudden death victims (accidents, etc.). These tissues were ascertained to be free of disease and were purchased from various commercial sources such as Clontech (Palo Alto, CA), Research Genetics, and Invitrogen. General oncology screening panel_v_2.4 is an updated version of Panel 2D. HASS Panel v 1.0
The HASS panel v 1.0 plates are comprised of 93 cDNA samples and two controls. Specifically, 81 of these samples are derived from cultured human cancer cell lines that had been subjected to serum starvation, acidosis and anoxia for different time periods as well as controls for these treatments, 3 samples of human primary cells, 9 samples of malignant brain cancer (4 medulloblastomas and 5 glioblastomas) and 2 controls. The human cancer cell lines are obtained from ATCC (American Type Culture Collection) and fall into the following tissue groups: breast cancer, prostate cancer, bladder carcinomas, pancreatic
cancers and CNS cancer cell lines. These cancer cells are all cultured under standard recommended conditions. The treatments used (serum starvation, acidosis and anoxia) have been previously published in the scientific literature. The primary human cells were obtained from Clonetics (Walkersville, MD) and were grown in the media and conditions recommended by Clonetics. The malignant brain cancer samples are obtained as part of a collaboration (Henry Ford Cancer Center) and are evaluated by a pathologist prior to CuraGen receiving the samples . RNA was prepared from these samples using the standard procedures. The genomic and chemistry control wells have been described previously.
ARDAIS Panel v 1.0
The plates for ARDAIS panel v 1.0 generally include 2 control wells and 22 test samples composed of RNA isolated from human tissue procured by surgeons working in close cooperation with Ardais Coφoration. The tissues are derived from human lung malignancies (lung adenocarcinoma or lung squamous cell carcinoma) and in cases where indicated many malignant samples have "matched margins" obtained from noncancerous lung tissue just adjacent to the tumor. These matched margins are taken from the tissue surrounding (i.e. immediately proximal) to the zone of surgery (designated "NAT", for normal adjacent tissue) in the results below. The tumor tissue and the "matched margins" are evaluated by independent pathologists (the surgical pathologists and again by a pathologist at Ardais). Unmatched malignant and non-malignant RNA samples from lungs were also obtained from Ardais. Additional information from Ardais provides a gross histopathological assessment of tumor differentiation grade and stage. Moreover, most samples include the original surgical pathology report that provides information regarding the clinical state of the patient.
Panel 3D, 3.1 and 3.2
The plates of Panel 3D, 3.1, and 3.2 are comprised of 94 cDNA samples and two control samples. Specifically, 92 of these samples are derived from cultured human cancer cell lines, 2 samples of human primary cerebellar tissue and 2 controls. The human cell lines are generally obtained from ATCC (American Type Culture Collection), NCI or the German tumor cell bank and fall into the following tissue groups: Squamous cell carcinoma of the tongue, breast cancer, prostate cancer, melanoma, epidermoid carcinoma, sarcomas, bladder carcinomas, pancreatic cancers, kidney cancers, leukemias/lymphomas,
ovarian/uterine/cervical, gastric, colon, lung and CNS cancer cell lines. In addition, there are two independent samples of cerebellum. These cells are all cultured under standard recommended conditions and RNA extracted using the standard procedures. The cell lines in panel 3D, 3.1, 3.2, 1, 1.1., 1.2, 1.3D, 1.4, 1.5, and 1.6 are of the most common cell lines used in the scientific literature.
AI.05 chondrosarcoma
The AI.05 chondrosarcoma plates are comprised of SW1353 cells that had been subjected to serum starvation and treatment with cytokines that are known to induce MMP (1, 3 and 13) synthesis (eg. ILlbeta). These treatments include: IL-lbeta (10 ng/ml), IL-lbeta + TNF-alpha (50 ng/ml), IL-lbeta + Oncostatin (50 ng/ml) and PMA (100 ng/ml). The
SW1353 cells were obtained from the ATCC (American Type Culture Collection) and were all cultured under standard recommended conditions. The SW1353 cells were plated at 3 xlO5 cells/ml (in DMEM medium-10 % FBS) in 6-well plates. The treatment was done in triplicate, for 6 and 18 h. The supematants were collected for analysis of MMP 1, 3 and 13 production and for RNA extraction. RNA was prepared from these samples using the standard procedures.
Panels 4D, 4R, and 4.1D
Panel 4 includes samples on a 96 well plate (2 control wells, 94 test samples) composed of RNA (Panel 4R) or cDNA (Panels 4D/4. ID) isolated from various human cell lines or tissues related to inflammatory conditions. Total RNA from control normal tissues such as colon and lung (Stratagene, La Jolla, CA) and thymus and kidney (Clontech) was employed. Total RNA from liver tissue from cirrhosis patients and kidney from lupus patients was obtained from BioChain (Biochain Institute, Inc., Hayward, CA). Intestinal tissue for RNA preparation from patients diagnosed as having Crohn's disease and ulcerative colitis was obtained from the National Disease Research Interchange (NDRI) (Philadelphia, PA).
Astrocytes, lung fibroblasts, dermal fibroblasts, coronary artery smooth muscle cells, small airway epithelium, bronchial epithelium, microvascular dermal endothelial cells, microvascular lung endothelial cells, human pulmonary aortic endothelial cells, human umbilical vein endothelial cells were all purchased from Clonetics (Walkersville, MD) and grown in the media supplied for these cell types by Clonetics. These primary cell types were activated with various cytokines or combinations of cytokines for 6 and/or
12-14 hours, as indicated. The following cytokines were used; IL-1 beta at approximately l-5ng/ml, TNF alpha at approximately 5-10ng/ml, IFN gamma at approximately 20-50ng/ml, IL-4 at approximately 5-10ng/ml, IL-9 at approximately 5-10ng/ml, IL-13 at approximately 5-10ng/ml. Endothelial cells were sometimes starved for various times by culture in the basal media from Clonetics with 0.1% serum.
Mononuclear cells were prepared from blood of employees at CuraGen Coφoration, using Ficoll. LAK cells were prepared from these cells by culture in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco/Life Technologies, Rockville, MD), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xl0"5M (Gibco), and lOmM Hepes (Gibco) and Interleukin 2 for 4-6 days. Cells were then either activated with 10-20ng/ml PMA and l-2μg/ml ionomycin, IL-12 at 5-10ng/ml, IFN gamma at 20-50ng/ml and IL-18 at 5-10ng/ml for 6 hours. In some cases, mononuclear cells were cultured for 4-5 days in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xlO"5M (Gibco), and lOmM Hepes (Gibco) with PHA (phytohemagglutinin) or PWM (pokeweed mitogen) at approximately 5μg/ml. Samples were taken at 24, 48 and 72 hours for RNA preparation. MLR (mixed lymphocyte reaction) samples were obtained by taking blood from two donors, isolating the mononuclear cells using Ficoll and mixing the isolated mononuclear cells 1:1 at a final concentration of approximately 2xl06cells/ml in DMEM 5%> FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol
(5.5x10"5M) (Gibco), and lOmM Hepes (Gibco). The MLR was cultured and samples taken at various time points ranging from 1- 7 days for RNA preparation.
Monocytes were isolated from mononuclear cells using CD 14 Miltenyi Beads, +ve VS selection columns and a Vario Magnet according to the manufacturer's instructions. Monocytes were differentiated into dendritic cells by culture in DMEM 5% fetal calf serum (FCS) (Hyclone, Logan, UT), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xl0"5M (Gibco), and lOmM Hepes (Gibco), 50ng/ml GMCSF and 5ng/ml IL-4 for 5-7 days. Macrophages were prepared by culture of monocytes for 5-7 days in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xlO"5M (Gibco), lOmM Hepes (Gibco) and 10% AB Human Serum or MCSF at approximately 50ng/ml. Monocytes, macrophages and dendritic cells were stimulated for 6 and 12-14 hours with
lipopolysaccharide (LPS) at lOOng/ml. Dendritic cells were also stimulated with anti-CD40 monoclonal antibody (Pharmingen) at lOμg/ml for 6 and 12-14 hours.
CD4 lymphocytes, CD8 lymphocytes and NK cells were also isolated from mononuclear cells using CD4, CD8 and CD56 Miltenyi beads, positive VS selection columns and a Vario Magnet according to the manufacturer's instructions. CD45RA and CD45RO CD4 lymphocytes were isolated by depleting mononuclear cells of CD8, CD56, CD14 and CD19 cells using CD8, CD56, CD14 and CD19 Miltenyi beads and positive selection. CD45RO beads were then used to isolate the CD45RO CD4 lymphocytes with the remaining cells being CD45RA CD4 lymphocytes. CD45RA CD4, CD45RO CD4 and CD8 lymphocytes were placed in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xl0"5M (Gibco), and lOmM Hepes (Gibco) and plated at 106cells/ml onto Falcon 6 well tissue culture plates that had been coated overnight with 0.5μg/ml anti-CD28 (Pharmingen) and 3ug/ml anti-CD3 (OKT3, ATCC) in PBS. After 6 and 24 hours, the cells were harvested for RNA preparation. To prepare chronically activated CD8 lymphocytes, we activated the isolated CD8 lymphocytes for 4 days on anti-CD28 and anti-CD3 coated plates and then harvested the cells and expanded them in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xlO"5M (Gibco), and lOmM Hepes (Gibco) and IL-2. The expanded CD8 cells were then activated again with plate bound anti-CD3 and anti-CD28 for 4 days and expanded as before. RNA was isolated 6 and 24 hours after the second activation and after 4 days of the second expansion culture. The isolated NK cells were cultured in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xlO"5M (Gibco), and lOmM Hepes (Gibco) and IL-2 for 4-6 days before RNA was prepared. To obtain B cells, tonsils were procured from NDRI. The tonsil was cut up with sterile dissecting scissors and then passed through a sieve. Tonsil cells were then spun down and resupended at 106 cells/ml in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xlO"5M (Gibco), and lOmM Hepes (Gibco). To activate the cells, we used PWM at 5 μg/ml or anti-CD40 (Pharmingen) at approximately lOμg/ml and IL-4 at 5-10ng/ml. Cells were harvested for RNA preparation at 24, 48 and 72 hours.
To prepare the primary and secondary Thl/Th2 and Trl cells, six-well Falcon plates were coated overnight with lOμg/ml anti-CD28 (Pharmingen) and 2μg/ml OKT3 (ATCC),
and then washed twice with PBS. Umbilical cord blood CD4 lymphocytes (Poietic Systems, German Town, MD) were cultured at 105-106cells/ml in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xl0"5M (Gibco), lOmM Hepes (Gibco) and IL-2 (4ng/ml). IL-12 (5ng/ml) and anti-IL4 (1 μg ml) were used to direct to Thl , while IL-4 (5ng/ml) and anti-IFN gamma (1 μg/ml) were used to direct to Th2 and IL-10 at 5ng/ml was used to direct to Trl. After 4-5 days, the activated Thl, Th2 and Trl lymphocytes were washed once in DMEM and expanded for 4-7 days in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xl0"5M (Gibco), lOmM Hepes (Gibco) and IL-2 (lng/ml). Following this, the activated Thl, Th2 and Trl lymphocytes were re-stimulated for 5 days with anti-CD28/OKT3 and cytokines as described above, but with the addition of anti-CD95L (1 μg/ml) to prevent apoptosis. After 4-5 days, the Thl, Th2 and Trl lymphocytes were washed and then expanded again with IL-2 for 4-7 days. Activated Thl and Th2 lymphocytes were maintained in this way for a maximum of three cycles. RNA was prepared from primary and secondary Thl, Th2 and Trl after 6 and 24 hours following the second and third activations with plate bound anti-CD3 and anti-CD28 mAbs and 4 days into the second and third expansion cultures in Interleukin 2.
The following leukocyte cells lines were obtained from the ATCC: Ramos, EOL-1, KU-812. EOL cells were further differentiated by culture in O.lmM dbcAMP at 5xl05cells/ml for 8 days, changing the media every 3 days and adjusting the cell concentration to 5xl05cells/ml. For the culture of these cells, we used DMEM or RPMI (as recommended by the ATCC), with the addition of 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xlO"5M (Gibco), lOmM Hepes (Gibco). RNA was either prepared from resting cells or cells activated with PMA at lOng/ml and ionomycin at 1 μg/ml for 6 and 14 hours. Keratinocyte line CCD106 and an airway epithelial tumor line NCI-H292 were also obtained from the ATCC. Both were cultured in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol 5.5xl0"5M (Gibco), and lOmM Hepes (Gibco). CCD1106 cells were activated for 6. and 14 hours with approximately 5 ng/ml TNF alpha and lng/ml IL-1 beta, while NCI-H292 cells were activated for 6 and 14 hours with the following cytokines: 5ng/ml IL-4, 5ng/ml IL-9, 5ng/ml IL-13 and 25ng/ml IFN gamma.
For these cell lines and blood cells, RNA was prepared by lysing approximately 107cells/ml using Trizol (Gibco BRL). Briefly, 1/10 volume of bromochloropropane (Molecular Research Coφoration) was added to the RNA sample, vortexed and after 10 minutes at room temperature, the tubes were spun at 14,000 φm in a Sorvall SS34 rotor. The aqueous phase was removed and placed in a 15ml Falcon Tube. An equal volume of isopropanol was added and left at —20 °C overnight. The precipitated RNA was spun down at 9,000 φm for 15 min in a Sorvall SS34 rotor and washed in 70% ethanol. The pellet was redissolved in 300μl of RNAse-free water and 35μl buffer (Promega) 5μl DTT, 7μl RNAsin and 8μl DNAse were added. The tube was incubated at 37 °C for 30 minutes to remove contaminating genomic DNA, extracted once with phenol chloroform and re-precipitated with 1/10 volume of 3M sodium acetate and 2 volumes of 100% ethanol. The RNA was spun down and placed in RNAse free water. RNA was stored at -80 °C.
AI_comprehensive panel_vl.0 The plates for AI_comprehensive panel vl .0 include two control wells and 89 test samples comprised of cDNA isolated from surgical and postmortem human tissues obtained from the Backus Hospital and Clinomics (Frederick, MD). Total RNA was extracted from tissue samples from the Backus Hospital in the Facility at CuraGen. Total RNA from other tissues was obtained from Clinomics. Joint tissues including synovial fluid, synovium, bone and cartilage were obtained from patients undergoing total knee or hip replacement surgery at the Backus Hospital. Tissue samples were immediately snap frozen in liquid nitrogen to ensure that isolated RNA was of optimal quality and not degraded. Additional samples of osteoarthritis and rheumatoid arthritis joint tissues were obtained from Clinomics. Normal control tissues were supplied by Clinomics and were obtained during autopsy of trauma victims.
Surgical specimens of psoriatic tissues and adjacent matched tissues were provided as total RNA by Clinomics. Two male and two female patients were selected between the ages of 25 and 47. None of the patients were taking prescription drugs at the time samples were isolated. Surgical specimens of diseased colon from patients with ulcerative colitis and
Crohns disease and adjacent matched tissues were obtained from Clinomics. Bowel tissue from three female and three male Crohn's patients between the ages of 41-69 were used. Two patients were not on prescription medication while the others were taking
dexamethasone, phenobarbital, or tylenol. Ulcerative colitis tissue was from three male and four female patients. Four of the patients were taking lebvid and two were on phenobarbital.
Total RNA from post mortem lung tissue from trauma victims with no disease or with emphysema, asthma or COPD was purchased from Clinomics. Emphysema patients ranged in age from 40-70 and all were smokers, this age range was chosen to focus on patients with cigarette-linked emphysema and to avoid those patients with alpha-lanti-trypsin deficiencies. Asthma patients ranged in age from 36-75, and excluded smokers to prevent those patients that could also have COPD. COPD patients ranged in age from 35-80 and included both smokers and non-smokers. Most patients were taking corticosteroids, and bronchodilators.
In the labels employed to identify tissues in the AI_comprehensive panel vl.O panel, the following abbreviations are used: Al = Autoimmunity Syn = Synovial
Normal = No apparent disease Rep22 /Rep20 = individual patients RA = Rheumatoid arthritis Backus = From Backus Hospital OA = Osteoarthritis
(SS) (BA) (MF) = Individual patients Adj = Adjacent tissue Match control = adjacent tissues -M = Male -F = Female
COPD = Chronic obstructive pulmonary disease
Panels 5D and 51
The plates for Panel 5D and 51 include two control wells and a variety of cDNAs isolated from human tissues and cell lines with an emphasis on metabolic diseases.
Metabolic tissues were obtained from patients enrolled in the Gestational Diabetes study. Cells were obtained during different stages in the differentiation of adipocytes from human mesenchymal stem cells. Human pancreatic islets were also obtained.
In the Gestational Diabetes study subjects are young (18 - 40 years), otherwise healthy women with and without gestational diabetes undergoing routine (elective) Caesarean section. After delivery of the infant, when the surgical incisions were being repaired/closed, the obstetrician removed a small sample (<1 cc) of the exposed metabolic tissues during the closure of each surgical level. The biopsy material was rinsed in sterile saline, blotted and fast frozen within 5 minutes from the time of removal. The tissue was then flash frozen in liquid nitrogen and stored, individually, in sterile screw-top tubes and kept on dry ice for shipment to or to be picked up by CuraGen. The metabolic tissues of interest include uterine wall (smooth muscle), visceral adipose, skeletal muscle (rectus) and subcutaneous adipose. Patient descriptions are as follows:
Patient 2 Diabetic Hispanic, overweight, not on insulin
Patient 7-9 Nondiabetic Caucasian and obese (B >30) Patient 10 Diabetic Hispanic, overweight, on insulin Patient 11 Nondiabetic African American and overweight Patient 12 Diabetic Hispanic on insulin
Adipocyte differentiation was induced in donor progenitor cells obtained from Osirus (a division of Clonetics/BioWhittaker) in triplicate, except for Donor 3U which had only two replicates. Scientists at Clonetics isolated, grew and differentiated human mesenchymal stem cells (HuMSCs) for CuraGen based on the published protocol found in Mark F. Pittenger, et al., Multilineage Potential of Adult Human Mesenchymal Stem Cells Science Apr 2 1999: 143-147. Clonetics provided Trizol lysates or frozen pellets suitable for mRNA isolation and ds cDNA production. A general description of each donor is as follows:
Donor 2 and 3 U: Mesenchymal Stem cells, Undifferentiated Adipose Donor 2 and 3 AM: Adipose, AdiposeMidway Differentiated
Donor 2 and 3 AD: Adipose, Adipose Differentiated Human cell lines were generally obtained from ATCC (American Type Culture Collection), NCI or the German tumor cell bank and fall into the following tissue groups: kidney proximal convoluted tubule, uterine smooth muscle cells, small intestine, liver HepG2 cancer cells, heart primary stromal cells, and adrenal cortical adenoma cells. These cells are all cultured under standard recommended conditions and RNA extracted using the standard procedures. All samples were processed at CuraGen to produce single stranded cDNA.
Panel 51 contains all samples previously described with the addition of pancreatic islets from a 58 year old female patient obtained from the Diabetes Research Institute at the University of Miami School of Medicine. Islet tissue was processed to total RNA at an outside source and delivered to CuraGen for addition to panel 51. 5 In the labels employed to identify tissues in the 5D and 51 panels, the following abbreviations are used:
GO Adipose =. Greater Omentum Adipose SK= Skeletal Muscle UT = Uterus 10 PL = Placenta
AD = Adipose Differentiated
AM = Adipose Midway Differentiated
U = Undifferentiated Stem Cells
15 Panel CNSD.01
The plates for Panel CNSD.01 include two control wells and 94 test samples comprised of cDNA isolated from postmortem human brain tissue obtained from the Harvard Brain Tissue Resource Center. Brains are removed from calvaria of donors between 4 and 24 hours after, death, sectioned by neuroanatomists, and frozen at -80°C in
20 liquid nitrogen vapor. All brains are sectioned and examined by neuropathologists to confirm diagnoses with clear associated neuropathology.
Disease diagnoses are taken from patient records. The panel contains two brains from each of the following diagnoses: Alzheimer's disease, Parkinson's disease, Huntington's disease, Progressive Supernuclear Palsy, Depression, and "Normal controls".
25 Within each of these brains, the following regions are represented: cingulate gyrus, temporal pole, globus palladus, substantia nigra, Brodman Area 4 (primary motor strip), Brodman Area 7 (parietal cortex), Brodman Area 9 (prefrontal cortex), and Brodman area 17 (occipital cortex). Not all brain regions are represented in all cases; e.g., Huntington's disease is characterized in part by neurodegeneration in the globus palladus, thus this
30. region is impossible to obtain from confirmed Huntington's cases. Likewise Parkinson's disease is characterized by degeneration of the substantia nigra making this region more difficult to obtain. Normal control brains were examined for neuropathology and found to be free of any pathology consistent with neurodegeneration.
In the labels employed to identify tissμes in the CNS panel, the following abbreviations are used:
PSP = Progressive supranuclear palsy Sub Nigra = Substantia nigra Glob Palladus= Globus palladus
Temp Pole = Temporal pole Cing Gyr = Cingulate gyrus BA 4 = Brodman Area 4 Panel CNS_Neurodegeneration_V1.0 The plates for Panel CNS STeurodegeneration Vl .0 include two control wells and
47 test samples comprised of cDNA isolated from postmortem human brain tissue obtained from the Harvard Brain Tissue Resource Center (McLean Hospital) and the Human Brain and Spinal Fluid Resource Center (VA Greater Los Angeles Healthcare System). Brains are removed from calvaria of donors between 4 and 24 hours after death, sectioned by neuroanatomists, and frozen at -80°C in liquid nitrogen vapor. All brains are sectioned and examined by neuropathologists to confirm diagnoses with clear associated neuropathology.
Disease diagnoses are taken from patient records. The panel contains six brains from Alzheimer's disease (AD) patients, and eight brains from "Normal controls" who showed no evidence of dementia prior to death. The eight normal control brains are divided into two categories: Controls with no dementia and no Alzheimer's like pathology (Controls) and controls with no dementia but evidence of severe Alzheimer's like pathology, (specifically senile plaque load rated as level 3 on a scale of 0-3; 0 = no evidence of plaques, 3 =. severe AD senile plaque load). Within each of these brains, the following regions are represented: hippocampus, temporal cortex (Brodman Area 21), parietal cortex (Brodman area 7), and occipital cortex (Brodman area 17). These regions were chosen to encompass all levels of neurodegeneration in AD. The hippocampus is a region of early and severe neuronal loss in AD; the temporal cortex is known to show neurodegeneration in AD after the hippocampus; the parietal cortex shows moderate neuronal death in the late stages of the disease; the occipital cortex is spared in AD and therefore acts as a "control" region within AD patients. Not all brain regions are represented in all cases.
In the labels employed to identify tissues in the CNSJSTeurodegeneration Vl .0 panel, the following abbreviations are used:
AD = Alzheimer's disease brain; patient was demented and showed AD-like pathology upon autopsy
Control = Control brains; patient not demented, showing no neuropathology
Control (Path) = Control brains; pateint not demented but showing sever AD-like pathology
SupTemporal Ctx = Superior Temporal Cortex
Inf Temporal Ctx = Inferior Temporal Cortex
A. CG101683-01: COT. Expression of gene CG101683-01 was assessed using the primer-probe sets Ag3116,
Ag3551 and Ag4828, described in Tables AA, AB and AC. Results of the RTQ-PCR runs are shown in Tables AD, AE, AF, AG, AH, Al and AJ.
Table AA. Probe Name Ag3116
Table AB. Probe Name Ag3551
Table AC. Probe Name Ag4828
Table AD. CNS_neurodegeneration_vl.O
Table AE. General_screening_panel_vl.4
Table AF. Panel 1.3D
Table AG. Panel 2D
Table AH. Panel 4D
Table Al. Panel 5D
Table AJ. general oncology screening panel_v_2.4
CNS_neurodegeneration_vl.O Summary: Ag3551 This panel confirms the expression of this gene at low levels in the brains of an independent group of individuals. However, no differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1.4 for a discussion of the potential utility of this gene in treatment of central nervous system disorders.
General_screening^_panel_ l.4 Summary: Ag3116/Ag3551/Ag4828 Results of three experiments with two different probes and primer sets are in excellent agreement. Highest expression of this gene is detected in adipose, fetal lung, and breast cancer MCF-7 cell lines (CTs=27-30). Interestingly, this gene is expressed at much higher levels in fetal (CTs=27-30) when compared to adult lung (CT =31-35). This observation suggests that expression of this gene can be used to distinguish fetal from adult lung. In addition, the relative overexpression of this gene in fetal lung suggests that the protein product may enhance lung growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of lung related diseases.
In addition significant expression of this gene is found in a number of cancer (pancreatic, CNS, colon, lung, breast, ovary, prostate, melanoma) cell lines. Therefore, therapeutic
modulation of the activity of this gene or its protein product, through the use of small molecule drugs, might be beneficial in the treatment of these cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high to moderate levels in pancreas, adipose, adrenal gland, thyroid, skeletal muscle, heart, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
This gene encodes a protein that is homologous to mitogen-activated protein kinase kinase kinase 8 (MAP3K8)(COT proto-oncogene serine/threonine-protein kinase) (C-COT) (Cancer osaka thyroid oncogene). COT is able to enhance the TNF alpha production and to activate NF-kB. Both events are connected with insulin resistance and type II diabetes (1, 2, 3). Inhibition of COT kinase would prevent overproduction of TNF alpha and activation of NF-kB, thus improving insulin resistance and diabetes.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Recently, MKK6, a related protein, has been shown to associated with Alzheimer's disease (4). Therefore, based on the homology of this protein to MKK6 and the presence of this gene in the brain, we predict that this putative MAP3K8 may play a role in central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Ag3551 Results from one experiment (run 213391203) are not included. The amp plot indicates that there were experimental difficulties with this run. (Data not shown).
References:
1. Ballester A, Velasco A, Tobena R, Alemany S. Cot kinase activates tumor necrosis factor-alpha gene expression in a cyclosporin A-resistant manner. J. Biol. Chem. 1998. 273, 14099-106. PMID: 9603908.
2. Bierhaus A, Schiekofer S, Schwaninger M, Andrassy M, Humpert PM, Chen J, Hong M, Luther T, Henle T, Kloting I, Morcos M, Hofmann M, Tritschler H, Weigle B, Kasper M, Smith M, Perry G, Schmidt AM, Stern DM, Haring HU, Schleicher E, Nawroth PP.
Diabetes-associated sustained activation of the transcription factor nuclear factor-kappaB. Diabetes, 2001 50, 2792-808. PMID: 11723063.
3. Belich MP, Salmeron A, Johnston LH, Ley SC. TPL-2 kinase regulates the proteolysis of the NF-kappaB-inhibitory protein NF-kappaBl pl05. Nature. 1999397, 363-8.PMID: 9950430.
4. Zhu X, Rottkamp CA, Hartzler A, Sun Z, Takeda A, Boux H, Shimohama S, Perry G, Smith MA. (2001) Activation of MKK6, an upstream activator of p38, in Alzheimer's disease. J Neurochem 79(2): 311-8
Panel 1.3D Summary: Ag3116 Highest expression of this gene is detected in adipose (32.7). Low to moderate expression of this gene is also seen in number of ovarian cancer cell lines, liver adenocarcinoma and breast cancer MCF-7 cell line. Therefore, therapeutic modulation of the activity of this gene or its protein product, through the use of small molecule drugs, might be beneficial in the treatment of these cancers.
In addition, low expression of this gene is also seen in fetal kidney and lung. Interestingly, this gene is expressed at much higher levels in fetal (CT=34.3) when compared to adult kidney (CT=37). This observation suggests that expression of this gene can be used to distinguish fetal from adult kidney. In addition, the relative overexpression of this gene in fetal lung suggests that the protein product may enhance lung growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of lung related diseases.
Panel 2D Summary: Ag3116 Highest expression of this gene is detected in normal bladder (OD04718-03) sample (CT=31.4). Low to moderate expression of this gene is seen in large number of normal and cancer samples. Please see Panel 1.4 for a discussion of the potential utility of this gene.
Panel 4D Summary: Ag3116/Ag3551 Results from two experiments with same primer and probe set are in excellent agreement. Highest expression of this gene is detected in PWM treated PBMC and LPS treated monocytes (CTs=28-29). Interestingly, expression of this gene is stimulated in activated primary Th2 and Trl, activated secondary Thl, Th2,
Trl, PWM treated PBMC, LPS treated monocytes, TNFalpha + IL-lbeta treated astrocytes and keratinocytes. Thus, expression of this gene can be used to distinguish between these activated or treated cells from the corresponding untreated or resting cells.
In addition low expression of this gene is seen in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
Panel 5D Summary: Ag3116/Ag4828 Results from two experiments with different primer and probe set are in excellent agreement. Highest expression of this gene is detected in adipose tissue (CTs=29-33). Low to moderate expression of this gene is seen in wide range of samples used in this panel including adipose, skeletal muscle, uterus, and placenta. This wide spread expression of this gene in tissues with metabolic or endocrine function, suggests that this gene plays a role in endocrine/metabolically related diseases, such as obesity and diabetes.
This gene codes for mitogen-activated protein kinase kinase kinase 8 (MAP3K8). Recently, activation of MAP kinase, ERK, a related protein, by modified LDL in vascular smooth muscle cells has been implicated in the development of atherosclerosis in diabetes (Ref.l). Therefore, MAP3K8 may also play a role in the development of this disease and therapeutic modulation of the activity of this gene or its protein product, through the use of small molecule drugs, might be beneficial in the treatment of artherosclerosis and diabetes.
References.
1. Velarde V, Jenkins AJ, Christopher J, Lyons TJ, Jaffa AA. (2001) Activation of MAPK by modified low-density lipoproteins in vascular smooth muscle cells. J Appl Physiol 91(3):1412-20. PMID: 11509543.
General oncology screening panel_v_2.4 Summary: Ag3551 Highest expression of this gene is detected in lung cancer (CT=32.3). Moderate to low expression of this gene is detected in metastatic melanoma, prostate, lung and kidney cancers. Interestingly, expression of this gene is higher in cancer as compared to normal tissues. Therefore, expression of this gene may be used as diagnostic marker to detect the presence of these cancers and therapeutic modulation of this gene through the use of antibodies or small molecule may be useful in the treatment of metastatic melanoma, prostate, lung and kidney cancers.
B. CG101996-02: Phosphorylase kinase gamma full length. Expression of gene CG101996-02 was assessed using the primer-probe sets Ag3882 and Ag5945, described in Tables BA and BB. Results of the RTQ-PCR runs are shown in Tables BC, BD, BE, BF and BG.
Table BA. Probe Name Ag3882
Table BB. Probe Name Ag5945
Table BC. Al comprehensive panel v 1.0
Table BD. General_screening_panel_vl.4
Table BE. General_screening_panel_vl.5
459
Table BF. Panel 4. ID
Table BG. Panel 5D
AI_comprehensive panel_vl.0 Summary: Ag5945 Highest expression is seen in OA synovium (CT=29). In addition, moderate levels of expression are also seen in a cluster of samples from OA bone, synovium, and cartilage. Thus, expression of this gene could be used to differentiate between OA derived samples and other samples on this panel and as a marker of OA. Furthermore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of O A.
General_screeningj}anel_vl.4 Summary: Ag3882 Three experiments with the same probe and primer produce results that are in excellent agreement. Highest expression of this gene is seen in skeletal muscle (CTs=26 -27). This gene is also expressed at moderate to low levels in pituitary, adipose, adrenal gland, pancreas, thyroid, fetal liver and adult and fetal skeletal muscle and heart. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is widely expressed in this panel, with moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
This gene is also expressed at moderate to low levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex.
Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
General_screening _panel_vl.5 Summary: Ag3882 Highest expression of this gene is seen in skeletal muscle (CT=24). Overall, expression of this gene is in agreement with Panel 1.4. Please see that panel for discussion of utility of this gene.
Panel 4.1D Summary: Ag5945 Expression is limited to dermal fibroblasts, with highest expression in resting dermal fibroblasts (CT=32.3). Thus, expression of this gene could be used to differentiate between resting and activated dermal fibroblasts. This expression also suggests that this gene may be involved in inflammatory conditions of the skin.
Panel 5D Summary: Ag5945 Moderate levels of expression are seen in skeletal muscle, while this gene is not expressed in the liver derived samples on adult liver or liver cell line samples on Panels 1.4 and 1.5 and this panel.
C. CG102822-03: Glutamine synthase. Expression of gene CG 102822-03 was assessed using the primer-probe sets Ag4225 and Ag5106, described in Tables CA and CB. Results of the RTQ-PCR runs are shown in Tables CC, CD, CE and CF.
Table CA. Probe Name Ag4225
Table CB. Probe Name Ag5106
Table CC. CNS_neurodegeneration_vl.O
Table CD. General_screening_panel_vl.5
Table CE. Panel 5 Islet
Table CF. Panel 5D
CNS_neurodegeneration_vl.O Summary: Ag4225/Ag5106 Two experiments with two different probe and primer sets produce results that are in excellent agreement, with highest expression in the hippocampus of an Alzheimer's patient (CTs=23-24). This panel does not show differential expression of this gene in Alzheimer's disease. However, this profile confirms the expression of this gene at moderate levels in the brain. Please see Panel 1.5 for discussion of utility of this gene in the central nervous system.
General_screening_panel_vl.4 Summary: Ag4225 Results from one experiment with this gene are not included. The amp plot indicates that there were experimental difficulties with this run.
General_screening_panel_vl.5 Summary: Ag5106 Expression of this gene appears to have a brain-preferential distribution among normal tissues, with highest expression seen in the cerebellum (CT=22). This gene is also expressed at high levels throughout the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurological disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Among tissues with metabolic function, this gene is expressed at high levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
Panel 5 Islet Summary: Ag4225/Ag5106 Multiple experiments with two different probe and primer sets produce results that are in excellent agreement, with highest expression in a liver cell line and adipose from a diabetic patient (CTs=26.5). In addition, high to moderate levels of expression are seen in metabolic tissues, including placenta, adipose and skeletal muscle, in agreement with Panel 1.5. This gene encodes glutamine synthase (GS) and also
appears to be slightly up-regulated in diabetic skeletal muscle (patient 12). Up-regulation of glutamine synthase, which is critical for glutamine production, has been reported in obesity and diabetes, as well as in some myopathies. Muscle catabolism leads to the release of glutamine and contributes to gluconeogenesis in the liver. Inhibition of GS may decrease glutamine production, inhibit gluconeogenesis and necessitate fatty acid oxidation for energy generation. Therefore, an antagonist of glutamine synthase may be beneficial in treatment of obesity and diabetes.
Panel 5D Summary: Ag4225 Highest expression is in a liver cell line (CT=26.6). Expression is in agreement with Panel 51. Please see that panel for further discussion of expression and utility of this gene in obesity and diabetes.
D. CG103241-02: UDPGAL:GLCNAC Bl,4 GALACTOSYLTRANSFERASE.
Expression of gene CGI 03241-02 was assessed using the primer-probe set Ag7620, described in Table DA.
Table DA. Probe Name Ag7620
CNS_neurodegeneration_vl.O Summary: Ag7620 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.
Panel 4.1D Summary: Ag7620 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.
E. CG106249-02: Kinesin. Expression of gene CGI 06249-02 was assessed using the primer-probe set Ag7282, described in Table EA. Results of the RTQ-PCR runs are shown in Tables EB and EC.
Table EA. Probe Name Ag7282
Primers Sequences Length Start SEO D3
Table EB. CNS_neurodegeneration_vl.0
Table EC. Panel 4. ID
CNS_neurodegeneration_vl.0 Summary: Ag7282 This panel confirms the expression of this gene at very low. levels in the brains of an independent group of individuals. No
differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. However, this panel confirms the expression of this gene at very low levels in the brains of an independent group of individuals. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 4.1D Summary: Ag7282 Low levels of expression of this gene is seen mainly in kidney (CT=34.3). Therefore, expression of this gene may be used to distinguish kidney from other samples used in this panel. In addition, therapeutic targeting of the expression or function of this gene may modulate kidney function and be important in the treatment of inflammatory or autoimmune diseases that affect the kidney, including lupus and glomerulonephritis.
F. CG119418-01: farnesyl-diphosphate farnesyltransferase 1.
Expression of gene CG119418-01 was assessed using the primer-probe set Ag4508, described in Table FA. Results of the RTQ-PCR runs are shown in Tables FB and FC.
Table FA. Probe Name Ag4508
Table FB. General_screening_panel_vl.4
Table FC. Panel 5 Islet
General_screeningjιanel_vl.4 Summary: Ag4508 Highest expression of this gene is detected in a breast cancer BT 549 cell line (CT=23.6). High expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene
may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Interestingly, this gene is expressed at much higher levels in fetal (CT=25) when compared to adult liver (CT=29). This observation suggests that expression of this gene can be used to distinguish fetal from adult liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of liver related diseases.
Panel 5 Islet Summary: Ag4508 Highest expression of this gene is detected in liver cancer HepG2 cell line (CT=25.3). This gene shows a wide spread expression in this panel, which correlates with the expression in panel 1.4. High expression of this gene is detected in islet cells, adipose, skeletal muscle, uterus, placenta, heart smooth muscle, small intestine and kidney. This gene codes for Farnesyl-diphosphate farnesyltransferase. Farnesyl-diphosphate farnesyltransferase is involoved in the cholesterol biosynthetic pathway. The operation of this pathway appears to be important for glucose homeostasis and insulin secretion in pancreatic beta cells (Flamez D, Berger N, Kruhoffer M, Orntoft T, Pipeleers D, Schuit FC, 2002, Critical role for cataplerosis via citrate in glucose-regulated insulin release. Diabetes. 2002 Jul;51(7):2018-24. PMID: 12086928). Therefore, therapeutic modulation of this gene product may enhance insulin secretion in Type 2 diabetes.
G. CG120359-01: acetyl-CoA synthetase.
Expression of gene CG120359-01 was assessed using the primer-probe set Ag4830, described in Table GA. Results of the RTQ-PCR runs are shown in Tables GB and GC.
Table GA. Probe Name Ag4830
Table GB. General_screening_panel_vl.4
Table GC. Panel 5 Islet
Generaljscreeningjane^vl^ Summary: Ag4830 Highest expression of this gene is seen in a renal cancer cell line (CT=26.2). This gene is widely expressed in this panel, with high to moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at high to moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes. This gene encodes acetyl coA synthase. Inhibiting the production of acetyl CoA from one pathway may increase the utilization (energy generation) of acetyl CoA produced from other pathways. Decreased acetyl CoA will be available for lipid synthesis. Therefore, an inhibitor of ACS may facilitate weight loss and prevent weight gain, and be useful in the treatment of obesity.
In addition, this gene is expressed at much higher levels in fetal liver tissue (CT=27) when compared to expression in the adult counterpart (CT=30). Thus, expression of this gene may be used to differentiate between the fetal and adult source of this tissue.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 5 Islet Summary: Ag4830 Highest expression of this gene is seen in diabetic skeletal muscle (CT=29) (patient 12). This gene is also expressed in other metabolic
tissues, including adipose and placenta. Please see Panel 1.4 for discussion of utility of this gene in metabolic disease.
H. CG124907-01: omithine decarboxylase.
Expression of gene CGI 24907-01 was assessed using the primer-probe set Ag4751, described in Table HA. Results of the RTQ-PCR runs are shown in Tables HB and HC.
Table HA. Probe Name Ag4751
Table HB. General_screening_panel_vl .4
Renal ca. 786-0 1 5.8 (Salivary Gland 1.0
Renal ca. A498 1.7 (Thyroid (female) 7.0 jPancreatic ca.
Renal ca. ACHN 5.9 4.2 ICAPAN2
Renal ca. UO-31 1 10.2 (Pancreas Pool 4.2
Table HC. Panel 5D
General_screening_panel_vl.4 Summary: Ag4751 Highest expression of this gene is detected in prostate cancer PC3 cell line (CT=23.5). High expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene maybe effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high to moderate levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
This gene codes for omithine Decarboxylase 1 (ODC). ODC is one of the key enzymes in polyamine biosynthesis. Preventing the accumulation of polyamines and their antilipolytic effects by inhibition of ODC at an earlier stage of obesity may inhibit progression of the obesity. In multiple GeneCalling studies at Curagen, enzyme spermidine/spermine acetyl fransferase is found to be dysregulated in various disease models. This enzyme is one of the rate-limiting enzymes in the production of polyamines, spermidine and spermine. Previously, it was shown that oxidation of polyamines leads to generation of hydrogen
peroxide, which has been shown to have antilipolytic effects on adipose and may be involved in the progression of obesity.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Interestingly, this gene is expressed at much higher levels in fetal (CT=27) when compared to adult liver (CT=31 ). This observation suggests that expression of this gene can be used to distinguish fetal from adult liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of liver related diseases.
References:
1: Taylor JL, Turo KA, McCann PP, Grossberg SE.Inhibition of the differentiation of 3T3- Ll cells by interferon-beta and difluoromejhyl omithine. J. Biol. Regul. Homeost. Agents 1988 Jan-Mar;2(l): 19-24. PMID: 3140600.
2: Brown AP, Morrissey RL, Crowell JA, Levine BS. Difluoromethylornithine in combination with tamoxifen in female rats: 13-week oral toxicity study. Cancer Chemother Pharmacol 1999;44(6):475-83. PMID: 10550568. 3: Olefsky JM. Comparison of the effects of insulin and insulin-like agents on different aspects of adipocyte metabolism. Horm. Metab. Res. 1979 Mar; 11(3):209-13. PMID: 447201.
4: Richelsen B, Pedersen SB, Hougaard DM. Characterization of antilipolytic action of polyamines in isolated rat adipocytes. Biochem. J. 1989 Jul 15;261(2):661-5. PMID: 2476118.
5: Livingston JN, Gurny PA, Lockwood DH. Insulin-like effects of polyamines in fat cells. Mediation by H2O2 formation. J. Biol. Chem. 1977 Jan 25 ;252(2): 560-2. PMTD:833144.
Panel 5D Summary: Ag4751 Highest expression of this gene is detected in liver cancer HepG2 cell line (CT=29.5). This gene shows a wide spread expression in this panel, which correlates with the expression in panel 1.4. Moderate expression of this gene is detected in adipose, skeletal muscle, uterus, placenta, heart smooth muscle, small intestine and kidney. Therefore, therapeutic modulation of this gene may be useful in the treatment of obesity and diabetes including type II diabetes.
I. CG128347-02: kinesin-like.
Expression of gene CG128347-02 was assessed using the primer-probe set Ag5691, described in Table IA. Results of the RTQ-PCR runs are shown in Table IB.
Table IA. Probe Name Ag5691
Table IB. Panel 4. ID
CNS_neurodegeneration_vl.0 Summary: Ag5691 Results from one experiment with this gene are not included. The amp plot indicates that there were experimental difficulties with this run (Data not shown).
GeneraljscreeningjaneLvLS Summary: Ag5691 Results from one experiment with this gene are not included. The amp plot indicates that there were experimental difficulties with this run (Data not shown).
Panel 4.1D Summary: AG5691 Highest expression of this gene is seen in resting neutiophils (CT=31.3). This expression is reduced to background level (CT=35.2) in neutrophils activated by TNF-alpha+LPS. This expression profile suggests that the protein encoded by this gene is produced by resting neutrophils but not by activated neutrophils. Therefore, the gene product may reduce activation of these inflammatory cells and modulation of its expression or activity may reduce or eliminate the symptoms in patients with Crohn's disease, ulcerative colitis, multiple sclerosis, chronic obstructive pulmonary disease, asthma, emphysema, rheumatoid arthritis, lupus erythematosus, or psoriasis. In addition, antagonists of this gene product may be effective in increasing the immune response in patients with AIDS or other immunodeficiencies.
J. CG135823-01 and CG135823-02: TAT.
Expression of gene CG135823-01 and CG135823-02 was assessed using the primer-probe sets Ag3173 and Ag4906, described in Tables JA and JB. Results of the RTQ-PCR runs are shown in Tables JC and JD. Please note that probe-primer set Ag4906 is specific for CG135823-01 variant.
Table JA. Probe Name Ag3173
Table JB. Probe Name Ag4906
Table JC. General_screening_panel_vl.5
Table JD. Panel 5 Islet
General_screening_panel_vl.5 Summary: Ag4906 This gene seems to be almost exclusively expressed in liver (CT=24.6). A lower level of expression has been detected in fetal liver (CT=28) and brain. Thus, expression of this gene could be used to differentiate between liver and fetal liver tissues. In addition, the relative overexpression of this gene in fetal liver suggests that the protein product may enhance liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of liver and metabolic related diseases, including obesity and diabetes.
Panel 5 Islet Summary: Ag4906 This gene is expressed in hepatocyte-derived HepG2 cell line (CT=29.8), which is in accordance with the liver expression seen in panel 1.5.
K. CG140122-01: Polyamine Oxidase.
Expression of gene CG140122-01 was assessed using the primer-probe sets Ag4986 and Ag5105, described in Tables KA and KB. Results of the RTQ-PCR runs are shown in Tables KC and KD.
Table KA. Probe Name Ag4986
Table KB. Probe Name Ag5105
Table KC. CNS_neurodegeneration_vl.O
Table KD. General_screening_panel_vl.5
CNS_neurodegeneration_vl.O Summary: Ag5105 This panel confirms the expression of this gene at low levels in the brain in an independent group of individuals. This gene is found to be upregulated in the temporal cortex of Alzheimer's disease patients. Therefore, therapeutic modulation of the expression or function of this gene may decrease neuronal death and be of use in the treatment of this disease.
General screening panel vl.4 Summary: Ag4986 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
General_screening panel_vl.5 Summary: Ag5105 Two experiments with the same probe and primer set produce results that are in excellent agreement. Highest expression of
this gene is seen in a breast cancer cell line (CTs=24-26). This gene is widely expressed in this panel, with high to moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 5 Islet Summary: Ag4986 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 5D Summary: Ag5105 Results from one experiment with this gene are not included. The amp plot indicates that there were experimental difficulties with this run.
L. CG140316-01: Malic enzyme isoforml (MB_X77244 ).
Expression of gene CG140316-01 was assessed using the primer-probe set Ag4998, described in Table LA. Results of the RTQ-PCR runs are shown in Tables LB and LC.
Table LA. Probe Name Ag4998
Table LB. General_screening_panel_vl.4
General_screeningj)anel_vl.4 Summary: Ag4998 Cytosolic malic enzyme is ubiquitously expressed including endocrine/metabolically-relevant tissues such as, adipose,
GI, liver, and skeletal muscle. These results indicate that this enzyme is critical for normal physiology. Furthermore, disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
Highest expression of this gene is seen in a prostate cancer cell line (CT=25.4). This gene is widely expressed in this panel, with high to moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 5D Summary: Ag4998 Cytosolic malic enzyme has low to moderate expression in fully differentiated adipose, and adipose found in diabetic gestational diabetics.
M. CG142427-01: ATP citrate lyase.
Expression of gene CG142427-01 and CG142404-01 £vere assessed using the primer-probe set Ag6008, described in Table MA. Results of the RTQ-PCR runs are shown in Tables MB and MC.
Table MA. Probe Name Ag6008
Table MB. General_screening_panel_vl.5
Table MC. Panel 5 Islet
General_screeningL_panel_vl.5 Summary: Ag6008 Highest expression of this gene is detected in a lung cancer A549 cell line (CT=22.4). High expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers.
Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene through the use of small molecule drug may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
Interestingly, this gene is expressed at much higher levels in fetal (CTs=24-25), when compared to adult liver and lung (CTs=28-29). This observation suggests that expression of this gene can be used to distinguish fetal from adult lung and liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance lung and liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of lung and liver related diseases.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 5 Islet Summary: Ag6008 Highest expression of this gene is detected in differentiated adipose (CT=27.7). This gene shows widespread expression in this panel. Moderate to high expression of this gene is detected in the tissues with metabolic/endocrine functions including islet cells, adipose, skeletal muscle, and gastrointestinal tracts.
This gene codes for ATP-citrate lyase. It is a major source of acetyl CoA that is the building block of lipid biosynthesis and provides substrate for the production of cholesterol. Reduced flux of acetyl CoA through the cholesterol biosynthetic pathway will prevent excess production of LXR alpha ligands. LXR alpha is a nuclear hormone receptor that is abundantly expressed in tissues associated with lipid metabolism. Activation of LXR alpha leads to the up-regulation of fatty acid synthesis. Thus, ATP-citrate lyase may be a
target for the treatment and/or prevention of obesity because its inhibition will decrease the availability of acetyl CoA for the synthesis of LXR alpha ligands, fatty acids, and triglycerides.
References:
1. Chawla A, Repa JJ, Evans RM, Mangelsdorf DJ. Nuclear receptors and lipid physiology: opening the X-files. Science. 2001 Nov 30;294(5548): 1866-70. Review. PMID: 11729302.
2. Moon YA, Lee JJ, Park SW, Ahn YH, Kim KS. The roles of sterol regulatory element- binding proteins in the transactivation of the rat ATP citrate-lyase promoter. J Biol Chem. 2000 Sep 29;275(39):30280-6. PMID: 10801800.
3. Sato R, Okamoto A, Inoue J, Miyamoto W, Sakai Y, Emoto N, Shimano H, Maeda M. Transcriptional regulation of the ATP citrate-lyase gene by sterol regulatory element- binding proteins. J Biol Chem. 2000 Apr 28;275(17): 12497-502. PMID: 10777536.
N. CG142631-01: serine dehydratase. Expression of gene CG142631-01 was assessed using the primer-probe set Ag6006, described in Table NA. Results of the RTQ-PCR runs are shown in Tables NB, NC, ND andNE.
Table NA. Probe Name Ag6006
Table NB. General_screening_panel_vl.5
Table NC. Oncology_cell_line_screening_panel_v3.1
Table ND. Panel 4. ID
Table NE. Panel 5 Islet
General_screening panel vl.5 Summary: Ag6006 Two experiments with same probe- primer sets are in excellent agreement with highest expression of this gene detected in liver (CTs=26). Interestingly, expression of this gene is higher in adult as compared to fetal liver
(CTs=32-33). Therefore, expression of this gene may be useful in distinguishing between adult and fetal liver.
In addition, moderate to low expression of this gene is also detected in tissues with metabolic/endocrine functions including pancreas, adipose, adrenal gland, thyroid, and stomach. This gene codes for Serine dehydratase (SD). SD catalyzes the PLP-dependent alpha, beta-elimination of L-serine to pyruvate and ammonia. It is one of three enzymes that are regarded as metabolic exits of the serine-glycine pool. SD is critical for hepatic glucose production. Therefore, inhibition of SD would decrease gluconeogenesis, thus an antagonist of SD would be beneficial for treatment hyperglycemia and diabetes.
In addition moderate levels of expression of this gene is in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Oncology_cell_line_screeningjpanel_v3.1 Summary: Ag6006 Two experiments with same probe-primer sets are in excellent agreement, with highest expression of this gene detected in cerebellum (CTs=32-33.7). In addition, low levels of expression of this gene is also detected in histiocytic lymphoma. Therefore, therapeutic modulation of this gene may be useful in the treatment of ataxia, autism and histiocytic lymphoma.
Panel 4.1D Summary: Ag6006 Highest expression of this gene is detected in liver cirrhosis sample (CT=29). In addition, moderate to low expression of this gene resting macTophage, LPS activated monocytes and macrophages, dendritic cells, resting and PMA/ionomycin activated LAK cells and normal tissues represented by thymus and kidney. Therefore, therapeutic modulation of this gene may be useful in the treatment of liver cirrhosis, asthma, emphysema, inflammatory bowel disease, arthritis and psoriasis.
Results from another experiment with this gene (run 225245206) are not included. The amp plot indicates that there were experimental difficulties with this run.
Panel 5 Islet Summary: Ag6006 Three experiments with same probe and primer sets are in good agreement. Low expression of this gene is detected mainly in islet cells and adrenocortical adenoma cells (CTs=33-34.8). Therefore, therapeutic modulation of this gene of SD encoded by this gene through the use of small molecule drug may be useful in the treatment of adrenocortical adenoma and metabolic disorders especially type Et diabetes.
O. CG151359-01: LACTATE DEHYDROGENASE A Like.
Expression of gene CG151359-01 was assessed using the primer-probe set Ag5225, described in Table OA. Results of the RTQ-PCR runs are shown in Table OB.
Table OA. Probe Name Ag5225
Table OB. General_screening_panel_vl.5
CNS_neurodegeneration_vl.0 Summary: Ag5225 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
General_screeningjpanel_vl.5 Summary: Ag5225 Expression of this gene is limited to a few samples on this panel, with highest expression seen in testis (CT=31.8). Moderate to low levels of expression are also seen in normal colon, a colon cancer cell line, and a brain cancer cell line.
Panel 4.1D Summary: Ag5225 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 5 Islet Summary: Ag5225 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
P. CG152227-01: 3-HYDROXYISOBUTYRYL-COENZYME A HYDROLASE.
Expression of gene CG152227-01 was assessed using the primer-probe set Ag6857, described in Table PA.
Table PA. Probe Name Ag6857
General_screening_panel_vl.6 Summary: Ag6857 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Q. CG152547-01: Similar to Zinc transporter 1. Expression of gene CG 152547-01 was assessed using the primer-probe set Ag7619, described in Table QA.
Table OA. Probe Name Ag7619
CNS_neurodegeneration_vl.0 Summary: Ag7619 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 4.1D Summary: Ag7619 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
R. CG152646-01: Amidase.
Expression of gene CG152646-01 was assessed using the primer-probe set Ag6876, described in Table RA.
Table RA. Probe Name Ag6876
General_screening_panel_vl.6 Summary: Ag6876 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
S. CG152959-01: Prenyl protein-specific endoprotease 2.
Expression of gene CG152959-01 was assessed using the primer-probe set Aglll2, described in Table SA. Results of the RTQ-PCR runs are shown in Table SB. Please note that CG152959-01 represents a full-length physical clone.
Table SA. Probe Name Ag7172
Table SB. General screening panel vl.7
General_jscreeningjpanel_vl.7 Summary: Ag7172 Highest expression of this gene is detected in ovarian cancer IGROV-1 cell line (CT=28.3). Moderate levels of expression of this gene is also seen in cluster of cancer cell tines derived from pancreatic, gastric, colon,
lung, liver, renal, breast, ovarian, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at moderate to low levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, fetal skeletal muscle, heart, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at low levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
T. CG153033-01: NA-DEPENDENT INORGANIC PHOSPHATE COTRANSPORTER.
Expression of gene CGI 53033-01 was assessed using the primer-probe set Ag5798, described in Table TA. Results of the RTQ-PCR runs are shown in Tables TB and TC.
Table TA. Probe Name Ag5798
Table TB. CNS_neurodegeneration_vl.O
Table TC. General_screening_panel_vl.5
CNS neurodegeneration vl.O Summary: Ag5798 This panel does not show differential expression of this gene in Alzheimer's disease. However, this profile confirms the expression of this gene at moderate levels in the brain. Please see Panel 1.5 for discussion of utility of this gene in the central nervous system.
General_sereening _panel_vl.5 Summary: Ag5798 Highest expression of this gene is seen in the thalamus (CT=31.3). This gene is also expressed at low to significant levels in the amygdala, hippocampus, cerebral cortex, substantia nigra, and whole and fetal brain samples. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurological disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
In addition, this gene is expressed at much higher levels in fetal liver tissue (CT=32.5) when compared to expression in the adult counterpart (CT=37). Thus, expression of this gene may be used to differentiate between the fetal and adult source of this tissue.
Moderate expression is also seen in a single lung cancer cell line (CT=31). Thus, expression of this gene could be used as a marker to detect the presence of lung cancer. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the tieatment of lung cancer.
Panel 4.1D Summary: Ag5798 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 5 Islet Summary: Ag5798 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
U. CG153818-01: kinesin 19A.
Expression of gene CGI 53818-01 was assessed using the primer-probe set Ag5692, described in Table UA. Results of the RTQ-PCR runs are shown in Tables UB, UC and UD.
Table UA. Probe Name Ag5692
Table UB. CNS_neurodegeneration_vl.O
Table UC. General_screening_panel_vl.5
Table UP. Panel 4. ID
CNS_neurodegeneration_vl.O Summary: Ag5692 Two experiments with the same probe and primer set produce results that are in excellent agreement. This panel confirms the expression of this gene at moderate levels in the brain in an independent group of individuals. This gene is found to be upregulated in the temporal cortex of Alzheimer's disease patients. This gene encodes a putative kinesin, a microtubule-based motor protein involved in the transport of organelles. Axonal transport of APP in neurons is mediated by binding with kinesin. (Gunewardena S, Neuron 2001 Nov 8;32(3):389-401). Kamal et al. suggest that impaired APP transport leads to enhanced axonal generation and deposition of Abeta, resulting in disruption of neurotrophic signaling and neurodegeneration (Nature 2001 Dec 6;414(6864):643-8). Thus, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurodegenerative disorders, and specifically may decrease neuronal death and be of use in the treatment of Alzheimer's disease.
General_screening_panel_vl.5 Summary: Ag5692 Highest expression of this gene is seen in a lung cancer cell line (CT=29.4). Moderate levels of expression are also seen in fetal lung (CT=30) and interestingly, are much higher than expression of this gene in the adult counterpart (CT=32). Thus, expression of this gene could be used to differentiate between the adult and fetal source of this tissue. In addition, therapeutic modulation of the expression or function of this gene may be useful in the treatment of diseases that affect the lung, including lung cancer.
Moderate to low levels of expression are seen in all regions of the CNS examined. Please see CNS_neurodegeneration_vl.O for discussion of utility of this gene in CNS disorders.
Low but significant levels of expression are also seen in pancreas, thyroid, fetal skeletal muscle, adipose and adult and fetal liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
Panel 4.1D Summary: Ag5692 Expression of this gene is limited to a few samples in this panel, with highest expression in IFN-gamma treated HUVEC cells (CT=31.2). Low but
significant levels of expression are also seen in PMA/ionomycin treated basophils and resting NK cells. This expression profile suggests that expression of this gene could be a marker of activated HUVEC cells. In addition, modulation of the expression or function of this gene product may reduce or eliminate the symptoms in patients with autoimmune and inflammatory diseases that involve endothelial cells, such as lupus erythematosus, asthma, emphysema, Crohn's disease, ulcerative colitis, rheumatoid arthritis, osteoarthritis, and psoriasis.
V. CG154435-01: Dynein beta chain, ciliary.
Expression of gene CG154435-01 was assessed using the primer-probe set Ag5694, described in Table VA. Results of the RTQ-PCR runs are shown in Tables VB, VC, VD, VE andVF.
Table VA. Probe Name Ag5694
Table VB. AI_comprehensive panel_vl.O
Table VC. CNS_neurodegeneration_vl.O
Table VD. General_screening_panel_vl.5
Table VE. Panel 4. ID
Table VF. Panel 5 Islet
AI_comprehensive panel_vl.0 Summary: Ag5694 Highest expression of this gene is detected in ulcerative colitis sample (CT=30.2). Interestingly, expression of this gene is higher in ulcerative colitis sample as compared to matching control sample (CT=35). Therefore, expression of this gene may be used to distinguish between these two samples and also as a marker to detect ulcerative colitis. In addition, moderate expression of this gene is seen in cartilage, bone and synovium from rheumatoid arthritis patient, low expression in normal lung, psoriasis, and normal cartilage Rep22. Therefore, therapeutic modulation of this gene may be useful in the treatment of rheumatoid arthritis, ulcerative colitis, and psoriasis.
CNS_neurodegeneration_vl.0 Summary: Ag5694 Low expression of this gene is detected in temporal cortex of an Alzheimer's patient. Therefore, therapeutic modulation of this gene may be useful in the tieatment of Alzheimer's disease. ,
General_screeningjjanel_vl.5 Summary: Ag5694 Highest expression of this gene is detected in testis (CT=29.8). Therefore, expression of this gene may be used to differentiate testis from other samples in this panel. In addition, therapeutic modulation of this gene may be useful in the treatment of testis related diseases including fertility and hypogonadism.
In addition, moderate to low levels of expression of this gene is detected in number of cancer cell lines derived from melanoma, pancreatic, renal, liver, lung, and ovarian cancers. Therefore, expression of this gene may be used as diagnostic marker to detect these cancers and also, therapeutic modulation of this gene through the use of antibodies or small molecule drug may be useful in the treatment of melanoma, pancreatic, renal, liver, lung, and ovarian cancers.
Panel 4.1D Summary: Ag5694 Moderate expression of this gene is detected mainly in LPS treated monocytes (CT=29.9). In addition, low levels of expression of this gene is also seen in TNF alpha and LPS treated neutrophils. Therefore, expression of this gene may be used to distinguish activated monocytes and neutrophils from other samples in this panel. The expression of this gene in LPS treated monocytes, cells that play a crucial role in linking innate immunity to adaptive immunity, suggests a role for this gene product in initiating inflammatory reactions. Therefore, modulation of the expression or activity of this gene through the application of monoclonal antibodies may reduce or prevent early stages of inflammation and reduce the severity of inflammatory diseases such as psoriasis, asthma, inflammatory bowel disease, rheumatoid arthritis, osteoarthritis and other lung inflammatory diseases. In addition, small molecule or antibody antagonists of this gene product may be effective in increasing the immune response in patients with ADDS or other immunodeficiencies.
Panel 5 Islet Summary: Ag5694 Low levels of expression of this gene is exclusively seen in liver cancer HepG2 cell line (CT=34.7). Please see panel 1.5 for further utility of this gene.
W. CG154465-01: kinesin 18B.
Expression of gene CGI 54465-01 was assessed using the primer-probe set Ag5695, described in Table WA. Results of the RTQ-PCR runs are shown in Tables WB and WC.
Table WA. Probe Name Ag5695
Table WB. General_screening_panel_vl.5
Table WC. Panel 4. ID
CNS_neurodegeneration_vl.0 Summary: Ag5695 Expression of this gene is low/undetectable (CTs > 35) across all of the samples on this panel (data not shown).
General_screenmg_panel_vl.5 Summary: Ag5695 Highest expression of this gene is detected in a colon cancer HCT-116 cell line (CT=27). Moderate expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
In addition, significant expression of this gene is seen in fetal tissues, including fetal lung, liver, kidney, heart, and skeletal muscle. Expression of this gene is higher in fetal (CTs=28- 32) compared to corresponding adult lung, liver, kidney, heart, and skeletal muscle tissues.
Therefore, expression of this gene may be useful in distinguishing between fetal and adult lung, liver, kidney, heart, and skeletal muscle. In addition, expression in fetal tissue suggests a role for the protein encoded by this gene in growth and development of these tissues in the fetus and thus may also act in a regenerative capacity in the adult.
Panel 4.1D Summary: Ag5695 Highest expression of this gene is detected in dermal fibroblast (CT=29.2). Moderate to low levels of expression of this gene is detected in polarized T cells (primary and secondary Thl, Th2, and Trl), activated CD45RA CD4 and CD45RO CD4 lymphocytes, LAK cells, resting IL-2 treated NK cells, activated PBMC cells, Ramos B cells, B lymphocytes, eosinophils, endothelial cells, basophils, NCI-H292 cells, lung and dermal fibroblasts and thymus. Interestingly, expression of this gene is upregulated in activated polarized T cells, stimulted PBMC cells, and activated Ramos B cells. Therefore, therapeutic modulation of this gene may be useful in the tieatment of autoimmune and inflammatory disorders including psoriasis, allergy, asthma, inflammatory bowel disease, rheumatoid arthritis and osteoarthritis.
X. CG154492-01: HIGH-AFFINITY CGMP-SPECIFIC 3',5'-CYCLIC PHOSPHODIESTERASE 9A.
Expression of gene CG154492-01 was assessed using the primer-probe set Ag6818, described in Table XA. Results of the RTQ-PCR runs are shown in Table XB.
Table XA. Probe Name Ag6818
Table XB. General screening panel vl.6
CNS_neurodegeneration_vl.O Summary: Ag6818 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
General_screeningjpanel_vl.6 Summary: Ag6818 Expression of this gene is limited to the fetal brain (CT=34.5). Thus, expression of this gene could be used to differentiate between fetal and adult brain tissue and as a marker of fetal neural tissue.
Panel 4.1D Summary: Ag6818 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 5 Islet Summary: Ag6818 Expression of this gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Y. CG154509-01 : CYTOPLASMIC DYNEIN HEAVY CHAIN.
Expression of gene CGI 54509-01 was assessed using the primer-probe setAg5696, described in Table YA. Results of the RTQ-PCR runs are shown in Tables YB, YC and YD.
Table YA. Probe Name Ag5696
Table YB. AI_comprehensive panel_vl.O
Table YC. CNS_neurodegeneration_vl.O
Table YD. Panel 4.1D
Tissue Name Rel. EXΌ.(%) Tissue Name Rel. Exo.f %)
AI_comprehensive panel_vl.0 Summary: Ag5696 Highest expression of this gene is seen in a normal bone sample adjacent to OA bone (CT=28). Overall, this gene is widely expressed on this panel, with moderate levels of expression in a wide range of tissues and samples related to autoimmune disease. Thus, modulation of the expression or function of this gene may be useful in the treatment of autoimmune diseases, including RA, OA, allergy, emphysema and asthma.
CNS_neurodegeneration_vl.O Summary: Ag5696 Two experiments with the same probe and primer set produce results that are in very good agreement. This panel does not
show differential expression of this gene in Alzheimer's disease. However, this panel does show that this gene is expressed at high to moderate levels in the hippocampus and cerebral cortex. Thus, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurological disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epUepsy.
Panel 4.1D Summary: Ag5696 Highest expression of this gene is seen in IL-9 treated NCI-H292 goblet cells. Moderate levels of expression are seen in clusters of samples derived from lung and dermal fibroblasts. Low but significant levels of expression are seen in endothelial cells from the lung and skin, as well as small airway and bronchial epithelium. The prominent expression in cells and cell lines derived from the lung and skin suggest that this gene product may be involved in inflammatory conditions of the lung and skin, including psoriasis, asthma, emphysema, allergy, and chronic obstructive pulmonary disease.
Z. CG155595-01: kinesin 7. Expression of gene CGI 55595-01 was assessed using the primer-probe set Ag5284, described in Table ZA. Results of the RTQ-PCR runs are shown in Tables ZB, ZC, ZD and ZE.
Table ZA. Probe Name Ag5284
Table ZB. AI_comprehensive panel_vl.O
Table ZC. CNS_neurodegeneration_vl.O
Table ZD. General_screening_panel_ l.5
Table ZE. Panel 4. ID
AI_comprehensive panel_vl.0 Summary: Ag5284 Highest expression of this gene is seen in a normal tissue sample adjacent to psoriatic tissue (CT=33).
CNS_neurodegeneration_vl.O Summary: Ag5284 Expression is limited to a single inferior temporal cortex sample from an Alzheimer's patient (CT=34.9).
General jscreening panel_vl.5 Summary: Ag5284 Highest expression is seen in a colon cancer cell line (CT=31). Prominent levels of expression are also seen in cell lines derived from brain, lung, colon, gastric, pancreatic, breast, ovarian, and melanoma cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of brain, lung, colon, gastric, pancreatic, breast, ovarian, and melanoma cancers.
Panel 4.1D Summary: Ag5284 Highest expression of this gene is seen in TNF-a treated dermal fibroblasts (CT=33). Low but significant levels of expression are also seen in clusters of samples derived from basophils, NCI-H292 cells, resting NK cells, and secondary activated T cells.
AA. CG157477-01: MYOSTN I.
Expression of gene CG157477-01 was assessed using the primer-probe set Ag5289, described in Table AAA. Results of the RTQ-PCR runs are shown in Tables AAB, AAC and AAD.
Table AAA. Probe Name Ag5289
Table AAB. CNS_neurodegeneration_vl.O
Table AAC. General_screening_panel_vl.5
Table AAD. Panel 4. ID
CNS_neurodegeneration_vl.O Summary: Ag5289 This panel does not show differential expression ofthis gene in Alzheimer's disease. However, this profile confirms the expression ofthis gene at moderate levels in the brain. Please see Panel 1.5 for discussion of utility ofthis gene in the central nervous system.
General_screening_panel_vl.5 Summary: Ag5289 Highest expression ofthis gene is seen in a colon cancer cell line (CT=23.5). This gene is widely expressed in this panel, with high levels of expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation ofthis gene product may be useful in the tieatment of cancer.
Among tissues with metabolic function, this gene is expressed at high to moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle,
heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression ofthis gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
In addition, this gene is expressed at much higher levels in fetal liver tissue (CT=26.7) when compared to expression in the adult counterpart (CT=30.3). Thus, expression ofthis gene may be used to differentiate between the fetal and adult source ofthis tissue.
This gene is also expressed at high levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function ofthis gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 4.1D Summary: Ag5289 Highest expression is seen in IL-4 treated dermal fibroblasts (CT=26.5). Moderate levels of expression are also seen in clusters of samples derived from lung and dermal fibroblasts, endothelial cells ftom lung, skin, umbilical vein, and pulmonary artery, small airway and bronchial epithelial cells, and NCI-H292 mucoepidermoid cells. The preponderance of expression in cells derived from the lung and skin suggests that this gene product may be involved in inflammatory processes that involve these organs. Therefore, therapeutic modulation of the expression or function ofthis gene product may be useful in the treatment of psoriasis, asthma, allergy, and emphysema. A second run with the same probe and primer set, run 233229299, is not included because the amp plot indicates there were experimental difficulties with this run.
AB. CG157486-01: Ephrin receptor A2.
Expression of gene CGI 57486-01 was assessed using the primer-probe set Ag2620, described in Table ABA. Results of the RTQ-PCR runs are shown in Tables ABB, ABC, ABD, ABE andABF.
Table ABA. Probe Name Ag2620
Primer Sequences [Length Start SEQ ID
Position No
Forward 5 ' -gaagtggtactgctggactttg-3 ' 22 195 552
Table ABB. General_screening_panel_vl.5
Table ABC. Oncology_cell_line_screening_panel_v3.1
Table ABD. Panel 1.3D
Table ABE. Panel 2.2
Table ABF. general oncology screening panel_v_2.4
General_screening_panel_vl.5 Summary: Ag2620 Highest expression ofthis gene is seen in a prostate cancer cell line (CT=25.9). In addition, high to moderate levels of expression are seen in all the clusters of cancer cell line samples on this panel, including brain, colon, gastric, pancreatic, renal, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in ceU survival and proliferation. Modulation ofthis gene product may be useful in the tieatment of cancer.
This gene encodes an ephrin receptor A2-like protein (EphA2) which is activated by phosphorylation both in the tumor itself and the endothelial cells associated with the tumor. This activation is especially prominent in tumor types that are highly vascularized like colon, kidney and ovarian cancers. It appears that without the proper ligand, this overexpression and activation leads to cell transformation and the promotion of tumor- related angiogenesis which affect the overall balance between survival/apoptotic stimuli. Modications in the signaling emanating from this receptor will impact that balance resulting either in increased survival (stimulation of angiogenesis) or increased apoptosis (inhibition of tumorogenesis both directly against tumor cells and indirectly against endothelial cells. Therefore, therapeutic targeting ofthis gene product with a human monoclonal antibody will affect the overall balance between survival/apoptotic stimuli in cell expressing it, preferably endothelial, tumor and neuronal cells and will therefore affect the outcome of diseases where these stimuli are involved in the pathogenesis, tumors, preferably colon, kidney and ovarian cancer, pathogenic angiogenesis, preferably wound healing, neurodegenaritive diseases.
Among tissues with metabolic function, this gene is expressed at moderate to low levels in adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at low but significant levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, and cerebellum. Therefore, therapeutic modulation of the expression or function ofthis gene maybe useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Oncology_cell_line_screening_panel_v3.1 Summary: Ag2620 Highest expression is seen in a pancreatic cancer cell line (CT=27.8). Moderate levels of expression are also seen in many of the cell lines on this panel. Please see Panel 1.5 for discussion of utility ofthis gene in the treatment of cancer.
Panel 1.3D Summary: Ag2620 Highest expression ofthis gene is seen in an ovarian cancer cell line (CT=29.3). In addition, moderate to low levels of expression are seen in many of the clusters of cancer cell line samples on this panel, including brain, colon, gastric, pancreatic, renal, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation ofthis gene product may be useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at low levels in adipose, pancreas, and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
In addition, this gene is expressed at much higher levels in fetal heart tissue (CT=32) when compared to expression in the adult counterpart (CT=35). Thus, expression ofthis gene may be used to differentiate between the fetal and adult source ofthis tissue.
Panel 2.2 Summary: Ag2620 Highest expression is seen in a sample of normal kidney (CT=31). In addition, this gene appears to be more highly expressed in kidney cancer than in the corresponding normal adjacent tissue. Thus, expression ofthis gene could be used as a marker ofthis cancer. Furthemore, therapeutic modulation of the expression or function ofthis gene product may be useful in the tieatment of kidney cancer.
general oncology screenmg panel_v_2.4 Summary: Ag2620 Highest expression is seen in a sample of lung cancer (CT=29.5). In addition, this gene appears to be more highly expressed in colon and kidney cancers than in the corresponding normal adjacent tissue. Thus, expression ofthis gene could be used as a marker of these cancers. Furthemore, therapeutic modulation of the expression or function of this gene product may be useful in the treatment of colon and kidney cancer.
AC. CG157505-01: kinesin 16A.
Expression of gene CGI 57505-01 was assessed using the primer-probe set Ag5721, described in Table ACA. Results of the RTQ-PCR runs are shown in Tables ACB, ACC andACD.
Table ACA. Probe Name Ag5721
Table ACB. CNS_neurodegeneration_vl.O
Table ACC. General_screening_panel_vl.5
Table ACD. Panel 4.1D
CNS_neurodegeneration_vl.O Summary: Ag5721 This panel confirms the expression of this gene at moderate levels in the brain in an independent group of individuals. This gene is found to be upregulated in the temporal cortex of Alzheimer's disease patients. This gene encodes a putative kinesin* a microtubule-based motor protein involved in the transport of
organelles. Axonal transport of APP in neurons is mediated by binding with kinesin. (Gunewardena S, Neuron 2001 Nov 8;32(3):389-401). Kamal et al. suggest that impaired APP transport leads to enhanced axonal generation and deposition of Abeta, resulting in disruption of neurotrophic signaling and neurodegeneration (Nature 2001 Dec 6;414(6864):643-8). Thus, therapeutic modulation of the expression or function ofthis gene may be useful in the treatment of neurodegenerative disorders, and specifically may decrease neuronal death and be of use in the treatment of Alzheimer's disease.
General screening panel vl.5 Summary: Ag5721 Highest expression ofthis gene is seen in the fetal lung (CT=27.5). In addition, this gene is expressed at much higher levels in fetal lung tissue when compared to expression in the adult counterpart (CT=31). Thus, expression ofthis gene may be used to differentiate between the fetal and adult source of this tissue. In addition, therapeutic modulation of the expression or function ofthis gene may be useful in the tieatment of diseases that affect the lung, including lung cancer.
Moderate to low levels of expression are seen in all regions of the CNS examined. Please see CNS_neurodegeneration_y 1.0 for discussion of utility of this gene in CNS disorders.
Moderate to low levels of expression are also seen in pancreas, thyroid, fetal skeletal muscle, adipose and adult and fetal liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression ofthis gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
Low but significant levels of expression are seen in many of the cancer cell lines on this panel. Interestingly, expression appears to be overexpressed in the normal tissue samples when compared to expression in the cell lines. Thus, modulation of the expression or function of this gene may be useful in the treatment of cancer.
Panel 4.1D Summary: Ag5721 Highest expression ofthis gene is seen in TNF-alpha treated dermal fibroblasts (CT=30.2). Moderate levels of expresison are also seen in resting NK cells. Low but significant levels of expression are seen in activated T cells, endothelial cells and lung and dermal fibroblasts. Thus, expression ofthis gene could be used as a marker of activated dermal fibroblasts and modulation of the gene product may be useful in the treatment of psoriasis.
AD. CG157629-01: SERINE/THREONINE PROTEIN PHOSPHATASE WITH EF-HANDS-1.
Expression of gene CGI 57629-01 was assessed using the primer-probe set Ag5447, described in Table ADA. Please note that CG157629-01 represents a full-length physical clone.
Table ADA. Probe Name Ag5447
AI_comprehensive panel_vl.O Summary: Ag5447 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
General screening panel yl.5 Summary: Ag5447 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 4.1D Summary: Ag5447 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
AE. CG157704-01: kinesin 24.
Expression of gene CGI 57704-01 was assessed using the primer-probe set Ag5734, described in Table AEA. Results of the RTQ-PCR runs are shown in Tables AEB, AEC and AED.
Table AEA. Probe Name Ag5734
Table AEB. CNS_neurodegeneration_vl.O
Table AEC. General_screening_panel_ l.5
Table AED. Panel 4. ID
CNS_neurodegeneration_vl.O Summary: Ag5734 This panel does not show differential expression of this gene in Alzheimer's disease. However, this profile confirms the expression ofthis gene at moderate levels in the brain. Please see Panel 1.5 for discussion of utility ofthis gene in the central nervous system.
General_screening panel_vl.5 Summary: Ag5734 Highest expression ofthis gene is seen in a gastric cancer cell line (CT=29). This gene is widely expressed in this panel, with moderate expression seen in brain, colon, gastric, lung, breast, pancreatic, renal, ovarian, and melanoma cancer cell lines. This expression profile with prominent cell line expression suggests a role for this gene product in cell survival and proliferation. Modulation ofthis gene product may be useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at low but significant levels in pituitary, skeletal muscle, adrenal gland, pancreas, thyroid, fetal liver, and adult and fetal liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated
expression ofthis gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at low but significant levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 4.1D Summary: Ag5734 Highest expression is seen in TNF-a treated dermal fibroblasts. Low but significant expression is sene in activated T cells, resting NK cells, eosinophils, activated B cells, HUVECs, basophils and NCI-H292 goblet cells. This expression suggests that this gene product may be involved in autoinflammatory processes. Thus, expression ofthis gene could be used as a marker of activated dermal fibroblasts. Modulation of the expression or function ofthis gene may be useful in the treatment of RA, OA, lupus, asthma, allergy, emphysema, and psoriasis.
AF. CG158218-01: kinesin 6.
Expression of gene CG158218-01 was assessed using the primer-probe set Ag5797, described in Table AFA. Results of the RTQ-PCR runs are shown in Tables AFB and AFC.
Table AFA. Probe Name Ag5797
Table AFB. CNS_neurodegeneration_vl.O
Table AFC. General_screening_panel_vl.5
CNS_neurodegeneration_vl.0 Summary: Ag5797 This panel does not show differential expression ofthis gene in Alzheimer's disease. However, this profile confirms the expression ofthis gene at moderate levels in the brain. Please see Panel 1.5. for discussion of utility ofthis gene in the central nervous system.
General_screening_panel_vl.5 Summary: Ag5797 Highest expression ofthis gene is seen in the fetal liver. Interestingly, this gene is expressed at much higher levels in fetal (CT = 29) when compared to adult liver tissue (CT = 40). This observation suggests that expression ofthis gene can be used to distinguish fetal from adult liver. In addition, the relative overexpression ofthis gene in fetal liver suggests that the protein product may enhance liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of liver related diseases.
This gene is also expressed at low levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function ofthis gene may be useful in the treatment of neurological disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 4.1D Summary: Ag5797 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
AG. CG158583-01 and CG158583-04: SYNAPTIC VESICLE AMINE TRANSPORTER Expression of gene CG158583-01 and CG158583-04 was assessed using the primer-probe set Ag7590, described in Table AGA. Results of the RTQ-PCR runs are shown in Table AGB. Please note that CGI 58583-04 represents a full-length physical clone.
Table AGA. Probe Name Ag7590
Table AGB. Panel 5 Islet
Panel 5 Islet Summary: Ag7590 Expression ofthis gene is restricted to a sample of pancreatic islet cells (CT=34.5). Thus, expression ofthis gene could be used to differentiate between this sample and other samples on this panel and as a marker of islet cells. Furthermore, therapeutic modulation of the expression or function ofthis gene maybe useful in the treatment of diabetes.
AH. CG159084-01: Glutamate Decarboxylase like.
Expression of gene CG159084-01 was assessed using the primer-probe sets Ag5799 and Ag5799, described in Tables AHA and AHB.
Table AHA. Probe Name Ag5799
Table AHB. Probe Name Ag5799
CNS_neurodegeneration_vl.O Summary: Ag5799 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
General_screening_panel_vl.5 Summary: Ag5799 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
General_screening_panel_vl.6 Summary: Ag5799 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 4.1D Summary: Ag5799 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel 5 Islet Summary: Ag5799 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
Panel CNS_1.1 Summary: Ag5799 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
AI. CG159130-01: HYPERPOLARTZATION-ACTIVATED CYCLIC NUCLEOTΓDE-GATED CHANNEL I.
Expression of gene CG159130-01 was assessed using the primer-probe set Ag7494, described in Table AIA. Results of the RTQ-PCR runs are shown in Table AIB.
Table AIA. Probe Name Ag7494
Table AIB. CNSjneurodegeneration vl.O
CNS_neurodegeneration_vl.O Summary: Ag7494 This panel does not show differential expression ofthis gene in Alzheimer's disease. However, this profile confirms the expression ofthis gene at high to moderate levels in the brain. Therefore, therapeutic modulation of the expression or function ofthis gene may be useful in the treatment of neurological disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
AJ. CG159178-01: Carbonic anhydrase VI precursor.
Expression of gene CG159178-01 was assessed using the primer-probe set Ag4880, described in Table AJA. Results of the RTQ-PCR runs are shown in Tables AJB, AJC and AJD.
Table AJA. Probe Name Ag4880
Table AJB. General_screening_panel_vl.5
Table AJC. Panel 4.1D
Table AJD. Panel 5 Islet
General screening panel vl.5 Summary: Ag4880 Expression ofthis gene is highest in salivary gland (CT=20.3). Thus expression ofthis gene could be used to differentiate between this sample and other samples on this panel and as a marker ofthis tissue.
Panel 4.1D Summary: Ag4880 Highest expression ofthis gene is seen a sample derived from chronically activated Thl cells (CT=32.2). Low but significant expression is seen in primary activated Thl and Th2 cells, LAK cells, NK cells, eosinophils, TNF-a activated
dermal fibroblasts and thymus. This expression profile suggests that this gene product may be involved in autoimmune disease.
Panel 5 Islet Summary: Ag4880 Expression ofthis gene is limited to the small intestine (CT=23.7). Thus expression ofthis gene could be used to differentiate between this sample and other samples on this panel and as a marker ofthis tissue.
AK. CG160131-01: GLYCEROL KINASE.
Expression of gene CG160131-01 was assessed using the primer-probe set Ag5581, described in Table AKA. Results of the RTQ-PCR runs are shown in Tables AKB, AKC, AKD, AKE, AKF, AKG and AKH.
Table AKA. Probe Name Ag5581
Table AKB. Al comprehensive panel_vl.O
Table AKC. General_screening_panel_vl.5
Table AKD. General_screenin^_panel_vl.6
Table AKE. Panel 4. ID
Table AKF. Panel 5 Islet
Table AKG. Panel 5D
Table AKH. general oncology screening panel_y_2.4
AI_comprehensive panel_vl.O Summary: Ag5581 Two experiments with the same probe and primer set show detectable expression ofthis gene limited to a sample of normal tissue adjacent to ulcerative colitis (CTs=33.5-34.5) and a sample derived from RA synovial fluid.
General_screening_panel_vl.5 Summary: Ag5581 Highest expression is seen in fetal liver (CT=30.6). In addition, this gene is expressed at much higher levels in fetal liver tissue when compared to expression in the adult counterpart (CT=34). Thus, expression of this gene may be used to differentiate between the fetal and adult source of his tissue.
General_screening_panel_vl.6 Summary: Ag5581 Highest expression is seen in fetal liver (CT=30.3). Overall, expression is in agreement with Panel 1.5. Please see that panel for further discussion of expression and utility ofthis gene.
Panel 4.1D Summary: Ag5581 Highest expression is seen in LPS treated monocytes (CT=27.4). Moderate levels of expression are seen in TFN-aLPS treated neutropils and PMA/ionomycin treated LAKs. Low but significant levels of expression are seen in macrophages. Upon activation with pathogens such as LPS, monocytes contribute to the innate and specific immunity by migrating to the site of tissue injury and releasing inflammatory cytokines. This release contributes to the inflammation process. Therefore expression ofthis gene could be used as a marker of activated monocytes. Furthermore,
modulation of the expression of the protein encoded by this transcript may prevent the recruitment of monocytes and the initiation of the inflammatory process, and reduce the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, or rheumatoid arthritis.
Panel 5 Islet Summary: Ag5581 Two experiments with the same probe and primer set show detectable expression ofthis gene limited to a liver cancer cell line sample (CTs=33.5-34.5). This expression is in agreement with expression seen in Panels 1.5 and 1.6.
Panel 5D Summary: Ag5581 Expression ofthis gene limited to a liver cancer cell line sample (CT=34). This expression is in agreement with expression seen in Panels 1.5 and 1.6.
General oncology screening panel_v_2.4 Summary: Ag5581 Highest expression is seen in a kidney sample (CT=32). In addition, this gene is more highly expressed in lung and colon cancer than in the corresponding normal adjacent tissue. Thus, expression ofthis gene could be used as a marker of these cancers. Furthemore, therapeutic modulation of the expression or function ofthis gene product may be useful in the treatment of lung and colon cancer.
AL. CG160131-04: FL_1_552 GLYCEROL KINASE. Expression of gene CG 160131 -04 was assessed using the primer-probe set Ag7439, described in Table ALA. Results of the RTQ-PCR runs are shown in Tables ALB and ALC. Please note that CG160131-04 represents a full-length physical clone.
Table ALA. Probe Name Ag7439
Table ALB. Al comprehensive panel vl.O
Table ALC. Panel 4. ID
AI_comprehensive panel_vl.O Summary: Ag7439 Highest expression is seen in normal tissue adjacent to psoriasis (CT=29.8). In addition, moderate to low levels of expression are seen in many samples on this panel. Thus, this gene product may be involved in autoimmune disease.
CNS_neurodegeneration_vl.O Summary: Ag7439 Results from one experiment with this gene are not included. The amp plot indicates that there were experimental difficulties with this run.
Panel 4.1D Summary: Ag7439 Highest expression is seen in a sample of IFN gama lung derived fibroblasts (CT=29). Low but significant levels of expression are also seen in clusters of samples derived from lung and dermal fibroblasts. Thus, this gene product may be involved in inflammatory processes of the lung and skin, including psoriasis, asthma, emphysema, and allergy.
Panel 5 Islet Summary: Ag7439 Expression ofthis gene is low/undetectable in all samples on this panel (CTs>35). (Data not shown.)
AM. CG166282-01: CHKl-variant.
Expression of gene CG166282-01 was assessed using the primer-probe set Ag5448, described in Table AMA. Results of the RTQ-PCR runs are shown in Tables AMB, AMC and AMD.
Table AMA. Probe Name Ag5448
Table AMB. General_screening_panel_vl.5
Table AMC. Panel 4.1D
Table AMD, general oncology screening panel_v_2.4
AI_comprehensive panel_vl.O Summary: Ag5448 The amp plot indicates that there were experimental difficulties with this run; therefore, no conclusions can be drawn from this data. (Data not shown).
General_screening_panel_vl.5 Summary: Ag5448 Two experiments with same probe- primer sets are in excellent agreement, with highest expression ofthis gene detected in gastric cancer KATO III cell line (CTs=30-33). Moderate to low levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression ofthis gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function ofthis gene maybe effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Oncology_cell_line_screening_panel_v3.2 Summary: Ag5448 The amp plot indicates that there were experimental difficulties with this run; therefore, no conclusions can be drawn from this data. (Data not shown).
Panel 4.1D Summary: Ag5448 Highest expression ofthis gene is detected in activated secondary Th2 cells (CT=33). Low expression ofthis gene is detected in activated polarized T cells, resting IL-2 treated NK cells, activated Ramos B cells and B lymphocytes, eosinophils, activated HUVEC cells and NCI-H292 cells, basophils and TNF alpha stimulated dermal fibroblasts. Therefore, therapeutic modulation ofthis gene product may ameliorate symptoms/conditions associated with autoimmune and inflammatory disorders including psoriasis, allergy, asthma, inflammatory bowel disease, rheumatoid arthritis and osteoarthritis.
General oncology screening panel_v_2.4 Summary: Ag5448 Highest expression ofthis gene malignant colon cancer (CT=34.4). Higher expression ofthis gene is associated with the colon cancer as compared to adjacent contiol tissue. Therefore, expression ofthis gene may be used as diagnostic marker to detect colon cancer and also, therapeutic modulation ofthis gene or its protein product may be useful in the treatement of colon cancer.
AN. CG170739-01: PENDRIN.
Expression of gene CG170739-01 was assessed using the primer-probe set Ag6134, described in Table ANA.
Table ANA. Probe Name Ag6134
AI_comprehensive panel_vl.O Summary: Ag6134 Expression ofthis gene is low/undetectable (CTs > 35) across all of the samples on this panel (data not shown). The amp plot indicates that there is a high probability of a probe failure.
General_screening_panel_vl.5 Summary: Ag6134 Expression ofthis gene is low/undetectable (CTs > 35) across all of the samples on this panel (data not shown). The amp plot indicates that there is a high probability of a probe failure.
Panel 4.1D Summary: Ag6134 Expression ofthis gene is low/undetectable (CTs > 35) across all of the samples on this panel (data not shown). The amp plot indicates that there is a high probability of a probe failure.
AO. CG51213-07: CG51213-(13-364).
Expression of gene CG51213-07 was assessed using the primer-probe sets Agl425, Ag813, Ag871 and Ag924, described in Tables AOA, AOB, AOC and AOD. Results of the RTQ- PCR runs are shown in Tables AOE, AOF, AOG, AOH, AOI, AOJ and AOK.
Table AOA. Probe Name Agl425
Table AOB. Probe Name Ag813
Table AOC. Probe Name Ag871
Table AOD. Probe Name Ag924
Table AOE. AI_comprehensive panel_vl .0
Table AOF. CNS_neurodegeneration_vl.O
Table AOG. General_screening_panel_vl.5
Table AOH. Panel 1.2
Table AOL Panel 4. ID
Table AO J. Panel 5 Islet
Table AOK. Panel CNS 1
AI_comprehensive panel_vl.O Summary: Ag813 Two experiments with same probe- primer sets are in excellent agreement. Highest expression ofthis gene is detected in orthoarthritis bone (CTs=29-30.6). In addition significant expression ofthis gene is detected in samples derived from orthoarthitis bone, cartilage, synovium and synovial fluid samples, from normal lung, COPD lung, emphysema, atopic asthma, asthma, allergy, Crohn's disease (normal matched contiol and diseased), ulcerative colitis(normal matched control and diseased), and psoriasis (normal matched contiol and diseased). Interestingly, expression ofthis gene in normal and rheumatoid arthritis bone, synovium and synovial fluid is very low or undectectable. Therefore, therapeutic modulation ofthis gene product may ameliorate symptoms/conditions associated with autoimmune and inflammatory disorders including psoriasis, allergy, asthma, inflammatory bowel disease, and osteoarthritis.
CNS_neurodegeneration_vl.O Summary: Ag813 This panel confirms the expression of this gene at low levels in the brains of an independent group of individuals. However, no differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1.5 for a discussion of the potential utility ofthis gene in treatment of central nervous system disorders.
General_screening_panel_vl.5 Summary: Ag813 Highest expression ofthis gene is detected in fetal brain and brain cancer SNB-75 cell line (CTs=31). In addition, moderate expression ofthis gene is seen all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. This gene codes for a variant of ADAMTS-10, a member of Matrix metalloproteinases (MMPs). MMPs are a gene family of neutral proteases that are important in noπnal development, wound healing, and a wide variety of pathological
(8 processes, including the spread of metastatic cancer cells, arthritic destruction of joints, atherosclerosis, and neuroinflammation. In the central nervous system (CNS), MMPs have been shown to degrade components of the basal lamina, leading to disruption of the blood- brain barrier (BBB), and to contribute to the neuroinflammatory response in many neurological diseases (Rosenberg GA, 2002, Glia 39(3):279-91, PMID: 12203394).
Therefore, therapeutic modulation ofthis gene product may be useful in the treatment of neurological disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple
sclerosis, schizophrenia, depression, allergic encephalomyelitis (EAE), allergic neuritis (EAN), and cerebral ischemia.
Moderate to low expression ofthis gene is also detected in tissues with metabolic/endocrine function including pancreas, adipose, adrenal gland, skeletal muscle, heart, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity ofthis gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at moderate to low levels in number of cancer cell lines derived from melanoma, ovarian, breast, lung, renal, colon and brain cancers. Therefore, therapeutic modulation ofthis gene through the use of protein therapeutics, antibodies or small molecule drug may be useful in the treatment of these cancer.
Using Curagen PathCalling technology, the ADAMTS-10 protein encoded by this gene was shown to interact with amphiregulin (AREG). AREG is shown to inhibit growth of certain human tumor cells and stimulates proliferation of human fibroblasts and other normal and tumor cells (Shoyab et al., 1988, Proc. Nat. Acad. Sci. 85: 6528-6532. PubMed ID : 3413110). Recently, AREG has been implicated in the regulation of neural stem cell proliferation and neurogenesis in the adult brain.
Panel 1.2 Summary: Ag813 Highest expression ofthis gene is detected in fetal brain (CT=27.5). In addition, moderate expression ofthis gene is all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Moderate to low expression ofthis gene is also detected in tissues with metabolic/endocrine function and number of cancer cell lines derived from melanoma, ovarian, lung, renal, colon and brain cancers. Please see panel 1.5 for further discussion on the utility ofthis gene.
Panel 4.1D Summary: Ag813 Highest expression ofthis gene is detected in IL-2 treated resting NK cells (CT=32.8). Moderate to low levels of expression ofthis gene is also detected in activated primary, polarized T cells, eosinophils, lung microvascular endothelial cells, coronery artery SMC, liver c rhosis and activated dermal fibroblasts. Therefore, therapeutic modulation ofthis gene or the protein encoded by this gene may be useful in the treatment of autoimmune and inflammatory diseases including asthma, aUergies,
inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
Results from one experiment (Run 247683477) with this gene are not included. The amp plot indicates that there were experimental difficulties with this run.
Panel 5 Islet Summary: Ag813 Highest expression of this gene is detected in differentiated adipose (CT=33.5). Low expression ofthis gene is seen mainly in adipose and small intestine. Therefore, therapeutic modulation ofthis gene or its protein product may be useful in the treatment of obesity, and diabetes, including Type II diabetes.
Panel CNS_1 Summary: Ag813 This panel confirms the expression ofthis gene at low levels in the brains of an independent group of individuals. Please see Panel 1.5 for a discussion of the potential utility of this gene in treatment of central nervous system disorders.
AP. CG56155-02: PLASMA KALLIKREIN PRECURSOR
Expression of gene CG56155-02 was assessed using the primer-probe set Agl688, described in Table APA. Results of the RTQ-PCR runs are shown in Tables APB, APC, APD, APE, APF, APG and APH.
Table APA. Probe Name Agl688
Table APB. Al comprehensive panel vl.O
Table APC. CNS_neurodegeneration_vl.O
Table APD. Panel 1.3D
Table APE. Panel 2D
Table APG. Panel 5 Islet
Table APH. general oncology screening panel_v_2.4
AI_comprehensive panel_vl.O Summary: Agl688 Highest expression ofthis gene is detected in psoriasis sample (CT=31.9). Moderate to low levels of expression ofthis gene
is also seen in samples derived from orthoarthitis/ rheumatoid arthritis bone, cartilage, synovium and synovial fluid samples, from normal lung, COPD lung, emphysema, atopic asthma, asthma, Crohn's disease (normal matched control and diseased), ulcerative colitis(normal matched control and diseased), and psoriasis (normal matched contiol and diseased). Therefore, therapeutic modulation ofthis gene product may ameliorate symptoms/conditions associated with autoimmune and inflammatory disorders including psoriasis, asthma, inflammatory bowel disease, rheumatoid arthritis and osteoarthritis.
CNS_neurodegeneration_vl.0 Summary: Agl688 This panel confirms the expression of this gene at low levels in the brains of an independent group of individuals. However, no differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1.3D for a discussion of the potential utility ofthis gene in treatment of central nervous system disorders.
Panel 1.3D Summary: Agl688 Expression ofthis gene, a plasma kallikrein, is significantly higher in liver (CTs=28) than in any other sample on this panel. Thus, expression ofthis gene could be used as a marker of liver tissue. In addition, low levels of expression ofthis gene is also detected in tissues with metabolic/endocrine functions including pancreas, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, and the gastrointestinal tract. Plasma prekallikrein is a glycoprotein that participates in the surface- dependent activation of blood coagulation, fibrinolysis, kinin generation and inflammation. It is synthesized in the liver and secreted into the blood as a single polypeptide chain. It is converted to plasma kallikrein by factor Xlla. Recently, plasma kallikrein has been implicated in adipose differentiation by remodeling of the fibronectin-rich ECM of preadipocytes. Pig -/- mice show a reduction of fat deposit (Ref. 1, 2). At Curagen, it was found that plasma kallikrein significantly down-regulated in the liver of mice with 'lean' phenotype. Thus, based on Curagen GeneCalling data it is hypothesized that plasma kallikrein might cause disruption of adipose differentiation thus leading to obesity if over expressed and to a leaner phenotype if expression is below normal. Therefore, an antagonist to this gene product in the form of small molecule or antibody may be beneficial in the treatment of obesity.
Moderate to low levels of expression ofthis gene is also seen levels in some of the regions of central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebral cortex, and spinal cord. Therefore, therapeutic modulation ofthis gene product may be useful in the tieatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
References:
1. Hoover-Plow J, Yuen L. Plasminogen binding is increased with adipocyte differentiation. Biochem.Biophys.Res.Commun. (2001) 284, 389-394. PMID: 11394891.
2. Selvarajan S, Lund LR, Takeuchi T, Craik CS, Werb Z.A plasma kallikrein-dependent plasminogen cascade required for adipocyte differentiation. Nature Cell Biol. (2001) 3, 267-275. PMID: 11231576
Panel 2D Summary: Agl688 The expression of the CG56155-01 gene appears to be highest in a sample derived from a sample of normal liver tissue adjacent to a metastatic colon cancer CT=26.2). In addition, there is substantial expression in other samples of normal liver, and to a much lesser degree, malignant liver tissue. This liver specific expression is consistent with the expression seen in Panel 1.3D. Thus, the expression ofthis gene could be used to distinguish liver derived tissue from the toher samples in the panel, and more specifically the expression ofthis gene could be used to distinguish normal liver from malignant liver tissue. Moreover, therapeutic modulation ofthis gene, through the use of small molecule drugs, protein therapeutics or antibodies might be of benefit in the treatment of liver cancer.
Panel 4.1D Summary: Agl688 Highest expression ofthis gene is detected in liver cirrhosis (CT=31.8). In addition, moderate to low levels of expression ofthis gene in IL-2 treated NK cells, CD40L and IL-4 treated B lymphocytes and normal kidney. Therefore, therapeutic modulation of the protein encoded for by this gene may be useful in the treatment of inflammatory or autoimmune diseases which effect the liver and kidney including liver cirrhosis and fibrosis, lupus erythematosus and glomerulonephritis.
Panel 5 Islet Summary: Agl688 Expression of the CG56155-01 gene is limited to pancreatic islets and small intestines. Please see Panel 1.3 for discussion of utility ofthis gene in metabolic disease.
General oncology screening panel_v_2.4 Summary: Agl688 Highest expression ofthis gene is detected in kidney cancer (CT=28.4). Higher expression ofthis gene is associated with cancer compared to normal kidney. Therefore, expression ofthis gene may be used as diagnostic marker for kidney cancer and therapeutic modulation ofthis gene or protein encoded by this gene may through the use of antibodies or small molecule drug may be useful in the treatment of kidney cancer.
AQ. CG59595-01: Ribonuclease 6 precursor.
Expression of gene CG59595-01 was assessed using the primer-probe set Ag3488, described in Table AQA. Results of the RTQ-PCR runs are shown in Tables AQB, AQC, AQD, AQE, AQF and AQG.
Table AOA. Probe Name Ag3488
Table AOB. CNS_neurodegeneration_vl.0
Table AOC. General_screening_panel_vl.4
Table AOD. Panel 2.2
Table AOE. Panel 3D
Table AOF. Panel 4D
Table AOG. general oncology screening panel_v_2.4
CNS_neurodegeneration_vl.O Summary: Ag3488 This panel does not show differential expression ofthis gene in Alzheimer's disease. However, this profile confirms the expression ofthis gene at moderate levels in the brain. Please see Panel 1.4 for discussion of utility ofthis gene in the central nervous system.
General_screeningj>anel_vl.4 Summary: Ag3488 Highest expression ofthis gene is seen in a renal cancer cell line (CT=23.2). This gene is widely expressed in this panel, with high to moderate levels of expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation ofthis gene product maybe useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at high to moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression ofthis gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function ofthis gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 2.2 Summary: Ag3488 Highest expression is seen in a kidney cancer (CT=28). In addition, this gene is more highly expressed in kidney cancer than in the coπesponding noπnal adjacent tissue. Thus, expression ofthis gene could be used as a marker ofthis cancer. Furthemore, therapeutic modulation of the expression or function ofthis gene product may be useful in the tieatment of kidney cancer.
Panel 3D Summary: Ag3488 Highest expression is seen in a pancreatic cancer cell line (CT=29.6). Moderate levels of expression are also seen in many cancer cell lines on this panel. Please see Panel 1.4 for discussion of utility ofthis gene in cancer.
Panel 4D Summary: Ag3488 Highest expression is seen in resting monocytes (CT=25.3). This gene is also expressed at moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_vl.4 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory
diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
General oncology screening panel_v_2.4 Summary: Ag3488 Highest expression is seen in kidney cancer (CT=23.2). In addition, this gene is more highly expressed in colon and kidney cancer than in the corresponding normal adjacent tissue. Thus, expression of this gene could be used as a marker of these cancers. Furthemore, therapeutic modulation of the expression or function ofthis gene product may be useful in the treatment of colon and kidney cancer.
AR. CG92142-01: GLYCEROL-3-PHOSPHATE ACYLTRANSFERASE. Expression of gene CG92142-01 was assessed using the primer-probe set Ag3774, described in Table ARA. Results of the RTQ-PCR runs are shown in Tables ARB, ARC, ARD, ARE and ARF.
Table ARA. Probe Name Ag3774
Table ARB. CNS_neurodegeneration_vl.0
Table ARC. General_screening_panel_vl.4
Table ARP. Panel 2.2
Table ARE. Panel 4. ID
Table ARF. Panel 5D
CNS_neurodegeneration_vl.O Summary: Ag3774 This panel confirms the expression of the CG92142-01 gene at low levels in the brains of an independent group of individuals. However, no differential expression ofthis gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1.4 for a discussion of the potential utility ofthis gene in treatment of centeal nervous system disorders.
General_screeningjpanel_vl.4 Summary: Ag3774 Highest expression of the CG92142- 01 gene is detected in CNS cancer (glio) SF-295 cell line (CT=26). High expression ofthis gene is also in number of cancer cell lines (pancreatic, CNS, colon, gastric, renal, lung, breast, ovarian, squamous cell carcinoma, prostate and melanoma). Therefore, therapeutic modulation of the activity of this gene or its protein product, through the use of small molecule drugs might be beneficial in the treatment of these cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high to moderate levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity ofthis gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
The CG92142-01 gene codes for mitochondrial glycerol-3 -phosphate acyltransferase (GPAT). GPAT is an adipocyte determination and differentiation factor 1 (ADDl) and sterol regulatory element-binding protein- 1 (SREBP-1) regulated differentiation gene (Ref.l). It is up-regulated by insulin and high-carbohydrate diets (Ref.2). GPAT up- regulation increases triglyceride (TG) synthesis and fat deposition. Inhibition of GPAT activiy could lead to decreased TG synthesis and fat deposition. Troglitazone, a thiazolidinedione compound used to treat non-insulin-dependent diabetes mellitus (NIDDM), was shown to decreases GPAT activity and adipogenesis in ZDF rat islets (ref.3). Therefore, therapeutic modulation of the activity ofthis gene may prove useful in the tieatment of diabetes.
In addition, this gene is expressed at moderate levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, this gene may play a role in centeal nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
References.
1. Ericsson J, Jackson SM, Kim JB, Spiegelman BM, Edwards PA. (1997) Identification of glycerol-3-phosphate acyltransferase as an adipocyte determination and differentiation factor 1- and sterol regulatory element-binding protein-responsive gene. J Biol Chem 272(11):7298-305. PMID: 9054427
2. Dircks LK, SulHS. (1997) Mammalian mitochondrial glycerol-3-phosphate acyltransferase. Biochim Biophys Acta 1348(l-2):17-26 PMID: 9370312
3. Shimabukuro M, Zhou YT, Lee Y, Unger RH. (1998) Troglitazone lowers islet fat and restores beta cell function of Zucker diabetic fatty rats. J Biol Chem 273(6):3547-50 PMID: 9452481.
Panel 2.2 Summary: Ag3774 Highest expression of the CG92142-01 gene is detected in 5 liver cancer 1025 sample (CT=28.7). In addition, low to moderate expression ofthis gene is seen in number of cancer and normal samples used in this panel. Please see Panel 1.4 for a discussion of the potential utility ofthis gene.
Panel 4.1D Summary: Ag3774 Highest expression of the CG92142-01 gene is detected in resting dermal fibroblast CCD1070 (CT=31). This gene is expressed at low to moderate
10. levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product
15 may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_vl .4 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of 0 patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
Interestingly, expression ofthis gene is stimulated in PWM treated PBMC cells (CT=32.5) as compared to resting PBMC (35.6). Therefore, expression ofthis gene can be used to 5 distinguish between resting and stimulated PBMC cells.
Panel 5D Summary: Ag3774 Highest expression of the CG92142-01 gene is detected in 94733_Donor 3 AD-A_adipose sample(CT=27.6). In addition, high to moderated expression ofthis gene is also seen in number of adipose, small intestine, uterus, skeletal muscle, placenta and mesenchymal stem cell samples. Please see Panel 1.4 for a discussion 0 of the potential utility of this gene.
AS. CG98102-03: Diamine AcetylTransferase.
Expression of gene CG98102-03 was assessed using the primer-probe sets Ag4695, Ag4700, Ag4705 and Ag5877, described in Tables ASA, ASB, ASC and ASD. Results of the RTQ-PCR runs are shown in Tables ASE, ASF and ASG.
Table ASA. Probe Name Ag4695
Table ASB. Probe Name Ag4700
Table ASC. Probe Name Ag4705
Table ASP. Probe Name Ag5877
Table ASE. General_screening_panel_vl.4
Table ASF. General_screening_panel_vl.5
Table ASG. Panel 5D
General_screening_panel_vl.4 Summary: Ag4695/Ag4700/Ag4705 Three experiments using three probe-primer sets gave results that are in good agreement. This gene is expressed at moderate to high levels in all of the tissues on this panel, with highest expression in bladder and a lung cancer cell line (CTs=24-28). Interestingly, expression of this gene is higher in fetal lung and lung cancer cell lines when compared to adult lung. Expression ofthis gene is also upregulated in colon cancer cell lines when compared to normal colon. Therefore, therapeutic modulation of the activity ofthis gene or its protein product, through the use of small molecule drugs, protein therapeutics or antibodies, might be beneficial in the treatment of lung and colon cancer.
In addition, this gene is expressed at moderate levels in all regions of the centeal nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, this gene may play a role in centeal nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Among tissues with metabolic or endocrine function, this gene is expressed at high to moderate levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity ofthis gene may prove useful in the tieatment of endocrine/metabolically related diseases, such as obesity and diabetes.
General_screening_panel_vl.5 Summary: Ag5877 Expression ofthis gene is highest in bladder (CT = 23.6). This gene is expressed at moderate to high levels in all of the tissues on this panel, consistent with what is observed in Panel 1.4. Interestingly, expression ofthis gene is higher in fetal lung (CT = 23.7)and a subset of lung cancer cell lines (CTs = 24) when compared to adult lung (CT = 28.2). Expression ofthis gene is also upregulated in colon cancer cell lines (CTs = 24) when compared to normal colon (CT =.27.2). Therefore, therapeutic modulation of the activity ofthis gene or its protein product, through the use of smaU molecule drugs, protein therapeutics or antibodies, might be beneficial in the treatment of lung and colon cancer. Please see Panel 1.4 for additional discussion of the potential relevance ofthis gene in human disease.
Panel 5D Summary: Ag4695/Ag4705 Three experiments using two probe-primer sets gave results that are in good agreement. This gene is expressed at moderate to high levels
in the majority of metabolic tissues on this panel, with highest expression in a placenta sample from a diabetic patient (CTs =.23-28). Ag4700 Two experiment with same probe- primer sets are in excellent agreement. This gene shows widespread expression with highest expression ofthis gene in placenta of non-diabetic patient (CTs=30-30.7).
Spermine has been demonstrated to enhance insulin receptor binding in a dose dependent manner [Pedersen et al., Mol Cell Endocrinol., 1989 Apr;62(2):161-6]. Thus, it was proposed that polyamines may act as intracellular or intercellular (autocrine) regulators to modulate insulin binding. It has also been shown that the insulin-like effects elicited by polyamines in fat cells (e.g. enhancement of glucose transport and inhibition of cAMP- mediated lipolysis) are dependent on H2O2 production (Livingston et al., J. Biol. Chem., 1977 Jan 25;252(2):560-2). Inhibiting polyamine catabolism through an inhibitor ofthis rate-limiting enzyme may abolish the insulin-like antilipolytic effects of polyamines. Therefore, therapeutic inhibition of the activity ofthis gene using small molecule drugs may be of benefit in the treatment of obesity.
Example D: Identification of Single Nucleotide Polymorphisms in NOVX nucleic acid sequences
Variant sequences are also included in this application. A variant sequence can include a single nucleotide polymorphism (SNP). A SNP can, in some instances, be refeπed to as a "cSNP" to denote that the nucleotide sequence containing the SNP originates as a cDNA. A SNP can arise in several ways. For example, a SNP may be due to a substitution of one nucleotide for another at the polymoφhic site. Such a substitution can be either a transition or a tiansversion. A SNP can also arise from a deletion of a nucleotide or an insertion of a nucleotide, relative to a reference allele. In this case, the polymorphic site is a site at which one allele bears a gap with respect to a particular nucleotide in another allele. SNPs occurring within genes may result in an alteration of the amino acid encoded by the gene at the position of the SNP. Intiagenic SNPs may also be silent, when a codon including a SNP encodes the same amino acid as a result of the redundancy of the genetic code. SNPs occurring outside the region of a gene, or in an intron within a gene, do not result in changes in any amino acid sequence of a protein but may result in altered regulation of the expression pattern. Examples include alteration in temporal expression, physiological response regulation, cell type expression regulation, intensity of expression, and stability of transcribed message.
SeqCalling assemblies produced by the exon linking process were selected and extended using the following criteria. Genomic clones having regions with 98% identity to all or part of the initial or extended sequence were identified by BLASTN searches using the relevant sequence to query human genomic databases. The genomic clones that resulted were selected for further analysis because this identity indicates that these clones contain the genomic locus for these SeqCalling assemblies. These sequences were analyzed for putative coding regions as well as for similarity to the known DNA and protein sequences. Programs used for these analyses include Grail, Genscan, BLAST, HMMER, FASTA, Hybrid and other relevant programs. Some additional genomic regions may have also been identified because selected
SeqCalling assemblies map to those regions. Such SeqCalling sequences may have overlapped with regions defined by homology or exon prediction. They may also be included because the location of the fragment was in the vicinity of genomic regions identified by similarity or exon prediction that had been included in the original predicted sequence. The sequence so identified was manually assembled and then may have been extended using one or more additional sequences taken from CuraGen Corporation's human SeqCalling database. SeqCalling fragments suitable for inclusion were identified by the CuraTools™ program SeqExtend or by identifying SeqCalling fragments mapping to the appropriate regions of the genomic clones analyzed. The regions defined by the procedures described above were then manually integrated and coπected for apparent inconsistencies that may have arisen, for example, from miscalled bases in the original fragments or from discrepancies between predicted exon junctions, EST locations and regions of sequence similarity, to derive the final sequence disclosed herein. When necessary, the process to identify and analyze SeqCalling assemblies and genomic clones was reiterated to derive the full length sequence (Alderborn et al., Determination of Single Nucleotide Polymoφhisms by Real-time Pyrophosphate DNA Sequencing. Genome Research. 10 (8) 1249-1265, 2000).
Variants are reported individually but any combination of all or a select subset of variants are also included as contemplated NOVX embodiments of the invention.
RESULTS:
NOV 3b SNP Data
Two polymoφhic variants of NOV3b have been identified and are shown in
Table 3S.
NOV 5b SNP Data
One polymoφhic variant of NOV5b has been identified and are shown in Table 5S.
NOV 8a SNP Data
Four polymoφhic variants of NOV8a have been identified and are shown in
Table 8S.
Four polymoφhic variants of NOV9a have been identified and are shown in
Table 9S.
NOV 10a SNP Data
One polymoφhic variant of NOVlOa has been identified and are shown in
Table 10S.
NOV 12a SNP Data
Two polymoφhic variants of NOV12a have been identified and are shown in
Table 12S.
Thirteen polymoφhic variants of NOVl 3a have been identified and are shown in
Table 13S.
NOV 14a SNP Data
One polymoφhic variant of NOVl 4a has been identified and are shown in
Table 14S.
NOV 19 SNP Data
One polymoφhic variant of NOVl 9 has been identified and are shown in
NOV 20c SNP Data
One polymoφhic variant of NOV20c has been identified and are shown in
Table 20S.
NOV 48a SNP Data
One polymoφhic variant of NOV48a has been identified and are shown in
Table 48S.
NOV 50a SNP Data
Two polymoφhic variants of NOV50a have been identified and are shown in
Table 50S.
NOV 53b SNP Data
Six polymoφhic variants of NOV53b have been identified and are shown in
Table 53S.
NOV 54b SNP Data
Two polymoφhic variants of NOV54b have been identified and are shown in
Table 54S.
NOV 55a SNP Data
One polymoφhic variant of NO V55a has been identified and are shown in Table 55S.
Table 55S
Nucleotides Amino Acids
Variant
No. Base Position of Base Position of
Wild-type Variant Wild-type Variant
NOV 56a SNP Data
Six polymoφhic variant of NOV56a has been identified and are shown in Table 56S.
NOV 57b SNP Data
Two polymoφhic variants of NOV57b have been identified and are shown in
Table 57S.
NOV 58a SNP Data
Two polymoφhic variant of NOV58a has been identified and are shown in Table 58S.
Table 58S
Variant Nucleotides Amino Acids
NOV 59b SNP Data
Three polymoφhic variant of NOV59b has been identified and are shown in
Table 59S.
Example E. Method of Use
The present invention is partially based on the identification of biological macromolecules differentially modulated in a pathologic state, disease, or an abnormal condition or state, and/or based on novel associations of proteins and polypeptides and the nucleic acids that encode them, as identified in a yeast 2-hybrid screen using a cDNA library or one-by-one matrix reactions. Among the pathologies or diseases of present interest include metabolic diseases including those related to endocrinologic disorders, cancers, various tumors and neoplasias, inflammatory disorders, centeal nervous system disorders, and similar abnormal conditions or states. Important metabolic disorders with which the biological macromolecules are associated include obesity and diabetes mellitus, especially obesity and Type II diabetes. It is believed that obesity predisposes a subject to Type II diabetes. In very significant embodiments of the present invention, the biological macromolecules implicated in these pathologies and conditions are proteins and polypeptides, and in such cases the present invention is related as well to the nucleic acids that encode them. Methods that may be employed to identify relevant biological macromolecules include any procedures that detect differential expression of nucleic acids encoding proteins and polypeptides associated with the disorder, as well as procedures that detect the respective proteins and polypeptides themselves. Significant methods that have been employed by the present inventors, include GeneCalling ® technology and SeqCalling TM technology, disclosed respectively, in U. S. Patent No. 5,871,697, and in U. S. Ser. No. 09/417,386, filed Oct. 13, 1999, each of which is incoφorated herein by reference in its entirety. GeneCalling® is also described in Shimkets, et al, Nature Biotechnology 17:198- 803 (1999).
The invention provides polypeptides and nucleotides encoded thereby that have been identified as having novel associations with a disease or pathology, or an abnormal state or condition, in a mammal. Included in the invention are nucleic acid sequences and their encoded polypeptides. The sequences are collectively referred to as "obesity and/or diabetes nucleic acids" or "obesity and/or diabetes polynucleotides" and the coπesponding encoded polypeptide is referred to as an "obesity and/or diabetes polypeptide" or "obesity and/or diabetes protein". For example, an obesity and/or diabetes nucleic acid according to the invention is a nucleic acid including an obesity and/or diabetes nucleic acid, and an obesity and/or diabetes polypeptide according to the invention is a polypeptide that includes the amino acid sequence of an obesity and/or diabetes polypeptide. Unless
indicated otherwise, "obesity and/or diabetes" is meant to refer to any of the sequences having novel associations disclosed herein.
The present invention identifies a set of proteins and polypeptides, including naturally occurring polypeptides, precursor forms or proproteins, or mature forms of the polypeptides or proteins, which are implicated as targets for therapeutic agents in the treatment of various diseases, pathologies, abnormal states and conditions. A target may be employed in any of a variety of screening methodologies in order to identify candidate therapeutic agents which interact with the target and in so doing exert a desired or favorable effect. The candidate therapeutic agent is identified by screening a large collection of substances or compounds in an important embodiment of the invention. Such a collection may comprise a combinatorial library of substances or compounds in which, in at least one subset of substances or compounds, the individual members are related to each other by simple structural variations based on a particular canonical or basic chemical structure. The variations may include, by way of nonlimiting example, changes in length or identity of a basic framework of bonded atoms; changes in number, composition and disposition of ringed structures, bridge structures, alicyclic rings, and aromatic rings; and changes in pendent or substituents atoms or groups that are bonded at particular positions to the basic framework of bonded atoms or to the ringed structures, the bridge structures, the alicyclic structures, or the aromatic structures. The present invention discloses novel associations of proteins and polypeptides and the nucleic acids that encode them, as identified in a yeast 2-hybrid screen using a cDNA library or one-by-one matrix reactions. The proteins and related proteins that are similar to them are encoded by a cDNA and/or by genomic DNA and were identified in some cases by CuraGen Coφoration. In the cuπent invention, protein interactions may include the interaction of a protein fragment with full-length protein, a protein fragment with another protein fragment, or full- length proteins with each other. The protein interactions disclosed in the present invention may also represent significant discoveries of functional importance to specific diseases or pathological conditions in which novel proteins are found to be components of known pathways, known proteins are found to be components of novel pathways, or novel proteins are found to be components of novel pathways.
A polypeptide or protein described herein, and that serves as a target in. the screening procedure, includes the product of a naturally occurring polypeptide or precursor
form or proprotein. The naturally occurring polypeptide, precursor or proprotein includes, e.g., the full-length gene product, encoded by the coπesponding gene. The naturally occurring polypeptide also includes the polypeptide, precursor or proprotein encoded by an open reading frame described herein. A "mature" form of a polypeptide or protein arises as a result of one or more naturally occurring processing steps as they may occur within the cell, including a host cell. The processing steps occur as the gene product arises, e.g., via cleavage of the amino-terminal methionine residue encoded by the initiation codon of an open reading frame, or the proteolytic cleavage of a signal peptide or leader sequence. Thus, a mature form arising from a precursor polypeptide or protein that has residues 1 to N, where residue 1 is the N-terminal methionine, would have residues 2 through N remaining. Alternatively, a mature form arising from a precursor polypeptide or protein having residues 1 to N, in which an amino-terminal signal sequence from residue 1 to residue M is cleaved, includes the residues from residue M+l to residue N remaining. A "mature" form of a polypeptide or protein may also arise from non-proteolytic post- teanslational modification. Such non-proteolytic processes include, e.g., glycosylation, myristylation or phosphorylation. In general, a mature polypeptide or protein may result from the operation of only one of these processes, or the combination of any of them.
As used herein, "identical" residues coπespond to those residues in a comparison between two sequences where the equivalent nucleotide base or amino acid residue in an alignment of two sequences is the same residue. Residues are alternatively described as
"similar" or "positive" when the comparisons between two sequences in an alignment show that residues in an equivalent position in a comparison are either the same amino acid or a conserved amino acid as defined below.
As used herein, a "chemical composition" relates to a composition including at least one compound that is either synthesized or extracted from a natural source. A chemical compound may be the product of a defined synthetic procedure. Such a synthesized compound is understood herein to have defined properties in terms of molecular formula, molecular structure relating the association of bonded atoms to each other, physical properties such as electropherographic or spectioscopic characterizations, and the like. A compound extracted from a natural source is advantageously analyzed by chemical and physical methods in order to provide a representation of its defined properties, including its molecular formula, molecular structure relating the association of bonded atoms to each
other, physical properties such as electropherographic or specteoscopic characterizations, and the like.
As used herein, a "candidate therapeutic agent" is a chemical compound that includes at least one substance shown to bind to a target biopolymer. In important embodiments of the invention, the target biopolymer is a protein or polypeptide, a nucleic acid, a polysaccharide or proteoglycan, or a lipid such as a complex lipid. The method of identifying compounds that bind to the target effectively eliminates compounds with little or no binding affinity, thereby increasing the potential that the identified chemical compound may have beneficial therapeutic applications. In cases where the "candidate therapeutic agent" is a mixture of more than one chemical compound, subsequent screening procedures may be carried out to identify the particular substance in the mixture that is the binding compound, and that is to be identified as a candidate therapeutic agent.
As used herein, a "pharmaceutical agent" is provided by screening a candidate therapeutic agent using models for a disease state or pathology in order to identify a candidate exerting a desired or beneficial therapeutic effect with relation to the disease or pathology. Such a candidate that successfully provides such an effect is termed a pharmaceutical agent herein. Nonlimiting examples of model systems that may be used in such screens include particular cell lines, cultured cells, tissue preparations, whole tissues, organ preparations, intact organs, and nonhuman mammals. Screens employing at least one system, and preferably more than one system, may be employed in order to identify a pharmaceutical agent. Any pharmaceutical agent so identified may be pursued in further investigation using human subjects.
The following sections describe the study design(s) and the techniques used to identify these proteins, and any variants thereof, and to demonstrate its suitability as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for Obesity and Diabetes.
Methods
1. RTQ-PCR (Real Time Quantitative Polymerase Chain Reaction) Technology: The quantitative expression of various clones was assessed using microtiter plates containing RNA samples from a variety of normal and pathology-derived cells, cell lines and tissues using real time quantitative PCR (RTQ PCR). RTQ PCR was performed on a Perkin-Elmer Biosystems ABI PRISM® 7700 Sequence Detection System. Various
collections of samples are assembled on the plates, and refeπed to as Panel 1 (containing cells and cell lines from normal and cancer sources), Panel 2 (containing samples derived from tissues, in particular from surgical samples, from normal and cancer sources), Panel 3 (containing samples derived from a wide variety of cancer sources), Panel 4 (containing cells and cell lines from normal cells and cells related to inflammatory conditions) and Panel CNSD.01 (containing samples from normal and diseased brains).
First, the RNA samples were normalized to reference nucleic acids such as constitutively expressed genes (for example, β-actin and GAPDH). Normalized RNA (5 ul) was converted to cDNA and analyzed by RTQ-PCR using One Step RT-PCR Master Mix Reagents (PE Biosystems; Catalog No. 4309169) and gene-specific primers according to the manufacturer's instructions. Probes and primers were designed for each assay according to Perkin Elmer Biosystem's Primer Express Software package (version I for Apple Computer's Macintosh Power PC) or a similar algorithm using the target sequence as input. Default settings were used for reaction conditions and the following parameters were set before selecting primers: primer concentration = 250 nM, primer melting temperature (Tm) range = 58°-60° C, primer optimal Tm = 59° C, maximum primer difference = 2° C, probe does not have 5' G, probe Tm must be 10° C greater than primer Tm, amplicon size 75 bp to 100 bp. The probes and primers selected (see below) were synthesized by Synthegen (Houston, TX, USA). Probes were double purified by HPLC to remove uncoupled dye and evaluated by mass specteoscopy to verify coupling of reporter and quencher dyes to the 5' and 3' ends of the probe, respectively. Their final concentrations were: forward and reverse primers, 900 nM each, and probe, 200nM.
PCR conditions: Normalized RNA from each tissue and each cell line was spotted in each well of a 96 well PCR plate (Perkin Elmer Biosystems). PCR cocktails including two probes (a probe specific for the target clone and another gene-specific probe multiplexed with the target probe) were set up using IX TaqMan™ PCR Master Mix for the PE Biosystems 7700, with 5 mM MgC12, dNTPs (dA, G, C, U at 1:1:1:2 ratios), 0.25 U/ml AmpliTaq Gold™ (PE Biosystems), and 0.4 U/μl RNase inhibitor, and 0.25 U/μl reverse teanscriptase. Reverse transcription was performed at 48° C for 30 minutes followed by amplification/PCR cycles as follows: 95° C 10 min, then 40 cycles of 95° C for 15 seconds, 60° C for 1 minute. Results were recorded as CT values (cycle at which a given sample crosses a threshold level of fluorescence) using a log scale, with the difference in RNA concentration between a given sample and the sample with the lowest
CT value being represented as 2 to the power of delta CT. The percent relative expression is then obtained by taking the reciprocal ofthis RNA difference and multiplying by 100.
In the results for Panel 1, the following abbreviations are used: ca. = carcinoma, * = established from metastasis, met = metastasis, s cell var = small cell variant, non-s = non-sm = non-small, squam = squamous, pi. eff = pi effusion = pleural effusion, glio = glioma, astro =. astrocytoma, and neuro = neuroblastoma.
Panel 1.4
The plates for panel 1.4 include 2 control wells (genomic DNA control and chemistry control) and 94 wells containing cDNA from various samples. The samples in panel 1.4 are broken into 2 classes; samples derived from cultured cell lines and samples derived from primary normal tissues. The cell lines are derived from cancers of the following types: lung cancer, breast cancer, melanoma, colon cancer, prostate cancer, CNS cancer, squamous cell carcinoma, ovarian cancer, liver cancer, renal cancer, gastric cancer and pancreatic cancer. Cell lines used in panel 1.4 are widely available through the American Type Culture Collection, a repository for cultured cell lines. The normal tissues found on panel 1.4 are comprised of pools of samples from 2 to 5 different adult individuals derived from all major organ systems. These samples are derived from the following organs: adult skeletal muscle, fetal skeletal muscle, adult heart, fetal heart, adult kidney, fetal kidney, adult liver, fetal liver, adult lung, fetal lung, various regions of the brain, the spleen, bone marrow, lymph node, pancreas, salivary gland, pituitary gland, adrenal gland, spinal cord, thymus, stomach, small intestine, colon, bladder, trachea, breast, ovary, uterus, placenta, prostate, testis and adipose.
RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electropherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide (2: 1 to 2.5: 1 28s: 18s) and the absence of low molecular weight RNAs that would
be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse teanscriptase using probe and primer sets designed to amplify across the span of a single exon.
Panel 2
The plates for Panel 2 generally include 2 control wells and 94 test samples composed of RNA or cDNA isolated from human tissue procured by surgeons working in close cooperation with the National Cancer Institute's Cooperative Human Tissue Network (CHTN) or the National Disease Research Initiative (NDRI). The tissues are derived from human malignancies and in cases where indicated many malignant tissues have "matched margins" obtained from noncancerous tissue just adjacent to the tumor. These are termed normal adjacent tissues and are denoted "NAT" in the results below. The tumor tissue and the "matched margins" are evaluated by two independent pathologists (the surgical pathologists and again by a pathologists at NDRI or CHTN). This analysis provides a gross histopathological assessment of tumor differentiation grade. Moreover, most samples include the original surgical pathology report that provides information regarding the clinical stage of the patient. These matched margins are taken from the tissue surrounding (i.e. immediately proximal) to the zone of surgery (designated "NAT", for normal adjacent tissue, in Table RR). In addition, RNA and cDNA samples were obtained from various human tissues derived from autopsies performed on elderly people or sudden death victims (accidents, etc.). These tissue were ascertained to be free of disease and were purchased from various commercial sources such as Clontech (Palo Alto, CA), Research Genetics, and Invitrogen.
RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electeopherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide (2:1 to 2.5:1 28s: 18s) and the absence of low molecular weight RNAs that would be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse teanscriptase using probe and primer sets designed to amplify across the span of a single exon.
Panel 3D
The plates of Panel 3D are comprised of 94 cDNA samples and two control samples. Specifically, 92 of these samples are derived from cultured human cancer
cell lines, 2 samples of human primary cerebellar tissue and 2 controls. The human cell lines are generally obtained from ATCC (American Type Culture Collection), NCI or the German tumor cell bank and fall into the following tissue groups: Squamous cell carcinoma of the tongue, breast cancer, prostate cancer, melanoma, epidermoid carcinoma, sarcomas, bladder carcinomas, pancreatic cancers, kidney cancers, leukemias/lymphomas, ovarian/uterine/cervical, gastric, colon, lung and CNS cancer cell lines. In addition, there are two independent samples of cerebellum. These cells are all cultured under standard recommended conditions and RNA extracted using the standard procedures. The cell lines in panel 3D and 1.3D are of the most common cell lines used in the scientific literature.
RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electropherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide (2:1 to 2.5:1 28s: 18s) and the absence of low molecular weight RNAs that would be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse transcriptase using probe and primer sets designed to amplify across the span of a single exon.
Panel 4
Panel 4 includes samples on a 96 well plate (2 control wells, 94 test samples) composed of RNA (Panel 4r) or cDNA (Panel 4d) isolated from various human cell lines or tissues related to inflammatory conditions. Total RNA from control normal tissues such as colon and lung (Steatagene ,La Jolla, CA) and thymus and kidney (Clontech) were employed. Total RNA from liver tissue from chrhosis patients and kidney from lupus patients was obtained from BioChain (Biochain Institute, Inc., Hayward, CA). Intestinal tissue for RNA preparation from patients diagnosed as having Crohn's disease and ulcerative colitis was obtained from the National Disease Research Interchange (NDRI) (Philadelphia, PA).
Astiocytes, lung fibroblasts, dermal fibroblasts, coronary artery smooth muscle cells, small airway epithelium, bronchial epithelium, microvascular dermal endothelial cells, microvascular lung endothelial cells, human pulmonary aortic endothelial cells, human umbilical vein endothelial cells were all purchased from Clonetics (Walkersville, MD) and grown in the media supplied for these cell types by Clonetics. These primary cell types were activated with various cytokines or combinations of cytokines for 6 and/or 12-
14 hours, as indicated. The following cytokines were used; IL-1 beta at approximately 1-5 ng/ml, TNF alpha at approximately 5-10 ng/ml, IFN gamma at approximately 20-50 ng/ml, IL-4 at approximately 5-10 ng/ml, IL-9 at approximately 5-10 ng ml, IL-13 at approximately 5-10 ng/ml. Endothelial cells were sometimes starved for various times by culture in the basal media from Clonetics with 0.1% serum.
Mononuclear cells were prepared from blood of employees at CuraGen Coφoration, using Ficoll. LAK cells were prepared from these cells by culture in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco/Life Technologies, Rockville, MD), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco) and Interleukin 2 for 4-6 days. Cells were then either activated with 10-20 ng/ml PMA and 1-2 μg/ml ionomycin, IL-12 at 5-10 ng/ml, IFN gamma at 20- 50 ng/ml and IL-18 at 5-10 ng/ml for 6 hours. In some cases, mononuclear cells were cultured for 4-5 days in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco) with PHA (phytohemagglutinin) or PWM (pokeweed mitogen) at approximately 5 μg/ml. Samples were taken at 24, 48 and 72 hours for RNA preparation. MLR (mixed lymphocyte reaction) samples were obtained by taking blood from two donors, isolating the mononuclear cells using Ficoll and mixing the isolated mononuclear cells 1:1 at a final concentration of approximately 2xl06 cells/ml in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol (5.5 x 10"5 M) (Gibco), and 10 mM Hepes (Gibco). The MLR was cultured and samples taken at various time points ranging from 1- 7 days for RNA preparation.
Monocytes were isolated from mononuclear cells using CD14 Miltenyi Beads, +ve VS selection columns and a Vario Magnet according to the manufacturer's instructions. Monocytes were differentiated into dendritic cells by culture in DMEM 5% fetal calf serum (FCS) (Hyclone, Logan, UT), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco), 50 ng/ml GMCSF and 5 ng/ml IL-4 for 5-7 days. Macrophages were prepared by culture of monocytes for 5-7 days in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), 10 mM Hepes (Gibco) and 10% AB Human Serum or MCSF at approximately 50 ng/ml. Monocytes, macrophages and dendritic cells were stimulated for 6 and 12-14 hours with
lipopolysaccharide (LPS) at 100 ng/ml. Dendritic cells were also stimulated with anti- CD40 monoclonal antibody (Pharmingen) at 10 μg/ml for 6 and 12-14 hours.
CD4 lymphocytes, CD8 lymphocytes and NK cells were also isolated from mononuclear cells using CD4, CD8 and CD56 Miltenyi beads, positive VS selection columns and a Vario Magnet according to the manufacturer's instructions. CD45RA and CD45RO CD4 lymphocytes were isolated by depleting mononuclear cells of CD8, CD56, CD14 and CD19 cells using CD8, CD56, CD14 and CD19 Miltenyi beads and +ve selection. Then CD45RO beads were used to isolate the CD45RO CD4 lymphocytes with the remaining cells being CD45RA CD4 lymphocytes. CD45RA CD4, CD45RO CD4 and CD8 lymphocytes were placed in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco) and plated at 106 cells/ml onto Falcon 6 well tissue culture plates that had been coated overnight with 0.5 μg/ml anti-CD28 (Pharmingen) and 3 ug/ml anti- CD3 (OKT3, ATCC) in PBS. After 6 and 24 hours, the cells were harvested for RNA preparation. To prepare chronically activated CD8 lymphocytes, we activated the isolated CD8 lymphocytes for 4 days on anti-CD28 and anti-CD3 coated plates and then harvested the cells and expanded them in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco) and IL-2. The expanded CD8 cells were then activated again with plate bound anti-CD3 and anti-CD28 for 4 days and expanded as before. RNA was isolated 6 and 24 hours after the second activation and after 4 days of the second expansion culture. The isolated NK cells were cultured in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco) and IL-2 for 4-6 days before RNA was prepared. To obtain B cells, tonsils were procured from NDRI. The tonsil was cut up with sterile dissecting scissors and then passed through a sieve. Tonsil cells were then spun down and resupended at 106 cells/ml in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco). To activate the cells, we used PWM at 5 μg/ml or anti-CD40 (Pharmingen) at approximately 10 μg/ml and IL-4 at 5-10 ng/ml. Cells were harvested for RNA preparation at 24,48 and 72 hours.
To prepare the primary and secondary Thl/Th2 and Trl cells, six-well Falcon plates were coated overnight with 10 μg/ml anti-CD28 (Pharmingen) and 2 μg/ml OKT3
(ATCC), and then washed twice with PBS. Umbilical cord blood CD4 lymphocytes
5 6
(Poietic Systems, German Town, MD) were cultured at 10 -10 cells/ml in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10'5 M (Gibco), 10 mM Hepes (Gibco) and IL-2 (4 ng/ml). IL-12 (5 ng/ml) and anti-IL4 (1 μg/ml) were used to direct to Thl, while IL-4 (5 ng/ml) and anti-IFN gamma (1 μg ml) were used to direct to Th2 and IL-10 at 5 ng/ml was used to direct to Trl. After 4-5 days, the activated Thl, Th2 and Trl lymphocytes were washed once in DMEM and expanded for 4-7 days in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), 10 mM Hepes (Gibco) and IL-2 (1 ng/ml). Following this, the activated Thl, Th2 and Trl lymphocytes were re-stimulated for 5 days with anti-CD28/OKT3 and cytokines as described above, but with the addition of anti-CD95L (1 μg/ml) to prevent apoptosis. After 4-5 days, the Thl, Th2 and Trl lymphocytes were washed and then expanded again with IL-2 for 4-7 days. Activated Thl and Th2 lymphocytes were maintained in this way for a maximum of three cycles. RNA was prepared from primary and secondary Thl, Th2 and Trl after 6 and 24 hours following the second and third activations with plate bound anti-CD3 and anti-CD28 mAbs and 4 days into the second and third expansion cultures in Interleukin 2.
The following leukocyte cells lines were obtained from the ATCC: Ramos, EOL-1, KU-812. EOL cells were further differentiated by culture in 0.1 mM dbcAMP at 5 xlO5 cells/ml for 8 days, changing the media every 3 days and adjusting the cell concentration to 5 xlO5 cells/ml. For the culture of these cells, we used DMEM or RPMI (as recommended by the ATCC), with the addition of 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), 10 mM Hepes (Gibco). RNA was either prepared from resting cells or cells activated with PMA at 10 ng/ml and ionomycin at 1 μg/ml for 6 and 14 hours. Keratinocyte line CCD 106 and an airway epithelial tumor line NCI-H292 were also obtained from the ATCC. Both were cultured in DMEM 5% FCS (Hyclone), 100 μM non essential amino acids (Gibco), 1 mM sodium pyruvate (Gibco), mercaptoethanol 5.5 x 10"5 M (Gibco), and 10 mM Hepes (Gibco). CCDl 106 cells were activated for 6 and 14 hours with approximately 5 ng/ml TNF alpha and 1 ng/ml IL-1 beta, while NCI-H292 cells were activated for 6 and 14 hours with the following cytokines: 5 ng/ml IL-4, 5 ng/ml IL-9, 5 ng/ml IL-13 and 25 ng/ml IFN gamma.
For these cell lines and blood cells, RNA was prepared by lysing approximately 107 cells/ml using Trizol (Gibco BRL). Briefly, 1/10 volume of bromochloropropane (Molecular Research Coφoration) was added to the RNA sample, vortexed and after 10 minutes at room temperature, the tubes were spun at 14,000 φm in a Sorvall SS34 rotor. The aqueous phase was removed and placed in a 15 ml Falcon Tube. An equal volume of isopropanol was added and left at -20 degrees C overnight. The precipitated RNA was spun down at 9,000 φm for 15 min in a Sorvall SS34 rotor and washed in 70% ethanol. The pellet was redissolved in 300 μl of RNAse-free water and 35 μl buffer (Promega) 5 μl DTT, 7 μl RNAsin and 8 μl DNAse were added. The tube was incubated at 37 degrees C for 30 minutes to remove contaminating genomic DNA, extracted once with phenol chloroform and re-precipitated with 1/10 volume of 3 M sodium acetate and 2 volumes of 100% ethanol. The RNA was spun down and placed in RNAse free water. RNA was stored at -80 degrees C.
Panel 5D and 51
The plates for Panel 5D and 51 include two control wells and a variety of cDNAs isolated from human tissues and cell lines with an emphasis on metabolic diseases. Metabolic tissues were obtained from patients enrolled in the Gestational Diabetes study. Cells were obtained during different stages in the differentiation of adipocytes from human mesenchymal stem cells. Human pancreatic islets were also obtained.
In the Gestational Diabetes study subjects are young (18 - 40 years), otherwise healthy women with and without gestational diabetes undergoing routine (elective) Caesarean section. After delivery of the infant, when the surgical incisions were being repaired/closed, the obstetrician removed a small sample (<1 cc) of the exposed metabolic tissues during the closure of each surgical level. The biopsy material was rinsed in sterile saline, blotted and fast frozen within 5 minutes from the time of removal. The tissue was then flash frozen in liquid nitrogen and stored, individually, in sterile screw-top tubes and kept on dry ice for shipment to or to be picked up by CuraGen. The metabolic tissues of interest include uterine wall (smooth muscle), visceral adipose, skeletal muscle (rectus) and subcutaneous adipose. Patient descriptions are as follows:
Patient 2 Diabetic Hispanic, overweight, not on insulin
Patient 7-9 Nondiabetic Caucasian and obese (BMI>30) Patient 10 Diabetic Hispanic, overweight, on insulin Patient 11 Nondiabetic African American and overweight Patient 12 Diabetic Hispanic on insulin
Adiocyte differentiation was induced in donor progenitor cells obtained from Osirus (a division of Clonetics/BioWhittaker) in triplicate except for Donor 3U which had only two replicates. Scientists at Clonetics isolated, grew and differentiated human mesenchymal stem cells (HuMSCs) for CuraGen based on the published protocol found in Mark F. Pittenger, et al., Multilineage Potential of Adult Human Mesenchymal Stem Cells Science Apr 2 1999: 143-147. Clonetics provided Trizol lysates or frozen pellets suitable for mRNA isolation and ds cDNA production. A general description of each donor is as follows:
Donor 2 and 3: U Mesenchymal Stem Cells Undifferentiated
Donor 2 and 3: AM Adipose Adipose Midway Differentiated
Donor 2 and 3: AD Adipose Adipose Differentiated
Human cell lines were generally obtained from ATCC (American Type Culture Collection), NCI or the German tumor cell bank and fall into the following tissue groups: kidney proximal convoluted tubule, uterine smooth muscle cells, small intestine, liver
HepG2 cancer cells, heart primary stromal cells, and adrenal cortical adenoma cells. These cells are all cultured under standard recommended conditions and RNA extracted using the standard procedures. AU samples were processed at CuraGen to produce single stranded cDNA. RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electeopherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide
(2:1 to 2.5:1 28s: 18s) and the absence of low molecular weight RNAs that would be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse teanscriptase using probe and primer sets designed to amplify across the span of a single exon.
Panel 51 contains all samples previously described with the addition of pancreatic islets from a 58 year old female patient obtained from the Diabetes Research Institute at the
University of Miami School of Medicine. Islet tissue was processed to total RNA at an outside source and delivered to CuraGen for addition to panel 51.
In the labels employed to identify tissues in the 5D and 51 panels, the following abbreviations are used:
GO Adipose = Greater Omentum Adipose
SK = Skeletal Muscle
UT = Uterus
PL = Placenta AD = Adipose Differentiated
AM = Adipose Midway Differentiated
U = Undifferentiated Stem Cells
Panel CNSD.01 : Central Nervous System (CNS) Panel
The plates for Panel CNSD.01 include two control wells and 94 test samples comprised of cDNA isolated from postmortem human brain tissue obtained from the Harvard Brain Tissue Resource Center. Brains are removed from calvaria of donors between 4. and 24 hours after death, sectioned by neuroanatomists, and frozen at -80°C in liquid niteogen vapor. All brains are sectioned and examined by neuropathologists to confirm diagnoses with clear associated neuropathology.
Disease diagnoses are taken from patient records. The panel contains two brains from each of the following diagnoses: Alzheimer's disease, Parkinson's disease, Huntington's disease, Progressive Supernuclear Palsy, Depression, and "Noπnal controls". Within each of these brains, the following regions are represented: cingulate gyms, temporal pole, globus palladus, substantia nigra, Brodmann Area 4 (primary motor strip), Brodmann Area 7 (parietal cortex), Brodmann Area 9 (prefrontal cortex), and Brodman area 17 (occipital cortex). Not all brain regions are represented in all cases; e.g., Huntington's disease is characterized in part by neurodegeneration in the globus palladus, thus this region is impossible to obtain from confirmed Huntington's cases. Likewise Parkinson's disease is characterized by degeneration of the substantia nigra making this region more difficult to obtain. Normal control brains were examined for neuropathology and found to be free of any pathology consistent with neurodegeneration.
RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electeopherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide (2:1 to 2.5:1 28s: 18s) and the absence of low molecular weight RNAs that would be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse teanscriptase using probe and primer sets designed to amplify across the span of a single exon.
In the labels employed to identify tissues in the CNS panel the following abbreviations are used:
PSP: Progressive supranuclear palsy
Sub Nigra: Substantia nigra
Glob Palladus: Globus pallidus
Temp Pole: Temporal pole
Cing Gyr: Cingulate gyrus
BA: Brodmann Area
Method of Identifying the Differentially Expressed Gene and Gene Product:
The GeneCalling ™ method makes a comparison between experimental samples in the amount of each cDNA fragment generated by digestion with a unique pair of restriction endonucleases, after linker-adaptor ligation, PCR amplification and chromatographic separation. Computer analysis is employed to assign potential identity to the gene fragment. Three methods are routinely used in the identification of a gene fragment found to have altered expression in models of or patients with obesity and/or diabetes.
Direct Sequencing: The differentially expressed gene fragment is isolated, cloned into a plasmid and sequenced. Afterwards the sequence information is used to design an oligonucleotide coπesponding to either or both termini of the gene fragment. This oligonucleotide, when used in a competitive PCR reaction, will ablate the chromatographic band from which the sequence is derived.
Competitive PCR: In competitive PCR, the chromatographic peaks coπesponding to the gene fragment of the gene of interest are ablated when a gene-specific primer
(designed from the sequenced band or available databases) competes with primers in the linker-adaptors during the PCR amplification.
PCR with Perfect or Mismatched 3' Nucleotides (Trapping): This method utilizes a competitive PCR approach using a degenerate set of primers that extend one or two nucleotides into the gene-specific region of the fragment beyond the flanking restriction sites. As in the competitive PCR approach, primers that lead to the ablation of the chromatographic band add additional sequence information. In conjunction with the size of the gene fragment and the 12 nucleotides of sequence derived from the restriction sites, this additional sequence data can uniquely define the gene after database analysis.
Antibodies
The invention further encompasses antibodies and antibody fragments, such as Fab, (Fab)2 or single chain FV constructs, that bind immunospecifically to any of the proteins of the invention. Also encompassed within the invention are peptides and polypeptides comprising sequences having high binding affinity for any of the proteins of the invention, including such peptides and polypeptides that are fused to any carrier particle (or biologically expressed on the surface of a carrier) such as a bacteriophage particle.
Methods of Use of the Compositions of the Invention The protein similarity information, expression pattern, cellular localization, and map location for the protein and nucleic acid disclosed herein suggest that this protein may have important structural and/or physiological functions characteristic of the Omithine Decarboxylase 1 family. Therefore, the nucleic acids and proteins of the invention are useful in potential diagnostic and therapeutic applications and as a research tool. These include serving as a specific or selective nucleic acid or protein diagnostic and/or prognostic marker, wherein the presence or amount of the nucleic acid or the protein are to be assessed. These also include potential therapeutic applications such as the following: (i) a protein therapeutic, (ii) a small molecule drug target, (iii) an antibody target (therapeutic, diagnostic, drug targeting/cytotoxic antibody), (iv) a nucleic acid useful in gene therapy (gene delivery/gene ablation), (v) an agent promoting tissue regeneration in vitro and in vivo, and (vi) a biological defense weapon.
The nucleic acids and proteins of the invention have applications in the diagnosis and/or tieatment of various diseases and disorders. For example, the compositions of the
present invention will have efficacy for the treatment of patients suffering from: Obesity and/or Diabetes.
These materials are further useful in the generation of antibodies that bind immunospecifically to the substances of the invention for use in diagnostic and/or therapeutic methods.
A. NOVlOa - Human Omithine Decarboxylase 1 - CG124907-01
Discovery Process
The following sections describe the study design(s) and the techniques used to identify the omithine decarboxylase 1-gene, encoded protein and any variants, thereof, as being suitable as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for Obesity and Diabetes.
Studies: MB04. Mouse obesity model (genetic)
Study Statements:
A large number of mouse steains have been identified that differ in body mass and composition. The AKR and NZB steains are obese, the SWR, C57L and C57BL/6 steains are of average weight whereas the SM/J and Cast/Ei steains are lean. Understanding the gene expression differences in the major metabolic tissues from these strains will elucidate the pathophysiologic basis for obesity. These specific strains of rat were chosen for differential gene expression analysis because quantitative trait loci (QTL) for body weight and related teaits had been reported in published genetic studies. Tissues included whole brain, skeletal muscle, visceral adipose, and liver.
MB.08. Human Mesenchymal Stem Cell differentiation
Bone maπow-derived human mesenchymal stem cells have the capacity to differentiate into muscle, adipose, cartilage and bone. Culture conditions have been established that permit the differentiation in vitro along the pathway to adipose, cartilage and bone. Understanding the gene expression changes that accompany these distinct differentiation processes would be of considerable biologic value. Regulation of adipocyte differentiation would have importance in the treatment of obesity, diabetes and hypertension. Human
mesenchymal stem cells from 3 donors were obtained and differentiated in vitro according to published methods. RNA from samples of the undifferentiated, mid-way differentiated and fully differentiated cells was isolated for analysis of differential gene expression.
BP24.2. Diet induced obesity
The predominant cause for obesity in clinical populations is excess caloric intake. This so-called diet-induced obesity (DIO) is mimicked in animal models by feeding high fat diets of greater than 40% fat content. The DIO study was established to identify the gene expression changes contributing to the development and progression of diet-induced obesity. In addition, the study design seeks to identify the factors that lead to the ability of certain individuals to resist the effects of a high fat diet and thereby prevent obesity. The sample groups for the study had body weights +1 S.D., + 4 S.D. and + 7 S.D. of the chow- fed controls (below). In addition, the biochemical profile of the + 7 S.D. mice revealed a further stratification of these animals into mice that retained a normal glycemic profile in spite of obesity and mice that demonstrated hyperglycemia. Tissues examined included hypothalamus, brainstem, liver, retioperitoneal white adipose tissue (WAT), epididymal WAT, brown adipose tissue (BAT), gasteocnemius muscle (fast twitch skeletal muscle) and soleus muscle (slow twitch skeletal muscle). The differential gene expression profiles for these tissues should reveal genes and pathways that can be used as therapeutic targets for obesity.
Omithine Decarboxylase 1:
In multiple genecalling studies the enzyme spermidine/spermine acetyl teansferase has been found to be dysregulated in various disease models. This enzyme is one of the rate-limiting enzymes in the production of polyamines spermidine and spermine. Previously, it was shown that oxidation of polyamines leads to generation of hydrogen peroxide, which has been shown to have antilipolytic effect of adipose and may therefore be involved in the progression of obesity. Omithine decarboxylase catalyzes the first step in polyamine production, which is the conversion of omithine to putrescine. The polyamine pathway can be detrimental for the obesity phenotype, since hydrogen peroxide produced during oxidation of polyamines in known to have anti-lipolytic, insulin-like effect on adipocytes. Therefore, inhibiting the production of polyamines and generation of H2O2 by
inhibiting this first enzyme in the polyamine pathway may be beneficial in the treatment for obesity.
The Ornithine Decarboxylase 1 (ODC) is one of the key enzymes in polyamine biosynthesis. Preventing the accumulation of polyamines and their antilipolytic effects by inhibition of ODC at an earlier stage of obesity may inhibit progression of the obesity.
The following is a summary of the findings from the discovery studies, supplementary investigations and assays that also incoφorates knowledge in the scientific literature for use of omithine decarboxylase las a diagnostic and/or target for small molecule drugs and antibody therapeutics.. Taken in total, the data indicates that an inhibitor/antagonist of the human ornithine decarboxylase 1 would be beneficial in the treatment of obesity and/or diabetes.
SPECIES #1 mouse (NZB vs SM/J): A gene fragment of the mouse spermine/spermidine N-acetylteansferase was initially found to be upregulated by 1.9 fold in the adipose of NZB mice relative to SM/J mice using CuraGen' s GeneCalling ™ method of differential gene expression. A differentially expressed mouse gene fragment migrating at approximately 411 nucleotides in length (Figure la. - red vertical line) was definitively identified as a component of the mouse spermine/speπnidine N-acetylteansferase cDNA in NZB and SM/J mouse steains. The method of competitive PCR was used for conformation of the gene assessment. The chromatographic peaks coπesponding to the gene fragment of the mouse spermidine/spermine N-acetylteansferase are ablated when a gene-specific primer (see below) which competes with primers in the linker-adaptors during the PCR amplification. The peaks at 411 nt in length are ablated (green trace) in the sample from both the NZB and the SM/J mice. The altered expression in of these genes in the animal model support the role of Omithine Decarboxylase 1 in the pathogenesis of obesity and/or diabetes. SPECIES #1 mouse (C57B1/6 obese euglycemic sd7 vs obese sdl):
A gene fragment of the mouse spermine/spermidine N-acetyltiansferase was initially found to be upregulated by 1.8 fold in the epididymal fat pad of the obese euglycemic sd7 mice relative to the obese sdl mice using CuraGen's GeneCalling ™ method of differential gene expression. A differentially expressed rat gene fragment migrating at approximately 178 nucleotides in length (Figure la. - red vertical line) was
definitively identified as a component of the mouse spermine/spermidine N- acetylteansferase cDNA in the Troglitazone treated and the untreated SHR control rats. The method of competitive PCR was used for conformation of the gene assessment. The chromatographic peaks corresponding to the gene fragment of the mouse spermidine/spermine N-acetylteansferase are ablated when a gene-specific primer (see below) which competes with primers in the linker-adaptors during the PCR amplification. The peaks at 178 nt in length are ablated (green trace) in the sample from both the C57B1/6 obese euglycemic sd7 and obese sdl mice. The altered expression in of these genes in the animal model support the role of Omithine Decarboxylase 1 in the pathogenesis of obesity and/or diabetes.
SPECIES #2 human (adipocyte mid-way vs undifferentiated):
A gene fragment of the human spermine/spermidine N-acetylteansferase was initially found to be upregulated by 1.6 fold in the mid-way human adipocytes relative to the undifferentiated human adipocytes using CuraGen's GeneCalling ™ method of differential gene expression. A differentially expressed human gene fragment migrating at approximately 194 nucleotides in length (Figure la. - red vertical line) was definitively identified as a component of the human spermine/spermidine N-acetyltiansferase cDNA in human mid-way differentiated and undifferentiated adipocytes. The method of competitive PCR was used for conformation of the gene assessment. The chromatographic peaks coπesponding to the gene fragment of the human spermine/spermidine N-acetyltiansferase are ablated when a gene-specific primer (see below) which competes with primers in the linker-adaptors during the PCR amplification. The peaks at 194 nt in length are ablated (green trace) in the sample from both the human mid-way differentiated and undifferentiated adipocytes. The altered expression of these genes in the human cellular model support the role of Ornithine Decarboxylase 1 in the pathogenesis of obesity and/or diabetes.
Table 1. Spermidine/spermine N-acetyltiansferase Gene Sequence identified in NZB vs SM/J mice (Identified fragment from 206 to 616 in bold, band size: 411)
1 GCTCCCGGGA AACGAATGAG GAACCACCTC CTCCTGCTGT TCAAGTACAG GGGCCTGGTG
61 CGCAAAGGGA AGAAAAGCAA AAGACGAAAA TGGCTAAATT TAAGATCCGT CCAGCCACTG
121 CCTCTGACTG CAGTGACATC CTGCGACTGA TCAAGGAACT GGCTAAATAT GAATACATGG 181 AAGATCAAGT CATTTTAACT GAGAAAGATC TCCAAGAGGA TGGCTTTGGA GAACACCCCT
.241 TCTACCACTG CCTGGTTGCA GAAGTGCCTA AAGAGCACTG GACCCCTGAA GGACATAGCA . 301 TTGTTGGGTT CGCCATGTAC TATTTTACCT ATGACCCATG GATTGGCAAG TTGC-GTATC .. 361 TTGAAGACTT CTTCGTGATG AGTGATTACA GAGGCTT GG TATAGGATCA GAAATTTTGA
421 AGAATCTAAG CCAGGTTGCC ATGAAGTGTC GCTGCAGCAG TATGCACTTC TTGGTAGCAG
481 AATGGAATGA ACCATCTATC AACTTCTACA AAAGAAGAGG TGCTTCGGAT CTGTCCAGTG
541 AAGAGGGATG GAGGCTCTTC AAGATTGACA AAGAGTACTT GCTAAAAATG GCAGCAGAGG
601 AGTGAGGCGT GCCGGTGTAG ACAATGACAA CCTCCATTGT GCTTTAGAAT AATTCTCAGC
5 661 T CCCTTGCT TTCTATCT G TGTGTAGTGA AATAATAGAG CGAGCACCCA TTCCAAAGCT
721 T ATTACCAG TGACGTTGTT GCATGTTTGA AATTCGGTCT GTTTAAAGTG GCAGTCATGT
781 ATGTGGT TG GAGGCAGAAT TCTTGAACAT CTTTTGATGA AGAACAAGGT GGTATGATCT
, 841 TACTATATAA GAAAAACAAA ACTTCATTCT TGTGAGTCAT TTAAATGTGT ACAATGTACA
901 CACTGGTACT TAGAGTTTCT GTTTTGATTC TTTTTTTTTA AATAAACTCG CTCTTTGATT
10 ' 961 T
Table 2. Spermidine/spermine N-acetylteansferase Gene Sequence identified in C57B1/6 15 obese euglycemic sd7 vs obese sdl (Identified fragment from 716 to 893 in bold, band size: 178)
235 ACCCCTTCTA CCACTGCCTG GTTGCAGAAG TGCCTAAAGA GCACTGGACC CCTGAAGGAC 295 ATAGCATTGT TGGGTTCGCC ATGTACTATT TTACCTATGA CCCATGGATT GGCAAGTTGC
20 . 355 TGTATCT GA AGACTTCTTC GTGATGAGTG ATTACAGAGG CTTTGGTATA GGATCAGAAA 415 TTTTGAAGAA TCTAAGCCAG GTTGCCATGA AGTGTCGCTG CAGCAGTATG CACTTCTTGG 475. TAGCAGAATG GAATGAACCA TCTATCAACT TCTACAAAAG AAGAGGTGCT TCGGATCTGT 535 CCAGTGAAGA GGGATGGAGG CTCTTCAAGA TTGACAAAGA GTACTTGCTA AAAATGGCAG 595 CAGAGGAGTG AGGCGTGCCG GTGTAGACAA TGACAACCTC CATTGTGCTT TAGAATAATT
25 655 CTCAGCTTCC CTTGCTTTCT ATCTTGTGTG TAGTGAAATA ATAGAGCGAG CACCCATTCC
715 AAAGCTTTAT TACCAGTGAC GTTGTTGCAT GTTTGAAATT CGGTCTGTTT AAAGTGGCAG
.775 TCATGTATGT GGTTXGGAGG CAGAATTCTT GAACATCTTT TGATGAAGAA CAAGG-GGTA
835 TGATCTTACT ATATAAGAAA AACAAAACTT CATTCTTCTG AGTCATTTAA ATGTGTACAA
895. TGTACACACT GGTACTTAGA GTTTCTGTTT TGATTCTTTT TTTTTAAATA AACTCGCTCT
30 955 TTGATTT
Table 3. Spermidine/spermine N-acetyltiansferase Gene Sequence identified in human 35 adipocyte mid-way versus undifferentiated (Identified fragment from 162 to 355 in bold. band size: 149).
1 CTGGTGTTTA TCCGTCACTC GCCGAGGTTC CTTGGGTCAT GGTGCCAGCC TGACTGAGAA
61 GAGGACGCTC CCGGGAGACG AATGAGGAAC CACCTCCTCC TACTGTTCAA GTACAGGGGC
40. 121 CTGGTCCGCA AAGGGAAGAA AAGCAAAAGA CGAAAATGGC TAAATTCGTG ATCCGCCCAG
181 CCACTGCCGC CGACTGCAGT GACATACTGC GGCTGATCAA GGAGCTGGCT AAATATGAAT
.241 ACATGGAAGA ACAAGTAATC TTAACTGAAA AAGATCTGCT AGAAGATGGT TTTGGAGAGC
301 ACCCCTTTTA CCACTGCCTG GTTGCAGAAG TGCCGAAAGA GCACTGGACT CCGGAAGGTT
361 ACAGTCTCTA GCTTCGCCAT GTACATGGCC CTTCCGTGTA CATGGATGGG CGGGGAGGTA
45 421 ACTAAAAGAT CCTTTACACA ATAAAGTAGA TGATCATGAT AAATGAGGAC ACAGCATTGT
481 TGGTTTTGCC ATGTACTATT TTACCTATGA CCCGTGGATT GGCAAGTTAT TGTATCTTGA
541 GGACTTCTTC GTGATGAGTG ATTATAGAGG CTTTGGCATA GGATCAGAAA TTCTGAAGAA
601 TCTAAGCCAG GTTGCAATGA GGTGTCGCTG CAGCAGCATG CACTTCTTGG TAGCAGAATG
661 GAATGAACCA TCCATCAACT TCTATAAAAG AAGAGGTGCT TCTGATCTGT CCAGTGAAGA
50 721 GGGTTGGAGA CTGTTCAAGA TCGACAAGGA GTACTTGCTA AAAATGGCAA CAGAGGAGTG
781 AGGAGTGCTG CTGTAGATGA CAACCTCCAT TCTATTTTAG AATAAATTCC CAACT
Table 4. Human Omithine Decarboxylase 1 gene and protein sequence.
55 >CG124907-01 1958 nt
GCAGGCCAGCCCCATGGGGAAGCGCAGACGCCGGNGCCTGGGCGCTCTGAGATTGTCACT GCTGT CC-__GGCaCACGC_ιGAGGGATT GGAATTCCTG_AGAGTTGCCTTTGTGAGAA G_ _GAAATATTTCTTTC-__ -C__CTCT^
GAACAACTTTGGTAATGAAGAGTTTGACTGCCACTTCCTCGATGAAGGTTTTACTGCCAA GGACATTCTGGACCAGAAAATTAATGAAGTTTCTTCTTCTGATGATAAGGATGCCTTCTA TGTGGCAGACCTGGGAGACATTCTAAAGAAACATCTGAGGTGGTTAAAAGCTCTCCCTCG TGTCACCCCCTTTTATGCAGTCAAATGTAATGATAGCAAAGCCATCGTGAAGACCCTTGC TGCTACCGGGACAGGATTTGACTGTGCTAGCAAGACTGAAATACAGTTGGTGCAGAGTCT G_3GGTGCCTCCAGAGAGGATTATCTATGΑ_ATCCTTGTAAACAAGTATCTCAAATTAA GTATGCTGCTAATAATGGAGTCCAGATGATGACTTTTGATAGTGAAGTTGAGTTGATGAA AGTTGCCΛGAGCACATCCCAAAGCAAAGTTGGTTTTGCGGATTGCCACTGATGATTCCAA AGCAGTCTGTCGTCΓCAGTGTGAAATTCGGTGCCACGCTCAGAACCAGCAGGCTCCTTTT GGAACGGGCGAAAGAGCTAAATATCGATGTTGTTGGTGTCAGCTTCCATGTAGGAAGCGG CTGTACCGATCCTGAGACCTTCGTGCAGGCAATCTCTGATGCCCGCTGTGTTTTTGACAT GGGGGCTGAGGTTGGTTTCAGCATGTATCTGCTTGATATTGGCGGTGGCTTTCCTGGATC TGAGGATGTGAAACTTAAATTTGAAGAGATCACCGGCGTAATCAACCCAGCGTTGGACAA ATACTTTCCGTCAGACTCTGGAGTGAGAATCATAGCTGAGCCCGGCAGATACTATGTTGC ATCAGCTTTCACGCTTGCAGTTAATATCATTGCCAAGAAAATTGTATTAAAGGAACAGAC GGGCTCTGATGACGAAGATGAGTCGAGTGAGCAGACCT TATGTATTATGTGAATGATGG CGTCTATGGATCATTTAATTGCATACTCTATGACCACGCACATGTAAAGCCCCTTCTGCA AAAGAGACCTAAACCAGATGAGAAGTATTATTCATCCAGCATATGGGGACCAACATGTGA TGGCCTCGATCGGATTGTTGAGCGCTGTGACC GCCTGAAATGCATGTGGGTGATTGGAT GCTCTTTGAAAACATGGGCGCTTACACTGTTGCTGCTGCCTCTACGTTCAATGGCTTCCA GAGGCCGACGATCTACTATGTGATGTCAGGGCCTGCGTGGCAACTCATGCAGCAATTCCA GAACCCCGACTTCCCACCCGAAGTAGAGGAACAGGATGCCAGCACCCTGCCTGTGTCTTG TGCCTGGGAGAGTGGGATGAAACGCCACAGAGCAGCCTGTGCTTCGGCTAGTATTAATGT GTAGATAGCACTCTGGTAGCTGTTAACTGCAAGTTTAGCTTGAATTAAGGGAT TGGGGG GACCATGTAACTTAATTACTGCTAGTTTTGAAATGTCT TGTAAGAGTAGGGTCGCCATG ATGCAGCCATATGGAAGACTAGGATATGGGTCACACTTATCTGTGTTCCTATGGAAACTA T GAATATTTGTTTTATATGGATTTTTATTCACTCTTCAGACACGCTACTCAAGAGTGC CCCTCAGCTGCTGAACAAGCATTTGTAGCTTGTACAATGGCAGAATGGGCCAAAAGCTTA GTGTTGTGACCTGTTTTTAAAATAAAGTATCTTGAAATAAACAAAAAAAAAAAAGGGGGG CCGCCCTAGGGGTTCCCAAGTTTACGTACGCTGCATGG
Table 5. Human Omithine Decarboxylase 1 protein sequence.
ORF Start: 179 ORF Stop: 1562 Frame: 2
Human Ornithine Decarboxylase 1 Protein Sequence:
>CG124907-01-prot 461 aa NNFGNEEFDCHFLDEGFTAKDILDQKI_SVSSSDDKDAFYVADLGDILKKHLRWLKALP RVTPFYAVKCNDSKAIVKT AATGTGFDCASKTEIQ VQSLGVPPERIIYANPCKQVSQI KYA !_IGVQ^I^π:FDSEVELMKVARAHPK-__V RIA DDSKAVCR SVKFGAT R SR L LERAKE NI D WGVS FHVGSGCTDPE FVQAI SDARCVFDMGAEVGFS YLLD I GGGFPG SEDVKLKFEEITGVINP ALDKYFPSDSGVRI IAEPGRYYVASAF LAVNI IAKKIVLKEQ TGSDDEDESSEQTFMYYVNDGλnrGSF CILyDHAHVKPLLQKRPKPDE YYSSSIWGPTC DG DRIVERCD PEMHVGDVMLFErølGAYTVAAASTFNGFQRPTIΥYVMSGPAWQLMQQF QNPDFPPEVEEQDASTLPVSCA ESGMKRHRAACASASINV
Table 6. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of the human (CG124907-01), rat and mouse versions of the Omithine Decarboxylase 1.
In addition to the human version of the Omithine Decarboxylase 1 identified as being differentially expressed in the experimental study, other variants have been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases. No splice-form variants have been identified at CuraGen whereas several amino acid-changing cSNPs were identified. These are found below. The prefeπed variant of all those identified, to be used for screening puφoses, is CGI 24907-01.
Table 7. Variants of human Omithine Decarboxylase 1 obtained from direct cloning and/or public databases.
Figures IA and IB show differential regulation of spermidine/spermine N-acetylteansferase in the expressed gene fragment in Discovery Study MB.04 of NZB vs SM/J mice. The abscissa on each graph is measured in length of nucleotides, and the ordinate is measured in signal response.
Figures 2A and 2B show differential regulation of spermidine/spermine N-acetylteansferase in the expressed gene fragment in Discovery Study MB.04 of NZB vs SM/J mice. The abscissa on each graph is measured in length of nucleotides, and the ordinate is measured in signal response.
Figure 3. Differentially expressed gene fragment in Discovery Study MB.08 identified in human adipocyte mid-way versus undifferentiated, from the human spermidine/spermine N-acetyltransferase.
Body Weight Distribution by STD
mean mean mean mean mean mean mean mean mean chow + chow + chow + chow + chow + chow + chow + chow + chow +
<1SD 2 SD 3 SD 4 SD 5 SD 6 SD 7 SD 8 SD 9 SD
Figure 4. Diet induced obesity Under Discovery Process BP24.2.
Species #1 mouse Strains NZB, SM/J, C56B1/6 Species # 2 Human
Figure 5 summarize the biochemistry suπounding the human Omithine Decarboxylase 1 and potential assays that may be used to screen for antibody therapeutics or small molecule drugs to treat obesity and/or diabetes. Cell lines expressing the Omithine Decarboxylase 1 can be obtained from the RTQ-PCR results shown above. These and other Omithine Decarboxylase 1 expressing cell lines could be used for screening puφoses. In the schematic, the biochemistry of "PAO" is that it catalyses oxidation of the secondary amino group of spermine, spermidine and their acetyl derivatives; FAD is the cofactor implicated; and the schematic is shown in monomeric units. 0 Ornithine putrescine spermidine spermine
H202 Nac-Sperrnidine H202 Nac-Spermine
Figure 6 suggests how alterations in expression of the human omithine decarboxylase 1 and associated gene products function in the etiology and pathogenesis of 0 obesity and/or diabetes. The scheme incoφorates the unique findings of these discovery studies in conjunction with what has been reported in the literature. The outcome of inhibiting the action of the human ornithine decarboxylase 1 would be a way to increase lypolysis by inhibiting anti-lypolytic effects of hydrogen peroxide.
5 Ornithine putrescine spermidine spermine
An Vtilipolysis Increased obesity
Omithine decarboxylase catalyzes the first step in polyamine production, the conversion of ornithine to putiescine. Inhibiting the production of polyamines and H2O2 by inhibiting this first enzyme in the pathway will eliminate the lipolytic effects of H2O2 and therefore may be beneficial in the treatment for obesity.
The following is a summary of the findings from the discovery studies, supplementary investigations and assays that also incoφorates knowledge in the scientific literature. Taken in total, the data indicates that an inhibitor/antagonist of the human
Omithine Decarboxylase 1 would be beneficial in the treatment of obesity and/or diabetes. In multiple genecalling studies the enzyme spermidine/spermine acetyl fransferase was found to be dysregulated in various disease models. This enzyme is one of the rate- limiting enzymes in the production of polyamines spermidine and spermine. Previously, it was shown that oxidation of polyamines leads to generation of hydrogen peroxide, which has been shown to have antilipolytic effect of adipose and may therefore be involved in the progression of obesity. Omithine decarboxylase catalyzes the first step in polyamine production, which is the conversion of ornithine to putrescine. The polyamine pathway can be detrimental for the obesity phenotype, since hydrogen peroxide produced during oxidation of polyamines in known to have anti-lipolytic, insulin-like effect on adipocytes. Therefore, inhibiting the production of polyamines and generation of H2O2 by inhibiting this first enzyme in the polyamine pathway may be beneficial in the treatment for obesity.
B. NOV12A - Tyrosine aminotransferase - CG135823-01
The present invention discloses novel associations of proteins and polypeptides and the nucleic acids that encode them with various diseases or pathologies. The proteins and related proteins that are similar to them, are encoded by a cDNA and/or by genomic DNA. 5 The proteins, polypeptides and their cognate nucleic acids were identified by CuraGen Coφoration in certain cases. The Tyrosine Aminotransferase -encoded protein and any variants, thereof, are suitable as diagnostic markers, targets for an antibody therapeutic and targets for small molecule drugs. As such the cuπent invention embodies the use of recombinantly expressed and/or endogenously expressed protein in various screens to 10 identify such therapeutic antibodies and/or therapeutic small molecules.
Table 1. SPECIES #1, Rat Tyrosine Aminotransferase Gene Fragment used for competitive PCR (fragment from 845 to 989 in bold, band size: 145)
15.
364 CCTACAGACC CTGAAGTTAC CCAAGCCATG AAAGATGCMC TGGACTCGGG GAAGTACAAT 424 GGCTATGCCC CGTCCATCGG CTACCTATCC AGTCGGGAGG AGGTCGCTTC TTACTACCAC 484 TGTCATGAGG CTCCTCTGGA AGCTAAGGAT GTCATTCTGA CAAGCGGCTG CAGTCAGGCC 544 ATTGAGCTAT GTCTAGCTGT GTTGGCCAAT CCTGGACAAA ACATCCTCAT TCCAAGGCCC . 0 604 GGGTTTTCCC TCTATAGGAC TTTGGCTGAG TCTATGGGAA TTGAGGTCAA GCTCTACAAT 664 CTCCTGCCCG AGAAGTCTTG GGAAATTGAC CTAAAACAAC TGGAATCTCT GATCGATGAA 724 AAAACAGCGT GTCTTGTTGT CAACAACCCA TCCAATCCCT GTGGCTCCGT GTTCAGTAAG 784 CGACACCTTC AGAAGATTTT GGCAGTGGCT GAAAGGCAGT GTGTCCCCAT CTTAGCTGAC 844 GAGATCTATG GTGACATGGT GTTTTCAGAT TGCAAATACG AACCACTGGC CAACCTCAGC 5 904 ACCAATGTTC CCATCCTGTC CTGTGGTGGG CTGGCCAAGC GCTGGCTGGT CCTTGGCTGG
9G4 AGGTTGGGCT GGATCCTCAT TCATGATCGA AGAGACATTT TTGGCAATGA GATTCGAGAC 1024 GGGCTGGTGA AACTGAGTCA GCGGATCCTG GGACCATGCA CCATAGTCCA GGGTGCTCTG 1084 AAGAGCATCC TTCAGCGAAC CCCTCAGGAG TTCTATCACG ACACGTTAAG CTTCCTCAAG . 0 1144 TCCAATGCGG ACCTCTGCTA TGGGGCACTG GCTGCCATCC CTGGACTCCA GCCGGTCCGC 1204 CCTTCTGGAG CCATGTACCT TATGGTGGGA ATTGAGATGG AGCATTTCCC GGAATTCGAG 1264 AACGACGTGG AGTTCACAGA GCGGTTGAT GCGGAGCAGG CTGTCCACTG TCTCCCAGCA 1324 ACGTGCTTCG AGTACCCAAA TTTCTTCCGA GTGGTCATCA CAGTCCCCGA GGTGATGATG 1384 CTGGAGGCTT GTAGCCGGAT CCAGGAGTTC TGTGAACAGC ACTACCACTG TGCTGAAGGC 5 1444 AGCCAGGAGG AGTGTGACAA ATAAGC
(gene length is 2364, only region from 364 to 1469 shown)
Table 2. SPECIES #2, Rat Tyrosine Aminotransferase Gene Fragment used for competitive PCR (fragment from 1 to 277 in bold, band size: 277). 0
1 TCATGATCGA AGAGACGTTT TTGGCAATGA GATTCGAGAC GGGCTGGTGA AACTGAGTCA 61 GCGGATCCTG GGACCATGCA CCATAGTCCA GGGTGCTCTG AAGAGCATCC TTCAGCGAAC
, 121 CCCTCAGGAG TTCTATCACG ACACGTTAAG CTTCCTCAAG TCCAATGCGG ACCTCTGCTA 181 TGGGGCACTG GCTGCCATCC CTGGACTCCA GCCGGTCCGC CCTTCTGGAG CCATGTACCT 241 TATGGTGGGA ATTGAGATGG AGCATTTCCC GGAATTC
(gene length is 277, only region from 1 to 277 shown)
Table 3. SPECIES #3, Mouse Tyrosine Aminotransferase Gene Fragment used for competitive PCR (fragment from 57 to 275 in bold, band size: 220)
1 CCTTCAGAAG ATTTTGGCAG TGGCTGAAAG GCAATGCGTC CCCATCTTAG CCGATGAGAT 61 CTATGGTGAC ATGGTGTTTT CAGATTGCAA ATATGAACCA ATGGCCACCC TCAGCACCAA . 121 TGTCCCCATC CTGTCCTGTG GTGGGCTGGC CAAGCGCTGG CTGGTTCCTG GCTGGAGGCT 181 GGGCTGGATC CTTATCCATG ATCGAAGAGA CATTTTTGGC AATGAGATTC GGGACGGGCT 241 GGTGAAGCTG AGTCAGCGGA TCCTGGGCCC GTGCACCATC GTCCAAGGTG CCCTGAAGAG 301 CATCCTTCAG CGCACCCCTC AGGAGTTCTA CCAGGACACT TTAAGCTTCC TTAAGTCCAA 361 TGCGGACCTC TGCTATGGGG CGTTGTCTGC AATTCCTGGA CTCCAGCCAG TCCGCCCATC 421 TGGAGCCATG TACCTTATGG TGGGAATTGA GATGGAGCAC TTCCCAGAAT TTGAGAATGA 481 CGTGGAATTC ACAGAGCGGT TAATTGCGGC AGNNTCTGTC GNACTGCTCC AGCACGTGCT 541 TCGAGTACCA ATTTCTTCCG GGTGTCATAC AGTCCCCGAG TGATGATCCT G (gene length is 592, only region from 1 to 592 shown)
Table 4. Human Tyrosine Aminotransferase gene and protein sequence. >CG135823-01 2754 nt ATTGCCCCTGTAACCTGTCAAAGAAGAGCTAAGGGAGCTTTCGGGGTTGGCTTCTTGGAG
GCTGCTTTCTCCTTTACTTGGAAGGCTTCGCTAGTGATGGACCCATACATGATTCAGATG
AGCAGO-iAGGCAACCTCCCCTCAATTCTGGACGTGCATGTCAACGTTGGTGGGAGAAGC
TCTGTGCCGGGAAAAATGAAAGGCAGAAAGGCCAGGTGGTCTGTGAGGCCCTCAGACATG
GCC_ΛGAAAACTTTCΪ-\CCCC-vTCCGAGCC-VTTGTGGACAA(^TGAAGGTGAAACCAAAT CC__i_ΛAACCATGATTTCCCTGTCCATTGGGGACCCTACTGTGTTTGGAAACCTGCCT
ACAGACCCTGAAGTTACCCAGGCAATGAAAGATGCCCTGGACTCGGGCAAATATAATGGC
TATGCCCCATCCATCGGCTTCCTATCCAGTCGGGAGGAGATTGCTTCTTATTACCACTGT
CCTGAGGCACCCCTAGAAGCTAAGGACGTCATTCTGACAAGTGGCTGCAGCCAAGCTATT
GACCTTTGTTTAGCTGTGTTGGCCAACCCAGGGCAGAACATCCTGGTTCCAAGACCTGGT TTCTCTCTCTAO_\GACTCTGGCTGAGTCTATGGGAATTGAGGTCAAACTCTACAATTTG
TTGCCAGAGAAATCTTGGGAAATTGACCTGAAACAACTGGAATATCTAATTGATGAAAAG
AC-iGCTTGTCTCΛTTGTC-_iTAATCCATCAAACCCCTGTGGGTCAGTGTTCAGCAAACGT
CATCTTCAGAAGATTCTGGCAGTGGCTGCACGGCAGTGTGTCCCCATCTTAGCTGATGAG
ATCTATGGAGACATGGTGTTTTCGGATTGCAAATATGAACCACTGGCCACCCTCAGCACC GATGTCCCCATCCTGTCCTGTGGAGGGCTGGCCAAGCGCTGGCTGGTTCCTGGCTGGAGG
TTGGGCTGGATCCTCATTCATGACCGAAGAGACATTTTTGGCAATGAGATCCGAGATGGG
CTGGTGAAGCTGAGTCAGCGCATTTTGGGACCCTGTACCATTGTCCAGGGAGCTCTGAAA
AGCATCCTATGTCGCACCCCGGGAGAGTTTTACCACAACACTCTGAGCTTCCTCAAGTCC
AATGCTGATC^CTGTTATGGGGCGTTGGCTGCCATCCCTGGACTCCGGCCAGTCCGCCCT TCTGGGGCTATGTACCTCATGGTTGGAATTGAGATGGAACATTTCCCAGAATTTGAGAAC
GATGTGGAGTTCACGGAGCGGTTAGTTGCTGAGCAGTCTGTCCACTGCCTCCCAGCAACG
TGCTTTGAGTACCCGAATTTCATCCGAGTGGTCATCACAGTCCCCGAGGTGATGATGCTG
GAGGCGTGCAGCCGGATCCAGGAGTTCTGTGAGCAGCACTACCATTGTGCTGAAGGCAGC
CAGGAGGAGTGTGATAAATAGGCCTGCATCCATTCTCCTGAGGATGTGTCCCATCTAGGG AAGGCTGGACTAGGCCTTGCGGCTCCTCAGGGACTCAGGTGGCCCTACTGGGAGAGGGGC
CTC-_ATGCACCATGTC_AGGGTT(_AGATTGTTCCTGCTTTTCCCCAAGTAC_ACCACA
CCCACaCTCAGATCCTCCT^TTCΛCATCG(_ιGATTACrCCCTTGCTCTGCGCTGCTAGA
GTGACTCACTAATTCATTAATCTGCCTCCCTCTCGTAAGATTTCCTTCTTTTTTTTCTTG
AAAGTAC(_vGGTGAAα__GTTTACCAGAAAGCaGTTGAGACAAGAAAATAAGAGCTCAG GATGAGGGAAAAGAAAAAGATTGAGAGAATTTGTGCCCCCAACCATTTCCTCAGACTCTA
AGAAAGAAC-iCGCTCTCTCCAGGC-iGGTCTGAAGCTCAACTCTCTTATTGCCTCACTTCA
GGTATACCTCaCTTTACACAATAGAATTATAACTGGAAAGAAGTTGGGGACACATGTATT
TGGTGATTACaTTTTAAAC_caTTAGGAAAAGTTGCTATTTGAACTTTTTATTGATTTTT
GGGGGGAGTAAAGAATTATTTTGGATGCAAATAAATATCCTTTAATTGATCGACTTGCCA AATTTAGATTTGTGTGCATCAGGCTTTCTTTTTTTTCTTTTTTTAGAGAAGTTCAATATA
AGCTTTTCTTTTCTTTGTTTCTTTCTTTCTTTATTTTGAGATGGAGTCTTGCTCTGTCGC
C_\TGCTGGAGTGCAGTGGCGCGATCTCGGCTCACTGαΛCCTCra.CCTCCTGGGTTCAA
GCGATTCTCTTGCCTCAACCTCCCAAGCAGTTGGGACTACAGGCGTGAGCCACCATGCCC
GGCTAATTTTTGTATTTTTAGTAGAGACAGGGTTTCACCATGTTAGCCAGGCTGGTCTCA AACTCCTGACCTCAGGCAATCTGCCCGCCTGGGTCTCCTAAAGTACTGGGATTACAGGCG
TGAGCCACCTCGCCCAGCGGCATCAGGCTTTCTTAAAGTGAGAGCACGCCTGTACTAGAG
C-U\G_ιGGAATaGAGACCTTCCAGAAATACTACTGTGTAAGGGCC-iGAAATATCTTCAC
TTGTCATTGTTATATAATCATTATTACTTTTGCTGTAATGTTAATATTGATTTATTAATA
TATATTATCTTTTCATACATTTTCTAAGAAACATTTATATTGATAAGATCTTTTATTTTG C-_VGGG_ιTAAATTATTGTTTTTCTTTTTTTTTTTTTAATAAATTTCACCAAGT
Table 5. Amino Acid sequence of Human Aminotransferase ORF Start: 97 ORF Stop: 1459 Frame: 1
Human Tyrosine Aminotransferase Protein Sequence: >CG135823-01-prot 454 aa
MDPYMIQMSSKGN PSI1_)VHVNVGGRSSVPGKMKGRKARWSVRPSD AKKTFNPIRAIV
DmKVKPNPNKTMISLSIGDPTVFGl—PTDPEOTQAM^
EIASYYHCPEAPLEAKDVI TSGCSQAID CIΛVLANPGQNILVPRPGFS YKTLAESMG
I_^KLYNIJLPEKSWEID_KQ EYLIDEKTAC IVNNPSNPCGSVFSKRHLQKILAVAARQ
CVPI ADEIYGDMVFSDCKYEPLATLSTDVPI SCGG AKRW VPGWR GWI IHDRRDI
FGNEIRDG VKLSQRILGPCTIVQGALKSI CRTPGEFYHNT SF KSNADLCYGALAAI
PG RPVRPSGAMY MVGIEMEHFPEFE DVEFTERLVAEQSVHC PATCFEYPNFIRWI
TVPEVMM EACSRIQEFCEQHYHCAEGSQEECDK
Table 6. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of the human (CG135823-01) and rat versions of the Tyrosine Aminotransferase.
TAT rat TDVDDSMSB CGli5823-01 SS GNHPf ______.A _B.ϋ-l;!fll1J
TAT_rat CG135823-01 ______________________
TAT rat CG135823-01 ____________ ! ______________
TAT rat CG135823-01 ______________ SH______ffl
TAT_rat CG135823-01 _________U_ϋ_ϋϋ.:il:_____β El
TAT_rat CG135823-01 g__§______ϋ__ϋli
Human Tyrosine Aminotransferase:
Locus: 16q22.1 (QTL for intracellular fat on 16q22) Intracellular
Biochemistry and Cell Line Expression
Tyrosine Aminotransferase catalyses the following reaction:
L-Tyrosine + 2-Oxoglutarate = 4-hydroxyphenylpyruvate + L-glutamate, using pyridoxal 5 '-phosphate as a cofactor.
Tyrosine Aminotransferase activity was measured usually by fix-time assay (measurement of tyrosine absorbance by spectrophotometry). Liver extract, primary hepatocytes and different hepatocyte cell lines were reported to utilize as a source of TAT. Cell lines expressing the Tyrosine Aminotransferase can be obtained from the RTQ-PCR results shown above. These and other Tyrosine Aminotransferase expressing cell lines could be used for screening puφoses.
In addition to the human version of the Tyrosine Aminotransferase identified as being differentially expressed in the experimental study, other variants have been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases. No splice-form variants have been identified at CuraGen whereas several amino acid-changing cSNPs were identified in literature. Described below SNPs cause activity deficiency of TAT and were associated with disease called tyrosinemia, type II.
Natt E, Kida K, Odievre M, Di Rocco M, Scherer G.
Point mutations in the tyrosine aminotransferase gene in tyrosinemia type II.
Proc. Natl. Acad. Sci. U S A 1992 Oct 1;89(19):9297-301.
PMID: 1357662
Table 7. Variants of the human Tyrosine Aminotransferase obtained from direct cloning and/or public databases.
There are several reasons to use tyrosine aminotiansferase as a diagnostic and/or target for small molecule drugs and antibody therapeutics.:
1. Tyrosine Aminotransferase is a rate-limiting enzyme in phenylalanine/tyrosine catabolism, which may contribute to gluconeogenesis and lipid biosynthesis. The level of enzyme is induced by glucocorticoids, and the excess of glucocorticoids frequently results in obesity, insulin resistance and glucose intolerance.
2. Up-regulation of TAT in MB.05 study may contribute to insulin resistance in HTG rats, in MB.01 - to hyperglycemia in SHR rats. Down-regulation of TAT in response to teoglitazone treatment in MB.01 study suggests that TAT may be one of downstream targets for this antidiabetic drug.
3. On the other hand, down-regulation of TAT in BP24.02 study may represent the compensatory mechanism to decrease lipid biosynthesis in obese animals.
4. Taken in total, the data indicates that an inhibitor of the human Tyrosine Aminotransferase would be beneficial in the treatment of obesity.
Body Weight Distribution by STD
mean mean mean mean mean mean mean mean mean chow + chow + chow + chow + chow + chow + chow + chow + chow +
<1SD 2 SD 3 SD 4 SD 5 SD 6 SD 7 SD 8 SD 9 SD
Figure 1. Bar Graph of Diet induced obesity Under Discovery Process BP24.2.
Species #1 Rat Strains HTG, Lewis, istar
Species #2 Rat Strains SHR, SD
Species #3 Mouse Strains C57BL/6J
Figures 2A, 2B, 2C, 2D, 2E, and 2F. Differentially expressed gene fragments in rat (SPECIES #1); rat (SPECIES #2) and mouse (SPECIES #3) Tyrosine Aminotransferase. SPECIES #1. Figures 2 A and 2B show differentially expressed gene fragments in Discovery Study MB.05 from the rat tyrosine aminotiansferase (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as a signal response). A gene fragment of the rat Tyrosine Aminotiansferase was initially found to be up-regulated by 1.7 fold in the muscle and liver tissues of HTG rat relative to normal contiol rat strain using CuraGen's GeneCalling ™ method of differential gene expression. A differentially expressed rat gene fragment migrating, at approximately 145 nucleotides in length (Figure 2A - red vertical line) was definitively identified as a component of the rat Tyrosine Aminotiansferase cDNA. The method of competitive PCR was used for conformation of the gene assessment. The electiopherogramatic peaks coπesponding to the gene fragment of the rat Tyrosine Aminotransferase are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The peaks at 145 nt in length are ablated (green trace) in the sample from both the HTG and control rats.
SPECIES #2. Figures 2C and 2D show differentially expressed gene fragments in Discovery Study MB.01 from rat tyrosine aminotransferase (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as a signal response). The gene fragments coπesponding to the rat TAT were found to be up-regulated in liver tissues of SHR rat relative to normal control rat strain, and to be down-regulated in the liver of SHR rat in response to tioglitazone treatment. A differentially expressed rat gene fragment migrating, at approximately 277.4 nucleotides in length (Figure 2C - red vertical line) was definitively identified as a component of the rat Tyrosine Aminotransferase cDNA by the method of competitive PCR. The electiopherogramatic peaks coπesponding to the gene fragment of the rat Tyrosine Aminotransferase are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The
peaks at 277.4 nt in length are ablated (green teace) in the sample from both the SHR rat liver treated and untreated with teoglitazone.
SPECIES #3 Figures 2E and 2F show differentially expressed gene fragments in Discovery Study BP24.02 from mouse tyrosine aminotransferase (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as a signal response). Additionally, gene fragments coπesponding to the mouse TAT were found to be down-regulated in liver tissues of hyperglycemic fat mouse (hgsd7) relative to normal animal on low fat diet (chow) in a mouse model of dietary-induced obesity. A differentially expressed mouse gene fragment migrating, at approximately 220.3 nucleotides in length (Figure 2 A - red vertical line) was definitively identified as a component of the mouse Tyrosine Aminotransferase cDNA by the method of competitive PCR. The chromatographic peaks corresponding to the gene fragment of the mouse Tyrosine Aminotransferase are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification in the sample from both the hyperglycemic fat mouse relative and normal animals. The altered expression in of these genes in the animal model support the role of the Tyrosine Aminotransferase in the pathogenesis of obesity and/or diabetes.
SPECIES #1
SPECIES #3
Se BQEA Q control (PID:251301)| j-poison (PE:251301)
Figure 3. SAGE Data Results
SAGE Duke 1273 128 * 5 38836 SAGE Pake H1020 76 ^β 4 52371 SAGEHCTU6 11 o ^PJPJ ' 7 60322 SAGE CAP H1 158 :Bβ 6 37926
SAGEQV1063-3 105? Mϋlttf 5 38938 SAGET-102 121 ^βlBfe 7 57636
SAGE293-IND !_!_■ ^^K ^ 3 24481
adrenal gland
p-hydrophenvlpyruvate
homogentisate
ΉCD Dopamine maleylacetoacetate
10 Nonepinephrine GSTZ fumarylacetoacetate
Epinephrine
lipolysis fumarate + acetoacetate GJgiconeogenesis Lipid biosynthesis
Figure 4 shows pathways that are relevant to the etiology and pathogenesis of obesity and/or diabetes. This figure illustrates the catabolism of tyrosine and phenylalanine
20 and suggests how alterations in expression of the human Tyrosine Aminotransferase and associated gene products function in the etiology and pathogenesis of obesity and/or diabetes. The scheme incoφorates the unique findings of these discovery studies in conjunction with what has been reported in the literature. The outcome of inhibiting the action of the human Tyrosine Aminotransferase would inhibit the contribution of these
25 catabolic pathways to gluconeogenesis and lipid biosynthesis and would be beneficial for the treatment of obesity and/or diabetes.
C. NOV13A - Human Polyamine oxidase - CG140122-01
The present invention discloses novel associations of proteins and polypeptides and the nucleic acids that encode them with various diseases or pathologies. The proteins and related proteins that are similar to them, are encoded by a cDNA and/or by genomic DNA. The proteins, polypeptides and their cognate nucleic acids were identified by CuraGen Coφoration in certain cases. The Polyamine Oxidase -encoded protein and any variants, thereof, are suitable as diagnostic markers, targets for an antibody therapeutic and targets for small molecule drugs. As such the current invention embodies the use of recombinantly expressed and/or endogenously expressed protein in various screens to identify such therapeutic antibodies and/or therapeutic small molecules.
Discovery Process
The following sections describe the study design(s) and the techniques used to identify the Polyamine oxidase-encoded protein and any variants, thereof, as being suitable as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for Obesity and Diabetes.
Studies: MB04. Mouse obesity model (genetic) Study Statements:
A large number of mouse strains have been identified that differ in body mass and composition. The AKR and NZB steains are obese, the SWR, C57L and C57BL/6 strains are of average weight whereas the SM/J and Cast/Ei steains are lean. Understanding the gene expression differences in the major metabolic tissues ftom these steains will elucidate the pathophysiologic basis for obesity. These specific steains of rat were chosen for differential gene expression analysis because quantitative trait loci (QTL) for body weight and related teaits had been reported in published genetic studies. Tissues included whole brain, skeletal muscle, visceral adipose, and liver.
MB.08. Human Mesenchymal Stem Cell differentiation
Bone maπow-derived human mesenchymal stem cells have the capacity to differentiate into muscle, adipose, cartilage and bone. Culture conditions have been established that permit the differentiation in vitro along the pathway to adipose, cartilage and bone. Understanding the gene expression changes that accompany these distinct differentiation
processes would be of considerable biologic value. Regulation of adipocyte differentiation would have importance in the treatment of obesity, diabetes and hypertension. Human mesenchymal stem cells from 3 donors were obtained and differentiated in vitro according to published methods. RNA ftom samples of the undifferentiated, mid-way differentiated and fully differentiated cells was isolated for analysis of differential gene expression.
BP24.2. Diet induced obesity
The predominant cause for obesity in clinical populations is excess caloric intake. This so-called diet-induced obesity (DIO) is mimicked in animal models by feeding high fat diets of greater than 40% fat content. The DIO study was established to identify the gene expression changes contributing to the development and progression of diet-induced obesity. In addition, the study design seeks to identify the factors that lead to the ability of certain individuals to resist the effects of a high fat diet and thereby prevent obesity. The sample groups for the study had body weights +1 S.D., + 4 S.D. and + 7 S.D. of the chow- fed contiols (below). In addition, the biochemical profile of the + 7 S.D. mice revealed a further stratification of these animals into mice that retained a normal glycemic profile in spite of obesity and mice that demonstrated hyperglycemia. Tissues examined included hypothalamus, brainstem, liver, reteoperitoneal white adipose tissue (WAT), epididymal WAT, brown adipose tissue (BAT), gasteocnemius muscle (fast twitch skeletal muscle) and soleus muscle (slow twitch skeletal muscle). The differential gene expression profiles for these tissues should reveal genes and pathways that can be used as therapeutic targets for obesity. The bar graph in Figure 1 indicates results.
Polyamine oxidase: In multiple genecalling studies we have found the enzyme spermidine/spermine acetyl fransferase to be dysregulated in various disease models (see below). This enzyme is one of the rate-limiting enzymes in the production of polyamines spermidine and spermine (see Figure 6). Figure 6 shows pathways where alterations in expression of the human polyamine oxidase and associated gene products function in the etiology and pathogenesis of obesity and/or diabetes. The scheme incorporates the unique findings of these discovery studies in conjunction with what has been reported in the literature. The outcome of inhibiting the action of the human polyamine oxidase would be a way to increase lypolysis by inhibiting anti-lypolytic effects of hydrogen peroxide..
Previously, it was shown that oxidation of polyamines leads to generation of hydrogen peroxide, which has been shown to have antilipolytic effect of adipose and may therefore be involved in the progression of obesity. The enzyme catalyzing the reaction where hydrogen peroxide is produced, i.e. oxidation of secondary amino group of spermine, 5 spermidine and their acetyl derivatives, is polyamine oxidase. Therefore, we nominate the enzyme polyamine oxidase as a valuable tool to inhibit the polyamine pathway and the production of hydrogen peroxide.
Rationale for use as a diagnostic and/or target for small molecule drugs and antibody 10 therapeutics:
The following is a summary of the findings from the discovery studies, supplementary investigations and assays that also incoφorates knowledge in the scientific literature. Taken in total, the data indicates that an inhibitor/antagonist of the human Polyamine oxidase would be beneficial in the treatment of obesity and/or diabetes (Figure 5
15 shows biochemistry for human polyamine oxidase and assays that may be used to screen for antibody therapeutics or small molecule drugs to treat obesity and/or diabetes. Cell lines expressing the polyamine oxidase can be obtained from the RTQ-PCR results shown above. These and other polyamine oxidase-expressing cell lines could be used for screening puφoses.
20
Table 1. Spermidine/spermine N-acetylteansferase Gene Sequence identified in NZB vs SM/J mice
(Identified fragment from 206 to 616 in bold, band size: 411) 25
.1 GCTCCCGGGA AACGAATGAG GAACCACCTC CTCCTGCTGT TCAAGTACAG GGGCCTGGTG
61 CGCAAAGGGA AGAAAAGCAA AAGACGAAAA TGGCTAAATT TAAGATCCGT CCAGCCACTG.
121 CCTCTGACTG CAGTGACATC CTGCGACTGA TCAAGGAACT GGCTAAATAT GAATACATGG
30. 181 AAGATCAAGT CATTTTAACT GAGAAAGATC TCCAAGAGGA TGGCTTTGGA GAACACCCCT
241 TCTACCACTG CCTGGTTGCA GAAGTGCCTA AAGAGCACTβ GACCCCTGAA GGACATAGCA
301 TTGTTGGGTT CGCCATGTAC TATTTTACCT ATGACCCATG GATTGGCAAG TTGCTGTATC
.361 TTGA&GACTT C-TCGTGATG AGTGATTACA GAGGCTTTGG TATAGGATCA GAAATTTTGA
421 AGAATCTAAG CCAGGTTGCC ATGAAGTGTC GCTGCAGCAG TA-GCACTTC TTGGTAGCAG
35 . 481 AATGGAATGA ACCATCTATC AACTTCTACA AAAGAAGAGG TGCTTCGGAT CTGTCCAGTG
541 AAGAGGGATG GAGGCTCTTC AAGATTGACA AAGACTACTT GC.AAAAATG GCAGCAGAGG
601 AGTGAGGCGT GCCGGTGTAG ACAATGACAA CCTCCATTGT GCTTTAGAAT. AATTCTCAGC
661 TTCCCTTGCT TTCTATCTTG TGTGTAGTGA AATAATAGAG CGAGCACCCA TTCCAAAGCT
721 TTATTACCAG TGACGTTGTT GCATGTTTGA AATTCGGTCT GΪTTAAAGTG GCAGTCATGT
40 781. ATGTGGTTTG GAGGCAGAAT TCTTGAACAT CTTTTGATGA AGAACAAGGT GGTATGATCT.
..841 TACTATATAA GAAAAACAAA ACTTCATTCT TGTGAGTCAT TTAAATGTGT ACAATGTACA
901. CACTGGTACT TAGAGTTTCT GTTTTGATTC TTTTTTTTTA AATAAACTCG CTCTTTGATT
961 T
45
Table 2. Spermidine/spermine N-acetylteansferase Gene Sequence identified in C57B1/6 obese euglycemic sd7 vs obese sdl
(Identified fragment from 716 to 893 in bold, band size: 178) 235 ACCCCTTCTA CCACTGCCTG GTTGCAGAAG TGCCTAAAGA GCACTGGACC CCTGAAGGAC 295 ATAGCATTGT TGGGTTCGCC ATGTACTATT TTACCTATGA CCCATGGATT GGCAAGTTGC 355 TGTATCTTGA AGACTTCTTC GTGATGAGTG ATTACAGAGG CTTTGGTATA GGATCAGAAA 415 TTTTGAAGAA TCTAAGCCAG GTTGCCATGA AGTGTCGCTG CAGCAGTATG CACTTCTTGG 475 TAGCAGAATG GAATGAACCA TCTATCAACT TCTACAAAAG AAGAGGTGCT TCGGATCTGT 535 CCAGTGAAGA GGGATGGAGG CTCTTCAAGA TTGACAAAGA GTACTTGCTA AAAATGGCAG 595 CAGAGGAGTG AGGCGTGCCG GTGTAGACAA TGACAACCTC CATTGTGCTT TAGAATAATT 655 CTCAGCTTCC CTTGCTTTCT ATCTTGTGTG TAGTGAAATA ATAGAGCGAG CACCCATTCC 715 AAAGCTTTAT TACCAGTGAC GTTGTTGCAT GTTTGAAATT CGGTCTGTT AAAGTGGCAG 775 TCATGTATGT GGXTTGGAGG CAGAATTCTT GAACATCTTT TGATGAAGAA CAAGGTGGTA 835 TGATCTTACT. ATATAAGAAA AACAAAACTT CATTCTTGTG AGTCATTTAA ATGTGTACAA 895 TGTACACACT GGTACTTAGA GTTTCTGTTT TGATTCTTTT TTTTTAAATA AACTCGCTCT 955 TTGATTT
Table 3. Spermidine/spermine N-acetylteansferase Gene Sequence identified in human adipocyte mid-way vs undifferentiated (Identified fragment from 162 to 355 in bold, band size: 149)
1 CTGGTGTTTA TCCGTCACTC GCCGAGGTTC CTTGGGTCAT GGTGCCAGCC TGACTGAGAA 61 GAGGACGCTC CCGGGAGACG AATGAGGAAC CACCTCCTCC TACTGTTCAA GTACAGGGGC 121 CTGGTCCGCA AAGGGAAGAA AAGCAAAAGA CGAAAATGGC TAAATTCGTG ATCCGCCCAG 181 CCACTGCCGC CGACTGCAGT GACATACTGC GGCTGATCAA GGAGCTGGCT AAATATGAAT 241 ACATGGAAGA ACAAGTAATC TTAACTGAAA AAGATCTGCT AGAAGATGGT TTTGGAGAGC 301 ACCCCTTTTA CCACTGCCTG GTTGCAGAAG TGCCGAAAGA GCACTGGACT CCGGAAGGTT 361 ACAGTCTCTA GCTTCGCCAT GTACATGGCC CTTCCGTGTA CATGGATGGG CGGGGAGGTA 421 ACTAAAAGAT CCTTTACACA ATAAAGTAGA TGATCATGAT AAATGAGGAC ACAGCATTGT 481 TGGTTTTGCC ATGTACTATT TTACCTATGA CCCGTGGATT GGCAAGTTAT TGTATCTTGA 541 GGACTTCTTC GTGATGAGTG ATTATAGAGG CTTTGGCATA GGATCAGAAA TTCTGAAGAA 601 TCTAAGCCAG GTTGCAATGA GGTGTCGCTG CAGCAGCATG CACTTCTTGG TAGCAGAATG 661 GAATGAACCA TCCATCAACT TCTATAAAAG AAGAGGTGCT TCTGATCTGT CCAGTGAAGA 721 GGGTTGGAGA CTGTTCAAGA TCGACAAGGA GTACTTGCTA AAAATGGCAA CAGAGGAGTG 781 AGGAGTGCTG CTGTAGATGA CAACCTCCAT TCTATTTTAG AATAAATTCC CAACT
Table 4. Human Polyamine Oxidase (CG140122-01) DNA and Protein Sequence
CGCCGCTCGCCGCAGACTTACTTCCCCGGCTCAGCAGGGAAAGGTTCCTAGAAGGTGAGC GCGGACGGTATGCAAAGTTGTGAATCCAGTGGTGACAGTGCGGATGACCCTCTCAGTCGC
GGCCTACGGAGAAGGGGACAGCCTCGTGTGGTGGTGATCGGCGCCGGCTTGGCTGGCCTG
GCTG_IGCC___IGCACTTCTTGAGCAGGGTTTCACGGATGTCACTGTGCTTGAGGCTTCC
AGCCACATCGGAGGCCGTGTGCAGAGTGTGAAACTTGGACACGCCACCTTTGAGCTGGGA
GCCACCTGGATCCATGGCTCCCATGGGAACCCTATCTATCATCTAGCAGAAGCCAACGGC CTCCTGGAAGAGACAACCGATGGGGAACGCAGCGTGGGCCGCATCAGCCTCTATTCCAAG
AATGGCGTGGCCTGCTACCTTACCAACCACGGCCGCAGGATCCCCAAGGACGTGGTTGAG
GAATTCAGCGATTTATACAACGAGGTCTATAACTTGACCCAGGAGTTCTTCCGGCACGAT
AAAC_\GTCAATGCTGAAAGTCAAAATAGCGTGGGGGTGTTCACCCGAGAGGAGGTGCGT
AACCGCATCAGGAATGACCCTGACGACCCAGAGGCTACCAAGCGCCTGAAGCTCGCCATG ATCCAGCAGTACCTGAAGGTGGAGAGCTGTGAGAGCAGCTCACACAGCATGGACGAGGTG
TCCCTGAGCGCCTTCGGGGAGTGGACCGAGATCCCCGGCGCTCACCACATCATCCCCTCG
GGCTTCATGCGGGTTGTGGAGCTGCTGGCGGAGGGCATCCCTGCCCACGTCATCCAGCTA
GGGAAACCTGTCCGCTGCATTCACTGGGACCAGGCCTCAGCCCGCCCCAGAGGCCCTGAG
ATTGAGCCCCGGGGTGAGGGCGACCACAATCACGACACTGGGGAGGGTGGCCAGGGTGGA
GAGGAGCCCCGGGGGGGCAGGTGGGATGAGGATGAGCAGTGGTCGGTGGTGGTGGAGTGC
GAGGACCGTGAGCTGATCCCGGCGGACCATGTGATTGTGACCGTGTCGCTAGGTGTGCTA
AAGAGGCAGTACACCAGTTTCTTCCGGCCAGGCCTGCCCACAGAGAAGGTGGCTGCCATC
CACCGCCTGGGCATTGGCACCACCGACAAGATCTTTCTGGAATTCGAGGAGCCCTTCTGG
GGCCCTGAGTGCAACAGCCTACAGTTTGTGTGGGAGGACGAAGCGGAGAGCCACACCCTC
ACCTACCCACCTGAGCTCTGGTACCGCAAGATCTGCGGCTTTGATGTCCTCTACCCGCCT
GAGCGCTACGGCCATGTGCTGAGCGGCTGGATCTGCGGGGAGGAGGCCCTCGTCATGGAG
AAGTGTGATGACGAGGCAGTGGCCGAGATCTGCACGGAGATGCTGCGTCAGTTCACAGGG
AACCCCAACATTCC__ACCΓCGGCGAATCTTGCGCTCGGCCTGGGGCAGCAACCCTTAC
TTCCGTGGCTCCTATTCATACACGCAGGTGGGCTCCAGCGGGGCGGATGTGGAGAAGCTG
GCCAAGCCCCTGCCGTACACGGAGAGCTCAAAGACAGCGCCCATGCAGGTGCTGTTTTCC GGTGAGGCCACCCACCGCAAGTACTATTCCACCACCCACGGTGCTCTGCTGTCCGGCCAG CGTGAGGCTGCCCGCCTCATTGAGATGTACCGAGACCTCTTCCAGCAGGGGACCTGAGGG CTGTCCTCGCTGCTGAGAAGAGCCACTAACTCGTGACCTCCAGCCTGCCCCTTGCTGCCG TGTGCTCCTGCCTTCCTGATCCTCTGTAGAAAGGATTTTTATCTTCTGTAGAGCTAGCCG CCCTGACTGCCTTCAGACCTGGCCCTGTAGCTTT
Table 5. CG140122-01-prot 325 aa
MQSCESSGDSADDP SRGLRRRGQPRVWIGAGLAG AAAKALLEQGFTDVTVLEASSHI GGRVQSVK GHATFE GATWIHGSHGNPIYH AEANG LEETTDGERSVGRISLYSKNGV ACY TNHGRRIPKDWEEFSDLΎNEVYNLTQEFFRHDKPVNAESQNSVGVFTREEVRNRI RM5PDDP_^TKRLKIΛMIQQYLK_SCESSSHSMDEVSLSAFGEWTEIPGAHHIIPSGFM RVVELLAEGIPAHVIQ GKPVRCIH DQASARPRGPEIEPRGEGDH HDTGEGGQGGEEP RGGRWBEDEQWSVWECEDRE-IPADHVIV VSLGV KRQYTSFFRPG-PTEKVAAIHRI GIGTTDKIFLEFEEPFWGPECNSLQFVWEDEAESHT TYPPE WYRKICGFDV YPPERY GHVLSGWICGEEALVMEKCDDEAVAEICTEM RQFTGNPNIPKPRRI RSAWGSNPYFRG _YSYTQVGSSGAD-_K__PLPYTE_SKTAPMQVLFSGEATHRKYYSTTHGAL_SGQREA AR I EMYRD FQQGT
Table 6. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of CGI 40122-01 and its alternative spliced variant CGI 40122-02, which are the equivalent of the public sequences AY033889 and BC000669.1, respectively. They are clustalled with the polyamine oxidase of Zea Mays, of which the structural analysis has revealed much of the domain structure of this amine oxidase. The region in bold represents the amine oxidase domain. The dotted region reprsents the signal peptide.
CG140122_0l_AY033889 555
CG140122_02_BC000669.1 502
Q9FXZ9_PAO_Zea_ma s 500
The variants of the human Polyamine oxidase obtained from direct cloning and/or public databases:
In addition to the human version of the Polyamine oxidase identified as being differentially expressed in the experimental study, no other variants have been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases. The two alternative spliced variants (see clustalW above) are public sequences; no other splice variants have been identified at CuraGen. No SNPs have been found for polyamine oxidase. The prefeπed variant of all those identified, to be used for screening puφoses, is CGI 40122-01.
Figure 1. Bar Graph of Diet induced obesity Under Discovery Process BP24.2.
Body Weight Distribution by STD
mean mean mean mean mean mean mean mean mean chow + chow + chow + chow + chow + chow + chow + chow ÷ chow +
<1SD 2 SD 3 SD 4 SD 5 SD 6 SD 7 SD 8 SD 9 SD
Species #1 mouse Strains NZB, SM/J, C56B1/6 Species # 2 Human
SPECIES #1 mouse (NZB vs SM/J):
A gene fragment of the mouse spermine/speπnidine N-acetylteansferase was initially found to be upregulated by 1.9 fold in the adipose of NZB mice relative to SM/J
mice using CuraGen's GeneCalling ™ method of differential gene expression. A differentially expressed mouse gene fragment migrating at approximately 411 nucleotides in length (Figure la. - red vertical line) was definitively identified as a component of the mouse spermine/spermidine N-acetyltiansferase cDNA in NZB and SM/J mouse strains. The method of competitive PCR was used for conformation of the gene assessment. The chromatographic peaks coπesponding to the gene fragment of the mouse speimidine/spermine N-acetylteansferase are ablated when a gene-specific primer (see below) which competes with primers in the linker-adaptors during the PCR amplification. The peaks at 411 nt in length are ablated (green teace) in the sample from both the NZB and the SM/J mice. The altered expression in of these genes in the animal model support the role of Polyamine Oxidase in the pathogenesis of obesity and/or diabetes.
SPECIES #1 mouse (C57B1/6 obese euglycemic sd7 vs obese sdl):
Figures 3 A and 3B show that a differentially expressed gene fragment of the mouse spermine/spermidine N-acetylteansferase was initially found to be upregulated by 1.8 fold in the epididymal fat pad of the obese euglycemic sd7 mice relative to the obese sdl mice using CuraGen's GeneCalling ™ method of differential gene expression. A differentially expressed rat gene fragment migrating at approximately 178 nucleotides in length (Figures 3 A and 3B- vertical line) was definitively identified as a component of the mouse spermine/speπnidine N-acetylteansferase cDNA in the Troglitazone treated and the untreated SHR control rats (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as signal response). The method of competitive PCR was used for conformation of the gene assessment. The electiopherogramatic peaks coπesponding to the gene fragment of the mouse spermidine/spermine N-acetylteansferase are ablated when a gene-specific primer (see below) which competes with primers in the linker-adaptors during the PCR amplification. The peaks at 178 nt in length are ablated (green trace) in the sample from both the C57B1/6 obese euglycemic sd7 and obese sdl mice. The altered expression in of these genes in the animal model support the role of Polyamine Oxidase in the pathogenesis of obesity and/or diabetes.
SPECIES #2 human (adipocyte mid-way vs undifferentiated):
Figure 4 shows a differentially expressed gene fragment in Discovery Study MB.08 identified in human adipocyte mid-way vs undifferentiated is from the human
spermidine/spermine N-acetylteansferase A gene fragment of the human spermine/speπnidine N-acetylteansferase was initially found to be upregulated by 1.6 fold in the mid-way human adipocytes relative to the undifferentiated human adipocytes using CuraGen's GeneCalling ™ method of differential gene expression. A differentially expressed human gene fragment migrating at approximately 194 nucleotides in length (Figure 3 A - vertical line) was definitively identified as a component of the human spermine/speπnidine N-acetylteansferase cDNA in human mid-way differentiated and undifferentiated adipocytes (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as signal response). The method of competitive PCR was used for conformation of the gene assessment. The chromatographic peaks coπesponding to the gene fragment of the human spermine/spermidine N-acetylteansferase are ablated when a gene-specific primer (see below) which competes with primers in the linker-adaptors during the PCR amplification. The peaks at 194 nt in length are ablated (green teace) in the sample from both the human mid-way differentiated and undifferentiated adipocytes. The altered expression of these genes in the human cellular model support the role of Polyamine Oxidase in the pathogenesis of obesity and/or diabetes.
Figures 2A and 2B. Differential Expression of Gene Fragment from Mouse Spermidine/speπnine N-acetylteansferase.
Figures 3A and 3B. Differentially Expressed Gene Fragment from C57BI/6 Obese Euglycemic sd7 Mouse Spermidine/spermine N-acetylteansferase.
Figure 4. Differentially Expressed Gene Fragment in Human from Human Spermidine/speπnine N-acetyltiansferase.
Figure 5. Human Polyamine Oxidase and Assays for Cell Line Expression
■ Ornithine putrescine spermidine spermine
H202 Nac-Spermidine H202 Nac-Spermi]
ODC = omithine decarboxylase PAO = polyamine oxidase
SSAT = spermidine/spermine N-acetylteansferase
Biochemistry of PAO:
•Catalyses oxidation of secondary amino group of spermine, spermidine and their acetyl derivatives
• CofactorFAD
•Monomeric
The following illustration suggests how alterations in expression of the human polyamine oxidase and associated gene products function in the etiology and pathogenesis of obesity and/or diabetes. The scheme incoφorates the unique findings of these discovery studies in conjunction with what has been reported in the literature. The outcome of inhibiting the action of the human polyamine oxidase would be a way to increase lypolysis by inhibiting anti-lypolytic effects of hydrogen peroxide.
Ornithine
An Vtilipolysis Increased obesity
ODC = ornithine decarboxylase
PAO = polyamine oxidase
SSAT = spermidine/spermine N-acetylteansferase
D. NOV 14a - Human Cytoplasmic Malic Enzyme- CGI 40316-01
The present invention discloses novel associations of proteins and polypeptides and the nucleic acids that encode them with various diseases or pathologies. The proteins and related proteins that are similar to them are encoded by a cDNA and/or by genomic DNA. The proteins, polypeptides and their cognate nucleic acids were identified by CuraGen Coφoration in certain cases. The Cytoplasmic Malic Enzyme -encoded protein and any variants, thereof, are suitable as diagnostic markers, targets for an antibody therapeutic and targets for small molecule drugs. As such the cuπent invention embodies the use of recombinantly expressed and/or endogenously expressed protein in various screens to identify such therapeutic antibodies and/or therapeutic small molecules.
Discovery Process
The following sections describe the study design(s) and the techniques used to identify the Cytoplasmic Malic Enzyme - encoded protein and any variants, thereof, as being suitable as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for Obesity and Diabetes.
Studies:
BP24.02 Dietary Induced Obesity in Mice MB .04 : Genetic Models of Obesity in Mice
Study Statements:
BP24.02: The predominant cause for obesity in clinical populations is excess caloric intake.
This so-called diet-induced obesity (DIO) is mimicked in animal models by feeding high fat diets of greater than 40% fat content. The DIO study was established to identify the gene expression changes contributing to the development and progression of diet-induced obesity. In addition, the study design seeks to identify the factors that lead to the ability of certain individuals to resist the effects of a high fat diet and thereby prevent obesity. The sample groups for the study had body weights +1. S.D., + 4 S.D. and + 7 S.D. of the chow- fed controls (below). In addition, the biochemical profile of the + 7 S.D. mice revealed a further stratification of these animals into mice that retained a normal glycemic profile in spite of obesity and mice that demonstrated hyperglycemia. Tissues examined included hypothalamus, brainstem, liver, retroperitoneal white adipose tissue (WAT), epididymal
WAT, brown adipose tissue (BAT), gastiocnemius muscle (fast twitch skeletal muscle) and soleus muscle (slow twitch skeletal muscle). The differential gene expression profiles for these tissues should reveal genes and pathways that can be used as therapeutic targets for obesity.
MB.04: A large number of mouse strains have been identified that differ in body mass and composition. The AKR and NZB steains are obese, the SWR, C57L and C57BL/6 strains are of average weight whereas the SM/J and Cast/Ei steains are lean. Understanding the gene expression differences in the major metabolic tissues from these steains will elucidate the pathophysiological basis for obesity. These specific steains of rat were chosen for differential gene expression analysis because quantitative trait loci (QTL) for body weight and related traits had been reported in published genetic studies. Tissues included whole brain, skeletal muscle, visceral adipose, and liver.
Species #1 Mouse Strains C57BL/6
Species #2 Mouse Steains NZB, SMJ
Cytoplasmic Malic Enzyme: This gene encodes a cytosolic, NADP-dependent enzyme that generates NADPH for fatty acid biosynthesis. The NADP-dependent malic enzyme (EC 1.1.1.40) has two forms: cytosolic and mitochondrial, that differ significantly in their activity and tissue distribution. The activity of the cytosolic enzyme, the reversible oxidative decarboxylation of malate, links the glycolytic and citric acid cycles. The reaction it catalyzes is: Malate + NADP+ => Pyruvate +CO2 + NADPH
Cytoplasmic malic enzyme is one of the anaplerotic reactions, replenishing intermediates of the citrate cycle that are utilized for biosynthesis. It also participates in the pyruvate-citiate shuttle, enabling the export of acetyl CoA from the mitochondrion to cytoplasm for fatty acid synthesis.The regulation of expression for this gene is complex.
Increased expression can result from elevated levels of thyroid hormones or by higher proportions of carbohydrates in the diet.
The direct sequence of the nucleotide-long gene fragment and the gene-specific primers used for competitive PCR are indicated on the cDNA sequence of the Cytoplasmic Malic Enzyme and shown below in bold.
Competitive PCR Primer for the mouse Cytoplasmic Malic Enzyme:
Table 1. Sequence Gene Sequence #1 (fragment from 1520 to 1801 in bold, band size: 282)
1039 AAAGGACTAA TAGTTAAGGG TCGTGCATCT CTCACAGAAG AGAAAGAGGT GTTTGCCCAT 1099 GAACATGAAG AAATGAAGAA TCTGGAAGCC ATTGTTCAAA AGATAAAACC AACTGCCCTC
1159 ATAGGAGTTG CTGCAATTGG TGGTGCTTTC ACTGAACAAA TTCTCAAGGA TATGGCTGCC
1219 TTCAACGAGC GGCCCATCAT CTTTGCTTTG AGTAATCCGA CCAGCAAAGC GGAGTGCTCT
1279 GCAGAGCAGT GCTACAAGGT GACCAAGGGA CGTGCAATCT TTGCCAGCGG CAGTCC TTT
1339 GATCCAGTCA CTCTCCCAGA TGGACGGACT CTGTTTCCTG GCCAAGGCAA CAATTCCTAC 1399 GTGT CCCTG GAGTTGCTCT TGGGGTGGTG GCCTGCGGAC TGAGACACAT CGATGATAAG
1459 GTCTTCCTCA CCACTGCTGA GGTCATATCT CAGCAAGTGT CAGATAAACA CCTGCAAGAA
1519 GGCCGGCTCT ATCCTCCTTT GAATACCATT CGAGGCGTTT CGTTGAAAAT TGCAGTAAAG
1579 ATTGTGCAAG ATGCATACAA AGAAAAGATG GCCAC-GTTT ATCCTGAACC CCAAAACAAA
1639 GAAGAATTTG TCTCCTCCCA GATGTACAGC ACTAATTATG ACCAGATCCT ACCTGATTGT 1699 TATCCGTGGC CTGCAGAAGT CCAGAAAATA CAGACCAAAG TCAACCAGTA ACGCAACAGC
1759 TAGGATTTTT AACTTTATTA GTAAAATCTT GAAGTTTTCA TGATCTTTAA GGGTCAGAAT
1819 CTTTTATGAT GATTCATAGT GTGCTTAGAA TAAGGTGATT TTAGTTTAAT AACAAACTCA
1879 TGGGAGTCTA TTAGGATAAA TTAGGATAAA TTTCACACCA GACGGTTTTG TTTCACTTAC
1939 TGTGGATATT TATGTTTTCT CTTGTGATTA T CTCTTTAT GAATTCTGTT TAAAAGCTAC 1999 TGTACCTGCT GCTGAGAAAG TCCTCACTGA TATGTAGGAA GCTAATGGAA GACCCACACT
2059 AGTAATAAAT TAATATAGCA TAACTTGATT ACATTTAATG CCTACAGTTC TTTCTTGACT
2119 ATTTTGCTAA AATCTCTTAA ACAGAAAAGA TAAACACAAA CTTGGGTATA GC GAACTTT
2179 TACTAAACAG AAGCACTACT TTGTTGCCTA GAGAAAATCT TCTCAGGACT TTTATTCCAG
2239 GCCTCCGTTA GCTTTGTTCT CTTTGTACAC CTGACTCAAC ACC (gene length is 3105, only region from 1039 to 2281 shown)
Table 2. Sequence #2 Gene Sequence (fragment from 245 to 420 in bold, band size: 176)
1 CGCCGGGCGG CTTGGGGGGC CGCCGCCCGC CGGACTCCGC GTCCGCCCCG CCACCGGTGC 61 CAGCCATGGA GCCCCGAGCC CCCCGCCGCC GACACACCCA CCAGCGCGGC TACCTGCTGA 121 CGCGGGACCC GCATCTCAAC AAGGACTTGG CTTTTACTCT GGAAGAGAGA CAGCAGTTGA 181 ACATTCATGG ATTGTTGCCG CCCTGCATCA TCAGCCAGGA GCTCCAGGTC CTTAGAATAA 241 T AAGAATTT CGAACGACTG AACTCTGACT TCGACAGGTA TCTCCTGTTA ATGGACCTGC 301 AAGACAGAAA TGAGAAGCTC TTCTACAGCG TGCTCATGTC TGATGTTGAA AAGTTCATGC 361 CTATTGTTTA CACCCCCACC GTGGGCCTCG CATGCCAGCA GTACAGTT G GCATTCCGGA 421 AGCCAAGAGG CCTCTTTATT AGTATCCATG ACAAAGGGCA CATTGCTTCA GTTCTTAATG 481 CATGGCCAGA GGATGTCGTC AAGGCTATTG TGGTAACTGA TGGAGAGCGC ATCCTTGGCT 541 TGGGAGACCT TGGCTGTAAT GGGATGGGCA TCCCTGTGGG TAAACTGGCC CTTTACACGG 601 CATGTGGAGG GGTGAACCCA CAACAGTGTC TACCCATCAC TTTGGATGTG GGAACAGAAA 661 ATGAGGAGTT ACTTAAGGAT CCACTGTACA TCGGGCTGCG GCACCGGCGA GTCAGAGGCC 721 CTGAGTATGA CGCCTTCCTG GATGAGTTCA TGGAGGCAGC GTCTTCCAAA TATGGCATGA 781 ATTGCCTTAT TCAGTTTGAA GATTTTGCCA ATCGGAATGC ATTTCGTCTC CTGAACAAGT 841 ATCGAAACAA GTATTGCACA TTTAACGATG ATAT CAAGG AACAGCGTCT GTTGCGGTTG
(gene length is 3129, only region from 1 to 900 shown)
Table 3. Human Cytoplasmic Malic Enzyme Gene Sequence
>CG140316-01 2058 nt
ATGGAGCCCGAAGCCCCCCGTCGCCGCCACACCCATCAGCGCGGCTACCTGCTGACACGG AACCCTCACC^CAAC AGGACTTGGCCTTACCCTGGAAGAGAGACAGCAATTGAACATT CATGGATTGTTGCCACCTTCCTTCAACAGTCAGGAGATCCAGGTTCTTAGAGTAGTAAAA
AATTTCGAGCATCTGAACTCTGACTTTGACAGGTATCTTCTCTTAATGGATCTCCAAGAT AGAAATGAAAAACTCTTTTATAGAGTGCTGACATCTGACATTGAGAAATTCATGCCTATT GTTTATACTCCCACTGTGGGTCTGGCTTGCCAACAATATAGTTTGGTGTTTCGGAAGCCA AGAGGTCTCTT AT ACTATCCACGATCGAGGGCATATTGCTTCAGTTCTCAATGCATGG CCAGAAGATGTCATCAAGGCCATTGTGGTGACTGATGGAGAGCGTATTCTTGGCTTGGGA GACCT GGCTGTAATGGAATGGGCATCCCTGTGGGTAAATTGGCTCTATATACAGCTTGC GGAGGGATGAATCCTCAAGAATGTCTGCCTGTCATTCTGGATGTGGGAACCGAAAATGAG GAGTTACTTAAAGATCCACTCTACATTGGACTACGGCAGAGAAGAGTAAGAGGTTCTGAA TATGATGATTTTTTGGACGAATTCATGGAGGCAGTTTCTTCCAAGTATGGCATGAATTGC CTTATTCAGTTTGAAGATTTTGCCAATGTGAATGCATTTCGTCTCCTGAACAAGTATCGA AACCAGTATTGC_<_VTTC_ATGATGATATCAAGGAACAGCATCTGTTGCAGTTGCAGGT CTCC TGCΆGCTCTTCGAATAACCAAGAACAAACTGTCTGATCAAACAATACTATTCCAA GGAGC GGAGAGGCTGCCCTAGGGATTGCACACCTGATTGTGATGGCCTTGGAAAAAGAA
GGTTTACCAAAAGAGAAAGCC-^TCAAAAAGATATGGCTGGT GATTCAAAAGGATTAATA
GTTAAGGGACGTGCTTCCTTAACACAAGAGAAAGAGAAGTTTGCCCATGAACATGAAGAA ATGAAGAACCTAGAAGCCATTGT CAAGAAATAAAACCAACTGCCCTCATAGGAGTTGCT GCAATTGGTGGTGC_TTCTCAGAACA!_\TTCTCAAAGATATGGCTGCCTTCAATGAACGG CCTATTATTTTTGCTTTGAGTAATCCAACTAGCAAAGCAGAATGTTCTGCAGAGCAGTGC TAC-V__ITAACC-_GGGACGTGC-_\TTTT GCCAGTGGCAGTCCTTTTGATCCAGTCACT CTTCC-__VTGGACAGACCCTATATCC GGCCAAGGΑ_\CAATTCCTACGTGTTCCCTGGA GTTGCΓCTTGGTGTTGTGGCGTGTGGATTGAGGCAGATCACAGATAATATTTTCCTCACT ACTGC GAGGTTATAGCTCAGCAAGTGTCAGATAAACACTTGGAAGAGGGTCGGCTTTAT CCTCCTTTGAATACCATTAGAGATGTTTCTCTGAAAATTGCAGAAAAGAT GTGAAAGAT GCATACCAAGAAAAGACAGCCACAGTTTATCCTGAACCGC-IAAACAAAGAAGCATTTGTC CGCTCCCAGATGTATAGTACTGATTATGACCAGATTCTACCTGATTGTTATTCTTGGCCT GAAGAGGTGCAGAAAATACAGACCAAAGTTGACCAGTAGGATAATAGCAAACATTTCTAA CTCTATTAATGAGGTCTTAAACCTTTCATAATTT TAAAGGTTGGAATCTTTTATAATG ATTCATAAGACACTTAGATTAAGATTTTACTTTAACAGTCTAAAAA1TGATAGAAGAATA TCGATATAAATGGGATAAACATCΑC^TGAGACAATTTTGCTTC-ICTTTGCCT CTGGT ATTTATGGTTTCTGTCTGAATTATTCTGCCTACGTTCTCTTTAAAAGCTGTTGTACGTAC TACGGAGAAAC CATCATTTTTATACAGGACACTAATGGGAAGACCAAAATTACTAATAA ATTGAAATAACCAACATT
Table 4. Amino acid sequence ofHuman Cytoplamic Malic Enzyme Protein Sequence ORF Start: 1 ORF Stop: 1717 Frame: 1
Human Cytoplasmic Malic Enzyme Protein Sequence: >CG140316-01-prot 572 aa
MΞPEAPRI_3THQRGYLLTRNPHLNKD_AFTLEERQQI_IIHGL PPS-NSQEIQVLRVVK
NFEHLNSDFDRYL I^DLQDRNEKLFYRV TSDIEKFMPIVYTPTVGLACQQYSLVFRKP
RGLFITIHDRGHIASVLNA PEDVIKAIVVTDGERI GGDLGCNGMGIPVGK ALYTAC
GGMNPQEC PVI DVGTENEE LKDPYIGRQRRVRGSEYDDFLDEFMEAVSS YGMNC _IQFEDFAVNAFR NKYRNQYCTF_5DIQGTASVAVAGLI___RITK_Ji_SDQTILFQ
GAGEAALGIAH IVMALEKEG PJCEKAIKKIW VDSKG IVKGRASLTQEKEKFAHEHEE
MKNLEAIVQEIKPTA IGVAAIGGAFSEQILKDMAAFNERPIIFA SNPTSKAECSAEQC
YKITKGRAIFASGSPFDPVTLPNGQTYPGQGNNSYVFPGVAGWACGRQITDNIFLT,
TAEVIAQQVSDKHLEEGRLYPPIJ^IRDVS-KIAEKIVKDAYQEK ATVYPEPQNKEAFV RSQMYSTDYDQILPDCYSWPEEVQKIQTKVDQ
Table 5. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of the human (CGI 40316- 01), mouse (BCOl 1081.1) and pig (X93016.1) versions of the Cytoplasmic Malic Enzyme.
Also included are a variant of this enzyme cloned from liver (CG140316-02) and the mitochondrial NADP-dependent malic enzyme (X79440.1). The domain delineated by the bold line indicates the malic enzyme domain.
Human Cytoplasmic Malic Enzyme: 572 aa
Locus: 6ql2 (syntenic to mouse quantitative trait locus coπelated with percentage of body fat. Ref: Mehrabian et al., J Clin Invest 1998; 101(11): 2485-2496)
Intracellular
In addition to the human version of the Cytoplasmic Malic Enzyme identified as being differentially expressed in the experimental study, one other variant has been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases (CG140316-02, Figure IC). No splice-form variants have been identified at CuraGen nor were any SNPs identified. The prefeπed variant of all those identified, to be used for screening puφoses, is CG140316-01.
Biochemistry and Cell Line Expression:
The following illustrations summarizes the biochemistry suπounding the human
Cytoplasmic Malic Enzyme and potential assays that may be used to screen for antibody therapeutics or small molecule drugs to treat obesity and/or diabetes. Generation of the reducing equivalents in form of NADPH may be coupled to enzymatic or fluorescent detection systems to provide a readout of the screening.
Malate + NADP+ <= Pyruvate +CO2 + NADPH
Cell lines that express the Cytoplasmic Malic Enzyme include PC-3, CaCo-2 and A549, as seen in the RTQ-PCR results shown in Table 6. These and other Cytoplasmic Malic Enzyme expressing cell lines could be used for screening puφoses.
Findings:
The following is a summary of the findings from the discovery studies, supplementary investigations and assays that also incoφorates knowledge in the scientific literature. Taken in total, the data indicates that an inhibitor/antagonist of the human Cytoplasmic Malic Enzyme would be beneficial in the treatment of obesity and/or diabetes.
1. Cytoplasmic malic enzyme is upregulated in both liver and adipose of obese mice in different studies.
2. Upregulation of cytoplasmic malic enzyme promotes fatty acid synthesis and anaplerotic reactions replenishing TCA cycle. 3. Inhibiting cytoplasmic malic enzyme will decrease lipid synthesis and force utilization of stored fatty acids for energy generation. 4. An inhibitor ofthis enzyme would therefore be an effective therapeutic for obesity.
SPECIES #1 (ngsd7 vs. sdl liver): Figures IA and IB show that a gene fragment of the mouse Cytoplasmic Malic
Enzyme was initially found to be up-regulated by 4 fold in the liver tissues of obese mice fed a high fat diet relative to mice resistant to weight gain (on the same diet) using CuraGen's GeneCalling® method of differential gene expression. A differentially
expressed mouse gene fragment migrating, at approximately 283 nucleotides in length (Figure IA. - vertical line) was definitively identified as a component of the mouse Cytoplasmic Malic Enzyme cDNA (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as signal response). The method of competitive PCR was used for conformation of the gene assessment. The electeopherogramatic peaks coπesponding to the gene fragment of the mouse Cytoplasmic Malic Enzyme are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The peaks at 283 nt in length are ablated (green trace) in the sample from both the obese and non-obese mice.
SPECIES #2 (NZB vs. SMJ adipose):
Figures 2A and 2B show that a gene fragment of the mouse Cytoplasmic Malic Enzyme was also found to be up-regulated by 3.2 fold in the adipose of obese NZB mice relative to lean SMJ mice using CuraGen's GeneCalling® method of differential gene expression. A differentially expressed mouse gene fragment migrating, at approximately 175.9 nucleotides in length (Figure 2A. - vertical line) was definitively identified as a component of the mouse Cytoplasmic Malic Enzyme cDNA (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as signal response). The method of competitive PCR was used for conformation of the gene assessment. The electeopherogramatic peaks coπesponding to the gene fragment of the mouse Cytoplasmic Malic Enzyme are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The peaks at 175.9 nt in length are ablated (green trace) in the sample from both the obese and non-obese mice.
Figures IA and IB. Sequence #1. Differentially Expressed Mouse Cytoplasmic Malic Enzyme Gene Fragment.
SetB QEA Q control |H
(PID 252514) ||| r-poison (PID 252514) 13
Figures 2A and 2B. Sequence #2. Differentially Expressed Mouse Cytoplasmic Malic Enzyme Gene Fragment.
E. NOV15a - Human ATP Citrate Lyase - CG142427-01, CG142427-02, CG142427-03 and CG142427-04
The present invention discloses novel associations of proteins and polypeptides and the nucleic acids that encode them with various diseases or pathologies. The proteins and related proteins that are similar to them are encoded by a cDNA and/or by genomic DNA. The proteins, polypeptides and their cognate nucleic acids were identified by CuraGen Coφoration in certain cases. The ATP Citrate Lyase-encoded protein and any variants, thereof, are suitable as diagnostic markers, targets for an antibody therapeutic and targets for small molecule drugs. As such the cuπent invention embodies the use of recombinantly expressed and/or endogenously expressed protein in various screens to identify such therapeutic antibodies and/or therapeutic small molecules.
Discovery Process
The following sections describe the study design(s) and the techniques used to identify the ATP Citiate Lyase - encoded protein and any variants, thereof, as being suitable as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for obesity and/or diabetes.
Studies: MB.04: Lean vs. Obese Genetic mouse model Study Statements:
MB.04 : A large number of mouse strains have been identified that differ in body mass and composition. The AKR and NZB strains are obese, the SWR, C57L and C57BL/6 steains are of average weight whereas the SM/J and Cast/Ei steains are lean. Understanding the gene expression differences in the major metabolic tissues from these stiains will elucidate the pathophysiologic basis for obesity. These specific stiains of rat were chosen for differential gene expression analysis because quantitative trait loci (QTL) for body weight and related teaits had been reported in published genetic studies. Tissues included whole brain, skeletal muscle, visceral adipose, and liver.
Species #1: Mouse Stiains NZB vs SMJ, C57L, Cast, SWR
ATP Citrate Lyase:
ATP citrate-lyase is the primary enzyme responsible for the synthesis of cytosolic acetyl-CoA in many tissues, has a central role in de novo lipid synthesis, in nervous tissue it may be involved in the biosynthesis of acetylchohne. Figure 1 shows a differentially expressed gene fragment from the mouse ATP Citrate Lyase.
Competitive PCR Primer for the Human ATP Citrate Lyase
Confirmatory Result - Human ATP Citrate Lyase (Discovery Study MB.04):
Table 1. Human ATP Citrate Lyase Gene Sequence
(Identified fragment from 1213 to 1277 in italic, band size: 65)
1 CTGGGTTGTTTATCGATΓTTACTCGATGGCCGATGCCCATGATCAGCTTCCCC CCTTCTTCATCTTGTTGACGAACTCC 81 ATGGGAATGATGCCGCTGTCAAAGGCTTTACTGAACATCTTTGCTO^
161 GGTGAGCAGCCCTGAGGTGAGGCTGGAGACCAGGTCCTTCCCAGCCCGAGCACAGATGATGGTGTTATGGGCTCCAGAGA
241 CAGCTGGCCCGTGATCAGCTGTGACC&TCAGAC&CA^
321 CAGAGGAGGCCGAGGACACCACCGATGCCCATCTCCTCCTTGAAGACC CGGTGATGGGCATGCCCGCATAAATGAGCTC
401 CTGCCCTCGCTCATCA(_IGATGCTGGTCATGAATGAGGCAGGTTTTCGGATCAAACCCAGCTCTC GGCCCAAGAGTAGT 481 CCΛ-GGGCACTGTTGGAGKΪ-ΩCACΪTC^
56I ATGAT TCTCCAAGCTCATCGAAGCTTCGGGGCACAAACACTCCTGCTTCCTTCAAGGCCTGGTTCTTGGCTACTGCAGT
641 TTCAGAAGTCTGGTTGGCAC-_GCTCCAGCATGGCC-_ACTGGACCTCGGAGGAGAACATGGTGGCACAGGTCCCGATAC
721 AC_\GCAGACCACTGGCTTGGTGAGGCGGCCCTCCTTGATGCCCCGGCAGATCTTATATTCCTCTGTGCCCCCTATCTCC
801 CCAAGAACTACGATCATCTTGACTCCTGGAGTGTCCTGGTAGCGCAGCACGTGATCCATGAATGTGGACCCAGGGTACCT 881 GTCCCCGCCGATGGCCACGCCCTATAGACACCATCTGTGGTCCGGGAGATGATGTTATTGAGTTCATTAGACATGCCTC
961 CTGAACGTGAGACGTAGGCCACGCTGCCTGGGCGGTACAGTTTGGAGGCCAGGATGTTGTCCAGCA
Table 2. Nucleotide and protein sequence of Human ATP Citiate Lyase
CG142427-01
GGCACGAGGCCGGGACAAAAGCCGGATCCCGGGAAGCTACCGGCTGCTGGGGTGCTCCGGATTTTGCGGG GTTCGTCGGGCCTGTGGAAGAAGCGCCGCGCACGGACTTCGGCAGAGGTAGAGCAGGTCTCTCTGCAGCC ATGTCGGCC_^GGCAATTTCAGAGCAGACGGGCAAAGAACTCCTTTACAAGTTCATCTGTACCACCTCAG CC-VTCCAGAATCGGTTCAAGTATGCTCGGGTCaCTCCTGACACAGACTGGGCCCGCTTGCTGCAGGACCA CCCCTGGCTGCTCAGCCAGAACTTGGTAGTCAAGCCAGACCAGCTGATCAAACGTCGTGGAAAACTTGGT CTCGTTGGGGTO_iCCTC-iCTCTGGATGGGGTCAAGTCCTGGCTGAAGCCACGGCTGGGACAGGAAGCCA C»GTTGGC_\GGCC_C-IGGCTTCCTCAAGAACT GGAGTTCTATGTCTGCATCTATGCCACCCGAGAAGGGGACTACGTCCTGTTCCACCACGAGGGGGGTGTG GACGTGGGTGATGTGGACGCCAAGGCCCAGAAGCTGCTTGTTGGCGTGGATGAGAAACTGAATCCTGAGG ACATCAAAAAACACCTGTTGGTCCACGCCCCTGAAGACAAGAAAGAAATTCTGGCCAGTTTTATCTCCGG CCTC TCAATTTCTACGAGGACTTGTACTTCACCTACCTCGAGATCAATCCCCTTGTAGTGACCAAAGAT GGAGTCTATGTCCTTGACTTGGCGGCCAAGGTGGACGCCACTGCCGACTACATCTGCAAAGTGAAGTGGG GTGACATCGAGTTCCCTCCCCCCTTCGGGCGGGAGGCATATCCAGAGGAAGCCTACATTGCAGACCTCGA TGCC-_λAAGTGGGGC__\GCCTGAAGCTGACCTTGCTGAACCCC-_\AGGGAGGATCTGGACCATGGTGGCC GGGGGTGGCGCCTCTGTCGTGTACAGCGATACCATCTGTGATCTAGGGGGTGTCAACGAGCTGGCAAACT ATGGGGAGTACTCAGGCGCCCCCAGCGAGCAGCAGACCTATGACTATGCCAAGACTATCCTCTCCCTCAT GACCCGAGAGAAGCaCCCaGATGGCAAGATCCTCATCATTGGAGGCAGCATCGCAAACTTCACCAACGTG GCTGCCACGTTCAAGGGCATCGTGAGAGCAATTCGAGATTACCAGGGCCCCCTGAAGGAGCACGAAGTCA <_AATCTTTGTCCGAAGAGGTGGCCCCAACTATCAGGAGGGCTTACGGGTGATGGGAGAAGTCGGGAAGAC CACTGGGATCCCCATCCATGTCTTTGGCACAGAGACTCACATGACGGCCATTGTGGGCATGGCCCTGGGC CaCCGGCCC_lTCCCCAACC_GCCACCCACAGCGGCCCAC^C_GI__\ACTTCCTCCTCAACGCCAGCGGGA GC-VCATCGACGCCAGCCCCCAGCAGGACAGCATCTTTTTCTGAGTCCAGGGCCGATGAGGTGGCGCCTGC AAAGAAGGCCAAGCCTGCCATGCCACAAGATTCAGTCCCAAGTCCAAGATCCCTGCAAGGAAAGAGCACC ACCCTCTTCAGCCGCCACACCAAGGCCATTGTGTGGGGCATGCAGACCCGGGCCGTGCAAGGCATGCTGG ACTTTGACTATGTCTGCTCCCGAGACGAGCCCTC^GTGGCTGCC.iTGGTCTACCCTTTCACTGGGGACCA
CAAGCAGAAGTTTTACTGGGGGCACAAAGAGATCCTGATCCCTGTCTTCAAGAACATGGCTGATGCCATG AGGAAGCATCCGGAGGTAGATGTGCTCATCAACTTTGCCTCTCTCCGCTCTGCCTATGACAGCACCATGG AGACCATGAACTATGCCCAGATCCGGACCATCGCCATCATAGCTGAAGGCATCCCTGAGGCCCTCACGAG AAAGCTGATCAAGAAGGCGGACCAGAAGGGAGTGACCATCATCGGACCTGCCACTGTTGGAGGCATCAAG CCTGGGTGCTTTAAGATTGGCAACACAGGTGGGATGCTGGACAACATCCTGGCCTCCAAACTGTACCGCC C_GGC-_3CGTGGCCTATGTCTCACGTTCCGGAGGCATGTC_^
CACGGATGGCGTCTATGAGGGCGTGGCCATTGGTGGGGACAGGTACCCGGGCTCCACATTCATGGATCAT GTGTTACGCTATCAGGACACTCCAGGAGTCAAAATGATTGTGGTTCTTGGAGAGATTGGGGGCACTGAGG AATATAAGATTTGCCGGGGCATCAAGGAGGGCCGCCTCACTAAGCCCATCGTCTGCTGGTGCATCGGGAC GTGTGCCACCATGT CTCCTCTGAGGTCCAGTTTGGCCATGCTGGAGCTTGTGCCAACCAGGCTTCTGAA ACTGCAGTAGCC__vGAACCAGGCTTTGAAGGAAGCAGGAGTGTTTGTGCCCCGGAGCTTTGATGAGCTTG GAGAGATCATCCAGTCTGTATACGAAGATCTCGTGGCCAATGGAGTCATTGTACCTGCCCAGGAGGTGCC GCCCCCAACCGTGCCCATGGACTACTCCTGGGCCAGGGAGCTTGGTTTGATCCGCAAACCTGCCTCGTTC ATGACCAGCATCTGCGATGAGCGAGGACAGGAGCTCATCTACGCGGGCATGCCCATCACTGAGGTCTTCA AGGAAGAGATGGGCATTGGCGGGGTCCTCGGCCTCCTCTGGTTCCAGAAAAGGTTGCCTAAGTACTCTTG CCAGTTCATTGAGATGTGTCTGATGGTGACAGCTGATCACGGGCCAGCCGTCTCTGGAGCCCACAACACC ATCATTTGTGCGCGAGCTGGGAAAGACCTGGTCTCCAGCCTCACCTCGGGGCTGCTCACCATCGGGGATC GGTTTGGGGGTGCCTTGGATGCAGCAGCCAAGATGTTCAGTAAAGCCTTTGACAGTGGCATTATCCCCAT GGAGTTTGTGAACAAGATGAAGAAGGAAGGGAAGCTGATCATGGGCATTGGTCACCGAGTGAAGTCGATA AACAACCCAGA_ιTGCGAGTGraGATCCTCS__iGATTACGT(_iGGCAGCACTTCCCTGCC_CTCCTCTGC TCGATTATGCACTGGAAGTAGAGAAGATTACCACCTCGAAGAAGCCAAATCTTATCCTGAATGTAGATGG TCTCATCGGAGTCGCATTTGTAGACATGCTTAGAAACTGTGGGTCCTTTACTCGGGAGGAAGCTGATGAA ATATTGACΑTTGGAGCCCTCAATGGCATCTTTGTGCTGGGAAGGAGTATGGGGTTCAT GGACACTATC TTGATCAGAAGAGGCTGAAGCAGGGGCTGTATCGTCATCCGTGGGATGATATTTCATATGTTCTTCCGGA ACACATGAGCATGTAACAGAGCCAGGAACCCTACTGCAGTAAACTGAAGACAAGATCTCTTCCCCCAAGA AAAAGTGTACAGACAGCTGGCaGTGGAGCCTGCTTTATTTAGCAGGGGCCTGGAATGTAAACAGCCACTG GGGTACAGGCACCGAAGACO_CATCCACAGGCTAACACCCCTTCAGTCCACACAAAGAAGCTTCATATT TTTTTTATAAGCATAGAAATAAAAACCAAGCCAATATTTGTGACTTTGCTCTGCTACCTGCTGTATTTAT TATATGGAAGCATCTAAGTACTGTCAGGATGGGGTCTTCCTCATTGTAGGGCGTTAGGATGTTGCTTTCT TTTTCCATTAGTTAAACATTTTTTTCTCCTTTGGAGGAAGGGAATGAAACATTTATGGCCTCAAGATACT ATACATTTAAAGCACCCα-.TGTCTCTCTTTTTTTTTTTTTACTTCCCTTTCTTCTTCCTTATATAACAT GAAGAACATTGTATTAATCTGATTTTTAAAGATCTTTTTGTATGTTACGTGTTAAGGGCTTGTTTGGTAT CCCACTGAAATGTTCTGTGTTGCAGACCAGAGTCTGTTTATGTCAGGGGGATGGGGCCATTGCATCCTTA GCCΛTTGTCΛCAAAATATGTGGAGTAGTAACTTAATATGTAAAGTTGTAACATACATACΛTTTAAAATGG AAATGCAGAAAGCTGTGAAATGTCTTGTGTCTTATGTTCTCTGTATTTATGCAGCTGATTTGTCTGTCTG TAACTGAAGTGTGGGTCC_AGGACTCCTAACTACTTTGCATCTGTAATCCACAAAGATTCTGGGCAGCTG CCftCCTCAGTCTCTTCTCTGTATTATCATAGT^
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAA
Table 3. Amino acid sequence of Human ATP Citrate Lyase ORF Start: 141 ORF Stop: 3444 Frame: 3
Human ATP Citrate Lyase Protein Sequence: CG142427-01-prot 1101 aa
MSAKAISEQTGKELLYKFICTTSAIQNRFKYARVTPDTDWARLLQDHPWLLSQ-^VVKPD QLIKPJIGKLGLVGV-^TLDGVKSWLKPRXGQEATVGKATGFLKNFLIEPFWHSQAEEFYV CIYATREGDYVLFHHEGGVDVGDVDAKAQKLLVGVDEKLNPEDIKKHLLVHAPEDKKE AS SGLFNFYEDLYFTYLE_>IPLVVTKDGVYVLDLAAKVDATADYICKV GDIEFPPPFG P EAYPEEAYIADLDAKSGASLKLTLLNPKGRIWTMVAGGGASVVYSDTICDLGGVNELAN YGEYSGAPSEQQTYDYAKTILSLMTRJEKΉPDGKILΠGGSLANFΠWAATFKGIVRAΠΦ GPLKΈHΈVΉFΛ^GGPNYQEGLRVMGEVGKTTGIPΠΪW^ QPPTAA_ A_^LLNASGSTSTPAPSRTASFSESR_ EVAPAKKAKPAMPQDSVPSPRSLQG KSTTLFSRHTKAIVWGMQTRAVQGMLDFDYVCSRDEPSVAAMVYPF GDHKQKJ^ KEILLPWKNMADAMR__FFEVDVL_ FASLRSAYDSTMETM ^ LIK_ADQKGVTΠGPATVGGΠ_PGCFKIGNTGGMLDNILASKLYRPGSVAYVSRSGGMSNEL NNΠSRTTDGVYEGVAIGGDRYPGSTFMDHVLRYQDTTGVKMΓVVLGEIGGTEEYKICRGIK EGRLTKPIVCWCIGTCATMFSSEVQFGHAGACANQASETAVAKNQALKEAGVFVPRSFDE LGEΠQSVYEDLVANGVIVPAQEVPPPTΎPMDYSWARELGLIRKPASFMTSICDERGQELIY AGMPITEVFKEEMGIGGVLGLLWFQKRLPKYSCQFI_MCLMVTADHGPAVSGAHNΉICAR AGKDLVSSLTSGLLΗGDRFGGALDAAAKMFSK_VFDSGI_'MEFVNKM_-_IGK^
VKSINNPDMRVQILKDYVRQHFPATPLLDYALEVEKm
RJ CGSFTREEADEYIDIGALNGIFVLGRSMGFIGHYLDQKPXKQGLYFΗPWDDISYVLPEH
MSM
Table 4. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of the human (CG142427-01), rat
(J05210) and mouse (AF332052) versions of the ATP Citrate Lyase.
MMiffllMfflBiiMii
i_IHtl___fi__i ifflMiJjifflHimiBai maiii
maiM_iMia«Mtiiiii8ffiaii
■illllHllii^ll-HBI
■ffliMMϋMiϋam
Human ATP Citeate Lyase 1105 amino acids; 121 kd Locus: 17ql2-q21 Intracellular (Cytoplasmic)
In addition to the human version of the ATP Citiate Lyase identified as being differentially expressed in the experimental study, other variants have been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases. No splice-form variants have been identified at CuraGen whereas several amino acid-changing cSNPs were identified. These are found below. The prefeπed variant of all those identified, to be used for screening purposes, is CGI 42427-01.
Table 5: The variants of the human ATP Citrate Lyase obtained from direct cloning and/or public databases
Biochemistry and Cell Line Expression The following summarizes the biochemistry suπounding the human ATP Citrate
Lyase enzyme: ATP Citeate Lyase catalyzes the conversion of Citeate plus CoA in the presence of ATP into orthophosphate + Acetyl CoA + Oxaloacetate with a release of ADP. Acetyl CoA can then be used as a substrate for Fatty Acid synthesis.
Cell lines expressing the ATP Citrate Lyase enzyme can be obtained from the RTQ- PCR results shown above. These and other ATP Citiate Lyase enzyme expressing cell lines could be used for screening purposes.
Findings:
An inhibitor to ATP Citeate Lyase will force Acetyl CoA to be produced by alternative pathways, thus decreasing the available pool for fatty acid and triglyceride
synthesis. The decreased pool of Acetyl CoA will cause a down-regulation of the Cholesterol biosynthetic pathway preventing excess production of LXRa ligands
Taken in total, the data indicates that an inhibitor of the human ATP Citrate Lyase enzyme would be beneficial in the treatment of obesity and/or diabetes.
Sequences: The sequence of Ace. No. CG142427-01 is an In silico prediction based on sequences available in CuraGen's proprietary sequence databases or in the public human sequence databases, and provided either the full length DNA sequence, or some portion thereof.
SPECIES #1 A gene fragment of the mouse ATP Citrate Lyase was initially found to be up-regulated by 2 fold in the adipose tissues of the NZB mouse relative to the SMJ mouse strain using CuraGen's GeneCalling ™ method of differential gene expression. Similar results were found in adipose in NZB vs C57L, Cast and SWR mouse steains (All were up- regulated; 2.7x, 5x, and 2.4x respectively). A differentially expressed mouse gene fragment migrating, at approximately 161.7 nucleotides in length (Figures IA and IB. - vertical line) was definitively identified as a component of the mouse ATP Citeate Lyase cDNA (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as signal response). The method of competitive PCR was used for conformation of the gene assessment. The chromatographic peaks coπesponding to the gene fragment of the rat ATP Citiate Lyase are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The peaks at 161.7 nt in length are ablated in the sample from both the NZB and SMJ mice.
The direct sequence of the 65 nucleotide-long gene fragment and the gene-specific primers used for competitive PC are indicated on the complete cDNA sequence of the ATP Citeate Lyase and shown below in bold. The gene-specific primers at the 5' and 3' ends of the fragment are in bold.
NZB adipose
NZB vs SMJ adipose 2X
NZB vs Cast adipose 5X
NZB vs SWR adipose 2.4X
SMJ adipose
Figure 2. Schematic Showing the Role of ATP Citiate Lyase in Lipid and Cholesterol Biosynthesis.
Acetyl CoA Synthetase 1
Amino Acid Ace Catabolism Ityl CoA ATP Citrate Lyase
Lipid and Cho Ilesterol Biosynthesis
F. NOV16a - Human Serine Dehydratase - CG142631-01
Discovery Process
The following sections describe the study design(s) and the techniques used to identify the Serine Dehydratase - encoded protein and any variants, thereof, as being suitable as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for obesity and/or diabetes.
Studies:
MB.01: Insulin Resistance in rat Study Statements:
MB.01: The spontaneously hypertensive rat (SHR) is a strain exhibiting features of the human Metabolic Syndrome X. The phenotypic features include obesity, hyperglycemia, hypertension, dyslipidemia and dysfibrinolysis. Tissues were removed from adult male rats and a control strain (Wistar - Kyoto) to identify the gene expression differences that underlie the pathologic state in the SHR and in animals treated with various anti- hyperglycemic agents such as teoglitizone. Tissues included sub-cutaneous adipose, visceral adipose and liver.
Species #1 Rat Stiains SHR
Serine Dehydratase:
Serine dehydratase catalyzes the PLP-dependent alpha, beta-elimination of L-serine to pyruvate and ammonia. It is one of three enzymes that are regarded as metabolic exits of the serine-glycine pool. Serine dehydratase is found predominantly in the liver.
Table 1. Competitive PCR Primer for the Human Serine Dehydratase Confirmatory Result- Human Serine Dehydratase (Discovery Study MB.01): (Identified fragment from 221 to 545 in italic, band size: 325)
1 GCTTTATAAACATATATATATTAATTTTTATT^^
8X ACTGTCAGGCGGACGCCI-^CCCaGCCTACTCAGGGGTGCTGGTGACCCCTCAGGGTGGCCAGGGCAGCAGCAGATATCAC
161 TTGAGTAGCT _.TTCA_GCC<_iGCTGTGCCTTGAGTGCCT
241 GAC-_CCAGCGAGGCCAGTGGGGTTTGCAGTCGGGCCTCAGCCTGCAGCCTGCACACCACACCGCTGTACACTGCAGCCA
321 GGGCAGCGCCACACGCGGGCTCCACCAGGATCT CTCATCGTCTACGAACTTCTCGATAGCAGTCACAGCCTCCTGGTCT
401 GAGaTGACC CAGAGAAAATGGGGTGTTCGTAAAACAGCTTCAGGGTC GTGCCCCCACAGTGTTCACACCCAAGGCCTT
481 GGCAACACTGGTGATCTTGGGCAGGGTGACCAGCTTTCCTTCCTTGACGGCAGCGTGGAAGCTGTGGGCGCCGAAGGTCT
561 CCATGGCGATGATGGGCACATCCTCCCAGCCCACCTCCCGCAGCCCCTGGACCACTCCGCACAGCAGGCCTCCACCGCCC
641 ACAGACAGC^ΑUCT∞CCCCGGGCTTGGCGCTCAGTGTCTCCT^
721 GAGAGGGTCATCGAAGGGGGAGATGTAC&CCCAACCTGGGRRE 801 CCAGCΆTCTCTCCCACCAC TCAACTGTGGCCCCTTCGTTCTTCAGCCGCTCAATGGTGAGGGCAGGTGTGGTGCTTGGC
881 ACAACAATAGTGGCTGGGAGGCCCΆGCCTCCTGGCΆGCATAGG ΆGTCGCCATGCCCXSCGT GCCCGCTGAAGAGCAGAC
961 GAAATGTTTACAGCCTTGTTTTGCCT CATCTTGCAGAGATGCCCAATGCCTCGGATCTTGAAGGAGCCAGAGGGCTGAG
1041 AGCΓGΓCCTTCTΓAAGGAACH^CTAGTC
1121 AGGGAC_CCTGGGCAGCCATGGCATGTAGCTTTGAAGGTTGGATCCTCCTGTCTCAGTCTCCCAATTGCTGGGATCACAG 1201 GTATGCCCCGCCGCACCCGGCACAGGAGGAGCTGGACAGAGCGAGCGAGAAGGGTAGATTTTGTCTGTGTCCTGGGAGAG
1281 TGGAAAGT
Table 2. Nucleotide and protein sequence of Human Serine Dehydratase, CG142631-01
CCTTCTCTTCGTGGGCTATCTACTCAGTTGATCCCTCCCTCGCTGGCTTGGCTCTGACTCCTG CTCAGACCCATCACCTTTGCCGGGGAATGATGTCTGGAGAACCCCTGCACGTGAAGACCCCC ATCCGTGACAGCATGGCCCTGTCCAAAATGGCCGGCACCAGCGTCTACCTCAAGATGGACAG TGCCCAGCCCTCCGGCTCCTTCAAGATCCGGGGCATTGGGCACTTCTGCAAGAGGTGGGCCA AGCAAGGCTGTGCACATTTTGTCTGCTCCTCGGCGGGCAACGCAGGCATGGCGGCTGCATAT GCGGCCAGGCAACTCGGCGTCCCCGCCACCATCGTAGTGCCCGGCACCACACCTGCTCTCA CCATTGAGCGCCTCAAGAATGAAGGTGCCACATGCAAGGTGGTGGGTGAGTTATTGGATGAA GCCTTCGAGCTGGCCAAGGCCCTAGCGAAGAACAACCCGGGTTGGGTCTACATTCCCCCCTT TGATGACCCCCTCATCTGGGAAGGCCACGCTTCCATCGTGAAAGAGCTGAAGGAGACACTGT GGGAAAAGCCGGGGGCCATCGCGCTGTCAGTGGGCGGCGGGGGCCTGCTGTGTGGAGTGG TCCAGGGGCTGCAGGAGTGTGGCTGGGGGGACGTGCCTGTCATCGCCATGGAGACTTTTGGT GCCCACAGCTTCCACGCTGCCACCACCGCAGGCAAACTTGTCTCCCTGCCCAAGATCACCAG TGTTGCCAAGGCCCTGGGCGTGAAGACTGTGGGGTCTCAGGCCCTGAAGCTGTTTCAGGAAC ACCCCATTTTCTCTGAAGTTATCTCGGACCAGGAGGCTGTGGCCGCCATTGAGAAGTTCGTGG ATGATGAGAAGATCCTGGTGGAGCCCGCCTGGGGCGCAGCCCTGGCCGCTGTCTATAGCCAC GTGATCCAGAAGCTCCAACTGGAGGGGAATCTCCGAACCCCGCTGCCATCCCTCGTGGTCAT CGTCTGCGGGGGCAGCAACATCAGCCTGGCCCAGCTGCGGGCGCTCAAGGAACAGCTGGGC ATGACAAATAGGTTGCCCAAGTGAGGACGGACCCCTTACCGATCTGTGCTCTCCTAGCCCAAG AGACCCCTGGAGGGGCTGGAGTTTATCCAGCGCCTCGTCGTATGTTTGGCTGAGCACCTGTG GCCCTGGGTGCAGGTTAACTTCTTGTTATCAGGAGCCCACTATGCAGAGGCCAAAGGTCGGC AGCCAGCGAGGCTATGAATTGGACCTTTTTGGTATCTGTGTGACTGCTCTGTGCCCATCCTTA GCCAACTTGCTGGCGTGACAAGTGCCCACAAGTAACACACCAGGTACCCAGAGCAGGGTGGA CAGGAGAGACCTGAATCACAGCAGTGAGG
Table 3. ORF Start: 90 ORF Stop: 1074 Frame: 3
Human Serine Dehydratase Protein Sequence:
CG142631-01-prot 328 aa
MMSGEPLHVKTPIRDSMALSKMAGTSVYLK DSAQPSGSFKIRGIGHFCKRWAKQGCAHF
VCSSAGNAGMAAAYAARQLGVPATIWPGTTPALTIERLKNEGATCKWGELLDEAFELA
KALAKNNPGWVYIPPFDDPLIWEGHASIVKELKETLWEKPGAIALSVGGGGLLCGWQGL
QECGWGDVPVIAMETFGAHSFHAATTAGKLVSLPKITSVAKALGVKTVGSQALKLFQEHP
IFSEVISDQEAVAAIEKFVDDEKILVEPAWGAALAAVYSHVIQKLQLEGNLRTPLPSLVV
IVCGGSNISLAQLRALKEQLGMTNRLPK
Table 4. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of the human (CG142631-01), rat and mouse versions of the Serine Dehydratase.
Multiple Alignment:
Human Serine Dehydratase 328 amino acids; 34 kd Locus: 12 Intracellular
In addition to the human version of the Serine Dehydratase identified as being differentially expressed in the experimental study, other variants have been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases. No splice-form variants have been identified at CuraGen whereas several amino acid-changing cSNPs were identified. These are found below. The prefeπed variant of all those identified, to be used for screening purposes, is CG142631-01.
Table 5. The variants of the human Serine Dehydratase obtained from direct cloning and/or public databases
Biochemistry:
The following illustrations summarizes the biochemistry suπounding the human Serine Dehydratase enzyme. L-Serine is converted to Pyruvate by pyridoxal phosphate requiring Serine Dehydratase with the release of ammonia as a by product. Pyruvate is a primary substrate in the process of gluconeogenesis. Cell lines expressing the Serine Dehydratase enzyme can be obtained from the RTQ-PCR results shown above. These and other Serine Dehydratase enzyme expressing cell lines could be used for screening purposes.
Findings:
Serine Dehydratase (SDH) is critical for gluconeogenesis. In models of Diabetes SDH is up-regulated and in studies utilizing TZDs expression of SDH is down-regulated. An inhibitor ofthis enzyme would decrease glucose production. By improving daily blood glucose levels and maintaining HbAlc at or below 7.5 may prevent many diabetic complications.
Taken in total, the data indicates that an inhibitor of the human Serine Dehydratase enzyme would be beneficial in the treatment of obesity and/or diabetes.
Sequences
The sequence of Ace. No. CG142631-01 is an In silico prediction based on sequences available in CuraGen's proprietary sequence databases or in the public human sequence databases, and provided either the full length DNA sequence, or some portion thereof.
10
Treatment
Vehicle
Figures 1 A and IB. Differentially Expressed Gene Fragment from Rat Serine Dehydratase.
MB01: Troglitazone LD10 vs 0.02% DMSO WKY/72 hr -4
Vehicle
G. NOV53a - Human Plasma KaUikrein - CG56155-01 Discovery Process
The following sections describe the study design(s) and the techniques used to identify the Plasma Kallikrein - encoded protein and any variants, thereof, as being suitable as diagnostic markers, targets for an antibody therapeutic and targets for a small molecule drugs for Obesity and Diabetes.
MB .01 : Metabolic Syndrome X in Rat
MB.04: Mouse Obesity
Study Statements:
MB.01 The spontaneously hypertensive rat (SHR) is a strain exhibiting features of the human Metabolic Syndrome X. The phenotypic features include obesity, hyperglycemia, hypertension, dyslipidemia and dysfibrinolysis. Tissues were removed from adult male rats and a conteol strain (Wistar - Kyoto) to identify the gene expression differences that underlie the pathologic state in the SHR and in animals tieated with various anti-hyperglycemic agents such as teoglitizone. Tissues included sub-cutaneous adipose, visceral adipose and liver.
MB.04 A large number of mouse stiains have been identified that differ in body mass and composition. The AKR and NZB stiains are obese, the SWR, C57L and
C57BL/6 stiains are of average weight whereas the SM/J and Cast/Ei strains are lean.
Understanding the gene expression differences in the major metabolic tissues from these seatrains will elucidate the pathophysiologic basis for obesity. These specific stiains of rat were chosen for differential gene expression analysis because quantitative trait loci (QTL) for body weight and related teaits had been reported in published genetic studies. Tissues included whole brain, skeletal muscle, visceral adipose, and liver.
Species #1 Rat Strains SHR, WKY Species #2 Mouse Strains C57BL, Cast/Ei
Plasma Kallikrein:
Plasma Kallikrein (PK) has been shown to activate specifically plasminogen during adipose differentiation. Plasminogen activation, followed by fibrinolysis, has been
implicated in adipose differentiation by remodeling of the fibronectin-rich extiacellular matrix of preadipocytes.
Table 1. SPECIES #1 Rat Plasma Kallikrein Gene Fragment used for competitive PCR (fragment from 1516 to 1658 in bold, band size: 143)
1035 TCCCCAAGAC TGCAAGGCAG AGGGGTGTAA ATGTTCCTTA AGGTTATCCA CGGATGGCTC 1095 TCCAACTAGG ATCACCTATG AGGCACAGGG GAGCTCTGGT TATTCTCTGA GACTGTGTAA
10 1155 AGTTGTGGAG AGCTCTGACT GTACGACAAA AATAAATGCA CGTATTGTGG GAGGAACAAA
1215 CTCTTCTTTA GGAGAGTGGC CATGGCAGGT CAGCCTGCAA GTGAAGTTGG TTTCTCAGAA
1275 CCATATGTGT GGAGGGTCCA TCATTGGACG CCAATGGATA CTGACGGCTG CCCATTGCTT
.1335 TGATGGGATT CCCTATCCAG ACGTGTGGCG TATATATGGC GGGATTCTA ATCTGTCAGA
. 1395 GATTACAAAC AAAACGCCTT TCTCAAGTAT. AAAGGAGCTT ATTATTCATC AGAAATACAA
15 1455 AATGTCAGAA GGCAGTACG ATATTGCCTT AATAAAGCTT CAGACACCGT TGAATTATAC
1515 TGAATTCCAA AAACCAATAT GCCTGCCTTC CAAAGCTGAC ACAAATACAA TTTATACCAA
1575 CTGCTGGGTG ACTGGATGGG GCTACACAAA GGAACGAGGT GAGACCCAAA ATATTCTACA
.1635 AAAGGCAACT ATTCCCTTGG TACCAAATGA AGAATGCCAG AAAAAATATA GAGATTATGT
1695 TATAACCAAG CAGATGATCT GTGCTGGCTA CAAAGAAGGT GGAATAGATG CTTGTAAGGG
20 1755 AGATTCCGGT GGCCCCTTAG TTTGCAAACA TAGTGGAAGG TGGCAGTTGG TGGGTATCAC 1815 CAGCTGGGGT GAAGGCTGTG CCCGCAAGGA GCAACCAGGA GTCTACACCA AAGTTGCTGA 1875 GTACATTGAC TGGATATTGG AGAAGATACA GAGCAGCAAG GAAAGAGCTC TGGAGACATC 1935 TCCAGCATGA GGAGGCTGGG TACTGACGGG GAAGAGCCCA GCTGGCACCA GCTTTACCAC 1995 CTGCCCTCAA GTCCTACTAG AGC CCAGAG TTCTCTTCTG CAAAATGTCG ATAGTGGTGT.
25 2055 CTACCTCGCA TCCTTACCAT. AGGATTAAAA GTCCAAATGT AGACACAGTT GCTAAAGACA 2115 GCGCCATGCT CAAGCGTGCT TCCT
(gene length is 2444, only region from 1035 to 2138 shown)
Table 2. SPECIES #2. Mouse Plasma Kallikrein Gene Fragment used for competitive PCR 30 (fragment from 2807 to 2902 in bold, band size: 96)
2326 GTAAGGGAGA TTCCGGTGGC CCCTTAGTCT GTAAACACAG TGGACGGTGG CAGTTGGTGG 2386 GTATCACCAG CTGGGGTGAA GGCTGCGGCC GCAAGGACCA ACCAGGAGTC TACACCAAAG . 2446 TTTCTGAGTA CATGGACTGG ATATTGGAGA AGACACAGAG CAGTGATGTA AGAGCTCTGG 2506 AGACATCTTC AGCCTGAGGA GGCTGGGTAC CAAGGAGGAA GAACCCAGCT GGCTTTACCA
35 2566 CCTGCCCTCA AGGCAAACTA GAGCTCCAGG ATTCTCGGCT GTAAAATGTT GATAATGGTG
2626 TCTACCTCAC ATCCGTATCA TTGGATTGAA AATTCAAGTG TAGATATAGT TGCTGAAGAC
2686 AGCGTTTTGC TCAAGTGTGT. TTCCTGCCT GAGTCACAGG AGCTCCAATG GGAGCATTAC
2746 AAAGATCACC AAGCTTGTTA GGAAAGAGAA TGATCAAAGG GTTTTATTAG GTAATGAAAT
. 2806 GTCTAGATGT GATGCAATTG AAAAAAAβAC CCCAGATTTT AGCACAGTCC TTGGGACCAT
40 2866 TTTCATG-AA CTGTTGAC-T TGGACCTCAG CAGATCTCAG AGTTACCTGT CCACTTCTGA 2926 CATTTGTTTA TTAGAGCCTG ATGCTATTCT TTCAAGTGGA GCAAAAAAAA AAAAAAAAAA 2986 AAAAA
(gene length is 2990, only region from 2326 to 2990 shown)
45.
Table 3. Human Plasma Kallikrein Gene and Protein Sequence. >CG56155-01 2245 nt
50 AGAACAGCTT__VGACCGTTCATTT TAAGTGACAAGAGACTCACCTCCAAGAAGCAATT GTGTTTTCAGAATGATT TATTCAAGCAAGCAACTTATTTCATTTCCTTGTTTGCTACAG TT CCTGTGGATGTCTGACTCAACTCTATGAAAACGCCTTCTCAGAGGTGGGGATGTAG CTTCCATGTACACCCCAAATGCCCAATACTGCCAGATGAGGTGCACATTCCACCCAAGGT GT TGCTATTC^GTTTTCTTCCAGCAAGTTCAATCAATGACATGGAGAAAAGGTTTGGTT
55 GCTTCTTGAAAGATAGTGTTACAGGAACCCTGCCAAAAGTACATCGAACAGGTGCAGTT CTGGACAT CCTTGAAGCAATGTGGTCATCAAATAAGTGCTTGCCATCGAGACATTTATA AAGGAGTTGATATGAGAGGAGTCAAT TTAATGTGTCTAAGGTTAGCAGTGTTGAAGAAT
GCI-AAAAAAGGTGCACO-vTAACATTCGCTGCCAGTTT TTTCATATGCCACGCAAACAT TTCACAAGGCAGAGTACCGGAACAATTGCCTATTAAAGTACAGTCCCGGAGGAACACCTA CCGCTATAAAGGTGCTGAGTAACGTGGAATCTGGATTCTCACTGAAGCCCTGTGCCCTTT CAGAAATTGGTTGCCACATGAACATCTTCCAGCATCTTGCGTTCTCAGATGTGGATGTTG 5. CCAGGGTTCTCACTCCAGATGCTTTTGTGTGTCGGACCATCTGCACCTATCACCCCAACT GCCTCTTCTTTACATTCTATACAAATGTATGGAAAATCGAGTCACAAAGAAATGTTTGTC TTCTTAAAACATCTGAAAGTGGCACACCAAGTTCCTCTACTCCTCAAGAAAACACCATAT CTGGATATAGCCTTTTAACC GC___GAACT TACCTGAACCCTGCCAT CTAAAATTT ACCCGGGAGTTGACTTTGGAGGAGAAGAATTGAATGTGACTTTTGTTAAAGGAGTGAATG
10. T TGCCy_VGAGACT GCA(_AAGATGATTCGC GTC^GTTT TCAC TATTCTTTACTCC CAGAAGACTGTAAGGAAGAGAAGTGTAAGTGTTTCTTAAGATTATCTATGGATGGTTCTC C__CTAGGATTGCGTATGGGACACAAGGGAGCTCTGGTACTCT TGAGATTGTGTAACA CTGGGGAC__CTCTGTCTGCACAACAAAAAC_^GCACACGCATTGTTGGAGGAACAAACT CTTCTTGGGGAGAGTGGCCC GGCAGGTGAGCCTGCAGGTGAAGCTGACAGCTCAGAGGC
15 ACCTGTGTGGAGGGTCACTCATAGGACACCAGTGGGTCCTCACTGCTGCCCACTGCTTTG ATGGGCTTCCCCTGCAGGATGTTTGGCGCATCTATAGTGGCATTTTAAATCTGTCAGACA TTACAAAAGATACACCTTTCTCACAAATAAAAGAGATTATTATTCACCAAAACTATAAAG TCTCAGAAGGGAATCATGATATCGCCTTGATAAAACTCCAGGCTCCTTTGAATTACACTG AATTCC___ΛCC-^TATGCCTACCTTCC-__ιGGTGACACAAGCACAATTTATACC-_
20 GTTGGGTAACCGGATGGGGCTTCTCGAAGGAGAAAGGTGAAATCCAAAATATTCTACAAA AGGTAAATATTCCT TGGTAACAAATGAAGAATGCCAGAAAAGATATCAAGATATAAAA TAACCC_^CGGATGGTCTGTGCTGGCTATAAAGAAGGGGGAAAAGATGCTTGTAAGGGAG ATTCAGGTGGTCCCTTAGTTTGC-__^CAC_\CGGAATGTGGCGTTTGGTGGGCATCACAA GCTGGGGTGAAGGCTGTGCCCGCAGGGAGCAACCTGGTGTCTACACCAAAGTCGCTGAGT 5 ACATGGACTGGATTTTAGAGAAAACACAGAGCAGTGATGGAAAAGCTCAGATGCAGTCAC CAGCATGAGAAGCAGTCCAGAGTCTAGGCAATTTTTACAACCTGAGTTCAAGTCAAATTC TGAGCCTGGGGGGTCCTCATCTGCAAAGCATGGAGAGTGGCATCTTCTTTGCATCCTAAG GACGAAAGACACAGTGCACTCAGAGCTGCTGAGGACAATGTCTGCTGAAGCCCGCTTTCA GCACGCCGTAACCAGGGGCTGACAATGCGAGGTCGCAACTGAGATCTCCATGACTGTGTG
30 TTGTGAAATAAAATGGTGAAAGATC
Table 4. Amino acid sequence for Human Plasma Kallikrein 5 ORF Start: 72 ORF Stop: 1986 Frame: 3
Human Plasma Kallikrein Protein Sequence:
>CG56155-01-prot 638 aa
MILFKQATYFIS FATVSCGCLTQLYENAFFRGGDVASMY PNAQYCQMRCTPHPRCL F SFLPASSINDMEKRFGCF KDSV GT PKVHRTGAVSGHS KQCGHQISACHRDIYKGVD MRG FWSKVSSVEECQKRCT^raIRCQFFSYA OTFHKAEYRNNCL, KYSPGGTPTAIK V SNVESGFS KPCaLSEIGCHMNIFQHLAFSDVDVARVTPDAFVCRTICTYHPNC FF TFYTNV KIESQRNVCLLKTSESGTPSSSTPQENTISGYSLLTCKRTLPEPCHSKIYPGV DFGGEE NVTFV GλraVCQETCTKMIRCQFFTYS LPEDCKEEKCKCFLR SMDGSPTRI AYGTQGSSGYS R C TGDNSVCTTKTSTRIVGGTNSSWGEWPWQVSLQVKLTAQRH CG GSLIGHQ VLTAAHCFDGLPLQDVWRIYSGILNLSDITKDTPFSQIKE111HQNYKVSEG NHDIALI LQAP NYTEFQKPIC PSKGDTSTIYTNCWV GWGFSKEKGEIQNILQKV I PLVTNEECQKRYQDYKITQRMVCAGYKEGGKnACKGDSGGPLVCKHNGMWRLVGITSWGE GCARREQPGVYTKVAEYMD ILEKTQSSDGKAQMQSPA
0 Table 5. Clustal W, Protein Domains, Cellular Location and Locus
The following is an alignment of the protein sequences of the human (CG56155-01), rat and mouse versions of the Plasma Kallikrein.
Human Plasma Kallikrein Locus: 4q35 Extiacellular
In addition to the human version of the Plasma Kallikrein identified as being differentially expressed in the experimental study, other variants have been identified by direct sequencing of cDNAs derived from many different human tissues and from sequences in public databases. No splice-form variants have been identified at CuraGen whereas several amino acid-changing cSNPs were identified. These are found below. The prefeπed variant of all those identified, to be used for screening purposes, is CG56155-01.
Table 6. The variants of the human Plasma Kallikrein obtained from direct cloning and/or public databases
Expression Profiles:
Table 7. CG56155-01: Plasma kallikrein - isoforml, submitted to study DDAT on 01/09/01 by sspaderna; clone status=FIS; novelty=Public; ORF start=72, ORF stop=1986, frame=3; 2245 bp.
Expression of gene CG56155-01 was assessed using the primer-probe set Agl688, described in Table 7. Results of the RTQ-PCR runs are shown in Tables 8 and 9.
Table 7. Probe Name Agl 688
Table 9. Panel 5 Islet
Biochemistry and Cell Line Expression
Plasma Kallikrein is a protease which is implicated in the conversion of plasminogen to the plasmin. Plasma Kallikrein activity was measured usually by spectiophotometric assays using artificial fluorescent peptide substrates. Plasma Kallikrein is commercially available enzyme with known inhibitors. The procedure of purification of Plasma Kallikrein from serum by affinity chromatography was described in literature. Cell lines expressing the
Plasma Kallikrein can be obtained from the RTQ-PCR results shown above. These and other Plasma Kallikrein expressing cell lines could be used for screening purposes.
Rationale for use as a diagnostic and/or target for small molecule drugs and antibody therapeutics.
1. Plasminogen activation, followed by fibrinolysis, is implicated recently in adipose differentiation by remodeling of the fibronectin-rich ECM of the preadipocytes. Knock out of the plasminogen gene in mouse lead to the reduction of fat deposit. 2. Plasma Kallikrein activates plasminogen, thus promoting adipose differentiation.
3. Plasma Kallikrein is significantly down-regulated in the liver of mice with the lean phenotype, which may cause disruption of the adipose differentiation ion this strain.
4. Taken in total, the data indicates that an inhibitor/antagonist of the human Plasma Kallikrein would be beneficial in the tieatment of obesity.
SPECIES #1 A gene fragment of the rat Plasma Kallikrein was initially found to be down-regulated by 2 fold in MB.01 study in the liver of SHR rat relative to normal control rat strain using CuraGen's GeneCalling ™ method of differential gene expression. Additionally, the expression of the enzyme was increased in the response to tioglitazone treatment. A differentially expressed rat gene fragment migrating, at approximately 142.3 nucleotides in length (Figure la. - vertical line) was definitively identified as a component of the rat Plasma Kallikrein cDNA (in the graphs, the abscissa is measured in lengths of nucleotides and the ordinate is measured as signal response). The method of competitive PCR was used for conformation of the gene assessment. The electiopherogram peaks corresponding to the gene fragment of the rat Plasma Kallikrein are ablated when a gene- specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The peaks at 142.3 nt in length are ablated in the sample from both the SHR and control rats.
SPECIES #2 The gene fragments coπesponding to the mouse Plasma Kallikrein were found to be down-regulated by 52.1 fold in liver tissues of normal mice relative to the lean mice. A differentially expressed mouse gene fragment migrating, at approximately 96 nucleotides in length (Figure la. - red vertical line) was definitively identified as a
component of the mouse Plasma Kallikrein cDNA by the method of competitive PCR. The electropherogramatic peaks coπesponding to the gene fragment of the mouse Plasma Kallikrein are ablated when a gene-specific primer (see below) competes with primers in the linker-adaptors during the PCR amplification. The peaks at 96 nt in length are ablated in the sample from both the normal and lean mice.
The sequence of the nucleotide-long gene fragment and the gene-specific primers used for competitive PCR are indicated on the cDNA sequence of the Plasma Kallikrein and shown below in bold. The gene-specific primers at the 5' and 3' ends of the fragment are in color.
Figures 1 A and IB. Differentially Expressed Rat Plasma Kallikrein in Study MB.01.
SPECIES #1
Figures 2A and 2B. Differentially Expressed Mouse Plasma Kallikrein in Study MB.04.
SPECIES #2
Example F. CG56155-03 Expression data:
Construction of the mammalian expression vector pCEP4/Sec. The oligonucleotide primers, pSec-N5-His Forward (CTCGTCCTCGAGGGTAAGCCTATCCCT AAC) and the pSec-N5-His Reverse (CTCGTCGGGCCCCTGATCAGCGGGTTTAAAC), were designed to amplify a fragment from the pcDΝA3.1-V5His (Invitiogen, Carlsbad, CA) expression vector. The PCR product was digested with Xhol and Apal and ligated into the Xhol/Apal digested pSecTag2 B vector (Invitrogen, Carlsbad CA). The coπect structure of the resulting vector, pSecV5His, was verified by DNA sequence analysis. The vector pSecV5His was digested with Pmel and Nhel, and the Pmel-Nhel fragment was ligated into the BamHI/Klenow and Nhel treated vector pCEP4 (Invitiogen, Carlsbad, CA). The resulting vector was named as pCEP4/Sec.
Expression of CG56155-03 in human embryonic kidney 293 cells. A 0.4 kb BamHI- XhoI fragment containing the CG56155-03 sequence was subcloned into BamHI-XhoI digested pCEP4/Sec to generate plasmid 1061. The resulting plasmid 1061 was transfected into 293 cells using the LipofectaminePlus reagent following the manufacturer's instructions (Gibco/BRL). The cell pellet and supernatant were harvested 72h post transfection and examined for CG56155-03 expression by Western blot (reducing conditions) using an anti-V5 antibody. Fig. 1 shows that CG56155-03 is expressed as a 74 kDa protein secreted by 293 cells.
Fig. 1. CG56155-03 protein secreted by 293 cells.
PAGE INTENTIONALLY LEFT BLANK
OTHER EMBODIMENTS
Although particular embodiments have been disclosed herein in detail, this has been done by way of example for purposes of illustration only, and is not intended to be limiting with respect to the scope of the appended claims, which follow. In particular, it is contemplated by the inventors that various substitutions, alterations, and modifications may be made to the invention without departing from the spirit and scope of the invention as defined by the claims. The choice of nucleic acid starting material, clone of interest, or library type is believed to be a matter of routine for a person of ordinary skill in the art with knowledge of the embodiments described herein. Other aspects, advantages, and modifications considered to be within the scope of the following claims. The claims presented are representative of the inventions disclosed herein. Other, unclaimed inventions are also contemplated. Applicants reserve the right to pursue such inventions in later claims.