RU2392324C2 - Concerned sequences linkage method - Google Patents
Concerned sequences linkage method Download PDFInfo
- Publication number
- RU2392324C2 RU2392324C2 RU2006112833/13A RU2006112833A RU2392324C2 RU 2392324 C2 RU2392324 C2 RU 2392324C2 RU 2006112833/13 A RU2006112833/13 A RU 2006112833/13A RU 2006112833 A RU2006112833 A RU 2006112833A RU 2392324 C2 RU2392324 C2 RU 2392324C2
- Authority
- RU
- Russia
- Prior art keywords
- cells
- primers
- chain
- sequences
- pcr
- Prior art date
Links
Images


































































































































































Landscapes
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
Description
Область техники, к которой относится изобретениеFIELD OF THE INVENTION
Настоящее изобретение относится к способу множественной молекулярной амплификации, способной к связыванию интересующих нуклеотидных последовательностей с помощью амплификации, в частности с помощью полимеразной цепной реакции (множественная PCR). Способ является особенно эффективным для создания библиотек родственных пар, а также комбинаторных библиотек последовательностей, кодирующих вариабельные области иммуноглобулинов, Т-клеточных рецепторов или В-клеточных рецепторов.The present invention relates to a multiple molecular amplification method capable of binding nucleotide sequences of interest by amplification, in particular by polymerase chain reaction (multiple PCR). The method is particularly effective for creating libraries of related pairs, as well as combinatorial libraries of sequences encoding the variable regions of immunoglobulins, T-cell receptors or B-cell receptors.
Уровень техникиState of the art
Антигенсвязывающие белки, участвующие в иммунной реакции, присутствуют в организме млекопитающих в виде большого поликлонального набора, представляющего собой широкое разнообразие специфичностей связывания. Подобное разнообразие создается реаранжировкой генных последовательностей, кодирующих вариабельные области указанных связывающих белков. Такие связывающие белки, имеющие вариабельные области, включают растворимые и мембраносвязанные формы В-клеточного рецептора (известные также как иммуноглобулины или антитела) и мембраносвязанные Т-клеточные рецепторы (TcR). Что касается иммуноглобулинов, то их сродство усиливается после распознавания антигена рецептором антигена В-клеток вследствие процесса, именуемого “созреванием аффинности”, в который вовлечены циклы соматической сверхмутации этих генов вариабельных областей.Antigen-binding proteins involved in the immune response are present in mammals in the form of a large polyclonal set, which represents a wide variety of binding specificities. Such diversity is created by rearrangement of gene sequences encoding the variable regions of these binding proteins. Such binding proteins having variable regions include soluble and membrane bound forms of the B cell receptor (also known as immunoglobulins or antibodies) and membrane bound T cell receptors (TcR). As for immunoglobulins, their affinity increases after recognition of the antigen by the B-cell antigen receptor due to a process called “affinity maturation”, which involves the cycles of somatic overmutation of these variable region genes.
Кроме того, иммуноглобулины или их фрагменты, такие как Fab-фрагменты, Fv-фрагменты и одноцепочечные Fv-фрагменты (scFv), являются предметом клонирования и рекомбинантной экспрессии. Однако все другие связывающие белки, имеющие вариабельные области, в принципе могут быть клонированы и экспрессированы так же, как и антитела.In addition, immunoglobulins or fragments thereof, such as Fab fragments, Fv fragments, and single chain Fv fragments (scFv), are subject to cloning and recombinant expression. However, all other binding proteins having variable regions can, in principle, be cloned and expressed in the same way as antibodies.
Известные методы выделения антител с требуемой специфичностью связывания чаще всего включают получение гибридом у иммунизированных хозяев с последующим скринингом специфических клонов или создание комбинаторных библиотек экспрессируемых последовательностей в E.coli, состоящих из вариабельных доменов иммуноглобулинов, которые затем обогащают при помощи таких методов, как, например, фаговый дисплей.Known methods for isolating antibodies with the required binding specificity most often include obtaining hybridomas from immunized hosts followed by screening for specific clones or creating combinatorial libraries of expressed sequences in E. coli, consisting of variable domains of immunoglobulins, which are then enriched using methods such as, for example, phage display.
Главным ограничением, связанным с применением технологии гибридом для получения терапевтических антител, является отсутствие лимфомы человека, которая может использоваться в качестве сливающихся клеток для В-лимфоцитов человека. Гетерогибридомы (то есть В-клетки человека, слитые с лимфомами мыши) яляются, как известно, неустойчивыми и, таким образом, редко позволяют получить приемлемые линии клеток для целей продукции антител. В-клетки человека, иммортализованные в результате инфицирования вирусом Эпштейна - Барра, характеризуются такими же признаками неустойчивости. Отсутствие надежных клеточных методов получения антител человека для лечебных целей может быть компенсировано последними достижениями в области молекулярной биологии.The main limitation associated with the use of hybrid technology to produce therapeutic antibodies is the absence of human lymphoma, which can be used as fusion cells for human B-lymphocytes. Heterohybridomas (i.e., human B cells fused to mouse lymphomas) are known to be unstable and thus rarely allow obtaining acceptable cell lines for the production of antibodies. Human B cells immortalized as a result of infection with the Epstein-Barr virus are characterized by the same signs of instability. The lack of reliable cellular methods for the production of human antibodies for therapeutic purposes can be offset by recent advances in molecular biology.
Применение комбинаторных библиотек и фагового дисплея позволяет создать большой спектр клонов антител с потенциальным разнообразием, превышающим 1010. Из вышеуказанного спектра можно выбрать тип связывания со специфической мишенью, создав таким образом подбиблиотеку. Такую подбиблиотеку можно использовать для создания поликлональных или моноклональных антител. Последовательности, кодирующие вариабельные области (например, последовательности, кодирующие вариабельную область тяжелой цепи и вариабельную область легкой цепи иммуноглобулина), которые образуют библиотеку, можно амплифицировать из лимфоцитов, плазматических клеток, гибридом или любой другой популяции клеток, экспрессирующей иммуноглобулин. Современные методы создания комбинаторных библиотек предусматривают раздельное выделение из популяции клеток последовательностей, кодирующих вариабельные области. Таким образом утрачивается первоначальное спаривание последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи иммуноглобулина. В комбинаторной библиотеке указанные последовательности спариваются произвольно, и первоначальные комбинации указанных вариабельных последовательностей образуются лишь случайно. Поэтому для выделения последовательностей, кодирующих вариабельные области, которые отвечают за требуемую специфичность связывания, необходимо произвести многостадийный скрининг. Такой скрининг обычно выполняют в сочетании с методами обогащения клонов, обладающих требуемой специфичностью, такими как фаговый или рибосомный дисплей. Даже после того как разнообразие достигнуто, оно может быть недостаточным для выделения пар последовательностей, кодирующих вариабельные области, с целью получения связывающих белков, обладающих таким же высоким сродством, которое может быть обнаружено в исходных клетках. Кроме того, методы обогащения, обычно применяемые для скрининга комбинаторных библиотек, вносят значительную стандартную ошибку, например, в случае полипептидов с особенно низкой токсичностью в E.coli, которая влияет на эффективность укладки цепи, замедляется скорость выделения или ухудшаются другие параметры, находящиеся в зависимости от системы, что еще больше уменьшает разнообразие библиотеки. Помимо этого клоны, полученные из таких комбинаторных библиотек, чаще продуцируют связывающие белки с перекрестной реактивностью против аутоантигенов, так как указанные пары белков, в отличие от первоначальных пар (далее именуемых родственными парами), не подвергаются происходящей in vivo отрицательной селекции на аутоантигены, как это имеет место в случае рецепторов В- и Т-лимфоцитов на определенных стадиях их развития. Поэтому желательно клонировать первоначальные пары последовательностей, кодирующих вариабельные области. Кроме того, ожидается, что частота встречаемости клонов, обладающих требуемой специфичностью связывания, будет значительно выше в библиотеке родственных пар, чем в обычной комбинаторной библиотеке, особенно если клетки исходного материала взяты от донора с высокой частотой встречаемости клеток, кодирующих пары со специфическим связыванием, то есть у иммунокомпетентных или иммунизированных доноров. Из вышеизложенного следует, что библиотека родственных пар необязательно должна быть такой же большой, как комбинаторная библиотека: библиотека родственных пар, содержащая 104-105 клонов или даже 102-103 клонов, полученных от донора с соответствующей иммунной реакцией, может быть вполне достаточной для получения связывающих белков, представляющих собой широкое разнообразие требуемых специфичностей связывания.The use of combinatorial libraries and phage display allows you to create a wide range of antibody clones with potential diversity in excess of 10 10 . From the above spectrum, one can select the type of binding to a specific target, thus creating a sub-library. Such a sub-library can be used to create polyclonal or monoclonal antibodies. The sequences encoding the variable regions (e.g., sequences encoding the variable region of the heavy chain and the variable region of the light chain of the immunoglobulin) that form the library can be amplified from lymphocytes, plasma cells, hybridomas, or any other population of cells expressing immunoglobulin. Modern methods for creating combinatorial libraries provide for the separate selection of sequences encoding variable regions from a population of cells. Thus, the initial pairing of sequences encoding the variable region of the heavy chain and the variable region of the light chain of immunoglobulin is lost. In the combinatorial library, these sequences are mated randomly, and the initial combinations of these variable sequences are formed only randomly. Therefore, to isolate sequences encoding the variable regions that are responsible for the required binding specificity, it is necessary to perform multi-stage screening. Such screening is usually performed in combination with enrichment methods for clones having the required specificity, such as phage or ribosome display. Even after diversity has been achieved, it may not be sufficient to isolate pairs of sequences encoding the variable regions in order to obtain binding proteins having the same high affinity that can be found in the original cells. In addition, the enrichment methods commonly used for screening combinatorial libraries introduce a significant standard error, for example, in the case of polypeptides with particularly low toxicity in E. coli, which affects the efficiency of chain folding, the rate of isolation slows down, or other parameters depending from the system, which further reduces the diversity of the library. In addition, clones derived from such combinatorial libraries often produce binding proteins with cross-reactivity against autoantigens, since these protein pairs, unlike the original pairs (hereinafter referred to as related pairs), are not subjected to in vivo negative selection for autoantigens like this occurs in the case of receptors for B- and T-lymphocytes at certain stages of their development. Therefore, it is desirable to clone the original pairs of sequences encoding variable regions. In addition, it is expected that the frequency of occurrence of clones with the required binding specificity will be significantly higher in the library of related pairs than in a conventional combinatorial library, especially if the cells of the source material were taken from a donor with a high frequency of occurrence of cells encoding pairs with specific binding, then immunocompetent or immunized donors have. From the above it follows that the library of sibling pairs does not have to be as large as the combinatorial library: a library of sibling pairs containing 10 4 -10 5 clones or even 10 2 -10 3 clones obtained from a donor with an appropriate immune response can be quite sufficient to obtain binding proteins, representing a wide variety of required binding specificities.
Для создания библиотек родственных пар необходимо связать последовательности, кодирующие вариабельные области, которые были выделены из одной клетки. В настоящее время описаны два разных подхода, обеспечивающих родственное спаривание последовательностей, кодирующих вариабельные области.To create libraries of related pairs, it is necessary to bind sequences encoding the variable regions that were isolated from one cell. Currently, two different approaches are described that provide for related pairing of sequences encoding variable regions.
Внутриклеточная PCR представляет собой подход, при котором обеспечивают проницаемость фиксированной популяции клеток и осуществляют внутриклеточное связывание последовательностей иммуноглобулинов, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи. Указанное связывание можно осуществить методом RT-PCR с перекрыванием цепи (WO 93/03151) или путем рекомбинантного метода (Chapal, N. et al. 1997, Bio Techniques 23, 518-524). Процесс амплификации, описанный в указанных публикациях, является трех- или четырехстадийным процессом, предусматривающим i) обратную транскрипцию с использованием праймеров для константной области, образующих кДНК иммуноглобулина, ii) амплификацию методом PCR последовательностей, кодирующих вариабельные области тяжелой и легкой цепи, с использованием наборов праймеров, с сайтами перекрывания или рекомбинации, iii) связывание путем рекомбинации, если выбран данный метод, iv) осуществление гнездовой PCR продуктов, образующих сайты рестрикции для клонирования. Так как клетки являются проницаемыми, существует значительный риск выхода продуктов амплификации из клеток, в результате чего может произойти перестановка последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи, что ведет к утрате родственного спаривания. Поэтому такой метод предусматривает стадии промывки после каждой реакции, что делает процесс трудоемким и уменьшает эффективность реакций.Intracellular PCR is an approach in which the permeability of a fixed population of cells is ensured and intracellular binding of immunoglobulin sequences encoding the variable region of the heavy chain and the variable region of the light chain is performed. Said binding can be accomplished by RT-PCR with chain overlapping (
Как правило, внутриклеточная PCR является неэффективной и приводит к низкой чувствительности. Поэтому метод связывания при помощи внутриклеточной PCR не нашел широкого распространения, причем первоначальное исследование невозможно было повторить с получением надежных результатов, подтверждающих, что внутри клетки действительно происходит связывание. Между тем при этом методе необходимо избегать перестановки последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи, в результате которой происходит разрушение родственных пар.Typically, intracellular PCR is ineffective and leads to low sensitivity. Therefore, the method of binding using intracellular PCR was not widely used, and the initial study could not be repeated to obtain reliable results confirming that binding actually occurs inside the cell. Meanwhile, with this method, it is necessary to avoid the rearrangement of sequences encoding the variable region of the heavy chain and the variable region of the light chain, as a result of which the destruction of related pairs occurs.
Другой внутриклеточный метод описан в WO 01/92291. Указанный метод основан на транссплайсинге РНК и при нем достигается соединение VН- и VL-кодирующей мРНК внутри клетки. Указанный подход требует наличия конструкции ДНК, осуществляющей транссплайсинг внутри клеток.Another intracellular method is described in WO 01/92291. The indicated method is based on RNA transplacing and it achieves the connection of V H and V L coding mRNA inside the cell. This approach requires the presence of a DNA construct that carries out trans-splicing inside cells.
Одноклеточная PCR представляет собой другой метод родственного спаривания последовательностей, кодирующих варибельную область тяжелой цепи и вариабельную область легкой цепи (см., например, публикации Coronella, J.A. et al. 2000, Nucleic Acids Res. 28, E85; Wang, X., et al. 2000, J. Immunol. Methods 20, 217-225). В указанных публикациях описан метод, в соответствии с которым популяцию иммуноглобулин-экспрессирующих клеток распределяют по пробиркам, разводя до плотности, соответствующей одной клетке в одной реакционной смеси, в результате чего в процессе клонирования устраняется перестановка последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи. Описанный метод состоит из трех-четырех стадий, включающих i) обратную транскрипцию с использованием олиго-dT-праймеров, произвольных гексамерных праймеров или праймеров для константной области, образующих кДНК, ii) фракционирование продукта кДНК в нескольких пробирках и амплификацию при помощи PCR отдельных последовательностей, кодирующих вариабельные области цепей (в отдельных пробирках), с использованием наборов праймеров, содержащих сайты рестрикции для клонирования, iii) осуществление гнездовой PCR продуктов, образующих сайты рестрикции для клонирования (необязательно), и iv) связывание последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи, из отдельных пробирок путем клонирования их в соответствующем векторе, что само по себе является многостадийным процессом.Unicellular PCR is another method of related mating of sequences encoding the variable region of the heavy chain and the variable region of the light chain (see, for example, Coronella, JA et al. 2000, Nucleic Acids Res. 28, E85; Wang, X., et al . 2000, J. Immunol.
У человека присутствуют легкие цепи двух типов: лямбда (λ) и каппа (κ). Из этого следует, что для кДНК, полученной из каждой отдельной клетки, необходимо выполнить по крайней мере три отдельные реакции PCR с последующим анализом и клонированием соответствущих фрагментов в единичном векторе для достижения родственного спаривания. Таким образом, вышеописанный метод одноклеточной РCR требует большого числа манипуляций для создания библиотеки родственных пар. Хотя библиотека родственных пар не обязательно должна быть такой же большой, как комбинаторная библиотека, для получения связывающих белков, представляющих собой широкое разнообразие специфичностей связывания, создание библиотеки, содержащей, например, 104-105 клонов, вышеописанным методом одноклеточной PCR по-прежнему остается трудоемкой задачей. Кроме того, большое число манипуляций значительно увеличивает риск загрязнения и ошибки, вызванной человеческим фактором.A person has two types of light chains: lambda (λ) and kappa (κ). It follows that for cDNA obtained from each individual cell, it is necessary to perform at least three separate PCR reactions, followed by analysis and cloning of the corresponding fragments in a single vector to achieve related mating. Thus, the above-described unicellular PCR method requires a large number of manipulations to create a library of related pairs. Although the library of sibling pairs does not have to be as large as a combinatorial library to obtain binding proteins representing a wide variety of binding specificities, the creation of a library containing, for example, 10 4 -10 5 clones, by the above-described unicellular PCR method still remains laborious task. In addition, a large number of manipulations significantly increases the risk of contamination and error caused by the human factor.
Для получения связывающих белков с высоким сродством, соответствующим сродству, обычно наблюдаемому при возникновении иммунной реакции, весьма перспективным является родственное спаривание последовательностей, кодирующих вариабельные области, в сочетании с их амплификацией. Для создания библиотеки с большим разнообразием клонов необходимо разработать высокоэффективный метод клонирования, отличающийся минимальным риском загрязнения и перестановки последовательностей.To obtain binding proteins with a high affinity corresponding to the affinity that is usually observed when an immune reaction arises, the pairing of sequences encoding variable regions in combination with their amplification is very promising. To create a library with a wide variety of clones, it is necessary to develop a highly efficient cloning method with a minimal risk of contamination and sequence rearrangement.
Кроме того, желательно сократить число стадий клонирования для достижения высокоэффективного создания комбинаторных библиотек.In addition, it is desirable to reduce the number of stages of cloning to achieve highly efficient creation of combinatorial libraries.
Сущность усовершенствованияThe essence of improvement
Настоящее изобретение относится к эффективному способу связывания двух или нескольких интересующих нуклеотидных последовательностей, то есть последовательностей, кодирующих вариабельные области, применяя множественную молекулярную амплификацию, такую как множественная RT-PCR с удлинением цепи путем перекрывания или множественная RT-PCR с последующим связыванием путем лигирования или рекомбинации. Этот способ может быть выполнен в формате одной клетки, что делает возможным высокоэффективное клонирование родственных пар.The present invention relates to an efficient method for linking two or more nucleotide sequences of interest, i.e. sequences encoding variable regions using multiple molecular amplification, such as multiple RT-PCR with chain extension by overlapping or multiple RT-PCR followed by ligation or recombination . This method can be performed in a single cell format, which makes highly efficient cloning of related pairs possible.
Краткое описание чертежейBrief Description of the Drawings
На фиг.1 схематически изображены разные типы концевых сегментов удлинения цепи путем перекрывания. Жирные линии соответствуют геноспецифической части праймера, а обычные линии соответствуют перекрывающему концевому сегменту. Вертикальные линии иллюстрируют комплементарные области. Праймеры облегчают связывание двух интересующих нуклеотидных последовательностей. На фиг.1 (I) показаны два варианта концевых сегментов удлинения цепи путем перекрывания типа I, где полностью или частично перекрываются только удлиняющие сегменты; на фиг.1 (II) показаны концевые сегменты удлинения цепи путем перекрывания типа II, где некоторые 5'-концевые нуклеотиды удлиняющего сегмента первого праймера комплементарны геноспецифической части соседнего праймера; на фиг.1 (III) показаны концевые сегменты удлинения цепи путем перекрывания типа III, где все удлиняющие сегменты являются комплементарными геноспецифической области соседнего праймера.Figure 1 schematically shows the different types of end segments of chain extension by overlapping. Bold lines correspond to the gene-specific part of the primer, and normal lines correspond to the overlapping end segment. Vertical lines illustrate complementary areas. Primers facilitate the binding of two nucleotide sequences of interest. Figure 1 (I) shows two variants of the end segments of the chain extension by overlapping type I, where only the extension segments overlap fully or partially; figure 1 (II) shows the end segments of the chain extension by overlapping type II, where some 5'-terminal nucleotides of the extension segment of the first primer are complementary to the gene-specific part of the adjacent primer; figure 1 (III) shows the end segments of chain extension by overlapping type III, where all the extension segments are complementary to the gene-specific region of the adjacent primer.
На фиг.2 схематически изображена смесь множественных праймеров для удлинения цепи путем перекрывания, используемая для связывания последовательностей, кодирующих вариабельные области иммуноглобулина. Подлежащие связыванию кДНК, кодирующие легкую цепь (LC) и вариабельную область тяжелой цепи (VH), изображены в виде трубок с обозначением 5'- и 3'-концов смысловых цепей, а также предполагаемого размера амплифицированного продукта. Множественные наборы праймеров для удлинения цепи путем перекрывания, используемые для амплификации кодирующей последовательностей, показаны стрелками. Изогнутые стрелки с пунктирными краями, направленные в сторону 5'-концов, показывают клонирующие концевые сегменты. Концевые сегменты удлинения цепи путем перекрывания изображены жирными линиями. Сайты рекстрикции, присутствующие в концевых сегментах, указаны рядом с концевым сегментом. Общее число праймеров в смеси множественных праймеров для удлинения цепи путем перекрывания равно шестнадцати и разделено на внешние праймеры, включающие один праймер для Ск и один праймер для СН1, и праймеры для удлинения цепи путем перекрывания, включающие шесть праймеров для VL и восемь праймеров для VН. Праймер для СН1 гибридизируется с 5'-концом константного домена 1 тяжелой цепи. Предполагается, что продукт, образующийся в результате множественной RT-PCR с удлинением цепи путем перекрывания, равен примерно 1070 п.о. и содержит всю легкую каппа-цепь, состоящую из константной области, J-гена и V-гена (Ск + JL + VL), и вариабельную область тяжелой цепи, состоящую из V-гена, D-сегмента и J-гена (VH + D + JH). 5'- и 3'-концы обозначают направление открытой рамки считывания. Только небольшая часть последовательности, кодирующей СН1-область, амплифицирована множественной смесью праймеров для удлинения цепи путем перекрывания, так как положение гибридизации праймера для СН1 находится рядом с J-областью тяжелой цепи.Figure 2 schematically depicts a mixture of multiple primers to extend the chain by overlapping, used to bind sequences encoding the variable regions of immunoglobulin. Binding cDNAs encoding a light chain (LC) and a variable region of a heavy chain (V H ) are shown as tubes with the 5 ′ and 3 ′ ends of the sense strands as well as the estimated size of the amplified product. Multiple primer sets for overlapping strand extension used to amplify coding sequences are shown by arrows. Curved arrows with dotted edges directed towards the 5'-ends show the cloning end segments. The end segments of chain elongation by overlapping are shown in bold lines. Restriction sites present in the end segments are indicated next to the end segment. The total number of primers in the mixture of multiple primers for extending the chain by overlapping is sixteen and divided into external primers including one primer for C k and one primer for C H1 , and primers for extending the chain by overlapping, including six primers for V L and eight primers for V N The primer for C H1 hybridizes with the 5'-end of the
На фиг.3 изображено несколько схем, показывающих разные направления связывания получаемых продуктов в зависимости от того, какие праймеры имеют концевой связывающий сегмент. Черным цветом показана область перекрывания. 5'- и 3'-концы обозначают направление открытой рамки считывания. На фиг.3А изображена схема, иллюстрирующая ориентацию продуктов “головной сегмент - головной сегмент”. На фиг.3В изображена схема, иллюстрирующая ориентацию продуктов “концевой сегмент - концевой сегмент”. На фиг.3С изображена схема, иллюстрирующая ориентацию “головной сегмент - концевой сегмент”, где первой является последовательность, кодирующая легкую цепь. На фиг.3D изображена схема, иллюстрирующая ориентацию “головной сегмент - концевой сегмент”, где первой является последовательность, кодирующая тяжелую цепь.Figure 3 shows several schemes showing different directions of binding of the obtained products, depending on which primers have an end binding segment. The overlap area is shown in black. The 5'- and 3'-ends indicate the direction of the open reading frame. On figa depicts a diagram illustrating the orientation of the products “head segment - head segment”. 3B is a diagram illustrating the orientation of end-to-end segment products. On figs depicts a diagram illustrating the orientation of the “head segment - end segment”, where the first is the sequence encoding the light chain. 3D is a diagram illustrating the orientation of the “head segment - end segment”, where the first is the sequence encoding the heavy chain.
На фиг.4 схематически изображен вектор экспрессии иммуноглобулина pLL113, где кодирующие последовательности находятся в ориентации “головной сегмент - концевой сегмент”. Показанный вектор включает нижеследующие элементы: bla = промотор, экспрессии гена устойчивости к ампициллину. Amp = ген, кодирующий устойчивость к ампициллину. pUC ori = точка начала репликации pUC. AdMLP = главный поздний промотор аденовируса. Human IgG1 = последовательность, кодирующая тяжелую цепь иммуноглобулина изотипа G1 человека. hGH pA = поли-А-сигнальная последовательность гормона роста человека. bGH polyA = поли-А-последовательность гормона роста крупного рогатого скота. LC каппа человека = последовательность, кодирующая легкую каппа-цепь иммуноглобулина человека. FRT = сайт-мишень узнавания Flp. Гигромицин = ген, кодирующий устойчивость к гигромицину. SV40 polyA = поли-А-сигнальная последовательность вакуолизирующего обезьяньего вируса.Figure 4 schematically shows the expression vector of the immunoglobulin pLL113, where the coding sequences are in the orientation of “head segment - end segment”. The vector shown includes the following elements: bla = promoter, expression of the ampicillin resistance gene. Amp = gene encoding ampicillin resistance. pUC ori = pUC replication start point. AdMLP = major late adenovirus promoter. Human IgG1 = sequence encoding an immunoglobulin heavy chain of the human G1 isotype. hGH pA = poly-A signal sequence of human growth hormone. bGH polyA = poly-A sequence of cattle growth hormone. Human kappa LC = human immunoglobulin light kappa chain coding sequence. FRT = Flp recognition target site. Hygromycin = gene encoding hygromycin resistance. SV40 polyA = poly-A signal sequence of vacuolating monkey virus.
На фиг.5А изображен гель после электрофореза, показывающий результаты двухстадийной множественной RT-PCR с удлинением цепи путем перекрывания с последующей полугнездовой РCR. Продукты амплификации получены из кДНК, выделенной из отдельных клеток яичника китайского хомячка (СНО) Flp-In pLL113. Полосы 1-12 обозначают образцы, а стрелки показывают правильные продукты множественной гнездовой RT-PCR с удлинением цепи путем перекрывания длиной 1076 п.о.; М1 обозначает лэддер длиной 100 п.о. W обозначает воду, использованную в качестве отрицательного контрольного образца. С обозначает положительный контрольный образец кДНК, выделенный из линии клеток НВ-8501. Отдельно представлено менее контрастное изобретение тех же самых полос W, C и лэддера длиной 100 п.о. для выделения отдельных фрагментов ДНК. На фиг.5В дано схематическое изображение геля, показанного на фиг.5А, которое иллюстрирует соответствущие фрагменты геля.Fig. 5A shows a gel after electrophoresis showing the results of a two-stage multiple RT-PCR with chain extension by overlapping followed by a semi-nested PCR. Amplification products were obtained from cDNA isolated from individual cells of Chinese hamster ovary (CHO) Flp-In pLL113. Lanes 1-12 indicate samples, and arrows indicate the correct products of multiple RT-PCR nested with chain extension by overlapping 1076 bp in length .; M1 stands for 100 bp ladder. W denotes water used as a negative control. C denotes a positive control cDNA sample isolated from the HB-8501 cell line. Separately, a less contrasting invention of the same W, C bands and a 100 bp ladder is presented. to isolate individual DNA fragments. On figv given a schematic representation of the gel shown in figa, which illustrates the corresponding fragments of the gel.
На фиг.6 показано несколько фотографий и дано графическое изображение гелей после электрофореза, на которых представлены результаты одностадийной множественной RT-PCR с удлинением цепи путем перекрывания без дополнительной амплификации методом РCR. Во всех блоках М1 обозначает лэддер длиной 100 п.о., а М2 обозначает лэддер длиной 500 п.о. На фиг.6А изображен гель после электрофореза с продуктами амплификации, выделенными из лизата, соответствующего 100, 10, 1 или 0 клеток. Стрелка показывает продукт удлинения цепи путем перекрывания. На фиг.6В дано схематическое изображение геля, показанного на фиг.6А. На фиг.6С показан гель после электрофореза, подтверждающий наличие продукта, полученного удлинением цепи путем перекрывания, в полосах, соответствующих 100 и 1 клетке, на фиг.6А. На фиг.6D изображен гель после электрофореза, на котором видно расщепление рестрикционными ферментами NheI и NcoI продукта, полученного удлинением цепи путем перекрывания, из полосы, соответствующей 1 клетке, на фиг.6С.Figure 6 shows several photographs and a graphical representation of the gels after electrophoresis, which presents the results of a single-stage multiple RT-PCR with chain extension by overlapping without additional amplification by the method of PCR. In all blocks, M1 stands for a 100 bp ladder, and M2 stands for a 500 bp ladder. 6A shows a gel after electrophoresis with amplification products isolated from a lysate corresponding to 100, 10, 1 or 0 cells. The arrow indicates the product of chain extension by overlapping. On figv given a schematic representation of the gel shown in figa. On figs shows the gel after electrophoresis, confirming the presence of the product obtained by lengthening the chain by overlapping, in bands corresponding to 100 and 1 cell, figa. On fig.6D shows the gel after electrophoresis, which shows the cleavage by restriction enzymes NheI and NcoI of the product obtained by elongation of the chain by overlapping, from the strip corresponding to 1 cell in figs.
На фиг.7 изображен гель после электрофореза, на котором видны результаты одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и последующей амплификации методом полугнездовой PCR. М1 обозначает лэддер длиной 100 п.о., и М2 обозначает лэддер длиной 500 п.о. Указанные результаты получены при использовании смесей множественных праймеров для удлинения цепи путем перекрывания, содержащих праймер для СН1, СН2, СН3, СН4 или СН5 в качестве внешнего праймера при выполнении множественной RT-PCR с удлинением цепи путем перекрывания. Указанные реакции выполняли в клеточных лизатах, соответствующих 100, 10, 1 или 0 клеток. Размер продукта, полученного удлинением цепи путем перекрывания, показан стрелкой.Figure 7 shows the gel after electrophoresis, which shows the results of a single-stage multiple RT-PCR with chain extension by overlapping and subsequent amplification by the method of semi-nested PCR. M1 denotes a 100 bp ladder, and M2 denotes a 500 bp ladder. These results were obtained by using mixtures of multiple primers for chain extension by overlapping, containing a primer for C H1 , C H2 , C H3 , C H4 or C H5 as an external primer when performing multiple RT-PCR with chain extension by overlapping. These reactions were performed in cell lysates corresponding to 100, 10, 1 or 0 cells. The size of the product obtained by extending the chain by overlapping is shown by the arrow.
На фиг.8 изображен гель после электрофореза, на котором видны результаты одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и последующей амплификации методом полугнездовой PCR с использованием обогащенных В-лимфоцитов человека в качестве матрицы. М1 обозначает лэддер длиной 100 п.о. Полосы 5 и 6 соответствуют размеру продукта, полученного удлинением цепи путем перекрывания.Figure 8 shows the gel after electrophoresis, which shows the results of a single-stage multiple RT-PCR with chain extension by overlapping and subsequent amplification by the method of semi-nested PCR using enriched human B-lymphocytes as a matrix. M1 stands for 100 bp ladder.
На фиг.9А схематически изображены экспрессирущие векторы млекопитающих (Em465/01P582/Em465/01P581), использованные для получения линий клеток, экспрессирующих лямбда-цепь IgG1, где кодирующие последовательности находятся в ориентации “головной сегмент - головной сегмент”. Указанные векторы включают нижеследующие элементы: Amp = ген, кодирующий устойчивость к ампициллину. pUC ori = точка начала репликации pUC. AdMLP = главный поздний промотор аденовируса. EFP = промотор фактора элонгации. Лидерная AP = лидерная последовательность щелочной фосфатазы. VH = последовательность, кодирующая вариабельную область тяжелой цепи. IgG1 HC = последовательность, кодирующая константную область тяжелой цепи иммуноглобулина изотипа G1. rBG polyA = поли-А-сигнальная последовательность бета-глобулина кролика. bGH polyA = поли-А-последовательность гормона роста крупного рогатого скота. Лидерная IgK = последовательность, кодирующая лидерную последовательность каппа-цепи мыши. IgL (1b или 1с) = последовательность, кодирующая легкую лямбда-цепь иммуноглобулина семейства 1b или 1с. FRT = сайт-мишень узнавания Flp. Гигромицин = ген, кодирующий устойчивость к гигромицину. SV40 polyA = поли-А-сигнальная последовательность вакуолизирующего обезьяньего вируса. На фигурах 9В и 9С показаны агарозные гели, окрашенные этидием бромида, содержащие продукты PCR, выделенные из линий клеток СНО Flp-In/Em464/01P581 и CHOFlp-In/Em464/01P582 соответственно. Полосы 1-4 соответствуют концентрациям матрицы общей РНК, равным 50 пг, 5 пг, 0,5 пг или 0 пг, которые были использованы для выполнения множественной RT-PCR с удлинением цепи путем перекрывания. М обозначает лэддер длиной 100 п.о. (New England Biolabs, New England, USA). Стрелки показывают продукт PCR с удлинением цепи путем перекрывания.On figa schematically shows the expression vectors of mammals (Em465 / 01P582 / Em465 / 01P581) used to obtain cell lines expressing the lambda chain of IgG1, where the coding sequences are in the orientation of the “head segment - head segment”. These vectors include the following elements: Amp = gene encoding ampicillin resistance. pUC ori = pUC replication start point. AdMLP = major late adenovirus promoter. EFP = promoter of elongation factor. Leader AP = leader sequence of alkaline phosphatase. VH = sequence encoding the variable region of the heavy chain. IgG1 HC = sequence encoding the constant region of the heavy chain of the immunoglobulin isotype G1. rBG polyA = poly-A signal sequence of rabbit beta globulin. bGH polyA = poly-A sequence of cattle growth hormone. Leader IgK = sequence encoding the leader sequence of the kappa chain of the mouse. IgL (1b or 1c) = sequence encoding the lambda light chain of an immunoglobulin family of 1b or 1c. FRT = Flp recognition target site. Hygromycin = gene encoding hygromycin resistance. SV40 polyA = poly-A signal sequence of vacuolating monkey virus. Figures 9B and 9C show agarose gels stained with ethidium bromide containing PCR products isolated from CHO cell lines Flp-In / Em464 / 01P581 and CHOFlp-In / Em464 / 01P582, respectively. Lanes 1-4 correspond to concentrations of the total RNA template equal to 50 pg, 5 pg, 0.5 pg or 0 pg, which were used to perform multiple RT-PCR with chain extension by overlapping. M stands for 100 bp ladder. (New England Biolabs, New England, USA). The arrows indicate the product of the PCR with the extension of the chain by overlapping.
На фиг.10 изображена блок-схема, показывающая стадии создания библиотеки экспрессируемых родственных антител, из которой могут быть экспрессированы поликлональные или моноклональные антитела.10 is a flowchart showing the steps for creating a library of expressed related antibodies from which polyclonal or monoclonal antibodies can be expressed.
На фиг.11 схематически изображен вектор JSK301 E.coli, используемый для создания библиотеки векторов экспрессии Fab-фрагментов путем введения в вектор фрагментов удлинения цепи путем перекрывания, содержащих родственные последовательности, кодирующие вариабельные области, на указанных сайтах рестрикции NotI/XhoI. Указанный вектор содержит нижеследующие элементы: Amp и Amp pro = ген устойчивости к ампициллину и его промотор. pUC19 Ori = точка начала репликации. СН1 человека = последовательность, кодирующая домен 1 тяжелой цепи иммуноглобулина гамма 1 человека. Вставка = вставка неродственной последовательности, которую вырезают при введении фрагментов удлинения цепи путем перекрывания. tac P и lac Z = бактериальные промоторы, которые могут быть вырезаны на сайтах рестрикции NheI и AscI.11 schematically depicts the E. coli JSK301 vector used to create a library of expression vectors for Fab fragments by introducing overlapping chain extension fragments into the vector containing related sequences encoding variable regions at the indicated NotI / XhoI restriction sites. The specified vector contains the following elements: Amp and Amp pro = ampicillin resistance gene and its promoter. pUC19 Ori = origin of replication. Human CH1 = sequence encoding the
На фиг.12 изображена схема, иллюстрирующая создание библиотеки векторов экспрессии родственных Fab-фрагментов. Стадия 1 иллюстрирует вставку родственных пар последовательностей, кодирующих вариабельные области (VH1-VL1 - VHХ-VLХ), в вектор JSK301 E.coli путем гидролиза XhoI-NotI. Стадия II иллюстрирует вставку кластера бактериального промотора и лидерной последовательности (лидерная последовательность pelB и Р tac-промотор, стимулирующие экспрессию VHx, Р lac-промотор и лидерная последовательность pelB, стимулирующие экспрессию VLx) путем гидролиза AscI-NheI.12 is a diagram illustrating the creation of a library of expression vectors of related Fab fragments.
На фиг.13 показано связывание α-, β- и γ-субъединиц, образующих G-белок, при помощи одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и дополнительной амплификации при помощи PCR. На изображениях указаны размеры отдельных кодирующих областей, а также размер связанного продукта. Для конечного продукта указаны сайты рестрикции, введенные при помощи концевых сегментов праймера во время амплификации.13 shows the binding of the α-, β- and γ-subunits forming the G protein using a single-step multiple RT-PCR with chain extension by overlapping and further amplification using PCR. The images show the sizes of individual coding regions, as well as the size of the associated product. For the final product, restriction sites introduced by the end segments of the primer during amplification are indicated.
На фиг.14 показаны точечные диаграммы окрашивания при выполнении FACS-анализа (A) мононуклеарных клеток периферической крови (РВМС), выделенных из крови донора; (В) фракции немеченных CD19-отрицательных клеток, полученных методом магнитной сортировки клеток, и (С) фракции CD19+ клеток, полученных методом магнитной сортировки клеток. Для каждой фракции изображена диаграмма рассеяния, диаграмма CD19/CD38 и диаграмма CD38/CD45.On Fig shows a dot diagram of staining when performing FACS analysis (A) of peripheral blood mononuclear cells (PBMC), isolated from the blood of the donor; (B) fractions of unlabeled CD19-negative cells obtained by magnetic cell sorting, and (C) fractions of CD19 + cells obtained by magnetic cell sorting. For each fraction, a scatter chart, a CD19 / CD38 chart, and a CD38 / CD45 chart are shown.
На фиг.15 показана фракция CD19+ клеток, изображенных на фиг.9С, которые предварительно хранили в жидком азоте, оттаивали и окрашивали антителом против CD19, CD38 и CD45. Изображены точечные диаграммы, соответствующие показанным на фиг.9С.On Fig shows the fraction of CD19 + cells depicted in figs, which were previously stored in liquid nitrogen, thawed and stained with anti-CD19, CD38 and CD45 antibody. Scatter plots corresponding to those shown in FIG. 9C are shown.
На фиг.16 показаны диаграммы совпадений, используемые для сортировки фракции СD19+ клеток. Диаграмма рассеяния и диаграмма флуоресценции на основе CD38 и CD45 были использованы для выделения высокопродуктивных CD38 клеток (CD38hi) и промежуточных CD45 клеток (CD45in).Fig. 16 shows coincidence diagrams used to sort the CD19 + cell fraction. A scatter plot and a fluorescence plot based on CD38 and CD45 were used to isolate high producing CD38 cells (CD38hi) and intermediate CD45 cells (CD45in).
На фиг.17 изображен гель после электрофореза, на котором видно успешное выполнение множественной RT-PCR с удлинением цепи путем перекрывания с использованием пробы крови, полученной от донора ТТ03 (ряд А, лунки 1-12 из восьми 96-луночных планшетов). Образцы наносили на агарозный гель в два ряда (А и В) по 48 образцов в каждом. Ожидаемый размер фрагмента удлинения цепи путем перекрывания составлял примерно 1070 п.о. Предполагаемые фрагменты удлинения цепи путем перекрывания отмечены стрелками.17 shows the gel after electrophoresis, which shows the successful completion of multiple RT-PCR with chain extension by overlapping using a blood sample obtained from a TT03 donor (row A, wells 1-12 from eight 96-well plates). Samples were applied to agarose gel in two rows (A and B), 48 samples each. The expected fragment size of the chain extension by overlapping was approximately 1070 bp Alleged fragments of chain elongation by overlapping are indicated by arrows.
На фиг.18 показан анализ ELISA периплазматических экстрактов с планшета G060. Планшет для ELISA сенсибилизировали антителом козы против каппа-цепи человека, при этом захваченные Fab-фрагменты были обнаружены при помощи HRP-конъюгированного антитела козы против Fab-фрагмента человека.On Fig shows the ELISA analysis of periplasmic extracts from the tablet G060. The ELISA plate was sensitized with a goat anti-human kappa chain antibody, and trapped Fab fragments were detected using a HRP-conjugated goat anti-human Fab antibody.
На фиг.19 показан анализ ELISA периплазматических экстрактов с планшета G060. Планшет для ELISA сенсибилизировали 10 мкг/мл овальбумина (Sigma A-5503), при этом захваченные Fab-фрагменты были обнаружены при помощи HRP-конъюгированного антитела козы против Fab-фрагмента человека.On Fig shows the ELISA analysis of periplasmic extracts from the tablet G060. The ELISA plate was sensitized with 10 μg / ml ovalbumin (Sigma A-5503), while the captured Fab fragments were detected using a HRP-conjugated goat antibody against the human Fab fragment.
На фиг.20 показан анализ ELISA периплазматических экстрактов с планшета G060. Планшет для ELISA сенсибилизировали столбнячным токсином, при этом захваченные Fab-фрагменты были обнаружены при помощи HRP-конъюгированного антитела козы против Fab-фрагмента человека.On Fig shows the ELISA analysis of periplasmic extracts from the tablet G060. The ELISA plate was sensitized with a tetanus toxin, and the captured Fab fragments were detected using a HRP-conjugated goat antibody against human Fab fragment.
На фиг.21 показан одностадийный конкуретный анализ ELISA периплазматических экстрактов с планшета G060. Планшет на ELISA сенсибилизировали столбнячным токсином (ТТ) и в каждую лунку добавляли растворимый ТТ в количестве 10-7 М для конкурентного связывания Fab-фрагментов бактериальных супернатантов с иммобилизованным ТТ. Захваченные Fab-фрагменты обнаруживали при помощи HRP-конъюгированного антитела козы против Fab-фрагмента человека.On Fig shows a one-stage competitive ELISA analysis of periplasmic extracts from the tablet G060. The ELISA plate was sensitized with tetanus toxin (TT) and soluble TT in an amount of 10 -7 M was added to each well to competitively bind Fab fragments of bacterial supernatants with immobilized TT. Trapped Fab fragments were detected using an HRP-conjugated goat antibody against a human Fab fragment.
На фиг.22 показан сравнительный анализ белковых последовательностей вариабельной области тяжелой цепи, полученных из клонов, связывающих ТТ-антиген, с планшета G060. Степень гомологии последовательностей выражена разными оттенками; 100%, 80% и 60% гомология изображена соответственно черным, серым и светло-серым цветом. CDR1 находится в сравниваемых положениях 34-41. CDR2 находится в сравниваемых положениях 55-73. CDR3 находится в сравниваемых положениях 107-127. Незрелые терминирующие кодоны обозначены звездочкой. Результаты сравнительного анализа показаны на восьми отдельных фигурах (a-h), расположенных в два ряда слева направо, при этом фиг.22а-d находятся в верхнем ряду и фиг.22е-h находятся в нижнем ряду.On Fig shows a comparative analysis of the protein sequences of the variable region of the heavy chain obtained from clones that bind TT antigen, from the tablet G060. The degree of sequence homology is expressed in different shades; 100%, 80% and 60% homology is depicted in black, gray and light gray, respectively. CDR1 is in comparable positions 34-41. CDR2 is in comparable positions 55-73. CDR3 is in comparable positions 107-127. Immature termination codons are indicated by an asterisk. The results of the comparative analysis are shown in eight separate figures (a-h) arranged in two rows from left to right, with FIGS. 22a-d in the upper row and FIGS. 22e-h in the lower row.
На фиг.23 показан сравнительный анализ белковых последовательностей вариабельной области легкой цепи, полученных из клонов, связывающих ТТ-антиген, с планшета G060. Степень гомологии последовательностей выражена разными оттенками; 100%, 80% и 60% гомология изображена соответственно черным, серым и светло-серым цветом. CDR1 находится в сравниваемых положениях 26-42. CDR2 находится в сравниваемых положениях 58-64. CDR3 находится в сравниваемых положениях 97-106. Незрелые терминирующие кодоны обозначены звездочкой. Результаты сравнительного анализа показаны на восьми отдельных фигурах (a-h), расположенных в два ряда слева направо, при этом фиг.23а-d находятся в верхнем ряду и фиг.23е-h находятся в нижнем ряду.On Fig shows a comparative analysis of protein sequences of the variable region of the light chain obtained from clones that bind TT antigen, with the tablet G060. The degree of sequence homology is expressed in different shades; 100%, 80% and 60% homology is depicted in black, gray and light gray, respectively. CDR1 is in comparable positions 26-42. CDR2 is in comparable positions 58-64. CDR3 is in comparable positions 97-106. Immature termination codons are indicated by an asterisk. The results of the comparative analysis are shown in eight separate figures (a-h) arranged in two rows from left to right, with FIGS. 23a-d in the upper row and FIGS. 23e-h in the lower row.
На фиг.24 показан конкурентный анализ ELISA, выполненный для определения кажущегося сродства отобранных клонов с планшета G060. Растворимый ТТ, разведенный в концентрациях от 100 нМ до 25 пМ (четырехкратные разведения), добавляли к Fab-фрагментам, вызывая конкурентное связывание Fab-фрагментом с иммобилизованным ТТ. Степени взаимодействия выражены в виде соотношения наблюдаемого связывания при данной концентрации растворимого ТТ со связыванием, обнаруженным без добавления растворимого ТТ к реакционным смесям.On Fig shows a competitive ELISA analysis performed to determine the apparent affinity of the selected clones from the tablet G060. Soluble TT diluted in concentrations from 100 nM to 25 pM (four-fold dilutions) was added to the Fab fragments, causing competitive binding of the Fab fragment to the immobilized TT. The degrees of interaction are expressed as the ratio of the observed binding at a given concentration of soluble TT to the binding detected without adding soluble TT to the reaction mixtures.
На фиг.25 представлена двойная филогенетическая гистограмма, показывающая внутригенетическую и межгенетическую взаимосвязь между последовательностями вариабельного домена тяжелой и легкой цепи антитела. Филогенетические группы из трех VН- и VL-последовательностей спарены на гистограмме для обозначения действительного спаривания конкретных V-генов. А) Клоны, связывающие ТТ-антиген, полученные из комбинаторной библиотеки методом отображения на фаге. В) Клоны, связывающие ТТ-антиген, полученные из библиотеки родственных пар способом по настоящему изобретению.On Fig presents a double phylogenetic histogram showing the intragenetic and intergenetic relationship between the sequences of the variable domain of the heavy and light chains of the antibodies. Phylogenetic groups of three V H and V L sequences are paired on a histogram to indicate the actual pairing of specific V genes. A) Clones linking the TT antigen obtained from the combinatorial library by the method of display on the phage. C) Clones that bind TT antigen obtained from a library of related pairs by the method of the present invention.
Описание изобретенияDescription of the invention
Настоящее изобретение относится к способу амплификации и связывания двух или нескольких интересующих несмежных нуклеотидных последовательностей, который обеспечивает высокоэффективное клонирование таких последовательностей. Указанный результат достигается главным образом за счет уменьшения числа стадий, необходимых для амплификации и связывания клонируемых последовательностей.The present invention relates to a method for amplification and binding of two or more interesting non-contiguous nucleotide sequences, which provides highly efficient cloning of such sequences. This result is achieved mainly by reducing the number of stages required for amplification and binding of cloned sequences.
Одним из объектов настоящего изобретения является способ связывания нескольких несмежных нуклеотидных последовательностей, который предусматривает множественную молекулярную амплификацию интересующих нуклеотидных последовательностей с использованием матрицы, полученной из выделенной отдельной клетки, популяции изогенных клеток или популяции генетически разных клеток, и последующее связывание амплифицированных последовательностей. Если в качестве матрицы использована выделенная отдельная клетка или популяция изогенных клеток, то в результате связывания образуется сегмент нуклеиновой кислоты, содержащий родственные связанные интересующие нуклеотидные последовательности. Если в качестве матрицы использована популяция генетически разных клеток, то в результате связывания образуется библиотека сегментов, в которой каждый сегмент содержит произвольно связанные интересующие последовательности нуклеиновой кислоты; такая библиотека именуется также комбинаторной библиотекой.One of the objects of the present invention is a method for linking several non-contiguous nucleotide sequences, which involves multiple molecular amplification of the nucleotide sequences of interest using a matrix derived from a single cell, a population of isogenic cells or a population of genetically different cells, and subsequent binding of the amplified sequences. If an isolated single cell or a population of isogenic cells is used as a matrix, then a nucleic acid segment containing related related nucleotide sequences of interest is formed as a result of binding. If a population of genetically different cells is used as a matrix, then as a result of binding a library of segments is formed in which each segment contains randomly linked nucleic acid sequences of interest; such a library is also called a combinatorial library.
В одном из вариантов осуществления настоящего изобретения вышеуказанная множественная молекулярная амплификация представляет собой амплификацию методом множественной PCR, которой предпочтительно предшествует стадия обратной транскрипции. В предпочтительном варианте осуществления изобретения обратную транскрипцию, амплификацию и связывание выполняют в виде одной стадии при помощи множественной RT-PCR с удлинением цепи путем перекрывания или, альтернативно, в виде двух стадий при помощи множественной RT-PCR и последующего связывания путем лигирования или рекомбинации.In one embodiment of the present invention, the above multiple molecular amplification is a multiple PCR amplification, which is preferably preceded by a reverse transcription step. In a preferred embodiment, reverse transcription, amplification and binding are performed in a single step using multiple RT-PCRs with chain extension by overlapping or, alternatively, in two steps using multiple RT-PCRs and subsequent binding by ligation or recombination.
Другой вариант осуществления настоящего изобретения относится к созданию библиотек родственных пар, включающих связанные последовательности, кодирующие вариабельные области, в частности последовательности, кодирующие вариабельные области тяжелой и легкой цепи, или последовательности, кодирующие альфа-цепь и бета-цепь Т-клеточного рецептора (TcR). Этот способ предусматривает получение лимфоцитсодержащей фракции клеток по крайней мере у одного приемлемого донора и, необязательно, обогащение определенной популяции лимфоцитов в указанной фракции, например В-лимфоцитов или Т-лимфоцитов, в зависимости от того, какие последовательности, кодирующие вариабельные области, желательно получить из иммуноглобулинов или TcR. Лимфоцитсодержащую фракцию клеток или обогащенную фракцию клеток распределяют в несколько сосудов, получая одну клетку в каждом сосуде. Несколько отдельных клеток подвергают обратной транскрипции (RT) или альтернативной процедуре получения кДНК, используя в качестве матрицы нуклеиновые кислоты, выделенные из популяции отдельных клеток. После стадии обратной транскрипции выполняют множественную молекулярную амплификацию и связывание пар полученных из каждой клетки последовательностей, кодирующих вариабельные области, одним из способов по настоящему изобретению.Another embodiment of the present invention relates to the creation of libraries of related pairs, including linked sequences encoding the variable regions, in particular sequences encoding the variable regions of the heavy and light chains, or sequences encoding the alpha chain and beta chain of the T cell receptor (TcR) . This method involves obtaining a lymphocyte-containing fraction of cells from at least one acceptable donor and, optionally, enriching a specific population of lymphocytes in the specified fraction, for example B-lymphocytes or T-lymphocytes, depending on which sequences encoding the variable regions, it is desirable to obtain from immunoglobulins or TcR. The lymphocyte-containing cell fraction or enriched cell fraction is distributed into several vessels, obtaining one cell in each vessel. Several individual cells are subjected to reverse transcription (RT) or an alternative procedure for producing cDNA using nucleic acids isolated from a population of individual cells as a template. After the reverse transcription step, multiple molecular amplification and binding of pairs of sequences encoding variable regions obtained from each cell is performed using one of the methods of the present invention.
Способы клонирования, описанные в настоящем изобретении, позволяют избежать трудоемкого и неэффективного клонирования и, кроме того, уменьшают риск загрязнения и потерю разнообразия на протяжении многочисленных стадий клонирования.The cloning methods described in the present invention avoid time-consuming and inefficient cloning and, in addition, reduce the risk of contamination and loss of diversity during the numerous stages of cloning.
Другим объектом настоящего изобретения являются библиотеки родственных пар, получаемых в результате множественной молекулярной амплификации и связывания. Исходная библиотека родственных пар (первичная библиотека), полученная способом по настоящему изобретению, может быть подвергнута скринингу с созданием подбиблиотеки родственных пар, кодирующих вариабельные домены мишень-специфических связывающих белков или непроцессированные связывающие белки.Another object of the present invention are libraries of related pairs resulting from multiple molecular amplification and binding. The source library of related pairs (primary library) obtained by the method of the present invention can be screened to create a sub-library of related pairs encoding the variable domains of target specific binding proteins or unprocessed binding proteins.
В другом варианте осуществления изобретения библиотеки и подбиблиотеки по настоящему изобретению могут быть использованы для экспрессии рекомбинантных моноклональных или поликлональных белков, в которых сохранено присущее донору первоначальное сродство и специфичность связывания.In another embodiment of the invention, the libraries and sub-libraries of the present invention can be used to express recombinant monoclonal or polyclonal proteins that retain the original donor's inherent affinity and binding specificity.
Определения терминовDefinitions of terms
Термин “родственная пара” обозначает первоначальную пару интересующих несмежных нуклеиновых кислот, которые находятся внутри отдельной клетки или выделены из отдельной клетки. В предпочтительных вариантах осуществления изобретения родственная пара содержит две последовательности, кодирующие вариабельные области, которые вместе кодируют вариабельный домен связывающего белка и имеют генные последовательности, выделенные из одной и той же клетки. Таким образом, при экспрессии в виде полного связывающего белка или его устойчивого фрагмента они сохраняют сродство и специфичность связывания связывающего белка, первоначально экспрессированного из данной клетки. Родственная пара, например, может состоять из последовательности, кодирующей вариабельную область тяжелой цепи антитела, связанной с последовательностью, кодирующей вариабельную область легкой цепи, из той же клетки, или последовательности, кодирующей α-цепь Т-клеточного рецептора, связанной с последовательностью, кодирующей β-цепь, из той же клетки. Библиотека родственных пар представляет собой коллекцию таких родственных пар.The term “related pair” refers to the original pair of non-contiguous nucleic acids of interest that are inside a single cell or isolated from a single cell. In preferred embodiments of the invention, the related pair contains two sequences encoding variable regions that together encode the variable domain of the binding protein and have gene sequences isolated from the same cell. Thus, when expressed as a complete binding protein or a stable fragment thereof, they retain the affinity and specificity of binding of the binding protein originally expressed from a given cell. A related pair, for example, may consist of a sequence encoding a variable region of a heavy chain of an antibody linked to a sequence encoding a variable region of a light chain from the same cell, or a sequence encoding an α-chain of a T cell receptor linked to a sequence encoding β -chain from the same cell. The library of couples is a collection of such couples.
Под термином “полимераза, активируемая при нагревании” понимают полимеразы, которые являются неактивными или обладают очень низкой активностью при температурах, используемых для обратной транскрипции. Для активации таких полимераз нужны высокие температуры (90-95°С). Это является преимуществом выполнения одностадийных RT-PCR, так как при этом не происходит включение интерференции полимеразы в реакцию с участием обратной транскриптазы.By the term “heat activated polymerase” is meant polymerases that are inactive or have very low activity at temperatures used for reverse transcription. To activate such polymerases, high temperatures (90-95 ° C) are needed. This is an advantage of performing one-step RT-PCR, as this does not include the inclusion of polymerase interference in the reaction involving reverse transcriptase.
Термин “изогенная популяция клеток” обозначает популяцию генетически идентичных клеток. В частности, особый интерес при осуществлении настоящего изобретения представляет изогенная популяция клеток, полученная в результате клональной экспансии одной выделенной клетки.The term “isogenic population of cells” means a population of genetically identical cells. In particular, of particular interest in the practice of the present invention is an isogenic population of cells resulting from the clonal expansion of one isolated cell.
Термин “выделенная отдельная клетка” обозначает клетку, которая физически отделена от популяции клеток и соответствует определению “одна клетка в одном сосуде”. Популяцию выделенных отдельных клеток получают при распределении популяции клеток в несколько сосудов. Как указано в разделе, озаглавленном “Источники матрицы”, число сосудов с одной клеткой необязательно должно быть пропорционально 100%, чтобы такую популяцию можно было назвать популяцией отдельных клеток.The term “isolated single cell” means a cell that is physically separated from the cell population and corresponds to the definition of “one cell in one vessel”. A population of isolated individual cells is obtained by distributing a population of cells into several vessels. As indicated in the section entitled “Sources of the matrix”, the number of vessels with one cell does not have to be proportional to 100% so that such a population can be called a population of individual cells.
Термины “связывать” или “связывание” применительно к амплификации обозначают соединение интересующих амплифицированных последовательностей нуклеиновых кислот в один сегмент. Применительно к родственным парам сегмент содержит последовательности нуклеиновых кислот, кодирующие вариабельный домен, например вариабельную область тяжелой цепи антитела, связанную с последовательностью, кодирующей вариабельную область легкой цепи антитела, полученной из той же клетки. Связывание может происходить одновременно с амплификацией или в виде стадии, выполняемой сразу же после амплификации. К форме или функциональности сегмента не предъявляется никаких требований, он может быть линейным, кольцевым, одноцепочечным или двухцепочечным. Указанное связывание необязательно должно быть постоянным, одна из интересующих последовательностей нуклеиновых кислот при желании может быть выделена из сегмента, например из сегмента родственной пары может быть выделена одна из последовательностей, кодирующих вариабельную область. Однако до тех пор, пока исходные вариабельные области, образующие родственную пару, не будут заменены другими вариабельными областями, они по-прежнему считаются родственной парой, даже не будучи связанными вместе в одном сегменте. Указанное связывание предпочтительно представляет собой связывание нуклеотидов фосфодиэфирной связью. Однако связывание может быть произведено другими химическими методами перекрестного сшивания.The terms “bind” or “binding” as applied to amplification mean connecting the amplified nucleic acid sequences of interest in one segment. For related pairs, a segment contains nucleic acid sequences encoding a variable domain, for example, an antibody heavy chain variable region, linked to a sequence encoding an antibody light chain variable region derived from the same cell. Linking can occur simultaneously with amplification or in the form of a stage, performed immediately after amplification. No requirements are imposed on the shape or functionality of a segment; it can be linear, ring, single-chain or double-chain. Said binding does not have to be constant, one of the nucleic acid sequences of interest can be isolated from a segment, if desired, for example, one of the sequences encoding the variable region can be isolated from a segment of a related pair. However, until the original variable regions forming a related pair are replaced by other variable regions, they are still considered a related pair, without even being tied together in one segment. Said binding is preferably nucleotide binding by a phosphodiester bond. However, binding can be accomplished by other chemical cross-linking methods.
Термин “множественная молекулярная амплификация” обозначает одновременную амплификацию двух или более заданных последовательностей в ходе одной реакции. Приемлемые методы амплификации включают полимеразную цепную реакцию (PCR) (патент США № 4683202), лигазную цепную реакцию (LCR) (Wu and Wallace, 1989, Genomics 4, 560-9), амплификацию с заменой цепи (SDA) (Walker et al., 1992, Nucl. Acids Res. 20, 1691-6), аутоустойчивую репликацию последовательности (Guatelli et al., 1990, Proc. Nat. Acad. Sci USA, 87, 1874-8) и амплификацию последовательности на основе нуклеиновой кислоты (NASBA) (Compton J., 1991, Nature 350, 91-2). Два последних метода амплификации предусматривают выполнение изотермических реакций на основе изотермической транскрипции с образованием как одноцепочечной РНК (ssРНК), так и двухцепочечной ДНК (dsДНК).The term “multiple molecular amplification" means the simultaneous amplification of two or more given sequences in a single reaction. Suitable amplification methods include polymerase chain reaction (PCR) (US Pat. No. 4,683,202), ligase chain reaction (LCR) (Wu and Wallace, 1989,
Термин “множественная PCR” обозначает вариант PCR, при котором происходит одновременная амплификация двух или нескольких заданных последовательностей в результате введения в реакционную смесь нескольких наборов праймеров, из которых, например, один набор праймеров предназначен для амплификации вариабельной области тяжелой цепи, а другой набор праймеров предназначен для амплификации вариабельной области каппа-цепи в ходе одной реакции PCR. Кроме того, с вышеуказанными наборами праймеров может быть объединен набор праймеров, предназначенный для амплификации вариабельной области лямбда-цепи.The term “multiple PCR” means a variant of PCR in which two or more given sequences are amplified simultaneously by introducing several sets of primers into the reaction mixture, of which, for example, one set of primers is designed to amplify the variable region of the heavy chain and the other set of primers is intended for amplification of the variable region of the kappa chain in a single PCR reaction. In addition, a set of primers designed to amplify the variable region of the lambda chain can be combined with the above primer sets.
Термин “множественная RT-PCR” обозначает множественную PCR, которой предшествует стадия обратной транскрипции (RT). Множественная RT-PCR может быть выполнена в виде двухстадийного процесса с отдельной стадией RT, выполняемой перед множественной PCR, или в виде одностадийного процесса, при осуществлении которого все компоненты, необходимые для RT и множественной PCR, объединяют в одной пробирке.The term "multiple RT-PCR" means a multiple PCR, which is preceded by a stage of reverse transcription (RT). Multiple RT-PCR can be performed as a two-stage process with a separate RT stage, performed before the multiple PCR, or as a single-stage process, in which all the components necessary for RT and multiple PCR are combined in one tube.
Термин “множественная PCR с удлинением цепи путем перекрывания” и “множественная RT-PCR с удлинением цепи путем перекрывания” обозначает, что множественную PCR или множественную RT-PCR выполняют, используя смесь множественных праймеров для удлинения цепи путем перекрывания, предназначенную для амплификации заданных последовательностей, благодаря чему происходит одновременная амплификация и связывание заданных последовательностей.The term “multiple overlap extended PCR” and “overlap extended RT-PCR” means that multiple PCR or multiple RT-PCR is performed using a mixture of multiple overlapping extended chain primers designed to amplify predetermined sequences, due to which there is a simultaneous amplification and binding of given sequences.
Термин “несколько сосудов” обозначает любой объект (или совокупность объектов), которые обеспечивают физическое разделение одной клетки от популяции клеток. Такими сосудами могут быть пробирки, многолуночные планшеты (например, 96-луночные планшеты, 384-луночные планшеты, титрационные микропланшеты или другие многолуночные планшеты), матрицы, микроматрицы, микрочипы, гели или гелевая матрица. Указанный объект предпочтительно используют для амплификации методом PCR.The term “multiple vessels” means any object (or set of objects) that provide a physical separation of one cell from a population of cells. Such vessels may include tubes, multi-well plates (e.g., 96-well plates, 384-well plates, microtiter plates or other multi-well plates), arrays, microarrays, microarrays, gels, or gel matrices. The specified object is preferably used for amplification by PCR.
Термин “поликлональный белок” или “поликлональность” в используемом здесь значении обозначает белок, в состав которого входят разные, но гомологичные белковые молекулы, предпочтительно, отобранные из надсемейства иммуноглобулинов. Таким образом, каждая белковая молекула гомологична другим молекулам в композиции, но содержит один или несколько фрагментов вариабельной области полипептидной последовательности, которые отличаются аминокислотной последовательностью от других членов поликлонального белка. Известные примеры таких поликлональных белков включают молекулы антител или иммуноглобулинов, Т-клеточные рецепторы и В-клеточные рецепторы. Поликлональный белок может состоять из определенной субпопуляции белковых молекул, которые имеют общий признак, такой как общая активность связывания требуемой мишени, например таким белком может быть поликлональное антитело, характеризующееся специфичностью связывания требуемого антигена-мишени.The term “polyclonal protein” or “polyclonality” as used herein means a protein that contains different but homologous protein molecules, preferably selected from the superfamily of immunoglobulins. Thus, each protein molecule is homologous to the other molecules in the composition, but contains one or more fragments of the variable region of the polypeptide sequence, which differ in amino acid sequence from other members of the polyclonal protein. Known examples of such polyclonal proteins include antibody or immunoglobulin molecules, T-cell receptors, and B-cell receptors. A polyclonal protein may consist of a specific subpopulation of protein molecules that have a common characteristic, such as the total binding activity of the desired target, for example, such a protein may be a polyclonal antibody characterized by specificity of binding of the desired target antigen.
Термин “популяция генетически разных клеток” в используемом здесь значении обозначает популяцию клеток, в которой отдельные клетки отличаются друг от друга на уровне генома. Популяцией генетически разных клеток является, например, популяция клеток, полученных от донора, или фракция таких клеток, в частности фракция клеток, содержащая В-лимфоциты или Т-лимфоциты.The term “population of genetically different cells” as used herein means a population of cells in which individual cells differ from one another at the genome level. A population of genetically different cells is, for example, a population of cells obtained from a donor, or a fraction of such cells, in particular a fraction of cells containing B-lymphocytes or T-lymphocytes.
Термин “набор праймеров”, или взаимозаменяемый термин “пара праймеров”, обозначает два или несколько праймеров, которые вместе способны инициировать амплификацию интересующей нуклеотидной последовательности (то есть одного из членов родственной пары). Набор праймеров по настоящему изобретению может быть предназначен для инициации семейства нуклеотидных последовательностей, содержащих последовательности, кодирующие вариабельные области. Примерами разных семейств являются легкие каппа-цепи антитела, легкие лямбда-цепи, вариабельные области тяжелой цепи и вариабельные области α-, β-, γ- или δ-цепи Т-клеточного рецептора. Набор праймеров для амплификации семейства нуклеотидных последовательностей, содержащих последовательности, кодирующие вариабельные области, часто состоит из нескольких праймеров, часть которых может быть вырожденными праймерами.The term “primer set”, or the interchangeable term “primer pair”, refers to two or more primers that together are capable of initiating amplification of a nucleotide sequence of interest (that is, one of a member of a cognate pair). The primer set of the present invention can be designed to initiate a family of nucleotide sequences containing sequences encoding variable regions. Examples of different families are antibody light kappa chains, lambda light chains, variable regions of the heavy chain, and variable regions of the α, β, γ, or δ chain of the T cell receptor. A set of primers for amplifying a family of nucleotide sequences containing sequences encoding variable regions often consists of several primers, some of which may be degenerate primers.
Термин “идентичность последовательностей” обозначает тождество, выраженное в процентах, которое определяет степень идентичности последовательностей нуклеиновых кислот на протяжении всей длины самой короткой из двух последовательностей. Идентичность можно вычислить как (Nref - Ndif)x100/Nref, где Nref обозначает число остатков в более короткой последовательности, Ndif обозначает общее число неидентичных остатков в оптимально совмещенном числе остатков Nref двух последовательностей. Следовательно, последовательность ДНК AGTCAGTC будет на 75% идентична последовательности TAATCAATCGG (Ndif = 2 и Nref = 8) (подчеркнуты оптимально совмещенные остатки и жирным шрифтом выделены два неидентичных остатка из 8).The term "sequence identity" means the identity, expressed as a percentage, which determines the degree of sequence identity of nucleic acids over the entire length of the shortest of the two sequences. Identity can be calculated as (N ref - N dif ) x100 / N ref , where N ref denotes the number of residues in a shorter sequence, N dif denotes the total number of non-identical residues in the optimally combined number of residues N ref of two sequences. Therefore, the AGTCAGTC DNA sequence will be 75% identical to the TAATCAATC GG sequence (N dif = 2 and N ref = 8) (optimally aligned residues are underlined and two non-identical residues of 8 are highlighted in bold).
Термины “произвольно” или “произвольный” применительно к связыванию обозначают связывание нуклеотидных последовательностей, выделенных из разных клеток, но поперечно-связанных в популяции генетически разных клеток. Если интересующие нуклеотидные последовательности являются последовательностями, кодирующими вариабельные области, то будет создана комбинаторная библиотека связанных последовательностей. Если, с другой стороны, интересующие нуклеотидные последовательности кодируют идентичный гетеромерный белок, то произвольно связанные последовательности, по-видимому, будут аналогичны последовательностям, связанным в отдельной клетке.The terms “arbitrary” or “arbitrary” as applied to binding mean the binding of nucleotide sequences isolated from different cells but transversely linked in a population of genetically different cells. If the nucleotide sequences of interest are sequences encoding variable regions, then a combinatorial library of linked sequences will be created. If, on the other hand, the nucleotide sequences of interest encode an identical heteromeric protein, then the randomly linked sequences are likely to be similar to the sequences linked in a single cell.
Термин “матрица, полученная из выделенной отдельной клетки” применительно к обратной транскрипции обозначает нуклеиновые кислоты такой выделенной клетки. Нуклеиновые кислоты могут представлять собой, например, РНК, мРНК, ДНК или геномную ДНК. Нуклеиновые кислоты могут быть выделены из клетки или находиться в клетке, которая может быть интактной или лизированной.The term “matrix derived from an isolated single cell” as applied to reverse transcription refers to the nucleic acids of such an isolated cell. Nucleic acids can be, for example, RNA, mRNA, DNA or genomic DNA. Nucleic acids may be isolated from a cell or located in a cell, which may be intact or lysed.
Способ амплификации и связыванияAmplification and Binding Method
Одним из отличительных признаков настоящего изобретения является уменьшение числа пробирок, необходимых для амплификации интересующих нуклеотидных последовательностей, благодаря осуществлению варианта PCR, в котором две или несколько заданных последовательностей амплифицируют одновременно в одной пробирке путем введения нескольких наборов праймеров, например всех праймеров, необходимых для амплифицикации последовательностей, кодирующих вариабельные области, в одну реакционную смесь. Подобный метод известен как множественная полимеразная цепная реакция (множественная PCR).One of the distinguishing features of the present invention is the reduction in the number of tubes required for amplification of nucleotide sequences of interest, due to the implementation of the PCR variant, in which two or more predetermined sequences are amplified simultaneously in the same tube by introducing several sets of primers, for example, all primers necessary for amplification of sequences, coding for variable regions in a single reaction mixture. A similar technique is known as multiple polymerase chain reaction (multiple PCR).
Множественная PCR или множественная PCR с предшествующим выполнением обратной транскрипции (множественная RT-PCR) являются хорошо известными методами в области диагностики, применяемыми, например, при выполнении анализа мутаций, делеций и полиморфизмов ДНК, количественных анализов содержания мРНК и идентификации вирусов, бактерий и паразитов (см. публикацию Markoulatos, P. et al., 2002, J. Clin. Lab. Anal. 16, 47-51). Однако существует очень мало примеров амплификации последовательностей, кодирующих вариабельные области легкой цепи, в одном сосуде, а также последовательностей, кодирующих вариабельные области тяжелой цепи иммуноглобулинов, с использованием смеси множественных праймеров, состоящей из более чем четырех праймеров и включающей набор праймеров для Vк и/или Vλ вместе с набором праймеров для VH (Chapal, N. et al., 1997, BioTechniques 23, 518-524; Liu, A.H. et al., 1992, Proc. Natl. Acad. Sci. USA 89, 7610-7614; Embleton, M.J. et al., 1992, Nucleic Acids Res. 20, 3831-3837). Причиной этого может быть тот факт, что наборы праймеров, которые могут использоваться для амплификации последовательностей, кодирующих вариабельные домены антигенсвязывающих белков, обычно включают несколько вырожденных праймеров для соответствия разнообразию последовательностей, кодирующих вариабельные области. Таким образом, сложность реакции РCR значительно увеличивается при выполнении амплификации последовательностей, кодирующих вариабельные области, при помощи множественной PCR.Multiple PCR or multiple PCR with previous reverse transcription (multiple RT-PCR) are well-known diagnostic methods used, for example, in analysis of mutations, deletions and polymorphisms of DNA, quantitative analysis of mRNA content and identification of viruses, bacteria and parasites ( see Markoulatos, P. et al., 2002, J. Clin. Lab. Anal. 16, 47-51). However, there are very few examples of amplification of sequences encoding the variable regions of the light chain in one vessel, as well as sequences encoding the variable regions of the heavy chain of immunoglobulins, using a mixture of multiple primers consisting of more than four primers and including a set of primers for V to and / or V λ together with a set of primers for V H (Chapal, N. et al., 1997,
Другим отличительным признаком настоящего изобретения является связывание двух нескольких заданных последовательностей, амплифицированных при помощи множественной РCR, сразу же после выполнения амплификации. В частности, указанным способом связывают родственные пары последовательностей, кодирующих вариабельные области.Another distinguishing feature of the present invention is the binding of two several predetermined sequences amplified using multiple PCR immediately after amplification. In particular, related pairs of sequences encoding variable regions are linked in this manner.
Один из вариантов осуществления настоящего изобретения относится к созданию смеси множественных праймеров, предназначенной для выполнения PCR с удлинением цепи путем перекрывания, в результате чего происходит одновременная амплификация и связывание интересующих нуклеотидных последовательностей. Указанная множественная PCR с удлинением цепи путем перекрывания позволяет уменьшить число реакций, необходимых для выделения и связывания интересующих нуклеотидных последовательностей, в частности, родственных пар связанных вариабельных областей.One of the embodiments of the present invention relates to the creation of a mixture of multiple primers designed to perform PCR with extension of the chain by overlapping, resulting in simultaneous amplification and binding of the nucleotide sequences of interest. The specified multiple PCR with chain extension by overlapping allows to reduce the number of reactions necessary for the isolation and binding of nucleotide sequences of interest, in particular, related pairs of linked variable regions.
Другие варианты осуществления настоящего изобретения относятся к связыванию путем лигирования или рекомбинации в качестве альтернативы множественной PCR с удлинением цепи путем перекрывания. В указанных способах связывание выполняют отдельно от амплификации при помощи множественной PCR, но сразу же после амплификации. Однако связывание может быть выполнено в той же пробирке, что и множественная PCR.Other embodiments of the present invention relate to ligation binding or recombination as an alternative to overlapping multiple extension PCR. In these methods, binding is performed separately from amplification using multiple PCR, but immediately after amplification. However, binding can be performed in the same tube as the multiple PCR.
Для выполнения множественной PCR с удлинением цепи путем перекрывания необходимо наличие двух или нескольких наборов праймеров (смесь множественных праймеров), в которых по крайней мере один праймер в каждом наборе имеет концевой сегмент удлинения цепи путем перекрывания. Концевые сегменты удлинения цепи путем перекрывания позволяют производить связывание продуктов, образованных каждым набором праймеров, в процессе амплификации. Такая смесь праймеров именуется множественной смесью праймеров для удлинения цепи путем перекрывания. Множественная PCR с удлинением цепи путем перекрывания отличается от обычной PCR с удлинением цепи путем перекрывания тем, что связываемые последовательности образуются одновременно в одной пробирке, благодаря чему происходит немедленное связывание заданных последовательностей во время амплификации без какой-либо промежуточной очистки. Кроме того, при обычной РCR с удлинением цепи путем перекрывания требуется выполнение отдельной реакции связывания при помощи PCR с использованием внешнего набора праймеров или гнездового набора праймеров для получения связанного продукта (Horton, R.M. et al., 1989, Gene 77, 61-68). Такая дополнительная стадия амплификации является необязательной при выполнении множественной PCR с удлинением цепи путем перекрывания по настоящему изобретению.To perform multiple PCR with chain extension by overlapping, two or more sets of primers (a mixture of multiple primers) are required in which at least one primer in each set has an end segment of chain extension by overlapping. The end segments of chain elongation by overlapping allow the products formed by each set of primers to be coupled during amplification. Such a primer mixture is referred to as a multiple primer mixture to extend the chain by overlapping. Multiple overlapping chain extension PCRs are different from regular overlapping chain extension PCRs in that the sequences to be linked are formed simultaneously in a single tube, thereby immediately binding the desired sequences during amplification without any intermediate purification. In addition, with a conventional PCR with chain extension by overlapping, a separate PCR binding reaction is required using an external primer set or a nested set of primers to produce a bound product (Horton, R. M. et al., 1989,
Другим отличительным признаком настоящего изобретения является стадия обратной транскрипции (RT), предшествующая амплификации множественной PCR или множественной PCR с удлинением цепи путем перекрывания, с использованием матрицы, полученной из выделенной отдельной клетки или популяции изогенных клеток.Another feature of the present invention is the reverse transcription (RT) step, prior to amplification of multiple PCR or multiple PCR with chain extension by overlapping, using a matrix derived from an isolated single cell or a population of isogenic cells.
Другим отличительным признаком настоящего изобретения является использование нуклеотидных последовательностей, полученных из выделенной отдельной клетки или популяции изогенных клеток, в качестве матрицы для амплификации методом множественной PCR. РНК из отдельной клетки, предпочтительно, подвергают обратной транскрипции с образованием кДНК перед выполнением множественной РCR. Для амплификации некоторых интересующих последовательностей нуклеиновых кислот в качестве альтернативы мРНК можно использовать геномную ДНК. Используя выделенные отдельные клетки или популяцию изогенных клеток, полученную в результате клональной экспансии выделенной отдельной клетки, в качестве источника матрицы, можно избежать замены нуклеотидных последовательностей, кодирующих интересующий гетеромерный белок, нуклеотидными последовательностями, полученными из других клеток в популяции клеток. Это имеет важное значение, если желательно получить первоначальный состав интересующих последовательностей. Для образования родственной пары последовательностей, кодирующих вариабельные области, в качестве источника матрицы важно использовать выделенную отдельную клетку или популяцию изогенных клеток.Another hallmark of the present invention is the use of nucleotide sequences obtained from an isolated single cell or a population of isogenic cells as a matrix for amplification by multiple PCR. RNA from a single cell is preferably reverse transcribed to form cDNA before performing multiple PCR. Genomic DNA can be used as an alternative to mRNA to amplify some nucleic acid sequences of interest. Using isolated individual cells or a population of isogenic cells obtained as a result of clonal expansion of an isolated individual cell as a matrix source, one can avoid replacing the nucleotide sequences encoding the heteromeric protein of interest with nucleotide sequences obtained from other cells in the cell population. This is important if it is desired to obtain the initial composition of the sequences of interest. To form a related pair of sequences encoding variable regions, it is important to use an isolated single cell or a population of isogenic cells as a matrix source.
Множественная PCR с удлинением цепи путем перекрывания является редко используемым методом. В публикации WO 99/16904 описано связывание экзонов из геномной последовательности при выполнении одной реакции, в результате которой образуется кДНК без применения обратной транскрипции. В описанном способе использован один набор праймеров (состоящий из двух праймеров) на один экзон, подлежащий связыванию, при котором образуется смесь множественных праймеров для удлинения цепи путем перекрывания. С помощью каждого отдельного набора праймеров можно удлинять цепь путем перекрывания со смежным набором праймеров при помощи комплементарных концевых сегментов удлинения цепи путем перекрывания. кДНК образуется из матрицы геномной ДНК в результате осуществления PCR с удлинением цепи путем перекрывания с использованием смеси множественных праймеров для удлинения цепи путем перекрывания и последующей гнездовой PCR, которая в соответствии с описанием является необходимой стадией.Multiple overlap extension PCR is a rarely used method. WO 99/16904 describes the binding of exons from a genomic sequence in a single reaction, resulting in cDNA formation without reverse transcription. In the described method, one set of primers (consisting of two primers) per exon to be bound is used, in which a mixture of multiple primers is formed to extend the chain by overlapping. With each individual set of primers, the chain can be extended by overlapping with an adjacent set of primers using complementary end segments of chain extension by overlapping. The cDNA is generated from the genomic DNA template by performing PCR with chain extension by overlapping using a mixture of multiple primers to extend the chain by overlapping and subsequent nested PCR, which, as described, is a necessary step.
Образование кДНК из экзонов геномной ДНК, описанное в WO 99/16904, не имеет отношения к клонированию последовательностей, кодирующих гетеромерные белки. Прежде всего, гетеромерные белки обычно получают из разных генов, в то время как связывание экзонов в соответствии с описанием, приведенным в публикации WO 99/16904, относится к связыванию экзонов из одного гена. Кроме того, настоящее изобретение облегчает создание библиотек интересующих связанных последовательностей нуклеиновых кислот, в частности комбинаторных библиотек и библиотек родственных пар вариабельных областей, что полностью отличается от связывания серии экзонов из одного гена, в результате которого образуется одна невариабельная кДНК. В настоящем изобретении использованы нуклеиновые кислоты, выделенные из отдельных клеток, предпочтительно, в форме РНК, которая не требует отделения от остального содержимого клетки перед ее использованием в качестве матрицы.The formation of cDNA from exons of genomic DNA described in WO 99/16904 is not related to the cloning of sequences encoding heteromeric proteins. First of all, heteromeric proteins are usually obtained from different genes, while exon binding as described in WO 99/16904 refers to exon binding from a single gene. In addition, the present invention facilitates the creation of libraries of interesting linked nucleic acid sequences, in particular combinatorial libraries and libraries of related pairs of variable regions, which is completely different from linking a series of exons from a single gene, resulting in a single non-variable cDNA. The present invention uses nucleic acids isolated from individual cells, preferably in the form of RNA, which does not require separation from the rest of the cell before using it as a template.
В нескольких публикациях описана множественная RT-PCR с удлинением цепи путем перекрывания, применяемая для связывания последовательностей, кодирующих вариабельные области.Several publications describe multiple overlap-extended RT-PCRs used to bind sequences encoding variable regions.
Наиболее простая форма множественной RT-PCR с удлинением цепи путем перекрывания описана для выделения последовательности, кодирующей scFv-фрагмент, из линии клеток гибридомы (Thirion, S. et al. 1996, Eur. J. Cancer Prev. 5, 507-511 and Mullinax, R.L. et al. 1992, BioTechniques 12, 864-869). Способы, описанные в публикации Thirion и Mullinax, предусматривают выполнение обратной транскрипции мРНК с использованием олиго-dT-праймеров в отношении общей РНК, экстрагированной из линии клеток гибридомы, с последующим выполнением отдельной стадии связывания. Стадию связывания выполняют с использованием в общей сложности четырех праймеров, включающих две пары праймеров для амплификации последовательностей, кодирующих соответственно вариабельную область тяжелой цепи и вариабельную область легкой цепи. Основной праймер для VL и обратный праймер для VН или СН содержат комплементарные концевые сегменты удлинения цепи путем перекрывания, что позволяет одновременно производить амплификацию и связывание последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи. В указанных способах не применяется гнездовая PCR для повышения чувствительности способа связывания.The simplest form of overlapping extension of RT-PCR with overlapping chain is described to isolate a sequence encoding an scFv fragment from a hybridoma cell line (Thirion, S. et al. 1996, Eur. J. Cancer Prev. 5, 507-511 and Mullinax , RL et al. 1992,
Другой пример множественной RT-PCR с удлинением цепи путем перекрывания, относящийся к связыванию последовательностей, кодирующих вариабельные области, описан в вышеуказанной публикации WO 93/03151, в которой рассмотрен способ клонирования последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи, которые были получены из одной клетки без выделения отдельных клеток перед клонированием. Способ, описанный в WO 93/03151, требует выполнения промывки между стадией RT и стадией множественной PCR с удлинением цепи путем перекрывания. Кроме того, одной из конкретных целей публикации WO 93/03151 является решение проблемы выделения отдельных клеток для получения родственных пар последовательностей, кодирующих вариабельные области.Another example of an overlapping extension of RT-PCRs with overlapping extension related to the binding of sequences encoding variable regions is described in the above publication WO 93/03151, which describes a method for cloning sequences encoding a variable region of a heavy chain and a variable region of a light chain that were obtained from a single cell without isolation of individual cells before cloning. The method described in WO 93/03151 requires flushing between the RT step and the multiple overlap chain extension PCR step. In addition, one of the specific goals of WO 93/03151 is to solve the problem of isolating individual cells to obtain related pairs of sequences encoding variable regions.
Ни один из известных методов множественной RT-PCR с удлинением цепи путем перекрывания не предназначен для осуществления на матрице, полученной из выделенной отдельной клетки. Кроме того, ни один из известных методов не может быть выполнен в виде одностадийных реакций RT-PCR.None of the known methods of multiple RT-PCR with chain extension by overlapping is not designed to be implemented on a matrix obtained from an isolated single cell. In addition, none of the known methods can be performed in the form of single-stage RT-PCR reactions.
Один из вариантов осуществления настоящего изобретения относится к связыванию нескольких интересующих несмежных нуклеотидных последовательностей. Такой способ предусматривает амплификацию при помощи множественной PCR или множественной RT-PCR интересующих нуклеотидных последовательностей с использованием матрицы, полученной из выделенной отдельной клетки или популяции изогенных клеток, и связывание интересующих амплифицированных нуклеотидных последовательностей. Кроме того, способ предусматривает необязательную стадию выполнения дополнительной амплификации связанных продуктов.One embodiment of the present invention relates to the binding of several non-contiguous nucleotide sequences of interest. Such a method involves amplification using multiple PCR or multiple RT-PCR of nucleotide sequences of interest using a matrix derived from an isolated single cell or a population of isogenic cells, and linking the amplified nucleotide sequences of interest. In addition, the method provides an optional step for performing additional amplification of the bound products.
Другой вариант осуществления настоящего изобретения относится к способу создания библиотеки родственных пар, включающей связанные последовательности, кодирующие вариабельные области. Этот способ предусматривает получение от донора лимфоцитсодержащей фракции клеток, которую, необязательно, обогащают определенной популяцией лимфоцитов из указанной фракции клеток. Затем получают популяцию выделенных отдельных клеток, распределяя клетки из лимфоцитсодержащей фракции клеток или обогащенной фракции клеток в несколько сосудов. Затем выполняют множественную молекулярную амплификацию (амплификация методом множественной RT-PCR) последовательностей, кодирующих вариабельные области, которые находятся в популяции выделенных отдельных клеток, и связывание пар последовательностей, кодирующих вариабельные области, при этом отдельную пару получают из одной клетки в популяции выделенных отдельных клеток. Кроме того, этот способ предусматривает две необязательные стадии: на первой стадии происходит деление отдельной клетки, выделенной из популяции отдельных клеток, до образования популяции изогенных клеток перед выполнением амплификации методом множественной RT-PCR. Таким образом получают несколько сосудов с разной популяцией изогенных клеток (одна популяция изогенных клеток в одном сосуде). Вторая необязательная стадия предполагает выполнение дополнительной амплификации связанных последовательностей, кодирующих вариабельные области.Another embodiment of the present invention relates to a method for creating a library of cognate pairs comprising linked sequences encoding variable regions. This method involves obtaining from the donor a lymphocyte-containing fraction of cells, which, optionally, is enriched with a specific population of lymphocytes from the specified fraction of cells. Then, a population of isolated individual cells is obtained by distributing cells from the lymphocyte-containing fraction of cells or the enriched fraction of cells into several vessels. Then, multiple molecular amplification (amplification by the multiple RT-PCR method) of sequences encoding variable regions that are in a population of isolated individual cells is performed, and pairing of pairs of sequences encoding variable regions is performed, and a single pair is obtained from one cell in a population of isolated individual cells. In addition, this method involves two optional steps: in the first step, a single cell is isolated that is isolated from a population of individual cells, until a population of isogenic cells is formed before amplification by the multiple RT-PCR method. Thus, several vessels with a different population of isogenic cells are obtained (one population of isogenic cells in one vessel). The second optional step involves performing additional amplification of the linked sequences encoding the variable regions.
В предпочтительных вариантах осуществления настоящего изобретения один из членов указанной библиотеки родственных пар представляет собой последовательность, кодирующую вариабельную область легкой цепи иммуноглобулина, связанную с последовательностью, кодирующей вариабельную область тяжелой цепи иммуноглобулина, которые получены из одной клетки, или последовательности, кодирующие домен связывания Т-клеточного рецептора, состоящий из вариабельной области альфа-цепи, связанной с вариабельной областью бета-цепи, или вариабельной области гамма-цепи, связанной с вариабельной областью дельта-цепи, при этом связанные вариабельные области получают из одной клетки.In preferred embodiments of the present invention, one of the members of said library of related pairs is a sequence encoding an immunoglobulin light chain variable region associated with a sequence encoding an immunoglobulin heavy chain variable region that are derived from a single cell, or sequences encoding a T-cell binding domain receptor, consisting of the variable region of the alpha chain associated with the variable region of the beta chain, or variable about Asti gamma chain variable region linked with delta chain, wherein the associated variable regions are obtained from a single cell.
Амплификация методом множественной RT-PCR по настоящему изобретению может быть выполнена в виде двухстадийного способа, в котором обратную транскрипцию (RT) осуществляют отдельно от амплификации методом множественной PCR (или альтернативной множественной молекулярной амплификации), или в виде одностадийного способа, в котором стадии RT и амплификации методом множественной PCR выполняют с использованием одних и тех же праймеров в одной пробирке.Multiple RT-PCR amplification of the present invention can be performed as a two-step method in which reverse transcription (RT) is performed separately from amplification by multiple PCR (or alternative multiple molecular amplification), or as a one-step method in which the stages of RT and PCR amplifications are performed using the same primers in a single tube.
Обратную транскрипцию (RT) выполняют при помощи фермента, обладающего активностью обратной транскриптазы, получая при этом кДНК из общей РНК, мРНК или заданной специфической РНК в выделенной отдельной клетке. Праймеры, которые могут быть использованы для обратной транскрипции, представляют собой, например, олиго-dT-праймеры, произвольные гексамеры, произвольные декамеры, другие произвольные праймеры или праймеры, специфичные к представляющим интерес нуклеотидным последовательностям.Reverse transcription (RT) is performed using an enzyme with reverse transcriptase activity, thereby obtaining cDNA from total RNA, mRNA, or a given specific RNA in an isolated single cell. Primers that can be used for reverse transcription are, for example, oligo-dT primers, random hexamers, arbitrary decamers, other arbitrary primers or primers specific for the nucleotide sequences of interest.
Двухстадийный способ амплификации при помощи множественной RT-PCR позволяет распределить кДНК, полученную на стадии RT, в несколько сосудов для хранения матричной фракции до выполнения амплификации. Кроме того, распределение кДНК в несколько пробирок делает возможным выполнение нескольких амплификаций методом множественной PCR нуклеиновой кислоты, полученной из одной и той же матрицы. Хотя этот способ характеризуется большим числом отдельных реакций, он позволяет, при желании, упростить смесь множественных праймеров. Указанный двухстадийный способ, например, может быть использован для амплификации и связывания последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой каппа-цепи, в одной пробирке и последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой лямбда-цепи, в другой пробирке с использованием одной и той же матрицы. Отдельная клетка обычно экспрессирует только одну из легких цепей. Однако часто гораздо проще выполнять реакции одновременно, не ожидая результата одной из реакций, прежде чем начать выполнение другой реакции. Кроме того, амплификация каппа-цепи и лямбда-цепи служит в качестве внутреннего отрицательного контроля, так как следует ожидать, что из отдельной клетки может быть амплифицирована только каппа-цепь или лямбда-цепь.The two-stage amplification method using multiple RT-PCR allows you to distribute the cDNA obtained in stage RT, in several vessels for storing the matrix fraction until amplification. In addition, the distribution of cDNA in several tubes makes it possible to perform multiple amplifications by the multiple PCR method of nucleic acid obtained from the same matrix. Although this method is characterized by a large number of individual reactions, it allows, if desired, to simplify the mixture of multiple primers. The specified two-stage method, for example, can be used to amplify and bind sequences encoding the variable region of the heavy chain and the variable region of the light Kappa chain in one tube and sequences encoding the variable region of the heavy chain and the variable region of the light lambda chain, in another tube using the same matrix. A single cell usually expresses only one of the light chains. However, it is often much easier to carry out the reactions simultaneously, without waiting for the result of one of the reactions, before starting to carry out the other reaction. In addition, the amplification of the kappa chain and lambda chain serves as an internal negative control, since it is expected that only a kappa chain or lambda chain can be amplified from a single cell.
В одностадийном способе множественной RT-PCR обратную транскрипцию и амплификацию при помощи множественной PCR выполняют в одном сосуде. В сосуды вводят все компоненты, необходимые для выполнения как обратной транскрипции, так и множественной PCR в одной стадии, и затем осуществляют указанную реакцию. Как правило, не нужно вводить дополнительные компоненты после начала реакции. Преимуществом одностадийного способа амплификации при помощи множественной RT-PCR является сокращение числа стадий, необходимых для получения связанных нуклеотидных последовательностей по настоящему изобретению. Этот способ является особенно эффективным для выполнения множественной RT-PCR с использованием целого ряда отдельных клеток, когда одна и та же реакция должна быть выполнена в нескольких сосудах. Одностадийный способ множественной RT-PCR выполняют, используя обратные праймеры, присутствующие в смеси множественных праймеров, необходимой для амплификации методом множественной PCR, также в качестве праймеров для обратной транскрипции. Композиция, необходимая для одностадийного способа множественной RT-PCR, содержит матрицу нуклеиновой кислоты, фермент, обладающий активностью обратной транскриптазы, фермент, обладающий активностью ДНК-полимеразы, смесь дезоксинуклеозидтрифосфатов (смесь dNTP, содержащую dATP, dCTP, dGTP и dTTP) и смесь множественных праймеров. Матрицей нуклеиновой кислоты предпочтительно является общая РНК или мРНК, полученная из выделенной отдельной клетки в очищенном виде, содержащаяся в лизате клетки или находящаяся внутри интактной клетки. Точный состав реакционной смеси обычно требует некоторой оптимизации каждой смеси множественных праймеров по настоящему изобретению. Это относится как к двухстадийному, так и одностадийному методу множественной RT-PCR.In a one-step multiple RT-PCR method, reverse transcription and amplification using multiple PCR are performed in a single vessel. All components necessary for performing both reverse transcription and multiple PCR in one stage are introduced into the vessels, and then this reaction is carried out. As a rule, it is not necessary to introduce additional components after the start of the reaction. An advantage of the one-step amplification method using multiple RT-PCR is the reduction in the number of steps required to obtain the linked nucleotide sequences of the present invention. This method is particularly effective for performing multiple RT-PCR using a number of separate cells, when the same reaction must be performed in several vessels. The one-step multiple RT-PCR method is performed using reverse primers present in the multiple primer mixture necessary for amplification by multiple PCR, also as reverse transcription primers. The composition required for the one-step multiple RT-PCR method comprises a nucleic acid matrix, an enzyme having reverse transcriptase activity, an enzyme having DNA polymerase activity, a mixture of deoxynucleoside triphosphates (dNTP mixture containing dATP, dCTP, dGTP and dTTP) and a mixture of multiple primers . The nucleic acid matrix is preferably total RNA or mRNA obtained from an isolated single cell in purified form, contained in a cell lysate, or within an intact cell. The exact composition of the reaction mixture usually requires some optimization of each mixture of multiple primers of the present invention. This applies to both the two-stage and one-stage multiple RT-PCR methods.
В альтернативных вариантах осуществления настоящего изобретения в качестве матрицы может быть желательно использовать геномную ДНК вместо РНК. В таких случаях стадию обратной транскрипции пропускают и остальные стадии по настоящему изобретению выполняют в соответствии с приведенным описанием.In alternative embodiments of the present invention, it may be desirable to use genomic DNA instead of RNA as a template. In such cases, the reverse transcription step is skipped and the remaining steps of the present invention are performed as described.
При выполнении некоторых одностадийных множественных RT-PCR во время реакции может быть желательно ввести дополнительные компоненты. Например, после выполнения стадии RT можно добавить полимеразу. Другие компоненты могут включать, например, смесь dNTP или смесь множественных праймеров, возможно, с другим составом праймеров. Такой способ может рассматриваться как множественная RT-PCR, выполняемая в одной пробирке, которая обладает такими же преимуществами, что и одностадийный способ множественной RT-PCR, так как он также ограничивает число пробирок, необходимых для получения требуемых связанных продуктов.When performing some one-step multiple RT-PCR during the reaction, it may be desirable to introduce additional components. For example, after performing the RT step, polymerase can be added. Other components may include, for example, a mixture of dNTP or a mixture of multiple primers, possibly with a different composition of primers. This method can be considered as multiple RT-PCR performed in a single tube, which has the same advantages as the single-stage method of multiple RT-PCR, as it also limits the number of tubes required to obtain the required related products.
Интересующие нуклеотидные последовательности, амплифицированные при помощи множественной RT-PCR, могут быть связаны друг с другом разными способами, такими как множественная RT-PCR с удлинением цепи путем перекрывания, лигирование или рекомбинация, с использованием разных смесей множественных праймеров. Амплификацию методом множественной RT-PCR и связывание осуществляют одностадийным или двухстадийным способом. Однако связывание может быть также выполнено путем многостадийного процесса с использованием, например, заполняющего фрагмента, служащего для связывания интересующих последовательностей нуклеиновых кислот при помощи PCR, лигирования или рекомбинации. Такой заполняющий фрагмент может содержать цис-элементы, промоторные элементы, соответствующую кодирующую последовательность или узнающую последовательность. В предпочтительном варианте осуществления изобретения связывание выполняют в том же сосуде, что и амплификацию методом множественной RT-PCR.The nucleotide sequences of interest amplified by multiple RT-PCR can be linked to each other in different ways, such as multiple RT-PCR with chain extension by overlapping, ligation or recombination using different mixtures of multiple primers. Multiple RT-PCR amplification and binding are performed in a one-step or two-step manner. However, binding can also be accomplished by a multi-step process using, for example, a filling moiety that serves to bind nucleic acid sequences of interest by PCR, ligation, or recombination. Such a filling fragment may contain cis elements, promoter elements, a corresponding coding sequence or recognition sequence. In a preferred embodiment of the invention, the binding is performed in the same vessel as the amplification by multiple RT-PCR.
В одном из вариантов осуществления настоящего изобретения связывание нескольких интересующих несмежных нуклеотидных последовательностей осуществляют вместе с амплификацией методом множественной РCR, используя смесь множественных праймеров для удлинения цепи путем перекрывания. Такой способ позволяет объединить амплификацию и связывание заданных последовательностей. Композиция, необходимая для выполнения множественной PCR с удлинением цепи путем перекрывания, обычно содержит матрицу нуклеиновой кислоты, фермент, обладающий активностью ДНК-полимеразы, смесь дезоксинуклеозидтрифосфатов (смесь dNTP, содержащую dATP, dCTP, dGTP и dTTP) и смесь множественных праймеров для удлинения цепи путем перекрывания.In one embodiment of the invention, the binding of several non-contiguous nucleotide sequences of interest is carried out together with amplification by the multiple PCR method using a mixture of multiple primers to extend the chain by overlapping. This method allows you to combine the amplification and binding of given sequences. The composition required to perform multiple overlapping chain extension PCRs typically comprises a nucleic acid matrix, an enzyme having DNA polymerase activity, a mixture of deoxynucleoside triphosphates (a mixture of dNTPs containing dATP, dCTP, dGTP and dTTP) and a mixture of multiple primers for chain extension by overlapping.
В конкретном варианте осуществления настоящего изобретения несколько интересующих несмежных нуклеотидных последовательностей связывают при помощи множественной RT-PCR с удлинением цепи путем перекрывания, используя матрицу, полученную из выделенной отдельной клетки или популяции изогенных клеток. Кроме того, этот способ предусматривает необязательную стадию выполнения дополнительной молекулярной амплификации связанных продуктов. Множественную RT-PCR с удлинением цепи путем перекрывания, предпочтительно, выполняют в виде одностадийной реакции в одной пробирке.In a specific embodiment of the present invention, several non-contiguous nucleotide sequences of interest are linked using multiple RT-PCR with chain extension by overlapping using a matrix derived from an isolated single cell or population of isogenic cells. In addition, this method provides an optional step for performing additional molecular amplification of the coupled products. Multiple overlap extended RT-PCRs are preferably performed as a one-step reaction in a single tube.
Смесь множественных праймеров для удлинения цепи путем перекрывания по настоящему изобретению включает по крайней мере два набора праймеров, способных инициировать амплификацию и связывание по крайней мере двух последовательностей, кодирующих вариабельные области, например амплификацию и связывание последовательностей из семейств вариабельных областей тяжелой цепи иммуноглобулина с семействами вариабельных областей легкой каппа- или лямбда-цепи либо амплификацию и связывание последовательностей из семейств α-, β-, γ- или δ-цепей Т-клеточных рецепторов.A mixture of multiple primers to extend the chain by overlapping the present invention includes at least two sets of primers capable of initiating amplification and binding of at least two variable region coding sequences, for example, amplification and binding of sequences from the immunoglobulin heavy chain variable region families to variable region families light kappa or lambda chains or amplification and binding of sequences from the families of α-, β-, γ- or δ-chains of T- letochnyh receptors.
В другом варианте осуществления настоящего изобретения несколько интересующих нуклеотидных последовательностей, амплифицированных при помощи множественной RT-PCR, связывают лигированием. Для этого смесь множественных праймеров, используемую для множественной RT-PCR, создают с таким расчетом, чтобы амплифицированные заданные последовательности можно было расщепить соответствущими рестрикционными ферментами и произвести ковалентное связывание путем лигирования ДНК (создание праймеров описано в разделе “Смеси праймеров и их создание”). После амплификации методом множественной RT-PCR с использованием такой смеси множественных праймеров к реакционной смеси вместе с лигазой добавляют рестрикционные ферменты, необходимые для образования совместимых концов заданных последовательностей. Продукты PCR перед этой стадией можно не очищать, хотя такая очистка может быть произведена. Температура реакции для объединенного рестрикционного расщепления и лигирования находится в пределах от около 0 до 40°С. Однако, если в смеси все еще присутствует полимераза, используемая в множественной РCR, предпочтительной является температура инкубации ниже комнатной температуры, наиболее предпочтительными являются температуры от 4 до 16°С.In another embodiment of the present invention, several nucleotide sequences of interest amplified by multiple RT-PCR are linked by ligation. For this, the multiple primer mixture used for the multiple RT-PCR is designed so that amplified target sequences can be cleaved with the appropriate restriction enzymes and covalently linked by DNA ligation (the creation of primers is described in the section “Primer mixtures and their creation”). After amplification by multiple RT-PCR using such a mixture of multiple primers, the restriction enzymes necessary for the formation of compatible ends of the desired sequences are added to the reaction mixture together with the ligase. PCR products may not be cleaned prior to this step, although such purification may be performed. The reaction temperature for combined restriction cleavage and ligation is in the range of about 0 to 40 ° C. However, if the polymerase used in the multiple PCR is still present in the mixture, an incubation temperature below room temperature is preferred, temperatures from 4 to 16 ° C are most preferred.
В другом варианте осуществления настоящего изобретения несколько интересующих нуклеотидных последовательностей, амплифицированных методом множественной RT-PCR, связывают рекомбинацией. В данном случае амплифицированные заданные последовательности могут быть связаны с использованием идентичных сайтов рекомбинации. Связывание выполняют, добавляя рекомбиназы, облегчащие рекомбинацию. Некоторые приемлемые системы рекомбиназ включают Flp-рекомбиназу с несколькими сайтами FRT, Сre-рекомбиназу с несколькими сайтами lox, интегразу ΦС31, которая осуществляет рекомбинацию между сайтом attP и сайтом attB, систему из шести β-рекомбиназ, а также систему Gin-gix. Связывание рекомбинацией было показано на примере двух нуклеотидных последовательностей (связывание VH с VL) (публикация Chapal, N. et al. 1997, Bio Techniques 23, 518-524, включенная в данное описание изобретения в качестве ссылки).In another embodiment of the invention, several RT-PCR amplified nucleotide sequences of interest are coupled by recombination. In this case, amplified target sequences can be linked using identical recombination sites. Binding is performed by adding recombinases that facilitate recombination. Some suitable recombinase systems include Flp recombinase with multiple FRT sites, Cre recombinase with multiple lox sites, ΦC31 integrase that recombines between the attP site and attB site, a system of six β-recombinases, and the Gin-gix system. Recombination binding was shown by the example of two nucleotide sequences (V H binding to V L ) (published by Chapal, N. et al. 1997,
В предпочтительном варианте осуществления настоящего изобретения интересующие нуклеотидные последовательности включают последовательности, кодирующие вариабельные области, при этом в результате связывания образуется родственная пара последовательностей, кодирующих вариабельные области. Такая родственная пара может содержать одну или несколько последовательностей, кодирующих константные области помимо вариабельных областей.In a preferred embodiment of the present invention, the nucleotide sequences of interest include sequences encoding the variable regions, resulting in the binding of a related pair of sequences encoding the variable regions. Such a related pair may contain one or more sequences encoding constant regions in addition to variable regions.
В еще более предпочтительном варианте осуществления настоящего изобретения интересующие нуклеотидные последовательности включают последовательности, кодирующие вариабельные области иммуноглобулина, при этом в результате связывания образуется родственная пара последовательностей, кодирующих вариабельную область легкой цепи и вариабельную область тяжелой цепи. Такая родственная пара может содержать одну или несколько последовательностей, кодирующих константные области помимо вариабельных областей. Кроме того, такая родственная пара может быть выделена из матрицы, полученной из клеток линии В-лимфоцитов, обогащенных из лимфоцитсодержащей фракции клеток, такой как цельная кровь, мононуклеарные клетки или лейкоциты.In an even more preferred embodiment of the present invention, the nucleotide sequences of interest include sequences encoding the immunoglobulin variable regions, and as a result of binding, a related pair of sequences encoding the variable region of the light chain and the variable region of the heavy chain is formed. Such a related pair may contain one or more sequences encoding constant regions in addition to variable regions. In addition, such a related pair can be isolated from a matrix obtained from cells of the B-lymphocyte line enriched from a lymphocyte-containing fraction of cells, such as whole blood, mononuclear cells or leukocytes.
В таком же предпочтительном варианте осуществления настоящего изобретения интересующие нуклеотидные последовательности включают последовательности, кодирующие вариабельные области TcR, при этом в результате связывания образуется родственная пара последовательностей, кодирующих вариабельную область α-цепи и вариабельную область β-цепи, или последовательностей, кодирующих вариабельную область γ-цепи и вариабельную область δ-цепи. Такая родственная пара может содержать одну или несколько последовательностей, кодирующих константные области помимо вариабельных областей. Кроме того, такая родственная пара может быть выделена из матрицы, полученной из клеток линии Т-лимфоцитов, обогащенных из лимфоцитсодержащей фракции клеток, такой как цельная кровь, мононуклеарные клетки или лейкоциты.In the same preferred embodiment of the present invention, the nucleotide sequences of interest include sequences encoding the variable regions of TcR, and as a result of binding, a related pair of sequences encoding the variable region of the α chain and variable region of the β chain, or sequences encoding the variable region of γ- chains and the variable region of the δ-chain. Such a related pair may contain one or more sequences encoding constant regions in addition to variable regions. In addition, such a related pair can be isolated from a matrix obtained from cells of the T-lymphocyte line enriched from a lymphocyte-containing fraction of cells, such as whole blood, mononuclear cells or leukocytes.
Другим объектом настоящего изобретения является применение множественной RT-PCR с использованием в качестве источника матрицы популяции генетически разных клеток. Большинство последовательностей, кодирующих гетеромерные белки, являются одинаковыми в разных клетках в отличие от последовательностей, кодирующих вариабельные области, в связывающих белках. Таким образом, при применении настоящего изобретения для клонирования таких последовательностей, кодирующих невариабельные области гетеромерных белков, не нужно производить первоначальное выделение отдельных клеток.Another object of the present invention is the use of multiple RT-PCR using genetically different cells as a matrix source. Most sequences encoding heteromeric proteins are the same in different cells, unlike sequences encoding variable regions in binding proteins. Thus, when applying the present invention to clone such sequences encoding the non-variable regions of heteromeric proteins, it is not necessary to initially isolate individual cells.
В этом варианте осуществления настоящего изобретения несколько интересующих несмежных нуклеотидных последовательностей произвольно связывают способом, предусматривающим амплификацию методом множественной RT-PCR интересующих нуклеотидных последовательностей с использованем матрицы, полученной из популяции генетически разных клеток, и связывание интересующих амплифицированных нуклеотидных последовательностей. Кроме того, этот способ предусматривает необязательную стадию выполнения дополнительной амплификации связанных продуктов. Как и в случае способа на основе отдельной клетки, связывание можно выполнять при помощи смеси множественных праймеров для удлинения цепи путем перекрывания, используемой для амплификации, или, альтернативно, лигированием или рекомбинацией. Матрица, полученная из популяции клеток, предпочтительно находится внутри клеток. Популяция клеток, например, может быть лизирована.In this embodiment of the present invention, several non-contiguous nucleotide sequences of interest are randomly linked in a manner involving amplification by multiple RT-PCR methods of the nucleotide sequences of interest using a matrix derived from a population of genetically different cells and binding of the amplified nucleotide sequences of interest. In addition, this method provides an optional step for performing additional amplification of the coupled products. As in the case of the method based on a single cell, binding can be performed using a mixture of multiple primers to extend the chain by overlapping used for amplification, or, alternatively, ligation or recombination. The matrix obtained from the cell population is preferably located within the cells. A cell population, for example, may be lysed.
Применение способа произвольного связывания к популяции клеток, экспрессирующих вариабельные области связывающих белков, позволяет упростить создание комбинаторных библиотек последовательностей, кодирующих вариабельные области. Популяция клеток, предпочтительно, содержит клетки, экспрессирующие вариабельные области связывающих белков, такие как В-лимфоциты, Т-лимфоциты, клетки гибридомы, плазматические клетки или смесь указанных клеток.The application of the method of arbitrary binding to a population of cells expressing the variable regions of binding proteins allows us to simplify the creation of combinatorial libraries of sequences encoding variable regions. The cell population preferably contains cells expressing variable regions of binding proteins, such as B-lymphocytes, T-lymphocytes, hybridoma cells, plasma cells, or a mixture of these cells.
Популяция клеток в вышеуказанном варианте осуществления, например, может быть сделана проницаемой или лизирована без дополнительной очистки, или матричные нуклеиновые кислоты могут быть выделены из клеток стандартными методами. Предпочтительным является одностадийный способ множественной RT-PCR. Однако в данном варианте осуществления изобретения можно также использовать двухстадийный способ.A population of cells in the above embodiment, for example, can be made permeable or lysed without further purification, or matrix nucleic acids can be isolated from cells by standard methods. A one-step multiple RT-PCR method is preferred. However, in this embodiment, a two-step process can also be used.
Настоящее изобретение также относится к комбинаторной библиотеке, включающей связанные пары последовательностей, кодирующих вариабельную область легкой цепи и вариабельную область тяжелой цепи иммуноглобулина.The present invention also relates to a combinatorial library comprising linked pairs of sequences encoding the variable region of the light chain and the variable region of the heavy chain of immunoglobulin.
Эффективным способом повышения специфичности, чувствительности и выхода продукта при осуществлении множественной RT-PCR и связывания является выполнение дополнительной молекулярной амплификации связанных нуклеотидных последователностей, полученных в результате множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации либо при помощи множественной RT-PCR с удлинением цепи путем перекрывания. Дополнительную амплификацию, предпочтительно, выполняют при помощи PCR, используя смесь праймеров, для амплификации интересующих связанных последовательностей нуклеиновых кислот. Смесь праймеров может включать внешние праймеры из смеси множественных праймеров или смеси множественных праймеров для удлинения цепи путем перекрывания, в частности праймеры, гибридизирующие с 5'-концом и 3'-концом смысловой цепи связанных последовательностей, кодирующих вариабельные области, что позволяет производить амплификацию всего связанного продукта. Внешние праймеры также можно определить как праймеры из смеси множественных праймеров для удлинения цепи путем перекрывания, не содержащие концевых сегментов удлинения цепи путем перекрывания. Альтернативно, для дополнительной амплификации связанных нуклеотидных последовательностей можно использовать набор праймеров для гнездовой или полугнездовой PCR. Такая гнездовая PCR особенно эффективна для повышения специфичности способа, а также для увеличения количества связанного продукта. В соответствии с целями настоящего изобретения полугнездовая PCR (описанная в разделе, озаглавленном “Смеси праймеров и их создание”) считается такой же эффективной, что и гнездовая PCR. Таким образом, желательным, хотя и необязательным, условием для настоящего изобретения является выполнение дополнительной амплификации при помощи PCR связанных продуктов, полученных в результате множественной RT-PCR с удлинением цепи путем перекрывания, или продуктов, связанных путем лигирования или рекомбинации, методом гнездовой PCR или полугнездовой PCR.An effective way to increase the specificity, sensitivity and yield of a product when performing multiple RT-PCR and binding is to perform additional molecular amplification of the linked nucleotide sequences resulting from multiple RT-PCR followed by ligation or recombination, or using multiple RT-PCR with chain extension by overlapping. Additional amplification is preferably performed using PCR using a mixture of primers to amplify the linked nucleic acid sequences of interest. The primer mixture may include external primers from a mixture of multiple primers or a mixture of multiple primers to extend the chain by overlapping, in particular, primers hybridizing to the 5'-end and 3'-end of the sense strand of linked sequences encoding variable regions, which allows amplification of the entire linked product. External primers can also be defined as primers from a mixture of multiple primers for chain extension by overlapping, not containing end segments of chain extension by overlapping. Alternatively, for further amplification of the linked nucleotide sequences, a primer set for nested or half-nested PCR can be used. Such nested PCR is especially effective for increasing the specificity of the method, as well as for increasing the amount of bound product. In accordance with the objectives of the present invention, a semi-nested PCR (described in the section entitled “Mixtures of primers and their creation”) is considered as effective as nested PCR. Thus, a desirable, although optional, condition for the present invention is to perform additional PCR amplification of coupled products resulting from multiple RT-PCRs with overlapping chain extension, or products associated by ligation or recombination, by nested PCR or semi-nested PCR
Дополнительную амплификацию можно выполнить, непосредственно используя фракцию или весь продукт, полученный в результате множественной RT-PCR с удлинением цепи путем перекрывания, продукт, полученный лигированием или рекомбинацией, фракцию любого из указанных продуктов или частично очищенные связанные продукты, полученные в результате любой из указанных реакций, например, при помощи электрофореза в агарозном геле и вырезания фрагмента, соответствующего предполагаемому размеру связанных последовательностей, кодирующих вариабельные области. Для продуктов, связанных при помощи множественной RT-PCR с удлинением цепи путем перекрывания, дополнительную амплификацию предпочтительно выполняют непосредственно во фракции, полученной в результате множественной RT-PCR с удлинением цепи путем перекрывания, так как это способствует связыванию отдельных заданных последовательностей, которые не были связаны в ходе первой реакции.Additional amplification can be performed directly using the fraction or the entire product resulting from multiple RT-PCR with chain extension by overlapping, the product obtained by ligation or recombination, a fraction of any of these products or partially purified related products obtained from any of these reactions , for example, by agarose gel electrophoresis and cutting out a fragment corresponding to the estimated size of the linked sequences encoding variable domain. For products linked by multiple RT-PCRs with overlapping chain extension, additional amplification is preferably performed directly in the fraction resulting from multiple RT-PCRs with chain extension by overlapping, as this facilitates the binding of individual predetermined sequences that have not been linked during the first reaction.
Интересующие последовательностиSequences of Interest
Интересующие нуклеотидные последовательности по настоящему изобретению могут быть выбраны из последовательностей, кодирующих разные субъединицы или домены, в результате экспрессии которых образуются белок или часть белка. Такие белки, состоящие по крайней мере из двух неидентичных субъединиц, известны как гетеромерные белки. Гетеромерные белки присутствуют во всех биологических видах. Некоторыми классами, к которым относятся такие белки, являются, например, ферменты, ингибиторы, структурные белки, токсины, каналообразующие белки, G-белки, рецепторные белки, белки надсемейства иммуноглобулинов, транспортирующие белки и т.д. Нуклеотидные последовательности, кодирующие такие гетеромерные белки, являются несмежными, из чего следует, например, что они образуются разными генами или разными молекулами мРНК. Однако термин “несмежные” в значении, используемом в настоящем изобретении, может также обозначать нуклеотидные последовательности, кодирующие домены одного белка, в котором указанные домены разделены неинтересующими нуклеотидными последовательностями.The nucleotide sequences of interest of the present invention can be selected from sequences encoding different subunits or domains, the expression of which produces a protein or part of a protein. Such proteins, consisting of at least two non-identical subunits, are known as heteromeric proteins. Heteromeric proteins are present in all species. Some classes to which such proteins belong are, for example, enzymes, inhibitors, structural proteins, toxins, channel-forming proteins, G-proteins, receptor proteins, immunoglobulin superfamily proteins, transporting proteins, etc. The nucleotide sequences encoding such heteromeric proteins are non-contiguous, which implies, for example, that they are formed by different genes or different mRNA molecules. However, the term “non-contiguous” as used in the present invention may also refer to nucleotide sequences encoding the domains of one protein in which these domains are separated by uninteresting nucleotide sequences.
В одном из вариантов осуществления настоящего изобретения интересующие нуклеотидные последовательности включают последовательности, кодирующие вариабельные области, из надсемейства иммуноглобулинов, таких как иммуноглобулины (антитела), В-клеточные рецепторы и Т-клеточные рецепторы (TcR). Особенно интересными являются последовательности, кодирующие вариабельные области иммуноглобулинов. Такие последовательности, кодирующие вариабельные области, включают непроцессированные антитела, а также Fab-, Fv-, scFv-фрагменты и комбинации фрагментов последовательностей, кодирующих вариабельные области, например гипервариабельные участки (CDR), J-гены, или V-гены, или их сочетания. Как правило, настоящее изобретение относится к любым комбинациям последовательностей, кодирующим вариабельные области, и к сочетаниям их фрагментов. В настоящей заявке рассмотрено связывание всей легкой цепи с вариабельным доменом тяжелой цепи. Однако настоящее изобретение также относится к связыванию только вариабельных доменов тяжелой и легкой цепей, образующих Fv- или scFv-кодирующие последовательности, или к связыванию всей легкой цепи с вариабельной областью тяжелой цепи, доменом константной области СН1 и частями шарнирной области, образующими Fab, Fab' или F(ab)2. Кроме того, к вариабельной области тяжелой цепи можно добавить любую область доменов константной области тяжелой цепи, в результате чего будут получены процессированные антителокодирующие последовательности или непроцессированные антителокодирующие последовательности.In one embodiment of the present invention, nucleotide sequences of interest include variable region coding sequences from a superfamily of immunoglobulins such as immunoglobulins (antibodies), B-cell receptors, and T-cell receptors (TcRs). Of particular interest are sequences encoding the variable regions of immunoglobulins. Such variable region coding sequences include unprocessed antibodies, as well as Fab, Fv, scFv fragments, and combinations of variable region coding sequences, for example, hypervariable regions (CDRs), J genes, or V genes, or combinations thereof . Typically, the present invention relates to any combination of sequences encoding variable regions, and combinations of their fragments. This application discusses the binding of the entire light chain to the variable domain of the heavy chain. However, the present invention also relates to the binding of only the variable domains of the heavy and light chains forming Fv or scFv coding sequences, or to the binding of the entire light chain to the variable region of the heavy chain, the domain of the constant region With H1 and the parts of the hinge region forming Fab, Fab 'or F (ab) 2 . In addition, any domain region of the constant region of the heavy chain can be added to the variable region of the heavy chain, as a result of which processed antibody coding sequences or unprocessed antibody coding sequences will be obtained.
В другом варианте осуществления настоящего изобретения последовательности, кодирующие вариабельные области, включают последовательность, кодирующую легкую цепь (каппа или лямбда) иммуноглобулина одного типа и одну последовательность, кодирующую вариабельную область тяжелой цепи иммуноглобулина.In another embodiment of the present invention, sequences encoding the variable regions include a sequence encoding the immunoglobulin light chain (kappa or lambda) of the same type and one sequence encoding the variable region of the immunoglobulin heavy chain.
Кроме того, интерес представляют последовательности, кодирующие вариабельные области, которые были получены из Т-клеточных рецепторов (TcR). Такие TcR-кодирующие последовательности включают кодирующие последовательности для непроцессированных альфа- и бета-цепей или гамма- и дельта-цепей, а также растворимые TcR, или только вариабельные домены указанных цепей, или их одноцепочечные слитые белки (например, одиночная αβ-цепь или одиночная γδ-цепь).In addition, the sequences encoding the variable regions that were derived from T cell receptors (TcR) are of interest. Such TcR coding sequences include coding sequences for unprocessed alpha and beta chains or gamma and delta chains, as well as soluble TcRs, or only the variable domains of these chains, or their single chain fusion proteins (e.g., single αβ chain or single γδ-chain).
Источники матрицыMatrix sources
Одним из отличительных признаков настоящего изобретения является возможность связывать нуклеотидные последовательности, полученные из выделенной отдельной клетки, популяции изогенных клеток или генетически разной популяции клеток, которые не были распределены по отдельным сосудам. Клетки, используемые в настоящем изобретении, могут быть, например, бактериальными клетками, дрожжевыми клетками, грибными клетками, клетками насекомых, растительными клетками, клетками млекопитающих или фракциями таких клеток. Клетки крови млекопитающих являются одним примером фракции клеток, которые могут быть использованы в настоящем изобретении.One of the distinguishing features of the present invention is the ability to bind nucleotide sequences obtained from an isolated single cell, a population of isogenic cells, or a genetically different population of cells that have not been distributed across individual vessels. The cells used in the present invention can be, for example, bacterial cells, yeast cells, fungal cells, insect cells, plant cells, mammalian cells, or fractions of such cells. Mammalian blood cells are one example of a fraction of cells that can be used in the present invention.
Предпочтительным отличительным признаком настоящего изобретения является использование выделенных отдельных клеток или популяции изогенных клеток в качестве источника матрицы, так как таким образом можно избежать замены интересующих последовательностей нуклеиновых кислот, в частности последовательностей, кодирующих вариабельные области. Это имеет особенно важное значение в том случае, если желательно получить первоначальную пару последовательностей, кодирующих вариабельные области.A preferred feature of the present invention is the use of isolated single cells or a population of isogenic cells as a matrix source, since in this way replacement of nucleic acid sequences of interest, in particular sequences encoding variable regions, can be avoided. This is especially important if it is desired to obtain an initial pair of sequences encoding variable regions.
Другим предпочтительным отличительным признаком настоящего изобретения является получение отдельной клетки или популяции отдельных клеток из лимфоцитсодержащей фракции клеток, таких как В-лимфоциты, Т-лимфоциты, плазматические клетки и/или линии указанных клеток на разных стадиях развития. Для получения отдельных клеток также можно использовать другие популяции клеток, экспрессирующих связывающие белки из надсемейства иммуноглобулинов. В настоящем изобретении можно также использовать такие линии клеток, как клетки гибридомы, линии клеток В-лимфоцитов или Т-лимфоцитов, иммобилизованные линии клеток вирусов или клетки, полученные от донора, которые участвуют в возбуждении иммунной реакции. Фракции лимфоцитсодержащих клеток, полученных от донора, можно выделить из естественных тканей или жидкостей с большим содержанием таких клеток, например из крови, костного мозга, лимфатических узлов, ткани селезенки, ткани миндалины, из инфильтратов внутри и вокруг опухолей или из инфильтратов воспалительной ткани. Приемлемыми донорами клеток по настоящему изобретению могут быть позвоночные с приобретенной иммунной системой. Донорами могут быть индивидуумы, не подвергавшиеся ранее какому-либо воздействию или гипериммунизированные против требуемой мишени. Для выделения антигенсвязывающих белков, обладающих специфичностью связывания к определенной мишени, предпочтительными являются гипериммунизированные доноры. Такими гипериммунизированными донорами могут быть доноры, иммунизированные антигеном-мишенью или его фрагментами, выздоравливающие или больные индивидуумы, у которых возникает естественная иммунная реакция на антиген-мишень, например индивидуумы, страдающие аутоиммунными заболеваниями, раком или инфекционными болезнями, такие как ВИЧ-инфицированные индивидуумы, индивидуумы, страдающие гепатитом А, В или С, тяжелым острым респираторным синдромом (SARS) и тому подобное, или индивидуумы, страдающие хроническими заболеваниями.Another preferred feature of the present invention is the preparation of a single cell or a population of individual cells from a lymphocyte-containing fraction of cells, such as B-lymphocytes, T-lymphocytes, plasma cells and / or lines of these cells at different stages of development. Other cell populations expressing binding proteins from the immunoglobulin superfamily can also be used to produce single cells. Cell lines such as hybridoma cells, B-lymphocyte or T-lymphocyte cell lines, immobilized virus cell lines or cells obtained from a donor that are involved in initiating an immune response can also be used in the present invention. Fractions of lymphocyte-containing cells obtained from a donor can be isolated from natural tissues or fluids with a high content of such cells, for example, from blood, bone marrow, lymph nodes, spleen tissue, tonsil tissue, from infiltrates in and around tumors or from inflammatory tissue infiltrates. Acceptable cell donors of the present invention may be vertebrates with an acquired immune system. Donors can be individuals who have not previously been exposed to any effect or hyperimmunized against the desired target. Hyperimmunized donors are preferred for isolating antigen binding proteins having binding specificity for a particular target. Such hyperimmunized donors may be donors immunized with a target antigen or fragments thereof, recovering or sick individuals that have a natural immune response to a target antigen, for example, individuals suffering from autoimmune diseases, cancer or infectious diseases, such as HIV-infected individuals, individuals suffering from hepatitis A, B or C, severe acute respiratory syndrome (SARS) and the like, or individuals suffering from chronic diseases.
При использовании рекомбинантных белков в лечебных целях желательно, что они были выделены из последовательностей, характеризующихся видовой идентичностью с подлежащим лечению индивидуумом (например, для лечения людей должны быть использованы человеческие последовательности). Прежде всего потому, что рекомбинантные белки, выделенные из чужеродной последовательности (то есть отличные от человеческих), будут распознаны иммунной системой, в результате чего возникнет иммунная реакция с участием поликлональных антибелковых антител. Указанные антибелковые антитела могут блокировать действие лекарственного средства, заняв активный сайт, ускорить выведение лекарственного средства и вызвать вредные реакции, в частности аллергические реакции при повторном воздействии.When using recombinant proteins for therapeutic purposes, it is desirable that they be isolated from sequences characterized by species identity with the individual to be treated (for example, human sequences should be used to treat people). First of all, because recombinant proteins isolated from a foreign sequence (that is, different from human ones) will be recognized by the immune system, resulting in an immune reaction involving polyclonal anti-protein antibodies. These anti-protein antibodies can block the action of the drug by occupying the active site, accelerate drug elimination and cause harmful reactions, in particular allergic reactions when repeated exposure.
Иммуногенность, тем не менее, также может наблюдаться в тех случаях, когда рекомбинантный белок выделен из последовательности, характеризующейся видовой идентичностью. Такая иммуногенность, например, может быть индуцирована посттрансляционными модификациями, которые могут отличаться от наблюдаемых in vivo. Комбинаторные библиотеки последовательностей, кодирующих вариабельные области, также могут вызвать иммуногенность, так как они состоят из созданных in vitro произвольных пар последовательностей, кодирующих вариабельные области. Правила, определяющие образование in vivo пар последовательностей, кодирующих тяжелые и легкие цепи антитела (или Т-клеточных рецепторов), еще полностью не изучены. Из вышеизложенного следует, что некоторые образованные in vitro пары могут быть распознаны иммунной системой как чужеродные, даже если обе последовательности, образующие пару, принадлежат человеку. Связывающие белки, полученные из библиотек родственных пар, с другой стороны, не образуют таких аномальных комбинаций и поэтому являются потенциально менее иммуногенными, чем связывающие белки, полученных из комбинаторных библиотек. Это не значит, что продукты, полученные из комбинаторных библиотек, не пригодны для лечения, они просто требуют более тщательного контроля с целью выявления вышеуказанных побочных эффектов.Immunogenicity, however, can also be observed in cases where a recombinant protein is isolated from a sequence characterized by species identity. Such immunogenicity, for example, can be induced by post-translational modifications, which may differ from those observed in vivo. Combinatorial libraries of sequences encoding variable regions can also cause immunogenicity, since they consist of arbitrary pairs of sequences encoding variable regions created in vitro. The rules governing the formation of in vivo pairs of sequences encoding the heavy and light chains of antibodies (or T-cell receptors) have not yet been fully studied. It follows from the foregoing that some pairs formed in vitro can be recognized by the immune system as foreign, even if both sequences forming a pair belong to a person. Binding proteins obtained from libraries of related pairs, on the other hand, do not form such abnormal combinations and therefore are potentially less immunogenic than binding proteins obtained from combinatorial libraries. This does not mean that products obtained from combinatorial libraries are not suitable for treatment, they simply require more careful monitoring in order to identify the above side effects.
В соответствии с настоящим изобретением доноры клеток предпочтительно должны относиться к такому же биологическому виду, что и индивидуумы, подлежащие лечению продуктами, полученными из связанных нуклеотидных последовательностей по настоящему изобретению. Донором клеток предпочтительно является домашнее животное, комнатное животное, человек или трансгенное животное. Трансгенные животные, несущие локусы иммуноглобулина человека, описаны в патенте США № 6111166 и в публикации Kuroiwa, Y. et al. Nature Biotechnology; 2002; 20:889-893. Такие трансгенные животные могут продуцировать иммуноглобулины человека. Таким образом, полностью человеческие антитела против специфической мишени могут быть получены обычными методами иммунизации таких трансгенных животных. Это позволяет создать библиотеки, кодирующие связывающие белки, обладающие специфичностью в отношении более трудных мишеней, таких как антигены человека, в отношении которых у человека отсутствует или существует ограниченная естественная гуморальная иммунная реакция. Аналогичным образом могут быть созданы трансгенные животные, продуцирующие Т-клеточные рецепторы человека.In accordance with the present invention, the cell donors should preferably be of the same species as the individuals to be treated with products derived from the linked nucleotide sequences of the present invention. The cell donor is preferably a pet, companion animal, human or transgenic animal. Transgenic animals carrying human immunoglobulin loci are described in US Pat. No. 6,111,166 and in Kuroiwa, Y. et al. Nature Biotechnology; 2002; 20: 889-893. Such transgenic animals can produce human immunoglobulins. Thus, fully human antibodies against a specific target can be obtained by conventional methods of immunization of such transgenic animals. This allows the creation of libraries encoding binding proteins that are specific for more difficult targets, such as human antigens, for which a person has no or has a limited natural humoral immune response. Similarly, transgenic animals producing human T-cell receptors can be created.
В другом варианте осуществления настоящего изобретения лимфоцитсодержащая фракция клеток состоит из цельной крови, костного мозга, мононуклеарных клеток или лейкоцитов, полученных от донора. Мононуклеарные клетки могут быть выделены из крови, костного мозга, лимфатических узлов, селезенки, инфильтратов вокруг раковых клеток и воспалительных инфильтратов. Мононуклеарные клетки могут быть выделены методами центрифугирования в градиенте плотности, например в градиентах фиколла. При выделении мононуклеарных клеток из образцов ткани используемую ткань разрушают до выполнения центрифугирования в градиенте плотности. Ткань может быть разрушена механическими методами, такими как, например, измельчение, электропорацией и/или химическими методами, такими как обработка ферментами. Лейкоциты можно выделить непосредственно у доноров при помощи лейкофереза. В настоящем изобретении можно также использовать неочищенные препараты костного мозга или ткани, содержащие лимфоциты. Такие препараты необходимо разрушить, например, вышеописанными методами для облегчения распределения отдельных клеток.In another embodiment of the present invention, the lymphocyte-containing fraction of the cells consists of whole blood, bone marrow, mononuclear cells or leukocytes obtained from a donor. Mononuclear cells can be isolated from blood, bone marrow, lymph nodes, spleen, infiltrates around cancer cells and inflammatory infiltrates. Mononuclear cells can be isolated by density gradient centrifugation, such as ficoll gradients. When mononuclear cells are isolated from tissue samples, the tissue used is destroyed prior to density gradient centrifugation. The tissue can be destroyed by mechanical methods, such as, for example, grinding, electroporation and / or chemical methods, such as treatment with enzymes. White blood cells can be isolated directly from donors using leukopheresis. Untreated bone marrow preparations or tissues containing lymphocytes can also be used in the present invention. Such preparations must be destroyed, for example, by the methods described above to facilitate the distribution of individual cells.
Другим отличительным признаком настоящего изобретения является обогащение лимфоцитсодержащей фракции клеток, например, цельной крови, мононуклеарных клеток, лейкоцитов или костного мозга, в отношении определенной популяции лимфоцитов, такой как клетки из линий В-лимфоцитов или Т-лимфоцитов. Обогащение В-лимфоцитов можно произвести, например, при помощи сортировки клеток методом магнитных гранул или сортировки клеток с возбуждением флуоресценции (FACS), используя специфичные к данной линии маркерные белки клеточной поверхности, такие как CD19 или другие маркеры, специфичные к линии В-клеток. Обогащение Т-лимфоцитов можно произвести, например, при помощи маркера клеточной поверхности, такого как CD3, или других маркеров, специфичных к линии Т-клеток.Another hallmark of the present invention is the enrichment of a lymphocyte-containing fraction of cells, for example, whole blood, mononuclear cells, white blood cells or bone marrow, in relation to a specific population of lymphocytes, such as cells from lines of B-lymphocytes or T-lymphocytes. Enrichment of B-lymphocytes can be done, for example, by sorting cells using magnetic beads or sorting cells with fluorescence stimulation (FACS), using cell surface-specific marker proteins of the cell surface, such as CD19 or other markers specific to the B-cell line. Enrichment of T-lymphocytes can be performed, for example, using a cell surface marker, such as CD3, or other markers specific to the T-cell line.
Предпочтительным отличительным признаком настоящего изобретения является дополнительная сортировка обогащенных В-лимфоцитов для получения плазматических клеток до распределения отдельных клеток в несколько сосудов. Плазматические клетки обычно выделяют при помощи сортировки методом FACS, используя поверхностные маркеры, такие как CD38, возможно, в сочетании с CD45. Кроме того, можно использовать другие поверхностные маркеры, специфичные к плазматическим клеткам, или их комбинации, например CD138, CD20, CD21, CD40, CD9, HLA-DR или CD62L, причем выбор маркера зависит от источника плазматических клеток, такого как миндалины, кровь или костный мозг. Плазматические клетки можно также выделить из необогащенной лимфоцитсодержащей популяции клеток, полученной из любых вышеуказанных источников. Плазматические клетки, выделенные из крови, иногда называют ранними плазматическими клетками или лимфобластами. В настоящем изобретении указанные клетки также именуются плазматическими клетками, хотя они являются CD19-положительными клетками в отличие от плазматических клеток, находящихся в костном мозге. Для выделения родственных пар последовательностей, кодирующих иммуноглобулины, желательно использовать плазматические клетки, так как при более высокой частоте встречаемости указанные клетки продуцируют антигенспецифические антитела, которые отражают приобретенный иммунитет к требуемому антигену, при этом большинство указанных клеток подверглось соматической сверхмутации и поэтому кодирует высокоаффинные антитела. Кроме того, в плазматических клетках повышены уровни мРНК по сравнению с остальной популяцией В-лимфоцитов, благодаря чему обратная транскрипция оказывается более эффективной при использовании отдельных плазматических клеток. В качестве альтернативы выделению плазматических клеток из лимфоцитсодержащей фракции клеток можно выделить В-клетки памяти, используя маркер клеточной поверхности, такой как CD22.A preferred feature of the present invention is the additional sorting of enriched B lymphocytes to produce plasma cells prior to the distribution of individual cells into several vessels. Plasma cells are usually isolated by FACS sorting using surface markers such as CD38, possibly in combination with CD45. In addition, you can use other surface markers specific to plasma cells, or combinations thereof, for example CD138, CD20, CD21, CD40, CD9, HLA-DR or CD62L, and the choice of marker depends on the source of plasma cells, such as tonsils, blood or Bone marrow. Plasma cells can also be isolated from an unenriched lymphocyte-containing population of cells obtained from any of the above sources. Plasma cells isolated from the blood are sometimes called early plasma cells or lymphoblasts. In the present invention, these cells are also referred to as plasma cells, although they are CD19-positive cells in contrast to plasma cells located in the bone marrow. To isolate related pairs of sequences encoding immunoglobulins, it is desirable to use plasma cells, since at a higher frequency of occurrence, these cells produce antigen-specific antibodies that reflect acquired immunity to the desired antigen, while most of these cells underwent somatic overmutation and therefore encode high affinity antibodies. In addition, plasma cells have increased mRNA levels compared to the rest of the B-lymphocyte population, which makes reverse transcription more effective when using individual plasma cells. As an alternative to isolating plasma cells from a lymphocyte-containing fraction of cells, memory B cells can be isolated using a cell surface marker such as CD22.
Альтернативным отличительным признаком настоящего изобретения является отбор обогащенных В-лимфоцитов в отношении антигенной специфичности до распределения клеток в несколько сосудов. Антигенспецифические В-лимфоциты отбирают, осуществляя контактирование обогащенных В-лимфоцитов с требуемым антигеном или антигенами, в результате которого происходит связывание антигена с поверхностным иммуноглобулином и последующее выделение связанных клеток. Вышеуказанный отбор можно произвести путем нанесения на магнитные гранулы требуемого антигена или антигенов и путем сортировки клеток методом магнитных гранул, FACS, введения антигенов в колонку и выполнения аффинной хроматографии, скрининга на фильтре или других методов, известных в данной области. При желании отбору на антигенную специфичность можно подвергнуть плазматические клетки, а также В-лимфоциты, необогащенные мононуклеарные клетки, лейкоциты, цельную кровь, костный мозг или препараты ткани.An alternative distinguishing feature of the present invention is the selection of enriched B lymphocytes for antigenic specificity before the distribution of cells into several vessels. Antigen-specific B-lymphocytes are selected by contacting the enriched B-lymphocytes with the desired antigen or antigens, which results in the binding of the antigen to surface immunoglobulin and the subsequent isolation of bound cells. The above selection can be made by applying the desired antigen or antigens to the magnetic granules and sorting the cells by magnetic granule method, FACS, introducing the antigens into the column and performing affinity chromatography, filter screening or other methods known in the art. If desired, plasma cells as well as B-lymphocytes, unenriched mononuclear cells, white blood cells, whole blood, bone marrow or tissue preparations can be selected for antigenic specificity.
Другим отличительным признаком настоящего изобретения является сортировка обогащенных Т-лимфоцитов (например, CD3-положительных клеток) с использованием поверхностных маркеров CD45R0 и/или CD27 для получения фракции Т-клеток памяти. Т-лимфоциты можно также отобрать с учетом МНС-антигенной специфичности, используя комплексы МНС-пептид (см., например, публикации Callan, M.F et al. 1998, J. Exp. Med. 187, 1395-1402; Novak, E.J. et al. 1999, J. Clin. Invest. 104, R63-R67).Another hallmark of the present invention is the sorting of enriched T-lymphocytes (eg, CD3-positive cells) using surface markers CD45R0 and / or CD27 to obtain a fraction of memory T cells. T lymphocytes can also be selected taking into account MHC antigenicity using MHC-peptide complexes (see, for example, Callan, MF et al. 1998, J. Exp. Med. 187, 1395-1402; Novak, EJ et al . 1999, J. Clin. Invest. 104, R63-R67).
Другим отличительным признаком настоящего изобретения является иммортализация любых вышеописанных выделенных фракций клеток (например, В-лимфоцитов, плазматических клеток, клеток памяти или Т-лимфоцитов). Иммортализация может быть, например, выполнена при помощи вируса Эпштейна - Барра (Traggiai, E. et al., 2004, Nat. Med. 10, 871-875) перед распределением клеток по пробиркам. Альтернативно, выделенные отдельные клетки могут быть иммортализованы и размножены до выполнения обратной транскрипции. (Traggiai et al., Nat. Med. 2004, Aug.; 10(8):871-5).Another hallmark of the present invention is the immortalization of any of the isolated cell fractions described above (e.g., B-lymphocytes, plasma cells, memory cells or T-lymphocytes). Immortalization can, for example, be performed using the Epstein-Barr virus (Traggiai, E. et al., 2004, Nat. Med. 10, 871-875) before cell distribution to the tubes. Alternatively, isolated individual cells may be immortalized and propagated before reverse transcription is performed. (Traggiai et al., Nat. Med. 2004, Aug .; 10 (8): 871-5).
Другим отличительным признаком настоящего изобретения является распределение популяции требуемых клеток (например, клеток гибридомы, линий клеток В-лимфоцитов или Т-лимфоцитов, клеток цельной крови, клеток костного мозга, мононуклеарных клеток, лейкоцитов, В-лмфоцитов, плазматических клеток, антигенспецифических В-лимфоцитов, В-клеток памяти, Т-лимфоцитов, антиген/МНС-специфических Т-лимфоцитов или Т-клеток памяти) в несколько сосудов для получения популяции выделенных отдельных клеток. Выделение отдельных клеток обозначает физическое отделение клеток от популяции клеток таким образом, чтобы в одном сосуде находилась одна клетка, или нанесение клеток на микроматрицу, чип или гелевую матрицу с возможностью получения отдельных клеток. Клетки можно распределить непосредственно в несколько рядом стоящих сосудов методом ограниченного разведения. Сосуды, используемые в настоящем изобретении, предпочтительно, аналогичны сосудам, применяемым для выполнения PCR (например, пробирки для РCR, 96-луночные или 384-луночные планшеты для РCR или более крупные массивы сосудов). Однако также можно использовать другие сосуды. При распределении отдельных клеток в большое число отдельных сосудов (например, 384-луночные планшеты) получают популяцию отдельных клеток. Распределение можно произвести путем дозированного введения определенного объема в отдельный сосуд, в котором средняя концентрации клеток равна одной, 0,5 или 0,3 клетки, в результате чего получают сосуды, в среднем содержащие одну клетку или меньше. Так как распределение клеток методом ограниченного разведения является статистическим методом, то часть сосудов будет пуста, основная часть сосудов будет содержать одну клетку и незначительная часть сосудов будет содержать две или несколько клеток. При нахождении в сосуде двух или несколько клеток может произойти некоторая перестановка последовательностей, кодирующих вариабельные области, из клеток, присутствующих в сосуде. Однако, так как такой результат является несущественным, он не будет влиять на общую применимость настоящего изобретения. Кроме того, сочетания последовательностей, кодирующих вариабельные области, которые не обладают требуемым сродством и специфичностью связывания, по-видимому, не будут отобраны и, следовательно, будут исключены в процессе скрининга. Поэтому незначительные случаи перестановки последовательностей не будут существенно влиять на конечную библиотеку по настоящему изобретению.Another hallmark of the present invention is the distribution of the population of desired cells (e.g., hybridoma cells, B-lymphocyte or T-lymphocyte cell lines, whole blood cells, bone marrow cells, mononuclear cells, white blood cells, B-lymphocytes, plasma cells, antigen-specific B-lymphocytes , Memory B cells, T lymphocytes, antigen / MHC-specific T lymphocytes or memory T cells) in several vessels to obtain a population of isolated individual cells. Isolation of individual cells means the physical separation of cells from a population of cells so that there is one cell in one vessel, or the deposition of cells on a microarray, chip or gel matrix with the possibility of obtaining individual cells. Cells can be distributed directly into several adjacent vessels by limited dilution. The vessels used in the present invention are preferably similar to the vessels used to perform PCR (e.g., PCR tubes, 96-well or 384-well PCR plates, or larger arrays of vessels). However, other vessels may also be used. When individual cells are distributed into a large number of individual vessels (for example, 384-well plates), a population of individual cells is obtained. Distribution can be made by dosing a certain volume into a separate vessel, in which the average concentration of cells is one, 0.5 or 0.3 cells, resulting in vessels that, on average, contain one cell or less. Since the distribution of cells by the limited dilution method is a statistical method, part of the vessels will be empty, the main part of the vessels will contain one cell and a small part of the vessels will contain two or more cells. When two or more cells are in the vessel, some rearrangement of the sequences encoding the variable regions from the cells present in the vessel may occur. However, since such a result is not significant, it will not affect the general applicability of the present invention. In addition, combinations of sequences encoding variable regions that do not have the required affinity and binding specificity are not likely to be selected and therefore will be excluded during the screening process. Therefore, minor cases of sequence rearrangement will not significantly affect the final library of the present invention.
Существуют альтернативы распределению клеток методом ограниченного разведения, например клеточные сортеры, такие как FACS или роботы, которые могут быть запрограммированы на точное распределение отдельных клеток в отдельные сосуды. Подобные альтернативные методы более предпочтительны, так как они являются менее трудоемкими и более эффективными для достижения однородного распределения отдельных клеток в отдельные сосуды.There are alternatives to the distribution of cells by the limited dilution method, for example, cell sorters, such as FACS or robots, which can be programmed to accurately distribute individual cells into separate vessels. Such alternative methods are more preferable, as they are less time consuming and more effective to achieve a uniform distribution of individual cells in separate vessels.
Вышеописанные методы обогащения, сортировки и выделения клеток выполняют таким образом, чтобы большинство клеток оставалось интактными. Разрушение клеток во время обогащения или сортировки может привести к перестановке последовательностей, кодирующих вариабельные области. Однако данная проблема не должна иметь серьезных последствий, так как предполагается, что частота разрушения клеток будет низкой. Благодаря промывке и возможной обработке клеток РНКазой до их распределения в отдельные сосуды будет удалена любая РНК, выделившаяся из клеток.The above methods of enrichment, sorting and selection of cells are performed in such a way that most of the cells remain intact. Destruction of cells during enrichment or sorting may result in permutation of sequences encoding variable regions. However, this problem should not have serious consequences, since it is assumed that the frequency of cell destruction will be low. Thanks to the washing and possible treatment of the cells with RNase, any RNA released from the cells will be removed before they are distributed into separate vessels.
Кроме того, при ознакомлении с приведенным выше описанием распределения клеток для получения популяции отдельных клеток в нескольких отдельных сосудах указанное требование нельзя интерпретировать как абсолютно необходимый отличительный признак, в соответствии с которым в каждом сосуде должна находиться одна клетка. Вышеуказанный признак скорее предполагает, что в большинстве сосудов должны находиться отдельные клетки, например число сосудов с двумя или более клетками составляет менее 25% от общего количества распределенных клеток или даже менее 10%.In addition, when reviewing the above description of the distribution of cells to obtain a population of individual cells in several separate vessels, this requirement cannot be interpreted as an absolutely necessary distinguishing feature, according to which one cell must be in each vessel. The above symptom rather suggests that in most vessels there should be separate cells, for example, the number of vessels with two or more cells is less than 25% of the total number of distributed cells, or even less than 10%.
Другим отличительным признаком настоящего изобретения является выполнение обратной транскрипции с использованием матрицы, полученной из клеток, распределенных по одной в несколько сосудов.Another hallmark of the present invention is the implementation of reverse transcription using a matrix obtained from cells distributed one at a time in several vessels.
В соответствии с целями обратной транскрипции (RT) по настоящему изобретению нуклеиновые кислоты в отдельной клетке, которая должна служить источником матрицы для RT, должны быть получены из одной клетки, хотя они, необязательно, должны быть отделены от остального содержания данной отдельной клетки.For the purposes of the reverse transcription (RT) of the present invention, nucleic acids in a single cell, which should serve as the source of the matrix for RT, must be obtained from a single cell, although they need not be separated from the rest of the content of this single cell.
После окончательного распределения отдельных клеток по отдельным сосудам отдельные клетки могут быть размножены для получения популяции изогенных клеток до выполнения обратной транскрипции. Таким образом увеличивается выход мРНК, используемой в качестве матрицы, что может иметь важное значение при амплификации и связывании редкой мишени. Однако клетки должны оставаться генетически идентичными в отношении гена-мишени во время размножения. Изолированные клетки или популяция изогенных клеток могут быть интактными или лизированными, если при этом не вырождается матрица для обратной транскрипции. Клетки предпочтительно лизируют, чтобы облегчить последующую обратную транскрипцию и амплификацию методом PCR.After the final distribution of individual cells to individual vessels, individual cells can be propagated to obtain a population of isogenic cells before reverse transcription is performed. Thus, the yield of mRNA used as a template increases, which may be important in the amplification and binding of a rare target. However, the cells must remain genetically identical with respect to the target gene during propagation. Isolated cells or a population of isogenic cells can be intact or lysed if the matrix for reverse transcription does not degenerate. Cells are preferably lysed to facilitate subsequent reverse transcription and PCR amplification.
В другом варианте осуществления настоящего изобретения описанный метод множественной RT-PCR c удлинением цепи путем перекрывания или множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации также может быть выполнен на матрице, полученной из генетически разной популяции клеток, которые не были распределены по отдельным сосудам и остаются вместе в виде пула клеток. Указанный метод может быть использован для создания комбинаторных библиотек. Такой метод не требует распределения отдельных клеток. Однако клетки, которые могут быть использованы при осуществлении данного метода, должны быть аналогичны клеткам, применяемым в методе с использованием отдельных клеток, и представлять собой, например, популяцию (пул) сортированных В-лимфоцитов или Т-лимфоцитов. При выполнении одностадийной множественной RT-PCR с удлинением цепи путем перекрывания или одностадийной множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации в такой популяции клеток желательно лизировать клетки до осуществления реакции, при этом при желании из лизата может быть выделена общая РНК или мРНК.In another embodiment of the present invention, the described method of multiple RT-PCR with chain extension by overlapping or multiple RT-PCR followed by ligation or recombination can also be performed on a matrix obtained from a genetically different population of cells that were not distributed in separate vessels and stay together as a pool of cells. The specified method can be used to create combinatorial libraries. This method does not require the distribution of individual cells. However, the cells that can be used in the implementation of this method should be similar to the cells used in the method using individual cells, and represent, for example, a population (pool) of sorted B-lymphocytes or T-lymphocytes. When performing one-step multiple RT-PCR with chain extension by overlapping or one-step multiple RT-PCR followed by ligation or recombination in such a population of cells, it is desirable to lyse the cells before the reaction, and total RNA or mRNA can be isolated from the lysate if desired.
Чувствительность одностадийной множественной RT-PCR с удлинением цепи путем перекрывания по настоящему изобретению позволяет использовать очень небольшое количество матрицы. Как показано в примерах 2 и 3, одностадийная множественная RT-PCR с удлинением цепи путем перекрывания может быть выполнена на матрице, количество которой соответствует лизату отдельной клетки.The sensitivity of the one-step multiple RT-PCR with chain extension by overlapping of the present invention allows the use of a very small amount of matrix. As shown in examples 2 and 3, one-step multiple RT-PCR with chain extension by overlapping can be performed on a matrix, the amount of which corresponds to the lysate of a single cell.
Смеси праймеров и их созданиеMixtures of primers and their creation
Смеси праймеров по настоящему изобретению включают по крайней мере четыре праймера, образующих наборы праймеров, содержащие по два праймера в каждом, которые способны амплифицировать по крайней мере две интересующие разные заданные последовательности. Смеси двух или нескольких таких наборов праймеров образуют смесь множественных праймеров. Смесь множественных праймеров, предпочтительно, содержит по крайней мере 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 или 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140 или 150 наборов праймеров (пар праймеров). В частности, для амплификации последовательностей, кодирующих вариабельные области, отдельные наборы праймеров в составе смеси множественных праймеров содержат более двух праймеров. Отдельный набор праймеров, предпочтительно, содержит по крайней мере 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 20, 25, 30, 35, 45, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 220, 240, 260, 280 или 300 праймеров. Общее число праймеров в смеси множественных праймеров, предпочтительно, составляет по крайней мере 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 20, 25, 30, 35, 45, 50, 60, 70, 80, 90, 100, 125, 150 или 200 и самое большее 225, 250, 275, 300, 325, 350, 375 или 400 праймеров.The primer mixtures of the present invention include at least four primers forming primer sets containing two primers in each, which are capable of amplifying at least two different desired sequences of interest. Mixtures of two or more of these sets of primers form a mixture of multiple primers. The mixture of multiple primers preferably contains at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140 or 150 sets of primers (pairs of primers). In particular, for amplification of sequences encoding variable regions, individual sets of primers in a mixture of multiple primers contain more than two primers. A separate set of primers preferably contains at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 20, 25, 30, 35, 45, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 220, 240, 260, 280, or 300 primers. The total number of primers in the multiple primer mixture is preferably at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 20, 25, 30, 35, 45, 50, 60, 70, 80, 90, 100, 125, 150 or 200 and at most 225, 250, 275, 300, 325, 350, 375 or 400 primers.
Все праймеры по настоящему изобретению содержат геноспецифическую область, и, предпочтительно, все праймеры дополнительно имеют концевой сегмент у 5'-конца праймера, то есть 5'-концевые некодирующие последовательности, которые слиты с 3'-концом геноспецифической части праймера. Такой концевой сегмент праймера содержит примерно от 6 до 50 нуклеотидов, но при желании может быть длиннее. В процессе амплификации концевые сегменты праймера присоединяются к заданным последовательностям.All primers of the present invention contain a gene-specific region, and preferably all primers additionally have an end segment at the 5'-end of the primer, i.e. 5'-end non-coding sequences that are fused to the 3'-end of the gene-specific part of the primer. This end segment of the primer contains from about 6 to 50 nucleotides, but may be longer if desired. In the amplification process, the end segments of the primer are attached to predetermined sequences.
Концевые сегменты праймера по настоящему изобретению являются, например, клонирующими и связывающими концевыми сегментами, концевыми сегментами, адаптированными для связывания лигированием, концевыми сегментами, адаптированными для связывания рекомбинацией, или концевыми сегментами удлинения цепи путем перекрывания.The end segments of the primer of the present invention are, for example, cloning and binding end segments, end segments adapted for ligation binding, end segments adapted for recombination binding, or end chain extension segments by overlapping.
Клонирующие концевые сегменты могут содержить 6-20 или большее число нуклеотидов и содержать сайты рестрикции и/или сайты рекомбинации, которые могут использоваться для вставки связанного продукта в соответствущий вектор.Cloning end segments may contain 6-20 or more nucleotides and contain restriction sites and / or recombination sites that can be used to insert the bound product into the corresponding vector.
Для связывания лигированием наборы праймеров в составе смеси множественных праймеров создают таким образом, чтобы одна часть (основной или обратный праймер) первого набора праймеров имела связывающий концевой сегмент, содержащий сайт рестрикции, который при расщеплении должен быть совместим с сайтом рестрикции, расположенным в связывающем концевом сегменте одной части второго набора праймеров. Для связывания более двух заданных последовательностей вторая часть второго набора праймеров содержит сайт рестрикции, который при расщеплении должен быть совместим с сайтом рестрикции, расположенным в одной части третьего набора праймеров. Второй сайт рестрикции, расположенный во втором наборе праймеров, должен быть несовместим с вышеуказанным сайтом рестрикции первого набора праймеров. Благодаря подобному созданию наборов праймеров можно связать значительное число заданных последовательностей. В заданных последовательностях должны быть выбраны редко встречающиеся или вообще отсутствующие сайты рестрикции. Кроме того, желательно, чтобы совместимые сайты рестрикции не были идентичными, чтобы сайт лигирования был устойчив к расщеплению определенными используемыми рестрикционными ферментами. Благодаря этому реакция должна быть направлена на связывание первой заданной последовательности со второй заданной последовательностью, так как связь между идентичными заданными последовательностями будет расщепляться рестрикционными ферментами. Приемлемыми парами сайтов рестрикции являются, например, SpeI и XbaI (альтернативно NheI или AvrII могут заменять один или оба указанных фермента), NcoI и BspHI, EcoRI и MfeI или PstI и NsiI. Для осуществления связывания SpeI может находиться, например, в первой заданной последовательности, XbaI может находиться во второй заданной последовательности, NcoI может находиться у другого конца второй заданной последовательности, BsрHI может находиться в третьей заданной последовательности и так далее. Для дальнейшего облегчения процесса желательно использовать указанные рестрикционные ферменты в одном буфере.For ligation binding, primer sets in a multiple primer mixture are designed so that one part (primary or reverse primer) of the first set of primers has a binding end segment containing a restriction site, which, when cleaved, must be compatible with the restriction site located in the binding end segment one part of the second set of primers. To bind more than two given sequences, the second part of the second set of primers contains a restriction site, which upon cleavage must be compatible with the restriction site located in one part of the third set of primers. The second restriction site located in the second set of primers must not be compatible with the above restriction site of the first set of primers. Due to the similar creation of primer sets, a significant number of given sequences can be linked. In predetermined sequences, rare or non-existent restriction sites should be selected. In addition, it is desirable that the compatible restriction sites are not identical, that the ligation site is resistant to cleavage by the specific restriction enzymes used. Due to this, the reaction should be aimed at linking the first given sequence with the second given sequence, since the connection between identical given sequences will be cleaved by restriction enzymes. Suitable pairs of restriction sites are, for example, SpeI and XbaI (alternatively, NheI or AvrII can replace one or both of these enzymes), NcoI and BspHI, EcoRI and MfeI, or PstI and NsiI. For binding, SpeI may be, for example, in the first predetermined sequence, XbaI may be in the second predetermined sequence, NcoI may be at the other end of the second predetermined sequence, BspHI may be in the third predetermined sequence, and so on. To further facilitate the process, it is desirable to use these restriction enzymes in one buffer.
Для связывания рекомбинацией наборы праймеров в смеси множественных праймеров могут быть, например, созданы в соответствии с описанием, приведенным в статье Чапала (Chapal, 1997, Bio Techniques 23, 518-524), которая включена в данное описание изобретения в качестве ссылки.For recombination binding, primer sets in a mixture of multiple primers can, for example, be designed as described in Chapal (1997,
Для связывания интересующих нуклеотидных последовательностей на одной стадии с амплификацией методом множественной PCR по крайней мере к одному праймеру в каждом наборе праймеров смеси множественных праймеров добавляют концевые сегменты, адаптированные для PCR с удлинением цепи путем перекрывания, в результате чего получают смесь множественных праймеров для удлинения цепи путем перекрывания.To link the nucleotide sequences of interest in one step with multiple PCR amplification, end segments adapted for PCR with chain extension by overlapping are added to at least one primer in each set of primers, resulting in a mixture of multiple primers for chain extension by overlapping.
Концевые сегменты удлинения цепи путем перекрывания обычно являются более длинными, включая от 8 до 75 нуклеотидов, и могут содержать сайты рестрикции или сайты рекомбинации, которые обеспечивают последующую вставку регуляторных элементов, таких как промоторы, сайты связывания рибосом, терминирующие последовательности или линкерные последовательности, как, например, в scFv. Концевой сегмент удлинения цепи путем перекрывания может также при желании содержать терминирующий кодон. Обычно существуют три типа концевых сегментов удлинения цепи путем перекрывания, как показано на фиг.1. Концевые сегменты удлинения цепи путем перекрывания типа I в двух наборах праймеров перекрывают только друг друга. Все нуклеотиды двух концевых сегментов удлинения цепи путем перекрывания необязательно являются комплементарными друг другу. В соответствии с одним объектом настоящего изобретения комплементарные нуклеотиды составляют 60-85% концевого сегмента удлинения цепи путем перекрывания. В концевых сегментах удлинения цепи путем перекрывания типа II 4-6 5'-концевых нуклеотидов являются комплементарными геноспецифической области смежной заданной последовательности. В концевых сегментах удлинения цепи наложением типа III все перекрывающие нуклеотиды являются комплементарными смежной заданной последовательности. Концевые сегменты удлинения цепи путем перекрывания типа I и II являются предпочтительными при последующем введении регуляторных и подобных элементов между связанными заданными последовательностями. Концевые сегменты удлинения цепи путем перекрывания типа II являются предпочтительными, если заданные последовательности должны быть связаны определенным линкером, как это имеет место в случае scFv. Концевые сегменты удлинения цепи путем перекрывания типа III являются предпочтительными, если заданные последовательности должны быть связаны друг с другом в рамке считывания.The overlapping end segments of the chain extension are usually longer, including from 8 to 75 nucleotides, and may contain restriction sites or recombination sites that allow subsequent insertion of regulatory elements, such as promoters, ribosome binding sites, termination sequences or linker sequences, such as for example in scFv. The end segment of chain extension by overlapping may also optionally comprise a termination codon. Typically, there are three types of end segments of chain extension by overlapping, as shown in FIG. The end segments of the chain extension by overlapping type I in two sets of primers overlap only each other. All nucleotides of the two terminal segments of chain extension by overlapping are not necessarily complementary to each other. In accordance with one aspect of the present invention, complementary nucleotides comprise 60-85% of the end segment of chain extension by overlapping. In the terminal segments of chain extension by overlapping type II, the 4-6 5'-terminal nucleotides are complementary to the gene-specific region of an adjacent predetermined sequence. In the terminal segments of chain extension by type III overlay, all overlapping nucleotides are complementary to an adjacent predetermined sequence. End segments of chain extension by overlapping type I and II are preferable in the subsequent introduction of regulatory and similar elements between related predetermined sequences. End segments of chain extension by type II overlapping are preferred if the desired sequences are to be linked by a specific linker, as is the case with scFv. End segments of chain extension by type III overlapping are preferred if predetermined sequences are to be linked together in a reading frame.
Создание концевых сегментов удлинения цепи путем перекрывания зависит от отличительных признаков последователности, таких как длина, относительное содержание GC (GC%), наличие сайтов рестрикции, палиндромы, температура плавления, геноспецифическая часть, с которой они связаны, и т.д. Длина концевых сегментов удлинения цепи путем перекрывания должна быть равна 8-75 нуклеотидам, предпочтительно 15-40 нуклеотидам. Длина таких сегментов еще предпочтительнее равна 22-28 нуклеотидам. Использование очень длинных концевых сегментов удлинения цепи путем перекрывания (50-75 нуклеотидов) может способствовать связыванию продуктов, продуцированных каждым набором праймеров. Однако при использовании очень длинных концевых сегментов удлинения цепи путем перекрывания необходимо отрегулировать соотношение между длиной концевого сегмента удлинения цепи путем перекрывания и геноспецифической областью. Выбор значения GC% зависит от длины концевого сегмента удлинения цепи путем перекрывания. Так как более короткие концевые сегменты имеют меньшую площадь, то в тех случаях, когда они являются комплементарными, необходимо более высокое значение GC% для усиления взаимодействия, чем при использовании более длинных концевых сегментов. Необходимо соблюдать другие принципы создания праймеров, например, следует мининизировать димеризацию праймеров и образование “шпилек”. Праймеры не должны вызывать ложную инициацию. Кроме того, известно, что Taq ДНК-полимераза часто добавляет аденозин (А) к 3'-концу только что синтезированной цепи ДНК, и это должно быть учтено при создании концевого сегмента удлинения цепи путем перекрывания путем адаптации концевых сегментов удлинения цепи путем перекрывания к нематричному добавлению аденозина к 3'-концу.The creation of end segments of chain elongation by overlapping depends on the distinguishing features of the sequence, such as length, relative GC content (GC%), the presence of restriction sites, palindromes, the melting point, the gene-specific part with which they are associated, etc. The length of the end segments of chain extension by overlapping should be 8-75 nucleotides, preferably 15-40 nucleotides. The length of such segments is even more preferably 22-28 nucleotides. The use of very long end segments of chain extension by overlapping (50-75 nucleotides) can facilitate the binding of products produced by each set of primers. However, when using very long end segments of chain extension by overlapping, it is necessary to adjust the ratio between the length of the end segment of chain extension by overlapping and the genespecific region. The choice of GC% depends on the length of the end segment of the chain extension by overlapping. Since shorter end segments have a smaller area, in those cases when they are complementary, a higher GC% value is needed to enhance the interaction than when using longer end segments. Other principles for creating primers must be observed, for example, dimerization of primers and the formation of hairpins should be minimized. Primers should not cause false initiation. In addition, it is known that Taq DNA polymerase often adds adenosine (A) to the 3'-end of a newly synthesized DNA strand, and this should be taken into account when creating the end segment of chain extension by overlapping by adapting the end segments of chain extension by overlapping to non-matrix adding adenosine to the 3'-end.
Выбор праймеров, несущих связывающий концевой сегмент, например концевой сегмент удлинения цепи путем перекрывания, концевой сегмент, адаптированный для связывания лигированием, или концевой сегмент, адаптированный для связывания рекомбинацией, определяет порядок и направление связывания заданных последовательностей. Для настоящего изобретения неважно, являются ли праймеры, имеющие связывающий концевой сегмент, основными или обратными праймерами в наборе праймеров или, возможно, как верхними, так и нижними праймерами. Однако данному вопросу необходимо уделить внимание, так как порядок и направление заданных последовательностей в конечном продукте может иметь определенное значение, например, для вставки регуляторных элементов, таких как промоторы и терминирующие последовательности, или для связывания отдельных заданных последовательностей внутри рамки считывания.The choice of primers carrying a binding end segment, for example, an end segment of chain extension by overlapping, an end segment adapted for ligation binding, or an end segment adapted for recombination binding determines the order and direction of binding of the desired sequences. For the present invention, it is unimportant whether the primers having the connecting end segment are the main or reverse primers in the primer set, or possibly both the upper and lower primers. However, attention needs to be paid to this issue, since the order and direction of the given sequences in the final product may have a certain value, for example, for inserting regulatory elements, such as promoters and termination sequences, or for linking individual given sequences within the reading frame.
Для связывания двух интересующих нуклеотидных последовательностей связывающий концевой сегмент может быть добавлен к обратным или основным праймерам в каждом наборе праймеров, используемом для амплификации методом PCR каждой заданной последовательности. В настоящем изобретении описано добавление концевых сегментов удлинения цепи путем перекрывания и концевых сегментов, адаптированных для связывания лигированием, к основным праймерам для VН и VL в каждом наборе (см. соответственно фиг.1 и пример 9). В данном случае связывание продуктов происходит в направлении от 5'-конца к 5'-концу (головной сегмент с головным сегментом и двунаправленное связывание). Однако связывающие концевые сегменты могут быть также добавлены к обратным праймерам в каждом наборе (например, праймеры для Ск и/или Сλ в первом наборе и праймеры для СH или JH во втором наборе). В данном случае связывание продуктов происходит в направлении от 3'-конца к 3'-концу (концевой сегмент с концевым сегментом и двунаправленное связывание). Третьим вариантом является добавление связывающих концевых сегментов к обратным праймерам в первом наборе праймеров (например, праймеры для Ск и/или Сλ) и к основным праймерам во втором наборе праймеров (например, праймеры для VН) или наоборот. Таким образом, получают ориентацию в направлении от 3'-конца к 5'-концу (головной сегмент с концевым сегментом и однонаправленное связывание). На фиг.3 показаны возможные направления, которые могут быть получены в зависимости от того, какие праймеры в каждом наборе праймеров имеют связывающий концевой сегмент.To bind the two nucleotide sequences of interest, a binding end segment can be added to the reverse or main primers in each set of primers used for PCR amplification of each given sequence. The present invention describes the addition of end segments of chain extension by overlapping and end segments adapted for ligation binding to the main primers for V H and V L in each set (see, respectively, FIG. 1 and Example 9). In this case, the binding of products occurs in the direction from the 5'-end to the 5'-end (the head segment with the head segment and bidirectional binding). However, the binding end segments can also be added to the reverse primers in each set (for example, primers for C to and / or C λ in the first set and primers for C H or J H in the second set). In this case, the binding of products occurs in the direction from the 3'-end to the 3'-end (end segment with end segment and bidirectional binding). A third option is to add the binding end segments to the reverse primers in the first set of primers (e.g., primers for C to and / or C λ ) and to the main primers in the second set of primers (e.g., primers for V H ) or vice versa. In this way, an orientation is obtained in the direction from the 3'-end to the 5'-end (head segment with end segment and unidirectional binding). Figure 3 shows the possible directions that can be obtained depending on which primers in each set of primers have a connecting end segment.
При связывании более двух интересующих нуклеотидных последовательностей в некоторых наборах праймеров связывающие концевые сегменты должны быть как у основных, так и у обратных праймеров, при этом один концевой сегмент является комплементарным концевому сегменту предшествующего набора праймеров и другой концевой сегмент является комплементарным одному из праймеров в последующем наборе праймеров. Этот принцип должен соблюдаться в отношении всех наборов праймеров, служащих для амплификации заданных последовательностей, предназначенных для связывания между двумя другими заданными последовательностями.When more than two nucleotide sequences of interest are linked in some primer sets, the binding end segments must be on both the primary and reverse primers, with one end segment being complementary to the end segment of the previous set of primers and the other end segment being complementary to one of the primers in the subsequent set primers. This principle must be observed for all sets of primers used to amplify given sequences, designed to bind between two other given sequences.
При создании геноспецифической части праймера обычно необходимо соблюдать известные правила создания праймеров, такие как минимизация димеризации праймеров, образования “шпилек” и неспецифической гибридизации. Кроме того, по возможности необходимо избегать нескольких нуклеотидов G и С в качестве основы 3'-конца. Температура плавления (Тm) геноспецифических областей в наборе праймеров предпочтительно должна быть одинаковой плюс/минус 5°С. В настоящем изобретении желательны значения Тm в интервале от 45°С до 75°С, при этом для большинства применений оптимальными являются значения Тm около 60°С. Праймер может быть первоначально создан при помощи компьютерных программ, разработанных для выполнения данной задачи. Однако созданные праймеры обычно требуют лабораторной проверки и оптимизации. Такую проверку можно произвести, анализируя размер и полиморфизм длины рестрикционных фрагментов (RFLP) и секвенируя продукты амплификации, полученные с использованием созданных наборов праймеров. Можно успешно использовать вырожденные положения в праймерах для амплификации последовательностей с вариабельными областями или для поиска новых членов семейства, относящихся к установленному классу белков. Число вырожденных положений может также потребовать оптимизации.When creating a gene-specific part of a primer, it is usually necessary to follow known rules for creating primers, such as minimizing dimerization of primers, formation of hairpins, and nonspecific hybridization. In addition, if possible, several nucleotides G and C should be avoided as the basis of the 3'-end. The melting temperature (Tm) of the gene-specific regions in the primer set should preferably be the same plus / minus 5 ° C. In the present invention, Tm values in the range of 45 ° C to 75 ° C are desirable, with Tm values of about 60 ° C being optimal for most applications. The primer can be initially created using computer programs designed to perform this task. However, primers created usually require laboratory testing and optimization. Such a check can be performed by analyzing the size and length polymorphism of restriction fragments (RFLP) and sequencing amplification products obtained using the created sets of primers. It is possible to successfully use degenerate positions in primers to amplify sequences with variable regions or to search for new family members belonging to an established class of proteins. The number of degenerate positions may also require optimization.
Настоящее изобретение относится к усовершенствованным наборам праймеров, которые могут быть использованы вместе в очень сложной смеси. В качестве основы был использован набор праймеров, описанный в публикации de Haard (de Haard, H.J. et al., 1999, J. Biol. Chem. 274, 18218-18230), который был модифицирован путем обрезки 3'-концов праймеров для уменьшения неспецифических взаимодействий и добавления концевых сегментов удлинения цепи путем перекрывания или концевых сегментов, адаптированных для связывания лигированием.The present invention relates to improved sets of primers that can be used together in a very complex mixture. The primer set used was the one described in de Haard (de Haard, HJ et al., 1999, J. Biol. Chem. 274, 18218-18230), which was modified by trimming the 3 ′ ends of the primers to reduce non-specific interactions and adding end segments of chain extension by overlapping or end segments adapted for ligation binding.
Одним из отличительных признаков настоящего изобретения являются смеси праймеров, состоящие по крайней мере из двух наборов праймеров, способных инициировать амплификацию и стимулировать связывание по крайней мере двух интересующих нуклеотидных последовательностей. Смеси праймеров по настоящему изобретению могут инициировать амплификацию по крайней мере двух субъединиц или доменов в гетеромерных белках, например, относящихся к классу ферментов, ингибиторов, структурных белков, токсинов, каналообразующих белков, G-белков, рецепторных белков, белков надсемейства иммуноглобулинов, транспортирующих белков и т.д.One of the distinguishing features of the present invention are primer mixtures consisting of at least two sets of primers capable of initiating amplification and stimulating the binding of at least two nucleotide sequences of interest. The primer mixtures of the present invention can initiate the amplification of at least two subunits or domains in heteromeric proteins, for example, belonging to the class of enzymes, inhibitors, structural proteins, toxins, channel-forming proteins, G-proteins, receptor proteins, immunoglobulin superfamily proteins, transporting proteins and etc.
Другим отличительным признаком настоящего изобретения является смесь множественных праймеров для удлинения цепи путем перекрывания, включающая наборы праймеров, в которых по крайней мере один праймер в каждом наборе праймеров имеет концевой сегмент удлинения цепи путем перекрывания, способный гибридизировать с концевым сегментом удлинения цепи путем перекрывания одного праймера в другом наборе праймеров.Another feature of the present invention is a mixture of multiple primers for elongation of the chain by overlapping, comprising sets of primers in which at least one primer in each set of primers has an end segment of chain extension by overlapping capable of hybridizing with the end segment of chain extension by overlapping one primer in another set of primers.
Концевые сегменты удлинения цепи путем перекрывания делают возможным немедленное связывание интересующих нуклеотидов в процессе амплификации методом множественной PCR с удлинением цепи путем перекрывания благодаря тому, что к каждому продукту, образующемуся при помощи наборов праймеров, добавляется концевой сегмент, комплементарный присоединяемому продукту. Из вышеизложенного, однако, не следует, что связывание обязательно произойдет во время первой амплификации методом PCR. В зависимости от характера реакции большая часть фактического связывания может произойти во время дополнительной амплификации при помощи внешних праймеров, используемых в первой амплификации методом PCR (амплификация методом множественной PCR).The end segments of chain extension by overlapping make it possible to immediately bind nucleotides of interest during amplification by the multiple PCR method with chain extension by overlapping, because an end segment complementary to the attached product is added to each product formed using primer sets. However, it does not follow from the foregoing that binding will necessarily occur during the first PCR amplification. Depending on the nature of the reaction, most of the actual binding can occur during additional amplification using external primers used in the first PCR amplification (multiple PCR amplification).
Другим отличительным признаком настоящего изобретения является набор праймеров, предназначенный для амплификации семейства нуклеотидных последовательностей, содержащих последовательности, кодирующие вариабельные области. Примерами таких семейств являются легкие каппа-цепи (например, VKI-VI у человека), легкие лямбда-цепи (например, VL1-10 у человека) и вариабельные области тяжелых цепей (например, VH1-7 у человека и VH1-15 у мышей) иммуноглобулинов, а также варибельные области α-, β-, γ- или δ-цепей ТсR. Набор праймеров для амплификации семейства нуклеотидных последовательностей, содержащих последовательности, кодирующие вариабельные области, часто включает несколько праймеров, часть которых может быть вырожденными праймерами. Амплификацию последовательностей, кодирующих вариабельные области легкой цепи семейств иммуноглобулинов, например, выполняют при помощи набора праймеров, содержащего несколько праймеров, комплементарных 5'-концу вариабельной области каппа-цепи (праймера для VLк), или лидерной последовательности каппа-цепи (праймер для VLкL) и/или лямбда-цепи (праймер для VLλ), или лидерной последовательности лямбда-цепи (праймер для VLλL) (основные праймеры), вместе с несколькими праймерами для константной области каппа-цепи (праймер для Ск) и/или лямбда-цепи (праймер для Сλ) (обратные праймеры). Альтернативно праймеры для соединительной области легкой цепи (праймеры для JLк и/или JLλ) можно использовать в качестве обратных праймеров вместо праймеров для константной области. Альтернативно основные праймеры гибридизируют с областью UTR, предшествующей лидерной последовательности вариабельной области легкой цепи. Последовательности, кодирующие вариабельную область тяжелой цепи семейств иммуноглобулинов, могут быть также амплифицированы при помощи одного набора праймеров с использованием разных комбинаций праймеров. Например, несколько праймеров, комплементарных 5'-концу вариабельной области тяжелой цепи (праймер для VН) или лидерной последовательности данной области (праймер для VHL) (основные праймеры), можно использовать вместе с несколькими праймерами для соединительной области тяжелой цепи (праймер для JН) или праймерами для константной области тяжелой цепи (обратные праймеры). Праймер для СН может быть изотип-специфическим, и в принципе можно использовать любой праймер для СН (например, СН1, СН2, СН3 или СН4), а также праймер, который позволит получить непроцессированную тяжелую цепь. Альтернативно, основные праймеры гибридизируют с областью UTR, предшествующей лидерной последовательности вариабельной области тяжелой цепи.Another hallmark of the present invention is a set of primers designed to amplify a family of nucleotide sequences containing sequences encoding variable regions. Examples of such families are light kappa chains (e.g., VKI-VI in humans), light lambda chains (e.g., VL1-10 in humans) and variable regions of heavy chains (e.g., VH1-7 in humans and VH1-15 in mice ) immunoglobulins, as well as the variable regions of the α-, β-, γ- or δ-chains of TcR. A set of primers for amplifying a family of nucleotide sequences containing sequences encoding variable regions often includes several primers, some of which may be degenerate primers. Amplification of sequences encoding the variable regions of the light chain of immunoglobulin families, for example, is performed using a set of primers containing several primers complementary to the 5 ′ end of the variable region of the kappa chain (primer for V Lc ) or the leader sequence of the kappa chain (primer for V LкL ) and / or lambda chains (primer for V Lλ ), or the leader sequence of a lambda chain (primer for V LλL ) (main primers), together with several primers for the constant region of the kappa chain (primer for C to ) and / or lambda-ts epi (primer for C λ ) (reverse primers). Alternative primers for the connecting region of the light chain (primers for J LK and / or J Lλ ) can be used as reverse primers instead of primers for the constant region. Alternatively, the main primers hybridize to the UTR region preceding the leader sequence of the light chain variable region. The sequences encoding the variable region of the heavy chain of the families of immunoglobulins can also be amplified using one set of primers using different combinations of primers. For example, several primers complementary to the 5'-end of the variable region of the heavy chain (primer for V H ) or the leader sequence of this region (primer for V HL ) (main primers) can be used together with several primers for the connecting region of the heavy chain (primer for J H ) or primers for the constant region of the heavy chain (reverse primers). The primer for C H can be isotype-specific, and in principle, any primer for C H (for example, C H1 , C H2 , C H3 or C H4 ), as well as a primer that allows an unprocessed heavy chain, can be used. Alternatively, the main primers hybridize to the UTR region preceding the leader sequence of the heavy chain variable region.
Использование основных праймеров, гибридизирующих с лидерной последовательностью вместо 5'-конца вариабельной области, является особенно полезным при обнаружении перекрестной гибридизации праймеров для вариабельной области, так как мутации, возникающие вследствие перекрестной гибридизации, будут удалены из конечного белка вследствие отщепления лидерных последовательностей во время процессинга белка внутри клетки. В примере 9 описано создание праймеров для лидерных последовательностей вариабельной области тяжелой цепи и легкой каппа-цепи антитела. То, что сайт инициации находится в 3'-конце последовательности, кодирующей лидерную последовательность (С-концевая), является преимуществом по сравнению с ранее известными праймерами для лидерной последовательности антитела, так как это позволяет переносить амплифицированные последовательности между бактериальными и эукариотическими экспрессирующими векторами с получением функциональных лидерных последовательностей в обеих системах. Система, описанная в примере 9, может быть легко применена к легким лямбда-цепям антитела, а также к α-, β-, γ- или δ-цепям ТсR.The use of basic primers hybridizing with a leader sequence instead of the 5'-end of the variable region is especially useful in detecting cross hybridization of primers for the variable region, since mutations resulting from cross hybridization will be removed from the final protein due to cleavage of the leader sequences during protein processing inside the cell. Example 9 describes the creation of primers for leader sequences of the variable region of the heavy chain and light Kappa chain of the antibody. The fact that the initiation site is located at the 3'-end of the sequence encoding the leader sequence (C-terminal) is an advantage compared to previously known primers for the leader sequence of antibodies, as this allows you to transfer amplified sequences between bacterial and eukaryotic expression vectors to obtain functional leader sequences in both systems. The system described in Example 9 can be easily applied to the light lambda chains of an antibody, as well as to the TcR α, β, γ, or δ chains.
Одним из отличительных признаков настоящего изобретения являются праймеры, гибридизирующие c 3'-концом последовательности, кодирующей лидерную последовательность, которая предшествует последовательности, кодирующей вариабельную область, и их применение для амплификации последовательностей, кодирующих вариабельные области.One of the distinguishing features of the present invention are primers hybridizing to the 3'-end of a sequence encoding a leader sequence that precedes a sequence encoding a variable region, and their use for amplifying sequences encoding variable regions.
Предпочтительным отличительным признаком настоящего изобретения является применение праймеров, характеризующихся по крайней мере 90% идентичностью последовательностей (предпочтительно по крайней мере 95% идентичностью) с геноспецифической областью SEQ ID NO:86-92, которые соответствуют праймерам, гибридизирующим с С-концом последовательностей, кодирующих лидерную последовательность тяжелой цепи (праймер для VHL). Геноспецифическая последовательность указанных SEQ ID NO соответствует 18-му основанию в направлении 3'-конца указанных последовательностей (см. также таблицу 11).A preferred feature of the present invention is the use of primers characterized by at least 90% sequence identity (preferably at least 95% identity) with a gene-specific region of SEQ ID NOS: 86-92, which correspond to primers hybridizing to the C-terminus of leader coding sequences heavy chain sequence (primer for V HL ). The gene-specific sequence of these SEQ ID NOs corresponds to the 18th base in the direction of the 3'-end of these sequences (see also table 11).
Другим предпочтительным отличительным признаком настоящего изобретения является применение праймеров, характеризующихся по крайней мере 90% идентичностью последовательностей (предпочтительно по крайней мере 95% идентичностью) с геноспецифической областью SEQ ID NO:93-98, которые соответствуют праймерам, гибридизирующим с С-концом последовательностей, кодирующих лидерные последовательности легкой каппа-цепи (праймер для VLкL). Геноспецифическая последовательность указанных SEQ ID NO соответствует 25-му основанию в направлении 3'-конца указанных последовательностей (см. также таблицу 11).Another preferred feature of the present invention is the use of primers characterized by at least 90% sequence identity (preferably at least 95% identity) with a gene-specific region of SEQ ID NOS: 93-98, which correspond to primers hybridizing to the C-terminus of coding sequences leader sequences of the light Kappa chain (primer for V LkL ). The gene-specific sequence of these SEQ ID NOs corresponds to the 25th base in the direction of the 3'-end of these sequences (see also table 11).
В одном варианте осуществления настоящего изобретения смесь множественных праймеров для удлинения цепи путем перекрывания, используемая для выполнения множественной PCR с удлинением цепи путем перекрывания и, возможно, для осуществления стадии обратной транскрипции, включает также а) по крайней мере один праймер для CL или JL, комплементарный смысловой цепи последовательности, кодирующей область легкой цепи иммуноглобулина; b) по крайней мере один 5'-концевой праймер для VL или праймер для лидерной последовательности VL, комплементарный антисмысловой цепи последовательности, кодирующей вариабельную область легкой цепи иммуноглобулина, и способный образовывать набор праймеров с праймерами по пункту а); с) по крайней мере один праймер для СH или JH, комплементарный смысловой цепи последовательности, кодирующей константный домен тяжелой цепи иммуноглобулина или соединительной области тяжелой цепи; и d) по крайней мере один 5'-концевой праймер для VH или праймер для лидерной последовательности VH, комплементарный антисмысловой цепи последовательности, кодирующей вариабельную область тяжелой цепи иммуноглобулина, и способный образовывать набор праймеров с праймерами по пункту с).In one embodiment of the present invention, a mixture of multiple primers for overlapping strand extension used to perform multiple strand overlapping PCRs and possibly for the reverse transcription step also includes a) at least one primer for C L or J L complementary to the sense strand of a sequence encoding an immunoglobulin light chain region; b) at least one 5'-terminal primer for V L or a primer for the leader sequence V L , complementary to the antisense strand of the sequence encoding the variable region of the immunoglobulin light chain, and capable of forming a set of primers with primers according to paragraph a); c) at least one primer for C H or J H complementary to the sense strand of the sequence encoding the constant domain of an immunoglobulin heavy chain or heavy chain connecting region; and d) at least one 5'-terminal primer for V H or a primer for the V H leader sequence complementary to the antisense strand of a sequence encoding the variable region of an immunoglobulin heavy chain and capable of forming a primer set with primers according to c).
Наборы праймеров по настоящему изобретению, например, могут представлять собой VLк + Cк, VLλ + Cλ, VLк + JLк, VLλ + JLλ, VLкL + Cк, VLλL + Cλ, VLкL + JLк, VLλL + JLλ, VH + JH, VH + CH, VHL + JН, VHL + CН или их комбинации, способные амплифицировать заданную последовательность, кодирующую вариабельную область.The primer sets of the present invention, for example, can be V Lk + C k , V Lλ + C λ , V Lk + J Lk , V Lλ + J Lλ , V LkL + C k, V LλL + C λ , V LkL + J Lк , V LλL + J Lλ , V H + J H , V H + C H , V HL + J H , V HL + C H, or combinations thereof capable of amplifying a given sequence encoding a variable region.
В другом варианте осуществления изобретения использованы праймеры для СL (JL) и праймеры для VL (VLL), адаптированные для амплификации последовательностей, включающих вариабельные области легкой каппа-цепи или вариабельные области легкой лямбда-цепи.In another embodiment, primers for C L (J L ) and primers for V L (V LL ) are used, adapted to amplify sequences comprising variable regions of the light Kappa chain or variable regions of the light lambda chain.
В предпочтительном варианте осуществления настоящего изобретения использованы праймеры для CL (JL) и праймеры для VL (VLL), адаптированные для амплификации последовательностей, кодирующих вариабельные области как легких каппа-цепей, так и легких лямбда-цепей.In a preferred embodiment of the present invention, primers for C L (J L ) and primers for V L (V LL ) are used, adapted to amplify sequences encoding the variable regions of both light kappa chains and light lambda chains.
В еще более предпочтительном варианте осуществления настоящего изобретения использованы основные праймеры для амплификации легких цепей VLL, характеризующиеся по крайней мере 90% идентичностью последовательностей (предпочтительно по крайней мере 95% идентичностью) с геноспецифической областью SEQ ID NO:93-98, и основные праймеры для амплификации тяжелых цепей VHL, характеризующиеся по крайней мере 90% идентичностью (предпочтительно по крайней мере 95% идентичностью) с геноспецифической областью SEQ ID NO:86-92.In an even more preferred embodiment of the present invention, primary primers for amplification of V LL light chains are used, characterized by at least 90% sequence identity (preferably at least 95% identity) with the gene-specific region of SEQ ID NOS: 93-98, and basic primers for amplification of the heavy chains of V HL , characterized by at least 90% identity (preferably at least 95% identity) with the gene-specific region of SEQ ID NO: 86-92.
В другом варианте осуществления настоящего изобретения праймеры для VL/VLL и VH/VHL иммуноглобулина имеют связывающие концевые сегменты, предпочтительно в форме комплементарных концевых сегментов удлинения цепи путем перекрывания. Указанные праймеры позволяют получить последовательности, кодирующие вариабельные области, которые связаны в направлении “головной сегмент - головной сегмент”. Для связывания последовательностей, кодирующих вариабельные области, в направлении “головной сегмент - концевой сегмент” праймеры для CL/JL и VH/VHL содержат связывающие концевые сегменты или праймеры для VL/VLL и CH/JH содержат связывающие концевые сегменты предпочтительно в форме комплементарных концевых сегментов удлинения цепи путем перекрывания. Для связывания последовательностей, кодирующих вариабельные области, в направлении “концевой сегмент - концевой сегмент” праймеры для CL/JL и CH/JH имеют связывающие концевые сегменты предпочтительно в форме комплементарных концевых сегментов удлинения цепи путем перекрывания (фиг.3).In another embodiment of the present invention, the primers for V L / V LL and V H / V HL of immunoglobulin have binding end segments, preferably in the form of complementary overlapping end segments of the chain. The indicated primers make it possible to obtain sequences coding for variable regions that are linked in the direction “head segment - head segment”. To bind sequences encoding the variable regions in the “head segment - end segment” direction, the primers for C L / J L and V H / V HL contain binding end segments or the primers for V L / V LL and C H / J H contain binding end segments are preferably in the form of complementary end segments of chain extension by overlapping. To bind sequences encoding the variable regions in the “end segment - end segment” direction, the primers for C L / J L and C H / J H have binding end segments, preferably in the form of complementary end extension segments by overlapping (FIG. 3).
Смеси множественных праймеров, в том числе смеси множественных праймеров для удлинения цепи путем перекрывания по настоящему изобретению, включают два набора праймеров. Таким образом, смесь множественных праймеров включает по крайней мере четыре разных праймера. В соответствии с другим объектом настоящего изобретения смесь множественных праймеров включает более четырех разных праймеров. Смесь множественных праймеров по настоящему изобретению используют для амплификации заданных последовательностей в одном сосуде. Например, в одном сосуде можно амплифицировать все вариабельные области каппа-, лямбда-цепей и тяжелых цепей. Одна смесь множественных праймеров по настоящему изобретению содержала 16 разных вырожденных праймеров, распределенных следующим образом: восемь праймеров для VH, один праймер для СH1, шесть праймеров для VLк и один праймер для Ск (фиг.2). Другой набор праймеров включал 19 вырожденных праймеров, распределенных следующим образом: восемь праймеров для VH, четыре праймера для JH, шесть праймеров для VLк и один праймер для Ск. Третий набор праймеров включал 22 вырожденных праймера, распределенных следующим образом: восемь праймеров для VH, один праймер для СH1, одиннадцать праймеров для VLλ и два праймера для Cλ. Четвертый набор праймеров включал 27 вырожденных праймеров, распределенных следующим образом: восемь праймеров для VH, один праймер для СH1, шесть праймеров для VLк, один праймер для Ск, одиннадцать праймеров для VLλ и два праймера для Сλ.Mixtures of multiple primers, including mixtures of multiple primers for chain extension by overlapping of the present invention, include two sets of primers. Thus, a mixture of multiple primers includes at least four different primers. According to another aspect of the present invention, a multiple primer mixture comprises more than four different primers. A mixture of multiple primers of the present invention is used to amplify desired sequences in a single vessel. For example, in one vessel, all the variable regions of the kappa, lambda chains and heavy chains can be amplified. One mixture of multiple primers of the present invention contained 16 different degenerate primers, distributed as follows: eight primers for V H , one primer for C H1 , six primers for V L k and one primer for C k (FIG. 2). Another set of primers included 19 degenerate primers, distributed as follows: eight primers for V H , four primers for J H , six primers for V L k and one primer for C k . The third set of primers included 22 degenerate primers, distributed as follows: eight primers for V H , one primer for C H1 , eleven primers for V Lλ and two primers for C λ . The fourth set of primers included 27 degenerate primers distributed as follows: eight primers for V H , one primer for C H1 , six primers for V Lк , one primer for C k , eleven primers for V Lλ and two primers for C λ .
Настоящее изобретение относится также к праймерам для дополнительной амплификации методом РCR связанных продуктов, полученных при помощи множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации либо при помощи множественной RT-PCR с удлинением цепи путем перекрывания. Дополнительную амплификацию методом PCR можно выполнить, используя смесь праймеров, адаптированную для амплификации связанных заданных последовательностей. Такая смесь праймеров может содержать внешние праймеры смеси множественных праймеров или смеси множественных праймеров для удлинения цепи путем перекрывания, которые являются праймерами, гибридизирующими с крайним 5'-концом и 3'-концом смысловой цепи связанных нуклеотидных последовательностей, делая возможной амплификацию всего связанного продукта. Одним примером праймеров, которые могут быть использованы в качестве внешних праймеров в настоящем изобретении, являются праймеры для Cк/Jк и/или Сλ/Jλ, образующие набор праймеров с праймерами для JН или СН. Дополнительная амплификация обычно служит для увеличения количества связанного продукта, полученного в результате множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации либо в результате множественной RT-PCR с удлинением цепи путем перекрывания.The present invention also relates to primers for further amplification by the PCR method of coupled products obtained using multiple RT-PCR followed by ligation or recombination, or using multiple RT-PCR with chain extension by overlapping. Additional amplification by PCR can be performed using a mixture of primers adapted to amplify related given sequences. Such a primer mixture may contain external primers of a multiple primer mixture or a mixture of multiple primers to extend the chain by overlapping, which are primers that hybridize to the extreme 5 ′ end and 3 ′ end of the sense strand of the linked nucleotide sequences, making it possible to amplify the entire bound product. One example of primers that can be used as external primers in the present invention are primers for C to / J to and / or C λ / J λ , forming a set of primers with primers for J H or C H. Additional amplification typically serves to increase the amount of bound product resulting from multiple RT-PCR followed by ligation or recombination, or from multiple RT-PCR with chain extension by overlapping.
Альтернативно, для дополнительной амплификации связанных нуклеотидных последовательностей можно использовать набор праймеров, который является гнездовым по сравнению с внешними праймерами, используемыми при выполнении первичной реакции множественной RT-PCR или множественной RT-PCR с удлинением цепи путем перекрывания. В настоящем изобретении такой набор праймеров именуется гнездовым набором праймеров. Гнездовые праймеры обычно создают в соответствии с такими же правилами, что и ранее описанные геноспецифические праймеры, за исключением того, что они инициируют 3'-конец в положении гибридизации внешних праймеров, используемых в множественной RT-PCR или множественной RT-PCR с удлинением цепи путем перекрывания. Поэтому продукт, образующийся в результате выполнения гнездовой PCR, является короче связанного продукта, полученного в результате множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации либо в результате множественной RT-PCR с удлинением цепи путем перекрывания. Помимо увеличения количества связанного продукта гнездовая PCR служит также для повышения общей специфичности, особенно метода множественной RT-PCR с удлинением цепи путем перекрывания. Однако следует отметить, что не все вышеописанные смеси множественных праймеров/смеси множественных праймеров для удлинения цепи путем перекрывания пригодны для использования в комбинации с гнездовым набором праймеров при выполнении дополнительной амплификации. В таких случаях для дополнительной амплификации можно использовать внешние праймеры смеси множественных праймеров/смеси множественных праймеров для удлинения цепи путем перекрывания или выполнить полугнездовую PCR, которая будет описана ниже.Alternatively, for further amplification of the linked nucleotide sequences, a primer set can be used that is nested compared to the external primers used to perform the primary reaction of multiple RT-PCR or multiple RT-PCR with overlapping chain extension. In the present invention, such a set of primers is referred to as a nested set of primers. Nested primers are usually created in accordance with the same rules as the previously described gene-specific primers, except that they initiate the 3'-end in the hybridization position of the outer primers used in multiple RT-PCR or multiple RT-PCR with chain extension by overlapping. Therefore, the product resulting from the execution of the nested PCR is shorter than the bound product obtained from the multiple RT-PCR followed by ligation or recombination, or as a result of multiple RT-PCR with chain extension by overlapping. In addition to increasing the amount of bound product, nested PCR also serves to increase overall specificity, especially the overlap extended RT-PCR method. However, it should be noted that not all of the multiple primer / multiple primer blends described above for extending the chain by overlapping are suitable for use in combination with a nested primer kit when performing additional amplification. In such cases, for further amplification, external primers of the multiple primer mixture / multiple primer mixture can be used to extend the chain by overlapping, or a semi-nested PCR will be performed, which will be described later.
В одном из вариантов осуществления настоящего изобретения в качестве гнездовых праймеров для дополнительной амплификации связанных последовательностей, кодирующих вариабельные области иммуноглобулина, используют праймеры для JL и JH.In one embodiment of the present invention, primers for J L and J H are used as nested primers for further amplification of the linked sequences encoding the variable regions of the immunoglobulin.
Гнездовые наборы праймеров по настоящему изобретению могут также включать обратные (или основные) внешние праймеры из первой смеси множественных праймеров/смеси множественных праймеров для удлинения цепи путем перекрывания и второй гнездовой смеси праймеров, которые инициируют 3'-конец в положении гибридизации основных (или обратных) внешних праймеров первой смеси множественных праймеров/смеси множественных праймеров для увеличения цепи путем перекрывания. Использование такого набора праймеров для дополнительной амплификации методом PCR известно как полугнездовая PCR. Полугнездовая PCR может быть выполнена, например, в том случае, если трудно создать гнездовой праймер в одной специфической области, например, для последовательностей, кодирующих вариабельные области, (праймеры для V и J), так как такой праймер должен гибридизировать с гипервариабельными участками (CDR). Кроме того, полугнездовую PCR можно использовать в тех случаях, когда желательно сохранить интактным один конец связанных последовательностей, например, для клонирования.Socket primer sets of the present invention may also include reverse (or main) external primers from the first multiple primer / multiple primer mixture to extend the chain by overlapping and the second female primer mixture that initiate the 3'-end in the hybridization position of the main (or reverse) external primers of the first mixture of multiple primers / mixture of multiple primers to increase the chain by overlapping. The use of such a set of primers for additional PCR amplification is known as semi-nested PCR. Semi-nested PCR can be performed, for example, if it is difficult to create a nested primer in one specific region, for example, for sequences encoding variable regions (primers for V and J), since such a primer must hybridize with hypervariable regions (CDR ) In addition, semi-nested PCR can be used in cases where it is desirable to keep one end of the linked sequences intact, for example, for cloning.
В соответствии с одним из отличительных признаков настоящего изобретения последовательность, кодирующая константную область легкой цепи, остается интактной в процессе дополнительной амплификации. (Обратные) праймеры для CL, используемые для дополнительной амплификации, лишь незначительно модифицируются по сравнению с внешними праймерами, используемыми для первичной реакции (множественная RT-PCR или множественная RT-PCR с удлинением цепи путем перекрывания). Модификация включает добавление нескольких оснований к 3'-концу праймеров для CL, используемых для первичной амплификации. Кроме того, к гнездовым праймерам для СL может быть добавлен другой клонирующий концевой сегмент. Основные праймеры, используемые для дополнительной амплификации, являются полностью гнездовыми по сравнению с внешними праймерами, специфичными к константной области тяжелой цепи, используемыми в первичной реакции. Объединенное использование внешних праймеров в первичной реакции и незначительно модифицированных гнездовых праймеров для CL вместе с полностью гнездовыми основными праймерами в реакции дополнительной амплификации вызывает увеличение специфичности, сравнимое с достигаемым при выполнении гнездовой PCR с использованием полностью гнездового набора праймеров.In accordance with one of the distinguishing features of the present invention, the sequence encoding the constant region of the light chain remains intact in the process of additional amplification. The (reverse) primers for C L used for additional amplification are only slightly modified compared to the external primers used for the primary reaction (multiple RT-PCR or multiple RT-PCR with chain extension by overlapping). Modification involves the addition of several bases to the 3'-end of the primers for C L used for primary amplification. In addition, another cloning end segment can be added to the nested primers for C L. The main primers used for additional amplification are completely nested compared to external primers specific for the constant region of the heavy chain used in the primary reaction. The combined use of external primers in the primary reaction and slightly modified nested primers for C L together with fully nested primary primers in the additional amplification reaction causes an increase in specificity comparable to that achieved when performing nested PCR using a fully nested primer set.
В предпочтительном варианте осуществления настоящего изобретения гнездовую PCR выполняют с использованием праймеров для JН и модифицированных праймеров для СL, к 3'-концу которых добавляют от 2 до 10 геноспецифических пар оснований по сравнению с первыми праймерами для СL в смеси множественных праймеров/смеси множественных праймеров для удлинения цепи путем перекрывания.In a preferred embodiment of the present invention, nested PCRs are performed using primers for J H and modified primers for C L , to the 2 ′ end of which 2 to 10 gene-specific base pairs are added compared to the first primers for C L in a multiple primer / mixture multiple primers to extend the chain by overlapping.
Оптимизация множественной PCR с удлинением цепи путем перекрыванияOverlapping Multiple PCR Optimization with Overlap
Параметры множественной PCR с удлинением цепи путем перекрывания как в двухстадийном методе, так и в одностадийном методе могут быть оптимизированы в нескольких отношениях (см., например, публикации Henegariu, O. et al. 1997, BioTechniques 23, 504-511; Markoulatos, P. et al. 2002, J. Clin. Lab. Anal. 16, 47-51). Обычно в множественной RT-PCR используют одинаково оптимизированные параметры, хотя соотношение между внешними и внутренними праймерами имеет менее важное значение для такой реакции.The parameters of multiple PCR with chain extension by overlapping in both the two-stage method and the one-stage method can be optimized in several respects (see, for example, publications Henegariu, O. et al. 1997,
а. Концентрация праймеровbut. Primer Concentration
Концентрация праймеров, имеющих концевой сегмент удлинения цепи путем перекрывания (например, праймеры для VН и VL), предпочтительно является ниже концентрации внешних праймеров, не имеющих концевого сегмента удлинения цепи путем перекрывания (например, праймеры для JH и каппа-цепи).The concentration of primers having an end segment of chain extension by overlapping (e.g., primers for V H and V L ) is preferably lower than the concentration of external primers having no end segment of chain extension by overlapping (e.g., primers for J H and kappa chain).
Если одна из заданных последовательностей амплифицируется менее эффективно, чем другие последовательности, например в результате более высокого значения GC%, можно уравновесить эффективность амплификации. Такой результат можно получить, увеличивая концентрацию набора праймеров, которая менее эффективно опосредует амплификацию, или уменьшая концентрацию другого набора праймеров. Например, последовательности, кодирующие вариабельные области тяжелой цепи, характеризуются более высоким значением GC% и, следовательно, более низкой эффективностью амплификации по сравнению с вариабельными областями легкой цепи. Из вышеизложенного следует, что праймер для VL следует использовать в меньшей концентрации, чем праймер для VH.If one of the given sequences amplifies less efficiently than the other sequences, for example, as a result of a higher GC% value, the amplification efficiency can be balanced. This result can be obtained by increasing the concentration of the set of primers, which is less effective in mediating amplification, or by reducing the concentration of another set of primers. For example, sequences encoding the variable regions of the heavy chain are characterized by a higher GC% value and, therefore, lower amplification efficiency compared to the variable regions of the light chain. From the above it follows that the primer for V L should be used in a lower concentration than the primer for V H.
Кроме того, при использовании большого числа праймеров может возникнуть проблема с определением общей концентрации праймеров. Верхний предел определяют экспериментально путем титрования. Для системы PCR “AmpliTaq Gold” компании Applied Biosystems верхний предел концентрации всех олигонуклеотидов установлен равным 1,1 мкМ, хотя для других систем верхний предел может достигать 2,4 мкМ. Такой верхний предел концентрации всех олигонуклеотидов влияет на максимальную концентрацию отдельных праймеров. Слишком низкая концентрация отдельного праймера вызывает плохую чувствительность PCR.In addition, when using a large number of primers, there may be a problem with determining the total concentration of primers. The upper limit is determined experimentally by titration. For the Applied Biosystems AmpliTaq Gold PCR system, the upper concentration limit of all oligonucleotides is set to 1.1 μM, although for other systems the upper limit can reach 2.4 μM. Such an upper limit on the concentration of all oligonucleotides affects the maximum concentration of individual primers. Too low an individual primer concentration causes poor PCR sensitivity.
Было также установлено, что качество олигонуклеотидных праймеров имеет важное значение для множественной PCR с удлинением цепи путем перекрывания. Лучшие результаты были получены при использовании олигонуклеотидов, очищенных ВЭЖХ.It was also found that the quality of oligonucleotide primers is important for multiple overlap-extended PCR. The best results were obtained using oligonucleotides purified by HPLC.
b. Условия циклизации PCRb. PCR cyclization conditions
Условиями циклизации предпочтительно являются нижеследующие значения:The cyclization conditions are preferably the following values:
Для одностадийной множественной RT-PCR с удлинением цепи путем перекрывания в программу циклизации были введены нижеследующие стадии до вышеуказанной циклизации амплификации:For one-step multiple RT-PCR with chain extension by overlapping, the following steps were introduced into the cyclization program prior to the above amplification cyclization:
Все вышеуказанные параметры можно оптимизировать. Особенно важное значение имеет температура гибридизации. Таким образом, все отдельные наборы праймеров, которые должны образовать конечную смесь праймеров, необходимо испытать отдельно, чтобы установить оптимальную температуру и время гибридизации, а также время элонгации и денатурации. Благодаря этому будет определен диапазон, внутри которого указанные параметры могут быть оптимизированы для смеси множественных праймеров для удлинения цепи путем перекрывания.All the above parameters can be optimized. Of particular importance is the temperature of hybridization. Thus, all individual sets of primers that should form the final primer mixture must be tested separately to establish the optimum temperature and hybridization time, as well as elongation and denaturation times. This will determine the range within which these parameters can be optimized for a mixture of multiple primers to extend the chain by overlapping.
Проблемы, связанные с плохой чувствительностью PCR, например, вследствие низкой концентрации праймеров или матрицы можно преодолеть, используя большое число тепловых циклов. Большое число тепловых циклов включает 35-80 циклов, предпочтительно около 40 циклов.Problems associated with poor PCR sensitivity, for example, due to the low concentration of primers or template can be overcome using a large number of thermal cycles. A large number of thermal cycles include 35-80 cycles, preferably about 40 cycles.
Кроме того, более продолжительное время удлинения цепи может повысить эффективность множественной PCR с удлинением цепи путем перекрывания. Продолжительное время удлинения цепи равно 1,5-4 минутам х EPL по сравнению с нормальным временем удлинения цепи, равным 1 минуте.In addition, longer chain extension times can increase the efficiency of multiple overlapping PCRs with chain extension. The long chain elongation time is 1.5-4 minutes x EPL compared to a normal chain elongation time of 1 minute.
с. Применение адъювантовfrom. The use of adjuvants
Эффективность реакции множественной PCR можно значительно улучшить, используя добавку для PCR, такую как ДМСО, глицерин, формамид или бетаин, которые релаксируют ДНК, облегчая таким образом денатурацию матрицы.The effectiveness of the multiple PCR reaction can be significantly improved by using an additive for PCR, such as DMSO, glycerin, formamide or betaine, which relax the DNA, thereby facilitating matrix denaturation.
d. dNTP и MgCld. dNTP and MgCl 22
Качество и концентрация дезоксинуклеозидтрифосфата (dNTP) имеют важное значение для множественной РCR с удлинением цепи путем перекрывания. Лучшая концентрация dNTP составляет от 200 до 400 мкМ каждого dNTP (dATP, dCTP, dGTP и dTTP), при превышении которой происходит быстрое ингибирование амплификации. Более низкие концентрации dNTP (100 мкМ каждого dNTP) являются достаточными для амплификации методом РCR. Запасы dNTP чувствительны к циклам оттаивания/замораживания. После трех-пяти таких циклов множественная PCR часто оказывается неэффективной. Во избежание таких проблем можно получать небольшие аликвоты dNTP и держать их замороженными при -20°С.The quality and concentration of deoxynucleoside triphosphate (dNTP) are important for multiple overlapping PCRs. The best concentration of dNTP is from 200 to 400 μM of each dNTP (dATP, dCTP, dGTP and dTTP), above which there is a rapid inhibition of amplification. Lower dNTP concentrations (100 μM of each dNTP) are sufficient for amplification by the PCR method. DNTP stocks are sensitive to thawing / freezing cycles. After three to five such cycles, multiple PCR is often ineffective. To avoid such problems, small aliquots of dNTP can be obtained and kept frozen at -20 ° C.
Оптимизация концентрации Mg2+ имеет важное значение, так как большая часть ДНК-полимераз представляет собой магнийзависимые ферменты. Помимо ДНК-полимеразы Mg2+ связывают праймеры для матричной ДНК и dNTP. Поэтому оптимальная концентрация Mg2+ будет зависеть от концентрации dNTP, матричной ДНК и состава буфера для образца. Если праймеры и/или буферы для матричной ДНК содержат хелаторы, такие как EDTA или EGTA, оптимальная концентрация Mg2+ может быть изменена. Избыточная концентрация Mg2+ стабилизирует двойную цепь ДНК и предотвращает полную денатурацию ДНК, в результате чего уменьшается выход продукта. Избыточная концентрация Mg2+ может также стабилизировать ложную гибридизацию праймера с неправильными сайтами матрицы, что уменьшает специфичность. С другой стороны, недостаточная концентрация Mg2+ сокращает количество продукта.Optimization of the concentration of Mg 2+ is important, since most of the DNA polymerases are magnesium-dependent enzymes. In addition to Mg 2+ DNA polymerase, primers for template DNA and dNTP are linked. Therefore, the optimal concentration of Mg 2+ will depend on the concentration of dNTP, template DNA and the composition of the sample buffer. If primers and / or matrix DNA buffers contain chelators, such as EDTA or EGTA, the optimal concentration of Mg 2+ can be changed. Excess concentration of Mg 2+ stabilizes the double strand of DNA and prevents the complete denaturation of DNA, resulting in a decrease in product yield. Excess concentration of Mg 2+ can also stabilize false hybridization of the primer with irregular matrix sites, which reduces specificity. On the other hand, an insufficient concentration of Mg 2+ reduces the amount of product.
Хороший баланс между dNTP и MgCl2 равен примерно 200-400 мкМ dNTP (каждого) на 1,5-3 мМ MgCl2.A good balance between dNTP and MgCl 2 is approximately 200-400 μM dNTP (each) per 1.5-3 mM MgCl 2 .
е. Концентрация буфера для РCRe. Concentration of buffer for PCR
Буферы на основе KCl обычно удовлетворяют требованиям множественной РCR с удлинением цепи путем перекрывания; однако буферы на основе других компонентов, таких как (NH4)2SO4, MgSO4, трис-HCl, или их комбинаций также могут быть оптимизированы для использования в множественной PCR с удлинением цепи перекрыванием. Пары праймеров, участвующие в амплификации более длинных продуктов, действуют лучше при более низких концентрациях солей (например, 20-50 мМ KCl), в то время как пары праймеров, участвующие в амплификации коротких продуктов, действуют лучше при более высоких концентрациях солей (например, 80-100 мМ KCl). Двукратное увеличение концентрации буфера вместо однократного увеличения может повысить эффективность множественной реакции.KCl-based buffers typically satisfy the requirements of multiple overlap-extended PCRs; however, buffers based on other components, such as (NH 4 ) 2 SO 4 , MgSO 4 , Tris-HCl, or combinations thereof can also be optimized for use in multiple overlap extended PCRs. Primer pairs involved in the amplification of longer products perform better at lower salt concentrations (e.g. 20-50 mM KCl), while primer pairs involved in the amplification of short products perform better at higher salt concentrations (e.g. 80-100 mM KCl). A double increase in buffer concentration instead of a single increase can increase the efficiency of the multiple reaction.
f. ДНК-полимеразаf. DNA polymerase
Настоящее изобретение описано на примере использования Taq полимеразы. Альтернативно можно использовать другие типы теплостойких ДНК-полимераз, включающих, например, Pfu, Phusion, Pwo, Tgo, Tth, Vent, Deep-vent. Полимеразы, не обладающие или обладающие активностью 3'-5'-концевой экзонуклеазы, могут быть использованы отдельно или в комбинации друг с другом.The present invention is described using Taq polymerase as an example. Alternatively, other types of heat-resistant DNA polymerases can be used, including, for example, Pfu, Phusion, Pwo, Tgo, Tth, Vent, Deep-vent. Polymerases lacking or possessing the activity of a 3'-5'-terminal exonuclease can be used alone or in combination with each other.
Векторы и библиотекиVectors and libraries
В результате связывания интересующих нуклеотидных последовательностей по настоящему изобретению образуется нуклеотидный сегмент, включающий интересующие связанные нуклеотидные последовательности. Кроме того, способами по настоящему изобретению получают библиотеки таких интересующих связанных последовательностей нуклеиновых кислот, в частности библиотеки последовательностей, кодирующих вариабельные области.As a result of the binding of the nucleotide sequences of interest of the present invention, a nucleotide segment is formed comprising the linked nucleotide sequences of interest. In addition, by the methods of the present invention, libraries of such related linked nucleic acid sequences of interest are obtained, in particular libraries of sequences encoding variable regions.
Одним из отличительных признаков настоящего изобретения является введение в приемлемые векторы сегмента, содержащего интересующие связанные нуклеотидные последовательности, или библиотеки интересующих связанных нуклеотидных последовательностей, полученных способом по настоящему изобретению. Указанные библиотеки могут быть комбинаторными библиотеками или библиотеками родственных пар последовательностей, кодирующих вариабельные области. Сайты рестрикции, образованные внешними праймерами, гнездовыми праймерами или полугнездовыми праймерами, предпочтительно должны быть совместимы с соответствующими сайтами рестрикции выбранного вектора. Интересующие связанные последовательности нуклеиновых кислот можно также ввести в векторы путем рекомбинации, если одна из полугнездовых, гнездовых или внешних праймеров имеет приемлемый сайт рекомбинации и выбранный вектор содержит такой же сайт.One of the hallmarks of the present invention is the introduction into acceptable vectors of a segment containing the linked nucleotide sequences of interest, or libraries of the linked nucleotide sequences of interest obtained by the method of the present invention. These libraries may be combinatorial libraries or libraries of related pairs of sequences encoding variable regions. The restriction sites formed by external primers, nested primers or semi-nested primers should preferably be compatible with the corresponding restriction sites of the selected vector. Interesting linked nucleic acid sequences can also be introduced into vectors by recombination if one of the half-nested, nested or external primers has an acceptable recombination site and the selected vector contains the same site.
В основном не существует ограничений относительно векторов, которые можно использовать в качестве носителей продуктов, полученных одним из способов выполнения множественной RT-PCR и связывания по настоящему изобретению. Выбранные векторы могут использоваться для амплификации и экспрессии в клетках, включающих, например, бактериальные клетки, дрожжевые клетки, клетки других грибов, клетки насекомых, растительные клетки или клетки млекопитающих. Такие векторы могут быть использованы для облегчения последующих стадий клонирования, переноса между векторными системами, отображения продукта, введенного в вектор, экспрессии введенного продукта и/или встраивания в геном клетки-хозяина.Basically, there are no restrictions on the vectors that can be used as carriers of products obtained by one of the methods for performing multiple RT-PCR and binding of the present invention. Selected vectors can be used for amplification and expression in cells, including, for example, bacterial cells, yeast cells, cells of other fungi, insect cells, plant cells or mammalian cells. Such vectors can be used to facilitate the subsequent stages of cloning, transfer between vector systems, display of the product introduced into the vector, expression of the introduced product and / or incorporation into the genome of the host cell.
Клонирующие векторы и шаттл-векторы, предпочтительно, являются бактериальными векторами. Однако в процессе клонирования и переноса можно также использовать векторы других типов.Cloning vectors and shuttle vectors are preferably bacterial vectors. However, other types of vectors can also be used in the process of cloning and transfer.
Векторные дисплеи могут быть, например, фаговыми векторами или фагмидными векторами, полученными из нитевидных бактериофагов класса fd, M13 или f1. Такие векторы способны облегчить дисплей белков, включая, например, связывающий белок или его фрагмент, на поверхности нитевидного бактериофага. В данной области известны также векторные дисплеи, которые могут быть использованы для дисплея на рибосомах, ДНК, дрожжевых клетках или клетках млекопитающих. Указанные векторы включают, например, вирусные векторы или векторы, кодирующие химерные белки.Vector displays can be, for example, phage vectors or phagemid vectors derived from filamentous bacteriophages of class fd, M13 or f1. Such vectors are able to facilitate the display of proteins, including, for example, a binding protein or fragment thereof, on the surface of a filiform bacteriophage. Vector displays are also known in the art that can be used to display on ribosomes, DNA, yeast or mammalian cells. These vectors include, for example, viral vectors or vectors encoding chimeric proteins.
Экспрессирующие векторы существуют для всех указанных видов, и выбор вектора полностью зависит от экспрессируемого белка. Некоторые экспрессирующие векторы дополнительно способны встраиваться в геном клетки-хозяина в результате произвольной интеграции или сайт-специфической интеграции с использованием соответствующих сайтов рекомбинации. Экспрессирующие векторы могут иметь дополнительные кодирующие последовательности, которые при введении связанного продукта в указанные последовательности в рамке считывания могут экспрессировать более длинный белок, например непроцессированное моноклональное антитело, в соответствующей клетке-хозяине. Такое введение в рамке считывания может также облегчить экспрессию химерных белков, что в свою очередь облегчает отображение на поверхности нитевидного бактериофага или клетки. В системе дисплея на основе бактериофага интересующие связанные нуклеотидные последовательности могут быть введены в рамке считывания в последовательность, кодирующую белок оболочки, такой как pIII или pVIII (Barbas, C.F et al. 1991, Proc. Natl. Acad. Sci. USA 88, 7978-7982; Kang, A.S. et al. 1991, Proc. Natl. Acad. Sci. USA 88, 4363-4366).Expression vectors exist for all of these species, and the choice of vector depends entirely on the expressed protein. Some expression vectors are additionally able to integrate into the genome of the host cell as a result of arbitrary integration or site-specific integration using appropriate recombination sites. Expression vectors may have additional coding sequences that, when a bound product is introduced into the indicated sequences in the reading frame, can express a longer protein, for example, an unprocessed monoclonal antibody, in the corresponding host cell. Such an introduction in the reading frame can also facilitate the expression of chimeric proteins, which in turn facilitates the display of a filamentous bacteriophage or cell on the surface. In a bacteriophage-based display system, the associated nucleotide sequences of interest can be introduced into the reading frame into a sequence encoding a coat protein, such as pIII or pVIII (Barbas, CF et al. 1991, Proc. Natl.
В одном из вариантов осуществления настоящего изобретения отдельные сегменты интересующих связанных нуклеотидных последовательностей включают последовательность, кодирующую вариабельную область тяжелой цепи иммуноглобулина, которая связана с последовательностью, кодирующей вариабельную область легкой цепи. Указанные связанные последовательности предпочтительно вводят в вектор, содержащий последовательности, кодирующие один или несколько константных доменов иммуноглобулина. Вставку осуществляют таким образом, чтобы связанные последовательности, кодирующие вариабельную область тяжелой цепи и/или вариабельную область легкой цепи, находились в рамке считывания последовательностей, кодирующих константные области. В результате такой вставки может быть создан, например, вектор экспрессиии Fab-фрагмента, вектор экспрессии непроцессированного антитела или экспрессирующий вектор, кодирующий фрагмент непроцессированного антитела. Такой вектор предпочтительно является экспрессирующим вектором, пригодным для скрининга (например, векторы на основе E.coli, фагомида или вектора млекопитающего), при этом последовательности, кодирующие константную область тяжелой цепи, выбирают из иммуноглобулина человека классов IgG1, IgG2, IgG3, IgG4, IgM, IgA1, IgA2, IgD или IgE, в результате чего происходит экспрессия Fab-фрагмента или непроцессированного рекомбинантного антитела. Помимо последовательностей, кодирующих константную область тяжелой цепи, указанный вектор может также содержать последовательность, кодирующую константную область легкой цепи, которую выбирают из лямбда- или каппа-цепей человека. Такой подход является обоснованным в тех случаях, когда связанные нуклеотидные последовательности кодируют только последовательности, кодирующие вариабельную область иммуноглобулина (Fv-фрагменты).In one embodiment of the present invention, individual segments of the linked nucleotide sequences of interest include a sequence encoding an immunoglobulin heavy chain variable region that is linked to a sequence encoding a light chain variable region. These linked sequences are preferably introduced into a vector containing sequences encoding one or more constant domains of immunoglobulin. The insertion is carried out so that the linked sequences encoding the variable region of the heavy chain and / or the variable region of the light chain are in the reading frame of sequences encoding constant regions. As a result of such an insertion, for example, an expression vector of a Fab fragment, an expression vector of an unprocessed antibody or an expression vector encoding a fragment of an unprocessed antibody can be created. Such a vector is preferably an expression vector suitable for screening (e.g., vectors based on E. coli, phagomide or a mammalian vector), wherein sequences encoding the constant region of the heavy chain are selected from human immunoglobulin of classes IgG1, IgG2, IgG3, IgG4, IgM , IgA1, IgA2, IgD or IgE, resulting in the expression of a Fab fragment or an unprocessed recombinant antibody. In addition to sequences encoding the constant region of the heavy chain, this vector may also contain a sequence encoding the constant region of the light chain, which is selected from lambda or kappa chains of a person. This approach is justified in cases where the linked nucleotide sequences encode only sequences encoding the variable region of the immunoglobulin (Fv fragments).
В другом варианте осуществления настоящего изобретения отдельные сегменты связанных нуклеотидных последовательностей включают последовательность, кодирующую вариабельную область α-цепи TcR, которая связана с последовательностью, кодирующей вариабельную область β-цепи, или последовательность, кодирующую вариабельную область γ-цепи, которая связана с последовательностью, кодирующей вариабельную область δ-цепи. Указанные связанные последовательности предпочтительно вводят в вектор, который содержит последовательности, кодирующие один или несколько константных доменов TcR. Вставку осуществляют таким образом, чтобы введенные связанные последовательности, кодирующие вариабельные области, находились в рамке считывания соответствующих последовательностей, кодирующих константные области TcR. В другом варианте осуществления изобретения такой вектор является химерным экспрессирующим вектором, включающим последовательности, кодирующие лейциновый зиппер, в рамке считывания константных областей TcR. Установлено, что такие конструкции увеличивают устойчивость растворимых TcR (Willcox, B.E. et al. 1999, Protein Sci. 8, 2418-2423).In another embodiment of the present invention, individual segments of the linked nucleotide sequences include a sequence encoding a variable region of a TcR α chain that is linked to a sequence encoding a variable region of a β chain, or a sequence encoding a variable region of a γ chain that is linked to a sequence encoding variable region of the δ-chain. These linked sequences are preferably introduced into a vector that contains sequences encoding one or more constant TcR domains. The insertion is carried out so that the introduced linked sequences encoding the variable regions are in the reading frame of the corresponding sequences encoding the constant regions of TcR. In another embodiment of the invention, such a vector is a chimeric expression vector comprising sequences encoding a leucine zipper in the reading frame of TcR constant regions. It has been found that such constructs increase the stability of soluble TcRs (Willcox, B.E. et al. 1999, Protein Sci. 8, 2418-2423).
Библиотеки родственных пар по настоящему изобретению могут быть введены в векторы двумя разными способами. В соответствии с первым способом в приемлемый вектор вводят отдельные родственные пары. Такая библиотека векторов может находиться в разрозненном или объединенном виде. В соответствии со вторым способом все родственные пары объединяют до введения в вектор и затем все вместе вводят в приемлемые векторы с образованием объединенной библиотеки векторов (иллюстрация на фиг.12). Такая библиотека векторов содержит большое разнообразие пар последовательностей, кодирующих вариабельные области.The pairing libraries of the present invention can be introduced into vectors in two different ways. According to the first method, separate related pairs are introduced into an acceptable vector. Such a library of vectors can be in a disparate or combined form. According to the second method, all related pairs are combined before being introduced into the vector and then all together are introduced into acceptable vectors to form a combined library of vectors (illustration in FIG. 12). Such a vector library contains a wide variety of pairs of sequences encoding variable regions.
Одним объектом настоящего изобретения является библиотека родственных пар связанных последовательностей, кодирующих вариабельные области. Отдельные родственные пары библиотеки предпочтительно включают последовательность, кодирующую вариабельную область легкой цепи иммуноглобулина, связанную с последовательностью, кодирующей вариабельную область тяжелой цепи.One object of the present invention is a library of related pairs of linked sequences encoding variable regions. Individual related library pairs preferably include a sequence encoding an immunoglobulin light chain variable region associated with a sequence encoding a heavy chain variable region.
Другая предпочтительная библиотека родственных пар содержит связанные последовательности, кодирующие области TcR, в которых каждая отдельная последовательность, кодирующая область TcR, включает последовательность, кодирующую вариабельную область альфа-цепи, связанную с последовательностью, кодирующей вариабельную область бета-цепи, и/или последовательность, кодирующую вариабельную область гамма-цепи TcR, связанную с последовательностью, кодирующей вариабельную область дельта-цепи.Another preferred library of related pairs contains linked sequences encoding TcR regions in which each individual sequence encoding a TcR region includes a sequence encoding a variable region of an alpha chain associated with a sequence encoding a variable region of a beta chain and / or a sequence encoding the variable region of the gamma chain TcR associated with the sequence encoding the variable region of the delta chain.
Один вариант осуществления настоящего изобретения относится к подбиблиотеке родственных пар связанных последовательностей, кодирующих вариабельные области, которые определяют требуемые специфичности связывания в отношении определенной мишени. Указанные родственные пары предпочтительно включают связанные последовательности, кодирующие вариабельную область легкой цепи и вариабельную область тяжелой цепи иммуноглобулина, последовательности, кодирующие вариабельную область альфа-цепи и вариабельную область бета-цепи TcR, и/или последовательности, кодирующие вариабельную область гамма-цепи и вариабельную область дельта-цепи TcR.One embodiment of the present invention relates to a sub-library of related pairs of linked sequences encoding variable regions that determine the desired binding specificity for a particular target. These related pairs preferably include linked sequences encoding the variable region of the light chain and the variable region of the heavy chain of the immunoglobulin, sequences encoding the variable region of the alpha chain and the variable region of the beta chain TcR, and / or sequences encoding the variable region of the gamma chain and variable region delta chain TcR.
Другой вариант осуществления изобретения относится к подбиблиотеке, отобранной из исходной библиотеки родственных пар последовательностей, кодирующих вариабельные области, по настоящему изобретению.Another embodiment of the invention relates to a sub-library selected from a source library of related pairs of sequences encoding variable regions of the present invention.
Предпочтительный вариант осуществления настоящего изобретения относится к библиотеке или подбиблиотеке, кодирующей родственные пары непроцессированных иммуноглобулинов, отобранных из иммуноглобулина человека классов IgA1, IgA2, IgD, IgE, IgG1, IgG2, IgG3, IgG4 или IgM.A preferred embodiment of the present invention relates to a library or sub-library encoding related pairs of unprocessed immunoglobulins selected from human immunoglobulin of classes IgA1, IgA2, IgD, IgE, IgG1, IgG2, IgG3, IgG4 or IgM.
Другим предпочтительным отличительным признаком настоящего изобретения является библиотека или подбиблиотека, кодирующая растворимые и устойчивые родственные пары TcR.Another preferred feature of the present invention is a library or sub-library encoding soluble and stable TcR related pairs.
Отличительным признаком настоящего изобретения является разнообразие указанных библиотек, которые включают по крайней мере 5, 10, 20, 50, 100, 1000, 104, 105 или 106 разных родственных пар.A distinctive feature of the present invention is the variety of these libraries, which include at least 5, 10, 20, 50, 100, 1000, 10 4 , 10 5 or 10 6 different related pairs.
В другом варианте осуществления настоящего изобретения указанные библиотеки родственных пар связанных последовательностей, кодирующих вариабельные области, получают способом, включающим вышеописанные стадии. Такая библиотека именуется также исходной библиотекой.In another embodiment of the present invention, said libraries of related pairs of linked sequences encoding variable regions are prepared by a method comprising the steps described above. Such a library is also referred to as the source library.
Скрининг и отборScreening and screening
Можно предположить, что исходная библиотека пар связанных последовательностей, кодирующих вариабельные области, которые были получены от донора одним из способов по настоящему изобретению, должна представлять собой разнообразие связывающих белков, часть которых окажется непригодной, то есть не будет связываться с требуемой мишенью, что является особенно верным для комбинаторных библиотек. Поэтому в объем настоящего изобретения входят обогащение и скрининг для получения подбиблиотеки, кодирующей подмножество специфичностей связывания, направленных против определенной мишени.It can be assumed that the original library of pairs of linked sequences encoding variable regions that were obtained from a donor by one of the methods of the present invention should be a variety of binding proteins, some of which will be unsuitable, that is, they will not bind to the desired target, which is especially true for combinatorial libraries. Therefore, enrichment and screening is included in the scope of the present invention to obtain a sub-library encoding a subset of binding specificities directed against a specific target.
Что касается библиотек родственных пар, то разнообразие библиотеки предположительно соответствует разнообразию материала донора при наличии незначительного числа произвольно связанных вариабельных областей. Таким образом, в библиотеке, состоящей из родственных пар, стадия обогащения может быть необязательной до скрининга мишень-специфического сродства связывания.As regards the libraries of related pairs, the diversity of the library presumably corresponds to the diversity of the material of the donor in the presence of a small number of arbitrarily connected variable regions. Thus, in a library consisting of related pairs, an enrichment step may not be necessary prior to screening for target specific binding affinity.
В другом варианте осуществления настоящего изобретения способ создания библиотеки пар связанных последовательностей, кодирующих вариабельные области, далее включает создание подбиблиотеки путем отбора подмножества пар связанных последовательностей вариабельных областей, которые кодируют связывающие белки с требуемой специфичностью к мишени. Такой отбор связанных последовательностей, кодирующих вариабельные области, именуется также библиотекой мишень-специфических родственных пар.In another embodiment of the present invention, a method of creating a library of pairs of linked sequences encoding variable regions further comprises creating a sub-library by selecting a subset of pairs of linked sequences of variable regions that encode binding proteins with the desired specificity for the target. Such a selection of linked sequences encoding variable regions is also referred to as a library of target-specific related pairs.
Предпочтительный вариант осуществления настоящего изобретения относится к библиотеке мишень-специфических родственных пар последовательностей, кодирующих вариабельные области, которые введены в экспрессирующий вектор млекопитающего.A preferred embodiment of the present invention relates to a library of target-specific related pairs of sequences encoding variable regions that are introduced into a mammalian expression vector.
Отбор последовательностей, кодирующих вариабельные области мишень-специфических иммуноглобулинов, обычно производят при помощи иммунологических анализов. Такие анализы хорошо известны в данной области и включают, например, ELISPOTS, ELISA, мембранные анализы (например, вестерн-блоттинги), матрицы на фильтрах или FACS. Указанные анализы могут быть выполнены непосредственно с использованием полипептидов, полученных из последовательностей, кодирующих вариабельные области иммуноглобулина. Альтернативно иммуноанализы могут быть выполнены в комбинации или после обогащения такими методами, как отображение на фагах, рибосомах, бактериальной поверхности, дрожжах, эукариотических вирусах и РНК или ковалентное отображение (см. FitzGerald, K., 2000, Drug Discov. Today 5, 253-258). Как показано на фиг.10, скринингу могут быть подвергнуты как библиотеки экспрессируемых родственных Fab-фрагментов, так и библиотеки экспрессируемых родственных непроцессированных антител, в результате чего будет создана подбиблиотека положительных клонов. Такие методы скрининга и обогащения пригодны также для Fv- или scFv-фрагментов или комбинаторных библиотек связанных вариабельных областей.The selection of sequences encoding the variable regions of target-specific immunoglobulins is usually carried out using immunological assays. Such assays are well known in the art and include, for example, ELISPOTS, ELISA, membrane assays (e.g. western blotting), filter matrices, or FACS. These analyzes can be performed directly using polypeptides derived from sequences encoding the variable regions of immunoglobulin. Alternatively, immunoassays can be performed in combination or after enrichment with methods such as imaging on phages, ribosomes, the bacterial surface, yeast, eukaryotic viruses and RNA or covalent imaging (see FitzGerald, K., 2000, Drug Discov.
В предпочтительном варианте осуществления настоящего изобретения отбор подбиблиотеки мишень-специфических родственных пар или комбинаторных пар последовательностей, кодирующих вариабельные области, выполняют методом высокоэффективного скрининга. Методы высокоэффективного скрининга включают, не ограничиваясь ими, анализы ELISA, выполняемые при помощи полуавтоматического и автоматического оборудования. Могут быть также использованы мембранные анализы, при выполнении которых бактерии автоматически собирают и помещают на соответствующую мембрану поверх агаровых пластинок с образованием массивов колоний, экспрессирующих антигенсвязывающие молекулы. Указанные молекулы проникают через мембрану на вторую расположенную ниже мембрану, сенсибилизированную антигеном, которая может быть проявлена и использована для идентификации клонов, секретирующих антигенсвязывающие молекулы к требуемой мишени (de Wildt, R.M., et al. 2000, Nat. Вiotechnol. 18, 989-994).In a preferred embodiment of the present invention, the selection of a sub-library of target-specific related pairs or combinatorial pairs of sequences encoding variable regions is performed by a highly efficient screening method. Highly effective screening methods include, but are not limited to, ELISA assays performed using semi-automatic and automatic equipment. Membrane assays can also be used, in which bacteria are automatically collected and placed on an appropriate membrane over agar plates to form colonies that express antigen binding molecules. These molecules penetrate through the membrane onto the second antigen sensitized membrane below, which can be developed and used to identify clones secreting antigen-binding molecules to the desired target (de Wildt, RM, et al. 2000, Nat. Biotechnol. 18, 989-994 )
После отбора соответствующим методом подбиблиотеки родственных пар или комбинаторных пар антигенсвязывающих клонов могут быть выполнены дополнительные анализы путем секвенирования ДНК связанных последовательностей, кодирующих вариабельную область легкой цепи и вариабельную область тяжелой цепи иммуноглобулина. Во-первых, такое секвенирование ДНК позволяет получить информацию о разнообразии библиотеки, таком как происхождение зародышевой линии, распределение семейства и созревание на гипервариабельных участках. Такой анализ позволяет отобрать клоны, характеризующиеся широким разнообразием, и удалить повторяющиеся клоны. Во-вторых, секвенирование ДНК позволяет выявить мутации, возникшие в процессе выделения.After selection by a suitable method of a sub-library of related pairs or combinatorial pairs of antigen-binding clones, additional analyzes can be performed by DNA sequencing of linked sequences encoding the variable region of the light chain and the variable region of the heavy chain of immunoglobulin. First, such DNA sequencing provides information on library diversity, such as the origin of the germ line, family distribution, and maturation in hypervariable regions. This analysis allows you to select clones, characterized by a wide variety, and remove duplicate clones. Secondly, DNA sequencing allows you to identify mutations that have arisen in the process of isolation.
При анализе последовательностей, кодирующих вариабельные области, необходимо рассмотреть три типа мутаций, прежде чем принять решение о приемлемости мутации: i) мутации наиболее часто встречающегося типа возникают в результате перекрестного связывания внутри семейства, когда праймеры для V-гена связываются с неправильным подмножеством в одном конкретном семействе V-генов. Введенные изменения являются главным образом заменами природных кодонов в одном конкретном положении. Из-за высокой степени гомологии последовательностей в семействе V-генов такие замены могут рассматриваться как консервативные и приемлемые замены; ii) менее часто встречающиеся мутации возникают в результате перекрестного связывания между семействами (например, праймер для семейства VH3 инициирует последовательность, кодирующую семейство VH1) и вызывают более значительные структурные изменения, иногда не имеющие природного варианта. Такие изменения потенциально могут влиять на иммуногенность вариабельной области в результате создания новых эпитопов. Такие изменения можно легко идентифицировать и затем устранить стандартными методами молекулярной биологии или исключить обнаруженные клоны из библиотеки; iii) ошибки, вызванные Taq ДНК-полимеразой, легче всего идентифицировать в последовательностях, кодирующих константные области, после чего их можно легко устранить. Однако мутации, индуцированные Taq полимеразой, несомненно будут также присутствовать в последовательностях, кодирующих вариабельные области, где их невозможно отличить от природных соматических мутаций, которые также являются результатом произвольных мутаций в последовательностях, кодирующих вариабельные области. Учитывая, что указанные мутации не являются системными и по-разному влияют только на определенные пары, кажется обоснованным не принимать во внимание таких изменения.When analyzing sequences encoding variable regions, three types of mutations must be considered before deciding on the acceptability of the mutation: i) the most common type of mutation results from cross-linking within the family when the primers for the V gene bind to the wrong subset in one particular family of V genes. The introduced changes are mainly replacements of natural codons in one specific position. Due to the high degree of sequence homology in the V gene family, such substitutions can be considered as conservative and acceptable substitutions; ii) less frequent mutations result from cross-linking between families (for example, a primer for the VH3 family initiates a sequence encoding the VH1 family) and cause more significant structural changes, sometimes without a natural variant. Such changes can potentially affect the immunogenicity of the variable region as a result of the creation of new epitopes. Such changes can be easily identified and then eliminated by standard molecular biology methods or excluded detected clones from the library; iii) Errors caused by Taq DNA polymerase are most easily identified in sequences encoding constant regions, after which they can be easily eliminated. However, Taq polymerase-induced mutations will undoubtedly also be present in sequences coding for variable regions, where they cannot be distinguished from natural somatic mutations, which are also the result of random mutations in sequences coding for variable regions. Considering that these mutations are not systemic and only affect certain pairs in different ways, it seems reasonable not to take such changes into account.
Кроме того, анализ последовательностей можно использовать для идентификации степени перестановки последовательностей в библиотеке родственных пар, как показано в таблице 20 для VH группы Н4.In addition, sequence analysis can be used to identify the degree of sequence permutation in the library of related pairs, as shown in table 20 for the VH group H4.
Как описано в примере 9, мутации, рассмотренные в пунктах i) и ii), могут быть устранены в библиотеке экспрессируемых последовательностей при использовании праймеров, гибридизирующих с лидерным пептидом последовательностей, кодирующих вариабельные области, вместо праймеров, гибридизирующих с 5'-концом вариабельных областей.As described in Example 9, the mutations discussed in i) and ii) can be eliminated in the library of expressed sequences by using primers hybridizing to the leader peptide of sequences encoding the variable regions instead of primers hybridizing to the 5 ′ end of the variable regions.
В другом варианте осуществления настоящего изобретения подбиблиотеку мишень-специфических и, возможно, подвергнутых анализу пар связанных последовательностей, кодирующих вариабельную область легкой цепи и вариабельную область тяжелой цепи иммуноглобулина, переносят в экспрессирующий вектор млекопитающего. Такой перенос можно произвести в любые векторы, описанные в предыдущем разделе, которые позволяют экспрессировать непроцессированное рекомбинантное антитело. Если скрининг выполняют в отношении библиотеки родственных пар экспрессируемых непроцессированных антител, такой перенос может быть не нужен.In another embodiment of the present invention, a sub-library of target-specific and possibly analyzed pairs of linked sequences encoding the variable region of the light chain and the variable region of the heavy chain of immunoglobulin is transferred to the mammalian expression vector. Such transfer can be made to any vectors described in the previous section, which allow the expression of an unprocessed recombinant antibody. If screening is performed for a library of related pairs of expressed unprocessed antibodies, such transfer may not be necessary.
В другом варианте осуществления настоящего изобретения исходную библиотеку создают из лимфоцитсодержащей фракции клеток, обогащенной Т-лимфоцитами. Пары связанных последовательностей, кодирующих вариабельные области, которые образуют исходную библиотеку, можно отобрать с учетом кодирования подмножества пар связанных последовательностей вариабельных областей, состоящих из альфа- и бета-цепей и/или гамма- и дельта-цепей, кодирующих связывающие белки с требуемой специфичностью к мишени, в результате чего будет создана подбиблиотека родственных пар или комбинаторных пар. Антигенспецифические Т-клеточные рецепторы затем могут быть идентифицированы в пуле трансфецированных клеток стандартными методами, такими как окрашивание тетрамерными комплексами МНС-пептид (см., например, публикации Callan, M.F. et al. 1998, J. Еxp. Med. 187, 1395-1402; Novak, E.J. et al. 1999, J. Clin. Invest. 104, R63-R67), измерение клеточных реакций в виде высвобождения IL-2, или более сложными методами, такими как методы отображение на дрожжах или ретровирусах.In another embodiment of the present invention, the source library is created from a lymphocyte-containing fraction of cells enriched in T-lymphocytes. Pairs of linked sequences encoding the variable regions that form the source library can be selected taking into account the coding of a subset of pairs of linked sequences of variable regions consisting of alpha and beta chains and / or gamma and delta chains encoding binding proteins with the required specificity for targets, as a result of which a sub-library of related pairs or combinatorial pairs will be created. Antigen-specific T cell receptors can then be identified in a pool of transfected cells by standard methods, such as staining with MHC peptide tetrameric complexes (see, for example, Callan, MF et al. 1998, J. Ex. Med. 187, 1395-1402 ; Novak, EJ et al. 1999, J. Clin. Invest. 104, R63-R67), measuring cellular reactions in the form of IL-2 release, or by more sophisticated methods, such as yeast or retrovirus imaging methods.
Клетки-хозяева и экспрессияHost Cells and Expression
Библиотеки по настоящему изобретению можно перенести в векторы, пригодные для экспрессии и продуцирования белков, кодированных представляющими интерес связанными последовательностями нуклеиновых кислот, в частности связывающих белков, содержащих вариабельные области, или их фрагментов. Такие векторы описаны в разделе “Векторы и библиотеки” и применяются для экспрессии, например, непроцессированных антител, Fab-фрагментов, Fv-фрагментов, scFv-фрагментов, мембраносвязанных или растворимых TcR или фрагментов TcR выбранного вида.The libraries of the present invention can be transferred to vectors suitable for the expression and production of proteins encoded by interest nucleic acid linked sequences, in particular binding proteins containing variable regions, or fragments thereof. Such vectors are described in the “Vectors and Libraries” section and are used to express, for example, unprocessed antibodies, Fab fragments, Fv fragments, scFv fragments, membrane-bound or soluble TcRs, or TcR fragments of a selected species.
Одним из отличительных признаков настоящего изобретения является введение в клетку-хозяина библиотеки или подбиблиотеки векторов, содержащих родственные пары связанных последовательностей, кодирующих вариабельные области, или единичный клон, включающий родственную пару связанных последовательностей, кодирующих вариабельные области, для амплификации и/или экспрессии. Клетки-хозяева могут быть выбраны из бактериальных клеток, дрожжевых клеток, клеток других грибов, клеток насекомых, растительных клеток или клеток млекопитающих. Для экспрессии предпочтительными являются клетки млекопитающих, такие как клетки яичника китайского хомячка (СНО), клетки COS, клетки ВНК, миеломные клетки (например, клетки Sp2/0, NS0), NIH 3T3, фибробласты или иммортализованные клетки человека, такие как клетки HeLa, клетки НЕК 293 или PERC6.One of the hallmarks of the present invention is the introduction into the host cell of a library or sub-library of vectors containing related pairs of linked sequences encoding variable regions, or a single clone comprising a related pair of linked sequences encoding variable regions for amplification and / or expression. Host cells can be selected from bacterial cells, yeast cells, cells of other fungi, insect cells, plant cells, or mammalian cells. For expression, mammalian cells such as Chinese hamster ovary (CHO) cells, COS cells, BHK cells, myeloma cells (e.g. Sp2 / 0, NS0 cells), NIH 3T3, fibroblasts or immortal human cells such as HeLa cells are preferred.
Введение векторов в клетки-хозяева осуществляют при помощи целого ряда методов трансформации или трансфекции, известных специалистам в данной области, которые включают осаждением фосфатом кальция, электропорацию, микроинъекции, слияние с липосомами, слияние с гомолизированными эритроцитами, слияние с протопластами, вирусную инфекцию и тому подобные. Хорошо известны методы получения моноклональных непроцессированных антител, Fab-фрагментов, Fv-фрагментов и scFv-фрагментов.The vectors are introduced into the host cells using a variety of transformation or transfection methods known to those skilled in the art, which include calcium phosphate precipitation, electroporation, microinjection, fusion with liposomes, fusion with homolized red blood cells, fusion with protoplasts, viral infection and the like. . Well-known methods for producing monoclonal unprocessed antibodies, Fab fragments, Fv fragments and scFv fragments.
Продуцирование рекомбинантных поликлональных антител, предназначенных для использования в лечебных целях, является новой областью. Способ получения рекомбинантных поликлональных антител описан в заявке РСТ WO 2004/061104. Указанный способ включает создание коллекции клеток, пригодной для использования в качестве линии продуцирующих клеток. Нижеследующее описание данного способа относится к библиотеке родственных пар, хотя он применим также к комбинаторной библиотеке. Отдельные клетки в коллекции клеток могут экспрессировать один член рекомбинантного поликлонального связыващего белка, например, из библиотеки родственных пар. Для гарантии экспрессии отдельными клетками одной родственной пары, а не нескольких родственных пар поликлонального связывающего белка, последовательности нуклеиновых кислот, кодирующие родственные пары, вводят в один специфический сайт генома каждой отдельной клетки. Это является важной особенностью коллекции клеток, так как предотвращает перестановку тяжелых и легких цепей, экспрессируемых каждой клеткой, а также позволяет получить клетки, по существу идентичные друг другу, за исключением небольших различий вариабельных областей отдельных родственных пар. Данная особенность делает возможным несмещенный рост коллекции клеток в течение периода времени, необходимого для продуцирования. Для гарантии единичной сайт-специфической интеграции необходимо использовать коммерчески доступную линию клеток-хозяев, имеющих только один сайт интеграции, например клетки CHO Flp-In компании Invitrogen, содержащие один сайт FRT. Векторы, пригодные для данной линии клеток, содержат соответствующий сайт FRT и встраиваются в геном при помощи Flp-рекомбиназы. Существует несколько других известных рекомбиназ, например Cre, бета-рекомбиназа, Gin, Pin, PinB, PinD, R/RS, лямбда-интеграза или фаговая интеграза ФС31, которые могут быть использованы в комбинации с соответствующими сайтами рекомбинации. Кроме того, приемлемые векторы содержат селектируемый маркер, который позволяет произвести выбор сайт-специфических интегрантов.The production of recombinant polyclonal antibodies intended for therapeutic use is a new area. A method for producing recombinant polyclonal antibodies is described in PCT application WO 2004/061104. The specified method includes creating a collection of cells suitable for use as a line of producing cells. The following description of this method relates to a library of related pairs, although it is also applicable to a combinatorial library. Individual cells in a cell collection can express one member of a recombinant polyclonal binding protein, for example, from a library of related pairs. To guarantee the expression by individual cells of one related pair, rather than several related pairs of the polyclonal binding protein, nucleic acid sequences encoding the related pairs are introduced into one specific site of the genome of each individual cell. This is an important feature of the cell collection, since it prevents the rearrangement of the heavy and light chains expressed by each cell, and also allows you to get cells essentially identical to each other, with the exception of small differences in the variable regions of individual related pairs. This feature allows unbiased growth of the cell collection over the period of time necessary for production. To guarantee a single site-specific integration, it is necessary to use a commercially available line of host cells having only one integration site, for example Invitrogen CHO Flp-In cells containing one FRT site. Vectors suitable for a given cell line contain the corresponding FRT site and are inserted into the genome using Flp recombinase. There are several other known recombinases, for example, Cre, beta recombinase, Gin, Pin, PinB, PinD, R / RS, lambda integrase or phage integrase FS31, which can be used in combination with the corresponding recombination sites. In addition, acceptable vectors contain a selectable marker that allows the selection of site-specific integrants.
Создание линии поликлональных продуцирующих клеток и продуцирование рекомбинантного поликлонального белка такой линией клеток может быть произведено несколькими разными методами трансфекции и продуцирования.The creation of a polyclonal producing cell line and the production of a recombinant polyclonal protein with such a cell line can be accomplished by several different transfection and production methods.
Одним из методов является использование библиотеки векторов, смешанных с образованием одной композиции, предназначенной для трансфекции линии клеток-хозяев, имеющих в одной клетке один сайт интеграции. Данный метод именуется массовой трансфекцией. Ранее описанная структура вектора и клетки-хозяина гарантирует, что в результате соответствующего отбора должна быть получена линия поликлональных клеток, характеризующихся несмещенным ростом. Необходимо создать замороженный запас линии поликлональных клеток до начала продуцирования рекомбинантного поликлонального белка.One method is to use a library of vectors mixed to form one composition, designed to transfect a line of host cells that have one integration site in one cell. This method is called mass transfection. The previously described structure of the vector and the host cell ensures that, as a result of appropriate selection, a line of polyclonal cells characterized by unbiased growth should be obtained. It is necessary to create a frozen supply of the polyclonal cell line before starting production of the recombinant polyclonal protein.
Другим методом является использование для трансфекции библиотеки векторов, разделенных на части, содержащие в композиции примерно 5-50 отдельных векторов библиотеки. Одна часть библиотеки предпочтительно содержит 10-20 отдельных векторов. Каждую композицию затем трансфецируют в одну аликвоту клеток-хозяев. Данный метод именуется полумассовой трансфекцией. Число трансфецированных аликвот зависит от размера библиотеки и числа отдельных векторов в каждой части. Если библиотека включает, например, 100 отдельных родственных пар, разделенных на части, содержащие в композиции 20 отдельных членов, необходимо трансфецировать 5 аликвот клеток-хозяев композицией библиотеки, составляющей отдельную часть исходной библиотеки. Аликвоты клеток-хозяев отбирают с учетом сайт-специфической интеграции. Разные аликвоты предпочтительно отбирают отдельно. Однако они могут быть также объединены до селекции. Указанные аликвоты могут быть подвергнуты анализу в отношении их клонального разнообразия, причем для создания запаса библиотеки поликлональных родственных пар используют только аликвоты, характеризующиеся достаточным разнообразием. Для получения требуемой линии поликлональных клеток аликвоты могут быть смешаны до создания замороженного запаса сразу же после их получения из запаса или после непродолжительного периода пролиферации и адаптации. Аликвоты клеток находятся отдельно в процессе продуцирования, и поликлональный белок получают, объединяя продукты всех аликвот, а не аликвоты клеток до продуцирования.Another method is to use for transfection of a library of vectors, divided into parts, containing about 5-50 individual library vectors in the composition. One part of the library preferably contains 10-20 individual vectors. Each composition is then transfected into one aliquot of the host cells. This method is called half-mass transfection. The number of transfected aliquots depends on the size of the library and the number of individual vectors in each part. If the library includes, for example, 100 separate related pairs, divided into parts containing 20 separate members in the composition, it is necessary to transfect 5 aliquots of the host cells with the composition of the library, which is a separate part of the original library. Aliquots of host cells are selected based on site-specific integration. Different aliquots are preferably selected separately. However, they can also be combined before breeding. These aliquots can be analyzed for their clonal diversity, and only aliquots of sufficient diversity are used to stock the library of polyclonal related pairs. To obtain the desired polyclonal cell line, aliquots can be mixed until a frozen stock is created immediately after they are obtained from the stock or after a short period of proliferation and adaptation. Aliquots of the cells are separately in the production process, and a polyclonal protein is obtained by combining the products of all aliquots, rather than aliquots of the cells prior to production.
Третьим методом является высокоэффективный метод, в котором клетки-хозяева трансфецируют отдельно, используя отдельные векторы, составляющие библиотеку родственных пар. Такой метод именуется индивидуальной трансфекцией. Индивидуально трансфецированные клетки-хозяева предпочтительно отбирают отдельно с учетом сайт-специфической интеграции. Отдельные клоны клеток, полученные в результате отбора, могут быть подвергнуты анализу для определения времени пролиферации, причем для создания запаса библиотеки поликлональных родственных пар предпочтительно используют клетки, характеризующиеся одинаковыми скоростями роста. Отдельные клоны клеток могут быть смешаны для получения требуемой линии поликлональных клеток до создания запаса сразу же после их получения из запаса или после непродолжительной пролиферации и адаптации. Такой подход позволяет устранить любое возможное смещение последовательностей остатков во время трансфекции, интеграции и отбора. Альтернативно отдельно трансфецированные клетки-хозяева смешивают до выполнения отбора, что позволяет контролировать смещение последовательностей вследствие трансфекции.The third method is a highly efficient method in which host cells are transfected separately using separate vectors that make up the library of related pairs. This method is called individual transfection. Individually transfected host cells are preferably selected separately for site-specific integration. Individual cell clones obtained by selection can be analyzed to determine the proliferation time, and cells with the same growth rates are preferably used to stock the library of polyclonal related pairs. Individual cell clones can be mixed to produce the desired polyclonal cell line before stockpiling immediately after being obtained from stock or after short proliferation and adaptation. This approach eliminates any possible shift in residual sequences during transfection, integration, and selection. Alternatively, individually transfected host cells are mixed prior to selection, which allows control of sequence displacement due to transfection.
Общим отличительным признаком вышеописанных методов является то, что все отдельные родственные пары, образующие рекомбинантный поликлональный белок, могут быть получены в одном или ограниченном числе биореакторов. Единственным отличием является стадия, на которой отбирают коллекцию клеток, которая образует линию поликлональных продуцирующих клеток.A common hallmark of the above methods is that all individual related pairs forming a recombinant polyclonal protein can be obtained in one or a limited number of bioreactors. The only difference is the stage at which a collection of cells is selected that forms a line of polyclonal producing cells.
Один из вариантов осуществления настоящего изобретения относится к популяции клеток-хозяев, образующих библиотеку родственных пар или подбиблиотеку связанных пар последовательностей, кодирующих вариабельные области.One embodiment of the present invention relates to a population of host cells forming a library of related pairs or a sub-library of linked pairs of sequences encoding variable regions.
Другой вариант осуществления настоящего изобретения относится к популяции клеток-хозяев, образующих библиотеку, полученную из популяции выделенных отдельных клеток, включающих лимфоциты, с использованием для связывания родственных пар метода множественной RT-PCR с последующим связыванием путем лигирования или рекомбинации либо множественной RT-PCR с удлинением цепи путем перекрывания по настоящему изобретению.Another embodiment of the present invention relates to a population of host cells forming a library obtained from a population of isolated single cells including lymphocytes using the multiple RT-PCR method to bind related pairs, followed by ligation or recombination or multiple RT-PCR extension chains by overlapping of the present invention.
Другой вариант осуществления настоящего изобретения относится к популяции клеток-хозяев, образующих комбинаторную библиотеку или подбиблиотеку связанных пар последовательностей, кодирующих вариабельные области.Another embodiment of the present invention relates to a population of host cells forming a combinatorial library or a sub-library of linked pairs of sequences encoding variable regions.
Популяция клеток-хозяев по настоящему изобретению включает популяцию разных клеток, соответствующих разнообразию библиотеки, использованной для трансформации и трансфекции клеток. Каждая клетка в популяции клеток предпочтительно образует только одну родственную пару из всей библиотеки родственных пар, и ни один член библиотеки родственных пар не превышает более 50%, более предпочтительно 25% или наиболее предпочтительно 10% от общего числа отдельных членов, экспрессированных из популяции клеток-хозяев.The host cell population of the present invention includes a population of different cells corresponding to the variety of the library used to transform and transfect cells. Each cell in the cell population preferably forms only one related pair from the entire library of related pairs, and not a single member of the library of related pairs exceeds 50%, more preferably 25% or most preferably 10% of the total number of individual members expressed from the cell population - the hosts.
В предпочтительном варианте осуществления настоящего изобретения популяция клеток-хозяев включает клетки млекопитающих.In a preferred embodiment of the present invention, the host cell population includes mammalian cells.
Вышеописанную популяцию клеток-хозяев можно использовать для экспрессии рекомбинантного поликлонального связывающего белка, так как отдельные клетки популяции образуют разные последовательности, кодирующие вариабельные области.The above population of host cells can be used to express a recombinant polyclonal binding protein, as individual cells in a population form different sequences encoding variable regions.
Один из вариантов осуществления настоящего изобретения относится к рекомбинантному поликлональному белку, экспрессируемому популяцией клеток-хозяев, включающих библиотеку векторов, содержащих разные родственные пары связанных последовательностей, кодирующих вариабельные области, которая была создана способом по настоящему изобретению. Рекомбинантный поликлональный белок по настоящему изобретению обычно включает 2, 5, 10, 20, 50, 100, 1000, 104, 105 или 106 белков, состоящих из разных родственных пар.One embodiment of the present invention relates to a recombinant polyclonal protein expressed by a population of host cells comprising a library of vectors containing different related pairs of linked sequences encoding variable regions that was created by the method of the present invention. The recombinant polyclonal protein of the present invention typically includes 2, 5, 10, 20, 50, 100, 1000, 10 4 , 10 5 or 10 6 proteins consisting of different related pairs.
Предпочтительный вариант осуществления настоящего изобретения относится к рекомбинантному поликлональному иммуноглобулину, экспрессированному популяцией клеток-хозяев, включающих библиотеку векторов, содержащих разные родственные пары последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи.A preferred embodiment of the present invention relates to a recombinant polyclonal immunoglobulin expressed by a population of host cells comprising a library of vectors containing different related pairs of sequences encoding the variable region of the heavy chain and the variable region of the light chain.
Другой предпочтительный вариант осуществления настоящего изобретения относится к рекомбинантному поликлональному TcR, экспрессированному популяцией клеток-хозяев, включающих библиотеку векторов, содержащих разные родственные пары последовательностей, кодирующих вариабельную область альфа-цепи TcR, связанную с вариабельной областью бета-цепи, и/или последовательностей, кодирующих вариабельную область гамма-цепи, связанную с вариабельной областью дельта-цепи.Another preferred embodiment of the present invention relates to a recombinant polyclonal TcR expressed by a population of host cells comprising a library of vectors containing different related pairs of sequences encoding the variable region of the TcR alpha chain linked to the variable region of the beta chain and / or sequences encoding the variable region of the gamma chain associated with the variable region of the delta chain.
Другой вариант осуществления настоящего изобретения относится к клетке-хозяину, пригодной для продуцирования моноклонального белка. В частности, моноклонального антитела, содержащего родственную пару вариабельной области легкой цепи и вариабельную область тяжелой цепи, или моноклонального TcR, содержащего родственную пару вариабельной области альфа-цепи и вариабельную область бета-цепи или вариабельную область дельта-цепи и вариабельную область гамма-цепи. Такая линия клеток, продуцирующих моноклональный белок, предпочтительно не является линией клеток гибридомы.Another embodiment of the present invention relates to a host cell suitable for producing a monoclonal protein. In particular, a monoclonal antibody containing a cognate pair of the variable region of the light chain and a variable region of the heavy chain, or a monoclonal TcR containing a cognate pair of the variable region of the alpha chain and the variable region of the beta chain or the variable region of the delta chain and the variable region of the gamma chain. Such a monoclonal protein producing cell line is preferably not a hybridoma cell line.
Такое моноклональное антитело или TcR может быть получено в результате добавления нижеследующих стадий к способу связывания нескольких интересующих несмежных нуклеотидных последовательностей: а) введение в вектор указанных связанных последовательностей нуклеиновых кислот; b) введение указанного вектора в клетку-хозяина; с) культивирование указанных клеток-хозяев в условиях, пригодных для экспрессии; и d) получение белкового продукта, экспрессированного вектором, введенным в указанную клетку-хозяина. Вектор, введенный в клетку-хозяина, предпочтительно содержит отдельную родственную пару последовательностей, кодирующих вариабельные области.Such a monoclonal antibody or TcR can be obtained by adding the following steps to a method for linking several interesting non-contiguous nucleotide sequences: a) introducing into the vector of said linked nucleic acid sequences; b) introducing the specified vector into the host cell; c) culturing said host cells under conditions suitable for expression; and d) preparing a protein product expressed by a vector introduced into said host cell. The vector introduced into the host cell preferably contains a separate related pair of sequences encoding variable regions.
Применение изобретенияApplication of the invention
Основным применением настоящего изобретения является связывание родственных пар последовательностей, кодирующих вариабельные области, в частности последовательностей, кодирующих вариабельные области тяжелой и легкой цепи иммуноглобулина, или последовательностей, кодирующих вариабельные области альфа- и бета-цепи или гамма- и дельта-цепи TcR, при помощи высокоэффективного способа создания библиотек родственных пар. Помимо создания библиотек родственных пар множественную RT-PCR с последующим связыванием путем лигирования или рекомбинации или множественную RT-PCR с удлинением цепи перекрыванием по настоящему изобретению можно использовать для создания комбинаторных библиотек для популяции генетических разных клеток, клеточных лизатор из такой популяции клеток или РНК, выделенной из такой популяции клеток. Библиотеки, подбиблиотеки или единичные клоны из одной из таких библиотек облегчают экспрессию поликлональных или моноклональных белков. Из библиотек по настоящему изобретению могут быть получены, в частности, моноклональные или поликлональные антитела.The main application of the present invention is the binding of related pairs of sequences encoding the variable regions, in particular sequences encoding the variable regions of the immunoglobulin heavy and light chains, or sequences encoding the variable regions of the alpha and beta chain or the gamma and delta chains of TcR, using a highly efficient way to create related pair libraries. In addition to creating libraries of related pairs, multiple RT-PCR followed by ligation or recombination binding or multiple RT-PCR overlapping chain extension of the present invention can be used to create combinatorial libraries for a population of different genetic cells, a cell lyser from such a population of cells or RNA isolated from such a population of cells. Libraries, sub-libraries, or single clones from one of these libraries facilitate the expression of polyclonal or monoclonal proteins. From the libraries of the present invention, in particular, monoclonal or polyclonal antibodies can be obtained.
Хорошо известно применение рекомбинантных моноклональных антител для диагностики, лечения и профилактики заболеваний. Рекомбинантные моноклональные и поликлональные антитела, полученные способом по настоящему изобретению, имеют такое же применение, что и антитела, полученные существующими методами. В частности, способом по настоящему изобретению может быть получена фармацевтическая композиция, содержащая в качестве активного ингредиента поликлональный рекомбинантный иммуноглобулин, объединенный по крайней мере с одним фармацевтически приемлемым наполнителем. Более предпочтительными являются фармацевтические композиции, в которых поликлональный рекомбинантный иммуноглобулин содержит родственные пары последовательностей, кодирующих вариабельные области. Фармацевтические композиции на основе поликлональных рекомбинантных иммуноглобулинов могут быть использованы в качестве лекарственных средств. Поликлональный рекомбинантный иммуноглобулин, входящий в состав композиции, может быть специфичным к заранее определенному заболеванию, поэтому такая композиция может быть использована для лечения, уменьшения интенсивности или профилактики таких заболеваний, как рак, инфекционные заболевания, воспалительные заболевания, аллергии, астма и другие респираторные заболевания, аутоиммунные заболевания, нарушения функции иммунной системы, сердечно-сосудистые заболевания, заболевания центральной нервной системы, заболевания обмена веществ и эндокринные заболевания, отторжение трансплантата или нежелательная беременность у млекопитащих, таких как человек, домашние или комнатные животные.The use of recombinant monoclonal antibodies for the diagnosis, treatment and prevention of diseases is well known. Recombinant monoclonal and polyclonal antibodies obtained by the method of the present invention have the same use as antibodies obtained by existing methods. In particular, a pharmaceutical composition comprising, as an active ingredient, a polyclonal recombinant immunoglobulin combined with at least one pharmaceutically acceptable excipient can be prepared by the method of the present invention. Pharmaceutical compositions in which the polyclonal recombinant immunoglobulin contains related pairs of sequences encoding variable regions are more preferred. Pharmaceutical compositions based on polyclonal recombinant immunoglobulins can be used as medicines. The polyclonal recombinant immunoglobulin included in the composition may be specific for a predetermined disease, therefore, such a composition can be used to treat, reduce the intensity or prevention of diseases such as cancer, infectious diseases, inflammatory diseases, allergies, asthma and other respiratory diseases, autoimmune diseases, dysfunctions of the immune system, cardiovascular diseases, diseases of the central nervous system, metabolic diseases in and endocrine diseases, transplant rejection, or undesired pregnancy in mammals, such as humans, domestic or pet animals.
Дальнейшее применение настоящего изобретения не имеет аналогов среди современных методов на основе моноклональных химерных антител. Когда защитные антигены плохо исследованы или совершенно неизвестны, как это имеет место в случае появления новых инфекционных заболеваний, невозможно найти моноклональное антитело, защищающее от данного заболевания.Further application of the present invention has no analogues among modern methods based on monoclonal chimeric antibodies. When protective antigens are poorly studied or completely unknown, as is the case with the emergence of new infectious diseases, it is impossible to find a monoclonal antibody that protects against this disease.
Однако настоящее изобретение позволяет получить антитело-экспрессирующие клетки непосредственно у доноров с выработанной гуморальной иммунной реакцией, например у выздоравливающих индивидуумов, и использовать исходный материал, полученный у указанных индивидуумов, для создания библиотеки родственных пар последовательностей, кодирующих вариабельные области тяжелой и легкой цепей иммуноглобулина.However, the present invention allows to obtain antibody-expressing cells directly from donors with a developed humoral immune response, for example, in recovering individuals, and to use the starting material obtained from these individuals to create a library of related pairs of sequences encoding the variable regions of the heavy and light chains of immunoglobulin.
В тех случаях когда, например, вирус известен, но неизвестны защитные антигены, можно создать подбиблиотеку родственных пар генов антитела с широкой реактивностью в отношении антигенных структур вируса. Рекомбинантное поликлональное антитело, полученное из такой подбиблиотеки, по-видимому, будет содержать защитные антитела.In those cases when, for example, the virus is known, but the protective antigens are unknown, it is possible to create a sub-library of related pairs of antibody genes with broad reactivity with respect to the antigenic structures of the virus. The recombinant polyclonal antibody obtained from such a sub-library is likely to contain protective antibodies.
В тех случаях когда антигены совершенно неизвестны, рекомбинантное поликлональное антитело, полученное из библиотеки родственных пар, созданной на основе исходного материала выздоравливающих индивидуумов, можно использовать точно так же, как в настоящее время используются гипериммунные иммуноглобулины. Основанием для такого применения является родственное спаривание, которое гарантирует близкое соответствие полученного рекомбинантного поликлонального антитела гуморальной иммунной реакции выздоравливающего индивидуума.In cases where the antigens are completely unknown, the recombinant polyclonal antibody obtained from the library of related pairs, created on the basis of the starting material of recovering individuals, can be used in the same way as hyperimmune immunoglobulins are currently used. The basis for this application is related mating, which guarantees close correspondence of the obtained recombinant polyclonal antibody to the humoral immune response of a recovering individual.
Способы связывания родственных пар вариабельных областей, описанные в настоящем изобретении, находят применение в диагностических и аналитических методах. При введении индивидууму лекарственного средства всегда существует вероятность возникновения иммунной реакции против такого лекарственного средства. Иммуногенность можно определить существующими методами, такими как специфичные для лекарственного средства анализы связывания с сывороткой или плазмой, полученной у индивидуума, принимающего данное лекарственное средство. Альтернативно способы по настоящему изобретению можно использовать для отображения иммунной реакции индивидуумов сразу же после введения лекарственного средства путем выделения родственных пар последовательностей, кодирующих вариабельные области тяжелой и легкой цепей. Антитела, экспрессированные из такой библиотеки, можно исследовать на реактивность в отношении данного лекарственного средства или его компонентов. Указанный способ является особенно полезным в тех случаях, когда наличие лекарственного средства в плазме или сыворотке препятствует применению существующего метода. Такими лекарственными средствами являются, например, антитела. Иммунную реакцию против лекарственного средства (например, антиидиотипическую иммунную реакцию, иммунную реакцию на рамку считывания или Fc-фрагмент), вызванную введением антитела, нельзя идентифицировать известными методами до тех пор, пока антитело, используемое для лечения, не будет полностью выведено из крови. В соответствии с настоящим изобретением у подвергаемого лечению индивидуума можно выделить последовательности, кодирующие такие антитела против данного лекарственного средства, и исследовать в течения двух недель. Таким образом, настоящее изобретение является альтернативным методом исследования иммуногенности лекарственных средств вообще и лекарственных средств на основе антител, в частности.Methods of binding related pairs of variable regions described in the present invention are used in diagnostic and analytical methods. When a drug is administered to an individual, there is always the possibility of an immune response against such a drug. Immunogenicity can be determined by existing methods, such as drug-specific serum or plasma binding assays obtained from an individual taking the drug. Alternatively, the methods of the present invention can be used to display the immune response of individuals immediately after drug administration by isolating related pairs of sequences encoding the variable regions of the heavy and light chains. Antibodies expressed from such a library can be tested for reactivity with a given drug or its components. This method is particularly useful in cases where the presence of a drug in plasma or serum prevents the use of the existing method. Such drugs are, for example, antibodies. An immune response against a drug (e.g., an anti-idiotypic immune response, an immune response to a reading frame, or an Fc fragment) caused by administration of an antibody cannot be identified by known methods until the antibody used for treatment has been completely removed from the blood. In accordance with the present invention, sequences coding for such antibodies against a given drug can be isolated from the subject being treated and examined for two weeks. Thus, the present invention is an alternative method for studying the immunogenicity of drugs in general and antibody-based drugs in particular.
Еще одним применением настоящего изобретения является проверка и сравнение вакцин и программ вакцинации. Это является особенно полезным в процессе создания вакцины, так как позволяет оценить и сравнить разнообразие последовательностей, участвующих в гуморальных иммунных реакциях, возникающих в ответ на воздействие новых вакцин-кандидатов, дополнительно к выполняемым в настоящее время сравнениям сродства связывания антитела и сывороточного титра. Кроме того, настоящее изобретение можно использовать для анализа, контроля и сравнения гуморальных иммунных реакций при осуществлении надзора за эффективностью вакцины у населения.Another application of the present invention is the testing and comparison of vaccines and vaccination programs. This is especially useful in the process of creating a vaccine, as it allows you to evaluate and compare the variety of sequences involved in humoral immune responses that occur in response to the effects of new candidate vaccines, in addition to ongoing comparisons of antibody binding affinity and serum titer. In addition, the present invention can be used to analyze, control and compare humoral immune responses in monitoring the effectiveness of a vaccine in a population.
Настоящее изобретение находит также применение за пределами области связывающих белков, содержащих вариабельные области. Специалист в данной области может легко адаптировать способ, описанный в настоящем изобретении, для связывания двух или более транскрибированных нуклеотидных последовательностей, кодирующих гетеромерный белок, не являющийся связывающим белком. Такое связывание последовательностей, кодирующих домены или субъединицы гетеромерного белка, может быть весьма полезным для выделения кодирующих белок последовательностей, так как позволит значительно уменьшить число стадий. Кроме того, можно выделить, например, сплайсированные варианты, мутации или новые члены семейства таких белков, используя только одну смесь множественных праймеров/смесь множественных праймеров для удлинения цепи путем перекрывания.The present invention also finds use outside the field of binding proteins containing variable regions. One of skill in the art can easily adapt the method described in the present invention to bind two or more transcribed nucleotide sequences encoding a heteromeric non-binding protein. Such linking of sequences encoding domains or subunits of a heteromeric protein can be very useful for isolating protein coding sequences, since it will significantly reduce the number of stages. In addition, it is possible to isolate, for example, spliced variants, mutations or new members of the family of such proteins, using only one mixture of multiple primers / mixture of multiple primers to extend the chain by overlapping.
Кроме того, возможно связывание последовательностей, кодирующих удаленные домены одного белка. Такой способ должен облегчить исследование значимости определенных доменов в мультидоменном белке, так как он упрощает делецию промежуточных доменов.In addition, it is possible to bind sequences encoding the remote domains of a single protein. This method should facilitate the study of the significance of certain domains in a multidomain protein, since it simplifies the deletion of intermediate domains.
Создание химерных или связанных белков также является областью, в которой может быть использовано настоящее изобретение. Даже если подлежащие связыванию белки имеют разное происхождение, например представляют собой химерный белок, созданный из белка человека и мыши, настоящее изобретение можно использовать, смешивая клетки до выполнения обратной транскрипции. Такая смесь клеток может включать популяцию клеток из каждого вида или отдельную клетку из каждого вида.The creation of chimeric or bound proteins is also an area in which the present invention can be used. Even if the proteins to be bound are of different origin, for example, they are a chimeric protein made from human and mouse proteins, the present invention can be used by mixing cells before reverse transcription is performed. Such a mixture of cells may include a population of cells from each species or a single cell from each species.
ПримерыExamples
Пример 1. Двухстадийная множественная RT-PCR с удлинением цепи путем перекрыванияExample 1. Two-stage multiple RT-PCR with chain extension by overlapping
В данном примере рассмотрено выполнение обратной транскрипции (RT) с применением матрицы, полученной из выделенной отдельной клетки, при этом продуцированную кДНК используют в качестве матрицы для выполнения нескольких множественных PCR с удлинением цепи путем перекрывания.This example describes the implementation of reverse transcription (RT) using a matrix obtained from an isolated single cell, and the produced cDNA is used as a matrix to perform multiple multiple PCRs with chain extension by overlapping.
а. Клеткиbut. Cells
Линия клеток яичника китайского хомячка (СНО), экспрессирующих каппа-цепь IgG1, была получена методом Flp-In (Invitrogen, Carlsbad, CA, USA).The Chinese Hamster Ovary (CHO) cell line expressing the kappa chain of IgG1 was obtained by Flp-In (Invitrogen, Carlsbad, CA, USA).
Плазмидный вектор pLL113, экспрессирующий каппа-цепь IgG (фиг.4), был создан на основе экспрессирующего вектора Flp-In, pcDNA5/FRT. Клетки СНО-Flp-In котрансфецировали вектором pLL113, содержащим гены антитела и pOG44, вызывающим временную экспрессию Flp-рекомбиназы, используя липофектамин 2000 (Invitrogen, Carlsbad, CA, USA), в соответствии с инструкциями изготовителя. Трансформанты отбирали и проверяли в отношении продуцирования каппа-цепи IgG при помощи иммуноанализов. Отобранную линию клеток, получившую название СНО Flp-In pLL113, помещали в среду F-12 Хэма, содержащую 2 мМ L-глутамина, 10% FCS и 900 гигромицин В (поддерживающая среда).The plasmid vector pLL113 expressing the kappa chain of IgG (FIG. 4) was created based on the Flp-In expression vector, pcDNA5 / FRT. CHO-Flp-In cells were cotransfected with the pLL113 vector containing the antibody and pOG44 genes causing transient expression of Flp recombinase using Lipofectamine 2000 (Invitrogen, Carlsbad, CA, USA), according to the manufacturer's instructions. Transformants were selected and tested for IgG kappa chain production by immunoassays. A selected cell line, dubbed CHO Flp-In pLL113, was placed in Ham F-12 medium containing 2 mM L-glutamine, 10% FCS and 900 hygromycin B (support medium).
Клетки СНО Flp-In pLL113 собирали при помощи трипсина и трижды промывали в поддерживающей среде. После выполнения последней промывки клетки вторично суспендировали в исходном объеме поддерживающей среды. Концентрацию клеток определяли при помощи системы Casy-1 (Scharfe System GmbH, Reutlingen, Germany) и разводили в поддерживающей среде до концентрации 1 клетка/5 мкл.CHO Flp-In pLL113 cells were harvested with trypsin and washed three times in a support medium. After the last wash, the cells were re-suspended in the initial volume of the support medium. Cell concentration was determined using the Casy-1 system (Scharfe System GmbH, Reutlingen, Germany) and diluted in a support medium to a concentration of 1 cell / 5 μl.
b. Обратная транскрипцияb. Reverse transcription
Взвесь клеток СНО Flp-In pLL113, содержащую в среднем одну клетку, распределяли по отдельным лункам 96-луночного планшета для PCR (Thermo-Fast 96, skirted AB-0800, ABgene, Epsom, Surrey, UK).A suspension of CHO Flp-In pLL113 cells containing on average one cell was distributed into individual wells of a 96-well PCR plate (Thermo-
кДНК синтезировали из распределенных клеток на стадии обратной транскрипции с использованием обратной транскриптазы (RT) в соответствии с одностадийным методом RT-PCR Qiagen (набор для выполнения одностадийной RT-PCR Qiagen, № по каталогу 210210 Hilden, Germany).cDNA was synthesized from distributed cells at the reverse transcription stage using reverse transcriptase (RT) in accordance with the Qiagen RT-PCR one-step method (Qiagen one-step RT-PCR kit, catalog number 210210 Hilden, Germany).
Каждая лунка содержала нижеследующие реагенты в общем объеме 20 мкл:Each well contained the following reagents in a total volume of 20 μl:
однократный буфер для одностадийной RT-PCR,single buffer for single-stage RT-PCR,
dNTP в конечной концентрации, равной 1 мМ каждого реагента,dNTP at a final concentration of 1 mM of each reagent,
5 пмоль олигонуклеотида поли-dT (18),5 pmol of poly-dT oligonucleotide (18),
26 ед. ингибитора РНКазы (RNasin, Promega, Madison USA, № по каталогу N2111),26 units RNase inhibitor (RNasin, Promega, Madison USA, catalog number N2111),
2 мкл смеси ферментов для одностадийной RT-PCR,2 μl enzyme mixture for one-step RT-PCR,
5 мкл взвеси клеток СНО Flp-In pLL113.5 μl suspension of CHO cells Flp-In pLL113.
Реакцию обратной транскрипции с использованием RT выполняли, инкубируя реакционные смеси при 55°С в течение 30 минут. Затем обратную транскриптазу инактивировали, инкубируя реакционную смесь при 94°С в течение 10 минут.The reverse transcription reaction using RT was performed by incubating the reaction mixtures at 55 ° C for 30 minutes. Then reverse transcriptase was inactivated by incubating the reaction mixture at 94 ° C for 10 minutes.
с. Множественная PCR с удлинением цепи путем перекрыванияfrom. Multiple overlap extended PCR
Часть продуктов кДНК, полученных на стадии b), использовали в качестве матрицы для множественной PCR с удлинением цепи путем перекрывания. Реакцию выполняли на 96-луночных планшетах.A portion of the cDNA products obtained in step b) was used as a template for multiple overlap extended PCR. The reaction was performed on 96-well plates.
Каждая лунка содержала нижеследующие реагенты в общем объеме 40 мкл:Each well contained the following reagents in a total volume of 40 μl:
однократный буфер для одностадийной RT-PCR,single buffer for single-stage RT-PCR,
dNTP в конечной концентрации, равной 500 мкМ каждого реагента,dNTP at a final concentration of 500 μM of each reagent,
смесь множественных праймеров для удлинения цепи путем перекрывания в концентрациях, указанных в таблице 1,a mixture of multiple primers for lengthening the chain by overlapping at the concentrations indicated in table 1,
26 ед. ингибитора РНКазы (RNasin, Promega, Madison USA, № по каталогу N2111),26 units RNase inhibitor (RNasin, Promega, Madison USA, catalog number N2111),
2 мкл смеси ферментов для одностадийной RT-PCR,2 μl enzyme mixture for one-step RT-PCR,
1 мкл матрицы кДНК (выделенной из отдельной клетки (стадия b)).1 μl cDNA template (isolated from a single cell (step b)).
Использованная смесь множественных праймеров для удлинения цепи путем перекрывания содержала праймеры, показанные в таблице 1.The mixture of multiple primers used to extend the chain by overlapping contained the primers shown in Table 1.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
W=A/T, S=G/C, R=A/G. Последовательности, обозначенные заглавными буквами, соответствуют геноспецифической области.W = A / T, S = G / C, R = A / G. The sequences indicated in capital letters correspond to the genespecific region.
Реакции выполняли в 96-луночном термоблоке Primus НT MWG (MWG Biotech AG, Ebersberg, Germany) при нижеследующих условиях циклизации:Reactions were performed in a 96-well Primus HT MWG thermoblock (MWG Biotech AG, Ebersberg, Germany) under the following cyclization conditions:
d. Гнездовая PCRd. Socket PCR
Гнездовую PCR выполняли, используя в качестве матрицы продукты множественной РCR с удлинением цепи путем перекрывания. Реакции выполняли на 96-луночных планшетах.Nested PCR was performed using multiple chain extension products by overlapping as the template. Reactions were performed on 96-well plates.
Каждая лунка содержала нижеследующие реагенты в общем объеме 50 мкл:Each well contained the following reagents in a total volume of 50 μl:
однократный буфер для Bio Taq,one-time buffer for Bio Taq,
dNTP в конечной концентрации, равной 400 мкМ каждого реагента,dNTP at a final concentration of 400 μM of each reagent,
2 мМ MgCl2,2 mm MgCl 2 ,
смесь праймеров для гнездовой PCR,PCR primer mix
1,25 ед. ДНК-полимеразы BIOTAQ (№ по каталогу BIO-21040, Bioline, UK),1.25 units BIOTAQ DNA Polymerase (BIO-21040, Bioline, UK),
1 мкл продукта множественной PCR с удлинением цепи путем перекрывания (стадия с).1 μl product of overlapping multiple PCR with chain elongation (step c).
Использованные праймеры показаны в таблице 2.The primers used are shown in table 2.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Последовательности, обозначенные заглавными буквами, соответствуют геноспецифической области.The sequences indicated in capital letters correspond to the genespecific region.
Реакции выполняли в 96-луночном термоблоке Primus НT MWG (MWG Biotech AG, Ebersberg, Germany) в нижеследующих условиях циклизации:The reactions were performed in a 96-well Primus HT MWG thermoblock (MWG Biotech AG, Ebersberg, Germany) under the following cyclization conditions:
Продукты гнездовой РCR анализировали электрофорезом в 1% агарозном геле, используя для обнаружения этидий бромид (фиг.5). Ожидаемый размер продукта, полученного удлинением цепи путем перекрывания, был равен 1076 п.о. Такой продукт показан в полосах 1, 5, 6, 7, 8 и 12, отмеченных стрелками (фиг.5А). В рассмотренном эксперименте отрицательный контрольный образец является загрязненным, и аналогичное загрязнение характерно также для испытуемых образцов. На фиг.5В показаны фрагменты, изображенные на фиг.5А, которые относятся к настоящему эксперименту.Nesting PCR products were analyzed by 1% agarose gel electrophoresis using ethidium bromide to detect (Figure 5). The expected size of the product obtained by chain elongation by overlapping was 1076 bp. Such a product is shown in
В настоящем эксперименте иллюстрируется один из способов выполнения двухстадийной множественной PCR с удлинением цепи путем перекрывания с использованием матрицы, выделенной из отдельной клетки. Кроме того, было показано, что можно выполнить примерно двадцать множественных РCR с удлинением цепи путем перекрывания, используя кДНК, полученную из выделенной отдельной клетки.This experiment illustrates one way of performing two-stage multiple PCR with chain extension by overlapping using a matrix isolated from a single cell. In addition, it has been shown that approximately twenty multiple PCRs can be performed with chain extension by overlapping using cDNA obtained from an isolated single cell.
Пример 2. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияExample 2. One-stage multiple RT-PCR with chain extension by overlapping
В данном примере рассмотрено выполнение обратной транскрипции и множественной PCR с удлинением цепи путем перекрывания в виде одной стадии с использованием матрицы, полученной из лизированных клеток, в концентрациях, соответствующих 100, 10 или 1 клетке.In this example, the implementation of reverse transcription and multiple PCR with chain extension by overlapping in a single stage using a matrix obtained from lysed cells in concentrations corresponding to 100, 10 or 1 cell.
а. Клеткиbut. Cells
Линию клеток гибридомы человека НВ-8501, продуцирующую противостолбнячное антитело с каппа-цепью IgG1, которая была получена из Американской коллекции типовых культур, культивировали в среде Дульбекко, модифицированной по способу Исков (Vitacell, Kiev, Ukrain, № по каталогу 30-2005), содержащей 10% фетальной телячьей сыворотки. До выполнения множественной RT-PCR с удлинением цепи путем перекрывания клетки собирали, подсчитывали и замораживали при -80°С в культуральной среде в концентрации 200 клеток/мкл.The HB-8501 human hybridoma cell line producing an anti-tetanus antibody with IgG1 kappa chain, which was obtained from the American Type Culture Collection, was cultured in Dulbekko medium modified according to the Claims method (Vitacell, Kiev, Ukrain, catalog number 30-2005), containing 10% fetal calf serum. Prior to performing multiple chain extension RT-PCR by overlapping, cells were harvested, counted and frozen at -80 ° C in culture medium at a concentration of 200 cells / μl.
b. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияb. Single-Stage Multiple Overlap RT-PCR with Overlap
Для выполнения множественной RT-PCR с удлинением цепи путем перекрывания использовали набор для одностадийной RT-PCR Qiagen (Qiagen, № по каталогу 210212, Hilden, Germany) в соответствии с рекомендациями изготовителя. Перед добавлением в пробирки для PCR клеточные лизаты оттаивали и разводили в Н2О до концентрации лизата, соответствущей 100, 10 и 1 клетке на 5 мкл.To perform multiple RT-PCRs with chain extension by overlapping, the Qiagen Single-Stage RT-PCR Kit (Qiagen, Catalog No. 210212, Hilden, Germany) was used in accordance with the manufacturer's recommendations. Before being added to PCR tubes, cell lysates were thawed and diluted in H 2 O to a lysate concentration corresponding to 100, 10 and 1 cell per 5 μl.
Каждая пробирка для PCR содержала нижеследущие реагенты в общем объеме 50 мкл:Each PCR tube contained the following reagents in a total volume of 50 μl:
однократный буфер для одностадийной RT-PCR,single buffer for single-stage RT-PCR,
dNTP в конечной концентрации, равной 400 мкМ каждого реагента,dNTP at a final concentration of 400 μM of each reagent,
смесь множественных праймеров для удлинения цепи путем перекрывания в концентрациях, указанных в таблице 3,a mixture of multiple primers for lengthening the chain by overlapping at the concentrations indicated in table 3,
2 мкл смеси ферментов для одностадийной RT-PCR,2 μl enzyme mixture for one-step RT-PCR,
50 ед. ингибитора РНКазы (RNasin, Promega, Madison USA, № по каталогу N2515),50 units RNase inhibitor (RNasin, Promega, Madison USA, catalog number N2515),
5 мкл разведенного клеточного лизата.5 μl of diluted cell lysate.
Использованная смесь множественных праймеров для удлинения цепи путем перекрывания содержала праймеры, показанные в таблице 3.The mixture of multiple primers used to extend the chain by overlapping contained the primers shown in Table 3.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакции выполняли в нижеследующих условиях циклизации:The reactions were carried out under the following cyclization conditions:
Реакция PCR:PCR reaction:
Десять микролитров продуктов реакций анализировали электрофорезом в 1,5% агарозном геле, используя для обнаружения бромид этидия (фиг.6А).Ten microliters of reaction products were analyzed by 1.5% agarose gel electrophoresis using ethidium bromide for detection (FIG. 6A).
Ожидаемый размер фрагментов (точный размер зависит от длины вариабельных областей):The expected size of the fragments (the exact size depends on the length of the variable regions):
VН: 410 п.о.V H : 410 bp
LC: 680 п.о.LC: 680 bp
Фрагмент удлинения цепи путем перекрывания: 1070 п.о.Fragment of chain extension by overlapping: 1070 bp
Отдельные фрагменты ДНК с подвижностью, соответствующей длине вариабельной области тяжелой цепи (VH) и длине вариабельной и константной областей легкой цепи (LC), присутствуют при всех разведениях клеточного лизата. Менее интенсивный фрагмент с подвижностью, соответствующей предполагаемому фрагменту удлинения цепи путем перекрывания, присутствует в лизатах от 100 до 10 клеток. Фрагмент удлинения цепи путем перекрывания в образце лизата одной клетки обнаружен с трудом, хотя он присутствует в исходном геле (см. стрелку на фото, показанном на фиг.6А, и изображение, показанное на фиг.6В).Individual DNA fragments with mobility corresponding to the length of the variable region of the heavy chain (V H ) and the length of the variable and constant regions of the light chain (LC) are present at all dilutions of the cell lysate. A less intense fragment with motility corresponding to the putative fragment of chain extension by overlapping is present in lysates from 100 to 10 cells. A fragment of chain extension by overlapping a single cell lysate in the sample was hardly detected, although it was present in the original gel (see the arrow in the photo shown in FIG. 6A and the image shown in FIG. 6B).
с. Идентификация фрагмента удлинения цепи путем перекрыванияfrom. Overlapping fragment identification
В результате выполнения вышеописанного эксперимента было подтверждено наличие полосы, соответствующей фрагменту удлинения цепи путем перекрывания. Области агарозного геля в положении 1070 п.о. полосы, соответствующей 1 клетке, и полосы, соответствующей 100 клеткам, вырезали, ДНК очищали при помощи набора Qiaex II (Qiagen, № по каталогу 20051, Hilden, Germany) и разводили в 20 мкл воды.As a result of the above experiment, the presence of a strip corresponding to a fragment of chain extension by overlapping was confirmed. Areas of agarose gel at 1070 bp bands corresponding to 1 cell and bands corresponding to 100 cells were excised, DNA was purified using a Qiaex II kit (Qiagen, catalog No. 20051, Hilden, Germany) and diluted in 20 μl of water.
Один микролитр элюата подвергали PCR (набор Biotaq, Bioline, UK № по каталогу BIO-21040) в соответствии с инструкциями изготовителей с использованием праймеров, фланкирующих предполагаемый фрагмент удлинения цепи путем перекрывания (праймеры для JH, соответствующие SEQ ID NO:32-35, и праймер для CLк, соответствующий SEQ ID NO:17, при использовании каждого праймера в концентрации 0,5 мкМ). Реакции выполняли в нижеследущих условиях циклизации:One microliter of eluate was subjected to PCR (Biotaq kit, Bioline, UK catalog number BIO-21040) in accordance with the manufacturer's instructions using primers flanking the proposed fragment of the chain extension by overlapping (primers for J H corresponding to SEQ ID NO: 32-35, and a primer for C Lk corresponding to SEQ ID NO: 17, using each primer at a concentration of 0.5 μM). The reactions were carried out under the following cyclization conditions:
Десять микролитров каждого продукта реакции анализировали электрофорезом в 1% агарозном геле, используя для обнаружения бромид этидия. Было обнаружено несколько фрагментов, в том числе с подвижностью ожидаемого фрагмента удлинения цепи путем перекрывания в образцах от 1 до 100 клеток (стрелка на фиг.6С). Фрагмент длиной 1 т.п.о. вырезали из полосы геля, соответствующей одной клетке, и очищали при помощи вышеописанного набора Qiaex II. Очищенный фрагмент гидролизовали рестрикционными ферментами NheI и NcoI (отдельно) и продукты реакции анализировали электрофорезом в 1% агарозном геле, используя для обнаружения бромид этидия (фиг.6D). Указанные сайты рестрикции присутствуют на участке перекрывания VH и LC, и ожидаемые размеры цепи после гидролиза равны примерно 410 и 680 п.о. (фиг.2). Гидролиз NheI был неполным, так как большая фракция все еще имеет первоначальный размер.Ten microliters of each reaction product were analyzed by electrophoresis on a 1% agarose gel using ethidium bromide for detection. Several fragments were found, including those with the mobility of the expected fragment of chain extension by overlapping from 1 to 100 cells in the samples (arrow in Fig. 6C).
Пример 3. Объединенные реакции одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и гнездовой PCRExample 3. Combined reactions of one-stage multiple RT-PCR with chain extension by overlapping and nested PCR
В данном примере рассмотрены реакции обратной транскрипции и множественной PCR с удлинением цепи путем перекрывания, выполненные в виде одной стадии, с последующей амплификацией при помощи полугнездовой PCR с использованием матрицы из лизированных клеток в концентрациях, соответствующих 100, 10 или 1 клетке.In this example, reverse transcription and multiple PCR overlap-extended PCR reactions are performed as a single step, followed by amplification using semi-nested PCR using a matrix of lysed cells at concentrations corresponding to 100, 10, or 1 cell.
а. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияbut. Single-Stage Multiple Overlap RT-PCR with Overlap
Множественную RT-PCR с удлинением цепи путем перекрывания выполняли, используя клеточный лизат НВ-8501, в соответствии с описанием, приведенным в примере 2, с применением смеси множественных праймеров для удлинения цепи путем перекрывания, включающей праймеры, показанные в таблице 4.Multiple overlap extension RT-PCRs were performed using the HB-8501 cell lysate, as described in Example 2, using a mixture of multiple overlap extension primers comprising the primers shown in Table 4.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Однако следует отметить, что для каждой смеси множественных праймеров для удлинения цепи путем перекрывания использовали только однин из праймеров для СН1-5, в результате чего было получено пять разных смесей множественных праймеров для удлинения цепи перекрыванием.However, it should be noted that for each mixture of multiple primers for chain extension by overlapping, only one of the primers for C H1-5 was used , resulting in five different mixtures of multiple primers for chain extension by overlapping.
Остальные параметры были аналогичны указанным в примере 2 для множественной RT-PCR с удлинением цепи путем перекрывания за исключением изменения температуры гибридизации, которая была равна 50°С. Реакцию выполняли с использованием каждого обратного праймера для константной области тяжелой цепи (СН1, СН2, СН3, СН4, СН5, соответствущие SEQ ID NO:49-53) и лизатов, соответствующих 100, 10, 1 и 0 клеткам.The remaining parameters were similar to those shown in example 2 for multiple RT-PCR with chain extension by overlapping with the exception of a change in hybridization temperature, which was equal to 50 ° C. The reaction was performed using each reverse primer for the constant region of the heavy chain (C H1 , C H2 , C H3 , C H4 , C H5 , corresponding to SEQ ID NOS: 49-53) and lysates corresponding to 100, 10, 1 and 0 cells.
b. Полугнездовая PCRb. Semi-slot PCR
Один микролитр продукта реакции множественной RT-PCR с удлинением цепи путем перекрывания подвергали полугнездовой РCR (набор Biotaq, Bioline, UK, № по каталогу BIO-21040) в соответствии с рекомендациями изготовителя. Общий объем реакционных смесей был равен 50 мкл. Использованные праймеры показаны в таблице 5.One microliter of the reaction product of the multiple RT-PCR reaction with chain extension by overlapping was subjected to a semi-nested PCR (Biotaq kit, Bioline, UK, catalog number BIO-21040) in accordance with the manufacturer's recommendations. The total volume of the reaction mixtures was 50 μl. The primers used are shown in table 5.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакцию выполняли в нижеследующих условиях циклизации:The reaction was carried out under the following cyclization conditions:
Десять микролитров каждой реакционной смеси анализировали электрофорезом в 1,5% агарозном геле, используя для обнаружения бромид этидия (фиг.7).Ten microliters of each reaction mixture were analyzed by 1.5% agarose gel electrophoresis using ethidium bromide for detection (Fig. 7).
Предполагаемый фрагмент удлинения цепи путем перекрывания, полученный в результате выполнения полугнездовой PCR с использованием праймера для СН4 в первой реакции и соответствующий лизату одной клетки (см. стрелку на фиг.7), вырезали из агарозного геля, очищали при помощи набора Qiaex II (Qiagen, № по каталогу 20051, Hilden, Germany) и вводили в pCR2.1-TOPO, используя набор для клонирования ТОРО ТА компании Invitrogen (Invitrogen, № по каталогу 45-0641, Carlsbad, CA, USA). Вставки из восьми клонов секвенировали, в результате чего было установлено, что семь из указанных вставок состояли из вариабельной области тяжелой цепи, связанной с вариабельной и константной областью легкой цепи, в предполагаемой области перекрывания.The putative overlapping chain extension fragment obtained by performing a semi-nested PCR using a primer for C H4 in the first reaction and corresponding to a single cell lysate (see arrow in Fig. 7) was excised from agarose gel, purified using Qiaex II kit (Qiagen Catalog No. 20051, Hilden, Germany) and introduced into pCR2.1-TOPO using the Invitrogen TOPO TA cloning kit (Invitrogen, Catalog No. 45-0641, Carlsbad, CA, USA). Inserts of eight clones were sequenced, and it was found that seven of these inserts consisted of the variable region of the heavy chain associated with the variable and constant region of the light chain in the proposed region of overlap.
Можно отметить, что чувствительность объединенной реакции множественной RT-PCR с удлинением цепи путем перекрывания и полугнездовой PCR была весьма удовлетворительной, при этом 4 из 5 праймеров для константной области амплифицировали значительные количества продуктов удлинения цепи путем перекрывания из лизата, соответствущего отдельной клетке.It can be noted that the sensitivity of the combined reaction of multiple RT-PCR with chain extension by overlapping and half-nested PCR was very satisfactory, while 4 out of 5 constant region primers amplified significant amounts of chain extension products by overlapping from a lysate corresponding to a single cell.
Пример 4. Объединенные реакции одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и гнездовой PCR с использованием в качестве источника матрицы обогащенных В-имфоцитов человекаExample 4. Combined reactions of one-step multiple RT-PCR with chain extension by overlapping and nested PCR using enriched human B-lymphocytes as a matrix source
В данном примере рассмотрены реакции обратной транскрипции и множественной РCR с удлинением цепи путем перекрывания, выполненные в виде одной стадии, с последующей амплификацией при помощи полугнездовой РCR с использованием в качестве источника матрицы выделенных отдельных В-лимфоцитов человека.In this example, reverse transcription and multiple PCR reactions with chain extension by overlapping, performed in a single stage, followed by amplification using semi-nested PCR using isolated individual human B lymphocytes as a matrix source, are considered.
а. Выделение В-клетокbut. B cell isolation
Мужчину-донора иммунизировали столбнячным токсином. Через 6 дней после иммунизации от донора брали пробу крови, равную 120 мл, и выделяли мононуклеарные клетки периферической крови (РВМС) в устройстве Lymphoprep (Axis-Shield, Oslo, Norway, производственный № 1001967) в соответствии с инструкциями изготовителя. Популяцию CD19-положительных клеток обогащали методом сортировки клеток с использованием магнитных гранул. РВМС окрашивали FITC-конъюгированным антителом против CD19-леток (Becton Dickinson, NJ, USA, № по каталогу 345776). Магнитную сортировку клеток с использованием магнитных микрогранул, конъюгированных с анти-FITC-антителом, и очистку в колонке производили в соответствии с инструкциями изготовителей (Miltenyi Biotec, Gladbach, Germany, № по каталогу 130-042-401). Клетки разводили до концентрации, равной 200 клеткам на 1 мл в PBS, содержащем 2 нМ EDTA и 0,5% BSA. Пять микролитров разведенных клеток распределяли по пробиркам для PCR, содержащим приблизительно одну клетку в одной пробирке. Пробирки хранили до применения при -80°С.The male donor was immunized with tetanus toxin. 6 days after immunization, a blood sample of 120 ml was taken from the donor and peripheral blood mononuclear cells (PBMC) were isolated in a Lymphoprep device (Axis-Shield, Oslo, Norway, production No. 1001967) in accordance with the manufacturer's instructions. The population of CD19-positive cells was enriched by cell sorting using magnetic beads. PBMCs were stained with a FITC-conjugated anti-CD19-year-old antibody (Becton Dickinson, NJ, USA, catalog number 345776). Magnetic sorting of cells using magnetic microbeads conjugated to an anti-FITC antibody and purification in a column was performed in accordance with the manufacturers instructions (Miltenyi Biotec, Gladbach, Germany, catalog number 130-042-401). Cells were diluted to a concentration of 200 cells per 1 ml in PBS containing 2 nM EDTA and 0.5% BSA. Five microliters of diluted cells were distributed in PCR tubes containing approximately one cell in one tube. The tubes were stored until use at -80 ° C.
b. Множественная RT-PCR с удлинением цепи путем перекрывания и полугнездовая PCRb. Multiple overlap extended RT-PCR and semi-nested PCR
Условия выполнения множественной RT-PCR с удлинением цепи путем перекрывания и полугнездовой РCR были аналогичны описанным в примере 3. Однако указанные реакции выполняли только с использованием смеси множественных праймеров для удлинения цепи путем перекрывания, включающей праймер для CН3, соответствующий SEQ ID NO:51. Шестнадцать образцов, полученных в результате выполнения объединенных реакций множественной RT-PCR с удлинением цепи путем перекрывания и полугнездовой РCR, анализировали электрофорезом в 1% агарозном геле, используя по 10 мкл продукта реакции каждой полугнездовой PCR и производя обнаружение бромидом этидия (фиг.8).The conditions for performing multiple overlapping extension RT-PCRs with overlapping strands and half-nested PCRs were similar to those described in Example 3. However, these reactions were performed only using a mixture of multiple overlapping extending primers comprising a primer for C H3 corresponding to SEQ ID NO: 51. Sixteen samples obtained by performing the combined multiple extension RT-PCR chain extension reactions by overlapping and half-nested PCR were analyzed by electrophoresis on a 1% agarose gel using 10 μl of the reaction product of each semi-nested PCR and detecting ethidium bromide (Fig. 8).
Как показано на фиг.8, 2 из 16 полос (полосы 5 и 6) содержали фрагменты с ожидаемой подвижностью (примерно 1 т.п.о.). Кроме того, полоса 2 содержала менее интенсивный фрагмент при ожидаемой подвижности. Фрагменты длиной 1 т.п.о., присутствующие в полосах 5 и 6, вырезали из агарозного геля, очищали при помощи набора Qiaex II (Qiagen, № по каталогу 20051) и вводили в pCR2.1-TOPO, используя набор для клонирования TOPO TA компании Invitrogen (Invitrogen, № по каталогу 45-0641 Carlsbad, CA, USA). Два клона из каждого выделенного фрагмента имели вставки правильного размера. В результате гидролиза рестрикционными ферментами (отдельно NcoI и NheI) были обнаружены фрагменты ожидаемых размеров (410 и 680 п.о.), что свидетельствует о правильном связывании последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную и константную области легкой цепи.As shown in FIG. 8, 2 of the 16 bands (
Два клона, полученных из фрагмента, присутствующего в полосе 5, секвенировали, обнаружив при этом их идентичность, указывающую на то, что связанные VН и LC были родственными парами.Two clones obtained from the fragment present in
Пример 5. Объединенные реакции одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и гнездовой PCR с использованием VExample 5. Combined reactions of one-stage multiple RT-PCR with chain extension by overlapping and nested PCR using V λλ -специфических праймеров-specific primers
В данном примере рассмотрены реакции обратной транскрипции и множественной PCR с удлинением цепи, выполненные в виде одной стадии, с использованием Vλ-специфических праймеров с последующим осуществлением полугнездовой PCR. В качестве матриц использовали общую РНК, выделенную из двух разных линий клеток, экспрессирующих семейства генов лямбда-цепи 1b и 1е в комбинации с одной и той же вариабельной областью тяжелой цепи.In this example, the reactions of reverse transcription and multiple PCR with extension of the chain, performed in a single stage, using V λ- specific primers with the subsequent implementation of semi-nested PCR. As matrices, total RNA isolated from two different cell lines expressing the lambda chain gene families 1b and 1e in combination with the same variable region of the heavy chain was used.
а. Клеткиbut. Cells
Две линии клеток яичника китайского хомячка (СНО), экспрессирующих лямбда-цепь IgG1, были получены методом Flp-In (Invitrogen, Carlsbad, CA, USA).Two Chinese Hamster Ovary (CHO) cell lines expressing the IgG1 lambda chain were obtained by Flp-In (Invitrogen, Carlsbad, CA, USA).
Векторы pEm465/01P581 и pEm465/01P582, экспрессирующие лямбда-цепь IgG1 млекопитающего (фиг.9А) и представляющие два семейства генов лямбда-цепи IgG, были созданы на основе экспрессирующего вектора pcDNA5/FRT, полученного методом Flp-In. Клетки СНО-Flp-In котрансфецировали вышеуказанными плазмидами, содержащими гены антитела и pOG44, вызывающий временную экспрессию Flp рекомбиназы, с использованием фугена 6 (Roche, Mannheim, Germany), в соответствии с инструкциями изготовителя. Затем производили отбор трансформантов в отношении вставок. Отобранные линии клеток, получившие названия СНО Flp-In/Em464/01P581 и CHO Flp-In/Em464/01P582, помещали в среду F-12 Хэма, содержащую 2 мМ L-глутамина, 10% FCS и 900 мкг/мл гигромицина В (поддерживающая среда).The vectors pEm465 / 01P581 and pEm465 / 01P582 expressing the mammalian IgG1 lambda chain (Fig. 9A) and representing two families of IgG lambda chain genes were created based on the pcDNA5 / FRT expression vector obtained by Flp-In. CHO-Flp-In cells were cotransfected with the above plasmids containing the antibody and pOG44 genes, causing the temporary expression of Flp recombinase using fugen 6 (Roche, Mannheim, Germany), in accordance with the manufacturer's instructions. Then made the selection of transformants in relation to the inserts. Selected cell lines, called CHO Flp-In / Em464 / 01P581 and CHO Flp-In / Em464 / 01P582, were placed in Ham F-12 medium containing 2 mM L-glutamine, 10% FCS and 900 μg / ml hygromycin B ( supporting environment).
Линии клеток собирали при помощи трипсина и трижды промывали в поддерживающей среде. Примерно 107 клеток использовали для очистки общей РНК при помощи набора Nucleo Spin L (Macherey-Nagel, Duren, Germany) в соответствии с инструкциями изготовителя. Конечные концентрации РНК определяли методами измерения оптической плотности OD260.Cell lines were harvested using trypsin and washed three times in a support medium. About 10 7 cells were used to purify total RNA using the Nucleo Spin L kit (Macherey-Nagel, Duren, Germany) in accordance with the manufacturer's instructions. Final RNA concentrations were determined by optical density measurement methods OD 260 .
b. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияb. Single-Stage Multiple Overlap RT-PCR with Overlap
Множественную RT-PCR с удлинением цепи путем перекрывания выполняли аналогично примеру 3, используя 50 пг, 5 пг или 0,5 пг общей РНК в качестве матрицы и смесь множественных праймеров для удлинения цепи путем перекрывания, содержащую праймеры, показанные в таблице 6, в указанных ниже условиях циклизации.Multiple overlapping extension RT-PCRs were performed as in Example 3, using 50 pg, 5 pg, or 0.5 pg of total RNA as template and a mixture of multiple overlapping extension primers containing the primers shown in Table 6 in the indicated lower cyclization conditions.
Реакция PCR:PCR reaction:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
с. Полугнездовая PCRfrom. Semi-slot PCR
Один микролитр продукта реакции множественной RT-PCR с удлинением цепи путем перекрывания подвергали полугнездовой PCR (набор Biotaq, Bioline, UK, № по каталогу BIO-21040) в соответствии с инструкциями изготовителя. Общие объемы реакционных смесей были равны 20 мкл. Использованные праймеры показаны в таблице 7.One microliter of the product of the reaction of the multiple RT-PCR chain extension by overlapping was subjected to a semi-nested PCR (set Biotaq, Bioline, UK, catalog number BIO-21040) in accordance with the manufacturer's instructions. The total volumes of the reaction mixtures were 20 μl. The primers used are shown in table 7.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакцию выполняли в нижеследующих условиях циклизации:The reaction was carried out under the following cyclization conditions:
Десять микролитров продуктов реакции гнездовой PCR анализировали электрофорезом в 1,5% агарозном геле, используя для обнаружения бромид этидия (фиг.9В и 9С). Стрелками показаны продукты удлинения цепи путем перекрывания с ожидаемыми свойствами миграции длиной примерно 1 т.п.о.Ten microliters of the nested PCR reaction products were analyzed by 1.5% agarose gel electrophoresis using ethidium bromide for detection (Figs. 9B and 9C). The arrows show the products of chain extension by overlapping with the expected migration properties of approximately 1 kb in length.
Данный эксперимент показывает, что смесь множественных праймеров для удлинения лямбда-цепи путем перекрывания, представленная в таблице 6, может быть использована в одностадийной множественной RT-PCR с удлинением цепи путем перекрывания независимо от используемой матрицы. Кроме того, специфические продукты реакции PCR с удлинением цепи путем перекрывания были получены при использовании 0,5 пг общей РНК. Обнаруженная чувствительность позволяет предположить, что родственные связанные последовательности, кодирующие вариабельную область тяжелой цепи и вариабельную область легкой цепи, могут быть амплифицированы из отдельной клетки.This experiment shows that the multiple primer mixture for lambda chain extension by overlapping, shown in Table 6, can be used in a single-stage multiple RT-PCR with chain extension by overlapping, regardless of the template used. In addition, specific overlapping extension PCR reaction products were obtained using 0.5 pg of total RNA. The detected sensitivity suggests that related related sequences encoding the variable region of the heavy chain and the variable region of the light chain can be amplified from a single cell.
Пример 6. Создание подбиблиотеки родственных пар последовательностей, кодирующих противостолбнячное антителоExample 6. Creating a sub-library of related pairs of sequences encoding anti-tetanus antibody
В настоящем примере рассмотрены стадии, изображенные на блок-схеме, показанной на фиг.10, с использованием столбнячного токсина (ТТ) в качестве антигена-мишени.The present example describes the steps depicted in the flowchart of FIG. 10 using tetanus toxin (TT) as the target antigen.
а. Донорыbut. Donors
Доноров, которых ранее иммунизировали противостолбнячной вакциной, подвергали бустер-иммунизации противостолбнячной вакциной (Statens Serum Institut, Denmark). Через шесть дней после бустер-иммунизации противостолбнячной вакциной у доноров брали пробу крови, равную примерно 200 мл, которую вводили в пробирку с антикоагулянтом.Donors previously immunized with the tetanus vaccine were boosted with the tetanus vaccine (Statens Serum Institut, Denmark). Six days after booster immunization with an anti-tetanus vaccine, a blood sample of approximately 200 ml was taken from a donor and introduced into an anticoagulant tube.
Доноры должны быть здоровы и не иметь дремлющих или хронических инфекций. Они не должны страдать аутоиммунными заболеваниями или принимать любые иммунодепрессивные средства и не должны подвергаться никаким вакцинациям в течение последних 3 месяцев. Кроме того, во время бустер-иммунизации ТТ-вакциной доноры не должны иметь каких-либо серьезных инфекций на протяжении последнего месяца.Donors should be healthy and not have dormant or chronic infections. They should not suffer from autoimmune diseases or take any immunosuppressive drugs and should not be subjected to any vaccinations in the last 3 months. In addition, donors should not have any serious infections during the last month during booster immunization with the TT vaccine.
b. Получение мононуклеарных клеток периферической крови (РВМС)b. Getting peripheral blood mononuclear cells (PBMC)
РВМС выделяют из проб крови при помощи устройства Lymphoprep (Axis-Shield PoC AS, Norway, производственный № 1001967) в соответствии с рекомендациями изготовителей. Кровь разводят в отношении 1:1 в РBS и вводят полученную взвесь в Lymphoprep в отношении 2:1. Пробирки центрифугируют с ускорением 800 g в течение 20 минут при 25°С и собирают полосу, соответствующую интерфазе лимфоцитов. Клетки промывают в PBS, содержащем 2 мМ EDTA.PBMCs were isolated from blood samples using a Lymphoprep device (Axis-Shield PoC AS, Norway, production No. 1001967) in accordance with the recommendations of the manufacturers. Blood was diluted in a 1: 1 ratio in PBS and the resulting suspension was introduced into Lymphoprep in a 2: 1 ratio. The tubes are centrifuged with an acceleration of 800 g for 20 minutes at 25 ° C and a strip corresponding to the lymphocyte interphase is collected. Cells were washed in PBS containing 2 mM EDTA.
с. Обогащение В-клетокfrom. B cell enrichment
Линию В-клеток (CD19+ клетки) в PBMC обогащают методом сортировки клеток с использованием магнитных гранул в соответствии с нижеследующим описанием.The B cell line (CD19 + cells) in the PBMC is enriched by magnetic bead sorting of cells as described below.
Выделенные РВМС окрашивают анти-CD19-FIТC (флуоресцинизотиоцианат) (Becton Dickenson, NJ, USA, № по каталогу 345776). Все стадии выполняют в темном помещении при 4°С. Окрашивание производят 10 мкл анти-CD19-FITC на 1х106 клеток в объеме, равном 100 мкл на 1х106 клеток, используя М-буфер (PBS, рН 7,2, 0,5% BSA, 2 мМ EDTA). В вышеуказанных условиях происходит окрашивание линии В-клеток РВМС. Клетки инкубируют в течение 20 минут и затем дважды промывают М-буфером. Клетки, окрашенные анти-CD19-FITC, подвергают магнитному мечению при помощи микрогранул, конъюгированных с анти-FITC-антителом, используя 10 мкл магнитных гранул, сенсибилизированных анти-FITC-антителом (Miltenyi Biotec, Gladbach, Germany, № по каталогу 130-042-401), на 1х106 клеток в объеме, равном 100 мкл М-буфера на 1х106 клеток. Клетки инкубируют в течение 15 минут и затем один раз промывают М-буфером. Клетки вторично суспендируют в дегазированном М-буфере.The isolated PBMCs are stained with anti-CD19-FITC (fluorescein isothiocyanate) (Becton Dickenson, NJ, USA, catalog number 345776). All stages are performed in a dark room at 4 ° C. Staining is performed with 10 μl of anti-CD19-FITC per 1x10 6 cells in a volume equal to 100 μl per 1x10 6 cells using M-buffer (PBS, pH 7.2, 0.5% BSA, 2 mm EDTA). Under the above conditions, staining of the PBMC B-cell line occurs. Cells are incubated for 20 minutes and then washed twice with M-buffer. Cells stained with anti-CD19-FITC are magnetically labeled with microbeads conjugated to an anti-FITC antibody using 10 μl of magnetic beads sensitized with anti-FITC antibody (Miltenyi Biotec, Gladbach, Germany, Cat. No. 130-042 -401), per 1x10 6 cells in a volume equal to 100 μl of M-buffer per 1x10 6 cells. Cells are incubated for 15 minutes and then washed once with M-buffer. Cells are resuspended in a degassed M-buffer.
Колонку МACS LS (Miltenyi Biotec, Gladbach, Germany, № по каталогу 130-042-401) предварительно обрабатывают дегазированным М-буфером в соответствии с инструкциями изготовителей. Взвесь клеток, окрашенных анти-CD19-FITC и меченных магнитными гранулами, сенсибилизированными анти-FITC-антителом, вводят в колонку с возможностью прохождения через нее. Окрашенные и меченые клетки (CD19+) остаются в магнитном поле, окружающем колонку, в то время как неокрашенные клетки (CD19-) проходят через колонку. Колонку промывают дегазированным М-уфером. Магнитное поле отключают и собирают CD19+ клетки.The MACS LS column (Miltenyi Biotec, Gladbach, Germany, catalog number 130-042-401) is pretreated with a degassed M-buffer in accordance with the manufacturers instructions. A suspension of cells stained with anti-CD19-FITC and labeled with magnetic beads sensitized with anti-FITC antibody is introduced into the column with the possibility of passing through it. Stained and labeled cells (CD19 +) remain in the magnetic field surrounding the column, while unpainted cells (CD19-) pass through the column. The column is washed with degassed M-ufer. The magnetic field is turned off and CD19 + cells are collected.
d. Сортировка плазматических клетокd. Plasma cell sorting
Элюат из колонки MACS центрифугируют и вторично суспендируют в буфере для FACS (PBS, рН 7,2, 2% BSA) в концентрации, равной 1х106 клеток/60 мкл буфера для FACS. Добавляют анти-CD19-FITC (Becton Dickenson, NJ, USA, № по каталогу 345776) (10 мкл/106 клеток), анти-CD38-РЕ (Becton Dickenson, NJ, USA, № по каталогу 555460) (10 мкл/106 клеток) и анти-CD45-PerCP (Becton Dickenson, NJ, USA, № по каталогу 345809) (20 мкл/106 клеток). Клетки инкубируют в темном помещении при 4°С в течение 20 минут, затем два раза промывают и вторично суспендируют в буфере для FACS.The eluate from the MACS column is centrifuged and resuspended in FACS buffer (PBS, pH 7.2, 2% BSA) at a concentration of 1x10 6 cells / 60 μl of FACS buffer. Add anti-CD19-FITC (Becton Dickenson, NJ, USA, 345776 No.) (10 μl / 10 6 cells), anti-CD38-PE (Becton Dickenson, NJ, USA, 555460 No.) (10 μl / 10 6 cells) and anti-CD45-PerCP (Becton Dickenson, NJ, USA, catalog number 345809) (20 μl / 10 6 cells). Cells were incubated in a dark room at 4 ° C for 20 minutes, then washed twice and resuspended in FACS buffer.
Клетки сортируют методом сортировки клеток с возбуждением флуоресценции (FACS), используя нижеследующие параметры сортировки:Cells are sorted by Fluorescence Excited Cell Sort (FACS) using the following sorting options:
1. Прямое и боковое рассеяние для сохранения лимфоцитов и моноцитов, включая плазматические бласты и плазматические клетки, и удаление мертвых клеток и клеток с очень высоким боковым рассеянием, которые могут быть агрегатами или гранулоцитами.1. Direct and lateral scattering to preserve lymphocytes and monocytes, including plasma blasts and plasma cells, and the removal of dead cells and cells with very high lateral scattering, which may be aggregates or granulocytes.
2. Клетки, которые являются CD19-положительными и экспрессируют повышенные уровни CD38 (CD38hi). Подобным образом происходит улавливание в основном CD38 клеток, так как РВМС были обогащены в колонке MACS CD19 клетками, но указанный способ позволяет обнаружить любые загрязнения.2. Cells that are CD19-positive and express elevated levels of CD38 (CD38 hi ). Similarly, mainly CD38 cells are captured, since PBMCs were enriched in the MACS column of CD19 cells, but this method allows any contamination to be detected.
3. CD45-положительные клетки. Все лимфоциты экспрессируют CD45. Однако плазматические клетки характеризуются меньшей экспрессией CD45 по сравнению с более ранними стадиями дифференцировки лимфоцитов. Поэтому при улавливании CD45 можно получить дискретную популяцию клеток, соответствующую плазматическим клеткам.3. CD45-positive cells. All lymphocytes express CD45. However, plasma cells are characterized by lower expression of CD45 compared to the earlier stages of lymphocyte differentiation. Therefore, by capturing CD45, a discrete cell population corresponding to plasma cells can be obtained.
Клетки, сортированные методом FACS, собирают в виде отдельных клеток и сразу же помещают в отдельные лунки 96-луночных планшетов, содержащих 5 мкл буфера РBS с 5 ед. ингибитора РНКазы (RNasin, Promega, Madison USA, № по каталогу N2515) в одной лунке. На данном этапе клетки могут быть заморожены для последующего выполнения RT-PCR или сразу же использованы для выполнения RT-PCR.Cells sorted by FACS are collected as single cells and immediately placed in separate wells of 96-well plates containing 5 μl of PBS buffer with 5 units. RNase inhibitor (RNasin, Promega, Madison USA, catalog number N2515) in one well. At this stage, the cells can be frozen for subsequent RT-PCR or immediately used for RT-PCR.
е. Связывание родственных пар последовательностей, кодирующих вариабельные области иммуноглобулинаe. Linking related pairs of sequences encoding the variable regions of immunoglobulin
Метод множественной RT-PCR с удлинением цепи путем перекрывания применим к отдельным клеткам, обеспечивая родственное связывание транскрибированных последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи антитела против столбнячного токсина.The overlap extension RT-PCR method with overlapping chain is applicable to individual cells, providing for the related binding of transcribed sequences encoding the variable region of the heavy chain and the variable region of the light chain of an anti-tetanus toxin antibody.
е-1. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияe-1. Single-Stage Multiple Overlap RT-PCR with Overlap
Набор для одностадийной RT-PCR компании Qiagen (Qiagen, № по каталогу 210212, Hilden, Germany) используют для выполнения множественной RT-PCR с удлинением цепи путем перекрывания в соответствии с рекомендациями изготовителя. Замороженные 96-луночные планшеты, содержащие одну клетку в одной лунке, удаляют из холодильника и, когда в лунках не остается кристаллов льда, к каждому образцу (отдельной клетке) сразу же добавляют 15 мкл реакционной смеси для RT-PCR.Qiagen's one-stage RT-PCR kit (Qiagen, 210212, Hilden, Germany) is used to perform multiple RT-PCRs with chain extension by overlapping according to the manufacturer's recommendations. Frozen 96-well plates containing one cell in one well are removed from the refrigerator and, when there are no ice crystals left in the wells, 15 μl of RT-PCR reaction mixture is immediately added to each sample (single cell).
Реакционная смесь для RT-PCR содержит в общем объеме, равном 20 мкл, нижеследующие реагенты:The reaction mixture for RT-PCR contains in a total volume equal to 20 μl, the following reagents:
однократный буфер для одностадийной RT-PCR,single buffer for single-stage RT-PCR,
dNTP в конечной концентрации, равной 400 мкМ каждого реагента,dNTP at a final concentration of 400 μM of each reagent,
смесь множественных праймеров для удлинения цепи путем перекрывания в концентрациях, указанных в таблице 8,a mixture of multiple primers for lengthening the chain by overlapping at the concentrations indicated in table 8,
0,8 мкл смеси ферментов для одностадийной RT-PCR,0.8 μl of enzyme mixture for one-step RT-PCR,
20 ед. ингибитора РНКазы (RNasin, Promega, Madison, USA, № по каталогу N2515).20 units an RNase inhibitor (RNasin, Promega, Madison, USA, catalog number N2515).
Состав смеси множественных праймеров для удлинения цепи путем перекрывания показан в таблице 8.The composition of the mixture of multiple primers to extend the chain by overlapping is shown in table 8.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакцию выполняют в нижеследующих условиях циклизации:The reaction is carried out under the following cyclization conditions:
Реакция PCR:PCR reaction:
е-2. Дополнительная амплификацияe-2. Additional amplification
Один микролитр продукта реакции множественной RT-PCR с удлинением цепи путем перекрывания из каждого образца подвергают полугнездовой РCR (набор Biotaq, Bioline, UK, № по каталогу BIO-1040) в соответствии с рекомендациями изготовителя набора, используя 96-луночные планшеты. Каждая реакционная смесь имеет общий объем, равный 50 мкл, и содержит однократный буфер Buiotaq, 200 мкМ dNTP (каждого реагента), 2 мМ MgCl2, 1,25 ед. Bio Taq полимеразы в конечной концентрации и праймеры, показанные в таблице 9.One microliter of the reaction product of the multiple RT-PCR chain extension by overlapping from each sample is subjected to a semi-nested PCR (Biotaq kit, Bioline, UK, BIO-1040 No.) according to the kit manufacturer's recommendations using 96-well plates. Each reaction mixture has a total volume of 50 μl and contains a single Buiotaq buffer, 200 μM dNTP (each reagent), 2 mm MgCl 2 , 1.25 units. Bio Taq polymerase at final concentration and primers are shown in table 9.
Реакцию выполняют в нижеследующих условиях циклизации:The reaction is carried out under the following cyclization conditions:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Последовательности, обозначенные заглавными буквами, соответствуют геноспецифической области.The sequences indicated in capital letters correspond to the genespecific region.
Десять микролитров ограниченной серии образцов анализируют электрофорезом в 1,5% агарозном геле, используя для визуализации бромид этидия, для проверки успешного выполнения множественной RT-PCR с удлинением цепи путем перекрывания.Ten microliters of a limited series of samples were analyzed by 1.5% agarose gel electrophoresis using ethidium bromide for visualization to verify the success of multiple RT-PCR with chain extension by overlapping.
Ожидаемый размер фрагментов (точный размер зависит от длины вариабельных областей):The expected size of the fragments (the exact size depends on the length of the variable regions):
VН: ~410 п.о.V H : ~ 410 bp
LC: ~680 п.о.LC: ~ 680 bp
Фрагмент удлинения цепи путем перекрывания: ~1070 п.о.Fragment of chain elongation by overlapping: ~ 1070 bp
По два микролитра из всех образцов, полученных у одного донора, которые культивировали на 96-луночных планшетах, объединяют в одной пробирке. Собранные образцы гидролизуют XhoI и NotI. Гидролизованные фрагменты удлинения цепи путем перекрывания очищают препаративным электрофорезом в 1% агарозном геле; фрагменты удлинения цепи путем перекрывания вырезают из агарозного геля и очищают при помощи набора Qiaex II (Qiagen, № по каталогу 20051, Hilden, Germany). На данной стадии не нужно объединять родственные пары, если этого не требуется. В таком случае каждую отдельную реакционная смесь расщепляют рестрикционными ферментами и полученные продукты клонируют отдельно в описанном ниже векторе.Two microlitres of all samples obtained from one donor, which were cultured on 96-well plates, are combined in one tube. Collected samples hydrolyze XhoI and NotI. Hydrolyzed chain extension fragments by overlapping are purified by preparative electrophoresis on a 1% agarose gel; chain elongation fragments are cut out from the agarose gel and purified using a Qiaex II kit (Qiagen, Catalog No. 20051, Hilden, Germany). At this stage, you do not need to combine related pairs if this is not required. In this case, each individual reaction mixture is digested with restriction enzymes and the resulting products are cloned separately in the vector described below.
f. Библиотека экспрессируемых родственных Fab-фрагментовf. Library of expressed related Fab fragments
Библиотеку векторов экспрессии Fab-фрагментов создают путем введения пула фрагментов удлинения цепи путем перекрывания, гидролизованных XhoI/NotI, в вектор JSK301 E.coli (фиг.11), при помощи лигирования. E.coli (ТОР10) трансформируют методом электропорации библиотекой векторов экспрессии Fab-фрагментов и отбирают трансформанты на 2хYT агаре, содержащем 100 мкг/мл карбенициллина. Плазмидную ДНК получают из колоний сразу же после удаления с агаровых пластинок. Для сохранения разнообразия плазмидный препарат получают из минимального числа колоний одного донора, соответствующих трехкратному общему числу первоначально сортированных отдельных плазматических клеток. Библиотеку экспрессируемых родственных Fab-фрагментов создают путем введения кластера прокариотического промотора и лидерной последовательности, выделенного из phh3 (Den, W. et al. 1999, J. Immunol. Methods 222, 45-57), в полученный плазмидный препарат методом гидролиза AscI и NheI и последующего лигирования. Процесс создания библиотеки показан на фиг.12. E.coli (TG1) трансформируют методом электропорации библиотекой экспрессируемых родственных Fab-фрагментов и отбирают трансформанты на 2хYT агаре, содержащем 100 мкг/мл карбенициллина. Доноры не контактируют во время выполнения процеруды, описанной в публикации Den et al., J. Immunol. Methods, 1999, Jan. 1; 222(1-2):45-57. Однако при желании они могут находиться вместе на любой стадии.A library of expression vectors for Fab fragments is created by introducing a pool of chain extension fragments by overlapping, XhoI / NotI hydrolyzed, into the E. coli JSK301 vector (FIG. 11) by ligation. E. coli (TOP 10) is transformed by electroporation with a library of expression vectors of Fab fragments and transformants are selected on 2xYT agar containing 100 μg / ml carbenicillin. Plasmid DNA is obtained from colonies immediately after removal from agar plates. To preserve diversity, the plasmid preparation is obtained from the minimum number of colonies of one donor, corresponding to three times the total number of initially sorted individual plasma cells. A library of expressed related Fab fragments is created by introducing a prokaryotic promoter cluster and leader sequence isolated from phh3 (Den, W. et al. 1999, J. Immunol.
g. Скрининг клоновg. Clone Screening
Fab-экспрессирующие клоны исследуют в отношении связывания ТТ-антигена методом антиген-специфического анализа ELISA.Fab-expressing clones were examined for binding of TT antigen by antigen-specific ELISA.
g-1. Создание базовых планшетов и экспрессия Fab-фрагментовg-1. Creation of base plates and expression of Fab fragments
Отобранные колонии клеток TG1, каждая из которых содержит вектор экспрессии родственных Fab-фрагментов из библиотеки, созданной на стадии (f), помещают в отдельные лунки 96-луночных планшетов, содержащие 2хYT/100 мкг/мл Amp/1% глюкозы. Колонии выращивают, осторожно встряхивая, в течение ночи при 37°С. Указанные планшеты, именуемые базовыми планшетами, хранят при -80°С после добавления глицерина до конечной концентрации, равной 15%.Selected TG1 cell colonies, each of which contains an expression vector of related Fab fragments from the library created in step (f), are placed in separate wells of 96-well plates containing 2xYT / 100 μg / ml Amp / 1% glucose. Colonies are grown by shaking gently overnight at 37 ° C. These tablets, referred to as base plates, are stored at -80 ° C after glycerol is added to a final concentration of 15%.
До передачи базовых планшетов на хранение их используют для инокуляции одного или нескольких 384-луночных планшетов, содержащих 2хYT/100 мкг/мл Amp/0,1% глюкозы, при помощи 96-канального репликатора. Планшеты заклеивают и встряхивают в течение 2-3 часов при 37°С.Prior to transferring the base plates for storage, they are used to inoculate one or more 384-well plates containing 2xYT / 100 μg / ml Amp / 0.1% glucose using a 96-channel replicator. The tablets are sealed and shaken for 2-3 hours at 37 ° C.
Экспрессию Fab-фрагментов индуцируют, добавляя равное количество 2хYT/100 мкг/мл Amp/0,2 мМ IPTG с достижением конечной концентрации IPTG, равной 0,1 мМ. Планшеты заклеивают и встряхивают в течение ночи при 30°С. На следующий день Fab-содержащие супернатанты анализируют в отношении специфичности связывания ТТ-антигена методом ELISA.Expression of Fab fragments was induced by adding an equal amount of 2xYT / 100 μg / ml Amp / 0.2 mM IPTG to achieve a final IPTG concentration of 0.1 mM. The plates are sealed and shaken overnight at 30 ° C. The next day, Fab-containing supernatants were analyzed for binding specificity for TT antigen by ELISA.
g-2. Анализ ELISAg-2. ELISA analysis
384-луночные планшеты для ELISA (Nunc, Roskilde, Denmark, № по каталогу 265196) сенсибилизируют в течение ночи при 4°С антигеном столбнячного токсина (ТТ), разведенным до конечной концентрации 0,1 мкг/мл в PBS в объеме, равном 25 мкл на одну лунку. Избыток сайтов связывания в лунках блокируют в течение 1 часа при комнатной температуре, добавляя 2% М-PBS-T (2% сухого обезжиренного молока в PBS, 0,05% твина-20). Лунки дважды промывают PBS-T (PBS, 0,05% твина-20).384-well ELISA plates (Nunc, Roskilde, Denmark, 265196 No.) are sensitized overnight at 4 ° C. with tetanus toxin (TT) antigen diluted to a final concentration of 0.1 μg / ml in PBS in a volume of 25 μl per well. Excess binding sites in the wells are blocked for 1 hour at room temperature by adding 2% M-PBS-T (2% skimmed milk powder in PBS, 0.05% Tween-20). Wells are washed twice with PBS-T (PBS, 0.05% Tween-20).
Fab-содержащие бактериальные супернатанты, полученные на стадии g-1, разводят в отношении 1:2 в 2% M-PBS-T и переносят в двух копиях в лунки планшета для ELISA. Культуру инкубируют в течение 1 часа при комнатной температуре. Лунки четыре раза промывают РBS-T. В лунки добавляют антитело козы к комплексу Fab/HRP человека (Sigma, St.Louis, MO, USA, № по каталогу А0293), разведенное в отношении 1:10000 в 2% M-PBS-T. Культуру инкубируют в течение 1 часа при комнатной температуре. Лунки четыре раза промывают PBS-T. Добавляют субстрат ТМВ Plus (KemEnTec, Copenhagen, Denmark, № по каталогу 4390L) и инкубируют в течение 5-15 минут. Реакции прекращают, добавляя равный объем 1М раствора Н2SO4. Степень выполнения реакций определяют в спектрофотометре для прочтения планшетов для ELISA при 450 нм (Multiscan Ascent, Labsystems, Franklin, USA).Fab-containing bacterial supernatants obtained in g-1 are diluted 1: 2 in 2% M-PBS-T and transferred in duplicate to the wells of an ELISA plate. The culture is incubated for 1 hour at room temperature. Wells are washed four times with PBS-T. Goat antibody is added to the wells to the human Fab / HRP complex (Sigma, St. Louis, MO, USA, Catalog No. A0293), diluted 1: 10000 in 2% M-PBS-T. The culture is incubated for 1 hour at room temperature. Wells are washed four times with PBS-T. Add TMB Plus substrate (KemEnTec, Copenhagen, Denmark, catalog number 4390L) and incubate for 5-15 minutes. The reaction is stopped by adding an equal volume of a 1M solution of H 2 SO 4 . The degree of reaction is determined in a spectrophotometer for reading ELISA plates at 450 nm (Multiscan Ascent, Labsystems, Franklin, USA).
Затем из базовых планшетов удаляют исходные бактериальные клоны, соответствующие клонам, связывающим ТТ-антиген. Из выделенных антиген-положительных клонов Fab-фрагментов получают плазмидную ДНК и создают подбиблиотеку экспрессируемых родственных Fab-фрагментов клонов, связывающих ТТ-антиген.Then, original bacterial clones corresponding to the TT antigen binding clones are removed from the base plates. Plasmid DNA is obtained from the isolated antigen-positive clones of Fab fragments and a sub-library of expressed related Fab fragments of clones that bind TT antigen is created.
Указанные клоны могут быть также подвергнуты анализу ELISA с использованием антитела против легкой цепи для установления корреляции между числом антиген-связывающих клонов и числом Fab-экспрессирующих клонов. Кроме того, такой анализ позволяет получить информацию о легких каппа- и лямбда-цепях в указанных клонах.These clones can also be subjected to ELISA using antibodies against light chains to establish a correlation between the number of antigen-binding clones and the number of Fab-expressing clones. In addition, such an analysis provides information on the light kappa and lambda chains in these clones.
h. Библиотека экспрессируемых родственных антителh. Expressed Related Antibody Library
Для облегчения экспрессии непроцессированных антител человека родственные вариабельные области из бактериального вектора экспрессии Fab-фрагментов должны быть перенесены в экспрессирующий вектор млекопитающего, содержащий константные области иммуноглобулина человека одного из изотипов. Такой перенос можно осуществить в результате последовательного или массового переноса клонов. Ниже описан способ массового переноса.To facilitate the expression of unprocessed human antibodies, related variable regions from the bacterial expression vector of Fab fragments should be transferred to a mammalian expression vector containing constant regions of a human immunoglobulin of one of the isotypes. Such transfer can be accomplished by sequential or mass transfer of clones. The mass transfer method is described below.
Массовый перенос выполняют в виде двух стадий. Сначала собирают плазмидные препараты отдельно выделенных антигенсвязыващих клонов Fab-фрагментов. Кластер, содержащий прокариотический промотор и лидерную последовательноть, заменяют кластером промотора и лидерной последовательности млекопитающего, состоящим из лидерной последовательности щелочной фосфатазы человека (лидерная последовательность АР), промотора фактора элонгации 1-альфа человека (EFP), аденовирусного главного позднего промотора (AdMLP), лидерной последовательности IgK, путем гидролиза подбиблиотеки собранных экспрессируемых Fab-фрагментов при помощи AscI и NheI с последующим введением кластера промотора и лидерной последовательности млекопитающего, выполняемого лигированием. E.coli (ТОР10) трансформируют методом электропорации полученной библиотекой экспрессируемых Fab-фрагментов с замененным промотором и отбирают трансформанты на 2хYT агаре, содержащем 100 мкг/мл карбенициллина. Плазмидную ДНК получают из колоний сразу же после удаления с агаровых пластинок. Для сохранения разнообразия плазмидный препарат получают из минимального числа колоний одного донора, соответствующего примерно трехкратному общему числу клонов в исходной библиотеке.Mass transfer is performed in two stages. First, plasmid preparations of separately isolated antigen binding clones of Fab fragments are collected. The cluster containing the prokaryotic promoter and leader sequence is replaced by a mammalian promoter and leader sequence cluster consisting of a human alkaline phosphatase leader sequence (AP leader sequence), a human 1-alpha elongation factor (EFP) promoter, an adenovirus late late promoter (AdMLP), a leader IgK sequences by hydrolysis of a sub-library of assembled expressed Fab fragments using AscI and NheI followed by the introduction of a promoter cluster and leader sequence ligation of a mammal. E. coli (TOP 10) was transformed by electroporation with the resulting library of expressed Fab fragments with a replaced promoter and transformants were selected on 2xYT agar containing 100 μg / ml carbenicillin. Plasmid DNA is obtained from colonies immediately after removal from agar plates. To preserve diversity, the plasmid preparation is obtained from the minimum number of colonies of one donor, corresponding to approximately three times the total number of clones in the source library.
Затем, осуществляя гидролиз плазмидного препарата при помощи XhoI и NotI, из вектора экспрессии Fab-фрагментов с замененным промотором выделяют родственные вариабельные последовательности. Выделенный фрагмент вводят лигированием в экспрессирующий вектор млекопитающего, получая при этом библиотеку экспрессируемых родственных антител. Используемый вектор аналогичен показанному на фиг.9А за исключением того, что IgL в данном случае соответствует последовательности, кодирующей легкую каппа-цепь. Вышеуказанный экспрессирующий вектор млекопитающего получен на основе сайт-специфической системы Flp-In (Invitrogen Corporation, Carlsbad, CA, USA, № по каталогу К6010-01). E.coli (TOP10) трансформируют методом электропорации полученной библиотекой экспрессируемых родственных антител и отбирают трансформанты на 2хYT агаре, содержащем 100 мкг/мл карбенициллина. Плазмидную ДНК получают из колоний сразу же после удаления с агаровых пластинок. Для сохранения разнообразия плазмидный препарат снова получают из минимального числа колоний одного донора, соответствующего примерно трехкратному общему числу клонов в исходной библиотеке. Полученный плазмидный препарат из библиотеки экспрессируемых родственных антител можно использовать для трансфекции клетки-хозяина млекопитающего, например клеток СНО из системы Flp-In компании Invitrogen (Invitrogen Corporation, Carlsbad, CA, USA, № по каталогу К6010-01), с целью создания устойчивых экспрессирующих линий клеток млекопитающего путем интеграции, опосредуемой Flp-рекомбиназой. Такую линию клеток можно использовать для продуцирования рекомбинантных поликлональных антител.Then, carrying out the hydrolysis of the plasmid preparation using XhoI and NotI, related variable sequences are isolated from the expression vector of Fab fragments with a replaced promoter. The isolated fragment is introduced by ligation into the mammalian expression vector, thereby obtaining a library of expressed related antibodies. The vector used is similar to that shown in FIG. 9A, except that the IgL in this case corresponds to the sequence encoding the kappa light chain. The above mammalian expression vector was obtained based on the site-specific Flp-In system (Invitrogen Corporation, Carlsbad, CA, USA, catalog number K6010-01). E. coli (TOP10) was transformed by electroporation with the resulting library of expressed related antibodies and transformants were selected on 2xYT agar containing 100 μg / ml carbenicillin. Plasmid DNA is obtained from colonies immediately after removal from agar plates. To preserve diversity, the plasmid preparation is again obtained from the minimum number of colonies of one donor, corresponding to approximately three times the total number of clones in the source library. The obtained plasmid preparation from the library of expressed related antibodies can be used to transfect a mammalian host cell, for example, CHO cells from the Invitrogen Flp-In system (Invitrogen Corporation, Carlsbad, CA, USA, catalog number K6010-01), in order to create resistant expressing mammalian cell lines by integration mediated by Flp recombinase. Such a cell line can be used to produce recombinant polyclonal antibodies.
Пример 7. Скрининг при помощи мембранного анализа высокой плотностиExample 7. Screening using high density membrane analysis
Fab-экспрессирующие клоны по примеру 6f исследуют при помощи мембранного анализа высокой плотности.The Fab-expressing clones of Example 6f were examined by high density membrane analysis.
а. Создание базовых планшетовbut. Creating basic tablets
Базовые планшеты создают в соответствии с описанием, приведенным на стадии (g-1) примера 6.Base plates are made as described in step (g-1) of Example 6.
b. Получение PVDF мембранb. Obtaining PVDF membranes
PVDF (поливинилиденфторидные) мембраны (Amersham, Uppsala, Sweden, № по каталогу RPN2020F) сенсибилизируют ТТ-антигеном, разведенным до конечной концентрации 1 мкг/мл в PBS, в течение ночи при 4°С в соответствии с инструкциями изготовителя. Избыток сайтов связывания на мембранах блокируют в течение 1 часа в 2% М-PBS (2% сухого обезжиренного молока в PBS). Мембраны трижды промывают в PBS. Мембраны вымачивают в 2хYT в течение нескольких минут.PVDF (polyvinylidene fluoride) membranes (Amersham, Uppsala, Sweden, catalog number RPN2020F) were sensitized with TT antigen diluted to a final concentration of 1 μg / ml in PBS overnight at 4 ° C according to the manufacturer's instructions. Excess membrane binding sites are blocked for 1 hour in 2% M-PBS (2% skimmed milk powder in PBS). Membranes are washed three times in PBS. Membranes are soaked in 2xYT for several minutes.
с. Консолидация клоновfrom. Clone Consolidation
Консолидацию клонов на 384-луночных планшетах выполняют путем переноса клонов с базовых планшетов на один или несколько 384-луночных планшетнов, содержащих 20 мкл 2хYT/лунку, используя 96-канальный репликатор.Clone consolidation on 384-well plates is accomplished by transferring the clones from the base plates to one or more 384-well plates containing 20 μl of 2xYT / well using a 96-channel replicator.
При помощи 384-канального репликатора бактерии переносят в двух копиях на одну или несколько найлоновых мембран (Amersham, Uppsala, Sweden, № по каталогу RPN2020B), расположенных на агаровых пластинках, содержащих 2хYT/Carb/1% глюкозы. Планшеты инкубируют в течение 4-6 часов при 37°С.Using a 384-channel replicator, bacteria are transferred in duplicate onto one or more nylon membranes (Amersham, Uppsala, Sweden, RPN2020B catalog number) located on agar plates containing 2xYT / Carb / 1% glucose. The plates are incubated for 4-6 hours at 37 ° C.
d. Индукция экспрессии Fab-фрагментовd. Induction of expression of Fab fragments
PVDF мембраны, полученные на стадии b, помещают на агаровые пластинки, содержащие 2хYT/Carb/0,1 мМ IPTG. Найлоновые мембраны с растущими бактериальными колониями помещают поверх PVDF мембран (одну найлоновую мембрану на одну PVDF мембрану) на IPTG-содержащую агаровую пластинку. IPTG-содержащую агаровую пластинку инкубируют при 30°С в течение ночи для облегчения IPTG-индуцируемой экспрессии Fab-фрагментов из колоний. Молекулы Fab-фрагментов проникают через найлоновую мембрану на PVDF мембрану, которая задерживает Fab-фрагменты, связывающие ТТ-антиген.PVDF membranes obtained in step b are placed on agar plates containing 2xYT / Carb / 0.1 mM IPTG. Nylon membranes with growing bacterial colonies are placed on top of the PVDF membranes (one nylon membrane per PVDF membrane) on an IPTG-containing agar plate. The IPTG-containing agar plate was incubated at 30 ° C. overnight to facilitate IPTG-induced expression of Fab fragments from the colonies. Molecules of Fab fragments penetrate through the nylon membrane onto the PVDF membrane, which retains Fab fragments that bind the TT antigen.
е. Обнаружениеe. Detection
Найлоновые мембраны удаляют и PVDF мембраны промывают PBS-T (PBS, 0,05% твина-20) 2 раза по 5 минут. Мембраны инкубируют в течение 30 минут с 2% М-PBS. PVDF мембраны промывают PBS-T 2 раза по 5 минут и инкубируют в течение 1 часа с антителом козы к комплексу IgG/HRP человека (Sigma, St. Louis, MO, USA, № по каталогу А0293) при разведении в 2% М-PBS в отношении 1:10000. PVDF мембраны промывают PBS-T 3 раза по 5 минут. И, наконец, PVDF мембраны инкубируют в течение 5 минут с хемилюминесцентным субстратом SuperSignal West Femto (Pierce, Rockford, Il, USA, № по каталогу 34095) в соответствии с инструкциями изготовителей. Избыток субстрата удаляют и PVDF мембраны помещают под видеокамеру на основе устройства с зарядовой связью (CCD) для обнаружения хемилюминесцентного сигнала, возникающего в тех положениях PVDF мембраны, где Fab-фрагмент связывает ТТ-антиген.The nylon membranes are removed and the PVDF membranes are washed with PBS-T (PBS, 0.05% Tween-20) 2 times for 5 minutes. Membranes are incubated for 30 minutes with 2% M-PBS. PVDF membranes were washed with PBS-
Положительные клоны, связывающие ТТ-антиген, появляются на изображении в виде точек. Исходный бактериальный клон затем удаляют с базовых планшетов. Из выделенных антиген-положительных клонов Fab-фрагментов получают плазмидную ДНК, создавая таким образом подбиблиотеку экспрессируемых родственных Fab-фрагментов клонов, связывающих ТТ-антиген.Positive clones that bind the TT antigen appear in the image as dots. The original bacterial clone is then removed from the base plates. Plasmid DNA is obtained from the isolated antigen-positive clones of Fab fragments, thus creating a sub-library of expressed related Fab fragments of clones that bind TT antigen.
f. Корреляция между антигенсвязывающими клонами и Fab-экспрессирующими клонамиf. Correlation between antigen-binding clones and Fab-expressing clones
Найлоновые мембраны, удаленные на стадии е., помещают на вторую серию PVDF мембран, сенсибилизированных антителом против легкой цепи или антителом против Fab-фрагментов, способом, описанным на стадии b. Затем повторяют стадии d. и е.The nylon membranes removed in step e. Are placed on a second series of PVDF membranes sensitized with an anti-light chain antibody or anti-Fab antibody, according to the method described in step b. Then repeat stage d. and e.
Fab-положительные клоны появляются на изображении в виде точек, при этом можно установить корреляцию между числом клонов, связывающих ТТ-антиген, и числом Fab-экспрессирующих клонов.Fab-positive clones appear as dots on the image, and a correlation can be established between the number of clones that bind the TT antigen and the number of Fab-expressing clones.
Пример 8. Пример, иллюстрирующий выделение последовательностей, кодирующих гетеромерный белокExample 8. An example illustrating the selection of sequences encoding a heteromeric protein
Настоящий пример иллюстрирует возможность одностадийного выделения тримерного белка, связывающего гуаниннуклеотид (G-белок), при помощи множественной RT-PCR с удлинением цепи путем перекрывания по настоящему изобретению. Семейство субъединиц G-белка является обширным, только у человека насчитывается примерно 16 разных альфа-субъединиц, 5 бета-субъединиц и 12 гамма-субъединиц. Для настоящего примера были выбраны субъединица GαS (№ доступа в банке генов GenBank Х04408), субъединица Gβ1 (№ доступа в банке генов GenBank AF501822) и субъединица Gγ1 (№ доступа в банке генов GenBank BC029367). Способ связывания показан на фиг.13, где стадия 1 является стадией множественной RT-PCR с удлинением цепи путем перекрывания и стадия 2 является стадией дополнительной амплификации связанного продукта.This example illustrates the possibility of a one-step isolation of a trimeric guanine nucleotide binding protein (G protein) using multiple chain extension RT-PCR by overlapping of the present invention. The family of G protein subunits is extensive, only in humans there are approximately 16 different alpha subunits, 5 beta subunits and 12 gamma subunits. For the present example, the GαS subunit (access number in the GenBank gene bank X04408), the Gβ1 subunit (access number in the GenBank gene bank AF501822) and the Gγ1 subunit (access number in the GenBank gene bank BC029367) were selected. The binding method is shown in FIG. 13, where
а. Клеткиbut. Cells
Популяцию клеток печени человека получают из образцов, уничтожаемых после выполнения хирургических операций. Клетки печени разрушают и лизируют, общую РНК выделяют из лизата при помощи набора RNA L (Macherey - Nagel, Duren, Germany, № по каталогу 740962.20) в соответствии с инструкциями изготовителей.A population of human liver cells is obtained from samples destroyed after performing surgical operations. Liver cells are destroyed and lysed, total RNA is isolated from the lysate using the RNA L kit (Macherey - Nagel, Duren, Germany, catalog number 740962.20) in accordance with the manufacturers instructions.
b. Множественная RT-PCR с удлинением цепи путем перекрыванияb. Multiple overlap extended RT-PCR
Для выполнения множественной RT-PCR с удлинением цепи путем перекрывания используют набор для одностадийной RT-PCR компании Qiagen (Qiagen, № по каталогу 210212, Hilden, Germany) в соответствии с рекомендациями изготовителя.To perform multiple overlap extended RT-PCR with overlapping chain, use the Qiagen one-step RT-PCR kit (Qiagen, 210212, Hilden, Germany) according to the manufacturer's recommendations.
Каждая пробирка для PCR содержит в общем объеме, равном 50 мкл, нижеследующие реагенты:Each PCR tube contains, in a total volume of 50 μl, the following reagents:
однократный буфер для одностадийной RT-PCR,single buffer for single-stage RT-PCR,
dNTP в конечной концентрации 400 мкМ каждого реагента,dNTP at a final concentration of 400 μM of each reagent,
смесь множественных праймеров для удлинения цепи путем перекрывания в концентрациях, указанных в таблице 10,a mixture of multiple primers to extend the chain by overlapping at the concentrations indicated in table 10,
2 мкл смеси ферментов для одностадийной RT-PCR,2 μl enzyme mixture for one-step RT-PCR,
1 ед/мкл ингибитора РНКазы (RNasin, Promega, Madison USA, № по каталогу N2515),1 unit / μl of an RNase inhibitor (RNasin, Promega, Madison USA, catalog No. N2515),
50 нг общей РНК.50 ng of total RNA.
Использованная смесь множественных праймеров для удлинения цепи путем перекрывания содержит праймеры, показанные в таблице 10.The used mixture of multiple primers to extend the chain by overlapping contains the primers shown in table 10.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакцию выполняют в нижеследующих условиях циклизации:The reaction is carried out under the following cyclization conditions:
Реакция PCR:PCR reaction:
с. Амплификация методом PCRfrom. PCR amplification
Один микролитр продукта реакции множественной RT-PCR с удлинением цепи путем перекрывания подвергают дополнительной амплификации методом PCR (набор Biotaq, Bioline, UK, № по каталогу BIO-21040) в соответствии с рекомендациями изготовителя. Используют праймеры α1 и γ2, показанные в таблице 10, которые соответствуют SEQ ID NO:80 и 85. Общий объем реакционной смеси равен 50 мкл.One microliter of the product of the reaction of multiple RT-PCR chain extension by overlapping is subjected to additional amplification by PCR method (set Biotaq, Bioline, UK, catalog number BIO-21040) in accordance with the manufacturer's recommendations. Use primers α1 and γ2 shown in table 10, which correspond to SEQ ID NO: 80 and 85. The total volume of the reaction mixture is 50 μl.
Реакцию выполняют в нижеследующих условиях циклизации:The reaction is carried out under the following cyclization conditions:
Пять микролитров продукта реакции анализируют электрофорезом в 1% агарозном геле, используя для обнаружения бромид этидия. Ожидаемый размер продукта равен 2215 п.о. Однако могут присутствовать дополнительные несвязанные фрагменты указанных субъединиц. Ожидаемые размеры указанных фрагментов равны: Gα - 1228 п.о., Gβ - 1064 п.о. и Gγ - 262 п.о.Five microliters of the reaction product was analyzed by electrophoresis on a 1% agarose gel using ethidium bromide for detection. The expected size of the product is 2215 bp However, additional unbound fragments of these subunits may be present. The expected sizes of these fragments are equal: Gα - 1228 bp, Gβ - 1064 bp and Gγ - 262 bp
d. Клонированиеd. Cloning
Остальной продукт реакции подвергают электрофорезу в 1% агарозном геле, используя для обнаружения бромид этидия, фрагмент удлинения цепи путем перекрывания длиной 2215 п.о. вырезают из агарозного геля, очищают при помощи набора Qiaex II (Qiagen, Hilden, Germany, № по каталогу 20051) и вводят в pCR2.1-TOPO, используя набор для клонирования ТОРО ТА компании Invitrogen (Invitrogen, № по каталогу 45-0641, Carlsbad, CA, USA).The remaining reaction product is subjected to electrophoresis on a 1% agarose gel, using ethidium bromide to detect a chain extension fragment by overlapping 2215 bp in length. excised from the agarose gel, purified using a Qiaex II kit (Qiagen, Hilden, Germany, catalog No. 20051) and introduced into pCR2.1-TOPO using Invitrogen TOPO TA cloning kit (Invitrogen, catalog number 45-0641, Carlsbad, CA, USA).
Кроме того, вверху от последовательности, кодирующей каждую субъединицу, могут быть вставлены промоторные последовательности или сайты связывания рибосомы, для облегчения их экспрессии из вектора. Для такой вставки могут быть использованы сайты рестрикции, присутствующие в последовательностях для удлинения цепи путем перекрывания.In addition, promoter sequences or ribosome binding sites can be inserted at the top of the sequence encoding each subunit to facilitate their expression from the vector. For such an insertion, restriction sites present in the sequences for chain extension by overlapping can be used.
е. Общие соображенияe. General considerations
Вышеописанное связывание последовательностей, кодирующих субъединицы, образующие гетеромерный белок, может быть выполнено для большинства гетеромерных белков, в которых известна последовательность отдельных субъединиц. Кроме того, при использовании смеси множественных праймеров для удлинения цепи путем перекрывания, способной амплифицировать несколько членов определенного семейства, например все α-, β- и γ-субъединицы G-белка, можно идентифицировать и связать любую комбинацию субъединиц из любой клетки без предварительного анализа, позволяющего определить, клетками какого типа какие члены семейства экспрессируются. Например, способ по вышеуказанному примеру может быть выполнен с использованием матрицы, полученной из выделенных отдельных клеток печени при помощи смеси множественных праймеров для удлинения цепи путем перекрывания, способной амплифицировать и связывать все 16 субъединиц Gα с 5 субъединицами Gβ и 12 субъединицами Gγ, благодаря чему можно определить, какая комбинация субъединиц экспрессирована в каждой клетке, и одновременно выделить кодирующие последовательности, определяющие данную комбинацию субъединиц. Кроме того, вырожденные праймеры могут даже служить для идентификации новых членов определенного семейства.The above linking of sequences encoding subunits forming a heteromeric protein can be performed for most heteromeric proteins in which the sequence of individual subunits is known. In addition, when using a mixture of multiple primers to extend the chain by overlapping, capable of amplifying several members of a particular family, for example, all the α, β, and γ subunits of the G protein, any combination of subunits from any cell can be identified and linked without prior analysis, which allows to determine what type of cells express which family members. For example, the method of the above example can be performed using a matrix obtained from isolated individual liver cells using a mixture of multiple primers to extend the chain by overlapping, able to amplify and bind all 16 Gα subunits to 5 Gβ subunits and 12 Gγ subunits, so that determine which combination of subunits is expressed in each cell, and simultaneously isolate the coding sequences that define this combination of subunits. In addition, degenerate primers can even serve to identify new members of a particular family.
При связывании субъединиц гетеромерного белка при помощи множественной RT-PCR с удлинением цепи путем перекрывания по настоящему изобретению необходимо учесть общий размер связанного продукта, так как существуют пределы для числа пар оснований, амплифицируемых ДНК-полимеразой. Полимераза Deep Vent компании New England Biolabs, MA, USA, является одной ДНК-полимеразой, способной образовывать очень длинные удлинения праймеров, содержащие до 14000 п.о. Теоретически 14000 п.о. могут кодировать белок со средней массой 510 кДа. Таким образом, способом по настоящему изобретению можно выделить кодирующие последовательности для очень больших гетеромерных белков. Удлинение цепи можно еще больше увеличить, используя смеси ДНК-полимераз.When linking subunits of a heteromeric protein using multiple RT-PCR with chain extension by overlapping of the present invention, it is necessary to take into account the total size of the bound product, since there are limits to the number of base pairs amplified by DNA polymerase. New Vent Biolabs, MA, USA, Deep Vent Polymerase, is a single DNA polymerase capable of forming very long primer extensions containing up to 14,000 bp. Theoretically, 14,000 bp can encode a protein with an average weight of 510 kDa. Thus, by the method of the present invention, coding sequences for very large heteromeric proteins can be isolated. Chain elongation can be further increased by using a mixture of DNA polymerases.
Пример 9. Создание праймеров для лидерных последовательностейExample 9. Creating primers for leader sequences
В данном примере рассмотрено создание множественного набора праймеров, в которых сайт инициации находится в последовательности, кодирующей лидерную область семейств тяжелой цепи и легкой каппа-цепи антитела человека.In this example, the creation of a multiple set of primers in which the initiation site is in the sequence encoding the leader region of the heavy chain and light kappa chains of a human antibody is considered.
При использовании праймеров, гибридизирующих с N-концевыми кодирующими последовательностями семейства вариабельных областей, может наблюдаться некоторая степень перекрестной гибридизации. Праймеры для последовательности одного определенного семейства генов могут гибридизировать с кДНК другого семейства генов, что во многих случаях вызывает образование новых последовательностей. Белки, образованные из таких последовательностей, являются потенциально иммуногенными при использовании в лечебных целях. Указанные новые последовательности обычно можно исправить при помощи PCR или удалить из библиотеки.When using primers hybridizing with the N-terminal coding sequences of the variable region family, some degree of cross hybridization may be observed. Primers for the sequence of one particular gene family can hybridize with cDNA of another gene family, which in many cases causes the formation of new sequences. Proteins formed from such sequences are potentially immunogenic when used for therapeutic purposes. These new sequences can usually be corrected using PCR or removed from the library.
Альтернативным решением является введение сайта инициации в последовательность, кодирующую лидерный пептид вариабельной области антитела. Гибридные последовательности, образовавшиеся в результате перекрестной гибридизации, будут удалены во время внутриклеточного процессинга антитела, в результате которого лидерный пептид, содержащий потенциальные иммуногенные последовательности, будет расщеплен и, следовательно, не будет присутствовать в секретированном антителе. Известные наборы праймеров для лидерных пептидов, предназначенные для клонирования антитела, располагались у 5'-конца последовательности, кодирующей лидерный пептид, делая возможной прямую экспрессию эукариотической клеткой (Campbell M.J. et al. 1992, Mol. Immunol. 29, 193-203). К сожалению, лидерные пептиды эукариотической клетки плохо пригодны для процессинга в прокариотической клетке.An alternative solution is to introduce the initiation site into a sequence encoding a leader peptide of an antibody variable region. Hybrid sequences resulting from cross-hybridization will be removed during intracellular processing of the antibody, as a result of which the leader peptide containing potential immunogenic sequences will be cleaved and therefore will not be present in the secreted antibody. Known leader peptide primer kits for antibody cloning were located at the 5 ′ end of the leader peptide coding sequence, allowing direct expression by a eukaryotic cell (Campbell M.J. et al. 1992, Mol. Immunol. 29, 193-203). Unfortunately, leader peptides of a eukaryotic cell are poorly suited for processing in a prokaryotic cell.
Простота манипуляции последовательностями нуклеиновых кислот в бактериях делает привлекательным создание систем клонирования, в которых возможен перенос последовательностей между бактериальными векторами и векторами для других организмов-хозяев. Поэтому в настоящем примере был создан множественный набор праймеров, в которых сайт инициации находится в положении последовательности, кодирующей область лидерного пептида, что делает возможной функциональную экспрессию антител или фрагментов антител как в эукариотических, так и в прокариотических экспрессирующих системах.The ease of manipulation of nucleic acid sequences in bacteria makes it attractive to create cloning systems in which sequence transfer between bacterial vectors and vectors is possible for other host organisms. Therefore, in the present example, a multiple set of primers was created in which the initiation site is in the position of the sequence encoding the region of the leader peptide, which makes possible the functional expression of antibodies or antibody fragments in both eukaryotic and prokaryotic expression systems.
Требования, предъявляемые к расщеплению последовательностей сигнальной пептидазой в С-концевой области любого лидерного пептида, по-видимому, очень схожи для прокариотических и эукариотических систем (Nielsen H et al., 1997, Protein Eng. 10, 1-6). Кроме того, из вышеизложенного следует, что мутации в С-концевой области лидерного пептида, вероятно, оказывают незначительное влияние на конформацию N-концевой области и наоборот. Таким образом, можно ожидать, что С-концевые последовательности могут переноситься из одного вида в другой без утраты функциональной активности.The requirements for cleavage of sequences by signal peptidase in the C-terminal region of any leader peptide appear to be very similar for prokaryotic and eukaryotic systems (Nielsen H et al., 1997, Protein Eng. 10, 1-6). In addition, it follows from the foregoing that mutations in the C-terminal region of the leader peptide are likely to have little effect on the conformation of the N-terminal region and vice versa. Thus, it can be expected that C-terminal sequences can be transferred from one species to another without loss of functional activity.
Основным принципом создания праймеров в настоящем примере было размещение сайта инициации в последних шести кодонах С-концевой области лидерного пептида. Остальная часть последовательности, кодирующей лидерный пептид, вверху от сайта инициации (примерно 50 нуклеотидов) должна быть введена приемлемым экспрессирующим вектором, соответствующим биологическому виду хозяину. Например, векторы, пригодные для экспрессии в грамотрицательных бактериях, могут быть созданы с использованием процессированной или непроцессированной лидерной последовательности PelB. Для экспрессии антител в эукариотах пригоден вектор с процессированной последовательностью, кодирующей лидерный пептид тяжелой цепи нативного антитела, и процессированной последовательностью, кодирующей лидерный пептид вариабельной области каппа-цепи. Независимо от экспрессирующей системы последние шесть аминокислот лидерного пептида образуются из последовательности, кодирующей лидерный пептид эндогенного антитела, которая находится в сегменте нуклеиновой кислоты, вставленном в вектор.The main principle of creating primers in this example was the placement of the initiation site in the last six codons of the C-terminal region of the leader peptide. The remainder of the leader peptide coding sequence upstream of the initiation site (approximately 50 nucleotides) should be introduced with an acceptable expression vector corresponding to the host species. For example, vectors suitable for expression in gram-negative bacteria can be created using a processed or unprocessed PelB leader sequence. For expression of antibodies in eukaryotes, a vector with a processed sequence encoding a leader peptide of a heavy chain of a native antibody and a processed sequence encoding a leader peptide of a kappa chain variable region is suitable. Regardless of the expression system, the last six amino acids of the leader peptide are formed from the sequence encoding the leader peptide of the endogenous antibody, which is located in the nucleic acid segment inserted into the vector.
Для использования в множественной RT-PCR с удлинением цепи путем перекрывания были созданы нижеследующие праймеры (таблица 11). Однако концевые сегменты удлинения цепи путем перекрывания (строчные буквы) могут быть легко изменены для использования при связывании путем лигирования или рекомбинации.The following primers have been developed for use in multiple RT-PCR with chain extension by overlapping (table 11). However, the end segments of the chain extension by overlapping (lowercase letters) can be easily changed for use in binding by ligation or recombination.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Необходимо отметить, что сайты рестрикции в данной конформации праймеров были несколько модифицированы по сравнению с праймерами, описанными в предыдущих примерах. Так, перекрывающая последовательность, расположенная между последовательностями, кодирующими вариабельные области тяжелой и легкой цепей, содержит сайт рестрикции NotI и NheI, и в затравке для константной области каппа-цепи (CLк) ранее существующий сайт NotI был заменен сайтом AscI. Последняя модификация должна быть обязательно произведена при создании праймеров для дополнительной амплификации методом PCR. Кроме того, сайт NotI в клонирующем векторе, показанном на фиг.11, должен быть заменен сайтом AscI, и сайт AscI в промоторе должен быть заменен сайтом NotI.It should be noted that the restriction sites in this conformation of the primers were slightly modified in comparison with the primers described in the previous examples. Thus, the overlapping sequence located between the sequences encoding the variable regions of the heavy and light chains contains the NotI and NheI restriction site, and in the seed for the constant region of the kappa chain (C Lc ), the previously existing NotI site was replaced by the AscI site. The last modification must be made when creating primers for additional amplification by PCR. In addition, the NotI site in the cloning vector shown in FIG. 11 should be replaced by the AscI site, and the AscI site in the promoter should be replaced by the NotI site.
Функциональные свойства, относящиеся к расщеплению лидерного пептида, были проверены in silico с использованием программы SignalP, предоставленной CBS Датского технического университета.Functional properties related to cleavage of the leader peptide were tested in silico using the SignalP software provided by CBS of the Danish Technical University.
Химерные лидерные пептиды, проверенные на наличие вариабельной области тяжелой цепи, были кодированы последовательностями нуклеиновых кислот, состоящими из процессированной последовательности PelB, С-концевого сайта NotI (SEQ ID NO 100: ATG AAA TAT CTT CTA CCA ACA GCG GCA GCT GGA TTA TTG GCG GCC GCC), и связаны с сайтом NotI геноспецифической части одной из SEQ ID NO 86-92, кодирующей шесть С-концевых аминокислот из нативных членов семейства VHL. При помощи программы SignalP было установлено, что все семь последовательностей характеризуются расщеплением сигнального пептида в грамотрицательных бактериях.Chimeric leader peptides tested for the presence of the variable region of the heavy chain were encoded by nucleic acid sequences consisting of a processed PelB sequence, NotI C-terminal site (SEQ ID NO 100: ATG AAA TAT CTT CTA CCA ACA GCG GCA GCT GGA TTA TTG GCG GCC GCC), and are associated with the NotI site of the gene-specific part of one of SEQ ID NOS 86-92, encoding six C-terminal amino acids from native members of the V HL family. Using the SignalP program, it was found that all seven sequences are characterized by cleavage of the signal peptide in gram-negative bacteria.
Химерные лидерные пептиды, проверенные на наличие вариабельной области легкой цепи, были кодированы последовательностями нуклеиновых кислот, состоящими из процессированной последовательности PelB, С-концевого сайта NheI (SEQ ID NO 101: ATG AAA TAT TTG CTA CCA ACA GCG GCA GCT GGA TTA TTG TTA CTA GCG), и связаны с сайтом NheI геноспецифической части одной из SEQ ID NO 93-98, кодирующей шесть С-концевых аминокислот из нативных членов семейства VLкL. При помощи программы SignalP было установлено, что все шесть последовательностей характеризуются расщеплением сигнального пептида в грамотрицательных бактериях.Chimeric leader peptides tested for the presence of a variable region of the light chain were encoded by nucleic acid sequences consisting of a processed PelB sequence, NheI C-terminal site (SEQ ID NO 101: ATG AAA TAT TTG CTA CCA ACA GCG GCA GCT GGA TTA TTG TTA CTA GCG), and are associated with the NheI site of the gene-specific part of one of SEQ ID NOS 93-98, encoding six C-terminal amino acids from native members of the V LkL family. Using the SignalP program, it was found that all six sequences are characterized by cleavage of the signal peptide in gram-negative bacteria.
Последовательности SEQ ID NO 100 и 101 пригодны для создания бактериального экспрессирующего вектора, аналогичного показанному на фиг.11, так как сайт AscI, показанный на фиг.11, заменен SEQ ID NO 100 и сайт NheI заменен SEQ ID NO 101. Кроме того, сайт NotI, показанный на фиг.11, должен быть заменен сайтом AscI.The sequences of
Экспрессирующий вектор млекопитающего (фиг.9) аналогичным образом может быть изменен с возможностью экспрессии в клетках млекопитающих после переноса сегментов, кодирующих вариабельные области, из только что описанного бактериального вектора.The mammalian expression vector (Fig. 9) can likewise be modified to be expressed in mammalian cells after transferring segments encoding the variable regions from the bacterial vector just described.
Пример 10. Выполнение множественной RT-PCR и связывания лигированием в одной пробиркеExample 10. Performing multiple RT-PCR and ligation binding in a single tube
В настоящем примере рассмотрен способ получения родственной пары, включающей связанные последовательности, кодирующие вариабельную область тяжелой цепи и вариабельную область легкой цепи, в одной пробирке при выполнении связывания лигированием вместо PCR с удлинением цепи путем перекрывания.The present example describes a method for producing a related pair, including linked sequences encoding the variable region of the heavy chain and the variable region of the light chain, in one tube when performing ligation binding instead of PCR with chain extension by overlapping.
а. Множественная RT-PCRbut. Multiple RT-PCR
Полученную в собственной лаборатории линию клеток, экспрессирующих молекулы Fab-фрагментов со специфичностью в отношении столбнячного токсина, распределяют методом ограниченного разведения с получением одной клетки в одной пробирке для PCR.The cell line obtained in our own laboratory expressing molecules of Fab fragments with specificity for tetanus toxin was distributed by limited dilution to obtain one cell in one PCR tube.
Помимо одной клетки каждая пробирка для PCR содержит нижеследующие реагенты в общем объеме, равном 20 мкл:In addition to one cell, each PCR tube contains the following reagents in a total volume of 20 μl:
однократный буфер Phusion HF,one-time buffer Phusion HF,
dNTP в конечной концентрации, равной 200 мкМ каждого реагента,dNTP at a final concentration of 200 μM of each reagent,
смесь множественных праймеров в концентрациях, указанных в таблице 12,a mixture of multiple primers in the concentrations indicated in table 12,
0,8 ед. полимеразы Phusion (FinnZymes, № по каталогу F-530-L),0.8 units Phusion polymerase (FinnZymes, catalog number F-530-L),
1 мкл обратной транскриптазы Sensiscript (Qiagen, № по каталогу 205213),1 μl Sensiscript reverse transcriptase (Qiagen, Catalog No. 205213),
20 ед. ингибитора РНКазы.20 units RNase inhibitor.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакцию выполняют в нижеследующих условиях циклизации:The reaction is carried out under the following cyclization conditions:
b. Связывание лигированиемb. Ligation binding
Для выполнения связывания лигированием рестрикционные ферменты и лигазу добавляют непосредственно к продуктам реакции множественной RT-PCR. Альтернативно продукт реакции множественной RT-PCR может быть очищен до вышеуказанного добавления для максимального освобождения смеси от полимеразы.To perform ligation binding, restriction enzymes and a ligase are added directly to the products of the multiple RT-PCR reaction. Alternatively, the multiple RT-PCR reaction product may be purified prior to the above addition to maximize the release of the mixture from polymerase.
В каждую пробирку добавляют нижеследующие реагенты в общем объеме, равном 40 мкл:The following reagents are added to each tube in a total volume of 40 μl:
однократный буфер NEBII,NEBII single buffer
1 мМ АТР,1 mm ATR
50 ед. XbaI (New England Biolabs, № по каталогу R0145L),50 units XbaI (New England Biolabs, Catalog No. R0145L),
25 ед. SpeI (New England Biolabs, № по каталогу R0133S),25 units SpeI (New England Biolabs, Cat. No. R0133S),
100 мкг/мл BSA,100 μg / ml BSA,
400 ед. ДНК-лигазы Т4 (New England Biolabs, № по каталогу М0202S).400 units T4 DNA Ligases (New England Biolabs, Catalog No. M0202S).
Реакционную смесь инкубируют при 16°С в течение ночи.The reaction mixture was incubated at 16 ° C. overnight.
Связанные последовательности, кодирующие вариабельные области тяжелой и легкой цепей, очищают от реакционной смеси при помощи гель-электрофореза и вырезают полосу, равную примерно 1000 п.о.The linked sequences encoding the variable regions of the heavy and light chains are purified from the reaction mixture by gel electrophoresis and a strip of about 1000 bp is cut out.
В альтернативном варианте данного способа множественную RT-PCR выполняют с использованием праймера для СН вместо праймеров для JН в множественном наборе праймеров. Указанный праймер может иметь клонирующий концевой сегмент, который делает возможным введение в рамке считывания вариабельной области тяжелой цепи в экспрессирующий вектор, либо может быть выполнена полугнездовая PCR с использованием праймеров, показанных в таблице 5.In an alternative embodiment of this method, multiple RT-PCRs are performed using a primer for C H instead of primers for J H in a multiple set of primers. The specified primer may have a cloning end segment, which makes it possible to introduce in the reading frame the variable region of the heavy chain into the expression vector, or semi-nested PCR can be performed using the primers shown in table 5.
Пример 11. Создание рекомбинантного поликлонального иммуноглобулина со специфичностью в отношении столбнячного токсинаExample 11. The creation of recombinant polyclonal immunoglobulin with specificity for tetanus toxin
В настоящем примере рассмотрены результаты иммунизации одного донора (ТТ03) столбнячным токсином (ТТ) с описанием стадий, показанных на блок-схеме, изображенной на фиг.10.In this example, the results of immunization of a single donor (TT03) with tetanus toxin (TT) are described with a description of the stages shown in the flowchart shown in FIG.
а. Донорыbut. Donors
Восемь доноров, которых ранее иммунизировали противостолбнячной вакциной, подвергали бустер-иммунизации противостолбнячной вакциной (Statens Serum Institut, Denmark). Донорам были присвоены номера ТТ01 - ТТ08. Через шесть дней после бустер-иммунизации противостолбнячной вакциной у доноров брали пробу крови, равную примерно 200 мл, которую вводили в пробирку с антикоагулянтом.Eight donors previously immunized with the tetanus vaccine were boosted with the tetanus vaccine (Statens Serum Institut, Denmark). Donors were assigned numbers TT01 - TT08. Six days after booster immunization with an anti-tetanus vaccine, a blood sample of approximately 200 ml was taken from a donor and introduced into an anticoagulant tube.
Доноры были здоровы, не имели хронических инфекций и аутоиммунных заболеваний, не принимали иммунодепрессивных средств и не подвергались никаким вакцинациям в течение последних 3 месяцев.The donors were healthy, had no chronic infections and autoimmune diseases, did not take immunosuppressive drugs, and did not receive any vaccinations in the last 3 months.
а-1. Проверка качества проб крови, полученных у доноровa-1. Quality control of blood samples obtained from donors
Во время иммунизации у доноров брали предварительные пробы крови. Через четырнадцать дней у доноров брали дополнительные пробы крови для определения сывороточного титра. У всех доноров наблюдалось увеличение титра столбнячного токсина (ТТ). Кроме того, выполняли анализ ELISPOT для измерения частоты встречаемости ТТ-специфических плазматических клеток. Для выполнения анализа ELISPOT можно использовать разные фракции клеток, например цельную кровь, полученную на 6-й день, фракцию РВМС, фракцию, полученную в результате магнитной сортировки, или фракцию, полученную в результате сортировки методом FACS. Анализ ELISPOT можно использовать для оценки материала донора и идентификации лучших клеток-респондеров, которые затем могут быть использованы на стадии сортировки и множественной RT-PCR с удлинением цепи путем перекрывания. Анализ ELISPOT выполняли для донора ТТ03 с использованием фракции CD19+ клеток (см. раздел с). Анализ ELISPOT был выполнен в соответствии с описанием, приведенным в публикации Lakew, M. et al., 1997, J. Immunol. Methods 203, 193-198, с внесением незначительных изменений. Частота встречаемости ТТ-специфических плазматических клеток во фракции РВМС были вычислена равной 0,021%.Preliminary blood samples were taken from donors during immunization. Fourteen days later, additional blood samples were taken from donors to determine serum titer. All donors showed an increase in titer of tetanus toxin (TT). In addition, an ELISPOT assay was performed to measure the incidence of TT-specific plasma cells. For ELISPOT analysis, different cell fractions can be used, for example, whole blood obtained on
b. Получение мононуклеарных клеток периферической крови (РВМС)b. Getting peripheral blood mononuclear cells (PBMC)
Клетки РВМС выделяли из пробы крови в устройстве Lymphoprep (Axis-Shield РоС AS, Norway, производственный № 1001967) в соответствии с рекомендациями изготовителей. Кровь разводили в PBS в отношении 1:1 и полученную взвесь вводили в устройство Lymphoprep в отношении 2:1. Пробирки центрифугировали с ускорением 800 g в течение 20 минут при 25°С и собирали полосу интерфазы лейкоцитов. Клетки промывали в PBS, содержащем 2 мМ EDTA.PBMC cells were isolated from a blood sample in a Lymphoprep device (Axis-Shield PoC AS, Norway, production No. 1001967) in accordance with the recommendations of the manufacturers. Blood was diluted in PBS at a ratio of 1: 1 and the resulting suspension was introduced into the Lymphoprep device at a ratio of 2: 1. The tubes were centrifuged with an acceleration of 800 g for 20 minutes at 25 ° C and a leukocyte interphase band was collected. Cells were washed in PBS containing 2 mM EDTA.
Из 200 мл цельной крови, отобранной от донора ТТ03, было получено примерно 2х108 РВМС.From 200 ml of whole blood taken from a TT03 donor, approximately 2 × 10 8 PBMCs were obtained.
с. Обогащение В-клетокfrom. B cell enrichment
Линию В-клеток (CD19+ клетки) из РВМС обогащали путем сортировки клеток с использованием магнитных гранул нижеследующим способом.The B cell line (CD19 + cells) from PBMC was enriched by sorting the cells using magnetic beads in the following manner.
Выделенные клетки РВМС окрашивали анти-CD19-FITC (Becton Dickenson, NJ, USA, № по каталогу 345776). Все стадии выполняли в темном помещении при 4°С. Окрашивание производили 10 мкл анти-CD19-FITC на 1х106 клеток в объеме 100 мкл на 1х106 клеток с использованием М-буфера (РBS, рН 7,2, 0,5% BSA, 2 мМ EDTA). Указанный краситель окрашивает линию В-клеток РВМС. Клетки инкубировали в течение 20 минут и затем дважды промывали М-буфером. Клетки, окрашенные анти-CD19-FITC, подвергали магнитному мечению при помощи микрогранул, конъюгированных с анти-FITC-антителом, используя 10 мкл магнитных гранул, сенсибилизированных анти-FITC-антителом (Miltenyi Biotec, Gladbach, Germany, № по каталогу 130-042-401), на 1х106 клеток в объеме 100 мкл М-буфера на 1х106 клеток. Клетки инкубировали в течение 15 минут и затем один раз промывали М-буфером. Клетки вторично суспендировали в дегазированном М-буфере.Isolated PBMC cells were stained with anti-CD19-FITC (Becton Dickenson, NJ, USA, catalog number 345776). All stages were performed in a dark room at 4 ° C. Staining was performed with 10 μl of anti-CD19-FITC per 1x10 6 cells in a volume of 100 μl per 1x10 6 cells using M-buffer (PBS, pH 7.2, 0.5% BSA, 2 mm EDTA). The specified dye stains the line of b-cells RVMS. Cells were incubated for 20 minutes and then washed twice with M-buffer. Cells stained with anti-CD19-FITC were magnetically labeled with microbeads conjugated to anti-FITC antibody using 10 μl of magnetic beads sensitized with anti-FITC antibody (Miltenyi Biotec, Gladbach, Germany, Cat. No. 130-042 -401), per 1x10 6 cells in a volume of 100 μl of M-buffer per 1x10 6 cells. Cells were incubated for 15 minutes and then washed once with M-buffer. Cells were resuspended in a degassed M-buffer.
Колонку MACS LS (Miltenyi Biotec, Gladbach, Germany, № по каталогу 130-042-401) предварительно обрабатывали дегазированным М-буфером в соответствии с инструкциями изготовителей. Взвесь клеток, окрашенных анти-CD19-FITC и меченных магнитными гранулами, сенсибилизованными анти-FITC-антителом, вводили в колонку с возможностью прохождения через нее. Окрашенные и меченые клетки (CD19+) оставались в магнитном поле, окружающем колонку, в то время как неокрашенные клетки (CD19+) проходили через колонку. Колонку промывали дегазированным М-буфером. Магнитное поле отключали и собирали CD19+ клетки.The MACS LS column (Miltenyi Biotec, Gladbach, Germany, catalog number 130-042-401) was pretreated with a degassed M-buffer in accordance with the manufacturers instructions. A suspension of cells stained with anti-CD19-FITC and labeled with magnetic beads sensitized with anti-FITC antibody was introduced into the column with the possibility of passing through it. Stained and labeled cells (CD19 +) remained in the magnetic field surrounding the column, while unpainted cells (CD19 +) passed through the column. The column was washed with degassed M-buffer. The magnetic field was turned off and CD19 + cells were harvested.
Аналитическое окрашивание исходного материала (РВМС), немеченой фракции и CD19 меченой фракции донора ТТ03 производили, используя анти-CD19-FITC, анти-CD38-РЕ и анти-CD45-PerCP (фиг.14). Полученные данные показывают, в результате магнитной сортировки клеток образуются две разные фракции по сравнению с фракцией РВМС. CD19-отрицательные клетки, показанные в блоке В, и CD19-положительные клетки, показанные в блоке С. Фракция РВМС содержала 11% CD19+ клеток, причем степень очистки CD19-положительных клеток была равна 99,5% R1 (диаграмма рассеяния, показанная на фиг.14С) для ТТ03.Analytical staining of the starting material (PBMC), unlabeled fraction and CD19 of the labeled TT03 donor fraction was performed using anti-CD19-FITC, anti-CD38-PE and anti-CD45-PerCP (Fig. 14). The data obtained show that, as a result of magnetic sorting of the cells, two different fractions are formed in comparison with the PBMC fraction. CD19-negative cells shown in block B and CD19-positive cells shown in block C. The PBMC fraction contained 11% of CD19 + cells, and the degree of purification of CD19-positive cells was 99.5% R1 (scatter plot shown in FIG. .14C) for TT03.
Как показано на фиг.14С, диаграмма рассеяния анти-CD38/CD45 позволила выявить отдельную популяцию CD38hi, CD45in клеток (R2), соответствующую 1,1% R1. Данная популяция содержала плазматические клетки и была собрана на последующей стадии сортировки. Из вышеизложенного следует, что во фракции РВМС 0,12% клеток соответствовало плазматическим клеткам.As shown in FIG. 14C, an anti-CD38 / CD45 scatter plot revealed a single population of CD38hi, CD45in cells (R2) corresponding to 1.1% R1. This population contained plasma cells and was collected at a subsequent sorting stage. From the foregoing, it follows that in the PBMC fraction, 0.12% of the cells corresponded to plasma cells.
Фракцию CD19-положительных клеток замораживали в FCS (Invitrogen, № по каталогу 16000-044), содержащей 10% ДМСО (Sigma, № по каталогу D2650), для последующей сортировки. Анализ, аналогичный показанному на фиг.14, выполняли в отношении клеток, очищенных в колонке MACS, которые были заморожены для гарантии целостности клеток (фиг.15). Картины окрашивания, показанные на фиг.15, были аналогичны изображенным на фиг.14С, хотя наблюдалась несколько большая интенсивность окрашивания. Клетки, собранные в результате сортировки, представляют собой субпопуляцию R1 и R2. Указанная субпопуляция соответствует примерно 1,1% клеток, очищенных в колонке MACS.The fraction of CD19-positive cells was frozen in FCS (Invitrogen, catalog number 16000-044) containing 10% DMSO (Sigma, catalog number D2650), for subsequent sorting. An analysis similar to that shown in FIG. 14 was performed on cells purified in a MACS column that were frozen to ensure cell integrity (FIG. 15). The staining patterns shown in FIG. 15 were similar to those shown in FIG. 14C, although a slightly higher staining intensity was observed. Cells collected by sorting are a subpopulation of R1 and R2. This subpopulation corresponds to approximately 1.1% of the cells purified on a MACS column.
d. Сортировка плазматических клетокd. Plasma cell sorting
Замороженный элюат, полученный из колонки MACS, оттаивали, центрифугировали и вторично суспендировали в буфере для FACS (PBS, рН 7,2, 2% BSA) в концентрации 1х106 клеток/60 мкл буфера для FACS. Добавляли анти-CD19-FITC (Becton Dickenson, NJ, USA, № по каталогу 345776) (10 мкл/106 клеток), анти-CD38-РЕ (Becton Dickenson, NJ, USA, № по каталогу 555460) (10 мкл/106 клеток) и анти-CD45-PerCP (Becton Dickenson, NJ, USA, № по каталогу 345809) (20 мкл/106 клеток), смесь инкубировали в темном помещении при 4°С в течение 20 минут, затем дважды промывали и вторично суспендировали в буфере для FACS.The frozen eluate obtained from the MACS column was thawed, centrifuged and resuspended in FACS buffer (PBS, pH 7.2, 2% BSA) at a concentration of 1x10 6 cells / 60 μl FACS buffer. Anti-CD19-FITC (Becton Dickenson, NJ, USA, catalog number 345776) (10 μl / 10 6 cells), anti-CD38-PE (Becton Dickenson, NJ, USA, catalog number 555460) (10 μl / 10 6 cells) and anti-CD45-PerCP (Becton Dickenson, NJ, USA, catalog number 345809) (20 μl / 10 6 cells), the mixture was incubated in a dark room at 4 ° C for 20 minutes, then washed twice and resuspended in FACS buffer.
Клетки сортировали методом сортировки клеток с возбуждением флуоресценции (FACS), используя нижеследующие параметры сортировки:Cells were sorted by Fluorescence Excited Cell Sort (FACS) using the following sorting options:
1. Прямое и боковое рассеяние для сохранения лимфоцитов и моноцитов, включая плазматические бласты и плазматические клетки, и удаление мертвых клеток и клеток с очень высоким боковым рассеянием, которые могут быть агрегатами или гранулоцитами.1. Direct and lateral scattering to preserve lymphocytes and monocytes, including plasma blasts and plasma cells, and the removal of dead cells and cells with very high lateral scattering, which may be aggregates or granulocytes.
2. Клетки, которые являются CD19-положительными и экспрессируют повышенные уровни CD38 (CD38hi). Подобным образом происходит улавливание в основном CD38 клеток, так как РВМС были обогащены в колонке MACS CD19 клетками, но указанный способ позволяет обнаружить любые загрязнения.2. Cells that are CD19-positive and express elevated levels of CD38 (CD38hi). Similarly, mainly CD38 cells are captured, since PBMCs were enriched in the MACS column of CD19 cells, but this method allows any contamination to be detected.
3. CD45-промежуточно положительные клетки. Все лимфоциты экспрессируют CD45. Однако плазматические клетки характеризуются меньшей экспрессией CD45 по сравнению с более ранними стадиями дифференцировки лимфоцитов. Поэтому при улавливании CD45 можно получить дискретную популяцию клеток, соответствующую плазматическим клеткам.3. CD45-intermediate positive cells. All lymphocytes express CD45. However, plasma cells are characterized by lower expression of CD45 compared to the earlier stages of lymphocyte differentiation. Therefore, by capturing CD45, a discrete cell population corresponding to plasma cells can be obtained.
FACS-сортированные клетки, полученные от донора ТТ03, собирали в виде субпопуляции, полученной в результате двух сортировок Р2 и Р1 (фиг.16А и 16В). Указанные клетки представляли собой CD38hi (FL2-A), CD45in (FL3-A) и CD19+, причем последние клетки были получены в результате очистки в колонке MACS. Клетки собирали в общей массе, подсчитывали и разводили в RPMI (Invitrogen, № по каталогу 21875-034), содержащем 10% FCS (Invitrogen, № по каталогу 16000-044), 100 единиц/мл пенициллина-стрептомицина (Invitrogen, № по каталогу 15140-122), 2 мМ L-глутамина (№ по каталогу 25030-024). Затем клетки распределяли в пятьдесят 96-луночных планшетов для PCR (ABgene, № по каталогу АВ-0800) в количестве одной клетки на одну лунку в 5 мкл среды. Планшеты заклеивали, сразу же замораживали и хранили для последующего выполнения анализа RT-PCR.FACS-sorted cells obtained from a TT03 donor were collected as a subpopulation obtained from two sorts P2 and P1 (FIGS. 16A and 16B). These cells were CD38hi (FL2-A), CD45in (FL3-A) and CD19 +, the latter cells being obtained by purification in a MACS column. Cells were harvested in total, counted and bred in RPMI (Invitrogen, catalog number 21875-034) containing 10% FCS (Invitrogen, catalog number 16000-044), 100 units / ml penicillin-streptomycin (Invitrogen, catalog number 15140-122), 2 mM L-Glutamine (catalog number 25030-024). Cells were then dispensed into fifty 96-well PCR plates (ABgene, AB-0800 catalog number) in the amount of one cell per well in 5 μl of medium. The plates were sealed, immediately frozen and stored for subsequent RT-PCR analysis.
е. Связывание родственных пар последовательностей, кодирующих вариабельные области иммуноглобулинаe. Linking related pairs of sequences encoding the variable regions of immunoglobulin
Множественную RT-PCR с удлинением цепи путем перекрывания выполняли в отношении отдельных клеток, полученных от донора ТТ03, в результате чего было произведено родственное связывание транскрибированных последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи антитела против столбнячного токсина.Multiple overlapping extension RT-PCRs were performed on individual cells obtained from a TT03 donor, resulting in a kinship between the transcribed sequences encoding the variable region of the heavy chain and the variable region of the light chain of the anti-tetanus toxin antibody.
е-1. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияe-1. Single-Stage Multiple Overlap RT-PCR with Overlap
Для выполнения множественной RT-PCR с удлинением цепи путем перекрывания использовали набор для одностадийной RT-PCR компании Qiagen (Qiagen, № по каталогу 210212, Hilden, Germany) в соответствии с рекомендациями изготовителя. Пятьдесят замороженных 96-луночных планшетов для PCR, содержащих примерно одну клетку в одной лунке, удаляли из холодильника и, когда в лунках не оставалось кристаллов льда, в каждую лунку сразу же добавляли 15 мкл реакционной смеси для RT-PCR.Qiagen's one-step RT-PCR kit (Qiagen, Catalog No. 210212, Hilden, Germany) was used to perform multiple RT-PCRs with chain extension by overlapping according to the manufacturer's recommendations. Fifty frozen 96-well PCR plates containing approximately one cell in one well were removed from the refrigerator and, when there were no ice crystals left in the wells, 15 μl of RT-PCR reaction mixture was immediately added to each well.
Реакционная смесь для RT-PCR содержала в общем объеме, равном 20 мкл, нижеследующие реагенты:The reaction mixture for RT-PCR contained in a total volume of 20 μl of the following reagents:
однократный буфер для одностадийной RT-PCR,single buffer for single-stage RT-PCR,
dNTP в конечной концентрации, равной 400 мкМ каждого реагента,dNTP at a final concentration of 400 μM of each reagent,
смесь множественных праймеров для удлинения цепи путем перекрывания в концентрациях, указанных в таблице 13,a mixture of multiple primers to extend the chain by overlapping at the concentrations indicated in table 13,
0,8 мкл смеси ферментов для одностадийной RT-PCR,0.8 μl of enzyme mixture for one-step RT-PCR,
20 ед. ингибитора РНКазы (RNasin, Promega, Madison, USA, № по каталогу N2515).20 units an RNase inhibitor (RNasin, Promega, Madison, USA, catalog number N2515).
Состав смеси множественных праймеров для удлинения цепи путем перекрывания показан в таблице 13.The composition of the mixture of multiple primers to extend the chain by overlapping is shown in table 13.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Реакцию выполняли в нижеследующих условиях циклизации:The reaction was carried out under the following cyclization conditions:
Реакция PCR:PCR reaction:
е-2. Дополнительная амплификацияe-2. Additional amplification
Один микролитр продукта реакции множественной RT-PCR с удлинением цепи путем перекрывания из каждого образца подвергали полугнездовой PCR (набор Biotaq, Bioline, № по каталогу BIO-21040) в соответствии с рекомендациями изготовителя, используя 96-луночные планшеты для PCR (ABgene, № по каталогу АВ-0800). Каждая реакционная смесь, объем которой был равен 50 мкл, содержала однократный буфер Biotaq, 200 мкМ dNTP (каждого реагента), 2 мМ MgCl2, 1,25 ед. Bio Taq полимеразы и праймеры, показанные в таблице 14.One microliter of the product of the multiple extension RT-PCR chain extension reaction by overlapping from each sample was subjected to semi-nested PCR (Biotaq kit, Bioline, BIO-21040 catalog number) according to the manufacturer's recommendations, using 96-well PCR plates (ABgene, Nos. catalog AB-0800). Each reaction mixture, the volume of which was equal to 50 μl, contained a single Biotaq buffer, 200 μM dNTP (each reagent), 2 mm MgCl 2 , 1.25 units. Bio Taq polymerase and primers are shown in table 14.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Последовательности, обозначенные заглавными буквами, соответствуют геноспецифической области.The sequences indicated in capital letters correspond to the genespecific region.
Реакцию выполняли в нижеследующих условиях циклизации:The reaction was carried out under the following cyclization conditions:
Десять микролитров образцов из ряда А, лунки 1-12 каждого планшета, анализировали электрофорезом в 1,5% агарозном геле, используя для визуализации бромид этидия, с целью проверки успешного выполнения множественной RT-PCR с удлинением цепи путем перекрывания. Ожидаемая длина фрагмента удлинения цепи путем перекрывания была равна примерно 1070 п.о. (точный размер зависит от длины вариабельных областей). На фиг.17 показаны образцы, отобранные из восьми 96-луночных планшетов. В результате успешного выполнения RT-PCR с удлинением цепи путем перекрывания с пятидесяти 96-луночных планшетов было получено в среднем по восемь фрагментов с одного планшета. Таким образом, общее число фрагментов, полученных в результате успешного выполнения RT-PCR с удлинением цепи путем перекрывания, было равно примерно 400.Ten microliters of samples from row A, wells 1-12 of each plate, were analyzed by 1.5% agarose gel electrophoresis using ethidium bromide to visualize, in order to verify the success of the multiple RT-PCR chain extension by overlapping. The expected length of the chain elongation fragment by overlapping was approximately 1070 bp (the exact size depends on the length of the variable regions). 17 shows samples taken from eight 96-well plates. As a result of the successful completion of RT-PCR with chain extension by overlapping with fifty-96 well plates, an average of eight fragments were obtained from one plate. Thus, the total number of fragments resulting from the successful completion of RT-PCR with chain extension by overlapping was approximately 400.
По десять микролитров всех продуктов реакций на 96-луночных планшетах, принадлежащих одному донору, объединяли в одной пробирке. Аликвоту, состоящую из 200 мкл объединенных продуктов PCR, очищали при помощи набора для очистки продуктов PCR QIAquick в соответствии с рекомендациями изготовителей (Qiagen, № по каталогу 28106, Hilden, Germany), используя 60 микролитров буфера ЕВ для элюирования. Очищенный пул продуктов реакции PCR с удлинением цепи путем перекрывания гидролизовали XhoI и NotI и затем очищали препаративным электрофорезом в 1% агарозном геле; фрагменты удлинения цепи путем перекрывания вырезали из агарозного геля и очищали при помощи набора Qiaex II (Qiagen, № по каталогу 20051, Hilden, Germany).Ten microliters of all reaction products on 96-well plates belonging to one donor were combined in one tube. An aliquot of 200 μl of the combined PCR products was purified using a QIAquick PCR product cleaning kit in accordance with the manufacturer's recommendations (Qiagen, Catalog No. 28106, Hilden, Germany) using 60 microliters of EB elution buffer. The purified pool of PCR reaction products with chain extension by overlapping was hydrolyzed by XhoI and NotI and then purified by preparative electrophoresis on a 1% agarose gel; overlapping chain elongation fragments were excised from the agarose gel and purified using a Qiaex II kit (Qiagen, Catalog No. 20051, Hilden, Germany).
f. Библиотека экспрессируемых родственных Fab-фрагментовf. Library of expressed related Fab fragments
Библиотека экспрессируемых Fab-фрагментов была создана методом двухстадийного лигирования. Пул вышеописанных гидролизованных фрагментов удлинения цепи путем перекрывания лигировали с вектором JSK301 E.coli, гидролизованным XhoI/NotI (фиг.11). Лигированный продукт затем переносили в электрокомпетентные клетки E.coli (компетентные к электропорации XL1-Blue, Stratagen, № по каталогу 200228, La Jolla, USA) в соответствии с инструкциями изготовителя. Трансформированные клетки E.coli культивировали на 2xYT агаре, содержащем 100 мкг/мл карбенициллина. Биомассу, соответствующую примерно 1010-1011 клеткам, полученную из независимых колоний, число которых по крайней мере в 5 раз превышает общее число продуктов PCR с удлинением цепи путем перекрывания, использовали в качестве исходного материала для получения плазмидного препарата с использованием набора для получения плазмид Maxi компании Qiagen (Qiagen, № по каталогу 12163, Hilden, Germany). Для экспрессии Fab-фрагментов клонированных родственных и связанных VH- и VL-кодирующих последовательностей на второй стадии лигирования в вектор вводили кластер прокариотического промотера и лидерной последовательности. Использованный фрагмент двунаправленного промотора (SEQ ID NO:321) экстрагировали из исходного вектора JSK301 гидролизом AscI/NheI. Очищенный пул плазмид аналогичным образом гидролизовали рестрикционными эндонуклеазами AseI/NheI и очищали от геля вышеописанным способом. Очищенные фрагменты затем лигировали и переносили в электрокомпетентные клетки E.coli (TG1, Stratagene, № по каталогу 200123, La Jolla, USA) и культивировали на 2хYT агаре, содержащем 100 мкг/мл карбенициллина и 1% глюкозы. Процесс создания библиотеки экспрессируемых Fab-фрагментов показан на фиг.12.The library of expressed Fab fragments was created by two-stage ligation. The pool of the above hydrolyzed chain extension fragments by overlapping was ligated with the E. coli JSK301 vector hydrolyzed by XhoI / NotI (FIG. 11). The ligation product was then transferred to E. coli electrocompetent cells (electroporation competent XL1-Blue, Stratagen, catalog No. 200228, La Jolla, USA) in accordance with the manufacturer's instructions. Transformed E. coli cells were cultured on 2xYT agar containing 100 μg / ml carbenicillin. Biomass corresponding to approximately 10 10 -10 11 cells obtained from independent colonies, the number of which is at least 5 times higher than the total number of PCR products with chain extension by overlapping, was used as starting material for the preparation of a plasmid preparation using the plasmid preparation kit Maxi by Qiagen (Qiagen, Cat. No. 12163, Hilden, Germany). To express Fab fragments of the cloned related and associated VH and VL coding sequences at the second stage of ligation, a cluster of prokaryotic promoter and leader sequence was introduced into the vector. The bi-directional promoter fragment used (SEQ ID NO: 321) was extracted from the original JSK301 vector by AscI / NheI hydrolysis. The purified pool of plasmids was likewise hydrolyzed with AseI / NheI restriction endonucleases and purified from the gel as described above. The purified fragments were then ligated and transferred to E. coli electrocompetent cells (TG1, Stratagene, catalog No. 200123, La Jolla, USA) and cultured on 2 × YT agar containing 100 μg / ml carbenicillin and 1% glucose. The process of creating a library of expressed Fab fragments is shown in FIG.
g. Скрининг клоновg. Clone Screening
Fab-экспрессирующие клоны исследовали в отношении связывания ТТ-антигена при помощи антигенспецифических анализов ELISA.Fab-expressing clones were examined for TT antigen binding using antigen-specific ELISA assays.
g-1. Создание базовых планшетов и экспрессия Fab-фрагментовg-1. Creation of base plates and expression of Fab fragments
Отобранные колонии клеток TG1, каждая из которых содержала вектор экспрессии родственных Fab-фрагментов из библиотеки, созданной в разделе (f), вводили в отдельные лунки 96-луночных планшетов, содержащих 2хYT/100 мкг/мл Сarb/1% глюкозы. Планшеты инкубировали, осторожно встряхивая, в течение ночи при 37°С. Четыре 96-луночных планшета объединяли в лунках одного 384-луночного планшета, содержащего 2хYT/100 мкг/мл Carb/1% глюкозы, при помощи 96-канальных репликаторов. 384-луночные планшеты инкубировали в течение дня при 37°С. Указанные планшеты, получившие название базовых планшетов, хранили при -80°С после добавления глицерина до конечной концентрации, равной 15%.Selected TG1 cell colonies, each of which contained an expression vector of related Fab fragments from the library created in section (f), were introduced into separate wells of 96-well plates containing 2xYT / 100 μg / ml Carb / 1% glucose. The plates were incubated by gently shaking overnight at 37 ° C. Four 96-well plates were pooled in the wells of one 384-well plate containing 2xYT / 100 μg / ml Carb / 1% glucose using 96-channel replicators. 384-well plates were incubated during the day at 37 ° C. These tablets, called base plates, were stored at -80 ° C after the addition of glycerol to a final concentration of 15%.
Базовые планшеты использовали для инкубации глубоких 384-луночных планшетов, содержащих 2хYT/100 мкг/мл Carb/0,1% глюкозы, при помощи 96-канального репликатора. Планшеты заклеивали и инкубировали, встряхивая, в течение 2-3 часов при 37°С.Base plates were used to incubate deep 384-well plates containing 2xYT / 100 μg / ml Carb / 0.1% glucose using a 96-channel replicator. The tablets were sealed and incubated, shaking, for 2-3 hours at 37 ° C.
Экспрессию Fab-фрагментов индуцировали, добавляя равный объем 2хYT/100 мкг/мл Carb/0,2 мМ IPTG с достижением конечной концентрации IPTG, равной 0,1 мМ. Планшеты заклеивали и инкубировали, встряхивая, в течение ночи при 30°С. На следующий день супернатанты, содержащие Fab-фрагменты, анализировали методом ELISA на специфичность связывания ТТ-антигенов.Expression of Fab fragments was induced by adding an equal volume of 2xYT / 100 μg / ml Carb / 0.2 mM IPTG to achieve a final IPTG concentration of 0.1 mM. The tablets were sealed and incubated, shaking, overnight at 30 ° C. The next day, supernatants containing Fab fragments were analyzed by ELISA for binding specificity of TT antigens.
g-2. Анализ ELISAg-2. ELISA Analysis
384-луночные планшеты для ELISA (Corning Inc., Corning, NY, USA, № по каталогу 3700) сенсибилизировали в течение ночи при 4°С антигеном столбнячного токсина (ТТ), разведенным до конечной концентрации 1 мкг/мл в PBS в объеме, равном 25 мкл на одну лунку. Избыток сайтов связывания в лунках блокировали в течение 1 часа при комнатной температуре (RT), добавляя 2% М-PBS-T (2% сухого обезжиренного молока в PBS, 0,05% твина-20). Лунки дважды промывали PBS-T (PBS, 0,05% твина-20).384-well ELISA plates (Corning Inc., Corning, NY, USA, 3700 catalog No.) were sensitized overnight at 4 ° C. with tetanus toxin (TT) antigen diluted to a final concentration of 1 μg / ml in PBS in volume, equal to 25 μl per well. Excess binding sites in the wells were blocked for 1 hour at room temperature (RT) by adding 2% M-PBS-T (2% skimmed milk powder in PBS, 0.05% Tween-20). Wells were washed twice with PBS-T (PBS, 0.05% Tween-20).
Fab-содержащие бактериальные супернатанты, полученные на стадии g-1, разводили в отношении 1:2 в 2% M-PBS-T и переносили в двух копиях в лунки планшета для ELISA. Культуру инкубировали в течение 1 часа при комнатной температуре. Лунки четыре раза промывали РBS-T. В лунки добавляли антитело козы к комплексу Fab/HRP человека (Sigma, St.Louis, MO, USA, № по каталогу А0293), разведенное в отношении 1:10000 в 2% M-PBS-T. Культуру инкубировали в течение 1 часа при комнатной температуре. Лунки четыре раза промывали PBS-T. Добавляли субстрат ТМВ Plus (KemEnTec, Copenhagen, Denmark, № по каталогу 4390L) и инкубировали в течение 5-15 минут. Реакции прекращали, добавляя равный объем 1М раствора Н2SO4, и продукт реакции анализировали в спектрофотометре при 450 нм (Multiscan Ascent, Labsystems, Franklin, USA).Fab-containing bacterial supernatants obtained in g-1 were diluted 1: 2 in 2% M-PBS-T and transferred in duplicate to the wells of an ELISA plate. The culture was incubated for 1 hour at room temperature. The wells were washed four times with PBS-T. Goat antibody was added to the wells to the human Fab / HRP complex (Sigma, St. Louis, MO, USA, Catalog No. A0293), diluted in a ratio of 1: 10000 in 2% M-PBS-T. The culture was incubated for 1 hour at room temperature. The wells were washed four times with PBS-T. TMB Plus substrate was added (KemEnTec, Copenhagen, Denmark, catalog number 4390L) and incubated for 5-15 minutes. The reactions were terminated by adding an equal volume of a 1M solution of H 2 SO 4 , and the reaction product was analyzed in a spectrophotometer at 450 nm (Multiscan Ascent, Labsystems, Franklin, USA).
Первичные бактериальные клоны, соответствующие клонам, связывающим ТТ-антиген, затем могут быть удалены с базовых планшетов. Из выделенных антигенположительных клонов Fab-фрагментов может быть получена плазмидная ДНК с созданием подбиблиотеки экспрессируемых родственных Fab-фрагментов клонов, связывающих ТТ-антиген.Primary bacterial clones corresponding to TT antigen binding clones can then be removed from the base plates. Plasmid DNA can be obtained from the isolated antigen-positive clones of Fab fragments with the creation of a sub-library of expressed related Fab fragments of clones that bind TT antigen.
Субпопуляцию клонов далее анализировали методом ELISA с использованием антитела против каппа-цепи для установления корреляции между числом антигенсвязывающих клонов и числом Fab-экспрессирующих клонов. Анализ с использованием антитела против каппа-цепи обычно выполняли в виде анализа с использованием ТТ-антигена за исключением тех случаев, когда лунки сенсибилизировали антителом козы против каппа-цепи человека, разведенным в отношении 1:1000 (Caltag, California, USA, № по каталогу Н16000), используя карбонатный буфер, рН 9,6.The clone subpopulation was further analyzed by ELISA using an anti-kappa chain antibody to establish a correlation between the number of antigen-binding clones and the number of Fab-expressing clones. Antibody Kappa antibody assays were typically performed as TT antigen assays unless the wells were sensitized with a goat anti-human Kappa antibody diluted 1: 1000 (Caltag, California, USA, Catalog No. H16000) using carbonate buffer, pH 9.6.
g-3. Результаты скринингаg-3. Screening Results
Клоны из четырех 384-луночных планшетов исследовали на реактивность в отношении антитела против каппа-цепи и ТТ-антигена при помощи анализов ELISA способом, описанным в разделе g-2. Полученные результаты суммированы в таблицах 15-19. Результаты анализа ELISA с использованием антитела против каппа-цепи свидетельствуют об экспрессии Fab-фрагментов в данном клоне, и результаты анализа ELISA с использованием ТТ-антигена свидетельствуют о функциональной активности Fab-фрагментов.Clones from four 384-well plates were tested for reactivity with Kappa chain antibodies and TT antigen using ELISA assays as described in section g-2. The results obtained are summarized in tables 15-19. The results of ELISA analysis using antibodies against the kappa chain indicate the expression of Fab fragments in this clone, and the results of ELISA analysis using TT antigen indicate the functional activity of Fab fragments.
Из 1440 отдельных клонов, подвергнутых анализу, 482 клона или 34% обладали реактивностью в отношении антитела против каппа-цепи на уровне, превышающем 2-кратную фоновую реактивность. 395 клонов или 27% обладали реактивностью, превышающей 3-кратную фоновую реактивность, и т.д.Of the 1,440 individual clones that were analyzed, 482 clones, or 34%, had an anti-kappa chain reactivity greater than 2-fold background reactivity. 395 clones or 27% had a reactivity in excess of 3-fold background reactivity, etc.
Те же самые клоны анализировали методом ELISA на реактивность в отношении ТТ-антигена; полученные результаты приведены в нижеследующей таблице 16.The same clones were analyzed by reactivity ELISA for TT antigen; the results are shown in the following table 16.
Из приведенной выше таблицы видно, что 9,0% клонов обладают реактивностью в отношении ТТ-антигена на уровне 2-кратной фоновой реактивности (определенной в виде сигнала, полученного на основании реактивности Fab-фрагмента с безотносительной специфичностью). 104 клона взаимодействовали на уровне 3-кратной фоновой реактивности (7,2%) и т.д.From the above table it is seen that 9.0% of the clones are reactive with respect to the TT antigen at the level of 2-fold background reactivity (defined as a signal obtained based on the reactivity of the Fab fragment with irrelevant specificity). 104 clones interacted at the level of 3-fold background reactivity (7.2%), etc.
Из Fab-положительных клонов (всего 482 клона) примерно 27% клонов (130/482) обладали реактивностью в отношении ТТ-антигена на уровне 2-кратной фоновой реактивности. Указанный уровень существенно не меняется при других уровнях фоновой реактивности.Of Fab-positive clones (a total of 482 clones), approximately 27% of the clones (130/482) were reactive with TT antigen at the level of 2-fold background reactivity. The indicated level does not change significantly at other levels of background reactivity.
Шесть 384-луночных планшетов исследовали с целью обнаружения клонов с реактивностью в отношении ТТ-антигена. Число клонов, обладающих реактивность в отношении данного антигена, показано в таблице 17. Для данных планшетов не выполняли анализ ELISA с использованием антитела против каппа-цепи.Six 384-well plates were examined to detect clones with reactivity against TT antigen. The number of clones having reactivity for this antigen is shown in Table 17. For these plates, ELISA analysis using an anti-kappa chain antibody was not performed.
Процентное значение ТТ-положительных клонов на планшетах G054-G059 было сравнимо с аналогичным значением, обнаруженным для планшетов G050-G053 (таблица 16).The percentage of TT-positive clones on the G054-G059 plates was comparable to the same value found for the G050-G053 tablets (Table 16).
Результаты, полученные для всех клонов, исследованных в отношении ТТ-антигена (таблицы 16 и 17), суммированы в таблице 18.The results obtained for all clones studied in relation to the TT antigen (tables 16 and 17) are summarized in table 18.
В общей сложности 339 клонов обладали реактивностью в отношении ТТ-антигена по крайней мере на уровне 2-кратной фоновой реактивности (таблица 18). Полученный результат соответствует 9,4% всех исследованных клонов.A total of 339 clones were reactive with respect to the TT antigen at least at the level of 2-fold background reactivity (Table 18). The result obtained corresponds to 9.4% of all investigated clones.
Все положительные клоны, обладающие реактивностью в отношении ТТ-антигена на уровне 2-кратной фоновой реактивности, инокулировали с базового планшета на вышеописанные 96-луночные планшеты. На следующий день бактерии собирали центрифугированием со скоростью 4000 оборотов/мин в течение 15 минут, осадок вторично суспендировали в 0,8 мМ EDTA, 0,4 х PBS, 0,8 M NaCl и инкубировали на льду в течение 15 минут. Периплазматический экстракт собирали центрифугированием и анализировали реактивность клонов. Ниже приведены результаты реактивности для одного такого планшета (G060) в отношении антитела против каппа-цепи (фиг.18), овальбумина (неродственный антиген) (фиг.19), ТТ-антигена (фиг.20) и результаты одностадийного конкурентного анализа с использованием ТТ-антигена в концентрации 10-7 М в растворе (фиг.21). Вышеуказанные анализы ELISA выполняли на одном и том же периплазматическом экстракте при одинаковом разведении.All positive clones having a TT antigen reactivity of 2x background reactivity were inoculated from the base plate onto the 96-well plates described above. The next day, the bacteria were collected by centrifugation at 4000 rpm for 15 minutes, the pellet was resuspended in 0.8 mM EDTA, 0.4 x PBS, 0.8 M NaCl and incubated on ice for 15 minutes. The periplasmic extract was collected by centrifugation and clone reactivity was analyzed. Below are the results of the reactivity for one such tablet (G060) in relation to an antibody against the kappa chain (Fig. 18), ovalbumin (unrelated antigen) (Fig. 19), TT antigen (Fig. 20) and the results of a one-stage competitive analysis using TT-antigen at a concentration of 10 -7 M in solution (Fig.21). The above ELISA assays were performed on the same periplasmic extract with the same dilution.
Большинство указанных клонов экспрессировали Fab-фрагменты (90/96) (фиг.13), при этом ни один из клонов не взаимодействовал с овальбумином (фиг.19). Реактивность в отношении иммобилизованного ТТ-антигена была ниже или полностью подавлялась ТТ-антигеном в растворе (фиг.21), указывая на то, что клоны специфически взаимодействуют с ТТ-антигеном. Показатели реактивности клонов на планшете G060 суммированы в таблице 19.Most of these clones expressed Fab fragments (90/96) (FIG. 13), with none of the clones interacting with ovalbumin (FIG. 19). The immobilized TT antigen reactivity was lower or completely suppressed by the TT antigen in solution (FIG. 21), indicating that clones specifically interact with the TT antigen. Clone reactivity indices on the G060 tablet are summarized in table 19.
h. Анализ разнообразия и подтверждение клоновh. Diversity analysis and confirmation of clones
Плазмиду, выделенную из 47 клонов (с планшета G060) подбиблиотеки экспрессируемых родственных Fab-фрагментов, связывающих ТТ-антиген, подвергали анализу последовательности. Последовательности, кодирующие вариабельную область тяжелой цепи, секвенировали при помощи праймера LSH-HCP: AGGAAACAGGAGATATACAT (SEQ ID NO:131) и гибридизировали с Р tac промотором; последовательности, кодирующие легкую цепь, секвенировали при помощи праймера LSN-LCP: TCGCCAAGGAGACAGTCATA (SEQ ID NO:132) и гибридизировали с Р lac промотором. Данные секвенирования последовательностей анализировали при помощи программного обеспечения Vector NTI (Informax, Frederick, MD, USA). Данные, полученные для последовательности тяжелой цепи, отсекали до одной пары оснований у 5'-конца вверху от сайта рестрикции AscI и у 3'-конца внизу от сайта рестрикции XhoI. Данные, полученные для последовательности легкой цепи, отсекали до второй пары оснований у 5'-конца вверху от сайта рестрикции NheI и у 3'-конца последнего кодона “ААА”, кодирующего С-концевой лизин вариабельной цепи. Отсечение производили для облегчения дальнейшего анализа, такого как трансляция каждой последовательности ДНК.A plasmid isolated from 47 clones (from G060 plate) of a sub-library of expressed related Fab fragments that bind TT antigen was subjected to sequence analysis. The sequences encoding the variable region of the heavy chain were sequenced using primer LSH-HCP: AGGAAACAGGAGATATACAT (SEQ ID NO: 131) and hybridized with the P tac promoter; light chain coding sequences were sequenced using primer LSN-LCP: TCGCCAAGGAGACAGTCATA (SEQ ID NO: 132) and hybridized to the P lac promoter. Sequencing data was analyzed using Vector NTI software (Informax, Frederick, MD, USA). The data obtained for the heavy chain sequence were cut to one base pair at the 5'end at the top of the AscI restriction site and at the 3'end at the bottom of the XhoI restriction site. The data obtained for the light chain sequence were cut off to the second base pair at the 5'end at the top of the NheI restriction site and at the 3'end of the last AAA codon encoding the C-terminal variable chain lysine. Clipping was performed to facilitate further analysis, such as the translation of each DNA sequence.
Последовательности, кодирующие вариабельные области тяжелой и легкой цепей, анализировали в отношении использования гена зародышевой линии путем сравнения указанных последовательностей с базой данных последовательностей, кодирующих вариабельную область зародышевой линии на основе V-гена (MRC Centre for Protein Engineering, Cambridge, UK). Таким образом был определен ближайший родственный аллель зародышевой линии для каждой последовательности, содержащей набор V-генов из 12 разных аллелей зародышевой линии вариабельной области тяжелой цепи, относящихся к VH-семейству VH1-VH5, и из 8 разных аллелей зародышевой линии вариабельной области легкой каппа-цепи, относящихся к VK1, VKIII и VKIV (таблица 20).The sequences encoding the variable regions of the heavy and light chains were analyzed for the use of the germline gene by comparing these sequences with a database of sequences encoding the variable region of the germline based on the V gene (MRC Center for Protein Engineering, Cambridge, UK). Thus, the closest related germline allele was determined for each sequence containing a set of V genes from 12 different germline alleles of the heavy chain variable region belonging to the VH1-VH5 family and from 8 different germline alleles of the variable kappa chains related to VK1, VKIII and VKIV (table 20).
Кроме того, последовательности вариабельной области гена транслировали в белковые последовательности, которые подвергали сравнительному анализу при помощи программного обеспечения AlignX (Informax, Frederick, MD, USA), как показано на фигурах 22 и 23. На основании сравнительного анализа белковых последовательностей последовательности вариабельной области цепи можно было распределить по группам в соответствии с реаранжировкой V(D)J, обозначенной буквой Н для последовательности вариабельной области тяжелой цепи и буквой L для последовательности вариабельной области каппа-цепи с последующим указанием идентификационного номера. В каждой группе реаранжировки последовательности распределяли в соответствии с генотипом созревания (М-тип в таблице 20) по гипервариабельным участкам CDR1, 2 и 3, обозначенным строчной буквой в алфавитном порядке. Семь клонов содержали недозрелые терминирующие кодоны, из которых 6 клонов имели амбер-мутацию (TAG) (идентификационные номера клонов g060:b12, d08, f06, c12, f03, c04) и 1 клон имел опал-мутацию (TGA) (идентификационный номер клона g060:h12). Указанные кодоны были наиболее вероятно подавлены E.coli с образованием функциональных Fab-фрагментов. Четыре из указанных клонов были членами групп, содержащих аналогичные клоны, что делало их избыточными. Необходимо было произвести анализ дополнительных клонов, чтобы заменить остальные 3 клона с недозрелыми терминирующими кодонами, так как они были единственными членами своих групп. Альтернативно указанные последовательности можно было исправить стандартными методами молекулярной биологии, такими как PCR, замена терминирующего кодона приемлемым кодоном.In addition, the variable region sequences of the gene were translated into protein sequences, which were subjected to comparative analysis using AlignX software (Informax, Frederick, MD, USA), as shown in figures 22 and 23. Based on the comparative analysis of the protein sequences of the variable region sequences of the chain, was divided into groups in accordance with the rearrangement V (D) J indicated by the letter H for the sequence of the variable region of the heavy chain and the letter L for the sequence of variab flaxen region of the kappa chain followed by an identification number. In each rearrangement group, the sequences were distributed according to the maturation genotype (M-type in Table 20) among the hypervariable sections of CDR1, 2, and 3, indicated in lower case in alphabetical order. Seven clones contained immature termination codons, of which 6 clones had an amber mutation (TAG) (clone identification numbers g060: b12, d08, f06, c12, f03, c04) and 1 clone had an opal mutation (TGA) (clone identification number g060: h12). These codons were most likely suppressed by E. coli to form functional Fab fragments. Four of these clones were members of groups containing similar clones, which made them redundant. It was necessary to analyze additional clones in order to replace the remaining 3 clones with immature termination codons, since they were the only members of their groups. Alternatively, these sequences could be corrected by standard molecular biology methods such as PCR, replacing the termination codon with an acceptable codon.
47 анализированных последовательностей V-области можно было разделить на 20 групп с однозначной реаранжировкой V(D)J (обозначенных “группы” в таблице 20) в зависимости от гена вариабельной области тяжелой цепи и вариабельной области каппа-цепи. Четыре из указанных групп реаранжировки можно было далее разделить на 1-4 типа созревания (а-d), в результате чего было получено 27 однозначных антителокодирующих последовательностей (таблица 12). Специфические группы реаранжировки тяжелой цепи обычно объединяются со специфическими группами реаранжировки легкой цепи (например, Н1 с L1, Н12 с L24 и так далее). Кроме того, тип созревания согласуется в парах последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи (например Н4с согласуется с L13c). Такая строгость спаривания в группах реаранжировки и типов созревания свидетельствует о родственном спаривании последовательностей, кодирующих вариабельные области.The 47 analyzed V-region sequences could be divided into 20 groups with a unique rearrangement of V (D) J (designated “groups” in Table 20) depending on the gene for the variable region of the heavy chain and the variable region of the kappa chain. Four of these rearrangement groups could be further divided into 1-4 types of maturation (a-d), resulting in 27 unambiguous antibody-coding sequences (table 12). Specific heavy chain rearrangement groups are usually combined with specific light chain rearrangement groups (e.g., H1 with L1, H12 with L24, and so on). In addition, the type of maturation is consistent in pairs of sequences encoding the variable region of the heavy chain and the variable region of the light chain (for example, H4c is consistent with L13c). Such stringency of pairing in rearrangement groups and types of maturation indicates a related pairing of sequences encoding variable regions.
Однако группа реаранжировки тяжелой цепи Н4 представляет исключение. Н4 спаривается с двумя разными легкими цепями L28 и L13. L13 была единственной цепью для Н4, включающей типы созревания а, b и с, которые согласуются с типами созревания L13. С другой стороны, было также обнаружено, что L28 спаривается с одним из членов в группе тяжелой цепи Н2. Две из семи последовательностей тяжелой цепи Н4а спариваются с тяжелой цепью L13a, и пять из семи последовательностей тяжелой цепи Н4а спариваются с L28a. Указанные наблюдения позволили предположить, что при выполнении множественной RT-PCR с удлинением цепи путем перекрывания в одной лунке находились две плазматические клетки, продуцирующие ТТ-специфическое антитело, с комбинациями генотипов Н2-L28 и Н4а-L13a. Редкие перестановки последовательностей при спаривании генов легкой и тяжелой цепей, таких как Н2 и Н4а с L28, были ожидаемыми, так как эксперимент выполнялся методом ограниченного разведения плазматических клеток.However, the H4 heavy chain rearrangement group is an exception. H4 mates with two different light chains L28 and L13. L13 was the only chain for H4, including maturation types a, b and c, which are consistent with the types of maturation L13. On the other hand, it was also found that L28 mates with one of the members in the H2 heavy chain group. Two of the seven H4a heavy chain sequences mate with the L13a heavy chain, and five of the seven H4a heavy chain sequences mate with L28a. These observations suggest that when performing multiple RT-PCR with chain extension by overlapping in one well there were two plasma cells producing a TT-specific antibody, with combinations of the H2-L28 and H4a-L13a genotypes. Rare sequence shifts during pairing of the light and heavy chain genes, such as H2 and H4a with L28, were expected, since the experiment was performed by the method of limited dilution of plasma cells.
Идентичность последовательностей в отдельных родственных парах последовательностей, кодирующих вариабельную область тяжелой и вариабельную область легкой цепи, относящихся к одной и той же группе и типу созревания, равна по крайней мере 90% и предпочтительно по крайней мере 95%. При рассмотрении, например, g060g03 и g060a01 из группы Н1 с типом созревания а оказывается, что клон g060g03 соответствует паре нуклеотидных последовательностей SEQ ID NO 168:215, где последовательность, кодирующая вариабельную область тяжелой цепи, соответствует SEQ ID NO 168 и последовательность, кодирующая вариабельную область легкой цепи, соответствует SEQ ID NO 215. Клон g060a01 соответствует паре нуклеотидных последовательностей SEQ ID NO 133:180. При сравнении SEQ ID NO 168 с SEQ ID NO 133 (вариабельные области тяжелых цепей) 4 из 369 оснований не являются идентичными и вариабельных областей легких цепей (SEQ ID NO 215 и 180) 8 из 327 оснований не являются идентичными, что соответствует 98,3% идентичности последовательностей в двух родственных парах (g060g03 и g060a01). Однако при рассмотрении идентичности последовательностей в разных группах нельзя ожидать высокой идентичности последовательностей, так как данная библиотека является поликлональной подбиблиотекой, в которой желательно разнообразие. В данном примере самая низкая идентичность в родственных парах равна примерно 40% (например, g060b11 и g060h11 характеризуются идентичностью последовательностей, равной 39,5%).The identity of the sequences in separate related pairs of sequences encoding the variable region of the heavy and the variable region of the light chain belonging to the same group and type of maturation is at least 90% and preferably at least 95%. When considering, for example, g060g03 and g060a01 from group H1 with the type of maturation a, it turns out that clone g060g03 corresponds to a pair of nucleotide sequences of SEQ ID NO 168: 215, where the sequence encoding the variable region of the heavy chain corresponds to
Один вариант осуществления настоящего изобретения относится к подбиблиотеке родственных пар последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи иммуноглобулина, причем иммуноглобулины, получаемые из указанной библиотеки, могут взаимодействовать или связываться со столбнячным токсином.One embodiment of the present invention relates to a sub-library of related pairs of sequences encoding the variable region of the heavy chain and the variable region of the light chain of immunoglobulin, and immunoglobulins obtained from the library can interact or bind with a tetanus toxin.
Другой вариант осуществления настоящего изобретения относится к такой подбиблиотеке родственных пар последовательностей, кодирующих вариабельную область тяжелой цепи и вариабельную область легкой цепи иммуноглобулина, которая содержит отдельные родственные пары с идентичностью последовательностей, равной по крайней мере 90%, выбираемые из группы, включающей пары SEQ ID NO 135:182, 168:215, 146:193, 151:198, 173:220, 152:199, 164:211, 148:195, 137:184, 169:216, 138:185, 143:190, 161:208, 166:213, 157:204, 139:186, 134:181, 150:197, 156:203, 158:205, 170:217, 178:225, 141:188 или 144:191.Another embodiment of the present invention relates to such a sub-library of related pairs of sequences encoding the variable region of the heavy chain and the variable region of the light chain of immunoglobulin, which contains individual related pairs with sequence identity of at least 90% selected from the group consisting of pairs SEQ ID NO 135: 182, 168: 215, 146: 193, 151: 198, 173: 220, 152: 199, 164: 211, 148: 195, 137: 184, 169: 216, 138: 185, 143: 190, 161: 208, 166: 213, 157: 204, 139: 186, 134: 181, 150: 197, 156: 203, 158: 205, 170: 217, 178: 225, 141: 188 or 144: 191.
Таблица 20Table 20

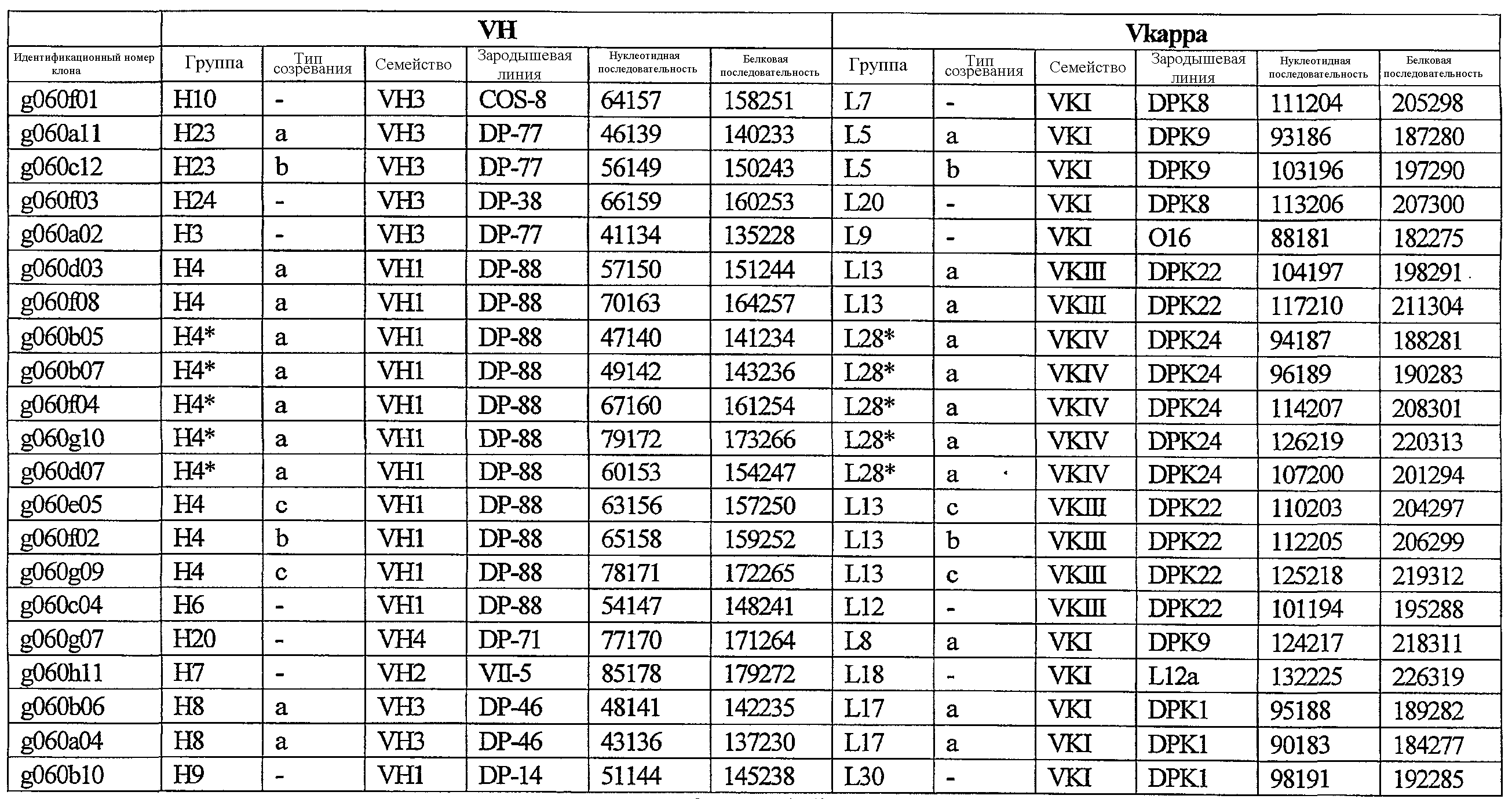
Звездочкой обозначены последовательности, кодирующие вариабельные области, которые подвергаются перестановке. В столбце “белковая последовательность” (Seq.prot.) указаны номера SEQ ID из списка последовательностей, соответствующие белковым последовательностям, и в столбце “нуклеотидная последовательность” (Seq nucl.) указаны номера SEQ ID, соответствующие последовательностям нуклеиновых кислот в списке последовательностей.An asterisk denotes sequences encoding variable regions that undergo permutation. The “protein sequence” column (Seq.prot.) Shows the SEQ ID numbers from the sequence list corresponding to the protein sequences, and the “nucleotide sequence” column (Seq nucl.) Shows the SEQ ID numbers corresponding to the nucleic acid sequences in the sequence list.
i. Кажущееся сродствоi. Apparent affinity
Конкурентный анализ был выполнен для определения кажущегося сродства или IC50 отобранных клонов с планшета G060.Competitive analysis was performed to determine the apparent affinity or IC 50 of the selected clones from the G060 tablet.
Fab-фрагменты экспрессировали в 50 мл культур следующим образом: к 50 мл 2хYT/100 мкг/мл Carb/0,1% глюкозы добавляли 0,5 мл культуры, выдержанной в течение ночи, и встряхивали в течение 2 часов при 37°С. Затем добавляли IPTG до конечной концентрации, равной 0,1 мМ, и продолжали встряхивать в течение ночи при 30°С. На следующий день бактерии собирали центрифугированием со скоростью 4000 оборотов/мин в течение 15 минут, осадок вторично суспендировали в 1 мл 0,8 мМ EDTA, 0,4 х PBS, 0,8 M NaCl и инкубировали на льду в течение 15 минут. Периплазматический экстракт собирали центрифугированием и хранили при -20°С.Fab fragments were expressed in 50 ml of cultures as follows: 0.5 ml of an overnight culture was added to 50 ml of 2xYT / 100 μg / ml Carb / 0.1% glucose and shaken for 2 hours at 37 ° C. Then IPTG was added to a final concentration of 0.1 mM and continued to shake overnight at 30 ° C. The next day, bacteria were collected by centrifugation at 4000 rpm for 15 minutes, the pellet was resuspended in 1 ml of 0.8 mM EDTA, 0.4 x PBS, 0.8 M NaCl and incubated on ice for 15 minutes. The periplasmic extract was collected by centrifugation and stored at -20 ° C.
Конкурентный анализ выполняли следующим образом: периплазматические экстракты с соответствующим разведением, определяемым титрованием, вводили в несколько пробирок. В качестве положительного контрольного образца использовали Fag-фрагмент mp584, полученный отображением на фаге, который был выделен из линии клеток гибридомы человека НВ8501, экспрессирующих антитело против ТТ-антигена. Растворимый ТТ добавляли в первую пробирку в концентрации, равной 100 нМ, и на протяжении четырех стадий последовательно разводили в других пробирках, в результате чего было получено в общей сложности семь разведений ТТ (от 100 нМ до 25 пМ). Реакционные смеси инкубировали в течение примерно 45 минут при комнатной температуре. Образцы переносили на планшеты для ELISA, сенсибилизированные ТТ в количестве 1 мкг/мл и блокировали вышеописанным способом. Планшеты инкубировали в течение 1 часа при комнатной температуре, затем четыре раза промывали PBS-T, добавляли антитело козы к комплексу Fab/HRP человека в отношении 1:10000 и инкубировали в течение 1 часа. Добавляли субстрат ТМВ Plus (KemEnTech, Denmark, № по каталогу 4390А), культуру инкубировали в течение примерно 10 минут и прекращали реакции, добавляя 1 М раствор Н2SO4. Планшеты считывали при 450 нм. График данных показан на фиг.24.Competitive analysis was performed as follows: periplasmic extracts with the appropriate dilution determined by titration were introduced into several tubes. The mp584 Fag fragment obtained by imaging on a phage that was isolated from the HB8501 human hybridoma cell line expressing an anti-TT antigen antibody was used as a positive control sample. Soluble TT was added to the first tube at a concentration of 100 nM and diluted sequentially in other tubes over four stages, resulting in a total of seven dilutions of TT (from 100 nM to 25 pM). The reaction mixtures were incubated for approximately 45 minutes at room temperature. Samples were transferred onto ELISA plates, sensitized with TT in an amount of 1 μg / ml and blocked as described above. The plates were incubated for 1 hour at room temperature, then washed four times with PBS-T, a goat antibody was added to the human Fab / HRP complex in a ratio of 1: 10000 and incubated for 1 hour. TMB Plus substrate was added (KemEnTech, Denmark, catalog number 4390A), the culture was incubated for about 10 minutes and the reaction was stopped by adding a 1 M solution of H 2 SO 4 . Plates were read at 450 nm. A data graph is shown in FIG.
Величины кажущегося сродства анализированных клонов приведены в таблице 21.The apparent affinity values of the analyzed clones are shown in table 21.
Как показано в таблице 21, Fab-фрагменты обладают кажущимся сродством в более низком наномолекулярном или более высоком пикомолекулярном диапазоне. Кроме того, все родственные спаренные Fab-фрагменты характеризуются более высоким кажущимся сродством по сравнению с Fab-фрагментом, полученным отображением на фаге.As shown in table 21, Fab fragments have an apparent affinity in the lower nanomolecular or higher picomolecular range. In addition, all related paired Fab fragments are characterized by a higher apparent affinity compared to the Fab fragment obtained by imaging on the phage.
j. Краткий обзорj. Short review
Частота встречаемости ТТ-специфических плазматических клеток во фракции моноцитов периферической крови от донора ТТ03 была вычислена равной 0,022%. Из крови донора ТТ03 было создано примерно 400 родственных пар. 3600 клонов из клеток, трансформированных библиотекой родственных пар, исследовали методом ELISA, при этом было установлено, что 339 из указанных клонов характеризовались реактивностью в отношении ТТ при выполнении скрининга методом ELISA. 47 из указанных клонов анализировали для определения их клонального разнообразия. Из 47 указанных клонов 27 клонов имели сходство с однозначными, не подвергшимися перестановке последовательностями, кодирующими вариабельные области. Три из указанных клонов содержали недозрелый терминирующий кодон, который требует коррекции до переноса в экспрессирующий вектор млекопитающего. Перенос в экспрессирующие векторы млекопитающего описан в примере 1, раздел h. Кажущееся сродство, измеренное в отобранных клонах, находилось в пределах от более низкого наномолекулярного до более высокого пикомолекулярного диапазона.The frequency of TT-specific plasma cells in the peripheral blood monocyte fraction from the TT03 donor was calculated to be 0.022%. About 400 related pairs were created from the blood of the TT03 donor. 3600 clones from cells transformed with the library of related pairs were examined by ELISA, and it was found that 339 of these clones were characterized by TT reactivity when screened by ELISA. 47 of these clones were analyzed to determine their clonal diversity. Of the 47 indicated clones, 27 clones were similar to single-valued, not transposed, sequences encoding variable regions. Three of these clones contained an immature termination codon, which requires correction before being transferred to the mammalian expression vector. Transfer to mammalian expression vectors is described in Example 1, section h. The apparent affinity measured in the selected clones ranged from a lower nanomolecular to a higher picomolecular range.
k. Перспективыk. Prospects
Столбнячный токсин является одним из наиболее известных токсических веществ, летальная доза которого равна нескольким нанограммам. Указанный токсин продуцируют Clostridium tetani, почвенные бактерии, присутствующие также в пищеварительном тракте у 25% людей. Программа вакцинации против столбняка позволила эффективно побороть данное заболевание в западном мире, хотя в ведущих западных странах все еще ежегодно выявляют 100-200 случаев заболевания, причем соотношение между заболеваемостью и смертностью равно 50%. В развивающихся странах заболеваемость столбняком является значительно выше. Рост бактерий в загрязненных проникающих ранах вызывает высвобождение токсина, что в конечном счете ведет к ригидности, спазмам, нарушению дыхания и смерти.Tetanus toxin is one of the most famous toxic substances, the lethal dose of which is several nanograms. The specified toxin is produced by Clostridium tetani, soil bacteria also present in the digestive tract in 25% of people. The tetanus vaccination program has made it possible to effectively overcome this disease in the Western world, although 100-200 cases of the disease are still detected annually in leading Western countries, and the ratio between morbidity and mortality is 50%. In developing countries, the incidence of tetanus is significantly higher. The growth of bacteria in contaminated penetrating wounds causes the release of toxin, which ultimately leads to stiffness, cramping, respiratory failure and death.
Продукты гипериммунных иммуноглобулинов, выделенные из донорской крови людей с высоким титром гуморальной иммунной реакции против столбнячного токсина, можно использовать для профилактики или лечения столбняка на ранней стадии, а также в сочетании с активной вакцинацией. Однако из-за недостатка человеческого продукта в развивающихся странах используют гипериммунное антитело лошади против столбнячного токсина. Рекомбинантные моноклональные или поликлональные антитела против столбнячного токсина могут заменить продукты гипериммунных глобулинов в лечебных и/или профилактических целях. В научной литературе было описано успешное применение против ТТ рекомбинантных моноклональных антител, полученных известным методом на основе клеток гибридомы (Chim, J. et al. 2003, Biolоgicals 31, 45-53). Интересно отметить наличие синергичного действия при смешивании двух моноклональных антител. Таким образом, рекомбинантное поликлональное антитело против столбнячного токсина, способное взаимодействовать или связываться со столбнячным токсином, потенциально может быть очень эффективным для лечения или профилактики индивидуумов с повышенным риском заболевания столбняком.Products of hyperimmune immunoglobulins isolated from donated blood of people with a high titer of humoral immune response against tetanus toxin can be used to prevent or treat tetanus at an early stage, as well as in combination with active vaccination. However, due to a lack of human product in developing countries, a horse’s hyperimmune anti-tetanus toxin antibody is used. Recombinant monoclonal or polyclonal antibodies against tetanus toxin can replace the products of hyperimmune globulins for therapeutic and / or prophylactic purposes. The scientific literature has described the successful use of anti-TT recombinant monoclonal antibodies obtained by a known method based on hybridoma cells (Chim, J. et al. 2003,
Один вариант осуществления настоящего изобретения относится к рекомбинантному поликлональному иммуноглобулину или его фрагментам, способным взаимодействовать или связываться со столбнячным токсином.One embodiment of the present invention relates to recombinant polyclonal immunoglobulin or fragments thereof capable of interacting with or binding to a tetanus toxin.
Предпочтительный вариант осуществления настоящего изобретения относится к рекомбинантному поликлональному иммуноглобулину, способному взаимодействовать или связываться со столбнячным токсином, который состоит из родственных пар вариабельной области тяжелой цепи и вариабельной области легкой цепи иммуноглобулина.A preferred embodiment of the present invention relates to a recombinant polyclonal immunoglobulin capable of interacting with or binding to a tetanus toxin, which consists of related pairs of the heavy chain variable region and the immunoglobulin light chain variable region.
Другой вариант осуществления настоящего изобретения относится к рекомбинантному поликлональному иммуноглобулину, способному взаимодействовать или связываться со столбнячным токсином, который получают способом по настоящему изобретению.Another embodiment of the present invention relates to a recombinant polyclonal immunoglobulin capable of interacting or binding to a tetanus toxin, which is obtained by the method of the present invention.
Другой вариант осуществления настоящего изобретения относится к рекомбинантному поликлональному иммуноглобулину, способному взаимодействовать или связываться со столбнячным токсином, который содержит отдельные родственные пары вариабельной области тяжелой цепи и вариабельной области легкой цепи иммуноглобулина, обладающие по крайней мере 90% идентичностью последовательностей с одной отдельной парой SEQ ID, выбранной из пар SEQ ID 229:276, 262:309, 240:287, 245:292, 267:314, 246:293, 258:305, 242:289, 231:278, 263:310, 232:279, 237:284, 255:302, 260:307, 251:298, 233:280, 228:275, 244:291, 250:297, 252:299, 264:311, 272:319, 235:282 или 238:285.Another embodiment of the present invention relates to a recombinant polyclonal immunoglobulin capable of interacting or binding to a tetanus toxin, which contains separate related pairs of the variable region of the heavy chain and the variable region of the light chain of immunoglobulin having at least 90% sequence identity with one separate pair of SEQ ID, selected from the pairs SEQ ID 229: 276, 262: 309, 240: 287, 245: 292, 267: 314, 246: 293, 258: 305, 242: 289, 231: 278, 263: 310, 232: 279, 237 : 284, 255: 302, 260: 307, 251: 298, 233: 280, 228: 275, 244: 291, 250: 297, 252: 299, 264: 311, 272: 319, 2 35: 282 or 238: 285.
Другой вариант осуществления изобретения относится к фармацевтической композиции, содержащей в качестве активного ингредиента рекомбинантное поликлональное антитело, способное взаимодействовать или связываться со столбнячным токсином, которая предназначена для лечения или профилактики столбняка. Рекомбинантное поликлональное антитело предпочтительно объединяют с фармацевтически приемлемым наполнителем.Another embodiment of the invention relates to a pharmaceutical composition comprising, as an active ingredient, a recombinant polyclonal antibody capable of interacting with or binding to a tetanus toxin, which is intended to treat or prevent tetanus. The recombinant polyclonal antibody is preferably combined with a pharmaceutically acceptable excipient.
Другой вариант осуществления настоящего изобретения относится к применению рекомбинантного поликлонального иммуноглобулина, способного взаимодействовать или связываться со столбнячным токсином, в качестве лекарственного средства для лечения или профилактической защиты индивидуума с повышенным риском заболевания столбняком.Another embodiment of the present invention relates to the use of a recombinant polyclonal immunoglobulin capable of interacting with or binding to a tetanus toxin as a medicament for the treatment or prophylactic protection of an individual with an increased risk of tetanus disease.
Дополнительный вариант осуществления изобретения относится к способу профилактики или лечения индивидуума с повышенным риском заболевания столбняком путем введения нуждающемуся индивидууму композиции, содержащей рекомбинантное поликлональное антитело, способное взаимодействовать или связываться со столбнячным токсином.An additional embodiment of the invention relates to a method for preventing or treating an individual with an increased risk of tetanus disease by administering to a needy individual a composition comprising a recombinant polyclonal antibody capable of interacting or binding to a tetanus toxin.
Пример 12. Сравнение результатов, полученных у двух доноровExample 12. Comparison of the results obtained from two donors
В нижеследующем примере результаты, полученные от донора ТТ08, сравниваются с результатами, полученными от донора ТТ03 в примере 11. Результаты суммированы в таблице 22.In the following example, the results obtained from the TT08 donor are compared with the results obtained from the TT03 donor in example 11. The results are summarized in table 22.
Данный пример ясно показывает, что у двух разных доноров, иммунизированных ТТ, могут быть получены библиотеки одинакового качества.This example clearly shows that libraries of the same quality can be obtained from two different donors immunized with TT.
Наличие большего числа однозначных родственных пар в библиотеке, полученной от донора ТТ08, скорее всего связано с большим числом анализированных последовательностей.The presence of a larger number of unambiguous related pairs in the library obtained from the TT08 donor is most likely due to the large number of analyzed sequences.
Пример 13. Сравнение библиотеки родственных пар по примеру 11 с отображаемой на фаге комбинаторной библиотекой, полученной у того же донораExample 13. Comparison of the library of related pairs in example 11 with displayed on the phage combinatorial library obtained from the same donor
В настоящем примере отображаемая на фаге комбинаторная библиотека была получена от донора, кровь которого была ранее использована для получения библиотеки родственных пар, с целью сравнения разнообразия, сродства и специфичности библиотек родственных пар и комбинаторных библиотек.In the present example, the combinatorial library displayed in the phage was obtained from a donor whose blood had previously been used to obtain a library of related pairs, in order to compare the diversity, affinity and specificity of the libraries of related pairs and combinatorial libraries.
а. Создание комбинаторной библиотеки на фагеbut. Creating a combinatorial library in phage
Отображаемая на фаге библиотека была создана из фракции CD19+ клеток, полученных от донора ТТ03 (идентичной фракции клеток, полученной в примере 11с).The library displayed on the phage was created from the fraction of CD19 + cells obtained from the TT03 donor (identical to the cell fraction obtained in Example 11c).
Общая РНК была получена примерно из 5×106 CD19+ клеток при помощи набора NucleoSpin RNA L (Machery-Nagel, № по каталогу 740962.20). Затем синтезировали кДНК, выполняя реакцию, инициируемую олиго(dT)-затравкой, с использованием обратной транскриптазы ThermoScript (Invitrogen, № по каталогу 11146-016).Total RNA was obtained from approximately 5 × 10 6 CD19 + cells using the NucleoSpin RNA L kit (Machery-Nagel, Catalog No. 740962.20). Then cDNA was synthesized by performing an oligo (dT) seed-initiated reaction using ThermoScript reverse transcriptase (Invitrogen, catalog number 11146-016).
VН- и каппа-цепи амплифицировали методом PCR, используя Taq ДНК-полимеразу HotMaster (Eppendorf, № по каталогу 0032002.692) и праймеры, по существу аналогичные описанным в публикации de Haard et al., J. Biol. Chem. 274, 18218-18230; 1999), в которых были модифицированы только последовательности узнавания рестрикционных ферментов у 5'-конца.V H and kappa chains were PCR amplified using HotMaster Taq DNA polymerase (Eppendorf, 0032002.692) and primers substantially similar to those described by de Haard et al., J. Biol. Chem. 274, 18218-18230; 1999), in which only recognition sequences of restriction enzymes at the 5'-end have been modified.
Отображаемая на фаге комбинаторная библиотека была создана в результате последовательного введения продуктов PCR каппа- и VН-цепи в отображающий фаговый вектор Em351 (модифицированных из вектора phh3, описанного в публикации Den, W. et al. 1999, J. Immunol. Methods 222, 45-57).Displayed on phage combinatorial library was created by sequentially introduction of PCR products kappa and V H -chain in displaying phage vector Em351 (modified vector of phh3, described in the publication Den, W. et al. 1999, J. Immunol.
Конечную библиотеку электропорировали в штамм TG1 E.coli (Stratagene). Комбинаторная библиотека содержала 3х106 независимых клонов с высокой частотой вставок.The final library was electroporated into E. coli TG1 strain (Stratagene). The combinatorial library contained 3x10 6 independent clones with a high insertion frequency.
b. Пэннинг комбинаторной библиотекиb. Panning Combinatorial Library
Фаговые частицы, отображающие Fab-фрагменты, были получены стандартными методами (например, Antibody Engineering, A Practical Approach, 1996, ed. McCafferty, Hoogenbоom and Chiswell).Phage particles displaying Fab fragments were obtained by standard methods (e.g., Antibody Engineering, A Practical Approach, 1996, ed. McCafferty, Hoogenboom and Chiswell).
Пэннинг выполняли в отношении столбнячного токсина (ТТ; SSI, № партии 89-2), разведенного до 1 мкг/мл в PBS и иммобилизованного в пробирках для иммуноанализа MaxiSorp (Nunc, № по каталогу 444202). Культуру инкубировали в течение одного часа и несколько раз промывали, связанные фаговые частицы элюировали, используя 100 мМ ТЕА (триэтиламин).Panning was performed for tetanus toxin (TT; SSI, lot No. 89-2), diluted to 1 μg / ml in PBS and immobilized in MaxiSorp immunoassay tubes (Nunc, catalog number 444202). The culture was incubated for one hour and washed several times, bound phage particles were eluted using 100 mM TEA (triethylamine).
Элюат фаговых частиц нейтрализовали и использовали для инфицирования экспоненциально растущих клеток TG1, из которых были получены фаговые частицы, отображающие Fab-фрагменты, с повышенной специфичностью к ТТ-антигену. Второй цикл пэннинга с использованием элюированных фагов выполняли вышеописанным стандартным способом.The phage particle eluate was neutralized and used to infect exponentially growing TG1 cells, from which phage particles displaying Fab fragments with increased specificity for TT antigen were obtained. The second panning cycle using eluted phages was performed as described above in a standard manner.
Параллельно выполняли три цикла пэннинга в отношении С-фрагмента молекулы столбнячного токсина (Sigma, № по каталогу Т3694) после осуществления вышеописанного способа.In parallel, three panning cycles were performed with respect to the C-fragment of the tetanus toxin molecule (Sigma, catalog No. T3694) after the implementation of the above method.
Отдельные колонии исследовали на связывание со столбнячным токсином и С-фрагментом из неотобранной библиотеки и после каждого цикла пэннинга в обеих сериях вышеописанного пэннинга.Separate colonies were examined for binding to tetanus toxin and C-fragment from an unselected library and after each panning cycle in both series of the above panning.
с. Сравнение специфичности и сродства комбинаторных клонов на фаговых частицах и клонов родственных парfrom. Comparison of the specificity and affinity of combinatorial clones on phage particles and clones of related pairs
Отдельные колонии получали из неотобранной библиотеки и после каждого цикла пэннинга (в отношении интактного столбнячного токсина (ТТ) и С-фрагмента столбнячного токсина). Фаговые частицы, отображающие Fab-фрагменты, анализировали на реактивность при помощи анализов ELISA. Число Fab-положительных клонов, обладающих реактивностью к ТТ и/или С-фрагменту, равной по крайней мере 2-кратной фоновой реактивности и по крайней мере 4-кратной фоновой реактивности, указано в приведенных ниже таблицах 23-25. Все результаты выражены в виде отношения числа специфических клонов к числу Fab-положительных клонов.Separate colonies were obtained from an unselected library and after each panning cycle (for intact tetanus toxin (TT) and tetanus toxin C-fragment). Phage particles displaying Fab fragments were analyzed for reactivity using ELISA assays. The number of Fab-positive clones with a reactivity to TT and / or C-fragment equal to at least 2-fold background reactivity and at least 4-fold background reactivity are shown in tables 23-25 below. All results are expressed as the ratio of the number of specific clones to the number of Fab-positive clones.
Пэннинг отображаемой на фаге библиотеки против ТТ позволил выявить возрастающее число ТТ-специфических клонов при увеличении числа циклов пэннинга, при этом в неотобранной библиотеке было идентифицировано всего несколько клонов. В неотобранной библиотеке или после двух циклов пэннинга библиотеки против ТТ не было обнаружено клонов с реактивностью к С-фрагменту столбнячного токсина. Для получения Fab-фрагментов со специфичностью к С-фрагменту из отображаемой на фаге комбинаторной библиотеки указанную библиотеку необходимо было подвергнуть пэннингу специально против С-фрагмента.The panning of the anti-TT library displayed on the phage revealed an increasing number of TT-specific clones with an increase in the number of panning cycles, while only a few clones were identified in the unselected library. No clones with reactivity to the C-fragment of tetanus toxin were found in the unselected library or after two cycles of panning against the TT library. In order to obtain Fab fragments with specificity for the C fragment from the combinatorial library displayed on the phage, this library had to be specifically panned against the C fragment.
Для сравнения тринадцать ТТ-специфических клонов из семи клонов с реактивностью выше 2-кратной фоновой реактивности по примеру 11 подвергали анализу ELISA, специфичному к С-фрагменту. Таким образом, Fab-фрагменты со специфичностью к С-фрагменту столбнячного токсина можно было экспрессировать из библиотеки родственных пар, полученной из крови ТТ-иммунизированного индивидуума.For comparison, thirteen TT-specific clones of seven clones with reactivity above 2-fold background reactivity of Example 11 were subjected to C-fragment specific ELISA. Thus, Fab fragments with specificity for the tetanus toxin C fragment could be expressed from a library of cognate pairs obtained from the blood of a TT immunized individual.
Данный пример ясно показывает недостаток использования пэннинга для идентификации клонов со специфичностью к определенному антигену. Неизвестные важные фрагменты или эпитопы антигена могут быть пропущены во время пэннинга, в результате чего будет получен менее эффективный продукт.This example clearly shows the disadvantage of using panning to identify clones with specificity for a particular antigen. Unknown important fragments or epitopes of the antigen may be skipped during panning, resulting in a less effective product.
Кроме того, способом, описанным в анализе по примеру 11i, измеряли кажущееся сродство комбинаторных клонов. Анализировали десять комбинаторных клонов, полученных после двух циклов пэннинга в отношении ТТ, при этом были получены величины кажущегося сродства связывания в пределах от 1 до 15 нМ.In addition, the apparent affinity of combinatorial clones was measured by the method described in the analysis of Example 11i. Ten combinatorial clones obtained after two panning cycles for TT were analyzed, with apparent binding affinities ranging from 1 to 15 nM obtained.
При сравнении четырех из девяти клонов, подвергнутых анализу из библиотеки родственных пар (таблица 21), были получены величины сродства в пикомолекулярном диапазоне.When comparing four of the nine clones that were analyzed from a library of related pairs (table 21), affinity values in the picomolecular range were obtained.
Полученные результаты показывают, что спаривание вариабельных областей, первоначально отобранных иммунной системой донора, в сочетании с соматическими гипермутациями, которым были подвергнуты пары, потенциально увеличивает кажущееся сродство связывания по сравнению с произвольными комбинациями таких вариабельных областей.The results show that the pairing of the variable regions originally selected by the donor’s immune system, combined with the somatic hypermutations to which the pairs were subjected, potentially increases the apparent binding affinity compared to arbitrary combinations of such variable regions.
d. Сравнение последовательностей ТТ-специфических комбинаторных клонов на фаговых частицах и клонов родственных парd. Comparison of the sequences of TT-specific combinatorial clones on phage particles and clones of related pairs
Большой объем данных о последовательностях, полученных из двух библиотек, препятствует выполнению прямого сравнения неочищенных последовательностей. Для визуализации различий между парами VН- и VL-последовательностей в отображаемой на фаге библиотеке и в библиотеке родственных пар было воссоздано филогенетическое дерево для VН- и VL-последовательностей, и пары были проиллюстрированы в виде точечной матрицы. Попарное сравнение филогенетической информации в точечной матрице (фиг.25) выявило очень разные профили распределения пар VН- и VL-последовательностей в двух библиотеках. Рассеянное изображение пар VН- и VL-последовательностей в отображаемой на фаге библиотеке (фиг.25А) свидетельствовало о небольшой филогенетической взаимосвязи между VН- и VL-генами, что согласуется с произвольным спариванием V-генов в данной библиотеке. В отличие от этого пары VН- и VL-последовательностей из библиотеки родственных пар (фиг.25В) характеризуются кластерным изображением, свидетельствующим о коэволюции V-генов, ожидаемой для родственных пар. Кроме того, генетическое разнообразие гораздо больше для V-генов в библиотеке родственных пар по сравнению с V-генами из комбинаторной библиотеки, указывая на то, что метод выделения родственных спаренных V-генов является менее ошибочным.The large volume of sequence data obtained from two libraries prevents direct comparisons of the crude sequences. For visualization of differences between pairs of V H - and V L -sequences displayed on a phage library and the library of related pairs were reconstituted phylogenetic tree for the V H - and V L-sequences, and pairs were illustrated in a dot matrix. A pairwise comparison of phylogenetic information in a point matrix (Fig. 25) revealed very different distribution profiles of pairs of V H and V L sequences in two libraries. The scattered image of pairs of V H and V L sequences in the library displayed on the phage (Fig. 25A) indicated a small phylogenetic relationship between the V H and V L genes, which is consistent with the random pairing of V genes in this library. In contrast, pairs of V H and V L sequences from the library of related pairs (FIG. 25B) are characterized by a cluster image indicative of the co-evolution of V genes expected for related pairs. In addition, genetic diversity is much greater for V genes in a library of related pairs compared to V genes from a combinatorial library, indicating that the method of isolating related paired V genes is less erroneous.
Пример 14. Объединенные реакции одностадийной множественной RT-PCR с удлинением цепи путем перекрывания и гнездовой PCR с использованием Т-клеток в качестве источника матрицыExample 14. The combined reactions of one-stage multiple RT-PCR with chain extension by overlapping and nested PCR using T cells as a matrix source
В данном примере описано выполнение одностадийной множественной RT-PCR с удлинением цепи путем перекрывания с использованием Т-лимфоцитов человека.This example describes the implementation of a one-stage multiple RT-PCR with chain extension by overlapping using human T-lymphocytes.
а. Получение лимфоцитсодержащей фракции клетокbut. Obtaining a lymphocyte-containing fraction of cells
Пробу крови получают у доноров, подвергнутых воздействию требуемого антигена, например, в результате иммунизации, естественного инфицирования, неоплазии, аутоиммунной реакции или других заболеваний. Мононуклеарные клетки периферической крови (РВМС) выделяют в устройстве Lymphoprep (Axis-Shield, Oslo, Norway, производственный № 1001967) в соответствии с инструкциями изготовителя.A blood sample is obtained from donors exposed to the desired antigen, for example, as a result of immunization, natural infection, neoplasia, autoimmune reaction or other diseases. Peripheral blood mononuclear cells (PBMCs) are isolated in a Lymphoprep device (Axis-Shield, Oslo, Norway, production No. 1001967) in accordance with the manufacturer's instructions.
В настоящем примере антиген-специфические Т-клетки были получены в результате дальнейшей стимуляции фракции РВМС. Однако множественная RT-PCR с удлинением цепи путем перекрывания может быть также выполнена с использованием отдельных клеток из фракции РВМС или фракции клеток, обогащенной Т-клетками (например, путем сортировки методом FACS для CD3-положительных клеток).In the present example, antigen-specific T cells were obtained by further stimulation of the PBMC fraction. However, overlapping multiple RT-PCRs with overlapping chain extension can also be performed using single cells from a PBMC fraction or a cell fraction enriched in T cells (for example, by FACS sorting for CD3-positive cells).
b. Создание антиген-специфических Т-клетокb. The creation of antigen-specific T cells
Фракцию клеток РВМС вторично суспендируют в соответствующей культуральной среде, содержащей необходимые цитокиты, такие как IL2. Затем к культуре добавляют требуемый антиген, где антиген-представляющие клетки (АРС), присутствующие во фракции РВМС, представляют его Т-лимфоцитам. Альтернативно к фракции РВМС могут быть добавлены АРС-питающие клетки, предварительно обработанные с возможностью представления требуемого антигена. Такие АРС-питающие клетки могут быть АРС, подвергнутыми воздействию требуемого антигена, например, в форме пептида, белка или других молекул, АРС, инфицированными микробами, клетками, трансфецированными для экспрессии и представления антигена, или АРС, сокультивируемыми с другими антигенными клетками, например с раковыми клетками в форме первичной ткани или линий клеток. В научной литературе описаны многочисленные разные типы АРС-питающих клеток, включая линии трансформированных клеток, линии В-клеток, дендритные клетки и т.д.The PBMC cell fraction is resuspended in an appropriate culture medium containing the necessary cytokites, such as IL2. Then, the desired antigen is added to the culture, where the antigen-presenting cells (APC) present in the PBMC fraction represent its T-lymphocytes. Alternatively, APC-feeding cells pretreated to present the desired antigen can be added to the PBMC fraction. Such APC-feeding cells can be APC exposed to the desired antigen, for example, in the form of a peptide, protein or other molecules, APC infected with microbes, cells transfected to express and present the antigen, or APC co-cultivated with other antigenic cells, for example cancer cells in the form of primary tissue or cell lines. The scientific literature describes numerous different types of APC-feeding cells, including transformed cell lines, B-cell lines, dendritic cells, etc.
Фракцию РВМС культивируют в течение примерно 3-5 недель, на протяжении которых добавляют свежие антиген-представляющие клетки вместе с цитокинами, например, один раз в неделю. В результате этого происходит пролиферация, активация и созревание Т-лимфоцитов. В конце культивирования в культуре клеток преобладают антиген-специфические Т-клетки. Будут ли указанные клетки CD4+ или CD8+ клетками, зависит от заболевания, антигена, клеток АРС и смесей цитокинов, использованных во время стимуляции.The PBMC fraction is cultured for about 3-5 weeks, during which fresh antigen-presenting cells are added along with cytokines, for example, once a week. As a result of this, proliferation, activation and maturation of T-lymphocytes occurs. At the end of cultivation, antigen-specific T cells predominate in the cell culture. Whether these cells are CD4 + or CD8 + cells depends on the disease, antigen, APC cells and mixtures of cytokines used during stimulation.
Антигенную специфичность можно проверить, например, при помощи анализа CTL, анализов пролиферации и тетрамеров МНС, сенсибилизированных требуемым антигеном (Altman, J.D. et al., 1996, Science 274, 94-96).Antigenic specificity can be checked, for example, by CTL analysis, proliferation assays and MHC tetramers sensitized with the desired antigen (Altman, J.D. et al., 1996, Science 274, 94-96).
Антиген-специфические Т-клетки распределяют по пробиркам для PCR методом ограниченного разведения или FACS, получая при этом одну клетку в одном сосуде. Сосуд можно хранить при -80°С до использования.Antigen-specific T cells are distributed in tubes for PCR by the method of limited dilution or FACS, while receiving one cell in one vessel. The vessel can be stored at -80 ° C until use.
b. Одностадийная множественная RT-PCR с удлинением цепи путем перекрыванияb. Single-Stage Multiple Overlap RT-PCR with Overlap
Для выполнения множественной RT-PCR с удлинением цепи путем перекрывания используют набор для одностадийной RT-PCR компании Qiagen (Qiagen, № по каталогу 210212, Hilden, Germany) в соответствии с рекомендациями изготовителя. Перед добавлением реакционной смеси PCR в пробирки для PCR клетки оттаивают.To perform multiple overlap extended RT-PCR with overlapping chain, use the Qiagen one-step RT-PCR kit (Qiagen, 210212, Hilden, Germany) according to the manufacturer's recommendations. Before the PCR reaction mixture is added to the PCR tubes, the cells are thawed.
Реакционные смеси РCR и условия циклизации первоначально определяют в соответствии с описанием, приведенным в примере 11 е-1. Однако при использовании нового набора праймеров может потребоваться некоторая оптимизация условий.PCR reaction mixtures and cyclization conditions are initially determined as described in Example 11 e-1. However, when using a new set of primers, some optimization of the conditions may be required.
Используемая смесь множественных праймеров для удлинения цепи путем перекрывания включает праймеры, показанные в таблице 26.The mixture of multiple primers used to extend the chain by overlapping includes the primers shown in table 26.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
с. Полугнездовая PCRfrom. Semi-slot PCR
Полугнездовая PCR может быть выполнена в соответствии с описанием, приведенным в примере 11 е-2, при этом может потребоваться некоторая оптимизация условий.A semi-nested PCR may be performed as described in Example 11 e-2, and some optimization of the conditions may be required.
![]()
![]()
![]()
![]()
Для проверки успешного выполнения множественной RT-PCR с удлинением цепи путем перекрывания часть образцов из реакционных смесей полугнездовой РCR анализируют, подвергая 10 мкл каждой реакционной смеси полугнездовой PCR электрофорезу в 1% агарозном геле с использованием для обнаружения бромида этидия. Ожидаемый размер фрагмента удлинения цепи путем перекрывания равен примерно 850 п.о. (точный размер зависит от длины вариабельных областей).To verify the success of the multiple chain extension RT-PCR by overlapping part of the samples from the reaction mixtures, the semi-nested PCR was analyzed by subjecting 10 μl of each reaction mixture to semi-nested PCR electrophoresis in 1% agarose gel using ethidium bromide to detect it. The expected fragment size of the chain elongation by overlapping is approximately 850 bp. (the exact size depends on the length of the variable regions).
Примерно десять микролитров из всех реакционных смесей, полученных у одного донора, объединяют в одной пробирке. Аликвоту объединенных продуктов PCR затем очищают при помощи набора для очистки PCR QIAquick в соответствии с инструкциями изготовителей (Qiagen, № по каталогу 28106, Hilden, Germany). Очищенный пул продуктов PCR с удлинением цепи путем перекрывания может быть гидролизован соответствующими рестрикционными ферментами, очищен и введен в приемлемый вектор.About ten microliters of all reaction mixtures obtained from one donor are combined in one tube. An aliquot of the combined PCR products is then purified using the QIAquick PCR Cleaning Kit according to the manufacturers instructions (Qiagen, Catalog No. 28106, Hilden, Germany). The purified overlap-extended PCR product pool can be hydrolyzed with the appropriate restriction enzymes, purified and introduced into an acceptable vector.
В настоящем эксперименте праймеры для константной области (SEQ ID NO 376 и 377), используемые при выполнении полугнездовой PCR, создают для субклонирования продукта полугнездовой PCR в приемлемом векторе. При создании праймера для Сβ-цепи остаток SER заменяют остатком Met в положении 21 пептида константной области β-цепи, благодаря чему в указанную последовательность нуклеиновой кислоты можно ввести сайт NsiI:In the present experiment, constant region primers (

Такой переход должен быть относительно безопасным, так как SER 21 находится в константной области β-цепи в петле у проксимального конца домена мембраны. Поэтому вышеуказанная относительно консервативная замена, по-видимому, не нарушит общую структуру домена.Such a transition should be relatively safe, since
При создании праймера для Сα-цепи заменяют нуклеотиды, соответствующие положениям 15-17 в пептиде константной области α-цепи, благодаря чему в последовательность нуклеиновой кислоты можно ввести сайт SacI:When creating a primer for the α-chain, nucleotides corresponding to positions 15-17 in the peptide of the constant region of the α-chain are replaced, so that the SacI site can be introduced into the nucleic acid sequence:

Поэтому приемлемые векторы содержат остальные части константных областей α- и β-цепей TcR и включают соответствующую модификацию сайтов рестрикции. Указанные замены можно произвести стандартными методами РCR и субклонирования.Therefore, acceptable vectors contain the remaining parts of the constant regions of the α and β chains of TcR and include the corresponding modification of restriction sites. These replacements can be made using standard PCR and subcloning methods.
е. Дополнительные соображенияe. Additional considerations
Многие праймеры для вариабельных областей потенциально могут взаимодействовать друг с другом с оказанием ингибирующего действия во время амплификации методом множественной РCR с удлинением цепи путем перекрывания. Во избежание этого праймеры для вариабельных областей могут быть разделены на поднаборы и использованы отдельно в соответствующих комбинациях.Many variable region primers can potentially interact with each other to exert an inhibitory effect during amplification by multiple PCR with chain extension by overlapping. To avoid this, primers for variable regions can be divided into subsets and used separately in appropriate combinations.
Другие варианты осуществления изобретенияOther embodiments of the invention
Все публикации и заявки на патент, приведенные в данном описании изобретения, включены в настоящую заявку в качестве ссылки, как если бы все отдельные публикации или заявки на патент были полностью приведены в качестве ссылки. Хотя настоящее изобретение было подробно описано на примере отдельных иллюстративных вариантов осуществления для простоты понимания, специалистам в данной области должно быть понятно в свете приведенного описания, что в данное изобретение могут быть внесены определенные изменения и модификации, не выходящие за пределы объема и сущности прилагаемой формулы изобретения.All publications and patent applications cited in this specification are incorporated herein by reference, as if all individual publications or patent applications were incorporated by reference in their entirety. Although the present invention has been described in detail by way of separate illustrative embodiments for ease of understanding, it will be understood by those skilled in the art in light of the above description that certain changes and modifications may be made to the invention without departing from the scope and spirit of the appended claims .
Claims (51)
a) амплификацию интересующих нуклеотидных последовательностей при помощи множественной молекулярной амплификации с использованием матрицы, полученной из выделенной отдельной клетки; и
b) связывание интересующих нуклеотидных последовательностей, амплифицированных на стадии а);
в котором интересующие нуклеотидные последовательности содержат последовательности, кодирующие вариабельную область, и в результате связывания образуется родственная пара последовательностей, кодирующих вариабельные области.1. A method of binding a plurality of non-contiguous nucleotide sequences of interest, which comprises:
a) amplification of nucleotide sequences of interest using multiple molecular amplification using a matrix derived from an isolated single cell; and
b) binding of the nucleotide sequences of interest amplified in step a);
in which the nucleotide sequences of interest contain sequences encoding a variable region, and as a result of binding, a related pair of sequences encoding variable regions is formed.
a) по крайней мере один праймер для CL или JL, комплементарный смысловой последовательности, кодирующей вариабельную область легкой цепи иммуноглобулина;
b) по крайней мере один 5'-концевой праймер для VL или праймер для VLL, комплементарный антисмысловой последовательности, кодирующей вариабельную область легкой цепи иммуноглобулина, или лидерной последовательности вариабельной области легкой цепи, и способный образовывать набор праймеров с праймером(ами) по пункту а);
c) по крайней мере один праймер для СH или JH, комплементарный смысловой последовательности, кодирующей константный домен тяжелой цепи иммуноглобулина, или последовательности, кодирующей соединяющую область тяжелой цепи; и
d) по крайней мере один 5'-концевой праймер для VH или праймер для VHL, комплементарный антисмысловой цепи последовательности, кодирующей вариабельную область тяжелой цепи иммуноглобулина, или лидерной последовательности вариабельной области тяжелой цепи, и способный образовывать набор праймеров с праймером(амии) по пункту с).22. The method according to p, in which the mixture of multiple primers to extend the chain by overlapping includes:
a) at least one primer for C L or J L complementary to a sense sequence encoding an immunoglobulin light chain variable region;
b) at least one 5'-terminal primer for V L or a primer for V LL complementary to the antisense sequence encoding the variable region of the light chain of the immunoglobulin or leader sequence of the variable region of the light chain, and capable of forming a set of primers with primer (s) at paragraph a);
c) at least one primer for C H or J H complementary to a sense sequence encoding an immunoglobulin heavy chain constant domain, or a sequence encoding a connecting region of a heavy chain; and
d) at least one 5'-terminal primer for V H or a primer for V HL complementary to the antisense chain of the sequence encoding the variable region of the heavy chain of the immunoglobulin or leader sequence of the variable region of the heavy chain, and capable of forming a set of primers with a primer (s) under item c).
a) получение от донора фракции клеток, содержащей лимфоциты;
b) необязательное обогащение определенной популяции лимфоцитов указанной фракции клеток;
c) получение популяции выделенных отдельных клеток, предусматривающее распределение по одной клетке из указанной фракции клеток в несколько сосудов; и
d) амплификацию и связывание последовательностей, кодирующих вариабельные области, находящихся в указанной популяции выделенных отдельных клеток, способом по любому из пп.1-24.24. A method of creating a library of related pairs containing linked sequences encoding variable regions, said sequences encoding variable regions being sequences of the immunoglobulin superfamily, the method comprising:
a) receiving from the donor a fraction of cells containing lymphocytes;
b) optional enrichment of a particular population of lymphocytes of a specified fraction of cells;
c) obtaining a population of isolated individual cells, comprising distributing one cell from the specified fraction of cells into several vessels; and
d) amplification and binding of sequences encoding the variable regions located in the specified population of isolated individual cells, by the method according to any one of claims 1 to 24.
a) введения вектора, кодирующего сегмент связанных нуклеотидных последовательностей, в клетку-хозяин;
b) культивирование указанных клеток-хозяев в условиях, адаптированных для экспрессии; и
c) получение белкового продукта, экспрессируемого вектором, введенным в указанную клетку-хозяин.39. The method according to p, which further comprises the steps of:
a) introducing a vector encoding a segment of linked nucleotide sequences into a host cell;
b) culturing said host cells under conditions adapted for expression; and
c) obtaining a protein product expressed by a vector introduced into the specified host cell.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US50458903P | 2003-09-18 | 2003-09-18 | |
| US50445503P | 2003-09-18 | 2003-09-18 | |
| US60/504,455 | 2003-09-18 | ||
| US60/504,589 | 2003-09-18 | ||
| DKPA200301867 | 2003-12-17 | ||
| DKPA200400782 | 2004-05-15 | ||
| DKPA200400782 | 2004-05-15 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2006112833A RU2006112833A (en) | 2007-10-27 |
| RU2392324C2 true RU2392324C2 (en) | 2010-06-20 |
Family
ID=38955500
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2006112833/13A RU2392324C2 (en) | 2003-09-18 | 2004-09-17 | Concerned sequences linkage method |
Country Status (1)
| Country | Link |
|---|---|
| RU (1) | RU2392324C2 (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012174214A1 (en) * | 2011-06-15 | 2012-12-20 | The Regents Of The University Of California | High resolution analysis of mammalian transcriptome using gene pool specific primers |
| RU2565550C2 (en) * | 2010-09-24 | 2015-10-20 | Те Борд Оф Трастиз Оф Те Лилэнд Стэнфорд Джуниор Юниверсити | Direct capture, amplification and sequencing of target dna using immobilised primers |
| RU2630656C2 (en) * | 2011-09-12 | 2017-09-11 | Джензим Корпорейшн | ANTIBODIES AGAINST αβTCR |
| US11697690B2 (en) | 2014-03-19 | 2023-07-11 | Genzyme Corporation | Site-specific glycoengineering of targeting moieties |
| US11807690B2 (en) | 2013-03-11 | 2023-11-07 | Genzyme Corporation | Hyperglycosylated binding polypeptides |
| RU2809113C2 (en) * | 2018-02-21 | 2023-12-06 | Борд Оф Риджентс, Дзе Юниверсити Оф Техас Систем | Universal antigen presenting cells and their use |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5669397B2 (en) * | 2007-03-01 | 2015-02-12 | シムフォゲン・アクティーゼルスカブSymphogen A/S | Methods for cloning cognate antibodies |
-
2004
- 2004-09-17 RU RU2006112833/13A patent/RU2392324C2/en not_active IP Right Cessation
Non-Patent Citations (3)
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2565550C2 (en) * | 2010-09-24 | 2015-10-20 | Те Борд Оф Трастиз Оф Те Лилэнд Стэнфорд Джуниор Юниверсити | Direct capture, amplification and sequencing of target dna using immobilised primers |
| WO2012174214A1 (en) * | 2011-06-15 | 2012-12-20 | The Regents Of The University Of California | High resolution analysis of mammalian transcriptome using gene pool specific primers |
| RU2630656C2 (en) * | 2011-09-12 | 2017-09-11 | Джензим Корпорейшн | ANTIBODIES AGAINST αβTCR |
| US11186638B2 (en) | 2011-09-12 | 2021-11-30 | Genzyme Corporation | Anti-αβTCR antibody |
| US11807690B2 (en) | 2013-03-11 | 2023-11-07 | Genzyme Corporation | Hyperglycosylated binding polypeptides |
| US11697690B2 (en) | 2014-03-19 | 2023-07-11 | Genzyme Corporation | Site-specific glycoengineering of targeting moieties |
| RU2809113C2 (en) * | 2018-02-21 | 2023-12-06 | Борд Оф Риджентс, Дзе Юниверсити Оф Техас Систем | Universal antigen presenting cells and their use |
Also Published As
| Publication number | Publication date |
|---|---|
| RU2006112833A (en) | 2007-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4651619B2 (en) | Method for concatenating desired sequences | |
| JP5669397B2 (en) | Methods for cloning cognate antibodies | |
| Meijer et al. | Isolation of human antibody repertoires with preservation of the natural heavy and light chain pairing | |
| US20100069262A1 (en) | Method for Cloning Avian-Derived Antibodies | |
| WO2001092291A2 (en) | Antibody and t-cell receptor libraries | |
| RU2392324C2 (en) | Concerned sequences linkage method | |
| Abi-Ghanem et al. | Phage display selection and characterization of single-chain recombinant antibodies against Eimeria tenella sporozoites | |
| KR101135134B1 (en) | Method for linking sequences of interest | |
| MXPA06002894A (en) | Method for linking sequences of interest |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| MM4A | The patent is invalid due to non-payment of fees |
Effective date: 20130918 |