KR20170090128A - Index construction and utilization method for processing data based on MapReduce in Hadoop environment - Google Patents
Index construction and utilization method for processing data based on MapReduce in Hadoop environment Download PDFInfo
- Publication number
- KR20170090128A KR20170090128A KR1020160010619A KR20160010619A KR20170090128A KR 20170090128 A KR20170090128 A KR 20170090128A KR 1020160010619 A KR1020160010619 A KR 1020160010619A KR 20160010619 A KR20160010619 A KR 20160010619A KR 20170090128 A KR20170090128 A KR 20170090128A
- Authority
- KR
- South Korea
- Prior art keywords
- value
- file
- index
- offset
- key
- Prior art date
Links
Images



Classifications
-
- G06F17/30336—
-
- G06F17/30091—
-
- G06F17/30318—
-
- G06F17/30946—
Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The present invention relates to a method of processing data based on MapReduce and more particularly to a method of constructing a secondary index for effectively processing big data in a MapReduce method in a Hadoop environment, And a method for constructing and utilizing indexes for improving data processing performance based on MapReduce in Hadoop environment used for processing.
Description
The present invention relates to a method of processing data based on MapReduce, and more particularly, to a method and apparatus for constructing a secondary index for effectively processing big data in a MapReduce method in a Hadoop environment, And to a method for constructing and utilizing an index for improving data processing performance based on MapReduce in a Hadoop environment for use in deuce-based data processing.
In general, MapReduce-based task execution is a task of processing large-scale data by dividing detailed tasks into several small units, loading them into several computers, processing them in parallel (Map operation), and combining the results And the final result is generated.
Since the MapReduce operation is performed in parallel using one or more general computers, large-scale data processing becomes possible, and it is actively used in recent big data analysis and machine learning fields. In addition, more complicated tasks are divided into multiple MapReduce tasks, which are then executed in a sequential or parallel manner. Currently, related technologies are being developed for processing various composite map deuce tasks such as Pig and Hive for processing this type of work.
In general, MapReduce Big data processing method is mainly used for reading and analyzing large amount of data continuously accumulating such as social media log data or sensor measurement values, but it is an effective big data processing method using a large scale computer The application field is gradually expanding to the existing DBMS application field. Especially, in case of data application where data change is not very frequent, it is expected that using MapReduce method will show excellent performance for the method using existing DBMS in large scale data processing.
Existing DBMSs use indexes as a way to process large amounts of data quickly. The data processing performance is improved by accessing only the data required for analysis without using the entire data by utilizing the index, with a small number of I / Os.
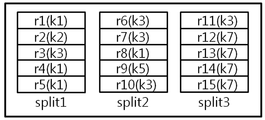
In the data processing method based on the MapReduce method, data stored in a file is read in units of file slices (hereinafter referred to as a slice), and sequentially processed. 1 is a diagram showing an example of a file composed of three pieces.
As shown in FIG. 1, it can be seen that 15 records are stored in the entire three-piece file.
Generally, the size of a piece is fixed to a predetermined size for each file, but the size of a record may be different depending on the size of data actually stored.
However, since the existing index is assumed to access the record-based data directly and arbitrarily, unlike the Hadoop file system that handles fragmented data, there are many problems in applying the existing index structure and utilization method.
SUMMARY OF THE INVENTION The present invention has been made to solve the above problems, and it is an object of the present invention to provide a method and apparatus for quickly accessing data stored in an HDFS file system of a Hadoop environment, A method of generating an index, and a method of utilizing the MapReduce processing method in accessing data.
According to another aspect of the present invention, there is provided an index construction method for enhancing data processing performance based on MapReduce in a Hadoop environment, wherein each mapper that processes a fragment reads file fragment information allocated to the fragment, S), calculates the offset and length of the corresponding record, obtains the value of the designated key column, obtains the key value (K), and uses the offset, length, and key value (K) Outputting; And the reducer reads a key and a value list (K, S: list (offset, length)) input from the mapper, stores key and value in a fragmented Hadoop index file, extracts the smallest sffset And calculating the entire offset and length, and then storing the offset and length in the fragment level Hadopo index file.
According to the present invention, an index structure for MapReduce, a method for index-based indexing based on MapReduce, and a data processing method for MapReduce method using index are proposed to enhance the performance of the data processing process of the MapReduce method. Effect.
First, it is possible to reduce the number of unnecessary disk block I / Os by providing the index configuration and utilization method that can be utilized in the data processing of the map-de-miss method for performing the operation of the file fragment unit, It is possible to reduce the decoding time of unnecessary records in the file fragment.
Second, since there is a high probability that one record is normally overlapped between two file blocks, the disk block I / O occurs twice in many cases when reading the file fragments. However, Even if all the records corresponding to the key value exist, one disk block I / O can be reduced except for the case where both the first record and the last record of the piece are records of a given key value.
Third, using the index can reduce memory usage because only the area containing related records in the fragment is loaded into memory.
Fourth, since the index generation method of the MapReduce method is provided, the index creation for a large-scale data file can be completed quickly.
1 is a diagram showing an example of a file composed of three pieces
Fig. 2 is a diagram showing distribution positions of target records in a file according to a car value to be searched according to an embodiment of the present invention; Fig.
3 illustrates a utilization index structure according to an embodiment of the present invention.
4 is a flowchart illustrating a process of mapping a fragment file in the index file generation method according to the present invention.
FIG. 5 is an operation flow chart showing a process of reducing a data fragment file mapped by the process of FIG. 4; FIG.
FIG. 6 is a flowchart illustrating a file fragmenting process for a maple deuce method using an index in data access using an index file according to the present invention. FIG.
FIG. 7 is an operation flow chart illustrating a process of loading a record in a file fragment for accessing an index-based file according to the present invention; FIG.
BRIEF DESCRIPTION OF THE DRAWINGS The advantages and features of the present invention and the manner of achieving them will become apparent with reference to the embodiments described in detail below with reference to the accompanying drawings. The present invention may, however, be embodied in many different forms and should not be construed as being limited to the embodiments set forth herein. Rather, these embodiments are provided so that this disclosure will be thorough and complete, and will fully convey the concept of the invention to those skilled in the art. And the present invention is defined by the description of the claims. It is to be understood that the terminology used herein is for the purpose of describing particular embodiments only and is not intended to be limiting of the invention. In the present specification, the singular form includes plural forms unless otherwise specified in the specification. It is noted that " comprises, " or "comprising," as used herein, means the presence or absence of one or more other components, steps, operations, and / Do not exclude the addition.
Hereinafter, a method for constructing and utilizing an index for improving data processing performance based on MapReduce in a Hadoop environment according to the present invention will be described in detail with reference to the accompanying drawings.
2 is a diagram showing distribution positions of target records in a file in accordance with a key value to be searched. In FIG. 2, all records are assumed to have a size of 10 bytes for convenience of explanation.
As shown in FIG. 2, when a record having a key value k7 is accessed, all of the 15 pieces of records stored in each piece are decoded by using the conventional maple deuce method. However, In this case, data access time can be reduced because only one piece ('split3') is read and only four records are decoded.
On the other hand, when the key value is k3, a total of 3 pieces of I / O is triggered as in the method without an index, but only a total of 5 record decoding times is required.
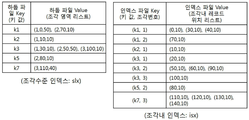
In the present invention, a method of generating and using a total of two index files for a column targeted for an index target file and a key will be described. First, the structure and content of the two index files used will be described.
FIG. 3 is a diagram showing the structure and contents of two index files used in the present invention. In FIG. 3, a "split-level index " : slx) ".
As shown in FIG. 3 (a), the fragment level index file is composed of a file having a (key, value) pair type record like a normal HDFS file, and a key value of an index target column is recorded in a key part , the value portion contains the number of the fragment containing the key value, the offset to the first record (R first ) with the corresponding index key value in the fragment, and the length between R first and the last record in the fragment. For example, since the records corresponding to the key value "k1" are all in the first and second pieces, and the first record corresponds to the records r1, r4, and r5, the offset is 0 corresponding to the offset of r1, 50 corresponding to the lengths of r1 and r5 are recorded. And since r8 corresponds to the second piece, the offset is 70, and the length is 10.
The second index file as shown in FIG. 3 (b) shows "intra-split index (isx)".
The index in the fragment also has a file (key, value) in the form of a pair of records. The key part consists of each key value and the piece number with the corresponding key value, and the value part records the position (offset and length) of the records having the key value in the piece. For example, since the records corresponding to the key value "k1" are all located in the first and second pieces, (k1, 1) and (k1, 2) exist as the keys of the records in the index file, And the position information of the corresponding records r1, r4, r5 and r8 in the piece 2 are recorded.
A method of generating an index file having such a structure will be described with reference to FIG. 4 and FIG. 5. FIG.
First, the index file generation in the present invention is performed by reading all the records belonging to the file to be indexed and reading the key value of the corresponding column value of each read record, and this process is performed by the map deuce method. That is, the data file is divided into pieces, and the divided pieces are subjected to the first-order processing through respective mappers (not shown, maps), and the result of the first-order processing is rearranged according to the key value, The index file is created by performing the second processing in the Reducer).
In the index creation process, the process performed by the mapper and the reducer will be described step by step with reference to FIG. 4 and FIG. 5, respectively.
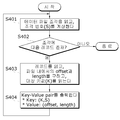
4 is a diagram illustrating a process performed by a mapper during an index creation process.
As shown in FIG. 4, each mapper that processes a piece reads file fragment information allocated to itself, and calculates each piece number S (S401). Here, the method of calculating the piece number can be calculated by dividing the offset of the provided file piece by the piece size used in the mapping process.
When the slice number is calculated as described above, it is determined whether there is a next record included in the slice (S402). If the next record exists as a result of the determination, the following operations are performed on all records included in the allocated slice do.
First, the next record is read, and the offset and length of the read record are obtained. Here, the method of calculating the offset and length may be different depending on the encoding method of the record.
If the offset and length of the corresponding record are obtained as described above, the value of the specified key column is obtained to obtain the key value K (S403).
In step S404, an intermediate result value to be sent to the reducer is output using the slice number S obtained in step S401 and the offset, length, and key value K obtained in step S403. Here, the intermediate result value is composed of a key-value, the key is composed of (K, S), and the value is composed of (offset, length).
Thus, the process is performed on all records, and when all records have been processed, the mapper operation is terminated.
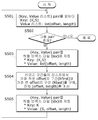
Referring to FIG. 5, a process for reducing the output value of the mapper to the reducer using the intermediate result value as described above will be described.
FIG. 5 is a diagram illustrating a process performed by a reducer during an index creation process. FIG.
First, the input of the reducer is generated from the (K, S: offset, length) value generated in the mapper as shown in FIG. In this case, all the data values generated by the mapper are grouped into (K, S) corresponding to the key and provided as a key-value type. In this case, the key value is (K, S) And a list of (offset, length) having the same length (S501).
If there is a key and value list to be generated next (S502), the following process is performed. That is, in the reducer process, all of the above-described two indexes (fragment level index, fragment index) are generated. The reducer performs the following operations on each input data (K, S: list (offset, length)) as mentioned above.
First, the input (K, S: list (offset, length)) is stored in the fragmented Hadoop index file (S503).
Then, a record 1 (R first ) having the smallest offset value and a record 2 (R last ) having the largest offset value are obtained from each record position (offset and length) list, and then the offset R first value and, offset in the last R record2 - and by calculating the total length calculated by the length of the first record1 offset R + record2 of stored (S504) a piece Hadoop level index file (S505). At this time, the key of the data to be stored is K, and the value is composed of S, offsetR, and lengthR
After all input data has been processed, the reducer operation is terminated.
On the other hand, the data file access using the index file is used when accessing the data using the column value in which the index is generated. Hereinafter, a method for utilizing data when accessing through the MapReduce method will be described.
First, a method of accessing data in the MapReduce method includes an operation of dividing an input file into pieces of a predetermined size and allocating the divided files to a plurality of mappers, a process of decoding a record in a file fragment allocated by each mapper, reading and processing the record, And transmits the processed result to the reducer. Then, the reducer processes the processed result. Hereinafter, referring to FIG. 6, a description will be made of a method of constructing file fragments after the input file is quickly divided using the index, and a process of reading records to be processed in the divided pieces.
FIG. 6 is a diagram illustrating a process of dividing an input file into pieces of a predetermined size in the MapReduce method.
6, when receiving the index key value K to be queried (S601), it reads the fragment level index file (slx) and accesses each key-value data (S602).
Then, if the key value of the data is compared with the index key value (K) to be input, the next key-value data is accessed. If they are the same, the corresponding value (S, offset, length) And creates a file fragment (S603 to S605).
FIG. 7 is a diagram illustrating a process of obtaining a record having a corresponding key value in each generated file fragment.
7 is performed by the mapper to which the file fragment is allocated. First, the key value K and the target FileSplit to be searched are input through the Hadoop setting information (S701).
The mapper calculates the number S of the piece from the given file fragment (S702). That is, the FileSplit number (S) of the data file including the input FileSplit is calculated. Here, the method of calculating the fragment number is defined as a quotient obtained by dividing the offset of the file fragment by the set fragment size.
Then, in step S703, the corresponding key-value data is accessed by using the key value K and the slice number S read as the key index file isx in step S703.
Then, the file area corresponding to the file fragment is read (S704). Since the value of the key-value data obtained in step S703 is the location information of the records having the given key value, the corresponding record is decoded and loaded using this information (S705).
Through the mapping method described above, a record having a given key value can be accessed and processed without unnecessary file I / O and unnecessary record decoding process.
Although the present invention has been described in connection with the exemplary embodiments, it is to be understood that the scope of the present invention is not limited to the specific embodiments, It is to be understood that the invention may be embodied otherwise without departing from the spirit and scope of the invention.
Therefore, the embodiments described in the present invention and the accompanying drawings are intended to illustrate rather than limit the technical spirit of the present invention, and the scope of the technical idea of the present invention is not limited by these embodiments and accompanying drawings . The scope of protection of the present invention should be construed according to the claims, and all technical ideas within the scope of equivalents should be interpreted as being included in the scope of the present invention.
Claims (1)
The reducer reads the key and value list (K, S: list (offset, length)) input from the mapper and stores the key and value in the fragmented Hadoop index file, and stores the smallest sffset interval And calculating the full offset and length, and then storing the offset and length in the fragment level Hadoop index file. The method of constructing an index for improving the data processing performance based on MapleDesktop in the Hadoop environment.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020160010619A KR20170090128A (en) | 2016-01-28 | 2016-01-28 | Index construction and utilization method for processing data based on MapReduce in Hadoop environment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020160010619A KR20170090128A (en) | 2016-01-28 | 2016-01-28 | Index construction and utilization method for processing data based on MapReduce in Hadoop environment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20170090128A true KR20170090128A (en) | 2017-08-07 |
Family
ID=59653890
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020160010619A KR20170090128A (en) | 2016-01-28 | 2016-01-28 | Index construction and utilization method for processing data based on MapReduce in Hadoop environment |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20170090128A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111414527A (en) * | 2020-03-16 | 2020-07-14 | 腾讯音乐娱乐科技(深圳)有限公司 | Similar item query method and device and storage medium |
-
2016
- 2016-01-28 KR KR1020160010619A patent/KR20170090128A/en unknown
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111414527A (en) * | 2020-03-16 | 2020-07-14 | 腾讯音乐娱乐科技(深圳)有限公司 | Similar item query method and device and storage medium |
| CN111414527B (en) * | 2020-03-16 | 2023-10-10 | 腾讯音乐娱乐科技(深圳)有限公司 | Query method, device and storage medium for similar items |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9600507B2 (en) | Index structure for a relational database table | |
| CN106897322B (en) | A kind of access method and device of database and file system | |
| US10866971B2 (en) | Hash collision tables for relational operations | |
| US9971770B2 (en) | Inverted indexing | |
| EP2711856B1 (en) | Method and device for metadata query | |
| TWI603211B (en) | Construction of inverted index system based on Lucene, data processing method and device | |
| US8396862B2 (en) | Product join dynamic partition elimination for multilevel partitioning | |
| CN108897761B (en) | Cluster storage method and device | |
| EP3308303B1 (en) | Mechanisms for merging index structures in molap while preserving query consistency | |
| CN103914483B (en) | File memory method, device and file reading, device | |
| JP2005267600A5 (en) | ||
| O'Neil et al. | Bitmap index design choices and their performance implications | |
| CN108475266B (en) | Matching fixes to remove matching documents | |
| CN103514210A (en) | Method and device for processing small files | |
| US10120860B2 (en) | Methods and apparatus to identify a count of n-grams appearing in a corpus | |
| JP6726690B2 (en) | Performing multidimensional search, content-associative retrieval, and keyword-based retrieval and retrieval on losslessly reduced data using basic data sieves | |
| CN104778182A (en) | Data import method and system based on HBase (Hadoop Database) | |
| WO2023143095A1 (en) | Method and system for data query | |
| EP3173947A1 (en) | Paged inverted index | |
| CN104035822A (en) | Low-cost efficient internal storage redundancy removing method and system | |
| US9275091B2 (en) | Database management device and database management method | |
| KR101772333B1 (en) | INTELLIGENT JOIN TECHNIQUE PROVIDING METHOD AND SYSTEM BETWEEN HETEROGENEOUS NoSQL DATABASES | |
| Mittal et al. | Efficient random data accessing in MapReduce | |
| US9400817B2 (en) | In-place index repair | |
| US9471612B2 (en) | Data processing method, data query method in a database, and corresponding device |