JP6675463B2 - 自然言語の双方向確率的な書換えおよび選択 - Google Patents
自然言語の双方向確率的な書換えおよび選択 Download PDFInfo
- Publication number
- JP6675463B2 JP6675463B2 JP2018189730A JP2018189730A JP6675463B2 JP 6675463 B2 JP6675463 B2 JP 6675463B2 JP 2018189730 A JP2018189730 A JP 2018189730A JP 2018189730 A JP2018189730 A JP 2018189730A JP 6675463 B2 JP6675463 B2 JP 6675463B2
- Authority
- JP
- Japan
- Prior art keywords
- token
- rewrite
- tokens
- probability
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000002457 bidirectional effect Effects 0.000 title description 4
- 230000002441 reversible effect Effects 0.000 claims description 42
- 238000000034 method Methods 0.000 claims description 34
- 238000012545 processing Methods 0.000 claims description 12
- 230000008569 process Effects 0.000 claims description 10
- 230000004044 response Effects 0.000 claims description 9
- 238000004590 computer program Methods 0.000 claims 1
- 230000014509 gene expression Effects 0.000 description 67
- 238000010586 diagram Methods 0.000 description 34
- 238000013519 translation Methods 0.000 description 11
- 238000003780 insertion Methods 0.000 description 10
- 230000037431 insertion Effects 0.000 description 10
- 238000004364 calculation method Methods 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 238000003058 natural language processing Methods 0.000 description 5
- 230000000694 effects Effects 0.000 description 4
- 235000015243 ice cream Nutrition 0.000 description 4
- 238000006467 substitution reaction Methods 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- 241000283690 Bos taurus Species 0.000 description 2
- 241000287828 Gallus gallus Species 0.000 description 2
- 235000013330 chicken meat Nutrition 0.000 description 2
- 230000001934 delay Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000012958 reprocessing Methods 0.000 description 2
- 238000010845 search algorithm Methods 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 238000000844 transformation Methods 0.000 description 2
- 241000282412 Homo Species 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000010079 rubber tapping Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
- 238000010183 spectrum analysis Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
Images























































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2453—Query optimisation
- G06F16/24534—Query rewriting; Transformation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation or dialogue systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/3332—Query translation
- G06F16/3338—Query expansion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/55—Rule-based translation
- G06F40/56—Natural language generation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/58—Use of machine translation, e.g. for multi-lingual retrieval, for server-side translation for client devices or for real-time translation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/183—Speech classification or search using natural language modelling using context dependencies, e.g. language models
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Mathematical Physics (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Acoustics & Sound (AREA)
- Evolutionary Computation (AREA)
- Pure & Applied Mathematics (AREA)
- Computational Mathematics (AREA)
- Algebra (AREA)
- Probability & Statistics with Applications (AREA)
- Mathematical Analysis (AREA)
- Software Systems (AREA)
- Mathematical Optimization (AREA)
- Computing Systems (AREA)
- Machine Translation (AREA)
Description
本発明は、音声認識および自然言語理解の分野に属する。
自動音声認識(ASR)には、エラーが発生しやすい。

本発明は、正方向および反方向SLMの組み合わせを用いて音声認識から得られたトークンシーケンスを書き換えるためのシステムをプログラムするための方法、システム、およびソフトウェアに関し、トークンシーケンス内のトークンの確率の組合せに従って、トークンシーケンスのスコアを計算することを含むことができる。
序論
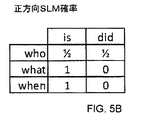
統計言語モデル(SLM)は、表現を含む所定のコーパス内の隣接ワードの統計値を取得する。SLMを仮定トークンシーケンスに適用することにより、ASRシステムの精度が大幅に改善する。
いくつかの実施形態は、確率を閾値と比較することによって、低い確率を決定する。いくつかの実施形態は、閾値を使用せず、単に最も低い確率の位置を書き換える。いくつかの実施形態において、正方向の閾値と反方向の閾値とは異なる。いくつかの実施形態において、閾値は、隣接するトークンの確率に依存する。
最も有用な書換えの選択は、精確なSLMの有無に依存する。SLMは、書き換える表現と同一種類の表現を含むコーパスから構築された場合、最も精確である。例えば、Twitter(登録商標)のツイートの表現を含むコーパスは、ニューヨークタイムズ紙の新聞記事の表現を含むコーパスとは非常に異なるSLM確率を有する。同様に、仮想アシスタント用の表現を含むコーパスは、一般的に天気ドメインに特有の表現を含むコーパスとは異なるSLM確率を有する。
図11は、トークン置換を行うためのトークンシーケンス書換えフロー図を示している。このフロー図は、タグモジュール116が入力トークンシーケンスを受け取り、タグを用いて、トークンを置換することによって、確率モジュール41および43用のトークンシーケンスを作成することを除き、図4のフロー図と同様である。
正方向および反方向の各々において低い確率を有するトークンの位置のコロケーションまたは隣接は、可能なエラーの種類(不正確なトークン、余分なトークン、欠落トークン、および重複トークン)に関するヒントを与え、その結果、トークンシーケンスを書き換えるための可能な最良種類の編集(トークンの挿入、トークンの削除、およびトークンの置換)に関するヒントを与える。
スコアは、整数、浮動小数点数、または英数字などの様々な方法で表すことができる。いくつかの実施形態において、スコアは、有効性のブール値(有効/無効)として表される。
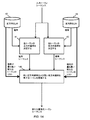
いくつかの実施形態は、SLM確率および重み付きスコアよりもさらに進化した処理を用いて、最良の書換えを決定する。図22は、統語解析を使用する実施形態を示している。示された実施形態は、トークン置換モジュール225が複数の書換えを生成し、最高のスコアを有する1つの書換えを選択して、新たな書換えトークンシーケンスを生成する点を除き、図14と同様である。また、トークン置換モジュール225は、統語解析入力を用いて、書換えスコアに重みを付ける。
いくつかの実施形態は、成功した書換えを見出すと、処理を完了し、成功した書換えトークンシーケンスを出力として提供する。いくつかの実施形態は、入力トークンシーケンスの可能な書換えのリストを生成する。これらの可能な書換えは、同一の疑わしい場所で異なる編集を行うことによって、異なる疑わしい場所で編集を行うことによって、またはその両方によって得ることができる。
トークンシーケンスの書換えは、連続翻訳応用、例えば、テレビライブ放送の自動字幕付けまたは書き取りに有用であり得る。
いくつかの実施形態は、1つ以上のキャッシング技術を用いて性能を向上させる。いくつかの実施形態は、少なくとも限定された期間において、高い音響仮定スコアを有するトークンをキャッシュする。このような実施形態は、正方向SLMおよび反方向SLMの最も高い確率のトークンリストからトークンを選択する場合、キャッシュに存在するトークンの確率スコアを増加させる。この方法は、会話中の単語の時間的局所性を利用して、認識精度を向上させる。様々な実施形態は、実体にタグを付ける前に単語をキャッシュすることによって実体名の認識を向上させる、または実体にタグを付けた後に単語をキャッシュすることによって、実体に依存しない書換えの統合を容易にする。
本明細書に示され説明された実施形態は、多くのオプション特徴の例示である。示され説明された特徴の異なる組み合わせによって、多くの実施形態が可能である。本明細書に示され説明された例は、英語および中国語を使用している。様々な実施形態は、他の言語または言語の組み合わせに対しても同様の効果を奏する。本明細書に示され説明された例は、天気ドメインを使用している。様々な実施形態は、他のドメインまたはドメインの組み合わせに対しても同様の効果を奏する。本明細書に示され説明された例は、トークンを置換するためのモジュールを示している。同様に配置されたモジュールは、トークンの削除およびトークンの挿入を行うことができる。
図32は、いくつかの実施形態に従って、システムオンチップチップ313内の機能要素を示すブロック図である。コンピュータプロセッサコア321およびグラフィックプロセッサコア322は、相互接続323およびRAMインターフェイス324を介して一時データを記憶するためのランダムアクセスメモリ(RAM)と通信し、相互接続323およびフラッシュインターフェイス325を介してフラッシュRAMと通信し、並びに相互接続323およびネットワークインターフェイス328を介してサーバと通信することによって処理を行う。表示インターフェイス326は、表示情報の利用をユーザに提供し、I/Oインターフェイス327は、ユーザ入力を受け取り、ユーザに出力を提供する。
Claims (20)
- クエリ結果をユーザに提供する際に、ユーザクエリの入力トークンシーケンスを書き換えるためのコンピュータ実装方法であって、
コンピュータネットワークを介して、遠隔クライアント装置上で動作するアプリケーションから、システムユーザからのユーザクエリを受信するステップを含み、前記ユーザクエリは、前記入力トークンシーケンスを含み、
正方向統計言語モデルに従って、前記入力トークンシーケンス内の複数のトークンの正方向確率を決定するステップと、
反方向統計言語モデルに従って、前記入力トークンシーケンス内の複数のトークンの反方向確率を決定するステップと、
低い反方向確率を有する第1のトークンの後方且つ低い正方向確率を有する隣接の第2のトークンの前方の位置に新たなトークンを挿入することによって、新たな書換えトークンシーケンスを作成するステップと、
前記新たな書換えトークンシーケンスを処理することによって、結果を生成するステップと、
前記処理による前記結果を示す応答を前記システムユーザに提供するステップとを含む、方法。 - 入力トークンシーケンスを書き換えるためのコンピュータ実装方法であって、
正方向統計言語モデルに従って、前記入力トークンシーケンス内の複数のトークンの正方向確率を決定するステップと、
反方向統計言語モデルに従って、前記入力トークンシーケンス内の複数のトークンの反方向確率を決定するステップと、
前記複数のトークンの各トークンの確率スコアを前記正方向確率のうち最も低いものと前記反方向確率のうち最も低いものとに基づいて計算するステップと、
新たなトークンを用いて、最も低いスコアを有するトークンを置換することによって、新たな書換えトークンシーケンスを作成するステップとを含む、方法。 - 入力トークンシーケンスを書き換えるためのコンピュータ実装方法であって、
正方向統計言語モデル(SLM)に従って、前記入力トークンシーケンス内の複数のトークンの正方向確率を決定するステップと、
反方向統計言語モデルに従って、前記入力トークンシーケンス内の複数のトークンの反方向確率を決定するステップと、
新たなトークンを用いて、第1の閾値未満の正方向確率且つ第2の閾値未満の反方向確率を有する疑わしいトークンを置換することによって、新たな書換えトークンシーケンスを生成するステップとを含む、方法。 - 確率を決定する前に、タグを用いて、前記入力トークンシーケンス内の少なくとも1つのトークンを置換するステップをさらに含む、請求項3に記載の方法。
- 前記正方向SLMに従って得られた最も高い確率を有するトークンのリストおよび前記反方向SLMに従って得られた最も高い確率を有するトークンのリストの両方に存在するトークンを前記新たなトークンとして選択するステップをさらに含む、請求項3または4に記載の方法。
- 構文規則に従って、前記入力トークンシーケンスの統語解析を実行するステップと、
前記構文規則に従って、前記選択を隣接トークンの文脈において構文上合法的なトークンのみに制限するステップとをさらに含む、請求項5に記載の方法。 - 前記新たな書換えトークンシーケンスに対して、少なくとも前記正方向SLMにおける前記新たなトークンの確率および前記反方向SLMにおける前記新たなトークンの前記確率に依存する書換えスコアを計算するステップをさらに含む、請求項5または6に記載の方法。
- 多種多様なトピックに関連する表現から構築された多様コーパスSLMにおける前記新たなトークンの前記確率に基づいて、前記書換えスコアをスケーリングする、請求項7に記載の方法。
- 代替の新たなトークンを用いて、前記疑わしいトークンを置換することによって、代替の書換えトークンシーケンスを作成するステップと、
前記代替の書換えトークンシーケンスの代替スコアを、前記正方向SLMにおける前記代替の新たなトークンの確率および前記反方向SLMにおける前記代替の新たなトークンの確率の両方の組み合わせとして計算するステップと、
前記新たな書換えトークンシーケンスと前記代替の書換えトークンシーケンスとのうち、より高いスコアを有するいずれか一方を選択するステップとをさらに含む、請求項5〜8のいずれか1項に記載の方法。 - 最近の連続音声から仮定されたトークンのトークンバッファを維持するステップをさらに含み、
前記入力トークンシーケンスは、前記トークンバッファ内のトークンからなるシーケンスである、請求項5〜9のいずれか1項に記載の方法。 - 最近のトークンシーケンスに存在するトークンの履歴キャッシュを記憶するステップと、
正方向確率が最も高いトークンのリストおよび反方向確率が最も高いトークンのリストの各々から、前記疑わしいトークンを置換するための前記新たなトークンを選択するステップと、
前記履歴キャッシュに存在する少なくとも1つのトークンの前記確率スコアを増加させるステップとをさらに含む、請求項3〜10のいずれか1項に記載の方法。 - 自然言語パーサを用いて、文法に従って前記新たな書換えトークンシーケンスを構文解析することによって、解析スコアを生成するステップをさらに含む、請求項3〜11のいずれか1項に記載の方法。
- 前記疑わしいトークンとは異なる代替の疑わしいトークンを置換することによって、代替の書換えトークンシーケンスを作成するステップと、
自然言語パーサを用いて、前記文法に従って前記代替の書換えトークンシーケンスを構文解析することによって、代替の解析スコアを生成するステップと、
前記新たな書換えトークンシーケンスと前記代替の書換えトークンシーケンスとのうち、より高い解析スコアを有するいずれか一方を選択するステップとをさらに含む、請求項12に記載の方法。 - 代替の新たなトークンを用いて、前記疑わしいトークンを置換することによって、代替の書換えトークンシーケンスを作成するステップと、
自然言語パーサを用いて、前記文法に従って前記代替の書換えトークンシーケンスを構文解析することによって、代替の解析スコアを生成するステップと、
前記新たな書換えトークンシーケンスと前記代替の書換えトークンシーケンスとのうち、より高い解析スコアを有するいずれか一方を選択するステップとをさらに含む、請求項12または13に記載の方法。 - ツリー型アルゴリズムを用いて、書換えを反復的に行い、各書換えのスコアを計算することによって、書換えのセットを生成し、前記書換えのセットから最高のスコアを有する書換えを選択するステップをさらに含む、請求項12〜14のいずれか1項に記載の方法。
- 前記入力トークンシーケンスをキャッシュに格納するステップと、
前記入力トークンシーケンスに関連して、前記新たな書換えトークンシーケンスを前記キャッシュに格納するステップと、
前記キャッシュを検索することによって、前記入力トークンシーケンスを探し出すステップとをさらに含む、請求項3〜15のいずれか1項に記載の方法。 - 前記キャッシュを分析することによって、前記新たな書換えトークンシーケンスに対して、前記新たな書換えトークンシーケンスに書換えられた最も頻繁な入力トークンシーケンスを特定するステップをさらに含む、請求項16に記載の方法。
- 前記新たな書換えトークンシーケンスに書換えられた前記最も頻繁な入力トークンシーケンスを含むように、文法規則を作成するステップをさらに含む、請求項17に記載の方法。
- 前記新たな書換えトークンシーケンスに書換えられた前記最も頻繁な入力トークンシーケンスを含むように、文法規則を改変するステップをさらに含む、請求項17または18に記載の方法。
- コンピュータプロセッサによって実行されるコンピュータプログラムであって、前記コンピュータプロセッサによって実行されると、前記コンピュータプロセッサに、請求項1〜19のいずれか1項に記載の方法を実行させる、コンピュータプログラム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/726,394 | 2017-10-06 | ||
| US15/726,394 US10599645B2 (en) | 2017-10-06 | 2017-10-06 | Bidirectional probabilistic natural language rewriting and selection |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2019070799A JP2019070799A (ja) | 2019-05-09 |
| JP2019070799A5 JP2019070799A5 (ja) | 2020-01-09 |
| JP6675463B2 true JP6675463B2 (ja) | 2020-04-01 |
Family
ID=65992537
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018189730A Active JP6675463B2 (ja) | 2017-10-06 | 2018-10-05 | 自然言語の双方向確率的な書換えおよび選択 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US10599645B2 (ja) |
| JP (1) | JP6675463B2 (ja) |
| CN (1) | CN109635270B (ja) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109325227A (zh) * | 2018-09-14 | 2019-02-12 | 北京字节跳动网络技术有限公司 | 用于生成修正语句的方法和装置 |
| US11437025B2 (en) * | 2018-10-04 | 2022-09-06 | Google Llc | Cross-lingual speech recognition |
| CN112151024B (zh) * | 2019-06-28 | 2023-09-22 | 声音猎手公司 | 用于生成语音音频的经编辑的转录的方法和装置 |
| US11205052B2 (en) * | 2019-07-02 | 2021-12-21 | Servicenow, Inc. | Deriving multiple meaning representations for an utterance in a natural language understanding (NLU) framework |
| US11886461B2 (en) * | 2019-07-31 | 2024-01-30 | Salesforce, Inc. | Machine-learnt field-specific standardization |
| KR20210044056A (ko) * | 2019-10-14 | 2021-04-22 | 삼성전자주식회사 | 중복 토큰 임베딩을 이용한 자연어 처리 방법 및 장치 |
| CN110660384B (zh) * | 2019-10-14 | 2022-03-22 | 内蒙古工业大学 | 一种基于端到端的蒙古语异形同音词声学建模方法 |
| US11276391B2 (en) * | 2020-02-06 | 2022-03-15 | International Business Machines Corporation | Generation of matched corpus for language model training |
| US11373657B2 (en) * | 2020-05-01 | 2022-06-28 | Raytheon Applied Signal Technology, Inc. | System and method for speaker identification in audio data |
| US11315545B2 (en) * | 2020-07-09 | 2022-04-26 | Raytheon Applied Signal Technology, Inc. | System and method for language identification in audio data |
| US11489793B2 (en) | 2020-11-22 | 2022-11-01 | International Business Machines Corporation | Response qualification monitoring in real-time chats |
| CN112528980B (zh) * | 2020-12-16 | 2022-02-15 | 北京华宇信息技术有限公司 | Ocr识别结果纠正方法及其终端、系统 |
| US20220284193A1 (en) * | 2021-03-04 | 2022-09-08 | Tencent America LLC | Robust dialogue utterance rewriting as sequence tagging |
| CN113869069A (zh) * | 2021-09-10 | 2021-12-31 | 厦门大学 | 基于译文树结构解码路径动态选择的机器翻译方法 |
| CN115064170B (zh) * | 2022-08-17 | 2022-12-13 | 广州小鹏汽车科技有限公司 | 语音交互方法、服务器和存储介质 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6848080B1 (en) * | 1999-11-05 | 2005-01-25 | Microsoft Corporation | Language input architecture for converting one text form to another text form with tolerance to spelling, typographical, and conversion errors |
| US7822597B2 (en) * | 2004-12-21 | 2010-10-26 | Xerox Corporation | Bi-dimensional rewriting rules for natural language processing |
| GB2424742A (en) * | 2005-03-31 | 2006-10-04 | Ibm | Automatic speech recognition |
| US20080270110A1 (en) * | 2007-04-30 | 2008-10-30 | Yurick Steven J | Automatic speech recognition with textual content input |
| US9552355B2 (en) * | 2010-05-20 | 2017-01-24 | Xerox Corporation | Dynamic bi-phrases for statistical machine translation |
| US8762156B2 (en) * | 2011-09-28 | 2014-06-24 | Apple Inc. | Speech recognition repair using contextual information |
| CN103198149B (zh) * | 2013-04-23 | 2017-02-08 | 中国科学院计算技术研究所 | 一种查询纠错方法和系统 |
| CN104157285B (zh) * | 2013-05-14 | 2016-01-20 | 腾讯科技(深圳)有限公司 | 语音识别方法、装置及电子设备 |
| CN105912521A (zh) * | 2015-12-25 | 2016-08-31 | 乐视致新电子科技(天津)有限公司 | 一种解析语音内容的方法及装置 |
-
2017
- 2017-10-06 US US15/726,394 patent/US10599645B2/en active Active
-
2018
- 2018-09-29 CN CN201811151807.XA patent/CN109635270B/zh active Active
- 2018-10-05 JP JP2018189730A patent/JP6675463B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN109635270A (zh) | 2019-04-16 |
| CN109635270B (zh) | 2023-03-07 |
| US10599645B2 (en) | 2020-03-24 |
| JP2019070799A (ja) | 2019-05-09 |
| US20190108257A1 (en) | 2019-04-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6675463B2 (ja) | 自然言語の双方向確率的な書換えおよび選択 | |
| JP6484236B2 (ja) | オンライン音声翻訳方法及び装置 | |
| Mairesse et al. | Stochastic language generation in dialogue using factored language models | |
| US8688435B2 (en) | Systems and methods for normalizing input media | |
| US9460080B2 (en) | Modifying a tokenizer based on pseudo data for natural language processing | |
| US20050154580A1 (en) | Automated grammar generator (AGG) | |
| CN109637537B (zh) | 一种自动获取标注数据优化自定义唤醒模型的方法 | |
| CN109858038B (zh) | 一种文本标点确定方法及装置 | |
| CN113614825A (zh) | 用于自动语音识别的字词网格扩增 | |
| WO2017107518A1 (zh) | 一种解析语音内容的方法及装置 | |
| US10565982B2 (en) | Training data optimization in a service computing system for voice enablement of applications | |
| US10553203B2 (en) | Training data optimization for voice enablement of applications | |
| US11907665B2 (en) | Method and system for processing user inputs using natural language processing | |
| US20200394258A1 (en) | Generation of edited transcription for speech audio | |
| KR101677859B1 (ko) | 지식 베이스를 이용하는 시스템 응답 생성 방법 및 이를 수행하는 장치 | |
| CN113225612B (zh) | 字幕生成方法、装置、计算机可读存储介质及电子设备 | |
| Comas et al. | Sibyl, a factoid question-answering system for spoken documents | |
| CN109800430B (zh) | 一种语义理解方法及系统 | |
| KR102204395B1 (ko) | 개체명 인식을 이용한 음성인식 띄어쓰기 보정 방법 및 시스템 | |
| Fenogenova et al. | A general method applicable to the search for anglicisms in russian social network texts | |
| KR20120045906A (ko) | 코퍼스 오류 교정 장치 및 그 방법 | |
| US11361761B2 (en) | Pattern-based statement attribution | |
| Mekki et al. | COTA 2.0: An automatic corrector of tunisian Arabic social media texts | |
| JP2007018462A (ja) | 機械翻訳装置、およびプログラム | |
| CN112151024B (zh) | 用于生成语音音频的经编辑的转录的方法和装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20190911 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191121 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20191121 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20191125 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200212 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200310 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6675463 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |