JP5653003B2 - Object identification device and object identification method - Google Patents
Object identification device and object identification method Download PDFInfo
- Publication number
- JP5653003B2 JP5653003B2 JP2009105662A JP2009105662A JP5653003B2 JP 5653003 B2 JP5653003 B2 JP 5653003B2 JP 2009105662 A JP2009105662 A JP 2009105662A JP 2009105662 A JP2009105662 A JP 2009105662A JP 5653003 B2 JP5653003 B2 JP 5653003B2
- Authority
- JP
- Japan
- Prior art keywords
- image
- partial area
- region
- feature vector
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images











Landscapes
- Image Analysis (AREA)
Description
本発明は、オブジェクト識別装置及びオブジェクト識別方法に関する。 The present invention relates to an object identification device and an object identification method.
画像データ中の被写体であるオブジェクトが、別の画像中の被写体であるオブジェクトと同一のものであると識別する技術として、例えば、個人の顔を識別する顔識別技術がある。以下、本明細書では、オブジェクトの識別とは、オブジェクトの個体の違い(例えば、個人としての人物の違い)を判定することを意味する。一方、オブジェクトの検出は、個体を区別せず同じ範疇に入るものを判定する(例えば、個人を区別せず、顔を検出する)、ことを意味するものとする。
顔識別技術として、例えば非特許文献1のような方法がある。これは、顔による個人の識別問題を、差分顔と呼ばれる特徴クラスの2クラス識別問題に置き換えることによって、顔の登録・追加学習をリアルタイムに行うことを可能にしたアルゴリズムである。
As a technique for identifying that an object that is a subject in image data is the same as an object that is a subject in another image, for example, there is a face identification technique for identifying an individual's face. Hereinafter, in this specification, the identification of an object means that a difference between individual objects (for example, a difference between persons as individuals) is determined. On the other hand, detection of an object means that an object that falls within the same category is determined without distinguishing individuals (for example, a face is detected without distinguishing individuals).
As a face identification technique, for example, there is a method as described in Non-Patent Document 1. This is an algorithm that makes it possible to perform face registration and additional learning in real time by replacing an individual identification problem by a face with a two-class identification problem of a feature class called a differential face.
例えば、一般によく知られているサポートベクターマシン(SVM)を用いた顔識別では、n人分の人物の顔を識別するために、登録された人物の顔と、それ以外の顔を識別するn個のSVM識別器が必要になる。人物の顔を登録する際には、SVMの学習が必要となる。SVMの学習には、登録したい人物の顔と、既に登録されている人物とその他の人物の顔データが大量に必要で、非常に計算時間がかかるため、予め計算しておく手法が一般的であった。
しかし、非特許文献1の方法によれば、個人識別の問題を、次に挙げる2クラスの識別問題に置き換えることよって、追加学習を実質的に不要にすることができる。即ち、
・intra−personal class:同一人物の画像間の、照明変動、表情・向き等の変動特徴クラス
・extra−personal class:異なる人物の画像間の、変動特徴クラス
の2クラスである。上記2クラスの分布は、特定の個人によらず一定であると仮定して、個人の顔識別問題を、上記2クラスの識別問題に帰着させて識別器を構成する。予め、大量の画像を準備して、同一人物間の変動特徴クラスと、異なる人物間の変動特徴クラスと、の識別を行う識別器を学習する。新たな登録者は、顔の画像(若しくは必要な特徴を抽出した結果)のみを保持すればよい。識別する際には2枚の画像から差分特徴を取り出し、上記識別器で、同一人物なのか異なる人物なのかを判定する。これにより、個人の顔登録の際にSVM等の学習が不要になり、リアルタイムで登録を行うことができる。
For example, in the face identification using a generally well-known support vector machine (SVM), in order to identify the faces of n persons, n faces that are registered and other faces are identified. SVM discriminators are required. When registering a person's face, SVM learning is required. SVM learning requires a large amount of face data of a person to be registered and face data of already registered persons and other persons, which requires a lot of calculation time. there were.
However, according to the method of Non-Patent Document 1, additional learning can be made substantially unnecessary by replacing the problem of personal identification with the following two classes of identification problems. That is,
Intra-personal class: variation feature class such as illumination variation, facial expression / direction, etc. between images of the same person. Extra-personal class: two classes of variation feature class between images of different people. Assuming that the distribution of the two classes is constant regardless of a specific individual, the classifier is configured by reducing the face identification problem of the individual to the classification problem of the two classes. A large number of images are prepared in advance, and a discriminator for discriminating between a variation feature class between the same persons and a variation feature class between different persons is learned. The new registrant need only hold the face image (or the result of extracting the necessary features). When discriminating, the difference feature is extracted from the two images, and the discriminator determines whether the person is the same person or a different person. This eliminates the need for learning such as SVM at the time of personal face registration, and registration can be performed in real time.
上記のような、オブジェクト(より具体的には、人物の顔)の識別を行う装置及び方法において、識別性能を低下させる要因として、登録用画像と認証用画像の変動が挙げられる。即ち、識別対象であるオブジェクト(人物の顔)の変動、より具体的には、照明条件、向き・姿勢、他のオブジェクトによる隠れや、表情による変動等である。上記のような変動が大きくなると、識別性能が大幅に低下してしまう。
この問題に対して、特許文献1では、部分領域ごとのパターンマッチングを複数行い、それらの結果のうち、外れ値を取り除いて、各部分領域のマッチ度を統合することによって、変動に対するロバスト性を確保している。
In the apparatus and method for identifying an object (more specifically, the face of a person) as described above, a factor that degrades the identification performance is a change in the registration image and the authentication image. That is, there are fluctuations in the object to be identified (person's face), more specifically, lighting conditions, orientation / posture, hiding by other objects, fluctuations due to facial expressions, and the like. When the above fluctuations become large, the identification performance is greatly reduced.
With respect to this problem, Patent Document 1 performs a plurality of pattern matching for each partial region, removes outliers from those results, and integrates the matching degree of each partial region, thereby improving robustness against fluctuations. Secured.
しかしながら、複数の部分領域の類似度から、単純に外れ値を取り除いたり、その重み付き平均等を取ったりするだけでは、性能的に改善の余地があると考えられる。例えば、上記複数の部分領域の設定に誤りがあった場合、特に入力画像の範囲外に部分領域が設定された場合、上記処理だけでは、誤りを十分に訂正できる可能性は低いと考えられる。人間の顔のように変動が大きく、更に撮影条件が様々な環境においても、識別性能を維持するためには、上記複数の部分領域設定に誤りがあった場合に、その誤りをある程度吸収できる処理を組み込むことが有効であると考えられる。
デジタルカメラやWebカメラ等への応用を想定すると、画像の撮影条件及びオブジェクトの変動(大きさ、向き、表情等)が、大きい場合にも識別性能が劣化しないことが望まれる。
However, it is considered that there is room for improvement in performance by simply removing outliers or taking a weighted average or the like from the similarity of a plurality of partial areas. For example, when there is an error in the setting of the plurality of partial areas, particularly when a partial area is set outside the range of the input image, it is considered that there is a low possibility that the error can be sufficiently corrected only by the above processing. In order to maintain discrimination performance even in environments with large fluctuations such as the human face and various shooting conditions, if there is an error in the multiple partial area settings, the process can absorb the error to some extent Is considered effective.
Assuming application to a digital camera, a web camera, etc., it is desirable that the identification performance does not deteriorate even when the image capturing condition and the variation (size, orientation, facial expression, etc.) of the object are large.
本発明はこのような問題点に鑑みなされたもので、照明や大きさ、向き等の変動に対して、ロバスト性と識別性能を向上させることを目的とする。 The present invention has been made in view of such problems, and it is an object of the present invention to improve robustness and identification performance against variations in illumination, size, orientation, and the like.
そこで、本発明は、オブジェクト識別装置であって、前記オブジェクトを含む入力画像を入力する入力手段と、オブジェクトを含む登録画像を取得する取得手段と、前記入力画像に対してアフィン変換を行い、該変換された画像に部分領域を設定する第1の部分領域設定手段と、前記アフィン変換後の画像に設定された部分領域の少なくとも一部が、前記アフィン変換する前の入力画像の領域からはみ出しているか否かを判定する第1の判定手段と、前記部分領域が前記入力画像の領域からはみ出していないと判定された場合には、前記部分領域から特徴ベクトルを設定し、前記部分領域が前記入力画像の領域からはみ出していると判定された場合には、前記部分領域のうち、前記入力画像の領域からはみ出している領域に対し、乱数を設定し、該乱数が設定された前記はみ出している領域と前記入力画像からはみ出していない領域とを含む領域から特徴ベクトルを設定する第1の設定手段と、前記登録画像の特徴ベクトルと前記第1の設定手段により設定される前記部分領域の特徴ベクトルとの相関を算出し、該算出された結果に基づいて前記オブジェクトを識別する識別手段とを有することを特徴とする。
また、本発明は、オブジェクト識別方法としてもよい。
Accordingly, the present invention provides an object identification device, wherein an input unit that inputs an input image including the object, an acquisition unit that acquires a registered image including the object, affine transformation is performed on the input image, First partial area setting means for setting a partial area in the converted image, and at least a part of the partial area set in the image after the affine transformation protrudes from the area of the input image before the affine transformation. A first determination means for determining whether or not the partial area is not protruding from the area of the input image, a feature vector is set from the partial area, and the partial area is the input If it is determined that extends off region of an image, of the partial region, for a region that protrudes from the region of the input image, sets a random number , Set the region and the first setting means for setting a feature vector, the registered image feature vector and the first including a region not protrude from the region and the input image extends off the said random number is set And an identification unit for calculating a correlation with the feature vector of the partial region set by the unit and identifying the object based on the calculated result.
The present invention may also be an object identification method.
本発明によれば、照明や大きさ、向き等の変動に対して、ロバスト性と識別性能を向上させることができる。 According to the present invention, it is possible to improve robustness and identification performance against variations in illumination, size, orientation, and the like.
以下、本発明の実施形態について図面に基づいて説明する。 Hereinafter, embodiments of the present invention will be described with reference to the drawings.
≪実施形態1≫
以下、図面を参照して本発明の第1の実施形態を詳細に説明する。
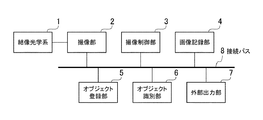
図1は、オブジェクト識別装置100のハードウェア構成の一例を示す図(その1)である。図1に示すように、オブジェクト識別装置100は、結像光学系1、撮像部2、撮像制御部3、画像記録部4、オブジェクト登録部5、オブジェクト識別部6、を含む。またオブジェクト識別装置100は、オブジェクト識別結果を出力する外部出力部7、各構成要素の制御・データ接続を行うためのバス8、を含む。
なお、オブジェクト登録部5、オブジェクト識別部6は、典型的には、それぞれ専用回路(ASIC)、プロセッサ(リコンフィギュラブルプロセッサ、DSP、CPU等)であってもよい。また、オブジェクト登録部5、オブジェクト識別部6は、単一の専用回路及び汎用回路(PC用CPU)内部において実行されるプログラムとして存在してもよい。
Embodiment 1
Hereinafter, a first embodiment of the present invention will be described in detail with reference to the drawings.
FIG. 1 is a diagram (part 1) illustrating an example of a hardware configuration of the object identification device 100. As shown in FIG. 1, the object identification device 100 includes an imaging optical system 1, an
The
結像光学系1は、ズーム機構を備えた光学レンズで構成される。また、結像光学系1は、パン・チルト軸方向の駆動機構を備えてもよい。
撮像部2の映像センサとしては、典型的にはCCD又はCMOSイメージセンサが用いられ、不図示のセンサ駆動回路からの読み出し制御信号により所定の映像信号(例えば、サブサンプリング、ブロック読み出しして得られる信号)が画像データとして出力される。
撮像制御部3は、撮影者からの指示(画角調整指示、シャッター押下等)及び、オブジェクト登録部5又はオブジェクト識別部6からの情報を基に、実際に撮影が行われるタイミングを制御する。撮像制御部3は、自動露出(AE)や自動焦点(AF)の制御を行う制御装置を含んでもよい。
画像記録部4は、半導体メモリ等で構成され、撮像部2から転送された画像データを保持し、オブジェクト登録部5、オブジェクト識別部6からの要求に応じて、所定のタイミングで、画像データを転送する。
The imaging optical system 1 includes an optical lens having a zoom mechanism. Further, the imaging optical system 1 may include a driving mechanism in the pan / tilt axis direction.
A CCD or CMOS image sensor is typically used as the image sensor of the
The imaging control unit 3 controls the timing of actual shooting based on an instruction from the photographer (viewing angle adjustment instruction, shutter pressing, etc.) and information from the
The image recording unit 4 is composed of a semiconductor memory or the like, holds image data transferred from the
オブジェクト登録部5は、画像データから識別の対象とするオブジェクトの情報を抽出し、記録・保持する。オブジェクト登録部5のより詳細な構成及び実際に行われる処理のより具体的な内容については、後述する。
オブジェクト識別部6は、画像データ及びオブジェクト登録部5から取得したデータを基に、画像データ中のオブジェクトの識別を行う。オブジェクト識別部6に関して、より具体的な構成及び行われる処理の詳細については、後で詳しく説明する。
外部出力部7は、典型的には、CRTやTFT液晶等のモニタであり、撮像部2及び画像記録部4から取得した画像データを表示、又は、画像データにオブジェクト登録部5及びオブジェクト識別部6の結果出力を重畳表示する。また、外部出力部7は、オブジェクト登録部5及びオブジェクト識別部6の結果出力を電子データとして、外部メモリ等に出力する形式をとってもよい。
接続バス8は、上記構成要素間の制御・データ接続を行うためのバスである。
The
The
The
The connection bus 8 is a bus for performing control and data connection between the above components.
<全体フロー>
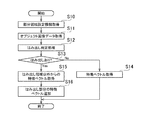
図2は、オブジェクト識別装置100の全体処理の一例を示したフローチャートである。この図2を参照しながら、このオブジェクト識別装置100が、画像からオブジェクトの識別を行う実際の処理について説明する。なお、以下では、識別するオブジェクトが人物の顔である場合について説明するが、本実施形態はこれに限るものでない。
初めに、オブジェクト識別部6は、画像記録部4から画像データを取得(画像データ入力)する(S00)。続いて、オブジェクト識別部6は、取得した画像データに対して、人の顔の検出処理を行う(S01)。画像中から、人物の顔を検出する方法については、公知の技術を用いればよい。オブジェクト識別部6は、例えば、「特許3078166号公報」や「特開2002−8032号公報」で提案されているような技術を用いることができる。
対象オブジェクトである人物の顔の検出処理をしたのち、画像中に人の顔が存在するならば(S02でYesの場合)、オブジェクト識別部6は、オブジェクト識別処理、即ち個人の識別処理を行う。画像中に人の顔が存在しない場合(S02でNoの場合)、オブジェクト識別部6は、図2に示す処理を終了する。オブジェクト識別処理(S03)のより具体的な処理内容については、あとで詳しく説明する。
<Overall flow>
FIG. 2 is a flowchart showing an example of the overall processing of the object identification device 100. With reference to FIG. 2, an actual process in which the object identification device 100 identifies an object from an image will be described. In the following, a case where the object to be identified is a human face will be described, but the present embodiment is not limited to this.
First, the
If the human face exists in the image after the process of detecting the face of the person who is the target object (Yes in S02), the
オブジェクト識別部6は、オブジェクト識別処理の結果から、登録済みの人物に該当する顔があるか判定する(S04)。(S01)で検出された顔と同一人物が、登録済みの人物の中にある場合(S04でYesの場合)、オブジェクト識別部6は、(S07)の処理に進む。検出された顔が、登録済み人物の誰とも一致しない場合(S04でNoの場合)、オブジェクト識別部6は、その人物を登録するか判定する(S05)。これは、予め設定されている場合もあるが、例えばユーザが外部インターフェースやGUI等を通じて、その場で登録するかどうか決定するようにしてもよい。登録すると判定された場合(S05でYesの場合)、オブジェクト識別部6は、後述するオブジェクト(人物の顔)の登録処理を行う(S06)。登録を行わない場合(S05でNoの場合)、オブジェクト識別部6は、そのまま処理を続行する。(S06)のオブジェクト登録処理後、及び(S05)で登録を行わない場合、オブジェクト識別部6は、検出されたオブジェクト全てについて処理が終わったかどうかを判定する(S07)。未処理のオブジェクトがある場合(S07でNoの場合)、オブジェクト識別部6は、(S03)まで戻る。検出された全てのオブジェクトについて処理が終わった場合(S07でYesの場合)、オブジェクト識別部6は、一連のオブジェクト識別処理の結果を、外部出力部7に出力する。
以上が、本実施形態にかかるオブジェクト識別装置100の全体の処理フローである。
The
The above is the overall processing flow of the object identification device 100 according to the present embodiment.
<オブジェクト登録部>
オブジェクト登録処理について説明する。図3は、オブジェクト登録部5の構成の一例を示す図である。図3に示すように、オブジェクト登録部5は、オブジェクト辞書データ生成部21、オブジェクト辞書データ保持部22、オブジェクト辞書データ選択部23、を含む。
オブジェクト辞書データ生成部21は、画像記録部4から取得した画像データから、オブジェクトの個体を識別するために必要なオブジェクト辞書データを生成する。オブジェクト辞書データ生成部21は、例えば、非特許文献1にあるようなintra−class及びextra−classの2クラス問題を判別する場合、典型的には、人物の顔画像を辞書データとすればよい。オブジェクト辞書データ生成部21は、オブジェクト検出処理によって検出されたオブジェクトの画像データを、大きさや向き(面内回転方向)等を正規化したのち、オブジェクト辞書データ保持部22に格納するようにしてもよい。
ここで、オブジェクト辞書データ生成部21は、回転方向の正規化、特に面内回転を補正するアフィン変換を行う際に、以下のようにするとよい。即ち、オブジェクト辞書データ生成部21は、顔の傾きを補正するアフィン変換処理において、アフィン変換後の画像が、参照する元画像に対して、その領域外を参照してしまう場合、変換後の値を乱数で置き換える。通常、上記のような場合には、所定の固定値をアフィン変換後の画像に設定する場合が多い。しかしながら、固定値にすると、部分領域が、対象オブジェクトからはみ出した場合、問題になることがある。より具体的には、オブジェクト辞書データの画像と識別用データの画像とで、固定値に設定された部分が、部分領域の一部に入った場合、両者の類似度が大きくなってしまい、識別に影響を与える。このような事態を避けるため、オブジェクト辞書データ生成部21は、アフィン変換後の画像において、参照元画像に対応点のないデータを乱数で置き換えるようにするとよい。
<Object registration part>
The object registration process will be described. FIG. 3 is a diagram illustrating an example of the configuration of the
The object dictionary
Here, the object dictionary
画像データそのものではなく、識別時に必要なデータのみを保持するようにすることによって、辞書データ量を削減することもできる。当該オブジェクトの部分領域のベクトル相関(類似度)をとって識別演算を行う場合、オブジェクト辞書データ生成部21は、予めその部分領域のみを切り出しておけばよい。
以上のように、オブジェクト辞書データ生成部21は、適宜必要な情報を画像から抽出し、後述する所定の変換を行った後、オブジェクトの識別を行うための特徴ベクトルとして、オブジェクト辞書データ保持部22に格納する。オブジェクト辞書データ生成部21で行われるより具体的な処理の内容については、あとで詳しく説明する。
オブジェクト辞書データ選択部23は、後述するオブジェクト識別部6の要求に応じて、オブジェクト辞書データ保持部から必要なオブジェクト辞書データを読み出して、オブジェクト識別部6にオブジェクト辞書データを転送する。
It is possible to reduce the amount of dictionary data by holding only the data necessary for identification, not the image data itself. When the identification calculation is performed by taking the vector correlation (similarity) of the partial area of the object, the object dictionary
As described above, the object dictionary
The object dictionary
<オブジェクト辞書データ生成部>
図4は、オブジェクト辞書データ生成部21の構成の一例を示すブロック図である。図4に示すように、オブジェクト辞書データ生成部21は、部分領域設定部31、特徴ベクトル抽出部32、特徴ベクトル変換部33、特徴ベクトル変換用データ保持部34、を含む。
部分領域設定部31は、画像データに対して、特徴ベクトル抽出部32が特徴ベクトルを抽出する位置と範囲を設定する。部分領域の位置と範囲とは、機械学習の方法を用いて予め決めておくとよい。例えば、部分領域設定部31は、部分領域の候補を複数設定しておいて、上記複数候補から、AdaBoostを用いて選択するようにしてもよい。AdaBoostを適用して、実際に部分領域を決める方法については、後述するオブジェクト識別部の説明で詳しく述べる。部分領域設定部31は、部分領域の数として、処理時間等に応じて予め所定の数を決めておく。部分領域設定部31は、予め用意した学習用サンプルに対して、十分な識別性能を得られる数を計測して決める、等すればよい。
<Object dictionary data generator>
FIG. 4 is a block diagram illustrating an example of the configuration of the object dictionary
The partial
特徴ベクトル抽出部32は、登録用のオブジェクトデータから特徴ベクトルを抽出する。オブジェクトが人物の顔である場合、特徴ベクトル抽出部32は、典型的には、顔を含む画像から、識別に必要なデータを取り出す処理を行う。特徴ベクトル抽出部32は、識別に必要なデータを、部分領域設定部31によって設定された部分領域から、その輝度値を特徴ベクトルとして抽出する。また、特徴ベクトル抽出部32は、輝度値を直接取得するのではなく、ガボアフィルタ等何らかのフィルタ演算を施した結果から特徴ベクトルを抽出してもよい。特徴ベクトル抽出部32で行われる処理の内容については、あとで詳しく説明する。
特徴ベクトル変換部33は、特徴ベクトル抽出部32によって抽出された特徴ベクトルに所定の変換を施す。特徴ベクトル変換部33は、特徴ベクトルの変換として、例えば、主成分分析(PCA)による次元圧縮や、独立成分分析(ICA)による次元圧縮等を行う。また、特徴ベクトル変換部33は、フィッシャー判別分析(FDA)による次元圧縮を行ってもよい。
The feature
The feature
特徴ベクトルの変換方法にPCAを用いた場合、その基底数(特徴ベクトルの次元削減数)や、どの基底を用いるか等のパラメータを用いることになる。なお、特徴ベクトル変換部33は、基底数の代わりに、基底ベクトルに対応する固有値の和、即ち累積寄与率を指標としてもよい。特徴ベクトル変換部33は、これらのパラメータを、部分領域ごとに異なったものにすることもできる。実際にどのようなパラメータを設定するかは、予め学習によって決めることができる。
以上のように、特徴ベクトル変換部33は、特徴ベクトルを変換したデータを、オブジェクト辞書データの出力として、オブジェクト辞書データ保持部22に格納する。
特徴ベクトル変換用データ保持部34は、特徴ベクトル変換部33において、特徴ベクトルの変換を行う際に必要なデータを保持している。ここで、特徴ベクトルの変換に必要なデータとは、上述したような、基底数(次元削減数)等の設定情報である。
When PCA is used as a feature vector conversion method, parameters such as the number of bases (dimension reduction number of feature vectors) and which base to use are used. Note that the feature
As described above, the feature
The feature vector conversion
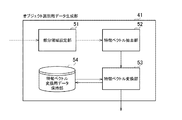
図5は、特徴ベクトル抽出部32で行われる処理の一例を表したフローチャートである。以下、これを用いて説明する。初めに、特徴ベクトル抽出部32は、部分領域設定部31より部分領域の設定情報を取得する(S10)。続いて特徴ベクトル抽出部32は、画像記録部4からオブジェクトの画像データを取得する(S11)。特徴ベクトル抽出部32は、取得した画像データから、(S10)で取得した部分領域の情報を基に、部分領域のはみ出し判定を行う(S13)。ここで、はみ出しとは、(S10)で取得した部分領域が、(S11)で取得した画像の有効な範囲から外れている状態を指す。例えば、画像記録部4から取得する画像データが、オブジェクト検出の情報に基づきオブジェクト領域を切り出したものである場合、後段の処理のため、画像データに固定値ののりしろがつけられる場合がある。部分領域が、オブジェクトの境界付近に設定されている場合、上記のようなケースでは、必ず固定値が特徴ベクトルとして取得されてしまうため、後段の識別用データとの相関演算によくない影響を及ぼす可能性がある。
FIG. 5 is a flowchart showing an example of processing performed by the feature
はみ出しがなかった場合(S13でNoの場合)、特徴ベクトル抽出部32は、画像データから特徴ベクトルを取得する(S14)。ここで、特徴ベクトルは、典型的には部分領域の画像データから取得した輝度データをベクトル化したものであってもよい。また、特徴ベクトルは、LBP(Local Binary Pattern)変換等、所定の変換を施したものから、対応する部分領域を特徴ベクトル化するようにしてもよい。はみ出しがあった場合(S13でYesの場合)、特徴ベクトル抽出部32は、一旦、はみ出した領域以外から特徴ベクトルを取得する(S15)。次に、特徴ベクトル抽出部32は、はみ出した部分の特徴ベクトルの追加処理を行う(S16)。(S15)で取得した特徴ベクトルは、領域が狭いため、(S14)で取得する特徴ベクトルに比べて次元が小さくなる。特徴ベクトル抽出部32は、この少ない分を追加する際に、固定値ではなく、乱数を生成して、ランダムな値をはみ出し部分の特徴ベクトルとする。
乱数を特徴ベクトルとして設定することにより、上述のような、固定値が特徴ベクトルとして設定されることが回避され、後段の識別用データとの相関演算に与えるよくない影響を少なくすることができる。
以上が、特徴ベクトル抽出部で行われる一処理例の説明である。
When there is no protrusion (No in S13), the feature
By setting a random number as a feature vector, it is possible to avoid setting a fixed value as a feature vector as described above, and to reduce unfavorable influence on correlation calculation with subsequent identification data.
The above is the description of one processing example performed by the feature vector extraction unit.
<オブジェクト識別部>
オブジェクト識別処理について説明する。図6は、オブジェクト識別部6の一例を示す図である。図6に示すように、オブジェクト識別部6は、オブジェクト識別用データ生成部41、オブジェクト辞書データ取得部42、オブジェクト識別演算部43、を含む。
オブジェクト識別用データ生成部41は、画像記録部4から取得した画像データから、オブジェクトの識別に必要な情報の抽出を行う。
オブジェクト辞書データ取得部42は、オブジェクト登録部5より、オブジェクトの識別に必要な辞書データを取得する。
オブジェクト識別演算部43は、オブジェクト識別用データ生成部41から取得した識別用データとオブジェクト辞書データ取得部42から得た辞書データとから、オブジェクトの識別処理を行う。ここで行われる処理については、後で詳しく説明する。
<Object identification part>
The object identification process will be described. FIG. 6 is a diagram illustrating an example of the
The object identification
The object dictionary
The object
図7は、オブジェクト識別部6で行われる識別処理の一例を示したフローチャートである。まず、オブジェクト識別部6は、オブジェクト登録部5からオブジェクト辞書データを取得する(S20)。次に、オブジェクト識別部6は、画像記録部4よりオブジェクト画像データを取得する(S21)。続いて、オブジェクト識別部6は、オブジェクト識別用データ生成処理を行う(S22)。ここで行われる処理については、あとで詳しく説明する。次に、オブジェクト識別部6は、オブジェクト識別演算処理を行う(S23)。オブジェクト識別演算処理の出力として、登録済みデータ(辞書データ)との一致をバイナリ(0or1)で出力する場合と正規化した出力値(0〜1の実数値)で出力する場合とがある。更に登録オブジェクト(登録者)が複数(複数人)ある場合には、それぞれの登録オブジェクト(登録者)に対して、出力値を出力してもよいが、最も良く一致した登録データだけを出力してもよい。なお、オブジェクト識別演算処理のより具体的な内容についても、後で詳しく説明する。
以上が、オブジェクト識別部6における処理フロー例の説明である。
FIG. 7 is a flowchart illustrating an example of identification processing performed by the
The above is the description of the processing flow example in the
<オブジェクト識別用データ生成部>
図8は、オブジェクト識別用データ生成部41の構成の一例を示した図である。図8に示すように、オブジェクト識別用データ生成部41は、部分領域設定部51、特徴ベクトル抽出部52、特徴ベクトル変換部53、特徴ベクトル変換用データ保持部54、を含む。オブジェクト識別用データ生成部41の構成及びそこで行われる処理は、オブジェクト辞書データ生成部21でのそれとほぼ同じであるので、詳細は割愛する。
<Object identification data generator>
FIG. 8 is a diagram illustrating an example of the configuration of the object identification
<オブジェクト識別演算処理>
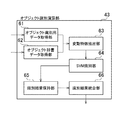
オブジェクト識別演算処理について説明する。ここでは、一例として、intra−class,extra−classの2クラス問題を、SVM識別器を用いて判定する場合について説明する。図9は、オブジェクト識別演算部43の構成の一例を示す図である。オブジェクト識別演算部43は、オブジェクト識別用データ取得部61、オブジェクト辞書データ取得部62、変動特徴抽出部63、SVM識別器64、識別結果保持部65、識別結果統合部66、を含む。
<Object identification calculation processing>
The object identification calculation process will be described. Here, as an example, a case where a two-class problem of intra-class and extra-class is determined using an SVM classifier will be described. FIG. 9 is a diagram illustrating an example of the configuration of the object
図10は、オブジェクト識別演算処理の一例を示したフローチャートである。以下この図を用いて説明する。
始めに、オブジェクト識別用データ取得部61において、オブジェクト識別用データを取得する(S30)。続いて、オブジェクト辞書データ取得部62で、オブジェクトの辞書データを取得する(S31)。次に、変動特徴抽出部63において、(S30)及び(S31)で取得したオブジェクト識別用データとオブジェクト辞書データから、変動特徴抽出処理を行う(S32)。ここで、変動特徴とは、典型的には2枚の画像から抽出される、同一オブジェクト間の変動、又は、異なるオブジェクト間の変動、の何れかに属する特徴のことである。変動特徴の定義は様々なものが考えられる。ここでは一例として、変動特徴抽出部63は、辞書データと、識別用データとで、同じ領域に対応する特徴ベクトル間で類似度(相関値、内積)を計算し、その類似度を成分とするベクトルを変動特徴ベクトルとする。上記定義によれば、変動特徴ベクトルの次元数は、部分領域数と一致する。
FIG. 10 is a flowchart illustrating an example of the object identification calculation process. This will be described below with reference to this figure.
First, the object identification
変動特徴抽出部63は、(S32)で取得した取得した変動特徴ベクトルをサポートベクターマシン(SVM)識別器64に投入する(S33)。SVM識別器64は、同一オブジェクト間の変動(intra−class)と異なるオブジェクトとの間の変動(extra−class)の2クラスを識別する識別器として予め訓練しておく。一般に、部分領域の数を増やすと、それだけ変動特徴ベクトルの次元数が増え、演算時間が増加する。このため、処理時間を優先した場合、カスケード接続型のSVM識別器が有効である。この場合、SVM識別器は、特定の部分領域ごとに訓練されたもので構成される。変動特徴抽出部63は、変動特徴ベクトルを部分領域ごとに分割し、対応するSVM識別器に投入する。このようにすることにより、演算時間を削減することができる。SVM識別器を1つの部分領域だけに対応させて学習するのではなく、2つ以上の部分領域の組み合わせを、SVM識別器の入力として学習させてもよい。
The variation
一方、識別精度を重視する場合、SVM識別器を並列に演算し、演算結果について重み付け和をとるようにするとよい。この場合でも、サポートベクター数を削減するアルゴリズムを適用することで、ある程度演算時間を短縮することは可能である。サポートベクター数を削減する方法は、「Burges, C.J.C(1996). "Simplified support vector decision rules." International Conference on Machine Learning (pp.71−77).」に記載されているような公知の技術を用いることができる。 On the other hand, when importance is attached to the identification accuracy, the SVM classifiers are preferably operated in parallel, and a weighted sum is calculated for the calculation result. Even in this case, it is possible to reduce the calculation time to some extent by applying an algorithm for reducing the number of support vectors. A method for reducing the number of support vectors is described in “Burges, CJC (1996).” Simplified support vector decision rules. A well-known technique as described in "International Conference on Machine Learning (pp.71-77)." Can be used.
SVM識別器64は、(S33)で算出された、辞書データとオブジェクト識別用データとの識別結果を識別結果保持部65に保持する(S34)。次に、例えばSVM識別器64は、全ての辞書データについて、識別演算が終わったかどうか判定する(S35)。まだ辞書データがある場合(S35でNoの場合)には(S31)に戻る。全ての辞書データについて識別演算が終わった場合(S35でYesの場合)、識別結果統合部66で識別結果統合処理を行う(S36)。識別結果統合部66は、例えば、最も単純には、SVM識別器が回帰値を出力する識別器であった場合、最も値の高かった辞書データを、識別結果として出力するような処理を行う。また、識別結果統合部66は、一致度の高かった上位オブジェクトの結果をリストとして出力してもよい。
以上が、オブジェクト識別演算処理の説明である。
The
The above is the description of the object identification calculation process.
<部分領域の学習方法>
次に、部分領域の位置と範囲の学習に、AdaBoostを用いた場合の手順について、説明する。
図11は、部分領域の学習処理の一例を示したフローチャートである。まず、オブジェクト識別装置100は、学習データを取得する(S40)。人物の顔を扱う場合は、学習データとして、個人の識別子を表すラベルのついた顔を含む画像を多数用意する。この際、1人あたりの画像数が十分用意されていることが望ましい。照明変動や、表情の変動に頑健な部分領域及び特徴ベクトルの変換方法を学習するためには、学習データに上記変動を十分含んだサンプルを用意することが重要である。ラベルつきの顔画像から、個人の顔の変動を表すデータと、他人間の顔の変動を表すデータと、の2種類を生成することができる。次に、オブジェクト識別装置100は、弱仮説の選択処理を行う(S41)。ここで弱仮説とは、典型的には、登録データと識別用データとの部分領域間の類似度を算出する処理を行う。オブジェクト識別装置100は、部分領域の位置と範囲との組み合わせの数だけ、弱仮説を用意しておく。そして、オブジェクト識別装置100は、(S40)で取得した学習データに対して、AdaBoostの枠組みに沿って、もっとも性能のよい弱仮説、即ち、位置と範囲とが最適な部分領域を選択する(S42)。性能評価を行うためのより具体的な手順は、オブジェクト識別演算部43の説明で述べた、変動特徴抽出処理の例のようにするとよい。即ち、オブジェクト識別装置100は、学習データに対して、特徴ベクトルの類似度(内積)を求め、変動特徴ベクトルを生成し、SVM識別器に入力する。オブジェクト識別装置100は、同一ラベルの人物間(画像は異なる)と、異なるラベルの人物間とで、それぞれ正しい識別結果になっているか判定し、学習データの重み付き誤り率を求める。
<Learning method of partial area>
Next, a procedure when AdaBoost is used for learning the position and range of the partial area will be described.
FIG. 11 is a flowchart illustrating an example of the learning process of the partial area. First, the object identification device 100 acquires learning data (S40). When dealing with a human face, a large number of images including a face with a label representing an individual identifier are prepared as learning data. At this time, it is desirable that a sufficient number of images per person is prepared. In order to learn a method of converting a partial region and a feature vector that are robust against illumination fluctuations and facial expression fluctuations, it is important to prepare a sample that sufficiently includes the fluctuations in the learning data. Two types of data can be generated from a labeled face image: data representing the variation of an individual's face and data representing the variation of another person's face. Next, the object identification device 100 performs weak hypothesis selection processing (S41). Here, the weak hypothesis typically includes a process of calculating the similarity between the partial areas of the registration data and the identification data. The object identification device 100 prepares as many weak hypotheses as the number of combinations of positions and ranges of partial areas. Then, the object identification device 100 selects the weak hypothesis with the best performance, that is, the partial region having the optimum position and range, based on the AdaBoost framework for the learning data acquired in (S40) (S42). ). A more specific procedure for performing the performance evaluation may be as in the example of the variation feature extraction process described in the description of the object
もっとも性能のよい弱仮説を選択した場合、オブジェクト識別装置100は、その弱仮説の学習データに関する識別結果を基に、学習データの重み付けを更新する(S42)。次に、オブジェクト識別装置100は、弱仮説数が所定数に達しているか判定する(S43)。所定数に達している場合(S43でYesの場合)、オブジェクト識別装置100は、学習処理を終了する。所定数に達していない場合(S43でNoの場合)、オブジェクト識別装置100は、新たな弱仮説の選択を行う。
なお、重みつき誤り率の算出や、学習データの重み付けの更新方法等、AdaBoostによる学習の詳細な手順は、「Viola & Jones (2001) ”Rap
id Object Detection using a Boosted Cascade of Simple Features”, Computer Vision
and Pattern Recognition.」等に記載されている方法を適宜採用すればよい。
When the weak hypothesis with the best performance is selected, the object identification device 100 updates the weighting of the learning data based on the identification result regarding the learning data of the weak hypothesis (S42). Next, the object identification device 100 determines whether the number of weak hypotheses has reached a predetermined number (S43). If the predetermined number has been reached (Yes in S43), the object identification device 100 ends the learning process. If the predetermined number has not been reached (No in S43), the object identification device 100 selects a new weak hypothesis.
The detailed procedure of learning by AdaBoost, such as the calculation of the weighted error rate and the updating method of the weighting of the learning data, is described in “Viola & Jones (2001)” Rap.
id Object Detection using a Boosted Cascade of Simple Features ", Computer Vision
and Pattern Recognition. Or the like may be adopted as appropriate.
オブジェクト識別装置100は、弱仮説を、複数の部分領域の組み合わせから構成するようにしてもよい。即ち、オブジェクト識別装置100は、1つの弱仮説に含まれる部分領域数を一定(所定数、例えば5個、10個等)にする。この場合、オブジェクト識別装置100は、1弱仮説中の部分領域数を増やすと、組み合わせの数が指数関数的に増加するので、何らかの拘束条件をつけて学習するようにするとよい。より具体的には、オブジェクト識別装置100は、部分領域の位置関係を参照して、互いに近い位置にある部分領域が含まれないようにするようにしてもよい。
また、オブジェクト識別装置100は、複数部分領域の組み合わせを作る際に、遺伝的アルゴリズム(GA)等の最適化手法を適用するようにしてもよい。この場合、オブジェクト識別装置100は、弱仮説の候補は、AdaBoostの手続きに入る前に予め全て用意されるのではなく、弱仮説を選択しならが、動的に候補を構築していく。即ち、オブジェクト識別装置100は、予め一部用意された弱仮説の候補(例えば、ランダムに領域候補を組み合わせる等して生成しておく)から、性能のよいものを選択しておくようにする。そして、オブジェクト識別装置100は、その性能のよいもの同士を、組み合わせながら、新しい弱仮説の候補を生成し、性能を評価していく。このようにすることにより、弱仮説の候補を効率的に絞り込むことができる。以上のようにして、学習時間の増加を抑えるようにするとよい。
以上が、部分領域の位置と範囲とを学習する手順の説明である。
The object identification device 100 may configure the weak hypothesis from a combination of a plurality of partial areas. That is, the object identification device 100 makes the number of partial areas included in one weak hypothesis constant (a predetermined number, for example, five, ten, etc.). In this case, since the number of combinations increases exponentially when the number of partial areas in the one weak hypothesis is increased, the object identification device 100 may be learned with some constraint condition. More specifically, the object identification device 100 may refer to the positional relationship of the partial areas so that the partial areas at positions close to each other are not included.
Further, the object identification device 100 may apply an optimization method such as a genetic algorithm (GA) when creating a combination of a plurality of partial regions. In this case, the object identification apparatus 100 does not prepare all weak hypothesis candidates in advance before entering the AdaBoost procedure, but dynamically builds candidates even if a weak hypothesis is selected. In other words, the object identification device 100 selects one with good performance from weak hypothesis candidates prepared in advance (for example, randomly generated by combining region candidates). Then, the object identification device 100 generates new weak hypothesis candidates while combining those having good performance, and evaluates the performance. In this way, the weak hypothesis candidates can be narrowed down efficiently. As described above, it is preferable to suppress an increase in learning time.
The above is the description of the procedure for learning the position and range of the partial region.
≪実施形態2≫
実施形態2は実施形態1に対して、オブジェクト登録部とオブジェクト識別部との処理内容が異なる。
より具体的には、実施形態1では、オブジェクトの属性は考えなかったのに対し、実施形態2では、オブジェクトの属性を推定し、オブジェクトの属性に応じた部分領域の設定がなされる点が異なる。
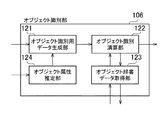
以下、より具体的に説明する。なお、重複を避けるため、以下の説明において、前実施形態と同じ部分は、省略する。図12は、オブジェクト識別装置100のハードウェア構成の一例を示す図(その2)である。各部の基本的な機能は実施形態1と同一であるが、以下の点が異なる。即ち、オブジェクト識別装置100に、オブジェクト辞書データ入力部109と、オブジェクト辞書データ書き換え部110と、が追加されている。
オブジェクト辞書データ入力部109は、オブジェクト辞書データを外部から入力するための処理を実行し、典型的には半導体メモリ等の外部記憶装置から、オブジェクト辞書データを読み取る。オブジェクトデータ書き換え部110は、オブジェクト辞書データ及びオブジェクト識別用データを所定の手順に従って書き換える。オブジェクトデータ書き換え部110は、典型的には、オブジェクトのデータが画像であった場合、コントラストの補正や、ノイズの除去、解像度の変更等を行う。
なお、説明の便宜上、識別する対象となるオブジェクトを、画像中の人物の顔としているが、本実施形態は、人物の顔以外のオブジェクトに適用可能である。
<<
The second embodiment differs from the first embodiment in the processing contents of the object registration unit and the object identification unit.
More specifically, the attribute of the object is not considered in the first embodiment, whereas the attribute of the object is estimated in the second embodiment, and a partial area is set according to the attribute of the object. .
More specific description will be given below. In addition, in order to avoid duplication, the same part as previous embodiment is abbreviate | omitted in the following description. FIG. 12 is a diagram (part 2) illustrating an example of a hardware configuration of the object identification device 100. The basic function of each part is the same as that of the first embodiment, but the following points are different. That is, an object dictionary
The object dictionary
For convenience of explanation, the object to be identified is the face of a person in the image, but this embodiment is applicable to objects other than the face of a person.
<オブジェクト登録部>
図13は、オブジェクト登録部105の構成の一例を示す図である。オブジェクト登録部105は、オブジェクト辞書データ生成部111、オブジェクト辞書データ保持部112、オブジェクト辞書データ選択部113、オブジェクト属性推定部114、を含む。実施形態1とは、オブジェクト属性推定部114が追加されている点が異なる。
オブジェクト属性推定部114は、画像記録部104から入力された画像データから、オブジェクトの属性を推定する処理を行う。推定を行う具体的な属性は、オブジェクトの大きさ、姿勢・向き、照明条件等が含まれる。オブジェクトが人物の顔である場合、オブジェクト属性推定部114は、顔の器官位置を検出する。より具体的には、オブジェクト属性推定部114は、目、口、鼻等構成要素の端点を検出する。端点を検出するアルゴリズムは、例えば、特許3078166号公報に記載の畳み込み神経回路網を用いた方法等を用いることができる。オブジェクト属性推定部114は、端点として、左右の目、口の両端点、鼻、等個人の特徴を現すと考えられる部位を予め選択しておく。オブジェクト属性推定部114は、顔器官の端点の位置関係を、その属性として検出する。また、他の属性として、オブジェクト属性推定部114は、人物の年齢、性別、表情、等の属性を推定してもよい。これらの属性推定には公知の技術を用いることができる。例えば「特開2003−242486号公報」のような方法を用いることで、人物の属性を推定することができる。
<Object registration part>
FIG. 13 is a diagram illustrating an example of the configuration of the
The object
学習データを変えることによって、上記の方法で、人物だけでなく、一般の物体についても検出することができる。それによって、人物の顔にある顔器官以外の要素、例えば、メガネや、マスク、手等、オクリュージョンとなる物体を検出することもできる。上記のようなオクリュージョンがある人物の顔として、その属性に含めて考えることができる。
オブジェクト属性推定部114は、属性推定に、撮像パラメータの一例であるカメラパラメータを用いるようにしてもよい。例えば、オブジェクト属性推定部114は、撮像制御部103から制御用のAE、AFに関するパラメータを取得することによって、照明条件等の属性を精度良く推定することが可能になる。ここで、カメラパラメータのより具体的な例として、露出条件、ホワイトバランス、ピント、オブジェクトの大きさ等があげられる。例えば、オブジェクト属性推定部114は、露出条件及びホワイトバランスと、肌色成分領域に対応する色成分の対応表を予め作成し、ルックアップテーブルとして保持しておくことで、撮影条件に影響されないオブジェクトの色属性を推定することができる。
By changing the learning data, not only a person but also a general object can be detected by the above method. Accordingly, it is possible to detect elements other than the facial organs on the face of the person, such as glasses, masks, hands, and other objects that are occluded. It can be considered as a face of a person who has the occlusion as described above.
The object
また、オブジェクト属性推定部114は、被写体であるオブジェクトまでの距離をAF等の距離測定手段を用いることによって測定し、オブジェクトの大きさを推定することができる。より詳細にはオブジェクト属性推定部114は、以下の式に従ってオブジェクトの大きさを推定することができる。
s = ( f/d − f )・S
ここで、sは、オブジェクトの画像上での大きさ(ピクセル数)である。fは、焦点距離である。dは、装置からオブジェクトまでの距離である。Sは、オブジェクトの実際の大きさである。但し、(d>f)であるとする。
Further, the object
s = (f / d−f) · S
Here, s is the size (number of pixels) of the object on the image. f is a focal length. d is the distance from the device to the object. S is the actual size of the object. However, it is assumed that (d> f).
このように、オブジェクト属性推定部114は、撮影条件に影響されないオブジェクトの大きさを属性として推定することが可能になる。
オブジェクト属性推定部114で推定されたオブジェクトの属性情報は、オブジェクト辞書データ生成部111から出力されるオブジェクト辞書データと共に、オブジェクト辞書データ保持部112に格納される。
オブジェクト辞書データ生成部111での処理も前記実施形態と一部、異なる。図14は、オブジェクト辞書データ生成部111における特徴ベクトル抽出部での処理の一例を示したフローチャートである。以下、これを用いて説明する。始めに、オブジェクト辞書データ生成部111は、オブジェクト属性推定部114からオブジェクトの属性情報を取得する(S100)。取得するオブジェクトの属性情報は、典型的には、人物の顔の器官位置及びその端点である。次に、オブジェクト辞書データ生成部111は、画像記録部104から画像データを取得する(S101)。オブジェクト辞書データ生成部111は、(S100)で取得したオブジェクト属性情報を用いて、オブジェクト画像データに対して、部分領域を設定する(S102)。
In this manner, the object
The object attribute information estimated by the object
The processing in the object dictionary
部分領域の設定は、より具体的には以下のようにする。まず、オブジェクト辞書データ生成部111は、属性情報として取得した、顔器官の複数端点のうち、所定の1点を基準点として設定する。更にオブジェクト辞書データ生成部111は、他の少なくとも2つ端点間の距離を測り、その2点間距離の所定倍の長さだけ、前記基準点から離れた所に部分領域を設定する。オブジェクト辞書データ生成部111は、基準点からの方向も予め定められた値を用いる。ここで、基準点となる端点、距離の基準となる2点、2点間距離の何倍かを決める定数、基準点からの方向等は、予め学習によって決めることができる。これらのパラメータの学習は、部分領域のパラメータの中に含めることによって、実施形態1で説明したAdaBoostを用いた部分領域の選択方法によって実現することができる。部分領域が設定された後の処理は、実施形態1における特徴ベクトル抽出部の処理と同じであるので説明は割愛する。
More specifically, the partial area is set as follows. First, the object dictionary
上記のような部分領域の設定方法、即ち、顔器官の端点を基準とした方法をとる場合、はみ出し判定をして、はみ出した領域の特徴ベクトルを無相関データにすることは、特に効果的である。一般に、斜光や逆光等撮影条件が厳しい場合や、奥行き方向の回転が入った人物の顔について、その顔器官の端点を高精度に検出することは難しい。仮に端点が誤検出であった場合、部分領域の設定も誤ってしまい、結果的に部分領域が、画像の範囲外に設定されることは、十分あり得る。はみ出した領域の特徴ベクトルを固定値にすると、登録辞書データと識別用データの両方にはみ出しがあると、その部分の類似度が大きくなり、識別結果によくない影響を及ぼす。オブジェクト辞書データ生成部111及びオブジェクト識別用データ生成部121が、はみ出し領域に固定値ではない、オブジェクト辞書データとオブジェクト識別用データとで無相関になる値、より具体的には、乱数を設定する。このことによって、上記のような問題を回避できる。
When using the method for setting the partial area as described above, that is, the method based on the end points of the facial organ, it is particularly effective to make the feature vector of the protruded area by making it an uncorrelated data. is there. In general, it is difficult to detect the end points of a facial organ with high accuracy when photographing conditions such as oblique light and backlight are severe, or for a human face that has been rotated in the depth direction. If the end point is erroneously detected, it is possible that the setting of the partial area is also incorrect, and as a result, the partial area is set outside the range of the image. If the feature vector of the protruded area is set to a fixed value, if both the registered dictionary data and the identification data are protruded, the degree of similarity of the portion increases, which adversely affects the identification result. The object dictionary
オブジェクト属性推定部114は、オブジェクトの属性として、オクリュージョン情報を用いることもできる。オブジェクト辞書データ生成部111は、部分領域に設定されるはずの範囲に、メガネや、マスク等他の物体があった場合、その物体の範囲を、無相関データ、より具体的には乱数によって置き換えてしまう。このようにすることによって、例えば、たまたまマスクをしていた他人同士の口領域の類似度が極端に大きくなってしまうような状況を避けることができる。
また、オブジェクト属性推定部114は、属性として、表情を用いることもできる。例えば、笑った顔の頬には、しわが出やすいが、これが識別によくない影響を与えることもあり得るので、オブジェクト辞書データ生成部111は、上記のように無相関データに置き換えてしまってもよい。表情と、無相関データに置き換える部分領域との関係は、予め学習サンプルによって決めた、ルックアップテーブルを作成し、オブジェクト辞書データ生成部111がこれを参照するようにすればよい。
同様に、人物の年齢を用いて、経年変化の現れやすい領域をオブジェクト辞書データ生成部111が無相関データにすることにより、登録時と認証時とで時間がたっている場合の識別性能を向上させることができる。
以上が、オブジェクト登録部の説明である。
The object
The object
Similarly, by using the age of the person, the object dictionary
The above is the description of the object registration unit.
<オブジェクト識別部>
図15は、オブジェクト識別部106の構成の一例を示す図である。オブジェクト識別部106は、オブジェクト識別用データ生成部121、オブジェクト識別演算部122、オブジェクト辞書データ取得部123、オブジェクト属性推定部124、を含む。実施形態1とは、オブジェクト属性推定部124が追加されている点が異なる。
オブジェクト属性推定部124の処理の内容は、オブジェクト登録部のオブジェクト属性推定部114と同じであるので、説明は割愛する。
オブジェクト識別用データ生成部121は、画像記録部104からの入力と共に、オブジェクト属性推定部114の出力を用いて、特徴ベクトル及びその変換処理を行う。この処理は、オブジェクト登録部の処理とほぼ同じになるので、説明は割愛する。
オブジェクト識別演算部122は、オブジェクト識別用データ生成部121及びオブジェクト辞書データ取得部123からの入力を基に、オブジェクトの識別処理を行う。オブジェクト識別演算部122で行われる処理のより具体的な内容については、あとで説明する。
オブジェクト辞書データ取得部123は、オブジェクト識別演算部122からのリクエストに基づいて、オブジェクト登録部105中のオブジェクト辞書データ保持部112より、オブジェクト辞書データを取得する。
<Object identification part>
FIG. 15 is a diagram illustrating an example of the configuration of the
Since the content of the processing of the object
The object identification
The object
The object dictionary
<オブジェクト識別演算処理>
次に、オブジェクト識別演算処理の内容について説明する。
オブジェクト識別処理の全体的な処理は、実施形態1とほぼ同じである。
以下では、オブジェクト識別器として、多数の識別器(以下弱識別器と呼ぶ)をツリー状に構成したオブジェクト識別器を用いてオブジェクト識別処理を行う場合について説明する。典型的には弱識別器は、1つの部分領域に対応しているが、弱識別器を複数の部分領域に対応させてもよい。
図16は、オブジェクト識別器を弱識別器のツリー構造で構成した場合の模式図である。図中の枠1つが1つの弱識別器を表している。以下、ツリー構造をなす各弱識別器のことをノード識別器と呼ぶことがある。識別時は、矢印の方向に沿って処理が行われる。即ち、上位にある弱識別器から処理を行って、処理が進むにつれ、下位の弱識別器で処理を行う。一般に、上位にある弱識別器は、変動に対するロバスト性が高いが、誤識別率は高い傾向にある。下位にある弱識別器ほど変動に対するロバスト性は低い一方で、変動範囲が一致したときの識別精度は高くなるように学習してある。ある特定の変動範囲(顔の奥行き方向や、表情変動、照明変動等)に特化した弱識別器系列を複数用意し、ツリー構造をとることで、全体としての対応変動範囲を確保している。図16では、5系列の弱識別器系列がある場合について示している。また、図16では、最終的に5つの弱識別器系列が1つのノード識別器に統合されている。この最終ノード識別器は、例えば5系列の累積スコアを比較して、最も高いスコアをもつ系列の識別結果を採用する等の処理を行ってもよい。また、1つの識別結果に統合して出力するのではなく、各系列の識別結果をベクトルとして出力するようにしてもよい。
<Object identification calculation processing>
Next, the contents of the object identification calculation process will be described.
The overall process of the object identification process is almost the same as in the first embodiment.
Hereinafter, a case will be described in which object identification processing is performed using an object classifier in which a large number of classifiers (hereinafter referred to as weak classifiers) are configured in a tree shape as object classifiers. Typically, the weak classifier corresponds to one partial area, but the weak classifier may correspond to a plurality of partial areas.
FIG. 16 is a schematic diagram when the object classifier is configured with a tree structure of weak classifiers. One frame in the figure represents one weak classifier. Hereinafter, each weak classifier having a tree structure may be referred to as a node classifier. At the time of identification, processing is performed along the direction of the arrow. That is, processing is performed from the weak classifier at the upper level, and processing is performed at the lower weak classifier as the processing proceeds. In general, weak classifiers at the top have high robustness to fluctuations, but have a high misclassification rate. The weak classifier at the lower level is less robust to fluctuations, while learning is performed so that the classification accuracy when the fluctuation ranges match is higher. Multiple weak classifier series specialized for a specific variation range (face depth direction, facial expression variation, illumination variation, etc.) are prepared and a tree structure is used to secure the corresponding variation range as a whole. . FIG. 16 shows a case where there are five weak classifier sequences. In FIG. 16, finally, five weak classifier sequences are integrated into one node classifier. For example, the final node discriminator may perform processing such as comparing cumulative scores of five sequences and adopting a discrimination result of a sequence having the highest score. Further, instead of being integrated into one identification result and output, the identification result of each series may be output as a vector.
各弱識別器は、intra−class, extra−classの2クラス問題を判別する識別器であるが、分岐の基点にあるノード識別器は、どの弱識別器系列に進むか、分岐先を決める判定を行う。もちろん、2クラス判定を行いつつ、分岐先も決めるようにしてもよい。また、分岐先を決めず、全ての弱識別器系列で処理するようにしてもよい。また、各ノード識別器は、2クラス判定の他に、演算を打ち切るかどうか判定するようにしてもよい(打ち切り判定)。打ち切り判定は、各ノード識別器単体の判定でもよいが、他のノード識別器の出力値(判定スコア)を累積したものを閾値処理する等して判定してもよい。
以上が、オブジェクト識別演算処理の説明である。
Each weak classifier is a classifier that discriminates two-class problems of intra-class and extra-class, but the node classifier at the base point of the branch determines which weak classifier sequence to proceed to and determines the branch destination I do. Of course, the branch destination may be determined while performing the two-class determination. Further, the processing may be performed for all weak classifier series without determining the branch destination. Further, each node discriminator may determine whether or not to cancel the calculation in addition to the 2-class determination (canceling determination). The abort determination may be performed for each node discriminator alone, or may be performed by performing threshold processing on an accumulation of output values (determination scores) of other node discriminators.
The above is the description of the object identification calculation process.
以上、上述した各実施形態によれば、照明や大きさ、向き等の変動に対して、ロバスト性と識別性能を向上させることができる。
また、上述したように、オブジェクト識別装置100は、部分領域の設定が、例えば、画像データの範囲外に設定された場合、登録オブジェクトの辞書データと、識別用データとで無相関になる値を設定する。このことにより、高精度な識別を行うことができる。
なお、上述したように、オブジェクト識別装置100は、部分領域の属性が、オクリュージョンであった場合、登録オブジェクトの辞書データと、識別用データとで無相関になる値を設定するようにしてもよい。このようにすることによっても、高精度な識別を行うことができる。
As described above, according to each embodiment described above, robustness and identification performance can be improved with respect to variations in illumination, size, orientation, and the like.
Further, as described above, the object identification device 100 sets a value that is uncorrelated between the dictionary data of the registered object and the identification data when the setting of the partial area is set outside the range of the image data, for example. Set. As a result, highly accurate identification can be performed.
As described above, when the attribute of the partial area is occlusion, the object identification device 100 sets a value that is uncorrelated between the dictionary data of the registered object and the identification data. Also good. In this way, highly accurate identification can be performed.
以上、本発明の好ましい実施形態について詳述したが、本発明は係る特定の実施形態に限定されるものではなく、特許請求の範囲に記載された本発明の要旨の範囲内において、種々の変形・変更が可能である。 The preferred embodiments of the present invention have been described in detail above, but the present invention is not limited to such specific embodiments, and various modifications can be made within the scope of the gist of the present invention described in the claims.・ Change is possible.
1 結像光学系、2 撮像部、3 撮像制御部、4 画像季肋部、5 オブジェクト登録部、6 オブジェクト識別部、7 外部出力部 1 imaging optical system, 2 imaging unit, 3 imaging control unit, 4 image seasoning unit, 5 object registration unit, 6 object identification unit, 7 external output unit
Claims (10)
前記オブジェクトを含む登録画像を取得する取得手段と、
前記入力画像に対してアフィン変換を行い、該変換された画像に部分領域を設定する第1の部分領域設定手段と、
前記アフィン変換後の画像に設定された部分領域の少なくとも一部が、前記アフィン変換する前の入力画像の領域からはみ出しているか否かを判定する第1の判定手段と、
前記部分領域が前記入力画像の領域からはみ出していないと判定された場合には、前記部分領域から特徴ベクトルを設定し、前記部分領域が前記入力画像の領域からはみ出していると判定された場合には、前記部分領域のうち、前記入力画像の領域からはみ出している領域に対し、乱数を設定し、該乱数が設定された前記はみ出している領域と前記入力画像からはみ出していない領域とを含む領域から特徴ベクトルを設定する第1の設定手段と、
前記登録画像の特徴ベクトルと前記第1の設定手段により設定される前記部分領域の特徴ベクトルとの相関を算出し、該算出された結果に基づいて前記オブジェクトを識別する識別手段と
を有することを特徴とするオブジェクト識別装置。 An input means for inputting an input image including an object;
An acquisition unit configured to acquire a registration image including the object,
First partial area setting means for performing affine transformation on the input image and setting a partial area in the converted image;
First determination means for determining whether or not at least a part of the partial area set in the image after the affine transformation protrudes from the area of the input image before the affine transformation;
When it is determined that the partial area does not protrude from the area of the input image, a feature vector is set from the partial area, and when it is determined that the partial area protrudes from the area of the input image , of the partial region, a region for a region that protrudes from the region of the input image, and sets the random number, and a region that does not protrude from the region and the input image extends off the said random number is set First setting means for setting a feature vector from
An identification unit for calculating a correlation between the feature vector of the registered image and the feature vector of the partial area set by the first setting unit, and identifying the object based on the calculated result. Feature object identification device.
前記第1の設定手段は、検出された前記部位の位置に基づいて、前記部分領域を設定することを特徴とする請求項1に記載のオブジェクト識別装置。 And further comprising detection means for detecting a specific part of the object in the input image,
It said first setting means, based on the detected position of the said site, the object identification device as claimed in claim 1, characterized in that to set the partial area.
前記アフィン変換後の画像に設定された前記部分領域の少なくとも一部が、前記アフィン変換する前の登録画像の領域からはみ出しているか否かを判定する第2の判定手段と、
前記部分領域が前記入力画像の領域からはみ出していないと判定された場合には、前記部分領域から特徴ベクトルを設定し、前記登録画像の前記部分領域が前記登録画像の領域からはみ出していると判定された場合には、前記登録画像の前記部分領域のうち、前記登録画像の領域からはみ出している領域に対し、乱数を設定し、該乱数が設定された前記はみ出している領域と前記入力画像からはみ出していない領域とを含む領域から特徴ベクトルを設定する第2の設定手段と
をさらに有し、
前記識別手段は、前記登録画像及び前記入力画像それぞれの対応する前記部分領域の特徴ベクトルの相関を算出し、該算出された結果に基づいて、前記オブジェクトを識別することを特徴とする請求項1又は2に記載のオブジェクト識別装置。 And second setting means performs an affine transformation, and sets the partial area in the converted image to the registered image,
Least for the even part of the partial region set in the image after the affine transformation, a second determination means for determining whether protrudes from the area in front of the registered image to the affine transformation,
When it is determined that the partial area does not protrude from the area of the input image, a feature vector is set from the partial area, and it is determined that the partial area of the registered image protrudes from the area of the registered image. in a case where it is, the one of the segment of the registered image, to region protrudes from the region of the registered image, sets a random number, from the region and the input image extends off the said random number is set Second setting means for setting a feature vector from a region including a region that does not protrude,
The identification unit calculates a correlation between feature vectors of the partial areas corresponding to the registered image and the input image, and identifies the object based on the calculated result. Or the object identification device of 2.
前記識別手段は、前記辞書と、前記入力画像の前記部分領域との相関を算出することを特徴とする請求項1乃至3の何れか1項に記載のオブジェクト識別装置。 A dictionary holding means for holding a partial region of the object of the registered image as a dictionary;
4. The object identification device according to claim 1, wherein the identification unit calculates a correlation between the dictionary and the partial area of the input image. 5.
前記登録画像の前記部分領域の特徴ベクトルを抽出する第2の特徴ベクトル抽出手段と
をさらに有し、
前記識別手段は、前記入力画像の前記部分領域の前記特徴ベクトルと、前記登録画像の前記部分領域の前記特徴ベクトルとに基づいて、前記登録画像の前記部分領域と、前記入力画像の前記部分領域との相関を算出することを特徴とする請求項3乃至8の何れか1項に記載のオブジェクト識別装置。 First feature vector extraction means for extracting a feature vector of the partial region of the input image;
Second feature vector extracting means for extracting a feature vector of the partial area of the registered image;
Further comprising
The identification unit is configured to determine the partial area of the registered image and the partial area of the input image based on the feature vector of the partial area of the input image and the feature vector of the partial area of the registered image. The object identification device according to claim 3, wherein the correlation is calculated .
前記オブジェクトを含む登録画像を取得する取得ステップと、An acquisition step of acquiring a registered image including the object;
前記入力画像に対してアフィン変換を行い、該変換された画像に部分領域を設定する第1の部分領域設定ステップと、A first partial area setting step of performing affine transformation on the input image and setting a partial area in the transformed image;
前記アフィン変換後の画像に設定された部分領域の少なくとも一部が、前記アフィン変換する前の入力画像の領域からはみ出しているか否かを判定する第1の判定ステップと、A first determination step of determining whether at least a part of the partial region set in the image after the affine transformation protrudes from the region of the input image before the affine transformation;
前記部分領域が前記入力画像の領域からはみ出していないと判定された場合には、前記部分領域から特徴ベクトルを設定し、前記部分領域が前記入力画像の領域からはみ出していると判定された場合には、前記部分領域のうち、前記入力画像の領域からはみ出している領域に対し、乱数を設定し、該乱数が設定された前記はみ出している領域と前記入力画像からはみ出していない領域とを含む領域から特徴ベクトルを設定する第1の設定ステップと、When it is determined that the partial area does not protrude from the area of the input image, a feature vector is set from the partial area, and when it is determined that the partial area protrudes from the area of the input image Is a region that includes a region that protrudes from the region of the input image and includes a region that protrudes from the input image and a region that does not protrude from the input image. A first setting step for setting a feature vector from
前記登録画像の特徴ベクトルと前記第1の設定ステップにおいて設定された前記部分領域の特徴ベクトルとの相関を算出し、該算出された結果に基づいて前記オブジェクトを識別する識別ステップとAn identification step of calculating a correlation between the feature vector of the registered image and the feature vector of the partial area set in the first setting step, and identifying the object based on the calculated result;
を含むことを特徴とするオブジェクト識別方法。An object identification method comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009105662A JP5653003B2 (en) | 2009-04-23 | 2009-04-23 | Object identification device and object identification method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009105662A JP5653003B2 (en) | 2009-04-23 | 2009-04-23 | Object identification device and object identification method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010257158A JP2010257158A (en) | 2010-11-11 |
| JP5653003B2 true JP5653003B2 (en) | 2015-01-14 |
Family
ID=43318003
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009105662A Active JP5653003B2 (en) | 2009-04-23 | 2009-04-23 | Object identification device and object identification method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5653003B2 (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5800494B2 (en) * | 2010-11-19 | 2015-10-28 | キヤノン株式会社 | Specific area selection device, specific area selection method, and program |
| JP5759161B2 (en) * | 2010-12-16 | 2015-08-05 | キヤノン株式会社 | Object recognition device, object recognition method, learning device, learning method, program, and information processing system |
| JP5777380B2 (en) * | 2011-04-05 | 2015-09-09 | キヤノン株式会社 | Image recognition apparatus, image recognition method, and program |
| JP6090286B2 (en) * | 2014-10-31 | 2017-03-08 | カシオ計算機株式会社 | Machine learning device, machine learning method, classification device, classification method, program |
| JP6494253B2 (en) * | 2014-11-17 | 2019-04-03 | キヤノン株式会社 | Object detection apparatus, object detection method, image recognition apparatus, and computer program |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4696857B2 (en) * | 2005-11-02 | 2011-06-08 | オムロン株式会社 | Face matching device |
| JP4788525B2 (en) * | 2006-08-30 | 2011-10-05 | 日本電気株式会社 | Object identification parameter learning system, object identification parameter learning method, and object identification parameter learning program |
| JP2009075868A (en) * | 2007-09-20 | 2009-04-09 | Toshiba Corp | Apparatus, method, and program for detecting object from image |
-
2009
- 2009-04-23 JP JP2009105662A patent/JP5653003B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010257158A (en) | 2010-11-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5247480B2 (en) | Object identification device and object identification method | |
| US9098760B2 (en) | Face recognizing apparatus and face recognizing method | |
| JP5554987B2 (en) | Object identification device and control method thereof | |
| JP4345622B2 (en) | Eye color estimation device | |
| JP5424819B2 (en) | Image processing apparatus and image processing method | |
| JP4443722B2 (en) | Image recognition apparatus and method | |
| US8942436B2 (en) | Image processing device, imaging device, image processing method | |
| KR101280920B1 (en) | Image recognition apparatus and method | |
| US8542887B2 (en) | Object identification apparatus and object identification method | |
| US9626553B2 (en) | Object identification apparatus and object identification method | |
| JP5241606B2 (en) | Object identification device and object identification method | |
| JP5588180B2 (en) | Pattern identification apparatus and control method therefor | |
| JP2007140823A (en) | Face collation device, face collation method and program | |
| JP6822482B2 (en) | Line-of-sight estimation device, line-of-sight estimation method, and program recording medium | |
| JP5653003B2 (en) | Object identification device and object identification method | |
| JPWO2019003973A1 (en) | Face authentication device, face authentication method and program | |
| WO2020195732A1 (en) | Image processing device, image processing method, and recording medium in which program is stored | |
| JP2005149370A (en) | Imaging device, personal authentication device and imaging method | |
| CN114360039A (en) | Intelligent eyelid detection method and system | |
| JP5791361B2 (en) | PATTERN IDENTIFICATION DEVICE, PATTERN IDENTIFICATION METHOD, AND PROGRAM | |
| JP2012234497A (en) | Object identification device, object identification method, and program | |
| US10140503B2 (en) | Subject tracking apparatus, control method, image processing apparatus, and image pickup apparatus | |
| JP2008015871A (en) | Authentication device and authenticating method | |
| JP4789526B2 (en) | Image processing apparatus and image processing method | |
| JP7103443B2 (en) | Information processing equipment, information processing methods, and programs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20120420 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130222 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130305 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130507 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130618 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130917 |
|
| A911 | Transfer of reconsideration by examiner before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20130926 |
|
| A912 | Removal of reconsideration by examiner before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20131025 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140903 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20141118 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 5653003 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |