JP5595701B2 - ファイル管理方法及びストレージシステム - Google Patents
ファイル管理方法及びストレージシステム Download PDFInfo
- Publication number
- JP5595701B2 JP5595701B2 JP2009214007A JP2009214007A JP5595701B2 JP 5595701 B2 JP5595701 B2 JP 5595701B2 JP 2009214007 A JP2009214007 A JP 2009214007A JP 2009214007 A JP2009214007 A JP 2009214007A JP 5595701 B2 JP5595701 B2 JP 5595701B2
- Authority
- JP
- Japan
- Prior art keywords
- file
- server
- fragment
- data string
- fragment data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/17—Details of further file system functions
- G06F16/174—Redundancy elimination performed by the file system
- G06F16/1748—De-duplication implemented within the file system, e.g. based on file segments
- G06F16/1752—De-duplication implemented within the file system, e.g. based on file segments based on file chunks
Description
<図1:概要>
図1は、本発明の第一の実施形態に係る計算機システムの概要を説明する図である。
<図2:メタデータサーバ>
図2は、本発明の第一の実施形態に係るメタデータサーバ1の一例を説明する図である。
<図3:ストレージサーバ管理テーブル>
図3は、本発明の第一の実施形態に係るストレージサーバ管理テーブル121の一例を説明する図である。
<図4:レイアウトテーブル>
図4は、本発明の第一の実施形態に係るレイアウトテーブル122の一例を説明する図である。
<図5:ファイル属性テーブル>
図5は、本発明の第一の実施形態に係る分散ファイル属性テーブル123の一例を説明する図である。
ここで、Qは、分散ファイルのファイル断片の番号の集合、Hは任意のバイト列を取って32ビットのハッシュ値を出力するハッシュ関数、Siは分散ファイルのi番目のファイル断片のバイト列、sizeは分散ファイルのサイズをバイト列で表わしたデータである。また上記の二項演算+はバイト列を連結することを意味し、Σi∈Q Siは、全てのSiに二項演算+を適用し、連結することを意味する。
<図6:類似グループテーブル>
図6は、本発明の第一の実施形態に係る類似グループテーブル124の一例を説明する図である。
<図7:ストレージサーバ>
図7は、本発明の第一の実施形態に係るストレージサーバ2の構成を説明する図である。
<図8:ファイルシステムの構造>
図8は、本発明の第一の実施形態に係るファイルシステム26の一例を説明する図である。図8は、例として、ストレージサーバ2aのファイルシステム26の構造と格納されるデータを示している。各ストレージサーバ2のファイルシステム26の構造は同じである。
図8では、ストレージサーバ2aのファイルシステム26に格納されているローカルファイルの内、3個のローカルファイル(識別番号1100、2100、3100)を図示している。以下、識別番号が1100のローカルファイルを、単にローカルファイル1100のように表記する。
<図9:グループ化処理>
図9は、本発明の第一の実施形態に係る類似グループ作成処理の一例を説明するフローチャートである。
(1)類似グループと、類似グループに含まれる分散ファイルの識別情報
(2)上記(1)の各分散ファイルのレイアウト
(3)重複排除ポリシー125に格納されている情報
重複排除ポリシー125には、分散ファイルの重複排除を実行する場合に、ファイル断片を消去するストレージサーバ2を選択する方針に関する情報が格納される。この方針とは、例えば、最もファイルシステム利用率(容量利用率)の少ないストレージサーバ2のファイル断片を残し、他のストレージサーバ2のファイル断片を削除する、等である。また、ストレージサーバ2のCPU利用率が少ないストレージサーバ2のファイル断片を残すというポリシーであってもよい。
<図10:重複排除処理>
図10は、本発明の第一の実施形態に係る重複排除処理の一例を説明するフローチャートである。重複排除処理は、各ストレージサーバ2が、メタデータサーバ1または前のストレージサーバ2からの重複排除処理実行の指示を受け、重複排除処理プログラム222によって実行される。以下、重複排除処理プログラム222の処理の流れである。
<図11、図12:ファイル断片排除サーバ合意処理>
図11及び図12は、本発明の第一の実施形態に係るファイル断片排除サーバ間合意処理の一例を説明するフローチャートである。
<図13:ファイル断片排除処理>
図13は、本発明の第一の実施形態に係るファイル断片排除処理の一例を説明するフローチャートである。
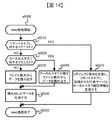
<図14:リード処理>
図14は、本発明の第一の実施形態に係るファイルリード処理の一例を説明するフローチャートである。
<図15:ライト処理>
図15は、本発明の第一の実施形態に係るファイルライト処理の一例を説明するフローチャートである。
<図16:第二の実施形態>
図16は、本発明の第二の実施形態に係る計算機システムの概要を説明する図である。
(1)ステップs1010および、ステップs1020において、類似ファイル抽出プログラム53は、メタデータサーバ1より、レイアウトテーブル122および分散ファイル属性テーブル123に格納されている分散ファイルのレイアウトと属性を取得する。
(2)ステップs1040において、類似ファイル抽出プログラム53は、類似グループの情報を類似グループテーブル51へ格納する。
<他の実施形態>
以上、本発明を実施形態に基づいて説明したが、本発明は上述した実施の形態に限られず、他の様々な態様に適用可能である。
<L2を使う>
例えば、上記実施形態では、LAN4を介した通信で用いるネットワークプロトコルとしてIPを利用したが、本発明はこれに限られず、例えばイーサネット(登録商標)プロトコル等のデータリンクプロトコルを利用してもよい。これにより、IPアドレスの消費を低減できる。
<複数のLANを使う>
また、上記実施形態では、一つのLAN4のみを通信用ネットワークとしたが、本発明はこれに限られず、例えば複数のLAN4を用いてもよい。これにより、通信用ネットワークを高信頼化できる。
<データの比較を行う>
また、上記実施形態では、ローカルファイルの同一性の検査のために十分に大きな値域のハッシュ関数を用いたが、本発明はこれに限られず、例えば、ローリングハッシュを用いてローカルファイルを少量ずつ比較するようにし、さらに負荷を低減するようにしてもよい。また、ローカルファイルのデータ本体を比較することを否定するものではない。
<パリティのアップデートを行う>
また、上記実施形態では、分散ファイルを障害から保護する機能を持たないが、本発明はこれに限られず、例えば、分散ファイルごとにそのパリティデータを持つローカルファイルを備えさせ、分散ファイルのファイル断片を更新した場合には、パリティデータを併せて更新するようにし、分散ファイルを保護するようにしてもよい。分散ファイルのいずれかのファイル断片がローカルスタブまたはリモートスタブを含む場合であっても、これらの更新に併せてパリティデータを更新するようにしてもよい。
<排除ポリシー>
また、上記実施形態では、重複排除ポリシーとして、各ストレージサーバのファイルシステム利用率の平準化を設定した場合を示したが、本発明はこれに限られず、例えば、以下のような重複排除ポリシーを設定してもよい。
(1)各ストレージサーバ2のCPU利用率やメモリ利用率を平準化する。すなわち、CPU利用率やメモリ利用率の高いストレージサーバ2からは、優先的にローカルファイルを排除する。これにより、ストレージサーバ2のCPU負荷の平準化が可能である。
(2)各ストレージサーバ2が備える記憶装置24の種類に応じてファイルを蓄積する。例えば、記憶装置24が高価かつ高性能なSAS(Serial Attached SCSI)ディスクならば優先的にローカルファイルを排除する。更新頻度の低いファイルを排除することで、高性能な記憶装置をより更新頻度の高いファイルの格納に利用でき、ストレージシステム10全体の性能向上を図れる。
<メタデータストレージでもよい>
また、上記実施形態では、メタデータサーバ1とストレージサーバ2を異なるサーバとしたが、本発明はこれに限られず、メタデータサーバ1がストレージサーバ2の機能を備え、ストレージサーバ2を兼ねるようにしてもよい。これにより、装置数を低減できる。
<並列処理する>
また、上記実施形態では、メタデータサーバ1は、分散ファイルの先頭のファイル断片を持つストレージサーバ2に対して重複排除を指示し、2番目以降のファイル断片を持つストレージサーバ2は、前のファイル断片を持つストレージサーバ2から重複排除指示が伝達されるようにしたが、本発明はこれに限られず、メタデータサーバ1が、2番目以降のファイル断片を持つストレージサーバ2に対しても重複排除の実行を指示するようにしてもよい。重複排除を並列処理することで、重複排除処理の時間を短縮できる。
2 ストレージサーバ
3 計算機
4 LAN
10 ストレージシステム
Claims (16)
- 第一の記憶領域を有する、第一のファイルサーバと、
第一のファイルサーバに接続され、第二の記憶領域を有する、1以上の第二のファイルサーバと、
前記第一のファイルサーバおよび前記第二のファイルサーバに接続される1以上の計算機と、
前記第一のファイルサーバ、前記1以上の第二のファイルサーバ及び前記1以上の計算機に接続されるメタデータサーバと、
を有するストレージシステムにより実現されるファイル管理方法であって、
前記計算機は、第一のファイルに格納されるデータ列を、第一の断片データ列を含む1以上の断片データ列へ分割し、
前記第一のファイルサーバは、前記第一の断片データ列を格納する第一の断片ファイルを、前記第一の記憶領域に格納し、
前記計算機は、第二のファイルに格納されるデータ列を、第二の断片データ列を含む1以上の断片データ列へ分割し、
前記1以上の第二のファイルサーバは、前記第二の断片データ列を格納する第二の断片ファイルを前記第二の記憶領域に格納し、
前記メタデータサーバは、一定期間更新されていないファイルの特徴情報に一致する複数のファイルで構成される類似グループに含まれるファイルの数が、既定数となった場合に、前記類似グループに含まれる前記複数のファイルのレイアウトを含む重複排除処理の実行指示を、前記類似グループに含まれるファイルを分割して格納する複数のファイルサーバに送信し、
前記第一のファイルサーバは、
前記類似グループに含まれるファイルを分割して格納する前記複数のファイルサーバのうちの任意の1のファイルサーバであり、
前記重複排除処理の実行指示を受信し、
前記第一の断片データ列から第一の特徴情報を算出し、
前記1以上の第二のファイルサーバは、
前記類似グループに含まれるファイルを分割して格納する前記複数のファイルサーバのうちの、第一のファイルサーバを除くファイルサーバであり、
前記重複排除処理の実行指示を受信し、
前記複数のファイルのレイアウトから前記第一のファイルを格納する前記第一のファイルサーバを、コーディネータの役割をになうファイルサーバであると特定し、
前記第二の断片データ列から第二特徴情報を算出し、
前記第二の特徴情報を前記第一のファイルサーバへ送信し、
前記第一のファイルサーバは、
前記1以上の第二のファイルサーバから1以上の第二の特徴情報を受信し、
前記第一のファイルサーバ及び前記1以上の第二のファイルサーバのうち、前記第一の特徴情報と前記1以上の第二の特徴情報とで一致する特徴情報を有する2以上のファイルサーバをグループ化し、グループ化された2以上のファイルサーバから、前記第一または第二の断片データ列のうち削除対象の断片データ列以外の断片データ列を有するファイルサーバである代表サーバを決定し、
前記代表サーバの識別情報を前記代表サーバ以外の前記第二のファイルサーバへ送信し、
前記第一のファイルサーバは、
自身が前記代表サーバ以外のファイルサーバならば、前記第一の断片データ列を削除し、
前記第一の断片ファイルを、前記代表サーバが有する第二の断片データ列を指示するスタブへ変更し、
第二のファイルサーバは、
自身が前記代表サーバ以外のファイルサーバならば、前記第二の断片データ列を削除し、
前記第二の断片ファイルを、前記代表サーバが有する第一又は第二の断片データ列を指示するスタブへ変更することを特徴とする
ファイル管理方法。 - 請求項1に記載のファイル管理方法であって、
前記第一のファイルサーバは、前記第一の断片ファイルを格納する第一の記憶領域に、第一のファイルシステムを構成し、
前記1以上の第二のファイルサーバは、前記第二の断片ファイルを格納する第二の記憶領域に、第二のファイルシステムを構成し、
前記第一のファイルサーバは、前記第二のファイルシステムの容量利用率を前記1以上の第二のファイルサーバから取得し、
前記第一のファイルサーバは、前記第一のファイルシステム及び一以上の第二のファイルシステムの容量利用率に応じて、前記容量利用率が最も少ないファイルシステム以外のファイルシステムが有する第一又は第二の断片データ列を前記削除対象の断片データ列として決定することを特徴とする
ファイル管理方法。 - 請求項1に記載のファイル管理方法であって、
前記第一のファイルサーバは、第一のプロセッサを有し、
前記1以上の第二のファイルサーバは、第二のプロセッサを有し、
前記第一のファイルサーバは、前記第二のプロセッサの利用率を前記1以上の第二のファイルサーバから取得し、
前記第一のファイルサーバは、前記第一及び第二のプロセッサの利用率に応じて、前記プロセッサの利用率が少ないファイルサーバ以外のファイルサーバが有する第一又は第二の断片データ列を前記削除対象の断片データ列として決定することを特徴とする
ファイル管理方法。 - 請求項2又は3に記載のファイル管理方法であって、
前記第一の断片データ列が、削除対象の断片データ列として削除された場合、
前記第一のファイルサーバは、前記計算機より前記スタブに対してデータの読み出し要求を受けた場合には、前記計算機に対して、前記第二の断片データ列が格納されている、前記1以上の第二のファイルサーバの識別情報を応答することを特徴とする
ファイル管理方法。 - 請求項4に記載のファイル管理方法であって、
前記第一のファイルサーバは、計算機より前記スタブに対してデータの書き込み要求を受けた場合には、前記スタブを第三の断片ファイルへ変更し、前記第二の断片データ列の複製を前記第三の断片ファイルへ格納し、前記第三の断片ファイルに、前記計算機より書き込みを要求された前記データを格納することを特徴とする
ファイル管理方法。 - 請求項5に記載のファイル管理方法であって、
前記1以上の第二のファイルサーバは、計算機より前記第二の断片ファイルに対してデータの書き込み要求を受けた場合には、前記第二の断片ファイルを第四の断片ファイルへ複製し、前記第二の断片ファイルに前記計算機より書き込みを要求された前記データを格納することを特徴とする
ファイル管理方法。 - 請求項6に記載のファイル管理方法であって、
前記第一のファイルと前記第二のファイルは、前記1以上の断片データ列の内、特定の1以上の断片データ列から算出されるハッシュ値が同一であることを特徴とする
ファイル管理方法。 - 請求項7に記載のファイル管理方法であって、
前記第一のファイルと前記第二のファイルは、サイズが同一であることを特徴とする
ファイル管理方法。 - 第一の記憶領域を有する、第一のファイルサーバと、
第一のファイルサーバに接続され、第二の記憶領域を有する、1以上の第二のファイルサーバと、
前記第一のファイルサーバおよび前記1以上の第二のファイルサーバに接続される1以上の計算機と、
前記第一のファイルサーバ、前記1以上の第二のファイルサーバ及び前記1以上の計算機に接続されるメタデータサーバと、
を有するストレージシステムにおいて、
前記計算機は、第一のファイルに格納されるデータ列を、第一の断片データ列を含む1以上の断片データ列へ分割し、
前記第一のファイルサーバは、前記第一の断片データ列を格納する第一の断片ファイルを、前記第一の記憶領域に格納し、
前記計算機は、第二のファイルに格納されるデータ列を、第二の断片データ列を含む1以上の断片データ列へ分割し、
前記1以上の第二のファイルサーバは、前記第二の断片データ列を格納する第二の断片ファイルを前記第二の記憶領域に格納し、
前記メタデータサーバは、一定期間更新されていないファイルの特徴情報に一致する複数のファイルで構成される類似グループに含まれるファイルの数が、既定数となった場合に、前記類似グループに含まれる前記複数のファイルのレイアウトを含む重複排除処理の実行指示を、前記類似グループに含まれるファイルを分割して格納する複数のファイルサーバに送信し、
前記第一のファイルサーバは、
前記類似グループに含まれるファイルを分割して格納する前記複数のファイルサーバのうちの任意の1のファイルサーバであり、
前記重複排除処理の実行指示を受信し、
前記第一の断片データ列から第一の特徴情報を算出し、
前記1以上の第二のファイルサーバは、
前記類似グループに含まれるファイルを分割して格納する前記複数のファイルサーバのうちの、第一のファイルサーバを除くファイルサーバであり、
前記重複排除処理の実行指示を受信し、
前記複数のファイルのレイアウトから前記第一のファイルを格納する前記第一のファイルサーバを、コーディネータの役割をになうファイルサーバであると特定し、
前記第二の断片データ列から第二特徴情報を算出し、
前記第二の特徴情報を前記第一のファイルサーバへ送信し、
前記第一のファイルサーバは、
前記1以上の第二のファイルサーバから1以上の第二の特徴情報を受信し、
前記第一のファイルサーバ及び前記1以上の第二のファイルサーバのうち、前記第一の特徴情報と前記1以上の第二の特徴情報とで一致する特徴情報を有する2以上のファイルサーバをグループ化し、グループ化された2以上のファイルサーバから、前記第一または第二の断片データ列のうち削除対象の断片データ列以外の断片データ列を有するファイルサーバである代表サーバを決定し、
前記代表サーバの識別情報を前記代表サーバ以外の前記第二のファイルサーバへ送信し、
前記第一のファイルサーバは、
自身が前記代表サーバ以外のファイルサーバならば、前記第一の断片データ列を削除し、
前記第一の断片ファイルを、前記代表サーバが有する第二の断片データ列を指示するスタブへ変更し、
第二のファイルサーバは、
自身が前記代表サーバ以外のファイルサーバならば、前記第二の断片データ列を削除し、
前記第二の断片ファイルを、前記代表サーバが有する第一又は第二の断片データ列を指示するスタブへ変更することを特徴とする
ストレージシステム。 - 請求項9に記載のストレージシステムであって、
前記第一のファイルサーバは、前記第一の断片ファイルを格納する第一の記憶領域に、第一のファイルシステムを構成し、
前記1以上の第二のファイルサーバは、前記第二の断片ファイルを格納する第二の記憶領域に、第二のファイルシステム構成し、
前記第一のファイルサーバは、前記第二のファイルシステムの容量利用率を前記1以上の第二のファイルサーバから取得し、
前記第一のファイルサーバは、前記第一のファイルシステム及び一以上の第二のファイルシステムの容量利用率に応じて、前記容量利用率が最も少ないファイルシステム以外のファイルシステムが有する第一又は第二の断片データ列を前記削除対象の断片データ列として決定することを特徴とする
ストレージシステム。 - 請求項9に記載のストレージシステムであって、
前記第一のファイルサーバは、第一のプロセッサを有し、
前記1以上の第二のファイルサーバは、第二のプロセッサを有し、
前記第一のファイルサーバは、前記第二のプロセッサの利用率を前記1以上の第二のファイルサーバから取得し、
前記第一のファイルサーバは、前記第一及び第二のプロセッサの利用率に応じて、前記プロセッサの利用率が少ないファイルサーバ以外のファイルサーバが有する第一又は第二の断片データ列を前記削除対象の断片データ列として決定することを特徴とする
ストレージシステム。 - 請求項10又は11に記載のストレージシステムであって、
前記第一の断片データ列が、削除対象断片データ列として削除された場合、
前記第一のファイルサーバは、前記計算機より前記スタブに対してデータの読み出し要求を受けた場合には、前記計算機に対して、前記第二の断片データ列が格納されている、前記1以上の第二のファイルサーバの識別情報を応答することを特徴とする
ストレージシステム。 - 請求項12に記載のストレージシステムであって、
前記第一のファイルサーバは、計算機より前記スタブに対してデータの書き込み要求を受けた場合には、前記スタブを第三の断片ファイルへ変更し、前記第二の断片データ列の複製を前記第三の断片ファイルへ格納し、前記第三の断片ファイルに、前記計算機より書き込みを要求された前記データを格納することを特徴とする
ストレージシステム。 - 請求項13に記載のストレージシステムであって、
前記1以上の第二のファイルサーバは、計算機より前記第二の断片ファイルに対してデータの書き込み要求を受けた場合には、前記第二の断片ファイルを第四の断片ファイルへ複製し、前記第二の断片ファイルに前記計算機より書き込みを要求された前記データを格納することを特徴とする
ストレージシステム。 - 請求項14に記載のストレージシステムであって、
前記第一のファイルと前記第二のファイルは、前記1以上の断片データ列の内、特定の1以上の断片データ列から算出されるハッシュ値が同一であることを特徴とする
ストレージシステム。 - 請求項15に記載のストレージシステムであって、
前記第一のファイルと前記第二のファイルは、サイズが同一であることを特徴とする
ストレージシステム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009214007A JP5595701B2 (ja) | 2009-09-16 | 2009-09-16 | ファイル管理方法及びストレージシステム |
| US12/622,963 US8112463B2 (en) | 2009-09-16 | 2009-11-20 | File management method and storage system |
| US13/348,292 US8307019B2 (en) | 2009-09-16 | 2012-01-11 | File management method and storage system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009214007A JP5595701B2 (ja) | 2009-09-16 | 2009-09-16 | ファイル管理方法及びストレージシステム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011065314A JP2011065314A (ja) | 2011-03-31 |
| JP5595701B2 true JP5595701B2 (ja) | 2014-09-24 |
Family
ID=43731541
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009214007A Expired - Fee Related JP5595701B2 (ja) | 2009-09-16 | 2009-09-16 | ファイル管理方法及びストレージシステム |
Country Status (2)
| Country | Link |
|---|---|
| US (2) | US8112463B2 (ja) |
| JP (1) | JP5595701B2 (ja) |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9135268B2 (en) * | 2009-12-30 | 2015-09-15 | Symantec Corporation | Locating the latest version of replicated data files |
| US8443231B2 (en) | 2010-04-12 | 2013-05-14 | Symantec Corporation | Updating a list of quorum disks |
| US8244992B2 (en) * | 2010-05-24 | 2012-08-14 | Spackman Stephen P | Policy based data retrieval performance for deduplicated data |
| US9489133B2 (en) | 2011-11-30 | 2016-11-08 | International Business Machines Corporation | Optimizing migration/copy of de-duplicated data |
| US20130218847A1 (en) | 2012-02-16 | 2013-08-22 | Hitachi, Ltd., | File server apparatus, information system, and method for controlling file server apparatus |
| JP5929326B2 (ja) * | 2012-03-02 | 2016-06-01 | 日本電気株式会社 | ストレージシステム |
| US20130232124A1 (en) * | 2012-03-05 | 2013-09-05 | Blaine D. Gaither | Deduplicating a file system |
| JPWO2013145222A1 (ja) * | 2012-03-29 | 2015-08-03 | 富士通株式会社 | 情報処理装置およびデータ保存処理プログラム |
| US8776236B2 (en) * | 2012-04-11 | 2014-07-08 | Northrop Grumman Systems Corporation | System and method for providing storage device-based advanced persistent threat (APT) protection |
| US9064106B2 (en) * | 2012-04-25 | 2015-06-23 | Hitachi, Ltd. | Method and apparatus to keep consistency of ACLs among a meta data server and data servers |
| US9177028B2 (en) | 2012-04-30 | 2015-11-03 | International Business Machines Corporation | Deduplicating storage with enhanced frequent-block detection |
| US9659060B2 (en) | 2012-04-30 | 2017-05-23 | International Business Machines Corporation | Enhancing performance-cost ratio of a primary storage adaptive data reduction system |
| US8898121B2 (en) | 2012-05-29 | 2014-11-25 | International Business Machines Corporation | Merging entries in a deduplication index |
| WO2013187901A2 (en) * | 2012-06-14 | 2013-12-19 | Empire Technology Development Llc | Data deduplication management |
| US9092446B2 (en) * | 2012-11-29 | 2015-07-28 | Hitachi, Ltd. | Storage system and file management method |
| GB2509504A (en) | 2013-01-04 | 2014-07-09 | Ibm | Accessing de-duplicated data files stored across networked servers |
| US8938417B2 (en) | 2013-02-22 | 2015-01-20 | International Business Machines Corporation | Integrity checking and selective deduplication based on network parameters |
| US10191934B2 (en) | 2013-05-13 | 2019-01-29 | Hitachi, Ltd. | De-duplication system and method thereof |
| US9600201B2 (en) | 2014-03-27 | 2017-03-21 | Hitachi, Ltd. | Storage system and method for deduplicating data |
| WO2016095152A1 (en) * | 2014-12-18 | 2016-06-23 | Nokia Technologies Oy | De-duplication of encrypted data |
| US20160224993A1 (en) * | 2015-02-03 | 2016-08-04 | Bank Of America Corporation | System for determining relationships between entities |
| TWI557673B (zh) * | 2015-05-06 | 2016-11-11 | 張勃鈞 | 將具有相同運動目的之人連結的方法及其互動網路平台 |
| JP6113816B1 (ja) * | 2015-11-18 | 2017-04-12 | 株式会社東芝 | 情報処理システム、情報処理装置、及びプログラム |
| CN105335530B (zh) * | 2015-12-11 | 2018-10-19 | 上海爱数信息技术股份有限公司 | 一种提升大数据块重复数据删除性能的方法 |
| WO2017149592A1 (ja) * | 2016-02-29 | 2017-09-08 | 株式会社日立製作所 | ストレージ装置 |
| US10725970B2 (en) * | 2017-10-05 | 2020-07-28 | Spectra Logic Corporation | Block storage device with optional deduplication |
| WO2020026036A1 (en) | 2018-07-31 | 2020-02-06 | Marvell World Trade Ltd. | Metadata generation at the storage edge |
| CN109726212A (zh) * | 2018-12-29 | 2019-05-07 | 杭州宏杉科技股份有限公司 | 数据存储系统及方法 |
| KR20210026143A (ko) | 2019-08-29 | 2021-03-10 | 삼성전자주식회사 | 파일 시스템에 저장된 파일 또는 디렉토리의 크기를 획득하기 위한 전자 장치 및 방법 |
| KR20230079633A (ko) * | 2021-11-29 | 2023-06-07 | 성균관대학교산학협력단 | 파일 단편화 제거 방법 및 그 장치 |
| CN116107979B (zh) * | 2023-04-14 | 2023-06-27 | 大熊集团有限公司 | 一种数据分布式读取方法及系统 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5493671A (en) * | 1993-06-04 | 1996-02-20 | Marcam Corporation | Method and apparatus for conversion of database data into a different format on a field by field basis using a table of conversion procedures |
| JPH10301818A (ja) * | 1997-04-28 | 1998-11-13 | Matsushita Electric Ind Co Ltd | ファイルシステム及びその管理方法 |
| JP2000207370A (ja) * | 1999-01-20 | 2000-07-28 | Matsushita Electric Ind Co Ltd | 分散ファイル管理装置及び分散ファイル管理システム |
| US6704730B2 (en) * | 2000-02-18 | 2004-03-09 | Avamar Technologies, Inc. | Hash file system and method for use in a commonality factoring system |
| JP2005165729A (ja) * | 2003-12-03 | 2005-06-23 | Mitsukawa Yoshikazu | 情報管理システムと、情報管理システムに用いる情報管理装置および記憶装置 |
| JP4671738B2 (ja) * | 2005-04-01 | 2011-04-20 | 株式会社日立製作所 | ストレージシステム及び記憶領域割当て方法 |
| US7506005B2 (en) * | 2005-07-14 | 2009-03-17 | Microsoft Corporation | Moving data from file on storage volume to alternate location to free space |
| JP4749266B2 (ja) * | 2006-07-27 | 2011-08-17 | 株式会社日立製作所 | 情報資源の重複を省いたバックアップ制御装置及び方法 |
| US8214517B2 (en) * | 2006-12-01 | 2012-07-03 | Nec Laboratories America, Inc. | Methods and systems for quick and efficient data management and/or processing |
| JP2008225740A (ja) * | 2007-03-12 | 2008-09-25 | Konica Minolta Holdings Inc | 情報処理装置および情報処理方法 |
| JP2009080671A (ja) * | 2007-09-26 | 2009-04-16 | Hitachi Ltd | 計算機システム、管理計算機、及びファイル管理方法 |
| US8140746B2 (en) * | 2007-12-14 | 2012-03-20 | Spansion Llc | Intelligent memory data management |
-
2009
- 2009-09-16 JP JP2009214007A patent/JP5595701B2/ja not_active Expired - Fee Related
- 2009-11-20 US US12/622,963 patent/US8112463B2/en not_active Expired - Fee Related
-
2012
- 2012-01-11 US US13/348,292 patent/US8307019B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20110066666A1 (en) | 2011-03-17 |
| JP2011065314A (ja) | 2011-03-31 |
| US8307019B2 (en) | 2012-11-06 |
| US8112463B2 (en) | 2012-02-07 |
| US20120110045A1 (en) | 2012-05-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5595701B2 (ja) | ファイル管理方法及びストレージシステム | |
| US10853274B2 (en) | Primary data storage system with data tiering | |
| US10891054B2 (en) | Primary data storage system with quality of service | |
| US20200019516A1 (en) | Primary Data Storage System with Staged Deduplication | |
| US9043287B2 (en) | Deduplication in an extent-based architecture | |
| US20230013281A1 (en) | Storage space optimization in a system with varying data redundancy schemes | |
| US10146786B2 (en) | Managing deduplication in a data storage system using a Bloomier filter data dictionary | |
| US9842114B2 (en) | Peer to peer network write deduplication | |
| JP5320557B2 (ja) | ストレージシステム | |
| US20130290248A1 (en) | File storage system and file cloning method | |
| US8661055B2 (en) | File server system and storage control method | |
| US10929042B2 (en) | Data storage system, process, and computer program for de-duplication of distributed data in a scalable cluster system | |
| US20180074903A1 (en) | Processing access requests in a dispersed storage network | |
| WO2015118865A1 (ja) | 情報処理装置、情報処理システム及びデータアクセス方法 | |
| US20210248107A1 (en) | Kv storage device and method of using kv storage device to provide file system | |
| US9015124B2 (en) | Replication system and method of rebuilding replication configuration | |
| US11947419B2 (en) | Storage device with data deduplication, operation method of storage device, and operation method of storage server | |
| WO2021187194A1 (ja) | 分散処理システム、分散処理システムの制御方法、及び、分散処理システムの制御装置 | |
| WO2021142768A1 (zh) | 一种文件系统的克隆方法及装置 | |
| KR101589122B1 (ko) | 네트워크 분산 파일 시스템 기반 iSCSI 스토리지 시스템에서의 장애 복구 방법 및 시스템 | |
| WO2015198371A1 (ja) | ストレージシステム及び記憶制御方法 | |
| WO2014109053A1 (ja) | ファイルサーバ、ストレージ装置及びデータ管理方法 | |
| JP6683160B2 (ja) | ストレージシステム、および通信方法 | |
| JP2019008418A (ja) | データ転送装置およびデータ転送方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20120123 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130606 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130702 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20130807 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130828 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20130924 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20131210 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140207 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140708 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140806 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5595701 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |