JP5595112B2 - robot - Google Patents
robot Download PDFInfo
- Publication number
- JP5595112B2 JP5595112B2 JP2010109213A JP2010109213A JP5595112B2 JP 5595112 B2 JP5595112 B2 JP 5595112B2 JP 2010109213 A JP2010109213 A JP 2010109213A JP 2010109213 A JP2010109213 A JP 2010109213A JP 5595112 B2 JP5595112 B2 JP 5595112B2
- Authority
- JP
- Japan
- Prior art keywords
- phrase
- unit
- angle
- sound source
- estimated
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images








Description
本発明は、ロボットに関し、特に、頭部に複数のマイクロフォンが設置され、全方向から音を取得して、音源方向を推定するロボットに関する。 The present invention relates to a robot, and more particularly, to a robot in which a plurality of microphones are installed in a head and a sound source direction is estimated by acquiring sound from all directions.
従来のロボットは、回動可能な頭部と、音を360度全方向から取得できるように頭部に複数のマイクロフォンとを備え、発話者がいる方向を推定することが開示されている。
しかしながら、従来のロボットは、雑音(ノイズ音)を出力してしまうノイズ発生源となる装置を自身が備えている場合や、自身が設置された場所の近傍にノイズ発生源がある場合などにおいて、発話者の音声だけでなく、そのノイズ発生源から出力されたノイズ音を取得してしまう。そのため、ノイズ音の騒音レベルが高い場合に、ロボットは、ノイズ発生源のある方向を発話者がいる方向として推定してしまい、本来の発話者がいる方向(推定すべき音源方向)を推定できないという問題点があった。
特にロボットは、自身を駆動するための動力機器やコンピュータなどを冷やすための冷却ファンを有し、この冷却ファンが回転する音の騒音レベルが高いため、推定すべき音源方向を推定できないという問題点があった。
It is disclosed that a conventional robot includes a rotatable head and a plurality of microphones on the head so that sound can be acquired from all directions of 360 degrees, and estimates the direction in which the speaker is present.
However, in the case where the conventional robot itself has a device that becomes a noise generation source that outputs noise (noise sound), or when there is a noise generation source in the vicinity of the place where the robot is installed, In addition to the voice of the speaker, the noise sound output from the noise source is acquired. Therefore, when the noise level of the noise sound is high, the robot estimates the direction in which the noise is generated as the direction in which the speaker is present, and cannot estimate the direction in which the original speaker is present (the sound source direction to be estimated). There was a problem.
In particular, a robot has a cooling fan for cooling a power device or a computer for driving itself, and the noise level of the sound of rotation of the cooling fan is high, so that the sound source direction to be estimated cannot be estimated. was there.
そのため、特許文献1の移動ロボットは、音声認識結果に基づいて、自身が備えるノイズ発生源(冷却ファン)から出力されるノイズ音の騒音レベルが低くなるように、冷却ファンの回転数を減らすといった、ノイズ発生源となる装置自体を制御する技術や、発話者に再度の発声を依頼する技術が開示されている。
For this reason, the mobile robot of
しかしながら、従来の回動可能な頭部に音声入力部を備えるロボットは、発話者がいる方向(推定すべき音源方向)を推定するために、ノイズ音を出力してしまうノイズ発生源となる装置を制御しなければならないという問題点があった。 However, a conventional robot having a voice input unit on a rotatable head is a noise source that outputs a noise sound in order to estimate the direction in which the speaker is present (the sound source direction to be estimated). There was a problem that had to be controlled.
本発明は、以上のような問題を解決するためになされたものであり、回動可能な頭部に備えられた音声入力部に、360度全方向から入力される音声から、ノイズ音が出力される方向を除外して、発話者がいる方向(推定すべき音源方向)を推定するロボットを提供することを課題とする。 The present invention has been made to solve the above-described problems, and noise sound is output from a sound input from 360 degrees in all directions to a sound input unit provided in a rotatable head. It is an object of the present invention to provide a robot that estimates a direction in which a speaker is present (a sound source direction to be estimated) by excluding a direction in which the speaker is present.
前記課題を解決するために、本発明の請求項1に記載のロボットは、胴部と、前記胴部の上面で回動可能に支持軸に支持される頭部と、前記頭部が回動する回動方向に前記支持軸を中心に所定の角度で離間して前記頭部に配設され、入力された音声を音声データに変換して出力する3以上の音声入力部と、前記音声入力部それぞれから入力された前記音声データに、信号分解アルゴリズムを用いて、前記頭部の向きを基準とした360度全方向からの音圧値を示す全方向音圧成分データを生成する音声データ処理部と、前記胴部の向きを基準とした前記頭部の回動角度を測定する回動角測定部と、前記胴部の向きを基準とした音源として推定しない方向の範囲が予め設定された除外角度範囲が記憶された記憶部と、音源方向を推定する音源方向推定部とを備えるロボットにおいて、前記音源方向推定部は、測定された回動角度を用いて、前記全方向音圧成分データから前記除外角度範囲内にあるデータを除去して有効方向音圧成分データを生成するフィルタ部を備えることを特徴とする。 In order to solve the above-mentioned problem, a robot according to a first aspect of the present invention includes a torso, a head supported by a support shaft so as to be rotatable on an upper surface of the torso, and the head is turned. Three or more voice input units arranged on the head and spaced apart at a predetermined angle around the support shaft in the rotating direction to convert the input voice to voice data, and the voice input Audio data processing for generating omnidirectional sound pressure component data indicating sound pressure values from 360 degrees in all directions with reference to the direction of the head, using the signal decomposition algorithm for the sound data input from each of the units A rotation angle measuring unit that measures the rotation angle of the head with respect to the direction of the body, and a range of directions that are not estimated as a sound source based on the direction of the body A storage unit storing the excluded angle range and a sound source method for estimating the sound source direction In the robot including the estimation unit, the sound source direction estimation unit removes data within the excluded angle range from the omnidirectional sound pressure component data by using the measured rotation angle, and an effective direction sound pressure component A filter unit for generating data is provided.
かかる構成によれば、ロボットは、音声入力部が設置された頭部の回動角度に係わらず、胴部の向きを基準とした除外角度範囲で示す方向からの音(例えば、ロボットの背面でファンが回転することで出力されるノイズ音)を除去することができる。
また、ロボットは、除外角度範囲外から入力される有効方向音圧成分データを取得することができる。
According to such a configuration, the robot can generate sound from the direction indicated by the exclusion angle range based on the direction of the torso (for example, on the back of the robot) regardless of the rotation angle of the head on which the voice input unit is installed. Noise noise output by the rotation of the fan can be removed.
Also, the robot can acquire effective direction sound pressure component data input from outside the excluded angle range.
また、請求項2に記載のロボットは、請求項1に記載のロボットにおいて、前記記憶部は、前記支持軸を中心とした前記音声入力部それぞれの方向を示す音声入力角度が記憶され、前記音源方向推定部が、前記フィルタ部が生成した前記有効方向音圧成分データから、直前の角度の音圧値と直後の角度の音圧値との双方より大きい音圧値の角度を少なくとも1以上抽出する角度抽出部を有し、前記音声入力部が出力した音声データから、前記音声入力角度に基づき、前記角度抽出部が抽出した推定音源角度それぞれの方向から入力された音声データを分離抽出する推定音源分離部と、前記推定音源分離部に抽出された推定音源方向音声データに音声認識を行い、複数の仮説フレーズを生成し、各仮説フレーズの正しさを示す音声認識尤度を算出する音声認識部と、前記仮説フレーズと、前記仮説フレーズに係る前記推定音源方向音声データが入力される方向との関係の正しさを示す音声入力方向適合度で、前記仮説フレーズに係る前記音声認識尤度を重み付けて、前記仮説フレーズそれぞれのフレーズ確信度を算出し、前記算出したフレーズ確信度に基づいて音源方向を推定するフレーズ確信度算出部とを備えることを特徴とする。
The robot according to
かかる構成によれば、ロボットは、音声認識部が行った音声認識結果と、推定音源分離部が分離抽出した推定音源方向音声データが入力される方向との関係の正しさを音声入力方向適合度で示すことができる。
また、ロボットは、音声認識部における音声認識結果の正しさを示す音声認識尤度を、前記音声入力方向適合度で重み付けすることで、音声認識結果の正しさと、その音声が入力された方向の正しさとの双方を評価する値を算出することができる。
According to this configuration, the robot determines the correctness of the relationship between the speech recognition result performed by the speech recognition unit and the direction in which the estimated sound source direction speech data separated and extracted by the estimated sound source separation unit is input. Can be shown.
In addition, the robot weights the speech recognition likelihood indicating the correctness of the speech recognition result in the speech recognition unit by the speech input direction suitability, so that the correctness of the speech recognition result and the direction in which the speech is input It is possible to calculate a value that evaluates both the correctness and the correctness.
また、請求項3に記載のロボットは、請求項2に記載のロボットにおいて、前記フレーズ確信度算出部は、前記仮説フレーズそれぞれのフレーズ確信度から、最大のフレーズ確信度を抽出し、そのフレーズ確信度に係る仮説フレーズを生成した前記推定音源方向音声データに係る前記推定音源角度を音源方向に推定することを特徴とする。
The robot according to
かかる構成によれば、ロボットは、フレーズ確信度が最大となる音声認識結果に係る推定音源角度を音源方向とすることができる。 According to such a configuration, the robot can set the estimated sound source angle related to the speech recognition result that maximizes the phrase certainty as the sound source direction.
また、請求項4に記載のロボットは、請求項3に記載のロボットが、フレーズ記憶部と、フレーズ決定部とを備え、前記フレーズ記憶部は、予め入力され得るフレーズを集めた複数のフレーズパターンと、前記支持軸を中心とし前記頭部の向きを基準とした方向を示す方向角度値パターンと、前記フレーズパターンが前記方向角度値パターンの方向から入力される正しさを示す前記音声入力方向適合度との3つが対応付けられて記憶され、前記フレーズ確信度算出部は、前記音声認識部に生成された複数の仮説フレーズとその音声認識尤度とを取得すると共に、前記仮説フレーズおよび前記角度抽出部が抽出した推定音源角度を用いて、前記フレーズ記憶部に記憶された前記フレーズパターンおよび前記方向角度値パターンに対応付けられた前記音声入力方向適合度を抽出し、その音声入力方向適合度で前記音声認識尤度を重み付けして、フレーズ確信度を算出し、前記フレーズ決定部は、前記フレーズ確信度算出部が抽出した前記最大のフレーズ確信度に係る仮説フレーズを、当該仮説フレーズに係る前記フレーズ確信度算出部が推定した音源方向からの音声を音声認識したフレーズとすることを特徴とする。
According to a fourth aspect of the present invention, there is provided a robot according to the third aspect, wherein the robot according to the third aspect includes a phrase storage unit and a phrase determination unit, and the phrase storage unit collects a plurality of phrase patterns in which phrases that can be input in advance are collected. And a direction angle value pattern indicating a direction centered on the support shaft and based on the direction of the head, and the voice input direction adaptation indicating the correctness of the phrase pattern being input from the direction of the direction angle value pattern Are stored in association with each other, and the phrase certainty calculation unit acquires a plurality of hypothesis phrases generated by the speech recognition unit and the speech recognition likelihood thereof, and the hypothesis phrase and the using the estimated sound source angle angle extracting unit has extracted, associated with the phrase pattern and the direction angle value patterns stored in the phrase storage unit Serial extract audio input direction fit, by weighting the speech recognition likelihoods that the speech input direction fitness, calculates the phrase confidence, the phrase determiner, the phrase confidence factor computing unit has extracted the the hypothesis phrase according to the maximum phrases confidence, characterized by the phrases and to Turkey recognized speech sound from the sound source direction in which the phrase confidence factor computing unit is estimated according to the hypothesis phrase.
かかる構成によれば、ロボットは、角度抽出部が取得した推定音声角度と、音声認識部が音声認識して生成した仮説フレーズとの関係の正しさを音声入力方向適合度で示すことができる。
また、ロボットは、音声認識部が生成した仮説フレーズの正しさを示す音声認識尤度を、その仮説フレーズが入力される方向の正しさ音声入力方向適合度で重み付けすることで、仮説フレーズの音声認識結果の正しさを示す判断基準となるフレーズ確信度を算出することができる。
そして、ロボットは、フレーズ確信度が最大値となる仮説フレーズを正しいフレーズとすることができる。
さらに、ロボットは、音声認識尤度の値が大きくても、音声入力方向適合度の小さい仮説フレーズを、除去することができる。
According to such a configuration, the robot can indicate the correctness of the relationship between the estimated speech angle acquired by the angle extraction unit and the hypothesis phrase generated by speech recognition by the speech recognition unit as the speech input direction suitability.
In addition, the robot weights the speech recognition likelihood indicating the correctness of the hypothetical phrase generated by the speech recognition unit by the correctness of the direction in which the hypothetical phrase is input, and the speech input direction suitability, so that It is possible to calculate a phrase certainty factor that serves as a determination criterion indicating the correctness of the recognition result.
Then, the robot can set the hypothesis phrase having the maximum phrase certainty as a correct phrase.
Furthermore, even if the value of the speech recognition likelihood is large, the robot can remove a hypothesis phrase having a low speech input direction suitability.
また、請求項5に記載のロボットは、請求項4に記載のロボットにおいて、前記フレーズ記憶部は、前記フレーズパターン毎の、前記方向角度値パターンと前記音声入力方向適合度とからなる2次元のヒストグラムを記憶することを特徴とする。
Further, the robot according to
かかる構成によれば、ロボットは、フレーズ確信度を、フレーズパターン毎の、方向角度値パターンと前記音声認識尤度とからなる2次元のヒストグラムから抽出することができる。 According to this configuration, the robot can extract the phrase certainty factor from a two-dimensional histogram composed of the direction angle value pattern and the speech recognition likelihood for each phrase pattern.
また、請求項6に記載のロボットは、請求項2ないし請求項5のいずれか1項に記載されたロボットにおいて、前記角度抽出部が抽出した推定音源角度に至るまで、前記頭部に回動させる行動制御部を備えることを特徴とする。 A robot according to a sixth aspect of the present invention is the robot according to any one of the second to fifth aspects, wherein the robot rotates to the head until the estimated sound source angle extracted by the angle extraction unit is reached. The behavior control part to be provided is provided.
かかる構成によれば、ロボットは、呼びかけられた方向に頭部を回動することができる。 With this configuration, the robot can turn the head in the called direction.
請求項1の発明によれば、音源として推定しない方向の範囲(除外角度範囲)を予め記憶部に記憶しておくことで、回動する頭部に音声入力部が備えられ、ノイズ発生源と音声入力部との相対位置が変化しても、ロボットは、有効方向音圧成分データの音圧成分値から、除外角度範囲外に位置する発話者(音源)が発声した方向を推定することができる。 According to the first aspect of the present invention, the range of the direction not to be estimated as the sound source (excluded angle range) is stored in the storage unit in advance, whereby the rotating head is provided with the voice input unit, and the noise generation source Even if the relative position to the voice input unit changes, the robot can estimate the direction in which a speaker (sound source) located outside the excluded angle range uttered from the sound pressure component value of the effective direction sound pressure component data. it can.
また、請求項1の発明によれば、ノイズ発生源の位置に基づいて除外角度範囲を設定することで、そのノイズ発生源からの音を除去することができるため、ノイズ発生源となる装置を制御する必要がない。
Further, according to the invention of
請求項2に記載の発明によれば、ロボットは、音声認識結果の正しさと、その音声が入力された方向の正しさとの双方を評価する値を求めることができ、その算出値が大きいほど、音声認識結果が正しいという確率が高いことを示すため、音声認識の誤認識率を低減することができる。また、例えば、認識率の正誤に基づく基準値を設けることで、その基準値以上となる算出値の方向が、音源方向であると推定することもできる。 According to the second aspect of the invention, the robot can obtain a value for evaluating both the correctness of the speech recognition result and the correctness of the direction in which the speech is input, and the calculated value is large. The higher the probability that the speech recognition result is correct, the higher the recognition rate of speech recognition can be reduced. For example, by providing a reference value based on whether the recognition rate is correct or incorrect, it is possible to estimate that the direction of the calculated value that is equal to or greater than the reference value is the sound source direction.
請求項3に記載の発明によれば、ロボットは、複数の算出値から最大値を抽出することで、音声認識結果が正しいという確率が最高の音声認識結果を取得することができるため、さらに音声認識の誤認識率を低減することができる。 According to the third aspect of the present invention, the robot can acquire the voice recognition result with the highest probability that the voice recognition result is correct by extracting the maximum value from the plurality of calculated values. The recognition error rate of recognition can be reduced.
請求項4および請求項5に記載の発明によれば、ロボットは、音声認識結果の正しさを示す判断基準となるフレーズ確信度が最大値となる仮説フレーズを、音源方向からの音声を音声認識したフレーズとすることで、誤認識率を低減することができる。 According to the fourth and fifth aspects of the present invention, the robot recognizes the hypothesis phrase having the maximum phrase certainty as a determination criterion indicating the correctness of the speech recognition result, and the speech from the sound source direction. By using the phrase, the recognition error rate can be reduced.
請求項6に記載の発明によれば、ロボットは、呼びかけた発話者のいる方向に顔面を向けることができる。 According to the sixth aspect of the present invention, the robot can turn its face in the direction of the calling speaker.
以下、図面を参照して、本発明の実施の形態(以下、「本実施形態」と称する)に係るロボットについて説明する。なお、各図は、本発明を十分に理解できる程度に、概略的に示してあるに過ぎない。よって、本発明は、図示例のみに限定されるものではない。また、各図において、共通する構成要素や同様な構成要素については、同一の符号を付し、それらの重複する説明を省略する。 Hereinafter, a robot according to an embodiment of the present invention (hereinafter referred to as “this embodiment”) will be described with reference to the drawings. Each figure is only schematically shown so that the present invention can be fully understood. Therefore, the present invention is not limited to the illustrated example. Moreover, in each figure, the same code | symbol is attached | subjected about the common component and the same component, and those overlapping description is abbreviate | omitted.
[ロボットシステムの構成]
まず、図1を参照して、本実施形態に係るロボットを含むロボットシステムの全体構成について説明する。ここでは、自律移動型の2足歩行ロボットを一例として説明する。
図1に示すように、ロボットシステムは、ロボットRと、このロボットRと無線通信によって接続された基地局1と、この基地局1とロボット専用ネットワーク2を介して接続された管理用コンピュータ3と、この管理用コンピュータ3にネットワーク4を介して接続された端末5から構成される。このロボットシステムでは、図示は省略しているが複数のロボットRを想定している。
[Robot system configuration]
First, an overall configuration of a robot system including a robot according to the present embodiment will be described with reference to FIG. Here, an autonomous mobile biped robot will be described as an example.
As shown in FIG. 1, the robot system includes a robot R, a
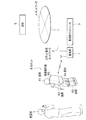
本実施形態に係るロボットRは、図1に示すように、頭部R1、腕部R2、脚部R3、胴部R4、および背面格納部R5を有しており、胴部R4にそれぞれ接続された頭部R1、腕部R2、および脚部R3は、それぞれアクチュエータ(駆動手段)により駆動され、後記する自律移動制御部50(図2参照)により2足歩行の制御がなされる。この2足歩行についての詳細は、例えば、特開2001−62760号公報に開示されている。
ここで、ロボットRは胴部R4の背面に背面格納部R5を備えている。この背面格納部R5には、頭部R1、腕部R2、脚部R3、および胴部R4の動作を制御する制御装置(主制御部40など)や、この制御装置が処理した熱を排熱するためのファンF(ノイズ発生源)、後記するバッテリ70などが格納されている。このファンFが回転することでノイズ音が出力される。
As shown in FIG. 1, the robot R according to the present embodiment has a head R1, an arm R2, a leg R3, a trunk R4, and a back housing R5, and is connected to the trunk R4. The head R1, arm R2, and leg R3 are each driven by an actuator (driving means), and bipedal walking is controlled by an autonomous movement controller 50 (see FIG. 2) described later. Details of this bipedal walking are disclosed in, for example, Japanese Patent Application Laid-Open No. 2001-62760.
Here, the robot R includes a back surface storage portion R5 on the back surface of the body portion R4. In the rear storage portion R5, a control device (such as the main control portion 40) that controls the operations of the head portion R1, the arm portion R2, the leg portion R3, and the torso portion R4, and heat processed by the control device are exhausted. A fan F (noise generation source), a
ロボット専用ネットワーク2は、基地局1と、管理用コンピュータ3と、ネットワーク4とを接続するものであり、LAN(Local Area Network)などにより実現されるものである。
The robot dedicated
管理用コンピュータ3は、複数のロボットRを管理するものであり、基地局1、ロボット専用ネットワーク2を介してロボットRの移動・発話などの各種制御を行うと共に、ロボットRに対して必要な情報を提供する。ここで、必要な情報とは、発話するための音声データや、検知された人物の氏名、ロボットRの周辺の地図などがこれに相当し、これらの情報は、管理用コンピュータ3に設けられた記憶部(不図示)に記憶されている。
The
端末5は、ネットワーク4を介して管理用コンピュータ3に接続し、管理用コンピュータ3に設けられた記憶手段(不図示)に、人物に関する情報などを登録する、もしくは登録されたこれらの情報を修正するものである。また、端末5は、ロボットRに実行させるタスクの登録や、管理用コンピュータ3において設定されるタスクスケジュールの変更や、ロボットRの動作命令の入力などを行うものである。
The
以下、ロボットRと、管理用コンピュータ3とについてそれぞれ詳細に説明する。
[ロボット]
図2は、ロボットの全体構成を示すブロック図である。図2に示すように、ロボットRは、頭部R1、腕部R2、脚部R3、胴部R4、および背面格納部R5に加えて、カメラC、スピーカS、音声入力部MC、画像処理部10、音声処理部20、記憶部30、主制御部40、自律移動制御部50、無線通信部60、および対象検知部80を有する。
Hereinafter, the robot R and the
[robot]
FIG. 2 is a block diagram showing the overall configuration of the robot. As shown in FIG. 2, the robot R includes a camera C, a speaker S, a voice input unit MC, and an image processing unit in addition to a head R1, an arm R2, a leg R3, a trunk R4, and a rear storage unit R5. 10, a
頭部R1は、自律移動制御部50(行動制御部)に制御された後記する頭回動部R11により、胴部R4上で支持軸Oを中心に左右に回動する。これにより、頭部R1(顔面)が向いている方向(H軸)は、回動角θだけ、胴部R4の正面が向いている方向(B軸)とずれることとなる。ここで、自律移動制御部50(回動角測定部)は、頭回動部R11に回動させた角度(回動角θ)を保持する。つまり、自律移動制御部50は、頭部R1の回動角度の測定値である回動角θを保持する。
さらに、ロボットRは、ロボットRの現在位置を検出するため、ジャイロセンサSR1や、GPS受信器SR2を有している。
このカメラC、スピーカS、および音声入力部MCは、いずれも頭部R1の内部に配設される。
The head R1 is rotated left and right about the support shaft O on the trunk R4 by a head rotation unit R11 described later controlled by the autonomous movement control unit 50 (behavior control unit). As a result, the direction (H axis) in which the head R1 (face) faces is shifted from the direction (B axis) in which the front of the torso R4 faces by the rotation angle θ. Here, the autonomous movement control unit 50 (rotation angle measurement unit) holds the angle (rotation angle θ) rotated by the head rotation unit R11. That is, the autonomous
Further, the robot R has a gyro sensor SR1 and a GPS receiver SR2 in order to detect the current position of the robot R.
The camera C, the speaker S, and the voice input unit MC are all disposed inside the head R1.
[カメラ]
カメラC(C1,C2)は、映像をデジタルデータとして取り込むことができるものであり、例えば、カラーCCD(Charge-Coupled Device)カメラが使用される。カメラC1とカメラC2とは、左右に平行に並んで配置され、撮影した画像は画像処理部10に出力される。
[camera]
The camera C (C1, C2) is capable of capturing video as digital data, and for example, a color CCD (Charge-Coupled Device) camera is used. The camera C1 and the camera C2 are arranged side by side in parallel on the left and right, and the captured image is output to the image processing unit 10.
[画像処理部]
画像処理部10は、カメラCが撮影した画像を処理して、撮影された画像からロボットRの周囲の状況を把握するため、周囲の障害物や人物の認識を行う部分である。この画像処理部10は、ステレオ処理部11a、移動体抽出部11b、および顔認識部11cを含んで構成される。以下に各構成部について簡単に記載する。
[Image processing unit]
The image processing unit 10 is a part for recognizing surrounding obstacles and persons in order to process the image captured by the camera C and grasp the situation around the robot R from the captured image. The image processing unit 10 includes a stereo processing unit 11a, a moving
ステレオ処理部11aは、左右のカメラCが撮影した2枚の画像の一方を基準としてパターンマッチングを行い、左右の画像中の対応する各画素の視差を計算して視差画像を生成し、生成した視差画像および元の画像を移動体抽出部11bに出力する。なお、この視差は、ロボットRから撮影された物体までの距離を表すものである。
The stereo processing unit 11a performs pattern matching using one of the two images taken by the left and right cameras C as a reference, calculates the parallax of each corresponding pixel in the left and right images, and generates a parallax image. The parallax image and the original image are output to the moving
移動体抽出部11bは、ステレオ処理部11aから出力されたデータに基づき、撮影した画像中の移動体を抽出するものである。移動する物体(移動体)を抽出するのは、移動する物体が人物であると推定して、人物の認識をするためである。
移動体を抽出するために、移動体抽出部11bは、過去の数フレーム(コマ)の画像を記憶しており、最も新しいフレーム(画像)と、過去のフレーム(画像)を比較して、パターンマッチングを行い、各画素の移動量を計算し、移動量画像を生成する。そして、視差画像と、移動量画像とから、カメラCから所定の距離範囲内で、移動量の多い画素がある場合に、人物があると推定し、その所定距離範囲のみの視差画像として、移動体を抽出し、顔認識部11cへ移動体の画像を出力する。
The moving
In order to extract the moving object, the moving
顔認識部11cは、抽出した移動体から肌色の部分を抽出して、その大きさ、形状などから顔の位置を認識する。なお、同様にして、肌色の領域と、大きさ、形状などから手の位置も認識される。
認識された顔の位置は、ロボットRが移動するときの情報として、また、その人とのコミュニケーションを取るため、主制御部40に出力される。
The
The recognized face position is output to the
[音声入力部]
音声入力部MCは、ロボットRの周囲の音を電気信号(音響信号)として取り出すマイクロホンと、当該音響信号をデジタル化して音響信号データ(音声データを含む)を生成するアナログ−デジタル変換器(A/D変換器)を含み、音声処理部20(後記する音声データ処理部22および推定音源分離部24)に出力する。
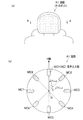
図3(a)は、頭部R1の正面図であり、図3(b)は、頭部R1のA−A断面図である。そして、図3(b)に、頭部R1の内部に配設された音声入力部MCを示す。
音声入力部MC1,MC2,・・・,MC8は、それぞれ支持軸Oを中心に顔面が向いている方向(H軸)から配設角度∠Hmc(∠Hmc1(=H軸),∠Hmc2,∠Hmc3,・・・)だけ離間して、頭部R1外部からの音を集音するように配設される。
[Voice input section]
The voice input unit MC includes a microphone that extracts sound around the robot R as an electrical signal (acoustic signal), and an analog-digital converter (A) that digitizes the acoustic signal and generates acoustic signal data (including voice data). / D converter) and output to the speech processing unit 20 (speech
Fig.3 (a) is a front view of head R1, and FIG.3 (b) is AA sectional drawing of head R1. FIG. 3B shows the voice input unit MC arranged inside the head R1.
The voice input parts MC1, MC2,..., MC8 are arranged at angles ∠H mc (∠H mc1 (= H axis), ∠H from the direction (H axis) in which the face faces around the support axis O, respectively. mc2, ∠H mc3, ···) only at a distance, is disposed so as to collect the sound from the head R1 outside.
ここで、配設角度∠Hmcは、360度全方向からの音声を集音できるように音声入力部MCを配設できる角度であればよいが、図3(b)に示すように、音声入力部MCが8個ある場合、等角度(45度)であることが望ましい。
また、後記する除外角度範囲rの範囲外に、音声入力部MCが随時2台以上存在するように、音声入力部MCの数および配設角度∠Hmcは設定される。ここで、本実施形態では、複数の方向から入力された音響信号データに基づき、音源方向を求めるため、除外角度範囲rの範囲外に2台存在する必要がある。
Here, the disposition angle ∠H mc may be any angle that allows the sound input unit MC to be disposed so that sound from all directions of 360 degrees can be collected, but as shown in FIG. When there are eight input parts MC, it is desirable that they are equiangular (45 degrees).
Also, outside the exclusion angular range r to be described later, so that the voice input unit MC is present two or more at any time, the number and disposed angle ∠H mc speech input unit MC is set. Here, in the present embodiment, in order to obtain the sound source direction based on the acoustic signal data input from a plurality of directions, it is necessary that two units exist outside the excluded angle range r.
[スピーカ]
スピーカSは、音声処理部20(後記する音声合成部21)により生成された音声データに基づき、音声を出力する。
[Speaker]
The speaker S outputs sound based on the sound data generated by the sound processing unit 20 (
[音声処理部]
音声処理部20は、音声合成部21と、音声データ処理部22と、音源方向推定部23と、推定音源分離部24と、音声認識部25と、音源定位部26とを有する。
音声合成部21は、主制御部40により決定された発話行動の指令に基づき、文字情報(テキストデータ)から発話音声データを生成し、スピーカSに音声を出力する部分である。発話音声データの生成には、予め記憶部30に記憶されている文字情報(テキストデータ)と、その文字情報が読み上げられた音声データとの対応関係を利用する。なお、この文字情報と音声データとは、管理用コンピュータ3から取得され、記憶部30に保存される。
[Audio processor]
The
The
本実施形態の音源方向推定処理に係る処理は、音声処理部20が備える音声データ処理部22と、音源方向推定部23と、推定音源分離部24と、音声認識部25と、音源定位部26とにより行われる。これら構成部により行われる音源方向推定処理の詳細な説明は後記するため、ここでは、音声処理部20が行う音源方向推定処理について簡単に説明する。
音声処理部20は、音声入力部MC(MC1,MC2,MC3,・・・)から入力された音響信号データに信号分解アルゴリズム(例えば、MUSIC(MUltiple SIgnal Classification)法)を用いて、頭部の向きを基準とした360度全方向からの音圧値を示す全方向音圧成分データ(例えば、MUSICスペクトラム)を生成する。そして、音声処理部20は、その全方向音圧成分データから音源方向を推定する。次に、音声処理部20は、推定した音源方向から入力される音響信号データを、音声入力部MCから入力された音響信号データから分離抽出して、分離抽出した音響信号データに対して音声認識を行う。
The processing related to the sound source direction estimation process of the present embodiment includes a sound
The
[記憶部]
記憶部30は、例えば、一般的なハードディスクなどから構成され、管理用コンピュータ3から送信された音声合成部21が発話音声データを生成する際に用いる文字情報および音声データ、後記する対象検知部80が用いる必要な情報(人物の氏名、ローカル地図データ、会話用データなど)、ロボットRが識別した人物の識別番号や位置情報の他に、本実施形態の音源方向推定処理に係るデータを記憶するものである。
この音源方向推定処理に係るデータは、音声入力角度DB31と、除外角度範囲DB32と、フレーズDB33(フレーズ記憶部)と、伝達関数DB34とに記憶されており、これらについての詳細な説明は後記する。
[Storage unit]
The
Data related to the sound source direction estimation processing is stored in the voice
[主制御部]
主制御部40は、画像処理部10、音声処理部20、記憶部30、自律移動制御部50、無線通信部60、および対象検知部80を統括制御するものである。
[Main control section]
The
[自律移動制御部]
自律移動制御部(自律移動制御手段)50は、主制御部40の指示に従い頭部R1、腕部R2、脚部R3を駆動する。
また、ジャイロセンサSR1、およびGPS受信器SR2が検出したデータは、主制御部40に出力され、ロボットRの行動を決定するために利用される。
[Autonomous Movement Control Unit]
The autonomous movement control unit (autonomous movement control means) 50 drives the head R1, the arm R2, and the leg R3 in accordance with instructions from the
The data detected by the gyro sensor SR1 and the GPS receiver SR2 is output to the
[無線通信部]
無線通信部60は、管理用コンピュータ3とデータの送受信を行う通信装置である。無線通信部60は、公衆回線通信装置61aおよび無線通信装置61bを有する。
公衆回線通信装置61aは、携帯電話回線やPHS(Personal Handyphone System)回線などの公衆回線を利用した無線通信手段である。一方、無線通信装置61bは、IEEE802.11b規格に準拠するワイヤレスLANなどの、近距離無線通信による無線通信手段である。
無線通信部60は、管理用コンピュータ3からの接続要求に従い、公衆回線通信装置61aまたは無線通信装置61bを選択して管理用コンピュータ3とデータ通信を行う。
[Wireless communication part]
The
The public
The
[バッテリ]
バッテリ70は、ロボットRの各部(頭部R1、腕部R2、脚部R3、および胴部R4)の動作や、ファンFの回転駆動、背面格納部R5に格納された制御装置の処理などに必要な電力の供給源である。このバッテリ70は、充填式の構成をもつものが使用される。
[Battery]
The
[対象検知部]
対象検知部80は、ロボットRの周囲にタグTを備える人物が存在するか否かを検知するものである。例えば、LEDから構成され、ロボットRの頭部R1外周に沿って前後左右などに配設される複数の発光部を備える(図示は省略する)。
対象検知部80は、発光部から、各発光部を識別する発光部IDを示す信号を含む赤外光をそれぞれ発信すると共に、この赤外光を受信したタグTから受信報告信号を受信する。いずれかの赤外光を受信したタグTは、その赤外光に含まれる発光部IDに基づいて、受信報告信号を生成するので、ロボットRは、この受信報告信号に含まれる発光部IDを参照することにより、当該ロボットRから見てどの方向にタグTが存在するかを特定することができる。また、対象検知部80は、タグTから取得した受信報告信号の電波強度に基づいて、タグTまでの距離を特定する機能を有する。したがって、対象検知部80は、受信報告信号に基づいて、タグTの位置(距離および方向)を、人物の位置として特定することができる。
さらに、対象検知部80は、発光部から赤外光を発光するだけではなく、ロボットIDを示す信号を含む電波を図示しないアンテナから発信する。これにより、この電波を受信したタグTは、赤外光を発信したロボットRを正しく特定することができる。なお、対象検知部80およびタグTについての詳細は、例えば、特開2006−192563号公報に開示されている。
[Target detection unit]
The
The
Furthermore, the
次に、本実施形態に係るロボットRの音源方向推定処理に係る構成について、図4を参照して説明する。
[記憶部の構成]
図4に示すように、記憶部30は、音声入力角度DB31と、除外角度範囲DB32と、フレーズDB33とを含んで構成される。
Next, a configuration related to the sound source direction estimation process of the robot R according to the present embodiment will be described with reference to FIG.
[Configuration of storage unit]
As shown in FIG. 4, the
(音声入力角度DB)
音声入力角度DB31は、音声入力部MCの識別番号と、その音声入力部MCが顔面が向いている方向(H軸)からなす配設角度∠Hmc(∠Hmc1,∠Hmc2,∠Hmc3,・・・)とを対応付けて記憶するデータベースである。
図5は、図3(b)に示すように、音声入力部MCが頭部R1の内部に配設されたときの音声入力角度DBの一例を示す図である。音声入力角度DBには、音声入力部MC1に相当する識別番号“MC1”に、配設角度(∠Hmc1)=0度が記録されており、音声入力部MC2に相当する識別番号“MC2”に、配設角度(∠Hmc2)=45度が記録されている。
(Audio input angle DB)
The voice
FIG. 5 is a diagram illustrating an example of the voice input angle DB when the voice input unit MC is disposed inside the head R1, as shown in FIG. In the voice input angle DB, an arrangement angle (∠H mc1 ) = 0 degrees is recorded in an identification number “MC1” corresponding to the voice input unit MC1, and an identification number “MC2” corresponding to the voice input unit MC2 is recorded. In addition, an arrangement angle (∠H mc2 ) = 45 degrees is recorded.
(伝達関数DB)
伝達関数DB34は、後記する音声データ処理部22にて、MUSICスペクトラムPavg(θ)を生成するために、予めシミュレーションして取得した、頭部の向きを基準としたθ方向に音源がある場合の伝達関数ベクトルv(θ)が記録されている。この伝達関数ベクトルv(θ)は、シミュレーション時に行った方向の数だけ記録されている。伝達関数ベクトルv(θ)についての詳細は、後記する音声データ処理部22の説明にて記載する。
本実施形態では、360度全方向を5度で等分した72方向に音源がある場合のシミュレーションを予め行っておき、72個の伝達関数ベクトルv(θ)(v1,v2,・・・,v72)を算出しておく。
(Transfer function DB)
The
In the present embodiment, a simulation is performed in advance when there is a sound source in 72 directions obtained by equally dividing 360 degrees in all directions at 5 degrees, and 72 transfer function vectors v (θ) (v 1 , v 2 ,. ·, V 72 ) is calculated in advance.
(除外角度範囲DB)
除外角度範囲DB32は、ロボットRの管理者により端末5から入力され、管理用コンピュータ3を介して、ロボットRに設定される除外角度範囲rを記憶する記憶手段である。
除外角度範囲rは、支持軸Oを中心に胴部R4の正面が向いている方向(B軸,図7参照)からなす、音源として推定しない方向の範囲である。例えば、除外角度範囲rとして、∠B=+120〜+180〜+240度で記憶されている。
(Exclusion angle range DB)
The exclusion
The excluded angle range r is a range in a direction not estimated as a sound source, which is formed from a direction (B axis, see FIG. 7) in which the front surface of the trunk portion R4 faces around the support axis O. For example, it is stored as 。B = + 120 to +180 to +240 degrees as the excluded angle range r.
この除外角度範囲rは、音声入力部MCとロボットRの動作環境とに基づき予め設定される範囲である。例えば、ロボットRの背面格納部R5に格納されたファンF(ノイズ発生源)から出力されるノイズ音を除去するために、予め、音声入力部MCから入力される、ファンFによるノイズ音の音響信号データに対して、音声データ処理部22に全方向音圧成分データ(例えば、MUSICスペクトラム)を生成させる。この全方向音圧成分データからノイズ音の音圧成分を抽出して、ノイズ音が与える影響の範囲を考慮する。
ここで、ノイズ音が与える影響とは、後記する音声認識部25が、ファンF(ノイズ発生源)以外からの音声を、ノイズ音により音声として認識しないことである。
This exclusion angle range r is a range set in advance based on the voice input unit MC and the operating environment of the robot R. For example, in order to remove the noise sound output from the fan F (noise generation source) stored in the back surface storage unit R5 of the robot R, the noise of the noise sound by the fan F input from the audio input unit MC in advance is removed. For the signal data, the audio
Here, the influence given by the noise sound is that the
(フレーズDB)
フレーズDB33は、フレーズパターン331と、方向角度値パターン332と、フレーズ入力方向適合度333(音声入力方向適合度)とを対応付けて記憶するデータベースである。
図6は、フレーズDBの一例を示す図である。
フレーズパターン331は、人間が発声するフレーズであり、特に、人(発話者Y,図1参照)が他人(ロボットR,図1参照)を自分に振り向かせるために、呼びかけるときに発するフレーズが複数記憶されている。例えば、「こっち向いて」や「こっち見て」、「おーい」、「ごめんください」などである。
(Phrase DB)
The
FIG. 6 is a diagram illustrating an example of the phrase DB.
The phrase pattern 331 is a phrase uttered by a person, and in particular, there are a plurality of phrases that are uttered when a person (speaker Y, see FIG. 1) calls to another person (robot R, see FIG. 1) to turn around. It is remembered. For example, “Look here”, “Look here”, “Oi”, “I'm sorry”, etc.
方向角度値パターン332は、顔面が向いている方向(H軸)(図3(b)参照)からなす角度であり、360度全方向の方向角度値が記憶されている。
図6において、方向角度値は、20度毎の値としているが、1度毎の値であってもよい。
The direction angle value pattern 332 is an angle formed from the direction in which the face is facing (H axis) (see FIG. 3B), and 360 degree directional angle values are stored.
In FIG. 6, the direction angle value is a value every 20 degrees, but may be a value every 1 degree.
フレーズ入力方向適合度333(音声入力方向適合度)は、人間が発声するフレーズが、ロボットRに対してどの角度から発話(入力)されやすいかを示す値であり、つまり、フレーズと方向角度値との関係の正しさ(フレーズと方向角度値との関係が正しい確率)を示す値である。
例えば、「こっち向いて」というフレーズは、ロボットRの顔面が向いている方向(H軸上、方向角度値=0度)から言われるフレーズではなく、ロボットRの顔面が向いていない方向(横や背面)から言われるフレーズであることに着目して、フレーズ入力方向適合度333は、ロボットRの管理者により予め設定された値である。
The phrase input direction suitability 333 (speech input direction suitability) is a value indicating from which angle a phrase uttered by a human is likely to be spoken (input) to the robot R, that is, the phrase and the direction angle value. Is a value indicating the correctness of the relationship (the probability that the relationship between the phrase and the direction angle value is correct).
For example, the phrase “Look here” is not a phrase that is said to be from the direction in which the face of the robot R is facing (on the H axis, the direction angle value = 0 degree), but the direction in which the face of the robot R is not facing (horizontal Paying attention to the phrase that is said to be from the back), the phrase input direction suitability 333 is a value preset by the administrator of the robot R.
図6においてフレーズが「こっち向いて」の場合は、方向角度値が「0度」におけるフレーズ入力方向適合度333の値は低く設定され(=0.00)、一方、方向角度値が「180度」におけるフレーズ入力方向適合度333の値は高く設定されている(=0.10)。
また、フレーズが「あなたのお名前は?」の場合は、ロボットRの顔面が向いている方向(H軸上、方向角度値=0度)から言われるフレーズである。そのため、方向角度値が「0度」におけるフレーズ入力方向適合度333の値は高く設定され(=0.30)、一方、方向角度値が「180度」におけるフレーズ入力方向適合度333の値は低く設定されている(=0.00)。
ここで、図6のフレーズDB33は、フレーズそれぞれで、全方向角度値のフレーズ入力方向適合度333の値の合計が1となるように、方向角度値ごとに、フレーズ入力方向適合度333の値が設定されている。
In FIG. 6, when the phrase is “Looking over here”, the value of the phrase input direction suitability 333 when the direction angle value is “0 degree” is set low (= 0.00), while the direction angle value is “180”. The value of the phrase input direction suitability 333 in “degree” is set high (= 0.10).
When the phrase is “What is your name?”, It is a phrase that is said from the direction in which the face of the robot R is facing (on the H axis, the direction angle value = 0 degrees). Therefore, the value of the phrase input direction fitness 333 when the direction angle value is “0 degree” is set high (= 0.30), while the value of the phrase input direction fitness 333 when the direction angle value is “180 degrees” is It is set low (= 0.00).
Here, the
[音声処理部の構成]
図4に示すように、音声処理部20は、音声データ処理部22と、音源方向推定部23と、推定音源分離部24と、音声認識部25と、音源定位部26とを含んで構成される。
[Configuration of audio processing unit]
As shown in FIG. 4, the
(音声データ処理部)
本実施形態において、音声データ処理部22は、信号分解アルゴリズムとしてMUSIC法を用いる。音声データ処理部22は、音声入力部MC(MC1,MC2,MC3,・・・)から入力された音響信号データからMUSIC法を用いて、雑音信号の空間を推定して、予め準備しておいた72方向の伝達関数ベクトルv(θ)それぞれを、その雑音信号の空間に射影することにより、MUSICスペクトラムPavg(θ)(全方向音圧成分データ)を生成する処理部である。
(Audio data processing unit)
In the present embodiment, the audio
伝達関数ベクトルv(θ)は、予めシミュレーションして取得したベクトル値である。
シミュレーションは、頭部の向きを基準としたθ方向の音源からインパルスを出力する。そのインパルスが入力された各音声入力部MC(MC1,MC2,MC3,・・・)が出力するインパルス応答を音声データ処理部22が取得する。そして、音声データ処理部22は、そのインパルス応答に離散フーリエ変換を施し、周波数領域に変換することで、伝達関数ベクトルv(θ)が得られる。
The transfer function vector v (θ) is a vector value obtained by simulation in advance.
In the simulation, an impulse is output from a sound source in the θ direction with reference to the head direction. The voice
シミュレーションは次のように行う。頭部の向きを基準とした0度の方向(θ=0)に位置する音源に対応する伝達関数ベクトルv1を算出する場合、0度の方向からインパルスを出力する。音声データ処理部22は、各音声入力部MC(MC1,MC2,MC3,・・・)から取得したインパルス応答に離散フーリエ変換を施し、周波数領域に変換することで、伝達関数ベクトルv1を算出することができる。
本実施形態では、360度全方向を5度で等分した72方向に音源がある場合のシミュレーションを予め行っておき、72個の伝達関数ベクトルv(θ)(v1,v2,・・・,v72)を算出しておく。
The simulation is performed as follows. When calculating the transfer function vector v 1 corresponding to the sound source located in the direction of 0 degrees (θ = 0) with respect to the head direction, an impulse is output from the direction of 0 degrees. The voice
In the present embodiment, a simulation is performed in advance when there is a sound source in 72 directions obtained by equally dividing 360 degrees in all directions at 5 degrees, and 72 transfer function vectors v (θ) (v 1 , v 2 ,. ·, V 72 ) is calculated in advance.
(MUSICスペクトラム算出処理)
そして音声データ処理部22は、MUSICスペクトラム算出処理を行う。
まず、音声データ処理部22は、音声入力部MCから音響信号データを取得し、そして、記憶部30の伝達関数DB34から72個の伝達関数ベクトルv(θ)(v1,v2,v3,・・・,v72)を取得する。
そして、音声データ処理部22は、式(1)を用いてMUSICスペクトラムP(θ)を計算する。eは固有ベクトルであり、音響信号データから算出される値である。算出手段は後記する。
ここで、Mは音声入力部MCの数である。また、Nは音源として認識可能な最大数を示し、所定の値に設定することができる。本実施形態では、「N=3」と設定しておく。Tは転置行列であることを示す。
(MUSIC spectrum calculation process)
Then, the audio
First, the audio
Then, the audio
Here, M is the number of voice input units MC. N indicates the maximum number that can be recognized as a sound source, and can be set to a predetermined value. In this embodiment, “N = 3” is set. T indicates a transposed matrix.

(固有ベクトルeの算出)
ここで、固有ベクトルeは次のようにして、音響信号データから算出する。
まず、音声データ処理部22は、音響信号データに離散フーリエ変換を施して、周波数領域に変換し、スペクトルxを算出する。
そして、相関行列Rxxは、次の期待値Eで示す式(2)で示すことができる。
(Calculation of eigenvector e)
Here, the eigenvector e is calculated from the acoustic signal data as follows.
First, the audio
Then, the correlation matrix R xx can be expressed by Expression (2) indicated by the next expected value E.
![]()
![]()
この相関行列Rxxが式(3)を満たすような固有値λと、固有ベクトルeとを算出する。これにより、雑音信号の空間への射影行列である固有ベクトルeを取得することができる。 An eigenvalue λ and an eigenvector e such that the correlation matrix R xx satisfies the equation (3) are calculated. Thereby, the eigenvector e which is a projection matrix of the noise signal onto the space can be acquired.
![]()
![]()
音声データ処理部22は、式(3)を満たすすべての固有値λと固有ベクトルeとの組を保持する。このとき保持した組の数をKとする。
そして、音声データ処理部22は、固有値λが一番大きい組からN+1〜K番目の固有値λと固有ベクトルeとの組を取得する。このK−N個の固有ベクトルeを用いて、式(1)に示すMUSICスペクトラムP(θ)を算出する。
The audio
Then, the audio
ここで、通常、式(3)を満たす組は、音声入力部MCの数(M)だけ存在する。そのため、音源として認識可能な最大数として設定されるNの値は、N<Mであることが好ましい。 Here, normally, there are as many pairs (M) as the number of voice input units MC that satisfy the formula (3). Therefore, the value of N set as the maximum number that can be recognized as a sound source is preferably N <M.
以上のようにして、音声データ処理部22は、MUSICスペクトラム算出処理を行い、時刻tにおける、周波数ωのMUSICスペクトラムP(θ)を取得することができる。
そして、音声データ処理部22は、周波数毎にMUSICスペクトラムP(θ)の算出処理を行い、所定の周波数帯域のMUSICスペクトラムP(θ)を取得する。
ここで、所定の周波数帯域とは、発話者が発する音声の音圧が大きい周波数帯域であり、かつ雑音の音圧が小さい周波数帯域が望ましく、例えば、0.5〜2.8kHzであればよい。
As described above, the audio
Then, the audio
Here, the predetermined frequency band is a frequency band in which the sound pressure of the voice uttered by the speaker is high, and a frequency band in which the sound pressure of the noise is low, for example, may be 0.5 to 2.8 kHz.
そして、音声データ処理部22は、各周波数帯域のMUSICスペクトラムP(θ)を広帯域信号に拡張する。
音声データ処理部22は、音響信号データからS/N比がよい(ノイズが少ない)周波数帯域ωを抽出し、広帯域信号へと拡張したときに、周波数帯域ωのMUSICスペクトラムP(θ)が強く反映されるように、周波数帯域ωの音響信号データから式(3)で得た一番大きい固有値λmaxを用いて、式(4)に示すように、MUSICスペクトラムP(θ)に重み付けをして、総和を計算する。これにより、広帯域のMUSICスペクトラムPavg(θ)を取得する。
Then, the audio
When the audio
Ω:周波数帯域の集合、|Ω|:集合Ωの要素数
Ω: Set of frequency bands, | Ω |: Number of elements in set Ω
以上により、音声データ処理部22は、MUSICスペクトラムPavg(θ)(全方向音圧成分データ)を生成することができる。
As described above, the audio
(音源方向推定部)
音源方向推定部23は、フィルタ部231と、角度抽出部232とを含んで構成される。
フィルタ部231は、音声データ処理部22からMUSICスペクトラムPavg(θ)(全方向音圧成分データ)を取得して、除外角度範囲DB32から除外角度範囲rを取得して、自律移動制御部50から頭回動部R11の回動角θを取得する。
そして、フィルタ部231は、H軸が基準となるMUSICスペクトラムPavg(θ)から、B軸を基準とした回動角θを考慮して、B軸を基準とした除外角度範囲rに該当する範囲内のデータを除去して、推定範囲スペクトラム(有効方向音圧成分データ)を抽出する。
(Sound source direction estimation unit)
The sound source
The
The
角度抽出部232は、推定範囲スペクトラムからすべてのピーク音圧値(Peak1,Peak2,・・・)と、それらピーク音圧値の角度(推定音源角度)とを抽出する。この推定音源角度が成す方向が推定音源方向である。ここで、本実施形態における推定音源角度は、H軸を基準とした角度∠φH(∠φH1,∠φH2,・・・)とする。
ここで、ピーク音圧値について説明する。推定範囲スペクトラムにおいて、角度θの音圧値が、直前の角度の音圧値および直後の角度の音圧値よりも大きな値である場合に、その角度θの音圧値がピーク音圧値である。また、その角度θが推定音源角度∠φHである。
そして、角度抽出部232は、抽出したすべてのピーク音圧値の推定音源角度∠φH(∠φH1,∠φH2,・・・)を推定音源分離部24に出力する。
この推定音源角度∠φHは、頭部R1の正面(顔面)を推定音源方向に向けるまでに必要な回動角度でもある。
The
Here, the peak sound pressure value will be described. In the estimated range spectrum, when the sound pressure value at the angle θ is larger than the sound pressure value at the immediately preceding angle and the sound pressure value at the immediately following angle, the sound pressure value at the angle θ is the peak sound pressure value. is there. The angle θ is the estimated sound source angle ∠φ H.
Then, the
This estimated sound source angle ∠φ H is also a rotation angle necessary until the front surface (face) of the head R1 faces the estimated sound source direction.
ここで、音声入力部MCから入力された音響信号データから音声データ処理部22が生成したMUSICスペクトラムPavg(θ)(全方向音圧成分データ)を取得して、音源方向推定部23(フィルタ部231および角度抽出部232)が、音源方向を推定するまでの処理について、図7と図8とを用いて説明する。図7は、B軸と、H軸と、除外角度範囲rとの一例を示す図であり、図8は、音声データ処理部22にて生成されたMUSICスペクトラムの一例を示す図である。
Here, the MUSIC spectrum P avg (θ) (omnidirectional sound pressure component data) generated by the sound
この図7は、頭部R1の顔面が向いている方向(H軸)が、胴部R4の正面が向いている方向(B軸)から右に(θ=)30度の方向である場合の図である。このとき、H軸(∠H=0度)は、B軸を基準(0度)として換算すると、∠B=+30度で示される。
そして、背面格納部R5に格納されたファンF(ノイズ発生源)から出力されるノイズ音を除去するために、除外角度範囲r(r=120度)は、∠B=+120〜+180〜+240度の範囲で記憶されている。これは、H軸で換算すると、∠H=+80〜+140〜+200度の範囲である。
In FIG. 7, the direction in which the face of the head R1 faces (H axis) is the direction (θ =) 30 degrees to the right from the direction in which the front of the torso R4 faces (B axis). FIG. At this time, the H axis (∠H = 0 degree) is represented by ∠B = + 30 degrees when the B axis is converted with reference (0 degree).
In order to remove the noise sound output from the fan F (noise generation source) stored in the rear storage unit R5, the excluded angle range r (r = 120 degrees) is ∠B = + 120 to +180 to +240 degrees. It is memorized in the range. This is a range of ∠H = + 80 to +140 to +200 degrees in terms of the H axis.
図8は、図7で示す状態であるときに、音声データ処理部22が、頭部R1の音声入力部MC(MC1〜MC8)に入力された音響信号データにMUSIC法を用いて生成した360度全方向からの音圧値(スペクトラム強度)を示すMUSICスペクトラムPavg(θ)(全方向音圧成分データ)である。そして、縦軸は、スペクトル強度を示す音圧[dB]、横軸は、H軸を基準とした方向を示す角度[度]である。
FIG. 8 shows the 360 generated by the audio
フィルタ部231は、このMUSICスペクトラムPavg(θ)において除外角度範囲rに該当する範囲のデータを除去して、スペクトラム(推定範囲スペクトラム)を取得する。図8における推定範囲スペクトラムは、除外角度範囲r(∠H=+80〜+140〜+200)以外の∠H=−160〜±0〜+80度で示されるスペクトラムデータである(図8で太線で示す)。
The
角度抽出部232は、この推定範囲スペクトラムから、ピーク音圧値Peak1の推定音源角度∠φH1(∠φH)(∠H=−70度)と、ピーク音圧値Peak2の推定音源角度∠φH2(∠φH)(∠H=+10度)とを抽出する。そして、推定音源角度∠φH1および∠φH2を、推定音源分離部24に出力する。
From this estimated range spectrum, the
以上のように、フィルタ部231と角度抽出部232との処理により、MUSICスペクトラムにおける最大音圧値(MAX)(図8参照)は、除外角度範囲r(∠H=+80〜+140〜+200)内であるために、削除される。
As described above, the maximum sound pressure value (MAX) (see FIG. 8) in the MUSIC spectrum is within the excluded angle range r (∠H = + 80 to +140 to +200) by the processing of the
(推定音源分離部)
推定音源分離部24は、角度抽出部232から推定音源方向を示すすべての推定音源角度∠φH(∠φH1,∠φH2,・・・)を取得し、音声入力部MC(MC1,MC2,MC3,・・・)から音響信号データを取得する。そして、推定音源分離部24は、取得した複数の音響信号データから得られる360度全方向からの音響信号データのうち、各推定音源角度∠φHの方向から入力された音響信号データを分離抽出する。最後に、推定音源分離部24は、すべての推定音源角度∠φH(∠φH1,∠φH2,・・・)とともに、それぞれの角度方向に基づき分離抽出した推定音源方向音声データを音声認識部25に出力する。
(Estimated sound source separation unit)
The estimated sound
ここで、推定音源分離部24が行う複数の音声入力部MCから入力された音響信号データから、特定の音響信号データを分離抽出する処理については、特開2008−306712号公報などに開示された公知の技術を利用した処理である。
当該処理について、簡単に記載する。
Here, a process for separating and extracting specific acoustic signal data from acoustic signal data input from a plurality of sound input units MC performed by the estimated sound
The process will be briefly described.
複数の音声入力部MCそれぞれには、複数の音源それぞれから個別の音源信号が重畳された音声信号が入力される。推定音源分離部24は、それら音声入力部MCから音響信号データを取得する。そして、推定音源分離部24は、ブラインド音源分離法(BSS:Blind Source Separation)を用いて、音響信号データそれぞれから、音源それぞれからの音源信号(音響信号データ)を分離する。そして、推定音源分離部24は、推定音源角度∠φHの方向から入力された音響信号データ(推定音源方向音声データ)を抽出する。
BSSとして、DSS(Decorrelation based Source Separation)や、ICA(Independent Component Analysis)、HDSS(Higher-order DSS)に基づく音源分離法や、これらの手法それぞれに幾何的情報を加えたGSS(Geometric constrained Source Separation)や、GICA(Geometric constrained ICA)、GHDSS(Geometric constrained HDSS)といった音源分離法を用いてもよい。
Each of the plurality of sound input units MC receives a sound signal on which individual sound source signals are superimposed from each of the plurality of sound sources. The estimated sound
As BSS, DSS (Decorrelation based Source Separation), ICA (Independent Component Analysis), HDSS (Higher-order DSS) based sound source separation method, GSS (Geometric constrained Source Separation with geometric information added to each of these methods) ), GICA (Geometric constrained ICA), or GHDSS (Geometric constrained HDSS) may be used.
(音声認識部)
音声認識部25は、推定音源分離部24から、すべての推定音源角度∠φH(∠φH1,∠φH2,・・・)と、それぞれの角度方向の推定音源方向音声データとを取得する。
音声認識部25は、推定音源方向音声データそれぞれに対して音声認識を行い、文字情報(テキストデータ)を生成する機能を有し、1つの推定音源方向音声データから、複数の仮説フレーズを生成する。この仮説フレーズはテキストデータで生成される。
(Voice recognition unit)
The
The
さらに、音声認識部25は、仮説フレーズの正しさ(仮説フレーズが正しい確率)を示す音声認識尤度を算出する機能を有する。この音声認識尤度は、仮説フレーズの内容や前後の文章内容(前後の仮説フレーズ)などから、仮説フレーズが正しい文章内容であるかを示すものである。
<音声認識部25の音声認識尤度算出処理>
音声認識部25にて行われる音声認識尤度算出処理について説明する。
一般的な音声認識における音声認識尤度(P(W|X))は、音声信号をX、フレーズ(単語の列)をWとして、以下の式(5)で示すことができる。
Furthermore, the
<Voice Recognition Likelihood Calculation Processing of
A speech recognition likelihood calculation process performed by the
The speech recognition likelihood (P (W | X)) in general speech recognition can be expressed by the following equation (5), where X is a speech signal and W is a phrase (word string).
![]()
P(W|X):音声認識尤度、P(X|W):音響尤度、P(W):言語確率
![]()
P (W | X): speech recognition likelihood, P (X | W): acoustic likelihood, P (W): language probability
ここで、言語確率P(W)を算出するとき、文法を用いてもよいし、統計言語モデルを用いてもよい。
文法を用いて言語確率P(W)を算出する場合には、フレーズWが文法に定義されていればP(W)=1とし、定義されていなければP(W)=0とする。そして、確率の定義に従い、最後にはP(W)の合計が1になるように正規化する。
一方、統計言語モデルを用いて言語確率P(W)を算出する場合には、単語と単語との繋がりやすさを大量の文から学習したN−gramが用いられる。一般的にN−gramとは、N個の単語の繋がりやすさを学習させたものである。
Here, when calculating the language probability P (W), a grammar may be used, or a statistical language model may be used.
When calculating the language probability P (W) using the grammar, P (W) = 1 if the phrase W is defined in the grammar, and P (W) = 0 if not defined. Then, according to the definition of the probability, finally, normalization is performed so that the sum of P (W) becomes 1.
On the other hand, when the language probability P (W) is calculated using a statistical language model, an N-gram learned from a large amount of sentences for the ease of connection between words is used. In general, N-gram is a learning of the ease of connection of N words.
ここでは、統計言語モデルを用い、多くの場合に利用されているN=3の場合について説明する。一般的に、3−gramの統計言語モデルを用いて学習する際には、同時に2−gramも学習している。
例えば、「はしをわたって(橋を渡って)」の場合、「橋|を|渡っ|て」といった4つの単語に分解して考えます。そして、2つの単語「橋|を」の次に、「渡っ」という単語がどれだけ現れやすいかという確率P(渡っ|橋,を)を学習してデータベース(3−gramのデータベース、2−gramのデータベース)として持っている。
このように、「橋|を|渡っ|て」というフレーズWが現れる確率P(橋|を|渡っ|て)は、以下の式(6)で示すことができる。
Here, a case where N = 3, which is used in many cases, will be described using a statistical language model. Generally, when learning using a 3-gram statistical language model, 2-gram is also learned at the same time.
For example, in the case of “crossing the bridge (crossing the bridge)”, it is divided into four words such as “bridge | Then, after the two words “bridge | o”, learning the probability P (cross | bridge, o) how easily the word “cross” appears, and database (3-gram database, 2-gram) As a database).
Thus, the probability P (the bridge | is crossed) that the phrase W “bridge | cross | cross” can be expressed by the following equation (6).
右辺は3−gramおよび2−gramのデータベースから得られるもので、左辺が言語確率P(W)である。
以上により、音声認識部25は、「橋を渡って」とする仮説フレーズの音声認識尤度(P(W|X))は大きい値で算出され(仮説フレーズが正しい確率が高い)、一方、「箸を渡って」とする仮説フレーズの音声認識尤度(P(W|X))は小さい値で算出される(仮説フレーズが正しい確率が低い)。
以上のように、音声認識部25にて音声認識尤度算出処理が行われ、音声認識尤度(P(W|X))が算出される。
The right side is obtained from the 3-gram and 2-gram databases, and the left side is the language probability P (W).
From the above, the
As described above, the speech recognition likelihood calculation process is performed in the
そして、音声認識部25は、推定音源角度∠φHで示される角度方向の推定音源方向データから生成したすべての仮説フレーズと、各仮説フレーズの音声認識尤度(P(W|X))とを、推定音源角度∠φHと対応付けて、音源定位部26(フレーズ確信度算出部261)に出力する。
なお、音声データとテキストデータとの対応関係は、記憶部30に予め記憶されている。
The
Note that the correspondence between the voice data and the text data is stored in the
(音源定位部)
音源定位部26は、フレーズ確信度算出部261と、フレーズ決定部262とを含んで構成される。
(フレーズ確信度算出部)
フレーズ確信度算出部261は、音声認識部25からすべての推定音源角度∠φH(∠φH1,∠φH2,・・・)と、推定音源角度∠φHそれぞれと対応付けられた仮説フレーズのすべてと、各仮説フレーズの音声認識尤度(P(W|X))とを取得する。
そして、フレーズ確信度算出部261は、すべての推定音源角度∠φHから1つの推定音源角度∠φHを抽出し、さらに、その推定音源角度∠φHと対応付けられたすべての仮説フレーズから1つの仮説フレーズを抽出する(以下、抽出仮説フレーズとする)。
次に、フレーズ確信度算出部261は、フレーズDB33(図6)のフレーズパターン331から、抽出仮説フレーズと一致するフレーズを抽出する。次に、その抽出したフレーズと対応付けられた方向角度値パターン332から、推定音源角度∠φHと一致する方向角度値を抽出する。最後に、その抽出した方向角度値と対応付けられたフレーズ入力方向適合度333(フレーズと方向角度値との関係が正しい確率)を抽出する。
(Sound source localization part)
The sound source localization unit 26 includes a phrase certainty
(Phrase certainty calculator)
The phrase certainty
Then, the phrase
Next, the phrase
次に、フレーズ確信度算出部261は、フレーズの音源方向とフレーズの音声認識結果との関係を示すフレーズ確信度を算出する。このフレーズ確信度の値が大きいほど、抽出仮説フレーズ(音声認識部25が音声認識した仮説フレーズ)の音声認識結果が正しいという確率が高いことを示す。
<フレーズ確信度算出部261のフレーズ確信度算出処理>
フレーズ確信度算出部261にて行われるフレーズ確信度算出処理について説明する。
前記した、仮説フレーズの正しさ(仮説フレーズが正しい確率)を示す音声認識尤度を算出するための式(5)を、フレーズ入力方向適合度333を用いて拡張することで、フレーズ確信度P(W|X,d)は、以下の式(7)で示すことができる。ここで、音声信号をX、フレーズ(単語の列)をW、方向をdとする。
Next, the phrase
<Phrase certainty calculation processing of the phrase
The phrase certainty factor calculation process performed by the phrase certainty
By expanding the expression (5) for calculating the speech recognition likelihood indicating the correctness of the hypothesis phrase (probability that the hypothesis phrase is correct) by using the phrase input direction suitability 333, the phrase confidence P (W | X, d) can be expressed by the following equation (7). Here, X is an audio signal, W is a phrase (word string), and d is a direction.
![]()
P(W|X):音声認識尤度、P(X|W):音響尤度、P(W):言語確率
P(W|X,d):フレーズ確信度、P(d|W):フレーズ入力方向適合度
![]()
P (W | X): speech recognition likelihood, P (X | W): acoustic likelihood, P (W): language probability P (W | X, d): phrase confidence, P (d | W): Phrase input direction suitability
以上のように、フレーズ確信度算出処理を行うことで、フレーズ確信度算出部261は、フレーズ確信度(P(W|X,d))を、フレーズDB33から取得したフレーズ入力方向適合度333(P(d|W))に、音声認識尤度(P(W|X))を乗算することで算出できる。
As described above, by performing the phrase certainty factor calculation process, the phrase certainty
ここで、音響尤度P(X|W)は、入力した音声信号Xと音響モデルと呼ばれるデータベースから計算される尤度であり、入力音声信号XがフレーズWであると仮定すると、入力音声信号XがどれだけそのフレーズWらしいかを表す。この音響モデルには、隠れマルコフモデル(Hidden Markov Model)が用いられることが一般的で、フレーズWに対する入力音声信号Xの音響尤度を計算するアルゴリズムとして、ビタビ(Viterbi)アルゴリズムなどがある。 Here, the acoustic likelihood P (X | W) is a likelihood calculated from the input speech signal X and a database called an acoustic model, and assuming that the input speech signal X is the phrase W, the input speech signal X represents how much the phrase W seems to be. As this acoustic model, a hidden Markov model is generally used. As an algorithm for calculating the acoustic likelihood of the input speech signal X with respect to the phrase W, there is a Viterbi algorithm or the like.
そして、フレーズ確信度算出部261は、推定音源角度∠φHと、仮説フレーズと、算出したフレーズ確信度(P(W|X,d))との3つの値を対応付けてフレーズ決定部262に出力する。
この処理を、フレーズ確信度算出部261は、音声認識部25から取得したすべての推定音源角度∠φHに対して行い、各推定音源角度∠φHのすべての仮説フレーズのフレーズ確信度(P(W|X,d))を算出し、フレーズ決定部262に出力する。
Then, the phrase
The phrase
(フレーズ決定部)
フレーズ決定部262は、フレーズ確信度算出部261から取得したすべての推定音源角度∠φHに対して以下の処理を行う。
まず、フレーズ決定部262は、1つの推定音源角度∠φHに対応付けられたすべての仮説フレーズのフレーズ確信度を取得する。そして、フレーズ決定部262は、取得したフレーズ確信度P(W|X,d)から最大値のフレーズ確信度を抽出し、そのフレーズ確信度が最大値の仮説フレーズを、音声認識したフレーズと決定する。そして、このフレーズ確信度が最大値の仮説フレーズWmaxが、ロボットRの正面から推定音源角度∠φHを成す方向に位置する音源(発話者Y,図1参照)から発話された発話フレーズであるとする。
そして、主制御部40に、当該発話フレーズと、推定音源角度∠φHとを出力する。
ここで、フレーズ確信度が最大値の仮説フレーズWmaxは、以下の式(8)で示すことができる。
(Phrase determination part)
The
First, the
Then, the utterance phrase and the estimated sound source angle ∠φ H are output to the
Here, the hypothesis phrase W max having the maximum phrase certainty factor can be expressed by the following equation (8).
![]()
X:音声認識したフレーズ、W:仮説フレーズ
![]()
X: Phrase recognized speech, W: Hypothesis phrase
以上の処理を、フレーズ決定部262は、フレーズ確信度算出部261から取得したすべての推定音源角度∠φHに対して行い、各推定音源角度∠φHの発話フレーズを主制御部40に出力する。
The
本実施の形態に係るロボットRによれば、以下に示す動作ができるようになる。
各推定音源角度∠φHの発話フレーズを取得した主制御部40は、記憶部30に記憶された文字情報を参照して、発話フレーズの内容を取得する。ここで、発話フレーズが相手を呼びかける内容の文章であったときに、主制御部40は、自律移動制御部50へ、頭部R1の正面(顔面)が推定音源角度∠φHに至るまで、頭回動部R11を回動させる指示を出力させることができる。これにより、発話者が「おーい」と呼びかけることで、ロボットRはその発話者がいる方向へ顔面を向けることができる。
また、各推定音源角度∠φHの発話フレーズを取得した主制御部40が、角度抽出部232が推定範囲スペクトラムから取得した、それら推定音源角度∠φHの角度のピーク音圧値を取得する。そして、主制御部40は、自律移動制御部50へ、頭部R1の正面(顔面)が、ピーク音圧値が最大となる推定音源角度∠φHに至るまで、頭回動部R11を回動させる指示を出力させてもよい。これにより、ロボットRは、音圧が最大の発話者がいる方向へ顔面を向けることができる。そのため、近くで話している発話者よりも大きな声で呼びかけた発話者がいる方向へ顔面を向けることができる。
The robot R according to the present embodiment can perform the following operations.
The
Further, the
[ロボットの音源方向推定処理]
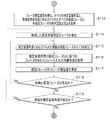
次に、図9〜図11のフローチャートを参照して、ロボットの音源方向推定処理について説明する(適宜、図1ないし図8を参照)。
まず、ロボットRの音声入力部MC(MC1,MC2,MC3,・・・)に、ユーザが発話した音声が入力され(ステップS101)、音声データ処理部22に音響信号データが入力される(ステップS102)。
次に、音声データ処理部22は、記憶部30の音声入力角度DB31から、各音声入力部MCの配設角度∠Hmc(∠Hmc1,∠Hmc2,∠Hmc3,・・・)を取得し、伝達関数DB34から、伝達関数ベクトルv(θ)を取得する(ステップS103)。
そして、音声データ処理部22は、MUSIC法を用いて、各音声入力部MCから入力された音響信号データと、配設角度∠Hmcと、伝達関数ベクトルv(θ)とから、MUSICスペクトラムを生成する(ステップS104)。
[Robot sound source direction estimation processing]
Next, the sound source direction estimation process of the robot will be described with reference to the flowcharts of FIGS. 9 to 11 (refer to FIGS. 1 to 8 as appropriate).
First, the voice uttered by the user is input to the voice input unit MC (MC1, MC2, MC3,...) Of the robot R (step S101), and the acoustic signal data is input to the voice data processing unit 22 (step S101). S102).
Next, the voice
The audio
フィルタ部231は、音声データ処理部22からMUSICスペクトラム(全方向音圧成分データ)を取得して、除外角度範囲DB32から除外角度範囲rを取得して、自律移動制御部50から頭回動部R11の回動角θを取得する(ステップS105)。
そして、フィルタ部231は、MUSICスペクトラムから、回動角θを考慮して、除外角度範囲rに該当する範囲内のデータを除去して、推定範囲スペクトラム(有効方向音圧成分データ)を抽出する(ステップS106)。
The
Then, the
角度抽出部232は、推定範囲スペクトラムからすべてのピーク音圧値(Peak1,Peak2,・・・)と、それらピーク音圧値の角度(推定音源角度∠φH)とを抽出する(ステップS107)。そして、角度抽出部232は、抽出したすべての推定音源角度∠φH(∠φH1,∠φH2,・・・)を、推定音源分離部24に出力する。
The
推定音源分離部24は、角度抽出部232からすべての推定音源角度∠φH(∠φH1,∠φH2,・・・)を取得し、音声入力部MC(MC1,MC2,MC3,・・・)から入力された音響信号データを取得する(ステップS108)。そして、取得した音響信号データから、各推定音源角度∠φHの方向から入力された音響信号データを分離抽出する(ステップS109)。最後に、推定音源分離部24は、推定音源角度∠φH(∠φH1,∠φH2,・・・)とともに、それぞれの角度方向に基づき分離抽出した推定音源方向音声データを音声認識部25に出力する。
The estimated sound
音声認識部25は、推定音源分離部24からすべての推定音源角度∠φH(∠φH1,∠φH2,・・・)と、それぞれの角度方向の推定音源方向音声データを取得する(ステップS110)。
(音声認識処理)
音声認識部25は、推定音源分離部24から入力された推定音源方向音声データに音声認識を行って、複数の仮説フレーズを生成し(ステップS111)、所定の算出手段を用いて、仮説フレーズの正しさを示す音声認識尤度を算出する(ステップS112)。そして、音声認識部25は、すべての推定音源角度∠φH方向の推定音源方向音声データに対して、当該音声認識処理を行う。
The
(Voice recognition processing)
The
以上の処理により、音声認識部25は、推定音源方向音声データ毎に、その推定音源方向音声データから生成された複数の仮説フレーズと、各仮説フレーズの音声認識尤度を取得する。そして、音声認識部25は、推定音源角度∠φHと対応付けて、その推定音源角度∠φH方向の推定音源方向音声データから生成したすべての仮説フレーズと、各仮説フレーズの音声認識尤度とを、フレーズ確信度算出部261に出力する。
Through the above processing, the
フレーズ確信度算出部261は、音声認識部25からすべての推定音源角度∠φH(∠φH1,∠φH2,・・・)と、各推定音源角度∠φHに対応付けられたすべての仮説フレーズと、各仮説フレーズの音声認識尤度とを取得する(ステップS113,図10)。
そして、フレーズ確信度算出部261は、取得した推定音源角度∠φH(∠φH1,∠φH2,・・・)から、1つの推定音源角度∠φHを抽出し(ステップS114)、その推定音源角度∠φHに対応付けられた複数の仮説フレーズから1つを抽出する(ステップS115)。
次に、フレーズ確信度算出部261は、抽出した推定音源角度∠φHと仮説フレーズとに基づき、フレーズDB33のフレーズパターン331から、仮説フレーズと一致するフレーズを抽出する。次に、フレーズ確信度算出部261は、抽出したフレーズと対応付けられた方向角度値パターン332から、推定音源角度∠φHと一致する方向角度値を抽出する。そして、フレーズ確信度算出部261は、抽出した方向角度値と対応付けられたフレーズ入力方向適合度333を取得する(ステップS116)。
Phrase confidence
Then, the phrase
Next, the phrase
次に、フレーズ確信度算出部261は、フレーズDB33から取得したフレーズ入力方向適合度333に、音声認識部25から取得した仮説フレーズの音声認識尤度を乗算して、仮説フレーズのフレーズ確信度を算出する(ステップS117)。そして、フレーズ確信度算出部261は、推定音源角度∠φHと、仮説フレーズと、算出したフレーズ確信度との3つの値を対応付けてフレーズ決定部262に出力する。
そして、フレーズ確信度算出部261は、ステップS115にて未抽出仮説フレーズがあるか否かを判定する(ステップS118)。未抽出仮説フレーズがあれば(ステップS118,Yes)、ステップS115に戻る。
Next, the phrase
And the phrase
一方、未抽出仮説フレーズがなければ(ステップS118,No)、フレーズ確信度算出部261は、ステップS114にて未抽出推定音源角度があるか否かを判定する(ステップS119)。未抽出推定音源角度があれば(ステップS119,Yes)、ステップS114に戻る。
一方、未抽出推定音源角度がなければ(ステップS119,No)、フレーズ決定部262に処理を移す。
On the other hand, if there is no unextracted hypothesis phrase (No in step S118), the phrase
On the other hand, if there is no unextracted estimated sound source angle (step S119, No), the process proceeds to the
フレーズ決定部262は、すべての推定音源角度∠φH(∠φH1,∠φH2,・・・)と、各推定音源角度∠φHに対応付けられたすべての仮説フレーズのフレーズ確信度を取得する(ステップS120,図11)。
まず、フレーズ決定部262は、取得した推定音源角度∠φH(∠φH1,∠φH2,・・・)から、1つの推定音源角度∠φHを抽出する(ステップS121)。
そして、フレーズ決定部262は、抽出した推定音源角度∠φHに対応付けられたすべてのフレーズ確信度から、最大値のフレーズ確信度を抽出し(ステップS122)、その抽出したフレーズ確信度の仮説フレーズを、ロボットRが音声認識した推定音源角度∠φHの方向からのフレーズに決定する(ステップS123)。これにより、1つの推定音源角度∠φHの方向に対して、1つのフレーズが決定する。
The
First, the
Then, the
そして、フレーズ決定部262は、ステップS114にて未抽出推定音源角度があるか否かを判定する(ステップS124)。未抽出推定音源角度があれば(ステップS124,Yes)、ステップS121に戻る。
一方、未抽出推定音源角度がなければ(ステップS124,No)、フレーズ決定部262は、これまでの処理により、決定した各推定音源角度∠φHのフレーズを、主制御部40に出力する(ステップS125)。そして、ロボットRは音源方向推定処理を終了する。
Then, the
On the other hand, if there is no unextracted estimated sound source angle (No in step S124), the
以上、本発明の実施形態について説明したが、本発明は前記した実施形態に限定されず、適宜変更して実施することが可能である。
例えば、除外角度範囲DB32には、除外角度範囲rを記憶するとしたが、360−rで算出される角度範囲を記憶してもよい。これにより、MUSICスペクトラムから、有効方向音圧成分データを抽出することができる。
また、角度抽出部232は推定音源角度として、H軸を基準とした角度∠φHの代わりに、B軸を基準とした角度∠φBを用いてもよい。
Although the embodiments of the present invention have been described above, the present invention is not limited to the above-described embodiments, and can be implemented with appropriate modifications.
For example, the exclusion
In addition, the
また、除外角度範囲DB32において、除外角度範囲rを、音声入力部が3つであれば120°未満、4つであれば180°未満の値に設定することで、少なくとも2つの音声入力部MCが除外角度範囲rの範囲外に位置するため、発話者Y(図1参照)がいる方向(推定すべき音源方向)を推定することができる。
Further, in the exclusion
フレーズDB33は、フレーズパターン331毎の、方向角度値パターン332とフレーズ入力方向適合度333とからなる2次元のヒストグラムを記憶してもよい。これにより、フレーズ確信度算出部261は、音声認識部25から取得した推定音源角度∠φHに該当する方向角度値と、2次元のヒストグラムで対応付けられたフレーズ入力方向適合度333を取得することになる。
The
ロボットRは、発話者Yとコミュニケーションをするロボットであってもよいが、物音がする方向にカメラCと高性能マイクロフォン(音声入力部MC)を向ける警備用のロボットであっても良い。 The robot R may be a robot that communicates with the speaker Y, but may also be a security robot that directs the camera C and the high-performance microphone (voice input unit MC) in the direction in which a sound is heard.
20 音声処理部
22 音声データ処理部
23 音源方向推定部
24 推定音源分離部
25 音声認識部
26 音源定位部
30 記憶部
31 音声入力角度DB
32 除外角度範囲DB
33 フレーズDB
40 主制御部
50 自律移動制御部(行動制御部)(回動角測定部)
231 フィルタ部
232 角度抽出部
261 フレーズ確信度算出部
262 フレーズ決定部
MC(MC1,MC2,MC3,・・・) 音声入力部
O 支持軸
R ロボット
R1 頭部
R11 頭回動部
DESCRIPTION OF
32 Exclusion angle range DB
33 Phrase DB
40
231
Claims (6)
前記胴部の上面で回動可能に支持軸に支持される頭部と、
前記頭部が回動する回動方向に前記支持軸を中心に所定の角度で離間して前記頭部に配設され、入力された音声を音声データに変換して出力する3以上の音声入力部と、
前記音声入力部それぞれから入力された前記音声データに、信号分解アルゴリズムを用いて、前記頭部の向きを基準とした360度全方向からの音圧値を示す全方向音圧成分データを生成する音声データ処理部と、
前記胴部の向きを基準とした前記頭部の回動角度を測定する回動角測定部と、
前記胴部の向きを基準とした音源として推定しない方向の範囲が予め設定された除外角度範囲が記憶された記憶部と、
音源方向を推定する音源方向推定部と
を備えるロボットであって、
前記音源方向推定部は、
測定された回動角度を用いて、前記全方向音圧成分データから前記除外角度範囲内にあるデータを除去して有効方向音圧成分データを生成するフィルタ部を備えるロボット。 The torso,
A head supported by a support shaft so as to be rotatable on the upper surface of the body part;
Three or more audio inputs arranged in the head and spaced apart at a predetermined angle around the support shaft in the direction of rotation in which the head rotates, and converting the input sound into sound data and outputting it And
Using the signal decomposition algorithm, omnidirectional sound pressure component data indicating sound pressure values from 360 degrees omnidirectional with respect to the head direction is generated for the sound data input from each of the sound input units. An audio data processing unit;
A rotation angle measurement unit for measuring the rotation angle of the head with respect to the direction of the body,
A storage unit storing an exclusion angle range in which a range of directions not estimated as a sound source based on the direction of the body is set;
A sound source direction estimating unit for estimating a sound source direction,
The sound source direction estimation unit
A robot including a filter unit that generates effective direction sound pressure component data by removing data within the excluded angle range from the omnidirectional sound pressure component data using the measured rotation angle.
前記音源方向推定部が、前記フィルタ部が生成した前記有効方向音圧成分データから、直前の角度の音圧値と直後の角度の音圧値との双方より大きい音圧値の角度を少なくとも1以上抽出する角度抽出部を有し、
前記音声入力部が出力した音声データから、前記音声入力角度に基づき、前記角度抽出部が抽出した推定音源角度それぞれの方向から入力された音声データを分離抽出する推定音源分離部と、
前記推定音源分離部に抽出された推定音源方向音声データに音声認識を行い、複数の仮説フレーズを生成し、各仮説フレーズの正しさを示す音声認識尤度を算出する音声認識部と、
前記仮説フレーズと、前記仮説フレーズに係る前記推定音源方向音声データが入力される方向との関係の正しさを示す音声入力方向適合度で、前記仮説フレーズに係る前記音声認識尤度を重み付けて、前記仮説フレーズそれぞれのフレーズ確信度を算出し、前記算出したフレーズ確信度に基づいて音源方向を推定するフレーズ確信度算出部と
を備えることを特徴とする請求項1に記載されたロボット。 The storage unit stores voice input angles indicating directions of the voice input units around the support shaft,
The sound source direction estimation unit has at least one angle of sound pressure values larger than both of the sound pressure value at the immediately preceding angle and the sound pressure value at the immediately following angle from the effective direction sound pressure component data generated by the filter unit. It has an angle extraction unit to extract above,
An estimated sound source separation unit that separates and extracts the sound data input from each direction of the estimated sound source angle extracted by the angle extraction unit based on the sound input angle from the sound data output by the sound input unit;
A speech recognition unit that performs speech recognition on the estimated sound source direction speech data extracted by the estimated sound source separation unit, generates a plurality of hypothesis phrases, and calculates a speech recognition likelihood indicating the correctness of each hypothesis phrase;
With the speech input direction suitability indicating the correctness of the relationship between the hypothesis phrase and the direction in which the estimated sound source direction speech data related to the hypothesis phrase is input, weighting the speech recognition likelihood related to the hypothesis phrase, The robot according to claim 1 , further comprising: a phrase certainty calculation unit that calculates a phrase certainty factor of each of the hypothesis phrases and estimates a sound source direction based on the calculated phrase certainty factor.
前記仮説フレーズそれぞれのフレーズ確信度から、最大のフレーズ確信度を抽出し、そのフレーズ確信度に係る仮説フレーズを生成した前記推定音源方向音声データに係る前記推定音源角度を音源方向に推定することを特徴とする請求項2に記載されたロボット。 The phrase certainty calculation unit
Extracting the maximum phrase certainty factor from the phrase certainty factor of each of the hypothetical phrases, and estimating the estimated sound source angle related to the estimated sound source direction sound data that generated the hypothetical phrase related to the phrase certainty factor in the sound source direction. The robot according to claim 2, wherein
前記フレーズ記憶部は、予め入力され得るフレーズを集めた複数のフレーズパターンと、前記支持軸を中心とし前記頭部の向きを基準とした方向を示す方向角度値パターンと、前記フレーズパターンが前記方向角度値パターンの方向から入力される正しさを示す前記音声入力方向適合度との3つが対応付けられて記憶され、
前記フレーズ確信度算出部は、前記音声認識部に生成された複数の仮説フレーズとその音声認識尤度とを取得すると共に、前記仮説フレーズおよび前記角度抽出部が抽出した推定音源角度を用いて、前記フレーズ記憶部に記憶された前記フレーズパターンおよび前記方向角度値パターンに対応付けられた前記音声入力方向適合度を抽出し、その音声入力方向適合度で前記音声認識尤度を重み付けして、フレーズ確信度を算出し、
前記フレーズ決定部は、前記フレーズ確信度算出部が抽出した前記最大のフレーズ確信度に係る仮説フレーズを、当該仮説フレーズに係る前記フレーズ確信度算出部が推定した音源方向からの音声を音声認識したフレーズとする
ことを特徴とする請求項3に記載されたロボット。 A phrase storage unit and a phrase determination unit;
The phrase storage unit includes a plurality of phrase patterns obtained by collecting phrases that can be input in advance, a direction angle value pattern that indicates a direction with the support shaft as a center and a direction of the head, and the phrase pattern is the direction. Three of the voice input direction matching degree indicating correctness input from the direction of the angle value pattern is stored in association with each other,
The phrase certainty calculation unit obtains a plurality of hypothesis phrases generated by the speech recognition unit and the speech recognition likelihood thereof, and uses the hypothesis phrase and the estimated sound source angle extracted by the angle extraction unit, The speech input direction suitability associated with the phrase pattern and the direction angle value pattern stored in the phrase storage unit is extracted, the speech recognition likelihood is weighted by the speech input direction suitability, and the phrase Calculate confidence,
The phrase determination unit recognizes the speech from the sound source direction estimated by the phrase certainty calculation unit related to the hypothesis phrase as a hypothesis phrase related to the maximum phrase certainty factor extracted by the phrase certainty calculation unit. The robot according to claim 3, wherein the robot is a phrase.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010109213A JP5595112B2 (en) | 2010-05-11 | 2010-05-11 | robot |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010109213A JP5595112B2 (en) | 2010-05-11 | 2010-05-11 | robot |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011237621A JP2011237621A (en) | 2011-11-24 |
| JP5595112B2 true JP5595112B2 (en) | 2014-09-24 |
Family
ID=45325664
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010109213A Active JP5595112B2 (en) | 2010-05-11 | 2010-05-11 | robot |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5595112B2 (en) |
Families Citing this family (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9318108B2 (en) | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| US8977255B2 (en) | 2007-04-03 | 2015-03-10 | Apple Inc. | Method and system for operating a multi-function portable electronic device using voice-activation |
| US8676904B2 (en) | 2008-10-02 | 2014-03-18 | Apple Inc. | Electronic devices with voice command and contextual data processing capabilities |
| US10706373B2 (en) | 2011-06-03 | 2020-07-07 | Apple Inc. | Performing actions associated with task items that represent tasks to perform |
| US10417037B2 (en) | 2012-05-15 | 2019-09-17 | Apple Inc. | Systems and methods for integrating third party services with a digital assistant |
| JP2016508007A (en) | 2013-02-07 | 2016-03-10 | アップル インコーポレイテッド | Voice trigger for digital assistant |
| US10652394B2 (en) | 2013-03-14 | 2020-05-12 | Apple Inc. | System and method for processing voicemail |
| US10748529B1 (en) | 2013-03-15 | 2020-08-18 | Apple Inc. | Voice activated device for use with a voice-based digital assistant |
| US10176167B2 (en) | 2013-06-09 | 2019-01-08 | Apple Inc. | System and method for inferring user intent from speech inputs |
| US9286897B2 (en) * | 2013-09-27 | 2016-03-15 | Amazon Technologies, Inc. | Speech recognizer with multi-directional decoding |
| US9966065B2 (en) | 2014-05-30 | 2018-05-08 | Apple Inc. | Multi-command single utterance input method |
| US9715875B2 (en) | 2014-05-30 | 2017-07-25 | Apple Inc. | Reducing the need for manual start/end-pointing and trigger phrases |
| US10170123B2 (en) | 2014-05-30 | 2019-01-01 | Apple Inc. | Intelligent assistant for home automation |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| US9886953B2 (en) | 2015-03-08 | 2018-02-06 | Apple Inc. | Virtual assistant activation |
| US10200824B2 (en) | 2015-05-27 | 2019-02-05 | Apple Inc. | Systems and methods for proactively identifying and surfacing relevant content on a touch-sensitive device |
| US20160378747A1 (en) | 2015-06-29 | 2016-12-29 | Apple Inc. | Virtual assistant for media playback |
| US10331312B2 (en) | 2015-09-08 | 2019-06-25 | Apple Inc. | Intelligent automated assistant in a media environment |
| US10740384B2 (en) | 2015-09-08 | 2020-08-11 | Apple Inc. | Intelligent automated assistant for media search and playback |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10956666B2 (en) | 2015-11-09 | 2021-03-23 | Apple Inc. | Unconventional virtual assistant interactions |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| JP6485370B2 (en) * | 2016-01-14 | 2019-03-20 | トヨタ自動車株式会社 | robot |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| CN106328137A (en) * | 2016-08-19 | 2017-01-11 | 镇江惠通电子有限公司 | Voice control method, voice control device and voice control system |
| US10170110B2 (en) * | 2016-11-17 | 2019-01-01 | Robert Bosch Gmbh | System and method for ranking of hybrid speech recognition results with neural networks |
| JP6889597B2 (en) * | 2017-04-21 | 2021-06-18 | 日本放送協会 | robot |
| US10726832B2 (en) | 2017-05-11 | 2020-07-28 | Apple Inc. | Maintaining privacy of personal information |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| DK201770429A1 (en) | 2017-05-12 | 2018-12-14 | Apple Inc. | Low-latency intelligent automated assistant |
| US10303715B2 (en) | 2017-05-16 | 2019-05-28 | Apple Inc. | Intelligent automated assistant for media exploration |
| US20180336892A1 (en) | 2017-05-16 | 2018-11-22 | Apple Inc. | Detecting a trigger of a digital assistant |
| US20210031378A1 (en) * | 2018-01-09 | 2021-02-04 | Sony Corporation | Information processor, information processing method, and program |
| US10818288B2 (en) | 2018-03-26 | 2020-10-27 | Apple Inc. | Natural assistant interaction |
| US10928918B2 (en) | 2018-05-07 | 2021-02-23 | Apple Inc. | Raise to speak |
| US11145294B2 (en) | 2018-05-07 | 2021-10-12 | Apple Inc. | Intelligent automated assistant for delivering content from user experiences |
| DK180639B1 (en) | 2018-06-01 | 2021-11-04 | Apple Inc | DISABILITY OF ATTENTION-ATTENTIVE VIRTUAL ASSISTANT |
| DK179822B1 (en) | 2018-06-01 | 2019-07-12 | Apple Inc. | Voice interaction at a primary device to access call functionality of a companion device |
| US10892996B2 (en) | 2018-06-01 | 2021-01-12 | Apple Inc. | Variable latency device coordination |
| WO2020138943A1 (en) * | 2018-12-27 | 2020-07-02 | 한화테크윈 주식회사 | Voice recognition apparatus and method |
| KR20200081274A (en) | 2018-12-27 | 2020-07-07 | 한화테크윈 주식회사 | Device and method to recognize voice |
| CN111383649A (en) * | 2018-12-28 | 2020-07-07 | 深圳市优必选科技有限公司 | Robot and audio processing method thereof |
| DK201970509A1 (en) | 2019-05-06 | 2021-01-15 | Apple Inc | Spoken notifications |
| US11140099B2 (en) | 2019-05-21 | 2021-10-05 | Apple Inc. | Providing message response suggestions |
| DK180129B1 (en) | 2019-05-31 | 2020-06-02 | Apple Inc. | User activity shortcut suggestions |
| DK201970511A1 (en) | 2019-05-31 | 2021-02-15 | Apple Inc | Voice identification in digital assistant systems |
| US11183193B1 (en) | 2020-05-11 | 2021-11-23 | Apple Inc. | Digital assistant hardware abstraction |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3522954B2 (en) * | 1996-03-15 | 2004-04-26 | 株式会社東芝 | Microphone array input type speech recognition apparatus and method |
| JP2005250233A (en) * | 2004-03-05 | 2005-09-15 | Sanyo Electric Co Ltd | Robot device |
| JP2005342862A (en) * | 2004-06-04 | 2005-12-15 | Nec Corp | Robot |
| JP4476870B2 (en) * | 2005-05-18 | 2010-06-09 | 中部電力株式会社 | Correction method of microphone output for sound source search, low frequency generator, sound source search system, and microphone frame |
| EP1941411B1 (en) * | 2005-09-30 | 2011-09-14 | iRobot Corporation | Companion robot for personal interaction |
| JP2007221300A (en) * | 2006-02-15 | 2007-08-30 | Fujitsu Ltd | Robot and control method of robot |
| JP4910568B2 (en) * | 2006-08-25 | 2012-04-04 | 株式会社日立製作所 | Paper rubbing sound removal device |
| JP2009020423A (en) * | 2007-07-13 | 2009-01-29 | Fujitsu Ten Ltd | Speech recognition device and speech recognition method |
| JP2009239348A (en) * | 2008-03-25 | 2009-10-15 | Yamaha Corp | Imager |
-
2010
- 2010-05-11 JP JP2010109213A patent/JP5595112B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2011237621A (en) | 2011-11-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5595112B2 (en) | robot | |
| CN109141620B (en) | Sound source separation information detection device, robot, sound source separation information detection method, and storage medium | |
| CN112088315B (en) | Multi-mode speech localization | |
| JP6520878B2 (en) | Voice acquisition system and voice acquisition method | |
| EP3480820B1 (en) | Electronic device and method for processing audio signals | |
| Valin et al. | Localization of simultaneous moving sound sources for mobile robot using a frequency-domain steered beamformer approach | |
| US7536029B2 (en) | Apparatus and method performing audio-video sensor fusion for object localization, tracking, and separation | |
| JP5724125B2 (en) | Sound source localization device | |
| US10127922B2 (en) | Sound source identification apparatus and sound source identification method | |
| JP5328744B2 (en) | Speech recognition apparatus and speech recognition method | |
| KR100754384B1 (en) | Method and apparatus for robust speaker localization and camera control system employing the same | |
| JP5952692B2 (en) | Sound source direction estimating apparatus, sound processing system, sound source direction estimating method, and sound source direction estimating program | |
| EP1643769B1 (en) | Apparatus and method performing audio-video sensor fusion for object localization, tracking and separation | |
| CN111370014A (en) | Multi-stream target-speech detection and channel fusion | |
| US11605179B2 (en) | System for determining anatomical feature orientation | |
| JP6467736B2 (en) | Sound source position estimating apparatus, sound source position estimating method, and sound source position estimating program | |
| JP2011191423A (en) | Device and method for recognition of speech | |
| JP2007221300A (en) | Robot and control method of robot | |
| CN111048113A (en) | Sound direction positioning processing method, device and system, computer equipment and storage medium | |
| Wakabayashi et al. | Multiple sound source position estimation by drone audition based on data association between sound source localization and identification | |
| JP2018169473A (en) | Voice processing device, voice processing method and program | |
| TW202147862A (en) | Robust speaker localization in presence of strong noise interference systems and methods | |
| CN108665907B (en) | Voice recognition device, voice recognition method, recording medium, and robot | |
| US8548802B2 (en) | Acoustic data processor and acoustic data processing method for reduction of noise based on motion status | |
| JP5535746B2 (en) | Sound data processing apparatus and sound data processing method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20121127 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130808 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130827 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131028 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140422 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140612 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140708 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140805 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5595112 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |