JP4987623B2 - ユーザと音声により対話する装置および方法 - Google Patents
ユーザと音声により対話する装置および方法 Download PDFInfo
- Publication number
- JP4987623B2 JP4987623B2 JP2007213828A JP2007213828A JP4987623B2 JP 4987623 B2 JP4987623 B2 JP 4987623B2 JP 2007213828 A JP2007213828 A JP 2007213828A JP 2007213828 A JP2007213828 A JP 2007213828A JP 4987623 B2 JP4987623 B2 JP 4987623B2
- Authority
- JP
- Japan
- Prior art keywords
- candidate
- response
- recognition result
- phrase
- sentence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images













Description
上記実施の形態では、図6に示したような固定のテンプレートにしたがって応答フレーズを生成し、生成した応答フレーズを順次出力していた。
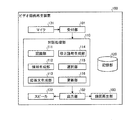
52 ROM
53 RAM
54 通信I/F
61 バス
100 ビデオ録画再生装置
101 受付部
102 出力部
103 録画再生部
110 対話処理部
111 認識部
112 候補生成部
113 応答文生成部
114 修正語句生成部
115 選択部
116 更新部
120 記憶部
131 マイク
132 スピーカ
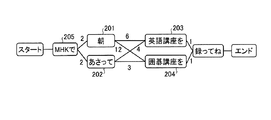
201〜205 ノード
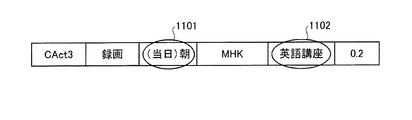
1101、1102 属性値
Claims (7)
- 入力した音声を認識し、認識結果の候補を複数生成する認識部と、
第1音声に対する複数の第1認識結果の候補を解析して、複数の第1認識結果の候補それぞれに対応する応答の候補と、第1認識結果の候補に対する応答の候補の確からしさを表す尤度とを生成する候補生成部と、
前記尤度が最大となる第1認識結果の第1候補に対する応答の候補を選択し、選択した前記第1認識結果の第1候補に対する応答の候補を表す語句を含む第1認識結果の第1候補に対する応答文を生成する応答文生成部と、
第1認識結果の第1候補に対する応答文を音声信号に変換した合成音声を出力する出力部と、
前記合成音声の出力中に第2音声が入力された場合、前記候補生成部で生成された第2音声に対する第2認識結果の候補を解析して、前記第1認識結果の第1候補に対する応答文に含まれる語句を修正した修正語句を生成する修正語句生成部と、
複数の第1認識結果の候補に対する応答の候補から、前記修正語句と同一の語句を含む第1認識結果の別の候補に対する応答の候補を取得し、第1認識結果の別の候補に対する応答の候補のうち前記尤度が最大の第1認識結果の別の候補に対する応答の候補を選択する選択部と、
選択された第1認識結果の別の候補に対する応答の候補の語句で前記応答文を更新する更新部と、を備え、
前記出力部は、前記応答文が更新された場合、更新前の前記応答文の合成音声に代えて、更新後の前記応答文の合成音声を出力し、
前記応答文生成部は、前記応答の候補を表す語句を、該語句の曖昧性が少ない順に文頭から含む前記応答文を生成すること、
を特徴とする音声対話装置。 - 前記出力部は、前記応答文が更新された場合、更新前の前記応答文で出力されていない語句に対応する語句から更新後の前記応答文の合成音声を出力すること、
を特徴とする請求項1に記載の音声対話装置。 - 入力した音声を認識し、認識結果の候補を複数生成する認識部と、
第1音声に対する複数の第1認識結果の候補を解析して、複数の第1認識結果の候補それぞれに対応する応答の候補と、第1認識結果の候補に対する応答の候補の確からしさを表す尤度とを生成する候補生成部と、
前記尤度が最大となる第1認識結果の第1候補に対する応答の候補を選択し、選択した前記第1認識結果の第1候補に対する応答の候補を表す語句を含む第1認識結果の第1候補に対する応答文を生成する応答文生成部と、
第1認識結果の第1候補に対する応答文を音声信号に変換した合成音声を出力する出力部と、
前記合成音声の出力中に第2音声が入力された場合、前記候補生成部で生成された第2音声に対する第2認識結果の候補を解析して、前記第1認識結果の第1候補に対する応答文に含まれる語句を修正した修正語句を生成する修正語句生成部と、
複数の第1認識結果の候補に対する応答の候補から、前記修正語句と同一の語句を含む第1認識結果の別の候補に対する応答の候補を取得し、第1認識結果の別の候補に対する応答の候補のうち前記尤度が最大の第1認識結果の別の候補に対する応答の候補を選択する選択部と、
選択された第1認識結果の別の候補に対する応答の候補の語句で前記応答文を更新する更新部と、を備え、
前記出力部は、前記応答文が更新された場合、更新前の前記応答文で出力されていない語句に対応する語句から、更新前の前記応答文の合成音声に代えて、更新後の前記応答文の合成音声を出力すること、
を特徴とする音声対話装置。 - 前記出力部は、前記応答文に含まれる語句のうち、更新前の前記応答文で出力済みの語句が、更新された語句のうち最も文頭に近い語句より文末側に含まれる場合に、更新された語句のうち最も文頭に近い語句から更新後の前記応答文の合成音声を出力すること、
を特徴とする請求項1〜3のいずれか1つに記載の音声対話装置。 - 前記出力部は、前記応答文に含まれる語句のうち、更新前の前記応答文で出力済みの語句が、更新された語句のうち最も文頭に近い語句より文頭側に含まれる場合に、出力済みの語句の次に文末側に含まれる語句から更新後の前記応答文の合成音声を出力すること、
を特徴とする請求項1〜3のいずれか1つに記載の音声対話装置。 - 認識部が、入力した音声を認識し、認識結果の候補を複数生成する認識ステップと、
候補生成部が、第1音声に対する複数の第1認識結果の候補を解析して、複数の第1認識結果の候補それぞれに対応する応答の候補と、第1認識結果の候補に対する応答の候補の確からしさを表す尤度とを生成する候補生成ステップと、
応答文生成部が、前記尤度が最大となる第1認識結果の第1候補に対する応答の候補を選択し、選択した前記第1認識結果の第1候補に対する応答の候補を表す語句を含む第1認識結果の第1候補に対する応答文を生成する応答文生成ステップと、
出力部が、第1認識結果の第1候補に対する応答文を音声信号に変換した合成音声を出力する第1出力ステップと、
修正語句生成部が、前記合成音声の出力中に第2音声が入力された場合、前記候補生成ステップで生成された第2音声に対する第2認識結果の候補を解析して、前記第1認識結果の第1候補に対する応答文に含まれる語句を修正した修正語句を生成する修正語句生成ステップと、
選択部が、複数の第1認識結果の候補に対する応答の候補から、前記修正語句と同一の語句を含む第1認識結果の別の候補に対する応答の候補を取得し、第1認識結果の別の候補に対する応答の候補のうち前記尤度が最大の第1認識結果の別の候補に対する応答の候補を選択する選択ステップと、
更新部が、選択された第1認識結果の別の候補に対する応答の候補の語句で前記応答文を更新する更新ステップと、
出力部が、前記応答文が更新された場合、更新前の前記応答文の合成音声に代えて、更新後の前記応答文の合成音声を出力する第2出力ステップと、を備え、
前記応答文生成ステップは、前記応答の候補を表す語句を、該語句の曖昧性が少ない順に文頭から含む前記応答文を生成すること、
を特徴とする音声対話方法。 - 認識部が、入力した音声を認識し、認識結果の候補を複数生成する認識ステップと、
候補生成部が、第1音声に対する複数の第1認識結果の候補を解析して、複数の第1認識結果の候補それぞれに対応する応答の候補と、第1認識結果の候補に対する応答の候補の確からしさを表す尤度とを生成する候補生成ステップと、
応答文生成部が、前記尤度が最大となる第1認識結果の第1候補に対する応答の候補を選択し、選択した前記第1認識結果の第1候補に対する応答の候補を表す語句を含む第1認識結果の第1候補に対する応答文を生成する応答文生成ステップと、
出力部が、第1認識結果の第1候補に対する応答文を音声信号に変換した合成音声を出力する第1出力ステップと、
修正語句生成部が、前記合成音声の出力中に第2音声が入力された場合、前記候補生成ステップで生成された第2音声に対する第2認識結果の候補を解析して、前記第1認識結果の第1候補に対する応答文に含まれる語句を修正した修正語句を生成する修正語句生成ステップと、
選択部が、複数の第1認識結果の候補に対する応答の候補から、前記修正語句と同一の語句を含む第1認識結果の別の候補に対する応答の候補を取得し、第1認識結果の別の候補に対する応答の候補のうち前記尤度が最大の第1認識結果の別の候補に対する応答の候補を選択する選択ステップと、
更新部が、選択された第1認識結果の別の候補に対する応答の候補の語句で前記応答文を更新する更新ステップと、
出力部が、前記応答文が更新された場合、更新前の前記応答文で出力されていない語句に対応する語句から、更新前の前記応答文の合成音声に代えて、更新後の前記応答文の合成音声を出力する第2出力ステップと、を含むこと、
を特徴とする音声対話方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007213828A JP4987623B2 (ja) | 2007-08-20 | 2007-08-20 | ユーザと音声により対話する装置および方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007213828A JP4987623B2 (ja) | 2007-08-20 | 2007-08-20 | ユーザと音声により対話する装置および方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2009047920A JP2009047920A (ja) | 2009-03-05 |
| JP4987623B2 true JP4987623B2 (ja) | 2012-07-25 |
Family
ID=40500197
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007213828A Active JP4987623B2 (ja) | 2007-08-20 | 2007-08-20 | ユーザと音声により対話する装置および方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4987623B2 (ja) |
Families Citing this family (159)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8645137B2 (en) | 2000-03-16 | 2014-02-04 | Apple Inc. | Fast, language-independent method for user authentication by voice |
| US8677377B2 (en) | 2005-09-08 | 2014-03-18 | Apple Inc. | Method and apparatus for building an intelligent automated assistant |
| US9318108B2 (en) * | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| US8977255B2 (en) | 2007-04-03 | 2015-03-10 | Apple Inc. | Method and system for operating a multi-function portable electronic device using voice-activation |
| US10002189B2 (en) | 2007-12-20 | 2018-06-19 | Apple Inc. | Method and apparatus for searching using an active ontology |
| US9330720B2 (en) | 2008-01-03 | 2016-05-03 | Apple Inc. | Methods and apparatus for altering audio output signals |
| US8996376B2 (en) | 2008-04-05 | 2015-03-31 | Apple Inc. | Intelligent text-to-speech conversion |
| US10496753B2 (en) | 2010-01-18 | 2019-12-03 | Apple Inc. | Automatically adapting user interfaces for hands-free interaction |
| US20100030549A1 (en) | 2008-07-31 | 2010-02-04 | Lee Michael M | Mobile device having human language translation capability with positional feedback |
| US8676904B2 (en) | 2008-10-02 | 2014-03-18 | Apple Inc. | Electronic devices with voice command and contextual data processing capabilities |
| JP4992925B2 (ja) * | 2009-03-23 | 2012-08-08 | トヨタ自動車株式会社 | 音声対話装置及びプログラム |
| US20120309363A1 (en) | 2011-06-03 | 2012-12-06 | Apple Inc. | Triggering notifications associated with tasks items that represent tasks to perform |
| US10241644B2 (en) | 2011-06-03 | 2019-03-26 | Apple Inc. | Actionable reminder entries |
| US9858925B2 (en) | 2009-06-05 | 2018-01-02 | Apple Inc. | Using context information to facilitate processing of commands in a virtual assistant |
| US10241752B2 (en) | 2011-09-30 | 2019-03-26 | Apple Inc. | Interface for a virtual digital assistant |
| US9431006B2 (en) | 2009-07-02 | 2016-08-30 | Apple Inc. | Methods and apparatuses for automatic speech recognition |
| US10705794B2 (en) | 2010-01-18 | 2020-07-07 | Apple Inc. | Automatically adapting user interfaces for hands-free interaction |
| US10276170B2 (en) | 2010-01-18 | 2019-04-30 | Apple Inc. | Intelligent automated assistant |
| US10679605B2 (en) | 2010-01-18 | 2020-06-09 | Apple Inc. | Hands-free list-reading by intelligent automated assistant |
| US10553209B2 (en) | 2010-01-18 | 2020-02-04 | Apple Inc. | Systems and methods for hands-free notification summaries |
| WO2011089450A2 (en) | 2010-01-25 | 2011-07-28 | Andrew Peter Nelson Jerram | Apparatuses, methods and systems for a digital conversation management platform |
| US8682667B2 (en) | 2010-02-25 | 2014-03-25 | Apple Inc. | User profiling for selecting user specific voice input processing information |
| US9262612B2 (en) | 2011-03-21 | 2016-02-16 | Apple Inc. | Device access using voice authentication |
| US10057736B2 (en) | 2011-06-03 | 2018-08-21 | Apple Inc. | Active transport based notifications |
| US8994660B2 (en) | 2011-08-29 | 2015-03-31 | Apple Inc. | Text correction processing |
| US10134385B2 (en) | 2012-03-02 | 2018-11-20 | Apple Inc. | Systems and methods for name pronunciation |
| US9483461B2 (en) | 2012-03-06 | 2016-11-01 | Apple Inc. | Handling speech synthesis of content for multiple languages |
| US9280610B2 (en) | 2012-05-14 | 2016-03-08 | Apple Inc. | Crowd sourcing information to fulfill user requests |
| US10417037B2 (en) | 2012-05-15 | 2019-09-17 | Apple Inc. | Systems and methods for integrating third party services with a digital assistant |
| US9721563B2 (en) | 2012-06-08 | 2017-08-01 | Apple Inc. | Name recognition system |
| US9495129B2 (en) | 2012-06-29 | 2016-11-15 | Apple Inc. | Device, method, and user interface for voice-activated navigation and browsing of a document |
| US9547647B2 (en) | 2012-09-19 | 2017-01-17 | Apple Inc. | Voice-based media searching |
| EP3809407A1 (en) | 2013-02-07 | 2021-04-21 | Apple Inc. | Voice trigger for a digital assistant |
| US9582608B2 (en) | 2013-06-07 | 2017-02-28 | Apple Inc. | Unified ranking with entropy-weighted information for phrase-based semantic auto-completion |
| WO2014197334A2 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for user-specified pronunciation of words for speech synthesis and recognition |
| WO2014197336A1 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for detecting errors in interactions with a voice-based digital assistant |
| WO2014197335A1 (en) | 2013-06-08 | 2014-12-11 | Apple Inc. | Interpreting and acting upon commands that involve sharing information with remote devices |
| US10176167B2 (en) | 2013-06-09 | 2019-01-08 | Apple Inc. | System and method for inferring user intent from speech inputs |
| KR101922663B1 (ko) | 2013-06-09 | 2018-11-28 | 애플 인크. | 디지털 어시스턴트의 둘 이상의 인스턴스들에 걸친 대화 지속성을 가능하게 하기 위한 디바이스, 방법 및 그래픽 사용자 인터페이스 |
| US10296160B2 (en) | 2013-12-06 | 2019-05-21 | Apple Inc. | Method for extracting salient dialog usage from live data |
| US10170123B2 (en) | 2014-05-30 | 2019-01-01 | Apple Inc. | Intelligent assistant for home automation |
| US10078631B2 (en) | 2014-05-30 | 2018-09-18 | Apple Inc. | Entropy-guided text prediction using combined word and character n-gram language models |
| US9633004B2 (en) | 2014-05-30 | 2017-04-25 | Apple Inc. | Better resolution when referencing to concepts |
| US9715875B2 (en) | 2014-05-30 | 2017-07-25 | Apple Inc. | Reducing the need for manual start/end-pointing and trigger phrases |
| US9785630B2 (en) | 2014-05-30 | 2017-10-10 | Apple Inc. | Text prediction using combined word N-gram and unigram language models |
| US9760559B2 (en) | 2014-05-30 | 2017-09-12 | Apple Inc. | Predictive text input |
| US9430463B2 (en) | 2014-05-30 | 2016-08-30 | Apple Inc. | Exemplar-based natural language processing |
| US9966065B2 (en) | 2014-05-30 | 2018-05-08 | Apple Inc. | Multi-command single utterance input method |
| US9842101B2 (en) | 2014-05-30 | 2017-12-12 | Apple Inc. | Predictive conversion of language input |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| US10659851B2 (en) | 2014-06-30 | 2020-05-19 | Apple Inc. | Real-time digital assistant knowledge updates |
| US10446141B2 (en) | 2014-08-28 | 2019-10-15 | Apple Inc. | Automatic speech recognition based on user feedback |
| US9818400B2 (en) | 2014-09-11 | 2017-11-14 | Apple Inc. | Method and apparatus for discovering trending terms in speech requests |
| US10789041B2 (en) | 2014-09-12 | 2020-09-29 | Apple Inc. | Dynamic thresholds for always listening speech trigger |
| US9886432B2 (en) | 2014-09-30 | 2018-02-06 | Apple Inc. | Parsimonious handling of word inflection via categorical stem + suffix N-gram language models |
| US10127911B2 (en) | 2014-09-30 | 2018-11-13 | Apple Inc. | Speaker identification and unsupervised speaker adaptation techniques |
| US10074360B2 (en) | 2014-09-30 | 2018-09-11 | Apple Inc. | Providing an indication of the suitability of speech recognition |
| US9646609B2 (en) | 2014-09-30 | 2017-05-09 | Apple Inc. | Caching apparatus for serving phonetic pronunciations |
| US9668121B2 (en) | 2014-09-30 | 2017-05-30 | Apple Inc. | Social reminders |
| US10552013B2 (en) | 2014-12-02 | 2020-02-04 | Apple Inc. | Data detection |
| US10152299B2 (en) | 2015-03-06 | 2018-12-11 | Apple Inc. | Reducing response latency of intelligent automated assistants |
| US9865280B2 (en) | 2015-03-06 | 2018-01-09 | Apple Inc. | Structured dictation using intelligent automated assistants |
| US9721566B2 (en) | 2015-03-08 | 2017-08-01 | Apple Inc. | Competing devices responding to voice triggers |
| US10567477B2 (en) | 2015-03-08 | 2020-02-18 | Apple Inc. | Virtual assistant continuity |
| US9886953B2 (en) | 2015-03-08 | 2018-02-06 | Apple Inc. | Virtual assistant activation |
| US9899019B2 (en) | 2015-03-18 | 2018-02-20 | Apple Inc. | Systems and methods for structured stem and suffix language models |
| US9842105B2 (en) | 2015-04-16 | 2017-12-12 | Apple Inc. | Parsimonious continuous-space phrase representations for natural language processing |
| US10460227B2 (en) | 2015-05-15 | 2019-10-29 | Apple Inc. | Virtual assistant in a communication session |
| US10083688B2 (en) | 2015-05-27 | 2018-09-25 | Apple Inc. | Device voice control for selecting a displayed affordance |
| US10127220B2 (en) | 2015-06-04 | 2018-11-13 | Apple Inc. | Language identification from short strings |
| US9578173B2 (en) | 2015-06-05 | 2017-02-21 | Apple Inc. | Virtual assistant aided communication with 3rd party service in a communication session |
| US10101822B2 (en) | 2015-06-05 | 2018-10-16 | Apple Inc. | Language input correction |
| US11025565B2 (en) | 2015-06-07 | 2021-06-01 | Apple Inc. | Personalized prediction of responses for instant messaging |
| US10186254B2 (en) | 2015-06-07 | 2019-01-22 | Apple Inc. | Context-based endpoint detection |
| US10255907B2 (en) | 2015-06-07 | 2019-04-09 | Apple Inc. | Automatic accent detection using acoustic models |
| US20160378747A1 (en) | 2015-06-29 | 2016-12-29 | Apple Inc. | Virtual assistant for media playback |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US9697820B2 (en) | 2015-09-24 | 2017-07-04 | Apple Inc. | Unit-selection text-to-speech synthesis using concatenation-sensitive neural networks |
| US10366158B2 (en) | 2015-09-29 | 2019-07-30 | Apple Inc. | Efficient word encoding for recurrent neural network language models |
| US11010550B2 (en) | 2015-09-29 | 2021-05-18 | Apple Inc. | Unified language modeling framework for word prediction, auto-completion and auto-correction |
| US11587559B2 (en) | 2015-09-30 | 2023-02-21 | Apple Inc. | Intelligent device identification |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10049668B2 (en) | 2015-12-02 | 2018-08-14 | Apple Inc. | Applying neural network language models to weighted finite state transducers for automatic speech recognition |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| US10446143B2 (en) | 2016-03-14 | 2019-10-15 | Apple Inc. | Identification of voice inputs providing credentials |
| US9934775B2 (en) | 2016-05-26 | 2018-04-03 | Apple Inc. | Unit-selection text-to-speech synthesis based on predicted concatenation parameters |
| US9972304B2 (en) | 2016-06-03 | 2018-05-15 | Apple Inc. | Privacy preserving distributed evaluation framework for embedded personalized systems |
| US11227589B2 (en) | 2016-06-06 | 2022-01-18 | Apple Inc. | Intelligent list reading |
| US10249300B2 (en) | 2016-06-06 | 2019-04-02 | Apple Inc. | Intelligent list reading |
| US10049663B2 (en) | 2016-06-08 | 2018-08-14 | Apple, Inc. | Intelligent automated assistant for media exploration |
| DK179309B1 (en) | 2016-06-09 | 2018-04-23 | Apple Inc | Intelligent automated assistant in a home environment |
| US10509862B2 (en) | 2016-06-10 | 2019-12-17 | Apple Inc. | Dynamic phrase expansion of language input |
| US10067938B2 (en) | 2016-06-10 | 2018-09-04 | Apple Inc. | Multilingual word prediction |
| US10490187B2 (en) | 2016-06-10 | 2019-11-26 | Apple Inc. | Digital assistant providing automated status report |
| US10192552B2 (en) | 2016-06-10 | 2019-01-29 | Apple Inc. | Digital assistant providing whispered speech |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| DK179049B1 (en) | 2016-06-11 | 2017-09-18 | Apple Inc | Data driven natural language event detection and classification |
| DK179343B1 (en) | 2016-06-11 | 2018-05-14 | Apple Inc | Intelligent task discovery |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| US10474753B2 (en) | 2016-09-07 | 2019-11-12 | Apple Inc. | Language identification using recurrent neural networks |
| US10043516B2 (en) | 2016-09-23 | 2018-08-07 | Apple Inc. | Intelligent automated assistant |
| US11281993B2 (en) | 2016-12-05 | 2022-03-22 | Apple Inc. | Model and ensemble compression for metric learning |
| US10593346B2 (en) | 2016-12-22 | 2020-03-17 | Apple Inc. | Rank-reduced token representation for automatic speech recognition |
| US11204787B2 (en) | 2017-01-09 | 2021-12-21 | Apple Inc. | Application integration with a digital assistant |
| US10417266B2 (en) | 2017-05-09 | 2019-09-17 | Apple Inc. | Context-aware ranking of intelligent response suggestions |
| DK201770383A1 (en) | 2017-05-09 | 2018-12-14 | Apple Inc. | USER INTERFACE FOR CORRECTING RECOGNITION ERRORS |
| DK201770439A1 (en) | 2017-05-11 | 2018-12-13 | Apple Inc. | Offline personal assistant |
| US10726832B2 (en) | 2017-05-11 | 2020-07-28 | Apple Inc. | Maintaining privacy of personal information |
| US10395654B2 (en) | 2017-05-11 | 2019-08-27 | Apple Inc. | Text normalization based on a data-driven learning network |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| US11301477B2 (en) | 2017-05-12 | 2022-04-12 | Apple Inc. | Feedback analysis of a digital assistant |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| DK201770429A1 (en) | 2017-05-12 | 2018-12-14 | Apple Inc. | LOW-LATENCY INTELLIGENT AUTOMATED ASSISTANT |
| DK201770431A1 (en) | 2017-05-15 | 2018-12-20 | Apple Inc. | Optimizing dialogue policy decisions for digital assistants using implicit feedback |
| DK201770432A1 (en) | 2017-05-15 | 2018-12-21 | Apple Inc. | Hierarchical belief states for digital assistants |
| US10311144B2 (en) | 2017-05-16 | 2019-06-04 | Apple Inc. | Emoji word sense disambiguation |
| DK179549B1 (en) | 2017-05-16 | 2019-02-12 | Apple Inc. | FAR-FIELD EXTENSION FOR DIGITAL ASSISTANT SERVICES |
| US10403278B2 (en) | 2017-05-16 | 2019-09-03 | Apple Inc. | Methods and systems for phonetic matching in digital assistant services |
| US10303715B2 (en) | 2017-05-16 | 2019-05-28 | Apple Inc. | Intelligent automated assistant for media exploration |
| US10657328B2 (en) | 2017-06-02 | 2020-05-19 | Apple Inc. | Multi-task recurrent neural network architecture for efficient morphology handling in neural language modeling |
| EP3671730A4 (en) * | 2017-08-17 | 2020-07-15 | Sony Corporation | INFORMATION PROCESSING DEVICE, INFORMATION PROCESSING PROCESS AND PROGRAM |
| US10445429B2 (en) | 2017-09-21 | 2019-10-15 | Apple Inc. | Natural language understanding using vocabularies with compressed serialized tries |
| US10755051B2 (en) | 2017-09-29 | 2020-08-25 | Apple Inc. | Rule-based natural language processing |
| US10636424B2 (en) | 2017-11-30 | 2020-04-28 | Apple Inc. | Multi-turn canned dialog |
| US10733982B2 (en) | 2018-01-08 | 2020-08-04 | Apple Inc. | Multi-directional dialog |
| US10733375B2 (en) | 2018-01-31 | 2020-08-04 | Apple Inc. | Knowledge-based framework for improving natural language understanding |
| US10789959B2 (en) | 2018-03-02 | 2020-09-29 | Apple Inc. | Training speaker recognition models for digital assistants |
| US10592604B2 (en) | 2018-03-12 | 2020-03-17 | Apple Inc. | Inverse text normalization for automatic speech recognition |
| US10818288B2 (en) | 2018-03-26 | 2020-10-27 | Apple Inc. | Natural assistant interaction |
| US10909331B2 (en) | 2018-03-30 | 2021-02-02 | Apple Inc. | Implicit identification of translation payload with neural machine translation |
| US11145294B2 (en) | 2018-05-07 | 2021-10-12 | Apple Inc. | Intelligent automated assistant for delivering content from user experiences |
| US10928918B2 (en) | 2018-05-07 | 2021-02-23 | Apple Inc. | Raise to speak |
| US10984780B2 (en) | 2018-05-21 | 2021-04-20 | Apple Inc. | Global semantic word embeddings using bi-directional recurrent neural networks |
| DK179822B1 (da) | 2018-06-01 | 2019-07-12 | Apple Inc. | Voice interaction at a primary device to access call functionality of a companion device |
| US10892996B2 (en) | 2018-06-01 | 2021-01-12 | Apple Inc. | Variable latency device coordination |
| US11386266B2 (en) | 2018-06-01 | 2022-07-12 | Apple Inc. | Text correction |
| DK180639B1 (en) | 2018-06-01 | 2021-11-04 | Apple Inc | DISABILITY OF ATTENTION-ATTENTIVE VIRTUAL ASSISTANT |
| DK201870355A1 (en) | 2018-06-01 | 2019-12-16 | Apple Inc. | VIRTUAL ASSISTANT OPERATION IN MULTI-DEVICE ENVIRONMENTS |
| US10496705B1 (en) | 2018-06-03 | 2019-12-03 | Apple Inc. | Accelerated task performance |
| US11010561B2 (en) | 2018-09-27 | 2021-05-18 | Apple Inc. | Sentiment prediction from textual data |
| US10839159B2 (en) | 2018-09-28 | 2020-11-17 | Apple Inc. | Named entity normalization in a spoken dialog system |
| US11170166B2 (en) | 2018-09-28 | 2021-11-09 | Apple Inc. | Neural typographical error modeling via generative adversarial networks |
| US11462215B2 (en) | 2018-09-28 | 2022-10-04 | Apple Inc. | Multi-modal inputs for voice commands |
| US11475898B2 (en) | 2018-10-26 | 2022-10-18 | Apple Inc. | Low-latency multi-speaker speech recognition |
| US11638059B2 (en) | 2019-01-04 | 2023-04-25 | Apple Inc. | Content playback on multiple devices |
| US11348573B2 (en) | 2019-03-18 | 2022-05-31 | Apple Inc. | Multimodality in digital assistant systems |
| US11423908B2 (en) | 2019-05-06 | 2022-08-23 | Apple Inc. | Interpreting spoken requests |
| DK201970509A1 (en) | 2019-05-06 | 2021-01-15 | Apple Inc | Spoken notifications |
| US11475884B2 (en) | 2019-05-06 | 2022-10-18 | Apple Inc. | Reducing digital assistant latency when a language is incorrectly determined |
| US11307752B2 (en) | 2019-05-06 | 2022-04-19 | Apple Inc. | User configurable task triggers |
| US11140099B2 (en) | 2019-05-21 | 2021-10-05 | Apple Inc. | Providing message response suggestions |
| DK180129B1 (en) | 2019-05-31 | 2020-06-02 | Apple Inc. | USER ACTIVITY SHORTCUT SUGGESTIONS |
| US11289073B2 (en) | 2019-05-31 | 2022-03-29 | Apple Inc. | Device text to speech |
| US11496600B2 (en) | 2019-05-31 | 2022-11-08 | Apple Inc. | Remote execution of machine-learned models |
| US11360641B2 (en) | 2019-06-01 | 2022-06-14 | Apple Inc. | Increasing the relevance of new available information |
| WO2021056255A1 (en) | 2019-09-25 | 2021-04-01 | Apple Inc. | Text detection using global geometry estimators |
| US11810578B2 (en) | 2020-05-11 | 2023-11-07 | Apple Inc. | Device arbitration for digital assistant-based intercom systems |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0831021B2 (ja) * | 1986-10-13 | 1996-03-27 | 日本電信電話株式会社 | 音声ガイダンス出力制御方法 |
| JPH01237597A (ja) * | 1988-03-17 | 1989-09-22 | Fujitsu Ltd | 音声認識訂正装置 |
| JPH02126300A (ja) * | 1988-11-04 | 1990-05-15 | Nippon Telegr & Teleph Corp <Ntt> | 音声修正方式 |
| JP2000029492A (ja) * | 1998-07-09 | 2000-01-28 | Hitachi Ltd | 音声翻訳装置、音声翻訳方法、音声認識装置 |
| JP3892302B2 (ja) * | 2002-01-11 | 2007-03-14 | 松下電器産業株式会社 | 音声対話方法および装置 |
| JP2003330488A (ja) * | 2002-05-10 | 2003-11-19 | Nissan Motor Co Ltd | 音声認識装置 |
| JP2006039120A (ja) * | 2004-07-26 | 2006-02-09 | Sony Corp | 対話装置および対話方法、並びにプログラムおよび記録媒体 |
| JP4542974B2 (ja) * | 2005-09-27 | 2010-09-15 | 株式会社東芝 | 音声認識装置、音声認識方法および音声認識プログラム |
-
2007
- 2007-08-20 JP JP2007213828A patent/JP4987623B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2009047920A (ja) | 2009-03-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4987623B2 (ja) | ユーザと音声により対話する装置および方法 | |
| US20200226327A1 (en) | System and method for direct speech translation system | |
| US7668718B2 (en) | Synchronized pattern recognition source data processed by manual or automatic means for creation of shared speaker-dependent speech user profile | |
| JP4542974B2 (ja) | 音声認識装置、音声認識方法および音声認識プログラム | |
| JP4734155B2 (ja) | 音声認識装置、音声認識方法および音声認識プログラム | |
| US6446041B1 (en) | Method and system for providing audio playback of a multi-source document | |
| US20120016671A1 (en) | Tool and method for enhanced human machine collaboration for rapid and accurate transcriptions | |
| US8155958B2 (en) | Speech-to-text system, speech-to-text method, and speech-to-text program | |
| US10522133B2 (en) | Methods and apparatus for correcting recognition errors | |
| US8954333B2 (en) | Apparatus, method, and computer program product for processing input speech | |
| JP4481972B2 (ja) | 音声翻訳装置、音声翻訳方法及び音声翻訳プログラム | |
| US20090138266A1 (en) | Apparatus, method, and computer program product for recognizing speech | |
| JP2007264471A (ja) | 音声認識装置および音声認識方法 | |
| JP5787780B2 (ja) | 書き起こし支援システムおよび書き起こし支援方法 | |
| CN110740275B (zh) | 一种非线性编辑系统 | |
| CN110798733A (zh) | 一种字幕生成方法、装置及计算机存储介质、电子设备 | |
| JP2008243080A (ja) | 音声を翻訳する装置、方法およびプログラム | |
| JP7326931B2 (ja) | プログラム、情報処理装置、及び情報処理方法 | |
| JP2010169973A (ja) | 外国語学習支援システム、及びプログラム | |
| US11922944B2 (en) | Phrase alternatives representation for automatic speech recognition and methods of use | |
| JP2000047683A (ja) | セグメンテーション補助装置及び媒体 | |
| JP3958908B2 (ja) | 書き起こしテキスト自動生成装置、音声認識装置および記録媒体 | |
| US20230386475A1 (en) | Systems and methods of text to audio conversion | |
| EP4261822A1 (en) | Setting up of speech processing engines | |
| JP6340839B2 (ja) | 音声合成装置、合成音声編集方法及び合成音声編集用コンピュータプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100601 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111101 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20111115 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120110 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120403 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120425 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 4987623 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150511 Year of fee payment: 3 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313114 Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |