JP4602675B2 - CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM, CONFIDENTIAL INFORMATION MANAGEMENT METHOD, CONFIDENTIAL INFORMATION MANAGEMENT PROGRAM, AND CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM TERMINAL PROGRAM - Google Patents
CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM, CONFIDENTIAL INFORMATION MANAGEMENT METHOD, CONFIDENTIAL INFORMATION MANAGEMENT PROGRAM, AND CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM TERMINAL PROGRAM Download PDFInfo
- Publication number
- JP4602675B2 JP4602675B2 JP2004033352A JP2004033352A JP4602675B2 JP 4602675 B2 JP4602675 B2 JP 4602675B2 JP 2004033352 A JP2004033352 A JP 2004033352A JP 2004033352 A JP2004033352 A JP 2004033352A JP 4602675 B2 JP4602675 B2 JP 4602675B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- confidential information
- divided
- information management
- divided data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 238000007726 management method Methods 0.000 title claims description 89
- PWPJGUXAGUPAHP-UHFFFAOYSA-N lufenuron Chemical compound C1=C(Cl)C(OC(F)(F)C(C(F)(F)F)F)=CC(Cl)=C1NC(=O)NC(=O)C1=C(F)C=CC=C1F PWPJGUXAGUPAHP-UHFFFAOYSA-N 0.000 title 2
- 238000000034 method Methods 0.000 claims description 110
- 238000004891 communication Methods 0.000 claims description 23
- 230000006870 function Effects 0.000 claims description 13
- 230000005540 biological transmission Effects 0.000 claims description 10
- 238000013500 data storage Methods 0.000 claims description 7
- 230000008569 process Effects 0.000 description 28
- 239000011159 matrix material Substances 0.000 description 23
- 238000004364 calculation method Methods 0.000 description 12
- 238000002347 injection Methods 0.000 description 10
- 239000007924 injection Substances 0.000 description 10
- 230000011218 segmentation Effects 0.000 description 8
- 238000010586 diagram Methods 0.000 description 7
- 238000005192 partition Methods 0.000 description 5
- 230000008859 change Effects 0.000 description 2
- 238000013523 data management Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000014509 gene expression Effects 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images











Description
本発明は、利用者の機密情報を管理する機密情報管理システム、機密情報管理方法、および機密情報管理プログラム、並びに機密情報管理システム用端末プログラムに関する。 The present invention relates to a confidential information management system, a confidential information management method, a confidential information management program, and a confidential information management system terminal program for managing confidential information of a user.
IT(Information Technology)技術の発展に伴って、パスワード、クレジット番号などが入った携帯電話および携帯情報端末、並びにPKI秘密鍵が入ったICカードなどを用いて、所望のサービスの提供を受ける機会が増えている。例えば、ユーザのパスワードを使用してログインし、情報を閲覧したり、ユーザのクレジットカード番号を使用して物品購入したりするようなサービスが普及している。 With the development of IT (Information Technology) technology, there is an opportunity to receive provision of desired services using mobile phones and personal digital assistants containing passwords, credit numbers, etc., and IC cards containing PKI private keys. is increasing. For example, services such as logging in using a user's password, browsing information, and purchasing goods using the user's credit card number are widespread.
このような機会において、ユーザが上述した機密情報(例えば、パスワード、クレジット番号およびPKI秘密鍵など)が記憶されている携帯電話、携帯情報端末およびICカードなどを紛失した場合には、紛失した旨を発行元に申告して、該機密情報を失効させ、新たに機密情報を再発行してもらう必要がある。
そのため、ユーザが保持する機密情報を紛失した際には、セキュリティ維持のため、紛失した機密情報を失効させるとともに、機密情報を変更しなければならないという課題がある。また、機密情報を変更するため、再発行まではサービスの提供を受けることができないという課題もある。 Therefore, when the confidential information held by the user is lost, there is a problem that the lost confidential information must be invalidated and the confidential information must be changed in order to maintain security. In addition, since confidential information is changed, there is a problem that the service cannot be provided until reissue.
本発明は、上記の課題を解決するためになされたものであり、ユーザが保持する携帯電話、携帯情報端末、ICカードを紛失しても、機密情報を変更することなくサービスの提供を受けることが可能な機密情報管理システム、機密情報管理方法、および機密情報管理プログラム、並びに機密情報管理システム用端末プログラムを提供することを目的とする。 The present invention has been made to solve the above-mentioned problems, and even if a mobile phone, a personal digital assistant, or an IC card held by a user is lost, a service can be provided without changing confidential information. It is an object to provide a confidential information management system, a confidential information management method, a confidential information management program, and a terminal program for the confidential information management system.
上記目的を達成するため、請求項1記載の本発明は、利用者の機密情報を秘密分散法を用いて管理する機密情報管理システムであって、前記秘密分散法は、前記機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、前記機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、前記機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、前記各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、前記所望の分割数の再分割データを生成するデータ分割方法であり、前記機密情報を前記秘密分散法を用いて複数の分割データに分割するデータ分割手段と、前記複数の分割データの一部を、前記利用者が保持するための分割データとして第1の記憶部に記憶させるとともに、前記複数の分割データの残りを、1又は複数の第2の記憶部それぞれに記憶させるデータ記憶手段と、前記秘密分散法を用いて、前記第2の記憶部に記憶された各分割データのうち、復元可能な所定の個数の分割データの組み合わせから、複数の再分割データを作成するデータ再分割手段と、前記複数の再分割データの一部を新たな分割データとして前記第1の記憶部に記憶させるとともに、前記第2の記憶部に記憶された各分割データを無効にして、前記複数の再分割データの残りを新たな分割データとして前記第2の記憶部それぞれに記憶させるデータ再記憶手段と、を有することを特徴とする。
In order to achieve the above object, the present invention according to
請求項2記載の本発明は、請求項1記載の発明において、前記機密情報を使用する場合には、前記利用者が保持する分割データを取得し、該分割データと前記第2の記憶部に記憶された各分割データのうち前記所定の個数の分割データの組み合わせから前記秘密分散法を用いて前記機密情報を復元するデータ復元手段を有することを特徴とする。 According to a second aspect of the present invention, in the first aspect of the invention, when the confidential information is used, the divided data held by the user is acquired, and the divided data and the second storage unit are acquired. Data recovery means for recovering the confidential information from the combination of the predetermined number of pieces of divided data among the stored pieces of divided data using the secret sharing method is provided.
請求項3記載の本発明は、請求項2記載の発明において、前記機密情報を使用するときは、使用した事実を使用履歴情報として記憶する使用履歴記憶手段を有することを特徴とする。 According to a third aspect of the present invention, in the second aspect of the present invention, when the confidential information is used, there is provided usage history storage means for storing the used fact as usage history information.
請求項4記載の本発明は、請求項1記載の発明において、前記機密情報を使用する場合には、前記第2の記憶部に記憶された各分割データのうち、前記所定の個数から前記利用者が保持する分割データの個数を引いた個数の分割データの組み合わせを前記利用者が有する端末に通信ネットワークを介して送信する分割データ送信手段を有することを特徴とする。 According to a fourth aspect of the present invention, in the first aspect of the present invention, when the confidential information is used, the utilization is started from the predetermined number of pieces of divided data stored in the second storage unit. And a divided data transmission unit configured to transmit a combination of divided data obtained by subtracting the number of divided data held by a user to a terminal of the user via a communication network.
請求項5記載の本発明は、請求項1乃至4のいずれか1項に記載の発明において、前記データ再分割手段は、前記所定の個数の分割データの組み合わせに含まれる各分割データを構成するそれぞれの分割部分データ同士の排他的論理和演算によって、前記利用者が保持した分割データを生成することを特徴とする。 According to a fifth aspect of the present invention, in the invention according to any one of the first to fourth aspects, the data re-dividing means configures each divided data included in a combination of the predetermined number of divided data. The divided data held by the user is generated by an exclusive OR operation between the respective divided partial data.
請求項6記載の本発明は、請求項1乃至5のいずれか1項に記載の発明において、前記秘密分散法は、前記各分割部分データと、該各分割部分データを生成する際に用いたそれぞれの乱数部分データに対応する新たな乱数部分データそれぞれとの排他的論理和演算により、各再分割部分データを生成することを特徴とする。 According to a sixth aspect of the present invention, in the invention according to any one of the first to fifth aspects, the secret sharing method is used to generate the divided partial data and the divided partial data. Each subdivision partial data is generated by exclusive OR operation with each new random number partial data corresponding to each random number partial data.
請求項7記載の本発明は、前記秘密分散法は、さらに、前記各再分割部分データと、該各再分割部分データ生成前の各分割部分データを生成する際に用いた古い乱数部分データそれぞれとの排他的論理和演算により、前記再分割部分データから古い乱数部分データを消去することを特徴とする。
In the present invention according to
請求項8記載の本発明は、請求項1乃至7のいずれか1項に記載の発明において、前記第1の記憶部に記憶される分割データを通信ネットワークを介して前記利用者が有する端末に送信する送信手段を有することを特徴とする。 According to an eighth aspect of the present invention, there is provided the terminal according to any one of the first to seventh aspects, wherein the divided data stored in the first storage unit is stored in the terminal held by the user via a communication network. It has the transmission means to transmit, It is characterized by the above-mentioned.
請求項9記載の本発明は、請求項1乃至8のいずれか1項に記載の発明において、前記機密情報を前記利用者が有する端末から通信ネットワークを介して受信する受信手段を有することを特徴とする機密情報管理システム。
The present invention according to claim 9 is the invention according to any one of
請求項10記載の本発明は、機密情報管理システムが行う、利用者の機密情報を秘密分散法を用いて管理する機密情報管理方法であって、前記秘密分散法は、前記機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、前記機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、前記機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、前記各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、前記所望の分割数の再分割データを生成するデータ分割方法であり、前記機密情報管理システムは、第1の記憶部と第2の記憶部と、を備え、前記機密情報を前記秘密分散法を用いて複数の分割データに分割するデータ分割ステップと、前記複数の分割データの一部を、前記利用者が保持するための分割データとして前記第1の記憶部に記憶するとともに、前記複数の分割データの残りを、1又は複数の前記第2の記憶部それぞれに記憶するデータ記憶ステップと、前記秘密分散法を用いて、前記第2の記憶部に記憶された各分割データのうち、復元可能な所定の個数の分割データの組み合わせから、複数の再分割データを作成するデータ再分割ステップと、前記複数の再分割データの一部を新たな分割データとして前記第1の記憶部に記憶するとともに、前記第2の記憶部に記憶された各分割データを無効にして、前記複数の再分割データの残りを新たな分割データとして前記第2の記憶部のそれぞれに記憶するデータ再記憶ステップと、を行うことを特徴とする。
The present invention according to
請求項11記載の本発明は、利用者の機密情報を秘密分散法を用いて管理する機密情報管理プログラムであって、前記秘密分散法は、前記機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、前記機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、前記機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、前記各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、前記所望の分割数の再分割データを生成するデータ分割方法であり、コンピュータを、前記機密情報を前記秘密分散法を用いて複数の分割データに分割するデータ分割手段、前記複数の分割データの一部を、前記利用者が保持するための分割データとして第1の記憶部に記憶させるとともに、前記複数の分割データの残りを、1又は複数の第2の記憶部それぞれに記憶させるデータ記憶手段、前記秘密分散法を用いて、前記第2の記憶部に記憶された各分割データのうち、復元可能な所定の個数の分割データの組み合わせから、複数の再分割データを作成するデータ再分割手段、および、前記複数の再分割データの一部を新たな分割データとして前記第1の記憶部に記憶させるとともに、前記第2の記憶部に記憶された各分割データを無効にして、前記複数の再分割データの残りを新たな分割データとして前記第2の記憶部それぞれに記憶させるデータ再記憶手段、として機能させる。
The present invention according to
請求項12記載の本発明は、請求項11記載の発明において、前記コンピュータを、 前記機密情報を使用する場合には、前記利用者が保持する分割データを取得し、該分割データと前記第2の記憶部に記憶された各分割データのうち前記所定の個数の分割データの組み合わせから前記秘密分散法を用いて前記機密情報を復元するデータ復元手段、として機能させる。 According to a twelfth aspect of the present invention, in the invention according to the eleventh aspect, when the computer uses the confidential information , the computer acquires the divided data held by the user, and the divided data and the second data And functioning as data restoring means for restoring the confidential information by using the secret sharing method from a combination of the predetermined number of divided data among the divided data stored in the storage unit .
請求項13記載の本発明は、前記コンピュータを、前記機密情報を使用する場合には、前記第2の記憶部に記憶された各分割データのうち、前記所定の個数から前記利用者が保持する分割データの個数を引いた個数の分割データの組み合わせを前記利用者が有する端末に通信ネットワークを介して送信する分割データ送信手段、として機能させる。 According to a thirteenth aspect of the present invention, when the confidential information is used , the computer holds the computer from the predetermined number of pieces of divided data stored in the second storage unit. A combination of the number of pieces of divided data obtained by subtracting the number of pieces of divided data is caused to function as a divided data transmission unit that transmits the terminal of the user to a terminal through the communication network .
請求項14記載の本発明は、請求項4記載の機密情報管理システムから送信された分割データを用いて前記利用者の機密情報を使用する機密情報管理システム用端末プログラムであって、端末コンピュータを、前記利用者が保持する分割データを取得し、該分割データと前記送信された分割データの組み合わせから前記秘密分散法を用いて前記機密情報を復元する復元手段、および、前記復元した機密情報を、前記サービスを提供するシステムに通信ネットワークを介して送信する送信手段、として機能させる。
The present invention is claimed in
本発明によれば、機密情報を秘密分散法を用いて複数に分割して、そのうちの一部をユーザに保持させるので、ユーザが保持する分割データの紛失があったとしても、残りの分割データから機密情報を復元できるとともに、秘密分散法を用いて新たに再分割データを生成し、該再分割データの一部を新たにユーザに保持させるので、機密情報の変更は不要である。 According to the present invention, since the confidential information is divided into a plurality of parts using the secret sharing method and a part of them is held by the user, even if the divided data held by the user is lost, the remaining divided data The confidential information can be restored from the information, the re-divided data is newly generated using the secret sharing method, and a part of the re-divided data is newly held by the user, so that the confidential information does not need to be changed.
この結果、ユーザが保持する分割データの紛失があったとしても、機密情報の再発行処理をすることなく、紛失の申告をするだけで、再びサービス提供を受けることができる。 As a result, even if the divided data held by the user is lost, it is possible to receive the service again only by reporting the loss without re-issuing the confidential information.
特に、本発明における秘密分散法は、機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、所望の分割数の再分割データを生成するので、機密情報を復元することなく、機密情報を再分割することができる。
In particular, the secret sharing method according to the present invention is a data division method for dividing confidential information into divided data of a desired number of divisions based on a desired processing unit bit length. The secret information is divided into processing unit bit lengths. Generating a plurality of original part data, and corresponding to each of the plurality of original part data, a plurality of random part data having a processing unit bit length from a random number having a length equal to or shorter than the bit length of the confidential information. Generate and generate each divided partial data constituting each divided data for each processing unit bit length by exclusive OR of the original partial data and the random number partial data, and generate divided data of a desired number of divisions. A plurality of random number part data of processing unit bit length is generated from the random number generated in
これにより、ユーザの機密情報をよりセキュアに管理することができる。 Thereby, the confidential information of the user can be managed more securely.
以下、本発明の実施の形態を図面を用いて説明する。 Hereinafter, embodiments of the present invention will be described with reference to the drawings.
<システム構成>
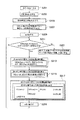
図1は、本発明の実施の形態に係る機密情報管理システム1が適用されるコンピュータシステム10全体の概略構成を示すブロック図である。
<System configuration>
FIG. 1 is a block diagram showing a schematic configuration of an
図1に示すように、機密情報管理システム1は、インターネット等の通信ネットワーク4を介してユーザが備えるクライアント端末2(以下、単に端末とよぶ)と接続されているとともに、通信ネットワーク4を介してユーザに所定のサービスを提供するサービス提供システム5と接続されている。また、機密情報管理システム1は、ハードウェア的に互いに独立した複数(本実施の形態では2とする)のデータ保管用サーバコンピュータ(以下、単に保管サーバとよぶ)3a,3bと接続されている。
As shown in FIG. 1, the confidential
尚、本実施の形態における機密情報とは、ユーザがサービス提供システム5を利用するために必要なパスワード、クレジットカード番号、PKI秘密鍵などの個人情報をいう。
Note that the confidential information in the present embodiment refers to personal information such as a password, a credit card number, and a PKI private key necessary for the user to use the
上記構成のコンピュータシステム10においては、端末2が所定のサービスをサービス提供システム5から受ける際に必要とされる機密情報Sを機密情報管理システム1に送信すると、機密情報管理システム1において後述する独自の秘密分散アルゴリズムによる秘密分散法(以下、秘密分散法Aとよぶ)を用いて該機密情報Sを複数のデータに分割し、該分割データを保管サーバ3a,3bおよび端末2にそれぞれ送信し、保管させるようになっている。この結果、機密情報Sが機密情報管理システム1に登録されたことになり、ユーザはサービス利用の準備が整ったことになる。尚、図1では、機密情報管理システム1は、端末2からの機密情報Sを3つの分割データD(1),D(2) ,D(3)に分割し、それぞれを複数の保管サーバ3a,3bおよび端末2に保管するようになっている。
In the
また、サービス利用時は、端末2から機密情報管理システム1に対して、分割データD(3)を送信すると、機密情報管理システム1は、該分割データD(3)および保管サーバ3a,3bの分割データD(1),D(2)のうち任意の2つから秘密分散法Aを用いてもとの機密情報Sを復元し、該機密情報Sをサービス提供システム5に送信するようになっている。これにより、ユーザは、所定のサービスの提供を受けることができる。
Further, when the service is used, if the divided data D (3) is transmitted from the
尚、本実施の形態においては、機密情報Sを3分割して保管する場合を例に説明するが、本発明は機密情報Sを3分割する場合に限定されるわけではなく、n分割(n=2以上の整数)の場合にも適用されるものである。また、端末2に送信される分割データは1つとは限らず複数であってもよいものである。さらに、本実施の形態においては、分割データD(1),D(2)を保管サーバ3、分割データD(3)を利用端末2に割り当てたが、どの分割データをどの保管サーバ3および利用端末2に割り当ててもよいものである。
In the present embodiment, the case where the confidential information S is divided and stored will be described as an example. However, the present invention is not limited to the case where the confidential information S is divided into three. = Integer greater than or equal to 2). Further, the divided data transmitted to the
機密情報管理システム1は、詳しくは、機密情報Sから秘密分散法Aを用いて複数の分割データDに分割する分割データ生成部11、複数の分割データDから秘密分散法Aを用いて元データ(機密情報)Sを復元する元データ復元部12、機密情報Sから複数の分割データDを生成するために使用される乱数Rおよび再分割データD’を生成するために使用される乱数R’を発生させる乱数発生部13、ユーザが保持する分割データを紛失した際には、秘密分散法Aを用いて保管サーバ3に保管された分割データから複数の再分割データD’を生成する再分割データ生成部14、機密情報管理システム1が機密情報Sを復元しサービス提供システム5に機密情報Sを送信した事実を使用履歴として生成する使用履歴生成部15、並びに端末2、保管サーバ3a,3b、およびサービス提供システム5とそれぞれとデータの送受信を行う通信部16を具備する構成となっている。
Specifically, the confidential
また、端末2は、ユーザが携行可能な携帯情報端末、携帯電話、ICカードなどの携帯記憶媒体などが想定されるが、他にモバイルを用途としないコンピュータ機器であってもよいものである。
The
ここで、上述した機密情報管理システム1、端末2、保管サーバ3a,3bおよびサービス提供システム5は、それぞれ少なくとも演算機能および制御機能を備えた中央演算装置(CPU)、プログラムやデータを格納する機能を有するRAM等からなる主記憶装置(メモリ)を有する電子的な装置から構成されているものである。また、上記装置およびシステムは、主記憶装置の他、ハードディスクなどの補助記憶装置を具備していてもよい。
Here, the above-described confidential
また、本実施の形態に係る各種処理を実行するプログラムは、前述した主記憶装置またはハードディスクに格納されているものである。そして、このプログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVD−ROMなどのコンピュータ読み取り可能な記録媒体に記録することも、通信ネットワークを介して配信することも可能である。 A program for executing various processes according to the present embodiment is stored in the main storage device or the hard disk described above. The program can be recorded on a computer-readable recording medium such as a hard disk, a flexible disk, a CD-ROM, an MO, or a DVD-ROM, or can be distributed via a communication network.
<秘密分散法A>
ここで、本実施の形態における独自の秘密分散アルゴリズムによる秘密分散法Aについて説明する。
<Secret Sharing Method A>
Here, the secret sharing method A based on the unique secret sharing algorithm in the present embodiment will be described.
本実施形態における元データ(機密情報Sに相当する)の分割および復元では、元データを所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するが、この場合の処理単位ビット長は任意の値に設定することができ、元データを処理単位ビット長毎に区分けして、この元部分データから分割部分データを分割数より1少ない数ずつ生成するので、元データのビット長が処理単位ビット長の(分割数-1)倍の整数倍に一致しない場合は、元データの末尾の部分に0を埋めるなどして元データのビット長を処理単位ビット長の(分割数-1)倍の整数倍に合わせることにより本実施形態を適用することができる。 In the division and restoration of the original data (corresponding to the confidential information S) in the present embodiment, the original data is divided into divided data having a desired number of divisions based on a desired processing unit bit length. The length can be set to any value, and the original data is divided into processing unit bit lengths, and the divided partial data is generated from this original partial data by a number one less than the number of divisions, so the bit length of the original data Does not match an integral multiple of (divided number – 1) times the processing unit bit length, the source data bit length is set to the processing unit bit length (divided number – 1) This embodiment can be applied by adjusting to an integral multiple of twice.
また、上述した乱数も(分割数-1)個の元部分データの各々に対応して処理単位ビット長のビット長を有する(分割数-1)個の乱数部分データとして乱数発生部13から生成される。すなわち、乱数は処理単位ビット長毎に区分けされて、処理単位ビット長のビット長を有する(分割数-1)個の乱数部分データとして生成される。更に、元データは処理単位ビット長に基づいて所望の分割数の分割データに分割されるが、この分割データの各々も(分割数-1)個の元部分データの各々に対応して処理単位ビット長のビット長を有する(分割数-1)個の分割部分データとして生成される。すなわち、分割データの各々は、処理単位ビット長毎に区分けされて、処理単位ビット長のビット長を有する(分割数-1)個の分割部分データとして生成される。
The random numbers described above are also generated from the
なお、以下の説明では、上述した元データ、乱数、分割データ、分割数および処理単位ビット長をそれぞれS,R,D,nおよびbで表すとともに、また複数のデータや乱数などのうちの1つを表わす変数としてi(=1〜n)およびj(=1〜n-1)を用い、(分割数n-1)個の元部分データ、(分割数n-1)個の乱数部分データ、および分割数n個の分割データDのそれぞれのうちの1つをそれぞれS (j),R(j)およびD(i)で表記し、更に各分割データD(i)を構成する複数(n-1)の分割部分データをD(i,j)で表記するものとする。すなわち、S (j)は、元データSの先頭から処理単位ビット長毎に区分けして1番から順に採番した時のj番目の元部分データを表すものである。 In the following description, the above-described original data, random numbers, divided data, number of divisions, and processing unit bit length are represented by S, R, D, n, and b, respectively, and one of a plurality of data, random numbers, and the like. I (= 1 to n) and j (= 1 to n-1) are used as variables to represent one, (division number n-1) original partial data, (division number n-1) random number partial data , And one of each of the divided data D of the number n of divisions is represented by S (j), R (j) and D (i), respectively, and a plurality of ( The divided partial data of (n-1) is represented by D (i, j). That is, S (j) represents the j-th original partial data when the original data S is numbered in order from the top by dividing the processing unit bit length from the top.
この表記を用いると、元データ、乱数データ、分割データとこれらをそれぞれ構成する元部分データ、乱数部分データ、分割部分データは、次のように表記される。 When this notation is used, the original data, random number data, and divided data, and the original partial data, random number partial data, and divided partial data that constitute these, respectively, are represented as follows.
元データS=(n-1)個の元部分データS(j)
=S(1),S(2),…,S(n-1)
乱数R=(n-1)個の乱数部分データR(j)
=R(1),R(2),…,R(n-1)
n個の分割データD(i)=D(1),D(2),…,D(n)
各分割部分データD(i,j)
=D(1,1),D(1,2),…,D(1,n-1)
D(2,1),D(2,2),…,D(2,n-1)
… … …
D(n,1),D(n,2),…,D(n,n-1)
(i=1〜n), (j=1〜n-1)
本実施形態は、上述したように処理単位ビット長毎に区分けされる複数の部分データに対して元部分データと乱数部分データの排他的論理和演算(XOR)を行って、詳しくは、元部分データと乱数部分データの排他的論理和演算(XOR)からなる定義式を用いて、元データの分割を行うことを特徴とするものであり、上述したデータ分割処理に多項式や剰余演算を用いる方法に比較して、コンピュータ処理に適したビット演算である排他的論理和(XOR)演算を用いることにより高速かつ高性能な演算処理能力を必要とせず、大容量のデータに対しても簡単な演算処理を繰り返して分割データを生成することができるとともに、また分割データの保管に必要となる記憶容量も分割数に比例した倍数の容量よりも小さくすることができる。更に、任意に定めた一定の長さ毎にデータの先頭から順に演算処理を行うストリーム処理により分割データが生成される。
Original data S = (n-1) original partial data S (j)
= S (1), S (2), ..., S (n-1)
Random number R = (n-1) random number partial data R (j)
= R (1), R (2), ..., R (n-1)
n divided data D (i) = D (1), D (2),..., D (n)
Each partial data D (i, j)
= D (1,1), D (1,2), ..., D (1, n-1)
D (2,1), D (2,2), ..., D (2, n-1)
………
D (n, 1), D (n, 2), ..., D (n, n-1)
(i = 1 ~ n), (j = 1 ~ n-1)
In the present embodiment, an exclusive OR operation (XOR) of the original partial data and the random number partial data is performed on the plurality of partial data divided for each processing unit bit length as described above. The original data is divided using a definition formula consisting of exclusive OR (XOR) of data and random number partial data, and a method of using a polynomial or a remainder operation for the data division processing described above Compared with, it uses the exclusive OR (XOR) operation, which is a bit operation suitable for computer processing, and does not require high-speed and high-performance processing power, and it is simple operation even for large volumes of data. The divided data can be generated by repeating the processing, and the storage capacity required for storing the divided data can be made smaller than the multiple capacity proportional to the divided number. Further, the divided data is generated by stream processing in which calculation processing is performed in order from the top of the data for each predetermined fixed length.
なお、本実施形態で使用する排他的論理和演算(XOR)は、以下の説明では、「*」なる演算記号で表すことにするが、この排他的論理和演算のビット毎の演算規則での各演算結果は下記のとおりである。 In the following description, the exclusive OR operation (XOR) used in the present embodiment is expressed by an operation symbol “*”. However, in the bitwise operation rule of this exclusive OR operation, Each calculation result is as follows.
0 * 0 の演算結果は 0
0 * 1 の演算結果は 1
1 * 0 の演算結果は 1
1 * 1 の演算結果は 0
また、XOR演算は交換法則、結合法則が成り立つ。すなわち、
a*b=b*a
(a*b)*c=a*(b*c)が成り立つことが数学的に証明される。
The operation result of 0 * 0 is 0
The result of 0 * 1 is 1
The result of 1 * 0 is 1
The result of 1 * 1 is 0
In addition, the XOR operation has an exchange law and a joint law. That is,
a * b = b * a
It is mathematically proved that (a * b) * c = a * (b * c) holds.
また、a*a=0,a*0=0*a=aが成り立つ。 Also, a * a = 0, a * 0 = 0 * a = a holds.
ここでa,b,cは同じ長さのビット列を表し、0はこれらと同じ長さですべて「0」からなるビット列を表す。 Here, a, b, and c represent bit strings having the same length, and 0 represents a bit string having the same length and consisting of all “0”.
次に、フローチャートなどの図面も参照して、本実施の形態における秘密分散法Aの作用について説明するが、この説明の前に図2乃至6、図8および図10のフローチャートに示す記号の定義について説明する。 Next, the operation of the secret sharing method A in the present embodiment will be described with reference to drawings such as flowcharts. Before this description, definitions of symbols shown in the flowcharts of FIGS. Will be described.
(1)Πi=1 nA(i)は、A(1)*A(2)*…A(n)を意味するものとする。 (1) Π i = 1 n A (i) means A (1) * A (2) *... A (n).
(2)c(j,i,k)を(n-1)×(n-1)行列であるU[n-1,n-1]×(P[n-1,n-1])^(j-1)のi行k列の値と定義する。 (2) c (j, i, k) is (n-1) × (n-1) matrix U [n-1, n-1] × (P [n-1, n-1]) ^ It is defined as the value of i row and k column of (j-1).
このときQ(j,i,k)を下記のように定義する。 At this time, Q (j, i, k) is defined as follows.
c(j,i,k)=1 のとき Q(j,i,k)=R((n-1)×m+k)
c(j,i,k)=0 のとき Q(j,i,k)=0
ただし、mはm≧0の整数を表す。
When c (j, i, k) = 1 Q (j, i, k) = R ((n-1) × m + k)
Q (j, i, k) = 0 when c (j, i, k) = 0
However, m represents an integer of m ≧ 0.
(3)U[n,n]とは、n×n行列であって、i行j列の値をu(i,j)で表すと、
i+j<=n+1 のとき u(i,j)=1
i+j>n+1 のとき u(i,j)=0
である行列を意味するものとし、「上三角行列」ということとする。具体的には下記のような行列である。

When i + j <= n + 1, u (i, j) = 1
When i + j> n + 1, u (i, j) = 0
It means that the matrix is “upper triangular matrix”. Specifically, the matrix is as follows.
(4)P[n,n]とは、n×n行列であって、i行j列の値をp(i,j)で表すと、
j=i+1 のとき p(i,j)=1
i=n,j=1 のとき p(i,j)=1
上記以外のとき p(i,j)=0
である行列を意味するものとし、「回転行列」ということとする。具体的には下記のような行列であり、他の行列の右側からかけると当該他の行列の1列目を2列目へ、2列目を3列目へ、…,n-1列目をn列目へ、n列目を1列目へ移動させる作用がある。つまり、行列Pを他の行列に右側から複数回かけると、その回数分だけ各列を右方向へ回転させるように移動させることができる。
When j = i + 1, p (i, j) = 1
p (i, j) = 1 when i = n, j = 1
For other cases p (i, j) = 0
It means that the matrix is “rotation matrix”. Specifically, the matrix is as follows, and when multiplied from the right side of another matrix, the first column of the other matrix is changed to the second column, the second column to the third column,. Is moved to the nth column, and the nth column is moved to the first column. That is, when the matrix P is applied to another matrix a plurality of times from the right side, each column can be moved so as to rotate rightward by that number of times.
(5)A,Bをn×n行列とすると、A×Bとは行列AとBの積を意味するものとする。行列の成分同士の計算規則は通常の数学で用いるものと同じである。 (5) If A and B are n × n matrices, A × B means the product of the matrices A and B. The calculation rules for the matrix components are the same as those used in normal mathematics.
(6)Aをn×n行列とし、iを整数とすると、A^iとは行列Aのi個の積を意味するものとする。また、A^0とは単位行列Eを意味するものとする。 (6) When A is an n × n matrix and i is an integer, A ^ i means i products of the matrix A. A ^ 0 means the unit matrix E.
(7)単位行列E[n,n]とは、n×n行列であって、i行j列の値をe(i,j)で表すと、
i=j のとき e(i,j)=1
上記以外のとき e(i,j)=0
である行列を意味するものとする。具体的には下記のような行列である。Aを任意のn×n行列とすると
A×E=E×A=A
となる性質がある。
e (i, j) = 1 when i = j
For other cases e (i, j) = 0
Let's mean a matrix that is Specifically, the matrix is as follows. Let A be any n × n matrix
A × E = E × A = A
There is a property to become.
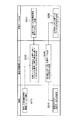
次に、図2に示すフローチャートおよび図3および図4に示す具体的データなどを参照して、まず元データSの分割処理について説明する。これは、機密情報管理システム1の分割データ生成部11の機能を説明するものである。
Next, with reference to the flowchart shown in FIG. 2 and the specific data shown in FIGS. This explains the function of the divided
まず、元データSを機密情報管理システム1に与える(図2のステップS201)。なお、本例では、元データSは、16ビットの「10110010 00110111」とする。 First, the original data S is given to the confidential information management system 1 (step S201 in FIG. 2). In this example, the original data S is 16 bits “10110010 00110111”.
次に、機密情報管理システム1は、分割数nとして3と指示する(ステップS203)。なお、この分割数n=3に従って機密情報管理システム1で生成される3個の分割データをD(1),D(2),D(3)とする。この分割データD(1),D(2),D(3)は、すべて元データのビット長と同じ16ビット長のデータである。
Next, the confidential
それから、元データSを分割するために使用される処理単位ビット長bを8ビットと決定する(ステップS205)。この処理単位ビット長bは、利用者が端末2から機密情報管理システム1に対して指定してもよいし、または機密情報管理システム1において予め定められた値を用いてもよい。なお、処理単位ビット長bは、任意のビット数でよいが、ここでは元データSを割り切れることができる8ビットとしている。従って、上記16ビットの「10110010 00110111」の元データSは、8ビットの処理単位ビット長で区分けされた場合の2個の元分割データS(1)およびS(2)は、それぞれ「10110010」および「00110111」となる。
Then, the processing unit bit length b used for dividing the original data S is determined to be 8 bits (step S205). The processing unit bit length b may be designated by the user from the
次のステップS207では、元データSのビット長が8×2の整数倍であるか否かを判定し、整数倍でない場合には、元データSの末尾を0で埋めて、8×2の整数倍に合わせる。なお、本例のように処理単位ビット長bが8ビットおよび分割数nが3に設定された場合における分割処理は、元データSのビット長として16ビットに限られるものでなく、処理単位ビット長b×(分割数n-1)=8×2の整数倍の元データSに対して有効なものである。 In the next step S207, it is determined whether or not the bit length of the original data S is an integer multiple of 8 × 2, and if it is not an integer multiple, the end of the original data S is padded with zeros to obtain 8 × 2 Fit to an integer multiple. Note that the division processing when the processing unit bit length b is set to 8 bits and the division number n is set to 3 as in this example is not limited to 16 bits as the bit length of the original data S. This is effective for the original data S that is an integral multiple of the length b × (number of divisions n−1) = 8 × 2.
次に、ステップS209では、変数m、すなわち上述した整数倍を意味する変数mを0に設定する。本例のように、元データSが処理単位ビット長b×(分割数n-1)=8×2=16ビットである場合には、変数mは0であるが、2倍の32ビットの場合には、変数mは1となり、3倍の48ビットの場合には、変数mは2となる。 Next, in step S209, the variable m, that is, the variable m meaning the integer multiple described above is set to zero. As in this example, when the original data S has a processing unit bit length b × (number of divisions n−1) = 8 × 2 = 16 bits, the variable m is 0, but is doubled to 32 bits. In this case, the variable m is 1, and in the case of 3 times 48 bits, the variable m is 2.
次に、元データSの8×2×m+1ビット目から8×2ビット分のデータが存在するか否かが判定される(ステップS211)。これは、このステップS211以降に示す分割処理を元データSの変数mで特定される処理単位ビット長b×(分割数n-1)=8×2=16ビットに対して行った後、元データSとして次の16ビットがあるか否かを判定しているものである。本例のように元データSが16ビットである場合には、16ビットの元データSに対してステップS211以降の分割処理を1回行うと、後述するステップS219で変数mが+1されるが、本例の元データSでは変数mがm+1の場合に相当する17ビット以降のデータは存在しないので、ステップS211からステップS221に進むことになるが、今の場合は、変数mは0であるので、元データSの8×2×m+1ビット目は、8×2×0+1=1となり、元データSの16ビットの1ビット目から8×2ビット分にデータが存在するため、ステップS213に進む。 Next, it is determined whether or not there is data for 8 × 2 bits from the 8 × 2 × m + 1 bit of the original data S (step S211). This is because the division processing shown after step S211 is performed on the processing unit bit length b × (number of divisions n−1) = 8 × 2 = 16 bits specified by the variable m of the original data S, It is determined whether or not there is the next 16 bits as data S. In the case where the original data S is 16 bits as in this example, when the dividing process after step S211 is performed once on the 16-bit original data S, the variable m is incremented by 1 in step S219 described later. However, in the original data S of this example, there is no data of 17 bits or more corresponding to the case where the variable m is m + 1, so the process proceeds from step S211 to step S221. In this case, however, the variable m is Since it is 0, the 8 × 2 × m + 1 bit of the original data S is 8 × 2 × 0 + 1 = 1, and the data is 8 × 2 bits from the first 16 bits of the original data S. Since it exists, it progresses to step S213.
ステップS213では、変数jを1から2(=分割数n-1)まで変えて、元データSの8×(2×m+j-1)+1ビット目から8ビット分(=処理単位ビット長)のデータを元部分データS(2×m+j)に設定し、これにより元データSを処理単位ビット長で区分けした2(分割数n-1)個の元部分データS(1),S(2)を次のように生成する。 In step S213, the variable j is changed from 1 to 2 (= number of divisions n-1), and 8 bits (= processing unit bits) from the 8 × (2 × m + j-1) +1 bit of the original data S Data) is set to the original partial data S (2 × m + j), thereby dividing the original data S by the processing unit bit length 2 (number of divisions n-1) original partial data S (1) , S (2) is generated as follows.
元データS=S(1),S(2)
第1の元部分データS(1)=「10110010」
第2の元部分データS(2)=「00110111」
次に、変数jを1から2(=分割数n-1)まで変えて、乱数部分データR(2×m+j)に乱数発生部13から発生する8ビットの長さの乱数を設定し、これにより乱数Rを処理単位ビット長で区分けした2(分割数n-1)個の乱数部分データR(1),R(2)を次のように生成する(ステップS215)。
Original data S = S (1), S (2)
First original partial data S (1) = “10110010”
Second original partial data S (2) = “00110111”
Next, the variable j is changed from 1 to 2 (= division number n-1), and a random number of 8 bits length generated from the
乱数R=R(1),R(2)
第1の乱数部分データR(1)=「10110001」
第2の乱数部分データR(2)=「00110101」
次に、ステップS217において、変数iを1から3(=分割数n)まで変えるとともに、更に各変数iにおいて変数jを1から2(=分割数n-1)まで変えながら、ステップS217に示す分割データを生成するための元部分データと乱数部分データの排他的論理和からなる定義式により複数の分割データD(i)の各々を構成する各分割部分データD(i,2×m+j)を生成する。この結果、次に示すような分割データDが生成される。
Random number R = R (1), R (2)
First random number partial data R (1) = “10110001”
Second random number partial data R (2) = “00110101”
Next, in step S217, the variable i is changed from 1 to 3 (= number of divisions n), and the variable j is further changed from 1 to 2 (= number of divisions n-1) in each variable i, as shown in step S217. Each divided partial data D (i, 2 × m + j) that constitutes each of the plurality of divided data D (i) by a definition formula consisting of exclusive OR of the original partial data and random number partial data for generating the divided data ) Is generated. As a result, the following divided data D is generated.
分割データD
=3個の分割データD(i)=D(1),D(2),D(3)
第1の分割データD(1)
=2個の分割部分データD(1,j)=D(1,1),D(1,2)
=「00110110」,「10110011」
第2の分割データD(2)
=2個の分割部分データD(2,j)=D(2,1),D(2,2)
=「00000011」,「00000010」
第3の分割データD(3)
=2個の分割部分データD(3,j)=D(3,1),D(3,2)
=「10110001」,「00110101」
なお、各分割部分データ(i,j)を生成するためのステップS217に示す定義式は、本例のように分割数n=3の場合には、具体的には図4に示す表に記載されているものとなる。図4に示す表から、分割部分データD(1,1)を生成するための定義式はS(1)*R(1)*R(2)であり、D(1,2)の定義式はS(2)*R(1)*R(2)であり、D(2,1)の定義式はS(1)*R(1)であり、D(2,2)の定義式はS(2)*R(2)であり、D(3,1)の定義式はR(1)であり、D(3,2)の定義式はR(2)である。また、図4に示す表にはm>0の場合の任意の整数についての一般的な定義式も記載されている。
Split data D
= 3 pieces of divided data D (i) = D (1), D (2), D (3)
First divided data D (1)
= 2 pieces of partial data D (1, j) = D (1,1), D (1,2)
= "00110110", "10110011"
Second divided data D (2)
= 2 pieces of partial data D (2, j) = D (2,1), D (2,2)
= "00000011", "00000010"
Third divided data D (3)
= 2 pieces of partial data D (3, j) = D (3,1), D (3,2)
= "10110001", "00110101"
Note that the definition formula shown in step S217 for generating each divided partial data (i, j) is specifically described in the table shown in FIG. 4 when the number of divisions n = 3 as in this example. Will be. From the table shown in FIG. 4, the definition formula for generating the divided partial data D (1,1) is S (1) * R (1) * R (2), and the definition formula for D (1,2) Is S (2) * R (1) * R (2), the definition of D (2,1) is S (1) * R (1), and the definition of D (2,2) is S (2) * R (2), the defining formula for D (3,1) is R (1), and the defining formula for D (3,2) is R (2). The table shown in FIG. 4 also describes general definition formulas for arbitrary integers when m> 0.
このように整数倍を意味する変数m=0の場合について分割データDを生成した後、次に変数mを1増やし(ステップS219)、ステップS211に戻り、変数m+1に該当する元データSの17ビット以降について同様の分割処理を行おうとするが、本例の元データSは16ビットであり、17ビット以降のデータは存在しないので、ステップS211からステップS221に進み、上述したように生成した分割データD(1),D(2),D(3)を保管サーバ3及び端末2にそれぞれ保存して、分割処理を終了する。なお、このように保管された分割データD(1),D(2),D(3)はそれぞれ単独では元データが推測できない。
In this way, after the divided data D is generated for the variable m = 0 which means an integer multiple, the variable m is then incremented by 1 (step S219), the process returns to step S211 and the original data S corresponding to the variable m + 1 is returned. However, since the original data S in this example is 16 bits and there is no data after 17 bits, the process proceeds from step S211 to step S221 and is generated as described above. The divided data D (1), D (2), and D (3) are stored in the
ここで、上述した図2のフローチャートのステップS217における定義式による分割データの生成処理、具体的には分割数n=3の場合の分割データの生成処理について詳しく説明する。 Here, the divided data generation process based on the definition formula in step S217 in the flowchart of FIG. 2 described above, specifically, the divided data generation process when the number of divisions n = 3 will be described in detail.
まず、整数倍を意味する変数m=0の場合には、ステップS217に示す定義式から各分割データD(i)=D(1)〜D(3)の各々を構成する各分割部分データD(i,2×m+j)=D(i,j)(i=1〜3,j=1〜2)は、次のようになる。 First, in the case of a variable m = 0 meaning an integer multiple, each divided partial data D constituting each of the divided data D (i) = D (1) to D (3) from the definition formula shown in step S217. (i, 2 × m + j) = D (i, j) (i = 1 to 3, j = 1 to 2) is as follows.
D(1,1)=S(1)*Q(1,1,1)*Q(1,1,2)
D(1,2)=S(2)*Q(2,1,1)*Q(2,1,2)
D(2,1)=S(1)*Q(1,2,1)*Q(1,2,2)
D(2,2)=S(2)*Q(2,2,1)*Q(2,2,2)
D(3,1)=R(1)
D(3,2)=R(2)
上記の6つの式のうち上から4つの式に含まれるQ(j,i,k)を具体的に求める。
D (1,1) = S (1) * Q (1,1,1) * Q (1,1,2)
D (1,2) = S (2) * Q (2,1,1) * Q (2,1,2)
D (2,1) = S (1) * Q (1,2,1) * Q (1,2,2)
D (2,2) = S (2) * Q (2,2,1) * Q (2,2,2)
D (3,1) = R (1)
D (3,2) = R (2)
Specifically, Q (j, i, k) included in the above four formulas among the above six formulas is obtained.
これはc(j,i,k)を2×2行列であるU[2,2]×(P[2,2])^(j-1)のi行k列の値としたとき下記のように定義される。 When c (j, i, k) is a value of i rows and k columns of U [2,2] × (P [2,2]) ^ (j-1) which is a 2 × 2 matrix, Is defined as
c(j,i,k)=1 のとき Q(j,i,k)=R(k)
c(j,i,k)=0 のとき Q(j,i,k)=0
ここで、
j=1のときは
Q (j, i, k) = 0 when c (j, i, k) = 0
here,
When j = 1
j=2のときは
これを用いると、各分割部分データD(i,j)は次のような定義式により生成される。 If this is used, each division | segmentation partial data D (i, j) is produced | generated by the following definitional expressions.
D(1,1)=S(1)*Q(1,1,1)*Q(1,1,2)=S(1)*R(1)*R(2)
D(1,2)=S(2)*Q(2,1,1)*Q(2,1,2)=S(2)*R(1)*R(2)
D(2,1)=S(1)*Q(1,2,1)*Q(1,2,2)=S(1)*R(1)*0=S(1)*R(1)
D(2,2)=S(2)*Q(2,2,1)*Q(2,2,2)=S(2)*0*R(2)=S(2)*R(2)
上述した各分割部分データD(i,j)を生成するための定義式は、図3にも図示されている。
D (1,1) = S (1) * Q (1,1,1) * Q (1,1,2) = S (1) * R (1) * R (2)
D (1,2) = S (2) * Q (2,1,1) * Q (2,1,2) = S (2) * R (1) * R (2)
D (2,1) = S (1) * Q (1,2,1) * Q (1,2,2) = S (1) * R (1) * 0 = S (1) * R (1 )
D (2,2) = S (2) * Q (2,2,1) * Q (2,2,2) = S (2) * 0 * R (2) = S (2) * R (2 )
The definition formula for generating each of the divided partial data D (i, j) described above is also illustrated in FIG.
図3は、上述したように16ビットの元データSを8ビットの処理単位ビット長に基づいて分割数n=3で3分割する場合の各データと定義式および各分割部分データから元データを復元する場合の計算式などを示す表である。 FIG. 3 shows the original data from the respective data, definition formulas, and divided partial data when the 16-bit original data S is divided into three with the division number n = 3 based on the 8-bit processing unit bit length as described above. It is a table | surface which shows the calculation formula in the case of decompress | restoring.
ここで、上述した定義式により分割データD(1),D(2),D(3)および各分割部分データD(1,1),D(1,2),D(2,1),D(2,2),D(3,1),D(3,2)を生成する過程と定義式の一般形について説明する。 Here, the divided data D (1), D (2), D (3) and the respective divided partial data D (1,1), D (1,2), D (2,1), The process of generating D (2,2), D (3,1), and D (3,2) and the general form of the definition formula will be described.
まず、第1の分割データD(1)に対しては、第1の分割部分データD(1,1)は、上述した定義式S(1)*R(1)*R(2)で定義され、第2の分割部分データD(1,2)は定義式S(2)*R(1)*R(2)で定義される。なお、この定義式の一般形は、D(1,j)に対してはS(j)*R(j)*R(j+1)であり、D(1,j+1)に対してS(j+1)*R(j)*R(j+1)である(jは奇数とする)。定義式に従って計算すると、D(1,1)は00110110, D(1,2)は10110011となるので、D(1)は00110110 10110011である。なお、定義式の一般形は、図4にまとめて示されている。 First, for the first divided data D (1), the first divided partial data D (1,1) is defined by the above-described definition formula S (1) * R (1) * R (2). Then, the second divided partial data D (1, 2) is defined by the definition formula S (2) * R (1) * R (2). The general form of this defining formula is S (j) * R (j) * R (j + 1) for D (1, j), and for D (1, j + 1) S (j + 1) * R (j) * R (j + 1) (j is an odd number). When calculated according to the definition formula, D (1,1) is 00110110 and D (1,2) is 10110011, so D (1) is 00100110 10110011. The general form of the defining formula is shown collectively in FIG.
また、第2の分割データD(2)に対しては、D(2,1)はS(1)*R(1)で定義され、D(2,2)はS(2)*R(2)で定義される。この定義式の一般形は、D(2,j)に対してはS(j)*R(j)であり、D(2,j+1)に対してはS(j+1)*R(j+1)である(jは奇数とする)。定義式に従って計算すると、D(2,1)は00000011, D(2,2)は00000010となるので、D(2)は00000011 00000010である。 For the second divided data D (2), D (2,1) is defined by S (1) * R (1), and D (2,2) is S (2) * R ( Defined in 2). The general form of this definition is S (j) * R (j) for D (2, j) and S (j + 1) * R for D (2, j + 1) (j + 1) (j is an odd number). When calculated according to the definition formula, D (2,1) becomes 00000011 and D (2,2) becomes 00000010, so D (2) is 00000011 00000010.
更に第3の分割データD(3)に対しては、D(3,1)はR(1)で定義され、D(3,2)はR(2)で定義される。この定義式の一般形は、D(3,j)に対してはR(j)であり、D(3,j+1)に対してはR(j+1)である(jは奇数とする)。定義式に従って計算すると、D(3,1)は10110001, D(3,2)は00110101となるので、D(3)は10110001 00110101である。 Further, for the third divided data D (3), D (3,1) is defined by R (1) and D (3,2) is defined by R (2). The general form of this definition is R (j) for D (3, j) and R (j + 1) for D (3, j + 1) (j is an odd number) To do). When calculated according to the definition formula, D (3,1) is 10110001, D (3,2) is 00110101, and D (3) is 10110001 00110101.
上記説明は、S,R,D(1),D(2),D(3)の長さを16ビットとしたが、データの先頭から上記分割処理を繰り返すことにより、どのような長さの元データSからでも分割データD(1),D(2),D(3)を生成することができる。また、処理単位ビット長bは任意にとることができ、元データSの先頭から順にb×2の長さ毎に上記分割処理を繰り返すことにより任意の長さの元データ、具体的には処理単位ビット長b×2の整数倍の長さの元データに対して適用することができる。なお、元データSの長さが処理単位ビット長b×2の整数倍でない場合は、例えば、データ末尾の部分を0で埋めるなどして元データSの長さを処理単位ビット長b×2の整数倍に合わせることにより上述した本実施形態の分割処理を適用することができる。 In the above description, the length of S, R, D (1), D (2), D (3) is 16 bits. Even from the original data S, the divided data D (1), D (2), and D (3) can be generated. In addition, the processing unit bit length b can be arbitrarily set, and the original data having an arbitrary length, specifically, processing is performed by repeating the above division processing for each length of b × 2 in order from the top of the original data S. The present invention can be applied to original data having an integral multiple of the unit bit length b × 2. If the length of the original data S is not an integral multiple of the processing unit bit length b × 2, for example, the length of the original data S is set to the processing unit bit length b × 2 by filling the end portion of the data with 0, for example. The division processing of this embodiment described above can be applied by adjusting to an integral multiple of.
次に、図3の右側に示す表を参照して、分割データから元データを復元する処理について説明する。これは、機密情報管理システム1の元データ復元部13の機能を説明するものである。
Next, processing for restoring original data from divided data will be described with reference to the table shown on the right side of FIG. This explains the function of the original
まず、機密情報管理システム1に元データSの復元を要求する。機密情報管理システム1は、保管サーバ3および端末2から分割データD(1),D(2),D(3)を取得し、この取得した分割データD(1),D(2),D(3)から次に示すように元データSを復元する。
First, the confidential
まず、分割部分データD(2,1),D(3,1)から第1の元部分データS(1)を次のように生成することができる。 First, the first original partial data S (1) can be generated from the divided partial data D (2,1) and D (3,1) as follows.
D(2,1)*D(3,1)=(S(1)*R(1))*R(1)
=S(1)*(R(1)*R(1))
=S(1)*0
=S(1)
具体的に計算すると、D(2,1)は00000011, D(3,1)は10110001なので、S(1)は10110010となる。
D (2,1) * D (3,1) = (S (1) * R (1)) * R (1)
= S (1) * (R (1) * R (1))
= S (1) * 0
= S (1)
Specifically, since D (2,1) is 00000011 and D (3,1) is 10110001, S (1) is 10110010.
また、別の分割部分データから次のように第2の元部分データS(2)を生成することができる。 Further, the second original partial data S (2) can be generated from the other divided partial data as follows.
D(2,2)*D(3,2)=(S(2)*R(2))*R(2)
=S(2)*(R(2)*R(2))
=S(2)*0
=S(2)
具体的に計算すると、D(2,2)は00000010, D(3,2)は00110101なので、S(2)は00110111となる。
D (2,2) * D (3,2) = (S (2) * R (2)) * R (2)
= S (2) * (R (2) * R (2))
= S (2) * 0
= S (2)
Specifically, since D (2,2) is 00000010 and D (3,2) is 00110101, S (2) is 00110111.
一般に、jを奇数として、
D(2,j)*D(3,j)=(S(j)*R(j))*R(j)
=S(j)*(R(j)*R(j))
=S(j)*0
=S(j)
であるから、D(2,j)*D(3,j)を計算すれば、S(j)が求まる。
In general, let j be an odd number
D (2, j) * D (3, j) = (S (j) * R (j)) * R (j)
= S (j) * (R (j) * R (j))
= S (j) * 0
= S (j)
Therefore, S (j) can be obtained by calculating D (2, j) * D (3, j).
また、一般に、jを奇数として、
D(2,j+1)*D(3,j+1)=(S(j+1)*R(j+1))*R(j+1)
=S(j+1)*(R(j+1)*R(j+1))
=S(j+1)*0
=S(j+1)
であるから、D(2,j+1)*D(3,j+1)を計算すれば、S(j+1)が求まる。
In general, j is an odd number,
D (2, j + 1) * D (3, j + 1) = (S (j + 1) * R (j + 1)) * R (j + 1)
= S (j + 1) * (R (j + 1) * R (j + 1))
= S (j + 1) * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D (2, j + 1) * D (3, j + 1).
次に、D(1),D(3)を取得してSを復元する場合には、次のようになる。 Next, when acquiring D (1) and D (3) and restoring S, it is as follows.
D(1,1)*D(3,1)*D(3,2)=(S(1)*R(1)*R(2))*R(1)*R(2) =S(1)*(R(1)*R(1))*(R(2)*R(2))
=S(1)*0*0
=S(1)
であるから、D(1,1)*D(3,1)*D(3,2)を計算すれば、S(1)が求まる。具体的に計算すると、D(1,1)は00110110, D(3,1)は10110001, D(3,2)は00110101なので、S(1)は10110010となる。
D (1,1) * D (3,1) * D (3,2) = (S (1) * R (1) * R (2)) * R (1) * R (2) = S ( 1) * (R (1) * R (1)) * (R (2) * R (2))
= S (1) * 0 * 0
= S (1)
Therefore, S (1) can be obtained by calculating D (1,1) * D (3,1) * D (3,2). Specifically, since D (1,1) is 00110110, D (3,1) is 1010001, and D (3,2) is 0110101, S (1) is 10110010.
また同様に、
D(1,2)*D(3,1)*D(3,2)=(S(2)*R(1)*R(2))*R(1)*R(2)
=S(2)*(R(1)*R(1))*(R(2)*R(2))
=S(2)*0*0
=S(2)
であるから、D(1,2)*D(3,1)*D(3,2)を計算すれば、S(2)が求まる。具体的に計算すると、D(1,2)は10110011, D(3,1)は10110001, D(3,2)は00110101なので、S(2)は00110111となる。
Similarly,
D (1,2) * D (3,1) * D (3,2) = (S (2) * R (1) * R (2)) * R (1) * R (2)
= S (2) * (R (1) * R (1)) * (R (2) * R (2))
= S (2) * 0 * 0
= S (2)
Therefore, S (2) can be obtained by calculating D (1,2) * D (3,1) * D (3,2). Specifically, since D (1,2) is 10110011, D (3,1) is 10110001, and D (3,2) is 00110101, S (2) is 00110111.
一般に、jを奇数として、
D(1,j)*D(3,j)*D(3,j+1)=(S(j)*R(j)*R(j+1))*R(j)*R(j+1)
=S(j)*(R(j)*R(j))*(R(j+1)*R(j+1))
=S(j)*0*0
=S(j)
であるから、D(1,j)*D(3,j)*D(3,j+1)を計算すれば、S(j)が求まる。
In general, let j be an odd number
D (1, j) * D (3, j) * D (3, j + 1) = (S (j) * R (j) * R (j + 1)) * R (j) * R (j +1)
= S (j) * (R (j) * R (j)) * (R (j + 1) * R (j + 1))
= S (j) * 0 * 0
= S (j)
Therefore, S (j) can be obtained by calculating D (1, j) * D (3, j) * D (3, j + 1).
また、一般に、jを奇数として、
D(1,j+1)*D(3,j)*D(3,j+1)=(S(j+1)*R(j)*R(j+1))*R(j)*R(j+1)
=S(j+1)*(R(j)*R(j))*(R(j+1)*R(j+1))
=S(j+1)*0*0
=S(j+1)
であるから、D(1,j+1)*D(3,j)*D(3,j+1)を計算すれば、S(j+1)が求まる。
In general, j is an odd number,
D (1, j + 1) * D (3, j) * D (3, j + 1) = (S (j + 1) * R (j) * R (j + 1)) * R (j) * R (j + 1)
= S (j + 1) * (R (j) * R (j)) * (R (j + 1) * R (j + 1))
= S (j + 1) * 0 * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D (1, j + 1) * D (3, j) * D (3, j + 1).
次に、D(1),D(2)を取得してSを復元する場合には、次のようになる。 Next, when acquiring D (1) and D (2) and restoring S, it is as follows.
D(1,1)*D(2,1)=(S(1)*R(1)*R(2))*(S(1)*R(1))
=(S(1)*S(1))*(R(1)*R(1))*R(2)
=0*0*R(2)
=R(2)
であるから、D(1,1)*D(2,1)を計算すれば、R(2)が求まる。具体的に計算すると、D(1,1)は00110110, D(2,1)は00000011なので、R(2)は00110101となる。
D (1,1) * D (2,1) = (S (1) * R (1) * R (2)) * (S (1) * R (1))
= (S (1) * S (1)) * (R (1) * R (1)) * R (2)
= 0 * 0 * R (2)
= R (2)
Therefore, R (2) is obtained by calculating D (1,1) * D (2,1). Specifically, since D (1,1) is 00110110 and D (2,1) is 00000011, R (2) is 00110101.
また同様に、
D(1,2)*D(2,2)=(S(2)*R(1)*R(2))*(S(2)*R(2))
=(S(2)*S(2))*R(1)*(R(2)*R(2))
=0*R(1)*0
=R(1)
であるから、D(1,2)*D(2,2)を計算すれば、R(1)が求まる。具体的に計算すると、D(1,2)は10110011, D(2,2)は00000010なので、R(1)は10110001となる。
Similarly,
D (1,2) * D (2,2) = (S (2) * R (1) * R (2)) * (S (2) * R (2))
= (S (2) * S (2)) * R (1) * (R (2) * R (2))
= 0 * R (1) * 0
= R (1)
Therefore, R (1) is obtained by calculating D (1,2) * D (2,2). Specifically, since D (1,2) is 10110011 and D (2,2) is 00000010, R (1) is 10110001.
このR(1),R(2)を使用してS(1),S(2)を求める。 Using these R (1) and R (2), S (1) and S (2) are obtained.
D(2,1)*R(1)=(S(1)*R(1))*R(1)
=S(1)*(R(1)*R(1))
=S(1)*0
=S(1)
であるから、D(2,1)*R(1)を計算すれば、S(1)が求まる。具体的に計算すると、D(2,1)は00000011, R(1)は10110001なので、S(1)は10110010となる。
D (2,1) * R (1) = (S (1) * R (1)) * R (1)
= S (1) * (R (1) * R (1))
= S (1) * 0
= S (1)
Therefore, S (1) can be obtained by calculating D (2,1) * R (1). Specifically, since D (2,1) is 00000011 and R (1) is 10110001, S (1) is 10110010.
また同様に、
D(2,2)*R(2)=(S(2)*R(2))*R(2)
=S(2)*(R(2)*R(2))
=S(2)*0
=S(2)
であるからD(2,2)*R(2)を計算すればS(2)が求まる。具体的に計算するとD(2,2)は00000010, R(2)は00110101なので、S(2)は00110111となる。
Similarly,
D (2,2) * R (2) = (S (2) * R (2)) * R (2)
= S (2) * (R (2) * R (2))
= S (2) * 0
= S (2)
Therefore, S (2) can be obtained by calculating D (2,2) * R (2). Specifically, since D (2,2) is 00000010 and R (2) is 00110101, S (2) is 00110111.
一般に、jを奇数として、
D(1,j)*D(2,j)=(S(j)*R(j)*R(j+1))*(S(j)*R(j))
=(S(j)*S(j))*(R(j)*R(j))*R(j+1)
=0*0*R(j+1)
=R(j+1)
であるからD(1,j)*D(2,j)を計算すればR(j+1)が求まる。
In general, let j be an odd number
D (1, j) * D (2, j) = (S (j) * R (j) * R (j + 1)) * (S (j) * R (j))
= (S (j) * S (j)) * (R (j) * R (j)) * R (j + 1)
= 0 * 0 * R (j + 1)
= R (j + 1)
Therefore, R (j + 1) can be obtained by calculating D (1, j) * D (2, j).
また同様に、
D(1,j+1)*D(2,j+1)=(S(j+1)*R(j)*R(j+1))*(S(j+1)*R(j+1))
=(S(j+1)*S(j+1))*R(j)*(R(j+1)*R(j+1))
=0*R(j)*0
=R(j)
であるからD(1,j+1)*D(2,j+1)を計算すればR(j)が求まる。
Similarly,
D (1, j + 1) * D (2, j + 1) = (S (j + 1) * R (j) * R (j + 1)) * (S (j + 1) * R (j +1))
= (S (j + 1) * S (j + 1)) * R (j) * (R (j + 1) * R (j + 1))
= 0 * R (j) * 0
= R (j)
Therefore, R (j) can be obtained by calculating D (1, j + 1) * D (2, j + 1).
このR(j),R(j+1)を使用してS(j),S(j+1)を求める。 Using these R (j) and R (j + 1), S (j) and S (j + 1) are obtained.
D(2,j)*R(j)=(S(j)*R(j))*R(j)
=S(j)*(R(j)*R(j))
=S(j)*0
=S(j)
であるからD(2,j)*R(j)を計算すればS(j)が求まる。
D (2, j) * R (j) = (S (j) * R (j)) * R (j)
= S (j) * (R (j) * R (j))
= S (j) * 0
= S (j)
Therefore, S (j) can be obtained by calculating D (2, j) * R (j).
また同様に、
D(2,j+1)*R(j+1)=(S(j+1)*R(j+1))*R(j+1)
=S(j+1)*(R(j+1)*R(j+1))
=S(j+1)*0
=S(j+1)
であるからD(2,j+1)*R(j+1)を計算すればS(j+1)が求まる。
Similarly,
D (2, j + 1) * R (j + 1) = (S (j + 1) * R (j + 1)) * R (j + 1)
= S (j + 1) * (R (j + 1) * R (j + 1))
= S (j + 1) * 0
= S (j + 1)
Therefore, S (j + 1) is obtained by calculating D (2, j + 1) * R (j + 1).
上述したように、元データの先頭から処理単位ビット長bに基づいて分割処理を繰り返し行って、分割データを生成した場合には、3つの分割データD(1),D(2),D(3)のすべてを用いなくても、3つの分割データのうち、2つの分割データを用いて上述したように元データを復元することができる。 As described above, when the divided data is repeatedly generated from the beginning of the original data based on the processing unit bit length b to generate divided data, the three divided data D (1), D (2), D ( Even if not all of 3) is used, the original data can be restored as described above using two divided data of the three divided data.
本発明の他の方法として、乱数Rのビット長を元データSのビット長よりも短いものを使用して、元データの分割処理を行うことができる。 As another method of the present invention, the original data can be divided by using a random number R having a bit length shorter than that of the original data S.
すなわち、上述した乱数RはS,D(1),D(2),D(3)と同じビット長のデータとしたが、乱数Rを元データSのビット長より短いものとし、分割データD(1),D(2),D(3)の生成にこの短いビット長の乱数Rを繰り返し用いるものである。 That is, the random number R described above is data having the same bit length as S, D (1), D (2), D (3), but the random number R is shorter than the bit length of the original data S, and the divided data D This short bit length random number R is repeatedly used to generate (1), D (2), and D (3).
尚、本実施の形態に係る機密情報管理システム1においては、3つの分割データD(1),D(2),D(3)を生成するようになっていたので、分割数が3の場合について説明したが、秘密分散法Aは、分割数がnの場合にも適用できるものである。
In the confidential
次に、図5に示すフローチャートを参照して、分割数がnで、処理単位ビット長がbである場合の一般的な分割処理について説明する。 Next, a general division process when the number of divisions is n and the processing unit bit length is b will be described with reference to the flowchart shown in FIG.
まず、元データSを機密情報管理システム1に与える(ステップS401)。また、機密情報管理システム1に、分割数n(n≧3である任意の整数)を指示する(ステップS403)。処理単位ビット長bを決定する(ステップS405)。なお、bは0より大きい任意の整数である。次に、元データSのビット長がb×(n-1)の整数倍であるか否かを判定し、整数倍でない場合には、元データSの末尾を0で埋める(ステップS407)。また、整数倍を意味する変数mを0に設定する(ステップS409)。
First, the original data S is given to the confidential information management system 1 (step S401). In addition, the confidential
次に、元データSのb×(n-1)×m+1ビット目からb×(n-1)ビット分のデータが存在するか否かが判定される(ステップS411)。この判定の結果、データが存在しない場合は、ステップS421に進むことになるが、今の場合は、ステップS409で変数mは0に設定された場合であるので、データが存在するため、ステップS413に進む。 Next, it is determined whether or not there is data of b × (n−1) bits from the b × (n−1) × m + 1 bit of the original data S (step S411). As a result of this determination, if there is no data, the process proceeds to step S421. However, in this case, since the variable m is set to 0 in step S409, the data exists, so step S413. Proceed to
ステップS413では、変数jを1からn-1まで変えて、元データSのb×((n-1)×m+j-1)+1ビット目からbビット分のデータを元部分データS((n-1)×m+j)に設定する処理を繰り返し、これにより元データSを処理単位ビット長bで区分けした(n-1)個の元部分データS(1),S(2),…S(n-1)が生成される。 In step S413, the variable j is changed from 1 to n-1, and b bits ((n-1) × m + j-1) +1 bit data of the original data S is converted into the original partial data S. ((n-1) × m + j) is repeated, whereby (n-1) pieces of original partial data S (1), S (2 ),... S (n-1) is generated.
次に、変数jを1からn-1まで変えて、乱数部分データR((n-1)×m+j)に乱数発生部15から発生する処理単位ビット長bの乱数を設定し、これにより乱数Rを処理単位ビット長bで区分けしたn-1個の乱数部分データR(1),R(2),…R(n-1)が生成される(ステップS415)。
Next, the variable j is changed from 1 to n-1, and a random number of the processing unit bit length b generated from the
次に、ステップS417において、変数iを1からnまで変えるとともに、更に各変数iにおいて変数jを1からn-1まで変えながら、ステップS417に示す分割データを生成するための定義式により複数の分割データD(i)の各々を構成する各分割部分データD(i,(n-1)×m+j)を生成する。この結果、次に示すような分割データDが生成される。 Next, in step S417, while changing the variable i from 1 to n and further changing the variable j from 1 to n-1 in each variable i, a plurality of definition expressions for generating the divided data shown in step S417 are used. Each divided partial data D (i, (n−1) × m + j) constituting each of the divided data D (i) is generated. As a result, the following divided data D is generated.
分割データD
=n個の分割データD(i)=D(1),D(2),…D(n)
第1の分割データD(1)
=n-1個の分割部分データD(1,j)=D(1,1),D(1,2),…D(1,n-1)
第2の分割データD(2)
=n-1個の分割部分データD(2,j)=D(2,1),D(2,2),…D(2,n-1)
… … …
… … …
第nの分割データD(n)
=n-1個の分割部分データD(n,j)=D(n,1),D(n,2),…D(n,n-1)
このように変数m=0の場合について分割データDを生成した後、次に変数mを1増やし(ステップS419)、ステップS411に戻り、変数m=1に該当する元データSのb×(n-1)ビット以降について同様の分割処理を行う。最後にステップS411の判定の結果、元データSにデータがなくなった場合、ステップS411からステップS421に進み、上述したように生成した分割データD(1), …,D(n)を保管サーバ3および端末2にそれぞれ保存して、分割処理を終了する。
Split data D
= n pieces of divided data D (i) = D (1), D (2), ... D (n)
First divided data D (1)
= n-1 divided partial data D (1, j) = D (1,1), D (1,2), ... D (1, n-1)
Second divided data D (2)
= n-1 divided partial data D (2, j) = D (2,1), D (2,2), ... D (2, n-1)
………
………
N-th divided data D (n)
= n-1 divided partial data D (n, j) = D (n, 1), D (n, 2), ... D (n, n-1)
In this way, after generating the divided data D for the variable m = 0, the variable m is then incremented by 1 (step S419), and the process returns to step S411 to return b × (n of the original data S corresponding to the variable m = 1. -1) Similar division processing is performed for the bits after the bit. Finally, if there is no data in the original data S as a result of the determination in step S411, the process proceeds from step S411 to step S421, and the divided data D (1),..., D (n) generated as described above are stored in the
さて、上述した実施形態においては、ここの分割データのみから、それを構成する部分データ間の演算を行うことによって乱数成分が失われる場合がある。即ち、例えば3分割の場合、各分割部分データは次のように定義される。 In the embodiment described above, the random number component may be lost by performing an operation between the partial data constituting only the divided data. That is, for example, in the case of three divisions, each divided partial data is defined as follows.
D(1,1)=S(1)*R(1)*R(2), D(1,2)=S(2)*R(1)*R(2), …
D(2,1)=S(1)*R(1), D(2,2)=S(2)*R(2), …
D(3,1)=R(1), D(3,2)=R(2), …
D(1)について見ると、例えば、D(1,1)、D(1,2)が取得できると、
D(1,1)*D(1,2)=(S(1)*R(1)*R(2))*(S(2)*R(1)*R(2))
=S(1)*S(2)*((R(1)*R(1))*((R(2)*R(2))
=S(1)*S(2)*0*0
=S(1)*S(2)
となる。一般にはD(1,j)*D(1,j+1)=S(j)*S(j+1)である。ここでjはj=2×m+1、mはm≧0の任意の整数である。
D (1,1) = S (1) * R (1) * R (2), D (1,2) = S (2) * R (1) * R (2),…
D (2,1) = S (1) * R (1), D (2,2) = S (2) * R (2),…
D (3,1) = R (1), D (3,2) = R (2),…
Looking at D (1), for example, if D (1,1) and D (1,2) can be acquired,
D (1,1) * D (1,2) = (S (1) * R (1) * R (2)) * (S (2) * R (1) * R (2))
= S (1) * S (2) * ((R (1) * R (1)) * ((R (2) * R (2))
= S (1) * S (2) * 0 * 0
= S (1) * S (2)
It becomes. In general, D (1, j) * D (1, j + 1) = S (j) * S (j + 1). Here, j is j = 2 × m + 1, and m is an arbitrary integer satisfying m ≧ 0.
D(1,1)、D(1,2)は、上記の定義より、元データと乱数の演算により生成されたものであり、D(1,1)、D(1,2)それぞれを見ても元データの内容は分からないが、D(1,1)*D(1,2)の演算を行うことによりS(1)*S(2)が算出される。これは元データそのものではないが、乱数成分を含んでいない。 D (1,1) and D (1,2) are generated by the calculation of the original data and random numbers based on the above definition. However, although the contents of the original data are not known, S (1) * S (2) is calculated by calculating D (1,1) * D (1,2). This is not the original data itself, but does not include a random number component.
このように乱数成分が失われると、個々の元部分データについて、例えばS(2)の一部が既知である場合にはS(1)の一部が復元可能となるので、安全ではないと考えられる。例えば、元データが標準化されたデータフォーマットに従ったデータであって、S(2)がそのデータフォーマット中のヘッダ情報やパディング(例えば、データ領域の一部を0で埋めたもの)などを含む部分であった場合には、これらのデータフォーマット固有のキーワードや固定文字列などを含むため、その内容は予測され得る。また、S(2)のうち既知の部分とS(1)*S(2)の値から、S(1)の一部が復元可能である。 If the random component is lost in this way, for each original partial data, for example, if part of S (2) is known, part of S (1) can be restored, so it is not safe. Conceivable. For example, the original data is data according to a standardized data format, and S (2) includes header information and padding (for example, a part of the data area padded with 0), etc. If it is a part, it includes keywords specific to these data formats, fixed character strings, and the like, so the contents can be predicted. Further, a part of S (1) can be restored from the known part of S (2) and the value of S (1) * S (2).
この問題を解決する方法は以下の通りである。図6におけるD(1,j+1)とD(2,j+1)は、図4におけるD(1,j+1)とD(2,j+1)を入れ替えたものである。ここでjはj=2×m+1、mはm≧0の任意の整数である。 The method for solving this problem is as follows. D (1, j + 1) and D (2, j + 1) in FIG. 6 are obtained by replacing D (1, j + 1) and D (2, j + 1) in FIG. Here, j is j = 2 × m + 1, and m is an arbitrary integer satisfying m ≧ 0.
この場合、個々の分割データのみでは、それを構成する分割部分データ間で演算を行っても乱数成分が失われない。これは、図6より
D(1,j)*D(1,j+1)=(S(j)*R(j)*R(j+1))*(S(j+1)*R(j+1))
=S(j)*S(j+1)*R(j)*((R(j+1)*R(j+1))
=S(j)*S(j+1)*R(j)*0
=S(j)*S(j+1)*R(j)
D(2,j)*D(2,j+1)=(S(j)*R(j))*(S(j+1)*R(j)*R(j+1))
=S(j)*S(j+1)*(R(j)*R(j))*R(j+1))
=S(j)*S(j+1)*0*R(j+1)
=S(j)*S(j+1)*R(j+1)
D(3,j)*D(3,j+1)=R(j)*R(j+1)
となるからである。
In this case, with only the individual divided data, the random number component is not lost even if the calculation is performed between the divided partial data constituting the divided data. This is from FIG.
D (1, j) * D (1, j + 1) = (S (j) * R (j) * R (j + 1)) * (S (j + 1) * R (j + 1))
= S (j) * S (j + 1) * R (j) * ((R (j + 1) * R (j + 1))
= S (j) * S (j + 1) * R (j) * 0
= S (j) * S (j + 1) * R (j)
D (2, j) * D (2, j + 1) = (S (j) * R (j)) * (S (j + 1) * R (j) * R (j + 1))
= S (j) * S (j + 1) * (R (j) * R (j)) * R (j + 1))
= S (j) * S (j + 1) * 0 * R (j + 1)
= S (j) * S (j + 1) * R (j + 1)
D (3, j) * D (3, j + 1) = R (j) * R (j + 1)
Because it becomes.
また、この場合、3つの分割データのうち2つから、元データを復元することができるという特性は失われていない。これは、D(1)、D(2)を取得してSを復元する場合には、図6におけるD(1)、D(2)は、図4におけるD(1)、D(2)を構成する分割部分データを入れ替えたものにすぎないので、明らかにこれらから元データを復元することができ、また、D(1)とD(3)またはD(2)とD(3)を取得してSを復元する場合には、D(3)は乱数のみからなる分割データであるので、D(1)またはD(2)の分割部分データ毎に必要な個数の乱数との排他的論理和演算を行うことにより、乱数部分を消去して元データを復元することができるからである。 In this case, the characteristic that the original data can be restored from two of the three divided data is not lost. This is because when D (1) and D (2) are acquired and S is restored, D (1) and D (2) in FIG. 6 are D (1) and D (2) in FIG. Is simply a replacement of the divided part data, so the original data can obviously be restored from these, and D (1) and D (3) or D (2) and D (3) When acquiring and restoring S, since D (3) is divided data consisting only of random numbers, it is exclusive with the required number of random numbers for each divided partial data of D (1) or D (2). This is because the original data can be restored by erasing the random number portion by performing a logical OR operation.
次に、一旦分割された分割データにさらに乱数を与えて新たな分割データ(再分割データ)を生成する再分割処理について説明する。これは、ユーザが保持する分割データを紛失した場合における機密情報管理システム1の再分割データ生成部14の機能を説明するものであるが、これに関しても、分割数が3の場合を例に説明する。尚、本実施の形態における再分割処理は、2つの方法があるので、以下、それぞれについて説明する。
Next, a re-division process for generating new division data (re-division data) by giving a random number to the division data once divided will be described. This explains the function of the re-divided
(乱数追加注入方式)
図7は、乱数追加注入方式におけるデータ再分割処理の概要を説明するフローチャート図である。同図によれば、まず分割データD(1),D(2),D(3)を取得し(ステップS501)、次に、乱数発生部13で再分割の際に用いる乱数R’を発生させる(ステップS503)。
(Random number additional injection method)
FIG. 7 is a flowchart for explaining an outline of data re-division processing in the random number additional injection method. According to the figure, first, the divided data D (1), D (2), D (3) are acquired (step S501), and then the
次に、分割データD(1),D(2),D(3)それぞれに乱数R’を所定のルールで注入する(ステップS505)。これは、後述するようなルールにより分割データD(1),D(2),D(3)の分割部分データと乱数R’の乱数部分データの排他的論理和をとり、新たな分割データD’(1),D’(2),D’(3)を生成するものである(ステップS507)。 Next, a random number R 'is injected into each of the divided data D (1), D (2), and D (3) according to a predetermined rule (step S505). This is based on the rule described later, and exclusive OR of the divided part data of the divided data D (1), D (2), D (3) and the random number part data of the random number R ′ is performed, and the new divided data D '(1), D' (2), D '(3) is generated (step S507).
図8は、元データSを、元データの半分の長さの処理単位ビット長bに基づいて分割数n=3で3分割する場合の分割部分データの定義式、乱数の再注入後の分割部分データの定義式、および各分割部分データから元データを復元する場合の計算式などを示す表である。 FIG. 8 shows a definition formula of divided partial data when the original data S is divided into three with the division number n = 3 based on the processing unit bit length b that is half the length of the original data, and the division after reinjection of random numbers It is a table | surface which shows the definition formula of partial data, the calculation formula in the case of decompress | restoring original data from each division | segmentation partial data, etc.
ここで、分割部分データD(i,j)の定義式について説明する。 Here, the definition formula of the divided partial data D (i, j) will be described.
まず、第1の分割データD(1)に対しては、図6に示すように、第1の分割部分データD(1,1)は、定義式S(1)*R(1)*R(2)で定義され、第2の分割部分データD(1,2)は定義式S(2)*R(2)で定義される。なお、この定義式の一般形は、D(1,j)に対してはS(j)*R(j)*R(j+1)であり、D(1,j+1)に対してS(j+1)*R(j+1)である(jは奇数とする)。 First, as shown in FIG. 6, for the first divided data D (1), the first divided partial data D (1,1) is defined as S (1) * R (1) * R. The second divided partial data D (1, 2) is defined by the definition formula S (2) * R (2). The general form of this defining formula is S (j) * R (j) * R (j + 1) for D (1, j), and for D (1, j + 1) S (j + 1) * R (j + 1) (j is an odd number).
また、第2の分割データD(2)に対しては、図6に示すように、D(2,1)はS(1)*R(1)で定義され、D(2,2)はS(2)*R(1)*R(2)で定義される。この定義式の一般形は、D(2,j)に対してはS(j)*R(j)であり、D(2,j+1)に対してはS(j+1)*R(j)*R(j+1)である(jは奇数とする)。 For the second divided data D (2), as shown in FIG. 6, D (2,1) is defined by S (1) * R (1), and D (2,2) is Defined by S (2) * R (1) * R (2). The general form of this definition is S (j) * R (j) for D (2, j) and S (j + 1) * R for D (2, j + 1) (j) * R (j + 1) (j is an odd number).
更に第3の分割データD(3)に対しては、図6に示すように、D(3,1)はR(1)で定義され、D(3,2)はR(2)で定義される。この定義式の一般形は、D(3,j)に対してはR(j)であり、D(3,j+1)に対してはR(j+1)である(jは奇数とする)。 Furthermore, for the third divided data D (3), as shown in FIG. 6, D (3,1) is defined by R (1) and D (3,2) is defined by R (2). Is done. The general form of this definition is R (j) for D (3, j) and R (j + 1) for D (3, j + 1) (j is an odd number) To do).
次に、新たな乱数R’注入後の分割部分データD’(i,j)の定義式について説明する。 Next, the definition formula of the divided partial data D ′ (i, j) after the new random number R ′ is injected will be described.
まず、第1の分割データD’(1)に対しては、図8に示すように、第1の分割部分データD’(1,1)は、定義式D(1,1)* R’(1)*R’(2)、即ち、S(1)*R(1)*R(2)*R’(1)*R’(2)で定義され、第2の分割部分データD’(1,2)は、定義式D(1,2)*R’(2)、即ち、S(2)*R(2)* R’(2)で定義される。なお、この定義式の一般形は、D’(1,j)に対してはD(1,j)*R’(j)*R’(j+1)であり、D’(1,j+1)に対してD(1,j+1)*R’(j+1)である(jは奇数とする)。 First, as shown in FIG. 8, for the first divided data D ′ (1), the first divided partial data D ′ (1,1) is defined by the definition formula D (1,1) * R ′. (1) * R '(2), that is, S (1) * R (1) * R (2) * R' (1) * R '(2) (1,2) is defined by the definition formula D (1,2) * R ′ (2), that is, S (2) * R (2) * R ′ (2). Note that the general form of this defining formula is D (1, j) * R '(j) * R' (j + 1) for D '(1, j), and D' (1, j +1) is D (1, j + 1) * R ′ (j + 1) (j is an odd number).
また、第2の分割データD’(2)に対しては、図8に示すように、D’(2,1)はD(2,1)* R’(1)、即ち、S(1)*R(1)* R’(1)で定義され、D’(2,2)はD (2,2)*R’(1)*R’(2)、即ち、S(2)*R(1)* R(2)*R’(1)*R’(2)で定義される。この定義式の一般形は、D’(2,j)に対してはD(2,j)* R’(j)であり、D’(2,j+1)に対してはD(2,j+1)* R’(j)*R’(j+1)である(jは奇数とする)。 For the second divided data D ′ (2), as shown in FIG. 8, D ′ (2,1) is D (2,1) * R ′ (1), that is, S (1 ) * R (1) * R '(1) and D' (2,2) is D (2,2) * R '(1) * R' (2), that is, S (2) * R (1) * R (2) * R '(1) * R' (2) is defined. The general form of this definition is D (2, j) * R '(j) for D' (2, j) and D (2 for D '(2, j + 1) , j + 1) * R ′ (j) * R ′ (j + 1) (j is an odd number).
また、第3の分割データD’(3)に対しては、図8に示すように、D’(3,1)はD(3,1)* R’(1)、即ち、R(1)* R’(1)で定義され、D’(3,2)はD (3,2)*R’(2)、即ち、R(2)* R’(2)で定義される。この定義式の一般形は、D’(3,j)に対してはD(3,j)* R’(j)*であり、D’(3,j+1)に対してはD (3,j+1)* R’(j+1)である(jは奇数とする)。 For the third divided data D ′ (3), as shown in FIG. 8, D ′ (3,1) is D (3,1) * R ′ (1), that is, R (1 ) * R ′ (1) and D ′ (3,2) is defined by D (3,2) * R ′ (2), that is, R (2) * R ′ (2). The general form of this definition is D (3, j) * R '(j) * for D' (3, j) and D (3, j + 1) for D '(3, j + 1). 3, j + 1) * R ′ (j + 1) (j is an odd number).
このように、再分割部分データD’(i,j)はそれぞれ、分割部分データD (i,j)に、分割部分データD (i,j)の定義式で注入されていた乱数部分データR(j)に対応する乱数部分データR’(j)を注入して排他的論理和を計算して求めるものである。 In this way, the re-partitioned partial data D ′ (i, j) is respectively random number partial data R that has been injected into the divided partial data D (i, j) by the definition formula of the divided partial data D (i, j). This is obtained by injecting random number partial data R ′ (j) corresponding to (j) and calculating exclusive OR.
尚、ユーザが保持する分割データを紛失した場合には、上述した分割データD(1),D(2),D(3)のうちいずれか1つを紛失しているので、紛失した分割データに関しては、残りの2つの分割データから復元し、その後、再分割データを生成する必要がある。ここで、残りの2つの分割データから紛失した分割データを生成する方法について説明する。 In addition, when the divided data held by the user is lost, any one of the above-mentioned divided data D (1), D (2), D (3) is lost. With respect to, it is necessary to restore from the remaining two divided data, and then generate re-divided data. Here, a method for generating lost divided data from the remaining two divided data will be described.
まず、分割データD(3)を紛失し、分割データD(1),D(2)から分割データD(3)を生成する場合について説明する。具体的には、図8の例で説明すると
D(1,1)* D(2,1)=((S(1)*R(1)*R(2))*(S(1)*R(1))
=R(2)* (S(1)* S(1))* (R(1)* R(1))
=R(2)
D(1,2)* D(2,2)=((S(2)*R(2))*(S(2)*R(1)*R(2))
=R(1)* (S(2)* S(2))* (R(2)* R(2))
= R(1)
であり、また、D(3,1)= R(1)、D(3,2)= R(2)であるから、D(1,1)* D(2,1)およびD(1,2)* D(2,2)から分割データD (3)を生成することができる。
First, a case where the divided data D (3) is lost and the divided data D (3) is generated from the divided data D (1) and D (2) will be described. Specifically, in the example of FIG.
D (1,1) * D (2,1) = ((S (1) * R (1) * R (2)) * (S (1) * R (1))
= R (2) * (S (1) * S (1)) * (R (1) * R (1))
= R (2)
D (1,2) * D (2,2) = ((S (2) * R (2)) * (S (2) * R (1) * R (2))
= R (1) * (S (2) * S (2)) * (R (2) * R (2))
= R (1)
And D (3,1) = R (1), D (3,2) = R (2), so D (1,1) * D (2,1) and D (1, 2) * Divided data D (3) can be generated from D (2,2).
また、分割データD(1)を紛失し、分割データD(2),D(3)から分割データD(1)を生成する場合については、
D(1,1)= D(2,1)*R(2)
D(1,2)= D(2,2)*R(1)
であり、また、D(3,1)= R(1)、D(3,2)= R(2)であるから、D(2,1)*R(2)およびD(2,2)*R(1)から分割データD (1)を生成することができる。
In the case where the divided data D (1) is lost and the divided data D (1) is generated from the divided data D (2), D (3),
D (1,1) = D (2,1) * R (2)
D (1,2) = D (2,2) * R (1)
And D (3,1) = R (1), D (3,2) = R (2), so D (2,1) * R (2) and D (2,2) The divided data D (1) can be generated from * R (1).
また、分割データD(2)を紛失し、分割データD(1),D(3)から分割データD(2)を生成する場合については、
D(2,1)= D(1,1)*R(2)
D(2,2)= D(1,2)*R(1)
であり、また、D(3,1)= R(1)、D(3,2)= R(2)であるから、分割データD (1),D (3)から分割データD (2)を生成することができる。
In addition, when the divided data D (2) is lost and the divided data D (2) is generated from the divided data D (1), D (3),
D (2,1) = D (1,1) * R (2)
D (2,2) = D (1,2) * R (1)
Since D (3,1) = R (1) and D (3,2) = R (2), the divided data D (1), D (3) to the divided data D (2) Can be generated.
次に、図8の右側に示す表を参照して、再分割データから元データを復元する処理について説明する。これは、ユーザが再分割データを受け取った後のサービス利用時において、機密情報管理システム1の元データ復元部12の機能を説明するものである。
Next, a process for restoring the original data from the repartitioned data will be described with reference to the table shown on the right side of FIG. This explains the function of the original
まず、分割部分データD’(2,1),D’(3,1)から第1の元部分データS(1)を次のように生成することができる。 First, the first original partial data S (1) can be generated from the divided partial data D ′ (2,1), D ′ (3,1) as follows.
D’(2,1)*D’(3,1)=(S(1)*R(1)*R’(1))*(R(1)*R’(1))
=S(1)*(R(1)*R(1))* (R’(1)* R’(1))
=S(1)*0*0
=S(1)
また、別の分割部分データから次のように第2の元部分データS(2)を生成することができる。
D '(2,1) * D' (3,1) = (S (1) * R (1) * R '(1)) * (R (1) * R' (1))
= S (1) * (R (1) * R (1)) * (R '(1) * R' (1))
= S (1) * 0 * 0
= S (1)
Further, the second original partial data S (2) can be generated from the other divided partial data as follows.
D’(2,2)*D’(3,1)*D’(3,2)=(S(2)*R(1)*R(2)*R’(1)*R’(2))*
(R(1)* R’(1))* (R(2)* R’(2))
=S(2)*(R(1)*R(1))*(R(2)*R(2))*
(R’(1)* R’(1))* (R’(2)* R’(2))
=S(2)*0*0*0*0
=S(2)
一般に、jを奇数として、
D’(2,j)*D’(3,j)=(S(j)*R(j)*R’(j))*(R(j)* R’(j))
=S(j)*(R(j)*R(j))*(R’(j)*R’(j))
=S(j)*0*0
=S(j)
であるから、D’(2,j)*D’(3,j)を計算すれば、S(j)が求まる。
D '(2,2) * D' (3,1) * D '(3,2) = (S (2) * R (1) * R (2) * R' (1) * R '(2 )) *
(R (1) * R '(1)) * (R (2) * R' (2))
= S (2) * (R (1) * R (1)) * (R (2) * R (2)) *
(R '(1) * R' (1)) * (R '(2) * R' (2))
= S (2) * 0 * 0 * 0 * 0
= S (2)
In general, let j be an odd number
D '(2, j) * D' (3, j) = (S (j) * R (j) * R '(j)) * (R (j) * R' (j))
= S (j) * (R (j) * R (j)) * (R '(j) * R' (j))
= S (j) * 0 * 0
= S (j)
Therefore, S (j) can be obtained by calculating D ′ (2, j) * D ′ (3, j).
また、一般に、jを奇数として、
D’(2,j+1)* D’(3,j)*D’(3,j+1)=(S(j+1)*R(j)*R(j+1)*R’(j)*R’(j+1))*
(R(j)* R’(j))*(R(j+1)* R’(j+1))
=S(j+1)*((R(j)*R(j))*(R(j+1)*R(j+1))*
*(R’(j)*R’(j))*(R’(j+1)*R’(j+1))
=S(j+1)*0*0*0*0
=S(j+1)
であるから、D’(2,j+1)* D’(3,j)*D’(3,j+1)を計算すれば、S(j+1)が求まる。
In general, j is an odd number,
D '(2, j + 1) * D' (3, j) * D '(3, j + 1) = (S (j + 1) * R (j) * R (j + 1) * R' (j) * R '(j + 1)) *
(R (j) * R '(j)) * (R (j + 1) * R' (j + 1))
= S (j + 1) * ((R (j) * R (j)) * (R (j + 1) * R (j + 1)) *
* (R '(j) * R' (j)) * (R '(j + 1) * R' (j + 1))
= S (j + 1) * 0 * 0 * 0 * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D ′ (2, j + 1) * D ′ (3, j) * D ′ (3, j + 1).
次に、D’(1),D’(3)を取得してSを復元する場合には、次のようになる。 Next, when D ′ (1) and D ′ (3) are acquired and S is restored, it is as follows.
D’(1,1)*D’(3,1)*D’(3,2)=(S(1)*R(1)*R(2)*R’(1)*R’(2))*
(R(1)* R’(1))* (R(2)* R’(2))
= S(1)*(R(1)*R(1))* (R(2)*R(2)) *
(R’(1)* R’(1))* (R’(2)* R’(2))
=S(1)*0*0*0*0
=S(1)
であるから、D’(1,1)*D’(3,1)*D’(3,2)を計算すれば、S(1)が求まる。
D '(1,1) * D' (3,1) * D '(3,2) = (S (1) * R (1) * R (2) * R' (1) * R '(2 )) *
(R (1) * R '(1)) * (R (2) * R' (2))
= S (1) * (R (1) * R (1)) * (R (2) * R (2)) *
(R '(1) * R' (1)) * (R '(2) * R' (2))
= S (1) * 0 * 0 * 0 * 0
= S (1)
Therefore, S (1) can be obtained by calculating D ′ (1,1) * D ′ (3,1) * D ′ (3,2).
また同様に、
D’(1,2)* D’(3,2)=(S(2)*R(2)*R’(2))*(R(2)*R’(2))
=S(2)*(R(2)*R(2))*(R’(2)*R’(2))
=S(2)*0*0
=S(2)
であるから、D’(1,2)* D’(3,2)を計算すれば、S(2)が求まる。
Similarly,
D '(1,2) * D' (3,2) = (S (2) * R (2) * R '(2)) * (R (2) * R' (2))
= S (2) * (R (2) * R (2)) * (R '(2) * R' (2))
= S (2) * 0 * 0
= S (2)
Therefore, S (2) can be obtained by calculating D '(1,2) * D' (3,2).
一般に、jを奇数として、
D’(1,j)*D’(3,j)*D’(3,j+1)=(S(j)*R(j)*R(j+1)*R’(j)*R’(j+1))*
(R(j)*R’(j))*(R(j+1)*R’(j+1))
=S(j)*(R(j)*R(j))*(R(j+1)*R(j+1))*
(R’(j)*R’(j))* (R’(j+1)*R’(j+1))
=S(j)*0*0*0*0
=S(j)
であるから、D’(1,j)*D’(3,j)*D’(3,j+1)を計算すれば、S(j)が求まる。
In general, let j be an odd number
D '(1, j) * D' (3, j) * D '(3, j + 1) = (S (j) * R (j) * R (j + 1) * R' (j) * R '(j + 1)) *
(R (j) * R '(j)) * (R (j + 1) * R' (j + 1))
= S (j) * (R (j) * R (j)) * (R (j + 1) * R (j + 1)) *
(R '(j) * R' (j)) * (R '(j + 1) * R' (j + 1))
= S (j) * 0 * 0 * 0 * 0
= S (j)
Therefore, S (j) can be obtained by calculating D ′ (1, j) * D ′ (3, j) * D ′ (3, j + 1).
また、一般に、jを奇数として、
D’(1,j+1)* D’(3,j+1)=(S(j+1)*R(j+1)*R’(j+1)) *(R(j+1)*R’(j+1))
=S(j+1)*(R(j+1)*R(j+1))*(R’(j+1)*R’(j+1))
=S(j+1)*0*0
=S(j+1)
であるから、D’(1,j+1)* D’(3,j+1)を計算すれば、S(j+1)が求まる。
In general, j is an odd number,
D '(1, j + 1) * D' (3, j + 1) = (S (j + 1) * R (j + 1) * R '(j + 1)) * (R (j + 1 ) * R '(j + 1))
= S (j + 1) * (R (j + 1) * R (j + 1)) * (R '(j + 1) * R' (j + 1))
= S (j + 1) * 0 * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D ′ (1, j + 1) * D ′ (3, j + 1).
次に、D’(1),D’(2)を取得してSを復元する場合には、次のようになる。 Next, when D ′ (1) and D ′ (2) are acquired and S is restored, it is as follows.
D’(1,1)*D’(2,1)=(S(1)*R(1)*R(2)*R’(1)*R’(2))*(S(1)*R(1)*R’(1))
=(S(1)*S(1))*(R(1)*R(1))*(R’(1)*R’(1))*R(2)* R’(2)
=0*0*0*R(2)*R’(2)
=R(2)*R’(2)
であるから、D’(1,1)*D’(2,1)を計算すれば、R(2)*R’(2)が求まる。
D '(1,1) * D' (2,1) = (S (1) * R (1) * R (2) * R '(1) * R' (2)) * (S (1) * R (1) * R '(1))
= (S (1) * S (1)) * (R (1) * R (1)) * (R '(1) * R' (1)) * R (2) * R '(2)
= 0 * 0 * 0 * R (2) * R '(2)
= R (2) * R '(2)
Therefore, by calculating D ′ (1,1) * D ′ (2,1), R (2) * R ′ (2) can be obtained.
また同様に、
D’(1,2)*D’(2,2)=(S(2)*R(2)*R’(2))*(S(2)*R(1)*R(2)*R’(1)*R’(2))
=(S(2)*S(2))*R(1)*R’(1)*(R(2)*R(2))*(R’(2)*R’(2))
=0*R(1)*R’(1)*0*0
=R(1)*R’(1)
であるから、D’(1,2)*D’(2,2)を計算すれば、R(1)*R’(1)が求まる。
Similarly,
D '(1,2) * D' (2,2) = (S (2) * R (2) * R '(2)) * (S (2) * R (1) * R (2) * R '(1) * R' (2))
= (S (2) * S (2)) * R (1) * R '(1) * (R (2) * R (2)) * (R' (2) * R '(2))
= 0 * R (1) * R '(1) * 0 * 0
= R (1) * R '(1)
Therefore, if D ′ (1,2) * D ′ (2,2) is calculated, R (1) * R ′ (1) is obtained.
このR(1)*R’(1),R(2)*R’(2)を使用してS(1),S(2)を求める。 Using these R (1) * R ′ (1) and R (2) * R ′ (2), S (1) and S (2) are obtained.
D’(2,1)* R(1)*R’(1)=(S(1)*R(1)*R’(1))* R(1)*R’(1)
=S(1)*(R(1)*R(1))* (R’(1)*R’(1))
=S(1)*0*0
=S(1)
であるから、D’(2,1)*R(1)*R’(1)を計算すれば、S(1)が求まる。
D '(2,1) * R (1) * R' (1) = (S (1) * R (1) * R '(1)) * R (1) * R' (1)
= S (1) * (R (1) * R (1)) * (R '(1) * R' (1))
= S (1) * 0 * 0
= S (1)
Therefore, S (1) can be obtained by calculating D ′ (2,1) * R (1) * R ′ (1).
また同様に、
D’(1,2)*R(2)*R’(2)=(S(2)*R(2)*R’(2))* R(2)*R’(2)
=S(2)*(R(2)*R(2))* (R’(2)*R’(2))
=S(2)*0*0
=S(2)
であるからD’(2,2)*R(2)*R’(2)を計算すればS(2)が求まる。
Similarly,
D '(1,2) * R (2) * R' (2) = (S (2) * R (2) * R '(2)) * R (2) * R' (2)
= S (2) * (R (2) * R (2)) * (R '(2) * R' (2))
= S (2) * 0 * 0
= S (2)
Therefore, S (2) can be obtained by calculating D '(2,2) * R (2) * R' (2).
一般に、jを奇数として、
D’(1,j)*D’(2,j)=(S(j)*R(j)*R(j+1)*R’(j)*R’(j+1))*(S(j)*R(j)*R’(j))
=(S(j)*S(j))*(R(j)*R(j))*(R’(j)*R’(j))*R(j+1) *R’(j+1)
=0*0*0*R(j+1)*R’(j+1)
= R(j+1)*R’(j+1)
であるからD’(1,j)*D’(2,j)を計算すればR(j+1)*R’(j+1)が求まる。
In general, let j be an odd number
D '(1, j) * D' (2, j) = (S (j) * R (j) * R (j + 1) * R '(j) * R' (j + 1)) * ( S (j) * R (j) * R '(j))
= (S (j) * S (j)) * (R (j) * R (j)) * (R '(j) * R' (j)) * R (j + 1) * R '(j +1)
= 0 * 0 * 0 * R (j + 1) * R '(j + 1)
= R (j + 1) * R '(j + 1)
Therefore, if D ′ (1, j) * D ′ (2, j) is calculated, R (j + 1) * R ′ (j + 1) is obtained.
また同様に、
D’(1,j+1)*D’(2,j+1)=(S(j+1)* R(j+1)*R’(j+1))*
(S(j+1)*R(j)*R(j+1)* R’(j)*R’(j+1))
=(S(j+1)*S(j+1))*R(j)* R’(j)*
(R(j+1)*R(j+1))*(R’(j+1)* R’(j+1))
=0* R(j)* R’(j)*0*0
= R(j)* R’(j)
であるからD’(1,j+1)*D’(2,j+1)を計算すればR(j)* R’(j)が求まる。
Similarly,
D '(1, j + 1) * D' (2, j + 1) = (S (j + 1) * R (j + 1) * R '(j + 1)) *
(S (j + 1) * R (j) * R (j + 1) * R '(j) * R' (j + 1))
= (S (j + 1) * S (j + 1)) * R (j) * R '(j) *
(R (j + 1) * R (j + 1)) * (R '(j + 1) * R' (j + 1))
= 0 * R (j) * R '(j) * 0 * 0
= R (j) * R '(j)
Therefore, if D ′ (1, j + 1) * D ′ (2, j + 1) is calculated, R (j) * R ′ (j) is obtained.
このR(j)* R’(j),R(j+1)*R’(j+1)を使用してS(j),S(j+1)を求める。 Using these R (j) * R ′ (j) and R (j + 1) * R ′ (j + 1), S (j) and S (j + 1) are obtained.
D’(2,j)*R(j)* R’(j)=(S(j)*R(j)*R’(j))*R(j)*R’(j)
=S(j)*(R(j)*R(j))*(R’(j)*R’(j))
=S(j)*0*0
=S(j)
であるからD’(2,j)*R(j)* R’(j)を計算すればS(j)が求まる。
D '(2, j) * R (j) * R' (j) = (S (j) * R (j) * R '(j)) * R (j) * R' (j)
= S (j) * (R (j) * R (j)) * (R '(j) * R' (j))
= S (j) * 0 * 0
= S (j)
Therefore, S (j) can be obtained by calculating D '(2, j) * R (j) * R' (j).
また同様に、
D’(1,j+1)*R(j+1)* R’(j+1)=(S(j+1)*R(j+1)*R’(j+1))*R(j+1)* R’(j+1)
=S(j+1)*(R(j+1)*R(j+1))* (R’(j+1)*R’(j+1))
=S(j+1)*0*0
=S(j+1)
であるからD’(1,j+1)*R(j+1)* R’(j+1)を計算すればS(j+1)が求まる。
Similarly,
D '(1, j + 1) * R (j + 1) * R' (j + 1) = (S (j + 1) * R (j + 1) * R '(j + 1)) * R (j + 1) * R '(j + 1)
= S (j + 1) * (R (j + 1) * R (j + 1)) * (R '(j + 1) * R' (j + 1))
= S (j + 1) * 0 * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D ′ (1, j + 1) * R (j + 1) * R ′ (j + 1).
以上、乱数追加注入方式により再分割データを生成した場合には、3つの再分割データD’(1),D’(2),D’(3)のすべてを用いなくても、3つの再分割データのうち、2つの再分割データを用いて上述したように元データを復元することができる。 As described above, when subdivision data is generated by the random number additional injection method, three subdivision data D ′ (1), D ′ (2), and D ′ (3) are not used without using all three subdivision data. Of the divided data, the original data can be restored as described above using two re-divided data.
また、乱数追加注入方式においては、一旦元データを復元することなく(元データが見える形で現れない)、データの再分割処理を行うことができるので、よりセキュアなデータ管理が可能となる。 In addition, in the random number additional injection method, the data can be re-divided without restoring the original data (the original data does not appear in a visible form), so that more secure data management is possible.
(乱数書き換え方式)
図9は、乱数書き換え方式におけるデータ再分割処理の概要を説明するフローチャート図である。同図によれば、まず分割データD(1),D(2),D(3)を取得し(ステップS601)、次に、乱数発生部13で再分割の際に用いる乱数R’を発生させる(ステップS603)。
(Random number rewriting method)
FIG. 9 is a flowchart for explaining an outline of data re-division processing in the random number rewriting method. According to the figure, first, the divided data D (1), D (2), D (3) are acquired (step S601), and then the
次に、分割データD(1),D(2),D(3)それぞれに乱数R’を上述した乱数追加注入方式により注入する(ステップS605)。次に、乱数R’を注入された分割データから旧乱数であるRを消去して、新たな再分割データD’(1),D’(2),D’(3)を生成する(ステップS607,S609)。 Next, a random number R ′ is injected into each of the divided data D (1), D (2), and D (3) by the random number additional injection method described above (step S605). Next, R, which is an old random number, is deleted from the divided data into which the random number R ′ has been injected, and new re-divided data D ′ (1), D ′ (2), D ′ (3) are generated (step) S607, S609).
図10は、元データSを、元データの半分の長さの処理単位ビット長bに基づいて分割数n=3で3分割する場合の分割部分データの定義式、乱数R’の再注入後の分割部分データの定義式、さらに乱数Rを消去後の分割部分データの定義式および各分割部分データから元データを復元する場合の計算式などを示す表である。 FIG. 10 shows a divided partial data definition formula when the original data S is divided into three with a division number n = 3 based on the processing unit bit length b which is half the length of the original data, after reinjection of the random number R ′. 4 is a table showing a definition formula of the divided partial data, a definition formula of the divided partial data after erasing the random number R, a calculation formula when restoring the original data from each divided partial data, and the like.
本方式においては、ステップS605までは、上述した乱数追加注入方式と同様であるため、説明は省略し、古い乱数Rを消去した分割部分データの定義式について説明する。 Since this method is the same as the random number additional injection method described above up to step S605, the description is omitted, and the definition formula of the divided partial data from which the old random number R is deleted will be described.
まず、第1の分割データD’(1)に対しては、図10に示すように、第1の分割部分データD’(1,1)は、定義式(S(1)*R(1)*R(2)*R’(1)*R’(2))*(R(1)*R(2))、即ち、S(1)* R’(1)*R’(2)で定義され、第2の分割部分データD’(1,2)は、定義式(S(2)*R(2)* R’(2))*R(2)、即ち、S(2)*R’(2)で定義される。なお、この定義式の一般形は、D’(1,j)に対してはS(j) *R’(j)*R’(j+1)であり、D’(1,j+1)に対してS(j+1)*R’(j+1)である(jは奇数とする)。 First, for the first divided data D ′ (1), as shown in FIG. 10, the first divided partial data D ′ (1,1) is defined by the definition formula (S (1) * R (1 ) * R (2) * R '(1) * R' (2)) * (R (1) * R (2)), that is, S (1) * R '(1) * R' (2) The second divided partial data D ′ (1, 2) is defined by the definition formula (S (2) * R (2) * R ′ (2)) * R (2), that is, S (2) * R '(2) is defined. The general form of this defining formula is S (j) * R '(j) * R' (j + 1) for D '(1, j), and D' (1, j + 1 ) Is S (j + 1) * R ′ (j + 1) (j is an odd number).
また、第2の分割データD’(2)に対しては、図10に示すように、D’(2,1)は(S(1)*R(1)* R’(1))* R(1)、即ち、S(1)* R’(1)で定義され、D’(2,2)は(S(2)*R(1)* R(2)*R’(1)*R’(2))*R(1)*R(2)、即ち、S(2)*R’(1)*R’(2)で定義される。この定義式の一般形は、D’(2,j)に対してはS(j)* R’(j)*であり、D(2,j+1)に対してはS(j+1)* R’(j)*R’(j+1)である(jは奇数とする)。 For the second divided data D ′ (2), as shown in FIG. 10, D ′ (2,1) is (S (1) * R (1) * R ′ (1)) *. R (1), that is, S (1) * R '(1), and D' (2,2) is defined as (S (2) * R (1) * R (2) * R '(1) * R ′ (2)) * R (1) * R (2), that is, S (2) * R ′ (1) * R ′ (2). The general form of this definition is S (j) * R '(j) * for D' (2, j) and S (j + 1) for D (2, j + 1) ) * R ′ (j) * R ′ (j + 1) (j is an odd number).
また、第3の分割データD’(3)に対しては、図10に示すように、D’(3,1)は(R(1)* R’(1))*R(1)、即ち、R’(1)で定義され、D’(3,2)は(R(2)* R’(2))* R(2)、即ち、R’(2)で定義される。この定義式の一般形は、D’(3,j)に対してはR’(j)*であり、D(3,j+1)に対してはR’(j+1)である(jは奇数とする)。 For the third divided data D ′ (3), as shown in FIG. 10, D ′ (3,1) is (R (1) * R ′ (1)) * R (1), That is, R ′ (1) is defined, and D ′ (3,2) is defined by (R (2) * R ′ (2)) * R (2), that is, R ′ (2). The general form of this definition is R '(j) * for D' (3, j) and R '(j + 1) for D (3, j + 1) ( j is an odd number).
このように、再分割部分データD’(i,j)はそれぞれ、分割部分データD (i,j)に、分割部分データD (i,j)の定義式で注入されていた乱数部分データR(j)に対応する乱数部分データR’(j)を注入した後、さらに乱数部分データR(j)を消去するように乱数部分データR(j)を注入して排他的論理和を計算し、求めるものである。 In this way, the re-partitioned partial data D ′ (i, j) is respectively random number partial data R that has been injected into the divided partial data D (i, j) by the definition formula of the divided partial data D (i, j). After injecting random number partial data R '(j) corresponding to (j), inject random number partial data R (j) so as to erase random number partial data R (j) and calculate exclusive OR. , What you want.
その結果、もとの分割部分データD (i,j)の定義式において、乱数部分データR(j)を乱数部分データR’(j)に置換したものが、再分割部分データD ’(i,j)の定義式となる。 As a result, in the definition formula of the original divided partial data D (i, j), the random partial data R (j) replaced with the random partial data R ′ (j) is the re-divided partial data D ′ (i , j).
次に、図10の右側に示す表を参照して、再分割データから元データを復元する処理について説明する。これは、ユーザが再分割データを受け取った後のサービス利用時において、機密情報管理システム1の元データ復元部12の機能を説明するものである。
Next, a process for restoring the original data from the repartitioned data will be described with reference to the table shown on the right side of FIG. This explains the function of the original
まず、分割部分データD’(2,1),D’(3,1)から第1の元部分データS(1)を次のように生成することができる。 First, the first original partial data S (1) can be generated from the divided partial data D ′ (2,1), D ′ (3,1) as follows.
D’(2,1)*D’(3,1)=(S(1)*R’(1))*R’(1)
=S(1)*(R’(1)*R’(1))
=S(1)*0
=S(1)
また、別の分割部分データから次のように第2の元部分データS(2)を生成することができる。
D '(2,1) * D' (3,1) = (S (1) * R '(1)) * R' (1)
= S (1) * (R '(1) * R' (1))
= S (1) * 0
= S (1)
Further, the second original partial data S (2) can be generated from the other divided partial data as follows.
D’(2,2)*D’(3,1)*D’(3,2)=(S(2)*R’(1)*R’(2))*R’(1)* R’(2)
=S(2)* (R’(1)*R’(1))*(R’(2)* R’(2))
=S(2)*0*0
=S(2)
一般に、jを奇数として、
D’(2,j)*D’(3,j)=(S(j)*R’(j))* R’(j)
=S(j)*(R’(j)*R’(j))
=S(j)*0
=S(j)
であるから、D’(2,j)*D’(3,j)を計算すれば、S(j)が求まる。
D '(2,2) * D' (3,1) * D '(3,2) = (S (2) * R' (1) * R '(2)) * R' (1) * R '(2)
= S (2) * (R '(1) * R' (1)) * (R '(2) * R' (2))
= S (2) * 0 * 0
= S (2)
In general, let j be an odd number
D '(2, j) * D' (3, j) = (S (j) * R '(j)) * R' (j)
= S (j) * (R '(j) * R' (j))
= S (j) * 0
= S (j)
Therefore, S (j) can be obtained by calculating D ′ (2, j) * D ′ (3, j).
また、一般に、jを奇数として、
D’(2,j+1)* D’(3,j)*D’(3,j+1)=(S(j+1)*R’(j)*R’(j+1))* R’(j)* R’(j+1)
=S(j+1)*(R’(j)*R’(j))*(R’(j+1)*R’(j+1))
=S(j+1)*0*0
=S(j+1)
であるから、D’(2,j+1)* D’(3,j)*D’(3,j+1)を計算すれば、S(j+1)が求まる。
In general, j is an odd number,
D '(2, j + 1) * D' (3, j) * D '(3, j + 1) = (S (j + 1) * R' (j) * R '(j + 1)) * R '(j) * R' (j + 1)
= S (j + 1) * (R '(j) * R' (j)) * (R '(j + 1) * R' (j + 1))
= S (j + 1) * 0 * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D ′ (2, j + 1) * D ′ (3, j) * D ′ (3, j + 1).
次に、D’(1),D’(3)を取得してSを復元する場合には、次のようになる。 Next, when D ′ (1) and D ′ (3) are acquired and S is restored, it is as follows.
D’(1,1)*D’(3,1)*D’(3,2)=(S(1)*R’(1)*R’(2))* R’(1)*R’(2)
= S(1)*(R’(1)* R’(1))* (R’(2)* R’(2))
=S(1)*0*0
=S(1)
であるから、D’(1,1)*D’(3,1)*D’(3,2)を計算すれば、S(1)が求まる。
D '(1,1) * D' (3,1) * D '(3,2) = (S (1) * R' (1) * R '(2)) * R' (1) * R '(2)
= S (1) * (R '(1) * R' (1)) * (R '(2) * R' (2))
= S (1) * 0 * 0
= S (1)
Therefore, S (1) can be obtained by calculating D ′ (1,1) * D ′ (3,1) * D ′ (3,2).
また同様に、
D’(1,2)* D’(3,2)=(S(2)*R’(2))*R’(2)
=S(2)*(R’(2)*R’(2))
=S(2)*0
=S(2)
であるから、D’(1,2)* D’(3,2)を計算すれば、S(2)が求まる。
Similarly,
D '(1,2) * D' (3,2) = (S (2) * R '(2)) * R' (2)
= S (2) * (R '(2) * R' (2))
= S (2) * 0
= S (2)
Therefore, S (2) can be obtained by calculating D '(1,2) * D' (3,2).
一般に、jを奇数として、
D’(1,j)*D’(3,j)*D’(3,j+1)=(S(j)*R’(j)*R’(j+1))* R’(j)*R’(j+1)
=S(j)*(R’(j)*R’(j))*(R’(j+1)*R’(j+1))
=S(j)*0*0
=S(j)
であるから、D’(1,j)*D’(3,j)*D’(3,j+1)を計算すれば、S(j)が求まる。
In general, let j be an odd number
D '(1, j) * D' (3, j) * D '(3, j + 1) = (S (j) * R' (j) * R '(j + 1)) * R' ( j) * R '(j + 1)
= S (j) * (R '(j) * R' (j)) * (R '(j + 1) * R' (j + 1))
= S (j) * 0 * 0
= S (j)
Therefore, S (j) can be obtained by calculating D ′ (1, j) * D ′ (3, j) * D ′ (3, j + 1).
また、一般に、jを奇数として、
D’(1,j+1)* D’(3,j+1)=(S(j+1)*R’(j+1)) *R’(j+1)
=S(j+1)*(R’(j+1)*R’(j+1))
=S(j+1)*0
=S(j+1)
であるから、D’(1,j+1)* D’(3,j+1)を計算すれば、S(j+1)が求まる。
In general, j is an odd number,
D '(1, j + 1) * D' (3, j + 1) = (S (j + 1) * R '(j + 1)) * R' (j + 1)
= S (j + 1) * (R '(j + 1) * R' (j + 1))
= S (j + 1) * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D ′ (1, j + 1) * D ′ (3, j + 1).
次に、D’(1),D’(2)を取得してSを復元する場合には、次のようになる。 Next, when D ′ (1) and D ′ (2) are acquired and S is restored, it is as follows.
D’(1,1)*D’(2,1)=(S(1)* R’(1)*R’(2))*(S(1)*R’(1))
=(S(1)*S(1))*(R’(1)*R’(1))*R’(2)
=0*0* R’(2)
= R’(2)
であるから、D’(1,1)*D’(2,1)を計算すれば、R’(2)が求まる。
D '(1,1) * D' (2,1) = (S (1) * R '(1) * R' (2)) * (S (1) * R '(1))
= (S (1) * S (1)) * (R '(1) * R' (1)) * R '(2)
= 0 * 0 * R '(2)
= R '(2)
Therefore, R ′ (2) can be obtained by calculating D ′ (1,1) * D ′ (2,1).
また同様に、
D’(1,2)*D’(2,2)=(S(2)*R’(2))*(S(2)*R’(1)*R’(2))
=(S(2)*S(2))*(R’(2)*R’(2))*R’(1)
=0*0*R’(1)
= R’(1)
であるから、D’(1,2)*D’(2,2)を計算すれば、R’(1)が求まる。
Similarly,
D '(1,2) * D' (2,2) = (S (2) * R '(2)) * (S (2) * R' (1) * R '(2))
= (S (2) * S (2)) * (R '(2) * R' (2)) * R '(1)
= 0 * 0 * R '(1)
= R '(1)
Therefore, R ′ (1) can be obtained by calculating D ′ (1,2) * D ′ (2,2).
このR’(1), R’(2)を使用してS(1),S(2)を求める。 Using these R ′ (1) and R ′ (2), S (1) and S (2) are obtained.
D’(2,1)* R’(1)=(S(1)*R’(1))* R’(1)
=S(1)*(R’(1)*R’(1))
=S(1)*0
=S(1)
であるから、D’(2,1)* R’(1)を計算すれば、S(1)が求まる。
D '(2,1) * R' (1) = (S (1) * R '(1)) * R' (1)
= S (1) * (R '(1) * R' (1))
= S (1) * 0
= S (1)
Therefore, S (1) can be obtained by calculating D ′ (2,1) * R ′ (1).
また同様に、
D’(1,2)*R’(2)=(S(2)*R’(2))* R’(2)
=S(2)* (R’(2)*R’(2))
=S(2)*0
=S(2)
であるからD’(1,2)* R’(2)を計算すればS(2)が求まる。
Similarly,
D '(1,2) * R' (2) = (S (2) * R '(2)) * R' (2)
= S (2) * (R '(2) * R' (2))
= S (2) * 0
= S (2)
Therefore, S (2) can be obtained by calculating D '(1,2) * R' (2).
一般に、jを奇数として、
D’(1,j)*D’(2,j)=(S(j)*R’(j)*R’(j+1))*(S(j)* R’(j))
=(S(j)*S(j))*(R’(j)*R’(j)) *R’(j+1)
=0*0*R’(j+1)
= R’(j+1)
であるからD’(1,j)*D’(2,j)を計算すればR’(j+1)が求まる。
In general, let j be an odd number
D '(1, j) * D' (2, j) = (S (j) * R '(j) * R' (j + 1)) * (S (j) * R '(j))
= (S (j) * S (j)) * (R '(j) * R' (j)) * R '(j + 1)
= 0 * 0 * R '(j + 1)
= R '(j + 1)
Therefore, R ′ (j + 1) can be obtained by calculating D ′ (1, j) * D ′ (2, j).
また同様に、
D’(1,j+1)*D’(2,j+1)=(S(j+1)* R’(j+1))* (S(j+1)*R’(j)*R’(j+1))
=(S(j+1)*S(j+1))*(R’(j+1)* R’(j+1))*R’(j)
=0*0*R’(j)
=R’(j)
であるからD’(1,j+1)*D’(2,j+1)を計算すればR’(j)が求まる。
Similarly,
D '(1, j + 1) * D' (2, j + 1) = (S (j + 1) * R '(j + 1)) * (S (j + 1) * R' (j) * R '(j + 1))
= (S (j + 1) * S (j + 1)) * (R '(j + 1) * R' (j + 1)) * R '(j)
= 0 * 0 * R '(j)
= R '(j)
Therefore, R ′ (j) can be obtained by calculating D ′ (1, j + 1) * D ′ (2, j + 1).
このR’(j), R’(j+1)を使用してS(j),S(j+1)を求める。 Using these R ′ (j) and R ′ (j + 1), S (j) and S (j + 1) are obtained.
D’(2,j)*R’(j)=(S(j)* R’(j))* R’(j)
=S(j)*(R’(j)*R’(j))
=S(j)*0
=S(j)
であるからD’(2,j)*R’(j)を計算すればS(j)が求まる。
D '(2, j) * R' (j) = (S (j) * R '(j)) * R' (j)
= S (j) * (R '(j) * R' (j))
= S (j) * 0
= S (j)
Therefore, S (j) can be obtained by calculating D '(2, j) * R' (j).
また同様に、
D’(1,j+1)* R’(j+1)=(S(j+1)* R’(j+1))*R’(j+1)
=S(j+1)* (R’(j+1)*R’(j+1))
=S(j+1)*0
=S(j+1)
であるからD’(1,j+1)* R’(j+1)を計算すればS(j+1)が求まる。
Similarly,
D '(1, j + 1) * R' (j + 1) = (S (j + 1) * R '(j + 1)) * R' (j + 1)
= S (j + 1) * (R '(j + 1) * R' (j + 1))
= S (j + 1) * 0
= S (j + 1)
Therefore, S (j + 1) can be obtained by calculating D ′ (1, j + 1) * R ′ (j + 1).
以上、乱数書き換え方式により再分割データを生成した場合には、3つの再分割データD’(1),D’(2),D’(3)のすべてを用いなくても、3つの再分割データのうち、2つの再分割データを用いて上述したように元データを復元することができる。 As described above, when subdivision data is generated by the random number rewriting method, three subdivisions can be performed without using all three subdivision data D ′ (1), D ′ (2), and D ′ (3). Of the data, the original data can be restored as described above by using two subdivision data.
また、乱数書き換え方式においても、一旦元データを復元することなく(元データが見える形で現れない)、データの再分割処理を行うことができるので、よりセキュアなデータ管理が可能となる。 Also in the random number rewriting method, the data can be re-divided without restoring the original data once (the original data does not appear in a visible form), so that more secure data management is possible.
<動作>
次に、本実施の形態に係る機密情報管理システム1が適用されるコンピュータシステム10全体の動作について説明する。ここで、図11は、ユーザが機密情報Sを機密情報管理システム1に登録する動作を説明するシーケンス図であり、図12は、ユーザがサービスを利用する時の機密情報管理システム1の動作を説明するシーケンス図であり、図13は、ユーザが保持する分割データDを紛失したときの機密情報管理システム1の動作を説明するシーケンス図である。
<Operation>
Next, the operation of the
(1) 機密情報登録処理
まず、ユーザが端末2から通信ネットワーク4を介して機密情報管理システム1に機密情報Sを送信する(ステップS10)。機密情報システム1は、機密情報Sを受け取ると、上述した秘密分散法Aを用いて3つのデータ(分割データ)D(1),D(2),D(3)に分割する(ステップS20)。
(1) Confidential Information Registration Process First, the user transmits confidential information S from the
次に、機密情報管理システム1は、このようにして生成された分割データを各保管サーバ3a,3bおよび端末2にネットワーク4を介して送信する(ステップS30)。
Next, the confidential
次に、保管サーバ3a,3bは、それぞれ送信されてきた分割データD(1),D(2)をハードディスク等の記憶装置に記憶する(ステップS40)。また、端末2は、送信されてきた分割データD(3)をハードディスク等の記憶装置に記憶する(ステップS50)。
Next, the
これにより、端末2、保管サーバ3a,3bのうちいずれか1つの分割データに紛失、破壊等があっても、残りの2つの分割データからもとの機密情報Sを復元できる。
As a result, even if any one of the divided data of the
(2)サービス利用処理
ユーザがサービス提供システム5を利用する場合には、まず、端末2に保持する分割データD(3)を通信ネットワークを介して機密情報管理システム1に送信する(ステップS110)。
(2) Service use processing When the user uses the
機密情報管理システム1は、端末2から分割データD(3)を受け取ると、残りの分割データD(1), D(2)を保管サーバ3a,3bに要求し、該分割データD(1), D(2)を受け取る(ステップS120)。
Upon receiving the divided data D (3) from the
次に、機密情報管理システム1は、分割データD(1), D(2),D(3)のいずれか2つから秘密分散法Aを用いて機密情報Sを復元する(ステップS130)。そして、復元した機密情報Sをサービス提供5に送信して(ステップS140)、機密情報Sを復元し送信した事実を使用履歴として生成する(ステップS150)。
Next, the confidential
サービス提供システム5は、機密情報管理システム1から機密情報Sを受け取ると、該機密情報Sの正当性を判断して、端末2に通信ネットワーク4を介してサービス提供を行う(ステップS160,S170)。これにより、ユーザは所望のサービスの提供を受けることができる。
Upon receiving the confidential information S from the confidential
(3)分割データ紛失時処理
ユーザが分割データD(3)を紛失した場合(例えば、分割データD(3)を記憶している端末2を紛失した場合)には、まず、機密情報管理システム1にその旨を申告する(例えば、機密情報管理システム1の運用者へ電話連絡する)(ステップS210)。
(3) Processing when the divided data is lost When the user loses the divided data D (3) (for example, when the
これにより、機密情報管理システム1は、保管サーバ3a,3bに分割データを要求し、保管サーバ3a,3bからそれぞれ分割データD(1), D(2)を受け取る(ステップS220)。
Thereby, the confidential
次に、機密情報管理システム1は、分割データD(1),D(2)から秘密分散法Aを用いて、新たに3つのデータ(再分割データ)D’(1),D’(2),D’(3)を生成する(ステップS240)。
Next, the confidential
ここで、再分割データD’(1),D’(2)に関しては、上述した乱数追加注入方式又は乱数書き換え方式に従って、分割データD(1),D(2)からそれぞれ生成するものである。一方、D’(3)は、まず、分割データD (1),D (2)から分割データD (3)を生成し、その後、乱数追加注入方式又は乱数書き換え方式に従って、分割データD (3)からD’(3)を生成するものである。 Here, the re-divided data D ′ (1) and D ′ (2) are respectively generated from the divided data D (1) and D (2) according to the random number addition injection method or the random number rewriting method described above. . On the other hand, D ′ (3) first generates divided data D (3) from the divided data D (1) and D (2), and then the divided data D (3 (3) according to the random number addition injection method or the random number rewriting method. ) To generate D ′ (3).
次に、機密情報管理システム1は、このようにして生成された再分割データを各保管サーバ3a,3bおよび端末2(例えば、ユーザが分割データD(3)を記憶している端末2を紛失した場合には、ユーザが新たに購入した端末2)にネットワーク4を介して送信する(ステップS250,S260)。
Next, the confidential
次に、保管サーバ3a,3bは、それぞれ送信されてきた再分割データD’(1),D’(2)をハードディスク等の記憶装置に記憶する(ステップS250)。また、端末2は、送信されてきた分割データD’(3)をハードディスク等の記憶装置に記憶する(ステップS260)。これにより、ユーザは再びサービス利用が可能となる。
Next, the
従って、本実施の形態によれば、所定のサービスを受ける際に必要とされる機密情報Sを秘密分散法Aを用いて複数に分割して、そのうちの一部をユーザに保持させるので、ユーザが保持する分割データの紛失があったとしても、残りの分割データから機密情報Sを復元できるとともに、秘密分散法Aを用いて新たに再分割データを生成し、該再分割データの一部を新たにユーザに保持させるので、機密情報Sの変更は不要である。 Therefore, according to the present embodiment, the confidential information S required when receiving a predetermined service is divided into a plurality of pieces using the secret sharing method A, and a part of them is held by the user. Even if there is a loss of the divided data held by the data, the confidential information S can be restored from the remaining divided data, and the re-divided data is newly generated using the secret sharing method A, and a part of the re-divided data is Since it is newly held by the user, it is not necessary to change the confidential information S.
この結果、ユーザが保持する分割データの紛失があったとしても、機密情報Sの再発行処理をすることなく、紛失の申告をするだけで、再びサービス提供を受けることができる。 As a result, even if the divided data held by the user is lost, it is possible to receive the service again only by reporting the loss without re-issuing the confidential information S.
特に、本発明における秘密分散法は、機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、生成した分割データのうちの所定の個数の分割データから機密情報が復元することができ、また、新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、所望の分割数の再分割データを生成するとともに、生成した再分割データのうちの所定の個数の再分割データから機密情報が復元することができるので、機密情報を復元することなく、機密情報を再分割することができる。 In particular, the secret sharing method according to the present invention is a data division method for dividing confidential information into divided data of a desired number of divisions based on a desired processing unit bit length. The secret information is divided into processing unit bit lengths. Generating a plurality of original part data, and corresponding to each of the plurality of original part data, a plurality of random part data having a processing unit bit length from a random number having a length equal to or shorter than the bit length of the confidential information. Generate and generate each divided part data constituting each divided data for each processing unit bit length by exclusive OR of the original partial data and the random number partial data to generate divided data of a desired number of divisions and generate Confidential information can be restored from a predetermined number of pieces of divided data, and a plurality of random number partial data with a processing unit bit length is generated from newly generated random numbers , By generating the re-partitioned partial data for each processing unit bit length by exclusive OR of each divided partial data and the random number partial data, and generating the re-divided data of the desired number of divisions, Since the confidential information can be restored from a predetermined number of the re-divided data, the confidential information can be re-divided without restoring the confidential information.
これにより、ユーザの機密情報をよりセキュアに管理することができる。
また、紛失した分割データを取得した第3者が機密情報管理システム1にアクセスしても機密情報Sを復元することができないので、サービスを利用することができず、安全性が確保される。
Thereby, the confidential information of the user can be managed more securely.
Moreover, since the confidential information S cannot be restored even if a third party who acquired the lost divided data accesses the confidential
さらに、ユーザの使用履歴が機密情報管理システム1に保管されるので、ユーザが分割データを紛失してから紛失した旨を申告するまでの間に、仮に第3者が機密情報Sを取得して悪用したとしても、使用履歴により悪用の有無を判別することができる。
Furthermore, since the user's usage history is stored in the confidential
尚、本実施の形態における秘密分散法Aは、多項式演算・剰余演算などを含む多倍長整数の演算処理を必要としないので、大容量データを多数処理する場合においても簡単かつ迅速にデータの分割および復元を行うことができるという効果を得ることができる。 Note that the secret sharing method A in the present embodiment does not require multi-precision integer arithmetic processing including polynomial arithmetic, remainder arithmetic, etc., so even when processing a large amount of large volume data, it is easy and quick. The effect that division and restoration can be performed can be obtained.
以上、本発明の実施の形態について説明してきたが、本発明の要旨を逸脱しない範囲において、本発明の実施の形態に対して種々の変形や変更を施すことができる。例えば、上記実施の形態においては、端末2から機密情報Sの機密情報管理システム1への受け渡しを通信ネットワーク4を介して行ったが、本発明はこれに限定されず、例えば、機密情報Sを記録した記録媒体を郵送など通信ネットワーク3以外の手段を介して受け渡してもよい。また、同様に、ユーザが保持する分割データも通信ネットワーク4を介して受け取ったが、本発明はこれに限定されず、例えば、分割データを記録した記録媒体を郵送など通信ネットワーク3以外の手段を介して受け渡してもよい。
As mentioned above, although embodiment of this invention has been described, various deformation | transformation and change can be performed with respect to embodiment of this invention in the range which does not deviate from the summary of this invention. For example, in the above embodiment, the confidential information S is transferred from the
また、上記実施の形態においては、ユーザがサービス利用時には、機密情報管理システム1が機密情報を復元したが、本発明はこれに限定されず、ユーザの端末2が、端末2に記憶される分割データと機密情報管理システム1から取得した分割データから、秘密分散法Aを用いて機密情報を復元し、該機密情報をサービス提供システム5に送信してもよいものである。尚、この場合には、復元された機密情報が端末2に記憶されたままユーザが端末2を紛失すると、本発明が解決しようとする課題が解決できないことになるため、該機密情報をサービス提供システム5に送信後すぐに端末2から消去する仕組み、あるいは、端末2のデータの第三者による不正な取り出しを防止する仕組みなどを備えることが必要である。
In the above embodiment, when the user uses the service, the confidential
さらに、上記実施の形態においては、ユーザからの要求により再分割処理を行ったが、機密情報管理システム1が自発的に所定の契機により再分割処理を行ってもよいものである。
Furthermore, in the above-described embodiment, the re-division process is performed according to a request from the user. However, the confidential
1…機密情報管理システム
2…端末
3a,3b…保管サーバ
4…通信ネットワーク
5…サービス提供システム
10…コンピュータシステム
11…分割データ生成部
12…元データ復元部
13…乱数発生部
14…再分割データ生成部
15…使用履歴生成部
16…通信部
DESCRIPTION OF
Claims (14)
前記秘密分散法は、
前記機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、前記機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、前記機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、
新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、前記各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、前記所望の分割数の再分割データを生成するデータ分割方法であり、
前記機密情報を前記秘密分散法を用いて複数の分割データに分割するデータ分割手段と、
前記複数の分割データの一部を、前記利用者が保持するための分割データとして第1の記憶部に記憶させるとともに、前記複数の分割データの残りを、1又は複数の第2の記憶部それぞれに記憶させるデータ記憶手段と、
前記秘密分散法を用いて、前記第2の記憶部に記憶された各分割データのうち、復元可能な所定の個数の分割データの組み合わせから、複数の再分割データを作成するデータ再分割手段と、
前記複数の再分割データの一部を新たな分割データとして前記第1の記憶部に記憶させるとともに、前記第2の記憶部に記憶された各分割データを無効にして、前記複数の再分割データの残りを新たな分割データとして前記第2の記憶部それぞれに記憶させるデータ再記憶手段と、
を有することを特徴とする機密情報管理システム。 A confidential information management system for managing confidential information of users using a secret sharing method,
The secret sharing method is:
A data division method that divides the confidential information into a desired number of divided data based on a desired processing unit bit length, and divides the confidential information into processing unit bit lengths to generate a plurality of original partial data Then, corresponding to each of the plurality of original partial data, a plurality of random part data having a processing unit bit length is generated from a random number having a length equal to or shorter than the bit length of the confidential information. Generate each divided partial data to be configured for each processing unit bit length by exclusive OR of the original partial data and the random number partial data to generate a desired number of divided data,
Generate a plurality of random part data of processing unit bit length from the newly generated random number, and generate re-partitioned partial data for each processing unit bit length by exclusive OR of the respective divided part data and the random part data A data division method for generating the desired number of subdivision data,
Data dividing means for dividing the confidential information into a plurality of divided data using the secret sharing method;
A part of the plurality of divided data is stored in the first storage unit as divided data to be held by the user, and the rest of the plurality of divided data is respectively stored in one or a plurality of second storage units. Data storage means for storing in
Using said secret sharing scheme, among the divided data stored in the second storage unit, a combination of the divided data can be restored predetermined number, and the data re-division means for creating a plurality of re-divided data ,
A part of the plurality of subdivision data is stored in the first storage unit as new division data, and each of the subdivision data stored in the second storage unit is invalidated, and the plurality of subdivision data Data re-storing means for storing the remainder of the data as new divided data in each of the second storage units;
A confidential information management system characterized by comprising:
前記秘密分散法は、
前記機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、前記機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、前記機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、
新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、前記各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、前記所望の分割数の再分割データを生成するデータ分割方法であり、
前記機密情報管理システムは、
第1の記憶部と第2の記憶部と、を備え、
前記機密情報を前記秘密分散法を用いて複数の分割データに分割するデータ分割ステップと、
前記複数の分割データの一部を、前記利用者が保持するための分割データとして前記第1の記憶部に記憶するとともに、前記複数の分割データの残りを、1又は複数の前記第2の記憶部それぞれに記憶するデータ記憶ステップと、
前記秘密分散法を用いて、前記第2の記憶部に記憶された各分割データのうち、復元可能な所定の個数の分割データの組み合わせから、複数の再分割データを作成するデータ再分割ステップと、
前記複数の再分割データの一部を新たな分割データとして前記第1の記憶部に記憶するとともに、前記第2の記憶部に記憶された各分割データを無効にして、前記複数の再分割データの残りを新たな分割データとして前記第2の記憶部のそれぞれに記憶するデータ再記憶ステップと、
を行うことを特徴とする機密情報管理方法。 A confidential information management method for managing confidential information of a user using a secret sharing method performed by a confidential information management system ,
The secret sharing method is:
A data division method that divides the confidential information into a desired number of divided data based on a desired processing unit bit length, and divides the confidential information into processing unit bit lengths to generate a plurality of original partial data Then, corresponding to each of the plurality of original partial data, a plurality of random part data having a processing unit bit length is generated from a random number having a length equal to or shorter than the bit length of the confidential information. Generate each divided partial data to be configured for each processing unit bit length by exclusive OR of the original partial data and the random number partial data to generate a desired number of divided data,
Generate a plurality of random part data of processing unit bit length from the newly generated random number, and generate re-partitioned partial data for each processing unit bit length by exclusive OR of the respective divided part data and the random part data A data division method for generating the desired number of subdivision data,
The confidential information management system includes:
A first storage unit and a second storage unit,
A data dividing step of dividing the confidential information into a plurality of divided data using the secret sharing method;
A portion of the plurality of divided data, together with the user stored in the first storage unit as the divided data to hold, the remaining of the plurality of divided data, one or a plurality of the second memory A data storage step for storing each of the units;
Using said secret sharing scheme, among the divided data stored in the second storage unit, a combination of the divided data can be restored predetermined number, and the data re-division step of creating a plurality of re-divided data ,
Stores in the first storage unit a part of the plurality of re-divided data as new division data, disable the divided data stored in the second storage unit, the plurality of re-division data a data re-storing step of storing in each of said second storage unit the remainder as a new data segment of,
Confidential information management method and performing.
前記秘密分散法は、
前記機密情報を所望の処理単位ビット長に基づいて所望の分割数の分割データに分割するデータ分割方法であり、前記機密情報を処理単位ビット長毎に区分けして、複数の元部分データを生成し、この複数の元部分データの各々に対応して、前記機密情報のビット長と同じまたはこれより短い長さの乱数から処理単位ビット長の複数の乱数部分データを生成し、各分割データを構成する各分割部分データを元部分データと乱数部分データの排他的論理和によって処理単位ビット長毎に生成して、所望の分割数の分割データを生成するとともに、
新たに発生させた乱数から処理単位ビット長の複数の乱数部分データを生成し、前記各分割部分データと該乱数部分データの排他的論理和により処理単位ビット長毎に再分割部分データを生成して、前記所望の分割数の再分割データを生成するデータ分割方法であり、
コンピュータを、
前記機密情報を前記秘密分散法を用いて複数の分割データに分割するデータ分割手段、
前記複数の分割データの一部を、前記利用者が保持するための分割データとして第1の記憶部に記憶させるとともに、前記複数の分割データの残りを、1又は複数の第2の記憶部それぞれに記憶させるデータ記憶手段、
前記秘密分散法を用いて、前記第2の記憶部に記憶された各分割データのうち、復元可能な所定の個数の分割データの組み合わせから、複数の再分割データを作成するデータ再分割手段、および、
前記複数の再分割データの一部を新たな分割データとして前記第1の記憶部に記憶させるとともに、前記第2の記憶部に記憶された各分割データを無効にして、前記複数の再分割データの残りを新たな分割データとして前記第2の記憶部それぞれに記憶させるデータ再記憶手段、
として機能させるための機密情報管理プログラム。 A confidential information management program for managing confidential information of users using a secret sharing method,
The secret sharing method is:
A data division method that divides the confidential information into a desired number of divided data based on a desired processing unit bit length, and divides the confidential information into processing unit bit lengths to generate a plurality of original partial data Then, corresponding to each of the plurality of original partial data, a plurality of random part data having a processing unit bit length is generated from a random number having a length equal to or shorter than the bit length of the confidential information. Generate each divided partial data to be configured for each processing unit bit length by exclusive OR of the original partial data and the random number partial data to generate a desired number of divided data,
Generate a plurality of random part data of processing unit bit length from the newly generated random number, and generate re-partitioned partial data for each processing unit bit length by exclusive OR of the respective divided part data and the random part data A data division method for generating the desired number of subdivision data,
Computer
Data dividing means for dividing the confidential information into a plurality of divided data using the secret sharing method;
A part of the plurality of divided data is stored in the first storage unit as divided data to be held by the user, and the rest of the plurality of divided data is respectively stored in one or a plurality of second storage units. Data storage means for storing
Using said secret sharing scheme, the second one of the divided data stored in the storage unit, a combination of the divided data can be restored predetermined number, the data re-division means for creating a plurality of re-divided data, and,
A part of the plurality of subdivision data is stored in the first storage unit as new division data, and each of the subdivision data stored in the second storage unit is invalidated, and the plurality of subdivision data Data re-storing means for storing the remainder of the data as new divided data in each of the second storage units,
As a confidential information management program.
前記機密情報を使用する場合には、前記利用者が保持する分割データを取得し、該分割データと前記第2の記憶部に記憶された各分割データのうち前記所定の個数の分割データの組み合わせから前記秘密分散法を用いて前記機密情報を復元するデータ復元手段、
として機能させるための請求項11記載の機密情報管理プログラム。 The computer,
When using the confidential information, the division data held by the user is acquired, and the division data and a combination of the predetermined number of division data among the division data stored in the second storage unit Data restoring means for restoring the confidential information using the secret sharing method from
12. The confidential information management program according to claim 11, wherein the confidential information management program is made to function as:
前記機密情報を使用する場合には、前記第2の記憶部に記憶された各分割データのうち、前記所定の個数から前記利用者が保持する分割データの個数を引いた個数の分割データの組み合わせを前記利用者が有する端末に通信ネットワークを介して送信する分割データ送信手段、
として機能させるための請求項11記載の機密情報管理プログラム。 The computer,
When using the confidential information, among the pieces of divided data stored in the second storage unit, a combination of pieces of divided data obtained by subtracting the number of pieces of divided data held by the user from the predetermined number Divided data transmission means for transmitting the terminal to a terminal of the user via a communication network ,
12. The confidential information management program according to claim 11, wherein the confidential information management program is made to function as:
端末コンピュータを、
前記利用者が保持する分割データを取得し、該分割データと前記送信された分割データの組み合わせから前記秘密分散法を用いて前記機密情報を復元する復元手段、および、
前記復元した機密情報を、前記サービスを提供するシステムに通信ネットワークを介して送信する送信手段、
として機能させるための機密情報管理システム用端末プログラム。 A terminal program for a confidential information management system that uses the confidential information of the user using the divided data transmitted from the confidential information management system according to claim 4,
Terminal computer,
Restoration means the user obtains the divided data held to restore the secret information using the secret sharing scheme from the combination of the divided data the transmission and the divided data and,
Transmitting means for transmitting the restored confidential information to a system providing the service via a communication network ;
Terminal program for confidential information management system to function as
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004033352A JP4602675B2 (en) | 2004-02-10 | 2004-02-10 | CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM, CONFIDENTIAL INFORMATION MANAGEMENT METHOD, CONFIDENTIAL INFORMATION MANAGEMENT PROGRAM, AND CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM TERMINAL PROGRAM |
| US10/588,155 US8085938B2 (en) | 2004-02-10 | 2005-02-10 | Secret information management scheme based on secret sharing scheme |
| EP05710362.4A EP1714423B1 (en) | 2004-02-10 | 2005-02-10 | Secret information management scheme based on secret sharing scheme |
| CN2005800043932A CN1918844B (en) | 2004-02-10 | 2005-02-10 | Secret information management scheme based on secret sharing scheme |
| PCT/JP2005/002514 WO2005076518A1 (en) | 2004-02-10 | 2005-02-10 | Secret information management scheme based on secret sharing scheme |
| HK07105595.1A HK1099152A1 (en) | 2004-02-10 | 2007-05-28 | Secret information management system and method based on secret sharing scheme |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004033352A JP4602675B2 (en) | 2004-02-10 | 2004-02-10 | CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM, CONFIDENTIAL INFORMATION MANAGEMENT METHOD, CONFIDENTIAL INFORMATION MANAGEMENT PROGRAM, AND CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM TERMINAL PROGRAM |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005229178A JP2005229178A (en) | 2005-08-25 |
| JP2005229178A5 JP2005229178A5 (en) | 2006-12-14 |
| JP4602675B2 true JP4602675B2 (en) | 2010-12-22 |
Family
ID=35003572
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004033352A Expired - Lifetime JP4602675B2 (en) | 2004-02-10 | 2004-02-10 | CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM, CONFIDENTIAL INFORMATION MANAGEMENT METHOD, CONFIDENTIAL INFORMATION MANAGEMENT PROGRAM, AND CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM TERMINAL PROGRAM |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP4602675B2 (en) |
| CN (1) | CN1918844B (en) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4820688B2 (en) * | 2006-05-12 | 2011-11-24 | 富士通株式会社 | Data distribution apparatus, information processing apparatus having information distribution function, information processing apparatus program, and information distribution storage system |
| JP4881119B2 (en) | 2006-09-29 | 2012-02-22 | 株式会社東芝 | User authentication method, user side authentication device, and program |
| JP2008234017A (en) * | 2007-03-16 | 2008-10-02 | Fuji Electric Holdings Co Ltd | Ic card system, its information processing terminal, and program |
| JP4966232B2 (en) * | 2008-03-13 | 2012-07-04 | 株式会社東芝 | Distributed information adding apparatus, method and program |
| EP2357753A1 (en) * | 2008-11-14 | 2011-08-17 | Oki Semiconductor Co., Ltd. | Confidential information transmission method, confidential information transmission system, and confidential information transmission device |
| CN103141056B (en) * | 2010-10-06 | 2015-08-26 | 日本电信电话株式会社 | Secret decentralized system, secret dispersal device, secret, secret sorting technique, secret dispersion |
| JP6108970B2 (en) * | 2013-06-10 | 2017-04-05 | エヌ・ティ・ティ・コミュニケーションズ株式会社 | Data regeneration device, data regeneration method, and program |
| WO2017134759A1 (en) * | 2016-02-03 | 2017-08-10 | 株式会社情報スペース | Authentication device, authentication system, and authentication program |
| JP6534478B1 (en) * | 2018-08-16 | 2019-06-26 | 行徳紙工株式会社 | File sharing system and method |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11506222A (en) * | 1995-06-05 | 1999-06-02 | サートコー・エルエルシー | Multi-step digital signature method and system |
| JP2001034164A (en) * | 1999-07-23 | 2001-02-09 | Toshiba Corp | Privacy distributed system and recording medium |
| JP2001103045A (en) * | 1999-09-29 | 2001-04-13 | Advanced Mobile Telecommunications Security Technology Research Lab Co Ltd | Storage device for backing up cryptographic key |
| JP2002091301A (en) * | 2000-09-19 | 2002-03-27 | Ntt Data Corp | Key information dispersion device, arithmetic unit and signature verification device |
| JP2002312317A (en) * | 2001-04-11 | 2002-10-25 | Casio Comput Co Ltd | Certification system and certification method |
| JP2004048479A (en) * | 2002-07-12 | 2004-02-12 | Kddi Corp | Encryption key management method of shared encryption information |
| JP2004053969A (en) * | 2002-07-22 | 2004-02-19 | Global Friendship Inc | Electronic tally generating method and program |
| JP2004053968A (en) * | 2002-07-22 | 2004-02-19 | Global Friendship Inc | Electronic information transmitting system |
| JP2004213650A (en) * | 2002-12-19 | 2004-07-29 | Ntt Communications Kk | Data fragmentation method, data fragmentation device and computer program |
| JP2004336702A (en) * | 2003-04-15 | 2004-11-25 | Ntt Communications Kk | Data originality securing method and system, and program for securing data originality |
| WO2005076518A1 (en) * | 2004-02-10 | 2005-08-18 | Ntt Communications Corporation | Secret information management scheme based on secret sharing scheme |
| JP2006513641A (en) * | 2003-01-07 | 2006-04-20 | クゥアルコム・インコーポレイテッド | System, apparatus and method for exchanging encryption key |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5825880A (en) * | 1994-01-13 | 1998-10-20 | Sudia; Frank W. | Multi-step digital signature method and system |
| US5625692A (en) * | 1995-01-23 | 1997-04-29 | International Business Machines Corporation | Method and system for a public key cryptosystem having proactive, robust, and recoverable distributed threshold secret sharing |
| US5675649A (en) * | 1995-11-30 | 1997-10-07 | Electronic Data Systems Corporation | Process for cryptographic key generation and safekeeping |
| JP3794457B2 (en) * | 1998-02-13 | 2006-07-05 | 株式会社ルネサステクノロジ | Data encryption / decryption method |
| EP1075108A1 (en) * | 1999-07-23 | 2001-02-07 | BRITISH TELECOMMUNICATIONS public limited company | Cryptographic data distribution |
| WO2004057461A2 (en) * | 2002-12-19 | 2004-07-08 | Ntt Communications Corporation | Data division method and device using exclusive or calculation |
-
2004
- 2004-02-10 JP JP2004033352A patent/JP4602675B2/en not_active Expired - Lifetime
-
2005
- 2005-02-10 CN CN2005800043932A patent/CN1918844B/en active Active
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11506222A (en) * | 1995-06-05 | 1999-06-02 | サートコー・エルエルシー | Multi-step digital signature method and system |
| JP2001034164A (en) * | 1999-07-23 | 2001-02-09 | Toshiba Corp | Privacy distributed system and recording medium |
| JP2001103045A (en) * | 1999-09-29 | 2001-04-13 | Advanced Mobile Telecommunications Security Technology Research Lab Co Ltd | Storage device for backing up cryptographic key |
| JP2002091301A (en) * | 2000-09-19 | 2002-03-27 | Ntt Data Corp | Key information dispersion device, arithmetic unit and signature verification device |
| JP2002312317A (en) * | 2001-04-11 | 2002-10-25 | Casio Comput Co Ltd | Certification system and certification method |
| JP2004048479A (en) * | 2002-07-12 | 2004-02-12 | Kddi Corp | Encryption key management method of shared encryption information |
| JP2004053969A (en) * | 2002-07-22 | 2004-02-19 | Global Friendship Inc | Electronic tally generating method and program |
| JP2004053968A (en) * | 2002-07-22 | 2004-02-19 | Global Friendship Inc | Electronic information transmitting system |
| JP2004213650A (en) * | 2002-12-19 | 2004-07-29 | Ntt Communications Kk | Data fragmentation method, data fragmentation device and computer program |
| JP2006513641A (en) * | 2003-01-07 | 2006-04-20 | クゥアルコム・インコーポレイテッド | System, apparatus and method for exchanging encryption key |
| JP2004336702A (en) * | 2003-04-15 | 2004-11-25 | Ntt Communications Kk | Data originality securing method and system, and program for securing data originality |
| WO2005076518A1 (en) * | 2004-02-10 | 2005-08-18 | Ntt Communications Corporation | Secret information management scheme based on secret sharing scheme |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005229178A (en) | 2005-08-25 |
| CN1918844B (en) | 2010-09-01 |
| CN1918844A (en) | 2007-02-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1714423B1 (en) | Secret information management scheme based on secret sharing scheme | |
| EP2301185B1 (en) | Format-preserving cryptographic systems | |
| US8345876B1 (en) | Encryption/decryption system and method | |
| US8533489B2 (en) | Searchable symmetric encryption with dynamic updating | |
| CN107077469B (en) | Server device, search system, terminal device, and search method | |
| US20130103685A1 (en) | Multiple Table Tokenization | |
| EP3134994B1 (en) | Method of obfuscating data | |
| JP2011041326A (en) | Data division method, data division device, and computer program | |
| CN111512590B (en) | Homomorphic encryption for password authentication | |
| CN1918844B (en) | Secret information management scheme based on secret sharing scheme | |
| CN111314069A (en) | Block chain-based shaking system and method, electronic device and storage medium | |
| CN103607420A (en) | Safe electronic medical system for cloud storage | |
| JP4676695B2 (en) | Data division method, data division apparatus, and computer program | |
| JP5396352B2 (en) | Data originality ensuring method and system, and data originality ensuring program | |
| JP4708713B2 (en) | Confidential information management system, confidential information management method, and confidential information management program | |
| JP4486851B2 (en) | CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM, CONFIDENTIAL INFORMATION MANAGEMENT METHOD, CONFIDENTIAL INFORMATION MANAGEMENT PROGRAM, AND CONFIDENTIAL INFORMATION MANAGEMENT SYSTEM TERMINAL PROGRAM | |
| JP4619045B2 (en) | Data concealment device, data concealment method, and data concealment program | |
| JP4664008B2 (en) | ACCESS RIGHT MANAGEMENT SYSTEM, ACCESS RIGHT MANAGEMENT DEVICE, ACCESS RIGHT MANAGEMENT METHOD, TERMINAL PROGRAM, AND ACCESS RIGHT MANAGEMENT PROGRAM | |
| CN115913725A (en) | Forward security dynamic searchable encryption method and system based on XOR encryption chain | |
| JP2007041199A (en) | Data dividing device, data dividing method, and computer program | |
| US11809588B1 (en) | Protecting membership in multi-identification secure computation and communication | |
| KR102391952B1 (en) | System, device or method for encryption distributed processing | |
| JP2020064245A (en) | Secret distribution device, secret distribution system, and secret distribution method | |
| Rani et al. | Piecewise symmetric magic cube: application to text cryptography | |
| CN112291355B (en) | Key backup and recovery method and device for block chain wallet |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060929 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061026 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100223 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100422 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100928 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100930 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131008 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4602675 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |