JP4274962B2 - 音声認識システム - Google Patents
音声認識システム Download PDFInfo
- Publication number
- JP4274962B2 JP4274962B2 JP2004028542A JP2004028542A JP4274962B2 JP 4274962 B2 JP4274962 B2 JP 4274962B2 JP 2004028542 A JP2004028542 A JP 2004028542A JP 2004028542 A JP2004028542 A JP 2004028542A JP 4274962 B2 JP4274962 B2 JP 4274962B2
- Authority
- JP
- Japan
- Prior art keywords
- speech
- acoustic
- acoustic model
- noise
- hmm
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 230000006978 adaptation Effects 0.000 claims abstract description 58
- 230000010354 integration Effects 0.000 claims abstract description 31
- 238000000034 method Methods 0.000 claims description 58
- 230000003044 adaptive effect Effects 0.000 claims description 24
- 238000009826 distribution Methods 0.000 claims description 17
- 239000000203 mixture Substances 0.000 claims description 12
- 238000010606 normalization Methods 0.000 claims description 6
- 238000003860 storage Methods 0.000 claims description 5
- 238000012545 processing Methods 0.000 abstract description 62
- 238000004364 calculation method Methods 0.000 abstract description 17
- 238000007476 Maximum Likelihood Methods 0.000 description 17
- 238000001228 spectrum Methods 0.000 description 17
- 238000010586 diagram Methods 0.000 description 15
- 238000002474 experimental method Methods 0.000 description 15
- 238000011156 evaluation Methods 0.000 description 9
- 230000008569 process Effects 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 7
- 241001014642 Rasta Species 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 238000012549 training Methods 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 3
- 230000007613 environmental effect Effects 0.000 description 3
- 238000012417 linear regression Methods 0.000 description 3
- 230000003595 spectral effect Effects 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 241000408659 Darpa Species 0.000 description 2
- 230000005534 acoustic noise Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 230000001629 suppression Effects 0.000 description 2
- 238000001308 synthesis method Methods 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000011514 reflex Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images


























Description
通常発声と言直し発話という二種類の発話に対応する音響モデル構造を用いることにより、話者の発話スタイルの変化に対しても頑健に音声認識を行なうことができる。
D(i,k)=|Y(i,k)−Y(i,k+1)| (1)
有声母音などのピッチを含む音声から抽出されたパワースペクトラムは、基本周波数の高調波の影響によって櫛型の形状を持つ。このようなパワースペクトラムからDPS係数を計算した場合、隣り合うパワースペクトラム係数間の差が大きいため、DPS係数の値も同様に大きなパワーとして計算される。一方、雑音などの特徴を持たない波形のパワースペクトラムから計算されるDPS係数は、隣り合うパワースペクトラム係数間の差が小さいため、DPS係数の値も小さくなると考えられる。雑音重畳音声のパワースペクトラムを無雑音音声のパワーと雑音のパワーの和であると仮定した場合、DPS係数を計算することによって、音声と比較してなだらかに変化する雑音のパワー成分を減衰させることができると考えられる。
[実験1]
上記した実施の形態に係る雑音適応化手法の評価を行なうため、日本語大語彙連続音声認識実験を行なった。実験においては、予め出願人において作成した言語モデルを準備した。言語モデルの作成に使用された自然発話音声・言語データベースに含まれていた単語は670万語程度である。実験に使用した音声波形は、サンプリング周波数16kHz、分析窓長20ms、分析周期10msで分析を行ない、MFCC及びDMFCC特徴量を抽出した。MFCCの音響特徴パラメータは、12次元MFCC、ΔC0、12次元DMFCCの計25次元である。DMFCCの音響特徴パラメータは、12次元DMFCC、Δpow、12次元ΔDMFCCの計25次元である。使用した音素は、日本語分析でよく用いられる26種類の音素である。
[実験2]
さらに、言直し発話に対し頑健な音響モデルに対して雑音と発話スタイルの変動に対する単語正解精度への影響を調べるため、日本語大語彙連続音声認識実験を行なった。評価用音声として、実験1で用いた通常発声の音声と、意図的に音節ごとに区切って発声した音節強調発声の音声とを用いた。音節強調発声データは、旅行会話文、男性2名女性2名、各話者10文の計40文である。評価用音声には30dB、20dB、10dBのSNRで、実験2で用いた3種類の雑音が重畳されている。
最後に、MFCC特徴量とDMFCC特徴量のデコーダから得られた仮説を統合することによる性能の改善を調べるための評価実験を行なった。予備実験から、上記実施の形態で述べたように仮説統合時における言語モデルウェイトを0.06とした。図27に、仮説統合を行なった場合の単語正解精度を示す。図27に示すように、通常発声に対してはMFCC特徴量の正解精度と同等の結果が得られた。さらに、音節強調発声に対しては、MFCCとDMFCCの各々の正解精度以上の性能が得られた。これは、仮説統合により、MFCCによる仮説とDMFCCによる仮説とが互いに相補的であったため、仮説統合によって精度が高くなったためと考えられる。
Claims (13)
- それぞれ所定の音響特徴量をパラメータとする複数の音響モデル群を記憶するための記憶手段を含む音声認識システムであって、前記複数の音響モデル群の各々は、それぞれ異なる発話環境での発話音声のデコードに最適化された、同種の複数の音響モデルを含み、
前記音声認識システムはさらに、
入力される音声から前記所定の音響特徴量を算出するための特徴量算出手段と、
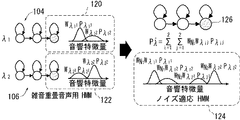
前記入力される音声のうち、発話がない部分の前記音響特徴量に基づいて、前記複数の音響モデル群の各々に対して、それぞれ前記複数の音響モデル群の混合重み適応化により、前記入力される音声の発話環境に適応化された複数の適応化音響モデルを作成するためのモデル適応化手段と、
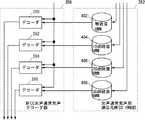
前記複数の音響モデル群の各々に対して設けられ、前記入力される音声の発話部分に応答し、前記複数の適応化音響モデルをそれぞれ用いて、前記入力される音声の前記発話部分の前記所定の音響特徴量をデコードし、複数の仮説を出力するための複数のデコード手段と、
前記複数のデコード手段が出力する前記複数の仮説を統合することにより音声認識結果を出力するための統合手段とを含み、
前記統合手段は、
前記複数の音響モデル群の各々に対し、前記複数のデコード手段により得られる前記複数の仮説から、各単語の音響言語尤度の和が最大となる仮説を選択するための仮説選択手段と、
前記仮説選択手段によって前記複数の音響モデル群の各々に対して選択された仮説から、単語ラティスを作成するためのラティス作成手段と、
前記ラティス内の単語列の中で、単語の音響尤度とN−グラム単語列(Nは1以上の整数)の言語尤度とから算出される値が所定条件を満足するものを認識結果として選択するための単語列選択手段とを含む、音声認識システム。 - 前記複数の音響モデル群の各々は、それぞれ異なる雑音が重畳された発話音声のデコードに最適化された複数の音響モデルを含む、請求項1に記載の音声認識システム。
- 前記モデル適応化手段は、
前記入力される音声の前記音響特徴量に基づいて、前記複数の音響モデル群の各々について、当該音響モデル群に含まれる複数の音響モデルのうち、前記入力される音声の前記音響特徴量に関連する予め定める条件を充足する、所定個数の音響モデルを選択するための手段と、
前記選択するための手段により前記複数の音響モデル群の各々について選択された前記所定個数の音響モデルから、雑音ガウス混合分布の混合重み適応化手法により前記適応化音響モデルを作成するための手段とを含む、請求項2に記載の音声認識システム。 - 前記複数の音響モデル群は、
互いに異なる複数種類の雑音が第1のSNR(信号対雑音比)で重畳された発話音声のデコードに最適化された複数の音響モデルを含む第1の音響モデル群と、
前記複数種類の雑音が、前記第1のSNRと異なる第2のSNRで重畳された発話音声のデコードに最適化された複数の音響モデルを含む第2の音響モデル群とを含む、請求項1に記載の音声認識システム。 - 前記複数の音響モデル群は、
それぞれ異なる発話環境での発話音声のデコードに最適化された、第1の音響モデル構造に基づく第1の音響モデル群と、
それぞれ異なる発話環境での発話音声のデコードに最適化された、前記第2の音響モデル構造とは異なる第2の音響モデル構造に基づく第2の音響モデル群とを含む、請求項1に記載の音声認識システム。 - 前記第1の音響モデル構造は、通常発話に対して想定される音響モデル構造である、請求項5に記載の音声認識システム。
- 前記第2の音響モデル構造は、言直し発話に対して想定される音響モデル構造である、請求項5又は請求項6に記載の音声認識システム
- 前記複数の音響モデル群は、
それぞれ異なる発話環境での発話音声のデコードに最適化された、第1の種類の音響特徴量をパラメータとする第1の音響モデル群と、
それぞれ異なる発話環境での発話音声のデコードに最適化された、前記第1の種類の音響特徴量と異なる第2の音響特徴量をパラメータとする第2の音響モデル群とを含む、請求項1に記載の音声認識システム。 - 前記第1の種類の音響特徴量はMFCC(メル周波数ケプストラム係数)である、請求項8に記載の音声認識システム。
- 前記第2の種類の音響特徴量はDMFCC(差分メル周波数ケプストラム係数)である、請求項8又は請求項9に記載の音声認識システム。
- 前記モデル適応化手段は、
前記入力される音声の前記音響特徴量に基づいて、前記第1の音響モデル群に含まれる音響モデルのうち、前記入力される音声の前記音響特徴量に関連する予め定める条件を充足する、所定個数の音響モデルを選択するための第1の音響モデル選択手段と、
前記第1の音響モデル選択手段により選択された音響モデルから、雑音GMMの混合重み適応化手法により第1の適応化音響モデルを作成するための手段と、
前記入力される音声の前記音響特徴量に基づいて、前記第2の音響モデル群に含まれる音響モデルのうち、前記入力される音声の前記音響特徴量に関連する予め定める条件を充足する、所定個数の音響モデルを選択するための第2の音響モデル選択手段と、
前記第2の音響モデル選択手段により選択された音響モデルから、雑音GMMの混合重み適応化手法により第2の適応化音響モデルを作成するための手段とを含む、請求項4〜請求項10のいずれかに記載の音声認識システム。 - 前記単語列選択手段は、前記ラティス内の単語列の中で、前記算出される値が最大となるものを認識結果として選択するための手段を含む、請求項1〜請求項11のいずれかに記載の音声認識システム。
- 前記単語列選択手段は、
前記ラティス内の単語の音響尤度と、N−グラム単語列の言語尤度とを、それぞれ所定の正規化方式により正規化するための正規化手段と、
前記ラティス内の単語列ごとに、前記正規化手段により正規化された当該単語列内の単語の音響尤度と前記N−グラム単語列の言語尤度とにそれぞれ所定の重みを加算して得られる値が前記所定条件を満足するものを認識結果として選択するための手段とを含む、請求項1〜請求項11のいずれかに記載の音声認識システム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004028542A JP4274962B2 (ja) | 2004-02-04 | 2004-02-04 | 音声認識システム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004028542A JP4274962B2 (ja) | 2004-02-04 | 2004-02-04 | 音声認識システム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005221678A JP2005221678A (ja) | 2005-08-18 |
| JP2005221678A5 JP2005221678A5 (ja) | 2005-09-29 |
| JP4274962B2 true JP4274962B2 (ja) | 2009-06-10 |
Family
ID=34997370
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004028542A Expired - Lifetime JP4274962B2 (ja) | 2004-02-04 | 2004-02-04 | 音声認識システム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4274962B2 (ja) |
Families Citing this family (118)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8645137B2 (en) | 2000-03-16 | 2014-02-04 | Apple Inc. | Fast, language-independent method for user authentication by voice |
| US8677377B2 (en) | 2005-09-08 | 2014-03-18 | Apple Inc. | Method and apparatus for building an intelligent automated assistant |
| JP4836076B2 (ja) * | 2006-02-23 | 2011-12-14 | 株式会社国際電気通信基礎技術研究所 | 音声認識システム及びコンピュータプログラム |
| US9318108B2 (en) | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| US8977255B2 (en) | 2007-04-03 | 2015-03-10 | Apple Inc. | Method and system for operating a multi-function portable electronic device using voice-activation |
| US9330720B2 (en) | 2008-01-03 | 2016-05-03 | Apple Inc. | Methods and apparatus for altering audio output signals |
| US8996376B2 (en) | 2008-04-05 | 2015-03-31 | Apple Inc. | Intelligent text-to-speech conversion |
| US10496753B2 (en) | 2010-01-18 | 2019-12-03 | Apple Inc. | Automatically adapting user interfaces for hands-free interaction |
| US20100030549A1 (en) | 2008-07-31 | 2010-02-04 | Lee Michael M | Mobile device having human language translation capability with positional feedback |
| WO2010067118A1 (en) | 2008-12-11 | 2010-06-17 | Novauris Technologies Limited | Speech recognition involving a mobile device |
| US10241644B2 (en) | 2011-06-03 | 2019-03-26 | Apple Inc. | Actionable reminder entries |
| US10241752B2 (en) | 2011-09-30 | 2019-03-26 | Apple Inc. | Interface for a virtual digital assistant |
| US9858925B2 (en) | 2009-06-05 | 2018-01-02 | Apple Inc. | Using context information to facilitate processing of commands in a virtual assistant |
| US20120309363A1 (en) | 2011-06-03 | 2012-12-06 | Apple Inc. | Triggering notifications associated with tasks items that represent tasks to perform |
| US9431006B2 (en) | 2009-07-02 | 2016-08-30 | Apple Inc. | Methods and apparatuses for automatic speech recognition |
| US10276170B2 (en) | 2010-01-18 | 2019-04-30 | Apple Inc. | Intelligent automated assistant |
| US10553209B2 (en) | 2010-01-18 | 2020-02-04 | Apple Inc. | Systems and methods for hands-free notification summaries |
| US10705794B2 (en) | 2010-01-18 | 2020-07-07 | Apple Inc. | Automatically adapting user interfaces for hands-free interaction |
| US10679605B2 (en) | 2010-01-18 | 2020-06-09 | Apple Inc. | Hands-free list-reading by intelligent automated assistant |
| WO2011089450A2 (en) | 2010-01-25 | 2011-07-28 | Andrew Peter Nelson Jerram | Apparatuses, methods and systems for a digital conversation management platform |
| US8682667B2 (en) | 2010-02-25 | 2014-03-25 | Apple Inc. | User profiling for selecting user specific voice input processing information |
| US10762293B2 (en) | 2010-12-22 | 2020-09-01 | Apple Inc. | Using parts-of-speech tagging and named entity recognition for spelling correction |
| US9262612B2 (en) | 2011-03-21 | 2016-02-16 | Apple Inc. | Device access using voice authentication |
| US10057736B2 (en) | 2011-06-03 | 2018-08-21 | Apple Inc. | Active transport based notifications |
| US8994660B2 (en) | 2011-08-29 | 2015-03-31 | Apple Inc. | Text correction processing |
| US20130073286A1 (en) * | 2011-09-20 | 2013-03-21 | Apple Inc. | Consolidating Speech Recognition Results |
| US10134385B2 (en) | 2012-03-02 | 2018-11-20 | Apple Inc. | Systems and methods for name pronunciation |
| US9483461B2 (en) | 2012-03-06 | 2016-11-01 | Apple Inc. | Handling speech synthesis of content for multiple languages |
| US9280610B2 (en) | 2012-05-14 | 2016-03-08 | Apple Inc. | Crowd sourcing information to fulfill user requests |
| US9721563B2 (en) | 2012-06-08 | 2017-08-01 | Apple Inc. | Name recognition system |
| US9495129B2 (en) | 2012-06-29 | 2016-11-15 | Apple Inc. | Device, method, and user interface for voice-activated navigation and browsing of a document |
| US9576574B2 (en) | 2012-09-10 | 2017-02-21 | Apple Inc. | Context-sensitive handling of interruptions by intelligent digital assistant |
| US9547647B2 (en) | 2012-09-19 | 2017-01-17 | Apple Inc. | Voice-based media searching |
| EP3809407A1 (en) | 2013-02-07 | 2021-04-21 | Apple Inc. | Voice trigger for a digital assistant |
| US9368114B2 (en) | 2013-03-14 | 2016-06-14 | Apple Inc. | Context-sensitive handling of interruptions |
| AU2014233517B2 (en) | 2013-03-15 | 2017-05-25 | Apple Inc. | Training an at least partial voice command system |
| WO2014144579A1 (en) | 2013-03-15 | 2014-09-18 | Apple Inc. | System and method for updating an adaptive speech recognition model |
| WO2014197334A2 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for user-specified pronunciation of words for speech synthesis and recognition |
| WO2014197336A1 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for detecting errors in interactions with a voice-based digital assistant |
| US9582608B2 (en) | 2013-06-07 | 2017-02-28 | Apple Inc. | Unified ranking with entropy-weighted information for phrase-based semantic auto-completion |
| WO2014197335A1 (en) | 2013-06-08 | 2014-12-11 | Apple Inc. | Interpreting and acting upon commands that involve sharing information with remote devices |
| US10176167B2 (en) | 2013-06-09 | 2019-01-08 | Apple Inc. | System and method for inferring user intent from speech inputs |
| KR101922663B1 (ko) | 2013-06-09 | 2018-11-28 | 애플 인크. | 디지털 어시스턴트의 둘 이상의 인스턴스들에 걸친 대화 지속성을 가능하게 하기 위한 디바이스, 방법 및 그래픽 사용자 인터페이스 |
| JP2016521948A (ja) | 2013-06-13 | 2016-07-25 | アップル インコーポレイテッド | 音声コマンドによって開始される緊急電話のためのシステム及び方法 |
| AU2014306221B2 (en) | 2013-08-06 | 2017-04-06 | Apple Inc. | Auto-activating smart responses based on activities from remote devices |
| US9620105B2 (en) | 2014-05-15 | 2017-04-11 | Apple Inc. | Analyzing audio input for efficient speech and music recognition |
| US10592095B2 (en) | 2014-05-23 | 2020-03-17 | Apple Inc. | Instantaneous speaking of content on touch devices |
| US9502031B2 (en) | 2014-05-27 | 2016-11-22 | Apple Inc. | Method for supporting dynamic grammars in WFST-based ASR |
| US9633004B2 (en) | 2014-05-30 | 2017-04-25 | Apple Inc. | Better resolution when referencing to concepts |
| US10078631B2 (en) | 2014-05-30 | 2018-09-18 | Apple Inc. | Entropy-guided text prediction using combined word and character n-gram language models |
| US9785630B2 (en) | 2014-05-30 | 2017-10-10 | Apple Inc. | Text prediction using combined word N-gram and unigram language models |
| US10170123B2 (en) | 2014-05-30 | 2019-01-01 | Apple Inc. | Intelligent assistant for home automation |
| US9760559B2 (en) | 2014-05-30 | 2017-09-12 | Apple Inc. | Predictive text input |
| US9842101B2 (en) | 2014-05-30 | 2017-12-12 | Apple Inc. | Predictive conversion of language input |
| US9966065B2 (en) | 2014-05-30 | 2018-05-08 | Apple Inc. | Multi-command single utterance input method |
| US9734193B2 (en) | 2014-05-30 | 2017-08-15 | Apple Inc. | Determining domain salience ranking from ambiguous words in natural speech |
| US10289433B2 (en) | 2014-05-30 | 2019-05-14 | Apple Inc. | Domain specific language for encoding assistant dialog |
| US9430463B2 (en) | 2014-05-30 | 2016-08-30 | Apple Inc. | Exemplar-based natural language processing |
| US9715875B2 (en) | 2014-05-30 | 2017-07-25 | Apple Inc. | Reducing the need for manual start/end-pointing and trigger phrases |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| US10659851B2 (en) | 2014-06-30 | 2020-05-19 | Apple Inc. | Real-time digital assistant knowledge updates |
| US10446141B2 (en) | 2014-08-28 | 2019-10-15 | Apple Inc. | Automatic speech recognition based on user feedback |
| US9818400B2 (en) | 2014-09-11 | 2017-11-14 | Apple Inc. | Method and apparatus for discovering trending terms in speech requests |
| US10789041B2 (en) | 2014-09-12 | 2020-09-29 | Apple Inc. | Dynamic thresholds for always listening speech trigger |
| US9606986B2 (en) | 2014-09-29 | 2017-03-28 | Apple Inc. | Integrated word N-gram and class M-gram language models |
| US9886432B2 (en) | 2014-09-30 | 2018-02-06 | Apple Inc. | Parsimonious handling of word inflection via categorical stem + suffix N-gram language models |
| US10127911B2 (en) | 2014-09-30 | 2018-11-13 | Apple Inc. | Speaker identification and unsupervised speaker adaptation techniques |
| US9646609B2 (en) | 2014-09-30 | 2017-05-09 | Apple Inc. | Caching apparatus for serving phonetic pronunciations |
| US10074360B2 (en) | 2014-09-30 | 2018-09-11 | Apple Inc. | Providing an indication of the suitability of speech recognition |
| US9668121B2 (en) | 2014-09-30 | 2017-05-30 | Apple Inc. | Social reminders |
| US10552013B2 (en) | 2014-12-02 | 2020-02-04 | Apple Inc. | Data detection |
| US9711141B2 (en) | 2014-12-09 | 2017-07-18 | Apple Inc. | Disambiguating heteronyms in speech synthesis |
| US9865280B2 (en) | 2015-03-06 | 2018-01-09 | Apple Inc. | Structured dictation using intelligent automated assistants |
| US10567477B2 (en) | 2015-03-08 | 2020-02-18 | Apple Inc. | Virtual assistant continuity |
| US9886953B2 (en) | 2015-03-08 | 2018-02-06 | Apple Inc. | Virtual assistant activation |
| US9721566B2 (en) | 2015-03-08 | 2017-08-01 | Apple Inc. | Competing devices responding to voice triggers |
| US9899019B2 (en) | 2015-03-18 | 2018-02-20 | Apple Inc. | Systems and methods for structured stem and suffix language models |
| US9842105B2 (en) | 2015-04-16 | 2017-12-12 | Apple Inc. | Parsimonious continuous-space phrase representations for natural language processing |
| US10083688B2 (en) | 2015-05-27 | 2018-09-25 | Apple Inc. | Device voice control for selecting a displayed affordance |
| US10127220B2 (en) | 2015-06-04 | 2018-11-13 | Apple Inc. | Language identification from short strings |
| US9578173B2 (en) | 2015-06-05 | 2017-02-21 | Apple Inc. | Virtual assistant aided communication with 3rd party service in a communication session |
| US10101822B2 (en) | 2015-06-05 | 2018-10-16 | Apple Inc. | Language input correction |
| US11025565B2 (en) | 2015-06-07 | 2021-06-01 | Apple Inc. | Personalized prediction of responses for instant messaging |
| US10255907B2 (en) | 2015-06-07 | 2019-04-09 | Apple Inc. | Automatic accent detection using acoustic models |
| US10186254B2 (en) | 2015-06-07 | 2019-01-22 | Apple Inc. | Context-based endpoint detection |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US9697820B2 (en) | 2015-09-24 | 2017-07-04 | Apple Inc. | Unit-selection text-to-speech synthesis using concatenation-sensitive neural networks |
| US10366158B2 (en) | 2015-09-29 | 2019-07-30 | Apple Inc. | Efficient word encoding for recurrent neural network language models |
| US11010550B2 (en) | 2015-09-29 | 2021-05-18 | Apple Inc. | Unified language modeling framework for word prediction, auto-completion and auto-correction |
| US11587559B2 (en) | 2015-09-30 | 2023-02-21 | Apple Inc. | Intelligent device identification |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10049668B2 (en) | 2015-12-02 | 2018-08-14 | Apple Inc. | Applying neural network language models to weighted finite state transducers for automatic speech recognition |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| US10446143B2 (en) | 2016-03-14 | 2019-10-15 | Apple Inc. | Identification of voice inputs providing credentials |
| US9934775B2 (en) | 2016-05-26 | 2018-04-03 | Apple Inc. | Unit-selection text-to-speech synthesis based on predicted concatenation parameters |
| US9972304B2 (en) | 2016-06-03 | 2018-05-15 | Apple Inc. | Privacy preserving distributed evaluation framework for embedded personalized systems |
| US10249300B2 (en) | 2016-06-06 | 2019-04-02 | Apple Inc. | Intelligent list reading |
| US10049663B2 (en) | 2016-06-08 | 2018-08-14 | Apple, Inc. | Intelligent automated assistant for media exploration |
| DK179309B1 (en) | 2016-06-09 | 2018-04-23 | Apple Inc | Intelligent automated assistant in a home environment |
| US10192552B2 (en) | 2016-06-10 | 2019-01-29 | Apple Inc. | Digital assistant providing whispered speech |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| US10490187B2 (en) | 2016-06-10 | 2019-11-26 | Apple Inc. | Digital assistant providing automated status report |
| US10067938B2 (en) | 2016-06-10 | 2018-09-04 | Apple Inc. | Multilingual word prediction |
| US10509862B2 (en) | 2016-06-10 | 2019-12-17 | Apple Inc. | Dynamic phrase expansion of language input |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| DK179049B1 (en) | 2016-06-11 | 2017-09-18 | Apple Inc | Data driven natural language event detection and classification |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| DK179343B1 (en) | 2016-06-11 | 2018-05-14 | Apple Inc | Intelligent task discovery |
| US10043516B2 (en) | 2016-09-23 | 2018-08-07 | Apple Inc. | Intelligent automated assistant |
| US10593346B2 (en) | 2016-12-22 | 2020-03-17 | Apple Inc. | Rank-reduced token representation for automatic speech recognition |
| DK201770439A1 (en) | 2017-05-11 | 2018-12-13 | Apple Inc. | Offline personal assistant |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| DK201770432A1 (en) | 2017-05-15 | 2018-12-21 | Apple Inc. | Hierarchical belief states for digital assistants |
| DK201770431A1 (en) | 2017-05-15 | 2018-12-20 | Apple Inc. | Optimizing dialogue policy decisions for digital assistants using implicit feedback |
| DK179549B1 (en) | 2017-05-16 | 2019-02-12 | Apple Inc. | FAR-FIELD EXTENSION FOR DIGITAL ASSISTANT SERVICES |
| JP7143665B2 (ja) * | 2018-07-27 | 2022-09-29 | 富士通株式会社 | 音声認識装置、音声認識プログラムおよび音声認識方法 |
-
2004
- 2004-02-04 JP JP2004028542A patent/JP4274962B2/ja not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005221678A (ja) | 2005-08-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4274962B2 (ja) | 音声認識システム | |
| O’Shaughnessy | Automatic speech recognition: History, methods and challenges | |
| JP3933750B2 (ja) | 連続密度ヒドンマルコフモデルを用いた音声認識方法及び装置 | |
| Bhardwaj et al. | Effect of pitch enhancement in Punjabi children's speech recognition system under disparate acoustic conditions | |
| US20070239444A1 (en) | Voice signal perturbation for speech recognition | |
| Gaurav et al. | Development of application specific continuous speech recognition system in Hindi | |
| Liao et al. | Uncertainty decoding for noise robust speech recognition | |
| JP4836076B2 (ja) | 音声認識システム及びコンピュータプログラム | |
| Behravan | Dialect and accent recognition | |
| Aggarwal et al. | Integration of multiple acoustic and language models for improved Hindi speech recognition system | |
| Nidhyananthan et al. | Language and text-independent speaker identification system using GMM | |
| Williams | Knowing what you don't know: roles for confidence measures in automatic speech recognition | |
| Sinha et al. | Continuous density hidden markov model for context dependent Hindi speech recognition | |
| Renals et al. | Speech recognition | |
| Sawada et al. | The nitech text-to-speech system for the blizzard challenge 2016 | |
| Fu et al. | A survey on Chinese speech recognition | |
| Sharma et al. | Soft-Computational Techniques and Spectro-Temporal Features for Telephonic Speech Recognition: an overview and review of current state of the art | |
| Junqua et al. | Robustness in language and speech technology | |
| Matsuda et al. | Speech recognition system robust to noise and speaking styles. | |
| Yamagishi et al. | Improved average-voice-based speech synthesis using gender-mixed modeling and a parameter generation algorithm considering GV | |
| Matsuda et al. | ATR parallel decoding based speech recognition system robust to noise and speaking styles | |
| Shahnawazuddin et al. | A fast adaptation approach for enhanced automatic recognition of children’s speech with mismatched acoustic models | |
| Huang et al. | Speech-Based Interface for Visually Impaired Users | |
| Sarikaya | Robust and efficient techniques for speech recognition in noise | |
| Khalifa et al. | Statistical modeling for speech recognition |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050613 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20050613 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20080310 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080415 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080610 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20080812 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080910 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081009 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20081022 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20081125 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081126 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090210 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090303 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4274962 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120313 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120313 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130313 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130313 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140313 Year of fee payment: 5 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |