JP4185103B2 - 実行可能プログラムをスケジューリングするためのシステム及び方法 - Google Patents
実行可能プログラムをスケジューリングするためのシステム及び方法 Download PDFInfo
- Publication number
- JP4185103B2 JP4185103B2 JP2006039467A JP2006039467A JP4185103B2 JP 4185103 B2 JP4185103 B2 JP 4185103B2 JP 2006039467 A JP2006039467 A JP 2006039467A JP 2006039467 A JP2006039467 A JP 2006039467A JP 4185103 B2 JP4185103 B2 JP 4185103B2
- Authority
- JP
- Japan
- Prior art keywords
- scheduling
- group
- weights
- processors
- groups
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multi Processors (AREA)
Description
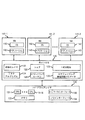
121・・・仮想化レイヤ
122・・・シェア
123・・・1組の配分
124・・・IPPアルゴリズム
125・・・スケジューリングルーチン
126・・・スケジューリング履歴性能パラメータ
130・・・ハードウェアレイヤ
132・・・メモリ
133・・・ネットワークインターフェース
134・・・I/Oインターフェース
143・・・アプリケーション
Claims (8)
- 複数のプロセッサ(131)と、
実行可能プログラムの複数のグループ(143)であって、各グループ(143)について、前記グループ(143)の実行可能プログラムをサポートするプロセッサ資源の量を表す各シェアパラメータ(122)が定義される、実行可能プログラムの複数のグループ(143)と、
前記シェアパラメータ(122)を使用して複数の重みを配分し、前記複数のプロセッサ(131)間における前記重みの配分を生成するソフトウェアルーチン(124)であって、前記配分が、各グループ(143)についてのプロセッサのサブセットと、前記グループ(143)の実行可能プログラムとをスケジューリングするための、前記サブセット内の各プロセッサの比率を定義するソフトウェアルーチン(124)と、
前記配分に従ったスケジューリング間隔の期間中に、前記複数のグループ(143)の各実行可能プログラムを前記複数のプロセッサ(131)の特定のプロセッサにスケジューリングするためのスケジューリングソフトウェアルーチン(125)と
を備え、
前記ソフトウェアルーチン(124)は、
複数の整数区画問題(IPP;integer partition problem)アルゴリズムを使用して、前記複数のグループ(143)の少なくとも1つに割り当てられるシェアパラメータ(122)から生成された重みの個数を変化させることによって複数の配分を生成し、生成された前記複数の配分をスケジューリングに使用する
コンピュータシステム。 - 前記可変の個数の重みは、
デフォルトのグループに割り当てられるシェアパラメータ(122)から生成される
請求項1に記載のコンピュータシステム。 - 前記スケジューリングソフトウェアルーチン(125)は、
前記複数のグループ(143)の間のスケジューリングの相違を補償するように前記複数の配分を交互に行う
請求項1に記載のコンピュータシステム。 - 前記複数のグループ(143)の実行可能プログラムのスケジューリングパラメータを保持するためのソフトウェアルーチンであって、各スケジューリングパラメータが、グループの平均に関連した(relate)、各実行可能プログラムが受け取るプロセッサ資源の量を示すソフトウェアルーチン
をさらに備える
請求項1に記載のコンピュータシステム。 - 前記スケジューリングソフトウェアルーチン(125)は、
前記スケジューリングパラメータの値に従って、前記複数のグループ(143)の実行可能プログラムのサブセットを、割り当て期間内にプロセッサ資源を受け取る付加的な機会を実行可能プログラムの前記サブセットに提供する1つ又は数個のプロセッサに割り当てる
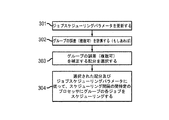
請求項4に記載のコンピュータシステム。 - 複数のグループの実行可能プログラムをスケジューリングするためのプロセッサ資源の量を表す複数のシェアパラメータを定義すること(202)と、
前記複数のシェアパラメータを使用して、整数区画問題(IPP;integer partition problem)に従い複数の重みを生成すること(204)と、
複数のIPPアルゴリズムを使用して、前記重みの個数を変化させることによって、複数のプロセッサ間における前記重みの配分を複数決定すること(206〜210)と、
前記複数の配分を使用して、前記複数のプロセッサにグループの実行可能プログラムをスケジューリングすること(304)と
を含む方法。 - 前記複数のグループの実行可能プログラムのスケジューリングパラメータを保持することであって、各スケジューリングパラメータが、グループの平均に関連した、各実行可能プログラムが受け取るプロセッサ資源の量を示すこと
をさらに含む請求項6に記載の方法。 - 前記スケジューリングすることは、
1つ又は数個のプロセッサについて、前記スケジューリングパラメータの値に従って実行可能プログラムを選択することであって、前記1つ又は数個のプロセッサが、前記選択された実行可能プログラムに、スケジューリング間隔内でプロセッサ資源を受け取る付加的な機会を提供すること
を含む請求項7に記載の方法。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/067,852 US20060195845A1 (en) | 2005-02-28 | 2005-02-28 | System and method for scheduling executables |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006244479A JP2006244479A (ja) | 2006-09-14 |
| JP4185103B2 true JP4185103B2 (ja) | 2008-11-26 |
Family
ID=36848286
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006039467A Expired - Fee Related JP4185103B2 (ja) | 2005-02-28 | 2006-02-16 | 実行可能プログラムをスケジューリングするためのシステム及び方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20060195845A1 (ja) |
| JP (1) | JP4185103B2 (ja) |
| DE (1) | DE102006004838A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111732455B (zh) * | 2020-06-30 | 2022-05-31 | 苏州蓝晶研材料科技有限公司 | 一种双锡层陶瓷导电材料及其制备方法 |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7844968B1 (en) | 2005-05-13 | 2010-11-30 | Oracle America, Inc. | System for predicting earliest completion time and using static priority having initial priority and static urgency for job scheduling |
| US7984447B1 (en) * | 2005-05-13 | 2011-07-19 | Oracle America, Inc. | Method and apparatus for balancing project shares within job assignment and scheduling |
| US8214836B1 (en) | 2005-05-13 | 2012-07-03 | Oracle America, Inc. | Method and apparatus for job assignment and scheduling using advance reservation, backfilling, and preemption |
| US20070061813A1 (en) * | 2005-08-30 | 2007-03-15 | Mcdata Corporation | Distributed embedded software for a switch |
| US8286170B2 (en) * | 2007-01-31 | 2012-10-09 | International Business Machines Corporation | System and method for processor thread allocation using delay-costs |
| US8087028B2 (en) * | 2007-03-07 | 2011-12-27 | Microsoft Corporation | Computing device resource scheduling |
| US8046766B2 (en) | 2007-04-26 | 2011-10-25 | Hewlett-Packard Development Company, L.P. | Process assignment to physical processors using minimum and maximum processor shares |
| US20090077550A1 (en) * | 2007-09-13 | 2009-03-19 | Scott Rhine | Virtual machine schedular with memory access control |
| US8291424B2 (en) * | 2007-11-27 | 2012-10-16 | International Business Machines Corporation | Method and system of managing resources for on-demand computing |
| US8245234B2 (en) * | 2009-08-10 | 2012-08-14 | Avaya Inc. | Credit scheduler for ordering the execution of tasks |
| WO2016196757A1 (en) | 2015-06-05 | 2016-12-08 | Shell Oil Company | System and method for replacing a live control/estimation application with a staged application |
| WO2017141249A1 (en) * | 2016-02-16 | 2017-08-24 | Technion Research & Development Foundation Limited | Optimized data distribution system |
| US11282027B2 (en) | 2019-04-26 | 2022-03-22 | Walmart Apollo, Llc | System and method of delivery assignment |
Family Cites Families (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4325120A (en) * | 1978-12-21 | 1982-04-13 | Intel Corporation | Data processing system |
| GB2256514B (en) * | 1991-05-21 | 1994-11-16 | Digital Equipment Corp | Commitment ordering for guaranteeing serializability across distributed transactions |
| CA2077061C (en) * | 1991-11-22 | 1998-04-21 | Mark J. Baugher | Scheduling system for distributed multimedia resources |
| US5287508A (en) * | 1992-04-07 | 1994-02-15 | Sun Microsystems, Inc. | Method and apparatus for efficient scheduling in a multiprocessor system |
| US5414845A (en) * | 1992-06-26 | 1995-05-09 | International Business Machines Corporation | Network-based computer system with improved network scheduling system |
| US5418953A (en) * | 1993-04-12 | 1995-05-23 | Loral/Rohm Mil-Spec Corp. | Method for automated deployment of a software program onto a multi-processor architecture |
| US5623404A (en) * | 1994-03-18 | 1997-04-22 | Minnesota Mining And Manufacturing Company | System and method for producing schedules of resource requests having uncertain durations |
| US5768389A (en) * | 1995-06-21 | 1998-06-16 | Nippon Telegraph And Telephone Corporation | Method and system for generation and management of secret key of public key cryptosystem |
| US6373846B1 (en) * | 1996-03-07 | 2002-04-16 | Lsi Logic Corporation | Single chip networking device with enhanced memory access co-processor |
| US5961585A (en) * | 1997-01-07 | 1999-10-05 | Apple Computer, Inc. | Real time architecture for computer system |
| US5948065A (en) * | 1997-03-28 | 1999-09-07 | International Business Machines Corporation | System for managing processor resources in a multisystem environment in order to provide smooth real-time data streams while enabling other types of applications to be processed concurrently |
| US6112304A (en) * | 1997-08-27 | 2000-08-29 | Zipsoft, Inc. | Distributed computing architecture |
| GB2332289A (en) * | 1997-12-11 | 1999-06-16 | Ibm | Handling processor-intensive data processing operations |
| US6345240B1 (en) * | 1998-08-24 | 2002-02-05 | Agere Systems Guardian Corp. | Device and method for parallel simulation task generation and distribution |
| US6295602B1 (en) * | 1998-12-30 | 2001-09-25 | Spyrus, Inc. | Event-driven serialization of access to shared resources |
| US6393012B1 (en) * | 1999-01-13 | 2002-05-21 | Qualcomm Inc. | System for allocating resources in a communication system |
| US6438704B1 (en) * | 1999-03-25 | 2002-08-20 | International Business Machines Corporation | System and method for scheduling use of system resources among a plurality of limited users |
| US6448732B1 (en) * | 1999-08-10 | 2002-09-10 | Pacific Steamex Cleaning Systems, Inc. | Dual mode portable suction cleaner |
| US6757897B1 (en) * | 2000-02-29 | 2004-06-29 | Cisco Technology, Inc. | Apparatus and methods for scheduling and performing tasks |
| US6868447B1 (en) * | 2000-05-09 | 2005-03-15 | Sun Microsystems, Inc. | Mechanism and apparatus for returning results of services in a distributed computing environment |
| EP1182550A3 (en) * | 2000-08-21 | 2006-08-30 | Texas Instruments France | Task based priority arbitration |
| JP2002202959A (ja) * | 2000-12-28 | 2002-07-19 | Hitachi Ltd | 動的な資源分配をする仮想計算機システム |
| US6535238B1 (en) * | 2001-10-23 | 2003-03-18 | International Business Machines Corporation | Method and apparatus for automatically scaling processor resource usage during video conferencing |
| US7174354B2 (en) * | 2002-07-31 | 2007-02-06 | Bea Systems, Inc. | System and method for garbage collection in a computer system, which uses reinforcement learning to adjust the allocation of memory space, calculate a reward, and use the reward to determine further actions to be taken on the memory space |
| US7437446B2 (en) * | 2002-09-30 | 2008-10-14 | Electronic Data Systems Corporation | Reporting of abnormal computer resource utilization data |
| US7007183B2 (en) * | 2002-12-09 | 2006-02-28 | International Business Machines Corporation | Power conservation by turning off power supply to unallocated resources in partitioned data processing systems |
| US7178062B1 (en) * | 2003-03-12 | 2007-02-13 | Sun Microsystems, Inc. | Methods and apparatus for executing code while avoiding interference |
| US20050149940A1 (en) * | 2003-12-31 | 2005-07-07 | Sychron Inc. | System Providing Methodology for Policy-Based Resource Allocation |
| US20060095690A1 (en) * | 2004-10-29 | 2006-05-04 | International Business Machines Corporation | System, method, and storage medium for shared key index space for memory regions |
| US7689993B2 (en) * | 2004-12-04 | 2010-03-30 | International Business Machines Corporation | Assigning tasks to processors based at least on resident set sizes of the tasks |
-
2005
- 2005-02-28 US US11/067,852 patent/US20060195845A1/en not_active Abandoned
-
2006
- 2006-02-02 DE DE102006004838A patent/DE102006004838A1/de not_active Ceased
- 2006-02-16 JP JP2006039467A patent/JP4185103B2/ja not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111732455B (zh) * | 2020-06-30 | 2022-05-31 | 苏州蓝晶研材料科技有限公司 | 一种双锡层陶瓷导电材料及其制备方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006244479A (ja) | 2006-09-14 |
| DE102006004838A1 (de) | 2006-09-07 |
| US20060195845A1 (en) | 2006-08-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4185103B2 (ja) | 実行可能プログラムをスケジューリングするためのシステム及び方法 | |
| KR101626378B1 (ko) | 병렬도를 고려한 병렬 처리 장치 및 방법 | |
| US20050081208A1 (en) | Framework for pluggable schedulers | |
| US8332862B2 (en) | Scheduling ready tasks by generating network flow graph using information receive from root task having affinities between ready task and computers for execution | |
| US20190220309A1 (en) | Job distribution within a grid environment | |
| WO2018120991A1 (zh) | 一种资源调度方法及装置 | |
| US20030056091A1 (en) | Method of scheduling in a reconfigurable hardware architecture with multiple hardware configurations | |
| Chen et al. | Adaptive multiple-workflow scheduling with task rearrangement | |
| US8082546B2 (en) | Job scheduling to maximize use of reusable resources and minimize resource deallocation | |
| US7920282B2 (en) | Job preempt set generation for resource management | |
| Raj et al. | Enhancement of hadoop clusters with virtualization using the capacity scheduler | |
| Muthuvelu et al. | On-line task granularity adaptation for dynamic grid applications | |
| CN110084507B (zh) | 云计算环境下分级感知的科学工作流调度优化方法 | |
| Moulik et al. | COST: A cluster-oriented scheduling technique for heterogeneous multi-cores | |
| JP4121525B2 (ja) | リソース利用率を制御する方法およびコンピュータシステム | |
| Sodan | Loosely coordinated coscheduling in the context of other approaches for dynamic job scheduling: a survey | |
| Lu et al. | Overhead aware task scheduling for cloud container services | |
| JP6156379B2 (ja) | スケジューリング装置、及び、スケジューリング方法 | |
| Kambatla et al. | UBIS: Utilization-aware cluster scheduling | |
| Nickolay et al. | Towards accommodating real-time jobs on HPC platforms | |
| GB2485019A (en) | Assigning cores to applications based on the number of cores requested by the application | |
| Ahmad et al. | A novel dynamic priority based job scheduling approach for cloud environment | |
| KR101639947B1 (ko) | 하둡 선점 데드라인 제약 스케줄링 방법 및 그 방법을 수행하는 컴퓨터프로그램과, 그 프로그램이 기록된 매체 | |
| Massa et al. | Heterogeneous quasi-partitioned scheduling | |
| EP1630671A1 (en) | Framework for pluggable schedulers |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20070627 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20070926 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20071001 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071221 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20080811 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20080904 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110912 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110912 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120912 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130912 Year of fee payment: 5 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees | ||
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R360 | Written notification for declining of transfer of rights |
Free format text: JAPANESE INTERMEDIATE CODE: R360 |
|
| R360 | Written notification for declining of transfer of rights |
Free format text: JAPANESE INTERMEDIATE CODE: R360 |
|
| R371 | Transfer withdrawn |
Free format text: JAPANESE INTERMEDIATE CODE: R371 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |