JP3673034B2 - Mail address area detection device - Google Patents
Mail address area detection device Download PDFInfo
- Publication number
- JP3673034B2 JP3673034B2 JP25993796A JP25993796A JP3673034B2 JP 3673034 B2 JP3673034 B2 JP 3673034B2 JP 25993796 A JP25993796 A JP 25993796A JP 25993796 A JP25993796 A JP 25993796A JP 3673034 B2 JP3673034 B2 JP 3673034B2
- Authority
- JP
- Japan
- Prior art keywords
- address
- line
- area
- lines
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Landscapes
- Sorting Of Articles (AREA)
Description
【0001】
【発明の属する技術分野】
この発明は郵便物の処理装置、特に郵便物の宛名を読み取ってその配達先に従って区分する際に用いられる郵便物の宛名領域検出装置に関する。
【0002】
【従来の技術】
郵便物の処理分野においては、連日大量に送られてくる郵便物を限られた時間内に処理して行かねばならない。そこで郵便業務の機械化が進められ、郵便局員の負担の軽減がはかられている。その一例が、光学的文字読取装置を用いて、郵便物上の郵便番号を読み取り、その読取結果によって郵便物を複数の配達郵便局ごとに区分する差立区分機、あるいは、更に郵便物上の宛名を読み取りその読取結果によって郵便物を複数の送達区域ごとに区分する配達区分機である。
【0003】
配達区分機では、郵便物上に書かれた宛名を読みとる際、従来は画像処理によって宛名が書かれていると推定される領域を1つ確定させ、その領域に対して行検出、文字検出、文字識別、町名識別をパイプライン処理することにより宛名を自動認識している。
【0004】
しかし、現行の郵便物の宛名に関しては、その宛名記載位置、記載方法などの書式にほとんど制約が設けられていないため様々な書式の郵便物が存在し、しかも郵便物上には広告等の宛名以外の文字情報、絵および写真も存在し、それらの画像情報が混在する中から宛名情報を正しく抽出することは非常に困難である。したがって、今後もますます郵便物の量が増加していくことを考えると、従来手法よりも高性能の宛名読み取り手法を開発することが求められている。
【0005】
【発明が解決しようとする課題】
従来の技術では宛名領域を確定してからその領域に含まれる情報を読み取るように構成されているために、誤った領域を宛名領域として決定した場合、当該郵便物は配達区分機からリジェクトされるので、再投入するしかなく、最初に投入された配達区分機における以降の処理で宛名を正しく認識することは不可能である。しかも確定された1つの領域内に書かれている文字を全て認識してからこの領域が宛名領域であるか否かを決定するため、1領域当たりの処理時間が長くなる。
【0006】
一般に宛名領域検出の成功率を上げるには一度リジェクトされた郵便物について他の領域の検出動作を続行できるようにすればよいが、郵便1通あたりの処理時間が制限されているため、従来の方法で複数の領域を検出することは時間が多く掛り、実現が困難であった。
【0007】
そこで、この発明は、郵便物表面の画像から宛名領域を簡単、正確に検出し、郵便物処理を高速で行うことを可能とする郵便物の宛名領域検出装置を提供することを目的とする。
【0008】
【課題を解決するための手段】
この発明の郵便物の宛名検出装置は、郵便物表面より光電変換して画像信号を得る画像入力手段と、この画像入力手段により得られた前記画像信号を格納する画像メモリと、この画像メモリの前記画像信号を2値画像判定した黒画素連結領域とこの黒画素連結領域に外接する外接矩形情報を抽出する黒画素連結領域抽出部と、この黒画素連結領域抽出部により抽出された前記外接矩形情報から行候補の矩形情報を抽出する行候補検出部と、この行候補検出部により抽出された矩形情報から宛名領域候補を検出する宛名領域候補検出部と、前記宛名領域候補に含まれる文字情報から宛名領域を確定する宛名領域確定手段と、を具備することを特徴としている。
【0009】
上記の構成により、最初に文字行を検出し、それを統合して複数の宛名領域候補を検出し、各領域候補から宛名書きだし部であると推定される文字行を検出し、その文字行に対して文字検出、文字識別、町名識別を行なって宛名書きだし部であるか否か調べることにより、その文字行を含む領域が宛名記載領域であるか否かを高速に判定することができる。文字認識の結果、その文字行が宛名情報を含んでいなければその行を含む領域には宛名情報が書かれていないと判断し、次の領域候補について同様の処理を行う。ここで、この発明では各領域につき一行から数行分の文字認識を行うだけでよいため、1領域あたりの処理時間が短くてすむため、複数領域の候補について確認をとることが可能となる。
【0010】
【発明の実施の形態】
以下、この発明の第1の実施の形態について図面を参照して説明する。
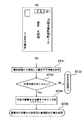
図1はこの発明の第1の実施の形態に係わる光学的文字読取装置の構成を示すブロック図であり、図2は図1の宛名領域検出部の内部構成を示すブロック図である。
【0011】
図1において、郵便物Mの画像が光学的文字読取装置1の光電変換回路2により電気信号に変換され、2値化処理部3により白画素と黒画素を示す2値信号に変換される。2値化処理部3から得られた2値信号は黒画素連結領域抽出部4の画像メモリに一時格納され、この画像メモリ上で黒画素連結領域が抽出される。一般に郵便物の宛名記載は黒字で行われ、かつ宛名文字は1行または複数行に亘って記載される。したがって、郵便物の画像中から黒画素連結領域を検出すると、この検出された黒画素連結領域には宛名文字列を構成する文字もしくは文字の一部分が含まれている可能性が高い。検出された黒画素連結領域からは、その領域に外接する矩形情報が求められる。
【0012】
黒画素連結領域抽出部4により抽出された黒画素連結領域に外接する矩形情報は、宛名領域の検出のために宛名領域検出部5に送られる。宛名領域検出部5により検出された領域に含まれる宛名文字の読取りは、宛名文字行から個々の文字の検出を次の文字検出切り出し回路6にて行い、この切り出された文字一つ一つについて行う。
【0013】
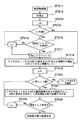
ここで、宛名領域検出部5の内部の構成を図2を参照して説明する。図2において、黒画素連結領域抽出部4により抽出された黒画素連結領域に外接する矩形情報は、宛名領域の検出のために宛名領域検出部5の行候補検出部5aに送られてチェックされる。この宛名領域検出部5には、基準宛名領域データベース5Rが関連して設けられ、後述する行候補検出部5a、宛名領域候補検出部5b、行、領域評価部5c,および宛名筆頭部候補検出部5d夫々において予め用意されている基準となる情報を参照して、あるいは基準情報との比較に基づく類似度の大小により夫々の段階に於ける候補の検出が行われる。
【0014】
まず行候補検出部5aでは、黒画素連結領域抽出部4により抽出された各々の外接矩形情報に含まれる矩形領域の形状、郵便物上の位置などを表す情報が基準宛名領域データベース5Rに格納されている対応する基準情報と比較され、この比較結果をもとに複数の外接矩形領域を統合して行候補領域を切り出して、その行候補の矩形情報を抽出するようになっている。
【0015】
検出された行候補情報は次に宛名領域候補検出部5bにより処理され、基準宛名領域データベース5Rに格納されている対応する基準情報と比較され、この比較結果をもとに一つもしくは複数箇所の宛名領域候補が検出される。
【0016】
検出された宛名候補領域に対しては、検出された宛名候補領域に行がいくつ含まれているか、あるいは行数が所定数nよりも多いか少ないか、検出された行の平均幅が所定の寸法より大きいか、小さいか、あるいは検出された行の幅の分布がどのようになっているか、検出された宛名候補領域に含まれている行の位置の分布がどのようなものかなどが行、領域の評価部5cにより評価される。この行、領域の評価部5cによる評価の方法の詳細は後で説明する。
【0017】
行、領域の評価部5cにより宛名領域であると評価する際には、宛名領域候補検出部5bにより検出された宛名領域候補の一つ一つについて同様に基準宛名領域データベース5Rに格納されている対応する基準情報と比較され、その中に含まれる行の数、サイズ、および行位置の分布から宛名の記載書式を判定し、この判定された書式に応じて次の宛名筆頭部行候補検出部5dにおいて、宛名筆頭行の候補を検出する。
【0018】
検出された宛名候補領域が複数の場合は、この複数の宛名候補領域の夫々についてその中の筆頭部候補を宛名筆頭部行候補検出部5dにより検出し、所定の記憶エリアに格納しておく。
【0019】
このようにして宛名領域検出部5により検出された宛名筆頭行部候補の一つ、例えば最も筆頭部として可能性の高い行を一つ選択し、この行について次の文字検出切り出し回路6で個々の文字を切り出し、順次認識回路7に送り、文字辞書8を用いて文字認識を行う。宛名筆頭行部の文字全てについて文字認識が行われ、認識された文字は次の知識処理回路9に送られ、知識辞書10を用いて市区町村名の宛名識別が行われる。識別された市区町村名が予め知識辞書10に格納された実在の宛名と一致すれば、処理された宛名筆頭行部候補が含まれる宛名領域中の全ての行についても同様に識別し、読み取られた宛名情報は読取り結果処理回路11に送られ、所定の配達区分処理が行われる。
【0020】
図1の光電変換回路2で読取られた郵便物Mの画像が、例えば図3の(a)に示したように縦方向の中央部に横書きでL1,L2の2行にわたって記載された宛名部分を持つ場合を例に取って図1、図2に示した光学的文字読取装置1の動作を説明する。処理対象となる郵便物Mの画像には更に広告文字行L3,L4ならびに切手L5の画像が含まれているものとする。なお、以下の説明では通常の書状で切手や郵便番号枠が上にきて長手方向の辺が縦になるような書状の置き方を縦置き、切手や郵便番号枠が右手にきて短手方向の辺が縦になるような書状の置き方を横置きと呼ぶことにする。また縦行とは書状長手方向に長い行のことを指し、横行とは書状短手方向に長い行のことを指すものとする。
【0021】
光電変換回路2で読取られた郵便物Mの画像データからは、2値化処理部3により微分・2値化処理を施したのち、黒画素連結領域抽出部4にて図3の(b)に示したような行L1,L2,L3,L4に対応する連結黒画素領域に外接する矩形情報を求める。この矩形情報はそれぞれの文字に対応しており、この情報は宛名領域検出部5内の行候補検出部5aにおいて横方向に隣接する外接矩形情報を統合することによって、図3(c)に示したような行L1,L2,L3,L4を検出する。
【0022】
これらの検出された行L1,L2,L3,L4の情報は宛名領域候補検出部5bにおいてさらに隣接する行を統合して、図3(d)に示したように行L1,L2に対応する第1の宛名領域候補A1ならびに第2の宛名領域候補A2を検出する。各領域A1,A2内の夫々の行L1〜L4は、行サイズ・相対位置を図3(e)において基準宛名領域データベース5Rに格納されているあらかじめ用意された評価基準にかけられ、夫々の領域A1,A2内において類似度あるいは評価値の高いものが宛名書きだし行候補、即ち宛名筆頭行部として選択される。領域A1,A2内において筆頭行候補として選択された行は図3(f)に示したようにハッチングで示される。
【0023】
宛名書きだし行候補は複数箇所選択され、評価値の高いものから順に図3(g)に示したフィードバック処理にかけられる。フイードバック処理では、まず、図3(h)において宛名書きだし行候補の中から行L1を選択し、図3(i)においてその行L1の各々の文字検出を行い、図3(j)において個々の文字識別を行い、識別された文字列に対して図3(k)において市町村名識別、たとえば町名識別処理を行う。次に図3(l)においてその識別結果が宛名情報として読めるか調べる。もし知識辞書10を参照した結果、識別された文字列が意味をなしていなければ、別の領域A2の筆頭行、例えばL3を選択して同様の処理を繰り返す。もし図3(l)において意味をなしていれば、その行L1の前または後の行、ここでは後の行L2を認識処理にかけ,宛名情報を完成させる。
【0024】
次に、図2の行、領域の評価部5cにおいて宛名がどのような書式で記載されているか判断する処理について説明する。これは、最初に郵便物に宛名が記載される主な書式をいくつか情報として持っておき、与えられた書状がどの書式で書かれている可能性が高いか判断する処理を行う。図4は、宛名の記載される書式の分類方式の一例である。図4に挙げているのは、宛名行の方向および記載位置に注目して縦置き横書き(a)、縦置き横書き(b)、横置き横書きの正方向(c)および逆方向(d)の4通りに宛名の書式を分類した例である。この例以外の宛名行方向・位置の場合を宛名記載書式に追加登録してもよい。また、宛名の方向・記載位置の他に宛名行サイズも考慮してさらに宛名記載書式を細かく分類して定義してもよい。
【0025】
宛名の記載書式を判断する手法の一例として、書状画像から行を切り出した後縦置きした時の画像上部から横書き行が見つかった場合は縦置き横書き方向に宛名が書かれていると判断する方法が考えられる。またこの場合、書状上部に書かれている横行ほど宛名行書きだし候補の検出処理にかける優先順位を高くする処理を行うことが考えられる。
【0026】
以下、図2の行、領域評価部5cにおける行、領域の評価の具体例を図5乃至図11を参照して詳細に説明する。
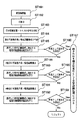
図5の例では、図5(a)に示したように縦置きの書状に2行の縦書で宛名が記載された郵便物の場合であり、図5(b)はこの郵便物の画像から宛名記載領域を判定し、宛名が手書きで表示された場合の宛名行を検出する処理を示すフローチャートを示す。図2の宛名領域候補検出部5bで検出された領域に含まれた行を切り出した後、図5(b)の最初のステップST1において検出された行数がn行以下、例えば4行以下であるか否かを判定し、n行以下でなければ宛名領域ではないものとしてステップST2の別の判定処理にうつる。
【0027】
ここではn行以下であるから、宛名が手書きであり、手書きフラグをステップST3でセットし、ステップST4で手書きの宛名用に用意した筆頭宛名行検出処理を行う。この筆頭宛名行検出処理は図2の宛名筆頭部候補行検出部5dにおいて行われる。
【0028】
上記の宛名行が4行以下か否かという判定条件は、別の条件と組み合わせて使用してもよい。一例として宛名が書状長手方向であるという条件と組み合わせた場合を図6に示す。図6(a)に示した書状画像から行を切り出した後、ステップST11で検出された行のうち書状長手方向の行数がn行以下であるか否かを判定し、n行以上であれば別の判定処理(ST12)にうつる。n行以下であれば宛名が書状長手方向に手書きで書かれていると判断(ST13)し、宛名行が手書きの縦行である場合用に用意した宛名行検出処理を行う(ST14)。例えば、書状から検出された縦行数が4行以下であれば宛名が手書きであると判断する。なお、行方向の条件を書状長手方向とする代わりに書状短手方向としても良い。
【0029】
宛名の記載領域を判断する手法の別の例を図7に示す。図7(a)に示す書状画像から行を切り出した後、書状から検出された行の平均幅を図7(b)のステップST21にて計算し、行平均幅がWミリメートル以上であるか否かを判定(ST22)し、Wミリメートル以上でなければ別の判定処理(ST23)にうつる。
【0030】
Wミリメートル以上であれば宛名が手書きであると判断(ST24)し、手書きの宛名用に用意した筆頭宛名行検出処理を行う(ST25)。例えば、書状から検出された行の平均幅が20mm以上であれば宛名が手書きであると判断する。なお行平均幅のしきい値は、ミリメートル単位の代わりに画素数単位で与えても良い。また上の例では平均幅を求めるために書状画像から検出した全ての行を使用しているが、書状画像の特定領域に書かれた行のみを用いて平均幅を算出しても良い。
【0031】
上記の判定条件は、別の条件と組み合わせて使用してもよい。一例として宛名行が書状長手方向であるという条件と組み合わせた場合を図8に示す。図8(a)に示した書状画像から行を切り出した後、図8(b)のステップST31にて書状から検出された行のうち縦行の平均幅を計算し、行平均幅がWミリメートル以上であるか否かを判定(ST32)し、Wミリメートル以上でなければ別の判定処理(ST33)にうつる。Wミリメートル以上であれば宛名が書状長手方向に手書きで書かれていると判断(ST34)し、宛名行が手書きの縦行である場合用に用意した筆頭宛名行検出処理を行う(ST35)。例えば、書状から検出された縦行の平均幅が20mm以上であれば宛名が手書きであると判断する。なお行平均幅のしきい値は、ミリメートル単位の代わりに画素数単位で与えても良い。また、行方向の条件を書状長手方向とする代わりに書状短手方向としても良い。さらに、上の例では平均幅を求めるために書状画像から検出した全ての行を使用しているが、書状画像の特定領域に書かれた行のみを用いて平均幅を算出しても良い。
【0032】
画像から検出した行の平均幅を用いて宛名の記載形式を推定するためには、行の平均幅が宛名行幅に近い値である必要がある。画像から検出した行の幅サイズにばらつきがある場合の筆頭宛名行検出手法の例を図9に示す。図9(a)に示す書状画像から行を切り出した後、図9(b)に矩形で囲んで示すように宛名行の可能性の高い行を選択し、選択した行の平均幅によって宛名の記載書式を判定する。
【0033】
まず書状から検出された行の幅サイズの分布を調べておき(ST41)、行の平均幅を計算(ST42)する。次に検出した行のうち、平均幅の1/mよりは幅が広くかつn倍以下の幅である行を選択(ST43)し、選択した行の平均幅を計算して、宛名書式判定用の基準幅とする(ST44)。基準幅がWミリメートル以上であるか否かを判定(ST45)し、Wミリメートル以上でなければ別の判定処理(ST46)にうつる。
【0034】
Wミリメートル以上であれば宛名が手書きであると判断(ST47)し、手書きの宛名用に用意した筆頭宛名行検出処理を行う(ST48)。例えば、m=2,n=1.5,基準幅が20mm以上であれば宛名が手書きであると判断する。なお行平均幅のしきい値は、ミリメートル単位の代わりに画素数単位で与えても良い。また上の例では基準幅を求めるために書状画像から検出した全ての行を使用しているが、書状画像の特定領域に書かれた行のみを用いて基準幅を算出しても良い。
【0035】
上記の判定条件は、別の条件と組み合わせて使用してもよい。一例として宛名が書状長手方向であるという条件と組み合わせた場合を図10に示す。図10(a)に示す書状画像から行を切り出した後、図10(b)に示したように宛名行の可能性の高い縦行を選択し、図10(c)の各々のステップにおいて選択した行の平均幅によって宛名の記載書式を判定する。
【0036】
まず書状から検出された縦行の幅サイズの分布を調べておき(ST51)、縦行の平均幅を計算(ST52)する。次に検出した縦行のうち、平均幅の1/mよりは幅が広くかつn倍以下の幅である行を選択(ST53)し、選択した縦行の平均幅を計算して、宛名書式判定用の基準幅とする(ST54)。基準幅がWミリメートル以上であるか否かを判定(ST55)し、Wミリメートル以上でなければ別の判定処理(ST56)にうつる。Wミリメートル以上であれば宛名が書状長手方向に手書きで書かれていると判断(ST57)し、宛名行が手書きの縦行である場合用に用意した筆頭宛名行検出処理を行う(ST58)。例えば、m=2,n=1.5,基準幅が20mm以上であれば宛名が手書きであると判断する。なお行平均幅のしきい値は、ミリメートル単位の代わりに画素数単位で与えても良いし、行方向の条件を書状長手方向とする代わりに書状短手方向としても良い。また上の例では基準幅を求めるために書状画像から検出した全ての行を使用しているが、書状画像の特定領域に書かれた行のみを用いて基準幅を算出しても良い。
【0037】
宛名の記載書式を判断する手法の別の例を図11に示す。図11(a)のステップST61において、書状から検出された行の記載位置の分布を調べ、検出した行のうち、ステップST62において書状を縦置きした時の右半分の領域に行領域全部または行領域の一部がかかっている行がどれだけあるか調ベる。行総数のうちn%以上でなければ図12(a)の別の判定処理(ステップST71)にうつる。
【0038】
n%以上であれば宛名が図11(b)または図11(d)に示したように書状右半分に縦置き縦書き方向または横置き横書き方向に書かれていると判断する(ST63)。例えば図11(b)または図11(d)に示した書状では、いずれの書状もその右半分に全行数の70%以上の行が書かれており、書状右半分に縦置き縦書き、または横置き横書きに書かれていると判断する。
【0039】
反対に、図12(b)に示したように書状の左半分に全行数の70%以上の行が書かれている場合、図12(a)のステップST71いおいて検出した行のうち書状を縦置きした時の左半分の領域に行領域全部または行領域の一部がかかっている行がどれだけあるか調ベ、行総数のうちn%(例えばn=70)以上でなければ別の判定処理(ST72)にうつる。
【0040】
70%以上であれば宛名が書状左半分に書状下から上方向に横置き横書きで書かれていると判断する(ST73)。例えば図12(b)の書状が与えられて、書状左半分に全行数の70%以上の行が書かれていた場合、図12(c)のように書状左半分に書状下から上方向に横置き横書きに書かれていると判断する。
【0041】
ここで、郵便物画像から宛名記載領域を検出する処理の具体例について図13を参照してさらに説明する。図13(a)に示した書状画像から同図(b)の行情報を検出する。次に、宛名の記載書式ごとに宛名行を検出するデフォルトの領域および宛名行方向を定義しておき、宛名行と方向が同じで行デフォルト領域に行領域がかかる行を選択して宛名行候補とする。例えば宛名が縦置き横書きで書かれていると仮定した時は図13(c)の斜線領域にかかっている横行を選択し、横置き横書きまたは縦置き縦書きで書かれていると仮定した時は図13(d)または(e)の斜線領域にかかっている縦行を選択する。図13(a)の書状の場合は、図13(f),(g)に示したように、縦置き横書きと正方向の横置き横書きの宛名領域候補および宛名行候補が検出されるが、図13(e)に示したように斜線部が逆方向の右端に偏った場合には図13(h)において横置き横書きの宛名行候補は検出されない。
【0042】
以上のように検知された各記載書式ごとに、選択された行の中から宛名行を見つける処理を行う。以下、郵便物画像から宛名行を検出し読みとる処理について説明する。図14は郵便物画像から宛名の書きだしの行をまず検出し、そのあと宛名の続きの行を順次文字認識にかける処理の一例である。
【0043】
図14のステップST181において郵便物画像を入力し、この入力された郵便物画像からステップST182において行情報を検出し、ステップST183にて検出した各行の記載位置および行サイズの分布を調べ分析する。
【0044】
分析の結果最も可能性の高い宛名の記載書式を判定(ST184)し、その宛名記載書式に対応する宛名行検出処理を行い1行または複数の宛名の書きだしすなわち筆頭行候補を選択する(ST185)。選択された宛名書きだし行候補は優先順位の高い順に文字検出および文字認識処理にかけられ、例えば町名の一部として読めるかどうか判断される(ST186)。
【0045】
宛名書きだし行候補の中に町名として読める行が存在すればその行の郵便物画像上での位置の近くから続きの行を見つけ、宛名行として順次文字検出および文字認識処理にかけていく(ST187)。町名として読める宛名書きだし行候補がなかった場合は2番目に可能性の高い宛名記載書式を選択(ST188)し、その宛名記載書式に対応する宛名行検出処理を行い1行または複数の宛名の書きだし行候補を選択する(ST189)。以下、町名の一部として読める宛名書きだし行候補が見つかる(ST190)まで可能性の高い宛名記載書式を順次選択(ST191)し、その宛名記載書式に対応する宛名行検出処理を行って1行または複数の宛名の書きだし行候補を選択(ST192)し、選択された宛名書きだし行候補は優先順位の高い順にn番目まで文字検出および文字認識処理にかけて、町名として読めるかどうか判断する(ST193)処理を繰り返す。
【0046】
第n番目の宛名記載処理まで処理して宛名書きだし行が見つからなかった場合は処理を打ち切りリジェクトする。ここで可能性があまり低い場合はエラーとなることが多いので、nの値は例えば3などの固定値であってもよい。また、最初に選択した宛名記載書式によってnの値を変えても良い。一例として、縦置き横書きと最初に判定した場合は最初の候補で宛名が読めることが多いのでn=1とし、それ以外の場合はn=4とする処理が考えられる。
【0047】
次に郵便物画像に書かれた行の位置やサイズの分布を調べて宛名の記載書式を判定する際、記載書式を1つに絞りきれない場合の処理の一例を図15に示す。ここではほとんどの処理が図14の場合と同じなので対応する処理は同じ番号を付してある。図15において、郵便物画像(181)から行情報を検出(ST182)し、検出した各行の記載位置および行サイズの分布を調べ分析(ST183)して可能性の高い宛名記載書式をいくつか選択する(ST184A)。
【0048】
可能性の高い宛名記載書式がn通りあった場合、まずn個の中で最も可能性の高い宛名記載書式を1つ選択(ST184B)し、その書式に対応する宛名行検出処理を行って宛名行候補を検出する(ST185)。検出した宛名行候補に順次文字検出処理および文字認識処理をほどこし、その行が宛名の一部として読めるか調ベる(ST186)。宛名として読めた場合はその行の続きの行を順次宛名読み取り処理にかけていく(ST187)。
【0049】
読める行が見つからなかった場合は、第1の宛名記載書式に類似した宛名記載書式を優先的に選択し(ST188A)、その宛名記載書式に対応する宛名行検出処理を行って宛名行候補を検出(ST189)し、検出した候補の中から宛名の一部として読める行を探し(ST190)、宛名行が見つからなければ別の宛名記載書式で同様の処理を繰り返す(ST190),(ST191),(ST192),(ST193)。n番目の宛名記載書式でも宛名行が見つからなかった場合はリジェクトする。
【0050】
次に郵便物画像に書かれた行の位置やサイズの分布を調べて宛名の記載書式を判定する際、記載書式を1つに絞りきれない場合の処理の別の例を図16に示す。これは、たとえば図16(a)および図16(b)に示すように、宛名が書状右半分に書かれている2つの書状において、行の書かれた位置およびサイズが非常に類似していて、宛名の書式が縦置き縦書きなのか横置き横書きなのかは文字認識処理を行うまで判断することが困難であるような場合である。このような場合、一方の宛名記載書式で書かれた書状が他方の宛名記載書式で書かれた書状よりも郵便局に多く届く時には、一番多く届く宛名記載書式に対応する宛名行検出処理を行い、見つからなかった場合に2番目に多く届く宛名記載書式に対応する宛名行検出処理処理を行うのが有効である。以下の説明は宛名が書状右半分に縦置き縦書き方向に書かれている場合の宛名行検出処理を先に行う場合である。
【0051】
図16(c)の最初のステップST201において宛名が書状右半分に書かれていると判断された書状から、ST202において宛名行の探索対象とする行を選択する。次に(a)のように、宛名が書状右半分に縦置き縦書き方向に書かれている場合の宛名行検出処理(ST203)を行い、宛名探索対象となる行の中から宛名行候補を選択する。
【0052】
宛名行候補を順次文字検出および文字認識処理にかけ、宛名の一部として読める行が存在するか調べる(ST204)。宛名行が見つかった場合は、その行の付近の行を順次宛名読みとり処理にかける(ST205)。宛名行が見つからなかった場合は、図16(b)に例示したように宛名が書状右半分に横置き縦書き正方向に書かれている場合の宛名行検出処理(ST206)を行い、宛名探索対象となる行の中から宛名行候補を選択する。宛名行候補を順次文字検出および文字認識処理にかけ、宛名の一部として読める行が存在するか調べる(ST207)。宛名行が見つかった場合は、その行の付近の行を順次宛名読みとり処理にかける(ST208)。
【0053】
これでも宛名行が見つからなかった場合はその他の宛名記載書式を選択した場合の宛名行検出処理を行う(ST209)。
この例では宛名が書状右半分に書かれている書状の場合について述べたが、他の制約条件と組み合わぜて使用しても良い。例えば(ST201)の部分を「宛名が手書きで書状右半分に書かれていると判断された書状」としても良い。
【0054】
次に、郵便物画像から宛名行を検出し読みとる処理のさらに別の例について説明する。図17は郵便物画像からハイフン「−」を含む行を検出しその行の付近に書かれた行を宛名行候補とする処理の一例である。これは、たとえば図4(a)に示した郵便物画像の最上行の郵便番号記載枠列210の中間に含まれているハイフン「−」211に基づき宛名に含まれる行情報,および番地表示行212中のハイフン213を検出するものである。
【0055】
図17の最初のステップST211において図4(a)に示したような郵便物の画像が取り込まれ、その最上部に横方向の文字行210をステップST212により検出する。
【0056】
次にステップST213において行数カウンタiに0をセットし、ステップST214にてiが検出した全行数よりも小さければ、すなわち1行以上の横行があれば、ステップST215において例えば行210中にハイフン「−」211が存在するか否かを調べる。このハイフン211の存在は、行210の2値化画像の射影情報を用いたり、行210内の黒画素外接矩形の形状を調べることによって判定する。行210中にハイフンが存在していなければステップST216にてiの値を1つ増やしてST214の処理に戻る。
【0057】
ハイフン211が見つかった場合はステップST217で行210のフラグをセットして(ST214)の処理に戻る。iの値が行数と等しくなった時点(この場合はi=3)で処理を終了する。同様に3行目の行212にもハイフン213が検出される。全ての行を評価し終ったあと、ST218にて書状上でフラグがセットされた2行(210、212)で挟まれた1行(214)または複数行から構成される行セットを検出する。
【0058】
ついで、行セット数カウン夕jに0をセット(ST219)し、jが検出した全行セット数よりも小さければ(ST220),フラグがセットされた2行(210,212)を郵便番号行および街区情報を含む行とし、2行に挟まれた行セットjに属する行(214)を順次文字検出および文字認識処理にかけて(ST221)宛名として読めるか調べる(ST222)。なおフラグがセットされた2行のどちらが郵便番号行か判定出来た場合は行セットjの中でその行に近い側の行から順に宛名読み取り処理にかける。2行のどちらが郵便番号行か判定出来なかった場合は、一方の行が郵便番号行であった場合の処理を両方の行について行う。行セットjが宛名読み取り処理にかけた結果宛名として読めた場合は、読み取り結果を出力する。宛名として読めなかった場合はjの値を1つ増やして(ST223)、(ST220)の処理に戻る。
jの値が全行セット数と等しくなって宛名が見つかっていない場合は別の宛名検出処理に移るか、リジェクト処理を行う。
【0059】
【発明の効果】
以上詳述したようにこの発明によれば、宛名領域候補を迅速に検出でき、また各領域候補のごく一部分に対して文字認識を行なうことによって宛名領域か否かの確認が速やかにできるので、1領域あたりの宛名領域か否かの判定処理が高速に実行でき、したがって、郵便物画像から複数の宛名領域候補をとり、個々について順次宛名領域か否かの確認が可能となり、宛名読み取り性能を向上させることが可能となる。また、各宛名領域候補において、領域内の行に読みとり順序を設定しているため、宛名書きだし行として選択した行がそうでなかった場合も次の候補をすぐ選択できる。上記の効果により、宛名書きだし行以降の住所情報を読みとる際、認識すべき行を選択することが容易である。書状上の行のサイズ、分布、記載位置を評価して宛名の記載書式を推定するため、宛名行の検出が容易になる。更に宛名の記載書式ごとに宛名行を検索する領域を用意し、その領域から宛名行検出を行うため一書式あたりの宛名行検出処理時間が短い。複数の宛名記載書式を書状に適用するため、最初に推定した宛名記載書式が正しくなくても、2番目以降に適用した宛名記載書式に正解があれば宛名情報を読みとることが出来る。
【図面の簡単な説明】
【図1】この発明の一実施の形態に係る郵便物の宛名領域検出装置の回路構成を示すブロック図。
【図2】図1の一部の回路の内部を詳細に示すブロック図。
【図3】この発明の一実施の形態に係る郵便物の宛名領域検出の処理の流れを示すフローチャート。
【図4】種々の宛名記載書式の例を示す図。
【図5】宛名記載書式の判定処理の一例を示す図。
【図6】宛名記載書式の判定処理の他の例を示す図。
【図7】宛名記載書式の判定処理の他の例を示す図。
【図8】宛名記載書式の判定処理のさらに他の例を示す図。
【図9】宛名記載書式の判定処理のさらに他の例を示す図。
【図10】宛名記載書式の判定処理のさらに他の例を示す図。
【図11】宛名記載書式の判定処理のさらに他の例を示す図。
【図12】宛名記載書式の判定処理のさらに他の例を示す図。
【図13】宛名記載領域検出の種々の例を示す図。
【図14】この発明の一実施の形態に係る郵便物の宛名行検出の処理の流れを示すフローチャート。
【図15】この発明の他の実施の形態に係る郵便物の宛名行検出の処理の流れを示すフローチャート。
【図16】この発明の更に他の実施の形態に係る郵便物の宛名行検出の処理の流れを示すフローチャート。
【図17】この発明の更に他の実施の形態に係る郵便物の宛名行検出の処理の流れを示すフローチャート。
【符号の説明】
1…光学的文字読取り装置
2…光電変換回路
3…2値化処理部
4…黒画素連結領域抽出部
5…宛名領域検出部
5a…行候補検出部
5b…宛名領域候補検出部
5c…行、領域の評価部
5d…宛名筆頭部行候補検出部
5R…基準宛名領域データベース
6…文字検出切り出し部
7…認識回路
8…文字辞書
9…知識処理回路
10…知識辞書
11…読取り結果処理回路
M…郵便物[0001]
BACKGROUND OF THE INVENTION
BACKGROUND OF THE
[0002]
[Prior art]
In the mail processing field, mails sent in large quantities every day must be processed within a limited time. Therefore, the mechanization of postal services has been promoted, and the burden on post office staff has been reduced. One example is an optical sorting device that uses an optical character reader to read a postal code on a postal item, and sorts the postal item into a plurality of delivery post offices based on the reading result, or even on a postal item. It is a delivery sorting machine that reads an address and sorts mail items into a plurality of delivery areas based on the read result.
[0003]
In the delivery sorting machine, when reading the address written on the mail piece, conventionally, it is determined one area where the address is estimated to be written by image processing, and line detection, character detection, The address is automatically recognized by pipeline processing of character identification and town name identification.
[0004]
However, with regard to the current mail address, there are almost no restrictions on the format of the address description, description method, etc., so there are various forms of mail, and the address of advertisements etc. on the mail. There are other character information, pictures, and photographs, and it is very difficult to correctly extract the address information from a mixture of these image information. Therefore, considering that the amount of mails will continue to increase in the future, it is required to develop an address reading method with higher performance than conventional methods.
[0005]
[Problems to be solved by the invention]
Since the conventional technology is configured to read the information contained in the address area after determining the address area, if the wrong area is determined as the address area, the mail is rejected from the delivery sorting machine. Therefore, there is no choice but to re-input, and it is impossible to correctly recognize the address in the subsequent processing in the first delivery sorter. Moreover, since all the characters written in one determined area are recognized and then it is determined whether or not this area is a destination area, the processing time per area becomes longer.
[0006]
In general, in order to increase the success rate of address area detection, it is only necessary to continue the detection operation of other areas for mail that has been rejected once. However, since the processing time per mail is limited, It has been difficult to detect a plurality of regions by the method because it takes a lot of time.
[0007]
SUMMARY OF THE INVENTION Accordingly, an object of the present invention is to provide a mail address area detection apparatus that can easily and accurately detect an address area from an image on the surface of a mail object and perform mail process at high speed.
[0008]
[Means for Solving the Problems]
The mail address detecting device of the present invention is More photoelectric conversion and image signal Image input means to obtain; An image memory for storing the image signal obtained by the image input means, a black pixel connection area obtained by performing binary image determination on the image signal in the image memory, and circumscribed rectangle information circumscribing the black pixel connection area are extracted. From the black pixel connection region extraction unit, the line candidate detection unit that extracts the rectangle information of the line candidate from the circumscribed rectangle information extracted by the black pixel connection region extraction unit, and the rectangular information extracted by the line candidate detection unit An address area candidate detection unit for detecting an address area candidate; and Addressing area determining means for determining the addressing area from the character information included in the addressing area candidate.
[0009]
With the above configuration, character lines are first detected, integrated to detect a plurality of address area candidates, character lines that are estimated to be address writing portions are detected from each area candidate, and the character lines are detected. By performing character detection, character identification, and town name identification on the address, it is possible to determine at high speed whether or not the area including the character line is an address description area. . As a result of character recognition, if the character line does not include address information, it is determined that address information is not written in an area including the line, and the same process is performed for the next area candidate. Here, in the present invention, since it is only necessary to perform character recognition for one to several lines for each area, the processing time per area can be shortened, so that it is possible to check a plurality of area candidates.
[0010]
DETAILED DESCRIPTION OF THE INVENTION
Hereinafter, a first embodiment of the present invention will be described with reference to the drawings.
FIG. 1 is a block diagram showing the configuration of the optical character reading apparatus according to the first embodiment of the present invention, and FIG. 2 is a block diagram showing the internal configuration of the address area detection unit of FIG.
[0011]
In FIG. 1, an image of a postal matter M is converted into an electric signal by the photoelectric conversion circuit 2 of the
[0012]
The rectangular information circumscribing the black pixel connection area extracted by the black pixel connection area extraction unit 4 is sent to the address
[0013]
Here, the internal configuration of the address
[0014]
First, in the line
[0015]
The detected line candidate information is then processed by the address area
[0016]
For the detected address candidate area, how many lines are included in the detected address candidate area, or the number of lines is larger or smaller than the predetermined number n, or the average width of the detected lines is predetermined. Whether the distribution is larger or smaller than the size, the distribution of the detected line width, the distribution of the position of the lines included in the detected address candidate area, etc. Evaluation is performed by the
[0017]
When the row /
[0018]
When there are a plurality of detected address candidate areas, the head candidate among the plurality of address candidate areas is detected by the address head line candidate detecting unit 5d and stored in a predetermined storage area.
[0019]
One of the address head line candidate candidates detected by the address
[0020]
The mail portion M read by the photoelectric conversion circuit 2 in FIG. 1 is written in two lines L1 and L2 in horizontal writing at the center in the vertical direction as shown in FIG. The operation of the
[0021]
The image data of the postal matter M read by the photoelectric conversion circuit 2 is subjected to differentiation / binarization processing by the binarization processing unit 3, and then the black pixel connection region extraction unit 4 in FIG. The rectangle information circumscribing the connected black pixel area corresponding to the rows L1, L2, L3, and L4 as shown in FIG. This rectangular information corresponds to each character, and this information is shown in FIG. 3C by integrating the circumscribed rectangular information adjacent in the horizontal direction in the line
[0022]
The information of these detected rows L1, L2, L3, and L4 is obtained by integrating the adjacent rows in the address area
[0023]
A plurality of address writing line candidates are selected and subjected to the feedback processing shown in FIG. 3 (g) in descending order of evaluation value. In the feedback process, first, the line L1 is selected from the address writing line candidates in FIG. 3 (h), each character of the line L1 is detected in FIG. 3 (i), and each character in FIG. 3 (j) is detected. 3 is identified, and the identified character string is subjected to municipality identification, for example, town name identification processing in FIG. Next, in FIG. 3L, it is checked whether the identification result can be read as address information. If the identified character string does not make sense as a result of referring to the
[0024]
Next, a description will be given of a process for determining in what format the address is described in the row and
[0025]
As an example of a method for determining the address description format, if a horizontal line is found from the top of the image when the line is cut out from the letter image, it is determined that the address is written in the vertical and horizontal direction. Can be considered. Further, in this case, it is conceivable to perform a process of increasing the priority applied to the address line writing candidate detection process as the horizontal line written in the upper part of the letter.
[0026]
Hereinafter, specific examples of row and region evaluation in the row and
In the example of FIG. 5, as shown in FIG. 5A, it is a case of a mail piece in which the address is described in two lines of vertical letters on the letter placed vertically, and FIG. 5B is an image of this mail piece. The flowchart which shows the process which determines an address description area | region from A, and detects an address line when an address is displayed by handwriting is shown. After cutting out the lines included in the area detected by the address area
[0027]
Since the address is n lines or less, the address is handwritten, the handwriting flag is set in step ST3, and the first address line detection process prepared for the handwritten address is performed in step ST4. This head address line detection process is performed in the address head head candidate line detector 5d shown in FIG.
[0028]
The determination condition as to whether the address line is 4 lines or less may be used in combination with another condition. As an example, FIG. 6 shows a case where the address is combined with the condition that the address is in the longitudinal direction of the letter. After cutting out lines from the letter image shown in FIG. 6A, it is determined whether or not the number of lines in the longitudinal direction of the letter among the lines detected in step ST11 is n or less. In other words, the process proceeds to another determination process (ST12). If it is n lines or less, it is determined that the address is handwritten in the longitudinal direction of the letter (ST13), and address line detection processing prepared for the case where the address line is a handwritten vertical line is performed (ST14). For example, if the number of vertical lines detected from the letter is 4 or less, it is determined that the address is handwritten. The row direction condition may be the letter short direction instead of the letter longitudinal direction.
[0029]
FIG. 7 shows another example of a method for determining the address description area. After cutting out lines from the letter image shown in FIG. 7 (a), the average width of the lines detected from the letter is calculated in step ST21 of FIG. 7 (b), and whether the line average width is equal to or greater than W millimeters. If it is not greater than W millimeters, another determination process (ST23) is performed.
[0030]
If it is greater than or equal to W millimeters, it is determined that the address is handwritten (ST24), and the first address line detection process prepared for the handwritten address is performed (ST25). For example, if the average width of a line detected from a letter is 20 mm or more, it is determined that the address is handwritten. The row average width threshold may be given in units of pixels instead of in millimeters. In the above example, all lines detected from the letter image are used to obtain the average width. However, the average width may be calculated using only lines written in a specific area of the letter image.
[0031]
The above determination conditions may be used in combination with other conditions. As an example, FIG. 8 shows a case where the address line is combined with the condition that the address line is in the longitudinal direction of the letter. After cutting out lines from the letter image shown in FIG. 8A, the average width of the vertical lines among the lines detected from the letter in step ST31 of FIG. 8B is calculated, and the average line width is W millimeters. It is determined whether or not this is the case (ST32). If it is greater than or equal to W millimeters, it is determined that the address is handwritten in the longitudinal direction of the letter (ST34), and the first address line detection process prepared for the case where the address line is a handwritten vertical line is performed (ST35). For example, if the average width of the vertical lines detected from the letter is 20 mm or more, it is determined that the address is handwritten. The row average width threshold may be given in units of pixels instead of in millimeters. The row direction condition may be the letter short direction instead of the letter longitudinal direction. Further, in the above example, all lines detected from the letter image are used to obtain the average width, but the average width may be calculated using only lines written in a specific area of the letter image.
[0032]
In order to estimate the address description format using the average line width detected from the image, the average line width needs to be a value close to the address line width. FIG. 9 shows an example of the head addressed line detection method when there is a variation in the width size of the line detected from the image. After a line is cut out from the letter image shown in FIG. 9A, a line with a high possibility of a destination line is selected as shown in FIG. 9B surrounded by a rectangle, and the address of the address is selected according to the average width of the selected line. Determine the format.
[0033]
First, the distribution of the width sizes of the lines detected from the letter is checked (ST41), and the average width of the lines is calculated (ST42). Next, among the detected lines, a line having a width that is wider than 1 / m of the average width and not more than n times is selected (ST43), and the average width of the selected lines is calculated to determine the address format. (ST44). It is determined whether or not the reference width is greater than or equal to W millimeter (ST45). If it is not greater than or equal to W millimeter, the process proceeds to another determination process (ST46).
[0034]
If it is greater than or equal to W millimeters, it is determined that the address is handwritten (ST47), and the first address line detection process prepared for the handwritten address is performed (ST48). For example, if m = 2, n = 1.5, and the reference width is 20 mm or more, it is determined that the address is handwritten. The row average width threshold may be given in units of pixels instead of in millimeters. In the above example, all the lines detected from the letter image are used to obtain the reference width. However, the reference width may be calculated using only the lines written in a specific area of the letter image.
[0035]
The above determination conditions may be used in combination with other conditions. As an example, FIG. 10 shows a case where the address is combined with the condition that the address is in the longitudinal direction of the letter. After cutting out lines from the letter image shown in FIG. 10 (a), select a vertical line with a high possibility of the address line as shown in FIG. 10 (b), and select it in each step of FIG. 10 (c). The address description format is determined by the average width of the selected lines.
[0036]
First, the distribution of width sizes of the vertical lines detected from the letter is checked (ST51), and the average width of the vertical lines is calculated (ST52). Next, among the detected vertical lines, a line having a width that is wider than 1 / m of the average width and not more than n times is selected (ST53), the average width of the selected vertical lines is calculated, and the address format A reference width for determination is used (ST54). It is determined whether or not the reference width is equal to or greater than W millimeter (ST55), and if it is not equal to or greater than W millimeter, the process proceeds to another determination process (ST56). If it is greater than or equal to W millimeters, it is determined that the address is handwritten in the longitudinal direction of the letter (ST57), and the first address line detection process prepared for the case where the address line is a handwritten vertical line is performed (ST58). For example, if m = 2, n = 1.5, and the reference width is 20 mm or more, it is determined that the address is handwritten. The threshold value of the row average width may be given in units of the number of pixels instead of in millimeters, or the row direction condition may be in the short side direction of the letter instead of the long side of the letter. In the above example, all the lines detected from the letter image are used to obtain the reference width. However, the reference width may be calculated using only the lines written in a specific area of the letter image.
[0037]
FIG. 11 shows another example of a method for determining the address description format. In step ST61 of FIG. 11A, the distribution of the written positions of the lines detected from the letter is checked, and among the detected lines, the entire line area or the line in the right half area when the letter is placed vertically in step ST62. Investigate how many lines are covered by part of the area. If not more than n% of the total number of rows, the process proceeds to another determination process (step ST71) in FIG.
[0038]
If it is n% or more, it is determined that the address is written vertically or horizontally on the right half of the letter as shown in FIG. 11B or 11D (ST63). For example, in the letter shown in FIG. 11 (b) or FIG. 11 (d), each letter has 70% or more of the total number of lines written in the right half of the letter. Or it is judged that it is written horizontally.
[0039]
Conversely, when 70% or more of the total number of lines is written in the left half of the letter as shown in FIG. 12B, among the lines detected in step ST71 of FIG. Determine how many lines are covered by the entire line area or a part of the line area in the left half area when the letter is placed vertically, and if it is not more than n% (for example, n = 70) of the total number of lines The process proceeds to another determination process (ST72).
[0040]
If it is 70% or more, it is determined that the address is written horizontally in the left half of the letter from the bottom to the top (ST73). For example, when the letter of FIG. 12 (b) is given and 70% or more of the total number of lines is written in the left half of the letter, the lower half of the letter is directed upward from the bottom of the letter as shown in FIG. 12 (c). Judge that it is written horizontally in horizontal writing.
[0041]
Here, a specific example of the process of detecting the address description area from the mail image will be further described with reference to FIG. The line information shown in FIG. 13B is detected from the letter image shown in FIG. Next, by defining the default area and address line direction for detecting the address line for each address format, select the line that has the same direction as the address line and the line area in the line default area, and select the address line candidate. And For example, when it is assumed that the address is written in vertical and horizontal writing, when the horizontal line in the hatched area in FIG. 13C is selected and it is assumed that the address is written in horizontal writing or vertical writing Selects the vertical line that covers the shaded area in FIG. 13 (d) or (e). In the case of the letter shown in FIG. 13A, as shown in FIGS. 13F and 13G, address area candidates and address line candidates for vertical horizontal writing and horizontal horizontal writing in the forward direction are detected. As shown in FIG. 13 (e), when the hatched portion is biased to the right end in the reverse direction, the horizontally-addressed addressee candidates are not detected in FIG. 13 (h).
[0042]
For each description format detected as described above, a process for finding an address line from the selected lines is performed. Hereinafter, processing for detecting and reading an address line from a mail image will be described. FIG. 14 shows an example of a process in which a line of address writing is first detected from the postal image, and subsequent lines of the address are sequentially subjected to character recognition.
[0043]
In step ST181 of FIG. 14, a mail image is input, line information is detected in step ST182 from the input mail image, and the description position and line size distribution of each line detected in step ST183 are examined and analyzed.
[0044]
The description format of the most likely address as a result of the analysis is determined (ST184), address line detection processing corresponding to the address description format is performed, and one line or a plurality of address writing, that is, the first line candidate is selected (ST185). ). The selected address writing line candidates are subjected to character detection and character recognition processing in descending order of priority, and it is determined whether they can be read as part of a town name, for example (ST186).
[0045]
If there is a line that can be read as a town name in the address writing line candidates, a subsequent line is found near the position on the postal image of the line, and character detection and character recognition processing are sequentially performed as the address line (ST187). . If there is no address writing line candidate that can be read as a town name, the second most likely address description format is selected (ST188), address line detection processing corresponding to the address description format is performed, and one or more address addresses are selected. A writing line candidate is selected (ST189). Hereinafter, the address writing format having high possibility is sequentially selected until the address writing line candidate that can be read as a part of the town name is found (ST190) (ST191), and the address line detection processing corresponding to the address writing format is performed. Alternatively, a plurality of address writing line candidates are selected (ST192), and the selected address writing line candidates are subjected to character detection and character recognition processing up to n-th in descending order of priority to determine whether they can be read as town names (ST193). ) Repeat the process.
[0046]
If the address writing line is not found after processing up to the nth address description process, the process is aborted and rejected. Here, if the possibility is very low, an error often occurs, so the value of n may be a fixed value such as 3, for example. Further, the value of n may be changed according to the address description format selected first. As an example, if it is first determined that the vertical writing is horizontal writing, the address can often be read with the first candidate, so that n = 1, and in other cases, n = 4 can be considered.
[0047]
Next, FIG. 15 shows an example of processing in the case where the description format of the address is determined by examining the position and size distribution of the lines written in the mail image, and the description format cannot be narrowed down to one. Since most processes are the same as those in FIG. 14, the corresponding processes are given the same numbers. In FIG. 15, line information is detected from the mail image (181) (ST182), and the description position and line size distribution of each detected line are examined and analyzed (ST183), and several possible address description formats are selected. (ST184A).
[0048]
If there are n possible address description formats, first select one of the n most likely address description formats (ST184B), perform address line detection processing corresponding to that format, and perform addressing. A line candidate is detected (ST185). The detected address line candidates are sequentially subjected to character detection processing and character recognition processing to determine whether the line can be read as part of the address (ST186). If it can be read as the address, the subsequent lines are sequentially subjected to the address reading process (ST187).
[0049]
If no readable line is found, an address description format similar to the first address description format is preferentially selected (ST188A), and address line detection processing corresponding to the address description format is performed to detect address line candidates. (ST189) Then, a line that can be read as a part of the address is searched from the detected candidates (ST190). If the address line is not found, the same processing is repeated with another address description format (ST190), (ST191), ( ST192), (ST193). If the address line is not found even in the nth address description format, it is rejected.
[0050]
Next, FIG. 16 shows another example of processing in the case where the description format of the address is determined by examining the position and size distribution of the lines written in the mail image, and the description format cannot be narrowed down to one. This is because, for example, as shown in FIGS. 16 (a) and 16 (b), in the two letters whose addresses are written in the right half of the letter, the positions and sizes of the lines are very similar. In this case, it is difficult to determine whether the address format is vertical writing or horizontal writing until character recognition processing is performed. In such a case, when a letter written in one addressing format reaches more post offices than a letter written in the other addressing format, the address line detection process corresponding to the most frequently addressed format is performed. It is effective to perform the address line detection processing corresponding to the address description format that reaches the second most frequently when it is not found. In the following explanation, the address line detection process is performed first when the address is written vertically in the right half of the letter in the vertical writing direction.
[0051]
In ST202, from the letter determined that the address is written in the right half of the letter in the first step ST201 in FIG. Next, as shown in (a), address line detection processing (ST203) is performed when the address is written vertically in the right half of the letter in the vertical writing direction, and address line candidates are selected from the lines to be searched for the address. select.
[0052]
Address line candidates are sequentially subjected to character detection and character recognition processing to check whether there is a line that can be read as a part of the address (ST204). When the address line is found, the lines near the line are sequentially subjected to address reading processing (ST205). If the address line is not found, as shown in FIG. 16B, address line detection processing (ST206) is performed when the address is written horizontally and vertically in the right half of the letter. Select a candidate address line from the target lines. The address line candidates are sequentially subjected to character detection and character recognition processing to check whether there is a line that can be read as a part of the address (ST207). When the address line is found, the lines near the line are sequentially subjected to address reading processing (ST208).
[0053]
If the address line is still not found, the address line detection process is performed when another address description format is selected (ST209).
In this example, the case where the address is written on the right half of the letter is described, but it may be used in combination with other constraints. For example, the part of (ST201) may be “a letter determined that the address is handwritten and written on the right half of the letter”.
[0054]
Next, still another example of the processing for detecting and reading the address line from the mail image will be described. FIG. 17 shows an example of processing in which a line including a hyphen “-” is detected from a postal image and a line written in the vicinity of the line is used as a candidate address line. For example, the line information included in the address based on the hyphen “-” 211 included in the middle of the postal code
[0055]
In the first step ST211 of FIG. 17, the mail image as shown in FIG. 4A is taken in, and the
[0056]
Next, in step ST213, the row number counter i is set to 0, and if i is smaller than the total number of rows detected in step ST214, that is, if there is one or more horizontal rows, a hyphen in the
[0057]
If the
[0058]
Then, 0 is set to the row set count count j (ST219), and if j is smaller than the total number of row sets detected (ST220), the two rows (210, 212) with the flag set are set to the zip code line and A row including block information and a row (214) belonging to row set j sandwiched between two rows is sequentially subjected to character detection and character recognition processing (ST221) to check whether it can be read as an address (ST222). If it is possible to determine which of the two lines with the flag set is the postal code line, the address reading process is performed in order from the line closer to that line in the line set j. If it is not possible to determine which of the two lines is a zip code line, the process when one of the two lines is a zip code line is performed for both lines. When the row set j can be read as the addressee as a result of the address reading process, the reading result is output. If the address cannot be read, the value of j is incremented by 1 (ST223), and the process returns to (ST220).
If the value of j is equal to the total number of rows and no address is found, the process proceeds to another address detection process or a reject process.
[0059]
【The invention's effect】
As described above in detail, according to the present invention, addressable area candidates can be quickly detected, and confirmation of whether or not the addressable area can be performed quickly by performing character recognition on a small portion of each area candidate. Judgment processing of whether or not the address area per area can be executed at high speed. Therefore, a plurality of address area candidates can be taken from the mail image, and it can be confirmed whether or not each address area is addressed sequentially, and address reading performance is improved. It becomes possible to improve. Further, in each address area candidate, the reading order is set for the lines in the area, so that even if the line selected as the address writing line is not, the next candidate can be selected immediately. Due to the above effects, it is easy to select a line to be recognized when reading address information after the address writing line. Since the format of the address is estimated by evaluating the size, distribution, and description position of the line on the letter, it is easy to detect the address line. Furthermore, since an address line search area is prepared for each address description format and address line detection is performed from the area, address line detection processing time per format is short. Since a plurality of address description formats are applied to the letter, even if the first estimated address description format is not correct, the address information can be read if there is a correct answer in the second and subsequent address description formats.
[Brief description of the drawings]
FIG. 1 is a block diagram showing a circuit configuration of a mail address area detection apparatus according to an embodiment of the present invention.
FIG. 2 is a block diagram showing in detail the interior of a part of the circuit of FIG. 1;
FIG. 3 is a flowchart showing a flow of mail address area detection processing according to an embodiment of the present invention;
FIG. 4 is a diagram showing examples of various address description formats.
FIG. 5 is a diagram showing an example of an address description format determination process.
FIG. 6 is a diagram showing another example of address description format determination processing;
FIG. 7 is a diagram showing another example of address description format determination processing;
FIG. 8 is a diagram showing still another example of the address description format determination process.
FIG. 9 is a diagram showing still another example of address description format determination processing;
FIG. 10 is a diagram showing still another example of the address description format determination process.
FIG. 11 is a diagram showing still another example of the address description format determination process.
FIG. 12 is a diagram showing still another example of address description format determination processing;
FIG. 13 is a diagram showing various examples of address description area detection.
FIG. 14 is a flowchart showing a flow of mail address line detection processing according to an embodiment of the present invention;
FIG. 15 is a flowchart showing a flow of mail address line detection processing according to another embodiment of the present invention;
FIG. 16 is a flowchart showing the flow of mail address line detection processing according to still another embodiment of the present invention;
FIG. 17 is a flowchart showing a flow of mail address line detection processing according to still another embodiment of the present invention;
[Explanation of symbols]
1 ... Optical character reader
2 ... Photoelectric conversion circuit
3 ... Binarization processing unit
4 ... Black pixel connection area extraction unit
5 ... Address area detector
5a ... line candidate detection unit
5b ... Address area candidate detection unit
5c: Row and region evaluation section
5d ... Address head part candidate detection part
5R ... Standard address area database
6 ... Character detection cutout unit
7 ... Recognition circuit
8 ... Character dictionary
9 ... Knowledge processing circuit
10 ... Knowledge Dictionary
11 ... Read result processing circuit
M ... Mail
Claims (7)
この画像入力手段により得られた前記画像信号を格納する画像メモリと、
この画像メモリの前記画像信号を2値画像判定した黒画素連結領域とこの黒画素連結領域に外接する外接矩形情報を抽出する黒画素連結領域抽出部と、
この黒画素連結領域抽出部により抽出された前記外接矩形情報から行候補の矩形情報を抽出する行候補検出部と、
この行候補検出部により抽出された矩形情報から宛名領域候補を検出する宛名領域候補検出部と、
前記宛名領域候補に含まれる文字情報から宛名領域を確定する宛名領域確定手段と、
を具備することを特徴とする郵便物の宛名領域検出装置。Image input means for obtaining an image signal by photoelectric conversion from the mail surface;
An image memory for storing the image signal obtained by the image input means;
A black pixel connection region obtained by performing binary image determination on the image signal of the image memory, and a black pixel connection region extraction unit that extracts circumscribed rectangle information circumscribing the black pixel connection region;
A line candidate detection unit that extracts rectangular information of line candidates from the circumscribed rectangle information extracted by the black pixel connection region extraction unit;
An address area candidate detection section for detecting address area candidates from the rectangular information extracted by the line candidate detection section;
Address area determination means for determining the address area from the character information included in the address area candidate;
A mail address area detection apparatus comprising:
郵便物表面の宛名領域に含まれる行画像の種々の特徴パターンを類型化して記憶する手段と、
前記検出された行画像の特徴と記憶された行画像の種々の特徴パターンとの類似度を検出する手段と、
この検出された類似度の高い順に宛名領域候補を決定する手段と、
を具備することを特徴とする請求項1に記載の郵便物の宛名領域検出装置。The line candidate detection unit
Means for typifying and storing various feature patterns of line images included in the address area on the mail surface;
Means for detecting a similarity between the feature of the detected row image and various feature patterns of the stored row image;
Means for determining address area candidates in descending order of the detected similarity;
The mail address area detection apparatus according to claim 1, further comprising:
この2値画像情報から郵便物中の文字行情報を検出する手段と、
郵便物表面画像中の文字行情報に応じて宛名記載位置および方向を検出する手段と、
前記郵便物表面画像から検出された行数があらかじめ用意したしきい値より少ない場合は宛名が手書きでなされていると判断する手段と、
この判断手段の結果により手書き宛名文字の認識処理を実行する手段と、
検出された宛名が縦置き郵便物の右側か左側に集中して記載されていることを検知する手段と、
縦置き郵便物の右側に集中して記載されている場合は宛名が縦書きであるものとして認識処理し、左側に行が集中している場合に横置き横書きとして認識処理する手段と、
を具備することを特徴とする郵便物の宛名領域検出装置。Means for obtaining binary image information on the mail surface;
Means for detecting character line information in the postal matter from the binary image information;
Means for detecting the address description position and direction according to the character line information in the mail surface image;
Means for determining that the address is handwritten when the number of lines detected from the mail surface image is less than a threshold value prepared in advance;
Means for executing recognition processing of handwritten address characters according to the result of the determination means;
Means for detecting that the detected address is concentrated on the right or left side of the vertical mail;
If the address is written on the right side of the vertically placed mail, the address is recognized as vertical writing, and if the lines are concentrated on the left side, it is recognized and processed as horizontal writing.
A mail address area detection apparatus comprising:
この2値画像情報から郵便物中の文字行情報を検出する手段と、
郵便物表面画像中の文字行情報の分布状態に応じて宛名記載位置および方向を検出する手段と、
前記検出した各行についてハイフンが含まれているか調べる手段と、
この手段によりハイフンを含む行が2行ある場合に、それぞれを郵便番号行および街区行と判断する手段と、
前記ハイフンを含む2行にはさまれた1行または複数行を宛名行と判断する手段と、を具備することを特徴とする郵便物の宛名領域検出装置。Means for obtaining binary image information on the mail surface;
Means for detecting character line information in the postal matter from the binary image information;
Means for detecting the address description position and direction according to the distribution state of the character line information in the mail surface image;
Means for checking whether a hyphen is included in each detected line;
When there are two lines including hyphens by this means, means for determining each of them as a postal code line and a block line,
Address area detecting apparatus of mail, characterized in that it comprises, means for determining the address line of one or more lines sandwiched by two lines including the hyphen.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP25993796A JP3673034B2 (en) | 1996-09-30 | 1996-09-30 | Mail address area detection device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP25993796A JP3673034B2 (en) | 1996-09-30 | 1996-09-30 | Mail address area detection device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH1099788A JPH1099788A (en) | 1998-04-21 |
| JP3673034B2 true JP3673034B2 (en) | 2005-07-20 |
Family
ID=17341004
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP25993796A Expired - Fee Related JP3673034B2 (en) | 1996-09-30 | 1996-09-30 | Mail address area detection device |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3673034B2 (en) |
-
1996
- 1996-09-30 JP JP25993796A patent/JP3673034B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JPH1099788A (en) | 1998-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100324847B1 (en) | Address reader and mails separater, and character string recognition method | |
| US20060291692A1 (en) | Information processing apparatus having learning function for character dictionary | |
| JPH11226513A (en) | Mail address reader and mail address classifier | |
| KR100536509B1 (en) | Method and device for recognition of delivery data on mail matter | |
| JP3485020B2 (en) | Character recognition method and apparatus, and storage medium | |
| JP4855698B2 (en) | Address recognition device | |
| JP2000285190A (en) | Method and device for identifying slip and storage medium | |
| JPH06501801A (en) | Character recognition method and apparatus including locating and extracting predetermined data from a document | |
| JPH0739820A (en) | Street zone recognizing device and address reading and classifying machine | |
| JP3673034B2 (en) | Mail address area detection device | |
| JPH06124366A (en) | Address reader | |
| JP3162552B2 (en) | Mail address recognition device and address recognition method | |
| JP3673616B2 (en) | Gift certificate identification method and apparatus | |
| CA2473278C (en) | Sorting apparatus and address information determination method | |
| JP5178851B2 (en) | Address recognition device | |
| JPH07271899A (en) | Character recognition device | |
| JP3160347B2 (en) | Mail address reading device | |
| JPH11179289A (en) | Mail classifier | |
| JP2571236B2 (en) | Character cutout identification judgment method | |
| JPH10432A (en) | Method and apparatus for reading address of mail | |
| JP4659947B2 (en) | Reading device, reading method, sorting device, and sorting method | |
| JPH08164365A (en) | Address reader | |
| JP3088038B2 (en) | Mail sorting device and mail sorting method | |
| JP2007511842A (en) | System and method for smart polling | |
| JPH1185901A (en) | Device and method for document image processing, device and method for postal address automatic recognition, and recording medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20040720 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20040831 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20041101 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20050208 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050325 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20050419 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20050421 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20080428 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20090428 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100428 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100428 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110428 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130428 Year of fee payment: 8 |
|
| LAPS | Cancellation because of no payment of annual fees |