JP2009031809A - Speech recognition apparatus - Google Patents
Speech recognition apparatus Download PDFInfo
- Publication number
- JP2009031809A JP2009031809A JP2008240988A JP2008240988A JP2009031809A JP 2009031809 A JP2009031809 A JP 2009031809A JP 2008240988 A JP2008240988 A JP 2008240988A JP 2008240988 A JP2008240988 A JP 2008240988A JP 2009031809 A JP2009031809 A JP 2009031809A
- Authority
- JP
- Japan
- Prior art keywords
- learning
- unit
- voice
- signal
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Abstract
Description
本発明は、マイクロフォンから得た音声信号に基づいて、利用者がマイクロフォンに入力した音声を認識する音声認識装置に関する。 The present invention relates to a speech recognition apparatus that recognizes speech input to a microphone by a user based on a speech signal obtained from a microphone.
従来より、利用者から発せられた音声をマイクロフォンで集音し、これを予め認識語として記憶された音声のパターンと比較し、一致度の高い認識語を利用者が発声した語彙であると認識する音声認識装置が知られている。この種の音声認識装置は、例えばカーナビゲーション装置などに組み込まれている。 Conventionally, a voice uttered by a user is collected by a microphone, and compared with a voice pattern stored in advance as a recognized word, a recognized word with a high degree of matching is recognized as a vocabulary spoken by the user. A voice recognition device is known. This type of speech recognition device is incorporated in, for example, a car navigation device.
このような音声認識装置の音声認識率(音声認識の正解率)は、マイクロフォンから入力される音声信号に含まれる雑音量によって左右されることがよく知られているが、特に自動車などの車両内においては、車載オーディオ機器の動作時に、再生される音楽等が雑音として利用者の音声と共にマイクロフォンで集音されてしまう問題がある。 It is well known that the speech recognition rate (accuracy rate of speech recognition) of such a speech recognition device depends on the amount of noise included in the speech signal input from the microphone. However, there is a problem that music or the like to be reproduced is collected by a microphone together with the user's voice as noise during operation of the in-vehicle audio device.
この問題に対し、従来では、車載オーディオ機器と、音声認識装置とを連動させ、音声認識処理の際に、車載オーディオ機器にて再生される音楽等のボリュームを調節する(例えば車載オーディオ機器をミュートに設定する)ことで、再生される音楽等がマイクロフォンに入力されないようにし、一定度以上の音声認識率を確保するようにしていた。尚、このような先行技術は周知公用のため、関連文献を非開示とする。 To solve this problem, conventionally, the volume of music played on the in-vehicle audio device is adjusted during the speech recognition process by linking the in-vehicle audio device and the voice recognition device (for example, muting the in-vehicle audio device). In other words, the reproduced music or the like is not input to the microphone, and a voice recognition rate of a certain level or more is ensured. Since such prior art is well known and publicly used, related documents are not disclosed.
しかしながら、従来の音声認識装置では、車載オーディオ機器にて再生される音楽等のボリュームを調節するので、一時的に音楽等が利用者に聞こえなくなってしまい、その事が原因で利用者に不満が及ぶ可能性があった。 However, the conventional speech recognition apparatus adjusts the volume of music or the like played on the in-vehicle audio device, so the music or the like is temporarily inaudible to the user, which causes the user to be dissatisfied. There was a possibility.
そこで、本発明者らは、雑音源(車載オーディオ機器)から得られる参照信号に基づき、マイクロフォンから得られる音声信号に含まれる雑音成分を学習し、その音声信号から学習した雑音成分を除去する雑音除去部を音声認識装置に設けることにした。 Therefore, the present inventors learn a noise component included in an audio signal obtained from a microphone based on a reference signal obtained from a noise source (vehicle audio device), and remove noise learned from the audio signal. The removal unit is provided in the speech recognition apparatus.
しかしながら、最小二乗平均(Least Mean Square:LMS)法などの周知の学習法では、雑音除去後の信号が小さくなる方向に学習を繰り返すため、利用者がマイクロフォンに音声を入力している間に雑音成分の学習が繰り返されると、その利用者による発話の影響を受けて雑音除去部が誤学習をし、音声信号に含まれる雑音成分が適切に除去できなくなってしまう問題があった。したがって、このような雑音除去部を音声認識装置に導入しても、音声認識の精度向上には限界があった。 However, in a known learning method such as the least mean square (LMS) method, learning is repeated in such a direction that the signal after noise reduction becomes smaller, so that noise is generated while the user is inputting sound into the microphone. When the component learning is repeated, there is a problem in that the noise removing unit erroneously learns due to the influence of the utterance by the user, and the noise component included in the voice signal cannot be removed appropriately. Therefore, even if such a noise removing unit is introduced into the speech recognition apparatus, there is a limit to improving speech recognition accuracy.
本発明はこうした問題に鑑みなされたものであり、音声認識対象の音声信号に含まれる雑音成分を適切に除去して高精度に音声認識可能な音声認識装置を提供することを目的とする。 The present invention has been made in view of these problems, and an object of the present invention is to provide a speech recognition apparatus capable of accurately recognizing speech by appropriately removing a noise component contained in a speech signal to be recognized.
かかる目的を達成するためになされた請求項1に記載の音声認識装置によれば、予め設定されたフィルタ係数に従い雑音源から入力される参照信号を濾波することで雑音除去信号生成手段が生成した雑音除去信号を用いて、雑音除去手段が、マイクロフォンから入力される音声信号に含まれる雑音成分を除去し、雑音除去後の音声信号を出力する。また、この音声認識装置は、係数更新手段を備えており、雑音除去手段から出力される音声信号に基づき、係数更新手段にて、雑音除去信号生成手段に設定すべきフィルタ係数を学習し、その結果得たフィルタ係数を、雑音除去信号生成手段に対して設定する。 According to the speech recognition apparatus of claim 1 made to achieve the above object, the noise removal signal generating means generates the reference signal input from the noise source in accordance with a preset filter coefficient. Using the noise removal signal, the noise removal means removes a noise component included in the voice signal input from the microphone, and outputs the voice signal after the noise removal. In addition, the speech recognition apparatus includes a coefficient updating unit. The coefficient updating unit learns a filter coefficient to be set in the noise removal signal generation unit based on the voice signal output from the noise removal unit. The obtained filter coefficient is set for the noise removal signal generating means.
一方、音声認識手段は、外部(例えば、PTTスイッチ等の操作スイッチ)から動作開始指令が入力されると、所定期間、雑音除去手段から出力される音声信号を取得し、その音声信号に基づき、マイクロフォンに入力された音声を認識する。 On the other hand, when an operation start command is input from the outside (for example, an operation switch such as a PTT switch), the voice recognition unit acquires a voice signal output from the noise removal unit for a predetermined period, and based on the voice signal, Recognizes the voice input to the microphone.
また、この音声認識装置では、学習速度切替手段が、音声認識手段の非動作時に、第一の学習速度で、係数更新手段にフィルタ係数を学習させ、音声認識手段が雑音除去手段から出力される音声信号を取得している間には、第一の学習速度より低い第二の学習速度で、係数更新手段にフィルタ係数を学習させる。 In this speech recognition apparatus, the learning speed switching means causes the coefficient updating means to learn the filter coefficient at the first learning speed when the speech recognition means is not operating, and the speech recognition means is output from the noise removal means. While the voice signal is being acquired, the coefficient updating means is made to learn the filter coefficient at a second learning speed lower than the first learning speed.
マイクロフォンに入力される利用者の音声は、定常及び準定常的な音とは異なり、突発的に発生する非定常的な音声であることから、音声認識手段が雑音除去手段から出力される音声信号を取得している期間、フィルタ係数の学習速度を遅くすれば、フィルタ係数の学習時に利用者の音声が与える影響を抑えることができ、係数更新手段によるフィルタ係数の誤学習を抑制することができる。 Unlike the normal and quasi-stationary sounds, the user's voice input to the microphone is a non-stationary voice that occurs suddenly. Therefore, the voice signal output from the noise removal unit by the voice recognition unit If the learning rate of the filter coefficient is slowed during the period when the filter coefficient is acquired, the influence of the user's voice during learning of the filter coefficient can be suppressed, and erroneous learning of the filter coefficient by the coefficient updating means can be suppressed. .
即ち、請求項1に記載の音声認識装置によれば、従来と比較して、適切にフィルタ係数の学習を係数更新手段に実行させることができ、雑音除去の精度を向上させることができる。したがって、本発明によれば、音声認識装置における音声認識の精度を向上させることができる。 That is, according to the speech recognition apparatus of the first aspect, the coefficient update unit can appropriately perform learning of the filter coefficient, and the noise removal accuracy can be improved as compared with the conventional case. Therefore, according to the present invention, the accuracy of speech recognition in the speech recognition apparatus can be improved.
尚、学習速度切替手段は、少なくとも音声認識手段が雑音除去手段から音声信号の取得を開始した時点から終了する時点まで、第二の学習速度で、係数更新手段にフィルタ係数の学習を行わせる構成にされていればよく、例えば、音声信号の取得完了後、音声認識手段による音声の認識が完了し音声認識手段の動作が停止するまで、第二の学習速度で、フィルタ係数の学習を係数更新手段に実行させても構わない。 The learning speed switching means is configured to cause the coefficient updating means to learn the filter coefficient at the second learning speed at least from the time when the voice recognition means starts to acquire the voice signal from the noise removal means to the time when it ends. For example, after the acquisition of the audio signal is completed, the learning of the filter coefficient is updated at the second learning speed until the recognition of the audio by the audio recognition unit is completed and the operation of the audio recognition unit stops. The means may be executed.
また、学習速度切替手段は、少なくとも音声認識手段の非動作時に第一の学習速度で係数更新手段にフィルタ係数を学習させる構成にされていればよく、音声認識手段の非動作時に加え、音声認識手段の動作時であって音声認識手段が雑音除去手段から出力される音声信号を取得していない期間に、第一の学習速度で係数更新手段にフィルタ係数を学習させる構成にされていてもよい。即ち、学習速度切替手段は、音声認識手段が音声の認識を行っているか否かにかかわらず、音声認識手段が音声信号を取得した直後から第一の学習速度で係数更新手段にフィルタ係数の学習を行わせる構成にされていてもよい。 The learning speed switching means may be configured to cause the coefficient updating means to learn the filter coefficient at the first learning speed at least when the speech recognition means is not operating. The filter updating unit may be made to learn the filter coefficient at the first learning speed during the operation of the unit and during the period when the voice recognition unit does not acquire the voice signal output from the noise removing unit. . That is, the learning speed switching means learns the filter coefficient to the coefficient updating means at the first learning speed immediately after the voice recognition means acquires the voice signal regardless of whether or not the voice recognition means performs voice recognition. It may be configured to perform.
その他、本発明の音声認識装置における音声認識手段は、外部から動作開始指令が入力された後、利用者による発声がなされた発声期間に限定して、雑音除去手段から出力される音声信号を取得する構成にされていると良い。音声認識手段をこのような構成とすれば、利用者による発話内容が含まれない雑音区間の音声信号を、音声認識の際に用いずに済み、音声認識の精度が向上する。 In addition, the speech recognition means in the speech recognition apparatus of the present invention acquires the speech signal output from the noise removal means only during the utterance period in which the user uttered after the operation start command was input from the outside. It is good to be configured to do. If the speech recognition means has such a configuration, it is not necessary to use a speech signal in a noise section that does not include the content of the utterance by the user at the time of speech recognition, and the accuracy of speech recognition is improved.
また、このように利用者による発声期間の音声信号を選択的に音声認識手段に取得させる場合には、雑音除去手段から出力される音声信号に基づいて、利用者による発声がなされた発声期間を判別し、雑音除去手段から出力される音声信号の内、その発声期間に該当する音声信号のみを選択的に、音声認識手段に取得させる取得制御手段を装置内に設ければ良い。 Further, when the voice recognition unit selectively acquires the voice signal during the utterance period by the user as described above, the utterance period during which the user uttered is changed based on the voice signal output from the noise removal unit. It is only necessary to provide in the apparatus an acquisition control means for making the voice recognition means selectively obtain only the voice signal corresponding to the utterance period among the voice signals output from the noise removal means.
ところで、動作開始指令と同時に音声認識手段が雑音除去手段から音声信号を取得しない場合には、音声認識手段が雑音除去手段から出力される音声信号を取得している期間のみ第二の学習速度でフィルタ係数が学習されるようにすると、装置構成が煩雑になる可能性がある。 By the way, when the voice recognition unit does not acquire a voice signal from the noise removal unit at the same time as the operation start command, only the period during which the voice recognition unit acquires the voice signal output from the noise removal unit is obtained at the second learning speed. If the filter coefficients are learned, the apparatus configuration may become complicated.
したがって、上述の音声認識装置においては、動作開始指令が音声認識手段に入力されると同時に、第二の学習速度で、係数更新手段にフィルタ係数を学習させ、音声認識手段が音声信号の取得を終了するまでの期間は、第二の学習速度によるフィルタ係数の学習を係数更新手段に継続させるように、学習速度切替手段を構成するとよい。 Therefore, in the above-described voice recognition device, the operation start command is input to the voice recognition unit, and at the same time, the coefficient update unit learns the filter coefficient at the second learning speed, and the voice recognition unit acquires the voice signal. The learning speed switching means may be configured so that the coefficient update means continues to learn the filter coefficient at the second learning speed during the period until the end.
このような構成にされた請求項2に記載の音声認識装置によれば、音声認識手段に外部から動作開始指令が入力されたか否かを監視する程度で、音声認識手段が雑音除去手段から音声信号を取得する際には、係数更新手段に第二の学習速度でフィルタ係数を学習させることができる。つまり、この音声認識装置によれば、簡単な装置構成(制御)で、係数更新手段の学習速度を適切に切り替えることができる。 According to the speech recognition apparatus of the second aspect configured as described above, the speech recognition means performs speech to the speech recognition means from the noise removal means only by monitoring whether or not an operation start command is externally input to the speech recognition means. When acquiring the signal, the coefficient updating means can learn the filter coefficient at the second learning speed. That is, according to this voice recognition device, the learning speed of the coefficient updating means can be appropriately switched with a simple device configuration (control).
その他、上述した発明は、請求項3に記載のように、係数更新手段が、LMS法を用いて、雑音除去信号生成手段に設定すべきフィルタ係数を学習する音声認識装置に適用される良い。 In addition, the above-described invention may be applied to a speech recognition apparatus in which the coefficient updating unit learns a filter coefficient to be set in the noise removal signal generating unit using the LMS method.
LMS法を用いる場合には、マイクロフォンに入力される音声に、雑音源以外の音源から発生した音声(即ち、利用者の音声)が含まれると、フィルタ係数の誤学習を引き起こしやすい。したがって、請求項3に記載のように、LMS法を用いて学習を行う音声認識装置に、本発明(請求項1又は請求項2)を適用すれば、音声認識の精度を効果的に向上させることができる。
When the LMS method is used, if the voice input to the microphone includes voice generated from a sound source other than the noise source (that is, user voice), erroneous learning of the filter coefficient is likely to occur. Therefore, if the present invention (Claim 1 or Claim 2) is applied to a speech recognition apparatus that performs learning using the LMS method as described in
また、請求項1〜請求項3に記載の発明は、請求項4に記載のように、雑音源がオーディオ機器である音声認識装置に適用されるとよい。
請求項4に記載の音声認識装置によれば、オーディオ機器の動作によりスピーカから再生される音楽等のボリュームを調節しなくても、高精度に音声認識を行うことが可能であるので、便利である。
In addition, the invention described in claims 1 to 3 may be applied to a speech recognition apparatus in which the noise source is an audio device as described in claim 4.
According to the voice recognition device of the fourth aspect, it is possible to perform voice recognition with high accuracy without adjusting the volume of music or the like reproduced from the speaker by the operation of the audio device. is there.
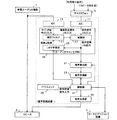
以下に本発明の実施例について、図面とともに説明する。尚、図1は、音声認識装置1の概略構成を表すブロック図である。
図1に示す本実施例の音声認識装置1は、カーナビゲーション装置3に接続されており、マイクロフォン5に入力された利用者の音声を認識し、その音声に従う操作信号をカーナビゲーション装置3に入力することで、利用者の音声に従った操作をカーナビゲーション装置3に対して施す。
Embodiments of the present invention will be described below with reference to the drawings. FIG. 1 is a block diagram illustrating a schematic configuration of the speech recognition apparatus 1.
A voice recognition device 1 according to this embodiment shown in FIG. 1 is connected to a
この音声認識装置1は、主に、マイクロフォン5及び車載オーディオ機器7にアナログ−デジタル変換器(ADC)11,13を介して接続されたオーディオキャンセラ部20と、音声抽出部31と、音声認識部33と、PTT(Push to Talk)スイッチ35と、制御部37と、音声合成部39と、から構成されている。
The speech recognition apparatus 1 mainly includes an
オーディオキャンセラ部20は、主に、適応フィルタ21と、減算部23と、LMS学習部25と、から構成されており、マイクロフォン5からADC11を介して入力される音声信号y(t)を減算部23に入力すると共に、車載オーディオ機器7からスピーカ9に入力されるオーディオ信号x(t)をADC13から取得し、そのオーディオ信号x(t)を適応フィルタ21に入力する。
The
適応フィルタ21は、フィルタ係数wを記憶する図示しないレジスタ等を備えている。
w=(w[0],w[1],…,w[J])T …式(1)
尚、上付き記号Tは、転置行列を意味する。また、パラメータJ+1は、タップ長を表す。
The adaptive filter 21 includes a register (not shown) that stores the filter coefficient w.
w = (w [0], w [1], ..., w [J]) T ... Formula (1)
The superscript T means a transposed matrix. The parameter J + 1 represents the tap length.
この適応フィルタ21は、LMS学習部25の動作(詳細後述)により予めレジスタに設定されたフィルタ係数wと、雑音源としての車載オーディオ機器7から参照信号として得た上記オーディオ信号x(t)とを、次式に代入し演算することで、オーディオ信号x(t)をフィルタ係数wに従い濾波し、音声信号y(t)から雑音成分を除去するための雑音除去信号c(t)を生成する。そして、雑音除去信号c(t)を減算部23に入力する。
The adaptive filter 21 includes a filter coefficient w set in a register in advance by an operation of the LMS learning unit 25 (details will be described later), and the audio signal x (t) obtained as a reference signal from the in-
c(t)=xT・w …式(2)
但し、パラメータxは、下式で表されるオーディオ信号x(t)の時系列ベクトルである。また、ここでいうパラメータtは、サンプリング周期を単位とする時間パラメータである。
c (t) = x T · w Equation (2)
However, the parameter x is a time series vector of the audio signal x (t) represented by the following equation. The parameter t here is a time parameter with a sampling period as a unit.
x=(x(t),x(t−1),
x(t−2),…x(t−J))T …式(3)
一方、減算部23は、ADC11を介してマイクロフォン5より入力される音声信号y(t)から雑音除去信号c(t)を減算することで、音声信号y(t)に含まれる雑音成分(即ち、車載オーディオ機器7の動作によりスピーカ9から再生される音声成分)を除去し、雑音除去後の音声信号z(t)を得る。
x = (x (t), x (t−1),
x (t-2), ... x (t-J)) T ... Formula (3)
On the other hand, the subtracting
z(t)=y(t)−c(t) …式(4)
また、減算部23は、減算した結果得られた雑音除去後の音声信号z(t)を、音声抽出部31に入力する。
z (t) = y (t) −c (t) (formula 4)
Further, the
音声抽出部31は、制御部37からの動作開始指令を受けて動作を開始する構成にされており、動作を開始すると、オーディオキャンセラ部20から入力された雑音除去後の音声信号z(t)が、音声区間(即ち、利用者による発声がなされた発声期間)の信号であるか、それとも、利用者の音声が含れず音声区間に属さない雑音区間の信号であるのかを判定し、音声区間の信号であると判定した場合には、その音声信号z(t)を音声認識部33に入力する。そして音声区間が終了すると、動作を停止する。
The
尚、判定方法としては、例えば入力信号の短時間パワーを一定時間毎に抽出していき、所定の閾値以上の短時間パワーが一定以上継続したか否かによって音声区間であるか雑音区間であるかを判定する手法がよく採用されている。 As a determination method, for example, the short-time power of the input signal is extracted at fixed time intervals, and is a voice interval or a noise interval depending on whether or not the short-time power equal to or greater than a predetermined threshold continues for a certain time. The method of determining whether or not is often adopted.
一方、音声認識部33は、制御部37から入力される動作開始指令に従い動作を開始し、音声抽出部31から出力される音声信号z(t)を取得することにより、音声抽出部31を介して、減算部23から音声区間の信号z(t)を選択的に取得する。また、音声認識部33は、音声信号z(t)の取得後に、その音声信号z(t)を音響分析し、音声信号z(t)から特徴量(例えばケプストラム)を抽出することで、特徴量の時系列データを得る。
On the other hand, the
その後、音声認識部33は、特徴量の時系列データを、周知の技法を用いて、自身が備える図示しない音声辞書に登録された音声パターンと比較し、一致度の高い音声パターンに対応する語彙を、利用者が発声した語彙であると認識して、その認識結果を制御部37に入力し、この後動作を停止する。
After that, the
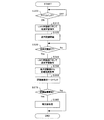
制御部37は、PTTスイッチ35が押されたタイミングや戻されたタイミングを監視する構成にされており、PTTスイッチ35が押され、PTTスイッチ35から動作開始指令信号が入力されたと判断すると(S100でYes)、オーディオキャンセラ部20のLMS学習部25に対して学習禁止指令を入力し(S110)、その後に音声認識部33及び音声抽出部31に動作開始指令を入力することで、音声認識部33及び音声抽出部31を作動させて、音声認識を開始する(S120)。尚、図2は、制御部37の処理動作を表すフローチャートである。
The
その後、制御部37は、音声区間が終了し音声認識部33による音声信号の取得が完了したか否かを、音声抽出部31の動作状態に基づき判断し(S130)、音声区間が終了したと判断すると(S130でYes)、LMS学習部25に学習再開指令を入力する(S140)と共に、音声認識部33から認識結果を取得する(S150)。そして認識結果が正しいか否かを利用者に問い合わせるために、認識結果をトークバックする(S160)。
After that, the
即ち、制御部37は、音声合成部39を制御して、音声合成部39に、認識結果に従う音声信号を生成させ、その音声信号をスピーカ9に入力させる。尚、音声合成部39は、図示しない波形データベース内に格納されている音声波形を用い、制御部37からの音声の出力指示に基づく音声信号を合成してスピーカ9に出力する。従って、S160においては、認識結果が音声で利用者に通知される。
That is, the
この後、制御部37は、利用者の操作によりPTTスイッチ35等の操作スイッチから認識結果が正しいことを表す認識結果確定信号が入力されたか否か判断し(S170)、認識結果確定信号が入力されたと判断すると(S170でYes)、確定後処理を実行する(S180)。一方、認識結果確定信号が入力されなかったと判断すると(S170でNo)、確定後処理を実行せずに、当該処理を終了する。
Thereafter, the
尚、S180で行われる確定後処理において、制御部37は、認識結果に従う操作信号をカーナビゲーション装置3に入力する。このような確定後処理は、周知の技術を用いたものであるので、詳細な説明を省略する。
In the post-confirmation process performed in S180, the
次に、オーディオキャンセラ部20のLMS学習部25の処理動作について図3を用いて説明する。図3は、音声認識装置1に電源が投入されると同時に、LMS学習部25が実行する学習処理を表すフローチャートである。
Next, the processing operation of the
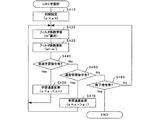
LMS学習部25は、学習処理の実行を開始すると、まず最初に、適応フィルタ21に対して初期設定を施す(S210)。即ち、LMS学習部25は、予め定められた所定のフィルタ係数(初期値)を適応フィルタ21に設定する。
When the
その後、LMS学習部25は、減算部23から出力される音声信号z(t)を用い、LMS法に基づく次式に従い係数w’を算出することで、次に適応フィルタ21に設定すべきフィルタ係数w’を学習する(S220)。
Thereafter, the
![]()
![]()
S220におけるフィルタ係数w’の計算が完了すると、LMS学習部25は、S220で算出したフィルタ係数w’を、新たなフィルタ係数wとして、適応フィルタ21に設定する(S230)。
When the calculation of the filter coefficient w ′ in S220 is completed, the
この後、LMS学習部25は、学習禁止指令が制御部37より入力されているか否か判断し(S240)、入力されていなければ(S240でNo)、当該装置の電源オフやエラー等により学習処理の終了指令が制御部37から入力されているか否か判断する(S250)。そして、終了指令が入力されていれば(S250でYes)、当該処理を終了し、終了指令が入力されていなければ(S250でNo)、処理をS220に戻して、フィルタ係数w’を学習し、その後フィルタ係数を更新する(S230)。
Thereafter, the
また、S240において、学習禁止指令が制御部37より入力されていると判断すると(S240でYes)、LMS学習部25は、処理をS260に移して、学習再開指令が制御部37から入力されているか否か判断する。そして学習再開指令が入力されていなければ(S260でNo)、続くS270にて終了指令が入力されているか否か判断し、終了指令が入力されていれば(S270でYes)、当該処理を終了し、終了指令が入力されていなければ(S270でNo)、処理をS260に戻して、学習再開指令が制御部37より入力されるまで待機する。
In S240, if it is determined that the learning prohibition command is input from the control unit 37 (Yes in S240), the
そして、学習再開指令が入力されたと判断すると(S260でYes)、処理をS220に戻して、フィルタ係数w’を学習し、その結果得られたフィルタ係数w’を、新たなフィルタ係数wとして、適応フィルタ21に設定する(S230)。 If it is determined that a learning restart command has been input (Yes in S260), the process returns to S220, the filter coefficient w ′ is learned, and the filter coefficient w ′ obtained as a result is set as a new filter coefficient w. The adaptive filter 21 is set (S230).
LMS学習部25は、このような動作を繰り返すことによって、図4に示すように、PTTスイッチ35が押下(オン)されてから音声区間が終了するまでの間、フィルタ係数の学習動作を停止する。また、音声区間が終了して学習再開指令が入力されると、再び、次の学習禁止指令が入力されるまで、フィルタ係数の学習を継続する。尚、図4は、LMS学習部25の動作切替タイミングを表すタイムチャートである。
By repeating such an operation, the
以上、本実施例の音声認識装置1について説明したが、この音声認識装置1では、制御部37の動作により、音声認識部33が音声抽出部31を介してオーディオキャンセラ部20から音声信号を取得している間、LMS学習部25によるフィルタ係数の学習が禁止されるので、音声認識のために利用者が発した音声がマイクロフォン5に入力される際に、フィルタ係数wの学習更新が行われるのを防止することができる。
The speech recognition device 1 according to the present embodiment has been described above. In this speech recognition device 1, the
したがって、この音声認識装置1によれば、音声認識部33による音声信号取得の際に、マイクロフォン5に入力される利用者の音声の影響によって、フィルタ係数が不適切に学習更新されるのを防止することができ、音声認識の対象となる音声信号から精度よく雑音成分を取り除くことができる。結果、本実施例によれば、音声認識装置1における音声認識の精度を高めることができ、高い音声認識率を実現することが可能である。
Therefore, according to the voice recognition apparatus 1, when the voice signal is acquired by the
その他、本実施例では、オーディオキャンセラ部20から出力される音声信号z(t)に基づき、音声抽出部31にて、利用者による発声がなされた発声期間を判別し、オーディオキャンセラ部20から出力される音声信号の内、その発声期間に該当する音声信号のみを選択的に音声認識部33に入力するようにしているので、利用者による発話内容が含まれない雑音区間の音声信号を、音声認識部33に入力せずに済み、雑音に影響されず、音声認識部33に正確な音声認識を行わせることができる。また、本実施例では、音声抽出部31が、自動で発声期間を判別するので、利用者に発声期間に関する情報を操作スイッチから入力させなくて済み便利である。
In addition, in this embodiment, based on the audio signal z (t) output from the
また、本実施例では、PTTスイッチ35から動作開始指令が入力されると同時に、その時点から音声抽出部31が音声区間の検出を終了して音声認識部33が音声信号の取得を終了するまでの期間、LMS学習部25によるフィルタ係数の学習を禁止するように制御部37を構成しているので、簡単な制御で、利用者の発声期間には、フィルタ係数の学習を停止することができる。
Further, in this embodiment, at the same time when an operation start command is input from the
さて、上記実施例ではフィルタ係数の学習を禁止することにより音声認識装置1の高性能化を実現したが、利用者の発声期間中に、フィルタ係数の学習速度を遅くすることで、従来と比較して高精度に音声認識を行えるようにすることも可能である。 In the above embodiment, the speech recognition apparatus 1 has been improved in performance by prohibiting the learning of filter coefficients. However, during the user's utterance period, the learning speed of the filter coefficients is slowed down, so that the comparison with the prior art is achieved. Thus, it is possible to perform voice recognition with high accuracy.
次には、このような構成にされた変形例の音声認識装置について説明することにする。尚、変形例の音声認識装置は、制御部37及びLMS学習部25の一部処理動作が異なる程度の構成であり、その他の装置内各部の構成は上述の音声認識装置1と同一である。したがって、以下では、上述の音声認識装置1と同一構成の各部の説明を省略することにし、図5及び図6を用いて、制御部37及びLMS学習部25の動作を説明する程度に留める。
Next, a modified speech recognition apparatus having such a configuration will be described. Note that the modified speech recognition apparatus has a configuration in which the partial processing operations of the
図5は、変形例の音声認識装置における制御部37の処理動作を表すフローチャートである。図5に示すように、制御部37は、PTTスイッチ35から動作開始指令信号が入力されたと判断すると(S300でYes)、フィルタ係数の学習速度を遅くするための低速学習指令をオーディオキャンセラ部20のLMS学習部25に入力し(S310)、その後に音声認識部33及び音声抽出部31を作動させて音声認識を開始する(S320)。
FIG. 5 is a flowchart showing the processing operation of the
その後、制御部37は、音声区間が終了し音声抽出部31から音声認識部33への音声信号入力が完了したか否かを、音声抽出部31の動作状態に基づき判断し(S330)、音声区間が終了したと判断すると(S330でYes)、フィルタ係数の学習速度を通常の学習速度に変更するための通常学習指令をLMS学習部25に入力する(S340)。また、同時に、音声認識部33から認識結果を取得する(S350)。そして認識結果が正しいか否かを利用者に問い合わせるために、認識結果をトークバックする(S360)。
Thereafter, the
この後、制御部37は、利用者の操作によりPTTスイッチ35等の操作スイッチから認識結果が正しいことを表す認識結果確定信号が入力されたか否か判断し(S370)、認識結果確定信号が入力されたと判断すると(S370でYes)、確定後処理を実行する(S380)。一方、認識結果確定信号が入力されなかったと判断すると(S370でNo)、確定後処理を実行せずに、当該処理を終了する。
Thereafter, the
次に、変形例の音声認識装置におけるLMS学習部25の処理動作について図6を用いて説明する。図6は、音声認識装置に電源が投入されると同時に、変形例のLMS学習部25が実行する学習処理を表すフローチャートである。
Next, the processing operation of the
LMS学習部25は、学習処理を開始するとS410で、初期設定として、予め定められた所定のフィルタ係数(初期値)を適応フィルタ21に対して設定すると共に、フィルタ係数w’算出の際に用いる式(5)のパラメータμを、初期値μHに設定する(μ=μH)。
When the learning process is started, the
この後、LMS学習部25は、減算部23から出力される音声信号z(t)を用いて、LMS法に基づく式(5)に従い係数w’を算出する(S420)。この動作によりLMS学習部25は、次に適応フィルタ21に設定すべきフィルタ係数w’を学習し、S430にて、フィルタ係数w’を、新たなフィルタ係数wとして、適応フィルタ21に設定する。
Thereafter, the
続いて、LMS学習部25は、低速学習指令が制御部37より入力されているか否か判断し(S440)、入力されていると判断すると(S440でYes)、S450にて、学習速度を表すパラメータμに、予め定められた値μLを設定する(μ=μL)。尚、値μL及び値μHには、不等式μL<μHの関係が成立する。
Subsequently, the
式(5)を見れば理解できるように、パラメータμの値を小さくすると、フィルタ係数w’の変化量を、小さくすることができる。つまり、パラメータμを小さくすることで、フィルタ係数w’が収束するまでの時間を長期化することができ、学習速度を抑えることができる。LMS学習部25は、このようにパラメータμを通常より小さい値μLに設定することで、フィルタ係数の学習速度を低くしているのである。
As can be understood from the expression (5), when the value of the parameter μ is reduced, the amount of change in the filter coefficient w ′ can be reduced. That is, by reducing the parameter μ, the time until the filter coefficient w ′ converges can be lengthened, and the learning speed can be suppressed.
この後、制御部37は、処理をS420に移して、μ=μLである式(5)に従い、フィルタ係数w’を算出し、その後フィルタ係数wを更新する(S430)。
一方、制御部37は、S440にて、低速学習指令が入力されていないと判断すると(S440でNo)、S460にて、制御部37から通常学習指令が入力されているか否か判断する。
Thereafter, the
On the other hand, when determining that the low speed learning command is not input in S440 (No in S440), the
ここで、通常学習指令が入力されていると判断すると(S460でYes)、制御部37は、S470にて、学習速度を表すパラメータμを、μHに変更する(μ=μH)。そして、再び処理をS420に移し、μ=μHである式(5)に従い、フィルタ係数w’を算出し、その後フィルタ係数wを更新する(S430)。
Here, the normal learning command is judged to be inputted (Yes in S460), the
また、制御部37は、S440及びS460でNoと判断すると、S480にて、当該学習処理の終了指令が制御部37から入力されているか否か判断する。そして、終了指令が入力されていないと判断すると(S480でNo)、処理をS420に戻して、フィルタ係数w’を学習し、その後フィルタ係数を更新する(S430)。一方、終了指令が入力されていると判断すると(S480でYes)、当該学習処理を終了する。
In addition, when the
LMS学習部25は、このような処理を実行することによって、図7に示すように、PTTスイッチ35が押下(オン)されてから、音声区間が終了するまでの間は、フィルタ係数の学習速度を低くする。また、音声区間が終了して通常学習指令が入力されると、再び、次の低速学習指令が入力されるまで、通常の学習速度でフィルタ係数の学習を行う。尚、図7は、学習速度の切替タイミングを表すタイムチャートである。
As shown in FIG. 7, the
以上、変形例について説明したが、変形例の音声認識装置では、音声認識部33及び音声抽出部31の作動と共にLMS学習部25に低速学習指令を入力することで、音声認識部33が音声抽出部31を介してオーディオキャンセラ部20から音声信号を取得している間、通常より低学習速度で、LMS学習部25に、フィルタ係数を学習させているので、その期間においてフィルタ係数の学習動作に及ぶ利用者の音声の影響を抑えることができ、LMS学習部25におけるフィルタ係数の誤学習を抑制することができる。
Although the modification has been described above, in the voice recognition device of the modification, the
この結果、変形例の音声認識装置によれば、LMS学習部25に適切にフィルタ係数の学習を行わせることができ、オーディオキャンセラ部20における雑音除去の精度を向上させることができる。したがって、変形例によれば、高精度に音声認識可能な音声認識装置を提供することができる。
As a result, according to the speech recognition apparatus of the modification, the
また、変形例では、制御部37が、音声認識部33の非動作時に加え、音声認識部33が音声信号を取得した直後(即ち音声区間が終了した直後)から通常の学習速度でLMS学習部25にフィルタ係数の学習を行わせる構成にされているので、連続してPTTスイッチ35から動作開始指令信号が入力され音声認識部33が動作する場合にも、オーディオキャンセラ部20にて適切な雑音除去が可能である。
In the modification, the LMS learning unit is operated at a normal learning speed immediately after the
その他、変形例においても、音声抽出部31が、利用者による発声がなされた発声期間に該当する音声信号のみを選択的に音声認識部33に入力するので、利用者による発話内容が含まれない雑音区間の音声信号を、音声認識部33に入力せずに済み、雑音に影響されず、音声認識部33にて正確な音声認識を行うことができる。
In addition, in the modified example, since the
また、変形例の音声認識装置においては、PTTスイッチ35から動作開始指令信号が入力されると同時に、低学習速度でLMS学習部25にフィルタ係数を学習させる手法を採用しているので、簡単な制御で確実に、フィルタ係数の誤学習を抑制することができる。
In the modified speech recognition apparatus, since the operation start command signal is input from the
その他、上記実施例の音声認識装置によれば、車載オーディオ機器7の動作によりスピーカ9から再生される音楽等のボリュームを調節しなくても、高精度に音声認識を行うことができるので、ボリューム調整などによって利用者に不満が及ぶといった従来問題を解消することができる。
In addition, according to the speech recognition apparatus of the above embodiment, since the volume of music or the like reproduced from the
以上、本発明の実施例について説明したが、本発明の雑音除去信号生成手段は、本実施例の適応フィルタ21に相当し、本発明の雑音除去手段は、減算部23に相当する。また、係数更新手段は、LMS学習部25に相当し、音声認識手段は、音声区間における音声信号z(t)を取得して音声認識を行う音声認識部33に相当する。
Although the embodiments of the present invention have been described above, the noise removal signal generating means of the present invention corresponds to the adaptive filter 21 of this embodiment, and the noise removal means of the present invention corresponds to the subtracting
その他、学習速度切替手段は、制御部37が図5に示す処理に従うタイミングで低速学習指令及び通常学習指令をLMS学習部25に入力する動作にて実現されている。尚、学習速度切替手段が、第二の学習速度で係数更新手段にフィルタ係数を学習させる動作は、本実施例において、LMS学習部25に、第二の学習速度に対応するパラメータμ=μLでフィルタ係数w’の演算を行わせる動作にて実現されている。また、学習速度切替手段が、第一の学習速度で係数更新手段にフィルタ係数を学習させる動作は、本実施例において、LMS学習部25に、第一の学習速度に対応するパラメータμ=μHでフィルタ係数w’の演算を行わせる動作にて実現されている。
In addition, the learning speed switching means is realized by an operation in which the
また、本発明の音声認識装置は、上記実施例に限定されるものではなく、種々の態様を採ることができる。
例えば、制御部37は、少なくとも音声認識部33による音声信号の取得期間において、LMS学習部25の動作を禁止する、若しくは、LMS学習部25におけるフィルタ係数の学習速度を低速度化する構成にされていればよく、音声区間の終了後音声認識部33における音声認識が完了し、音声認識の結果が得られるまで、LMS学習部25によるフィルタ係数の学習を禁止してもよいし、低学習速度でLMS学習部25を動作させてもよい。
Moreover, the speech recognition apparatus of the present invention is not limited to the above-described embodiments, and can take various forms.
For example, the
また、上記実施例では、フィルタ係数の学習方法としてLMS法、具体的にはNormalizedLMS(NLMS)アルゴリズムが採用された音声認識装置に、本発明を適用した例を示したが、その他の学習方法でフィルタ係数を学習する音声認識装置に本発明を適用しても構わない。尚、本発明を適用可能な学習方法としては、上述した適応アルゴリズム以外に、例えば、複素LMSアルゴリズム、FastLMS(FLMS)アルゴリズム、射影アルゴリズム、RLS(Recursive Least Square)アルゴリズム、SHARF(Simple Hyperstable Adaptive Recursive Filter)アルゴリズム、DCT(Discrete Cosine Transform)を用いた適応フィルタ、SAN(Single Frequency Adaptive Notch)フィルタ、ニューラルネットワーク、遺伝的アルゴリズム等が挙げられる。 In the above embodiment, an example in which the present invention is applied to a speech recognition apparatus that employs the LMS method, specifically, the Normalized LMS (NLMS) algorithm, as a filter coefficient learning method has been described. The present invention may be applied to a speech recognition apparatus that learns filter coefficients. As a learning method to which the present invention can be applied, in addition to the adaptive algorithm described above, for example, complex LMS algorithm, FastLMS (FLMS) algorithm, projection algorithm, RLS (Recursive Least Square) algorithm, SHARF (Simple Hyperstable Adaptive Recursive). ) Algorithm, adaptive filter using DCT (Discrete Cosine Transform), SAN (Single Frequency Adaptive Notch) filter, neural network, genetic algorithm, and the like.
1…音声認識装置、3…カーナビゲーション装置、5…マイクロフォン、7…車載オーディオ機器、9…スピーカ、11,13…ADC、20…オーディオキャンセラ部、21…適応フィルタ、23…減算部、25…LMS学習部、31…音声抽出部、33…音声認識部、35…PTTスイッチ、37…制御部、39…音声合成部 DESCRIPTION OF SYMBOLS 1 ... Voice recognition apparatus, 3 ... Car navigation apparatus, 5 ... Microphone, 7 ... Car-mounted audio equipment, 9 ... Speaker, 11, 13 ... ADC, 20 ... Audio canceller part, 21 ... Adaptive filter, 23 ... Subtraction part, 25 ... LMS learning unit, 31 ... speech extraction unit, 33 ... speech recognition unit, 35 ... PTT switch, 37 ... control unit, 39 ... speech synthesis unit
Claims (4)
該雑音除去信号生成手段が生成した前記雑音除去信号を用いて、マイクロフォンから入力される音声信号に含まれる雑音成分を除去し、その雑音除去後の音声信号を出力する雑音除去手段と、
該雑音除去手段が出力する音声信号に基づいて、前記雑音除去信号生成手段に設定すべきフィルタ係数を学習し、学習した結果得たフィルタ係数を、前記雑音除去信号生成手段に設定する係数更新手段と、
外部から動作開始指令が入力されると、所定期間、前記雑音除去手段から出力される音声信号を取得して、その音声信号に基づき、前記マイクロフォンに入力された音声を認識する音声認識手段と、
該音声認識手段の非動作時に、第一の学習速度で、前記係数更新手段にフィルタ係数を学習させ、前記音声認識手段が前記雑音除去手段から出力される音声信号を取得している期間には、前記第一の学習速度より低い第二の学習速度で、前記係数更新手段にフィルタ係数を学習させる学習速度切替手段と、
を備えることを特徴とする音声認識装置。 A noise removal signal generating means for generating a noise removal signal for removing noise by filtering a reference signal input from a noise source according to a preset filter coefficient;
Using the noise removal signal generated by the noise removal signal generation means, a noise removal means for removing a noise component included in a voice signal input from a microphone and outputting the voice signal after the noise removal;
Coefficient updating means for learning filter coefficients to be set in the noise removal signal generating means based on the audio signal output from the noise removing means, and setting the filter coefficients obtained as a result of learning in the noise removal signal generating means When,
When an operation start command is input from the outside, a voice recognition unit that acquires a voice signal output from the noise removal unit for a predetermined period and recognizes a voice input to the microphone based on the voice signal;
When the voice recognition means is not operating, the coefficient update means learns the filter coefficient at the first learning speed, and the voice recognition means acquires the voice signal output from the noise removal means. Learning speed switching means for causing the coefficient update means to learn the filter coefficient at a second learning speed lower than the first learning speed;
A speech recognition apparatus comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008240988A JP2009031809A (en) | 2008-09-19 | 2008-09-19 | Speech recognition apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008240988A JP2009031809A (en) | 2008-09-19 | 2008-09-19 | Speech recognition apparatus |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002368441A Division JP2004198810A (en) | 2002-12-19 | 2002-12-19 | Speech recognition device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009031809A true JP2009031809A (en) | 2009-02-12 |
Family
ID=40402290
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008240988A Pending JP2009031809A (en) | 2008-09-19 | 2008-09-19 | Speech recognition apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009031809A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012163788A (en) * | 2011-02-07 | 2012-08-30 | Jvc Kenwood Corp | Noise cancellation apparatus and noise cancellation method |
| CN106796779A (en) * | 2014-06-13 | 2017-05-31 | 美国思睿逻辑有限公司 | System and method for selectively enabling and disabling the adjustment of self-adapted noise elimination system |
| US11183180B2 (en) | 2018-08-29 | 2021-11-23 | Fujitsu Limited | Speech recognition apparatus, speech recognition method, and a recording medium performing a suppression process for categories of noise |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60103400A (en) * | 1983-11-11 | 1985-06-07 | 日産自動車株式会社 | Voice recognitioin equipment |
| JPH09311698A (en) * | 1996-05-21 | 1997-12-02 | Oki Electric Ind Co Ltd | Background noise eliminating apparatus |
| JP2001195085A (en) * | 1999-11-05 | 2001-07-19 | Alpine Electronics Inc | Audio canceling device for speech recognition |
-
2008
- 2008-09-19 JP JP2008240988A patent/JP2009031809A/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60103400A (en) * | 1983-11-11 | 1985-06-07 | 日産自動車株式会社 | Voice recognitioin equipment |
| JPH09311698A (en) * | 1996-05-21 | 1997-12-02 | Oki Electric Ind Co Ltd | Background noise eliminating apparatus |
| JP2001195085A (en) * | 1999-11-05 | 2001-07-19 | Alpine Electronics Inc | Audio canceling device for speech recognition |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012163788A (en) * | 2011-02-07 | 2012-08-30 | Jvc Kenwood Corp | Noise cancellation apparatus and noise cancellation method |
| CN106796779A (en) * | 2014-06-13 | 2017-05-31 | 美国思睿逻辑有限公司 | System and method for selectively enabling and disabling the adjustment of self-adapted noise elimination system |
| CN106796779B (en) * | 2014-06-13 | 2020-12-22 | 美国思睿逻辑有限公司 | System and method for selectively enabling and disabling adjustment of an adaptive noise cancellation system |
| US11183180B2 (en) | 2018-08-29 | 2021-11-23 | Fujitsu Limited | Speech recognition apparatus, speech recognition method, and a recording medium performing a suppression process for categories of noise |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4333369B2 (en) | Noise removing device, voice recognition device, and car navigation device | |
| JP2005084253A (en) | Sound processing apparatus, method, program and storage medium | |
| JP6545419B2 (en) | Acoustic signal processing device, acoustic signal processing method, and hands-free communication device | |
| JP2006163231A (en) | Device, program, and method for noise elimination | |
| KR20120072243A (en) | Apparatus for removing noise for sound/voice recognition and method thereof | |
| JP5431282B2 (en) | Spoken dialogue apparatus, method and program | |
| JP4520596B2 (en) | Speech recognition method and speech recognition apparatus | |
| JP2009527024A (en) | Communication device with speaker-independent speech recognition | |
| JP3907194B2 (en) | Speech recognition apparatus, speech recognition method, and speech recognition program | |
| JP4705414B2 (en) | Speech recognition apparatus, speech recognition method, speech recognition program, and recording medium | |
| JP2004198810A (en) | Speech recognition device | |
| JP2009031809A (en) | Speech recognition apparatus | |
| JP2018072599A (en) | Voice recognition device and voice recognition method | |
| JP2016061888A (en) | Speech recognition device, speech recognition subject section setting method, and speech recognition section setting program | |
| JP2019020678A (en) | Noise reduction device and voice recognition device | |
| JP2007292814A (en) | Voice recognition apparatus | |
| JP3270866B2 (en) | Noise removal method and noise removal device | |
| JPH1185185A (en) | Voice recognition system and storage medium with voice recognition control program | |
| JP4608670B2 (en) | Speech recognition apparatus and speech recognition method | |
| JP2006145694A (en) | Voice recognition method, system implementing the method, program, and recording medium for the same | |
| JP4924652B2 (en) | Voice recognition device and car navigation device | |
| JP2007058237A (en) | Noise removing method | |
| JP2010041188A (en) | Speech recognition device | |
| JP5025753B2 (en) | Echo canceling apparatus and method | |
| JP2005321539A (en) | Voice recognition method, its device and program and its recording medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110705 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20111108 |