JP2008060622A - Video editing system, video processing apparatus, video editing device, video processing method, video editing method, program, and data structure - Google Patents
Video editing system, video processing apparatus, video editing device, video processing method, video editing method, program, and data structure Download PDFInfo
- Publication number
- JP2008060622A JP2008060622A JP2006231429A JP2006231429A JP2008060622A JP 2008060622 A JP2008060622 A JP 2008060622A JP 2006231429 A JP2006231429 A JP 2006231429A JP 2006231429 A JP2006231429 A JP 2006231429A JP 2008060622 A JP2008060622 A JP 2008060622A
- Authority
- JP
- Japan
- Prior art keywords
- video
- video data
- metadata
- unit
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


























Landscapes
- Television Signal Processing For Recording (AREA)
- Signal Processing For Digital Recording And Reproducing (AREA)
- Management Or Editing Of Information On Record Carriers (AREA)
Abstract
Description
本発明は、映像編集システムに関し、特に映像データにおける特徴量を示すメタデータを生成する映像編集システム、映像処理装置、または、そのメタデータに基づいて映像データを編集する映像編集装置、これらにおける処理方法ならびに当該方法をコンピュータに実行させるプログラムおよびこれらに用いられるデータ構造に関する。 The present invention relates to a video editing system, and in particular, a video editing system, a video processing apparatus, or a video editing apparatus that edits video data based on the metadata, and processing in these, The present invention relates to a method, a program for causing a computer to execute the method, and a data structure used for them.
記録再生装置における記録形式の一つとして、QuickTimeファイルフォーマットが知られている。このQuickTimeファイルフォーマットは、マルチメディアデータを扱うためのファイルフォーマットであり、映像データ(ビデオデータおよびオーディオデータ)の実データをメディアデータアトム(ムービーデータともいう。)に保持して、その管理情報をムービーアトム(ムービーリソースともいう。)に保持する。これにより、実データに直接手を加えることなく、映像データを"非破壊的に"編集できるようになっている。このQuickTimeファイルフォーマットをベースとしたファイルフォーマットには、ISOベースメディア(ISO Base Media)ファイルフォーマット、そのアプリケーションフォーマットであるMPEG4(MP4)ファイルフォーマット、MJ2(Motion JPEG2000)ファイルフォーマット、AVC(Advanced Video Coding:MPEG4-part10)ファイルフォーマットなどがある。 A QuickTime file format is known as one of recording formats in the recording / reproducing apparatus. This QuickTime file format is a file format for handling multimedia data. Real data of video data (video data and audio data) is held in a media data atom (also referred to as movie data), and management information thereof is stored. Stored in a movie atom (also called a movie resource). This allows video data to be edited "non-destructively" without having to modify the actual data directly. File formats based on this QuickTime file format include ISO base media file format, MPEG4 (MP4) file format, MJ2 (Motion JPEG2000) file format, and AVC (Advanced Video Coding: MPEG4-part10) file format.
このような実データ格納部と管理情報格納部に分かれた形式のファイルフォーマットにおいては、オリジナルデータを外部から参照して、再生上の時間軸管理を行うエディットアトムと呼ばれるデータ構造により編集を行う方法が知られている。例えば、そのようなエディットアトムを用いて、記録中の映像に対して非破壊的にマークを付与する映像記録装置が提案されている(例えば、特許文献1参照。)。
しかしながら、エディットアトムにより構成されるムービーファイルでは、最終的な編集結果が1つだけ保存されるに留まり、他の条件で編集を行うためには最初から処理をやり直さなければならない。例えば、映像データもしくはその映像データに同期する他の映像データにおける何らかの特徴量を解析して、その解析結果に基づいて編集を行う場合、編集条件を変えるたびに特徴量の解析からやり直すことになり、処理効率上の問題がある。 However, in a movie file composed of edit atoms, only one final editing result is stored, and in order to perform editing under other conditions, the process must be restarted from the beginning. For example, when analyzing some feature quantity in video data or other video data synchronized with the video data, and editing based on the analysis result, it will start from the analysis of the feature quantity every time the editing condition is changed. There is a problem in processing efficiency.
そこで、本発明は、映像データもしくはその映像データに同期する他の映像データについて、その特徴量を映像データに同期して保持するメタデータを生成し、または、そのメタデータに基づいて映像データを編集することを目的とする。 Therefore, the present invention generates metadata that holds the feature amount of the video data or other video data synchronized with the video data in synchronization with the video data, or stores the video data based on the metadata. The purpose is to edit.
本発明は、上記課題を解決するためになされたものであり、その第1の側面は、時系列に管理される第1の映像データに同期した第2の映像データを取得する映像取得手段と、上記第2の映像データにおける特徴量を解析する映像解析手段と、上記第1の映像データと同期して上記特徴量を保持するメタデータを生成するメタデータ生成手段とを具備することを特徴とする映像処理装置である。これにより、第1の映像データに同期した第2の映像データの特徴量を、第1の映像データに同期するメタデータに保持させるという作用をもたらす。 The present invention has been made to solve the above problems, and a first aspect of the present invention is a video acquisition means for acquiring second video data synchronized with the first video data managed in time series. A video analysis unit that analyzes a feature quantity in the second video data; and a metadata generation unit that generates metadata that holds the feature quantity in synchronization with the first video data. Is a video processing apparatus. This brings about the effect that the feature quantity of the second video data synchronized with the first video data is held in the metadata synchronized with the first video data.
また、この第1の側面において、上記特徴量は、上記第2の映像データに含まれる顔の表情であってもよい。顔の表情として、笑い、驚き、怒り、眠いといった種別を表現することができる。 In the first aspect, the feature amount may be a facial expression included in the second video data. Types of facial expressions such as laughter, surprise, anger, and sleepiness can be expressed.
また、この第1の側面において、上記第1の映像データを撮像する第1の撮像手段をさらに具備し、上記映像取得手段は、上記第1の映像データの撮像と同時に上記第2の映像データを撮像する第2の撮像手段を含んでもよい。これにより、撮像されている第1の映像データに関する映像を第2の映像データとして撮像させるという作用をもたらす。 In the first aspect, the image processing device further includes a first imaging unit that captures the first video data, and the video acquisition unit is configured to capture the first video data and the second video data simultaneously. Second imaging means for imaging the image may be included. This brings about the effect | action that the image | video regarding the 1st image data currently imaged is imaged as 2nd image data.
また、この第1の側面において、上記第1の映像データを再生する再生手段をさらに具備し、上記映像取得手段は、上記再生手段による上記第1の映像データの再生と同時に上記第2の映像データを撮像する撮像手段を含んでもよい。これにより、再生されている第1の映像データに関する映像を第2の映像データとして撮像させるという作用をもたらす。 In the first aspect, the image processing device further includes a reproducing unit that reproduces the first video data, and the video obtaining unit is configured to simultaneously reproduce the first video data by the reproducing unit. An imaging means for imaging data may be included. This brings about the effect | action that the image | video regarding the 1st image data currently reproduced | regenerated is imaged as 2nd image data.
また、この第1の側面において、上記第1の映像データを再生する再生手段をさらに具備し、上記映像取得手段は、上記再生手段により再生された上記第1の映像データを上記第2の映像データとして入力する映像入力手段を含んでもよい。これにより、再生されている第1の映像データをそのまま第2の映像データとして入力させるという作用をもたらす。 Further, in the first aspect, the image processing device further includes a reproduction unit that reproduces the first video data, and the video acquisition unit converts the first video data reproduced by the reproduction unit into the second video. Video input means for inputting as data may be included. Thereby, the effect | action that the 1st video data currently reproduced | regenerated is input as 2nd video data as it is brought about is brought about.
なお、この第1の側面において、上記第1の映像データおよび上記メタデータは、QuickTimeフォーマットにおけるメディアデータアトムの形式で記録されてもよい。 In the first aspect, the first video data and the metadata may be recorded in a media data atom format in the QuickTime format.
また、本発明の第2の側面は、時系列に管理される第1の映像データに同期した第2の映像データにおける特徴量を保持するメタデータを取得した後に所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成する位置探索手段と、上記探索情報に基づいて上記第1の映像データから上記合致する時系列上の位置に対応する部分を抽出する映像抽出手段とを具備することを特徴とする映像編集装置である。これにより、メタデータに含まれる特徴量が所定の条件に合致する時系列上の位置について、第1の映像データの対応する部分を抽出して、非破壊的に編集させるという作用をもたらす。 Further, the second aspect of the present invention provides a time series that meets a predetermined condition after acquiring metadata that holds the feature amount in the second video data synchronized with the first video data managed in time series. A position search means for searching the upper position and generating the result as search information, and a video extraction for extracting a portion corresponding to the matching time-series position from the first video data based on the search information And a video editing apparatus. As a result, the corresponding portion of the first video data is extracted and edited nondestructively with respect to the position on the time series where the feature amount included in the metadata matches a predetermined condition.
また、この第2の側面において、上記位置探索手段は、上記メタデータを管理する管理情報を取得して、上記管理情報が上記メタデータに上記特徴量は保持されない旨を示している場合には上記メタデータを取得しないようにしてもよい。これにより、無意味なメタデータへのアクセスを回避させるという作用をもたらす。 Further, in this second aspect, when the position search means acquires management information for managing the metadata, and the management information indicates that the feature amount is not retained in the metadata. The metadata may not be acquired. This brings about the effect of avoiding access to meaningless metadata.
また、本発明の第3の側面は、時系列に管理される第1の映像データに同期した第2の映像データを取得する映像取得手段と、上記第2の映像データにおける特徴量を解析する映像解析手段と、上記第1の映像データと同期して上記特徴量を保持するメタデータを生成するメタデータ生成手段と、上記メタデータから所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成する位置探索手段と、上記探索情報に基づいて上記第1の映像データから上記合致する時系列上の位置に対応する部分を抽出する映像抽出手段とを具備することを特徴とする映像編集システムである。これにより、第2の映像データの特徴量を保持するメタデータを中間状態として、第1の映像データを非破壊的に編集させるという作用をもたらす。 In addition, according to a third aspect of the present invention, video acquisition means for acquiring second video data synchronized with the first video data managed in time series, and a feature amount in the second video data are analyzed. A video analysis unit, a metadata generation unit that generates metadata that holds the feature amount in synchronization with the first video data, and a time-series position that matches a predetermined condition is searched from the metadata. Position search means for generating the result as search information, and video extraction means for extracting a portion corresponding to the matching time-series position from the first video data based on the search information. Is a video editing system characterized by Accordingly, there is an effect that the first video data is edited nondestructively with the metadata holding the feature amount of the second video data as an intermediate state.
また、本発明の第4の側面は、時系列に管理される第1の映像データと、上記第1の映像データに同期した第2の映像データにおける特徴量を上記第1の映像データと同期して保持するメタデータとを具備するデータ構造であって、コンピュータが、上記メタデータを取得して、上記メタデータにおいて所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成して、上記探索情報に基づいて上記第1の映像データから上記合致する時系列上の位置に対応する部分を抽出することを特徴とするデータ構造である。これにより、第1の映像データの編集のための中間状態としてメタデータを保持させるという作用をもたらす。 According to a fourth aspect of the present invention, the feature amount in the first video data managed in time series and the second video data synchronized with the first video data is synchronized with the first video data. A data structure having metadata stored therein, wherein the computer acquires the metadata, searches the metadata for a position in time series that matches a predetermined condition, and searches for the result The data structure is characterized in that it is generated as information and a portion corresponding to the matching time-series position is extracted from the first video data based on the search information. As a result, the metadata is held as an intermediate state for editing the first video data.
本発明によれば、映像データもしくはその映像データに同期する他の映像データについて、その特徴量を映像データに同期して保持するメタデータを生成し、または、そのメタデータに基づいて映像データを編集することができるという優れた効果を奏し得る。 According to the present invention, with respect to video data or other video data synchronized with the video data, metadata that retains the feature amount in synchronization with the video data is generated, or video data is generated based on the metadata. An excellent effect of being able to edit can be achieved.
次に本発明の実施の形態について図面を参照して詳細に説明する。 Next, embodiments of the present invention will be described in detail with reference to the drawings.
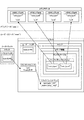
図1は、本発明の実施の形態における映像編集システム100の一構成例を示す図である。この映像編集システム100は、メタデータ103に基づいて第1のビデオデータ101を編集した編集ビデオデータ105を出力する映像編集装置120と、第2のビデオデータ102の特徴量を解析してメタデータ103を出力する映像処理装置110とを備えている。
FIG. 1 is a diagram illustrating a configuration example of a video editing system 100 according to an embodiment of the present invention. The video editing system 100 analyzes the feature quantity of the
第1のビデオデータ101および第2のビデオデータ102は、時系列に管理される映像データであり、動画像データに加えて音声データを含んでもよい。第1のビデオデータ101は、映像編集装置120における編集対象となる映像データである。第2のビデオデータ102は、第1のビデオデータ101に同期しており、第1のビデオデータ101の撮像または再生と同時に撮像され得る。また、第1のビデオデータ101および第2のビデオデータ102は、同一の内容であってもよい。
The
メタデータ103は、第1のビデオデータ101に同期しており、第2のビデオデータ102の特徴量を時間軸で管理しながら保持するものである。特徴量としては、後述のように、第2のビデオデータ102に含まれる顔の表情が想定される。
The
映像処理装置110は、映像取得部111と、映像解析部112と、メタデータ生成部113とを備えている。また、映像編集装置120は、抽出条件受付部121と、位置探索部122と、映像抽出部123とを備えている。
The
映像取得部111は、第2のビデオデータ102を取得するものである。この映像取得部111は、映像を光学レンズにより撮像するビデオカメラであってもよく、また、電子信号を入力する入力端子などであってもよい。
The
映像解析部112は、映像取得部111によって取得された第2のビデオデータ102における特徴量を解析するものである。映像解析部112は、例えば、特徴量として第2のビデオデータ102に含まれる顔の画像を抽出して、その顔の表情を判断する。顔の表情を判断する処理手順は公知の技術を使用することができる。例えば、顔画像中の外眼角点を結ぶ線分と口角点を結ぶ線分との比から笑顔の判断をする技術(例えば、特開2005−266984)や、顔の構成要素毎に基準画像と評価ポイントを設けて平均値を算出して被撮影者の表情を判断する技術(例えば、特開2004−46591)等が提案されている。
The
メタデータ生成部113は、映像解析部112によって解析された特徴量を保持するメタデータ103を生成するものである。この生成されたメタデータ103は、第1のビデオデータ101の各時刻に対応して、第2のビデオデータ102の特徴量を保持している。これにより、例えば、第1のビデオデータ101の各時刻において、第2のビデオデータ102にどのような顔の表情が含まれているかを、編集のための中間状態として保持することができる。
The
抽出条件受付部121は、抽出条件の入力を受け付けるものである。例えば、顔の表情を条件とするのであれば、笑顔を抽出するのか、または、驚いた顔を抽出するのか、といった条件を受け付ける。これらの条件は論理積(AND)や論理和(OR)などにより組み合わせた条件にすることができる。
The extraction
位置探索部122は、抽出条件受付部121によって受け付けられた抽出条件によりメタデータ103を探索するものである。これにより、抽出条件に合致する時系列上の位置が得られ、エディットリスト104として保持される。
The
映像抽出部123は、エディットリスト104に基づいて、第1のビデオデータ101から抽出条件に合致する時系列上の位置に対応する部分を抽出して、編集ビデオデータ105に出力するものである。
The
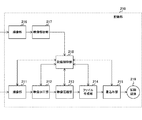
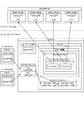
図2は、本発明の実施の形態における映像処理装置110の第1の構成例を示す図である。この第1の構成例では、記録部210に、撮像部211と、映像加工部212と、映像圧縮部213と、ファイル生成部214と、書込み部215と、撮像部216と、映像解析部217と、記録制御部218と、記録媒体219とが備えられている。
FIG. 2 is a diagram illustrating a first configuration example of the
撮像部211は、被写体を第1のビデオデータ101として撮像するものである。映像加工部212は、撮像部211によって撮像された映像に対してエフェクト処理などの加工を施すものである。映像圧縮部213は、映像加工部212によって加工された映像を圧縮するものである。
The
撮像部216は、被写体を撮像している撮影者(もしくは、被写体の様子を鑑賞している鑑賞者)の顔を第2のビデオデータ102として撮像するものである。映像解析部217は、撮像部216によって撮像された映像を解析するものである。すなわち、映像解析部217は、映像に含まれる撮影者の顔の表情を解析する。この解析結果は、メタデータ103となる。
The
ファイル生成部214は、映像圧縮部213によって圧縮された映像(第1のビデオデータ101)および映像解析部217によって解析された撮影者の顔の表情の解析結果(メタデータ103)を含むファイルをそれぞれ所定のファイル形式として生成するものである。
The
書込み部215は、ファイル生成部214によって生成されたファイルを記録媒体219に書き込むものである。記録媒体219としては、ハードディスクなどのディスク状記録媒体やメモリスティックなどの半導体記録媒体を想定することができる。
The
記録制御部218は、記録部210における記録媒体219への記録動作を制御するものである。
The
この第1の構成例では、撮像部211によって被写体を第1のビデオデータ101として撮像しながら、同時に撮像部216によって撮影者の顔の表情を第2のビデオデータ102として撮像し、その表情を解析してメタデータ103を生成している。
In this first configuration example, the
図3は、本発明の実施の形態における映像処理装置110の第1の構成例による使用態様を示す図である。図3(a)では、ビデオカメラ装置520の前面のカメラ521によって被写体501が撮像されているのと同時に、ビデオカメラ装置520の操作面のカメラ522によって撮影者502の顔が撮像されている。これにより、ビデオカメラ装置520の内部で撮影者502の顔の表情を解析することによって、メタデータを生成することができる。
FIG. 3 is a diagram illustrating a usage mode according to the first configuration example of the
また、ビデオカメラ装置520はネットワーク510に接続されてもよい。このネットワーク510によって、ビデオカメラ装置520の前面のカメラ521によって撮像された被写体501の映像を、図3(b)のテレビ装置530や図3(c)のコンピュータ装置540に配信することができる。
In addition, the
図3(b)のテレビ装置530にはビデオカメラ装置531が接続され、鑑賞者503の顔が撮像されている。これにより、テレビ装置530またはビデオカメラ装置531の内部で鑑賞者503の顔の表情を解析することによって、メタデータを生成することができる。
A
図3(c)のコンピュータ装置540の前面にはカメラ541が設けられ、鑑賞者504の顔が撮像されている。これにより、コンピュータ装置540の内部で鑑賞者504の顔の表情を解析することによって、メタデータを生成することができる。
A
このように、映像処理装置110の第1の構成例では、第1のビデオデータ101の撮像と同時に第2のビデオデータ102を撮像して、この第2のビデオデータ102からメタデータ103を生成する。第2のビデオデータ102に含まれる顔の表情には、第1のビデオデータ101の映像に対する何らかの反応が反映されているものと考えられるため、その特徴量をメタデータ103に中間状態として保存しておいて、第1のビデオデータ101の編集に利用しようとするものである。
As described above, in the first configuration example of the
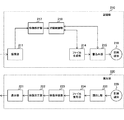
図4は、本発明の実施の形態における映像処理装置110の第2の構成例を示す図である。この第2の構成例では、記録部210に、撮像部211と、ファイル生成部214と、書込み部215と、映像解析部217と、記録制御部218と、記録媒体219とが備えられている。また、再生部220に、表示部221と、映像加工部222と、映像伸張部223と、ファイル復号部224と、読出し部225と、記録媒体229とが備えられている。
FIG. 4 is a diagram illustrating a second configuration example of the
記録媒体229は、第1のビデオデータ101を所定のファイル形式により記録するものである。読出し部225は、第1のビデオデータ101を含むファイルを記録媒体229から読み出すものである。ファイル復号部224は、読出し部225によって読み出されたファイルを復号するものである。映像伸張部223は、ファイル復号部224によって復号されたファイル内の圧縮された映像を伸張するものである。映像加工部222は、映像伸張部223によって伸張された映像に対してエフェクト処理などの加工を施すものである。
The
表示部221は、映像加工部222から出力された映像を表示するものである。これにより、記録媒体229に記録されていた第1のビデオデータ101が表示部221に再生表示される。
The
撮像部211は、被写体を第2のビデオデータ102として撮像するものである。映像解析部217は、撮像部211によって撮像された映像を解析するものである。すなわち、映像解析部217は、映像に含まれる鑑賞者の顔の表情を解析する。この解析結果は、メタデータ103となる。
The
ファイル生成部214は、映像解析部217によって解析された鑑賞者の顔の表情の解析結果(メタデータ103)を含むファイルを所定のファイル形式として生成するものである。
The
書込み部215は、ファイル生成部214によって生成されたファイルを記録媒体219に書き込むものである。記録制御部218は、記録部210における記録媒体219への記録動作を制御するものである。
The
なお、記録媒体219および229としては、ハードディスクなどのディスク状記録媒体やメモリスティックなどの半導体記録媒体を想定することができるが、両者は互いに異なる種類の記録媒体であってもよい。
As the
この第2の構成例では、表示部221によって第1のビデオデータ101を再生表示しながら、同時に撮像部211によって鑑賞者の顔の表情を第2のビデオデータ102として撮像し、その表情を解析してメタデータ103を生成している。
In the second configuration example, the
図5は、本発明の実施の形態における映像処理装置110の第2の構成例による使用態様を示す図である。図2(a)では、ビデオカメラ装置520の操作面に再生表示画面が表示されており、その操作面のカメラ522によって鑑賞者505の顔が撮像されている。これにより、ビデオカメラ装置520の内部で鑑賞者505の顔の表情を解析することによって、メタデータを生成することができる。
FIG. 5 is a diagram illustrating a usage mode according to the second configuration example of the
図5(b)のテレビ装置530にはビデオカメラ装置531が接続され、鑑賞者503の顔が撮像されている。これにより、テレビ装置530またはビデオカメラ装置531の内部で鑑賞者503の顔の表情を解析することによって、メタデータを生成することができる。
A
図5(c)のコンピュータ装置540の前面にはカメラ541が設けられ、鑑賞者504の顔が撮像されている。これにより、コンピュータ装置540の内部で鑑賞者504の顔の表情を解析することによって、メタデータを生成することができる。
A
このように、映像処理装置110の第2の構成例では、第1のビデオデータ101の再生と同時に第2のビデオデータ102を撮像して、この第2のビデオデータ102からメタデータ103を生成する。第2のビデオデータ102に含まれる顔の表情には、第1のビデオデータ101の映像に対する何らかの反応が反映されているものと考えられるため、その特徴量をメタデータ103に中間状態として保存しておいて、第1のビデオデータ101の編集に利用しようとするものである。
As described above, in the second configuration example of the
図6は、本発明の実施の形態における映像処理装置110の第3の構成例を示す図である。この第3の構成例では、記録部210に、映像入力部206と、ファイル生成部214と、書込み部215と、映像解析部217と、記録制御部218と、記録媒体219とが備えられている。また、再生部220に、映像加工部222と、映像伸張部223と、ファイル復号部224と、読出し部225と、記録媒体229とが備えられている。
FIG. 6 is a diagram illustrating a third configuration example of the
再生部220の構成は、第2の構成例の場合と同様であるが、表示部221は省かれ、映像加工部222の出力が記録部210にそのまま供給されている点が異なる。
The configuration of the
記録部210の構成も、第2の構成例の場合と同様であるが、撮像部211の代わりに、再生部220からの映像を入力する映像入力部206を備える点が異なる。
The configuration of the
すなわち、この第3の構成例では、再生部220によって再生された映像(第1のビデオデータ101)をそのまま記録部210の入力映像(第2のビデオデータ102)として供給して、それに含まれる顔の表情を解析してメタデータ103を生成している。
That is, in the third configuration example, the video (first video data 101) reproduced by the
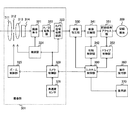
図7は、本発明の実施の形態における映像処理装置110の一実施例であるカメラ一体型撮像装置の構成例を示す図である。この撮像装置は、撮像部301と、映像加工部330と、映像圧縮部341と、圧縮制御部342と、記録媒体アクセス部351と、ドライブ制御部352と、操作受付部360と、表示部370と、システム制御部390とを備えている。
FIG. 7 is a diagram illustrating a configuration example of a camera-integrated imaging apparatus that is an example of the
撮像部301は、被写体を撮像して映像データとして出力するものである。映像加工部330は、撮像部301から出力された映像データにエフェクト処理を施すものである。映像圧縮部341は、映像加工部330によって加工された映像データを圧縮するものである。圧縮制御部342は、映像圧縮部341における圧縮処理の制御を行うものである。
The
記録媒体アクセス部351は、記録媒体309に対する書込みや読出しを行うものである。ドライブ制御部352は、記録媒体アクセス部351による書込みや読出しを制御するものである。
The recording
操作受付部360は、ユーザによる操作入力を受け付けるものであり、各種ボタンやGUI(Graphical User Interface)などが想定される。表示部370は、撮像中の映像や再生映像、または、ユーザに対する各種メッセージなどを表示するものである。
The
システム制御部390は、撮像装置の全体を制御するものであり、例えば、マイクロプロセッサなどにより実現され得る。このシステム制御部390は、操作受付部360によって受け付けられた操作入力によって映像の録画の開始、停止や、録画の経過時間情報などを制御するとともに、ユーザに対する表示部370における表示を制御する。また、システム制御部390は、カメラ制御部329や圧縮制御部342との間で情報をやり取りして、ドライブ制御部352を介して記録媒体309に対する書込み制御を行う。
The
また、撮像部301は、ズームレンズ311と、アイリス(絞り)312と、フォーカスレンズ313と、フィルタ314と、撮像素子321と、A/D変換器322と、カメラ信号処理回路323と、検波部324と、ズーム制御部325と、角速度センサ326と、カメラ制御部329とを備えている。
The
ズームレンズ311は、ズーム(拡大)処理を行うためのレンズである。アイリス312は、被写体からの光量を調整するための絞りである。フォーカスレンズ313は、被写体に焦点を合わせるためのレンズである。フィルタ314は、赤外線を除去するためのフィルタである。
The zoom lens 311 is a lens for performing zoom (enlargement) processing. The
撮像素子321は、光学レンズ群から供給された光を電気信号に変換する光電変換素子であり、例えば、CCD(Charge Coupled Devices)などにより実現され得る。この撮像素子321により、被写体の画像が、例えばRGB(赤、緑、青)の3原色に相当する3つの映像信号として取り出される。
The
A/D変換器322は、撮像素子321から供給されたアナログの電気信号をデジタル信号に変換するものである。カメラ信号処理回路323は、A/D変換器322により変換されたデジタル信号に対して、白色の基準を定めるホワイトバランスなどの信号処理を施すものである。
The A /
検波部324は、カメラ信号処理回路323によって信号処理の施された映像信号のフィードバックを受けて、各種の検波処理を行うものである。例えば、自動的に被写体に焦点を合わせるためのオートフォーカス(AF:Auto Focus)検波、自動的に露光を行うためのオートエクスポージャ(AE:Auto Exposure)検波、自動的にホワイトバランスを行うためのオートホワイトバランス(AWB:Auto White Balance)検波などを行うものである。
The
ズーム制御部325は、ユーザからの操作入力などに従ってズームレンズ311を移動させてズーム処理を制御するものである。角速度センサ326は、撮像装置の角速度を検出するものであり、例えば、ジャイロスコープなどにより手ぶれの度合いを検出するものである。
The
カメラ制御部329は、撮像部301の制御を行うものである。例えば、カメラ制御部329は、角速度センサ326において検知された手ぶれに対して手ぶれ補正を行って画質の劣化を低減するように制御を行う。また、カメラ制御部329は、撮像素子321からの映像入力の制御、検波部324における処理の制御、ズーム制御部325における処理の制御などを行う。
The
図8は、QuickTimeファイルフォーマットをベースとしたファイル形式(以下、QuickTimeベースファイル形式という。)の構造例を示す図である。このファイル形式では、ファイルの内容が実データ格納部と、その実データを参照するために必要な場所情報などを格納する管理情報格納部とに分かれている。QuickTimeファイルフォーマットでは、実データ格納部はメディアデータアトム(media data atom、タイプ名:'mdat')と呼ばれ、管理情報格納部はムービーアトム(movie atom、タイプ名:'moov')と呼ばれる。なお、「アトム(atom)」は「ボックス(box)」と表現されることもある。また、ムービーアトムはムービーリソースと表現されることがあり、メディアデータアトムは単にメディアデータまたはムービーデータと表現されることがある。 FIG. 8 is a diagram showing a structure example of a file format based on the QuickTime file format (hereinafter referred to as QuickTime base file format). In this file format, the content of the file is divided into an actual data storage unit and a management information storage unit that stores location information necessary for referring to the actual data. In the QuickTime file format, the actual data storage unit is called a media data atom (type name: 'mdat'), and the management information storage unit is called a movie atom (movie atom, type name: 'moov'). “Atom” may also be expressed as “box”. A movie atom may be expressed as a movie resource, and a media data atom may be expressed simply as media data or movie data.
これらメディアデータアトムおよびムービーアトムは、同一のファイルに含まれていてもよく、別ファイルに分かれていてもよい。例えば、図8のように、動画像(V1等)や音声(A1等)のメディアデータを含むメディアデータアトム612と、それを参照するムービーアトム611とを同一のファイル610に格納するようにしてもよく、また、メディアデータアトム612を参照するムービーアトム621を別のファイル620に格納するようにしてもよい。前者の形式を有するファイルは自己内包型ファイルと呼ばれ、後者の形式を有するファイルは外部参照型ファイルと呼ばれる。そのため、ムービーアトムは、外部参照するメディアデータアトムが含まれる外部ファイルの相対パスまたは絶対パスを示す管理情報を格納できるようになっている。
These media data atom and movie atom may be included in the same file or may be separated into different files. For example, as shown in FIG. 8, a media data atom 612 including media data of a moving image (V1 or the like) or sound (A1 or the like) and a
メディアデータアトム612には、例えばMPEG1オーディオ(MPEG1 Audio Layer2)に基づく圧縮符号化方式によって符号化されたオーディオデータおよびMPEG2ビデオ(MPEG2 Video)規定に従う圧縮符号化方式によって符号化された画像データが格納される。符号化方式はこれらに限定されるものではなく、例えば、ビデオデータであればモーションJPEG(Motion JPEG)やMJ2(Motion JPEG2000)、MPEG4(MP4)やAVC(Advanced Video Coding:MPEG4-part10)、オーディオデータであればドルビーAC3(Dolby AC3)やATRAC(Adaptive TRansform Acoustic Coding)などでもよく、また、圧縮符号化が施されていないリニアデータを格納することも可能である。 The media data atom 612 stores, for example, audio data encoded by a compression encoding method based on MPEG1 audio (MPEG1 Audio Layer2) and image data encoded by a compression encoding method conforming to the MPEG2 Video (MPEG2 Video) standard. Is done. The encoding method is not limited to these. For example, in the case of video data, motion JPEG (Motion JPEG), MJ2 (Motion JPEG2000), MPEG4 (MP4), AVC (Advanced Video Coding: MPEG4-part10), audio If it is data, Dolby AC3 (Dolby AC3), ATRAC (Adaptive TRansform Acoustic Coding), etc. may be sufficient, and it is also possible to store the linear data which has not been compression-encoded.
図9は、QuickTimeファイルフォーマットにおける階層構造を示す図である。メディアデータアトム('mdat')における実データはサンプル(sample)と呼ばれる最小管理単位に分かれており、このサンプルを任意の個数分集めたものがチャンク(chunk)と呼ばれる。メディアデータアトム('mdat')の管理情報であるムービーアトム('moov')では、サンプルのサイズや、チャンクの先頭格納場所、各サンプルの表示時間等が格納される。 FIG. 9 is a diagram showing a hierarchical structure in the QuickTime file format. Actual data in the media data atom ('mdat') is divided into minimum management units called samples, and a collection of an arbitrary number of samples is called a chunk. The movie atom ('moov'), which is management information of the media data atom ('mdat'), stores the sample size, the chunk storage location, the display time of each sample, and the like.
ムービーアトム('moov')は、ムービーヘッダアトム('mvhd')と、トラックアトム('trak')等から構成される。 The movie atom ('moov') is composed of a movie header atom ('mvhd'), a track atom ('trak'), and the like.
ムービーヘッダアトム('mvhd')は、ムービーアトムのヘッダ情報を保持する部分であり、ムービー全体の特徴を示すものである。例えば、ムービー全体の期間や時間スケール、作成日等を項目として含む。 The movie header atom ('mvhd') is a part that holds movie atom header information, and indicates the characteristics of the entire movie. For example, the period, time scale, creation date, etc. of the entire movie are included as items.
トラックアトム('trak')は、サウンド、ビデオ、テキストといった異なるタイプのデータをそれぞれ別のトラックにより格納するものであり、この図では、ビデオのトラックアトムとして、トラックヘッダアトム('tkhd')と、エディットアトム('edts')と、ユーザデータアトム('udta')と、メディアアトム('mdia')とを含んで構成される。また、オーディオのトラックアトムについては省略されているが、ビデオの場合と同様の構成を備えて構成される。 A track atom ('trak') stores different types of data such as sound, video, and text in different tracks. In this figure, a track header atom ('tkhd') and a video track atom are shown. , An edit atom ('edts'), a user data atom ('udta'), and a media atom ('mdia'). Although the audio track atom is omitted, it has the same configuration as in the case of video.
トラックヘッダアトム('tkhd')は、トラックアトムのヘッダ情報を保持する部分であり、そのトラックの特徴を示すものである。例えば、ビデオのピクセル数やサウンドの音量、作成日等を項目として含む。 The track header atom ('tkhd') is a part that holds the track atom header information, and indicates the characteristics of the track. For example, the number of video pixels, sound volume, creation date, and the like are included as items.
エディットアトム('edts')は、トラックの編集情報をエディットリストアトム('elst')として保持するものである。なお、このエディットアトムについては、図27により詳述する。 The edit atom ('edts') holds track editing information as an edit restore tom ('elst'). This edit atom will be described in detail with reference to FIG.
ユーザデータアトム('udta')は、必要に応じてユーザにより定義された任意の情報を含むものである。例えば、ムービーのウィンドウ位置や再生方法、作成情報等を保持することができる。このユーザデータアトムは、ムービーユーザデータをリスト形式により保持する。 The user data atom ('udta') includes arbitrary information defined by the user as necessary. For example, it is possible to hold a movie window position, a playback method, creation information, and the like. This user data atom holds movie user data in a list format.
メディアアトム('mdia')は、そのトラックで実際に用いられる実データに関する情報を格納するものである。すなわち、メディアアトムは、メディア全体に関する情報、メディアデータの取扱いに関する情報、メディアの構成に関する情報等を格納する。実データはサンプル(sample)と呼ばれる最小管理単位に分かれており、このサンプルを任意の個数分集めたものがチャンク(chunk)と呼ばれる。メディアアトムでは、サンプルのサイズや、チャンクの先頭格納場所、各サンプルの表示時間等が格納される。 The media atom ('mdia') stores information regarding actual data actually used in the track. That is, the media atom stores information on the entire medium, information on handling of media data, information on the configuration of the media, and the like. Actual data is divided into minimum management units called samples, and a collection of an arbitrary number of samples is called a chunk. In the media atom, the sample size, the chunk storage location, the display time of each sample, and the like are stored.
このメディアアトムは、メディアヘッダアトム('mdhd')と、メディアハンドラアトム('hdlr')と、メディア情報アトム('minf')等から構成される。 The media atom includes a media header atom ('mdhd'), a media handler atom ('hdlr'), a media information atom ('minf'), and the like.
メディアヘッダアトム('mdhd')は、メディアアトムのヘッダ情報を保持する部分であり、メディア全体としての特徴を示すものである。 The media header atom ('mdhd') is a part that holds the header information of the media atom, and indicates the characteristics of the entire medium.
メディアハンドラアトム('hdlr')は、メディア毎の取り扱いに関する情報を保持するものである。 The media handler atom ('hdlr') holds information regarding handling for each medium.
メディア情報アトム('minf')は、そのメディアタイプで表現される情報を保持するものである。このメディア情報アトムは、ビデオメディア情報ヘッダアトム('vmhd')と、データハンドラアトム('hdlr')と、データ情報アトム('dinf')と、サンプルテーブルアトム('stbl')等から構成される。 The media information atom ('minf') holds information expressed by the media type. This media information atom is composed of a video media information header atom ('vmhd'), a data handler atom ('hdlr'), a data information atom ('dinf'), a sample table atom ('stbl'), and the like. The
ビデオメディア情報ヘッダアトム('vmhd')は、ビデオトラックにおいて、ビデオメディアに関するヘッダ情報を保持するものである。なお、オーディオトラックの場合、サウンドメディアに関するヘッダ情報を保持するサウンドメディア情報ヘッダアトム('smhd')が、ビデオメディアヘッダアトム('vmhd')の代わりに含まれる。 The video media information header atom ('vmhd') holds header information related to video media in the video track. In the case of an audio track, a sound media information header atom ('smhd') that holds header information related to sound media is included instead of the video media header atom ('vmhd').
データハンドラアトム('hdlr')は、ビデオメディアの取り扱いに関する情報を保持するものである。 The data handler atom ('hdlr') holds information relating to handling of video media.
データ情報アトム('dinf')は、実際に参照する実データの格納先に関する情報を保持するものである。このデータ情報アトムには、参照する実データの格納方法、格納場所、ファイル名に関する情報を保持するデータリファレンスアトム('dref')が含まれる。 The data information atom ('dinf') holds information related to the storage location of actual data that is actually referred to. The data information atom includes a data reference atom ('dref') that holds information regarding the storage method, storage location, and file name of the actual data to be referenced.
サンプルテーブルアトム('stbl')は、そのメディアの実データの最小管理単位であるサンプルに関する情報を保持するものである。このサンプルテーブルアトムは、サンプルディスクリプションアトム('stsd')と、時間対サンプルアトム('stss')と、サンプルサイズアトム('stsz')と、サンプル対チャンクアトム('stsc')と、チャンクオフセットアトム('stco')等から構成される。 The sample table atom ('stbl') holds information about a sample that is a minimum management unit of actual data of the medium. The sample table atom includes a sample description atom ('stsd'), a time-to-sample atom ('stss'), a sample size atom ('stsz'), a sample-to-chunk atom ('stsc'), and a chunk It consists of an offset atom ('stco') or the like.
サンプルディスクリプションアトム('stsd')は、各サンプルに関する圧縮方式やその特性に関する情報を保持するものである。時間対サンプルアトム('stss')は、各サンプルと時間との関係を保持するものである。サンプルサイズアトム('stsz')は、各サンプルのデータ量を保持するものである。サンプル対チャンクアトム('stsc')は、チャンクとそのチャンクを構成するサンプルの関係を保持するものである。チャンクオフセットアトム('stco')は、ファイル先頭からの各チャンクの先頭位置までのオフセットを保持するものである。 The sample description atom ('stsd') holds information regarding the compression method and characteristics of each sample. Time vs. sample atom ('stss') holds the relationship between each sample and time. The sample size atom ('stsz') holds the data amount of each sample. Sample-to-chunk atom ('stsc') holds the relationship between a chunk and the samples that make up that chunk. A chunk offset atom ('stco') holds an offset from the file head to the head position of each chunk.
本発明の実施の形態では、第1のビデオデータ101をQuickTimeベースファイル形式により保持するのみならず、メタデータ103もこのQuickTimeベースファイル形式により保持する。これにより、第2のビデオデータ102の特徴量を時間軸で管理しながらメタデータ103に保持することができる。
In the embodiment of the present invention, not only the
図10は、本発明の実施の形態におけるファイルの保存形式の一例を示す図である。 FIG. 10 is a diagram showing an example of a file storage format according to the embodiment of the present invention.
図10(a)は、第1のビデオデータ101を含むビデオファイル630の構成例を示す図である。このビデオファイル630は、第1のビデオデータ101を有するメディアデータ632と、メディアデータ632を管理するムービーリソース631とを備えている。メディアデータ632は、第1のビデオデータ101の各サンプル633を含んでおり、これらはムービーリソース631によって管理される。
FIG. 10A is a diagram illustrating a configuration example of a video file 630 including the
図10(b)は、メタデータ103を含むメタファイル640の構成例を示す図である。このメタファイル640は、メタデータ103を有するメディアデータ642と、メディアデータ642を管理するムービーリソース641とを備えている。メディアデータ642は、メタデータ103の各サンプル643を含んでおり、これらはムービーリソース641によって管理される。また、ムービーリソース641は、メディアデータ632も外部参照する形式で、同様に一つの時間軸によって管理している。
FIG. 10B is a diagram illustrating a configuration example of the metafile 640 including the
図10(c)は、ビデオファイル630およびメタファイル640によって実現されるビデオトラック650およびメタトラック660の時間軸上の流れを示す図である。ここでは、簡略化のため、ビデオファイル630の映像信号および音声信号のうち、ビデオトラック650のみを図示している。
FIG. 10C is a diagram illustrating the flow on the time axis of the
ビデオトラック650では、各サンプル653が時間軸上に並んでいる。また、メタトラック660では、ビデオトラック650のサンプル653と同期して、各サンプル663が時間軸上に並んでいる。例えば、第2のビデオデータ102の時刻t1からt2の区間において笑顔が特徴量として抽出された場合、その旨がメタトラック660の時刻t1からt2の区間において記録される。同様に、第2のビデオデータ102の時刻t3からt4の区間において驚いた顔が特徴量として抽出された場合、その旨がメタトラック660の時刻t3からt4の区間において記録される。
In the
すなわち、メタデータ103を示すメタトラック660は、第2のビデオデータ102を介して、第1のビデオデータ101を示すビデオトラック650と同期していることになる。
That is, the
なお、図中では省略されているが、顔の表情の分類上、無表情である区間においては、無表情である旨を示す情報がメタトラック660に記録される。
Although omitted in the figure, information indicating that there is no expression is recorded in the
図11は、本発明の実施の形態におけるメタトラックの階層構造の一例を示す図である。このメタトラックは、図9で説明したビデオトラックと基本的に同様の構成を有している。但し、トラック配下にトラックリファレンスアトム('tref')を有し、メディアアトム配下にトラックインプットマップアトム('imap')を有する点でビデオトラックとは異なっている。 FIG. 11 is a diagram showing an example of the hierarchical structure of the meta track in the embodiment of the present invention. This meta track has basically the same configuration as the video track described in FIG. However, it differs from a video track in that it has a track reference atom ('tref') under the track and a track input map atom ('map') under the media atom.
トラックリファレンスアトム('tref')は、ソーストラック(第1のビデオデータ101)との参照関係を指定するための情報を保持するものである。そのため、トラックリファレンスアトムは、指定対象となるトラックのトラックヘッダアトム('tkhd')に格納されているトラック固有のトラックIDを指定するトラックリファレンスタイプアトム('ssrc')を含む。このトラックリファレンスタイプアトムに含まれるトラックIDの数は、ソーストラックの数と一致する。 The track reference atom ('tref') holds information for designating a reference relationship with the source track (first video data 101). Therefore, the track reference atom includes a track reference type atom ('ssrc') that designates a track ID unique to the track stored in the track header atom ('tkhd') of the track to be designated. The number of track IDs included in this track reference type atom matches the number of source tracks.
トラックインプットマップアトム('imap')は、ソーストラックに関する情報を保持するものであり、QuickTimeにおけるQTアトム構造と呼ばれるデータ構造により構成される。このトラックインプットマップアトムには、QTアトムコンテナ('sean')を最上位アトムとするコンテナによってパッキングされたトラックインプットQTアトム(' in')が1つ以上含まれる。このトラックインプットQTアトムの数は、ソーストラックの数と一致する。 The track input map atom ('imap') holds information relating to the source track, and is configured by a data structure called a QT atom structure in QuickTime. The track input map atom includes one or more track input QT atoms ('in') packed by a container having a QT atom container ('sean') as the highest level atom. The number of track input QT atoms matches the number of source tracks.
トラックインプットQTアトム(' in')は、インプットタイプQTアトム(' ty')およびデータソースタイプQTアトム('dtst')を保持する。インプットタイプQTアトム(' ty')は、ソーストラックがビデオメディアであることを指定するものである。また、データソースタイプQTアトム('dtst')は、ソーストラックに対して固有の名称を与えるものである。 The track input QT atom ('in') holds an input type QT atom ('ty') and a data source type QT atom ('dtst'). The input type QT atom ('ty') specifies that the source track is video media. The data source type QT atom ('dtst') gives a unique name to the source track.
図12は、本発明の実施の形態におけるメタトラックを含むムービーアトムの記載例を示す図である。この記載例では、ソーストラック(第1のビデオデータ101)としてビデオトラックアトム(video)が1つだけ含まれている。そのため、メタトラックアトムにおけるトラックインプットQTアトム(' in')も1つだけ含まれている。 FIG. 12 is a diagram showing a description example of a movie atom including a meta track in the embodiment of the present invention. In this example, only one video track atom (video) is included as a source track (first video data 101). Therefore, only one track input QT atom ('in') in the meta track atom is included.
図13は、本発明の実施の形態におけるメタトラックを含むムービーアトムの他の記載例を示す図である。また、図14は、図13のムービーアトムにおけるメタトラックアトムの記載例を示す図である。この記載例では、ソーストラック(第1のビデオデータ101)としてビデオトラックアトムが2つ含まれている(video 1およびvideo 2)。そのため、図14に示すように、メタトラックアトムにおけるトラックインプットQTアトム(' in')も2つ含まれている。
FIG. 13 is a diagram showing another description example of the movie atom including the meta track in the embodiment of the present invention. FIG. 14 is a diagram showing a description example of the meta track atom in the movie atom of FIG. In this description example, two video track atoms are included as a source track (first video data 101) (
図15は、本発明の実施の形態におけるメタトラックのサンプルディスクリプションアトム('stsd')の記載例を示す図である。この記載例では、メタサンプルディスクリプションエントリがM個(Mは1以上の整数)含まれている。このメタサンプルディスクリプションエントリの数は、特徴量の種類の数と一致する。例えば、特徴量の種類として、無表情の顔と笑顔の2種類の分類をするのであれば、メタサンプルディスクリプションエントリの数は2つになる。 FIG. 15 is a diagram showing a description example of the meta description sample description atom ('stsd') in the embodiment of the present invention. In this description example, M meta sample description entries (M is an integer of 1 or more) are included. The number of metasample description entries matches the number of feature types. For example, if there are two types of feature amounts, that is, an expressionless face and a smile, the number of metasample description entries is two.
なお、同図において、かっこ内の数字は各フィールドのバイト数を表す。 In the figure, the numbers in parentheses indicate the number of bytes in each field.
メタサンプルディスクリプションエントリは、QuickTimeにおけるサンプルディスクリプションエントリに対してストリームディスクリプターアトムを拡張追加した構造になっている。サンプルディスクリプションエントリにおけるデータフォーマット(Data Format)フィールドは、本来、エフェクト効果を指定するためのものである。本発明の実施の形態では、このフィールドを拡張のために用いている。これにより、通常のQuickTimeファイルフォーマットとの間で互換性を維持しながら、拡張を施すことができる。 The meta sample description entry has a structure in which a stream descriptor atom is extended and added to the sample description entry in QuickTime. The data format field in the sample description entry is originally for specifying the effect. In the embodiment of the present invention, this field is used for expansion. As a result, the extension can be performed while maintaining compatibility with the normal QuickTime file format.
図16は、本発明の実施の形態におけるデータフォーマットフィールドの一例を示す図である。この図に示すように、データフォーマットフィールドは、本来、エフェクト効果を指定するためのものである。同図において、アルファベット小文字で示している種別は、QuickTimeにおいて定義済のエフェクト種別である。例えば、タイプ名'brco'は、明るさを示すブライトネス(brightness)と画像における黒色および白色の幅を示すコントラスト(contrast)とを変化させる効果を指定するものである。 FIG. 16 is a diagram showing an example of the data format field in the embodiment of the present invention. As shown in this figure, the data format field is originally for designating an effect. In the figure, the types indicated by lowercase letters are the effect types defined in QuickTime. For example, the type name “brco” designates the effect of changing the brightness indicating brightness and the contrast indicating the width of black and white in the image.
一方、アルファベット大文字で示している種別はQuickTimeにおいて定義されていないエフェクト種別である。本発明の実施の形態では、同図最下欄にあるユーザ定義のメタデータであることを示すタイプ名'UDEF'をこのデータフォーマットフィールドで指定することによって、メタデータとして独自拡張された意味を有することを示している。 On the other hand, the type indicated by the capital letter is an effect type not defined in QuickTime. In the embodiment of the present invention, by specifying the type name “UDEF” indicating user-defined metadata in the bottom column of the figure in this data format field, the meaning uniquely expanded as metadata is provided. It shows that it has.
図17は、本発明の実施の形態におけるストリームディスクリプターアトム('strd')の記載例を示す図である。このストリームディスクリプターアトムは、QuickTimeにおける他のアトム構造と同様に、サイズ(Size)、タイプ(Type)、バージョン(Version)およびフラグ群(Flags)の各フィールドを保持している。 FIG. 17 is a diagram illustrating a description example of the stream descriptor atom ('strd') according to the embodiment of the present invention. This stream descriptor atom holds fields of size (Size), type (Type), version (Version), and flags (Flags), as with other atom structures in QuickTime.
サイズフィールドは、このサイズフィールドを含むストリームディスクリプターアトム全体の大きさを保持するものである。タイプフィールドは、ストリームディスクリプターアトムのタイプ名として'strd'を保持するものである。バージョンフィールドおよびフラグ群フィールドは、将来の拡張用に確保されているものであり、ここでは全てゼロが設定されるものとする。 The size field holds the size of the entire stream descriptor atom including this size field. The type field holds “strd” as the type name of the stream descriptor atom. The version field and the flag group field are reserved for future expansion, and all zeros are set here.
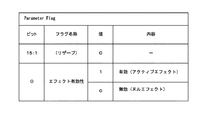
ストリームディスクリプターアトム('strd')は、以下に説明するように、データフォーマット(Data Format)、ユーザデファインドメタタイプ(User Defined Meta Type)、パラメータフラグ(Parameter Flag)の3つのフィールドをさらに保持している。 As described below, the stream descriptor atom ('strd') further holds three fields of data format (Data Format), user defined meta type (User Defined Meta Type), and parameter flag (Parameter Flag). is doing.
データフォーマットフィールドは、図16により説明したメタサンプルディスクリプションエントリのデータフォーマットフィールドと形式上同じものを保持するフィールドであり、本発明の実施の形態ではタイプ名'UDEF'を示すことになる。 The data format field is a field that holds the same format as the data format field of the metasample description entry described with reference to FIG. 16, and indicates the type name “UDEF” in the embodiment of the present invention.
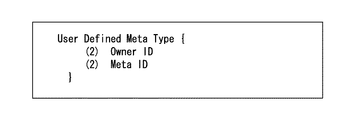
ユーザデファインドメタタイプフィールドは、図18に示すように、2バイトのオーナーID(Owner ID)と2バイトのメタID(Meta ID)とを保持している。オーナーIDは、メーカー毎に割り当てられたIDであり、これにより、各メーカーは、メタIDによって独自の拡張定義を用いることができるようになる。これらオーナーIDおよびメタIDは、データフォーマットフィールドがタイプ名'UDEF'を示す場合にのみ有効になるものである。例えば、メタIDとして、図19に示すように、顔の表情として、笑い(smile)、驚き(surprise)、怒り(angry)、眠い(sleepy)といった種別を表現することができる。 As shown in FIG. 18, the user-defined metatype field holds a 2-byte owner ID (Owner ID) and a 2-byte meta ID (Meta ID). The owner ID is an ID assigned to each manufacturer, and thus each manufacturer can use a unique extension definition by using a meta ID. These owner IDs and meta IDs are valid only when the data format field indicates the type name “UDEF”. For example, as shown in FIG. 19, as a meta ID, types such as smile, surprise, angry, and sleepy can be expressed as facial expressions.
なお、オーナーIDおよびメタIDの2つのフィールドに分けて詳細メタデータ種別を定義するのは、メーカー内で閉じて、重複なくメタデータ種別の管理運用を行うためである。仮に、このような区別を設けないと、新規に定義したいメーカー間で名称が重複し、もしくは、申請順番などの管理が煩雑になるおそれがある。そこで、メタサンプルディスクリプションエントリ側のデータフォーマットフィールドにて指定する独自定義メタデータ種別には、'UDEF'として独自定義メタデータ大別であることだけを指示し、詳細な独自拡張定義メタデータ種別はオーナーIDおよびメタIDの両フィールドを組み合わせることによって、どのメーカーが定義したどのようなメタデータ種別かを指示するものである。 The reason that the detailed metadata type is defined separately in the two fields of the owner ID and the meta ID is that it is closed in the manufacturer and the metadata type is managed and operated without duplication. If such a distinction is not provided, names may be duplicated between manufacturers to be newly defined, or management of application order may become complicated. Therefore, the unique definition metadata type specified in the data format field on the metasample description entry side only indicates that it is broadly classified as “UDEF”, and the detailed unique extended definition metadata type. Indicates the metadata type defined by which manufacturer by combining both the owner ID and meta ID fields.
パラメータフラグフィールドは、メタデータによる効果が有効であるか否かを示すフィールドである。例えば、図20に示すように、16ビットのうちの1ビットを用いて、メタデータによる効果が「有効」であるか「無効」であるかを示す。これにより、ムービーリソース('moov')におけるパラメータフラグフィールドが「無効」を示している場合には、メディアデータ('mdat')をアクセスするまでもなく、メタデータによる効果がないものと判断することができ、処理の負荷を低減することができる。 The parameter flag field is a field indicating whether or not the effect by metadata is effective. For example, as shown in FIG. 20, 1 bit out of 16 bits is used to indicate whether the effect of metadata is “valid” or “invalid”. As a result, when the parameter flag field in the movie resource ('moov') indicates "invalid", it is determined that the media data ('mdat') has no effect without accessing the media data ('mdat'). And the processing load can be reduced.
図21は、本発明の実施の形態におけるメタトラックのメディアデータ(メタデータ103)のサンプルの記載例を示す図である。メタトラックのサンプルは、ビデオトラックのサンプルと同様に、サンプル毎にメディアデータアトムに格納される。 FIG. 21 is a diagram illustrating a sample description example of media data (metadata 103) of a meta track according to the embodiment of the present invention. The meta track samples are stored in the media data atom for each sample in the same manner as the video track samples.
ここでは、第2のビデオデータ102の対応するサンプルにおいて抽出された顔の数(face_number)と、それぞれの顔についてその表情の度合いを示すことができるようになっている。例えば、笑顔度合い、驚き度合い、怒り度合い、眠さ度合いをそれぞれ示すことができる。
Here, it is possible to indicate the number of faces (face_number) extracted in the corresponding sample of the
図22は、本発明の実施の形態におけるメタデータを含むファイルの階層構造の一例を示す図である。この例では、ソーストラック(第1のビデオデータ101)が1つ(ソーストラック1)だけであることが想定されている。このソーストラック1のムービーリソース('moov')のトラックヘッダアトム('tkhd')には、そのトラックIDである「#1」が保持されている。また、メタトラック(メタデータ103)のムービーリソースのトラックヘッダアトムには、そのトラックIDである「#2」が保持されている。
FIG. 22 is a diagram showing an example of a hierarchical structure of a file including metadata in the embodiment of the present invention. In this example, it is assumed that there is only one source track (first video data 101) (source track 1). The track header atom ('tkhd') of the movie resource ('moov') of the
メタトラックのムービーリソースでは、トラックリファレンスアトム('tref')のトラックリファレンスタイプアトム('ssrc')に、ソーストラック1のトラックID「#1」が保持されている。
In the meta-track movie resource, the track ID “# 1” of the
また、メディアアトム('mdia')のトラックインプットマップアトム('imap')には、インプットタイプQTアトム(' ty')としてビデオメディアを表す'vide'が設定され、データソースタイプQTアトム('dtst')としてソーストラック1の名称'srcA'が設定されている。
Also, in the track input map atom ('imap') of the media atom ('mdia'), 'video' representing the video media is set as the input type QT atom ('ty'), and the data source type QT atom (' The name “srcA” of the
また、メタトラックのムービーリソースにおいて、サンプルディスクリプションアトム('stsd')のメタIDにより、2つの種別「meta_type1」および「meta_type2」が定義されている。 Also, in the metatrack movie resource, two types “meta_type1” and “meta_type2” are defined by the meta ID of the sample description atom ('stsd').
この例では、メタトラックのメディアデータ('mdat')において、メタサンプルが4つ設けられている。ソーストラックは1つだけであり、全て同じソーストラック1を示している。また、メタサンプル#1および#3が「meta_type1」を示し、メタサンプル#2および#4が「meta_type2」を示している。
In this example, four meta samples are provided in the media data ('mdat') of the meta track. There is only one source track, and all indicate the
図23は、図22の例におけるソーストラック(第1のビデオデータ101)とメタトラック(メタデータ103)との関係を示す図である。この例では、ソーストラックは1つだけであり、全て同じソーストラック1('srcA')を対象としている。 FIG. 23 is a diagram illustrating the relationship between the source track (first video data 101) and the meta track (metadata 103) in the example of FIG. In this example, there is only one source track, and all are the same source track 1 ('srcA').
ここで、「meta_type2」を特定区間として抽出する場合には、ソーストラックからこの特定区間のみが抽出されることになり、それ以外の区間は不要な区間として扱われる。 Here, when “meta_type2” is extracted as a specific section, only this specific section is extracted from the source track, and other sections are treated as unnecessary sections.
図24は、本発明の実施の形態におけるメタデータを含むファイルの階層構造の他の例を示す図である。この例では、ソーストラック(第1のビデオデータ101)が2つ(ソーストラック1およびソーストラック2)存在することが想定されている。ソーストラック1のムービーリソース('moov')のトラックヘッダアトム('tkhd')には、そのトラックIDである「#1」が保持されている。ソーストラック2のムービーリソースのトラックヘッダアトム('tkhd')には、そのトラックIDである「#2」が保持されている。また、メタトラック(メタデータ103)のムービーリソースのトラックヘッダアトム('tkhd')には、そのトラックIDである「#3」が保持されている。
FIG. 24 is a diagram showing another example of a hierarchical structure of a file including metadata in the embodiment of the present invention. In this example, it is assumed that there are two source tracks (first video data 101) (
メタトラックのムービーリソースでは、トラックリファレンスアトム('tref')のトラックリファレンスタイプアトム('ssrc')に、ソーストラック1のトラックID「#1」およびソーストラック2のトラックID「#2」がそれぞれ保持されている。
In the meta track movie resource, the track reference type atom ('ssrc') of the track reference atom ('tref') has the track ID "# 1" of the
また、メディアアトム('mdia')のトラックインプットマップアトム('imap')には、2つのトラックインプットQTアトム(' in')が含まれており、1つ目のトラックインプットQTアトムには、インプットタイプQTアトム(' ty')としてビデオメディアを表す'vide'が設定され、データソースタイプQTアトム('dtst')としてソーストラック1の名称'srcA'が設定されている。2つ目のトラックインプットQTアトムには、インプットタイプQTアトムとしてビデオメディアを表す'vide'が設定され、データソースタイプQTアトムとしてソーストラック2の名称'srcB'が設定されている。
The track input map atom ('imap') of the media atom ('mdia') includes two track input QT atoms ('in'), and the first track input QT atom is 'Video' representing video media is set as the input type QT atom ('ty'), and the name 'srcA' of the
また、メタトラックのムービーリソースにおいて、サンプルディスクリプションアトム('stsd')のメタIDにより、2つの種別「meta_type1」および「meta_type2」が定義されている。 Also, in the metatrack movie resource, two types “meta_type1” and “meta_type2” are defined by the meta ID of the sample description atom ('stsd').
この例では、メタトラックのメディアデータ('mdat')において、メタサンプルが4つ設けられている。ソーストラックは2つ存在しており、メタサンプル#1および#2が'srcA'を参照し、メタサンプル#3および#4が'srcB'を参照している。また、メタサンプル#1および#3が「meta_type1」を示し、メタサンプル#2および#4が「meta_type2」を示している。
In this example, four meta samples are provided in the media data ('mdat') of the meta track. There are two source tracks,
図25は、図24の例におけるソーストラック(第1のビデオデータ101)とメタトラック(メタデータ103)との関係を示す図である。この例では、ソーストラックは2つ存在しており、メタサンプル#1および#2が'srcA'を参照し、メタサンプル#3および#4が'srcB'を参照している。
FIG. 25 is a diagram showing the relationship between the source track (first video data 101) and the meta track (metadata 103) in the example of FIG. In this example, there are two source tracks,
ここで、「meta_type2」を特定区間として抽出する場合には、ソーストラックからこの特定区間のみが抽出されることになり、それ以外の区間は不要な区間として扱われる。 Here, when “meta_type2” is extracted as a specific section, only this specific section is extracted from the source track, and other sections are treated as unnecessary sections.
図26は、本発明の実施の形態におけるソーストラック(第1のビデオデータ101)およびメタトラック(メタデータ103)と編集トラック(編集ビデオデータ105)との関係例を示す図である。この例では、ソーストラックは、時刻0から始まり、時刻ts6に終了している。また、メタトラックはソーストラックに同期しており、時刻ts1から時刻ts2の区間に笑顔を検出した旨を示し、時刻ts3から時刻ts4の区間に驚いた顔を検出した旨を示し、時刻ts5から時刻ts6の区間に笑顔を検出した旨を示している。
FIG. 26 is a diagram showing a relationship example between the source track (first video data 101) and meta track (meta data 103) and the edit track (edit video data 105) in the embodiment of the present invention. In this example, the source track starts at
また、編集していないムービーファイルにおいては、ソーストラック時間の時間軸はメディア時間の時間軸と一対一対応していることが多いため、ここでは、時刻ts1=時刻tm1、時刻ts2=時刻tm2、時刻ts3=時刻tm3、時刻ts4=時刻tm4、時刻ts5=時刻tm5、時刻ts6=時刻tm6としている。 In a movie file that has not been edited, the time axis of the source track time often has a one-to-one correspondence with the time axis of the media time. Therefore, here, time ts1 = time tm1, time ts2 = time tm2, Time ts3 = time tm3, time ts4 = time tm4, time ts5 = time tm5, time ts6 = time tm6.
ここで、メタトラックにおいて笑顔または驚いた顔を示す区間を抽出条件としてソーストラックを編集することを想定すると、その出力として図のような編集トラックが生成される。すなわち、ソーストラック時間の時刻ts1から時刻ts2の区間のソーストラックの部分が、編集トラックにおける編集トラック時間の時刻0から時刻te1の区間になり、ソーストラック時間の時刻ts3から時刻ts4の区間のソーストラックの部分が、編集トラックにおける編集トラック時間の時刻te1から時刻te2の区間になり、ソーストラック時間の時刻ts5から時刻ts6の区間のソーストラックの部分が、編集トラックにおける編集トラック時間の時刻te2から時刻te3の区間になる。
Here, if it is assumed that the source track is edited using a section showing a smiling face or a surprised face in the meta track as an extraction condition, an edit track as shown in the figure is generated as the output. That is, the portion of the source track in the section from the time ts1 to the time ts2 of the source track time becomes the section from the
図27は、QuickTimeファイルフォーマットにおけるエディットアトム('edts')の記載例を示す図である。このエディットアトムは、図17により説明したストリームディスクリプターアトム('strd')と同様に、サイズ、タイプ、バージョンおよびフラグ群の各フィールドを保持している。このエディットアトムでは、タイプ名として'edts'が保持されている。 FIG. 27 is a diagram illustrating a description example of edit atoms ('edts') in the QuickTime file format. As with the stream descriptor atom ('strd') described with reference to FIG. 17, this edit atom holds fields of size, type, version, and flag group. In this edit atom, “edts” is held as a type name.
このエディットアトムは、さらにエディットリストアトム('elst')を保持する。このエディットリストアトムは、エディットアトムと同様に、サイズ、タイプ、バージョンおよびフラグ群の各フィールドを保持している。このエディットリストアトムでは、タイプ名として'elst'が保持されている。エディットリストアトムは、さらにN個(Nは1以上の整数)のエディットリストエントリ(Edit List Entry)と、その数(Number of Entries)とを含んでいる。 This edit atom further holds an edit restore tom ('elst'). Similar to the edit atom, this edit restore atom holds fields of size, type, version, and flag group. In this edit restore tom, “elst” is held as the type name. The edit restore tom further includes N (N is an integer of 1 or more) edit list entries (Edit List Entry) and the number (Number of Entries).
エディットリストエントリの各々は、セグメント期間(Segment duration)と、メディア時間(Media time)と、メディアレート(Media rate)とを備えている。 Each of the edit list entries includes a segment duration, a media time, and a media rate.
このエディットアトム('edts')を模式的に表したものが図28である。図28(a)のように、エディットアトム680は、エディットアトム680の大きさを示すサイズ681と、エディットアトムであることを示すタイプ682と、エディットアトムのバージョン683と、未使用のフラグ群694と、エディットリストアトム570とから構成される。
FIG. 28 schematically shows the edit atom ('edts'). As shown in FIG. 28A, the
エディットリストアトム690は、エディットリストアトム690の大きさを示すサイズ691と、エディットリストアトムであることを示すタイプ692と、エディットリストアトムのバージョン693と、未使用のフラグ群694と、エディットリストテーブル696と、エディットリストテーブル696のエントリ数695とから構成される。
The edit restore
エディットリストテーブル696はエントリ数695により示される数のエントリから構成される。図28(b)のようにエディットリストテーブル696の各エントリは、セグメント期間697と、メディア時間698と、メディアレート699とから構成される。セグメント期間697は、対応する編集単位の期間を示す。メディア時間698は、対応する編集単位のメディアデータアトムにおける開始時刻を示す。なお、このメディア時間698が「−1」を示している場合には、対応する編集単位はメディアデータアトムに存在しないことを意味する。メディアレート699は、再生の際の時間比率を示すものであり、メディアデータアトムにおける時間軸と編集後の時間軸とで再生時間が変わらない場合には「1.0」を示すことになる。
The edit list table 696 is composed of the number of entries indicated by the number of
図29は、図26の例におけるエディットリストアトム('elst')の内容例を示す図である。図29(a)は編集前のエディットリストアトムの内容である。編集前の状態では、エントリは1つだけ存在する。セグメント期間は全期間のts6を示す。メディア時間は先頭時刻の0を示す。また、メディアレート699は、「1.0」である。
FIG. 29 is a diagram showing an example of the contents of the edit restore tom ('elst') in the example of FIG. FIG. 29A shows the contents of the edit restore tom before editing. In the state before editing, there is only one entry. The segment period indicates ts6 of the entire period. The media time indicates 0 at the start time. The
図29(b)は編集後のエディットリストアトムの内容である。編集後は、3つのエントリが生成される。 FIG. 29B shows the contents of the edited restore tom after editing. After editing, three entries are generated.
第1のエントリでは、最初の笑顔の期間te1(=tm2−tm1)を示す。メディア時間は最初の笑顔の先頭時刻tm1を示す。また、メディアレート699は、「1.0」である。
The first entry indicates the first smile period te1 (= tm2-tm1). The media time indicates the start time tm1 of the first smile. The
第2のエントリでは、驚いた顔の期間te2−te1(=tm4−tm3)を示す。メディア時間は驚いた顔の先頭時刻tm3を示す。また、メディアレート699は、「1.0」である。
The second entry indicates the surprised face period te2-te1 (= tm4-tm3). The media time indicates the start time tm3 of the surprised face. The
第3のエントリでは、2回目の笑顔の期間te3−te2(=tm6−tm5)を示す。メディア時間は2回目の笑顔の先頭時刻tm5を示す。また、メディアレート699は、「1.0」である。
The third entry indicates the second smile period te3-te2 (= tm6-tm5). The media time indicates the start time tm5 of the second smile. The
図30は、本発明の実施の形態におけるソーストラック(第1のビデオデータ101)およびメタトラック(メタデータ103)と編集トラック(編集ビデオデータ105)との他の関係例を示す図である。この例では、ソーストラックおよびメタトラックは図26の例と同様の関係になっている。 FIG. 30 is a diagram showing another example of the relationship between the source track (first video data 101) and the meta track (meta data 103) and the edit track (edit video data 105) in the embodiment of the present invention. In this example, the source track and the meta track have the same relationship as in the example of FIG.
ここで、メタトラックにおいて笑顔を示す区間を抽出条件としてソーストラックを編集することを想定すると、その出力として図のような編集トラックが生成される。すなわち、ソーストラック時間の時刻ts1から時刻ts2の区間のソーストラックの部分が、編集トラックにおける編集トラック時間の時刻0から時刻te1の区間になり、ソーストラック時間の時刻ts5から時刻ts6の区間のソーストラックの部分が、編集トラックにおける編集トラック時間の時刻te1から時刻te2の区間になる。
Here, if it is assumed that the source track is edited using the section showing smile in the meta track as an extraction condition, an edit track as shown in the figure is generated as the output. That is, the portion of the source track in the section from the time ts1 to the time ts2 of the source track time becomes the section from the
図31は、図30の例におけるエディットリストアトム('elst')の内容例を示す図である。この図は編集後のエディットリストアトムの内容である。編集後は、2つのエントリが生成される。 FIG. 31 is a diagram showing an example of the contents of the edit restore tom ('elst') in the example of FIG. This figure shows the contents of Edit Restore Tom after editing. After editing, two entries are generated.
第1のエントリでは、最初の笑顔の期間te1(=tm2−tm1)を示す。メディア時間は最初の笑顔の先頭時刻tm1を示す。また、メディアレート699は、「1.0」である。
The first entry indicates the first smile period te1 (= tm2-tm1). The media time indicates the start time tm1 of the first smile. The
第2のエントリでは、2回目の笑顔の期間te2−te1(=tm6−tm5)を示す。メディア時間は2回目の笑顔の先頭時刻tm5を示す。また、メディアレート699は、「1.0」である。
The second entry indicates the second smile period te2-te1 (= tm6-tm5). The media time indicates the start time tm5 of the second smile. The
このようにして生成されたエディットリストアトム(エディットリスト104)は映像抽出部123に供給され、この映像抽出部123においてソーストラック(第1のビデオデータ101)から編集トラック(編集ビデオデータ105)が生成される。すなわち、元のソーストラックを破壊することのない非破壊型編集を実現することができる。
The edit restore tom (edit list 104) generated in this way is supplied to the
次に本発明の実施の形態における映像編集システムの動作について図面を参照して説明する。 Next, the operation of the video editing system in the embodiment of the present invention will be described with reference to the drawings.
図32は、本発明の実施の形態における映像処理装置110による処理手順の一例を示す図である。まず、映像取得部111によって、第2のビデオデータ102の映像が取得される(ステップS911)。この第2のビデオデータ102は、第1のビデオデータ101に同期しており、図2の例のように第1のビデオデータ101の撮像と同時に撮像されたものでもよく、図4の例のように第1のビデオデータ101の再生と同時に撮像されたものでもよく、また、図6の例のように第1のビデオデータ101と同一の内容であってもよい。
FIG. 32 is a diagram illustrating an example of a processing procedure performed by the
ステップS911で映像が取得されると、取得された第2のビデオデータ102における特徴量が映像解析部112によって解析される(ステップS912)。例えば、特徴量として第2のビデオデータ102に含まれる顔の画像が抽出されて、その顔の表情が判断される。
When the video is acquired in step S911, the feature amount in the acquired
そして、ステップS912において解析された特徴量を時間軸により管理するメタデータ103がメタデータ生成部113によって生成される(ステップS913)。この生成されたメタデータ103は、第1のビデオデータ101の各時刻に対応して、第2のビデオデータ102の特徴量を保持するものである。
Then,
これらステップS911乃至S913の処理手順は、第2のビデオデータ102の映像が全て処理されるまで繰り返される(ステップS914)。
The processing procedure of these steps S911 to S913 is repeated until all the images of the
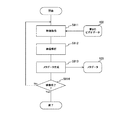
図33は、本発明の実施の形態における映像編集装置120による処理手順の一例を示す図である。まず、抽出条件受付部121によって、抽出条件の入力が受け付けられる(ステップS921)。そして、その抽出条件によってメタデータ103における位置が探索される(ステップS930)。これにより、抽出条件に合致する時系列上の位置が得られ、エディットリスト104として保持される。
FIG. 33 is a diagram showing an example of a processing procedure performed by the
このエディットリスト104に基づいて、第1のビデオデータ101から抽出条件に合致する時系列上の位置に対応する部分が映像抽出部123によって抽出され、編集ビデオデータ105として出力される(ステップS923)。
Based on the
図34は、図33の位置探索処理(ステップS930)における処理手順の一例を示す図である。まず、メタデータのムービーリソース(図11のメタトラック)が取得される(ステップS931)。そして、このムービーリソースのサンプルディスクリプションアトム('stsd')に含まれるパラメータフラグ(図20参照)によりエフェクトの有効性、すなわち特徴量の記録の有効性が判断される(ステップS932)。 FIG. 34 is a diagram showing an example of a processing procedure in the position search process (step S930) of FIG. First, a metadata movie resource (meta track in FIG. 11) is acquired (step S931). Then, the effectiveness of the effect, that is, the effectiveness of recording the feature amount is determined based on the parameter flag (see FIG. 20) included in the sample description atom ('stsd') of the movie resource (step S932).
ステップS932において「有効」であると判断された場合には、メタデータの対応するメディアデータのサンプルが取得される(ステップS933)。その結果、メタデータのサンプルの示す特徴量が抽出条件と一致していれば(ステップS934)、その該当する区間(セグメント)がエディットリストアトム(エディットリスト104)のエントリとして登録される(ステップS935)。 If it is determined in step S932 that it is “valid”, a sample of media data corresponding to the metadata is acquired (step S933). As a result, if the feature amount indicated by the metadata sample matches the extraction condition (step S934), the corresponding section (segment) is registered as an entry in the edit restore tom (edit list 104) (step S935). ).
一方、ステップS932において「無効」であると判断された場合には、メタデータのメディアデータは取得されることなく、そのサンプルに関する処理は終了する。 On the other hand, if it is determined as “invalid” in step S932, the media data of the metadata is not acquired, and the processing relating to the sample ends.
これらステップS931乃至S935の処理手順は、メタデータ103のサンプルが全て処理されるまで繰り返される(ステップS936)。
The processing procedures in steps S931 to S935 are repeated until all the samples of the
このように、本発明の実施の形態によれば、第1のビデオデータ101に同期する第2のビデオデータ102から映像処理装置110によってメタデータ103が生成される。このメタデータ103は、第1のビデオデータ101に同期しており、第2のビデオデータ102の特徴量を時間軸で管理しながら保持するものである。また、本発明の実施の形態によれば、メタデータ103において抽出条件に合致する位置が映像編集装置120の位置探索部122によって探索され、エディットリスト104が生成される。このエディットリスト104に従って、第1のビデオデータ101から映像抽出部123によって映像が抽出され、編集ビデオデータ105が生成される。すなわち、本発明の実施の形態によれば、メタデータ103を中間状態として、第1のビデオデータ101を非破壊的に編集することができる。
As described above, according to the embodiment of the present invention, the
なお、本発明の実施の形態は本発明を具現化するための一例を示したものであり、以下に示すように特許請求の範囲における発明特定事項とそれぞれ対応関係を有するが、これに限定されるものではなく本発明の要旨を逸脱しない範囲において種々の変形を施すことができる。 The embodiment of the present invention is an example for embodying the present invention and has a corresponding relationship with the invention-specific matters in the claims as shown below, but is not limited thereto. However, various modifications can be made without departing from the scope of the present invention.
すなわち、請求項1において、映像取得手段は例えば映像取得部111、撮像部211、216、または、映像入力部206に対応する。また、映像解析手段は例えば映像解析部112または217に対応する。また、メタデータ生成手段は例えばメタデータ生成部113またはファイル生成部214に対応する。
That is, in
また、請求項3において、第1の撮像手段は例えば撮像部211に対応する。また、第2の撮像手段は例えば撮像部216に対応する。
Further, in
また、請求項4において、再生手段は例えば再生部220に対応する。また、撮像手段は例えば撮像部211に対応する。
Further, in
また、請求項5において、再生手段は例えば再生部220に対応する。また、映像入力手段は例えば映像入力部206に対応する。
Further, in
また、請求項7において、位置探索手段は例えば位置探索部122に対応する。また、映像抽出手段は例えば映像抽出部123に対応する。
Further, in
また、請求項9において、映像取得手段は例えば映像取得部111、撮像部211、216、または、映像入力部206に対応する。また、映像解析手段は例えば映像解析部112または217に対応する。また、メタデータ生成手段は例えばメタデータ生成部113またはファイル生成部214に対応する。また、位置探索手段は例えば位置探索部122に対応する。また、映像抽出手段は例えば映像抽出部123に対応する。
Further, in claim 9, the video acquisition unit corresponds to, for example, the
また、請求項10および11において、映像取得手順は例えばステップS911に対応する。また、映像解析手順は例えばステップS912に対応する。また、メタデータ生成手順は例えばステップS913に対応する。 Further, in claims 10 and 11, the video acquisition procedure corresponds to, for example, step S911. The video analysis procedure corresponds to, for example, step S912. The metadata generation procedure corresponds to step S913, for example.
また、請求項12および13において、メタデータ取得手順は例えばステップS933に対応する。また、位置探索手順は例えばステップS934に対応する。また、映像抽出手順は例えばステップS923に対応する。
Further, in
また、請求項14において、第1の映像データは例えば第1のビデオデータ101に対応する。また、第2の映像データは例えば第2のビデオデータ102に対応する。また、メタデータは例えばメタデータ103に対応する。
In claim 14, the first video data corresponds to, for example, the
なお、本発明の実施の形態において説明した処理手順は、これら一連の手順を有する方法として捉えてもよく、また、これら一連の手順をコンピュータに実行させるためのプログラム乃至そのプログラムを記憶する記録媒体として捉えてもよい。 The processing procedure described in the embodiment of the present invention may be regarded as a method having a series of these procedures, and a program for causing a computer to execute these series of procedures or a recording medium storing the program May be taken as
100 映像編集システム
101 第1のビデオデータ
102 第2のビデオデータ
103 メタデータ
104 エディットリスト
105 編集ビデオデータ
110 映像処理装置
111 映像取得部
112 映像解析部
113 メタデータ生成部
120 映像編集装置
121 抽出条件受付部
122 位置探索部
123 映像抽出部
206 映像入力部
210 記録部
211 撮像部
212 映像加工部
213 映像圧縮部
214 ファイル生成部
215 書込み部
216 撮像部
217 映像解析部
218 記録制御部
219 記録媒体
220 再生部
221 表示部
222 映像加工部
223 映像伸張部
224 ファイル復号部
225 読出し部
229 記録媒体
301 撮像部
309 記録媒体
311 ズームレンズ
312 アイリス
313 フォーカスレンズ
314 フィルタ
321 撮像素子
322 A/D変換器
323 カメラ信号処理回路
324 検波部
325 ズーム制御部
326 角速度センサ
329 カメラ制御部
330 映像加工部
341 映像圧縮部
342 圧縮制御部
351 記録媒体アクセス部
352 ドライブ制御部
360 操作受付部
370 表示部
390 システム制御部
501 被写体
502 撮影者
503〜505 鑑賞者
510 ネットワーク
520、531 ビデオカメラ装置
521、522、541 カメラ
530 テレビ装置
540 コンピュータ装置
DESCRIPTION OF SYMBOLS 100
Claims (14)
前記第2の映像データにおける特徴量を解析する映像解析手段と、
前記第1の映像データと同期して前記特徴量を保持するメタデータを生成するメタデータ生成手段と
を具備することを特徴とする映像処理装置。 Video acquisition means for acquiring second video data synchronized with the first video data managed in time series;
Video analysis means for analyzing the feature quantity in the second video data;
A video processing apparatus comprising: metadata generation means for generating metadata that holds the feature amount in synchronization with the first video data.
前記映像取得手段は、前記第1の映像データの撮像と同時に前記第2の映像データを撮像する第2の撮像手段を含む
ことを特徴とする請求項1記載の映像処理装置。 Further comprising first imaging means for imaging the first video data;
The video processing apparatus according to claim 1, wherein the video acquisition unit includes a second imaging unit that captures the second video data simultaneously with the imaging of the first video data.
前記映像取得手段は、前記再生手段による前記第1の映像データの再生と同時に前記第2の映像データを撮像する撮像手段を含む
ことを特徴とする請求項1記載の映像処理装置。 Replay means for replaying the first video data;
The video processing apparatus according to claim 1, wherein the video acquisition unit includes an imaging unit that captures the second video data simultaneously with the reproduction of the first video data by the reproduction unit.
前記映像取得手段は、前記再生手段により再生された前記第1の映像データを前記第2の映像データとして入力する映像入力手段を含む
ことを特徴とする請求項1記載の映像処理装置。 Replay means for replaying the first video data;
2. The video processing apparatus according to claim 1, wherein the video acquisition means includes video input means for inputting the first video data reproduced by the reproduction means as the second video data.
前記探索情報に基づいて前記第1の映像データから前記合致する時系列上の位置に対応する部分を抽出する映像抽出手段と
を具備することを特徴とする映像編集装置。 Search for a position on the time series that matches a predetermined condition after obtaining metadata holding the feature amount in the second video data synchronized with the first video data managed in time series, and search for the result Position search means for generating information;
A video editing apparatus, comprising: a video extracting unit that extracts a portion corresponding to the matching time-series position from the first video data based on the search information.
前記第2の映像データにおける特徴量を解析する映像解析手段と、
前記第1の映像データと同期して前記特徴量を保持するメタデータを生成するメタデータ生成手段と、
前記メタデータから所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成する位置探索手段と、
前記探索情報に基づいて前記第1の映像データから前記合致する時系列上の位置に対応する部分を抽出する映像抽出手段と
を具備することを特徴とする映像編集システム。 Video acquisition means for acquiring second video data synchronized with the first video data managed in time series;
Video analysis means for analyzing the feature quantity in the second video data;
Metadata generation means for generating metadata for holding the feature amount in synchronization with the first video data;
A position search means for searching a position on the time series that matches a predetermined condition from the metadata and generating the result as search information;
A video editing system comprising: a video extracting unit that extracts a portion corresponding to the matching time-series position from the first video data based on the search information.
前記第2の映像データにおける特徴量を解析する映像解析手順と、
前記第1の映像データと同期して前記特徴量を保持するメタデータを生成するメタデータ生成手順と
を具備することを特徴とする映像処理方法。 A video acquisition procedure for acquiring second video data synchronized with the first video data managed in time series;
A video analysis procedure for analyzing a feature amount in the second video data;
A video processing method comprising: a metadata generation procedure for generating metadata that holds the feature amount in synchronization with the first video data.
前記第2の映像データにおける特徴量を解析する映像解析手順と、
前記第1の映像データと同期して前記特徴量を保持するメタデータを生成するメタデータ生成手順と
をコンピュータに実行させることを特徴とするプログラム。 A video acquisition procedure for acquiring second video data synchronized with the first video data managed in time series;
A video analysis procedure for analyzing a feature amount in the second video data;
A program that causes a computer to execute a metadata generation procedure for generating metadata that holds the feature amount in synchronization with the first video data.
前記メタデータにおいて所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成する位置探索手順と、
前記探索情報に基づいて前記第1の映像データから前記合致する時系列上の位置に対応する部分を抽出する映像抽出手順と
を具備することを特徴とする映像編集方法。 A metadata acquisition procedure for acquiring metadata that retains feature quantities in the second video data synchronized with the first video data managed in time series;
A position search procedure for searching for a position on a time series that matches a predetermined condition in the metadata and generating the result as search information;
A video editing method comprising: extracting a portion corresponding to the matching time-series position from the first video data based on the search information.
前記メタデータにおいて所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成する位置探索手順と、
前記探索情報に基づいて前記第1の映像データから前記合致する時系列上の位置に対応する部分を抽出する映像抽出手順と
をコンピュータに実行させることを特徴とするプログラム。 A metadata acquisition procedure for acquiring metadata that retains feature quantities in the second video data synchronized with the first video data managed in time series;
A position search procedure for searching for a position on a time series that matches a predetermined condition in the metadata and generating the result as search information;
A program causing a computer to execute a video extraction procedure for extracting a portion corresponding to the matching position on the time series from the first video data based on the search information.
前記第1の映像データに同期した第2の映像データにおける特徴量を前記第1の映像データと同期して保持するメタデータと
を具備するデータ構造であって、
コンピュータが、前記メタデータを取得して、前記メタデータにおいて所定の条件に合致する時系列上の位置を探索してその結果を探索情報として生成して、前記探索情報に基づいて前記第1の映像データから前記合致する時系列上の位置に対応する部分を抽出することを特徴とするデータ構造。
First video data managed in time series;
A data structure comprising metadata for holding a feature amount in second video data synchronized with the first video data in synchronization with the first video data,
A computer acquires the metadata, searches a position on the time series that matches a predetermined condition in the metadata, generates a result as search information, and based on the search information, the first information A data structure, wherein a portion corresponding to the matching time-series position is extracted from video data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006231429A JP2008060622A (en) | 2006-08-29 | 2006-08-29 | Video editing system, video processing apparatus, video editing device, video processing method, video editing method, program, and data structure |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006231429A JP2008060622A (en) | 2006-08-29 | 2006-08-29 | Video editing system, video processing apparatus, video editing device, video processing method, video editing method, program, and data structure |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008060622A true JP2008060622A (en) | 2008-03-13 |
| JP2008060622A5 JP2008060622A5 (en) | 2009-07-02 |
Family
ID=39242919
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006231429A Pending JP2008060622A (en) | 2006-08-29 | 2006-08-29 | Video editing system, video processing apparatus, video editing device, video processing method, video editing method, program, and data structure |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2008060622A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012510190A (en) * | 2008-11-26 | 2012-04-26 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | Technology for handling media content that can be accessed via multiple media tracks |
| JP2022501891A (en) * | 2018-09-20 | 2022-01-06 | ノキア テクノロジーズ オーユー | Devices and methods for artificial intelligence |
| WO2023047657A1 (en) * | 2021-09-22 | 2023-03-30 | ソニーグループ株式会社 | Information processing device and information processing method |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004159192A (en) * | 2002-11-07 | 2004-06-03 | Nippon Telegr & Teleph Corp <Ntt> | Video image summarizing method, program, and storage medium for storing video image summarizing program |
| JP2007097047A (en) * | 2005-09-30 | 2007-04-12 | Seiko Epson Corp | Contents editing apparatus, contents editing method and contents editing program |
| JP2007104091A (en) * | 2005-09-30 | 2007-04-19 | Fujifilm Corp | Image selection apparatus, program, and method |
-
2006
- 2006-08-29 JP JP2006231429A patent/JP2008060622A/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004159192A (en) * | 2002-11-07 | 2004-06-03 | Nippon Telegr & Teleph Corp <Ntt> | Video image summarizing method, program, and storage medium for storing video image summarizing program |
| JP2007097047A (en) * | 2005-09-30 | 2007-04-12 | Seiko Epson Corp | Contents editing apparatus, contents editing method and contents editing program |
| JP2007104091A (en) * | 2005-09-30 | 2007-04-19 | Fujifilm Corp | Image selection apparatus, program, and method |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012510190A (en) * | 2008-11-26 | 2012-04-26 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | Technology for handling media content that can be accessed via multiple media tracks |
| US8798264B2 (en) | 2008-11-26 | 2014-08-05 | Telefonaktiebolaget Lm Ericsson (Publ) | Technique for handling media content to be accessible via multiple media tracks |
| JP2022501891A (en) * | 2018-09-20 | 2022-01-06 | ノキア テクノロジーズ オーユー | Devices and methods for artificial intelligence |
| US11442985B2 (en) | 2018-09-20 | 2022-09-13 | Nokia Technologies Oy | Apparatus and a method for artificial intelligence |
| WO2023047657A1 (en) * | 2021-09-22 | 2023-03-30 | ソニーグループ株式会社 | Information processing device and information processing method |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3632703B2 (en) | Video recording apparatus and video recording method | |
| US20070201832A1 (en) | Recording apparatus, recording method, program for recording method, recording medium recording program for recording method, reproducing apparatus, reproduction method, program for reproduction method, and recording medium recording program for reproduction method | |
| US10356379B2 (en) | Image storage apparatus, image reproducing apparatus, method of storing image, method of reproducing an image, recording medium and photographing apparatus | |
| JP4379491B2 (en) | Face data recording device, playback device, imaging device, image playback system, face data recording method and program | |
| TW200414763A (en) | Apparatus for receiving a digital information signal | |
| US7929028B2 (en) | Method and system for facilitating creation of content | |
| JP4881210B2 (en) | Imaging apparatus, image processing apparatus, and control method thereof | |
| JP2011142585A (en) | Image processing device, information recording medium, image processing method, and program | |
| KR20090012152A (en) | Recording apparatus, reproducing apparatus, recording/reproducing apparatus, image pickup apparatus, recording method and program | |
| CN107251551B (en) | Image processing device, image capturing apparatus, image processing method, and storage medium | |
| JP2009260748A (en) | Storage and playback device | |
| JP2008060622A (en) | Video editing system, video processing apparatus, video editing device, video processing method, video editing method, program, and data structure | |
| JP4946935B2 (en) | Imaging device | |
| JP5045254B2 (en) | RECORDING DEVICE, IMAGING DEVICE, PLAYLIST GENERATION METHOD, AND PROGRAM | |
| JP6278353B2 (en) | RECORDING DEVICE, RECORDING METHOD, PROGRAM, AND IMAGING DEVICE | |
| US10410674B2 (en) | Imaging apparatus and control method for combining related video images with different frame rates | |
| JP2009159314A (en) | Recording apparatus, playback apparatus, recording method, playback method and program | |
| WO2021117481A1 (en) | Data processing device, data processing method, and program | |
| US20230229689A1 (en) | Media file generation apparatus, media file playback apparatus, media file generation method, media file playback method, program, and storage medium | |
| JP2002290901A (en) | Viewer video recording and reproducing device | |
| JP7374698B2 (en) | Imaging device, control method and program | |
| JP4462290B2 (en) | Content management information recording apparatus, content reproduction apparatus, content reproduction system, imaging apparatus, content management information recording method and program | |
| JP2020170998A (en) | Image processing apparatus, imaging apparatus, image processing method, and program | |
| KR101447190B1 (en) | Input-output System for eding and playing of UHD image contents | |
| KR20090020180A (en) | Mothod for setting highlight scene of moving picture and terminal using the same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090518 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090518 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20101215 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101221 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110412 |