JP2006202081A - メタデータ生成装置 - Google Patents
メタデータ生成装置 Download PDFInfo
- Publication number
- JP2006202081A JP2006202081A JP2005013693A JP2005013693A JP2006202081A JP 2006202081 A JP2006202081 A JP 2006202081A JP 2005013693 A JP2005013693 A JP 2005013693A JP 2005013693 A JP2005013693 A JP 2005013693A JP 2006202081 A JP2006202081 A JP 2006202081A
- Authority
- JP
- Japan
- Prior art keywords
- content information
- word
- keyword
- text
- metadata
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/50—Information retrieval; Database structures therefor; File system structures therefor of still image data
- G06F16/58—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/583—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G06F16/5846—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content using extracted text
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/50—Information retrieval; Database structures therefor; File system structures therefor of still image data
- G06F16/58—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Library & Information Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Character Discrimination (AREA)
Abstract
【課題】 個人コンテンツに対して適合度が高く、検索を容易に行うことができるメタデータを容易に生成する。
【解決手段】 個人のコンテンツ情報を読込む個人コンテンツ情報読込み手段20と、該個人コンテンツ情報読込み手段20で読込んだ個人コンテンツ情報に関連する他のコンテンツ情報からテキストを抽出するテキスト抽出手段22と、該テキスト抽出手段22で抽出した単語に基づいて前記個人コンテンツ情報読込み手段13で読込んだ個人コンテンツ情報に対する検索用メタデータを生成するメタデータ生成手段42とを備えている。
【選択図】 図2
【解決手段】 個人のコンテンツ情報を読込む個人コンテンツ情報読込み手段20と、該個人コンテンツ情報読込み手段20で読込んだ個人コンテンツ情報に関連する他のコンテンツ情報からテキストを抽出するテキスト抽出手段22と、該テキスト抽出手段22で抽出した単語に基づいて前記個人コンテンツ情報読込み手段13で読込んだ個人コンテンツ情報に対する検索用メタデータを生成するメタデータ生成手段42とを備えている。
【選択図】 図2
Description
本発明は、個人が製作した静止画像データや動画像データ等で構成される個人コンテンツを検索する際に使用する検索用メタデータを容易に生成することができるメタデータ生成装置に関する。
近年、デジタルカメラやカメラ付携帯電話機の普及により、大量の映像や画像を撮影し、撮影した画像データを個人コンテンツとしてパーソナルコンピュータ等の記憶装置やコンパクトデスク、デジタルビデオデスク等の記憶媒体に格納することが極めて容易になってきている。このように、大量の画像・映像データを含む個人コンテンツを効率的に検索するためにメタデータを付加することは必要不可欠である。
デジタルカメラやデジタルビデオの画像・映像には、撮影日時がメタデータとして自動的に記憶されるが、効率的な検索という意味では不十分である。さらに、ダブリンコアやMPEG−7などのメタデータを作成する体系も整備されているが、これらの体系に基づいてメタデータを作成、入力する作業に熟練を要し、専門家ではない一般のユーザーではメタデータの作成作業が困難である。
そこで、従来、少なくとも時間に関する情報を含むスケジュールデータ等の複数のイベント情報を記憶可能なイベント記憶部と、少なくとも時間に関する情報を含む付属情報(イベント情報)を有する画像データ等の対象データを記憶可能な情報記憶部とを有し、イベント情報関連判定部で、イベント情報と付属情報とに基づいてイベントと対象データとの間の関連の有無を判定し、その判定結果を認識可能に対象データを表す情報としてイベント表示部に表示するようにした情報処理方法、情報処理装置及び記録媒体が知られている(例えば、特許文献1参照)。
特開2003−303210号公報(第1頁、図1,図13)
しかしながら、上記特許文献1に記載された従来例にあっては、スケジュールデータ等のイベント情報を用意する必要があり、このイベント情報の日時を信頼性高く保守しなければならず、これが面倒であるという未解決の課題を有すると共に、イベント情報が用意されていないときには検索することができないという未解決の課題もある。
そこで、本発明は、上記従来例の未解決の課題に着目してなされたものであり、個人コンテンツに対して適合度が高く、検索を容易に行うことができる検索用メタデータを容易に生成することができるメタデータ生成装置を提供することを目的としている。
そこで、本発明は、上記従来例の未解決の課題に着目してなされたものであり、個人コンテンツに対して適合度が高く、検索を容易に行うことができる検索用メタデータを容易に生成することができるメタデータ生成装置を提供することを目的としている。
第1の発明に係るメタデータ生成装置は、個人のコンテンツ情報を読込む個人コンテンツ情報読込み手段と、該個人コンテンツ情報読込み手段で読込んだ個人コンテンツ情報に関連する他のコンテンツ情報からテキストを抽出するテキスト抽出手段と、該テキスト抽出手段で抽出したテキストに基づいて前記個人コンテンツ情報読込み手段で読込んだ個人コンテンツ情報に対する検索用メタデータを生成するメタデータ生成手段とを備えたことを特徴としている。
この第1の発明では、個人コンテンツ情報読込み手段でデジタルカメラやデジタルビデオ等の静止画像データや動画動データで構成される個人コンテンツ情報を読込む一方、テキスト抽出手段で、個人コンテンツ情報に関連する他のコンテンツ情報例えばインターネットのホームページやイベントを印刷した印刷物からテキストを抽出し、抽出したテキストに基づいて検索用メタデータを生成することにより、個人コンテンツ情報に対して検索が容易となる検索用メタデータを容易に自動生成することができる。
また、第2の発明に係るメタデータ生成装置は、第1の発明において、前記メタデータ生成手段は、前記テキスト抽出手段で抽出したテキストからキーワードを選択するキーワード選択手段を備え、該キーワード選択手段で選択したキーワードに基づいて前記個人コンテンツ情報作成手段で読込んだ個人コンテンツ情報に対する検索用メタデータを生成するように構成されていることを特徴としている。
この第2の発明では、テキスト抽出手段で抽出したテキストからキーワード選択手段でキーワードを選択し、選択したキーワードに基づいて個人コンテンツ情報に対する検索用メタデータを生成するので、個人コンテンツ情報に最適な検索用メタデータを正確且つ容易に生成することができる。
さらに、第3の発明に係るメタデータ生成装置は、第2の発明において、前記キーワード選択手段は、テキスト中の特徴ある文字データをキーワードとして選択するように構成されていることを特徴としている。
さらに、第3の発明に係るメタデータ生成装置は、第2の発明において、前記キーワード選択手段は、テキスト中の特徴ある文字データをキーワードとして選択するように構成されていることを特徴としている。
この第3の発明では、テキスト中の見出しや太文字等の特徴ある文字データをキーワードとして選択するので、事象を短く且つ端的に表すキーワードを正確且つ容易に選択することができる。
さらにまた、第4の発明に係るメタデータ生成装置は、第3の発明において、前記文字データはテキスト中に含まれる他の文字データと比較して特徴あるフォントを有していることを特徴としている。
さらにまた、第4の発明に係るメタデータ生成装置は、第3の発明において、前記文字データはテキスト中に含まれる他の文字データと比較して特徴あるフォントを有していることを特徴としている。
この第4の発明では、他の文字データに比較して大きなフォントや色、フォント種類、修飾等が異なって目立つ文字データをキーワードとすることができ、事象を短く且つ端的に表すキーワードを正確且つ容易に選択することができる。
なおさらに、第5の発明に係るメタデータ生成装置は、第2乃至第4の何れか1つの発明において、前記キーワード選択手段は、単語を分割して抽出する単語分割手段を有し、該単語分割手段で抽出した単語の品詞情報に基づいて選択した単語をキーワードとして選択するように構成されていることを特徴としている。
なおさらに、第5の発明に係るメタデータ生成装置は、第2乃至第4の何れか1つの発明において、前記キーワード選択手段は、単語を分割して抽出する単語分割手段を有し、該単語分割手段で抽出した単語の品詞情報に基づいて選択した単語をキーワードとして選択するように構成されていることを特徴としている。
この第5の発明では、テキストから単語分割手段で、単語を分割して抽出し、単語の品詞情報例えば固有名詞等に基づいて選択した単語をキーワードとして選択するので、接続詞、前置詞等の検索用メタデータとして採用不可能な単語を除いてキーワードを選択することができ、個人コンテンツ情報に最適なキーワードを選択することができる。
また、第6の発明に係るメタデータ生成装置は、第2乃至第5の何れか1つの発明において、前記キーワード選択手段は、所定のキーワードを記憶するキーワード記憶手段を有し、前記テキスト抽出手段で抽出したテキストのうち前記キーワード記憶手段に記憶されているキーワードと一致する単語をキーワードとして選択するように構成されていることを特徴としている。
また、第6の発明に係るメタデータ生成装置は、第2乃至第5の何れか1つの発明において、前記キーワード選択手段は、所定のキーワードを記憶するキーワード記憶手段を有し、前記テキスト抽出手段で抽出したテキストのうち前記キーワード記憶手段に記憶されているキーワードと一致する単語をキーワードとして選択するように構成されていることを特徴としている。
この第6の発明では、キーワード記憶手段に記憶されている所定のキーワードを辞書としてテキスト抽出手段で抽出したテキストのうちキーワード記憶手段に記憶されているキーワードと一致する単語をキーワードとして選択するので、より効率的な検索が可能なキーワードのみを抽出することが可能となり、個人コンテンツ情報に最適なキーワードを選択することができる。
さらに、第7の発明に係るメタデータ生成装置は、第6の発明において、前記キーワード記憶手段は、記憶しているキーワードをデジタル放送電波、ネットワーク、記憶媒体の何れか1つ又は複数を使用して更新するように構成されていることを特徴としている。
この第7の発明によれば、キーワード記憶手段に記憶されているキーワードをデジタル放送電波やネットワークで送信されるキーワードや記憶媒体に記憶されたキーワードによって更新するので、常時最適なキーワードを確保することができる。
この第7の発明によれば、キーワード記憶手段に記憶されているキーワードをデジタル放送電波やネットワークで送信されるキーワードや記憶媒体に記憶されたキーワードによって更新するので、常時最適なキーワードを確保することができる。
さらにまた、第8の発明に係るメタデータ生成装置は、第1乃至第7の何れかの発明において、前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データから特定領域を識別する領域識別手段と、該領域識別手段で識別した特定領域の画像データを文字認識する文字認識手段とを少なくとも備えていることを特徴としている。
この第8の発明では、印刷物に印刷されている文章中のユーザーが抽出したい単語に対して他の単語と区別するための領域識別マークを施すことにより、この印刷物を画像読取手段で画像データとして読取り、この画像データから領域式識別マークが施された領域を抽出し、抽出した領域に含まれる単語を文字認識手段で文字認識して単語を抽出し、抽出単語からキーワードを選択し、選択したキーワードに基づいて個人コンテンツ情報に対する検索用メタデータを形成するので、印刷物のうちからユーザーが特定した単語を検索用メタデータとして生成することができる。
なおさらに、第9の発明に係るメタデータ生成装置は、第1乃至第7の何れか1つの発明において、前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データを文字認識する文字認識手段と、該文字認識手段で認識した文字を単語に分割して抽出する単語分割手段とを少なくとも備えていることを特徴としている。
この第9の発明では、画像読取手段で読取った画像データを文字認識手段で文字認識してテキストデータに変換し、このテキストデータを単語分割手段で単語に分割するので、任意の印刷物から単語を抽出することができる。
また、第10の発明に係るメタデータ生成装置は、第1乃至第7の何れか1つの発明において、前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データから特定領域を識別する領域識別手段と、該領域識別手段で識別した特定領域の画像データを文字認識する文字認識手段と、該文字認識手段で認識した文字を単語に分割して抽出する単語分割手段とを少なくとも備えていることを特徴としている。
また、第10の発明に係るメタデータ生成装置は、第1乃至第7の何れか1つの発明において、前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データから特定領域を識別する領域識別手段と、該領域識別手段で識別した特定領域の画像データを文字認識する文字認識手段と、該文字認識手段で認識した文字を単語に分割して抽出する単語分割手段とを少なくとも備えていることを特徴としている。
この第10の発明では、特定領域の画像データを文字認識手段で文字認識してテキストデータを抽出し、このテキストデータから単語分割手段で単語を分割して抽出するので、ユーザーが形成した特定領域にかかわらず、見出し等の枠線で囲まれた領域等の任意の領域の画像データから単語を容易に抽出することができる。
さらに、第11の発明に係るメタデータ生成装置は、第1又は第2の発明において、前記テキスト抽出手段は、ネットワークを介してコンテンツ情報提供手段からコンテンツ情報を収集するコンテンツ情報収集手段と、該コンテンツ情報収集手段で収集したコンテンツ情報からテキストを抽出し、抽出したテキストから単語を分割して抽出する単語分割手段とを少なくとも備えていることを特徴としている。
さらに、第11の発明に係るメタデータ生成装置は、第1又は第2の発明において、前記テキスト抽出手段は、ネットワークを介してコンテンツ情報提供手段からコンテンツ情報を収集するコンテンツ情報収集手段と、該コンテンツ情報収集手段で収集したコンテンツ情報からテキストを抽出し、抽出したテキストから単語を分割して抽出する単語分割手段とを少なくとも備えていることを特徴としている。
この第11の発明では、ホームページ、電子メール等のコンテンツ提供手段からコンテンツ情報を収集し、収集したコンテンツ情報を単語分割して単語を抽出するので、例えば新聞社等の地域毎のニュースサイトを指定することにより、その日のイベント情報を時刻情報と共に収集することができる。
さらにまた、第12の発明に係るメタデータ生成装置は、第11の発明において、前記キーワード選択手段は、前記テキスト抽出手段のコンテンツ情報提供手段以外の複数のコンテンツ情報提供手段からの比較用コンテンツ情報を収集する比較用コンテンツ情報収集手段と、該比較用コンテンツ情報収集手段で収集したコンテンツ情報を単語に分割して比較用単語を抽出する単語分割手段と、該単語分割手段で抽出した比較用単語と、前記テキスト抽出手段から入力されるテキストとを比較し、当該テキスト抽出手段から入力される単語がキーワードとする重要単語か否かを判定する重要単語判定手段とを備えていることを特徴としている。
さらにまた、第12の発明に係るメタデータ生成装置は、第11の発明において、前記キーワード選択手段は、前記テキスト抽出手段のコンテンツ情報提供手段以外の複数のコンテンツ情報提供手段からの比較用コンテンツ情報を収集する比較用コンテンツ情報収集手段と、該比較用コンテンツ情報収集手段で収集したコンテンツ情報を単語に分割して比較用単語を抽出する単語分割手段と、該単語分割手段で抽出した比較用単語と、前記テキスト抽出手段から入力されるテキストとを比較し、当該テキスト抽出手段から入力される単語がキーワードとする重要単語か否かを判定する重要単語判定手段とを備えていることを特徴としている。
この第12の発明では、テキスト抽出手段がコンテンツ情報提供手段からコンテンツ情報を収集するように構成されている場合に、抽出される単語数が膨大となるので、該当するコンテンツ情報提供手段とは異なる他の複数のコンテンツ情報提供手段から比較用コンテンツ情報を収集し、収集した比較用コンテンツ情報を単語分割手段で単語に分割して比較用単語を抽出し、抽出した比較用単語とテキスト抽出手段で抽出した単語とを比較してからキーワードとする重要単語であるか否かを判定することにより、個人コンテンツ情報に適合するキーワードを選択することができる。
なおさらに、第13の発明に係るメタデータ生成装置は、第12の発明において、前記重要単語判定手段は、前記テキスト抽出手段から入力される単語で出現頻度が高い単語で且つ前記比較用単語では出現頻度が低い単語を重要単語とし、これをキーワードとして抽出するように構成されていることを特徴としている。
この第13の発明では、重要単語を抽出する際に、テキスト抽出手段から入力される単語で出現頻度が高く、比較用単語では出現頻度が低い単語は、新しい単語である可能性が高く、例えばテキスト抽出手段でローカル及び全国的なコンテンツ情報から単語を抽出するようにすると、ローカルなコンテンツ情報から抽出される単語のうち全国的なコンテンツ情報に現れる単語を除いた単語がキーワードとして選択され、個人コンテンツ情報に最適なキーワードを選択することができる。
この第13の発明では、重要単語を抽出する際に、テキスト抽出手段から入力される単語で出現頻度が高く、比較用単語では出現頻度が低い単語は、新しい単語である可能性が高く、例えばテキスト抽出手段でローカル及び全国的なコンテンツ情報から単語を抽出するようにすると、ローカルなコンテンツ情報から抽出される単語のうち全国的なコンテンツ情報に現れる単語を除いた単語がキーワードとして選択され、個人コンテンツ情報に最適なキーワードを選択することができる。
以下、本発明の実施の形態を図面に基づいて説明する。
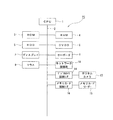
図1は、本発明の第1の実施形態を示すブロック図であって、図中、PCはパーソナルコンピュータ、サーバー等で構成される情報処理装置であって、この情報処理装置PCは、中央演算処理装置(CPU)1を有し、この中央演算処理装置1にシステムバス2を介して中央演算処理装置1が実行するプログラムを記憶したROM3、中央処理装置1で実行する演算処理に必要なデータ等を記憶するRAM4、アプリケーションプログラムや後述する個人及び一般コンテンツ情報等を記憶するハードディスク装置(HDD)5、デジタル多用途ディスク(DVD)に対する書込及び読出しを行うDVDドライブ装置(DVDD)6、データを表示するディスプレイ7、データを入力するためのキーボード8及びマウス9等が接続されている。
図1は、本発明の第1の実施形態を示すブロック図であって、図中、PCはパーソナルコンピュータ、サーバー等で構成される情報処理装置であって、この情報処理装置PCは、中央演算処理装置(CPU)1を有し、この中央演算処理装置1にシステムバス2を介して中央演算処理装置1が実行するプログラムを記憶したROM3、中央処理装置1で実行する演算処理に必要なデータ等を記憶するRAM4、アプリケーションプログラムや後述する個人及び一般コンテンツ情報等を記憶するハードディスク装置(HDD)5、デジタル多用途ディスク(DVD)に対する書込及び読出しを行うDVDドライブ装置(DVDD)6、データを表示するディスプレイ7、データを入力するためのキーボード8及びマウス9等が接続されている。
また、システムバス2には、インターネット等のネットワークに接続するネットワーク接続部10、個人コンテンツ情報作成手段としてのデジタルカメラ13を接続するデジタルカメラ接続インタフェース14及び各種メモリカード15を接続するメモリカードインタフェース16が接続されている。
中央演算処理装置1は、機能ブロック図で表すと、図2に示すように、デジタルカメラ13から後述するように画像データ及び撮影メタデータで構成される個人コンテンツ情報を読込む個人コンテンツ情報読込部20と、この個人コンテンツ情報読込部20で読込んだ個人コンテンツ情報を記憶する個人コンテンツ情報記憶部21と、個人コンテンツ情報を検索する場合にその検索を容易にする検索用メタデータを生成する元になるコンテンツ情報を収集して固有名詞等の単語を抽出するテキスト抽出部22と、このテキスト抽出部22で抽出した単語に基づいてキーワードを選択するキーワード選択部23と、このキーワード選択部23で選択されたキーワードを検索用メタデータに変換するメタデータ生成部24と、このメタデータ生成部24で生成した検索用メタデータを個人コンテンツ情報記憶部21に記憶されている個人コンテンツ情報のメタデータに付加して記憶するメタデータ記憶部25とを備えている。
中央演算処理装置1は、機能ブロック図で表すと、図2に示すように、デジタルカメラ13から後述するように画像データ及び撮影メタデータで構成される個人コンテンツ情報を読込む個人コンテンツ情報読込部20と、この個人コンテンツ情報読込部20で読込んだ個人コンテンツ情報を記憶する個人コンテンツ情報記憶部21と、個人コンテンツ情報を検索する場合にその検索を容易にする検索用メタデータを生成する元になるコンテンツ情報を収集して固有名詞等の単語を抽出するテキスト抽出部22と、このテキスト抽出部22で抽出した単語に基づいてキーワードを選択するキーワード選択部23と、このキーワード選択部23で選択されたキーワードを検索用メタデータに変換するメタデータ生成部24と、このメタデータ生成部24で生成した検索用メタデータを個人コンテンツ情報記憶部21に記憶されている個人コンテンツ情報のメタデータに付加して記憶するメタデータ記憶部25とを備えている。
ここで、テキスト抽出部22は、個人コンテンツ情報を検索する場合にその検索を容易にする検索用メタデータを生成する元になるコンテンツ情報提供手段としての新聞社におけるニュースサイト等のホームページにインターネットを経由してアクセスするためのURL(Uniform Resource Locator)を入力するURL入力部31と、このURL入力部31で入力したURLに基づいてアクセスされるホームページからコンテンツ情報を読込むコンテンツ情報読込部32と、このコンテンツ情報読込部32で読込んだコンテンツ情報を記憶するコンテンツ情報記憶部33と、このコンテンツ情報記憶部33に記憶されたコンテンツ情報を形態素解析して単語を抽出する単語分割手段としての形態素解析部34とを備えている。
また、キーワード選択部23は、キーワード辞書となる多数のキーワードを記憶するキーワード記憶部36と、予め設定した参照用のホームページを指定する複数のURLを記憶したURL記憶部37と、このURL記憶部37に記憶されたURLに基づいてアクセスしたホームページから参照用コンテンツ情報を読込む参照用コンテンツ情報読込部38と、この参照用コンテンツ情報読込部38で読込んだ参照用コンテンツ情報を形態素解析して単語を抽出する単語分割手段としての形態素解析部39と、テキスト抽出部22から入力される単語と形態素解析部39から出力される参照用コンテンツ情報の単語とに基づいて重要単語を判定する重要単語判定部40と、重要単語判定部40で判定された重要単語とキーワード記憶部36に記憶されているキーワードとを比較して一致する重要単語をキーワードとして抽出するキーワード抽出部41とを備えている。なお、キーワード記憶部36に記憶されているキーワードはデジタル放送電波、インターネット等の通信媒体を介して定期的に又は所望時に逐次最新のキーワードに更新される。また、更新用キーワードを記憶したフレキシブル磁気ディスクやCD等の記憶媒体に基づいてキーワードを更新するようにしてもよい。
そして、中央演算処理装置1では、図3に示すデジタルカメラ13からの静止画像データを読込む個人コンテンツ情報読込処理、図5に示す個人コンテンツ情報を検索する場合にその検索を容易にするメタデータを生成する元になるコンテンツ情報を読込んで単語を抽出する単語抽出処理、図7に示す単語抽出処理で抽出された単語から重要単語を抽出してキーワードを選択し、選択したキーワードを検索用メタデータに変換して検索用メタデータを生成するメタデータ生成処理を実行する。
個人コンテンツ情報読込処理は、デジタルカメラ接続インタフェース12にデジタルカメラ13が接続されたときに実行され、図3に示すように、先ず、ステップS11で、デジタルカメラ13に内蔵された撮影した画像データ及びそのメタデータを関連付けして記憶するメモリカードにアクセスして、これに記憶されている画像データ及びメタデータを順次読込む。
ここで、カードメモリに記憶されている画像データは、図4に示すように、デジタルカメラ13で撮影したバイナリデータの画像データを圧縮した例えばJPEG圧縮形式のデータのデータ記録領域RDと、このデータ記録領域RDに続くXML(Extensible Markup Language)データで記述されるメタデータを記録する撮影メタデータ記録領域RMとが連結された形式で記憶されている。撮影メタデータ記録領域RMに記録されたメタデータは、メタデータ領域ヘッダーRM1、メタデータボディRM2及びメタデータ領域フッターRM3とで構成されている。メタデータ領域ヘッダーRM1及びメタデータ領域フッターRM3は、画像データにメタデータが連結されているか否かを正しく認識するために、撮影メタデータ領域RMの識別情報、サイズ情報が記録され、メタデータボディRM2には、撮影した画像情報の日時情報、シャッター速度、絞り等の撮影情報等がXMLファイル形式で記録されている。
このように、画像データ記録領域RDの次にメタデータ記録領域RMを形成することにより、他のアプリケーションには影響を与えずに、メタデータを登録することができる。すなわち、画像データのヘッダー部分の情報はメタデータの接続前から変化しないので、画像データを一般的なブラウザによって画像再生が行えることになる。
次いで、ステップS12に移行して、読込んだ画像データをディスプレイ7に表示して、読込みたい画像データを選択する選択処理を行い、次いでステップS13に移行して、選択処理で選択された画像データが存在するか否かを判定し、選択された画像データが存在しない場合には読込処理を終了し、選択された画像データが存在する場合には、ステップS14に移行して、選択された画像データ及びこれに付属するメタデータとを例えばハードディスク装置5の指定された個人コンテンツ情報記憶領域としての画像データ記憶領域に記憶してから画像データ読込処理を終了する。
次いで、ステップS12に移行して、読込んだ画像データをディスプレイ7に表示して、読込みたい画像データを選択する選択処理を行い、次いでステップS13に移行して、選択処理で選択された画像データが存在するか否かを判定し、選択された画像データが存在しない場合には読込処理を終了し、選択された画像データが存在する場合には、ステップS14に移行して、選択された画像データ及びこれに付属するメタデータとを例えばハードディスク装置5の指定された個人コンテンツ情報記憶領域としての画像データ記憶領域に記憶してから画像データ読込処理を終了する。
また、単語抽出処理は、図5に示すように、先ず、ステップS21で、URL入力部31で例えば新聞社のニュースサイト等のURLが入力されたか否かを判定し、URLが入力されていないときにはこれが入力されるまで待機し、URLが入力されたときにはステップS22に移行する。
このステップS22では、URLに基づいて該当するホームページをアクセスし、該当するホームページに記載されているテキストデータを読込み、次いでステップS23に移行して、読込んだテキストデータをハードディスク5に形成したコンテンツ情報記憶部に記憶してからステップS24に移行する。
このステップS22では、URLに基づいて該当するホームページをアクセスし、該当するホームページに記載されているテキストデータを読込み、次いでステップS23に移行して、読込んだテキストデータをハードディスク5に形成したコンテンツ情報記憶部に記憶してからステップS24に移行する。
このステップS24では、コンテンツ情報記憶部に記憶したテキストデータについて形態素解析処理を行って単語を抽出し、次いでステップS25に移行して、抽出した単語をRAM4に一時的に記憶し、次いでステップS26に移行して、図6に示すメタデータ生成処理を起動してから単語抽出処理を終了する。
さらに、メタデータ生成処理は、図6に示すように、単語抽出処理の終了時に起動され、先ず、ステップS31で、ハードディスク装置5の画像データ記憶領域から画像データの検索を容易にする検索用メタデータを付加する対象となる画像データを読込んでディスプレイ7に表示する画像データ選択処理を行い、次いでステップS32に移行して、画像データ選択処理で、検索用メタデータを付加する対象となる画像データが選択されたか否かを判定し、画像データが選択されていないときにはステップS33に移行して、メタデータ生成処理を終了する処理終了ボタンの選択等による処理終了指示があったか否かを判定し、処理終了指示があったときにはそのままメタデータ生成処理を終了し、処理終了指示がないときには前記ステップS31に戻る。
さらに、メタデータ生成処理は、図6に示すように、単語抽出処理の終了時に起動され、先ず、ステップS31で、ハードディスク装置5の画像データ記憶領域から画像データの検索を容易にする検索用メタデータを付加する対象となる画像データを読込んでディスプレイ7に表示する画像データ選択処理を行い、次いでステップS32に移行して、画像データ選択処理で、検索用メタデータを付加する対象となる画像データが選択されたか否かを判定し、画像データが選択されていないときにはステップS33に移行して、メタデータ生成処理を終了する処理終了ボタンの選択等による処理終了指示があったか否かを判定し、処理終了指示があったときにはそのままメタデータ生成処理を終了し、処理終了指示がないときには前記ステップS31に戻る。
一方、ステップS32の判定結果が、選択された画像データが存在するものであるときには、ステップS34に移行して、予めURL記憶部37に記憶されている例えば全国的な複数の新聞社のニュースサイトにおけるURL1〜URLnの最初の1つURL1を読出し、次いでステップS35に移行して、読み出したURL1に基づいて該当するホームページをアクセスし、該当するホームページに記載されているテキストデータを読込み、次いでステップS36に移行して、読込んだテキストデータについて形態素解析処理を行って例えば固有名詞でなる単語を抽出し、次いでステップS37に移行して、抽出した単語を参照用単語としてRAM4の所定記憶領域に一時格納してからステップS38に移行する。
このステップS38では、読込んでいないURLが存在するか否かを判定し、読込んでいないURLが存在するときには、ステップS39に移行して、現在のURL番号URLi(i=1〜n)に“1”を加算した値を新たなURL(i+1)を算出し、該当するURL(i+1)をURL記憶部37より読出してから前記ステップS35に戻る。
また、ステップS38の判定結果が、全てのURLについてテキストデータの読込みが完了したものであるときには、ステップS40に移行して、重要テキスト抽出部に対応する重要単語判定処理を実行してキーワードを抽出する。
また、ステップS38の判定結果が、全てのURLについてテキストデータの読込みが完了したものであるときには、ステップS40に移行して、重要テキスト抽出部に対応する重要単語判定処理を実行してキーワードを抽出する。
ここで、重要単語判定処理は、TFIDF(Term Frequency & Inverse Document Frequency)処理を行うことにより単語の重みWを算出して重要単語を抽出する。TFIDFは、下記(1)式に示すように、単語抽出処理で抽出した単語の出現頻度(TF)と、参照用単語を含めたテキストデータ全体でのその単語が使われているテキストデータ数の頻度の逆数(IDF)との積で求め、数値が大きいほど、その単語が重要であるということを表している。TFは頻出する単語は重要であるという指標であり、IDFは、多くの文書データに出現する単語は重要ではない、つまり、特定の文書データに出現する単語が重要であるという指標であり、ある単語が使われているテキストデータ数が減少すると大きくなる性質を持っている。以下、説明を簡単にするために、コンテンツ情報提供手段として新聞社のホームページを使用する場合で例示する。全国紙とローカル紙のホームページを考慮すると、地方の情報を記載するローカル紙の方がより身近であり、個人コンテンツのメタデータとして使用する単語を抽出するのにより適していると考えることができ、且つ全国紙のホームページにこれらの単語が出現する頻度が低いと考えることができる。
したがって、TFIDFの値は、頻出するが多くのテキストデータに出現する単語(接続詞、助詞など)や、特定のテキストデータにのみ出現するがそのテキストデータでも頻度が小さい単語に対しては小さくなり、逆に、特定の文書データに高頻度で出現する単語に対しては大きくなる性質を持っている。TFIDFによって全国紙に記載されている単語とローカル紙に記載されている単語とを弁別してローカル紙に記載されている単語を重要単語として判定することができる。
W(t,d)=TF(t,d)×IDF(t) …………(1)
ここで、TF(t,d)はテキストデータdに単語tが出現する頻度を表し、IDF(t)=log(D/DF(t))であり、DF(t)はテキストデータ全体で単語tが出現するテキストデータ数の頻度、Dは全テキストデータ数である。
URLi(i=1〜m)をホームページのURLとし、出現する単語をTj(j=1〜n)とすると、(1)式を用いて、以下の行列Wijを算出することができる。

ここで、TF(t,d)はテキストデータdに単語tが出現する頻度を表し、IDF(t)=log(D/DF(t))であり、DF(t)はテキストデータ全体で単語tが出現するテキストデータ数の頻度、Dは全テキストデータ数である。
URLi(i=1〜m)をホームページのURLとし、出現する単語をTj(j=1〜n)とすると、(1)式を用いて、以下の行列Wijを算出することができる。
ローカル紙のホームページがURLmであるとすると、行列の要素Wm1、Wm2、……Wmmのうち、大きい値を示すWijの順に単語Tjを抽出し、重要単語と判定すればよい。
次いで、ステップS41に移行して、重要単語と、キーワード記憶部36に記憶されている記憶キーワードとを比較し、次いでステップS42に移行して、重要単語と一致するキーワードが存在するか否かを判定し、一致するキーワードが存在するときには後述するステップS46にジャップし、一致するキーワードが存在しないときには、ステップS43に移行して、テキストデータから抽出した重要単語をキーワードを採用するか否かを選択する選択画面をディスプレイ7に表示し、次いでステップS44に移行して、キーワードとして採用が設定されたか否かを判定し、キーワードとしての採用が選択されないときには後述するステップS47にジャンプし、キーワードとしての採用が選択されたときにはステップS45に移行して、採用されたキーワードをキーワード記憶部に追加してからステップS46に移行する。
次いで、ステップS41に移行して、重要単語と、キーワード記憶部36に記憶されている記憶キーワードとを比較し、次いでステップS42に移行して、重要単語と一致するキーワードが存在するか否かを判定し、一致するキーワードが存在するときには後述するステップS46にジャップし、一致するキーワードが存在しないときには、ステップS43に移行して、テキストデータから抽出した重要単語をキーワードを採用するか否かを選択する選択画面をディスプレイ7に表示し、次いでステップS44に移行して、キーワードとして採用が設定されたか否かを判定し、キーワードとしての採用が選択されないときには後述するステップS47にジャンプし、キーワードとしての採用が選択されたときにはステップS45に移行して、採用されたキーワードをキーワード記憶部に追加してからステップS46に移行する。
ステップS46では、抽出されたキーワードを検索キーワードとしてRAM4に一時記憶し、次いでステップS47に移行し、上述したキーワード抽出処理をしていない重要単語が存在するか否かを判定し、キーワード抽出処理を終了していない重要単語が存在する場合にはステップS48に移行して、次の重要単語を読込んでから前記ステップS41に戻り、抽出した全ての重要単語に対してキーワード抽出処理が終了したときにはステップS49に移行する。
このステップS49では、選択したキーワードを検索用キーワードとして採用するか否かを選択する選択画面をディスプレイ7に表示し、次いでステップS50に移行して検索用キーワードとして選択されているか否かを判定し、検索用キーワードとして選択されていないときには後述するステップS53にジャンプし、検索用キーワードとして選択されているときにはステップS51に移行して、検索用キーワードを検索用メタデータに変換し、次いでステップS52に移行して、変換した検索用メタデータを該当する画像データのメタデータ記憶領域RMに付加すると共に、メタデータ領域ヘッダーRM1及びメタデータ領域フッターRM3ヘッダーを変更してからステップS53に移行する。
ステップS53では、他の個人コンテンツ情報を選択するか否かを判定し、他の個人コンテンツ情報を選択する場合には前記ステップS31に戻り、他の個人コンテンツ情報を選択しない場合にはメタデータ生成処理を終了する。
なお、図3の処理が個人コンテンツ情報読込手段に対応し、図5の処理がテキスト抽出手段に対応し、このうちステップS21〜S23の処理がコンテンツ情報収集手段に対応し、ステップS24処理が単語分割手段に対応し、図6の処理において、ステップS34〜S47の処理がキーワード抽出手段に対応し、このうちステップS34、S35、S38、S39の処理が参照用コンテンツ情報収集手段に対応し、S37の処理が単語分割手段に対応し、ステップS40の処理が重要単語判定手段に対応し、ステップS49〜ステップS52の処理がメタデータ生成手段に対応している。
なお、図3の処理が個人コンテンツ情報読込手段に対応し、図5の処理がテキスト抽出手段に対応し、このうちステップS21〜S23の処理がコンテンツ情報収集手段に対応し、ステップS24処理が単語分割手段に対応し、図6の処理において、ステップS34〜S47の処理がキーワード抽出手段に対応し、このうちステップS34、S35、S38、S39の処理が参照用コンテンツ情報収集手段に対応し、S37の処理が単語分割手段に対応し、ステップS40の処理が重要単語判定手段に対応し、ステップS49〜ステップS52の処理がメタデータ生成手段に対応している。
次に、上記第1の実施形態の動作を説明する。
先ず、 ユーザーがデジタルカメラ13で例えば花火大会の風景や人物の写真を撮影し、そのビットマップ画像データと撮影日時、撮影データ等の撮影メタデータとで構成される個人コンテンツ情報をデジタルカメラ13のメモリカードに格納する。
その後、デジタルカメラ13を自宅に持ち帰って、デジタルカメラ13を直接デジタルカメラ接続インタフェース14に接続するか又はデジタルカメラ13からメモリカードを抜き出し、これをメモリカードインタフェース16に接続されたメモリカードリーダー15に装着した状態で、図3に示す個人コンテンツ情報読込処理を実行する。
先ず、 ユーザーがデジタルカメラ13で例えば花火大会の風景や人物の写真を撮影し、そのビットマップ画像データと撮影日時、撮影データ等の撮影メタデータとで構成される個人コンテンツ情報をデジタルカメラ13のメモリカードに格納する。
その後、デジタルカメラ13を自宅に持ち帰って、デジタルカメラ13を直接デジタルカメラ接続インタフェース14に接続するか又はデジタルカメラ13からメモリカードを抜き出し、これをメモリカードインタフェース16に接続されたメモリカードリーダー15に装着した状態で、図3に示す個人コンテンツ情報読込処理を実行する。
これにより、メモリカードアクセスして、これに格納された各個人コンテンツ情報を読込み(ステップS11)、読込んだ各個人コンテンツ情報をディスプレイ7に表示して、必要な個人コンテンツ情報を選択する画像データ選択処理を行い(ステップS12)、この画像データ選択処理で選択された画像データと撮影メタデータとで構成される個人コンテンツ情報がハードディスク装置5の指定した個人コンテンツ情報記憶領域としての画像データ記憶領域に記憶される(ステップS14)。
この個人コンテンツ情報のハードディスク装置5への記憶が完了した時点で又はその後に、記憶した個人コンテンツ情報に対して検索を容易にするための検索用メタデータを付加するには、例えばディスプレイ7に表示されているアイコンをクリックして図5に示す単語抽出処理を実行させる。
この単語抽出処理では、ユーザーが撮影した個人コンテンツ情報に関連する情報が得られる可能性が高い例えば地方紙のニュースサイトを指定するURLをURL入力部31から入力すると、該当するURLのホームページにアクセスしてテキストデータを読込み(ステップS22)、読込んだテキストデータをコンテンツ情報記憶部33に記憶する(ステップS23)。
この単語抽出処理では、ユーザーが撮影した個人コンテンツ情報に関連する情報が得られる可能性が高い例えば地方紙のニュースサイトを指定するURLをURL入力部31から入力すると、該当するURLのホームページにアクセスしてテキストデータを読込み(ステップS22)、読込んだテキストデータをコンテンツ情報記憶部33に記憶する(ステップS23)。
そして、記憶されたテキストデータに対して形態素解析処理を行って固有名詞を含む単語を抽出し(ステップS24)、抽出した単語をRAM4の所定記憶領域に一時記憶し(ステップS25)、次いで図6に示すメタデータ生成処理を起動してから(ステップS26)単語抽出処理を終了する。このとき、例えば見出しが「花火大会」で、記事として「○月○日墨田川で花火大会があり、数十万人の観衆が集まった。……」が記載されているものとすると、抽出される単語としては花火大会、○月○日、隅田川、数十万人、観衆、……となる。
メタデータ生成処理では、先ず、検索用メタデータを付加する個人コンテンツ情報を選択する選択処理を実行する。この選択処理では、ハードディスク5の個人コンテンツ情報記憶領域に記憶されている個人コンテンツ情報をディスプレイ7に表示し、表示された個人コンテンツ情報から所望の個人コンテンツ情報を選択する(ステップS31)。この場合、個人コンテンツ情報は1つの画像データを選択してもよく、複数の画像データをグループに纏めてグループ単位で選択するようにしてもよい。
そして、個人コンテンツ情報の選択が行われない場合には処理終了ボタンをマウスでクリックする等の処理終了指示が入力されたか否かを判定し(ステップS33)、処理終了指示が入力されたときには、そのままメタデータ生成処理を終了するが、処理終了指示が入力されていないときにはステップS31に戻って個人コンテンツ情報選択処理を継続する。
このメタ個人コンテンツ情報選択処理で、任意の個人コンテンツ情報が1つ又はグループ単位で選択されると、ステップS32からステップS34に移行して、URL記憶部31に記憶されている参照用コンテンツ情報を指定する例えば全国紙のニュースサイトを指定する複数のURLから最初のURL(URL1)を読込み、次いで該当するURL1のホームページにアクセスしてテキストデータを読込み(ステップS35)、読込んだテキストデータに対して形態素解析処理して固有名詞の単語を抽出する(ステップS36)。
次いで抽出した単語を参照用単語としてRAM4の所定記憶領域に一時記憶し、次いでURL記憶部37に記憶されているURLで読込んでいないURLが存在するか否かを判定し(ステップS38)、読込んでいないURLが存在する場合には、新たなURL(=URL(i+1)を算出し、これをURL記憶部37から読出してから(ステップS39)ステップS35に戻って該当するホームページのテキストデータを読込み、形態素解析処理して参照用単語を抽出してRAM4に一時記憶する処理を繰り返す。
そして、URL記憶部37に記憶されている全てのURLについて単語抽出が終了すると、図5の単語抽出処理で抽出したユーザーの好みに応じたローカル紙のホームページから取得したテキストデータから抽出した単語とURL記憶部37に記憶されている全国紙等の参照用URLのホームページから取得したテキストデータから抽出した参照用単語とに基づいて重要単語抽出処理を行って、ローカル紙のホームページから取得したテキストデータから抽出した単語の中で出現頻度が高く、全国紙のホームページから取得したテキストデータから抽出した単語には出現頻度が低い単語を重要単語として抽出する(ステップS40)。このため、全国紙でニュースとして扱われている単語については重要単語として抽出されることはなく、ローカル紙でニュースとして扱われているユーザーが撮影した個人コンテンツ情報に関連する単語が重要単語として抽出される。すなわち、全国紙のニュースサイトでは、隅田川の花火は記事として扱われず、例えば隅田川で重大な事件が発生した場合にはこの事件の記事やその外の全国的に重要な記事のみが掲載される(一部重複する記事もある)。このため、前述したように図5の単語抽出処理で抽出された単語のうち「○月○日」「墨田川」は全国紙の記事としても記載されているので、全国紙で記事として採用されない「花火大会」が重要単語として抽出される。
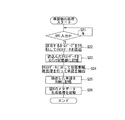
そして、抽出された重要単語がキーワード記憶部36に記憶されているキーワードと一致するか否かを判定し、一致する場合には検索用キーワードとしてRAM4に一時記憶し、抽出された重要単語がキーワード記憶部36に記憶されているキーワードと一致しないときには重要単語をキーワードとして採用するか否かを選択する選択画面をディスプレイ7に表示し、キーワードとして採用されたときには重要単語をキーワードとしてキーワード記憶部36に追加記憶してから(ステップS45)該当する重要単語を検索用キーワードとしてRAM4に一時記憶する。重要単語がキーワードとして採用されないときにはキーワード記憶部36に記憶することなく次の重要単語のキーワード設定処理を行う。
そして、全ての重要単語についてキーワード抽出処理を終了したときには、RAM4に一時記憶されている検索用キーワードを個人コンテンツ情報に対する検索用キーワードとして採用するか否かを選択する選択画面をディスプレイ7に表示し(ステップS49)、検索用キーワードとして選択されたときに選択された検索用キーワード「花火大会」「隅田川」等をメタデータに変換し(ステップS51)、このメタデータを該当する個人コンテンツ情報のメタデータ記憶領域RMに付加すると共に、メタデータ領域ヘッダー及びメタデータ領域フッターを変更し(ステップS52)。次いで、ステップS53に移行する。このときの検索用メタデータは、図7に示すように、例えば「DrivedKeyword」として「花火大会」が記憶される。
そして、ステップS53で他の個人コンテンツ情報を選択するか否かを判定し、他の個人コンテンツ情報を選択する場合には前記ステップS21に戻り、他の個人コンテンツ情報を選択しない場合にはメタデータ生成処理を終了する。
ところで、前述したステップS42で重要単語がキーワード記憶部36に記憶されているキーワードと一致しない場合には、ステップS42からステップS43に移行して、重要単語をキーワードとして採用するか否かの選択画面をディスプレイ7に表示し、重要単語をキーワードとして採用する場合には、ステップS44からステップS45に移行して、採用したキーワードを新たなキーワードとしてキーワード記憶部に追加してからステップS46に移行して検索用キーワードとしてRAM4に一時記憶する。
ところで、前述したステップS42で重要単語がキーワード記憶部36に記憶されているキーワードと一致しない場合には、ステップS42からステップS43に移行して、重要単語をキーワードとして採用するか否かの選択画面をディスプレイ7に表示し、重要単語をキーワードとして採用する場合には、ステップS44からステップS45に移行して、採用したキーワードを新たなキーワードとしてキーワード記憶部に追加してからステップS46に移行して検索用キーワードとしてRAM4に一時記憶する。
このため、キーワード記憶部36に記憶されていない重要単語でもユーザーの好みによってキーワードとして採用することができ、検索用キーワードとして採用することができる。
このようにして、ハードディスク装置5に記憶された個人コンテンツ情報に検索用メタデータが自動的に付加されることにより、後日個人コンテンツ情報を検索する際、個人コンテンツ情報の日時が正確に思い出せない場合に、検索用キーワード例えば上記の場合「花火大会」を入力して検索することにより、該当する個人コンテンツ情報を正確に検索することができる。この場合、個人コンテンツ情報の内容と検索用メタデータで記述されたキーワードの内容とが一致する必要はなく、花火大会の頃に撮影した個人コンテンツ情報を検索したい場合に花火大会の前後の個人コンテンツ情報に「花火大会」を記述する検索用メタデータが付加されることになるため、「花火大会」をキーワードとして時期的に関連する個人コンテンツ情報を正確に検索することができる。
このようにして、ハードディスク装置5に記憶された個人コンテンツ情報に検索用メタデータが自動的に付加されることにより、後日個人コンテンツ情報を検索する際、個人コンテンツ情報の日時が正確に思い出せない場合に、検索用キーワード例えば上記の場合「花火大会」を入力して検索することにより、該当する個人コンテンツ情報を正確に検索することができる。この場合、個人コンテンツ情報の内容と検索用メタデータで記述されたキーワードの内容とが一致する必要はなく、花火大会の頃に撮影した個人コンテンツ情報を検索したい場合に花火大会の前後の個人コンテンツ情報に「花火大会」を記述する検索用メタデータが付加されることになるため、「花火大会」をキーワードとして時期的に関連する個人コンテンツ情報を正確に検索することができる。
このように、上記第1の実施形態によれば、ユーザーが選択したURLで指定されるホームページからテキストデータを収集し、このテキストデータから形態素解析を行って単語を抽出し、抽出した単語と、他の予め記憶された他のURLで指定されるホームページから取得したテキストデータから形態素解析を行って抽出した参照用単語とを重要単語抽出処理で、TFIDF処理によって、ユーザーの好みによるホームページのテキストデータに出現頻度が高く、参照用URLのホームページには出現頻度が少ない単語を重要単語として抽出し、抽出した重要単語のうちキーワード記憶部36に記憶されているキーワードと一致するものを検索用キーワードとして選択するので、地方特有のイベント情報を的確に抽出して検索用メタデータとすることができ、検索用メタデータを煩わしい操作を伴うことなく容易に生成することができ、操作に不慣れなユーザーであっても個人コンテンツ情報に検索用メタデータを容易に付加することができる。
しかも、検索用メタデータを作成する対象となるコンテンツ情報をユーザーが選択することができるので、ユーザー個人に最適なキーワードを抽出することができ、後の個人コンテンツ情報を検索する際のキーワードとして最適なキーワードを設定することができる。
しかも、キーワード選択処理で抽出した重要単語のうちキーワード記憶部に記憶されているキーワードと比較して一致するキーワードを検索用キーワードとして設定するので、不用意に多数のキーワードが検索用キーワードとして設定されることがなく、ユーザーが必要とするキーワードのみが検索用メタデータとして設定され、全体の検索用メタデータ数を制限することができる。
しかも、キーワード選択処理で抽出した重要単語のうちキーワード記憶部に記憶されているキーワードと比較して一致するキーワードを検索用キーワードとして設定するので、不用意に多数のキーワードが検索用キーワードとして設定されることがなく、ユーザーが必要とするキーワードのみが検索用メタデータとして設定され、全体の検索用メタデータ数を制限することができる。
なお,上記第1の実施形態においては、ローカル紙のニュースサイトのホームページと全国紙のニュースサイトのホームページとを選択する場合について説明したが、これに限定されるものではなく、ユーザーの指定するURLと指定したURLから平均的な単語を削除するために参照する参照用URLとは任意に設定することができる。
また、個人コンテンツ情報に関する受信電子メールとその他の受信電子メールがあれば、これらの電子メールを選択するようにしてもよい。
また、個人コンテンツ情報に関する受信電子メールとその他の受信電子メールがあれば、これらの電子メールを選択するようにしてもよい。
また、上記第1の実施形態においては、URLを指定する場合について説明したが、これに限定されるものではなく、インターネットに限らず、他のネットワークを利用して、検索用メタデータを生成する元となるコンテンツ情報を入手するようにしてもよい。
また、上記第1の実施形態においては、テキストデータから重要単語を抽出する場合について説明したが、これに限定されるものではなく、単語抽出処理で、ホームページのテキストデータからフォントの大きい単語や斜体フォント、太字フォント等を採用している単語を重要単語として抽出するようにしてもよい。
また、上記第1の実施形態においては、テキストデータから重要単語を抽出する場合について説明したが、これに限定されるものではなく、単語抽出処理で、ホームページのテキストデータからフォントの大きい単語や斜体フォント、太字フォント等を採用している単語を重要単語として抽出するようにしてもよい。
次に、本発明の第2の実施形態を図8〜図14について説明する。
この第2の実施形態は、ホームページからコンテンツ情報を取得する場合に代えて、文章が印刷された印刷物からコンテンツ情報を取得するようにしたものである。
この第2の実施形態では、図8に示すように、システムバス2に、カラーイメージスキャナ17がスキャナ接続インタフェース部18を介して接続され、カラーイメージスキャナ17で読込んだ印刷物の画像データを中央処理装置1で読込み、文字認識して重要単語を抽出するように構成されている。
この第2の実施形態は、ホームページからコンテンツ情報を取得する場合に代えて、文章が印刷された印刷物からコンテンツ情報を取得するようにしたものである。
この第2の実施形態では、図8に示すように、システムバス2に、カラーイメージスキャナ17がスキャナ接続インタフェース部18を介して接続され、カラーイメージスキャナ17で読込んだ印刷物の画像データを中央処理装置1で読込み、文字認識して重要単語を抽出するように構成されている。
このときの、中央処理装置1の機能ブロック図は、図9に示すように、テキスト抽出部22が、カラーイメージスキャナ17から画像データを読込む画像データ読込部51と、この画像データ読込部51で読込んだ画像データから特定の領域の文字を文字認識処理して単語を抽出する文字認識部52とで構成され、キーワード選択部23がキーワード記憶部36と、文字認識部52から入力される単語とキーワード記憶部36に記憶されたキーワードとを比較して、両者が一致する単語を重要単語として判定する重要単語判定部53とで構成されていることを除いては図2と同様の構成を有し、図2との対応部分には同一符号を付し、その詳細説明はこれを省略する。
この第2の実施形態では、図10に示すように、ユーザーが撮影した個人コンテンツ情報に関連する文章が記載された新聞、チラシや学校で配布されたお知らせ等の例えば白地に黒色で文章が印刷された印刷物61を用意し、この印刷物61に記載されている文章のうちユーザーが検索用メタデータとして使用したい単語に対して、図11でハッチング領域で示すように例えば文章が判読可能な赤色の抽出単語の領域を表す領域識別マーク62を施し、この領域識別マーク62を施した単語を重要単語として抽出する。
すなわち、第2の実施形態では、中央処理部1で、図12のメタデータ生成処理を実行する。
このメタデータ生成処理は、前述した第1の実施形態における図6の処理において、ステップS34〜ステップS41が省略され、これらに代えて、ステップS32の判定結果が対象画像データが選択されたときにステップS51に移行し、カラーイメージスキャナ17から画像データが入力されたか否かを判定し、画像データが入力されていないときにはこれが入力されるまで待機し、画像データが入力されたときにはステップS52に移行する。
このメタデータ生成処理は、前述した第1の実施形態における図6の処理において、ステップS34〜ステップS41が省略され、これらに代えて、ステップS32の判定結果が対象画像データが選択されたときにステップS51に移行し、カラーイメージスキャナ17から画像データが入力されたか否かを判定し、画像データが入力されていないときにはこれが入力されるまで待機し、画像データが入力されたときにはステップS52に移行する。
このステップS52では、領域識別マーク62が施されている領域を全て抽出し、次いでステップS53に移行して、抽出した領域のうちの先頭の領域を指定してその領域の画像データを読込んでからステップS54に移行し、読込んだ画像データを文字認識処理して重要単語として抽出する文字認識処理を行ってからステップS55に移行し、抽出した重要単語をRAM4の所定記憶領域に記憶してからステップS56に移行する。
このステップS56では、文字認識していない領域識別マーク62が存在するか否かを判定し、文字認識していない領域識別マーク62が存在する場合には、ステップS57に移行して、次に識別する領域識別マーク62で表される領域を指定してその領域の画像データを読込んでから前記ステップS54に戻り、文字認識していない領域識別マーク62が存在しないときには、前記第1の実施形態における図6の処理におけるステップS41に移行する。
この第2の実施形態によれば、ユーザーが例えば運動会に行って、デジタルカメラ13で撮影を行い、画像データをメモリカードに記憶させてから、自宅に戻って情報処理装置PCにデジタルカメラ13を、デジタルカメラ接続インタフェース部14を介して接続するか、又はデジタルカメラ13からメモリカードを引き出して、引き出したメモリカードをメモリカードリーダー15に装着することにより、前述した第1実施形態と同様に図3の個人コンテンツ情報読込処理を行って、画像データ及び撮影メタデータをハードディスク5に形成した画像データ記憶領域に記憶する。
その後、ディスプレイ7に表示されているメタデータ生成処理を表すアイコンを選択することにより、図12のメタデータ生成処理を実行し、検索用メタデータを付加する画像データを選択する。
その後、又はその前に例えば図10に示す撮影した個人コンテンツ情報に関連する文章が記載された印刷物61に、図11に示すように、抽出したい単語に赤色の領域識別マーク62を施してからカラーイメージスキャナ17にセットし、印刷物61をスキャンして画像データを形成し、この画像データをイメージスキャナ接続インタフェース部18を介して中央処理装置1に入力する。
その後、又はその前に例えば図10に示す撮影した個人コンテンツ情報に関連する文章が記載された印刷物61に、図11に示すように、抽出したい単語に赤色の領域識別マーク62を施してからカラーイメージスキャナ17にセットし、印刷物61をスキャンして画像データを形成し、この画像データをイメージスキャナ接続インタフェース部18を介して中央処理装置1に入力する。
このとき、図12のメタデータ生成処理では、カラーイメージスキャナ17から画像データが入力されることにより、この画像データから領域識別マーク62を検出して文字認識を行う領域を切り出す。このときの領域の切出しは、例えば図13(a)に示すように、画像データを横方向にスキャンして、輝度が少ない文字が印刷されている文字領域を検出すると共に、図13(b)に示すようにカラーデータで赤色を表す領域を検出し、両検出領域から領域識別マーク62が施されている領域位置を特定し、この領域識別マーク62が施されている文字領域を抽出する。
そして、領域識別マーク62が施されている先頭の文字領域について画像データを読込んで文字認識処理を行うことにより、例えば図10におけるタイトル部の「運動会」をテキストデータに変換して、重要単語としてRAM4に一時記憶し、次いで、次の領域識別マーク62が施されている領域を指定して「2004年10月10日(日)」をテキストデータに変換して、重要単語としてRAM4に一時記憶し、以下順次「新町」、「新町公園」、「徒歩競走」、「マラソン」を重要単語としてRAM4に一時記憶する。
その後、キーワード記憶部36に記憶されているキーワードと比較して、キーワードとして記憶されている重要単語を検索用キーワードとして採用し、採用された検索用キーワードをキーワードとして選択したときに、検索用キーワードをメタデータに変換することにより、図14に示す検索用メタデータを生成して、変換した検索用メタデータを画像データ記憶領域におけるメタデータ記憶領域RMに付加してからヘッダー及びフッターを変更する。
この第2の実施形態によると、ユーザーが検索用メタデータとしたい文章が記載されている印刷物61を指定して、この印刷物61から抽出したい単語に対して領域識別マーク62を施してからカラーイメージスキャナ17にセットしてスキャンを開始して、印刷物61の画像データを形成し、これを情報処理装置PCに入力することにより、メタデータ生成処理で、デジタルカメラ13で撮影した画像データを選択してからイメージスキャナ17から画像データを取込むことにより、領域識別マーク62を施した領域の画像データを文字認識して重要単語として抽出し、抽出した重要単語のうちキーワード記憶部36に記憶されているキーワードと一致する重要単語を検索用キーワードとして選択し、選択した検索用キーワードを検索用メタデータに変換して個人コンテンツ情報としての画像データに付加するようにしたので、ユーザーが必要としている検索用メタデータを正確に生成して画像データに付加することができる。
なお、上記第2の実施形態においては、領域識別マークとして赤色表示を行う場合について説明したが、これに限定されるものではなく、文字を認識可能な状態であれば、任意の色表示をすることができる。また、色表示に代えて下線表示や枠表示を適用することもできる。
また、上記実施形態においては、領域識別マーク62を施した印刷物61をカラーイメージスキャナ17で画像データとして読込む場合について説明したが、これに限定されるものではなく、印刷物61に領域識別マーク62を施すことなくイメージスキャナで画像データとして読込み、この画像データを文字認識してテキストデータに変換してからこのテキストデータをディスプレイ7に表示して、表示されたテキストデータに対してキーボード又はマウスを使用して重要単語を抽出するようにしてもよい。
また、上記実施形態においては、領域識別マーク62を施した印刷物61をカラーイメージスキャナ17で画像データとして読込む場合について説明したが、これに限定されるものではなく、印刷物61に領域識別マーク62を施すことなくイメージスキャナで画像データとして読込み、この画像データを文字認識してテキストデータに変換してからこのテキストデータをディスプレイ7に表示して、表示されたテキストデータに対してキーボード又はマウスを使用して重要単語を抽出するようにしてもよい。
PC…情報処理装置、1…中央演算処理装置、2…システムバス、3…ROM、4…RAM、5…ハードディスク装置、6…DVDドライブ装置、7…ディスプレイ、8…キーボード、9…マウス、10…ネットワーク接続部、13…デジタルカメラ、15…メモリカードリーダー、17…カラーイメージスキャナ、18…スキャナ接続インタフェース部、20…個人コンテンツ情報読込部、21…個人コンテンツ情報記憶部、22…テキスト抽出部、23…キーワード選択部、31…URL入力部、32…コンテンツ情報読込部、33…コンテンツ情報記憶部、34…形態素解析部、36…キーワード記憶部、37…URL記憶部、38…参照用コンテンツ情報読込部、39…形態素解析部、40…重要単語判定部、41…キーワード抽出部、42…メタデータ生成部、43…メタデータ記憶部、51…画像データ読込部、52…文字認識部、53…重要単語判定部、61…印刷物、62…領域識別マーク
Claims (13)
- 個人のコンテンツ情報を読込む個人コンテンツ情報読込み手段と、該個人コンテンツ情報読込み手段で読込んだ個人コンテンツ情報に関連する他のコンテンツ情報からテキストを抽出するテキスト抽出手段と、該テキスト抽出手段で抽出したテキストに基づいて前記個人コンテンツ情報読込み手段で読込んだ個人コンテンツ情報に対する検索用メタデータを生成するメタデータ生成手段とを備えたことを特徴とするメタデータ生成装置。
- 前記メタデータ生成手段は、前記テキスト抽出手段で抽出したテキストからキーワードを選択するキーワード選択手段を備え、該キーワード選択手段で選択したキーワードに基づいて前記個人コンテンツ情報読込み手段で読込んだ個人コンテンツ情報に対する検索用メタデータを生成するように構成されていることを特徴とする請求項1に記載のメタデータ生成装置。
- 前記キーワード選択手段は、テキスト中の特徴ある文字データをキーワードとして選択するように構成されていることを特徴とする請求項2に記載のメタデータ生成装置。
- 前記文字データはテキスト中に含まれる他の文字データと比較して特徴あるフォントを有していることを特徴とする請求項3に記載のメタデータ生成装置。
- 前記キーワード選択手段は、単語を分割して抽出する単語分割手段を有し、該単語分割手段で抽出した単語の品詞情報に基づいて選択した単語をキーワードとして選択するように構成されていることを特徴とする請求項2乃至4の何れか1項に記載のメタデータ生成装置。
- 前記キーワード選択手段は、所定のキーワードを記憶するキーワード記憶手段を有し、前記テキスト抽出手段で抽出したテキストのうち前記キーワード記憶手段に記憶されているキーワードと一致する単語をキーワードとして選択するように構成されていることを特徴とする請求項2乃至5の何れか1項に記載のメタデータ生成装置。
- 前記キーワード記憶手段は、記憶しているキーワードをデジタル放送電波、ネットワーク、記憶媒体の何れか1つ又は複数を使用して更新するように構成されていることを特徴とする請求項6に記載のメタデータ生成装置。
- 前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データから特定領域を識別する領域識別手段と、該領域識別手段で識別した特定領域の画像データを文字認識する文字認識手段とを少なくとも備えていることを特徴とする請求項1乃至7の何れか1項に記載のメタデータ生成装置。
- 前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データを文字認識する文字認識手段と、該文字認識手段で認識した文字を単語に分割して抽出する単語分割手段とを少なくとも備えていることを特徴とする請求項1乃至7の何れか1項に記載のメタデータ生成装置。
- 前記テキスト抽出手段は、テキストを印刷した印刷物を読取る画像読取手段と、該画像読取手段で読取った画像データから特定領域を識別する領域識別手段と、該領域識別手段で識別した特定領域の画像データを文字認識する文字認識手段と、該文字認識手段で認識した文字を単語に分割して抽出する単語分割手段とを少なくとも備えていることを特徴とする請求項1乃至7の何れか1項に記載のメタデータ生成装置。
- 前記テキスト抽出手段は、ネットワークを介してコンテンツ情報提供手段からコンテンツ情報を収集するコンテンツ情報収集手段と、該コンテンツ情報収集手段で収集したコンテンツ情報からテキストを抽出し、抽出したテキストから単語を分割して抽出する単語分割手段とを少なくとも備えていることを特徴とする請求項1又は2に記載のメタデータ生成装置。
- 前記キーワード選択手段は、前記テキスト抽出手段のコンテンツ情報提供手段以外の複数のコンテンツ情報提供手段からの比較用コンテンツ情報を収集する比較用コンテンツ情報収集手段と、該比較用コンテンツ情報収集手段で収集したコンテンツ情報を単語に分割して比較用単語を抽出する単語分割手段と、該単語分割手段で抽出した比較用単語と、前記テキスト抽出手段から入力されるテキストとを比較し、当該テキスト抽出手段から入力される単語がキーワードとする重要単語か否かを判定する重要単語判定手段とを備えていることを特徴とする請求項11に記載のメタデータ生成装置。
- 前記重要単語判定手段は、前記テキスト抽出手段から入力される単語で出現頻度が高い単語で且つ前記比較用単語では出現頻度が低い単語を重要単語とし、これをキーワードとして抽出するように構成されていることを特徴とする請求項12に記載のメタデータ生成装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005013693A JP2006202081A (ja) | 2005-01-21 | 2005-01-21 | メタデータ生成装置 |
| US11/334,619 US20060167899A1 (en) | 2005-01-21 | 2006-01-18 | Meta-data generating apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005013693A JP2006202081A (ja) | 2005-01-21 | 2005-01-21 | メタデータ生成装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2006202081A true JP2006202081A (ja) | 2006-08-03 |
Family
ID=36698160
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005013693A Withdrawn JP2006202081A (ja) | 2005-01-21 | 2005-01-21 | メタデータ生成装置 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20060167899A1 (ja) |
| JP (1) | JP2006202081A (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008176748A (ja) * | 2007-01-22 | 2008-07-31 | Fujitsu Ltd | 情報付与プログラム、情報付与装置、および情報付与方法 |
| JP2010504567A (ja) * | 2006-08-11 | 2010-02-12 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | コンテンツ拡張方法及びサービスセンタ |
| JP2010515167A (ja) * | 2006-12-28 | 2010-05-06 | グーグル インコーポレイテッド | 文書保存システム |
| JP2019207628A (ja) * | 2018-05-30 | 2019-12-05 | 京セラドキュメントソリューションズ株式会社 | 電子機器 |
| JP2022013603A (ja) * | 2020-06-30 | 2022-01-18 | 株式会社リコー | データ出力システム、情報処理システム、データ出力方法、プログラム |
| US11887391B2 (en) | 2020-06-30 | 2024-01-30 | Ricoh Company, Ltd. | Information processing system, data output system, image processing method, and recording medium |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9910909B2 (en) * | 2013-01-23 | 2018-03-06 | 24/7 Customer, Inc. | Method and apparatus for extracting journey of life attributes of a user from user interactions |
| US10089639B2 (en) | 2013-01-23 | 2018-10-02 | [24]7.ai, Inc. | Method and apparatus for building a user profile, for personalization using interaction data, and for generating, identifying, and capturing user data across interactions using unique user identification |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5819259A (en) * | 1992-12-17 | 1998-10-06 | Hartford Fire Insurance Company | Searching media and text information and categorizing the same employing expert system apparatus and methods |
| US6415307B2 (en) * | 1994-10-24 | 2002-07-02 | P2I Limited | Publication file conversion and display |
| EP0822502A1 (en) * | 1996-07-31 | 1998-02-04 | BRITISH TELECOMMUNICATIONS public limited company | Data access system |
| US5999664A (en) * | 1997-11-14 | 1999-12-07 | Xerox Corporation | System for searching a corpus of document images by user specified document layout components |
| US6044375A (en) * | 1998-04-30 | 2000-03-28 | Hewlett-Packard Company | Automatic extraction of metadata using a neural network |
| AU2002239297A1 (en) * | 2000-11-16 | 2002-06-03 | Mydtv, Inc. | System and methods for determining the desirability of video programming events |
| US20030061206A1 (en) * | 2001-09-27 | 2003-03-27 | Richard Qian | Personalized content delivery and media consumption |
| JP4226862B2 (ja) * | 2002-08-29 | 2009-02-18 | 株式会社リコー | 文書検索装置 |
| US20060106793A1 (en) * | 2003-12-29 | 2006-05-18 | Ping Liang | Internet and computer information retrieval and mining with intelligent conceptual filtering, visualization and automation |
-
2005
- 2005-01-21 JP JP2005013693A patent/JP2006202081A/ja not_active Withdrawn
-
2006
- 2006-01-18 US US11/334,619 patent/US20060167899A1/en not_active Abandoned
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010504567A (ja) * | 2006-08-11 | 2010-02-12 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | コンテンツ拡張方法及びサービスセンタ |
| JP2010515167A (ja) * | 2006-12-28 | 2010-05-06 | グーグル インコーポレイテッド | 文書保存システム |
| JP2008176748A (ja) * | 2007-01-22 | 2008-07-31 | Fujitsu Ltd | 情報付与プログラム、情報付与装置、および情報付与方法 |
| JP2019207628A (ja) * | 2018-05-30 | 2019-12-05 | 京セラドキュメントソリューションズ株式会社 | 電子機器 |
| JP7135446B2 (ja) | 2018-05-30 | 2022-09-13 | 京セラドキュメントソリューションズ株式会社 | 電子機器 |
| JP2022013603A (ja) * | 2020-06-30 | 2022-01-18 | 株式会社リコー | データ出力システム、情報処理システム、データ出力方法、プログラム |
| JP7124859B2 (ja) | 2020-06-30 | 2022-08-24 | 株式会社リコー | データ出力システム、情報処理システム、データ出力方法、プログラム |
| US11887391B2 (en) | 2020-06-30 | 2024-01-30 | Ricoh Company, Ltd. | Information processing system, data output system, image processing method, and recording medium |
Also Published As
| Publication number | Publication date |
|---|---|
| US20060167899A1 (en) | 2006-07-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8990235B2 (en) | Automatically providing content associated with captured information, such as information captured in real-time | |
| JP4977452B2 (ja) | 情報管理装置、情報管理方法、情報管理プログラム、記録媒体及び情報管理システム | |
| EP1980960A2 (en) | Methods and apparatuses for converting electronic content descriptions | |
| CN101178725B (zh) | 用于信息检索的设备和方法 | |
| US7908284B1 (en) | Content reference page | |
| US8126294B2 (en) | Video structuring device | |
| US8482808B2 (en) | Image processing apparatus and method for displaying a preview of scanned document data | |
| US20080079693A1 (en) | Apparatus for displaying presentation information | |
| US20060136803A1 (en) | Creating visualizations of documents | |
| US7743347B2 (en) | Paper-based interface for specifying ranges | |
| US8539344B2 (en) | Paper-based interface for multimedia information stored by multiple multimedia documents | |
| JP2006202081A (ja) | メタデータ生成装置 | |
| US7606797B2 (en) | Reverse value attribute extraction | |
| US7584217B2 (en) | Photo image retrieval system and program | |
| JPH11250071A (ja) | 画像データベースの構築方法および画像データベース装置並びに画像情報記憶媒体 | |
| JP2006120125A (ja) | ドキュメント画像情報管理装置及びドキュメント画像情報管理プログラム | |
| JP2006163877A (ja) | メタデータ生成装置 | |
| JP2009163743A (ja) | 画像処理装置および画像処理方法 | |
| JP2004139466A (ja) | 電子ドキュメント印刷プログラムおよび電子ドキュメント印刷システム | |
| US20080168024A1 (en) | Document mangement system, method of document management and computer readable medium | |
| JP2008226110A (ja) | 情報処理装置、情報処理方法および制御プログラム | |
| WO2004036486A1 (en) | System and method for automatic preparation of data repositories from microfilm-type materials | |
| JPH11250077A (ja) | 情報処理装置、情報処理方法及び記録媒体 | |
| JP4934181B2 (ja) | 付加画像処理システム、画像形成装置及び付加画像追加方法 | |
| WO1997004409A1 (fr) | Dispositif de recherche de fichiers |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20070404 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20071217 |