EP1826692A2 - Query correction using indexed content on a desktop indexer program. - Google Patents
Query correction using indexed content on a desktop indexer program. Download PDFInfo
- Publication number
- EP1826692A2 EP1826692A2 EP07250743A EP07250743A EP1826692A2 EP 1826692 A2 EP1826692 A2 EP 1826692A2 EP 07250743 A EP07250743 A EP 07250743A EP 07250743 A EP07250743 A EP 07250743A EP 1826692 A2 EP1826692 A2 EP 1826692A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- indexed
- query
- keyword
- keywords
- similar
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3322—Query formulation using system suggestions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/14—Details of searching files based on file metadata
- G06F16/148—File search processing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/242—Query formulation
- G06F16/2425—Iterative querying; Query formulation based on the results of a preceding query
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/9032—Query formulation
- G06F16/90324—Query formulation using system suggestions
Definitions
- the invention generally pertains to digital data processing and, more particularly, to searching.
- the invention has application, by way of non-limiting example, in correcting or modifying queries for searching on a personal computer, desktop, or workstation, among others.
- an exemplary computerized method of searching computer files is provided.
- the method evaluates whether similar queries would give more, or significantly more, results. If so, one or more of the similar queries are suggested to the user. Similar queries are based on indexed content so the corrections always lead to at least one result.
- the method involves applying a query, e.g., having a query keyword and possibly query operators, to a database of indexed keywords extracted from computer files.
- the database of indexed keywords can be created by indexing computer files, which may be located on a personal computer, workstation, desktop computer, handheld computer, personal digital assistant, music player, and so on, and the indexed keywords can be such things as file names, directory names, metadata, and the content of computer files.
- the method involves obtaining, by the application of the query, a query result score that represents the number of computer files associated with indexed keywords satisfying the query.
- a similarity list is identified from the indexed keyword database.
- the similarity list contains one or more similar indexed keywords, e.g., indexed keywords that are similar to the query keyword.
- a similar indexed keyword from the similarity list is substituted for the query keyword in the query, creating a similar query.
- the method applies the similar query to the indexed keyword database to obtain a similar query result score.
- the similar query result score represents the number of computer files associated with indexed keywords that satisfy the similar query. Similar queries having a similar query result score that exceeds a threshold score (for example, a score higher than the query result score, or a score that is a multiple of the query result score, and so on) are suggested to the user.
- a threshold score for example, a score higher than the query result score, or a score that is a multiple of the query result score, and so on
- a similarity value is determined for an indexed keyword in the database of indexed keywords. If the similarity value exceeds a threshold value, the indexed keyword is treated as a similar indexed keyword.
- the similarity value can be determined based on an edit distance between the indexed keyword and the query keyword, the edit distance based at least on a measure of deleted characters, inserted characters, substituted characters, and swapped characters.
- a subset of indexed keywords from the database of indexed keywords is defined based on the query keyword.
- the definition can exclude from the subset indexed keywords based on at least one of indexed keyword length and indexed keyword beginning character.
- a similarity value is determined for an indexed keyword in the subset, and the indexed keyword is treated as a similar indexed keyword if the similarity value exceeds a threshold value, as described above.
- identifying the similarity list involves defining a subset of indexed keywords from the database of indexed keywords based on the query keyword.
- a similarity value is determined for each indexed keyword in the subset of indexed keywords that has a length identical to the query keyword, if there are any. If the first step results in no similar indexed keywords, in a second step a similarity value is determined for each indexed keyword in the subset of indexed keywords differing in length from the query keyword by one character, if there are any. If the second step results result in no similar indexed keywords, in a third step a similarity value is determined for each indexed keyword in the subset of indexed keywords differing in length from the query keyword by two characters, if there are any. In this way, it may be possible to avoid making determinations for some indexed keywords, e.g., if the first step is successful.
- a computerized method of searching computer files involves applying a query, which can include one or more query keywords, to a database of indexed keywords extracted from computer files.
- a query result score is thereby obtained, which represents the number of computer files associated with indexed keywords that satisfy the query.
- a similarity list is created from the database of indexed keywords, the similarity list including one or more similar indexed keywords.
- the similar indexed keywords are similar to the query keyword.
- the method further involves repeatedly replacing each query keyword with each of the similar indexed keywords in its similarity list. The replacement proceeds until all combinations of query keywords and similar indexed keywords in the query have been exhausted. Each combination represents a similar query.
- Each similar query is applied to the indexed keyword database to obtain, for each similar query, a similar query result score.
- the similar query result score is representative of the number of computer files associated with indexed keywords that satisfy the similar query.
- Each similar query having a similar query result score that exceeds a threshold score is suggested to a user.
- the step of repeatedly replacing proceeds in a particular way.
- the similar indexed keywords in each similarity list are sorted by frequency of occurrence in the indexed keyword database.
- the step of repeatedly replacing begins by substituting the similar indexed keyword having the highest frequency of occurrence in the indexed keyword database and proceeds in order of decreasing frequency of occurrence in the indexed keyword database. This proceeds only until the resulting similar query has a similar query result score below the threshold score, at which point it can be terminated.
- a method of query correction for desktop searching includes indexing content, such as computer files, to create a database of indexed keywords.
- a query is applied to the database of indexed keywords, the query including a query keyword.
- a first list of computer files associated with indexed keywords that satisfy the query is thereby obtained.
- a similarity list is identified from the database of indexed keywords, the similarity list including a similar indexed keyword similar to the query keyword.
- the query keyword is replaced with the similar indexed keyword to create a similar query.
- the similar query is applied to the indexed keyword database to obtain a second list of computer files associated with indexed keywords that satisfy the similar query.
- the similar query is suggested to a user if the number of computer files on the second list exceeds a threshold number.
- the systems and methods disclosed herein can have wide applicability, and can be used with a wide variety of devices, including personal computers, workstations, desktop computers, handheld computers, personal digital assistants, and music players.
- the computer files to be searched or queried can include virtually any type of file, such as word processing files, "pdf" files, e-mail files, music files, picture files, video files, executable files, data files, configuration files, operating system files, folder information, and metadata.
- FIG. 1 is a block diagram illustrating an exemplary method of desktop searching
- FIG. 1A is a continuation of the block diagram shown in FIG. 1.
- the terms “desktop,” “PC,” “personal computer,” and the like refer to computers on which systems (and methods) according to the invention operate.
- these are personal computers, such as portable computers and desktop computers; however, in other embodiments, they may be other types of computing devices (e.g., workstations, mainframes, handheld computers, personal digital assistants or PDAs, music or MP3 players, and the like).
- the terms "content,” “file,” or “document,” unless otherwise evident from context, refers to computer files indexed by systems according to the invention. These include, by way of non-limiting example, word processing files, "pdf" files, e-mail files, music files, picture files, video files, executable files, data files, configuration files, operating system files, folder information, metadata, and so forth.
- each query For each query, our system evaluates if similar ones would give more results. If so, the system suggests the user with one or several similar queries. Similar queries are based on indexed content so corrections conduct to at least one result. More specifically, for each keyword of the query, a similarity value is computed for a subset of all keywords of the index database. The subset is composed of all keywords minus the ones too short and too lengthy to be similar. Therefore, each keyword from the query gets a list of similar indexed keywords. Finally, each query keyword is replaced one after another by a member of its similarity list until all combinations of substitutions are listed. The number of results for each similar query is calculated. Corrected queries giving significantly more results than the original query are suggested to the user.
- the query correction system described here can be used on a desktop search application.
- a desktop search application is one which searches the contents of a user's own computer files (for example, all the information that is available on the user's PC, including web browser histories, e-mail archives, word-processor documents, music files, video files and so on), rather than searching the Internet.
- Desktop searching also includes indexing and searching network content. In that case, even though the original content is hosted on the network, the indexed content can be kept on the user's computer.
- a desktop search application builds and maintains an index database.
- the application first crawls the computer and network in search of files to index. For each file, extractors parse the document to determine keywords to store into its database called the index. Keywords include, but are not limited to:
- keywords need not be limited to words and the like but can also be or include numerals, symbols, or virtually any character string having some significance.
- the numerical size of file in bytes can be indexed and searched for as a keyword.
- the index database Once the index database has content, i.e., it has been built and populated, it can be searched with a query.
- the desktop search application looks into its index which documents contain the keywords of the query including the relation between them.
- the list of documents corresponding to the query is returned to the user.
- the desktop search application receives a query, for example, from a user via a personal computer, workstation, personal digital assistant, through the Internet, and so on, as previously mentioned.
- the query can also be automated or computer-generated.
- the query is a sequence of keywords which relation between each other is indicated with operators such as, but not limited to, AND, OR, NOT, NEAR, parentheses ( ) and quotes "".
- operators such as, but not limited to, AND, OR, NOT, NEAR, parentheses ( ) and quotes "”.
- the AND operator can be implicit between keywords.
- the similarity algorithm is based on the Edit distance algorithm suggested by Vladimir Levenshtein in 1965. This measure gives the cost to transpose one word into another in terms of deletions, insertions and substitutions. We modified the original edit distance algorithm to include the measure of swapped characters.
- our system evaluates if similar ones would give more results. If so, the system suggests the user one or several similar queries. It is especially useful in cases where one or several keywords are misspelled in the query.
- the query is split into separate keywords and operators. (Creating the indexed keyword database, as previously described, is not shown in FIG. 1 but can occur prior to step 1.) Each keyword and operator is attributed a position that will be used later in the process.
- each keyword of the query is compared to those stored in the index to find the most similar ones.
- the system does not search similarity for operators, however in some embodiments doing so can be advantageous.
- step 3 to reduce operations for use on a desktop application, comparison is limited to indexed keywords beginning with the same letter instead of all indexed keywords. For instance, for the misspelled keyword penting , only keywords beginning with the letter p are considered.
- comparison is further restricted to keywords that have, at most, a length difference of two characters instead of all indexed keywords beginning with the same letter. For instance, for the misspelled keyword penting of length 7, only indexed keywords of length 5 to 9 will be considered.
- Steps 5 to 7 are meant to reduce the number of computing operations for use on a desktop search.
- indexed keywords of same length are compared first. Since those keywords have the same length, the only possible differences between them are character swaps and/or character substitutions. Based on this assumption, if one or several keywords get the highest possible similarity score (e.g., per the Similarity Algorithm described above), then those strings are put in a list and the comparison process is complete. Indeed, if swap and substitution costs (e.g., per the Similarity Algorithm described above) are set appropriately, keywords different from each other by a character swap will get the highest score. If such a case is not found, keywords different from each other by one character substitution will get the highest score. If operation costs are set appropriately, the score of those situations can be recognized.
- swap and substitution costs e.g., per the Similarity Algorithm described above
- the search process can stop there.
- the list of similar indexed keywords is associated with the corresponding query keyword. For instance, if the indexed keyword pending is found, it is associated to the misspelled keyword penting . In that case, the search for a similar word can stop there because indexed keywords having one or two characters more or less would necessarily have a lower similarity score. Note: exact matching strings (the query keyword is the same as the indexed keyword being compared) are skipped.
- step 6 if no similar indexed keywords have been found in the previous step, indexed keywords having one extra character and one character less are processed. Indexed keywords having a difference of one character with no swap and no substitution will get the highest score. If operation costs (e.g., per the Similarity Algorithm described above) are set appropriately, the score of this situation can be recognized. If indexed keywords happen to get this score, they are put in a list and associated with the corresponding query keyword. The comparison process can stop there.
- step 7 if no similar indexed keywords have been found in the previous step, indexed keywords having two extra characters and two characters less are processed. If one or several keywords get the highest possible score then those strings are put in a list and the comparison process is complete.
- each list of similar indexed keywords is sorted in decreasing order of frequency in the index.
- the original keyword in included in the list, with its frequency with the appropriate rank.
- step 9 the minimum number of documents a corrected query must retrieve to be suggested is computed, using the number of documents retrieved by the original query:
- each keyword of the query is permuted with a member of its list of similar indexed keywords. Positions of step 1 are used to reproduce the syntax where each operator is at the same place.
- the recursive process uses the frequency of the similar keywords to evaluate, each time a keyword is permuted, if the correction will fail to retrieve more then the minimum number of documents required (see, e.g., step 9). Since the similar keyword lists are sorted from the most frequent to the less frequent, the recursive process completes similar queries from the most probable to the less probable. As soon as the number of threshold falls below the threshold, the process is stopped because no better queries can be found. For instance, a combination containing a similar keyword of frequency 10 will never retrieve enough documents if the threshold is higher (except if the similar keyword is preceded by the operator NOT). Since the list of similar keywords is sorted in decreasing order of frequency, all remaining similar keywords are discarded.
Abstract
Description
- This application claims the benefit of
U.S. Provisional Application No. 60/776,177, filed February 22, 2006 - The invention generally pertains to digital data processing and, more particularly, to searching. The invention has application, by way of non-limiting example, in correcting or modifying queries for searching on a personal computer, desktop, or workstation, among others.
- Automated searching of the personal computer "desktop" has become increasingly popular during the past few years. As software publishers have learned, however, many of the tools and techniques traditionally used for searching the Internet cannot be readily applied to desktop searching. Query correction provides one example. Traditional query correction techniques are too resource-intensive to be supported by personal computers. To compensate, some software developers have attempted to use Internet search engines to suggest corrections to user queries. However, such techniques may result in a query that gives no results (e.g., return zero or few hits) on the user's computer.
Embodiments of the invention can provide the following: - improved methods and apparatus for digital data processing;
- such methods and apparatus as can be applied to searching;
- such methods and apparatus as can be applied to searching the "desktop" of a personal computer; and
- such methods and apparatus as can be applied to searching network devices connected to
- a personal computer.
- These and other advantages are attained by the invention which provides, among other things, a system and method of query correction which can be used for example, by a desktop search application.
The present invention is as claimed in the claims. - In one embodiment of the invention, an exemplary computerized method of searching computer files is provided. Generally, for each query, the method evaluates whether similar queries would give more, or significantly more, results. If so, one or more of the similar queries are suggested to the user. Similar queries are based on indexed content so the corrections always lead to at least one result. More particularly, the method involves applying a query, e.g., having a query keyword and possibly query operators, to a database of indexed keywords extracted from computer files. The database of indexed keywords can be created by indexing computer files, which may be located on a personal computer, workstation, desktop computer, handheld computer, personal digital assistant, music player, and so on, and the indexed keywords can be such things as file names, directory names, metadata, and the content of computer files. The method involves obtaining, by the application of the query, a query result score that represents the number of computer files associated with indexed keywords satisfying the query. A similarity list is identified from the indexed keyword database. The similarity list contains one or more similar indexed keywords, e.g., indexed keywords that are similar to the query keyword. A similar indexed keyword from the similarity list is substituted for the query keyword in the query, creating a similar query. The method applies the similar query to the indexed keyword database to obtain a similar query result score. The similar query result score represents the number of computer files associated with indexed keywords that satisfy the similar query. Similar queries having a similar query result score that exceeds a threshold score (for example, a score higher than the query result score, or a score that is a multiple of the query result score, and so on) are suggested to the user.
- The identification of the similarity list can occur in a variety of ways. In one embodiment, a similarity value is determined for an indexed keyword in the database of indexed keywords. If the similarity value exceeds a threshold value, the indexed keyword is treated as a similar indexed keyword. The similarity value can be determined based on an edit distance between the indexed keyword and the query keyword, the edit distance based at least on a measure of deleted characters, inserted characters, substituted characters, and swapped characters. The similarity value can also be determined based on an algorithm according to the following: edit(m,n) = min[edit(m-1, n) + Deletion cost, edit(m, n-1) + Insertion cost, edit(m-1, n-1) + Substitution cost, edit(m-1, n-1) + Swap cost], where m and n are the lengths of two strings s and t, Deletion cost, Insertion cost, Substitution cost, and Swap cost are predefined values, and edit() is an edit distance algorithm.
- In another embodiment, a subset of indexed keywords from the database of indexed keywords is defined based on the query keyword. For example, the definition can exclude from the subset indexed keywords based on at least one of indexed keyword length and indexed keyword beginning character. A similarity value is determined for an indexed keyword in the subset, and the indexed keyword is treated as a similar indexed keyword if the similarity value exceeds a threshold value, as described above.
- In some embodiments, identifying the similarity list involves defining a subset of indexed keywords from the database of indexed keywords based on the query keyword. In a first step, a similarity value is determined for each indexed keyword in the subset of indexed keywords that has a length identical to the query keyword, if there are any. If the first step results in no similar indexed keywords, in a second step a similarity value is determined for each indexed keyword in the subset of indexed keywords differing in length from the query keyword by one character, if there are any. If the second step results result in no similar indexed keywords, in a third step a similarity value is determined for each indexed keyword in the subset of indexed keywords differing in length from the query keyword by two characters, if there are any. In this way, it may be possible to avoid making determinations for some indexed keywords, e.g., if the first step is successful.
- A wide range of other embodiments and/or variations are possible. For example, in another embodiment, a computerized method of searching computer files is provided. The method involves applying a query, which can include one or more query keywords, to a database of indexed keywords extracted from computer files. A query result score is thereby obtained, which represents the number of computer files associated with indexed keywords that satisfy the query. For each query keyword, a similarity list is created from the database of indexed keywords, the similarity list including one or more similar indexed keywords. The similar indexed keywords are similar to the query keyword. The method further involves repeatedly replacing each query keyword with each of the similar indexed keywords in its similarity list. The replacement proceeds until all combinations of query keywords and similar indexed keywords in the query have been exhausted. Each combination represents a similar query. Each similar query is applied to the indexed keyword database to obtain, for each similar query, a similar query result score. The similar query result score is representative of the number of computer files associated with indexed keywords that satisfy the similar query. Each similar query having a similar query result score that exceeds a threshold score is suggested to a user.
- In some embodiments, the step of repeatedly replacing, as mentioned above, proceeds in a particular way. The similar indexed keywords in each similarity list are sorted by frequency of occurrence in the indexed keyword database. Then, the step of repeatedly replacing begins by substituting the similar indexed keyword having the highest frequency of occurrence in the indexed keyword database and proceeds in order of decreasing frequency of occurrence in the indexed keyword database. This proceeds only until the resulting similar query has a similar query result score below the threshold score, at which point it can be terminated.
- In yet another embodiment, a method of query correction for desktop searching is also provided. The method includes indexing content, such as computer files, to create a database of indexed keywords. A query is applied to the database of indexed keywords, the query including a query keyword. A first list of computer files associated with indexed keywords that satisfy the query is thereby obtained. A similarity list is identified from the database of indexed keywords, the similarity list including a similar indexed keyword similar to the query keyword. In the query, the query keyword is replaced with the similar indexed keyword to create a similar query. The similar query is applied to the indexed keyword database to obtain a second list of computer files associated with indexed keywords that satisfy the similar query. The similar query is suggested to a user if the number of computer files on the second list exceeds a threshold number.
- The systems and methods disclosed herein can have wide applicability, and can be used with a wide variety of devices, including personal computers, workstations, desktop computers, handheld computers, personal digital assistants, and music players. Moreover, the computer files to be searched or queried can include virtually any type of file, such as word processing files, "pdf" files, e-mail files, music files, picture files, video files, executable files, data files, configuration files, operating system files, folder information, and metadata.
- The invention will be more fully understood from the following detailed description of exemplary embodiments taken in conjunction with the accompanying drawings, in which:
- FIG. 1 is a block diagram illustrating an exemplary method of desktop searching; and
- FIG. 1A is a continuation of the block diagram shown in FIG. 1.
- Certain exemplary embodiments will now be described to provide an overall understanding of the principles of the structure, function, manufacture, and use of the devices and methods disclosed herein. One or more examples of these embodiments are illustrated in the accompanying drawings. Those skilled in the art will understand that the devices and methods specifically described herein and illustrated in the accompanying drawings are non-limiting exemplary embodiments and that the scope of the present invention is defined solely by the claims. The features illustrated or described in connection with one exemplary embodiment may be combined with the features of other embodiments. Such modifications and variations are intended to be included within the scope of the present invention.
- As used herein, the terms "desktop," "PC," "personal computer," and the like, refer to computers on which systems (and methods) according to the invention operate. In the illustrated embodiments, these are personal computers, such as portable computers and desktop computers; however, in other embodiments, they may be other types of computing devices (e.g., workstations, mainframes, handheld computers, personal digital assistants or PDAs, music or MP3 players, and the like).
- Likewise, the terms "content," "file," or "document," unless otherwise evident from context, refers to computer files indexed by systems according to the invention. These include, by way of non-limiting example, word processing files, "pdf" files, e-mail files, music files, picture files, video files, executable files, data files, configuration files, operating system files, folder information, metadata, and so forth.
- Overview
- We have developed a system of query correction designed especially for use by a desktop search application. Traditional query correction is too heavy to be supported by desktop resources while some desktop search applications rely on internet search engines to suggest corrections. In that case, a corrected query may give no results on the user's computer.
- For each query, our system evaluates if similar ones would give more results. If so, the system suggests the user with one or several similar queries. Similar queries are based on indexed content so corrections conduct to at least one result. More specifically, for each keyword of the query, a similarity value is computed for a subset of all keywords of the index database. The subset is composed of all keywords minus the ones too short and too lengthy to be similar. Therefore, each keyword from the query gets a list of similar indexed keywords.
Finally, each query keyword is replaced one after another by a member of its similarity list until all combinations of substitutions are listed. The number of results for each similar query is calculated. Corrected queries giving significantly more results than the original query are suggested to the user. - Desktop Search Engine
- The query correction system described here can be used on a desktop search application. A desktop search application is one which searches the contents of a user's own computer files (for example, all the information that is available on the user's PC, including web browser histories, e-mail archives, word-processor documents, music files, video files and so on), rather than searching the Internet. Desktop searching also includes indexing and searching network content. In that case, even though the original content is hosted on the network, the indexed content can be kept on the user's computer.
- A desktop search application builds and maintains an index database. The application first crawls the computer and network in search of files to index. For each file, extractors parse the document to determine keywords to store into its database called the index. Keywords include, but are not limited to:
- 1. file and directory names
- 2. meta data, such as titles, authors, comments
- 3. content of supported documents
- As will be apparent to one skilled in the art, keywords need not be limited to words and the like but can also be or include numerals, symbols, or virtually any character string having some significance. For example, the numerical size of file in bytes can be indexed and searched for as a keyword.
- Once the index database has content, i.e., it has been built and populated, it can be searched with a query. The desktop search application looks into its index which documents contain the keywords of the query including the relation between them. The list of documents corresponding to the query is returned to the user.
- The desktop search application receives a query, for example, from a user via a personal computer, workstation, personal digital assistant, through the Internet, and so on, as previously mentioned. The query can also be automated or computer-generated. The query is a sequence of keywords which relation between each other is indicated with operators such as, but not limited to, AND, OR, NOT, NEAR, parentheses ( ) and quotes "". When a query does not contain operator, the AND operator can be implicit between keywords.
- Described below are algorithms used for evaluating the received query and for generating corrected queries
- Similarity Algorithm
- The similarity algorithm is based on the Edit distance algorithm suggested by Vladimir Levenshtein in 1965. This measure gives the cost to transpose one word into another in terms of deletions, insertions and substitutions. We modified the original edit distance algorithm to include the measure of swapped characters.
- The algorithm for computing the Edit distance involves the use of an (n+1)*(m+1) matrix, where n and m are the lengths of the two strings. Therefore, for two strings s and t of length m and n, respectively, edit(m, n) is computed by the following recurrence relation:
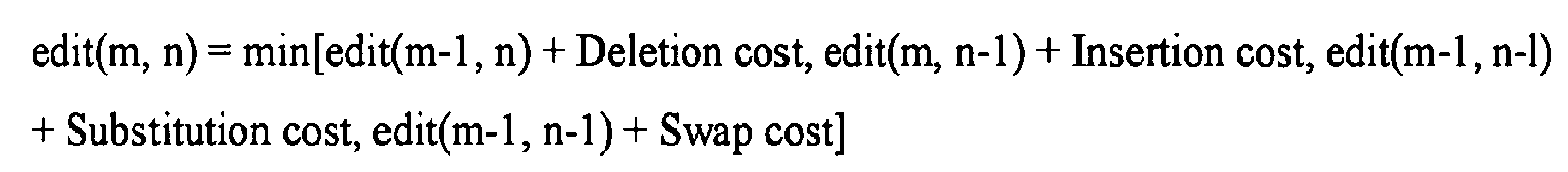
where Deletion cost, Insertion cost, Substitution cost and Swap cost are predefined values. - Query Correction Algorithm
- For each query, our system evaluates if similar ones would give more results. If so, the system suggests the user one or several similar queries. It is especially useful in cases where one or several keywords are misspelled in the query.
- The system works as follows, with reference to steps illustrated in FIGS. 1 and 1A:
- At
step 1, the query is split into separate keywords and operators. (Creating the indexed keyword database, as previously described, is not shown in FIG. 1 but can occur prior tostep 1.) Each keyword and operator is attributed a position that will be used later in the process. - Example for the query "patent filing NOT penting," where pending is misspelled as penting:

- At
step 2, each keyword of the query is compared to those stored in the index to find the most similar ones. The system does not search similarity for operators, however in some embodiments doing so can be advantageous. - At
step 3, to reduce operations for use on a desktop application, comparison is limited to indexed keywords beginning with the same letter instead of all indexed keywords. For instance, for the misspelled keyword penting, only keywords beginning with the letter p are considered. - At
step 4, to reduce operations for use on a desktop application, comparison is further restricted to keywords that have, at most, a length difference of two characters instead of all indexed keywords beginning with the same letter. For instance, for the misspelled keyword penting oflength 7, only indexed keywords oflength 5 to 9 will be considered. - At
step 5, indexed keywords of same length are compared first. Since those keywords have the same length, the only possible differences between them are character swaps and/or character substitutions. Based on this assumption, if one or several keywords get the highest possible similarity score (e.g., per the Similarity Algorithm described above), then those strings are put in a list and the comparison process is complete. Indeed, if swap and substitution costs (e.g., per the Similarity Algorithm described above) are set appropriately, keywords different from each other by a character swap will get the highest score. If such a case is not found, keywords different from each other by one character substitution will get the highest score. If operation costs are set appropriately, the score of those situations can be recognized. If one of those cases happens, the most similar indexed keywords have been found and the comparison process can stop there. The list of similar indexed keywords is associated with the corresponding query keyword. For instance, if the indexed keyword pending is found, it is associated to the misspelled keyword penting. In that case, the search for a similar word can stop there because indexed keywords having one or two characters more or less would necessarily have a lower similarity score. Note: exact matching strings (the query keyword is the same as the indexed keyword being compared) are skipped. - At
step 6, if no similar indexed keywords have been found in the previous step, indexed keywords having one extra character and one character less are processed. Indexed keywords having a difference of one character with no swap and no substitution will get the highest score. If operation costs (e.g., per the Similarity Algorithm described above) are set appropriately, the score of this situation can be recognized. If indexed keywords happen to get this score, they are put in a list and associated with the corresponding query keyword. The comparison process can stop there. - At
step 7, if no similar indexed keywords have been found in the previous step, indexed keywords having two extra characters and two characters less are processed. If one or several keywords get the highest possible score then those strings are put in a list and the comparison process is complete. - At
step 8, each list of similar indexed keywords is sorted in decreasing order of frequency in the index. The original keyword in included in the list, with its frequency with the appropriate rank. - At
step 9, the minimum number of documents a corrected query must retrieve to be suggested is computed, using the number of documents retrieved by the original query: - a) If the original query returned 0 document, then corrections that return at least 1 result are valid;
- b) If the original query returned between 1 and 9 documents, then corrections that return at least 3 times the number of original results are valid;
- c) If the original query returned between 10 and 99 documents, then corrections that return at least 5 times the number of original results are valid;
- d) If the original query returned 100 documents or more, then corrections that return at least 10 times the number of original results are valid. This number is used as a threshold to avoid suggesting corrections at each query.
- At
step 10, recursively, each keyword of the query is permuted with a member of its list of similar indexed keywords. Positions ofstep 1 are used to reproduce the syntax where each operator is at the same place. - To reduce operations for use on a desktop application, the recursive process uses the frequency of the similar keywords to evaluate, each time a keyword is permuted, if the correction will fail to retrieve more then the minimum number of documents required (see, e.g., step 9). Since the similar keyword lists are sorted from the most frequent to the less frequent, the recursive process completes similar queries from the most probable to the less probable. As soon as the number of threshold falls below the threshold, the process is stopped because no better queries can be found. For instance, a combination containing a similar keyword of
frequency 10 will never retrieve enough documents if the threshold is higher (except if the similar keyword is preceded by the operator NOT). Since the list of similar keywords is sorted in decreasing order of frequency, all remaining similar keywords are discarded. - At
step 11, remaining corrections are considered valid. - One skilled in the art will appreciate further features and advantages of the invention based on the above-described embodiments. Accordingly, the invention is not to be limited by what has been particularly shown and described, except as indicated by the appended claims.
Claims (19)
- A computerized method of searching computer files, comprising:applying a query to a database of indexed keywords extracted from computer files, the query including a query keyword;obtaining, by said application of the query, a query result score representative of the number of computer files associated with indexed keywords that satisfy the query;identifying a similarity list from the database of indexed keywords, the similarity list including a similar indexed keyword that is similar to the query keyword;substituting the similar indexed keyword for the query keyword in the query to create a similar query;applying the similar query to the indexed keyword database to obtain a similar query result score representative of the number of computer files associated with indexed keywords that satisfy the similar query; andsuggesting the similar query to a user if the similar query result score exceeds a threshold score.
- The method of claim 1, and any of:a) further comprising receiving the query from a user of a device selected from the group consisting of: personal computer, workstation, desktop computer, handheld computer, personal digital assistant, music player;b) wherein the computer files comprise files selected from the group consisting of: word processing files, "pdf" files, e-mail files, music files, picture files, video files, executable files, data files, configuration files, operating system files, folder information, and metadata;c) further comprising indexing computer files to create the database of indexed keywords; andd) wherein the indexed keywords comprise file names, directory names, metadata, and the content of computer files.
- The method of claim 1, wherein the step of identifying the similarity list comprises:determining a similarity value for an indexed keyword stored in the database of indexed keywords; andtreating the indexed keyword as the similar indexed keyword if the similarity value exceeds a threshold similarity value.
- The method of claim 3, wherein the similarity value is determined based on an edit distance between the indexed keyword and the query keyword, the edit distance based at least on a measure of deleted characters, inserted characters, substituted characters, and swapped characters.
- The method of claim 1, wherein the step of identifying the similarity list comprises:defining a subset of indexed keywords from the database of indexed keywords based on the query keyword;determining a similarity value for an indexed keyword in the subset of indexed keywords; andtreating the indexed keyword as the similar indexed keyword if the similarity value exceeds a threshold similarity value.
- The method of claim 5, wherein the subset of indexed keywords is defined to exclude indexed keywords based on at least one of indexed keyword length and indexed keyword beginning character.
- The method of claim 1, and any of:a) wherein the step of identifying the similarity list comprises:defining a subset of indexed keywords from the database of indexed keywords based on the query keyword;in a first step, determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, that has a length identical to the query keyword;if the first step results in no similar indexed keywords, in a second step determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, differing in length from the query keyword by one character;if the second step results result in no similar indexed keywords, in a third step determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, differing in length from the query keyword by two characters;b) further comprising sorting the similarity list by frequency of occurrence in the indexed keyword database; andc) wherein the threshold score is based on the query result score.
- A computerized method of searching computer files, comprising:applying a query to a database of indexed keywords extracted from computer files, the query including one or more query keywords;obtaining, by said application of the query, a query result score representative of the number of computer files associated with indexed keywords that satisfy the query;for each query keyword, creating a similarity list from the database of indexed keywords, the similarity list including one or more similar indexed keywords, each similar indexed keyword being similar to the query keyword;repeatedly replacing each query keyword with each of the similar indexed keywords in the similarity list associated therewith until all combinations of query keywords and similar indexed keywords in the query have been exhausted, each combination representing a similar query;applying each similar query to the indexed keyword database to obtain, for each similar query, a similar query result score representative of the number of computer files associated with indexed keywords that satisfy the similar query; andsuggesting to a user each similar query having a similar query result score that exceeds a threshold score.
- The method of claim 8, further comprising indexing computer files to create the database of indexed keywords.
- The method of claim 8, wherein the step of creating comprises:defining a subset of indexed keywords from the database of indexed keywords based on the query keyword;determining a similarity value for each indexed keyword in the subset of indexed keywords; andtreating each indexed keyword in the subset of indexed keywords as one of the one or more similar indexed keywords based on the similarity value for the indexed keyword.
- The method of claim 10, and any of:a) wherein the step of determining a similarity value comprises:in a first step, determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, that has a length identical to the query keyword;if the first step results in no similar indexed keywords, in a second step determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, differing in length from the query keyword by one character;if the second step results result in no similar indexed keywords, in a third step determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, differing in length from the query keyword by two characters;b) wherein the similarity value is determined based on an edit distance between the indexed keyword and the query keyword, the edit distance including measurement of deleted characters, inserted characters, substituted characters, and swapped characters; andc) wherein the similarity value is determined according to the algorithm: edit(m,n) = min[edit(m-1, n) + Deletion cost, edit(m, n-1) + Insertion cost, edit(m-1, n-1) + Substitution cost, edit(m-1, n-1) + Swap cost], where m and n are the lengths of two strings s and t, Deletion cost, Insertion cost, Substitution cost, and Swap cost are predefined values, and edit() is an edit distance algorithm.
- The method of claim 8, further comprising:sorting the one or more similar indexed keywords in each similarity list by frequency of occurrence in the indexed keyword database,wherein, for each query keyword, the step of repeatedly replacing begins by substituting the similar indexed keyword having the highest frequency of occurrence in the indexed keyword database and proceeds in order of decreasing frequency of occurrence in the indexed keyword database only until the resulting similar query has a similar query result score below the threshold score.
- The method of claim 12, wherein the threshold score is based on the query result score.
- The method of claim 8, wherein the threshold score is based on the query result score.
- A method of query correction for desktop searching, comprising:indexing content to create a database of indexed keywords, the content including computer files;applying a query to the database of indexed keywords, the query including a query keyword;obtaining, by said application of the query, a first list of computer files associated with indexed keywords that satisfy the query;identifying a similarity list from the database of indexed keywords, the similarity list including a similar indexed keyword similar to the query keyword;replacing the similar indexed keyword for the query keyword in the query to create a similar query;applying the similar query to the indexed keyword database to obtain a second list of computer files associated with indexed keywords that satisfy the similar query; andsuggesting the similar query to a user if the number of computer files on the second list exceeds a threshold number.
- The method of claim 15, and any of:a) wherein the content is local content residing on a personal computer;b) further comprising storing the indexed keyword database on a personal computer,
wherein the content is network content;c) wherein the indexed keywords comprise file names, directory names, metadata, and data in documents;d) wherein the step of indexing comprises:crawling computer files;extracting keywords from computer files for storage in the indexed keyword database; ande) wherein the step of identifying the similarity list comprises:determining a similarity value for an indexed keyword; andtreating the indexed keyword as the similar indexed keyword if the similarity value exceeds a threshold similarity value. - The method of claim 15, wherein the step of identifying the similarity list comprises:defining a subset of indexed keywords from the database of indexed keywords based on the query keyword;determining a similarity value for an indexed keyword in the subset of indexed keywords;treating the indexed keyword as the similar indexed keyword if the similarity value exceeds a threshold similarity value.
- The method of claim 17, wherein the subset of indexed keywords is defined to exclude indexed keywords based on at least one of indexed keyword length and indexed keyword beginning character.
- The method of claim 15, and either;a) wherein the step of identifying the similarity list comprises:defining a subset of indexed keywords from the database of indexed keywords based on the query keyword;in a first step, determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, that has a length identical to the query keyword;if the first step results in no similar indexed keywords, in a second step determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, differing in length from the query keyword by one character;if the second step results in no similar indexed keywords, in a third step determining a similarity value for each indexed keyword in the subset of indexed keywords, if any, differing in length from the query keyword by two characters; orb) wherein the threshold number is based on the number of computer files on the first list.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US77617706P | 2006-02-22 | 2006-02-22 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP1826692A2 true EP1826692A2 (en) | 2007-08-29 |
| EP1826692A3 EP1826692A3 (en) | 2009-03-25 |
Family
ID=38016666
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP07250743A Withdrawn EP1826692A3 (en) | 2006-02-22 | 2007-02-22 | Query correction using indexed content on a desktop indexer program. |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20070208733A1 (en) |
| EP (1) | EP1826692A3 (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012151166A1 (en) * | 2011-04-30 | 2012-11-08 | Tibco Software Inc. | Integrated phonetic matching methods and systems |
| US8914356B2 (en) | 2012-11-01 | 2014-12-16 | International Business Machines Corporation | Optimized queries for file path indexing in a content repository |
| WO2015108530A1 (en) * | 2014-01-17 | 2015-07-23 | Hewlett-Packard Development Company, L.P. | File locator |
| US9323761B2 (en) | 2012-12-07 | 2016-04-26 | International Business Machines Corporation | Optimized query ordering for file path indexing in a content repository |
| US11487707B2 (en) | 2012-04-30 | 2022-11-01 | International Business Machines Corporation | Efficient file path indexing for a content repository |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8145620B2 (en) * | 2008-05-09 | 2012-03-27 | Microsoft Corporation | Keyword expression language for online search and advertising |
| US8079065B2 (en) * | 2008-06-27 | 2011-12-13 | Microsoft Corporation | Indexing encrypted files by impersonating users |
| US8533579B2 (en) * | 2009-10-21 | 2013-09-10 | Symantec Corporation | Data loss detection method for handling fuzziness in sensitive keywords |
| GB0921669D0 (en) | 2009-12-10 | 2010-01-27 | Chesterdeal Ltd | Accessing stored electronic resources |
| EP2633393A4 (en) * | 2010-10-26 | 2015-12-09 | Google Inc | Rich results relevant to user search queries for books |
| US10311054B2 (en) * | 2014-01-08 | 2019-06-04 | Red Hat, Inc. | Query data splitting |
| CN104899214B (en) | 2014-03-06 | 2018-05-22 | 阿里巴巴集团控股有限公司 | A kind of data processing method and system established input and suggested |
| US11334800B2 (en) * | 2016-05-12 | 2022-05-17 | International Business Machines Corporation | Altering input search terms |
| CN112100313B (en) * | 2020-08-05 | 2024-04-12 | 山东鲁软数字科技有限公司 | Data indexing method and system based on finest granularity segmentation |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20010054042A1 (en) * | 1996-05-17 | 2001-12-20 | Richard M. Watkins | Computing system for information management |
| GB2393541A (en) * | 2002-09-27 | 2004-03-31 | Hewlett Packard Development Co | Method for management of synonymic searching |
| US20040186827A1 (en) * | 2003-03-21 | 2004-09-23 | Anick Peter G. | Systems and methods for interactive search query refinement |
| US20050091204A1 (en) * | 1999-12-19 | 2005-04-28 | Melman Haim Z. | Apparatus and method for retrieval of documents |
Family Cites Families (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US2003220A (en) * | 1931-10-23 | 1935-05-28 | William J Pearson | Type-setting device |
| US2003084A (en) * | 1933-12-13 | 1935-05-28 | Bethlehem Steel Corp | Method of making nut blanks |
| US5170466A (en) * | 1989-10-10 | 1992-12-08 | Unisys Corporation | Storage/retrieval system for document |
| US5446891A (en) * | 1992-02-26 | 1995-08-29 | International Business Machines Corporation | System for adjusting hypertext links with weighed user goals and activities |
| GB9220404D0 (en) * | 1992-08-20 | 1992-11-11 | Nat Security Agency | Method of identifying,retrieving and sorting documents |
| US5724567A (en) * | 1994-04-25 | 1998-03-03 | Apple Computer, Inc. | System for directing relevance-ranked data objects to computer users |
| US5724571A (en) * | 1995-07-07 | 1998-03-03 | Sun Microsystems, Inc. | Method and apparatus for generating query responses in a computer-based document retrieval system |
| US5867799A (en) * | 1996-04-04 | 1999-02-02 | Lang; Andrew K. | Information system and method for filtering a massive flow of information entities to meet user information classification needs |
| US6006248A (en) * | 1996-07-12 | 1999-12-21 | Nec Corporation | Job application distributing system among a plurality of computers, job application distributing method and recording media in which job application distributing program is recorded |
| US5920854A (en) * | 1996-08-14 | 1999-07-06 | Infoseek Corporation | Real-time document collection search engine with phrase indexing |
| US6182068B1 (en) * | 1997-08-01 | 2001-01-30 | Ask Jeeves, Inc. | Personalized search methods |
| US6064814A (en) * | 1997-11-13 | 2000-05-16 | Allen-Bradley Company, Llc | Automatically updated cross reference system having increased flexibility |
| US6094649A (en) * | 1997-12-22 | 2000-07-25 | Partnet, Inc. | Keyword searches of structured databases |
| US6060481A (en) * | 1998-05-28 | 2000-05-09 | The Penn State Research Foundation | Method for improving insulin sensitivity using an adenosine receptor antagonist |
| US6424966B1 (en) * | 1998-06-30 | 2002-07-23 | Microsoft Corporation | Synchronizing crawler with notification source |
| US6243713B1 (en) * | 1998-08-24 | 2001-06-05 | Excalibur Technologies Corp. | Multimedia document retrieval by application of multimedia queries to a unified index of multimedia data for a plurality of multimedia data types |
| US6253198B1 (en) * | 1999-05-11 | 2001-06-26 | Search Mechanics, Inc. | Process for maintaining ongoing registration for pages on a given search engine |
| US6631369B1 (en) * | 1999-06-30 | 2003-10-07 | Microsoft Corporation | Method and system for incremental web crawling |
| US6547829B1 (en) * | 1999-06-30 | 2003-04-15 | Microsoft Corporation | Method and system for detecting duplicate documents in web crawls |
| US6928432B2 (en) * | 2000-04-24 | 2005-08-09 | The Board Of Trustees Of The Leland Stanford Junior University | System and method for indexing electronic text |
| US6760339B1 (en) * | 2000-05-20 | 2004-07-06 | Equipe Communications Corporation | Multi-layer network device in one telecommunications rack |
| US6631374B1 (en) * | 2000-09-29 | 2003-10-07 | Oracle Corp. | System and method for providing fine-grained temporal database access |
| US7185001B1 (en) * | 2000-10-04 | 2007-02-27 | Torch Concepts | Systems and methods for document searching and organizing |
| US7925967B2 (en) * | 2000-11-21 | 2011-04-12 | Aol Inc. | Metadata quality improvement |
| AUPR208000A0 (en) * | 2000-12-15 | 2001-01-11 | 80-20 Software Pty Limited | Method of document searching |
| US6775666B1 (en) * | 2001-05-29 | 2004-08-10 | Microsoft Corporation | Method and system for searching index databases |
| US7526425B2 (en) * | 2001-08-14 | 2009-04-28 | Evri Inc. | Method and system for extending keyword searching to syntactically and semantically annotated data |
| US7007074B2 (en) * | 2001-09-10 | 2006-02-28 | Yahoo! Inc. | Targeted advertisements using time-dependent key search terms |
| EP1472633A2 (en) * | 2002-01-08 | 2004-11-03 | Sap Ag | Enhanced email management system |
| US20030135480A1 (en) * | 2002-01-14 | 2003-07-17 | Van Arsdale Robert S. | System for updating a database |
| US6681309B2 (en) * | 2002-01-25 | 2004-01-20 | Hewlett-Packard Development Company, L.P. | Method and apparatus for measuring and optimizing spatial segmentation of electronic storage workloads |
| US7010522B1 (en) * | 2002-06-17 | 2006-03-07 | At&T Corp. | Method of performing approximate substring indexing |
| US7424510B2 (en) * | 2002-09-03 | 2008-09-09 | X1 Technologies, Inc. | Methods and systems for Web-based incremental searches |
| US20040153481A1 (en) * | 2003-01-21 | 2004-08-05 | Srikrishna Talluri | Method and system for effective utilization of data storage capacity |
| US20050033771A1 (en) * | 2003-04-30 | 2005-02-10 | Schmitter Thomas A. | Contextual advertising system |
| US7308464B2 (en) * | 2003-07-23 | 2007-12-11 | America Online, Inc. | Method and system for rule based indexing of multiple data structures |
| US20050222989A1 (en) * | 2003-09-30 | 2005-10-06 | Taher Haveliwala | Results based personalization of advertisements in a search engine |
| US7707039B2 (en) * | 2004-02-15 | 2010-04-27 | Exbiblio B.V. | Automatic modification of web pages |
| US20050203892A1 (en) * | 2004-03-02 | 2005-09-15 | Jonathan Wesley | Dynamically integrating disparate systems and providing secure data sharing |
| US7254774B2 (en) * | 2004-03-16 | 2007-08-07 | Microsoft Corporation | Systems and methods for improved spell checking |
| US8275839B2 (en) * | 2004-03-31 | 2012-09-25 | Google Inc. | Methods and systems for processing email messages |
| US7784054B2 (en) * | 2004-04-14 | 2010-08-24 | Wm Software Inc. | Systems and methods for CPU throttling utilizing processes |
| US20050283464A1 (en) * | 2004-06-10 | 2005-12-22 | Allsup James F | Method and apparatus for selective internet advertisement |
| US7870147B2 (en) * | 2005-03-29 | 2011-01-11 | Google Inc. | Query revision using known highly-ranked queries |
| US7444328B2 (en) * | 2005-06-06 | 2008-10-28 | Microsoft Corporation | Keyword-driven assistance |
-
2007
- 2007-02-22 EP EP07250743A patent/EP1826692A3/en not_active Withdrawn
- 2007-02-22 US US11/677,757 patent/US20070208733A1/en not_active Abandoned
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20010054042A1 (en) * | 1996-05-17 | 2001-12-20 | Richard M. Watkins | Computing system for information management |
| US20050091204A1 (en) * | 1999-12-19 | 2005-04-28 | Melman Haim Z. | Apparatus and method for retrieval of documents |
| GB2393541A (en) * | 2002-09-27 | 2004-03-31 | Hewlett Packard Development Co | Method for management of synonymic searching |
| US20040186827A1 (en) * | 2003-03-21 | 2004-09-23 | Anick Peter G. | Systems and methods for interactive search query refinement |
Non-Patent Citations (1)
| Title |
|---|
| GIFFORD D K ET AL: "Semantic File System" ACM SOSP. PROCEEDINGS OF THE ACM SYMPOSIUM ON OPERATING SYSTEMSPRINCIPLES, ACM, US, 13 October 1991 (1991-10-13), pages 16-25, XP002410203 * |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012151166A1 (en) * | 2011-04-30 | 2012-11-08 | Tibco Software Inc. | Integrated phonetic matching methods and systems |
| US10275518B2 (en) | 2011-04-30 | 2019-04-30 | Tibco Software Inc. | Integrated phonetic matching methods and systems |
| US11487707B2 (en) | 2012-04-30 | 2022-11-01 | International Business Machines Corporation | Efficient file path indexing for a content repository |
| US8914356B2 (en) | 2012-11-01 | 2014-12-16 | International Business Machines Corporation | Optimized queries for file path indexing in a content repository |
| US9323761B2 (en) | 2012-12-07 | 2016-04-26 | International Business Machines Corporation | Optimized query ordering for file path indexing in a content repository |
| US9990397B2 (en) | 2012-12-07 | 2018-06-05 | International Business Machines Corporation | Optimized query ordering for file path indexing in a content repository |
| WO2015108530A1 (en) * | 2014-01-17 | 2015-07-23 | Hewlett-Packard Development Company, L.P. | File locator |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1826692A3 (en) | 2009-03-25 |
| US20070208733A1 (en) | 2007-09-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1826692A2 (en) | Query correction using indexed content on a desktop indexer program. | |
| US7853587B2 (en) | Generating search result summaries | |
| US6615209B1 (en) | Detecting query-specific duplicate documents | |
| US6212525B1 (en) | Hash-based system and method with primary and secondary hash functions for rapidly identifying the existence and location of an item in a file | |
| US7783626B2 (en) | Pipelined architecture for global analysis and index building | |
| US8504578B2 (en) | System and method for near and exact de-duplication of documents | |
| US8145617B1 (en) | Generation of document snippets based on queries and search results | |
| AU2009234120B2 (en) | Search results ranking using editing distance and document information | |
| JP5522743B2 (en) | Duplicate document detection and display function | |
| KR100451978B1 (en) | A method of retrieving data and a data retrieving apparatus | |
| EP2172853B1 (en) | Database index and database for indexing text documents | |
| US8024322B2 (en) | Ordered index | |
| WO2008097856A2 (en) | Search result delivery engine | |
| JPH11282876A (en) | Document retrieving device | |
| US9529908B2 (en) | Tiering of posting lists in search engine index | |
| US8423885B1 (en) | Updating search engine document index based on calculated age of changed portions in a document | |
| US7657513B2 (en) | Adaptive help system and user interface | |
| WO2008106670A1 (en) | Efficient retrieval algorithm by query term discrimination | |
| US7783589B2 (en) | Inverted index processing | |
| EP1903457A1 (en) | Computer-implemented method, computer program product and system for creating an index of a subset of data | |
| US20110113052A1 (en) | Query result iteration for multiple queries | |
| US20050071333A1 (en) | Method for determining synthetic term senses using reference text | |
| US7991756B2 (en) | Adding low-latency updateable metadata to a text index | |
| CN111259145A (en) | Text retrieval classification method, system and storage medium based on intelligence data | |
| US20160314125A1 (en) | Predictive Coding System and Method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI SK TR |
|
| AX | Request for extension of the european patent |
Extension state: AL BA HR MK YU |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI SK TR |
|
| AX | Request for extension of the european patent |
Extension state: AL BA HR MK RS |
|
| AKX | Designation fees paid | ||
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: 8566 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION IS DEEMED TO BE WITHDRAWN |
|
| 18D | Application deemed to be withdrawn |
Effective date: 20090901 |